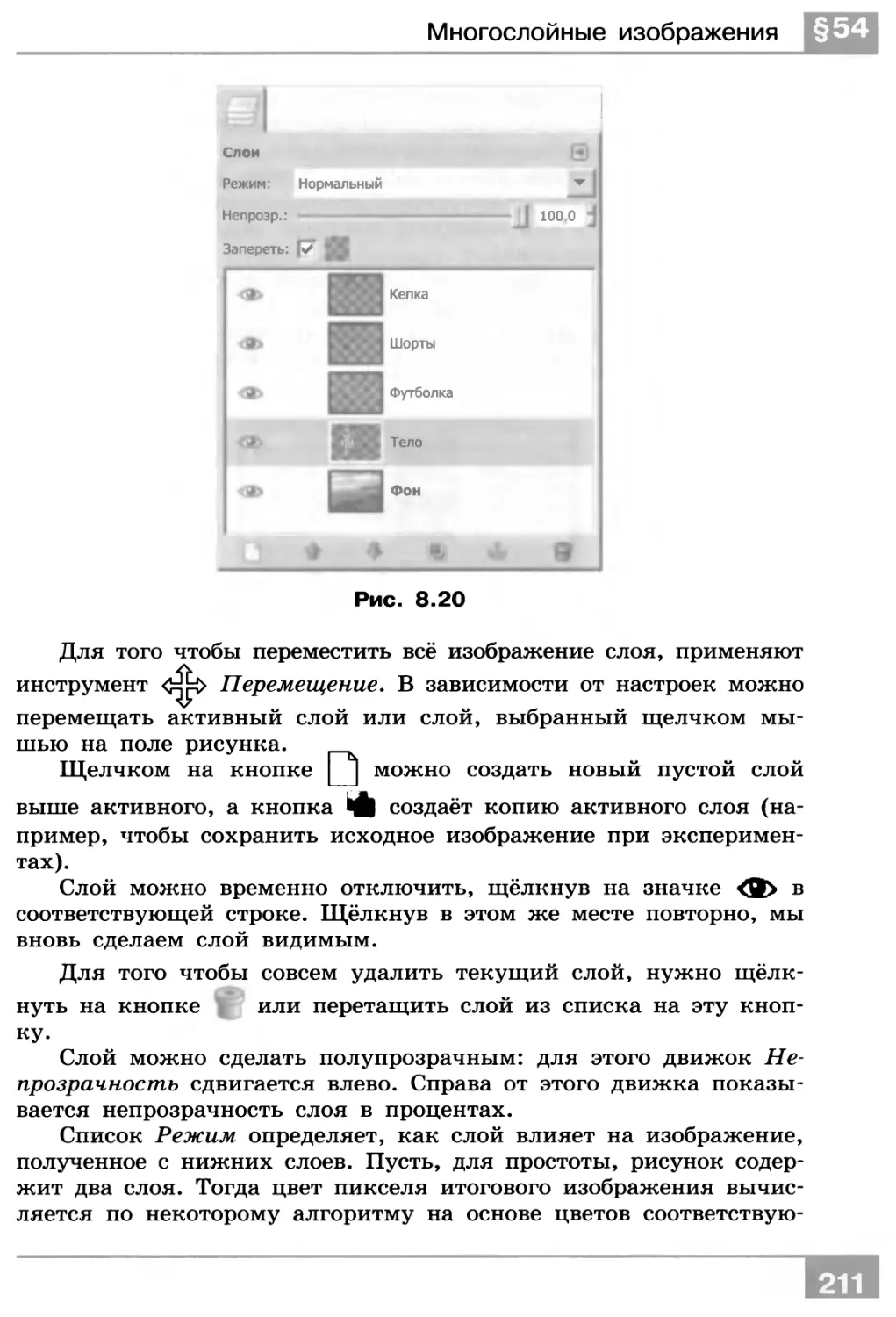
/






















































































































































































































































































































Текст
ИНФОРМАТИКА
БАЗОВЫЙ И УГЛУБЛЕННЫЙ УРОВНИ
НОВАЯ ШКОЛА БИНОМ
©ИЗДАТЕЛЬСТВО
Учебное издание соответствует федеральному государственному образовательному стандарту среднего общего образования и примерной основной образовательной программе среднего общего образования.
Состав УМК
• Информатика. 7-9 классы. Информатика. 10-11 классы. Базовый и углублённый уровни:учебные издания
• Информатика. 10-11 классы: методическое пособие (содержит примерную рабочую программу: авторы К. Ю. Поляков, Е. А. Еремин)
• Авторская мастерская К. Ю. Полякова, Е.А. Еремина на сайте www.metodist.Lbz.ru
Константин Юрьевич Поляков — доктор технических наук, профессор кафедры судовой автоматики и измерений Санкт-Петербургского государственного морского технического университета, учитель информатики школы №163 Санкт-Петербурга. Победитель Всероссийского конкурса для педагогов по включению ресурсов Единой коллекции цифровых образовательных ресурсов в образовательный
процесс. Лауреат профессиональной премии «Лучший учитель Санкт-Петербурга». Награжден знаком «Почетный работник общего образования РФ».
Евгений Александрович Еремин — кандидат физико-математических наук. Начиная с 1974 года, работает с вычислительной техникой. Преподает связанные с информатикой курсы с момента появления этого предмета в школе в 1985 году.
Фильтр Байера
Режим замены в анимации
Режим объединения в анимации
Трассировка
К. Ю. Поляков, Е. А. Еремин
ИНФОРМАТИКА
11 класс
Часть 2
Базовый и углубленный уровни
*
Москва БИНОМ. Лаборатория знаний 2017
УДК 004.9
ББК 32.97
П54
Поляков К. Ю.
П54 Информатика. 11 класс. Базовый и углубленный уровни : в 2 ч. Ч. 2 /К. Ю. Поляков, Е. А. Еремин. — М. : БИНОМ. Лаборатория знаний, 2017. — 304 с. : ил.
ISBN 978-5-9963-3139-0(4. 2)
ISBN 978-5-9963-3140-6 (общ)
Учебное издание предназначено для изучения информатики на базовом и углубленном уровнях в 11 классах общеобразовательных организаций. Содержание учебного издания является продолжением курса 10 класса и опирается на изученный в 7-9 классах курс информатики для основной школы.
Рассматриваются вопросы передачи информации, информационные системы и базы данных, разработка веб-сайтов, компьютерное моделирование, методы объектно-ориентированного программирования, компьютерная графика и анимация.
Учебное издание входит в учебно-методический комплект, включающий также учебное издание для 10 класса, методическое пособие и компьютерный практикум.
Предполагается широкое использование ресурсов портала Федерального центра электронных образовательных ресурсов (http://fcior.edu. TU/).
Соответствует федеральному государственному образовательному стандарту среднего общего образования и примерной основной образовательной программе среднего общего образования.
УДК 004.9
ББК 32.97
ISBN 978-5-9963-3139-0 (Ч. 2)
ISBN 978-5-9963-3140-6 (общ)
© ООО «БИНОМ. Лаборатория знаний», 2016
Глава 5
ЭЛЕМЕНТЫ ТЕОРИИ АЛГОРИТМОВ
§31 Уточнение понятия алгоритма
Ключевые слова:
алгоритм теория алгоритмов универсальный исполнитель
• машина Тьюринга
• машина Поста
• нормальный алгорифм Маркова
Зачем нужно определение алгоритма?
Как вы знаете, алгоритмом называют точный набор инструкций для исполнителя, который приводит к решению задачи за конечное время.
Особый интерес проявляли к алгоритмам математики. Один из древнейших известных алгоритмов — алгоритм Евклида для вычисления наибольшего общего делителя (НОД) двух натуральных чисел.
Само слово «алгоритм» ввёл в науку в XVII веке немецкий математик Г. В. Лейбниц. Оно образовано от имени математика IX века алъ-Хорезми, которого считают основателем алгебры.
Долгое время считалось, что для любой математической задачи можно найти метод (алгоритм) решения, просто для ряда задач такие алгоритмы ещё не найдены. Эту идею высказал ещё аль-Хорезми, такой же точки зрения придерживались и другие математики вплоть до начала XX века.
Однако, несмотря на все усилия, решить некоторые задачи не удавалось в течение столетий. Например, безуспешно закончились многочисленные попытки найти алгоритм доказательства правильности любой теоремы на основе заданной системы аксиом.
В 1931 году австрийский математик Курт Гёдель доказал теорему о неполноте, смысл которой состоит в том, что в любой достаточно сложной формальной системе, основанной на аксиомах (например, в арифметике, где введены натуральные числа
3
5
Элементы теории алгоритмов
и операции сложения и умножения), есть утверждение, которое невозможно ни доказать, ни опровергнуть в рамках этой системы. Поэтому было высказано предположение о том, что некоторые задачи алгоритмически неразрешимы, т. е. для них в принципе не существует алгоритма решения, и поэтому искать его бессмысленно. Чтобы строго доказать или опровергнуть эту гипотезу, нужно было ввести математическое понятие алгоритма.
«Определение» алгоритма, которое мы привели в начале главы, часто называют интуитивным, потому что оно содержит такие «нематематические» понятия, как «точный набор», «инструкция», «исполнитель», «решение задачи». Эти термины невозможно записать строго, используя язык математики и логики, поэтому для математического доказательства такое определение не подходит.
Исследования в этой области, которые начали активно проводиться в 30-х годах XX века, привели к возникновению теории алгоритмов, которая занимается:
• доказательством алгоритмической неразрешимости задач;
• анализом сложности алгоритмов;
• сравнительной оценкой качества алгоритмов.
Значительный вклад в развитие теории алгоритмов внесли математики А. Тьюринг (Великобритания), Э. Пост (США), А. Чёрч (Великобритания), С. Клини (США) и А. А. Марков (СССР).
Что такое алгоритм?
Про любой алгоритм можно сказать следующее:
• алгоритм получает на вход дискретный объект (например, символьную строку);
• алгоритм обрабатывает входной объект по шагам (дискретно), строя на каждом шаге промежуточные дискретные объекты; этот процесс может закончиться или не закончиться;
• если выполнение алгоритма заканчивается, его результат — это объект, построенный на последнем шаге;
• если выполнение алгоритма не заканчивается (алгоритм зацикливается) или заканчивается аварийно (например, в результате деления на 0), то результат его работы при данном входе не определён.
Любой алгоритм рассчитан на определённого исполнителя: он должен использовать только понятные этому исполнителю команды. Задание для исполнителя — это текст на специальном (формальном) языке, который обычно называют программой. Поэтому можно определить алгоритм как программу для некоторого исполнителя.
4
Уточнение понятия алгоритма
§31
Первые известные алгоритмы — это правила выполнения арифметических действий с числами. В них чётко определены объекты (числа в десятичной записи) и элементарные шаги (сложить, вычесть, перемножить два однозначных числа — вспомните таблицы сложения и умножения). Постепенно сложность задач, которые решались с помощью алгоритмов, увеличивалась, и понятие «шаг алгоритма» оказалось нечётким, размытым. Например, можно ли считать элементарным шагом разложение числа на простые множители или сложение многозначных чисел?
Со временем понятие алгоритма расширилось — сейчас мы говорим об алгоритмах для исполнителей, которые работают с текстами и другими объектами реального мира. Однако оказалось, что все эти объекты можно тем или иным способом закодировать в виде цепочек символов, так что любой алгоритм сводится к преобразованию одной символьной строки в другую. Например, в алгоритме шахматной игры объекты — это фигуры на доске, но их расположение легко закодировать в символьной форме (вспомните запись шахматных партий). Таким же способом можно представить и классические вычислительные алгоритмы — операции с цифрами. Поэтому можно рассматривать только алгоритмы обработки символьных строк, а полученные результаты будут применимы к любым алгоритмам.
Как вы знаете, текст, записанный с помощью любого алфавита, всегда можно перевести в двоичный код, поэтому, вообще говоря, достаточно рассматривать только алгоритмы, работающие с двоичными последовательностями.
Каждый алгоритм задаёт (вычисляет) функцию, которая преобразует входное слово в результат (выходное слово) — рис. 5.1. Такая функция может быть не определена для некоторых входных слов, если алгоритм зацикливается.
Входное слово — Выходное слово
муха — Алгоритм слон
Рис. 5.1
Может быть и так, что функция, заданная алгоритмом, нигде не определена. Например, алгоритм
нц пока да кц
выходит в бесконечный цикл при любом входном слове.
5
Элементы теории алгоритмов
Алгоритмы называются эквивалентными, если они задают одну и ту же функцию. То есть при любом входном слове оба алгоритма должны приводить к одному и тому же результату или зацикливаться (оба алгоритма не дают никакого результата). Например, следующие алгоритмы для выбора минимального из значений переменных а и Ъ эквивалентны:
если а < Ь то
М: = а иначе
М:= Ь все
М: = Ь если а < Ь то
М: = а все
Универсальные исполнители
Как мы уже видели, понятие алгоритма оказывается «привязанным» к его исполнителю и некоторому языку программирования. Это не позволяет определить алгоритм как математический объект. Поэтому возникла идея попытаться построить универсальный исполнитель.
Универсальный исполнитель — это исполнитель, который может моделировать работу любого другого исполнителя. Это значит, что для любого алгоритма, написанного для любого исполнителя, существует эквивалентный алгоритм для универсального исполнителя.
Такой исполнитель можно было бы использовать для доказательства разрешимости или неразрешимости задач. Если удаётся построить алгоритм решения задачи для универсального исполнителя, то задача разрешима. Если доказано, что алгоритма не существует, то задача неразрешима. Система команд такого исполнителя должна быть как можно проще — так его будет легче использовать в доказательствах.
Универсальный исполнитель — это некоторая модель вычислений, которая задаёт способ описания алгоритмов и их выполнения. Эта модель вычислений должна содержать:
• «процессор», задающий систему команд и способ их выполнения;
• «память», определяющую способ хранения данных;
• язык программирования (способ записи программ);
• способ ввода данных (чтения входного слова);
• способ вывода слова-результата.
6
Уточнение понятия алгоритма
§31
В середине XX века разными учёными независимо друг от друга было предложено несколько исполнителей, претендующих на роль универсальных (они будут рассмотрены далее). В теории алгоритмов доказано, что все они эквивалентны друг другу, т. е. алгоритм, который можно запрограммировать для одного универсального исполнителя, можно запрограммировать также и для остальных.
Как же связан универсальный исполнитель с проблемой строгого определения алгоритма?
Любой алгоритм может быть представлен как программа для универсального исполнителя.
Это основная идея теории алгоритмов. Строго доказать это утверждение невозможно, потому что здесь используется интуитивное понятие « алгоритм ».
Как мы увидим, каждый универсальный исполнитель описывается с помощью математических терминов, поэтому на его основе можно дать строгое определение алгоритма:
Алгоритм — это программа для универсального исполнителя.
Все универсальные исполнители эквивалентны, поэтому такое определение алгоритма не зависит от конкретного исполнителя.
Машина Тьюринга
Первым предложил универсальный исполнитель английский математик Алан Тьюринг. Придуманное им воображаемое устройство состоит из трёх частей:
• бесконечной ленты, разделённой на ячейки;
• каретки (читающей и записывающей головок);
• программируемого автомата.
Программируемый автомат управляет кареткой, посылая ей команды в соответствии с заложенной в него сменяемой программой. Лента выполняет роль внешней памяти компьютера, автомат — роль процессора, а каретка служит
А. Тьюринг (1912-1956)
7
Элементы теории алгоритмов
для ввода и вывода данных. Такое устройство называют машиной Тьюринга. Теоретически лента в машине Тьюринга бесконечна, однако в каждый момент работы машины времени используется лишь конечная её часть.
Каретка в любой момент времени находится над одной ячейкой, автомат может читать и изменять содержимое этой ячейки, которая называется текущей (рабочей) ячейкой (рис. 5.2).
В каждую ячейку ленты можно записать один любой символ, принадлежащий выбранному алфавиту. Алфавит обязательно содержит пробел (пустой символ, соответствующий «чистым» участкам ленты), который мы будем обозначать знаком □. Алфавит обычно обозначается буквой А, а его элементы — строчными буквами а с индексами: А = {а15 а2, ..., aN}. Например, алфавит машины Тьюринга, работающей с двоичными числами, задаётся в виде А = {0, 1, □}.
Непрерывную цепочку символов на ленте называют словом. На рисунке 5.2 лента содержит слово «1011», которое можно воспринимать как двоичное число.
Автоматом называют устройство, работающее без участия человека. Автомат в машине Тьюринга имеет несколько состояний и при определённых условиях переходит из одного состояния в другое. Состояние автомата определяет ту промежуточную задачу, которую решает автомат в данный момент. Это напоминает состояния человека: ночью он спит (состояние 1), утром встаёт и умывается (состояние 2), завтракает (состояние 3), идёт на работу (состояние 4) и т. д.
Множество всех состояний автомата обозначается буквой Q, а его элементы — строчными буквами q с индексами: Q = {91» ?2» •••’ Принято, что в начальный момент машина Тьюринга находится в состоянии qr.
Особое состояние qQ — это состояние останова. Если машина переходит в это состояние, выполнение программы прекращается.
8
Уточнение понятия алгоритма
§31
Автомат работает по программе. Во время каждого шага программы автомат выполняет последовательно три действия:
1) изменяет символ в рабочей ячейке на другой (или оставляет без изменений);
2) перемещает каретку влево или вправо (или оставляет на месте);
3) переходит в другое состояние (или остаётся в прежнем состоянии).
Поэтому при составлении программы для каждой пары {символ, состояние) нужно определить три параметра: символ at из выбранного алфавита А, направление перемещения каретки (<— — влево, —> — вправо, точка — нет перемещения) и новое состояние автомата qk. Например, команда 1 <— q2 обозначает «заменить символ на 1, переместить каретку влево на 1 ячейку и перейти в состояние q2».
Пример 1. На ленте записано число в двоичной системе счисления. Каретка находится где-то над числом. Требуется увеличить число на единицу.
Для решения задач такого типа нужно:
• определить алфавит машины Тьюринга А;
• выделить простейшие подзадачи и определить набор возможных состояний Q; задать начальное состояние qr и конечное состояние д0 (в котором машина останавливается);
• составить программу, т. е. для каждой пары (az, qk) определить команду, которую должен выполнить автомат.
Как мы уже выяснили, алфавит машины Тьюринга, работающей с двоичными числами, включает символы 0, 1 и пробел: А = {0, 1, □}. Определим возможные состояния (разобьём задачу на элементарные подзадачи):
1) qr — автомат ищет правый конец слова (числа) на ленте;
2) q2 — автомат увеличивает число на 1, проходя его слева направо, и останавливается, закончив работу.
Теперь займёмся программой. На первом этапе, когда автомат ищет конец слова, его работа может быть описана так:
1) если в рабочей ячейке записана цифра 0, переместиться вправо;
2) если в рабочей ячейке записана цифра 1, переместиться вправо;
3) если в рабочей ячейке пробел, переместить каретку влево и перейти в состояние q2.
Тогда действия автомата в состоянии qx можно представить в виде таблицы, где в заголовках строк записываются символы алфавита, а в заголовках столбцов — состояния (рис. 5.3).
9
5
Элементы теории алгоритмов
<h
0 0 -> Q1
1 1 -> 91
□ □ <- q2
Рис. 5.3
Заметим, что во всех случаях символ под кареткой не меняется. Кроме того, состояние меняется только в последней ячейке. Поэтому для упрощения записи не будем указывать в таблице то, что остаётся без изменений. Так, на наш взгляд, более кратко и понятно (рис. 5.4).
41
0 —>
1 —>
□ <- 42
Рис. 5.4
Второй этап — увеличение двоичного числа на единицу. Это можно сделать следующим способом (вспомните тему «Системы счисления»):
1) если в рабочей ячейке записана цифра 0, записать в неё 1 и стоп;
2) если в рабочей ячейке записана цифра 1, выполнить перенос в старший разряд — записать в ячейку 0, — и переместиться влево;
3) если в рабочей ячейке пробел, записать в неё 1 и стоп.
Для того чтобы остановить работу машины Тьюринга, нужно перевести её в состояние останова д0. Теперь можно добавить в таблицу столбец, соответствующий состоянию q2 (рис. 5.5).
41 42
0 1 • 4о
1 0«-
□ 42 1 • 4о
Рис. 5.5
10
Уточнение понятия алгоритма
§31
Построенная полная таблица и есть программа для машины Тьюринга. Обратите внимание, что мы разбили исходную задачу на подзадачи, для каждой из них составили программу, а потом их соединили. Две подзадачи связаны через ячейку (□, дх), в которой состояние автомата изменяется на q2.
В данном простейшем случае в каждом из двух алгоритмов было использовано только одно состояние, но это не обязательно — можно таким же способом соединять и более сложные алгоритмы. Если алгоритмы А и Б можно запрограммировать на машине Тьюринга, то и любую их комбинацию тоже можно запрограммировать.
Тьюринг предположил, что:
Любой алгоритм (в интуитивном смысле этого слова) может быть представлен как программа для машины Тьюринга.
о
Это утверждение в теории алгоритмов известно как тезис Чёрча-Тьюринга.
Машина Тьюринга может быть строго задана с точки зрения математики. Алфавит А и набор возможных состояний Q могут быть записаны в виде множеств, а программа — в виде пятёрок вида (az, qk, dik, qm), задающих команды вида «если машина находится в состоянии qk и в рабочей ячейке записан символ az, то записать в рабочую ячейку символ а;, сместиться в направлении dik и перейти в состояние qm». Например, приведённая выше программа увеличения двоичного числа на 1, записанная в виде таких пятёрок, выглядит так:
(О, qlt 0, gj, (1, qlt 1, qj, (□, □, q2),
(0, q2, 1, q0), (1, q2, 0, q2), (□, q2, 1, q0).
Эта машина — математический объект, и данное на её основе определение алгоритма может использоваться для доказательств. Едва ли можно применить машину Тьюринга для решения практических задач, но эта простая модель алгоритма очень удобна для проведения теоретических исследований. В отличие от «интуитивного» определения алгоритма новое определение не содержит таких неопределённых понятий, как инструкция», «исполнитель», «решение задачи». Таким образом, формальное определение слова «алгоритм» (по Тьюрингу) выглядит так:
Алгоритм — это программа для машины Тьюринга.
о
11
5
Элементы теории алгоритмов
Машина Поста
Э. Л. Пост
(1897-1954)
Практически одновременно с Тьюрингом (в том же 1936 году) и независимо от него американский математик Эмиль Леон Пост предложил ещё более простую систему обработки данных, на основе которой позднее была построена так называемая машина Поста.
Лента в машине Поста (так же, как и в машине Тьюринга) бесконечна и разбита на ячейки. Каждая ячейка может содержать метку (быть отмечена) или не содержать её (пустая ячейка) (рис. 5.6).
Бесконечная лента
Ка етка
Рис. 5.6
Таким образом, Пост сократил алфавит всего до двух цифр. Это допустимо, потому что любые данные можно перекодировать в двоичный код, сопоставив каждой букве исходного алфавита уникальную последовательность нулей и единиц.
Кроме того, алгоритм работы машины Поста задаётся не в виде таблицы, а как программа, состоящая из отдельных команд. Система команд машины Поста содержит только 6 команд:
<— — переместить каретку на 1 ячейку влево;
-> — переместить каретку на 1 ячейку вправо;
О — стереть метку в рабочей ячейке (записать 0);
1 — поставить метку в рабочей ячейке (записать 1);
? п0, пг — если в рабочей ячейке нет метки, перейти к строке п0, иначе перейти к строке пх;
стоп — остановить машину.
Попытка стереть метку там, где её нет, или поставить метку повторно считается ошибкой, и машина аварийно останавливается.
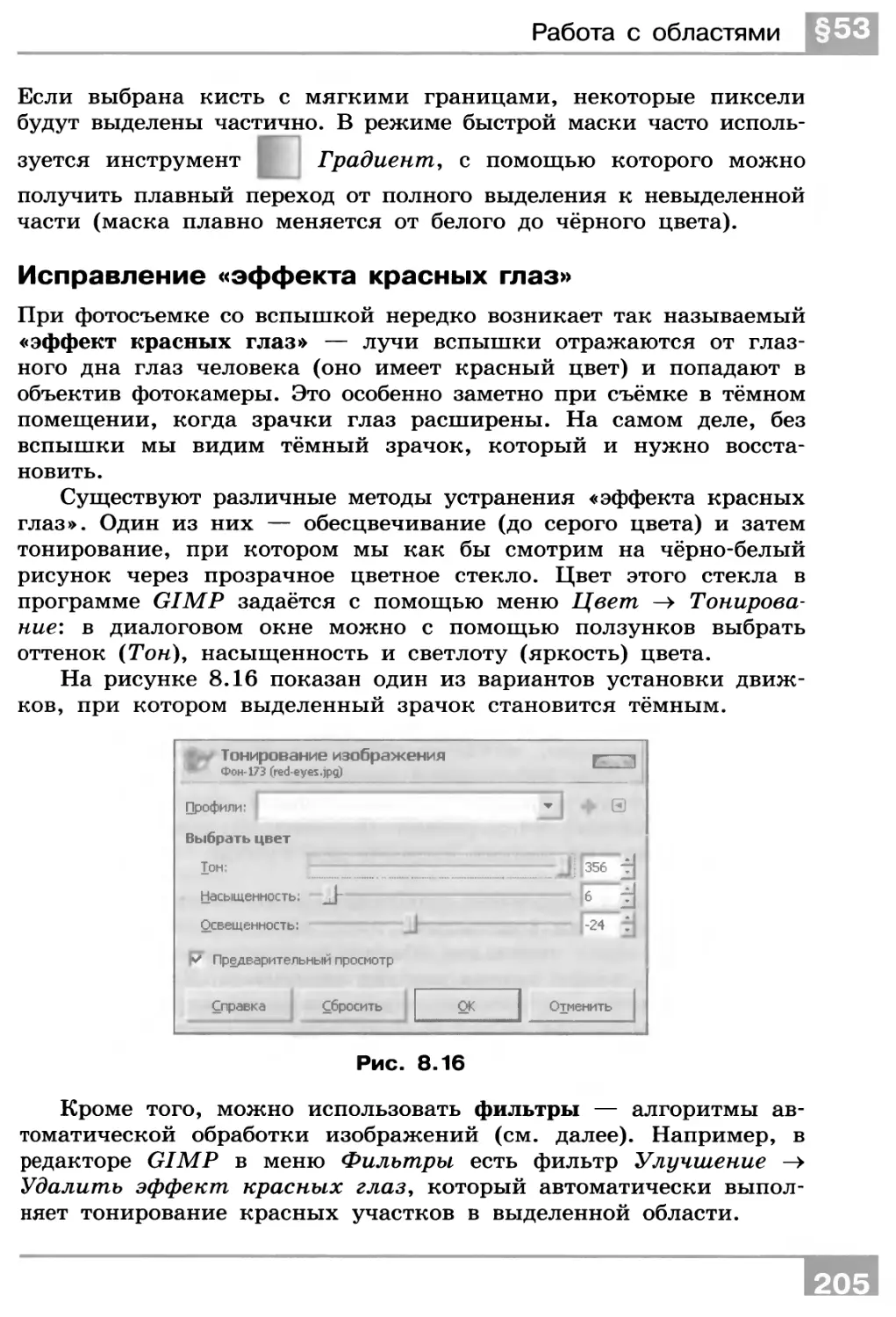
Все строки в программе нумеруются по порядку, это необходимо для работы команды ветвления (? п0, пх). С помощью этой команды можно также строить циклы как с предусловием, так
12
Уточнение понятия алгоритма
§31
и с постусловием. Например, следующая программа перемещает каретку влево до первой отмеченной ячейки:
1. <-
2. ? 1, 3
3. стоп
Если после выполнения команды 0 или 1 требуется
перейти не на следующую строку, а на какую-то другую, номер этой строки можно записать в конце команды. Например, команда
<г- 3
означает «переместить каретку влево и перейти на строку 3».
При работе с машиной Поста числа обычно записывают в унарной (единичной) системе счисления, в виде непрерывной цепочки меток нужной длины (вспомните счётные палочки в младшей школе). Например, на ленте, показанной на рис. 5.6, записано число 4.
Пост предположил, что любой алгоритм может быть записан как программа для предложенного им вычислителя. В теории алгоритмов доказано, что машины Поста и Тьюринга одинаковы по своим возможностям. Это значит, что круг задач, который они решают, тоже одинаков.
Нормальные алгорифмы Маркова
Советский математик А. А. Марков (младший), который в середине XX века изучал разрешимость некоторых задач алгебры, предложил новую модель вычислений, которую он назвал нормальными алгорифмами.
Нормальные алгорифмы Маркова (НАМ) — это строгая математическая форма записи алгоритмов обработки символьных строк, которую можно использовать для доказательства разрешимости или неразрешимости различных задач. Марков предположил, что любой алгоритм можно записать как НАМ. В отличие от машин Тьюринга и Поста НАМ — это «чистый» алгоритм, который не связан ни с каким «аппаратным обеспечением» (лентой, кареткой и т
А. А. Марков (младший) (1903-1979) п.).
НАМ преобразует одно слово (цепочку символов некоторого
алфавита) в другое и задаётся алфавитом и системой подстановок. Заметьте, что в жизни мы нередко применяем такие замены.
13
5
Элементы теории алгоритмов
Например, при умножении в столбик мы не вычисляем каждый раз произведение 7 х 8, а просто помним, что оно равно 56.
Пусть алфавит НАМ — это русские буквы, и задана система подстановок:
а —> н
ух ло м —> с
Применим эту систему подстановок к начальному слову «муха». Подстановки нужно просматривать по порядку, начиная с первой. Первая подстановка означает «если в слове есть буквы "а", заменить первую букву "а” на букву "н"». В слове «муха» есть буква «а», поэтому заменяем её на «н». Получается «мухн».
Начинаем просмотр подстановок сначала. Букв «а» больше нет, поэтому переходим ко второй подстановке. Сочетание «ух» есть в слове «мухн», поэтому вторая подстановка срабатывает, и мы заменяем «ух» на «ло»: получается «млон».
Теперь ни первая, ни вторая подстановки не применимы, а использование третьей даёт в результате слово «слон». Больше ни одну подстановку сделать нельзя, и НАМ заканчивает работу. Таким образом, приведённая система подстановок преобразует слово «муха» в слово «слон».
При поиске образца рабочая цепочка символов просматривается с начала. Если в строке слово-образец встречается несколько раз, то за один шаг заменяется только первое из них. Так как на следующем шаге просмотр опять начинается с начала цепочки, после первой выполненной замены может «сработать» совсем другая подстановка.
В записи подстановок слово-образец может быть пустым, в этом случае слово-замена приписывается в начало рабочей строки:
-> О
Такая подстановка всегда должна быть последней в списке, иначе программа зациклится: в начало слова будут постоянно дописываться всё новые и новые нули.
Если после слова-замены стоит точка, то после выполнения такой подстановки работа программы заканчивается. Например, если применить НАМ
а -> о.
к слову «карова», то в результате получим «корова», потому что после первого же действия работа программы закончится, и последняя буква не будет заменена.
14
Уточнение понятия алгоритма
§31
Пример 2. Построим НАМ для следующей задачи: удалить из строки, состоящей из букв «а» и «6», первый символ. Например, строка «abba» должна быть преобразована в «66а». Казалось бы, здесь нужно использовать систему подстановок а . b -+ .
Однако такой НАМ будет неправильно работать для слов, начинающихся с буквы «6», например для слова «66а», в котором будет удалена последняя буква, потому что первая подстановка выполнится раньше, чем вторая. Перестановка двух строк также не даёт решения — теперь алгоритм неправильно работает для слов, начинающихся с буквы «а». Чтобы решить эту задачу, в алфавит НАМ добавляют ещё один специальный символ, например символ *. Этим символом помечают начало слова, используя подстановку
— > *
Полный алгоритм выглядит так:
* а -> .
*_Ь -> . *
Сначала срабатывает третья подстановка (ставим * в начало строки), затем, в зависимости от первой буквы исходного слова, работает первая или вторая подстановка, и алгоритм заканчивает работу.
Дополнительный символ похож на маркер в текстовом редакторе — он отмечает место в тексте, с которым потом будут выполняться какие-то действия.
Как показано в теории алгоритмов, любой алгоритм для машин Тьюринга и Поста можно записать как НАМ, и наоборот. Поэтому все три рассмотренных подхода к строгому определению понятия «алгоритм» эквивалентны (равносильны).
Выводы
• Интуитивное понятие алгоритма, которое мы использовали ранее, непригодно для математического доказательства неразрешимости задач.
• Про любой алгоритм можно сказать следующее:
— алгоритм получает на вход дискретный объект (например, слово);
15
Элементы теории алгоритмов
— алгоритм обрабатывает входной объект по шагам (дискретно), строя на каждом шаге промежуточные дискретные объекты; этот процесс может закончиться или не закончиться;
— если выполнение алгоритма заканчивается, его результат — это объект, построенный на последнем шаге;
— если выполнение алгоритма не заканчивается (алгоритм зацикливается) или заканчивается аварийно, то результат его работы при данном входе не определён.
• Входные и выходные данные любого алгоритма можно закодировать в виде последовательностей символов некоторого алфавита (и даже двоичного алфавита).
• Универсальный исполнитель — это исполнитель, который может моделировать работу любого другого исполнителя. Это значит, что для любого алгоритма, написанного для любого исполнителя, существует эквивалентный алгоритм для универсального исполнителя.
• Алгоритм — это программа для универсального исполнителя.
• Все универсальные исполнители эквивалентны между собой.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Зачем понадобилось уточнять понятие «алгоритм»?
2. Какие задачи рассматриваются в теории алгоритмов?
3. Почему можно ограничиться алгоритмами обработки символьных строк? Можно ли рассматривать только алгоритмы для преобразования двоичных кодов?
4. Как связаны понятия «алгоритм» и «исполнитель»?
5. В каком случае говорят, что два алгоритма эквивалентны?
6. Сравните интуитивное и строгое понятия алгоритма.
7. Что такое состояние машины Тьюринга?
8. Сопоставьте устройство машины Тьюринга с устройством компьютера. Какие устройства машины Тьюринга выполняют те же функции, что и аналогичные устройства компьютера?
9. В чём особенность состояний q0 и qr машины Тьюринга?
10. Как можно построить программу для машины Тьюринга, которая последовательно выполняет операции А и Б, если уже есть две программы, которые выполняют две эти операции по отдельности?
11. Сравните машины Тьюринга и Поста.
12. Зачем нумеруются строки в программе для машины Поста?
16
Алгоритмически неразрешимые задачи
§32
13. Что такое нормальный алгорифм Маркова?
14. Зачем используют специальные символы в НАМ?
15. Что означает эквивалентность различных универсальных исполнителей?
Подготовьте сообщение
« История слова ” алгоритм ” »
Проекты
а) Машина Поста
б) Моделирование НАМ
§32
Алгоритмически неразрешимые задачи
Ключевые слова:
• вычислимая функция
• алгоритмически неразрешимая задача
Вычислимые и невычислимые функции
Мы уже говорили, что любой алгоритм определяет некоторую функцию, которая для каждого допустимого входного слова, к которому применим алгоритм, однозначно задаёт результат — выходное слово. Такие функции называются вычислимыми.
Вычислимая функция — это функция, для вычисления которой существует алгоритм.
о
Любая вычислимая функция может задаваться разными алгоритмами (разными программами для выбранного универсального исполнителя). Например, следующие два нормальных алгорифма Маркова решают одну и ту же задачу — заменяют во входном двоичном слове все буквы «а» на нули и все буквы «б» на единицы:
а -> О
б -> 1
б -> 1 а -> О
17
5
Элементы теории алгоритмов
Кп) =
Любая вычислимая функция может быть вычислена с помощью любого универсального исполнителя: машин Тьюринга и Поста, нормальных алгорифмов Маркова и др.
Рассмотрим, например, такую функцию, определённую для всех натуральных чисел:
1, если п — чётное;
О, если п — нечётное.
Попробуем составить программу для машины Тьюринга, которая вычисляет эту функцию. Будем считать, что число записано в единичной системе счисления (в виде цепочки единиц1)) и каретка в начальный момент стоит над самой левой единицей. Оказывается, такая программа действительно существует (рис. 5.7).
91 «2 <7з «4
1 q2 91 □ <-
□ ^<1з <-94 9о
Рис. 5.7
Как принято, в начальный момент машина находится в состоянии qv Затем она движется вправо вдоль числа, поочерёдно переходя из состояния (пройдено чётное число единиц) в состояние q2 (пройдено нечётное число единиц) и обратно. Таким образом, если встречен пробел и машина находится в состоянии д2> то число нечётное и нужно просто стереть все единицы (состояние д4). Если машина закончила просмотр в состоянии то число чётное; при этом нужно оставить одну единицу (состояние q3) и перейти в состояние q4 (стереть все остальные единицы). Обратите внимание, что ячейка (□, q3) в таблице пустая — это невозможное состояние (покажите это самостоятельно).
Таким образом, рассмотренная функция вычислима, т. е. её можно вычислить с помощью машины Тьюринга, а значит и с помощью любого универсального исполнителя. Например, нормальный алгоритм Маркова для алфавита А = {1} выглядит так:
11 —> «»
1 .
1.
В первой подстановке две соседние единицы удаляются (слово-замена здесь пустое, для ясности оно взято в кавычки, которы-
Пустая лента соответствует числу 0.
18
Алгоритмически неразрешимые задачи
§32
ми можно ограничивать слова в НАМ). Это происходит до тех пор, пока не будут удалены все пары, поскольку эта подстановка стоит первой. Если остаётся одна единица, она удаляется с помощью второй подстановки, и работа программы заканчивается. Если все единицы удалены (число чётное), то с помощью третьей подстановки мы ставим одну единицу и останавливаем автомат.
Существуют и невычислимые функции. Рассмотрим простой пример, предложенный В. А. Успенским в книге «Машина Поста». Известно, что математическая постоянная л — иррациональное число, его десятичная запись бесконечна и непериодична. Введём функцию h(n), которая для любого натурального числа п равна 1, если в десятичной записи числа л есть п стоящих подряд девяток, окружённых другими цифрами, и равна нулю, если такой цепочки девяток нет. Как вычислить значение этой функции при некотором заданном и? Конечно, можно вычислять друг за другом десятичные знаки числа л (такие алгоритмы математикам известны!) и проверять, не нашлась ли в полученной последовательности цифр цепочка из и девяток. С помощью такого «наивного» алгоритма можно найти такие значения и, при которых й(а) = 1: обнаружив требуемую цепочку, алгоритм закончит работу. Например, анализ первых 800 знаков показывает, что Л(п) = 1 при п = 0, 1, 2, 6. Но если для какого-то и функция h(n) равна нулю, то «наивный» алгоритм никогда не остановится. Более того, для этой функции вообще не существует алгоритма, который при любом и останавливается и выдаёт значение h(n) в качестве результата. Поэтому такая функция невычислима.
Когда задача алгоритмически неразрешима?
Как вы знаете, невозможно создать вечный двигатель, потому что это противоречит универсальным физическим законам сохранения. Точно так же в математике и информатике существуют задачи, для которых общее решение не только неизвестно сейчас, но и вообще отсутствует. Поэтому искать его бесполезно.
Поскольку алгоритм работает только с дискретными объектами, любая алгоритмическая задача — это функция, заданная на множестве дискретных объектов (входных слов). Пусть, например, требуется по шахматной позиции определить, кто выигрывает при правильной игре — белые, чёрные или будет ничья. Построим функцию, соответствующую этому алгоритму. Для этого выберем способ кодирования, при котором каждая позиция может быть закодирована словом (символьной строкой) v в подходящем алфавите. Тогда приведённой задаче может соответствовать функция f(y), заданная на множестве таких слов:
19
5
Элементы теории алгоритмов
’Б’, если v — код позиции, в которой выигрывают белые;
’Ч’, если v — код позиции, в которой выигрывают чёрные;
’О’, если v — код позиции, в которой будет ничья;
’?’, если v — ошибочный код позиции.
Если функция, соответствующая задаче, вычислима, то задача называется алгоритмически разрешимой — для её вычисления можно построить алгоритм. Если определённая в задаче функция невычислима, то алгоритма для её решения не существует.
Алгоритмически неразрешимая задача — это задача, соответствующая невычислимой функции.
В 1900 году на Международном математическом конгрессе в Париже известный математик Давид Гильберт сформулировал 23 нерешённые математических проблемы1*. В знаменитой «десятой проблеме Гильберта» требуется найти метод, который позволяет определить, имеет ли заданное алгебраическое уравнение с целыми коэффициентами решение в целых числах. Например, уравнение
х2 +у3 +2 = 0
имеет два целочисленных решения — (5; -3) и (-5; -3). Сложность состояла в том, что требовалось найти единый метод (алгоритм), позволяющий решить задачу для любого такого уравнения со многими неизвестными.
В начале XX века была уверенность, что такой алгоритм есть, и поэтому его упорно искали. Однако в 1970 году советскому математику Юрию Матиясевичу удалось доказать, что общего алгоритма решения этой задачи не существует.
Немецкий математик Г. В. Лейбниц в XVII веке безуспешно пытался найти метод проверки правильности любых математических утверждений. Как вы знаете, почти все математические теории основаны на ис-
Ю. В. Матиясевич пользовании аксиом (положений, принимае-
(род. в 1947)
мых без доказательства), из которых выво-
дятся все остальные утверждения (теоремы). Задача заключалась в том, чтобы разработать алгоритм, позволяющий установить,
1* Сейчас большинство из них решено полностью или частично.
Алгоритмически неразрешимые задачи
§32
можно ли вывести формулу Б из формулы А х
в рамках заданной системы аксиом («пробле-
ма распознавания выводимости»). В 1936 году американский математик Алонзо Чёрч доказал, что эта задача в общем виде алгоритмически неразрешима, поэтому нельзя сформулировать универсальный алгоритм, пригодный для доказательства любой теоремы1).
Таким образом, уточнённые определения алгоритма, основанные на понятии универсальных исполнителей, сыграли в науке очень д. Чёрч важную роль — позволили получить отрица- (1903-1995) тельные результаты, т. е. доказать, что алго-
ритмов решения некоторых задач в общем виде в принципе не существует.
Для того чтобы доказать неразрешимость какой-то новой задачи, пытаются свести её к уже известным алгоритмически неразрешимым задачам. Если это удаётся, то и новая задача алгоритмически неразрешима1 2).
Существуют также задачи, про которые неизвестно, алгоритмически разрешимы они или нет — решение не найдено, но алгоритмическая неразрешимость не доказана.
Алгоритмически неразрешимые задачи встречаются не только в математике, но и в информатике, например при разработке программ. Оказывается, невозможно написать программу для машины Тьюринга (алгоритм), которая по тексту любой программы Р и её входным данным X определяет, завершается ли программа Р при входе X за конечное число шагов или зацикливается. Это так называемая проблема останова. Её неразрешимость означает, в частности, что нельзя полностью автоматизировать тестирование любых программ, поручив это компьютеру. Однако для некоторых классов алгоритмов проблему останова решить можно. Например, линейная программа, не содержащая ветвлений и циклов, всегда завершится.
Было доказано, что алгоритмически неразрешима проблема эквивалентности: по двум заданным алгоритмам определить, будут ли они выдавать одинаковые результаты для любых допустимых исходных данных. Следовательно, невозможно полностью автоматизировать решение многих важных задач, связанных с разработкой программ, например:
1) Тем не менее отдельные классы теорем компьютер способен доказывать.
2) Допустим, что (1) задача А неразрешима и (2) если мы можем построить алгоритм для решения задачи Б, то с его помощью можно построить алгоритм решения задачи А. Тогда задача Б тоже неразрешима.
21
5
Элементы теории алгоритмов
• по заданному тексту программы определить, что она «делает»;
• определить, правильно ли работает программа при любых допустимых исходных данных;
• найти ошибку в программе, работающей неправильно.
Поэтому при отладке программы большую роль играет интуиция. Помогают (но не решают проблему полностью!) стандартные приёмы, позволяющие найти ошибку:
• сравнение результатов работы программы с результатами ручного счёта;
• эксперименты с программой при различных исходных данных для того, чтобы выявить закономерность появления ошибок;
• временное отключение (комментирование) частей программы и др.
Поскольку многие этапы разработки программного обеспечения в принципе невозможно представить в виде алгоритмов, программирование всегда останется работой человека. Полностью поручить её компьютеру не удастся, хотя решение некоторых конкретных задач всё же можно автоматизировать.
Выводы
• Каждый алгоритм задаёт (вычисляет) функцию, которая преобразует входное слово в результат (выходное слово).
• Алгоритмы называются эквивалентными, если они задают одну и ту же функцию.
• Вычислимая функция — это функция, для вычисления которой существует алгоритм. Любая вычислимая функция может задаваться разными алгоритмами.
• Алгоритмически неразрешимая задача — это задача, соответствующая невычислимой функции.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Что такое вычислимая функция?
2. Приведите пример невычислимой функции.
3. Что такое алгоритмически неразрешимые задачи? Приведите известные вам примеры.
4. Что такое проблема останова? Каковы её следствия?
5. Что такое проблема эквивалентности?
6. Как обычно доказывается алгоритмическая неразрешимость новых задач?
22
Сложность вычислений
§33
§33
Сложность вычислений
Ключевые слова:
• временная сложность
• пространственная сложность • асимптотическая сложность
Что такое сложность вычислений?
Центральная задача теории алгоритмов — выяснить, существует ли алгоритм решения той или иной задачи. Если да, то возникает следующий вопрос: можно ли им воспользоваться на практике, при современном уровне развития вычислительной техники? То есть способен ли компьютер за приемлемое время получить результат? Например, в игре в шахматы возможно лишь конечное количество позиций и, значит, только конечное количество различных партий. Поэтому теоретически можно перебрать все возможные партии и выяснить, кто побеждает при правильной игре — белые или чёрные. Однако количество вариантов настолько велико, что современные компьютеры не могут выполнить такой перебор за приемлемое время.
Что мы хотим от алгоритма? Во-первых, чтобы он работал как можно быстрее. Во-вторых, чтобы объём необходимой памяти был как можно меньше. В-третьих, чтобы алгоритм был как можно более прост и понятен, что позволяет легче отлаживать программу. К сожалению, эти требования противоречивы, и в серьёзных задачах редко удаётся найти алгоритм, который был бы лучше остальных по всем показателям.
Часто говорят о временной сложности алгоритма (быстродействии) и пространственной сложности, которая определяется объёмом необходимой памяти. Поскольку память постоянно дешевеет, а быстродействие компьютеров растёт медленно, мы будем рассматривать главным образом временную сложность — время выполнения программы, работающей по данному алгоритму.
Говоря о сложности алгоритма, нужно уточнить, о каком исполнителе идёт речь, какие элементарные операции мы используем. Как правило, это один из универсальных исполнителей (во многих случаях универсальным исполнителем можно считать компьютер). Временем работы алгоритма называется количество выполненных им элементарных операций Т. Такой подход позволяет оценивать именно качество алгоритма, а не свойства
23
5
Элементы теории алгоритмов
исполнителя (например, быстродействие компьютера, на котором выполняется алгоритм).
Как правило, величина Т будет существенно зависеть от объёма исходных данных: поиск в массиве из 10 элементов завершится гораздо быстрее, чем в массиве из 10 000 элементов. Поэтому сложность алгоритма обычно связывают с размером входных данных п и определяют как функцию Т(п). Например, для алгоритмов обработки массивов в качестве размера п используют длину массива. Функция Т(п) называется временной сложностью алгоритма.
Примеры
Рассмотрим алгоритмы выполнения различных операций с массивом А длины п, который может быть объявлен в программе на алгоритмическом языке как
целтаб А[1:п]
Пример 1. Вычислить сумму первых трёх элементов массива (при п>3).
Решение этой задачи содержит всего один оператор:
Sum := А[1] + А [ 2 ] + А[3]
Этот алгоритм включает две операции сложения и одну операцию записи значения в память, поэтому его сложность Т(п) = 3 не зависит от размера массива вообще.
Пример 2. Вычислить сумму значений всех элементов массива.
В этой задаче уже не обойтись без цикла:
Sum := О
нц для i от 1 до п
Sum := Sum + A[i] кц
Здесь выполняется п операций сложения и п +1 операций записи в память1*, поэтому его сложность Т(п) = 2п + 1 возрастает линейно с увеличением длины массива1 2).
1) Здесь и далее для упрощения выводов мы не учитываем команды, необходимые для организации цикла, потому что при больших п время их выполнения очень мало в сравнении со временем выполнения остальных операторов.
2) Предполагается, что сложение любых двух чисел выполняется одинаковое время.
24
Сложность вычислений
§33
Пример 3. Отсортировать все элементы массива по возрастанию методом выбора.
Напомним, что метод выбора предполагает поиск на каждом шаге минимального из оставшихся неупорядоченных значений (здесь i, j, nMin и с — целочисленные переменные):
нц для i от 1 до п-1
nMin:=i;
нц для j от i+1 до п
если A[i]<A[nMin] то nMin := i все кц если nMin о i то
с:=А[i]; А[i]:=А[nMin]; А[nMin]:=с все кц
Подсчитаем отдельно количество сравнений Тс(п) и количество перестановок Тр(п). Количество сравнений элементов массива не зависит от данных и определяется числом шагов внутреннего цикла:
/ ч / ч z ч п(п-1) 1 9 1
Тс (п) = (п-1) + (п-2) + ... + 2 + 1 = ——- = — и2 ~~п .
Число перестановок зависит от данных. Например, если массив уже отсортирован в нужном порядке, перестановок не будет вообще. В худшем случае на каждом шаге основного цикла происходит перестановка, всего их будет Тр(п) = п-1.
Что такое асимптотическая сложность?
Допустим, что нужно выбрать между несколькими алгоритмами, которые имеют разную сложность. Какой из них лучше (работает быстрее)? Для этого необходимо знать размер массива данных, которые нужно обрабатывать. Сравним, например, три алгоритма, сложность которых
Тх(п) = 10000-п , Т2(п) = 100 п2 и T3(n) = n3 .
Построим эти зависимости в виде графиков (рис. 5.8).
25
5
Элементы теории алгоритмов
При п < 100 получаем Т3 (п) < Т2 (п) < 7\ (и), при п = 100 количество операции для всех трёх алгоритмов совпадает, а при больших п имеем Т3(п)>Т2(п)>Т1(п).
Обычно в теоретической информатике при сравнении алгоритмов используется их асимптотическая сложность, т. е. скорость роста количества операций при больших значениях п. При этом запись О(п) (читается «О большое от п») обозначает, что, начиная с некоторого значения п = п0, количество операций ограничено функцией сп, где с — некоторая константа:
Т(п)<с п для п>п0 .
Такие алгоритмы имеют линейную сложность, т. е. при увеличении размера данных в 10 раз объём вычислений увеличивается тоже примерно в 10 раз.
Пусть, например, Т(п) = 2п-1, как в алгоритме поиска суммы значений элементов массива. Очевидно, что при этом Т(п)<2п для всех п>1, поэтому алгоритм имеет линейную сложность.
Многие известные алгоритмы имеют квадратичную сложность, которая обозначается как О(п1 2) . Это значит, что количество операций ограничено функцией с • п2 :
Т(п) <с п2 для п > п0 .
При этом если размер данных увеличивается в 10 раз, то количество операций (и время выполнения) увеличивается примерно в 100 раз. Пример такого алгоритма — сортировка методом прямого выбора, для которой число сравнений
1 2 1 12
Тс(п) = — п —п< — п длявсехп>0.
26
Сложность вычислений
§33
Алгоритм имеет асимптотическую сложность О(/(п)), если найдётся такая постоянная с, что, начиная с некоторого п = п0 , выполняется условие Т(п) < с • f(n).
о
Это значит, что график функции cf(n) идёт выше, чем график функции Т(п), по крайней мере, при п>п0 (рис. 5.9).
Если количество операций не зависит от размера данных, то говорят, что сложность алгоритма 0(1), т. е. количество операций меньше некоторой постоянной при любых п.
Существует также немало алгоритмов с кубичной сложностью, О(п3). При больших значениях п алгоритм с кубичной сложностью требует большего количества вычислений, чем алгоритм со сложностью О(п2), а тот, в свою очередь, работает дольше, чем алгоритм с линейной сложностью. Заметьте, что при малых значениях п всё может быть наоборот, это зависит от постоянной с для каждого из алгоритмов.
Известны и алгоритмы, для которых количество операций растёт быстрее, чем любой полином, например как О(2П) или О(п!). Как правило, это переборные алгоритмы в задачах оптимизации. Перебор состоит в том, что мы рассматриваем все возможные варианты решений, проверяем каждый из них и выбираем лучший по какому-то критерию (или останавливаемся, когда найдём первый подходящий вариант).
Рассмотрим, например, известную задачу о рюкзаке. Есть п предметов, для каждого из которых известны вес и стоимость.
27
5
Элементы теории алгоритмов
Путешественник хочет взять набор из этих предметов наибольшей стоимости так, чтобы их суммарный вес был не больше, чем вместимость рюкзака. Для каждого из предметов возможно два варианта — он может быть выбран или не выбран. Таким образом, количество вариантов выбора для п предметов равно 2", и асимптотическая сложность переборного алгоритма — О(2Д).
Известная задача о Ханойских башнях (см. учебник для 10 класса) тоже имеет асимптотическую сложность 0(2"). Её рекурсивное решение состоит из трёх этапов:
1) переносим п - 1 дисков со стержня 1 на вспомогательный стержень 2;
2) переносим один диск со стержня 1 на стержень 3;
3) переносим п - 1 дисков со стержня 2 на стержень 3.
Таким образом, количество операций переноса равно
Т(п) = 2 • Т(п - 1) + 1.
При больших значениях п единицей можно пренебречь, так что получаем Т(п) « 2-Т(п - 1). Один диск переносится за одну операцию: Т(1) = 1, поэтому Т(п) = 0(2").
Ещё один пример сложной задачи, которая решается только полным перебором всех вариантов, — задача выполнимости. Дано логическое выражение, которое содержит только имена логических переменных, скобки, а также операции И, ИЛИ и НЕ. Требуется определить, существует ли набор значений логических переменных, при котором заданное выражение истинно. Каждая логическая переменная может принимать два значения — «истина» или «ложь». Поэтому в задаче с п переменными нужно проверить 2" вариантов, асимптотическая сложность алгоритма — 0(2").
Одна из самых известных сложных переборных задач — задача коммивояжёра (бродячего торговца), который должен посетить по одному разу каждый из указанных п городов и вернуться в начальную точку. Для него нужно выбрать оптимальный маршрут, при котором стоимость поездки (или общая длина пути) будет минимальной. За начальную точку маршрута можно принять любой из п городов. Из него коммивояжёр может поехать в любой из п - 1 оставшихся городов, далее — в любой из п - 2 городов, которые он ещё не посещал и т. д., так что общее количество возможных маршрутов равно п • (п - 1) ... • 3 • 2 • 1 = п\ Для каждого из этих маршрутов нужно подсчитать длину — это ещё цикл из п шагов. Поэтому алгоритм полного перебора требует п\-п операций, его асимптотическая сложность — О(п! • п).
28
Сложность вычислений
§33
Алгоритмы поиска
Сравним вычислительную сложность двух наиболее известных алгоритмов поиска.
Пример 4 (линейный поиск). Дан неупорядоченный массив, в котором элементы расположены в произвольном порядке. Найти в нём заданное значение X или сообщить, что его нет.
Решение этой задачи сводится к последовательному просмотру всех элементов массива:
пХ:=0
нц для i от 1 до п если А[i]=Х то nX: =i выход
все кц если пХ>0 то
вывод "А[", пХ, х
иначе
вывод "Элемент не найден" все
В этом алгоритме число сравнений (в худшем случае) равно Т(п) = п, поэтому он имеет линейную сложность.
Пример 5 (двоичный поиск). Дан массив, в котором элементы упорядочены по возрастанию. Найти в нём заданное значение X или сообщить, что его нет.
