/







































































































































































































































































































Автор: Воеводин В.В.
Теги: вычислительная математика численный анализ математика вычислительная техника
Год: 11986




Текст
В. В. ВОЕВОДИН
МАТЕМАТИЧЕСКИЕ
МОДЕЛИ И МЕТОДЫ
В ПАРАЛЛЕЛЬНЫХ
ПРОЦЕССАХ
МОСКВА «НАУКА»
ГЛАВНАЯ РЕДАКЦИЯ
ФИЗИКО-МАТЕМАТИЧЕСКОЙ ЛИТЕРАТУРЫ
1986
ББК 22.18
В63
УДК 519.6
Воеводин В. В. Математические модели и методы в параллельных
процессах.—М.: Наука. Гл. ред. физ.-мат. лит., 1986.— 296 с.
Книга содержит систематизированное изложение математических основ
совместного изучения параллельных численных методов и параллельных
вычислительных систем. Исследуются математические модели, описывающие процесс
функционирования параллельных систем. Устанавливаются различные
соотношения и факты, отражающие особенности их работы. Изучаются основные
этапы выявления и реализации параллелизма в численных методах от
математических формул и программ на алгоритмических языках до вычислительных
систем.
Для студентов, аспирантов и научных сотрудников, деятельность которых
связана с современной вычислительной техникой.
Ил. 33. Библиогр. 1030 назв.
Рецензент
доктор физико-математических наук В. Г. Карманов
Валентин Васильевич ВОЕВОДИН
МАТЕМАТИЧЕСКИЕ МОДЕЛИ И МЕТОДЫ
В ПАРАЛЛЕЛЬНЫХ ПРОЦЕССАХ
Редактор Е. Е. Тыртьииников
Художественный редактор Г. М. Коровина
Технический редактор В. Н. Кондакова
Корректоры М. Л. Смирнов, М. Л. Медведская
ИБ № 12819
Сдано в набор 05.12.85. Подписано к печати 18.04.86. Т-11004. Формат 60χ90/16. Бумаг,
книжно-журнальная. Гарнитура литературная. Печать высокая. Усл. печ. л. 18, 5. Уел,
кр.-отт. 19, 5. Уч.-изд. л. 22,41. Тираж 8400 экз. Заказ № 1906. Цена 2 р. 30 к.
Ордена Трудового Красного Знамени издательство «Наука»
Главная редакция физико-математической литературы
117071 Москва, В-71, Ленинский проспект, 15
Набрано в ордена Октябрьской Революции и ордена Трудового Красного Знамени МПО
«Первой Образцовой типографии» имени А. А. Жданова Союзполиграфпрома при
Государственном комитете СССР по делам издательств, полиграфии и книжной торговли.
113054 Москва, Валовая, 28
Отпечатано во 2-й типографии издательства «Наука», 121099 Москва, Г-99, Шубин-
ский пер., 6. Зак. 2563.
1702070000—079
В ntro /лоч ос 4-86 © Издательство сНаука».
иоо ^UzJ-oO Главная редакция
физико-математической
литературы, 1 986
ОГЛАВЛЕНИЕ
Предисловие 4
Глава 1. Особенности параллельных вычислительных систем и
алгоритмов 17
§ 1. Параллельные вычислительные системы 18
§ 2. Параллельные алгоритмы 31
§ 3. Концепция неограниченного параллелизма 40
§ 4. Численное программное обеспечение * 49
Глава 2. Совместное исследование параллельных вычислительных систем
и алгоритмов 57
§ 5. Графы 57
§ 6. Граф алгоритма 64
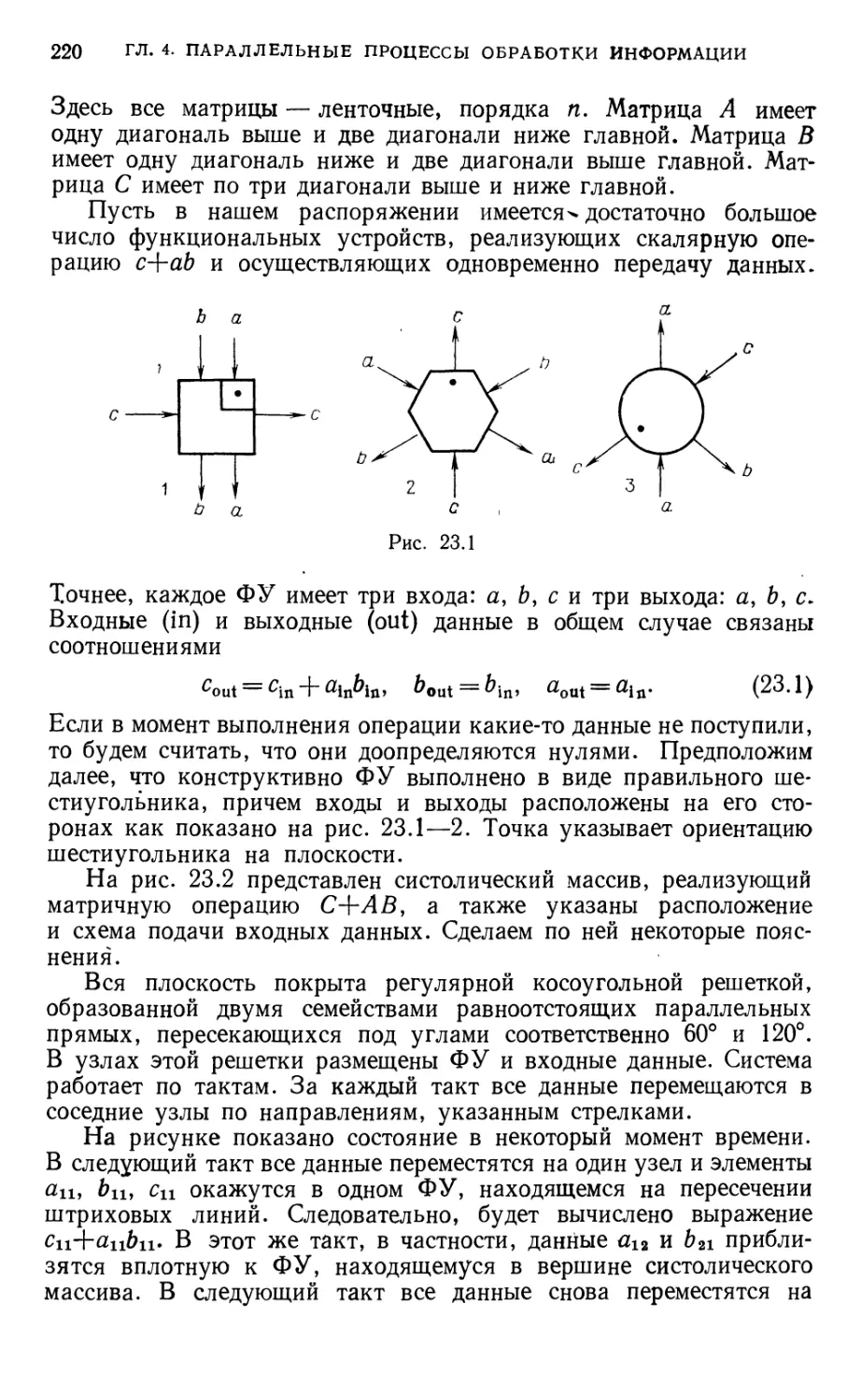
§ 7. Функциональные устройства 71
§ 8. Алгоритмы и вычислительные системы 81
§ 9. Программы реализации алгоритмов 92
§ 10. Графы и матрицы 102
§11. МР-сложность общей задачи ИЗ
Глава 3. Параллельные структуры алгоритмов и программ 117
§ 12. Формы записи алгоритмов 117
§ 13. Решетчатый граф алгоритма 125
§ 14. Расщепление решетчатого графа 133
§ 15. Элементарный решетчатый граф 143
§ 16. Информационная значимость в графах 154
§ 17. Регулярные графы 164
Глава 4. Параллельные процессы обработки информации 176
§ 18. Конвейерные вычислители 177
§ 19. Периодические графы 185
§ 20. Расщепление информационных потоков 192
§ 21. Конвейерные вычислители и матрицы графов 203
§ 22. Векторные вычислители 211
§ 23. Систолические массивы 218
§ 24. Алгебраический вычислитель 238
Библиографические указания 243
Список литературы 246
Предметный указатель ♦♦·· 295
ПРЕДИСЛОВИЕ
Начиная знакомство с работами в области параллельных
вычислений, автору настоящей книги хотелось узнать совсем
немногое. Именно нужно было всего лишь понять, что нового по
сравнению с классическими однопроцессорными ЭВМ вносят супер-ЭВМ
и большие параллельные системы в разработку численных методов
и создание численного программного обеспечения в традиционных
для математиков областях линейной алгебры, численного анализа,
математической физики, оптимизации и т. п. Однако это
знакомство затянулось надолго.
Чтение первых работ ничего не прояснило. Более того, они
поставили много новых вопросов. Количество вопросов, на
которые не удавалось найти ответы, неуклонно возрастало по мере
расширения и углубления знаний в данной области. Процесс
знакомства продолжался до тех пор, пока наконец не был осознан
тот простой факт, что, по-видимому, и нельзя найти ответы на
многие вопросы, так как этих ответов пока еще нет.
За многие годы существования однопроцессорных ЭВМ
произошло довольно четкое разделение сфер развития
вычислительной техники, алгоритмических языков и численных методов. По
отношению к таким ЭВМ подобное разделение вполне оправданно,
и в настоящее время каждое из направлений, по существу,
развивается самостоятельно. Поэтому можно понять, почему идеи
параллельной реализации процессов во всех этих направлениях
также стали развиваться практически независимо друг от друга.
В особой степени это относится к численным методам. Но, как
оказывается, для параллельных процессов все три направления
связаны между собой исключительно тесно. Их уже нельзя ни
исследовать, ни развивать порознь, если, конечно, иметь в виду в
качестве цели эффективную реализацию алгоритмов.
Эти обстоятельства и определили основной замысел книги —
исследовать с точки зрения математика основные этапы анализа и
реализации параллелизма в алгоритмах от математических формул
и программ до вычислительных систем.
Бурное развитие микроэлектроники позволило достичь в
последние годы большого прогресса в создании новой
вычислительной техники. Уже функционируют вычислительные системы с про-
ПРЕДИСЛОВИЕ
5
изводительностью от нескольких десятков до нескольких сотен
миллионов операций в секунду; мощность проектируемых систем
определяется миллиардами операций. Перспективы
вычислительной техники в настоящее время таковы, что в недалеком будущем
можно ожидать появление вычислительных систем, содержащих
огромное число отдельных устройств и процессоров. Проекты
создания таких систем активно обсуждаются во всем мире как
проекты ЭВМ пятого поколения.
Расширение возможностей в конструировании вычислительной
техники всегда оказывало влияние на развитие вычислительной
математики — в первую очередь численных методов и численного
программного обеспечения. До недавнего времени технический
прогресс не приводил к коренному изменению структуры
вычислительных систем. Поэтому повышение быстродействия
однопроцессорных ЭВМ и даже появление комплексов машин и систем с
относительно небольшим числом одновременно работающих
процессоров не потребовали существенного изменения ни численных
методов, ни разработанного ранее программного обеспечения. Теперь
положение меняется принципиально.
Характерной чертой всех новых вычислительных систем
является возможность одновременного или параллельного
использования для обработки информации большого числа процессоров.
Для таких систем собирательным стало название параллельные.
Их создание определило один из важнейших путей повышения
скорости решения сложных и трудоемких задач. Однако опыт
эксплуатации первых параллельных систем показал, что для
эффективного их применения нужно радикально изменять структуру
численных методов.
В настоящее время опубликовано достаточно большое число
работ по численным методам, ориентированным на параллельные
вычислительные системы. Имеется ряд обзоров, посвященных как
самим методам, так и смежным проблемам параллельного
программирования и архитектуры параллельных вычислительных систем.
Уже при первом знакомстве с методами решения различных
задач на параллельных системах виден значительный разрыв
между уровнями развития последовательных и параллельных
численных методов. Если последовательные численные методы
составляют вполне сложившуюся область вычислительной математики, то
в параллельных методах пока идет в основном процесс
накопления отдельных фактов и делаются попытки их осмысления с
некоторой общей точки зрения. По-видимому, уровень развития
параллельных численных методов сейчас такой же, какой имели
последовательные методы в начале 50-х годов.
Особых проблем с созданием параллельных численных методов
не возникало до тех пор, пока вычислительные системы позволяли
выполнять одновременно лишь небольшое число операций. Для
таких систем приемлемое ускорение в большинстве случаев дости-
6
ПРЕДИСЛОВИЕ
галось путем распараллеливания в соответствующем
последовательном методе операций, образующих линейные участки. Процесс
подобного распараллеливания легко автоматизируется, и это
обстоятельство на долгое время снизило остроту внимания к
исследованию специальных параллельных численных методов.
Появление больших параллельных систем изменило ситуацию.
Очень скоро стало ясно, что построение для них эффективных
численных методов является делом и трудным, и мало изученным.
Трудности определяются главным образом значительным
разнообразием архитектур самих систем и, как следствие, таким же
разнообразием способов организации вычислений. Различные способы
организации вычислений влекут за собой различные способы
организации данных, требуют создания различных численных методов
и алгоритмов, различного численного программного обеспечения,
новых средств и языков общения с вычислительной· техникой.
Переделать существующее программное обеспечение в
соответствии с требованиями больших параллельных систем уже не просто.
Не всегда даже ясно, можно ли вообще его переделать. Несмотря
на то что имеется достаточно много работ, посвященных алгоритмам
распараллеливания программ, практически в данной области нет
сколько-нибудь общей конструктивной методологии. Поэтому чаще
всего для больших параллельных систем разрабатываются новые
численные методы и заново пишутся все программы. Такой путь
создания нового программного обеспечения трудно назвать
эффективным.
Использование ЭВМ всегда сопровождалось развитием многих
научных проблем, связанных с эффективным их применением.
Эти проблемы исключительно разнообразны и охватывают такие
вопросы, как создание алгоритмических языков и трансляторов,
разработка операционных и инструментальных систем и средств
взаимодействия с ЭВМ, построение библиотек и пакетов программ,
конструирование и исследование численных методов и т. п.
Понятие эффективности затрагивает не только сферу
обеспечения пользователей различными услугами, упрощающими и
облегчающими общение с вычислительной техникой. Существенным
образом с этим понятием связано и достижение максимальной
производительности. Последний фактор имеет особое значение для
суперЭВМ и больших параллельных систем, предназначенных для
исключительно сложных и трудоемких задач, решаемых на грани
возможностей вычислительной техники. Для супер-ЭВМ и больших систем
обеспечение максимальной эффективности использования играет
не меньшую роль, чем увеличение их технических возможностей.
Эффективность использования вычислительной техники всегда
была и остается предметом постоянной заботы. Но если для
разработчиков технических устройств, операционных систем, языков
и трансляторов эта забота осуществляется прежде всего на этапе
проектирования, то для пользователей, в первую очередь матема-
ПРЕДИСЛОВИЕ
7
тиков, с созданием вычислительной техники она только начинается.
Особенность положения математиков как пользователей состоит
в том, что в процессе решения своих задач они во всей полноте
ощущают на себе достоинства и недостатки принятых технических
и системных решений.
В условиях появления больших параллельных систем и
перспективы создания сверхмощных новых систем перед
математиками, и в особенности математиками-прикладниками, открывается
обширнейшая и мало освоенная область исследований, связанная
с совместным изучением параллельных структур численных
методов и вычислительных систем. Однако факты говорят о том, что
они пока еще не принялись всерьез за освоение данной области.
Приведем некоторые статистические данные на начало 80-х
годов. К этому времени по различным проблемам, связанным только
с освоением параллельных ЭВМ, было опубликовано заведомо
более 5000 работ и поток публикаций имел явную тенденцию к
расширению. В этом потоке заметную часть составляли работы,
связанные с обсуждением особенности реализации параллельных
численных методов, в основном линейной алгебры. Интерес к этим
методам вполне понятен, так как они составляют основу процессов
решения многих сложных проблем. Согласно данным, взятым из
библиографических указателей на начало 80-х годов, в области
вычислительных методов линейной алгебры было опубликовано
примерно 7700 работ. При этом около 120 ученых мира имели по
этой тематике более чем по 10 работ. Эти ученые оказали
наибольшее влияние на развитие данного раздела науки. Казалось бы, что
именно им и развивать параллельные методы линейной алгебры.
Но среди них на тот период лишь около 10 человек имели по одной-
две публикации, косвенно относящиеся к параллельным
численным методам и их применению на параллельных вычислительных
системах. И только несколько человек имели работы, прямо
посвященные обсуждению этих проблем. В настоящее время
положение существенно не изменилось. Аналогичная ситуация имеет место
и в других областях вычислительной математики.
Основные публикации по параллельным численным методам
и их применению на существующих и перспективных
параллельных вычислительных системах сейчас идут не от математиков —
специалистов в области разработки и создания численных методов,
а от специалистов смежных областей. В первую очередь они идут
от лиц, разрабатывающих принципы конструирования
параллельных систем, создающих программное обеспечение и занимающихся
абстрактными вопросами сложности алгоритмов. Естественно, что
при этом оказываются вне сферы исследований многие важные
проблемы численной реализации алгоритмов.
Интересно отметить, что в определенном смысле история
повторяется. Аналогичной была ситуация на рубеже появления первых
вычислительных машин. Тогда численные методы и программы для
8
ПРЕДИСЛОВИЕ
ЭВМ тоже разрабатывались не математиками. Прошло много лет,
прежде чем положение изменилось. Последствия же этого периода
ощущаются до сих пор.
Среди различных этапов исследований, ориентированных на
применение ЭВМ, обычно выделяются следующие крупные этапы:
— описание изучаемого явления;
— построение математической модели;
— разработка численных методов;
— выбор языка и написание программы;
— прохождение программы на ЭВМ.
Основные усилия математиков до сих пор направляются на
первые три этапа, определенное, хотя и недостаточное, внимание
уделяется ими четвертому этапу, и почти выпадает из поля зрения
математиков пятый этап. На наш взгляд, такая ситуация связана
прежде всего с устойчивой недооценкой и даже непониманием
трудных математических проблем, возникающих на последних
этапах.
За долгие годы существования ЭВМ сложился устойчивый
стереотип отношений математиков к вычислительной технике. Как
правило, они решают свои задачи на ЭВМ, не зная устройства
самих ЭВМ. При использовании многомашинных комплексов и
вычислительных сетей математики нередко могут узнать о том, на
какой ЭВМ в действительности решались их задачи, лишь после
решения самих задач. Внешнее совпадение операций
алгоритмических языков с математическими операциями создает устойчивую
иллюзию совпадения их свойств и скрывает от математиков
большинство проблем реализации алгоритмов на ЭВМ. Все это и
определяет слабый интерес математиков к тому, что стоит за
алгоритмическими языками, т. е. к вычислительной технике и ее
структуре.
Традиционные алгоритмические языки достаточно хорошо
согласованы с классическими однопроцессорными ЭВМ. Именно это
согласование в конечном счете дает возможность математикам не
изучать детально устройство традиционных ЭВМ и создавать для
них машинно-независимое численное программное обеспечение.
По отношению к параллельным вычислительным системам такой
возможности пока нет. Для этих систем нерешенные проблемы
согласованности алгоритмов и алгоритмических языков с их
структурой стали особенно многочисленными и актуальными.
Существует принципиальное различие между реализацией
алгоритмов на классической однопроцессорной ЭВМ и реализацией
тех же алгоритмов на параллельных вычислительных системах.
Оно определяется следующими обстоятельствами.
Любой алгоритм описывается в конечном счете направленным
графом, вершины которого отождествляются с выполняемыми
операциями, а дуги — с информационными связями между ними.
Процерс его реализации на классической однопроцессорной ЭВМ
ПРЕДИСЛОВИЕ
9
можно трактовать как процесс последовательного исключения
по одной из входных вершин графа до полного его исчерпывания.
Так как такой процесс можно осуществить для любого
бесконтурного графа, то нет принципиальных ограничений в
эффективной реализации любого алгоритма на однопроцессорной ЭВМ.
Если вычислительная система имеет ρ процессоров и ρ
достаточно большое, то положение изменяется радикально. Во-первых,
эффективная реализация алгоритма теперь означает, что каждый
раз в графе должно исключаться ρ вершин. Но при р>\ граф
алгоритма в силу своей внутренней структуры может просто не
обладать возможностью допускать каждый раз исключение ρ вершин.
В этом случае ни на какой вычислительной системе, имеющей ρ
процессоров, при реализации данного алгоритма нельзя загрузить
процессоры полностью и, следовательно, нельзя достичь
максимальной производительности системы. Во-вторых, эффективной
реализации алгоритма могут помешать особенности
коммуникационной сети, связывающей процессоры между собой. При большом ρ
эта сеть не может обеспечить быстрые передачи информации от
каждого процессора к каждому. Поэтому ограниченные
возможности быстрых связей коммуникационной сети могут также быть
не согласованными со структурой связей в алгоритме. При р>\
на'эффективность реализации алгоритма значительно сильнее, чем
в случае однопроцессорной ЭВМ, влияет структура памяти
системы.
В целом сказанное означает, что, чем выше быстродействие
параллельной вычислительной системы, достигаемое за счет
архитектурных решений, тем уже класс алгоритмов, которые на ней
эффективно реализуются.
Задача разработки параллельных численных методов и их
программного обеспечения оказывается неизмеримо сложнее, чем
для последовательных методов. Сложнее в первую очередь из-за
того, что на ее решение самым существенным образом влияют
индивидуальные особенности параллельных систем. Конечно, эту
задачу можно решить непосредственно для каждой из конкретных
систем, особенно если не считаться с затратами. Но уже сейчас
существует много различных типов параллельных систем, а
проектируется их еще больше. Поэтому путь создания индивидуального
обеспечения нельзя считать приемлемым.
К сожалению, проблема унификации численного программного
обеспечения для различных параллельных систем и его
эффективной переносимости с одной системы на другую всерьез даже не
обсуждается. Пока ее решение заменяется попытками создания
универсальных алгоритмических языков для описания параллельных
процессов. Однако стоит напомнить, что на пути использования
универсальных языков проблема унификации и переносимости
практически осталась нерешенной даже для традиционных
однопроцессорных ЭВМ. ■
10
ПРЕДИСЛОВИЕ
Математиков не может не беспокоить перспектива снова и снова'
переделывать алгоритмы и переписывать программы на различные
типы вычислительных систем, хотя бы и с такими современными
названиями как «супер», «параллельные» и т. п. Неблагоприятные
последствия этой ситуации были осознаны еще в 50-х годах.
Нагромождение большого числа проблем, возникших вокруг
параллельных систем, требует систематизированного и
комплексного подхода к их решению. В книге отражена попытка автора
взглянуть на различные математические аспекты конструирования
и освоения супер-ЭВМ и больших параллельных систем с
некоторых общих позиций. Основная стратегия проводимых исследований
направлена на выявление и изучение тех факторов, которые могут
помочь или помешать математикам эффективно решать свои задачи
на существующих и проектируемых вычислительных системах.
Прежде чем приступать к изучению особенностей
конструирования параллельных численных методов, необходимо понять,
какие ограничения, накладываемые особенностями вычислительных
систем, являются для математика принципиальными, а какие
вызваны существующей ограниченностью технических
возможностей.
Математический анализ супер-ЭВМ и других
высокопроизводительных систем в значительной мере затрудняется большим их
разнообразием, многочисленными плохо определенными понятиями
и отсутствием формализованных принципов исследования. Уже
при первом знакомстве с такими системами на математиков
буквально обрушивается поток одних только типов систем:
конвейерные, матричные, многопроцессорные, с программируемой
архитектурой, параллельные, систолические, спецпроцессоры и т.' д.
Естественно, что при этом возникает и очень много вопросов,
например: что общего в этих системах и чем они различаются как
ухитриться обеспечить все системы необходимыми программами, можно
ли добиться преемственности существующего программного
обеспечения, как нужно строить вычислительные системы, чтобы лучше
отразить потребность вычислений?
Однако, какой бы ни была вычислительная система, она
представляет совокупность связанных между собой устройств. В
каждый момент времени эти устройства либо простаивают, либо
выполняют полезную работу, т. е. заняты хранением, пересылкой
или переработкой информации. Системы различаются как
составом устройств, так и видом связей. Как правило, в любой системе
имеется много устройств с постоянными связями. Но некоторые из
устройств могут быть объединены изменяемыми связями, причем
их число в различных системах может колебаться в довольно
широких пределах.
Поэтому исследование параллельных численных методов в
действительности должно начинаться с построения математической
модели работы большого числа устройств с изменяемыми в общем
ПРЕДИСЛОВИЕ
11
случае связями и с анализа на основе данной модели особенностей
информационных потоков, проходящих через всю совокупность
устройств. Лишь после этого можно приступать к разработке
методологии построения и исследования параллельных алгоритмов
и численных методов.
В книге проведен детальный анализ процессов
функционирования произвольной системы взаимосвязанных устройств.
Обнаружены инвариантные соотношения, позволяющие выделять
неэффективные и трудно реализуемые алгоритмы. Одни из них,
например, показывают, что ни на какой вычислительной системе с
конвейерными функциональными устройствами нельзя добиться
хорошей загруженности устройств на алгоритмах типа прогонки.
Другие говорят о необходимости жесткой согласованности числа
используемых процессоров и каналов связи при реализации
алгоритмов с малым средним числом операций, приходящихся на единицу
входной и выходной информации.
Совместное исследование структур вычислительных алгоритмов
и систем позволило установить много интересных свойств. В
частности, показано, что информационный поток, проходящий через
любую систему с постоянными или редко меняющимися связями
между устройствами, обязательно расщепляется на независимые,
однотипно обрабатываемые ветви. Это означает, что если число
ветвей больше единицы, то алгоритм, соответствующий отдельной
ветви, нельзя эффективно реализовать на данной системе. Однако
на ней эффективно реализуется поток таких алгоритмов. Поэтому
наличие в алгоритме большого числа независимых и однотипных
ветвей вычислений должно в общем случае помогать эффективной
его реализации на параллельных системах.
Проводя наши исследования, мы не делали никаких
предположений о связи различных способов организации вычислений.
Автоматически оказались в поле зрения параллелизация вычислений,
конвёйерность функциональных устройств, возможность
образовывать сложные конвейеры, векторные и матричные вычисления
и т. п. Как показали результаты исследований, эффективное
использование многих функциональных устройств, вообще говоря,
эквивалентно возможности организовывать конвейерные вычис
ления. При этом конвейеры надо понимать не в традиционном, а
в более широком смысле, в том числе с изменяемыми связями.
На одном полюсе конвейерных вычислений находятся макро-
конвейерные вычисления. Для процессов этого типа характерно
наличие большого числа длинных ветвей независимых вычислений
и возможность пренебрежения связями и временами передачи
информации при реализации этих ветвей. На другом полюсе
находятся конвейерные вычисления, реализуемые с помощью
систолических массивов. Для процессов этого типа характерно
осуществление всех необходимых, в том числе длинных, передач информации
на фоне выполнения самих операций.
12
ПРЕДИСЛОВИЕ
Вычисления, реализуемые на векторных системах, занимают
промежуточное положение и дополнительно характеризуются всего
лишь векторной организацией данных. Интересно отметить, что
возможность векторной организации данных является
отличительной чертой любых вычислений, реализуемых на системе устройств
с редко изменяющимися связями. При этом длины векторов
полностью определяются графом связей реализуемого алгоритма.
Тот факт, что на конкретных вычислительных системах длины
векторов часто выбираются постоянными, отражает особенности
технических решений и не имеет отношения к структуре алгоритмов.
Совместное исследование вычислительных систем и алгоритмов
является исключительно сложной задачей и весьма заманчиво,
хотя бы в перспективе, поставить ее решение на ЭВМ. Возможность
осуществления этого можно понять лишь в том случае, если
проводимые исследования будут не только систематизированными и
комплексными, но и алгоритмичными. По существу, весь материал
в книге подчинен также изучению и этой идеи.
Пожалуй, самым сложным моментом в решении данной задачи
является выбор единых средств математического описания как
вычислительных систем, так и алгоритмов. Сложность выбора
определяется не столько тем, что с помощью этих средств надо
фиксировать описание каких-то объектов, сколько необходимостью
задавать и распознавать различные их свойства, а также
сравнивать и преобразовывать описания отдельных объектов.
В качестве средства описания вычислительных систем и
алгоритмов в книге широко используются графы. В той или иной мере
графы для этих целей применялись давно, тем не менее их
использование до сих пор было лишь фрагментарным и не получило
нужного развития. На наш взгляд, это объясняется следующим
обстоятельством. Сравнение свойств систем и алгоритмов на уровне
графов неизбежно приводит к операциям сравнения графов,
например, на изоморфизм, гомоморфизм и т. п. Если считать, что
алгоритм задается произвольным графом, то такое сравнение
является yVP-сложной задачей, и для его осуществления требуется,
вообще говоря, полный перебор всех вариантов. Так как граф
алгоритма содержит огромное число вершин, то отсюда нередко
делаются различные пессимистические выводы.
В основе этих выводов лежит методологическая ошибка,
связанная с предположением о произвольности графа алгоритма.
В действительности граф алгоритма никогда не является таковым.
Во всяком случае, не являются произвольными графы алгоритмов,
ориентированных на использование вычислительной техники и
записанных в виде математических соотношений и программ на
алгоритмических языках. Поэтому выявление особенностей
графов алгоритмов является на самом деле первостепенной по
важности задачей в кругу математических проблем, связанных с
параллельными вычислительными системами. Возможность спол-
ПРЕДИСЛОВИЕ
13
зания при этом к Λ/Ρ-сложным задачам говорит всего лишь о
постоянной опасности зайти в тупик в совместных исследованиях
алгоритмов и систем, если не учитывать каких-то важных деталей.
В книге уделяется много внимания изучению свойств графой
алгоритмов. Выбрана форма записи, объединяющая в себе основные
особенности представлений алгоритмов в виде математических
соотношений и программ на алгоритмических языках. По ней
специальным образом строится граф алгоритма. Процесс построения
основан на выборе для каждого алгоритма некоторой естественной
прямоугольной системы координат, связанной с индексами
используемых переменных. В этой системе строится регулярная
прямоугольная решетка и вершины^графа размещаются в ее узлах в
соответствии с индексами переменных, определяющих выполняемые
операции. Связь координат вершин графа алгоритма с индексами
переменных в значительной мере облегчила анализ параллельных
структур алгоритмов и программ. Разработана методология
проведения такого анализа. Обнаружены и изучены классы графов,
являющиеся общими для большого числа алгоритмов численного
анализа, математической физики и линейной алгебры.
Использование графов оказалось также успешным при
построении и исследовании математических моделей параллельных
вычислительных систем. Удалось описать графы систем,
реализующих заданный алгоритм, и изучить их свойства. При этом
установлена взаимосвязь между многими характеристиками
вычислительного процесса, например такими, как синхронный и асинхронный
режим функционирования, загруженность устройств и время
реализации алгоритма и т. д. Проведенные исследования позволили
разработать общие принципы отображения алгоритмов на классы
параллельных систем.
Комплексное исследование различных вычислительных проблем,
представленное в настоящей книге, позволило дать ответы на
многие вопросы, касающиеся установления оптимальных соотношений
между перспективными вычислительными системами и
вычислительными методами. Оно дало возможность также нащупать пути
создания унифицированного математического обеспечения
современных ЭВМ с целью обеспечения его преемственности. Но это же
исследование показало, что нерешенных проблем осталось еще
очень много и нужны большие усилия, чтобы добиться в данной
области заметных успехов.
С формальной точки зрения в книге обсуждаются в основном
проблемы, связанные с решением крупных вычислительных
задач. "Однако в действительности многие результаты исследований
имеют более широкое применение, в том числе для задач
невычислительного характера.
Решение крупных прикладных задач выдвигает сейчас
существенно более высокие требования к математическим моделям,
описывающим различные явления. Повышаются требования к качест-
14
ПРЕДИСЛОВИЕ
ву численных методов. Все большую роль начинает играть уровень
развития вычислительной техники. В настоящее время
технологические возможности позволяют выбор архитектуры
вычислительной системы сделать математической задачей. Появляется
возможность объединить исследования математических моделей
в естествознании и технике, вычислительных методов и архитектур
вычислительных систем в единый процесс.
Соответствующее направление исследований сформировано
академиком Г. И. Марчуком и получило название «отображение
проблем вычислительной математики на архитектуру вычислительных
систем». Это направление активно развивается в Отделе
вычислительной математики АН СССР. Оно включает в себя структурный
анализ алгоритмов, изучение математических особенностей
архитектур вычислительных систем, автоматизацию процессов
распараллеливания программ, построение и исследование
параллельных численных методов.
Книга написана на основе результатов, полученных автором
в процессе освоения этой новой области. Ее содержание и характер
изложения материала определились не сразу. На их выбор в
значительной мере повлияли те трудности, о которых говорилось
выше. Первоначальный план заключался в систематизированном
изложении параллельных численных методов и их свойств. По мере
накопления сведений о параллельных методах стало ясно, что
никакого систематизированного изложения не получится до тех пор,
пока не будет описана методология исследования численных
методов. Однако после того, как методология была разработана,
изучение различных свойств параллельных вариантов известных
методов превратилось в основном в скучную полутехническую
работу, которая должна быть поручена ЭВМ. Поэтому главное
внимание в книге уделяется именно изложению различных вопросов
методологии исследования параллельных численных методов и
параллельных вычислительных систем.
Книга состоит из предисловия, четырех глав и обширного списка
литературы.
Глава 1 является вводной. Основное ее назначение состоит
в том, чтобы помочь читателю, не знакомому с параллельными
вычислительными системами и параллельными численными методами,
войти в курс дела и составить общее представление о том круге
проблем, с которыми приходится сталкиваться математикам в
данных и смежных областях. В этой главе обсуждается взаимосвязь
численных методов и используемой вычислительной техники, а
также влияние алгоритмических языков как посредников между
математиками и техникой. Обсуждается сложившаяся концепция
математических исследований, связанная с построением и
изучением параллельных численных методов.
Глава 2 посвящена совместному исследованию параллельных
вычислительных систем и алгоритмов. Для его проведения широко
ПРЕДИСЛОВИЕ
15
применяются ориентированные графы. Одно из центральных мест
в главе занимает изучение особенностей работы системы
функциональных устройств. Устанавливаются некоторые соотношения,
позволяющие оценить различные характеристики, такие как
загруженность устройств, ускорение, число каналов связи и т. п.
Эти соотношения помогают, в частности, выделять алгоритмы,
реализуемые неэффективно на любых параллельных
вычислительных системах. Описываются классы систем, на которые
отображение вычислительных алгоритмов осуществляется эффективно.
В этой главе приводится описание матричных постановок некоторых
из рассматриваемых задач.
В гл. 3 рассматриваются различные вопросы, связанные с
построением и анализом решетчатых графов алгоритмов. Обсуждаются
формы записи алгоритмов и выделяется одна из них, объединяющая
в себе характерные особенности математических соотношений и
программ на алгоритмических языках. Основной принцип
исследования свойств решетчатых графов алгоритмов связан с
расщеплением этих графов на простейшие, изучением свойств простейших
графов и последующим выявлением свойств исходных графов на
основе проведенного анализа. Особое внимание уделяется
исследованию специальных классов решетчатых графов, соответствующих
часто встречающимся в практической деятельности алгоритмам.
Глава 4 посвящена исследованию математических особенностей
параллельных процессов обработки информации, реализуемых на
различных вычислительных устройствах и системах. Глава
начинается с изучения конвейерных вычислителей, т. е. систем
функциональных устройств, связанных постоянными или мало
изменяемыми во времени связями и не имеющих памяти для
долговременного хранения результатов промежуточных вычислений.
Устанавливается, что во многих случаях информационный поток,
проходящий через такую систему, расщепляется на независимые
однотипно обрабатываемые ветви. Это позволяет дать ряд практических
рекомендаций по исследованию и разработке параллельных
алгоритмов. Проводится анализ конкретных вычислительных систем,
таких как векторные, систолические и т. п. Заканчивается глава
описанием модели специализированной вычислительной системы,
предназначенной для решения больших задач линейной алгебры
с плотными матрицами.
Характер изложения материала в книге во многом определен
основной целью — дать описание методологии исследования
параллельных численных методов и параллельных вычислительных
систем. С одной стороны, было необходимо соблюсти приемлемый
уровень строгости изложения, чтобы не потерять какие-то важные
связи между отдельными фактами. С другой стороны, нельзя было
увлекаться деталями изложения, чтобы не утопить в них главные
факты. Попытка держаться где-то посередине и определила
характер изложения материала.
16
ПРЕДИСЛОВИЕ
Основные факты зафиксированы в утверждениях, хотя немало
сведений, конечно, приводится и в самом тексте. Утверждения
выделены не по степени их сложности, а для того, чтобы обратить
внимание читателя на тот или иной факт. Многие доказательства
даны схематично и без подробностей, а наиболее простые из них
опущены. Как правило, для облегчения понимания излагаемого
материала в каждом параграфе приводятся иллюстративные
примеры.
В процессе проведения исследований по параллельным
вычислительным системам и параллельным численным методам
пришлось познакомиться в той или иной мере с очень большим объемом
литературы. Значительная ее часть приведена в конце книги. На
формирование точки зрения автора оказали существенное влияние
многие работы. При этом, возможно, даже большее влияние имели
работы, сформировавшие убеждение в том, что и как не надо
делать, чем работы, определившие выбранный путь. При изложении
не приводится никаких ссылок. Однако для облегчения работы
с приведенным списком литературы даны краткие
библиографические указания о том, в каких работах можно более подробно
познакомиться с тем или иным материалом.
Автору приятно выразить свою искреннюю признательность
Г. И. Марчуку за постоянную поддержку в проведении
исследований в области параллельных вычислительных систем и
параллельных алгоритмов. Без его внимания и заинтересованности эти
исследования проходили бы не столь широко и интенсивно, а книга
вряд ли была бы написана. Автору хочется также поблагодарить
всех своих коллег, с которыми вместе пришлось осваивать новую
область. Рукопись книги была прочитана С. А. Красновым,
Ю. М. Нечепуренко и Ε. Ε. Тыртышниковым. Их замечания и
проведенные обсуждения были исключительно полезны. Наконец, автор
с благодарностью отмечает большой труд, выполненный А. А. Гри-
горенко и С. А. Красновым по формированию использованной при
написании книги библиографической картотеки по параллельным
процессам.
В. Воеводин
Глава 1
ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ
СИСТЕМ И АЛГОРИТМОВ
Эта глава является вводной. Основное ее назначение состоит
в том, чтобы помочь читателю, не знакомому с параллельными
вычислительными системами и параллельными численными методамиу
войти в курс дела и составить общее представление о том круге
проблем, с которыми приходится сталкиваться математикам в
данных и смежных областях. При изложенцд материала главное
внимание уделяется не описанию деталей параллельных систем и
методов, а обсуждению различных особенностей процесса
взаимодействия математиков с параллельными вычислительными системами.
Большинство из этих особенностей не проявлялось при разработке
и применении традиционных однопроцессорных ЭВМ. Поэтому
возможно, что читатель, искушенный в деле использования
вычислительной техники, также найдет для себя в этой главе что-нибудь
полезное.
Основной интерес математиков, решающих задачи с помощью
вычислительной техники, связан прежде всего с разработкой
численных методов. Однако на конечный результат оказывают
влияние не только численные методы, но и используемая техника, а
также алгоритмические языки как посредники между математиками
и вычислительной техникой. Эти составляющие процесса решения
задач всегда были связаны между собой, но при использовании
параллельных методов, языков и систем их связь оказалась
исключительно тесной. В данной главе в той или иной степени
обсуждаются все три составляющие и их особенности.
Особое внимание в главе уделяется обсуждению сложившейся
в настоящее время концепции математических исследований,
связанной с построением и изучением параллельных численных
методов и получившей название концепции неограниченного
параллелизма.
18 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
§ 1. Параллельные вычислительные системы
■> ι
!
Ввод-
-вывод
-
ι
Устро
ЙСТВО
управления
I
1
Память
\
1
Центральной
прои,
ессор
Рис. 1.1
Прежде чем начинать изучение особенностей параллельных вы
числительных систем, обсудим коротко причины ограниченности
возможностей классических однопроцессорных ЭВМ, которые,
вообще говоря, и привели к созданию вычислительных систем
нового типа.
Несмотря на огромное фактическое разнообразие, все
однопроцессорные ЭВМ принципиально устроены одинаково (рис. 1.1).
Имеются два основных
устройства. Одно из них, называемое
процессором (центральным
процессором, решающим
устройством, арифметико-логическим
устройством и т. п.),
предназначено для выполнения над
операндами некоторого
ограниченного набора операций. В
набор операций обычно
входят операции сложения,
вычитания, умножения и деления
чисел, логические операции над
отдельными разрядами и их
последовательностями, операции над
символами и многое другое. Наборы операций, выполняемые
процессорами разных ЭВМ, могут отличаться друг от друга как
частично, так и полностью. Другое устройство, называемое памятью
(запоминающим устройством), предназначено для хранения всей
информации, необходимой для организации работы процессора.
Процессор является активным устройством, т. е. он имеет
возможность преобразовывать информацию. Память является
пассивным устройством, т. е. она не имеет такой возможности. Процессор
и память связаны между собой каналами обмена информацией.
Работа однопроцессорной ЭВМ заключается в
последовательном выполнении отдельных команд. Каждая команда содержит
информацию о том, какая операция из заданного набора должна
быть выполнена, а также из каких ячеек памяти должны быть
взяты аргументы операции и в какие ячейки помещен результат.
Описание упорядоченной последовательности команд в виде
программы находится в памяти. Там же размещаются необходимые для
реализации алгоритма начальные данные и результаты
промежуточных вычислений. Координирует работу всех узлов ЭВМ
устройство управления. Оно организует последовательную выборку
команд из памяти и их расшифровку, передачу из памяти в процессор
операндов, а из процессора в память результатов выполнения
команд, управляет работой процессора. Ввод начальных данных и
выдачу результатов осуществляет устройство ввода-вывода.
§ 1. ПАРАЛЛЕЛЬНЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ \$
Описанная схема устройства ЭВМ и процесса ее
функционирования в действительности обрастает большим числом
дополнительных деталей. Процессор является единственным устройством ЭВМ,
которое выполняет полезную с точки зрения реализации
алгоритма работу. В этом смысле все остальные устройства ЭВМ по
отношению к нему оказываются обслуживающими, и их работа
направлена только на то, чтобы обеспечить наиболее эффективный
режим функционирования процессора. Процессор классической
ЭВМ всегда устроен достаточно сложно, и при реализации каждой
отдельной команды, как правило, бывает задействована лишь
некоторая его часть. Чтобы максимально загрузить оборудование
процессора выполнением полезной работы, в современных
однопроцессорных ЭВМ организуется несколько параллельных потоков
информации, характеризующихся спецификой обработки.
Например, разделяются потоки команд и потоки данных, каждый из этих
потоков в свою очередь может разделяться по типам команд и т. п.
На сложность процесса функционирования ЭВМ влияют иерархия
памяти, работа операционной системы и устройств ввода-вывода
и многое другое.
Однако какой-бы сложной ни была однопроцессорная ЭВМ,
построенная по классическим канонам, в основе ее архитектуры и
организации процесса функционирования лежит принцип
последовательного выполнения отдельных команд. Отклонения от этого
принципа, как правило, не существенны. Именно поэтому такие
ЭВМ часто называют последовательными.
Принцип последовательного выполнения команд
однопроцессорной ЭВМ является основной причиной возникновения того
стереотипа отношений математиков к ЭВМ, о котором говорилось в
предисловии. В условиях использования таких ЭВМ главной задачей
конструирования алгоритмов оказывается их представление в виде
последовательности выполнения отдельных операций. Никаких
других принципиальных ограничений на формы представления
алгоритмов структура однопроцессорных ЭВМ не накладывает.
Следовательно, при решении задач на этих ЭВМ математикам
приходится в первую очередь заботиться о минимизации числа
операций и размера требуемой памяти. Это означает, что от ЭВМ
математик также требует только необходимые ему скорости выполнения
операций и объем памяти, в первую очередь оперативной.
Подобное отношение к ЭВМ, вполне оправданное в случае
однопроцессорных машин, довольно часто без всякого основания
переносится на современные вычислительные системы других типов.
В немалой степени этому способствует и тот факт, что математик в
действительности имеет дело не с ЭВМ, а с алгоритмическими
языками, которые взяли на себя роль посредника во взаимоотношениях
с ЭВМ. Он может даже не знать, что используемые им языки,
такие как алгол, фортран и т. п., хорошо отражают структуру
классических однопроцессорных ЭВМ и совершенно не приспособлены
20 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
для отражения особенностей современной вычислительной техники.
Только тщательный учет всех особенностей ЭВМ может привести к
высокой эффективности реализации на ней. алгоритмов. Поэтому
процессы создания эффективных численных методов и исследования
структур вычислительных систем оказываются тесно связанными.
Это обстоятельство всегда имело важное значение, но особую роль
оно начинает играть в настоящее время.
Быстродействие ЭВМ до недавнего времени повышалось в
основном за счет увеличения скорости срабатывания логических
элементов. Благодаря достижениям новой технологии скорость
выполнения операций и взаимодействия с памятью за последние десятилетия
возросла на несколько порядков. Однако дальнейшее
увеличение скорости срабатывания элементов стало ограничиваться
причинами физического характера. Оставаясь в рамках классических
структур однопроцессорных ЭВМ, сейчас трудно рассчитывать на
обеспечение практических потребностей вычислительными
мощностями. Выход из создавшегося положения можно искать в создании
вычислительных систем принципиально иной архитектуры, чем
классические однопроцессорные ЭВМ.
Одна из основных идей, как говорится, лежит на поверхности.
Если ЭВМ с одним процессором и одним устройством памяти не
удовлетворяет потребностям решения больших задач, то возьмем
несколько устройств памяти, несколько процессоров и объединим
их в единую систему, связав каналами передачи информации. Пусть
при решении некоторого класса задач удалось заставить каким-то
образом каждый процессор выполнять полезную работу и при этом
использовать каждое устройство памяти. Тогда при благоприятных
условиях можно рассчитывать на то, что на данном классе задач
такая система будет обладать большей производительностью и
давать возможность решать задачи большего размера, чем ЭВМ с
одиночным процессором и одиночным устройством памяти. При
самых благоприятных условиях можно рассчитывать на
пропорциональное числу процессоров и числу устройств памяти увеличение
эффективности. Собственно говоря, эта идея была реализована уже
в самых ранних многомашинных комплексах. Тогда же были
обнаружены и узкие места подобных систем. Одним из них оказалась
коммуникационная сеть каналов связи.
Не возникло бы много проблем, если бы большое число устройств
всегда можно было связать коммуникационной сетью,
обеспечивающей передачу информации от каждого устройства к каждому со
скоростью, существенно превышающей скорость переработки
информации процессорами и скорость взаимодействия с памятью или хотя
бы соизмеримой с ними. Однако пока не видно путей создания
таких коммуникационных сетей.
Прямая связь каждого устройства с каждым приводит к резкому
усложнению сети с ростом числа устройств. Оказывается, что в
случае ее создания на удается обеспечить даже нужный минимум про-
§ 1. ПАРАЛЛЕЛЬНЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ 21
тяженностей линий связи, не говоря уже о необходимости
использования очень большого числа самих линий связи. Применение же
различного рода коммутаторов увеличивает время передачи
информации от устройства к устройству. С ростом миниатюризации
элементной базы и устройств вычислительной техники проблема
построения коммуникационных сетей не только не снимается, но
становится еще более сложной и актуальной.
Построение вычислительных систем с многими процессорами и
распределенной памятью, по-видимому, должно приводить к тому,
что возможности коммуникационной сети в обеспечении быстрых
передач информации неизбежно окажутся в значительной мере
ограниченными. Это в свою очередь означает, что стремление
достичь увеличения быстродействия за счет использования в
системе большого числа процессоров может быть несовместимо в условиях
применения конкретного численного метода с возможностями
коммуникационной сети. Это также означает, что любая
Вычислительная система с многими процессорами будет эффективной только на
определенном классе алгоритмов и методов.
Трудности использования многопроцессорных систем связаны
не только с ограниченными возможностями коммуникационных
сетей. Большая производительность вычислительной системы будет
достигнута лишь в том случае, если в процессе решения задачи все
процессоры или большая их часть будут постоянно загружены
выполнением полезной работы. Но алгоритм решения задачи в силу
причин, вызванных его собственной структурой, может просто не
обладать возможностью обеспечить постоянную загрузку большого
числа процессоров независимо от устройства коммуникационной
сети. Имеется много численных методов, которые нельзя эффективно
реализовать ни на каких многопроцессорных системах.
С подобной ситуацией математики не встречались при решении
задач на однопроцессорных ЭВМ классической архитектуры. Вообще
говоря, на таких ЭВМ, по крайней мере с принципиальных позиций,
одинаково эффективно решаются все задачи. В отношении
многопроцессорных вычислительных систем теперь возникает много
новых вопросов: если есть многопроцессорная система, то какие
алгоритмы реализуются на ней эффективно; если нужно эффективно
решать конкретный класс задач, то как должна быть устроена
соответствующая многопроцессорная система и какими должны быть
численные методы и т. п.? Перечень аналогичных вопросов можно
продолжать довольно долго.
Таким образом, использование многопроцессорных систем
заставляет их пользователей обращать внимание на совершенно
новые проблемы. Именно, стремление эффективно решать задачи на
таких системах должно обязательно сопровождаться согласованием
структуры численных методов и архитектуры вычислительных
систем. В противном случае необходимая эффективность может быть
не достигнута.
22 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
Следующая идея повышения быстродействия менее заметна, хотя
она давно реализуется в самых разных областях. Как уже
отмечалось, процессор является сложным устройством, и при реализации
каждой отдельной команды бывает задействована лишь некоторая
его часть.
Процессор классической ЭВМ всегда универсальный, т. е. имеет
возможность выполнять различные операции, такие как
сложение, умножение, сдвиг, логическое умножение и т. п. Фактически
он представляет некоторую совокупность разнородных устройств,
объединенных в единое целое в силу тех или иных технических
причин. Если эти устройства разъединить, то каждое из них можно
использовать более эффективно, но уже не как универсальное, а как
специализированное.
Давно известен и широко используется один из самых
эффективных принципов выполнения специализированных работ. Это —
организация конвейера. Конвейеры можно организовать и при
выполнении различных операций. Рассмотрим, например, процесс
выполнения операции сложения двух чисел с плавающей запятой.
Реально он распадается на такие этапы: сравнение порядков, сдвиг
мантиссы большего числа, сложение мантисс, нормализация,
округление результата. К этим этапам могут быть добавлены и некоторые
другие. Сумматор, реализующий операцию сложения, в своей
работе следует указанным этапам. Технически он конструируется в
виде нескольких устройств, последовательно выполняющих этап
за этапом.
В общем случае при реализации одной операции в каждый
момент времени работает только одно из устройств, остальные
вынуждены простаивать из-за отсутствия работы. Положение существенно
изменяется, если нужно выполнить не одну операцию, а
достаточно большое их число, причем не зависящих друг от друга. Теперь
выполнение всего потока операций можно организовать по
принципу конвейера. Для того чтобы начать выполнение следующей
операции, совсем не нужно ждать окончания всего процесса
выполнения предыдущей операции. Достаточно, чтобы у предыдущей
операции был закончен только первый этап. Если конвейер имеет г
последовательных этапов, то в то время, когда /-я операция
проходит s-й этап, (i+k)-n операция может проходить (s—k)-& этап,
где l^s, s—k^r. Общая схема реализации потока операций на
последовательном конвейере представлена на рис. 1.2.
Реализация конвейера позволяет максимально загрузить
процессоры выполнением полезной работы. Однако за достижение этого
эффекта приходится "платить необходимостью организовывать
данные специальным образом, объединяя в отдельные потоки
независимые однотипные операции. Снова мы сталкиваемся с ситуацией,
когда эффективность процесса реализации задачи решающим
образом зависит от степени согласования структуры численных методов
и особенностей архитектуры вычислительных систем.
§ 1. ПАРАЛЛЕЛЬНЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ 23
С точки зрения математика относительное быстродействие любой
вычислительной системы определяется в основном составом
используемых функциональных устройств, выполняющих необходимые
для алгоритма операции, и степенью их общей загруженности в
каждый момент времени. В соответствии с этим можно выделить две
тенденции повышения быстродействия. Первая связана с
использованием большого числа одновременно работающих функциональных
устройств, вторая — с увеличением эффективности использования
0 ■—*- О, В, А
1 -тгг Д С, В
L·
77- E,D4C а, А.
5 -ТГГ Η,β,Γ Κι Pzl^l^Ms
L^
^
^
C4
~il
G1 ζ Кз Г4 Кб
4 -
%*№
г
Рис. 1.2
самих устройств. Ускорение в первом случае определяется в
основном числом устройств, во втором — степенью общей загруженности
всех элементов каждого из устройств.
Это две разные тенденции со своими достоинствами и
недостатками. Использование многих функциональных устройств обычно
связывается с проблемой распараллеливания вычислений,
повышение загруженности устройств — с конвейеризацией вычислений.
Однако, если отвлечься от типа операций, реализуемых
функциональными устройствами, оба способа повышения быстродействия
приводят к отличиям лишь в множествах допустимых связей между
устройствами.
Множества допустимых связей и различия между ними
определяются не только архитектурными особенностями вычислительных
систем, но и набором используемых функциональных устройств и
смысловым содержанием реализуемых ими операций. Если,
например, устройства реализуют такие операции, как сложение,
умножение, деление и т. п., то в этом случае связи между
устройствами практически могут быть любыми, и их выбор в конечном счете
диктуется только возможностями коммуникационных сетей. Если
же устройства реализуют более мелкие операции, например
сравнение порядков чисел, выравнивание мантисс и т. п., то последова-
24 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
тельность выполняемых операций, а следовательно, и связи между
устройствами уже не могут быть произвольными. Аналогичное
положение возникает и в том случае, когда устройства реализуют
достаточно крупные операции, такие как решение систем линейных
алгебраических уравнений, быстрое дискретное преобразование
Фурье *и аналогичные им.
Если при реализации какого-либо алгоритма мы сможем так
организовать вычисления, что все функциональные устройства будут
загружены выполнением полезной работы, то в целом (без учета
потерь на организационные расходы) на данной вычислительной
системе будет достигнута максимально возможная при данном составе
устройств скорость решения задачи. При этом в математическом
отношении безразлично, как отдельные устройства связаны между
собой, хотя в действительности именно характер связей во многом
определяет как архитектуру системы, так и сложность разработки
алгоритма.
Ни при каком другом способе организации вычислений с тем же
составом оборудования нельзя достичь большей скорости реализации
алгоритма. Но среди различных способов, обеспечивающих полную
загрузку оборудования, можно искать лучший, например, с точки
зрения простоты связей функциональных устройств.
По своей сути конвейеризация процессов направлена именно на
полную загрузку всего оборудования. При этом весьма простой
оказывается и система связей отдельных устройств. Поэтому
конвейерный способ обработки информации часто применяется при решении
такой важной проблемы, как создание специализированных
процессоров или блоков высокопроизводительных систем,
предназначенных для решения типовых задач.
Итак, повышение быстродействия вычислительной системы,
достигаемое за счет увеличения количественного или изменения
качественного состава устройств, занятых переработкой
информации, приводит к тому, что в вычислительной системе появляется
большое число устройств, работающих одновременно или, как
говорят, параллельно. Для подобных систем предложено много
различных названий, каждое из которых отражает ту или иную
особенность. Мы будем называть все такие системы параллельными
независимо от их специфических особенностей, подчеркивая тем
самым только тот факт, что вычислительные системы имеют много
(точнее, больше одного) устройств, выполняющих нужные для
реализации алгоритмов операции или их части одновременно. В
случае необходимости мы будем, конечно, пользоваться и более
конкретными названиями.
Имеется много различных классификаций параллельных
вычислительных систем. В качестве основных признаков классификации,
характеризующих структуру и функционирование системы с точки
зрения параллельности работы, чаще всего рассматриваются
следующие:
§ 1. ПАРАЛЛЕЛЬНЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ 25
— тип потока команд;
— тип потока данных;
— способ обработки данных;
— тип строения памяти;
— тип коммуникационной сети;
— степень однородности компонент системы;
— степень согласованности режимов работы устройств.
Наибольшее распространение получила классификация
вычислительных систем, введенная М. Флинном. Она охватывает только
два первых признака и определяет в самых общих чертах
функционирование параллельных систем и их структуру.
Первый признак соответствует разделению систем по типу потока
команд между устройствами памяти и устройствами управления или
процессорами. Погок может быть одиночным (Single Instruction)
или множественным (Multiple Instruction). В одиночном потоке в
один момент времени может выполняться только одна команда.
В этом случае эта единственная команда определяет работу всех
или по крайней мере многих устройств в данный момент. В
множественном потоке в один момент времени может выполняться много
команд. В этом случае каждая из таких команд определяет работу
только одного или в крайнем случае нескольких устройств в данный
момент. В одиночном потоке последовательно выполняются
отдельные команды, в множественном потоке — группы команд.
Второй признак соответствует разделению систем по типу потока
данных между процессорами и устройствами памяти. Поток может
быть одиночным (Single Data) или множественным (Multiple Data).
Одиночный поток обязательно предполагает использование только
одного устройства памяти и одного процессора. Однако при этом
процессор может быть как очень простым, так и настолько сложным, что
процесс обработки каждой единицы информации потока будет
требовать выполнения многих команд. Множественный поток состоит
из многих одиночных потоков. Эти потоки могут быть либо полно-
ностью независимыми, либо связаны использованием общей
памяти или общего процессора.
В соответствии с данной классификацией все параллельные
системы делятся на четыре класса: SIMD, MIMD, SISD, MISD.
Сокращенные обозначения этих классов составлены из первых букв
английских названий потоков команд и данных. Однопроцессорная
ЭВМ классической структуры является типичным представителем
класса SISD. К классу MISD можно отнести систему, имеющую
сложный процессор, например конвейерного типа. Системы класса
SIMD и MIMD всегда имеют много процессоров, работающих
параллельно. В системах MIMD процессоры, как правило,
универсальные, имеют собственную память и редко обмениваются
информацией между собой. Коммуникационная сеть таких систем
обеспечивает быстрые передачи информации только между процессорами
и их собственной памятью; остальные обмены осуществляются зна-
26 ЕГЛ. 1 ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
чительно медленнее. В системах SIMD процессоры могут быть как
универсальными, так и специализированными. Обычно они имеют
небольшую собственную память или не имеют ее совсем.
Коммуникационная сеть систем SIMD обеспечивает быстрые передачи
информации как между процессорами и их собственной памятью, так
и между некоторыми из процессоров; остальные обмены
осуществляются значительно медленнее.
Подчеркнем еще раз, что классификация систем по типу потоков
команд и данных определяет лишь самые общие черты
параллельных систем. Далеко не всегда конкретную параллельную систему
можно однозначно отнести к одному из четырех классов и не так
просто охарактеризовать особенности каждого класса.
Классификация параллельных систем по остальным признакам разработана
еще в меньшей степени.
По способу обработки данных системы разделяются на системы
с пословной и поразрядной обработкой. В системах первого типа
все разряды каждого слова обрабатываются процессором
последовательно слово за словом, в системах второго типа одноименные
разряды большого числа слов обрабатываются одним процессором
параллельно. Основным примером этих систем являются так
называемые ассоциативные системы.
Каждый процессор параллельной системы может иметь свою
собственную память, и тогда память системы называется
распределенной. Для распределенной памяти характерно наличие большого
числа быстрых каналов, связывающих отдельные ее части с
отдельными процессорами. Обмен информацией между частями
распределенной памяти обычно осуществляется довольно медленно. Если
процессоры общаются с памятью через общие каналы связи, то в
этом случае память называется общей. Для параллельных систем
с общей памятью одним из самых узких мест, затрудняющих
достижение максимального быстродействия, являются именно каналы
связи с памятью. Естественно, что одна и та же вычислительная
система может иметь как общую, так и распределенную память.
Коммуникационные сети образуют исключительно обширное
множество. Практически каждая параллельная вычислительная
система имеет свою собственную оригинальную коммуникационную
сеть. Как уже отмечалось, большое разнообразие видов сетей
объясняется в основном невозможностью соединить много устройств
быстрыми каналами связи по типу «каждое с каждым». Поэтому в
любой параллельной системе быстрый обмен информацией
осуществляется не между всеми устройствами, а только между некоторыми.
Все остальные обмены осуществляются относительно медленно. Это
разделение связей на быстрые и медленные, с одной стороны,
порождает многообразие типов коммуникационных сетей и, с другой
стороны, является одной из основных причин ограниченности
класса алгоритмов, эффективно реализуемых на параллельных
вычислительных системах. Быстрый обмен информацией обычно осу-
§ 1. П£'г»АЛЛЕЛь;.ЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ 27
ществляется по некоммутируемым линиям связи, соединяющим
устройства непосредственно друг с другом. Медленный обмен
осуществляется либо через коммутаторы, либо как некоторая
последовательность быстрых обменов по цепочке связанных друг с другом
устройств. Последний принцип реализован, например, в так
называемых тасовочных схемах, коммуникационные сети которых
позволяют эффективно осуществлять произвольную сортировку. В общем
случае коммуникационная сеть параллельной вычислительной
системы может иметь несколько уровней иерархии, а также быть
программно перестраиваемой.
Степень однородности компонент вычислительной системы
показывает, насколько велико в ней разнообразие устройств и типов
связей. Естественно, что, чем больше степень однородности
компонент, тем проще устройство системы и технологичней ее
изготовление. В однородных системах можно надеяться на достижение
максимальной эффективности реализации алгоритмов. Однако не очень
ясно, насколько широк круг алгоритмов, эффективно реализуемых
на таких системах. Один из типов однородных вычислительных
систем широко обсуждается в последнее время. Это — так называемые
систолические массивы. Основная их часть состоит из
функциональных устройств только одного типа, объединенных с помощью
регулярной периодической коммуникационной сети.
По степени согласованности режимов работы устройств
параллельные вычислительные системы разделяются на синхронные и
асинхронные. В синхронных системах управление в основном
централизовано и управляющие команды подаются периодически и
синхронно по всем устройствам независимо от того, какой конкретно
процесс реализуется в вычислительной системе в данный момент.
В асинхронных системах управление децентрализовано. Степень
децентрализации управления может быть очень высокой и доходить
до того, что каждое устройство будет работать в самостоятельном
режиме. В этом случае процесс, реализуемый в вычислительной
системе, управляет собой самостоятельно с помощью потока данных
без вмешательства извне. Большинство современных
вычислительных систем являются синхронными. Асинхронный принцип
управления получил наиболее яркое воплощение в потоковых системах.
Рассмотренные признаки классификации параллельных
вычислительных систем, конечно, не исчерпывают всех возможных их
характеристик. Существует разделение систем по способам
организации данных, по способам организации устройств, по степени
связности компонент, по степени близкодействия устройств, по
типам каналов связи и т. п. Общая классификация параллельных
систем во многом затрудняется неопределенностью терминов. Нередко
одному и тому же термину в разных ситуациях приписывается
разный смысл. Например, с понятием «матричный процессор»
связываются три совершенно различные характеристики: способ
организации данных, способ организации устройств и класс решаемых задач.
28 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
Аналогичное положение с понятиями «векторный процессор»,
«ассоциативный процессор» и некоторыми другими.
Некоторые параллельные системы по ряду признаков трудно
отнести к какому-нибудь определенному классу. Системы с
признаками отличающихся друг от друга классов естественно считать
системами с комбинированной архитектурой. Некоторые системы в
Знешние устройства
5-6500
Ввод- вывод
Устройство управления
Массовая
память·
ТТтттттт
ΤτττΤιτττ
ТттттТтт
ттТттТТТ
Процессоры
Рис. 1.3
процессе работы могут перестраивать свою структуру и переходить
из одного класса в другой по одному или нескольким признакам.
Такие системы называются системами с перестраиваемой
архитектурой. Они получили быстрое развитие в последние годы.
Сложность классификации параллельных вычислительных
систем и систематизированного описания их особенностей не случайна.
Она объясняется тем, что данная область в настоящее время
переживает период исключительно бурного технического развития и
совершенно не устоялась как раздел науки.
Рассмотрим общие схемы некоторых разработанных
параллельных систем. Одной из самых известных является система ILLIAC-IV,
введенная в эксплуатацию в 1974 г. (рис. 1.3). Она имеет 64
универсальных процессора и может выполнять от 100 до 200 млн. операций
в секунду над 64 разрядными словами. Каждый процессор имеет
собственную оперативную память емкостью 2048 слов. Все
процессоры конструктивно расположены в виде матрицы размером 8x8.
Система имеет одно устройство управления, и в каждый момент
времени все процессоры синхронно выполняют одну и ту же команду
§ 1. ПАРАЛЛЕЛЬНЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ 29
над данными из собственной памяти. С помощью аппарата масок
некоторым из процессоров разрешается не выполнять отдельные
команды.
