/































































































































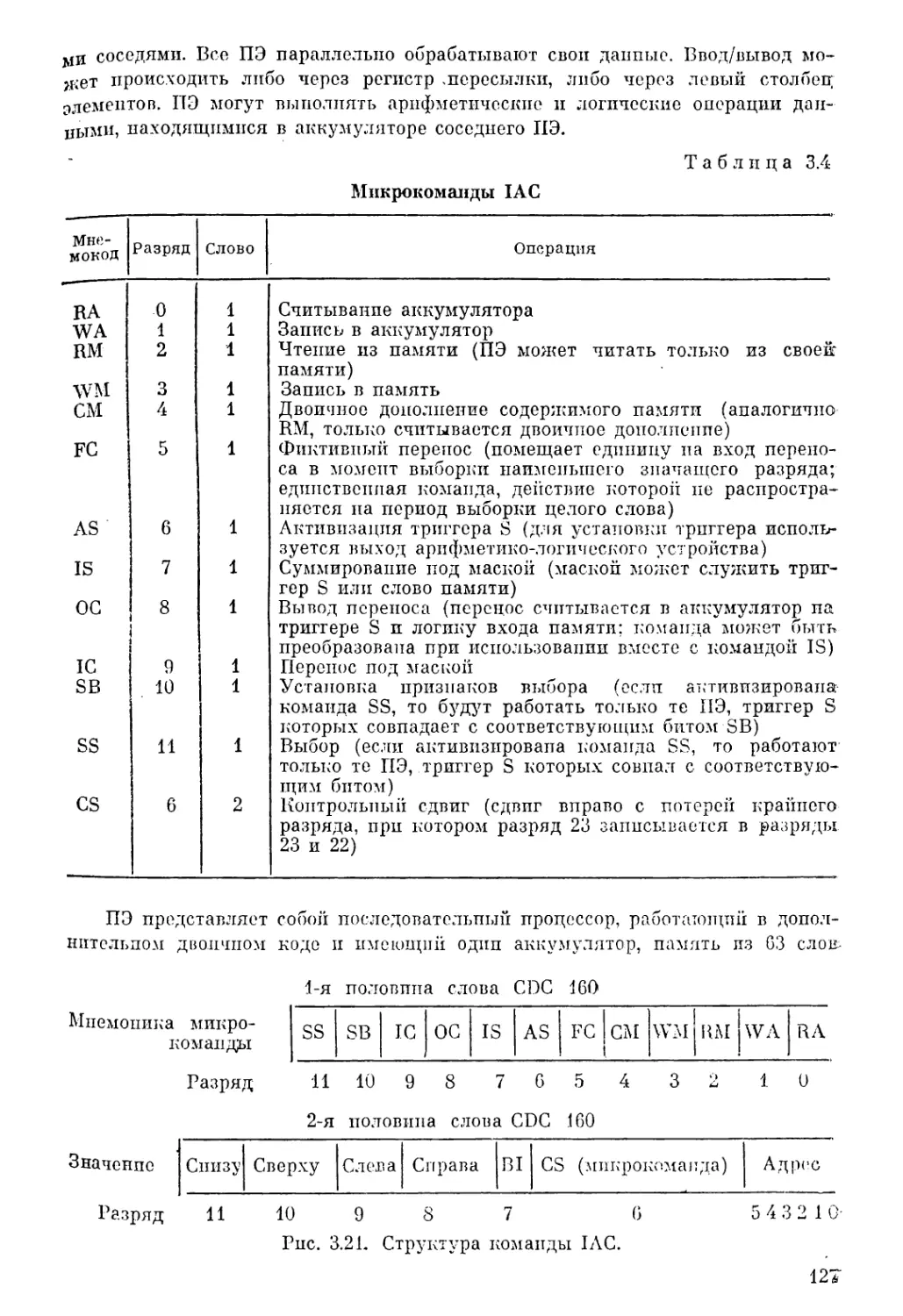
















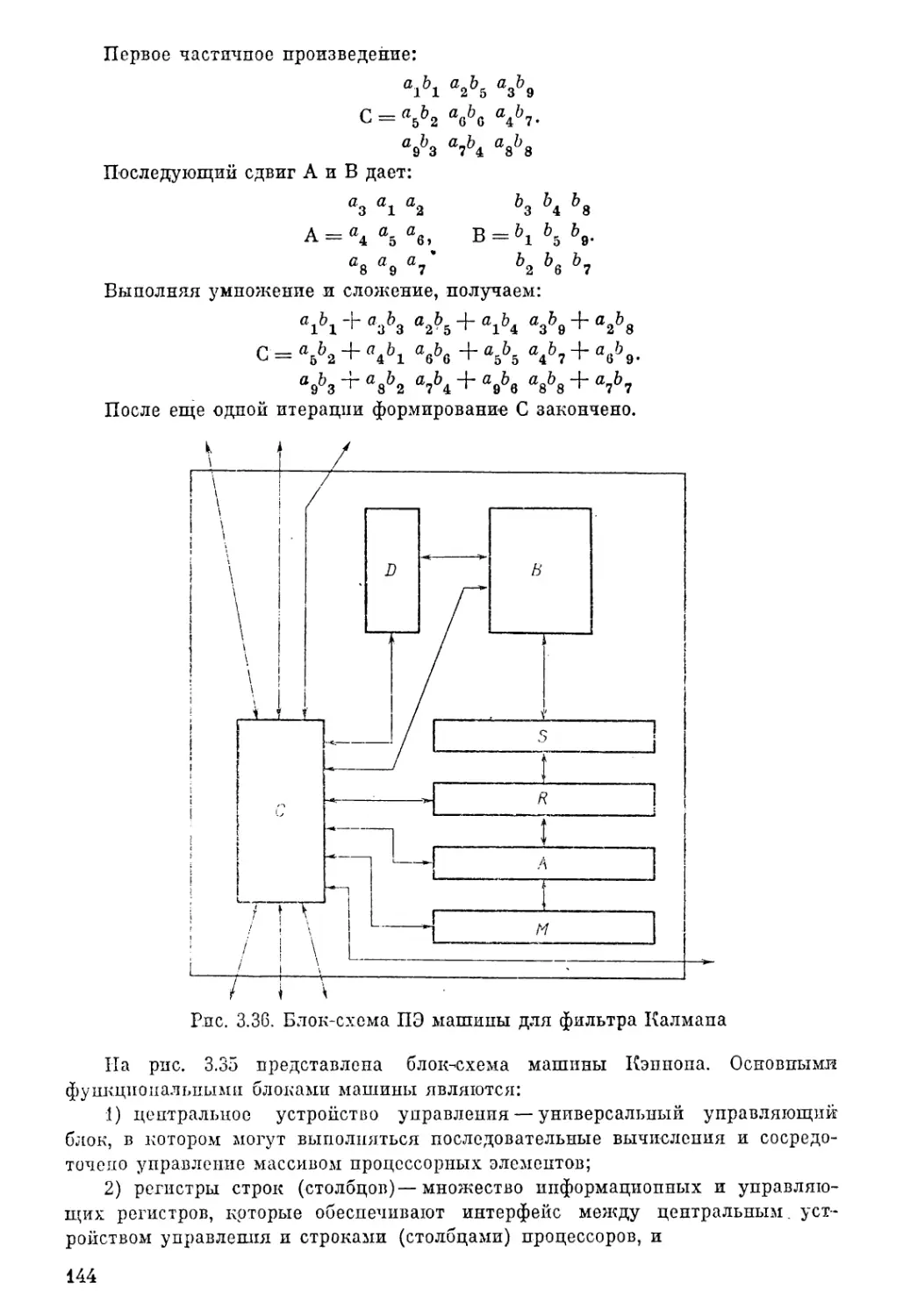





















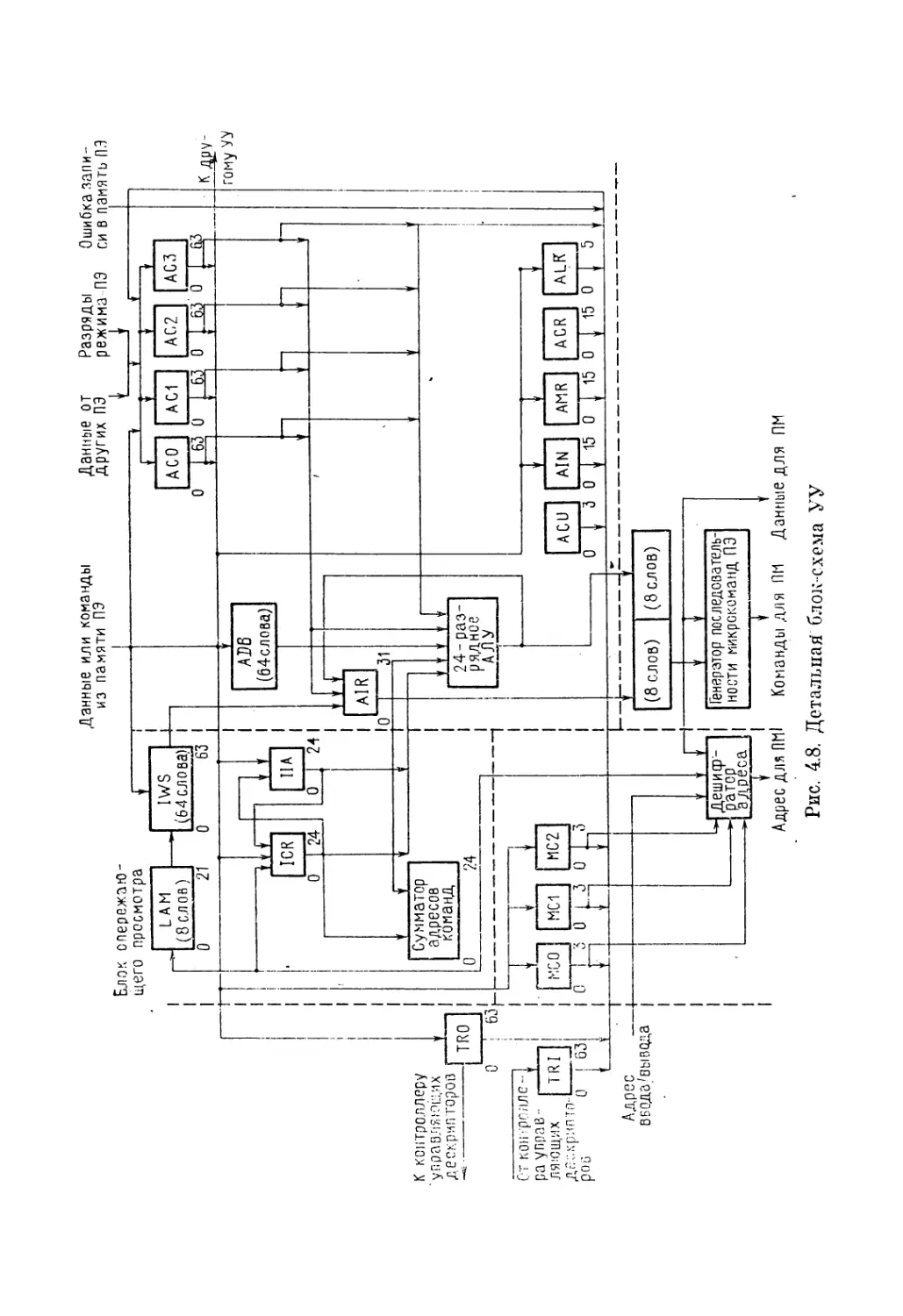













































































































Текст
К. ДЖ. ТЕРБЕР
АРХИТЕКТУРА
ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ
ВЫЧИСЛИТЕЛЬНЫХ
СИСТЕМ
Перевод с английского
В. М. АМОЧКИНА, А. С. МИРКОТАН
МОСКВА «НАУКА»
ГЛАВНАЯ РЕДАКЦИЯ
ФИЗИКО-МАТЕМАТИЧЕСКОЙ ЛИТЕРАТУРЫ
ББК 22:18
Т35
УДК 519.6
LARGE SCALE
COMPUTER
ARCHITECTURE
_ PARALLEL
AND ASSOCIATIVE
PROCESSORS
KENNETH J. THURBER
1976
T e p б e p К. Дж. Архитектура высокопроизводительных вы¬
числительных систем/Пер. с англ.— М.: Наука. Главная редакция
физико-математической литературы, 1985.— 272 с.
К. Дж. Тербер
Архитектура высокопроизводительных вычислительных систем
Редактор И. А. Рудпев
Художественный'редактор Г. М. Коровина
Технический редактор И. Ш. Апсельрод
Корректоры: О. А. Бутусова, О. М. Березипа
ИБ Ло 11795
Сдано в набор 25.02.85. Подписано к печати 05.10.85. Формат бОхЭО'Ле. Бумага тип. № 3.
Гарнитура обыкновенная. Печать высокая. Уел. печ. л. 17. Уел. кр.-отт. 17. Уч.-изд.
л. 21,24. Тираж 8400 экз. Заказ № 618. Цена 2 р. 30 к.
Ордена Трудового Красного Знамени издательство «Наука»
Главная редакция физико-математической литературы
4-я типография издательства «Наука»
. 630077 Новосибирск-77, Станиславского, 25
© 1976, by Hayden
Book Company, Inc.
Перевод на русский язык.
Издательство «Наука»,
Главная редакция
физико-математической
литературы, 1985
1702070000—155 ,
Т 053 (02) -85 34-85
ОГЛАВЛЕНИЕ
Предисловие к русскому переводу . .........
Предисловие
Глава 1. ВВЕДЕНИЕ
Для чего нужны специализированные вычислительные машины? .
Классификация архитектур машин .
Типовые задачи для ОКМД-машин . . . . ' . . . .. .
ОКМ Д-процессоры . .
Вычислительные системы' с массивом процессоров (параллельные
процессоры)
Ассоциативные процессоры
Заключение
Упражнения ...
Г л а в а 2. АССОЦИАТИВНАЯ ОБРАБОТКА ■ .
Введение
'Применения . . . . . • .
Наиболее общий тип архитектуры ассоциативного процессора
Принцип перехода состояния _ .
-МЕМЕХ — первая ассоциативная архитектура4
Криогенная каталоговая память — первая аппаратная реализация
ассоциативной памяти *
Разрешение множественных откликов и алгоритм Левина
Ассоциативные процессоры в роли универсальных вычислительных
машин . . . . . . . . - . ,
SIMDA — машина с обработкой битовых срезов
Запоминающие устройства с распределенной логикой ....
Процессоры с ассоциативпой базой данных, вычислительные машипы
для информационных систем . . .
Ассоциативные процессоры с высокой степенью параллелизма
Л1 погомерпые миогорежимные запоминающие устройства .
Заключение
Упражнения ....
Глава 3. ОСНОВНЫЕ ТИПЫ АРХИТЕКТУР ПАРАЛЛЕЛЬНЫХ ПРО¬
ЦЕССОРОВ
Введение ....
Ячеечные автоматы фон Неймана
Яростраиствепная машина Унгера
Уашипа Холланда .
фтогоиальная машина .
V \ л п~>11а СквайРа п Пеле
v лли^ — вычислительная
устройством
Система SOLOMON ‘ I
Система SOLOMON II
машина с векторным арифметическим
G
7
9
9
10
12
13
14
15
10
17
18
18
19
20
37
45
46
48
52
56
59
71
79
92
95
96
98
98
99
102
105
108
110
111
114
121
Применение системы SOLOMON
Система ILLTAC III ’ * ’
IAC — итерационная вычислительная система с массивом процессоров
PC — планарная вычислительная машина
ALPS параллельная вычислительная система с ассоциативными про¬
цессорами
Система ILLIAC IV
Maiггины I и II Рорбахера . . . . .
РЕРЕ — параллельная вычислительная система с ансамблем процес¬
сорных элементов
Вычислительная мантина с ячеечной структурой на базе языка APL
Совершенная тасовка
Машина Кэннона !!!*'*
Машина Jloyca для расшифровки кодов Хэмминга
Еще один параллельный процессор на базе языка APL .
Другие типы итерационных вычислительных машин
Заключение
Упражнения !!!!!!!**
Глава 4. ILLIAC IV. ....
Введение
Архитектура ILLIAC IV ... *
Аппаратная часть ILLIAC “IV . ’
Программное обеспечение ILLIAC IV
Заключение
Упражнения
Глава 5. СИСТЕМА РЕРЕ .
Введение
Архитектура РЕРЕ
Программное обеспечение РЕРЕ .
Заключение
Упражнения
Глава 6. ПРОЦЕССОР STARAN . .
Введение
Архитектура STARAN .
Процессор STARAN . ' .
Программное обеспечение STARAN .
Система ввода/вывода STARAN . . .
Варианты процессора STARAN . .
Заключение .
Упражнения .
Глава 7. СЕМЕЙСТВО OMEN . .
Введение
Описание архитектуры OMEN ...
Ортогональная память ...
Взаимосвязи ПЭ в OMEN .
ВАУ системы OMEN ....... . . .
Программное обеспечение OMEN .... ...
Конфигурация машин семейства OMEN . . ...
Заключение
Упражнения .... ... ....
Глава 8. ОЦЕНКА ПРОИЗВОДИТЕЛЬНОСТИ .
Введение
Оценка производительности ,
122
122
125
128
129
130
131
130
137
142
142
141)
149
152
150
157
159
159
159
К)!
180
185
185
180
18(5
195
195
204:
205
207
207
207
213
217
221
222
224
224
220
220
220
230
234
235
238
23 S
289
240
241
24 I
24.2
4
Оценка ОКМД-машин
Заключение .
Упражнения . *
Глава 9. БУДУЩЕЕ ОКМД-МАШИН
Введение . • • • •
Аргументы против ОКЛГД машин
Параллельные или миогоматпитшые системы? .
ТТотепнстальнъте возможности ОКМД-процессоров
Показатели стоимости
Эффективность параллельных процессоров .
Заключение
Список литературы
24 7
24 S
248
240
240
2Г)()
2 о 8
2 5 (>
2 о 0
2(H)
2(32
204
ПРЕДИСЛОВИЕ К РУССКОМУ ПЕРЕВОДУ
Распараллеливание и конвейеризация составляют основной структурный
принцип повышения производительности вычислительных систем. Непосредст¬
венный подход к реализации в явном виде распараллеливания ветвей вычисле¬
ний приводит к построению ОКМД-систсм, имеющих один поток ко.манд и мно¬
го потоков данных (т. е. одно устройство управления и много параллельных
обрабатывающих устройств). Характерными представителями последних явля¬
ютсяПараллельные системы с общим'управлением н ассоциативные системы,
которым посвящена предлагаемая в переводе па русский язык книга известно¬
го американского специалиста К. Дж. Тербера.
В отечественной и зарубежной литературе большое внимание уделено
разного типа параллельным и ассоциативным системам, их примеры даны в це¬
лом ряде книг. Данная книга отличается тем. что она целиком ориентирована
только на ОКМД-снстемы и содержит систематически и достаточно полно из¬
ложенный материал но основам построения и оценки ОК.МД-снсяем с подроб¬
ными описаниями таких их характерных представителей, как ILLIAC IV, РЕРЕ,
OMEN, ST ARAN и другие.
Книга выдержала проверку временем. Приведенные в иен исходные кон¬
цепции положены в основу многих новых проблемно ориентированных и спе¬
циализированных параллельных систем и процессоров. Концепции построения
функциональных аналогов физических систем находят применение в полу¬
пивших, в последние годы быстрое развитие специализированных параллельных
процессорах на базе сверхбольших интегральных схем с прямой аппаратурной
реализацией многих таких функций, которые традиционно возлагались на про¬
граммное обеспечение.
Концентрированный и систематически изложенный материал книги
К. ,Дж* Тербера может служить как развернутым справочником по основам
построения высокопроизводительных параллельных систем с общим управле¬
нием и ассоциативных систем, так и учебным пособием но этим вопросам.
ПРЕДИСЛОВИЕ
Полью кппгп является систематизированное описание ассоциативных п па¬
ра ТЛСЛЫ1ЫХ процессоров, а также технических идей п решений, заложенных в
их архитектуре?
В книге рассматривается только один класс архитектур, а именно, архитек¬
туры характеризующиеся Одиночным потоком Команд и Множественным пото¬
ком Данных (ОКМД). .Материал охватывает следующие темы:
Г) Соотношение между ОКМД-архитектурой п другими типами архитектур
(глава I).
‘ 2) Важнейшие принципы, заложенные в архитектурах ассоциативных (гла¬
ва 2) и параллельных (глава 3) процессоров.
3) Описание четырех существующих вычислительных систем, являющихся
главными представителями семейства ОКМ Д-машин: ILLIAC IV (глава 4),
РЕРЕ (глава 5), STARAN (глава G) и OMEN (глава 7).
4) Основные методы оценки характеристик ОКМД-машпн, включая уже ап¬
робированные методы п методы, которые можно было бы или, вернее сказать,
следовало бы применять (глава 8).
- 5) Аргументы за и против ОКМД-архптектуры (глава 9).
Книга призвана служить справочным и учебным пособием по основным ти¬
пам ОКМД-машпн, созданных до 1974 г. В виде конспекта отта ужо была ис¬
пользована кате пособие на факультете вычислительной техники, информатики
и управления университета штата Миннесота в 1974—1975 учебном году. На ос¬
новании опыта, полученного в процессе преподавания настоящего курса, пред¬
ставляется целесообразным следующий порядок изучения книги.
1) Аспирантам специализированных групп рекомендуется двухсеместровыгг
курс, при этом в первом семестре следует изучить главы 1, 2, 3, 8 и 9, а во вто¬
ром — главы 4, 5, 6 и 7. Изучение курса может быть продолжено и в третьем
семестре в форме самостоятельной работы над специальными вопросами, инте¬
рес к которым возник в процессе изучения материала в двух предыдущих се¬
местрах.
2) Для аспираптов л студентов, прослушавших курсы по логической орга¬
низации вычислительных машин, программированию на языке ассемблера и тео¬
рии принятия решений, изучение книги может проходить в рамках дв\гх курсов,
а пмоппо:
пт-лпт кРаткп,\ обзорный одпос-емсстровый курс по теоретическим основам
ОКМД-машттщ базирующийся па материале глав 2 и 3, с привлечением тех раз¬
делов глав 4, 5, В и 7, в которых оштсаиы конкретные машины;
о) трехсеместровый курс с изучением в первом семестре глав 1 л 2, во вто-
ром семестре — глав 3. 8 и 9 и в третьим семестре — глав 4. 5. В и 7.
Книга может служить дополнительным учебным пособием поп изучении
~V™T0T'/VP вьгшслителытых машин, при этом в основном используется матери¬
ал глав 4, о, В и 7.
точполПеС0ПИе ВЫМИСЛЯТ0ЛЫ1°п машины к той пли пион категории по поддается-
ОКМЛ-\ отгсашпо и может рассматриваться как особое искусство. В области
пнейню1™!11 ТТМС0ТСЯ много проблем, связанных с терминологией, классифпка-
пнкщолгу311аЧ°11ИеМ П Т‘ ^1ТИга посвящена перспективному паправлеппто, воз-
касается ■ В^П^01*0(»Се РазвТ1Т11Я вычислительной техники. Перспективность эта
ставляет с ,(-°^.ыио“ ст°по1тн создателей машин, чем пользователей. Книга пред-
восколько го0*1 П°™У представить в рациональной и упорядоченной форме
пструкцпп вычислительных машин, взаимосвязь которых обуслов-
7
леиа наличием некоторого общего с нонет на, называемого ОКМД-иараллслизмом.
Очевидно, рассматриваемые машины не идентичны друг другу, но они сходны
в том, что их создали для решения задач, в которых используются свойства
ОКМД архлт е кт у ры.
Используя книгу в качестве руководства, студент может проникнуться тех¬
ническими идеями; эти идеи, возможно, встретятся при рассмотрении конструк¬
ций, созданных на базе основных принципов рассматриваемой архитектуры я
воплощающих эти принципы с учетом различных ограничений. И вычислитель¬
ных системах общего назначения, таких как, например, семейство IBM .‘UiU, кон¬
структорские решении обычно бывает трудно вы делит г» на фоне множества фак¬
торов (обусловленных участием в разработке большого количества людей, не¬
совершенством фирменной документации и т. д.). Однако в области ОКМД-ма-
шин имеются документы и официальные доклады, которые детально отражают
замыслы разработчиков и то. как эти замыслы воплощены в созданных конст¬
рукциях. Цель книги состоит в том, чтобы с единых позиций рассмотреть все
конструкции данного типа.
Основная черта рассматриваемых конструкций состоит в том, что при ре¬
шении широкого круга задач используется одно общее свойство (ОКМД) или
общая совокупность свойств (ассоциативность и ОКМД).
Автор надеется, что. увидев, как другие пытаются использовать указанные
свойства, читатель захочет ближе познакомиться с процессом конструирования.
Помимо того, что книга полностью охватывает всю область ОКМД-архитектур,
в ней еще есть стремление объяснить читателю причины того, что один и тот
же базовый принцип под влиянием тех или иных требований может порождать
различные, по взаимосвязанные архитектуры. Конструкторские задачи должны
быть поставлены так, чтобы дать студенту необходимый практический опыт,
благодаря которому он сможет участвовать в развитии и совершенствовании
конструкций конкретных вычислительных машин. ОКМД-архитектуры пред¬
ставляют собой хорошее ноле деятельности дли студентов, поскольку задачи
конструирования оказываются точно очерченными благодаря присущим данной
архитектуре ограничениям. Автор надеется, что книга позволит читателю с раз¬
личных сторон рассмотреть одну нз основных концепций современной вычисли¬
тельной техники (концепцию параллелизма) и послужит стимулом дальнейшего
сове рнт с и с т в о в а ни я э т о й кон ц е и ции.
Книга состоит из описаний машин, каждое из которых по объему соответст¬
вует одной лекции. Общим для всех рассматриваемых машин является заложен¬
ный .в них основной принцип построения. Отдельное описание какой-либо ма¬
шины по возможности представляет собой замкнутый раздел книги. При напи-
ч анпп каждого раздела автор стремился в краткой н содержательной форме по¬
казать области применения и основные конструкторские идеи.
Архитектуры машин объединены в несколько групп по признаку свойств,
которые определяют их сущность. Разные архитектуры, описанные в книге, от¬
личаются друг от друга скорее по способу технической реализации, нежели по
принципу построения. Совокупность разработанных архитектур настолько мно¬
гообразна, что бесспорное отнесение какой-либо из тшх к той или пион катего¬
рии практически невозможно из-за большого числа переменных величин, опи¬
сывающих архитектуру. Например, ассоцпацивпые процессоры охватывают диа¬
пазон от процессоров с обработкой простых битовых срезов (глава 2) до про¬
цессоров с обработкой сложных битовых срезов (глава 0), от процессоров с про¬
стой распределенной логикой (глава 0) до вычислительных систем со сложной
распределсчшои логикой и высокой степенью параллелизма (глава 2).
По мере того как читатель будет знакомиться с описываемыми конструк¬
циями, у пего могут возникнуть другие предложения по классификации ма¬
шин. что, отчасти, является целью данной книги, а именно, сопоставление ма¬
шин. отличающихся по конструкции, с целью выявить заложенные в них прин¬
ципы. Кроме того, читатель всегда будет иметь возможность без предубеждения
относиться к новым видам архитектур, пути создания которых ыамечепы в этой
книге.
Глава 1
ВВЕДЕНИЕ
Для чего нужны специализированные вычислительные машины?
Большинство задач пользователей может быть решено с помощью широко
распространенных универсальных вычислительных машин. Однако существует
немало сфер примепения, в которых к характеристикам вычислительных
средств предъявляются специальные требования. Многие задачи просто не мо¬
гут быть решены на серийных универсальных машинах. В частности, во мно¬
гих случаях применение специализированных машин продиктовано соображе¬
ниями надежности.
Имеется класс задач, требующих очень высокой скорости вычислений,
обеспечение которой с помощью универсальной вычислительной системы со¬
вершенно нецелесообразно с точки зрения стоимости. Такие задачи требуют
высокой пропускной способности при обработке структурированных данных.
Одним из подобных применений является противоракетная оборона. Большое
число задач такого типа пе может быть решено на вычислительных машинах
общего назначения при сколько-нибудь приемлемой стоимости решения. Этот
класс задач образует область применения, в которой с успехом могут быть
использованы ассоциативные и параллельные вычислительные системы.
Ассоциативные п параллельные процессоры всех типов являются специа¬
лизированными вычислительными машинами. Хотя на них могут решаться
различные задачи, но все они должны быть основаны па похожих вычисли¬
тельных методах. ТТн в коем случае подобные машины пе следует считать
универсальными. Благодаря наличию повторяющихся структурных элементов
они открывают простор для эффективного (с точки зрения стоимости) приме¬
нения оольших пптегралытьтх схем. Развитие в последние годы, микропроцес¬
соров может в значительной степени способствовать тому, что специализиро¬
ванные системы станут эффективными во многих применениях.
Ассоциатнвпые и параллельные процессоры оказываются полезными при
решении задач, требующих очепь высокой пропускной способности и рабо¬
тающих со структурированными данными. Характерными примерами обла¬
стей, в которых могут потребоваться такпо процессоры, являются обработка
метеорологических данных, обработка в реальпом масштабе времепи радио-
вациоциьтх сигналов, противоракетная оборона, управление воздушным
механизмы внртуальпой памяти, механизмы защиты в операци¬
ях системах, а также решение систем дифференциальных уравнений. Рас-
риваемый тип машин следует применять в тех случаях, когда:
быть имототся БТ)ТС°ъне требования по быстродействию, которые пе могут
выполиепы при использовании обычных вычислительных систем;
9
2) необходимо обеспечить системе возможность приспосабливаться к из¬
меняющимся требованиям путем более прогрессивной технологии наращива¬
ния оборудования;
3) одним из непременных требований пользователя является возмож¬
ность поэтапной модернизации системы.
Если имеются две различные вычислительные машины, удовлетворяющие
предъявляемому требованию, то решающим фактором при выборе следует
считать показатель стоимостной эффективности. Однако нельзя отдать
предпочтение машине, имеющей самый лучший показатель удельной стоимо¬
сти, если эта машина пе удовлетворяет требованиям, обусловленным специ¬
фикой применения, рти требования включают все критерии, по которым
должна оцениваться система; К ним следует отнести наличие математичес¬
кого обеспечения, возможности наращивания, требования к размеру помеще¬
ния, коэффициент готовности и надежность.
^Соображения стоимости не ограничиваются только цепой машины, но
также включают расходы в течение жизненного цикла, стоимость установки,
стоимость электроэнергии и расходы по перепрограммированию. Если предъ¬
являемым требованиям удовлетворяет несколько машин, то главным крите¬
рием, определяющим окончательный выбор, является критерий стоимостной
эффективности.
Классификация архитектур машин
Описапие машин с точки зрения потоков команд (инструкций) и даппых
было предложено Флинном [1.2], который ввел понятия одиночного и мно¬
жественного потоков как для команд, так и для данных. Это привело к рас¬
пределению всех машин по четырем классам архитектур. Из рассмотрения
характера потока может быть выведен ряд свойств машин различных типов.
На рис. 1.1 показаны четыре класса машин в соответствии с типами потоков.
ОД: Одиночный по¬
ток данных
МД: Множественный
поток данных
ОК: Одиночный
поток команд
Однопроцессорная
система
Параллельный!
процессор и ассоциа¬
тивный процессор
МК: Множествен¬
ный поток
команд
Процессор поточной
обработки
(конвейерная систе¬
ма)
Многопроцессорная или
многомашинная вычис¬
лительная система
Рис. 1.1. Классификация основных типов архитектур процессоров
Эти классы следующие: одиночный поток команд и одиночный поток дапных
(ОКОД, однопроцессорная система); множественный поток команд и множе¬
ственный поток данных (МКМД, миогрпроцессорпая и мпогомашинная вы¬
числительные системы); одиночный поток команд и множественный поток
10
ых (ОКМД, ассоциативный пли параллельный процессор); множествен¬
ный поток команд и одиночный поток данных (МКОД, нроцессо'р поточной
обработки*)). Примерами перечисленных архитектур являются IBM 300,
Univac 1108, ILLIAC IV и CDC STAR 100 соответственно.
В последующих главах ОКМД-архитектура будет подвергнута детально¬
му исследованию. В этой главе будут суммированы характерные черты рас¬
сматриваемой архитектуры. В ОКМД-системах заложен принцип,, согласно
которому одип набор базовых управляющих команд ’ применяется к несколь¬
ким процессорным элементам, с каждым из которых, в свою очередь, связа¬
на последовательность данных. Все процессорные элементы должны рабо¬
тать синхронно и согласованно, каждый со своим набором данных. Эта осо¬
бенность определяет свойства задач, которые целесообразно решать на
ОКМД-процессорах, а именно: 1) множественность наборов данных; 2) оди¬
наковость вычислительных операций, выполняемых па всех наборах; 3) от¬
сутствие непредсказуемых изменений в характере потоков данных; 4) не¬
различимость процессорных элементов с точки зрения обработки любых
наборов.
Бывают случаи, когда у разработчика может возникнуть потребность
создать внутри системы некоторую структуру с целыо извлечь выгоду из
особенностей решаемой задачи. С этой точки зрения конструкция ОКМД-про-
цессора имеет ограничения, обусловленные самим принципом его работы а
временной зависимостью потоков данных. Необходимо учитывать особенно¬
сти источника потоков информации и имеющиеся в этих потоках разрывы,
смысловое содержимое потоков и его взаимосвязь с предыдущим содержимым.
Система должна быть настроена на частоту поступления информации в
потоке. Если процессор может быть адекватно согласован с частотой поступ¬
ления дапных и имеются алгоритмы, построенные такцм образом, что вычис¬
ления производятся параллельно над большинством потоков, то ОКМД-про-
цессор позволяет достичь производительности, на несколько порядков пре¬
вышающей производительность последовательных процессоров. Вдобавок
может быть использовано менее сложное оборудование и математическое обес¬
печение, чем те, которые понадобились бы при последовательном решении за¬
дачи, если, конечно, такое решение вообще возможно.
Дальнейшее обсуждение, касающееся анализа машин с позиции потоков
команд и дапных, можно найти в работах Хоббса и др. [1.3], Холлаидера
[1.4] и Белла [1.5]. В работе Холлаидера ^дается сравнительный анализ при¬
менимости различных основных типов архитектур. ОКМД-архитектура рас¬
сматривается как имеющая применение, ограниченное несколькими высоко-
быстродействующими типами систем или такими задачами, в которых стро¬
ятся функциональные модели физических систем.
ОКМД-процессоры оказываются полезными в ограниченной области спе-
ппальпых применений, которую очень легко охарактеризовать. ОКМД-архи¬
тектура представляет собой новое соотношение между объемом оборудова¬
ли, приходящегося па логику, и объемом оборудования, приходящегося на
память, с целыо получения более высокой скорости обработки. Полезность
Данной архитектуры обусловлена существованием задач, требующих очень
высокого быстродействия, и тем, что она позволяет разработчику так строить
(Jlpin ^аКПе пР°ДессоРы иногда называют конвейерными или магистральными.
11
систему, что эти высокие требования по быстродействию могут быть удовлет-
В'Ф с и ы э ф ф е кт и в и ы м с i т о с о б о м.
Из четырех категорий машин, выделенных па основе концепции пото¬
ков команд и данных, только ОКМД-архлтектура является существенно спе¬
циализированной. Другие категории, а именно, однопроцессорная система,
процессор поточной обработки и многопроцессорный или многомашинный
комплекс, находят широкое применение в универсальных вычислительных
системах. Па базе машин названных классов можно построить и специализи¬
рованные вычислительные системы, но в этих случаях сиециализнрованиость
выражается, в основном, в изменении таких характеристик, как- коэффици¬
ент готовности, надежность, возможность приспособить конфигурацию систе¬
мы к конкретной задаче, наличие специализированных вычислительных
операций.
Типовые задачи для ОКМД-машин
Область применения ОКМД-машин включает: аппарат сохраняющих бу¬
феров в механизме виртуальной памяти [1.0], распределение ресурсов [1.7],
аппаратные диспетчеры [1.8], обработку прерываний [1.9], механизм за¬
щиты [1.0], составление расписаний [1.7], сложные алгоритмы фильтрации
в радиолокационных станциях [1.1], расчет траекторий в реальном масштабе
времени [1.10], управление воздушным движением [1.11], сжатие информа¬
ции [1.12], мультиплексирование каналов связи [1.13], информационно-поис¬
ковые системы [1.14], сортировку [1.15], обработку символьной информации
[1.10]. распознавание образов [1.17], обработку изображений [1.18], обработ¬
ку данных от гидролокатора [1.19], обработку данных наблюдения за поверх¬
ностью морей и океанов [1.20], обработку графической информации [1.21],
динамическое программирование [1.22], дифференциальные уравнения [1.23],
нахождение собственных значений и собственных векторов [1.24], операции
с матрицами [1.25], анализ потоков в сетях [1.20], воспроизведение докумен¬
тов [1.27], машинную обработку документов [1.28], поиск информационных
файлов [1.29], компиляцию [1.30], автоматическое реферирование [1.31], уп¬
равление данными [1.32], доказательство теорем [1.33], машинную графику
[1.34], обработку метеорологической информации [1.35] и противоракетную
оборону [1.1].
Реальная потребность в ОКМД-машлшах основывается на стоимостных
соображениях. Например, для того чтобы ускорить процесс получения резуль¬
тате» при расчете прогноза погоды, министерство военно-морского флота ис¬
пользовало программу, работающую на четырехмашпипом комплексе, который
создан па базе универсальных машин, связанных между собой по принципу
ОК.МД-архитектуры с целью сократить время расчета прогноза. Такое реше¬
ние позволило при четырехкратном увеличении количества оборудования
увеличить быстродействие приблизительно в три раза. До сих пор ОКМД-
процесеоры были слишком дорогостоящими, и поэтому считалось, что они
имеют ограниченное применение. Чем более специализированным является
процессор, тем меньше возможность его использования в универсальных си¬
стемах. В то же время чем более специализированным является процессор,
тем лучше он может подойти для решения отдельпых задач.
В пастолщое время главной причиной, по которой пользователи не уста¬
навливают у себя ОКМД-процессоры, является объем неокупаемых затрат,
12
за чего пользователи предпочитают обходиться менее быстро действу ющн-
ми* машинами. Решение «опроса о том, являются ли потребности действи¬
тельными или надуманными, останется за рынком.
J3 последующих главах будут подробно рассмотрены (ЖМД-архитсктура
и ряд требований, которым она должна удовлетворять, с точки зрения при¬
менения. Будут обсуждены вопросы, касающиеся архитектуры, характерис¬
тик конструктивных особенностей и структуры ОКМД-процессоров в сопо¬
ставлении с ожидаемыми или запроектированными показателями. Проблема
неокупасмых затрат при разработке остается открытой.
С разработкой недорогих микропроцессоров на БИСах появляется воз¬
можность создавать ОКМД-машины, имеющие очень небольшую стоимость.
По мере развития вычислительной техники ОКМД-машины будут играть все
более значительную роль. Будущее ОКМД-машпн никогда ранее не представ¬
лялось столь благоприятным.
ОКМД-процессоры
ОКМД-архитектура — это архитектура специализированных вычисли¬
тельных машин. Существуют две основные формы ОКМД-архитектуры, а
именно, ассоциативный процессор и вычислительная система с массивом
процессоров или параллельный процессор*). Ассоциативный процессор —
это ОКМД-лроцессор, базовым процессорным элементом которого является
слово ассоциативной памяти. Параллельные процессоры имеют более слож¬
ные элементы, и эти элементы определенным образом связаны между собой.
Каждая из этих концепций будет подробно обсуждаться в последующих
главах.
Для того чтобы различать типы процессоров, будем пользоваться следуй^
щей термине логи ой:
1) ОКМ Д-процессор — вычислительная система, архитектура которой ха¬
рактеризуется одиночным потоком команд и множественным гготоком данных.
2) Вычислительная система с массивом процессоров (параллельный про¬
цессор) — ОКМД-процедсор, в котором каждый процессорный элемент опре¬
деленным образом связап с другими элементами. В общем случае элементы
могут выполнять довольно сложные функции. В ряде ранних систем (пыне
ушедших в историю) представление о таких процессорах ограничивалось
двумерным массивом процессорных элементов. Данная формулировка опре¬
деляет вычислительную систему с массивом процессоров или параллельпый
процессор как ОКМ Д-процсссор, предназначенный для обработки массивов
данных.
3) Ансам.пль — вычислительная система с массивом процессоров (па¬
раллельный процессор), в котором связи между отдельными элементами ие
обладают регулярной структурой. Это определение относится к особому виду
параллельного процессора, элементы которого не имеют определенного вида
связи друг с другом.
4) Ассоциативный процессор — ОКМД-процессор, в котором главным
средством активации элемента является ассоциативный процесс. В общем
случае элементы ассоциативного процессора имеют произвольные взаимо-
*) Такие процессоры часто называют матричными. {Примеч. пер.)
13
связи и функционально являются очень простыми. Подобный процессор обыч¬
но строится на базе ассоциативной памяти.
Как легко видеть, данные определения являются интуитивными и, сле¬
довательно, неточными. Этого следовало ожидать, поскольку имеется большое
число мелких особенностей, делающих каждую систему уникальной. Все по¬
следующие главы посвящены всестороннему анализу как ассоциативных,
так и параллельных процессоров. Ансамбли будут рассмотрены в гл. 3, в ко¬
торой описываются параллельные процессоры.
| Ввод/вывод
Вычислительные системы с массивом процессоров
(параллельные процессоры)
Структурная схема типичной вычислительной системы с массивом про¬
цессоров (параллельный процессор — Г1П) приведена на рис. 1.2. Основыва¬
ясь на предыдущих определениях, следует отметить следующие характерные
черты параллельных процессоров.
Управление множеством процессорных элементов осуществляется одним
управляющим устройством. Имеются два типа накопителей: одни — для хра¬
нения программ,, другой — для хранения дапных. В устройстве управления
отсутствует локальная память как для программ (за исключением микро¬
программ), так и для данных. Все процессорные элементы идентичны и име¬
ют идентичные устройства для хранения данных. Между процессорными эле¬
ментами существует связь некоторого определенного типа. Наконец, данные
могут поступать в систему как
путем непосредственного ввода в
процессорные элементы, так б
через устройство управления.
Все активные процессорные-
элементы должны работать стро¬
го согласованно друг с другом*
Они работают параллельно, т. е.
синхронно. Процессорный эле¬
мент называется активным
тогда и только тогда, когда
обрабатывается выделенная ему
порция данных из потока. Если
процессорный элемспт не обра¬
батывает поток дапных, он счи¬
тается неактгСвным. Всякий раз.
когда процессорный элемецт- по¬
лучает очередную управляющую
команду, он может либо выпол¬
нить ее, либо проигнорировать
(в зависимости от предыдущих
состояний и/или числовых значе¬
ний обрабатываемых величии),
при этом - он не может сделать ничего другого. Если нужно, процессор может
работать как единое целое. Обычно параллельный процессор взаимодействует с
универсальной- машипой через устройство управления. Универсальный процес-
Рпс. 1.2. Блок-схема параллельного про¬
цессора
14
лор называемый обычно ведущим, осуществляет управление всем мас¬
сивом процессорных элементов. Устройство управления непосредственно ру¬
ководит исполнением программ. Если структура внутренних перекрестных
связей очень проста или вообще отсутствует, то параллельный процессор с та¬
ким произвольным способом взаимодействия между элементами называется
ансамблем.
Ассоциативные процессоры
Ассоциативный процессор определяется как устройство обработки дан¬
ных, в котором данпые хранятся, считываются и обрабатываются без точной
адресации их расположения в памяти. Структурная схема типичного ассоциа¬
тивного процессора показана па рис. 1.3. Этот ОКМДгпроцессор иостроен на
| Ввод / вывод
! Регистр Регистр Обрабатывающее
i резудьта- выборки устройство
I уоз по- слов (логика и/или
| иска арифметика.)
Рис. 1.3. Блок-схема ассоциативного процессора
оазе ассоциативного запоминающего устройства, состоящего из ассоциа¬
тивных ячеек памяти. Данные могут быть сопоставлены по некоторому кри¬
терию (равно, меньше чем и т. д.) с информацией, хранящейся в памяти,
для чего выполняются следующие действия: 1) запись данных в регистр
Данных; 2) выделение' разрядов, подлежащих сравнению, с использованием
регистра маски и 3) запись битового набора, описывающего искомое подмно¬
жество данных в файле, в регистр выборки слов. Результатом сравнения бу^
Дет битовый набор в регистре результатов поиска, снабженного указателем
15
па «первое откликнувшееся слово». Этот указатель называется устройством
разрешения множественных откликов, он указывает на «самое верхнее сло¬
во», удовлетворяющее критерию поиска, т. е. на «самый верхний бит» реги¬
стра результатов поиска.
Ячейка ассоциативной памяти является основным элементом, из которых
строится система. При желании ассоциативный процессор может быть создан
и без использования специальных устройств, но за выполнение функ¬
ций ассоциативной памяти придется поплатиться потерей быстродействия.
Процессорное оборудование, обеспечивающее соответствующую аппаратную
поддержку, включает, по крайней мере, одно полное последовательное ариф¬
метическое устройство на каждое слово ассоциативной памяти.
Два главных отличия ассоциативных процессоров от параллельных за¬
ключается в типе запоминающего устройства и в отсутствии взаимных свя¬
зей ме'/кду процессорными элементами. Если рассматривать ассоциативное
запоминающее устройство как память для хранения данных, то ассоциатив¬
ный процессор может быть назван параллельным процессором или ансамб¬
лем. Однако, поскольку свойство ассоциативности является очень лажным,
ассоциативные процессоры будут рассматриваться как самостоятельный
класс машин с ОКМД-архитектурой.
Заключение
Имеется много оснований для разработки, создания и применения спе¬
циализированных вычислительных систем. Главная причина состоит в том,
что такие системы способны обеспечить высокую производительность, могут
функционировать в жестких внешних условиях или иметь высокие показате¬
ли надежности, недостижимые для вычислительных систем общего назначе¬
ния. Комбинация универсальной и специализированной вычислительных ма¬
шин представляет собой наиболее эффективное гГо стоимости решение в тех
областях, где требуются высокие вычислительные возможности и где нет же¬
стких внешних условий.
В последующих главах подробно обсуждаются несколько типов вычисли¬
тельных систем, относящихся к категории ОКМД. Процессоры данного типа
могут быть отнесены либо к классу ассоциативных, либо к классу параллель¬
ных систем. Будут исследованы основпые типы архитектур в каждом из этих
классов и обсуждены их особенности. Параллельные системы показывают на¬
илучшие характеристики при решении таких задач, как расчет прогноза по¬
годы или противоракетная оборона. Ассоциативные процессоры оказываются
наиболее полезпыми в таких применениях, как управление виртуальной па¬
мятью или механизм защиты памяти. Главные из создаппых к настоящему
времени ОКМД-процсссоров подробно обсуждаются в последующих главах.
Цель книги состоит в том, чтобы помочь читателю увидеть, как различ¬
ные фирмы, производящие вычислительную технику, воплощают в своих кон¬
струкциях идею ОКМД-архитсктуры. В книге не будет никаких попыток су¬
дить о правомерности топ или иной конструкции. Первыми будут рассмат¬
риваться ассоциативные процессоры как более простые.
Об ОКМД-машипах написано несколько хороших обзоров. Наиболее суще¬
ственные из них цитируются [ 1.36—1.44].
16
У it р а ж нения
1. расскажите о наиболее существенных различиях между архитектурами
О КОД, МКОД, ОКМД и мкмд.
2. Приведите пример вычислительной системы для каждой из архитектур
/0КОД, МКОД, ОКМД и МКМД).
3. Покажите, почему конвейерный процессор не является адекватной реа¬
лизацией МКОД-архитсктурьт. Расскажите о тех особенностях МКОД-архптек-
турьт, которые -затрудняют ее реализацию. Расскажите о скрытых трудностях,,
возникающих при попытке дать классификацию архитектур на простой одно¬
родной основе.
' 4. Покажите основные различия между ассоциативными и параллельными
процессорами. %
5. Покажите основные различия между ансамолями и ассоциативными
процессорами.
6. Расположите ОКОД. МКОД, ОКМД и МКМД-архитектуры в ряд по та¬
ким показателям, как гибкость, функциональная расширяемость, отказоустой¬
чивость и модульность.
Глава 2
АССОЦИАТИВНАЯ ОБРАБОТКА
Введение
Глава посвящена обсуждению базовой архитектуры/ реализующей ассо¬
циативную обработку информации. Будут рассмотрены исторические предпо¬
сылки ассоциативности и возможные применения ассоциативных процессоров.
Будет дано описание и анализ работы ассоциативного процессора наиболее
■общего типа, а также приведены примеры* использования ассоциативного про¬
цессора общего типа.
Концепция ассоциативности или ассоциаций не пова. Она уходит в глубь
вёковг во времена Аристотеля. Ассоциация может рассматриваться как уста¬
новление соответствия мождУ объектами. В труде «О памяти и воспомина¬
ниях» Аристотель определил три вида ассоциаций. Это ассоциации по сходст¬
ву, контрасту ,и близости. Лок и Хыо дополнили этот перечень ассоциацией
идей, а также ассоциациями, соответственно, по причине и следствию. Позже
возникло философское учение об ассоциациях. Это учение утверждало, что
знание извлекается из отдельного простого практического опыта.. Поэтому
оно может быть представлено в терминах таких основных опытов. Более позд¬
ние исследования механизма, ассоциаций проводились на основе биологиче¬
ских наук, изучения нервной системы и деятельности мозга. Обширный обзор
истории учения об ассоциациях и связанных с ними философских концепций
■содержится в работе Замепека [2.1].
Принципы построения ассоциативных процессоров обсуждались почти
двадцать лет [2.2, 2.3]. Однако реальные применения ассоциативных систем
рассматривались лишь последние пять лет*). В течение этого периода прин¬
цип ассоциативной обработки был воплощен в различных формах, известных
под различными названиями. К числу таких форм относятся: каталоговые за¬
поминающие устройства [2.3], ассоциативные запоминающие устройства [2.4],
накопители с параллельным поиском [2.5], запоминающие устройства с ад¬
ресацией по данным [2.6], запоминающие устройства с адресацией по содер¬
жимому [2.7], ассоциативные процессоры [2.8], ассоциативные вычислитель¬
ные системы [2.9], машины с распределенной логикой [2.10], накопители с рас¬
пределенной логикой [2.11], ассоциативные параллельные процессоры [2.12],
тегированные запоминающие устройства [2.13], магазинные ассоциативные
запоминающие устройства [2.14], процессоры с ассоциативной памятью [2.15].
Поскольку эти устройства работают по одному и тому .же основному принци¬
пу (ассоциативности), то все они в книге будут именоваться ассоциативными
процессорами.
*) Речь идет о периоде до 1975 г. (Примеч. пер.)
18
Применения
Для ассоциативных процессоров предлагались многочисленные области?
применения. До середипы 70-х годов с практической точки зрения были рас¬
смотрены лишь немногие из них. Дело в том, что технические проблемы, стоя¬
щие на пути реального воплощения ассоциативных процессоров, очень слож¬
ны. Было предложено большое число различных применении, по практиче¬
ски ни одно из них не было детально исследовано. Работы велись с целью-
доказать применимость ассоциативного процессора вообще, а не с целыо полу¬
чить экономически эффективную конструкцию такого процессора. Сейчас
наблюдается отход от этой позиции. В настоящее время в очень немногих слу¬
чаях доказана эффективность применения ассоциативного процессора. Зато
там, где их эффективность доказана, ассоциативные процессоры показывают
очень высокие характеристики и действительно оказываются очень полезны¬
ми. Примечательным примером эффективного решения задачи является ме¬
ханизм виртуальной памяти [2.16].
ВеДутся детальные исследования ряда перспективных применений. Этш
перспективные применения включают проблемы, имеющие высокую степень*
общности. Имеется в виду устранение узких мест в машинах общего назначе¬
ния, аппаратная поддержка критических участков вычислительного процесса
в системах реального времени, а также улучшение характеристик существую¬
щих систем путем увеличения их пропускной- способности без переработки^
всей конструкции. В большинстве таких применений используются небольшие
ассоциативные устройства, ограниченные несколькими сотнями слов памяти*,
в отличие от ассоциативпых процессоров, предлагавшихся на раннем этапе-
развития этих устройств, когда считалось, что они могут иметь тысячи или
миллионы слов.
Типичными применениями в машинах общего назначения, где ассоциатив¬
ные устройства используются для ликвидации узких мест, являются меха¬
низмы защиты, механизмы виртуальной памяти, а также ассоциативные про-'
цессоры, работающие с дисковой памятью для хранения файлов. Ассоциатив*
ные процессоры используются как управляющие устройства при выполнении,
таких "функций, как обработка прерываний, управление памятью, распреде¬
ление ресурсов, а также в аппаратных диспетчерах.
Ассоциативные процессоры используются для улучшения характеристик-
машин общего назначения в таких применениях, как сжатие данных, ком¬
мутация и мультиплексирование данных,. управление воздушным движением
и обработка радиолокационной информации. Другими сферами применения,,
в которых ассоциативные процессоры представлялись эффективными, по сте¬
пень их истинной полезности не выяснена до конца, являются поиск и печать-
Документов, компиляция программ, матричные вычисления, работа с больши¬
ми файлами данных и решение дифференциальных уравнепий.
Очевидно, области применения для ассоциативных процессоров #существу¬
ют- Практика же показывает, что использование ассоциативпых процессоров
пока ограничено из-за технических трудностей их разработки. В настоящее
премя технические возможности построения ассоциативных процессоров до¬
статочно развиты для того, чтобы можно было вплотную рассматривать во¬
просы их практического осуществления. Будущее ассоциативных процессоров
представляется блестящим.
Наиболее общий тип архитектуры ассоциативного процессора
Ведущая концепция архитектуры ассоциативного процессора уже сформи¬
ровалась. Она может использоваться в разнообразных применениях от меха¬
низма виртуальной памяти до решения ряда задач управления воздушным
движением, таких как обнаружение конфликтных ситуаций, выявление кор¬
реляций между трассами, уточнение параметров трасс и подготовка данных
для отображения. В последующих параграфах описываются эта наиболее об¬
щая архитектура и способы ее воплощения, поясняемые примерами конкрет¬
ных конструкций.
Принцип работы. Па рис. 2.1 изображена блок-схема, отражающая наибо¬
лее общую архитектуру ассоциативного процессора [2.17]. Эта архитектура
содержит четыре регистра (данных, маски, результатов поиска и выборки
ОЮ
111
110
000
ООО
000
[oooj
000
Per и от р
Регистр
данных
маски
Слыо
1 110
111
101
0
и
□
□
С/030
2 011
111
101
0
[~о~|рпорГ|
□
Слово
3 010
110
101
0
□
□
□
С л озо
4 101
110
101
1101 |
И
□
□
С по во
5 110
000
001
0
Ш
□
□
С о о а о
6 010
110
000
[oioj
□
□
□
Олово
7 010
110
010
0
И
и
□
Слово
8 111
111
011
0
□
□
□
Доле
’
-
4 Рсгислр
[10';V (1 b -
Чатов
no'/с ка
Регистр
выборки
слов
Аппарат¬
ные сред¬
ства об -
работки
Рис. 2.1. Принцип работы ассоциативного процессора
слов), устройство разрешения множественных откликов (РМО), массива ассо¬
циативной памяти и аппаратных средств обработки слов. Процессор, изобра¬
женный на рис. 2.1, имеет 8 слов памяти. Важно отметить отсутствие каких-
либо устройств преобразования адресов. По существу, адресов вообще нет. Ад¬
ресация данных в процессоре осуществляется по их содержимому или по ка¬
ким-либо параметрам, связанным с содержимым.
Каждое слово памяти разбито на разрядные группы переменной длины,
называемые полями. Поля не обязательно должпы состоять из последователь¬
но расположенных разрядов. Регистры данных и маски содержат такое же ко-
20
личество разрядов, что п слово памяти. Регистры результатов поиска и вы-
tfopnu слов содержат но одному разряду па каждое слово памяти.
Битовый срез (например, г-й битовый срез) представляет собой битовый
гектор’ составленный из i-x разрядов всех выбранных слов и не зависящий
от содержимого остальных слов.
Пример]»! операций, осуществляемых ассоциативными процессором: маски¬
рованный поиск иа равенство, различные виды последовательно-поразрядных
операций поиска па неравенство, последовательно-поразрядные арифметиче¬
ские операции над полями, последовательно-поразрядный поиск максимума
(минимума), позволяющий находить максимальное (минимальное) записан¬
ное в памяти слово.
В ассоциативных процессорах, ориентированных на пекоторые примене¬
ния, отдельные элемент],г базовой архитектуры могут выступать пеявно. В ме¬
ханизме виртуальной памяти может оказаться ненужным регистр выборки
слов. Каждое слово памяти может понадобиться в любой момент времени. Ре¬
гистр маски может использоваться но умолчанию. Поля поиска могут быть
■известны и предусмотрены заранее. В некоторых системах обработки данных,
таких как управление воздушным движением, может быть введено' большее
количество регистров. В вычислительной системе STARAN (см. гл. 6) имеется
три регистра, указывающих направление поиска слов (X, У и W), чьи функ¬
ции аналогичны функциям регистров выборки слов и результатов поиска, по¬
казанных на рис. 2.1 [2.18].
Организация работы системы осуществляется устройством управления,
выполняющим разнообразные функции. В некоторых применениях устройство
управления может быть очень простым. В системе STARAN устройство уп¬
равления включает вычислительную машину PDP-11 и дополнительный мик¬
росеквенсор *).
Ассоциативный процессор, работающий с восемью словами и четырьмя
■3-битовыми нолями, изображенный на рис. 2.1, дан в качестве небольшого при¬
мера, иллюстрирующего работу ассоциативных систем. В регистре данных за¬
писано слово, которое нужно сравнить с содержимым памяти. Регистр маски
указывает те разряды искомых слов, которые должны быть включены в опе¬
рацию поиска. В регистре результата записан результат поиска. Регистр вы¬
борки слов выбирает слова, участвующие в поиске.
В данном примере слово 7, как показывает содержимое регистра выборки
слов, не вошло в число выбранных. Содержимое регистра маски показывает,
что в поиске участвует содержимое только первого поля регистра данных.
В процессе выполнения операций ассоциативного процессора, а именно, по¬
иска па равенство, будет произведено сравнение содержимого первого поля
регистра поиска с содержимым соответствующих полей всех выбранных слов.
И* таких слов только слова 3 и 6 удовлетворяют условию поиска; эти слова
после завершения поиска отмечены единицей в регистре результата. Слово 7
также должно было бы удовлетворить условию поиска. Однако содержимое ре¬
гистра выборки слов показывает, что оно не вошло в набор слов, выбранных
Для участия в операции сравнения.
Устройство, определяющее порядок выполнения операций иа уровне
рззрядов. {Примеч. пер.)
21
Во многих системах за операцией поиска должпа следовать операция счи¬
тывания (идентифицируемые слова последовательно считываются) или дру¬
гая операция поиска (регистр результатов может быть переписан в регистр
выборки, чтобы сто можно было использовать в качестве нового содержимого-
регистра выборки).
Может быть произведена серия операций поиска, результаты которых ло¬
гически объединятся, т. е. данные, находящиеся в регистре результатов поис¬
ка, логически перемножаются с содержимым регистра выборки слов, форми¬
руя тем самыхг новое содержимое последнего.
Число встроенных логических функций может быть весьма велико. Эти
логические функции нужны для повышения эффективности вычислений. К не¬
отъемлемым атрибутам системы относится устройство разрешения множест¬
венных откликов*) (РМО). На рис. 2.1 устройство РМО показапо стрелкой. Ес¬
ли в результате поиска получены отклики от пескольких слов, то РМО указы¬
вает па «первый отклик» или, ипаче, па «самое верхнее» слово, для которога
выполнилось условие поиска.
Архитектура ассоциативного процессора и проблемы реализации. Раньше
считалось, что ассоциативные процессоры должны заменить вычислительные
машины общего назначения. В конце концов они стали рассматриваться как
специализированные системы. В качестве технологической базы вместо крио¬
тронов стали использоваться запоминающие устройства на магнитной прово¬
локе или на полупроводниковых элементах. В настоящее время основной упор
в технологии сделан на специализированные полупроводниковые процессоры.
Ниже описывается ряд конструкторских проблем, которые обычно приходится,
решать при разработке рассматриваемых устройств. .
Первая проблема, которую необходимо решить при разработке, состоит
в том, хранить ли программу в некоторой области ассоциативной памяти ас¬
социативного процессора или в отдельной памяти с произвольным доступом,
связанной с устройством управления. Учитывая факторы стоимости, програм¬
мы обычно хранятся в отдельной памяти с произвольным доступом (ОЗУ),
В тех случаях, когда программа всегда- остается неизменной, может исполь¬
зоваться память с доступом только по чтению (ПЗУ). Хранение программ в
ОЗУ обеспечивает защиту содержимого-ассоциативной памяти от программных
сшибок, снижает требования к пропускной способности шип, по которым пе¬
ремещаются данные, хранящиеся в ассоциативной памяти, экономит ячейки
ассоциативной памяти (которые стоят дороже ячеек ОЗУ), а также дает воз¬
можность иметь разные временные циклы для ОЗУ и ассоциативной памяти.
Это обеспечивает гибкость при подборе быстродействия системы применитель¬
но к решаемой задаче.
Другой проблемой, возникающей при разработке, является выбор типа
связи между ячейками. Эвиитом и Дэвисом [2.19] были описаны четыре ва¬
рианта связи: 1) передача общего операнда во все выбранные ячейки памяти;
2) управление выбором полей для обеспечения работы с парой операндов,
находящихся в одном слове, 3) использование сдвиговых регистров для орга¬
низации связи между соседними словами, и 4) построение многозвенных се¬
тей с попарными связями по входу/выходу для организации взаимодействия
*) В качества сипоппма слова «отклик» употребляется слово «совпадение».
{Примеч. пер.)
22
Л16/КДУ несмежными словами. При реализации упор обычно делаются на типы
связи 1, 2 и 3 и ограниченное применение связи типа 4, которая осуществля¬
йся путем многократных сдвигов в сдвиговом регистре. Обычно в сдвиго¬
вом регистре сдвиг производится только по направлению вверх. Счетчик, под¬
считывающий число откликов, может быть реализован на базе автономного
сдвигового регистра, эквивалентного регистру результатов поиска,, в обход
счетчика в устройстве управления/
Необходимо также рассмотреть схему извлечения данных. В одном из
■возможных вариантов используется схема разрешения множественных совпа¬
дений, реализованная в виде отдельного устройства или на базе внешнего уп¬
равляющего устройства и набора регистров памяти. Другим методом извле¬
чения является алгоритм Левина [2.20] (подробно описанный ниже в этой же
главе). Ввиду того, что для реализации алгоритма Левина требуется аппарату¬
ра с уникальными свойствами, в устройстве обработки слов обычно реализу¬
ется модифицированный вариант этого алгоритма (двойной опрос каждого
-столбца разрядов, один раз на единицу и один раз на пуль, чтобы определить
•столбец, который бы отвечал состоянию X в системе Левина).
Конструкторские решения в части внешних *) элементов касаются опре¬
деления количества и размера регистров и объема аппаратных средств, необ¬
ходимых для ассоциативного процессора с пословной обработкой. Аппаратные
средства, закрепляемые за каждым словом, могут включать от одного до не¬
скольких регистров и последовательный сумматор. В некоторых системах ис¬
пользуется байтовая арифметика [2.21]. Многие ассоциативные процессоры со¬
держат только два регистра и РМО [2.22]. В системе STARAN имеется три
регистра, для которых может быть задана последовательность микроопераций,,
делающая их аналогичными последовательному арифметическому устройству,
а в системе SIMDA [2.21] обеспечивается обработка 4-битовых полей. Могут
использоваться группы, состоящие из нескольких регистров, обеспечивающие
аппаратную поддержку текущих операций по загрузке и выгрузке регистров.
В архитектуре системы SIMDA реализованы параллельные операции над
•словами. Конструкторские решения, касающиеся обеспечения поразрядной об¬
работки, связаны, с выбором между принципами обработки битовых срезов,
байтовых срезов или параллельной обработки слов. Количество логических уст¬
ройств, которыми окружается массив ассоциативной памяти, играет важную
роль в определении пропускной способности системы.
Из числа упомянутых архитектур для арифметических операций обычно
используется схема с поразрядно-последовательной обработкой, показанная
па рис. 2.2. Этот подход мож-ет быть реализован путем использования -запоми¬
нающего устройства с произвольным доступом и неразрушающим чтением,
п котором направление расположения информации повернуто на-90° по срав¬
нению с обычными устройствами памяти. Слово обычной памяти образует
битовый срез ассоциативного процессора. Размеры запоминающего устройства
Должны быть выбраны такими, чтобы ассоциативный процессор имел значи¬
тельно больше слов, чем битовых срезов. Стоимость реализации такого под-
хода, без учета стоимости внешнего оборудования, столь же невелика, как и
стоимость памяти с произвольным доступом.
*) По отношению к ассоциативной памяти. (Примеч. пер.)
23
Все операции выполняются с битовыми срезами с помощью внешнего уст¬
ройства обработки слов. Вели каждую ячейку памяти можно было бы снаб¬
дить аппаратными средствами для выработки сигналов наличия/отсутствия от¬
клика, то это увеличило бы быстродействие системы с ассоциативной обра¬
боткой. Обычно сначала происходит считывание битового среза и затем во
внешних по отношению к памяти цепях генерируются сигналы наличия/отсут¬
ствия отклика. Таким образом, слова ОЗУ становятся битовыми срезами ассо¬
циативного процессора.
Если но каким-либо причинам невозможно использовать память с пераз-
рушаюгцим считыванием, то во избежание потерь информации вводится цикл?
Регистр операнда —
Регистр маски
Адрес
Ввод
словных
срезов
IL
Входной регистр
I
слово 1
Внешнее
обрабаты¬
вающее уст-
ройст во, па ¬
мять резуль¬
татов. вывод
битовых
срезав
5 б од
битового
среза _
С л с в о N
♦
Вывод срезов
~СЛОЙ
Рис. 2.2. Ассоциативный процессор с обработкой битовых срезов
«чтение/восстановление». В этом случае ввод или вывод слов обычно произво¬
дится в поразрядно-последовательной форме. Внешние логические элементы и
устройство запоминания откликов могут состоять из одного сигнального раз¬
ряда на каждое слово и схемы поэтапного выбора слов или нескольких ре¬
гистров, последовательного сумматора и схемы поэтапного выбора слов. В со¬
став внешнего оборудования могут быть включены каналы и средства ввода/
/вывода. Одним из возможных вариантов организации ввода/вывода является
параллельный канал, с помощью которого выводятся или вводятся бито¬
вые срезы.
Основной поиск па равенство осуществляется поразрядпо-иоследователь-
по. Поиск на равенство с полем, содержащим п разрядов, выполняется за п
циклов обработки битовых срезов. Читатель должен был уже догадаться, что
описанный процессор с фуикдпопалыюй точки зрения является стандартным
24
.1СС(>цпатппым процессором. о кото])ом шла речь в начало главы. Принцип об-
-работв1 и битовых срезов был использован фирмой Goodyear при создании си¬
стемы STARAN [2.20].
Процессор с побайтово-последовательной обработкой очень похож па про¬
цессор с обработкой битовых срезов за исключенном того, что информация из¬
влекается в виде байтов. Произвольный доступ осуществляется с точностью
-(О байта. 13 случаях, когда не используются большие поля или требуется до¬
ступ к битовым разрезам, скорость обработки уменьшается. С другой стороны,
поиск па равенство будет производиться быстрее, чем в машинах, работающих
с битовыми срезами, во столько раз, сколько разрядов содержится в байте,
при условии, конечно, что байт используется целиком. В системах такого ти¬
па логические элементы обычно не встраиваются в память процессора и, сле¬
довательно, их функции могут быть реализованы отдельными устройствами.
Входное слово т
Слово 1
Слово п
Рис. 2.3. Ассоциативный процессор с распределенной логикой
Вычислительная система SIMDA фирмы Texas Instruments [2.21] представля¬
ет собой пример подобного процессора. В машинах с обработкой как бито¬
вых. так и байтош,их срезов, когда имеется необходимость считывания инфор¬
мации. возникают очевидные проблемы ввода/вывода.
Большую активность в области технологии создания ассоциативных про¬
цессоров проявила фирма Honeywell. Ею выбран вариант, основанный на ирип-
Цппе распределенной логики, показанной на рис. 2.3. Втот подход характери¬
зуется тем, что логические элементы распределены по памяти и встроены в
каждую запоминающую ячейку. Вместо того чтобы считывать содержимое
ячейки памяти во внешнее обрабатывающее устройство, операнд предоставля¬
ется ей самой.
Ячейка памяти в запоминающем устройстве такого типа состоит из за¬
поминающего триггера и, по крайней мере, элемента типа ИСКЛЮЧАЮЩЕЕ
IU»- Сигнал наличия или отсутствия отклика, поступающий от каждой ячей¬
25
Регистр операнда
Регистр маски
Ячейка 1
Ячейка 2
Ячейка m
—
Массив г
? * m ячеек
!
1
—*
Выход
Выходной
регистр
ки, комбинируется с другими сигналами с привязкой к словам, что обеспе¬
чивает выработку сигнала о наличии или отсутствии отклика в слове. За
один временной никл памяти может быть осуществлен параллельный поиск на
равенство по всем ячейкам памяти. Для облегчения решения проблемы вво¬
да/вывода, которая является главной в системах с обработкой битовых срезов,
может быть реализована возможность записи как битовых, "так и словпых
срезов. Время, затрачиваемое на выработку сигнала о наличии или отсутствии
отклика при обработке словпых срезов, может быть больше, чем время счи¬
тывания одиночного битового среза. Однако это время будет меньше, чем то,
которое необходимо для осуществления всех поисков на равенство с помощью
битовых срезов. Длительность цикла в памяти с распределенной логикой может
быть больше, чем длительность цикла в памяти с битовыми срезами.
Считывание битового среза может быть осуществлено с помощью одной
одноразрядной операции поиска на равенство. Операции поиска на неравенст¬
во должны производиться поразрядно-последовательно, как в машине с би¬
товыми срезами. Эти операции могут быть ускорены путем одновременного
манипулирования с целыми наборами разрядов, образующими в слове поиска
непрерывные поля из нулей или единиц. Ускорение обработки происходит
всегда за исключением случая, когда искомое слово состоит из чередующихся:
пулей и единиц.
Могут быть сконструированы специализированные процессоры с распре¬
деленной логикой, в которых некоторые операции поиска на неравенство или
на максимум производятся одновременно для всей памяти. Процессоры тако¬
го типа являются сугубо специализированными. Для осуществления опера¬
ции сложения в системе, построенной по принципу распределенной логики и:
снабженной тогулчО устройством хранения откликов, внешнему устройству уп¬
равления необходимо выполнить четыре операции поиска и шесть операций:
записи на каждый бит. Для осуществления сложения в системе, работающей
с битовыми срезами, при использовании последовательного сумматора и одного-
запоминающего регистра требуется две операции чтения и одна операция
записи па каждый бит.
Потребовалось немало времспи для разработки конструкции аппаратных
средств, применяемых в ассоциативных процессорах. В следующем параграфе
более подробно дается сравнительная оценка процессоров с обработкой бито¬
вых срезов и с распределенной логикой. Машипы с обработкой битовых срезов-
имеют более высокие показатели при выполнении арифметических операций
и применяются сравнительно недавно.
Основное различие между машинами, работающими с битовыми срезами,
и машппами с распределенной логикой обусловлено различием решаемых ими
задач. Стороиппкн машин, работающих с битовыми срезами, сделали оснезной
упор па задачи с вычислительным уклопом, для которых применяются боль¬
шие ассоциативные процессоры. Приверженцы процессоров с распределенной
логикой сконцентрировали внимание на применении этих устройств для уп¬
равления многопроцессорными вычислительными системами. Машины с обра-
работкой байтовых срезов предназначены для решения задач вычислительного-
характера. Во всех подходах наблюдается тенденция К небольшим процессо¬
рам, содержащим -порядка одпой-двух сотен слов. Сторонники систем с рас¬
пределенной логикой отстаивают, похоже, более полезную концепцию, по-
крайней мере она выглядит более предпочтительной для тех применений, ко-
26
ч>рм° MOJiK.no назвать пли боглом анализе. Примеров же применении, в кото-
•iix процессоры с обработкой битовых пли байтовых срезов могут быть эф¬
фективно использованы, пока недостаточно.
Схема типичного устройства управления показана па рис. 2.4. Оно состоит
из логических схем, предназначенных для активации цепей разрядов и слов
ассоциативного процессора; счетчиков и ограничивающих регистров, служа¬
щих чдля начальной, конечной и текущей локализации поля, находящегося в
Рис. 2.4. Устройство управления ассоцпативпым процессором
обработке; регистров ввода/вывода; регистра преобразования параллельного
кода в последовательный; памяти с произвольным доступом, в которой могут
храниться данные, и регистра команд, служащего для хранения команды, вы¬
полняемой устройством управления. С помощью счетчиков Л и В и связанных
с ними ограничивающих регистров могут быть заданы два совершенно неза¬
висимых поля. Счетчик С служит для обработки разрядов тега*). При ариф¬
метических операциях разряды тега могут использоваться как значащие.
В следующем параграфе приведен практический пример, который .должеп
-Поя;нить многое из изложенных положений. Этот пример также явится даль¬
ни Тегом называется группа служсбпых разрядов, предназначенных для
ДСхгп1фикац1Ш типа данного. {Прицеп, пер.)
*
27
пошлей детализацией принципов построения управляющего устройства, не¬
обходимого для управления типичным ассоциативным процессором.
Достижение баланса между обрабатывающим устройством и памятью.
В рассматриваемом примере будет показано применение ассоциативной об¬
работки в системе управления воздушным движением [2.23]. Задачи, реша¬
емые системой, включают определение корреляции между трассами, уточне¬
ние и прогнозирование трасс, обнаружение конфликтов п отображение данных
на экранах дисплеев.
Процесс расчета взаимного расположения трасс занимает большую часть
времени универсальной вычислительной машины типа ARTS III [2.21]. На
ассоциативном процессоре эта задача может быть решена значительно быст¬
рее и проще. Рассмотрим использование ассоциативной памяти для хранения
трасс. Поместим каждую трассу в слово памяти. Параллельно для всех коор¬
динатных позиций каждой отдельной трассы введем дескриптор отклонений в
сторону увеличения или уменьшения. Эта операция создала вокруг каждой
трассы блоки или кубы. Выполним серию операций поиска на неравенство но
отношению к заданной принадлежащей к трассе, находящейся на входе ко¬
ординате. Это дает возможность определить блок или куб, с которыми пере¬
сечется данная трасса. Затем программа записывает входное слово в ну ясный
формуляр в файле трасс. Позже все трассы могут быть одновременно
уточнены.
Не создает больших трудностей ситуация, когда новая трасса отождеств¬
лялась более чем с одной трассой из числа хранящихся в файле. Питатель,
интересующийся решением этой задачи, может обратиться к исследованию
системы управления воздушным движением, выполненному фирмой 1'iiiva'c
[2.2-4].
При записи трассы в процессор модифицируется ее системный номер, ис¬
пользуемый в процедуре уточнения параметров. Таким образом обрабатыва¬
ется каждая трасса, полученная от локатора. В ассоциативном процессоре
эта обработка реализуется очень просто. Степейь трудности задачи опреде¬
ления корреляции между трассами с помощью ассоциативного процессора оп¬
ределяется количеством операций ввода/вывода, требуемых для реализации,
корреляционной процедуры, и количеством битовых срезов, участвующих в
операции поиска на неравенство.
Задача уточнения и прогнозирования включает решение системы урав¬
нений движения. Эти вычисления могут .выполняться параллельно, благодаря
способности системы' работать с множественным потоком данных. Чтобы на
вычислительных операциях система была эффективной, ассоциативный про¬
цессор должен иметь достаточно малую длительность цикла. Федеральное
авиациопное агентство (ФАЛ) использует систему уравнений движения в уг¬
ловых координатах, которые легко решаются на ассоциативном процессоре.
Решение уравнений в угловых координатах требует большого количества опе¬
раций ввода/вывода, необходимых для табличного просмотра угловых коэффи¬
циентов и значений sin и соя, участвующих в уравнениях. Для того чтобы
решение уравнений в угловых коордипатах осуществлялось достаточно быст¬
ро,- требуются хорошие средства обработки битовых срезов.
В настоящее время в рассматриваемой системе управления воздушным
движением не реализован алгоритм обнаружения конфликтных ситуаций. В ис¬
следовании системы [2.23] был предложен двухэтаиный алгоритм обнаружо-
28
рия конфликтов. На первом этапе путем обследования трех- или двумерной
области воздушного пространства, окружающей каждую трассу, па предмет
обнаружения других самолетов, находящихся поблизости, производилось пред¬
варительное выявление трасс, которые могут вступить в конфликт между со¬
бой. Если в окрестности трассы, находился другой самолет, то производился
детальный расчет с использованием аэродинамических параметров на предмет
возможности возникновения конфликтной ситуации. Расчет выполнялся ме¬
тодом построения полуокружностей с центром в точке нахождения самолета
и ориентированных в направлении его полета.
Ассоциативный процессор с успехом справляется с обеими операциями.
Однако для достижения требуемого показателя пропускной способности про¬
цессор должен обладать хорошими средствами для выполнения поиска па не¬
равенство и арифметических операций. Если вначале производить грубую
отбраковку, то реальный объем вычислений, который необходимо выполнить*
можно значительно сократить.
Отображение информации почти целиком состоит из операций ввода/вы¬
вода. Функция системы отображения заключается в периодическом считыва¬
нии правильных трасс, с которыми была произведена операция уточнения*
и помещении их в обновляемый буферный массив. Таким образом, пультам
управления предоставляется доступ к самой последней информации. Одновре¬
менно, на случай машинного сбоя, фиксируются контрольные точки возврата.
Операторьт-уиравлснцы имеют возможность наблюдать за разными зонами
воздушного пространства, центры которых определяются (с помощью соответ¬
ствующих программ) районом, находящимся в секторе контроля, за которым
ведется наблюдение. При отображении информации необходимо выполнять,
большое количество преобразований координат. Реализация отображения тре¬
бует хорошей системы ввода/вывода и эффективных средств выполнения
арифметических операций над битовыми срезами.
При исследовании системы управления воздушным движением ставилась
задача определить, могут ли применяться в этой системе ассоциативные про¬
цессоры, и после этого разработать и настроить ассоциативный процессор*
предназначенный для использования в системе управления воздушным дви¬
жением; процессор должен иметь достаточные возможности для выполнения
арифметических операций над битовыми срезами и достаточную пропускную
способность ввода/вы вода.
В принципе было показано, что ассоциативный процессор применим для
решения данной задачи. Испытания, проведенные в Кпоксвнлле, шт. Теннесси,
подтвердили полезность ассоциативного процессора [2.24]. Основываясь на
Данных эксперимента в Кпоксвилло, ФАА заказало три опытных разработки,
Цель которых состоит в определении того, какой тин ассоциативного процес¬
сора следует воплотить в жизнь, имея в виду применение в системе управ¬
ления воздушным движением.
Как было установлено выше при обсуждении вопроса о том, являются
ли требования реалистическими или пет, требования к ассоциативному про¬
цессору основаны на возрастающей интенсивности воздушного движения. Энер¬
гетический кризис может явиться причиной того, что реальная интенсивность
воздушного движения, приводящая к критической нагрузке, наступит не так
скоро, как ожидалось, во всяком случае позже, чем ФАА заменит свое обо¬
рудование.
29
Таблица 2.1
Сравнительные данные для двух типов ассоциативных процессоров
Операции
Процессор с распределенной
логикой
Процессор с обработкой бито¬
вых срезов
Поиск на равенство
Поразрядно-параллельный
Поразрядно-последова¬
тельный
Прочие операции по¬
Поразрядно-последова¬
Поразрядно-последова¬
иска
тельные
тельные
Арифметические
Поразрядно-последова¬
Поразрядно-последова¬
операции
тельные
тельные
Запись слов
Поразрядно-параллельная
11 о р а з р я д но-п ос л е д ов а-
тсльная
Чтение слов
Поразрядно-параллельное
Поразрядно-последова¬
тельное
Хотя в настоящее время представляется вероятным выдвижение требова¬
ния об увеличении возможностей вычислительной машины ARTS III, работа¬
ющей в системе управления воздушным движением, за счет ввода ассоциатив¬
ного процессора, все же имеется ряд дополнительных обстоятельств, которые
могут привести к тому, что это требование не будет воплощено в жизнь. Не¬
смотря па это, пример ассоциативного процессора, способного работать в си¬
стеме управления воздушным движением, все же будет рассмотрен.
Конструкция ассоциативного процессора для системы управления воздуш¬
ным движением была предложена Тербсром [2.23]. Она объединяет черты,
присущие схемам ассоциативных процессоров с распределенной логикой и с
обработкой битовых срезов. Основная особенность предлагаемого процессора
заключается в том, что он предназначается для решения задачи, требующей,
чтобы коне груктор при создании ассоциативного процессора стремился к до¬
стижению как высоких показателей системы ввода/вывода, так и к балансу
между обрабатывающими устройствами и памятью; II-з этого, очевидно, выте¬
кает необходимость учета временных соотношений и Создания специализиро¬
ванных аппаратных средств ассоциативной обработки.
Предложенный ассоциативный процессор состоит из ассоциативной памя¬
ти, позволяющей производить арифметические операции над словами. Ариф¬
метический блок представляет собой последовательный сумматор. Ассоциа¬
тивный процессор может производить арифметические операции над храня¬
щимися в ном данными поразрядно-последовательным способом параллельно
над всеми словами. Рассматриваемый процессор' создай на оспове объедине¬
ния «концепции распределенной логики и обработки битовых срезов. Требова¬
ния, вытекающие из необходимости применения процессора в системе управ¬
ления воздушным движением, были сформулированы исходя из постановки
задачи федеральным авиационным агентством. Основное условие, поставленное
ФАА, заключалось в том, чтобы увеличить вычислительные возможности си¬
стемы ARTS III до уровня, отвечающего состоянию воздушного движения в
1980 г., и при этом не производить замены всей системы в целом.
Рассматривались два основных типа ассоциативных процессоров: процес¬
соры с распределенной логикой и процессоры с обработкой битовых срезов.
50
Наиболее существенное различие между этими двумя типами процессорами?
состоит в том, что в процессоре с распределенной логикой для каждого раз¬
ряда имеется свое обрабатывающее устройство, а в процессоре с обработкой
битовых срезов обрабатывающее устройство связано с целым словом. Разли¬
чия' между этими двумя тинами процессоров просуммированы в табл. 2.1.
Рис. 2.5. Блок-схема гибридного ассоциативного процессора. (Типичное слово
ассоциативного процессора включает слово А из части А, последовательный
сумматор, разряд регистра результатов поиска, разряд регистра выборки слов-
и слово В из части В (слово -из части В образовано из разрядов, взятых из от¬
дельных слов памяти с произвольным доступом).)