По сравнению с предыдущей задачей, элементы массива отсортированы, и это ускоряет решение, потому что можно применить метод двоичного поиска (дихотомии):
L:=l; R:=n+1
нц пока L<R-1 c:=div(L + R, 2) | или с:=L+div(R-L, 2) если Х<А[с] то
R:=c иначе
L: —с все кц если A[L]=X то вывод "А[", L, "]=", X
29
5
Элементы теории алгоритмов
иначе
вывод "Элемент не найден" все
Попробуем определить, сколько раз выполняется основной цикл при двоичном поиске. Сначала диапазон поиска — все п элементов массива. На каждом шаге этот диапазон делится на 2, процесс завершается, когда левая и правая границы диапазона совпадут.
Предположим, что число элементов — это целая степень двойки, т. е. п = 2т . Тогда за т шагов ширина диапазона сужается до 1, а на следующем шаге его границы совпадут и цикл закончится. Таким образом, количество шагов цикла равно тп + 1. Из равенства п = 2т получаем т = log2 п > так что
T(n) = log2 п + 1 •
Например, при п = 216 линейный поиск потребует в худшем случае 216 =65536 сравнений, а двоичный — всего 16 + 1 = 17 сравнений.
Как мы показали, алгоритм двоичного поиска имеет асимптотическую сложность O(logn). Основание логарифма обычно не указывают, потому что выражения loga п и logd п различаются на постоянный множитель (который можно включить в постоянную с):
1 1 1
logan = ----logfcn.
log6a
Можно ли сказать, что алгоритм двоичного поиска лучше алгоритма линейного поиска? Нет! Ведь алгоритм линейного поиска применим к любым массивам данных, а алгоритм двоичного поиска — только к упорядоченным (отсортированным). А если мы сначала отсортируем массив, а потом применим к нему двоичный поиск, то общее время работы будет больше, чем при линейном поиске.
Ситуация меняется, если нам нужно многократно выполнять операцию поиска для одних и тех же данных (так, как правило, бывает при работе с базами данных). Тогда имеет смысл заранее отсортировать массив (применить предварительную обработку данных), а затем, используя двоичный поиск, экономить время при каждом новом поисковом запросе.
30
Сложность вычислений
§33
Алгоритмы сортировки
Ранее мы проанализировали один из простых методов сортировки массивов — метод выбора, и выяснили, что его асимптотическая сложность О(п2). Повторим анализ для метода пузырька, который также изучался в 10 классе:
нц для i от 1 до п-1
нц для j от п-1 до i шаг -1
если А[j]>А[j +1] то
с:=А[j]; А[j]:=А[j+1]; A [j+1]:=с; все кц кц
На первом шаге основного цикла выполняется п-1 шагов внутреннего цикла, т. е. п-1 сравнений. Далее количество сравнений уменьшается до 1, так что общее количество сравнений равно
/ ч / ч / х п(п-1) 191
Тс(п) = (п-1) + (п-2) + ... + 2 + 1 = - = -п --п,
так же как и у алгоритма выбора. В то же время в худшем случае при каждом сравнении выполняется перестановка, что требует
1 п IПI — о---— — П П
р 2 2 2
операций присваивания. Таким образом, этот алгоритм имеет асимптотическую сложность О(п2) как по числу сравнений, так и по числу присваиваний.
Существуют ли более эффективные сортировки, имеющие, например, линейную сложность? Да, для некоторых особых случаев существуют. Например, если известно, что все значения исходного массива находятся в диапазоне от 1 до некоторого значения МАХ, можно использовать сортировку подсчётом. Для этого выделяется дополнительный массив счётчиков
цел С[1:МАХ]
который предварительно обнуляется:
нц для i от 1 до МАХ
С[i]:=0
кц
31
5
Элементы теории алгоритмов
Затем в цикле проходим весь массив с данными, и для каждого элемента A[i] увеличиваем счётчик C[A[i]]. Например, если A[i] =20, счётчик С [20] увеличивается на 1. После окончания цикла в каждом счётчике С [ i ] находится количество значений исходного массива, равных i.
нц для i от 1 до п
С [A [i]]:=C[A[i]] + 1
КЦ
Теперь остаётся расставить их в массиве А в нужном количестве. Например, если С [20] =5, то в массив А записывается последовательно 5 значений, равных 20:
к:=1
нц для i от 1 до МАХ
нц для j от 1 до С[i]
А[к]:=i к:=к+1 кц
КЦ
Попробуем подсчитать количество операций для этого алгоритма. Заполнение массива С нулями требует МАХ присваиваний. Цикл подсчёта элементов содержит п сложений и присваиваний, т. е. его сложность линейная — О(п). Наконец, последний вложенный цикл выполняет также п сложений и присваиваний (по числу элементов массива А), поэтому алгоритм в целом имеет линейную сложность по п.
Однако нужно учитывать, что принципиальное ускорение алгоритма в сравнении с предыдущими получено за счёт того, что: • все значения — целые числа в ограниченном диапазоне;
• есть возможность использовать дополнительный массив размером МАХ, который может значительно превышать размер исходного массива.
Здесь проявляется компромисс «скорость — память», который присутствует во многих задачах: ускорение алгоритма возможно за счёт использования дополнительной памяти и наоборот, экономия памяти приводит к замедлению работы алгоритма.
Доказано, что в общем случае вычислительная сложность сортировки, основанной только на использовании операций «сравнить» и «переставить», не может быть меньше, чем О(п log и).
32
Сложность вычислений
§33
Такую сложность имеют сортировки, включающие log п этапов, каждый из которых имеет сложность О(п). К ним относятся известная вам из курса 10 класса сортировка слиянием (англ. merge sort) и пирамидальная сортировка (англ, heap sort), которые применяются при работе с большими наборами данных.
Быстрая сортировка (англ. Quick sort), которая также изучалась в 10 классе, в среднем тоже имеет сложность O(nlogn), однако в худшем случае (когда на каждом шаге массив делится на две части, одна из которых состоит из одного элемента) требуется О(п2) обменов.
Выводы
• Говорят, что алгоритм имеет асимптотическую сложность O(f(n)), если найдётся такая постоянная с , что, начиная с некоторого п = п0 , выполняется условие Т(п) < с • f (п).
• Задачи оптимизации, которые решаются только полным перебором вариантов, могут иметь, например, асимптотическую сложность О(2П) или О(п!). Эти функции при больших п возрастают быстрее, чем многочлен любой степени.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Какие критерии используются для оценки качества алгоритмов?
2. Почему скорость работы алгоритма оценивается не временем выполнения, а количеством элементарных операций?
3. Как учитывается размер данных при оценке скорости алгоритма?
4. Что означают записи 0(1), О(п), О(п2) и О(2П)?
5. В каких случаях алгоритм, имеющий асимптотическую сложность О(п2), может работать быстрее, чем алгоритм с асимптотической сложностью О(п) ?
Проект
Экспериментальное исследование сложности алгоритмов сортировки
33
5
Элементы теории алгоритмов
§34
Доказательство правильности программ
Ключевые слова:
• тестирование
• доказательное
программирование
• инвариант цикла
• спецификация
• корректная программа
• надёжная программа
• верификация программы
Как доказать правильность программы?
Как правило, программист разрабатывает программу на заказ, и от него требуется не только написать код, но и убедиться, что он работает правильно, т. е. в соответствии с требованиями заказчика.
Очевидно, что если программа выдаёт неверный результат хотя бы для одного варианта входных данных, можно сразу сказать, что она некорректна, т. е. содержит ошибки.
Сложнее доказать правильность программы — убедиться, что она выдаёт верные результаты при любых допустимых входных ж* данных. Программисты-практики для решения этой задачи используют тестирование: проверяют работу программы с помощью набора тестовых данных, для которых известен правильный результат. Если полученный результат не совпадает с заданным, выполняется отладка программы, т. е. поиск и исправление ошибок.
Э В Дейкстра Однако, как писал замечательный нидер-(1930-2002) ландский учёный, один из создателей современного программирования Эдсгер Дейкстра, «отладка может показать лишь наличие ошибок и никогда — их отсутствие». В результате можно гарантировать верную работу программы только при тех данных, которые использовались в контрольных тестах. Кроме того, неясно, как определить, что все ошибки выявлены и нужно завершить отладку.
34
Доказательство правильности программ
§34
Пример 1. Рассмотрим следующую программу для выбора максимального из трёх значений, записанных в переменных а, Ь и с:
если а>Ь то М:=а иначе М:=Ь все если Ь>с то М:=Ь иначе М:=с все
Проверяя её на тестах
(а, Ь, с) = (1, 2, 3), (1, 3, 2), (2, 1, 3) и (2, 3, 1)
мы во всех этих случаях получаем в переменной М верный ответ 3. Однако это не означает, что программа правильная, так как существует контрпример (3, 2, 1): для этого набора входных данных в переменной М в результате оказывается число 2.
Чтобы быть уверенным в том, что программа работает правильно при любых допустимых исходных данных, применяют методы доказательного программирования: для каждого блока программы составляют требования к входным и выходным данным, и строго доказывают, что программа всегда работает верно.
К сожалению, доказывать правильность программ не так просто, и в таких доказательствах тоже возможны ошибки. Однако при этом автор должен глубоко разобраться в алгоритме и его «подводных камнях», и часто при этом обнаруживаются ошибки, которые могли бы проявиться уже после выпуска программы в свет.
На практике редко доказывают правильность всей программы в целом. В то же время очень полезно доказывать правильность отдельных блоков (циклов, процедур и функций) для уменьшения количества «необъяснимых» ошибок и сокращения времени отладки.
Покажем метод доказательства правильности программы на простом примере.
Пример 2. Доказать, что после выполнения следующей программы значения переменных а и b меняются местами:
b:=a+b | 1
а:=Ь—а | 2
b:=Ь—a | 3
Предполагается, что сумма исходных чисел не приводит к переполнению разрядной сетки. Для удобства операторы программы пронумерованы.
35
Элементы теории алгоритмов
Обозначим начальные значения переменных а и b через а0 и &0. После выполнения оператора 1 в переменной b будет записано значение а0 + &0. Оператор 2 записывает в переменную а значение b - а = а0 + &0 - а0 = &0. В результате выполнения оператора 3 получаем новое значение переменной Ь, равное b - а = а0 + &0 - &0 = а0. Таким образом, в результате выполнения программы переменные а и b будут равны &0 и а0 соответственно, что и требовалось доказать. Поэтому приведённая программа — правильная.
Пример 3. Попробуем доказать или опровергнуть правильность уже встречавшейся ранее программы для выбора максимального из трёх значений, записанных в переменных а, b и с:
если а>Ь то М:=а иначе М:=Ь все | 1 если Ь>с то М:=Ь иначе М:=с все | 2
Анализируя строку 2, выясняем, что в ней значение переменной М всегда будет изменено, т. е. результат работы первой строки программы стирается, и
(Ь, если Ь>с;
м = <
[с, если с>Ь.
Конечно, эта величина не совпадает с определением максимального значения из а, b и с. Таким образом, программа неправильная: она выдаёт неверное значение, если максимальное из трёх чисел хранилось в переменной а. Контрпример мы уже приводили: (3, 2, 1).
Алгоритм Евклида
Теперь докажем, что один из древнейших известных алгоритмов — алгоритм Евклида действительно вычисляет наибольший общий делитель (НОД) двух натуральных чисел (мы рассматривали его в 10 класе).
Алгоритм Евклида. Пусть заданы два натуральных числа тп и п, причём т>п. Для вычисления НОД(тп, п) следует многократно заменять большее число остатком от деления большего на меньшее до тех пор, пока меньшее число не станет равным нулю. Тогда оставшееся ненулевое число и есть НОД(тп, п).
Программа, основанная на алгоритме Евклида, может выглядеть, например, так (здесь а, b и г — целочисленные переменные):
36
Доказательство правильности программ
§34
a:=m; Ь:=п | 1 НОД (а, Ь) = НОД(т, п)
нц пока Ь<>0 1 2
г: =1110(1(3, Ь) 1 з
a:=b; Ь:=г | 4 НОД (а, Ь) = НОД (т, п)
кц 1 5
вывод а | б НОД(а, Ь) = НОД(т, п), Ь = 0
Докажем, что в результате этого алгоритма в переменной а находится НОД(ш, п).
В строке 1 исходные значения копируются из переменных m и п соответственно в переменные а и Ь. Очевидно, что при этом выполнено условие НОД(а, Ь) = НОД(ш, п).
На каждом шаге цикла (в строках 3-4) вычисляется остаток г от деления а на Ь, и пара (а, Ь) заменяется на пару (Ь, г). Какими свойствами обладают полученные значения b и г?
Поскольку г — это остаток от деления а на Ь, до выполнения строк 3-4 было справедливо равенство а = Ьр + г, где р — некоторое целое число. Тогда если а и b имеют общий делитель, то такой же делитель имеет и г. Следовательно, НОД(Ь, г) = НОД(а, Ь) = = НОД(ш, п). Это значит, что условие НОД(а, Ь) = НОД(ш, п) по-прежнему выполняется после каждого шага цикла.
Поскольку остаток г с каждым шагом строго уменьшается, в конце концов он станет равным нулю и запишется в переменную b при выполнении строки 4. Цикл сразу же закончится, поскольку нарушится условие его выполнения. После завершения работы цикла условие НОД(а, Ь) = НОД(ш, п) по-прежнему выполняется, но, кроме того, b = 0. Отсюда следует, что а = НОД(ш, п).
Инвариант цикла
Таким образом, для алгоритма Евклида существует условие НОД(а, Ь) = НОД(ш, п), которое остаётся справедливым на протяжении всего выполнения алгоритма: перед началом цикла, после каждого шага цикла и после окончания работы цикла. Такое условие называется инвариантом цикла (англ, invariant — неизменный).
Инвариант цикла — это соотношение между значениями переменных, которое остается справедливым после завершения любого шага цикла.
Как мы увидели, выделение инварианта каждого цикла в явном виде — первый шаг к доказательству правильности всей программы, позволяющий избежать многих возможных ошибок
37
5
Элементы теории алгоритмов
А. п. Ершов (1931-1988)
на начальной стадии. Как писал академик А. П. Ершов1*, один из первых теоретиков программирования в СССР, «программиста бьют по рукам, если он посмеет написать оператор цикла, не найдя перед этим его инварианта».
Рассмотрим несколько примеров.
Пример 4. Двое играют в следующую игру: перед ними лежат в ряд 7V + 1 камней, сначала N белых и в конце цепочки — один чёрный. За один ход каждый может взять от 1 до 3 камней. Проигрывает тот, кто берет чёр
ный («несчастливый») камень.
Начнём анализ с простейших случаев. Если N = 0, то первый игрок проиграл, он может взять только чёрный камень. Если N = 1, 2, 3, то, наоборот, при правильной игре проигрывает второй игрок, потому что первый может забрать все камни, кроме чёрного. Вариант 7V = 4 снова приводит к проигрышу первого,
потому что забрать все белые камни он не может, а после его хода второй оставит только чёрный камень. Также проигрышными будут позиции при N = 8, 12, 16, ..., т. е. при любых значениях N, которые делятся на 4.
Таким образом, для своего выигрыша игрок должен каждым своим ходом восстанавливать инвариант: число оставшихся белых камней должно быть кратно 4. Если инвариант выполнен в начальной позиции, положение проигрышное и первый игрок может надеяться только на ошибку соперника.
Пример 5. Пусть задан массив А длины п. Найдём инвариант цикла в программе суммирования элементов массива:
Sum:=0
нц для i от 1 до п Sum:=Sum+A[i]
кц
Здесь на каждом шаге к переменной Sum добавляется элемент массива А [ i ], так что при любом i после окончания очередного шага цикла в Sum хранится сумма всех элементов массива с номерами от 1 до i. Это и есть инвариант цикла. Поэтому сразу можно сделать вывод о том, что после завершения цикла в переменной Sum будет записана сумма всех элементов массива.
х* Портрет А. П. Ершова взят из газеты «Информатика», № 12, 2006.
38
Доказательство правильности программ
§34
В алгоритме поиска наименьшего значения в массиве
Min:=А[1]
нц для i от 2 до п если A[i]<Min то Min:=А[i]
все кц
инвариант формулируется так: после выполнения каждого шага цикла в переменной Min записан минимальный из первых i элементов. Отсюда сразу следует, что после завершения цикла (при i = п) в этой переменной будет минимальный из всех элементов.
Пример 6. Для того же массива найдём инвариант цикла в программе сортировки элементов массива методом пузырька:
нц для i от 1 до п-1
нц для j от п-1 до i шаг -1
если А [ j ] > А [ j +1 ] то
с:=А[j]; А[j]:=А[j+1]; A[j+l]:=c; все кц кц
До начала алгоритма элементы расположены произвольно. На каждом шаге внешнего цикла на своё место «всплывает» один элемент массива. Поэтому инвариант этого цикла можно сформулировать так: «после выполнения i-го шага цикла первые i элементов массива отсортированы и установлены на свои места» .
Теперь построим инвариант внутреннего цикла. В этом цикле очередной «лёгкий» элемент поднимается вверх к началу массиву. Перед первым шагом внутреннего цикла элемент, который будет стоять на i-м месте в отсортированном массиве, может находиться в любой ячейке от А [ i ] до А [ п ] . После каждого шага его «зона нахождения» сужается на одну позицию, так что инвариант внутреннего цикла можно сформулировать так: «элемент, который будет стоять на i-м месте в отсортированном массиве, может находиться в любой ячейке от A[i] до А[ j ] ». Очевидно, что, когда в конце этого цикла j = i, элемент A[i] встаёт на своё место.
39
5
Элементы теории алгоритмов
В предыдущих примерах мы определяли инвариант готового цикла. Теперь покажем, как можно строить цикл с помощью заранее выбранного инварианта.
Пример 7. Рассмотрим алгоритм быстрого возведения в степень, основанный на использовании операций возведения в квадрат и умножения. Он использует две очевидные формулы:
ак=ак~х а при нечётной степени k и (1)
ak =(a2)k/2 при чётной степени k. (2)
Покажем, как работает алгоритм на примере возведения числа а в степень 7:
а7 = aQ - [а] = (а2)3 • [а] = (а2)2 [а2 • а] = (а4)1 • [а2 • а\ = = (а4)0 • [а4 • а2 • а] = [а4 • а2 • а].
Здесь поочерёдно применяются первая и вторая формулы. Заметим, что на каждом этапе выражение ап можно представить в виде ап = bk • р, где через р обозначена часть, взятая выше в квадратные скобки. Если нам каким-то образом удастся уменьшить k до нуля, сохранив это равенство, то мы получим ап = р, т. е. задача будет решена, а результат будет находиться в переменной р.
Таким образом, равенство ап = bk • р можно использовать как инвариант цикла. Для того чтобы обеспечить выполнение этого равенства в начальный момент, можно принять, например, b = a, k = п и р = 1. Далее в цикле применяются формулы (1) и (2) (в зависимости от чётности k на данном шаге). Цикл заканчивается, когда k = 0. В результате получаем следующее решение:
b:=a; k:=n; р:=1
нц пока ко О
если mod (к, 2)=0 то k:=div(k, 2) b:=Ъ * Ъ
иначе
к:=к-1
р:=Ъ*р все кц вывод р
40
Доказательство правильности программ
§34
Заметим, что инвариант цикла ап = bk • р выполняется до начала цикла, после каждого шага, а также после завершения цикла. Таким образом, мы написали код программы и одновременно доказали правильность этого блока.
Доказательное программирование
Для доказательства правильности программы необходимо иметь спецификацию — точное описание того, что должно быть сделано в результате работы программы.
Спецификация — точная и полная формулировка задачи, содержащая информацию, необходимую для построения алгоритма решения задачи.
На практике спецификации программ обычно формулируют на естественном языке, в котором слова могут иметь несколько разных значений. Для строгого доказательства желательно, чтобы спецификация была задана в формальном виде, с помощью формул или соотношений между величинами.
По предложению английского учёного Чарльза Хоара, спецификация записывается в форме {Q}S{7?}, где Q — начальное условие (предусловие), S — программа и R — утверждения, описывающие конечный результат (постусловие). Запись {Q}S{7?} означает следующее: «если выполнение программы S началось в состоянии, удовлетворяющем Q, то гарантируется, что оно завершится через конечное время в состоянии, удовлетворяющем R».
Корректная программа — это программа, соответствующая спецификации.
Если для исходных данных не удовлетворяется предусловие Q, программа должна сообщать об этом пользователю и закончить работу. В этом случае программу называют надёжной.
Надёжная программа — это программа, которая корректна и, кроме того, не завершается аварийно при недопустимых входных данных.
Например, для алгоритма Евклида условия Q и R могут выглядеть так:
Q: т > п > О, R\ а = НОД(т, п),
о
о
о
41
5
Элементы теории алгоритмов
а для программы суммирования элементов массива А[1:п] (см. пример 5) так:
Q: n>0, R: Suzn = £A[i] = A[l]+A[2] + ...+A[n].
1=1
Спецификации могут (и должны) быть составлены не только для программы в целом, но и для её отдельных блоков (процедур, функций, циклов и т. д.). Полезно вносить утверждения Q и R прямо в текст программы. Построенная таким образом аннотированная программа — это ещё один шаг к доказательному программированию.
Ч. Хоар разработал специальный аппарат, позволяющий доказывать правильность программы на основе спецификаций отдельных блоков. Приведём простейшие правила преобразования:
• если {Q}S{P} и Р => R (из истинности Р следует истинность /?), то {Q}S{7?};
• если {Q}S{P} и R => Q, то {R}S{P};
• если программа S — это последовательное выполнение блоков и S2, для которых выполняются спецификации {QJS^P} и
{P}S2{R}, то выполняется спецификация {Q}S{R}.
Доказательство правильности программ используют в двух ситуациях:
• доказывают правильность готовых программ (верификация программ);
• строят программы одновременно с доказательством их правильности (синтез программ).
Как правило, верификация — это очень трудоёмкий и сложный процесс, и оказывается значительно проще использовать доказательства правильности во время разработки программы. При этом программы получаются проще, эффективнее и значительно надёжнее.
Выводы
• Чтобы обеспечить надёжность программы, используют методы доказательного программирования: разработка программы ведётся одновременно с доказательством её правильности.
• Инвариант цикла — это соотношение между величинами, которое остаётся справедливым после завершения любого шага цикла.
42
Доказательство правильности программ
§34
• Спецификация — точная и полная формулировка задачи, содержащая информацию, необходимую для построения алгоритма решения задачи.
• Корректная программа — это программа, соответствующая спецификации.
• Надёжная программа — это программа, которая корректна и, кроме того, не завершается аварийно при недопустимых входных данных.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Зачем нужно доказывать правильность программ?
2. Почему с помощью тестирования сложно доказать правильность программы? В каких случаях это всё же можно сделать?
3. Что изменится в доказательстве алгоритма Евклида, если т и п — это произвольные натуральные числа (неравенство т>п может не выполняться)?
4. Зачем нужно определять инвариант цикла?
5. Почему желательно формулировать спецификацию в виде формальных утверждений, а не на естественном языке?
6. Что такое предусловие и постусловие? Объясните запись
7. В чём различие между надёжной и корректной программами?
8. Как вы думаете, можно ли назвать корректной программу, которая «зависает» при неверных исходных данных? Обсудите этот вопрос в классе.
9. Что такое верификация программы?
10. Как вы думаете, что сложнее — доказывать правильность готовой программы или сразу писать программу, доказывая правильность отдельных блоков? Почему? Обсудите этот вопрос в классе.
Проект
Доказательство правильности выбранного алгоритма
43
5
Элементы теории алгоритмов
WWW
ЭОР к главе 5 на сайте ФЦИОР (http://fcior.edu.ru)
• Алгоритмически неразрешимые задачи
WWW
Практические работы к главе 5
Работа № 34 «Машина Тьюринга»
Работа № 35 «Машина Поста»
Работа № 36 «Нормальные алгорифмы Маркова»
Работа № 37 «Вычислимые функции»
Работа № 38 «Инвариант цикла»
44
Глава 6
АЛГОРИТМИЗАЦИЯ И ПРОГРАММИРОВАНИЕ
§35
Целочисленные алгоритмы
Ключевые слова:
• решето Эратосфена
• «длинные» числа
• целочисленный квадратный корень
Во многих задачах все исходные данные и необходимые результаты — целые числа. При этом желательно, чтобы все промежуточные вычисления тоже проводились только с целыми числами. На это есть, по крайней мере, две причины:
• процессор, как правило, выполняет операции с целыми числами значительно быстрее, чем с вещественными;
• целые числа всегда точно представляются в памяти компьютера, и вычисления с ними также выполняются без ошибок (если, конечно, не происходит переполнения разрядной сетки).
Решето Эратосфена
Во многих прикладных задачах, например при шифровании с помощью алгоритма RSA, используются простые числа. Основные задачи при работе с простыми числами — это проверка числа на простоту и нахождение всех простых чисел в заданном диапазоне.
Пусть задано некоторое натуральное число N и требуется найти все простые числа в диапазоне от 2 до N. Самое простое (но неэффективное) решение этой задачи состоит в том, что в цикле перебираются все числа от 2 до АГ, и каждое из них отдельно проверяется на простоту. Например, можно проверить, есть ли у числа k делители в диапазоне от 2 до y/k . Если ни одного такого делителя нет, то число k простое.
Описанный метод при больших N работает очень медленно, он имеет асимптотическую сложность O(N\[N). Греческий мате
45
Алгоритмизация и программирование
матик Эратосфен Киренский (275-194 гг. до н. э.) предложил другой алгоритм, который работает намного быстрее (сложность O(N log log N)):
1) выписать все числа от 2 до N;
2) начать с k = 2;
3) вычеркнуть все числа, кратные k (2й,3й,4й и т. д.);
4) найти следующее невычеркнутое число и присвоить его переменной й;
5) повторять шаги 3 и 4, пока k<N.
Покажем работу алгоритма при N = 16:
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Первое не вычеркнутое число — 2, поэтому вычёркиваем все чётные числа:
2 3 4 5 6 7 R 9 10 11 12 13 14 15 14
Далее вычёркиваем все числа, кратные 3:
2 3 4 5 6 7 г 9 1-0 11 12 13 14 15 15
Все числа, кратные 5 и 7, уже вычеркнуты. Таким образом, получены простые числа 2, 3, 5, 7, 11 и 13.
Классический алгоритм можно улучшить, уменьшив количество операций. Заметьте, что при вычёркивании чисел, кратных 3, нам не пришлось вычёркивать число 6, так как оно уже было вычеркнуто. Кроме того, все числа, кратные 5 и 7, к последнему шагу тоже оказались вычеркнутыми.
Предположим, что мы хотим вычеркнуть все числа, кратные некоторому й, например й = 5. При этом числа 2й, Зй и 4й уже были вычеркнуты на предыдущих шагах, поэтому нужно начать не с 2й , а с й2. Тогда получается, что при k2>N вычеркивать уже будет нечего, что мы и увидели в примере. Поэтому можно использовать улучшенный алгоритм:
1) выписать все числа от 2 до У;
2) начать с й = 2;
3) вычеркнуть все числа, кратные й, начиная с й2;
4) найти следующее невычеркнутое число и присвоить его переменной й;
5) повторять шаги 3 и 4, пока й2 <N.
Целочисленные алгоритмы
§35
Чтобы составить программу, нужно определить, что значит «выписать все числа» и «вычеркнуть число». Один из возможных вариантов хранения данных — массив логических величин с индексами от 2 до N.
Как и в 10 классе, для программирования алгоритмов мы будем использовать язык Python.
Поскольку индексы элементов списков в Python всегда начинаются с нуля, для того чтобы работать с нужным диапазоном индексов, необходимо выделить массив из N -h 1 элементов. Если число i не вычеркнуто, будем хранить в элементе массива A [i] истинное значение (True), если вычеркнуто — ложное (False). В самом начале нужно заполнить массив истинными значениями:
N = 100
А = [True]*(N+1)
В основном цикле выполняется описанный выше алгоритм:
к = 2
while к*к <= N:
if А[к]: i = к*к while i <= N: A[i] = False i += к к += 1
Обратите внимание, что для того, чтобы вообще не применять вещественную арифметику, мы заменили условие к < Vn на равносильное условие к2 < N, в котором используются только целые числа.
После завершения этого цикла невычеркнутыми остались только простые числа, для них соответствующий элемент массива содержит истинное значение. Эти числа нужно вывести на экран:
for i in range(2, N+1): if A[i]: print(i)
Теперь попробуем переписать это решение в стиле языка Python. Поскольку при вызове функции range нам нужно указывать не последнее значение переменной цикла, а ограничитель,
47
6
Алгоритмизация и программирование
который на единицу больше, в начале программы увеличим N на 1:
N += 1
Для того чтобы задать конечное значение к в цикле, используем функцию sqrt из модуля math, округляя её результат до ближайшего меньшего числа1) и добавляя 1:
from math import sqrt
for k in range (2, int(sqrt(N))+1) :
Здесь многоточие обозначает операторы, составляющие тело цикла.
Теперь преобразуем внутренний цикл: переменная i изменяется в диапазоне от к2 до N с шагом к, поэтому окончательно получаем:
for к in range (2, int(sqrt(N))+1):
if A[k]:
for i in range(k*k, N, k): A[i] = False
Массив для вывода сформируем с помощью генератора списка из тех значений i, для которых соответствующие элементы массива A[i] остались истинными (числа не вычеркнуты):
Р = [i for i in range (2, N) if A[i]]
print(P)
«Длинные» числа
Современные алгоритмы шифрования используют достаточно длинные ключи, которые представляют собой числа длиной 256 бит и больше. С ними нужно выполнять разные операции: складывать, умножать, находить остаток от деления.
К счастью, в Python целые числа могут быть произвольной длины, т. е. размер числа (точнее, отведённый на него объём памяти) автоматически расширяется при необходимости. Однако в других языках (С, C++, Паскаль) для целых чисел отводятся
г) Здесь нужно рассмотреть пограничный случай, когда N — квадрат целого числа, т. е. число непростое. Вспомним, что мы предварительно увеличили N на единицу. Тогда результат выражения int(sqrt(N)) в точности будет равен Vn, это значение нужно тоже включить в цикл перебора, поэтому добавляем 1.
48
Целочисленные алгоритмы
§35
ячейки фиксированных размеров (обычно до 64 бит). Поэтому остро состоит вопрос о том, как хранить такие числа в памяти. Ответ достаточно очевиден: нужно «разбить» длинное число на части так, чтобы использовать несколько ячеек памяти.
Далее мы рассмотрим общие алгоритмы, позволяющие работать с «длинными» числами, при ограниченном размере ячеек памяти. Это позволит вам научиться решать такие задачи с помощью любого языка программирования.
«Длинное число» — это число, которое не помещается в переменную одного из стандартных типов данных языка программирования. Алгоритмы работы с длинными числами называют «длинной арифметикой».
о
Для хранения «длинного» числа будем использовать массив целых чисел. Например, число 12345678 можно записать в массив с индексами от 0 до 7 таким образом:
01 2 3456789
А 1 2 3 4 5 6 7 8 0 0
Такой способ имеет ряд недостатков:
1) неудобно выполнять арифметические операции, которые начинаются с младшего разряда;
2) память расходуется неэкономно, потому что в одном элементе массива хранится только один разряд — число от 0 до 9.
Чтобы избавиться от первой проблемы, достаточно «развернуть» массив наоборот, так чтобы младший разряд находился в А[0]. В этом случае на рисунках удобно применять обратный порядок элементов:
98765 4 3210
А 0 0 1 2 3 4 5 6 7 8
Теперь нужно найти более экономичный способ хранения длинного числа. Например, разместим в одной ячейке массива три разряда числа, начиная справа:
2 1 0
А 12 345 678
49
6
Алгоритмизация и программирование
Здесь использовано равенство
12345678 = 12 • 10002 + 345 • 10001 + 678 • 1000°.
Фактически мы представили исходное число в системе счисления с основанием 1000!
Сколько разрядов можно хранить в одной ячейке массива? Это зависит от её размера. Во многих современных языках программирования стандартная ячейка для хранения целого числа занимает 4 байта, так что допустимый диапазон её значений:
от - 231 = - 2 147 483 648 до 231 - 1 = 2 147 483 647.
В такой ячейке можно хранить до 9 разрядов десятичного числа, т. е. использовать систему счисления с основанием 1 000 000 000. Однако нужно учитывать, что с такими числами будут выполняться арифметические операции, результат которых должен помещаться в такую же ячейку памяти. Например, если надо умножать разряды этого числа на число fe<100 и в языке программирования нет 64-битных целочисленных типов данных, то в элементе массива можно хранить не более 7 разрядов.
Задача 1. Требуется вычислить точно значение факториала 100! = 1 • 2 • 3 • ... • 99 • 100 и вывести его на экран в десятичной системе счисления (это число состоит более чем из сотни цифр и явно не помещается в одну ячейку памяти).
Мы рассмотрим решение этой задачи, которое подходит для большинства распространённых языков программирования. Для хранения «длинного» числа будем использовать целочисленный массив А. Определим необходимую длину массива. Заметим, что
1 • 2 • 3 • ... • 99 • 100 < 1ОО100.
Число 1ОО100 содержит 201 цифру, поэтому число 100! содержит не более 200 цифр. Если в каждом элементе массива записано 6 цифр, для хранения всего числа требуется не более 34 ячеек. В решении на языке Python мы не будем заранее строить массив (список) такого размера, а будем наращивать длину списка по мере увеличения длины числа-результата.
Чтобы найти 100!, нужно сначала присвоить «длинному» числу значение 1, а затем последовательно умножать его на все
50
Целочисленные алгоритмы
§35
числа от 2 до 100. Запишем эту идею на псевдокоде, обозначив через {А} длинное число, находящееся в массиве А:
{А} = 1
for k in range(2, 101):
{А} *= к
Записать в длинное число единицу — это значит создать массив (список) из одного элемента, равного 1. На языке Python это запишется так:
А = {1}
Таким образом, остаётся научиться умножать длинное число на «короткое» (к <100). «Короткими» обычно называют числа, которые помещаются в переменную одного из стандартных типов данных.
Попробуем сначала выполнить такое умножение на примере. Предположим, что в каждой ячейке массива хранится 6 цифр «длинного» числа, т. е. используется система счисления с основанием d = 1 000 000. Тогда число {А} = 12345678901734567 хранится в трёх ячейках:
2 10
12345 678901 734567
Пусть k = 3. Начинаем умножать с младшего разряда: 734567 • 3 = 2203701. В нулевом разряде может находиться только 6 цифр, значит, старшая двойка перейдёт в перенос в следующий разряд. В программе для выделения переноса г можно использовать деление на основание системы счисления d с отбрасыванием остатка. Сам остаток — это то, что остаётся в текущем разряде. Поэтому получаем:
s = А[0]*к
А[0] = s%d г = s//d
Для следующего разряда будет всё то же самое, только в первой операции к произведению нужно добавить перенос из предыдущего разряда, который был записан в переменную г. Приняв в самом начале г = 0, запишем умножение длинного числа на короткое в виде цикла по всем элементам массива А:
51
6
Алгоритмизация и программирование
г = О
for i in range(len(А)):
s = A[i]*k + r
A[i] = s%d r = s//d if r > 0:
A.append(r)
Обратите внимание на последние две строки: если перенос из последнего разряда не равен нулю, он добавляется к массиву как новый элемент.
Такое умножение нужно выполнять в другом (внешнем) цикле для всех к от 2 до 100:
for к in range(2, 101):
{А} * = к
После этого в массиве А будет находиться искомое значение 100!, остаётся вывести его на экран. Нужно учесть, что в каждой ячейке хранятся 6 цифр, поэтому в массиве
2 1 0
1 2 3
хранится значение 1000002000003, а не 123. Поэтому при выводе требуется:
1) вывести (старший) ненулевой разряд числа без лидирующих нулей;
2) вывести все следующие разряды, добавляя лидирующие нули до 6 цифр.
Старший разряд выводим обычным образом (без лидирующих нулей):
h = 1еп(А)-1
print(A[h], end = "")
Здесь h — номер самого старшего разряда числа. Для остальных разрядов будем использовать возможности функции format:
for i in range(h-1, -1, -1):
print("{:06d}".format(A[i]) , end = "")
Напомним, что фигурные скобки обозначают место для вывода очередного элемента данных. Формат 0 6d говорит о том, что
52
Целочисленные алгоритмы
§35
нужно вывести целое число в десятичной системе (d, от англ. decimal — десятичный), используя 6 позиций, причём пустые позиции нужно заполнить нулями (первая цифра 0).
Отметим, что показанный выше метод применим для работы с «длинными» числами в любом языке программирования. Как мы говорили, в Python по умолчанию используется «длинная» арифметика, поэтому вычисление 100! может быть записано значительно короче:
А = 1
for i in range(2, 101):
A *= i
print(A)
или с использованием функции factorial из модуля math:
import math
print(math.factorial(100) )
Квадратный корень
Рассмотрим ещё одну задачу: вычисление целого квадратного корня из целого числа. На этот раз мы будем использовать встроенную «длинную арифметику» языка Python, так что число может быть любой длины. К сожалению, стандартная функция sqrt из модуля math не поддерживает работу с целыми числами произвольной длины, и результат её работы — вещественное число1). Поэтому в том случае, когда нужно именно целое значение, приходится использовать специальные методы.
Один из самых известных алгоритмов вычисления квадратного корня, полученный ещё в Древней Греции, — метод Герона Александрийского, который сводится к многократному применению формулы* 2)
Здесь а — число, из которого извлекается корень, a xt — предыдущее и следующее приближения (см. главу 9 учебника для 10 класса). Фактически здесь вычисляется среднее арифме
h Заметим, что возведение целого числа в степень 0,5 тоже даёт вещественное число.
2) Фактически эта формула — результат применения метода Ньютона для решения нелинейных уравнений к уравнению х =а .
53
6
Алгоритмизация и программирование
тическое чисел xt_Y и а / х^. Пусть одно из этих значений меньше >/а , тогда второе обязательно больше 4а . Поэтому их среднее арифметическое с каждым шагом приближается к значению корня.
Метод Герона «сходится» (т. е. приводит к правильному решению) при любом начальном приближении х0 (не равном нулю). Например, можно выбрать начальное приближение х0 = а.
Приведённая формула служит для вычисления вещественного значения корня. Для того чтобы найти целочисленное значение корня (т. е. максимальное целое число, квадрат которого не больше, чем а), можно заменить оба деления на целочисленные. На языке Python это запишется так:
х = (х+а//х)//2
или привести выражение в скобках к общему знаменателю для того, чтобы использовать всего одно целочисленное деление:
х = (х*х+а)//(2*х)
Функция для вычисления квадратного корня может выглядеть так:
def isqrt(а): х = а while True: xl = (х*х+а)//(2*х) if xl >= х: return х х = xl
Здесь наиболее интересный момент — условие выхода из цикла. Как вы знаете, цикл с заголовком while True — это бесконечный цикл, из которого можно выйти только с помощью оператора break или (в функции) с помощью return. Мы начинаем поиск с начального приближения х0 = а, которое (при больших а) заведомо больше правильного ответа. Поэтому каждое следующее приближение будет меньше предыдущего. А как только очередное приближение окажется большим или равным предыдущему, квадратный корень будет найден.
Выводы
• Если все данные и необходимые результаты — целые числа, желательно выполнять вычисления, используя только операции с целыми числами.
54
Целочисленные алгоритмы
§35
• «Длинное» число — это число, которое не помещается в переменную одного из стандартных типов данных языка программирования. Алгоритмы работы с длинными числами называют « длинной арифметикой ».
• Для хранения «длинного» числа в памяти можно использовать массив.
• В языке Python используется «длинная арифметика»: размер памяти для хранения числа автоматически увеличивается, если это необходимо.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Какие преимущества и недостатки имеет алгоритм «решето Эратосфена» по сравнению с проверкой каждого числа на простоту?
2. В каких случаях необходимо применять «длинную арифметику»?
3. Какое максимальное число можно записать в ячейку размером 64 бита? Рассмотрите варианты хранения чисел со знаком и без знака.
4. Можно ли использовать для хранения «длинного» числа символьную строку? Оцените достоинства и недостатки такого подхода.
5. Почему неудобно хранить «длинное» число, записывая первую значащую цифру в начало массива?
6. Сколько разрядов десятичной записи числа можно хранить в одной 16-битной ячейке?
7. Объясните, какие проблемы возникают при выводе длинного числа. Как их можно решать?
*8. Предложите способ вывода «длинного» числа без использования возможностей функции format.
*9. Предложите алгоритм поиска целого кубического корня из целого числа.
Подготовьте сообщение
а) «Простые числа в криптографии»
б) «Применение факториалов»
в) «Извлечение квадратного корня из больших чисел»
55
6
Алгоритмизация и программирование
□>
Проекты
а) Программа для генерации ключей алгоритма RSA
б) Исследование скорости работы алгоритмов поиска простых чисел
Интересный сайт
ru.numberempire.com/primenumbers.php — онлайн-калькулятор
простых чисел
§36 Структуры
Ключевые слова:
• структура
• поле
• точечная запись
О
• исключение
• сортировка
• ключ
Зачем нужны структуры?
Представим себе базу данных библиотеки, в которой хранится информация о книгах. Для каждой из них нужно запомнить автора, название, год издания, количество страниц, число экземпляром и т. д. Как хранить эти данные?
Поскольку книг много, нужен массив. Но информация о книгах разнородна, она содержит целые числа и символьные строки разной длины. Конечно, можно разбить эти данные на несколько массивов (массив авторов, массив названий и т. д.), так чтобы i-й элемент каждого массива относился к книге с номером i. Но такой подход оказывается слишком неудобным и ненадёжным. Например, при сортировке нужно переставлять элементы всех массивов (отдельно!) и можно легко ошибиться и нарушить связь данных.
Возникает естественная идея — объединить все данные, относящиеся к книге, в единый блок памяти, который в программировании называется структурой или записью.
Структура — это тип данных, который может включать в себя несколько полей — элементов разных типов (в том числе и другие структуры).
56
Структуры
§36
Классы
В Python для работы со структурами используют специальные типы данных — классы. В программе можно вводить свои классы (новые типы данных). Введём новый класс ТВоок — структуру, с помощью которой можно описать книгу в базе данных библиотеки. Будем хранить в структуре только1*:
• фамилию автора (символьная строка);
• название книги (символьная строка);
• имеющееся в библиотеке количество экземпляров (целое число).
Класс можно объявить так:
class ТВоок:
pass
Объявление начинается с ключевого слова class. Имя нового класса (типа данных) — ТВоок — это удобное сокращение от английских слов Type Book (тип «книга»), хотя можно было использовать и любое другое имя, составленное по правилам языка программирования.
Слово pass (англ, pass — пропустить) стоит во второй строке только потому, что оставить строку совсем пустой нельзя — будет ошибка. В данном случае пока мы не определяем какие-то новые характеристики для объектов этого класса, просто говорим, что есть такой класс.
В отличие от других языков программирования (С, C++, Паскаль) при объявлении класса не обязательно сразу перечислять все поля (данные) структуры, они могут добавляться по ходу выполнения программы. Такой подход имеет свои преимущества и недостатки. С одной стороны, программисту удобнее работать, больше свободы. С другой стороны, повышается вероятность случайных ошибок. Например, при опечатке в названии поля может быть создано новое поле с неверным именем, и сообщение об ошибке не появится.
Теперь уже можно создать объект этого класса:
В = ТВоок ()
или даже массив (список) из таких объектов:
Books = []
for i in range (100):
Books.append(TBook())
h Конечно, в реальной ситуации данных больше, но принцип не меняется.
57
6
Алгоритмизация и программирование
Обратите внимание, что при создании массива нельзя было написать
Books = [ТВоок()]*100 # ошибочное создание массива
Дело в том, что список Books содержит указатели (адреса) объектов типа ТВоок, и в последнем варианте фактически создаётся один объект, адрес которого записывается во все 100 элементов массива. Поэтому изменение одного элемента массива «синхронно» изменит и все остальные элементы.
Для того чтобы работать не со всей структурой, а с отдельными полями, используют так называемую точечную запись, разделяя точкой имя структуры и имя поля. Например, В. author обозначает «поле author структуры В», a Books [ 5 ]. count — «поле count элемента массива Books [5]».
С полями структуры можно обращаться так же, как и с обычными переменными соответствующего типа. Можно вводить их с клавиатуры (или из файла):
В.author = input ()
В.title = input ()
В.count = int(input())
присваивать им новые значения:
В.author = "Пушкин А.С."
В.title = "Полтава"
В.count = 1
использовать их при обработке данных:
fam = В.author.split () [0] # только фамилия
print(fam)
В.count -= 1 # одну книгу взяли
if В.count == 0: print("Этих книг больше нет!")
и выводить на экран:
print(В.author, В.title + В.count, "шт.")
Работа с файлами
В программах, которые работают с данными на диске, бывает нужно читать массивы структур из файла и записывать в файл. Конечно, можно хранить структуры в текстовых файлах, например, записывая все поля одной структуры в одну строку и раз де-
58
Структуры
§36
ляя их каким-то символом-разделителем, который не встречается внутри самих полей.
Но есть более грамотный способ, который позволяет хранить данные в файлах во внутреннем формате, т. е. так, как они представлены в памяти компьютера во время работы программы. Для этого в Python используется стандартный модуль pickle, который подключается с помощью команды import:
import pickle
Запись структуры в файл выполняется с помощью процедуры dump:
В = ТВоокО
F = open("books.dat", "wb")
В.author = "Тургенев И.С. "
В.title = "Муму"
В.count = 2
pickle.dump(В, F);
F.close()
Обратите внимание, что файл открывается в режиме wb; первая буква w, от англ, write — писать, нам уже знакома, а вторая — Ь — сокращение от англ, binary — двоичный, она говорит о том, что данные записываются в файл в двоичном (внутреннем) формате.
С помощью цикла можно записать в файл массив структур:
for В in Books:
pickle.dump(В, F)
а можно даже обойтись без цикла:
pickle.dump(Books, F) ;
При чтении этих данных нужно использовать тот же способ, что и при записи: если структуры записывались по одной, читать их тоже нужно по одной, а если записывался весь массив за один раз, так же его нужно и читать.
Прочитать из файла одну структуру и вывести её поля на экран можно следующим образом:
F = open("books.dat", "rb")
В = pickle.load(F)
print(B.author, B.title, B.count, sep = ", ")
F.close ()
59
6
Алгоритмизация и программирование
Если массив (список) структур записывался в файл за один раз, его легко прочитать, тоже за один вызов функции load:
Books = pickle.load (F)
Если структуры записывались в файл по одной и их количество известно, при чтении этих данных в массив можно применить цикл с переменной:
for i in range (N) :
Books[i] = pickle.load(F)
Если же число структур неизвестно, нужно выполнять чтение до тех пор, пока файл не закончится, т. е. при очередном чтении не произойдет ошибка:
Books = []
while True:
try:
Books.append (pickle.load(F))
except: break
Мы сначала создаём пустой список Books, а затем в цикле читаем из файла очередную структуру и добавляем её в конец списка с помощью метода append.
Обработка ошибки выполнена с помощью исключений.
Исключение (англ, exception — исключительная ситуация) — это аварийная ситуация, которая делает дальнейшие вычисления по основному алгоритму невозможными или бессмысленными.
Исключением может быть, например, деление на ноль, ошибка при вводе или выводе данных, нехватка памяти и т. п. В нашем случае исключение — это неудачное чтение структуры из файла.
«Опасные» операторы, которые могут вызвать ошибку, записываются в виде блока (со сдвигом) после слова try. После этого в следующем блоке, который начинается с ключевого слова except, записывают команды, которые нужно выполнить в случае ошибки (в данном случае — выйти из цикла).
Сортировка
Для сортировки массива структур применяют те же методы, что и для сортировки массива простых переменных. Структуры
60
Структуры
§36
обычно сортируют по возрастанию или убыванию одного из полей, которое называют ключевым полем или ключом, хотя можно, конечно, использовать и сложные условия, зависящие от нескольких полей (составной ключ, как в базах данных).
Отсортируем массив Books (типа ТВоок) по фамилиям авторов в алфавитном порядке. В данном случае ключом будет поле author. Предположим, что фамилия состоит из одного слова, а за ней через пробел следуют инициалы. Тогда сортировка методом пузырька выглядит так:
N = len(Books)
for i in range(0, N-l):
for j in range(N-2, i-1, -1):
if Books[j].author > Books[j+1].author: Booksfj], Books[j+1] = Books[j+1], Booksfj]
Как вы знаете из курса 10 класса, при сравнении двух символьных строк они рассматриваются посимвольно до тех пор, пока не будут найдены первые различающиеся символы. Далее сравниваются коды этих символов по кодовой таблице. Так как код пробела меньше, чем код любой русской (и латинской) буквы, строка с фамилией «Волк» окажется выше в отсортированном списке, чем строка с более длинной фамилией «Волков», даже с учётом того, что после фамилии есть инициалы. Если фамилии одинаковы, сортировка происходит по первой букве инициалов, затем — по второй букве.
Отметим, что при такой сортировке данные, входящие в структуры, не перемещаются. Дело в том, что в массиве Books хранятся указатели (адреса) отдельных элементов, поэтому при сортировке переставляются именно эти указатели. Это очень важно, если структуры имеют большой размер или их по каким-то причинам нельзя перемещать в памяти.
Теперь покажем сортировку в стиле Python. Попытка просто вызвать метод sort для списка Books приводит к ошибке, потому что транслятор не знает, как сравнить два объекта класса ТВоок. Здесь нужно ему помочь — указать, какое из полей играет роль ключа. Для этого используем именованный параметр key метода sort. Например, можно указать в качестве ключа функцию, которая выделяет поле author из структуры:
def getAuthor (В):
return В.author
Books.sort (key = getAuthor)
61
6
Алгоритмизация и программирование
Более красивый способ — использовать так называемую «лямбда-функцию», т. е. функцию без имени (вспомните материал учебника для 10 класса):
Books.sort(key = lambda x: x.author )
Здесь в качестве ключа указана функция, которая из переданного ей параметра х выделяет поле author, т. е. делает то же самое, что и показанная выше функция getAuthor.
Если не нужно изменять сам список Books, можно использовать не метод sort, а функцию sorted, например, так:
for В in sorted (Books, key = lambda x: x.author): print(B.author, B.title+".", B.count, "шт.")
Выводы
• Структура — это сложный тип данных, который позволяет объединить данные разных типов. Элементы структуры называют полями.
• Структуры в языке Python вводятся как классы — новые типы данных.
• При обращении к полям структуры используется точечная запись:
<имя структуры>.<имя поля>
• Для сохранения структур в файле используются подпрограммы модуля pickle.
• При сортировке массива структур необходимо задать функцию, возвращающую ключ, по которому выполняется сортировка.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Что такое структура? В чём её отличие от массива?
2. В каких случаях использование структур даёт преимущества? Какие именно?
3. Как объявляется новый тип данных для хранения структур в Python? Выделяется ли при этом память?
4. Как обращаются к полю структуры?
5. Что такое двоичный файл? Чем он отличается от текстового?
6. Как можно сортировать структуры?
62
Словари
§37
Подготовьте сообщение
а) «Структуры (записи) в языке Паскаль»
б) «Структуры в языке Си»
в) «Структуры в языке JavaScript»
Проект
База данных текстового формата
§37 Словари
Ключевые слова:
• словарь • значение
• ключ
Что такое словарь?
Задача. В файле находится список слов, среди которых есть повторяющиеся. Каждое слово записано в отдельной строке. Построить алфавитно-частотный словарь: все различные слова должны быть записаны в другой файл в алфавитном порядке, справа от каждого слова указано, сколько раз оно встречается в исходном файле.
Для решения задачи нам нужно составить особую структуру данных — словарь (англ, dictionary), в котором хранить пары «слово — количество». Таким образом, мы хотим искать нужные нам данные не по числовому индексу элемента (как в обычном массиве), а по слову (символьной строке). Например, вывести на экран количество найденных слов «бегемот» можно было бы так:
print (D["бегемот”])
где D — имя словаря.
Тип данных «словарь» есть в некоторых современных языках программирования. В языке Python он называется diet (от англ. dictionary)1^.
В других языках программирования используются другие названия, например «ассоциативный массив» или «хэш».
63
6
Алгоритмизация и программирование
Словарь — это неупорядоченный набор элементов, в котором доступ к элементу выполняется по ключу.
Слово «неупорядоченный» в этом определении говорит о том, что порядок элементов в словаре никак не задан, он определяется внутренними механизмами хранения данных в языке. Поэтому сортировку словаря выполнить невозможно, как невозможно, в отличие от списка, указать для какого-то элемента словаря его соседей (предыдущий и следующий элементы).
Ключом могут быть данные любого неизменяемого типа, например число, символьная строка или кортеж (неизменяемый набор значений). В одном словаре можно использовать ключи разных типов.
Алфавитно-частотный словарь
Вернёмся к нашей задаче построения алфавитно-частотного словаря. Алгоритм, записанный в виде псевдокода, может выглядеть так:
создать пустой словарь
while есть слова в файле: прочитать очередное слово if слово есть в словаре: увеличить на 1 счётчик для этого слова else:
добавить слово в словарь
записать 1 в счётчик слова
Теперь нужно записать все шаги этого алгоритма с помощью операторов языка программирования.
Словарь определяется с помощью фигурных скобок, например:
D = {"бегемот”: 0, "пароход": 2}
В этом словаре два элемента, ключ «бегемот» связан со значением 0, а ключ «пароход» — со значением 2. Пустые фигурные скобки задают пустой словарь:
D = { }
Для того чтобы добавить элемент в словарь, используют присваивание:
D["самолёт"] = 1
64
Словари
§37
Если ключ «самолёт» уже есть в словаре, соответствующее значение будет изменено, а если такого ключа нет, то он будет добавлен и связан со значением 1.
Нам нужно увеличивать значение счётчика слов на 1, это можно сделать так:
D["самолёт"] += 1
Однако, если ключа «самолёт» нет в словаре, такая команда вызовет ошибку. Для того чтобы определить, есть ли в словаре какой-то ключ, можно использовать оператор in:
if "самолёт" in D:
D["самолёт"] += 1
else:
D["самолёт"] = 1
Если есть ключ «самолёт», соответствующее значение увеличивается на 1. Если такого ключа нет, то он создаётся и связывается со значением, равным 1.
Можно обойтись вообще без условного оператора, если использовать метод get для словаря, который возвращает значение, связанное с существующим ключом. Если ключа нет в словаре, метод возвращает значение по умолчанию, которое задаётся как второй параметр:
В["самолёт"] = D.get("самолёт", 0)+1
В данном случае значение по умолчанию — 0, если ключа «самолёт» нет, создаётся элемент с таким ключом и после выполнения приведённой команды соответствующее значение будет равно 1.
Теперь у нас есть всё для того, чтобы написать полный цикл ввода данных и составления списка:
D = {}
F = open("input.txt")
while True:
word = F.readline().strip() # (*) if not word: break
D[word] = D.get(word, 0)+l
F.close ()
Обратим внимание на строку (*) в программе. После чтения очередной строки из файла F (это делает метод readline, вспомните
65
6
Алгоритмизация и программирование
материал главы 8 учебника для 10 класса) вызывается ещё и метод strip (в переводе с англ, «лишать», «удалять»), который удаляет лишние пробелы и завершающий символ перевода строки \п.
Теперь остаётся вывести результат в файл. В отличие от списка к элементам словаря нельзя обращаться по индексам. Тогда возникает вопрос — как же перебрать все возможные ключи? Для этой цели мы запросим у словаря список всех ключей, используя метод keys:
allKeys = D.keys()
Эти ключи нужно отсортировать, тут работает функция sorted, которая вернёт отсортированный по алфавиту список:
sortKeys = sorted(D.keys())
В последних версиях языка Python вместо этого можно записать просто
sortKeys = sorted(D)
не вызывая явно метод keys.
Остаётся только перебрать в цикле for все элементы этого списка, например, так:
F = open("output.txt", "w")
for k in sorted(D):
F.write("{}: {}\n".format(k, D[k]))
F.close ()
Ключи из отсортированного списка ключей попадают по очереди в переменную к, для каждого ключа выводится сам ключ и через двоеточие — связанное с ним значение, т. е. количество таких слов в исходном файле. Для того чтобы преобразовать данные перед выводом в символьную строку, используется функция format. Две пары фигурных скобок в строке форматирования обозначают места для вывода первого и второго аргументов функции.
Отметим, что у словарей есть метод values, который возвращает список значений в словаре. Например, вот так можно вывести значения для всех ключей:
for i in D.values():
print (i)
66
Словари
§37
Если же нас интересуют пары «ключ — значение», удобно использовать метод items, который возвращает список таких пар. Перебрать все пары и вывести их на экран можно с помощью следующего цикла:
for к, v in D.items(): print (к, v)
В этом цикле две изменяемых переменных: к (ключ) и v (значение). Поскольку D. items () — это список пар «ключ — значение», при переборе первый элемент пары (ключ) попадает в переменную к, а второй (значение) — в переменную v.
Выводы
• Словарь — это набор пар «ключ — значение».
• Элементы в словаре неупорядочены, т. е. нельзя указать для элемента предыдущий и следующий.
• Ключом может быть любое неизменяемое значение: число, строка, кортеж.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Какие операции можно выполнять со словарём?
2. Можно ли обратиться к элементам словаря по индексу? Как вы думаете, почему сделано именно так?