Коммуникационная сеть обеспечивает для каждого процессора
быстрый обмен информацией только с четырьмя соседними
процессорами. Если процессоры занумеровать числами от 0 до 63, то для
i-ro процессора соседями будут процессоры с номерами ί±1 и /±8
по модулю 64. Обмен между другими процессорами осуществляется
как последовательность обменов между соседями. Каждое из
запоминающих устройств связано двумя магистралями с остальной
частью системы для приема и выдачи информации одновременно со
счетом. Общее управление работой всей системы осуществляется
с помощью ЭВМ В-6500.
. Система ILLIAC-IV является типичным представителем класса
SIMD. Ее часто называют также матричным процессором, что
отражает конфигурацию связей отдельных процессоров между собой.
Оперативная память системы распределенная, режим работы
синхронный. Большое число процессоров позволяет на некоторых
задачах достигать высокого быстродействия. Однако однотипность
выполняемых команд и ограниченность числа быстрых каналов связи
сделали класс таких задач очень узким. Опыт эксплуатации
системы ILLIAC-IV убедительно показал необходимость согласования
структуры параллельной вычислительной системы с классом
решаемых задач и используемых численных методов.
Другой известной системой является система CRAY-I, первый
образец которой введен в эксплуатацию в 1976 г. (рис. 1.4).
Основана она на конвейерном принципе обработки информации и
обеспечивает быстродействие от 80 до 140 млн. операций в секунду над
64 разрядными словами. Система имеет 12 функциональных
конвейерных устройств с единым циклом выполнения одной ступени,
равным 12,5 не. Все устройства могут работать одновременно.
Высокая производительность достигнута благодаря организации
структуры системы, обеспечивающей как одновременное
выполнение вычислений в нескольких конвейерах, так и возможность
быстрого объединения конвейеров в разнообразные цепочки с
передачей данных от одного конвейереа к другому через регистры без
отсылки в память. Все функциональные устройства для получения
операндов и отсылки результатов используют только регистры.
Наличие емкой и быстрой регистровой памяти, а также конвейер-
ность функциональных устройств являются существенной
особенностью системы.
Принципиальное ядро системы образуют шесть конвейерных
функциональных устроств, каждое из которых выполняет одну и
ту же операцию над данными, расположенными в восьми векторных
регистрах по 64 слова. По этой причине данные устройства также
называются векторными. Быстродействие системы в основном
обеспечивается за счет работы этих устройств. Среди них имеются только
SO ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
;дин векторный сумматор и векторный умножитель. Оперативная
память системы имеет 1М слов.
Система CRAY-I является наиболее ярким представителем
конвейерных систем, и ее можно отнести к классу MISD. Ее часто на-
Устройство управления
Адресные
операции
Скалярные
операции
Операции
с плавающей
запятой
Векторные
операции
А\
А2
ΑΊ
/48
ВЛ
вг
ΒΊ
ВЬ
Адресные
регистры
51
52
57
S8
ТЛ
тг
ΤΊ
Τδ
Скалярные
регистры
ММ
М-н~У2| m
V63
V64
^Ξ
Ввод-
вывод
Векторные
регистры
Рис. 1.4
зывают также векторным процессором, что отражает способ
организации данных. Режим работы синхронный. На этой же системе
весьма отчетливо видно, как структура системы влияет на класс
эффективно реализуемых алгоритмов. Именно, введение конвейерных
устройств повлекло за собой введение векторных регистров, и все
это вместе потребовало представления алгоритмов в виде последова-
§ 2. ПАРАЛЛЕЛЬНЫЕ АЛГОРИТМЫ
31
тельностей операций над векторами достаточно большой длины.
Если алгоритм можно представить в таком виде, то можно
надеяться, что при его реализации на системе CRAY-I будет достигнуто
высокое быстродействие.
Обсуждая особенности параллельных систем, мы не ставим
перед собой задачу дать сколько-нибудь детальное их описание. Эти
описания в достаточном количестве имеются в соответствующей
литературе. Главная наша цель состояла в том, чтобы обратить
внимание читателя, главным образом математика, на основные отличия
параллельных вычислительных систем от однопроцессорных ЭВМ
классической архитектуры. Мы еще раз настоятельно обращаем
внимание на то, что эти отличия не только помогают, но и мешают
эффективному решению конкретных задач на конкретных
параллельных системах.
До недавнего времени развитие алгоритмов и численных методов
в основном следовало за развитием вычислительной техники.
Создание параллельных систем показало, что алгоритмы и системы плохо
согласованы друг с другом, а параллельные структуры методов
изучены слабо. Сейчас наступает период совместного исследования
параллельных свойств алгоритмов и вычислительных систем.
Возможно, что уже в недалеком будущем положение изменится радикально,
и архитектура вычислительных систем будет в первую очередь
определяться классом решаемых задач и используемых численных
методов. Но чтобы это будущее наступило, сегодня математикам
приходится изучать и вычислительные системы, и численные методы.
§ 2. Параллельные алгоритмы
Как бы ни были устроены параллельные вычислительные
системы, все они обладают одной общей особенностью. Именно, в каждый
момент времени преобразование информации может осуществляться
одновременно на многих функциональных устройствах, причем на
каждом устройстве информация в данный момент преобразуется
независимо от остальных. Это означает, что для того, чтобы алгоритм
мог быть реализуем на параллельной системе, он должен быть
представим в виде последовательности групп операций. Все операции
одной группы должны быть независимыми и обладать возможностью
быть выполненными одновременно на имеющихся в системе
функциональных устройствах.
Пусть операции алгоритма разбиты на группы, упорядоченные
так, что каждая операция любой группы зависит либо от начальных
данных алгоритма, либо от результатов выполнения операций,
находящихся в предыдущих группах. Представление алгоритма в
подобном виде называется параллельной формой алгоритма. Каждая
группа операций называется ярусом параллельной формы, число
групп — высотой параллельной формы, максимальное число
операций в ярусе — шириной параллельной формы.
32 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
Если известна параллельная форма алгоритма, то сам алгоритм
можно реализовать на параллельной вычислительной системе по
шагам последовательно ярус за ярусом. Если состав функциональных
устройств системы таков, что параллельно могут выполняться все
операции любого яруса, то при подходящим образом
организованной коммуникационной сети алгоритм может быть реализован на
параллельной системе за время, пропорциональное высоте
параллельной формы.
Естественно, что один и тот же алгоритм может иметь много
параллельных форм, различающихся как высотой, так и шириной.
Среди всех параллельных форм имеется одна или несколько форм
минимальной высоты. Такие параллельные формы алгоритма
называются максимальными, а их высота называется высотой алгоритма.
Максимальные параллельные формы алгоритмов представляют
предмет особого интереса, так как определяют минимально возможное
время реализации алгоритмов если не на реальных, то по крайней
мере на некоторых гипотетических параллельных вычислительных
системах.
Рассмотрим следующий пример. Пусть требуется вычислить
выражение (а^г+Язйи) (аьав+а7а8), соблюдая лишь тот порядок
выполнения операций, который фиксирован формой записи. Это
можно осуществить многими способами. По существу, здесь фиксирован
не один алгоритм, а несколько математически эквивалентных.
Различные порядки выполнения операций и различные разбиения
операций на группы порождают различные параллельные формы.
Одна из них такая:
Данные аг а2 а3 а4 аъ ав αι α8
Ярус 1 ага2 а3а^ а5а6 а7а8
Ярус 2 а1а2 + а3а4с аъа6 + а7а8
Ярус 3 (a1a2 + a3a4t) (a5aQ + a7a8)
Высота этой параллельной формы равна трем, ширина —
четырем. Она может быть реализована на параллельной системе,
имеющей четыре процессора, способных выполнять операции
умножения и сложения. Сначала выполняются четыре операции умножения,
соответствующие ярусу 1, затем две операции сложения из яруса 2
и, наконец, одна операция умножения, соответствующая ярусу 3.
При этом мы не обращаем внимания ни на какие другие аспекты
реализации, кроме того, чтобы число процессоров совпадало с
шириной схемы и сами процессоры имели возможность выполнять
операции каждого яруса.
Заметим, что в рассмотренной схеме все четыре процессора
задействованы только на первом шаге, затем работают только два
процессора и на третьем шаге лишь один процессор загружен
выполнением полезной работы, а все остальные простаивают. Поэтому можно
попытаться построить другие параллельные формы, в которых
высота, конечно, будет больше, но зато число операций будет изме-
§ 2. ПАРАЛЛЕЛЬНЫЕ АЛГОРИТМЫ
33
няться от яруса к ярусу меньше. Рассмотрим две такие формы.
Одна из них следующая:
Данные аг а2 а3 а4 аъ ав а7 а8
Ярус 1 а±а2 αζα^
Ярус 2 аьаь αΊα8
ЯруС 3 (21(22 + #3α4 #5αβ + α7α8
Я рус 4 (а^+а3а^) (а&ав+α7α8)
Другая имеет вид
Данные а^ а2 а3 а4 аь ав αΊ а8
Ярус 1 аха2 αζα^
Ярус 2 αχ^ + αβ^ «δ^β
Ярус 3 α7α8
Ярус 4 αδαβ + αΊα8
Ярус 5 (^2 + ^4) (^6+07^8)
Высота второй параллельной формы равна четырем, третьей —
пяти. Ширина этих форм равна двум. Обе эти параллельные формы
могут быть реализованы на параллельной системе с двумя
процессорами. Во второй параллельной форме оба процессора работают
на всех шагах, кроме последнего. На третьей параллельной форме
хорошо видно, как неудачный выбор порядка выполнения операций
на ярусе 2 привел к тому, что один из процессоров оказался
вынужден простаивать на ярусах 3 и 4, и это увеличило высоту
параллельной формы при сохранении ее ширины.
Этот простой пример показывает некоторые из проблем, с
которыми придется встретиться при реализации алгоритмов на
параллельных вычислительных системах. Одной из них является
проблема загруженности процессоров. По-видимому, сложной окажется
и проблема построения параллельных форм с заданными
свойствами.
Для решения одной и той же задачи могут применяться
алгоритмы, имеющие различную параллельную сложность. Среди них могут
быть и алгоритмы наименьшей высоты. Рассмотрим важный
пример вычисления произведения η чисел аи а2, . . ., ап, в котором
отчетливо видна идея, играющая большую роль в построении
алгоритмов малой высоты.-
Пусть я=8. Обычная схема, реализующая процесс
последовательного умножения, выглядит следующим образом:
Данные ах а2 а3 а^ аъ α6 αΊ а8
Ярус 1 ага2
Ярус 2 (axa2)az
Ярус 3 (аха^а^а^
Ярус 4 (αχαφζα^) аъ
Ярус 5 (αχαφφ^α^ αβ
Ярус 6 (μχα2αζα^α^ α7
Ярус 7 (а^ач^а^а^^) а8
2 В. В. Воеводин
34 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
Высота параллельной формы равна семи, ширина — одному.
Если вычислительная система имеет более одного процессора, то
при данной схеме вычислений все они, кроме одного, на всех шагах
будут простаивать. Следующая параллельная форма алгоритма
вычисления произведения чисел использует процессоры более
эффективно:
Данные а± а2 а3 а4 аъ а6 а7 а8
Ярус 1 а±а2 а3а^ а5ав αηα%
Ярус 2 (ага2){а3а^ (ад?) (cl^s)
Ярус 3 (а1а2а3а^ (α5α6αΊα8)
Высота параллельной формы равна трем, ширина — четырем.
Существенное снижение высоты произошло за счет более полной
загруженности процессоров выполнением полезной работы. Последняя
схема очевидным образом распространяется на случай
произвольного п. Для ее реализации необходимо на каждом ярусе осуществить
максимально возможное число произведений непересекающихся
пар чисел, взятых на предыдущем ярусе. В общем случае высота
параллельной формы равна [~ \og2n ~] , где [~ α ~] означает ближайшее
сверху к а целое число. Эта параллельная форма реализуется на
Г я/2~] процессорах, но в ней загруженность процессоров
уменьшается от яруса к ярусу. Процесс построения чисел каждого яруса по
описанной схеме называется процессом сдваивания. Очевидно, что
с его помощью можно строить параллельные формы с
логарифмической высотой не только для операции умножения чисел, но и для
любой ассоциативной операции, например сложения чисел,
умножения матриц и т. п.
При вычислении произведения η чисел часто требуется знать
не только этот результат, но и все частичные произведения а1у
ага2, а1а2а3 и т. д. Эта задача реализуется по схеме сдваивания
исключительно эффективно. Снова рассмотрим ее для п=8:
Данные аг а2 а3 а4 аъ ав ач ав
Ярус 1 ага2 α3α± α5αβ αηα8
Ярус 2 (ага2)а3 (μχα2) (α3α4) (аъаь) αΊ (аъав) (а7а8)
Я рус 3 (аг... а4) аъ (аг... α4) (а^в) («ι · ·. сц) {аъа^т) (αι · · ·а*) (аъ··· «s)
Высота параллельной формы равна трем, ширина — четырем.
Все процессоры на всех шагах загружены полностью. На этом
примере можно заметить одну характерную особенность параллельных
алгоритмов. По сравнению с соответствующими последовательными
алгоритмами реализация параллельных алгоритмов требует
выполнения «лишних» операций, и их число может быть очень
большим. В рассмотренном примере получено пять лишних чисел,
которые в схеме подчеркнуты.
Обратим внимание еще на одну не заметную, но очень важную
особенность параллельных алгоритмов. Анализируя обе схемы вы-
§ 2. ПАРАЛЛЕЛЬНЫЕ АЛГОРИТМЫ
£5
числения произведения η чисел, нетрудно видеть, что они реализуют
разные алгоритмы. Хотя в силу ассоциативности операции оба
алгоритма дают одинаковые результаты в условиях точных
вычислений, они будут давать разные результаты в условиях влияния
ошибок округления. Этот факт обязательно нужно учитывать при
конструировании параллельных алгоритмов. Общая ситуация такова,
что устойчивость параллельных алгоритмов при большом числе
процессоров оказывается хуже устойчивости последовательных
алгоритмов. По крайней мере области устойчивости для
последовательных и параллельных алгоритмов оказываются различными.
Исследование сложности параллельных алгоритмов приносит
новые идеи и неожиданные результаты. Так, например, вычисление
выражения хп по схеме сдваивания асимптотически при больших η
требует выполнения log2 n параллельных умножений. Если же
воспользоваться тождеством
/ η \-ι
Xя = 1 + η ί 2 е*к2я*п (х—е^^)"1 ) ,
то в терминах параллельных операций выражение хп
асимптотически можно вычислить за два деления и log2 n сложений. Если
предположить, что сложение выполняется быстрее умножения, и не
принимать во внимание никакие другие аспекты реализации, то можно
считать, что второй алгоритм вычисления выражения хп
эффективнее первого.
Рассмотренные примеры позволяют сделать один вывод, весьма
важный в методологическом отношении. Пусть с помощью бинарных
и унарных операций вычисляется некоторое выражение,
существенным образом зависящее от η переменных. Предположим, что имеется
некоторый алгоритм высоты s, позволяющий это выражение
вычислить. Не ограничивая общности, можно допустить, что каждая
операция любого яруса хотя бы в качестве одного аргумента
использует результат выполнения какой-нибудь операции,
находящейся в предыдущем ярусе, и каждый результат, кроме последнего,
где-то используется. Так как результат зависит от всех входных
переменных и число аргументов всех операций не больше двух, то
число операций в каждом ярусе не более чем в два раза превышает
число операций в следующем ярусе. Следовательно, результат
вычисления выражения при s ярусах будет зависеть не более чем от 2s
входных данных. Отсюда вытекает, чтоя^р log2n~] . Очевидно, что
если для вычисления выражения используются операции,
имеющие не более ρ аргументов, то s^ f logp η"] .
Таким образом, если какая-нибудь задача определяется η
входными данными, то мы не можем рассчитывать в общем случае на
существование алгоритма ее решения с высотой по порядку меньше
log п. Если получен алгоритм высоты порядка logan, то такой
алгоритм мы должны считать эффективным с точки зрения времени
реализации на параллельной вычислительной системе, если не при-
36 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
нимать во внимание все другие аспекты реализации. В частности,
высота порядка log n является оценкой снизу почти для всех задач
линейной алгебры с матрицами порядка п.
Пусть вектор у вычисляется как произведение матрицы А и
вектора χ порядка п. Если yt, а,ц, Xj суть элементы соответствующих
векторов и матрицы, то
η
#/= Σ аих9
/=ι
для всех /. Предположим, что вычислительная система имеет п2
процессоров. Тогда на первом шаге можно параллельно вычислить
все п2 произведений а^х^ а затем, используя схему сдваивания для
сложения, за f loggft"] шагов вычислить параллельно все η сумм,
определяющих координаты вектора у. Следовательно, можно
построить алгоритм вычисления произведения матрицы и вектора
порядка η высоты порядка log2 п. При этом ширина алгоритма равна
п2. Процессоры используются неравномерно. Только на первом шаге
задействованы все процессоры, затем число работающих процессоров
на каждом шаге уменьшается вдвое. Нельзя построить алгоритм,
имеющий меньшую высоту, но существует алгоритм, имеющий при
логарифмической высоте несколько меньшую ширину.
Задачу вычисления произведения двух матриц порядка η можно
рассматривать как задачу вычисления η произведений одной
матрицы и η векторов порядка п, считая векторами столбцы второй
матрицы. Если все эти произведения вычислять параллельно по
описанному алгоритму, то полученный алгоритм будет иметь
высоту порядка log2 it и ширину пъ. Снова процессоры используются
неравномерно, и опять нельзя построить алгоритм, имеющий
меньшую высоту, но существует алгоритм, имеющий при
логарифмической высоте несколько меньшую ширину.
Построение параллельных алгоритмов наименьшей высоты для
матрично-векторных сумм и произведений не вызвало никаких
затруднений, и это'может создать впечатление, что такие алгоритмы
легко строятся и для других матрично-векторных задач. Такое
впечатление, конечно, неверно, и рассмотренные алгоритмы скорее
являются исключением, чем правилом.
Рассмотрим процесс вычисления векторов xt (l^i^s) при
заданных векторах х0, х_1У . . ., х_г+1 с помощью линейных
рекуррентных соотношений следующего вида:
xt=Ailxl_1+... + Alrxi_r + bi. (2.1)
Здесь Atj, bt— заданные матрицы и векторы порядка п\ при п=\
они становятся числами. Предположим, что мы хотим построить
при фиксированном s параллельный алгоритм вычисления векторов
#ι, . . ., xs по возможности меньшей высоты. Очевидно, что,
используя порядка п2г процессоров, правую часть соотношений (2.1)
можно вычислить примерно за log2 nr шагов. Это дает параллельный
§ 2. ПАРАЛЛЕЛЬНЫЕ АЛГОРИТМЫ
37
алгоритм высоты порядка s log2 nr. Однако совсем не очевидно, как
построить алгоритм с существенно более слабой зависимостью
высоты от s. Не очевидно даже, что вообще существуют такие
алгоритмы.
Рекуррентное соотношение (2.1) можно записать несколько
иначе — через матрицы и векторы большего порядка:
xi-i
xi-r + i
LI
Лп.
Ε .
0 .
0 .
•.Λ/#-ι
.0
.Ε
.0
Air
0
0
0
bi
0
0
1
Xi-i
xi-2
xi -r
1
Обозначим
<?,=
An.
Ε .
0 .
0 .
• -Air.
..0
.E
.0
-1
Air
0
0
0
0
0
1 .
. У1 =
'Xi
Xi-i
xi-r + l
.1
тогда будем иметь
yi = Qlyi^1 = ... = (Q^.j.. .QJtfo, 1 <i<s.
Матрицы Qt и векторы yt имеют порядок nr+l. Согласно
алгоритму сдваивания, все произведения (Qz· · -Qi) У о можно вычислить
за ρ log2 (s+1)"] макрошагов, используя при этом f s+1 ~|
макропроцессоров, выполняющих в качестве макрооперации умножение двух
матриц порядка nt+l. Принимая во внимание построенный
параллельный алгоритм для нахождения произведения двух матриц,
теперь легко построить параллельный алгоритм для вычисления всех
векторов xl9 . . ., xs с высотой порядка log2 s log2 nr и шириной
порядка (nr)3s. Этот алгоритм получил название процесса реку ρ рент-
ного сдваивания.
В отношении процесса рекуррентного сдваивания сделаем
следующие замечания. Этот процесс принципиально отличается от
алгоритма, основанного на прямом вычислении векторов xt из (2.1).
Поэтому, хотя он обладает хорошей характеристикой с точки
зрения высоты, практически им пользоваться следует с
осторожностью из-за возможной неустойчивости к влиянию ошибок
округления. Оба алгоритма дают эквивалентные результаты только в
условиях точных вычислений. На основе использования
рекуррентных соотношений типа (2.1) построены очень многие численные
методы линейной алгебры, математической физики и анализа.
Процесс рекуррентного сдваивания указывает путь понимания того,
что можно ожидать от этих методов с точки зрения построения
алгоритмов малой высоты, если использовать большое число
процессоров.
38 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
Предположим теперь, что решается система линейных
алгебраических уравнений с трехдиагональной матрицей А порядка п.
В построении параллельного алгоритма будем следовать
общепринятой линии. Сначала разложим матрицу А в произведение двух двух-
диагональных матриц В-С, а затем сведем решение исходной
системы к решению двух систем с двухдиагональными матрицами J3, С.
Пусть для простоты матрица А имеет ненулевые главные миноры.
Представим ее в следующем виде:
Γαη α12 Ί
α21 α22 #23
» Ι =
αη-1,η-2 αη-1, η-1 αη-ί,η\
L- αηΛ η-1 αηη -Ι
Γ^ΐϊ Ci2 "1
C22 "^23
cn — ϊ, η — 1 crt-l, η \
Ι~ Cn, η -*
Известно, что в соответствии с компактной схемой метода Гаусса
справедливы формулы
Сц = а11У ci_ui = ai_lyi, (2.2)
Cii==aii — fy, /-ιβ/-ΐ, ί> "/, l-i = ai, i-ilCi-i, f-i> -1 = 2, 3,..., /2.
Отсюда получаем равенство
CiiCi-U i-i = aiici-U i-i — ai%i-\ai-U i-
Умножив обе части равенства на произведение ct_^ /_2 · · · °и и
обозначив qi=Ciicl_u г_г . . .сп, находим, что
q{ = fl„ qt-i—at, ,.χ fl,_lf £ ?,_2.
Это есть линейное рекуррентное соотношение. Согласно
принципу рекуррентного сдваивания, все числа qu - - ·, qn можно
вычислить за O(log2 η) шагов, используя 0(п) процессоров. Используя
О (ή) процессоров, за 1 шаг можно вычислить все диагональные
элементы ciU исходя из формулы cii=qi/qi_1. И наконец, за 1 шаг,
используя 0(п) процессоров, можно вычислить в соответствии с (2.2)
все внедиагональные элементы biH_x.
Разложение трехдиагональной матрицы в произведение двух
двухдиагональных матриц можно осуществить за O(log2 n) шагов,
используя 0(п) процессоров. Решение систем с двухдиагональными
матрицами после деления уравнений на диагональные элементы
также сводится к процессу рекуррентного сдваивания и может быть
найдено за O(\og2n) шагов при использовании О (п) процессоров.
Объединяя прямой и обратный ходы, мы получаем параллельный
алгоритм решения системы линейных алгебраических уравнений с
трехдиагональной матрицей высоты O(log2 ή) и ширины 0(п). Хотя
ι
Ьп-1,п-2 1
§ 2. ПАРАЛЛЕЛЬНЫЕ АЛГОРИТМЫ
39
этот алгоритм был получен на основе формул метода Гаусса, он
обладает совершенно другими характеристиками в отношении
устойчивости. Никакого алгоритма с принципиально меньшей
высотой для решения этой задачи не существует.
Рассмотрим задачу решения систем линейных алгебраических
уравнений с треугольной матрицей Л порядка п. Для
определенности будем считать матрицу системы левой треугольной. Не
ограничивая существенно общности, можно считать также, что
диагональные элементы равны 1. Выполнения этого условия можно добиться,
проведя за один шаг параллельное деление всех уравнений на
диагональные элементы. Предположим еще, что п=2р, добавив при
необходимости нужное число уравнений. Представим такую
систему уравнений в клеточном виде:
Ε
Л η
А гх
Aki
Ε
AS2
Ak2
Ε
Акз-
~1
.£_
Xl
X 2
*3
pr
b*
b3
(2.3)
где все клетки и векторы имеют порядок 2Г и, следовательно, k =
=2р~г. Это возможно сделать по крайней мере при г=0.
Для каждого нечетного s умножим s-e блочное уравнение
системы (2.3) на клетку As+Us и вычтем его из (s+l)-ro уравнения. В
матрице полученной системы все клетки, находящиеся в позициях
(s+l,s) для нечетных s, будут нулевыми. Поэтому новую систему
снова можно представить в клеточном виде (2.3), но при этом ее
клеточный порядок будет вдвое меньше.
Такое преобразование системы будет представлять один макро-
шаг параллельного алгоритма. На каждом макрошаге все четные
строки можно преобразовывать параллельно, к тому же
параллельно преобразуются каждая клетка строки и правая часть. Для
реализации одного макрошага требуется выполнить 0(k2)
параллельных операций умножения и сложения клеток порядка nlk. Это
можно осуществить за log2(n/6) шагов, используя 0(n4k)
процессоров. Всего требуется выполнить log2 n макрошагов, что и
определяет алгоритм решения системы линейных алгебраических уравнений
е треугольной матрицей высоты О (log| η ) и ширины 0(п3).
Пусть, наконец, рассматривается задача вычисления обратной
матрицы Л"1 для квадратной матрицы А порядка п. В основе
построения быстрого параллельного алгоритма лежит следующая идея.
Обозначим /(λ)=λ"+ί?ιλη""1Η-. . .+с„ характеристический
многочлен матрицы Л. Согласно теореме Кели — Гамильтона, /(Л)=0;
поэтому
A-1 = — ±(A»-i + clA»-*+...+cH_1E).
(2.4)
40 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
η
Если %i — корни характеристического многочлена и sk= 2 Щ*
i- 1
то известно, что коэффициенты ck и числа sk связаны так
называемыми соотношениями Ньютона, представляющими относительно
ck систему линейных алгебраических уравнений с треугольной
матрицей. Именно,
J
[C1
с2
Сз
Lc„-
—
"Sl
s2
s3
_S„J
Числа sh вычисляются как следы матриц Ak.
Параллельный алгоритм определения матрицы Л-1 состоит из
следующих этапов. Сначала по схеме сдваивания находятся все
степени матрицы А от первой до (п—1)-й. Этот этап имеет log2 n
макрошагов, где каждый макрошаг есть вычисление не более п/2
произведений двух матриц порядка п. Весь первый этап может быть
выполнен за O(log2 n) шагов на 0(п4) процессорах. На втором этапе
за O(log2 n) шагов при использовании 0(п2) процессоров
вычисляются все числа sk как следы матриц Ak. На третьем этапе за O(log| n)
шагов на 0(п3) процессорах находятся коэффициенты ck
характеристического многочлена путем решения треугольной системы (2.5).
На четвертом этапе матрица А'1 определяется, согласно формуле
(2.4), за O(log2 n) шагов с использованием 0(п3) процессоров. В
целом параллельный алгоритм вычисления матрицы А~г имеет
высоту О (log! п) и ширину О (п4). В настоящее время для этой задачи
не известны алгоритмы меньшей высоты; ширина же может быть
уменьшена до 0(na+I/2/log! n), где 2^α^3.
Этот алгоритм интересен лишь в теоретическом отношении и не
имеет сколько-нибудь серьезного практического значения. Он
требует для своей реализации огромного числа процессоров, загружает
процессоры очень мало и катастрофически неустойчив к влиянию
погрешностей округления.
§ 3. Концепция неограниченного параллелизма
Как уже отмечалось, знание параллельной формы алгоритма
определяет возможность его реализации на некоторой
гипотетической параллельной вычислительной системе за время,
пропорциональное высоте параллельной формы. Это обстоятельство привело к
появлению большого числа математических исследований,
направленных на построение для классов задач алгоритмов и
параллельных форм минимальной высоты.
В § 2 были рассмотрены некоторые из параллельных алгоритмов.
Даже поверхностный анализ показывает возможность улучшения
« 3. КОНЦЕПЦИЯ НЕОГРАНИЧЕННОГО ПАРАЛЛЕЛИЗМА 41
приведенных оценок и характеристик параллельных форм, в
первую очередь числа необходимых для их реализации процессоров.
Нетрудно улучшить и константы, определяющие высоты
алгоритмов. Можно было бы уже там начать подробное изучение таких
характеристик параллельных алгоритмов и систем как загруженность
процессоров, достигаемое ускорение, эффективность и многое
другое. Однако подобные исследования пока не проводились, и к этому
имеются достаточно веские основания.
Читатель, возможно, уже обратил внимание на существенное
различие в акцентах, сделанных при изложении первых двух
параграфов. В § 1 постоянно указывалось на необходимость тщательного
учета особенностей параллельных вычислительных систем при
конструировании параллельных алгоритмов. В § 2 внимание на
большинство из особенностей не обращалось, но постоянно повторялась
одна и та же сцасительная фраза «если не принимать во внимание
другие аспекты реализации».
Конечно, проводя широкие исследования совместных свойств
параллельных вычислительных систем и параллельных
алгоритмов, невозможно учесть все особенности систем. В этих случаях
математики вынуждены пользоваться некоторой идеализированной
моделью вычислительной системы. Однако для того, чтобы
исследования параллельных свойств алгоритмов не были бесполезными для
практических целей, необходимо, чтобы математическая модель
параллельной системы в достаточной мере адекватно отражала
особенности ее структуры.
Общий характер изложения §2, за исключением комментариев,
типичен для математических исследований параллельных свойств
алгоритмов. Он возник в конце 50-х — начале 60-х годов, когда о
параллельных вычислительных системах, по существу, только
начали говорить. В то время относительно структуры этих систем
было известно очень мало, разве только то, что в них одновременно
может работать большое число устройств. Тогда же появилась и
стала активно развиваться определенная концепция математических
исследований, связанная с построением и изучением параллельных
численных методов и получившая впоследствии название концепция
неограниченного параллелизма. В основе данной концепции явно или
неявно лежит предположение, что алгоритм реализуется на
параллельной вычислительной системе, не накладывающей на него
никаких других ограничений, кроме числа используемых процессоров.
В этих условиях основными объектами в исследовании
параллельных свойств алгоритма становятся число необходимых для его
реализации процессоров и высота.
Концепция неограниченного параллелизма оказалась очень
живучей. Несмотря на то что давно стала ясной зависимость
эффективности реализации алгоритма на параллельных системах от
состава и номенклатуры процессоров, строения памяти, вида
коммуникационной сети, режима функционирования и многих других фак-
42 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
торов, исследование параллельных свойств алгоритмов и
численных методов до сих пор в основном осуществляется в рамках этой
концепции. Причиной данного факта, по-видимому, является
простое незнание многих действительных проблем, связанных с
параллельными системами, параллельными алгоритмами и
необходимостью согласования их свойств между собой.
Значение дополнительных сведений о вычислительной системе,
привлекаемых к изучению параллельных алгоритмов, легко видеть
уже на простых примерах. Пусть вычисляется произведение двух
квадратных матриц порядка п. Наименьшая высота алгоритма здесь
имеет порядок log2 η и достигается при использовании п3
процессоров. На первом этапе вычисляются все пъ попарных произведений
элементов сомножителей и затем элементы произведения матриц
находятся по схеме сдваивания. Так как каждый элемент
сомножителей входит в η произведений, то для реализации первого этапа
вычислительного процесса необходимо обеспечить доступ к
каждому элементу входной информации η различным
процессорам.
Ясно, что реализация первого этапа в сильной степени зависит
от возможностей вычислительной системы. Если она не обеспечивает
одновременный доступ многих процессоров к одной и той же
информации, то при решении даже такой простой задачи, как вычисление
произведения матриц, процессоры вынуждены выстраиваться в
очередь за этой информацией. При этом реализация первого этапа
увеличивается во времени с одного шага до η шагов, что приводит к
такому же увеличению высоты. Но высоты порядка η можно
достичь при использовании лишь п2 процессоров. Соответствующий
алгоритм основан на параллельном вычислении групп из η
элементов произведения матриц, расположенных в разных строках и
столбцах. Поэтому, если вычислительная система не обеспечивает
одновременный доступ многих процессоров к одной и той же
информации, то алгоритм перемножения матриц, наилучший с точки зрения
концепции неограниченного параллелизма, является плохим по
отношению к данной системе.
Большинство математиков начинает изучение проблем
параллельных вычислений с численных методов линейной алгебры в
рамках концепции неограниченного параллелизма. Не был исключением
и автор этой книги. В свое время пришлось потратить много
времени и прочитать немало работ, прежде чем осознать, что
концепция неограниченного параллелизма слишком идеализирована и
уводит научные исследования в сторону от насущных практических
работ.
Поэтому обсудим сейчас некоторые стороны данной концепции
и'вытекающие из нее выводы. За основу обсуждения читатель может
взять методы, изложенные в § 2. Как уже отмечалось, по стилю их
описания они являются характерными. Сделанные же ниже выводы
в действительности основаны на анализе широкого круга численных
§ 3. КОНЦЕПЦИЯ НЕОГРАНИЧЕННОГО ПАРАЛЛЕЛИЗМА 43
методов линейной алгебры с полной матрицей порядка п.
Подробный анализ этих методов не приводится, так как он весьма
громоздок и не имеет последующего развития.
Вычислительная система. Концепция
неограниченного параллелизма предполагает использование следующей
идеализированной модели параллельной вычислительной системы.
Система имеет любое нужное число идентичных процессоров и
произвольно большую память, одновременно доступную всем
процессорам. Каждый процессор за единицу времени может выполнить
абсолютно точно любую унарную или бинарную операцию. Время
выполнения всех вспомогательных операций, а также время
взаимодействия с памятью и время, затрачиваемое на управление
процессом, считаются пренебрежительно малыми. Никакие
конфликты при общении с памятью не возникают. Все входные данные
перед началом вычислений записаны в памяти. Каждый процессор
считывает свои операнды из памяти и после выполнения операции
записывает результат в память. После окончания вычислительного
процесса все результаты остаются в памяти.
Эта модель параллельной системы плохо подходит для
практического исследования параллельных численных методов. Несмотря на
впечатляющие успехи электроники, трудно ожидать, что для
решения больших задач линейной алгебры с матрицами порядка η
будет представлена возможность использовать параллельную
вычислительную систему, имеющую порядка п2 и тем более я4
универсальных процессоров. Трудно также предположить, что при
большом числе процессоров каждый из них будет иметь быстрый доступ
к любому участку памяти, причем независимо от других
процессоров. Не будут процессоры выполнять операции точно.
Если требования на число процессоров и их связь с памятью
сделать более жесткими, то многие из методов, рассматриваемых в
рамках концепции неограниченного параллелизма, сразу оказываются
несостоятельными. При малом числе процессоров приходится
иначе организовывать вычислительные процессы. При большом числе
процессоров с ограниченной связью с памятью трудности начинают
появляться даже при реализации таких простых операций, как
вычисление сумм чисел или скалярных произведений векторов по
схеме сдваивания. Если число слагаемых сравнимо с числом
процессоров или больше, то операции становятся весьма
чувствительны к различным особенностям параллельных вычислительных
систем.
Высота алгоритма. Эта характеристика является
одной из важнейших в параллельных методах и отражает время
выполнения алгоритма на параллельной системе. Так, например, в
случае решения линейных алгебраических уравнений с полной
матрицей порядка η при использовании η процессоров высоты
колеблются от п2 log2 η до η2 в зависимости от выбранного метода. При
использовании п2 процессоров высоты уменьшаются до η log2 n или
44 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
п. И" наконец, при использовании я3 и п4 процессоров построены
алгоритмы с высотой log2, п.
Алгебраическая задача с матрицей порядка η имеет порядка п2
входных данных. Поэтому для ее решения, вообще говоря, не
существует алгоритма с высотой по порядку меньше log2 п.
Следовательно, алгоритмы с высотой порядка log| n можно считать с точки
зрения значения высоты эффективными.
Общая тенденция зависимости высот параллельных форм
алгоритмов от числа используемых процессоров такова: высоты
уменьшаются с увеличением числа процессоров; при числе процессоров,
не превосходящем п2, высоты в целом обратно пропорциональны
числу процессоров; при дальнейшем увеличении числа процессоров
скорость снижения высоты уменьшается.
Загруженность процессоров. Эта
характеристика показывает, насколько эффективно параллельный алгоритм
использует на данной задаче выделенные для его реализации
процессоры. Если не вдаваться в детали, то ее можно определить как
отношение числа выполненных операций к числу операций, которые
можно было бы выполнить за то же самое время. Для параллельных
алгоритмов типичным является проведение вычислений по схеме
сдваивания. Но при данной схеме быстро уменьшается число
промежуточных результатов, и это приводит к уменьшению
загруженности процессоров. А это в свою очередь означает, что процессоры
простаивают и не полностью используются возможности
параллельной вычислительной системы с точки зрения быстродействия,
т. е. именно того ее свойства, ради которого в основном она и
создавалась.
Общая тенденция зависимости загруженности процессоров от их
числа такова: при числе процессоров, не превосходящем п2,
загруженность процессоров либо является постоянной, либо есть
величина порядка log2_1 n в зависимости от используемого метода;
при увеличении числа процессоров их загруженность падает.
Устойчивость. Несмотря на то что исследование
устойчивости к влиянию ошибок округления является обязательным при
решении, вопроса о целесообразности практического применения
того или иного метода, концепция неограниченного параллелизма не
акцентирует внимание на необходимости проведения такого
исследования. Выполненные исследования параллельных методов
решения задач алгебры показали исключительно сильную
неустойчивость новых алгоритмов, имеющих высоты порядка log2, п.
По-видимому, без радикального изменения они не имеют сколько-нибудь
серьезной перспективы для использования в больших параллельных
вычислительных системах.
Интересно отметить, что на настоящий момент не известно ни
одного устойчивого метода решения алгебраических задач с полной
матрицей высоты порядка log| п. Неизвестно даже, существуют ли
такие методы. Что же касается параллельных алгоритмов, получен-
§3. КОНЦЕПЦИЯ НЕОГРАНИЧЕННОГО ПАРАЛЛЕЛИЗМА 45
ных путем формального распараллеливания соответствующих
последовательных алгоритмов, то оценки влияния в них ошибок
округления увеличиваются не более чем в η раз, да и то лишь при
отсутствии операции накопления скалярных произведений.
05щ£я тенденция зависимости устойчивости к влиянию ошибок
округления от числа используемых процессоров такова: при числе
процессоров, не превосходящем п2, устойчивость остается более или
менее постоянной; при дальнейшем увеличении числа процессоров
устойчивость резко ухудшается.
Конфликты в памяти. Под этим термином в данном
случае понимается ситуация, когда несколько процессоров выбирают
из памяти одну и ту же информацию. Конфликты в памяти всегда
можно ликвидировать за счет увеличения высоты, устанавливая
фактически для процессоров очередность получения информации.
Иногда их можно устранить за счет изменения вычислительной
схемы. Во многих случаях для достижения необходимой скорости
работы технический путь разрешения конфликтов оказывается
единственно возможным и связан с наличием в параллельной,
вычислительной системе средств размножения информации. Хотя конфликты
в памяти в значительной мере мешают достижению теоретически
возможной высоты, концепция неограниченного параллелизма не
акцентирует внимание на необходимости их исследования.
. Общая тенденция зависимости числа конфликтов от числа
процессоров такова: число конфликтов в различных методах
колеблется в довольно широких пределах, но всегда увеличивается с ростом
числа процессоров.
Сточки зрения математика, единственное достоинство
параллельных вычислительных систем заключается в том, что они дают
принципиальную возможность реализовывать алгоритмы быстрее, чем
на последовательных ЭВМ, за счет использования большого числа
процессоров. Но за достижение этой возможности приходится
платить. Эта плата определяется не только числом процессоров, но
и ухудшением свойств методов и систем. Среди рассмотренных
характеристик параллельных численных методов и параллельных
систем только высота улучшается с увеличением числа
процессоров, все остальные характеристики ухудшаются. В
действительности ухудшаются и многие другие характеристики. Все это приводит
к тому, что либо плата за достижение теоретически возможной
высоты оказывается очень большой, либо ухудшение тех или иных
характеристик приводит просто к невозможности достижения этой
высоты. Концепция неограниченного параллелизма потому и
является практически несостоятельной, что исключает из сферы своего
внимания все такие вопросы.
Вокруг концепции неограниченного параллелизма появилось
немало исследований. Возникли даже новые направления. Одно из
них связано со сложностью параллельных алгоритмов.
Основными изучаемыми объектами этого направления являются верхние и
46 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
нижние оценки высот алгоритмов для решения классов задач.
Верхние оценки определяются по высотам наиболее быстрых
известных алгоритмов. Нижние оценки представляют, собственно говоря,
основной предмет исследований. Интерес к сложности параллельных
алгоритмов вызывается во многом тем, что анализ этой проблемы
может дать результаты, отличающиеся от результатов для
последовательных вычислений.
Известно, например, что сложности задач нахождения
произведения двух квадратных матриц и обратной матрицы в случае
последовательных вычислений совпадают. Этот факт подтверждается
наличием для обеих задач алгоритмов одинаковой сложности.
Доказано, что, с некоторыми оговорками, алгоритм одной задачи
порождает алгоритм той же сложности для другой задачи. Однако для
параллельных вычислений подобное утверждение неизвестно. Как
вытекает из результатов, приведенных в § 2, для задачи
нахождения произведения матриц существует параллельный алгоритм,
высота которого по порядку зависимости от η совпадает с нижней
оценкой высоты и равна log2 n. Для задачи вычисления обратной
матрицы самый быстрый из известных алгоритмов, также приведенный
в § 2, имеет высоту порядка log! n-
Заметим, что сложность параллельных алгоритмов изучается
при тех же предположениях, при которых развивается концепция
неограниченного параллелизма. Поэтому ее результаты и выводы
также далеко не всегда соответствуют условиям практики.
.Для сравнения параллельных алгоритмов между собой, а также
для сравнения параллельных и последовательных алгоритмов
предложены различные характеристики. Самые известные и
распространенные из них — это ускорение и эффективность. Ускорением
называется величина, показывающая, во сколько раз быстрее
конкретная задача может быть решена при помощи параллельного алгоритма
по сравнению с последовательной реализацией того же алгоритма.
Так как при этом обычно не учитываются никакие особенности
функционирования параллельной системы, то фактически
ускорение есть отношение числа операций алгоритма к его высоте.
Понятие эффективности близко к понятию средней загруженности
процессоров.
Подробно загруженность, эффективность, ускорение и другие
характеристики будут обсуждаться позднее — при изучении работы
системы функциональных устройств. Сейчас же мы хотим обратить
внимание на следующее обстоятельство. Оценивая параллельный
алгоритм, необходимо дать ответ на вопрос, насколько он хорош.
При этом очевидно, что одним из важных факторов является выбор
объекта сравнения. Обычно параллельный алгоритм
сравнивается с последовательной формой того же алгоритма. Если при этом
достигаются приемлемые ускорение и загруженность, то
считается, что параллельный алгоритм является вполне
подходящим.
§3. КОНЦЕПЦИЯ НЕОГРАНИЧЕННОГО ПАРАЛЛЕЛИЗМА
На наш взгляд, в таком подходе цель подменяется средствами.
Можно придумать настолько плохой параллельный алгоритм, что
он будет решать задачу дольше, чем какой-нибудь
последовательный алгоритм. Но этот алгоритм придется считать хорошим только
на том основании, что при его реализации процессоры не
простаивают. Параллельные алгоритмы и параллельные системы создаются
для того, чтобы реально ускорить процесс решения задач. Поэтому
параллельный алгоритм следует сравнивать не с последовательной
формой того же алгоритма, а с тем последовательным алгоритмом,
который является лучшим на текущий момент времени. Только
такое сравнение позволит направить процесс создания параллельных
методов в нужное для практических целей русло.
Концепция неограниченного параллелизма со своим стремлением
получать алгоритмы наименьшей высоты не дала к настоящему
времени заметных практических результатов. Это отчетливо видно из
анализа типового численного программного обеспечения
существующих параллельных систем. По существу, оно почти целиком
состоит из программ, реализующих те же методы, которые хорошо
зарекомендовали себя при реализации на последовательных ЭВМ.
Ситуация здесь аналогичная, как в случае быстрых
последовательных алгоритмов. Например, методы типа Штрассена для решения
систем линейных алгебраических уравнений в теоретическом плане
являются весьма эффективными в смысле скорости. Однако
реализующие их программы не всегда конкурентоспособны по сравнению
с программами, реализующими обычные методы исключения.
Критическое отношение к концепции неограниченного
параллелизма вызвано главным образом характером исследований
параллельных численных методов, а не способами построения этих
методов. Характер же исследований полностью определяется моделью
параллельной вычислительной системы, принятой данной
концепцией. Поэтому практическая несостоятельность многих
параллельных численных методов есть в конечном счете прямое следствие
нереалистичности модели системы. В том виде, как она изложена здесь,
концепция неограниченного параллелизма полезна лишь на первом
этапе исследований, когда нужно понять, что принципиально можно
ожидать от той или иной группы численных методов с точки зрения
их реализации на параллельных системах. Чем раньше отойти от
этой концепции и полнее учесть особенности конкретных
параллельных систем, тем более реалистичными окажутся сделанные выводы.
Что же касается способов построения параллельных численных
методов малой высоты, применяемых в рамках концепции
неограниченного параллелизма, то они не вызывают каких-либо
возражений. В конце концов, все способы хороши, лишь бы они приводили
к нужному результату. Развиваемые в концепции способы, как
правило, применяются на уровне исследования задачи в целом, и
основные из них следующие:
— расщепление задачи на большие независимые подзадачи;
£8 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
— выделение в задаче большого потока независимых однотипных
подзадач;
— применение принципа «разделяй и властвуй» с рекурсивным
расщеплением большой задачи на две или несколько меньших задач.
Распараллеливание на уровне анализа задачи очень быстро
приводит к пониманию того факта, что существующие в настоящее
время рекомендации по построению численных методов не могут
привести ни к чему другому, кроме необходимости решать параллельно
типовые задачи линейной алгебры, численного анализа,
оптимизации, математической физики и т. п. Поэтому ускорение процесса
решения задачи в целом за счет использования параллельных
вычислительных систем достигается в основном следующим образом.
Сначала исходная задача сводится к параллельному решению
типовых математических задач. Это сведение осуществляется любым
подходящим способом, например одним из перечисленных выше.
Более того, на данном этапе вполне уместно проводить исследования
в рамках концепции неограниченного параллелизма. Если таких
задач оказалось много и они настолько большие, что можно
пренебречь временами обмена информацией между ними, то ситуация
весьма удачная. В этом случае дальнейшее распараллеливание может
не делаться, так как задача уже эффективно решается на системах
класса MIMD. Если типовые задачи к-тому же однотипные, то более
выгодной может быть реализация задачи в целом на системах
класса SIMD или на конвейерных системах. С подобной ситуацией
связывается словосочетание «крупноблочное распараллеливание».
Однако, возможность крупноблочного распараллеливания задачи
имеется далеко не всегда. Параллельных типовых задач может
оказаться очень мало, сами задачи могут иметь небольшие размеры,
могут появиться и другие особенности. В этом случае
обязательным является привлечение дополнительных сведений относительно
параллельной системы и нельзя далее оставаться на позициях
концепции неограниченного параллелизма.
Дальнейшее ускорение может осуществляться только за счет
распараллеливания процесса решения типовых математических задач.
Как показывает практика использования параллельных
вычислительных систем, ускорение, достигаемое на этом этапе, чаще всего
дает основной эффект. Исключительно большое внимание, уделяемое
построению параллельных алгоритмов для типовых задач, объясне-
ется именно этим обстоятельством.
Для типовых задач параллельные алгоритмы также можно
строить на.основе перечисленных выше способов. Применение
принципа «разделяй и властвуй» и его разновидности — принципа
сдваивания уже дало немало таких алгоритмов. Но структура
типовых задач такова, что в них редко удается осуществить
крупноблочное распараллеливание. Поэтому здесь концепция
неограниченного параллелизма обычно оказывается несостоятельной.
Основной трудностью в разработке алгоритмов для решения типовых ма
§ 4. ЧИСЛЕННОЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ 4£
тематических задач является необходимость жесткого согласования
структуры связей между операциями алгоритма и возможностью
коммуникационной сети параллельной вычислительной системы.
Заметим, что новые параллельные алгоритмы для решения
типовых задач, как правило, имеют более сложную структуру
связей между операциями, чем последовательные алгоритмы, и не
очень хорошо отображаются на архитектуру существующих
параллельных систем. К тому же они обладают несходными
вычислительными характеристиками, в первую очередь в отношении
устойчивости. И наконец, их реальное преимущество становится заметным
только при достаточно большом числе процессоров. В силу этих и
ряда других причин новые параллельные алгоритмы не внедрились
пока широко в практику их использования на параллельных
системах.
В настоящее время основное внимание в деле создания
параллельных методов и соответствующего программного обеспечения
направлено на выявление параллельных структур в традиционных
последовательных алгоритмах. Эта задача исключительно сложна, и ей
будет уделено большое внимание в данной книге.
§ 4. Численное программное обеспечение
Создание параллельных вычислительных систем не только
привело к появлению новых научных направлений, но и в значительной
мере обострило внимание к некоторым старым проблемам. Одной иа
таких проблем является разработка и внедрение численного
программного обеспечения.
Как уже отмечалось, математики решают свои задачи на ЭВМ,
не зная, как правило, устройства самих ЭВМ. Роль посредника
между ними и вычислительной техникой передана алгоритмическим
языкам. Возникла противоречивая ситуация. С одной стороныг
алгоритмические языки отгородили математика от конкретных
вычислительных систем и избавили его от необходимости изучать их
особенности; именно поэтому в наиболее распространенных языках
не содержится никаких средств описания ЭВМ, что и позволяет
называть эти языки машинно-независимыми. С другой стороны,
необходимость решать трудоемкие задачи заставляет математика
добиваться эффективности процесса решения на ЭВМ, о которой он
почти ничего не знает. Эти противоречия далеко не всегда удается
разрешить. Но даже в тех случаях, когда оказывается возможным
найти приемлемое компромиссное решение, его поиск обходится
математику очень дорого.
Машинная арифметика имеет свои характерные особенности.
Какими бы малыми ни были ошибки округления, их появление
существенно меняет математические свойства арифметических
операций. Точные операции являются коммутативными, ассоциативными
и связаны между собой законом дистрибутивности. Операции на
50 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
ЭВМ уже не являются таковыми. Поэтому, чтобы указать порядок
вычислений, необходимо в записи алгоритма нужным образом
расставить скобки. С точки зрения точного выполнения операций
расстановка скобок обычно не бывает однозначной. Однако при
неточных операциях различные расстановки скобок в одних и тех же
арифметических выражениях будут приводить к различным
результатам.
Таким образом, любой численный метод, заданный
последовательностью математических формул и соотношений, в действительности
порождает огромную совокупность алгоритмов, отличающихся друг
от друга последовательностью выполнения отдельных операций.
На множестве таких алгоритмов различие реальных характеристик,
особенно в отношении точности и времени реализации, оказывается
очень большим. Если к тому же принять во внимание, что для
решения одной и той же задачи, как правило, предлагается значительное
число различных методов, то становится ясно, насколько трудно
найти оптимальный алгоритм.
Внешнее совпадение операций алгоритмических языков с
математическими операциями скрывает эти трудности. Действительное
же их различие приводит к тому, что свойство «машинной
независимости» алгоритмических языков оказывается весьма условным и
должно быть взято в кавычки.
Формальная машинная независимость алгоритмических
языков позволяет накапливать на этих языках математические знания
с последующим их использованием на различных ЭВМ. Это
накопление осуществляется в форме библиотек и пакетов программ.
Однако оптимистические надежды на возможность создания
высококачественных банков вычислительных знаний в подобной форме
практически не оправдались. Имеется лишь небольшое число
библиотек на алгоритмических языках, которые действительно
переносятся без ручного изменения на различные ЭВМ. При этом
стоимость разработки лучших таких комплексов по зарубежным
данным доходит до нескольких десятков долларов за одну инструкцию
языка. К тому же библиотеки быстро устаревают, а их поддержание
на уровне современных достижений требует значительных
дополнительных усилий.
Именно разработка алгоритма с характеристиками, близкими к
оптимальным и слабо зависящими от особенностей конкретных ЭВМ,
является наиболее узким местом создания высококачественных
библиотек программ, и на этом этапе тратятся основные средства.
Данный факт вызывает большое беспокойство, особенно в
преддверии появления ЭВМ пятого поколения. Одной из важнейших
характеристик этих ЭВМ объявлена высокая степень их
интеллектуальности. Но интеллектуальность ЭВМ лишь обеспечивается
техническими средствами, а наполняться будет специалистами в
конкретных областях, в первую очередь математиками. И очень важно,
чтобы язык общения с ЭВМ позволял передавать знания в ЭВМ с
§4. ЧИСЛЕННОЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ 51
гарантированным уровнем искажения, причем достаточно проста
и дешево.
Библиотеки программ как форма организации программной
продукции стали создаваться практически одновременно с
построением первых ЭВМ. Идея их создания привлекает внимание прежде
всего простотой постановки самой проблемы. Однако эта
кажущаяся простота скрывает за собой серьезные трудности, недооценка
которых в течение многих лет приводила и приводит к широкому
по своим масштабам дублированию работ, к снижению качества
библиотек и эффективности их использования. Несмотря на
длительную историю развития, библиотеки программ до сих пор
вызывают большие нарекания. Основные замечания обычно сводятся
к следующим:
— библиотеки не полны и не отражают последних достижений
вычислительной математики;
— для пользователя, не являющегося специалистом в
предметной области, трудно выбрать в библиотеке программу, наиболее
полно учитывающую особенности его задачи;
— трудно быстро и надежно оценить качество той или иной
программы из библиотеки на основе объективной проверки;
— программы, реализующие однотипные алгоритмы на разных
ЭВМ, обладают не только разными, но часто несопоставимыми
характеристиками;
— документация по библиотекам плохого качества, с ней
неудобно работать, а для больших библиотек она к тому же и очень
объемна;
— нет инструментальных средств для облегчения процесса
составления и формирования как отдельных программ, так и пакетов
программ.
На первый взгляд кажется, что эти замечания направлены в
основном в адрес математиков. В действительности же это верно
только в определенной мере. Важно отметить, что даже те математики,
которые хотят и могут создавать высококачественные программы,
на самом деле их не включают в библиотеки. Одна из причин этого
явления заключается, на наш взгляд, в том, что существующие
библиотеки программ не имеют системной поддержки,
обеспечивающей высокий уровень функционирования программ, в которые
математики вложили свой труд.
Чтобы лучше понять, какие требования могут быть предъявлены
к системной поддержке, рассмотрим сначала общую схему работы
пользователя ЭВМ с библиотекой программ.
Предположим, что пользователю нужно решить какую-то задачу.
Первое, что он хочет узнать, есть ли хотя бы одна программа в
библиотеке, пригодная для решения его задачи. Поэтому нужна
информационно-справочная система. Большинство пользователей не
являются специалистами именно в той области, задачу из которой
ему необходимо решить. Тем не менее, чтобы выбрать нужную про-
52 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
грамму, требуется дать профессиональное описание задачи. Эту
трудность можно преодолеть, если создать диалоговую систему,
работая с которой пользователь будет описывать свою задачу путем
выбора подходящего ответа на заданный системой вопрос из
некоторой совокупности ответов, подготовленных профессионалами. На
основе работы диалоговой системы возможно не только реализовать
свой выбор нужной программы, но и осуществить генерацию
сложной программы из имеющихся простых. Попутно можно
сгенерировать или сконструировать и документацию, описывающую
получаемую программу. Поэтому нужна система генерации программ и
документации. Обычно пользователь относится с недоверием к
предложенной ему программе в отношении ее качества. Поэтому нужна
система удостоверения качества программ, в которую обязательно
будут входить банк тестов и система автоматизации процесса
тестирования. Важно, чтобы это тестирование было осуществлено
максимально быстро и максимально удобно для пользователя.
В качестве основного режима работы всех систем,
обслуживающих работу пользователя с библиотеками программ, должен быть
режим работы с удаленным терминалом.
Другая группа требований определяется разработчиками
библиотек. Если алгоритм построен, то нет больших проблем в
написании отдельной программы. Как правило, для этого вполне
достаточно средств, представляемых алгоритмическими языками.
Ситуация существенно изменяется, если нужно создавать крупные про
граммные комплексы и пакеты, покрывающие большие предметные
области. В этом случае приходится писать очень много программ,
но среди этих программ обычно немало таких, которые
незначительно отличаются друг от друга или получаются одна из другой с
помощью каких-то преобразований. При создании больших комплексов
могут быть полезны общие системы генерации программ. Но
значительно более необходимы специализированные
инструментальные системы преобразования программ.
Необходимость в подобных системах хорошо видна при
рассмотрении проблемы переносимости численных библиотек на различные
типы ЭВМ. Эта проблема всегда была и, наверное, еще долго будет
одной из острейших. Вообще говоря, каждую конкретную
библиотеку, можно перенести вручную на другую машину. Однако тот,
кто хотя бы раз делал такую работу, вряд ли возьмется за нее
второй раз. Причина простая и объясняется огромным объемом
рутинной работы. По существу, решение проблемы переносимости
численного программного обеспечения может быть осуществлено только
одним способом: сделать хорошую библиотеку на одной из
базовых ЭВМ и создать систему автоматизированного переноса
программ с базовой ЭВМ на любые другие ЭВМ и вычислительные
системы. Но пока таких систем мало, и они обладают очень
ограниченными возможностями. К обсуждению именно этой проблемы мы еще
вер нем г л.
§4. ЧИСЛЕННОЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ
53
Таким образом, для организации системной поддержки работы
пользователей и разработчиков в области библиотек и пакетов
программ необходимы следующие компоненты:
— диалоговая система работы с удаленным терминалом;
— информационно-справочная система;
— система генерации программ и документации;
— системы преобразования программ;
— система автоматизации процесса тестирования;
— банк тестов.
Наличие всего комплекса системной поддержки не только дало бы
возможность поднять на существенно более высокий уровень
обслуживание пользователей вычислительными услугами, но и
существенно облегчило бы процессы разработки высококачественного
численного программного обеспечения.
Обсуждаемые проблемы были осознаны более десяти лет назад.
Их актуальность не уменьшилась и в настоящее время и,
по-видимому, не уменьшится еще долго. И хотя они в основном далеки от
своего решения, тем не менее какое-то время назад стало казаться,
что в деле создания высококачественного машинно-независимого
численного программного обеспечения появились реальные
надежды, так как стали ясны основные трудности и пути их преодоления.
Эти надежды серьезно зашатались, как только стали появляться
современные супер-ЭВМ и большие параллельные системы.
Строго говоря, имеется только одна принципиальная трудность
создания машинно-независимого численного программного
обеспечения на алгоритмических языках для классических
однопроцессорных ЭВМ и связана она с неточным представлением данных в
ЭВМ и неточным выполнением арифметических операций. Тем не
менее прошли многие годы и потребовались значительные усилия
большого числа специалистов высшей квалификации в области
вычислительной математики, прежде чем удалось понять
действительное значение этой трудности и то, как все-таки с ней бороться.
Естественно, что эта трудность остается и в параллельных системах.
Но теперь к ней добавляются другие, возможно, еще большие
трудности.
Как уже неоднократно подчеркивалось, эффективность
реализации алгоритмов на параллельных вычислительных системах
решающим образом зависит от степени учета индивидуальных
особенностей систем, т. е. числа функциональных устройств, их конвейер-
ности, коммуникационной сети, режима работы и т. п. Особенности
вычислительных систем в свою очередь влекут за собой
индивидуальные особенности организации вычислительных процессов.
Естественно, возникает вопрос: кто и как должен учитывать все эти
особенности при создании численного программного обеспечения
для параллельных вычислительных систем?
Ответ на этот вопрос может быть найден, вообще говоря, на
одном из двух путей: либо индивидуальные особенности параллель-
54 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
ных вычислительных систем учитываются человеком при создании
программного обеспечения, либо они учитываются автоматически
в процессе перевода программ с языка высокого уровня на язык
вычислительных систем.
Первый путь позволяет, хотя и дорогой ценой, создать численное
программное обеспечение для любой конкретной параллельной
системы. Однако в целом он не имеет перспективы. На этом пути
практически невозможно обеспечить совместимость и преемственность
программного обеспечения, так как придется программировать на
языках низкого уровня. Вследствие большого разнообразия
параллельных систем для создания программного обеспечения таким
способом просто не хватит квалифицированных специалистов в
области вычислительной математики. На этом пути создателей
программного обеспечения ожидают еще большие трудности, чем имевшие
место при программировании для однопроцессорных ЭВМ в
машинных кодах.
Во втором пути видна перспектива. По-видимому, в настоящее
время основные усилия здесь направлены на разработку
подходящего алгоритмического языка для описания параллельных
процессов. В реализации данного пути выбор языка составляет один из
начальных этапов, но даже он требует проведения больших
предварительных исследований.
Алгоритмические языки как посредники между алгоритмами и
вычислительными системами должны хорошо отражать и свойства
алгоритмов, и свойства систем, по крайней мере они должны иметь
возможность для описания их свойств. Но спектр свойств
параллельных вычислительных систем очень широк, а параллельные
свойства алгоритмов практически только начали изучаться. Поэтому не
очень ясно, какие именно свойства параллельности должны
отражать алгоритмические языки. Очевидно, что надо описывать
параллельные ветви вычислений; очевидно также, что этого недостаточно,
так как, например, длинных независимых ветвей в алгоритме может
не быть. В общих чертах ясно, что нужно отражать структуру
связей в алгоритме, и совсем не ясно, как это делать. Длинный список
неясных мест в параллельных свойствах алгоритмов и систем
говорит о том, что параллельные алгоритмические языки также будут
нести на себе отпечаток этой неясности, которая почти неизбежно
перейдет в численное программное обеспечение, если только не
устранить ее по мере возможности с самого начала.
Реальность перспективы выполнения огромного объема
рутинной работы по созданию численного программного обеспечения для
различных параллельных вычислительных систем требует
проведения комплексных исследований, направленных на подготовку
процесса пересмотра алгоритмического багажа, выявление
параллельных структур алгоритмов, поиск оптимальных конструкций
параллельных алгоритмических языков и принципов создания численного
программного обеспечения для параллельных систем. В этот же узел
§4. ЧИСЛЕННОЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ
5S
оказываются завязанными исследование структур параллельных
вычислительных систем и разработка численного программного
обеспечения классических однопроцессорных ЭВМ (рис. 4.1).
При разработке математической модели параллельной
вычислительной системы и создании численного программного обеспечения
Научно-технические проблемы
Классы задач вычислительной математики
Исследование
алгоритмов и
вычислительных
систем
гт
Исследование
алгоритмов и
вычислительных
систем
Пакет
программ для
современных
ГЭВМ
Пакет
программ для
современных
ЭВМ
Сервисное
обеспечение
пакетов
программ
Математическая
модель
спецпроцессора
Численное
программное
обеспечение
современных ЭВМ
Математическая
модель
спецпроцессора
Синтез спецпроцессоров
Численное
программное обеспечение
параллельных
вычислительных систем
Имитация
параллельной
вычислительной
системы
Математическая
модель парал -
лельной
вычислительной системы
Системное
и языковое
обеспечение
Рис. 4.1
во многом приходится делать одно и то же: классифицировать
предметную область, конструировать численные методы, исследовать
алгоритмы и вычислительные схемы, проводить тестовые расчеты,
искать доводы для принимаемых решений и т. п.
Математическая модель системы и численное программное обеспечение, по
существу, являются двумя различными формами результатов
выполнения одних и тех же исследований. Нельзя разработать хорошую
модель вычислительной системы, отражающую интересы какой-
либо предметной области, и не уметь создать для той же области
хорошее программное обеспечение.
56 ГЛ. 1. ОСОБЕННОСТИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
В выполнении этой работы существенную роль может играть
численное программное обеспечение существующих последовательных
ЭВМ. С его помощью можно контролировать правильность
проведения сравнительного анализа алгоритмов, имитировать работу
будущего вычислительного комплекса и приобретать опыт создания для
него численного программного обеспечения. Более того, еще далеко
не полностью исчерпаны, на наш взгляд, резервы существующего
программного обеспечения как источника получения параллельных
программ на основе некоторых автоматизированных процедур.
Таким образом, численное программное обеспечение является той
ниточкой, потянув за которую можно попытаться распутать весь
клубок проблем, связанных с параллельными алгоритмами и
параллельными системами. Поэтому мы и уделили достаточно много внимания
обсуждению различных вопросов, связанных с программным
обеспечением. Эти вопросы обсуждаются не так уж часто, а их
решение с созданием высококачественных супер-ЭВМ и параллельных
систем становится особенно актуальной задачей.
Глава 2
СОВМЕСТНОЕ[ИССЛЕДОВАНИЕ ПАРАЛЛЕЛЬНЫХ
ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ И АЛГОРИТМОВ
Эта глава посвящена изучению различных математических
свойств алгоритмов и вычислительных систем. Основной акцент
делается на исследование влияния их свойств друг на друга. В
качестве математических объектов, используемых как посредники для
описания и алгоритмов, и вычислительных систем, в книге широко
применяются ориентированные графы. Поэтому сначала приводится
соответствующая терминология и излагаются нужные для
дальнейшего факты из теории графов. Вводится граф алгоритма, изучаются
его параллельные формы.