Ассоциативный процессор с распределенной логикой потенциально имеет
значительное преимущество по быстродействию на операциях поиска на ра¬
венство благодаря тому, что эти операции выполняются одновременно над все¬
ми разрядами каждого слова. Процессор с обработкой битовых срезов может
иметь преимущество по быстродействию при выполнении операций обработки
благодаря тому, что операции по чтению и записи оптовых срезов на нем выпол¬
няются быстрее, чем на- процессоре с распределенной логикой. При решении
конкретной задачи быстродействие зависит от соотношения числа операций
того или иного вида. Схема ассоциативного процессора, в котором объединены
преимущества каждого из рассмотренных типов, изображена па рис. 2.5.
На рис. 2.G показана общая блок-схема системы с ассоциативной обработ¬
кой. Такая система состоит из ведущего процессора (универсальной последо¬
вательной вычислительной машины), устройства управления для ассоциатив¬
ного процессора (играющего роль интерфейса с ведущим процессором),
ассоциативного процессора и интерфейса ассоциативного процессора с era
Устройством управлении: Интерфейс в ассоциативную систему введен из-за
несовместимости ассоциативного процессора и ведущего процессора. В процес-
С()ро с обработкой битовых срезов ввод/вывод осуществляется поразрядно-по-
слндоватслыю. В ведущем процессоре ввод/вывод осуществляется пословно¬
параллельно. Это обстоятельство играет роль ограничивающего фактора при
31
конструировании системы. Решение этой проблемы состоит в том, ч£тобы по¬
строить интерфейс ввода/вывода в виде ассоциативной памяти с распределен-
дюн логикой. Это обеспечит наличие в системе буфера ввода/вывода в качест¬
ве интерфейса, сделав этот буфер неотъемлемой частью самого ассоциативною
процессора.
Получившийся в результате ассоциативный процессор изображен па
рис. 2.5. Он состоит из двух главных блоков, которые делят между собой ариф¬
метические регистры и регистры ре¬
зультата. Первый блок представляет
собой ассоциативную память с рас¬
пределенной логикой. Преимущество
этой памяти состоит в том, что чте¬
ние и запись в ней выполняются в
пословно-параллельной форме, ис¬
ключая тем самым узкое место, ка¬
ковым оказался бы ввод/вывод при
наличии тол 1,ко поразрядно-последо¬
вательной формы ввода/вывода. Вто¬
рой блок процессора состоит из
запоминающего устройства с произ¬
вольным доступом, ..ориентирован¬
ного таким образом, чтобы обеспе¬
чить возможность работы в режиме
битовых срезов. При добавлении
арифметического оборудования для
работы со словами процессор, по¬
строенный по принципу обработки
битовых срезов, стал таким, какой
требуется для выполнения арифме¬
тических операций. Таким образом, в одном процессоре объедипены свойст¬
ва схемы с распределенной логикой (параллельный поиск па равенство и воз¬
можности осуществления операций ввода/вывода) с высоким быстродействием
па арифметических операциях, присущим процессору с обработкой битовых
срезов.
Для работы процессора требуется, чтобы намять с произвольным доступом
была организована следующим образом. Она должна быть повернута на 90° по
отношению к обычной ориентации. При поступлении адреса по входным ши¬
нам на дешифратор из памяти выбирается слово. Благодаря ориентации это
выбранное слово является битовым срезом, поступающим в ассоциативный
процессор. Дачный битовый срез может быть считан в регистры или в ариф¬
метическое устройство. Он же может быть отбракован регистром выборки слов.
Может быть выбрано подмножество сл'ов. Просто реализуется ассоциативный
поиск. Если позиции битового среза сравниваются с единицей, то такой срез
просто считывается. Если производится поиск на равенство 0, то битовый
срез считывается и преобразуется в дополнительный код. Дапная процедура
приводит к тому, что в регистре результатов поиска появляются единицы в
тех позициях, для которых выполняется условие поиска.
В табл. 2.2 при веден ы сравнительные данные, характеризующие быстро¬
действие, которое может быть достигнуто на современных ассоциативных про¬
Веду щи й
процессор
(универсальная
вычислительная
машина)
Интерфейс
и устройство
управления
вводом/выводом
t
Рис. 2.G. Блок-схема вычислительной
системы с ассоциативным процессором
32
цессорах. Временные характеристики системы с распределенной логикой бази¬
руются на данных, относящихся к полупроводпиковой ассоциативной памяти
фирмы Honeywell* [2.22]. Временные характеристики процессора с обработкой
битовых срезов основаны на параметрах биполярной памяти с произволь¬
ным доступом.
Таблица 2.2
Сравнительные данные о быстродействии ассоциативных процессоров
Процессор с
распределен¬
ной логикой
Процессор с об¬
работкой бито¬
вых срезов
Гибридный процессор
Операции
Часть А..
Ассоциатив¬
ная память
Часть В. Память
с произвольным
доступом
Чтбпие битового сре¬
300 пс
100 ПС
300 пс •
100 ис
за
Запись битового сре¬
200 ис
100 ис
200 не
. 100 ыс
за
Поиск по битовому
'срезу
300 не
100 пс
300 пс
100 не
Параллельный мас¬
кированный поиск
на равенство
300 ис
отсутствует
(100 нс/бит)
300 не
отсутствует
(100 нс/бит)
Поиск на равенство
300 не
100 нс/бит
300 пс
100 нс/бит
Параллельное считы¬
100 нс/слово
отсутствует
100 нс/сло¬
отсутствует
вание слов
(100 нс/бит/
/слово)
во
(100 нс/бит/
/слово)
Параллельная запись
слов
100 нс-
отсутствует
(100 нс/бит/
/слово)
100 не
отсутствует
Сложение битового
среза с битовым сре¬
зом и запись в бито¬
вый срез
900 не
400 пс
900 не
400 пс
Разрешение мно¬
жественных совпаде¬
ний
100 пс
100 ис
100 пс
100 не
Р> процессоре с обработкой битовых срезов в качестве регистра маски ис¬
пользуется декодер, а для храпения данных используется одиночный триг¬
герный регистр. Если адрес в дешифраторе изменится, то в триггерпом ре¬
гистре произойдет последовательный сдвиг информации. Важнейшая особен¬
ность гибридного процессора состоит в том, что две его части взаимно допол¬
няют друг друга. В случае, если данные могут быть распределены в системе
соответствующим образом, программист одновременно получает преимущества
как одной, так и другой схемы процессора.
Гибридный процессор может обеспечить высокое быстродействие ввода/вы¬
вода. Не допускается поразрядно-последовательное извлечение данных из ча¬
сти битового среза процессора. Для считывания пятидесяти слов по 20 разря¬
дов при условии, что слова находятся в той части процессора, которая построе¬
на по принципу распределенной логики, требуется 5 мке (для процессора с
обработкой битовых срезов —11 мкс). Чтение 20 битовых срезов памяти с про¬
извольным доступом с последующей записью их в процессор с распределенной
логикой занимает не более 6 мкс. Сравним эту величину с той, которую дает
^ К. Дж. Тербер 33
процессор с обработкой битовых срезов, а имепно, 100 мке (20 X 60 X 200 пс)
требуемых для выполнения той же операции ввода/вывода. Было установлено,
что в .большинстве практически важных случаев быстродействие вЪода/вывода
у комбинированного процессора примерно в десять раз выше, чем у процессо¬
ра с обработкой битовых срезов, и примерно вдвое выше, чем у процессоре
с распределенной логикой.
Рассмотрим скорость выполнения арифметической операции умножепия.
Умножение 20-разрядных операндов с получением 40-разрядпого результата за¬
нимает около 360 мке (202 X 0,9 или п2 операций сложения над битовыми среза¬
ми) на процессоре с распределенной логикой и 160 мке на процессоре с обра¬
боткой битовых срезов. В гибридном процессоре наихудший случай будет со¬
ответствовать ситуации, когда оба 20-разрядных операнда находятся в ассо¬
циативной памяти с распределенной логикой, и результат операции также
должен быть помещен в ассоциативную память с распределенной логикой. Сле¬
дуя тривиальному алгоритму, необходимо считать 40 разрядов в процессор с
обработкой битовых срезов, выполнить операцию умножепия и записать 40 раз¬
рядов в секцию процессора с распределенной логикой. Все это заняло бы
188 мке. Умножение в гибридном процессоре выполняется почти вдвое быст ¬
рее, чем в процессоре с распределенной логикой, и. практически за то же са¬
мое время, как в обычпом процессоре с обработкой битовых срезов.
Скорость выполнения операций арифметического сложения в таком ком¬
бинированном процессоре практически пе повышается и соответствует скоро¬
сти процессора с обработкой битовых срезов или процессора с распределенной
логикой в зависимости от того, где хранятся операнды и куда должен быть
помещен результат.
Таблица 2.3
Нормализованные данные о быстродействии ас¬
социативных процессоров (в единицах/с)
Процессор
с распре¬
деленной
логикой
Процессор
с обработ¬
кой бито¬
вых срезов
Гиб¬
рид¬
ный
про¬
цессор
Операции поиска па
равенство
10
1
7
Операции ввода/вы¬
вода
20
1
10
Арифметические опе¬
рации
1
3
2-3
Обработка битовых
срезов
1
3
2-3
В табл. 2.3 просуммировали результаты сравнения трех типов процессоров.
На основании приведенных характеристик гибридного процессора можно сде¬
лать вывод о том, что по быстродействию и гибкости этот процессор превос¬
ходит обе стандартные схемы ассоциативных процессоров. Значения в табл. 2.3
34
©зяты для типовых операции, встречающихся в большом количестве задач,
послуживших материалом для исследования.
Применительно к системе управления воздушным движением концепция
гибридного процессора оказывается гораздо предпочтительней, чем обе обыч¬
ные схемы. Для решения задачи управления воздушным движением были ис¬
пробованы все три схемы.
Элементная база машин с распределенной логикой или с обработкой би¬
товых срезов и элементная база гибридного процессора, с которым должны
были сравниваться первые две схемы, предполагались аналогичными. В задаче
управления воздушным движение?.! вычислительные возможности гибридного
процессора были на 30% выше, чем у каждого из двух других типов. Пока¬
затели у процессора с распределенной логикой и процессора с обработкой би¬
товых срезов в применении к рассматриваемой задаче оказались в целом
«близкими за счет того, что ограниченные возможности при выполпейши ариф¬
метических операций у одного и операции ввода/вывода у другого взаимно
уравновешивают друг друга.
Главная проблема при создании системы состояла в том, чтобы подобрать*
размеры той части процессора, которая построена но принципу обработки би¬
товых срезов, и той части, которая построена но принципу распределенной
логики, таким образом, чтобы задачи, входящие в общую систему управления
воздушным движением и требующие быстрых ввода/вывода и операций поис¬
ка на равенство, целиком могли поместиться в части ассоциативного процес¬
сора, построенной но принципу распределенной логики, а задачи, требующие
высокого быстродействия на арифметических операциях,— в части, построен¬
ной по принципу обработки битовых срезов. Преимущества процессору такого
чипа может дать хранение некоторых данных в обеих частях процессора.
Причины, по которым гибридная схема оказалась для системы управле¬
ния воздушным движением предпочтительнее, чем схемы с распределенной
логикой и обработкой битовых срезов, состоят в следующем: 1) процессор с
обработкой битовых срезов имеет ограниченные возможности ввода/вывода,
а взаимодействие с дисплеями требует развитой системы ввода/вывода, 2) про¬
цессор с обработкой битовых срезов имеет ограниченные возможности как в
части операций поиска, так п в части обнаружения конфликтных ситуаций и
корреляций между трассами, которые 'требуют хороших поисковых характе¬
ристик, и 3) схема с распределенной логикой имеет большие времена циклов,
что вредит ей с точки зрения уточнения трасс и вычислительных функций,
связанных с задачей: обнаружения конфликтов. В рассматриваемом случае
недостатки процессора с обработкой битовых срезов (ввод/вывод и поиск па
равенство) и недостатки процессора с распределенной логикой (более медлен¬
ная обработка битовых срезов) взаимно компенсируют друг друга. Если оце¬
нивать применимость той или иной схемы к общей системе управлепия воз¬
душным движением, то схемы с обработкой битовых срезов и с распределен¬
ной логикой оказались эквивалентными но своим характеристикам.
Устройство управления для описанного выше процессора показано па
рис. 2.7. Описываемое устройство получает из ARTS III макросы, служащие
Для инициализации выполнения программ, которые хранятся в памяти с про¬
извольным доступом, имеющейся в устройстве управления. Эти программы
содержат операции ассоциатнвпого процессора, такие как сложение полей, по¬
иск па неравенство, поиск на максимум/минимум, а также операции ввода/
з* 35
Рис. 2.7. Блок-схема устройства управления
/вывода. Необходимость использования макрокоманд связана с медленностью
работы аппаратуры ввода/вывода машины ARTS III и ее канальной программы
ввода/вывода. Процессор ввода/вывода, входящий в состав ARTS III, не может
непосредственно управлять ассоциативным процессором. Рассмотренное уст¬
ройство управления является типичным для устройств** такого рода, использу¬
емых в настоящее время в ассоциативпых процессорах.
Принцип перехода состояния
При использовании схемы с обработкой битовых срезов или даже схемы
с распределенной логикой реализация некоторых основных операций, таких
как сложение или поиск, может быть очень сложпой. Имеется простой способ
описания этих алгоритмов, делающий их общедоступными для понимания.
Этот способ называется принципом перехода состояния [2.25]. Принцип пе¬
рехода состояпия заключается в очень подробном отображении пе¬
реходов, возникающих по ходу алгоритма, с помощью диаграмм перехода со¬
стояния или таблиц изменепия состояния. Принцип перехода состояния яв¬
ляется хорошим способом сделать алгоритмы прозрачными, однако наиболее
Исходное •
состояние
—
! Текущее
Исходное I значение
состояние j бита частям-
! НОЙ СУММЫ
|
Bi б: ■ р:.
Перенос
R следующее
состояние
6;:+ 1
0
1
0 0 П ! G 0
чо о 1 : • о)
')
0 1 Q 1 0
; J
(о 1 1 | it ! Г)
- ‘ L". ■ " t ...
4
о о с ; 1 ! о)
-
10 1; С
1
6
(1 1 о ! о
D
7 '
I-,,; 1
1
Рис. 2.8. Таблицы переходов состояпия при операции сложения
битовых срезов
сложные алгоритмы порождают слишком большие таблицы, что пе позволяет
использовать этот принцип за рамками учебных задач.
Для реализации ассоциативной обработки дапных в ассоцпативпом процес¬
соре нужны две операции: поиск по содержимому и операция множественной
записи. Операция множественной записи состоит в том, чтобы одновременно
записывать информацию в выделепные разряды параллельно в несколько вы¬
37
бранных слов. Запись битовых срезов является одним пз примеров операции
множественной записи.
Рассмотрим задачу, заключающуюся в сложении слова А со словом В.
Эта операция может быть выполнена в виде последовательных понарпо-иораз-
рядных сложений (Л* сложить с Вг) с соответствующим переносом разряда
там, где ото необходимо.
Пусть разряд 1 — младший значащий разряд, а разряд п — старший зна¬
чащий разряд каждого слова. На рис. 2.S изображена диаграмма перехода со¬
стояния, соответствующая поразрядно-последовательному сложению А с В
с накоплением результата в В. Вi (результат) и Сг + i отличаются- от Вг- (опе¬
ранд) и Си в четырех состояниях 1, 3. 4 п G. Один возможный метод сложе¬
ния состоит в том, чтобы найти эти состояния п с помощью операции мно¬
жественной записи записать правильные значения Вг- и Q + i в соответствую¬
щие поля. Для реализации такого алгоритма сложения необходимо было вве¬
сти вспомогательное ноле, обозначенное через С* с начальной установкой
Q = 0.
Алгоритм обрабатывает пары операндов, двигаясь от младшего разряда к
старшему. В каждой разрядной позиции i производится поиск Л* и Вг- на со¬
ответствие их состоянию 1. Во все слова, где произошло совпадение, осущест¬
вляется множественная запись Сги = 0 и Вг- = 1. Затем необходимо просмот¬
реть память па предмет обнаружения состояния 3. Во все слова, отвечающие
этому состоянию, произвести множественную запись С; + 1 = 1 и В< = 0. Такую
же процедуру необходимо выполнить для состоянии 4 и G. Затем перейти к
обработке разрядной позиции i + 1. После того как слово попало иод любое
пз условий поиска, его следует удалить пз списка активных ячеек до тех пор,
пока алгоритм не перейдет от разрядной позиции i к позиции i + 1 так, что
запись результирующего значения В * и разряда переноса из- разрядной пози¬
ции i + 1 в память ие приведет к тому, что уже обработанные данные вновь
попадут на обработку. Использование принципа последовательного преобра¬
зования состояния позволяет с помощью простого поиска по содержимому п
множественной записи осуществить в ассоциативном процессоре любые же¬
лаемые преобразования. Требования к логическим устройствам обработки слов
являются мнипмальными.
Из рассмотрения принципа перехода состояпия можно вывести шесть об¬
щих положений, касающихся архитектуры ассоциативных процессоров:
1) Базовым-примитивом обработки является идентификация всех слов, в
которых встречается некоторая последовательность битов, описываемая двоич¬
ны ми перемеппыми.
2) До тех пор, пока обработка может производиться одновременно над
всеми наборами данных, представляющими интерес,- явная адресация ие
требуется.
3) Данпые обрабатываются последовательно по столбцам (поразрядно-по¬
следовательно), что ограничивает количество переходов состояпия, которые
нужно помнить на каждом данном шаге.
4) Очень полезными являются вспомогательные разряды^теги, хранящие¬
ся во временной памяти, предназначенной для битовых срезов (например, раз¬
ряд переноса записывался в тег битового среза).
5) Желательно иметь регистр результатов поиска, регистр выборки слов
и возможность для осуществления множественной записи.
38
б) Б ассоциативном процессоре желательно иметь средства управления
в виде загружаемых программ.
Фуллер и Берд [2.25] пе только ввели концепцию перехода состояния, но
й выявили тонкие взаимосвязи между способами хранения данных в памяти
процессора и скоростью их обработки. В качестве примера этого явления они
описали для своего ассоциативного процессора две схемы организации дан¬
ных: слово па ячейку и разряд на ячейку.
На рис. 2.9 п 2.10 показаны соответственно
пословная п поразрядная схемы организации
памяти для девяти 4-разрядных слов, обозна¬
ченных через Хп ... Х3з.
Пословная организация стала промыш¬
ленным стандартом. Это произошло благодаря
тому, что желательно производить обработку
битовых срезов одновременно над многими
! *« !
■ 1
. . .-р .
I Х'2 1
Г 'Г ■
! !
1 х !
| 1
1 1
1 х„ 1
! 1
1 1
! Х’1 !
Л I
*32 !
1 1
I х„ !
Рис. 2.9. Пословная организация памяти (ело- рис> 2.10. Поразрядная
во па ячейку) организация памяти
(разряд па ячейку)
наборами данных без привлечепия большого количества межсловных связей.
Пословная организация памяти является очень эффективной при участии
большого количества ячеек. Операнды могут храниться в одной и той же
ячейке, и с помощью каждой команды обработки битовых срезов может обра¬
батываться наибольшее число операпдов. В памяти, показанной па рис. 2.9, этот
способ организации оказался бы очень эффективным, если бы для всех опе¬
рандов Хп, Х,-2 и Хг3 потребовалось вычислить величину Хл + (Хг2*Хг-з) для
всех /. Все ячейки могли бы быть активизированы п вычисления производить¬
ся поразрядио-послсдовательпо над всеми операндами.
Имеются задачи, для которых более эффективным является принцип по¬
разрядной организации памяти. Хранение данных по принципу разряд на
ячейку было независимо открыто также Крейном и Гитсисом [2.26]. При по¬
разрядной организации памяти возможна одновременная обработка многих
операндов в параллельно-поразрядном режиме. Поскольку многие операции
производятся в параллельном режиме, поразрядным принцип организации
памяти может быть очень эффективным даже при небольшом колпчествещпо-
рапдов. Можно работать с операндами, находящимися в одном н том же би¬
товом срезе. Обработка данных, организованных по принципу разряд па ячей¬
ку, может быть эффективной в тех случаях, когда при выполнении команды
активизируется небольшое число операпдов или при решении задач, в кото¬
рых должны часто встречаться ситуации, попарного соответствия операпдов.
Было установлено, что операция сложения при поразрядной организации, как
правило, выполняется вдвое или втрое быстрее, чем при пословной организа¬
ции. Пословная п поразрядная схема обработки могут - быть реализованы
в одном и том же процессоре, давая возможности использовать в случае необ¬
ходимости поразрядную обработку.
Оценка ассоциативных процессоров. Выгне были рассмотрены области воз¬
можного применения, общие архитектурные концепции ассоциативных про¬
цессоров, конструкторские решения, характерные для этих архитектурных
концепций, а ташке результаты исследования конструкции ассоциативного
процессора, предназначенного для работы в системе управления воздушным
движением. Возникает вопрос о том, как оцепить эффективность рассмотрен¬
ных принципов обработки. Из-за недостатка материалов, посвященных вопро¬
сам-.применения, информация, па основе которой можно было бы делать оцен¬
ки, ограничена.
На поставленный вопрос можно ответить разными способами. На основа-
пип нескольких очень простых оцепок можно утверждать, что показатели ас¬
социативных процессоров не имеют ничего общего с запроектированными и что
эти процессоры неэффективны с точки зрения стоимости. На основании более
внимательного изучения того же практического опыта можно также утверж¬
дать, что этот отрицательный результат говорит о том, что оценка получена
в результате применения неправильной методики и что если данные тести¬
рования проинтерпретировать более тщательно, то они покажут значительные
преимущества, которые можно извлечь за счет применения ассоциативной об¬
работки. Можно также рассматривать механизмы виртуальной памяти и ука¬
зывать на значительное улучшение характеристик, получаемое за счет при¬
менения аппаратурных ассоциативных средств. Из-за недостатка данных прак¬
тически еще слйшком рано говорить о том, что может делать ассоциативный
процессор.
Гол [2.27] провел обширное исследование; задачей которого было выявить
достоинства и технические особенности в конструкциях ассоциативных про¬
цессоров. Целью исследования была оценка относительных показателей не¬
скольких архитектур ассоциативных процессоров в сравнении с обычной
универсальной вычислительной машиной. Для исследования был отобран ряд
задач из области обработки нечисловой информации в ВВС США. Было сконст¬
руировано несколько ассоциативных вычислительных систем. Для всех задач
было оценено время выполнения на каждой системе. В процессе исследования
была сделана попытка измерить время счета программы, стоимость решения
и сложность программирования. Произведена оценка характеристик системы
GAP — ассоциативного процессора фирмы Goodyear, который был построеп и
затем установлен в Авиационном научно-исследовательском центре ВВС США
Роум (RADC).
Двумя задачами, выбранными для оценки, были автоматическое рефери¬
рование и орфографическая коррекция. Исследование . показало, что, с точки
зрения времен решения задач, ассоциативный процессор оказывается полез¬
ным. Оно "также показало, что ассоциативный процессор может оказаться не¬
эффективным с точки зрения стоимости решения, если он самым тщательным
образом не настроен на данное конкретное применение.
Гол никогда не предпринимал попыток оцепить или разработ’ать какие-
либо абсолютные показатели или графики, которые.бы позволили оцепить до¬
стоинства ассоциативных процессоров как больших, так и малых конфигура¬
ций. Исследование позволило решить две заранее пе заплапироваппые задачи,
а именно, оцепить конструкцию логической части памяти и оцепить способы
40
подключит ассоциативного процессора к универсальной вычислительной ма¬
шине. Целыо исследования было, основываясь на первых оценках схем ассо¬
циативной обработки, установить более пли менее реальную отправную точку
для дальнейшей оценки.
Конфигурация системы состоит из ассоциативного процессора, вычпслитель-
Н0Й машины CDG 1604 и дисковой памяти CDG 818. Методическая основа ис¬
следования состояла в получении большого числа различных оценок ассоциа¬
тивных процессоров. GAP был выбран для получения разумных оценок в пер¬
вом приближении. Кроме того, он функционировал в RADC. В качестве других
Память машины 1604 6
Рис. 2.11. Конфигурация ассоциативного процессора, установленного в RADG
конфигураций исследовались модификации GAP. Конфигурации, подвергнутые
оценке, обозначались через НВ, Нь H2i, II22 и Н2з.
ИВ показана на рис. 2.11. Эта конфигурация представляла собой GAP с
запоминающим устройством объемом 2048 слов, носителем информации в ко¬
тором является цилиндрическая магнитная пленка, покрывающая бериллиево-
медиый проводник, который одновременно служит разрядной шиной. GAP
имел прямой доступ к памяти 1604, состоящей из 50-разрядных слов. Каждое
слово включало 48 разрядных позиций плюс 1 разряд контроля по четности и
1 разряд, служащий признаком занятости/незанятости. Процессор имел 64 опе-
; рации, из которых 46 проходили через регистр команд и декодировались уст¬
ройством управления, а 16 декодировались через регистр функций непосредст¬
венно из памяти 1604. Процессор состоял из двух массивов. Верхняя и пижпяя
половины массива имели по 1024 слова каждая. Предусматривалась пословпо-
параллельпая поразрядно-последовательная работа памяти. Были введены ре¬
гистры маски и данных. Имелось 1024-элементиое запоминающее устройство
Для хранения ответных сигналов, которое поочередно работало с каждой иоло-
41
виной памяти. N-c слово каждого массива памяти делило со словом из другой
половины все устройства логической обработки вплоть до устройств самого
нижнего уровня, за исключением регистров D и Е. Регистры D и Е были свя¬
заны с запоминающим устройством ответных сигналов и использовались верх¬
ней и нижней половиной памяти (соответственно) для временного хранения
содержимого этого запоминающего устройства.
Конфигурация Hi представляет собой модификацию НВ и предназнача¬
лась для решения задачи автоматического реферирования. Н2г- являлись мо¬
дифицированными вариантами НВ и предназначались для решеиня задачи
орфографической коррекции. 'Имелись три подобных архитектуры.
Для более эффективного решения задачи автоматического реферирования
г. конфигурацию Hi по сравнению с IIB были введены' дополнительные быст¬
родействующие локальные запоминающие устройства для хранения команд и
масок так, что в Hi команды и маски не нужно было извлекать из памяти
1604. В системе имелся запрограммированный массив команд, а все индексные
регистры и функции сложения/накопления были исключены.
H2i идентична Hi за исключением того, что в ней имелись средства для
индексации и некоторые специальные команды, введенные в интересах задачи
орфографической коррекции.
Н22 представляла собой расширенный ассоциативный процессор. Расшире¬
ние заключалось в там, что память, состоящая из 2048 50-разрядных слов, бы¬
ла увеличена до 10 ООО 98-разрядных слов. Память предполагалась единой
(т. е. без деления на части или подмассивы), однако регистры D, Е и запоми¬
нающее устройство ответных сигналов остались 1024-разрядпымн. Смысл со¬
здания модификации Н22 заключался в том, чтобы сделать ассоциативный про¬
цессор достаточно большим для размещения в нем целиком орфографическо¬
го словаря п, таким образом, избежать процедуры листания.
Н2з представляла собой основную модификацию, предназначенную для
орфографической коррекции. Она включала 10 ООО 98-разрядных слов, 10 000-
разрядное устройство хранения ответных сигналов и 10 000-разрядное решаю¬
щее устройство ответных сигналов. Н2з не имела регистра команд, и все коман¬
ды проходили через регистр фупкций. Осповной пабор специализированных
команд состоял из 12 команд, 11 из которых служили для выполнения внут¬
рисистемных функций.
Поскольку в действительности существовала только конфигурация НВ, не
все задачи могли быть запрограммированы на реальной аппаратуре. Ряд ста¬
тистических характеристик был взят из описаний задач, имевшихся в опуб¬
ликованных материалах, а времена выполнения для некоторых конфигураций
были получены путем аналитических расчетов.
В процессе исследования были выделепы три типа средств, которые же¬
лательно иметь в устройстве управления ассоциативным процессором. Этими
средствами являются: индексные операции, позволяющие ассоциативному
процессору работать с циклами независимо от ведущего процессора; сдвиговые
операции для регистров, участвующих в операциях сравнения, и выходных
регистров, позволяющие быстро упаковывать и распаковывать данные авто¬
номно от ведущего процессора; операция игнорирования маски, которая позво¬
ляет программисту указывать, что повая маска в операции не нужна, и тем
самым экономить время за счет исключения постоянных запросов маски, когда
в этом нет необходимости. Эти улучшения в архитектуре позволяют сделать
42
ассоциативный процессор более автономным при выполнении программ. Ип-
терфейс ввода/вывода для ассоциативного процессора является узким местом.
Задача автоматического реферирования была запрограммирована па трех
системах 1604, И В и Hi. Эта задача состоит в извлечении сути из документа
с цомощыо алгоритма локализации ключевых терминов. Результаты анализа
Таблица 2.4
Сравнительные данные для задачи рефе¬
рирования документов
нв
Система
1604 в
1С 0 4
В
.АП
160 4
В
АП
Количество
команд
472
448
47
448
47
Время реше-
пия для доку-
мепта, содер¬
жащего
3000 слов, с
1,434
0,864
0,768
приведены в табл. 2.4. Процессор ИВ (Hi) дает улучшение характеристик при¬
мерно в 1,68 (1,85) раза по сравнению с 1604. Количество команд в программе
не уменьшилось.
Таблица 2.5
Сравнительные данные для задачи орфографической коррекции
Система
1604 К
(память
64 К)
1604 В
(память
32 К)
НВ
Н;
21
И:
22
н.
160 4
В
АП
1604
В
АП
1604
В
АП
1604
В
ЛИ
Количество команд
230
63 '
| 210
63
210
67
139
27
3
Время решения
(мке) при отсутст¬
вии ошибок на входе
351,8
351,8
13812,0
13753,4
116,2
96,3
Время решения
(мке) при наличии
ошибок на входе
3211,2
31527,3
40450,8
40021,9
997,6
169,1
Сущность задачи орфографической коррекции заключалась в исправле¬
нии написания слов с помощью хранящегося в памяти словаря. Алгоритм, вы¬
бранный для исследования, мог обнаруживать и исправлять одиночные ошиб¬
ки в рамках ограниченного (10 000 слов) словаря. Результаты для этой задачи
приведены в табл. 2.5. Конфигурации ИВ и II2i не дали заметного выигрыша
но времени решения, Н22 и Н23 при наличии неправильных слов оказались
43
производительнее, чем 1604 (с памятью на феррптовых сердечниках объемом
61 К), в 3,02 и 19 раз соответственно. Объем программы в Ы22 и Н2з остался
прежним. Дальнейшее обсуждение путей уменьшения времени решения задач
•автоматического реферирования и орфографической коррекции приведено в
работе Гола [2.27].
Использование машины 1604 В, укомплектованной памятью объемом 64К,
было необходимо для обеспечения адекватных условий сравнения ее с Г122
и П23, так как в памяти последних может храниться весь словарь целиком. Ва¬
риант 1604 В с памятью объемом 32К не может хранить словарь целиком
и поэтому для обработки неправильных слов использует смешанные таблицы
адресов. Для того чтобы можно было оценить вариант с памятью 32К, потре¬
бовались бы незначительные изменения в рабочей программе.
Исследование показывает преимущества, получаемые за счет использо¬
вания ассоциативного процессора. Конфигурация Н23 превосходила 1604 в 19—
186 раз. В исследовании указывается потенциальная опасность, которая может
встретиться при использовании специализированной вычислительной системы
для решения неподходящих для нее задач. При некоторых конфигурациях
процессор имел проигрыш по сравнению с 1604 В более чем в два раза. За
исключением показателей для Н23, типичное значение выигрыша приблизи¬
тельно равно 3. Задачи, выбранные для исследования, были не очень удачными
примерами. Имелся класс задач, для которых исследовалась возможность при¬
менения ассоциативной памяти и результат оказался отрицательным. Большой
процепт времени ассоциативная память находится в‘ незагруженном состоянии
(порядка 70—80% для задачи реферирования и 70% для Н23 и И22). ИВ и Hi
при решении задачи орфографической коррекции взаимодействовали с 1604,
вследствие чего время простоя 1604 составило около 50%. Ассоциативный про¬
цессор не обеспечил показателей, которых он мог бы достичь при условии, ес¬
ли бы его конфигурация была более тщательно подобрана и приспособлена
к решаемым задачам.
В приложении к основному тексту можно найти подробное обсуждение
большинства несоответствий в аппаратурной части [2.27]. Будучи соответст¬
вующим образом сбалансированной для решения рассмотренных задач, дан¬
ная конфигурация могла бы дать улучшение характеристик па порядок.
В большинстве конфигураций 1604 была слишком медленной, чтобы управлять
ассоциативным процессором, или же алгоритмы были слишком тривиальными,
чтобы для них требовался ассоциативный процессор. *
Приведенный пример еще более подкрепляет уверенность пользователей
в том, что ассоциативные процессоры по самой своей сути являются специа¬
лизированными устройствами и что они требуют соответствующей подгонки
к решаемым задачам. В одном случае ассоциативный процессор дает выигрыш
в пропускной способности в 180 раз. Широкий разброс значений показателей
выигрыша (от 3 до 186 при использовании одной и той же базовой конфигу¬
рации) еще более подчеркивает необходимость учитывать специализированную
природу таких машин. Рассогласованность и низкий процент использования
как ассоциативного процессора, таг, и универсального процессора 1604 указы¬
вают на то, что ассрциативпый процессор должен иметь собственное устройст¬
во управления, которое позволило бы загружать ассоциативный процессор и
сделало бы возможным его работу в автономном режиме в то время, когда
ведущий процессор выполняет другую работу. В обеих задачах использовалась
44
техника перемешивания адресов в 1604. Показатели 1604 являлись, вероятно,
предельными для этого процессора, хотя возможности ассоциативного процес¬
сора, быть может, еще не исчерпаны.
В заключительной части исследования говорится о том, что ассоциатив¬
ные процессоры (перемешанная адресация в универсальных процессорах не
применима) целесообразно применять при решении задач, для которых харак¬
терно динамическое базирование данных, использование данных с множест¬
венными полями, а также требование, чтобы поиск данных осуществлялся по
критериям, отличным от точного совпадения.
В результате исследования обнаружился ряд очепь интересных моментов:
1) Система должна быть тщательно*сбалансирована и настроена на данное
конкретное применение.
2) Система должна иметь соответствующие ввод/вывод и интерфейс с уни¬
версальной машиной [2.28].
3) Существует широкий разброс величины выигрыша, возникающий из-за
различных рассогласований, имеющихся в конкретном процессоре.
В предыдущих разделах этой главы были описаны основные принципы
организации и особенности наиболее общего типа ассоциативного процессора.
Рассмотренные примеры и проведенный анализ исследования по оценкам по¬
зволяют перечислить основные факторы, которые необходимо учитывать при
разработке эффективного ассоциативного процессора и его интерфейса с сис¬
темой. Наиболее важными из этих факторов являются ввод/вывод, интерфейс
ассоциативного процессора с ведущим процессором, а также баланс между
запоминающими и обрабатывающими устройствами в ассоциативном процес¬
соре. Более экзотические ассоциативные архитектуры описаны в последующих
разделах этой главы.
Для решения различных задач было разработано множество различных ас¬
социативных архитектур. Многие из них значительно отличаются от наиболее
общего типа архитектуры, рассмотренного выше. Основная причина различий
заключается в различии решаемых задач. Ниже описываются наиболее важ¬
ные из этих архитектур и те задачи, благодаря которым они появились. Ради
краткости рассматриваются только наиболее важные требования, обусловлен¬
ные особенностями решаемых задач.
МЕМЕХ — первая ассоциативная архитектура
Впервые концепция ассоциативного процессора была представлена в виде
'гипотетической системы МЕМЕХ [2.29]. Были описаны лишь ее функциональ¬
ные характеристики. Каких-либо попыток рассмотреть практическую реали¬
зацию системы ие предпринималось. Требование, которому должна была удов¬
летворять система, заключалось в том, чтобы она работала подобно тому, как,
по тем временам, представляли работу человеческого мозга. Тем самым человек
-освобождался бы от рутинной работы и мог сосредоточиться на решении
творческих задач.
Система МЕМЕХ была описана в журнале Atlantic Monthly, вышедшем в
июле 1945 г., доктором Ванневаром Бушем, директором Управления научных
• исследований и развития. По мнению редактора Atlantic Monthly, статья д-ра
Буша по своему значению могла быть приравнена к известному выступле¬
нию Эмерсона в 1837 г. в журнале «Американский ученый». Д-р Буш призвал
45
по-новому взглянуть па взаимоотношение между мышлением человека и егс
знаниями.
Д-р Буш занимался вопросом аккумулирования человеческих зпаппй.
Сумма этих знании растет с каждым днем. Сложность проблем, связанных с
обеспечением доступа к данным, находится, почти за пределами человече¬
ских возможностей. Предвидя в будущем лавинообразный рост суммы зна¬
ний, д-р Буш пришел к выводу, что человеку нужна помощь, чтобы справить ¬
ся с переработкой информации. Он рассматривает различные аспекты такой
переработки.
Рассматривая средства, с помощью которых можно осуществлять доступ
к данным, д-р Буш отмечает, что поиск может проводиться методом последо¬
вательного перебора или с помощью разбиения па подклассы (по аналогии с
телефонным номером, каждая следующая цифра которого служит для обозна¬
чения очередного подкласса, подлежащего дальнейшему разбиению). В обеих
схемах каждый раз, когда после выбора одного объекта нужно выбрать дру¬
гой, необходимо начинать сначала.
Буш предположил, что человеческий мозг работает пе так. Мозг, счита¬
ет Буш, работает ассоциативно. Буш утверждает: «Выбор по ассоциации
легче поддается механизации, чем выбор с помощью механизма указа¬
телей».
Аппарат для осуществления механизированного ассоциативного доступа
к данным был назван МЕМЕХ и представлял собой устройство, в котором че¬
ловек мог хранить все сведения, которыми он пользуется. По замыслу,.
МЕМЕХ должен служить непосредственным расширением человеческой па¬
мяти. Предусматривалась возможность обычного доступа к памяти с по¬
мощью указателей. Отдельные порции данных сцеплялись друг с другом по¬
средством ассоциаций, аналогично тому, «как мы думаем», т. е. любая отдель¬
ная информация вызывает немедленный и автоматический выбор другой ин¬
формации.
Возможность использования любых форм ассоциативпых связей между
объектами открывает путь к созданию новых энциклопедических информаци¬
онных структур. Первый ассоциативный процессор, в котором данные храни¬
лись в виде микрофильмов и воспроизводились па особых графических тер¬
миналах с помощью сухого фотографирования, служит подтверждением про¬
зорливости д-ра Буша.
Криогенная каталоговая память — первая аппаратная
реализация ассоциативной памяти
Первое аппаратное устройство для ассоциативной обработки было проде¬
монстрировано Слейдом и Макмэхоном в 1956 г. [2.30]. С технологической
точки зрения криогенная каталоговая память устарела. Здесь ее описание
приводится из-за того, что она представляла собой важный этап в истории
разлития ассоциативной техники.
Ассоциативный процессор создавался для работы в системе, которая
предъявляла следующие три требования: 1) храпеппе большого количества
слов фиксирования длины; 2) ассоциативный доступ к памяти и 3) неболь¬
шое число операций стирания или записи информации по сравнению с чис¬
лом требуемых операций по обобщению данных.
46
Главными целями создания такого процессора явились демонстрация
возможностей криотроппой техники и выявление технических проблем, свя¬
занных с построением систем на базе криогенных приборов. Каталоговая па¬
мять сохраняет свое значение в историческом аспекте, так как она послужи¬
ла отправной точкой некоторых важных направлений в создании устройств,
которые позже могли бы использоваться в ассоциативных процессорах. Наи¬
более важными из этих направлений являются:
1) использование единственного выходного устройства для определения
того, содержится ли слово в процессоре;
2) определение не только факта присутствия обрабатываемого слова в
памяти, по и проверка на принадлежность его к определенному классу;
Источник входного потока
Рис. 2.12. Аппаратная часть первого ассоциативного процессора
«
3) использование схемы выборки слов, позволяющей выбрать отдельное
слово, которое должно быть записано в память или стерто из памяти.
Какие-либо схемы разрешения множественных совпадений не вводились,
так как в предполагаемых применениях данные в памяти в действительно¬
сти размещались по принципу каталога. В процессор вводилась информация,
характеризующая объект, и в ответ выдавался признак, показывавший, нахо¬
дится ли объект в каталоге пли пет. Аппаратные средства, обеспечивающие
получение результатов поиска, включали вольтметры, соединенные с кодо¬
вым шинами слов.
Предполагалось построить процессор со следующими характеристиками:
полпое время опроса памяти 10 мкс, цикл записи 500 мкс. Модель, оперирую¬
щая с 200 разрядами, находилась в стадии разработки. Она должна была со¬
стоять из' десяти 20-разрядпых плат. На каждой плате размещались четыре
^-разрядных слова. Предполагаемые габариты составляли 75Х75ХЮ0 мм-
Ассоциативный процессор имел возможность записывать слова в память.
Нельзя было явно прочитать слово из памяти. С помощью операции поиска
на точпое совпадение процессор мог установить, что слово содержится в па¬
мяти. Если входное слово, с которым нужно провести сравпение, было в па¬
мяти, то это отражалось на показаниях соответствующего вольтметра.
47
ITa рпс. 2.12 представлена блок-схема ассоциативного процессора. Вход¬
ной поток вводился в систему по шипам слов. Каждый разряд (В 1, В2, ВЗ,...)
каждого слова процессора представлял собой криотронное устройство, спо¬
собное хранить бит информации и откликаться ыа бит информации.
Входное • слово сравнивалось с содержимым каждого слова памяти пу¬
тем поразрядного сопоставления. Во всякой разрядной. позиции, где разряд
входного слова совпадает с разрядом слова из памяти, у криотрона появля¬
ется сопротивление (в отличие от состояния сверхпроводимости). Если вход¬
ное слово целиком соответствует слову из памяти, то во всех разрядах по¬
явится сопротивление. Факт совпадения отмечался вольтметром, подключен¬
ным к информационным шинам того слова, в котором произошло совпадение.
Данная операция сравнения выполнялась одновременно со всеми разрядами
всех слов.
Криогенная техника привлекала внимание исследователей вплоть до се¬
редины 60-х годов. Хотя устройства на криотронах не получили развития,
данный процессор имел мпогие черты, которые характерны для современной
техпики, в частности, для механизма виртуальной памяти.
Разрешение множественных откликов и алгоритм Левина
Во мпогих практических применениях данпые организованы не в форме
каталога. Обычно хранимые объекты необходимо уметь извлекать. Большое
значение имеет число обтюктов, для которых произошло совпадение. Иног¬
да требуется извлекать данные некоторым упорядоченным образом. Приклад¬
ной областью, в которой требуются эти свойства, является управление воз¬
душным движением. В процессе поиска данных, которые должны быть выз¬
ваны на дисплей, условию поиска, как правило, удовлетворяют несколько
трасс, которые должны быть извлечены. В задаче обнаружения конфликтных
ситуаций может оказаться необходимым определять число самолетов, с кото¬
рыми вступает в конфликт новый самолет, появившийся в воздушном прост¬
ранстве. Еще более существенным моментом в задаче обпаружепия конф¬
ликтов является обработка конфликтных ситуаций в порядке, определяемом
временем, оставшемся до их возникновения. Первым должен обрабатываться
самолет, у которого время до конфликта минимально.
Практические задачи, подобные рассмотренным примерам, приводят к
проблеме разрешепия множественных откликов. Каким образом выявить и
извлечь объекты в ситуации, когда несколько слов отвечают условию поиска,
задаваемому входпым словом? В некоторых практических задачах необходимо
подсчитывать число совпадений, либо извлекать объекты упорядоченным об¬
разом (по возрастапшо или убывапию).
Многие специалисты, занимавшиеся изучепнем ассоциативной обработки,
очепь давно указывали па эти проблемы. В пастоящее время все еще нет та¬
кого решения, которое было бы хорошим по совокупности таких критериев,
как объем оборудования, быстродействие и стоимость. Алгоритмы разрешения,
в принципе, могут быть реализованы аппаратно, однако реализации, обеспе¬
чивающие высокое быстродействие при низкой стоимости, связаны с трудно¬
стями.
Одпп простой способ заключается в том, чтобы вначале определять, име¬
ется ли более одного объекта, удовлетворяющего условию поиска. Если таких
48
объектов несколько, то происходит обращению к алгоритму разрешения. Сог¬
ласно другому методу непосредственное обращение к алгоритму разрешения
происходит всегда. Один алгоритм заключается в сдвиге регистра ответных
сигналов (нри сохранении нензменпьш величины сдвига) до тех пор, пока не
встретится первое совпадение. Затем производится обработка этого слова и
восстановление бита совпадения. Затем может обрабатываться «следующее
совпавшее» слово. Альтернативой использованию сдвигаемого регистра явля¬
ется применение статической логической сети, которая фиксирует факт сов¬
падения п выставляет указатель на первое совпавшее слово. Логическая сеть-
может работать быстрее, чем схема со сдвигаемым регистром, но является,
возможно, более дорогостоящей.
Другой способ заключается в разбиении памяти па части (блоки) и разрёше-
нии совпадений локально внутри каждого блока. Затем совокупность ответ¬
ных сигналов от каждого блока будет подана в общую схему ответных сигна¬
лов. Разрешение откликов становится более трудным и требующим больше
времени и затрат по мере увеличения размера ассоциативного процессора.
Проблемы, связаппые с разрешением откликов, выступают одним из главных
лимитирующих факторов для ассоциативных процессоров.
Другим средством, наличие которого желательно, является возможность
подсчитывать отклики. При наличии средств для такого подсчета возможно
принятие в процессе работы решепий типа «если число объектов, вырабо¬
тавших отклик, меньше некоторой величины, то данные этих объектов долж¬
ны быть считаны и обработаны в ведущем процессоре». К типичным средст¬
вам для разрешения, вводимым в процессор, относятся: 1) признак, позво¬
ляющий отличить ситуацию, когда число совпадений равно пулю, от ситуа¬
ции, когда оно пе меньше единицы; 2) признак, позволяющий различать си¬
туации, когда число совпадений равно пулю, единице или больше единицы;.
3) счетчик откликнувшихся объектов. Некоторые способы, используемые для
реализации подобных индикаторов откликов, описываются ниже.
Признак, служащий для различения ситуаций, когда число откликов рав¬
но 0 и когда оно пе меньше единицы, может быть сформпрован непосредст¬
венно на основе устройства разрешения множественных откликов, состояние
которого зависит от того, имеется ли отклик.
Признак, описывающий ситуации, когда число совпадений равно нулю,,
единице или превышает единицу, может быть получен путем подсчета откли¬
ков, который ведется до тех пор, пока пе станет ясно, что чпело откликнув¬
шихся объектов равно пулю, единице пли двум (т. е. превышает единицу).
В последующих реализациях различение ситуаций, когда пет пи одного сов¬
падения и когда имеется по крайней мере одно совпадение, может произво¬
диться путем запоминания информации, описывающей первый отклик, пос¬
ле чего выполняется повторпая проверЕШ на ситуации, когда совпадений нет
и когда есть по крайней мере одно; эта вторая проверка сопровождается соот¬
ветствующей индикацией с последующим восстановлением информации о-
первом откликнувшемся объекте.
Могут быть также разработаны спепиальиые аппаратные средства, соот¬
ветствующие двойному устройству разрешения множественных откликов, од¬
но из которых служит для маскирования первого откликнувшегося объекта.
Определение действительного числа откликнувшихся объектов может потре¬
бовать больших времеппых затрат, так как отклики нужно подсчитать. Одной
^ К. Дж. Тербер 49'
зтз альтернатив такому подсчету является суммирование выходных токов,
возникших на шинах откликнувшихся слов, с последующим преобразованием
-аналоговой величины тока в цифровую форму, дающую искомую величину.
Наконец, последним из средств манипулирования с откликами является
извлечение откликнувшихся объектов так, что они образуют упорядоченный
•список. Существует изящное решение этой задачи. Это так называемый алго¬
ритм Левина [2.31].
Рассмотрим следующую задачу. Предположим, что имеется 6-разрядпое
слово, содержащее данные, и G-разрядпое слово, содержащее маску. Пусть в
слове данных записан код 011101, а в’маске — 010011, причем 1 в слове маски
означает, что системе безразлично, стоит ли в этой позиции откликнувшего¬
ся слова пуль или единица. Операция поиска па равенство выявит все слова,
имеющие 1 в первой и пятой разрядной позиции и 0 во второй разрядпой
позиции (будем считать, что первая позиция — крайняя справа). При таком
поиске возможно несколько откликов. Предположим, что все откликнувшиеся
объекты должны быть последовательно считаны с памяти. Эта операция мо¬
жет быть осуществлена с помощью алгоритма, который предусматривает по¬
следовательную изоляцию каждого выбранного слова.
Решение этой задачи было предложено Фреем и Гольдбергом [2.32]. Их
метод основан па использовании очень простого датчика, который указывал,
выбрано ли одно слово или больше. Для того, чтобы использовать этот метод,
система должна последовательно заменять нули в слове маски на единицы
и опрашивать память до тех пор, пока не встретится точное совпадение.
Главная проблема в реализации этого метода заключается в большом коли¬
честве бесполезных операций поиска, в результате которых ни одно слово
не откликается. Процесс изолировапия слов требует больших временных
.затрат.
Сибер и Лгондквист [2.33] разработали систему с установленным на выхо¬
де датчиком, который указывает на отсутствие отклика, наличие одного отк¬
лика или более чем одного отклика. Основное улучшение метода Фрея и
Гольдберга заключается в том, что незначащие разряды регистра маски не
все должны быть превращены в 1. Слово может быть прочитано сразу после
того, как оно было проидентифицировано, без дальнейшей работы с маской и
просмотра данных. Это требует более сложных аппаратных средств.
Главной особенностью вышеописанных методов является то, что они за¬
висят от числа разрядов в слове данных, а не от количества слов, которые
должны быть считаны. Метод, предложенный Левиным [2.31], заключается
в следующем. Предположим, что в процессоре, слова которого состоят из
Ь разрядов, имеется Ь чувствительных датчиков, причем каждый датчик под¬
ключей к двум сигнальным шипам (в качестве которых могут выступать ши¬
ны чтения). Затем сигнальная шпна пропускается через все слова, подклю¬
чая г-й разряд каждого слова к i-му датчику. Сигнальные шипы могут вос¬
принимать четыре состояния:
1) Состояние 0—0,1. Во всех выбранных словах значение данного разря¬
да равно 0.
2) Состояние 1—1,0. Во всех выбранных словах значение данного разряда
равпо 1.
3) Состояние X —1,1. В некоторых выбранных словах зпачепие данпогэ
разряда равпо 0, а в некоторых 1.
50
4) Состояние Y — 0,0. Нп одно блово но выбрано (т. е. ни одно нз храня¬
щихся в памяти слов не удовлетворяет условию поиска).
Определим битовый разрез i как совокупность i-x разрядов всех выбрап-
цых слов. Предположим, что в ассоциативпом процессоре для каждого битово¬
го среза имеется устройство, эквивалентное требуемому датчику, реагирую¬
щему на несколько состояний. Битовые разрезы, в которых все позиции рав¬
ны 0, все позиции равны 1 или те, в которых часть позиций равна 0, а часть
Рис.. 2.13. Блок-схема алгоритма Левина
равна 1, известиы. Обработке подлежат только те срезы, в которых имеются
как 0, так п 1. В каждый момент времени, когда обрабатывается состояние
X, изолируется первоначальное подмножество слов, удовлетворяющих усло¬
вию поиска. Ни за какие два успешных цикла не может изолироваться одно
и то же множество слов. В битовых срезах, находящихся в с-остояпии X, по¬
иск нулей (шш единиц), принадлежащих словам, хранящимся в памяти, мо¬
жет производиться слева направо. Если в процессе поиска двигаться через
слова в другом направлении, то будут находиться единицы (пули). Направ¬
ление движения справа палево или слева направо по имеет значения. Здесь
направление слева направо было выбрано, следуя Левину [2.31]. Результатом
такого выбора является алгоритм, реализующий метод Левина н представлен¬
ный на рис. 2.13. С точки зрения аппаратных средств, реализация алгоритма
** 51
-Ловила требует обеспечения возможности определять состояние X в каждой
разрядной позиции п фиксировать положение самого левого разряда, в кото¬
ром имеется состояние X. Для извлечения в лексикографическом порядке т
слои алгоритму требуется 2т — 1 циклов чтения.
Эвпнг и Дэвис [2.34] предложили способ реализации алгоритма Леви¬
на, пе требующий специальных аппаратных средств для двойпого опроса.
Они использовали в качестве датчиков модифицированные логические схемы,
обрабатывающие битовые срезы, что позволило реализовать алгоритм Леви¬
на, в котором каждая колонка разрядов опрашивается дважды, одни раз па 1
и второй раз на 0, для того чтобы определить, какая колонка разрядов была
бы в методе Левпыа отнесена к состоянию X. Особенность такой реализации
заключается в использовании: логических схем, составляющих аппаратную
часть слов памяти п алгоритма двойного опроса, вместо использования двой¬
пого объема логических схем, образующих аппаратную часть разрядов слов.
Схема с двойным опросом по сравнению с непосредственной реализацией
алгоритма Левина могла занимать но крайней мере вдвое больше времени в
зависимости от конструкции аппаратной части слов, по, тем пе менее, эта
схема представляется хорошим техническим решением. Большинство полу¬
проводниковых ассоциативных запоминающих устройств ограничивается чис¬
лом выводов на кристалле. Это происходит из-за необходимости иметь выво¬
ды для каждого слова и каждого выделенного битового среза. Учитывая
возможности современной технологии изготовления полупроводниковых уст¬
ройств, нереально ожидать создания для реализации алгоритма Левина кри¬
сталлов с двойным количеством выводов. Подробный анализ многочисленных
■способов реализации, устройства разрешения множественных откликов, до¬
ступных с точки зрения сегодняшней полупроводниковой техники, имеется в
работе Апдерсена [2.62].
Ассоциативные процессоры
в роли универсальных вычислительных машин
В отличие от параллельных процессоров, которые могут рассматриваться
только как представители класса ОКМД, ассоциативные процессоры допуска¬
ют и другую интерпретацию. Наибольший объем оборудования ассоциативно¬
го процессора приходится на ассоциативную память. Таким образом, любой
ассоциативный процессор может рассматриваться как запоминающее устрой¬
ство. Запоминающее устройство такого тппа отличается «неправильным» спо¬
собом доступа к данным. В прикладных задачах, требующих большого коли¬
чества операций, связанных с поиском данных или обработкой списков, глав¬
ная память процессора может быть заменена на ассоциативную память. Та¬
кая замена приводит к тому, что вместо отношения процессора к специали¬
зированному ассоциативному процессору по принципу «ведущий—ведомый»
появляется отношение, основанное па принципе интеграции, при котором ас¬
социативный процессор играет роль памяти ведущего процессора. Учитывая
стоимость ассоциативпых запоминающих устройств, этот принцип, возможно,
пе является приемлемым с экономической точки зрепия. Однако па ранних
этапах развития техники ассоциативной обработки был разработан ряд инте¬
ресных конструкций, основанных на этом принципе. Если бы ассоциативные
запоминающие устройства были экономически приемлемыми, то их исполь-
52
зовапие в качество главной памяти вычислительной машины дало бы ряд
преимуществ.
Впервые ассоциативная вычислительная система универсального назпа-
■чеппя была разработана Розином [2.35] и предназначалась для обработки
.списковых структур. Утверждалось, что система имела следующие преимуще¬
ства: 1) легкость обслуживания, поскольку слова ассоциативного процессо¬
ра моелн быть сделаны незначащими с помощью бита отмены значимости
^J3J3 — disability Lit); 2) использование символических имен, упрощающее
■транслятор программ, загрузчик и схему адресации; 3) данные могли быть
опабжеиы тегами (для отделения индексов от прочей информации) и 4) обес¬
печивалось использование возможностей ассоциативного процессора для об¬
работки списковых структур и табличного поиска.
Розин указал основные проблемы, связанные с подобной архитектурой.
Что означает инструкция ЗАПОМНИТЬ В X, если X представляет собой
файл, распределенный по памяти процессора? Каков смысл X? Решение
этих задач привело к двум операциям запоминания. Первая операция запи¬
сывала в X, как если бы X представлял собой имя некоторой существующей
ячейки. Вторая операция запоминания создает новую ячейку, присваивает
ей тег X и затем записывает в X. Вторая проблема заключается в следую¬
щем. Каким образом извлекать данные из многоразрядного слова памяти,
пользуясь непревычпыми тегами и масками? Эта проблема была решена пу¬
тем введения трех инструкций: одна инструкция служила спецификацией
входного слова данных, одна ипструкция задавала маску и одна инструкция
•описывала набор поисковых команд, с помощью которых слово данных и ре¬
гистр маски сопоставлялись с соответствующими разрядами.
Примечательная черта машины Розина состоит в том, что все операции
;управления такие, как индексация или операции над специальными регист¬
рами, выполняются почти за то же самое время, что и операции чтения из
памяти или записи. Поэтому в конструкции должно быть пересмотрено соот¬
ношение между операциями управления и операциями с памятью. Машине
ше нужен дешифратор адресов, так как адресация осуществляется по содер¬
жимому, а не с помощью точного указания местоположения. Заметим, что
для извлечения слова из ассоциативного процессора требовалась возмож¬
ность маскировапия разрядов входного слова данных, с помощью которого
производилась адресация. Благодаря особому устройству ячеек, ассоциатив¬
ный процессор имел возможность выбирать первое откликнувшееся слово.
Эта функция была предшественником устройства разрешепия множествен¬
ных откликов В процессоре имелся разряд последовательной цепочки, кото¬
рый позволял устройству управления последовательно получать верхнее от¬
кликнувшееся слово путем чтения и' вычеркивания слова из списка отклик¬
нувшихся слов.
Заданный размер слова составлял 140 разрядов, как показано на
рпс. 2.14. Слово команды, как и слово дапных, разбито на несколько групп,
состоящих из фиксированного числа последовательных разрядов и называе¬
мых полями. Архитектура машипы обусловила ряд пеобычпых ограпичепий
на последовательность команд. Например, блоки, содержащие процедуры и
Дапные, являлись перемещаемыми при следующем ограничении: программа
внутри блока должна представлять собой линейпо-упорядочеппую последова¬
тельность команд. Однако данные могли быть распределены произвольно.
Апалогпчпоо ограничение имело место по отношению к блокам данных, г
которых доступ к данным осуществлялся с помощью индексации.
Что касается организации переходов и передачи управления, то обыч¬
ный способ присваивания командам тега имени, позволяющий выполнять пе¬
реходы и передавать управление по имени команды, здесь не применялся.
Вместо этого между любыми двумя соседними командами всегда вставля¬
лось слово данпых. Затем этому слову присваивался особый тег, являющийся
Слово
данных
Слово
команды
•Признак Признак
косвенной не о о среде т ве иной
— адресации адресации
Рис. 2.14. Форматы данных и команд
тегом контрольной точки*). Для облегчения реализации последовательного
выполнения команд и передачи управления были введены бит команды
(IB — Instruction Bit) и бит исполненной команды (IUB — Instruction Used
Bit). Этот способ позволил Розину сэкономить 1,5 млн разрядов памяти в
своей машине, память которой состоит из 32 ООО слов, за счет отказа от ис¬
пользования имен внутри командного слова для команд, являющихся конт¬
рольными точками. Множество команд, подлежащих исполнению, определя¬
ется с помощью операции поиска. Следовательно, команды считывались из
ассоциативного процессора.
Индексация в рассматриваемой машипе была совершенно особая. Она
была построена при учете того обстоятельства, что скорости выполнения опе¬
раций управления и операций работы с памятью были почти одинаковыми.
Поэтому любое слово памяти в ассоциативном процессоре могло использова¬
ться в качестве индексного регистра. Процесс выполнения команд показыва¬
ет многие особые черты, характерные для рассматриваемой машины: 1) ка¬
кие-либо счетчики, указывающие местоположение, или дешифраторы адресов,
пе требуются; 2) для модификации тега данных можно использовать в каче¬
стве адресов как данные, так и индексы; 3) адресация может быть либо кос¬
венной, либо непосредственной, либо прямой; 4) блоки данных являлись пе¬
ремещаемыми и могли иметь неограниченный размер п 5) список доступных
блоков храпения предоставлялся процессору непосредственно с помощью би¬
та доступности, содержащегося в каждом слове. Вычислительная машина
могла работать в мультипрограммном режиме. Защита информации осущест-*
Управ гяю.цие
раз о я ды
Тег
знформаципннзя
‘-I а г, 11)
/о разрядов
УпраБ.гя-ощае
р а з п ? д ы
А д р е е
48разрядов i. п4 разряда
'б разрядов!
2 разряда
о зазряда
48 разрядов
2 рлоояда
*) Здесь: ячейка, па которую передается управление. {Примеч. пер.)
54
клялась непосредственно в памяти па уровне слов. Программы могли оез
•опасении смешиваться произвольным образом.
Универсальный ассоциативный процессор, предложенный Дэвисом [2.3G],
изображен па рис. 2.15. С точки зрения функционирования этот процессор по¬
добен машине Розина. Имеется возможность хранить команды в ассоциатив¬
ной памяти процессора, а пе в отдельном запоминающем устройстве для хра¬
нения программ (па рибункс пе по- w
казано). Поэтому б.ыл введен регистр
данных, выполняющий функцию
передачи информации из памяти
к устройство управления. В процес¬
сор предполагалось ввести средст¬
ва для маршрутизации. Каждая
ячейка памяти могла иметь доступ
к информации, хранящейся в сосед¬
ней ячейке (образуя тем самым сеть
<с линейной структурой связей).
Длина слова процессора состав¬
ляла 27 разрядов. Первые три раз¬
ряда являлись тегом, обозначающим
пустое слово, слово данпых или
'Слово команды. Остальные 24 разря¬
да были разбиты на два 12-разряд-
ных поля. Одно поле использова¬
лось в качестве метки. Другое поло
служило для хранения слова дан¬
ных или команды. Система 'команд
машины включала тридцать одну
^базовую команду. Устройство управ¬
ления в данном случае определяло последовательность операций (микроко¬
манд), которые выполнялись управляющими модулями, и передавало микро¬
команды одновременно всем управляющим модулям. Каждый управляю¬
щий модуль управляет закрепленным за ним словом памяти. Главное пре¬
имущество рассматриваемого процессора перед машиной Розина состоит в том,
■что можно упростить процедуру определения последовательности операций.
Штурман [2.37, 2.38] предложил строить универсальные вычислительные
машины на базе ассоциативных запоминающих устройств. В основу разрабо¬
танной им конструкции процессора универсального назначения положен
•принцип памяти с распределенной логикой, выдвинутый Ли [2.39]. Этог
припцгш описывается ниже в этой главе. Так же как и остальпые ассоциа¬
тивные процессоры универсального назначения, машина Штурмана пе была
эффективной с точки зрения стоимости.
Принцип замены обычной памяти машины ассоциативной памятью и по¬
строения на этой основе вычислительной системы универсального назначе¬
ния оказался несостоятельным. В универсальных машинах оказались полез¬
ными небольшие ассоциативпые запоминающие устройства, используемые в
механизме виртуальной памяти, а также для обработки прерываний, состав¬
ления расписаний, распределения ресурсов и организации ассоциативной
памяти на дисках [2.40, 2.41].
55
Управляющая
часть
Область
хра нем и я
УпиапЛ/чепций
моду ль
Ячейка
памяти
t f
Г: 3 И Я ' Ь
,.L_J
Регистр
м аск и
Регистр
данных
Регистр
операнда
Рис. 2.15. Блок-схема ассоциативного
процессора, применяемого в качестве
универсальной вычислительной машины
Ли предложил улучшить вычислительные машппьт, в которых данпьте г
программы могли храниться раздельно. Суть предложения состоит в том,
чтобы осуществлять обмен с отдельным запоминающим устройством по одно¬
му слову за один обмен. Это устройство должно представлять собой ассоциа¬
тивную память, в которой каждое слово включает управляющую часть, поло
имени (именование объектов данных понимается так, как это принято н
виртуальной памяти), а также информационную часть, в которой находится
объект хранения. Процедура в такой системе исполняется обычным образом
путем вызова операндов по имени из ассоциативной памяти данных. Этот ме¬
тод не получил развития из-за малого количества задач, в которых данные
и процедуры могли быть полностью разделены.
Подводя итоги, можно сказать, что . ассоциативная память пе сможет
служить основой для построения универсальных вычислительных машин до
тех пор, пока ее стоимость не окажется сравнимой со стоимостью запоми¬
нающих устройств с произвольным доступом. Возможно, что сфера исполь¬
зования ассоциативных устройств в универсальных вычислительных маши¬
нах будет ограничена небольшим количеством оборудования, облегчающего
выполнение операций управления и помогающего устранять узкие места.
Вполне вероятно, что ассоциативные процессоры, способные решать множе¬
ство похожих задач, могут быть создапы для применения в широком мас¬
штабе.
SIMDA — машина с обработкой битовых срезов
В предыдущих параграфах были описаны процессоры с обработкой бито¬
вых срезов и с распределенной логикой. Этот раздел посвящен машине SIMDAr
построенной по принципу обработки битовых срезов [2.43, 2.44, 2.45]. SIMDA
не разрабатывалась для какого-либо специального применения. Ее скорее мож¬
но отнести к разряду ансамблей, нежели к ассоциативным процессорам.
SIMDA представляет собой конструкцию процессора, разработанную фирмой
Texas Instilments для RADG — Авиационного научно-исследовательского центра
ВВС США Роум, где она служит испытательным стендом, па котором отраба¬
тываются технологии ассоциативной обработки. Большое внимание системе
SIMDA (известной также под названием RADCAP) и ее применениям было
уделено на первой Сагоморской конференции. В Сагоморе было проведено не¬
сколько конференций по вопросам параллельной обработки. Много хороших
статей, посвящеппых параллельным процессорам, можно найти, например, в
трудах второй Сагоморской конференции [2.47].
Одна из важнейших особенностей системы SIMDA заключалась в заложен¬
ных в ней средствах для измерения производительности. SIMDA разрабаты¬
валась как высокопроизводительная (работающая с битовыми срезами) вычис¬
лительная система, рассчитанная на работу по специально разработанным
прикладным программам. Высокая производительность системы позволила спе¬
циалистам RADC отказаться от более медленных ассоциативных процессоров,
использовавшихся в режиме, близком к реальному времепи, несмотря на то,
что SIMDA не была непосредственно настроена на решение специальных за¬
дач, возложенных па эти процессоры; Способность к измерению характеристик
вычислительного процесса позволила набрать подробную статистику относи-
56
цельно выполнения программ, которая давала возможность оценить эффектив¬
ность ассоциативных процессоров. Заметим в скобках: в направлении разработ¬
ки Для ассоциативных и параллельных процессоров аппаратных средств, по¬
добных средствам измерения характеристик плп обеспечения отказоустойчи¬
вости, сделало очень мало.
Партами и Авпцспис [2.61] выполнили весьма ценное исследование по
•вопросу обеспечения отказоустойчивости, в котором отмечалась, что заложен¬
ные в системе SIaIDA средства для измерения характеристик создают основу
для решения этой задачи.
SIMDA со сто] Гг из шести главных подсистем (рис. 2.16). К ним относятся:
1) устройство управления (УУ), 2) обрабатывающий ансамбль, 3) устройство
ввода/вывода, 4) главная память, 5) последовательный процессор и 6) ком¬
плекс средств для измерения характеристик.
Далее будут рассмотрены только архитектура обрабатывающего ансамбля
я измерительный комплекс. В систему входит устройство управления и уст¬
ройство ввода/вывода, которые мо¬
гут контролировать работу ансамбля
из 1024 ПЭ. ПЭ сгруппированы
в блоки по 32 в каждом. Устройст¬
ва управления и ввод/вывод опери¬
руют поочередно на уровне блоков.
Любой блок ПЭ может работать ли¬
бо с устройством управления, либо
с устройством ввода/вывода, но ие
с обоими одновременно. Одни про¬
цессорные блоки могут выполнять
ввод/вывод, в то время как другие
могут производить вычислительные
операции, одпако все ПЭ внутри
одного блока обязательно должны
находиться под управлением одного
и того же устройства, либо все быть
неактивными. Главный обрабатывающий апсамбль состоит из 1024 ПЭ и
32 МДУ (мультиплексор двойного управления). МДУ обеспечивает режим ра¬
боты системы SIMDA, при котором процессорные элементы сгруппированы
в блоке по 32 в каждом так, что любой блок может находиться под контро¬
лем либо устройства ввода/вывода, либо устройства управления.
Процессорный элемент, схема которого показала на рис. 2.17, представляет
собой 4-разрядпый процессорный модуль. В его состав входит память (256 слов
но 5 разрядов, включая 1 разряд контроля четности, при этом собственно в
вычислениях используются 4 разряда), четыре регистра (основные арифмети¬
ческие регистры А п В II вспомогательные регистры С и D, используемые при
реализации в ПЭ последовательности микрокоманд) и 4-разрядное арифметико-
логическое устройство (АДУ). Конструкция ПЭ предусматривает работу с
^б-разрядпыми операндами, что требует четырехкратного обращения к АЛУ
при выполнении каждой команды. Данные передаются в виде 4-разрядпых
порций. Каждый ПЭ должен иметь восемь 16-разрядпых виртуальных регист¬
ров. Эти восемь регистров располагаются в 128 младших разрядах памяти с
произвольным доступом. Четыре рабочих регистра (А, В, С и D) могут
Рис. 2.16. Конфигурация системы
SIMDA
57
образовывать последовательную цепочку, по которой можно передвигать ин¬
формацию.
Ассоциативная обработка в системе SIMDA реализована в терминах 16-
разрядных слов. Произвольный доступ осуществляется к 16-разрядным сло¬
вам. Все алгоритмы оперируют с 16-разрядными словами и формируют 16-раз-
рядные результаты. По сравнению с другими машинами, работающими с би¬
товыми . срезами, может быть достигнуто значительное повышение скорости
Рис. 2.17. Схема процессорного элемента системы SIMDA
обработки. Если же требуется произвольный доступ к битовым срезам, хра¬
нящимся в произвольных словах процессора, то может произойти резкое сни¬
жение производительности. Ввод/вывод и взаимосвязи, реализуются в байто¬
вой форме.
ПЭ может выполнять сорок восемь команд. Основными командами явля¬
ются: передать содержимое регистра А, взять дополнение А, передать содер¬
жимое регистра В, взять дополнение В, увеличить, умепынить, сложить, вы¬
честь, а также логические операции И, НЕ — И, ИЛИ, НЕ — ИЛИ, ИСКЛЮ¬
ЧАЮЩЕЕ ИЛИ, ИСКЛЮЧАЮЩЕЕ НЕ — ИЛИ, логический 0 и логическая 1.
Имеются инструкции, позволяющие управлять состоянием процессорного эле¬
мента. ПЭ имеет два регистра состояния (на рис. 2/17 не показаны), в кото¬
рые записывается следующая информация, характеризующая состояние ПЭ:
1) признак активности ПЭ, 2) результаты сравнения (меньше, равно, больше),
3) признак переполнения, 4) признак сбоя и 5) разнообразные признаки, ха¬
рактеризующие состояние микропрограмм. ' •“ *
Для того чтобы показать особенности SIMDA, необходимо остановиться
па двух системах, обеспечивающих работу ПЭ. Это система поддержки ан¬
самбля* (СПА) и система межпроцессорных связей (СМПС). СПА состоит из
4-разрядпой однонаправленной шины для передачи данных от УУ к ПЭ, схе¬
мы приоритетов (эта схема переводит в активное состояние либо все помечен¬
ные ПЭ, либо помеченные ПЭ, имеющие высший приоритет), схемы экстре-
58
сальных значений, которая позволяет пользователю находить максимальное
(минимальное) значение, содержащееся в заданной области памяти всех ПЭ,
л схемы подсчета откликов, которая определяет число активных элементов
(она также определяет, что число активных элементов равно нулю, единице
или больше единицы), СМПС обеспечивает взаимосвязь между ПЭ. СМПС мож¬
но представить в виде трех столбцов, содержащих по 1024 мультиплексора,
,обозначенных X*, Y* и Z», где 1 ^ i ^ 1024. ПЭ; управляет мультиплексорами
X,-, Yi и Z*. Мультиплексоры имеют доступ к разным Г1Э. Мультиплексор Zг-
обеспечивает связь ПЭ с множеством ПЭ, имеющих номера от i + 7 до i — 8.
Мультиплексор Y* имеет доступ к мультиплексорам Zi, Zz-+i6, Zi+32... и муль¬
типлексор Х2- имеет доступ к мультиплексорам Y*, Уг--ы2з.. • Номера всех муль-
■тпплексорных связей берутся-по модулю 1024. Любой ПЭ может получить до¬
ступ к любому другому *ПЭ, хотя при этом возможны конфликты. За исклю¬
чением случая, когда все передачи осуществляются с постоянным шагом
f-/i), конфликты возможны, при этом передача-не может быть осущест¬
влена одновременно. -
Другой особенностью системы SIMDA была заложенная в нее возможность
измерения характеристик. Предполагалось, что исполнение программ пе бу¬
дет иметь достаточную продолжительность, позволяющую получить статисти¬
ческие данные, вот почему в аппаратуру были встроены средства для изме¬
рения характеристик. Измерительный комплекс позволяет регистрировать пять
основных параметров, характеризующих работу системы. К ним отпосятся:
1) характеристики потока команд (счетчики исполненных команд), 2) актив¬
ность памяти (счетчики обращений внутри блоков памяти), 3) ипформация
о линейных участках (представляется возможность выявлять и регистриро¬
вать линейные участки, встречающиеся в рабочих программах), 4) активность
процессорных элементов и 5) ипформация о работе системы (совокупность
32 счетчиков, в которых регистрируется число временных интервалов, па ко¬
торых выполняются условия, заданные программистом).
Главным преимуществом архитектуры SIMDA является быстродействие.
Возможны конфликты между вычислительными операциями и вводом/выво¬
дом. Система отличается высокой стоимостью оборудоваппя, большую часть
которого составляют 4-разрядпые АЛУ и коммуникационная аппаратура. Вы¬
сокая, по сравнению с другими системами, стоимость программирования обус¬
ловлена необходимостью принимать специальные меры по структурированию
данных таким образом, чтобы избежать бесполезного расходования вычисли¬
тельной-мощности, которое происходит при неэффективном программировании.
Запоминающие устройства с распределенной логикой
Задача извлечения информации, представленной в виде строк, была иссле¬
довала Ли [2.39]. В результате исследования был предложен принцип памяти
с распределенной логикой (ПРЛ). В общих словах, проблема извлечения дан¬
ных состоит в идентификации и извлечении информационных строк. Опреде¬
лим строку как объект, включающий (заголовок) (информационную часть)
(признак конца строки). При решении рассматриваемой задачи возникает ряд
трудностей, связанных со следующими факторами: 1) количество объектов,
'Составляющих, информационную часть, может быть перемеппым, 2) все строки,
принадлежащие исследуемому, множеству, должны проверяться иа факт вы¬
59
полнения критерия поиска, и 3) могут встречаться некоторые побочные фак
торы (или одинаковые строки), порождающие мпожествеппые отклики ш
заданный критерий. В отличие от ранее существовавших ассоциативных сне
тем, ПРЛ, по замыслу создателей, должна иметь следующие особенности,
1) меньшее число команд, 2) большую специализацию комапд, 3) отсутствие
внешних логических устройств, 4) новые методы взаимодействия между об¬
рабатывающими элементами и 5) специализированную структуру управления,
ПРЛ, предложенная Ли. Рассматриваемая ПРЛ создавалась специально ка гг
память для хранения и обработки строковой информации. Архитектура систе¬
мы показана па рис. 2.18. Эта архитектура представляет собой ассоциативный
Рис. 2.18. Блок-схема запоминающего устройства с распределенной логикой
процессор. В нем имеются взаимосвязи между ячейками и средства, обеспечи¬
вающие распространение сигнала. Целыо разработки ПРЛ было создание ма¬
шины, в которой: 1) ячейки являются неразличимыми, 2) время, затрачивае¬
мое па извлечение строки, не зависит от количества ячеек, 3) время, затра¬
чиваемое па перекресное извлечение (извлечение заглавной строки по задан¬
ной строке параметров), пе зависит от числа ячеек и 4) память является мо-
дульно расширяемой. Эта конструкция должна была прийти па смену обыч¬
ным системам, для которых характерно паличие сложной взаимосвязи между
информационным содержимым и адресом. По существу, проблемы сканирова¬
ния и адресации были сняты. Процессор осуществляет поиск строк. Исключа¬
ются строки, которые не удовлетворяют заданным критериям. После завер¬
шения поиска производится идентификация всех откликнувшихся строга
Элементарные операции процессора показаны па рис. 2.18 линиями. Ас¬
социативный процессор имеет четыре команды: ввести, вывести, распростра¬
нить и сопоставить. На рисунке изображены также линии, соответствующие
операциям ввода и вывода, а также желаемому направлению распространения
60
(папрапо пли налево). Ввод и вывод являются стандартными функциями. Опе¬
рация ввода производит запись информации, находящейся па входных шинах,
в активные ячейки. Операция вывода производит считывание информации из-
одной ячейки и помещение ее в выходной буфер. Возможна неоднозначность
при выводе, если в результате идентификации выявилась не единственная
ячейка. Вывод при наличии неоднозначности производится по логике ИЛИ
для содержимого всех откликнувшихся ячеек по мере считывания их в вы¬
ходной буфер. Для однозначного вывода необходимо, чтобы только одна ячей¬
ка была активной.
Ассоциативная обработка в процессоре обеспечивается с помощью опера¬
ции сопоставления. Выполнение команды сопоставления состоит в том, чтс
b d
Рис. 2.19. Представление запоминающей ячейки для памяти
с распределенной логикой
содержимое всех активных ячеек одновременно сравнивается с информацией,,
находящейся на входных шипах. Если результат сравнения в i-ii ячейке ока¬
зывается положительным, то формируется внутренний сигнал Mi, который)
передается к одной из соседних ячеек в зависимости от заданного направле¬
ния распространения (мы будем полагать, что сигнал распространяется спра¬
ва налево). Результатом передачи сигпала Mi к соседней справа ячейке яв¬
ляется то, что эта ячейка становится активной. Команда «распространить»
вызывает распространение битов активности всех ячеек, сигналы от которых
должны быть переданы к соседним ячейкам, в заданном направлении.
Большинство ассоциативных процессоров пе обладают данпой способ¬
ностью распространять сигпал. Поскольку в ПРЛ один объект строки хранится
в одпом элементе памяти (ячейке), то должна быть обеспечена возможность,
соединения всех соседпих ячеек, образующих строку. Ячейка является либо
активной, либо неактивной. Каждая ячейка может быть схематично представ¬
лена так, как эго изображено на рис. 2.19. Модель ячейки состоит из двух
частей: р обозначает символ, хранящийся в ячейке, a q обозначает состояние
ячейки. У пеактивной ячейки q равно 1, а у активной 2. В качестве символов
могут выступать любые символы входного языка, за исключением символов
а и (3. Последние являются зарезервированными символами. Символ а исполь¬
зуется для обозначения заголовка строк имен, а (3 — для обозначения заголовка-
строк параметров.
Строка образуется из двух частей: заглавной строки и строки параметров..
Пусть X — строка параметров для заглавной строки АВ. Тогда, в соответст¬
вии с общепринятым способом записи слева паправо, строка в ассоциативном
процессоре будет храниться в виде, показанном на рис. 2.20 (в предположе¬
нии, что все элементы строки неактивны). Пусть имя заголовка известно, тог¬
да извлечение строки параметров осуществляется следующим образом: 1) опе¬
рация сравнения пачипается с а, 2) соседние справа ячейки всех тех ячеек,
Для которых результат сравпепия положителен, устанавливаются этой опера¬
цией в активное состояние, и 3) операция сравпепия проходит через все эле¬
менты заглавной строки. В копце этого процесса только те заглавные строки
имеют признак [3 в текущей активной ячейке, которые точно совпали с заглав-
6t
■пой строкой, заданной на входе (напомним, что операция сравпения с поло¬
жительным результатом в активной ячейке активизирует соседнюю ячейку и
все ячейки одновременно передают сигналы своим соседям справа). В процес¬
се сравнения, начиная с первой ячейки, откликнувшейся на призпак а, рас¬
пространение сигнала активности происходит до тех пор, пока идет последо¬
вательность ячее];, для которых операция сравнения дает положительный ре¬
зультат. Строка параметров, удовлетворяющая условию поиска, может быть
Рис. 2.20. Порядок расположения информации в памяти с распре¬
деленной логикой
■извлечена путем распространения бита активности до тех пор, пока не встре¬
тится символ а. Описанный способ известен под названием непосредственного
извлечения, т. е. извлечения строки параметров по заданному имени заглавной
строки.
Перекрестное извлечение, т. е. извлечение заглавной строки но заданной
строке параметров, выполняется аналогичным способом. При перекрестном
извлечении осуществляется идентификация строки параметров, участвующей
в операции, с заданной строкой параметров, путем перемещения влево от
первого символа а, идущего после символа [J (обозначающего любую границу
■строки параметров). После этого может быть прочитано имя заголовка.
Принципы построения ассоциативных процессоров на базе ПРЛ были
обобщены до уровня, позволившего работать со строками, содержащими един¬
ственное имя и набор строк, параметры которых являлись объектами ассоци¬
ативного поиска. Успех практической реализации ПРЛ-архитектуры зависит
от того, насколько реальным окажется построение системы, содержащей ты¬
сячи или даже миллионы ячеек.
С концепцией ПРЛ связан целый ряд проблем. Если сравнивать ПРЛ
•с любой машиной, построенной на базе тех же элементов, то, с точки зрения
обработки строк, ПРЛ. превосходит но быстродействию любую из мыслимых
конструкций. Благодаря присущей ей высокой степени параллелизма ПРЛ спо¬
собна решать задачу извлечения строк за минимальное время. В то же время
это достоинство заключает в себе главный недостаток. Линейный принцип
организации ПРЛ выдвигает требование, чтобы система была компактной;
кроме того, наличие задержек в цепях распространения сигпала замедляет
скорость обработки при громоздких данных. Затраты па создание ПРЛ могли
бы оправдаться только в больших системах, в которых главным критерием
является быстродействие. Все эти проблемы побудили Липовски [2.48] искать
пути совершенствования данной конструкции, о чем пойдет речь в следующем
параграфе.
Процессор с древовидной структурой связей. Липовски [2.48] отталкивал¬
ся от основной конструкции Г1РЛ, изображенной на рис. 2.21. Архитектура
разработанной модели ПРЛ-процессора обладала следующими особеппостямп:
во всем множестве ячеек каждая имела, по крайней мере, одип регистр хра¬
нения, схему сравнения, триггер отклика и две шины для связи с другими
ячейками. Одна пиша соединяет пары ячеек и в дальнейшем будет называть¬
ся поперечной. Другая шипа, параллельно соединяющая все ячейки, служнт
62
для обеспечения общей взаимосвязи и передачи комапд ячейкам. Поскольку
ячейки являются ассоциативными, номера ячеек введены только в целях по¬
яснения архитектуры, а не как адреса. Информация, подлежащая сравнению,.
и маска, так же как и комадды, передаются вниз по каналу, при этом ячейка
(участвующая в операциях) является доступной тогда и только тогда, когда
ее триггер находится в состояпии, соответствующем активности.
Рис. 2.21. Структура памяти с распределенной логикой процессора
с древовидной структурой
В применении к информационно-поисковым системам множество информа¬
ционных элементов будет храниться в виде групп (агрегатов), образованных
непрерывными последовательностями ячеек, причем для каждого элемента
множества отводится своя ячейка. Поперечная шина должна обеспечивать
взаимосвязь между элементами мпожества таким образом, чтобы была воз¬
можность выявлять подмножества, части строк, а также чтобы подсчитывать
число элементов.