3. Как создать словарь из готовых пар «ключ — значение»? Найдите в литературе или в Интернете разные способы решения этой задачи.
4. Как обращаться к элементу словаря?
5. Чем можно заменить метод get?
6. Как получить список всех ключей словаря? Всех значений словаря?
7. Как перебрать все пары «ключ — значение»?
8. Зачем при чтении строк из файла используется метод strip?
Подготовьте сообщение
а) «Словари в языке C++ (библиотека STL)»
б) «Ассоциативные массивы в языках программирования»
Проект
Сравнение текстов разных авторов с помощью алфавитно-частотного словаря
> ® и
67
6
Алгоритмизация и программирование
§38
Стек, очередь, дек
Ключевые слова:
• стек
• дек
• очередь
Что такое стек?
Представьте себе стопку книг (подносов, кирпичей и т. п.). С точки зрения информатики, её можно воспринимать как список элементов, расположенных в определённом порядке. Этот список имеет одну особенность — удалять и добавлять элементы можно только с одной («верхней») стороны. Действительно, для того чтобы вытащить какую-то книгу из стопки, нужно сначала снять все те книги, которые находятся на ней. Положить книгу сразу в середину тоже нельзя.
Стек (англ, stack — стопка) — это линейная структура данных, в котором элементы добавляются и удаляются только с одного конца («последним пришёл — первым ушёл», англ. LIFO: Last In — First Out).
На рисунке 6.1 показаны примеры стеков вокруг нас, в том числе автоматный магазин и детская пирамидка.
Рис. 6.1
Как вы знаете из главы 8 учебника для 10 класса, стек используется при выполнении программ: в этой области оперативной памяти хранятся адреса возврата из подпрограмм; параметры, передаваемые функциям и процедурам, а также локальные переменные.
68
Стек, очередь, дек
§38
Задача 1. В файле записаны целые числа. Нужно вывести их в другой файл в обратном порядке.
В этой задаче очень удобно использовать стек. Для стека определены две операции:
• добавить элемент на вершину стека (англ, push — втолкнуть);
• получить элемент с вершины стека и удалить его из стека (англ, pop — вытолкнуть).
Запишем алгоритм решения на псевдокоде. Сначала читаем данные и добавляем их в стек:
while файл не пуст: прочитать х добавить х в стек
Теперь верхний элемент стека — это последнее число, прочитанное из файла. Поэтому остаётся «вытолкнуть» все записанные в стек числа, они будут выходить в обратном порядке:
while стек не пуст: вытолкнуть число из стека в х записать х в файл
Использование списка
Поскольку стек — это линейная структура данных с переменным количеством элементов, для работы со стеком в программе на языке Python удобно использовать список. Вершина стека будет находиться в конце списка. Тогда для добавления элемента на вершину стека можно применить уже знакомый нам метод append:
stack.append(х)
Чтобы вытолкнуть элемент из стека, используется метод pop:
х = stack.pop()
Метод pop — это функция, которая выполняет две задачи:
1) удаляет последний элемент списка (если вызывается без параметров1*);
2) возвращает удалённый элемент как результат функции, так что его можно сохранить в какой-либо переменной.
При вызове метода pop в скобках можно указать индекс удаляемого элемента.
69
6
Алгоритмизация и программирование
Теперь несложно написать цикл ввода данных в стек из файла:
F = open("input.txt") stack = [] while True:
s = F.readline() if not s: break stack.append(int(s) )
F.close ()
или даже так:
stack = []
for s in open("input.dat"): stack.append(int(s) )
Затем выводим элементы массива в файл в обратном порядке:
F = open("output.txt"r "w")
while len(stack) > 0:
x = stack.pop()
F.write(str(x)+"\n")
F.close ()
Заметим, что перед записью в файл с помощью метода write все данные нужно преобразовать в формат символьной строки, это делает функция str. Символ перехода на новую строку "\п" добавляется в конец строки вручную.
Поскольку пустой список воспринимается интерпретатором Python как ложное значение, программу можно ещё сократить, заодно избавившись от переменной х:
F = open("output.txt"r "w")
while stack:
F.write(str(stack.pop())+"\n")
F.close ()
Вычисление арифметических выражений
Вы не задумывались, как компьютер вычисляет арифметические выражения, записанные в такой форме: (5 + 15) / (4 + 7-1) ? Такая запись называется инфиксной — в ней знак операции расположен между операндами (данными, участвующими в операции). Инфиксная форма неудобна для автоматических вычислений из-за
70
того, что выражение содержит скобки и его нельзя вычислить за один проход слева направо.
В 1920 году польский математик Ян Лукашевич предложил префиксную форму, которую стали называть польской нотацией. В ней знак операции расположен перед операндами. Например, выражение (5 + 15)/(4 + 7-1) может быть записано в виде
/ + 5 15- + 471
Скобки здесь не требуются, так как порядок операций строго определён: сначала выполняются два сложения (+5 15и + 4 7), затем вычитание, и наконец, деление. Первой стоит последняя операция.
В середине 1950-х годов была предложена обратная польская нотация, или постфиксная форма записи, в которой знак операции стоит после операндов:
5 15 + 47 + 1- /
В этом случае также не нужны скобки, и выражение может быть вычислено за один просмотр с помощью стека следующим образом:
• если очередной элемент — число (или переменная), он записывается в стек;
• если очередной элемент — операция, то она выполняется с верхними элементами стека, и после этого в стек вталкивается результат выполнения этой операции.
На рисунке 6.2 показано, как работает этот алгоритм (стек «растёт» снизу вверх).
В результате в стеке остаётся значение заданного выражения.
Приведём программу, которая вводит с клавиатуры выражение, записанное в постфиксной форме, и вычисляет его:
71
6
Алгоритмизация и программирование
data = input().split () # (1)
stack = [] # (2)
for x in data: # (3)
if x in # (4)
op2 = int(stack.pop ()) # (5)
opl = int(stack.pop()) # (6)
if x == res = opl+op2 # (7)
elif x == res = opl-op2 # (8)
elif x == res = opl*op2 # (9)
else: res = opl//op2 # (Ю)
stack.append (res) # (11)
else: stack.append (x) # (12)
print(stack[0]) # (13)
В строке программы 1 (см. нумерацию в комментариях)
результат ввода разбивается на части по пробелам с помощью метода split, в результате получается список data, содержащий отдельные элементы постфиксной записи — числа и знаки арифметических действий.
В строке 2 создаётся пустой стек, в строке 3 в цикле перебираются все элементы списка. Если очередной элемент, попавший в переменную х, — это знак арифметической операции (строка 4), снимаем со стека два верхних элемента (строки 5-6), выполняем нужное действие (строки 7-10) и добавляем результат вычисления обратно в стек (строка 11).
Если же очередной элемент — это число (не знак операции), просто добавляем его в стек (строка 12). В конце программы в стеке должен остаться единственный элемент — результат, — который выводится на экран (строка 13).
Скобочные выражения
Задача 2. Вводится символьная строка, в которой записано некоторое (арифметическое) выражение, использующее скобки трёх типов: (), [ ] и {}. Проверить, правильно ли расставлены скобки.
Например, выражение ()[{()[]}] — правильное, потому что каждой открывающей скобке соответствует закрывающая, и вложенность скобок не нарушается. Выражения
[О [ [ [ О [ О } ) ( ([) ]
неправильные. В первых трёх есть непарные скобки, а в последних двух не соблюдается вложенность скобок.
Начнём с аналогичной задачи, в которой используется только один вид скобок. Её можно решить с помощью счётчика скобок.
72
Стек, очередь, дек
Сначала счётчик равен нулю. Строка просматривается слева направо, если очередной символ — открывающая скобка, то счётчик увеличивается на 1, если закрывающая — уменьшается на 1. В конце просмотра счётчик должен быть равен нулю (все скобки парные), кроме того, во время просмотра он не должен становиться отрицательным (должна соблюдаться вложенность скобок).
В исходной задаче (с тремя типами скобок) хочется завести три счётчика и работать с каждым отдельно. Однако это решение неверное. Например, для выражения ({[)}] условия «правильности» выполняются отдельно для каждого вида скобок, но не для выражения в целом.
Задачи, в которых важна вложенность объектов, удобно решать с помощью стека. Нас интересуют только открывающие и закрывающие скобки, на остальные символы можно не обращать внимания.
Строка просматривается слева направо. Если очередной символ — открывающая скобка, будем вталкивать на вершину стека соответствующую закрывающую скобку. Если это закрывающая скобка, то проверяем, что лежит на вершине стека: если там та же самая закрывающая скобка, то её нужно просто снять со стека. Если на вершине лежит другая скобка или стек пуст, выражение неверное и нужно закончить просмотр. В конце обработки правильной строки стек должен быть пуст. Кроме того, во время просмотра не должно быть ошибок. Работа такого алгоритма иллюстрируется на рис. 6.3 (для правильного выражения).
( )
Рис. 6.3
В программе нам будет удобно использовать функцию, которая для каждой открывающей скобки возвращает соответствующую закрывающую:
def pair (b) :
if с == ”(”: return ”)” elif c == ”[”: return ”]” elif c == ”{”: return ”}” else: return ”?”
73
6
Алгоритмизация и программирование
В основной программе создадим пустой стек:
stack = []
Логическая переменная err будет сигнализировать об ошибке.
Сначала ей присваивается значение False (ложь):
err = False
В основном цикле перебираем все символы строки s, в которой записано скобочное выражение:
for с in s: # (1)
if с in "([(": # (2)
stack.append(pair(с)); # (3)
elif c in # (4)
if len(stack) == 0 or c != stack.pop(): # (5)
err = True # (6)
break # (7)
Если очередной символ — открывающая скобка, вталкиваем в стек соответствующую ей закрывающую скобку (строка 3).
Далее ищем символ среди закрывающих скобок (строка 4). Если нашли, то в строке 5 проверяем два условия:
1) стек пуст;
2) текущий символ (в переменной с) не совпал с символом, который снят с вершины стека.
Если выполняется хотя бы одно из этих условий, то выражение ошибочно. При этом в переменную err в строке 6 записывается значение True (произошла ошибка) и происходит досрочный выход из цикла с помощью оператора break (строка 7). Заметим, что условие len (stack) ==0 в строке 5 можно заменить на равносильное условие not stack (пустой стек воспринимается как ложное значение).
После окончания цикла нужно проверить содержимое стека: если он не пуст, то в выражении есть незакрытые скобки, и оно ошибочно:
if stack: err = True
В конце программы остаётся вывести результат на экран:
if not err:
print("Выражение правильное.")
else:
print("Выражение неправильное.")
74
Стек, очередь, дек
Очереди, деки
Все мы знакомы с принципом очереди: первым пришёл — первым обслужен (англ. FIFO: First In — First Out). Соответствующая структура данных в информатике тоже называется очередью.
Очередь — это линейная структура данных, для которой введены две операции:
• добавление нового элемента в конец очереди;
• удаление первого элемента из очереди.
о
Очередь — это не просто теоретическая модель. Операционные системы используют очереди для организации сообщения между программами: каждая программа имеет свою очередь сообщений. Контроллеры жёстких дисков формируют очереди запросов ввода и вывода данных. В сетевых маршрутизаторах создаётся очередь из пакетов данных, ожидающих отправки.
Задача 3. Рисунок задан в виде матрицы А, в которой элемент A[x][z/] определяет цвет пикселя на пересечении столбца х и строки у. Перекрасить в цвет 2 одноцветную область, начиная с пикселя (х0, г/0).
На рисунке 6.4 показан результат такой заливки для матрицы из 5 строк и 5 столбцов с начальной точкой (1,0).
Отметим, что для удобства записи
0 12 4 5
0 2 0 1 1
2 2 2 2 2
0 2 0 2 2
3 3 1 2 2
0 1 1 0 0
мы храним матрицу по
столбцам: первый индекс обозначает столбец, а второй — строку.
75
6
Алгоритмизация и программирование
Эта задача актуальна для графических программ. Один из возможных вариантов решения использует очередь, элементы которой — координаты пикселей (точек):
добавить в очередь точку (х0, у0)
color = цвет точки (х0, у0)
while очередь не пуста:
взять из очереди точку (х, у)
if А[х][у] == color:
А[х][у] = новый цвет
добавить в очередь точку (х-1, у)
добавить в очередь точку (х+1, у)
добавить в очередь точку (х, у-1)
добавить в очередь точку (х, у+1)
Конечно, в очередь добавляются только те точки, которые на-
ходятся в пределах рисунка (матрицы А). Заметим, что в этом алгоритме некоторые точки могут быть добавлены в очередь несколько раз (подумайте, когда это может случиться). Поэтому решение можно несколько улучшить, как-то помечая точки, уже добавленные в очередь, чтобы не добавлять их повторно (попробуйте сделать это самостоятельно).
Пусть изображение записано в виде матрицы А, которая на языке Python представлена как список списков (каждый внутренний список — отдельный столбец матрицы). Тогда можно определить размеры матрицы так:
ХМАХ = 1еп(А)
УМАХ = 1еп(А[0])
Значение ХМАХ — число столбцов, а УМАХ — это число строк. Определим также цвет заливки:
NEW_COLOR = 2
Зададим координаты начальной точки, откуда начинается заливка:
(хО, уО) = (1, 0)
и запомним её цвет в переменной color*.
color = А[х0][уО]
Теперь создадим очередь (как список языка Python) и добавим в эту очередь точку с начальными координатами. Две координаты точки связаны между собой, поэтому в программе лучше объединить их в единый блок, который в Python называется
76
Стек, очередь, дек
§38
кортежем и заключается в круглые скобки. Таким образом, каждый элемент очереди — это кортеж из двух элементов:
Q = [(хО, уО)]
Кортеж очень похож на список (обращение к элементам также выполняется по индексу в квадратных скобках), но его, в отличие от списка, нельзя изменять.
Остаётся написать основной цикл1*:
while Q: # 1
х, у = Q.pop(O) # 2
if А[х][у] == color: # 3
А[х][у] = NEW_COLOR # 4
if х > 0: Q.append((х-1, у))
if х < ХМАХ-1: Q.append((х+1, у))
if у > 0: Q.append((х, у-1) )
if у < YMAX-1: Q.append( (х, у+1))
Цикл в строке 1 работает до тех пор, пока в очереди есть хоть один элемент: запись while Q для списков равносильна записи while len(Q) > 0. Начало очереди всегда совпадает с первым элементом списка (имеющим индекс 0), поэтому в строке 2 мы как раз получаем первый элемент очереди (и удаляем его из очереди). Элемент очереди — это кортеж из двух значений, поэтому мы сразу разбиваем его на отдельные координаты.
Если цвет текущей точки совпадает с цветом начальной точки, который хранится в переменной color (строка 3), эта точка закрашивается новым цветом (строка 4), и в очередь добавляются все точки, граничащие с текущей и попадающие на поле рисунка.
В некоторых языках программирования размер массива нельзя менять во время работы программы. В этом случае очередь моделируется иначе. Допустим, что мы знаем, что количество элементов в очереди всегда меньше N. Тогда можно выделить статический массив из N элементов и хранить в отдельных переменных номера первого элемента очереди («головы», англ, head) и последнего элемента («хвоста», англ. tail). На рисунке 6.5, а показана очередь из 5 элементов. В этом случае удаление элемента из очереди сводится просто к увеличению переменной Head (рис. 6.5, б).
Использование списка для моделирования очереди — не самый быстродействующий вариант, потому что удаление первого элемента массива выполняется долго. В практических задачах лучше использовать класс deque из модуля collections.
77
6
Алгоритмизация и программирование
При добавлении элемента в конец очереди переменная Tail увеличивается на 1. Если она перед этим указывала на последний элемент массива, то следующий элемент записывается в начало массива, а переменной Tail присваивается значение 1. Таким образом, массив целиком замкнутым «в кольцо». На рисунке 6.5, в показана целиком заполненная очередь, а на рис. 6.5, г — пустая очередь. Один элемент массива всегда остаётся незанятым, иначе невозможно будет различить состояния «очередь пуста» и «очередь заполнена».
Head Tail
! 1 I
1 2 3 4 5
Head Tail
2 3 4 5
в) Tail Head
1 I I
9 10 11 12 1 2 3 4 5 6 7 8
Tail Head
l I
Рис- 6-5
Отметим, что эта модель описывает работу кольцевого буфера клавиатуры, который может хранить до 15 двухбайтных слов.
Существует ещё одна линейная динамическая структура данных, которая называется дек.
Дек (от англ, deque: double ended queue — двусторонняя очередь) — это линейная структура данных, в которой можно добавлять и удалять элементы как с одного, так и с друго! о конца.
78
Стек, очередь, дек
§38
Из этого определения следует, что дек может работать и как стек, и как очередь. С помощью дека можно, например, моделировать колоду игральных карт (рис. 6.6).
В языке Python для моделирования дека также удобно использовать список. Основные операции с деком d выполняются так:
1) добавление элемента х в конец дека:
Рис. 6.6
d. append(х) ;
2) добавление элемента х в начало дека: d. insert (0, х) (добавляемый элемент будет иметь индекс 0);
3) удаление элемента с конца дека: d. pop ();
4) удаление элемента с начала дека: d. pop (0) .
Выводы
• Стек — это линейная структура данных, в которой добавление и удаление элементов разрешаются только с одного конца. Системный стек применяется для хранения адресов возврата из подпрограмм и размещения локальных переменных.
• Очередь — это линейная структура данных, для которой введены две операции: 1) добавление нового элемента в конец очереди; 2) удаление первого элемента из очереди.
• Дек — это линейная структура данных, в которой можно добавлять и удалять элементы как с одного, так и с другого конца.
Нарисуйте в тетради интеллект-карту этого параграфа. Pai
Вопросы и задания
1. Какие операции со стеком разрешены?
2. Какие ошибки могут возникнуть при использовании стека?
3. Какие операции допускает очередь?
4. Как построить очередь на основе массива с неизменяемым размером?
5. Приведите примеры задач, в которых можно использовать очередь.
6. Что такое дек? Чем он отличается от стека и очереди? Какая из этих структур данных наиболее общая (может выполнять функции других)?
©
79
6
Алгоритмизация и программирование
Подготовьте сообщение
а) «Стеки и очереди в языке Паскаль»
б) «Стеки и очереди в языке C++»
в) «Очереди с приоритетом»
Проекты
а) Стековый язык программирования
б) Моделирование системы массового обслуживания с помощью очереди
в) Сравнение алгоритмов закраски области
г) Программа для перевода арифметического выражения в постфиксную форму
§39
Деревья
Ключевые слова:
• двоичное дерево • обход в глубину
• дерево поиска • обход в ширину
• ключ
Что такое дерево?
Как вы знаете из учебника для 10 класса, дерево — это структура данных, отражающая иерархию (отношения подчинённости, многоуровневые связи). Напомним некоторые основные понятия, связанные с деревьями.
Дерево состоит из узлов и связей между ними (они называются дугами). Самый первый узел, расположенный на верхнем уровне (в него не входит ни одна стрелка-дуга), — это корень дерева. Конечные узлы, из которых не выходит ни одна дуга, называются листьями. Все остальные узлы, кроме корня и листьев, — это промежуточные узлы.
Из двух связанных узлов тот, который находится на более высоком уровне, называется родителем, а другой — сыном. Корень — это единственный узел, у которого нет родителя; у листьев нет сыновей.
Используются также понятия «предок» и «потомок». Потомок какого-то узла — это узел, в который можно перейти по стрелкам от узла-предка. Соответственно, предок какого-то узла — это узел, из которого можно перейти по стрелкам в данный узел.
80
Деревья
§39
В дереве на рис. 6.7 родитель узла Е — это узел В, а предки узла Е — это узлы А и В, для которых узел Е — потомок. Потомками узла А (корня дерева) являются все остальные узлы.
Высота дерева — это наибольшее расстояние (количество рёбер) от корня до листа. Высота дерева, приведённого на рис. 6.7, равна 2.
Формально дерево можно определить следующим образом:
1) пустая структура — это дерево;
2) дерево — это корень и несколько связанных с ним отдельных (не связанных между собой) деревьев.
Здесь множество объектов (деревьев) определяется через само это множество на основе простого базового случая (пустого дерева). Такой приём называется рекурсией. Согласно этому определению, дерево — это рекурсивная структура данных. Поэтому можно ожидать, что при работе с деревьями будут полезны рекурсивные алгоритмы.
Чаще всего в информатике используются двоичные (бинарные) деревья, т. е. такие, в которых каждый узел имеет не более двух сыновей. Их также можно определить рекурсивно.
Двоичное дерево:
1) пустая структура — это двоичное дерево;
2) двоичное дерево — это корень и два связанных с ним отдельных двоичных дерева (левое и правое поддеревья).
Деревья широко применяются в следующих задачах:
• поиск в большом массиве данных;
• сортировка данных;
• вычисление арифметических выражений;
• оптимальное кодирование данных (метод сжатия Хаффмана, см. главу 1).
81
6
Алгоритмизация и программирование
Деревья поиска
Известно, что для того, чтобы найти заданный элемент в неупорядоченном массиве из N элементов, может понадобиться N сравнений. Теперь предположим, что элементы массива организованы в виде специальным образом построенного дерева (рис. 6.8).
Рис. 6.8
Значения, связанные с каждым из узлов дерева, по которым выполняется поиск, называются ключами этих узлов (кроме ключа узел может содержать множество других данных). Перечислим важные свойства этого дерева:
• слева от каждого узла находятся узлы, ключи которых меньше или равны ключу данного узла;
• справа от каждого узла находятся узлы, ключи которых больше или равны ключу данного узла.
Дерево, обладающее такими свойствами, называется двоичным деревом поиска.
Например, нужно найти узел, ключ которого равен 4. Начинаем поиск по дереву с корня. Ключ корня — 6 (больше заданного), поэтому дальше нужно искать только в левом поддереве и т. д.
Скорость поиска наибольшая в том случае, если дерево сбалансировано, т. е. для каждой его вершины высота левого и правого поддеревьев различается не более чем на единицу. Если при линейном поиске в массиве за одно сравнение отсекается 1 элемент, здесь — сразу примерно половина оставшихся. Количество операций сравнения в этом случае пропорционально log2N, т. е. алгоритм имеет асимптотическую сложность O(log2Af). Конечно, нужно учитывать, что предварительно дерево должно быть построено. Поэтому такой алгоритм выгодно применять в тех случаях, когда данные меняются редко, а поиск выполняется часто (например, в базах данных).
82
Деревья
§39
Обход дерева
Обойти дерево — это значит «посетить» все узлы по одному разу. Если перечислить узлы в порядке их посещения, мы представим данные в виде списка.
Существуют несколько способов обхода двоичного дерева:
• КЛП = «корень — левый — правый» (обход в прямом порядке):
посетить корень
обойти левое поддерево
обойти правое поддерево
• Л КП = «левый — корень — правый» (симметричный обход):
обойти левое поддерево посетить корень
обойти правое поддерево
• Л ПК = «левый — правый — корень»:
обойти левое поддерево обойти правое поддерево посетить корень
Как видим, это рекурсивные алгоритмы. Они должны заканчиваться без повторного вызова, когда текущий корень — пустое дерево.
Рассмотрим дерево, которое может быть составлено для вычисления арифметического выражения (1 + 4) * (9 - 5) — рис. 6.9.
Выражение вычисляется по такому дереву снизу вверх, т. е. корень дерева — это последняя выполняемая операция.
Различные типы обхода дают последовательность узлов:
КЛП: *+14 — 95
ЛКП: 1 + 4 * 9 - 5
ЛПК: 1 4 + 9 5 - *
83
6
Алгоритмизация и программирование
В первом случае мы получили префиксную форму записи арифметического выражения, во втором — привычную нам инфиксную форму (только без скобок), а в третьем — постфиксную форму. Напомним, что в префиксной и в постфиксной формах скобки не нужны.
Обход КЛП называется обходом в глубину (англ. DFS: Depth-first search), потому что сначала мы идём вглубь дерева по левым поддеревьям, пока не дойдём до листа. Алгоритм обхода в глубину несложно записать и без рекурсии, используя вспомогательный стек:
записать в стек корень дерева while стек не пуст:
выбрать узел V с вершины стека посетить узел V
if у узла V есть правый сын: добавить в стек правого сына V
if у узла V есть левый сын: добавить в стек левого сына V
На рисунке 6.10 показано изменение состояния стека при та ком обходе дерева, изображенного на рис. 6.9. Под стеком записана метка узла, который посещается (например, данные из этого узла выводятся на экран).
Рис. 6.10
Существует ещё один способ обхода, который называют обходом в ширину (англ. BFS: Breadth-first search). Сначала посещают корень дерева, затем — всех его сыновей, затем — сыновей сыновей («внуков») и т. д., постепенно спускаясь на один уровень вниз. Обход в ширину для дерева на рис. 6.9 даст такую последовательность посещения узлов:
* + -1495
84
Деревья
§39
Для того чтобы выполнить такой обход, применяют очередь — в неё записывают узлы, которые необходимо посетить. На псевдокоде обход в ширину можно записать так:
записать в очередь корень дерева
while очередь не пуста:
выбрать первый узел V из очереди посетить узел V if у узла V есть левый сын: добавить в очередь левого сына V if у узла V есть правый сын: добавить в очередь правого сына V
Использование связанных структур
Теперь попробуем записать все эти операции в программе на языке Python. Поскольку двоичное дерево — это нелинейная структура данных, хранить данные в виде списка не очень удобно (хотя возможно). Вместо этого будем использовать связанные узлы. Каждый такой узел — это структура, содержащая три области: область данных, ссылка на левое поддерево и ссылка на правое поддерево. У листьев нет сыновей, в этом случае в указатели будем записывать специальное значение None («пусто», «ничто»). Дерево, состоящее из трёх таких узлов, показано на рис. 6.11.
Рис. 6.11
В нашем случае область данных узла будет содержать одно поле — символьную строку, в которую записывается знак операции или число в символьном виде.
Будем хранить дерево в памяти как набор связанных структур-узлов класса TNode:
class TNode: pass
85
6
Алгоритмизация и программирование
Каждый узел содержит три поля: данные d, ссылку на левое поддерево L и ссылку на правое поддерево R. Построим функцию, которая будет возвращать новую структуру этого класса:
def node(d, L = None, R = None) : newNode = TNode() # создаём новый узел
newNode.data = d newNode.left = L newNode.right = R return newNode
Запись L = None, R = None в заголовке функции означает, что если параметры L и R не заданы, их значения по умолчанию равны None. Функция возвращает новый узел дерева.
Теперь мы можем построить в памяти дерево, показанное на рис. 6.9:
Т = node("*", node("+", node("l"), node("4")), node(”-", node("9”), node("5")) )
Обход дерева в глубину (обход КЛП) очень просто записать в виде рекурсивной процедуры:
def DFS(Т): if not Т: return print(Т.data, end=" ") DFS(T.left) DFS(T.right)
А вот такой же обход без рекурсии, использующий стек:
def DFS_stack (Т): stack = [Т] while stack: V = stack.рор() print(V.data, end = " ") if V.right: stack.append(V.right) if V.left: stack.append(V.left)
86
Деревья
§39
Процедура для обхода в ширину использует очередь вместо стека:
def BFS (Т): queue = [Т] while queue:
V = queue.pop(0) # берём первый элемент из очереди print(V.data, end = " ") if V.left: queue.append(V.left) if V.right: queue.append(V.right)
Вычисление арифметических выражений
Один из способов вычисления арифметических выражений основан на использовании дерева. Сначала выражение, записанное в линейном виде (в одну строку), нужно «разобрать» и построить соответствующее ему дерево. Затем в результате прохода по этому дереву от листьев к корню вычисляется результат.
Для простоты будем рассматривать только арифметические выражения, содержащие числа и знаки четырёх арифметических действий: + - * /. Построим дерево для выражения
40-2*3-4*5
Так как корень дерева — это последняя операция, нужно сначала найти эту последнюю операцию, просматривая выражение слева направо. Здесь последнее действие — это второе вычитание, оно оказывается в корне дерева (рис. 6.12).
Как выполнить этот поиск в программе? Известно, что операции выполняются в порядке приоритета (старшинства): сначала операции с более высоким приоритетом (слева направо), потом — с более низким (также слева направо). Отсюда следует важный вывод:
В корень дерева нужно поместить последнюю из операций с наименьшим приоритетом.
87
6
Алгоритмизация и программирование
Теперь нужно построить таким же способом левое и правое поддеревья (рис. 6.13).
Левое поддерево требует ещё одного шага (рис. 6.14):
Рис. 6.14
Эта процедура рекурсивная, её можно записать на псевдокоде так:
найти последнюю выполняемую операцию
if операций нет:
создать узел-лист
return
поместить найденную операцию в корень дерева построить левое поддерево построить правое поддерево
Рекурсия заканчивается, когда в оставшейся части строки нет ни одной операции, значит, там находится число (это лист дерева).
Теперь вычислим выражение по дереву. Если в корне находится знак операции, её нужно применить к результатам вычисления поддеревьев:
nl = значение левого поддерева
п2 = значение правого поддерева
результат = операция (nl, п2)
Снова получился рекурсивный алгоритм.
88
Деревья
§39
Возможен особый случай (на нём заканчивается рекурсия), когда корень дерева содержит число (т. е. это лист). Тогда это число и будет результатом вычисления выражения.
Напишем программу на языке Python, используя введённые выше класс TNode и функцию node. Пусть s — символьная строка, в которой записано арифметическое выражение (будем предполагать, что это правильное выражение без скобок). Вычисление выражения сводится к двум вызовам функций:
Т = makeTree (s)
print ("Результат: ", calcTree(T))
Функция makeTree строит в памяти дерево по строке s, а функция calcTree — вычисляет значение выражения по готовому дереву.
При построении дерева нужно выделить в памяти место для нового узла, а затем искать последнюю выполняемую операцию — это будет делать функция lastOp. Она возвращает -1, если ни одной операции не обнаружено, в этом случае создаётся лист — узел без потомков. Если операция найдена, в поле data нового узла записывается её обозначение, а в поля left и right — адреса поддеревьев, которые строятся рекурсивно для левой и правой частей выражения:
def makeTree(s) :
k = lastOp(s)
if k < 0: # создать лист
Tree = node(s)
else: # создать узел-операцию
Tree = node(s[k])
Tree.left = makeTree(s[:k] )
Tree.right = makeTree(s[k+1:] )
return Tree
Функция calcTree (вычисление арифметического выражения по дереву) тоже будет рекурсивной:
def calcTree(Tree): if not Tree.left: return int(Tree.data) else:
nl = calcTree(Tree.left)
n2 = calcTree(Tree.right)
return oper(Tree.data, nl, n2)
89
6
Алгоритмизация и программирование
Если ссылка на узел, переданная функции, указывает на лист (нет левого поддерева), то значение выражения — это результат преобразования числа из символьной формы в числовую (с помощью функции int). В противном случае вычисляются значения для левого и правого поддеревьев, и к ним применяется операция, указанная в корне дерева, — эту работу выполняет функция орег:
def oper(op, nl, п2):
if op == return nl+n2
elif op == return nl-n2
elif op == return nl*n2
else: return nl//n2
Осталось написать функцию lastOp. Нужно найти в символьной строке последнюю операцию с минимальным приоритетом. Сначала составим функцию, возвращающую приоритет операции (для переданного ей символа):
def priority (op):
if op in return 1
if op in return 2
return 100
Сложение и вычитание имеют приоритет 1, умножение и деление — более высокий приоритет 2, а все остальные символы (не операции) — приоритет 100 (условное значение).
Функция lastOp может выглядеть так:
def lastOp (s):
minPrt =50 # любое между 2 и 100
k = -1
for i in range (len (s)) :
if priority(s[i]) <= minPrt:
minPrt = priority (s[i]) k = i return k
Обратите внимание, что в условном операторе используется нестрогое неравенство, чтобы найти именно последнюю операцию с наименьшим приоритетом.
Начальное значение переменной minPrt можно выбрать любое между наибольшим приоритетом операций (2) и условным кодом «не операции» (100). Тогда, если найдена любая операция, услов
90
Деревья
§39
ный оператор срабатывает, а если в строке нет операций, условие всегда ложно и в переменной к остаётся начальное значение -1, которое и вернёт функция lastOp.
Хранение двоичного дерева в массиве
Двоичные деревья можно хранить в массиве (списке). Вопрос о том, как сохранить структуру (взаимосвязь узлов), решается достаточно просто. Если нумерация элементов массива А начинается с 0, то сыновья элемента A[i] — это A[2*i+1] и A[2*i+2]. На рисунке 6.15 показан порядок расположения элементов в массиве для дерева, соответствующего выражению
40-2*3-4*5
Рис. 6.15
Алгоритм вычисления выражения остаётся прежним, изменяется только метод хранения данных. Обратите внимание, что некоторые элементы остались пустыми, это значит, что их «родитель» — лист дерева. В программе на Python в такие (неиспользуемые) элементы массива можно записывать «пустое» значение None. Конечно, лучше всего так хранить сбалансированные деревья, иначе будет много пустых элементов, которые зря расходуют память.
91
6
Алгоритмизация и программирование
Модульность
При разработке больших программ нужно разделить работу между программистами так, чтобы каждый делал свой независимый блок (модуль). Все подпрограммы, входящие в модуль, должны быть связаны друг с другом, но слабо связаны с другими процедурами и функциями.
В нашей программе в отдельный модуль можно вынести все операции с деревьями, т. е. определение класса TNode и все подпрограммы. Назовём этот модуль bintree (от англ, binary tree — двоичное дерево) и сохраним в файле с именем bintree, ру. Теперь в основной программе можно использовать этот модуль стандартным образом, загружая его с помощью команды import:
import bintree
Т = bintree.makeTree(s)
print("Результат: "r bintree.calcTree (T))
или загружая только нужные нам функции:
from bintree import makeTree, calcTree
T = makeTree (s)
print ("Результат: ", calcTree(T))
Обратите внимание, что нам не нужно знать, как именно устроены функции makeTree и calcTree: какие типы данных они используют, по каким алгоритмам работают и какие дополнительные функции вызывают. Для использования функции модуля достаточно знать интерфейс — соглашение о передаче параметров (какие параметры принимают подпрограммы и какие результаты они возвращают).
Модуль в чём-то подобен айсбергу: видна только надводная часть (интерфейс), а значительно более весомая подводная часть скрыта. За счёт этого все, кто используют модуль, могут не думать о том, как именно он выполняет свою работу. Это один из приёмов, которые позволяют справляться со сложностью больших программ. Разделение программы на модули облегчает понимание и совершенствование программы, потому что каждый модуль можно разрабатывать, изучать и оптимизировать независимо от других.
92
Деревья
§39
Выводы
• Дерево — это структура данных, которая моделирует иерархию — многоуровневую структуру. Как правило, дерево определяется рекурсивно, поэтому для его обработки удобно использовать рекурсивные алгоритмы.
• В двоичном дереве каждый узел имеет не более двух сыновей.
• Деревья используются в задачах поиска, сортировки, для вычисления арифметических выражений и оптимального кодирования.
• Существует несколько способов обхода всех узлов дерева, наиболее известные из них — обход в глубину и обход в ширину.
• Дерево может храниться в памяти как набор связанных структур или как список особой структуры.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания Q
1. Где используются структуры типа «дерево» в информатике и в других областях?
2. Объясните рекурсивное определение дерева.
3. Можно ли считать, что линейный список — это частный случай дерева?
4. Какими свойствами обладает дерево поиска?
5. Подумайте, как можно построить дерево поиска из массива данных.
6. Какие преимущества имеет поиск с помощью дерева?
7. Какие способы обхода дерева вы знаете? Придумайте какие-нибудь другие способы обхода.
8. Как строится дерево для вычисления арифметического выражения?
9. Как можно представить дерево в программе на Python?
10. Как указать, что узел дерева не имеет левого (правого) сына?
11. Как вы думаете, почему рекурсивные алгоритмы работы с деревьями получаются проще, чем нерекурсивные?
12. Как хранить двоичное дерево в массиве? Можно ли использовать такой приём для хранения деревьев, в которых узлы могут иметь больше двух сыновей?
Подготовьте сообщение
а) «Использование деревьев в базах данных»
б) «Префиксные деревья (trie)»
в) «Деревья в языке Паскаль»
93
Алгоритмизация и программирование
г) «Деревья в языке Си»
д) «Диаграммы связей (mind-maps)»
Проекты
а) Программа для сортировки данных с помощью дерева
б) Калькулятор арифметических выражений
§40 Графы
Ключевые слова:
• матрица смежности
• весовая матрица
• орграф
• «жадный» алгоритм
• остовное дерево
• кратчайший маршрут
• алгоритм Дейкстры
• алгоритм Флойда-Уоршелла
• список смежности
• количество путей
Что такое граф?
Как вы знаете из курса 10 класса, граф — это набор вершин (узлов) и связей между ними (рёбер). Информацию о вершинах и рёбрах графа обычно хранят в виде таблицы специального вида — матрицы смежности (рис. 6.16).
94
Графы
§40
Единица на пересечении строки А и столбца В означает, что между вершинами А и В есть связь. Ноль указывает на то, что связи нет. Матрица смежности симметрична относительно главной диагонали (серые клетки в таблице). Единица на главной диагонали обозначает петлю — ребро, которое начинается и заканчивается в одной и той же вершине (в данном случае — в вершине С).
В рассмотренном примере все узлы связаны, т. е. между любой парой вершин существует путь — последовательность рёбер, по которым можно перейти из одной вершины в другую. Такой граф называется связным.
Вспоминая материал предыдущего пункта, можно сделать вывод, что дерево — это частный случай связного графа, в котором нет замкнутых путей — циклов.
Если для каждого ребра указано направление, граф называют ориентированным (или орграфом). Рёбра орграфа называют дугами. Его матрица смежности не всегда симметричная. Единица, стоящая на пересечении строки А и столбца В, говорит о том, что существует дуга из вершины А в вершину В (рис. 6.17).
А в с D
А 0 1 1 1 0
В 0 0 1 1
С 0 0 1 1
D 0 0 0 0
Рис. 6.17
Часто с каждым ребром связывают некоторое число — вес ребра. Это может быть, например, расстояние между городами или стоимость проезда. Такой граф называется взвешенным. Информация о взвешенном графе хранится в виде весовой матрицы, содержащей веса рёбер (рис. 6.18).
95
6
Алгоритмизация и программирование
А В С D
А 12 8
В 12 5 6
С 8 5 4
D 6 4
Рис. 6.18
У взвешенного орграфа весовая матрица может быть несимметрична относительно главной диагонали (рис. 6.19).
Если связи между двумя вершинами нет, на бумаге можно оставить ячейку таблицы пустой, а при хранении в памяти компьютера записывать в неё условный код, например 0, -1 или очень большое число (оо), в зависимости от задачи.
96
Графы
§40
«Жадные» алгоритмы
Задача 1. Известна схема дорог между несколькими городами. Числа на схеме (рис. 6.20) обозначают расстояния (дороги не прямые, поэтому неравенство треугольника может нарушаться).
Рис. 6.20
Нужно найти кратчайший маршрут из города А в город F.
Первая мысль, которая приходит в голову: на каждом шаге выбирать кратчайший маршрут до ближайшего города, в котором мы ещё не были. Для заданной схемы на первом этапе едем в город С (длина 1), далее — в Е (длина 4), затем в D (длина 3) и наконец в F (длина 1) — жирные линии на рис. 6.20. Общая длина маршрута равна 9.
Алгоритм, который мы применили, называется «жадным». Он состоит в том, чтобы на каждом шаге многоходового процесса выбирать наилучший в данный момент вариант, не думая о том, что впоследствии этот выбор может привести к худшему решению.
Для данной схемы жадный алгоритм на самом деле даёт оптимальное решение, но так будет далеко не всегда. Например, для той же задачи с другой схемой, показанной на рис. 6.21, жадный алгоритм выберет маршрут A-B-D-F длиной 10, хотя существует более короткий маршрут A-C-E-F длиной 7.
Рис. 6.21
«Жадный» алгоритм не всегда позволяет получить оптимальное решение.
о
97
6
Алгоритмизация и программирование
Однако есть задачи, в которых жадный алгоритм всегда приводит к правильному решению. Одна из таких задач (её называют задачей Прима—Крускала в честь Р. Прима и Д. Крускала, которые независимо предложили её в середине XX века) формулируется так.
Задача 2. В стране Лимонии есть N городов, которые нужно соединить линиями связи. Между какими городами нужно проложить линии, чтобы все города были связаны в одну систему и общая длина линий связи была наименьшей?
В теории графов эта задача называется задачей построения минимального остовного дерева (т. е. дерева, связывающего все вершины). Остовное дерево для связного графа с N вершинами имеем N - 1 ребро.
Рассмотрим «жадный» алгоритм решения этой задачи, предложенный Крускалом:
1) начальное дерево — пустое;
2) на каждом шаге к будущему дереву добавляется ребро минимального веса, которое ещё не было выбрано и не приводит к появлению цикла.
На рисунке 6.22 показано минимальное остовное дерево для одного из рассмотренных выше графов (сплошные жирные линии).
Здесь возможна такая последовательность добавления рёбер: СЕ, DF, АВ, EF, АС. Обратите внимание, что после добавления ребра EF следующее «свободное» ребро минимального веса — это DE (длина 3), но оно образует цикл с рёбрами DF и EF и поэтому не было включено в дерево.
При программировании этого алгоритма сразу возникает вопрос: как определить, что ребро ещё не включено в дерево и не образует цикла в нём? Существует очень красивое решение этой проблемы, основанное на раскраске вершин.
Сначала все вершины раскрашиваются в разные цвета, т. е. все рёбра из графа удаляются. Таким образом, мы получаем
98
Графы
§40
множество элементарных деревьев (так называемый лес), каждое из которых состоит из одной вершины. Затем последовательно соединяем отдельные деревья, каждый раз выбирая ребро минимальной длины, соединяющее разные деревья (выкрашенные в разные цвета). Объединённое дерево перекрашивается в один цвет, совпадающий с цветом одного из вошедших в него поддеревьев. В конце концов все вершины оказываются выкрашенными в один цвет, т. е. все они принадлежат одному остовному дереву. Можно доказать, что это дерево будет иметь минимальный вес, если на каждом шаге выбирать подходящее ребро минимальной длины.
В программе сначала присвоим всем вершинам разные числовые коды:
col = [i for i in range(N)]
Здесь N — количество вершин, a col — «цвета» вершин (список из N элементов).
Затем в цикле N - 1 раз (именно столько рёбер нужно включить в дерево) выполняем следующие операции:
1) ищем ребро минимальной длины среди всех рёбер, концы которых окрашены в разные цвета;
2) найденное ребро в виде кортежа (iMin, jMin) добавляется в список выбранных, и все вершины, имеющие цвет col [jMin], перекрашиваются в цвет col [iMin].
Напишем полную программу на языке Python. Для описания графа используем весовую матрицу W размера N х N (индексы строк и столбцов начинаются с 0). Если связи между вершинами i и j нет, в элементе W [ i ] [ j ] матрицы будем хранить «бесконечность» — число, намного большее, чем длина любого ребра. Для графа на рис. 6.22 она может быть задана следующим образом:
N = 6
INF = 30000 # "бесконечность", нет связи
W = [
[0, 2, 4, INF, INF, INF] ,
[2, 0, 9, 7, INF, INF] ,
[4, 9, 0, 8, 1, INF] ,
[INF, 7, 8, o, 3, 1] ,
[INF, INF, 1, 3, o, 2],
[INF, INF, INF, 1, 2, 0]
]
99
6
Алгоритмизация и программирование
В список ostov будем записывать выбранные рёбра — каждое ребро хранится как кортеж из номеров двух вершин, которые оно соединяет.
Для поиска ребра с минимальной длиной используем переменную minDist, её начальное значение должно быть больше, чем INF. Приведём полностью основной цикл программы:
ostov = []
for k in range(N-l):
# поиск ребра с минимальным весом
minDist = lelO # очень большое число
for i in range(N):
for j in range(N):
if col[i] != col[j] and W[i][j] < minDist: iMin = i jMin = j minDist = W[i][ j ]
# добавление ребра в список выбранных ostov.append ((iMin, jMin))
# перекрашивание вершин
с = col[jMin]
for i in range(N): if col [ i] == c: col[i] = col[iMin]
После окончания цикла остаётся вывести результат — рёбра из массива ostov:
for edge in ostov:
print("(", edge[0], edge[l], ")")
В цикле перебираются все элементы списка ostov; каждый из них — кортеж из двух элементов — попадает в переменную edge, так что номера вершин определяются как edge [0] и edge[l].
Алгоритм Дейкстры
На примере задачи выбора кратчайшего маршрута (см. задачу 1) мы увидели, что в ней «жадный» алгоритм не всегда даёт правильное решение. В 1960 году Эдсгер Дейкстра предложил алгоритм, позволяющий найти все кратчайшие расстояния от одной вершины графа до всех остальных и соответствующие им маршруты. Предполагается, что длины всех рёбер (расстояния между вершинами) положительные, это справедливо для большинства реальных задач.
100
Графы
§40
Основная идея состоит в следующем: если сумма весов Ж[х][з] -I- W]z][y] меньше, чем вес VK[x][i/], то из вершины X лучше ехать в вершину У не напрямую, а через вершину Z (рис. 6.23).
W[xnzV^\W[z][y]
(хУ-------(?)
Рис. 6.23
Рассмотрим уже знакомую схему (рис. 6.24), для которой не сработал «жадный» алгоритм.
Рис. 6.24
Вершины, минимальные расстояния до которых мы уже определили, будем как-то отмечать («красить»). Сначала ни одна вершина не отмечена, длины кратчайших маршрутов до всех вершин неизвестны. Отмечаем стартовую вершину А, расстояние до которой, очевидно, равно 0. Из этой вершины можно попасть напрямую в вершины В и С, т. е. мы уже знаем, что есть маршрут из А и В длиной 2 и маршрут из А в С длиной 4; записываем эти числа около вершин В и С (рис. 6.25). Около остальных вершин (В, В и В) записываем знак оо («бесконечность»): они недостижимы напрямую из А.
Рис. 6.25
Теперь из всех «непокрашенных»
расстояние до которой от вершины
вершин выбираем такую, А минимально: в нашем
101
Алгоритмизация
и программирование
примере это вершина В (расстояние от А до В равно 2). Поскольку расстояние от А до остальных вершин не меньше 2 и длины всех ребёр неотрицательны, длина любого маршрута из А в В через другие вершины будет не меньше 2. Следовательно, мы нашли длину кратчайшего маршрута из А в В, поэтому отмечаем вершину В, длина маршрута 2 уже не изменится (рис. 6.26).
Рис. 6.26
Далее проверяем, не удастся ли сократить путь в другие вершины, если ехать через В. Для вершины С это не получается — нам уже известен маршрут длиной 4, а маршрут через В даёт 2 + 9 = 11. А вот для вершины D можно улучшить результат: до этого ни одного маршрута не было известно (условно длина равна бесконечности), а теперь найден маршрут длиной 2 + 7 = 9 (ABD) — см. рис. 6.26.
Следующей по такому же принципу отмечается вершина С. Это позволяет найти маршрут из А в Е длиной 5 (АСЕ) — рис. 6.27.
Рис. 6.27
Затем отмечаем вершину Е (длина маршрута из А в Е равна 5). Это позволяет сократить длину маршрута из А в В с 9 до 8 (ACED) и найти маршрут из А в В длиной 7 (ACEF) — рис. 6.28.
102
Графы
§40
После подключения вершин D и F результаты не изменяются.
В программе нам будут нужны два вспомогательных массива. В одном (назовём его selected) для каждой вершины будем хранить логическое значение: True («истина»), если она «покрашена» — кратчайший маршрут до неё уже определён, и False («ложь»), если не «покрашена». Во второй массив с именем dist будем записывать длины кратчайших найденных маршрутов для всех вершин. Сначала все вершины не выбраны и все маршруты неизвестны:
INF = 30000
selected = [False]*N
dist = [INF]*N
Выбираем стартовую вершину, записываем её номер в переменную V:
start = 0
dist[start] = 0
V = start
На каждом шаге алгоритма нужно выполнить два действия. Во-первых, улучшить (если возможно) длины маршрутов, используя пути, проходящие через вершину V:
selected[V] = True
for j in range(N):
if dist[V]+W [V] [ j] < dist[j]: dist[j] = dist[V]+W[V][j]
Во-вторых, найти следующую ещё не выбранную вершину V, для которой расстояние от стартовой вершины минимально:
minDist = 1е10
for j in range(N):
if not selected[j] and dist[j] < minDist: minDist = dist[j] V = j
103
6
Алгоритмизация и программирование
Приведём программу полностью:
INF = 30000 selected = [False]*N dist = [INF]*N start = 0 dist[start] = 0 V = start minDist = 0 while minDist < INF: selected[V] = True # проверка маршрутов через вершину V for j in range(N): if dist[V]+W[V][j] < dist[j]: dist[j] = dist[V] + W[V][j] # поиск новой рабочей вершины dist[j] -> min minDist = lelO # большое число for j in range(N): if not selected[j] and dist[j] < minDist: minDist = dist[j] V = j
После выполнения программы в массиве dist записаны длины оптимальных (кратчайших) маршрутов из вершины А во все вершины.
Остаётся только найти сами оптимальные маршруты (последовательность вершин). Эту задачу можно решить «обратным ходом». Например, найдём оптимальный маршрут из вершины А в вершину F. Как мы видели, его длина равна 7 (см. рис. 6.28).
Вершина F связана с двумя вершинами — D и Е. Если бы маршрут проходил через вершину D, его длина была бы равна 8 + 1 = 9, а маршрут через вершину Е даёт как раз 5 + 2 = 7, поэтому в А мы попадаем именно из Е. Таким образом, нужно перебрать все рёбра, связывающие вершину F с остальными вершинами, и выбрать такое ребро с номером i, для которого dist[i] + W[i] [V] == dist[V], где V — номер вершины F. Эта операция повторяется, пока мы не дойдём до стартовой вершины:
V = N - 1 print(V) while V != start: for i in range(N): if i != V and dist[i]+W[i][V] == dist[V]: V = i
104
Графы
§40
break
print(V)
Оценим сложность алгоритма Дейкстры. Основной цикл выполняется N - 1 раз, причём на каждом шаге этого цикла мы дважды просматриваем все N вершин. Поэтому алгоритм имеет асимптотическую сложность O(N2).
Алгорим Флойда-Уоршелла
Теперь рассмотрим более общую задачу: найти все кратчайшие маршруты из любой вершины во все остальные. Как мы видели, алгоритм Дейкстры находит все кратчайшие пути только из одной заданной вершины. Конечно, можно было бы применить этот алгоритм N раз, но существует более красивый метод — алгоритм Флойда-Уоршелла, основанный на той же самой идее сокращения маршрута: иногда бывает короче ехать через промежуточные вершины, чем напрямую.
На языке Python этот алгоритм записывается так:
for k in range(N):
for i in range(N):
for j in range(N):
if W[i][k]+W[k][j] < W[i][j]: W[i][j] = W[i][k]+W[k][j]
Фактически на каждом шаге цикла по переменной к мы строим матрицу W, в которой элемент W [ i ] [ j ] равен длине кратчайшего пути из вершины i в вершину j при использовании вершин от 1 до к в качестве промежуточных. Перед началом цикла (при к = 0) эта матрица совпадает с весовой матрицей, учитываются только прямые пути из вершины в вершину.
При подключении новой вершины к возможно два варианта: оптимальный маршрут из вершины i в вершину j либо проходит через вершину к, либо не проходит. Фактически нам нужно сравнить длины оптимального маршрута «без вершины к» (с использованием только промежуточных вершин от 1 до к - 1) и «с вершиной к». В первом случае длина маршрута равна W[i] [j] — это то значение, которое оказалось в матрице W после предыдущего шага. Во втором — длина кратчайшего маршрута, проходящего через вершину к, вычисляется как сумма кратчайших маршрутов из вершины i в вершину к и из вершины к в вершину j. Из двух этих значений алгоритм выбирает минимальное и сохраняет в матрице W (рис. 6.29).
105
6
Алгоритмизация и программирование
Рис. 6.29
В результате исходная весовая матрица графа W размером N х N превращается в матрицу, хранящую длины оптимальных маршрутов. Подробное описание и реализацию этого алгоритма вы можете найти в литературе или в Интернете.
Алгоритм Флойда-Уоршелла включает три вложенных цикла, каждый из которых выполняется N раз, поэтому его асимптотическая сложность — O(N3). Но, по сравнению с алгоритмом Дейкстры, он позволяет найти кратчайшие маршруты сразу для всех вершин. Если бы мы решали ту же задачу, используя N раз алгоритм Дейкстры, то сложность такого алгоритма тоже оценивалась бы как O(N3).
Заметим, что алгоритм Флойда-Уоршелла, в отличие от алгоритма Дейкстры, работает даже для графов, в которых веса рёбер могут быть отрицательными. Запрещены только циклы отрицательного веса (обход которых даёт отрицательный суммарный вес рёбер) — в этом случае кратчайших маршрутов может вообще не существовать.
Использование списков смежности
Информацию о графе можно хранить в памяти не только в виде матрицы смежности и весовой матрицы, но и в виде списков смежности. Список смежности для какой-то вершины — это множество вершин, с которыми связана данная вершина. Рассмотрим орграф на рис. 6.30, состоящий из 5 вершин.
Рис. 6.30
106
Графы
§40
Для него списки смежности (с учётом направлений рёбер) выглядят так:
вершина 1: (4)
вершина 2: (1, 3)
вершина 3: ()
вершина 4: (2, 3, 5)
вершина 5: (3)
Граф, показанный на рисунке выше, описывается в виде вложенного списка так:
graph = [ [ ] , # фиктивный элемент
[4], # список смежности для вершины 1
[1,3], # ... для вершины 2
[] , # ... для вершины 3
[2,3,5], # ... для вершины 4
[3] ] # ... для вершины 5
Для того чтобы использовать привычную нумерацию вершин с 1, мы добавили фиктивный элемент — пустой список смежности для несуществующей вершины 0.
Используя такое представление, построим функцию path-Count, которая находит количество путей из одной вершины в другую. Алгоритм её работы основан на следующей идее: общее количество путей из вершины X в вершину У равно сумме количеств путей из X в У через все остальные вершины. Чтобы избежать циклов (замкнутых путей), при этом нужно учитывать только те вершины, которые ещё не посещались. Эту информацию необходимо где-то запоминать, для этой цели мы будем использовать список посещённых вершин.
Таким образом, в функцию pathCount нужно передать следующие данные (аргументы):
• описание графа в виде списков смежности для каждой вершины — graph;
• номера начальной и конечной вершин — vStart и vEnd;
• список посещённых вершин — visited.
Тогда основной цикл функции pathCount приобретает вид
count = О
for v in graph[vStart]:
if not v in visited:
count += pathCount (graph, v, vEnd, visited)
Вы, конечно, заметили, что функция pathCount получилась рекурсивной, т. е. она вызывает сама себя (в цикле). Поэтому
107
6
Алгоритмизация и программирование
нужно определить условие окончания рекурсии: если начальная и конечная вершины совпадают, то существует только один путь, и можно сразу выйти из функции с помощью оператора return:
if vStart == vEnd:
return 1
Приведём полный текст функции:
def pathCount (graph, vStart, vEnd, visited = None): if vStart == vEnd: return 1
if visited is None: visited = []
visited.append (vStart)
count = 0
for v in graph[vStart]:
if not v in visited:
count += pathCount (graph, v, vEnd, visited) visited.pop() return count
и основную программу, которая находит количество путей из вершины 1 в вершину 3:
graph = [[], [4], [1,3], [], [2,3,5], [3]]
print (pathCount (Graph, 1, 3))
У этой программы есть два существенных недостатка. Во-первых, она не выводит сами маршруты, а только определяет их количество. Во-вторых, некоторые данные могут вычисляться повторно: если мы уже нашли количество путей из какой-то вершины X в конечную вершину, то когда это значение потребуется снова, желательно сразу использовать полученный ранее результат, а не вызывать функцию рекурсивно ещё раз. Попытайтесь улучшить программу самостоятельно так, чтобы исправить эти недостатки.
Некоторые задачи
С графами связаны некоторые классические задачи. Самая известная из них — задача коммивояжёра (бродячего торговца).
Задача 3. Бродячий торговец должен посетить N городов по одному разу и вернуться в город, откуда он начал путешествие. Известны расстояния между городами (или стоимость переезда из одного города в другой). В каком порядке нужно посещать
108
Графы
§40
города, чтобы суммарная длина пути (или стоимость) оказалась наименьшей?
Эта задача оказалась одной из самых сложных задач оптимизации. По сей день известно только одно надёжное решение — полный перебор вариантов, число которых равно факториалу числа N. Это число с увеличением N растёт очень быстро, быстрее, чем любая степень N. Уже для N = 20 такое решение требует огромного времени вычислений: компьютер, проверяющий 1 млн вариантов в секунду, будет решать задачу «в лоб» около четырёх тысяч лет. Поэтому математики прилагали большие усилия для того, чтобы сократить перебор, — не рассматривать те варианты, которые заведомо не дадут лучших результатов, чем уже полученные. В реальных ситуациях нередко оказываются полезны приближённые решения, которые не гарантируют точного оптимума, но позволяют получить приемлемый вариант.