Одно из центральных мест в главе занимает исследование
математической модели работы системы функциональных устройств, в том
числе конвейерного типа. Устанавливаются некоторые соотношения,
позволяющие оценить различные характеристики, такие как
загруженность устройств, ускорение, число каналов связи и т. п. Эти
соотношения помогают, в частности, выделять алгоритмы, реализуемые
не эффективно на любых параллельных вычислительных системах.
Вводится граф вычислительной системы и ставятся основные
математические задачи отображения графа алгоритма на граф
вычислительной системы. Описываются классы систем, для которых
такое отображение оказывается эффективным. Обсуждаются методы
реализации отображения. Исследуются различные режимы работы
параллельных вычислительных систем. Изучается связь
синхронного и асинхронного режимов с загруженностью устройств и
временем реализации алгоритма.
Заканчивается глава описанием матричных, постановок
некоторых из рассматриваемых задач. Обращается внимание на
особенность проводимых исследований, связанную с возможностью
появления AfP-сложных задач.
§5. Графы
Исследуя сложные системы, состоящие из большого числа
разнообразных объектов, часто поступают одним и тем же способом.
Сначала выбирают в системе интересующую группу объектов и в каж-
58 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
дом из них фиксируют наиболее важное при данном исследовании
свойство или группу свойств. Затем рисуют на бумаге точки,
соответствующие выбранным объектам. И наконец, соединяют линиями или
стрелками те пары точек, которые находятся между собой в какой-
либо связи по отношению к фиксированным свойствам выбранных
объектов. Изучай полученные схемы, пытаются понять строение или
функционирование системы в целом.
Подобные схемы получили общее название графы. Они широко
используются в самых различных областях знаний. Например,
исследуя транспортную сеть района, можно изобразить точками
населенные пункты, а линиями дороги; изучая работу сложного
конвейера на производстве, можно поставить в соответствие точкам
отдельные участки конвейера и отмечать стрелками факт обмена
продукцией между ними; рассматривая географическую карту, можно
изобразить точками отдельные государства, а линиями наличие
общих границ и т. п.
Графы являются полезным инструментом для изучения
совместных свойств алгоритмов и вычислительных систем, так как оба типа
объектов изображаются ими вполне естественным образом. Не
вдаваясь пока в детали обсуждения, заметим, что можно изображать
точками и операции алгоритма, и функциональные устройства
системы, а стрелками соответственно либо информационную зависимость
между операциями, либо возможность передачи информации от
одного устройства к другому. Если предположить, что
функциональные устройства системы обеспечивают в совокупности выполнение
всех операций алгоритма, то можно надеяться на то, что
исследование совместных свойств алгоритмов и систем удастся свести к
исследованию совместных свойств их графов.Эта задача должна быть более
простой хотя бы из-за того, что придется иметь дело с объектами
только одного типа. Но прежде чем перейти к ее обсуждению,
приведем основные определения и необходимые сведения из теории
графов.
Пусть задано любое конечное множество V каких-то элементов.
Будем называть эти элементы вершинами или точками и обозначать
их символами и, υ и т. п. Рассмотрим множество Ε неупорядоченных
пар {и, υ) элементов из V. Оно может состоять из всех возможных
пар или содержать лишь часть их, среди пар могут быть или не быть
одинаковые, элементы каждой пары могут быть либо различными,
либо совпадающими. Каждую такую пару будем называть ребром.
Говорят, что задан граф G=(F, £), если заданы непустое множество
вершин V и множество ребер Е.
Иногда при указании ребра задают только одну вершину.
Формально это означает, что при изучении графа о второй вершине не
нужно знать ничего, кроме того, что она существует.
Обычно граф изображается в виде некоторой схемы на плоскости.
При этом вершины графа изображаются точками, а пары точек и, vr
для которых существует ребро (и, υ), соединяются непрерывной
§ 5. ГРАФЫ
59
линией. На концах линии находится только одна точка, если ребро
определяется одной вершиной. Если для какой-то пары вершин
множество Ε содержит несколько ребер, то такие ребра
изображаются на схеме разными линиями. В ряде случаев граф удобно
изображать или задавать не только на плоскости, но и в пространстве,
в том числе абстрактном.
Если в графе имеется ребро (и, υ), то говорят, что это ребро
соединяет вершины и, υ, а сами вершины и, υ называются смежными.
В этом случае говорят также, что ребро (и, υ) инцидентно вершине
и и вершине υ. Вершины и, υ называются также концевыми для
ребра (и, υ). Все ребра с одинаковыми концевыми вершинами
называются кратными или параллельными, не кратные ребра называются
различными, ребро с совпадающими концевыми вершинами
называется петлей. Число инцидентных вершине ребер называется
степенью вершины. Вершина степени 1 называется висячей, степени 0—
изолированной.
Пусть дана упорядоченная последовательность вершин и каждые
две соседние вершины являются смежными. Последовательность
ребер, связывающих эти вершины, называется цепью. Цепь
называется простой, если среди ее ребер нет кратных, и составной —
в противном случае. Цикл — это конечная цепь, начинающаяся и
оканчивающаяся в одной и той же вершине. Цикл называется
составным или простым в зависимости от того, имеет ли он или не
имеет кратные ребра. Цикл, образованный последовательностью
вершин, среди которых нет одинаковых, кроме первой и последней;
называется элементарным.
Говорят, что граф связный, если любые две его вершины можно
соединить цепью. Граф называется простым, если он не содержит
петель и кратных ребер. Граф, содержащий кратные ребра,
называется мультиграфом. Если в графе допускаются и петли, и
кратные ребра, то такой граф иногда называется псевдографом. Граф,
не имеющий ребер, называется пустым.
Вводя понятие графа, мы рассматривали неупорядоченные пары
вершин. Однако во многих приложениях приходится иметь дело с
множествами, для которых порядок элементов в паре существен.
Упорядоченную пару элементов (и, υ) будем называть
ориентированным ребром или дугой и будем говорить, что вершина и является
начальной, υ — конечной. Говорят, что задан ориентированный
граф, или орграф G=(V, Ε), если заданы непустое множество
вершин V и множество дуг Е. Изображая ориентированный граф на
схеме, мы будем изображать дуги непрерывной линией со стрелкой
в конечной вершине. Иногда рассматриваются также частично
упорядоченные графы, в которых только часть ребер имеет ориентацию.
Заметим, что введение ориентации ребер можно трактовать как
задание на множестве вершин V некоторого, вообще говоря,
неоднозначного отображения Г. В этом случае существование дуги (и, ν)
означает, что u=Tu, где Ти £ V. Если же из вершины и не исходит
60 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
ни одной дуги, то будем считать, что Ти=0. Говорят, что и
предшествует υ, если υ—Tu, а отображение Г часто называют
отношением предшествования или отношением частичной упорядоченности.
Мы не будем, как правило, использовать для ориентированных
графов специальные обозначения, считая, что из текста ясно, о
каком из видов графов идет речь. В случае же необходимости будем
помечать буквы, обозначающие ориентированные графы, стрелкой
вверху. Для ориентированных графов сохраняется вся введенная
выше терминология с заменой слов «ребро», «цепь», «цикл», «связность»
соответственно на слова дуга, путь, контур, сильная связность.
Необходимо лишь уточнить понятие «путь». Теперь в упорядоченной
последовательности вершин начальная вершина должна находиться
раньше конечной. Число дуг, образующих путь, называется
длиной пути. Простой путь максимально возможной длины называется
критическим путем графа. Очевидно, что в ориентированном графе
с конечным числом вершин существует хотя бы один критический
путь. Если для ориентированного графа применяется
терминология, введенная для обычного графа, то это означает, что ориентация
ребер не принимается во внимание.
Граф называется ациклическим, если он не имеет циклов. Так же
называется ориентированный граф, если он не имеет контуров, т. е.
ориентированных циклов. Это название сохраняется даже в том
случае, когда ориентированный граф, рассматриваемый как
неориентированный, имеет циклы. Граф называется помеченным, если
его вершины снабжены какими-нибудь метками, индексами, цветом
и т. п.
Утверждение.5.1. В любом ориентированном
ациклическом графе существуют хотя бы одна вершина, для которой нет
предшествующей, и хотя бы одна вершина, для которой нет
последующей.
В самом деле, рассмотрим какой-нибудь критический путь графа.
Предположим, что первая его вершина имеет предшествующую.
В этом случае возможна одна из двух ситуаций. Или
предшествующая вершина совпадает с одной из вершин, образующих
критический путь, и тогда это означает, что в графе есть контур. Или
предшествующая вершина не совпадает ни с одной из вершин,
образующих критический путь, и тогда существует путь, имеющий большую
длину, чем критический. В обоих ситуациях мы приходим в
противоречие с условиями утверждения. Аналогично доказывается
существование вершины, не имеющей последующей.
Утверждение 5.2. Пусть задан ориентированный
ациклический граф, имеющий η вершин. Существует целое число sk^n,
для которого все вершины графа можно так пометить одним из
индексов 1,2, . . ., s, что если имеется дуга (Vi, Vj), то i<j.
Выберем в графе любое число вершин, не имеющих
предшествующих, и пометим их индексом 1. Удалим из графа помеченные
вершины и инцидентные им дуги. Оставшийся граф также является
§ 5. ГРАФЫ
61
ациклическим. Выберем в нем любое число вершин, не имеющих
предшествующих, и пометим их индексом 2. Снова удалим из графа
помеченные вершины и инцидентные им дуги. Продолжая этот
процесс, в конце концов исчерпаем весь граф. Так как при каждом шаге
помечается не менее одной вершины, то число различных индексов
не превышает числа вершин графа.
Следствие. Никакие две вершины с одним и тем же
индексом не связаны дугой.
Следствие. Минимальное число индексов, которыми можно·
пометить вершины графа, на 1 больше длины его критического пути.
Следствие. Для любого целого числа s, не превосходящего
общего числа вершин, но большего длины критического пути,
существует такая разметка вершин графа, при которой используются все
s индексов.
Разметка вершин графа, проведенная в соответствии с
утверждением 5.2, называется топологической сортировкой. Если при
топологической сортировке некоторая вершина помечена индексом k,
то это означает, что длины всех путей, оканчивающихся в данной
вершине, меньше k. Как следует из доказательства утверждения 5.2,
существует топологическая сортировка, при]|которой максимальная
из длин путей, оканчивающихся в вершине с индексом k, равна
k—1. Для этой сортировки число используемых индексов на 1
больше длины критического пути графа. По существу, доказательство-
утверждения 5.2 дает конструктивный способ нахождения всех·
критических путей.
Топологическая сортировка называется линейной, если индексы
любых вершин различны. В этом случае говорят также, что
ориентированный граф линейно упорядочен. Если топологическая
сортировка не является линейной, то из нее легко получить другие
сортировки, с большим числом индексов. Действительно, рассмотрим
какую-нибудь группу вершин, имеющих одинаковые индексы.
Разделим ее произвольным образом на две ч&сти. У вершин одной части
оставим индексы без изменения, а у вершин другой части увеличим
индексы на 1. Увеличим индексы на 1 также у всех вершин,
имевших больший индекс. Очевидно, что эта разметка дает
топологическую сортировку с числом индексов на 1 больше, чем
первоначальная.
Снова рассмотрим процесс вычисления выражения (аха2+
+а3а^) (α5α6+α7α8) и построим для него графы всех|трех
параллельных форм, описанных в § 2, Будем считать, что вершины графой
соответствуют выполняемым операциям, а дуги*показывают связь
аргументов операций и результатов их выполнения. Начальными
вершинами будем считать исходные данные аи . . ., #8· Все три
графа показаны на рис. 5.1. Так как эти графы задают эквивалентные
алгоритмы, то не удивительно, что в действительности все они
совпадают. Отличаются графы друг от друга лишь топологической
сортировкой. Если граф описывает некоторый алгоритм, то множество*
62 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
€го топологических сортировок определяет множество параллельных
форм. К этим вопросам мы будем еще обращаться неоднократно.
Два графа (орграфа) называются изоморфными, если между их
множествами вершин и ребер (вершин и дуг) можно установить
взаимно однозначное соответствие, сохраняющее смежность
(смежность и ориентацию). Очевидно, что изоморфизм есть отношение
эквивалентности на графах. Все три ориентированных графа на рис. 5.1
........ изоморфны между собой. Если графы
V; yi V; уг изображаются в виде схемы на
плоскости, то изоморфные графы отличаются
друг от друга только расположением
вершин и начертанием ребер или дуг.
Тем не менее в общем случае
распознать изоморфизм графов или
установить, что графы не изоморфны, очень
трудно.
Подграфом графа G называется граф,
у которого все вершины и ребра (дуги)
принадлежат G. Остовный подграф — это
подграф графа G, содержащий все его
вершины.
Рассмотрим теперь некоторые
бинарные или унарные операции над
графами. Все они определяются одинаково
как для неориентированных, так и для
Для определенности будем считать граф
с
л
2
3
О
л
2
3
4
2
3
4
5
Рис. 5.1
ориентированных графов
неориентированным.
Объединением графов G1=(Vli Ει) и G2=(V2, Е2) называется
граф G3 = (FiU V2, Ei(jE2)9 т. е. множество его вершин есть
объединение множеств Vi и V2, а множество ребер — объединение
множеств Ег и Е2. Эта операция обозначается равенством GZ=GX[}G2.
Пересечением графов G1=(VU Ех) и G2=(V2) E2) называется
граф G3=(V1r\V2, ^П^г), т. е. множество его вершин есть
пересечение множеств Fi и К2, а множество ребер — пересечение
множеств Ег и Е2. Эта операция обозначается равенством G3=GinG2.
Легко убедиться, что обе операции являются коммутативными
и ассоциативными. Определение этих операций можно
распространить на любое число графов.
Одними из важнейших унарных операций являются операции
гомоморфизма. Пусть дан граф G=(V, E). Выберем в множестве V
любые две вершины и, υ и построим множество Vu заменив и, υ
одной новой вершиной. Построим далее множество ребер Ег. Если
ребро в £ не инцидентно ни одной из вершин и, и, то это ребро
переносится в Εχ. Если же ребро в Ε инцидентно хотя бы одной из
вершин и, ν, то ребро в Ег получается из ребра в Ε заменой вершин и,
υ новой вершиной. Говорят, что граф G1 = (VU Ег) получается из
храфа G=(V, Ε) с помощью операции элемештрного гомомор-
§ 5. ГРАФЫ
63
физма. При изображении графа точками и линиями
реализацию этой операции можно трактовать как процесс слияния вершин
и, υ с непрерывным изменением всех связанных с ними линий.
Операции, заключающиеся в последовательном выполнении
операций элементарного гомоморфизма, называются операциями
гомоморфизма или гомоморфизмом. Так как получаемые при этих операциях
графы содержат меньшее число вершин, чем исходные, то процесс
гомоморфного преобразования графов будем называть сверткой.
Заметим, что операция элементарного гомоморфизма может
привести к появлению в графе циклов, петель и кратных ребер, даже если
исходный граф их не имел. Различают две разновидности
элементарного гомоморфизма. Если после описанной операции
исключаются все петли, а все кратные ребра отождествляются, то такая
операция называется простым элементарным гомоморфизмом. В
противном случае она называется кратным элементарным
гомоморфизмом или, как уже отмечалось, элементарным
гомоморфизмом. Операции, заключающиеся в последовательном выполнении
простого элементарного гомоморфизма, называются операциями
простого гомоморфизма или простым гомоморфизмом.
Говорят, что граф Η гомоморфен (просто гомоморфен) графу G,
если он изоморфен некоторому графу, который получается из графа
G с помощью операций гомоморфизма (простого гомоморфизма).
Отношение гомоморфизма графов не симметрично. Вершины графа
Я, соответствующие отождествляемым вершинам графа G,
называются их образами, вершины G — прообразами. Сам граф Η
называется гомоморфным образом графа G.
Имеется несколько частных типов гомоморфизмов. Гомоморфизм
называется независимым, если никакие две из отождествляемых kep-
шин не соединены ребром. Любой независимый гомоморфизм можно
рассматривать как последовательность элементарных независимых
гомоморфизмов, состоящих в отождествлении двух не соединенных.
ребром вершин. Гомоморфизм называется связным, если подграф,
образованный отождествляемыми вершинами, связен. Связный
гомоморфизм можно рассматривать как последовательность
элементарных связных гомоморфизмов, состоящих в отождествлении
концов одного ребра. В общем случае подграф, образованный
отождествляемыми вершинами, распадается на несколько связных
компонент. Поэтому гомоморфизм можно осуществить в два шага, сначала
отождествляя вершины каждой из компонент, а затем отождествляя
полученные независимые вершины. Теперь очевидно, что имеет
место следующее
Утверждение 5.3. Любой гомоморфизм можно
представить как последовательность связных и независимых гомоморфизмов.
В некотором смысле обратной по отношению к операции
элементарного гомоморфизма является операция добавление вершины.
Если в множество V графа (V, Е) добавляется вершина w, то при*
этом в множестве Ε одно из ребер (и, ν) заменяется парой ребер*
^4 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
{и, до), (до, ν). Отождествляя пару вершин и, до или до, ι; с помощью
операции простого гомоморфизма, возвращаемся к исходному графу.
Рассмотрим, наконец, общую операцию преобразования графов.
Пусть граф G=(V, Ε) задан как множества точек V и линий Ε
некоторого метрического пространства. Предположим, что в
пространстве определена некоторая однозначная непрерывная функция F
•со значениями на этом же или другом метрическом пространстве Ω.
Зта функция переводит граф G в граф Я, точки и линии которого
принадлежат Ω. Если, в частности, функция F осуществляет опера-
дию проектирования исходного пространства на Ω, то будем
говорить, что граф Я есть проекция графа G на Ω. При подходящем
выборе функции F могут быть реализованы и операции гомоморфизма.
§ 6. Граф алгоритма
Алгоритмы можно представлять графами. Однако, прежде чем
приступить к обсуждению этого способа представления, уточним
некоторые детали.
Говоря об алгоритме, обычно предполагают наличие какого-
нибудь правила, описывающего совокупность выполняемых
операций и связь отдельных операций между собой или указание
порядка их следования. Такое правило может быть задано в виде
математических формул, программы на алгоритмическом языке,
таблицы выполняемых действий и т. п.
Не всегда правило понимается однозначно. Пусть, например, оно
состоит в указании «вычислить сумму нескольких чисел». С точки
зрения точных математических операций результат не зависит от
порядка их суммирования, и поэтому сам порядок может не
задаваться. С точки зрения операций, выполняемых в ЭВМ, порядок
оказывается существенным. Это может быть вызвано либо влиянием
ошибок округления, либо просто отсутствием в языке,
используемом в ЭВМ, операции вычисления суммы многих чисел.
Будем считать, что алгоритм или описывающее его правило
позволяют каким-либо образом определить:
— множество переменных, в преобразовании которых (или
с помощью которых) заключается реализация алгоритма;
— множество операций, выполняемых в процессе реализации
-алгоритма;
— соответствие, показывающее, какие результаты выполнения
предшествующих операций являются аргументами для каждой
операции.
Заметим, что не накладывается никаких существенных
ограничений на вид переменных и операций. Переменными могут быть числа,
буквы алфавита, логические переменные, матрицы, массивы и т. п.,
операциями — любые арифметические, логические, матричные
операции и т. п. Будем только предполагать, что число входов и выходов
^аргументов и результатов) каждой из операций алгоритма в терми*
§6. ГРАФ АЛГОРИТМА
65
нах выбранных переменных ограничено и не зависит от общего числа
всех операций алгоритма. Поэтому, например, операция
вычисления суммы η чисел не является допустимой, если входными
переменными будут числа, но она может стать допустимой, если входной
переменной будет массив из η чисел.
Типичной является ситуация, когда все переменные и операции
алгоритма принадлежат небольшому числу классов,
характеризуемых некоторыми признаками. При этом существенным оказывается
только то, что переменные и соответственно операции принадлежат
одному или разным классам, а не то, чем они различаются внутри
класса. Например, все переменные алгоритма могут быть
вещественными числами, а операции — операциями сложения,
умножения или деления вещественных чисел, и совсем не важно, как
различаются вещественные числа между собой и как в
действительности выполняются операции. Если фиксированы такие классы, будем
говорить, что заданы базовые переменные и базовые
операции.
Теперь можно приступить к построению графа алгоритма.
Множеству операций алгоритма поставим во взаимно однозначное
соответствие какое-нибудь множество точек. Если аргумент одной
операции есть результат выполнения другой операции, то
соответствующие точки соединим дугой, направленной из той точки,
откуда берется результат. Из каждой точки выходит, как правило,
столько дуг, сколько выходов имеет соответствующая операция,
и входит в точку столько дуг, сколько входов у операции.
В случае, когда результат выполнения одной операции является
аргументом для нескольких операций, выходящих дуг может быть
больше. Если аргументом операции является начальное данное
или результат операции нигде не используется, то будем считать,
что соответствующие дуги или отсутствуют, или не имеют одной
из вершин.
Ничто не мешает рассматривать дуги прямолинейными, и
выполнение этого условия часто будет предполагаться без
дополнительных оговорок. При необходимости дуги и операции,
соответствующие разным классам, будем помечать, например, индексами или
цветом. Построенный таким образом граф и будем называть графом
алгоритма. Очевидно, это есть ориентированный ациклический
мультиграф. Для его обозначения будем использовать введенную
ранее символику. Если алгоритм или описывающее его правило
позволяет построить граф алгоритма, то тем самым на множестве
выполняемых операций вводится частичная упорядоченность. Любые
две операции либо находятся в отношении порядка, либо не
находятся. Если две операции находятся в отношении порядка, то
одна из операций должна быть выполнена раньше другой.
Выполняя операции в различном порядке, например в различное время,
мы будем получать полностью эквивалентные с точки зрения
получаемых результатов реализации алгоритмов, если только при этом
3 В. В. Воеводин
66 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
сохраняется частичный порядок. На множестве такцх реализаций
можно выбирать лучшие в том или ином отношении.
Как уже неоднократно отмечалось, при реализации алгоритма на
параллельной вычислительной системе большое значение
приобретает знание его параллельных форм. Теперь можно уточнить
соответствующие понятия.
Пусть задан некоторый алгоритм и G=(V, Ε) — его граф.
Предположим, что множество вершин V разбито на такие
непересекающиеся подмножества Vu . . ., Vk, что если v£Vi, u£ Vj и
существует дуга (ν, и), то К]. В этом случае разбиение
k
V= UV{
i=. 1
называется параллельной формой алгоритма, а подмножества Vu
..., Vk— ее ярусами. Число k называется высотой параллельной
формы, \Vt\ —шириной 1-го яруса, а максимальное из этих чисел — ши
риной параллельной формы. Параллельная форма минимальной
высоты называется максимальной, а ее высота — высотой алгоритма.
Максимальная ширина параллельных форм называется шириной
алгоритма. Параллельная форма шириной 1 называется
последовательной. Максимальная параллельная форма называется
канонической, если в каждую вершину ι-го яруса ведет хотя бы один путь
длиной ι—1.
Перечислим некоторые наиболее важные свойства параллельных
форм алгоритма:
— никакие две вершины одного яруса любой параллельной
формы не связаны ни одной дугой;
— все дуги, входящие в вершины первого яруса, не имеют
начальных вершин или отсутствуют;
— все дуги, выходящие из вершин последнего яруса, не имеют
концевых вершин или отсутствуют;
— высота алгоритма на 1 больше длины критического пути его
графа;
— произведение высоты любой параллельной формы на ее
ширину не меньше общего числа вершин графа алгоритма.
Справедливость всех этих свойств, а также факт существования
параллельных форм алгоритма с очевидностью вытекают из ранее
доказанных утверждений и их следствий.
Параллельные формы алгоритмов находить довольно трудно,
хотя на первый взгляд эта задача может показаться и не очень
сложной. В самом деле, при отыскании критического пути графа
применяется некоторый конструктивный метод, позволяющий найти
параллельную форму алгоритма, содержащего η операций, за число
действий порядка я2. С точки зрения теории сложности это очень
эффективный метод, так как число действий полиномиально зависит
от числа вершин графа. Однако заметим, что в реальных алгорит-
§ 6. ГРАФ АЛГОРИТМА
67
мах, подлежащих распараллеливанию, число операций очень
велико; поэтому не только полиномиальная, но даже линейная
сложность методов нахождения параллельных форм, как правило,
оказывается практически недопустимой. Именно поэтому приходится
разрабатывать более эффективные методы, принимая во внимание,
конечно, какие-нибудь дополнительные свойства алгоритмов.
Утверждение 6.1. Пусть задан ациклический
ориентированный граф, вершины которого расположены в некотором
арифметическом пространстве. Выберем в пространстве прямую линию
и спроектируем на нее граф. Предположим, что проекции всех дуг
либо являются точкой, либо направлены в одну сторону. Тогда длина
критического пути графа не превосходит сумму длин критических
путей всех подграфов, вершины которых проектируются в одну
точку, и критического пути проекции графа.
Возьмем любой критический путь графа и спроектируем его на
указанную в утверждении прямую. Ненулевые проекции его дуг
образуют на прямой путь. Следовательно, их число не больше, чем
длина критического пути проекции всего графа на эту прямую.
Рассмотрим теперь те дуги выбранного критического пути графа,
которые проектируются в одну точку. Эти дуги также образуют путь.
Поэтому их число не больше, чем длина критического пути всего
подграфа исходного графа, вершины которого проектируются в
ту же точку.
Разобьем все дуги критического пути на группы, одна из
которых дает ненулевые проекции дуг, а все дуги каждой из остальных
групп проектируются в точку. Число дуг любой из этих групп
оценено сверху, и теперь оценивается сверху общее их число.
. Утверждение 6.2. Пусть выбрана такая прямая, что
проекции на нее всех дуг графа алгоритма ненулевые и направлены в
одну сторону. Тогда эта прямая определяет некоторую
параллельную форму алгоритма. Именно, каждый ярус параллельной формы
содержит те и только те вершины, которые проектируются в одну
точку, все вершины одного яруса находятся в гиперплоскости,
перпендикулярной прямой и проходящей через соответствующую
проекцию, а сами ярусы упорядочиваются в соответствии с
упорядочиванием проекций.
Пронумеруем проекции вершин числами 1, . . ., k в
соответствии с направлением проекций дуг. Обозначим через Vt множество
вершин графа, проектируемых в i-ю точку. Очевидно, что для всех i
никакие две точки из Vt не связаны между собой дугой, так как в
противном случае соответствующая дуга имела бы нулевую
проекцию. Пусть взяты две вершины ν, и соответственно из Viy Vj ц
существует дуга (υ, и). Так как все проекции дуг направлены в одну
сторону и именно в этом направлении занумерованы проекции
вершин, то отсюда следует, что i</. Следовательно, построенное
разбиение Уь . .., Vk определяет параллельную форму алгоритма.
Все точки гиперплоскости, перпендикулярной прямой, и только они,
3*
68 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
проектируются в одну точку этой прямой; поэтому все вершины
одного яруса параллельной формы принадлежат таким
гиперплоскостям.
Следствие. В условиях утверждения 6.2 высота алгоритма
не превосходит числа проекций на прямой и ширина алгоритма не
меньше максимального числа вершин, проектируемых в одну точку.
Граф алгоритма, для которого существует хотя бы одна прямая,
удовлетворяющая условиям утверждения 6.1, называется
направленным, а направляющий вектор соответствующей прямой —
направляющим вектором графа. Если для графа существует хотя бы
одна прямая, удовлетворяющая условиям утверждения 6.2, то
такой граф называется строго направленным. Понятие
направленности графа зависит от
геометр ического расположения
вершин, поэтому оно может
не сохраняться при
изоморфном преобразовании.
Пример строго направленного
графа представлен на рис.
6.1.
Распознавание строгой
направленности графа
алгоритма и тем более определение
его направляющего вектора,
по существу, означают
построение параллельной формы
алгоритма. Целесообразно
ввести в пространстве вершин подходящую систему координат и
задавать вершины их координатами. Тогда можно дать
математические постановки для многих задач, и в частности для задачи
определения направляющего вектора, обеспечивающего минимальную
высоту параллельной формы.
Утверждение 6.3. Пусть все дуги графа алгоритма
имеют неотрицательные координаты. Тогда этот граф является строго
направленным и в качестве направляющего вектора можно взять
любой вектор с положительными координатами.
Все дуги имеют ненулевые проекции и направлены в одну
сторону. Поэтому справедливость данного утверждения сразу вытекает
из определения строгой направленности.
Следствие. Пусть одноименные координаты всех дуг графа
алгоритма либо неотрицательные, либо неположительные. Тогда
этот граф является строго направленным и в качестве направляюще-
го вектора можно взять вектор с ненулевыми координатами, знаки
которых совпадают со знаками одноименных координат дуг.
Следствие. Пусть координаты всех дуг с каким-то
номером сохраняют один и тот же знак. Тогда этот граф является строго
направленным и в качестве направляющего вектора можно взять век-
§6. ГРАФ АЛГОРИТМА
69
тор, у которого все координаты нулевые, кроме координаты с тем же
номером, которая имеет аналогичный знак.
Граф алгоритма определяется с точностью до изоморфизма.
Поэтому легкость или трудность определения параллельных форм
алгоритма решающим образом зависит от того, насколько удачно
расположены вершины графа в пространстве.
Утверждение 6.4. Пусть все вершины графа алгоритма
находятся в узлах прямоугольной целочисленной решетки и
принадлежат замкнутому прямоугольному параллелепипеду размерности
т с ребрами длиной du . .., dm. Предположим, что все дуги графа
имеют неотрицательные координаты. Тогда высота Η алгоритма
будет удовлетворять неравенству
т
я<2^+1. (6.1)
i— 1
Этот граф является строго направленным. Согласно следствию
из утверждения 6.2, высота алгоритма не превосходит числа
различных проекций целочисленных точек, принадлежащих
прямоугольному параллелепипеду, на прямую с направляющим вектором,
имеющим единичные координаты. Это число проекций и задается
правой частью . неравенства (6.1).
Легко построить много примеров графов, удовлетворяющих
условиям этого утверждения, для которых неравенство (6.1)
достигается. Обычно величину т имеет порядок нескольких единиц,
поэтому существенное улучшение оценки высоты возможно только в
том случае, когда удается разместить граф в прямоугольном
параллелепипеде большей размерности, но с существенно меньшей суммой
длин его ребер. Для некоторых алгоритмов их графы позволяют в
какой-то мере изменять размерность параллелепипеда, но эти
возможности, как правило, весьма ограниченны. Заметим, что любой
алгоритм допускает размещение его графа в параллелепипеде
размерности 1 (достаточно построить последовательную форму
алгоритма). Однако при этом правая часть неравенства (6.1) будет не
меньше числа всех вершин графа, и такая оценка высоты не
представляет какого-либо практического интереса.
Графы, вершины которых расположены в узлах целочисленной
прямоугольной решетки, будем называть решетчатыми. Несмотря
на то что существует большой произвол в расположении вершин
изоморфных решетчатых графов, выделение таких графов в особую
группу оказывается целесообразным. Дело в том, что в практически
используемых формах записи алгоритмов можно увидеть некоторые
естественные способы размещения вершин графа в узлах решетки.
Например, такие способы связаны с индексами используемых
переменных. При этом довольно часто удается построить максимальные
параллельные формы или формы, близкие к ним.
С понятием решетчатого графа мы будем связывать не только рас-
положение вершин графа в узлах прямоугольной решетки, но и вы-
70 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
бор естественной системы координат, отражающей в какой-то мере
структуру алгоритма. В направленных алгоритмах также
предполагается наличие системы координат, но эта система не обязательно
связана с алгоритмом.
Рассмотрим задачу вычисления произведения А=ВС двух
квадратных матриц В, С порядка п. Пусть вначале на месте элементов
матрицы А стоят нули. Будем последовательно их перевычислять
Рис. 6.2
так, чтобы в конце процесса получить нужные элементы.
Обозначим через bik, ckj элементы матриц/?, С, а через а(& элемент
матрицы А после /г-го его перевычисления. Пусть вычислительный
алгоритм определяется формулами
α^) = <·-1, + ^^/, ί, /, &=1, 2, .. , п.
Тогда αψ? есть элемент матрицы А в позиции i, /.
Построим решетчатый граф этого алгоритма. Возьмем в
качестве базовой операцию вида α+bc и рассмотрим прямоугольную
решетку с координатами /, /,&. Теперь в узел с координатами i, /, k
поместим вершину, соответствующую операции а$_1)+йгь£ь/. Так
как bik и ckj задают входные данные алгоритма, то в вершину с
координатами i, /, k будет идти только одна дуга — из вершины с
координатами i, /, k—1. Решетчатый граф для п=3 приведен на рис. 6.2.
Удачный выбор базовой операции, системы координат и
расположения вершин привел к тому, что граф рассматриваемого
алгоритма выглядит исключительно регулярно. По этому графу сразу
видно, как устроена максимальная параллельная форма алгоритма,
какова его высота, ширина и т. п.
Как следует из формы записи алгоритма, имеется явный
параллелизм вычислений. Формально он определяется тем, что все
индексы указываются равноправно. Поэтому не удивительно, что этот же
араллелизм обнаружен и в решетчатом графе. Если записать дан-
ый алгоритм в виде программы на фортране, то независимость
§ 7. ФУНКЦИОНАЛЬНЫЕ УСТРОЙСТВА
71
индексов уже не так очевидна, не очевиден и параллелизм
вычислений. Однако анализ программы снова приводит к аналогичному
решетчатому графу.
§ 7. Функциональные устройства
Любая вычислительная система есть работающая во времени
совокупность взаимосвязанных функциональных устройств (ФУ).
Описание процесса ее работы связано с указанием
последовательности выполнения на устройствах некоторых базовых операций
над входными данными и результатами промежуточных
вычислений. В зависимости от того, насколько сложен процесс и насколько
детально мы им интересуемся, описание процесса может быть
осуществлено в терминах различных операций. В различных
ситуациях одни и те же операции являются как базовыми, так и
небазовыми. Поэтому целесообразно выделить некоторые общие
характеристики функциональных устройств, не зависящие от
конкретного содержания реализуемых операций. ^
Пусть фиксирована величина некоторого отрезка времени.
Назовем ее временем цикла или тактом. Будем считать, что вся
работа вычислительной системы подчинена времени цикла в том
смысле, что любое изучаемое действие может начаться и закончиться
лишь в моменты времени, ему пропорциональные. По существу,
это означает, что работа системы описывается дискретным
временем. Конечно, ничто не мешает считать такт равным 1, и мы будем
придерживаться всюду в дальнейшем этого предположения, если
только не сделано специальной оговорки.
Вообще говоря, для выполнения ближайших исследований
достаточно потребовать, чтобы единому времени была подчинена не
вся система в целом, а только отдельные ее ФУ. Однако многие
дальнейшие исследования существенно упрощаются, если считать,
что каждое ФУ может включаться не в произвольное время, а
лишь в дискретные его моменты с шагом 1. При этом временные
характеристики процессов и особенности их реализации
изменяются не очень сильно. Подчеркнем особо, что введение единого
времени в системе не означает глобальную синхронизацию
вычислительного процесса. Синхронизируется лишь выполнение
отдельных операций, да и то в пределах интервала времени, равного 1.
Назовем функциональное устройство простым, если время
выполнения на нем любой операции определено априори и никакая
последующая операция не может начать выполняться раньше
момента окончания предыдущей операции. Функциональное
устройство назовем конвейерным, если время выполнения на нем любой
операции также определено априори, но последующая операция
может начать выполняться через один такт после начала
выполнения предыдущей операции.
72 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
Основное различие между простым и конвейерным ФУ состоит
в том, что простое ФУ монопольно использует свое оборудование
для выполнения одной операции, а конвейерное ФУ распределяет
его для одновременного выполнения нескольких операций.
Конвейерное ФУ имеет большие возможности, чем простое. Их
временные возможности совпадают тогда и только тогда, когда времена
выполнения операций равны 1. Если на конвейерном ФУ
выполняются одни и те же операции с временем τ, то формально работа
такого ФУ эквивалентна работе линейной цепочки из τ простых ФУ, с
временем срабатывания 1, выполняющих какие-то операции, в
совокупности равносильные исходной.
Будем считать, что ФУ не может одновременно выполнять
операцию и сохранять результат предыдущего срабатывания, т. е.
оно не имеет никакой собственной памяти. Если когда-либо
потребуется обеспечение подобной ситуации, то будем предполагать, что
к ФУ присоединяется та или иная память. Будем считать также,
что каждое ФУ работает по индивидуальным командам. В момент
подачи команды сначала из соседних ФУ передаются результаты
их срабатывания на входы данного ФУ как аргументы выполняемой
операции, затем уничтожается результат последнего срабатывания
и лишь после этого начинает выполняться новая операция.
Пересылка аргументов и уничтожение результата осуществляются
мгновенно. Если в момент подачи команды не все аргументы готовы, то
операция не выполняется, но результат предыдущего срабатывания
ФУ уничтожается. В случае, когда конвейерное ФУ может реали-
зовывать операции разных типов, будем предполагать, что ФУ
имеет возможность выдавать результаты выполнения операций
каждого типа, даже если их реализация заканчивается в один и
тот же момент.
Простым ФУ можно считать, например, универсальный
процессор, имеющий возможность последовательно выполнять
операции из ограниченного номенклатурного набора. Конвейерные ФУ,
как правило, являются специализированными и предназначены для
выполнения операций одного типа. В последнем случае время
выполнения операции иногда называется числом ступеней конвейера.
Объясняется это название тем, что довольно часто конвейерные
ФУ, выполняющие операции одного типа, конструктивно
проектируются и изготовляются как линейные цепочки простых ФУ с
временем срабатывания 1. Например, для конвейерного ФУ,
выполняющего операцию сложения чисел с плавающей запятой,
соответствующие простые ФУ последовательно выполняют такие
операции, как сравнение порядков, сдвиг мантиссы, сложение мантисс
и т. п.
Функциональные устройства предназначены для выполнения
операций. Поэтому необходимо ввести некоторую характеристику,
показывающую, насколько эффективно они это делают. Мы уже
рассматривали одну из таких характеристик, названную нами за-
§7. ФУНКЦИОНАЛЬНЫЕ УСТРОЙСТВА
73
груженностью функционального устройства или системы в целом,
понимая под ней отношение реально выполняемого объема работы
к максимально возможному. Теперь мы можем уточнить это
понятие.
Существует много различных определений загруженности. Их
разнообразие, по существу, объясняется различными способами
определения объема работы. Можно, например, определить
понятие «загруженность» как отношение времени выполнения полезной
работы ко времени занятости устройства или системы. Такое
определение вполне подходит для простых ФУ, но плохо отражает
работу конвейерного ФУ, так как не учитывает того факта, что
одновременно могут выполняться несколько операций. По этой же
причине подобное определение не подходит для описания работы
сложной системы.
Можно было бы определить понятие «загруженность» как
отношение числа реально выполненных операций к максимальному
числу операций, которое можно выполнить. Это определение
хорошо отражает работу простых и конвейерных ФУ, выполняющих
операции одной длительности. Однако оно плохо описывает работу
устройств и систем, выполняющих различные операции, в
особенности операции с большим разбросом длительностей.
Пусть выполняются операции с длительностями т1у . . ., τδ.
Назовем стоимостью операции время ее реализации, а стоимостью
работы стоимость всех выполненных операций. Стоимость работы—
это время реализации рассматриваемых операций на одном
простом ФУ, имеющем возможность выполнять данные операции за
заданное время. Загруженностью устройства или системы на
данном отрезке времени будем называть отношение стоимости реальна
выполненных операций за это время к максимально возможной
стоимости операций, которые можно выполнить за то же самое
время. Вычисляя стоимость работы и, в особенности, максимальную
стоимость, мы будем формально учитывать не только полностью
выполняемые операции, но и возможность выполнить их части.
При этом будем считать, что стоимость выполняемых частей
пропорциональна стоимости операций. Конечно, можно и не учитывать
части операций. Однако их учет оказывается полезным в ряде
случаев; к тому же они не оказывают заметного влияния при
исследовании процессов на больших отрезках времени. Асимптотической
загруженностью будем называть предел загруженности при
неограниченном увеличении времени работы.
Утверждение 7.1. Максимальная стоимость работы*
выполняемой простым ФУ на отрезке времени 7, равна Τ независимо
от возможности ФУ реализовывать различные по длительности
операции или одну операцию. Максимальная стоимость работы
для конвейерного ФУ> выполняющего операции с длительностями
ть ..,., τ5, равна 7\ умноженному на максимальное из чисел
Τι, . . ., Ts.
74 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
Расширим отрезок времени Τ слева и справа не меньше, чем
на время выполнения функциональным устройством самой длиной
операции. Для простого ФУ в каждый момент времени выполняется
только одна операция или не выполняется ни одной. Поэтому
стоимость работы, выполняемой в единицу времени, всегда равна либо
единице, либо нулю. Следовательно, максимальная стоимость
работы достигается в том случае, когда на заданном отрезке времени
Τ операции выполняются без пропусков. При этом длительность
операций на ее величину не влияет. Что же касается конвейерного
ФУ, то стоимость работы, выполняемой в единицу времени, теперь
равяа числу операций, выполняемых в данный момент.
Максимальная стоимость работы в этом случае достигается тогда, когда
операции выполняются не только без пропусков, но всегда к тому же и
максимальной длительности.
Следствие. Загруженность и асимптотическая
загруженность ρ любого ФУ или системы ФУ всегда удовлетворяют
соотношениям 0^/7^1. Значение р = 1 достигается тогда и только тогда,
когда выполняется объем работы максимальной стоимости. Если
на конвейерных ФУ выполняется целое число операций, то
загруженность ρ меньше 1.
В последнем случае загруженность действительно не может
равняться 1 потому, что в начале и конце процесса невозможно
обеспечить полную загрузку ФУ выполнением полезной работы. Однако
эти «хвосты» играют на больших отрезках времени очень
маленькую роль.
Максимальную стоимость работы, выполняемой ФУ в единицу
времени, будем называть номинальной производительностью ФУ.
Для простого ФУ номинальная производительность равна 1, для
конвейерного ФУ — длительности самой длинной из возможных
операций. Очевидно, что номинальная производительность системы
ФУ равна сумме номинальных производительностей всех
составляющих эту систему ФУ.
Утверждение 7.2. Пусть вычислительная сиотема
состоит из s простых или конвейерных ФУ с номинальными производи-
тельностями а1у . . ., as. Тогда на любом отрезке времени Τ
загруженность ρ системы есть взвешенная сумма загруженностей
/?ι, . . ., ps ее ФУ. При этом коэффициенты взвешенной суммы равны
отношению номинальной производительности ФУ к номинальной
производительности системы, т. е.
S
ρ=2η<Ρί, (7·ΐ)
ί=1
где
ίν V1
7. ФУНКЦИОНАЛЬНЫЕ УСТРОЙСТВА
75
Предположим, что на отрезке времени Τ i-e ФУ выполняет
объем работы стоимостью β,. Максимальная стоимость работы,
которую оно может выполнить, равна af7\ Объем работы,
который за время Τ реально выполняет система, имеет стоимость
βι+. . .+ВЯ, а максимальная стоимость выполняемой работы может
равняться агТ+. . .+asT. Следовательно,
S
ς β/ ς4Ιγ) £«<«
f=l t=l i=cl
Σ «<·Γ Σ «ί Σ °"
ί=1 issl t=l
откуда и вытекает справедливость высказанного утверждения.
Следствие. Если система состоит из устройств
одинаковой номинальной производительности, то на любом отрезке времени
ее загруженность равна среднему арифметическому загруженностей
составляющих систему устройств.
Ψ Следствие. Загруженность системы равна 1 тогда и
только тогда, когда равны 1 загруженности всех ее устройств.
Следствие. Для того чтобы при заданном составе системы
обеспечить выполнение объема работы заданной стоимости за
минимальное время, необходимо обеспечить максимальную
загруженность устройств наибольшей номинальной производительности.
Из соотношений (7.1) можно получить и другие полезные
следствия. Наиболее интересные из них касаются тех случаев, когда
вычислительная система имеет либо только простые ФУ, либо
только специализированные конвейерные ФУ, каждое из которых
выполняет операции одного типа.
Утверждение 7.3. Пусть s простых ФУ за время Τ
выполняют Ni операций длительностью тг (l^i^r). Если при этом
загруженность j-го ФУ есть р;-, то
S Г
ΣΡ/ = τΣ^ι· (7-2)
у=1 i=l
Утверждение 7.4. Пусть s конвейерных ФУ за время Τ
выполняют N операций и каждое из этих ФУ может выполнять
операции только одной длительности. Если загруженность j-го
ФУ есть pjy то
Σρ/=γ· (7·3)
Оба утверждения доказываются совершенно аналогично.
Установим справедливость, например, второго из них. Пусть на /-м
ФУ за время Τ выполняется Nj операций длительностью Xj. Стой-
76 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
мость реально выполненной работы равна τ,-ΛΓ/, а максимально
возможная стоимость работы, которую можно выполнить на данном
ФУ, равна %{Г. Поэтому загруженность pj рассматриваемого ФУ
есть отношение Nj/T. Суммируя все pj, убеждаемся в
справедливости высказанного утверждения.
Соотношения (7.2), (7.3) часто позволяют оценить эффективность
решения той или иной задачи на конкретной вычислительной
системе. Число устройств, число выполняемых операций и их
длительности, как правило, известны. Для оценки загруженности
используемых устройств не хватает лишь подходящих оценок времени
реализации задачи на системе. Эти оценки можно получить из
графов алгоритма.
Утверждение 7.5. Время реализации любого алгоритма
не меньше, чем время последовательного выполнения любого числа
операций, находящихся на любом пути графа алгоритма.
Доказательство почти очевидно, если заметить, что никакие
две операции, находящиеся на одном пути, не могут выполняться
одновременно, так как хотя бы один аргумент одной из них зависит
от результата выполнения другой.
Утверждение 7.6. Если исключить все временные
затраты при реализации алгоритма, кроме затрат на выполнение
его операций, то любой алгоритм при подходящем составе и
количестве ФУ может быть реализован за время, равное максимальному
из времен последовательного выполнения всех операций, находящихся
на отдельных путях графа алгоритма.
Исходя из возможностей ФУ, установим время выполнения
каждой операции алгоритма. Заменим далее все вершины графа
алгоритма линейными цепочками других вершин, число которых
совпадает с временем выполнения соответствующей операции, и
построим для нового графа его каноническую максимальную
параллельную форму. Очевидно, что ее высота равна максимальному
из времен последовательного выполнения всех операций,
находящихся на различных путях исходного графа. Предположим, что
в нашем распоряжении имеются конвейерные ФУ. Возьмем их
такими и в таком количестве, чтобы можно было одновременно
выполнять все операции, части которых находятся в любом отдельном
ярусе максимальной параллельной формы нового графа. Этот
набор ФУ обеспечивает решение исходной задачи за указанное в
утверждении время. Максимальная параллельная форма
построенного графа определяет временную развертку режима работы
выбранных ФУ. Если в нашем распоряжении имеются простые ФУ,
то общая схема рассуждений остается той же, но самих ФУ
придется взять больше.
Заметим, что если все операции выполняются за одинаковое
время, то для того, чтобы реализовать алгоритм за время,
указанное в утверждении 7.6, необходимо иметь простых ФУ примерно
во столько раз больше, чем конвейерных ФУ, какова длительность
§ 7. ФУНКЦИОНАЛЬНЫЕ УСТРОЙСТВА
77
выполнения операций. Этот факт вполне согласуется с формулами
{7.2), (7.3).
Несмотря на свою простоту, равенство (7.3) оказывается
полезным во многих исследованиях. В частности, из него вытекает
следующий вывод. Общее время решения задачи может изменяться при
использовании большого числа ФУ. Однако оно ограничено снизу.
Поэтому увеличение числа используемого оборудования может
давать соответствующие ускорения процесса решения лишь до
некоторого предела, определяемого самим алгоритмом и в какой-то
мере техническими характеристиками ФУ. После этого рост
ускорения замедляется и наконец прекращается совсем. Конечно, для
отдельных алгоритмов полная загруженность оборудования может
не реализоваться ни при каком составе функциональных устройств,
отличном от одного универсального процессора.
Рассмотрим один характерный пример. Во многих
вычислительных задачах, например задачах математической физики, часто
приходится решать системы линейных алгебраических уравнений с
вещественной трехдиагональной матрицей. С точки зрения времени
эта задача нередко является узким местом, в особенности при
реализации неявных итерационных методов. Поэтому постараемся
понять, можно ли создать специализированный процессор,
эффективно решающий единичную задачу.
Предположим, что по тем или иным причинам мы остановили
свой выбор на реализации метода прогонки. В наиболее
распространенных его вариантах для решения системы порядка η требуется
выполнить Зп операций сложения, An операций умножения и η
операций вычисления обратной величины. Пусть в нашем
распоряжении имеются самые современные конвейерные ФУ. Будем считать,
что времена выполнения операций сложения, умножения и
вычисления обратной величины равны соответственно 6, 7 и 14, что вполне
соответствует существующим принципам конструирования таких
ФУ. Анализируя граф алгоритма прогонки, легко показать, что
время реализации прогонки есть величина порядка 40д. Поэтому
сумма загруженностей всех используемых ФУ никогда не
превзойдет 0,20. Так как для реализации прогонки нужно не менее трех
ФУ, то средняя загруженность каждого из ФУ будет не больше
0,07. При этом мы получим ускорение процесса решения задачи
только в 1,5 раза по сравнению с ее решением на одном простом
универсальном процессоре с аналогичными временами выполнения
операций, причем независимо от того, сколько ФУ будет реально
■использовано.
Результат исследования оказался довольно неожиданным, и
естественно, что он вызывает много вопросов. В частности,
— нужно ли создавать для решения подобных задач
специализированные вычислительные системы, если имеет место столь низкая
загруженность функциональных устройств?
78 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
— что можно предпринять для повышения загруженности
функциональных устройств?
— как распознавать подобные неблагоприятные ситуации? На
все эти и другие аналогичные вопросы мы дадим ответы позднее.
Рассмотренный пример показывает, что не всегда использование
большого числа ФУ приводит к значительному ускорению процесса
решения задачи. Поэтому целесообразно ввести характеристику,
показывающую степень достигаемого ускорения. Как и в случае
загруженности, понятие «ускорение» может вводиться различными
способами, многообразие которых зависит от того, что с чем и как
сравнивается.
Нередко ускорение определяется, например, как отношение
времени решения задачи на одном универсальном процессоре к
времени решения той же задачи на системе из s таких же процессоров.
Очевидно, что в наилучшей ситуации ускорение может достигать s.
Отношение ускорения к s называется при этом эффективностью.
Однако заметим, что подобные определения применимы к очень
узкому классу систем и совсем не применимы к системам,
содержащим разнородные устройства. Понятие же «эффективность» в
рассматриваемом случае просто совпадает с понятием «загруженность».
Пусть алгоритм реализуется на вычислительной системе за
время Т. Рассмотрим гипотетическое простое ФУ, которое имеет
возможность выполнять все отдельные операции алгоритма за такие
же времена, как и соответствующие ФУ в самой системе.
Предположим, что время реализации того же алгоритма на гипотетическом
ФУ равно Т0. Отношение R — TJT будем называть ускорением
реализации алгоритма на данной вычислительной системе или просто
ускорением.
Выбор в качестве гипотетического простого, а не
какого-нибудь другого, например конвейерного, ФУ объясняется тем, что
одно простое ФУ может быть полностью загружено на любом
алгоритме. Никакое другое ФУ таким свойством не обладает. По этой
же причине загруженность ФУ тоже определялась через работу,
выполняемую на простом ФУ.
Утверждение 7.7. Пусть вычислительная система
состоит из s функциональных устройств с номинальными производитель-
ностями аь . . ., as. Если при реализации алгоритма загруженности
ФУ оказываются равными ри . . ., ps, то при этом достигается
ускорение
S
Время Т0 решения задачи на гипотетическом ФУ есть не что
иное, как общая стоимость выполненной работы. С другой стороны,
То=арТ, где a — номинальная производительность всех
устройств, ρ — загруженность системы, Τ — время решения той же
задачи на рассматриваемой системе. Так как номинальная произ-
§7. ФУНКЦИОНАЛЬНЫЕ УСТРОЙСТВА
79
водительность системы равна сумме номинальных производитель-
ностей ее ФУ, то справедливость утверждения непосредственно
вытекает из (7.1), (7.3).
Следствие. Максимально возможное ускорение равно
номинальной производительности вычислительной системы.
Следствие. Если вычислительная система состоит из s
простых ФУ, то максимально возможное ускорение равно s.
До сих пор мы предполагали, что при реализации алгоритма на
вычислительной системе нет никаких дополнительных временных
затрат на выполнение операций. В действительности это
предположение практически не осуществимо. Для того чтобы заставить
работать ФУ, необходимо на их входы подать соответствующие
данные. Но даже передача данных от одного ФУ к другому требует
временных затрат. Если же по каким-либо причинам нам приходится
для реализации алгоритма пользоваться одним из видов памяти
системы, то дополнительные временные затраты на работу с
памятью могут оказаться значительными. Более того, именно каналы
связи с памятью часто оказываются одним из самых узких мест
вычислительной системы. Поэтому может показаться, что
проведенные нами рассуждения далеки от реальности. На самом деле
это не так.
Все ФУ лю5ой конкретной системы можно разделить на две
группы: ФУ, выполняющие основные операции алгоритма, и ФУ,
обеспечивающие их эффективную работу. Наши рассуждения
касались ФУ первой группы. Ко второй группе можно отнести
устройства ввода-вывода, каналы передачи данных, каналы связи с
различными видами памяти и многое другое.
. Предположим, что основные и служебные ФУ можно описать
как простые или конвейерные. Тогда реализацию любого алгоритма
на конкретной вычислительной системе можно рассматривать как
реализацию некоторого расширенного алгоритма, полученного из
исходного добавлением операций, не меняющих каких-либо данных,
но требующих для своего выполнения определенного времени.
Граф расширенного алгоритма получается из графа исходного
алгоритма путем последовательного применения операций
«добавление вершины», соответствующих использованию служебных ФУ
вычислительной системы. Для расширенного алгоритма
справедливы все полученные здесь результаты. В частности, по нему на основе
утверждения 7.5 можно оценивать реальное время реализации
алгоритма, а затем исследовать эффективность использования ФУ,
основных или служебных, всех или только части их так, как это
диктуется необходимостью. Желая подчеркнуть связь графа
расширенного алгоритма с вычислительной системой, мы будем
называть его вычислительным графом алгоритма.
Подчеркнем еще раз, что в проведенных исследованиях, по
существу, нигде не указывалось, какую часть всей системы
составляют рассматриваемые в утверждениях ФУ. Это может быть и одно
80 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
конкретное ФУ системы, и любая часть их, и все ФУ системы.
Единственное место, в котором завязаны все ФУ системы,— это
оценка времени реализации алгоритма.
Пусть соотношение (7.3) касается только каналов связи ФУ с
памятью вычислительной системы. Тогда s означает число этих
каналов, pj— загруженность /-го канала, N — суммарное число
всех обменов с памятью. Величину Τ можно считать временем
занятости каналов, хотя в действительности она по-прежнему будет
совпадать со временем реализации алгоритма. Суммарное число
всех обменов с памятью не меньше, чем суммарное число входных
данных и результатов алгоритма, так как для его реализации надо
по крайней мере списать из памяти входные данные и записать в
нее результаты. В каждый момент времени из каналов связи
выходит не более s данных. Поэтому величину s можно назвать
пропускной способностью каналов.
Утверждение 7.8. Рассмотрим конвейерную
вычислительную систему, все ФУ которой связаны с памятью каналами
связи общей пропускной способности q. Пусть на этой системе за
время Τ реализуется алгоритм и при этом достигается ускорение R.
Если алгоритм требует выполнения N операций и суммарное число
его входных данных и результатов равно М, то выполняются
неравенства
■qT>M, f<«^, (7.4)
где а — число ступеней самого длинного из конвейерных устройству
выполняющих операции алгоритма.
Первое неравенство является следствием соотношения (7.3),
если рассмотреть его для каналов связи. Чтобы получить второе
наравенство, надо рассмотреть то же соотношение (7.3) для
устройств, выполняющих операции алгоритма, и принять во внимание
утверждение 7.2.
Во многих больших задачах число выполняемых операций
пропорционально числу входных данных. Для них достигаемое
ускорение решающим образом зависит не только от функциональных
устройств, выполняющих операции, но и, согласно (7.4), от каналов
связи.
Исследуя в дальнейшем различные вопросы реализации
алгоритмов на вычислительных системах, мы будем предполагать, что
ФУ системы работают по командам, определяемым некоторыми
программами действий, и обладают следующими свойствами:
— все ФУ являются простыми или конвейерными с единым
временем цикла;
— все ФУ рассматриваются как несоставные;
— каждое ФУ монопольно использует свое оборудование;
— результаты срабатывания ФУ являются однозначными
функциями аргументов;
§8, АЛГОРИТМЫ И ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ 81
— все результаты безусловного ФУ определены при любых
допустимых аргументах;
— некоторые или все результаты условного ФУ определены не
всегда; вместо неопределенного результата на выход поступает
сообщение об этом факте.
Заметим, что ФУ, работающие при раздельном включении
отдельных входов и выходов, сводятся к описанным присоединением
устройств задержек. Если цикл подачи входных данных меньше
времени их обработки в ФУ, то такие ФУ часто сводятся к системам
описанных ФУ, например к линейным цепочкам. Время передачи
информации между ФУ может быть учтено во времени их
срабатывания.
Указанным характеристикам удовлетворяют самые различные
ФУ, реализующие как микрооперации, так и алгебраические
операции и даже большие задачи численного анализа и комплексы
отдельных задач. Соответственно устройствами могут быть
триггеры, регистры, сумматоры, спецпроцессоры, отдельные
универсальные процессоры и ЭВМ вычислительных систем. К базовым
операциям можно отнести также операции передачи данных между
устройствами и операции взаимодействия с памятью. Поэтому к
ФУ можно отнести различные каналы связи. Естественно, что
список базовых операций и реализующих их ФУ можно продолжить,
принимая во взимание конкретные особенности алгоритмов,
вычислительных систем и задач, стоящих перед исследователем.
§ 8. Алгоритмы и вычислительные системы
. Вычислительные системы можно также представлять ориенти
рованными графами. При этом естественно вершинам графа
поставить в соответствие различные устройства, а дугами отмечать
передачи информации между ними. Если для двух устройств возможна
непосредственная передача информации от одного к другому, то
будем соединять вершины дугой с указанием направления передачи.
Если же передача информации возможна от каждого из них к
каждому, то соответствующие вершины будем соединять двумя
противоположно ориентированными дугами. Снова необходимо
уточнить некоторые детали.
Несмотря на огромное разнообразие вычислительных систем с
многими работающими устройствами, каждую из них описывают три
основные компоненты:
— множество функциональных устройств;
— коммуникационная сеть, обеспечивающая обмен информацией
между устройствами;
— множество допустимых программ работы всей совокупности
ФУ.
Будем считать, что все временные затраты, связанные с работой
вычислительной системы, определяются только программой и сами
32 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
ФУ функционируют в соответствии со свойствами, описанными в
·§ 7. Поэтому при выборе состава и номенклатуры ФУ будем
руководствоваться как возможностью реализации алгоритма, так и
необходимостью учёта соответствующих временных затрат. Например,
^если нас интересуют лишь временные характеристики выполнения
арифметических операций, то в качестве ФУ возьмем устройства,
выполняющие только такие операции.,Если же мы хотим учесть и
затраты времени на обмены с различными видами памяти, на работу
устройств ввода-вывода и т. п., то в состав ФУ должны быть
включены и устройства, реализующие такие операции. Количество
устройств одного типа выбирается из соображений реализации
алгоритмов за меньшее время при условии, конечно, учета имеющихся
ограничений на их число. Основой для выбора ФУ могут служить
также утверждения 7.3, 7.4 при соответствующем анализе графа
алгоритма.
Коммуникационная сеть образуется в основном из линий связи,
соединяющих отдельные ФУ между собой, и ФУ, обеспечивающих
передачу информации по этим линиям. Если необходимо учесть
временные затраты на работу устройств коммуникационной сети,
то будем включать эти устройства в состав ФУ вычислительной
системы, выделяя их в одну или несколько отдельных групп. Как
уже отмечалось, не ограничивая общности, можно предполагать,
что информация по каждой линии связи передается только в одном
направлении, так как любую линию с двухсторонней передачей
.всегда можно условно заменить двумя линиями с
противоположными односторонними передачами.
Итак, будем предполагать, что вычислительная система состоит
из какого-то числа ФУ и все ее временные затраты определяются
затратами на обеспечение функционирования этих ФУ. Все ФУ
разбиты на группы одинаковых устройств, каждое из которых
является простым или конвейерным. Как правило, мы будем
рассматривать ситуации, когда ФУ одного типа выполняют лишь одну
операцию. Но, вообще говоря, можно считать, что одно ФУ
способно выполнять и несколько разных операций. Будем
предполагать также, что коммуникационная сеть вычислительной системы
состоит только из линий связи, соединяющих все устройства или
часть из них между собой и обеспечивающих мгновенную
одностороннюю передачу информации. Конечно, состав ФУ
вычислительной системы должен быть таким, чтобы иметь возможность
выполнить все типы операций, которые по тем или иным причинам
выделены в графе алгоритма как самостоятельные.
Всюду в дальнейшем будем задавать математическое описание
вычислительной системы ориентированным графом. При этом
вершины графа отождествляются с функциональными устройствами и
могут быть разбиты на группы по их типам. Дуги отмечают наличие
линий связи. В отличие от вычислительного графа алгоритма граф
системы может иметь контуры.
§8. АЛГОРИТМЫ И ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ 83
Естественно, что одна и та же вычислительная система может
реализовывать как различные алгоритмы, так и один и тот же
алгоритм, но в различных временных режимах. Чтобы указать
конкретную реализацию конкретного алгоритма, необходимо задать
программу работы всей совокупности устройств. Под этим мы будем
понимать, что
— для каждого срабатывания каждого ФУ определены
устройства, поставляющие входные данные и потребляющие результат;
— указаны моменты включения ФУ, в которые начинают
выполняться операции;
— в каждый момент включения каждого ФУ определены тип:
выполняемой операции и время ее выполнения.
Заметим, что последняя характеристика программы необходима
лишь в том случае, когда одно ФУ может выполнять либо разные
операции, либо однотипные операции, но за разное время.
Теперь мы можем описать две основные задачи, определяющие
взаимосвязь алгоритмов и процессов их решения на
вычислительных системах с многими функциональными устройствами. *
Задача 1. Дан ориентированный граф, описывающий
вычислительный алгоритм, и указана спецификация операций,
отождествляемых с его вершинами. Известна номенклатура устройств,
в совокупности выполняющих все операции алгоритма. Необходима
в пределах выделенных лимитов выбрать состав ФУ, построить
ориентированный граф вычислительной системы и указать
программу или множество программ, обеспечивающих реализацию
данного алгоритма за минимальное время.
Задача 2. Дан ориентированный граф, описывающий
вычислительный алгоритм, и указана спецификация операций,
отождествляемых с его вершинами/Дан ориентированный граф,
описывающий вычислительную систему, и указана спецификация
устройств, отождествляемых с его вершинами. Необходимо ответить
на вопрос, можно ли реализовать алгоритм на данной системе, и в
случае положительного ответа указать программу или множества
программ, обеспечивающих реализацию алгоритма за минимальное
время.
Первая задача связана с проектированием вычислительных
систем и построением их математических моделей, вторая — с
использованием существующих систем. Обе задачи будем" называть
задачами отображения алгоритмов на вычислительные системы.
В математическом отношении решение второй задачи означает
следующее. Установим каким-нибудь способом взаимно
однозначное соответствие между вершинами графа алгоритма и некоторым
множеством последовательных срабатываний ФУ вычислительной
системы. Это соответствие определяет однозначно весь обмен
информацией, т. е. какие ФУ и после каких срабатываний должны
давать аргументы для каждого срабатывания ФУ во время era
работы. Теперь после выборов моментов включения ФУ возможны
84 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
две ситуации: либо система срабатывает и реализует алгоритм,
либо она не срабатывает до конца и останавливается. Но даже если
система срабатывает, процесс реализации алгоритма может нас не
удовлетворять по очень многим причинам. Например, может быть
слишком большим время реализации, слишком низкой
загруженность ФУ, не хватать каналов связи и т. п.
Далеко не всегда можно достичь желаемого эффекта. Как
правило, это происходит из-за того, что структура вычислительной
системы не соответствует структуре алгоритма. Поэтому и
приходится решать первую задачу.
Пусть задан вычислительный граф G=(V, E) алгоритма.
Возьмем в качестве графа системы тот же граф G, считая, что ФУ,
помещенное в соответствующую вершину, может выполнять
соответствующую операцию. В этом случае нет никакой необходимости
задавать обмен информацией каким-либо специальным образом. Будем
считать, что каждое ФУ получает информацию для своей работы
согласно графу G. Именно, если две вершины соединены дугой, то
ФУ, помещенное в концевую вершину, может использовать в
качестве соответствующего аргумента только результат срабатывания
ФУ, помещенного в начальную вершину. Если же какая-то дуга
отсутствует, или у нее нет начальной вершины, или начальная
вершина отождествляется с операцией ввода, то соответствующий
аргумент берется извне системы. Такую вычислительную систему
и всю совокупность программ, реализующих на ней заданный
алгоритм, будем называть базовыми для данного алгоритма. Согласно
предположениям, сделанным относительно ФУ, базовая
вычислительная система не имеет памяти и может сохранять результаты
.промежуточных вычислений только в самих ФУ.
Чтобы указать какую-либо программу базовой вычислительной
системы, остается лишь указать моменты включения ФУ.
Перенумеруем каким-либо способом вершины графа системы и обозначим
через tt момент включения ФУ, соответствующего ί-й вершине.
Вектор t=(tu tu ..·) назовем временной разверткой базовой
вычислительной системы. Естественно, что различных временных
разверток существует бесконечно много.