Главной проблемой, связанной с применением архитектуры памяти с рас¬
пределенной логикой в информациоппо-попсковых системах, является сниже¬
ние быстродействия из-за задержек, возникающих в линиях связи. Кроме того,
всегда желательно, чтобы система обладала быстродействующим вводом/выво¬
дом и способностью производить сегментацию процессорных ресурсов для вы¬
полнения подпрограмм. ПРЛ, обладающая линейной структурой, в недостаточ¬
ной степени отвечает этим требованиям. Ее реализация в виде больших сис¬
тем с практической точки зрения нецелесообразна из-за значительных задер¬
жек в линиях распространения сигнала. Учитывая вышеизложенные факторы,
был разработан процессор с древовидной структурой связей [ПДС], изобра¬
женный на рис. 2.22. Данная архитектура нозволяет значительно снизить ве¬
личину потенциально больших задержек в поперечных шипах. Предположим,
что в процессоре имеется одиночный канал и два идентичных комплекса для
передачи информации по поперечным шипам. На рис. 2.22 показан только один
такой комплекс. Каждая ячейка должна быть устроена таким образом, чтобы
63.
К кроне
дерева
К корню
дерева
■Рис. 2.22. Схема расположения
'функциональных ячеек в процес¬
соре с древовидной структурой
сигнал, который нужно передать от точкп А к точке В, мог бы обойти ячейку
1 и 2. Ячейка 3 может быть установлена в такое состояние, чтобы сигнал ьт
точки Л попал в ячейку В, минуя ячейку 3, а тте пошел бы по пути из А в 3,
затем в 1, затем в 2, затем в 3, л, наконец, в В. Далее, из рис.-2.22 читатель
-может заметить, что линейный порядок сохранен в том смысле, что ячейка i
находится над ячейкой / при 7 > i и ячей¬
ка i находится ниже ячейки к при i > к.
Корневая ячейка всегда будет иметь наи¬
больший номер и находиться ниже всех
остальных ячеек.
Существует трехмерная реализация
ПДС-архитектуры в с'емимерпом дере¬
ве, показанная на рис. 2.23. Чтобы пояс¬
нить конструкцию, изобразим куб и обо¬
значим его углы через 1, 2... 7, А. Поме¬
стим ячейку в цептр куба и соединим ее
с каждым из углов 1, 2, ..., 7, Л. Назовем
то, что получилось, листом-модулем. В об¬
щем случае для того чтобы построить дере¬
во, возьмем семь идентичных листьев-мо¬
дулей и соединим их таким образом, чтобы
все углы Л совпадали. Для формиро¬
вания большего листа-модуля соединим
этот угол со свободным углом, обозначен¬
ным на рис. 2.23 через В. Полагая А — В
тг повторяя процедуру, дерево можно расширить. Существуют также 25- и 50-
разморные реализации однородных деревьев. Задержка в распространении
-сигнала в подобных древовидных структурах поддается расчету и оказывает¬
ся значительно меньшей, чем в ПРЛ с линейной организацией.
Преимуществом древовидной структуры является то, что она может быть
разбита на сегмепты, образующие независимые поддеревья. Граница сегмента
в канале можеть быть выбрана в точке 3, обра¬
зуя поддерево, состоящее из ячеек 1, 2 и 3. На¬
личие поддеревьев воздвигает преграды на пути
передачи команд, вследствие чего появляются
командные домены. Командные домены действу¬
ют независимо друг от друга и могут изменять
содержимое как самих себя, так и других
доменов путем разграничения или соединения
каналов. Командпые домены могут сливаться
друг с другом. Ввод/вывод в процессорах с ПДС-
архптектурой имеет ограничения, так как соот¬
ветствующие устройства работают с заранее
выделенными ячейками, поэтому командные
домены должны так сегментпровать структуру, чтобы обеспечить себе доступ
к этим устройствам.
Кроме проблемы сегментирования процессора, в некоторых задачах возни¬
кает обратная проблема, т. е. требуется механизм, с номощыо которого можно
было бы формировать командные домены больших размеров. Рассмотрим дво-
1
г\
J I \
6
Рис. 2.23. Метод постро¬
ения однородного . дере¬
ва, обладающего семыо
измерениями
<64
ячпое дерево, изображенное на рис. 2.2 ±. На основе этого дерева может быть
достроена коммуникационная сеть. Добавим к дереву вершину (3, 2). Резуль¬
тат показан на рис. 2.25. Древовидная структура может быть восстановлена пу¬
тем исключения связей. Исключим пару связей (3, 4) (2, 2) и (3, 2) (2, 4),
либо пару (3, 4) (2, 4) и (3, 2) (2, 2) и получим два дерева. На рис. 2.26
доказано большое число структур. Путем исключения связей можно получить
(1,1) (1,2) (1,3) (1,4)
Рис. 2.24. Основное дерево
рево
Q±w х£дз-2)
четыре дерева. Таким способом для двоичных деревьев была получена ком¬
муникационная сеть, предусматривающая разделение каждого блока па вер¬
шины и образование внутри блока древовидной структуры. Эта конструкция мо¬
жет быть создана иа любом уровне в дереве и является полезной для древо¬
видных структур, отличных от двоичного дерева (например, для тг-мерных де¬
ревьев с веерной структурой).
В результате получается одпородпая структура, которая используется для
организации взаимодействия между процессором и каналами ввода/вывода, что
в конечном счете образует вычислительную систему. Каждая базовая ячейка
подключена к корневой ячейке процес¬
сора или к ячейке, которая управляет
доступом к капалу ввода/вывода. Всей
структурой управляет устройство уп¬
равления. Устройство управления под¬
ключено таким же образом, как блок
ввода/вывода. В этом случае устройство
управления заклгочепо в единственном
командном домене. Другие процессор¬
ные блоки могут функционировать не¬
зависимо от этого устройства управле¬
ния. Для того чтобы выбрать и подклю¬
чить к дереву, входящему в коммуни¬
кационную структуру, множество базо¬
вых вершин, выбираются блоки ввода/вывода и процессорные блоки. Выбира¬
ется вершина (ячейка), которая становится корнем дерева. Подключение
завершено. Для обеспечения описанной процедуры нужны три категории
ячеек (базовые, вершинные и связные) и, кроме того, должпы быть введены
Дополнительные линии связи, позволяющие передавать сигналы внутри сети.
^ К. Дщ. тербер
Другие возможные
ревья
65
Использование коммуникационной сети в большей степени, чем сегмец-
тирование процессора, приводит к тому, что частота запросов к устройствам
ввода/вывода и число конфликтов, встречающихся при сегментировании боль¬
шого процессора, значительно уменьшаются. Эффект от использования прин¬
ципа древовидных связей состоит в уменьшении на несколько (от 6 до 8) по¬
рядков величин задержек распространения сигналов для процессоров, имею¬
щих миллион слов (обычно сотни наносекупд против секунды или около того),
Массовая обработка с использованием ПРЛ. На основе концепции ПРЛ
Крейн и Гитенс [2.45] разработали архитектуру процессора с распределенной
Таблица 2.6
Система команд ПРЛ
Базовая операция ПРЛ
Действие
Совпадение
Чистое совпадение
Совпадение слева (справа)
Чистое совпадение слева (справа)
Распространить влево (вправо)
Активизировать крайнюю слева
(крайнюю справа)
Чисто активизировать крайнюю сле¬
ва (крайшою справа)
Условное запомипаппе
Безусловное запоминание
Чтение
Устанавливается М< = 1 для всех яче¬
ек г, содержимое которых совпадает с
входпым словом (т. е. установить М во
всех откликнувшихся ячейках в актив¬
ное состояние)
Устанавливаются М* = 1 для всех яче¬
ек i, содержимое которых совпадает с
входным словом; для всех остальных
ячеек устанавливается Мг = 0 (т. е. М
всех откликнувшихся ячеек устанав¬
ливаются в активное состояние, а ос¬
тальных ячеек — в пассивное)
Активизируются соседние ячейки, на¬
ходящиеся слева (справа) от каждой
откликнувшейся ячейки
Активизируются соседние ячейки, на¬
ходящиеся слева (справа) от -каждой
откликнувшейся ячейки, а остальные
переводятся в неактивное состояние
Активизируются все ячейки между те¬
ми, которые уже находятся в активном
состоянии, и ближайшими к ним слева
(справа) неактивными ячейками
M0(Mjv+i) устанавливается в 1
M0(MiY+i) устанавливается в 1, а ос¬
тальные — в О
Запись во все активные ячейки
Запись во все ячейки
Чтение содержимого всех активных
ячеек (если число активных ячеек
больше одной, то берется логическая
сумма содержимого; для получения од¬
нозначного результата нужпо, чтобы
активной была одна ячейка)
логикой с целью создать систему для одновременной поразрядпо-параллельной
обработки множественных наборов данных, т. е. для массовой обработки. Усо-
66
иершенствованне системы в этом направлении предусматривает скорее ис¬
пользование небольшого специализированного подмножества свойств IIPJI,
нежели использование свойств ПРЛ в полном объеме.
На рис. 2.27 представлена более детализированная схема памяти с распре¬
деленной логикой. В табл. 2.6 приведеп вариант набора команд ПРЛ. Процес¬
сорный элемент ПРЛ состоит из триггера совпадения (М), логического устрой¬
ства и памяти. Существуют два механизма храпения. Обозпачим память с по¬
словным хранением через X, слово данных через Xi, ..., Хп-2, Хп—ь Хп и будем
Таблица 2.7
Алгоритм сложения для ПРЛ
Алгоритм сложения
операция
назначение
Чистое совпадение слева
Условное запоминание
Точное совпадение слева
Распространение влево
Безусловное запоминание
Условное запоминание
Чистое совпадение
Совпадение
Совпадение
Совпадение
Установить стопор переноса (0, 0)
Пометить стопор переноса
Установить генераторы переноса (1, 1)
Распространить перенос влево до тех
пор, пока не встретится стопор
Установить метки стопоров переноса
Запомнить перенос па входе
Инициализировать последовательность
операций ИЛИ для четырех величин,
взятых из таблицы истинности, в кото¬
рой находятся слагаемые переноса. Эти
величины соответствуют 1 па выходе
суммы (0, 0, 1)
Логическая операция ИЛИ для выхо¬
да с суммой 1 (0, 1, 0)
Логическая операция ИЛИ для выхо¬
да с суммой 1 (1, 0, 0)
Логическая операция ИЛИ для выхо¬
да с суммой 1 (1, 1, 1)
считать, что иа одну ячейку приходится одно слово. Арифметические операции
могут производиться с данными только тогда, когда они хранятся таким об¬
разом. Операции выполняются в поразрядно-последовательной пословно-па¬
раллельной форме таге, как в процессоре с обработкой битовых срезов. При
решении некоторых задач скорость выполнения операций, обусловленная по¬
разрядно-последовательной пословно-параллельной обработкой, может оказать¬
ся недостаточной. Вот почему Крейн и Гитенс предлагают схему памяти с
поразрядным храпением, обозначенную на рис. 2.27 символами Y (т. е. Yn,
Yn-i, ..., Yi представляет собой слово данных). Слово образуется из i-x раз¬
рядов всех ячеек. Выбор такого механизма храпения обусловлен тем, что все
разряды слова работают с одним триггером совпадения. Это обеспечивает про¬
верку всех разрядов слова одновременно и позволяет выполнять арифмети¬
ческие операцпи с любым числом пар, где каждая пара относится к разным
Наборам ячеек; таким образом, операции выполняются одинаково параллельно
Вак на уровне разрядов, так п па уровне слов. Функционально такая схема
Памяти идентична предложенной Фуллером н Бердом [2.25].
5* 67
ассиз памяти с распределенной логикой, состоящей из N ячеек
Рис. 2.27. Блок-схема памяти с распределенной логикой
Массовая обработка является эффективной в тех применениях, где сущест¬
вует естественное группирование данных, причем над словами внутри каждой
группы требуется выполнять большое число операций. Новый термин мас¬
совая обработка был введен для обозначения поразрядпо- и одновременно по¬
словно-параллельного оперирования с данными. Алгоритм массового сложения
Представлен в табл. 2.7. Метод поразрядного хранения информации имеет не¬
достаток, проявляющийся при операциях ввода/вывода. Описываемый ниже
усовершенствованный вариант ПРЛ позволяет преодолеть эту трудность.
В большинстве архитектур процессоров класса ОКМД имеется тенденция
обращаться ко все меньшим п меньшим подмножествам данных, представляю¬
щих информацию в ходе вычислительного процесса в параллельном процес¬
соре. В самом деле, в таком ключе обычно используется принцип передачи
Ввод-вывод .из ячейки
Групповой вывод
Групповое управление
Рис. 2.28. Двумерпая память с распределенной логикой
бита активности. Операция проверки на точное совпадение в ПРЛ выполня¬
ется подобным же образом. Если вначале имеется подмножество активных
ячеек, то после выполнения операции проверки на точное совпадение количе¬
ство активных ячеек уменьшится. Практически это логическая операция П.
Специфическим свойством ПРЛ является операция проверки на совпадение.
Если имеется множество активных ячеек’, то любые ячейки, для которых опе¬
рация проверки на совпадение завершилась с положительным результатом,
Яо которые ранее не были активными, будут активизированы. Ото логическая
60
операция ИЛИ. Операции проверки на совпадение и проверки на точпое сок,
падение являются необходимыми, так как имеется только один бит активности
(т. е. регистр результатов поиска и регистр выборки слов управляются пабо,
ром триггеров, состояние которого определяется результатом проверки на сов¬
падение). Другая специфическая черта ПРЛ состоит в том, что взаимосвязь
между ячейками осуществляется с помощью целенаправленных операций про
верки на совпадение, а не путем активации ячеек и манипулирования битами
активности.
Для того чтобы преодолеть трудности, связанные с вводом/выводом, была
предложена двумерная ПРЛ, изображенная на рис. 2.28. ПРЛ сегментирована
на группы' ячеек. Например, ПРЛ, изображенная на рпс. 2.28, разбита на не¬
сколько сегментов и /с-й сегмент обведен пунктирной линией. Этот сегмент
состоит из гп ячеек ПРЛ. Отдельная ячейка также выделена пунктирной ли¬
нией. Каждая ячейка имеет триггер результата проверки на совпадение, уст¬
ройство проверки па совпадение и N элементарных ячеек ..., XiV. Все ячей¬
ки во всех группах подключены к общим шинам управления, ввода и вывода.
Триггеры активности М0 и M.v+i исключены из индивидуальных сегментов
Взаимосвязь между ячейками, принадлежащих разным группам, не предусмот¬
рена. Группа состоит из т ячеек.
Построение другой ПРЛ (во втором измерении) может осуществляться
так, чтобы основу архитектуры составляли логические устройства, управляю¬
щие группами. Каждой группе соответствует групповое логическое устройство
и набор, состоящий из т + / запоминающих ячеек. Таким образом, образуется
ПРЛ с групповыми шинами управления, ввода и вывода. Запоминающее уст¬
ройство в этой ПРЛ состоит из элементов Ут+я • • •* Уь Блок G служит для'уп¬
равления активностью.
Интерфейс, объединяющий обе ПРЛ, образован путем подключения груп¬
пы, состоящей'из т ячеек к набору триггеров хранения данных, Уь ..., Уг„,
соответствующих группе.
Получившаяся в результате конструкция может рассматриваться как ПРЛ,
содержащая в каждой группе т ячеек типа X и одну ячейку типа У, в кото¬
рых хранятся групповые переменные. Данные записываются в ячейки типа X
в поразрядной форме (разряд на ячейку) и в составе группы могут участво¬
вать в операциях массовой обработки. Если требуется считать слово (напри¬
мер, слово А, показанное на рис. 2.28), то величины, хранящиеся в ячейках Хп
каждой группы, считываются в Ym, ..., Уь Теперь данные хранятся в ячейке
типа У к-й группы в пословной форме (слово на ячейку) и допускают эффек¬
тивный вывод. Ячейки типа У являются более подходящими для участия в
операциях ввода/вывода, поскольку позволяют выполнять эти операции в по¬
разрядно-параллельной форме. Ячейки типа У можно было бы рассматривать
как буферные регистры, а ячейки типа X — как элементы ассоциативного про¬
цессора.
Из рассмотренных концепций ПРЛ единственной реализованной концеп¬
цией явилась двумерная ПРЛ для массовой обработки. Эта концепция была
воплощена в реальную конструкцию, предназначенную для расчета корреля¬
ций при обработке радиолокационных сигналов, а также для ввода/вывода. Она
была использована в секции расчета корреляций системы РЕРЕ (параллель¬
ного процессора, предназначенного для расчета траекторий баллистических
ракет, описанного в главах 3 и 5).
70
Процессоры с ассоциативной базой данных,
вычислительные машины для информационных систем
Концепция процессора с ассоциативной базой данных (ПАБД) была раз-
Савиттом и др. [2.50, 2.51, 2.52] с целыо повысить эффективность об¬
работки информации и организации доступа к данпым в информационных си¬
стемах, где осуществляется выработка сложных решений. ПАБД включает опи¬
сание языка, две специализированные вычислительные машины и интерпре¬
татор языка ПАБД. Аппаратная часть ПАБД разрабатывалась как средство
поддержки языка, который был специально ориентирован на решение задач
хранения и организации доступа к даппым.
ПАБД создавался для того, чтобы значительно повысить пропускную спо¬
собность и быстродействие при решении нечисловых задач и ввести проблем¬
но-ориентированный язык, который легко может использоваться непрофессио¬
нальными программистами, причем обе эти цели предполагалось достичь па
основе использования больших интегральных схем (БИС). Ключевой принцип
ПАБД заключался в конструкции языка. Вот почему язык ПАБД был разра¬
ботай раньше, чем аппаратная часть. Основной предпосылкой при создании
ЦАБД было то, что проблемно-ориентированные языки играют важную роль
в создании хорошей конструкции машины. В специализированных нестандарт¬
ных применениях роль языка особенно важна.
В конструкции языка для ПАБД заложены два существенных принципа.
Во-первых, данные и процессы создаются из упорядоченных троек объектов
(A, R, В). Эти тройки задают отношения и могут быть интерпретированы сле¬
дующим образом: А к В находится в отношении И. Графически это обозна¬
чается так, как показано на рис. 2.29. Например, LB является сокращенным
наименовапием слова POUND (фупт); это отношение изображено па рис. 2.30«
Во-вторых, все процессы могут быть представлены в виде структур, описыва¬
ющих совпадения (отклики) и замещения. Каждая команда ПАБД состоит из
двух структур данных. Одна структура служит для управления и представ¬
ляет собой спецификацию подструктур,. которые нужно пайти в структуре
данных. Вторая структура служит для организации замещения и представля¬
ет собой спецификацию структур данных, подлежащих записи на .место мно¬
жества данных, для которых операция проверки на совпадение дает положи¬
тельный результат.
Будем считать две структуры совпадающими в том и только в том слу¬
чае, когда соответствующие объекты и связывающие метки обоих структур
совпадают. Всякая структура данных, удовлетворяющая условию проверки на
совпадение, подлежит замещению. Объекты могут быть составными, как по¬
казано на рис. 2.31 и 2.32. Структуры данных могут быть представлены з виде
ориентированных графов. Язык ПАБД не лимитирует размер или сложность
гРафа. Для объекта может'быть определено более одного отпошеппя. В коман¬
де ПАБД может быть специфицирована команда, которую нужно выполнить
А
R
В
АББРЕВИАТУРА
СЛОВА
LB.
■> POUND
Рис. 2.29. Абстрактпая модель
отношения
Рис. 2.30. Отношение
(LB. АББРЕВИАТУРА POUND)
71
для того, чтооы процессор остановился по совпадению пли по несовпадению
или по какой-либо другой причине (с возвратом управления в вызвавший
процесс, если речь идет о подпрограмме). Разрешаются структуры, состоящие*
из пустого множества.
Символ X используется для обозначения неизвестных объектов, участвую,
щих в отношении; он может быть любым объектом или связующей меткой.
Неизвестные объекты могут быть специфицированы в терминах контекста от¬
ношения, в котором они найдены. Определенное выше условие совпадения под¬
разумевает прямое совпадение, поскольку это условие устанавливает взаимно
однозначное соответствие.
Существуют три средства задания непрямого совпадения. К пим отно¬
сятся: 1) правило неявного вывода, 2) встроенные функции и 3) подпро¬
граммы.
v'f
Рис. 2.31. Составное отношение Рис. 2.32. Составпое отношение
[(A, Ri, В), R2, С] [С, R5(E, R6, F)]
При использовании правила неявного вывода отношение считается удов¬
летворяющим условию совпадения, если существует множество отношении
между данными, которое подразумевает н наличие данного отношения. Этот
процесс может быть рекурсивным. Правила неявного вывода задаются как от¬
ношения со связующей меткой IMP (imply — подразумевать). Они могут со¬
держать символы X. Конец IMP связан с предыдущим членом правила, а за-
1 оловок — с последующим. Предыдущие члены могут заключать в себе логи¬
ческие функции, что делает их очень гибкими.
Имеется несколько встроенных интерпретируемых функций. Управляющая
структура локализует совпадения. Вместо замещения можно выполнить ряд
встроенных интерпретируемых функций таких, как DECONC (разорвать связь)
или COUNT (подсчитать число объектов или типов объектов).
Операция проверки на совпадение программным способом заключается
в том, что вызывается определенная подпрограмма, которая вырабатывает ре¬
зультат проверки на совпадение. Это средство оказывается полезным для вы¬
явления таких отношений, которые более удобно и гибко храпить в виде про¬
цедуры и интерпретировать в момент обращения, нежели хранить в явной
форме. Обобщенная блок-схема ПАБД изображена на рис. 2.33. Главпым эле¬
ментом этих машин является контекстно-адресуемая память — ключевой эле¬
мент концепции ПАБД, поэтому она будет подробно рассмотрена ниже. Гегистр
маски служит для маскирования разрядных позиций данных, находящихся
в регистре сравнения. В систему входят центральная управляющая машина,
выступающая ‘в качестве ведущего процессора, и контроллеры с микропро¬
граммным управлением, связанные с контекстно-адресуемой памятью. Ариф¬
метическое устройство обеспечивает ряд специальных аппаратно реализован¬
ных функций, используемых для облегчения процесса выполнения программ.
Могут быть реализованы также проблемно-ориентированные функции. Основ-
72
рое различие между ПЛБД, ориентированным па работу с предложениями,
. п ПАБД, ориентированным на работу с объектами, заключается в конструк¬
ции контекстно-адресуемой памяти.
Система, ориентированная ыа работу с предложениями, построена и отла¬
жена таким образом, чтобы обеспечивать хранение, поиск и замещение пред¬
ложений (т. е. последовательностей отношений). Вместо идентификации от¬
дельных объектов система,
ориентированная на работу с
предложениями, должпа обес¬
печивать сквозной просмотр
графов структур, содержащих
множество отношений. По этой
причине система, ориентиро¬
ванная па работу с предложе¬
ниями, строится па базе архи¬
тектуры ПРЛ, разработанной
Ли, причем данные в этой ар¬
хитектуре хранятся в виде па-
бора отношений. Для того что¬
бы выдержать требуемые вре¬
менные соотношения, в ассо¬
циативную память были вве¬
дены дополнительные логиче¬
ские устройства, позволяющие
в случае, когда существует
переменная, являющаяся об¬
щей для двух или более отношений в составе управляющей структуры, быст¬
ро идентифицировать содержащие общие величины набора данных, имеющие
положительный результат проверки на совпадение. Описываемое устройство
было названо контекстно-адресуемой памятью, где контекстный адрес пони¬
мается как набор отношений в составе управляющей структуры, содержащий
переменную величину, т. е. описываю¬
щий контекст отношений данных, в ко¬
тором должна быть найдена эта пере¬
менная. Данная намять позволяет ис¬
кать отношения и присваивать теги ве¬
личинам, являющимся метками связи
между объектами и удовлетворяющим
условию поиска.
Функционирование процессора, ори¬
ентированного па работу с предложе¬
ниями, поясняет рис. 2.34.
Каждое слово памяти разбито па
Два поля; поле отношения (содержа¬
щее метку связи) и поле объекта. На¬
пало фразы отмечено специальным символом PS, находящимся в поле метки.
Объект, ассоциированный с фразой, помещается в поле объекта того же слова,
гДс находится PS. После этого детально описываются все отношения, в кото¬
рых участвует рассматриваемый объект.
Слово i + 2
Слово i + 1
Слово i
Слово i — 1
Рис. 2.34. Организация храпения дап-
ных в ПАБД, ориентированном -на
работу с предложениями
PS
А
R1
В
R2
С
RS
D
Рис. 2.33. Блок-схема ПАБД
73
Как можно видеть из рис. 2.34, А указывает на В, С указывает па D. Кро¬
ме того, как показывает рис. 2.35, в системе имеется другой объект D. Схема
реального процессора изображена на рис. 2.3G. Каждая ячейка состоит из за¬
поминающего устройства (ЗУ), логического блока (JI) п триггера результата
проверки на совпадение (ТРС). ТРС может связываться с соответствующим
R2 R1
С
Рис. 2.35. Отношение, записанное в таблице, изображенной па рис. 2.34
логическим блоком. Логические блоки5 могут связываться с верхним или ниж¬
ним логическим блоком соответствующего ЗУ. ЗУ может связываться со сво¬
им логическим блоком и верхним и нижним ЗУ. В запоминающем устройство
могут храпиться: метка связи, объект и несколько разрядов тега. Рассматри¬
ваемая совокупность устройств способна выполнять двенадцать операций. Эти
операции распадаются на два класса:
параллельные операции (т. е. операции
поиска) и операции распространения
(т. е. контекстная адресация). Логиче¬
ский блок ячейки преобразует храня¬
щуюся в пей информацию с помощью
типовых параллельных операций. С по¬
мощью операций распространения орга¬
низуется связь между информацией,
хранящейся в данной ячейке, с инфор¬
мацией из соседней ячейки. Как видно
из рис. 2.37, в архитектуру процессора
введены некоторые усовершенствова¬
ния, направленные на повышение быст¬
родействия системы. Вместо того чтобы
строить систему на основе выбора
Рис. 2.36. Схема взаимосвязей ячеек
в ПАБД
Рпс. 2.37. Схема включения в ПАБД
ячеек маршрутизации
только ячеек памяти, конструкторы ввели в процессор ячейки маршрутизации.
Эти ячейки обеспечивают параллельное соединение групп ячеек и увеличивав
ют скорость распространения сигнала.
Организация данных в виде предложений была выбрана из-за того, что
одпо предложение содержит одип объект. Предложение состоит из заголовка,
объекта, меток связи и ассоциированных с ними объектов. В его состав вклю¬
чены также метки обратных связей. В процессе поиска выбираются предложе¬
ния, содержащие все отношения, описывающие контекстный адрес перемен¬
ной. Объекты, находящиеся в заголовках фраз, объявляются значениями
переменных. Признак PS, используемый в ПАБД, реализован в виде одноразряд¬
ного тега. Будучи ассоциативным процессором, ПАБД по накладывает ника¬
ких ограничений на дайну предложения, порядок расположения объектов
внутри предложения или порядок расположения предложений. Предложения
хранятся в виде непрерывной последовательности. Требование хранить пред¬
ложения в виде непрерывной последовательности могло быть снято, если бы
в ячейку на место одного из разрядов был помещен тег действительного име¬
ни. Существуют средства, облегчающие обработку составных отношений, но
здесь они подробно рассматриваться пе будут.
В ПАБД реализовано 12 операций. Эти операции работают с ячейками, вы¬
бираемыми либо по содержимому хранящихся дапных, либо по состоянию
триггера результата проверки на совпадение. Ниже приводится сводный пе¬
речень операций.
1) и 2) УСТАНОВКА (СБРОС) ВСЕХ ТРС — триггеры результатов провер¬
ки на совпадение устанавливаются в состояние, соответствующее наличию
совпадения (сбрасываются в начальное состояпие).
3) СРАВНЕНИЕ — все активные ячейки сравнивают записаппые в них
дапные с содержимым регистра сравнения с учетом информации, находящей¬
ся в регистре маски. Вслед за сравнением должна идти либо команда ПОИСК,
либо КОНТЕКСТНЫЙ АДРЕС.
4) ПОИСК — триггеры результатов проверки на совпадение всех ячеек,
для которых операция СРАВНИТЬ дала отрицательный результат, устанавли¬
ваются в начальное состояпие.
5) ЗАПИСЬ — берется содержимое регистра сравпепия и записывается во
все активные ячейки с маскированием разрядов, указанных в регистре маски.
6) УСТАНОВКА ПРЕДЛОЖЕНИЯ — операция, обратная операции КОН¬
ТЕКСТНЫЙ АДРЕС. Она устанавливает ТРС всех ячеек в каждом предложе¬
нии, в котором ТРС первоначально был установлен в начальной ячейке
предложения.
7) ЦЕПЬ — эта операция обеспечивает возможность получить отличный
от заложенного в аппаратуре порядок следования ячеек. В каждом ЗУ име¬
ется специальный триггер цепи. Данная операция локализует первую ячейку
ПАБД с установленным триггером цени и затем производит установку ТРС
этой ячейки.
8) ЧТЕНИЕ — содержимое одпой ячейки с признаком активности считы¬
вается в регистр сравнения. Если активными являются несколько ячеек, то
обычно считывание производится по логике ИЛИ, однако эта функция при
наличии более одной активной ячейки пе работает.
9) УСТАНОВКА СОСЕДА СНИЗУ — устанавливается ТРС ячеек, следую¬
щих за всеми теми ячейками, у которых ТРС уже установлен.
10) СДВИГ — эта операция открывает доступ ко всем ячейкам, находя¬
щимся ниже ячеек с установленным ТРС, что дает возможность хранить ин¬
формацию в виде непрерывной последовательности.
75
11) КОНТЕКСТНЫЙ АДРЕС — операция, используемая совместно с опе¬
рацией СРАВНИТЬ. Это ключевая операция в любом ПАБД, ориентирован¬
ном па работу с предложениями. Пусть в результате операции СРАВНИТЬ пи
одна из ячеек, содержащих фразу, ые откликнулась; тогда в каждой такой фра¬
зе ТРС ячейки, содержащей заголовок, сбрасывается. Для выполнения этой опе¬
рации необходимо, чтобы сигнал, начиная с триггера (PSFF), соответствую¬
щего началу предложения, пробежал сквозь все ячейки вплоть до следующе¬
го начала предложения. Схема логического устройства ячейки, реализующего
эту операцию, показана иа рис. 2.38. Для повышения скорости выполнения
операций контекстной адресации в схему введены ячейки маршрутизации.
Рис. 2.38. Логическая схема ячейки ПАБД
12) УКАЗАНИЕ ТРС (ТС) *) — используется совместно с операцией КОН-
ТЕКСТНЫЙ АДРЕС. При наличии совпадения аппаратура выполняет следу¬
ющую команду, иначе выполняет другую помеченную операцию.
Операции распространения (КОНТЕКСТНЫЙ АДРЕС, УСТАНОВИТЬ
ПРЕДЛОЖЕНИЕ, СДВИГ, ЦЕПЬ, УКАЗАТЬ ТРС, УКАЗАТЬ ТС) могут начи¬
нать выполпение своих функций при любом числе ТРС и распространяются
на переменное число ячеек. В каждый момент времени может выполняться
только один тип операций распространения, но количество активных ТРС мо¬
жет быть больше одного, что, таким образом, обеспечивает распараллелива¬
ние операций, порожденных в процессе исполнения одной команды. Ячейки
маршрутизации служат для повышения скорости исполнения этих операций.
В схеме маршрутизации линия Е представляет собой быстрый капал, по ко-
*) ТС — триггер связи. {Примеч. пер.)
76
^Орому осуществляется распространеппе сигнала контекстного адреса (W).
3Т0т капал позволяет сигналу YV обходить блоки ячеек, но являющихся ак¬
тивными. R1 представляет собой логическую сумму состояний триггеров, со¬
ответствующих началу предложений, хранящихся внутри блока памяти,
£2— логическую сумму всех линий Rl. W обозначает реальный распростра¬
няющийся сигнал. Эта схема обеспечивает последовательное соединение всех
Рис. 2.39. ПАБД, ориентированный на работу с объектами
блоков, у которых триггер начала предложения находится в состоянии ИС¬
ТИНА, с блоками, которые обходятся снизу; последние при этом оказывают¬
ся соединенными параллельно.
Главное отличие между ПАБД, ориентированным на работу с предложе¬
ниями, и ПАБД, ориентированным на работу с объектами, заключается в кон¬
струкции памяти. На рис. 2.39 показана схема контекстно-адресуемой памя¬
ти для ПАБД, ориентированного на работу с объектами. ПАБД, ориентиро¬
ванный на работу с объектами, имеет память в виде квадратной матрицы
ячеек с тремя структурами шин. Две из этих структур соединяют локальные
ячейки. Одип набор шин соединяет локальные ячейки по горизонтали, дру¬
гой — по вертикали. В обоих случаях ячейки непосредственно соедпнепы со
своими ближайшими соседями. Каждая ячейка способна передать локальный
сигнал только ячейкам, находящимся от нее слева или сверху. Третья струк¬
тура обеспечивает глобальную связь между управляющими устройствами всех
ячеек. Ячейки, находящиеся сверху (слева), соединены обратной связью
с ячейками, находящимися снизу (справа), таким образом, что любая ячейка
77
может передать сигнал (через цепочку промежуточных ячеек) любой дру¬
гой ячейке.
Каждая запоминающая ячейка устройства содержит пять полей и свой
собственный адрес. Отпошения задаются в терминах адресов ячеек. Ячейка,
содержащая отношепие (A, R, В), в действительности содержит в поле А ад¬
рес ячейки, в которой хранится А, и т. д. Два из пяти полей служат для хра¬
пения тега. Ячейки могут выполнять операции сравнения, чтения, записи к
генерировать сигналы взаимосвязи между ячейками. В состав каждой ячей-
'ки входит триггер результата проверки на совпадение. Локальные сигналы
распространяются по адресам: в вертикальном направлении (вверх) до
строки с заданным номером, в котором находится искомая ячейка, затем в
горизонтальном направлении (влево) до встречи с нужной- ячейкой. Ситуа¬
ция, возникающая при блокировке (блокировкой называется конфликт между
сигналами, распространяющимися справа налево и спизу вверх), разрешает¬
ся аппаратными средствами, при этом приоритет отдается сигналу, идущему
справа налево. Для локальных сигналов имеются быстрые каналы.
ПАБД, ориентированный па работу с объектами, имеет только восемь
команд. Назначение этих команд заключается в выборе объектов, удовлетво¬
ряющих заданному критерию, и обеспечении замещения этих объектов. Ниже
приводится сводный перечень команд.
1) ПОИСК — параллельно выбираются все ячейки, содержимое которых
(с учетом маски) совпадает с содержимым регистра сравнения.
2) КОНТЕКСТНЫЙ АДРЕС — параллельно выбираются все ячейки, за¬
данные в специальном поле передающих ячеек. Обычно эта операция выпол¬
няется вслед за операцией ПОИСК. Данная команда выбирает пробные зна¬
чения переменных в множестве, отвечающем отношениям, заданным в уп¬
равляющей структуре. ■
3) ЧТЕНИЕ — ячейка с взведенным ТРС считывается в регистр сравне¬
ния. Если имеется несколько активных ячеек, то может быть считана только
первая ячейка пли же могут быть считаны все ячейки в монопольном ре¬
жиме.
4) ЗАПИСЬ — берется содержимое (с учетом маски) регистра сравнения
п записывается во все ячейки, у которых взведен ТРС.
5) МАССОВАЯ ЗАПИСЬ — адреса множества ячеек записываются в дру¬
гое множество ячеек, которые затем снабжаются тегами, указывающими на
возможность пх использования для храпения таких данных. Эта операция
порождает новое множество отпошеипй для структур с переменным содержи¬
мым поля команда.
6) СБРОС — все ТРС переводятся в исходное состояние.
7) ИМПУЛЬС — используется для реализации логических функций на
ТРС. Эта операция сбрасывает триггер последовательности во всякой ячейке,
при условии, что ее ТРС не взведен, после чего одновременно сбрасывает
ТРС.
8) СБОРКА — параллельно выбираются все ячейки, относящиеся к левой
и правой частям отношения. Эта операция осуществляет окончательный вы¬
бор величии взаимосвязанных переменных. Рассмотрим отпошепие (XI, R,
Х2). С помощью операции КОНТЕКСТНЫЙ АДРЕС определяются пробпые-
значения для XI и Х2, однако искомыми величинами являются (XI, R, Х2).
Эти величины могут быть найдены с помощью двух операций сборки и двух
78
операций определения контекстного адреса. Во всех отношениях, содержа¬
щих В, устанавливается тег передачи. В каждую ячейку, содержащую XI,
записывается тег сборки. Ячейки, содержащие выставленные теги передачи,
управляются командами сборки. После выполнения этой команды единствен¬
ными ячейками, оставшимися активными, являются ячейки, содержащие
XI в качестве левого объекта и R в качестве метки связи. Аналогичная опе¬
рация выполняется для Х2 и R. В результате этой операции идентифициру¬
ются ячейки, содержащие XI в качестве левого объекта, R в качестве метки
связи и Х2 в качестве правого объекта. После этого устанавливается пара
величин XI и Х2, удовлетворяющих отношению R.
Так же как в ПАБД, ориентированных на работу с предложениями, в
ПАБД, ориентированных на работу с объектами, используются ячейки марш-
рутризации. В этом случае повышение скорости выполнения операций дости¬
гается за счет разделения общего массива на квадратные подмасспвы.
Ассоциативные процессоры с высокой степенью параллелизма
Существует тенденция к повышению степени параллелизма в ассоциа¬
тивных процессорах. Одним из путей создания новых принципов обработки
явилось совмещение параллельных средств со свойством ассоциативности.
Ниже описываются два основных варианта использования этой концепции.
В первом варианте для достижения большей степени использования оборудо¬
вания и увеличения пропускной способности применяются устройства мно¬
жественного управления и биты множественной активности. В другой архи¬
тектуре для достижения большего параллелизма управление встраивается
непосредственно в память.
Ассоциативный процессор с устройством множественного управления. Со¬
вершенно особый ассоциативный процессор был сконструирован Шмитцем и
др. для реализации сложных алгоритмов фильтрации в задаче обработки ра¬
диолокационной информации. В ассоциативный рроцессор, схема которого да¬
на на рис. 2.40, входят М устройств управления и N процессорных элемен¬
тов. Основная особенность данной архитектуры заключается в ассоциативном
управляющем переключателе (АУП), который служит для подключения уст¬
ройств управления к процессорным элементам. АУП позволяет подключать
ПЭ только к одному УУ. Каждый ПЭ может быть соединен с любым из М
УУ или же может оставаться неактивным. Система может рассматриваться
как совокупность М ассоциативных процессоров. Взаимосвязи в системе осу¬
ществляются с помощью АУП, позволяющего ассоциативно выбирать подхо¬
дящий процессорный элемент исхода из содержания программы, подлежащей
исполнению. Рассматриваемая машипа функционирует подобно набору ассо¬
циативных процессоров.
В этой системе сделана попытка решить одну из проблем, связанных с
обычным ассоциативным процессором, заключающуюся в том, что пока неко¬
торые из ПЭ работают, другие находятся в пеактивпом состоянии и пе вносят
своего вклада в решение задачи. В рассматриваемом ассоциативном процессоре
одновременно работают несколько различных его частей, причем эти части об¬
рабатывают разные потоки команд, повышая тем самым коэффицпепт исполь¬
зования оборудования. Ассоциативный управляющий переключатель работает
подобно расширенному регистру результатов поиска, т. е. АУП должен осу¬
79
ществлять выбор УУ, исходя из результата операции или последовательности
операций, выполняемых процессорным элементом.
В каждом УУ хранится последовательность команд, к которым оп будет
обращаться при управлении подмножеством ПЭ. УУ последовательно вызыва¬
ет одну команду за другой, генерирует свои собственные указания о порядке
дальнейшего выполнения команд, генерирует команды ПЭ и передает эти
комапды выбранному ПЭ. УУ выполняет только те арифметические опера¬
ции, которые необходимы для управле¬
ния последовательностью выполнения
его команд. Арифметические операции
в полном объеме выполняются про¬
цессорными элементами под управлени¬
ем соответствующих УУ. Каждый ПЭ
выполняет последовательность таких
операций, как вызовы данных, записи
данных в память, а также арифметиче¬
ские операции. Операнды поступают из
местной памяти данных процессорного
элемента, однако они могут извлекать¬
ся и из УУ, причем в этом случае все
ПЭ, связанные с УУ, одновременно
получают от него один и тот же операнд.
Описываемая архитектура дает вы¬
игрыш *в следующей ситуации. Пусть
в задаче имеется п независимых пото¬
ков данных. Независимость потоков
данных означает, что когда в потоке г
сегмент дапных / оказывается готовым
к обработке, в потоке i + 1 сегмент дан¬
ных у может не быть готовьш к обработ¬
ке. Пусть каждый поток должен пройти
обработку последовательностью про¬
грамм PI, Р2, ..., РМ. В то же время обработка дапных зависит от внеш¬
них факторов; эта зависимость выражается в том, что для i-ro потока может
требоваться последовательность программ PI, Р2,..., РМ, в то время как для
потока i +1 требуется последовательность Р1, Р4, Р8, Р9. Будем считать, что
в любом цикле повторения последовательности PI, Р2,..., РМ для любой за¬
данной программы Рг и любой следующей за ней программы Ру выполняют¬
ся условия / > г, / ^ т. Если бы программа Pj выполнялась на ассоциатив¬
ном процессоре с одиночным устройством управления, то последнее должно
было бы выполнить всю последовательность программ PI, Р2,..., РМ. Если пи
для одного из потоков дапных выполнение программы не требуется, то она,
в принципе, могла бы быть исключена. В результате, если некоторый поток
дапных не готов к обработке, когда началось выполнение Р1, то обработка
этих дапных откладывается до тех пор, пока не начнется следующий цикл
выполнения Р1. Применительно к рассматриваемой задаче архитектура с
одиночным У У имеет три главпых недостатка. К пим относятся:
1) временная задержка в выполнении последовательности PI, Р2,..., РМ
при пеготовиости набора даппых может быть слишком велика по сравнению
80
Рис. '2.40. Ассоциативный процессор
с высокой степенью параллелизма
с допустимым для потока временем ожидания; это может привести к потере
я ли разрушению информации или к снижению точности конечных резуль¬
татов;
2) в случае, когда задержка находится в допустимых пределах и не при¬
водит к искажению результатов, объем оборудования, необходимого для бу¬
феризации, может оказаться слишком большим;
3) аппаратная часть процессорных элементов используется неэффек¬
тивно.
Решением задачи могло бы стать создание многопроцессорной системы,,
т. е. выделение каждому потоку данных собственных УУ н ПЭ, по такой путь
привел бы к значительному росту стоимости оборудования и памяти, по¬
скольку сложность УУ для простых ПЭ не меньше сложности ПЭ, а в некото¬
рых случаях может превышать ее почти в 100 раз. Однпм из примеров явля-.
ется последовательный сумматор в сравнении с УУ с микропрограммным уп¬
равлением. Во всех УУ должны находиться полные копии всех программ.
Выбрапное решепие заключается в том, чтобы иметь столько УУ, сколько су¬
ществует отдельных функциональных программ, и обеспечить возможность
с помощью АУП переключать ПЭ от одного УУ к другому в зависнмостп от
результатов вычислений. Если задачи состоит из четырех процессов Р1, Р2?
РЗ и Р4, то нужны четыре УУ, при этом максимальная задержка начала обра¬
ботки равна максимальному из времен выполнения PI, Р2, РЗ и Р4, а не-
сумме этих времен. Каждое УУ циклически работает по своей программе, а
необходимая последовательность вычислений осуществляется ассоциативны¬
ми управляющими переключателями. По завершении процесса Р1 имя сле¬
дующего процесса помещается в АУП и производится следующий шаг в вы¬
полнении рассматриваемой программы, осуществляемый под управлением со¬
ответствующего УУ.
Использование АУП позволяет:
1) производить обработку каждого потока данных с эффективностью*
близкой к максимальной, с помощью такого числа УУ, которое соответствует
числу различных программных сегментов;
2) обеспечивать реализацию программных сегмептов в режиме, близком к
режиму реального времени;
3) управлять вычислительной нагрузкой па систему путем подбора вре¬
мен выполнения программных сегментов;
4) минимизировать объем памяти, используемой для храиепия программ;
5) минимизировать аппаратную часть УУ, дополнительно вводимых в си¬
стему;
6) увеличить степень использования Г1Э.
Гас-смотреиный принцип может быть распространен на ситуацию, когда
Р< передаст управление Р;- при отсутствии ппых условий, кроме требования^
чтобы i и / принадлежали множеству (1, 2, ..., т) н чтобы общее время обра¬
ботки было меньше, чем время между поступлением на вход двух последова¬
тельных порцый данных. Один ноток данных может обрабатываться програм¬
мами Р1 и Г2, Р1 п РМ, в то время как другой — программами Р1 и РЗ, РЗ к
Р4. Благодаря наличию АУП каждый поток данных обладает сове-ршепио не¬
зависимой последовательностью программ до тех пор, пока обработка этого
Потока не закончится и эти программы не будут готовы к обработке следую¬
щей порции входных данных. Это происходит благодаря независимости
® К. Дж. Тербер 81
устройств управления и их взаимно однозначному соответствию программным
сегментам. Поскольку в каждый момент времени только один процесс пере¬
дает команды процессорному элементу, проблем, связанных с организацией
доступа к данным, не возникает. Единственный недостаток связан с ситуа¬
цией, когда программы выполняются независимо и при этом практически не¬
возможно простым способом передавать данные между процессорными эле¬
ментами, за исключением случая, когда УУ могут быть синхронизированы
или когда ПЭ, желающие передавать данные, могут работать в одном и тог:
же программном сегменте в одной и той же итерации. Рассмотренная ар¬
хитектура, очевидно, применима к параллельным процессорам со слож¬
ными ПЭ.
Многофункциональная память с адресацией но содержимому. Много¬
функциональная память с адресацией по содержимому (МПАС), характери¬
зующаяся тем, что каждая ее ячейка способна выполнять широкий набор
Тактовые импульсы
а 2 ■
Ь -
У?\
-
У 22
„.
Угп
i i 1
I Я
1! 1
1 i 1
1 i 1
111
У ГГ) 1
—
У ml
Угпп
—
—
I * * 1 ' * ' * т
Рис. 2.41. Принципиальная схема системы ПАВС
арифметических операций наряду с другими функциями, была разработана
Котцем [2.54]. Большинство ассоциативных процессоров являются очень про
отыми и, как правило, содержат не более 10 логических схем на ячейку
В рассматриваемой памяти ячейка включает порядка 40 логических элемен¬
тов типа НЕ — ИЛИ. Массив ячеек организован так, как показано на
рис. 2.41. Типичный набор операций, осуществляемых ячейкой, представлен в
табл. 2.8.
82
Представим себе, что массив состоит из т слов по п разрядов в каждом.
Каждый разряд хранится в отдельной ячейке. Каждая из величин a*, bi и а
представляет собой программно-задаваемое значение, определяющее поведе¬
ние массива. Величины с указывают столбцы и используются в качестве би¬
товых масок, чтобы только выбраппьте столбцы включались в операции. На
каждый столбец приходится по одному выбираемому значению с, и это зна¬
чение играет точно такую же роль, что и механизм извлечения битового сре¬
за пли маска. Значения а и Ъ используются попарно и связаньг словами»
Таблица 2.8
Функции, выполняемые ячейкой МП А С
с Ъ
а
Триггер (синхронизо¬
ванный)
Горизонтальная функ¬
ция
Вертикальная функция
0
0
0
у' = у
z = z(x + y)
X = X
0
0
1
У9 = У
Z = z (я Фу)
х = х.
0
1
0
у' = У
?=yz + ух
х = ух + yz
0
1
1
у' = У
Z = Z
X = X + yz
1
0
0
у' = zy + ZX
Z — Z
х — x(&yz
1
0
1
у' = zy + ZX
Z = Z
X = у
1
1
0
у' = ху + XZ
Z — XZ + ху
X = X
1
1
1
у' — y®x0z
z — max (я, у, z)
X = X
Каждому слову массива соответствует пара аЪ. Эти величины аЪ служат для
выбора операции, производимой над тем словом, к которому они относятся.
По аналогии с величинами с (которые постоянно закреплены за столбцами)
величины аЪ постоянно закрепляются за словом. Совокупность величин с и
ab полностью задает функцию, которую выполняет ячейка.
Имеется ряд других параметров, которые требуют пояснения. Шины X
используются для перемещения ипформацин по вертикали как внутри массива,
так и для ввода и вывода, создавая, таким образом, канал ввода/вывода для
битовых срезов. Величины Z используются при операциях ввода/вывода бито¬
вых срезов и для организации обработки битовых срезов. Z служит также
средством для распространеппя сигнала сравнения и бита переноса.
Читатель должен заметить, что разные слова массива могут параллельно
участвовать в разных операциях (так, величины не обязательно должны
равняться величинам djbj, если что придает массиву гибкость. Раз¬
личные проверки входного слова X могут осуществляться одновременно. Из¬
держки, связапные с обеспечением гибкости, проявляются в двух главных
аспектах. Во-первых, каждая ячейка имеет 8 выводов, а массив размерностью
^ X и имеет А(т + п) внешних выводов (или 8(m-)-/i), если каждую ячей¬
ку поместить на двухслойную плату). Во-вторых, эффективное использова¬
ние массива является трудной задачей, за исключением ситуаций, когда вво¬
дится ограничение, чтобы все величины аЪ были равными, или когда отдель¬
ные слова маскируются целиком.
в* ва
В горизонтальном направлении массив может осуществлять сдвиг, ввод;
в столбцы, считывание из столбцов, поиск на равенство и операции имплика¬
ции. В вертикальном направлении массив производит сдвиг слов, ввод/вывод
слов, маскирование слов и операции дополнения. Другие функции, такие как.
организация стека пли очереди, могут быть синтезированы с помощью край¬
них левых пли правых столбцов, используемых в качестве теговых регист¬
ров, При практической реализации описанной схемы должны быть преду¬
смотрены регистры для храпения величин с, а и Ъ. Эти регистры предназна¬
чены для использования в качестве регистров маски и результатов. Регистры.
Z и X нужны для хранения данных, участвующих в операциях, и для ини¬
циализации операций поиска.
Массив может находиться в открытом или закрытом состояниях. В слу¬
чае открытого состояния любой столбец, у которого величина с имеет логиче¬
ский уровень 0, оказывается маскированным. Поэтому состояние любых триг¬
геров, находящихся в таком столбце, остается неизменным. Поэтому имеет
смысл рассматривать только следующие состояния сЪа — (100, 101, 110, 111).
Предположим, что слово типа Y состоит из маскированных слов, хранящихся
в строке.
В состоянии 100 крайний левый разряд слова Z служит в качестве разря¬
да выбора слова. Если Zi = 1, то слово Y, хранящееся в строке г, заменяется
на слово X, взятое из вышестоящей строки, а старое слово Y подвергается
поразрядной операции ИСКЛЮЧАЮЩЕЕ ИЛИ со словом X и становится сло¬
вом X для следующей строки, расположенной ниже строки L Когда Z* =0, то
никаких изменений ни с X, ни с Y не происходит.
Состояние 101 используется для сдвига слов вниз и считывания их во¬
вне. Если крайний левый разряд Z* = 1, то операция сдвига вниз производит¬
ся, т. е. слово X замещает слово Y, а слово Y становится словом X в следую¬
щей строке, расположенной ниже строки i. Если в строке, которой соответст¬
вует состояние 101, крайний левый разряд Z* =0, то слово Y становится на
место слова X, а старое слово Y не меняется. Это обеспечивает возможность
считывания информации с ее сохранением в памяти.
Регистр горизонтального сдвига, модифицируемый словом X, участвует в
работе при состоянии 110. При возникновении состояния 110 все цифры в
ячейках, которым соответствует 1 в слове X, сдвигаются вправо на одну по¬
зицию. Слово X играет роль сдвиговой маски. Благодаря маске сдвиг своего
содержимого производят только те ячейки, которые имеют 1 в маске. Если в
слове X стоит 0, то соответствующие цифры остаются неподвижными. Слово
X неизменяемое. Столбец, соответствующий самой левой едипице в слове X,
принимает крайнее левое слово Z в качестве входной величины. Битовой
срез, определяемый самой крайпей справа единицей в слове X, становится
выходом массива, формируемым на выходных выводах.
Арифметические операции выполняются в состоянии 111. В этом состоя¬
нии двоичные числа, соответствующие словам X и Y, складываются друг с
другом, с учетом разрядов переполпепия, появляющихся на выходе Z. Обыч-
, но при этой операции вход со стороны Z равен 0. Если вход со стороны Z ра¬
вен 1, то к сумме добавляется 1.
Вычитание осуществляется путем помещения дополнения X в какую-нибудь
из вышерасположеппых ячеек с помощью состояния 100 и последующего сло¬
жения с Y = (111, ..., 1).
84
В закрытом состоянии функционирование массива больше напоминает
работу обычной ассоциативной памяти, т. е. ячейки Y, в которых хранятся
.слова, пе изменяются, а участвуют в операциях сравнения между словом X,
с одной стороны, и словами Y — с другой.
В состоянии ООО слово X располагается но вертикали и пе претерпевает ка-
яих-либо изменений в процессе выполнения но горизонтали двоичной импли¬
кации. Более подробно, при наличии 1 па входе Z (выбранпое слово), на вь>
ходе Z (результат) появляется 0 тогда н только тогда, когда в слове X циф¬
ра 0 имеется хотя бы в одной такой позиции, для которой в слове Y стоит 1,
иными словами, выход Z равен 0 тогда п только тогда, когда Y не оказывает¬
ся включенным в X. В этом режиме массив работает аналогично тому, как ра¬
ботает ассоциативная память с распределенной логикой, выполняющая па¬
раллельные операции импликации.
Состояние 100 в любом столбце приводит к выполнению маскированного
поиска по критерию логической импликации, причем эта операция произво¬
дится с теми столбцами, которые отмечены в маске знамениями с =1.
Режим 001 аналогичен режиму ООО с той разницей, что производится по¬
иск на равенство. Если вход Z равен 1 (выбранное слово), то выход Z равен
«О тогда и только тогда, когда X и Y отличаются друг от друга хотя бы в од¬
ной разрядной позиции.
Состояние 101 дает пользователю возможность маскировать выделенные
' столбцы при операции поиска на равенство.
Состояние 010 приводит к тому, что ячейка ведет себя как перестановоч¬
ный переключатель: Y =0 означает, что ячейка пассивная, a Y =1 меняет
местами пгины X и Z для последующего распространения, что позволяет
«формировать перестановочную сеть. Этот режим нужен для операций сдвига
вправо и других. Возможна также операция маскированного сдвига вправо.
Чтение битового среза из столбца / осуществляется с помощью состояния
110 путем ввода слова X, крайная справа единица которого указывает на
-столбец, подлежащий считыванию.
Состояние 011 применяется очень ограниченно. Когда вход Z равен 0,
•строка маскируется так, как будто входящих в нее ячеек нет вообще в мас¬
сиве. Это состояние используется для операции маскирования. Если вход Z
равен 1, то слово X, подаваемое на строку, находящуюся ниже, представляет
собой логическую сумму слова X и слова Y. Это может оказаться полезным
Для маскирующих операций, когда нужно замаскировать некоторые позиции,
находящиеся в строках, расположенных ниже текущей строки. Если входное
слово X целиком состоит из 0, то любой выбранный набор строк с состояни¬
ем 011 может быть сравнен со всеми строками, расположенными пиже.
Состояние 111 образует память, в которой выполняется операция сравне¬
ния по размеру. Рассмотрим ситуацию, когда слово X и слова Y все пред¬
ставляют собой двоичные числа без зпака, в которых младший значащий
разряд находится в кр>айпей слева позиции. Если вход Z равен 1, то выход Z
равен 1 тогда и только тогда, когда дополнение слова X меньше или равно
слову Y. Если вход Z равен 0, то выход Z равен 0 тогда и только тогда, когда
Дополнение слова X строго меньше слова Y. Таким образом, может быть ор¬
ганизовала ассоциативпая память, способная выполнять поиск на перавепст-
При этой операции допускается маскирование путем установки зпачепия
с, равного 0 (состояние 011).
85
Необходимо подчеркнуть, что слово X может быть модифицировано т>
процессе проведения проверок, когда разные секции массива могут не только
устанавливаться в различные состояния, но и могут изменять слово X по ме¬
ре того, как оно проходит сквозь расположенные ниже строки. Такая гиб
кость сопровождается соответствующими издержками. С точки зрения аппара¬
туры эти издержки заключаются в необходимости иметь восемь выводов и
40 логических схем в каждой ячейке, что в 4—8 раз превышает сложность
логики, использованной в памяти, подобной памяти Вальда [2.22]. Массив
ориентирован на выполнение сложных операций и может быть использован
при решении многих задач. Например, массив может работать как стек, оче¬
редь, банк ипдексных регистров, сверхоперативная память, сориентированная
память, память со списковой структурой, а также как микропрограммная уп¬
равляющая матрица.
В следующем параграфе рассматривается пример конструкции, показы¬
вающий, как припцип МПАС может быть использован при рсшеппи конкрет¬
ных задач. Пример выбрап такпм образом, чтобы можно было провести срав¬
86
нение с параллельным процессором для калмановского фильтра конструкции
Кэпнона, описанного в гл. 3.
Ассоциативный процессор для калмановского фильтра. Котц и Пиз [2.55]
сконструировали ассоциативный процессор, предназначенный для использо¬
вания в создаваемой военно-морским ведомством системе противоракетной
оборопы. Главная цель состояла в разработке специализированной вычисли¬
тельной машины для решения задач сопровождения целей, оптимальной
фильтрации, обработки радиолокационных сигналов, управления связью и
многоканального корреляционного апализа.
Для решения первой нз перечисленных задач сопровождения целей при¬
меняется алгоритм фильтрации Калмана, что является определяющим фактом
в разработке конструкции в целом. Из анализа алгоритма калмановского
фильтра следует, что основными операциями являются умножение матриц,
обращепие матриц, сложение матриц, сложение векторов, умножение вектора
на матрицу, преобразование координат, скалярное произведение векторов,
сортировка, транспозиция матриц и загрузка данных. Можно показать, что
•включение в процессор перечисленных операций дает возможность с помо¬
щью небольших дополнительных затрат получить и другие важные функции.
К их числу относятся полиноминальная аппроксимация функций, вычисле¬
ние перекрестных корреляций,
вычисление автокорреляционных
функций, цифровая фильтрация,
быстрое преобразование Фурье,
а также решение уравнений в
частных производных релаксаци¬
онными методами. Кроме того,
в соответствии с требованиями
данные могут быть представлены
в формате с фиксированной за¬
пятой. В процессоре предусматри¬
вались операции масштабирова¬
ния, встроенные в команды та¬
ким образом, что данные пред¬
ставляются в виде целых чисел,
а отрицательные числа — в виде
двоичного дополнения.
Процессор показан на рис.
2.42. Он состоит из массива памя¬
ти (М), управляющих массивов
(V и W), маскирующего управ¬
ляющего массива (U), дешифра¬
торов (Т и D), массива переклю¬
чателей (S и 2) буфера ввода/
/вывода (I), микропрограммного
устройства управления (С) с микропрограммной управляющей памятью
(МРСМ), адресного регистра (А) и вспомогательного регистра Е, в .кото¬
ром храпятся команды, поступающие от центрального процессора системы.
Каждая ячейка (рис. 2.43) содержит некоторую логическую схему и
триггер хранения. Сложность ячейки соответствует примерно 50 логически:*
Рис. 2.43. ПЭ ассоциативного процессора
для фильтра Калмана
87
элементам. Сигналы на шине X образуют слово, которое затем передается от
одной строки процессора к другой. Сигналы на шине Z представляют собой
разряды переноса, битовые срезы и т. д. Величины на шине Y обозначают
текущие состояния триггеров в строке, т. е. текущее хранящееся слово. Так
же, как в МПАС, слова могут быть разбиты на одновременно обрабатывае¬
мые блоки, а обработка может производиться как с битовыми срезами, так ц
путем пропускания сверху вниз через память.
Функции ячейки у, х и z зависят от состояний х, у и z, а также от дру¬
гих сигналов, таких как сигналы V и W от управляющих массивов (распре¬
деленных по всем столбцам соответствующей строки), сигнала U от маски¬
рующего управляющего массива U (распределенного по всем строкам соот¬
ветствующего столбца), а также от величины а, Ь и с, которые поступают из
буферного регистра микропрограммной управляющей памяти и затем пере¬
даются всем массивам. Так же как в МП АС, большая часть работы по распа¬
раллеливанию производится внутри самого массива, а не в микропрограм¬
мном устройстве управления, при этом распараллеливание-идет путем раз¬
биения массива на блоки процессоров, параллельно обрабатывающих свои
данные.
Процессор был специально сконструирован для реализации алгорит¬
ма калмановского фильтра. На рис. 2.44 показана структура программно¬
го обеспечения системы. KALFIL обозначает программу калмановского
Состояние Микрсжо- Операции
строк манды
G
Е
А
I
Н
С
К
L
D
F
М
N
Макросы
Подпрограммы
MATR i
Стандартные
программы
Программы-
‘MATIN '
Рпс. 2.44. Структура программного обеспечения
фильтра. Сложность системных команд уменьшается справа палево. Линии,
проведенные между столбцами, указывают па основные ступени в иерархи¬
ческой структуре программного обеспечения. Показаны только зависимости
между соседними столбцами. Команды поступают в одном цикле задающего
генератора. В составе команды может находиться одна из четырех
микрокоманд плюс операторы адресации и маршрутизации (соответствую-
88
ядие пшиам V n W). Каждая микрокоманда включает выборочное
применение четырех режимов строк. Микрокоманды а, р, у и 6 озна¬
чают состояния ячейки 00, 01, 10, 11 соответственно. С представляет
собой шипу задающих импульсов. Состояния строк описываются в терминах
величин а, р, я(, 6 и VYV. Эти состояния собраны в табл. 2.9;
Таблица 2.9
Состояния строк для немаскированных столбцов (и = 1 пли х — 1) основного
массива М
ab
VW
\
00 а
01 3 1
u v
10 6
оо
I: Y' = Y
I: Y' = Y
N: Y' = Y
K: Y'= Y
Х = Х
X = X
X = X
X = X
Z-nepeiioc
Z-nepenoc
Z-перепос (—)
Z = 0
01
G: Y' = X + Y
II: Y' = X
M: Y' = X
L: Y' = X + Y
X = Y
X = X
X = Y
X = X
Z-перенос
Z-nepenoc
Z-перепос (—)
Z = Z(X + Y)
11
Е: Y' = X + Y
G: Y' = X + Y
J: Y' = X + Y
F: Y' = 2Y + 1
X = Y
X = X + Y
X = Y
X = X
^s.
Z-nepeuoc
Z-перенос
Z-nepenoc
Z-сдвиг
00
A: Y' = Y
A: Y' = Y
B: Y' == X
D: Y' = 2Y
X = Y
X = Y
X = Y
X = X
/S
—
Z-перенос
Z-nepenoc
Z-перенос
Z-перенос
■система команд представлена в табл. 2.10, а логические функции ячейки —
в табл. 2.11.
К числу встроенных макросов относятся умножение (MUL), деление
(DIV), возведение в квадрат (SQU), извлечение квадратного корня (SQT),
вычисление восходящих разностей (DIF), используемое в иптерполяциоппых
формулах п-то порядка, оператор сортировки файлов (SOF), оператор переме¬
шивания (SIIF), поразрядно-последовательное чт-епие (BRS), поразрядно-па¬
раллельное чтение (BRP), поразрядно-последовательная запись (BWS) и по¬
разрядно-параллельная запись (BWP). Рис. 2.45 иллюстрирует оператор DIV.
Делитель хранится в строке 1, делимое в строке 2, остаток появляется в стро¬
ке 3, а- частное — в строке 4. Основные этапы изменения управляющих состо¬
яний показаны па рис. 2.45. Для того что.бы сформировать знак результата,
необходим еще ряд предварительных и последующих операции. Все макро¬
сы, представляющие собой процедуры, подпрограммы и программы, подроб¬
но описаны в [2.55].
К числу основных встроеппых процедур относятся MATR (транспозиция
Матрицы), NAAQ (нормализация угловых аргументов), INTL (оцспка дейст¬
вительной фупкцин одной переменной с помощью хранимой табличной функ¬
ции на основе равновероятного распределения по осям), PEBV и РЕВР
(оценка полиномов m-ii степени), PEBV (одпп полином от множественных
Переменных), РЕВР (несколько полиномов от одиой переменной),.. РЕРМ
89
Таблица 2.10
Операции ассоциативного процессора
Группа операций
Имя
Описание
Формальные урав¬
нения
Сос¬
тояние
строк]
Команды поис¬
ка и проверок
ЕТ
Проверка на равенство: X =
= Y?
z = z (х0у)
L
(закрытое со¬
стояние мас¬
ZT
Проверка на 0: Y = 0?
z = zy; х0 = 0
L
сива М)
от
Проверка па переполнение
Х + Y^2"?
Z=zlJZ +
-f- х(у + z)-пе¬
ренос
L
и др.
IT
Проверка на неравенство:
X < Y?
2 = yz 4*
-j- х(у -]- z)-пе¬
репое (—)
M,V
BR
Считывание разрядов из Y
Столбец выбирается по X
z = xz + ху
D, F
Арифметиче¬
ские операции
ВА
Блочное сложение: Х0 со все¬
ми Y
у' = X + у, X = X
G
(открытое со¬
стояние
АА
Сложение со смежным: каж¬
дый Y складывается с пре¬
дыдущим Y
у' = X + 7/, X = у
Е, 1-
Арифметич ей¬
ские операции
(открытое со¬
стояние)
IN
Интегрирование:
Сложепие каждого Y со все¬
ми Y, расположенными ниже
Отрицательный Y
У' = х + у, X =
=•*+ у
у' = —у, X == X
С
L
Операции пе¬
ремещения
данных (от¬
RR
Считывание строки:
Строка Y помещается па ши¬
ны X
у' = у, х = у
А
крытое состоя¬
ние)
BW
Блочная запись: все Y заме¬
щаются па X
у' = х, х = х
Н
SD
Сдвиг вниз: каждый Y заме¬
щается на Y, находившийся
выше
у' = х, X = у
В, м •
SL
Сдвиг влево: каждый Y за¬
мещается па 2Y или 2Y + 1
уг = 2у или 2у +
4- i 'mod 2")
D, F
CW
Запись столбца (и чтение)
X = X
у7 = ху 4" xz, Z =
= XZ 4- ху
X = X
D, F
Операции ло¬
гических функ¬
ций (закрытое
LM
Логика, элементарные конъ¬
юнктивные формы и выраже¬
ния с X
z = z(x@y) и
XZ 4- ху
L
состояние)
LN
Логика, выражеппая с отри¬
цанием X
z — vz 4- х (у 4-z)
М, N
LP
i i
Логика, выражеппая с X
3 = yz -г х {у 4- z)
I
и др..
90
Таблица 2.11
Функции процессорной ячейки
[S == x0y0z, M=yz + x(y + z), М~ = yz + x(y + z)]
аЪ
V W
.00
01
И
10
у'
00
У
У
У
У
01
и у + us
и у + их
X
иу + bs
И
йу + us
йу + us
йх + us
ху + XZ
10
У
У
X
ху 4- XZ
X
00
X
X
X
х + У*й
01
X
х
У
х 4~ yzU
11
У
S
У
X
10
У
У
У
X
Z
00
iiz + иМ
Uz + иМ
Uz + иМ~
z[ а + (*®у)]
01
uz + иМ
Uz + иМ
Uz 4- иМ~
z[u + (*©!/)]
11
Uz + иМ
Uz + иМ
Uz 4- иМ
X Z + ху
10
uz -4- иМ
Uz + иМ
Uz 4- иМ
XZ 4- ху
(перестановка блоков хранимых слов в соответствии с ключом сортировки)»
COMU (умножение комплексных чисел) и DOPT (скалярное произведение).
Процедура ПОРТ изображена на рис. 2.46.
Всего имеется тринадцать стандартных программ. К числу первых шести
относятся sin(TRGSJ), cos(TRGCO), tg(TRGTA), arcsin(TRGAS), arccos(TRGAC)
и arctg (TRGAT). В преобразованиях Фурье используется программа COMUB
{приближенный вариант программы.COMU, рассчитанный на обработку блоков
трока Начало Ком ее,
1 -R -R
?. В :с)
.3 О Н
•4 - Q
о
VW
А
10
т
00
07
1
1, G
0W
т
ПО
1
Ьо
(0
©
VW W
©
VW
/V
00 №-
K,L
ov/
В
,а 4*1.
K,L
ovv
1), F
1W
К
00
В, F
IV/
к
00
Рис. 2.45. Алгоритм деления
комплексных переменных). Подпрограмма DOPT является главной составной
частью процедур MATMU (умножение матриц), AUTCO (вычисление автокор¬
реляции), CROGO (вычисление перекрестной корреляции), DIGFI (цифровой
нерекурсивный фильтр) и DIGFR (цифровой рекурсивный фильтр). Послед¬
ней подпрограммой является MATIN, представляющая собой процедуру об¬
ращения матриц с использованием параллельной версии алгоритма Гаусса.
91
Главной компонентой программного обеспечения является программе,
KALFIL (калмановский фильтр). К числу пяти остальных программ отпосят-
ся FFT (FASTFT) и четыре процедуры преобразования коордипат CCONRP,
CCONPR, CCONRS и CCONSR. Эти программы подробно описаны в [2.55].
а\
а 1
ах
а\
а2
Ьх
ахЬх
а\Ъ\
Аз
а2
а2
а2
а4
ь2
а2Ь2
<х\Ъ\ -f- а2Ъ2
Ьх
Аз
Аз
Аз
ь2
Ъз
А.з&з
(i\b\ -j- а2Ъ2 -{- азЬз
Ъг
а4
а4
а4
ЪА
Ъ4
а4Ъ4.
а\Ъ\ -)- а2Ъ2 -f- агЬъ -j- а4Ь4
Рис. 2.46. Алгоритм вычисления скалярного произведения (DOPT)
Основным преимуществом устройств, обладающих высокой степенью па¬
раллелизма, является их более полное соответствие специфическим особенно¬
стям той или иной задачи. Совершенствуя конструкции в атом направлении,
можно создать машины, вплотную ориентированные на решаемые задачи, щ
таким образом, получить более эффективные, с точки зрения стоимости, кон¬
струкции.
Многомерные многорежимпые запоминающие устройства
Техпика создания запоминающих устройств традиционно ограничива¬
лась схемами с последовательной пли произвольной выборкой слов, организо¬
ванных в виде одномерного списка. Основным исключением из этого прави¬
ла явились памяти с ассоциативной выборкой. Йенсен [2.56] расширил обще¬
принятые концепции памяти, предложив новый тип запоминающих уст¬
ройств, необычных по способам доступа и размерностям. Цели, которые по¬
ставил Йенсен, создавая необычные запоминающие устройства, заключались
Маска Память Данные
^ Рис. 2.47. Функциональная схема ассоциативпой памяти
в том, чтобы разработать нетрадиционные конструкции, позволяющие исполь¬
зовать преимущества БИС, в частности, такие, как регулярность и модуль-
пость. Г1о замыслу автора, достоинства таких типов памяти выражаются в
более высоких временных характеристиках, лучшем использовании памяти и
Солее легком программировании.
92
Способы выборки представляют собой средства, с помощью которых ад¬
ресуются даппые. Йенсен предлагает объединить в одном запоминающем уст¬
ройстве некоторые способы выборки (например, FIFO и ассоциативный), или
>ке прямо создавать памяти со специальным режимом выборки (например,
FIFO), вместо того чтобы эмулировать такие режимы, как это предлагают
другие авторы [2.14]# и [2.57].
Понятие размерности относится к числу координат, имеющихся в памяти.
В памяти с произвольной выборкой (пословной, одномерной и линейной) п-й
Рис. 2.48. Двумерная ассоциативная память со встроенной очередью
мерный массив должен быть липеаризован с помощью некоторого иреобразо-
ния адресов. В n-мерной же памяти гс-мерная структура данных может хра¬
ниться в исходном виде и быть адресуемой с помощью совокупности п чи¬
сел. Этот принцип был предложен для использования в машинах в качестве
поддержки реализации языка APL [2.58], который будет обсуждаться в гл. 3.
Ассоциативный ввод/ вывод
Рис. 2.49. Ассоциативная очередь
Рис. 2.50. Программное моделирова¬
ние очереди
Важно отметить, что в многомерной памяти пе обязательно иметь одинако¬
вый способ выборки по всем направлениям. Примером такого типа памяти
является двумерная ассоциативная память с выборкой по очереди, разработай-
пая Йснссном.
На рис. 2.47 изображена блок-схема простой ассоциативной памяти. На
рис. 2.48 показало, как в памяти с произвольной выборкой эмулируется
очередь (список FIFO), а на рпс. 2.49 изображена непосредственно реализован¬
ная очередь. Па рис. 2.50 приведен пример памяти со смешанным способом
выборки, т. е. по принципу ассоциативной очереди. В этой памяти выборку
данных может производиться либо по методу FIFO, либо ассоциативно. Ца,
мять такого типа оказывается очень эффективной при ее использовании 3
Рис. 2.51. Аппаратпо реализованная Рис. 2.52. Двумерная ассоциативная
очередь память со встроенной очередью
страпичном механизме для удаления страниц, к которым давно не было об¬
ращений. При тех же функциональных возможностях и характеристиках ас¬
социативная очередь требует для реализации упомянутого алгоритма в стра
пичпой памяти с N страницами в N'2 раз меньше ассоциативных разрядов,
чем обычпая ассоциативная память. Если в ассоциативную очередь ввести
между словами всего лишь простую сдвиговую логику, то в результате полу¬
чится устройство, весьма эффективное в ряде применений.
Двумерная память, построенная в виде ассоциативной очереди, изобра¬
жена на рис. 2.51. Это ассоциативная память, за каждым ассоциативным сло¬
вом которой выстроена очередь. Упрощенная схема ассоциативной памяти с
ассоциативной очередью, стоящей за каждым словом, показана на рис. 2.52.
Рис. 2.53. Ассоциативный стек Рис. 2.54. Стек в оперативной
памяти
Ото двумерная ассоциативная память с адресацией по содержимому и встроен¬
ной очередью. Такие тины структур запоминающих устройств с трудом под¬
даются эффективной эмуляции.
Ассоциативная очередь, изображенная на рпс. 2.50, работает следующим
образом. Новый объект может быть записан в память путем ассоциативного
сравнения его с объектами, находящимися в головных словах всех очередей.
Если произошло совпадение с одним из таких объектов, то новый объект по¬
94
вещается в последнее слово данной очереди и затем продвпгается вперед до
тех пор, пока есть ввободное место. Если какое-либо слово удаляется из ас¬
социативной памяти, то все оставшиеся слова продвигаются вперед на одну
позицию.
Возможны практически любые комбинации размерностей и способов вы¬
борки. Запоминающие устройства рассматриваемого типа, в особенности оче¬
реди, могут быть как синхронными, так и асипхронпыми. К другим типам па¬
мяти, предлагаемых Йенсеном, относятся ассоциативные стеки (рис. 2.53) и
двумерные памяти со стековой и произвольной выборкой (рис. 2.54).
Йеисен рассматривает эти типы памяти как небольшие устройства, рас¬
пределенные по вычислительной системе. Такие устройства особенно полез¬
ны в качестве аппаратной поддержки диспетчерских функций. Эрвин и Йен«
сен [2.59] исследовали задачи, связанные с обработкой «вложенных прерыва¬
ний. Возможности ассоциативной поддержки диспетчерских, функций [2.60]
были изучены с помощью небольших обычных ассоциативных процессоров.
Кроме того, ассоциативные запоминающие устройства нашли непосредствен¬
ное применение в механизмах виртуальной памяти.
Заключение
Наиболее характерной чертой ассоциативных процессоров является то,
что имеется огромное множество различных архитектур, обладающих совер¬
шенно различными характеристиками. Диапазон архитектур простирается от
простых машип с обработкой битовых срезов до сложных проблемно-ориен¬
тированных процессоров, решающих задач фильтрации па основе алгорит¬
ма Калмапа. Стоимости4 ячеек ассоциативных запоминающих устройств для
наиболее простых и наиболее сложпых машин отличаются на порядок.
Для такого незначительного различия в удельной стоимости различие в
архитектуре, гибкости и возможностях является очень большим. Основной
упор при практической реализации ассоциативпых процессоров сделан в ос¬
новном па создание простых устройств, в основу которых закладывается ли¬
бо принцип обработки битовых срезов, либо принцип распределенной логики.
Тенденции развития процессоров, предназначенных для исследовательских
целей, паправлены в сторону систем типа SIMDA и машин, подобных разра¬
ботанным Котцем [2.54] и [2.55], которые,, кроме ассоциативных возможно¬
стей, характеризуются значительным параллелизмом и высокой c-тепелью
связности ячеек.
С точки зрения настоящих примепепий (по сравнению с небольшими
специализированными устройствами типа управления памятью) будущее ас¬
социативной обработки остается многообещающим, одпако практические за¬
дачи должны быть хорошо изучены. Главное преимущество архитектур с
высокой степенью параллелизма состоит в том, что, к чести этих архитектур,
высокие характеристики обеспечиваются за счет пмеипо архитектуры, а не ее
компонентов. Будущее ассоциативпых процессоров для специальных приме¬
нений будет становиться все более блестящим по мере того, как будет повы¬
шаться уровень интеграции в БИС и улучшаться технология создания микро¬
процессоров. Доказательством тому является успех, который сопутствовал и
будет сопутствовать полупроводниковым запоминающим устройствам и мик¬
ропроцессорам, созданным к настоящему времени.
Упражнения
2.1. Нарисуйте блок-схему ассоциатывпого процессора и опишите наибо¬
лее существенные регистры.
2.2. Проиллюстрируйте работу ассоциатнвпого процессора, состоящего из
10 слов и используемого в отчестве анкетного файла. Локализуйте всех работ¬
ников, возраст которых около 30 лет, работающих в фирме более двух лет п
получающих более 1.25 долларов в час.
2.3. Объясните, почему в ассоциативном процессоре может оказаться не¬
существенным, чтобы число элементов было степенью двойки, в то время как
в памяти с произвольным доступом количество слов обязательно должпо быть
степенью двойки.
2.4. Сконструируйте устройство разрешения множественных откликов для
256-элементного ассоциативного процессора, имеющего счетчик числа откликов
при каждом поиске, используя две входных ячейки типа И, две входных ячей¬
ки типа ИЛИ, инверторы, сдвиговые регистры (длиной 16 разрядов) и восьми¬
разрядный счетчик.
2.5. Расскажите о наиболее важных конструкторских проблемах, которые
необходимо учитывать при разработке ассоциативного процессора.
2.6. Расскажите о конструктивных различиях между ассоциативной па¬
мятью с обработкой битовых срезов и ассоциативной памятью с распределен¬
ной логикой.
2.7. Дайте определение централизованной операции, операции над полями.
2.8. Детализируйте алгоритмы для: сложепия полей, умножения полей, на¬
хождения максимума в полях, централизованного сложения и централизован¬
ной операции сравпешгя («больше чем»). Расскажите, почему некоторые из
этих алгоритмов трудны для представления с помощью принципа перехода
состояния.
2.9. Нашипдте на языке APL моделирующую программу для ассоциатив¬
ного процессора, изображенного на рис. 2.1. Считайте, что этот процессор об¬
рабатывает битовые срезы.
2.10. Запрограммируйте па APL алгоритмы, указанные в задаче 2.8, для
модельного процессора задачи 2.9.
2.11. Опишите техническую реализацию двадцатипятимерного однородного
дерева.
2.12. Постройте список возможных мпкроопераций ассоциативного процес¬
сора и список команд па уровне языка ассемблера.
2.13. Расскажите, как ассоциативная память со встроенной очередью мо¬
жет быть использована в механизме виртуальпой памяти для реализации ал¬
горитма замещения но частоте обращения к страницам.
2.14. Сконструируйте ячейки синхронной и асинхронной ассоциативной
памяти со встроенной очередью. Сравните эти две ячейки с точки зрения слож¬
ности и количества выводов.
2.15. Сконструируйте ассоциативный процессор с аппаратпо-реализованным
алгоритмом Левина. Укажите, почему при реализации на базе полупроводни¬
ковой технологии могут встретиться трудности, связанные с количеством вы¬
водов.
2.16. Опишите на APL набор процедур, позволяющих работать в формате
с плавающей запятой на ассоциативном процессоре с обработкой битовых
срезов.
2.17. Сконструируйте ассоцнатпвпый процессор, который мог бы выполнять
функции интерфейса со считывающими головками диска пли барабапа. Объяс¬
ните, почему такой ассоциативный диск или барабан может использоваться
для осуществления поисковых операций в больших файлах данных.
2.18. Расскажите, каким образом механизм виртуальной памятп с алго¬
ритмом замещения страниц по частоте использования может быть реализован
без помощи ассоциативной памятп со встроенной очередью.
2.19. Сконструируйте ячейку для ассоциативной памяти с операциями по¬
иска гго критериям «равно» пли «больше чем».
2.20. Расскажите о потенциальной применимости ассоциативпых процессо¬
ров к решению задач со сложными структурами данных.
■96
2.21. Сравните алгоритмы построения списка, обратного связному списку
пз п объектов. Пусть один алгоритм строит обратный список в памяти с про¬
извольным доступом, а другой — в ассоциативной памяти.
2.22. Покажите, каким образом двумерная ассоциативная память со встро¬
енной очередью может служить аппаратной поддержкой механизму обработки
прерываний.
2.23. Пусть две прямоугольные матрицы А и В размером М X А7 хранятся
в ассоциативном процессоре в координатной форме. Это означает, что каждое
слово ассоциативной памяти содержит отдельный элемент — указатель того,
какой матрице он принадлежит, порядковый номер строки и порядковый номер
столбца. Напишите алгоритм сложения матриц. Пусть эти матрицы хранятся
в памяти с произвольным доступом. Придумайте структуру хранения и напи¬
шите алгоритм сложения. Сравните эти два решения задачи.
2.24. Придумайте структуру данных и алгоритм для умпожения прямо¬
угольных матриц размером N X М сначала для ассоциативного процессора,
а затем для памяти с произвольным доступом. Сравните алгоритмы.
2.25. Расскажите, как могут храниться матрицы с использованием прин¬
ципа смешанных адресов (хеширования). Сравните этот способ с хранением
в ассоциативном процессоре, если вы уже пе сделали этого раттыпе.
2.26. Покажите, каким образом двоичное дерево может быть разрешено в
ассоциативном процессоре. Расскажите, как нужно строить алгоритмы упоря¬
дочения сверху, упорядочения сттпзу и упорядочения по отпошештто к корню.
Сравните с тем, что получилось бы при реализации тех же функций с помо¬
щью списковых структур в памяти с произвольным доступом.
2.27. Предположим, что многопроцессорная вычислительная система пмеет
в качестве ресурса небольшую ассоциативную память. Пусть каждому систем¬
ному процессу соответствует одно слово этой ассоциативной памяти. Пред¬
положим ташке, что в каждом слове имеется поле, соответствующее определен¬
ному типу системного ресурса (типичными примерами ресурсов являются
процессоры, страницы главной памяти, файлы, находящиеся на внешней па¬
мяти и т. д.). Распишите слово ассоциативной памяти, выделяя поля, описы¬
вающие используемые в текущий момент ресурсы, флажки и т. д. Опишите
для такой многопроцессорной системы возможные алгоритмы составления рас¬
писаний и распределения ресурсов. Предположим, что операционная система
является одновходовой и рассматривается как временно предоставляемый ре¬
сурс; при этом она может быть представлена как процесс, имеющий соот¬
ветствующее поле в ассоциативной памяти. Как это обстоятельство отразится
иа вашем алгоритме? Должны ли вы изменить алгоритм? Почему? Оправдыва¬
ет ли рассмотрение операционной системы как ресурса дополнительные затра¬
ты? Обсудите конструкторские решения.