Приведём формулировки ещё некоторых задач, которые решаются с помощью теории графов. Алгоритмы их решения вы можете найти в литературе или в Интернете.
Задача 4 (о максимальном потоке). Есть система труб, которые имеют соединения в N узлах. Один узел S является источником, ещё один — стоком Т. Известны пропускные способности каждой трубы. Надо найти наибольший поток (количество жидкости, перетекающее за единицу времени) от источника к стоку.
Задача 5. Имеется N населённых пунктов, в каждом из которых живёт pL школьников (i = 1, ..., N). Надо разместить школу в одном из них так, чтобы общее расстояние, проходимое всеми учениками по дороге в школу, было минимальным. В каком пункте нужно разместить школу?
Задача 6 (о наибольшем паросочетании). Есть М мужчин и N женщин. Каждый мужчина указывает несколько женщин (от О до А), на которых он согласен жениться. Каждая женщина указывает несколько мужчин (от 0 до М), за которых она согласна выйти замуж. Требуется заключить наибольшее количество моногамных браков.
Выводы
• Граф — это набор вершин и связывающих их рёбер. Информация о графе чаще всего хранится в виде матрицы смежности или весовой матрицы.
109
6
Алгоритмизация и программирование
• «Жадный» алгоритм — это алгоритм, в котором на каждом шаге многоходового процесса выбирается наилучший в данный момент вариант, без учёта того, что впоследствии этот выбор может привести к худшему итоговому решению. «Жадный» алгоритм не всегда позволяет найти лучшее решение.
• Алгоритм Дейкстры позволяет определить кратчайшие маршруты из одной вершины во все остальные, его асимптотическая сложность O(N2).
• Алгоритм Флойда находит длины всех кратчайших маршрутов в графе (из каждой вершины во все остальные), его асимптотическая сложность O(N3).
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Сравните известные вам способы хранения информации о графах в памяти компьютера. Какие достоинства и недостатки имеет каждый из них?
2. Сравните понятия «матрица смежности» и «весовая матрица».
3. Какие особенности может иметь весовая матрица орграфа?
4. Что такое «жадный» алгоритм? Всегда ли он позволяет найти лучшее решение?
5. Как, на ваш взгляд, можно было бы ускорить работу алгоритма Крускала с помощью предварительной сортировки рёбер?
Подготовьте сообщение
а) «Задача о кенигсбергских мостах»
б) «Задача коммивояжёра»
в) «"Жадный" алгоритм в задаче коммивояжёра»
г) «Метод ветвей и границ»
д) «Алгоритм Литтла»
е) «Задача о максимальном потоке»
ж) «Задача о наибольшем паросочетании»
з) «Использование графов для анализа данных в Интернете»
и) «Теория графов в практических задачах»
Проекты
а) Лингвистический анализ текстов с помощью графов
б) Программа для решения выбранной задачи с помощью графов
110
Динамическое программирование
§41
Интересные сайты
algolist.manual.ru — сайт, посвящённый алгоритмам
uchimatchast.ru — онлайн-сервис для решения задач оптимизации
graphonline.ru — онлайн-сервис для работы с графами
§41
Динамическое программирование
Ключевые слова:
• динамическое программирование
• перебор вариантов
• рекуррентная формула
Что такое динамическое программирование?
Мы уже сталкивались с последовательностью чисел Фибоначчи (см. учебник для 10 класса):
^=^2=1; Fn=Fn-l+Fn-2 ПРИ П>2'
Для их вычисления можно использовать рекурсивную функцию: def Fib (n): if n < 3: return 1 return Fib(n-l) + Fib(n-2)
Каждое из этих чисел связано с предыдущими, вычисление F5 приводит к рекурсивным вызовам, которые показаны на рис. 6.31.
111
Алгоритмизация и программирование
Таким образом, мы два раза вычислили F3, три раза — F2 и два раза — Fx. Рекурсивное решение очень простое, но оно неоптимально по быстродействию: компьютер выполняет лишнюю работу, повторно вычисляя уже найденные ранее значения.
В чём же выход? Напрашивается такое решение — для того чтобы быстрее найти FN , будем хранить все предыдущие числа Фибоначчи в массиве. Пусть этот массив называется В, сначала заполним его единицами:
F = [1]*(N+1)
В этой задаче нам удобно применить нумерацию, начиная с 1, так что элемент массива F [ 0 ] использоваться не будет. Поэтому размер созданного списка на 1 больше, чем N. Для вычисления всех чисел Фибоначчи от Fr до FN можно использовать цикл:
for i in range (3, N+1): F[i] = F[i-1]+F[i-2]
Динамическое программирование — это способ решения сложных задач путём сведения их к более простым задачам того же типа (задачам меньшей размерности).
Обычно первые задачи-элементы такой последовательности имеют очень простое решение, а последний элемент — это исходная задача. Каждая задача этой последовательности может быть решена с использованием решений подзадач меньшей размерности.
Такой подход впервые систематически применил американский математик Р. Веллман при решении сложных многошаговых задач оптимизации. Его идея состояла в том, что оптимальная последовательность шагов оптимальна на любом участке. Например, пусть нужно перейти из пункта А в пункт Е через один из пунктов В, С или D (числами обозначены «стоимости» маршрутов) — рис. 6.32.
Рис. 6.32
112
Динамическое программирование
§41
Пусть уже известны оптимальные маршруты из пунктов В, С и В в пункт Е (они обозначены сплошными линиями) и их «стоимости». Тогда для нахождения оптимального маршрута из А в £ нужно выбрать вариант, который даст минимальную стоимость по сумме двух шагов. В данном случае это маршрут А-В-Е, стоимость которого равна 25. Как видим, такие задачи решаются «с конца», т. е. решение начинается от конечного пункта.
В информатике динамическое программирование часто сводится к тому, что мы храним в памяти решения всех задач меньшей размерности. За счёт этого удаётся ускорить выполнение программы. Например, на одном и том же компьютере вычисление £35 в программе на Python с помощью рекурсивной функции требует около 58 секунд, а с использованием массива — менее 0,001 с.
Заметим, что в данной простейшей задаче можно обойтись вообще без массива:
fl = 1 f2 = 1 for i in range (3, N 4- 1) : f2, fl = fl + f2, f2
Ответ всегда будет находиться в переменной f2.
Задача 1. Найти количество KN цепочек, состоящих из N нулей и единиц, в которых нет двух стоящих подряд единиц.
При больших N решение задачи методом перебора потребует огромного времени вычислений. Для того чтобы использовать метод динамического программирования, нужно:
1) выразить KN через предыдущие значения последовательности
2) выделить массив для хранения всех предыдущих значений £Дг = 1,...ЛГ-1).
Самое главное — вывести рекуррентную формулу, выражающую KN через решения аналогичных задач меньшей размерности. Рассмотрим цепочку из N бит, последний элемент которой — 0 (рис. 6.33).
1 2 N-2 N-1 N
Рис. 6.33
113
Алгоритмизация и программирование
Поскольку дополнительный О не может привести к появлению двух соседних единиц, подходящих последовательностей длиной N с нулём в конце существует столько, сколько подходящих последовательностей длины N - 1, т. е. KN_r. Если же последний символ — это 1, то слева от него обязательно должен быть О, а начальная цепочка из N - 2 бит должна быть правильной, т. е. не должна содержать двух стоящих подряд единиц (рис. 6.34). Поэтому подходящих последовательностей длина N с единицей в конце существует столько, сколько подходящих последовательностей длиной N — 2, т. е. KN_2.
О
Рис. 6.34
N-2 N-1
В результате получаем: KN = KN_r + KN_2 . Значит, для вычисления очередного числа нам нужно знать два предыдущих.
Теперь рассмотрим простые случаи. Очевидно, что есть две правильные последовательности длиной 1 (0 и 1), т. е. Кг=2. Далее, есть три подходящие последовательности длины 2 (00, О1 и 10), поэтому JT2=3. Легко понять, что решение нашей зада чи — число Фибоначчи: KN =FN+2 .
Поиск оптимального решения
Задача 2. В цистерне N литров молока. Есть бидоны объемом 1, 5 и 6 литров. Нужно разлить молоко в бидоны так, чтобы все используемые бидоны были заполнены и их количество было минимальным.
Человек, скорее всего, будет решать задачу перебором вари антов. Наша задача осложняется тем, что требуется напи( ать программу, которая решает задачу для любого введённого чис ла 2V.
Самый простой подход — заполнять сначала бидоны самого большого размера (6 л), затем — меньшие и т. д. Это «жадный» алгоритм. Как вы знаете, он не всегда приводит к оптимальному решению. Например, для N = 10 «жадный» алгоритм даёт решение 6+14-1 + 1 + 1 — всего 5 бидонов, в то время как можно обойтись двумя (5 + 5).
Как и в любом решении, использующем динамическое программирование, главная проблема — составить рекуррентную формулу. Сначала получим оптимальное число бидонов KN , а пото*
Динамическое программирование
§41
подумаем, как определить, какие именно бидоны нужно использовать.
Представим себе, что мы выбираем бидоны постепенно. Тогда последний выбранный бидон может иметь, например, объём 1 л, в этом случае KN = 1 + KN1. Если последний бидон имеет объём 5 л, то KN =l + /fN_5, а если 6 л, то KN = 1 + KN_Q . Так как нам нужно выбрать минимальное значение, получаем:
=l + min(^N-l>^N-5’^N-6) •
В качестве начального значения берём KQ = 0.
Полученная формула применима при N >6. Для меньших N используются только те данные, которые есть в таблице (рис. 6.35). Например:
tf3=l + .K2=3, A'5-l + min(A'4,A'0) = l.
На рисунке 6.35 показан заполненный массив К для N=10.
У0123456789 10
Рис. 6.35
Как теперь по массиву К определить оптимальный состав бидонов? Пусть, например, N = 10. По таблице определяем, что ЛГ10 = 2, т. е. требуются два бидона. На последнем шаге мы могли добавить, например, бидон объёмом 1 л, тогда было бы ЛГ10-1 = -Кд = 2-1 = 1, но это не так. Проверяем вариант, когда добавляется бидон объёмом 5 л: Jf10_5 = К5 = 1, т. е. этот вариант подходит. Далее таким же способом определяем, что первый бидон тоже имеет объём 5 л (см. рис. 6.35).
Можно заметить, что такая процедура очень похожа на алгоритм Дейкстры, и это не случайно. В алгоритмах Дейкстры и Флойда-Уоршелла, по сути, используется метод динамического программирования.
Задача 3 (задача о куче). Из камней весом pL (i = 1, ..., N) требуется набрать кучу весом ровно W или, если это невозможно, максимально близкую к W (но меньшую, чем ТУ). Все веса камней и значение W — неотрицательные целые числа.
115
6
Алгоритмизация и программирование
Эта задача относится к трудным задачам целочисленной оптимизации, которые решаются только полным перебором вариантов. Каждый камень может входить в кучу (обозначим это состояние как 1) или не входить (0). Поэтому нужно выбрать цепочку, состоящую из N бит. При этом количество вариантов равно 2N, и при больших N полный перебор практически невыполним.
Динамическое программирование позволяет найти решение задачи значительно быстрее. Идея состоит в том, чтобы сохранять в массиве решения всех более простых задач этого типа (при меньшем количестве камней и меньшем весе Ж).
Построим матрицу Т, где элемент Т|7][и>] — это оптимальный вес, полученный при попытке собрать кучу весом w из i первых по счёту камней. Очевидно, что первый столбец заполнен нулями (при заданном нулевом весе никаких камней не берём).
Рассмотрим первую строку (есть только один камень). В начале этой строки будут стоять нули, а дальше, начиная со столбца р19 — значения рг (взяли единственный камень). Это простые варианты задачи, решения для которых легко подсчитать вручную. Рассмотрим пример, когда требуется набрать вес 8 единиц из камней весом 2, 4, 5 и 7 единиц (рис. 6.36).
0 1
5 6 7 8
2
4
5
7
002222222
0
0
0
Рис. 6.36
Теперь предположим, что строки с 1-й по (i - 1)-ю уже заполнены. Перейдем к i-й строке, т. е. добавим в набор i-й камень. Он может быть взят или не взят в кучу. Если мы не добавляем его в кучу, то T[i][zr] = T[i - т. е. решение не меняется от добавления в набор нового камня. Если камень с весом pL добавлен в кучу, то остается «добрать» остаток w-pt оптимальным образом (используя только предыдущие камни), т. е. T[i][iv] = T[i-l][iv-Pi]+Pi.
Как же решить, брать или не брать камень? Надо проверить, в каком случае полученный вес будет больше (ближе к iv). Таким образом, получается рекуррентная формула для заполнения таблицы:
T[i - l][w], при w < Pit
max(T[i - l][u>], T[i - l][u> - p,] + pt), при w > Pi.
T[i]M =
116
Динамическое программирование
§41
Используя эту формулу, заполняем таблицу по строкам, сверху вниз; в каждой строке — слева направо (рис. 6.37).
0 1 2 3 4 5 6 7 _8
2 0 0 *\2 2 2 2 2 2
4 0 0 4 4 6 6 6
5 0 0 2 2 4 5 6 7"'(
7 0 0 2 2 4 5 6 7 (
Рис. 6.37
Видим, что сумму 8 набрать невозможно, ближайшее значение — 7 (правый нижний угол таблицы).
Эта таблица содержит все необходимые данные для определения выбранной группы камней. Действительно, если камень с весом pL не включён в набор, то T[i][ir] = T[i - 1 ][ir], т. е. число в таблице не меняется при переходе на строку вверх. Начинаем с правого нижнего угла таблицы, идём вверх, пока значения в столбце равны 7. Последнее такое значение — для камня с весом 5, поэтому он и выбран. Вычитая его вес из суммы, получаем 7 - 5 = 2, переходим во второй столбец на одну строку вверх, и снова идём вверх по столбцу, пока значение не меняется (равно 2). Так как мы успешно дошли до самого верха таблицы, взят первый камень с весом 2.
Как мы уже отмечали, количество вариантов в задаче для N камней равно 2Л\ т. е. алгоритм полного перебора имеет асимптотическую сложность O(2n ). В данном алгоритме количество операций равно числу элементов таблицы, т. е. сложность нашего алгоритма — O(NW). Однако нельзя сказать, что он имеет линейную сложность, так как есть ещё сильная зависимость от заданного веса, W. Такие алгоритмы называют псевдополиномиалъ-ными («как бы полиномиальными»). В них ускорение вычислений достигается за счёт использования дополнительной памяти для хранения промежуточных результатов.
Количество решений
Задача 4. У исполнителя Утроитель две команды, которым присвоены номера:
1. прибавь 1
2. умножь на 3
Первая из них увеличивает число на экране на 1, вторая — утраивает его. Программа для У троите л я — это последовательность
117
6
Алгоритмизация и программирование
команд. Сколько есть программ, которые число 1 преобразуют в число N = 20?
Заметим, что при выполнении любой из команд число увеличивается (не может уменьшаться). Начнём с простых случаев, с которых будем начинать вычисления. Понятно, что для начального значения N = 1 существует только одна программа — пустая, не содержащая ни одной команды. Для числа N = 2 тоже есть только одна программа, состоящая из команды сложения. Если через KN обозначить количество разных программ для получения числа N из 1, то Kr = К2 = 1.
Теперь рассмотрим общий случай, чтобы построить рекуррентную формулу, связывающую KN с предыдущими элементами последовательности Kr,K2,.. .,KN^ , т. е. с решениями таких же задач для меньших N.
Если число N не делится на 3, то последней командой для его получения может быть только операция сложения, поэтому KN = KN_r. Если N делится на 3, то последней командой может быть как сложение, так и умножение. Поэтому нужно сложить К’ЛГ_1 (количество программ с последней командой сложения) и К’ЛГ/3 (количество программ с последней командой умножения). В итоге получаем:
К’ЛГ_1, если N не делится на 3;
+ ^n/З’ если N делятся на 3.
Остаётся заполнить таблицу для всех значений от 1 до заданного tV = 20. Для небольших значений N эту задачу легко решить вручную — рис. 6.38.
KN =
N 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
KN 1 1 2 2 2 3 3 3 5 5 5 7 7 7 9 9 9 12 12 12
Рис. 6.38
Заметим, что количество вариантов меняется только в тех столбцах, где N делится на 3, поэтому из всей таблицы можно оставить только эти столбцы (и первый), добавляя следующее значение, кратное трём — рис. 6.39.
N 1 3 6 9 12 15 18 21
KN 1 2 3 5 7 9 12 15
Рис. 6.39
118
Динамическое программирование
§41
Заданное число 20 попадает в последний интервал (от 18 до 20), поэтому ответ в данной задаче — 12.
При составлении программы с полной таблицей нужно выделить в памяти целочисленный массив К, индексы которого изменяются от 0 до N + 1, и заполнить его по приведённым выше формулам:
К = [1]* (N+1)
for i in range(2, N+1):
K[i] = K[i-1] if i % 3 == 0:
K[i] += K[i//3]
Ответом будет значение K[N].
Задача 5 (Размен монет). Сколькими различными способами можно выдать сдачу размером W рублей, если есть монеты достоинством pt{i = 1, ..., N)2 Для того чтобы сдачу всегда можно было выдать, будем предполагать, что в наборе есть монета достоинством 1 рубль (рх = 1).
Это задача, так же как и задача о куче, решается полным перебором вариантов, число которых при больших N очень велико. Будем использовать динамическое программирование, сохраняя в массиве решения всех задач меньшей размерности (для меньших значений N и W).
В матрице Т значение T[i][u>] будет обозначать количество вариантов сдачи размером w рублей (w изменяется от 0 до W) при использовании первых i монет из набора. Очевидно, что при нулевой сдаче есть только один вариант (не дать ни одной монеты), так же и при наличии только одного типа монет (напомним, что рг=1) есть тоже только один вариант. Поэтому нулевой столбец и первую строку таблицы можно сразу заполнить единицами. Для примера мы будем рассматривать задачу для Ж = 10 и набора монет достоинством 1, 2, 5 и 10 рублей (рис. 6.40).
123456789 10
1
2
5
10
11111111111
1
1
1
Рис. 6.40
119
6
Алгоритмизация и программирование
Таким образом, мы определили простые базовые случаи, от которых «отталкивается» рекуррентная формула.
Теперь рассмотрим общий случай. Заполнять таблицу будем по строкам, слева направо. Для вычисления T[i][u>] предположим, что мы добавляем в набор монету достоинством pt. Если сумма w меньше, чем pz, то количество вариантов не увеличивается, и T[i][u>] = T[i - 1][и>]. Если сумма больше pz, то к этому значению нужно добавить количество вариантов с «участием» новой монеты. Если монета достоинством pt использована, то нужно учесть все варианты «разложения» остатка w - pL на все доступные монеты, т. е. Т|7][и>] = T[i - l][u>] + Т|7][и> - pt]. В итоге получается рекуррентная формула
T[i - l][u>], при w < pt;
T[i- l][u/| + T[i][u> -- pz], при w > pt.
T[i][u>] =
которая используется для заполнения таблицы (рис. 6.41).
0 1 2 3 4 5 6 7 8 9 10
1 1 1 1 1 1 1 1 1 1 1 1
2 1 1 2 2 3 3 4 4 5 5 6
5 1 1 2 2 3 4 5 6 7 8 10
10 1 1 2 2 3 4 5 6 7 8 (и)
Рис. 6.41
Ответ к задаче находится в правом нижнем углу таблицы.
Вы могли заметить, что решение этой задачи очень похоже на решение задачи о куче камней. Это не случайно, две эти задачи относятся к классу сложных задач, для решения которых известны только переборные алгоритмы. Использование методов динамического программирования позволяет ускорить решение за счёт хранения промежуточных результатов, однако требует дополнительного расхода памяти.
Выводы
• Динамическое программирование — это метод, позволяющий ускорить решение задачи за счёт хранения решений более простых задач того же типа.
120
Динамическое программирование
§41
• Для использования метода динамического программирования нужно вывести рекуррентную формулу, связывающее решение исходной задачи с решением подобных задач меньшей размерности, и определить простые базовые случаи.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Какой смысл имеет выражение «динамическое программирование» в теории многошаговой оптимизации?
2. Какие шаги нужно выполнить, чтобы применить динамическое программирование к решению какой-либо задачи?
3. За счёт чего удаётся ускорить решение сложных задач методом динамического программирования?
4. Какие ограничения есть у метода динамического программирования?
5. Сравните метод динамического программирования и рекурсивные решения.
Подготовьте сообщение
а) «Задача о рюкзаке»
б) «Задачи на подпоследовательности»
в) «Поиск оптимального маршрута»
г) «Динамическое программирование в задачах биоинформатики»
Проекты
а) Определение количества решений систем логических уравнений методом отображений
б) Программа для решения задач с исполнителем Калькулятор
в) Программа для решения выбранной задачи с помощью динамического программирования
ЭОР к главе 6 на сайте ФЦИОР (http://fcior.edu.ru)
• Решето Эратосфена
• Основные структуры данных
• Сущность модульного программирования. Программный модуль
• Работа с указателями и структурами (на примере языка Pascal)
• Линейные структуры данных. Список, стек, очередь
• Организация и работа со стеком
121
6
Алгоритмизация и программирование
• Организация и работа с очередью
• Основы теории графов. Способы представления графов. Обход графа
• Задача о кратчайших путях. Алгоритм Флойда, Дейкстры
• Задачи оптимизации. Динамическое программирование
WWW
Практические работы к главе 6
Работа № 39 «Решето Эратосфена» Работа № 40 «Длинные числа»
Работа № 41 «Структуры»
Работа № 42 «Словари»
Работа № 43 «Алфавитно-частотный словарь»
Работа № 44 «Вычисление арифметических выражений»
Работа № 45 «Скобочные выражения»
Работа № 46 «Очереди»
Работа № 47 «Заливка области»
Работа № 48 «Обход дерева»
Работа № 49 «Вычисление арифметических выражений»
Работа № 50 «Хранение двоичного дерева в массиве»
Работа № 51 «Задача Прима-Крускал а»
Работа № 52 «Алгоритм Дейкстры»
Работа № 53 «Алгоритм Флойда-Уоршелла»
Работа № 54 «Числа Фибоначчи»
Работа № 55 «Задача о куче»
122
Глава 7
ОБЪЕКТНО-ОРИЕНТИРОВАННОЕ ПРОГРАММИРОВАНИЕ
§42 Введение
Ключевые слова:
• объект
• декомпозиция
• абстракция
• объектная модель
• интерфейс
• свойство
• поведение
• состояние
• объектно-ориентированный анализ
• класс
• метод
Борьба со сложностью
Как вы знаете, работа первых компьютеров сводилась к вычислениям по заданным формулам различной сложности. Число переменных и массивов в программе было невелико, так что программист мог легко удерживать в памяти все взаимосвязи между ними и детали алгоритма.
С каждым годом производительность компьютеров росла, и человек «поручал» им всё более и более трудоёмкие задачи. Компьютеры следующих поколений стали использоваться для создания сложных информационных систем (например, банковских) и моделирования процессов, происходящих в реальном мире. Новые задачи требовали более сложных алгоритмов, объём программ вырос до сотен тысяч и даже миллионов строк, число переменных и массивов измерялось в тысячах.
Программисты столкнулись с проблемой сложности, которая превысила возможности человеческого разума. Один человек уже не способен написать надёжно работающую серьезную программу, так как не может «охватить взглядом» все её детали. Поэтому в разработке большинства современных программ принимает участие множество специалистов. При этом возникает новая проблема — нужно разделить работу между ними так, чтобы каждый мог работать независимо от других, а потом готовую програм
123
7
Объектно-ориентированное программирование
му можно было бы собрать вместе из готовых блоков, как из кубиков.
Как отмечал известный нидерландский программист Эдсгер Дейкстра, человечество ещё в древности придумало способ управления сложными системами: «разделяй и властвуй». Это означает, что исходную систему нужно разбить на подсистемы (выполнить декомпозицию) так, чтобы работу каждой из них можно было рассматривать и совершенствовать независимо от других.
Для этого в классическом (процедурном) программировании используют метод проектирования «сверху вниз»: сложная задача разбивается на части (подзадачи и соответствующие им алгоритмы)^ которые затем снова разбиваются на более мелкие подзадачи и т. д. (рис. 7.1).
Рис. 7.1
Однако при этом задачу «реального мира» приходится пере-формулировывать, представляя все данные в виде переменных, массивов, списков и других структур данных. При моделировании больших систем объём этих данных увеличивается, они становятся плохо управляемыми, и это приводит к большому числу ошибок. Так как любой алгоритм может обратиться к любым глобальным (общедоступным) данным, повышается риск случайного недопустимого изменения каких-то значений.
Объектный подход
В конце 60-х годов XX века появилась новая идея — применить в разработке программ тот подход, который использует человек в повседневной жизни. Люди воспринимают мир как множество объектов — предметов, животных, людей — это отмечал ещё в XVII веке французский математик и философ Рене Декарт. Все объекты имеют внутреннее устройство и состояние, свойства (внешние характеристики) и поведение. Чтобы справиться со сложностью окружающего мира, люди часто игнорируют многие свойства объектов, ограничиваясь лишь теми, которые необходи-
124
Введение
§42
мы для решения их практических задач. Такой приём называется абстракцией.
Абстракция — это выделение существенных характеристик объекта, отличающих его от других объектов.
Для разных задач существенные свойства одного и того же объекта могут быть совершенно разными. Например, услышав слово «кошка», многие подумают о пушистом усатом животном, которое мурлыкает, когда его гладят. В то же время ветеринарный врач представляет скелет, ткани и внутренние органы кошки, которую ему нужно лечить. В каждом из этих случаев применение абстракции даёт разные модели одного и того же объекта, поскольку различны цели моделирования.
Как применить принцип абстракции в программировании? Поскольку формулировка задач, решаемых на компьютерах, всё более приближается к формулировкам реальных жизненных задач, возникла такая идея: представить программу в виде множества объектов (моделей), каждый из которых обладает своими свойствами и поведением, но его внутреннее устройство скрыто от других объектов. Тогда решение задачи сводится к моделированию взаимодействия этих объектов. Построенная таким образом модель задачи называется объектной. Здесь тоже идёт проектирование «сверху вниз», только не по алгоритмам (как в процедурном программировании), а по объектам. Такую декомпозицию можно представить в виде графа, где каждый объект может обмениваться данными со всеми другими (рис. 7.2).
Здесь А, Б, В и Г — объекты «верхнего уровня»; Бх, Б2 и Б3 — под объекты объекта Б и т. д.
125
Объектно-ориентированное программирование
Для решения задачи «на верхнем уровне» достаточно определить, что делает тот или иной объект, не заботясь о том, как именно он это делает. Таким образом, для преодоления сложности мы используем абстракцию, т. е. сознательно отбрасываем второстепенные детали.
Если построена объектная модель задачи (выделены объекты и определены правила обмена данными между ними), то можно поручить разработку каждого из объектов отдельному программисту (или группе), которые должны написать соответствующую часть программы, т. е. определить, как именно объект выполняет свои функции. При этом конкретному разработчику не обязательно держать в голове полную информацию обо всех объектах, нужно лишь строго соблюдать соглашения о способе обмена данными (интерфейсе) «своего» объекта с другими.
Программирование, основанное на моделировании задачи реального мира как множества взаимодействующих объектов, принято называть объектно-ориентированным программированием (ООП). Более строгое определение мы дадим немного позже.
Объекты и классы
Как мы увидели, для того чтобы построить объектную модель, нужно:
• выделить взаимодействующие объекты, с помощью которых можно достаточно полно описать поведение моделируемой системы;
• определить их свойства, существенные в данной задаче;
• описать поведение (возможные действия) объектов, т. е. команды, которые объекты могут выполнить.
Этап разработки модели, на котором решаются перечисленные выше задачи, называется объектно-ориентированным анализом (ООА). Он выполняется до того, как программисты напишут самую первую строчку кода, и во многом определяет качество и надёжность будущей программы.
Рассмотрим объектно-ориентированный анализ на примере простой задачи. Пусть нам необходимо изучить движение автомобилей на шоссе, например, для того чтобы определить, достаточна ли его пропускная способность. Как построить объектную модель этой задачи? Прежде всего, нужно разобраться, что такое объект.
о
Объектом можно назвать то, что имеет чёткие границы и обладает состоянием и поведением.
126
Введение
§42
Состояние объекта определяет его возможное поведение. Например, лежачий человек не может прыгнуть, а незаряженное ружьё не выстрелит.
В нашей задаче объекты — это дорога и двигающиеся по ней машины. Машин может быть несколько, причём все они с точки зрения нашей задачи имеют общие свойства. Поэтому нет смысла описывать отдельно каждую машину: достаточно один раз определить их общие черты, а потом просто сказать, что все машины ими обладают. В ООП для этой цели вводится специальный термин — « класс».
Класс — это описание множества объектов, имеющих общую структуру и общее поведение.
о
Например, в рассматриваемой задаче можно ввести два класса — Дорога и Машина. По условию, дорога одна, а машин может быть много.
Будем рассматривать прямой отрезок дороги, в этом случае объект «дорога» имеет два свойства, важных для нашей задачи: длину и ширину — число полос движения (рис. 7.3).
Длина
Рис. 7.3
Эти свойства определяют состояние дороги. «Поведение»
дороги может заключаться в том, что число полос ся, например, из-за ремонта покрытия, но в нашей модели объект «дорога» не будет изменяться.
Схематично класс Дорога можно изобразить в виде прямоугольника с тремя секциями (рис. 7.4): в верхней записывают название класса, во второй части — свойства, а в третьей — возможные действия, которые называют методами. В нашей модели дороги два свойства и ни
уменыпает-простейшей
Дорога длина ширина
Рис. 7.4
одного метода.
127
7
Объектно-ориентированное программирование
Теперь рассмотрим объекты класса Машина. Их важнейшие свойства — координаты и скорость движения. Для упрощения будем считать, что:
• все машины одинаковы;
• все машины движутся по дороге слева направо с постоянной скоростью (скорости разных машин могут быть различными);
• по каждой полосе движения едет только одна машина, так что можно не учитывать обгон и перестроение на другую полосу;
• если машина выходит за правую границу дороги, вместо неё слева на той же полосе появляется новая машина.
Не все эти допущения выглядят естественно, но такая простая модель позволит понять основные принципы метода.
За координаты машины можно принять расстояние X от левого края рассматриваемого участка шоссе и номер полосы Р (натуральное число). Скорость автомобиля V в нашей модели — неотрицательная величина (рис. 7.5).
Машина
Х( координата) Р(полоса) V (скорость) двигаться
Рис. 7.6
Рис. 7.5
Теперь рассмотрим поведение машины. В данной модели она может выполнять всего одну команду — ехать в заданном направлении (назовём эту команду «двигаться»). Говорят, что объекты класса Машина имеют метод «двигаться» (рис. 7.6).
о
Метод — это процедура или функция, принадлежащая классу объектов.
Другими словами, метод — это некоторое действие, которое могут выполнять все объекты класса.
Пока мы построили только модели отдельных объектов (точнее, классов). Чтобы моделировать всю систему, нужно разобраться, как эти объекты взаимодействуют. Объект-машина должен уметь «определить», что закончился рассматриваемый участок
128
Введение
§42
дороги. Для этого машина должна обращаться к объекту «доро-
га», запрашивая длину дороги (рис. 7.7).
Рис. 7.7
Схема на рис. 7.7 определяет:
• свойства объектов;
• операции, которые они могут выполнять;
• связи (обмен данными) между объектами.
В то же время мы пока ничего не говорили о том, как устроены объекты и как именно они будут выполнять эти операции. Согласно принципам ООП, ни один объект не должен зависеть от внутреннего устройства и алгоритмов работы других объектов. Поэтому, построив такую схему, можно поручить разработку двух классов объектов двум программистам, каждый из которых может решать свою задачу независимо от другого. Важно только, чтобы все программисты чётко соблюдали интерфейс — правила, описывающие взаимодействие «своих» объектов с остальными.
Выводы
• Чтобы справиться со сложностью окружающего мира, люди игнорируют многие свойства объектов, ограничиваясь лишь теми, которые необходимы для решения их практических задач. Такой приём называется абстракцией.
• Объектно-ориентированное программирование основано на моделировании задачи реального мира как множества взаимодействующих объектов.
• Объектом можно назвать то, что имеет чёткие границы и обладает состоянием и поведением.
• Класс — это описание множества объектов, имеющих общую структуру и общее поведение.
• До того как начать написание программы, выполняется объектно-ориентированный анализ задачи: определяются классы объектов, их свойства и методы.
• Метод — это процедура или функция, принадлежащая классу объектов.
129
Объектно-ориентированное программирование
• Интерфейс — это правила взаимодействия объекта с остальными объектами.
• Согласно принципам ООП, ни один объект не должен зависеть от внутреннего устройства и алгоритмов работы других объектов.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Почему со временем неизбежно изменяются методы программирования?
2. Что такое декомпозиция, зачем она применяется?
3. Что такое процедурное программирование? Какой вид декомпозиции в нём используется?
4. Какие проблемы в программировании привели к появлению ООП?
5. Что такое абстракция? Зачем она используется в обычной жизни?
6. Объясните, как связана абстракция с моделированием.
7. Какой вид декомпозиции используется в ООП?
8. Какие преимущества даёт объектный подход в программировании?
9. Что такое интерфейс? Приведите примеры объектов, у которых одинаковый интерфейс и разное устройство.
10. Какие этапы входят в объектно-ориентированный анализ?
11. Сравните понятия «класс» и «объект».
12. Почему при объектно-ориентированном анализе не уточняют, как именно объекты будут устроены и как они будут решать свои задачи?
Подготовьте сообщение
а) «Объектно-ориентированный анализ»
б) «Объектно-ориентированные языки программирования»
Проект
Объектно-ориентированный анализ выбранной задачи
Интересный сайт
www.computer-museum.ru/histsoft/oophist.htm — краткая история ООП
130
Создание объектов в программе
§43
§43
Создание объектов в программе
Ключевые слова:
• класс
• поле
• метод
• конструктор
Класс Дорога
Объектно-ориентированная программа начинается с описания классов объектов. Класс в программе — это новый тип данных. Как и структура (см. главу 6), класс — это составной тип данных, который может объединять переменные различного типа в единый блок. Кроме того, класс обычно содержит не только данные, но и методы работы с ними (процедуры и функции).
В нашей программе самый простой класс — это Дорога (англ. road). Объекты этого класса имеют два свойства (в Python они называются атрибутами): длину (англ, length), которая может быть вещественным числом, и ширину (англ, width) — количество полос, целое число. Для хранения значений свойств используются переменные, принадлежащие объекту, которые называются полями.
Поле — это переменная, принадлежащая объекту.
о
Значения полей описывают состояние объекта (а методы — его поведение).
Простейшее описание класса Дорога в программе на Python выглядит так:
class TRoad:
pass
Эти строки вводят новый тип данных — класс TRoad1), т. е. сообщают транслятору, что в программе, возможно, будут использоваться объекты этого типа. При этом в памяти не создаётся ни одного объекта. Это описание — как чертёж, по которому в нужный момент можно построить сколько угодно таких объектов.
h Буква «Т» в начале названия класса — это сокращение от английского слова type — тип.
131
7
Объектно-ориентированное программирование
Чтобы создать объект класса TRoad, нужно вызвать специальную функцию без параметров, имя которой совпадает с именем класса:
road = TRoad()
Созданный объект относится к классу TRoad, поэтому его называют экземпляром класса TRoad.
При описании класса мы не определяли функцию, которую только что вызвали. Она добавляется транслятором ко всем классам автоматически и называется конструктором.
Конструктор — это метод класса, который вызывается для создания объекта этого класса.
У каждого объекта класса TRoad должно быть два поля (длина и ширина), которые мы сразу заполним нулями. Для этого нужно определить свой конструктор — метод класса с именем __init___ (от англ, initialization — начальные установки).
class TRoad:
def ___init__(self) : # конструктор
self.length = 0 self.width = 0
Первый параметр конструктора (как и любого метода класса) в Python — это ссылка на сам объект, который создаётся. По традиции он всегда называется self (от англ, self — сам). С помощью этой ссылки мы обращаемся к полям объекта, например self, length означает «поле length текущего объекта». Если вместо этого написать просто length, то транслятор будет считать, что речь идёт о локальной или глобальной переменной, а не о поле объекта. В этом конструкторе создаются и заполняются нулями два поля (атрибута) объекта — длина length и ширина width.
Свойства дороги можно изменить с помощью точечной записи, с которой вы познакомились, работая со структурами:
road.length = 60 road.width = 3
Полная программа, которая создаёт объект «дорога» (и больше ничего не делает) выглядит так:
class TRoad:
def _init____(self): # конструктор
132
Создание объектов в программе
§43
self.length = О self.width = О road = TRoad () road.length = 60 road.width = 3
Начальные значения полей можно задавать прямо при создании объекта. Для этого нужно изменить конструктор, добавив два параметра — начальные значения длины и ширины дороги:
class TRoad:
def __init__(self, lengthO, widthO): # конструктор
if lengthO > 0:
self.length = lengthO
else:
self.length = 0 if widthO > 0: self.width = widthO else: self.width = 0
В этом конструкторе проверяется правильность переданных параметров, чтобы по ошибке длина и ширина дороги не оказались отрицательными. Теперь создавать объект будет проще:
road = TRoad (60, 3)
Длина этой дороги — 60 единиц, она содержит 3 полосы. Обратите внимание, что мы передали только два параметра, а не три, как указано в заголовке метода _init_. Параметр self,
который указан самым первым, транслятор подставляет автоматически.
Таким образом, класс выполняет роль «фабрики», которая при вызове конструктора «выпускает» (создаёт) объекты «по чертежу» (описанию класса).
Класс Машина
Теперь можно описать класс Машина (в программе назовём его ТСаг). Объекты класса ТСаг имеют три свойства: координату X, номер полосы Р и скорость V:
class ТСаг:
def _init____(self, roadO, p0, vO): # конструктор
self.road = roadO
133
7
Объектно-ориентированное программирование
self.P = рО self.V = vO self.X = О
Так как объекты-машины должны обращаться к объекту «дорога», в область данных включено дополнительное поле road. Конечно, это не значит, что в состав машины входит дорога. Напомним, что это только ссылка, в которую сразу после создания объекта-машины нужно записать адрес заранее созданного объекта « дорога ».
Для того чтобы машина могла двигаться, нужно добавить к классу метод — процедуру move:
class TCar:
def ___init__(self, roadO, pO, vO): # конструктор
self.road = roadO self.P = pO self.V = vO self.X = 0
def move(self): # движение машины
self.X += self.V
if self.X > self.road.length:
self.X = 0
Первый параметр метода move, как и у любого метода класса в Python, называется self (ссылка на сам объект), других параметров нет, поэтому при вызове этого метода никаких данных ему передавать не нужно.
В методе move вычисляется новая координата X машины, и, если эта координата находится за пределами дороги, она устанавливается равной нулю (машина появляется слева на той же полосе). Изменение координаты при равномерном движении описывается формулой
X = Хо + V • м,
где Хо и X — начальная и конечная координаты, V — скорость, a At — время движения. Вспомним, что любое моделирование физических процессов на компьютере происходит в дискретном времени, с некоторым интервалом дискретизации. Для простоты мы измеряем время в этих интервалах, а за скорость V принимаем расстояние, проходимое машиной за один интервал. Тогда метод move описывает изменение положения машины за один интервал (Д£ = 1).
134
Создание объектов в программе
§43
Основная программа
После определения классов в основной программе создадим массив (список) объектов-машин, каждую из них «свяжем» с ранее созданным объектом Дорога*.
N = 3
cars = [ ]
for i in range(N):
cars.append(TCar(road, i + 1, 2* (i+1)))
При вызове конструктора класса TCar задаются три параметра: адрес объекта «дорога» (его нужно создать до выполнения этого цикла), номер полосы и скорость. В приведённом примере машина с номером i идёт по полосе с номером i+1 (считаем, что полосы нумеруются с единицы) со скоростью 2 (i 4- 1) единиц за один интервал моделирования.
Сам цикл моделирования получается очень простой: на каждом шаге вызывается метод move для каждой машины:
for k in range(100): # 100 шагов
for i in range(N): # для каждой машины
cars[i].move()
В данном случае выполнено 100 шагов моделирования. Теперь можно вывести на экран координаты всех машин:
print("После 100 шагов:")
for i in range(N):
print(cars[i].X)
Можно ли было написать такую же программу, не используя объекты? Конечно, да. И она получилась бы короче, чем наш объектный вариант (с учётом описания классов). В чём же преимущества ООП? Мы уже отмечали, что ООП — это средство разработки больших программ, моделирующих работу сложных систем. В этом случае очень важно, что при использовании объектного подхода:
• объекты реального мира проще всего описываются именно с помощью понятий «объект», «свойства», «действия» (методы);
• основная программа, описывающая решение задачи в целом, получается простой и понятной; все команды напоминают действия в реальном мире («машина № 2, вперед!»);
• разработку отдельных классов объектов можно поручить разным программистам, при этом каждый может работать независимо от других;
• если объекты Дорога и Машина понадобятся в других разработках, можно будет легко использовать уже готовые классы.
135
7
Объектно-ориентированное программирование
Выводы
• ООП — это средство разработки больших и сложных программ. Использование ООП при решении простых задач может приводить к увеличению длины программы.
• Класс в языке программирования — это описание нового типа данных, который объединяет данные и методы работы с ними.
• Поле — это переменная, принадлежащая объекту.
• Значения полей описывают состояние объекта, а методы — его поведение.
• Конструктор — это метод класса, который вызывается для создания объекта этого класса. Если конструктор не задан, транслятор автоматически создаёт конструктор по умолчанию. Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Как объявляется класс объектов в программе?
2. Сравните конструктор с обычным методом класса (функцией или процедурой).
3. Что такое точечная запись? Как она используется при работе с объектами?
4. Какими способами можно задать начальные значения для полей объекта?
5. Сравните преимущества и недостатки решения рассмотренной задачи «классическим» способом и с помощью ООП. Сделайте выводы.
Подготовьте сообщение
а) «Классы в языке Pascal (Delphi)»
б) «Классы в языке C++ (С#)»
в) «Классы в языке Java»
Проект
Программа моделирования на основе объектов для выбранной задачи
Интересные сайты
helloworld.ru — документация по языкам программирования younglinux.info/oopython.php — введение в ООП на Python ru.stackoverflow.com — сайт вопросов и ответов для програм-
мистов
136
Скрытие внутреннего устройства
§44
§44
Скрытие внутреннего устройства
Ключевые слова:
• инкапсуляция
• свойство
Во время построения объектной модели задачи мы выделили отдельные объекты, которые для обмена данными друг с другом используют интерфейс — внешние свойства и методы. При этом все внутренние данные и детали внутреннего устройства объекта должны быть скрыты от «внешнего мира». Такой подход позволяет:
• обезопасить внутренние данные (поля) объекта от изменений (возможно, разрушительных) со стороны других объектов;
• проверять данные, поступающие от других объектов, на корректность, тем самым повышая надёжность программы;
• переделывать внутреннюю структуру и код объекта любым способом, не меняя его внешние характеристики (интерфейс); при этом никакой переделки других объектов не требуется.
Скрытие внутреннего устройства объектов и алгоритмов обработки данных называют инкапсуляцией («помещением в капсулу»).
о
Для этого данные и методы их обработки объединяются вместе, и получается объект.
Разберём простой пример. Во многих системах программирования есть класс, описывающий свойства «пера», которое используется при рисовании линий в графическом режиме. Назовём этот класс ТРеп, в простейшем варианте он будет содержать только одно поле color, которое определяет цвет. Будем хранить код цвета в виде символьной строки, в которой записан шестнадцатеричный код составляющих модели RGB. Например, "FF00FF" — это фиолетовый цвет, потому что красная (R) и синяя (В) составляющие равны FF16 = 255, а зелёной составляющей нет вообще. Класс можно объявить так:
class ТРеп: def _____init__ (self) :
self.color = "000000"
137
7
Объектно-ориентированное программирование
По умолчанию в Python все члены класса (поля и методы) открытые, общедоступные (англ, public). Имена тех элементов, которые нужно скрыть, должны начинаться с двух знаков подчёркивания, например так:
class ТРеп:
def __init___(self):
self. color = "000000"
В этом примере поле ____color закрытое (англ, private — част-
ный). К закрытым полям нельзя обратиться извне (это могут делать только методы самого объекта), поэтому теперь невозможно не только изменить внутренние данные объекта, но и просто узнать их значения. Чтобы решить эту проблему, нужно добавить к классу ещё два метода: один из них будет возвращать текущее значение поля ___color, а второй — присваивать полю
новое значение. Эти методы доступа назовём getColor (в переводе с англ, «получить цвет») и setColor (в переводе с англ, «установить цвет»):
class ТРеп:
def ___init__(self) :
self.___color = "000000"
def getColor(self): return self._____color
def setColor(self, newColor): if len(newColor) != 6: self.________color = "000000"
else: self. color = newColor
Что же улучшилось в сравнении с первым вариантом (когда поле было открытым)? Согласно принципам ООП, внутренние поля объекта должны быть доступны только с помощью методов. В этом случае внутреннее представление данных может как угодно отличаться от того, как другие объекты «видят» эти данные.
В простейшем случае метод getColor просто возвращает значение поля. В методе setColor мы можем обрабатывать ошибки, не разрешая присваивать полю недопустимые значения. Например, в нашем методе требуется, чтобы символьная строка с кодом цвета состояла из шести символов. Если это не так, в поле __color записывается код чёрного цвета "000000" (цвет
по умолчанию).
138
Скрытие внутреннего устройства
§44
Теперь, если реп — это объект класса ТРеп, то для установки и чтения его цвета нужно использовать показанные выше методы:
реп = ТРеп()
pen.setColor ("FFFF00") # изменение цвета
print ("цвет пера:", реп.getColor()) # получение цвета
Итак, мы скрыли (защитили) внутренние данные, но одновременно обращение к свойствам стало выглядеть довольно неуклюже: вместо реп.color="FFFF00" теперь нужно писать pen.setColor("FFFF00”). Чтобы упростить запись, во многие объектно-ориентированные языки программирования ввели понятие свойства (англ, property), которое внешне выглядит как переменная объекта, но на самом деле при записи и чтении свойства вызываются методы объекта.
Свойство — это способ доступа к внутреннему состоянию объекта, имитирующий обращение к его внутренней переменной.
Свойство color в нашем случае можно определить так:
class ТРеп:
def _init___(self):
self.___color = "000000"
def __getColor (self):
return self.____color
def __setColor(self, newColor):
if len(newColor) != 6: self._____color = "000000"
else: self._____color = newColor
color = property(____getColor, __setColor)
Здесь добавили два подчёркивания в начало названий методов getColor и setColor. Поэтому они стали защищёнными, т. е. закрытыми от других объектов. Однако есть общедоступное свойство с названием color:
color = property(___getColor, ___setColor)
При чтении этого свойства вызывается метод _getColor, а при
записи нового значения — метод _____setColor. В программе
можно использовать это свойство так:
pen.color = "FFFF00" # изменение цвета
print("цвет пера:", pen.color); # получение цвета-
139
7
Объектно-ориентированное программирование
Поскольку функция getColor просто возвращает значение поля ___color и не выполняет никаких дополнительных действий, можно было вообще удалить метод ___getColor и вместо
него использовать «лямбда-функцию»:
class ТРеп:
def __init (self):
self.__color = "000000"
def __setColor(self, newColor):
if len (newColor) != 6:
self.__color = "000000"
else:
self.__color = newColor
color = property(lambda x: x.____color , ___setColor)
Эта «лямбда-функция» принимает единственный параметр-объект х, и возвращает его поле _color.
Таким образом, с помощью свойства color другие объекты могут изменять и читать цвет объектов класса ТРеп. Для обмена данными с «внешним миром» важно лишь то, что свойство color — символьного типа, и оно содержит 6-символьный код цвета. При этом внутреннее устройство объектов ТРеп может быть любым, и его можно менять как угодно. Покажем это на примере.
Хранение цвета в виде символьной строки неэкономно и неудобно, поэтому часто используют числовые коды цвета. Будем хранить код цвета в поле _color как целое число:
self.___color = 0
При этом необходимо поменять методы __________getColor и
__setColor, которые непосредственно работают с этим полем:
class ТРеп:
def __init___(self):
self.__color = 0
def getColor(self):
return "{:06x}".format (self.____color)
def setColor(self, newColor):
if len (newColor) != 6:
self.__color = 0
else:
self.__color = int (newColor, 16)
color = property(____getColor, __setColor)
Для перевода числового кода в символьную запись используется функция format. Формат 06х означает «вывести значение
140
Скрытие внутреннего устройства
§44
в шестнадцатеричной системе (х) в 6 позициях (6), свободные позиции слева заполнить нулями (0)». Для обратного преобразования применяем функцию int, которой передаётся второй аргумент — основание системы счисления.
В этом примере мы принципиально изменили внутреннее устройство объекта — заменили строковое поле на целочисленное. Однако другие объекты даже не «догадаются» о такой замене, потому что сохранился интерфейс — свойство color по-прежнему имеет строковый тип. Таким образом, инкапсуляция позволяет как угодно изменять внутреннее устройство объектов, не затрагивая интерфейс. При этом все остальные объекты изменять не требуется.
Иногда не нужно разрешать другим объектам менять свойство, т. е. требуется сделать свойство «только для чтения» (англ. read-only). Пусть, например, мы строим программную модель автомобиля. Как правило, другие объекты не могут непосредственно менять его скорость, однако могут получить информацию о ней — «прочитать» значение скорости. При описании такого свойства метод записи (второй аргумент в объявлении свойства) не указывают вообще (или указывается пустое значение None):
class TCar:
def __init___(self) :
self.__v = 0
v = property(lambda x: x.___v)
Таким образом, доступ к можен, как правило, только
внутренним данным объекта воз-с помощью методов. Применение
свойств {property) очень удобно, потому что позволяет исполь-
зовать ту же форму записи, что и при работе с общедоступной
переменной объекта.
При использовании скрытия данных длина программы чаще всего увеличивается, однако мы получаем и важные преимущества. Код, связанный с объектом, разделён на две части: общедоступную часть и закрытую. Объект взаимодействует с другими объектами только с помощью своих общедоступных свойств и методов (интерфейса) — рис. 7.8. Поэтому при сохранении интерфейса можно как угодно менять внутреннюю структуру данных и код методов, и это никак не будет влиять на другие объекты. Подчеркнём, что
Рис. 7.8
всё это становится действительно важно, когда разрабатывается
большая программа и необходимо обеспечить её надёжность.
141
7
Объектно-ориентированное программирование
Выводы
• Скрытие внутреннего устройства объектов называют инкапсуляцией («помещением в капсулу»). Инкапсуляцией также называют объединение данных и методов работы с ними в одном объекте.
• Доступ к внутренним данным объекта возможен, как правило, только с помощью методов класса.
• Свойство — это способ доступа к внутреннему состоянию объекта, имитирующий обращение к его внутренней переменной. Применение свойств позволяет использовать ту же форму записи, что и при работе с общедоступной переменной объекта.
• Обмен данными между объектами выполняется с помощью общедоступных свойств и методов, которые составляют интерфейс объектов. Изменение внутреннего устройства объектов (реализации) не влияет на взаимодействие с другими объектами, если не меняется интерфейс.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Что входит в понятие «интерфейс объекта»?
2. Чем различаются общедоступные и скрытые данные и методы в описании классов?
3. Почему рекомендуют делать доступ к полям объекта только с помощью методов?
4. Что такое свойство? Зачем во многие языки программирования введено это понятие?
5. Почему методы доступа, которые использует свойство, делают закрытыми?
6. Зачем нужны свойства «только для чтения»? Приведите примеры.
7. Подумайте, в каких ситуациях может быть нужно свойство «только для записи» (которое нельзя прочитать). Подумайте, как ввести такое свойство в описание класса.
Подготовьте сообщение
а) «Инкапсуляция в языке Pascal (Delphi)»
б) «Инкапсуляция в языке C++ (С#)»
в) «Инкапсуляция в языке Java»
Проекты
а) Сравнение инкапсуляции в языках Python и C++
б) «Лямбда-функции» в различных языках программирования
142
Иерархия классов
§45
Интересный сайт
javarush.ru
онлайн-курс обучения программированию на
языке Java
§45 Иерархия классов
Ключевые слова:
• наследование
• абстрактный метод
• абстрактный класс
• базовый класс
• класс-наследник
• полиморфизм
• модуль
Классификации
Как в науке, так и в быту важную роль играет классификация — разделение изучаемых объектов на группы (классы), объединённые общими признаками. Прежде всего, это нужно для того, чтобы не запутаться в большом количестве данных и не описывать каждый объект заново.
Например, есть много видов фруктов1* (яблоки, груши, сливы, апельсины и т. д.), но все они обладают некоторыми общими свойствами. Если перевести этот пример на язык ООП, то класс Яблоко — это подкласс (производный класс, класс-наследник, потомок) класса Фрукт, а класс Фрукт — это базовый класс (суперкласс, класс-предок) для класса Яблоко (а также для классов Груша, Слива, Апельсин и других).
Классы-наследники
Рис. 7.9
Стрелка с белым наконечником на схеме (рис. 7.9) обозначает наследование. Например, класс Яблоко — это наследник класса Фрукт.
Фруктами называют сочные съедобные плоды деревьев и кустарников.
143
7
Объектно-ориентированное программирование
О
Классический пример научной классификации — классификация животных или растений. Как вы знаете, она представляет собой иерархию (многоуровневую структуру). Например, горный клевер относится к роду Клевер семейства Бобовые класса Двудольные и т. д. Говоря на языке ООП, класс Горный клевер — это наследник класса Клевер, а тот, в свою очередь, — наследник класса Бобовые, который является наследником класса Двудольные и т. д.
Класс Б является наследником класса А, если можно сказать, что Б — это разновидность А.
Например, можно сказать, что яблоко — это фрукт, а горный клевер — одно из растений семейства двудольные.
В то же время мы не можем сказать, что «двигатель — это разновидность машины», поэтому класс Двигатель не является наследником класса Машина. Двигатель — это составная часть машины, поэтому объект класса Машина содержит в себе объект класса Двигатель. Отношения между двигателем и машиной — это отношение «часть — целое».
Иерархия логических элементов
Рассмотрим такую задачу: составить программу для моделирования управляющих схем, построенных на логических элементах. Нам нужно «собрать» заданную схему и построить её таблицу истинности.
Как вы уже знаете, перед тем как программировать, нужно выполнить объектно-ориентированный анализ. Все объекты, из которых состоит схема, — это логические элементы, однако они могут быть разными (НЕ, И, ИЛИ и другие). Попробуем выделить общие свойства и методы всех логических элементов.
Ограничимся только элементами, у которых один или два входа. Тогда иерархия классов может выглядеть так, как показано на рис. 7.10.
Рис. 7.10
144
Иерархия классов
§45
Среди всех элементов с двумя входами мы показали только элементы И и ИЛИ, остальные вы можете добавить самостоятельно.
Итак, для того чтобы не описывать несколько раз одно и то же, классы в программе должны быть построены в виде иерархии. Теперь можно дать классическое определение объектно-ориентированного программирования.
Объектно-ориентированное программирование — это такой подход к программированию, при котором программа представляет собой множество взаимодействующих объектов, каждый из которых является экземпляром определённого класса, а классы образуют иерархию наследования.
Базовый класс
Построим первый вариант описания класса Логический элемент (TLogElement). Обозначим его входы как ini и in2, а выход назовем res (от англ, result — результат) — рис. 7.11.
Здесь состояние логического элемента определяется тремя величинами (ini, in2 и res). С помощью такого базового класса можно моделировать не только статические
элементы (как НЕ, И, ИЛИ и т. п.), но и элементы с памятью (например, триггеры).
Для сохранения значений входов и запоминания выхода введём три поля, принимающих логические значения, и запол
ЛогЭлемент
Ini (вход 1) 1п2 (вход 2)
Res (результат) calc
Рис. 7.11
ним их в конструкторе:
class TLogElement:
def __init___(self):
self.___ini = False
self.___in2 = False
self, res = False
Названия полей ___ini и __in2 начинаются с двух подчёрки-
ваний, поэтому они будут скрытыми (доступными только внутри методов класса TLogElement). Имя поля res начинается с одного подчёркивания, т. е. оно не скрывается. В то же время одно подчёркивание говорит о его специальной роли, мы вернёмся к этому чуть позже.
145
Объектно-ориентированное программирование
Для доступа к полям введём свойства Ini, In2 и Res («только для чтения»):
class TLogElement:
def ___init__(self):
self.__ini = False
self.__in2 = False
self._res = False def ___setlnl(self, newlnl):
self.__ini = newlnl
self.calc()
def ___setln2(self, newln2):
self.__in2 = newln2
self.calc()
Ini = property(lambda x: x. ini, setlnl) In2 = property(lambda x: x. in2, setln2) Res = property(lambda x: x.res)
Методы чтения для всех свойств записаны как «лямбда-функции», они выполняют прямой доступ к соответствующим полям.