Временные развертки содержат много сведений относительно
.алгоритма. Например, время Τ реализации алгоритма определяется
по развертке следующим образом:
Г = max (^ + τζ.) — min th
i i
где %i — время реализации самой длинной операции, выполнение
которой начинается в момент /,. По временной развертке легко
определяется порядок выполнения операций. Каждая временная
развертка позволяет построить параллельную форму алгоритма. Для
этого нужно объединить в ярусы операции, выполнение которых
§8. АЛГОРИТМЫ И ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ 85
начинается в один и тот же момент, а сами ярусы упорядочить по
возрастанию времени. Во временных развертках имеются и другие
сведения, касающиеся алгоритма и его реализации. Однако главное
заключается в том, что с помощью самих временных разверток или
на основе их анализа можно установить и исследовать необходимое
соответствие между операциями алгоритма и работой ФУ
вычислительной системы.
Утверждение 8.1. Для любого вектора t имеет место
альтернатива: либо все ФУ базовой системы срабатывают и система
реализует алгоритм, либо срабатывают не все ФУ и работа системы
останавливается.
При заданном векторе / для каждого ФУ базовой системы
возможна одна из двух ситуаций. Если к моменту включения этого
•ФУ закончена работа всех ФУ, поставляющих для него аргументы,
то ФУ срабатывает. Если же не закончена работа хотя бы одного
Ή3 таких ФУ, то ФУ не срабатывает. Так как команда на включение
каждого ФУ подается только один раз, то либо срабатывают все
•ФУ и реализуется алгоритм, либо срабатывают не все ФУ и работа
базовой системы останавливается.
Утверждение 8.2. Для того чтобы алгоритм мог быть
реализован на базовой системе при заданном векторе t, необходимо
и достаточно выполнение следующих условий: если из i-й вершины
графа системы ведет дуга в j-ю вершину, то разность tj—ti должна
быть не меньше, чем время срабатывания ФУ, помещенного в i-ю
вершину.
Необходимость очевидна, так как к моменту включения каждого
ФУ должна быть закончена работа всех ФУ, поставляющих ему
аргументы. Для доказательства достаточности рассмотрим
каноническую максимальную параллельную форму графа алгоритма. Не
только при заданном, но и при любом векторе / можно начать и
закончить выполнение операций первого яруса. В соответствии с
условием, наложенным на вектор /, к моменту начала выполнения
операций второго яруса должно быть закончено выполнение
операций первого яруса, поставляющих для них аргументы.
Следовательно, могут быть выполнены все операции второго яруса. Продолжая
аналогичные рассуждения, показываем возможность полной
реализации алгоритма.
Следствие. Для того чтобы алгоритм мог быть реализован
на базовой системе при заданном векторе t, необходимо и достаточно
выполнение следующих условий: если из i-й вершины графа системы
ведет путь в j-ю вершину, то разность tj—tt должна быть не
меньше, чем время срабатывания всех ФУ, кроме последнего, находящихся
на этом пути.
Таким образом, совокупность всех базовых программ,
реализующих алгоритм на базовой вычислительной системе, полностью
описывается утверждением 8.2. Заметим, что вектор временной
развертки совсем не обязательно задавать целиком сразу. Если работа
£6 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
базовой вычислительной системы прекратилась из-за того, что
моменты включения каких-то ФУ либо не определены, либо
определены неправильно, то ничто не мешает продолжить работу
системы после корректировки моментов включения ФУ. Естественно,
что такую корректировку можно осуществлять многократно, по
существу строя динамически вектор временной развертки. Такой
способ выбора режима реализации алгоритма полезен, например,
тогда, когда по тем или иным причинам граф алгоритма не известен
весь сразу.
Конечно, на осуществление корректировки требуется
дополнительное время. Оно может оказаться довольно большим, особенно
в тех случаях, когда корректировка слабо связана с процессом
реализации алгоритма. Все это, как правило, приводит к увеличению
времени работы системы. Однако динамический выбор вектора
развертки можно осуществлять исключительно эффективно, если
поручить проведение данного процесса самим функциональным
устройствам системы. Предположим, что каждое ФУ начинает свою работу
сразу же после того, как вычислены все его аргументы. Если
входные данные алгоритма не задерживают работу системы, то при этом
будет достигнуто минимальное время реализации алгоритма. Это
типичный пример, когда результаты выполнения вычислительного
алгоритма управляют работой вычислительной системы.
Базовая вычислительная система имеет немало достоинств, среди
которых, пожалуй, самое главное — возможность реализации
алгоритма за минимальное время. Но сразу же видны ее серьезные
недостатки.
Число используемых ФУ и число линий связи зависят в целом
от числа выполняемых операций алгоритма. Как уже неоднократно
отмечалось, в реальных задачах это число очень велико. Каждое
ФУ за время реализации алгоритма срабатывает только один раз.
Следовательно, загруженность ФУ при реализации алгоритма будет
недопустимо малой. К тому же базовая, система не дает возможность
использовать эффективно конвейерные ФУ. Тем не менее, как мы
покажем в дальнейшем, даже такой способ построения
вычислительной системы иногда оказывается исключительно
эффективным. К тому же именно из этой системы строятся'и многие
другие.
Теперь на основе базовой вычислительной системы будем
строить другие системы, реализующие заданный алгоритм. В основу
построения положим следующие принципы:
— граф вычислительной системы получается из графа алгоритма
с помощью операций простого гомоморфизма для какого-то числа
однотипных вершин;
— если в базовой вычислительной системе одно ФУ получает
информацию от другого, то в любой системе образ этого ФУ может
получить соответствующую информацию только от образа другого
ФУ и никаким другим способом;
§8. АЛГОРИТМЫ И ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ 87
— в случае необходимости сохранить результаты отдельных
срабатываний ФУ для осуществления процесса реализации
алгоритма будем присоединять к ФУ локальную память нужного размера
с мгновенным доступом и разрешать самим ФУ использовать в
качестве аргументов свои собственные результаты; если в момент
подачи команды результат предыдущего срабатывания не
используется полностью и необходим для дальнейшего, то он пересылается
в память и затем выбирается уже из нее; внешняя выборка из
памяти осуществляется через выходные каналы ФУ и не может
происходить во время его работы.
— каждому ФУ разрешается брать в качестве аргумента
результат любого срабатывания другого ФУ, связанного с ним линией
связи, а некоторым или всем ФУ разрешается также брать входные
данные; соответствующие переключения связей осуществляются
программой. ш
На основе этих принципов можно построить много различных
моделей вычислительных систем. Каждая из таких систем будет
иметь возможность реализовывать в общем случае не все базовые
программы, а только некоторую часть из них. Кроме этого, в
отличие от базовой системы выполнение некоторых программ может
привести к реализации другого алгоритма, если установлен
неправильный обмен информацией между ФУ. Если же установлено
неправильное соответствие между вершинами графа алгоритма и
последовательными срабатываниями ФУ, то алгоритм может быть не
реализуем вообще. Поэтому важно понять, какие базовые
программы можно реализовать на конкретной вычислительной системе и
как надо задать режим ее работы, чтобы реализовать заданный
алгоритм. Говоря о возможности выполнений некоторой базовой
программы на вычислительной системе, мы предполагаем сохранение
всех моментов включения ФУ, соответствующих сливаемым
вершинам, при установлении, конечно, правильного соответствия между
вершинами графа алгоритма и срабатываниями ФУ, а также
осуществлении согласно этому правильной последовательности
обменов информацией между ФУ.
Утверждение 8.3. Пусть задан граф алгоритма.
Разобьем множество его вершин любым способом на непересекающиеся
подмножества и объединим вершины каждого из подмножеств в
одну вершину с помощью операций простого гомоморфизма. Возьмем
полученный граф в качестве графа вычислительной системы и каждой
его вершине поставим в соответствие простое или конвейерное ФУ,
в общем случае с памятью, которое может выполнять все те же
операции и за то же время, что и ФУ базовой системы,
соответствующие сливаемым вершинам. Тогда на построенной вычислительной
системе можно реализовать те базовые программы, для которых
разность последовательных моментов включения любых двух базовых
ФУ, соответствующих сливаемым вершинам, по модулю не меньше
некоторого числа δ. Это δ равно 1, если ФУ построенной системы
SS ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
конвейерное и две сливаемые вершины не связаны дугой. Во всех
остальных случаях оно равно времени срабатывания базового ФУ,
включаемого раньше.
Множество базовых программ, реализуемых на новой
вычислительной системе, заведомо не пусто. На любой системе, построенной
согласно утверждению 8.3, всегда можно реализовать базовую
программу, соответствующую любому последовательному выполнению
операций алгоритма. Заметим, что именно достаточная разнесен·
ность во времени моментов включения ФУ базовой программы
позволяет реализовывать ее на построенной системе. Однако именно
из-за требования этой разнесенности может быть потерян режим с
минимально возможным временем реализации алгоритма.
Утверждение 8.4. В условиях утверждения 8.3
загруженность каждого ФУ построенной вычислительной системы равна
сумме загруженностей ФУ, соответствующие сливаемым вершинам.
В разбиении вершин графа базовой системы на сливаемые
подмножества имеется исключительно широкий произвол. Тем не менее
при выборе конкретного разбиения приходится учитывать ряд
факторов. Чем меньше число подмножеств, тем меньше ФУ будет
в системе и в общем случае будет больше их загруженность. При
этом время реализации алгоритма может оказаться очень большим.
Например, если отождествить все вершины графа базовой системы,
то при этом останется только одно ФУ, но при максимальной его
загруженности будет максимальным и время реализации алгоритма.
С увеличением числа подмножеств увеличивается число ФУ в
системе, при этом имеет место тенденция к уменьшению их
загруженности и уменьшению времени реализации алгоритма.
В общем случае задача совместной оптимизации числа ФУ
вычислительной системы, их загруженности и времени реализации
алгоритма оказывается исключительно сложной. Невозможность
одновременного достижения наилучших характеристик по всем
параметрам следует из утверждений 7.3, 7.4. Поэтому весьма
важным является описание таких ситуаций, когда априори известно,
что оптимизация, например, по числу ФУ и их загруженностям не
приводит к увеличению времени реализации алгоритма.
Есть и другая причина рассмотрения частных ситуаций.
Утверждение 8.3 предлагает общий прием построения по графу
алгоритма графа вычислительной системы и указывает, какие из
базовых программ при этом можно реализовать. Однако оно ничего не
говорит о том, как конкретно устанавливать соответствие между
вершинами графа алгоритма и последовательными срабатываниями ФУ.
Для осуществления такого соответствия нужна дополнительная
информация. Наиболее полную информацию дает описание
множества допустимых временных разверток. Однако получить его очень
трудно. В ряде практически важных ситуаций установить
правильное соответствие между вершинами графа алгоритма и
срабатываниями ФУ можно без явного задания временных разверток.
§8. АЛГОРИТМЫ И ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ 89
Утверждение 8.5. Пусть разбиение вершин графа
базовой системы, проведенное в соответствии с утверждением 8.3,
таково, что для каждого подмножества все его вершины связаны одним
путем. Тогда на построенной системе реализуется весь спектр
базовых программ.
Достаточная разнесенность во времени моментов включения
соответствующих ФУ базовой программы гарантируется здесь тем,
что сливаемые вершины графа находятся на одном пути и операции
могут выполняться только последовательно друг за другом.
Подчеркнем также, что совсем не обязательно, чтобы подмножества
содержали все вершины, находящиеся на одном пути. Важно лишь,
чтобы. вершины были связаны одним путем. Это обстоятельство
имеет существенное значение, так как чаще всего объединяются
вершины, соответствующие однотипным операциям, а они обычно
в вычислениях перемешиваются с операциями других типов. Что
же касается установления соответствия между вершинами графа и
срабатываниями ФУ, то теперь оно очевидно. Именно, если из двух
вершин подмножества одна достижима из другой, то из двух
соответствующих срабатываний ФУ ей соответствует более позднее.
Итак, разбивая вершины графа алгоритма на подмножества,
лежащие на одном пути, и объединяя их с помощью операций
простого гомоморфизма, мы получаем конструктивный способ
построения математических моделей вычислительных систем. Естественно,
что таких систем может быть много, и они, вообще говоря, не
одинаковы с точки зрения состава ФУ, их загруженностей, размера
присоединяемой памяти, сложности коммуникационной сети и т. п.
Но все эти системы по всем основным параметрам, кроме размера
памяти, лучше, чем базовая вычислительная система. Они содержат
меньшее число ФУ, загруженность каждого ФУ больше, число
линий связи меньше и при этом всегда реализуется весь спектр
базовых программ, в том числе программ с минимально возможным
временем реализации алгоритма. Снова можно ставить задачу
оптимизации, пытаясь разбить вершины графа алгоритма на наименьшее
число подмножеств, лежащих на одном пути. И снова возникает
противоречивая ситуация: уменьшение числа ФУ может привести
к усложнению коммуникационной сети и увеличению объема памяти.
На каждой из таких систем кроме исходного алгоритма можно
реализовывать и другие алгоритмы. Точнее, можно реализовать
любой алгоритм, графу которого гомоморфен какой-нибудь подграф
вычислительной системы, если только каждое ФУ может выполнять
операции, соответствующие сливаемым вершинам, и при этом
использовать в качестве аргумантов необходимое число получаемых
им самим результатов. С точки зрения универсальности системы это
положительный фактор. Однако он приводит к усложнению
реализации конкретного алгоритма, так как приходится предпринимать
дополнительные усилия в установлении правильного обмена
информацией, чтобы случайно не реализовать другой алгоритм.
90 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
Как уже отмечалось, математические модели
вычислительных систем, построенные в соответствии с утверждением 8.5,
обладают примечательной особенностью. Для систем этого типа не
нужно знать временных разверток базовой системы, чтобы
установить правильное соответствие между операциями алгоритма и
последовательными срабатываниями ФУ. Необходимая информация
может быть получена априорно. В сочетании с возможностью
реализации алгоритма за минимально возможное время данная
особенность позволяет испольаовать вычислительную систему наиболее
эффективно. При этом легко избежать риска проведения
вычислений, относящихся к иным алгоритмам. Аналогичная ситуация имеет
место и в некоторых других случаях.
Утверждение 8.6. Пусть вычислительная система
строится в соответствии с утверждением 8.3. Предположим, что граф
алгоритма направленный и проекции никаких двух сливаемых вершин
на направляющий вектор не совпадают. Поставим в соответствие
k-му срабатыванию ФУ ту из сливаемых вершин графа, которая
дает k-ю по порядку проекцию на направляющий вектор. Такое
соответствие гарантирует правильную выполнимость алгоритма*
Для алгоритмов с направленным графом можно предложить
конструктивный способ построения графов систем,
удовлетворяющих условиям утверждения 8.6.
Утверждение 8.7. Предположим, что граф сиггоритма.
направленный. Спроектируем его на гиперплоскость,
перпендикулярную направляющему вектору. Если эту проекцию взять в качестве
графа вычислительной системы, то будут выполняться условия
утверждения 8.6.
Действительно, сливаться могут только такие вершины, которые
лежат на прямых, параллельных направляющему вектору. Но
проекции этих вершин заведомо не совпадают.
Говоря о проектировании графа на гиперплоскость, следует
сделать одно замечание. Эта операция эквивалентна
последовательности простых гомоморфизмов в том случае, когда все дуги
прямолинейны. Если же дуги криволинейны, то в проекции могут
появиться геометрически различные, но с точки зрения графа кратные
дуги. Естественно, что из всех кратных дуг можно оставить одну.
Утверждение 8.8. Пусть граф алгоритма связный и
строго направленный. Предположим, что длина проекции каждой
из дуг на направляющий вектор пропорциональна времени выполнения
операции, находящейся в начале дуги, а времена выполнения операций^
соответствующих вершинам, имеющим совпадающие проекции,
одинаковы. Тогда на вычислительной системе, построенной в
соответствии с утверждением 8.7, можно реализовать алгоритм за минимально
возможное время.
Так как граф алгоритма связный, то в этом случае крайние
проекции соответствуют начальным и конечным вершинам путей с
максимальной суммой времен выполнения относящихся к ним one-
§8. АЛГОРИТМЫ И ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ
91
раций. С точностью до выбора начала работы системы время
включения каждого ФУ однозначно определяется положением проекций.
Все рассмотренные способы построения графов вычислительных
систем основаны на свертке графа алгоритма с помощью операций
простого гомоморфизма. В некотором смысле этот подход является
единственно возможным в построении графов систем.
Утверждение 8.9. Пусть алгоритм реализуется на
некоторой вычислительной системе. Предположим, что при каждом
срабатывании каждого ФУ выполняется только одна операция
алгоритма и обмен информацией между двумя ФУ осуществляется
только по линии связи, связывающей эти ФУ непосредственно друг
с другом. Если после реализации алгоритма исключить из графа
вычислительной системы вершины и дуги, соответствующие не
работавшим ФУ и линиям связи, то останется подграф, который
получается из графа алгоритма с помощью операций простого
гомоморфизма.
Действительно, каждый путь' графа алгоритма может быть
уложен на подграф системы, при этом сливаемые вершины соответствуют
операциям простого гомоморфизма. Укладывая последовательно
все пути, мы получим весь подграф.
Рассмотрим следующий пример. Предположим, что граф
алгоритма имеет вид, показанный на рис. 8.1. Подобные графы
свойственны многим вычислительным методам линейной алгебры и
математической физики. Очевидно, что этот граф является строго
направленным относительно вектора, проходящего через вершины,
ссссссссоссссо
Рис. 8.1
обведенные кружками. Будем считать для простоты, что все
операции однотипны.
Построим, согласно утверждениям 8.3, 8.6, графы различных
вычислительных систем. Объединяя вершины по вертикалям,
получим граф системы, расположенный непосредственно под графом
алгоритма, а объединяя по горизонтали, получим граф,
расположенный справа. Если объединить вершины, находящиеся на прямых,
92 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
параллельных прямой, содержащей вершины с кружками, то
получим граф системы, расположенный внизу рисунка.
Вычислительные системы, имеющие указанные графы,
реализуют весь спектр базовых программ. Тем не менее все они имеют разное
число устройств, и загруженность этих устройств будет различная.
Коммуникационные сети систем также неодинаковы. В двух из них
осуществляется только односторонняя передача информации, в
одной — двухсторонняя. Наиболее простой представляется система,
граф которой расположен на рисунке справа. Однако учет
дополнительных факторов, таких как подача к ФУ входных данных
алгоритма, может в некоторых случаях сделать более
предпочтительными другие вычислительные системы.
Мы уже отмечали в качестве недостатка базовой системы тог
факт, что она не дает возможность эффективно использовать
конвейерные ФУ. Вычислительные системы, построенные в
соответствии с утверждениями 8.5, 8.8, также обладают аналогичным
недостатком. Согласно утверждению 8.3, его устранение возможно
только в том случае, когда на конвейерном ФУ выполняется большое
число независимых операций. О том, как добиваться большой
загруженности вычислительной системы, состоящей из конвейерных
ФУ, мы подробнее поговорим позднее. Сейчас же только заметим,
что один из возможных путей решения этого вопроса связан с
одновременным решением на конвейерной системе многих однотипных
задач.
§ 9. Программы реализации алгоритмов
В решении общей задачи отображения алгоритмов на
вычислительные системы имеется много различных этапов. Однако самыми
важными являются этапы построения графа вычислительной
системы и определения программы реализации алгоритма, причем по
возможности более близкой к оптимальной по тем или иным
параметрам. Остановимся несколько подробнее на этапе определения
программы.
Если на какой-либо вычислительной системе реализуется
алгоритм, то это означает, что на ней каким-то эквивалентным способом
выполняется некоторая его базовая программа и ничего больше.
Исследуя программы реализации алгоритма, мы в действительности
должны исследовать возможность выполнения на вычислительной
системе базовых программ алгоритма. Поэтому независимо от того,
какой конкретно вид имеют вычислительная система и алгоритм,
явно или неявно должны быть определены:
— функция, устанавливающая взаимно однозначное
соответствие между вершинами графа алгоритма и отдельными
срабатываниями ФУ вычислительной системы;
— потоки информации между ФУ системы;
— моменты включения ФУ системы.
§ 9. ПРОГРАММЫ РЕАЛИЗАЦИИ АЛГОРИТМОВ 93
Естественно, что все эти задачи можно решать многими способами.
При этом для каждой из них возможны две основные стратегии
принятия решений — статическая и динамическая. В статической
стратегии решение принимается до реализации алгоритма на основе
совместного анализа алгоритма и вычислительной системы. В
динамической стратегии решение принимается в процессе реализации
алгоритма. Эта стратегия является характерной чертой так
называемых потоковых машин. Возможны и смешанные стратегии.
Вообще говоря, функцию соответствия между вершинами графа
алгоритма и отдельными срабатываниями ФУ системы можно
выбирать случайным образом. Если после этого определить потоки
информации, то, согласно утверждению 8.1, возможна только такая
альтернатива: либо система срабатывает и реализует алгоритм,
либо она не срабатывает. Важно то, что система не может сработать
и выдать неправильный результат, т. е. результат, относящийся
к другому алгоритму. Тем не менее установление соответствия имеет
очень важное значение, так как именно оно определяет множество
реализуемых при этом соответствии базовых программ. Неудачная
функция соответствия может привести к тому, что хотя алгоритм и
реализуется, но множество допустимых программ будет настолько
малым, что не содержит в себе программ с приемлемым временем
реализации. Вот почему особую, значимость имеют утверждения
8.5, 8.8 и им аналогичные.
Утверждение 9.1. Для того чтобы при заданной функции
соответствия между вершинами графа алгоритма и отдельными-
срабатываниями ФУ вычислительной системы алгоритм был
реализуем, необходимо и достаточно, чтобы для любых двух вершин,
выполняемых на одном ФУ и связанных путем, более позднее
срабатывание соответствовало той вершине, которая находится в конце
пути.
По существу, это утверждение является прямым следствием
утверждения 8.2, так как при таком соответствии заведомо существует
хотя бы одна базовая программа. Подчеркнем, что здесь ничего не
утверждается относительно того, насколько эффективно алгоритм;
может быть реализован. Для того чтобы высказать об этом какое-
либо суждение, необходима дополнительная информация,
касающаяся связи алгоритма и вычислительной системы. Использование
этой информации и является ключевым моментом в утверждениях
8.5, 8.8.
Напомним, что мы отвлекаемся пока от обсуждения вопроса о
том, как подаются в вычислительную систему входные данные
алгоритма, считая, что их подача не задерживает реализацию и
соответствующие вопросы каким-то образом решены. Не будем мы также
обсуждать величину присоединенной к ФУ локальной памяти и ее
строение.
Количество ФУ вычислительной системы обычно невелико по
сравнению с числом выполняемых операций. Поэтому не представ*
94 1Л. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
ляет никакого труда задать каждое срабатывание каждого ФУ
парой натуральных чисел. Перенумеровать вершины графа алгоритма
подряд можно в основном только теоретически. В практически
приемлемых формах записи алгоритмов не указываются явно номера
вершин графа. Если же эти номера вычислять, то потребуется время,
соизмеримое с временем реализации алгоритма. Но практической
необходимости в такой нумерации нет.
Обычно запись алгоритма содержит некоторую систему индексов,
значения которых однозначно определяют выполняемые операции.
Самое главное, пожалуй, заключается в том, что эта же система
индексов определяет и структуру алгоритма. Фактически мы будем
иметь дело лишь с решетчатыми графами специального вида,
координаты вершин которых можно задавать через индексы
естественным образом. В больших преимуществах использования таких
графов мы убедимся очень скоро. Сейчас же отметим, что
установление соответствия между отдельными срабатываниями ФУ и
вершинами графа алгоритма будет сводиться к установлению
соответствия между узлами двумерной и в общем случае многомерной
решеток.
Граф алгоритма дает исчерпывающую информацию о том,
аргументами каких операций являются результаты выполнения каждой
операции. Следовательно, после установления функции соответствия
мы получаем по графу алгоритма сведения о том, к какому ФУ, к
какому его срабатыванию и зачем должны быть переданы
результаты каждого срабатывания каждого ФУ. При решении этих вопросов
также оказываются удобными решетчатые графы, о которых только
что упоминалось.
Теоретически можно представить такую схему. В каждый узел
двумерной решетки, описывающей множество срабатываний ФУ
системы, помещены некоторые носители информации, называемые
фишками. Число этих фишек совпадает с числом адресов, по
которым должен быть разослан результат. Каждая из фишек содержит
всю необходимую информацию об адресате, т. е. о другом узле
двумерной решетки, а также о результате срабатывания ФУ. После
того как результат срабатывания появляется, фишки узла
активизируются и передвигаются к своим адресатам — узлам решетки.
Каждый узел собирает все предназначенные для него фишки. Как
только фишки в узле собраны, узел становится в очередь для
выполнения соответствующей ему операции, т. е. ждет наступления
момента, когда может быть выполнено соответствующее ему
срабатывание ФУ. Первыми становятся в очередь те узлы, в которые
фишки несут информацию только относительно входных данных
алгоритма.
В этой схеме предполагается, что первоначальное распределение
фишек осуществлено до начала вычислительного процесса. По
существу, это означает, что реализована статическая стратегия
установления соответствия между вершинами графа алгоритма и опре-
§ 9. ПРОГРАММЫ РЕАЛИЗАЦИИ АЛГОРИТМОВ 95»
деленными срабатываниями ФУ системы. Однако первоначальное
распределение фишек можно осуществить не по узлам двумерной
решетки, а частично или даже полностью по узлам многомерной
решетки решетчатого графа алгоритма, устанавливая соответствие
между узлами этих решеток динамически. Напомним, что если
содержание фишек правильно отражает обмен информацией, то
никакое соответствие между обеими решетками не может привести к
неправильному выполнению алгоритма.
Выбор моментов включения ФУ вычислительной системы
является решающим фактором определения всей динамики процесса.
От этого выбора зависит, будет ли реализован алгоритм, и если
будет, то за какое время. Здесь возможна вполне определенная
оптимизация.
Утверждение 9.2. Пусть установлена такая функция
соответствия между вершинами графа алгоритма и срабатываниями
ФУ, при которой алгоритм может быть выполнен. Для того чтобы
при этой функции алгоритм выполнился за минимальное время, до-
статочно, чтобы каждый момент включения ФУ совпадал с моментом
получения последнего аргумента выполняемой при данном включении
операции.
Установление правильного соответствия означает построение
некоторой параллельной формы алгоритма. Разобьем вершины,
графа алгоритма на подмножества по отношению к одному и тому
же ФУ и распределим каждое из подмножеств следующим образом*
по ярусам параллельной формы. Вершину, соответствующую
первому срабатыванию, поместим в s-й ярус, если максимальная длина
ведущего в нее пути равна s—1. Вершину, соответствующую
каждому из последующих срабатываний, поместим в ярус с минимальным:
номером, удовлетворяющим двум условиям: он должен быть больше
номера яруса, в который помещена предшествующая вершина, и.
больше максимальной длины пути, ведущего в очередную вершину.
Рассмотрим два режима включения ФУ. Пусть первый режим
соответствует утверждению, а второй обеспечивает минимальное
время реализации алгоритма. Будем считать, что у них совпадают
моменты начала работы всей системы ФУ. Первый режим
единственный, и все ФУ первого яруса включаются в один момент.
Минимальное время реализации алгоритма не изменится, если мы
предположим, что у второго режима все ФУ первого яруса также
включаются в один момент. Но тогда у обоих режимов будут
одинаковыми моменты включения всех ФУ первого яруса. Для второго режима
ФУ второго яруса не могут включаться раньше, чем
соответствующие ФУ второго яруса первого режима. Снова минимальное время
реализации алгоритма не изменится, если мы предположим, что
оба режима имеют одинаковые моменты включения всех ФУ
второго яруса. Продолжая аналогичные рассуждения, заключаем, чта
режим включения ФУ, описанный в утверждении, реализует
алгоритм за минимальное время.
96 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
Возьмем любую упорядоченную последовательность вершин
графа алгоритма, в которой каждая вершина либо связана с
предыдущей дугой, либо обе соответствующие им операции выполняются на
одном ФУ. Очевидно, что операции, связанные с такой
последовательностью, могут начинать выполняться только последовательно
по времени. Следовательно, при фиксированном соответствии
между вершинами графа алгоритма и срабатываниями ФУ время
реализации алгоритма на вычислительной системе не меньше, чем
минимальное время выполнения на этой же системе при этом же
соответствии лишь выбранных операций. Рассмотрим
последовательности с максимальным из минимальных времен выполнения и будем
называть их максимальными.
Утверждение 9.3. Пусть установлена функция
соответствия между вершинами графа алгоритма и срабатываниями ФУ,
при которой алгоритм выполним. Тогда минимальное для этой
функции время реализации алгоритма равно минимальному времени
выполнения на этой же системе при этой же функции соответствия
операций, соответствующих максимальным последовательностям.
Время реализации алгоритма не может быть больше времени
выполнения операций максимальной последовательности, так как
для режима включений ФУ, описанного в утверждении 9.2, оба
времени совпадают.
Следствие. Для того чтобы режим включения ФУ
обеспечивал минимальное время реализации алгоритма при данной
функции соответствия между вершинами графа алгоритма и
срабатываниями ФУ, необходимо и достаточно, чтобы время реализации
алгоритма равнялось минимальному времени выполнения при этой же
функции соответствия хотя бы одной упорядоченной
последовательности операций, каждая из которых либо получает аргумент от
предыдущей, либо вместе с предыдущей выполняется на одном ФУ.
При любом режиме включения ФУ, обеспечивающем
минимальное время реализации алгоритма, все максимальные
последовательности начинают выполняться в одно и то же время и заканчивают
свое выполнение также в одно и то же время. Режим включения ФУ,
соответствующий выполнению операций одной максимальной
последовательности, описывается очень просто. Последующий момент
включения отстоит от предыдущего на 1, если соседние операции не
связаны и выполняются на конвейерном ФУ, и на время выполнения
предыдущей операции — во всех остальных случаях. Время
выполнения операций максимальных последовательностей будет
минимально возможным, если соответствие между вершинами графа
алгоритма и срабатываниями ФУ таково, что достигается
минимально возможное время реализации алгоритма.
Понятие максимальной последовательности можно
рассматривать как обобщение в некотором смысле понятия критического пути
графа в случае реализации алгоритма на вычислительной системе с
ограниченными возможностями. Критический путь, как известно,
§9. ПРОГРАММЫ РЕАЛИЗАЦИИ АЛГОРИТМОВ
97
характеризует минимально возможное время реализации алгоритма
на системе с неограниченными возможностями.
С точки зрения распределения моментов включения ФУ
различают два основных типа режимов — синхронный и асинхронный.
Режим называется синхронным или асинхронным в зависимости от
того, равномерную или неравномерную сетку образуют во времени
несовпадающие моменты включения ФУ. Как вытекает из
проведенных исследований, если операции выполняются за различные
времена или на конвейерных ФУ, то желание реализовать алгоритм за
минимальное время, вообще говоря, должно приводить к появлению
асинхронного режима. Если все операции выполняются за одно и
то же время и к тому же на простых ФУ, то при реализации
алгоритма за минимальное время операции, соответствующие
максимальным последовательностям, будут выполняться в синхронном
режиме. Поэтому в этом случае без потери времени можно
реализовать синхронно весь алгоритм.
В общем случае асинхронный режим свойствен процессам,
обеспечивающим скорейшую реализацию алгоритма; синхронный
режим свойствен процессам, обеспечивающим полную загруженность
оборудования. Согласно утверждениям 7.3, 7.4, оба эти свойства
процессов в известной мере связаны.
Предположим, что какое-нибудь ФУ работает с максимальной
загруженностью, асимптотически равной 1. Тогда очевидно, что
независимо от того, является ФУ конвейерным или простым,
моменты его включения почти всюду образуют равномерную сетку во
времени. Для конвейерного ФУ разность соседних моментов равна
1, для простых ФУ — времени реализации операции. Если
вычислительная система состоит только из конвейерных ФУ и работает
с полной загруженностью, то режим включения всей совокупности
ФУ почти всегда является синхронным с шагом 1. Если
вычислительная система содержит разнородные ФУ, положение
усложняется лишь незначительно. Теперь для появления синхронного
режима недостаточно факта полной загруженности. Необходимо еще,
чтобы сами ФУ были связаны друг с другом.
Утверждение 9.4. Пусть в вычислительной системе
выделено некоторое множество простых или конвейерных ФУ.
Предположим, что каждое ФУ получает хотя бы один аргумент от какого-то
одного ФУ всегда, кроме начального периода процесса. Составим
ориентированный граф только этих связей, и пусть он связный.
Если все выделенные ФУ работают асимптотически с полной
загруженностью, то это возможно только тогда, когда все ФУ работают
в основном в общем синхронном режиме.
Рассмотрим какие-нибудь две вершины составленного графа,
связанные путем. Обозначим через α, β разность соседних моментов
включения соответствующих ФУ и через t[, t'2, .·. ., ί\, ί\, . . .
сами последовательные моменты включения. Так как каждое из
ФУ работает с полной загруженностью, то tl = t[+(i—1)α, ί£=
98 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
= t'l+(i—1)β. Но разность ΐ\—1\ должна быть постоянной при
всех i, что возможно лишь в случае α = β. В силу того что граф
связный, любые две его вершины связаны некоторой цепью. Каждая
цепь может быть представлена конечным числом путей. Поэтому
все ФУ должны работать в общем синхронном режиме, за
исключением, может быть, начала и конца процесса.
Следствие. Если в утверждении 9.4 в выделенном
множестве имеется хотя бы одно конвейерное ФУ, то все простые ФУ
реализуют свои операции за время, равное 1, и общий синхронный режим
осуществляется с шагом по времени, равным 1.
Следствие. Если в утверждении 9.4 выделенное множество
состоит только из простых ФУ, то все они реализуют свои операции
за одно и то оюе время и общий синхронный режим осуществляется
с шагом, равным времени выполнения операции.
Следствие. Пусть в вычислительной системе одно ФУ всегда
получает аргумент непосредственно от другого ФУ. Если оба ФУ
не работают в основном в общем синхронном режиме, то хотя бы
одно из них не работает с полной загруженностью.
Синхронный и асинхронный режимы иногда связывают с
различием в типах источников подачи команд на включение ФУ. При
асинхронном режиме предполагается, что источник, подающий
команды для конкретного ФУ, находится в самом ФУ. Основанием
для такого предположения является возможность осуществления
в этом случае оптимального в отношении времени режима
реализации алгоритма в соответствии с утверждением 9.2. При синхронном
режиме предполагается существование внешнего по отношению к
ФУ источника синхронизации, обеспечивающего общую
ритмичность процесса. Одной из причин принятия такого решения является
тот факт, что процесс, который теоретически должен быть
синхронным, на практике превращается в асинхронный из-за случайных
помех. Общий внешний синхронизатор в ряде случаев приводит к
упрощению управления процессом, но довольно часто он является
причиной, затрудняющей реализацию алгоритма за минимально
возможное время, так как осуществление глобальной
синхронизации также требует временных затрат.
Несмотря на то что асинхронный режим позволяет реализовать
алгоритм за минимально возможное время, загруженность ФУ
может оказаться при этом очень малой. Достаточно вспомнить
пример, рассмотренный нами в §7 и касающийся решения системы
линейных алгебраических уравнений с трехдиагональной матрицей.
Однако проведенные исследования подсказывают путь повышения
загруженности.
Утверждение 9.5. Предположим, что базовая
вычислительная система начинает работать в нулевой момент времени и
на ней реализуется алгоритм в режиме, определенном утверждением
9.2. Тогда для любого ФУ и каждого его входа время получения соот-
§9. ПРОГРАММЫ РЕАЛИЗАЦИИ АЛГОРИТМОВ
S9
ветствующего аргумента равно максимальной сумме времен
срабатывания ФУ, находящихся на путях графа системы, связывающих
входы системы и данный вход ФУ.
Возьмем вершину графа базовой системы, в которой находится
ФУ, вырабатывающее необходимый аргумент, и рассмотрим
множество всех вершин, из которых данная вершина достижима. Это
и только это множество определяет алгоритм вычисления аргумента.
Согласно условиям.утверждения, он реализуется за минимально
возможное время. В базовой системе каждое ФУ срабатывает только
один раз, поэтому любая максимальная последовательность должна
быть связана одним путем. Теперь справедливость утверждения
вытекает из утверждения 9.3 и его следствий.
Будем называть базовую систему уравновешенной, если для
любого ее ФУ суммы времен срабатывания ФУ, находящихся на всех
путях, связывающих входы системы и входы данного ФУ,
одинаковы, а также одинаковы аналогичные суммы времен на всех путях,
связывающих любой вход системы и любой ее выход.
Уравновешенную систему, все ФУ которой или имеют одинаковые времена
выполнения операций, или являются конвейерными, будем называть
синхронизированной. В соответствии с утверждением 9.4 любая
уравновешенная базовая система обладает тем свойством, что
каждое ее ФУ получает все предназначенные для него аргументы
одновременно и одновременно получаются все ее результаты. Поэтому
здесь не возникает простоев ФУ из-за τοι^ο, что разные аргументы
одного ФУ поступают на его входы в разное время.
Утверждение 9.6. Любую базовую вычислительную
систему можно сделать уравновешенной с помощью добавления ФУ,
осуществляющих операцию задержки во времени.
Рассмотрим каноническую параллельную форму графа базовой
системы. Предположим, что для некоторого k и любого I, где 1 ^/^Ξ&,
равны суммы времен срабатывания всех ФУ, находящихся на
любых путях, связывающих входы базовой системы и входы любого
ФУ /-го яруса. Очевидно, что это верно при k=l. Но тогда будут
равны суммы времен срабатывания всех ФУ, находящихся на
любых путях, связывающих входы базовой системы с любым
фиксированным входом любого ФУ (&+1)-го яруса. Выберем среди этих
сумм максимальную и разомкнем все дуги, символизирующие входы
ФУ (&+1)-го яруса и соответствующие меньшим суммам. Теперь в
каждую разомкнутую дугу вставим ФУ задержки с временем
срабатывания, равным разности между максимальной суммой и суммой,
соответствующей данному входу. После этого станут равными
суммы времен срабатывания всех ФУ,# находящихся на любых путях,
связывающих входы базовой системы и входы любого ФУ (&+1)-го
яруса. Для всех предыдущих ярусов аналогичные суммы не
изменятся. Продолжая этот процесс и добавляя необходимые
ФУ задержки на выходах системы, убедимся в справедливости
утверждения.
100 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
Мы описали здесь лишь один способ уравновешивания базовой
вычислительной системы. Конечно, уравновешивание можно
осуществить и многими другими способами, распределяя по иному
устройства задержки. В математическом отношении подобное
преобразование базовой системы означает, что в алгоритм добавляется
некоторое число операций тождественного преобразования.
Введение ФУ задержки можно трактовать также как присоединение к
основным ФУ локальной памяти специального вида.
Рассмотрим снова базовую вычислительную систему. Некоторые
из ее ФУ имеют входы, на которые подаются входные данные
алгоритма. Будем считать, что через каждый такой вход может быть
подано столько данных, сколько необходимо. Заставим
принудительно систему работать в таком режиме, когда команда на
следующее срабатывание любого ФУ может быть подана, если результат
предыдущего срабатывания либо уже использовался, либо будет
использован в момент подачи команды хотя бы одним ФУ, и при
этом сами команды подаются без задержки по мере готовности
аргументов. Такой режим будем называть режимом максимального
быстродействия. Естественно, что в общем случае будет реализован
какой-то алгоритм, не совпадающий с реализуемым. В некоторых же
практически интересных ситуациях между обоими алгоритмами
имеется очень тесная связь.
Исследуем происходящий процесс более подробно. Все ФУ
работают многократно по мере поступления аргументов. В общем
случае аргументы будут поступать для каждого ФУ либо одновременно
во времени, либо не одновременно, что определяется графом
алгоритма и временами выполнения операций. Начиная с некоторого
момента, с каждого выхода системы многократно выходят
результаты работы системы. Однако теперь мы не можем, вообще говоря,
без дополнительных исследований использовать утверждения,
касающиеся работы базовой системы, так как все они относились к
тому случаю, когда на каждый вход системы подавалось только
одно данное.
Разобьем входные данные системы на группы, относя к s-й группе
те из них, которые поступают на вход какого-нибудь ФУ s-ми по
порядку. Аналогичным образом разобьем на группы выходные
данные системы.
Утверждение 9.7. Пусть базовая вычислительная
система является синхронизированной и работает в режиме
максимального быстродействия. Тогда выходные данные s-й группы
определяются только s-й группой входных данных и для всех s являются
результатом реализации именно того алгоритма, граф которого
задает граф системы.
Действительно, вычислительная система не только
уравновешена, но и синхронизирована. Поэтому в тот момент, когда результат
срабатывания ФУ используется каким-то одним ФУ, он на самом
деле используется всеми ФУ, для которых он предназначен по алго-
§ 9. ПРОГРАММЫ РЕАЛИЗАЦИИ АЛГОРИТМОВ
101
ритму. Именно Это обстоятельство и гарантирует справедливость
утверждения.
Таким образом, заставляя синхронизированную систему
работать в режиме максимального быстродействия, мы получаем
возможность максимально быстро реализовывать поток однотипных
алгоритмов. При этом каждое ФУ асимптотически загружено
полностью и система автоматически работает в синхронном режиме. На
получение первого результата требуется столько времени, сколько
необходимо для реализации алгоритма за минимально возможное
время. Для всех остальных результатов разность времен получения
результатов соседних групп равна 1, если ФУ системы
конвейерные, и равна времени выполнения одной операции, если ФУ
системы простые.
Утверждение 9.8. Если на синхронизированной системе
реализуется достаточно большой поток однотипных алгоритмов в
режиме максимального быстродействия, то среднее время реализации
одного алгоритма асимптотически равно 1, если ФУ системы
конвейерные, и равно времени выполнения одной операции, если ФУ
системы простые.
Вернемся еще раз к решению системы линейных алгебраических
уравнений с трехдиагональной матрицей методом прогонки. Как
уже отмечалось в § 7, для реализации одиночного алгоритма
невозможно построить вычислительную систему, обеспечивающую
приемлемое время решения и большую загруженность ФУ. Однако если
необходимо реализовать большой поток независимых прогонок, то
положение принципиально изменяется. Мы можем теперь
построить, например, синхронизированную базовую систему и пропустить
этот поток через нее. При этом будут обеспечены предельно малое
среднее время решения .одной задачи и, следовательно, всех задач,
а также предельно полная загруженность всех ФУ системы.
Может показаться, что недостатком рассмотренного подхода
реализации потока алгоритмов является тот факт, что требуется
очень много ФУ для построения базовой системы. В общем случае
подобные соображения, конечно, необходимо принимать во
внимание. Что же касается именно задачи решения системы с
трехдиагональной матрицей, то заметим, что любой метод ее решения,
обеспечивающий предельно возможную распараллеливаемость
вычислений, требует примерно такого же числа ФУ.
Одновременная реализация на вычислительной системе потока
независимых или слабо зависимых однотипных алгоритмов является
исключительно эффективным средством повышения загруженности,
системы и снижения времени решения задачи в целом. Важным
обстоятельством оказывается то, что такие потоки характерны для
многих крупных задач.
Рассмотрим пример, показывающий существенность требований
уравновешенности и синхронизированности вычислительной
системы для обеспечения правильности реализации алгоритма в режиме
102 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
максимального быстродействия. Пусть вычисляется выражение
(а+Ь)2с. Предположим, что операции сложения и умножения
выполняются за один такт. На рис. 9.1 представлены графы двух
систем: слева — базовая система алгоритма, справа —
уравновешенная базовая система. Здесь черными кружками обозначены
вершины, соответствующие сверху вниз операциям сложения, умножения
и снова умножения. Светлым
а ь кружком представлена
вершина, соответствующая
операции задержки на время,
равное 1.
Пусть обе системы
работают в режиме, определенном
утверждением 9.2. Тогда они
работают одинаково, если
реализуется одиночный алгоритм,
и результаты, получаемые
после каждого такта,
представлены на рисунке. Если же
реализуется поток однотипных
алгоритмов с данными aiy bu ct в режиме максимального
быстродействия, то положение изменяется. Теперь для левой системы после
i-ro такта на входы последней операции будут поданы cii+bi и
(аг_!+&/_!)£,·_ι. Поэтому будут получены не результаты вида (cii+
+bi)2Ci, как это необходимо, а (αί+&ί)(α/_1+&/_1)^/_1. Для правой
системы будут получены правильные результаты. Левая система
не уравновешена, правая система не только уравновешена, но и
синхронизирована.
В заключение отметим, что если базовая система
синхронизирована и имеет периодическое строение, то периодическая ее свертка
с помощью операций простого гомоморфизма приводит к
вычислительной системе, которая уже на ограниченном потоке однотипных
алгоритмов приводит к синхронному режиму и асимптотически
полной загруженности. Периодичность в графах алгоритмов является
типичной ситуацией, когда алгоритмы записываются на
алгоритмических языках с использованием операторов цикла.
§ 10. Графы и матрицы
Любой граф можно задать перечислением для каждой вершины
либо смежных с нею вершин, либо инцидентных ребер или дуг. Эту
информацию о графе удобно представить в матричной форме и
использовать ее при исследовании различных свойств графа. Так как
в книге приходится иметь дело с ориентированными графами,
причем не имеющими ни петель, ни кратных дуг, то и матрицы
вводятся только для таких графов. Изменения в случае
неориентированных графов незначительны. Для упрощения некоторых рассужде-
§ 10. ГРАФЫ И МАТРИЦЫ
103
ний будем также предполагать, что граф связный и, следовательно,
не имеет изолированных вершин.
Пусть задан ориентированный граф G=(V, E) без петель и
кратных дуг, имеющий η вершин и т дуг, причем все вершины и дуги
помечены. Прямоугольная матрица А размеров пХт с элементами
ац называется матрицей инциденций графа, если
(+1, если /-я дуга выходит из ί-й вершины;
— 1, если /-я дуга входит в ί-ю вершину;
0 во всех остальных случаях.
Квадратная матрица В размеров пХп с элементами btj называется
матрицей смежностей графа, если
_ ί 1, если из ί-й вершины в /-ю вершину идет дуга;
ij ~~\ 0, если из ί-й вершины в /-ю вершину не идет дуга.
Заметим, что в каждом столбце матрицы инциденций графа лишь
два элемента отличны от нуля и равны +1 и —1. Так как граф по
предположению не имеет кратных дуг, то матрица инциденций не
имеет одинаковых столбцов. В каждой строке и каждом столбце
матрицы смежностей в общем случае может находиться любое число
ненулевых элементов. Точнее, в ί-и строке (i-м столбце) матрицы
смежностей имеется s ненулевых элементов, если из i-й вершины
графа выходит (входит) s дуг. Так как граф не имеет по
предположению ни петель, ни кратных дуг, то все диагональные элементы
матрицы смежностей равны нулю, а все ее ненулевые внедиагональные
элементы равны +1.
Предположим, что алгоритм с матрицей инциденций А его графа
реализуется на некоторой вычислительной системе с каким-то
составом функциональных устройств. Снова рассмотрим вектор t=(tl9 ..*
. . ., tn)' временной развертки, где ti есть время включения ФУ,
начинающего выполнять операцию, находящуюся в ί-й вершине
графа алгоритма. Рассмотрим также вектор реализации h=(hu
/ι2, . .·., hm)\ где hj — время выполнения операции, находящейся
в начале /-й дуги. Согласно сделанным ранее предположениям,
будем всегда считать векторы /, h целочисленными и
неотрицательными.
Утверждение 10.1. Пусть задана некоторая
вычислительная система. Для того чтобы алгоритм с матрицей инциденций
А его графа был реализуем на данной системе с вектором временной
развертки t и вектором реализации h, необходимо, а в случае базовой
системы и достаточно выполнение неравенства
— A't^h. (10.1)
Действительно, реализация алгоритма на любой вычислительной
системе означает реализацию одной из его базовых программ. Но
строки матрично-векторного неравенства (10.1) представляют не
104 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
что иное, как формульное выражение условий утверждения 8.2,
определяющих возможность такой реализации.
По матрице А и векторам /, h определяются многие
характеристики процесса реализации алгоритма. Как уже отмечалось, время
выполнения алгоритма равно
Г = тах(/, + Т|) —mini,, (10.2)
i i
где %i — время реализации операции, начинающейся в момент U.
Порядок выполнения операций алгоритма соответствует
упорядочению по возрастанию координат вектора /. Если какие-то
координаты вектора / одинаковы, то это означает, что соответствующие
операции выполняются параллельно на разных ФУ. Перенумеруем
подряд все группы равных координат вектора / и произведем
топологическую сортировку вершин графа алгоритма, помечая одним
индексом вершины, соответствующие равным tt. Эта сортировка
определяет параллельную форму алгоритма, реализуемую на
вычислительной системе при временном режиме, определяемом
вектором /. Синхронность или асинхронность работы ФУ связывается с
равномерным или неравномерным распределением различных
координат вектора t.
Обозначим через q(t, τ) число координат вектора /, равных τ и
удовлетворяющих в общем случае некоторому
дополнительному условию. Предположим, что вершины vt графа G(V, E)
алгоритма помечены по принадлежности к какому-нибудь типу.
Например, одним способом могут быть помечены вершины,
соответствующие операциям сложения, другим — соответствующие операциям
умножения. Пусть операции одного типа выполняются на
однотипных конвейерных ФУ. Тогда число π устройств типа L,
необходимых для реализации алгоритма с вектором временной развертки /,
определяется следующим образом:
п= max q(t, x), tt = x, vt^L. (10.3)
Рассмотрим любую строку неравенства (10.1), и пусть она
соответствует дуге графа алгоритма с начальной вершиной vs и
конечной вершиной vr. Операция, соответствующая вершине v8,
выполняется за время hs. Если tr—ts>hS) то это означает, что в момент
t8+h8 операция будет выполнена и ее результат должен где-то
храниться на интервале времени от t8+h8 до tr, прежде чем будет
использован при выполнении операции, соответствующей вершине vr.
Поэтому вектор h+A't определяет режим использования памяти
вычислительной системы для хранения промежуточных
результатов. В частности, необходимое число ψ каналов записи в память и
число θ каналов считывания из памяти находятся по таким
§ 10. ГРАФЫ И МАТРИЦЫ
105
формулам:
ψ -max q (ί, τ), ts + hs = x9 tr — ts>hs,
τ
θ = max q{t> τ), ^ = τ, ίΓ—ts>hs.
(10.4)
mln7~(£)
Алгоритм
Вычислительная
система
Свойства
матрицы инциденций
графа алгоритма
Рассмотренные примеры подсказывают один из возможных
путей исследования совместных свойств алгоритмов и
вычислительных систем. Неравенство (10.1) определяет все ограничения и
требования, возникающие при реализации алгоритма из-за
внутренних особенностей самого алгоритма. Обозначим через φ (Л, /, К)
определяемые алгоритмом условия, которые должны быть учтены при
реализации, через φ (ВС)
— условия, которые
накладываются
вычислительной системой.
Очевидно, что должно
осуществляться вложение φ (Л, /,
/ζ)αφ (ВС). Если,
например, учитывается число
сумматоров, умножителей,
каналов связи с памятью и
т. п., то свойство
вложения условий превращается
в совокупность
ограничений типа неравенств для
функций вида (10.3), (10.4).
Таким образом, задача
отображения алгоритмов на
вычислительные системы
может быть описана как
задача минимизации
функционала T(t) времени реализации алгоритма на множестве решений
/ системы линейных неравенств с ограничениями (рис. 10.1). Не
следует думать, что подобную задачу можно легко решить
непосредственно, хотя бы с использованием вычислительной техники. Одна
из трудностей заключается в написании ограничений. Она
преодолима, но после этого необходимо каким-то способом описать
матрицу инциденций. Данная трудность уже достаточно серьезна, так
как при задании алгоритма матрица инциденций практически
никогда не приводится. Но и после этого остается главная трудность —
огромные размеры матрицы инциденций. К тому же ограничения,
как правило, не линейны и не выпуклы. Поэтому трудности
возникнут и при реализации процесса минимизации функционала Τ(ί).
Тем не менее такая постановка оказывается полезной по крайней
мере при выполнении различных исследований. При этом основной
акцент делается на изучение и учет особенностей матрицы инци-
ΝΡ-сложность общей задачи
Рис. 10.1
106 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
денций и ограничений, описывающих допустимые временные
развертки.
Пусть, например, не учитываются никакие ограничения,
накладываемые на реализацию алгоритма вычислительной системой,
т. е. фактически предполагается, что система имеет неограниченные
ресурсы и возможности (концепция неограниченного
параллелизма!). Тогда задача сводится к минимизации функционала (10.2) на
множестве (10.1). По существу это есть задача отыскания
максимальной параллельной формы алгоритма или критического пути его
графа, и она легко сводится к задаче линейного программирования.
Действительно, добавим к графу алгоритма две условные вершины
v0f ν„+ι- Из вершины υ0 проведем дуги во все начальные
вершины графа, а из всех конечных вершин графа проведем дуги в
вершину νη+1. Будем считать, что операции, соответствующие вершинам
v0y vn+1, выполняются мгновенно. Модифицировав соответствующим
образом матрицу инциденций А и вектор реализации h, получим
аналогичную задачу, но теперь функционал T(t) будет линейным.
Именно, T(t) = tn+1—10. Подобное преобразование функционала
T(t) можно осуществлять и в других ситуациях.
Утверждение 10.2. Пусть задана некоторая
вычислительная система. Если при временной развертке t алгоритм реализуется
за минимальное для данной системы время, то хотя бы одна строка
матрично-векторного неравенства (10.1) обращается в точное
равенство.
В самом деле, если все строки (10.1) являются строгими
неравенствами, то это означает, что каждый результат выполнения
операций записывается в память. В этом случае, очевидно, время
реализации алгоритма можно уменьшить, если начинать выполнение
операций сразу после получения последнего аргумента.
Следствие. Если при временной развертке t алгоритм
реализуется за минимально возможное время, то обращаются в точные
равенства те строки неравенства (10.1), которые соответствуют
дугам критических путей графа алгоритма с матрицей инциденций А.
Заметим, что обращение какой-нибудь строки (10.1) в точное
равенство говорит о том, что для соответствующей пары операций
результат выполнения одной из них сразу же используется как
аргумент для другой. Если такая ситуация имеет место для всех
операций, то при реализации алгоритма не используется память для
хранения каких-либо результатов промежуточных вычислений.
Утверждение 10.3. Пусть задана некоторая
вычислительная система. Для того чтобы при реализации на ней алгоритма
не использовалась память для хранения результатов
промежуточных вычислений, необходимо и достаточно, чтобы допустимый
вектор временной развертки удовлетворял равенству
1 —A't = h (10.5)
и ограничениям, накладываемым вычислительной системой.
§ 10. ГРАФЫ И МАТРИЦЫ
107
Следствие. В условиях выполнения равенства (10.5)
алгоритм реализуется за минимально возможное время при заданных
длительностях выполнения операций.
Итак, исследование реализаций алгоритма, наилучших с точки
зрения быстродействия и не требующих к тому же памяти для
хранения результатов промежуточных вычислений, связано с
исследованием множества решений системы линейных алгебраических
уравнений (10.5). Критерием существования таких реализаций является
разрешимость системы (10.5) на множестве временных разверток,
удовлетворяющих ограничениям, накладываемым вычислительной
системой. Необходимость существования хотя бы одного решения
системы (10.5) приводит к условию ортогональности правой части
h ко всем решениям ζ однородной системы Αζ=0.
Пусть ζ=(ζι, . . ., zmy — решение системы Αζ=0. Это означает,
что линейная комбинация векторов-столбцов матрицы А с
коэффициентами, равными соответственно zb . . ., zm, есть нулевой вектор-
столбец. Каждый вектор-столбец является образом некоторой дуги
графа алгоритма. Поэтому, понимая под дугой вектор-столбец
матрицы инциденций, можно говорить о линейной комбинации дуг,
линейно независимых дугах и т. п. В целях упрощения выкладок и
доказательств, а также большей наглядности в интерпретации
отдельных фактов перейдем от исходного графа к более подходящему
изоморфному графу.
Рассмотрим n-мерное арифметическое пространство Rn и
отождествим вершины иь . . ., υη графа G с единичными координатными
векторами еъ . . ., еп H3Rn. Если из вершины ν ι в вершину Vj идет
дуга (щ, Vj), то поставим ей в соответствие вектор et—ej того же
арифметического пространства Rn. Так как по предположению граф
G не имеет ни петель, ни кратных дуг, то очевидно, что построенный
граф изоморфен графу G. Если не возникает никакой
двусмысленности, то для обоих графов будем использовать одни и те же
обозначения. Но теперь (щ, Vj) означает vt—Vj и векторы viy vj без
ограничения общности можно считать координатными.
Предположим, что в графе G имеется некоторый цикл,
образованный вершинами υ*, . . ., щ , vit. Точнее, последовательность
S
этих вершин задает цикл после снятия ориентации дуг (pix, vi2)9
. . ., (vi , ViJ. Пройдем все вершины подряд слева направо и будем
говорить, что при этом какая-то дуга проходится в положительном
направлении, если сначала встречается ее начальная вершина, а
затем конечная. В противном случае будем говорить, что дуга
проходится в отрицательном направлении. Если при проходе цикла
fe-e ребро графа проходится rk раз в положительном направлении
и sk раз в отрицательном, то положим zk=rk—sk- Вектор z=
= (zb. . .,zm) называется вектором-циклом. Вектор-цикл,
соответствующий элементарному циклу, называется элементарным. Его
координаты всегда равны 0 или ±1.
108 гл· 2· СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
Утверждение 10.4. Любой вектор-цикл ζ является
решением уравнения Лг=0.
Справедливость этого утверждения вытекает из очевидного
векторного равенства для векторов-дуг любого цикла:
0=(Vi— Vi2) + (V{2 — Vh)+ . . .+(Ois — Oti).
Каждое выражение в скобках есть вектор-дуга с точностью до
множителя, равного ± 1. Множитель равен +1, если начальная
вершина стоит раньше конечной (дуга проходится в положительном
направлении), и равен —1, если начальная вершина стоит позже
конечной (дуга проходится в отрицательном направлении).
Следствие. Если А есть матрица инциденций графа с
циклами, то среди векторов ζ, являющихся решениями системы Αζ=0,
сущгствуют такие, координаты которых равны 0 или ± 1 ·
Следствие. Если граф имеет контуры, то среди векторов
ζ, являющихся решениями системы Αζ=0, существуют такие, все.
ненулевые координаты которых равны либо только +1, либо
только —1.
Следствие. Если столбцы матрицы инциденций линейно
независимы, то граф не имеет циклов.
Утверждение 10.5. Рассмотрим линейно зависимую
систему столбцов матрицы инциденций графа. Предположим, что она
обладает тем свойством, что при исключении любого столбца
остается линейно независимая система. Тогда совокупность дуг,
соответствующих рассматриваемым столбцам, образует элементарный
цикл и не содержит в себе никаких других циклов.
Любая система столбцов однозначно определяет вершины и дуги
некоторого подграфа исходного графа. Из условий утверждения
вытекает, что нулевой столбец можно представить в виде линейной
комбинации заданных столбцов с ненулевыми коэффициентами.
Предположим, что среди вершин подграфа есть хотя бы одна
висячая. Тогда координата вектора линейной комбинации,
соответствующая висячей вершине, не может обратиться в нуль при
ненулевых коэффициентах. Поэтому любая вершина подграфа инцидентна
более чем одному ребру. Такой подграф обязательно имеет циклы.
Если бы какой-нибудь цикл содержал не все дуги, то была бы
линейно зависимой некоторая подсистема рассматриваемых столбцов
матрицы инциденций, что невозможно согласно условиям.
Следовательно, из дуг подграфа можно составить цикл и притом только
один. Очевидцо, что этот цикл элементарный, так как в противном
случае существовали бы другие циклы.
Следствие. Если однородная система Αζ=0 имеет
ненулевое решение, то существует по крайней мере один элементарный
вектор-цикл.
В действительности можно утверждать значительно больше.
Рассмотрим любое ненулевое решение ζ системы Αζ=0. Среди столб-
§ 10. ГРАФЫ И МАТРИЦЫ
109
цов матрицы Л, соответствующих ненулевым координатам вектора ζ,
выберем любые столбцы, удовлетворяющие условиям
утверждения 10.5. Пусть им соответствует элементарный вектор-цикл w.
Подберем число α так, чтобы в векторе ζ—aw было меньше
ненулевых координат, чем в векторе ζ. Продолжая этот процесс, получим
разложение вектора ζ по элементарным векторам-циклам. Для
каждого конечного графа существует конечное число элементарных
циклов. К тому же среди всех элементарных векторов-циклов всегда
можно выбрать линейно независимые. Следовательно, справедливо
Утверждение 10.6. Пусть А — матрица инциденций
графа, имеющего циклы. Тогда в пространстве решений ζ однородной
системы линейных алгебраических уравнений Αζ=0 можно выбрать
базис, целиком состоящий из элементарных векторов-циклов.
Теперь можно сформулировать условие разрешимости системы
(10.5) и дать необходимую его интерпретацию.
Утверждение 10.7. Для того чтобы система (10.5) имела
решение, необходимо и достаточно, чтобы правая часть h была
ортогональна всем элементарным векторам-циклам.
Следствие. Если граф имеет контуры, то система (10.5)
не имеет решение ни при каком векторе h с положительными
координатами.
Напомним, что /-я координата вектора реализации h есть время
выполнения операции, находящейся в начале /-й дуги графа
алгоритма. Так как ненулевые координаты элементарного вектора-цикла
равны ±1, то из сказанного следует.
Утверждение 10.7. Пусть задана некоторая
вычислительная система. Для того чтобы при реализации на ней алгоритма
не использовалась память для хранения результатов
промежуточных вычислений, необходимо, чтобы при обходе любого элементарного
цикла графа алгоритма сумма времени выполнения операций,
соответствующих дугам, проходимым в положительном направлении,
равнялась сумме времени выполнения операций, соответствующих
дугам, проходимым в отрицательном направлении.
Если условие данного утверждения выполнено, то система (10.5)
разрешима. Поэтому поиск временных разверток, при которых
действительно не требуется память для хранения результатов
промежуточных вычислений, связан далее с поиском решения системы
(10.5), обеспечивающего удовлетворение ограничений,
накладываемых вычислительной системой.
Утверждение 10.8. Если граф алгоритма связный и
система (10.5) совместна, то множество ее решений представляет
прямую линию с направляющим вектором е=(\, 1, . . ., 1).
Зафиксируем какую-нибудь координату вектора /. Тогда в силу
связности графа все остальные координаты определяются из
системы (10.5) однозначно. Так как в каждой строке матрицы А' имеется
только два ненулевых элемента, равных +1 и —1, то разность двух
любых решений системы (10.5) пропорциональна вектору е.
НО ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
Следствие. Если граф алгоритма имеет ρ компонент
связности и система (10.5) совместна, то множество ее решений
представляет плоскость размерности р.
Следствие. Если граф алгоритма имеет ρ компонент связ-
ности,-п вершин и т дуг, то он имеет т—п-\-р независимых векторов-
циклов.
Следствие. Удаление одного ребра в графе алгоритма либо
увеличивает на 1 число компонент его связности, либо уменьшает на
1 число независимых векторов-цик/ιοβ.
Если граф алгоритма связный, то вся неоднозначность решений
системы (10.5), по существу, связана лишь с выбором момента
начала выполнения алгоритма. Поэтому исследование реализаций
алгоритма, наилучших с точки зрения быстродействия и не требующих
к тому же памяти для хранения результатов промежуточных
вычислений, оказывается очень простым. Именно, сначала проверяется
справедливость условия из утверждения 10.7, затем находится
какое-нибудь решение системы (10.5) и, наконец, для этого решения
или решения, сдвинутого на вектор, пропорциональный е,
проверяются ограничения, накладываемые вычислительной системой.
Формально проведенные исследования касались лишь
рассмотрения специального случая, когда в процессе выполнения
алгоритма не используется память вычислительной системы. В
действительности реальная ситуация тесно связана с рассмотренной. В самом
деле, добавим в каждую дугу графа алгоритма по одной вершине,
символизирующей обращение к памяти, понимая под этим
выполнение любой конкретной операции, не изменяющей информацию, но
тратящей на свою реализацию какое-то время. Расширенный
алгоритм уже не требует дополнительных обращений к памяти, и мы
снова приходим к системе вида (10.5). Но теперь в векторе h не
известны координаты, соответствующие временам выполнения
операций «хранение в памяти». Они находятся из условий
удовлетворения ограничениям, накладываемых вычислительной системой, и
утверждению 10.7.
Конечно, в общем случае совсем не обязательно добавлять
операции обращения к памяти в каждую дугу графа алгоритма.
Согласно утверждению 10.6, можно попытаться ограничиться
добавлением по одной такой операции в каждый из независимых циклов.
В частных случаях и подобное расширение графа алгоритма может
оказаться избыточным. К исследованию соответствующих задач мы
будем обращаться по мере необходимости.
В § 9 был рассмотрен процесс работы уравновешенных и
синхронизированных базовых вычислительных систем. Теперь свойства
этих систем можно получить алгебраическим путем.
Уравновешенная система характеризуется отсутствием обращений к памяти для
хранения результатов промежуточных вычислений. Это означает,
что вектор развертки t является решением системы (10.5), причем
выполняется условие утверждения 10.7. Если базовая система до-
§ 10. ГРАФЫ И МАТРИЦЫ
111
пускает синхронный режим работы, то наряду с вектором развертки
t допустимыми должны быть векторы развертки вида t+ye, где γ —
число. Очевидно, что вектор t+ye есть решение системы (10.5).
Обозначим через τ вектор размерности п, i-я координата которого
равна минимальному интервалу времени последовательной подачи
входных данных на функциональное устройство, выполняющее
операцию, соответствующую /-й вершине графа алгоритма. Если все
ФУ системы конвейерные, то х=е, если же ФУ системы простые,
то координаты вектора τ равны временам выполнения операций.