2.28. Объясните различия: между содержимым данных и их структурой;'
между организацией данных в запоминающей среде и методом доступа. Сопо¬
ставьте концептуальные различия с различиями в реализации между произ¬
вольным доступом к памяти и ассоциативным доступом.
2.29. С помощью ассоциативной памяти со встроенной очередью переставь¬
те элементы векторе (100 элементов) в обратном порядке. Объясните вашу
структуру данных. Сравпите результаты с тем, который получился бы при
выполнении этой операции в памяти с произвольным доступом.
2.30. Расскажите о различиях в командах распространения, как их опреде¬
ляют Ли для ПРЛ и Крепи п Гитеис для двумерной ПРЛ.
^ К. Дж. Тербер
Глава 3
ОСНОВНЫЕ ТИПЫ АРХИТЕКТУР
ПАРАЛЛЕЛЬНЫХ ПРОЦЕССОРОВ
Введение
В этой главе будут рассмотрели основные типы архитектур параллель¬
ных процессоров (ПН). Класс вычислительных систем, впоследствии называе¬
мых параллельными процессорами, сформировался на основе машин, постро¬
енных в виде массива процессорных элементов для выполнения параллель¬
ных, совмещенных, пе обязательно пошагово-сикхронизоваииых ОКМД-вычис-
ленпй над множествами данных типа матриц. Такие массивы из элементар¬
ных машин представляют определенный интерес, хотя они и пе полностью
удовлетворяют определению класса ОКМД. Поскольку книга посвящена
ОКМД-архитектурам, то в ней будут описаны в общих чертах наиболее важ¬
ные системы с массивом процессоров.
Параллельная обработка ведется главным образом в таких массивах, т<
которых каждый Г1Э связан с четырьмя ближайшими соседними элем опта ми.
и центральным устройством управления. Типичные представители такой ар¬
хитектуры— это системы SOLOMON и ILLIAC IV [3.20]. Создание подобных
систем вызвано двумя осповными причинами: потребностью в больших ма¬
шинах для выполнения специальных видов обработки типа распознавания
образов и желанием использовать преимущества БИС в системах с периоди¬
ческой организацией. Разработчики систем отдавали предпочтение таким ар¬
хитектурам, в которых каждый элемент связан с четырьмя ближайшими со¬
седями и имеет в своем составе небольшой процессор и блок локальной па¬
мяти.
Прежде чем изучать параллельные архитектуры, полезно сначала рас¬
смотреть идеи одного из их главных сторонников. Ниже дастся краткое из¬
ложение позиции Слотника по вопросу об архитектуре вычислительных
мапги п.
Прочитав введение Слотника к его статье «Нестандартные системы»
[3.20], читатель поймет, почему Холландеровская сессия SJCC (Spring Joint
Computer Conference) в 1967 г. получила пазвание «Большой дискуссии».
Слотппк рассматривает позицию изготовителей машин, согласно которой луч¬
шие образцы универсальных машин обладают всем необходимым для приме¬
нения в любых областях. Автор согласен, что такая политика правильна, ес¬
ли, скажем, ограничиваться такими задачами, как «управление расходом во¬
ды па водопапориых станциях». Оп считает, что как в паучпой, так и воен¬
ной областях есть очень важные задачи, для решения которых нужны пе
универсальные, а именно большие нестандартные мапптпы.
Критериями для оценки эффективности вычислительной машины явля¬
ются эффективная загрузка компонентов БИС и наиболее полное нсп-ользова-
98
ню памяти. Слотиик не принимает во внимание требование о совместимости
математического обеспечения снизу вверх. Он относится к совместимости
программного обеспечения как к проблеме «вечной» аппаратура, которая
зпоследствии будет представлять интерес лишь для историков и собирателей
древностей. Вопрос программной совместимости в связи с параллельными
тли ассоциативными процессорами не возникает. Он имеет значение тогда,
когда пользователем является банк или водонапорная станция; однако в этих
областях, по-видимому, параллельные или ассоциативные процессоры приме¬
нять -нецелесообразно. Результатом деятельности Слотппка в области органи¬
зации вычислительных машин стал параллельный процессор ILLIAC IV.
Главпым фактором, отрицательно влияющим на процесс создания парал¬
лельных машин, Слотиик назвал то, что человек мыслит и делает ручные
вычисления последовательно. Поэтому естественной моделью вычислитель¬
ной машины для пас является устройство последовательного действия. Па¬
раллельный же подход к вычислениям требует определенных усилий для пе¬
рестройки мышления, чтобы от использования параллельного процессора был
голк. Далее Слотиик утверждает: «Тем, кто не видит необходимости такой пе¬
рестройки, параллельный подход покажется обременительным».
Поскольку в гл. 2 был приведен подробный пример применения машин
рассматриваемого класса, то при обсуждении архитектур параллельных про¬
цессоров мы будем ограничиваться лишь краткими примерами их использо¬
вания. Таким образом, данная глава будет построена аналогично второй ча¬
сти предыдущей главы.
Ячеечные автоматы фон Неймана
В записках, датированных 1952 годом, фон Нейман описывает ячеечные
автоматы, состоящие из двумерного массива ячеек, каждая из которых мо¬
жет взаимодействовать с четырьмя своими ближайшими педиагональными
соседями (справа, слева, сверху и снизу). Модель [3.1] можно бесконечно
продолжить в любом направлении. При описании этой машины были введе¬
ны понятия однородной обработки и регулярности структуры вычислитель¬
ных машин. Каждая ячейка автомата представляет собой сложный логичес¬
кий нейронный модуль. Основным вычислительным модулем является нейрон
[3.2], представленный в виде простой математической мололи. Каждый мо¬
дуль имеет 29 состояний функционирования. Эти 29 состояний и правила пе¬
рехода были подробно описаны фон Нейманом. Ниже приводится их сводка.
На рис. 3.1 показаны 29 состоянии и сводка соответствующих правил пере¬
хода. Рис. 2.2 дает обобщенное описание связей между состояниями при пере¬
ходе нейрона от певозбужденного состояния -к возбужденному:
Множество состояний S состоит из нескольких категорий состояний. Со¬
стояния перехода определяются как Ти^е, где и = 0 либо 1 для обычного и
специального состояний соответственно, а = 0, 1, 2 или 3 для направлений на¬
право, вверх, налево или вниз и 6 = 0 либо 1 для покоящегося и возбужденно¬
го нейрона. Состояния перехода имеют одно входное направление и три воз¬
можных направлений выхода. Состояние перехода может быть возбуждено с
задержкой 1 (рис. 3.1). Существует четыре объединяющих состояния С£8,,
где е =0 либо 1 для покоящегося и возбужденного нейрона, а е' =0 или 1
в зависимости от того, покоится или возбужден следующий пейрон. Все на-
7* 99
Класс
Наз¬
Но¬
;
вание
Обозначение
мер
Сводка правил перехода состояния i
1
ф
|
Прямой процесс переводит U в чув-!
Я
ствительные состояния, а затем в;
о
и
1
РцлеО ИЛИ Соо !
О
Обратный процесс переводит Т^,|
или Сее'в U, как в конечную точку!
*1
8 =
= 0 (покой)
|
Принимает с объединением от Т0ас.|
8 =
= 1 (воз¬
буждение)
направленных к-нему. Передает с?
задержкой 2 во все ячейки с со-1
е'
= 0 (покой
стояниями Тйае, направленные от j
ф
следующей
него j
а
с«'
ячейки)
4
Переходит в U с помощью Tlai, на-j
Я
о _
8' =
= 1 (воз¬
правленного к нему; этот переход!
Я Я
М Я
буждение
доминирует над приемом j
Я ьн
следующей
1
о ®
j н
t3 о
VD С
С о
ячейки)
i
|
3
0
Класс:
Принимает раздельно от Т0ае, на¬
3
о
ц = 0
правленных к нему, и от C(S'. Пе¬
н
о
(обычное)
редает с задержкой 1 па выходы:
о
о
а) к состояниям Т0ае, пе направлен¬
ф
[0
\х = 1 (спе¬
ным к нему;
й
циальное)
б) к состоянию U или чувствитель¬
н
Возбужден
8
ному состоянию с помощью прямого
3
VO
ние:
процесса;
о
со
II
о
'£
0
1
в) к упичтожепию состояний Tiae с
^^
Тоае
о
кой)
помощью обратного процесса
а
8= 1 (воз¬
Переходит в U с помощью состоя¬
н
буждение)
ния Tiai, направленного к нему;
—
Направлен
этот переход доминирует над прие¬
§:
пия вы¬
мом
о
ё
|0
хода:
a = 0
PL,
Ф
Я
(вправо)
я
а — 1 -
Принимает раздельно от Tiae, на¬
я
1
(вверх)
правленных к нему, и от Сее'. Пе¬
я
a — 2
редает с задержкой 1 на выходы:
о
н
—>
(влево)
а) к состояниям Tiae, не направлен¬
«
о
a = 3
ным к нему;
я
я
о
(вниз)
б) к состоянию U или чувствитель¬
я
о
|-1
ным состояниям с помощью прямо- f
н
о
8
го процесса; 1
о
о
В) К уНИЧТОЖеНИЮ СОСТОЯНИЙ Toaei
о
или Сей ' с помощью обратного про¬
3
1
цесса
я
Tiae
Переходит в U с помощью состоя¬
03
ния Тоаь направленного к нему.
я
Переход в U доминирует над прие-|
о
6
|1
мом
Рис.. 3.1. Состояния ячейки автомата фон Неймаиа
100
Класс
Наз¬
вание
Обозначение
Но¬
мер
Сводка правил перехода состояния
Чувствительные состоя¬
ния
0ооо
/
^000
/ ^01
0 010
%
8
Это промежуточные состояния в
прямом процессе
Состояние Тцаь направленное к U.
превращает его данное состояние в
So, после чего идут:
а) Sv, если некоторое состояние па
правлено к ячейке;
б) Ss в противном случае, однако
здесь Ss относится к прямому про¬
цессу, завершающемуся в Тмао или
Соо (см. рис. 3.2)
Рис, 3.1 (продолжение). Состояния ячейки автомата фои Поймана
правления могут быть использованы как для входа, так и для выхода, однако
направление не может быть одновременно и входным, и выходным. Объеди¬
няющее состояние может быть возбуждено с задержкой 2.
Существует особое состояние U. Это устойчивое состояние, которое мо¬
жет служить конечной точкой для состояний перехода и объединяющих со¬
стояний. Есть восемь нестабильных состояний. Они обозначаются Ss. где
Рис, 3.2. Взаимосвязь между состояниями автомата фон Неймапа
2 = 0, 0, 1, 00, 01, 10, 11 и ООО. Кроме того, есть еще девять других состояний:
2 = 0000, 0001, 001, 010, 011, 100, 101, 110 и 111; однако они соответствуют
Т000, ТОЮ, Т020, ТОЗО, Т100, Т110, XI20, Т130 и С00, т. о. отождествляются с
устойчивыми переходными и объединяющими состояниями.
Алфавит состояний для автомата состоит из Т„ае (и = 0, 1. а = 0, 1,2, 3 и
е = 0, 1), Сее/(е = 0, 1, в' = 0, 1), U и (2 = 0, 0, 1, 00, 01, 10. 11, 111).
В данной машине имеется ряд интересных моментов. Каждая ячейка об¬
ладает признаком активности, который хотя и не управляет непосредственно
Этой ячейкой, по используется для возбуждения следующей. Бесконечный яче¬
ечный автомат легко может быть построен путем составления конечного спие-
101
ка исходного распределения ячеек, причем ячейкам в списке приписываются
состояния и предполагается, что но крайней мере одна ячейка конечного спи¬
ска находится: в состоянии, отличном от U. После итого автомат готов работать
в соответствии с Т. Его можно рассматривать как конечный автомат, образо¬
ванный из переключателей и элементов задержки. Кроме того, автомат можно
представить себе в виде множества подавтоматов с управляющим устройством
для их переключения. Состояниям можно придать определенные значения. Че¬
тыре состояния С£е, соответствуют логическому II, двойной задержке, раз¬
ветвлению проводов и замене раздражителей (обычных па специальные). Из
них могут быть образованы многочисленные конструкции. Для нас представ¬
ляет интерес универсальный строящий автомат D, предложенный: фон Нейма¬
ном. Автомату D он поставил в соответствие его ленточное описание Ld.
Г> этом случае можно показать, что такая модель бесконечного ячеечного ав¬
томата будет универсальным вычислителем в том же смысле, что и машина
Тыорипга. Можно также смоделировать биологические прототипы машины.
Пространственная машина Унгера
Прототип архитектуры параллельного процессора был описан Унгером
[3.3]. Машина предназначена для решения задач, данные в которых пред¬
ставлены в естественной пространственной форме. Это могли бы быть такие
области приложения, как игра в шахматы, распознавание образов и решение
линейных уравнений. Пространственная машина обрабатывает данные, орга¬
низованные в виде массива па плоскости. Если данные представлены не в
плоскостной форме, то машина может решить задачу, преобразовав ее к виду,
удобному для решения в плоскостной фор¬
ме. Пространственная машина изображе¬
на на рис. 3.3. Она состоит из регулярно¬
го двумерного массива ячеек. Каждая
ячейка соединена с четырьмя ближайши¬
ми соседями.
Массив обрабатывающих ячеек (моду¬
лей) находится под управлением централь¬
ного устройства управления. Центральное
устройство управления пе может обра¬
щаться к отдельному модулю независимо
от других. Оно передает команды всем
модулям массива. Центральный управля¬
ющий блок является универсальным уст¬
ройством и содержит память с произволь¬
ным доступом для команд, таймер, схему
синхронизации и блоки расшифровки ко¬
манд. Устройство управления производит
выборку команд, декодирует их и пе¬
ресылает расшифрованные команды во
все модули.
Каждый модуль представляет собой простейший процессор, обрабатываю¬
щий битовые срезы. Он состоят из одноразрядного накапливающего суммато¬
ра (аккумулятора), называемого главным регистром (ГР), регистров памяти
102
Рис. 3.3. Пространственная маши¬
на Унгера
(ячеек), обозначаемых через а, Ь, с, f, п содержит небольшое число логиче¬
ских ячеек. Входные данные поступают либо из центрального устройства уп¬
равления, либо пз аккумуляторов четырех ближайших соседей. Данные могут
быть направлены непосредственно в аккумуляторы отдельных ячеек из внеш¬
ней по отношению ко всему обрабатывающему комплексу среды.
Взаимодействие между массивом обрабатывающих модулей и централь¬
ным устройством управления осуществляется с помощью логического вентиля
ИЛИ. Этот интерфейс обеспечивает реализацию единственной команды пере¬
хода в системе. Вентиль ИЛИ связан с входом аккумулятора каждого модуля.
Этот выход вентиля ИЛИ снабжает информацией центральное устройство
управления. Он сообщает устройству управления, когда все аккумуляторы
содержат логический 0, позволяя тем самым выполнять пересылки при отсут¬
ствии команды. Выполнение этой команды не похоже на обычную работу бло¬
ка. активности или блока проверки на совпадение в параллельном процессоре.
Состояние вентиля ИЛИ по существу не является признаком активности. Этот
вентиль предназначен для реализации команды условного перехода, а его со¬
стояпие указывает на то, что в машине нет единиц (пет образа).
Прежде чем описать команды, обсудим кратко адресацию. В качестве
примера будет использована команда add (сложение). Команда имеет следую¬
щий вид: add X, где X может быть любым подмножеством набора а, Ь, с, ...
..., f, U, D, L и В. Здесь U, D. L и R указывают содержимое сумматоров верх¬
ней (U), нижней (D), левой (L) и правой (R) ячеек. Например, add a, R при¬
бавит к сумматору каждой ячейки значение, хранящееся в а, и текущее зна¬
чение сумматора правой ячейки. На границах массива ячеек команда будет
выполняться так, как если бы массив был окружен со всех сторон модулями,
содержащими нуль в своих сумматорах.
Система команд:
1) tr х (переход к х)—следующей выполнить команду х из памятп ко¬
манд центрального устройства управления;
2) trz х (условный переход) — если в поле зрепия нет единиц, то следую¬
щей выполнить команду х из памятп команд центрального устройства управ¬
ления; в противном случае продолжить выполнение команд в естественном
порядке;
3) in (инверсия) — инвертировать (взять дополнение) содержимое всех
сумматоров (помните, что главный регистр состоит только из одного
разряда);
A) add (сложение) —это команда логического сложения (логическое ИЛИ);
она позволяет выполнять одновременное сложение содержимого аккумулято¬
ра с любой ячейкой памяти модуля, либо с содержимым любого из соседних
аккумуляторов, либо с произвольной комбинацией этих операндов. Результат
помещается в сумматор, а память не меняется;
5) тру (умножение)—логическое умножение (логическое И). Подобно
сложению, команда тру перемножает содержимое аккумулятора и любой
требуемой ячейки памяти, или произвольных смежных сумматоров. Результат
попадает в аккумулятор, содержимое памяти не изменяется;
6) a dm (сложение в памятп) — эта команда выполняет логическое сло¬
жение содержимого аккумулятора с каждой указанной ячейкой памяти. Ко¬
манда adm а, с сложит содержимое аккумулятора с ячейками памяти а и с
во всех модулях. Содержимое аккумулятора не меняется;
7) mpm (умножошю в памяти)—выполняет логическое умножение со¬
держимого аккумулятора с содержимым каждой указанной ячейки памяти;
8) st (сохранение) — эта команда передает содержимое аккумулятора во
все указанные ячейки памяти;
9) wr (запись) —команда записывает в аккумулятор содержимое ячейки
памяти. Можно указывать только одну ячейку памяти, и ее содержимое по
меняется в результате выполнения команды:
10) SL, SR, SU, SD (сдвиг влево, сдвиг вправо, сдвиг вверх, сдвиг вниз) —
команда пересылает содержимое аккумулятора в соответствующий смежный
аккумулятор;
я
2-5
С 1
Команда
Комментарии
1
st а
Помещает следующий символ в ячейку памяти а; содержи¬
мое аккумулятора не меняется
2
SL
Переписывает содержимое аккумулятора в аккумулятор
соседнего слева элемента
3
ad m а
Прибавляет содержимое аккумулятора к содержимому а
4
mpy R
Стирает точку в нравом конце каждой строки (хранящуюся
trz 7
в аккумуляторе)
5
Если ни в каких строках не осталось больше точек, то про¬
цесс завершен и переходим к 7, в противном случае пере¬
tr 2
ходим К (>
6
Стирает но точке в каждой строке (команда 4); возвращаем¬
ся к 2 для продолжения процесса удваивания
7
wr а
Помещает результат в ячейку памяти а
Рис. 3.4. Программа удваивания длины строки
И) acid геГ (увеличение ссылки) — эта команда работает только с нижней
девой ячейкой. Она выполняет логическое сложение 1 с аккумулятором мо¬
дуля в нижнем левом углу, т. е. устанавливает значение нижнего левого ак¬
кумулятора равным 1;
12) ехр (расширение)—команда прибавляет 1 к аккумулятору каждого
модуля, связанного цепочкой межмодульных элементов памяти, с модулем,
у которого в аккумуляторе находится 1. Связь указывается. в команде и мо¬
жет идти по горизонтали, по вертикали, по диагонали (в положительном или
отрицательном направлении);
13) link (связь) — отмечает в памяти, что смежные пары модулей содер¬
жат единицы в обоих аккумуляторах, Смежными могут быть и диагональные
ячейки, как и в команде ехр;
14) SA (циклический сдвиг) — команда может быть использована для по¬
следовательного ввода-вывода. Берется вводимый бит и помещается в самую
пижшою левую ячейку матрицы. Каждая строка матрицы сдвигается вправо
на одну позицию, причем разряд крайней правой ячейки строки переходит
в крайнюю левую ячейку верхней строки. Самая верхняя правая ячейка на¬
правляет выходные данные своего аккумулятора в выходной регистр.
На рис. 3.4—3.G приводится пример обработки с помощью машины Унгера.
Пта программа и пример взяты из статьи Унгера. Функция программы — уд-
104
ионть строку по горизонтали, т. е. растянуть-каждую строку влево на величи¬
ну, равную ее длине. В программе есть цикл. Начальное содержимое поля ак¬
кумуляторов показано на рис. 3.5. Результат работы машины приведен на
рис. 3.(3.
1 111
1 1
1111
1111
1 [1 1 1 1 1
Рис. 3.5. Вид строк до преобразо- Рис. 3.6. Вид строк после операции
вания удвоения длины
Унгер подробно рассматривает аппаратную реализацию ячейки. В каждой
ячейке имеется 11 триггеров, 170 вентильных входов и 30 вентилей. Аппара¬
тура связи требует менее 10 вентилей на ячейку.
Позже Унгер предложил систему, эквивалентную пространственной вы¬
числительной машине.
Машина Холланда
Машина Холланда пе является параллельным процессором класса ОКМД.
Исторически она представляет большой интерес, так как обладает многими
важнейшими свойствами параллельного процессора. Однако первоначально
машина предназначалась для обеспечения одновременного выполнения не¬
скольких разных программ. Учитывая ее историческую ценность, в пей впер¬
вые было введено попятно бита активности элемента, мы и описываем здесь
эту систему.
Машина Холланда обладает тремя осповпыми признаками. Топологическая
структура — двумерный массив процессорных элементов. Исторически под тер¬
минами «вычислительная система с массивом процессоров» или «параллельный
процессор» подразумевается процессор, имеющий структуру массива, а пе про¬
цессор, обрабатывающий массивы данных. Программы («подпрограммы») могут
быть соответствующим образом распределены между процессорами и находить¬
ся в обработке одновременно. Структура машины создает основу для теорети¬
ческого исследования автоматов. Холланд предложил свою машину для того,
чтобы использовать ее в исследованиях в области расширяющихся автоматов.
Машина не обязательно должна ограничиваться рамками двумерного массива.
Автор ые касался проблемы ввода-вывода, равно как и других практических
1
1
1
1
1
1
1
1
1
1
аспектов архитектуры машины. Работа процессорных элементов синхронизиро¬
вана; время измеряется в дискретных шагах t0, К, 12, ... Хотя машина и явля¬
ется синхронной, т. е. процессорные элементы функционируют одновременно,
однако практическое выполнение программ и их взаимодействие осуществляет¬
ся асинхронно, т. е. одни программы могут быть вынуждены ждать результа¬
тов от других программ. В произвольный момент времени tn выполнение неко¬
торой команды может быть отложено из-за необходимости выполнить какие-
либо внешние функции, либо процесс может оказаться заблокированным во
избежание пересечения его маршрута с маршрутами других процессов.
Каждый процессорный элемент имеет память, логические элементы и ли¬
пни связи с четырьмя ближайшими соседями. В течение такта модуль либо ак¬
тивен, либо пассивен. Это реализовано так же, как и в параллельном процес¬
соре, т. е. существует бит активности, который указывает, активен данный
элемент (способен выполнять определенные действия на данпом интервале
времени) или пассивен (не назначен на выполнение каких-либо функций).
В машине Холланда процесс образует маршрут, определяемый признака¬
ми активности. В ячейке M(i, j) процесс активизирует либо ячейку M(i, j + 1),
либо M.(i, j — 1), либо Ivl(i + 1, j), либо M(i —1, j). Исключения из этого пра¬
вила могут быть только на границах массива, либо во время выполнения оп¬
ределенного типа управляющих действий (например, команды, соответствую¬
щей операции перехода). Пет причины, по которой пельзя было активизиро¬
вать более одной ячейки, т. е. реализованы функции типа команд fork и join
(разветвление и слияние). Один из способов выполнения параллельных вычи¬
слений с помощью многоячеечной активизации заключается в том, чтобы, на¬
ходясь в активном состоянии, передать управление сначала одному преемни¬
ку, а затем другому. Это делает оператор fork. Чтобы выполнить join, нужно
знать, где должны соединиться два маршрута, и обеспечить, чтобы та ветвь,
которая первой достигла точки слияния, удерживала процессорный элемепт
под своим управлением до тех пор, пока не подойдет другая ветвь. Параллель¬
ность вычислений реализуется в архитектуре с помощью возможности иметь
в данный момент времени несколько активных процессов.
За один шаг (период между tn п tn+i) выполняется три фазы. Первая фа¬
за является фазой ввода данных в регистр процессорного элемента. В это вре¬
мя в регистр может поступить извне произвольное значение. Не определяет¬
ся, каким образом это происходит (это часть задачи ввода/вывода). Вторая
фаза — это фаза выборки. Активный процессорный элемепт строит маршрут к
процессорному элементу, содержащему* нужный операнд, и выбирает его.
На третьей фазе происходит выполнение.
Построение маршрута — очень сложпый процесс. Каждый процессорный
элемепт знает направление к своему преемнику и предшественнику. Маршрут
может начинаться лишь в Р-модулс (процессорный элемент, разряд Р которо¬
го равен 1). В P-модуле может начинаться только один маршрут. Каждый
процессорный элемент может находиться в четырех разных маршрутах.
Поэтому процессорный элемент содержит четыре множества *-регистров, ко¬
торые указывают маршруты, частью которых является данный ПЭ. Алгоритм
построения маршрута включает множество сложных правил.
В выполнение вовлечены три процессорных элемента. Это активный мо¬
дуль, содержащий команды, регистр памяти, в котором находится операнд,
и A-модуль либо ПЭ, используемый в качестве аккумулятора.
106
Существует восемь основных операций, связаппых с процессорным
элементом:
1) Add (сложение) —прибавляет операнд к аккумулятору;
2) Store (сохранение) — значение из A-модуля направляется туда, где
находится операнд;
3) Transfer on minus (переход по минусу)—осуществляет передачу уп¬
равления в зависимости от значения аккумулятора. Управление переходит к
непосредственному преемнику либо к процессорному элементу, содержащему
операнд;
4) Iterate Segment (повторить сегмент)—выполняет генерацию длинных
маршрутов либо передачу управления к преемнику;
5) Set registers (установка регистров) — с помощью этой операции одна
программа может инициировать активность другой программы;
0) Record Registers (запись регистров) — осуществляет запись в аккуму¬
лятор определенных регистров в соответствии с операндом;
7) No order (пет операции) —в фазе выполнения пет операции;
8) Stop (останов) — завершает программу.
Па рис. 3.7 изображена общая архитектура системы. Каждый процессор¬
ный элемент содержит регистр памяти и следующие регистры:
1) EREG — бит активности;
2) A REG — признак А-модуля;
3) DREG — указывает, является ли регистр начальным для сегмента мар¬
шрута (подпоследовательности маршрута);
4) DiDoREG — двухразрядный регистр, который указывает паправлепие
сегмента либо направление преемника в зависимости от того, какой признак
установлен в обрабатывающем
ш элементе — DREG или AREG;
о) BiB2*REGS — четыре одно¬
разрядных регистра, указываю¬
щих вхождение в ориентирован¬
ный сегмент маршрута с направ¬
лением bib2.
Биты. Si, S2 и ср, q2 обознача¬
ют соответственно преемника и
предшественника. Бит Р описыва¬
ет состояние P-модуля, а биты
(р, а) = (0, 1) —состояние А-мо-
Дуля после выполнения операции
ввода или операции Store. Биты
1Д21з представляют код операции.
Биты d 1 cl2 показывают направле¬
ние сегмента, биты уп, yn-i ...
• • • У о — длины сегментов. Если
процессорный элемент является
A-модулем, то регистр интер¬
претируется как n + ll-разрядное число со знаком (уп ■
Уп—1 — старший разряд, а — младший разряд).
Другие предложенные Холландом варианты архитектуры позволяют осу¬
ществлять ветвление маршрутов и одновременную работу одного процесса с
*Рис. 3.7. Структура связей в машине Хол¬
ланда
• знаковый разряд,
107
нисколькими регистрами памяти (параллельный процессор). Машина Холлан¬
да очень трудна для программирования и очень дорога из-за большого ооъема
требуемой аппаратуры, которую в большинстве программ не удается эффек¬
тивно использовать. Эти проблемы привели к разработке машины Комфорта,
которая будет рассматриваться ниже [3.37].
Ортогональная машина
Ортогональная машина была предложена Шуманом [3.6]. Это один из са¬
мых оригинальных проектов параллельного процессора. В пей был достигпут
компромисс между классическим параллельным процессором, ассоциативным
процессором и универсальным процессором. Машина Шумана состоит из па¬
раллельного процессора и обычной универсальной вычислительной машины,
которые работают с обгцей ортогонально-адресуемой памятью. Эта система
послужила основой для семейства вычислительных машин OMEN, описанных
в гл. 7. Шуман считает, что существуют два различных способа достижения
вычислительной эффективности. Один из них — использование более современ¬
ных аппаратных средств. Другой — лучшая организация этих аппаратных
средств. Ортогональная машина является примером более эффективной орга¬
низации аппаратных компонент для решения некоторого класса задач.
Ортогональную машину можно рассматривать как ассоциативный процес¬
сор; однако первоначально цель была реализовать параллельную обработку
битовых срезов, извлекаемых из одного выбираемого подмножества модулей
памяти. Ортогональная машина выполняет ассоциативную обработку подобно
любому процессору с обработкой битовых срезов, имеющему отдельное устрой¬
ство управления, но, поскольку он предназначен преимущественно для расче¬
тов, его следует отнести к классу параллельных процессоров. Шуманом же
было введено понятие обработки битовых срезов.
На рис. 3.8 представлена блок-схема ортогональной машины. Изображены
следующие компоненты процессора:
1) горизонтальное арифметическое устройство (ГАУ), которое выполняет
обычную последовательную обработку слов;
2) вертикальное арифметическое устройство (ВАУ), которое выполняет
обработку битовых срезов и будет рассмотрено ниже;
3) устройство уиравлепия, которое управляет ГАУ и ВАУ. Оно может
быть реализовано в виде устройства управления для ведущей машины (уст¬
ройство управления ГАУ) и дополнительного блока управления ВАУ;
4) два процессора ввод/вывода (ПВВ) — один для ГАУ и один для ВАУ,
выполняющие операции ввода/вывода со словами или битовыми срезами со¬
ответственно;
5) ортогональная память, которая рассматривается ниже.
Ортогональная память состоит из слов длины L. Вся память целиком пе
обязательно должна быть ортогональной. Например, на рис. 3.8 память со¬
держит KR + Р ячеек, из которых только KR адресуются в ортогональном ре¬
ял: ме. Подробное это объясняется ниже. Ортогональный участок памяти раз¬
делен па К непсрекрывающихся модулей по R слов каждый (па рис. 3.8 для
удобства он изображен в виде первых КВ слов памяти). Адресация каждой
ячейки памяти в горизонтальном направлении может быть произвольной. По
вертикали можно обращаться к любому битовому срезу (столбцу разрядов)
108
слов, находящемуся в любом из К модулей. Существует KL адресуемых бито¬
вых срезов, причем каждый содержит И разрядов из одного модуля. Битовые
срезы обрабатываются ВАУ. Нельзя обратиться к некоторой части (например,
нижним II разрядам) одного модуля и верхним R — II разрядам соседнего
модуля, так как система может адресовать только лишь битовые срезы, со¬
держащие R разрядов из одного модуля. Это ограничение заставляет сегмен¬
тировать наборы данных таким образом, чтобы на один модуль приходилось
пвз
у
Горизон тальное
АУ
(последователь¬
ная обработкл
слов)
Ортогональная память
L
\kR + ^
I Ас/? + 2
I kR*
I
1 2—-L
1 2 L
i I
Вертикальное АУ
(обработка битовых срезов)
V, Vn С, Ст М
ПВВ
Рис. 3.8. Блок-схема ортогональной машины
мечюе R слов. Вот почему стоимость аппаратуры ВАУ была снижена за счет
разделения последнего между многими модулями памяти. В общем случае
ортогональной является вся память и Р равно нулю, т. е. ортогональная память
состоит из KR слов.
ВАУ состоит из набора R-разрядных регистров Vj, ..., Vn, R — разрядных
регистров хранения переноса Сь ..., Ст, R-разрядного регистра маски М и
R внешних логических и арифметических устройств. Регистры Vi, ..., Vn,
С[, ..., Cm образуют локальную память процессорных элементов. Регистр мас¬
ки действует как бит активности. Схема связи между процессорными эле¬
ментами ВАУ ие уточняется.
Ортогональпый процессор больше всего подходит для задач, требующих
реализации доступа к данным в двух направлениях, либо для задач, в которых
не нужпа обработка битовых срезов но всей памяти, зато необходима обра¬
109
ботка в двух направлениях. Фуллер [3.7] провел вравнителышй анализ орто¬
гонального процессора с обычным параллельным процессором типа ILLIAC IV.
В результате Фуллер пришел к выводу, что структура ILLIAC IV лучше, если
при решении задачи пе требуется ортогональный доступ к данным.
Машина Сквайра pi Пеле
Сквайр и Пеле [3.8] впервые рассмотрели параллельные процессоры с тол¬
ки зрения программирования. При создании своей машины они стремились
прежде всего к тому, чтобы сделать ее легкой для программирования, прене¬
брегая такими вопросами, как технологичность и экономное использование ап¬
паратуры. Время вычислений должйо было определяться lie аппаратными ог¬
раничениями, а качеством используемых численных методов и алгоритмов.
Архитектура рассматриваемой вычислительной машины включает в себя 2п
процессорных модулей. Каждый модуль соедипен с п другими модулями. Ма¬
шина топологически изоморфна n-мориому кубу, вершинами которого явля¬
ются процессорные модули, а ребрами — линии связи. Каждый процессорный
модуль имеет один запоминающий регистр (для команд либо данных), ариф¬
метико-логические аппаратные средства и средства декодирования, схему об¬
разования маршрутов и связь с центральным устройством синхронизации (ве¬
дущим процессором).
Выполнение команды происходит в четыре этапа. Первый шаг состоит в
активизации соответствующих модулей. На втором шаге формируются мар¬
шруты, направленные к операндам. На третьем шаге операнды засылаются в
активные модули, а четвертый шаг заключается в выполнении операции и за¬
писи результатов. Система команд трехадресная. Концептуально эта машина
находится между машиной Холланда и классическим параллельным процес¬
сором. В целом система процессоров работает синхронно, однако разные про¬
цессоры могут одновременно выполнять разпые команды.
При разработке процессора конструкторы стремились к следующему: 1) по¬
пользовать как можно больше декодирующих й арифметических устройств
(было принято по одному такому устройству на каждое слово памяти); 2) ог¬
раничиться применением идентичных модулей и 3) использовать структуру
/г-мерного куба, так как геометрия соединений в нем богата возможностями.
Условие помер один позволяет избежать проблемы очередей при распределе¬
нии команд но процессорам и обеспечивает одновременную произвольную вы¬
борку из каждой ячейки памяти. Соблюдение второго условия позволяет вос¬
пользоваться преимуществами технологии массового производства. Третий
принцип обеспечивает максимальную связность системы, позволяя, кроме то¬
го, в любой момент времени изолировать половину вершин системы от всех
остальных вершин. Эго решает задачу, связанную с одновременным обраще¬
нием двух модулей системы к третьему модулю.
Организация системы весьма сложна. Оценка аппаратных средств в 20 раз
превышает таковую для системы STRETCH, однако пропускная способность
на определенных задачах соотносилась как 50 или 100 к 1, т. е. в данной ма¬
шине требуется лишь один цикл выполнения там, где в обычной машине нуж¬
ны 50 или 100 циклов.
В этом проекте выделены две основные проблемы, с которыми приходится
сталкиваться при разработке матричных процессоров. Это сбалансированность
110
памяти и логики на уровне процессорного модуля и образование дешевой и
эффективной системы связей, достаточно гибкой для того, чтобы можно было
решать .многие задачи без траты огромного количества времени на обвод дан¬
ных вокруг заблокированных маршрутов. Сквайр и Пеле не приводят подроб¬
ностей решения первой задачи, кроме использования единственного регистра
памяти на процессорный элемент. Проблема перекрестных связей решена пу¬
тем образования очень плотной коммутационной сети и разработки весьма
эффективного метода построения маршрутов. Метод построения маршрутов
таков: сначала все модули с четным числом единиц в своих номерах расширя¬
ют маршруты на единицу. Затем оставшиеся модули увеличивают свои марш¬
руты на единицу. Процесс продолжается до тех пор, пока все маршруты пе
.завершены, т. е. никакой маршрут не пужпо больше увеличивать. Построение
маршрута по направлению к пункту назначения происходит с помощью при¬
соединения к нему такого модуля, который находится на одно расстояние по
'Хэммингу ближе к точке назначений, чем текущий модуль. Единственная за¬
дача приоритетности возникает, когда два маршрута, выходящих из одного
модуля, запрашивают одни и тот же участок маршрута. Поскольку участок
маршрута не является функцией состояний модулей, эта задача легко решает¬
ся путем логических преобразований и переориентацией одного из маршрутов.
Детальная разработка и реализация машины такого типа была бы труд¬
ной проблемой из-за сильной связности системы, однако программирование
,для нее могло бы быть проще, чем для машины Холланда.
У АМР — вычислительная машина
с векторным арифметическим устройством
Система VAMP была разработана Зенцигом и Смитом [3.9]. Она состоит
из трех основных блоков: векторного процессора, памяти и блока управления.
Векторный процессор представляет собой одномерный массив, состоящий из п
процессорных элементов. Даппые поступают в векторный процессор из памяти
но нескольким шипам. Блок управления организует совместную работу па¬
мяти и векторного процессора.
При создании системы VAMP
учитывались два главных требо¬
вания. Во-первых, предусмотреть
обработку больших массивов дан¬
ных. Во-вторых, повысить произ¬
водительность системы при реше¬
нии задач определенного класса
за счет увеличения, благодаря на¬
личию массива процессоров, объ¬
ема вычислительной работы, про¬
изводимой в единицу времени.
Ф ункциона л ьн ая блок-схем а
системы VAMP приведена па рис. 3.9. В отличие от других процессоров, па¬
мять которых распределена по ПЭ, VAMP имеет общую память. В процессор¬
ные элементы посылается команда, а адрес поступает в память. Логическое
Устройство памяти должно принять адрес и выдать п порций данных для п
ПЭ. Это обеспечивает гибкость системы, однако требует применения весьма
Рис. 3.9. Блок-схема системы VAMP
111
сложной логики генерации адресов. С функциональной точки зрения система
работает как параллельный процессор, хотя и обладает единой памятью
для данных.
Получив адрес, память должна выдать п порций данных. Существует пс-
сколько способов реализации такой систем!,г. В простейшем случае можно
взять один блок памяти, прочитать п слов, поместить их в п буферов и затем
переслать эти п слов. Из соображений быстродействия длина слова памяти бы¬
ла выбрана переменной, т. е. для получения разной производительности число
Базовый Индекс
адрес адреса
t I ’ ” i
к п Z-регистрам
Рис. 3.10. Структура памяти VAMP (предполагается 2k ^ п)
функциональных слов, приходящихся на одно физическое слово, может ме¬
няться. Другой способ заключается в считывании битовых срезов и последо¬
вательном формировании слов из этих срезов. В любом случае оказывается,
что, если логика генерации адресов такова, что никакой Г1Э не может обра¬
титься в чужое адресное пространство, то каждый Г1Э имеет как бы собствен¬
ную память. Метод организации такой системы памяти изображен на рис. ЗЛО
в предположении, что в момент обращения в память для записи и считывания
данных пе происходит конфликтов. Кроме того, система памяти позволяет
блоку управления обращаться в память в горизонтальном режиме, в резуль¬
тате чего последняя может функционировать как модифицированная ортого¬
нальная память. Во время работы векторпого процессора обращаться к памя¬
ти может также и цептральпое устройство управления. Все это позволяет
112
решить задачу сегментации, возшткповспие которой обусловлено физическими
ограничениями на память, непосредственно связанную с ПЭ.
Векторный процессор изображен па рис. 3.11. Каждый из п процессорных
элементов является полностью паралдельпьтм устройством, работающим с чи¬
слами с плавающей запятой. ПЭ имеет следующие регистры: регистр X—адре¬
суемый аккумулятор двойной длины и регистр Z — неадресуемый буферный ре¬
гистр памяти. Каждый ПЭ может выполнять обычные арифметические и логиче¬
ские операции, которые здесь
не будут рассматриваться.
Маска S и логический аккуму¬
лятор U — это регистры, состо¬
ящие из п разрядов. Маска со¬
держит биты активности эле¬
ментов. В регистр U помеща¬
ются результаты логических
операций. Чтобы обеспечить
управление теми элементами,
работа которых зависит от ви¬
да результатов и логических
проверок, регистр S может вы¬
ступать в роли U и наоборот.
Векторный аккумулятор W
дает возможность суммировать,
перемножать и т. д. все Х-ре-
гистры под маской S. Команды
поиска, типа МАХ или MIX,
помещают в W максимальное
либо минимальное значение,
обнаруженное среди элементов, хранящихся в Х-регисграх. Поскольку
машина предназначена для работы с массивами или векторами, организа¬
ция памяти может быть упрощена. В систему введены две специальные коман¬
ды, которые описываются в книге Айверсона по APL [3.10]. Это команды
расширения и сжатия. Пусть п = 8 и каждый элемент вектора X представля¬
ет собой число, записанное в Х-рсгистр. Тогда команда X-«-.U\X (сжатие), где-
и = (10 001 111) и X = (12 315 678), выдаст результат: Х= (156 780 000).
Команда X^-V/X, где V= (10 100 000), даст Х= (10-500 000), если X было-
равно (15 678 000). Подобные операции позволяют распаковывать, обрабаты¬
вать и вновь упаковывать массивы.
Устройство управления обращается в память по базовому адресу, моди¬
фицированному с помощью смещения или индекса. Па долю памяти отводится
задача генерации п абсолютных адресов и передача данных процессорам. До¬
полнительные подробности относительно процессора, устройства управления,
алгоритмов арифметики с плавающей запятой, языка и системы программиро¬
вания можно найти в [3.9]. Там, в частности, описывается один из приемов
изменения структуры процессора при решении задач, требующих выполнения
множества скалярных операций. Он состоит в использовании вместо процессор¬
ных элементов регистрового файла в сочетании с несколькими быстрыми об¬
рабатывающими устройствами. В результате считывание данных из 'памяти в
регистровый файл происходит в_ параллельном режиме. Поток скалярных
Векторный
аккумулятор
Логический
аккумулятор
ПЗ '
Пч ■
-U1
ПЗ N
Рис. 3.11. Блок-схема векторного арифме¬
тического устройства
8 К. Дш. Тербер
на
величии обрабатывается высокоскоростпым арифметическим устройством. Над
каждым множеством данных может выполняться своя операция. Ключ к эф¬
фективной реализации этого метода состоит в такой структурной организации
дапных, при которой их можно было бы выбирать в параллельпом режиме, об¬
рабатывать последовательно (или па магистрали) и параллельно размещать.
Система SOLOMON I
Система SOLOMON I воплощает в себе концепцию параллельного процес¬
сора, которая впоследствии привела к созданию ILLIAC IV. Существовали
две версии системы SOLOMON. Вначале будет описана система SOLOMON I
[3.11], а те изменения в архитектуре, которые позволили от SOLOMON I пе¬
рейти к SOLOMON II [3.12], будут описаны в следующем разделе. Будут рас¬
смотрены преимущества системы SOLOMON по производительности по срав-
иепию с универсальными вычислительными машинами.
SOLOMON I представляет собой массив процессорных элементов (ПЭ) с
горизонтальными и вертикальными связями между ближайшими соседями.
Рис. 3.12. Блок-схема системы SOLOMON
Система предназначена для обработки задач, в которые входят операции над
матрицами либо подобные операции над разнообразными массивами данных.
Характерными областями применения являются: 1) решение линейных урав¬
нений, 2) матричная арифметика, 3) вычисление корреляциопиых функций и
4) уравнения в частных производных.
Функциональные характеристики систоле SOLOMON позволяют решать за¬
дачи, включающие системы решения дифференциальных уравнений с част¬
ными производными, а также задачи сжатия п упаковки данных, управления
и планирования, распознавания символов, тепловых потоков, обработки дап-
.114
дых радиолокации, прогнозирования погоды, наблюдения за спутниками, кор¬
реляции между сигналами, управления воздушным движением, вычислений в
области атомной энергетики, криптоанализа, фоторазведки. Указанные задачи
обычно требуют много машинного времени и допускают распараллеливание.
Концептуальная схема системы SOLOMON I показана на рис. 3.12. Система
состоит из памяти программ, устройства управления (УУ), устройства опреде¬
ления последовательности операций (УОО), сети процессорных элементов,
устройства управления вводом/выводом (УВВ) и периферийных устройств
J3n ?п %п 1 4 Си Cz к прочим У
К процессорным элементам К устройствам памяти ПЭ.
Рис. 3.13. Блок-схема устройства определения последовательности команд сис¬
темы SOLOMON
ввода/вывода. Все программы вместе с константами размещаются в памяти
программ. У У управляет всем комплексом и распределяет команды. Это един¬
ственное устройство, которое может обращаться в память программ. Оно раз¬
личает команды ПЭ, команды ввода/вывода, комапды упорядочения операций
в программе и запросы сети ПЭ к устройствам ввода/вывода. Устройство уп¬
равления осуществляет выполнение операций пересылки, загрузки, перехода,
индексирования и операций ввода/вывода. УУ находит и подготавливает к вьы
полнению, включая индексацию, следующую команду для сети ПЭ. Когда сеть
ПЭ завершает выполнение текущей операции, УУ передает подготовленную
команду в устройство определения последовательности команд. УУ также вы¬
полняет частичное декодирование и индексацию адреса комапды ввода/вывода.
Команды управления ходом вычислений могут зависеть от данных, поступа¬
ющих из других блоков. Когда поступят все входпые данные, команда выпол¬
няется. К таким командам обычно относятся команды условного перехода в
зависимости от действий сети ПЭ. Поскольку в SOLOMON I имеется песколько
систем команд и несколько устройств, функционирующих параллельно, то ско¬
рость решения задачи в большой степени зависит от ис-куспости программиста.
8*
115
Ila рпс. 3.13 изображено устройство определения последовательности
(■команд. Его осповпые функции — декодирование команд УУ, генерация комапд
для сети ПЭ и управление адресацией. Команды декодируются по жесткой
схеме. Адресация памяти осуществляется с помощью двух счетчиков (цикли¬
ческих) и двух матричпых переключателей. Загрузка и уменьшение счетчи¬
ков производятся устройством управления и регистром операции устройства
Рис. 3.14. Сеть ПЭ системы SOLOMON
определения последовательности команд. Каждый матричный переключатель
сна реи со счетчиком, и каждая пара счетчик/переключатель адресует один из
двух буферов памяти ПЭ в каждом отдельном ПЭ.
Выбор режима работы (пересылка и т. п.) производится блоком управле¬
ния в устройстве определения последовательности команд. Этот блок также
устанавливает связь с устройством управления вводом/выводом для обеспече¬
ния синхронизации обмена между сетыо ПЭ и системой ввода/вывода.
Сеть Г1Э показана на рис. 3.14. На рис. 3.15 приведена блок-схема отдель¬
ного ПЭ. Каждый ПЭ имеет связь с четырьмя ближайшими соседями и внеш¬
ний вход, служащий для связи с устройством определения последовательности
команд. Ввод (вывод) данных в ПЭ может происходить от его четырех бли¬
жайших соседей либо от сетевого устройства определения последовательности
команд. Все операции маршрутизации в одном столбце ПЭ осуществляются од¬
новременно, так что, если ПЭ£ направляет данные к другому ПЭ, находящему¬
ся слева, то и ПЭ/ также направляет свои данные влево. Каждый буфер
116
центральное управляющее устройство
Рис. 3.15. Блок-схема ПЭ системы SOLOMON
Выборка позпчда из стека
Выборка разпчда из ста кг
Плоскости
У Г:
!
и н
СА1
СБ1
СЗ,
С А 2
—]-^
I т
п П
СВ2
: I
I .
САЗ
I
i
Г
С Во
—
i
I
i
—-
С Ап
па.
СВ/7
Рис. 3.16. Организация памяти ПЭ системы SOLOMON
Рис. 3.17. Блок-схема связей между ПЭ и устройствами ввода/вывода в системе
‘ SOLOMON
•дамятп содержит два спсциальпых разряда. Один пз пих используется как приз¬
нак режима чтения пз памяти, а другой показывает, что результат операции
должен быть записан в память. Буфер признаков служит для работы с сигна¬
лами, вырабатываемыми в результате деления к других операций. Переключа¬
тель фрагментов управляет пересылкой результата в пужпые фрагменты.
Арифметические действия выполняются с помощью устройства выбора оне-
Таблица 3.1
Список команд ПЭ системы SOLOMON
Мнемокод
Операция
ADD
Сложение с фиксированной запятой
ADM
Сложение абсолютных величин с фиксированной за¬
пятой
SUB
Вычитание с фиксированной запятой
SBM
Вычитание абсолютных величин с фиксированной за¬
пятой
MUL
Умножение с фиксированной запятой
DDV
Деление слова двойной длины (двойную длипу имеет
делимое)
DDL (DDR)
Деление левой (правой) половины делимого двойпой
длины
DDZ
Деление нуля (делимое находится в пулевой ячейке)
SLA (SRA)
Алгебраический сдвиг влево (вправо)
SLL (SRL)
Логический сдвиг влево (вправо)
AND
Логическое И
IOR (EOR)
Логическое ИЛИ (ИСКЛЮЧАЮЩЕЕ ИЛИ)
COM
Логическое дополнение
SBO (SBZ)
Занесение в разряд единицы (нуля)
MSA
Установка режима по команде
MSZ
Установка режима при равенстве разряда нулю
MSO
Установка режима при равенстве разряда единице
MLD
Загрузка режима
MST
Хранение режима
CEM
Логическое сравнение на эквивалентность и установ¬
ка режима в случае равенства
CAM
Алгебраическое сравнение и устаповка режима в слу¬
чае равенства
ITB
Передача информации от Х-регистра в память и об¬
ратно
раций и модифицированного полного сумматора. При вычислениях использу¬
ется двоичный дополнительный код, а арифметическое устройство работает
поразрядно-последовательно. Благодаря поразрядпо-последовательиому спосо¬
бу работы ПЭ длина слова является персмсппой. При умножении использует¬
ся схема последовательного поразрядного сдвига множителя и операция сло¬
жения. Выравнивание разрядов осуществляется с помощью циклических счет¬
чиков центрального устройства управления. Операция деления выполняется
без записи промежуточных результатов.
Способность паходпться во многих режпмах дает каждому ПЭ возможность
измспять ход выполнения программы как функцию своих дапных. Находясь
в режиме, заданном центральным устройством управления, ПЭ воспринимают
119
только его команды. Текущий режим ПЭ записывается в регистр режима уп¬
равления. Если в команде указано, что надо передать дальше некоторую внеш¬
нюю информацию, то те ПЭ, которые не находятся в выбранном режиме, лшщ
передают информацию дальше, но не воспринимают е«. Режимы, разрешен¬
ные в данном ПЭ, могут изменяться под воздействием признаков, вырабатыва¬
емых в арифметическом устройстве. Кроме того, с помощью соответствующий
Таблица 3.2
Список команд устройства управления системы SOLOMON
Мнемокод
Операция .
ADDC (SUBC)
Сложение (вычитание)
MULC (PMUL; IMUL)
Умножение (полиномиальпое умножение; умножение
целых чисел)
DIVC (RDIV)
Деление (повторное деление)
SQRT
Квадратный корень
BOOL
Булевская операция
SALG (SLOG; SCRG)
Логический сдвиг (алгебраический; циклический)
STIX (ICIX)
Приращение индекса
ICJP (SIJP)
Приращение индекса и переход
CPEA (CPID)
Вычисление исполнительного косвенного адреса
CNJP
Переход по счетчику
JMDX
Проверка режима ПЭ и переход
BCJP
Логическое сравнение и переход
AXJP
Алгебраическое сравнение и переход
TBJP
Проверка разрядов и переход
1ILJP
Останов и переход
JRUG
Безусловный переход
MACR
Макрокоманда
TERM
Завершение
DIRC
Передача данных
EXCII
Обмен
DTCIi
Команды канала данных
программных средств режимы может менять и программист. Существуют
команды загрузки и записи режимов, команды изменения тегов ы т. п. При
выполнении матричных операций громоздкими и требующими много времени
являются операции загрузки и записи, поэтому в логической схеме устройства
выбора режима предусмотрены команды выборки строк' или столбцов.
На каждой Г1Э приходится две секции памяти, состоящие из шестидесяти
четырех 32-разрядпых слов каждая. Секции 'организованы в виде стеков, как
показано на рис. 3.1(5. Можно обращаться одновременно к словам в разных
секциях, так как последние входят в разные стеки. Выборка разрядов проис¬
ходит независимо в каждом стеке. Все Г1Э, расположенные в одном столбце,
должны обращаться к одному и тому же слову плоскости *) и одному и тому
же биту. Плоскость существует для каждого ПЭ. Ввод/вывод выполняется че¬
рез регистр X в буферную память ввода/вывода, выполненную на сердечниках.
Крайние ПЭ (всех четырех сторон) могут быть связаны с регистром X
*) Совокупность слов, находящихся в вершинах стеков. {Примеч. пер.)
120
.(рис. 3.17). Для определения тех. столбцов и строк, которые могут взаимодейст¬
вовать непосредственно с регистром X, предусмотрено управление геометри¬
ческой структурой системы. Главное устройство обмена состоит из многока¬
нальной подсистемы на магнитных лептах, используемой в качестве буфера
для высокоскоростного барабана с параллельной выборкой. Вспомогательное
устройство обмена предназначено для связи с обычной перифериен типа пе¬
чатающих устройств. Геометрический контроль исключает передачу информа¬
ции в боковые элементы, позволяя, таким образом, осуществлять ввод/вывод
^непосредственно во внутреннюю область сети ПЭ.
В табл. 3.1 дается краткое описание системы команд ПЭ, а в табл. 3.2—
системы команд центрального устройства управления.
Система SOLOMON II
Система SOLOMON II [3.12] является усовершенствованной версией сис¬
темы SOLOMON 1. Самое существенное изменение состоит в том, что длина
слова ПЭ фиксирована и равна 24 разрядам. Переменная длипа слова
SOLOMON I песет в себе как преимущества, так и недостатки. Переменная
Рис. 3.18. Блок-схема ПЭ системы SOLOMON
Длина обеспечивает системе гибкость, однако при постояпной длине слова ПЭ
могут работать гораздо быстрее и ценой тех же затрат обеспечивать большую
■пропускную способность. В системе SOLOMON II почти 90% всех аппаратных
‘Средств приходится на сеть ПЭ, которую составляют 1024 элемента.
121
Процессорный элемент системы SOLOMON II изображен па рис. 3.18. В пе¬
го входит блок арифметических и булевских операций, блок управления, две
24-разрядных регистра (Р и Q), двухразрядный регистр управления режимом,
индикатор переноса, логическое устройство управления движением но марш¬
руту и память. Система команд ПЭ состоит из 53 операций. Арифметические
операции производятся над числами с фиксированной запятой.
Применение системы SOLOMON
Оценки эффективности системы SOLOMON приведены в статье Бэлла
[3.13]. Основная концепция системы SOLOMON, в припципе, позволяет умень¬
шить накладные расходы, сопровождающие выполнение команд, в 1024 раза»
Работу обычпой вычислительной машины можно упрощенно представить так:
одна выборка команды на одну выборку операнда. Тогда потенциальная ско¬
рость системы SOLOMON оказывается на три порядка выше, чем у универ¬
сальной машины со сравнимым временем цикла обращения к памяти. При из¬
мерении показателей увеличения быстродействия учитываются многие фак¬
торы. Вот главные из пих: 1) скорость ввода/вывода, 2) скорость обращения
в память, 3) взаимосвязь ПЭ, 4) длина слова, 5) неполная загрузка всех ИЗ
на каждом цикле и 6) система адресации. Оценка стоимостной эффективности:
еще более трудна из-за сложности задач, для решения которых предназнача¬
ется система SOLOMON.
Потенциальные области применения системы, такие как решение систем:
дифференциальных уравнений (при решении используются конечные разно¬
сти, одновременное смещение и метод последовательной верхней релаксации),
сопровождение спутников, многомерный функциональный анализ, связь, за¬
дачи переноса и сортировка, подробно описаны в литературе. В статье Бэлла
речь идет главным образом о решении дифференциальных уравнений и сопро¬
вождении спутников. Система SOLOMON I сравнивалась с универсальной ма¬
шиной (время сложения 4 мкс). SOLOMON I решает дифференциальные урав¬
нения методом последовательной верхпей релаксации примерно в 200 раз бы¬
стрее, чем обычная машина с длиной слова 18—24 разряда.
Оптимальный метод решения задачи для системы SOLOMON пе совпадает
с паилучшим алгоритмом для обычной машины. Эффективное использование
архитектур, подобных SOLOMON, предполагает наличие у разработчика спо¬
собности выходить за рамки привычных для последовательных машип мето¬
дов и в то же время работать с алгоритмами, которые могут оказаться непри¬
годными для обычной машины. Цель исследования нестандартных алгоритмов
не состоит в том, чтобы доказать, что матричные системы являются наилуч¬
шими из возможных, а в том, чтобы выделить те области применения, в ко¬
торых такие системы могут дать большую производительность или позволить
решать ранее неразрешимые или трудные задачи, пли обеспечить решение за¬
дачи с большей эффективностью.
Система ILLIAC III
Система ILLIAC III [3.14] создавалась для решения задач распознавания
образов. 13 ее конструкцию была заложена способность автоматически просмат¬
ривать и анализировать черно-белые изображения. Первоначально система
разрабатывалась как специализированная машина для анализа негативов из.
122
пузырьковой камеры, однако ос можно использовать для обработки любых
двумерных цифровых массивов. ILLIAC III выполняет операции типа проре¬
живания строк, заполнения интервалов в. строках, определения конечных то¬
чек, точек изгиба и точек пересечения строк.
Ниже перечислены пять основных подсистем ILLIAC III и их функций:
1) высокоскоростные осциллоскопическис сканирующие устройства — ис¬
пользуются для быстрого ввода фотоииформации в цифровом виде;
2) комплекс вывода — пе¬
чатающие устройства, дисплеи
и ленты для размещения и
вывода информации в системе;
3) арифметическое устрой¬
ство — выполняет статистиче¬
ские вычисления и восстанов¬
ление объемного изображения
при фотообработке;
4) таксок-рпшюо устройст¬
во — завершает процесс рас¬
познавания путем получепня и
классификации итогового гра¬
фа изображения (представлен¬
ного в виде списка);
5) устройство преобразо¬
вания изображений ПИ — это
устройство представляет особый интерес. ПИ состоит из массива 32 X 32
процессорных элемента, который сокращает вводимые данные до размера
строки.
В параллельном режиме выделяются узловые точки и другие элементы
изображения. Затем формируется граф взаимных связей между точками, ко¬
торый представляется в виде списка. ПИ снабжено устройством промежуточ¬
ной памяти (1111), которая мо/кет действовать как обычная ассоциативная па¬
мять. Каждая ячейка пз 32 X 32 ячеек массива ПИ имеет возможность взаимо¬
действовать с восемью соседями. Программист может выбрать схему либо в
виде ромба (с -шестью ближайшими соседями), либо в виде прямоугольника
(с восемью ближайшими соседями). Каждая ячейка ПИ называется сталак¬
титом. Блок-схема сталактита показана па рис. 3.19. Сталактит состоит из трех
основных секций. Одна из них является принимающей, она выбирает ячейку,
из которой нужно принять данные. Данные могут быть получены из самого
сталактита, либо от одного из восьми ближайших соседей.
Следующая секция — это секция передачи. Секция передачи передаст
значение одного из двух однобитовых регистров либов своему сталактиту, ли¬
бо одному из своих восьми соседей. Принимающая секция выбирает один пз
входов и подключает его к шипе. Секция хранения выбирает одну из десяти
запоминающих ячеек и помещает туда вводимые данные. При чтении ячейка
поступает.в шипу, где передающее устройство выбирает для нее один из девя¬
ти возможных пунктов назначения, в который будет направлено содоржимоо
этой ячейки. Чтобы избежать необходимости образования двухуровневой па¬
мяти, можно пойти по пути разбиения управляющих сигналов чтения и за-
загрузки иа два непересекающихся множества. Другим решением является
О
1 —
1Г
оэ
н »с
Ъ «=1
G0 Gi Gy G3 G8
!
j
I
f
*
„-J
■ ’3 h
- <D
со о
Управление входами
Рис. 3.19. Блок-схема сталактита
123
разделение управляющих триггеров между основной и промежуточной
памятью.
Из соображений быстродействия в системе ILLIAG III из множества внут¬
ренних триггеров динамически выделяются номера триггеров передачи управ¬
ления (одинаковые для всех сталактитов), которые затем меняются при пе¬
реходе от одной команды к другой. Это позволяет обойтись одним машинпым
циклом вместо двух. Передающая и принимающая секции сталактита явля¬
ются устройствами комбинаторной логики. Секция хранения состоит из десять,
триггеров с номерами М, 0, 1, —, 8. Триггер М служит в качестве буферного
регистра ПП. Триггер 0 является вспомогательным регистром, не участвующим:
в сортировке. Триггеры 1, 2, ..., 8 в совокупности служат в качестве регистре
пузырьковой сортировки.
ПП отображает систему на плоскость размера 32 X 32 (по одпому разряда
па сталактит). ПП образована из 54 плоскостей по 1024 разряда так, что г
процессе работы ПП может передать в ПИ 1024 бита в любом цикле обраще¬
ния. Сталактит воспринимает ПП как блок из 54 одноразрядных слов, которые
могут быть загружены в М и выгружены из М. При совместной работе с ПН
ПП обладает некоторыми свойствами ассоциативной памяти. Эти свойства мо¬
жно реализовать с помощью спискового оператора (c-м. ниже) и триггера М.
При совпадении содержимого ПП с ключом в М записывается нуль. Совпада¬
ющие элементы ПП идентифицируются списковым оператором. Поисковый
ключ должен посылаться в У ПИ но одному разряду за одни такт.
Проще всего представить себе работу ПП, если разбить команды па ка¬
тегории и исследовать потоки данных, порождаемые нестандартными катего¬
риями команд. Команду УПИ лучше всего изобразить в виде 40-разрядного сло¬
ва, разделенного па четыре поля по 10 разрядов. Первые десять разрядов уп¬
равляют логическим потоком обработки, следующие десять бит описывают
условия считывания, третье поле управляет вводом, последнее дссятиразряд-
нос поле является полем управления загрузкой. Существуют следующие типы,
команд ПИ: 1) команды перехода (условные и безусловные, с переходом па
границу сталактита и без такового), 2) команды попарной (или пузырьковой)
сортировки, 3) команды, работающие с промежуточной памятью, 4) команды
сквозного прохода, 5) списковые команды п команды маркировки и 6) комап-
ды ввода/вывода через границу.
В поле управления потоком разряды 1 и 3 (с и С) управляют вводом и
выводом. Бит 4 (обозначенный через F) управляет операцией сквозного про¬
хода. Операция сквозпого прохода позволяет «перепрыгнуть.*) через сталактит.
Единица в битс 2 (разряде С) указывает, что устройство ввода открыто, и вы¬
зывает опрос группы разрядов блока управления вводом (поле 3). Единица
в пятом разряде (разряде В) обозпачает режим сортировки. Разряды с шестого
по десятый обозначаются через U, D, N2, N«, N0 и'указывают, вверху пли вни¬
зу находится «пузырек», а также число итераций, которое нужно выполнить
в пузырьковой сортировке (двопчиоо представление этого числа образовано
разрядами N2, Nb N0).
Поле 2 (управление чтением) состоит из 10 разрядов п указывает, ин¬
формация какого из ближайших соседей пли какой зоны памяти будет счита¬
на в сталактит.
В поле 3 (управлепио вводом) -входят десять разрядов: С. 0. 1, ..., 8. Раз¬
ряд С эквивалентен разряду С, находящемуся в поле управления потоком.
124
Если С равен 1, то каждый вход, маркированный единицей, открыт и разре¬
шена запись в соответствующую ячейку. В нулевом разряде при прямоуголь¬
ной и ромбической конфигурации массива стоит 0; в случае ромба не исполь¬
зуются седьмой и восьмой разряды.
Для описания вывода используется группа управления загрузкой (поле 4,.
состоящее из 10 разрядов, обозначенных через М, 0, 1, ..., 8), прн этом содер¬
жимое регистров, указанных в данной группе, передается в шипу вывода. За¬
грузкой или разгрузкой ПИ управляет бит М сталактита.
Из шести типов команд ПИ только для команд сортировки, перехода и
сквозного прохода хватает сорока разрядов. Для образования командного сло¬
ва других тппов нужны дополнительные разряды. Другие операции не пред¬
ставляют особого интереса, кроме списковых команд и команд маркировки,
функциональное описание пузырьковой сортировки, списковых команд и
команд маркировки приводится ниже.
В процессе пузырьковой сортировки происходит считывапие значений
ближайших соседних ячеек. С помощью сортировки выполняется такое преоб¬
разование регистра сортировки (биты 1, 2, ..., 8), в результате которого все
нули оказываются в начале, т. е. произвольная восьмиразрядная последова¬
тельность цифр аь а2, ..., а8 принимает вид 0, 0, ..., 0, 1, 1, ..., 1. Это дости¬
гается многократной заменой каждой пары цифр 10 па пару 01. Этот прием
позволяет отсортировать регистр длины R за R — 1 итерацию, не добавляя и
не теряя пулей либо единиц. В приложениях такая операция используется для
определения и сглаживания точек. Процедура заключается в следующем. Для
каждой текущей ячейки берется строка значений соседних ячеек и подверга¬
ется сортировке. Затем подсчитывается число единиц (с помощью специаль¬
ной логической схемы подсчета смежных единиц), и каждая ячейка, для ко¬
торой это число превышает пороговое значение, помечается 1. В противном
случае ячейка помечается 0. Пузырьковая сортировка является наиболее важ¬
ной функцией в операциях прореживания строк и выделения точек.
Оператор MARK (метка) имеет вид MARK(Z). Он записывает единицу в
регистр М ячейки с координатами Z = (X, У).
Оператор LIST (список) последовательно составляет список координат Ъ
всех ячеек, у которых в регистре М находится 0.
IAC — итерационная вычислительная система
с массивом процессоров
В Авиациоппом паучно-псследователъском центре ВВС США Роум под ру¬
ководством Нэнпа [3.15] проводились работы по созданию вычислительной
системы с массивом процессоров, в которой в качестве ведущей машины пред¬
полагалось использовать CDC 160 (рис. 3.20). Основные функциональные эле¬
менты системы IAC таковы: 1) CDC 160, 2) буфер ввода/вывода, 3) регистр пе¬
ресылки, 4) блок управления и 5) массив ПЭ.
CDC 160 выполняет роль ведущего процессора, т. с. управляет массивом
ПЭ. Массив ПЭ вязан с CDC 160 капаламл ввода/вывода. Ширина канала вво-
Да/вьгвода 12 разрядов. Для пересылки команд в массив ПЭ используется
Двойное слово. Длина слова ПЭ 24 разряда.
Буфер ввода/вывода состоит из регистра сдвига, который осуществляет
преобразование слов для перехода от последовательного обмепа, используемо¬
125
го в ПЭ, к параллельному обмену CDC 100. Буфер соединен с процессорными
.элементами (1, 1), (2, 1), ..(10, 1). Он образован из десяти линий задержки.
Каждый раз, когда полуслово (12 разрядов) поступает на вход регистра сдви¬
га, буфер помещает новое полуслово в вершину стека и сдвигает на нолслокц
вниз все предыдущее содержимое. Процесс вывода происходит в обратном
порядке. В результате взаимодействия блока управления и буфера ввода/вы¬
вода два управляющих слова транслиру¬
ются в слово массива и наоборот. Содержи¬
мое буфера по команде поступает в самый
левый ПЭ.
24-разрядпая линия задержки, связан¬
ная со всеми ПЭ, образует регистр пере¬
сылки. Из регистра пересылки слово может
поступать одновременно во все ПЭ либо
в намять, либо в аккумулятор, иногда
предварительно оно может быть скомбини¬
ровано путем арифметических и логических
операций с данными, находящимися в па¬
мяти 11Э.
Последовательностью операций масси¬
ва ПЭ руководит блок управления, коман¬
дное слово которого образовано из двух
слов CDC 160. Слова данных поступают в
буфер ввода/вывода. Блок управления ин¬
терпретирует микрокоманды, связанные с организацией движения данных II-1
по маршруту п адресацией памяти ПЭ. Встретив команду ввода/вывода, блок
управления сигнализирует буферу ввода/вывода о необходимости принят.о
данные из CDC 100. Команды синхронизации массива ПЭ и С DC 160 выполня¬
ются логическим устройством блока управления. При работе канала ввода;
вывода взводится функциональный триггер в блоке управления. Код 77ХХ
сообщает УУ, что массив должен выполнять команду. Коды канала приводят
■си в табл. 3.3.
Таблица 3.3
Коды канала CDC 160, используемые для управления системой IAC
Код
Режим
Операция
7700
Быполнсиие ко¬
Прием двух слов С DC 160 и выполнение команд
манд
7720
Состояние считы¬
Сообщение С1)С 160, что либо 1) все активны.
7740
вания
либо 2) ни одни из них не активен, либо 3) не¬
которые ПЭ активны
-
Ввод/вывод
Установка маршрутов для ввода/вывода
7750
Пересылка
Установка линии пересылки
Массив ПЭ состоит из ста идентичных процессорных элементов, образую¬
щих квадрат размера 10 X 10, в котором каждый элемент связан с ближаншн-
Рис. 3.20. Блок-схема
ли соседями. Все ПЭ параллельно обрабатывают свои даипые. Ввод/вывод мо¬
жет происходить либо через регистр .пересылки, либо через левый столбец
элементов. ГГЭ могут выполнять арифметические и логические операции дан¬
ными, находящимися в аккумуляторе соседнего ПЭ.
Т а б л и ц а 3.4
Микрокоманды IAC
Мне¬
мокод
Разряд
Слово
Операция
RA
0
1
Считывание аккумулятора
WA
1
1
Запись в аккумулятор
RM
2
1
Чтение из памяти (ПЭ может читать только из своей
памяти)
WM
3
1
Запись в память
см
4
1
Двоичное дополнение содержимого памяти (аналогично
ИМ, только считывается двоичное дополнение)
FC
5
1
Фиктивный перенос (помещает единицу па вход перено¬
са в момент выборки наименьшего значащего разряда;
единственная команда, действие которой не распростра¬
няется на период выборки целого слова)
AS '
6
1
Активизация триггера S (для установки триггера исполь¬
зуется выход арифметико-логического устройства)
IS
7
1
Суммирование под маской (маской может служить триг¬
гер S или слово памяти)
ОС
8
1
Вывод переноса (перенос считывается в аккумулятор па
триггере S и логику входа памяти; команда может бьтть
преобразована при использовании вместе с командой IS)
1C
9
1
Перенос под маской
SB
. 10
1
Установка признаков выбора (если активизирована-
команда SS, то будут работать только те ПЭ, триггер S
которых совпадает с соответствующим битом SB)
ss
11
1
Выбор (если активизирована команда SS, то работают
только те Г1Э, триггер S которых совпал с соответствую¬
щим битом)
cs
6
2
Контрольный сдвиг (сдвиг вправо с потерей крайнего
разряда, при котором разряд 23 записывается в разряды
23 и 22)
ПЭ представляет собой последовательный процессор, работающий в допол¬
нительном двоичном коде и имеющий одни аккумулятор, память из 03 слов-
1-я половила слова CDC 160
Мнемоника микро¬
команды
SS
SB
1C
ОС
IS
AS
FC
CM
wmJhm
WA
RA
Разряд
11
10
9
8
7
6
5
4
3 2
1
0
2-я
половина слова CDC
160
Значенпс
Снизу
Сверху
Слева
Справа
BI
CS (микрокоманда)
Адрес
Разряд
И
10 9 8 7 6
Рнс. 3.21. Структура команды 1ЛС.
5 4 3 2 1 0'
127
(линия задержки), полный сумматор п триггер активности (триггер s)-. s-трвг-
гор может активизировать либо дсактпвп.з кровать ПЭ. Частота задаюнд,^
го генератора 1 мгц.
Таблица 3.5
Макрокоманды IAC
Мнемокод
Операция
LDA
Загрузка аккумулятора
LDN
Загрузка аккумулятора с обратным знаком
EDC
Загрузка двоичного дополнения аккумулятора
LDZ (LDO; LMO)
Загрузка аккумулятора нулем (единицей; мипус еди ¬
ницей)
TFN
Пересылка из аккумулятора соседнего элемента
STA
Храпение аккумулятора
STZ (STO; SMO)
Запись пуля (единицы; минус единицы)
ADD
Сложение
RAD
Сложение с замещением
ADA
И р и р а ищи и е акк у м у л я т ор а
SUB
Вычитание
RSB
Вычитание с замещением
'SO A
Уменьшение аккумулятора
AOR (ROR)
Логическое ИЛИ (с замещением содержимого аккуму¬
лятора)
AND (RAN)
Логическое И (с замещением)
XOR (RXOR)
ИСКЛЮЧАЮЩЕЕ ИЛИ (с замещением)
SSZ (SSO)
Установка S равным нулю (единице)
SSA (SSM)
Установка знака аккумулятора (элемента памяти)
CPA (CPU)
Алгебраическое (логическое) сравнение
ZTA (ZTM)
Проверка иа равенство пулю аккумулятора (элемен¬
та памяти)
EQT
Проверка па равенство
BSA
Сдвиг аккумулятора вправо (влево)
SUM
Сдвиг памяти
NOP
Отсутствие операции
На рис. 3.21 показано командное слово IAC. 24-разрядная команда разбита
па три поля: 13 разрядов для указания .13 микрокоманд, 5 разрядов для обозна¬
чения маршрута движения информации и G разрядов па адрес (для G3 слов
памяти). В табл. 3.4 приведена сводка, а в табл. 3.5 — основные комапды, об¬
разованные из микрокоманд [3.10].
PC — планарная вычислительная система
Система PC была предложена Хокппсом и Манси [3.17]. Они выдвинули
семь ключевых принципов, которые привели к созданию архитектуры, изобра¬
женной на рис. 3.22. Дапнуго машину можно представить в виде входной плос¬
кости, набора процессорных элементов и выходной плоскости. Основополага¬
ющие принципы таковы:
1) ноток данных может идтн только в одпом направлении — от входа
к выходу;
2) -каждый процессор получает входные дапиые из N элементов входпой
плоскости, причем N обычно выбирается много меньшим числа входных вс-
128
личин, чтобы сократить количество соединений, приходящихся на один
процессор;
3) в двумерной системе координат (XY) с -началом в точке (0, 0) все про¬
цессорные элементы одинаковым образом соединены с входной и выходной
плоскостями, например, элемент (1, 1) связан со входами (1, 1) и (1, 2) и
выходом (10, 1), т. е. в общем случае
элемент (£, /) должен быть подключен
ко входам (i, j) и (£, / + 1) и выходу
(i +9, /);
4) все процессоры одновременно
выполняют одну и ту же логическую
функцию;
5) множество допустимых логиче¬
ских функций ограничивается двоич¬
ным дополнением линейных входных
логич еских. вы р а ж сии й;
6) выходные данные поступают в
память, а входные дапные могут посту¬
пать как из памяти, так и с ..внешнего
входа, однако взаимосвязь входа (i, j)
с соответствующими выходами сохра¬
няется;
7) если размерность массива вход¬
ных данных N X М, то и выходной мас¬
сив имеет размерность N X М, а мно¬
жество из Р процессоров (Р ^ N X может образовывать любую частично
заполненную структуру, лишь бы выполнялось условие 3.
Команда рассматриваемой машины состоит из выходного адреса, выполня¬
емой функции и относительного адреса входных переменных. При последова¬
тельном выполнении команд, содержащих допустимые функции, за достаточно
большое число шагов машина может вычислить любую функцию. Для образо¬
вания более сложных вычислительных структур можно группировать несколь¬
ко планарных машин в виде матриц, поточных линий и т. п. Хокинс и Майей
[3.17] приводят несколько простых примеров работы машины, сообщают, как
реализовать машину на оптических элементах, п дают примеры того, ка¬
ким образом можно ее использовать для решения задач обработки изобра¬
жений.
ALPS — параллельная вычислительная система
с ассоциативными процессорами
Блок-схема ALPS [3.18] показана на рис. 3.23. Высокая производитель¬
ность системы ALPS достигается за счет суммирования производительности мно¬
жества небольших простых вычислительных блоков. Этот принцип позволяет
эффективно использовать преимущества серийного производства. В качестве
процессорных элементов в системе ALPS используются ассоциативные уст¬
ройства. Каждый ассоциативный процессор может функционировать незави¬
симо от других. Блоки управления устанавливают последовательность выпол¬
нения программ и загружают ассоциативпые процессоры. В ассоциативном
9 К. Дне. Тербер 129
Рис. 3.22. Функциональная блок-схе¬
ма PG
процессоре есть входная очередь, куда поступают команды от различных уп¬
равляющих блоков. Поэтому ассоциативные процессоры могут работать с по¬
шаговой синхронизацией (с точки зрения архитектуры сивтема ALPS в этом;
случае подобна параллельному процессору с ассоциативными процессорами н
качестве ПЭ или большому ассоциативному процессору с блочной структурой
Рис. 3.23. Блок-схема системы ALPS
типа системы STAPiAN) или в параллельном режиме (в этой случае ALPS ока¬
зывается подобпой группе параллельно работающих ассоциативных процес¬
соров и напоминает архитектуру класса МКМД).
В одном из режимов функционирования ALPS можно разбить па группы
синхронно работающих параллельных процессоров, каждой из которых управ¬
ляет один из N управляющих блоков. В этом случае ALPS становится похожей
на ассоциативный процессор Шмитца [3.19].
Система ILLIAC IV
Система ILLIAC IV [3.20] изображена на рис. 3.24. Один квадрат из
64 ПЭ представляет собой матрицу (8 X 8) процессорных элементов, каждый
из которых связан с четырьмя ближайшими соседями. Подробно ILLIAC IV
будет описан в гл. 4.
Причиной разработки и построения системы ILLIAC IV послужило нали¬
чие таких задач, при решении которых представлялось реальным за счет ар¬
хитектуры ILLIAC получить увеличение быстродействия в 256 раз. К подоб¬
ным задачам отпосятся:
1) обработка данных, получаемых при подземных испытаниях ядерпого
оружия, в частности, расчет распределении потоков частиц и деформаций зем¬
ной коры;
2) решение дифференциальных уравпепий методом неявной релаксации;
3) задачи прогнозирования погоды;
4) матричные вычисления;
5) линейное программирование;
6) быстрое преобразование Фурье;
7) многокапальпая свертка и фильтрация радиолокационных сигналов.
130
Машины I и II Рорбахера
Эффективность параллельных машин с фиксированной структурой ограни¬
чена возможностями фиксированной сети связи. Более гибкой, чем сети в
машинах Сквайра н Пеле [3.8] или Холланда [3.5], может быть только такая
сеть, в которой ■ каждый из идентичных модулей массива способен взаимодей¬
ствовать с любым другим модулем этого массива. С этой точки зрения наи¬
больший интерес представяет полиморфная машина с переменной структурой.
Основная проблема состоит в том, чтобы придумать такую архитектуру,
в которой не использовалось бы чрезмерное количество аппаратных средств.
Одно из решений заключается в построении некоторого коммутатора пере¬
крестных. связей, допускающего лишь ограниченное число коммутаций. Подоб¬
но тому как в машине с фиксированной структурой нужно приспосабливать
задания к структуре связей, в системе с ограниченной перекрестной комму¬
тацией также необходимо адаптировать поток заданий с учетом возможностей
коммутатора, который может обеспечить ограниченное число одновременных
сеансов связи. Если в систему входят N процессоров и N блоков памяти, то
число элементов, из которых должен состоять коммутатор перекрестных свя¬
зей при полной коммутации, пропорционально N2, и для больших N такой
коммутатор оказывается слишком дорогим.
9* 131
В машине Рорбахера [3.21] используется сеть перестановок, которая на¬
зывается двойным сортировщиком*) [3.22]. Двойной сортировщик представ¬
ляет собой коммутатор, который но гибкости ие уступает перекрестному ком¬
мутатору, однако требует меньше аппаратных средств. Для формирования
коммуникационной сети с нужной степенью гибкости подходит любой ком¬
мутатор, способный выполнять численную сортировку множества данных.
Сеть перестановок имеет N входов и N выходов (в предположении, что
нужно отсортировать N слов). Данные помещаются во входные линии в про¬
извольном порядке. По команде сеть размещает входные слова по выходным
линиям в соответствии с заданной перестановкой. Сортировщик упорядочи¬
вает слова но значению. Каждому элементу сартировщика приписывается чис¬
ловой адрес от 0 до N — 1. Входные элементы соединена с выходными эле¬
ментами в соответствии с определенной функцией перестановки. Распределе¬
ние выходных элементов произвольно. Входные элементы направляют в сеть
слова данных, снабженные адресами выходных элементов, сеть сортирует
дапные по этим адресам, после чего выходные элементы получают предназ¬
наченные им слова данных.
Сети сортировки могут использоваться и в качестве ассоциативпых памя¬
тей либо памятей с множественным доступом. Сеть такого же типа нужна для
эффективной реализации машины Тербера и Мирна [3.23]. Сеть с двойным
сортировщиком может быть образована из простых сравнивающих элементов.
Для сортировки 2N объектов сеть должна состоять из (N/4) и (log2N) элемен¬
тов. Для формирования сети, которая предусматривает одновременные сеансы
связи между 1024 модулями, понадобится около 26 ООО элементов,. что пример¬
но на миллион меньше, чем в матрице перекрестной коммутацией размера
1024X 1024. Нагрузка по выходу элементов сети сортировки невелика и ха¬
рактеризуется постоянной величиной, пе зависящей от N.
Для того чтобы избежать осложнений, возникающих, когда два или более
модуля пытаются одновременно передать данные третьему модулю (например,
в мультипроцессорном режнме), в коммутационной сети можно предусмот¬
реть определенную буферизацию. Это приводит к решению использовать в
центральной памяти системы коммуникационную сеть с буферизацией. Па¬
мять с сортировкой отличается от обычной памяти ЭВМ по двум основным
признакам. В памяти с сортировкой имеется много входных и выходных .линий,
которые могут все находиться в активном состоянии одновременно, что исклю¬
чает проблему очередей. Во-вторых, пб любому заданному адресу можно за¬
писать более одного слова. Слова, записанные по одному и тому же адресу,
упорядочены в соответствии с численными значениями хранящихся в них дан¬
ных. Запрос на чтение но некоторому адресу приведет к считыванию меньше¬
го по значению слова, находящегося по этому адресу. По определенным адресам
слов может вообще не быть. Запрос па чтение по «пустому» адресу вызовет
считывание меньшего по значению слова по следующему адресу. При сорти¬
ровке новые данные не затирают старые. Поэтому, чтобы избежать появления
лишних данных, нужно предусмотреть чистку памяти («сборку мусора»).
Машина I Рорбахера (рис. 3.25) состоит из 512 процессорных элементов,
которые функционируют под управлением своих локальных УУ и взаимоденст-
*) Название «двойной сортировщик» введено здесь потому, что сеть упо¬
рядочивает данные как по адресам, так и по значениям. (Примеч. пер.)
132
Еуют друг с другом и с впешпей средой через память с сортировкой, состо¬
ящей из 32К 72-разрядттых слов. Каждый процессорный элемент по сложности
соответствует универсальной вычислительной машине. В ком аппаратно реа¬
лизован полный набор арифметических операций с плавающей запятой над
26-разрядпьтми словами, имеется два аккумулятора двойной длины и шесть
индексных регистров. Система команд включает 75 операций. При работе с
Рис. 3.25. Блок-схема Машины I
памятью используется разновидность ассоциативной адресации. Запросы на
чтение но определенному адресу вызывают считывание первого слова по этому
адресу, в котором число, находящееся в поле данных, меньше или больше не¬
которой пороговой величины. Предполагаемая средняя скорость работы каж¬
дого ПЭ — одна команда за 15 мкс. Для связи машины с внешними устройст¬
вами предусмотрено 512 параллельных каналов ввода/вывода. Высокоскорост¬
ные устройства могут использовать параллельно несколько каналов. Если
время срабатывания логических элементов будет составлять 5 пс, длитель¬
ность цикла обращения к памяти из 32К слов будет равна 4 мкс. За каждый
никл можно выполнить одновременно 1024 обращепия к памяти, т. е. длитель¬
ность эффективного цикла может достигать 4 не.