Вы, наверное, заметили, что оба метода записи после присваивания нового значения входу вызывают какой-то метод calc, которого нет в описании класса. В то же время видно, что этот метод принадлежит классу, потому что перед его именем добавлена ссылка self.
Метод calc должен пересчитать значение выхода логического элемента сразу после изменения его входа. Проблема в том, что мы не можем написать метод calc, пока неизвестно, какой именно логический элемент моделируется. Вместе с тем мы знаем, что такую процедуру имеет любой логический элемент. В такой ситуации можно написать метод-«заглушку» (который ничего не делает):
class TLogElement:
def calc (self):
pass
Но это не совсем правильно, поскольку кто-то может создать такой элемент и пытаться его использовать, а он не будет работать! Поэтому не будем его определять вообще. Такой метод называется абстрактным методом.
Абстрактный метод — это метод класса, который используется, но не реализуется в классе.
146
Иерархия классов
§45
Более того, не существует логического элемента «вообще», как не существует «просто фрукта», не относящегося к какому-то виду. Такой класс в ООП называется абстрактным. Его отличительная черта — хотя бы один абстрактный (нереализованный) метод.
Абстрактный класс — это класс, содержащий хотя бы один абстрактный метод.
Для надёжности нужно совсем запретить создание объектов класса TLogElement, потому что это бессмысленно. Для этого в конструкторе класса определим, есть ли у объекта метод calc, и если нет — будем искусственно создавать аварийную ситуацию — исключение1*:
class TLogElement:
def __init (self): self. ini = False self. in2 = False self._res = False if not hasattr(self, "calc"): raise NotlmplementedError ("Нельзя создать такой объект!")
Функция hasattr возвращает логическое значение True, если у переданного ему объекта (здесь — self) есть указанное поле или метод (calc). Ключевое слово raise означает «создать исключение», тип этого исключения — NotlmplementedError (ошибка «не реализовано»), в скобках записана символьная строка, которую увидит пользователь в сообщении об ошибке.
Итак, полученный класс TLogElement — это абстрактный класс. Его можно использовать только для разработки классов-наследников, создать в программе объект этого класса нельзя. Чтобы класс-наследник не был абстрактным, он должен переопределить все абстрактные методы предка, в данном случае — метод calc. Как это сделать, вы увидите далее.
Получается, что классы-наследники могут по-разному реализовать один и тот же метод. Такая возможность называется полиморфизмом.
Полиморфизм (от греч. лоХи — много, и рорфг| — форма) — это возможность классов-наследников по-разному реализовать метод, описанный для класса-предка.
В Python есть и другие способы объявить класс абстрактным, например с помощью модуля ABCMeta.
147
7
Объектно-ориентированное программирование
Теперь давайте вспомним про поле с именем res, которое хранит значение выхода логического элемента. Очевидно, что оно должно быть доступно классам-наследникам, которые будут изменять его в методе calc. Поэтому делать его скрытым нельзя. Вместе с тем часто используют соглашение о том, что одно подчёркивание означает специальное поле, которое не должно изменяться другими объектами и функциями1*.
Классы-наследники
Теперь займёмся классами-наследниками класса TLogElement. Поскольку у нас будет единственный элемент с одним входом (НЕ), сделаем его наследником прямо от TLogElement (не будем вводить специальный класс «элемент с одним входом»):
class TNot(TLogElement):
def _init____(self):
TLogElement.__init___(self)
def calc(self):
self._res = not self.Ini
После названия нового класса TNot в скобках указано название базового класса. Все объекты класса TNot обладают всеми свойствами и методами класса TLogElement.
В конструкторе класса-наследника нужно обязательно вручную вызвать конструктор класса-предка. В отличие от других объектно-ориентированных языков, в Python этот вызов автоматически не выполняется.
Новый класс определяет метод calc, который записывает в поле res инверсию входного сигнала — результат применения логической операции not. Таким образом, класс TNot уже не абстрактный, в нём все нужные методы определены. Теперь можно создавать объект этого класса TNot и использовать его:
n = TNot ()
n.Inl = False
print(n.Res)
Все типы логических элементов, которые имеют два входа, будут наследниками класса
class TLog2In(TLogElement):
pass
x* В других объектно-ориентированных языках программирования (C++, Паскаль) кроме общедоступных и закрытых элементов класса есть ещё защищённые (англ, protected). Доступ к ним имеет только сам класс, в котором они объявлены, и наследники этого класса. К сожалению, в языке Python так сделать невозможно.
148
Иерархия классов
§45
В нашем случае этот класс пустой, но, если нам понадобится ввести какие-то свойства и методы, характерные для всех элементов с двумя входами, мы сможем это легко сделать в классе TLog2ln.
Класс TLog2In — это тоже абстрактный класс, потому что он не переопределил метод calc. Это сделают его наследники TAnd (элемент И) и ТОг (элемент ИЛИ), которые описывают конкретные логические элементы:
class TAnd(TLog2In): def _____init__(self) :
TLog2ln.___init__(self)
def calc (self):
self._res = self.Ini and self.In2
class TOr (TLog2In):
def _init____(self):
TLog2ln.___init__(self)
def calc (self):
self._res = self.Ini or self.In2
Теперь мы готовы к тому, чтобы создавать и использовать построенные логические элементы. Например, таблицу истинности для последовательного соединения элементов И и НЕ можно построить так:
elNot = TNot() elAnd = TAnd() print (" А | В | not(A&B) "); print ("--------------------”) ;
for A in range(2) :
elAnd.Ini = bool(A)
for В in range(2):
elAnd.In2 = bool(B) elNot.Ini = elAnd.Res print (" ", A, T, В, "I", int(elNot.Res))
Сначала создаются два объекта — логические элементы НЕ (класс TNot) и И (класс TAnd). Далее во вложенном цикле перебираются все возможные комбинации значений переменных А и В (каждая из них может быть равна 0 или 1). Они подаются на входы элемента И, а сигнал с его выхода — на вход элемента НЕ. Чтобы при выводе таблицы истинности вместо False и True выводились более компактные обозначения 0 и 1, значение выхода преобразуется к целому типу (int).
149
Объектно-ориентированное программирование
Модульность
При разработке больших программ нужно разделить работу между программистами так, чтобы каждый делал свой независимый блок (модуль). Все подпрограммы, входящие в модуль, должны быть связаны друг с другом, но слабо связаны с другими процедурами и функциями. Такой подход используется как в классическом программировании, так и в ООП.
В нашей программе с логическими элементами в отдельный модуль (сохраним его в виде файла logelement.ру) можно вынести всё, что относится к логическим элементам:
class TLogElement:
def ___init__(self):
self.___ini = False
self.___in2 = False
self._res = False
if not hasattr (self, "calc”):
raise NotlmplementedError
(’’Нельзя создать такой объект!")
def ___setlnl(self, newlnl):
self.___ini = newlnl
self.calc()
def ___setln2(self, newln2):
self.___in2 = newln2
self.calc()
Ini = property(lambda x: x. ini, setlnl)
In2 = property(lambda x: x. in2, setln2)
Res = property(lambda x: x.res)
class TNot (TLogElement):
def ___init__(self):
TLogElement.___init__(self)
def calc(self):
self._res = not self.Ini
class TLog2In(TLogElement): pass
class TAnd(TLog2In):
def __init___(self) :
TLog2In.___init__(self)
def calc(self):
self._res = self.Ini and self.In2
class TOr(TLog2In):
def ___init__(self):
TLog2In.___init__(self)
150
Иерархия классов
§45
def calc(self):
self._res = self.Ini or self.In2
Чтобы использовать такой модуль, нужно подключить его в основной программе с помощью ключевого слова import:
import logelement
elNot = logelement.TNot() elAnd = logelement.TAnd()
Обратите внимание, что при создании объектов нужно указывать имя модуля, где определены классы TNot и TAnd.
Сообщения между объектами
Когда логические элементы объединяются в сложную схему, желательно, чтобы передача сигналов между ними при изменении входных данных происходила автоматически. Для этого можно немного расширить базовый класс TLogElement, чтобы элементы могли передавать друг другу сообщения об изменении своего выхода.
Для простоты будем считать, что выход любого логического элемента может быть подключён к любому (но только одному!) входу другого логического элемента. Добавим к описанию класса два скрытых поля и один метод:
class TLogElement: def ____init___(self) :
self.__nextEl = None
self.__nextin = 0
def link(self, nextEl, nextin): self._____nextEl = nextEl
self.__nextin = nextin
Поле __nextEl хранит ссылку на следующий логический элемент, а поле _next In — номер входа этого следующего элемен-
та, к которому подключён выход данного элемента. С помощью общедоступного метода link можно связать данный элемент со следующим.
151
7
Объектно-ориентированное программирование
Нужно немного изменить методы ___setlnl и __setln2: при
изменении входа они должны не только пересчитывать выход данного элемента, но и отправлять сигнал на вход следующего элемента:
class TLogElement:
def setlnl(self, newlnl): self.____ini = newlnl
self.calc() if self.__nextEl:
if self.__nextin == 1:
self.__nextEl.Ini = self._res
elif self.__nextin == 2:
self.__nextEl.In2 = self._res
Запись if self.___nextEl означает: «если следующий элемент
задан». Если он не был установлен, значение поля ___nextEl
будет равно None, и никаких дополнительных действий не выполняется.
С учётом этих изменений вывод таблицы истинности функции И-НЕ можно записать так (операторы вывода заменены многоточиями):
elNot = logelement.TNot() elAnd = logelement.TAnd() elAnd.link (elNot, 1)
for A in range(2): elAnd.Ini = bool(A) for В in range(2): elAnd.In2 = bool(B)
Обратите внимание, что в самом начале мы установили связь элементов И и НЕ с помощью метода link (связали выход элемента И с первым входом элемента НЕ). Далее в теле цикла обращения к элементу НЕ нет, потому что элемент И автоматически сообщит ему об изменении своего выхода.
Выводы
• Как правило, классы образуют иерархию (многоуровневую структуру). Классы-потомки обладают всеми свойствами и методами классов-предков, к которым добавляются их собственные свойства и методы.
152
Иерархия классов
§45
• Объектно-ориентированное программирование — это такой подход к программированию, при котором программа представляет собой множество взаимодействующих объектов, каждый из которых является экземпляром определённого класса, а классы образуют иерархию наследования.
• Абстрактный метод — это метод класса, который используется, но не реализуется в классе. Абстрактный класс — это класс, содержащий хотя бы один абстрактный метод.
• Полиморфизм — это возможность классов-наследников по-разному реализовать метод, описанный для класса-предка.
• Большие программы обычно разбивают на модули — внутренне связные, но слабо связанные между собой блоки. Такой подход используется как в классическом программировании, так и в ООП.
• Объекты могут обмениваются сообщениями — вызывать общедоступные методы друг друга.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. В каком случае можно сказать: «класс Б — наследник класса А», а когда: «объект класса А содержит объект класса Б»? Приведите примеры.
2. Обсудите достоинства и недостатки построенной иерархии логических элементов.
3. Что такое базовый класс и класс-наследник? Какие синонимы используются для этих терминов?
4. На примере класса TLogElement покажите, как выполнена инкапсуляция.
5. Что такое абстрактный класс? Почему нельзя создавать объекты этого класса?
6. Что нужно сделать, чтобы класс-наследник абстрактного класса не был абстрактным?
7. Зачем нужен полиморфизм?
8. Какие преимущества даёт применение модулей в программе?
9. Объясните, как объекты могут передавать сообщения друг другу.
10. Как, на ваш взгляд, можно организовать передачу сигнала с выхода логического элемента сразу на несколько входов других элементов?
153
Объектно-ориентированное программирование
0>
Подготовьте сообщение
а) «Наследование в языке Pascal (Delphi)»
б) «Наследование в языке C++ (С#)»
в) «Наследование в языке Java»
г) «Наследование в языке Javascript»
Проекты
а) Сравнение наследования в языках Python и C++
б) Использование наследования классов в выбранной задаче
Интересный сайт
learn.javascript.ru/js — учебник по языку JavaScript
§46 Программы с графическим интерфейсом
Ключевые слова:
• графический интерфейс
• сообщение
очередь сообщений обработчик событий
• событие
Особенности современных прикладных программ
Большинство современных программ, предназначенных для пользователей, управляются с помощью графического интерфейса. Вы знакомы с понятиями «окно программы», «кнопка», «выключатель», «поле ввода», «полоса прокрутки» и т. п. Такие оконные системы чаще всего построены на принципах объектно-ориентированного программирования, т. е. все элементы окон — это объекты, которые обмениваются данными, посылая друг другу сообщения.
Сообщение — это блок данных определённой структуры, который используется для обмена информацией между объектами.
В сообщении указывается:
• адресат (объект, которому посылается сообщение);
• числовой код (тип) сообщения;
• параметры (дополнительные данные), например координаты щелчка мышью или код нажатой клавиши.
154
Программы с графическим интерфейсом
§46
Сообщение может быть широковещательным 9 в этом случае вместо адресата указывается особый код, и сообщение поступает всем объектам определённого типа (например, всем главным окнам программ).
В программах, которые мы писали раньше, последовательность действий заранее определена — основная программа выполняется строка за строкой, вызывая процедуры и функции, все ветвления выполняются с помощью условных операторов (рис. 7.12).
Рис. 7.12
В современных программах порядок действий определяется пользователем, другими программами или поступлением новых данных из внешнего источника (например, из сети), поэтому «классическая» схема не подходит. Пользователь текстового редактора может щёлкать на любых кнопках и выбирать любые пункты меню в произвольном порядке. Программа-сервер, передающая данные с веб-сайта на компьютер пользователя, начинает действовать только при поступлении очередного запроса. При программировании сетевых игр нужно учитывать взаимодействие многих объектов, информация о которых передается по сети в случайные моменты времени.
Во всех этих примерах программа должна «включаться в работу» только тогда, когда получит условный сигнал, т. е. когда произойдёт некоторое событие (изменение состояния).
Событие — это переход какого-либо объекта из одного состояния в другое.
События могут быть вызваны действиями пользователя (управление клавиатурой и мышью), сигналами от внешних устройств
155
Объектно-ориентированное программирование
(переход принтера в состояние готовности, получение данных из сети), получением сообщения от другой программы. При наступлении событий объекты посылают друг другу сообщения.
Таким образом, весь ход выполнения современной программы определяется происходящими событиями, а не жёстко заданным алгоритмом. Поэтому говорят, что программы управляются событиями, а соответствующий стиль программирования называют событийно-ориентированным, т. е. основанным на обработке событий.
Нормальный режим работы событийно-ориентированной программы — цикл обработки сообщений. Все сообщения (от мыши, клавиатуры и драйверов устройств ввода и вывода и т. п.) сначала поступают в единую очередь сообщений операционной системы. Кроме того, для каждой программы операционная система создаёт отдельную очередь сообщений и помещает в неё все сообщения, предназначенные именно этой программе (рис. 7.13).
Программа выбирает очередное сообщение из очереди и вызывает специальную процедуру — обработчик сообщения (если он есть . Когда пользователь закрывает окно программы, ей посылается специальное сообщение, при получении которого цикл (и работа всей программы) завершается.
Таким образом, главная задача программиста — написагь содержание обработчиков всех нужных сообщений. Ещё раз подчеркнём, что последовательность их вызовов точно не определена, она может быть любой в зависимости от действий пользователя и сигналов, поступающих с внешних устройств.
156
Программы с графическим интерфейсом
§46
RAD-среды для разработки программ
Разработка программ для оконных операционных систем до середины 1990-х годов была довольно сложным и утомительным делом. Очень много усилий уходило на то, чтобы написать команды для создания интерфейса с пользователем: разместить элементы в окне программы, написать и правильно оформить обработчики сообщений. Значительную часть своего времени программист занимался трудоёмкой работой, которая была почти никак не связана с решением главной задачи. Поэтому возникла естественная мысль — автоматизировать описание окон и их элементов так, чтобы весь интерфейс программы можно было построить без ручного программирования (чаще всего с помощью мыши), а человек думал бы о сути задачи, т. е. об алгоритмах обработки данных.
Такие системы программирования получили название сред быстрой разработки приложений — RAD-сред (от англ. Rapid Application Development). Разработка программы в RAD-системе состоит из следующих этапов:
1) создание формы (так называют шаблон, по которому строится окно программы или диалога); при этом минимальный код добавляется автоматически и сразу получается работоспособная программа;
2) расстановка на форме элементов интерфейса (полей ввода, кнопок, списков) с помощью мыши и настройка их свойств;
3) создание обработчиков событий;
4) написание алгоритмов обработки данных, которые выполняются при вызове обработчиков событий.
Обратите внимание, что при программировании в RAD-средах обычно говорят не об обработчиках сообщений, а об обработчиках событий. Событием в программе может быть не только нажатие клавиши или щелчок мышью, но и перемещёние окна, изменение его размеров, начало и окончание выполнения расчётов и т. д. Некоторые сообщения, полученные от операционной системы, библиотека RAD-среды «транслирует» (переводит) в соответствующие события, а некоторые — нет. Более того, программист может вводить свои события и определять процедуры для их обработки.
Одной из первых сред быстрой разработки стала среда Delphi, разработанная фирмой Borland в 1994 году. Самая известная современная профессиональная RAD-система — Microsoft Visual Studio — поддерживает несколько языков программирования. Существует свободная RAD-среда Lazarus, которая во многом аналогична Delphi, но позволяет создавать кроссплатформенные программы (для операционных систем Windows, Linux, macOS и др.).
157
7
Объектно-ориентированное программирование
Среды RAD позволили существенно сократить время разработки программ. Однако нужно помнить, что любой инструмент — это только инструмент, который можно использовать грамотно или безграмотно. Использование среды RAD само по себе не гарантирует, что у вас автоматически получится хорошая программа с хорошим пользовательским интерфейсом.
Выводы
• Сообщение — это блок данных определённой структуры, который используется для обмена информацией между объектами.
• Событие — это переход какого-либо объекта из одного состояния в другое. При наступлении событий объекты посылают друг другу сообщения.
• Современные программы с графическим интерфейсом основаны на обработке событий, которые вызваны действиями пользователя или поступлением данных из других источников, и могут происходить в любой последовательности.
• Для быстрого создания программ с графическим интерфейсом разработаны специальные системы программирования — RAD-среды.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Как связан графический интерфейс с объектно-ориентированным подходом к программированию?
2. Что такое сообщение? Какие данные в него входят?
3. Что такое широковещательное сообщение?
4. Что такое обработчик сообщения?
5. Чем принципиально отличаются современные программы от классических?
6. Что такое событие? Какое программирование называют событийно-ориентированным?
7. Как работает событийно-ориентированная программа?
8. Какие причины сделали необходимым создание сред быстрой разработки программ? В чём их преимущество?
9. Расскажите про этапы разработки программы в RAD-среде. 10. Объясните разницу между понятиями «событие» и «сообщение».
Подготовьте сообщение
а) «Событийно-ориентированное программирование»
б) «RAD-среды»
158
Графический интерфейс: основы
§47
Проекты
а) Сравнение сред для разработки программ на языке Python
б) Программа, управляемая событиями, для выбранной задачи
Интересные сайты
visualstudio.com/ru-ru/products/visual-studio-express-vs — бесплатная RAD-среда Visual Studio Express (Visual Basic, C#) lazarus-ide.org — свободная RAD-среда Lazarus для разработки на языке Паскаль
codeblocks.org — свободная RAD-среда Code::Blocks для разработки на языках С и C++
§47
Графический интерфейс: основы
Ключевые слова:
• форма • событие
• компонент • обработчик события
Общий подход
Продемонстрируем основные принципы построения программ с графическим интерфейсом на языке Python. К сожалению, для этого языка не создано сколько-нибудь надёжных средств визуальной разработки приложений (RAD).
Мы будем использовать графическую библиотеку t kin ter, которая входит в стандартную библиотеку Python. Существуют также и другие библиотеки для разработки интерфейсов на Python: wxPython, PyGTK, PyQt и некоторые другие. Их нужно устанавливать отдельно.
В программе с графическим интерфейсом может быть несколько окон, которые обычно называют формами1). На форме размещаются элементы графического интерфейса: поля ввода, флажки, кнопки и др., которые называются виджетами (англ, widget — украшение, элемент) или (как в большинстве аналогичных сред) компонентами. Каждый компонент — это объект определённого класса, у которого есть свойства и методы.
h В tkinter они называются окнами верхнего уровня (Toplevel).
159
7
Объектно-ориентированное программирование
Для событий, которые происходят с компонентом, можно задать функции-обработчики. Они будут выполняться тогда, когда происходит соответствующее событие. Примеры таких событий — это изменение состояния флажка, изменение размеров формы, щелчок мышью на объекте, нажатие клавиши на клавиатуре.
Далее в этой главе мы сосредоточимся на принципах проектирования программ с графическим интерфейсом, а не на особенностях библиотеки t kin ter. Для этого мы будем применять так называемую «обёртку» simpletk — оболочку, которая скрывает сложности использования исходной библиотеки. Она представляет собой небольшой модуль, разработанный авторами. Этот модуль может быть свободно загружен с сайта поддержки учебника1*.
Простейшая программа
Простейшая программа с графическим интерфейсом состоит из трёх строк:
from simpletk import * # (1)
арр = TApplication("Первая форма") # (2)
арр.Run()
# (3)
Вероятно, вам понятна первая строка: из модуля simpletk импортируются все функции (для того, чтобы не нужно было каждый раз указывать название модуля). В строке 2 создаётся объект класса TApplication — это приложение (программа, от англ, application — приложение). Конструктору передаётся заголовок главного окна программы.
В последней строке с помощью метода Run (от англ, run — запуск) запускается цикл обработки сообщений, который скрыт внутри этого метода, так что здесь тоже использован принцип инкапсуляции (скрытия внутреннего устройства). Приведённую выше программу можно запустить, и вы должны увидеть окно, показанное на рис. 7.14.
Рис. 7.14
1 * http://kpolyakov.spb.ru/school/probook/python.htm
Графический интерфейс: основы
§47
Свойства формы
Объект класса TApplication (наследник класса Тк библиотеки tkinter) имеет методы, позволяющие управлять свойствами окна. Например, можно изменить начальное положение окна на экране с помощью свойства position:
арр.position = (100, 300)
Позиция окна — это кортеж1* (неизменяемый набор данных), состоящий из х-координаты и у-координаты левого верхнего угла окна.
Аналогично изменяются и размеры окна:
арр.size = (500, 200)
Первый элемент кортежа — ширина, второй — высота окна.
Свойство resizable (в переводе с англ, «изменяемый размер») позволяет запретить изменение размеров окна по одному или обоим направлениям. Например, вызов
арр.resizable = (True, False)
разрешает только изменение ширины, а изменить высоту окна будет невозможно.
С помощью свойств minsize и maxsize можно установить минимальные и максимальные размеры формы, например:
арр.minsize = (100, 200)
Теперь ширина формы не может быть меньше 100 пикселей, а высота — меньше 200 пикселей.
Обработчик события
Рассмотрим простой пример. Вы знаете, что многие программы запрашивают подтверждение, когда пользователь завершает их работу. Для этого можно использовать обработчик события «удаление окна». Он устанавливается так:
арр.onCloseQuery = AskOnExit
Кортежи в Python записывают в круглых скобках. С ними можно делать практически всё то же самое, что и со списками, но нельзя изменять, добавлять и удалять элементы. Однако можно построить новый кортеж, используя срезы.
161
Объектно-ориентированное программирование
Здесь onCloseQuery — название обработчика события (от англ. on close query — при запросе на закрытие). Справа записано название функции AskOnExit, которая вызывается при этом событии. Эта функция определяет действия в том случае, когда пользователь закрывает окно программы, например, так:
def AskOnExit(): арр.destroy()
Всё действие этого обработчика сводится к вызову метода destroy (в переводе с англ, «разрушить»): окно удаляется из памяти и работа программы завершается. Нам нужно спросить пользователя, не ошибся ли он, т. е. выдать ему сообщение в диалоговом окне (рис. 7.15).
Подтверждение
Вы действительно хотите выйти из программы?
Рис. 7.15
и завершить работу программы только в том случае, когда он нажмёт кнопку ОК.
Для этого используем готовую функцию askokcancel (анг ask — спросить, ОК — кнопка OK, cancel — кнопка Отмена) из модуля messagebox пакета tkinter. Импортировать эту функцию можно так:
from tkinter.messagebox import askokcancel
Теперь функция-обработчик принимает следующий вид:
def AskOnExit():
if askokcancel("Подтверждение”,
"Вы действительно хотите выйти из программы?"): арр.destroy()
Функция askokcancel принимает два аргумента: заголовок окна и сообщения для пользователя. Она возвращает ненулевое значение, если пользователь нажал кнопку ОК. В этом случае срабатывает условный оператор и вызывается метод de st го завершающий работу программы.
162
Графический интерфейс: основы
§47
Выводы
• Программы с графическим интерфейсом на языке Python обычно строятся на основе графических библиотек (tkinter, wxPython, PyGTK, PyQt). Библиотека tkinter входит в стандартный набор, который устанавливается вместе с интерпретатором.
• В основной программе необходимо создать окно и все его компоненты, настроить (если нужно) их свойства, подключить обработчики событий и запустить бесконечный цикл обработки событий.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Какие средства для построения графического интерфейса в программах на Python входят в стандартную библиотеку языка?
2. Что такое форма?
3. В чём проявляется объектно-ориентированный подход к разработке интерфейса?
4. Что такое приложение? К какому классу библиотеки относится объект-приложение?
5. Почему в основной программе не виден цикл обработки сообщений?
6. Назовите некоторые важнейшие свойства формы. Какими способами можно их изменять?
7. Как создать обработчик события «закрытие формы»?
8. Какой модуль библиотеки tkinter содержит стандартные диалоги с пользователем?
9. Назовите известные вам методы объекта-приложения.
Подготовьте сообщение
«Библиотека tkinter»
Интересные сайты
ru.wikibooks.org/wiki/GUI_Help/Tkinter_book — описание библиотеки tkinter
wxpython.org — библиотека wxPython
pygtk.org — библиотека PyGTK
riverbankcomputing.com/software/pyqt/intro — библиотека PyQt
163
Объектно-ориентированное программирование
§48
Использование компонентов (виджетов)
Ключевые слова:
• компонент
• обработчик события
• исключение
Программа с компонентами
Теперь построим программу для просмотра файлов, которая умеет открывать файлы с диска и показывать их в нижней части окна в левом верхнем углу или по центру свободной области (рис. 7.16).
Т Image
Просмотр
Открыть файл I Ь* В центре
Рис. 7.16
К сожалению, наша программа будет работать только с файлами формата GIF, поскольку с остальными распространёнными форматами (JPEG, PNG, BMP) библиотека tkinter работать не умеет1*.
На форме (см. рис. 7.16) размещены четыре компонента:
• кнопка с надписью «Открыть файл» (компонент TButton, наследник класса Button библиотеки tkinter);
• выключатель с текстом «В центре» (компонент TCheckBox, наследник класса Checkbox библиотеки tkinter);
• панель, на которой лежат кнопка и выключатель (компонент TPanel, наследник класса Frame библиотеки tkinter);
• поле для рисунка, заполняющее всё остальное место на форме (компонент TImage, наследник класса Canvas библиотеки tkinter).
г) Для работы с рисунками других форматов (JPEG, PNG, BMP) нужно установить библиотеку Pillow.
164
Использование компонентов (виджетов)
§48
Начнём с простой программы, которая устанавливает свойства главного окна:
from simpletk import *
арр = TApplication("Просмотр рисунков")
арр.position = (200, 200)
арр.size = (300, 300)
арр.Run()
Теперь построим верхнюю панель:
panel = TPanel(арр, relief = "raised", height = 35, bd = 1)
Для создания объекта-панели вызывается конструктор класса TPanel. Ему передаётся несколько параметров:
• арр — ссылка на родительский объект;
• relief — объёмный вид, значение "raised" означает «приподнятый»; этот параметр может принимать также значения "flat" (плоский, по умолчанию), "sunken" («утопленный») и др.;
• height — высота в пикселях;
• bd (от англ, border — граница) — толщина границы в пикселях.
Родительский объект — это объект, отвечающий за перемещение и вывод на экран нашей панели, которая становится «дочерним» объектом для главного окна.
Расположим панель на форме, прижав её к верхней границе с помощью свойства align:
panel.align = "top"
Это свойство задаёт расположение панели внутри родительского окна, "top" означает «прижать вверх» ("bottom" — вниз, "left" — влево, "right" — вправо).
Теперь нужно разместить на панели компоненты TButton (кнопка) и TCheckBox (выключатель). Для них «родителем» уже будет не главное окно, а панель panel. Начнём с кнопки:
openBtn = TButton (panel, width = 15, text = "Открыть файл")
openBtn.position = (5, 5)
Для создания кнопки вызван конструктор класса TButton. Первый параметр — это родительский объект (панель), параметр width задаёт ширину кнопки в символах (не в пикселях!), а параметр text — надпись на кнопке. В следующей строке с помощью свойства position определяются координаты кнопки на панели.
165
7
Объектно-ориентированное программирование
Используя тот же подход, создаём и размещаем выключатель:
centerCb = TCheckBox(panel, text = "В центре") centerCb.position = (115, 5)
Можно запустить программу и убедиться, что все компоненты появляются на форме, но пока не работают (не реагируют на щелчки мышью).
В нижнюю часть формы нужно «упаковать» поле для рисунка — объект класса ТImage — так, чтобы он занимал всёостав-шееся место. Создаём такой объект:
image = TImage(app, bg = "white")
Его «родителем» будет главное окно арр, параметр bg (от англ. background — фон) задаёт цвет «холста» (англ, white — белый). Затем «упаковываем» его в окно так, чтобы он занимал всё оставшееся место, т. е. заполнял оставшуюся область по вертикали и горизонтали:
image.align = "client"
Теперь нужно задать обработчики событий. Нас интересуют два события:
• щелчок на кнопке (после него должен появиться диалог выбора файла);
• переключение флажка-выключателя (нужно изменить режим показа рисунка).
Сначала определим, какие действия нужно выполнить в случае щелчка мышью на кнопке. Псевдокод выглядит так:
выбрать файл с рисунком if файл выбран: загрузить рисунок в компонент image
Выбрать файл можно с помощью стандартного диалога операционной системы, который вызывает функция askopenfilename из модуля filedialog библиотеки t kin ter. Сначала этот модуль нужно импортировать:
from tkinter import filedialog
Теперь вызываем функцию askopenfilename и передаём ей расширения, который будет показан в выпадающем списке Тип файла.
fname = filedialog.askopenfilename(
filetypes = [("Файлы GIF", "*.gif"), ("Все файлы", "*.*")])
166
Использование компонентов (виджетов)
§48
Параметр filetypes — это список, составленный из двух кортежей. Каждый кортеж содержит два элемента: текстовое объяснение и расширение имени файлов. Результат работы функции — имя выбранного файла или пустая строка, если пользователь отказался от выбора (нажал кнопку Отмена). Если файл всё-та-ки выбран (строка не пустая), записываем имя файла в свойство picture объекта TImage:
if fname: image.picture = fname
При изменении этого свойства файл будет автоматически загружен и выведен на экран (это выполняет класс TImage). Обратите внимание, что пустая строка в Python воспринимается как значение «ложь». Теперь можно составить всю функцию:
def selectFile(sender):
fname = filedialog.askopenfilename( filetypes = [("Файлы GIF", "*.gif"),
("Все файлы", "*.*")]) if fname:
image.picture = fname
Функция-обработчик принимает единственный параметр sender — ссылку на объект, с которым произошло событие. Но в нашем случае эта ссылка не нужна, и мы её использовать не будем.
Теперь нужно установить обработчик события: сделать так, чтобы функция selectFile вызывалась после щелчка на кнопке. Свойство, определяющее обработчик события «щелчок мышью», называется onClick (от англ, click — щёлкнуть):
openBtn.onClick = selectFile
Теперь можно запустить программу и проверить загрузку файлов.
Остаётся добавить ещё один обработчик, который при изменении состояния выключателя centered переключает режим вывода рисунка (в левом углу «холста» или по центру»). Напишем код такого обработчика:
def cbChanged(sender): image.center = sender.checked image.redrawlmage()
У объекта TImage есть логическое свойство center, которое должно быть равно True, если нужно вывести рисунок по центру и False, если рисунок выводится в левом верхнем углу «холста». Вместе с тем у выключателя TCheckBox есть логическое
167
7
Объектно-ориентированное программирование
свойство checked, которое равно True, если выключатель включён (флажок отмечен). В первой строке функции cbChanged мы установили свойство center в соответствии с состоянием выключателя. Затем вызывается метод redrawlmage (от англ, redraw image — перерисовать рисунок), который выводит рисунок в новой позиции.
Этот обработчик нужно подключить к событию «изменение состояния выключателя», записав его адрес в свойство onChange:
centerCb.onChange = cbChanged
Если теперь запустить программу, мы должны увидеть правильную работу всех элементов управления. Более того, при изменении размеров окна перерисовка выполняется автоматически (за это также «отвечает» компонент ТImage).
Отметим следующие важные особенности:
• вся программа, согласно принципам ООП, строится на основе объектов;
• использование готовых компонентов скрывает от нас сложность выполняемых операций, поэтому скорость разработки программ значительно повышается.
Новый класс: всё в одном
Доведём объектный подход до логического завершения, собрав все элементы интерфейса в новый класс TImageViewer — оконное приложение для просмотра рисунков. При этом основная программа будет состоять всего из двух строк: создания главного окна и запуска программы:
class TImageViewer(TApplication):
арр = TImageViewer()
арр.Run()
Вместо многоточия нужно добавить описание класса: конструктор, который создаёт и размещает на форме все компоненты, и обработчики событий.
Начнём с конструктора:
class TImageViewer(TApplication):
def _init____(self):
TApplication.___init___ (self, "Просмотр рисунков")
self.position = (200, 200) self.size = (300, 300) self.panel = TPanel(self, relief = "raised", height = 35, bd = 1)
168
Использование компонентов (виджетов)
§48
self .panel. align = ’’top”
self, image = TImage (self, bg = ’’white”)
self . image . align = ’’client”
self.openBtn = TButton(self.panel, width = 15, text = ’’Открыть файл”)
self.openBtn.position = (5, 5)
self.openBtn.onClick = self.selectFile
self.centerCb = TCheckBox(self.panel,
text = ”B центре”)
self.centerCb.position = (115, 5)
self.centerCb.onChange = self.cbChanged
Сначала вызываем конструктор базового класса TApplication и настраиваем свойства окна. Вместо имени объекта арр (см. предыдущую программу) используем self — ссылку на текущий объект.
Затем строятся и размещаются компоненты, причём ссылки на них становятся полями объекта (см. «приставку» self, перед именами). Иначе мы не сможем обратиться к компонентам в обработчиках событий.
Обработчики событий — функции selectFile и cbChanged — тоже должны быть членами класса TImageViewer, поэтому их первым параметром будет self, а вторым — ссылка sender на объект, в котором произошло событие:
class TImageViewer(TApplication):
... # здесь должен быть конструктор ___init__
def selectFile(self, sender): fname = filedialog.askopenfilename( filetypes = [(’’Файлы GIF”, ”*.gif”), (’’Все файлы”, "*.*")]) if fname:
self.image.picture = fname
def cbChanged (self, sender):
self.image.center = sender.checked self.image.redrawlmage()
Поскольку при создании объекта в конструкторе мы запомнили адреса всех элементов в полях объекта, теперь можно к ним обращаться для изменения свойств.
В итоге получилась программа, полностью построенная на принципах объектно-ориентированного программирования: все данные и методы работы с ними объединены в классе TImageViewer.
169
Объектно-ориентированное программирование
Ввод и вывод данных
Во многих программах нужно, чтобы пользователь вводил текстовую или числовую информацию. Чаще всего для этого применяют поле ввода — компонент TEdit (наследник класса Entry библиотеки tkinter). Для доступа к введённой строке используют его свойство text.
Построим программу для перевода RGB-составляющих цвета в соответствующий шестнадцатеричный код, который используется для задания цвета в языке HTML (см. главу 4).
поле ввода rEdit
RGB кодирок 4иис
метка rgbLabel
TEdit
поле ввода bEdit
#7Ь3850^' TLabel
TEdit
метка rgbRect
поле ввода gEdit TLabel
TEdit
Рис. 7.17
На форме должны быть расположены (рис. 7.17):
• три поля ввода (в них пользователь может задать значения красной, зелёной и синей составляющих цвета в модели RGB);
• прямоугольник (компонент TLabel), цвет которого изменяется согласно введённым значениям;
• несколько меток (компонентов TLabel).
Метки — это надписи, которые пользователь не может редактировать, однако их содержание можно изменять из программы через свойство text.
Во время работы программы будут использоваться поля ввода rEdit, gEdit и bEdit, метка rgbLabel, с помощью которой будет выводиться результат — код цвета, и метка без текста rgbRect — прямоугольник, закрашенный нужным цветом. В качестве начальных значений полей ввода можно ввести любые целые числа от 0 до 255 (свойство text).
При изменении содержимого любого из трёх полей ввода нужно обработать введённые данные и вывести результат в свойство text метки rgbLabel, а также изменить цвет фона для метки rgbRect. Обработчик события, которое происходит при измене
Использование компонентов (виджетов)
§48
нии текста в поле ввода, называется onChange. Так как при изменении любого из трёх полей нужно выполнить одинаковые действия, для этих компонентов можно установить один и тот же обработчик.
Обработчик события onChange для поля ввода может выглядеть так:
def onChange (sender):
г = int(rEdit.text) # (1)
g = int(gEdit.text) # (2)
b = int(bEdit.text) # (3)
s = "#{:02x}{:02x}{:02x}". format(r, g, b) # (4)
rgbRect.background = s # (5)
rgbLabel.text = s # (6)
Содержимое всех полей ввода преобразуется в числа с помощью функции int (строки 1-3). Затем в строке 4 строится символьная строка — шестнадцатеричная запись цвета в HTML-формате. Значения красной, зелёной и синей составляющих (переменные г, g и Ь) выводятся по формату 02х, т. е. в шестнадцатеричной записи, состоящей из двух цифр с заполнением пустых позиций нулями. В строке 5 изменяется фон метки-прямоугольника rgbRect, а в строке 6 код цвета заносится в метку rgbLabel.
В основной программе создаём объект-приложение с главным окном:
арр = TApplication("RGB-кодирование") арр.size = (210, 90) арр.position = (200, 200)
и метки слева от полей ввода:
f = ("MS Sans Serif", 12)
IblR = TLabel(app, text = "R = ", font = f)
IblR.position = (5, 5)
IblG = TLabel(app, text = "G = ", font = f)
IblG.position = (5, 30)
IblB = TLabel(app, text = "B = ", font = f) IblB.position = (5, 55)
При создании меток мы изменили шрифт с помощью параметра font. Значение этого параметра — кортеж f, который в данном случае состоит из двух элементов: названия шрифта (MS Sans Serif) и его размера в пунктах (12).
171
7
Объектно-ориентированное программирование
Создаём ещё две метки для вывода результата:
fc = (’’Courier New”, 16, ’’bold”)
rgbLabel = TLabel (арр, text = ”#000000”, font = fc, fg = ’’navy”)
rgbLabel.position = (100, 5)
rgbRect = TLabel (app, text = width = 15, height = 3) rgbRect.position = (105, 35)
Размеры меток — ширина (англ, width) и высота (англ, height) указываются не в пикселях, а в текстовых единицах, т. е. в размерах символа. Шрифт для метки rgbLabel задаётся в виде кортежа из трёх элементов: названия шрифта, размера и свойства «жирный» (англ. bold). Параметр fg (от англ, foreground — цвет переднего плана) при вызове конструктора метки определяет цвет символов («navy» — тёмно-синий, от англ, navy — военно-морской).
Затем добавляем на форму три поля ввода:
rEdit = TEdit(app, font = f, width = 5)
rEdit.position = (45, 5)
rEdit.text = ”123”
gEdit = TEdit(app, font = f, width = 5)
gEdit.position = (45, 30)
gEdit.text = "56"
bEdit = TEdit(app, font = f, width = 5)
bEdit.text = "80”
bEdit.position = (45, 55)
Для каждого из них устанавливаем обработчик onChange, который вызывается при любом изменении текста в поле ввода:
rEdit.onChange = onChange
gEdit.onChange = onChange
bEdit.onChange = onChange
Запускаем программу:
арр.Run()
Обратите внимание, что назначение обработчика события нужно делать тогда, когда все объекты, используемые в обработчике onChange (поля ввода rEdit, gEdit, bEdit и метки rgbLabel и rgbRect), уже созданы.
При желании можно переписать программу в стиле ООП, как это мы сделали в конце предыдущего примера. Это вы уже можете сделать самостоятельно, используя образец.
172
Использование компонентов (виджетов)
§48
Обработка ошибок
Если в предыдущей программе пользователь введёт не числа, а что-то другое (или пустую строку), программа выдаст сообщение о необработанной ошибке на английском языке и завершит работу. Хорошая программа никогда не должна завершаться аварийно, для этого все ошибки, которые можно предусмотреть, надо обрабатывать.
В современных языках программирования есть так называемый механизм исключений, который позволяет обрабатывать практически все возможные ошибки. Для этого все «опасные» участки кода (при выполнении которых может возникнуть ошибка) нужно поместить в блок try — except:
try:
# "опасные" команды
except:
# обработка ошибки
Слово try по-английски означает «попытаться», except — «исключение» (исключительная или ошибочная, непредвиденная ситуация). Программа попадает в блок except только тогда, когда между try и except произошла ошибка.
В нашей программе «опасные» команды — это операторы преобразования данных из текста в числа (вызовы функции int). В случае ошибки мы выведем вместо кода цвета знак вопроса, а цвет фона метки-прямоугольника rgbRect изменим на стандартное значение "SystemButtonFace", которое означает «системный цвет кнопки». При этом прямоугольник становится невидимым, потому что сливается с фоновым цветом окна.
Улучшенный обработчик с защитой от неправильного ввода принимает вид:
def onChange(sender) :
s = "?"
bkColor = "SystemButtonFace"
try:
# получить новый цвет из полей ввода
except:
pass
rgbLabel.text = s
rgbRect.background = bkColor
Здесь переменная s обозначает шестнадцатеричный код цвета (в виде символьной строки), а переменная bkColor — цвет прямоугольника. Если при попытке получить новый код цвета
173
Объектно-ориентированное программирование
происходит ошибка, то в этих переменных остаются значения, установленные в первых строках обработчика.
Если значения полей ввода удалось преобразовать в числа, нужно убедиться, что все составляющие цвета не меньше 0 и не больше 255, добавив проверку диапазона range (256) для всех значений:
def onChange(sender): s = "?" bkColor = "SystemButtonFace" try:
r = int (rEdit.text)
g = int (gEdit.text)
b = int(bEdit.text)
if r in range(256) and \
g in range (256) and b in range(256):
s = "#{:02x}{:02x}{:02x}". format(r, g, b) bkColor = s
except: pass
rgbLabel.text = s
rgbRect.background = bkColor
Выводы
• Диалог с пользователем организуется с помощью компонентов (виджетов), размещаемых на форме. Свойства компонентов можно изменять.
• Компоненты имеют специальные свойства, которым можно присваивать адреса обработчиков событий. Обработчики будут вызваны автоматически при наступлении этих событий.
• Один обработчик может быть связан с событиями нескольких компонентов.
• Для обработки ошибок обычно используются исключения.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Что такое компоненты? Зачем они нужны?
2. Объясните, как связаны компоненты и идея инкапсуляции.
3. Что такое родительский объект?
4. Объясните роль свойства align в размещении элементов на форме.
5. Что такое стандартный диалог? Как его использовать?
174
Совершенствование компонентов
§49
6. Назовите основное свойство выключателя. Как его использовать?
7. Как обрабатываются ошибки в современных программах? В чём, на ваш взгляд, преимущества и недостатки такого подхода?
Подготовьте сообщение
а) «Использование компонентов в Lazarus»
б) «Использование компонентов в программах на С#»
Проект
Программа с графическим интерфейсом для выбранной задачи
Интересный сайт
pypi.python.org/pypi/Pillow/ — библиотека Pillow для работы с изображениями в Python
0>
§49
Совершенствование компонентов
Ключевые слова:
• компонент
• наследование
• обработчик события
• модуль
Как вы видели в предыдущем параграфе, на практике нередко нужны поля ввода особого типа, с помощью которых можно вводить целые числа. Компонент TEdit разрешает вводить любые символы и представляет результат ввода как текстовое свойство text. Поэтому для того, чтобы получить нужное нам поведение (ввод целых чисел), мы:
• добавили обработку ошибок в процедуру onChange;
• для перевода текстовой строки в число каждый раз использовали функцию int.
Если такие поля ввода нужны часто и в разных программах, можно избавиться от этих рутинных операций. Для этого создаётся новый компонент, который обладает всеми необходимыми свойствами.
Конечно, можно создавать компонент «с нуля», но так почти никто не делает. Обычно задача сводится к тому, чтобы как-то
175
7
Объектно-ориентированное программирование
улучшить существующий стандартный компонент, который уже есть в библиотеке.
Мы будем совершенствовать компонент TEdit (поле ввода), поэтому, согласно принципам ООП, наш компонент (назовём его TIntEdit) будет наследником класса TEdit, а класс TEdit будет соответственно базовым классом для нового класса TIntEdit:
class TIntEdit (TEdit):
Изменения стандартного класса TEdit сводятся к двум пунктам: • все некорректные символы, которые приводят к тому, что текст нельзя преобразовать в целое число, должны блокироваться автоматически, без установки дополнительных обработчиков событий;
• компонент должен уметь сообщать числовое значение целого типа; для этого мы добавим к нему свойство value (в переводе с англ. — «значение»).
Сначала добавим в новый класс конструктор:
class TIntEdit(TEdit):
def __init (self, parent, **kw): TEdit.____init___(self, parent, **kw)
При вызове этого конструктора нужно указать, по крайней мере, один параметр — ссылку на «родительский» объект parent. Затем могут следовать именованные параметры (подробности можно найти в Интернете в описании компонента Entry библиотеки tkinter). Запись с двумя звёздочками **kw говорит о том, что они «собираются» в словарь.
В приведённом варианте класс TIntEdit ничем не отличается от TEdit. Добавим к нему свойство value. Для этого введём закрытое поле __value, в котором будем хранить последнее пра-
вильное числовое значение:
class TIntEdit(TEdit):
def ___init___(self, parent, **kw):
TEdit.__init___ self, parent, **kw)
self.___value = 0
def ___setValue(self, value):
self.text = str (value)
value = property(lambda x: x._____value, ___setValue)
Для чтения введённого числового значения используется «лямбда-функция», которая возвращает значение поля __value
(вспомните материал из § 48). Метод записи _setValue записы-
вает в свойство text переданное число в виде символьной строки.
176
Совершенствование компонентов
§49
Для того чтобы заблокировать ввод нецифровых символов, будем использовать обработчик события onValidate (от англ, validate — проверять на правильность) компонента TEdit. Установим этот обработчик на скрытый метод нового класса TIntEdit, который назовём __validate. Обработчик должен возвращать
логическое значение: True, если символ допустимый и False, если нет (тогда ввод этого символа блокируется). В следующем коде оставлены только те строки, которые относятся к установке этого обработчика:
class TIntEdit(TEdit):
def _init____(self, parent, **kw):
self.onValidate = self.__validate
def validate(self) :
try:
newValue = int(self.text)
self.__value = newValue
return True
except:
return False
При получении сигнала о событии обработчик пытается преобразовать новое значение в число. Если это удаётся, полученное число записывается в переменную ___value и возвращается
результат True. Если произошла ошибка, функция вернёт False.
Готовый компонент лучше всего поместить в отдельный модуль, назовем его int_edit.py.
Построим новый проект: программа будет переводить целые числа из десятичной системы в шестнадцатеричную (рис. 7.18).
/ / /
Поле decEdit
\ Метка hexLabel
TIntEdit
TLabel
Рис. 7.18
Импортируем компонент TIntEdit из модуля int_edit: from int_edit import TIntEdit
177
7
Объектно-ориентированное программирование
Создадим объект-приложение:
арр = TApplication("Шестнадцатеричная система") арр.size = (250, 36) арр.position = (200, 200)
Поместим на форму метку hexLabel для вывода шестнадцатеричного значения и компонент класса TIntEdit для ввода:
f = ("Courier New", 14, "bold")
hexLabel = TLabel(арр, text = "?", font = f, fg = "navy") hexLabel.position = (155, 5) decEdit = TIntEdit(app, width = 12, font = f) decEdit.position = (5, 5) decEdit.text = "1001"
Добавим обработчик события onChange для поля ввода:
def onNumChange(sender): hexLabel.text = "{:X}". format (sender.value) decEdit.onChange = onNumChange
Этот обработчик читает значение свойства value объекта-источника события и выводит его на метку hexLabel в шестнадцатеричной системе. Формат X (а не х) означает, что будут использоваться прописные буквы A-F.
Теперь программа готова и можно проверить её работу.
Выводы
• В программе можно создавать новые компоненты. Обычно для этого используется наследование: новый компонент становится наследником существующего.
• К компоненту-наследнику можно добавлять свойства и методы.
• Рекомендуется помещать новый компонент в отдельный модуль для того, чтобы его можно было использовать повторно.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. В каких случаях имеет смысл разрабатывать свои компоненты?
2. Как вы думаете, в чём достоинства и недостатки использования своих компонентов?
178
Модель и представление
§50
3. Почему программисты редко создают свои компоненты «с нуля»?
4. Объясните, как связаны классы компонентов TIntEdit и TEdit. Чем они различаются?
5. Как получить запись числа в шестнадцатеричной системе счисления?
6. Объясните, как работает свойство value у компонента TIntEdit.
7. Почему мы не обрабатывали возможные ошибки в обработчике onChange?
8. Как установить обработчик события во время выполнения программы?
9. Почему можно использовать обработчик события onChange, который не был объявлен в классе TIntEdit?
Подготовьте сообщение
а) «Создание компонентов в Lazarus»
б) «Создание компонентов в программах на С#»
Интересный сайт
pythonicway.com — образовательный портал по языку Python
§50
Модель и представление
Ключевые слова:
• модель • контроллер
• представление
Одна из важнейших идей технологии быстрого проектирования программ (RAD) — повторное использование написанного ранее готового кода. Чтобы облегчить решение этой задачи, было предложено использовать ещё одну декомпозицию: разделить модель, т. е. данные и методы их обработки, и представление — способ взаимодействия модели с пользователем (интерфейс).
Пусть, например, данные об изменении курса доллара хранятся в виде массива, в котором требуется искать максимальное и минимальное значения, а также строить приближённые зависимости, позволяющие прогнозировать изменение курса в ближайшем будущем. Это описание задачи на уровне модели.
179
Объектно-ориентированное программирование
Для пользователя эти данные могут быть представлены в различных формах: в виде таблицы, графика, диаграммы и т. п. (рис. 7.19). Полученные зависимости, приближённо описывающие изменение курса, могут быть показаны в виде формулы или в виде кривой. Это уровень представления, или интерфейса с пользователем.
Рис. 7.19
Чем хорошо такое разделение? Его главное преимущество состоит в том, что модель не зависит от представления, поэтому одну и ту же модель можно использовать без изменений в программах, имеющих совершенно различный интерфейс.
Вычисление арифметических выражений: модель
Построим программу, которая вычисляет арифметическое выражение, записанное в символьной строке. Для простоты будем считать, что в выражении используются только:
• целые числа и
• знаки арифметических действий + - * /.
Предположим, что выражение не содержит ошибок и посторонних символов.
Какова модель для этой задачи? По условию данные хранятся в виде символьной строки. Обработка данных состоит в том, что нужно вычислить значение записанного в строке выражения.
Вспомните, что аналогичную задачу мы решали в главе 6, г использовалась структура типа «дерево». Теперь мы применим другой способ.
Как вы знаете, при вычислении арифметического выражения последней выполняется крайняя справа операция с наименьшим приоритетом (см. главу 6). Таким образом, можно сформулировать следующий алгоритм вычисления арифметического выражения, записанного в символьной строке s:
180
Модель и представление
§50
1. Найти в строке s последнюю операцию с наименьшим приоритетом (будем считать, что номер этого символа записан в переменной к).
2. Используя дважды этот же алгоритм, вычислить выражения слева и справа от символа с номером к и сохранить результаты вычисления в переменные nl и п2 (рис. 7.20).
3. Выполнить операцию, символ которой записан в s [к], с переменными nl и п2.
k
22 + 13 - 3*8
nl п2
Рис. 7.20
Обратите внимание, что в п. 2 этого алгоритма нужно решить ту же самую задачу для левой и правой частей исходного выражения. Как вы знаете, такой приём называется рекурсией.
Основную функцию назовём Calc (от англ, calculate — вычислить). Она принимает символьную строку и возвращает целое число — результат вычисления выражения, записанного в этой строке. Запишем алгоритм её работы на псевдокоде:
к = номер символа, соответствующего последней операции if к < 0: # нет знака операции
перевести всю строку в число else:
nl = результат вычисления левой части
п2 = результат вычисления правой части
применить найденную операцию к nl и п2
Мы будем использовать функцию lastOp, приведённую в главе 6, которая ищет последнюю выполняемую операцию. Если она вернула -1, то операция не найдена: вся переданная ей строка — это число. Тогда функция Calc может быть записана так:
def Calc(s):
k = lastOp(s)
if k < 0: # вся строка - число
return int(s)
else:
nl = Calc(s[:k]) # левая часть
n2 = Calc(s[k + 1:]) # правая часть # выполнить операцию
return oper(s[k], nl, n2)
181
Объектно-ориентированное программирование
Обратите внимание, что функция Calc — рекурсивная, она дважды вызывает сама себя. В последней строке вызывается функция орег, которая выполняет заданную операцию с переменными п и п2, она тоже приведена в главе 6.
Функции Calc, lastOp и орег (а также функцию priority, которая вызывается из lastOp) удобно объединить в отдельный модуль model.ру (модуль модели). Таким образом, наша модель — это функции, с помощью которых вычисляется арифметическое выражение, записанное в символьной строке.
Вычисление арифметических выражений: представление
Теперь построим интерфейс программы. В верхней части окна будет размещён выпадающий список (компонент TComboBox), в котором пользователь вводит выражение. При нажатии клавиши Enter выражение вычисляется и его результат выводится в первой строке обычного списка (компонента TListBox). Выпадающий список, в котором хранятся все вводимые выражения, полезен для того, чтобы можно было вернуться к уже введённому ранее варианту и исправить его (рис. 7.21).
Рис. 7.21
Итак, импортируем из модуля model функцию Calc и создаём приложение:
from model import Calc
арр = TApplication ("Калькулятор")
арр.size = (200, 150)
На форму нужно добавить компонент TComboBox. Чтобы прижа его к верху, установим для свойства align значение ’’top". Назовём этот компонент Input (в переводе с англ, «ввод»):
Input = TComboBox (арр, values = [], height = 1) Input.align = "top"
Input.text = "2+2"
182
Модель и представление
§50
При вызове конструктора кроме родительского объекта мы указали два именованных параметра: values (англ, value — значение) — пустой список (сначала в списке нет ни одного элемента) и height — высота компонента (одна строка).
Добавляем второй компонент — TListBox, устанавливаем для него выравнивание ”client” (заполнить всю свободную область) и имя Answers (в переводе с англ, «ответы»):
Answers = TListBox(арр)
Answers . align = ’’client”
Логика работы программы может быть записана в виде псевдокода:
if нажата клавиша Enter:
вычислить выражение
добавить результат вычислений в начало списка if выражения нет в выпадающем списке: добавить его в выпадающий список
Для перехвата нажатия клавиши Enter будем использовать обработчик события <Key-Return> («клавиша перевод каретки»), который подключается стандартным способом библиотеки tkinter — через метод bind (англ, bind — связать):
Input.bind(”<Key-Return>”, doCalc)
Здесь doCalc — это название нашей функции, принимающей один параметр — объект-структуру, которая содержит полную информацию о произошедшем событии:
def doCalc (event):
Вместо многоточия нужно написать операторы, выполняемые при вызове обработчика. Читаем текст, введённый в выпадающем списке, и вычисляем выражение с помощью функции Calc:
expr = Input.text
х = Calc (expr)
Затем добавляем в начало списка вычисленное выражение и его результат:
Answers.insert(0, expr + ”=” + str(x))
Здесь используется метод insert (англ, insert — вставить), первый аргумент — это номер вставляемого элемента (0 — вставить в начало списка).
183
7
Объектно-ориентированное программирование
Теперь проверим, есть ли такое выражение в выпадающем списке, и если нет — добавим его:
if not Input.findltem(expr): Input.addltem(expr)
Метод finditem (англ, find item — найти элемент) возвращает логическое значение: True, если переданная ему строка есть в списке и False, если нет. Метод addltem (англ, add item — добавить элемент) добавляет элемент в конец списка.