Для того чтобы базовая система была не только уравновешенной, но
и синхронизированной, необходимо отсутствие простоев работы
ФУ между реализациями алгоритмов с временами разверток t и
t+ye. Это возможно лишь в случае, когда х=уе, откуда и вытекает
сформулированное ранее условие синхронизированности базовой
вычислительной системы.
Все векторы временной развертки, определяющие работу
базовой вычислительной системы, удовлетворяют неравенству (10.1).
Если граф вычислительной системы получается из графа
вычислительного алгоритма с помощью гомоморфной свертки, то эта
процедура приводит к появлению ограничений, характеризующих процесс
свертки. В первую очередь они касаются допустимых векторов
развертки и размеров присоединяемой к ФУ локальной памяти.
Например, при отождествлении /-й и /-й вершин графа алгоритма
дополнительное ограничение имеет вид неравенства \tt—ί/Ι^Α^, где
htj есть время выполнения той из двух операций, которая
реализуется раньше. Конечно, многие из дополнительных ограничений на
вектор развертки в действительности являются следствием (10.1) и
поэтому могут не приниматься во внимание. Такая ситуация
заведомо будет иметь место в том случае, когда отождествляются
вершины, лежащие на одном пути графа алгоритма.
Матрица смежностей также оказывается полезной в ряде
исследований, связанных с изучением как свойств самого графа, так и
совместных свойств алгоритмов и вычислительных систем.
Утверждение 10.9. В ориентированном графе G—{V, E)
без петель с матрицей смежностей В контуры отсутствуют тогда
и только тогда, когда существует матрица перестановок Ρ такая,
что матрица Р'ВР является правой треугольной.
Переход от матрицы В к матрице Р'ВР связан с перенумерацией
вершин. Если граф не имеет контуров, то существуют его
различные параллельные формы. Возьмем любую из них и перенумеруем
вершины подряд сначала в первом ярусе, затем во втором и т. д.
При такой нумерации дуга всегда будет идти в вершину с большим
номером. Это означает, что матрица смежностей является правой
треугольной. Пусть теперь матрица смежностей правая
треугольная. Тогда, передвигаясь из какой-нибудь вершины по любому
пути, будем последовательно попадать в вершины с возрастающими
номерами и никогда не попадем снова в исходную вершину. Следо-
312 ГЛ.2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
вательно, граф не имеет контуры. Отсутствие петель в графе
говорит о том, что все диагональные элементы матрицы смежностей
нулевые.
В действительности процесс доказательства утверждения
позволяет установить более тесную связь между видом параллельной
формы графа и его матрицей смежностей.
Утверждение 10.10. Ациклический ориентированный граф
с матрицей смежностей В имеет параллельную форму высоты I и
ширины s тогда и только тогда, когда существует матрица
перестановок Ρ такая, что матрица Р'ВР является блочной правой
треугольной блочного порядка I с нулевыми квадратными
диагональными блоками порядка не выше s.
Для произвольного ациклического ориентированного графа
ничего больше о строении матрицы смежностей сказать нельзя.
Появление же дополнительных свойств у графа приводит к
появлению соответствующих свойств у матрицы смежностей.
Предположим, например, что все циклы графа уравновешены, т. е. при
обходе число дуг, проходимых в положительном направлении, равно
числу дуг, проходимых в отрицательном направлении. С точки
зрения свойств матрицы инциденций это означает, что существует
решение системы (10.5) при h=e.
Утвержден, ие 10.11. Ациклический ориентированный
граф с матрицей смежностей В имеет уравновешенные циклы тогда
и только тогда, когда существует матрица перестановок Ρ такая,
что матрица Р'ВР является блочной правой двухдиагональной с
нулевыми квадратными диагональными блоками.
Рассмотрим решение системы —A't=e. Вектору t можно
однозначно сопоставить параллельную форму графа, объединяя в ярус
те вершины, у которых совпадают времена начала выполнения
соответствующих операций, если под графом понимать граф какого-то
алгоритма. Каждая дуга связывает вершины, расположенные
только на соседних ярусах, так как соответствующие им времена
различаются на 1. Если вершины графа занумеровать по ярусам, то
матрица смежностей будет иметь указанный в утверждении вид. В
случае, когда матрица смежностей имеет такой вид, построим
параллельную форму графа, объединяя в один ярус вершины,
соответствующие одному диагональному блоку. При этом каждая вершина
оказывается связанной лишь с вершинами соседних ярусов, и,
следовательно, все циклы графа уравновешены.
Матрицы инциденций и смежностей позволяют дать
алгебраическую трактовку, по-видимому, всем доказанным ранее фактам,
касающимся тех или иных свойств графов, а также получать новые
факты. Но сейчас мы не будем продолжать эти исследования, а
вернемся к ним несколько позднее.
§11. NP-СЛОЖНОСТЬ ОБЩЕЙ ЗАДАЧИ
113
§11. WP-сложность общей задачи
Применение графов для описания и исследования общей задачи
отображения проблем вычислительной математики на архитектуру
вычислительных систем позволяет решить ряд важных вопросов.
Пожалуй, самый важный из них — выбор математического
фундамента, на котором может строиться изучение таких разнородных
компонент этой задачи, как математические модели тех или иных
явлений, численные методы, алгоритмы, программы,
вычислительные системы и их математические модели.
Многие из компонент общей задачи уже давно представляют
вполне сложившиеся области исследований, развивающиеся
самостоятельно, в том числе по своим внутренним законам. В
некоторых из них достаточно активно используются графы. Однако
большие достижения в отдельных областях пока еще не нашли
соответствующего отражения в решении общей задачи. Одна из причин
этого заключается в значительной разобщенности областей, почти
полном отсутствии общих средств и объектов исследований и, как
следствие, слабом понимании специалистами одной области
проблем, над решением которых работают специалисты других
областей. Для преодоления разобщенности отдельных областей и
создается общий математический фундамент.
Исследования, проведенные в данной главе, показали, что такие
далекие друг от друга компоненты общей задачи, как алгоритмы
и параллельные вычислительные системы, могут быть успешно
описаны и совместно исследованы с помощью графов. Появились
типичные задачи: отыскание параллельной формы ациклического
ориентированного графа; разложение множества вершин графа на
подмножества, образующие отдельные пути; гомоморфная свертка
графа к графу с заданными свойствами; установление гомоморфизма
между двумя графами и т. д. Эти и другие рассматриваемые в
книге задачи являются дискретными. Для их решения разрабатываются
специальные методы, и им присущи специфические трудности, не
свойственные непрерывным задачам. Использование единого
математического аппарата в комплексном изучении общей задачи
позволяет связать отдельные дискретные задачи между собой и понять,
какие из них образуют узкое место во всей цепи исследований и
что нужно делать для устранения этого узкого места.
Конечно, для решения общей задачи хотелось бы разработать
эффективный метод, к тому же применимый в самых различных
ситуациях. Многолетний опыт развития методов решения сложных
задач убедительно показал, что эти две стороны — эффективность
метода и его общность — находятся в достаточно большом
противоречии друг другу. Поэтому всегда важно знать, можно ли надеяться
на создание общих эффективных методов или надо обязательно
идти по пути разбиения всего множества задач на более узкие
классы и разрабатывать для них эффективные методы, учитывая спе-
114 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
цифику отдельных классов. Это обстоятельство полезно принимать
во внимание всегда, но особенно важно его учитывать при анализе
дискретных задач.
Большинство дискретных задач, вообще говоря, допускает
решение с помощью некоторого процесса перебора. Типичным
примером является построение параллельной формы алгоритма на
основе целенаправленного перебора вершин графа, изложенного при
доказательстве утверждения 5.2. Этот процесс имеет
полиномиальную сложность в отношении числа переборов, так как для его
реализации требуется просмотреть вершины графа порядка п2 раз, если
сам граф имеет η вершин. Однако в большинстве других случаев
число шагов переборного метода растет экспоненциально в
зависимости от размеров задачи.
Не будем особенно успокаиваться, установив, что при решении
общей задачи отображения проблем вычислительной математики на
архитектуру вычислительных систем встречаются такие задачи,
которые имеют «хорошую», т. е. полиномиальную, сложность.
Вспомним, что число вершин графа алгоритма совпадает с числом
выполняемых операций. Алгоритмы, требующие для своей
реализации применения параллельных вычислительных систем,
содержат огромное число операций. Предположим, что дискретные
задачи, связанные с анализом и преобразованием графов алгоритмов,
будут даже иметь линейную сложность относительно числа вершин.
Пусть к тому же их решение будет осуществляться с помощью
современной вычислительной техники. Тогда и в этих случаях на
исследование алгоритмов потребуется не меньше времени, чем на их
реализацию. Но ведь исследование алгоритмов осуществляется в
основном с единственной целью — сократить время реализации.
Поэтому идти на большие временные затраты при исследовании
каждого конкретного алгоритма целесообразно только тогда, когда
само исследование проводится один раз, а полученные при этом
результаты используются многократно. Если решение дискретной
задачи имеет сложность выше линейной, то и многократная
реализация алгоритма может не компенсировать временные затраты на
предварительные исследования.
Таким образом, в действительности не так уж важно, какую
сложность будут иметь встречающиеся в наших исследованиях
дискретные задачи. Установление общей полиномиальной или
экспоненциальной их сложности — это всего лишь установление степени
практической решаемости задач. Тем не менее определение
сложности дискретных задач оказывается полезным, так как говорит о
том, насколько большие трудности придется преодолевать при
поиске приемлемых частных случаев.
Не вдаваясь в детали обсуждения, можно сказать, что по
сложности получения решения все дискретные задачи делятся на два
класса. В класс Ρ (Polynomial — полиномиальный) входят задачи,
решение которых находится за полиномиальное число переборов от
§11. Л/Р-СЛОЖНССТЬ ОБЩЕЙ ЗАДАЧИ
115.
характерного размера задачи. В класс NP (Nonpolynomial —
неполиномиальный) входят все переборные задачи. Очевидно, что
P^NP. В классе NP имеются задачи, решение которых может
быть найдено с помощью перебора всех вариантов, но относительна
которых неизвестно, можно ли найти их решение за
полиномиальное число переборов. Более того, в классе NP выявлены так
называемые универсальные (iVP-сложные, iVP-полные) задачи, к
которым полиномиально сводится любая задача из NP. В настоящее
время установлена универсальность многих задач, эквивалентных
между собой с точностью до полиномиальной сводимости. Если бы
удалось доказать, что хотя бы одна такая задача принадлежит
классу Р, то тем самым было бы доказано, что Ρ совпадает с ΝΡΤ
и можно было бы в принципе надеяться на построение эффективных
методов решения различных классов дискретных задач. Опыт
решения дискретных задач дает основание считать, что iVP-сложные
задачи и задачи из класса Ρ сильно различаются по трудоемкости
решения, но в строгом смысле это различие не доказано.
К сожалению, нужно констатировать, что среди рассмотренных
нами задач на графах имеются iVP-сложные. Пусть заданы два
графа Gi=(Vi, £Ί), G2=(V2, E2) и ставится вопрос: можно ли из графа
όχ получить граф G2 с помощью операций простого гомоморфизма?
Пользуясь нашей терминологией, этот же вопрос можно задать
иначе: можно ли алгоритм, заданный графом Gb эффективно
реализовать на вычислительной системе, заданной графом G2?
Оказывается, что эта задача является iVP-сложной даже в том случае, когда
граф G2 есть треугольник. Среди iVP-сложных задач она известна
как задача «гомоморфизм графов».
Итак, нет никаких оснований надеяться на получение
эффективного решения общей задачи отображения проблем вычислительной
математики на архитектуру вычислительных систем с помощью
некоторого универсального метода. Отсюда можно было бы сделать
вывод о безнадежности поиска приемлемых решений общей задачи,
и подобные пессимистические выводы делаются. Более
оптимистически настроенные исследователи рекомендуют применять для
решения AfP-сложных задач какие-либо приближенные методы в
надежде на то, что в большинстве частных случаев решение будет
находиться значительно быстрее, чем реализуется полный перебор
всех вариантов. Как мы уже отмечали, для интересующих нас
дискретных задач подобные пути поиска решений также мало
перспективны.
Прежде чем делать окончательные выводы, полезно понять,
откуда все же возникает iVP-сложность задач в наших исследованиях
и появляется ли она по существу или из-за того, что мы
недостаточно хорошо знаем задачи, которые собираемся решать. Вернемся
снова к задаче «гомоморфизм графов». Ее NP-сложность доказана
в том случае, когда графы G± и G2 произвольные. Напомним, что
Gi есть граф алгоритма. Если допустить, что этот граф является
116 ГЛ. 2. СОВМЕСТНОЕ ИССЛЕДОВАНИЕ СИСТЕМ И АЛГОРИТМОВ
произвольным, то записать соответствующий алгоритм можно,
лишь записав независимо друг от друга все операции и связи между
ними. В практической деятельности не приходится иметь дела с
большими алгоритмами подобного рода, причем именно потому,
что их невозможно записать в компактном виде. Поэтому
используемые в действительности алгоритмы нельзя отнести к
произвольным. Они обладают рядом характерных отличий, связанных,
например, с существованием периодически повторяемых участков
вычислений. Следовательно, есть основания предполагать, что,
изучая реальные алгоритмы и выделяя их специфику, удастся
избежать А^Р-сложности больших дискретных задач и найти
эффективные методы решения общей задачи, по крайней мере в
практически важных случаях.
JVP-сложность — это та реальная трудность, которая постоянно
мешает проведению наших исследований. Чтобы избежать ее,
приходится рассматривать не весь класс алгоритмов, а обладающий
некоторыми дополнительными свойствами. Эти дополнительные
свойства, вообще говоря, можно задать аксиоматически. Однако
при этом реальной является опасность чрезмерного сужения
рассматриваемого класса алгоритмов. Именно, если задаваемые
свойства окажутся слишком сильными, то в классе исследуемых
алгоритмов могут оказаться в основном тривиальные или имеющие
малое практическое значение. Как всегда, истина находится где-то
посередине — в данном случае между Л^Р-сложностью и
тривиальностью.
Этот небольшой параграф написан специально для того, чтобы
обратить особое внимание читателя на трудности исследования
рассматриваемых в книге дискретных з^дач и предостеречь от
опасности как излишнего их обобщения, так и излишнего их
упрощения. Выбор правильного пути исследований должен начинаться с
изучения особенностей графов практически используемых
алгоритмов.
Глава 3
ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ
И ПРОГРАММ
В этой главе рассматриваются различные вопросы, связанные с
построением и анализом решетчатых графов алгоритмов. В
практической деятельности для записи алгоритмов приходится
пользоваться многими формами, например математическими
соотношениями, программами на алгоритмических языках, блок-схемами
и т. п. Все они эквивалентны в том смысле, что описывают один и
тот же граф алгоритма. Глава начинается с обсуждения форм
записей и описания одной из них, которая считается базовой для всех
дальнейших исследований. Эта форма является фортрано-подобной
и объединяет в себе характерные особенности записей алгоритмов
с помощью математических соотношений и программ на
алгоритмическом языке фортран.
Основной принцип исследования свойств решетчатых графов
алгоритмов заключается в расщеплении этих графов на
простейшие, изучении свойств простейших графов и последующем
выявлении свойств исходных графов, в том числе параллельных форм на
основе выполненного анализа. Особое внимание уделяется
исследованию специальных классов решетчатых графов,
соответствующих часто встречающимся в практической деятельности
алгоритмам. Более детально изучаются решетчатые графы, имеющие
регулярные структуры дуг. В этих случаях параллельные^структуры
алгоритмов могут быть описаны полностью.
§ 12. Формы записи алгоритмов
Существует распространенное мнение, что последовательный
характер традиционных алгоритмических языков искажает
информационные связи между соответствующими переменными в
математической записи алгоритма за счет наложения дополнительных
связей, определяемых необходимостью выполнять операции языка
последовательно. Вообще говоря, это мнение неверное, и его
существование во многом связано с различием смысловых
содержаний, вкладываемых в понятие алгоритма.
118 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
Если заданы математические соотношения, связывающие между
собой некоторые переменные, то возможны две ситуации: либо
точно определен порядок выполнения всех операций, входящих в
соотношения, либо он определен не полностью или даже совсем не
определен. В строгом смысле можно говорить о вычислительном
алгоритме только в первом случае; во втором случае в
действительности задан не один алгоритм, а множество алгоритмов,
отличающихся друг от друга порядком выполнения операций. На этом
множестве вычислительные алгоритмы могут быть не эквивалентны
даже при точном выполнении операций, не говоря уже об их
выполнении в условиях влияния ошибок округления.
Отсутствие указания порядка или частичное его указание
обычно означает следующее: при точном выполнении операций все
соответствующие алгоритмы дают одинаковые результаты; операции,
порядок выполнения которых не определен, описывают лишь
функциональное содержание более крупных операций, порядок
выполнения которых существен. Поэтому до некоторого уровня
детализации вычислений порядок выполнения операций имеет решающее
значение. Если же приходится иметь дело с множеством
алгоритмов, то среди них можно выбрать лучший с точки зрения тех или
иных характеристик, например лучшего распараллеливания.
Сделанный выбор также отмечается специальным порядком
выполнения операций.
Таким образом, указание порядка выполнения операций
является необходимой характеристикой вычислительного алгоритма.
Его соблюдение при реализации алгоритма на ЭВМ возможно
только потому, что точно определен порядок выполнения операций
алгоритмического языка, на котором записан сам алгоритм.
Конечно, в конкретных случаях нас может интересовать порядок
выполнения не всех операций языка, а только части их. Например,
довольно часто не имеет значения, в каком порядке выполнять
операции одного тела цикла, но очень важно сохранить порядок
выполнения совокупности тел циклов.
Пусть алгоритм задан каким-то способом и с какой-то степенью
определенности. Постараемся понять, что можно сказать о графе
алгоритма или его свойствах.
Рассмотрим сначала случай, когда точно определен порядок
выполнения всех операций. Построим граф, поставив в
соответствие его вершинам выполняемые операции и соединив вершины
дугами, если для соответствующих операций результат выполнения
одной из них является аргументом для другой. Это есть граф
исходного алгоритма. Выполняя операции в заданном порядке, мы
получим нужный результат. Но существуют и другие порядки
выполнения операций, приводящие к эквивалентным результатам.
Если связать их векторами временных разверток, то все они
определяются как решения неравенства (10.1). Ничто не мешает
использовать любой из порядков, и мы можем взять такой, который,
§ 12. ФОРМЫ ЗАПИСИ АЛГОРИТМОВ
119
например, обладает лучшими свойствами с точки зрения
распараллеливания вычислений.
На практике довольно часто приходится переводить алгоритмы
из одной формы записи в другую. Если при этом сохраняется вся
совокупность операций и определены (возможно, различными
способами) порядки их выполнения, то чаще всего оказывается, что
разные формы записи алгоритмов порождают один и тот же граф,
и в этом смысле они полностью эквивалентны. Если же разные
формы записи приводят к разным графам, то это говорит о
неэквивалентности алгоритмов, заданных этими записями.
Предположим далее, то определен порядок выполнения не всех
операций, участвующих в записи алгоритма. Всегда можно
выбрать более крупные макрооперации таким образом, что порядок их
выполнения уже определен однозначно, а вся неоднозначность
будет проявляться лишь при реализации этих макроопераций. Тем
не менее мы, конечно, будем считать, что разные способы
выполнения макроопераций приводят к одинаковым результатам, по
крайней мере при точных вычислениях. Построим макрограф, поставив
в соответствие его вершинам макрооперации и соединив вершины
дугами, если для соответствующих макроопераций результат
выполнения одной из них является аргументом для другой. Этот
макрограф есть обычный граф алгоритма, но заданный в терминах
более крупных операций. Согласно утверждениям 7.5, 7.6, время
реализации алгоритма определяется наибольшим временем
выполнения операций, находящихся на одном пути, т. е. взвешенной
длиной критического пути. Поэтому заботиться о реализации, и, в
частности, о распараллеливании, макроопераций необходимо лишь
в той мере, в какой они определяют критические и близкие к ним
пути графа алгоритма. Последнее замечание относится не только
к макрооперациям, у которых не определен порядок выполнения
входящих в них операций, но и к макрооперациям, которые по тем
или иным причинам приходится изменять с целью получить лучшие
характеристики всего вычислительного процесса или содержание
которых нас просто не интересует.
Рассмотрим описанные ситуации на примере обычного способа
вычисления произведения А=ВС двух квадратных матриц В, С
порядка п. Обозначим элементы матриц Л, β, С соответственно
через ац, bik, ckj. Имеем по определению
η
а{/=ЦЬ{кск/, i, /=1, 2,..., п. (12.1)
£= 1
Будем считать, что основной является алгебраическая
операция вида α+bc. Если приведенные формулы трактовать как запись
способа вычисления элементов матрицы Л, то мы должны отметить
следующее. Во-первых, полностью не определен порядок
выполнения операций сложения и умножения. И во-вторых, фактически
имеется указание на возможность параллельного вычисления эле-
120 ГЛ- 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
ментов а,ц, так как не заданы никакие ограничения на порядок
перебора индексов ί, /. Следуя сказанному выше, введем в качестве
макроопераций вычисление суммы η парных произведений. Тогда
макрограф алгоритма вычисления произведения матриц порядка
л будет состоять из п2 изолированных вершин. Следовательно,
минимальное время реализации процесса будет определяться при
достаточных ресурсах системы временем вычисления суммы η парных
произведений.
Определим теперь каким-нибудь способом порядок выполнения
всех операций под знаком суммы в (12.1), например так:
a% = a%-» + b{kckj, i, /, *Β1, 2, ..., η, (12.2)
Эта запись уже отражает реальный алгоритм. Снова указан
параллелизм вычисления элементов ац. Граф алгоритма состоит из п2
несвязных подграфов, каждый из которых представляет собой
линейную цепочку из η вершин. Данный граф очевидным образам
связан с только что рассмотренным макрографом.
Наконец, посмотрим, что дает запись того же алгоритма (12.2)
на алгоритмическом языке типа фортран. Имеем
DO 1 ι=1, η
DO 1 /=lf n
1 α// = 0
DO 2 ί=1, η (12.3)
DO 2 /=1, η
DO 2 &= 1, η
at/ = <*V + bihck/
2 CONTINUE
Здесь точно определен порядок выполнения всех операций, но нет
никаких явных указаний относительно возможности выполнять
параллельно какие-либо операции. Однако если мы на основе этой
записи алгоритма построим его граф, то снова получим я2
несвязных подграфов, представляющих линейные цепочки из η вершин.
Такая ситуация, когда явный или неявный параллелизм скрыт
в программе, является типичной для существующих записей
алгоритмов на алгоритмических языках. Но важно подчеркнуть, что
никакой имеющийся в алгоритме параллелизм при этом не
пропадает, необходимо лишь его «проявить». Процессам «проявки»
параллелизма и будут посвящены наши ближайшие исследования.
Большинство употребляемых на практике форм записи
алгоритмов базируется на использовании соотношений, связывающих
переменные, характеризующиеся некоторыми целыми числами. Такими
переменными могут быть переменные с индексами, если использу-
§ 12. ФОРМЫ ЗАПИСИ АЛГОРИТМОВ
121
ется, например, математическая форма записи разностной схемы,
или элементы массивов, если форма записи есть программа на одном
из алгоритмических языков.
Не существует принципиального различия между
математической формой записи алгоритма на основе использования
переменных с индексами и программой, описывающей тот же алгоритм,
например, на языке фортран. Основное различие состоит в том, что в
математической записи каждая переменная с индексами обычно
является однозначной функцией начальных данных и индексов,
а каждый элемент массива в программе — многозначной.
Возникновение этого различия объясняется очень просто. При
записи алгоритма в виде программы одновременно решается
проблема эффективности использования памяти ЭВМ, что и приводит
к многократному использованию одних и тех же элементов массивов.
Чтобы в этих условиях обеспечить правильность выполнения
алгоритма, фиксируется порядок выполнения индексных выражений.
Как правило, это связано с лексикографическим упорядочением
самих индексов. Лексикографическое упорядочивание индексов
позволяет распутать многократное использование элементов
массивов и определить все связи графа алгоритма.
Если в математической форме записи какого-либо алгоритма
фиксирован порядок выполнения операций и тот же алгоритм
записан в виде программы, например, на языке фортран, то с точностью
до не существенных деталей обе формы записи эквивалентны и
последовательный характер выполнения операций языка фортран не
накладывает никаких связей на переменные алгоритма. Более
сложный анализ программы связан только с тем, что в ней явно
представлена более подробная информация об алгоритме, чем в
математическом описании.
Прежде чем переходить к исследованию алгоритмов и их
графов, опишем ту форму записи самих алгоритмов, которую
предполагаем использовать. Мы будем придерживаться основных
конструкций языка фортран, таких как массивы, переменные с
индексами, операторы цикла DO, метки, безусловные и условные операции.
Объясняется это в основном желанием обеспечить автоматизацию
процесса анализа существующего программного обеспечения по
отношению к вычислительным системам со многими
функциональными устройствами, а также известной общностью математических
форм записи алгоритмов и их записей в виде программ для ЭВМ.
Пусть задано конечное множество произвольной природы,
элементы которого объединены некоторым признаком. В общем случае
оно может состоять из чисел, функций, матриц, операторов и т. п.
Перенумеруем элементы множества с помощью совокупности
независимых целочисленных индексов и назовем их переменными с
индексами, а само множество — массивом. Для обозначения
переменных с индексами будем использовать любую употребляемую
символику. Число независимых индексов, используемых для нуме-
122 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
рации элементов массива, будем называть размерностью массива.
Массив, состоящий из одного элемента, по определению имеет
нулевую размерность.
Введение переменных с индексами различной природы вызвано
тем, что одновременное рассмотрение таких переменных в
действительности является типичной ситуацией. Например, в
математических записях алгоритмов довольно часто приходится совместно
исследовать матрицы и векторы, дифференциальные и интегральные
операторы и т. п. В алгоритмах, записанных на языке фортран,
часто встречается использование подпрограмм. Если мы не
интересуемся по каким-либо причинам их внутренним строением, то снова
приходим к необходимости одновременного рассмотрения
переменных различной природы. Имеются и многие другие примеры.
Однозначное отображение любого подмножества элементов
одного декартова произведения массивов на какое-либо подмножество
этого или другого декартова произведения массивов будем называть
безусловной операцией или просто операцией. Операцию можно
трактовать как функцию, аргументом и значением которой
являются некоторые совокупности переменных с индексами. Заметим, что
мы не накладываем каких-либо существенных ограничений на вид
операции. Конкретное представление безусловной операции через
какие-нибудь другие операции, вообще говоря, может содержать и
условные переходы. Важно лишь, чтобы эти условные переходы не
отражались на числе входов и выходов безусловной операции, а
также на их содержании.
Более точно сказанное означает следующее. Рассмотрим любую
функцию F(xu . . ., xs; уи . . ., уг), которая по заданному набору
допустимых аргументов хь . . ., xs однозначно вычисляет величины
ух, · . ., уг. При этом не имеет никакого значения, как конкретно
устроена функция F. Чтобы получить безусловную операцию,
подставим вместо.#b . . ., xs некоторые переменные с индексами аь
. . ., as, вместо уи . . ., уТ переменные с индексами βι, . . ., βΓ.
Индексы подставляемых переменных могут быть произвольными
функциями от тех индексов, которые используются при описании
элементов массивов. Однако, согласно определению безусловной
операции, никакие вычисления над индексами переменных в f не
осуществляются. Поэтому индексы вычисляемых переменных
задаются априори и не зависят ни от индексов переменных,
используемых в качестве аргументов, ни от значений самих переменных.
Если, например, для описания каких-то массивов введены
индексы i, /, k, . . . и элементы массива А описываются буквой а с
двумя индексами, то подставляемой переменной может быть ay+b t_k,
ai*+k,j*, ai%jk и т. п. Пусть F(x, у, z; w) означает, что w=-x+yz.
Тогда F(dij, bik, ckj\ ац) задает безусловную операцию,
описывающую вторую операцию примера (12.3).
Не накладывается никаких ограничений на степень сложности
безусловной операции. Любую последовательность безусловных
§ 12. ФОРМЫ ЗАПИСИ АЛГОРИТМОВ
123
операций всегда можно объявить одной новой операцией. В
дальнейшем, если не сделано специальной оговорки, будем
предполагать, что в записях алгоритмов не встречается последовательное
выполнение двух или более безусловных операций. Если же в
записи две безусловные операции стоят рядом, то они должны быть
отмечены какими-нибудь различными признаками.
Функциональное содержание операции, а при необходимости и индексные
выражения будем задавать каким-либо способом отдельно от общей
записи алгоритма. Если входные или выходные переменные не
определены или их значения не зависят от индексов, то такие переменные
иногда будем обозначать символом *.
Одним из самых существенных моментов выбора формы записи
алгоритмов является обеспечение возможности компактного
задания многократного выполнения одной и той же операции в
зависимости от различных значений индексов входных и выходных
переменных. На языке фортран одна из таких возможностей
обеспечивается оператором DO. Мы тоже будем использовать аналогичный
оператор для указания циклических повторений выполнения одной
и той же операции.
Будем считать, что все или только некоторые операции,
участвующие в записи алгоритма, помечены целыми положительными
числами, которые назовем метками. Местоположение меток не
играет никакой роли, поэтому для определенности предположим,
что они находятся слева от операции. Оператор цикла DO имеет вид
DO n i = mly т2, m3.
Здесь η — метка некоторой операции, находящейся в записи ниже
оператора DO. Все то, что находится между оператором DO и
операцией с меткой п, включая саму операцию, будем называть телом
цикла. Тело цикла, вообще говоря, зависит от параметра i, который
называется параметром цикла. Выполнение оператора DO означает,
что последовательно выполняется тело цикла для всех значений
параметра цикла i от тх до т2 включительно с шагом т3. Сначала
тело цикла выполняется при i=mx, затем при i=m1+ms, после
этого при i=mx-\-2m3 и т. д. до тех пор, пока i^m2. Тело цикла
должно выполняться хотя бы один раз, т. е. должно быть т^т^
Величины ти т2) т3 будем считать целочисленными и
положительными. Если т3 опущено, то оно полагается равным 1. В теле цикла
могут находиться другие операторы DO с другими параметрами
цикла.
Мы не будем более подробно останавливаться на описании
оператора DO. В целом оно остается таким, как в языке фортран.
Однако, как уже отмечалось, от операции мы будем требовать, чтобы
никакие вычисления, изменяющие текущее значение параметра
цикла, в ней не производились.
Будем также предполагать, что индексы входных и выходных
переменных любой операции могут быть заданы любыми выраже-
124 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
ниями, зависящими от параметров циклов, и определены до
выполнения оператора DO. Если оператор цикла DO сам входит в тело
какого-нибудь цикла, то от соответствующих параметров циклов
могут зависеть и величины тх, т2, т3. Оператор DO также может
быть снабжен меткой.
Среди безусловных операций целесообразно выделить пустую
операцию, которую обозначим символом CONTINUE. Эта операция
не выполняет никаких действий и служит лишь носителем метки.
В некоторых ситуациях использование пустой операции
оказывается полезным. Кроме безусловных операций рассмотрим также две
условные операции. Одна из них имеет вид GO TO п. После
выполнения этой операции следующим всегда начинает выполняться то,
что имеет метку п. Другая условная операция такова: IF (Л, пи
п2, . . ., ns). Здесь А — некоторая функция, которая может
зависеть от значений переменных любых безусловных операций,
выполненных раньше операции IF, а также от всех текущих
значений параметров циклов; пи п2, . . ., ns — целые числа. Ее
функциональное содержание будем задавать каким-либо способом
отдельно. От чисел пи п2, . . ·, ns будем требовать, чтобы они не
являлись метками, относящимися к содержанию тела цикла хотя бы
одного оператора DO. Будем считать, что если значение функции
А равно пи то после выполнения операции IF следующим начинает
выполняться то, что имеет метку п%. Если же значение функции А
не равно ни одному из чисел пи п2, . . ., п8, то после выполнения
операции IF следующим начинает выполняться то, что в записи
стоит под этой операцией. Все эти операции также являются
аналогами соответствующих операций языка фортран.
Пусть теперь определены массивы, введены индексы,
описывающие их элементы, и каким-то образом задано функциональное
содержание каждой безусловной операции и функции,
определяющей операцию IF. Рассмотрим построчную сверху вниз запись,
где в каждой строке стоит (возможно, со своей меткой) либо
оператор цикла DO, либо одна из безусловных или условных операций.
Тогда каждой такой записи соответствует некоторый алгоритм,
который получается путем выполнения действий, описанных в
строках, начиная с верхней. Эту запись будем называть программой
алгоритма.
Программа и соответствующий алгоритм, описываемые
последовательностью операторов DO и одной безусловной операцией,
называются гнездом циклов. Если между двумя последовательными
операторами DO (не обязательно между каждыми) также имеется
не более одной безусловной операции, то такую программу и
соответствующий алгоритм будем называть составным гнездом
циклов. Каждому гнезду припишем размерность, понимая под этим
число описывающих это гнездо операторов DO. Отдельную
безусловную операцию будем считать входящей в гнездо
размерности 0.
§13. РЕШЕТЧАТЫЙ ГРАФ АЛГОРИТМА
125
Алгоритм, который описывается последовательностью операторов
DO и безусловных операций, назовем безусловным. Если в записи
алгоритма имеются условные операции, то такой алгоритм назовем
условным. Для безусловного алгоритма порядок выполнения
отдельных его операций определен однозначно самой записью до
выполнения алгоритма. Будем называть этот порядок
лексикографическим. Для условного алгоритма порядок выполнения операций
может зависеть от результатов промежуточных вычислений. Запись
(12.3) описывает безусловный алгоритм.
Всюду в дальнейшем, если не сделано специальной оговорки,
мы будем рассматривать только безусловные алгоритмы. К этому
есть веские основания, связанные не только с большей простотой
этих алгоритмов.
Заметим, что считать алгоритм условным или безусловным во
многом зависит от уровня детализации его рассмотрения. Алгоритм,
который является условным, если его рассматривать на уровне
алгебраических операций, довольно часто оказывается
безусловным, если его описать в терминах более крупных операций.
Поэтому мы не случайно ничего не говорили о функциональном
содержании наших операций. Вообще говоря, сами операции,
рассматриваемые как алгоритмы, могут быть условными.
Исследуя программу безусловного алгоритма, можно надеяться
на успех в построении графа и его параллельной формы. Если
удается найти для графа параллельную форму достаточно большой
ширины, то реализация алгоритма на вычислительной системе с
многими ФУ в конечном счете будет сводиться к реализации на
системе большого числа не связанных друг с другом однотипных
операций, а точнее — макроопераций. Даже в том случае, когда
эти макрооперации являются условными алгоритмами, мы будем
иметь более простую ситуацию, чем если бы с самого начала
рассматривали весь алгоритм как условный.
Упрощение заключается в наличии потока однотипных
вычислений. Об этом подробнее мы будем говорить ниже. Сейчас же только-
отметим, что если бы мы начали сразу изучать условные алгоритмы,
то рисковали бы увязнуть в таких ситуациях, которые на практике
встречаются довольно редко. Для безусловных алгоритмов их графы
всегда можно определить и исследовать до реализации самих
алгоритмов на вычислительных системах, для условных алгоритмов
это можно сделать далеко не всегда.
§ 13. Решетчатый граф алгоритма
Рассмотрим произвольный безусловный алгоритм. Наша
ближайшая задача будет заключаться в разработке общих принципов
построения и исследования решетчатых графов таких алгоритмов.
Для этого в первую очередь необходимо выбрать подходящие
системы координат, построить некоторое семейство решеток, разместить
■126 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
в их узлах вершины графа, указать соответствие выполняемым
операциям, установить, согласно порядку выполнения операций в
алгоритме, порядок прохождения вершин, определить дуги графа.
Перенумеруем подряд в записи алгоритма сверху вниз все
параметры циклов, а также все операции. Будем считать, что из двух
параметров циклов (операций) старшим является параметр
(операция), имеющий меньший номер. Обозначим параметры циклов
через /ь . . ., /и, операции через Fb · · ·, Fm.
В соответствии с соглашением о форме записи алгоритмов
множество реализаций каждой операции определяется единственным
гнездом циклов. Это гнездо можно получить, если в записи
алгоритма оставить только те операторы циклов DO, которые стоят раньше
операции, а их метки расположены либо на уровне операции, либо
ниже ее. Будем называть такое гнездо циклов опорным для данной
операции.
Пусть опорное гнездо операции Ft описывается параметрами
Iil9 . . ., U . Будем считать /ti, . . ., /t прямоугольными
координатными осями некоторого s-мерного пространства. Рассмотрим в
этом пространстве множество точек с целочисленными
координатами. Очевидно, оно образует регулярную прямоугольную решетку.
Поставим теперь в соответствие каждому узлу данной решетки
операцию Ft и обозначим через Vt множество узлов, которое
определяется допустимыми значениями параметров опорного гнезда для
операции Ft. Обозначим далее через V объединение множеств Vi
по всем i, l^t^m, и возьмем его в качестве множества вершин
решетчатого графа исследуемого алгоритма.
Построение множества Vi, вообще говоря, необходимо
несколько уточнить. Хотя мы и не интересуемся сейчас функциональным
содержанием операции Fi9 тем не менее нужно принять во внимание
тот факт, что оно может зависеть от конкретных значений
параметров /tl, . . ., Ii . В действительности так чаще всего и бывает.
В частности, от конкретных значений параметров зависят и индексы
переменных, стоящих на входах и выходах операции; от них может
зависеть и ход вычислительного процесса при реализации
операции. Поэтому на самом деле Ft определяет целое множество
операций, задаваемое параметрами Iit, . . ., U при описании
алгоритма.
Говоря о том, что каждому узлу решетки ставится в соответствие
операция Fb мы считаем, что узлу с конкретными значениями
координат ставится в соответствие операция типа Ft, определяемая
параметрами с такими же конкретными значениями. Так,
например, в рассмотренном в § 6 примере построения решетчатого графа
для алгоритма вычисления произведения А=ВС двух матриц 5, С
каждому узлу с координатами ί, /, k поставлена в соответствие не
просто операция вида а-\-Ьс, а операция, которая элементу a\f
присваивает значение a^_1)+6iAcA7·.
§ 13. РЕШЕТЧАТЫЙ ГРАФ АЛГОРИТМА
127
Естественно, что разные множества Vi, Vj соответствуют разным
операциям Ft, Fj алгоритма. Если среди параметров, описывающих
опорные гнезда этих операций, имеются общие, то некоторые из.
геометрических характеристик множеств Vi, Vj будут совпадать.
Утверждение 13.1. Предположим, что опорное гнездо
операции Ft описывается параметрами Iit, . . ., It , операции Fj —
параметрами 1^, . . ., /;· , и пусть, например, i<Cj. Тогда
— если пересечение параметров /ti, . . ., 1{ и 1}ί, . . ., /;· пусто,
то любой параметр It старше любого параметра 1} ;
— если пересечение параметров Iit, . . ., It и 1]х, . . ., /,· не
пусто, то любой параметр, входящий в пересечение, старше любого?
параметра, не входящего в пересечение; при этом любой из
параметров Ιι , не входящий в пересечение, старше любого из параметров I,- г
не входящего в пересечение.
Согласно свойствам операторов циклов DO, области действия
любых двух операторов могут быть только или вложенными одна
в другую, или следующими одна за другой. Поэтому, если в
пересечении есть хотя бы один общий параметр, χο это означает, что у
обоих опорных гнезд есть общий оператор цикла. В этом случае
любой оператор цикла, содержащий в своем теле рассматриваемый
общий оператор и присутствующий в одном из опорных гнезд,
должен присутствовать и в другом опорном гнезде. Новому общему
оператору цикла соответствует более старший параметр.
Следствие. Если среди координат вершин множеств Vi,
Vj имеются общие, то они образуют старшие группы и каждая:
из общих координат принимает одни и те же значения как в Vi,
так и в Vj-
Рассмотрим всю упорядоченную совокупность опорных гнезд,
циклов алгоритма и какое-нибудь фиксированное опорное гнездо.
Сравнивая параметры фиксированного гнезда последовательно с
параметрами всех гнезд, мы можем в общем случае сказать
следующее. Сначала все параметры фиксированного гнезда оказываются
младше любого из параметров первых гнезд. Затем у гнезд
появляются общие старшие параметры, и их число до какого-то момента-
не убывает, пока не сравняется с числом всех параметров
фиксированного гнезда. После этого число общих параметров не
возрастает, и, наконец, все параметры фиксированного гнезда становятся
старше любого из параметров остальных гнезд.
Итак, множество V всех вершин графа произвольного
безусловного алгоритма описано и установлено соответствие между
вершинами графа и операциями алгоритма. В множестве V осталось
неопределенным лишь расположение подмножеств Vi относительна
друг друга. Однако эта определенность нам нигде не потребуется-
Введенная ранее запись алгоритма предполагает
последовательное выполнение его операций в порядке, который назван
лексикографическим. Этот порядок выполнения операций задает порядок.
128 гл· 3· ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
обхода вершин решетчатого графа, т. е. устанавливает для них
некоторое отношение предшествования. В соответствии с
лексикографическим порядком будем говорить, что одна вершина ближе
к какой-то фиксированной, чем другая, причем ближе сверху или
ближе снизу в зависимости от того, обходится ли она позже
фиксированной или раньше.
Рассмотрим любые две операции. Пусть первая из них относится
к операциям типа Ft и ей соответствует множество параметров
/ti, . . ., Ιι , а вторая относится к Fj и ей соответствует множество
параметров Ifl, . . ., /;· .
Утверждение 13.2. Для того чтобы, согласно
предписанию алгоритма, первая операция выполнялась раньше второй,
необходимо и достаточно выполнение одного из следующих условий:
— в множествах параметров имеются общие, причем для части
старших из них соответствующие значения параметров обеих
операций совпадают и для первой операции значение параметра,
следующего за равными, меньше, чем значение соответствующего
параметра для второй операции',
— в множествах параметров имеются общие, все их
соответствующие значения для обеих операций совпадают, *</;
— в множествах параметров нет общих, ί</.
Справедливость этого утверждения устанавливается прямым
исследованием работы системы операторов циклов DO. Напомним,
что, прежде чем переходить к следующему значению параметра,
сначала выполняются с текущим значением все операции тела
цикла независимо от того, сколько других циклов входит в его
состав. Поэтому те операции, которые соответствуют меньшим
значениям общих старших параметров, всегда выполняются раньше.
Если же все соответствующие значения старших параметров
попарно совпадают или общих параметров нет, то определяющим
становится местоположение в записи программы самой операции.
Условия предшествования операций, указанные в утверждении
13.2, не удобны ни для теоретического, ни для практического
использования, так как не записаны в аналитическом виде. Однако
вершинам графа алгоритма, соответствующим выполняемым
операциям, приписаны координаты. Поэтому можно попытаться
построить функционал или систему функционалов, чтобы задачи,
связанные с установлением предшествования операций, решать на
основе сравнения результатов подстановки в эти функционалы
координат вершин. Вообще говоря, таких функционалов можно указать
достаточно много, и их вид определяется спецификой решаемых
задач. Мы будем в основном иметь дело со следующими задачами:
— установить отношение предшествования для двух вершин,
-если известно, каким опорным гнездам они соответствуют;
— установить отношение предшествования для трех вершин,
•если известно, что две из них соответствуют одному гнезду.
§ 13. РЕШЕТЧАТЫЙ ГРАФ АЛГОРИТМА
129
Для сравнения вершин /, / £ V на предшествование построим
функционал Ф(/, J) следующим образом. Обозначим через d
максимальное значение всех параметров циклов и возьмем любое
положительное число ε, не превосходящее (d+Ι)"1. Припишем каждому
параметру Ih вес ε^-1. Пусть вершина /ζ Vt имеет координаты Iit,
. . ., /f , вершина J ζ Vj — координаты Ifi, . . ., Ι}· .
Предположим, что первые г координат вершин из Vt, Vj описываются
общими параметрами. Функционал
ГО, г = 0,
Ф(/. A" [J;, .'<-(/,,-/,,). г>0, <13·])
будем называть опорным функционалом.
Утверждение 13.3. Опорный функционал (13.1) при г>0
равен нулю тогда и только тогда, когда Iit=Ijt для Х^Л^г.
Опорный функционал при г>0 положителен (отрицателен) тогда и
только тогда, когда для некоторого q, 1^д</, выполняются
равенства Ii=Lx при 1<£<я, но I{ >Ii IIt <// ).
В самом деле, в силу выбора числа ε изменение люэои из
координат на 1 не может быть скомпенсировано никаким изменением
более младших координат. Все эти свойства остаются
справедливыми при любых достаточно малых ε. Теперь справедливость
высказанного утверждения следует непосредственно из утверждения
13.2.
Утверждение 13.4. Для того чтобы вершина I ς К*
предшествовала вершине J £ Vj, необходимо и достаточно, чтобы либо
значение опорного функционала Ф(/, J) было отрицательно, либо
оно равнялось нулю при условии ί</.
Отрицательность опорного функционала означает, что
некоторое число старших координат вершин /, / определяется общими
параметрами циклов. При этом соответствующие значения части,
старших координат для обеих вершин могут совпадать, но Значение
общей координаты, следующей за совпадающими для вершины /,
должно быть меньше значения той же координаты для вершины J.
Равенство нулю опорного функционала говорит о том, что либо
общих координат у обеих вершин нет, либо соответствующие
значения общих координат попарно совпадают.
Следств ие. Если три вершины I, J, К соответствуют
одному опорному гнезду, то
Ф(/,У) = Ф(/, К) + Ф(К, J).
Следствие. Пусть вершины I, J соответствуют ному
опорному гнезду. Зафиксируем J и заставим I пробегать вершины
гнезда в порядке, соответствующем порядку выполнения операций.
Тогда значения функционала Φ (/, J) будут возрастать линейно и
принимать нулевое значение лишь при /=/.
5 В. В. Воеводин
130 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ ι
Следствие. Пусть из трех вершин /, 7, К вершины /, J >
различны и соответствуют одному опорному гнезду. Если обе
вершины /, J предшествуют К, то I ближе к /С, чем У, тогда и только
тогда, когда Φ (7, J)>0.
Определенная грубость введенного опорного функционала
объясняется тем, что нигде в дальнейшем нам не придется проводить
слишком тщательное исследование отношения предшествования
на всем множестве вершин. В случае необходимости нетрудно
модифицировать опорный функционал нужным образом.
В основе способа определения дуг решетчатого графа алгоритма
лежат следующие соображения. Любая вершина графа однозначно
задается своими координатами. Каждой вершине соответствует
единственный тип выполняемой операции. Аргументами и
результатами операции являются элементы вполне определенных массивов,
т. е. переменные с индексами. При этом все индексы всех
переменных, задействованных в каждой операции, однозначно
определяются координатами вершины. Поэтому все связи для конкретного
алгоритма должны находиться по координатам вершин.
Будем считать, что каждая дуга, связывающая две вершины
решетчатого графа алгоритма, означает наличие той и только той
ситуации, когда некоторый элемент массива, являющийся
результатом выполнения операции, соответствующей одной вершине,
является также одним из аргументов операции, соответствующей
другой вершине, причем ни одна из операций, выполняемых согласно
предписанию алгоритма между рассматриваемыми операциями, не
перевычисляет этот элемент. Каждая дуга символизирует перенос
аргумента конкретной операции от места его вычисления к месту
его использования, и направление дуги совпадает с направлением
переноса. Две вершины могут быть связаны несколькими дугами,
направленными в одну сторону. С каждым аргументом операции
связывается не более одной входящей в соответствующую вершину
дуги. Если для какого-то аргумента нет входящей дуги или входит
дуга, не имеющая начальной вершины, то будем считать, что этот
аргумент является начальным данным алгоритма.
Таким образом, для определения дуги, входящей в данную
вершину и соответствующей данному аргументу операции,
необходимо сделать следующее. Сначала по координатам вершины
находится элемент массива, являющийся аргументом операции. Затем
определяются все вершины, соответствующие тем операциям,
которые получают этот же элемент в качестве одного из своих
результатов. И наконец, среди найденных вершин выбирается та, которая
ближе снизу к данной в смысле отношения предшествования. Эта
процедура выполняется для всех входов каждой вершины
решетчатого графа алгоритма, после чего построение графа
заканчивается.
Напомним еще раз, что мы не интересуемся сейчас
функциональным содержанием выполняемых операций. Значение имеет только
§ 13. РЕШЕТЧАТЫЙ ГРАФ АЛГОРИТМА 13*
то, какие переменные и с какими индексами используются на
конкретных входах и выходах операций, находящихся в вершинах.
Не важно даже, что представляют собой эти переменные. Нужно
лишь уметь различать переменные, относящиеся к разным
массивам. Поэтому сказанное означает, что в действительности
решетчатый граф алгоритма полностью определяется описанием множества
V вершин / графа алгоритма и заданием на этом множестве двух
векторных функций Р(7), Q(/), описывающих входы и выходы
операций. Желая подчеркнуть зависимость графа О от V, P(I), Q(7),
будем писать 0=0(1£ К, P(I)> Q(/)).
Как уже говорилось, множество V есть объединение построенных
ранее множеств Уг·, состоящих из вершин опорных гнезд циклов.
На множестве V задано отношение предшествования. Не уменьшая
общности, можно считать, что оно определяется утверждением 13.4.
Операция алгоритма, соответствующая вершине /, в качестве
результата своей реализации вычисляет какие-то элементы каких-то
массивов и при этом берет в качестве аргументов также некоторые
элементы массивов. Если известно, к какому из множеств V-г
относится вершина /, то это однозначно определяет используемые
массивы и индексы элементов на входах и выходах операции как
функции координат вершины /. Заданные на множестве V функции —
это векторная функция Р(1) индексов выходных переменных и
векторная функция Q(I) индексов входных переменных. Возможно,
что элементы векторов Ρ (/), Q(I) придется пометить, чтобы
отличать отношение к разным массивам переменных. Размерность
вектор-индексов Ρ (/), Q(I) зависит как от размерности массивов
переменных, так и соответственно от числа выходов и входов операций
и может быть различной в различных вершинах /.
Рассмотрим один пример, иллюстрирующий изложенный в
данном параграфе материал. Среди многих задач линейной алгебры,
возникающих при решении уравнений математической физики
сеточными методами часто встречается задача решения систем
линейных алгебраических уравнений с блочно двухдиагональной
матрицей. При этом внедиагональные блоки представляют
диагональные матрицы, диагональные блоки — двухдиагональные
матрицы. Системы такого вида появляются, например, при реализации
попеременно-треугольного метода для решения сеточных
уравнений. Будем считать для определенности, что матрица системы
является левой треугольной, и пусть она имеет блочный порядок т и
порядок блоков, равный п.
Представим решение и правую часть системы в соответствующем
блочном виде и обозначим через xik, cik, Ь(_икУ bik) dik
элементы решения, правой части, поддиагоналей и диагоналей
диагональных блоков, диагоналей внедиагональных блоков. Здесь всюду k
означает номер блока; блоки нумеруются для векторов подряд, для
матриц—вдоль диагонали. Аналогично нумеруются элементы
внутри блоков. Алгоритм отыскания решения такой задачи может
132 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
быть записан следующим образом:
DO 1 /=1, т
1 х/0 = О
DO 2Ы, я
DO 2 ί=1, m
_ Cik — bi-l,k xi-i, k — di,k-l Xi, k-1
xik — -ζτ
2 CONTINUE
При этом предполагается, что ^г0=0, bok=0 для всех i, &.
Представленная запись является типичной для безусловных
алгоритмов. В заданном алгоритме имеется три опорных гнезда:
DO 1 /=1, т
1
2
х/0=0
DO 2 jfe=l,
CONTINUE
DO 2 Λ=1,
DO 2 t =
Cik—bi-
χ k
η
1, m
i,kxi-h
_
,ft-
-_di_
,k-
-\*i,b-
-1
2 CONTINUE
Параметры циклов имеют такое старшинство: /, k, i. Вершины /
решетчатого графа алгоритма располагаются в узлах трех
целочисленных множеств Vu V2, V3, где
Vx: l</<m;
Vs: 1<&<л, l<i<m.
Объединение этих множеств есть множество V.
Очевидно, что единственная изменяемая координата вершин
из V2 и первая координата вершин из V3 описываются общим
параметром k. Если, например, вершина / из V2 имеет координату k2>
а вершина J из V3 имеет координаты &3, ΐ3, то для данной пары
вершин опорный функционал имеет вид
Ф(/, /) = ε(&2-&3),
где 0<8<;(тах {т, п}+1)-1. Если же вершина / также
принадлежит V3 и имеет координаты к'ъ, i'3) то в этом случае
ф(/, у)-8(^-/?3)+в2(^-д.
§ 14. РАСЩЕПЛЕНИЕ РЕШЕТЧАТОГО ГРАФА
133
Каждое из трех опорных гнезд характеризуется своей
безусловной операцией. В порядке старшинства они записываются
следующим образом:
ν _ cik — bi-u **/-ь k—djik-ιΧί, k-i
Xik — —— .
Сокращенные обозначения этих операций таковы:
Λ(*; */о);
*з (cfb ^/-Ь/г> ^zfe> dLk_1, A:,-_lift, Х{щь-1> Xik)·
Согласно договоренности, символ * здесь означает, что
соответствующие входные переменные функций Fl9 F2 не зависят от
индексов. Для функции F3 необходимо также дополнительно указать,
какие переменные относятся к каким массивам. В данном случае
это указание осуществляется использованием одинаковых букв для
переменных одного массива.
Так как безусловные функции имеют не одинаковое число
входных переменных, то размерности вектор-индексов Q(I) будут
различными в зависимости от того, к какому из множеств Vu Vi, V9
принадлежит вершина /. Функции Р(7), Q(I) задаются так:
p(i) = \ (о>/о; iev2-,
I «, k)\ ie v3,
( 0, /€^;
Q(/)= 0, lev,;
{ (i, k\ i—1,&; i, k\ i, k—1; i—1, k\ i, k—\)[ I £VV
Снова необходимо каким-то способом дополнительно пояснить, к
каким переменным каких массивов относятся координаты векторов
P(I)y Q(I)· Здесь достаточно указать на соответствие сокращенным
обозначениям безусловных операций.
Конечно, векторные функции Р(7), Q(I) описываются несколько
не четко, впрочем, как и безусловные операции. Однако, чтобы не
загромождать изложение материала лишней символикой, будем
конкретизировать соответствующие детали описания только по
мере необходимости.
§ 14. Расщепление решетчатого графа
Рассмотрим ациклические графы d, . . ., Gs. Предположим, что
их объединение есть ациклический граф О. Пусть известна какая-
нибудь его параллельная форма. Все вершины любого графа G*
как вершины графа О распределены некоторым образом по ярусам
134 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
параллельной формы. Возможно, что при этом в каких-то ярусах
не окажется ни одной вершины графа Gt. Тем не менее
параллельная форма графа G порождает разбиение множества вершин графа
Qi на непересекающиеся подмножества по принадлежности вершин
к одному ярусу. Так как любое из подмножеств целиком входит
в один ярус параллельной формы, то это разбиение образует
параллельную форму графа Gt. Следовательно, каждая параллельная
форма графа О дает возможность построить параллельные формы
любого из графов Gj. Заметим, что даже в том случае, когда
рассматривается каноническая параллельная форма графа G,
построенные по ней параллельные формы графов Gi не обязательно будут
каноническими.
Пусть теперь известны канонические параллельные формы
графов Gi, . . ., Ge. Будем строить по ним каноническую форму графа G.
Очевидно, что если вершина графа G принадлежит r-му ярусу
этой формы, то она как вершина некоторого графа Qt принадлежит
ярусу его формы с номером, не превосходящим г. Напомним, что
для г>1 любая вершина из г-го яруса канонической параллельной
формы связана дугой с одной из вершин (г—1)-го яруса. Поэтому
для отыскания вершин первого яруса канонической формы графа G
необходимо найти в первых ярусах графов Gly . . ., Qs те
вершины, которые не встречаются в ярусах с номерами больше 1.
Вычеркнем из первых ярусов найденные вершины. Для отыскания вершин
второго яруса канонической формы графа G необходимо найти среди
оставшихся вершин первых двух ярусов графов Gly . . ., Gs
вершины, которые не встречаются в ярусах с номерами больше 2 и
связаны дугами с вершинами первого яруса графа G. Снова вычеркнем
из первых двух ярусов графов Gly . . ., Gs найденные вершины.
В общем случае для отыскания вершин г-го яруса канонической
формы графа G необходимо найти среди оставши зя вершин первых г
ярусов графов Gly . . ., Gs вершины, которые не встречаются в
ярусах с номерами больше г и связаны дугами с вершинами {г—1 >то
яруса графа G. Затем вычеркиваются из первых г ярусов графов
Gi, . . ., Gs найденные вершины. Процесс повторяется, пока не
будут исчерпаны все вершины графов 01у . . ., Gs и тем самым не будет
закончено построение канонической параллельной формы графа 6.
Таким образом, если из каких-либо соображений получено
расщепление графа G на графы Gly . . ., Gs, то, зная параллельные
формы этих графов, можно получить параллельную форму графа G.
Конечно, мы не будем заниматься исследованием данной задачи
в случае графов общего вида, а изучим ее только для решетчатых
графов алгоритмов. Решетчатые графы имеют естественное
расщепление на графы специального вида, которые достаточно просты
и отражают внутреннюю структуру алгоритмов в целом.
Подчеркнем сразу, что речь пойдет о расщеплении графа алгоритма, а не
самого алгоритма. Однако расщепление графа помогает изучению
структуры алгоритма.
§ 14. РАСЩЕПЛЕНИЕ РЕШЕТЧАТОГО ГРАФА
135
Пусть алгоритм описывается графом G(/£F, P(7), Q(/)).
Разобьем множество всех входных переменных операций алгоритма
произвольным образом на две непересекающиеся группы. Это
порождает в каждой вершине / разбиение вектора индексов Q(I) в
прямую сумму векторов Qi(I) и Q2(/), что будем обозначать
записью Q(/)=Qi(/)©Q2(/)· Размерности векторов Qi(I) и Q2(/) могут
зависеть от вершины, и в частности один из них может быть пустым.
Условно такое разбиение можно представить как замену операции,
соответствующей вершине /, какими-то двумя гипотетическими
операциями. Каждая из этих операций вычисляет те же элементы,
что и исходная, а аргументы исходной операции распределяются
между новыми операциями, образуя их аргументы. Существенным
является то обстоятельство, что при распределении аргументов
исходной операции сами аргументы не дублируются, и, следовательно,
ни один из них не может одновременно быть аргументом обеих
новых операций.
Утверждение 14.1. Всегда имеет место расщепление
G(/€V, P(I), Qi(/)©Q,(/)) =
= G(/<EV, P (I), Q^/JjuGi/gV, Ρ (I), Q,(/))·
Граф в левой части равенства заведомо является подграфом
графа в правой части равенства, причем множества их вершин
совпадают, и, следовательно, оба графа могут различаться только
дугами. Каждая дуга, входящая в любую вершину, единственным
образом определяется соответствующей входной переменной и
каким-то множеством выходных переменных, принадлежащих Р(1).
Так как никакая входная переменная при разбиении на группы не
дублировалась, то в объединении графов правой части равенства
не может появиться никакой лишней дуги.
Входные и выходные переменные оказывают не одинаковое
влияние на сложность процесса нахождения дуг решетчатого графа
алгоритма. Для каждой дуги этот процесс всегда зависит от одной
входной переменной и в общем случае от нескольких выходных
переменных, так как необходимо учесть возможность вычисления
одного и того же элемента как при разных операциях, так и на
разных выходах одной операции. Наличие дуги означает, что на
соответствующих входе и выходе находится общий элемент массива.
Поэтому на процесс определения отдельной дуги в действительности
оказывают влияние только входная и выходные переменные,
относящиеся либо к одному массиву, либо к общей части
пересекающихся массивов. Следовательно, справедливо
Утверждение 14.2. Если в записи алгоритма отсутст
вуют выходные переменные, или отсутствуют входные переменные,
или выходные переменные не имеют ни одного общего элемента с
входными переменными, то решетчатый граф алгоритма является
пустым.
136 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
Это утверждение имеет исключительно важное значение. Оно
позволяет в процессе расщепления графа алгоритма выбрасывать
все его составляющие, которые удовлетворяют одному из условий
утверждения, и тем самым значительно упрощать дальнейший
анализ.
Разобьем аналогичным образом на две непересекающиеся
группы множество всех выходных переменных операций. Однако теперь
дополнительно предположим, что в этих группах нет ни одного
общего элемента ни одного из массивов, преобразуемых при
реализации алгоритма. Это порождает в каждой ^вершине / разбиение
вектора индексов Р(1) в прямую сумму ^ι(/)φΡ2(/) векторов Ρι(Ι)
и />,(/).
Утверждение 14.3. В условиях данного разбиения имеет
место расщепление
G(I£V, Рг(1)®РЖ Qd)) =
= G(leV, PJ/), Q(/))UG(/6K, />,(/). Qi/))·
Действительно, снова граф в левой части равенства является
подграфом графа в правой части равенства, и множества их вершин
совпадают. Предположим, что граф слева имеет дугу, входящую в
вершину J. Эта дуга однозначно определяет некоторый элемент
какого-то массива, являющийся аргументом операции,
соответствующей вершине J. Но этот же элемент как результат выполнения
операции, согласно условию утверждения, не может быть
одновременно отражен и в векторах Ρι(Ι), и в векторах Р2(1)· Поэтому в
графах, стоящих в правой части равенства, не может появиться
никакой лишней дуги.
Не ограничивая существенно общности, можно предполагать,
что все массивы являются непересекающимися, так как массивы,
имеющие общие элементы, всегда можно считать единым массивом.
Теперь, многократно применяя на основе утверждений 14.1—14.3
процедуру разбиения входных и выходных переменных,
представим решетчатый граф алгоритма в виде объединения графов,
имеющих следующее описание. Согласно утверждению 14.1, можно
считать, что векторная функция Qt (/) каждого из таких графов во всех
вершинах / соответствует не более чем одной переменной, причем
одного и того же массива. Согласно утверждению 14.2, можно
считать, что векторная функция Ръ (/) каждого из таких графов
соответствует во всех вершинах / только тем выходным переменным,
которые принадлежат тому же массиву.
Подобных представлений существует очень много. Можно
разбить решетчатый граф алгоритма на подграфы, имеющие не более
одной дуги. Но это возможно только тогда, когда сам решетчатый
граф уже известен, так как в общем случае определение отдельной
дуги связано с рассмотрением многих вершин. Можно разбить граф
на крупные подграфы. Но такое разбиение не удобно для изучения
самих подграфов в силу их сложности. Мы выберем представления,
§ 14. РАСЩЕПЛЕНИЕ РЕШЕТЧАТОГО ГРАФА
137
наиболее подходящие для дальнейших исследований. При этом
каждый из подграфов будет устроен достаточно просто, а его строение
тем не менее не будет зависеть от наличия других подграфов.
Рассмотрим запись произвольного безусловного алгоритма.
Возьмем любой использующийся в ней массив переменных, в том
числе нулевой размерности, и построим семейство других записей
по следующим правилам. Сначала вычеркнем в исходной записи
все входные переменные, кроме одной, относящейся к данному
массиву, и все выходные переменные, не относящиеся к данному
массиву. Вычеркнем затем все операции, в которых не осталось ни
одного входа и ни одного выхода, связанного с выбранным
массивом. И наконец, вычеркнем все операторы DO с пустыми телами
циклов. Так как нас не интересует содержание операций, то
формально можно рассматривать полученные записи как записи
некоторых безусловных алгоритмов. Эти алгоритмы и их решетчатые
графы будем называть простыми. Независимо от того, сколько
операций имеется в записи простого алгоритма, все операции
определяются не более чем одной входной переменной.
Утверждение 14.4. Пусть вычисляемые массивы
алгоритма являются непересекающимися. Тогда решетчатый граф алгоритма
представим в виде объединения всех порожденных им простых
решетчатых графов, т. е.
G(iev, р(/), q(/)) = и г (/ еК pt(/), q,(/)), (н.ι>
где множества V'i и векторные функции Pi(I), Qi(I) строятся
в соответствии с описанными выше правилами.
Предположим, что в графе, стоящем в левой части равенства,
есть какая-то дуга, входящая в вершину J. Эта дуга однозначно
определяет некоторый элемент какого-то массива, являющийся
одним из аргументов операции, соответствующей вершине J. Но этот
же элемент как входной в вершине J присутствует только в одной
векторной функции Qi(J). К тому же в векторной функции Р*(/)
рассматриваемый элемент присутствует всюду, где он есть и в
векторной функции Р(/). Поэтому любая дуга из графа слева
обязательно присутствует в одном и только в одном графе справа. Так
как функции Pi (/) охватывают все выходные элементы,
относящиеся к одному массиву, а в функциях Qi(I) нет дублирования одного
и того же элемента, то в графах справа не может появиться лишней
Дуги.
Множества Vu указанные в разложении (14.1), описываются
очень просто. Это есть объединение вершин одного или нескольких
опорных гнезд циклов, соответствующих операциям, оставшимся
после рассмотренного выше процесса вычеркивания в записи
алгоритма. Легко описываются и векторные функции Р*(/), Qi{I).
Привлекательность разложения (14.1) заключается еще и в том, что
изучение любого из графов в правой части (14.1) может осущесТ-
138 гл. з. параллельные структуры алгоритмов и программ
вляться независимо от остальных. Поэтому порядок прохождения
вершин в множествах Vt по-прежнему определяется опорным
функционалом 13.1 и утверждением 13.4.