В отличие от других систем с высокой степенью параллелизма, Машипа I
не требует от программиста распределения заданий по конкретным процес¬
сорным элементам и даже осведомленности о числе доступных ПЭ. Процессор¬
ные элементы могут добавляться к системе, переводиться в автономный режим
для ремонта, либо передаваться в пользование другим программам без изме¬
нений в этих программах. Такая машина с децентрализованным управлением
идеально подходит для систем с разделением времени, так как она не чувстви¬
тельна к отказам отдельных элементов и в пей могут одновременно выполнять¬
ся несколько независимых программ. Недостатки этой машипы проявляются,
когда программы не являются полностью независимыми. Поскольку все взаи¬
модействие между одновременно выполняющимися частями одной программы
происходит через память, то координация процессоров, участвующих в испол¬
нении этих частей, требует больших затрат.
Некоторые команды Машипы I весьма необычны. Например, но команде
«переход по отсутствию» происходит переход, если адрес слова, запрошенного
в предыдущей операции выборки, пе совпадает с адресом операнда в текущей
Комапде. Эта команда пужпа для синхронизации нескольких процессоров,
работающих с общими данными. Все запросы на чтение вырабатывают какое-
То значение. Другие специальные команды позволяют производить поиск по
8аДанному значению.
133
Машина I лучше всего подходит для выполнения программ, состоящих из
независимых блоков, в которых можно использовать процедуры fork п join.
Машина I может присвоить любому слову памяти имя, после чего обращение
происходит по этому имени, пока оно не будет изменено.
Попытки упростить слишком сложную схему взаимодействия привели к
разработке версии машины с централизованным управлением, так называемой
Машины II. Машина II представляет собой параллельный процессор. В отли¬
чие от других параллельных систем, использование в Машине II принципа
централизованного управления привело к более эффективной обработке па¬
раллельных, активно взаимодействующих между собой цепочек команд. Как
видно па рис. 3.26, центральное устройство управления Машины II образовано
Рис. 3.26. Блок-схема Машины II
из трех компонент: устройства управления запросами к памяти (УУЗП), уст¬
ройства управления мультипроцессором (УУМ) и устройства управления за¬
даниями (УУЗ).
Устройство управления запросами к памяти представляет собой сеть сор¬
тировки, которая принимает запросы на запись и чтение от процессорных эле¬
ментов > и устройств ввода/вывода, упорядочивает эти запросы по адресам
и значениям данных и посылает их в главную память через шиыу адресов
памяти шириной 1024 слова. Сердцем машины является устройство управления
мультипроцессором. Оно состоит из памяти с сортировкой объемом 8К слов,
через которую осуществляется взаимодействие между всеми устройствами
машины. Ширина капала данных между УУМ и главной памятью составляет
1024 слова. Основная функция УУМ заключается в управлении опережаю¬
щим просмотром по 1024 командам. Сюда входит организация поиска команд и
блоков данных, подборка операндов к командам, передача пар команда —
операнд к соответствующим процессорам и хранение промежуточных резуль¬
татов.
Устройство управления задаппями реализует схему управления задания¬
ми с динамическими приоритетами, согласно которой в распоряжение каждого
задания или последовательности команд может выделяться определенная
часть вычислительных ресурсов машины. В каждый момент времени процессо¬
ры динамически перераспределяются между заданиями в зависимости от об¬
щего числа процессоров, которое требуется каждому заданию, и приоритетов
134
задании. Это гарантирует оптимальную загрузку аппаратных средств макси¬
мально .возможным числом программ даже при постоянно меняющихся ус¬
ловиях. УУЗ состоит из небольшой памяти с сортировкой н набора последо¬
вательных сумматоров.
Память Машины II больше по объему и медленнее, чем Машины I. Она
представляет собой память с сортировкой объемом 64К слов при длине слова
61 разряд и длительности цикла 12 мкс. За . каждый цикл можно выполнить
без возникновения конфликтов одновременно 1024 обращения в память, поэ¬
тому длительность эффективного цикла составляет 12 пс.
В Машине II 256 процессорных элементов (в Машине I — 512). ПЭ Маши¬
ны II значительно менее сложны, чем Машины I. Каждый процессор Маши¬
ны II содержит арифметическое устройство с плавающей занятой, включаю¬
щее три 32-разрядных регистра и около 100, различпых команд. Система
команд двухадресная, так что каждый процессор связан с устройством
управления запросами к памяти тремя параллельными шинами, работа¬
ющими в формате слова: одна шина для команды и две для операндов.
Среднее время выполнения команды — 50 мкс. Регистры типа счетчика команд
программно недоступны. Команды выполняются па основе доступных данных,
В Машине II есть 256 каналов ввода/вывода. Как и в Машине I, высокоско¬
ростные устройства могут использовать параллельно несколько каналов.
Машина II обладает полной структурной гибкостью. В любой момент вре¬
мени может выполняться переменное число программ, причем каждая из них
может иметь различную степень связности и параллелизма. Программам мо¬
гут быть присвоены приоритеты. При выполнении любой программы ее внут¬
ренний параллелизм реализуется настолько полно, насколько это возможно в
рамках заданной системы приоритетов и наличия вычислительных ресурсов.
Перекрестные ссылки между частями программы организуются без обраще¬
ния в. память. Программист полпостыо освобожден от решения вопросов рас¬
параллеливания задачи, распределения заданий, мультипрограммирования,
обеспечения отказоустойчивости и других системных вопросов.
Стоимость реализации столь гибкой и мощной машины меньше, чем может
показаться. Аппаратная часть системы требует примерно двадцати миллионов
логических элемептов (приблизительно в восемь раз больше, чем в ILLIAC IV).
На практике эта машипа может быть реализована только тогда, когда уро-
вепь развития БИС достигнет показателя 1000 логических элементов па одну
конструктивную единицу при стоимости 1 пенни за логический элемепт.
Сделать подобные проекты осуществимыми может микропроцессорная
техника.
При исследовании Машин I п II Рорбахер подробно проанализировал две
области применения. Рассматривались динамическое программирование (Ма¬
шипа I) и параллельная компиляция (Машипа II). Результаты выполпепия
программ па Машинах I и II сравнивались с результатами выполнения тех же
программ на IBM 7090. Система параллельных процессоров оказалась значи¬
тельно быстрее, чем 7090. Были рассмотрены п другие прикладные области
(например, метод Якобп для определения собственных значений). Обычно
Машипа I оказывалась в 9—14 раз быстрее, чем 7090 при наличии только
22 ПЭ. При использовании всех 512 ПЭ предполагаемое увеличение быстро¬
действия составляет примерно 76—119 раз. Машипа II оказалась приблизи¬
тельно в восемь раз быстрее, чем IBM 7090.
135
При сравнении Мапшп I и II можно отметить следующее:
1) обе олп образованы из значительного числа 11Э и сетей сортировки
(устройств памяти);
2) Машина II имеет небольшую дополнительную сеть сортировки (УУМ);
3) в Машине I более сложные П'Э;
4) Машина I больше всего подходит для иараллсльпого выполнения неза¬
висимых блоков (из-за децентрализованного управления);
5) Машина II может допускать распараллеливание на уровпе глобальных
команд (программно независимых);
6) в Машине II цепочки независимых команд выполняются по мере под-
гот о в к и о п е р a 11 д о в;
7) ПЭ Машины I весьма напоминают ЦП раппих универсальных вычисли¬
тельных машин.
PEFE — параллельная вычислительная система
с ансамблем процессорных элементов
РЕРЕ [3.24] представляет собой параллельный процессор, разработапцый
для обработки радиолокационных данных в системах противоракетной оборо¬
ны. Блок-схема РЕРЕ показана на рис. 3.27. Система РЕРЕ — это ансамбль
Рпс. 3.27. Блок-схема РЕРЕ
процессорных элементов. Она отличается от рапсе рассмотреппых ВС с мас¬
сивом процессоров. РЕРЕ не является массивом, в котором соседние элементы
связаны друг с другом. Набор элементов системы РЕРЕ не образует какой-
либо определенной структуры. Между элементами ист прямой связи. С этой
точки зрения РЕРЕ является ассоциативной системой. ‘Система процессоров
13G
является ассоциативпой по причине ассоциативной адресации ее элемсптов«
Поскольку структура системы РЕРЕ отлична от массива, то процессорные
элементы можно свободно добавлять н исключать. (Более полно система РЕРЕ
описана в гл. 5.) Ее можно отнести к разряду полностью параллельных ассо¬
циативных ансамблей.
Вычислительная машина с ячеечной структурой
на базе языка APL
Первый параллельный процессор на основе языка APL [3.10] был разра¬
ботан Тербером и Мирна [3.23]. Эта машина является одной из концептуаль¬
ных параллельных систем, предложенных Минииком, профессором универсп-»
тета штата Монтана. Она обладает рядом особенностей:
1) машина ориентирована па определенный язык программирования,
а именно APL, а не на область применения;
2) в процессорных элементах отсутствует бит активности, так как его
функция реализована с помощью средств маскирования языка APL;
3) линии связи между ПЭ отсутствуют; вместо этого имеется устройство
маршрутизации, которое обеспечивает интерфейс между памятью и системой
процессорных элементов;
4) небольшое подмножество операторов языка APL реализовано па аппа¬
ратном уровне, а множество всех остальных операторов реализовано с по¬
мощью ми кропрограмм;
' 5) машина стремится использовать внутренний параллелизм операторов
языка APL и структур данных.
Рассматриваемая вычислительная система построена так, .что она может
выполнять параллельно большое число операций, эффективно реализуя таким
образом параллельный по своей природе язык программирования APL. Вы¬
числительная система представляет собой однородную параллельную систему
с микропрограммным управлением, оперирующую с числами с фиксирован¬
ной запятой. Система изображена на рис. 3.28. В нее входят:
1) матричная функциональная память (МФГ1);
2) шестнадцать блоков памяти (МП1, MII2, ..., МП16);
3) память команд (ПК);
4) устройство маршрутизации (УМ);
5) тридцать два векторных накапливающих сумматора (аккумулятора)
(ВА1, ВА2, ..., В А 32);
G) устройство управления вводом/выводом (УУВВ);
7) преднроцессор (ПП).
Память состоит из шестнадцати идентичных блоков. Каждый блок памя¬
ти состоит из 32 X 32 ячеек. В ячейке может храниться одно слово. Общий
оба,ем блока памяти — 16 384 слова. Матрицы и векторы хранятся в своем ес¬
тественном представлении. Область памяти, в которой хранится матрица (вектор),
однозначно определяется адресом элемента (1, J) (адресом первого элемента
вектора) и размерностью матрицы (длиной вектора), что позволяет легко
находить данные, хранящиеся в системе. ПП управляет размещением мно¬
гомерных массивов и вообще всех векторов и матриц с учетом их размерно¬
стей. При практической реализации система будет выпускаться с различными
модификациями памяти. Предполагается, что будут использованы дополпитсль-
137
Рис. 3.28. Блок-схема вычислительной машиной., с ячеечной структурой на базе языка APL
яые запоминающие устройства, в которых будут храниться результаты выпол¬
нения оператора внешнего произведения*). Это требует увеличения объема
памяти по крайней мере до 324 = 1 048 576 слов.
МФП сравнима по объему с каждым из шестнадцати блоков памяти. Это
массив из 32 X 32 базовых элементов. МФП может выполнять определенные
операции с хранящейся в ней информацией. Каждый базовый элемспт (г, /)
в МФП помимо средств, позволяющих выполнять определенные арифметиче¬
ские и логические операции, имеет четыре накапливающих регистра Агц B*jt
Сц п Tfj. Другими словами, МФП организована в виде четырех плоскостей:
А, В, С н Т. Плоскости А, В и С используются для храпения и обработки дап-
ных. Плоскость Т применяется для временного храпелия результатов. Логика
МФП выполняет операции над плоскостями А и В (С и В) и помещает ре¬
зультат в С (А). МФП взаимодействует с массивами памяти через устройство
маршрутизации (УМ), изображенное на рис. 3.29. МФП пе может взаимодейст¬
вовать непосредственно с массивами памяти, так как ячейки операндов долж¬
ны быть загружены в соответствующие ячейки МФП.
Рис. 3.29. Устройство маршрутизации
Предположим, что нужно сложить М с N. Если М имеет размерпость 2X2
и хранится в Mniie, 16, МПКб, п, МП!^, ]6 и МП1|7, 17, а N — размерность 2X2
и находится в Mffii, ь MII2i,2, МП22. i и МП22,2 (рис. 3.30, 3.31 и 3.32), то М
и N нельзя загрузить непосредственно в плоскости А и В МФП таким образом,
чтобы при сложении получить требуемый результат (см. рис. 3.31). Нужпо
распределить М и N так, чтобы каждый элемент Мг;- и оказался в. столб¬
цах Ах, 1 и Вх, 1 МФП (см. рис. 3.32). Это'простой пример, но он иллюстрирует
едиу из основных проблем, возникающих при разработке этого процессора.
ПК представляет собой постоянное запоминающее устройство ’ (ПЗУ),, в
котором хранятся все команды, используемые в машине. В ПК паходятся все
микропрограммы. Применение отдельной памяти команд позволяет использо¬
вать для хранения данных всю оперативную память объемом в 16 384 слова.
*) Оператор языка APL, представляющий собой двухместную функцию, ар¬
гументами которой являются массивы, а результатом — все возможные произ¬
ведения элементов первого аргумента па элементы второго. {Примеч. пер.)
139
Маршрутизация дапных осуществляется с помощью УМ. УМ — ото боль-
шая система обмена, выполняющая важные функции. Предполагается, что
при пересылке векторов и матриц УМ будет выполнять их обобщенную ин¬
дексацию.
При разработке устройства маршрутизации было предложено два конст¬
руктивных решения. Одно из них [3.25] состоит во включении логических уст¬
ройств в массив сдвиговых регистров. Другое решение [3.26] предполагает
Т
В
I А
Рис. 3.30. Карта памяти Рис- 3-31- Выборка из памяти без об-
оощеииой индексации
использование сети перестановок. Интересный обзор средств коммутации пред¬
ставлен в [3.27]. Устройство маршрутизации может передать содержимое мас¬
сива памяти или его части в любую из плоскостей МФП. УМ переносит
строку (столбец) в векторный аккумулятор, либо в строку (столбец) любой
плоскости МФП. Маскирование осуществляется той частью УМ, которая изо¬
бражена на рис. 3.29. На этом же рисунке показан один из 32-х векторных
аккумуляторов. Преполагается, что век¬
торный аккумулятор может выполнять
любую операцию редукции *) из числа
имеющихся в языке APL. Ввод/вывод
для данной системы детально не рас¬
сматривался.
Основной частью преднроцсссора
является аппаратный метаинтерпрета¬
тор языка APL. Метаинтерпретатор пре¬
образует операторы и программы на
языке APL в цепочку параллельных ма¬
шинных операций. В зависимости от по¬
требностей пользователей ПП может быть построен с помощью различных ком¬
бинаций аппаратных п программных средств. ПП выполняет распределение па¬
мяти для матриц н векторов, элементарные машинные операции, а также вы¬
полняет все действия, связанные с опережающим просмотром команд. Он мо¬
жет содержать дополнительный вычислительный блок для таких вычислений,
которые неудобно выполнять в МФП.
Каждая ячейка любого из 1G массивов памяти состоит из одпого 32-раз-
рядпого регистра, допускающего параллельную загрузку и передачу инфор¬
мации. Ячейка памяти команд представляет собой 32-разрядыую запомннаю-
*) Одна из основных операций пад массивами в языке APL, результатом
которой является массив, имеющий меньшую размерность, чем исходный, на¬
пример, редукция вектора может заключаться в вычислении суммы его элемен¬
тов. (Примеч. пер.)
М +
н L
М
L.
N
i
1с
а
А
□
тт
МП 2
Рис. 3.32. Выборка из памяти с ис¬
пользованием обобщенной индекса¬
ция
М
□
2x2
МП1
|
□
м
J N
МП2
J
N
С
з-
м
т
_J N
2x2
С
В
А
140
дую ячейку с доступом только по чтению. На рис. 3.33 представлены основ¬
ные операции, выполняемые ячейками МФП. Поскольку каждая ячейка МФП
может вътполпять арифметические, логические и условные операции, то плос¬
кости МФП ..могут выполнять эти же операции одиозремепно, поэтому право¬
мерно представлять операции как выполняемые па уровне плоскостей, т. е.
Данный элемент содержит четыре 32-разрядных регистра (А,
В, С и Т), с которыми можно выполнять следующие действия:
Арифметические операции
Логические операции
С ч- А + В
C+-AVB
С+-А — В
С А Д В
С-*-АХ В
А ч- CVB
С^-Ач-В, В=^0
А-+-СДВ
А С + В
А+-~ А
А С — В
В
А С X В
С ч- ~ С
А^-Сн-В, В=^0
Т+--Т
Условные операции
(результат этих операций 0 либо 1)
С-*-А < В
А+-С = В
А -<■“ С = В
С А > В
С+-А = В
А-«- С > В
Рис. 3.33. Основные операции ячейки ФП
плоскость А складывается с плоскостью В, а результат записывается в пло¬
скость С (С = А + В). Это свойство обеспечивает потенциально высокую про¬
пускную способность системы.
Изображенное на рис. 3.29 устройство маршрутизации представляет со¬
бой сеть перекрестных связей, в которой 37 входов и до 32 выходов. Тридцать
два входа — от векторного аккумулятора, а по остальным пяти входам из ПП
поступает число от 0 до 31. Например, если это число 7, то восемь самых пра¬
вых входов от векторного аккумулятора становятся выходами сети перекрест¬
ных, связей. Это свойство УМ используется при маскировании. Векторный
аккумулятор показан на рис. 3.29. Он образован нз 32 запоминающихся ячеек
(в каждую нз которых входит 32-разрядиый регистр) и 31 вычислительной
ячейки. Каждая вычислительная ячейка содержит 32-разрядный аккумулятор,
память и аппаратные средства, необходимые для выполнения любой операции
редукции, имеющейся в языке APL. Поскольку УМ может выполнять обоб¬
щенную индексацию, векторы могут загружаться в векторный аккумулятор в
правильном виде, а операция маскирования позволяет выполнить любую
'редукцию языка APL с любым вектором. Это свойство играет очень важную
роль. Оно может использоваться для маскирования результатов вычислении,
что позволит обойтись без бита активности в элементах МФП.
В статье [3.23] обсуждается реализация всех операторов без плавающей
запятой и приводятся результаты моделирования некоторых алгоритмов, под¬
тверждающие адекватность реализации операторов. Арифметика с плавающей
запятой может быть реализована подобно тому, как это сделано в РЕРЕ [3.24]
или как описывают Тсрбср и Паттоп [3.28]. Кроме конструкций УМ, предло¬
женных Тербером, имеются другие попытки усовершенствования ячеек МФП
-(см., например, [3.29]).
141
Совершенная тасовка
Одним из ключевых пунктов в архитектуре всякого параллельного про¬
цессора является сеть перекрестных связей между элементами. В большинстве,
параллельных процессоров (ILLIAC IV и SOLOMON) элементы связаны с бли¬
жайшими соседними элементами. Стоун [3.30] предлагает сеть перекрестных
связей с совершенной тасовкой. Поня¬
тие совершенной тасовки впервые было
введено Пизом [3.31] при решении за¬
дачи адаптации алгоритма быстрого
преобразования Фурье к параллельным
системам.
Совершенная тасовка — это схема
перекрестных связей между элемента¬
ми. Ее можно представить с-ебеь если
разделить на две половины колоду карт
и перетасовать ее так, чтобы после та¬
совки карты из разных частей чередо¬
вались. Формально это означает, что
элементы вектора с индексами от 0 до
N —1, где N =2т, упорядочиваются в
соответствии с правилом: Р(£) = 2 i
(для 0 < i < (N/2) — 1) и P(i) = 2i +
+1— N (для N/2^ i ^ N—1). Резуль¬
тат этой операции показан на рис. 3.34.
Другое наглядное представление о со¬
вершенной тасовке дает ее взаимосвязь
с двоичным представлением индексов
элементов вектора. Пусть i-й элемент
вектора перемещается в позицию iгде
число i' получается в результате цик¬
лического сдвига двоичного представле¬
ния i па один разряд влево. Тогда, если i — + im-22m“2 + ...+ h2 + i0?
T0 i'=ir/l_22m~1+tm_32m“2-f...+ i20+im_v Это можно легко проверить. Дан¬
ное выражение описывает совершенную тасовку. Поскольку тасовка представ¬
ляет собой циклическую перестановку, то в копечпом итоге происходит воз¬
врат к исходному значению. В частности, im = i. Стоун использовал тасовку
в целом ряде приложений: в быстром преобразовании Фурье, вычислении по¬
линомов, сортировке и транспонировании матриц.
N-:
/V- 1
Рис. 3.34. Структура связей при со¬
вершенной тасовке
Машина Кэннона
Кэппон [3.32] предложил однородную вычислительную систему для реа¬
лизации и алгоритма фильтра Калмана. Фильтр Калмапа был выбран в ка¬
честве осповы конструкции, поскольку в нем представлено большинство мат¬
ричных и векторных операций, которые могут эффективно выполняться в си¬
стемах с матричной структурой. Вместо того чтобы делать машину, которая
может выполнять матричные и векторные операции, Кэпноп решил создать.
142
-систему, в которой был бы реализован конкретный оптимальный фильтр. Тре¬
бования таковы: машина должна выполнять сложение, вычитание, умноже¬
ние, транспонирование и обращение матриц. В машине Кэннона были опти¬
мизированы операции умножения и обращения, поскольку другие операции с
матрицами не вызывают затруднений в системах с матричной структурой.
Ниже рассматривается алгоритм умножения Кэннона. Пусть даны две мат¬
рицы А и В размера п X п и пусть С = А >< В. Обозначим Л и В следующим
образом (полагая п = 3):
А = а4 аъ aQ и
а1Ъ1 + а2Ь-2 + а363 “А + в265 + аз\ “А + а2Ь8 + ®«6»
аА + аьЬ2 + «А аА + аъЪь + ае&б °4Ь7 + *А + аЛ.
°7Ь1 + а862 + вв63 а7&4 + аА + аА 07&7 + e863 + ae59
Можно заметить, что матрица С симметрична в том смысле, что Сц и Сц
получаются, друг из друга путем перестановки индексов у а и Ь. Предположим,
что имеется машина с матричной структурой, каждый элемент (i, /) которой
имеет некоторые арифметические и логи¬
ческие средства и три регистра: a2-j, bi5 и
dj. В качестве примера предположим,
что размерности массива и матриц совпа¬
дают. Кроме того, пусть через Арег обозна¬
чено множество регистров а%содержащих¬
ся в машине (Врег и Срег обозначают
множества регистров bij и сц соответствен¬
но). Произведение С строится следующим
образом:
1) установить Срег = 0;
2) загрузить А в Арег;
3) загрузить В в Врег;
4) циклически сдвинуть i-io строку А
влево на i-1 позицию для всех i ^ щ
5) циклически сдвинуть /-й столбец В
вверх на / — 1 позицию для всех / ^ щ
6) умножить Арег на Врег и прибавить к частичному произведению в СРеР;
7) циклически сдвинуть А вправо на один столбец;
8) циклически сдвипуть В впиз па одну строку;
9) перейтп к п. 6, пока цикл пе выполнится п раз.
В рассматриваемом примере после первого выполнения пп. 4 и 5 матри¬
цы А и В будут иметь вид:
ап
ап
Ъ,
Ь
ъп
1
2
3
1
5
9
я.
о
ав
ал
4»
в = *2
я
а„
ь
Ьл
ъв
9
7
8
3
4
8
Центральное
Регистры ,
У У
_ \
столбцов
,
с. .И
—* у—
t j
i ;
’ 1 v
!
i : ,
г,. '“П
]
А *-
LLlj Lj LUj I
Реги ст ры
S
i
i
IJCJ LnJ °c ’ LliJ |
I j
строк
i :
j
! 00 CO 00
Рис. 3.35. Блок-схема машины
для фильтра Калмана
тогда
С =
Ъ1 К Ъ1
В=Ь2 Ь5 Ь»,
Ь3 \ Ьв
145
Первое частичное произведение:
“А “А й369
С = Я562 %Ь0 “А-
аА а1Ь1 аВЬВ
Последующий сдвиг А и В дает:
А = «
4 fl5 fl6
h h Ъв
В = bl 65 69
*2 66 &7
Выполняя умножение и сложение, получаем:
аА + °3&3 «2*6 + аА азЬ9 + а2Ь8
С = \Ъ2 + %Ь1 “А + аъЪЬ а4&7 + “А-
в9Ь3 + а8^2 а7&4 + «6*6 аВЬВ + а1Ь1
После еще одной итерации формирование С закончено.
Рлс. 3.36. Блок-схема ПЭ машины для фильтра Калмапа
На рис. 3.35 представлена блок-схема машины Кэннона. Основными
функциональными блоками машины являются:
1) центральное устройство управления — универсальный управляющий
блок, в котором могут выполняться последовательные вычисления и сосредо¬
точено управление массивом процессорных элементов;
2) регистры строк (столбцов)—множество информационных и управляю¬
щих регистров, которые обеспечивают интерфейс между центральным. уст¬
ройством управления и строками (столбцами) процессоров, и
144
3) массив процессорных элементов — матрица процессоров размера-
16 X 16» в которой каждый элемент может взаимодействовать с восемью
ближайшими соседями.
На рис. 3.36 изображена блок-схема процессорного элемента. Каждый-
процессор состоит из локального устройства управления (С), дешифратора
адреса памяти (D), памяти (В), селектора ячеек (S), устройства маршрути¬
зации (R), устройства сложения и вычитания (А) и устройства умножения
Таблица 3.6
Язык ассемблера машины, реализующей фильтр Калмапа
Мнемокод
Операция
ABSE
A(B, C)-c- |A(B, C)|
ADBE
Прибавить буфер к А (В, С)
ADDA
Сложить элементы массива
adeb
Прибавить А (В, С) к буферу
APBR
Прибавить к строке В элементы буфера А столько раз^
сколько элементов находится в строке С
ВСАС(BCAR)
Распространить столбец (строку) В по матрице А
ВСВС(BCBR)
Распространить содержимое буфера по столбцу (стро¬
ке) В в матрице А
BDIZ
Условный переход по не-пулю
СМРА (СМРВ)
Двоичное дополнение содержимого массива (буфера)
EXCC (EXCR)
Поменять местами столбцы (строки) В и С матрицы А*
INDA; INPB;
Команды ввода
INPC; INPI
INVA (INVB)
Инвертировать матрицу (буфер)
LDEB (LDIB)
Загрузить элемент (со сменой знака)
MLBC
Умножить столбец матрицы А па буфер
MLBE
Умножить буфер на А (В, С)
MLEB
Умножить А (В, С) на буфер
MLTA
Умножить A (i, у) на В (г, /) для всех i, /
MULT
Ум ножепие матриц
MOVA
Пересылка матрицы
OUTA; OUTB;
Команды вывода
QUTC; OUTR
ROTD(ROTU)
Циклически сдвинуть матрицу А вниз (вверх) па К
ROTL(ROTR)
строк
Циклически сдвинуть матрицу А влево (вправо) на В
столбдов
SETC(SETR)
Прочитать максимальное число столбцов (строк)
SETE
Записать единичную матрицу в А (В, С)
SKVVD (SKWL;
Сдвинуть матрицу А вниз (влево, вправо, вверх)
SKWR; SKWU)
SNEB
Поместить знак А (В, С) в буфер
SQRB
Возвести в квадрат содержимое буфера
STBE
Записать буфер в А (В, С)
SUMC (SUMR),
Сложить столбцы (строки) В и поместить в .строку
TRAC (TRAR)
(столбец) С матрицы А
Переслать столбец (строку) С матрицы В в А
TRNC
Переслать столбец С в столбец В матрицы А
TRPS
А^-Ат
ZERA
Обнулить массив
«Дс (ZERR)
Обнулить столбец (строку) матрицы А
uu
Конец последовательности команд
^ К. Дж. Тербер
145»
■■(М). Какой-дпбо язык ассемблера для машины пе определен. Все устройства
имеют ячеечную структуру, включающую следующие базовые блоки: 1) селек¬
тор линии; 2) блок сложения с единицей; 3) блок дополнения до 1 или 2;
4) блок сравнения; 5) блок сумматора; 6) блок сумматора-вычитателя и 7) об¬
щий регистр. После того как все функциональные блоки были разработаны в
унифицированном варианте, был написан функциональный имитатор для про¬
верки правильности выполнения операций. Все алгоритмы машина выполнила
верно.
Кроме того были сделаны временные оценки с целью определения коэф¬
фициента увеличения производительности. Оказывается, что пропускная
способность системы па матричпых алгоритмах при размерности массива по¬
рядка 10 X Ю примерно в 200—250 раз. выше, чем. в обычной последователь¬
ной машине.
Работу Кэннона продолжил Мелдер [3.33]. Он продвинулся дальше в ло¬
гической разработке машины Кэннона, особенно в той ее части, которая ка¬
сается устройства управления, спецификации языка ассемблера и средств
обеспечения отказоустойчивости. Кроме, того, Мелдер выполнил детальнее
(до уровня языка ассемблера) моделирование машины. Элементы языка ас¬
семблера, разработанного Мелдером для машины Кэннона, приводятся в
табл. 3.6. В университете штата Монтана ведется работа над созданием дру¬
гой, более сложной версии машины Каннона.
Машина Jloyca для расшифровки кодов Хэммингу
В 1948 г. Шэннон доказал, что вероятность ошибки при передаче сообще¬
ния по каналу может быть очень низкой, если скорость передачи невелика
по сравнению с пропускной способностью канала. Один из способов реализа¬
ции взаимодействия с такими характеристиками заключается в преобразова¬
нии последовательности разрядов, образующих сообщение в более длинную
последовательность. Процесс взаимодействия состоит из получения последо¬
вательности разрядов от источника, кодировки сообщения, передачи сообще¬
ния по каналу связи, расшифровки принятой последовательности и доставки
результата потребителю или отбраковки сообщения. Наиболее сложной ча¬
стью процесса является расшифровка сообщения, т. е. определепие того, ка¬
кие из полученных разрядов правильны, какие ошибочны и каково содержа¬
ние сообщения.
Существует множество различных кодов, например, коды максимального
правдоподобия. Коды Хэмминга образуют класс кодов, расшифровка которых
не требует сложной аппаратуры или временных затрат. Лоус [3.34] пред¬
ложил идею, разработал проект и промоделировал специализированный па¬
раллельный процессор, который расшифровывает коды Хэмминга. Процессор
Лоуса основывается на концепции процессора Берлекампа [3.35] (рис. 3.37).
Этот процессор преобразует контрольные цифры в коэффициенты полинома
локализации ошибки. Каждый процессор системы может выполнять операции
умножения и сложения, определенные для полей Галуа. Подчиненные про¬
цессоры могут взаимодействовать друг с другом в направлении снизу вверх,
ведущий процессор вырабатывает сигналы управления и посылает данные
подчиненным процессорам, а сеть сумматоров складывает величины, находя¬
щиеся во всех процессорах. Для дешифрации кодов с исправлением тг-крат-
146
L.U
цьхх ошибок нужен один ведущий я тг+1 подчиненных процессоров. Струк¬
турная схема декодировщика показана па рпс. 3.38. В трех блоках системы
реализованы три шага алгоритма декодирования: 1) вычисление значении
четности (контрольных цифр); 2) определение коэффициентов полинома ло¬
кализации ошибки и 3) определение кор¬
ней полинома локализации ошибки (каж- | г ■_
дый корень соответствует поправке в полу¬
ченном слове). При разработке конструкции
Лоус взял за основу концептуальную схе¬
му, изображенную на рис. 3.38.
Лоус привел алгоритм Берлекампа и
Чина к виду, допускающему параллель¬
ную реализацию. Ниже рассматриваются
получившиеся в результате процессорные
модули. Окончательный вариант машины
Лоуса показан на рис. 3.39. Она состоит из
irpex блоков: буфера, подчиненных процес¬
соров и ведущего процессора. Ведущий
процессор управляет работой подчиненных
процессоров. Блок-схема ведущего процес¬
сора приведена на рис. 3.40. Блок-схема
I
I
г~
i ".
I
процессора изооражена па
ГГ\
подчиненного
рис. 3.41.
Ведущий процессор принимает и пере¬
дает элементы дапных, инвертирует (по
правилам, определенным для полей Галуа)
элементы, принимает решения в соответ¬
ствии с алгоритмом Берлекампа и органя- рцс ^ 37
вует работу подчиненных процессоров.
Аккумулятор ведущего процессора (АВП)
является регистром данных. Ипвертор (для полей Галуа) (ИГ) инвертирует
элементы. Устройство управления и принятия решений (УУПР) управляет вы¬
полнением алгоритма.
~ J
Процессор
кампа
Берле-
Рис. 3.38. Блок-схема процессора расшифровки кодов Хеммпнга
Каждый подчинеппый процессор включает в себя семь основных функ¬
циональных блоков: 1) БУ (блок управления), 2) МИР (множество регист¬
ров подчиненного процессора), 3) ВСМ (внутренняя сеть маршрутов), 4) АУ
(арифметическое устройство), 5) ПУЧ (поисковое устройство Чина),
6) УКЧ1 (устройство контроля четности 1) и 7) УКЧ2 (устройство контроля
Ю*
147'
четности 2). УКЧ1 и УКЧ2 идентичны, за исключением взаимосвязей с други¬
ми элементами и значений внутренних констапт. Эти устройства генерируют
Подчиненный
процессор
Т
t ,
Подчиненным
продессор Т-1
Рис. 3.39. Блок-схема окончательно¬
го варианта процессора расшифров¬
ки кодов Хеммиига
I МА AC BS
*) t «
L
НЕ - ИЛИ
Г
COR
Рис. 3.40. Блок-схема веду¬
щего процессора
CQDS I DS
МЛ
АС А 5
Рис. 3.41. Блок-схема ПЭ
разряды контроля четности для поступающих элементов сообщения. ПУЧ
содержит полипом, корректирующий ошибки, и формирует части выходного
148
продукта. В состав МИР входят пять регистров данных (RO,..., R4) и два ре¬
гистра сдвига SR0 ы SR1. Эти регистры нужны для выполнения алгоритма
^ерлекампа. АУ состоит из множительного устройства и сумматора (по Га¬
луа). Это устройство выполняет основные арифметические действия. ВСМ уп¬
равляет пересылкой между внутренними регистрами и их взаимосвязью.
дБУ используется для управления степенью вычисляемого полинома и орга¬
низации работы подчиненных регистров.
Машина Лоуса значительно отличается от рассмотренных ранее в этой
книге параллельных процессоров. Она не является программируемой, не об¬
ладает языком ассемблера и предназначена только для одной задачи. Для
каждого вводимого разряда последовательность действий одна и та же. При
поступлении разряда процессор проходит через последовательность циклов,
которые выполняются под управлением аппаратной логики. Последователь¬
ность циклов, а также условные переходы и взаимосвязи регистров очень
-СЛОЖНЫ.
Еще один параллельный процессор на базе языка APL
Иыотон и Бреннер [3.36] предложили конструкцию еще одного парал¬
лельного процессора с ячеечной структурой для реализации языка APL. Для
того чтобы сделать язык APL машинным языком системы, приспособленпой
для работы в итерактивном режиме, в системах разделения времени, был ис¬
пользован метод микропрограммного управления. Эта машина представляет
интерес благодаря тому, что ее центральный процессор (ЦП) состоит из па¬
мяти с встроенной логикой (ПВЛ), в состав которой входят 1024 процессорных
элемента, предназначенных для параллельной обработки данных. В части уп¬
равления данными Ныотон и Бреннер предложили ряд очень ценных идей.
В отличие от машины Тербера и Мирна, которая представляет собой массив
процессоров и ориентирована на обработку матриц, машина Ныотона и Брен¬
нера ориентирована на обработку векторов. Ньютон и Бреннер утверждают,
что их конструкция обладает рядом преимуществ над архитектурой Тербера
и Мирна [3.23], наиболее существенными из которых они считают, видимо,
отказ от устройства маршрутизации (ценой потери возможности прямого до¬
ступа в массив) и более тщательную проработку арифметики.
Главпой частью машины с ячеечной структурой является центральный
процессор. Фактически ЦП представляет собой 1024-ячеечпый параллельный
процессор, называемый ПВЛ. ПВЛ содержит 1024 ячейки (процессорных эле¬
мента). В каждый элемепт входят три группы быстродействующих регистров,
блок арифметики, средства маршрутизации и связи и семь промежуточных
регистров. Кроме ПВЛ, ЦП содержит регистры для размещения дескрипто¬
ров, содержащих информацию об операндах, включая их размерности и ран¬
ги, базовые регистры, счетчики и регистры прерывания. Центральный про¬
цессор и все связанные с ним аппаратные средства описываются в этом
Параграфе.
Длина слова процессора равна 64 разрядам. Процессор оперирует с дву-
типами данных: числовыми и символьными. Числовые данные хранятся
в виде 64-разрядных чисел с плавающей запятой, где 1 разряд отводится на
8иак, ю — на порядок и 53 — па мантиссу. Символы изображаются в восьмиби¬
149
товом расгапреииом коде EBCDIC *) по восемь символов на слово. Векторы ра;^
мещаются в памяти в виде линейной непрерывной последовательное.!а
N-мерпые массивы располагаются но возрастанию индексов элементов, при¬
чем последние рассматриваются как целые числа, состоящие из п цифр. Эт ,г
способ размещения элементов принят в стандартном фортране. Массив
мерности 2X2X2 хранится как непрерывная последовательность вида (при¬
ведены только индексы): 111» 112, 121, 122, 211, 212, 221, 222.
Для управления элементами данных используются дескрипторы. Каждо¬
му объекту ставится в соответствие набор дескрипторов, называемых ДЗ (дес¬
криптор значения элемента). ДЗ соответствует ДР (дескриптор размерноеп:
элемента), который содержит размерность и ранг массива в виде набора to-
разрядных целых чисел. Первое целое число в дескрипторе размерности
обозначает число размерностей, т. е. количество следующих за ним 16-гг;
разрядпых целых чисел. Эти числа дают длину (количество элементов) по
каждой координате массива. Дескриптор матрицы 10 X 12 будет иметь вид (2,.
10, 12) и занимать первые три 16-разрядных поля в 64-разрядпом слове. В Д;>
содержится следующая информация:
1) ПР — доступный только чтению разряд, обозначающий режим до¬
ступа;
2) РЯФ — признак явной функции, указывающий на наличие результате
выполнения явной функции (определенной пользователем), чье значение вы¬
числено, но еще не использовано;
3) признак нескалярпостп — указывает, что объект не является скаляр¬
ной величиной и, следовательно, для пего необходим дескриптор размерности?.
4) признак наличия имеин — обозначает, что данные представляют со¬
бой переменную языка APL;
5) указатель длины — служит для различения символьных и числовых
данных;
6) ссылка на следующий ДЗ — обеспечивает средства связи элемептоп
при рекурсивном обращении к элементу данных с таким же пмепем на сле¬
дующем более низком уровне (в программе с блочной структурой);
7) адрес дескриптора размерности элемента — обеспечивает связь с дес¬
криптором размерности;
8) адрес данных — указывает адрес первого слова элемента данных.
Для пустого вектора поля адреса данных и дескриптора размерности за¬
полнены единицами.
Команды записываются в трехадреспом формате. Ньютон л Бреннер да¬
ют описание реализации операторов языка APL, но в этой кнпге будет рас¬
смотрена только архитектура машины в терминах ее регистров и счетчиков
Регистр команд состоит пз пяти полей: спецификации кода операция
(KOII), поля модификации КОП и трех адресов. В регистр ДЗ входят поля:
для каждой из ранее рассмотренных фупкций дескриптора ДЗ. Имеются три;
группы регистров: ранга, -длины п размерности. Для каждого операнда ис¬
пользуется набор, включающий по одному регистру из каждой группы, и та¬
кой же набор используется для результата. Регистр ранга состоит из обратио-
*) Расширенный двоично-десятичный код обмепа даппьгми: используется:
для представления алфавитно-цифровых данных при вводе и выводе информа¬
ции из ЭВМ. {Примеч. пер.)
150
-и здем{
ПВЛ
А _П У
Регистр 5 j
Регистр Т1
Регистр Т2
уо- 16-разрядпого счетчика и 16-разрядного регистра, в котором хранятся ее
модифицируются соответствующие ранги операндов (результата). В регист¬
ре длины (18 разрядов) паходптся произведение размерностей. Регистр раз¬
мерности (6т разряда: 4 ноля по 1G разрядов) содержит размерности операн¬
дов но четырем измерениям.
В ЦП находятся два счетчика адресов элементов данных. В этих счетчи¬
ках хранятся следы адресов операндов. Имеется регистр сдвига, предназна¬
ченный главным образом для перевода чисел из представления с фиксиро¬
ванной занятий в представление с плавающей запятой и обратно. Предусмот¬
рено четыре счетчика для адресов пара¬
метров, используемых в микропрограм- ' '
иных алгоритмах. В арифметическом бло¬
ке имеется четыре регистра. Два из них
(по 18 разрядов каждый) используются
в блоке умножения чисел с фиксирован¬
ной запятой. Другие два (по 18 разрядов)
используются в блоке сложения чисел с
фиксированной занятой. В ЦП имеются
также: для регистра адресов элементов
данных для сложения и вычитания из ба-
вового адреса; регистр данных; регистр
базы, прибавляемой к данным; регистр
базы, вычитаемой из данных; регистр
длипы программы (используется для про¬
верки динамических границ во время
выполнения); регистр индекса начального
адреса (используется в некоторых APL-
микропрограммах и как генератор индек¬
са); регистры связи строк (указатели на
предыдущую и последующую строки в
программе пользователя); регистр числа строк; регистр адреса команды;
регистр порогового значения (используется в операциях сравнения); регист¬
ры прерывания и маски прерывания; всевозможные триггеры состояний;
регистр списка активных функций; регистр адреса нулевой строки (указыва¬
ет на первую строку списка выполняемых в данный момент функций); два
регистра захвата (используется для промежуточного распределения памяти);
четыре регистра для управления списком доступных областей памяти и 4-раз-
рядпый регистр (разряды которого используются как флажки), содержащий
информацию, используемую при записи операндов.
ПВЛ состоит из 1024 идентичных элементов. Грубая блок-схема элемента
ПВЛ изображена на рис. 3.42. ПВЛ можно рассматривать с двух позиций.
В одпой стороны, это группа ячеек, составляющая параллельный процессор.
С другой — две регистровые группы А и В, причем каждая из них состоит из
1024 физических регистров. В этой книге ПВЛ будет рассматриваться как со¬
вокупность ячеек. Ниже приводится описание отдельной ячейки.
Ячейка ПВЛ очень проста. Каждая ячейка содержит восемь 64-разряд-
яых регистров, 65-разрядпый регистр (A-регистр) и арифметико-логическое
Устройство (АЛУ). Как показано на рис. 3.42, имеется семь регистров Tj, ...
• • •, Т7 для временного хранения данных и регистры А и В. Считая регистры
Регистр Т7
Рис. 3.42. Блок-схема ПЭ ПВЛ
151
1024-элемептпыми векторами, можно видеть, что для каждого из восьми
программно доступных векторов хранится экземпляр ДЗ (дескриптор зпач0..
пия элемента) и экземпляр ДР (дескриптор размерности элемента). Програм,
мист не может задавать содержимое регистра В. В каждую ячейку вход :т
также триггеры активности, два регистра (счетчики), используемые в опера¬
циях с плавающей запятой, семь триггеров для проверки условий и условно,,
го перехода и арифметическое устройство. На каждую ячейку приходится
шесть основных арифметических блоков: блок мантиссы, блок порядка, логи¬
ческое устройство, блок сравнения, блок оперирования с бесконечными и не¬
определенными величинами и группа из пяти блоков маскирования (исполь¬
зуется для выполнения операций маршрутизации, зависящих от данных).
Другие типы итерационных вычислительных машин
Существует несколько машин с матричной структурой, которые представ¬
ляют интерес, хотя и не являются в строгом смысле OKМД-машинами. Для
полноты обзора некоторые из них кратко рассматриваются ниже.
Комфорт [3.37] описал модифицированный вариант машины Холланд;.-
(рис. 3.43). Цели создания этой машины состояли в следующем:
1) облегчить программирование (для машины Комфорта, как утвержда¬
ется, можно построить компилятор, а для машины Холланда — пет);
• 2) уменьшить стоимость аппаратных средств путем упрощения арифме¬
тических устройств;
3) повысить коэффициенты использования аппаратуры путем использо¬
вания арифметического устройства в режиме разделе¬
ния времени;
4) минимизировать уменьшение производитель¬
ности системы, которое может повлечь за собой реали¬
зация первых трех условий.
В матричной машипе Комфорта имеется два типе
процессоров. Во-первых, массив идентичных процес¬
сорных элементов размера Р X Q, причем каждый эле¬
мент включает память, устройство управления и сек¬
цию связи, позволяющую взаимодействовать с любым:
из четырех ближайших ПЭ. Во-вторых, набор арифме¬
тических устройств (А1,..., AN), которые через комму¬
татор (программно управляемый) подключены к мас¬
сиву ПЭ. При этом соблюдается очевидное ограниче¬
ние, что никакой столбец Г1Э не может быть связан с
более чем одним арифметическим устройством и никакое арифметическое уст ¬
ройство не может быть подключено более чем к одному столбцу ПЭ. Процес ¬
сорные элементы хранят данные и команды, а арифметические устройства вы¬
полняют арифметические и логические операции. В архитектуре системы,
есть ряд интересных моментов:
1) массив ПЭ может рассматриваться как центральное устройство управ
ления с множественным выходом;
2) фазы определения последовательности команд и выполнения опера¬
ций разнесены так же, как и в большинстве ОКМД-машин, одпако это сдела¬
но двояким образом: определение последовательности производится в масс и -
I
113
пз
пз
*
Рис. 3.43. Блок-схема
машины Комфорта
152
а исполнение — в немногих (возможно, единственном) исполнительных
блоках;
3) система представляет собой параллельную сеть ПЭ;
4) выполнение начинается с выбора арифметического устройства, а за-
уже строится маршрут для получения необходимых команд и данных;
5) число арифметических устройств N не обязательно должно совпадать
4 Р или Q.
Таблица 3.7
Язык ассемблера машины Комфорта
Код операции
Операция
STP *
Остановить последовательность команд
TMI (TZE) *
Если условие не выполнено, то исполняется следую¬
щая команда. Если выполнено, то активизируется мо¬
дуль па конечной точке маршрута. Переход по ми¬
нусу (нулю)
ACT*
Активизируется модуль па конце маршрута и сле¬
дующий естественный преемник. Используется для
образования многокомандных потоков. Активизация
HLD i *
Осуществляет блокировку любой плоскости. ПЭ бло¬
* = 1, 2, 3
кируются и не начинают функционировать до тех
пор, пока не получат освобождения (REL) этого
уровня. Средство синхронизации. Действует подобно
семафору (операторам Р, V)
EEL i *
Служит для посылки стартового сигнала во все моду¬
««.
н
н*
СО
ли, которые выполняли блокировку соответствующей
плоскости, т. е. REL i освобождает для дальнейшего
функционирования все модули, выполнявшие команду
ШИН.
WAIT * ‘
Средство локальной синхронизации. Снабжается аргу¬
ментом N, и модуль блокирует выполнение программы
SET (RST; REC)*
до тех пор, пока не будет активизирован N раз
Установка управляемых триггеров ПЭ (сброс тригге¬
NOP
ров; запись триггеров)
Нет операции
COM
Двоичное выполнение
ALS (ARS)
Арифметический сдвиг влево (вправо)
LGL (LGR)
Логический сдвиг влево (вправо)
RES (RRS)
Циклический сдвиг влево (вправо)
CLA
Очистка и сложение
ADD
Сложение
SUB
Вычитание
MPY
Умножение
DIV
Деление
STO
Запись
ANA
Логическое II аккумулятора
ORA
era
Логическое ИЛИ аккумулятора
Исключающее ИЛИ аккумулятора
Краткий перечень команд приведен в табл. 3.7. Комапды имеют типич¬
ную структуру, характерную для одноадресной машины с фиксированной за¬
нятой. Есть несколько особых команд. В табл. 3.7 они помечены * (звез¬
дочкой) .
153
Проект многослойной итеративной вычислительной машины был разра¬
ботан Гонсалесом [3.38]. Управление было встроено в сеть. Система состоит
па трех обрабатывающих слоев. Каждый слой представляет собой идентич¬
ный массив процессорных элементов размера пгУп. Во всех слоях элементы
одинаковы, т. е. во всей системе присутствует единственный тин элементов,.
Каждый элемент в слое соединен с четырьмя ближайшими свседями, а са¬
мый верхний (самый левый) элемент соединен с соответствующим ему ниж¬
ним (самым правым) элементом и наоборот. Одна из плоскостей является
плоскостью программы. Она содержит исходные, а по мере выполнения —
модифицированные программы. Средний слой представляет собой плоскость
управления. Она осуществляет опережающий просмотр команд и подготовку
операндов. Управляющая плоскость просматривает вперед на одну команду,
определяет операнды, которые потребуются па следующем шаге, и помеща¬
ет их в команду. Третий слой (вычислительная плоскость) выполняет ариф¬
метические, логические и геометрические операции. Эти плоскости соединены;
с помощью шин следующим образом:
1) каждый модуль в плоскости программы соединен со своим образом
в плоскости управления;
2) каждый модуль в плоскости управления связан со своим образом в
вычислительной плоскости;
3) каждый модуль в плоскости программы соединен со своим образом
в вычислительной плоскости;
4) все модули в вычислительной плоскости подключены к общей шипе,,
по которой передается сигнал завершения операции в каждый модуль пло¬
скости программы и плоскости управления.
Машина Гонсалеса обладает большими потенциальными -возможностями
за счет перекрытия операций во времени и использования конвейера опера¬
ций. За это пришлось заплатить увеличением объема аппаратуры: она со¬
держит в три раза больше модулей, чем обычно используется в гГодобной
машине; однако проект системы рассчитан на доступность большого числа
дешевых идентичных модулей серийного производства, поэтому избыток мо¬
дулей не должен служить препятствием к ее реализации. Модули могут быть
нроще, чем в других машинах такого типа. Конвейерная обработка дает уве¬
личение общей пропускной способности системы. Программное обеспечение
должно быть очень сложным.- В модуле ПЭ нужен аккумулятор, регистр, де¬
кодер, устройство коммутации шин и небольшая память. Слово включает че¬
тыре поля: 1) операнд 1, 2) код операции, 3) операнд И и 4) преемник.
Маршруты строятся в двумерной системе координат X, Y. Плоскости разде¬
ляют потоки данпых и команд. Поскольку любой модуль может работать кат*
аккумулятор, то в качестве такого выбран модуль, содержащий операнд И.
Тем самым устраняется необходимость иметь верхнюю, нижнюю, правую и
левую версии команд в зависимости от расположения аккумулятора. Основ¬
ными являются следующие операции: LOAD (загрузка), ADD (сложепие),
COMPLEMENT (двоичное дополнение) и TRASFER ON NON ZERO (переход по
ке-нулю).
На рис. 3.44 изображена машина, описанная Конвэем [3.39]. Она состоит
из массива процессоров ввода/вывода (Г1ВВ), управляющих процессоров (УП)
и арифметических процессоров (АП). Все эти процессоры соединены с памя¬
тью (II) через устройство обмена н находятся под управлением диспетчера.
154
Диспетчер вводит программу, п она начинает выполняться. Последователь¬
ность операции fork и join вызывает активизацию и деактивизацию элементов
системы. Значение этой работы Конвэя заключается в том, что в ней вводится
понятие операций fork и join, которые., являются логическим развитием (от
пошагового синхронного к параллельному функционированию) принципа ак¬
тивности элементов. Управлять операциями fork и join диспетчеру позволяет
*СЛЭВ'0 состояния.
В статье Камтю [3.40] описала вычислительная машина с блочной струк¬
турой ВОС. В BOG предполагалось использовать БИС, собранные па общей
ячеистой плате, что позволило
сd
<=С
Диспетчер
и-н ’
! '
Й Й-Й
Т 1 i
Комн\
/татор памяти j
гШ
~"П’П
Рис. 3.44. Блок-схема машины Коивея
бы построить па основе архи¬
тектуры тина ILLIAC IV са-
зйрвосстаиавлпвающийся' про¬
цессорный комплекс с высокой
пропускной способностью.
Идея состояла в размещении
большого числа маленьких
-простых процессоров на одной
плате (не разграфленной па
квадраты), использование ко¬
торых в параллельпом режиме позволило бы достичь высокой производитель¬
ности. Связи предполагались лишь между ближайшими соседними элемента¬
ми, по при решении некоторых задач все процессоры могли находиться под
централизованным управлением и функционировать в режиме ОКМД.
Рис. 3.45 иллюстрирует -общую концепцию системы. Модули С изобража¬
ют подчиненные процессоры, а модуль У — устройство управления. 16 моду¬
лей С и модуль У изготовляются в виде одной ячеистой платы, которая мо¬
жет использоваться в качестве отдельного устройства (памяти, устройства
ввода/вывода либо процессора). Предпо¬
лагалось, что на одной плате может
.размещаться 36 базовых элементов,
причем для работы одного устройства
достаточно, чтобы только 17 из них
были исправными. Затем эти ячеистые
платы используются для построения
"вычислительной системы. Схема одной
из таких систем приведена на рис. 3.46.
-Преимущество концепции ВОС состоит
и том, что при выходе из строя ячеек
отдельных плат работоспособность системы
■запасные ячейки находятся на самой плате.
Моренофф и др. [3.41] описали использование параллельной машины
;Для ускорения вычислений по программе предсказания погоды, используе¬
мой в вычислительном синоптическом центре ВМФ США. Метод основан иа
. базовой системе уравнений. Первоначально эта система должна была решать¬
ся на одном процессоре. Затем она была реорганизована таким образом, что-
*Ы се можно было решать в системе из 4-х процессоров — двух CDC-3200
(взаимодействующих через магнитный барабан) и двух CDC-6500 (взаимодей¬
ствующих через расширенную ферритовую память). CDC-6500 и CDC-3200
С1
С 9
С 16
•
1
1
г:
!
Рис. 3.45. Общая
схема системы
ВОС
сохраняется за счет того, что
155
взаимодействуют друг с другом через вспомогательный процессор связи, на¬
ходящийся под их управлением.
В каждом цикле программы решается пять групп уравнений: для восточ¬
но-западного импульса, для северно-южиого импульса, для термодинамиче¬
ской эпергии, уравпения сохрапепня влажности и уравпепия непрерывности.
После того как решены уравнения непрерывности, остальные четыре группы:
АУ
АУ
АУ
УУ
процессором
Канавы ввода/вывода
Плата' в в ода/вывода
Устройстзо
ввода/вывода
Устройства
ввода/вывода
Блок
управления
в-водо м/вы водой
1 Устройство
ввода/ вывода
Плата памяти
УУ
памятью
Память j
Память
...
Память
Рис. 3.46. Пример системы BOG
уравнений могут решаться параллельно. Выполнение одного цикла програм¬
мы дает прогноз на час вперед. В целом погода предсказывается на 36 часов
(за 36 циклов). Вычисления па i-м временном цикле могут быть выполнены
лишь после их завершения на i — 1-м цикле. Четыре процессора функциониру¬
ют следующим образом: процессор 1 завершает ввод данных, процессоры 4,
2 и 3 инициируют модель, процессоры 1, 2, 3 и 4 вычисляют шаг 1 и т. д.
После того как завершены все циклы, выполняется вывод дапных. На любом
интервале времени происходит тщательное распределение уравнений по про¬
цессорам для получения максимально возможной параллельности действий..
Данпая система параллельных процессоров позволила сократить время счета
в 3 раза при увеличении стоимости аппаратных средств (за счет увеличения
числа процессоров) в 4 раза.
Заключение
Существует ряд существенных различий между архитектурами парал¬
лельных и ассоциативных процессоров. Архитектуры ассоциативных процес¬
соров были изучены более глубоко и в большем количестве вариантов. Парал¬
лельные же процессоры в основном выступают в виде массива процессорных
156
элементов со связью между ближайшим,и соседними элементами. Ассоцнатив-
яые процессоры оказываются более разнообразными, однако менее полезны-
• ли, нем параллельные процессоры (так как вычислительные возможности ас¬
социативных процессоров более ограничены, чем у параллельных). Парал¬
лельные процессоры превосходят ассоциативные по числу разработанных и
реализованных проектов.
В ближайшем будущем специализированные вычислительные комплексы,,
предназначенные для решения важных задач, скорее всего, будут создавать¬
ся на основе именно параллельных процессоров. Ассоциативные же процессо¬
ры, пока их не будет построено достаточно большое число, видимо, смогут вы¬
полнять лишь сравнительно простые вспомогательные функции в универсаль¬
ных вычислительных машинах.
Будущее обоих типов архитектур в большей степени связано с изучением
приложений, микропроцессорных технологий и оптимизацией существую¬
щих архитектур, чем с разработкой новых. Оценивая достоинства или недо¬
статки ассоциативных и параллельных процессоров, важно учитывать, что
хотя с точки зрения архитектуры как ассоциативные, так и параллельные
процессоры отличаются большим разнообразием, в них вкладывается значи¬
тельно меньше средств, чем в универсальные машины. Это происходит по
многим причинам, и не последней среди них является та, что данные специ¬
ализированные машины рождаются из потребностей конкретных задач, в от¬
личие от ситуации, когда задачи приспосабливаются к уже имеющимся уни¬
версальным машинам. Таким образом, число пользователей, определяющих
уровень финансирования, оказывается ограниченным. Из-за сложности при¬
кладных задач и высокой стоимости разработок больших ОКМД-процессоров
корпорации вообще не вкладывали средства в разработку машин, имеющих ог¬
раниченный рынок сбыта.
Несмотря на это, изучение ОКМД-процессоров может дать много полезных
сведений о том, каким образом по условиям задачи строить систему с надеж¬
ной архитектурой и каковы преимущества той пли иной архитектуры.
Упражнения
3.1. Обсудпте историческую эволюцию попятил бита активности.
3.2. Назовите основные характеристики систем SOLOMON I SOLOMON II и
illiac IV и сравните их. Проследите эволюцию архитектуры системы
SOLOMON и превращение ее в архитектуру ILLIAC IV.
3.3. Сравните время умножепия двух матриц с помощью алгоритма Кэп-
иона н с помощью такого метода: столбец умножается на матрицу и частич¬
ное произведение накапливается в ячейке промежуточной памяти соответст¬
вующего столбца в параллельном процессоре, у которого связи существуют
Между ближайшими соседними элементами.
3.4. Обсудите разницу между сетью сортировки и сетыо перестановок и
Их потенциальные возможности.
3.5. В параллельном процессоре размера 64 X 64, у которого связи суще¬
ствуют между четырьмя ближайшими соседями, постройте алгоритмы умноже¬
ния матриц для матриц размера 64 X 64 и 64 X 64, 64 X 64 и 64 X 32, 64 X 64
И 64 X 72.
Постройте алгоритм инвертирования для невырожденных матриц разме-
64X 64, 64X 32 и 64 X 72. Исследуйте влияние архитектуры на любую из
проблем, возникающих в процессе алгоритмизации.
„ 3.6. Используя машину Унгера, напишите программу выбрасывания сред-
си точки пз каждой строки, содержащей нечетное количество точек.
157
3.7. Напишите программу для машипы Холланда, которая суммирует
(в параллельном режиме) пять наборов но три числа в каждом и накапливав
сумму но адресу первого элемента в исходном размещения наборов.
3.8. Рассмотрите класс задач, для которого производительность ортогональ¬
ной вычислительной машины может оказаться выше, чем у ассоциативного
процессора, подобного изображенному на рис. 2.1.
3.9. Р1спользуя многопроцессорную систему, состоящую из р процессоров,
.имеющих доступ к общей памяти, упорядочьте по возрастанию список из ?!
элементов с помощью алгоритма сортировки. Шелла. Алгоритм постройте та¬
ким образом, чтобы число р-ценочек было меньше либо равно числу процес¬
соров. Разработайте аналогичный алгоритм для параллельного процессора.
Сравните время выполнения обоих алгоритмов. Обсудите, какова зависимость
алгоритмов от эффективной скорости обращения в память. Каким образом
конфликты при обращении в память влияют на выполнение алгоритма в муль¬
типроцессорной системе?
3.10. Исследуйте, каким образом можно использовать объединяющие сети
для построения сетей сортировки. Определите объединяющую сеть как аппа¬
ратную реализацию алгоритма объединения.
3.11. Рассмотрите вопросы синхронизации процессоров, которые встретят¬
ся при попытке использовать машины Рорбахера в качестве универсальных
мапттш.
3.12. Постройте алгоритм быстрого преобразования Фурье с помощью ал¬
горитма совершенной тасовки.
3.13. Промоделируйте ассоциативный процессор па параллельном процес¬
соре, у которого связаны ближайшие соседние элементы.
ЗЛ4. Разработайте для процессора VAMP подсистему памяти, в которой
разряды с двух концов адресного слова памяти используются для выборка
адресуемого модуля памяти. Сравните использование только младших, только
старших и разрядов с двух концов адресного слова для построения схемы ад¬
ресации модулей памяти.
Глава 4
ILLIAC IV
Введение
ILLIAC IV является самым крупным параллельным процессором. Он
был построен в сокращенном варианте, в виде одного квадранта. Основной
вклад в разработку архитектуры был сделан сотрудниками Иллииойского уни¬
верситета. Сам процессор был изготовлен фирмой Burroughs. Этот процессор
является дальнейшим развитием системы SOLOMON, разработанной Слотпи-
ком [4.1, 42, 4.3]. ILLIAC IV предназначался в первую очередь для предска¬
зывания погоды и обработки данных ядерпых экспериментов.
Архитектура ILLIAC IV
ILLIAC IV представляет собой одну из самых больших в мире вычисли¬
тельных машин. В одном из руководств по ILLIAC IV говорится: «ILLIAC IV
является заметной вехой в развитии вычислительной техники, поскольку в
нем реализована обработка, степень параллелизма которой во много раз вы¬
ше, чем в обычных машинах». ILLIAC IV имеет высокую степень связности,.
Рис. 4.1. Машина класса ОКОД
т. е. каждый процессор связан с четырьмя своими ближайшими соседями.
Группа из G4 элементов, построенных в форме матрицы размером 8 X 3, на¬
зывается квадрантом. По первоначальному проекту в состав ILLIAC IV долж¬
но было входить четыре квадранта. Квадранты могут работать отдельно друг
0т Друга или согласованно. Постройка только одпого квадранта была обуслов¬
лена главным образом стоимостными соображениями. Если бы в конфигура¬
ции с четырьмя квадрантами был реализован тип связи, когда элемент свя¬
зан с ближайшими соседями, то общий массив из 256 элементов также, харак¬
теризовался бы этим же типом связи. В максимальной конфигурации система
ILLIAC IV представляла бы собой массив элементов размером 16 X 16.
В руководстве по ILLIAC IV [4.2] выбран очень любопытный способ по¬
каза различий между ILLIAC п обычпыми машинами. Этот способ в общем
ккде представлен на рис. 4.1—4.3. JIa рис. 4.1 изображена ситуация, когда
Идентичные процедуры PI, Р2,..., PN, представляющие циклическую програм-
159
.му, последовательно обрабатывают паборы данных DI, D2,..., DN. Одтш сиг,,
•соб повышения пропускной способности системы за счет значительного
.дублирования оборудования показан да рис. 4.2. Подход, реализованный ц
А Л V
Рис. 4.2. Машина класса МКМД
Рис. 4.3. Машина класса ОКМД
(ILLIAC IV)
ILLIAC IV, йзображеи па рис. 4.3. Поскольку программные циклы PI, Р2, ...
..., PN предполагаются идентичными, то, как видно из рис. 4.3, для управления
идентичными арифметическими и логическими устройствами необходим толь¬
ко один управляющий блок. Прин¬
цип использования в ILLIAC IV од¬
ного устройства управления обеспе¬
чивает снижение стоимости этой
машины. Только устройство управле¬
ния имеется в одном экземпляре, в
то время как обрабатывающие эле¬
менты повторяются многократно.
Имеется ряд неявных допущений от¬
носительно задач, для решения ко¬
торых может быть использован
ILLIAC IV. Вот некоторые пз пих:
1) программный цикл много¬
кратно исполняется над разными
блоками данпых;
2) каждое из N арифметичес¬
ких и логических устройств выпол¬
няют одну и ту же программу парал¬
лельно ыад разными блоками дан¬
ных, увеличивая тем самым быстро¬
действие в N раз;
3) каждое арифметическое и ло¬
гическое устройство имеет свою соб¬
ственную локальпую намять, так, что элемент имеет неограниченный доступ
к обрабатываемому им блоку данпых (уменьшая тем самым число конфлик¬
тов при обращении к памяти и снижая требования к центральной памяти);
Рис. 4.4. Система ILLIAC IV
160
4) доля времени, затрачиваемая на перемещение даипых от одной памяти
К ДР>ГГ0Й’ мала-
На рис. 4.4 показаны основные функциональные блоки и общая конфигу¬
рация системы ILLIAC IV. Процессорные элементы соединены с четырьмя
своими ближайшими соседями слева, справа, сверху и снизу по направлени¬
ем в плане.
Аппаратная часть ILLIAC IV
Основными функциональными блоками ILLIAC являются блоки ввода/вы¬
вода, дисковая память файлов, вычислительная машина В 6700, устройство
управления и ПМ (процессорный модуль). В паучпо-исследоватсльском цент¬
ре AMSE, относящемся к NASA*), В 6700 для управления но используется.
Вместо нее управление предполагалось сосредоточить в большой главной
памяти, к которой могут быть подключены процессоры и запоминающие
устройства второго уровня. Это позволяет обойтись без буферной памяти
для ввода/вывода и машины В 6700, которые описапы в нашей книге. Однако
функции управления остаются такими же, поэтому здесь будет рассмотрела
конфигурация с В 6700. Будет описан каждый функциональный блок, но под¬
робно будут рассмотрены только процессорные модули и устройства управле¬
ния. Каждый ПФ функционально разбит на три части: память процессорного
модуля (ГШМ), логическое устройство памяти (ЛУП) и процессорный элемент.
Общая блок-схема ILLIAC IV разбита на детали таким образом, чтобы дать чи¬
тателю возможность увидеть подробную структуру аппаратной части маши¬
ны (рис. 4.5 и 4.6). Дисковая память, В 6700 и подсистемы ввода/вывода — все
они участвуют в операциях ввода/вывода.
В 6700 служит ведущей или управляющей машиной, дисковая память
файлов обеспечивает объем хранимых данных порядка миллиарда бит, а под¬
система ввода/вывода связывает дисковую память и В 6700 с массивом про¬
цессоров, как это в общих чертах показало на рис. 4.4 и более детально — па
рис, 4.5.
В 6700 является ведущей машиной для всего комплекса ILLIAC IV.
Она отвечает за диспетчеризацию, распределение ресурсов, управле¬
ние внешним оборудованием, ввод/вывод, устранение последствий сбоев и
сборку программы. Более того, опа работает как процессор ввода/вывода для
ILLIAC. В 6700 выполняет управляющую программу или подготавливает
функциональные программы для выполнения в ILLIAC. Диспетчер планирует
работы для ILLIAC, хранит таблицы распределения памяти, передает дес-
кринторы ввода/вывода контроллеру управляющих дескрипторов, находяще¬
муся в секции ввода/вывода, и производит обработку прерываний.
Подсистема ввода/вывода служит главным связующим звеном между
Г» 6700 и массивом процессоров ILLIAC. Управляющие слова передаются меж-
ДУ Центральным процессором (ЦП) В 6700 и контроллером управляющих дес¬
крипторов через шину сканирования. С помощью этой шины В 6700 может
Управлять словами состояния в каждом УУ (т. е. устанавливать счетчики ко¬
манд, задавать режим управления и конфигурацию массива). *
*) Где был установлен единственный изготовленный экземпляр
ПДЛАС IV. (Примеч. пер.)
^ К. Дж. Тербср 161
В 6700 может осуществлять управление квадрантами, работающими как
согласованно, так и независимо. Может также осуществляться управление к
'Синхронизация обмена данными между массивом ILLIAC IV и дисковой па¬
мятью файлов. Для того чтобы осуществить обмен, В 6700 помещает началь¬
ный адрес и количество слов в контроллер управляющего дескриптора, кото¬
рый, в свою очередь, выполняет необходимые операции по формированию ад¬
ресов, относящихся как к массиву ILLIAC, так и к дисковой памяти. Обмен
1
! Я т а и
| !••(.•:* р :
I
есть функциоиа пьио
бы я- заменена
ой глазной памятью
П амять
Па мат ь
В 6700
В 6700
В 6700
! ..Ли
Процессор
передач и
дамп ых
i Периптер
! устройс
4ультип лексор
В 6700
не:
-т
I
Шина сканирования
Буферная
память
в в ода/вы вода
Ъ п о к
К с и -
макс - ■
ЦСпТ-
—
п и т р, л я
ратор
Блок
Кон¬
н а к о -
....
цент¬
—
п и ■; ел я
ратор
• 1
364
.• I
128
Электрон¬
Дисковый
!
ный блок
' 1
1
контрол¬
1
1
лер
i
266
1
j
|
Дисковый
кон Тро.п-
Л P. D
Злектрой¬
ный блок
384
^4—
—1 1
I
! .
256
я п а м я т t.i
1
i
Ввод/ вывод
Г~
Контрол¬
лер уп -
равляю-
щих двек
ригп оров
-
!
1
1
1
1
1
Vr:: ги -
т в о
управ- .
.гоми я
Коммута¬
1
' 1
64-про¬
тор
1
цессор¬
в в ода /
1
ный
вывода
1
I
квадрант
Система
ввода,'выв-ода реаль¬
ного 'времени
Гис. 4.5. Детальная структурная схема
Устрой
с г во
управ -
л е и и я
64- пд
цессор
ный
квадрант
J
1024 i Уj а ПЗ
данпыми производится непосредствепно между дисковой памятью и ППМ
через переключатель ввода/вывода.
Между В 6700 и подсистемой ввода/вывода существует два осповных ти¬
па взаимодействия. Это взаимодействие через буферную память и через
контроллер управляющих дескрипторов. С точки зрения В 6700 буферная на¬
мять ввода/вывода рассматривается как совершенно обычный модуль памятп
(т. е. адреса этой памятп составляют одно целое с общим адресным прост¬
ранством). Со стороны массива ILLIAC буфер ввода/вывода может выглядеть
162
яибв как часть дисковой памяти, либо как часть памяти массива. Взаимо¬
действие с контроллером управляющего дескриптора должно осуществляться
через мультиплексор В 6700. Минимальная конфигурация В 0700 состоит из
одного процессора (второй является резервным), памяти объемом 32К слов
Подключение к другим ус>ройствзм
vnради ел/я и к?птроллеру ввода/ вывода
V У
(пасшифоовкз команд, опре
деление г, э с ледова1'е л ьно сг/
ЗлзерациЗ •/ индексация)
I
X
ПЗ 66
ПЗ 63
■р Процессор::э:И моду л. о
Л [скнме• и веские и
ПЗ 37
паз
!*3 ■
0
воцессор.пый
модуль
Памяти НЗ
1
f:
I
* • v л I а я общая
.u-м .1 около 260
N 1- < ». ЦИХ U.J И! I.
рф I 4i!ilX к ПЗ
I ИЗ 36
ПЗ 3
Про дс с с о о м ь: Д. модуль 63
ПЗ 63
Память ПЗ
ПЭ о
Связи по
102.4 - паз о я да а я
шипа ! комму
та года ввода.
БЫ В 0 До.
Рис. 4.6. Детальная блок-схема взаимных связей элемептов в ILLIAC IV
{расширяемой до 512К), мультиплексора ввода/вывода (второй является ре¬
зервным) и периферийных устройств. Стандартные контроллеры периферий¬
ных устройств фирмы Burroughs через интерфейс подключаются к мульти¬
плексору ввода/вывода.
Запоминающие устройства, входящие в состав процессорных модулей,
образуют главную память системы. Дисковая память файлов с параллельным
Доступом фирмы Burroughs является памятью второго уровпя. В машине
В 6700
также имеется дисковая память файлов, но она не является частью
Дисковой памяти системы ILLIAC. Последняя состоит нз двух дисковых уст¬
ройств ттша Модель II но 13 дисков в каждом. Модель II включает концен¬
тратор, электронный блок и механическую часть. Емкость диска составляет
/9 X J06 бит. Электронный блок н концентратор могут управлять 16 дисками.
Электронный блок содержит обычные схемы и регистры, обеспечивающие уп¬
ч* 163
равление электромеханическими дисковыми системами. В состав концентра¬
тора входит усилитель чтения, при этом считывание и запись на диск могут
производиться параллельно по 128 дорожкам. Время обращения к диску сос¬
тавляет в среднем 19,6 мс, а скорость обмена между диском и дисковым конт¬
роллером (входящим в систему ввода/вывода) —502ХЮ6 бит в секунду.
Система ввода/вывода ILLIAC IV состоит из коммутатора ввода/вывода,
буферной памяти ввода/вывода, контроллера управляющих дескрипторов и
двух дисковых контроллеров. Последние осуществляют обработку дескрипто¬
ров, содержащихся в контроллере управляющих дескрипторов; эти дескрип¬
торы содержат информацию об обмене данными между дисками и массивом
процессоров, между дисками и буферной памятью системы ввода/выводо,
между буферной памятью системы ввода/вывода и массивом процессоров, а
также между каналами ввода/вывода, работающими в реальном масштабе
времени, и массивом процессоров. Все обмены, идущие как в направлении
массива процессоров, так и от пего, обязательно проходят через коммутатор
ввода/вывода. Все обмепы, в которых участвует буферная память ввода/вы¬
вода, осуществляются под управлением дескрипторов дисковой памяти фай¬
лов, находящихся в контроллерах дисков. Контроллер управляющих дескрип¬
торов принимает пары управляющих слов обмена (каждая пара состоит из
дескриптора сканирования и дескриптора области), собираемых шиной скани¬
рования. Он также вызывает соответствующие дескрипторы ввода/вывода, от¬
носящиеся к интерфейсу мультиплексора машины В 6700. После завершспин
операций ввода/вывода эти дескрипторы возвращаются в В 6700. Некоторые
дескрипторы ввода/вывода могут вызывать передачу информации из интер¬
фейса мультиплексора в устройство контроля и защиты от сбоев, где опи вы¬
ступают в качестве команд.
Каждое устройство управления управляет одним квадраптом, состоящим
из 64 процессорных модулей. По нервопачалыюму проекту должно было
быть 4 квадранта. Обобщенная функциональная блок-схема УУ представлена
на рис. 4.7. Детальная блок-схема изображена на рис. 4.8. Функция УУ за¬
ключается в организации исполнения команд вплоть до генерации пошаговой
последовательности микрокоманд для процессорного модуля.
В У У имеется пять основных секций. Все они работают независимо. Эта-
ми секциями являются секция опережающего просмотра команд (ILA —
Instruction Look-Ahead), секция предварительных команд (ADVAST — Advan¬
ced Station), секция завершающих (окончательных) команд (FINST — Final
Station), секция обслуживания памяти (MSU — Memory Service Unit) п секция
контроля и защиты (TMU — Test Maintenance Unit). Все эти устройства пол
робпо рассматриваются ниже. В УУ имеются регистры и логические цепи,
являющиеся общими для всего квадранта.
УУ осуществляет декодирование команд для ПМ. В процессе работы УУ
манипулирует с командами двух типов: FINST/PE и ADVAST. Взаимодейст¬
вие между этими типами команд практически отсутствует, поэтому можно
считать, что существуют два переплетенных," но все же различных потока
команд, выполняемых параллельно. Команды типа ADVAST управляют внут¬
ренними функциями УУ. Команды типа FINST/PE служат для формирования
команд процессорных модулей. В варианте ILLIAC с четырьмя квадрантам;.'.
У У могут функционировать независимо (управляя 64 элементами) или сог¬
ласованно в группах, состоящих из двух или четырех УУ, которые унравля-
164
jqt двумя или четырьмя квадрантами соответственно. В режиме согласован¬
ной работы нескольких квадрантов все устройства управления будут выпол¬
нять одинаковые команды, создавая иллюзию, что одно УУ управляет мас¬
сивом из 64, 12S пли 256 элементов.
' Конфигурация квадраптов задается с помощью регистра управления
размером МСО, обеспечивающим режим, при котором определенные УУ по-
у правления ^аресов управления
Рис. 4.7. Упрощенная схема УУ (КУД — контроллер управляющих дескрипто¬
ров, ООК — очередь окончательных команд)
лучают для исполнения одинаковые команды. Последние вызываются из па¬
мяти массива, находящейся под коптролем тех УУ, которые указаны в реги¬
стре вызова команд MCL. Команды, зависящие от размера массива процессо¬
ров, такие как LOAD (загрузка), исполняются темп квадрантами, номера УУ
которых указаны в регистре исполнения команд МС2. Остальные комапды
(которые не зависят от размера массива) исполняются теми УУ, номера ко¬
торых указапы в регистре МСО. Конфигурация системы в виде трех квадрап¬
тов невозможна из-за того, что управляющие разряды регистров MCI и МС2
не позволяют ее описать (появление в MCI и МС2 набора, состоящего из трех
Разрядов, соответствует ошибочной ситуации).
Каждое устройство управления имеет такой же доступ к памяти процес¬
сорного модуля (ППМ), как и ПЭ. MSU (секция управления памятью) при
Каждом запросе к памяти определяет номера ППМ, к которым происходит об-
Ращепие. При исполнении команд типа FINST/PE, содержащих обращения к
Памяти, необходимо, чтобы все 64 ППМ квадранта были адресуемыми. Те, кто
Пользуется памятью массива, долиты задать номера адресуемых ППМ.
Устройства системы используют дополнительные разряды при формировании
165
Данные или команды Данные от Разряды Ошибка запи-
из памяти ПЭ Других ПЭ режима ПЭ си в память ПЭ
Адрес для ПМ1 Команды для ПМ Данные для ПМ
Рис. 4.8. Детальная блок-схема У У
запросов к памяти: FINST/PE — пет, ввод/вывод—2 разряда, ILA —3 разряда,
д[)VAST (через FINST)—6 разрядов. Например, команда BIN (типа AD-
VAST) задает восьмерку ППМ, к которой должно происходить обращение,
команда BIN формирует блок данных, вызываемых из ППМ на регистры
сверхоперативной памяти ADB.
Ниже приводится общий перечень программно-доступных регистров У У,
изображенных па рис. 4.8.
1) АСО, АС1, АС2, AG3 —четыре 64-разрядных накапливающих регистра
общего назначения (ACAR);
2) AGR — управляющий регистр' ADVAST, содержащий режим работы
УУ (доступен только по чтению);
3) ACU — регистр, содержащий число квадрантов (доступен только по
чтению);
4) ADB — 64 регисра по 64 разряда в каждом, образующих сверхоператив¬
ную память;
5) AIN — регистр прерывания ADVAST;
6) AMR —регистр маски для AIN;
7) ALR — регистр блокировки па время вызова данных из памяти;
8) МСО, MCI, МС2 — регистры, управляющие конфигурацией системы;
9) IIA — регистр запоминания ICR па время прерывания ILA (секции
опережающего просмотра команд);
10) IGR — счетчик команд ILA;
11) TRI — входной регистр TMU (секции контроля и защиты), доступный
только по чтению;
12) TRO — выходной регистр TMU.
Секция ILA, входящая в состав УУ, содержит регистры ICR и IIA. В ней
также имеется стек команд (IWS), сумматор адресов команд и ассоциатив¬
ная память (IAM), используемая в страничном механизме, служащем для
передачи блоков команд в память ILA. Команды вызываются из памяти масси¬
ва процессоров в виде страниц по 8 слов и записываются в IWS, ассоциатив¬
ную память из 64 слов с адресацией по содержимому, служащую стеком ко¬
манд. Так как IWS содержит 64-разрядиые слова, а длина команды составля¬
ет 32 разряда, то всего в IWS может храниться 128 команд.
ADVAST принимает команды из IWS секции ILA на регистр AIR (этот
регистр программно недоступен). Каждая команда подвергается проверке. Ко¬
манды, относящиеся к ADVAST, оставляются для исполнения. Команды, от¬
носящиеся к FINST/РЕ, индексируются, если это необходимо, и затем поме¬
щаются в FINQ (буфер команд между ADVAST и FINST) для их последую¬
щего исполнения процессорным элементом. После исполнения процессорным
элементом некоторые команды типа FINST/РЕ могут быть возвращены в AD-
VAST для какой-то дополнительной обработки. К таким комапдам относится,
например, BIN. Устройство ADVAST является главным организующим эле¬
ментом системы. Оно выполняет такие функции, как операции с адресами,
Управление циклами, управление конфигурацией и режимом системы, а так-
обработка прерываний. Все программное управление осуществляется
секцией ADVAST -одновременно и независимо от выполнения основной вы¬
числительной работы (т. е. функционирования ПМ). ADVAST включает реги-
СТРЫ АСО, АС1, АС2, АСЗ, ACU, A IN, AMR, ACR, AIR, ALR и ADB, а также
Cjio>KHOe комбинированное логическое устройство п 24-разрядиын сумматор.
167
Сравнивая общую (рпс. 47) п детальную (рпс. 4.8) блок-схему УУ. чпта-
толь должен заметите, что буферное устройство FIXQ пе показано явно iui
детальной схеме. Регистры FIQ и FDQ пе доступны для программиста. FJ.No
состоит из 8 слов и служит буфером команд между A I) VAST и F1NST. Секция
FIXST превращает команды в последовательность микрокоманд и передает
последние в квадрант для псиолнешш на процессорных элементах. FINST п
ее квадрант взаимно синхронизированы с точностью до задержки, связанной
с обменом но общей шине.
Секция MSU служит для разрешения конфликтов между FIXST, ILA ц
контроллером управляющих дескрипторов системы ввода/вывода. Все запросы
0 ... 4
5 ... 7
8 ... 15
16 ... 17
18
19
20 ... 23
24 ... 31
Поле А
кода
операций
АС А ИХ
Пропуск
ACAR
Глобаль¬
ный или
локаль¬
ный
Четность
Поле В
кода
операций
ADR
Рис. 4.9. Формат команды ADVAST
к памяти со стороны ADVAST обслуживаются через секцию FINST. MSU пе¬
редает адрес в память и управляет циклом памяти.
Секция TMU содержит два регистра: TRI и TRO. TMU обслуживает капал,
по которому тестовые данные от В 0700 поступают в УУ, а также обеспечива¬
ет некоторую аппаратную поддержку системе диагностики.
Независимость и аспнхрониость секций ADVAST п FINST таит в себе
опасность возникновения нежелательных эффектов. Большинство связанных
с этим проблем решены на аппаратном уровне. Однако некоторые из подвод¬
ных камней должен видеть сам программист. Все они описаны в инструкции
но программированию и требуют специальных мер, чтобы их избежать. Уп¬
равление конфигурацией системы в целом находится в сфере деятельности
программиста. В число таких средств входят команды FORKS и JOINS", ис¬
полняемые иа уровне квадрантов; эти команды дают возможность организо¬
вать параллельное 'выполнение локальных процедур на разных квадрантах
общего большого массива процессоров.
Поскольку система 1LLIAC, в отличие от РЕРЕ, пе предназначалась для
работы в реальном масштабе времени, ее система прерываний имеет очень
простую структуру. В ILLIAC имеются прерывания как с восстановлением,
так и без восстановления. При прерываниях без восстановления нет необхо¬
димости в средствах, обеспечивающих возврат машины к известному состоя¬
нию без специальных мер, предусматриваемых программистом при разработ¬
ке программу. Исчерпывающее обсуждение вопросов, связанных с управле¬
нием временными соотношениями, конфигурацией и прерываниями, выходит
за пределы книги, однако его можно найти в [4.2].