Таким образом, полная функция doCalc приобретает следующий вид:
def doCalc(event): expr = Input.text x = Calc (expr) Answers.insert(0, expr + ”=” + str(x)) if not Input.findltem(expr):
Input.addltem(expr)
Теперь программу можно запускать и испытывать.
Итак, в этой программе мы разделили модель (данные и средства их обработки) и представление (взаимодействие модели с пользователем), которые разнесены по разным модулям. Это позволяет использовать модуль модели в любых программах, где нужно вычислять арифметические выражения.
Обычно к паре «модель — представление» добавляют ещё управляющий блок (контроллер). Модель «отвечает» за хранение данных и выполнение расчётов, представление — за вывод информации пользователю, а контроллер работает как связующее звено между ними: получает запрос пользователя, передаёт его модели, получает ответ модели и выбирает нужное представление. Но довольно часто, например, при программировании в RAD-средах, контроллер и представление объединяются вместе — управление данными происходит в обработчиках событий.
Выводы
• В современных программах принято разделять модель (данные и алгоритмы их обработки) и представление (способ ввода исходных значений и вывода результатов). Это позволяет использовать модель в других программах.
• Часто для управления работой программы используется третий блок — контроллер, который принимает запрос пользователя, запрашивает данные у модели и выбирает нужный вариант представления этих данных.
Нарисуйте в тетради интеллект-карту этого параграфа.
184
Модель и представление
§50
Вопросы и задания
1. Чем хорошо разделение программы на модель и интерфейс? Как это связано с особенностями современного программирования?
2. Что обычно относят к модели, а что — к представлению?
3. Что от чего зависит (и не зависит) в паре «модель — представление»?
4. Приведите свои примеры задач, в которых можно выделить модель и представление. Покажите, что для одной модели можно придумать много разных представлений.
5. Объясните алгоритм вычисления арифметического выражения без скобок.
6. Пусть требуется изменить программу так, чтобы она обрабатывала выражения со скобками. Что нужно изменить: модель, интерфейс или и то, и другое?
Подготовьте сообщение
а) «Архитектура "модель — представление — контроллер"»
б) «Шаблоны проектирования»
Проекты
а) Программа, использующая архитектуру «модель — представление», для выбранной задачи
б) Веб-сайт с архитектурой «модель — представление — контроллер»
ЭОР к главе 7 на сайте ФЦИОР (http://fcior.edu.ru)
WWW
• Объектно-ориентированное программирование
• Основные понятия и принципы ООП
• Этапы объектно-ориентированного программирования
• Объектно-ориентированная модель программирования
• Основные принципы объектно-ориентированного программирования: инкапсуляции и полиморфизма, наследования и переопределения.
Практические работы к главе 7
Проект № 56 «Движение по дороге»
Работа № 59 «Скрытие внутреннего устройства объектов»
Проект № 60 «Классы логических элементов»
Работа №61 «Работа с формой»
Работа № 62 «Просмотр рисунков»
Работа № 63 «Ввод данных»
Работа № 64 «Совершенствование компонентов»
Работа № 65 «Калькулятор»
185
Глава 8
ОБРАБОТКА ИЗОБРАЖЕНИЙ
§51
Ввод изображений
Ключевые слова:
• разрешение • сканирование
• цветовые модели • кадрирование
• фотографирование
Растровый рисунок состоит из отдельных пикселей, каждый из которых закрашен своим цветом.
Цвет кодируется как набор чисел, например в модели RGB цвет пикселя задаётся тремя значениями — красной (англ. R: red), зелёной (англ. G: green) и синей (англ. В: blue) составляющими.
Что такое разрешение?
Любое изображение, в конечном счёте, предназначено для просмотра. При выводе на экран или на печать оно должно иметь определённые размеры, поэтому нужно установить связь между шириной и высотой рисунка в пикселях и его размерами (в сантиметрах или других единицах длины) на экране монитора или на бумаге. Эту связь определяет разрешение, т. е. число пикселей на некотором отрезке изображения (по ширине или высоте). Разрешение измеряется в пикселях на дюйм1* (англ, ppi: pixels per inch). Чем больше разрешение, тем выше качество изображения, но тем больше места оно занимает в памяти.
Например, пусть мы хотим вывести на экран изображение размером 10 х 15 см1 2. Каковы будут размеры рисунка в пикселях? Обычно стандартным разрешением для изображения на экране считается2) 72 ppi или 96 ppi. При разрешении 96 ppi размеры рисунка в пикселях должны быть равны
высота: 10-96 / 2,54 « 378 пикселей,
ширина: 15-96 / 2,54 ® 567 пикселей.
1) 1 дюйм = 2,54 см.
2) Разрешение 96 ppi, например, соответствует размерам экрана 1280 х 1024 пикселя для монитора с диагональю 17 дюймов.
186
Ввод изображений
§51
Конечно, нужно учитывать, что фактическое разрешение экрана может отличаться от 96 ppi, оно зависит от размера монитора и режима работы видеокарты (заданного в её настройках количества пикселей по ширине и высоте экрана).
Теперь предположим, что нам нужно напечатать на бумаге стандартную фотокарточку того же размера (10x15 см). Печатающие устройства могут обеспечить значительно более высокое разрешение, чем экран. Для получения отпечатков среднего качества (при котором уже практически незаметно, что изображение состоит из пикселей) требуется разрешение около 300 ppi, а для профессиональных работ — 600 ppi и более (до 2400 ppi). При разрешении 300 ppi размеры рисунка в пикселях будут совсем другие:
высота: 10-300 / 2,54 ® 1181 пиксель,
ширина: 15-300 / 2,54 « 1772 пикселя.
На рисунке 8.1 для сравнения показано одно и то же изображение с разным разрешением.
300 ppi 96 ppi 24 ppi
Рис. 8.1
Заметно, что изображение с разрешением 300 ppi смотрится вполне естественно (пиксели не видны), а при разрешении 24 ppi ромашки уже с трудом угадываются в получившемся наборе пикселей.
Разрешение хранится в служебной области файла с изображением. Определить и изменить разрешение можно, например, с помощью свободного растрового графического редактора GIMP (www.gimp.org), версии которого существуют для Windows, Linux и macOS. Другие популярные редакторы, например Adobe Photoshop, имеют аналогичные возможности.
Если в редактор GIMP загрузить некоторое изображение, с помощью меню Изображение Размер изображения можно посмотреть и изменить его параметры (рис. 8.2).
187
8
Обработка изображений
Рис. 8.2
По умолчанию размер изображения задаётся в пикселях (точках растра). Чтобы увидеть размеры отпечатка (в сантиметрах или миллиметрах), в выпадающем списке справа нужно выбрать соответствующую единицу измерения.
Это диалоговое окно позволяет также менять размеры рисунка и его разрешение. Изменяя размер изображения в пикселях, мы искажаем рисунок. Например, пусть при увеличении размера нужно заменить 5 пикселей на 8. В этом случае программе приходится с помощью математических методов перестроить картинку так, чтобы изображение сохранилось как можно лучше. Алгоритм такой обработки задаётся в поле Интерполяция^. Кубическая интерполяция считается одной из лучших, однако при использовании этого метода изображение немного размывается. Чтобы сохранить чёткие границы на рисунке, в списке Интерполяция нужно выбрать вариант Никакая.
При изменении только разрешения количество пикселей в рисунке остаётся тем же, поэтому никакой потери качества не происходит. Однако размеры отпечатка изменятся: если увеличить разрешение, при печати изображение уменьшится.
Цифровые фотоаппараты
Для ввода растровых изображений в компьютер чаще всего применяют цифровые фотоаппараты и сканеры.
Интерполяция — это восстановление промежуточных значений функции.
188
Ввод изображений
§51
Самый важный элемент цифрового фотоаппарата — это светочувствительная матрица —интегральная микросхема, которая состоит из большого количество светочувствительных элементов — фотодиодов. Свет, поступивший на фотодиод, преобразуется в электрический сигнал, который с помощью аналого-цифрового преобразователя (АЦП) переводится в числовой код.
У большинства профессиональных фотоаппаратов размер светочувствительной матрицы такой же, как размер кадра фотоплёнки: 36x24 мм (соотношение сторон 3:2), у любительских цифровых камер соотношение сторон обычно равно 4:3.
Разрешение матрицы фотоаппарата — это количество светочувствительных элементов, которое измеряется в мегапикселях (миллионах пикселей изображения, Мп). Как мы определили в начале параграфа, для качественной печати фотографии размером 10x15 см (с разрешением 300 ppi) размер изображения должен быть не меньше, чем 1181x1772 пикселя, это составляет примерно 2,1 Мп. Все современные фотоаппараты имеют намного более высокое разрешение (обычно больше 10 Мп).
Для того чтобы получить цветное изображение, каждый фотодиод «накрыт» светофильтром определённого цвета (чаще всего используют модель RGB — красные, зелёные и синие светофильтры). Таким образом, фотодиод измеряет яркость только одной составляющей цвета, а остальные компоненты восстанавливаются процессором фотокамеры по соседним пикселям. Во многих фотоаппаратах используют так называемый фильтр Байера, состоящий из 25% красных, 25% синих и 50% зелёных фильтров (см. рис. 8.3 и цветной рисунок на форзаце). Такое соотношение объясняется тем, что человеческий глаз более чувствителен к зелёному цвету.
Зелёный
Синий
Рис. 8.3
189
8
Обработка изображений
Цифровые фотоаппараты при съёмке сохраняют изображение на встроенной карте памяти в двух основных форматах: RAW и JPEG. Формат RAW — это необработанные данные (от англ. raw — «сырой», «сырьё», необработанный), т. е. коды сигналов, полученных каждым элементом чувствительной матрицы фотоаппарата. Снимок в формате RAW содержит наиболее полные данные, на каждый цветовой канал отводится 12-14 бит (в отличие от 8 бит при обычном 7?(?В-кодировании). Поскольку есть много разных моделей аппаратов, существует более сотни различных RA ГИ-форматов.
Если фотоаппарат сохраняет снимки в формате JPEG, «сырые» ЛАТУ-коды сразу после съёмки обрабатываются процессором с учётом настроек камеры, выбранных пользователем. Результат этой обработки затем и сохраняется на карте памяти, при этом:
• глубина кодирования уменьшается до 8 бит на канал (потеря информации!);
• изображение сжимается с потерями по алгоритму JPEG, в результате некоторые детали снимка безвозвратно теряются, хотя размер файла значительно уменьшается;
• все исходные данные уничтожаются.
Если камера была неверно настроена, полученное изображение будет низкого качества и восстановить его практически невоз-
можно.
Поэтому профессиональные фотографы всегда сохраняют фотографии в формате RAW. Это даёт значительно больше возможностей для коррекции (улучшения) с помощью программ.
Например, часто удаётся увеличить контраст при плохих условиях съемки. Для того чтобы получить изображение в одном из компьютерных форматов (JPEG, GIF, TIFF, BMP и др.), «сы-
рые» снимки нужно обработать одной из специальных программ,
которые называются ЙАУУ-конвертерами. Одна из известных про-
грамм-конвертеров
LR
Adobe Photoshop Lightroom.
Для ввода изображений с фотоаппарата в компьютер эти два устройства соединяются специальным кабелем. После подключения фотоаппарат обнаруживается как новый съёмный диск. Можно также использовать устройство для чтения карт памяти — кардридер (при этом карту памяти нужно вынуть из фотоаппарата).
Сканирование
Сканирование — это ввод изображения с помощью сканера. Многие растровые графические редакторы позволяют вводить сканиро
190
Ввод изображений
§51
ванное изображение с помощью собственного меню. Например, в GIMP для этого нужно выбрать пункт меню Файл —> Создать -> Сканер/Камера. После этого запускается программа, обслуживающая сканер, в которой требуется задать режимы сканирования.
В первую очередь требуется выбрать тип изображения:
• чёрно-белое (двухцветное),
• полутоновое (256 оттенков серого, от чёрного до белого) или • цветное.
Второй важный параметр — это разрешение. Его нужно выбирать с некоторым запасом, учитывая, что отсканированное изображение потом чаще всего обрабатывается. Если изображение сканируется для вывода на экран (с разрешением 72-96 ppi) и его не нужно увеличивать, при сканировании можно выбрать разрешение 150-200 ppi. Если же вы хотите обработать рисунок и потом напечатать его на принтере, нужно выбирать разрешение не меньше, чем 300-400 ppi.
Иногда нужно отсканировать текст, чтобы потом подготовить электронную версию документа. Если документ не нужно редактировать и можно сохранить его в виде рисунка, достаточно установить разрешение 150-200 ppi. Если же требуется распознать текст документа с помощью специальной программы (типа ABBYY FineReader или CuneiForm), нужно выбирать более высокое разрешение — не менее 300 ppi.
Кадрирование
После сканирования полученное изображение, как правило, нужно кадрировать, т. е. выбрать нужные границы изображения, обрезать лишнее. Рассмотрим случай, когда фотография была положена неровно (рис. 8.4), так что её нужно сначала повернуть, а потом кадрировать.
Рис. 8.4
191
Обработка изображений
Сначала выполним поворот так, чтобы линия горизонта была строго горизонтальна. Для этого нужно загрузить рисунок в GIMP, выбрать инструмент Вращение и щёлкнуть на рисунке. Появится окно, в котором можно установить нужный угол поворота (рис. 8.5).
Рис. 8.5
При изменении угла в основном окне виден результат применения этой операции. Можно также вращать изображение, схватив его мышью. При таком вращении границы холста (рабочей области рисунка) не меняются. Поэтому если ширина и высота изображения значительно различаются, при повороте на большой угол части рисунка могут оказаться за границами холста и будут обрезаны.
Если угол поворота не кратен 90 градусам, растровое изображение искажается. Для построения нового рисунка используют математические методы, так же как и при изменении его размеров.
Часто бывает удобно сразу выполнить поворот холста (рисунка вместе с границами) на 90 или 180 градусов. Это можно сделать с помощью меню Изображение —> Преобразования. Поворот на 90 градусов особенно полезен: так как рисунок вращается вместе с границами, ни одна его часть не будет потеряна. В меню Изображение -> Преобразования также есть команды, которые строят зеркальное отражение по горизонтали или вертикали.
Теперь можно выполнять кадрирование1*. Выберите инструмент Кадрирование и выделите прямоугольную область,
оставив только нужную часть рисунка. Углы выделенной области
В Adobe Photoshop кадрирование и поворот выполняются сразу (рамку кадра можно вращать).
192
Ввод изображений
§51
можно перетаскивать мышью. При нажатии на клавишу Enter поля будут обрезаны (рис. 8.6).
Рис. 8.6
При кадрировании нужно решить две задачи: выбрать размеры кадра и определить, что включать в кадр, а что обрезать. В большинстве случаев оптимальное соотношение сторон кадра — примерно 3:2 (такое же, как у матриц профессиональных фотоаппаратов!), что близко к соотношению золотого сечения, равному примерно 1,618. Это соотношение часто встречается в природе и считается красивым и гармоничным. Золотое сечение связано с числами Фибоначчи: 1, 2, 3, 5, 8, ... В этом ряду каждое следующее число равно сумме двух предыдущих, а отношение двух соседних чисел стремится к соотношению золотого сечения.
Самые важные объекты на кадре должны располагаться не в центре кадра, а немного сбоку, примерно на расстоянии одной трети от краёв кадра. Это правило называется «правилом третей», как вы поняли, оно тоже связано с золотым сечением (рис. 8.7). Линию горизонта тоже обычно размещают не посередине, а примерно на уровне одной трети от нижней или верхней границы кадра.
Рис. 8.7
193
8
Обработка изображений
Выводы
• Разрешение — это число пикселей на некотором отрезке изображения. Разрешение измеряется в пикселях на дюйм (ppi). Чем больше разрешение, тем выше качество изображения, но тем больше места оно занимает в памяти.
• Цифровые фотоаппараты сохраняют изображения в форматах RAW или JPEG (с потерей качества).
• Сканирование — это ввод изображения с помощью сканера.
• Кадрирование — это определение нужных границ изображения.
• В большинстве задач оптимальное соотношение сторон кадра — примерно 3:2, что близко к соотношению золотого сечения (около 1,618).
• Наиболее важные и значимые объекты на кадре рекомендуется размещать на расстоянии примерно одной трети от краёв кадра.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Какие два основных способа ввода растровых изображений вы знаете?
2. Как вы думаете, когда лучше использовать сканирование, а когда — фотографирование?
3. Сравните возможности форматов RAW и JPEG при сохранении фотографий.
4. Что такое /МТУ-конвертер?
5. Как можно загрузить в компьютер изображения, записанные на карте памяти цифрового фотоаппарата?
6. Какие параметры важны при сканировании?
7. Что такое кадрирование? Зачем оно нужно?
Подготовьте сообщение
а) «Светочувствительные матрицы фотоаппаратов»
б) «Что такое полный кадр?»
в) «RAW-конвертеры»
г) «Форматы RAW и JPEG»
д) «Правило третей при кадрировании»
е) «Золотое сечение»
Проекты
а) Сканирование и кадрирование выбранной старой фотографии.
б) Золотое сечение в работах профессиональных фотографов.
194
Коррекция изображений
§52
§52
Коррекция изображений
Ключевые слова:
• перспектива
• гистограмма
• уровни
• коррекция цвета
• ретушь
Качество многих фотографий можно значительно улучшить, устранив дефекты, возникшие из-за неправильной настройки фотокамеры. Кроме того, можно исправить некоторые искажения, которые вносит сам фотоаппарат.
Поскольку растровый рисунок хранится как набор чисел, кодирующих цвета пикселей, коррекция фотографий сводится к математической обработке этих данных с помощью специально разработанных алгоритмов.
Исправление перспективы
Оптическая система фотоаппаратов часто даёт искажения, в результате которых вертикальные линии (например, стены домов) становятся наклонными (рис. 8.8, а).
а) б)
Рис. 8.8
Этот дефект легко исправляется в современных графических редакторах (рис. 8.8, б). В GIMP нужно выделить всё изображение (кл виши Ctrl+A или меню Выделение Все) и выбрать инструмент А Перспектива. После этого углы рисунка, выде
195
Обработка изображений
ленные квадратами, надо перетащить так, чтобы выровнять вертикальные линии.
Гистограмма
Очень полезную информацию для оценки изображения даёт гистограмма — график специального вида, который показывает распределение пикселей по яркости, от чёрного к белому (рис. 8.9). Высота вертикальных отрезков определяет количество пикселей, имеющих одинаковую яркость, от самых тёмных (слева) до самых светлых (справа).
Чтобы увидеть гистограмму загруженного изображения, в редакторе GIMP нужно выбрать пункт меню Окна Прикрепля ющиеся диалоги Гистограмма.
По приведённым на рис. 8.9 гистограммам сразу видно, что: • фото 1 слишком тёмное, потому что все пиксели сосредоточены в области тёмных тонов (слева на гистограмме);
• фото 2 слишком светлое (нет тёмных тонов);
• фото 3 малоконтрастное (есть средние тона, но нет тёмных и светлых);
• фото 4 содержит пиксели всех уровней яркости1*.
Изображениям 1—3 не хватает контраста. Чтобы их улучшить, нужно «растянуть» гистограмму так, чтобы она занимала весь диапазон тонов, от чёрного до белого. Для этого в GIMP используется меню Цвет Уровни1 2*. В появившемся окне нужно отрегулировать положение чёрного, серого и белого движков под гистограммой (рис. 8.10, а).
1* На этой фотографии — картина «Пристань» художника К. А. Гоголева, вырезанная из дерева.
2* В Adobe Photoshop — меню Изображение Коррекция Уровни.
Коррекция изображений
§52
Все пиксели слева от чёрного движка становятся чёрными. Те, что оказались справа от белого движка, станут белыми. Таким образом, вся область между чёрным и белым движками растянется на весь диапазон. Передвигая серый движок (по умолчанию он находится посередине между чёрным и белым), можно менять контраст средних тонов. При этом в окне изображения мы сразу видим результат (такой эффект называется предварительным просмотром, т. е. просмотром результата какой-то операции до её окончательного применения).
После коррекции уровней внешний вид фотографии значительно улучшается, она становится более контрастной, содержит достаточно большое число ярких и тёмных пикселей. Однако гистограмма после коррекции не сплошная, а состоит из отдельных полосок (рис. 8.10, б). Это значит, что пикселей с некоторыми значениями яркости нет совсем (подумайте почему).
а)
Рис. 8.10
Заметим, что над гистограммой в окне Уровни расположен выпадающий список, в котором можно выбрать для коррекции один цветовой канал (красный, синий или зелёный) и настраивать его отдельно от остальных.
Для выравнивания уровней можно также использовать окно регулировки яркости и контраста (меню Цвет Яркость Контраст). Более сложную тоновую коррекцию выполняют с помощью кривых (Цвет Кривые).
197
Обработка изображений
Коррекция цвета
В некоторых изображениях явно видно, что какой-то оттенок явно сильнее, чем нужно, и из-за этого листва деревьев может оказаться синей, а красная крыша — зелёной. В этом случае можно применить коррекцию цвета, используя свои знания о том, какие цвета имеют объекты в действительности. В программе GIMP нужно выбрать пункт главного меню Цвет — Цветовой баланс (рис. 8.11).
Выберите изменяемый диапазон
Тени
(• Полутона
С Светлые части
Коррекция цветовых уровней
Г олубой Пурпурный
Желтый
Красный [о
Зеленый |0
Синий |о
Рис. 8.11
С помощью этого окна можно отдельно корректировать цвета тёмных участков (теней), пикселей средней яркости (полутонов) и светлых частей.
Обратите внимание, что невозможно скорректировать один какой-то цвет, оставив все остальные без изменения. Предположим, что для какого-то пикселя мы уменьшили красную составляющую (в модели RGB). Это автоматически означает, что увеличится относительная доля зелёной и синей составляющей, т. е. усилится голубой канал (англ. cyan). Пары красный — голубой, зелёный — пурпурный (фиолетовый) и синий — жёлтый — это так называемые дополнительные цвета (увеличение одного из них вызывает уменьшение парного).
Иногда нужно превратить цветное изображение в чёрно-белое (полутоновое, «серое»), например для публикации в книге. В этом случае информация о цвете будет потеряна и останется только тон (яркость). В редакторе GIMP для этого используется пункт главного меню Цвет Обесцвечивание.
Эта операция не так проста, поэтому программа предлагает на выбор несколько методов построения «серого» изображения (рис. 8.12). Например, при выборе варианта Светимость тон пикселя вычисляется по формуле 0,21 R + 0,72 G + 0,07 В,
198
Коррекция изображений
§52
В Обесцвечивание
Вставленный слой-169 (color.xcF)
Основа оттенков серого:
(• ; Свет лота;
Г Светимость
Г Среднее
Р* Предварительный просмотр
Справка
Сбросить
Отменить
Рис. 8.12
где R, G и В — значения яркостей красного, зелёного и синего каналов. В этой формуле учитывается, что человеческий глаз наиболее чувствителен к зелёному цвету. Нужно выбирать такой метод обесцвечивания, при котором полученное «серое» изображение выглядит, на ваш взгляд, лучше всего.
Ретушь
Ретушью называют устранение дефектов фотографий — пятен, царапин, трещин, вуали, дефектов съемки и обработки. Различают несколько видов ретуши.
Для портретов людей применяют косметическую ретушь — устранение дефектов (морщин, родимых пятен, складок кожи) и придание особой выразительности важным частям лица (глазам, бровям, губам). Этот процесс напоминает работу художника-визажиста или гримёра.
При обработке старых фотографий надо восстановить первоначальный вид изображения, внося как можно меньше изменений, поэтому говорят о реставрации.
Для устранения художественных дефектов применяют композиционную ретушь — кадрирование, удаление лишних элементов, добавление элементов, изменение фона, регулировку освещения.
Ретушь, которой раньше занимались специалисты-ретушёры, — сложное и утомительно занятие. Компьютерная ретушь обладает очень большими возможностями и абсолютно безопасна для оригинального изображения. На рисунке 8.13, а показана исходная фотография: она малоконтрастная, на лице ребёнка есть пятна, в левом верхнем углу видна граница фотокарточки. С помощью приёмов ретуширования можно исправить её (рис. 8.13, б).
199
Обработка изображений
Рис. 8.13
Сначала убирают дефект всего изображения — недостаток контраста, это можно сделать с помощью настройки уровней (см. выше).
Для исправления локальных (местных) дефектов используют специальные инструменты редактора GIMP*. & Штамп,
Лечащая кисть, Осветление/Затемнение Размывание/
Резкость.
Инструмент Штамп переносит изображение с одного участка на другой. Область-источник задаётся щелчком мышью при нажатой клавише CtrlV. После этого мы как бы рисуем кистью, копируя образец в другое место. В области параметров инструмента (рис. 8.14) можно настроить свойства инструмента, например непрозрачность, форму кисти и её размер (движок Масштаб) и ДР.
Инструмент Лечащая кисть работает практически так же, как и штамп, но при переносе изображения учитывает окружающие пиксели, поэтому «впечатывание» получается менее заметным (но изображение немного размывается).
При использовании инструмента Осветление/Затемнение кисть при рисовании осветляет или затемняет (в зависимости от режима, выбранного в окне параметров) отдельные области.
Инструмент Размывание/Резкость позволяет размыть или повысить резкость участков изображения. Размывание может понадобиться, например, для того, чтобы предметы заднего плана не отвлекали внимание зрителей от главного объекта. Повышение резкости — это некоторая операция с цветом пикселей, кото-
В Adobe Photoshop пля этого служит клавиша Alt.
Коррекция изображений
§52
Рис. 8.14
рая позволяет чётче выделить границы. Нужно понимать, что значительно увеличить резкость фотографии не удастся, потому что изображение не содержит нужной информации, и программа только пытается её восстановить математическими методами.
Выводы
• Оптическая система многих фотоаппаратов даёт искажения, в результате которых вертикальные линии (например, стены домов) становятся наклонными. Этот недостаток исправляется с помощью инструмента Перспектива.
• Гистограмма — это график, который показывает распределение пикселей изображения по яркости. Для исправления неравномерной гистограммы применяют коррекцию уровней.
• Коррекцию цвета выполняют отдельно для теней, полутонов и светлых частей рисунка.
• Ретушь — это устранение дефектов фотографий — пятен, царапин, трещин, вуали, дефектов съемки и обработки.
Нарисуйте в тетради интеллект-карту этого параграфа.
201
Обработка изображений
а>
Вопросы и задания
1. Почему на многих фотографиях возникает искажение перспективы? Как его убрать?
2. Что такое гистограмма и что она показывает?
3. Как выполняется коррекция уровней?
4. Почему после коррекции уровней гистограмма не сплошная, а состоит из отдельных полосок?
5. Как вы думаете, зачем может понадобиться редактирование уровней отдельных каналов?
6. Какие инструменты можно использовать для коррекции неконтрастных фотографий?
7. Как выполняется коррекция цвета?
8. Почему при сильном уменьшении яркости красного цвета фотография приобретает голубой оттенок?
9. Как получить из цветного изображения полутоновое чёрнобелое?
10. Почему многие алгоритмы обесцвечивания изображений учитывают в первую очередь зелёный цветовой канал?
11. Что такое ретушь? Какие виды ретуши вы знаете?
12. Какие инструменты можно использовать для ретуши? В каких случаях их применяют?
Подготовьте сообщение
а) «Коррекция цвета»
б) «Ретушь фотографий вчера и сегодня»
Проект
Восстановление выбранной старой фотографии
Интересный сайт
editor.pho.to/ru/ — онлайн-фоторедактор
§53
Работа с областями
Ключевые слова:
• выделение областей
• быстрая маска
эффект «красных глаз»
202
Работа с областями
§53
Выделение областей
Часто нужно бывает работать не с целым изображением, а только с некоторой областью, так что все пиксели вне этой области не должны изменяться. Сначала эту область нужно выделить. В редакторе GIMP есть несколько инструментов для выделения областей.
Простейшие инструменты — Прямоугольник и \ Эллипс. Если при их использовании удерживать нажатой клавишу Shifty будет выделена правильная фигура (квадрат или окружность), а при нажатой клавише Alt происходит выделение от центра, а не с угла области.
Инструмент Лассо позволяет выделить область, ограниченную ломаной линией (щелчками мышью в узлах ломаной) или вообще произвольную область (обводя её, не отпуская левую кнопку мыши).
Инструменты Волшебная палочка и Выделение по цвету применяют для выделения областей одного цвета (или близких цветов, если в параметрах инструмента установлен ненулевой порог чувствительности). Выделение начинается в той точке, где выполнен щелчок мышью.
Инструмент Умные ножницы используется для выделения областей с чёткими, но неровными границами. Пользователь щёлкает мышью в опорных точках, между которыми программа дорисовывает линию выделения, стараясь следовать границе между двумя цветами. Когда выделение закончено, нужно щёлкнуть мышью в середине области.
Если в момент начала выделения области была нажата клавиша Shifty новая область добавляется к уже выделенной, а при нажатой клавише Ctrl — вычитается из выделенной ранее. С помощью такого приёма можно строить сложные области.
Любой пиксель может быть выделен частично, например на 25%. Это значит, что для такого пикселя эффект, применённый к области (например, заливка), будет ослаблен в 4 раза. Частичное выделение получается при использовании двух параметров: сглаживания (англ, anti-aliasing) и растушёвки (они задаются в окне параметров выбранного инструмента). Выделим три одинаковых круга тремя способами (рис. 8.15):
1) без сглаживания и растушёвки;
2) со сглаживанием;
3) с растушёвкой.
203
Обработка изображений
Каждую из этих областей зальём чёрным цветом (пункт меню Правка Залить цветом переднего плана).
3
Рис. 8.15
В первом случае на рис. 8.15 мы видим резкую границу в виде «лесенки»: пиксели или выделены на 100% (они стали чёрными), или вообще не выделены (остались белыми). Во втором случае граница сглаживается за счет частично выделенных (серых) пикселей. При использовании растушёвки (случай 3) граница размыта.
В меню Выделение собраны команды для работы с областью (увеличение, уменьшение, растушёвка и т. д.).
Быстрая маска
Маска — это «накладка», которая скрывает часть объекта. В графических редакторах маска позволяет защитить от изменений некоторые части изображения. Например, когда мы выделяем область, создаётся маска, которая защищает всё, что не выделено.
В простейшем случае каждый пиксель изображения может быть полностью выделен (открыт для изменений) или не выделен (защищён). Кроме того, пиксель может быть частично выделен — есть 256 ступеней выделения, которые кодируются числами от О (чёрный цвет, защищенный пиксель) для 255 (белый цвет, полностью выделен). Таким образом, маска может быть закодирована как чёрно-белое полутоновое изображение.
При выделении сложных областей, которые нужно не раз редактировать, удобно использовать режим Быстрая маска. В этом режиме маску можно редактировать с помощью инструментов рисования. Для перехода в режим быстрой маски в редакторе GIMP используют клавиши Shift+Q. Вся закрытая (невыделенная) часть рисунка заливается полупрозрачным красным цветом, а выделенная — полностью прозрачна. Рисуя (например, карандашом или кистью ) чёрным цветом, мы скрываем область (удаляем из выделения), а при рисовании белым цветом открываем её.
Работа с областями
§53
Если выбрана кисть с мягкими границами, некоторые пиксели будут выделены частично. В режиме быстрой маски часто используется инструмент Градиент, с помощью которого можно получить плавный переход от полного выделения к невыделенной части (маска плавно меняется от белого до чёрного цвета).
Исправление «эффекта красных глаз»
При фотосъемке со вспышкой нередко возникает так называемый «эффект красных глаз» — лучи вспышки отражаются от глазного дна глаз человека (оно имеет красный цвет) и попадают в объектив фотокамеры. Это особенно заметно при съёмке в тёмном помещении, когда зрачки глаз расширены. На самом деле, без вспышки мы видим тёмный зрачок, который и нужно восстановить.
Существуют различные методы устранения «эффекта красных глаз». Один из них — обесцвечивание (до серого цвета) и затем тонирование, при котором мы как бы смотрим на чёрно-белый рисунок через прозрачное цветное стекло. Цвет этого стекла в программе GIMP задаётся с помощью меню Цвет Тонирование*. в диалоговом окне можно с помощью ползунков выбрать оттенок (Тон), насыщенность и светлоту (яркость) цвета.
На рисунке 8.16 показан один из вариантов установки движков, при котором выделенный зрачок становится тёмным.
Рис. 8.16
Кроме того, можно использовать фильтры — алгоритмы автоматической обработки изображений (см. далее). Например, в редакторе GIMP в меню Фильтры есть фильтр Улучшение Удалить эффект красных глаз, который автоматически выполняет тонирование красных участков в выделенной области.
205
8
Обработка изображений
Фильтры
Фильтр — это алгоритм автоматической обработки пикселей изображения, который применяется ко всему изображению или к выделенной области.
Фильтры используют некоторые математические преобразования (иногда достаточно сложные), в результате которых цвет (код) каждого пикселя изменяется с учётом кодов соседних пикселей. Большинство фильтров настраивается с помощью диалоговых окон, в которых можно изменять параметры и сразу видеть получаемый результат.
Если эффект оказался слишком слабым и действие фильтра надо повторить, достаточно выбрать первый сверху пункт меню Филыпр (в нём будет название последнего примененного фильтра) или нажать клавиши Ctrl+F.
Наоборот, если действие фильтра надо ослабить, можно выбрать пункт меню Правка Ослабить. В этом случае итоговое изображение строится как результат наложения отфильтрованного рисунка (с заданным уровнем непрозрачности) и исходного. Степень непрозрачности устанавливается в диалоговом окне.
Фильтры можно (очень условно) разделить на две группы: фильтры для коррекции изображений и фильтры для художественной обработки.
Современные графические редакторы не только содержат большой набор фильтров, но и позволяют пользователю создавать и подключать свои собственные фильтры. Их также называют плагинами (от англ, plug-in — независимый программный модуль, подключаемый к программе). Плагины для редактора GIMP обычно пишутся на языках Sript-Fu или Python.
Фильтры для коррекции изображений. Нередко изображение получается нечётким (размытым) из-за того, что автофокус фотоаппарата неверно определил объект, интересующий фотографа, или в момент съёмки камера немного сдвинулась. Для того чтобы повысить резкость, применяют специальные фильтры из группы Улучшение*. Нерезкая маска и Повышение резкости. При этом нужно понимать, что эти фильтры не позволяют восстановить потерянную информацию, поэтому в результате их применения мелкие детали не появятся. Во многих случаях результат можно значительно улучшить, однако при сильном размытии качественное изображение получить не удастся.
Достаточно часто применяются и фильтры группы Размывание. Они выполняют обратное действие — снижают резкость.
206
Работа с областями
§53
При обработке фотографий это может понадобиться, например, для того, чтобы не отвлекать внимание зрителя на второстепенные детали, оставив чётким только центральный объект. Из этой группы наиболее популярны фильтры Гауссово размывание (равномерное) и Размывание движением (позволяет создать эффект движения в определённом направлении).
Художественные фильтры предназначены имитации каких-то эффектов. На рисунке 8.17 показана фотография цветка и результат применения к нему нескольких фильтров редактора GIMP.
Изучать многочисленные художественные фильтры лучше всего на практике, экспериментируя с их настройками.
Исходное изображение
Фильтр «Кубизм»
Фильтр «Старое фото»
Рис. 8.17
Фильтр «Барельеф»
Выводы
• Области выделяются для того, чтобы указать, с каким участком изображения мы хотим работать.
• Каждый пиксель изображения может быть выделен полностью или частично.
• Сглаживание выделенной области — это смягчение её границы за счёт добавления частично выделенных пикселей вдоль этой границы.
• Растушёвка — это размытие границ выделенной области.
• Маска — это «накладка», которая позволяет защитить от изменений некоторые части изображения.
• Быстрая маска служит для выделения части изображения с помощью инструментов рисования.
• «Эффект красных глаз» исправляется с помощью тонирования или фильтров.
• Фильтр — это алгоритм автоматической обработки пикселей изображения, который применяется ко всему изображению или к выделенной области.
Нарисуйте в тетради интеллект-карту этого параграфа.
Q
207
8
Обработка изображений
Вопросы и задания
1. Зачем нужно выделять области? Какие инструменты для этого используют?
2. Какие способы выделения и редактирования сложных областей вы знаете?
3. Что такое частичное выделение пикселя?
4. Что такое сглаживание? В каких случаях без сглаживания получается граница области в виде «лесенки», а в каких — нет?
5. Что такое растушёвка? Чем она отличается от сглаживания?
6. В каких задачах можно использовать сильную растушёвку?
7. Что такое быстрая маска и зачем она нужна?
8. Объясните, почему возникает «эффект красных глаз» и как его исправить.
9. Что такое фильтр? Как можно применить фильтр к части изображения?
10. Как усилить или ослабить действие фильтра?
11. Можно ли подключить к графическому редактору GIMP свой фильтр?
Подготовьте сообщение
а) «Инструменты выделения графического редактора»
б) «Повышение резкости фотографий»
в) «Художественные фильтры»
Проекты
а) Художественная обработка фотографии с помощью фильтров
б) Создание коллажа на выбранную тему
§54
Многослойные изображения
Ключевые слова:
• слой
• текстовый слой
• растеризация
• маска слоя
Зачем нужны слои?
Пусть нам нужно поместить нарисованного человечка на некоторый фон так, как показано на рис. 8.18. Скорее всего, сделать рисунок с первого раза не удастся, и его придётся не раз переделывать, чтобы получился хороший результат.
208
Многослойные изображения
§54
Рис. 8.18
Как вы знаете, растровый рисунок — это просто множество пикселей, каждый из которых имеет свой цвет, независимый от других. Представим себе, что после того, как человечек был нарисован, мы захотели передвинуть его в другое место. К сожалению, сделать это весьма непросто, потому что при рисовании мы меняем цвет пикселей фона и таким образом уничтожаем существующую информацию, которую потом невозможно восстановить.
Такая же проблема возникает при добавлении надписей на рисунок — текст надписи очень сложно изменить, если изображение под ней испорчено.
Как же избежать необратимых изменений? Человек видит в рисунке не пиксели, а знакомые ему объекты: скалы, берег, воду, тело человечка, футболку, шорты, кепку. Поэтому нужно попытаться каждый объект рисовать отдельно, так, чтобы его можно было изменять независимо от других объектов.
Представим себе, что над фоновым рисунком расположено несколько стёкол, на каждом из которых нанесено изображение какого-то объекта (рис. 8.19).
Фактически мы разбили весь рисунок на отдельные слои (англ, layers), каждый из которых можно изменять и перемещать независимо от других. Однако, если посмотреть на эту стопку сверху, мы увидим полный рисунок. Через прозрачные области верхних слоёв видны изображения на нижних слоях. Этот принцип широко используется в графических редакторах, такие изображения называются многослойными. Применяя многослойные изображения, можно, например, составить портрет человека по описанию («фоторобот») или «примерить» ему новую одежду или прическу.
209
8
Обработка изображений
Кепка
Рис. 8.19
Шорты Футболка Тело
Фон
Не все форматы графических файлов поддерживают слои. Например, популярные форматы BMP, JPEG, GIF и PNG могут хранить только однослойные («плоские») рисунки. Для записи многослойных изображений чаще всего используют форматы PSD (редактор Adobe Photoshop) или XCF (редактор GIMP). Нужно учитывать, что при этом в файле фактически хранится несколько отдельных изображений, это значительно увеличивает его объём.
Работа со слоями
Для работы со слоями в редакторе GIMP предназначено специальное окно Слои (рис. 8.20). Если этого окна нет на экране, вызвать его можно с помощью меню Окна Прикрепляющиеся диалоги Слои или комбинации клавиш Ctrl+L.
Каждый слой имеет своё имя, двойной щелчок на имени слоя позволяет изменить его. Прозрачные области залиты клетчатым узором
Обычно самый нижний слой — фоновый, он полностью непрозрачен. При необходимости можно обойтись и без фона, например если нужно получить изображение с прозрачными областями.
Рисование происходит на активном (текущем) слое, который выделен в списке слоёв. Остальные слои при этом не изменяются. Выбрать ак и ный слой можно щелком мышью в списке слоёв.
Кнопки и ф позволяют переместить активный слой выше или ниже по списку (изменить порядок слоёв).
Если отметить флажок Запереть над списком слоёв, то все прозрачные области активного слоя будут сохранены (рисовать можно только там, где уже что-то нарисовано).
210
Многослойные изображения
§54
J 100 0 j
Слои
Режим: Нормальный
Непрозр.: ------—-------------
Рис. 8.20
Для того чтобы переместить всё изображение слоя, применяют инструмент <J^J> Перемещение. В зависимости от настроек можно перемещать активный слой или слой, выбранный щелчком мышью на поле рисунка.
Щелчком на кнопке | J можно создать новый пустой слой выше активного, а кнопка ЙЬ создаёт копию активного слоя (например, чтобы сохранить исходное изображение при экспериментах).
Слой можно временно отключить, щёлкнув на значке <Й> в соответствующей строке. Щёлкнув в этом же месте повторно, мы вновь сделаем слой видимым.
Для того чтобы совсем удалить текущий слой, нужно щёлкнуть на кнопке или перетащить слой из списка на эту кнопку.
Слой можно сделать полупрозрачным: для этого движок Непрозрачность сдвигается влево. Справа от этого движка показывается непрозрачность слоя в процентах.
Список Режим определяет, как слой влияет на изображение, полученное с нижних слоев. Пусть, для простоты, рисунок содержит два слоя. Тогда цвет пикселя итогового изображения вычисляется по некоторому алгоритму на основе цветов соответствую
211
Обработка изображений
щих пикселей этих двух слоев. Этот алгоритм и определяется в списке Режим. По умолчанию установлен режим Нормальный — это значит, что изображение верхнего слоя полностью перекрывает нижний (с учётом прозрачности). Другие режимы позволяют, например, перекрывать только тёмные или только светлые области, затемнять или осветлять рисунок, находить «разность» (различие двух рисунков).
Иногда нужно связать несколько слоёв так, чтобы они перемещались вместе. Для этого напротив каждого слоя нужно щёлкнуть мышью между значком <Я> и уменьшенным изображением слоя. В этом месте появится изображение звена цепи (рис. 8.21).
Рис. 8.21
Слои можно объединять, т. е. делать из двух или нескольких слоёв новый слой. Нужно учитывать, что если изображения на этих слоях перекрываются, разделить их будет практически невозможно. Существуют три варианта объединения:
• объединение текущего слоя с предыдущим (нижележащим);
• объединение всех видимых слоёв;
• сведение изображения (объединение всех слоёв в один фоновый слой).
В редакторе GIMP эти операции выполняются с помощью контекстного меню слоя, которое появляется при щелчке правой кнопкой мыши на нужном слое в окне Слои.
Текстовые слои
В простейших графических редакторах текст, размещённый на поле рисунка, «встраивается» в изображение и сразу становится набором пикселей. Такой текст нельзя редактировать, перемещать и т. п. В более совершенных программах надписи хранятся на отдельных слоях. Большинство используемых сейчас компьютер
212
Многослойные изображения
§54
ных шрифтов — векторные, в них буквы задаются узловыми точками и соединяющими их отрезками или кривыми. Это позволяет многократно изменять содержание и оформление текста (в том числе гарнитуру и размер шрифта), не теряя качество изображения. Например, можно легко исправить опечатку, замеченную не сразу.
В редакторе GIMP инструмент Текст обозначается кнопкой . После его выбора нужно щёлкнуть мышью в том месте, где будет левый верхний угол надписи и ввести текст в появившемся окне (рис. 8.22). Свойства текста настраиваются на панели свойств инструмента в нижней части панели инструментов.
Рис. 8.22
В окне Слои появляется новый слой с текстом, причем вместо уменьшенного изображения содержимого вы увидите значок . Это означает, что текст в этом слое хранится в векторном формате. Можно выполнить растеризацию слоя, т. е. превратить текстовый слой в обычный (растровый), выбрав в меню Слои Удалить текстовую информацию. После этого текст будет редактироваться только как точечный рисунок.
Маска слоя
При создании сложных изображений желаемый результат практически никогда не получается с первого раза. Поэтому важно применять по возможности неразрушающие методы обработки, при которых информация не теряется и всегда можно вернуться к исходным данным. Один из таких приёмов — маска слоя.
Маска — это «накладка», которая позволяет «открыть» или «закрыть» некоторые пиксели изображения (например, быстрая маска при выделении областей). Маска слоя — это полутоновое («серое») изображение, связанное с данным слоем. Чёрные
213
Обработка изображений
области в маске закрывают рисунок на слое (делают его прозрачным!), а белые — открывают. Серые тона — это частично открытые (полупрозрачные) области. Фактически маска слоя позволяет установить разную прозрачность для разных участков слоя. При этом рисунок на слое полностью сохраняется, что позволяет вернуться к исходному варианту в случае неудачи.
Чтобы добавить или удалить маску слоя, используют команду Добавить маску слоя из контекстного меню окна Слои. Если у слоя есть маска, в списке слоёв появляется второй значок: о Если выделен левый значок, вы меняете изображение слоя, а если правый — маску слоя. При редактировании маски используются только оттенки серого цвета. Чтобы увидеть маску, в контекстном меню слоя нужно выбрать пункт Показать маску. Действие маски можно временно отключить с помощью команды Скрыть маску из контекстного меню.
Выводы
• Слои нужны для того, чтобы отдельные части рисунка можно было изменять независимо от других частей.
• Для каждого слоя устанавливается режим наложения и уровень прозрачности.
• Текстовые слои содержат надписи в векторном формате.
• Растеризация слоя — это превращение текстового слоя в растровый. После этого текст будет редактироваться только как точечный рисунок.
• Маска слоя — это полутоновое («серое») изображение, связанное с данным слоем. Чёрные области в маске закрывают рисунок на слое (делают его прозрачным), а белые — открывают.
Q
©
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Что такое «неразрушающие методы обработки»?
2. Зачем используют слои? Что это даёт?
3. Какие форматы файлов используют для хранения многослойных изображений?
4. Какие операции можно выполнять со слоями?
5. Что такое фоновый слой?
6. Как обозначаются прозрачные области слоя?
7. Какие свойства слоя определяются с помощью выпадающего списка Режим*}
8. Какие образом можно объединить слои?
214
Каналы
§55
9. Какие особенности имеют текстовые слои?
10. Что такое маска слоя? Зачем она нужна?
Подготовьте сообщение
а) «Режимы наложения слоёв»
б) «Операции со слоями»
Проект
Создание коллажа на выбранную тему с использованием слоёв
§55
Каналы
Ключевые слова:
• канал • область выделения
• цветовые каналы • маска
• альфа-канал
Цветовые каналы
При RGB-кодировании с глубиной 24 бита на пиксель цвет каждого пикселя хранится как набор из трёх чисел (от 0 до 255), обозначающих яркости красной, зелёной и синей составляющих.
Возьмём одну из трёх цветовых составляющих (например, красную) и построим новое изображение, в котором каждому пикселю соответствует код от 0 до 255. Будем считать, что 0 обозначает чёрный цвет, 255 — белый, а промежуточные значения — оттенки серого цвета. Тогда получается, что мы построили полутоновое («серое») изображение, которое совпадает по размерам с исходным рисунком и показывает «вклад» выбранного цвета. Такое вспомогательное изображение называют каналом.
Канал — это чёрно-белое полутоновое изображение, которое показывает степень влияния какого-то эффекта на изображение.
На рисунке 8.23, а (и на цветном рисунке на форзаце) изображён светофор со всеми зажжёнными лампами, а на рис. 8.23, б-г — цветовые каналы модели RGB, показывающие влияние красного, зелёного и синего цветов.
215
Обработка изображений
а) б) в) г)
Red Green Blue
Рис. 8.23
Очевидно, что для области красного цвета будет активным только красный канал, в котором эта область закрашена белым цветом. Для области зелёного цвета также «открыт» только один канал — зелёный. Жёлтый цвет получается «сложением» красного и зелёного, поэтому в обоих этих каналах жёлтой области соответствует белый цвет. Синего цвета на рисунке нет вообще, поэтому синий канал залит чёрным цветом.
В редакторе GIMP цветовые каналы модели RGB можно увидеть в окне Каналы (меню Окна Прикрепляющиеся диалоги -> Каналы). Любой канал можно отключить, щёлкнув на значке в соответствующей строке, повторный щелчок в этом месте снова включает канал (рис. 8.24).
Рис. 8.24
По умолчанию выделены (синим фоном) все три цветовых канала, т. е. все инструменты рисования и коррекции применяются к ним одновременно. При желании можно выделить какой-то один канал и редактировать только его.
216
Каналы
§55
У изображений с прозрачными и полупрозрачными областями появляется четвёртый канал — так называемый альфа-канал, определяющий прозрачность (рис. 8.25). Чёрные пиксели альфа-канала определяют прозрачное изображение, белые — полностью непрозрачное. Чтобы построить такое изображение, нужно выбрать команду Добавить альфа-канал из контекстного меню окна Слои. При этом фоновый слой превращается в обычный слой, на нём теперь можно делать прозрачные участки (например, удалив выделенную область или используя инструмент а Ластик).
Рис. 8.25
Редактор GIMP не позволяет редактировать изображение в других цветовых моделях (например, в модели CMYK, которая используется при печати). Однако с помощью меню Цвет -» Составляющие -» Разобрать можно построить новое многослойное полутоновое изображение, в котором каждый слой будет представлять собой канал выбранной цветовой модели. После этого можно отдельно редактировать каждый канал и затем обратно «собрать» полное изображение с помощью меню Цвет -> Составляющие -> Собрать. Например, чтобы избежать искажения цветов при повышении резкости изображения, рекомендуется применять эту операцию только к каналу яркости (V-каналу) в модели HSV.
Сохранение выделенной области
Когда вы выделяете какую-то область рисунка, создаётся маска — временный канал, в котором чёрный цвет обозначает невыделенные пиксели, а белый — выделенные. Эту область можно запомнить как новый канал {Выделение — Сохранить в канале).
217
Обработка изображений
Каналы, полученные в результате сохранения выделенных областей (канал Цветок на рис. 8.26), располагаются в нижней части окна Каналы (ниже цветовых каналоь). Чтобы снова превратить такой канал в область выделения, нужно выделить его в списке и щёлкнуть на кнопке
Выводы
• Канал — это чёрно-белое полутоновое изображение, которое показывает степень влияния какого-то эффекта на изображение.
• Цветное изображение может быть «разложено» на составляющие (каналы) в какой-либо цветовой модели (например, в модели RGB или CMYK).
• Альфа-канал определяет прозрачность пикселей рисунка.
• Выделенную область (маску) можно сохранить как канал для того, чтобы использовать в дальнейшем.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Что такое канал? Альфа-канал?
2. Можно ли сказать, что маска — это канал? Ответ обоснуйте.
3. Сколько ступеней выделения можно применять, если использовать 16 бит на канал?
4. Как можно сделать изображение с прозрачными областями?
5. Как сохранять выделенные области в каналах и использовать их повторно?
218
Иллюстрации для веб-сайтов
§56
Подготовьте сообщение
а) «Что такое альфа-канал?»
б) «Монтаж с использованием каналов»
в) «Применение каналов для редактирования рисунков»
Проекты
а) Создание изображений для веб-сайта с прозрачными областями
б) Сравнение форматов файлов изображений, поддерживающих прозрачные области
§56
Иллюстрации для веб-сайтов
Ключевые слова:
• графические форматы
• сжатие
• артефакты
• палитра
• глубина цвета
• размывание цвета
Иллюстрации для веб-сайтов должны быть сохранены только в тех графических форматах, которые умеют отображать браузеры:
• JPEG (англ. Joint Photographic Experts Group — объединённая группа фотографов-экспертов, файлы с расширением jpg или jpeg)\
• GIF (англ. Graphics Interchange Format — формат для обмена изображениями, файлы с расширением gif);
• PNG (англ. Portable Network Graphics — переносимые сетевые изображения, файлы с расширением png).
Все эти форматы предназначены только для «плоских» (однослойных) изображений, поэтому все слои многослойных изображений при сохранении приходится сводить в один слой. При этом теряется информация (снова разделить слои практически невозможно), поэтому рекомендуется всегда оставлять на всякий случай исходные многослойные файлы (в форматах PSD или XCF).
В форматах JPEG, GIF и PNG используется сжатие данных для того, чтобы уменьшить объём файлов и таким образом ускорить загрузку веб-страницы.
219
8
Обработка изображений
При сохранении рисунков в формате JPEG можно регулировать степень сжатия. Если увеличивать степень сжатия, то качество рисунка ухудшается, и наоборот. Поэтому нужно выбирать максимальную степень сжатия, при которой изображение выглядит приемлемо.
При выборе формата для конкретного изображения нужно учитывать, что:
• в формате JPEG можно хранить только полноцветные изображения (с глубиной цвета 24 бита на пиксель); для уменьшения объёма файла использует сжатие с потерями, которое приводит к размытию границ объектов, появлению пятен вокруг них и одноцветных квадратов размером 8x8 пикселей (так называемые артефакты JPEG)',
• формат JPEG не поддерживает прозрачность;
• в формате GIF можно хранить только изображения с палитрой (от 2 до 256 цветов);
• анимация поддерживается только в формате GIF',
• в форматах GIF и PNG используется сжатие без потерь (рисунок при сжатии не искажается); для уменьшения объёма файла можно уменьшать количество цветов в палитре;
• полупрозрачные изображения можно сохранять только в формате PNG, где для каждого пикселя может храниться дополнительный байт, задающий прозрачность (альфа-канал).
В таблице 8.1 показаны изображения, полученные при сохранении одного и того же рисунка в разных форматах, а также указаны области применения каждого формата.
Чтобы при сохранении рисунка вручную задать количество используемых цветов, необходимо преобразовать его к индексированному режиму, т. е. закодировать с палитрой. Для этого используется пункт меню Изображение Режимы Индексированное. Если исходное изображение имеет глубину цвета 24 бита на пиксель (режим RGB), то при таком преобразовании происходит потеря информации о цвете. Поэтому лучше работать с копией рисунка, сохранив полноцветный оригинал в отдельном файле. Заметим, что формат PNG обеспечивает лучшее сжатие, чем GIF.
Как видно из табл. 8.1, кодирование с палитрой (форматы GIF и PNG) плохо подходит для хранения изображений с плавными переходами цветов (градиентами). Это связано с тем, что уменьшается количество используемых цветов и переходы становятся более резкими. Чтобы несколько улучшить результат, при переходе к индексированному изображению можно включить размывание цвета (англ, dithering — растрирование). Суть этого подхода состоит в том, что области, залитые в исходном рисунке
220
Иллюстрации для веб-сайтов
§56
Таблица 8.1
Формат Примеры Применение
JPEG Качество 100, 4743 байта Качество 20, 983 байта Качество 0, 518 байт Фотографии, непрозрачные изображения с размытыми границами объектов и плавными переходами цветов
GIF 256 цветов, 6165 байт 16 цветов, 1783 байта 8 цветов, 1184 байта Рисунки с небольшим количеством цветов; мелкие рисунки с чёткими границами; рисунки с прозрачными областями; анимация
PNG Режим RGB, 7283 байта 16 цветов, 10440 байт 8 цветов, 1061 байт Высококачественные изображения, рисунки с прозрачными и полупрозрачными областями
«отброшенными» цветами, строятся как мозаика из пикселей тех цветов, которые остались в палитре. На рисунке 8.27 показан результат применения размывания при использовании 8-цветной палитры (редактор GIMP, размывание Флойда-Стейнберга). Объём файла увеличился с 1184 до 1664 байт из-за того, что алгоритм сжатия LZW, используемый в формате GIF, хуже сжимает разноцветные области, чем строки одного цвета.
Рис. 8.27
221
8
Обработка изображений
Выводы
• На веб-страницах можно использовать только изображения в форматах JPEG, GIF и PNG. Эти форматы поддерживают только один слой.
• Фотографии и размытые изображения обычно хранятся в формате JPEG. При сохранении в этом формате можно выбирать степень сжатия.
• Формат GIF используется для мелких рисунков с палитрой, изображений с прозрачными областями и анимацией.
• Формат PNG применяется для хранения качественных изображений, в том числе с полупрозрачными областями.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Опишите особенности и области применения каждого из форматов.
2. Определите лучший формат для сохранения:
1) фотографии;
2) изображения с чёткими границами областей;
3) изображения с прозрачными областями;
4) изображения с полупрозрачными областями;
5) анимации.
3. Что такое индексированное изображение?
4. Что происходит при переходе от режима RGB к индексированному изображению? Как выбрать количество цветов в палитре?
5. Что такое размывание цвета и зачем оно используется?
Проект
Обработка изображений для веб-сайта на выбранную тему
§57 Анимация
Ключевые слова:
• анимация
• режим замены
• режим объединения
222
Анимация
§57
Анимация (англ, animation — одушевление) — это «оживление» изображения. При анимации несколько рисунков (кадров) сменяют друг друга через заданные промежутки времени.