Имеется существенное различие между строением векторов Qt (/)
и Pi (/). Каждый из векторов Qt (/) в вершинах / £ Vi либо является
пустым, либо содержит индексные выражения, описывающие только
один элемент массива, причем непустыми векторы Qt (/) могут быть
лишь в вершинах одного из опорных гнезд циклов, составляющих
множество Vi. Что же касается векторов Pi(I), то они могут быть
непустыми во всех вершинах Vt и могут содержать индексы более
чем одного элемента.
В задаче расщепления решетчатого графа алгоритма на
простейшие графы хотелось бы сделать еще один шаг, направленный на
упрощение строения векторов Pi(I). Снова рассмотрим запись
произвольного безусловного алгоритма. Опять возьмем любой массив
и вычеркнем в исходной записи все относящиеся к данному массиву
входные и выходные переменные, оставив не более чем по одной из
них. Вычеркнем далее все операции, в которых не осталось ни
одного входа и ни одного выхода, связанного с выбранным массивом,
и, наконец, вычеркнем все операторы DO с пустыми телами циклов.
Полученные с помощью описанных процедур формальные
алгоритмы и их решетчатые графы будем называть элементарными. В
случае элементарных решетчатых графов порождающие их векторы
Pi(I) устроены так же просто, как и векторы Qi(I). Однако теперь
нельзя утверждать о возможности расщепления решетчатого графа
алгоритма на элементарные, не проведя более детального
исследования.
Утверждение 14.5. В общем случае решетчатый граф
алгоритма является подграфом объединения всех порожденных им
элементарных графов, т. е.
G (/ € V, P\l), Q Щ) <= U G (/ 6 V,, Р, (/), Q{ (/)), (14.2)
i
где множества Vi и векторные функции Pi(I), Qi(I) строятся
в соответствии с описанными выше правилами.
Следствие. Решетчатый граф алгоритма в
действительности является остовным подграфом объединения всех своих
элементарных графов.
Следствие. Пусть вычисляемые массивы алгоритма
являются непересекающимися. Если из всех выходов всех операций
алгоритма с каждым массивом связан только один выход, то вложение
(14.2) превращается в равенство.
Следствие. Если алгоритм устроен таким образом, что
каждый элемент каждого массива вычисляется только один раз,
то вложение (14.2) превращается в равенство.
Основная причина того, что в утверждении 14.4 констатируется
§ 14. РАСЩЕПЛЕНИЕ РЕШЕТЧАТОГО ГРАФА
139
равенство, а в утверждении 14.5 — вложение, заключается в
следующем. Множества Vt и векторы Pt (/) в утверждении 14.4 выбраны
так, что все перевычисления любого фиксированного элемента
любого массива, используемого в качестве фиксированного аргумента
некоторой операции, могут происходить при выполнении операций,
соответствующих лишь одному множеству Vt. Именно это
обстоятельство гарантирует, что в правой части (14.1) не появляются
лишние дуги. Что же касается утверждения 14.5, то теперь
перевычисление одного и того же элемента может происходить при
выполнении операций, соответствующих разным множествам Vi. Поэтому
в правой части (14.2) по сравнению с левой частью могут быть
лишние дуги. Иногда тем не менее лишние дуги в правой части (14.2)
отсутствуют. Соответствующие ситуации описываются последними
двумя следствиями утверждения (14.5). Отметим, что как множества
Vif так и множества Vt в общем случае могут быть
пересекающимися.
Утверждение 14.6. Решетчатый граф алгоритма всегда
можно представить как объединение подграфов элементарных
графов.
Действительно, рассмотрим в разложении (14.1) простой
решетчатый граф, соответствующий множеству Уг. В каждую вершину
множества Vt либо не входит ни одна дуга простого графа, либо
входит только одна. Если в вершину из Vt входит дуга, то начальная
вершина этой дуги также принадлежит Vi. Любая из дуг
порождается единственным входом операций соответствующего простого
алгоритма и каким-то одним выходохм некоторой его операции. Все
конечные вершины дуг являются вершинами опорного гнезда
операции с входом, все начальные вершины дуг — вершинами одного из
опорных гнезд операций с выходом. Конечные вершины дуг можно
разбить на непересекающиеся подмножества, относя к одному подг
множеству те и только те из них, для которых начальные вершины
соответствующих им дуг определяются одним и тем же выходом.
Поэтому дуги простого решетчатого графа также разбиваются на
непересекающиеся подмножества и каждое из этих подмножеств
входит в множество дуг одного элементарного решетчатого графа.
Все эти элементарные графы^ порождаются одним входом, но
разными выходами. Вершины, не имеющие входящих дуг, можно
отнести к любому элементарному графу.
Проведенные исследования показывают, что для осуществления
расщепления решетчатого графа алгоритма в соответствии с
утверждением 14.6 необходимо сделать следующее:
— выделить массивы или группы массивов, которые заведомо
являются непересекающимися;
— для каждого из непересекающихся массивов выписать все
соответствующие ему гипотетические простые алгоритмы;
140 гл. з. параллельные структуры алгоритмов и программ
— выбросить все простые алгоритмы, удовлетворяющие одному
из условий утверждения 14.2;
— для каждого из оставшихся простых алгоритмов выписать
все соответствующие ему гипотетические элементарные алгоритмы;
— выбросить все элементарные алгоритмы, удовлетворяющие
одному из условий утверждения 14.2;
— выделить необходимые подграфы из графов оставшихся
элементарных алгоритмов.
Очевидно, что независимо от того, как конкретно будет реализо-
вываться последний этап, большую роль в расщеплении
решетчатого графа алгоритма будет играть знание структуры графов
отдельных элементарных алгоритмов с непустыми входом и выходом их
операций. Здесь возможны две различные ситуации: либо вход и
выход элементарного алгоритма соответствуют разным операциям
исходного алгоритма, либо они соответствуют одной и той же
операции.
Утверждение 14.7. Если вход и выход элементарного
алгоритма соответствуют разным операциям исходного алгоритма,
то решетчатый граф элементарного алгоритма не имеет путей
длиной больше 1.
Разным операциям соответствуют разные опорные гнезда
циклов. Согласно определению, разные опорные гнезда циклов не имеют
общих вершин даже в том случае, когда совпадают все
описывающие их параметры циклов. Поэтому множества начальных и
конечных вершин дуг графа элементарного алгоритма не пересекаются,
и, следовательно, в графе не существует путей длиной больше 1.
В общем случае граф элементарного алгоритма может иметь
изолированные вершины.
Таким образом, относительно сложное строение могут иметь
графы лишь тех элементарных алгоритмов, вход и выход которых
соответствуют одной и той же операции исходного алгоритма.
Любой из подобных элементарных алгоритмов задается одним гнездом
циклов. В расщеплении решетчатого графа алгоритма, описанном
утверждением 14.6, можно объединить все подграфы элементарных
графов, соответствующих одному опорному гнезду. Такое
объединение даст остовный подграф решетчатого графа алгоритма,
заданного этим опорным гнездом. Следовательно, справедливо
Утверждение 14.8. Решетчатый граф алгоритма всегда
можно представить как объединение остовных подграфов
решетчатых графов всех опорных гнезд циклов и некоторого числа графов,
не имеющих путей длиной больше 1.
Заметим, что число графов, не имеющих путей длиной больше1,
не зависит от общего числа вершин решетчатого графа алгоритма,
а определяется такими факторами, как число операций в записи
алгоритма, число используемых массивов и т. п. Поэтому
утверждение 14.8 дает веское основание к тому, чтобы заняться более
детальным изучением решетчатых графов алгоритма, заданных гнездом
§ 14. РАСЩЕПЛЕНИЕ РЕШЕТЧАТОГО ГРАФА
141
циклов, и в первую очередь элементарных решетчатых графов. Но
прежде чем переходить к этим исследованиям, проиллюстрируем
изложенный здесь материал на примере уже рассмотренного в § 13
алгоритма решения системы линейных алгебраических уравнений
с треугольной блочно двухдиагональной матрицей.
Будем считать, что массивы задаются перечислением
переменных с индексами, причем сами индексы меняются в соответствии с
изменением параметров циклов. В данном примере заведомо
непересекающиеся массивы описываются элементами
X/Q> X0k> Xlk> Xi-1, k> Xi, fc-l*> Clk> ^/-1,&> "iki dik
и отделены друг от друга точкой с запятой. Ни один из элементов
массивов с, b, d не перевычисляется. Следовательно, решетчатый
граф алгоритма в действительности можно представить как
объединение решетчатых графов простых алгоритмов, связанных лишь с
первым массивом. Эти простые алгоритмы имеют следующие записи:
DO 1 /=1, т
1 L(*; x/0)
DO 2 Λ=1, η
£(*; xok)
DO 2 i=l, m
L 'xi-i, k'y xik)
2 CONTINUE
DO 1 /=1, m
1 L(»; xJ0)
DO 2 k=l, η
Μ*; xok)
DO 2 / = 1, m
L (xi, fc-Γ» xik)
2 CONTINUE
Здесь L — гипотетические операции, символ * означает, что входы
первых двух операций L не принимаются во внимание.
Гипотетические операции не помечаются какими-нибудь отличительными
признаками, так как все необходимое их различие указывается
входными и выходными переменными. Других простых алгоритмов нет,
так как по отношению к рассматриваемому массиву в исходном
алгоритме имеется только два входных элемента.
В алгоритме каждый элемент массива вычисляется только один
раз. Согласно второму следствию из утверждения 14.5, решетчатый
граф алгоритма можно представить как объединение всех
порожденных им элементарных графов. Среди этих графов лишь шесть
графов соответствуют элементарным алгоритмам, имеющим опреде-
142 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
ленные входы и выходы. Только такие алгоритмы могут иметь
непустые графы, и все они выписаны ниже:
DO 1 /=1, т
1 #(*; Х/о)
DO 2 /г=1, η
DO 2 i = l, m
#(*/-ι.*; *)
2 CONTINUE
DO 2 k=l, η
DO 2 /=1, г-
2 CONTINUE
DO 2 ft=l, η
DO 2 i = l, m
° (xt-i, fe! ■%)
2 CONTINUE
DO 1 /=1, m
1 R{*\ x/t>)
D0 2bl, η
DO 2 ι = 1, m
#(·*/,*-ii *)
2 CONTINUE
DO 2 £=1, л
#(*; x0ft)
DO 2 i=l, m
#(**.*-i; *)
2 CONTINUE
DO 2Ы, я
DO 2 t=l, m
2 CONTINUE
Здесь R также указывают некоторые гипотетические операции.
Для элементарных алгоритмов 1, 5 выходные переменные не
имеют ни одного общего элемента с входными переменными. Соглас-
§ 15. ЭЛЕМЕНТАРНЫЙ РЕШЕТЧАТЫЙ ГРАФ
143
но утверждению 14.2, их графы пустые. Алгоритмы 2, 4 имеют графы
с путями, длины которых не превосходят 1. В действительности их
графы почти пустые. Множество вершин графа алгоритма 2 есть
объединение вершин второго и третьего опорных гнезд, а дуги
выходят только из вершин второго гнезда. Множество вершин графа
алгоритма 4 есть объединение вершин первого и третьего опорных
гнезд, а дуги выходят только из вершин первого гнезда.
Объединение графов элементарных алгоритмов 3, 6 есть решетчатый граф
алгоритма, описанного третьим опорным гнездом. Именно он
составляет основную часть решетчатого графа алгоритма решения систем
линейных алгебраических уравнений с треугольной блочно двухдиа-
гональной матрицей. Детальная структура всех этих графов будет
рассмотрена в следующем параграфе.
§ 15. Элементарный решетчатый граф
В элементарном алгоритме функции Р(/), Q(/) являются
векторами индексных выражений, определяющих соответственно
выходной и входной элементы некоторого массива размерности s.
В общем случае P(I), Q(I) определены на вершинах разных
опорных гнезд. Однако если элементарный алгоритм описан гнездом
циклов, то области определения P(I), Q(I) будут одинаковыми.
Будем называть элементарным (простым) гнездо циклов,
описывающее элементарный (простой) алгоритм.
Пусть /ь /2, · . ., 1<т — координаты вершины / из опорного
гнезда циклов, задающего область определения векторов Р(1),
и пусть 7/1Э //2, ...,// — координаты вершины / из опорного
гнезда циклов, задающего область определения векторов Q(/). Тогда
координаты ри qu l^i^s, векторов P(I), Q(I) можно считать
функциями этих переменных, т. е. Pi=Pi(Ii, /2, · . ., /m), qi=qt(Iit, I/2,
...,//). Будем предполагать, что обе группы переменных состоят
из каких-то параметров циклов исходного алгоритма и первая
группа упорядочена по их старшинству. Различные свойства
элементарных графов удобно изучать через свойства операторов P(I), Q(I) и
функций ри <7ΐ·
Утверждение 15.1. Для того чтобы вершина Г
элементарного графа была непосредственно предшествующей для
вершины /, необходимо и достаточно выполнение следующих
соотношений:
P(/') = Q(/), P(I") = Q(I),
max Φ (Г, /')<Φ(/', /)<тахФ(/', /")< 0, (15.1)
/* /"
Λ /', I£V,
где Φ (У, /) — опорный функционал и его максимумы берутся среди
отрицательных значений.
144 гл. з. параллельный структуры алгоритмов и программ
Пусть вершина /' непосредственно предшествует вершине /.
В вершине /' вычисляется элемент массива с индексами,
образующими вектор Р(1')> в вершине / аргументом операции является
элемент того же массива с индексами, образующими вектор Q(/).
Эти элементы совпадают. Следовательно, должно выполняться
равенство P(I')=Q(I). В общем случае данное равенство,
рассматриваемое как уравнение относительно /', может иметь не единственное
решение. Обозначим через I" любое из них. Во всех вершинах /"
вычисляется один и тот же элемент с индексами Q(/). Вершина /'
является решением, ближайшим снизу к вершине / в смысле
лексикографического порядка обхода вершин элементарного графа, или,
другими словами, в ней последний раз перед вершиной /
вычисляется рассматриваемый элемент массива. Вершина / не может
находиться от вершины /' очень далеко. Во всяком случае, она должна
быть не дальше, чем вершина /", в которой впервые после вершины
/' снова вычисляется тот же элемент. Именно эти факты и
отражены в соотношениях (15.1).
В элементарном решетчатом графе в каждую вершину входит
не более одной дуги, а выходить из каждой вершины, вообще
говоря, может много дуг. Пусть для вершины / ищется непосредственно
предшествующая вершина /'. Если задача (15.1) относительно /'
не имеет решения, то вершина / на множестве V не имеет
предшествующих. Это означает, что в вершине / аргумент операции
является начальным данным элементарного алгоритма. Если задача
(15.1) относительно / не имеет решение, то в этом случае результат
выполнения операции в вершине /' нигде в дальнейшем не
используется.
Подчеркнем, что утверждение 15.1 справедливо для любого
элементарного алгоритма, а не только для заданного гнездом циклов.
Поэтому соотношениями (15.1) можно пользоваться для анализа
структуры любых элементарных графов. В зависимости от того, на
каких опорных гнездах определены Р(1) и Q(/), опорный
функционал будет иметь соответствующий вид (13.1). Вершины /", /', /
принадлежат в общем случае не всему множеству V, а лишь
соответствующим опорным гнездам.
Утверждение 15.2. В элементарном графе G(l£V9
P(I), Q(/)) дуги могут выходить (входить) только из тех вершин,
которые являются прообразами пересечения областей значений
операторов Р(1) и Q(I).
Действительно, если из вершины /' идет дуга в вершину /, то,
согласно (15.1), выполняется равенство P(/')=Q(/). Но это
означает, что Г и I являются прообразами общего элемента Ρ (Г) и
Q(/).
Несмотря на свою простоту, это утверждение оказывается
весьма полезным при анализе графов. Например, с его помощью
определяются пустые графы. Если необходимо обнаружить граф, в
котором дуги выходят почти из всех вершин и заходят почти во все
§ 15. ЭЛЕМЕНТАРНЫЙ РЕШЕТЧАТЫЙ ГРАФ
145
вершины, то, согласно утверждению 15.2, подобный граф надо
искать среди таких, у которых почти совпадают области значений
операторов P(I), Q(I) и т. п.
Исследование задач, описываемых соотношениями (15.1),
становится существенно проще, если операторы P(I), Q(I) на своих
областях определения задают взаимно однозначные отображения,
т. е. являются обратимыми. Следующие утверждения указывают
некоторые ситуации, непосредственно вытекающие из
утверждения 15.1.
Утверждение 15.3. Если оператор Р(1) обратим, то
каждый элемент массива либо не изменяется в процессе реализации
элементарного алгоритма, либо изменяется только в одной вершине.
При этом
— единственная вершина Г, в которой вычисляется элемент
массива с вектором индексов f, определяется решением уравнения
Р(П=Ь
— множество вершин I, непосредственно следующих за вершиной
V, определя тся множеством решений задачи
P(I') = Q(I), Ф(/\ /)<0.
Утверждение 15.4. Если оператор Q(I) обратим, то
каждый элемент массива либо не используется в процессе реализации
элементарного алгоритма, либо используется на входе операции
только в одной вершине. При этом
— единственная вершина I, в которой используется элемент мае-
сива с вектором индексов /, определяется решением уравнения Q (/) =/.
Следствие. Если оператор Q(I) обратим, то
элементарный решетчатый граф расщепляется на не связанные подграфы,
состоящие из элементарных путей.
Таким образом, обратимость операторов Р(/), Q(/) позволяет
довольно просто установить структуру дуг элементарного
решетчатого графа.
Вообще говоря, оператор Р(1) всегда можно сделать обратимым
за счет увеличения размерности используемых массивов не более
чем на 1. Действительно, каждый элемент любого массива может
многократно перевычисляться в процессе реализации алгоритма.
Однако всегда можно однозначно установить, какой раз
перевычисляется элемент массива в той или иной вершине. Поэтому, если
добавить еще один индекс, показывающий номер перевычисления
элемента, то этот индекс является однозначной обратимой функцией
координат вершины. Оператор Р(1) с областью значений на расши-/
ренном множестве индексов будет обратимым. Естественно, что
соответствующим образом нужно изменить и оператор Q(/).
Обратимость оператора Р(1) является характерной чертой для
записей алгоритмов с помощью математических соотношений.
Использование операторов присваивания в алгоритмических языках
дает возможность более экономично записывать алгоритмы с точки
H6 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
зрения объема требуемой памяти ЭВМ. Это снижает размерность
описываемых переменных алгоритма, но приводит к многократному
перевычислению элементов массивов. Переход к обратимому
оператору Р(1), по существу, связан с возвращением к записи алгоритма
в виде обычных математических соотношений.
Предположим теперь, что функции /?ь . . ., pk зависят от
переменных /ь . . ., Ik. Пусть эти функции независимы, т. е. разным
наборам /ь . . ., Ik соответствуют разные наборы ръ . . ., ph. Будем
называть оператор Ρ (Ι) в этом случае обратимым на главном
координатном мнооюестве размерности k. Представим вектор координат
вершины / в виде прямой суммы векторов ID и 1И, где координаты
вектора ID содержат первые k координат /, координаты вектора 1И
содержат остальные координаты. Множество вершин / порождает
множества D и Η векторов ID и 1Н. На множестве D определен
обратимый оператор PD(ID), задаваемый функциями ри . . ., pk.
Область значений оператора PD(ID) будем обозначать Dp.
Рассмотрим множество вершин / из опорного гнезда циклов,
задающего область определения оператора Ρ (/). Зафиксируем любой
элемент вычисляемого массива. Этот элемент преобразуется в
каких-то вершинах /, и хотелось бы иметь некоторые характеристики
множества таких вершин. Если оператор Ρ (Ι) обратим, то множество
вершин /, в которых преобразуется любой элемент, состоит не более
чем из одной вершины, т. е. является минимально возможным.
Оказывается, что если оператор Р(1) обратим на главном
координатном множестве размерности £>1, то множество вершин пересчета
элементов также будет достаточно малым.
Вершины любого опорного гнезда образуют дискретное
множество узлов прямоугольной решетки арифметического пространства.
Будем считать, что в этом пространстве естественным образом
введены метрические понятия расстояния и объема. Тогда число
вершин, попадающих в некоторую область пространства, в целом будет
пропорционально объему области. Рассмотрим опорный
функционал Ф(/, J) на опорном гнезде циклов. Зафиксируем вершину /,
и пусть J есть произвольная точка арифметического пространства.
Множество точек </, удовлетворяющих уравнению Ф(/, /)=0, есть
гиперплоскость. Будем называть ее опорной.
Утверждение 15.5. Любая опорная гиперплоскость
Ф(/, J)=0 осуществляет следующее разбиение вершин опорного
гнезда циклов:
— на гиперплоскости находится только вершина /;
— по одну сторону гиперплоскости (в положительном
полупространстве) находятся вершины, предшествующие вершине 1\
— по другую сторону гиперплоскости (в отрицательном
полупространстве) находятся вершины, которым предшествует
вершина I.
Следствие. Разобьем координаты вершин на две
непересекающиеся группы. Для того чтобы вершина Г предшествовала вер-
§ 15. ЭЛЕМЕНТАРНЫЙ РЕШЕТЧАТЫЙ ГРАФ
[47
шине I, необходимо, чтобы ни одна из ее проекций на
соответствующие координатные подпространства не была последующей для
аналогичной проекции вершины I.
Это утверждение по существу является лишь геометрической
формулировкой утверждения 13.4. Однако оно позволяет дать
определенную характеристику множества вершин, в которых
осуществляется перевычисление любого элемента массива. Именно все такие
Еершины лежат в слое, ограниченном двумя опорными
гиперплоскостями. Одна из них проходит через вершину, где начинается
вычисление данного элемента, другая — через вершину, где
вычисление элемента заканчивается.
Утверждение 15.6. Пусть оператор Ρ (Ι) обратим на
главном координатном множестве размерности k. Тогда процесс
вычисления всех элементов массива, индексы которых имеют одну и
ту же составляющую β множестве Dp, осуществляется в слое,
толщина которого не более d&k(\—ε)"1, где d — диаметр области
определения оператора Р{1).
Если 1Ъ . . ., 1т и J и . . ., Jm суть координаты вершин /, J
из области определения оператора Ρ (/), то, согласно 13.1, опорный
функционал имеет вид
т
Ф(/, J) = £ut-Jt)&-\
Здесь ги . . ., гт — некоторая возрастающая последовательность
целых положительных чисел, соответствующих весам, приписанным
переменным циклов исходного алгоритма. Обозначим через /'
вершину, в которой начинается вычисление элементов, через /"
вершину, в которой заканчивается вычисление элементов. Тогда толщина
соответствующего слоя будет равна
т
*=1
Для всех элементов, имеющих одну и ту же составляющую в
множестве Dp, первые k индексов совпадают. В силу обратимости
оператора Ρ (Ι) на главном координатном множестве размерности k это
означает, что первые k координат вершин, в которых осуществляется
вычисление элементов, также совпадают. Следовательно, 1\ — 1'\
для l^t^k. Разность остальных координат не превосходит d. Так
как r^t, а ε<1, то теперь легко получить, что p^d&k(l—ε)-1.
Следствие. Пусть оператор Ρ (Ι) обратим на главном
координатном множестве размерности k. Если индексы, описывающие
два элемента массива, имеют различные составляющие в множестве
148 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
Dp, то слои, в которых осуществляется вычисление каждого из
элементов, не пересекаются.
Пусть D — главное координатное множество. Упорядочим
векторы в D и Я в лексикографическом порядке соответственно по
старшим и младшим координатам. Тогда лексикографическое
упорядочение вершин из области определения оператора Р(1)
эквивалентно следующему упорядочению. Все вершины разбиваются на
группы, каждая из которых включает в себя те из них, где
составляющая оператора Ρ (I) в множестве Dp будет одной и той же.
Группы упорядочиваются согласно лексикографическому порядку
векторов из D, а вершины в каждой группе упорядочиваются
согласно лексикографическому порядку векторов из Я.
В соответствии с утверждением 15.6 все вершины одной группы
находятся в тонком слое толщиной порядка &k, причем слои,
относящиеся к разным группам, не пересекаются. Вершинам одной
группы соответствует вычисление группы элементов массива с
индексами, имеющими одни и те же составляющие в множестве Dp. Для всех
элементов массива одной группы их вычисление начинается и
заканчивается на вершинах одной группы. Поэтому прохождение
групп вершин в каком-либо порядке однозначно определяет порядок
вычисления групп элементов массива.
Процесс прохождения вершин в лексикографическом порядке
можно связать с процессом параллельного перемещения опорной
гиперплоскости. Около гиперплоскости имеется тонкий слой,
обладающий тем свойством, что по одну его сторону находятся вершины,
в которых еще не проводилось никаких вычислений, а по другую
сторону — вершины, в которых уже не будет проводиться никаких
вычислений. При определенных условиях, накладываемых на
оператор Ρ (Ι), элементы массива, соответствующие вершинам тонкого
слоя, будут сами находиться в некотором тонком слое. Этот тонкий
слой образует фронт вычислений элементов массива. По одну его
сторону будут находиться элементы, вычисление которых уже
закончено, по другую — элементы, вычисление которых еще не
начиналось, а сам фронт будет содержать относительно небольшое число
элементов, вычисление которых уже началось, но еще не
закончилось. Если оператор Р(1) обратим, то тонкий слой содержит только
одну вершину, в которой вычисление элемента массива как
начинается, так и заканчивается.
Рассмотрим теперь опорное гнездо, соответствующее оператору
Q(/). В каждой его вершине / на вход операции подается элемент
массива с индексами Q(7). В момент выбора входного элемента
возможны следующие ситуации:
— вычисление входного элемента еще не начиналось;
— вычисление входного элемента уже закончилось;
— вычисление входного элемента началось, но не закончилось.
В первом случае на вход операции подается начальное данное
алгоритма, поэтому никакая дуга в вершину не входит. Во втором
§ 15. ЭЛЕМЕНТАРНЫЙ РЕШЕТЧАТЫЙ ГРАФ
149
случае дуга выходит из той вершины, в которой входной элемент
перевычисляется последний раз. Обычно такие вершины лежат на
«границе» области определения оператора Ρ (I). Вершин,
описывающих третий случай, должно быть немного, или должна иметь место
определенная связь между операторами Q(I) и Р(/), что диктуется
принадлежностью входного элемента тонкому слою фронта
вычислений.
Проведенные рассуждения подсказывают, что элементарный
решетчатый граф, по-видимому, довольно часто либо будет почти
пустым, либо будет обладать некоторой спецификой. Исследуем более
подробно элементарное гнездо циклов. Согласно утверждению 14.7,
графы только таких элементарных алгоритмов могут иметь
относительно сложное строение.
Рассмотрим произвольную однозначную функцию z=z(Ily . . .
..., Im). Предположим, что множество значений этой функции
разделено на какие-то непересекающиеся подмножества и при этом
установлено, что вершины, соответствующие разным подмножествам,
не связаны дугами. Тогда такое разбиение определяет расщепление
графа на не связанные подграфы, причем каждый связный подграф
исходного графа соответствует одному из подмножеств значений
функции ζ. В частности, если функция ζ осуществляет
проектирование на одну из координатных осей, то это означает, что если проекция
графа представляет систему не связанных подграфов, то и сам граф
расщепляется на аналогичную систему не связанных подграфов.
В ближайших исследованиях в качестве функции г(1и . . ., 1т) мы
будем брать одну из функций pi9 предполагая, что через нее
выражается и функция qt.
Утверждение 15.7. Пусть для некоторого i функции pt,
qt зависят от одного и того же аргумента ζ и совпадают при всех ζ.
Тогда элементарный решетчатый граф расщепляется на систему
не связанных между собой подграфов. На вершинах каждого из
таких подграфов координаты pt, qt постоянны и равны между
собой.
Возьмем любые смежные вершины /", /' и /', /. Уравнение
P(I')=Q(I) из (15.1) для 1-х координат дает равенство pi(z,) =
=<7ι (ζ)- Для паРы вершин /", /' 'находим, что р% {z")=qi (z').
Согласно условию, pi (z) =qt (ζ) при всех ζ. Поэтому ρί(ζ")=ρί(ζ,)=ρί(ζ)1
и аналогичные равенства имеем для qt (z).
Описанная в утверждении ситуация довольно часто встречается
в различных алгоритмах, и ее можно исключить из рассмотрения.
При этом понижается размерность используемого массива, а иногда
и размерность гнезда циклов.
Утверждение 15.8. Пусть для некоторого ι функции pi,
qi зависят от одного и того же аргумента ζ и являются одновременно
строго убывающими или строго возрастающими. Обозначим через
Ζι<ζ2<. . .<ζ{* различные корни уравнения pi(z)=qi(z). Тогда
элементарный решетчатый граф в общем случае расщепляется на 2/+1
150 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
не связанных между собой подграфов, вершины каждого из которых,
соответствуют точкам одного из множеств оси ζ:
z<zu z = zx, zx< z<z2, ..., z = zt, z>zt.
Рассмотрим смежные вершины Г, I и уравнение P(I')=Q(I)
из (15.1). Для ί-χ координат имеем равенство pi(z')=qi(z). Пусть ζ
принадлежит одному из указанных множеств. В силу строгой
одноименной монотонности функций pi (ζ), qt (z) корень ζ' всегда
единственный и принадлежит тому же множеству. Следовательно,
вершины, для которых значения ζ относятся к разным множествам, не
могут быть связаны путем.
Утверждение 15.9. Пусть для некоторого i функции
Pi, qt зависят от одного и того же аргумета ζ, являются строго
монотонными uqt (z)=pi (г+а)для целого числа а. Тогда
элементарный решетчатый граф расщепляется на\а\ не связанных подграфов,
вершины каждого из которых соответствуют равномерной сетке
с шагом а на оси ζ.
Действительно, из равенства ρ* (ζ')^* (ζ) сразу вытекает, что
ζ'=ζ+α, откуда и следует справедливость утверждения.
Утверждение 15.10. Пусть для некоторого ι функции
pi, qt зависят от одного и того же аргумента ζ; одна из них
является строго убывающей, другая — строго возрастающей.
Предположим также, что pi(z0+a)=qi(z0—α) при всех а и
фиксированном ζ0. Тогда элементарный решетчатый граф расщепляется на не
связанные подграфы, соответствующие либо ζ0, либо паре точек,
симметричных относительно ζ0.
Снова рассмотрим смежные вершины /", Г и Г, I. Имеем
pi(z)=qi(z), pi{z")=qi{z'). Если ζ=ζ0+α, то, согласно условию
утверждения, ζ'=ζ0—α и ζ"=ζ0+α, т. е. ζ"=ζ. При а=0 получаем,
что ζ"=ζ' =ζ=ζ0.
Предположим теперь, что все координаты pt, qt векторов Р{1),
Q(I) являются строго монотонными функциями, зависящими
только от одной из координат /χ, ..., Im вершины /. Координаты,
от которых не зависит Ρ (Ι), назовем ведущими, а элементарное
гнездо циклов, удовлетворяющее описанным условиям,—
нормальным.
Утверждение 15.11. Пусть в нормальном гнезде циклов
ведущей является (1г+1)-я координата и нет ведущих координат
с меньшими номерами. Тогда оператор Ρ (I) обратим на главном
координатном множестве размерности k.
Пусть координаты ριχ, ..., /?/ зависят соответственно от /χ, ...
...,/fc. В силу строгой монотонности каждая из функций ptl (Λ), ...
...->pik{Ih) осуществляет взаимно однозначное отображение точек
координатных осей, откуда и вытекает обратимость оператора
р(1) на главном координатном множестве размерности k.
Предположим для простоты, что в нормальном гнезде циклов
§ 15. ЭЛЕМЕНТАРНЫЙ РЕШЕТЧАТЫЙ ГРАФ 151
оператор Р(1) имеет ведущей (&+1)-ю координату, все функции р-г
возрастающие и для Κα^β функция pt зависит от /г. В этих
условиях вычисление элементов массива осуществляется в
лексикографическом порядке по первым k индексам, и большим
координатам вершины соответствует больший индекс преобразуемого
элемента. Рассмотрим уравнение P(I')=Q(I) из (15.1). В
координатной записи имеем
Pi(I'i) = qi(Iit)>
Pk(Ik) = qk(iik),
Первое уравнение определяет разбиение множества V на три
множества, координаты вершин которого удовлетворяют одному
из соотношений
PiViXqiVi), Ρι(/ι) = 9ι(/|1), Ρι(Λ)>?ι(Λι).
Если вершина / находится в первом множестве, из строго
монотонного возрастания функции рг (Λ) вытекает, что никакая дуга в
эту вершину не входит, так как входной элемент является
начальным данным алгоритма. Если вершина / находится в третьем
множестве, то из строго монотонного возрастания функции рг (/ι) теперь
следует, что входной элемент массива уже закончил
перевычисляться. Поэтому в вершины этого множества дуги могут идти
только из тех вершин, где заканчивается вычисление элемента.
Разобьем далее второе множество также на три множества,
координаты вершин которого удовлетворяют одному из дополнительных
соотношений:
Р2 ('2) < Цг (7/2)> Ρ* (72) = Яг (Λ,)> Р2 (/2) > Q* (!ι2)'
Для первого и третьего множеств имеют место аналогичные свойства.
Разложение второго множества можно продолжить.
Таким образом, множество V вершин элементарного гнезда
циклов, удовлетворяющего сформулированным выше условиям, можно
всегда разбить на три непересекающихся множества V, F", V",
где
— V есть множество вершин, в которых выполняются
соотношения
Ρι (Λ)< qi(Itl),
или
Ρι(Ιι) = 4ι(Ιι)> Ρ«('«Χ<7«(Λ,).
или
Pi(/i) = ?i(/J, ·.., p^-i(/fe-i) = ^-i(//fe_1), ρ(/*)<qu{hk)\
152 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
— V" есть множество вершин, в которых выполняются
соотношения
Pi(h) = Qi(Ih),
—V" есть множество вершин, в которых выполняются
соотношения
p1(I1)>q1(Il),
или
PiVi) = qiVi), Λ (Λ) ><7ι (Λ,).
или
Ρι(Ιι) = 1ι(Ιι), .·., Pbi(/bi) = ?bi(Vi)' PkVk)>4k(IiJ·
Утверждение 15.12. В условиях указанного разбиения
множества У, V", V" обладают такими свойствами:
— во все вершины V дуги графа не входят, выходить дуги могут
из разных вершин, в том числе из тех граничных вершин, где
заканчивается вычисление элементов массива;
— во все вершины V'" дуги графа могут входить только от тех
граничных вершин, где заканчивается вычисление элементов массива-,
— все вершины Vй лежат на многообразии размерности т—k>
где т — размерность" гнезда циклов.
Заметим, что ограничение на зависимость pt от 1-г для l<;feC&
не является существенным, так как его всегда можно устранить с
помощью перенумерации координат вершин. Если какая-то из
функций рг будет убывающей, то знаки неравенства, стоящие рядом
с ней в соотношениях, определяющих множества V, V", меняются
на противоположные.
Утверждение 15.13. Пусть алгоритм задан нормальным
гнездом циклов размерности т и ведущей является (к+1)-я
переменная. Тогда с точностью до вершин, определяемых многообразием
размерности т—k, все дуги решетчатого графа алгоритма выходят
только из тех вершин, где ведущая кордината принимает
максимальное значение.
Согласно утверждению 15.12, дуги могут входить лишь в
вершины из множеств V" и V". Но все вершины V" лежат на
многообразии размерности т—k, а в вершины из V" дуги входят от тех
вершин, где заканчивается вычисление элементов массива.
Вычисление одного и того же элемента заведомо осуществляется при
различных значениях ведущей переменной. Поэтому оно
заканчивается там, где ведущая координата принимает максимальное значение.
§ 15. ЭЛЕМЕНТАРНЫЙ РЕШЕТЧАТЫЙ ГРАФ
153
l1 1 L - L L L Τ lj
Г ~~' Γ~ι Г ι Ι ι ι Ι ι 1
j i 11 1 Ι ] ϊ ] Ι 11
I III ι ι τ τ ι I 1 |
in ι
ι 11 ι ι τ τ τ τ ι ι
l-'ll Ι ι " I I I I I !
ill ] [ J I 1
I |l | | w | | w w ν 1
-\ν·,
Рассмотрим снова пример решения систем линейных
алгебраических уравнений с треугольной блочно двухдиагональной
матрицей. Различные результаты выполненных исследований уже
иллюстрировались на нем в
§§ 13,14. На рис. 15.1
представлен решетчатый граф
соответствующего
алгоритма для случая т=5, п=8.
Алгоритм имеет три
опорных гнезда. Вершины
этих гнезд на рис. 15.1
обведены штриховыми
рамками. Как и в § 13, они
обозначены Ki, V2> V3- Согласно
исследованиям § 14,
решетчатый граф алгоритма есть
объединение четырех
элементарных графов, имеющих ^номера 2, 4
уравнения P(/')=Q(/) для них таковы:
VU·
Рис.
3, 6.
15.1
Соответствующие
GHVK-
= 1,
k.
О ' [к— 1J
=>
k = \,
[λ=[Λ<:-
[ν]-[*-ι]-^·
■ι,
1.
Отсюда выгекает, что для алгоритма 2 дуги идут из вершин
множества V2 лишь в те вершины множества V39 которые находятся в
первой строке на рис. 15.1. Аналогично для алгоритма 4 дуги идут
из вершин Vi лишь в те вершины множества К3, которые
находятся в первом столбце на рис. 15.1. Как и утверждалось в § 14, графы
этих алгоритмов оказались почти пустыми. Дуги алгоритма 3
связывают соседние по вертикали вершины множества Кз- Для
алгоритма 6 аналогичные дуги идут по горизонтали. Граф алгоритма 3
расщепляется на не связанные подграфы по координате k, граф
алгоритма 6 расщепляется по координате i. Оба алгоритма
задаются нормальными гнездами циклов. Соответствующие операторы^ (/)
обратимы. Обращаем внимание читателя на почти одинаковый вид
графов на рис. 8.1, 15.1.
154 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
§ 16. Информационная значимость в графах
^ условиях утверждения 15.13 элементарный граф обладает
очень большой спецификой, выражающейся в том, что почти из
всех его вершин не выходит ни одной дуги. Очевидно, что он, как
правило, будет давать очень мало информации о структуре графа
исходного алгоритма.
Согласно утверждению 14.8, решетчатый граф алгоритма
составляется ρ основном из решетчатых графов гнезд циклов. В свою
очередь решетчатые графы гнезд циклов образуются из элементарных
графов. Если бы типичной была ситуация, когда все элементарные
алгоритмы описывались гнездом циклов с не первой ведущей
переменной, то это бы означало, что само гнездо циклов определяет
алгоритм, в котором результаты отдельных операций почти не
используются. Именно этот вывод следует из того факта, что почти
из всех вершин графа подобного алгоритму а не будет выходить ни
одной дуги. Ясно, что такие гнезда циклсв не могут быть
типичными.
Предположим, что алгоритм не имеет большого числа избыточных
вычислений, т. е. результат почти каждой отдельной операции либо
используется для дальнейших вычислений, либо является одним из
результатов реализации алгоритма в целом. Для алгоритмов этого
типа характерным является то, что у их графов дуги выходят почти
из всех вершин. Исключение составляют вершины, в которых
получаются окончательные результаты, причем не используемые в то
же время для дальнейших вычислений. Так как общее число
элементарных графов в алгоритме конечно и не зависит от общего числа
выполняемых операций, то отсюда вытекает, что по крайней мере
дуги из одного элементарного графа составляют существенную часть
дуг графа исходного алгоритма. При этом они выходят также из
существенной части общего числа вершин.
Таким образом, среди элементарных графез, на которые
расщепляется решетчатый граф алгоритма, обычно должны быть такие, у
которых дуги выходят из существенной части вершин. Эти графы
будем называть информационно значимыми, подчеркивая данным
названием тот факт, что основная информация о графе алгоритма
содержится лишь в подобных элементарных графах. Заметим, что
в общем случае дуги не каждого информационно значимого
элементарного графа будут составлять существенную часть дуг графа
алгоритма. Это зависит не только от отдельного элементарного
графа, но от всей их совокупности. Однако если дуги какого-нибудь
элемен гарного графа составляют существенную часть дуг графа
алгоритма, то, как правило, это будут дуги информационно
значимого графа. Для нормальных гнезд циклов информационно
значимым графам соответствуют случаи, когда либо ведущая
переменная оказывается первой, либо ведущая переменная отсутствует,
§ 16. ИНФОРМАЦИОННАЯ ЗНАЧИМОСТЬ В ГРАФАХ 155
т. е. оператор Р(1) обратимый, либо возможно осуществить
сведение к таким случаям.
Определение информационно значимых элементарных
алгоритмов и их графов имеет исключительно важное значение для
исследования графа алгоритма в целом. В самом деле, как было показано
в § 8, выбор параллельной вычислительной системы, реализующей
алгоритм наиболее эффективно, связан с расщеплением множества
вершин его графа на минимальное число подмножеств, в каждом
из которых вершины лежат на одном пути. С точки зрения таких
характеристик, как время реализации алгоритма и число
используемых функциональных устройств, вообще говоря, безразлично,
как конкретно будет найдено необходимое расщепление множества
вершин. В частности, его можно находить на основе анализа
структуры путей отдельных элементарных графов. Существование
других элементарных графэв будет сказываться при этом на
характеристиках коммуникационной сети вычислительной системы и
режимах ее работы.
Проведенные исследования показывают, что для решения этой
задачи нужно в первую очередь попытаться обнаружить и изучить
информационно значимые элементарные графы. В случае
нормальных гнезд циклов утверждение 15.13 указывает принцип отбора
соответствующих элементарных алгоритмов. Этот класс гнезд
довольно часто встречается в практически используемых численных
методах. Особенно часто приходится иметь с ним дело в
стандартных задачах вычислительной математики. В случае необходимости
можно провести аналогичные исследования для других классов
элементарных алгоритмов и получить для принципа отбора
информационно значимых графов нужные утверждения. При этом
аппарат изучения структуры элементарных графов всегда основан
на решении задач, описанных утверждением 15.1, с учетом,
конечно, особенностей операторов P(I), Q(/)·
Нередко можно указать элементарные алгоритмы с
информационно значимыми графами непосредственно по виду операции гнезда
циклов. Пусть, например, гнездо циклов имеет операцию F(..., α,
...; ..., α, ...). Это означает, что при реализации алгоритма каждая
отдельная операция, в частности, пересчитывает элемент α
некоторого массива, причем данный элемент одновременно является
как входным, так и выходным. Подобная ситуация типична для
различных вычислительных алгоритмов. Элемент α определяет
элементарный алгоритм, в котором P(I)=Q(I).
Утверждение 16.1. Если операторы Ρ(/), Q(I)
определяются элементом а массива нулевой размерности, то все вершины
элементарного графа лежат на одном пути.
Уравнение P(I')=Q(I) из (15.1) отсутствует. Формально можно
считать, что ему удовлетворяет любая пара вершин /', /.
Предшествующей для вершины / будет всегда ближайшая к ней снизу в
смысле лексикографического порядка вершина /'.
156 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
Следствие. Если операция гнезда циклов имеет указанный
выше вид, где а есть элемент массива нулевой размерности, то
алгоритм, заданный этим гнездом, является последовательным и не
распараллеливается.
Утверждение 16.2. Предположим, что координаты
вершин гнезда циклов можно разбить на такие две непересекающиеся
группы, что от координат первой группы оператор Р(1) не зависит,
а на координатном подпространстве, соответствующем второй
группе, оператор Р(1) обратим. Тогда в случае P(I)=Q(I) все
вершины элементарного графа, имеющие одни и те же координаты вто-
ной группы, лежат на одном пути.
Согласно утверждению 15.7, элементарный граф расщепляется
на не связанные подграфы, у каждого из которых все вершины
имеют один и тот же набор координат второй группы. Рассмотрим
уравнение P(f)=Q(I) из (15.1). Ему удовлетворяют все вершины /'
с произвольными координатами первой группы и координатами
второй группы, совпадающими с соответствующими координатами
вершины /. Очевидно, что решением задачи (15.1) является
вершина /', у которой координаты первой группы задают проекцию,
ближайшую снизу в смысле лексикографического порядка к
аналогичной проекции вершины /. Так как все вершины с
фиксированными координатами второй группы можно упорядочить в
лексикографическом порядке, то сказанное означает, что все они должны
лежать на одном пути.
Следствие. Если оператор Р(1) обратим, то в случае
P(I)=Q(I) элементарный граф будет пустым. Теперь первая
группа координат пустая, вершина Г определяется из уравнения Ρ (Γ) =
= Q(I) однозначно и совпадает с вершиной I.
Итак, в условиях утверждений 16.1, 16.2 элементарный граф
будет информационно значимым. Исследование информационно
значимых графов некоторых других типов будет проведено в
следующих параграфах. Сейчас же подчеркнем еще раз, что дуги не
каждого информационно значимого элементарного графа составляют
существенную часть дуг графа алгоритма. Какова ситуация в
действительности — это определяется всей совокупностью
элементарных графов.
Утверждение 16.3. Пусть вычисляемые массивы
алгоритма являются непересекающимися. Если из всех выходов всех операций
алгоритма с каждым массивом связан только один выход, то все
дуги любого информационно значимого элементарного графа будут
одновременно дугами графа алгоритма.
Справедливость утверждения вытекает из того, что в данном
случае решетчатый граф алгоритма есть объединение всех порожденных
им элементарных графов. Формулировка утверждения акцентирует
внимание на том, что при изучении графов таких алгоритмов часто
можно ограничиться лишь рассмотрением одного или нескольких
информационно значимых элементарных графов.
§ 16. ИНФОРМАЦИОННАЯ ЗНАЧИМОСТЬ В ГРАФАХ 157
Утверждение 16.4. Пусть в утверждении 16.2 среди
координат первой группы имеется младшая. Тогда почти все дуги,
информационно значимого графа, определяемого условием Р(1) =
= Q(I), будут одновременно дугами графа алгоритма.
Рассмотрим любую вершину, в которой при фиксированных
остальных кЪординатах младшая координата не принимает
максимальное значение. В этом случае дуга из этой вершины идет в
ближайшую к ней в смысле лексикографического порядка. Такая дуга
обязательно является дугой графа алгоритма. Между ее концевыми
вершинами не только нет других вершин, в которых может
осуществляться пересчет соответствующего дуге элемента массива, но и
вообще нет никаких вершин. Не переноситься в граф алгоритма
могут в некоторых случаях лишь дуги, выходящие из вершин с
максимальным значением младшей координаты. Но таких дуг мало
по сравнению с их общим числом.
Следствие. Пусть в утверждении 16.2 координатное
подпространство, соответствующее второй группе, является
главным. Тогда все дуги информационно значимого графа,
определяемого условием P(I)=Q(I), будут одновременно дугами графа
алгоритма.
Обозначим Q(I) и Ρι(Ι), ···, Pr(I) соответственно единственный
вход и выходы операции простого алгоритма, и пусть V есть
множество вершин его графа. Назовем Рг(I), ..., Рг{1) операторами
последовательного действия, если для всех i оператор Рг (I) начинает
перевычислять любой элемент массива позднее в смысле
лексикографического порядка, чем заканчивает его перевычислять
оператор Pi.i(I).
Утверждение 16.5. Пусть Ρι(/), ..·, Рг{1) являются
операторами последовательного действия. Тогда в случае Q(I)=P1(I}
простой граф совпадает с элементарным, определяемым условиями
P(/)=Q(/)=Pl(/).
Рассмотрим дугу простого графа, идущую из вершины J в
вершину I. Имеем Pi(J)=Q(I) для некоторого г. Так как Q(I)=P1(I),.
то отсюда вытекает, что Pi (7)=Ρι(7). Если £>1, то, согласно
условию утверждения, вершина J должна быть старше вершины / в:
смысле лексикографического порядка. Это противоречит тому, что·
дуга идет из вершины J в вершину I. Следовательно, ί=1, и дуга
принадлежит элементарному графу, определяемому условиями.
P(I)=Q(I)=P1(I).
Следствие. Если операторы Рг (I), ..., Рг(1) удовлетворяют
условиям утверждения, то элементарный граф, определяемый
условиями Q(I)=Pi(I), P(I)=Pj(I) при j>i, является пустым для
l<i<r— 1.
Следствие. Если Q(I)=Pi(7), то простой граф состоит
из всех дуг информационно значимого элементарного графа,
определяемого условями^С1(1)=Р1(1), P(I)=Pi(I), и дуг элементарного
графа, определяемого условиями Q (I) =Pt (I), Ρ (I) =Р*_ ι (Ι)„
(58 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
входящих лишь в те вершины, в которых элементы массива перевы-
числяк^тся оператором Pt (I) впервые.
Мы не будем дальше заниматься рассмотрением частных
особенностей переноса дуг информационно значимых элементарных графов
в граф исходного алгоритма, а исследуем этот вопрос в общем виде.
Именно, определим в каждом элементарном графе множество всех
дуг, переносимых в граф алгоритма, т. е. выделим информационно
значимый подграф элементарного графа.
Согласна утверждениям 14.4, 14.8, основную часть графа любого
алгоритма составляют графы простых алгоритмов, заданных
гнездом циклов. Поэтому изучим более подробно строение простых
графов из одного гнезда. В соответствии с утверждением 14.6
решетчатый граф простого алгоритма всегда можно представить как
объединение подграфов элементарных алгоритмов, определенных одним
и тем же оператором Q(7), но разными операторами Pi (/).
Следовательно, основная задача сейчас будет заключаться в исследовании
структуры дуг отдельных элементарных графов, переносимых в
простой граф.
Пусть элементарный граф порожден на гнезде циклов парой
операторов Q(7), Ρι{1)· Введем условную вершину 0 с нулевыми
координатами. Каждому элементарному графу поставим в соответствие
следующую однозначную функцию /·, определенную на множестве V-
Если в вершину / идет дуга, то значением функции /· будет
начальная вершина этой дуги. В противном случае ее значением будем
считать условную вершину 0. Функция /· принимает значения из V
на некотором подмножестве Vi множества V- Область ее значений
обозначим Ut. Заметим, что в V есть вершины, не входящие в Vt,
и в Όt есть вершины, не входящие в Vi, так как в противном случае
элементарный граф имел бы контуры. Построение функции 1\
осуществляется на основе решения соответствующих задач (15.1).
Рассмотрим теперь два элементарных графа, соответствующих
операторам Pi(I), Pj{I), и возьмем какую-нибудь вершину / из V-
Если в вершину / входит дуга только одного элементарного
графа, то она может быть и дугой простого графа. Если же в
вершину I входят дуги из обоих графов, то в простой граф может быть
перенесена лишь одна из них. Именно, из двух дуг выбирается та, у
которой начальная вершина имеет больший номер в смысле
лексикографического порядка. Соответствующую проверку удобно
осуществлять по величине и знаку опорного функционала.
Утверждение 16.6. Пусть в вершине I известны значения
Ф(/, rt), Ф(/, /у) опорного функционала и эти значения не равны
между собой. Тогда в простой граф может быть перенесена дуга из
i-го элементарного графа, если Ф(/, /J)<0(/, /}), и из j-го графа,
если Ф(/, /;)>Ф(/, /;·).
Предположим, что Ф(/, Ц)<.Ф(1, I)). Если I) не является
условной вершиной 0, то это означает, что вершина /· имеет больший
лексикографический номер, чем вершина I). Поэтому дуга будет
§ 16. ИНФОРМАЦИОННАЯ ЗНАЧИМОСТЬ В ГРАФАХ 159
переноситься из /-го элементарного графа. Если же /у есть условная
вершина 0, то это тем более верно, так как дуга имеется только в
i-м графе. Аналогично рассматривается случай Ф(/, 7^)>Ф(/, /у).
Следствие.. Пусть в вершине I значение Φ (l\9 I'j) не равно
нулю. Тогда в простой граф может быть перенесена дуга из i-го
элементарного графа, если Φ (/|, 1})>0, и из j-го графа, если
ф(/г. /;хо.
Действительно, согласно первому следствию утверждения 13.4,
имеет место равенство Φ (Г{9 /у)=Ф(/, I])—Ф(/, 1\). Если Φ (1\, 1])Ф
ФО, тоФ(/, Г()фФ(19 I'D и выполняются условия утверждения 16.4·
Таким образом, любая пара элементарных алгоритмов,
порожденных одним простым алгоритмом, делит множество вершин в
основном на два подмножества. Одно из этих подмножеств может
принимать дуги от одного элементарного графа, другое — от
другого графа. Границей раздела подмножеств служат вершины,
удовлетворяющие равенству Ф(//, //)=0. К ним, во-первых, относятся
вершины, в которые не входят дуги ни одного, из двух элементарных
графов, и, во-вторых, вершины, в которые дуги входят от обоих
графов, но исходят эти дуги из одной и той же вершины. В
последнем случае возможны две ситуации. Если оба выхода элементарных
алгоритмов равноправны с точки зрения момента получения
результатов, то из двух дуг в простой граф может быть перенесена любая.
Если же выходы не равноправны, то в одном из выходов
соответствующий дуге элемент массива пересчитываете позднее, чем в
другом. Тогда в простой граф переносится дуга из того
элементарного графа, в котором элемент пересчитывается позднее. Как
правило, в практически используемых формах записи алгоритмов имеет
место вторая ситуация. Однако заметим, что в обеих ситуациях
алгоритм обязательно будет иметь избыточные вычисления, т. е.
некоторый элемент массива будет пересчитываться до того, как
используется его предыдущее значение.
Утверждение 16.7. Пусть для всех элементарных графовг
соответствующих одному простому алгоритму, построены функции
II и в вершине I известны значения Φ (/, I'D опорного функционала
для всех i. Тогда дуги простого графа образуются из дуг
элементарных графов согласно следующим правилам:
— если среди значений Ф(/, /·) минимальных имеется только
одно и оно соответствует /у, то в простой граф переносится дуга
из j-го элементарного графа;
— если среди значений Φ (/, I'D минимальных имеется более
одного и хотя бы одна из соответствующих вершин I) не является
вершиной 0, то в простой граф переносится дуга из того элементарного
графа, в котором элемент массива пересчитывается позднее;
— если все значения Φ (/, I'D равны между собой и все вершины Г{
являются вершинами 0, то в вершину I простого графа не входит
никакая дуга.
Все значения Φ (/, /·) всегда положительны. При фиксированной
160 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
вершине / максимальное значение Ф(/, 1\) принимает лишь в
случае, когда 1[ есть вершина 0. Если не все значения Ф(/, 1\) равны
между собой, то минимальное значение обязательно достигается в
вершине, не являющейся вершиной 0. Следовательно, в этом случае
в вершину I обязательно входит дуга из какого-нибудь
элементарного графа. Все остальное является прямым следствием
утверждения 16.6.
Это утверждение совместно с утверждениями 14.4, 14.6—14.8,
15.1 позволяет полностью описать структуру графа алгоритма и дает
конструктивную возможность его построения, исходя из записи
алгоритма в какой-нибудь из рассмотренных ранее форм. Из данного
утверждения можно получить много частных следствий, в том числе
ранее рассмотренные утверждения. Пусть, например, из всех
выходов всех операций алгоритма с каждым массивом связан только один
выход. Тогда· имеется лишь одно значение опорного функционала
Ф(/, /') и дуга, идущая из вершины /' в /, обязательно переносится
в простой граф и, следовательно, в граф алгоритма. Предположим
теперь, что функции pl9 ..., ps оператора Pi(I) не зависят от
младшей координаты вершин гнезда циклов. Если младшая координата
вершины / не принимает. минимального значения, то значение
Ф(/, I'j) будет не только минимальным, но и единственным. Снова
дуга, идущая из вершины 1\ в /, обязательно переносится и в
простой граф, и в граф алгоритма, если конечно, в самом алгоритме
нет избыточных вычислений.
Утверждение 16.8. Если алгоритм не имеет избыточных
вычислений, то при каждом срабатывании любой операции на всех
ее выходах вычисляются различные элементы.
Предположим, что при каком-то срабатывании на некоторых
выходах операции вычисляются одинаковые элементы. Если выходы
равноправны с точки зрения момента получения результатов, то
можно считать, что в дальнейшем используется элемент массива,
вычисленный на одном из выходов. Если же выходы не
равноправны, то это тем более верно. Поэтому результаты, вычисленные на
остальных выходах, не будут в дальнейшем нигде использоваться,
т. е. имеют место избыточные вычисления.
Следствие. Если алгоритм не имеет избыточных
вычислений, то различные элементарные графы, соответствующие одному
простому графу, не имеют ни одной общей дуги.
Действительно, пусть элементарные графы с оператором Q(I) и
операторами Pt(I), Pj(I) имеют общую дугу, идущую из вершины
J в вершину I. Тогда имеем Pi(J)=Q(I), Pj(J)=Q(I)- Отсюда
вытекает Pi(J)=Pj(J), что невозможно, так как алгоритм не имеет
избыточных вычислений.
Следствие. Если алгоритм не имеет избыточных
вычислений, то равенство Ф(/, /·)=Φ(/, I'j) в утверждении 16.7 возможно
лишь в том случае, когда оба элементарных графа не имеют дуги,
входящей в вершину I.
§ 16. ИНФОРМАЦИОННАЯ ЗНАЧИМОСТЬ В ГРАФАХ 151
Равенство Φ (/, I}) — ф(/, Г·) влечет совпадение вершин 1\, I].
Согласно первому следствию, эти вершины не могут быть вершинами
графа алгоритма. Следовательно, они являются обе вершиной 0.
Утверждение 16.9. Если области значений любых двух
операторов Р*(7), Pj{I), относящихся к одному массиву, не
пересекаются, то решетчатый граф алгоритма совпадает с объединением
всех элементарных графов.
Пусть некоторая дуга элементарного графа не входит в граф
алгоритма. Это означает по крайней мере, что элемент массива,
соответствующий данной дуге, перевычисляется в каком-то другом
элементарном алгоритме. Однако такое перевычисление
невозможно в силу условия утверждения.
Следствие. В условиях утверждения 16.9 равенство Φ(/,
/|)=Ф (/, Г.) в утверждении 16.7 возможно лишь в том случае, когда
оба элементарных графа не имеют дуги, входящей в вершину I.
Итак, утверждение 16.6 и различные следствия из него
позволяют выделять из элементарных графов иноформационно значимые
подграфы, составлять из этих подграфов простые графы и, наконец,
построить решетчатый граф алгоритма в целом. Если операторы
Р(7), Q(I) имеют не очень сложный вид, то функции /· часто можно
представить в приемлемом для исследования аналитическом виде.
Из этих функций можно составить и функцию /', задающую
начальные вершины дуг для простого графа. При этом границы ее
представления через функции /· выражаются через многообразия,
удовлетворяющие уравнениям Ф(/, /·)=Φ(/, Ij) для некоторых /, /.
Рассмотрим в качестве примера следующее гнездо циклов, на
которое приходится основной объем вычислений в методе вращений
для разложения матрицы на треугольную и ортогональную:
DO 1 /=1, л—1
DO 1 / = i+l, η
DO 1 k=i+l, n
<*tk = aik cos 4ij—ajk sin Φί/
ajk = aiksin Φί/ + aJk cos ffU
1 CONTINUE
Здесь q>ij — некоторые константы, вычисляемые на других этапах
реализации метода. В этом гнезде циклов имеются следующие
операторы:
*М'Щ). p.V)=(1), QiO-(i). Q.O = (i).
которым соответствуют четыре элементарных алгоритма с такими
сочетаниями операторов:
РЛП, Qi('); Л(/), Qi(/); Л О. Qi(/); Л С), Q,(/)·
6 В. В. Воеводин
: 162 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ!АЛГОРИТМОВ И ПРОГРАММ
Очевидно, что для первого элементарного алгоритма
выполняется равенство P1(I)=Q1(I), для четвертого элементарного алгоритма
выполняется равенство P2(/)=Q20O· Согласно утверждению 16.2,
графы обоих алгоритмов являются информационно значимыми, так
как операторы Pi(I)^ Q1(I) не зависят от /, а операторы Р2(1),
Q2(I) не зависят от ί. Согласно утверждению 15.7, графы всех
элементарных алгоритмов и, следовательно, в целом граф
алгоритма, заданного гнездом циклов, расщепляются на систему не
связанных между собой подграфов, соответствующих различным
значениям k.
Решая соответствующие задачи (15.1), находим для всех четырех
элементарных графов функции 1\, 1^ί^4. Если вершина /
имеет координаты i, /, k, то '
/>/+1,
;>ι,
Значения Ф(/, 1\) опорного функционала для функций ϊ\ таковы:
Φ (Λ П)
ф(/,./;)
Ф(/, А)
ф(/, /а
К одному простому графу относятся первый и третий, а также
второй и четвертый элементарные графы. Поэтому, согласно
утверждению 16.7, для выяснения того, какие дуги элементарных графов
являются одновременно дугами графа алгоритма, необходимо
сравнить на минимальность первое и третье, а также второе и четвертое
значения опорного функционала. Второй элементарный граф
является пустым. Следовательно, все дуги четвертого элементарного
графа будут переноситься в граф алгоритма. Такой же вывод,
естественно, вытекает и из сравнения соответствующих значений
опорного функционала. Первое значение опорного функционала меньше
третьего значения во всех вершинах, где />/+1, и меньше его в
вершинах, где /=ί+1, но £>1. Совпадают эти значения в вершинах
ί = 1, /=2, k>\. Отсюда заключаем, что в граф алгоритма будут
переноситься все дуги первого элементарного графа и только те дуги
r__iif = i9 /' = /—1» k' = k, если
1 10, если / == £ -f-1;
/; = 0 всюду;
r_/i' = i—1, /' = i, k' = k, если
3~~ I 0, если ί=1;
r__fi' = i—1, /' = /> k' = k, если
4 "ι 0, если i=l.
ί ε, если />i+l,
ΐί-[-ε/ + ε2&, если / = i-fl;
== i + ε/ + ε2£ всюду;
_ί1 + ε(/ — 0» если *">!»
~~ и" + ε/ -f ε2&, если i = 1;
_ ί 1, если i > 1,
~~ Ιί+ε/ + ε2&, если ί=1.
§ 16. ИНФОРМАЦИОННАЯ ЗНАЧИМОСТЬ В ГРАФАХ
163
третьего элементарного графа, концевые вершины которых
удовлетворяют условию /=£-+-1.
¥
I *
4 1
ί
ι ι
. 4
ί
φ ψ
φ φ -#
φ φ-
«Λ
<!
Α
1
S
V
§
У
Ι
\
ι
f
Λ
' с
»—
»—
»—
»—
ύ
—^
!»-<
»
» у ■
ι ~ '
■ > '
»
Рис. 16.1
Τ ^4.
ι ]
ι
4 *н
^4.
, Ι
Рис. 16.2
Проекции элементарных графов и графа алгоритма на плоскость
параметров i, / представлены соответственно на рис. 16.1 и 16.2
для случая /1=5. Кружками обведены вершины, в которых не опре-
164 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
делены функции 1\. Вершины без кружков показывают области
значений функций 1\. Рассматриваемый алгоритм не имеет
избыточных вычислений, что подтверждается отсутствием одинаковых дуг
у различных элементарных графов. В целом данный алгоритм
с точностью до перенумерации операторов Рг(/), Р2(1)
удовлетворяет условиям утверждения 16.5. Действительно, если Р1(Г)=Р2(1"),
то отсюда следует, что t'=/", k'—k". Так как /">Г, то имеем V>i",
т. е. оператор Ρι(Ι) начинает перевычислять любой элемент массива
позднее, чем заканчивает его перевычислять оператор Р2(1)·
§17. Регулярные графы
Как же отмечалось, конкретное представление дуг решетчатого
графа алгоритма не играет существенной роли в проводимых
исследованиях. При изучении графа алгоритма, заданного гнездом
циклов, начальные и конечные вершины дуг без ограничения общности
можно считать векторами одного и того же арифметического
пространства. Следовательно, дуги такого графа также можно
рассматривать как векторы. Для удобства проведения ближайших
исследований будем исходить из этого предположения.
Рассмотрим совокупность некоторых векторов /ь ..., /г с
целочисленными координатами. Назовем граф регулярным, если его
вершинами являются векторы с целочисленными координатами и
каждая дуга задается одним из векторов /ь ..., /г. Векторы /ь ..., fr
назовем базовыми.
Регулярный граф характерен тем, что в общем случае из каждой
его вершины выходит один и тот же пучок дуг, который переносится
параллельно от одной вершины к другой. В отдельных вершинах
некоторые или даже все дуги могут отсутствовать. В основном это
свойственно вершинам, находящимся вблизи «границы» области
задания вершин графа. Естественно, что в общем случае в каждую
вершину графа входит также один и тот же пучок дуг.
Чтобы не изучать детали, связанные с граничными нерегулярнос-
тями в задании вершин и дуг, рассмотрим бесконечный регулярный
граф. Множество вершин этого графа совпадает с множеством всех
векторов арифметического пространства, имеющих целочисленные
координаты, и из каждой вершины выходит один и тот же пучок
Дуг·
Основные свойства регулярных графов являются отражением
соответствующих свойств бесконечных регулярных графов.
Справедливо очевидное
Утверждение 17.1. Пусть регулярный граф имеет
базовыми векторы /ь ..., fr и каждый из этих векторов определяет в графе
хотя бы одну дугу. Тогда любой бесконечный регулярный граф,
содержащий заданный граф в качестве своего подграфа, содержит
также в качестве подграфа и бесконечный регулярный граф с базовыми
векторами fly ..., /г.
§ 17. РЕГУЛЯРНЫЕ ГРАФЫ
165
Предположим, что базовые векторы бесконечного регулярного
графа образуют базис арифметического пространства. Рассмотрим
множество векторов вида
/= 2 «,/„ (17.1)
ί = 1
где все числа а{ удовлетворяют соотношениям 0^аг<1. Это
множество образует полуоткрытый параллелепипед, который назовем
базовым параллелепипедом. В базовый параллелепипед попадает
некоторое число векторов с целочисленными координатами.
Назовем эти векторы опорными. Опорным, например, всегда является
нулевой вектор.