Основной формат команды ADVAST показан на рис. 4.9. Краткая сводка
состава команд приведена на рпс. 4.9. Операция ОР (рпс. 4.9) описывается
полями А п В. В поле ACARX пятый разряд задает индексацию. Поле SKIR
описывает количество команд, которые надо пропустить. Признак глобаль¬
ный/локальный описывает зависимость от устройства управления конфигура¬
цией массива процессоров. Поле ADR зависит от команды и обычно содержит
168
Система команд секции ADVAST
Таблица 4.1
Мнемокод
Операция
alit
BIN
BINX
CACRB
-CADD
CAND
ССВ
CEXOR
CLC
СОМРС
СОРУ
СОК
CRB
CROTL
CROTR
С SB
GSI.IL
CSIIR
CSUR
CTSBF
CTSBT
DUPT
DUPO
EQLX-
GRTR—
LESS —
ONES-
ONEX-
SKTP —
TXE —
TXE — M
TXG —
TXG - M
ZER —
ZERX —
WAIT
EXCHL
EXEC
HALT
IXCRXG
INR
JUMR
LDG
ldl
{£aoo
Сложение литерала с адресным полем ACAR
Блокировка вызова из памяти ПМ в ADB
То же, что BIN, но адрес модифицируется содержимым X
регистра модификации 1IM
Запись 1/0 в /г-й разряд управляющего регистра ADVAST
Сложение содержимого локальной памяти с ACAR
Логическое умножение содержимого локальной памяти с
ACAR
Дополнение w-разряда ACAR
Операция ИСКЛЮЧАЮЩЕЕ ИЛИ с содержимым локальной
памяти и ACAR
Очистка ACAR
Дополнение ACAR
Коп пров-аиие ACAR
Логическое сложение содержимого локальной памяти и
A CAR
Сброс 72-го разряда ACAR
Остапов при левом обходе ACAR
Остапов при правом обходе ACAR
Установка в 1 /z-го разряда ACAR
Останов по сдвигу ACAR влево
Останов по сдвигу ACAR вправо
Вычитание содержимого локальной памяти из ACAR
Переход, если /2-й разряд ACAR пе 1
Переход, если /г-й разряд ACAR равен 1
Дублирование внутренней половины слова памяти ADB
Дублирование внешней половины слова памяти ADB
Переход, если в ACAR находится такой же операнд
Переход, если ACAR содержит большой операнд
Переход, если ACAR содержит меньший операнд
Переход, если все разрядные позиции ACAR содержат 1
Переход, если поле ACAR содержит все 1
Переход по состоянию триггера У У (ложь или истина)
Переход, если содержимое поля ACAR равно содержимому
локальной памяти
Переход, если два поля одного и того же ACAR равны меж¬
ду собой
Переход, если содержимое поля ACAR больше, чем содер¬
жимое поля локальной памяти
Переход, если содержимое одного поля ACAR больше содер¬
жимого другого поля того же AGAR
П ереход, есл и все A CAR равны О
Переход, если все разряды поля* ACAR равны О
Синхронизовать (объединить) все УУ
Поменять местами локальный операнд и ACAR
Выполнение
Останов ADVACT до тех пор, пока пе освободится FINST
Перевод УУ в штатное состояние ожидания
Модификация поля индекса ACAR содержимым поля при¬
ращения того же ACAR
Возврат к нормальной работе после прерывания
Переход по адресу, содержащемуся в поле ADR
Передача заданного регистра ПМ в ACAR
Загрузка из локального адреса
Поиск первой единицы в ACAR
Таблица 4.1 (продолжение)
Мнемокод
Операция
LEADZ
Поиск первого нуля в AGAR
LIT
Запись следующих G4 разрядов в ACAR
LOAD
Вызов слова из памяти ПМ в локальную память УУ
LOADX
То же, что LOAD, за исключением того, что адрес модифи¬
цируется содержимым X, регистра модификации IIM
ORAG
Операция ИСКЛЮЧАЮЩЕЕ ИЛИ операнда в ACAR во
всех УУ, выполняющих команду
SETG
Описание передачи бита режима из каждого из 64 процес¬
соров в AGAR
SKIP
Переход вперед/назад
SLIT
Замена адресного поля ACAR
STL
Запоминание ACAR в локальной памяти
STORE
Перепись из ячейки локальной памяти в заданную позицию
массива, ПМ
STOREX
То же, что STORE, но с модификацией адреса содержимых X
регистра модификации ПМ
TGGW
Передача ACAR в соседнее УУ с меньшим' номером
TCW
Передача ACAR в соседнее У У с большим номером (переда¬
ча против часовой стрелки)
адрес ячейки локальной памяти, используемой в качестве источника вто¬
рого операнда.
В табл. 4.1 приведен перечень и краткое общее описание команд с исполь¬
зованием мнемоники языка ассемблера. Все команды условного перехода
сгруппированы в конце списка и имеют вид NAME—. Эти команды выполняют
операцию передачи .управления по заданному условию. Каждая команда типа
NAME — имеет следующие четыре варианта: NAMETA, NAMET, NAMEFA и
NAMEF, которые соответствуют четырем состояниям триггеров массива, при
этом ТА, Т, FA и F указывают па состояния: все истина, любой истина, все
ложь и любой ложь, соответственно. После выполнения проверки триггеров
массива будет выполнена операция пропуска, если удовлетворяется соответст¬
вующее условие, явно заданное в мнемокоде команды. Многие из команд про¬
пуска по условию работают только с полем ACAR, по это не отражено в крат¬
ком описании системы команд.
Процессорный модуль состоит пз трех основных подсистем. Это устрой¬
ство управления памятью (УУП), память процессорного элемента (ППЭ) и
процессорный элемент. Все процессорные модули имеют идентичную элект¬
ронную-и механическую часть п идентичные .функциональные возможности.
Здесь будет рассмотрен только процессорный элемент, функциональная схе¬
ма которого показана на рис. 4.10, детали же, касающиеся УУП и ППЭ, будут
опущены.у На рис. 4.11 представлена подробная схема ПЭ. Посколь¬
ку управляющие механизмы сосредоточены в основном в УУ, то отдельный
ПЭ не имеет независимого управляющего устройства, за исключением тех
немногих логических элементов, которые относятся к режиму и условным
операциям, зависящим от данных. Как видно из рис. 4.10, основную часть ПЭ
составляет арифметическое устройство с четырьмя регистрами.' Система ко¬
манд ПЭ включает широкий набор операций, которые могут производиться
170
рад 64-, 32- и 8-разрядными операндами. Операции с 64- и 32-разрядпыми
операндами могут выполняться в формате с фиксированной пли плавающей
запятой. В арифметическом устройстве имеются многочисленные аппаратные
средства, включающие систему сумматоров с последовательным переносом,
параллельный сумматор с опережающим переносом, схему циклического сдви¬
га, схему обнаружения первой единицы, а также логическое устройство для
Гис. 4.10. Процессорный элемент
булевских операций. Источниками операндов могут быть массив памяти, ре¬
гистры IIЭ, шипа данных, а также четыре ближайших соседних процессорных
элемента.
Всего в ПМ имеется семь регистров, по только четыре пз них представле-
ны в явном виде (регистры А, В, В, S).
# Вот эти регистры.
1) Регистр А — 64-разрядпый регистр результатов, работающий только
^гда, когда установлен соответствующий режим ПЭ.
2) Регистр В — 64-разрядный регистр операндов.
3) Регистр С — 64-разрядный регистр, в котором хранятся разряды пере¬
носа, подлежащие дальнейшему распространению; доступ к этим разрядам
171
'Номера ПЭ
Рис. 4.11. Детальная блок-схема Г1Э
жет быть осуществлен с помощью команды OFB, она может дать доступ к
8 разрядам.
4) Регистр D — 8-разрядный регистр режима взаимодействия между УУ
и ПЭ.
5) Регистр R — 64-разрядный регистр для промежуточного храпения, ко¬
торый доступен даже тогда, когда процессор находится в неактивном состоя¬
нии (этот регистр считается регистром маршрутизации и используется, в
припципе, для связи с другими ПЭ).
6) Регистр S — 64-разрядный регистр промежуточного хранения, который
работает только тогда, когда ПЭ находится в активном состоянии.
7) Регистр X— 16-разрядиый регистр, используемый в качестве адрес¬
ного модификатора.
Регистр режима (регистр D) управляет некоторыми операциями ПЭ и
хранит информацию об ошибках и результаты проверок. Два разряда регист¬
ра D, Е и Е1 используются для организации доступа к регистрам A, S и MIR
(регистр данных ППЭ). Разряд Е открывает доступ к регистру X (служаще¬
му в основном адресным модификатором). В режиме работы с 32-разрядпыми
словами Е и Е1 независимы.
Остальные шесть разрядов регистра D: F, F1, G, II, I и J используются
следующим образом. В F и F1 хранится информация о сбое, a G, II, I и J слу¬
жат временным хранилищем результатов проверок. Любой разряд регистра D
может либо обрабатываться программным путем со стороны УУ, либо пересы¬
латься в УУ.
Поскольку ПЭ находится в полном подчинении у устройства управления,
то он получает от УУ целиком раскодированные последовательности команд.
Большинство последовательностей используется непосредственно. Некоторые
модифицируются с помощью F и Е1. Для модификации команд могут ис¬
пользоваться знаковые разряды регистров А и В, а также операция обнару¬
жения первой единицы.
Другие внутренние управляющие сигналы могут вырабатываться в про¬
цессе исполнения операций ПЭ, например, при работе множительного устрой¬
ства, однако п в этом случае ПЭ находится в подчиненном положении. В си¬
стему команд ПЭ входит широкий набор арифметических операций и очень
незначительное число команд управления, которые ограничиваются команда¬
ми индексации. Имеется полпый набор команд тестирования, результаты ис¬
полнения которых помещаются в регистр режима D.
Адресация в ПЭ осуществляется с помощью 16-разрядного адресного сум¬
матора (ADA). Адрес может быть индексирован с помощью регистра X и 16-
разрядного поля регистра S. В ILLIAC возможна двойная индексация, т. е. по¬
мимо того, что комапды индексируются в УУ, опи также могут индексирова¬
ться в процессорных элементах. На вход адресного сумматора может пода¬
ваться информация с регистров X и S и со схемы выборки. С выхода адресно¬
го сумматора информация может быть возвращена на регистр X, либо подана
на регистр памяти, либо па универсальное сдвиговое устройство. Для того
чтобы вновь возвратиться на регистр X, выходная информация адресного сум¬
матора должна быть передапа на схему выборки. Адресный сумматор не име¬
ет возможности изменить содержимое 16-разрядного поля регистра S, исполь¬
зуемого в качество индекса. Операции формирования адресов могут выпол¬
няться параллельно с операциями, в которых не задействована схема выбор¬
173
ки it схема адресации памяти. Арифметические операции могут выполняться
параллельно с адресацией.
Основной сумматор может работать как с накоплением, так и с распрост¬
ранением бита переноса. В режиме с распространяющимся переносом в сум¬
маторе используются три уровня опережающего просмотра, четыре разряда
на второй уровне и четыре секции на третьем уровне. Вычисление 64-разряд-
ной суммы занимает только один такт. В режиме работы с 8-разрядными
Поле А кода
ACARX
Поле В кода
Четность
Специфика¬
ADR |
операций
операций
ция ADR
I
Рйс. 4.12. Формат команды F1NST/PE
операндами применяется нарезка на байты и прерывание распространения
переноса; доступ к восьмерке разрядов регистра С осуществляется непосред¬
ственно с помощью команды OFB (табл. 4.2). В процессе выполнения опера¬
ции умножения этот режим позволяет сохранять биты переноса. При опера¬
ции умножения одна итерация, выполняемая за один такт, состоит в том,
что берется восемь разрядов, которые обрабатываются четверкой параллель¬
ных сумматоров с сохранением переноса (в качестве четвертого используется
осповпой сумматор); при этом, однако, процесс переноса полностью не завер¬
шается. .
В ПЭ имеется универсальное сдвиговое устройство. Оно представляет со¬
бой 64-разрядпый циклический правосторонний сдвиговый регистр, который
позволяет осуществить за один такт произ!Вольный сдвиг регистров. Слова
могут сдвигаться как с потерей информации на правом конце, так и цикли¬
чески. Операция нормализации выполняемся с помощью устройства обнаруже¬
ния старшей единицы, которое берет содержимое регистра А и производит
нормализующий сдвиг, после чего устанавливается нужный порядок числа.
УУП (устройство управления памятью) образует интерфейс ПЭ с ППМ
(памятью процессорного модуля). УУП осуществляет обмен дапными между
ППМ и устройством управления, а также между ПЭ и подсистемой ввода/
вывода. В УУ11 входит только регистр данных, имеющий формат слова памя¬
ти, и небольшое логическое устройство.
ППМ представляет собой запоминающее устройство, содержащее 2048
64-разрядных слов. Максимальная длительность цикла чтепия составляет око¬
ло 250 не, максимальная длительность цикла записи также составляет около
250 пс. Время доступа к данным равно 188 не. Первые 128 слов ППМ могут
быть защищепы от записи с помощью установки в 1 13-го. разряда регистра
ACR, входящего в состав секции ADVAST устройства управлеппя. Защита по
записи дает гарантию, что цикл записи не может осуществиться.
В табл. 4.2 приведен общий список команд секции FINST/PE. Формат
команды FINS Г/РЕ показан на рис. 4.12.
Обозначение OP CODE применяется для полей А и В кода операции. По¬
ле ACARX игнорируется, если 5-й разряд равен 0. Когда 5-разряд равен 1, со¬
держимое разрядов 6 и 7 задает номер того ACAR в УУ, содержимое которого
прибавляется к содержимому поля ADR слова команды. В поле PARITY со¬
держится разряд контроля четности. Содержимое поля ADR USE определя¬
ет, индексируется ли команда регистром S пли X, а также передает ли УУ в
174
Команды FINST/РЕ
Таблица 4.2
Мнемокод
Операция
Сложение операнда (ADR) с регистром А
Сложение операнда (ADR) с регистром А, без зпака
Сложение операнда (ADR) с регистром А, с фиксированной
запятой
Сложение операнда (ADR) с регистром А, с фиксированной
занятой, без знака
Сложение операнда (ADR) с регистром А, с плавающей за¬
пятой
Сложение операнда (ADR) с регистром А, с плавающей за¬
пятой и с нормализацией результата
Сложение операнда (ADR) с регистром А, с округлением ре¬
зультата
Слояхение операнда (ADR) с регистром А, с округлением ре¬
зультата, без знака
Сложение операнда (ADR) с регистром А, с плавающей за¬
пятой и с округлением результата
Сложение операнда (ADR) с регистром А, с плавающей за¬
пятой, с округлением результата, без знака
Сложение операнда (ADR) с регистром А, в байтовом (8 раз¬
рядов) формате
Сложение 64-разрядпого числа без знака с фиксированной
запятой (ADR) с регистром А
Сложение содержимого поля (полей) порядка операнда
(ADR) с порядками в регистре RGA
Запись знака (знаков) регистра А в поле знака (зпаков)
регистра В
Логическая операция И операнда (ADR) с регистром А
Логическая операция И дополнения операнда (ADR) с ре¬
гистром А
Логическая операция ИСКЛЮЧАЮЩЕЕ ИЛИ регистра А
с операндом (ADR)
Логическая операция равнозначности регистра А с операн¬
дом (ADR)
Логическая операция И дополнения регистра А с операндом
(ADR)
Логическая операция И дополнения регистра А с дополне¬
нием операнда (ADR)
Логическая операция ИЛИ дополнения регистра А с операн¬
дом (ADR)
Логическая операция ИЛИ дополнения регистра А с допол¬
нением операнда (ADR)
Логическая операция ИЛИ регистра А с операндом (ADR)
Логическая операция ИЛИ регистра А с дополнением опе¬
ранда (ADR)
Инверсия разряда (разрядов) в регистре А
Изменение знакового разряда (разрядов) в регистре А
Сброс разряда (разрядов) в регистре А
Установка разряда (разрядов) в регистре А
Сброс зпакового разряда (разрядов) в регистре А
Установка зпакового разряда (разрядов) в регистре А
175
Т а б л и ц а 4.2 (продолжение)
Мнемокод
Операция
CLRA
Чистка регистра А
СОМРА
Дополнение регистра А
DV3 *)
Деление
1)VA3
Деление без знака
DVM3
Деление с фиксированной запятой
DVMA3
Деление с фиксированной запятой без знака
DVN
Деление нормализованное
DVNA3
Деление нормализованное без знака
DVR3
Деление с округлением
DVRA3
Деление с округлением без знака
DVRM3
Деление с фиксированной занятой с округлением
DVRMA3
Деление с фиксированной запятой с округлением без знака
DVRN3
Деление нормализованное с округлением
DVRNA3
Деление нормализованное с округлением без знака
EAD
Восстановление точности после сложения с плавающей за¬
пятой
ESB
Восстановление точности после вычитания с плавающей за¬
пятой
GN
Побайтовая проверка того, что значение регистра А превы¬
шает значение операнда (ADR)
ILZ4 **)
В разряд 1(G) записывается признак того, что регистр А ло¬
IM04
гически равен нулю
В разряд 1(G) записывается признак того, что мантисса ре¬
гистра А логически равна единице (все разряды мантиссы
IMZ4
равны 1)
В разряд 1(G) записывается признак того, что мантисса ре¬
JL04
гистра А логически равна нулю
В разряд J(II) записывается признак того, что регистр А ло¬
JLZ4
гически равен единице
В разряд J(II) записывается признак того, что регистр А ло¬
JM04
гически равен нулю
В разряд J (II) записывается признак того, что мантисса ре¬
гистра А равна единице
JMZ4
В разряд J(II) записывается признак того, что мантисса ре¬
IAG4
гистра А равна пулю
В разряд 1(G) записывается признак того, что регистр А
арифметически больше, чем операнд (ADR)
IAL4
В разряд 1(G) записывается признак того, что регистр А
арифметически меньше, чем операнд (ADR)
JAG4
В разряд J (II) записывается признак того, что регистр А
арифметически больше, чем операнд (ADR)
JAL4
В разряд J (IГ) записывается признак того, что регистр А
арифметически меньше, чем операнд (ADR)
Передача разряда (разрядов) регистра А в 1(G)
•
ТВ4
1SN4
Передача знака (знаков) регистра А в 1(G)
JB4
Передача разряда (разрядов) регистра А в J(II)
JSN4
ILE4
Передача знака (знаков) регистра А в J(II)
В разряд 1(G) записывается признак того, что регистр А
логически равен операнду (ADR)
*) В операциях, помеченных 3, деление следует понимать4' таким образом, что со¬
держимое регистра А и регистра В (мантисса удвоенной длины) делится на операнд
(АПК).
**) При работе в 32-разрядиом формате для операции, помеченных4, результат также
попадает в разряды 11 и G, указанные в скобках.
176
Т а б л и д а 4.2 (продолжение)
Мнемокод
Операция
ILG4
ItL4
1МБ4
IMG4
IML4
JLE4
JLG4
JLL4
JME4
' JMG4
JML4
ILO4
LDA
LDB
LDD
LDR
LDS
XD
XI
ISE5 *)
ISG5
ISL5
IXE5
IXG5
IXL5
JSE5
JSG5
JSL5
JXE5
В разряд 1(G) записывается признак того, что регистр А
логически больше, чем операнд (ADR)
В разряд 1(G) записывается признак того, что регистр А
.логически меньше, чем операнд (ADR)
В разряд 1(G) записывается признак того, что мантисса ре¬
гистра Л логически равиа мантиссе операнда (ADR)
В разряд 1(G) записывается признак того, что мантисса ре¬
гистра А логически больше, чем мантисса операнда (ADR)
В разряд 1(G) записывается признак того, что мантисса ре¬
гистра А логически меньше, чем мантисса операнда (ADR)
В разряд J(II) записывается признак того, - что регистр А
логически равен операнду (ADR)
В разряд J (II) записывается признак того, что регистр А
логически больше, чем операнд (ADR)
В разряд J(Н) записывается признак того, что регистр А
логически меньше, чем операнд (ADR)
В разряд J (II) записывается признак того, что мантисса ре¬
гистра А логически равна мантиссе операнда (ADR)
В разряд J(H) записывается признак того, что мантисса ре¬
гистра А логически больше, чем мантисса операнда (ADR)
В разряд J (II) записывается признак того, что мантисса ре¬
гистра А логически меньше, чем мантисса операнда (ADR)
В разряд 1(G) записывается признак того, что регистр А
логически равен единице (все разряды равны 1)
Передача данных из источника в регистр А
Передача данных из источника в регистр В
Передача данных из источника в регистр D
Передача данных из источника в регистр R
Передача данных из источника в регистр S
Вычитание содержимого поля операнда (ADR) из регист¬
ра X
Сложение содержимого поля операнда (ADR) с регистром X
В разряд I записывается признак того, что RGS арифмети¬
чески равен операнду (ADR)
В разряд I записывается признак того, что RGS арифмети¬
чески больше, чем операнд (ADR)
В разряд I записывается признак того, что RGS арифмети¬
чески меньше, чем операнд (ADR)
В разряд I записывается признак того, что RGX арифмети¬
чески равен операнду (ADR)
В разряд I записывается признак того, что RGX арифмети¬
чески больше, чем операнд (ADR)
В разряд I записывается признак того, что RGX арифмети¬
чески меньше, чем операнд (ADR)
В разряд J записывается признак того, что RGS арифмети¬
чески равен операнду (ADR)
В разряд .1 записывается признак того, что RGS арифмети¬
чески больше, чем операнд (ADR)
В разряд J записывается признак того, что RGS арифмети¬
чески меньше, чем операнд (ADR)
В разряд J записывается признак того, что RGX арифмети¬
чески равен операнду (ADR)
операций, помеченных 6, RGX означает регистр X, a RGS означает ре-
4 р
R. Дж. Тербер
177
Таблица 4.2 (продолжение)
Мнемокод
Операция
JXG5
JXL5
IXGI
JXGI
IXLD
JXLD
RTAL6 *)
RTAR6
SHABL
SIIABR
STIABML
SI1ABMR
SHAL
SIIAR
3HAML
SHAMR
LB
LDRAG
LDRAL
LEX
AIL7 **)
MLA7
.MLM7
А1ГА1А7
MLN7
A1LNA7
MLR7
MLRA7
MLRM7
MLRMA7
MLRN7
MLRN A7
ST A
STB
В разряд J записывается признак того, что RGX арифмети¬
чески больше, чем операнд (ADR)
В разряд J записывается призпак того, что RGX арифмети-
чески меньше, чем операнд (ADR)
Сложение поля ADR с регистром X и запись переполнения
в I
Сложение поля ADR с регистром X и запись переполнения
в J
Вычитание из поля ADR регистра X и’ запись дополнения
переполнения в I
Вычитание из поля ADR регистра X и запись дополнения
переполнения в J
Поворот регистра А влево
Поворот регистра А вправо
Сдвиг сдвоенпого регистра (регистр А плюс регистр
влево
(регистр А плюс
(регистр
(регистр
А плюс регистр
А плюс регистр
В)
В)
В)
В)
меньше, чем операнд
Сдвиг сдвоенного регистра (регистр А плюс регистр
вправо
Сдвиг в сдвоенном регистре
только мантиссы влево
Сдвиг в сдвоенном регистре
только мантиссы вправо
Сдвиг регистра А влево
Сдвиг регистра А вправо
. Сдвиг мантиссы регистра А влево
Сдвиг мантиссы регистра А вправо
Побайтовая проверка: регистр А
(ADR)
Вызов па регистр R данных из памяти, начиная с ППМ с
заданным номером, и возврат первого слова в Г1Э с номе¬
ром 0, если оно больше, чем операнд (ADR)
То же, что LDRAD, но условие заменяется на «меньше, чем»
Загрузка в регистр А значения порядка (порядков), взятого
из операнда (ADR)
* Умножение
Умножение без знака
Умножение с фиксированной запятой
Умножение с фиксированной запятой без знака
Умножение нормализованное
Умножение нормализованное без знака
Умножение с округлением
Умножение с округлением без знака
Умножение с округлением с фиксированной запятой
Умножение с округлением с фиксированной занятой без
31 гака
Умножение пормализовапное с округлением
У множение нормализованное с округлением без знака
Запись в память из регистра А
Запись в память из регистра В
*) Для операций, помеченных 6, поворот означает циклический сдвиг, при кото¬
ром цифры, выходящие за пределы разрядной сетки слова, вводятся в высвобождаю¬
щиеся позиции слова.
-••) К операциях умножения, помеченных7, подразумевается, что содержимое ре¬
гистра Л умножается на операнд (ADR).
478
Т а б л л н а 4.2 (продолжение)
Мнемокод
Операция
STR
Запись в память из регистра R
STS
Запись в память из регистра S
STX
Запись в память из регистра X
SUB
Вычитание из содержимого регистра А 64-разрядного операн¬
да без знака с фиксированной занятой (ADR)
SWAR8 *)
Перестановка местами (RGA) и (RGB)
SVVAPA
Перестановка местами внутреннего и внешнего операндов в.
регистре А
SWAPX
Перестановка местами внешнего операнда регистра А и внут¬
реннего операнда регистра В
гр8
Передача (RGC) в RGA
TGY9 **)
Передача данных из CDB в MAR
TCYS9
Сложение RGS с С DM и запись в MAR
TCYX
Сложение RGX с CDB и запись в MAR
LDE
Загрузить разряд Е
LDE1
Загрузить разряд Е1
LDEE1
Загрузить разряды Е и Е1
LDG
Загрузить разряд G
LDH
Загрузить разряд 11
LDI
Загрузить разряд I
LDJ
Загрузить разряд J
SETE
Установить разряд Е
SETE1
Установить разряд Е1
SETF
Установить разряд F
SETF1
Установить разряд F1
SETG
Установить разряд G
SETH
Установить разряд II
SETI
Установить разряд I
SETJ
Установить разряд J
MULT
В форме 64 выполняется так же, как в формате 32. В ре¬
жиме работы с 32-разрядпыми числами производится умно¬
жение регистра А на операнд (ADR), при этом внутренняя?
удвоенная мантисса произведения оставляется на регист¬
ре А, а внешняя часть — па регистре В
NEB
Побайтовая проверка: содержимое регистра А равно содер¬
жимому операнда (ADR)?
NORM
Нормализация
9FB
Разряды переполнения предыдущей байтовой команды пе¬
редаются из регистра С в регистр В
RTG
Передача регистра (Y) всех ПЭ в регистр R ПЭ с номером
(N + D) по модулю Л. где Y — заданный регистр ПЭ, N —
начальный номер ПЭ, D — шаг передачи, А — количество ПЭ
в массиве (64, 128, 256)
То же, что RTG, но для одного квадранта
Вычитание
rtl
SB10 ***)
SBA10
Вычитание без знака
SBM10
Вычитание с фиксированной запятой
*) Для операции, помеченных 8, RGA, RGB и RGG обозначают регистры А, В и G'
соответственно.
-
**) Команды, помеченные 9, являются частями команд, с помощью которых осу¬
ществляется ДОСТУП
к главной памяти. 13 процессе исполнения команд значение из
регистра Л помещается в регистр адреса памяти (MAR). CDB означает общую инфор¬
мационную шину между У У и ПЭ.
***) Для операций, помеченных10, при вычитании из регистра А вычитается опе¬
ранд (ADR).
12*
178>
Таблица 4.2 (продолжение)
Мнемокод
Операция
SBMA10
Вычитание с фиксированной запятой без знака
3BN10
Вычитание нормализованное
SBNA10
Вычитание нормализованное без зпака
SBR10
Вычитание с округлением
SBRA10
Вычитание с округлением без знака
3BRN10
Вычитание нормализованное с округлепием
SBRNA10
Вычитание нормализованное с округлепием без зпака
SBB
Побайтовое вычитание операнда (ADR) из регистра А
SBEX
Вычитание порядка (порядков) операнда (ADR) из порядка
регистра А
ЗСМ
Выполнение одного цикла умножепия
данный момент содержимое регистра или литерального кода, или же этот ре¬
гистр занят передачей. Поле ADR описывает адрес — источник операнда.
В некоторых контекстах это поле может определять величину сдвига, двоич¬
ное значение, количество индексов или длину маршрута.
Программное обеспечение ILLIAC IV
Несмотря на tos что для программирования на ILLIAC IV был предложен
целый ряд языков, таких как tranquil [4.4] и ivtran [4.5], фактическим
языком программирования стал язык glypnir [4.6], [4.7]. Ниже будут рас¬
смотрены основные характеристики языка и те цели, которые преследовали
его разработчики. Glypnir — это алголоподобиый язык с блочной структурой.
Он создавался как простой, гибкий и расширяемый язык, позволяющий поль¬
зователю тесно взаимодействовать с системой ILLIAC IV. Текст программы
может включать выражения на языке ассемблера, встречающиеся среди пред¬
ложений языка glypnir. Этот язык очень похож па алгол. В нем, например,
имеется возможность замещения некоторого выражения блоком выражений,
заключенных в скобки BEGIN END. Такое блочное выражение будет считать
ся одиночным выражением, когда оно снабжается меткой, используется при
ветвлении и т. д. Ниже рассматриваются такие элементы glypnir, как опе¬
раторы присваивания, блочная структура, объявления даппых и средства раз¬
мещения, индексации и доступа к данным.
Операторы присваивания служат для передачи значений из одной ячей¬
ки памяти в другую. Переменная может относиться^либо к УУ, либо к ПЭ.
В общем виде оператор присваивания представляет собой идентификатор (или
определитель содержимого поля), за которым стоит направленная влево
стрелка (или зпак : = ), далее идет индекс маршрута и, наконец, выражение
Оператор оканчивается знаком ;. Преобразование типов данных, стоящих в
левой и правой частях оператора, осуществляется автоматически. Типы дан¬
ных, получающиеся в результате процесса преобразования, сведены в табл.
4.3. Типы даппых, получающиеся в результате арифметических операций,
представлены в табл. 4.4. Если правая часть оператора присваивания является
переменной ПЭ, а левая часть — переменной УУ, то берутся значения перемен
ной из всех доступных ПЭ, логически складываются между собой и получен-
180
£0е значение присваивается переменной УУ. Если в правой части оператора
стоит переменная УУ, а в левой части — переменная ПЭ, то значение перемен¬
ной УУ передается во все доступные ПЭ. Типичный оператор присваивания
имеет вид
С : = [6] А + В
В этом выражении 6 означает индекс маршрута. В качестве индекса мо¬
жет выступать произвольное арифметическое выражение, значением которого
является целое положительное или отрицательное число. Положительное
Таблица 4.3
Соглашения о преобразовании типов данных
Тип данных в левой
части
Тип данных в правой части
вещест¬
венный
целый
литерный
булевский
ограни¬
ченный
указатель
неограни¬
ченный
указатель
Вещественный
1
1
X
X
X
Целый
2
X
X
X
Литерный
2, 3
3
X
X
X
Булевский
X
X
X
X
X
X
'Ограниченный указа¬
X
X
X
X
X
тель
'
Неограниченный
X
X
X
X
X
указатель
Примечание: пробел означает, что необходимость преобразования отсутствует,
X означает, что преобразование не разрешено.
1. Обычное преобразование.
2. Правая часть округляется и усекается до 48-разрядного представления с фикси¬
рованной занятой. Признак переполнения вырабатывается в случае, если для записи
числа не хватает 48 разрядов.
3. Отрицательный результат в правой части приводит к выработке признака пе¬
реполнения в случае, если в левой части стоит регистр А или 64-разрядное иоле.
■(отрицательное) целое описывает процесс маршрутизация вправо (влево).
В приведенном примере величина А + В будет вычислена па ставшем доступ-
Таблица 4.4
Результат применения соглашения о преобразовании типов данных
Первый
операнд
Второй
операнд
+
-
X
:
DIV
вещ
вещ
вещ
вещ
вещ
вещ
цел
вещ
цел
вещ
вещ
вещ
вещ
пел
вещ
лит
вещ
вещ
вещ
вещ
цел
цел
вещ
вещ
вещ
вещ
вещ
цел
цел
цел
цел
. цел
цел
вещ
цел
цел
лит
цел
цел
веш
вещ
цел
лит
вещ
вещ
вещ
вещ
вещ
цел
лит
дел
цел
пел
цел
вещ
цел
лит
лит
цел
цел
цел
вещ
цел
181
пъш шестом ПЭ, считая вправо от любого рассматриваемого доступного ПЭ,
Затем эта величина направляется вправо в 110, на который смотрят указатель
из шестого доступного Г1Э и которому присваивается это значение.
Существуют четыре типа операторов присваивания: арифметические, ал¬
фавитно-цифровые (литерные), булевские и указательные. Указательные опе¬
раторы очень просты, поскольку для формирования указателей специальны к
операций пе существует. Указательное выражение представляет собой просто
описатель поля или идентификатор типа указатель ограниченный или неогра¬
ниченный. Значением булевского выражения является 64-разрядное слово*
Выделенным является случай, когда значения ИСТИНА и ЛОЖЬ представля¬
ются 64-разрядными величинами, все разряды которых равны соответственно
либо 1, либо 0. Регистры режима Е и Е1 могут быть включены в булевские
выражения с помощью слова MODE (предшествующего булевской перемен¬
ной). Двоичный код режима может быть также встроен в произвольную бу¬
левскую комбинацию с помощью конструкции MODE (булевское выражение).
Булевские выражения могут содержать ссылки на регистры режима. Алфавит
ио-цттфровыо выражения состоят из пары алфавитно-цифровых операндов, раз ¬
деленных знаком одной из алфавитно-цифровых операций, приведенных г
табл. 4.5. Старшинство операций отсутствует, любой операнд, имеющий раз¬
мер меньше слова, считается -прижатым к правому краю, при этом избыточ¬
ные разряды обнуляются. Алфавитно-цифровые операции являются одновре ¬
менно и булевскими операциями. Арифметические выражения могут обрабаты ¬
ваться как выражения тина ALPHA, для чего они должны быть заключены
в круглые скобки, перед которыми ставится слово ALPHA.
Арифметические выражения в основном соответствуют правилам алгола
или фортрана, за исключением того, что отсутствует операция возведения
Таблица 4.5
Операции над литерными величинами
One ратт ия
Функция
Операция
Функция
COMR
Дополнение всех разрядов
XOR
Дополнение (WOR)
операнда А
(лув)
WAND
Логическое И АДВ
NA3VD
Дополнение (WAND)
WOR.
Логическое ИЛИ А\/В
(АДВ)
WIMR
Логическая импликация
ADB *)
АДВ
SB В *)
WEQV
Логическая эквивалент¬
ADD *)
ность А Д В VАДВ I
SVB *)
EOR
Дополнение (WEQV)
AVBVAAB
*) См. соответствующие операции ILLIAC IV.
в степень и имеется операция DIV, которая соответствует определению алго¬
ла, принятого в фирме Burroughs. Арифметические выражения могут комби¬
нироваться с алфавитно-цифровыми подвыражениями. Первыми вычисляются,
алфавитно-цифровые выражепия, которые затем используются как арифметп-
182
rqecirae величины тина целое без знака. Старшинство операций установлено
■таким образом, что операции деления и умножения выполняются раньше, чем
операции сложения и вычитания. В остальных случаях операции выполняют¬
ся слева направо. В арифметических выраяхениях может использоваться сло¬
во PEN. Это зарезервированное слово, означающее операцию, которая заклю¬
чается в том, что каждый активный ПЭ подставляет вместо него свой номер.
Если индекс маршрута является переменной ПЭ (и, следовательно, имеет
Объявление типа
;Метка Фан
Ьулезскии
Нетипизи-
ровэнная
подпрог¬
рамма
Поле
Переменные
Подпрограмма
типа вектоо
Вещественный
целый литерный
неограниченный
указатель
УУ
Вещественный
целый литерный
неограниченный
указатель
ПЗ
I
Вещественны
целый литере
ограниченный
указатель
Рис. 4.13. Типы объявляемых переменных
много зпачепий), то транслятор с glipnir генерирует выздв внешней управля¬
ющей подпрограммы, так как предполагается, что не все длины маршрутов
равны между собой. Эта подпрограмма позволяет каждому активному ПЭ вы¬
бирать свой собственный индекс маршрута путем распространепия по всем
доступным процессорам всех вычисленных зпачепий. Очевидно, такой способ
маршрутизации данных не является эффективным.
Язык glipnir имеет блочную структуру. Каждый оператор рассматривает¬
ся как одиночное выражение. Блок выражений, заключенный в ограничитель¬
ные скобки BEGIN и END, также может рассматриваться как одиночное вы¬
ражение. Блок выражений может заключать в себе одно выражение или це¬
лую программу. В блоке могут быть свои собственные описания данпых, под¬
программ и собственные подблоки. Описания переменных действуют только
Фпутри блока, в котором они объявлены.
Организация памяти включает два стандартных способа: статический и
.дипамичеекпп. При статическом способе размещение данных осуществляется
в процессе компиляции с помощью ■описаний. Описания данпых обсуждаются
ниже. Другой способ размещения данпых — динамический — реализуется с
помощью конструкций GETPEB п GETCUB. Этл конструкции используются
в процедурах типа указатель п осуществляют распределение памяти в ПЭ и
УУ соответственно в процессе исполнения программы. Конструкции FREE-
РЕВ и FREECUB служат для освобождения областей памяти, которые впос¬
ледствии могут использоваться для хранения других данных.
Рассмотрим типы данных и. их описания. На рис. 4.13 приведены типы
'Переменных, которые могут быть объявлены. В языке все описания данпых
Должны располагаться в начале блока. Не допускается, чтобы использование
беременных предшествовало их описанию. Типичное описание имеет вид
РЕ REAL Y
183
Здесь идентификатор Y обозначает действительную переменную. По¬
скольку эта величина является переменной процессорного модуля, то она
обозначает сразу целую строку, состоящую из 64 слов памяти ILLIAC IV. Ес¬
ли бы она была переменной УУ, то она занимала бы одно слово памяти. Су¬
ществует пять типов данных: действительные, целые, литерные, указатели и
булевские. Все типы являются тривиальными, за исключением указателя, ко¬
торый в процессе исполнения станет машинным адресом, определяющим
связь с блоком данных. Переменные, описанные как булевские, всегда зани¬
мают 04 разряда одного слова памяти, поэтому их не нужно дополнительно
обозначать как переменные Г1Э или УУ. Указатели могут быть двух типов:
ограниченные и неограниченные. Процессорные элементы могут иметь только
ограниченный указатель. Переменная этого типа должна содержать номер*
строки памяти ПЭ, который изменяется от 0 до 2047. Эта переменная указы¬
вает на целую строку памяти ПЭ. В УУ имеются указатели, которые могут со¬
держать произвольный адрес, относящийся к ППМ. Такие указатели называ¬
ются неограниченными.
Векторы — это одномерные массивы элементов. Они должны быть описа¬
ны. Например, запись
РЕ REAL VECTOR А [46]
описывает А как действительный вектор процессорного элемента, состоящий
из 47 строк, по 64 слова в строке. Доступ к этому вектору может осуществ¬
ляться как к индексированному множеству. Вектор УУ имеет одно слово на
строку. Индексация элементов вектора начинается с 0.
Подпрограммы также описываются. Подпрограмма может быть описана,
как с типом, так и без типа. Имя подпрограммы должно сразу же следовать
за описанием. Если подпрограмма имеет тип, то ее имя может попользовать¬
ся в качестве переменной. Подпрограмма не может иметь тип вектор. Приме¬
ры описаний подпрограмм с типом и без типа выглядят следующим образом;
РЕ Real Subroutine COSIN (Y);
Subroutine BIG (J, K);
В языке glipnir объявляются все программные метки. Типичное описание;
имеет вид:
LABEL START, STOP, LOOP;
Объявляются также имена файлов. Например:
FILE (LARGE, 906);
Это выражение описывает файл с имепем LARGE, в котором каждая за¬
пись ввода/вывода содержит 906 слов.
Переменные, за исключением булевских, могут модифицироваться с по¬
мощью описания маски или поля. Полю может быть присвоен один из пяти
типов: действительное, целое, алфавитно-цифровое, NPOINT (указатель УУ),
POINT (указатель ПЭ). Поле задает разрядную маску. Описание полей пред¬
ставляет собой сложную процедуру, рассмотрение которой выходит за рамки
книги.
В glypnir существует три способа обращения к данным. В случае простой
переменной на переменную (относящуюся либо к УУ, либо к Г1Э) ссылается
184
один идентификатор. В случае вектора его идентификатор ссылается на мас¬
сив, местоположение которого фиксируется в процессе трансляции. Обращение
ц данным также может быть организовано с помощью указателен. Ссылка че¬
рез указатели бывает статической или динамической. Ссылки, относящиеся
к векторам или указателям, могут индексироваться. Векторная ссылка V[/']
указывает па i-c слово вектора V. Если V представляет собой переменную УУ,
то считывается (г -f 1)-й элемент области памяти, так как нумерация начинает¬
ся с 0. Если i является переменной ПЭ, то различные ПЭ могут прочитать
разные значения, поскольку i отличается от разных процессорных элементов.
При индексировании указателей эти указатели могут использоваться в каче¬
стве адресов, которые прибавляются к некоторому базовому адресу, причем
последний может быть вычисляемым.
Заключение
Система ILLIAC IV установлена в научно-исследовательском центре
.AMES, принадлежащем NASA. Эффективность ее средств ввода/вывода, меж¬
процессорных связей и архитектуры оценивается по реальным программам,
решающим практические задачи. Полную мощность ILLIAC IV невозможно
оцепить, поскольку система в полной конфигурации с четырьмя квадрантами
не была построена. Это обстоятельство не позволило проверить и оценить взаи¬
модействие между квадрантами и возможные ограпичешия. Несмотря ни на
что, результаты работы над системой ILLIAC IV дают ценный материал, поз¬
воляющий глубже попять работу вычислительных систем с массивом процес¬
соров, в котором каждый элемент связан с ближайшими сеседями.
Упражнения
4.1. Расскажите, почему ILLIAC IV является оптимальной архитектурой
.для решения матричных задач.
4.2. Опишите для ILLIAC IV алгоритм обращения матрицы (64X64), вы¬
числения внешнего произведения матриц (64X64) X (64X64) и транспози¬
ции матриц (64 X 61).
4.3. Расскажите, как система ILLIAC IV могла бы быть примепеиа для
решения систем линейных уравнений, дифференциальных уравнений и задач
обработки радполокационной информации.
4.4. Расскажите, как можно улучшить систему прерываний ILLIAC IV та¬
ким образом, чтобы она могла работать в реальном масштабе времени.
Глава 5
СИСТЕМА РЕРЕ
Введение
Исторически система РЕРЕ (Parallel Element Processing Ensemble) связа
па с памятью с распределенной логикой (ПРЛ), предложенной Ли [5.1]. Прин¬
цип ПРЛ получил дальнейшее развитие, когда Крейп и Гитспс [5.2] распро¬
странили его на массовую обработку радиолокационной информации. Кон¬
цепция массовой обработки положена в основу устройства выполнения корре¬
ляционных операций, являющегося составной частью РЕРЕ модели 1C [5.3].
Модель 1C (Integrated Circuits), первая из запущенных в производство ма¬
шин семейства РЕРЕ, была построена из готовых интегральных схем, заменив¬
ших обычные схемы. Первоначально в состав РЕРЕ входили только два
устройства управления, а модель 1C включала только 16 процессорных элемен¬
тов [5.3]. '
Разработка концепции РЕРЕ и модели 1C была начата в фирме Bell La¬
boratories [5.3]. После того как эта фирма решила отказаться от участия в
проектах воепиого характера, работа над моделью 1C была продолжена фирма¬
ми System Development Corporation и Honeywell, в результате чего модель 1C
была создана и использована в системе противоракетной обороны, при этом
были опубликованы материалы, в которых описывалась конструкция машины
[5.4], [5.5]. Право изготовлять аппаратную часть РЕРЕ оспаривали несколько
конкурирующих фирм, и победителем вышла Burronghs Corporation. Разработку
программного обеспечения продолжила фирма System Development CorparatioiK
Новые образцы системы должны были включать 288 процессорных элементов,
Архитектура РЕРЕ
Система РЕРЕ — это ансамбль параллельно работающих процессорных
элемептов, в котором осуществляется ассоциативный доступ к данным. По¬
следний использован в РЕРЕ как метод обращения по чтению или записи к
информации, хранящейся в процессорных элементах. Между процессорными
элементами отсутствует прямая связь (как в ILLIAC IV), за исключением
связи через устройство управления; по этой причине система РЕРЕ называет¬
ся ансамблем.
Благодаря ассоциативной природе РЕРЕ процедура пазпачепия целей па
процессоры перестает быть узким местом. Архитектура РЕРЕ показана на
рис. 5.1. Архитектура процессорного элемента изображена па рис. 5.2. Архи¬
тектура системы в целом показана па рис. 5.3. Как видно из приведённых
схем, комплекс УКО/УУКО (устройство корреляционных операций/устройство
управления корреляционными операциями) служит для ввода данных, комп¬
лекс АУ/УУАО (арифметическое устройство/устройство управления арифметп-
186
вескими операциями) предназначен для траекторией обработки, а комплекс
удВ/УУЛВ (устройство ассоциативного вывода/устройство управления ассо¬
циативным выводом) служит для вывода даппых. Эти базовые функции отра¬
жают специфику тон среды, для работы в которой предназначена РЕ РЕ. Тре¬
бования по быстродействию, предъявляем!,те к вычислительной системе, обус¬
ловливают необходимость параллельного выполнения операций ввода, обработ¬
ки и вывода данных. В дальнейшем каждый вычислительный комплекс будет
рассмотрен отдельно.
РЕРЕ представляет собой лараллельпый процессор, предпазпачеппый для
-обработки радиолокационной информации в реальпом масштабе времени. Си¬
стема РЕРЕ была сконструирована специально для того, чтобы повысить ха¬
рактеристики вычислительного‘комплекса системы противоракетной обороны,
в котором использовались универсаль¬
ные машины типа CDC 7600. Разработка
РЕРЕ велась с начала 60-х годов. Здесь
будет рассмотрен только один вариант
системы, тот, который существует в на¬
стоящее время [5.6].
В [5.3] рассмотрела архитектура
ранних версий РЕРЕ, созданных в
Веду й процессор
У УКО
У У АО
XI
У УАБ
|Управление
^ Otjp.aPoi кл
от УУКО
ог У У Л ПЗ отУУАО к У УВД
УКО
АУ
ОТУУА13
УД В
Рис. 5.1. Блок-схема РЕРЕ
Рис. 5.2. Блок-схема процессорного эле¬
мента
результате развития концепций, изложенных в [5.1], [5.2]. Память с распреде¬
ленной логикой была применена в модели 1C, но в дальнейших модификациях
РЕРЕ не использовалась. Если учесть назначение и особенности системы, в ко¬
торой работает РЕРЕ, становится очевидным, что РЕРЕ будет получать от
ведущего процессора три типа заданий, включающих: 1) множественную обра¬
ботку траекторией информации по целям, 2) разделение траекторий и 3) уп¬
равление обзором пространства. Результаты испытаний приведены в [5.4].
На рис. 5.4 приведена функциональная схема комплекса АУ/УУАО. На
рис. 5.5 и 5.6 изображены подробные схемы АУ и УУАО соответственно. На
У У АО возложены функции управления комплексом АУ/УУАО. АУ отвечает
за выполнение арифметических операций. Б УУАО осуществляется также
маршрутизация данных и выполнение последовательных операций. Функцио-
187
нальпо это производится с помощью блока последовательных операций, ком,
мутатора перекрестных связей и блока ввода/вывода. Как видно из рис. 5.4.
блок ввода/вывода и блок последовательных операций являются независимы-
ми. Обмены между буфером ввода/вывода и ведущим процессором могут час¬
тично перекрываться с другими потоками команд и/или с выполнением команд.
Рис. 5.3. Система РЕРЕ
Прерывания, поступающие в УУАО, обрабатываются в коммутаторе пере¬
крестных связей.
УУАО работает следующим образом. Команды вызываются из памяти
программ па буферный регистр команд, начинается составление маршрута об¬
работки, увеличивается значение счетчика команд и начинается вызов следую¬
щей команды. В процессе вызова следующей команды производится анализ
команды, находящейся в буфере, и для нее вызываются операпды. В резуль¬
тате формируется 42-разрядное слово, в котором один разряд обозначает после¬
довательный или параллельный режим выполнения, 9 разрядов служат для.
обозначения кода операции, а остальные 32 разряда представляют собой сло¬
во данных. Если операция последовательная, то код операции помещается
па регистр последовательных команд, а данные — на регистр В. В процессе ис¬
полнения последовательной операции движение команд по маршрутам приос¬
танавливается, что необходимо для индексирования и сохранения баланси¬
ровки. Параллельные команды передаются в очередь параллельных команд,
при этом выполнение следующей команды в программе начинается с выше¬
описанного процесса.
Очередь параллельных команд представляет собой буфер, организованный
по принципу «первый: пришел, первый обслужен», в котором находятся 42-
разрядные слова, содержащие пару операнд/данные. Очередь используется для
того, чтобы сбалансировать процесс исполнения, поскольку смесь длинных
188
Рпс. 5.4. Комплекс АУ/УУАО
Глобальные Данные из
данные памяти
Рис. 5.5. Арифметическое устройство
и коротких операций в. этой части процессора предсказуема заранее. Это
также допускает частичное перекрытие последовательных и параллельных
команд в блоке последовательных операций. Очередь параллельных команд
невидима для программиста.
Блок управления параллельными операциями осуществляет исполие-
шие команд и управление реально существующим ансамблем арифметических
код операции/операнд и условия
Рис. 5.6. Устройство управления арифметическими операциями
устройств. Так же как и очередь параллельных команд, этот блок является не¬
видимым для программиста.
Арифметическое устройство исполняет те параллельные команды, для ко¬
торых оно является активным. Наличие или отсутствие состояния активности
указывается в разряде активности элемента.
Как УУАО, так и АУ выполнены по подобию обычных УУ и АУ. Здесь они
описываются в терминах доступных программисту регистров. В УУАО имеют¬
ся следующие регистры.
1) А и Q (накопитель и расширение) — 32-разрядные регистры (Q явля¬
ется сверхоперативным запоминающим регистром, А служит для хранения не¬
явного операнда и в качестве накапливающего регистра для арифметических
комаяд).
190
2) Индексные регистры — восемь 24-разрядпых ипдекспых регистров, ис¬
пользуемых для обычной индексации или же для храпения целых чисел,,
участвующих в параллельных операциях, поскольку они могут быть переданы-
в АУ в качестве непосредственных операндов.
3) Регистр условия — регистр, используемый для условных переходов.
4) Регистр режима системы — 16-разрядный регистр, содержащий маску
прерываний и дополнительные средства управления в виде стоп-битов, позво¬
ляющих УУАО безусловно останавливать другие элементы РЕРЕ.
5) Буферный регистр ввода/вывода. С помощью команд ввода/вывода про¬
изводятся обмены между этим буферным регистром и регистром А (ввод/вы¬
вод является независимым процессом по отношению к обработке в блоке по¬
следовательных операций и может осуществляться параллельно с этой об¬
работкой).
В АУ имеются следующие регистры.
1) А и Q (накопитель и расширение) —32-разрядные оперативные регист¬
ры АУ, поддерживающие аппаратно-реализованные арифметические операции:
с плавающей запятой, включая сложение, умножение и извлечение квадрат¬
ного корпя. v
2) OV (переполнение) — триггер, устанавливаемый при переполнении в
результате некорректной арифметической операции или когда появляется 1
в 20-м разряде стека активности (программным путем OV может быть только-
установлен в исходное состояние).
3) DPG (признак двойной точности) — этот регистр служит для выполне¬
ния некоторых простых операций с двойной точностью и является программно-
доступным, поскольку представляет собой часть описания состояния процесса
(при прерывании он должен быть сохранен).
4) ЕА и F (активность элемента и отказ) — ЕА определяет, должен ли про¬
цессорный элемент исполнять команды устройства управления (ЕА принуди¬
тельно отменяется, регистром F, состояние которого устанавливается програм¬
мной диагностики).
5) Регистр тега — 8-разрядный ассоциативный адресный регистр АУ (ас¬
социативные операции над этим регистром приводят к тому, что ЕА можег
быть либо взведен, либо сброшен).
6) Стек активности — 21-разрядный список, организованный по правилу
«последпий пришел, первый обслужен», используемый для работы с тригге¬
ром ЕА (логические операции между стеком и ЕА выполняются с помощью^
команд PUSH и POP).
Регистр В представляет собой 32-разрядный регистр, выполняющий ана¬
логичные функции в блоке последовательных операций и в АУ. Перед испол¬
нением команды блок управления параллельпымп операциями помещает в ре¬
гистр В либо явный операнд блока последовательных операции, либо явный
операнд из цамяти. Этот регистр программно доступен.
Основу системы вывода составляет комплекс УАВ/УУАВ. УАВ (устройство'
ассоциативного вывода) и УУАВ (устройство управления ассоциативным вы¬
водом) были дополнительно включены в состав РЕРЕ на основапии исследо¬
вания ввода/вывода [5.7]. Комплекс УАВ/УУАВ представляет собой сокращен¬
ный вариапт комплекса АУ/УУАО. Он выполняет функции сортировки и выво¬
да данных. Главное различие между УУАВ и УУАО заключается в том, что в
УУАВ отсутствует регистр режима, имеющийся в УУАО. Блок-схема "УУАВ;
19*
приведена на рис. 5.7. Главное различие между УАВ и АУ заключается в воз¬
можностях по выполнению арифметических операций.
Такие регистры, как В, OY, DPC, КА, регистр тега и регистр тега актив-
пости, идентичн ы в А У и УАВ. В устройстве ассоциативного вывода отсутст¬
вуют регистры Q и F. Регистр F, находящийся в АУ, воздействует на ЕА УАВ
Рис. 5.7. Устройство ассоциативного вывода УАО
аналогично тому, как ои воздействует па ЕА АУ. Основное различие заклю¬
чается в конструкции регистра А (накопителя). В УАВ отсутствуют операции
■с плавающей запятой, а операция сдвига осуществляется поразрядно-последо¬
вательным способом, в отличие от параллельного, который используется в па¬
раллельном циклическом сдвиговом устройстве АУ. Другое существенное раз¬
личие состоит в том, что в УАВ исключена очередь параллельных команд, так
как смесь команд такова, что быстродействие памяти УУАВ оказывается до¬
статочным, чтобы обслуживать запросы программы но мере их поступления.
Благодаря особенностям УАВ/УУАВ (отсутствие обработки прерываний, по¬
скольку зга функция возложена на У УАО) коммутатор перекрестных связей
.имеет упрощенную конструкцию и является невидимым для программиста.
В результате обобщенная схема комплекса УАВ/УУАВ выглядит так, как по¬
казано па рис. 5.8.
Обобщенная схема комплекса УКО/УУКО показана па рис. 5.9. Схема
устройства корреляционных операций изображена па рис. 5.10. Устройство
управления корреляционными операциями почти идентично УУАВ. Главное
различие заключается в способности контролировать активность элементов и
■определять точное количество активных элементов. В УКО регистр тега, ре¬
гистр В и триггер ЕА идентичны соответствующим компонентам УАВ. Общий
регистровый файл состоит из 16 регистров общего назначения. Этот комплекс
регистров играет роль одиночного регистра А, имеющегося в АУ и УАВ.
192
Рис. 5.8. Комплекс УАВ/УУАВ
Рис. 5.9. Комплекс УКО/УУКО
Дж. Тербер
В регистровом файле может находиться адресная часть некоторых команд, а так-,
же регистр А и как неявные, так и явные операнды. Устройство корреляцио!ь
пых операций оптимизировано с точки зрения ассоциативных операций срав¬
нения входных дапных и поэтому включает только целочисленную арифмети-
ку. Из состава комплекса исключена очередь параллельных команд, поскольку
Таблица 5.1
Характеристики запоминающих устройств, входящих в РЕРЕ
Местопо¬
ложение
памяти
Тип хра¬
нимой ин¬
формации
Объем (слов)
Длина слова
(разрядов)
Время до¬
ступа (не)
Длительность
цикла (не)
Тип памяти
Вид памяти
УУАО *)
програм¬
32 К
32
300
600
на сердеч¬
постоянная
ма
никах
УУАО *)
данные
ЗК
32
100
200
(или мень¬
полупро¬
оператив¬
ше)
водниковая
ная
УУАВ
програм¬
2 К
32
100
200
ма
(или мень¬
полупро¬
оператив¬
ше)
водниковая
ная
УУАВ
дапиые
2 К
32
100
200
(или мень¬
полупро¬
оператив¬
ше)
водниковая
ная
УУКО
програм¬
2 К
32
100
200
ма
(или мень¬
полупро¬
оператив¬
ше)
водниковая
ная
УУКО
даипые
2К
32
100
200
(пли мень¬
полупро¬
оператив¬
ше)
водниковая
ная
ПЭ **)
данные
1К
32
1
о
о
100
(или
(или мень¬
полупро¬
оператив¬
меньше)
ше)
водниковая
ная
*) Два взаимосвязанных блока ио 1G К, обеспечивающих эффективную адресацию
в линейном адресном пространстве с быстродействием около 300 не.
**) Эта память, делится между АУ/УУАО, УЛВ/УУАВ и УКО/УУКО.
характер вычислений и команд таков, что не приводит к образованию
очередей.
В системе РЕРЕ в целом имеется много различных запоминающих уст¬
ройств. Все типы используемой памяти сведены в табл. 5.1. Для упрощения
проблемы адресации модулям памяти устройств управления отведены особые
позиции в непрерывном множестве 512 К адресов. Даже несмотря па то, что
пространство адресов непрерывно, все запоминающие устройства не образуют
единого информационного поля. УУАО может обращаться ко всем модулям
памяти. У'УКО и УУАВ имеют доступ только к собственным множествам ад¬
ресов и к памяти данных УУАО (в которой хранятся общие резидентные дан¬
ные). Взаимодействие с модулямл памяти осуществляется через механизм
портов, который служит для разрешения конфликтов при обращениях. В слу¬
чае возпикповения конфликта удовлетворяется запрос к памяти, имеющий на-
ивысший приоритет.
194
В материалах, касающихся конструкции РЕРЕ, указывается, что каждый
процессорный элемент содержит около 8800 простых логических схем и запо-
Рис. 5.10. Устройство корреляцнонпых операций
мпнающее устройство. Подробности реализации РЕРЕ па базе больших ин¬
тегральных схем можно найти в [5.5].
Программное обеспечение РЕРЕ
Система РЕРЕ имеет развитые средства программного обеспечения. Зна¬
чительный интерес представляют собой языки, призванные дополнить возмож¬
ности аппаратной архитектуры. Обзорные материалы по программному обес¬
печению можно найти в [5.8], а подробное описание языка и систем програм¬
мирования содержится в [5.9]. Ниже будут рассмотрены языки PAL (Parallel
Assembly Language) и p-for (parallel fortran).
Для того чтобы наиболее полно использовать высокопроизводительное и
сложное оборудование системы, в качестве языка программирования высокого
Уровпя был выбран расширенный вариант фортрана (p-for). В язык p-for
добавлены существенные конструкции, позволяющие использовать все особен¬
ности аппаратной части РЕРЕ. Поскольку большинство программистов знако¬
мо с фортраном, изучение программирования на новом языке не представляет
больших трудностей.
Фортран был расширен путем впсссштя следующих четырех основных кон¬
струкций: параллельного описания, параллельного присваивания, параллельно¬
го оператора WHERE и параллельных операторов IF и DO. Использование
конструкции параллельного описания позволяет программисту объявлять пе¬
ременную, предназначенную для параллельной обработки, т. е, объявлять пе¬
13* 195
ременную, которая должна быть ассоциирована с одним и тем же местополо¬
жением в памяти во всех процессорных элементах. Основными типами таких
описаний являются PAR INTEGER, PAR REAL, PAL LOGICAL и т. д. Вы¬
ражение
PAR REAL PA, PB, PC
говорит о том, что три параллельные переменные РА, РВ и PC должны быть
ассоциированы с тремя ячейками в каждом процессорном элементе и рассмат¬
риваться как вещественные числа.
Параллельные описания обрабатываются па этапе компиляции. Из-за ма¬
лого объема запоминающих устройств параллельных элементов программист
должен заботиться о том, чтобы ие выйти за пределы этой памяти. С другой
стороны, программисту представлен большой объем общей памяти ансамбля,
позволяющий хранить все необходимые данные, однако объем данных, ассо¬
циированных с конкретными процессорными элементами, должен быть ог¬
раничен.
Имена параллсльпых переменных, вообще говоря, не обязательно должны
начинаться с буквы Р, однако, в целях удобства изложения, мы будем счи¬
тать, что это так. Переменные обозначаются так, как это принято в фортране.
В языке используются обычные операторы присваивания и арифметические
операции, принятые в фортране. Параллельное описание переменной означает,
что операции над этой переменной должны производиться в процессорном эле¬
менте. Оператор
РА = PB*PC + D
говорит о том, что в каждом активном процессоре величины РВ и PG должны
быть перемножены, величина D должна быть передана во все активные эле¬
менты и прибавлена к полученному ранее произведению. Результаты этой
операции должны быть, затем записаны в ячейки РА в каждом процессорном
элементе. Выражение РА = РВ + С * D означает, что должна быть вначале
выполнена последовательная операция умножения величин С и D и получен¬
ное произведение передано всем активным элементам, где оно должно быть
прибавлено к величинам РВ. Результат операции в каждом активном элемен¬
те записывается в ячейку РА.
Если в выражениях вместе с параллельными переменными участвуют
последовательные, то последние должны быть переданы в активные элементы.
Как можно заметить, выражения с параллельным оператором присваивания
действительно аналогичны выражениям, используемым в обычном фортране,
поэтому изучение языка p-for не вызывает трудностей. Имеется одна проблема,
связанная с p-for. Выражение X = PY означает попытку присвоить последо¬
вательной (единственной) переменной значение параллельной переменной.
Ясно, что это певозможпо, за исключением случаев, когда 1) только один эле¬
мент является активным, 2) значения PY одинаковы во всех элементах или
3) принято соглашение, согласно которому X присваивается значение PY,
взятое из процессорного элемента со старшим помером. Наиболее предпочти¬
тельным является, очевидно, решение 1). Ситуации 2) и 3) в РЕРЕ не раз¬
решены и трактуются как ошибочные.
Оператор WHERE является параллельным аналогом обычного оператора
IF, имеющегося в фортране. Назначение рассматриваемого оператора состоит
196
13 управлении активностью процессорных элементов РЕРЕ. Текущие операции
выполняют только активные элементы, множество которых определяется в за¬
висимости от значений обрабатываемых данных. Таким образом, в языке долж¬
на быть предусмотрена конструкция, реализующая эту функцию. Типичный
оператор имеет вид
WHERE (PLE) N
Здесь PLE означает любое параллельное логическое выражение, а N означает
метку оператора, иными словами, PLE является любым логическим выраже¬
нием, содержащим хотя бы одну параллельную переменную. Результатом вы¬
полнения данного оператора является новое состояние активности элементов,
которое остается в силе, пока пе выполнится оператор с меткой N. Первый
оператор, выполняемый после оператора с меткой N, работает с тем состоя¬
нием активности, которое было во время выполнения последнего оператора
перед WHERE. Благодаря требованию, заключающемуся в том, чтобы в выра¬
жении PLE была хотя бы одна параллельная переменная, это выражение ис¬
полняется ьо всех активных элементах н позволяет, таким образом, манипу*
лировать состоянием активности; иными словами, все те элементы, в которых
условие удовлетворяется, остаются активными, а тс элементы, в которых ус¬
ловие пе удовлетворяется, становятся пассивными. В результате выполнения
оператора WIIERE образуется подмножество множества активных элементов.
Аналогично фортрановскому оператору DO оператор WHERE может быть
вложенным, и тогда результатом выполнения внутреннего оператора WHERE
является подмножество множества активных элементов, образованного в ре¬
зультате выполнения внешнего оператора WHERE.
Двумя очень важными специальными случаями оператора WHERE явля¬
ются WHERE МАХ (РАЕ) N и WHERE MIN (РАЕ) N. В этих случаях РАЕ
представляет собой любое корректное арифметическое выражение, содержащее
хотя бы одну параллельную переменную. В процессе выполнения этих опе¬
раторов производится вычисление параллельного арифметического выражения,
и состояние активности остается только у того процессорного элемента, в ко¬
тором оказалось минимальное (максимальное) значение выражения. Таким
образом, остаются активными все элементы, в которых оказалось минималь¬
ное (максимальное) значение.
Другими важными специальными случаями оператора WHERE являются
WHERE NOT, WIIERE FIRST и WIIERE SET.
Подсчет числа активных элементов осуществляется с помощью функции
PEPECOUNT. Это целочисленная функция. Она может быть использована сов¬
местно с параллельным оператором IF для управления вычислительным про¬
цессом. Во многих случаях управление вычислительным процессом в ходе вы¬
полнения реальных прикладных программ осуществляется путем изменения
числа активных элементов. Параллельный оператор IF языка p-for аналогичен
условпому оператору IF обычного фортрана с учетом того, что параллельный
оператор должен содержать параллельное логическое выражение, позволяю¬
щее определить число активных элементов, в которых это выражение удов¬
летворяется. Типичный параллельный оператор IF имеет следующий вид: /
IF N (PX.LE.150) GO ТО 12
Здесь N означает ALL (все), NONE (пи одпого), ONE (один) или MANY (мно¬
197
го). В процессе выполнения этого оператора вычисляется параллельная логи¬
ческая функция, подсчитывается число элементов, удовлетворяющих условию,
и это число подставляется в условное выражение. После этого начинается вы¬
полнение соответствующей последовательности команд.
Наиболее часто встречающаяся форма параллельного оператора DO име¬
ет вид
DO ASC (РАЕ) N J = 1, М, К.
где РАЕ обозначает параллельное арифметическое выражение, N — метку опе¬
ратора, стоящего в конце цикла, М — максимальное число прохождении через
оператор DO и К — число, описывающее последнее прохождение (т. е. при
К = 10 число прохождений равно 10). Этот оператор вызывает вычисление
выражения РАЕ' во всех процессорных элементах. Затем полученные значе¬
ния подставляются в оператор DO, выполняемый последовательно в порядке
возрастания значений. Если два процессорных элемента выработали одно и
то же значение, то они обрабатываются так же, как если бы они были упо¬
рядочены, причем первым обрабатывается значение из процессорного элемен¬
та со старшим номером.
Оператор DO DESG (вьтполпить по убыванию) идентичен оператору DO
ASC за исключением того, что величины выбираются в порядке убывания. Ес¬
ли число активпых элементов меньше, чем М, то значение К в конце выпол¬
нения цикла делается равным числу активных, элементов.
Оператор DO SEQ (выполнить последовательно) отличается от DO ASG
тем. что после вычисления параллельного логического выражения элементы,
удовлетворяющие условию, обрабатываются в порядке их номеров от первого
до последнего.
Имеются также еще две формы оператора DO. Это DO UP и DO DOWN.
Они идентичны DO ASC и DO DESG соответственно за исключением того, что
множественные значения одной и той же арифметической величины обраба¬
тываются параллельно, а пе последовательно, так, что значение К всегда мень¬
ше или равно числу активпых элементов (если число активпых элементов
меньше, чем М). Значение К задает количество отдельных вычисляемых зна¬
чений параллельного логического выражения PLA.
Краткий обзор языка ассемблера РЕРЕ PAL (Parallel Assembly Language)
дан в [5.G] и содержится в таблицах, представленных пиже. Мнемоника и
краткое описание каждого мнемокода языка PAL составлены таким образом,
чтобы читатель мог понять суть операций и сравнить их с операторами, исполь¬
зуемыми в системах STARAN, ILLIAC и OMEN. Таблицы операторов состав¬
лены но категориям операций. В описании функционирования РЕРЕ [5.G] со¬
держится детальное определение всех операторов, приведены времспные ха¬
рактеристики системы в целом и ее отдельных частей и даны примеры опти¬
мального программирования. Рассматриваемая система настолько сложна, что
дальнейшая детализация се описания в данном разделе представляется не¬
целесообразным.
Одной из целей, которую преследовали создатели РЕРЕ, было достижение
единства между тремя слоями обработки, имеющимися в машине. Вот почему
была разработана система команд, которая может рассматриваться как состо¬
ящая из подмножеств комапд, ориентированных на каждую из подсистем
РЕРЕ. Поток команд в каждом из слоев РЕРЕ представляет собой вертикаль-
198
йый копвсйернын процесс. Этапы конвейерной обработки включают предвари¬
тельную обработку, последовательное выполнение, параллельное выполнение
и организацию очереди параллельных команд. Для достижения максимальной
Таблица 5.2
Последовательные арифметические комапды
Мнемокод
Операция
Исполнительное уст ройство
АУ '
УАВ
УКО
УУЛО |
,УУЛВ
УУКО
ADI
Сложение целочислспное
X
X
X
X
X
ADX, I
Сложение с индексом
X
X
X
LADI
Сложение младших разря¬
X
X
X
X
X
дов целочисленное
LSBI
Вычитание младших раз¬
X
X
X
X
X
рядов целочисленное
MLA
Умножение адреса цело¬
X
X
X
численное
ROV
Сброс переполнения
X
X
X
X
X
SBI
Вычитание целочисленное
X
X
X
X
X
SBX, I
Вычитание индекса
X
X
X
TCI
Дополнительный код двоич¬
X
X
X
X
X
X
ного числа целочисленный
TIADI
Сложение старших разря¬
X
X
X
X
X
дов целочисленное
USBI
Вычитание младших раз¬
X
X
X
X
X
рядов целочисленное
эффективности каждый этап конвейера должен быть загружеп, как только
возможно.
Последовательные арифметические команды сведепьт в табл. 5.2. Все они
представляют собой целочисленные операции пад младшими 21 разрядами
(старшие 6 разрядов всегда устанавливаются равными 0).
Таблица 5.3
Логические команды
Мнемокод
Операция
Исп о л ните л ыюе уст р о йети о
Л У
УАВ
УКО |
УУЛО |
УУЛВ |
УУКО
ANA
Логическое II
X
X
X
X
X
ANNT-
Логическое II — НЕ
X
X
X
X
X
X
OCL
Лог и ч е с к о е д о п о л п е пие
до 1
X
X
X
X
X
X
ORA
Логическое ИЛИ
X
X
X
X
X
SHAI
Арифметический сдвиг це¬
лого в А
X
X
X •
X
X
SHE
Логический сдвиг в А
X
X
X
X
X
ХОА
Логическое ИСКЛЮЧАЮ¬
ЩЕЕ ИЛИ
X
X
X
X
X
X
Последовательные логические операции, выполняемые устройством управ-
•ления последовательными операциями, производятся целиком над 32-разряд-
ными словами РЕРЕ без выделения каких-либо полей. Перечень этих операции
приведен в табл. 5.3. Поскольку непосредственный операнд представляет со¬
199
бой целое число с учетом зпакового разряда, то те логические операции, ко¬
торые не могут использовать в качестве явного операнда целочисленное сло¬
во РЕРЕ, должны организовать ссылку к памяти. Команда ANNT служит для
осуществления маскирующих операций для непосредственных операндов.
Загрузка и храпение последовательных команд производится в формате
32-разрядпых слов. Соответствующие команды приведены в табл. 5.4.
Т а б л п ц а 5.4
Команды загрузки и хранения
Исполнительное уст ройство
Мнемокод
Операция
и
О '
о
я
о
й
>>
Й
>>
>>
<
>>
>>
г*
■>J
LDA
Загрузка в регистр А
X
X
X
1
X
X
LDEA
Загрузка в Ас декрементом
X
X
X
/\
X
LDEX, I
Загрузка в индексный регистр I с дек¬
рементом
X
X
X
LDQ
Загрузка в регистр Q
X
X
X
X
LDX, I
Загрузка в индексный регистр
X
X
X
LINA
Загрузка в А с инкрементом
X
X
X
X
X
LINX, I
Загрузка в индексный регистр I с
инкрементом
X
1
X
X
LST
Загрузка состояния
X
X
X
ОТА
Вывод параллельного регистра А
X
X
RDA
Чтение активности*
X
X
RDIU
Чтение из блока интерфейса
X
X
х.
STA
Запоминание регистра А
X
X
X
V
X
STQ
Запоминание регистра Q
X
X
X
X
STS
Запоминание состояния блока последо¬
X
X
X
вательных команд SGL
X
X
X
STX, I
Запоминание индексного регистра I
TQA
Передача Q в А
X
X
\/
/\
X
ТХА, I
Передача индекса в А
X
X
X
TAQ
Передача А в Q
X
X
TAX, I
Передача А в иидекспьтй регистр I
X
X
X
WRIU
Запись в блок интерфейса
X
X
X
Команды программных переходов представлены в табл. 5.5. Эта группа
команд дает программисту возможность организовывать условные и безуслов¬
ные передачи управления в процессе исполнения программы. Как правило,
операнд, вызывающий передачу управления, является непосредственным опе¬
рандом и прямо указывает, куда передается управление. Программные пере¬
ходы могут осуществляться только внутри соответствующей памяти блока по¬
следовательного управления.
Для обеспечения взаимосвязи и синхронизации между элементами были
введены команды, связанные с прерываниями и супервнзориымп функциями,
Необходимость в таких командах продиктована полной независимостью трех
обрабатывающих комплексов системы. Главпым элементом системы связи яв¬
ляется устройство управления арифметическими операциями. Оно принимает
запросы от УУАВ или УУКО. В табл. 5.6 первыми стоят команды прерываний,
а следом за ними команды, связанные с супервизорнымн функциями. Полу¬
чив запрос па прерывание, УУАО выполняет некоторый набор супсрвнзориых
200
команд, предназначенных для управления УУАВ п УУКО. Команды преры¬
вания RQI и RINT используются в виде пары прерывающих команд, органи¬
зующих аппаратно поддержанную синхронизацию того устройства, от кото¬
рого пришел запрос, и устройства, которому этот запрос адресован. Команда
Т а б л и ц а 5.5
Команды передачи управления
Не п о л нительио е уст р о йство
Мнемокод
Операция
й
0
>>
<1
й
У УАО
УУАВ
УУКО
<
К*
BANY
Ветвление по любому прпзпаку актив¬
ности
X
X
X
BGE
Ветвлепие по признаку «больше или
равно 0»
X
X
X
BGZ
Ветвление по признаку «большо 0»
X
X
X
BLE
Ветвление по признаку «меньше или
равно 0»
X
X
X
BLZ
Ветвлепие по признаку «меньше 0»
X
X
X
BMNY
Ветвление по признаку «много актив¬
ных»
-X
X
X
BNON
Ветвлепие по признаку «пет активных»
X
X
X
BNOV
Ветвление по признаку «нет перепол¬
нения в последовательной операции»
X
X
X
BNZ
Ветвление по признаку «пе равно 0»
X
X
X
BONE
Ветвлепие по прпзпаку «один актив¬
ный»
X
X
X
BOV
Ветвление по признаку «переполнение
в последовательной операции»
X
X
■X
BZ
Ветвление по признаку «равно 0»
X
X
X
СМРА
Сравнение А с операндом
X
X
X
СМРХ, I
Сравнение индекса I с операндом
X
X
X
JGE
Переход, если больше или равно 0
X
X
X
JGZ
Переход, если больше 0
X
X
X
JLE
Переход, если меньше пли равно 0
X
X
X
JLZ
Переход, если меньше 0
X
X
X
JMP
Безусловный переход
X
X
X
JNZ
Переход, если не равно 0
X
X
X
JZ
Переход, если равно 0
X
X
X
nop"
Отсутствие операции
X
х
X
RTJX, I
Переход с возвратом
X
X
X
STOP
Останов
X
*
X
X
TR1 пе обеспечивает синхронизацию по запросу, как это делают RQI и RINT,
но она работает быстрее. В рамках супервизорпых функций УУЛО осуществ¬
ляет управление устройствами УУАВ, УУКО или очереди параллельных
команд путем выставления стоп-битов в регистре режима, чтения или записи
содержимого любых регистров этих устройств (при наличии допустимых ко¬
дов) и перезапуска устройств путем сброса стоп-бита. УУЛО имеет также воз¬
можность манипулировать с разрядами маски прерываний.
Система ввода/вывода пе будет рассматриваться как устройство управле¬
ния, поскольку она является стандартной для систем такого типа. В настоя¬
201
щее время ГЕРЕ подключена к машине CDG 7600 (играющей роль ведущей)
через три двухсторонних мультиплексных канала, соединенных с центральным
процессором. На каждое устройство управления назначен один капал.
Таблица 5.6
Команды прерываний
Исполнительное устройство
Мнемокод
Операция
о
<1
я
<
9
>>
<
к
>
5
<
>>
>>
>>
- >■
Преры¬
вания
HINT
Возврат после прерывания
X
RQI
Запрос па прерывание
X
X
TRI
Установка триггера прерывания
X
X
Суперви¬
зоры ы с
команды
MD
Сохранение информации и диагностика
X
SLD
Загруз ка с уиервизора
X
SMD
Установка регистра режима
X
SST
Сохранение супервизора
X
JSRT
Пуск устройства
X
JSTP
Останов устройства
X
Команды, относящиеся к АУ, УКО и УАЕ, представлены в табл. 5.7. Коман¬
ды разбиты на группы, включающие арифметические операции, логические
операции, операции загрузки и хранения и операции управления активностью
элементов. Идентификатор А обозначает, что операция выполняется только
в активных процессорных элементах. Все команды, не обозначенные симво¬
лом А, либо выполняются и в активных н пассивных элементах (такие коман¬
ды обозначен].! через В), либо вырабатывают один и тот же результат неза¬
висимо от того, выполняются ли они одновременно в активных и пассивных
элементах или исключительно в активных элементах (такие команды не обо¬
значены пи через А, ни через В).
Читатель может заметить, что из почти тридцати команд, управляющих
активностью элементов, только две команды вызывают повышение активпости,
ACT и СЛСТ. Остальные команды служат для образовапия подмножеств ак¬
тивных элементов или формирования стека активных элементов. Среди иден¬
тификаторов столбцов таблицы, обозначающих устройства, па которых ис¬
полняются команды, и призванных указывать на общность этих команд, от¬
сутствуют обозначения УУАВ, УУАО и УУКО. Это произошло из-за того, что
данные команды являются дополнительными командами, исполняемыми толь¬
ко устройствами АУ, УЛВ и УКО. Все операции, выполняемые устройствами
УУАО, УУАВ п УУКО, были уже описаны выше. Некоторые из ранее упомя¬
нутых команд (см. табл. 5.2—5.6) исполняются, как было указано, на АУ,
УЛВ и УКО.
Представление о производительности РЕРЕ могут дать следующие времеп-
пые характеристики системы: сложение — 800 ис, целочисленное сложение —
202
Команды АУ, УАВ и УКО
Таблица 5.7
Исп ол и ит ел ьное уст р о мств о
Мнемокод
Операция
А
В
АУ
УАВ
УКО
Арифметические к о май д ы
ADD
Сложение с плавающей запятой
X
X
ADE
Сложение порядков
X
X
DU
Деление с плавающей запятой
X
X
FIX
Перевод числа из представления с пла¬
X
X
вающей запятой в целое
FLOT
Перевод целого в нормализованное с
X
X
плавающей занятой
ML
Умножение с плавающей запятой
X
X
MLI
Умножен ire целочисленное
X
X
SB
Вычитание с плавающей запятой
X
X
SBE
Вычитание порядков
X
X
SQ
Извлечение квадратного корпя из чис¬
X
ла с плавающей запятой
ADR, I
Сложение с содержимым регистра
X
X
SBR, I
Вычитание из содержимого регистра
X
1
1
X
Логические команды
RBIT
Сброс признака
X
X
X
X
SBIT
Установка признака
X
X
X
X
ANR, I
Операция II в регистре
X
X
€RR. I
Операция ИЛИ в регистре
X
X
SIIAR, I
Сдвиг регистра арифметический
X
X
’ SIILR, I
Сдвиг регистра логический
X
X
Команды загрузки и сохранения
LDE
Загрузка порядка в А
X
X
LTAG
Загрузка тегов и стеков
X
X
X
X
STAG
Сохранение тегов и стека
X
X
X
X
LDR, I
Загруз ка регистра
X
X
STR, I
Сохрансипе регистра
X
X
Команды управления активностью
ACT
Актипация
X
X
X
X
AXS
Логическое умножение разрядов стека
X
X
X
X
СА
Дополнительная активация
X
\/
/\
X
САСТ
Обнуление и активация
X
X
X
X
CAS
Обнуление стека активности
X
X
X
CF
Обнуление ошибки
X
X
X
COPY
Снятие копии стека активности
X
X
X
ORS
Логическое сложение разрядов стека
X
X
X
POP
Представление стека активности в ви¬
X
X
X
PSEL
де позиционного онерапда
Продвижение и выборка одного раз¬
X
X
X
PUSH
ряда
Продвижение стека активности
X
X
X
SEG
. Выборка глобальная по равенству
X
X
SF
Выборка первого
X
X
X
SFF
Установка триггера ошибки
X
X
SGE
Выборка по критерию «больше или
равно 0>>
X
X
X
203
Таблица 5.7 (продолжение;
*
Исполнительное устройство
Мнемокод
Операция
А
в
АУ
УАВ
УКО
SELB
Выборка одного бита
X
X
SH
Выборка самого старшего
X
X
SL
Выборка самого младшего
X
X
SLE
Выборка по критерию «меньше или
равно 0»
X
X
SLZ
^Выборка по критерию «меньше 0»
.X
X
SOV
Выборка по переполнению накопителя
X
X
STG
Установка тега в активных элементах
X
X
X
STGA
Установка тега во всех элементах
X
X
X
STGI
Установка тега в пассивных элементах
X
X
X
SZL
Выборка по логическому нулю
X
X
SZR
Выборка по арифметическому пулю
X
X
SNG
Выборка -глобальная по неравенству
X
X
SNOV
Выборка по отсутствию переполнения
X
X
SNZ
Выборка по ненулевому (арифметиче¬
скому) содержимому
X
X
SNZL
Выборка по пепулевому (логическому)
X
X
содержимому
X
SREQI, I
Выборка по регистру по равенству це¬
лого
X
SREQ, I
Выборка по регистру по равенству
X
X
SRGEI, I
Выборка по регистру по критерию
«больше или равно целому» '
X
х .
SRGE, I
Выборка по регистру по критерию
«больше или равно»
X
X
SRGTI, I
Выборка по регистру по критерию
«больше, чем целочисленный код опе¬
X
X
ранда»
X
SRGT, I
Выборка по регистру по критерию
«больше»
X
SRLEI, I
Выборка по регистру по критерию
«меньше или равно целому»
X
X
SRLE, I
Выборка по регистру по критерию
«меньше или равно»
X
X
SRLTI, I
Выборка по регистру по критерию
X
X
«меньше, чем целое»
X
SRLT, I
Выборка по регистру по критерию
«меньше, чем»
X
SRNEI, I
Выборка по регистру по критерию «не
X
X
равно целому»
X
X
SRNE, I
Выборка по регистру по критерию «не
равно»
200 не в АУ/УУАО, но 300 не в УКО/УУКО, деление 3800 не, умноже¬
ние — 1900 не, активизация — 300 не, дополнительная активизация — 100 пс7
обнуление и активизация — 300 не.
Заключение
РЕРЕ в пастоящее время создается в виде сверхмощпой вычислительной:
системы. Новая система больше, чем 16-олемснтпая модель 1C, и будет обес¬
печивать высокую степень использования параллельных процессоров при ре-
204
плетши задач траекторпой обработки в рсальпом масштабе времспи. Большой
интерес будут представлять даппые о практически достигнутой эффективности
нри работе в реальпом времени.
Упражнения
5.1. Объясните, почему архитектура системы РЕРЕ является оптимальной
для задач обработки радиолокационной информации в реальном масштабе
времени.