Для создания анимации в графических редакторах обычно используются многослойные изображения, каждый слой соответствует одному кадру. В простейшем случае слои просто сменяют друг друга: сначала виден только первый слой, через заданное время он скрывается и показывается второй слой и т. д. (рис. 8.28 и цветной рисунок на форзаце). Такой режим называется заменой (англ, replace).
Рис. 8.28
Можно использовать и другой подход: новый слой «накладывается» на существующее изображение — это режим объединения (англ, combine). Порядок анимации такого типа показан на рис. 8.29 и цветном рисунке на форзаце.
Рис. 8.29
Тип анимации для каждого слоя устанавливается отдельно, поэтому в одной анимации можно совмещать оба метода.
Анимация строится в два шага:
1) готовятся изображения для всех слоев;
2) устанавливается время задержки и вид анимации (для каждого слоя отдельно).
Чтобы готовую анимацию можно было просматривать без графического редактора (например, на веб-странице), нужно сохранить её в файле формата GIF (т. е. экспортировать — записать в другом формате с преобразованием).
223
8
Обработка изображений
Некоторые графические редакторы могут достраивать недостающие изображения: если объект двигается, достаточно задать несколько ключевых (самых важных) кадров, а все промежуточные будут созданы программой автоматически.
В редакторе GIMP при сохранении файла с несколькими слоями в формате GIF появляется диалоговое окно (рис. 8.30), в котором нужно выбрать вариант Сохранить как анимацию и нажать кнопку Экспорт.
Рис. 8.30
В следующем окне (рис. 8.31) настраиваются параметры сохранения анимации.
Рис. 8.31
Если установлен флажок Бесконечный цикл, то анимация будет повторяться бесконечно, иначе она выполнится только один раз. Здесь же выбирается задержка между кадрами и вид анимации (список Расположение кадра).
224
Анимация
§57
Если теперь открыть сохранённый таким образом GTF-файл с анимацией, в названиях слоёв-кадров (рис. 8.32) мы увидим в скобках время задержки (например, 100ms обозначает 100 миллисекунд) и метод анимации (combine или replace). Изменив названия слоёв, можно задать задержку и метод анимации для каждого слоя отдельно.
Слои
Режим: Нормальный
Непрозр.:
Запереть: J
J 100 0 j
Кадр 5 [100 ms] (combine)
Кадр 3 [100 ms] (combine)
Кадр 2 [100 ms] (combine)
Фон [100 ms]
Рис. 8.32
Чтобы просмотреть анимацию, не выходя из редактора GIMP, нужно выбрать фильтр Анимация —> Воспроизвести в меню Фильтры.
В группе Анимация есть фильтр Оптимизация, с помощью которого можно существенно уменьшить объём GIF-файла с анимацией. Это особенно важно, если анимация размещается на вебстранице. Оптимизация основана на том, что многие пиксели разных кадров совпадают, поэтому можно удалить все повторяющиеся части и хранить их только один раз.
Выводы
• Анимация — это «оживление» изображения. При анимации несколько рисунков (кадров) сменяют друг друга через заданные промежутки времени.
• В графических редакторах можно использовать два режима анимации: замену и объединение слоёв.
Нарисуйте в тетради интеллект-карту этого параграфа.
225
Обработка изображений
Вопросы и задания
1. Сравните два режима анимации.
2. Что такое экспортирование документа? Зачем оно применяется?
3. Как в редакторе GIMP установить время задержки и способ анимации для каждого кадра отдельно?
4. На чём основана оптимизация файлов с анимацией?
0>
Подготовьте сообщение
а) «Веб-сервисы для создания G/F-анимации»
б) «G/F-анимация на мобильных устройствах»
Проект
Создание рекламного баннера для веб-сайта на выбранную тему
Интересные сайты
progimp.ru — уроки по графическому редактору GIMP
bestanimationgif.com/lessons/ — анимация в программе Adobe Photoshop
sourceforge.net/projects/qgifer/ — программа QGifer для создания GIF-анимаций
gifup.com — веб-сервис по созданию G/F-анимаций
makeagif.com — веб-сервис по созданию GZF-анимаций
imgur.com/vidgif — веб-сервис по созданию G/F-анимаций из видео
§58
Векторная графика
Ключевые слова:
• векторный рисунок
• векторный редактор
• примитивы
• выделение объектов
• изменение порядка объектов
• выравнивание
• распределение
• кривая Безье
• гладкий узел
• угловой узел
Векторное изображение хранится в памяти как описание множества геометрических фигур. Для каждой фигуры задаются координаты опорных точек (например, углов прямоугольника), свойства контура и заливки внутренней области.
226
Векторная графика
§58
Для чего нужна векторная графика?
Главный недостаток растровой графики состоит в том, что при изменении размеров рисунка он искажается: изменяется и форма объектов, и даже их цвет (вы наблюдали это во время практических работ). Всё дело в том, что программа воспринимает рисунок не как набор объектов, а как множество точек разного цвета. Человек же, глядя на рисунок, представляет нарисованные объекты у себя в сознании.
Растровая графика неприменима там, где нужно масштабировать рисунки, т. е. изменять их размеры без потери качества. Например, плакат должен хорошо выглядеть как на листе формата А4, так и на баннере, размеры которого измеряются в метрах. При увеличении растрового рисунка размер пикселей также увеличится, и изображение станет ступенчатым.
Сейчас инженеры разрабатывают новые автомобили, самолёты, приборы в системах автоматизированного проектирования. В них строится трёхмерная (объёмная) модель объекта, которую затем нужно просматривать с разных сторон и рассчитывать на прочность. В таких задачах растровая графика вовсе неприменима.
Поэтому появилась другая идея: хранить в памяти компьютера не отдельные пиксели, а информацию о геометрических фигурах, из которых составлен рисунок. Такие рисунки называют векторными. Векторный рисунок — это своеобразная программа для компьютера, выполняя которую, он рисует изображение на экране.
Для работы с векторными изображениями используют специальные программы — векторные графические редакторы, например Adobe Illustrator, CorelDraw, ff Inkscape.
Для выполнения практических работ можно использовать кроссплатформенную свободную программу — редактор Inkscape. Но это не обязательно — принципы работы с векторными изображениями одинаковы во всех редакторах, и рисовать простые схемы и рисунки можно даже с помощью офисных пакетов: в редакторе Word есть небольшой встроенный векторный редактор, а в состав OpenOffice входит векторный редактор Draw.
Примитивы
Векторный рисунок состоит из примитивов — элементарных фигур. К ним относятся отрезок, ломаная, прямоугольник, овал (эллипс), кривая и др.
Основные фигуры рисуются так же, как и в растровых редакторах, но после завершения рисования они не превращаются
227
8
Обработка изображений
в набор пикселей, а остаются отдельными объектами, каждый из которых можно редактировать (перемещать, изменять свойства и даже удалить) независимо от других. Например, если надо нарисовать на экране прямоугольник, в файл записывают команду для рисования прямоугольника, указывая координаты его левого верхнего угла, ширину, высоту, угол поворота и т. п. Это очень похоже на вызов процедуры (вспомогательного алгоритма) с параметрами.
Чтобы что-то сделать с объектом, его нужно выделить щелчком мышью. При нажатой клавише Shift можно выделить сразу несколько объектов.
На рамке выделенного объекта появляются маркеры, перетащив которые, можно изменить размеры фигуры. Оба конца отрезка тоже можно перетаскивать мышью.
Чтобы переместить сам объект, нужно схватить его за контур. Если при перетаскивании удерживать нажатой клавишу Ctrl, объект будет скопирован.
Нажатие клавиши Delete удаляет выделенные объекты.
Контур любой фигуры можно настраивать: задать цвет, толщину, стиль линии (сплошная, штриховая, точечная и др.). Для замкнутого контура можно определить стиль заливки:
• один цвет;
• градиент — плавный переход между двумя или несколькими цветами;
• рисунок (для заполнения области используется изображение из файла);
• текстуру — рисунок, имитирующий материал (бумага, холст, дерево и др.);
• узор — рисунок, составленный из двух цветов.
Изменение порядка объектов
Новые фигуры добавляются на рисунок поверх существующих, перекрывая их. Иногда нужно изменить порядок их расположения, например переместить какую-то фигуру впереди (выше) всех остальных объектов. Для этого в редакторе программы Inkscape служат команды верхнего меню Объект:
• Поднять на передний план (поверх всех остальных объектов);
• Поднять — поменять местами выделенный объект с тем, который находится непосредственно над ним;
• Опустить на задний план (позади всех остальных объектов);
• Опустить — поменять местами выделенный объект с тем, который находится непосредственно под ним.
228
Векторная графика
§58
Так можно перемещать (по уровням) сразу несколько выделенных объектов. Все эти команды доступны из контекстного меню.
На рисунке 8.33 показан результат применения команды На передний план к объекту с белой заливкой.
Рис. 8.33
Выравнивание, распределение
При работе с векторными рисунками часто возникают такие задачи:
• выровнять несколько объектов по какому-то краю (например, по верхней границе) — рис. 8.34;
Рис. 8.34
• распределить несколько объектов так, чтобы они оказались на равных расстояниях по горизонтали или по вертикали (рис. 8.35).
Рис. 8.35
229
Обработка изображений
Конечно, всё можно сделать вручную, передвигая мышью отдельно каждую фигуру, но это очень долго и неточно. В векторных графических редакторах эти операции автоматизированы. В программе Inkscape они выполняются с помощью меню Объект Выровнять и расставить.
Группировка
Предположим, что ваш векторный рисунок строится из сложных объектов (например, дом, автомобиль, собака, человек), каждый из которых, в свою очередь, тоже состоит из частей.
Для того чтобы передвинуть такой сложный объект, нужно переместить все его части, не сдвигая их друг относительно друга. Лучше всего заранее сгруппировать все эти части (например, все элементы дома) в единый объект. В редакторе Inkscape это можно сделать с помощью команды главного меню Объект -> Сгруппировать. После этого весь объект выделяется одним щелчком мышью и перетаскивается за один раз.
Сгруппированный объект имеет общую рамку, поэтому очень легко изменять его размеры с помощью маркеров этой рамки (рис. 8.36). Сделать это без группировки крайне сложно.
Рис. 8.36
Кривые
К сожалению, не все рисунки можно построить из готовых примитивов (отрезков, прямоугольников, овалов). Большинство элементов, из которых состоят рисунки профессиональных дизайнеров, — это кривые. В памяти компьютера хранятся координаты опорных точек (узлов), а сама форма кривой между узлами описывается математической формулой.
На рисунке 8.37 изображена кривая с опорными точками А, Б, В, Г и Д.
230
Векторная графика
§58
Рис. 8.37
У каждой из этих точек есть «рычаги» (управляющие линии), перемещая концы этих рычагов, можно менять кривизну всех участков кривой (сегментов). Если оба рычага находятся на одной прямой, получается гладкий узел (Б и Г), если нет — то угловой узел (В). Таким образом, форма кривой полностью задаётся координатами опорных точек и рычагов. Кривые, заданные таким образом, называют кривыми Безье в честь их изобретателя французского инженера Пьера Безье.
В редакторе Inkscape кривую можно нарисовать с помощью инструментов Кривая Безье. Одиночными щелчками мышью строится ломаная, щелчок на первой точке замыкает ломаную, а двойным щелчком в любом месте можно закончить построение, не замыкая её.
Для того, чтобы редактировать кривую, нужно включить инструмент ч Редактирование узлов. При этом появляется возможность.
• перемещать, удалять и добавлять узлы;
• изменять тип узла (с гладкого на угловой и обратно);
• изменять положение рычагов, регулирующих кривизну.
Форматы векторных рисунков
Векторные графические редакторы могут сохранять изображения в различных форматах:
• WMF (англ. Windows Metafile — метафайл Windows, файлы с расширениями wmf и emf) — стандартный формат векторных рисунков в операционной системе Windows',
• AI (файлы с расширением ai) — формат векторных рисунков программы Adobe Illustrator-,
• CDR (файлы с расширением cdr) — формат векторных рисунков программы CorelDRAW*,
• SVG (англ. Scalable Vector Graphics — масштабируемые векторные изображения, файлы с расширением svg) — текстовый формат для хранения векторных и растровых изображений, которые можно размещать на веб-страницах в Интернете;
231
Обработка изображений
• EPS (англ. Encapsulated Postscript, файлы с расширением eps) — универсальный формат для подготовки растровых и векторных изображений к печати.
Ввод векторных рисунков
Рисование сложных векторных рисунков графическом редакторе «от руки» — достаточно долгое и утомительное занятие. Художники-иллюстраторы часто предпочитают сначала нарисовать картинку на бумаге, а затем окончательно редактировать её на компьютере. При этом возникает проблема ввода: при обычном сканировании получается растровое изображение, а не векторное, как нам нужно. В этом случае можно использовать два подхода:
• выполнить трассировку — преобразовать растровое изображение в векторное (разбить его на отдельные фигуры) или
• загрузить растровое изображение в графический редактор и обвести его контуры.
Все современные векторные графические редакторы могут выполнять трассировку. На рисунке 8.38, а показано исходное растровое изображение, а на рис. 8.38, б и в и цветном рисунке на форзаце — векторные изображения, полученные в результате трассировки с разным качеством (4 цвета и 12 цветов).
а) б) в)
Рис. 8.38
При использовании второго метода — обводке контуров — отсканированный рисунок загружается в графический редактор. Затем, применяя инструменты рисования векторных кривых (кривых Безье), нужно аккуратно повторить контуры всех фигур, из которых состоит рисунок. В этой работе большую помощь может оказать графический планшет (рис. 8.39).
232
Векторная графика
§58
Рис. 8.39
Рабочая поверхность планшета — чувствительная, на нём рисуют специальным электронным пером. Именно рисование пером для человека удобнее всего, так как при этом мышцы кистей и рук почти не напрягаются. Перо чувствительно к нажиму: при надавливании пера линии будут толще. С помощью пера удобно обводить контуры отсканированных рисунков и таким образом строить векторное изображение.
Контуры в GIMP
Современные растровые графические редакторы (Adobe Photoshop, GIMP) могут работать с векторными изображениями — контурами (англ. path).
С помощью контуров удобно выделять области рисунка, которые должны иметь строго определённые «правильные» границы. Контуры сохраняются в файле (в форматах PSD и XCF), их можно многократно изменять.
Для создания нового контура в редакторе GIMP надо включить инструмент Контуры и щелчками мышью обозначить узлы. Чтобы построить гладкий узел, нужно «вытащить» из него управляющую линию, не отпуская левую кнопку мыши. Контур можно замкнуть, щёлкнув на первом узле при нажатой клавише Ctrl.
Контур может состоять из нескольких несвязанных частей. Чтобы начать новую часть контура, нужно при добавлении узла нажать клавишу Shift. Чтобы объединить две части, нужно выделить конечный узел одной из них и при нажатой клавише Ctrl щёлкнуть на узле, с которым его нужно соединить.
После создания контур можно изменять, перетаскивая узлы и управляющие рычаги. Если при этом удерживать клавишу Shift, оба рычага будут расположены на одной прямой и получится гладкий узел.
233
Новые узлы добавляются на соединяющие линии при нажатой клавише Ctrl. Для удаления узлов и соединяющих их линий нужно удерживать одновременно Ctrl и Shift.
Чтобы выделить одновременно несколько узлов, нужно удерживать клавишу Shift. При нажатой клавише Alt контур можно перемещать как одно целое.
Флажок Многоугольник на панели свойств инструмента Контуры позволяет работать с многоугольниками, состоящими только из прямых сегментов.
Новый контур появляется в окне Контуры (меню Окна -> Прикрепляющиеся диалоги Контуры) — рис. 8.40.
Контуры
< > А
Рис. 8.40
Это окно полностью аналогично окну Слои, с которым вы уже знакомы. Поскольку контуры в GIMP предназначены, главным образом, для выделения областей, основные операции — это преобразование контура в выделенную область (кнопка J) и обратно (кнопка и И J. Когда область с растушёванной границей преобразуется в контур, растушёвка пропадает, граница становится резкой.
Кроме того, можно расположить текст вдоль контура. В редакторе GIMP для этого надо выделить контур в окне Контуры, добавить новый текст (текстовый слой) с помощью инструмента Текст выбрать пункт главного меню Слой Текст по контуру. При этом строится новый контур по форме букв, размещенных вдоль контура. Затем можно залить эту область цветом (например, с помощью меню Правка —> Залить цветом переднего плана), а текстовый слой удалить, он больше не нужен. Конечно, редактировать такой текст уже нельзя, потому что он теперь хранится как растровая картинка.
234
Векторная графика
§58
Контуры, созданные в редакторе GIMP, можно сохранить на диске в виде файлов формата SVG. Для этого используют команду Экспортировать контур из контекстного меню Контуры, которое можно вызвать щелчком правой кнопкой мыши в списке контуров или с помощью кнопки <4 • Вместе с тем контуры, созданные в других программах (например, в Inkscape) и сохранённые в формате SVG, можно загружать в GIMP с помощью команды Импортировать контур того же меню.
Выводы
• Векторный рисунок хранится в памяти как набор команд для рисования простейших геометрических фигур (графических примитивов).
• Для каждой векторной фигуры определяются координаты, свойства контура (цвет, толщина, стиль линии, стрелки) и заливки (сплошной цвет, градиент, текстура или растровый рисунок).
• Фигуры — это независимые объекты, каждый из которых можно редактировать отдельно от других.
• Фигуры можно перемещать друг относительно друга (как в плоскости рисунка, так и по уровням), выравнивать, распределять равномерно по горизонтали и вертикали.
• Чтобы было удобнее работать с составными объектами, их можно сгруппировать.
• Векторные кривые хранятся в памяти как набор узлов. Узлы могут быть гладкие и угловые. Форма кривой между узлами рассчитывается по математическим формулам.
• Качество векторных изображений не снижается при изменении их размеров.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Обсудите, можно ли сохранить фотографию в векторном формате.
2. От чего зависит размер файла, в котором хранится векторный рисунок?
3. Почему векторные рисунки не искажаются при изменении размеров?
4. Как изменять порядок расположения элементов рисунка? Зачем это нужно?
5. Как можно переместить сложный объект, не группируя его? Сравните два способа — с группировкой и без группировки.
235
8
Обработка изображений
6. Как вы думаете, почему при преобразовании в редакторе GIMP выделенной области в контур пропадает растушёвка? Как можно сохранить область с растушёвкой для повторного использования?
7. Как расположить текст вдоль контура в редакторе GIMP1 Почему после этого текст нельзя редактировать?
Подготовьте сообщение
а) «Векторная графика вокруг нас»
б) «Векторный редактор OpenOffice Draw»
в) «Векторный редактор Inkscape»
г) «Векторная графика в редакторе GIMP» д) «Векторная графика на веб-страницах»
е) «Кривые Безье»
Интересные сайты
inkscape.org — редактор Inkscape
inkscapebook.ru — учебник и статьи по редактору Inkscape inkscapetutorials.org — уроки по редактору Inkscape inkscape.paint-net.ru — уроки по редактору Inkscape
wiki.linuxformat.ru/wiki/LXF74-75:Inkscape — уроки по редактору Inkscape
corel.demiart.ru — уроки по редактору Corel Draw coreldrawgromov.ru — уроки по редактору Corel Draw svg-edit.github.io/svgedit/releases/svg-edit-2.8.1/svg-editor.html — онлайн-редактор векторной графики
editor.method.ac — онлайн-редактор векторной графики
Проект «Фирменный стиль»
Разбейтесь на группы по 3-4 человека. Выберите координатора (руководителя) группы. Ваша задача — представить новую компанию и её фирменный стиль. Договоритесь, чем будет заниматься ваша фирма и как она будет называться. Выберите основные цвета и оттенки, которые будете использовать. Распределите работу между участниками группы. Вам нужно нарисовать:
• эмблему компании;
• бланк для документов;
• рекламный плакат.
236
Векторная графика
§58
ЭОР к главе 8 на сайте ФЦИОР (http://fcior.edu.ru)
WWW
• Растровые редакторы
• Размещение графики на интернет-странице
WWW
Практические работы к главе 8
Работа № 66 «Коррекция изображений»
Работа № 67 «Работа с областями»
Работа № 68 «Многослойные изображения»
Работа № 69 «Каналы»
Работа № 70 «Иллюстрации для веб-сайтов»
Работа № 71 «Анимация»
Работа № 72 «Векорная графика»
Работа № 73 «Кривые в GIMP»
237
Глава 9
ТРЁХМЕРНАЯ ГРАФИКА
§59 Введение
Ключевые слова:
• трёхмерная графика
• трёхмерное моделирование
• текстурирование
• рендеринг
• проекция
• перспективная проекция
• ортогональная проекция
Что такое трёхмерная графика?
Раньше, говоря о компьютерной графике, мы имели в виду двухмерные («плоские») изображения. Автомобиль, изображённый на таком рисунке, невозможно «повернуть» и посмотреть на него с другой стороны. В то же время реальный автомобиль — это трёхмерный объект, поэтому при решении многих задач его «плоской» модели (рисунка, фотографии) недостаточно.
Трёхмерная графика (ЗБ-графика, от англ. 3-Dimensions — 3 измерения) — графика, использующая трёхмерные модели объектов для выполнения вычислений и построения двумерных (2D) изображений.
В трёхмерной (пространственной) модели объекта каждая точка имеет три координаты (а не две, как на «плоском» рисунке). Пользователь может выбрать в пространстве точку наблюдения и получить плоское изображение, т. е. построить проекцию трёхмерной сцены на плоскость. Многие программы позволяют создавать анимацию, показывающую движение трёхмерных объектов в пространстве.
ЗВ-модели применяются не только для построения двухмерных изображений. Их используют для различных вычислений, например для расчёта деталей на прочность. С помощью ЗБ-прин-
238
Введение
§59
теров по трёхмерной модели можно отпечатать объёмный физический объект (чаще всего из пластика).
Перечислим важнейшие области применения трёхмерной графики:
• компьютерное проектирование машин и механизмов (САПР — системы автоматизированного проектирования1*);
• компьютерные тренажёры и обучающие программы;
• построение трёхмерных моделей в науке, промышленности, медицине;
• дизайн зданий и интерьера (внутренней обстановки);
• компьютерные эффекты в кино и телевидении; существуют даже полнометражные фильмы, которые полностью созданы с помощью трёхмерной графики и анимации;
• телевизионная реклама;
• интерактивные игры.
Создание изображений с помощью ЗВ-графики включает несколько этапов:
1) моделирование — создание трёхмерных объектов, персонажей; 2) текстурирование (раскраска) — наложение на модели рисунков (текстур), которые имитируют реальный материал (дерево, мрамор, металл и пр.);
3) освещение — установка и настройка источников света;
4) анимация — описание изменения объектов во времени (изменение положения, углов поворота, свойств);
5) съёмка — установка камер (выбор точек съёмки), перемещение камер по сцене;
6) рендеринг (визуализация) — построение фотореалистичного изображения или анимации.
Среди профессиональных программ ЗВ-моделирования наиболее популярны продукты фирмы Autodesk (www.autodesk.com): [§] 3D Studio MAX, Maya и AutoCAD, а также программа
Cinema4D фирмы MAXON (www.maxon.net). Мы будем использовать свободно распространяемую кроссплатформенную программу Blender (www.blender.org).
Для работы с программами трёхмерной графики нужен компьютер с мощным процессором и большим объёмом оперативной и дисковой памяти. Построение качественных фотореалистичных изображений (которые выглядят, как фотографии) занимает огромное время, иногда несколько часов расчетов на один кадр. Во многих программах есть возможность сетевого рендеринга, когда для расчёта изображения используются мощности большого
В английском языке — CAD-системы (CAD: Computer Aided Design — проектирование с помощью компьютера).
239
Трёхмерная графика
количества компьютеров, объединённых в сеть (англ, render farm. рендер-фермы).
Проекции
Хотя программы трёхмерной графики предназначены для создания трёхмерных моделей объектов, пользователь видит только проекцию — плоское (двумерное) изображение на мониторе или бумажном отпечатке. На рисунке 9.1 показаны четыре проекции модели головы обезьянки Сюзанны (объект Monkey), которая включена в набор стандартных объектов программы Blender, Вы видите три стандартных проекции этой модели (виды спереди, сверху и справа) и одну произвольную проекцию (проекцию пользователя).
Вид сверху
Произвольная проекция
Вид спереди
Вид справа
Рис. 9.1
Программа Blender позволяет видеть четыре проекции одновременно или оставить только одну проекцию пользователя, которая занимает всю рабочую область. Для переключения между этими режимами используется комбинация клавиш Ctrl+Alt+Q.
Обычно работают с одним видом, который занимает всю рабочую часть окна. Для быстрого перехода к стандартным проекциям (видам спереди, сверху, справа и др.) используется меню Вид (View) или дополнительная цифровая клавиатура (англ. numpad), расположенная в правой части стандартной клавиатуры (рис. 9.2).
240
Введение
§59
Вид справа
(+Ctrl: вид слева)
Рис. 9.2
Далее для обозначения этих клавиш будем использовать «приставку» Num, например Numl обозначает клавишу «1» на дополнительной цифровой клавиатуре.
Существует два типа проекций: перспективные и ортогональные (их также называют прямоугольными или ортографически-ми). На рисунке 9.3 показаны перспективная и ортогональная проекции куба.
Линия горизонта
Перспективная проекция
Рис. 9.3
Ортогональная проекция
Наш взгляд привык к перспективе: удалённые предметы кажутся меньше по размеру, параллельные линии «сходятся» в бесконечной точке (вспомните, как выглядит уходящее вдаль шоссе). Однако при трёхмерном моделировании такие проекции не совсем удобны, потому что искажают форму и размеры объектов.
Для ортогональной проекции всё по-другому: размеры не зависят от расстояния до предмета, а параллельные грани остаются параллельными и на проекции. Ортогональные проекции очень полезны, потому что делают трёхмерную сцену проще и позволяют оценить истинные размеры объектов.
241
9
Трёхмерная графика
В редакторе Blender тип проекции показывается в левом верхнем углу рабочего окна. Например, надпись Top Ortho означает «вид сверху» (англ, top view), ортогональная проекция (англ. orthograpgic). Надпись Front Persp означает «вид спереди» (англ. front view), перспективная проекция (англ, perspective).
Чтобы переключиться с ортогональной проекции на перспективную или наоборот, нужно нажать кнопку «5» на дополнительной клавиатуре (Num5).
Вращая колёсико мыши, пользователь может уменьшать и увеличивать масштаб изображения в окне, над которым находится курсор мыши (размеры самого объекта при этом не меняются). Для вращения произвольной проекции нужно перемещать мышь при нажатой средней кнопке (колёсике). Нажав одновременно колёсико мыши и клавишу Shift, можно перемещать изображение в окне, не поворачивая его.
Для вращения и перемещения удобно использовать клавиши-стрелки на дополнительной цифровой клавиатуре (Num2, Num4, Num6 и Num8): в обычном режиме они вращают сцену, а при нажатой клавише Ctrl — перемещают точку наблюдения.
Выводы
• Трёхмерная графика (ЗВ-графика, от англ. ^-Dimensions — 3 измерения) — графика, использующая трёхмерные модели объектов для выполнения вычислений и построения двухмерных (2D-) изображений.
• Создание изображений с помощью ЗВ-графики включает несколько этапов: моделирование, текстурирование, освещение, анимацию, съёмку и рендеринг (визуализация).
• При работе с трёхмерной моделью пользователь видит на экране только проекцию — плоское (двухмерное) изображение.
• Существует два типа проекций: перспективные и ортогональные.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Как вы думаете, в каком виде хранится в памяти информация о трёхмерных объектах?
2. На каких этапах создания изображений в программах ЗВ-мо-делирования используется векторная и растровая графика?
3. Что такое свободное программное обеспечение? Кроссплатфор-менное программное обеспечение?
242
Работа с объектами
§60
4. Почему для работы с программами ЗВ-графики требуются мощные компьютеры?
5. Сравните перспективные и ортогональные проекции. Когда удобно использовать проекции того или другого типа?
Подготовьте сообщение
«Программы для ЗВ-моделирования»
Проекты
а) Сравнение бесплатных программ для ЗВ-моделирования.
б) Создание макета выбранного объекта с помощью ЗВ-печати.
Интересные сайты
kompas.ru — программа КОМПАС 3D rjisl трёхмерного проектирования и построения чертежей
blender.org — свободно распространяемая программа Blender www.turbosquid.com/gmax — бесплатная программа для ЗВ-моделирования gmax
www.wings3d.com — свободно распространяемая программа Wings 3D
www.sketchup.com — бесплатная программа SketchUp
www.autodesk.com — сайт компании Autodesk
§60
Работа с объектами
Ключевые слова:
• примитив
• выделение
• трансформации
• манипулятор
Примитивы
• система координат
• слой
• связывание объектов
• родительский объект
Построение трёхмерных моделей обычно начинается с примитивов — простейших объектов. К ним относятся плоскость (точнее, её прямоугольная часть), куб, сфера, цилиндр, конус, тор и некоторые другие объекты (рис. 9.4).
243
9
Трёхмерная графика
Куб Сфера Цилиндр Конус Тор
Рис. 9.4
При создании объекта ему автоматически присваивается имя. Например, первый куб будет называться Cube, второй — СиЬе.001 и т. д. Это имя можно изменить на панели свойств объекта, которая расположена в правой части окна программы Blender (рис. 9.5).
Рис. 9.5
Выделение объектов
Для того чтобы работать с объектом, например изменять его свойства, предварительно нужно выделить его. В программе Blender этого используется правая кнопка мыши (а не левая, как в других программах).
При нажатой клавише Shift можно выделить правой кнопкой мыши несколько объектов одновременно. Если повторно щёлкнуть на объекте, выделение снимается.
С помощью клавиши «А» (от англ, all — всё) снимается выделение со всех объектов, а если ни один объект не был выделен, все они выделяются.
После нажатия клавиши «В» (от англ, border select — выделить рамкой) можно с помощью мыши обвести прямоугольной рамкой все объекты, которые нужно выделить. Если объект хотя бы частично попал в рамку, он будет выделен. Кроме того, можно нажать левую кнопку мыши и, удерживая нажатой клавишу Ctrl, «обвести» все нужные объекты произвольным контуром.
244
Работа с объектами
§60
Для мелких объектов удобно использовать круговое выделение. Этот инструмент включается при нажатии клавиши «С»: появляется окружность, размер которой регулируется колесиком мыши. Затем щелчком (или «протаскиванием») левой кнопки мыши выделяются все элементы, попадающие внутрь окружности. Если в этом режиме случайно будет выделен лишний объект, выделение можно снять, нажав на колесико мыши.
Существуют и другие, более сложные способы выделения объектов, которые доступны через меню Select.
С помощью клавиши Num. (точка на цифровой клавиатуре) можно приблизить выделенный объект, а клавиша Num/ временно скрывает остальные объекты (кроме выделенных).
Преобразования объектов
Любой объект можно перемещать, вращать и масштабировать (изменять размеры). Эти операции называются преобразованиями объектов или трансформациями (англ, transformations).
В опорной точке (англ, origin — начало координат) выделенного объекта появляется так называемый манипулятор с тремя стрелками, параллельными осям координат. Ось Z (синяя стрелка в Blender) направлена вверх, а оси X и У в горизонтальной плоскости (рис. 9.6).
Рис. 9.6
За эти стрелки объект можно перетаскивать левой кнопкой мыши, меняя его положение только по одной выбранной оси. Центральный круг даёт возможность произвольно перемещать объект в плоскости проекции.
Объекты можно вращать, как в плоскости проекции (нажав клавишу «R», от англ, rotate — вращение), так и вокруг одной выбранной оси (для этого после нажатия клавиши «R» нужно нажать клавишу с названием оси, «X», «У» или «Z»). Можно использовать специальный манипулятор вращения, позволяющий
245
9
Трёхмерная графика
поворачивать объект в нужное положение за выделенные части окружностей (рис. 9.7).
Манипулятор вращения
Манипулятор изменения размеров
Рис. 9.7
Чтобы изменить размеры объекта, нужно нажать клавишу «S» (от англ, scale — изменить масштаб) и перемещать мышь. Чтобы изменять размер только по одной из осей, надо после нажатия клавиши «S» нажать клавишу с названием оси. Манипулятор изменения размеров содержит небольшие кубики на концах указателей осей (см. рис. 9.7). Перетаскивая один из них, можно менять соответствующий размер.
Координаты, углы поворота и размеры объектов можно задавать с клавиатуры в числовой форме. В программе Blender для этого используют панель Преобразование (Transform), которая появляется при нажатии клавиши «N» (рис. 9.8). Числовые свойства можно также изменять с помощью мыши (перетаскивая влево и вправо стрелки рядом со значениями).
▼ Преобразование Положение:
r X: 0.00000 » П
> Y: 0.00000
, - Z: 0.00000 у
Вращение:
р X: 0°
П Y: 0° *Г
Масштаб:
X: 1.000 * 1
« Y: 1.000 »
” Z: 1.000 ~
Рис. 9.8
246
Работа с объектами
§60
Копия выделенного объекта создаётся с помощью клавиш Shift+D. Затем объект-копию перемещают мышью в нужное место и фиксируют щелчком левой кнопкой. Если предварительно нажать клавишу «X», «Y» или «Z», объект-копия будет перемещаться только вдоль указанной оси.
Удалить выделенный объект со сцены можно с помощью клавиши Delete.
Системы координат
По умолчанию используется глобальная («мировая») система координат, начало которой находится в точке с координатами (0, 0, 0) пространства сцены, она не зависит от положения объекта. Иногда бывает удобно перейти к локальной системе координат, которая связана с объектом. Её центр находится в опорной точке объекта, а оси меняют направление при его вращении, показывая, где у объекта «верх» (локальная ось Хлок), «право» (локальная ось Хлок) и т. д. На рисунке 9.9 показаны направления осей локальной и глобальной систем координат для повернутого конуса.
Глобальная
Локальная
система координат
система координат
Рис- 9-9
В программе Blender можно выбрать нужную в данный момент систему координат с помощью выпадающего списка в нижней части рабочего окна. Именно эти оси будут использоваться при перемещении, вращении и изменении размеров объекта.
Слои
Трёхмерная сцена в Blender может состоять из нескольких слоёв. В рабочем окне видны только те объекты, которые расположены на активном слое. Активный слой можно выбрать щелчком мышью на специальной панели в нижней части рабочего окна (рис. 9.10).
247
Трёхмерная графика
Всего можно использовать 20 слоёв, в данном случае (см. рис. 9.10) какие-то объекты есть на слоях 1, 2 и 4. Активный слой — слой 2, его клетка выделена тёмно-серым фоном. Если нужно показать объекты с нескольких слоев одновременно, нужно выделять их щелчками мыши при нажатой клавише Shift.
Объект может принадлежать не только одному, но и нескольким слоям. Для этого их нужно выделить в аналогичном элементе управления на панели свойств объекта. Здесь же можно перевести объект с одного слоя на другой. Для этих операций также используется всплывающее окно, которое появляется при нажатии клавиши «М».
Связывание объектов
Представим себе, что мы построили трёхмерную модель стола, на котором размещены тарелки, чашки и столовые приборы. Теперь нужно передвинуть стол в другое место сцены и немного развернуть его. При этом точно так же должны переместиться и все объекты, стоящие на столе. Чтобы проще решить эту задачу, нужно «привязать» к столу все стоящие на нём предметы: на панели свойств установить для них так называемый родительский объект (англ, parent — родитель) — стол. Можно поступить иначе: выделить, удерживая клавишу Shift, все нужные объекты (тарелки, чашки и т.д.), последним выделить родительский объект (стол) и нажать клавиши Ctrl+P.
После этого при всех преобразованиях объекта-родителя (перемещении, вращении, масштабировании) те же самые преобразования применяются и к объектам-потомкам. В то же время объекты-потомки по-прежнему можно перемещать независимо от родителя, т. е. мы можем свободно двигать чашку по столу.
Обратите внимание на отличие Blender от большинства программ, работающих с графикой: объекты в такой связанной группе не равноправны — среди них есть один родительский объект и несколько потомков.
Всю структуру сцены (иерархию объектов) можно посмотреть в специальном окне Структура проекта (Outliner) (см. рис. 9.11). Здесь видно, например, что объект Cube — родительский для объекта СиЪе.001.
248
Работа с объектами
§60
Рис. 9.11
Справа от имени объекта в окне Структура проекта показаны три значка: щелчок мышью на изображении глаза скрывает объект; если щелкнуть на значке то объект будет нельзя выделить (иногда это не нужно), а щелчком на значке можно запретить показ объекта при рендеринге.
Выводы
• Примитивы — это простейшие объекты: плоскость, куб, сфера, цилиндр, конус, тор и некоторые другие.
• Объекты в программе Blender выделяются с помощью правой кнопки мыши.
• Объекты можно перемещать, вращать и масштабировать (изменять размеры). Эти операции называются преобразованиями объектов или трансформациями.
• При работе с объектами можно использовать глобальную («мировую») или локальную (вязанную с объектом) системы координат.
• Объекты можно связывать в группы, в группе всегда есть один родительский объект и объекты-потомки.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Что такое примитивы? Зачем они нужны?
2. Как вы думаете, зачем каждому объекту сцены присваивается уникальное имя?
3. Какие преобразования объектов вы знаете?
4. Как можно применить преобразования только по одной оси?
5. Что такое манипуляторы? Как их использовать?
249
9
Трёхмерная графика
6. Какие системы координат применяются при трёхмерном моделировании? Чем они различаются и когда используются?
7. Зачем нужны слои?
8. В каких случаях удобно использовать связь объектов «родитель — потомок»?
Л Проект
ЗВ-моделирование выбранного объекта из примитивов
§61
Сеточные модели
Ключевые слова:
• каркас
• вершина
• ребро
• грань
• сеточная модель
• сечение
• выдавливание
• сглаживание
Как строятся объекты?
По умолчанию объекты в Blender изображаются как объёмные твёрдые тела (англ, solid — сплошной). При этом не сразу понятно, как же программа может быстро перестраивать изображение при изменении точки наблюдения. Для того чтобы понять внутреннее устройство объектов, нужно переключиться в другой режим, который называется Каркас (Wireframe). Мы увидим, что каркас куба (рис. 9.12) включает:
• 8 вершин — А, В, С, D, Е, F, G и Н;
• 12 рёбер, соединяющих вершины — АВ, AD, ВС, CD, EF, ЕН, FG, GH, АЕ, BF, CG и DH.
250
Сеточные модели
§61
Вершина (англ, vertex) — это точка в трёхмерном пространстве, которая задаётся тремя координатами. Ребро (англ, edge) — это отрезок, соединяющий две вершины. Ребра ограничивают грани (англ, face) — участки поверхностей. У куба — 6 граней: ABCD, EFGH, ABFE, CDHG, ADHE и BCGF.
Такие модели называются сеточными (англ, mesh), потому что они представляют собой поверхности, которые строятся на сетке из рёбер. Чаще всего используются треугольные и четырёхугольные грани, однако современные версии Blender могут работать с гранями, состоящими из большего числа рёбер (так называемыми N-угольниками или полигонами). Поэтому часто применяют выражение «полигональная модель» (от англ, polygon — многоугольник, полигон). Сфера и другие криволинейные поверхности тоже строятся из плоских граней, но их значительно больше, чем у куба.
Трёхмерные модели хранятся в векторном формате, для построения поверхности достаточно запомнить координаты вершин каркаса. По ним можно рассчитать координаты всех точек рёбер и граней. Каждая грань обрабатывается отдельно, поэтому чем больше граней, тем большее время требуется для расчётов.
Редактирование сетки
Для изменения положения элементов сетки нужно перейти в режим редактирования (англ. Edit mode). В программе Blender для этого используется клавиша Tab.
В режиме редактирования можно работать с отдельными вершинами, рёбрами и гранями. Нужный тип объектов выбирается с помощью показанного на рис. 9.13 элемента управления, который расположен в нижней части рабочего окна.
Рис. 9.13
или с помощью всплывающего меню, которое вызывается нажатием клавиш Ctrl+Tab. В данном случае включен режим работы с вершинами, потому что первая кнопка выделена тёмным фоном.
При нажатой клавише Shift можно включить несколько режимов выделения сразу, например выделять рёбра и грани.
Для выделения элементов сетки используются те же методы, что и при выделении объектов. Затем их можно перемещать,
251
9
Трёхмерная графика
вращать и масштабировать. Очень удобно использовать круговое выделение (клавиша «С»).
По умолчанию при работе с рёбрами и гранями выделяются не только видимые, но и невидимые элементы, расположенные на задней поверхности объекта. Чтобы этого не происходило, нужно ограничить выделение только видимыми элементами, щёлкнув по кнопке в нижней части рабочего окна.
В режиме работы с вершинами щелчок левой кнопкой мыши при нажатой клавише Ctrl создаёт новую вершину, которая соединяется с уже выделенной вершиной. Если выделить две вершины (используя клавишу Shift) и нажать клавишу «F», между ними строится новое ребро.
Чтобы создать новую грань, нужно выделить все вершины замкнутого треугольника или четырёхугольника и нажать клавишу «F».
Для доступа к другим операциям с элементами сеточной модели можно использовать всплывающие меню, которые появляются при нажатии клавиш Ctrl+V (меню для вершин), Ctrl+E (меню для ребёр) и Ctrl+F (меню для граней).
В Blender существует особый режим пропорционального редактирования (англ, proportional editing). В этом режиме перемещаемая вершина, ребро или грань увлекает за собой соседние. В примере, показанном на рис. 9.14, перемещалась вверх только центральная вершина сетки.
Исходная модель
После сдвига центральной вершины
Рис. 9.14
Деление рёбер и граней
Часто требуется разделить ребро или грань на несколько частей. Для этой цели проще всего использовать инструмент Подразделить (Subdivide), который делит выделенные ребра или грани на несколько равных частей. Примеры его использования показаны на рис. 9.15.
252
Сеточные модели
§61
Одно ребро
Треугольная грань
Рис. 9.15
Существует также инструмент Нож (Knife), который позволяет «разрезать» выделенные рёбра. Для этого нужно при нажатой клавише «К» нажать и не отпускать левую кнопку мыши, после чего курсор становится похожим на нож. Теперь остаётся провести мышь через точки деления рёбер. Если нажимать Shift+K вместо «К», ребра, через которые проходит нож, делятся ровно пополам.
Инструмент Разрезать петлей со сдвигом (Loop Cut and Slide, от англ, loop — петля, cut — разрезать, slide — скользить), который вызывается нажатием клавиш Ctrl+R, позволяет рассечь грани по контуру вокруг объекта и сдвинуть сечение в нужное место. Колёсиком мыши можно увеличивать число сечений (рис. 9.16).
Одиночное сечение
Множественное сечение
Рис. 9.16
Выдавливание
Один из самых полезных инструментов при работе с сеточными моделями — Выдавить (Extrude). Выдавливание состоит в том, что выбранная грань перемещается вдоль нормали (перпендикуляра к этой грани), и вокруг неё создаются новые грани.
253
Трёхмерная графика
На рисунке 9.17 показаны два типа выдавливания центральной верхней грани куба.
Выдавливание наружу
Выдавливание внутрь
Рис. 9.17
Для того чтобы выполнить выдавливание, нужно выделить грань, нажать клавишу «Е» и мышкой переместить грань в нужное положение.
Выдавливание можно применять также к выделенным рёбрам и вершинам. Чтобы они перемещались только по одной оси, нужно после клавиши «Е» нажать клавишу с названием этой оси («X», «Y» или «Z»).
Сглаживание
Вы уже знаете, что модель любой поверхности в программах трёхмерного моделирования строится из отдельных плоских граней. Однако во многих случаях реальный объект — гладкий, и на картинке нужно получить сглаженную поверхность.
Для сглаживания стыков между гранями используют инструмент Сглаживание (Smooth), который может применяться как ко всему объекту, так и к отдельным граням (рис. 9.18).
Без сглаживания
Со сглаживанием
Рис. 9.18
При этом важно, что геометрия объекта (количество граней, способ разбивки на грани) не изменяется. Обратите внимание на контур объекта — он остался угловатым. Программа выполняет
254
Модификаторы
§62
сглаживание («скругление») граней только при выводе изображения на экран, используя специальные алгоритмы затенения (см. рис. 9.18).
Есть и другой способ сглаживания — дополнительная разбивка на более мелкие грани, мы рассмотрим его в следующем параграфе.
Выводы
• Трёхмерные модели хранятся как векторные объекты, состоящие из вершин, рёбер и граней.
• Сеточная модель — это набор поверхностей, которые строятся на сетке из рёбер.
• В режиме редактирования можно работать с отдельными вершинами, рёбрами и гранями.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Подумайте, какими достоинствами и недостатками обладают сеточные модели.
2. Как связано количество граней модели и время расчёта изображения сцены? Какие рекомендации вы можете дать в связи с этим?
3. Расскажите о приёмах, которые можно использовать для редактирования сетки.
4. Что такое выдавливание?
ОН
5. Зачем нужно сглаживание?
Проект
ЗП-моделирование выбранного модели
§62
Модификаторы
Ключевые слова:
• модификатор
• стек модификаторов
• сглаживание
• симметрия
объекта с помощью сеточной
• логические операции
• массив
• деформация
255
9
Трёхмерная графика
Что такое модификатор?
Модификатор — это преобразование объекта, которое выполняется автоматически при выводе проекции на экран или построении готового изображения (рендеринге). При этом геометрия объекта не меняется, т. е. это неразрушающая операция (действие модификатора всегда можно отменить). Как правило, модификатор имеет настройки, которые можно менять в диалоговом режиме.
Для любого объекта можно использовать несколько модификаторов. Они действуют последовательно, т. е. первый модификатор (верхний в списке) «работает» с исходной сеточной моделью, второй — с результатом работы первого и т. д. Все применённые модификаторы образуют стек модификаторов (англ, stack — стопка). В программе Blender вершина стека (последний применяемый модификатор) находится в конце списка. Порядок применения модификаторов можно изменять.
Каждый раз, когда пользователь изменяет вид сцены (например, поворачивая или перемещая объекты), для построения проекции модификаторы применяются заново к изменённой сеточной модели, а это требует значительного времени и ресурсов компьютера. Однако исходная сеточная модель остаётся довольно простой, и её легко редактировать.
Когда модель полностью готова, можно раз и навсегда применить модификатор, т. е. внести соответствующие изменения в сеточную модель. Нужно учитывать, что во многих случаях (например, при сглаживании) новая модель будет содержать значительно большее число граней, занимать больше места на диске и требовать больше времени для рендеринга. Кроме того, редактировать её будет намного сложнее.
Далее мы познакомимся с некоторыми часто используемыми модификаторами программы Blender. Про остальные вы можете узнать в справочной системе.
Сглаживание
В природе редко встречаются чёткие и ровные углы. Поэтому для сеточных моделей животных, растений, людей, сказочных персонажей обязательно используют сглаживание.
В предыдущем параграфе уже рассматривался один вариант сглаживания — с помощью инструмента Сглаживание (Smooth). Подобную операцию можно выполнить с помощью модификатора Подразделение поверхности (Subsurf, от англ, subdivision surface — разбиение поверхностей).
256
Модификаторы
§62
У модификатора Подразделение поверхности есть настройки, с помощью которых можно регулировать степень сглаживания (рис. 9.19).
Без сглаживания (6 граней)
Уровень 1 (24 грани)
Уровень 4 (1536 граней)
Рис. 9.19
Симметрия
При моделировании симметричных объектов, например мордоч-
ки животного, хочется автоматически поддерживать одинаковую форму левой и правой частей. Для этого удобно применять мо-
Половина головы С модификатором Отражение
Рис. 9.20
Основной объект в примере на рис. 9.20 — это половина модели головы обезьянки Сюзанны, которая включена в Blender как тестовый объект1*. При использовании модификатора Отражение все изменения, которые выполняются с правой частью, автоматически применяются и ко второй (отражённой) половине.
Если применить модификатор, щёлкнув на кнопке Применить (Apply), будет построена новая симметричная сеточная модель, в которой левая и правая части независимы друг от друга (т. е. при изменении одной половины вторая уже не будет изменяться).
1) В других программах в качестве тестового объекта используют чайник.
257
Трёхмерная графика
Логические операции
С помощью модификатора Логический {Boolean) можно строить объединение, пересечение и «разность» двух объектов. На рисунке 9.21 показаны четыре возможных «логических» операции, которые можно применить к кубу и сфере.
Объединение Пересечение «Куб минус сфера» «Сфера минус куб»
(Union)
(Intersection) (Difference)
(Difference)
Рис. 9.21
Легко заметить, что объединение и пересечение можно сопоставить логическим операциям ИЛИ и И.
Модификатор применяется к одному объекту, а второй указывается в параметрах модификатора в поле Объект {Object). На рисунке 9.22 показаны настройки модификатора Логический для случая, когда нужно построить «разность» сферы (объект с именем Sphere) и куба (объект Cube). Список Операция: {Operation) позволяет выбрать нужную операцию (здесь — операция Разность (difference)). При этом куб никак не меняется, а вместо сферы, к которой применен модификатор, появляется объект «сфера минус куб», т. е. часть шара, которая не входит в куб.
С? * (J Sphere
Рис. 9.22
258
Модификаторы
§62
Если после этого сдвинуть куб, полученный объект-«разность» изменится, потому что он каждый раз строится заново с учётом текущего положения сферы и куба. Чтобы новый объект стал независимым, нужно применить модификатор с помощью кнопки Применить (Apply). Теперь изменения куба не будут на него влиять.
Сетка объекта, полученного в результате логической операции, значительно усложняется в местах стыковки исходных тел, поэтому потом её довольно сложно редактировать.
Массив
Модификатор Массив (Array) позволяет создать несколько копий (клонов) основного объекта, которые смещены друг относительно друга на одинаковое расстояние по осям X, Y и Z. Например, так можно из одной модели солдата построить модель целого взвода, стоящего в колонну или в шеренгу. Если в том же случае повторно использовать модификатор Массив и задать смещение по другой оси, мы сможем построить солдат в несколько колонн.
Копии (клоны) сохраняют связь с основным объектом, при любом его изменении клоны также меняются. Если применить модификатор Массив (с помощью кнопки Применить), связь копий с исходным объектом разрывается, после этого их можно редактировать независимо друг от друга.
Деформация
Для изменения формы объектов часто удобен модификатор Решётка (Lattice). Исходный объект (на рисунке — сфера) помещается внутрь специальной «клетки» — объекта Решётка. Объект Решётка — это вспомогательная сетка, которая не показывается при рендеринге, т. е. не влияет на итоговую картинку.
Затем к исходному объекту применяется модификатор Решётка. В результате объект и «клетка» оказываются связанными, так что при изменении формы клетки (например, при перемещении её вершин и ребер) меняется и форма основного объекта (рис. 9.23).
С помощью решётки удобно менять форму объекта при анимации, не меняя его сеточную модель. Например, мяч при отскоке от пола немного сплющивается, а потом опять принимает нормальную форму.
259
9
Трёхмерная графика
До
После
Рис. 9.23
Выводы
• Модификатор — это преобразование объекта, которое выполняется автоматически при выводе проекции на экран или при рендеринге.
• Модификатор не изменяет сеточную модель.
• Для любого объекта можно использовать несколько модификаторов. Они действуют последовательно: первый модификатор «работает» с исходной сеточной моделью, второй — с результатом работы первого и т. д.
• Когда модель полностью готова, можно внести изменения, сделанные модификатором, в сеточную модель. При этом количество граней может существенно увеличиться.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Почему модификаторы — это неразрушающий метод редактирования?
2. Что означает «применить модификатор»? Какие достоинства и недостатки имеет этот приём?
3. Что такое стек модификаторов? Как влияет расположение модификаторов в стеке на окончательный результат?
Проект
ЗВ-моделирование выбранного объекта с использованием модификаторов
260
Кривые
§63
§63 Кривые
Ключевые слова:
• кривые Безье
• узел
• сегмент
• рукоятка
• пластина
• профиль
• тело вращения
Основные понятия
Кривые используются в программах трёхмерной графики как вспомогательные векторные объекты, например для того, чтобы задать форму тела вращения или поперечное сечение трубы. С помощью кривых определяют траектории движения объектов при анимации, искривляют текстовые строки, моделируют провода и нитки. Замкнутую кривую называют контуром.
В программе Blender можно строить два типа кривых — кривые Безье и кривые NURBS (англ. Non Uniform Rational В-Splines — неравномерные рациональные В-сплайны). В этом параграфе мы рассмотрим только кривые Безье как самые простые. Как вы знаете, они состоят из узлов (опорных точек) и сегментов (соединяющих их линий). Кривизну сегментов определяют направляющие линии (касательные) в каждом узле, положение которых можно регулировать с помощью рычагов, их концы обозначены на рис. 9.24 белыми кружками.
Для построения каждого сегмента используются только 4 точки, показанные на рисунке: два узла, которые соединяет сегмент (А и Г), и концы рукояток (Б и В).
Рис. 9.24
Кривая на этом участке (см. рис. 9.24) выходит из точки А в направлении точки Б, затем изгибается к точке В и, наконец, входит по касательной в точку Г.
261
9
Трёхмерная графика
В программе Blender используются четыре типа узлов:
• векторные узлы (англ, vector — векторный), предназначенные для рисования ломаных (касательные направлены в соседнюю точку);
• гладкие узлы (англ, aligned — выровненный), в которых обе направляющих лежат на одной прямой;
• угловые, или свободные узлы (англ, free — свободный), в которых каждую направляющую можно настраивать независимо от другой;
• автоузлы (англ, auto — автоматический) — гладкие узлы, в которых положение направляющих выбирается программой.
При создании кривой Безье в Blender (меню Добавить —> Кривая Безье, Add —> Curve —> Bezier) строится стандартная кривая с двумя гладкими узлами, находящаяся в плоскости XY. Кривую в целом можно редактировать как обычный объект (перемещать, вращать, изменять размеры).
Для настройки отдельных узлов нужно перейти в режим редактирования (клавиша Tab), в котором можно перемещать сами узлы и их управляющие рычаги. Создать новый узел между двумя выделенными узлами можно с помощью всплывающего меню Специальные -> Подразделить (Specials —> Subdivide), которое появляется при нажатии клавиши «W». Меню для выбора типа узла вызывается клавишей «V».
Кривые часто используют как вспомогательные объекты для построения более сложных фигур, поэтому при рендеринге их не видно. Однако когда мы моделируем с помощью кривой, например, кабель, трубу, нитку и т. п., она должна присутствовать на готовом изображении. Для этого нужно изменить её свойства особым образом:
262
Кривые
§63
• сделать кривую трёхмерной (включить режим 3D);
• в списке Заполнение (Fill) выбрать вариант Полностью (Full); другие варианты позволяют построить половину или четверть трубы;
• применить Скос (Bevel).
После этого будет построена трубка, её диаметр определяется глубиной скоса (параметр Глубина (Depth)), а гладкость поверхности — параметром Разрешение (Resolution). Если нужно увеличить толщину стенок, к такой трубке можно применить модификатор Объёмность (Solidify).
Пластины
При нажатии клавиш Alt+C кривая замыкается (или размыкается, если она была замкнута). Контур (замкнутую кривую) можно превратить в пластинку, которая будет показана при рендеринге картинки. Для этого в свойствах объекта нужно установить режим 2D (англ. 2D: 2-dimensions, двухмерная или плоская кривая) и ненулевой параметр Выдавить (Extrude), который определяет толщину пластинки. Параметр Скос (Bevel) задаёт фаску, которая применяется ко всем граням (рис. 9.26).
Контур
Выдавливание
Рис. 9.26
Выдавливание и фаска
Эти операции фактически представляют собой модификаторы, применяемые к контуру. Это значит, что контур по-прежнему можно свободно редактировать. Чтобы сделать из такого объекта сеточную модель, нужно нажать клавиши Alt+C и выбрать во всплывающем меню команду Полисетка из кривой (Mesh from Curve). Если теперь выделить объект и перейти в режим редактирования узлов, мы увидим «обычную» сетку из узлов, ребер и граней.
Профили
Часто нужно смоделировать кабель, трубу или брусок, имеющий заданный профиль сечения. В программах трёхмерной графики
263
Трёхмерная графика
для этого обычно используются две кривые: одна задает профиль сечения, а вторая — путь. На рисунке 9.27 показаны кривые, с помощью которых построена модель балки с сечением в форме
Путь
Рис. 9.27
Для того чтобы связать два контура в программе Blender, нужно выделить контур-путь и перейти на страницу данных объекта (англ. Object Data). Затем в поле Форма скоса (Bevel object) из списка существующих контуров выбирается имя контура, задающего профиль. В некоторых программах, например в 3ds Мах, такой приём называется «лофтинг» (англ, lofting).
Объект, который мы видим, строится только при выводе на экран. В памяти он хранится как две кривые, а не как сеточная модель. Поэтому можно как угодно изменять форму пути и профиля, но нельзя работать с отдельными вершинами, ребрами и гранями.
К такому объекту можно применять модификаторы, например Подразделить (Subsurf) для получения гладкой поверхности. Можно также преобразовать его в сеточную модель с помощью комбинации клавиш Alt+C.