Утверждение 17.2. Если базовые векторы образуют базис
арифметического пространства, то число опорных векторов равно
модулю определителя матрицы F, столбцы которой образованы
координатами базовых векторов.
Модуль определителя матрицы равен объему базового
параллелепипеда. Рассмотрим арифметическое пространство, в котором
заданы вершины и дуги бесконечного регулярного графа. Это
пространство естественным образом разбивается на параллелепипеды,
получаемые путем параллельного переноса базового параллелепипеда
на векторы, являющиеся линейными комбинациями базовых
векторов с целочисленными коэффициентами линейных комбинаций.
Опорные векторы имеют целочисленные координаты. Такие же
координаты имеют базовые векторы. Поэтому все векторы с
целочисленными координатами, попадающие в параллелепипед при описанном
параллельном переносе, в действительности являются образами
опорных векторов при аналогичном параллельном переносе.
Возьмем, например, шар радиусом ρ с центром в нулевом векторе.
Асимптотически при больших ρ его объем равен числу попавших в него
векторов с целочисленными координатами. С другой стороны,
асимптотически его объем равен числу попавших в него
параллелепипедов, умноженному на объем базового параллелепипеда. Так как
в каждом параллелепипеде находится одно и то же число векторов
с целочисленными координатами и оно равно числу опорных
векторов, то отсюда вытекает справедливость высказанного
утверждения.
Бесконечный регулярный граф может содержать бесконечные
подграфы, также устроенные регулярно. Вершины одного из них
задаются линейными комбинациями базовых векторов с
всевозможными целочисленными коэффициентами линейных комбинаций.
При этом из каждой вершины подграфа выходит полный набор
дуг. Очевидно, что конечные вершины всех дуг являются
одновременно вершинами подграфа. Назовем такой подграф главным
регулярным подграфом. Согласно определению, главный подграф
связен. Подграф, получающийся путем параллельного переноса
166 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
главного регулярного подграфа на опорный вектор, будем называть
опорным регулярным подграфом.
Утверждение 17.3. Любой бесконечный регулярный граф,
базовые векторы которого образуют базис арифметического прост-,
ранства, расщепляется на конечное число не связанных между собой
опорных регулярных подграфов. Число таких подграфов равно числу
всех опорных векторов.
По существу, необходимо доказать только не связанность между
собой .и не пересекаемость опорных подграфов. Предположим, что
это не так. Тогда найдутся два подграфа, соответствующие двум
различным опорным векторам и, υ, и такие две вершины в них,
которые либо совпадают, либо связаны цепью. Отсюда вытекает,
что разность опорных векторов и—υ можно представить в виде
линейной комбинации базовых векторов с целочисленными
коэффициентами линейной комбинации. Согласно представлению (17.1)
векторов и, υ, это возможно лишь в том случае, когда векторы и, υ
совпадают. В самом деле, обозначим через а\, а'[ коэффициенты
для векторов и, υ из (17.1). Так как они неотрицательные и не
превосходят 1, то разность а\—а': может быть целым числом
только тогда, когда at'=aj. Так как по предположению опорные
векторы и, ν не совпадают, то в любых двух подграфах не может быть
ни совпадающих вершин, ни вершин, связанных цепью.
Естественно, что речь идет о вершинах, принадлежащих разным опорным
подграфам.
Следствие. Если базовые векторы линейно независимы, но
их число меньше размерности пространства, то бесконечный
регулярный граф расщепляется на бесконечное число не связанных между
собой регулярных подграфов, вершины каждого из которых совпадают
с векторами плоскости, имеющей в качестве направляющего
подпространства линейную оболочку базовых векторов. При этом все
подграфы получаются из одного путем параллельного переноса на
векторы, принадлежащие разным плоскостям.
Следствие. Если базовые векторы линейно независимы, но
их число меньше размерности пространства, то утверждения 17.2,
17.3 выполняются для подграфа предыдущего следствия, содержащего
вершину с нулевыми координатами. При этом понятие объема
рассматривается в направляющем подпространстве и вместо det F
берется (det /г*/г)1/2.
Если базовые векторы образуют базис пространства, то
бесконечный регулярный граф расщепляется на конечное число подграфов,
изоморфных главному регулярному подграфу. Поэтому изучение
такого подграфа равносильно изучению его главного подграфа. По
существу, к этому сводится исследование любого бесконечного графа
с линейно независимыми базовыми векторами, причем независимо
от их числа.
Если базовые векторы линейно зависимы, то строение
бесконечного регулярного графа может несколько измениться. Предположим,
§ 17. РЕГУЛЯРНЫЕ ГРАФЫ
167
что к линейно независимым базовым векторам добавляется еще один
вектор, линейно через них выражающийся. Если коэффициенты
линейной комбинации являются целыми числами, то снова
бесконечный граф расщепляется на изоморфные подграфы, причем их
число равно числу векторов с целочисленными координатами,
попадающими в полуоткрытый параллелепипед, образованный линейно
независимыми базовыми векторами. Однако в главном подграфе
появляются новые дуги, соответствующие добавленному вектору.
Теперь главный подграф есть объединение главного подграфа,
соответствующего линейно независимым базовым векторам, и главного
подграфа, соответствующего добавленному базовому вектору.
Если коэффициенты линейной комбинации являются
рациональными числами, то ситуация определяется их числовой природой.
В этом случае главный подграф есть объединение главного подграфа
и какого-то числа опорных подграфов, соответствующих линейно
независимым базовым векторам, а также главного подграфа,
соответствующего добавленному базовому вектору. В частности,
бесконечный регулярный граф может оказаться целиком связным.
Добавление новых линейно зависимых базовых векторов
приводит к усложнению главного регулярного подграфа и уменьшению
числа подграфов, изоморфных главному, на которые расщепляется
бесконечный регулярный граф. Тем не менее всегда имеет место
Утверждение 17.4. Любой бесконечный регулярный граф,
вершины которого расположены в линейной оболочке базовых векторов,
расщепляется на конечное число не связанных между собой подграфов,
получающихся из главного регулярного подграфа путем
параллельного переноса.
Итак, исследование регулярных графов можно осуществлять на
основе следующих соображений. Построим бесконечный регулярный
граф, имеющий те же базовые векторы, что и заданный граф. Если
бесконечный граф расщепляется на не связанные изоморфные
подграфы, то это приводит к соответствующему расщеплению
исходного регулярного графа. Поэтому, не ограничивая существенно
общности, можно считать, что подлежащий исследованию
регулярный граф является подграфом главного регулярного подграфа
бесконечного графа. Конечно, частные особенности заданного графа
могут привести к тому, что реальное расщепление окажется бол^е
дробным. Однако такие особенности встречаются исключительно
редко и не представляют общего интереса. Подобные соображения
дают основание к тому, чтобы более внимательно исследовать
свойства главного подграфа.
Утверждение 17.5. Рассмотрим главный подграф
бесконечного регулярного графа с базовыми векторами fx, ..., /г.
Предположим, что векторы Д, ..., ft линейно независимы и все базовые
векторы линейно выражаются через них с целочисленными коэффициентами
линейных комбинаций. Проведем любую прямую линию с
направляющим вектором, равным одному из базовых векторов /ь ..., /г. Тогда на
168 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
этой прямой либо нет ни одной вершины главного подграфа, либо все
вершины главного подграфа на ней лежат на одном пути.
Пусть направляющий вектор прямой совпадает с вектором ft и
на ней есть хотя бы одна вершина главного подграфа. Рассмотрим
на данной прямой все точки, образующие вместе с имеющейся
вершиной равномерную сетку. В качестве шага сетки возьмем вектор
filpi, где pi есть наибольший общий делитель модулей
коэффициентов линейной комбинации в разложении вектора ft по векторам
/ι, ...,//. Все точки этой сетки являются вершинами главного
подграфа. Действительно, любую точку сетки связывает с имеющейся
вершиной главного подграфа вектор вида a(filpi)i где α — целое
число. Согласно условию утверждения, вектор filpi при всех i
рсть линейная комбинация базовых векторов /ι, ..., ft с целыми
коэффициентами. Поэтому все точки сетки являются вершинами
главного подграфа и связаны одним путем.
Для доказательства справедливости высказанного утверждения
теперь достаточно показать, что никаких других вершин главного
подграфа на прямой линии нет. Допустим, что такие вершины есть.
Тогда найдутся две вершины, задаваемые, например, векторами ζ
и w, для которых разность z—w есть вектор вида β (filpi), где Ιβ|<1.
Однако это предположение приводит к противоречию. С одной
стороны, обе вершины являются вершинами главного подграфа и,
следовательно, векторы ζ и w должны быть целочисленными
линейными комбинациями векторов fu ..., /г. Согласно условию
утверждения , их можно также считать целочисленными комбинациями
векторов Д,..., ft. Так же должна представляться и разность ζ—w. С
другой стороны, в соответствии с выбором числа pt вектор fjpi есть
линейная комбинация векторов /ь ..., fr с целыми коэффициентами,
причем все коэффициенты являются взаимно простыми. Поэтому
вектор β (filpi) и, следовательно, разность ζ—w не могут быть
представлены как линейные комбинации векторов /ь ..., /г с целыми
коэффициентами. Указанное противоречие подтверждает
справедливость утверждения 17.5.
Это утверждение позволяет очень просто строить графы
вычислительных систем, эффективно реализующих алгоритмы с
регулярными графами. В самом деле, пусть граф алгоритма является
подграфом главного подграфа регулярного графа и базовые векторы
удовлетворяют условиям утверждения 17.5. Спроектируем граф
алгоритма на гиперплоскость, перпендикулярную одному из базовых
векторов. Операция проектирования разбивает множество вершин
графа на непересекающиеся подмножества. При этом в общем
случае вершины одного подмножества лежат на одном пути и прообразы
разных проекций принадлежат разным подмножествам. Согласно
утверждению 8.5, на вычислительной системе, граф которой
совпадает с графом проекции, реализуется весь спектр программ, в том
числе программ с минимально возможным временем. Конечно, на
системе такого вида можно реализовать любой регулярный алго-
§ 17. РЕГУЛЯРНЫЕ ГРАФЫ
169
ритм с аналогичными базовыми векторами. При этом в соответствии
с утверждением 17.4, возможно, придется решать не одну задачу, а
несколько однотипных.
Граф вычислительной системы также устроен регулярно. Именно,
каждая его дуга является вектором из некоторой ограниченной
совокупности, содержащей по крайней мере на один вектор меньше,
чем совокупность, определяющая дуги регулярного графа. В общем
случае граф вычислительной системы, построенный описанным
способом, может иметь контуры. Проектирование на гиперплоскости,
перпендикулярное разным базовым векторам, дает разные графы.
Среди них можно выбрать лучший, например имеющий меньшее
число вершин.
Заметим, что распознавание возможности реализации
регулярных алгоритмов на описанном классе вычислительных систем за
минимальное время является прямым следствием условий,
накладываемых на базовые векторы. Если базовые векторы не
удовлетворяют условиям утверждения 17.5, то в этом случае нельзя
гарантировать, что все вершины главного подграфа, лежащие на одной
прямой, будут обязательно связаны одним путем. Пусть, например,
базовые векторы таковы: /ι=(1, 1), /г=(1» —1), /з=(3, 0). Ясно,
что вектор /3 не выражется через векторы /ι и /2 в виде линейной
комбинации с целочисленными коэффициентами. Нетрудно
проверить также, что на прямой с направляющим вектором /3 никакие
две соседние вершины не связаны путем. Если спроектировать
данный граф на гиперплоскость, перпендикулярную вектору /3, то не
сразу видно, можно ли при этом обеспечить реализацию алгоритма
за минимально возможное время.
Несмотря на сделанное замечание, операция проектирования
всегда позволяет построить граф вычислительной системы, на
которой можно реализовать регулярный алгоритм. Основанием к этому
выводу служат утверждение 8.3 и тот факт, что при проектировании
вершин разным проекциям соответствуют разные вершины.
Предположим, что существует вектор q, образующий острые
углы со всеми базовыми векторами. Это означает, что по отношению
к данному вектору регулярный граф является строго
направленным. В этом случае возможность реализации алгоритма с
регулярным графом определяется утверждениями 8.6, 8.7, а сама
реализация становится значительно проще. Факт существования или не
существования вектора q, образующего острые углы со всеми
базовыми векторами, отражает одну из основных характеристик
регулярного графа.
Утверждение 17.6. Бесконечный регулярный граф не
имеет контуры тогда и только тогда, когда существует
целочисленный вектор, образующий острые углы со всеми базовыми векторами.
Пусть /ι, ..., fr — базовые векторы. Предположим, что
указанный вектор q существует, но регулярный граф имеет контур.
Проходя этот контур в положительном направлении дуг, заключаем,
170 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
что имеет место равенство
£«/// = 0, (17.2)
ι = 1
где все числа at целые, не отрицательные и не все равны нулю.
Умножая равенство (17.2) скалярно на вектор q и принимая во
внимание, что (fif q)>0 для всех ί, приходим к противоречию.
Следовательно, существование вектора, образующего острые углы со всеми
базовыми векторами, исключает существование у любого
регулярного графа, в том числе бесконечного, хотя бы одного контура.
Предположим теперь, что для заданных базовых векторов
fu ···, /г не существует ни одного век гора q с указанными
свойствами. Выберем среди векторов fly ..., fr максимальную подсистему,
для которой такой вектор существует. Не ограничивая общности,
можно считать, что это будут векторы /ь ..., fr где /</. Согласно
лемме Фаркаша — Минковского о сопряженных конусах, отсюда
следует, что каждый из векторов fl+1, ..., fr представляется в виде
линейной комбинации с отрицательными коэффициентами некоторых
из векторов /ь ..., /г Пусть, например, /,+1=βιΜ-··· +βδ/δ, где
s^/ и все числа β^ отрицательные. Это означает, что вектор и =
= (—βι> ···, —βδ> 1)' все координаты которого строго
положительны, является решением однородной системы линейных
алгебраических уравнений Фи=0, где столбцы матрицы Ф составлены из
координат векторов /ь ..., /s, fl + 1.
Рассмотрим систему кФи=0 более детально. Матрица Φ имеет
целочисленные коэффициенты. Воспользовавшись формулами
Крамера для нахождения фундаментальной системы решений,
заключаем, что все векторы фундаментальной, системы можно выбрать с
рациональными и, следовательно, с целочисленными
координатами. Как было установлено, система Фи=0 имеет решение с
положительными значениями неизвестных. Это решение есть линейная
комбинация векторов фундаментальной системы решений. В силу
непрерывной зависимости линейной,комбинации от коэффициентов
и целочисленности векторов фундаментальной системы следует, что
сколь угодно малыми изменениями коэффициентов линейной
комбинации можно получить решение системы Фи=0 с рациональными
положительными значениями неизвестных. Поэтому система Фи=0
обязательно будет иметь положительное целочисленное решение.
Если γι, ..., γ5, yi+1 — значения соответствующих неизвестных,
то векторы γι
/ъ ···> ysfs, Ίι+Ji+i образуют контур. Следовательно,
отсутствие вектора q, образующего острые углы со всеми базовыми
векторами, неизбежно влечет существование контуров в
бесконечном регулярном графе,( и, конечно, отсутствие контуров
гарантирует, что указанный вектор q существует.
Вектор q является внутренней точкой конуса, определенного
системой неравенств (/ь q)>0 для 1^Ξίζ>. Из соображений непре-
§ 17. РЕГУЛЯРНЫЕ ГРАФЫ
171
рывности его всегда можно выбрать рациональным, а в силу
однородности скалярных произведений и целочисленным.
Следствие. Бесконечный регулярный граф имеет контуры
тогда и только тогда, когда не существует ни одного целочисленного
вектора, образующего острые углы со всеми базовыми векторами.
Следствие. Имеет место альтернатива: или бесконечный
регулярный граф имеет контуры, или существует целочисленный
вектор, образующий острые углы со всеми базовыми векторами.
Следствие. Имеет место альтернатива: или все
достаточно большие подграфы бесконечного регулярного графа не являются
графами алгоритмов, или все его подграфы не только могут быть
графами алгоритмов, но и являются строго направленными.
Следствие. Утверждение и первые два следствия остаются
справедливыми, если в их формулировках исключить слово
«целочисленный».
Строгая направленность регулярных графов, пожалуй, есть
самое важное их свойство. Значение этого свойства определяется
прежде всего тем, что, согласно утверждению 6.2, для строго
направленных графов достаточно просто строятся параллельные формы,
причем очень часто эти формы оказываются близкими к
максимальным.
В общем случае направляющий вектор q регулярного графа с
базовыми векторами /ь ..., /г является решением системы линейных
неравенств (ft, q)>0 для l^i^r. В качестве такого вектора,
согласно утверждению 13.4, всегда можно взять вектор с координатами
1, ε, ε2, ..., где ε есть положительное число, определяющее опорный
функционал. Заметим, что этот вектор не дает никакой информации
о параллельной структуре графа, так как в каждую точку прямой
линии с подобным направляющим вектором проектируется не более
одной вершины. В действительности данный вектор определяет
параллельную форму, совпадающую с последовательной формой,
соответствующей лексикографическому порядку
прохождения'вершин. Тем не менее вектор с координатами 1, ε, ε*, ... может оказаться
полезным при конструировании алгоритмов отыскания нужных
направляющих векторов. Он явно указывает одно из решений
системы линейных неравенств (/*, q)>0, и его можно взять в качестве
начального вектора в процессе поиска нужного направляющего
вектора регулярного графа. '
' При отыскании направляющего вектора и исследований
параллельной формы регулярного графа алгоритма полезными явЛЙются
утверждения 6.3, 6.4 и их следствия. В некоторых случаях
направляющий вектор регулярного графа определяется достаточно просто.
Утверждение 17.7. Если базовые векторы /ь ..., fr
регулярного графа линейно независимы, то любое ненулевое решение q
системы линейных алгебраических уравнений
(/i, q) = <L· ?)=·-· =(/г. Q) (17.3)
172 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ПРОГРАММ
будет направляющим вектором графа с точностью до умножения
на —1.
В силу линейной независимости векторов /ь ..., /г однородная
система (17.3) имеет одномерное множество решений. Пусть q —
одно из решений и оно не равно нулю. Если скалярные
произведения в (17.3) положительны, то вектор q будет направляющим. Если
скалярные произведения отрицательны, то направляющим будет
вектор —q. Очевидно, что вектор q всегда можно взять
целочисленным.
Следствие. Пусть среди базовых векторов регулярного графа
векторы /ь ..., /г линейно независимы, а остальные векторы являются
их линейными комбинациями с неотрицательными коэффициентами.
Тогда вектор q, определенный из системы (17.3), будет для данного
графа направляющим.
Следствие. В условиях утверждения ПЛ или его
предыдущего следствия решение q системы линейных алгебраических
уравнений
М/х, <7) = М/2, q)=..-= δ, (/„ q),
где δι, ..., δΓ — любые положительные числа, будет направляющим
вектором графа с точностью до умножения на —1. В частности,
направляющим будет вектор q, являющийся решением системы
tfi,g).^(f2,g) _ _ (fn я)
II/ι [2 ΙΙ/2Ρ2 Wfrh
и образующий одинаковые углы с базовыми векторами /ь ..., /г.
Имеется определенная общность между регулярными графами
и решетчатыми графами алгоритмов, задаваемых гнездами циклов.
Действительно, вершины и дуги этих графов также можно задавать
векторами с целочисленными координатами. Основное различие
между графами обоих типов состоит лишь в числе векторов,
описывающих множество дуг. Тем не менее формально всегда можно
погрузить решетчатый граф гнезда циклов в некоторый регулярный
граф и считать граф гнезда циклов подграфом регулярного графа.
При этом количество базовых векторов может оказаться очень
большим и быть соизмеримым в общем случае с числом всех вершин
графа гнезда циклов. Однако эти векторы не могут быть произвольными.
Утверждение 17.8. Старшие ненулевые координаты
векторов-дуг решетчатого графа любого гнезда циклов являются целыми
положительными числами.
Целочисленность координат векторов есть следствие целочислен-
ности координат вершин, положительность старших координат
есть следствие утверждения 13.4.
По существу, это утверждение эквивалентно тому, что
решетчатый граф любого гнезда циклов является строго направленным по
отношению к вектору с координатами 1, ε, ε2, ... Регулярный граф,
определяющий какой-нибудь алгоритм, тоже является строго на-
§ 17. РЕГУЛЯРНЫЕ ГРАФЫЦ
173
правленным. Мало полезный направляющий вектор, который указан
для гнезда циклов, появился вследствие того, что не была
использована никакая информация о дугах решетчатого графа. Принималось
во внимание только то, что при проходе вершин графа в
лексикографическом порядке алгоритм может быть выполнен. Для
регулярного графа о дугах известно очень много, и это позволяет выбрать
значительно лучший направляющий вектор.
Вообще говоря, любой конечный строго направленный
решетчатый граф с помощью специальных преобразований можно свести
не только к регулярному графу, но даже к координатному
регулярному графу, дуги которого совпадают с координатными векторами.
Осуществляется это преобразование следующим образом.
Пусть векторы sb ..., sp описывают все множество дуг
решетчатого графа и каждый из них образует острый угол с некоторым
вектором <7, т. е. выполняются условия (st, q)>0 для всех i. Эти
условия позволяют выбрать базис пространства gly ..., gr такой,
что будут справедливы неравенства (siy gj)>0 для всех i, /. Подобных
базисов существует бесконечно много, и, среди них можно выбрать
наиболее подходящий. По отношению к исходному графу данные
базисы обладают следующим свойством.
Утверждение 17.9. Пусть фиксирован вектор g и какая-
нибудь вершина графа принадлежит замкнутому конусу (s—g, gj)^0,
1^/^г. Тогда открытому конусу (s—g, gj)>0, Ι^Ξ/^r,
принадлежат все вершины, в которые ведет хотя бы один путь из заданной
вершины.
Обозначим через и, ν векторы, характеризующие соответственно
положение заданной вершины и вершины, в которую из нее ведет
путь. Так как обе вершины связаны путем, то
Р
i = l
где все kt целые, неотрицательны и хотя бы одно отлично от нуля.
Для вектора и выполняются неравенства (и—g, gy)>0, 1^/^г.
Поэтому для всех / имеем
\"
t=l
(v—g> г/)=(и + 2м*—£, gj =(и—g, g/) + 2lMsi· gj)>°-
Возьмем любой полуоткрытый параллелепипед, гранями
которого являются гиперплоскости, перпендикулярные gly ..., gr, и
покроем такими параллелепипедами всю область, содержащую
вершины графа. Покрытие осуществляем без пропусков и
пересечений, используя параллельный перенос взятого параллелепипеда.
Предположим, что все вершины графа являются внутренними
точками параллелепипедов. Выполнения данного условия всегда
можно добиться сколь угодно малыми перемещениями вершин. Теперь
174 ГЛ. 3. ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ АЛГОРИТМОВ И ΠΡΟΓΡΑΜΛι.
построим новый граф. В качестве вершин этого графа возьмем па*
раллелепипеды вместе с попавшими в них вершинами исходного
графа и частями его дуг. Не ограничивая общности, можно считать,
что вершины нового графа расположены в соответствующих узлах
прямоугольной регулярной решетки. Будем считать, что две
соседние по оси координат вершины связаны дугой, если через грань,
разделяющую два соседних параллелепипеда, проходит хотя бы
одна дуга исходного графа. Все дуги исходного графа,
пересекающие одну и ту же грань параллелепипеда, образуют с ее
направляющим вектором острые углы. Поэтому дуга нового графа
определяется корректно и ее направление возьмем в соответствии с
направлением направляющего вектора грани.
Построенный граф будет координатным регулярным графом.
Согласно утверждению 17.9, он не имеет контуров и, следовательно,
является строго направленным. Все его дуги имеют
неотрицательные координаты, в силу чего справедливы утверждения 6.2—6.4
и вытекающие из них следствия. Наиболее подходящим во
многих отношениях является направляющий вектор с координатами
1, 1, ..., 1.
В связи с построением нового графа сделаем одно замечание.
Исследуя графы алгоритмов, мы почти нигде не делали различия
между отдельными его вершинами и дугами. Однако в действительности
разным вершинам могут соответствовать разные операции, а разные
дуги могут означать передачу информации разной природы. Это
обстоятельство отчетливо видно на примере процесса построения
нового графа. Объявляя параллелепипеды новыми вершинами, мы,
по существу, вводим новые операции. Каждая такая операция
реализует в общем случае некоторый алгоритм, граф которого
размещен внутри отдельного параллелепипеда. В частности, если в
параллелепипеде нет ни одной вершины исходного графа, то новая
операция либо будет пустой, либо будет осуществлять передачу
информации без какого-нибудь ее преобразования. Изоморфные
графы определяют одинаковые операции, поэтому число различных
новых операций, как правило, будет невелико. Их число
зависит в первую очередь от выбора параллелепипедов. Заменяя все
дуги, пересекающие одну и ту же грань параллелепипеда, одной
дугой, мы на самом деле подразумеваем, что эта дуга соответствует
передаче более сложной информации.
Таким образом, любой строго направленный граф можно
преобразовать в координатный регулярный граф. Особенно эффективно
это преобразование осуществляется для регулярных, но не
координатных графов. Координатный регулярный граф устроен настолько
просто, что о нем известно практически все: параллельная форма,
связи между ее ярусами, высота и ширина алгоритма,
вычислительные системы, реализующие соответствующий алгоритм наиболее
эффективно, и многое другое. Поэтому предварительное
преобразование решетчатых графов алгоритмов к некоторой суперпозиции
§ 17. РЕГУЛЯРНЫЕ ГРАФЫ
175
координатных регулярных графов значительно облегчает решение
многих вопросов.
Несмотря на то что к регулярному графу может быть сведен граф
любо го. алгоритма, регулярные графы довольно часто встречаются
и самостоятельно. Так, например, из рассмотренных нами примеров
регулярные графы имеют алгоритмы перемножения матриц,
решения систем линейных алгебраических уравнений с блочной двух-
диагональной матрицей. Мало отличается от регулярного граф
гнезда циклов, описывающего преобразование вращения. Вообще
говоря, регулярные графы характерны для многих алгоритмов
численного анализа, линейной алгебры и математической физики.
В качестве примера опишем структуру входных и выходных
элементов типичной операции гнезда циклов, порождающей регулярный
граф.
Пусть Ль ..., As — непересекающиеся массивы. Предположим,
что выходные переменные операции, реализующей тело цикла,
задаются операторами Рг (/),..., Ps (/) и относятся к разным массивам
Ль ..., As. Пусть входные переменные операции задаются
операторами Qi(/), ..., Qr(I), где каждый оператор Qj(I) либо получается
из оператора Pi(I) путем сдвига аргумента на постоянный вектор,
либо не относится ни к одному из массивов Ль ..., As. При
некотором дополнительном условии на операторы Ρι(/),..., Я8(/),
решетчатый граф такого гнезда циклов будет регулярным, что вытекает
из исследований, проведенных в §§ 14—16. Примером
дополнительного условия может быть следующее: каждый из
операторов Ρι(/), ..., Ρ8(Ι) принимает одинаковые значения лишь на
вершинах, отличающихся друг от друга только в тех координатах,
от которых он не зависит вообще. Именно этому условию
удовлетворяют рассмотренные примеры регулярных графов алгоритмов.
Глава 4
ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ
ИНФОРМАЦИИ
Основное внимание до сих пор уделялось изучению
параллельных структур алгоритмов и выбору моделей наиболее подходящих
вычислительных систем. Даже при совместном исследовании систем
и алгоритмов доминирующим объектом все же оставались
алгоритмы. Эти вопросы имеют отношение скорее к проектированию новых
систем, чем к использованию существующих, хотя, конечно,
практически невозможно провести четкую границу между
проектированием и использованием. Тем не менее в силу различных причин
вычислительная система или ее математическая модель могут быть
заданы заранее. В этом случае построение эффективных для данной
системы вычислительных алгоритмов неизбежно связано с
предварительным изучением особенностей организации на ней потоков
обработки информации.
Настоящая глава посвящена исследованию математических
особенностей параллельных процессов обработки информации,
реализуемых на различных вычислительных устройствах и системах. Как
уже отмечалось ранее, любая вычислительная система
представляет совокупность связанных между собой устройств. В каждый
момент времени эти устройства либо простаивают, либо выполняют
полезную работу, т. е. заняты хранением, пересылкой или
переработкой информации. Коммуникационная сеть, связывающая
отдельные устройства, обычно имеет ограниченные возможности. Поэтому
в реальных условиях каждый класс вычислительных систем
оказывается эффективным лишь для каких-то классов вычислительных
алгоритмов, и очень важно понимать, какие особенности присущи
этим классам.
Глава начинается с изучения конвейерных вычислителей, т. е.
систем функциональных устройств, связанных постоянными или
мало изменяющимися во времени связями. Устанавливается, что
во многих случаях информационный поток, проходящий через такую
систему, расщепляется на независимые однотипно обрабатываемые
ветви. Этот вывод позволяет дать ряд практических рекомендаций
по исследованию и разработке параллельных алгоритмов. В част-
§ 18. КОНВЕЙЕРНЫЕ ВЫЧИСЛИТЕЛИ
177
ности, обращается внимание на необходимость выделения потоков
однотипных вычислений внутри каждого алгоритма.
На основе исследования конвейерных вычислителей, а также
результатов, полученных в предыдущих главах, проводится анализ,
конкретных вычислительных систем: векторных, систолических
и т. п. Заканчивается глава описанием модели специализированной
вычислительной системы, предназначенной для решения больших
задач линейной алгебры с плотными матрицами.
§ 18. Конвейерные вычислители
Среди многочисленных способов организации вычислительных
процессов принцип конвейеризации вычислений представляется
одним из самых эффективных. Однако изучение конкретных
конвейерных систем не дает ответа на многие вопросы, касающиеся
потенциальных возможностей конвейеризации. Поэтому, выполняя
дальнейшие исследования, будем придерживаться следующего
плана. Во-первых, откажемся, по крайней мере на первом этапе, от
рассмотрения смыслового содержания операций, определяющих
работу отдельных функциональных устройств. Затем на основе
анализа конкретных систем выберем минимальное число общих
характеристик, типичных для конвейерных вычислений. И
наконец, принимая во внимание именно эти характеристики, будем
исследовать наиболее важные для нас задачи.
Пожалуй, главное свойство существующих конвейерных систем
можно сформулировать как возможность быстрой и однотипной
обработки больших массивов данных. Хотя это свойство и не
определено строго математически, тем не менее из него можно сделать ряд
полезных выводов.
Обеспечить высокую скорость обработки потока данных
значительно легче, если отделить собственно обработку данных от
процесса их поиска в памяти вычислительной системы. Поэтому одной,
из общих характеристик конвейерных вычислений является
предварительная упорядоченность входных данных. Упорядоченные
данные будем считать поступающими в любое конвейерное устройство
последовательно. Функции поиска данных в памяти, их
упорядочения и подкачки должны быть переданы другим устройствам.
Предполагая последовательное поступление входных данных,
мы можем теперь трактовать однотипность обработки как
неизменность коммутаций между отдельными элементами конвейерного
устройства во время обработки всего или почти всего потока данных.
Это означает, что можно выделить еще две взаимосвязанные общие
характеристики конвейерных вычислений. Одна из них
подчеркивает наличие трех различных этапов обработки: короткого
подготовительного, определяющего настройку конвейерного устройства
и связанного с нестандартными вычислениями в начале процесса;
длинного, во время которого происходит, по существу, вся обработ-
178 ГЛ.4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
яка; короткого заключительного, определяющего вывод результатов
и связанного с нестандартными вычислениями в конце процесса.
Другая характеристика фиксирует неизменность коммутаций на
протяжении второго этапа. Конечно, в частных случаях первый и
последний этапы могут отсутствовать.
В целях достижения максимального быстродействия нужно
выделить еще одну общую характеристику, требующую обеспечение
лолной или почти полной загруженности оборудования,
составляющего функциональную основу конвейерного устройства. Будем
считать также, что всегда результаты работы любого ФУ могут
быть непосредственно переданы другому ФУ без обращения к
общей памяти.
Выделенные характеристики конвейерных устройств являются
достаточно общими. Они свойственны современным конвейерным
системам, но не связаны с их внутренней структурой. Конечно, пока
остается открытым вопрос, насколько содержательные выводы
можно сделать из этих общих характеристик относительно
возможностей конвейерного способа организации вычислений и его
реализации. Конкретные устройства, удовлетворяющие общим
характеристикам, будем называть в дальнейшем конвейерными
вычислителями (KB).
Пусть определено некоторое множество скалярных операций.
Предположим, что каждая операция технически реализована в виде
некоторого функционального устройства. В соответствии со
сказанным выше не будем сейчас интересоваться ни внутренним строением
отдельных ФУ, ни организацией их работы. Единственное, что
пока будет представлять интерес,— это время выполнения
операции. Поэтому, не ограничивая общности, будем считать, что все
ФУ конвейерного вычислителя являются простыми. Это
предположение действительно оправданно, так как любое конвейерное ФУ
всегда представимо в виде линейной цепочки простых ФУ.
Каждое ФУ может иметь любое конечное число входов и
выходов. Информационно совместимые ФУ могут быть связаны между
собой путем соединения выходов одних ФУ со входами других
ФУ. В случае необходимости отнесем к функциональным
устройствам конвейерного вычислителя и устройства, обеспечивающие как
подачу входных данных, так и передачу результатов работы системы
ФУ либо на хранение, либо для дальнейшего использования.
Входные ФУ могут иметь несколько выходов, выходные — несколько
входов. Будем считать, что вся совокупность ФУ работает согласно
правилам, описанным в § 7.
Заметим, что в общем случае ФУ, выполняющие одинаковые по
смыслу операции, могут иметь различное число выходов. По
существу, число выходов ФУ строго не фиксируется лишь-для того,
чтобы иметь возможность размножать результаты работы ФУ.
Изучение конвейерных вычислителей в значительной мере
зависит от наличия или отсутствия в составе KB функциональных уст·
§18. КОНВЕЙЕРНЫЕ ВЫЧИСЛИТЕЛИ
1 79)
ройств, реализующих условные операции. Исследуем сначала
работу тех KB, в которых все операции являются безусловными.
Операции, определяющие режим работы конвейера, без существенного*
ограничения общнссти можно включить в состав устройства
управления. Такие KB назовем безусловными (БKB).
Предположим, что нам удалось построить некоторый
конвейерный вычислитель, удовлетворяющий сформулированным выше
общим характеристикам. В каждый момент времени KB представляет
совокупность ФУ, все входы и выходы которых каким-то образом
связаны между собой. Начиная с момента установления режима
счета, связк в KB остаются неизменными. Поэтому на период счета
структура KB может быть описана некоторым орграфом. Вершины
графа соответствуют отдельным ФУ конвейерного вычислителя,
дуги — имеющимся связям выходов и входов ФУ, причем
ориентация дуг указывает направление от выхода к. входу. Этот граф мы
будем называть графом конвейера. Не ограничивая общность, будем
предполагать в дальнейшем граф конвейера связным. Там, где эта
не вызывает недоразумений, мы не будем делать различия между
конвейерным вычислителем и его графом, говоря о вершинах,
контурах конвейера и т. п.
В действительности мы уже встречались с конвейерными
вычислителями. Так*, например, безусловным KB можно считать любое
конвейерное ФУ. Если ступени такого ФУ считать отдельными
устройствами, то граф соответствующего Б KB будет представлять,
один элементарный путь. Безусловным KB является также любая
базовая вычислительная система, работающая в режиме
максимального быстродействия. Граф этого Б KB совпадает с графом
реализуемого им алгоритма, если базовая система синхронизирована.
Пусть KB полностью загружен в некоторый момент времени,,
т. е. в этот момент времени каждое из его ФУ готово начать работу.
Если KB состоит из s функциональных устройств с длительностями
выполнения операций ть ..., xs, то, начиная с данного момента,
естественным режимом его работы представляется синхронный
режим с временем цикла, равным
τ= max xt.
1 < ι < s
Очевидно, что реализация этого режима работы возможна
независимо от вида графа конвейера.
Утверждение 18.1. Асимптотическая загруженность ρ
любого БКВу работающего β режиме синхронного выполнения
операций ФУ с циклом τ, равна
S
/> = 1Ϊ-Σν (18.1),
i— l
Согласно первому следствию утверждения 7.2, загруженность
Б KB равна среднему арифметическому загруженностей составляю-
\S0 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИЛ
щих Б KB устройств. Так как Б KB работает в синхронном режиме с
циклом τ, то i-e ФУ на любом цикле имеет загруженность xjx.
Следовательно,такой же будетиего асимптотическая загруженность.
Отсюда и вытекает справедливость высказанного утверждения.
Следствие. Для того чтобы при синхронном режиме с
циклом τ асимптотическая загруженность Б KB равнялась 1,
необходимо и достаточно, чтобы время срабатывания всех
используемых ФУ было одинаковым.
Синхронный режим с циклом τ является для Б KB оптимальным
с точки зрения его асимптотической загруженности. Это означает,
что при фиксированных составе ФУ и коммутационной сети
никакой другой режим включения ФУ не может обеспечить большей
загруженности.
Утверждение 18.2. Πустывычислитгльная система имеет
s простых безусловных ФУ с длительностями выполнения операций,
равными τи ..., xs. Если граф вычислительной системы связный, то
при любом режиме функционирования асимптотическая
загруженность ρ системы удовлетворяет неравенству
S
Κ^Σν (18.2)
Предположим, что на i-м ФУ за время Τ выполнено Nt
операций. Пусть из i-й вершины графа вычислительной системы идет
путь длиной г в /-ю вершину. Так как в конечном счете один из
аргументов /-го ФУ зависит от результатов последовательного
срабатывания всех ФУ, лежащих на данном пути, то справедливы
неравенства Nt—r^Nj^.Ni+r. Эти же неравенства остаются в силе и в
том случае, когда вершины связаны не путем, а цепью, так как
любую цепь всегда можно'рассматривать как последовательность
путей. Выберем любое устройство с номером t; тогда для всех i находим,
что
Nt—s^Nt<^Nt + s. (18.3)
Согласно (7.2),
S S
ΣΛ·=τΣτΛ·
i=l i=l
Следовательно, для любого t
i=l i=l /=l
Если t соответствует ФУ с временем срабатывания τ, то Nt^.T/r.
Поэтому
ι=1 i=l i=l
§ 18. КОНВЕЙЕРНЫЕ ВЫЧИСЛИТЕЛИ
181
Переходя в правом неравенстве к пределу при Т-+ оо и
вспоминая, что, согласно первому следствию утверждения 7.2,
загруженность системы равна среднему арифметическому загруженностей
составляющих систему устройств, получаем неравенство (18.2).
Следствие. Пусть вычислительная система состоит из
простых безусловных ФУ и граф системы связный. Если
асимптотическая загруженность хотя бы одного ФУ равна 1, то
— это ФУ имеет максимальную длительность выполнения
операций;
— выполняется равенство (18.1).
Аналогичных следствий можно получить довольно много. Если
граф системы связный, то справедливы неравенства (18.3).
Поэтому во всех случаях, когда для каких-нибудь ФУ известны
соотношения, связывающие число срабатываний и время функционирования,
различные следствия вытекают с учетом данных неравенств,
например, из равенств (7.2), (7.3) и им подобных. В качестве еще одного
примера приведем такое
Следствие. Пусть в условиях утверждения за время Τ
на всех ФУ системы выполняется N операций. Тогда имеет место
асимптотическое равенство
S S
Σ/^^Σν
Действительно, при каждом Τ найдется одно ФУ, для которого
число выполненных операций не превосходит N/s, и одно ФУ, для
которого число выполненных операций не меньше N/s. Все
остальное является прямым следствием соотношений (7.2), (18.3).
Для того чтобы обеспечить асимптотически полную
загруженность оборудования Б KB, необходимо стремиться к тому, чтобы
время срабатывания всех используемых ФУ было одинаковым.
Соответствующего эффекта можно добиться путем замены долго
работающих ФУ либо эквивалентной цепочкой быстро
работающих ФУ, либо совокупностью параллельно работающих ФУ с
циклической подачей на них обрабатываемых данных. В общем случае
приходится заменять долго работающие ФУ некоторым KB с
малым циклом. Синхронный режим во многих отношениях является
наиболее приемлемым. Поэтому, принимая во внимание сделанные
выводы, будем предполагать в дальнейшем, что Б KB работает в
синхронном режиме с циклом 1. Отступление от этих требований
сказывается в основном только на величине общей загруженности
БКВ.
Итак, будем считать, что время является целочисленной
величиной и данные поступают на входы БКВ одновременно в
последовательные моменты. Каждое ФУ, получив данные по всем своим
входам, в следующий момент времени выдает результаты их обра5о^к
182 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ 1
по всем своим выходам. Начиная с момента установления режима|
счета, такое функционирование возможно, и БКВ будет реализо-1
вывать некоторый алгоритм.
Чтобы вывести БКВ на режим счета, необходимо обеспечить^
данными все его ФУ. Это осуществляется в период загрузки БКВ.
В течение этого периода работают те же самые функциональные
устройства, что и во время счета. Однако данные они получают не
только через входы БКВ, ной через некоторые дополнительные входы,
работающие только в период загрузки. Если граф БКВ имеет
контуры, то появление дополнительных входов неизбежно. Через
основные входы БКВ в этом случае нельзя подать информацию,
достаточную для выполнения хотя бы одной операции контура.
Процесс загрузки можно осуществлять очень многими способа-j
ми. Однако мы выберем лишь один из них и будем считать его в
дальнейшем стандартным. Поставим в соответствие каждой дуге графа
БКВ число, равное длине минимального элементарного пути из.
какого-либо входа БКВ в ту вершину, для которой данная дуга
является входной. Для каждой вершины БКВ рассмотрим
множество целых чисел, соответствующих ее входам. Все дуги, входящие в
вершину и имеющие числа, большие, чем наименьшее для данной
вершины, разомкнем и образуем в графе БКВ дополнительные входы.
Пусть т — наименьшее число в множестве, соответствующем
некоторой вершине, и какой-то ее дуге приписано число М. Теперь
разомкнем эту дугу и образуем дополнительный вход. По
образованному здесь дополнительному входу в нужный момент начнем
подавать данные последовательно Μ — т раз, после чего
дополнительный вход устраним и данную дугу замкнем.
Загрузку БКВ нельзя реализовать существенно иным способом,
если в графе БКВ имеются неуравновешенные циклы, т. е. циклы,
при обходе которых встречается неодинаковое число дуг,
проходимых в положительном и отрицательном направлениях. Процесс,
связанный с разрезанием дуг и подключением дополнительных
входов, на самом деле осуществляет временное уравновешивание
циклов. Если все циклы графа БКВ уравновешены, то загрузка БКВ
может быть реализована только через основные входы. В случае,
когда граф БКВ не имеет контуров, его циклы можно уравновесить
путем добавления ФУ задержки согласно утверждению 9.6. Однако
при этом, вообще говоря, изменяется реализуемый БКВ алгоритм.
Тем не менее имеется определенная общность между стандартным
процессом загрузки БКВ и процессом уравновешивания графа
базовой вычислительной системы.
Каждый БКВ реализует целое семейство алгоритмов. Во-пер;
вых, алгоритмы, порождаются различными способами загрузки
БКВ. В случае стандартного процесса различия в работе БКВ,
связанные с его загрузкой, будут определяться лишь способами выбора
конкретных значений данных, посылаемых через дополнительные
£ходы. Во-вторых, алгоритмы зависят от числа обрабатываемых
§18. КОНВЕЙЕРНЫЕ ВЫЧИСЛИТЕЛИ
183
БКВ данных. И наконец, на алгоритмы оказывает влияние процесс
жончания работы БКВ.
Размыкание дуг и подключение дополнительных входов
являются необходимыми элементами процесса загрузки, так как в самом
БКВ нет никаких возможностей для формирования входных данных
всех его ФУ. В отличие от процесса загрузки процесс окончания
яе требует обязательного размыкания дуг. Поэтому будем считать,
по стандартное окончание работы БКВ заключается в том, что для
выдачи результатов в необходимые моменты времени к необходимым
1>У подключаются дополнительные выходы. Эти выходы не
оказывают никакого влияния на процесс работы БКВ. Функционирование
БКВ прекращается после получения всех нужных результатов.
Будем считать, что работа БКВ начинается в нулевой момент
зремени. К моменту времени t по каждому основному входу
передано t данных, некоторые дополнительные входы, возможно, уже
1иквидированы. Обозначим через G(t) граф алгоритма, содержащего
зсе операции, которые могут быть выполнены БКВ без привлечения
данных, прошедших по основным или дополнительным входам в
моменты времени x>t. Справедливо очевидное
Утверждение 18.3. Граф G(t) является подграфом графа
3 (τ) при %>t.
Существует минимальный бесконечный граф G, для которого
j(t) есть конечный подграф при любом t. Будем называть граф G
оазверткой БКВ. По существу, все семейство алгоритмов,
реализуемых БКВ, описывается подграфами его развертки, причем такими,
которые при некотором τ включают в себя ό(τ).
Таким образом, для изучения процесса функционирования
БКВ необходимо в первую очередь исследовать его развертку. Успех
>того исследования во многом определяется тем, насколько удачно
5удет выбрано представление самой развертки.
Перенумеруем функциональные устройства БКВ подряд числами
я 1 до s. Рассмотрим на плоскости прямоугольную систему коорди-
яат и будем считать ось абсцисс осью времени, а ось ординат осью
функциональных устройств. Если в момент времени t работает
г-е ФУ, то в точку плоскости с координатами (/, k) поместим
Берлину графа. Никаким другим способом размещать вершины на
июскости не будем. Тем самым устанавливается взаимно одно-
шачное соответствие между точками плоскости, в которых имеют-
:я вершины развертки БКВ, и срабатываниями отдельных ФУ. Для
завершения построения развертки БКВ соединим дугой каждую
iapy вершин, соответствующих последовательным срабатываниям
:вязанных ФУ. При этом будем считать, что направление дуги отра-
кает направление передачи информации, а дуги заданы векторами.
Предположим, что данные по дополнительным входам БКВ пода-
отся последний раз в момент U. Развертка естественным образом
разбивается на две части. Одна часть представляет граф G0 и
соответствует значениям t из интервала 0<^t^t0. Вторая часть соответ-
184 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
ствует значениям t>U. Она представляет дополнение G\G0 графа
G0 до графа G. Эта часть является периодическим графом. Так как
при t>U никакие связи в БКВ не меняются, то дуга развертки,
выходящая из вершины с коорди-
5*-* *4 натами (t0, k), переносится парал-
\ д лельно во все вершины с коорди-
\ \ >ш > натами (t, k) при t>U.
1 2 Ту б Если вторую часть продолжить
с тем же периодом на значения
Рис· 18,1 t^to, то это продолжение целиком
покроет граф G0, как, впрочем, и
любой граф G(t) при f^O. Объясняется это тем, что в период
загрузки по сравнению с периодом счета никакие новые ФУ и связи не
появляются. Поэтому множество всех реализуемых БКВ алгоритмов
в действительности определяется периодическим графом, заданным
на полуоси £Ξ^0. Различные процессы загрузки, связанные с размы-
канием дуг и подключением дополнительных входов БКВ, приводят
фу А
0 12 3 £0=4 5 6 7 8 Э 10 11 12 13 14 15 16 t
Рис. 18.2
к тому, что развертка БКВ получается из данного бесконечного
периодического графа исключением некоторых его дуг и вершин для
начальных значений t.
Заметим, что рассматриваемые здесь периодические графы
обладают ярко выраженной спецификой. Именно, проекции всех дуг
на ось t совпадают между собой и равны координатному вектору.
Рассмотрим следующий пример. Предположим, что БКВ имеет
граф, представленный на рис. 18.1. Стандартный процесс загрузки
связан с размыканием дуги, связывающей вершины 5 и 2.
Дополнительно образованный здесь вход БКВ подает входное данное,
соответствующее разомкнутой дуге, подряд четыре раза, начиная с
t=l. После этого дуга замыкается, дополнительный вход
ликвидируется, а необходимое данное для вершины 2 подается в
дальнейшем с выхода вершины 5.
На рис. 18.2 изображена развертка графа БКВ. Часть
развертки, описывающая процесс загрузки БКВ, соответствует значениям
§ 19. ПЕРИОДИЧЕСКИЕ ГРАФЫ
185
из интервала 0^ί^4. Остальная часть развертки является
периодической. Продолжение периодической части развертки с тем же
периодом влево от точки t=i, очевидно, покрывает первую часть
развертки.
На этом примере можно увидеть интересную особенность
развертки графа БКВ. Именно, она расщепляется на изоморфные не
связные между собой подграфы, получающиеся один из другого путем
параллельного переноса. В данном примере таких подграфов
четыре. Вершины одного из них обведены на рис. 18.2 кружками.
§ 19. Периодические графы
Пусть Но — произвольный конечный ориентированный граф,
не имеющий контуров. Разобьем его входы и выходы на г непустых
групп. Перенумеруем группы входов и выходов. В каждой паре
групп входов и выходов, имеющих одинаковые номера, выберем
по одинаковому числу соответственно входов и выходов и
перенумеруем их одинаковым способом. Теперь из графов, изоморфных
графу Н0, образуем бесконечный граф с помощью соединения выходов
и входов разных графов. Графам поставим в соответствие вершины
/•-мерного арифметического пространства так, чтобы каждой оси
отвечало соединение по одной группе и в каждой паре соседних
графов соединялись все соответствующие входы и выходы, относящиеся
к группам с одним и тем же номером. Каждая пара соседних графов
соединяется только по одной группе входов и выходов и к каждой
группе входов и выходов присоединяется по одному графу.
Направление соединяющих дуг будем всегда считать от выхода к входу.
Остальные входы и выходы оставим свободными. Построенный таким
образом граф Η назовем бесконечным периодическим графом
размерности г.
Предположим, что граф Н0 имеет s компонент связности.
Рассмотрим в (г+1)-мерном арифметическом пространстве
прямоугольную систему координат. Перенумеруем каким-нибудь способом
компоненты связности и будем считать, что во все точки
пространства, имеющие целочисленные координаты (tl9 ···, tr, k), где l^£^s,
помещены вершины, означающие k-ю компоненту связности графа
Я. Пусть ось tu 1^^", соответствует связям графов по 1-й группам
и направление связи определяется положительным направлением
оси ti. Предположим, что в k-и компоненте графа Н0 имеется хотя
бы один выход из 1-й группы, а в р-и компоненте имеется хотя
бы один вход из 1-й группы. Тогда все точки с координатами
(tu ..., tu ···> tr, k) соединим векторами-дугами с точками с
координатами (tu ..., ίί+1, ..., tri ρ).
Проделав эту процедуру для всех /, получим бесконечный
периодический граф G размерности г. Этот граф устроен очень просто.
Именно, весь пучок дуг, выходящих из вершины с координатами
(tu ···, tr, k), может быть получен путем параллельного переноса
1£6 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
пучка дуг, выходящих из вершины с координатами (0, ..., О, k).
Такие вершины и выходящие из них дуги можно считать некоторым
шаблоном, параллельное перемещение которого позволяет
построить весь граф G. Согласно процессу построения графа G, векторы
шаблона не могут быть произвольными. Если вектор выходит из
вершины с координатами (0, ..., О, k), то его конец должен
находиться в вершине с координатами вида (tu ···, tr, q), причем среди чисел
U, ..., tr только одно отлично от нуля, и оно равно 1, a q есть целое
число из интервала l^^s. На число векторов шаблона ограничения
не накладываются. Все эти особенности графа G являются
отражением соответствующих особенностей соединения графов, изоморфных
графу #о, в бесконечный периодический граф Н,
Утверждение 19.1. Бесконечный периодический граф G
просто гомоморфен бесконечному периодическому графу Н,
В графе Η в каждом из подграфов, изоморфных графу #0>
объединим с помощью операций простого гомоморфизма все
вершины, принадлежащие одной компоненте связности. Так как при этих
операциях исключаются все петли и все кратные дуги заменяются
одной дугой, то полученный граф будет отличаться от графа G
только расположением вершин.
Утверждение 19.2. Бесконечный периодический граф G
является строго направленным, и в качестве его направляющего
вектора можно взять вектор с координатами (1, ..., 1, 0).
Действительно, согласно построению графа G, любая его
вектор-дуга среди первых ее г координат имеет только одну ненулевую
координату, которая^ тому же равна 1. Поэтому скалярное
произведение любой дуги с выбранным направляющим вектором равно 1,
что и означает строгую направленность графа G.
Следствие. Бесконечный периодический граф G не имеет
контуров.
Проведем через вершины графа G гиперплоскости,
перпендикулярные вектору (1, ..., 1, 0). Очевидно, что различные
гиперплоскости параллельны, а соседние гиперплоскости отстоят друг от друга
на одно и то же расстояние, равное г"1/·. Как вытекает из
построения графа G, все его дуги обладают тем свойством, что их концевые
вершины всегда лежат на соседних гиперплоскостях. Следовательно,
справедливо
Утверждение 19.3. Пусть дан произвольный конечный
связный подграф графа G. Параллельная форма подграфа,
построенная в соответствии с утверждением 6.2 по вектору (1, ..., 1, 0),
является максимальной.
Следствие. Длина критического пути любого конечного
связного подграфа графа G равна dr1^, где d есть минимальное
расстояние между гиперплоскостями, перпендикулярными вектору
(1, ..., 1, 0) и содержащими между собой этот подграф.
Итак, параллельная структура произвольного связного
подграфа графа G полностью определена, и теперь исследуем возможность
§ 19. ПЕРИОДИЧЕСКИЕ ГРАФЫ
1S7
расщепления различных подграфов графа G на не связанные между
собой компоненты.
Рассмотрим максимальный связный подграф графа G, т. е.
содержащий в себе все связные подграфы, имеющие с ним хотя бы
одну общую вершину. Назовем любой такой подграф главным
подграфом графа G. Если главный подграф содержит некоторую
вершину, то он содержит все смежные с ней вершины и инцидентные с
ней ребра. Непосредственно из определения главного подграфа
вытекает
Утверждение 19.4. Если два главных подграфа графа G
имеют хотя бы одну общую вершину, то они совпадают.
В общем случае главный подграф может быть как конечным, так
и бесконечным, что определяется совокупностью дуг графа G. В
основе многих фактов, касающихся изучения строения графа G, лежит
Утверждение 19.5. Любой подграф графа G, сдвинутый
параллельно на любой целочисленный вектор с равной нулю
последней координатой, также является подграфом графа G.
Предположим, что сдвиг осуществляется на вектор / с
координатами (U, ..., tr, 0). Рассмотрим в выбранном подграфе некоторый
комплекс, состоящий из вершины Μ и выходящих из нее дуг.
Пусть вершина Μ имеет координаты (ти ..., тг, тг+1). Эго означает,
что при построении графа G рассматриваемый комплекс был
получен параллельным переносом аналогичного комплекса,
соответствующего вершине с координатами (0, ..., 0, тг+1). Но вершина Μ и
точка М', полученная сдвигом Μ на вектор /, имеют одинаковые
последние координаты. Следовательно, связанные с ними комплексы
имеют один и тот же прообраз, соответствующий вершине с
координатами (0, ..., 0, тг+1), и оба комплекса получены из него
параллельным переносом. Так как вектор / целочисленный, то точка М' и
выходящие из нее дуги принадлежат графу G.
Следствие. Главный подграф графа G, сдвинутый
параллельно на любой целочисленный вектор с равной нулю последней
координатой, является главным подграфом.
Следствие. Пусть некоторый подграф главного подграфа
сдвигается параллельно на целочисленный вектор с равной нулю
последней координатой. Если хотя бы одна вершина сдвинутого
подграфа принадлежит исходному главному подграфу, то ему
принадлежит весь сдвинутый подграф.
Сдвиг шаблона, задающего граф G, осуществляется
перпендикулярно (г+1)-й оси координат. Поэтому проекции графа G и его
главных подграфов на эту координатную ось дают определенную
информацию о структуре периодических графов.
Утверждение 19.6. Если множества проекций вершин
двух главных подграфов на (г+1)-ю ось координат имеют непустое
пересечение, то эти множества совпадают.
Предположим, что точка с координатами (0, . . ., 0, k) является
общей для указанных множеств. Тогда в первом подграфе имеется
188 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
вершина с координатами (ti, . . ., tr, k), во втором — вершина с
координатами (t[, . . ., frik). Перенесем первый главный подграф
параллельно на вектор (t[—tu . . ., t'r —tr, 0). При этом выделенная
вершина первого подграфа перейдет в выделенную вершину второго
подграфа. Согласно утверждению 19.4, первый главный подграф
после параллельного переноса совпадет со вторым главным
подграфом. Остается лишь заметить, что при указанном
параллельном переносе проекции вершин на (г+1)-ю координатную ось не
изменяются.
Следствие. Если в каждом из двух главных подграфов
имеется хотя бы по одной вершине с одинаковыми значениями (г+1)-х
координат, то один из этих подграфов получается из другого
параллельным переносом перпендикулярно (г+1)-й оси координат.
Следствие. Пусть в главном подграфе имеются две вершины
с одинаковыми значениями (г+1)-х координат. Тогда главному
подграфу принадлежат все вершины, лежащие на прямой линии,
проходящей через эти две вершины, и образующие на ней порожденную
ими равномерную сетку.
Следствие. Если в графе G существует конечный главный
подграф, то все его вершины имеют различные значения (г+1)-х
координат.
Следствие. Любой конечный главный подграф содержит
не более s вершин.
Следствие. Если конечный главный подграф сдвинуть
параллельно на любой целочисленный вектор с равной нулю последней
координатой, то это будет другой главный подграф, не совпадающий с
исходным.
Следствие. Любые две вершины, одна из которых
принадлежит конечному главному подграфу, а другая — бесконечному,
имеют различные значения (г+1)-х координат.
Таким образом, структура бесконечного периодического графа
G выглядит следующим образом. В общем случае этот граф
расщепляется на не связанные между собой главные подграфы. Все главные
подграфы можно разбить на непересекающиеся группы, относя к
одной группе те из них, множества проекций вершин которых на
(г+1)-ю координатную ось совпадают. Все главные подграфы,
входящие в одну группу, могут быть получены из одного подграфа
параллельным переносом. В одну группу входят либо только
конечные, либо только бесконечные главные подграфы. Если группа
состоит из конечных главных подграфов, то таких подграфов в ней
бесконечно много и каждый из них не дает кратных проекций вершин
на (г+1)-ю координатную ось. Если же группа состоит из
бесконечных главных подграфов, то этих подграфов может быть в ней как
бесконечно много, так и конечное число. Конкретная ситуация
определяется дугами шаблона, образующего периодический граф.
Рассмотрим более подробно одну из описанных групп главных
подграфов. По существу, она эквивалентна бесконечному периоди-
§ 19. ПЕРИОДИЧЕСКИЕ ГРАФЫ
189
ческому графу, расщепляемому на параллельные главные
подграфы. Такие периодические графы будем называть основными.
Структура основного графа определяется не только числом не связанных
друг с другом компонент, но и структурой отдельного главного
подграфа.
Утверждение 19.7. Пусть Vi есть мнооюество вершин
какого-нибудь бесконечного главного подграфа периодического графа*
имеющих последнюю координату, равную i. Тогда для всех /, /
множество Vj может быть получено из множества Vi параллельным
переносом.
Выберем в множестве Vt какую-нибудь вершину щ% а в множестве
Vj вершину Vj. Сдвигом на целочисленный вектор с равной нулю
последней координатой вершину vt можно совместить с любой вер»
шиной из Vi. Согласно последнему следствию из утверждения 19.5>
при всех таких сдвигах вершина Vj перейдет в какую-то
вершину из Vj. Следовательно, множество Vt, сдвинутое параллельно
на вектор Vj—vu содержится в множестве Vj. Аналогично заключаем,
что множество Vj, сдвинутое параллельно на вектор Vi—Vj,
содержится в множестве Vt. Поэтому при параллельном переносе на
вектор Vj—Vi множество Vi переходит в множество Vj.
Утверждение 19.8. Каждое из мнооюеств Vt образует
регулярную решетку.
Предположим, что множество Vt содержит более одной вершины.
Возьмем какие-нибудь две вершины и проведем через них прямую
линию. Как вытекает из второго следствия утверждения 19.6,.
все вершины Vif находящиеся на этой прямой, образуют
регулярную решетку. Пусть множество Vt содержит вершину, не лежащую
на этой прямой. Проведем прямую линию через эту вершину и
какую-нибудь вершину из регулярной решетки первой прямой. Как
вытекает из последнего следствия утверждения 19.5 и второго
следствия утверждения 19.6, все вершины множества Vi, лежащие в.
плоскости, проходящей через построенные прямые, образуют
регулярную двумерную решетку. Продолжая этот процесс, заключаем,,
что каждое из множеств Vi образует регулярную решетку.
Следствие. Если в основном периодическом графе
размерности г множества Vt образуют регулярные решетки размерности
г, то основной граф расщепляется на конечное число не связанных друг
с другом главных подграфов.
Следствие. В условиях предыдущего следствия число
различных главных подграфов равно числу точек с целыми
координатами, попавших в полуоткрытый базовый параллелепипед, образующий
регулярную решетку одного из множеств Vi.
Следствие. Если в основном периодическом графе
размерности г множества Vi образуют регулярные решетки размерности
меньше г, то основной граф расщепляется на бесконечное число не
связанных друг с другом главных подграфов. При этом имеется
конечное число различных главных подграфов, получающихся один из
190 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
другого параллельным переносом в плоскости, содержащей решетку,
и бесконечно большое число различных главных подграфов,
получающихся один из другого параллельным переносом, ортогональным
содержащей решетку плоскости.
Утверждение 19.9. β любом основном периодическом
графе существует конечный связный подграф, содержащий по одной
вершине с каждым из возможных для данного основного графа
значений (г+1)-й координаты и принадлежащий одному главному
подграфу.
Возьмем любую вершину основного графа. Если проекции всех
его вершин на (г+1)-ю координатную ось совпадают, то в качестве
указанного в утверждении подграфа можно взять подграф,
состоящий лишь из взятой вершины. Предположим теперь, что не все
проекции совпадают. Рассмотрим главный подграф, содержащий
взятую вершину. Так как главный подграф связный, то среди
вершин, смежных с выбранной, обязательно имеются вершины с
другими, чем у нее, значениями (г+1)-й координаты. Присоединим к
взятой вершине все или некоторые из смежных с ней вершин, чтобы
тюлученная совокупность вершин имела различные значения (г+1)-х
координат. К совокупности вершин добавим также все
связывающие их дуги. С каждой из присоединенных вершин проделаем
аналогичную операцию и т. д. В силу связности главного подграфа
процесс добавления новых вершин и связывающих их дуг не может
остановиться раньше, чем будет получен подграф, содержащий по одной
-вершине с каждым из возможных для данного главного подграфа
значений (г+1)-й координаты.
Назовем максимальный подграф из утверждения 19.9 базовым
для основного периодического графа. Согласно построению,
базовый подграф содержит все дуги образующего основной граф
шаблона, которые только могут связывать какие-нибудь две его вершины.
Дуги шаблона, не входящие в базовый подграф, назовем
связующими. В общем случае базовый подграф и связующие дуги
определяется неоднозначно. Из утверждения 19.9 непосредственно
вытекает следующие утверждения.
Утверждение 19.10. Если из основного периодического
графа исключить все дуги, параллельные связующим, то основной граф
расщепляется на не связанные друг с другом подграфы, получаемые
413 базового параллельным переносом. При этом любая дуга,
параллельная одной из связующих, соединяет два каких-то подграфа.
Утверждение 19.11. Основной периодический граф
расщепляется на конечные подграфы тогда и только тогда, когда
существует базовый подграф, содержащий все дуги шаблона. В этом и
только в этом случае базовый подграф совпадает с главным.
Итак, имеется определенная общность между основными
периодическими графами, расщепляемыми на конечные и бесконечные
главные подграфы. Точнее, основной-граф, расщепляемый на
бесконечные главные подграфы, можно превратить в основной граф, рас-
§ 19. ПЕРИОДИЧЕСКИЕ ГРАФЫ
19*
щепляемый на конечные главные подграфы, если удалить из
шаблона некоторые дуги. При этом главный подграф второго основного»
графа будет базовым подграфом для первого.
Большинство из приведенных результатов хорошо
иллюстрируется случаем г=1. Это видно на примере графа, приведенного на
рис. 18.2, если, конечно, расширить его до бесконечного
периодического графа при t^4. Он расщепляется на четыре бесконечных
\
\
\
\
»
/
Г7
L
и
1—ν
А
1
V
ч
и
/
у
\
\
1*
1/
1
Рис. 19.1
главных подграфа. Все множества Vt образуют одномерные
регулярные решетки с шагом 4. На рис. 19.1 показаны четыре разных
базовых подграфа. Единственная в каждом случае связующая дуга
отмечена штриховой линией. Однако для г=\ отдельные
результаты можно уточнить. Например, справедливо
Утверждение 19.12. При г= 1 любой основной
периодический граф расщепляется либо на конечные главные подграфы, либо на
конечное число бесконечных главных подграфов.
Если основной периодический граф расщепляется на
бесконечные главные подграфы, то в этом случае множества Vt всегда
образуют регулярные решетки размерности 1. Поэтому справедливость
высказанного утверждения вытекает из первого следствия утвер^
ждения 19.8.
В заключение заметим, что формально выполненные
исследования касались лишь периодических графов специального вида,
определяемых особенностями дуг шаблона. Другие виды шаблонов не
вносят существенных изменений. С помощью подходящих преобра-
192 гл· 4· ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
зований, подобных использованным в § 17 для перевода
произвольного графа в регулярный, можно почти всегда периодический граф
другого типа свести к изученному.