5.2. Опишите эффективный способ реализации в РЕРЕ алгоритмов, рабо¬
тающих с матрицами. Расскажите, как в РЕРЕ может быть реализована серия
преобразований координат.
5.3. Покажите, каким образом РЕРЕ может быть использована для быст¬
рых преобразований Фурье. -
5.4. Какие, по вашему мнению, дополнительные языковые конструкции
(если таковые найдутся) могут быть еще введены в p-for, PAL?
5.5. Имеет ли смысл рассматривать APL как потенциальный язык для
РЕРЕ?
Глава 6
ПРОЦЕССОР STARAN
Введение
Фирма Goodyear Aerospace Corporation занимает ведущее место г
области разработки ассоциативных вычислительных систем. Созданный этой
фирмой процессор STARAN является паиболее совершенным полностью ассо¬
циативным процессором из числа существующих в настоящее время процес¬
соров подобного типа. Goodyear занималась разработкой ассоциативных уст¬
ройств в течение многих лет. В ее ранних ассоциативных процессорах в ка¬
честве базы запоминающих устройств использовалась память на магнитной
проволоке. Принцип действия машин основывался па обработке битовых сре¬
зов. Главные недостатки таких устройств заключаются в высокой стоимости
памяти на магнитной проволоке и в поразрядно-последовательном способе ор¬
ганизации ввода/вывода информации. Ассоциативный процессор STARAN, соз¬
данный на полупроводниковых элементах фирмой Goodyear, свободен от этих
недостатков. Этот процессор построен на базе стандартных запонимающих
элементов с произвольным доступом, и в нем реализован параллельный ввод/
вывод информации [6.1—6.10].
В процессоре STARAN возможен доступ к информации как по строкам
так и по столбцам, одпако, в отличие от базового ассоциативного процессора,
описанного в гл. 2, в нем использован только один набор регистров М, X и.
Y вместо двух наборов, предназначенных для работы отдельно с вертикаль¬
ными и горизонтальными срезами. В целях эффективного использования яче¬
ек памяти STARAN разделен па массивы, каждый из которых представляе-
собой матрицу N X N, где N — степепь двойки. Адресация осуществляется с
точностью до строки пли столбца. Конструкция STARAN описана в [6.2]
В следующем параграфе рассмотрены основные черты его архитектуры.
Архитектура STARAN
STARAN представляет собой ассоциативпый процессор, основу которого
составляют стандартные полупроводниковые запоминающие ячейки, которые
благодаря особой ориентации адресных шип образуют массив памяти с ассо¬
циативными свойствами. Ключевым моментом в архитектуре STARAN явля¬
ется его особый механизм хранения дапных. С помощью обычных ячеек опе¬
ративной памяти фирме Goodyear Aerospace Corporation удалось создать за¬
поминающее устройство с -доступом как к вертикальным (битовым), так и •:
горизонтальным (словпым) срезам. Это свойство является локальным по от¬
ношению к массиву. STARAN образован путем объединения нескольких по¬
добных базовых массивов. Поскольку принципы построения STARAN весьма
206
специфичны, опи будут описаны поэтапно. В составе STARAN использована
универсальная вычислительная машина PDP-11, выполняющая функции по¬
следовательного устройства управления, а также последовательное устройство
управления ассоциативной памятью, быстродействие которого в десять раа
выше, чем у PDP-11.
С точки зрения программиста базовый массив выступает как память, ад¬
ресуемая либо по битовым срезам (рис. 6.1), либо по словам (рис. 6.2), либа
Адреса слов (словных срезов) -
Адреса битовых срезов
Рис. 6.1. Схема адресации
по битовым срезам
Рис. 6.2. Схема адре¬
сации по словам
некоторым смешанным способом, о котором речь пойдет позднее. Способы:
адресации только по битовым срезам или только по словам, используемые в
обычных ассоциативных процессорах, показаны на рпс. 6.3.
Стоун [6.11] предложил способ организации памяти для ассоциативного
процессора, суть которого заключается в том, что данные располагаются по
диагонали массива памяти, представляю¬
щего собой квадрат размером N X N. Ана¬
логичная схема хранения данпых в неко¬
торых ситуациях используется в ILLIAC IV
[6.12]. Диагональная схема хранения пока¬
зана на рис. 6.4.
Действие такого механизма памяти
можно описать на примере очень простого
процесса. Абсцисса ипдексов блока данных
совпадает с абсциссой модуля памяти, в
котором эти блоки хранятся. Ордината
индексов блока данных образуется как
сумма ипдексов блока данных, взятая
по модулю, равному размеру модуля памя¬
ти. Пусть слово представляет собой четвер¬
ку (а, 6, с, d). Обозначим i-c слово индексированной четверкой (аг'-ь ь d-u
di-1). Тогда все разряды слова 3, ыапрпмер, хранятся в позиции 2 соответству¬
ющего модуля памяти. Для того чтобы определить, в каком модуле храндтся
тот или иной разряд, падо сложить по модулю 4 число 2 с номером разрядной
позиции. Например, разряд а (пулевая разрядная позиция) хранится в пози¬
ции 2 модуля 2. Разряд d (третья разрядная позиция) хранится в пози¬
ции 1 модуля 2. Важно отметить, что поскольку гтрп любом способе доступа
к данным (по битовым срезам или по словам) отдельный бит соответствующей
адреса
Рис. 6.3. Типичные способы адре¬
сации в ассоциативных процес¬
сорах
20?
структуры данных находится в одпом-едипствепном модуле, в действительноет-г
неважно, считать ли четверку (а, &, с, d) битовым срезом или словом. Эт.>,
действительно так потому, что массив, смотреть ли на него со стороны абсцисс
адресов или же со стороны ординат адресов, оказывается упорядоченным един¬
ственным образом, хотя и со сдвигом, и, следовательпо, доступ к данным может
быть осуществлен без конфликтов.
Таким образом, с помощью диаго¬
нального способа храпения данных
параллельный доступ к ним может
осуществляться как по битовым, так
и по словпым срезам.
Для того чтобы получить доступ
к блокам данных, имеющим одну к
ту же абсциссу, абсцисса адреса по¬
мещается на адресную шипу, а сум¬
мирование не производится. Доступ
ко всем блокам данных, имеющим
одинаковую ординату, осуществ¬
ляется путем помещения адреса на
адресные шипы с последующим суммированием. На рис. 6.5 показана схема
устройства, реализующая диагональный механизм храпения четырех слов
3
Рис. 6.5. Пример, иллюстрирующий диагональную схему храпения
с помощью модулей памяти, имеющих один разряд па слово. На рис. 6.6
и 6.7 показан порядок доступа к блокам данных с помощью ординаты
и абсциссы адреса соответственно. Отметим, что в обоих случаях блок дан¬
ных является сдвинутым и должен быть переупорядочен с помощью сдви¬
говой схемы, показанной па рис. 6.5. Хотя метод доступа вызывает перекос
Модуль
со to °
Адрес модуля
0 12 3
До.
di
C2
bo
Ьо
а\
ch
Co
Со
bi
a2
do
do
Cl
b2
do
Рис. 6.4. Диагональный способ адре¬
сации
208
данных в памяти, данные хранятся в смещенном виде, который сохраняет
установленный порядок и допускает простую процедуру сдвига. Вот почему
сдвиговая схема, необходимая для переупорядочения данных, мОжст быть
просто реализована.
Диагональный способ хранения имеет два недостатка. Первый состоит в
том, что для его реализации необходимы сумматоры, характеристики кото¬
рых зависят от размера памяти. Стоимость и быстродействие этих сумматоров
Ордината
со to ^ о
Модуль
0 12 3
0
1
2
3
3
0
1
2
2
3
0
1
1
2
3
0
Абсцисса
СО Ю о
Модуль
0 12 3
0
1
2
3
3
0
1
2
2
3
0
1
1
о
3 -
0
Рис. 6.G. Выборка с помощью ордп- Рис. 6.7. Выборка с помощью абецне-
иатного адреса сиого адреса
пропорциональны их размерам. Второй недостаток связан с тем, что сдвиговая
схема не может быть простым способом разделена на секции, которые могли
бы быть легко распределены по отдельным печатным платам. Для решепия
этих проблем фирма Goodyear разработала совершенно особую схему хранения
Рис. 6.8. Ассоциативный массив фирмы Goodyear
Данных. Общая структура базового модуля показана на рис. 6.8. Схема раз¬
мещения информации в памяти показана на рис. 6.9 для п .= 8. Способ, приме¬
няемый для хранения данных, заключается в том, что разряд В слова W запи¬
сывается в разряд В модуля М, где М представляет собой результат операции
ИСКЛЮЧАЮЩЕЕ ИЛИ, выполненной над В и W последовательно разряд за
разрядом. Таким образом, как это показано па рис. 6.9, разряд 3 слова 1 хра¬
нится в модуле 2. Далее, разряд В модуля М содержит разряд В слова W, где
VV есть результат операции ИСКЛЮЧАЮЩЕЕ ИЛИ, выполненной над М и В
последовательно разряд за разрядом. Данное соотношение проиллюстрировано
^ К. Дж. Тербер 209
рис. С.9. По горизонтали расположены номера разрядов, по вертикали — помо¬
ра модулей, а в клетках — номера слов.
Примепяя этот принцип с помощью схемы формирования адресов, изо¬
браженной на рис. 6.10, можно реализовать целый ряд различных режиме к
Разряд
Рис. 6.9. Пример адресной выборки в системе Goodyear
доступа. Регистр режима доступа позволяет организовать доступ как к бито¬
вым срезам, так и к словным срезам. Кроме того, могут быть организованы
такие режимы доступа, при которых выбираются некоторые подмножества 2-;
разрядов из каждого 2^-го слова. Режимы доступа, использующие неквадрат¬
ные таблицы и педвоичную систему счисления, подробно обсуждаются также
Ре г и гм п
режиме
— j
/ЫхПеЮЛ tOUlht
доступа
”/-1 I
И.'! И
Y
Ойщий адрес
ный регистр
мае си ее
Рпс. 6.10. Схема выработки режима адре¬
сации в системе Goodyear
в [6.2]. Эти другие режимы доступа выходят за рамки нашей книги. Подробный
пример диагонального храпения данных был приведен с целыо показать осно¬
вополагающую методику и проиллюстрировать характер проблем, встречаю¬
щихся в таких применениях, к которым относится ассоциативный..процессор-.
210
Из приведенного примера читатель может увидеть всю сложность и преиму¬
щества системы Goodyear.
Схема организации храпения данных, разработанная фирмой Goodyear,
может оказаться очень эффективной при таких матричных операциях, как
транспозиция, приведение к диагональному виду, поворот и других подобпых
операциях. Коммутационная сеть перестановок *) (КСП) может быть реализо¬
вана на базе серийных схем выборки. Обеспечивается возможность чтения
i Ввод 'вывод
32 f
1
А д о в с
Масскз
256
Хранение
отклика
хранения
256 х 256
ОТКЛИКОВ
У
256 п
—„ » Параллельный ввод;вывод
Рис. 6.11. Уровни хранения данных в массиве с точки зрения системы програм¬
мирования '
слов и битовых срезов длиной до 256 разрядов. Кроме того, имеются операции
сдвига, используемые в различных алгоритмах обработки данных. Стоимость
КСП системы STAR AN составляет около 80% от стоимости массивов памяти,
т. е. если массив (256 слов по 256 разрядов) содержит 65 536 разрядов, то КСП
требует такого количества логических элементов, которое необходимо для хра¬
нения около 50 000 разрядов (в стоимостном выражении).
Основной ассоциативный массив показан па рис. 6.11. В его состав входит
ряд регистров, о которых ниже пойдет речь. Регистр X служит для хранения
промежуточных результатов и содержит но одному разряду на каждое слово
ассоциативной памяти. Регистр Y играет роль регистра результатов поиска.
Этот регистр содержит по одному разряду на каждое слово ассоциативной
памяти. В пем в общем случае находятся результаты поиска, а также ре¬
зультаты арифметических и логических операций. Регистр М представляет
собой регистр маски, используемый для задания активности элементов. В ре¬
жиме работы с битовыми срезами этот регистр играет роль регистра выборки
слов, а в режиме работы со слоеными срезами — регистра маски.
Обрабатывающий массив способсп выполнять любую из двуместных логи¬
ческих функций между регистрами. В процессоре STAR AN отсутствуют ка¬
кие-либо аппаратные средства пословной обработки, которые пе были бы свя¬
заны с регистрами М, X и Y. С помощью регистров X и Y, а также логических
функций и микропрограмм в системе организуется режим, при котором пара
регистров X и Y работает так же, как последовательный сумматор, опериру¬
ющий со словами. Это снижает стоимость массива, но требует аппаратной под¬
держки высокоскоростной обработки внутри комплекса регистров X, Y, М.
Вот почему набор регистров и КСП реализованы с помощью логических схем
со связанными эмиттерами. Все эти средства делают STARAN очень мощиой и
гибкой обрабатывающей системой.
*) Под этим термипом подразумевается устройство, управляющее выбор¬
кой информации из памяти при различных режимах адресации. {Примеч. пер.)
14* 211
Имеется несколько интересных побочных моментов, касающихся архитек¬
туры базового массива. Во-первых, при записи внешнего по отношению к мас¬
сиву слова в режиме битовых срезов это слово вначале должно быть подверг¬
нуто перестановке относительно своего нормального положения, как это тре¬
буют особенности механизма храпения. Эта процедура относится и к данным,
которые удаляются из массива в режиме битовых срезов. Запись одинаковых
Таблица G.1
Наиболее употребительные смешанные режимы адресации
Константа режима, на¬
ходящаяся в AMR0 или
AMR1
X
i a
lO й
3 Я
ияе>
о о я
Количество разря¬
дов, доступных в
каждом выбранном
| слове
Примечания
шестнад¬
цатерич¬
ный код
двоичный
код
й Ч и
Е-l О О
о о
о X Л
5 3 s
й о а
с сз о
К
00
00000000
256
1
Одип разряд всех слов
01
00000001
128
2
Нары разрядов каждого 2-го слова
03
00000011
64
4
Тетрады каждого 4-го слова
07
00000111
32
8
Байты каждого 8-го слова
0F
00001111
16
. 16
16-разрядные объекты каждого 16-го
слова
IF
00011111
8
32
32-разрядные объекты каждого 32-го
слова
3F
00111111
4
64
64-разрядпые объекты каждого 64-го
слова
7F
01111111
2
128
128-разрядиые объекты каждого 128-го
слова
FF
11111111
1
256
Все разряды одного слова
FE
11111110
2
128
Пара разрядов составлена из вторых
разрядов двух слов
FC
11111100
4
64
4 разряда, составленные из четвертых
разрядов четырех слов
F8
11111000
8
32
8 разрядов, составленные из восьмых
разрядов восьми слов
F0
11110000
16
16
16 разрядов, составленные из. 16-х раз¬
рядов 16 слов
E0
11100000
32
8
32 разряда, составленных из 32-х раз¬
рядов 32 слов
CO
11000000
64
4
64 разряда, составленные из 64-х разря¬
дов 64 слов
80
10000000
128
2
128 разрядов, составленные из 128-х
разрядов 128 слов
данных (операция множественной: записи была описана в гл. 2) в пабор слов
должна производиться в реяшме битовых срезов. КСП можно обойти при мно¬
жественной записи одиночного разряда во все слова по мере их выборки, по¬
скольку все слова принимают один и тот же разряд и, следовательно, в неко¬
тором смысле являются «идентичными». Какие-либо средства множественной
записи слов в реяшме работы со словньтми срезами отсутствуют; это означает,
что запись словного среза в память требует, чтобы было указано единствен¬
ное слово. Это очень ваяшос побочное свойство архитектуры. Существуют
212
способы поразрядпо-параллельиой записи в выбранное подмножество слов, по
для ого го требуется, чтобы эти слова удовлетворяли некоторым специальным
условиям. Такие режимы работы памяти называются «смешанными».
]3 табл. 6.1 приведены сводные данные о наиболее важных смешанных режи¬
мах и указаны их константы. Константа режима представляет собой величи¬
ну, подаваемую иа регистр режима доступа, изображенного иа рис. 6.10. По¬
скольку на этот регистр может быть помещено, любое желаемое число, то воз¬
можны и другие режимы. В процессоре STARAN имеются два регистра
режима доступа (AMR0 и AMR1), но они невидимы для программиста, рабо¬
тающего на языке ассемблера. Эти регистры могут быть установлены с по¬
мощью внешних команд, после чего программист может пользоваться сме¬
шанными режимами при программировании как в машинных кодах, так и иа
языке ассемблера.
Процессор STARAN
Для программиста и системы базовый массив выглядит так, как показано
на рис. 6.11. Детали структуры массива изображены иа рис. 6.12. Система име¬
ет набор ассоциативных массивов, каждый из которых состоит из 256 слов по
256 разрядов и 256-разряды ой системы разрешения множественных откликов.
Рис. 6.12. Схема внутреннего устройства массива памяти
Каждый разряд устройства разрешения множественных откликов соответству¬
ет одному из 256 слов массива памяти. Выходом устройства является 9-разряд-
Сое число. Разрешение всегда производится в каждом массиве, а системе пре¬
доставляется 9-разрядпый результат опроса. Восемь разрядов дают адрес
Первого откликнувшегося объекта, а девятый разряд представляет собой сум-
по модулю 2 регистра отклика.
213
Общая структура системы изображена на рис. С. 13. Ниже приводится опи¬
сание ее отдельных частей.
Управляющий модуль ассоциативного процессора показал на рис. 6.М.
Устройство управления АН включает восемь основных частей: 1) регистр
команд, 2) блок программного управления. 2) логику общей шины, 4) регистр
Рис. G.13. Блок-схема системы STARAN
аргумента (называемый ташке общим регистром), 5) блок управления-храпе¬
нием откликов, G) блоки управления массивами, 7) схему разрешения и
S) указатели полей и счетчики длины.
13 регистре команд находится текущая исполняемая команда.
Блок программного управления содержит устройство последовательного
исполнения команд, программный счетчик, регистр состояния, в котором хра¬
нится маска прерываний, рассчитанная па 15 управляющих прерываний АП,
и три устройства управления программными циклами (регистр начала цикла,
регистр окончания цикла и схема сравнения).
Логика общей шины обеспечивает общую магистраль для передачи данпых
между всеми управляющим.и регистрами и управляющей памятью. Разбиение
регистров на группы по отношению к шине показано на рис.‘6.15. Количество
разрядов в каждом регистре указано при разбиении шипы. Логика шипы со¬
держит схему сдвига, указатель данных и счетчик длины блока. Указатели
поля используются для за да пия полей, с которыми должеп работать аесоциа-
214
тхпзиьш процессор. Общий регистр содержит аргумент поиска пли данные вво-
да/вывода, относящиеся к ассоциативным массивам.
Блок управления храпением откликов контролирует состояние и времен¬
ную диаграмму работы всех регистров храпения откликов (X, У и М) во всех
массивах.
Блок управления массивами контролирует реальпые операции над мас¬
сивами. Обычно эти операции включают выбор массива, установку режима:
I—
Регистр
Програ ммное
команд.
у правление
аргумента
У
JL
Центральное
логическое
устройство
•
Указатели
и счетчики
; Ввод/вьжод
i к а с с. и в а
0т к .л и к
управляющие
С, х п w а
упр а вление
Г) л о к и
1 j J (3 |. О
памятью
массивов
f .t t
К моду.л ям массивов
д а н! I ы х
Рис. 6.14. Устройство управления ассоциативного процессора
адресации массива, управление коммутационной сстыо перестановок и маски¬
рование.
КСП показала па рис. 6.12. Ее функция состоит в установке режима адре¬
сации. Схема разрешения находит адрес «первого откликнувшегося объекта».
Этот адрес состоит из адреса массива и адреса слова внутри массива. Он по¬
лучается в результате выполнения над регистром Y каждого от,дельного мас¬
сива операций типа ИСКЛЮЧАЮЩЕЕ ИЛИ и операций разрешения.
Страничное устройство управляет тремя страницами сверхоперативной
памяти. При инициализации системы в первую страницу загружаются микро¬
программы и управляющие программы. Вторая и третья страницы использу¬
ются для храпения программ. В то время как одна страница используется,
в Другую производится загрузка. Устройство последовательного управления
(машина PDP-11) процессора STARAN контролирует все операции, связанные
с периферийным оборудованном и интерфейсами ввода/вывода. Внешнее обо¬
рудование и интерфейсы в значительной степени ориентированы па структуры
215
шины UX11) Г S. Использование машины PJ)P-1J. позволяет освободить STAPvAN
от управления внешним оборудованием.
Связь между элементами осуществляется с помощью логического уст¬
ройства внешних функций. С помощью этой системы элементы могут генери¬
ровать команды, опрашивающие другие элементы или управляющие имя.
Слово общей шины
Вари¬
ант
32 разряда
1
Регистр аргумента (32 разряда)
2
Регистр выбора массива (32 разряда)
3
Счетчик длины
поля (8 разря¬
дов)
Указатель по¬
ля (8 разря¬
дов)
Указатель ноля
(8 разрядов)
Указатель поля
(8 разрядов)
4
Счетчик длины блока (16 разря¬
дов)
Указатель данных
5
Информационная шина управляющей памяти АП (32 разряда)
6
Программный счетчик (16 раз¬
рядов)
Регистр режима (16 разрядов)
7
Счетчик длины
поля (8 разря¬
дов)
Указатель но¬
ля (8 разря¬
дов)
Регистр команды (16 разрядов)
Рис. 6.15. Варианты слова общей шины
Генерировать команды разрешено всем обрабатывающим элементам (к ним от¬
носятся устройство управления АП, машина PDP-11, страничное устройство,
контроллер ввода/вывода, а также «ведущий процессор», если таковой вклю¬
чен в канал внешних функций). ■»
Управляющая память АП разбита на ряд секций. Каждая секция выпол¬
няет определенную функцию. Секции взаимодействуют между собой но интер¬
фейсу, образуемому коммутатором портов. Имеются три одностраппчпых за¬
поминающих устройства по 512 слов каждое, буферная память данных объемом
512 слов, большая память па сердечниках объемом 16 К или 32 К слов и ка¬
нал прямого доступа к памяти, подключенный к ведущему процессору, если
таковой имеется. Капал прямого доступа позволяет адресовать около 30 ООО слов.
Особенности реальных запоминающих устройств, используемых в конкретных
системах, зависят от индивидуальных свойств той или иной конфигурации.
216
Программное обеспечение STARAN
В системе STARAN имеется исчерпывающий набор операторов языка ас¬
семблера. Язык ассемблера называется APPLE (Associative Processor Progra¬
ming LanguagE). Имеются трансляторы для APPLE, которые учитывают ин¬
дивидуальные особенности конкретной машины. Поскольку ввод/вывод в каж¬
дом конкретном экземпляре системы делается по специальному заказу, набор
команд ввода/вывода в APPLE невелик. В языке имеется развитой аппарат
макроопределений МAPPLE. APPLE содержит полный набор команд условных;
переходов (табл. С.2). Кроме того, в нем имеется несколько команд загрузки
Таблица G.2
Команды ветвления
Мнемокод
Операция
В
Безусловное ветвление
BZ
Ветвление по 0
BNZ
Ветвление по не 0
BBS
Ветвление, если разряд равен 1
BBZ
Ветвление, если разряд равен 0
BRS
Ветвление при наличии отклика
BNR
Ветвление при отсутствии отклика
BOV
Ветвление при переполнении
BXOV
Ветвление при отсутствии переполнения
BAL
Ветвление и связь
RPT
Повторение
LOOP
Цикл
Т а б лица 6.3
Команды работы с регистрами
Мнемокод
Операция
LRR
LI
LR
SR
INCR
DECR
LPSW
SPSW
Загрузка регистра пз регистра
Загрузка в регистр непосредственного операнда
Загрузка регистра из управляющей памятп
Запоминание регистра в управляющей памяти
Положительное приращение регистра
Отрицательное приращение регистра
Загрузка слова состояния программы
Перекачка слова состояпия программы
регистров (табл. 6.3). Команды ассоциативной загрузки, ассоциативной запи-
Си, поиска, перемещения, а также арифметические операции представлены в
табл. 6.4, 6.6, 6.6, 6.7 и 6.8 соответственно. Управляющие и тестовые команды
приведены в табл. 6.9, а команды страничного устройства — в табл. 6.10.
^ табл. 6.11 прсдставлопо несколько специально введенных команд управлепия
Параллельным вводом/выводом, которые были признаны полезными.
217
Таблица 6.4
Команда ассоциативной загрузки
Мнемокод
Операция
L
LN
LOR -
LORN
LAND
LANDN
LXOR
LXORN
LC
LCM
lcw
set
CLR
ROT
Загрузка регистра храиеиия откликов
Загрузка дополнения
Загрузка с операцией ИЛИ
Загрузка с операцией ИЛИ и преобразованием в дополни¬
тельный код
Загрузка с операцией И
Загрузка с операцией И и преобразованием в дополнитель¬
ный код
Загрузка с операцией ИСКЛЮЧАЮЩЕЕ ИЛИ
Загрузка с операцией ИСКЛЮЧАЮЩЕЕ ИЛИ и преобра¬
зованием в дополнительный код
Загрузка в общий регистр из слова ассоцпатпвпой памяти
Загрузка в поле общего регистра из слова ассоциативной
памяти -
Загрузка в общий регистр из регистра храиеиия откликов
Установка регистра хранения откликов
Чистка регистра храпения откликов
Поворот (циклический сдвиг) регистра хранения откликов
или общего регистра
Команды ассоциативного хранения
Таблица 6.5
Мнемокод
Операция
S
SM
SN
SNM
SOR
SORM
SORN
SORNM
SAND
SAN DM
SANDN
SANDNM
SC
SCM
Запоминание регистра храпения откликов в ассоциативной
памяти
Запись под маской регистра хранения откликов в ассоциа¬
тивной памяти
Запоминание дополнения в ассоциативпой памяти
Запоминание под маской дополнения в ассоциативной памяти
Запоминание с операцией ИСКЛЮЧАЮЩЕЕ ИЛИ в ассоци¬
ативной памяти
Запоминание под маской с операцией ИСКЛЮЧАЮЩЕЕ
ИЛИ в ассоциативной памяти
Запоминание с операцией ИСКЛЮЧАЮЩЕЕ ИЛИ и преоб¬
разованием в дополнительный код в ассоциативной памяти
Запоминание под маской с операцией ИСКЛЮЧАЮЩЕЕ ИЛИ
и преобразованием в дополнительный код в ассоциативпой
памяти
Запоминание с операцией II в ассоциативпой памяти
Запоминание под маской с операцией II в ассоциативно;!'!
памяти
Запоминание с операцией И и преобразованием в дополни¬
тельный код в ассоциативной памяти
Запоминание под маской с операцией II и преобразованном
в дополнительный код в ассоциативпой памяти
Запоминание' в ассоциативпой памяти общего регистра ил-1
регистра храпения откликов
Запоминание в ассоциативном слове общего регистра или
регистра храпения откликов
218
Т а б л и ц а 6.0
Команды ассоциативного поиска
Мнемокод
Операция
FIND
Нахождение первого взведенного разряда в Y-регистре хра¬
нения откликов
STER
Нахождение первого взведенного разряда в Y-регистре и
чистка его
RESVFST
Нахождение первого взведенного разряда в Y-регистре п чи¬
стка всех остальных
EQG
Поиск па равенство содержимому поля общего регистра
EQF
Поиск па равенство содержимому полон
NEQ
Поиск л а неравенство содержимому поля общего регистра
NEF
Поиск на неравенство содержимому полей
GTG
Поиск па «больше» содержимого поля общего регистра
GTF
Поиск па «больше» содержимого полей
GEG
Поиск па «больше или равно» содержимому поля общего
регистра
GEF
Поиск на «больше или равно» содержимому полей
LTG
Поиск па «меньше» содержимого ноля общего регистра
LTF
Поиск на «меньше» содержимого полей
LEG
Поиск на «меньше пли равно» содержимому поля общего
регистра
LEF
Поиск па «меньше или равно» содержимому нолей
MAXF
Поиск нолей с максимальным содержимым
MINF
Поиск полей с минимальным содержимым
Т а б л и ц а 0.7
Команды ассоциативных пересылок
Мнемокод
Операция
MVF
MVCF-
MVNF
MVAF
1.NCF
DECF
Перестилка поля
Пересылка дополнения содержимого поля до 1
Пересылка отрицания содержимого поля
Пересылка абсолютной величины содержимого поля
Пересылка содержимого поля с положительным прираще¬
нием
Пересылка содержимого поля с отрицательным прираще¬
нием
219
Таблица 6.S
Ассоциативные арифметические операции
Мнемокод
Операция
Л ПС
ADF
SBC
SBF
МРС
MPF
])VF
SQRTF
Сложение содержимого общего регистра с содержимым поля
Сложение содержимого полей
Вычитание содержимого общего регистра из содержимого
поля
Вычитание содержимого одного поля из содержимого дру¬
гого
Умножение содержимого поля па содержимое общего ре¬
гистра
Умножение содержимого одного поля на содержимое дру¬
гого
Деление содержимого одного поля на содержимое другого
Извлечение корня квадратного из содержимого поля
Таблица 6.9
Управляющие и тестовые команды
Мнемокод
Операция
I\ Т
ILOCK
WAIT
Прерывание управления и тестирования
Блокировка управления и тестирования
Перевод ассоциативного процессора в пассивное состояние
Таблица 6.10
Команды страничного устройства
Мнемокод
Операция
STRTSG
EXDSG
MVSG
MVSGI
pager
Начало сегмента
Окончание сегмента
Пересылка страничного сегмента
Экстренная пересылка страничного сегмента
Коптроль страничного устройства
Таблица 6.11
Команды устройства параллельного ввода/вывода
Мнемокод
Операция
TRIO
МАМ
SAM
Е AM
DJTO
П р и м е ч а п и
команды (наирпме]
Контроль параллельного ввода/вывода
Пересылка даппых нз одного массива в другой
Пересылка данных из массива в управляющую память
Пересылка данных пз управляющей памяти в массив
Задание буфера параллельного ввода/вывода
е. По желанию пользователя могут быть введены дополнительные
р, команды управления дисками).
220
Система ввода/вывода STARAN
Система ввода/вывода не поддается точному определению, поскольку каж¬
дая такая система индивидуальна и отличается от других по составу и типам
устройств ввода/вывода. Обычный вариапт системы ввода/вывода включает
канал прямого доступа к памяти, подключенный к ведущему процессору, бу¬
феризованный ввод/вывод для внешних устройств, систему связи, охватываю¬
щую средства реализации внешних функций, а также параллельный капал
ввода/вывода для любого массива.
Поскольку все реализации системы STARAN имеют одинаковый ввод/вы¬
вод, здесь приводится общее описание функций ввода/вывода. Базовая систе¬
ма, изображенная па рис. 6.13, может быть представлепа так, как показано
“j ПДП |”
Основное
оборудова¬
“I БВВ г
ние
%
■j УВФ|-
]пвв г
}
и
}
}
Прямой
доступ
к памяти
Буферизованный
ввод/вывод
VnpaBjieHHe
внешними
Функциями
Параллельный
ВБОД/ВЫВОД'
Рис. 6.16. Интерфейс ввода/вывода процессора STARAN
па рис. 6.16. Наличие капала прямого доступа позволяет памяти ведущего
процессора функционировать в качестве части управляющей памяти ассоциа¬
тивного процессора. Поэтому объекты, хранящиеся в памяти, одинаково до¬
ступны как для процессора STARAN, так и для ведущего процессора. В ряде
случаев оказывается необходимой передача адресов, которая осуществляется
в рамках специально разработанной системы ввода/вывода. Сопряжение про¬
цессора со стандартным оборудованием, например, печатающими устройствами,
осуществляется с помощью системы буферизованного ввода/вывода. Логический
канал внешних функций может быть использован в качестве интерфейса для
ведущего процессора (за исключением прерываний) или для управления про¬
цессором STARAN путем генерирования кодов внешних операций. Система
параллельного ввода/вывода служит для обеспечения прямого доступа уст¬
ройств к ассоциативным массивам, что расширяет возможности передачи ин¬
формации и позволяет процессору STARAN взаимодействовать с широким
•спектром устройств. Характеристики систем ввода/вывода приведены в
табл. 6.12.
221
Таблица 6.12
Функции устройств ввода/вывода и типовые показатели их быстродействие
Функции
Быстродействие
Прямой доступ к памяти:
ведущего процессора к памяти команд
ведущего процессора к управляющей
памяти ассоциативного процессора
управляющей памяти ассоциативного
процессора к памяти ведущего процес¬
сора
Буфер и зо в а пн ый в вод/вьт во д:
ведущего процессора в быстрый буфер
данных
из быстрого буфера данных в ведущий
процессор
ведущего процессора в память про¬
грамм па сердечниках
из памяти программ па сердечниках в
ведущий процессор
Внешние функции:
прерывание (прием и сообщение веду¬
щему процессору)
генерирование прерывания ведущего
процессора
Параллельный ввод/вьтвод:
из ассоциативного процессора па внеш¬
ние устройства
с внешнего устройства в ассоциатив¬
ный процессор
200 не па 32-разрядпос слово
600 не на 32-разрядиое слово
400 пс на 32-разрядное слово
200 не на 32-разрядное слово
200 пс на 32-разрядное слово
1 мкс на 32-разрядное слово
1 мкс на 32-разрядиое слово
1 мкс
1 мкс
200 пс на битовый срез или слов-
ный срез
400 не на битовый срез или слов-
ный срез
Варианты процессора STARAN
Сводные дагшые о конфигурации памяти представлены в табл. 6.13. Функ¬
циональное распределение системных регистров, обусловленное логикой общей
шины, приведено в табл. 6.14. Варианты применяемого оборудования даны в
табл. 6.15, а в табл. 6.16 приведены типовые данные по быстродействию
системы.
Таблица 6.13
Страница 0
Библиотека
стандартных
программ
512 слов
Страница 1
память команд
512 слов
Страница 2
Память команд
512 слов
Быстродейст¬
вующая буфер¬
ная память
данных
512 слов
Большая память на ферритовых
сердечниках
16 384 слова
Память с прямым доступом
30 720 слов
222
Система регистров
Таблица 6.14
Регистр
Наименование
Длина
Назначение
AR
Аргумент (общий ре¬
32
Хранение аргумента поиска
гистр)
I
Команда
16
Храпение текущей команды
PC
Программный счетчик
16
Храпение текущего значения
программного счетчика
АС
Селектор массива
32
Выбор массива
S
Состояпце
16
Описание состояпия системы
BL
Счетчик длины блока
16
Управление длиной порции
данных при обмене
DP
Указатель данных
16
Управление, адресацией при
обращении к данным
Е
Указатель внешнего по¬
8
Хранение промежуточного
ля
указателя
FL1 — FL2
Счетчики длины поля
8
Управление размерами полей
(1 и 2)
FP1 — FP3
Указатели полей
8
Хранение адресов битовых и
(1, 2, 3)
с л овны х срезов
R0-R7
Регистры возврата
16
Хранение адреса точки воз¬
(0, 1, ..1)
врата
Таблица 6.15
Варианты процессора STARAN
Стандартная конфигурация
Возможные дополнения
1 основной массив ассоциативной па¬
мяти
1 устройство управления ассоциатив¬
ным процессором
15 прерываний
Управляющая память АП:
3 страницы биполярной памяти по
512 слов каждая
1 биполярная быстродействующая бу-
ферпая память объемом 512 слов
1 большая ферритовая память объе¬
мом 16 К слов
Программное управление страницами:
PDP-11
Ферритовая память объемом 16 384
16-ти разрядных слов
Устройство ввода с перфоленты
Клавишпое печатающее устройство
8 прерываний
Дисковая память RK11
1 секция внешних логических функций
31 дополнительный массив
Двойное управление
Дополнительные прерывания
3 страницы биполярной памяти по
1024 слова каждая
1 биполярная быстродействующая бу¬
ферная память объемом 1024 слова
1 большая ферритовая память объемом
32 К слов
Внешняя память объемом 3072 слов
Феррптовая память объемом 20 К
16-ти разрядных слов
Расширенный состав внешних уст¬
ройств
Большое число прерываний
Интерфейсы:
Устройство прямого доступа к памяти
Внешние логические функции
Буферизованный ввод/вывод
Параллельный ввод/вывод -
2Э2::
Таблица G.IG
Быстродействие STARAN на типовых операциях
Операция
Время выпол¬
нения, •
мке/бнт
Операция
Время выпол¬
нения,
мне/б ИТ
Сравнение по критериям:
больше чем
0,15
Арифметические опера¬
ции:
меньше чем
0,15
сложепие аргумента с
0,85
точное совпадение
0,15
соде ржим ым поля
несовпадение
0,5
данного
0,85
вычитание аргумента.
из содержимого ноля
данного
0,85
сложение содержимо¬
го двух нолей
0,85
вычитание содержи¬
мого одного ноля из
другого
Заключение
STARAN является весьма необычной и мощной системой. В ней реализо¬
ван ряд структурных принципов, включая обработку битовых срезов наряду
с обработкой слов. Принцип, положенный в основу системы, дал возможность
создать на базе специально разработанных БИС ассоциативный процессор с
распределенной логикой, в котором значительно снижена удельная стоимость
обработки при пренебрежимо малом уменьшении быстродействия; во всяком
случае, реализованный принцип существенно превосходит обычный метод об¬
работки битовых срезов.
Схема разрешения множественных откликов стала более сложной ввиду
наличия взаимосвязей между массивами. В то же время процессор получил
широкие возможности по обработке битовых матриц (размер которых не пре¬
вышает 260 X 256) и способность работать (через FDP-11) в автономном
режиме.
Испытания процессора STARAN, проводимые в Исследовательском авиа¬
ционном центре ВВС США Роум, призваны выявить все существенные харак¬
теристики этого процессора, которые он может показать при работе в реаль¬
ных системах военного назначения. STARAN установлен в Топографической
лаборатории армии США для решения задач автокартографии и фотографии,
а также в Космическом центре ПАСА им. Джонсона для обработки данных от
спутников, осуществляющих исследование земных ресурсов в рамках экспери¬
мента по прогнозированию урожаев сельскохозяйственных культур.
Фирма Goodyear также поставляет заказчикам систему тестового конт¬
роля. Результаты тестовых проверок этой системы должны дать дальнейшую
информацию о характеристиках ассоциативных процессоров.
Упражнения
6.1. Каким образом программист может использовать преимущества осо¬
бой системы храпения дапных в процессоре STARAN?
6.2. Разработайте для процессора STARAN алгоритмы решения следую¬
щих задач: обращение матриц, транспозиция матриц, вычисление быстрого
224
преобразования Фурье, решение систем линейных уравнений, выполнение опе¬
раций над битовыми матрицами. Напишите ваши предложения относительно
того, какую размерность должны иметь указанные задачи, чтобы эффективно
работать в системе STARAN, а также обсудите вопрос о том, насколько ухуд¬
шатся показатели эффективности в случае, если расчетные размерности будут
превышены.
6.3. Как создать интерфейс для того, чтобы при взаимодействии процессо¬
ра STARAN с дисковой памятью последняя стала бы работать как ассоциатив¬
ная? Какую скорость обработки можно ожидать от подобной конструкции?
6А Макрокоманды какого уровня, по вашему мнению, следовало бы вве¬
сти в STARAN, чтобы создать видимость увеличения производительности при
работе с разрядными матрицами?
6.5. Для каких типов задач нужна система параллельного, ввода/вывода?
6.6. Изобразите карту памяти для различных режимов адресации, пере¬
численных в табл. 6.1.
РС. Дж. Тсрбер
Глава 7
СЕМЕЙСТВО OMEN
Введение
OMEN (Orthogonal Mini Embedme Nt) — это параллельный процессор,
созданный фирмой SANDERS на основе концепции ортогональной памяти,
предложенной Шуманом. Конструкторы фирмы SANDERS специализируются
па разработке высокопроизводительных вычислительных систем для обработ¬
ки сигналов [7.1—7.6]. Имеется несколько особенностей, отличающих OMEN
от других параллельных процессоров (ILLIAC IV и РЕРЕ), а также от ассо¬
циативных процессоров (STARAN).
Под системой OMEN понимается не одипочный экземпляр, а скорее ряд
машин: OMEN 61, OMEN 62, OMEN 63 и OMEN 64, построенных на основе
принципа ортогональной памяти Шумана. Наличие ряда обеспечивает более
эффективное удовлетворение требований, обусловленных той или иной обла¬
стью применения. Данный ряд машин был разработан без правительственных
субсидий.
Концепция ортогональной памяти пе получила в литературе широкого-
-освещения. Подобно процессору STARAN, OMEN благодаря искусству конст¬
рукторов создан не па базе специально разработанных БИС, а на обычных
готовых элементах. Различия между машинами ряда OMEN заключаются в
параметрах вертикального арифметического устройства (ВАУ). Поэтому вна¬
чале речь пойдет о конструкции процессора и памяти, являющихся общими
для членов ряда, а варианты ВАУ будут рассмотрены в конце главы. Выраже¬
ние «ведущий процессор» употребляется вместо выражения «устройство управ¬
ления». В рассматриваемой системе отдельное устройство управления отсут¬
ствует.
Описание архитектуры OMEN
Общая блок-схема системы OMEN приведена на рис. 7.1. OMEN состоит
из двух функциональных обрабатывающих комплексов, делящих между собой
общую ортогопальпую память. Вычислительная машина PDP-11 используется
в своем штатном варианте. В системе используется в полном объеме програм¬
мное обеспечение PDP-11, а ортогональная память оказывается по отношению
к PDP-11 как бы обычной памятью, состоящей из 16-разрядных слов. Со сторо¬
ны PDP-11 физическая основа мехапизма разделения памяти на слова не вид-
па. Память представляется в виде непрерывного адресного пространства раз¬
мером от 8 до 128 К 16-разрядпых слов с длительностью цикла, стравпимой с
величинами, характерными для обычпых запоминающих устройств. Впешние
устройства и программное обеспечение фирмы UNIBUS *) непосредственно
*) UNIBUS — торговая марка фирмы Digital Equipment Company.
226
подходят к PDP-11, что позволило фирме SANDERS значительно сэкономить
время разработки и сократить ее стоимость.
Взаимодействие между ортогональной памятью (ОП), центральным про¬
цессором PDP-11 и ВЛУ осуществляется с помощью общей шины UNIBUS.
ОП и ВАУ представляют собой как бы устройства UNIBUS. Как видно из:
рис. 7.2, главными функциоиаль-
иыми блоками OMEN являются: j i иг ■ • ~|
центральный процессор PDP-11,
ОП, ВАУ, регистры храпения дан¬
ных, блок управления циклами,
-блок микропрограмм, стек, шина
UNIBUS и коммутационная пла¬
та. Ниже будут рассмотрены фун¬
кции каждого из этих блоков.
Коммутационная плата явля¬
ется главным элементом систем¬
ных средств управления. В прин¬
ципе она аналогична коммутаци¬
онной панели вычислительной машины CDG 6600, хотя и является гораздо бо¬
лее простой. Коммутационная плата работает как списочный планировщик,
осуществляющий управление доступом к общим и разделенным ресурсам. Ее
можно себе представить в виде большого пабора управляющих условий, на¬
зываемых условиями выдачи, которые определяют, когда команды могут быть
0п
■1 - "1 Л Г
1
'а мчто
I
1
ВАУ
Рис. 7.1. Блок-схема системы OMEN
Рис. 7.2. Подсистемы, входящие в OMEN
выданы па исполнение в зависимости от наличия требуемых ресурсов. В ком¬
мутационной плате содержится также информация о том, по истечении какого
времени после того, как команда выдана на исполнение, занимаемые ею ресур¬
сы снова станут доступными. Существует много уровней сложности, в рамках
которых может быть реализована коммутационная плата. Коммутационная
плата системы OMEN имеет очень простую конструкцию. Ее главной функцией
является управление доступом к ОП. Она определяет, когда данные поступают
пз памяти, организует маршрутизацию’данных, выталкивает команды нз стека
и участвует в управлении циклами.
Таблица 7.1
Сокращенный список операций ВАУ
Операции
Примечание
Абсолютное значение
Адрес максимального или минимального числа
Булевская операция
Арифметическая операция
Загрузка, сохранение
Сравнение, вычисление корреляции
Сдвиг но горизонтали (внутри каждого ПЭ)
Взаимная перестановка, тасовка, разбиение, транспозиция
Циклический сдвиг, инвертирование
Подсчет числа единиц и нулей (для ПЭ с номерами от 0 до /
подсчитывается число нулей или единиц, находящихся в од¬
ной из 133 групп 1-разрядных регистров)
Перевод числа из представления с плавающей запятой в це¬
лое и обратно
Преобразование Фурье или Адамара
Подсчет числа пулей или единиц по горизонтали (в каждом
ПЭ)
Загрузка промежуточных регистров
Загрузка уровневых счетчиков
Решение системы линейных уравнений, обращение матриц
Вычисление полиномов
Загрузка комбинации нулей и единиц в вертикальные ре¬
гистры
Поиск с последующим вызовом или локализацией
Специальные арифметические операции
(ПЭ j ПЭ j о ПЭ,+2*, / == 0, 1, ...)
Специальные булевские операции
(ПЭ; ПЭ; о ПЭ;+2Ь, / = 0, 1, . . .)
Смешанные операции слоя^ения — вычитапия
1,2
3
4
1,2
1.4
1.4
4.5
4
4
7
4,2
8
9
9
10
Примечания.
1. Данные могут находиться в регистрах или в памяти, а также в промежуточ¬
ных регистрах.
2. Данные могут быть байтовые, целые, вещественные, целые комплексные, с пла¬
вающей запятой, целые с удвоенной длиной.
3. Данные могут быть байтовые, целые, с плавающей запятой, с удвоенной точ¬
ностью.
4. Данные могут иметь формат 1, 8, 16 или 32 разряда.
5. Логический или арифметический сдвиг для всех типов данных.
6. В операции участвуют целые комплексные числа; могут вводиться и вещест¬
венные числа.
7. Данные представляются в формате с плавающей запятой.
8. Могут быть найдены либо все данные, удовлетворяющие условию поиска, либо
только первые из них.
9. Используются любые арифметические или булевские операции; число резуль¬
татов может быть равно 1, 2, 4, . . ., N/2.
10. Факт наличия на каждом уровне операции сложения или вычитания определя¬
ется с гюмощыо маски.
Шина UNIBUS позволяет включать в состав системы периферийные уст¬
ройства и другое оборудование и обеспечивает их взаимодействие с коммута¬
ционной платой.
Стек служит хранилищем команд, исполняемых системой OMEN. Уровень
вложенности циклов, находящихся в стеке, ие может превышать 8 (ограниче¬
ние, накладываемое на организацию циклов). В стеке производится расшиф¬
ровка векторных команд для произвольного числа процессорных элементов,
228
при этом обстоятельство, что в системе имеются только 64 ПЭ, становятся
(видимым для программиста только через функционирование стека. OMEN
имеет 64 процессорных элемента п работает с векторами, состоящими из 64
компонент, и матрицами 8X8. Над векторами произвольной длины (вплоть
до 4096 элементов) могут производиться vтолько векторные операции. Типо¬
вой список команд, хранящихся в стеке, приведен в табл. 7.1.
Блок микропрограмм представляет собой память с разделенными средст¬
вами чтения и записи, содержащую микропрограммы, которые реализуют
команды, находящиеся в сте¬
ке. Для реализации вертикаль- Unifhis
ных микрокоманд (закодиро¬
ванных микрокоманд) с по¬
мощью горизонтальных микро¬
команд (нанокоманд) исполь¬
зуется принцип двухуровнево¬
го кодирования. Стековые
команды, определяющие по¬
следовательность операций
ВАУ, реализованы с помощью
вертикальных микрооперато¬
ров. Взаимосвязь между сте¬
ком, микропрограммами и на¬
нопрограммами показана иа
рис. 7.3. В стеке или микро¬
программе уровень вложенно¬
сти циклов не превышает 8.
Центральный процессор вычислительной машины PDP-11 является как бы
частью шины UNIBUS и осуществляет последовательное управление системой.
Блок управления циклами контролирует последовательность обработки в
OMEN сегментов стека, а также сегментов микропрограмм и нанопрограмм.
Описание работы ортогональной памяти было дано в гл. 2, а здесь будет
рассмотрена ее техническая реализация. Главными функциональными особен¬
ностями 011 в общем случае являются: способность работать как обычная
память с пословной структурой и способность работать как память, состоящая
из битовых срезов.
В машинах ряда OMEN ортогональная память является ключевым устрой¬
ством. Она реализована непосредственно на кристаллических запоминающих
элементах серии 1103, обладающих произвольным доступом. Так же, как и
STARAN, OMEN разрабатывался так, чтобы была возможность максимально
использовать готовую элементную базу. Ключевым моментом в системе STA¬
RAN было использование стандартных блоков памяти с произвольным досту¬
пом для получения ассоциативной (с функциональной точки зрения) памяти;
при этом конструкторы пожертвовали возможностью параллельно-пословной
записи (чтения). Такой подход позволил сэкономить на разработке специаль¬
ных элементов. В OMEN в жертву принесена возможность прямой адресации
с точностью до битового среза (адресация в OMEN осуществляется с точно¬
стью до байта), однако это дало выигрыш за счет использования для орга¬
низации ортогональной (с функциональной точки зрения) памяти кристаллов
памяти с произвольным доступом серии 1103. Кроме того, система адресации
60-разрядное слез о
Рис. 7.3. Принцип микропрограммирования,
реализованный в OMEN
229
с точностью до байта позволила фирме SANDERS использовать адресный ме¬
ханизм PDP-11.
Как было отмечено выше, существуют четыре представителя ряда OMEN,
обозначенные цифрами 61, 62, 63 и 64. Эти модели укомплектованы различны¬
ми модификациями памяти. Объем памяти колеблется от 8 до 128 К ^-раз¬
рядных слов для моделей 61 и 62 и от 16 до 128 К 16-разрядных слов для мо¬
делей 63 и 64. Все эти запоминающие устройства являются расширяемыми;
за счет удваивания размера модуля. Из-за особенностей конструкции наимень¬
шая (по объему) модификация, которая обеспечивает все функциональные
возможности ортогональной памяти при максимальном быстродействии, имеет
64 К 16-разрядиых слов.
Ортогональная память
Па рис. 7.4 показана упрощенная блок-схема памяти па кристаллах 1103.
Это полупроводниковый типовой конструктивный элемент, представляющий
собой 1 разряд 1024 слов. Время доступа к памяти составляет около 500 не.
Это создает предпосылки для возможности обращения к памяти с частотой
ВВОД/ ВЫВОД:
Память на .
элементах
модели 1103
1024 однораз¬
рядных слов
. Средства
чтения/записи'
Рис. 7.4. Структурная единица памяти модели 1103
1 мкс. Модуль памяти объемом 64 К может быть представлен так, как показа¬
но на рис. 7.5. Он состоит из кристаллов 1103, образующих 128 строк по
8 столбцов в каждой строке. При обычной адресации память может быть
изображена так, как показано на рис. 7.6 (столбцы слиты вместе). Байт О
представляет собой 8 разрядов слова О элемента, образующего строку О.
Каждая данная строка может содержать только четные (нечетные) адреса.
Это нз-за того, что слово PDP-11 (рис. 7.7) образовано из двух байтов, обоз¬
начаемых i и i + 1 (где г —четное целое число). Несмотря на то, что реаль¬
ная длительность цикла обращения к памяти составляет 1 мкс, пользователи
могут использовать послойную структуру памяти, позволяющую каждую
микросекунду считывать полное слово, благодаря тому, что байты с четными
и нечетными номерами (образующие полное слово) никогда не находятся в
одном физическом блоке. При пекоторых условиях длительность цикла обра¬
щения к памяти может быть доведена до 500 не. Тогда максимальная допусти¬
мая частота обращения к словам оказывается равной 2 мгц. Со сторопы
PDP-11 память выглядит так, как показано на рис. 7.7. Подумайте, каким об¬
разом память такого типа работает как вертикалыю-ориеитнровапная (режим
битовых срезов).
На ргтс. 7.8 показаны основные характерные черты режима работы с би¬
товыми срезами. Важно отметить, что структура памяти отчасти определяется
остальными элементами схемы обработки. Вследствие того, что PDP-11 адре¬
сует информацию с точностью до байта, а также из-за того, что фирма
gANDERS пыталась использовать средства адре¬
сации PDP-11 в возможно более полном объеме,
ортогональная память адресуется с точностью
до байтового среза, т. е. если пользователь же¬
лает получить битовый срез i, то оп должен обра¬
титься к байтовому срезу, содержащему бито¬
вый срез i (или по крайней мере к части байто¬
вого среза). Строка О
Столбец 7 Столбец б Столбец О
8 разрядов
Строка О
Строка 1
Байт 1
Байт 3
Байт Z047
Строка 1
Строка 126
Байт 12Э024
Байт 129026
Байт 131070
Строка
127 Строка 127
Рис. 7.5. Расположение структурных единиц па- Рис. 7.6. Структура памяти
мятн модели 1103 в ортогональной памяти OMEN, имеющей послов-
пую организацию
ВАУ содержит 64 процессорных блока, поэтому в битовом срезе имеется
ровпо 64 разрядных позиции. Структура элементов является такой же, как в
горизонтальной памяти, т. е. состоит из блоков, в каждом из которых содер¬
жится 128 строк и 8 столбцов (битовых срезов). Как видно из рис. 7.8, строки
попарно объединены.
Байт 123027
Байт 131071
231
Байт 0
Байт 1
Байт
Байт
131070
131071
Слово О
Слово 65535
Рис. 7.7. Диапазон адресов машипы PDP-11
Выход
О
Вентиль
Выход
1
Вентиль -
Битовый
срез
7
г ПОЗ
4t.
1103
Kt.
г 1103
1103
i-ot
1103
1103
г- 1103
г 1103
Цепи
синхрони -
зации
•• Битовый срез
О
1103
ж
п
1103
1103
1103
т:
за
Разряд
адреса
-<ь-
Выход
63
Вентиль J
г 1ЮЗ
1103
mj-
1103
1103
“Г
“0п
Ряс. 7.8. Структура базовой подсистемы ортогональной памяти
Битовый срез 16376
Битовый срез 16377
Битовый срез 16378
Битовый срез 16379
Битовый срез 16380
Битовый срез 16381
Битовый срез 16382
Битовый срез 16383
Набор строк с четными поморами (0,2,..., 126) образует 1024 байтовых
среза, состоящих, из байтов с четными номерами. Таким образом, байтовый
срез 0 состоит из снова 0 каждого из блоков (0, 2, ..126).
Набор блоков с нечетными номерами (строки 1, 3, 5, ..., 127) образует
1024 байтовых среза, состоящих из байтов с нечетными номерами. Функцио¬
нальная схема памяти (по вертикали) состоит
из 2048 байтовых срезов, каждый из которых
содержит 8 битовых срезов по 04 бита. Это по¬
казано на рис. 7.0.
Па рис. 7.8 изображена типовая схема, тре¬
буемая для реализации памяти рассмотренного
тина. С помощью адресного бита выбираются
либо четные, либо нечетные байтовые срезы,
к которым происходит обращение. Затем син¬
хронизирующее устройство считывает 8 бито¬
вых срезов с интервалом 1/16 икс. В то время
как одна группа байтовых срезов устанавлива¬
ется или обновляется, битовые срезы могут
считываться из «противоположной группы». При¬
няв для цикла памяти осторожную оценку в
\ мке, получим, что частота считывания бито¬
вых срезов (каждый битовый срез содержит
64 позиции) в ортогональной памяти может до¬
стигать 16 мгц.
Имеется возможность уменьшить время цик¬
ла до 500 не п/или удвоить количество выход¬
ных цепей (так, чтобы мог осуществляться до¬
ступ одновременно к четным и нечетным бито¬
вым срезам) и увеличить таким образом часто¬
ту считывания битовых срезов до 32 мгц. В ва¬
рианте системы с объемом памяти 128 К эта
память может быть реализована с помощью бло-
ков объемом 61 К, аналогичных описанным взл-
:шс и включенным в параллель. Таким образом,
верхняя граница быстродействия при работе
с битовыми срезами составляет 64 мгц, а вели¬
чина 32 мгц может быть достигнута без осо¬
бых усилий.
Как бзлло сказано выше, произвольный до¬
ступ осуществляется с точностью до байтового
среза, однако это не означает, что для получе¬
ния битового среза система должна прочитать
все 8 битовых срезов, составляющих байтовый
срез. Она должна прочитать все битовые срезы
с меньшими номерами, включая заданный срез.
Например, если требуется прочитать битовый срез 3, то считзлваются битовые
срезы 0, 1 и 2. Затем может быть прочитан битовый срез 3. После того как би¬
товый срез 3 прочитан, в1лходиые цепи могут быть замаскированы, по время,
затраченное на считывание бытовых срезов 0, 1 и 2, все же пропало впустую.
04 разряда
Битовый срез
0
Битовый срез 1
Битовый срез
1
Битовый срез
б
Битовый срез
4
Битовый срез
5
Битовый срез
6
Битовый срез
7
Битовый срез
8
Битовый срез
9
битовый срез
10
Битовый срез
11
Битовый срез
12
Битовый срез
13
Битовый срез
14
Битовый срез
15
Рис. 7.9. Структура памяти
OMEN, ориентированной на
работу с битовыми срезами
233
Время доступа к отдельному битовому срезу пе превышает время доступа к
байтовому срезу п зависит от номера позиции битового среза в байтовом сре¬
зе. Такое конструкторское решение следует признать удачным, учитывая
быстродействие PDP-11, т. е. половина микросекунды на один байт. Операции
над битовыми срезами осуществляются просто и естественно с помощью опе¬
раций маскирования и сдвига.
Применение метода расслоения памяти и а четную и нечетпуго компонен¬
ты позволяет наиболее полно использовать возможности запоминающего уст¬
ройства. Этот метод позволяет избежать задержек, которые могли бы возник¬
нуть в ходе вычислительного процесса, когда в течение одного цикла памяти
делаются попытки обращения к одному и тому же физическому блоку. Орто¬
гональная память работает аналогичным образом при обращении к векторам,
находящимся в послойно-организованной памяти, когда известно, что после¬
довательные элементы будут располагаться в разных физических блоках.
Поскольку память может быть построена из готовых элементов серии 1103, ео
стоимость относительно певелика. Введение послойной структуры увеличива¬
ет стоимость примерно па 19% по сравнению с памятью такого же объема па
элементах 1103, имеющей обычпый произвольный доступ. Существуют допол¬
нительные возможности в системе адресации. Это так называемый доступ к
памяти с распределенными обращениями. В данном режиме каждый процес¬
сорный элемент ВАУ может задать набор данных, к которым он собирается
обращаться. Имеется ограничение, заключающееся в том, что адресное про¬
странство, доступное каждому ПЭ, определяется номером этого ПЭ в ВАУ.
Таким образом, программист при обращении к данным имеет возможность в
одной общей команде задать для каждого из 64 ПЭ собственный адрес (хотя
и из ограниченного диапазона).
В режиме обычного горизонтального доступа память может быть построе¬
на па обращение к N-байтовым словам пли двойным словам. Для организации
доступа к двойным словам размеры блоков должны быть сделаны соизмери¬
мыми (адрес слова кратен N). Работа с двойными словами требуется для чи¬
сел с плавающей запятой или комплексных чисел, у которых отдельно хра¬
нятся старшая и младшая (действительная и мнимая) части. Такой вариант
организации памяти представляется наиболее целесообразным для модифика¬
ции с объемом 128 К и при работе с двойными словами.
Взаимосвязи ПЭ в OMEN
Для простоты описания регистров связи рассмотрим ВАУ, состоящее из
64 ПЭ. В OMEN имеется восемь регистров связи (НИ0, IIR7). Они подключе¬
ны к 64 ПЭ тремя способами.
Во-первых, регистр IIR0 соединен со всеми ПЭ. Во-вторых, регистры свя¬
зи подключены для выполнения операции умножения вектора-строки па мат¬
рицу (предумиожспие). В-третьих, регистры связи подключены для выполне¬
ния операции умножения матрицы на вектор-столбец (постумпожепие). Мо¬
гут производиться операции перемножения векторов и матриц, эквивалент¬
ные суммированию по строкам и столбцам хранимых массивов. Детальная
схема подключения приведена па рис. 7.10. Общие выражения, определяющие
схему взаимодействия всех N процессорных элементов ВАУ, следующие: НЕс
подключен ко всем ПЭ; ПИ* подключены к ПЭ.^1/2_^ (для к / = 0, 1, ,, >
234
„.., (N),/a —1): IlRi подключены к ПЭ . 1/0 (для г, / = 0, 1,..., (N)1/2—
— 1), при этом число регистров связи равно (Х)1/2.
Для системы, состоящей из 64 ПЭ, эти выражения имеют вид: IIR0 под¬
ключен ко всем ПЭ, ИRi подключены к ПЭ8г + ;? (Ф'1Я 6 / — 1, -.7); HR* под¬
ключены к Иdi+щ (для г, j = 0, 1, ..., 7), при этом всего имеется восемь реги¬
стров связи. Промышленный образец OMEN содержит 64 ПЭ и 8 регистров
Регистр хранения
Тип связи
IIR0
HRx
HR,
IIR3
HR*
HR6
II Re
HR,
Все
Ни
Ни
Ни
Ни
Ни
Ни
Ни
1
ПЭ
один
ПЭ
один
ПЭ
один
ПЭ
один
ПЭ
один
ПЭ
один
ПЭ
один
ПЭ
ПЭ
ПЭ
ПЭ
ПЭ
ПЭ
ПЭ
ПЭ
ПЭ
0
8
16
24
32
40
48
56
1
9
17
25
33
41
49
57
2
10
18
26
34
42
50
58
2
3
11
19
27
35
43
51
59
4
12
20
28
36
44
52
60
5
13
21
29
37
45
53
61
6
14
22
30
38
46
54
62
7
15
23
31
39
47
55
63
ПЭ
ПЭ
ПЭ
ПЭ
ПЭ
ПЭ
ПЭ
ПЭ
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
3
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
Рис. 7.10. Коммутация регистров хранения
связи. Из общих выражений, определяющих порядок подключения регистров
связи к ПЭ, следует, что для эффективной реализации памяти, регистров свя¬
зи и ВАУ число N должно быть четной степенью двойки.
ВАУ системы OMEN
Как было отмечено выше, кроме различия в используемых запоминающих
устройствах, машины ряда OMEN отличаются конструкцией ВАУ. Функцио¬
нально ВАУ состоит из 64 процессорных элементов. Каждый процессорный
■элемент имеет трн основные части: блок перестановок, регистровый файл и
арифметико-логическое устройство (АЛУ). Блок перестановок имеет одина¬
ковую конструкцию во всех машинах ряда OMEN. Блок перестановок выпол¬
няет следующие функции: инверсию (перемена местами содержимого пар ПЭ
(0,63), (1,62), (2.61) ...), полное перемешивание и циклический сдвиг.
235
Па рис. 7.11 показаны различия г> оборудовании между представителями
ряда OMEN. Основное различно между OMEN 01* и OMEN 02 (OMEN 03 к
OMEN 64) состоит в памяти (регистровых файлах), а по в конструкции АЛV
Арифметико-логическое устройство машин OMEN 61 и 62 называется ортого¬
нальным арифметическим устройством (ОАУ), а АЛУ OMEN 63 и 64—орто¬
гональным матричным, арифметическим устройством (ОМАУ). ОАУ сконструи¬
ровано в основном для обработки данных в виде битовых срезов и ассоциа¬
тивной обработки. ОМАУ ориентировано главным образом на вычислитель¬
ные операции, встречающиеся в алгоритмах обработки сигналов, такие как
Устройство
Модель
61 | 62
63 | 64
Регистры
8 разрядов
па ПЭ
37 разрядов
IIЭ (плюс \
16-разрядных
регистра об¬
щего назна¬
чения)
То же, что в
OMEN 64, за
исключением
постоянной
памяти для
коэффициен¬
тов быстрого
преобразова¬
ния Фурье
133 разряда
(плюс 8 16-
разрядных ре¬
гистров обще-1
го назначения) 1
1
1
)
. I
АЛУ
Поразрядно-
последователь¬
ная обработка
Поразрядно-
последователь¬
ная обработка
Пословно-па¬
раллельная об¬
работка с пла¬
вающей заня¬
той
ГТословио-па- j
раллельная
обработка сj
плавающей за- j
пятой
Рис. 7.11. Характеристики вертикального арифметического устройства OMEN
быстрое преобразование Фурье, управление обзором пространства и анализ
формы сигпалов. Здесь будет описано ВАУ OMEN 64.
Процессорный элемент OMEN 64 имеет: файл, состоящий из 8 универсаль¬
ных 16-разрядиых регистров, пять одноразрядных регистров маски и пять
псевдопостояппых масок (регистры связи, участвующие в комплексе ВАУ,
имеют по 32 разряда каждый). Только эти регистры ПЭ являются программно
доступными. Во всех машинах ряда OMEN Г1Э представляет собой 16-раз-
рядный процессор, имеющий 8 регистров (в другом режиме он может исполь¬
зоваться в качестве 133-разрядного процессора для обработки битовых срезов,
:хотя и неэффективно). Все 8 универсальных регистров используются в каче¬
стве либо регистров операндов, либо результатов, либо в качестве индексных
Регистры маски используются в интересах арифметического устройства —
для управления активностью, в процессе выполнения операций записи в ор¬
тогональную память — для блокировки памяти, для управления делением (вы¬
полняемым с помощью операций сложения и вычитания), для управления
умножением (выполняемым с помощью операции сложения) и управления
переносом (выполняемым с помощью сложения битовых срезов). Главным:;
псевдоиостояиньтми масками являются маски, состоящие из всех 1 и из всех
0. Эти маски избавляют программиста от необходимости заботиться о сохран¬
ности масок в процессе работы с векторами (матрицами), имеющими размер¬
236
ность более 64 (8X8). Единичная (пулевая) маска активизирует (дозакти-
визирует) все ПЭ в ВАУ. Если в обработке находится вектор размерностью 100,
то программист обычно использует единичную маску и, кроме того, задает
маску, в которой содержится 36 единиц. Оставшиеся 28 ПЭ должны с по¬
мощью программнозаданнои маски быть установлены в 0. Аппаратура способна
Шина UN I BUS
работать таким образом, что все операции с масками осуществляются авто¬
матически, создавая впечатление, что ВАУ имеет как бы 100 элементов вме¬
сто 64. Пример содержимого стека для программы, работающей с векторами
и матрицами, содержащими более 64 элемептов, приведен па рис. 7.12. Маски
и псевдопостоянпыс маски являются одинаковыми для всех ПЭ ряда.
237
Ввод/вывод может осуществляться через PDP-11 и UNIBUS или же пря¬
мо из ортогональной памяти. Имеется возможность соединить вместе два про¬
цессора OMEN через соответствующую ОН с помощью параллельной шипы
типа «память-память». Эта шина работает параллельно с 64-разряднымц
словами и является средством, обеспечивающим подключение к системе дис¬
ков с фиксированными головками или других быстродействующих внешних
устройств.
Все вышеизложенное может быть распространено на систему с 1024 про¬
цессорными элементами, поскольку число ПЭ в ВАУ является четной сте¬
пенью двойки. Архитектура системы никак не ограничивает количество ПЭ
числом 04.
Передача данных между ПЭ может осуществляться двумя' описанными
выше способами. Один из них использует блок перестановок, а другой—ре¬
гистры связи. Такое решение обеспечивает высокий уровень коммутативно¬
сти и не накладывает заметных ограничений на гибкость системы.
Программное обеспечение OMEN
С точки зрепия конструкции аппаратной части ряд OMEN значительно
отличается от систем РЕРЕ, ILLIAC IV и STARAN. С точки зрения програм¬
много обеспечения эти отличия являются еще более существенными. В ма¬
шинах ряда OMEN используются три языка: расширенный фортран, расши¬
ренный бэйспк и APL. Последний является единственным языком, специаль¬
но реализованным в OMEN. Как бэйсик, так и фортран являются расширен¬
ными версиями, имеющимися в PDP-11. Оба они могут быть еще расширены
с помощью средств макрогеперацпи. Команды ВАУ были закодированы в виде
библиотеки подпрограмм для бэйенка и фортрана. Кроме того, язык APL был
немного расширен, т. е. APL представляет собой ве»рсию APL/3670 с добавле¬
нием одной возможности. Оператор размерности был модифицирован таким
образом, что программу на APL стало возможным транслировать, а не интер¬
претировать. Это обеспечило эффективность генерации кода, что очень важно
при работе в реальном масштабе времени. Задание размерности 100 перемен¬
ной X на APL имеет простой вид:
о Dimension X (100).
Языковые средства ряда OMEN представляют собой язык, расшяреппый за
счет макросов и команд ВАУ. Набор доступных операций включает» все конст¬
рукции расширенных фортрана и бэисбика, все конструкции языка ассемблера
PDP-11, операцию обращепия матриц, операцию быстрого преобразования
Фурье, перемножение матриц, квадратный корень, поиск локального экстре¬
мума, поиск глобального экстремума, расчет корреляции н все векторные опе¬
рации языка APL (версии APL/3C0).
Конфигурация машин семейства OMEN
На рис. 7.13 приведепа типичная конфигурация двухмашинного комплекса
OMEN 01 и OMEN 64, ориентированного на обработку сигналов. В этом ва¬
рианте OMEN 01 осуществляет ввод/вывод, управление отображением и под-
238
готовку данных для OMEN 64. Процессоры взаимодействуют по данным через
Рис. 7.13. Типичная конфигурация системы OMEN. Пульт управления контро¬
лирует как OMEN 61, так и OMEN 64
UNIBUS. OMEN 64 осуществляет обработку сигналов, а результаты возвраща¬
ет на OMEN 61 для отображения.
Заключение
Как следует из конструкции машин ряда OMEN, главным элементом, соз¬
дание которого сопряжено с техническим риском, является выбранная конст¬
рукция ортогональной памяти, поскольку все прочие части системы представ¬
ляют собой стандартные или хорошо отработанные элементы и подсистемы.
Одним из главных характерных моментов является то обстоятельство, что
разработчики фирмы SANDERS сделали значительный упор на PDP-11 и ее
программное обеспечение. Это позволило использовать в системе проверен¬
ное и потенциально отлаженное программное обеспечение. Расширение прог¬
раммного обеспечения было выполнено на макроуровне, дав тем самым
пользователю мощные средства для специализации процессоров. Сред¬
ства языка APL также представляют собой мощный инструмент программи¬
рования. Основным недостатком машин ряда OMEN является то, что мини¬
мальный объем памяти ограпнчси снизу величиной 64 К слов по 16 разрядов.
Это ограничение продиктовано условием извлечения полных функциональных
возможностей ОП, заложенных в ней, благодаря техническим решениям, воп-
лощеппых в ее конструкции.
239
У п р а ж п е и и я
7.1. Расскажите о реализации алгоритмов построения структуры взаимных
связей между процессорными элементами в системе OMEN.
7.2. Покажите, каким образом преобразование 1024-элемепт1гого объекта
может быть отображено па С>4-элсмептную машшту ряда OMEN.
7.3. Расскажите, как в OMEN с помощью структуры связей между ПЭ мо¬
гут выполняться матричные операции.
7Л. Можно ли использовать в OMEN язык АПЛ без конструкции
DIMENSION? Если вы считаете, что да, то таково ожидаемое снижение эф¬
фективности оборудования п программного обеспечения и как изменятся ха¬
рактеристики системы. Могут ли проблемы, -связанные с размерностью, быть
решены каким-либо другим рациональным способом?
7.5. Дает ли структура межзлемситных связей системы OMEN какие-либо
преимущества нар ILLIAC IV, РЕРЕ или STARAN?
Глава 8
ОЦЕНКА ПРОИЗВОДИТЕЛЬНОСТИ
Введение
Проблема оценки характеристик вычислительных систем включает целый
ряд различных аспектов [8.1]. Важнейшими из них являются' прогнозирова¬
ние производительности, расчет оценок производительности и измерение па¬
раметров, характеризующих производительность.
Ни в какой другой области вычислительной техпики нет большей пута¬
ницы в оценке вычислительных систем, чем в области специализированных
машин. Каждая специализированная машина приспособлена для решения оп¬
ределенного круга задач. Сравнить их с универсальными машинами доволь¬
но трудно. В общем случае можно взять несколько универсальных машин,
рассчитать их показатели и сравнить между собой. Что касается специализи¬
рованных машин, то здесь обычно имеется только одна машина, которую не
с чем сравнивать. В этом случае дается описание машины и обсуждаются е.е
достоинства. Какие-либо количественные оценки получить очень трудно.
В наиболее тяжелом случае имеется несколько специализированных и
универсальных машин, которые нужно сравнить между собой. Пользуясь раз¬
нообразием возможностей и требований, искусный разработчик может про¬
вести анализ таким образом, чтобы представить в выгодном свете именно
свою конструкцию. Здесь может сыграть роль и умение убедительно гово¬
рить, и умение торговать. Обычно машина продается не па основе техниче¬
ских данпых, а с учетом политических соображений. Поскольку специализи¬
рованная вычислительная машина создается для выполнения одной опреде¬
ленной работы, то единственной характеристикой, по которой ее можно срав¬
нить с другими машинами, является отношение стоимости к производитель¬
ности.
В области ОКМД-машин оценка оказалась чрезвычайно сложной в связи
• с тем, что: 1) имеется очень много различных концепций, отличающихся свои¬
ми возможностями, 2) реально было создано очень небольшое число машин,
3) имеется несколько фирм, вложивших значительные средства в развитие
разных концепций, 4) на существующих машинах проведено ничтожное ко¬
личество экспериментов с целыо оценки характеристик и 5) многочисленные
сравнения машин но критерию МКС (миллион команд в секунду) неизмери¬
мо усложнили дело. Тем не менее в данной главе речь идет именно об МКС.
МКС — это коммерческая характеристика высокопроизводительных систем,
которая может служить хорошей оценкой по порядку величины для сравне¬
ния возможностей очень похожих между собой машин. МКС теряет смысл во
всех случаях, за исключением ситуации, когда архитектуры совершенно по¬
добны и разработаны для одних и тех же применений.
16 К. Дж. Тербер
241
Когда выполняются такие комапды, как чтение битовых срезов, запись
битовых срезов или сложение битовых срезов, то получить в вычислительных,
'системах с массивами процессоров производительность во много миллионов
или миллиардов операций в секунду не так трудно. Будучи соответствующим
образом определенным и рассмотренным в свете своих ограничений, показа¬
тель МКС может служить разумной предварительной оценкой вычислительных
возможностей (считая, что определены система команд, архитектура, круг ре¬
шаемых задач, процент использования процессоров и т. д.). В каком-либо
другом смысле, кроме предварительной сцепки производительности на случай¬
ном наборе задач, показатель МКС абсолютно не пригоден. С учетом этих об¬
стоятельств может быть проведено сравпепие основпых концепций. Примеры
такого анализа приведены в [8.2—8.6]. Даже эти примеры имеют свои недо¬
статки, которые будут рассмотрены ниже.
Цель, которую преследует сравнение машин, заключается в том, чтобы
определить «лучшую» машину для решения конкретной задачи. Другими ха¬
рактеристиками, требующими обсуждения, являются: логическая организация
машин; тип объектов (слово/байт/бит); расширяемость вверх/впиз (как для
аппаратной, так и для программной части); пропускная способность инфор¬
мационных шип; длина слова; иерархия памяти; развитость программного
обеспечения; возможности операционной системы; вероятность того, что фир¬
ма будет продолжать совершенствование конструкции; скорости сборки к
компиляции; состав периферийного оборудования; структура системы проры¬
ваний и аппаратные средства ее поддержки; система команд; экономичное гь
и качество (компактность и т. д.) объектного кода.
Оценка производительности
Сравнение характеристик машин важпо с точки зрения целого ряда кри¬
териев. Вот некоторые из них: оценка пропускной способности, оценка системы
ввода/вывода, оценка коэффициента использования ресурсов, оценка эффек¬
тивности тех или иных особенностей конструкции или архитектуры, оценка
возможностей программного обеспечения, оценка характеристик программ¬
ного обеспечения и оценка отношения стоимости к производительности.
Для машин класса ОКМД имеется гораздо больше факторов, требую¬
щих рассмотрения. В числе других к ним относятся: схема взаимосвязи про¬
цессоров, характеристики процессоров и наличие программного обеспечения.
Большинство попыток сравнить между собой вычислительные системы с
массивом процессоров базируется на качественном сопоставлении таких
свойств, как гибкость, стоимость изготовления, стоимость разработки и про¬
пускная способность на случайпом наборе задач. Немногие попытки дать ко¬
личественные оценки вычислительным системам с массивом процессоров не-
увенчались особым успехом. Для того чтобы обеспечить правильную оценку
производительности систем с массивом процессоров в условиях недостатка
адекватпых средств для измерения характеристик, пизкой производительно¬
сти ведущих процессоров, а также плохой совместимости ведущего процессо¬
ра и соответствующего массива процессоров, полученные результаты нужда¬
лись в дальнейшем анализе и уточнении.
Проблема оценки производительности детальпо рассмотрена в статье Лу¬
каша [8.1]. Он разбивает задачу на три части: оценка производительности при.
242
выборе машины, проектирование производительности и измерение производи¬
тельности. Эти три части Лукаш рассматривает в следующих аспектах:
1) оценка производительности при выборе машины представляет собой наибо¬
лее часто встречающийся вид оценки, поскольку является средством, исполь¬
зуемым потребителями при покупке машин; 2) проектирование производи¬
тельности в основном используется разработчиками, пькгающимися оценить
ожидаемую производительность, и 3) измерение производительности осущест¬
вляется для того, чтобы оценить работу машины в условиях решения реаль¬
ных задач и влияние возможного изменения состава задач па показатели ма¬
шины. Ниже будут приведены обобщенные результаты, полученные Лукашом
в каждой из этих трех направлений. Для тех, кто может быть связан с по¬
купкой, разработкой пли оценкой ОКМД-машин, важны все три направления.
Кроме этого будут рассмотрены другие показатели, которые пеобходимо при¬
нимать во внимание, имея дело к ОКМД-машинами.
Перед тем как приступить к оценке вычислительных систем, необходимо
ввести ряд понятий. Этими понятиями являются требования и атрибуты.
Требования — это спецификация того, что должна делать система. Требо¬
вание может быть сформулировано в терминах пропускной способности, разме¬
ра, веса, мощности, стоимости, наличия программной поддержки и вероятно¬
сти того, что фирма-изготовитель пе потерпит крах. Требования представляют
собой необходимые условия, которым должна удовлетворять система.
Атрибуты — это характеристики, которые делают одну систему более
предпочтительнее перед другой. Обычно это субъективно оцениваемые свой¬
ства, которые могут рассматриваться как отличительные признаки систем,
позволяющие делать на их основе выбор в ситуациях, когда по требованиям
•альтернативные варианты отличаются мало.
Чаще всего варианты систем, для которых характерны эти признаки, от¬
ражают то, что желает иметь покупатель.
То, что в одном применении является требованием, в другом применении
может быть атрибутом. Примеры требований и атрибутов, приведенные вы¬
ше, показывают, что может быть типичпым требованием или атрибутом.
Нельзя назвать ни одного свойства вычислительных систем, которое обяза¬
тельно классифицируется как требование или атрибут для всех конструкций.
Все конструкторы, потребители и специалисты, занимающиеся совершен¬
ствованием или реконфигурацией систем, должны отдавать себе отчет в том,
что есть требования, а что — атрибуты. Оценка производительности включает
определение того, отвечает ли система множеству требований (в типичном
случае, по отношению к пропускной способности). Если множеству требова¬
ний удовлетворяет более одной системы, то анализ и выбор этих систем осу¬
ществляется па базе атрибутов. Определение требований и атрибутов являет¬
ся трудной задачей. Целыо введения требований и атрибутов является клас¬
сификация систем, однако то, что для некоторых потребителей может быть
атрибутом (например, возможность мультипрограммной работы), для других
может оказаться требованием. В любом случае рассмотрение атрибутов и тре¬
бований будет плодотворным с той точки зрения, что оно должно помочь при
.выборе системы (при разработке или покупке).
4 К числу типичных архитектурных атрибутов вычислительных систем от¬
носятся гибкость, расширяемость и комплексируемость. Понятие «гиб¬
кость» означает легкость, с которой производятся изменения в функциях или
16*
243
используемых подсистемах. Гибкость ие подразумевает добавление новых
функций. В качестве мер для этого атрибута обычно принимаются объем си¬
стемы команд, программная поддержка, аппаратная поддержка, предоставляе¬
мая изготовителем, параметры и конструкция системы шип, наличие варьи¬
руемого периферийного оборудования и т. д.
Понятие «расширяемость» означает легкость, с которой в систему могут
быть введены (или выведены) функциональные возможности п подсистемы.
Мерами для этого атрибута обычно служат совместимость системы ввода/вы¬
вода с интерфейсами разных шин и связным оборудованием, типы и количе¬
ство возможных аппаратных конфигураций, а также возможность вводить в
конфигурацию дополнительный процессор.
Понятие «комплексируемость» означает легкость, с которой к системе мо¬
гут быть подключены различпые подсистемы или периферийные устройства,
после чего все опи образуют единое целое. Это может непосредственно зави¬
сеть от сложности функциональной полноты интерфейсов подсистем. Приве¬
денный выше перечепь атрибутов не является исчерпывающим. Его цель со¬
стоит в том, чтобы показать примеры свойств, которые могут рассматриваться
в качестве атрибутов. Разработчики разных уровней обычпо имеют дело и с
атрибутами разных уровней. Например, перечисленные выше атрибуты ориен¬
тированы на системных разработчиков. Конструктора центрального процессо¬
ра может в большей степени интересовать такой параметр, как гибкость си-,
■стемы комапд и средства микропрограммного управления. Имеются атрибуты,
которые, могут быть ассоциированы с модульностью аппаратной части систе¬
мы. Большинство из них зависит от размера аппаратного модуля и включа¬
ет такие параметры, как стоимость изготовления, стоимость разработки и
технический риск. Существуют торговые атрибуты и атрибуты, используемые
при выборе программного обеспечения. Эти атрибуты включают такие свойст¬
ва, как наличие средств функционального контроля, наличие прикладных
программ, предыдущий успех фирмы-изготовителя при комплекспровапин
системы п вероятность того, что фирма-изготовитель будет и в дальнейшем
успешно вести дела.
Дальнейшее обсуждение атрибутов и требований можпо найти в [8.2] и
[8.3]. Оставшаяся часть этой главы будет в основном посвящена существую¬
щим методам оценки производительности вычислительных систем.
В табл. 8.1 приведены итоговые результаты, отражающие точку зрения
Лукаша [8.1] относительно упомянутых методов оценки производитедьности
вычислительных систем п их применимости к системам. С помощью этой
таблицы Лукаш рассматривает и упорядочивает все основные методы уценки
производительности по степени применимости к оценке для выбора мзпшиы.
расчету производительности н измерению производительности. Каждый из
приведенных в таблице методов оценки производительности обсуждается
ниже.
Такая величипа, как длительность цикла пли время выполнения команды
(обычно сложения или чтения/записи), является совершенно неподходящей
мерой. В области ОКМД-машпн эта мера, вероятно, является преобладающей.
В лучшем случае эта величина может служить некоторой оценкой пропуск¬
ной способности при решепии случайного набора задач. Она полностью игно¬
рирует свойства архитектуры п должна быть отнесена к числу величии, ха¬
рактеризующих дижшою оценку производительности. МКС обычно устакавлж
244
Таблица 8.1
Показатели прпмснимостп методов сцепкп производительности (но Лукашу)
Цель оценки
Оценка йрн
выборе систе¬
мы (система
где-нибудь
имеется)
Расчет произ¬
водительно¬
сти (система
еще не су¬
ществует)
Измерение
производи¬
тельности
(система нахо¬
дится в УКС-
плуатации)
Метод оценки
Новое оборудо¬
вание
Новое программ¬
ное обеспечение
Создание нового
оборудования
Создание нового
программного
обеспечения
Реконфигурация
оборудования
Замена про¬
граммного обе¬
спечения
Длительность цикла
1
1
—
—.