Тела вращения
В жизни нас окружает множество объектов, которые могут быть построены как тела вращения: тарелки, стаканы, бокалы, вазы и т. п. Для их моделирования также можно использовать профили, но в данном случае путь — это окружность. На рисунке 9.28 показано, как построить трёхмерную модель тарелки.
Путь
Результат
Рис. 9.28
264
Кривые
§63
При создании профиля на окружности оказывается опорная точка кривой, определяющей сечение (начало локальных координат), поэтому эту точку нужно размещать на расстоянии радиуса окружности от края кривой (см. рис. 9.28). Для перемещения опорной точки можно щелчком мышью становить курсор в нужное место и выбрать в меню под проекцией команду Объект Преобразования Опорную точку к ЗИ-курсору (Object Transform Origin to 3D-Cursor).
Отметим, что в программе Blender существуют и другие способы построения тел вращения, например инструмент Spin (англ. spin — вращение), применяемый к сеточным моделям.
Выводы
• Кривые используются в программах трёхмерной графики как вспомогательные векторные объекты.
• Кривые состоят из узлов (опорных точек) и сегментов (соединяющих их линий). Кривизну сегментов можно регулировать с помощью «рычагов».
• В программе Blender существует четыре типа узлов: векторные, гладкие, угловые и автоузлы.
• С помощью кривых можно, например, задать форму пластины или профиль сечения детали.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Зачем используются кривые в программах трёхмерного моделирования?
2. Из каких элементов состоит кривая Безье? Как изменять форму такой кривой?
3. Какие типы узлов используются при построении кривых Безье? Как изменить тип узла?
4. Как сделать видимую нить или трубу с помощью кривых?
5. Как построить пластину?
6. Как используются кривые для моделирования объектов с заданным профилем сечения?
7. Как смоделировать тело вращения?
Проект
ЗБ-моделирование выбранного объекта с использованием кривых
св
265
9
Трёхмерная графика
§64 Материалы и текстуры
Ключевые слова:
• зеркальное отражение
• диффузное отражение
• материал
• шейдер
• текстура
• UV-проекция
В природе нет объектов, которые были бы абсолютно гладкими и ровно покрашены в один серый цвет. Сцена не будет смотреться реалистично, пока мы не применим материалы, т. е. не зададим какие-то свойства, по которым можно различить дерево, металл, мрамор, кирпич, песок. Без использования материалов невозможно сделать тела блестящими, прозрачными, светящимися и т. п.
Отражение света
Для того чтобы разобраться со свойствами материалов, нужно понять, как мы видим окружающие предметы. Какой-то источник света (солнце, лампочка и т. п.) излучает световые волны, которые попадают на объекты. При этом часть волн поглощается материалом, а остальные отражаются от поверхности. Глаз воспринимает попадающие в него отражённые световые волны, свойства которых определяют видимый цвет предмета. Например, если источник излучает «белый» свет (включающий волны всех частот видимого светового диапазона), а мы видим зелёную поверхность, это означает, что материал поглощает все волны, кроме тех, которые соответствуют зелёному цвету.
Из курса физики вам известен закон отражения света, согласно которому угол отражения равен углу падения. Такое отражение называется зеркальным (англ, specular), при этом предполагается, что поверхность идеально ровная (рис. 9.29). Однако на самом деле любой материал имеет шероховатости, отличается лишь их размер. Поэтому лучи света отражаются от большинства предметов во всех направлениях, такое отражение называется рассеянным или диффузным (англ, diffuse) — см. рис. 9.29. Именно диффузное отражение определяет цвет объекта, который мы видим.
Тип отражения зависит от степени шероховатости. Если размеры неровностей соизмеримы с длиной световой волны, происходит зеркальное отражение. Если неровности значительно больше длины волны, происходит рассеяние света (диффузия), и в глаз
266
Материалы и текстуры
§64
Зеркальное отражение
Камера
Источник света
Диффузное отражение
Рис. 9.29
(или в съёмочную камеру) попадают лучи, отражённые от всех точек поверхности.
Простые материалы
Для объектов трёхмерной сцены можно построить сколько угодно различных материалов, выбирая для каждого нужные свойства. Материалы можно использовать повторно, т. е. материал одного объекта можно применять к другим объектам.
При настройке материала в первую очередь задаются два цвета — цвет диффузного (рассеянного) отражения и цвет зеркального отражения (цвет бликов). В программе Blender для изменения свойств материала используется страница свойств Материал (Material) — рис. 9.30. В окне Предпросмотр (Preview) показан один из тестовых объектов, к которому применён выбранный материал.
Г ~1
•нт- н8НО: 0.:« О
Ламберт
S Градиентная карта
• Блик
Кук-Торренс
Интенсивно: 0.500 О ft «.иентная карта
Жёсткость: 50
Рис. 9.30
267
Трёхмерная графика
Цвета для диффузного и зеркального отражения задаются на панелях Диффузный {Diffuse) и Блик {Specular) соответственно, параметр Интенсивно (Intensity) определяет яркость цвета. В правой части каждой панели можно выбрать один из шейдеров (англ, shader) — так называют алгоритмы, с помощью которых рассчитывается цвет каждой точки изображения. По умолчанию в Blender используются алгоритмы Ламберт {Lambert) для диффузного отражения и Кук-Торренс {CookTorr) для зеркального. Включив флажок Градиентная карта {Ramp), можно задать градиент — плавный переход между двумя или несколькими цветами. Параметр Жёсткость {Hardness) определяет размытость бликов, чем он больше, тем более резкая граница у блика.
С помощью панели Прозрачность {Transparency) можно сделать материал полупрозрачным. Такой материал пропускает часть падающих на него лучей света, например красное стекло пропускает только красные лучи, а остальные поглощает.
Панель Отражение {Mirror) позволяет получить на предмете отражения окружающих объектов.
Многокомпонентные материалы
Разным граням (полигонам) одного объекта можно присвоить разные материалы. В этом случае объект должен быть связан с несколькими материалами, список которых находится на странице свойств Материал {Material). На рисунке 9.31 показан случай, когда для объекта используются три материала с именами Red, Green и Blue. Здесь выбран и редактируется материал Red.
Рис. 9.31
Если перейти в режим редактирования (когда можно работать с отдельными гранями), появляются три кнопки:
• Присвоить (Assign) — присвоить выбранный материал выделенным граням;
• Выделение {Select) — выделить грани, для которых установлен выбранный материал;
• Снять выделение {Deselect) — отменить выделение граней, для которых установлен выбранный материал.
Материалы и текстуры
§64
Текстуры
При создании фотореалистичных изображений часто используются не простые одноцветные материалы, а так называемые текстуры — точечные (растровые) изображения, которые накладываются на поверхность для изменения окраски или имитации рельефа (рис. 9.32).
Рисунок на сфере Имитация рельефа
Рис. 9.32
Текстура обычно относится к какому-то материалу, причём с каждым материалом можно связать несколько текстур (так же, как с одним объектом можно связать несколько материалов).
Текстуры можно разделить на два типа: готовые изображения и так называемые процедурные текстуры, которые строятся по различным математическим алгоритмам. В окне свойств есть страница ЕЭ Текстуры (Texture), где для материала, выбранного на странице Материал (Material), можно задать одну или несколько текстур.
При создании новой текстуры по умолчанию выбирается тип Облака (Clouds). Это одна из стандартных процедурных текстур. Чтобы загрузить текстуру из файла на диске, нужно выбрать тип Изображение или фильм (Image or Movie), а затем, щёлкнув на кнопке Открыть (Open), выбрать нужный файл на диске.
В простейшем случае для наложения рисунка на объект текстура загружается в цветовой канал Диффузный (Diffuse), который определяет «нормальный» цвет объекта. Кроме того, текстуры можно использовать для канала Блик (Specular), альфа-канала (прозрачность), рельефа. Эти режимы задаются на панели Влияние (Influence), где нужно отметить параметры, на которые влияет текстура. Кроме того, степень воздействия текстуры можно регулировать, например смешивать установленный для материала цвет и текстуру в некоторой пропорции.
Для того чтобы наложить рисунок на поверхность, каждой точке этой поверхности нужно сопоставить определённый пиксель рисунка. Это фактически означает переход к другой системе
269
Трёхмерная графика
координат. Способ такого преобразования координат задаётся на панели Отображение {Mapping) — рис. 9.33.
▼ Отображение
Рис. 9.33
В списке Координаты {Coordinates) по умолчанию установлен вариант Сгенерировать {Generated), т. е. построенные автоматически. В списке Проекция {Projection) выбирается форма тела: Плоское {Flat), Куб {Cube), Сфера {Sphere) или Трубка {Tube).
UV-проекция
Пользователь может вручную определить, как именно точки рисунка будут проецироваться на поверхность. Для этого применяется так называемая UV-проекция или UV-развёртка (англ. UV unwrap).
Чтобы вручную задать способ наложения текстуры на грани объекта, используется специальная система координат UV (рис. 9.34), которая похожа на стандартную прямоугольную систему XY на плоскости. Оси U и V аналогичны осям X и Y, но относятся не к трёхмерной модели, а к текстуре. Построить UV-проекцию означает сопоставить каждой точке {х, у, z) поверхности объекта некоторую точку текстуры {и, v).
Vi
О и
Рис. 9.34
Для каждой грани можно настраивать UV-проекцию отдельно с помощью специального окна Редактор UV-изображений {UV/ Image Editor). этого в окне трёхмерной проекции {3D View)
270
Материалы и текстуры
§64
надо перейти в режим редактирования сетки (клавиша Tab) и выделить нужную грань. Затем следует выбрать пункт меню Полисетка -> UV-развёртка -> Развернуть (Mesh UV Unwrap Unwrap), и в окне редактора CTV-проекций появляется плоская сетка, повторяющая форму грани (рис. 9.35).
Рисунок на грани куба
UV-проекция
Рис- 9-35
Положение вершин и рёбер такой сетки можно изменять так же, как и положение вершин и рёбер трёхмерной сеточной модели в режиме редактирования. С помощью этого приёма можно, например, вырезать из одной и той же текстуры разные рисунки для каждой грани.
Для того чтобы при построении изображения использовались координаты, заданные пользователем, а не построенные автоматически, в списке Координаты (Coordinates) на панели Отображение (Mapping) нужно выбрать вариант UV вместо Сгенерировать (Generated ).
Если граней много, возникают некоторые сложности. В этом случае удобно выделить в режиме редактирования сразу несколько граней объекта, тогда в окне редактора CTV-проекций будет показана вся соответствующая им сетка (рис. 9.36). Сетку и её части можно перемещать по текстуре (клавиша «G»), вращать (клавиша «R») и масштабировать (клавиша «S»).
UV-проекция
Рис. 9.36
271
9
Трёхмерная графика
Программа Blender позволяет построить развёртку поверхности сложного объекта, указав, где нужно сделать разрезы. После этого на такой развёртке можно рисовать текстуру для готовой модели. Такой приём широко используется при создании персонажей в играх: по готовой развёртке модели рисуют текстуру (кожу, волосы, шкуру, одежду и т. д.).
Выводы
• Диффузное отражение определяет цвет объекта, который мы видим.
• Зеркальное отражение определяет цвет бликов.
• Шейдер — это алгоритм, с помощью которого рассчитывается цвет каждой точки изображения.
• Разным граням (полигонам) одного объекта можно присвоить разные материалы.
• Текстура — это растровое изображение, которое накладывается на поверхность для изменения окраски или имитации рельефа.
• CTV-проекция задаёт способ наложения текстуры на грани объекта.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Расскажите об отличиях диффузного и зеркального отражения света. Почему чаще всего нужно учитывать оба варианта?
2. Приведите примеры материалов, у которых практически нет диффузного или зеркального отражения.
3. Что такое шейдер? Зачем нужны разные типы шейдеров?
4. Как регулируется размытость бликов?
5. Что такое многокомпонентные материалы? Зачем они используются?
6. Что такое текстуры? Зачем они используются?
7. Что такое процедурные текстуры? В чём их достоинства и недостатки?
8. Что означает выражение «fTV-проекция»?
9. Как наносят текстуру на сложные объекты?
Подготовьте сообщение
а) «Как работают шейдеры?»
б) «Рисование текстуры по развёртке модели»
272
Рендеринг
§65
Проект
Использование текстуры для ЗИ-модели выбранного объекта.
Интересные сайты
texturelovers.com — бесплатные текстуры texturearchive.com — архив бесплатных текстур freephototextures.com — архив бесплатных фототекстур
§65 Рендеринг
Ключевые слова:
• рендеринг
• источник света
• освещённость
• камера
• внешняя среда
• разрешение
• тень
Рендеринг — это построение готового изображения: проекции трёхмерной сцены на плоскость с учетом материалов, текстур, освещённости, свойств внешней среды и т. п. Для этого нужно после подготовки трёхмерной модели:
• расставить и настроить источники света;
• установить камеру, которая будет «снимать» сцену, и настроить её свойства;
• определить свойства внешней среды (цвет неба, туман и т. п.);
• выполнить рендеринг (нажать клавишу F12)\
• сохранить готовое изображение с помощью клавиши F3.
Результат рендеринга появляется в окне Редактор UV-изображений (UV/Image Editor). В этом окне есть так называемые слоты (англ, slot — позиция, ячейка), в каждом из которых можно хранить одно изображение. Это позволяет запомнить несколько результатов рендеринга, полученных в разных условиях, а затем сравнить их.
Источники света
Источники света в Blender называются лампами (англ. lamp). Существует несколько типов ламп, отличающихся по своим свойствам.
273
Трёхмерная графика
По умолчанию вновь созданная сцена содержит источник типа Точка (Point) — точечный источник света, лучи от которого расходятся во все стороны (радиально), см. рис. 9.37.
Освещённость зависит от расстояния между источником и поверхностью (согласно законам физики, она обратно пропорциональна квадрату этого расстояния). На рисунке 9.38 показаны элементы, позволяющие настраивать основные свойства лампы.
Солнце Прожектор Полусфера Область
▼ Лампа
Точка
Энергия: 3.000
Затухание:
Обратно-квадратичный
(В Инвертировать
К Только этот слой
о Q
Расстояние: 25.000 J Ш Сфера
Рис. 9.38
В верхней части панели Лампа (Lamp) находятся кнопки для выбора типа источника света, который можно в любой момент изменить.
Параметр Энергия (Energy) определяет силу света. Чуть выше расположено поле выбора цвета. По умолчанию цвет лампы — белый, однако в жизни крайне редко встречаются источники, излучающие белый свет (т. е. волны сразу всех длин светового диапазона). Для изменения цвета нужно щёлкнуть мышью на этом поле и выбрать нужный цвет из палитры.
274
Рендеринг
§65
Группа элементов Затухание (Falloff) определяет затухание света в зависимости от расстояния. Установленный по умолчанию метод Обратно-квадратичный (Inverse Square) лучше всего соответствует законам физики.
Параметр Расстояние (Distance) определяет расстояние (в условных единицах), на котором интенсивность света уменьшается в два раза. Если отметить флажок Сфера (Sphere), за пределами этого расстояния объекты не освещаются вообще.
Отключив флажок Блик (Specular), получаем источник, не дающий зеркального отражения. Флажок Диффузный (Diffuse) отключает рассеянное отражение света. Если отметить флажок Только этот слой (This layer only), источник не будет освещать объекты, которые находятся на других слоях. При включённом флажке Инвертировать (Negative) лампа не освещает, а затемняет поверхности.
Теперь рассмотрим другие типы ламп. Их основные параметры аналогичны настройкам лампы типа Точка (Point).
Солнце (Sun) — источник, моделирующий направленный солнечный свет (рис. 9.39). Поскольку солнце находится от нас на очень большом расстоянии, солнечные лучи можно считать параллельными .
। ।
Рис. 9.39
Освещённость не зависит от расположения лампы на сцене (в том числе от расстояния от лампы до объекта), а зависит только от направления лучей. Поэтому лампу типа Солнце можно ставить в любом месте сцены.
Полусфера (Hemi, от англ, hemisphere — полусфера) — источник, моделирующий рассеянный свет от большой полусферы (рис. 9.40). Такой световой поток содержат лучи разных направлений, поэтому освещение получается значительно мягче, чем при солнечном свете. Источники типа Полусфера можно использовать для подсветки теневых частей объектов. При освещении объекта таким источником падающей тени от объекта не будет.
275
9
Трёхмерная графика
Рис. 9.40
Так же как и для лампы типа Солнце, освещённость не зависит от расположения лампы на сцене (в том числе от расстояния от лампы до объекта), а зависит только от направления лучей. Такую лампу тоже можно ставить в любом месте сцены.
Область (Area) — это источник направленного света от прямоугольной площадки (рис. 9.41). Освещённость зависит от расстояния до источника и угла падения луча на поверхность. Его можно использовать, например, для моделирования подсветки от экрана телевизора.
Рис. 9.41
Прожектор (Spot) — это источник, который даёт направленный свет в пределах конуса (рис. 9.42). Освещённость зависит от расстояния до источника и угла падения луча на поверхность. Форма пятна может быть круглой или прямоугольной. Световой конус можно сделать видимым, используя эффект «гало» (англ. halo — ореол, сияние).
Рис. 9.42
276
Рендеринг
§65
Камеры
Камеры (рис. 9.43) — это специальные объекты, которые позволяют посмотреть на сцену с разных точек, как через видоискатель фотоаппарата или видеокамеры.
Камера
Рис. 9.43
По умолчанию на сцене находится одна камера. Если камера выделена, её можно перемещать (клавиша «G») и вращать (клавиша «R»), как и любой объект. Нажав клавишу 0 на цифровой клавиатуре (NumO), можно переключиться на вид с камеры, при этом часть сцены, не попавшая в «поле зрения» камеры, затемняется.
Если включён вид с камеры, удобно настраивать его в «режиме полёта», который включается при нажатии клавиш Shift+F. Колесико мышки приближает и удаляет камеру от объекта, а движение мыши поворачивает её в соответствующем направлении. Настроив вид, нужно завершить процедуру щелчком левой кнопкой мыши.
Ещё один вариант — получить нужный вид в окне проекции и затем поставить камеру в найденную таким образом точку наблюдения, нажав клавиши Ctrl+Alt+NumO.
Параметры камеры задаются на странице свойств !>• Камера (Camera). В режиме Перспективный (Perspective) камера снимает изображение с учётом перспективы, а в режиме Ортогональный (Orthographic) строит ортогональную проекцию (рис. 9.44).
▼ Объектив
0 Панорама
Сдвиг:______________________ Усечение:
X: 0.000 •"'l Г* Начало: 0.100
Y: 0.000 Конец: 100.000
Рис. 9.44
277
Трёхмерная графика
Параметр Фокусное расстояние (Angle) соответствует фокусному расстоянию объектива фотоаппарата. По умолчанию используется фокус 35 мм, который примерно соответствует углу зрения человека.
Флажок Панорама (Panorama) предназначен для съёмки панорамных сцен.
С помощью полей группы Сдвиг (Shift) можно сдвинуть «поле зрения» камеры, не меняя её положение на сцене.
Параметры группы Усечение (Clipping) определяют область видимости камеры. Все объекты, находящиеся ближе расстояния Начало (Start) и дальше расстояния Конец (End), камера «не видит», и на итоговой картинке их не будет.
На сцене можно использовать несколько камер, переключаясь между ними. Чтобы поместить на сцену новую камеру, нужно выбрать пункт меню Добавить —> Камера (Add Camera). Клавиши Ctrl+NumO делают выделенную камеру активной, т. е. при рендеринге будет построено изображение именно с этой камеры.
Камеру можно «привязать» к какому-то объекту сцены, т. е. сделать так, чтобы она была всё время направлена на этот объект. Для этого на странице свойств Ограничения объекта (Constraints) можно добавить ограничение Слежение (Track То, от англ, track — следовать, сопровождать1*), указав в качестве объекта-цели тот объект, на который нужно направить камеру. После этого при любых перемещениях камера будет всегда направлена на этот объект. Такая связь сохранится и при анимации — камера будет следить за объектом, если он движется.
Если в точке, куда должна смотреть камера, нет никакого объекта, можно добавить на сцену пустой объект (меню Добавить —> Пустышка, Add Empty). Пустой объект можно передвигать, так же как и другие объекты, но он не отображается на сцене при рендеринге.
Внешняя среда
Кроме источников света, установленных на сцене, на итоговое изображение влияют параметры внешней среды, которые задаются на странице свойств Мир (World).
▼ Мир
Псевдонебо Ы Смесь неба О Реал, небо
Цвет горизонта: Цвет зенита: Цвет окружения:
Рис. 9.45
1* В других программах это ограничение называется Look At («смотреть на»).
Рендеринг
§65
По умолчанию для сцены используется серый фон, который можно изменить с помощью поля Цвет горизонта (Horizon Color). Цвет окружения (Ambient Color) задаёт цвет теней (по умолчанию — чёрный).
Можно сделать градиентный фон — переход между двумя цветами, один из которых — цвет горизонта, а второй — Цвет зенита (Zenith Color). Для этого необходимо отметить флажок Смесь неба (Blend Sky). При включённом флажке Реал, небо (Real Sky) фон зависит от точки установки камеры: на уровне горизонта цвет совпадает с цветом горизонта, а выше и ниже горизонта переходит в цвет зенита. Если включить флажок Псевдонебо (Paper Sky), то цвет горизонта всегда будет располагаться по центру камеры, независимо от того, как она расположена.
В качестве фона можно установить растровый рисунок. Для этого нужно отменить выделение всех объектов на сцене и добавить новую текстуру на странице свойств Q Текстуры (Texture).
Кроме того, на странице свойств Мир есть панели Туман (Mist) и Звёзды (Stars), с помощью которых можно создать эффекты тумана и звёзд на небе.
Параметры рендеринга
Перед тем как выполнять рендеринг (нажав клавишу F12), нужно определить, какое именно изображение вам требуется. Для этого на странице свойств Рендер (Render) задаются следующие параметры:
• разрешение (англ, resolution) — размеры получаемой картинки в пикселях (по умолчанию — 1920 х 1080 пикселей);
• масштаб в процентах1* (рис. 9.46); при увеличении масштаба время расчёта сцены также увеличивается; для предварительного просмотра обычно достаточно установить масштаб 25%;
Масштаб 10% Масштаб 25% Масштаб 100%
Рис. 9.46
При уменьшении масштаба программа уменьшает размер получаемого изображения, т. е. при масштабе 10% размер картинки при стандартных настройках будет 192 х 108 пикселей.
279
Трёхмерная графика
• сглаживание острых граней (англ, anti-aliasing) — рис. 9.47;
Без сглаживания
Со сглаживанием
Рис. 9.47
• тип изображения:
— BW — чёрно-белое (от англ, black and white);
— RGB — цветное (цветовые каналы: Red — красный, Green — зелёный и Blue — синий);
— RGBA — цветное с альфа-каналом, определяющим степень прозрачности; нужно помнить, что альфа-канал можно сохранять только в некоторых форматах (например, в PNG);
• формат файла для сохранения (по умолчанию — PNG, часто выбирают другой популярный формат — JPEG);
• дополнительная информация (англ, stamp — штамп), которая «впечатывается» в картинку: дата и время, название файла, время рендеринга и др.
Тени
В реальном мире все предметы отбрасывают тени. В программах трёхмерного моделирования для построения теней используются алгоритмы трассировки лучей. Это значит, что программа «запускает» большое количество лучей света от источника и просчитывает эффект, который дает каждый луч при проходе через среду и отражении от граней, встречающихся на его пути. Такие расчёты требуют значительных вычислительных ресурсов, поэтому по умолчанию тени не строятся.
Чтобы включить построение теней, нужно настроить источники освещения и параметры рендеринга. Прежде всего, в свойствах источника света на панели Тень (Shadow) — рис. 9.48 — надо включить режим Трассировка лучей (Ray Shadow).
Цвет тени можно настроить с помощью поля в левой части панели (по умолчанию цвет теней — чёрный). При включённом
Рендеринг
§65
Рис. 9.48
флажке Только этот слой (This layer only) лампа будет создавать тени только у тех объектов, которые находятся на том же слое, что и сама лампа. Флажок Только для теней (Only Shadow) позволяет сделать лампу, которая не освещает объекты, а только создаёт тени.
В реальности редко бывают чёткие тени с резкими краями. Поэтому используют смягчение теней, которое задаётся параметром Размер мягкого освещения (Soft Size). Увеличение параметра Сэмплов (Samples) позволяет сделать более равномерную и качественную тень, но это требует дополнительного времени при расчёте. .
Кроме того, на странице параметров рендеринга ( Рендер) на панели Тень (Shadow) нужно отметить флажок Трассировка лучей (Ray Tracing).
Выводы
• Рендеринг — это построение проекции трёхмерной сцены на плоскость с учётом материалов, текстур, освещённости, свойств внешней среды и т. п.
• Для выполнения рендеринга нужно расставить и настроить источники света, установить камеру и настроить её свойства, определить свойства внешней среды.
• В программе Blender существует несколько типов источников света (ламп).
• Камеры — это специальные объекты, которые позволяют посмотреть на сцену с разных точек.
• В программах трёхмерного моделирования для построения теней используются алгоритмы трассировки лучей.
Нарисуйте в тетради интеллект-карту этого параграфа.
281
9
Трёхмерная графика
Вопросы и задания
1. Что влияет на результат рендеринга?
2. Сравните разные типы ламп в Blender. В каких случаях они используются?
3. Как вы думаете, зачем может понадобиться использовать несколько камер?
4. Почему по умолчанию для камеры установлено фокусное расстояние 35 мм?
5. Когда, на ваш взгляд, имеет смысл использовать ортогональную проекцию?
6. Как сделать, чтобы камера всегда была направлена в какую-то точку сцены? А если там нет никакого объекта?
7. Какие свойства внешней среды можно настраивать в Blender?
8. Что такое качество рендеринга? Как оно связано со временем рендеринга?
9. Объясните, почему при рендеринге качественных изображений необходимо сглаживание граней (anti-aliasing).
10. Что такое трассировка лучей? Почему эта операция очень трудоёмкая?
Подготовьте сообщение
а) «Источники света в программе Blender»
б) «Настройка свойств внешней среды»
в) «Трассировка лучей»
Проект
Сравнение режимов рендеринга для построенной сцены.
Интересные сайты
blender3d.com.ua — уроки по программе Blender render.ru/books/42 — уроки по программе Blender b3d.mezon.ru — вики-ресурс по программе Blender 3d-blender.ru — сайт, посвящённый программе Blender videotuts.ru/blender/ — видеоуроки по программе Blender
282
Анимация
§66
§66 Анимация
Ключевые слова:
• кадр
• шкала времени
• ключевой кадр
• анимация свойства
• анимация сеточной модели
• ключевая форма
• арматура
• оболочка
• прямая кинематика
• обратная кинематика
• система частиц
• мягкое тело
Анимация объектов
Анимация — это быстрая смена изображений, которые называются кадрами (англ, frames). Если кадры сменяют друг друга достаточно часто (не реже, чем 16-18 раз в секунду), человеческий глаз воспринимает это как непрерывное движение.
Для работы с кадрами в Blender используется окно Timeline (шкала времени). По умолчанию на шкале показаны первые 250 кадров (рис. 9.49). Курсор (зелёная линия, перемещается мышью) показывает текущий кадр, который изображается в окне трёхмерной проекции.
Рис. 9.49
Под шкалой размещаются поля, в которых записаны номера начального (англ, start), конечного (англ, end) и текущего кадров анимации (рис. 9.50).
Начало: 1 Конец: 50 )( 36
Рис. 9.50
Эти три значения можно ввести с клавиатуры или изменить с
помощью стрелок по сторонам полей. Здесь же расположена кнопочная панель управления: кнопки для просмотра (О — вперёд, |<] — назад) и перехода между ключевыми кадрами (рис. 9.51).
Рис. 9.51
283
9
Трёхмерная графика
Создание анимации в программах трёхмерной графики очень похоже на ручное рисование мультфильмов: сначала строятся ключевые кадры, в которых положение и свойства объектов точно задаются. Затем программа автоматически достраивает оставшиеся (промежуточные) кадры.
Для анимации движения объекта нужно
1) установить курсор на временной шкале на выбранный кадр;
2) задать положение объекта для этого кадра;
3) вставить ключевой кадр, нажав клавишу Т;
4) повторить эти действия для всех ключевых кадров.
При добавлении ключевого кадра появляется меню, в котором требуется выбрать тип нового кадра. Он зависит от того, какие изменения происходят с объектом: перемещение (тип Location). вращение {Rotation), масштабирование {Scaling) или их комбинации {LocRot, LocScale, LocRotScale, RotScale). Ключевые кадры обозначаются на временной шкале жёлтыми линиями. Чтобы удалить ключевой кадр, нужно сделать его текущим (установить на него курсор) и нажать клавиши Alt+I.
В программе Blender можно анимировать не только перемещение объекта, но и изменение любого свойства, например цвета. Для вставки ключевого кадра изменения цвета нужно нажать правую кнопку мыши на поле установки цвета и выбрать из контекстного меню пункт Вставить ключевые кадры {Insert keyframes).
Для каждого свойства, которое участвует в анимации, устанавливаются свои ключевые кадры. Например, для поворота объекта могут быть выбраны ключевые кадры 10, 20 и 100, а для изменения цвета — кадры 1, 20, 50 и 70.
Кнопка [®~| справа от кнопочной панели предназначена для включения режима автоматической записи: при каждом изменении свойств объекта на месте текущего кадра вставляется ключевой кадр.
Анимация в окне проекции запускается с помощью клавиш Alt+A (вперёд) или Shift+Alt+A (назад). Повторное нажатие останавливает анимацию на текущем кадре. Остановить и вернуться к начальному кадру можно с помощью клавиши Esc.
Редактор кривых
Когда установлены ключевые кадры, все изменяемые свойства объекта в промежуточных кадрах рассчитываются автоматически. По умолчанию программа выполняет плавное изменение пара-
284
Анимация
§66
метров от одного значения к другому. Иногда нужно изменить такое поведение, например сделать переход, который резко начинается и плавно заканчивается, или скачок значения. Для этого в Blender есть возможность ручной настройки переходов между ключевыми кадрами.
Изменение любого параметра (например, координаты или угла поворота) в зависимости от номера кадра можно изобразить на графике. Кривая на рис. 9.52 показывает изменение угла поворота вокруг оси X, рассчитанное программой.
Это окно называется Graph Editor (редактор кривых). В левой части перечислены все параметры, которые изменяются в ходе анимации. В данном случае изменяются только углы поворота объекта Cube (ключевые кадры типа Rotation). Тип перехода (постоянное значение, линейный, плавный) можно выбрать для каждого узла из всплывающего меню, которое появляется при нажатии клавиш Shift+T.
С помощью флажков можно отключать любую из кривых, например на рис. 9.52 показано только изменение угла поворота вокруг оси X, остальные линии скрыты.
Кривую можно редактировать так же, как и обычный контур. Узлы кривой расположены в ключевых кадрах (на рис. 9.52 это кадры 1 и 50). У выделенного узла показаны рычаги, с помощью которых можно менять кривизну линии. Узлы перемещаются с помощью правой кнопкой мыши (щелчок левой кнопкой заканчивает перемещение) или клавиши «G». Ключевые кадры (узловые точки) каждой кривой можно устанавливать независимо от других кривых.
Щелчок на значке с изображением глаза отключает изменение соответствующего параметра при анимации, а с помощью значка «замок» можно заблокировать кривую (защитить её от изменений).
285
Трёхмерная графика
Простая анимация сеточных моделей
Выше мы говорили только об изменении свойств объектов в целом. При создании анимационных фильмов необходимо уметь перемещать части сеточной модели, например, для того, чтобы персонаж моргнул глазами. Для этого используются ключи формы или ключевые формы (англ, shape keys) — так называются некоторые заранее заданные положения сеточной модели, между которыми выполняется переход. Есть одно важно ограничение: при создании таких ключевых форм нельзя менять геометрию модели, т. е. удалять и добавлять вершины, ребра и грани.
Сначала нужно создать сами ключевые формы и определить положение узлов сетки для каждой из них (в Blender для этого используется панель Ключи формы (Shape keys) на странице свойств сеточной модели Данные объекта (Object Data). Например, для анимации улыбающегося рта нужно построить, по крайней мере, две ключевые формы: рот без улыбки (основная форма, которая называется Basis) и рот с улыбкой (назовём её Smile) — рис. 9.53.
Основная форма (Basis)
Форма Smile
Рис. 9.53
Единственное различие этих форм в том, что вершины формы Smile передвинуты в другое положение.
В программе Blender удобно использовать окно Редактор ключей формы (ShapeKey Editor), в левой части которого перечислены все ключевые формы и показаны коэффициенты (от О до 1), определяющие степень влияния каждой формы на текущий кадр (рис. 9.54).
Рис. 9.54
Анимация
§66
Ключевые кадры в правой части обозначены маркерами-ромбами. Чтобы добавить новый ключевой кадр, достаточно установить на него курсор (светлую линию) и изменить значение параметра в левой части. Ключевые кадры можно перемещать (клавиша «G») и масштабировать (регулировать интервал между кадрами, клавиша «S»). Для удаления ключевого кадра нужно выделить соответствующий ему маркер-ромб и нажать клавишу Delete.
Можно использовать не один, а несколько каналов анимации, при этом ключевые кадры каждого канала задаются независимо от других каналов. Форма кривой изменения параметра настраивается в окне Редактора кривых (Graph Editor).
Арматура
Анимация с помощью ключевых форм хороша тогда, когда нужно изменить положение небольшого числа вершин сеточной модели. Во многих случаях, например при повороте шеи или сустава руки персонажа, необходимо передвинуть сотни вершин. В этом случае используют другой подход, суть которого состоит в том, что внутрь модели вставляют специальные объекты («кости», «арматуру»), играющие роль скелета1*. При рендеринге кости не видны. На рисунке 9.55 показана фигура шахматного короля с арматурой в двух положениях.
Рис. 9.55
Арматура
Обычно выделяют три этапа моделирования персонажа с использованием арматуры:
1) создание скелета из костей;
2) привязка вершин сеточной модели к определённым костям;
3) придание персонажу нужной позы (установка положения костей).
В английском языке эта процедура называется rigging (от англ, rig — оснастка).
287
Трёхмерная графика
На втором этапе арматуру, которая, как правило, состоит из нескольких связанных костей, нужно сделать родительским объектом для объекта-оболочки, установив между ними связь (клавиши Ctrl+P). В отличие от простой связи «объект-объект», когда преобразования объекта-родителя применяются ко всем потомкам, здесь устанавливается особая связь «арматура — оболочка».
Программа автоматически определяет, какие именно вершины сеточной модели оболочки попадают в «зону влияния» каждой из костей и будут перемещаться вслед за ней. Существует специальный режим Оболочка (Envelope), в котором можно увидеть и редактировать эти зоны влияния. Режим Оболочка включается на панели свойств арматуры (Данные объекта). При необходимости можно вручную назначить ведущую кость для каждой вершины. Для этого вершины объединяются в группы, названия которых должны совпадать с названиями объектов-костей.
Таким образом, для того чтобы изменить форму объекта, достаточно изменить положение костей. Вслед за костями переместятся и все связанные с ними вершины сеточной модели, а их могут быть тысячи!
Прямая и обратная кинематика
На рисунке 9.56 показана арматура, которую можно использовать для моделирования руки человека. Кости А, Б п В управляют соответственно плечом, предплечьем и кистью персонажа.
Прямая кинематика
Рис. 9.56
Обычно в модели эти кости связаны отношениями «родитель — потомок»: кость А — это родитель для Б, а Б — родитель для В. Перемещение родителя приводит к перемещению всех потомков, т. е. при перемещении кости А кости Б и В перемещаются вслед за ней. Такая связь называется прямой кинематикой (англ, forward kinematics).
В некоторых случаях прямая кинематика затрудняет построение анимации. Например, персонажу нужно взять что-то в руку.
288
Анимация
§66
При этом мы знаем точно положение кисти В, тогда как положения остальных костей (А и В) должны измениться соответственно, чтобы сохранилась связь в цепочке костей. Это значит, что перемещение кости В приводит к согласованному перемещению костей А и Б. Такая связь называется обратной кинематикой (англ, inverse kinematics), потому что движение передаётся в обратную сторону.
Для построения связи «обратная кинематика» на кость Б нужно наложить ограничение Обратная кинематика (Inverse kinematics). В Blender для этого используется специальная страница свойств Ограничения кости (Bone constraints), которая открывается в режим просмотра Режим позы (Pose mode). В параметрах этого ограничения нужно указать длину цепочки костей, на которую действует ограничение (параметр Chain length, длина цепи). В рассмотренном случае длина цепочки равна 3 (кости А, Б и В).
Физические явления
Современные программы трёхмерной графики содержат средства для моделирования физических процессов. Это значит, что при построении анимации тела перемещаются с учетом законов физики: дым поднимается вверх или стелется по ветру, вода капает или стекает вниз, тела сталкиваются между собой и отскакивают, ткань полощется на ветру и т. п. В этих моделях для создания реалистичной анимации используются достаточно сложные математические уравнения, их решение требует большого объёма вычислений и мощного компьютера.
В программе Blender для этой цели используют две панели свойств: Г | Частицы (Particles) и S Физика (Physics). С их помощью можно моделировать:
• системы частиц (дым, огонь, волосы, траву);
• жидкости;
• столкновения тел;
• силовые поля, например ветер и магнитное поле;
• ткань.
Математические модели, описывающие эти явления, уже заложены в программу. Изменяя их параметры, можно получать самые разнообразные эффекты.
Система частиц — это модель объекта, который не имеет чётких границ, например пара, огня, дыма, дождя, снега и т. п. Для таких объектов невозможно построить сеточную модель, поэтому они моделируются как поток маленьких частиц, каждая
289
Трёхмерная графика
из которых имеет скорость, цвет, направление движения. При движении частиц учитываются свойства внешней среды — сила тяготения (гравитация), ветер и т. п. Для системы частиц можно настраивать множество параметров, таким образом получая модели различных явлений (дыма, огня и т. д.).
В Blender есть особый тип системы частиц — «волосы» (англ. hair). С их помощью можно моделировать волосы человека, шерсть животных, а также траву (рис. 9.57).
Рис. 9.57
Жидкость (англ, fluid) моделируется как поверхность с большим числом граней, причём она может состоять из многих отдельных частей (капель). Для того чтобы построить анимацию жидкости, для каждого кадра положение всех вершин рассчитывается на основе предыдущего кадра и физических свойств жидкости (вязкости). Такой пересчёт иногда называют «выпечкой» (англ. bake). Он занимает длительное время, которое зависит от установленного разрешения (англ, resolution) и количества кадров анимации. При этом сеточные модели для каждого кадра создаются на диске в каталоге для временных файлов. При повторном просмотре анимации они уже не пересчитываются заново, а загружаются с диска (этот подход называют кэшированием). Однако если вы измените какой-либо параметр, всю анимацию придётся просчитывать заново с самого начала.
Ткань (англ, cloth) — это тоже сложная поверхность. В отличие от жидкости ткань создаётся и разбивается на грани вручную (например, используется плоскость, разбитая на части с помощью инструмента Подразделить (Subdivide)).
При построении анимации программа рассчитывает для каждого кадра положение всех вершин сеточной модели (падающей ткани) с учётом свойств выбранного типа ткани (хлопок, шёлк, кожа и др.). Чем мельче грани модели, тем точнее моделирование, но и больше время расчёта положения ткани в каждом кадре. Для объектов, которые должны задерживать ткань, нужно
290
Анимация
§66
установить свойство «столкновение» (англ, collision). Примеры использования ткани в трёхмерных моделях показаны на рис. 9.58. Для создания модели полощущегося флага использовалось силовое поле типа «ветер» (англ. wind).
Рис. 9.58
Мягкие тела (англ, soft bodies) — это специальный аппарат для реалистичного моделирования движения тел, обладающих упругостью. Без него (вручную) было бы практически невозможно грамотно построить анимацию, в которой предметы сталкиваются, сминаются, отскакивают друг от друга и т. п.
Когда для сеточной модели устанавливается свойство «мягкое тело», грани приобретают свойства пружинок. Их жёсткость можно регулировать с помощью настроек на панели Мягкое тело (Soft Body).
Рендеринг
Конечный результат анимации — это видеоролик, записанный в одном из видеоформатов, например AVI1*, MPEG, QuickTime, Ogg Theora. Рендеринг происходит покадрово, т. е. сначала программа строит полное изображение кадра 1, затем — кадра 2 и т. д. Важная характеристика видео — частота кадров (англ. FPS: frames per second, кадров в секунду). Обычно в кино используется частота 24 кадра в секунду* 2*, при которой человеческий глаз воспринимает смену кадров как непрерывное движение. В этом случае для создания ролика, длящегося 10 секунд, нужно построить анимацию из 240 кадров.
О Строго говоря, формат AVI — это контейнер, внутри которого видео и звук могут быть упакованы с помощью различных кодеков (алгоритмов сжатия).
2* В телевизионном стандарте PAL, который принят в Европе, используется частота 25 кадров с секунду, а в стандарте NTSC (США, Канада) — около 30 кадров в секунду.
291
Трёхмерная графика
Рендеринг сложных сцен, включающих миллионы граней, может занимать значительное время (дни и недели!) и требовать больших вычислительных мощностей компьютера. Прежде всего, важно быстродействие процессора и объём оперативной памяти. Поэтому рендеринг видеороликов выполняется, как правило, на мощных компьютерах, объединённых в локальную сеть. Существуют организации, предоставляющие такие услуги (их называют рендер-фермами).
В программе Blender режимы рендеринга настраиваются на странице свойств |^| Рендер. На панели Вывод (Output) нужно выбрать каталог для сохранения видеоролика, формат и имя файла. На панели Размеры (Dimensions) задаются размеры изображения, номера начального и конечного кадров анимации, а также частота кадров. По умолчанию установлена частота 24 кадра в секунду.
Рендеринг запускается с помощью кнопки Анимация (Animation) на странице свойств Рендер или комбинацией клавиш Ctrl+F12.
Выводы
• Анимация — это быстрая смена изображений, которые называются кадрами.
• Курсор на шкале времени показывает текущий кадр, который изображается в окне трёхмерной проекции.
• При создании анимации сначала строятся ключевые кадры, в которых положение и свойства объектов точно задаются. Затем программа автоматически достраивает промежуточные кадры.
• В программе Blender можно анимировать перемещение объекта, изменение любого свойства, изменение положения узлов сетки.
• Если необходимо сразу передвинуть большое количество вершин, используют арматуру («кости»), с которой связывают нужные вершины («оболочку»).
• Для анимации цепочки костей используют связи типа «прямая кинематика» и «обратная кинематика».
• Для анимации физических явлений применяют модели «система частиц», «жидкость», «ткань», «мягкое тело».
Нарисуйте в тетради интеллект-карту этого параграфа.
292
Язык VRML
§67
Вопросы и задания
1. Расскажите об основных принципах анимации по ключевым кадрам.
2. Как можно изменять поведение объектов в промежуточных кадрах?
3. Объясните, как выполняется анимация с ключевыми формами.
4. Сравните анимацию по ключевым формам и анимацию с помощью арматуры. Когда удобно использовать каждый из этих способов?
5. Объясните различие между связями «прямая кинематика» и «обратная кинематика».
6. Что такое система частиц и зачем она используется?
7. Вспомните, где ещё в компьютерной технике используется кэширование.
8. Что такое «мягкие тела»?
9. Почему рендеринг видеороликов представляет собой серьёзную проблему? Как она может быть решена?
Подготовьте сообщение
«Создание игр в Blender»
Проекты
а) Анимация выбранной ЗВ-модели
б) Построение анимации для физических тел в программе Blender
Интересные сайты
turborender.com/ru/ — рендер-ферма TURBORender
rentrender.com/all-render-farms-list/ — список рендер-ферм
§67
Язык VRML
Ключевые слова:
• сцена
• VRML
• XML
• узел
• класс
• свойство
293
9
Трёхмерная графика
Как вы уже знаете, трёхмерные сцены хранятся в компьютере как векторные изображения. Каждый объект в векторном формате задаётся координатами своих вершин и свойствами (например, характеристиками материала). Эти данные могут храниться во внутреннем («машинном») представлении, однако для ручной обработки (и для передачи через Интернет) удобнее, если 3D-mo-дель представляет собой обычный текст без оформления (англ. plain text).
В этом параграфе мы кратко познакомимся с языком VRML (Virtual Reality Modeling Language — язык моделирования виртуальной реальности), который позволяет сохранить трёхмерную сцену в текстовом файле и потом просматривать её в специальной программе или в веб-браузере (с помощью дополнительного модуля — плагина). Язык VRML «понимают» многие программы трёхмерного моделирования, в том числа системы автоматизированного проектирования (САПР). С помощью VRML сделаны виртуальная экскурсия по мемориалу на Мамаевом кургане1) и ЗВ-модели исторических событий (например, полёта в космос Юрия Гагарина) на сайте фирмы Parallel Graphics* 2 3 4 5^.
С помощью VRML можно описать не только форму трёхмерных объектов, но и их физические свойства: цвет, текстуру, блеск, прозрачность. Объекты могут быть гиперссылками на другие документы. Язык VRML позволяет создавать анимацию, менять освещение, включать и выключать звуки, а также добавлять к сцене программный код на языках Java или JavaScript. Современный стандарт для работы с трёхмерными моделями — X3D — считается наследником языка VRML и использует хранение данных в XML-формате.
Трёхмерную сцену в VRML называют миром (англ, world), поэтому VRML-файлы имеют расширение wrl. Это обычные текстовые файлы, которые можно редактировать в любом текстовом редакторе. Кроме того, существуют специальные VRML-редакторы, например WhiteDune2K
Для просмотра VRML-моделей нужно установить соответствующий плагин к браузеру (например, Cortona3D Viewer^) или самостоятельное приложение (например, кроссплатформенную программу view3dscene^).
Построим с помощью VRML трёхмерную модель комнаты. Её стены (а также пол и потолок) можно представить в виде плит
х) http://www.volgograd.ru/mamayev-kurgan/
2) http://www.parallelgraphics.com/products/showroom/event/
3) http://wdune.ourproject.org/
4) http://www.cortona3d.com/cortona
5) http://castle-engine.sourceforge.net/view3dscene.php
294
Язык VRML
§67
(блоков, параллелепипедов). Пусть длина каждой стены — 4 м, высота — 3 м, а толщина — 0,1 м. Тогда стена в плоскости XOY (рис. 9.59), описывается так:
#VRML V2.0 utf8
Shape { geometry Box { size 4 3 0.1 } }
У n
0
В первой строке указана версия языка VRML (2.0) и кодировка текста (utf-8 — это один из вариантов UNICODE). У единственного безымянного объекта Shape (англ, shape — форма, фигура) задано только одно свойство — геометрия (англ, geometry). Слово Box означает, что эта фигура — параллелепипед («коробка»), его размеры (по осям X, Y и Z соответственно) указаны после слова size (размер).
Объекты сцены в VRML называются узлами. Названия классов объектов начинаются с прописной буквы, а названия свойств (полей) — со строчных. В нашем примере объект класса Shape имеет поле geometry, определяющее форму тела. Значение этого поля — объект класса Box (параллелепипед)1^ Узел Box, в свою очередь, имеет поле size, определяющее размеры плиты по каждой координатной оси.
Кроме параллелепипедов, в языке VRML есть объекты других классов, например Sphere (шар), Cylinder (цилиндр), Cone (конус). Более сложные фигуры строятся из отдельных граней.
Объекты VRML имеют довольно много полей. Если значение поля не указано, используется некоторое стандартное значение (значение по умолчанию). Например, по умолчанию тело располагается так, чтобы его центр совпадал с началом координат, и равномерно «покрашено» в белый цвет.
Приведённый выше VRML-код можно записать в файл (назвав его, например, first.wri) и загрузить в программу-просмотрщик. При этом мы не просто увидим объёмную стену, но и сможем
Каждому объекту можно присвоить собственное имя, но делать это не обязательно.
295
Трёхмерная графика
«походить» вокруг неё. В программе view3dscene это будет выглядеть так (рис. 9.59).
Рис. 9.59
Программа должна выполнять рендеринг для загруженной трёхмерной модели очень быстро, поэтому качество картинки будет существенно хуже, чем в профессиональных программах ЗВ-моделирования типа Blender или 3ds Мах.
В нашем файле точка наблюдения не задана, и программа самостоятельно выбирает её (по умолчанию). Положение этой точки можно задать явно, добавив в VRML-файл код
Viewpoint
{ position 005 }
Здесь свойство position (положение) объекта Viewpoint (точка наблюдения) определяет начальные координаты наблюдателя. В данном случае он находится в точке с координатами X = О, У = 0 и Z = 5.
Существует несколько режимов просмотра трёхмерной сцены:
• Examine (рассматривать, исследовать) — наблюдатель неподвижен, объект можно поворачивать и рассматривать под разными углами;
Язык VRML
§67
• Walk (ходить, делать обход) — сцена неподвижна, а наблюдатель перемещается внутри неё «по поверхности земли»;
• Fly (летать) — отличается от предыдущего режима «выключенной» силой тяжести.
Кнопка Collisions (столкновения) определяет, может ли наблюдатель проходить сквозь стены и предметы (если она отключена, то может).
Чтобы придать стене более реальный вид, надо заполнить у объекта Shape ещё одно поле — appearance («внешность», «наружность»), отвечающее за то, как объект выглядит. Все свойства, влияющие на внешний вид объекта, собраны в единый объект с именем Appearance. Зададим для стены материал (свойство material объекта Appearance) и установим для этого материала цвет (свойство diffuseColor):
#VRML V2.0 utf8
Shape { geometry Box { size 430.1 } appearance Appearance { material Material { diffuseColor 0.7 0.7 0.7 } } }
Числа после названия свойства diffuseColor задают цвет стены в виде трёх составляющих модели RGB — красной, зелёной и синей, каждая из которых принимает значение от 0 до 1 (это соответствует диапазону от 0 до 255 при целочисленном RGB-кодировании цвета). В данном случае все они равны 0,7 — это светло-серый цвет.
Вместо того чтобы «красить» стену, можно было «оклеить её обоями», т. е. наложить рисунок (текстуру). Для этого нужно задать свойство texture (текстура):
#VRML V2.0 utf8
Shape
{
geometry Box { size 430.1 } appearance Appearance { texture ImageTexture { url["texture.png”] } }
}
297
9
Трёхмерная графика
В данном случае текстура относится к классу ImageTexture (текстура-рисунок) и находится в файле texture.png в текущем каталоге. Рисунок растягивается на всю поверхность, поэтому его пропорции должны соответствовать соотношению размеров стены.
Остальные стены строятся аналогично, но с одним существенным отличием: их придется смещать в пространстве (иначе по умолчанию их центр будет расположен в начале координат). Предположим, что созданная стена будет «дальней от нас». Тогда «левая» стена имеет размеры 0,1 х 3 х 4 м (по осям X, Y и Z соответственно), и её нужно передвинуть на 2,05 м влево вдоль оси X и на 1,95 м «в сторону наблюдателя» вдоль Z (величина 0,05 м — это половина толщины стены!).
Для перемещения объектов в виртуальном пространстве используется узел Transform (превращать, изменять). Он способен выполнять для присоединенных к нему узлов (перечисленных в списке children — «потомки», «подчиненные объекты») следующие действия (и любые их комбинации!):
• translation (смещение) — смещение центра объекта вдоль каждой из трёх осей координат;
• rotation (вращение, поворот) — поворот объекта вокруг трёх осей координат;
• scale (изменение масштаба) — умножение размеров объекта на коэффициенты, отдельно по каждой оси.
В нашем случае требуется только перемещение. В список children (он записывается в квадратных скобках) мы включим одну фигуру (объект Shape) — параллелепипед, изображающий левую стену. Этот код нужно добавить в конец VRML-файла:
Transform { translation -2.05 0 1.95 children [ Shape { geometry Box { size 0.134 } } ] }
Теперь вы можете самостоятельно построить «виртуальную комнату» целиком.
298
Язык VRML
§67
Выводы
• Язык VRML позволяет описывать трёхмерные сцены в текстовом формате.
• VRML-файл — это программа для построения сцены, где определяются объекты сцены и их свойства.
• Для просмотра VRML-сцен можно использовать дополнительные модули (плагины) в браузерах или специальные программы.
Нарисуйте в тетради интеллект-карту этого параграфа.
Вопросы и задания
1. Как вы понимаете термин «виртуальная реальность»?
2. Какие свойства трёхмерных объектов можно моделировать с помощью VRML?
3. Что представляет собой VRML-файл? Какое расширение он имеет и почему?
4. Сравните системы координат, которые используются в математике и в VRML 2.0.
5. Объясните, что такое сцена, узлы и поля. Приведите примеры.
6. Что такое «значение по умолчанию»? Какие преимущества даёт такой способ задания значений при передаче VRML-модели по сети?
7. Каково по умолчанию положение тел относительно начала координат? Что нужно сделать, чтобы изменить положение объекта?
8. Сравните различные режимы просмотра трёхмерных сцен.
9. Каким образом кодируется цвет в языке VRML?
10. Как нанести текстуру на поверхность объекта?
11. Какие действия можно выполнять с помощью узла Transform?
12. Обсудите, где можно использовать язык VRML.
Проекты
а) Программа для построения VRML-миров
б) Использование WebGL в выбранной задаче моделирования
Интересный сайт
blend4web.com/ru — пакет Blend4Web
299
9
Трёхмерная графика
WWW
ЭОР к главе 9 на сайте ФЦИОР (http://fcior.edu.ru)
• Изображения. Виды
• Общие понятия об аксонометрических проекциях
• Проекции простейших геометрических фигур на плоскость
Практические работы к главе 9
Работа № 74 «Введение в ЗВ-моделирование»
Работа № 75 «Работа с объектами»
Работа № 76 «Сеточные модели»
Работа № 77 «Модификаторы»
Работа № 78 «Кривые»
Работа № 79 «Материалы и текстуры»
Работа № 80 «Рендеринг»
Работа № 81 «Анимация»
Работа № 82 «Язык VRML»
300
ОГЛАВЛЕНИЕ
Глава 5. Элементы теории алгоритмов.....................3
§ 31. Уточнение понятия алгоритма....................3
§ 32. Алгоритмически неразрешимые задачи............17
§ 33. Сложность вычислений..........................23
§ 34. Доказательство правильности программ..........34
Глава 6. Алгоритмизация и программирование.............45
§ 35. Целочисленные алгоритмы.......................45
§ 36. Структуры.....................................56
§ 37. Словари.......................................63
§ 38. Стек, очередь, дек............................68
§ 39. Деревья.......................................80
§ 40. Графы.........................................94
§ 41. Динамическое программирование............... 111
Глава 7. Объектно-ориентированное программирование. . . . 123
§ 42. Введение.................................... 123
§ 43. Создание объектов в программе................131
§ 44. Скрытие внутреннего устройства.............. 137
§ 45. Иерархия классов............................ 143
§ 46. Программы с графическим интерфейсом..........154
§ 47. Графический интерфейс: основы................159
§ 48. Использование компонентов (виджетов).........164
§ 49. Совершенствование компонентов................175
§ 50. Модель и представление.......................179
Глава 8. Обработка изображений........................186
§ 51. Ввод изображений............................ 186
§ 52. Коррекция изображений....................... 195
§ 53. Работа с областями...........................202
301
Оглавление
§ 54. Многослойные изображения..................208
§ 55. Каналы....................................215
§ 56. Иллюстрации для веб-сайтов................219
§ 57. Анимация..................................222
§ 58. Векторная графика.........................226
Глава 9. Трёхмерная графика........................238
§ 59. Введение..................................238
§ 60. Работа с объектами........................243
§ 61. Сеточные модели...........................250
§ 62. Модификаторы..............................255
§ 63. Кривые....................................261
§ 64. Материалы и текстуры......................266
§ 65. Рендеринг.................................273
§ 66. Анимация..................................283
§ 67. Язык VRML.................................293
302
Учебное издание
Поляков Константин Юрьевич Еремин Евгений Александрович
ИНФОРМАТИКА
11 класс
Базовый и углубленный уровни
В 2 частях Часть 2
Ведущий редактор О. Полежаева Ведущий методист И. Хлобыстова Художник Н. Новак Технический редактор Е. Денюкова Корректор Е. Клитина Компьютерная верстка: Е. Голубова
Подписано в печать 01.03.17. Формат 70x100/16. Усл. печ. л. 24,7. Тираж 3000 экз. Заказ № м4366.
ООО «БИНОМ. Лаборатория знаний» 127473, Москва, ул. Краснопролетарская, д. 16, стр. 1, тел. (495)181-5344, e-mail: binom@Lbz.ru http://www.Lbz.ru, http://metodist.Lbz.ru
Отпечатано в филиале «Смоленский полиграфический комбинат» ОАО «Издательство «Высшая школа» 214020, Смоленск, ул. Смольянинова, 1 Тел.: +7 (4812) 31-11-96. Факс: +7 (4812) 31-31-70 E-mail: spk@smolpk.ru http://www.smolpk.ru