Смесь команд
1
—
1
—
—
—
Представительные программы
2
1
2
1
—
1
Аналитические модели
2
1
2
1
2
—
Испытательные программы
3
3
—
2
2
2
Синтетические программы
3
3
2
2
2
2
Моделирование
3
3
3
3
3
3
3
Измерительные средства (програм¬
мные н аппаратные)
2
2
2
2
3
Обозначения:—Метод неприменим. 1 — Метод использовался, но оказался
неадекватным, 2 — оказался полезным, но не достаточно: нужно применять совместно
с другими методами, 3 — дает хорошие результаты.
ваготся только для одной операции, которая может в значительной степени
характеризовать машину или ее пропускную способность. При использовании
этой меры игнорируется использование или наличие любого программного
обеспечения. Использование оценки, основанной па временных характеристи¬
ках, было преобладающим во многих исследованиях ранних ОКМД-машпп.
Метод, оспованный на использования смеси команд, дает несколько луч¬
шие результаты, чем временные характеристики. В этом методе выделяются
некоторые типы команд и взвешиваются в соответствии с частотой их появле¬
ния. Выбраппая смесь базируется па свойствах решаемой задачи и может да¬
же в некоторой степени отражать архитектуру машины. Основное преимуще¬
ство этого метода перед методом временных характеристик состоит в том,
что в нем задействовано больше комапд и, следовательно, большее число
свойств машины вовлечено в рассмотрение, однако и здесь все еще игнори¬
руются такие свойства, как длина слова и пропускная способность информа¬
ционных шин. Существует проблема с выбором подходящего состава смеси.
Полученные в результате оценки данные характеризуют только аппаратную
часть машины. :
Третий метод состоит в использовании представительных программ. Пред¬
ставительная программа — это типичная для данной системы программа, ко¬
торая кодируется полностью или частично. Затем делаются временные оценки.
Примеры применения этого метода приведены в [8.4] и [8.5]. Главный недо¬
статок метода представительных программ заключается в следующем: пе мо¬
245
гут учитываться все свойства машины (в особенности характеристики систе¬
мы ввода/вывода и уникальные свойства), однако метод и не направлен на
использование информации, выходящей за рамки системы команд. Неспособ¬
ность адекватно оцепить сложные, частично перекрывающиеся конструкции,
степень использования оборудования (число активных элементов), накладные
расходы на диспетчеризацию, взаимное влияние каналов и время, необходи¬
мое для кодирования прикладных программ,— все это относится к недостат¬
кам метода представительных программ. В процессе компиляции и счета пред¬
ставительных программ могут быть оценены некоторые части программного
обеспечения н ряд системных свойств.
Следующий метод заключается в использовании аналитических моделей. Он
основан па представлении вычислительной системы в терминах теории массо¬
вого обслуживания. Модели дают сведения о поведении системы в целом или
ее отдельной подсистемы. Главная проблема, связанная с моделями, состоит в
том, что каждая такая модель должна разрабатываться индивидуально для
каждой системы. Модели обеспечивают получение параметрических оценок
[8.4]. К недостаткам моделей относятся: 1) невозможность моделировать си¬
стемы программного обеспечения; 2) невозможность учитывать случайные
пли обусловленные результатом выполнения программ эффекты; 3) трудность
изменения параметров модели, если модель недостаточно хорошо построена;
4) трудность разработки; 5) моделирование системы может оказаться слишком
сложной задачей, в особенности в части взаимодействия между оборудовани¬
ем и программным обеспечением. Одна из главных проблем' состоит в том, что
модели, которые можно реально построить, обычно оказываются столь, упро¬
щенными, что не могут дать -сколько-нибудь информативные данные. Модели
теории массового обслуживания даже для простых систем обычно оказывают¬
ся очень сложными, и объем получаемых с их помощью знания оказывается
непропорционально малым с сравнении с затратами усилий па разработку
модели.
Испытательные программы представляют собой специально разработан¬
ные программы, предназначенные для трансляции и исполнения на исследуе¬
мой машине. Это первый из рассмотренных до сих пор методов, который мо¬
жет обеспечить получение адекватных результатов, учитывающих особенно¬
сти программного обеспечения н системы в целом. Главная проблема, связан¬
ная с применением испытательных программ, состоит в том, что эти прог¬
раммы могут не отражать черты реальных программ пользователя. Для того
чтобы обеспечить получение информативных данных, должна быть задейст¬
вована вся система. При оценивании специализированных машин метод испы¬
тательных программ является наиболее важным из имеющихся в наличии
средств. Поскольку область применения всегда известна, то особенности за¬
дач из этой области могут быть отражены в испытательных программах, что
дает возможность получить сравнительные оценки стоимостной эффективно¬
сти для конкурирующих машин.
Обобщением принципа испытательных программ является метод синтети¬
ческих программ. Синтетическая программа — это комбинация представитель¬
ной и испытательной программ. В качестве синтетической программы может
(выступать уже имеющаяся представительная программа, в которой учтены
особенности системы ввода/вывода и программного обеспечения. В этом мето¬
де сочетаются достоинства и недостатки как испытательных, так и предста-
246
вптельпых программ. Преимущество спптетической программы состоит в том,
что она может быть разработана для измерения специфических параметров л
их взаимосвязи. Для этого метода, существует проблема соответствия, заклю¬
чающаяся в том, насколько хорошо используемые программы отражают черты
потока заданий пользователя.
Моделирование является, вероятно, паплучшнм средством проникновения
в суть работы системы в целом. Имеется два основных подхода к моделиро¬
ванию: 1) событийный (когда моделируются реальпые системные операции)
и 2) эмпирический (когда используются данные, получепные при реальных
работах). Главная проблема, связанная с методом моделирования, состоят в
стоимости разработки и эксплуатации моделирующей программы? Определе¬
ние моделирования достаточно сложпо. Преимущества моделирования заклю¬
чаются в том, что опо дает средства (хотя и дорогостоящие) прогнозирования
параметров системы и, как следует из табл. 8.1, оказывается эффективным па
всех этапах разработки вычислительных систем, их оценки и измерения пара¬
метров. Одной из важных проблем при моделировании является вопрос
о доверительном интервале полученпых данных. Насколько точно модель,
ее входные параметры и т. д. отражают реальную систему? Для того чтобы
обойти эти вопросы, необходимо собрать большое число данных и произве¬
сти анализ чувствительности системы. Эта задача разрешима, одпако такой
анализ требует больших затрат машинного времени и человеческого труда.
Методы моделирования обладают большими потепциалыгымп возможностями,
но могут оказаться слишком дорогостоящим и требующими больших затрат
времени.
Измерение производительности является наилучшим способом отыскания
узких мест в существующих системах. Важное значение имеет оценка вно¬
симых в систему изменений. Процесс измерения параметров системы состо¬
ит из двух этапов: сбора данных и анализа данных. Разработчик измеритель¬
ных средств должен заботиться о том, чтобы в процессе сбора данных пе ока¬
зывать влияния на функционирование системы, чтобы пе исказить статисти¬
ку. Измерительные средства могут быть как программными, так и аппаратны¬
ми. Программные средства обычно являются более простыми и дешевыми в
реализации. Главпый недостаток измерителей состоит в том, что они лишь
собирают статистику, которая требует анализа.
Оценка ОКМД-машин
ОКМД-спстемы обычно описываются в терминах параметров блока обра¬
ботки команд, т. е. наиболее неудачным и бесполезным способом оценки. Был
проведен ряд исследований с использованием представительных п синтети¬
ческих программ. В [8.6] проведено сравнение производительности ОКМД-
процессоров с помощью синтетических и представительных программ приме¬
нительно к задачам обработки радиолокационной информации. Т. Чен [8.7]
разработал модели, которые применимы к системам параллельной обработки.
Вопросы построения испытательных программ для вычислительных систем с
массивом процессоров рассмотрены в [8.8—8.12]. Фуллер [8.13] сравнивает
архитектуру типа OMEN с архитектурой типа ILLIAC IV. Вывод этих иссле¬
дований состопт в том, что ОКМД-про’цессоры, как можно показать, обладают
большими потепциалытыми преимуществами при решении ограниченного кру¬
га задач, для которых характерно наличие жестких временных ограничений.
247
Заключение
По-виднмому, существует несколько направлений, по которым следует раз¬
вивать средства получения данных, необходимых для разработки, модерниза¬
ции и измерения характеристик ОКМД-машин. К ним относятся: • 1) создание
«универсального» моделирующего комплекса для вычислительных систем с
массивом процессоров, 2) осуществление программы измерений характеристик
действующих'параллельных процессоров и 3) создание и исследование моде¬
лей машин. До тех пор, пока все эти мероприятия не будут осуществлены
самым серьезным и добросовестным образом, ОКМД-машпны будут продол¬
жать оценивать в терминах МКС. К настоящему времени не известно, чтобы
кто-нибудь в достаточной степени занимался работой по оценке ОКМД-машин,
а такая работа необходима, чтобы навести порядок в этой области. Фирма
Goodyear предоставляет пользователям лабораторные средства проверки си¬
стемы STARAN с помощью представительных программ.
У и р а ж н е н и я
8.1. Почему показатель М.КС не годится для оценки производительности
систем?
8.2. Разработайте несколько представительных программ, которые моглп
бы использоваться для сравнения производительности систем ILLIAC IV,
OMEN, РЕРЕ и STARAN.
8.3. Напишите спецификацию моделирующего алгоритма для моделирова¬
ния ОКМД-процессора общего типа, в котором параметры процессорных эле¬
ментов, структура взаимных связей и т. д. являются переменными парамет¬
рами.
8.4. В предположении, что предложен некоторый метод сравнительной
оценки систем ILLIAC IV, OMEN, STARAN и РЕРЕ, обсудите критерии, кото¬
рые должны быть использованы для оценки качества этого метода.
Глава 9
БУДУЩЕЕ ОКМД-МАШИН
Введение
Вот уже более двадцати лет специалисты изучают круг задач, требования,
концепции и области применения, связанные с вычислительными системами
жласса ОКМД. К настоящему моменту создано лишь четыре системы этого
класса: OMEN [9.1], STARAN [9.2], ILLIAC IV [9.4] и РЕРЕ [9.5]. До сих пор
ILLIAC IV [9.17] оставался самой крупной из построенных машин класса
ОКМД. Раисе бьтд создан ряд систем, явившихся предвестниками этих мощ¬
ных машин. К и им относятся: ассоциативная память фирмы Honeywell [9.6],
ассоциативная память на БИС [9.7] и ILLIAC III [9.3].
Сторонники ОКМД-машии склонны преувеличивать их роль точпо так же,
как противники склонны ее преуменьшать. Сторонники заявляли о возмож¬
ности использования этих мантии в качестве универсальных. Это совершенно
неправильно. Специализированная вычислительная машина — это спецпализи-
ровапная машина, это... ОКМД-машина, которая, однако, может оказаться при¬
годной пе только для единственного применения и поэтому может рассматри¬
ваться как многоцелевая вычислительная система. Последнее свойство не ме¬
няет специализированную природу таких машин. В данной главе будет сдела¬
на попытка обсудить аргументы за и против СЖМД-архитектур.
Главные противники ОКМ Д-машин указывают на широкую поддержку,
оказанную правительством разработке этих машин,'и утверждают, что никогда
еще столь незначительные результаты пе достигались за счет столь больших
расходов. Они упускают из виду ряд важных моментов. Во-первых, в тече¬
ние первых нескольких лет развития систем класса ОКМД большая часть
средств была затрачена на создание ранее не существовавших технических
средств. Во-вторых, эти средства в сравпепил с затратами па производство
универсальных вычислительных машин являются, как говорится в пословице,
каплей в море. В-третьих, ОКМД-машипы являются специализированными и,
следовательно, применяются для решения узкого круга задач. В-четвертых, по
крайней мере небольшие по объему ассоциативные запоминающие устройства
нашли применение в универсальных машинах в качестве средств аппаратной
поддержки вычислительного процесса, например, в механизмах виртуальной
памяти. Последнее и самое главное — современные модели были создапы в
короткие сроки, в основном за счет последних достижений технологии изго¬
товления элемептов. Это, одпако, может продолжаться до некоторого предела.
По утверждению Во [9.8] характеристики элемептов могут быть улучшены па
четыре порядка. Если логические схемы с эмиттерными связями, имеющие
время срабатывания 1 не, должны стыковаться с проводом длиной 30 см, то
результирующее время срабатывания станет равным 3 не. При дальнейшем
249
повышении быстродействия конструкторы должны опираться па такие факто¬
ры, как повышенно уровня интеграции и улучшение системной структуры.
Создание процессоров класса ОКМД представляет собой одни из путей со¬
вершенствования системной структуры, позволяющий получать высокопроиз¬
водительные специализированные системы, ориитпровапные на такие приме¬
нения, в которых одни и те же операции должны одновременно производить¬
ся над множествами данных. Другим перспективным направлением является
создание систем с распределенной обработкой [9.9]. Очевидно, что для повы¬
шения производительности систем потребуется скорее совершенствование
структуры, нежели повышение быстродействия элементной базы. ОКМД-про-
цсссоры образуют фундаментальный класс машин, являющихся перспектив¬
ными по целому ряду причин. Во-первых, подобно запоминающим устройст¬
вам они имеют регулярную структуру, что облегчает их реализацию с по¬
мощью больших интегральных схем. Во-вторых, процессорные элементы имеют
тенденцию к упрощению, что делает их легче поддающимися регуляризации
и построению с помощью БИС. В-третьих, поскольку они состоят из большого
числа элементов, то невосполнимые затраты на разработку элементов могут
быть быстро скомпепсировапы. В-четвертых, успехи в развитии микропроцес¬
сорной технологии снижают стоимость микропроцессоров и делают возможным
их использование в больших количествах. Наиболее аргументированные воз¬
ражения против ОКМД-процсссоров выдвинуты Шором [9.10—9.12].
Аргументы против ОКМД-машин
Точка зрения Шора состоит в том, что параллельные процессоры являют¬
ся не чем иным, как расширением обычных машин, позволяющим как бы на
скорую руку улучшить отношение «производительности к памяти». Он ввел
определение шести машин, начиная от Машины I и кончая Машиной VI. Эти
машины показаны на рис. 9.1—9.6.
Сокращения, использованные па рис.
9.1—9.6 означают: ПД — память дан¬
ных, ПЭ — процессорный элемент,
ПК — память команд, УУ — устрой¬
ство управления, ПСВО — память со
встроенной обработкой. Связи между
этими устройствами показаны лини¬
ями, оканчивающимися стрелками,
которые указывают, с какой стороны
осуществляется доступ к памяти,
или то, каким образом осуществля¬
ется взаимодействие между УУ и
ПЭ. Машина I представляет собой
обычный цептралыгый процессор
(процессор с обработкой условных
срезов).
Машина II образована путем поворота памяти Машины I на 90°, в резуль¬
тате чего получился ассоциативный процессор с обработкой битовых срезов.
Для обеспечения эффективности количество бит в битовом срезе должно быть
большим, т. е. количество ПЭ должно быть увеличено.
Рис. 9.1. Машина I
250
Машина III объединяет в себе черты машпп I и II (ортогональная ма¬
шина Шумана).
Машина IV образована путем размножения ПЭ и ПД Мапшпы I. Это па¬
раллельный процессор, подобный РЕРЕ, совершенно аналогичный Машине II,
Рис. 9.2. Машина управления II
Рис. 9.3. Машина III
по имеющий более сложные процессорные элементы. ПЭ и ПД в Машине IV,
как правило, более сложные, чем в Машине II.
В Машине V введены взаимосвязи между процессорными элементами.
Примером такой структуры является ILLIAC IV.
Машина VI имеет память со встроенной обработкой. В Машине I и V по¬
вышение быстродействия достигается путем увеличения объема оборудования,
Память
Память
данных
данных
j Память
данных
Процессорный! j Процессорный
Процессорный
модуль j j модуль
модуль
Г' J
Память j
команд j
f
УУ
Рис. 9.4. Машина IV
окружающего память. В Машипе VI (МПЛС Котца) сделана попытка вклю¬
чить добавочные аппаратные средства в память. Шор утверждает, что между
всеми этими машинами существует очень маленькая разница. Он рассматри¬
вает данные машипы как различные варианты использования памяти. Шор
оспаривает специализированную природу таких машин. Он выдвигает несколь¬
ко интересных соображений относительно параллельных процессоров.
251
Бот они:
1) в рассматриваемых машинах имеется тенденция к увеличению отно¬
шения объема оборудования, связанного с обработкой и с памятью, в пользу
обработки;
2) коэффициент загрузки оборудования, а именно, доля логических схем
ПЭ, используемых в каждый момент времени, целесообразно применять в ка¬
честве меры эффективности машин;
3) чем больше отношение производительность/память, тем более спецыа-
лизованной является машипа;
4) эффективная пропускная способность есть количество результативной
активности (работы);
5) невозможность пайти иных применений для ОКМД-мапшн, кроме ха¬
рактеризующихся низкими значениями коэффициентов загрузки, указывает
Рис. 9.5. Машипа V
па трудности, связанные со специализированными машинами, т. е. на то, что
они применимы для решения ограниченного круга задач.
Далее рассматриваются несколько важных мыслей, высказанных Шором в
неявном виде. Суть его аргументов
можно сформулировать следующим
образом:
1) специализированные вычис¬
лительные машины по определению
являются бесполезными впе данно¬
го круга задач (состоящего, быть
может, из одной задачи);
2) коэффициент загрузки той
или иной аппаратуры не являются
информативными показателями (в
их число входит коэффициент загрузки памяти);
3) в высокопроизводительных моделях Машины I и в многопроцессорных
системах, создаваемых на ее основе, доминирующим фактором будет стоимость
программного обеспечения;
4) большие интегральные схемы, ив особенности микропроцессоры па БИС,
могут оказаться очень эффективными при создании параллельных систем.
Память
со встроенной
обработкой
Рис. 9.G. Машина VI
252
Шор является автором многих ценных мыслей, з полужив аюгцих серьез¬
ного рассмотрения. Он аргументированно ставит под сомнение принцип па¬
раллельной обработки. Возможно, именно сейчас, когда создано много разных
архитектур, настало время разобраться, что же действительно сделано. Шор
начал такое интроспективное исследование. Между тем вычислительные си¬
стемы с высокой степенью параллелизма неизбежно подвергаются оценке и
критическому анализу с целыо выявить их экономическую эффективность.
Анализ Шора представляет большой интерес.' Однако существует один фак¬
тор, из-за которого ценность исследования может быть снижена. Это вопрос
о размерах и сложности различных ПЭ, ПД, ПК и УУ, использованных при
сравнительных оценках.
В самом деле, невозможно провести корректное сравнение различных
концепций с аппаратной точки зрения, если оборудование отличается по раз¬
мерам и по сложности так сильно, как это имеет место для подсистем, попада¬
ющих в область, рассматриваемую Шором. Например, память даппых в Ма¬
шине I может быть иерархической, содержащей миллионы бит и включающей
накопители на сердечниках, диски и магнитные ленты. ПД в Машине II мо¬
жет быть выполнена в виде полупроводниковой памяти с произвольным до¬
ступом объемом 64 К, используемой в качестве ассоциативной памяти. Все¬
объемлющее сравпение шести совершенно различных архитектур и получение
информативных результатов является очень трудной задачей. Тем не менее
Шор выдвигает ряд интересных моментов, которыми не следует пренебрегать.
При внимательном и разумном подходе представленное обсуждение имеет
интересные продолжения.
Параллельные или многомашинные системы?
Мы живем в мире, который требует от пас последовательности действий.
Существующие архитектуры вычислительных систем ни в коей мере пе яв¬
ляются моделями физических явлений. Современные машины базируются па
модели вычислений. До сих пор последовательные машины представляли со¬
бой наиболее дешевый путь решепия задач* в большинстве практических об¬
ластей. Системы, для которых такие машины оказываются непригодными,—
это системы реального времепи или системы, требующие больших объемов вы¬
числений. В системах реального времени универсальные последовательные
машины ни в коей мере не отражают физическую среду и последовательность
осуществляемых ею действий. Если одна машина не обладает достаточной про¬
изводительностью, то и многопроцессорный вариант также не даст желаемого
результата из-за возникающих при этом больших накладных расходов на дис¬
петчирование п конфликтов при обращениях к памяти. Ввиду неприспособ¬
ленности универсальных машин обычно используются специализированные
машины, сконструированные с учетом требований задачи. В ряде случаев
универсальные машины используются в многопроцессорном варианте. Далее
будут рассмотрены вопросы, связанные с многопроцессорными машинами.
Bo-первьтх, существует проблема накладных расходов на диспетчировапие.
В системах общего назначения включение дополнительного центрального про¬
цессора приводит, из-за добавочных накладных расходов, к увеличению сум¬
марной производительности на величину, меньшую чем производительность
одного ЦП. В некоторых случаях эти расходы превышают возможности од-
253
пого ЦП, так что добавление нового процессора приводит к снижению общей
производительности системы.
Положение дел может быть улучшено в системах с относительно фикси¬
рованным составом решаемых задач, таких как сидтема управления воздуш¬
ным движением, по и здесь все еще останутся ситуации, когда добавление по-
вого ЦП уменьшает общую пропускую способность системы. Это явленно
Рпс. 9.7. Характеристики мно- Рис. 9.8. Характеристики многопро-
гопроцессорной системы 1108 цессорной системы CYBER 74
обусловлено накладными расходами па диспетчирование, конфликтами при
обращениях к памяти и к системе ввода/вывода. Один из обходных путей
решения проблемы заключается в распределении функции внутри системы.
Неверно было бы считать, что в этом случае добавление в многопроцессорную
конфигурацию нового процессора сопряжено
с потерей нескольких процентов его произво¬
дительности. На рис. 9.7, 9.8 и 9.9 изображены
характерные графики, показывающие эффект
падения производительности, о котором шла
речь. Эти кривые построены па основе данных,
полученных только с помощью испытательных
программ и моделирования Паттоном [9.13,
9.14]. Рис. 9.7 относится к системе Univac 1103,
рис. 9.8 — к системе CDG Cyber 74 и рис. 9.9—
к системе Honeywell 6050/60. Параметры точ¬
ки перегиба с некоторой! степенью вероят¬
ности могут быть распространены на системы
реального времени. Когда число процессоров
Рис. 9.9. Характеристики мно- д0стигает Трех, дальнейшее увеличение их ко-
гопроцессорнои системы ^ r J
6050/60 личества сопровождается заметным снижени¬
ем вклада в суммарную производительность.
В трсхпроцессорпой системе Univac этот вклад имеет отрицательный знак, а в
системах CDC и Honeywell, оставаясь положительным, уменьшается по абсо¬
лютной величипе. Данный эффект целиком происходит из-за конфликтов при
обращениях к памяти, поэтому завал кривой может быть уменьшен за счет
правильного подбора объемов локальной осповной памяти второго уровня.
Число процессоров 6050/60
254
Увеличение объемов локальных запоминающих устройств обычно приводит к
уменьшеншо числа конфликтов и росту производительности. Конструкторы
обычно считают, что относительное нрнрахценйе производительности в муль¬
типроцессорной системе становится практически неощутимым при числе про¬
цессоров больше четырех.
Даже предполагая, что проблема конфликтов между ЦП решена, конст¬
руктор должен учитывать другие недостатки мультипроцессорных систем, на¬
пример, увеличение стоимости наращивания оборудования. Ввод в систему
нового большого и сложного ЦП обходится зиачитсльио дороже по сравнению
с добавлением еще одного простого процессорного элемента в вычислитель¬
ную систему с массивом процессоров. Существует много видов «неявных»
затрат, сопряженных с вводом ЦП, такнх как перекомпоновка рабочих про¬
грамм, перераспределение их между процессорами, а также затрат, связанных
с разработкой повой операционной системы, способной управлять повой кон¬
фигурацией. Намного дешевле, например, добавить в систему РЕРЕ несколь¬
ко недорогих процессорных элементов, чем затратить миллион долларов на
дополнительный центральный процессор.
Стоимость развертывания системы, включая изготовление аппаратуры,
программного обеспечения, монтаж оборудования, изготовление местных и
удаленных периферийных устройств, разработку прикладных программ, реа¬
лизующих функциональные алгоритмы системы, а также сопровождение, за¬
висит от масштабов системы и, следовательно, является расчетной системной
.характеристикой. В больших многопроцессорных системах сложность прог¬
раммного обеспечения с добавлением нового центрального процессора растет
экспоненциально в сравнении с тем, когда к меньшему по производительно¬
сти ЦП для улучшения его характеристик добавляется матричный процессор.
Кроме того, настроить большую многопроцессорную систему па решение опре¬
деленной задачи более трудно. В большой многопроцессорной машине опера¬
ционная система более сложна, она является более трудной для программи¬
рования, может иметь большее время простоя и сложна в изготовлении.
В больших монолитных системах сложность распространяется незаметно и
повсеместно, скрадывая производительность и делая систему неэффективной
по стоимости или даже неработоспособной.
Данные, полученные в последние годы в процессе создания большинства
информационных систем для управления воздушным движением, обслужива¬
ния банковских операций, а также относящихся к системам военного назна¬
чения, подтверждают этот факт. Когда стоимость разработки системы будет
объективно сопоставляться с ее сложностью, то наступит время, когда уни¬
версальная вычислительная машина, снабженная дополнительным ОКМД-
процсссором, окажется экономически более эффективной, чем более мощная
универсальная машина, которая была бы способна удовлетворить системным
требованиям.
Процессоры с высокой степенью параллелизма являются более специали¬
зированными, чем универсальные машины, однако существуют специфические
области применения, в которых они призваны работать и в которых только
они имеют превосходство над сверхпроизводительными последовательными ма¬
шинами. К этим специфическим областям относятся обработка радиолокаци¬
онной информации, предсказание погоды, противоракетная оборопа, управле¬
ние воздушным движением, а также некоторые задачи управления большими
255
базами данных. В перечисленных областях увеличение производительности
согласно прогнозу Вестингауза [9.15] может достичь трех порядков по сравне¬
нию с последовательными универсальными машинами. В таких областях важ¬
нейшей задачей является обеспечение высокой готовности и реактивности.
Речь идет о системах реального времени, в которых быстрота реакции на
внешний сигнал является более важным параметром, чем пропускная способ¬
ность системы.
Потенциальные возможности ОКМД-процессоров
Начало развития ОКМД-маптип теспо связано с техникой .измерения ре¬
альной производительности. Как бы мпого предположений пи делалось отно¬
сительно этих процессоров, только испытания могут либо подтвердить их, ли¬
бо опровергнуть. Здесь уместпо рассмотреть различные подходы и гипотезы.
По мнению Флинна [9.10], дальнейшее развитие параллельной обработки бу¬
дет подобно курсу корабля, который должен пройти между Сцнллой и Хари¬
бдой, каковыми являются закон Гроша [9.18] и гипотеза Минского [9.19].
Закон Гроша гласит, что па каждой стадии развития производительность уни¬
версальных машин растет как квадрат их стоимости. Этот закоп подвергся
широкой проверке па экспериментальных данных, полученных в ходе разра¬
ботки трех поколений вычислительных мантии, и хотя некоторые последова¬
тели считают, что показатель степени роста равен 1,5, а другие являются сто¬
ронниками традиционного значения, равного 2, тс и другие очень мало вни¬
мания уделили тому, какие факторы реально определяют «стоимость» [9.18].
Другая угроза, гипотеза Минского, утверждает, что производительность ОКМД-
машин пропорциональна log2 яг, где т — количество потоков данных, прихо¬
дящихся па один поток команд.
Хотя закоп Гроша и гипотеза Минского основываются на мощных аргу¬
ментах и, по-видимому, подкрепляются экспериментальными данными, их не
следует принимать в качестве абсолютпой основы оценок при сравнении по¬
следовательных универсальных машин с параллельными вычислительными
системами. Существуют примеры, противоречащие гипотезе Минского. Эти
примеры рассматриваются ниже. Далее^ специализированные машппы могут
конструироваться и настраиваться на эффективную работу в определенной
среде. На задачах, приспособленных для решения на ОКМД-процсссорах, гипо¬
теза Минского может быть легко опровергнута.
Показатели стоимости
Показатель стоимости, фигурирующий в законе Гроша, заключает в себе
несколько факторов. Споры вокруг показателя степени (1,5 или 2 или како¬
го-либо еще) по крайпей мере частично объясняются расхождениями при
расчете стоимости. Непременным условием более реалистичной оценки сто¬
имости является точный учет составляющих ее компонент. Составляющие
стоимости жизпепиого цикла илп приравненные к ним показатели — вот фак¬
торы стоимости, которые необходимо принимать во внимание. Обычно хоро¬
шими мерами стоимости являются стоимость создапия эффективной операци¬
онной системы пли сумма ежегодных эксплуатационных расходов в
в течепие всего жнзненпого цикла. Некоторые показатели могут также быть
256
приняты в качестве подходящих факторов стоимости из-за их экономического
воздействия па общество. Для того чтобы адекватно определить стоимость мно¬
гих факторов, последние должны быть нормализованы. Необходимым условием
проведения информативного анализа является одинаковость расчетных мето¬
дов и допущенных упрощений.
Эти факторы редко напрямую связаны со стоимостью разработки логиче¬
ских схем элемептов, затратами на создание производственной базы для се¬
рийного выпуска элементов или продажной ценой оборудования вычислитель¬
ной системы. Связь рыночной цены вычислительной машины со стоимостью'
ее разработки мала, если имеется вообще. Закон Гроша, сопоставляющий
ориентировочную производительность, выраженную в МКС или в смешанных
тактах Гибсона, с продажной ценой, и аналогичный закон, связывающий про¬
изводительность в реальной среде со стоимостью развертывания системы или
затратами па весь жизненный цикл, выглядят совершенно по-разному. Сто¬
имость развертывания, включающая стоимость оборудования, программного-
обеспечения, монтажа, местных и удаленных периферийных устройств, со¬
провождения и модернизации, содержания штата операторов и обслуживающе¬
го персонала, определяется масштабом системы. По мере возрастания масш¬
таба с увеличением проектируемой производительности все перечисленные
стоимостные показатели также возрастают.
Следует рассмотреть еще один показатель, позволяющий пскоторым об¬
разом нормализовать по отношению к сложности как закон Гроша, так и ги¬
потезу Мппского. По мере роста масштаба и мощности универсальной вычи¬
слительной системы (увеличения ее ориентировочной производительности)
трудность ее успешного развертывания (или вероятность неуспеха разверты¬
вания) в составе реальной системы также возрастает [9.28]. Оказывается,,
в больших системах сложность растет экспоненциально, в отличие от малых
и средних систем подобной конфигурации; запрограммировать, отладить и со¬
провождать операционную систему оказывается слишком трудно, если вообще
возможно; чем больше система, тем меньше среднее время безотказной работы
и больше среднее время восстановления п т. д. В очень больших моно¬
литных системах сложпость будет распространяться незаметно и повсеместно^
скрадывая производительность системы, за исключением случая, когда послед¬
няя является полностью статической, и делая систему экономически неэф¬
фективной или даже неработоспособной. Это обстоятельство подтверждается-
экспериментальными данными последних лет из области систем управления
воздушным движением, систем управления банковскими операциями и систем
военного назначения.
Закон Гроша имеет характер относительного закона п может быть при¬
менен к любым системам с соблюдением мер предосторожности и только в ог¬
раниченном смысле. Бессмысленно использовать закон Гроша для сравнения
параллельных и универсальных вычислительных маштш. Если все показатели
стоимости объективно учтены, а затраты па конструирование системы взвеше¬
ны в соответствии с ее сложностью, то окажется, что как бы бесконечно ни
экстраполировать закон Гроша (либо неявно, поскольку это делалось истори¬
чески, либо явно, поскольку с проблемами быстродействия элементпой базы
придется столкнуться в недалеком будущем), ппкогда пельзя будет сказать,
что намного больший последовательный процессор всегда будет экономически
более эффективным, чем любой альтернативный параллельный процессор. Не¬
17 к. Дж. Тербер
25?
которые противники параллельных систем с помощью экстраполяции закона
Гроша доказывают, что всегда для любой заданной прикладной области через
некоторое время будет создана экономически более эффективная последова¬
тельная универсальная машина, причем это произойдет именно потому, что
вычислительная мощность растет как квадрат стоимости.
Самым большим недостатком универсальных машин оказывается то, что
является их главным достоинством, а именно универсальность. Машины тако¬
го рода создавались для универсальных применений, так чтобы удовлетворить
широкому спектру требований. В совокупности конструкторских критериев
.заложены некоторые компромиссы (например, для удовлетворения требова¬
ниям, выдвигаемым разработчиками военных систем), которые, хотя и сделали
машины коммерчески более выгодными, все же оставили большие системы ре¬
альною времени чужеродными областями. Системы реального времени состав¬
ляют незначительную долю от общего количества прикладных областей, по¬
этому естественно, что их требования не принимаются во внимание разработ¬
чиками коммерческих машпп. Для того чтобы сделать такие машины
пригодными для работы в реальном масштабе времени, необходимо произвести
крупные и дорогостоящие доработки аппаратурной части или системного про¬
граммного обеспечения, что делает закон Гроша неприменимым. Закон Гроша
не учитывает структуру вычислительной системы. В некоторых прикладных
областях вместо расширения мультипроцессорной системы лучше добавить к
пей матричньрй процессор, способный выполнять определенные функции, тог¬
да дальнейшее расширение объема этих функций будет проще.
Хотя сравнивать машины между собой трудно, все же можно вывести
оценки для граничных значений стоимостной эффективности. Стоимость про¬
цессорных элементов системы РЕРЕ, суммарная производительность которых
равна ориентировочной (выраженной в МКС) производительности универсаль¬
ной машины CDC 7600, составляет 10% от стоимости CDC 7600. Затраты па
развертывание комбинированной системы 7600-РЕРЕ составили бы 55% (49%)
от стоимости двухмашинной (трехмашинной) конфигурации CDC7600. Про¬
граммное обеспечение CDC 7600 в многомашинной конфигурации, состоящей
только из этих машин, потребовало бы значительной переработки. В конфи¬
гурации 7600-РЕРЕ объем переделок будет меньшим, и она лучше подходит
для решения задач противоракетной обороны, чем конфигурация, составляю¬
щая только из CD С 7600.
Хотя коэффициент использования ресурсов может быть не таким высоким,
как в последовательной машине, процесс распределения ресурсов требует от¬
носительно постоянного объема накладных расходов (этот процесс всегда один
и тот же независимо от количества активных элементов), тогда как в очень
больших последовательных машинах может наступить насыщение, означаю¬
щее, что процесс распределения ресурсов сам потребляет все больше и больше
этих ресурсов. Аппетит системы распределения ресурсов растет быстрее всего
•тогда, когда система имеет меньше всего возможностей его удовлетворить.
По мере того как все большее число процессов выстраиваются в очередь, что¬
бы получить свою часть определенного единственного ресурса, процесс распре¬
деления ресурсов потребляет некоторую долю этого ресурса, увеличивая тем
самым число процессов в очереди, что вызывает дальнейшее увеличение затрат
на процесс распределения ресурсов и т. д. Проблему усложняет то, что опи¬
санная ситуация может возникнуть в самое неподходящее время, например,
258
при насыщении системы, работающей в реальном масштабе времени, что вызы¬
вает лавинообразное снижепие характеристик в наиболее критический момент.
Расширение возможностей системы с параллельным процессором свободно
от ограничений, накладываемых программным обеспечением в последователь¬
ных машинах. Способность параллельной машины к росту является ее таким
же неоценимым и бесспорным преимуществом, как и относительная незави¬
симость времени обработки последовательных порций данных.
Если параллельный процессор содержит достаточное количество элемен¬
тов, то устройство управления никогда не знает, сколько элементов являются
активными. Первое из перечисленных свойств архитектуры систем с массивом
процессоров разрешает увеличивать число процессорных элементов (вплоть
до некоторого предела) без серьезного вмешательства в ту часть программного
обеспечения, которая формирует поток команд, разумеется, при условии, что
имеется устройство разрешения множественных совпадений; последнее обес¬
печивает постоянство времени получения решения независимо от потока дап-
ных (не превышающего порога насыщения). В условиях перегрузки можпо вы¬
делять согласно некоторому алгоритмическому' критерию «наиболее важные»
данные, создавая тем самым как бы сокращенный вариант обработки, что не¬
возможно реализовать в последовательной машине из-за больших затрат па
сортировку и сравнение данных, но легко реализуется в режиме ассоциатив¬
ного выбора в матричном процессоре. Данная функция легко и без больших
затрат реализуется па любом ОКМД-процессоре, включая параллельный про¬
цессор, причем в последнем не требуется наличие ассоциативных возможно¬
стей, так как указанный процесс может быть реализован с помощью средств
управления активностью. Эти сродства обеспечивают функциональную и ло¬
гическую модульность параллельного процессора, делая его мепее сложным,
чем большая последовательная машина. Параллельный процессор легче ремон¬
тировать и поддерживать в рабочем состоянии, поскольку процессорные эле¬
менты в уже готовой системе легко поддаются демонтажу и замене.
Даже если проблемы сложности и распределения ресурсов по делают за¬
дачу нерешаемой, то и в этом случае применение в системах реального вре¬
мени многопроцессорных машин на базе универсальных коммерческих про¬
цессоров сталкивается с проблемами конфликтов при обращениях к памяти.
В системах общего назначения график производительности многопроцессорной
машины имеет точку перегиба, после которой добавление нового центрального
процессора приводит к уменьшению пропускной способности. Основными при¬
чинами добавления центрального процессора должны быть повышение про¬
пускной способности, увеличение избыточности и повышение готовности
системы. Напомним, что в мультипроцессорных конфигурациях центральные
процессоры используются только иа 00—80%, поэтому пропускная способность
не может служить главным основанием для увеличения числа центральных
процессоров. Очевидно, что разработчик больших систем реального времени
в качестве главной трудности может столкнуться с проблемой, как создать
систему, отвечающую заданным требованиям по пропускной способности, без
использования специализированных машпп. Некоторое увеличение пропускной
способности может быть достигнуто за счет многопроцессорности, поскольку
в системах реального времени совокупность решаемых задач является более
статичной, мепее универсальной и требующей мспынсго количества передач
информации, что позволяет использовать стратегию планирования обращений
17*
к памяти, и тем самым обеспечить большему числу центральных процессоров
работу в достаточно эффективном реяшме. Дополнительное введение кэш-на-
мяти также способствует снижению остроты проблемы организации доступа
к памяти. Однако технически данная процедура является непростой.
Эффективность параллельных процессоров
Гипотеза Минского по отношению к ОКМД-процессорам справедлива в
случае последовательного выделения подмножеств активных элементов, т. е.
после того, как процесс охватил весь массив, последующие итерации активи¬
зируют сужающиеся подмножества процессорных элементов, и так до тех
пор, цока какой-нибудь один элемент или, быть может, небольшая группа эле¬
ментов не закончит процесс. Если на каждой стадии отсеивается половина из
оставшихся элементов, то, по аналогии с алгоритмом сортировки, гипотеза
Минского говорит, что среднее число активных элементов в матричном про¬
цессоре равно log2 т. Таким образом, показатель эффективности ОКМД-про-
цессора составляет log2 т, где т — число элементов в процессоре. Этот случай
имеет место только при выборе одиночного объекта из файла или при выпол¬
нении операций ввода/вывода. В гипотезе также предполагается (требуется)
использование очень плохих алгоритмов. Имеются факты (см., например, Берг
и Кинней [9.20]), доказывающие, что при корректном' подборе размерностей
задачи коэффициент использования элементов равен 100%.
Гипотеза Минского не учитывает разницу в прикладных областях между
специализированными и универсальными машинами и, следовательно, разни¬
цу в методах программирования. В областях, где применяются ОКМД-машины ■
(например, в системе противоракетной обороиы или в системе управления воз¬
душным движением), резидентная часть программы представляет собой модель
физической среды, в которой работает машина. Операции структурируются
таким образом, чтобы сохранить и улучшить эту модель, а не так, чтобы вы¬
бирать и поодиночке обрабатывать отдельные объекты.
Например, в системе управления воздушным движением сообщения о
цели привязываются к определенному файлу (это требует, самое большее,
идентификации одиночного объекта при вводе и выводе), однако эта отдельная
траектория не обязательно сразу подвергается обработке. Позже, в момент,
определяемый динамикой системы управления воздушным движением, все
траектории, которые были привязаны после последнего выполнения алгорит¬
ма уточнения, одповремеппо подвергаются обработке этим алгоритмом.
Гипотеза Минского явно подразумевает, что все вычисления производят¬
ся с конечной целыо выбрать единственный объект для обработки. В алгорит¬
мах, разрабатываемых для эффективной реализации па матричном процессо¬
ре, это не так. Корректно построенные алгоритмы решения задач, для кото¬
рых может быть использован параллельный процессор, работают пе так, как
предполагает гипотеза Минского.
Справедливость гипотезы Минского зависит от области примепенпя так
же, как и любой другой справедливый метод оценки производительности лю¬
бых архитектур вычислительных машпп. Если читатель обратится к короткой
истории применений вычислительных машин и попытается сопоставить эти
применения с возможностями параллельных машин, то он вповь откроет эф¬
фект Лмдала: для того чтобы достигнуть какой-либо эффективности в парал-
260
лелыюй машпнс, обрабатывающей пг потоков данных, прикладная задача
должна быть разбита на абсолютно последовательные сегменты команд, раз¬
мер которых значительно меньше i/m от размера программы. Эффект Амдала
[9.23] объясняется недостатком параллелизма в большинстве современных ис¬
ходных программах. Реальному миру присущ параллельный характер, в то
же время паше математическое восприятие в течение 300 лет находилось под
воздействием, главным образом, последовательной математики, 50 лет — под
воздействием создания последовательных алгоритмов, 15 лет — под воздействи¬
ем программирования на последовательном фортране. Стоит ли после этого
удивляться, что у разработчиков, пытающихся найти параллелизм в фортра-
повском операторе цикла DO, не хватило фантазии на большее?
Недавно Кук и др. [9.21] опубликовали ряд многообещающих результатов
в плане нахождения параллелизма в фортрапоподобпых программах, однако
эти результаты относятся к ограниченному набору задач. Можно предполо¬
жить, что существующие в настоящее время ОКМД-процессоры являются бо¬
лее специализированными, чем универсальные машины, однако имеются при¬
кладные области, в которых первые оказываются более работоспособными и
более эффективными, чем высокопроизводительные последовательные универ¬
сальные машины. Одну из таких областей составляют системы противоракет¬
ной обороны. Другим потенциальным применением является создание особого
вида внешних устройств, представляющих собой ОКМД-машину, работающую
совместно с накопителями большой емкости, образуя при этом ассоциативный
процессор, который может быть подключен к универсальным вычислительным
машинам.
В подобных прикладных областях готовность и реактивность системы яв¬
ляются более важными параметрами, чем показатель относительной пропуск¬
ной способности и коэффициенты загрузки той или иной аппаратуры. В самом
деле, какой мерой можно оценить стоимостную эффективность процессора, ко¬
торый служит для предотвращения столкновений самолетов в воздухе или спо¬
собствует спасению урожая? Экономические факторы пе сводятся только к
коэффициентам загрузки аппаратуры. Фуллер [9.22] предлагает вместо того,
чтобы пытаться быстрее решать существующие задачи, ставить перед маши¬
нами с высокой степенью параллелизма новые задачи. ОКМД-процессоры с
большим успехом могут создаваться для решения мпожества задач, чем для
одной задачи, становясь тем самым многофункциональными машинами.
Измерить эффективность аппаратурпой части параллельного процессора
трудно. Возьмем ILLIAC IV. Если в качестве меры эффективности взять ко¬
эффициент загрузки аппаратуры как функцию от доли стоимости, приходя¬
щейся на оборудование, то ILLIAC IV окажется очень эффективным. Половина
стоимости оборудования приходится па устройство управления. Каждый из
процессорных элементов содержит около 10 ООО логических схем. Устройство
управления также содержит около 10 000 логических схем. Однако логические
схемы ПЭ — это в основном арифметико-логические и регистровые ячейки, ко¬
торые имеют совершенно регулярную структуру, в то время как ячейки УУ
представляют собой уникальные логические схемы, выполняющие разные уп¬
равляющие функции. Таким образом, даже в максимальной конфигурации,
включающей 256 ПЭ, несмотря на то, что в них сосредоточена большая часть
логических элементов, стоимость этих элементов примерно равпа стоимости
элементов УУ. В конфигурации ILLIAC IV, содержащей 64 ПЭ, в случае, если
261
устройство управления контролирует даже ©дин процессорный элемент, то и
тогда используется около 50% оборудования (в стоимостном выражении).
Благодаря удачному техническому решению конструкторов ILLIAC, про¬
цессорные элементы являются простыми исполнительными устройствами, а все
управляющие функции централизованы и сосредоточены в УУ, которое, зани¬
мая большую часть оборудования, обычно находится в активном состоянии.
Поддержание как можно большей части оборудования в состоянии активности
является правильной целыо, однако не обязательно самой главной.
Нельзя утверждать, что ILLIAC IV представляет собой решение всех проб¬
лем и что степень использования оборудования в течение рабочего цикла яв¬
ляется рациональной мерой стоимости. В большинстве практических приме¬
нений ILLIAC IV, вероятно, не имеет смысла вычислять, какой-процент обо¬
рудования паходится в активном состоянии в каждый момент времени. Ма-
кинтайр [9.24] отмечает, что использование 256-элементной конфигурации
ILLIAC IV при решении задачи, связанной с табличным поиском, дает выиг¬
рыш только в 60 раз, потому что 80% времени затрачивается на перемещение
данных между запоминающими устройствами процессорных элементов; однако
нужно заметить, что эта величина на порядок больше, чем та, которую пред¬
сказывает гипотеза Минского.
Кук и Самех [9.25]' показали, что эффективность ILLIAC IV па задачах
нахождения собственных значений матриц лежит в диапазоне от И до 90%
для разных алгоритмов.
Стоун показывает, как с помощью ILLIAC IV можно сократить время ре¬
шения некоторых систем линейных уравнепий от п до log2 л, где п — числа
имеющихся процессоров. Используя п процессоров, Стоун получил увеличение
быстродействия в п log2 п раз. Согласно гипотезе Минского максимальная эф¬
фективность для п процессоров составляет log2/г, т. е. быстродействие может
максимально увеличиться в log2 п раз. Легко видеть, что если п больше 4, то.
решение Стоуна дает величину, превышающую прогноз по гипотезе Минского.
Например, при п = 8 решение Стоуна дает величину, в четыре раза превы¬
шающую ту, которую дает гипотеза Минского.
Чтобы полностью представить сложность проблемы оценки производи¬
тельности систем, нужно учесть разнообразие типов специализированных ма¬
шин. Как их сравнивать между собой? Согласно данным, полученным Гилмо¬
ром [9.27], комбинированная система, включающая CDC 6600 и STARAN, по¬
зволяет рассчитать прогноз погоды -примерно в семь раз быстрее, чем машина
IBM 360/65, усилепиая специализированным процессором IBM 2938, модель 2.
Последнее сравнепие иллюстрирует задачи, на которых основываются такого
рода оценки, т. е. задачи, в которых содержится большое количество операций
выбора и недостаточно развит математический аппарат.
Заключение
Процессоры с высокой степенью параллелизма представляют собой пер¬
вый шаг на пути создания вычислительных систем, которые являются функ¬
циональными аналогами рассматриваемой физической среды. Расширением
концепции функционального аналога физической системы могут служить рас¬
пределенные сети отдельных, по^ связанных между собой вычислительных ма¬
шин, обычно называемых распределенными системами. Существуют системы*
262
функционирование которых имеет столь много общего с параллельной обра¬
боткой, что они могут быть алгоритмически приведены к такому виду, который
можно назвать параллельным процессором.
При создании систем, для которых основными системными параметрами
являются такие величины, как время обработки, готовность, реактивность и
расширяемость, по соображениям экономической эффективности можно от¬
дать предпочтение специализированным параллельным процессорам перед боль¬
шими универсальными машинами, безотносительно к величине рабочего цикла
аппаратной части параллельного процессора. Стоимость системы является бо¬
люс важным фактором, чем коэффициенты загрузки логических схем; большие
интегральные схемы могут, оказать положительное влияние па стоимость си¬
стемы только тогда, когда система имеет высокую степень регуляриости и со¬
держит повторяющиеся элементы. Малая величина коэффициента загрузки в
■пересчете на одну логическую схему, может оказаться неинформативной ме¬
рой эффективности системы, когда единственным средством достижепия эф¬
фективности является операциопная система.
Существует очень немного высокопроизводительных машин,, в которых
значительные части логического оборудования не простаивали бы в процес¬
се работы. Примером может служить оборудование для выполнения операции
деления, имеющееся в большинстве универсальных вычислительных машин,
Выбор в качестве меры системной эффективности величины коэффициента
загрузки логических элементов бесполезен во всех случаях, за исключением си¬
туация:, когда сравниваются однотипные системы по одному и тому же па¬
раметру. Вот почему никто не сможет подвергнуть сомнению эффективность
ОКМД-ироцессоров просто потому, что часть времени процессорные элементы
могут простаивать; аналогичная ситуация имеет место и в уииверсальпой вы¬
числительно]! машине. Дорогостоящее устройство деления в большинстве вы¬
сокопроизводительных машин простаивает почти все время, поскольку коман¬
ды деления в программах используются крайне редко.
Справедливо мнение, что проблемы размерностей, имеющие место в жест¬
ко-структурированных вычислительных системах с массивами процессоров,
■таких как ILLIAC IV, создают некоторый риск при использовании этих ма¬
шин, однако подобпые машины являются специализированными и создаются
для работы в копкретпых областях. При использовании этих машин для ре¬
шения любых других задач следует ожидать снижения производительности.
Часто говорят (по аналогии с высказываниями об автомобильной промышлен¬
ности в 1920 г.), что главная область применения вычислительных машин еще
не открыта. Большинство пз существующих в настоящее время сомнепии, шь
дающихся ОКМД-маниш, проистекает из-за наличия в нашем мышлении трех-
ступепчатого (математического/алгоритмпческого/программистского) фильтра,
который искажает восприятие окружающего мира. Требуются большие иссле¬
дования в области непосредственного моделирования природпых явлений, ко¬
торым присущи какие-либо совместные или параллельные действия.
СПИСОК ЛИТЕРАТУРЫ
К главе 1
1.1.. Schmitz И. G. et al. «ABMDA» Prototype Bulk Filter Development Con¬
cept Definition Phase.— Final Report Contract No; DA1I 60-72-C-0050, 1972,.
April.
1.2. Flynn M. F. Some Computer Organizations and Their Effectiveness.—
1ЕЁЕТС, 1972', September, p. 948—960.
1.3. Ilobbs L. С., T h e i s D.. K. Survey of Parallel Processor Approaches and
Techniques. Parallel Processor Systems, Technologies and Applications/Ed.
L. C. Hobbs et al.) —N. Y.: Spartan Books, 1970, p. 3—20.
1.4. И о 11 a n d e r G. L. Architecture for Large Computing Svstems.—SJCC,.
1907, p. 463—466.
1.5. Bell C. G. et al. Effect of Technology of Near Term Computer Structures.—
Computer, 1972, March/April, p. 29—38.
1.6. Denning P. J. Virtual Memory.—Computing Surveys, 1970, September.,
p. 153—189.
1.7. Wald L. D., Anderson G. A. Associative Memory for Multprocessor
Control.— Final Report NAS 12—2087, 197.1, September.
1.8. Berg R. O., Johnson M. D. An Associative Memory for Executive Cont¬
rol Functions in an Advanced Avionics Computer System.— Proceedings of
the IEEE 1970 International Computer Group Conference, 1970, June,
p. 336—342.
1.9. Erwin J. D., J e n s e n E. D. Interrupt Processing with’Queued Content-
Addressable Memories.—FJCC, 197.1, p. 621—627.
1.10. Joseph E. C., Kaplan A. Target Track Correlation with a Search
Memory.—Proceedings of the 6th National MIL-E-CON, 1972, June, p. 255—
261.
1.11. Thurber K. J. An Associative Processor for Air Traffic Control.— SJCC.
1971, p. 49-59.
1.12. Johnson M. D., Gunderson D. C. An Associative Data Acquisition
System.— Proceedings of the 1970 International Telemetry Conference. 1970,
April, p. 109—115.
1.13. Wald L. D. Integrated Voice/Data Compression and Multiplexing using
Associative Processing 1974 NCC.— 1974, May.
1.14. Lee C. Y. Intercommunicating Cells, Basis for a Distributed Logic Compu¬
ter.—FJCC, 1962, p. 130—136.
1.15. Seeber R. R. Symbol Manipulation with an Associative Memory.— Pro¬
ceedings of the 16th National ACM Meeting, 1969, September.
1.16. Seeber R. R., Lindguist A. B. Associative Memory wiht Ordered
Retrieval.— IBM Journal of Research and Development, 1962, January,
p. 126—136.
1.17. M с С о r m i с В. II., D i v i 1 b i s s J. L. Tcnative Logical Realization of a
Pattern Recognition Computer.— Report No. 4031, Digital Computer Lab.,
University of Illinois, 1969.
1.18. Fuller R. II., R. M. Bird. An Associative Parallel Processor with Appli¬
cation to Picture Processing.— FJCC, 1965, p. 105—116.
1.19. Bird R. M. An Associative Memory Parallel Dcltic Realization for Activ
Sonar Signal Processing.— Parallel Processor Systems, Technologies,
264
and Applications/Ed. L. C. Hobbs et al.—N. Y.: Spartan Books, 1970, p. 107—
129.
'1.20. Auerbach. Associative Memory Invesligations-Substructuring. Searching and
Data Organizations.— Final Report Air Force Contract AF 30 (002) 4309, 1908,
May 15.
1.21. Crane B. A. Path Finding with Associative Memory.— IEEETC, 1968, July,
p. 091—693.
1.22. Es trin O., Fuller R. II. Some Applications for Content Addressable
Memories.— FJCC, 1903, p. 495—508.
1.23. Buss el B. Properties of a Variable Structure Computer System in the
Solution of Parabolic Partial Differential Equations.— Ph. D. thesis, UCLA,
1962, August.
1.24. Estrin G., Viswanathan C. R. Organization of a Fixed-Plus-Variab-
le Structure Computer for Computation of Eigenvalues and Eigenvectors of
Real Symmetric Matrices.— JACM, 1902, January, p. 41—00.
1.25. Katz J. 11. Matrix Computations on an Associative Processor.—Parallel
Processor Systems, Technologies and Applications/Ed. L. C. Ilobbs et al.—
Spartan N. Y.: Spartan Books, 1970, p. 131—149.
1.26. Orlando P.. Berra P. B. Associative Processors in the Solustions of
Network Problems.— 39th National Operations Research Society Meeting.—
Dallas, Texas, May 5—7, 1971.
.1.27. Choydlcur B. F. Dimensioning in an Associative Memory.—Vistas in
Information Ilandiing/Ed. P. W. Howerton, D. C. Weeks, Vol. I.—N. Т.:
Spartan Books, 1963, p. 55—57.
‘1.28. Hayes J. P. A Content Addressable Memory with Applications to Machine
Translation.— Report 227, University of Illinois Computer Lab., 1967,
June.
1.29. Goldberg J., Green M. W. Large Files for Information Retrieval Ba¬
sed on Simultaneous Interrogation of all Items.—Large Capacity Memory
Techniques for Computing Systems/Ed. М. C. Yovits.—N. Y.: MacMillan Co.,
1962, p. 63—77.
1.30. Peters C. Associative Memory Compiler Techniques Study.— 1967, No¬
vember. AD824213.
1.31. GFall R. G. Hybrid Associative Computer Study.—Vol. I, Basic Report,
1966, July, AD489929; Vol. II, Appendices, 1966, July, AD489930,
1.32. De Fiore C. R. et al. Associative Techniques in the Solution of Data
Management Problems.— Proceedings of the 1971 ACM National Meeting,
p. 28-36.
1.33. Stillman N. J. et al. Associative Processing of Line Drawings. SJCC,
1971, p. 557-562.
1.34. Stillman R. B. Computation Logic: The Subsumption and Unifications.
Ph. D. dissertation.— Syracuse University, 1972, January.
1.35. Moreno ff E. et al. 4-Way Parallel Processor Partition of an Atmospheric
Priinitive-Equation Prediction Model.— SJCC, 1971, p. 39—48.
*1.36. Mur tli a J. C. Highly Parallel Information Processing Systems. Advances
in Computers.— N. Y.: Academic Press, 19661
1.37. Hanlon Л. C. Content-Addressable and Associative Memory Systems:
A Survey.— IEEETEC, 1966, August, p. 509—521.
1.38. M inker J. An Overview of Associative Memory or Content-Addressable
Memory Systems and a KWIC Index to the Literature 1956—1970.—Compu¬
ting Reviews, 1971, October, p. 453—504.
1.39. M inker J. Associative Memories and Processors: A Description and
Appraisal.— Technical Report TR—195.— University of Maryland, 1972,
July.
1.40. Mukhopadhyay A. A Survey of Macrocellular Research. Technical Re¬
port, NSF Grant GJ-723.— University of Iowa, 1972, December.
1.41. С a n n e 1 М. II. et al. Concepts and Applications of Computerized Associa¬
tive Processing/Including an Associative Processing Bibliography, 1970, De¬
cember, AD879281.
1.42. Par ha mi B. Associative Memories and Processors: An Overview and Se¬
lected Sibliogrphy.—Proceedings of the IEEE, 1973, June, p. 722—730.
265
1.43. Min к or J. Л. Associative Memories and Processors: A Description and
Appraisal. Encyclopedia of Computer Science and Technology, Vol. 2/Ed».
Belzer .1. et a!.—N. Y.: Marcel Dekker, 1975.
1.44. T h u r her K. J., W a 1 d L. D. Associative and Parallel Processors. Compu¬
ting Surveys, 1975, December.
К главе 2
2.1. Zamenek H. Summation and Future Directions of Associative Informa¬
tion Techniques. Associative Information Techniques/Ed. E. L. Jacks.— N. Y.:
American Elsevier, 1971, p. 205—215.
2.2. M inker J. An Overview of Associative Memory or Content — Addressable
Memory Systems and a KWIC Index to the Literature: 1956—1970.—Compu¬
ting Reviews, 1971, October, p. 453—504.
2.3. Slade A. E., M с M ahon II. 0. A Cryotron Catalog Memory Svstcm.—
EJCC, 1956, p. 115-120.
2.4. Gunderson D. C. et al. Associative Memories in Space Applications.—
WESCON 1966, p. 9/2—1 to 9/2—9.
2.5. Kaplan A. A Search Memory Subsystem for A General-Purpose Compu¬
ter.— FJCC, 1963, p, 193—200.
2.6. Boucher on P. H. Data Addressed Memory.— U. S. Patent 3241123, 1966*
March 15.
2.7. Fuller R. IT. Content-Addressable Memory Systems.— UCLA Final Report
Contract NONR 233 (52), 1963, June, AD417644.
2.8. Fuller R. TI. Associative Parallel Processing.— Computer Design, 1967*
December, p. 43—46.
2.9. McKecver В. T. The Associative Memory Structure.— FJCC, 1965*
p. 371—388.
2.10. Lee C. Y. Intercommunicating Cells, Basis for a Distributed Logic Com¬
puter.— FJCC, 1962, p. 130—136. '
2.11. Lee C. Y., Pauli М. C. A Content — Addressable Distributed Logic Memo¬
ry with Application to Information Retrieval.— Proceedings of the IEEE*
1963, June, p. 924—932.
2.12. Feng T. Y. An Associative Parallel Processor and Some of its Applicati¬
ons.— Proceedings of the Fifth Annual Prinction Conference on Information
Sciences and Systems, 1971, March, p. 125—126.
2.13. Rogers J. L., Wo tin sky A. Associative Memory Algorithms and
their Cryogenic Implementations.— 1963, December, AD429521.
2.14. Dcrickson R. B. A Proposed Associative Push Down Memory.—Compu¬
ter Design, 1968, March, p. 60—66.
2.15. S a v i 11 D. A. et al. Association-Storing Processor Study.,— 1966, June..
AD488538.
2.16. Denning P. J. Virtual Memory.— Computing Surveys, 1970, September.
2.17. Thurber K. J., Berg R. O. Applications of Associative Processors.—
Computer Design, 1971, November, p. 103—110.
2.18. Goodyear, STARAN Reference Manual, September 1974, Coodyear Document
GER-15636.
2.19. Ewing R. G., Davies P. M. An Associative Processor.—FJCC, 1964,
p. 147—158.
2.20. L с w i n М. II. Retrieval of Ordered Lists from a Content — Addressed Me¬
mory.— RCA Reviews, 1962, June, p. 215—229.
2.21. Gonzalez M. J. SIMDA Overview. Proceedings of the 1972 Sagamoro
Computer Conference.— 1972, August, p. 17—28.
2.22. W aid L. D. An associative Memory Using Large-Scale Integration.—
NAECON ’70, p. 277—281.
2.23. T hurber K. J. An Associative Processor for Air Traffic Control.— SJCC*
1971, p. 49-59.
2.24. Univac, System and Interface Description for Associative Processor Evalua¬
tion at Knoxville.—FA A Contract Number L/C DOT FA-70WA-2289, Project
Number 19180, 1971, April 30.
266
oi м'
2.25. F nil с г R. ТТ., Bird R. M. An Associative Parallel Processor with Appli¬
cation to Picture Processing.— F.ICG. 1965, p. 105—110.
2.26. Crane B. A.. Git, hens J. A. Bulk Processing in Distributed Logic Mc-
mory.— IFF.BTC. 1905, April, p. 186—190.
2.27. Gall R. G. Ilvbrid Associative Computer Study.— Vol. I, Basic Report,
1966, July, AD489929, Vol. IT, Appendices, 196,6, July, AD489930.
2.28. N u s p 1 S. J., Johnson M. 1). The Effect of I/O Characteristics on the
Performance of a Parallel Processor.— IEEE International Computer Society
Conference, Digest, 1971, p. 127—128.
.29. В u s h V. As We May "flunk.— Atlantic Monthly, Vol. 176, 1945, July, p. 101.
.30. Slade A. If, M с M a h о n И. О. Л Cryotron Catalog Memory System.—
Proceedings FJCC, 1956, December, p. 115—120.
2.31. Lewin M. If. Retrieval of Ordered Lists from a Content-Addressed Me¬
mory.— RCA Review, 1962, June, p. 215—229.
2.32. Frei E. 11., G о i d b с r g 11. A. Method for Seolving Multiple Responses in
a Parallel Search File.— IRETEG, 1961, December, p. 718—722.
2.33. Sc с be г R. R., Lindquist Л. B. Associative Memory with Ordered
Retrieval.—IBM Journal of Res. and Dev., 1962, January, p. 126—136.
2.34. Ewing R. G., Davies P. M. An Associative Processor.—FJCC, 1904,
October, p. 117—158.
2.35. Rosin R. F. An Organization of an Associative Cryogenic Computer.—
SJCC, 1962, May, p. 203-213.
2.36. Davies P. M. Design for an Associative Computer.—Proceedings IEEE
Pacific Computer Conference.. 1963, March, p. 109—117.
2.37. Sturm an J. N. An Iteratively Structured General-Purpose Digital Com¬
puter.— IEEETC, Vol. C-17, 1968, January, p. 2-9.
2.38. Sturm an J. N. Asynchronous Operation of an Iteratively Structured Ge¬
neral-Purpose Digital Computer.— IEEETC, 1968, January, p. 10—17.
2.39. Lee C. Y. Intercommunicating Cells, Basis for a Distributed Logic Compu¬
ter.— FJCC, 1962, December, p. 130—136.
2.40. 11 e a 1 у L. D. ct al. The Architecture of a Context Addressed Segment-Se¬
quential Storage.— FJCC, 1972, p. 681—701.
2.41. Minsky N. Rotating Storage Devices as Partially Associative Memories.—
FJCC, 1972, p. 587-595.
2.42. Lee F. F. Study of Lookaside Memory.— Proceedings of the 1969 IEEE
Computer Group Conference, 1969, June (also AD761550), p. 161—165.
2.43. Gonzalez M. J. SIMDA Overviews.—In [2.46], p. 17-28.
2.44. D e F i о r e C. R. et al. Toward the Development of a Higher Order Lan¬
guage for RADGAP.— In [2.46], p. 99-112.
2.45. Green D. E. Terminal Operating System for a SIMDA Parallel Proces¬
sor.—In [2.46], p. 87—98.
2.46. Proceedings of the 1972 Sagamore Computer Conference.— N. Y.: Sagamore,
1972, August.
2.47. Proceedings of the 1973 Sagamore Computer Conference.— N. Y.: Sagamore.
1973, September.
2.48. L i p о v s к i G. J. The Architecture of a Large Associative Processor. SJCC,
1970, p. 385-396.
- 2.49. Crane B. A., Githens J. A. Bulk Processing in Distributed Logic Me¬
mory.— IEEETEC, Vol. EC-14, 1965, April, p. 186—196.
2.50. Savitt D. A. et al. Association-Storing Processor Study.— 1966. June,
AD488538.
2.51. Savitt D. A. ct al. An Association Storing Processor, Vol. II, Hughes
Aircraft Co., Final Report Air Force Contract 30(602) 3669, 1967, Juno,
AD818530.
2.52. Savitt D. A. ct al. ASP: A New Concept in Language and Machine Orga¬
nization.—SJCC, 1967, p. 87—102.
2.53. Schmitz II. G. ct al. ABMDA Prototype Bulk Filter Development Con¬
cept Definition Phase.—Final Report Contract Number DAII 60-72-C0050,
1972, April.
2.54. К a u t z W. II. An Augmented Content-Addressed Memory Array for Imple¬
mentation with Large-Scale Integration.— JACM, 1971, January, p. 19—33.
267
2.55. Kautz W. II., Poase М. C. Cellular Logic-in-Mcmory Arrays.—1071.,
November, AD763710.
2.5G. Jensen E. D. Mixed-Mode and Multidimensional Memories.— Comp-
con’72, p. 119—121.
2.57. King W. K. Design of an Associative Memory.—IEEETC, 1971, June,
p. 671-674.
2.55. T Ji u rber K. J., M у r n a J. W. System Design of a Cellular APL Com¬
puter.— IEEETC, 1970, April, p. 291—303.
2.59. Erwin J. D., Jensen E. D. Interrupt Processing With Queued Content-
Addressable Memories.— FJCC 1971, p. 621—627.
2.60. Berg R. О., T h u r b e r K. J. A ITardward Executive for the Advanced
Avionic Digital Computer System.— NAECON’71 Record, 1971, May,
p. 206—213.
2.61. P arli ami B., Avizienis A. A Study of Fault Tolerance Techniques
for Associative Processors.— NCC, 1974. p. 643—652.
2.62. Anderson G. A. Multiple Match Resolvers: A New Design Method,—
IEEETC, 1974, December.
К главе 3
3.1. von Neumann J. A System of 29 States with a General Transition Rule.
Theory of Self-Reproducing Automata/Ed. A. W. Burks.— University of Illi¬
nois Press, Urbana Illinois, 1966, p. 132—156, 305—317.
3.2. McCulloch W. S., Pitts W. A Logical Calculus of the Ideas Imma¬
nent in Nervous Activity.— Bulletin of Mathematical Biophvsics.—In:
McCulloch W. S. Embodiment of Mind, MIT Press, 1965.
3.3. Unger S. II. A Computer Oriented Toward Spatial Problems.— Proceedings
of the IRE, 1958, October, p. 1744—1750.
3.4. Unger S. II. Pattern Detection and Recognition.— Proceedings of IRE,
1959, October, p. 1737—1752.
3.5. Holland J. II. A Universal Computer Capable of Executing an Arbitrary
Number of Sub-Programs Simultaneously.— EJCC, 1959, p. 108—113.
3.6. Shoo m an W. Parallel Computing with Vertical Data.— EJCC, 1960, De¬
cember, p. Ill—115.
3.7. Fuller R. II., Bird R. M. An Associative Parallel Processor with Appli¬
cation to Picture Processing.— FJCC, 1965, November, p. 105—116.
3.8. Squire J. S., Palais S.. M. Programming and Design Considerations of
a Highly Parallel Computer.— SJCC, 1963, p. 395—400.
3.9. S e n z i g D. N.. Smit h R. V. Computer Organization for Array Proces¬
sing.—FJCC, 1965, December, p. 117—128.
3.10. Iverson К. E. A Programming Language.— N. Y.: John Wiley and Sons,
1962.
3.11. Slotniek D. L. et al. The SOLOMON Computer.—FJCC, 1962, December,
p. 97—107.
3.12. We sting house, Multiple Processing Techniques.— 1964, June, AD602693.
3.13. Ball J. R. et al. On the Use of the SOLOMON Parallel — Processing Com¬
puter. FJCC, 1962, December, p. 137—146.
3.14. McCormick В. II. The Illinois Pattern Recognition Computer ILLIAC
III.— 1EEETEC, 1963, December, p. 791—813.
3.15. Knapp M. A. Parallel Processing Computer Svstem, 1966, November,
A 1)803485.
3.16. Knapp M. A., Turner D. P. A Centrally Controlled Iterative Array
Computer (RADCIAC).— J964, July, ADj6|D5370.
3.17. Hawkins J. K., Munsey C. A. A Parallel Computer Organization and
Mechanizations.— IEEETEC, 1963, June, p. 251—262.
3.18. S e e b e r R. R., Lindquist A. B. Associative Logic for Highly Parallel
Systems.— FJCC, 1963, November, p. 489—493.
3.19. Schmitz II. G. et al. ABMDA Prototype Bulk Filter Development Con¬
cept Definition Phase.— Final Report Contract Number DAII 60-72-C0050,
1972, April.
3.20. Slotniek D. L. Unconventional Systems.— SJCC, 1967, p. 477—481.
268
3.2!. R о h г b а с h с г D. L. Advanced Computer Organization Study: Vol. I. Ba¬
sic Rcnort* Vol. II. Appendices.— Air Force Contract AF 30(602) 3550, 1966,
April, A 1)031870, AD631871.
3.22. Batcher К. E. Sorting Networks and Their Applications, SJCC. 1968,
p. 307—314.
3.23. Thurber K. J., Myrna .T. W. System Design of a Callular APL Compu¬
ter.- I EE ETC, 1970, April, p. 291-303.
3.24; Git hens J. A. A Fully Parallel Computer for Radar Data Processing.—
NAECON ’70 Record, 1970, May, p. 290—297.
3.25. Thurber K. J. Permutation Switching Networks.— 1971 Computer Desig¬
ners Conference.—1971, January, California: Anaheim, 1971, January,
p. 7-24.
3.26. T h u r b e r K. J. Programmable Indexing Networks.—SJCC, 1970, May,
p. 51—58.
3.27. Thurber K. J. Interconnection Networks: A Survey and Assessment.—
NCC, 1974, May, p. 909-919.
3.28. Thurber K. J., Patton P. C. Hardware Floating- Point Arithmetic on
an Associative Processor.— COMPCON, 1972, September, p. 275—278.
3.29. Mukhopadhyav A. et al. Minimization of Cellular Arrays.—Final
Report NSF Grant GJ-158, 1969, August.
3.30. Stone II. S. Parallel Processing with the Perfect Shuffle.— IEEF.TC, 1971,
February, p. 153—161.
3.31. Pease М. C. An Adaptation of the Fast Fourier.— Transform for Parallel
Processing.— JACM, 1968, April, p. 252-264.
3.32. CannoipL, E. A Cellular Computer to Implement the Kalman Filter Algo¬
rithm.— Ph. D. thesis, Montant State University, 1969, August.
3.33. Mulder М. C. The Design of a Matrix-Oriented Cellular Computer Capab¬
le of Fault-Tolerant Operation.— Ph. D. thesis, Montana State University,
1970, August.
3.34. L a w s B. A. A Parallel BCH Decoder.— Ph. D. Thesis, Mont ana State Uni¬
versity, 1970, June.
3.35. Berlekamp E. R. Algebraic Coding Theory.—N. Y.: McGraw-Hill. 1968.
3.36. Newton G. E., Brenner R. L. Design of a Ccllularly Organized APL
Machine.— Final Report NSF Grant GJ-723, University of Iowa. 1971, March.
3.37. Comfort W. T. A Modified Holland Machine.— FJCC, 1963, November,
p. 481-488.
3.38. Gonzales R. A Multi — Laver Iterative Circuit Computer.— IF.FETEC,
1963, December, p. 781—790.
3.39. Conway' М. E. A Multiprocessor System Design.—FJCC, 1963, November,
p. 139-146.
3.40. Campcau J. O. The Block-Oriented Computer.— IEEETC, 1969, August,
n. 706—718.
3.41. Morenoff E. et al. 4-Way Parallel Processor Partition of an Atmosphe¬
ric Primitive-Equation Prediction #Model.—SJ.CC, 1971, p. 39—48.
К главе 4
4.1. Slotnick D. L. Unconventionl Aystcms.—SJCC, 1967. p. 477—481.
4.2. Burroughs. ILLIAC IV Systems Characteristics and Programming Manual.—
Contract Report AF30(602) 4144, 1973, February.
4.3. Slotnick D. L. et al. The SOLOMON Computer.—FJCC. 1062, p. 97—107.
4.4. Abel N. E. et al. TRANQUIL: A Language for an Array Processing Com¬
puter.— SJCC, 1969, p. 57—75.
4.5. Mills to in R. E. Fourth Semi-Annual Technical Report (14 July 1971 —
13 January 1972) for the Project Compiler Design for the ILLIAC IV. Volu¬
me II.— 1972. January 13, AD7372CD.
4.6. Lawrie D. ТГ. GLYPNIR— A List Processing Language for ILLIAC IV.—
Department of Computer Science Report 322, University of Illinois, 1969,
April.
4.7. Lawrie D. IT. et al. GLYPNIR — A Programming Langugage for ILLIAC
IV.—СЛСМ, 1975, March, p. 157—164.
269
К главе 5
5.1. L о с С. У. Intercommunicating Cells, Basis for a Distributed Logic Compu¬
ter.—FJCC, 1902, p. 130—136.
5.2. Crane B. A., Githens J. A. Bulk Processing in Distributed Logic Me¬
mory.—IEEETEC, 1965, April, p. 186-190.
5:3. Githens ,T. A. A Fully Parallel-Computer for Radar Data Processing.— '
NAECON 70 Record, 1970>!ау, p. 290—297.
5.4. Berg R. O. et al. PEPE — An Overview of Architecture, Operation and
Implementation.— Proceedings of the National Electronics Conference, 1972,
p. 312-317.
5.5. Berg R. O. et al. PEPE Implementation Study.— Final Report System
Development Cornoration, subcontract number SCD-71-61, ABMDA contract
number DAI I C6072C0031, 1971, July.
5.6. Honeywell. PEPE System Functional Design Spacification.— CDRLA007,
Vol. I—III, prepared for System Development Corporation under, subcontract
SGD-72-305 lor ABMDA contract DAH C6072 C0031, 1972, November.
5.7. N и s p I S. J., Johnson M. D. The Effect of 1/0 Characteristics on the
Performance of a Parallel Processor.— 1971 IEEE International Computer So¬
ciety Conference Digest, 1971, September, p. 127—128.
5.S. Cornell J. A. PEPE Application and Support Software.— WESCON72, 1972,
September, p. 1/3—1 to 1/3—3.
*5.9. Cornell J. A. Parallel Processing of Ballistic Missile Defense Radar Data
with PEPE.— C0MPC0N72, 1972, September, p. 69—72.
К главе 6
6.1. Batcher К. E. STARAN Parallel Processor System Hardward.— NCC, 1974,
p. 405—410.
6.2. 13 a t с h e г К. E. Multi-Dimensional Access Solid State Memory.— U. S. Pa¬
tent 3800289, 1974, March 26.
6.3. Fcldma n J. D., Fulmer L. C. RADCAP — An Operational Parallel
Processing Facility.— NCC, 1974, p. 7—15.
6.4. Davis E. W. STARAN Parallel Processor System Software.— NCC, 1974,
p. 17—22.
8.5. System Description: STARAN... a New Class of Computer.— Document
8284C, 1974, May.
8.6. STARAN Reference Manual.— Document GER-15636B, 1974. September.
6.7. STARAN APPLE Programming Manual.— Document GER-15637B, 1974, Sep¬
tember.
6.8. STARAN MACRO-APPLE (MAPPLE) Programming.— Document GER-15643A,
1974. September.
6.9. STARAN User’s Guide.— Document GER-15644A, 1974, September.
6.10. STARAN Options Reference Manual.— Document GER-16139, 1974, Sep¬
tember.
6.11. Stone II. S. Associative Processing for General Purpose Computers
through the Use of Modified Memories.— FCC, 1968, p. 949—955.
8.12. Mur a oka Y. Report 297.— Department of Computer Science, University
of Illinois.
jК главе 7
7.1. Shooman W. Parallel Computing with Vertical Data.—EJCC, 1960,
p. 111—115.
7.2. Shooman W. Orthogonal. Computer.— U. S. Patent 3277449, 1966, Octo¬
ber 4.
7.3. Shooman W. Orthogonal Processing. Parallel Processor Systems, Techno¬
logies, and Applications/Ed. L. C. Hobbs et al.— N. Y.: Spartan, 1970,
p.'297—308.
7.4. II i g b i e L. C. The OMEN Computers: Associative Array Processors.—
COMPCON’72, p. 287—290.
270
7.5. ITigbie L. С. Special Tutorial: Super Computer Architecture.— Computer..
1973. December, p. 48—58.
7.6. Orthogonal Computer.— SANDERS Associates.
К главе 8
8.1. Lucas H. C. Performance Evaluation and Monitoring.—Computing Sur¬
veys, 1971, September, p. 79—91.
8.2. Johnson M. D. et al. A semiconductor Distributed Aerospace Processor/
/Memory Study.— Final Report Air Force Contract F33615-72-C-1709.
Vol. I—III, 1973, August.
8.3. Thurber K. J. et al. Aircraft Avionics Tradeoff Study, Vol. IT: Concept
Development and Tradeoff, Part 3, Data Processors Tradeoffs.— Final Report
Air Force Contract F33615-73-C-4075, 1973, September.
8.4. Thurber K. J. et al. Macter Executive Control for the Advanced Avionic
Digital' Computer.— Interim Report, Navy Contact N62269-72-C-005U
Vol. I—III, 1972, June. ' .
8.5. S с h m i t z II. G. et al. AMBDA Prototipe Bulk Filter Development Con¬
cept Difinition Phase.— Final Report Contract Number DAII 60-72--C-0050r/
1972, April.
8.6. Lloyd G. R., M or win R. E. Evaluation of Performance of Parallel Pro¬
cessors in a Real-time Environment.— NCC, 1973, p. 101—108.
8.7. Chen Т. C. Unconventional Supcrspeed Computer System.— SJCC. 197L
p. 365-371.
8.8. GAuerbac-h. Associative Memory Investigations: Substructuring and Data
Ortanizations.— Final Report Air Force Contract AF 30(602)-4309, 1968, May.
8.9. Cornell J. A. Parallel Processing of Ballistic Missile Defense Radar Data
with PEPE.— COMPCON’72, 1972, September, p. 69—72.
8.10. Gall R. G. Ilvbrid Associative Computer Study, Volumes I and II, Final
Report, 1966, July, AD489929, AD489930.
8.11. Univac. System and Interface Description for Associative Processor Evalua¬
tion at Knoxville.— FAA Contract Number L/C DOT FA-70WA-2289, Project
Number 19180, 1971, April 30.
8.12. Rudolph J. A. A Production Implementation of an Associative Array
Processor — STARAN.— FJCC, 1972, p. 229-241.
8.13. Fuller S. H. Orthogonal versus Array Computing.— Technical Note No. 4r
Digital Systems Laboratory, Stanford University Joint Services Electronic
Contract N-00014-67-A-0112-0044, 1970, October, AD720331.
К главе 9
9.1. ITigbie L. C. The OMEN Computers: Associative Array Processors.
COMPCON’72. 1972, September, p. 287—290.
9.2. Batcher К. E. Flexible Parallel Processing and STARAN.— WESCON’72,
1972, September, p. 1/5—1 to 1/5—3.
9.3. McCormick В. II. The Illinois Pattern Recognition Computer ILLIAC
III.— IEEETEC, 1963, December, p. 791—813.
9.4. Slotnick D. L. The Fastest Computer.— Scientific American, 1971, Feb¬
ruary, p. 76—87.
9.5. Berg R. O. et al. PEPE — An Overview of Architecture, Operations, and
Implementation .— Proceedings of the National Electronics Conference. 1972,
p. 312—317.
9.6. Wald L. D., Anderson G. A. Associative Memory for Multiprocessor
Control. Vol. I—III.— 1971, September, NASA Contract 12-2087.
9.7. Kressler R. R. et al. Development of an LSI Associative Processor.—
1970, August. AD873049.
9.8. Ware W. II. The Ultimate Compter.— IEEE Spectrum. 1972, -March,
p. 84—91.
9.9. Burnett G. J. A Distributed Processing System for General Purpose Com¬
puting.— FJCC, 1967, p. 757—768.
271
9.10. Shore J. E. Second Thoughts on Parallel Processing.—1971, December,
AD738422.
9.11. Shore J. E. Second Thoughts on Parallel Processing.— IEEE International
Convention Digest. 1972, March, p. 37)8—359.
9.12. Shore J. E. Second Thoughts ou Parallel Processing.—Comput. and Elect.
Engncr., Vol. 1 — Great Britain, Pergamon Press, 1973, p. 95—109.
9/13. Data Processing Special Studies Final Report.— AIC TR TlSU/72-006, Safe¬
guard Contract DAIIC 60-72-C-0155 CDRL A003, 1972, December.
9.14. Patton P. C. Estimated Performance Loss of 7600 Multiprocessors due
to LCS Memory Conflicts.—Analysts International Corporation Technical Note
1687-C-3, 1972, November.
9.15. Parallel Network Computer (SOLOMON) Applications Analyses, Vol. 3.—
Westinghouse, 19.64, August, AD606578.
9.16. Flynn M. J. Some Computer Organizations and Their Effectiveness.—
1ЕЁЕТС, 1972. September, p. 248—260.
9.17. Slotnick 1). L. Unconventional Systems.— Computer Design, 1967, De¬
cember, p. 47—52.
9.18. Knight К. E. Changes in Computer Performance.— Datamation, Vol. 12,
1966, September, p. 40—54.
9.19. Minsky М., Papert S. On Some Associative, Parallel and Analog Com¬
putations. Associative Information Teclmiques/Ed. E. L. Jacks.—N. Y.: Ame¬
rican Elsevier, 1971.
9.20. Berg R. O.. Kinney L. L. A Digital Signal Processor.— C0MPC0N72,
1972, September, p. 45—48.
9.21. Kuc к D. J., M uraoka Y., Chen S. C. On the Number of Operations
Simultaneously Executable in FORTRAN-like Programs and their Resulting
Speedup.—1ЕЁЕТС, Vol. С-21, Д972, December, p. 1293—1310.
9.22. Fuller R. IT. Associative Parallel Processing.— Computer Design, 1967,
December, p. 43—46.
9.23. Amdahl G. M. Validity of the Single Processor Approach to Achieving
Large Scale Computing Capabilities.— Thompson, Washington D. C., SJCC,
1967, Vol. 30, p. 483.
3.24. McIntyre D. E. The Table Lookup Problem Revisited.— 1968, April 26,
AD831943.
9.25. К u с к D. J., Sameh A. Parallel Computation of Eigenvalues of Real
Matrices.— 1971, November, AD737292.
9.26. Stone II. S. An Efficient Parallel Algorithm for the Solution of a Tridia¬
gonal Linear System of Equations.— JACM, 1973, January, p. 27—38.
9.27. Gilmore P. A. Numerical Solution to Partial Differential E.quations by
Associative Processing.— AFIPS Press, Montvale, N. J., FJCC, 1971, vol. 39,
p. 411-418.
9.28. Leavitt D. Software Complexity, The Limiting Factor.— Computer
World, 1972, December, p. 10.