§ 20. Расщепление информационных потоков
Снова вернемся к изучению процесса работы Б КВ. Как было
установлено в § 18, множество алгоритмов, реализуемых Б KB,
описывается некоторыми подграфами его развертки. Сама развертка
является минимальным бесконечным графом, содержащим в себе
последовательность вложенных один в другой параметрических
графов G(t). Для этой последовательности граф G(t) есть подграф графа
G(t) при x>t. Кроме того, графы алгоритмов, реализуемых БКВ,
также обладают свойством вложенности по отношению к данной
последовательности. Именно, всегда можно найти такие числа t,
τ, где x>t, что граф алгоритма включает в себя граф G(t), но
является подграфом графа G(t). Разность τ—t, как правило, может быть
выбрана небольшой, так как определяется только заключительным
этапом работы БКВ, на котором осуществляются нестандартные
вычисления в конце процесса и производится вывод результатов.
Поэтому, не ограничивая общности, можно считать, что граф любого
алгоритма, реализуемого БКВ, совпадает при некотором t с
графом G(t).
В § 18 уже отмечалось, что развертка БКВ разбивается на две
части: одна часть совпадает с графом G0, и U есть момент последней
подачи данных по дополнительным входам БКВ, а вторая часть
является периодическим графом. При этом в качестве шаблона,
образующего периодическую часть, можно взять набор дуг, выходящих
из вершин, соответствующих ί=ί0· Отмечалось также, что
периодическое продолжение второй части с тем же шаблоном на область
KU покрывает целиком развертку БКВ.
Используя терминологию, введенную в § 19, можно утверждать,
что каждый БКВ порождает бесконечный периодический граф
размерности 1, содержащий в себе развертку БКВ и, следовательно, все
графы G(f). Если этот граф строить описанным способом, то он,
очевидно, будет минимальным периодическим графом, обладающим
указанным свойством. Такой граф будем называть сопровождающим
графом БКВ.
Теперь можно сделать вывод, имеющий исключительно важное
значение для понимания многих проблем, связанных с реализацией
алгоритмов на параллельных вычислительных системах.
Предположим, что для решения некоторой задачи построен БКВ. Его работа
полностью определяется сопровождающим графом. Этот граф
является периодическим. Как любой периодический граф,
сопровождающий граф БКВ может расщепляться на не связанные между собой
главные подграфы. Если это расщепление действительно происходит,
то отсюда следует, что в процессе своей работы Б KB решает не одну
§ 20. РАСЩЕПЛЕНИЕ ИНФОРМАЦИОННЫХ ПОТОКОВ 193
задачу, а несколько независимых задач, и граф каждой из них будет
подграфом одного из главных подграфов сопровождающего графа.
БКВ является простейшей системой функциональных устройств,
и как составная часть он многократно встречается на разных
уровнях архитектуры любой вычислительной системы. Поэтому в общем
случае придется иметь дело с ситуацией, когда желание эффективно
использовать вычислительную систему для решения конкретной
задачи необходимо согласовывать с возможностью достижения
высокой эффективности только при решении нескольких независимых
задач.
Нельзя сказать, что этот вывод совсем неожиданный. В § 7 был
рассмотрен пример решения системы линейных алгебраических
уравнений с трехдиагональной матрицей. Там же было показано, что
при решении этой задачи методом прогонки ни на какой
вычислительной системе нельзя достичь эффективного использования
функциональных устройств. Поэтому существование плохо реализуемых
задач было установлено раньше. Однако тогда не было указано
никакого конструктивного пути повышения эффективности. Теперь
это можно сделать для вычислительных систем типа БКВ.
Утверждение 20.1. Если граф БКВ связный, то
сопровождающий граф БКВ расщепляется либо на конечное число
бесконечных, либо на бесконечное число конечных не связанных друг с
другом главных подграфов, получающихся один из другого параллельным
переносом вдоль оси времени.
Согласно утверждению 19.6 и его следствиям, для того чтобы
сопровождающий граф БКВ расщеплялся на параллельно сдвигаемые
главные подграфы, необходимо и достаточно, чтобы множества
проекций вершин разных главных подграфов на ось функциональных
устройств совпадали. Так как граф БКВ связный, то результаты
реализации алгоритма, соответствующего отдельному главному
подграфу, зависят от срабатывания всех ФУ при достаточно большом t.
Следовательно, множества проекций вершин разных главных
подграфов на ось функциональных устройств должны совпадать.
Таким образом, если сопровождающий граф БКВ расщепляется
на не связанные друг с другом главные подграфы, то это означает,
что в процессе своей работы БКВ не только решает несколько
независимых задач, но все эти задачи к тому же однотипные. При
бесконечно большом t графы однотипных задач совпадают, за
исключением, возможно, начальных участков, соответствующих процессу
загрузки. Поэтому в данном случае можно также говорить о том,
что БКВ решает несколько раз одну и ту же задачу, но для разных
начальных данных и разных характерных ее размеров.
Любой БКВ можно рассматривать как некоторое устройство.
На входы данного устройства регулярно подается поток входных
данных, этот поток каким-то образом обрабатывается, и с выходом
БКВ регулярно выдается поток выходных данных. Проведенные
исследования позволяют заключить, что информационный потокг
1/27 В. В. Воеводин
194 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
проходящий через БКВ, обязательно расщепляется на
независимые однотипно обрабатываемые ветви. При этом число ветвей
определяется лишь графом БКВ.
Можно указать структуру этого расщепления и определить,
какие входные и выходные данные к какой ветви вычислений
относятся. Перенумеруем ветви подряд по графу развертки натуральными
числами, начиная с 1. Перенумеруем так же все данные,
относящиеся к каждому входу или выходу БКВ, в том числе дополнительному.
Наконец, перенумеруем все входы и выходы.
Утверждение 20.2. Предположим, что сопровождающий
граф БКВ расщепляется на I не связанных друг с другом главных
подграфов. Пусть известно, что первое входное (выходное) данноег
относящееся к i-му входу (выходу), связано с 1гй ветвью
вычислений. Тогда k-e входное (выходное) данное, относящееся к тому же
входу (выходу), связано с той ветвью вычислений^ номер которой
равен остатку от деления k+l{ на I.
Предположим сначала, что сопровождающий граф БКВ
расщепляется на конечное число бесконечных главных подграфов.
Согласно утверждению 19.8, времена срабатываний любого ФУ
БКВ, соответствующие одной ветви вычислений, образуют
регулярную одномерную решетку. Согласно второму следствию
утверждения 19.8, шаг этой решетки равен /. Поэтому к одной ветви
вычислений относятся те срабатывания каждого ФУ, разность времен
которых кратна /. Данные, относящиеся к одному входу или выходу,
всегда связаны лишь с фиксированными ФУ БКВ. Если известно,
с какой ветвью связано первое данное, то следующее данное будет
связано со следующей ветвью и т. д. Все данные циклически
распределяются по / ветвям. В случае, когда /=оо, утверждение также
остается в силе Теперь сопровождающий граф расщепляется на
бесконечное число конечных главных подграфов. При этом, согласно
третьему следствию из утверждения 19.6, разные срабатывания
каждого ФУ всегда будут относиться к разным ветвям вычислений.
Предположим, что необходимо решить некоторую конкретную
задачу. Как было показано в § 8, наиболее эффективно это можно
сделать, вообще говоря, только на такой вычислительной системе,
граф которой получается из графа алгоритма решения задачи с
помощью операций простого гомоморфизма. При гомоморфной свертке
графа алгоритма во многих случаях может быть получен граф
вычислительной системы типа БКВ. Может оказаться также, что
сопровождающий граф этого БКВ расщепляется. Тогда на данной
вычислительной системе нельзя решить исходную задачу с
асимптотически полной загруженностью функциональных устройств,
причем их загруженность будет тем меньше, чем больше число не
связанных друг с другом главных подграфов, на которые расщепляется
сопровождающий граф БКВ.
Однако в этом случае можно указать конструктивный путь
повышения эффективности* необходимо на вычислительной системе
$20. РАСЩЕПЛЕНИЕ ИНФОРМАЦИОННЫХ ПОТОКОВ 195
одновременно решать не одну задачу, а несколько однотипных задач,
отличающихся друг от друга начальными данными и, возможно,
своими размерами. Необходимость одновременного решения
нескольких задач является платой за эффективное использование
конвейерных ФУ. Для конвейерных вычислений эта плата неизбежна.
Данное обстоятельство определяет важность обнаружения в
любом алгоритме однотипных и независимых ветвей вычислений. Если
такие ветви обнаружены, то можно надеяться на высокую
эффективность использования параллельных вычислительных систем,
причем не только типа БКВ, но и многих других. Для БКВ совместная
организация потоков входных и выходных данных осуществляется
в соответствии с утверждением 20.2.
Рассмотрим некоторые вопросы структуры и функционирования
БКВ. Напомним, что ФУ БКВ не имеют собственной памяти для
хранения результатов промежуточных вычислений. Это, конечно, не
исключает возможности использования ФУ задержки, осуществляя
с их помощью кратковременное хранение некоторых данных за счет
последовательной их пересылки от одного ФУ задержки к другому.
Будем по-прежнему предполагать, что все операции выполняются
соответствующими ФУ за время, равное 1, и реализуется
стандартный процесс загрузки БКВ.
В общем случае граф БКВ имеет циклы. Пройдем все вершины
цикла и будем говорить, что при этом какая-то дуга проходится
в положительном направлении, если сначала встречается ее
начальная вершина, а затем — конечная. В противном случае будем
говорить, что дуга проходится в отрицательном направлении. Если при
проходе цикла k-я дуга проходится rk раз в положительном
направлении и sk раз в отрицательном, то положим zk=rk—sk. Модуль
суммы величин zkf взятой по всем k, соответствующим дугам цикла,
назовем ориентированной длиной цикла. Рассмотрим два
вспомогательных утверждения.
Утверждение 20.3. Ориентированные длины всех циклов
ориентированного графа равны нут тогда и только тогда, когда
равны нулю ориентированные длины всех независимых элементарных
циклов.
Если ориентированные длины всех циклов равны нулю, то тем
более равны нулю ориентированные длины всех независимых
элементарных циклов. Согласно утверждениям 10.4, 10.6,
ориентированная длина любого цикла не превосходит линейной комбинации
с неотрицательными коэффициентами ориентированных длин
независимых элементарных циклов. Поэтому, если ориентированные
длины всех независимых элементарных циклов равны нулю, то
равны нулю ориентированные длины всех циклов.
Утверждение 20.4. Ненулевые ориентированные длины
всех циклов ориентированного графа имеют такой оюе наибольший
общий делитель, как и ненулевые ориентированные длины
независимых элементарных циклов.
7*
196 ГЛ. 4 ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
Так как множество независимых элементарных циклов является
подмножеством циклов, то наибольший общий делитель ненулевых
ориентированных длин циклов является делителем наибольшего
общего делителя ненулевых ориентированных длин лишь
независимых элементарных циклов. С другой стороны, согласно
утверждениям 10.4, 10.6, ориентированная длина любого цикла должна
делиться на наибольший общий делитель ненулевых
ориентированных длин независимых элементарных циклов. Следовательно,
наибольший общий делитель ненулевых ориентированных длин
элементарных независимых циклов является делителем ненулевых
ориентированных длин циклов. Поэтому оба наибольших общих
делителя совпадают.
Теперь можно перейти к исследованию взаимосвязи расщепления
сопровождающего графа Б KB на конечные или бесконечные главные
подграфы со структурой графа БКВ.
Утверждение 20.5. Сопровождающий граф БКВ
расщепляется на конечные главные подграфы тогда и только тогда,
когда, либо граф БКВ не имеет циклов, либо все элементарные
независимые циклы графа БКВ имеют ориентированные длины,
равные нулю.
Предположим, что сопровождающий граф БКВ расщепляется
на конечные главные подграфы. Согласно третьему следствию из
утверждения 19.6, в сопровождающем графе БКВ не может быть ни
одной пары вершин, соответствующих разным срабатываниям одного
и того же ФУ и связанных какой-нибудь цепью. Допустим тем не
менее, что в графе БКВ есть элементарный цикл. Выберем в цикле
любую вершину и, начиная с нее, обойдем цикл в любом
направлении. Обход цикла в графе БКВ однозначно отображается на обход
некоторой цепи сопровождающего графа БКВ, начальная и
конечная вершина которой соответствуют срабатываниям одного и того же
ФУ. При этом направления обхода дуг и их число в цикле и цепи
совпадают. Согласно сказанному, в данном случае цепь будет
замкнутой, т. е. является циклом. Проекция любой дуги
сопровождающего графа на ось t совпадает с координатным вектором. В силу
замкнутости цепи число ее дуг, проходимых в положительном и
отрицательном направлениях, совпадают. Поэтому ориентированная
длина рассматриваемого элементарного цикла графа БКВ равна
нулю.
Пусть теперь в графе БКВ все независимые элементарные циклы,
если они есть, имеют ориентированные длины, равные нулю.
Предположим, что сопровождающий граф БКВ расщепляется на
бесконечные главные подграфы. Тогда в сопровождающем графе
существует цепь, связывающая две различные вершины, соответствующие
разным срабатываниям одного и того же ФУ. Обход этой цепи даст
Ориентированную длину, равную разности времен срабатызания
ФУ, соответствующих граничным вершинам, и она будет отлична
от нуля. Следовательно, в графе БКВ должен быть контур с нерав-
§ 20. РАСЩЕПЛЕНИЕ ИНФОРМАЦИОННЫХ ПОТОКОВ 197
ной нулю ориентированной длиной. Согласно утверждению 20.3,
это может быть лишь в случае, когда в графе Б KB есть
элементарный контур с неравной нулю ориентированной длиной, что
невозможно по условию.
Следствие. Если в графе БКВ нет циклов или все
независимые элементарные циклы графа БКВ имеют нулевые
ориентированные длины, то БКВ реализует лишь алгоритмы, графы которых
изоморфны графу БКВ, за исключением, возможно, нескольких
алгоритмов, соответствующих этапам загрузки и окончания.
Следствие. При достаточно большом времени
функционирования БКВ среднее время реализации одного алгоритма в условиях
утверокдения асимптотически равно 1.
При выполнении условий утверждения 20.3 путем присоединения
к входам и выходам БКВ линейных цепочек ФУ задержки можно
добиться того, что длины всех путей, связывающих входы и выходы
БКВ, будут одинаковыми. При этом реализуемые алгоритмы, за
исключением соответствующих этапам загрузки и окончания, не
изменятся. Однако с формальной стороны графы алгоритмов
модифицируются за счет присоединения к входам и выходам цепочек
вершин, соответствующих добавляемым тождественным операциям.
Для модифицированного БКВ процесс загрузки не требует
подключения дополнительных входов. По существу, модифицированный
БКВ является синхронизированной базовой вычислительной
системой для модифицированного алгоритма. В этом случае,
естественно, справедливы утверждения 9.7, 9.8.
Утверждение 20.6. Сопровождающий граф БКВ
расщепляется на I бесконечных главных подграфов тогда и только тогда,
когда граф БКВ имеет циклы с ненулевыми ориентированными
длинами и наибольший общий делитель ненулевых ориентированных
длин всех независимых элементарных циклов равен I.
Предположим, что сопровождающий граф БКВ расщепляется
на / бесконечных главных подграфов. В этом случае в графе БКВ
обязательно имеется элементарный цикл с ненулевой
ориентированной длиной, так как в противном случае в соответствии с
утверждением 20.5 сопровождающий граф расщепился бы на конечные
главные подграфы. Рассмотрим какой-нибудь элементарный цикл в
графе БКВ с ненулевой ориентированной длиной. Обход этого цикла
однозначно отображается на обход цепи сопровождающего графа,
связывающей две вершины, соответствующие различным
срабатываниям одного ФУ. Расстояние между данными вершинами
кратно /. Следовательно, ориентированная длина любого элементарного
цикла графа БКВ кратна / и наибольший общий делитель
ненулевых ориентированных длин всех независимых элементарных циклов
также кратен /. Две вершины сопровождающего графа,
соответствующие соседним срабатываниям одного ФУ, всегда связаны цепью.
Поэтому существует цикл с ориентированной длиной, равной /.
Согласно утверждению 20.4, отсюда вытекает, что наибольший об-
7* В. В. Воеводин
198 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
щий делитель ненулевых ориентированных длин всех независимых
элементарных циклов не может быть больше /, т. е. он равен /.
Пусть теперь в графе Б KB имеется хотя бы один элементарный
цикл с ненулевой ориентированной длиной и наибольший общий
делитель ориентированных длин всех таких циклов равен I. В
соответствии с утверждением 20.5 сопровождающий граф Б KB
расщепляется на бесконечные главные подграфы. Как было только что
показано, число этих подграфов равно /.
Итак, каждому Б KB можно приписать вполне определенную
характеристику — число главных подграфов, на которое
расщепляется сопровождающий граф БКВ. Будем называть эту
характеристику индексом расщепления БКВ. Индекс расщепления показывает,
сколько однотипных задач необходимо одновременно решать, чтобы
все ФУ БКВ асимптотически были загружены полностью.
Первое следствие из утверждения 20.5 говорит о том, что если
индекс расщепления БКВ равен бесконечности, то графы почти
всех реализуемых алгоритмов изоморфны графу БКВ. Если же индекс
расщепления БКВ конечен, то аналогичного изоморфизма между
графами БКВ и алгоритмов не может быть в силу конечности числа
вершин графа БКВ. Однако между этими графами все же
существует очень много общего. Графы алгоритмов, реализуемых на БКВ,
являются подграфами главного подграфа сопровождающего графа
БКВ. В свою очередь главный подграф может быть получен
согласно утверждениям 19.9, 19.10 последовательным соединением
графов, изоморфных базовому, посредством связующих дуг.
Следовательно, таким же способом могут быть получены графы
реализуемых алгоритмов, за исключением, возможно, тех их частей, которые
соответствуют этапам загрузки и окончания. Имеется тесная связь
между графом БКВ и любым базовым подграфом сопровождающего
графа.
Утверждение 20.7. Базовым подграфом
сопровождающего графа БКВ может быть тот и только тот граф, который
изоморфен связному остовному подграфу графа БКВ, не имеющему
циклов с ненулевой ориентированной длиной и приобретающему по
крайней мере один такой цикл после присоединения любой
недостающей дуги графа БКВ.
Очевидно, необходимо рассмотреть лишь случай, когда индекс
расщепления БКВ конечен, так как случай бесконечного индекса
расщепления, по существу, описывается утверждением 20.5 и его
первым следствием.
Возьмем любой базовый подграф и отобразим его на граф БКВ.
Соответствие между вершинами графа БКВ и базового подграфа
установлено при построении развертки БКВ и, следовательно,
сопровождающего графа. При этом каждой дуге базового подграфа
ставится в соответствие одна дуга графа БКВ. Поэтому базовый
подграф изоморфен связному остовному подграфу графа БКВ.
В данном остовном подграфе нет ни одного цикла с ненулевой ориен-
§20. РАСЩЕПЛЕНИЕ ИНФОРМАЦИОННЫХ ПОТОКОВ 199
хированной длиной, так как в базовом подграфе нет ни одной пары
вершин, соответствующих разным срабатываниям одного ФУ.
Добавление любой связывающей дуги к базовому подграфу должно
образовывать одну такую пару вершин. Следовательно, добавление
любой недостающей дуги в остовный подграф должно приводить к
появлению по крайней мере одного цикла с ненулевой
ориентированной длиной. Если теперь взять любой связный остовный подграф
графа БКВ, не имеющий циклов с ненулевой ориентированной
длиной и приобретающий по крайней мере один такой цикл после
присоединения любой недостающей дуги графа БКВ, то аналогичные
рассуждения показывают, что подобный остовный подграф будет
изоморфен некоторому базовому подграфу.
Проведенные исследования позволяют дать ответ на вопрос,
какие алгоритмы и как отображаются на БКВ. Именно, с помощью
БКВ можно реализовывать лишь такие алгоритмы, графы которых
в основном имеют структуру главных подграфов периодических
графов.
Возможны две принципиально различные ситуации: либо
используется БКВ, число ФУ которого примерно равно числу вершин
графа алгоритма, либо используется БКВ, число ФУ которого намного
меньше числа вершин графа алгоритма. В первой ситуации граф
БКВ должен совпадать с графом алгоритма. Однако граф
алгоритма не может иметь циклов с ненулевой ориентированной длиной.
Устранить данное ограничение всегда можно с помощью добавления
в алгоритм операций тождественного преобразования, как это было
сделано при уравновешивании базовой вычислительной системы
в § 9. Во второй ситуации граф алгоритма должен быть представим
в периодическом виде. В этом случае граф БКВ получается из графа
алгоритма слиянием однотипных вершин из разных периодов с
помощью операций простого гомоморфизма.
В первой ситуации используется много ФУ и требуется иметь
много однотипных задач, чтобы асимптотически полностью
загрузить БКВ. Тем не менее здесь имеется возможность обработать весь
этот поток максимально быстро. Асимптотически в среднем решение
одной задачи осуществляется за один такт. Во второй ситуации
число используемых ФУ БКВ и число однотипных задач, необходимых
для полной загрузки БКВ, значительно меньше. Однако среднее
время решения одной задачи становится большим.
Утверждение 20.8. Пусть на различных БКВ
реализуется одна и та же достаточно большая совокупность однотипных
задач в режиме асимптотически полной загруженности БКВ. Тогда
среднее время решения одной задачи асимптотически обратно
пропорционально числу используемых ФУ в каждом БКВ.
Пусть решается η задач, требующих для реализации
выполнения по т операций на одну задачу. Обозначим для одного БКВ
число используемых ФУ и среднее время решения одной задачи
через Si и tl9 для второго БКВ — через s2 и t2 соответственно. Восполь-
200 гл· 4· ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
зуемся соотношением (7.2). Так как все ФУ работают с полной
загруженностью, то левая часть соотношения (7.2) для первого БКВ
равна su для второго — s2. Числитель правой части (7.2) в обоих
случаях равен тп, так как все xt равны 1. Наконец, для первого
БКВ время функционирования асимптотически равно ntu для
второго — nt2- Поэтому асимптотически выполняется равенство sj^
=s2t2, откуда и вытекает справедливость утверждения.
Заметим, что для обеспечения режима полной загруженности
БКВ необходимо совмещать для некоторых пар задач этапы
окончания одних и загрузки других. Во всяком случае, простои ФУ на
стыке двух задач должны быть небольшими. Реализации этого
условия не всегда легко добиться, особенно в тех случаях, когда число
выполняемых операций в одной задаче соизмеримо с числом ФУ в
БКВ.
В процессе работы БКВ в общем случае приходится изменять
связи между ФУ для подключения дополнительных входов.
Идеальной была бы такая ситуация, в которой не нужны
дополнительные входы, нет изменения связей между ФУ, процесс счета
осуществляется синхронно и все ФУ работают постоянно, за исключением
тех, которые вынуждены простаивать в начале и конце работы.
Степень отличия от этой ситуации может служить критерием
простоты организации работы БКВ. В частности, таким критерием может
быть число дополнительных входов.
Утверждение 20.9. Если БКВ при достаточно
длительной работе не использует дополнительные входы, то индекс
расщепления равен бесконечности.
Так как БКВ при достаточно длительной работе не использует
дополнительные входы, то это означает, что каждая вершина графа
БКВ может быть связана с входами БКВ лишь путями одной
длины. Поэтому граф БКВ не имеет контуры. Рассмотрим каноническую
параллельную форму графа БКВ. ФУ БКВ не имеют памяти для
хранения результатов промежуточных вычислений. Поэтому при
работе БКВ в каждый момент времени ФУ, находящиеся на одном
ярусе, получают информацию либо со входов БКВ, либо от ФУ,
находящихся на предыдущем ярусе. Следовательно, если в графе
БКВ есть цикл, то его ориентированная длина обязательно равна
нулю, т. е. БКВ реализует только конечные алгоритмы и его индекс
расщепления равен бесконечности.
Не каждый БКВ с бесконечным индексом расщепления не
требует подключения дополнительных входов. Однако любой БКВ,
индекс расщепления которого равен бесконечности, можно
модифицировать так, что он будет реализовывать в основном те же
алгоритмы и не будет нуждаться в использовании дополнительных
входов. Эта модификация была описана выше и заключается в
присоединении к входам и выходам БКВ цепочек ФУ задержки с целью
выравнивания длин всех путей, связывающих входы и выходы
БКВ.
§20. РАСЩЕПЛЕНИЕ ИНФОРМАЦИОННЫХ ПОТОКОВ 201
Такие БКВ исключительно просты в организации процесса
работы. Они не требуют подключения дополнительных входов. Их ФУ
работают на потоке однотипных задач с максимальной
загруженностью. Кроме этого, в них нет трудностей «стыковки» информации,
относящейся к разным задачам. Вся информация об одной задаче
входит в БКВ в один и тот же момент времени и выходит из БКВ
также в один и тот же момент. Асимптотически на большом потоке
среднее время решения одной задачи равно 1.
Если при загрузке БКВ отказаться от одновременности
включения всех его входов, то всеми перечисленными достоинствами будет
обладать любой БКВ с бесконечным индексом расщепления.
Времена включения входов всегда можно подобрать так, что вся
информация, относящаяся к одной задаче, входит во входы БКВ через
равные промежутки времени после их включения и выходит из
входов БКВ также через равные промежутки времени после начала
их функционирования.
Аналогичные факты имеют место и в отношении БКВ с конечным
индексом расщепления. Пусть сопровождающий граф БКВ
расщепляется на / бесконечных подграфов. Как отмечается в утверждении
20.2, данные, относящиеся к одной ветви вычислений, поступают на
каждый вход и выходят из каждого выхода с периодом /. Поэтому,
присоединяя к входам и выходам БКВ цепочки ФУ задержки
подходящей длины, можно добиться того, что в один и тот же момент все
входящие через основные входы данные будут относиться к одной
ветви вычислений, как, впрочем, и все выходящие данные.
Естественно, что при такой модификации число необходимых для работы
БКВ дополнительных входов уменьшается.
Начало работы БКВ однозначно определяет начало и конец
работы каждого дополнительного входа. Если реализуемые алгоритмы
таковы, что выдача последних результатов осуществляется в один
и тот же момент времени, то снова не будет трудностей «стыковки»
информации, относящейся к разным задачам. Непосредственно за
информацией об одной задаче сразу может идти информация о
следующей задаче. При этом первые входные данные каждой новой
задачи всегда включают все дополнительные входы по одному и тому
же временному режиму. Снова все ФУ работают с максимальной
загруженностью.
Если при загрузке БКВ опять отказаться от одновременности
включения всех его основных входов, то всеми перечисленными
возможностями будет обладать любой БКВ с конечным индексом.
Времена включения основных входов снова можно подобрать так, что
вся информация, относящаяся к одной ветви вычислений, поступает
на основные входы БКВ через равные промежутки времени после
их включения и выходит из выходов БКВ также через равные
промежутки времени после начала их функционирования.
Таким образом, по организации информационных потоков все
БКВ можно разбить на две группы, К первой группе отнесем БКВ,
202 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
в которых при одновременном включении основных входов все
данные, входящие или выходящие в один и тот же момент, связаны с
одной ветвью вычислений. Ко второй группе отнесем все остальные
БКВ. Как было установлено, любой БКВ второй группы можно
преобразовать в БКВ первой группы присоединением к входам и
выходам БКВ цепочек ФУ задержки подходящей длины. БКВ первой
группы и их графы будем называть полностью синхронными,
второй группы — почти синхронными.
Рассмотрим некоторые примеры. Граф БКВ, представленный на
рис. 18.1, имеет единственный контур, и его ориентированная длина,
Рис. 20.1
совпадающая, естественно, в данном случае с обычной длиной,
равна 4. Следовательно, сопровождающий граф БКВ и развертка БКВ
должны расщепляться на четыре не связанных между собой
подграфа. Это уже отмечалось как факт в § 18. Из графа БКВ можно
получить четыре различных подграфа, удовлетворяющих условиям
утверждения 20.7. Все они получаются исключением из контура
одной из дуг. Эти подграфы представлены на рис. 19.1. На рис. 20.1
представлены графы трех БКВ. Первые два из них очень похожи.
Но сопровождающий граф для первого БКВ расщепляется на два
главных подграфа, а сопровождающий граф для второго БКВ не
расщепляется. Согласно утверждению 20.6, это определяется тем,
что наибольший общий делитель длин циклов в первом случае
равен 2, а во втором случае равен 1. Третий БКВ реализует
конечные алгоритмы.
Во многих алгоритмах настолько часто приходится вычислять
суммы парных произведений чисел, что для реализации этой
процедуры целесообразно создать специализированное устройство.
Таким устройством может быть, в частности, БКВ. На рис. 20.2
представлен граф наиболее распространенного рекуррентного алгоритма
выполнения данной макрооперации через операции умножения и
сложения пар чисел. Слияние вершин графа, соответствующих
операциям умножения, с помощью операций простого гомоморфизма
приводит к графу слева на рис. 20.3. Последующее слияние вершин,
соответствующих операциям сложения, приводит к графу справа на
§21. КОНВЕЙЕРНЫЕ ВЫЧИСЛИТЕЛИ И МАТРИЦЫ ГРАФОВ 203
рис. 20.3. Если построить БКВ с таким графом для вычисления
сумм парных произведений, то на период загрузки необходимо
VV
о +
V
+гм
Рис. 20.2
разомкнуть дугу, помеченную волнистой линией. С целью
уменьшения среднего времени вычисления одной суммы в этом БКВ можно
использовать конвейерные умножитель и сумматор. Если считать,
+ + Σαιύϊ
Рис. 20.3
что число их ступеней равно соответственно семи и шести, то граф
БКВ, вершины которого отождествлены с отдельными ступенями,
изображен на рис. 20.4. Для полной загруженности этого БКВ
о-
Рис. 20.4
необходимо одновременно вычислять шесть сумм. При этом на
период загрузки также нужно разомкнуть дугу, помеченную
волнистой линией.
§ 21.^Конвейерные вычислители и матрицы графов
Рассмотрим произвольный конвейерный вычислитель. Это есть
вычислительная система с заданным набором ФУ и соединяющих
их каналов связи. Будем по-прежнему считать, что все ФУ работают
204 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
синхронно с тактом, равным 1. В конвейерном вычислителе ФУ не
имеют собственной памяти для хранения результатов выполнения
операции.
Поэтому после срабатывания любого ФУ реализуется одна
из двух ситуаций: либо результаты, срабатывания сразу
используются какими-то ФУ, связанными с данным ФУ прямыми
каналами связи, либо они пропадают. В последнем случае условно
можно считать, что результаты срабатывания ФУ выдаются как
результаты работы КВ.
Будем предполагать, что в произвольном KB одно ФУ может
выполнять несколько разных операций и среди базовых операций
могут присутствовать условные операции. Если в какой-то момент
времени на входы ФУ поступают не все данные, определяющие его
очередное срабатывание, то снова реализуется одна из двух
ситуаций: либо операция не выполняется, либо она выполняется. В
последнем случае недостающие данные должны быть каким-то
образом определены. Например, их может определить само ФУ по зало*
женной в него программе или они могут быть получены через
устройство управления. Возможно, что для их определения
придется открыть дополнительные входные каналы.
Каналы связи образуют коммуникационную сеть КВ. В каждое
ФУ может входить больше каналов, чем требуется аргументов для
выполнения базовых операций. Число выходящих каналов тоже
может превышать число получаемых результатов. Избыточное число
каналов позволяет размножать результаты и дает возможность
реализовать условные операции. Выполнение условных операций
предполагает осуществление специальных процедур по выяснению того,
из каких выходных каналов следует брать в каждый момент
необходимую информацию. Будем считать, что эти вопросы
функционирования ФУ также решены некоторым образом.
Конвейерный вычислитель представляет вычислительную
систему достаточно общего вида. По существу, имеется лишь одно
ограничение, связанное с отсутствием памяти для хранения
результатов выполнения операции. Но даже при такой общности класс
алгоритмов, реализуемых конвейерными вычислителями, может
быть описан достаточно точно.
Структура KB задается его графом. Такой же граф можно
поставить в соответствие некоторому БКВ. Будем называть KB и БКВ
смежными, если их графы совпадают. Имеются существенные
отличия в процессах функционирования KB и БКВ. Если в графе KB
есть путь, связывающий одну вершину с другой, то операция,
соответствующая второй вершине, не обязательно зависит от
результатов выполнения операции, соответствующей первой вершине.
Загруженность KB может быть достаточно произвольной. Зависимости
операций и загруженность ФУ в KB нельзя выяснить наг основе
лишь графа КВ. Несмотря на это, любой KB может быть «вложен»
в некотором смысле в смежный ему БКВ.
§21. КОНВЕЙЕРНЫЕ'ВЫЧИСЛИТЕЛИ И МАТРИЦЫ ГРАФОВ 205
Утверждение 21.1. Граф любого алгоритма,
реализуемого на KB, изоморфен некоторому подграфу сопровождающего
графа смежного БКВ.
Перенумеруем вершины графа KB и соответственно этой
нумерации построим сопровождающий граф смежного БКВ. Рассмотрим
процесс функционирования KB во времени. Каждая вершина графа
алгоритма, реализуемого на KB, однозначно определяется
некоторым срабатыванием какого-то ФУ, или, что то же самое, номером
какой-то вершины графа KB и некоторым моментом времени.
Поэтому между вершинами графа алгоритма, реализуемого на KB, и
вершинами сопровождающего графа смежного БКВ может быть
установлено взаимно однозначное соответствие. Пусть из одной
вершины графа алгоритма ведет дуга в другую его вершину. Это означает,
что один из результатов срабатывания ФУ, соответствующего
первой вершине, передается на вход ФУ, соответствующего второй
вершине. Но такая пара вершин обязательно отображается на пару
смежных вершин сопровождающего графа смежного БКВ. При этом,
естественно, сохраняется ориентация дуг. Следовательно,
высказанное утверждение справедливо.
Таким образом, при изучении произвольных конвейерных
вычислителей можно использовать многие факты, касающиеся БКВ.
В частности, если индекс расщепления смежного БКВ не равен 1,
то информационный поток, проходящий через KB, расщепляется на
независимые ветви, причем число этих ветвей не меньше, чем у
смежного БКВ. Граф алгоритма, соответствующего одной ветви,
изоморфен некоторому подграфу главного подграфа сопровождающего
графа смежного БКВ. Дальнейшее изучение свойств реализуемых на
KB алгоритмов связано с конкретизацией особенностей
функционирования ФУ КВ. Однако это является предметом специальных
исследований.
В § 10 были рассмотрены некоторые общие свойства матриц ин-
циденций и смежностей графов алгоритмов. Если алгоритм
реализуется на конвейерном вычислителе, в частности на БКВ, то специфика
его реализации должна отражаться в специфике строения этих
матриц. Эту специфику можно выявлять с помощью операций
перестановки строк и столбцов, что соответствует различным способам
нумерации вершин и дуг графов алгоритмов. Принимая во
внимание утверждение 21.1, рассмотрим особенности матриц инциденций
и смежностей графов алгоритмов, реализуемых только на БКВ.
Будем сейчас относить к одному алгоритму все операции,
выполняемые на БКВ, а не только те, которые соответствуют одной ветви
вычислений, и будем предполагать, что процесс реализации
продолжается неограниченно. i
Перенумеруем каким-нибудь образом вершины и дуги графа"
БКВ и обозначим через А и В соответственно матрицу инциденций
и матрицу смежностей графа БКВ. Без ограничения общности моЖ*
но считать, что граф алгоритма, реализуемого на БКВ, есть раз1·
206 гл· 4· ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
вертка БКВ. В этом случае граф алгоритма сразу задается в таком
виде, который определяет некоторую его параллельную форму.
Ярусы данной параллельной формы представляют вершины,
соответствующие срабатываниям ФУ в один и тот же момент времени,
дуги связывают вершины, находящиеся в соседних ярусах.
Перенумеруем теперь следующим образом вершины и дуги графа
алгоритма. Сначала перенумеруем вершины первого яруса, причем в
порядке, соответствующем росту номеров вершин графа БКВ. Затем
аналогично продолжим нумерацию вершин второго яруса и т. д. по
всем ярусам. Далее перенумеруем дуги, выходящие из вершин
первого яруса, причем в порядке, соответствующем росту номеров дуг
графа БКВ. Затем аналогично продолжим нумерацию дуг,
выходящих из вершин второго яруса и т. д. по всем ярусам. Эта нумерация
вершин и дуг графа алгоритма однозначно определяет его матрицу
инциденций и матрицу смежностей. Теперь справедливо
Утверждение 21.2. При нумерации вершин графа
алгоритма по группам, соответствующим одновременным
срабатываниям ФУ, матрица инциденций будет иметь клеточно двухдиаго-
нальный вид
Ли
^21 ^22
^32 ^33
Ak,k-i Akk
(21.1)
где число строк в клетках k-й строки матрицы равно числу вершин
k-й группы, а число столбцов в клетках k-го столбца матрицы равно
числу дуг, выходящих из вершин k-й группы.
Все свойства клеток Ак% к_г и A kh являются прямым отражением
установленных ранее свойств развертки БКВ. Укажем некоторые из
них:
— ненулевые элементы клеток Akh (Аклк_1) равны +1 (—1);
— клетка Ак_1чк_г (Ак_1чк_2) или совпадает с клеткой
Akk (ЛЛч ft_i), или получается из нее вычеркиванием некоторых
строк и столбцов;
— существует такое k0, что для всех k>kQ клетка Akh (Ак^ к_г)
совпадает с клеткой Ако, ко (ЛЙ01 ^.J;
— клетка Akoi ко (Ак^ы_^ получается из матрицы А заменой
элементов, равных —1 (+1), нулями;
— сумма клеток в k-и строке при k>k0 равна матрице А.
Итак, при соответствующей нумерации вершин и дуг графа
алгоритма, реализуемого на БКВ, матрица инциденций становится не
только клеточно двухдиагональной, но даже почти клеточно теп-
лицевой. Тем не менее из матрицы (21.1) трудно извлечь особенности,
связанные с особенностями самого БКВ. Это во многом связано с
выбранной нумерацией вершин и дуг графа алгоритма.
§21. КОНВЕЙЕРНЫЕ ВЫЧИСЛИТЕЛИ И МАТРИЦЫ ГРАФОВ 207
Если индекс расщепления БКВ не равен 1, то алгоритм должен
расщепляться на независимые ветви. Поэтому при подходящей
нумерации вершин и дуг графа алгоритма матрица инциденций
должна быть представима в клеточно диагональном виде, где число
диагональных клеток совпадает с индексом расщепления БКВ. Было бы
целесообразно рассмотреть матрицу инциденций графа одной ветви
вычислений. Это будет сделано несколько позднее. А сейчас покажем,
что дополнительную информацию можно получить и при другой
нумерации вершин и дуг.
Выберем какой-нибудь базовый подграф сопровождающего графа
БКВ. Будем рассматривать его как жесткий шаблон и начнем
перемещать его по развертке БКВ параллельно оси /. Такое
перемещение разбивает вершины развертки на непересекающиеся группы,
если к одной группе относить те и только те вершины, которые
одновременно накрываются выбранным шаблоном. Перенумеруем эти
группы подряд слева направо. Очевидно, что первые группы,
соответствующие процессу загрузки, могут быть неполными. Далее,
перенумеруем вершины и дуги графа алгоритма, реализуемого на
БКВ, в полном соответствии с проведенной выше нумерацией,
заменив только ярусы на построенные группы. Теперь справедливы
такие утверждения.
Утверждение 21.3. Пусть индекс расщепления БКВ равен
бесконечности. Тогда при нумерации вершин графа алгоритма по
группам, соответствующим базовому подграфу, матрица
инциденций будет клеточно диагональной:
IIАп
Akk
где число строк и столбцов в клетке Ahk равно соответственно числу
вершин и дуг в k-й группе.
Снова все свойства клеток A hk являются отражением
установленных ранее свойств развертки БКВ. В частности, клеточная диаго-
нальность матрицы (21.2) объясняется тем, что в случае
бесконечного индекса расщепления в развертке БКВ нет ни одной дуги,
связывающей вершины из разных групп. Некоторые из других
свойств клеток Ahh таковы:
— клетка Ak_u k_Y или совпадает с клеткой Ahh\'или1
получается из нее вычеркиванием некоторых строк или столбцов;
— существует такое k0, что для всех k>kQ клетка Akk
совпадает с клеткой Ako^ ko\
— клетка Ahk при k>k0 совпадает с матрицей А.
Утверждение 21.4. Пусть индекс расщепления БКВ
равен I. Тогда при нумерации вершин графа алгоритма по группам^
(21.2)
208 гл· 4· ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ. ОБРАБОТКИ ИНФОРМАЦИИ
соответствующим базовому подграфу, матрица инциденций будет
ищть клеточный левый треугольный вид
\\Ап I
где ненулевыми могут быть только те клетки /ι(// для которых
i—j кратно I и не превосходит числа функциональных устройств
БКВ, при этом число строк в клетках k-й строки матрицы равно
числу вершин k-й группы, а число столбцов в клетках k-го столбца
матрицы равно числу дуг, выходящих из вершин k-й группы.
Наличие клеточных диагоналей, отличных от главной,
объясняется существованием дуг, связывающих вершины из разных групп.
Легко проверить, что одной,ветви вычислений соответствуют те
строки и столбцы матрицы (21.3), на пересечении которых стоят
клетки Ац с равными по модулю / индексами i или /. Отметим
некоторые свойства клеток матрицы (21.3):
— ненулевые элементы поддиагональных клеток равны —1;
— клетка Ац или совпадает с клеткой Ai+1%/+1, или
получается из нее вычеркиванием некоторых строк и столбцов;
. — существует такое k0, что для всех k>kQ клетка Ak^k^s
совпадает с клеткой AUoiko_s при всех допустимых s;
— клетка Ako^ ko после вычеркивания столбцов, не содержащих
элементов, равных —1, будет совпадать с матрицей инциденций
базового подграфа;
— сумма клеток в k-й строке при k>k0 равна матрице А.
Подчеркнем, что матрицы (21.1) — (21.3) будут в основном
клеточно теплицевыми. Отклонение от клеточно теплицевых
определяется конечным числом клеток в верхнем левом углу,
соответствующих процессу загрузки БКВ. В некоторых случаях матрицы (21.2),
(21.3) могут быть полностью клеточно теплицевыми. Например, это
будет тогда, когда БКВ является полностью синхронным, все его
основные входы включаются одновременно и реализуется
стандартный процесс загрузки. В этом же случае' матрица инциденций
графа одной ветви вычислений также оказывается клеточно тепли-
цевой.
Согласно определению, при одной и той же нумерации вершин
графа алгоритма матрица смежностей легко получается из матрицы
инциденций. Приведенные факты говорят о том, что с точностью до
конечного члсла клеток в верхнем левом углу, соответствующих
процессу загрузки, матрицы смежностей будут в основном клеточно
теплицевыми и.к тому же правыми клеточно ленточными. В случае
полностью синхронного БКВ с одновременным включением
основных входов и стандартным процессом загрузки матрица смежностей
§21. КОНВЕЙЕРНЫЕ ВЫЧИСЛИТЕЛИ И МАТРИЦЫ ГРАФОВ 209
соответствующая матрице инциденций (21.3), будет иметь
следующий вид:
\ВХ В .,. £
Ζ?ι В% Вг
Здесь Вг является матрицей смежностей базового подграфа,
причем βχ+. . .+ВГ=В.
Если алгоритм реализуется на произвольном KB, то его
матрица инциденций может быть получена из матрицы инциденций
алгоритма, реализуемого на смежном Б KB, с помощью
вычеркивания некоторых строк и столбцов. В матрице смежностей отдельные
ненулевые элементы могут заменяться нулевыми. Все это вытекает
из утверждения 21.1. Заметим также, что KB является
вычислительной системой без памяти. Следовательно, вектор временной
развертки удовлетворяет системе линейных алгебраических
уравнений вида (10.5), где вектор h имеет все координаты, равные 1.
Знание структуры матрицы данной системы позволяет проводить
априорный анализ временной развертки и делать некоторые
полезные выводы.
Рассмотрим в качестве примера матрицы инциденций и
смежностей графа алгоритма, реализуемого на Б KB, граф которого
представлен на рис. 18.1. Пусть вершины графа БКВ перенумерованы
согласно рис. 18.1, а нумерация дуг совпадает с нумерацией
начальных вершин, кроме дуги с крнечной вершиной 6, которую будем
считать последней. Базовым возьмем подграф в верхнем левом углу
на рис. 19.1, так как именно он характеризует стандартный процесс
загрузки. Матрица инциденций с нумерацией, соответствующей
(21.1), будет такой:
IIΛι II
Λ'ί Α'2
Al А'ь
А'ъ А'ь
где
1 0 0 0 0 011
010 0 0 0
0 0 1 0 0 II
0 0 0 1 0 0 Г
0 0 0 0 10
о о о о.о о I)
Как уже говорилось, матрицы с меньшими индексами получаются
из матриц с большими индексами с помощью вычеркивания некото-
υ
•1
0
0
0
0
υ
0
—1
0
0
0
0ι
0
0
—1
0
0
0
0
0
0
—1
0
0
—1
0
0
0
0
0
■о
0
0
0
—1
л;=
210 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
рых строк и столбцов. В данном примере это осуществляется
следующим образом:
— А4 получается из А'ъ вычеркиванием столбца 5 и строки 6;
— А4 получается из А"ъ вычеркиванием столбца 5;
— А'ъ получается из А'± вычеркиванием столбца 4 и строк 4, 5;
— Лд получается из Al вычеркиванием столбца 4 и строки 5;
А2 получается из Лз вычеркиванием столбцов 3, 4 и
строки 3;
4, 5;
А2 получается из Л3' вычеркиванием столбцов 3, 4 и строк
А[ получается из А'2 вычеркиванием столбца 2 и строки 2;
— А'[ получается из А\ вычеркиванием столбца 2 и строки 3.
Матрица инциденций с нумерацией, соответствующей (21.3), будет
такой:
0 А[
0 0
0 0
А'1 0
0 ΑΪ
0 Αί
0 0
0 0
Лг
о л;
где
А';=
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
0 0
—1 0
0 0
0 0
0 0
0 0
• лН
1
— 1
о
о
о
о
1
— 1
о
о
о
о
1
—1
о
о о
о о
0 о
1 О
-1 1
О 0 0 0 0—1
Матрица инциденций одной ветви вычислений имеет следующий вид:
\ΑΙ А[
Al A[
И наконец, матрица смежностей с нумерацией, соответствующей
(21.3), такова:
В[ 0 0 0 Bl
В'г 0 0 0 El
где
Βίο ι о о о о
0 0 10 0 0
0 0 0 1
0 0 0 0
0 0 0 0
0 0 0 0
0 1
1 О
О О
О О
В1 =
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 10 0 0 0
0 0 0 0 0 0
§ 22. ВЕКТОРНЫЕ ВЫЧИСЛИТЕЛИ
211
Для одной ветви вычислений она имеет вид
в
Вг
§ 22. Векторные вычислители
Существенную часть многих численных методов составляют
простые векторные операции, такие как сложение векторов, умножение
вектора на число, покоординатное умножение векторов и т. п.
На определенном этапе развития вычислительной техники начали
создаваться специализированные вычислители, ориентированные
на быстрое выполнение векторных операций. Такие вычислители
стали называться векторными.
Векторные операции можно рассматривать как совокупности
независимых скалярных операций над координатами векторов с
одинаковыми номерами. Так как все операции однотипные, то для их
реализации исключительно эффективным является использование
конвейерных ФУ. Однако для того, чтобы конвейерные ФУ
действительно функционировали эффективно, необходимо обеспечить
быструю подачу данных на его входы и быстрое считывание
результатов с его выходов. Точнее, эти процедуры нужно осуществлять
каждый такт работы конвейерных ФУ.
Удовлетворить последнему требованию трудно, если
конвейерные ФУ взаимодействуют непосредственно с общей памятью.
Поэтому обычно в векторных вычислителях имеется сверхбыстрая
память относительно небольшого размера и все конвейерные ФУ при
выполнении векторных операций взаимодействуют в основном с этой
памятью. Через нее же осуществляется и обмен информацией с
общей памятью. Использование сверхбыстрой промежуточной
памяти позволяет отделить собственно обработку векторных данных от
процесса их поиска в памяти вычислительной системы и
предварительного упорядочивания.
Эту сверхбыструю память иногда называют векторной, имея в
виду тот факт, что в ней хранятся координаты обрабатываемых
векторов. Конструктивно она может быть выполнена в виде отдельных
блоков фиксированного размера, каждый из которых служит для
хранения координат одного вектора. Так, например, в системе
CRAY-1 векторная память представлена как 8 «векторов»
размерности 64 (рис. 1.4) и вся основная обработка информации также
осуществляется векторами размерности не более 64. При этом
отдельный вход или выход любого ФУ каждый раз подключается только
к одному «вектору» сверхбыстрой памяти.
Многие особенности функционирования и использования
векторных вычислителей можно увидеть на самых простых примерах.
Предположим, что нужно вычислить вектор с, равный сумме двух
векторов а и b размерности я, и, кроме этого, вычислить вектор d,
212 гл· 4· ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
равный произведению вектора с на число а. Пусть вычислительная
система имеет необходимое число «векторов» длиной η сверхбыстрой
памяти. Для удобства будем обозначать одинаковыми буквами
вычисляемые векторы и векторы начальных данных, а также соответ-
at
1
<Ъ
а 1^1 fel^l^sj^el I · · · ι
ν ν jr \/ \/ у
сЛ °2.\ \ · · · \ l^l^l^-zl^-ij cn
i'
Lii
F4F4 |^||«>|α||α|!,3!|
yy \\Шу
[2] ЯмИИгч!II II II
ι ΗΗγίΗΗγ
• · · /?-б /7-5\\пА /7-ЗМ/7-2 Ι Ι/Η /7
[/7-7 /7-6 /?-5 /7-4 /7^ /7-21 /7-1/7 1
1 Ι/7-8Π/7-7 /7-6 /7-5 Ι Ι/Μ /?-3 /7-2 /7-1 /7
τ ΥττττττΥτ
^1 ( · * - } I^Kyl^el^iJ^l^k^l^-il^
и
/7
Η
Μ
/7
/7
С
V
Μ
Μ
Α
Τ
0
ρ !
Ξ
Ξ
Рис. 22.1
ствующие «векторы» сверхбыстрой памяти. Одинаковым образом
будем обозначать координаты векторов и соответствующие ячейки
«векторов» памяти.
, Допустим, что имеются конвейерные сумматор и умножитель.
Пусть, например, каждый из них состоит из пяти ступеней. Будем
считать, что на включение конвейера дополнительное время не
требуется, но требуется один такт на считывание результата из пятой
ступени ФУ и размещение его в соответствующей ячейке нужного
«вектора» сверхбыстрой памяти.
§ i?2. ВЕКТОРНЫЕ ВЫЧИСЛИТЕЛИ
213
Рассмотрим сначала векторную операцию с=а+Ь. Для ее
реализации необходимо выполнить однотипные и независимые операции
Ci=cii+bi для Ι^α^η. В верхней части рис. 22.1 приведена схема
осуществления векторной операций с=а+Ь. Начальные векторы
a, b и вектор результатов с размещены в соответствующих «векторах»
памяти. На рисунке указано потактовое состояние всех ступеней
сумматора. Изменение по тактам осуществляется слева направо,
изменение по ступеням — сверху вниз. Если в каком-то квадратике
стоит число k, то это означает, что в соответствующий момент
времени данная ступень сумматора выполняет относящуюся к ней часть
операции ck^=ah+bk. Первый результат сх получается на шестом
такте, результат с2— на седьмом такте и т. д. Заканчивается
вычисление вектора с на (я+5)-м такте. При этом обеспечивается
загруженность сумматора, равная (I+5/az)"-1. Соответственно достигается
ускорение 5(1+5/п)-1.
Если конвейерное ФУ имеет г ступеней, то загруженность и
ускорение будут равны (l+r/η)-1 и г(1+г/п)~х. Заметим, что при
малых η загруженность всегда будет небольшой. В частности, в
рассмотренном примере при г=Ъ и я=1, 10, 50, 100 она равна
соответственно 0,17, 0,67, 0,91, 0,95. Поэтому для достижения близкой к
1 загруженности ФУ в векторных вычислителях приходится брать
размеры «векторов» памяти достаточно большими. Как уже
отмечалось, в системе CRAY-1 я=64.
Рассмотрим теперь векторную операцию d=a(a+b). Ее можно
представить в виде последовательности операций с= (α+b) и d=ac.
Кажется вполне естественным, что сначала надо выполнить
векторную операцию с=(а+Ь), а затем векторную операцию d=ac.
Реализация первой операции была рассмотрена, реализация второй
операции полностью аналогична. Снова необходимо выполнить
однотипные и независимые операции di=aCi.
В нижней части рис. 22.1 приведена схема осуществления
векторной операции d=ac. С формальной точки зрения она почти не
отличается от схемы для операции с=а+Ь. Единственное внешнее
отличие состоит в том, что «вектор» памяти для хранения второго
начального вектора заменен одной ячейкой памяти для хранения
числа а. Вычисление вектора d опять заканчивается на (я+5)-м
такте при такой же загруженности умножителя (l+5/n)-1 и
достигаемом ускорении 5(1+5/п)-1.
Однако если векторную операцию d=a(a+b) реализовывать
как последовательность операций с=а-\-Ь и d=ac, то нетрудно
видеть, что загруженность совокупности устройств, состоящей из
сумматора и умножителя, будет вдвое меньше, чем при отдельной
реализации каждой из операций с=а+Ь и d=ac, а достигаемое при
этом ускорение не увеличивается. Причина этого факта очевидна:
при реализации векторной операции с=а+Ь не загружен
выполнением полезной работы умножитель, при реализации операции d=ac
не загружен сумматор.
214 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
Указанные недостатки легко устранить. Действительно, первая
ячейка сх «вектора» памяти с заполняется результатом выполнения
операции cx=ai+bi на шестом такте. Каждая следующая ячейка
заполняется результатом выполнения следующей скалярной
операции на следующем такте по сравнению с предыдущей ячейкой.
В свою очередь, использование ячеек памяти «вектора» с для
реализации векторной операции d=ac на умножителе также происходит
последовательно по тактам друг за другом, начиная с первой.
Поэтому, чтобы начать выполнение векторной операции d=ac, совсем не
обязательно ждать, когда заполнятся результатами все ячейки
«вектора» с. Это можно делать сразу после заполнения результатом
лишь первой ячейки «вектора», т. е. в данном случае, начиная с
седьмого такта.
Описанный режим использования конвейерных ФУ называется
зацеплением функциональных устройств. Зацепление ФУ позволяет
увеличить их загруженность и достигаемое ускорение по сравнению
с последовательным использованием тех же конвейерных ФУ. В
рассматриваемом примере реализации векторной операции d=a(a+b)
в режиме зацепления обеспечивается совместная загруженность
сумматора и умножителя, равная (1 + 11/п)"1. Соответственно
достигается ускорение 10(1 + 1Г/п)-1. В частности, при я=1, 10, 50,
100 общая загруженность системы двух ФУ теперь будет равна
0,08, 0,48, 0,82, 0,90.
Сравнивая для конкретных значений η загруженности сумматора
и умножителя в автономном режиме и их совместную
загруженность в режиме зацепления, можно видеть, что совместная
загруженность всегда меньше. Следовательно, для достижения одинаковой
загруженности в режиме зацепления необходимо обрабатывать
более длинные векторы. В случае, когда в режиме зацепления работает
большое число конвейерных ФУ, загруженность снижается еще
сильнее. Если включение и зацепление ФУ осуществляется
согласно указанным выше правилам, то в общем случае ситуацию
описывает следующее утверждение и его следствия.
Утверждение 22.1. Пусть в режиме зацепления на
векторах длины η работают s конвейерных ФУ с числом ступеней
аъ . . ., as и при этом сами ФУ включаются последовательно друг за
другом. Тогда загруженность ρ системы этих ФУ и достигаемое
ускорение R таковы:
^-(^1+^-1 + 2^^/nj , R~p^av (22.1)
Первый результат на выходе'первого ФУ получается на (ах+1)-м
такте, первый результат на выходе второго ФУ получается на (αι+
+а2+2)-м|такте и т. д. Поэтому весь процесс осуществляется за
§22. ВЕКТОРНЫЕ ВЫЧИСЛИТЕЛИ
215
время
S
Τ = n + s—1 + Σ αι·
i = \
Согласно определениям, данным в § 7, стоимость реально
выполненных операций за время Τ равна я, умноженному на сумму
ступеней всех ФУ; максимально возможная стоимость операций,
которые можно было бы выполнить за время 7\ равна Г,
умноженному на ту же сумму. Загруженность системы ФУ равна отношению
этих стоимостей, откуда и вытекает первая формула (22.1).
Рассмотрим далее гипотетическое простое ФУ, которое имеет
возможность выполнять все отдельные операции за такие же времена,
что и конвейерные ФУ. На таком гипотетическом ФУ можно
выполнить все операции за время Г0, равное я, умноженному на сумму
ступеней всех ФУ. Ускорение есть отношение Г0/7\ что и дает
второю формулу (22.1).
Следствие. Пусть для достижения загруженности ρ в
автономном режиме 1-е ФУ требует проведения вычислений с
векторами длины не меньше щ. Тогда для достижения той же
загруженности ρ всей системы ФУ в режиме зацепления требуется
проводить вычисления с векторами, длина которых не меньше суммы
пг по всем i.
В самом деле, как вытекает из первой формулы (22.1),
справедливы равенства n^pa^l(\—р). Но, согласно этой же формуле,
\ /=1 / r itsl г 1=1
■Следствие. Пусть в автономном режиме для достижения
ускорения раь где 0</><1, i-e ФУ требует проведения вычислений
с векторами длиной не меньше щ. Тогда в режиме зацепления для
достижения ускорения всей системы ФУ, равного сумме ускорений
отдельных ФУ, требуется проводить вычисления с векторами,
длина которых не меньше суммы щ по всем i.
Согласно утверждению 7.7, величина ρ есть загруженность
ί-го ФУ. Поэтому справедливость данного следствия вытекает из
предыдущего следствия и второй формулы (22.1).
Отметим, что необходимость работы с более длинными
векторами для обеспечения заданного уровня загруженности более
сложной конвейерной системы не связана с какими-либо
недостатками именно векторных вычислителей. Это является
отражением общего факта: чем длиннее конвейер, тем больше нужно
данных для обеспечения его эффективного функционирования.
Если в векторном вычислителе имеется несколько конвейерных ФУ,
то с точки зрения уменьшения длины обрабатываемых векторов
при одной и той же загруженности всей системы более выгодно не
использовать режим зацепления, а заставлять различные ФУ
216 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ Щ
реализовывать независимые векторные операции параллельно, я
Однако при этом увеличивается число требуемых «векторов» сверх- щ
быстрой памяти, хотя сами «векторы» могут быть взяты более!
короткими. Поэтому при выборе различных способов использо-1
вания ФУ векторных вычислителей для реализации конкретного!
векторного алгоритма возможно проведение некоторой оптими-1
зации. 1
Высказанные соображения справедливы не только для рас-1
смотренного режима включения зацепленных ФУ, но и для других!
режимов. При этом могут незначительно изменяться коэффици-1
енты,.определяющие асимптотическую зависимость загруженности!
и ускорения от длины обрабатываемых векторов. I
Если выполняется векторная операция с=а+Ь, то «вектор»!
памяти с необходим, так как в нем размещается результат. Если!
же выполняется векторная операция а=а(а-\-Ь), то каждая ячейка |
«вектора» с используется лишь в течение одного такта, причем |
никакие две ячейки не бывают заняты одновременно. Поэтому в |
случае операции d=a(a+b) «вектор» памяти с, вообще говоря, не!
является необходимым, и для выполнения этой операции можно 1
было бы просто соединить непосредственно выход сумматора и \
вход умножителя. Более того, если при большом числе ФУ зацеп- ?
ляются друг с другом г пар входов и выходов ФУ, то, соединяя ,-
непосредственно соответствующие входы и выходы ФУ, можно ί
уменьшить на г необходимое число «векторов» сверхбыстрой па- ,
мяти. Принимая во внимание дефицитность данного вида памяти,
нетрудно понять преимущества прямого соединения зацепленных
ФУ в векторных вычислителях. Легко видеть, что можно осущест-^
вить еще большую экономию векторной памяти. Если при выпол-^
нении операции с=а+Ь хотя бы один из векторов a, b не нужен для ]
дальнейших вычислений, то ничто не мешает размещать результаты
на месте входных данных. Появление результата в ячейке ct всегда
происходит позднее, чем используются входные данные щ и frj.
Такая экономия тем более возможна при выполнении операции
d=a(a+b). Аналогичную экономию можно осуществлять и в
самом общем случае, когда имеется любое число ФУ и любое число
векторов входных данных и векторов результатов.
Исключим все «векторы» памяти, необходимые для хранения
результатов промежуточных вычислений. Тогда становится
очевидным, что векторный вычислитель есть не что иное, как почти
синхронный конвейерный вычислитель с бесконечным индексом
расщепления, причем независимо от того, сколько и каких ФУ
в нем используется. Оставшаяся векторная память служит при
этом только для организации быстрой подачи данных в
конвейерный вычислитель и сбора результатов его функционирования.
Заметим, что быструю подачу* данных и такой же быстрый сбор
результатов необходимо обеспечивать в любом" конвейерном
вычислителе. В рассмотренных векторных вычислителях всё входные
§22. ВЕКТОРНЫЕ ВЫЧИСЛИТЕЛИ
217
данные и результаты, относящиеся к одной и той же ветви
вычислений, размещаются в ячейках «векторов» памяти с одинаковыми
номерами.
Существующие векторные вычислители, вообще говоря, не
позволяют соединять непосредственно входы и выходы ФУ для
осуществления режима зацепления. Нет в них возможности
организовывать и более сложные конвейеры с конечным индексом
расщепления. Поэтому на них не очень эффективно решаются
однотипные задачи разной размерности, трудно решаются
однотипные задачи с зависимыми данными. Кроме того, как уже
отмечалось, тратится лишнее оборудование на организацию зацепления
через векторную память, что в свою очередь приводит к более
частым обменам между массовой памятью и векторной памятью.
Не всегда допускается размещение результатов на месте входных
данных.
Тем не менее существующая организация векторных
вычислений является вполне приемлемой. Это определяется в основном
малым числом имеющегося вычислительного оборудования и
универсальностью его применения в различных потоках однотипных
задач.
Если число единиц оборудования достаточно велико, то
векторные вычисления значительно выгоднее организовывать,
ориентируясь на конвейерные, а не векторные вычислители. При этом
уменьшается необходимый объем сверхбыстрой векторной памяти,
так как частично ее функции выполняют сами устройства.
Сокращаются обмены с массовой памятью. Не вызывает особых
трудностей решение задач разной размерности. Наконец, значительно
легче и, главное, эффективнее решаются однотипные задачи с
зависимыми данными, особенно такие простые, как суммирование
чисел, вычисление скалярного произведения и т. п.
Конвейерные вычислители могут иметь большую
универсальность, если число используемых ФУ будет достаточно велико, и
их можно организовывать в произвольные конвейеры программным
путем. При этом важно обеспечить программным путем доступность
формирования всех деталей конвейерного вычислителя, включая
присоединение дополнительных входов, размещение входных и
выходных данных на одном месте и т. п. Если же какие-то
конвейерные вычислители будут реализовываться в виде спецпроцессоров
для решения конкретных задач, то возможность их формирования
программным путем, по существу, становится не нужной. Опыт
создания таких спецпроцессоров уже имеется.
Для того чтобы достичь эффективной реализации алгоритма
на векторном вычислителе, необходимо преобразовать алгоритм
к такому виду, в котором явно представлены векторные операции.
В общем случае осуществить подобное преобразование не очень
просто. Однако если известна параллельная форма алгоритма,
то обычно ее яруеы содержат большое число не связанных друг с
218 гл· 4· ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
другом вершин, соответствующих одной и той же операции или
макрооперации в зависимости от того, простыми или сложными
являются базовые операции алгоритма. Поэтому знание
параллельной формы позволяет, как правило, сформировать поток
независимых вычислений. С формальной точки зрения этот поток
легко записать в векторной форме, если объединить в одну
векторную операцию все однотипные скалярные операции, взятые из
разных ветвей вычислений. После такого преобразования операции
каждого отдельного яруса уже легко реализуются на векторных
вычислителях. При «стыковке» входных данных и результатов,
относящихся к соседним ярусам, почти всегда возникают некоторые
дополнительные операции, связанные с необходимостью
выполнения сортировки данных. Чаще всего такая сортировка сводится
к постоянному сдвигу координат векторов.
Заметим, что на основе параллельной формы алгоритма можно
формировать также потоки вычислений для их реализации на
произвольных конвейерных вычислителях. В конвейерных
вычислителях трудности «стыковки» входных и выходных данных из
разных ярусов практически отсутствуют, так как могут быть
преодолены за счет подходящего соединения входов и выходов ФУ
и использования ФУ задержки.
§ 23. Систолические массивы
Уровень технологических возможностей микроэлектроники во
многом определяет уровень развития вычислительной техники.
Повышение плотности расположения элементов на кристалле,
увеличение скорости их переключения приводит не только к
повышению быстродействия ЭВМ и уменьшению их размеров, но и
позволяет разрабатывать вычислительные системы с
принципиально новыми архитектурными решениями. Достижения
микроэлектроники дают возможность уже в настоящее время создавать
достаточно сложные сверхминиатюрные вычислительные
устройства, расположенные целиком на одном кристалле. При массовом
производстве такие устройства оказываются, к тому же,
относительно дешевыми. Все эти обстоятельства не только открывают
новые перспективы конструирования вычислительных систем, но
и порождают многочисленные новые проблемы, в том числе
математические.
Одной из самых трудных является проблема создания
коммуникационных сетей, обеспечивающих быстрые необходимые связи
между отдельными функциональными устройствами. Пока скорости
срабатывания устройств были не очень большими, основными
факторами, препятствующими созданию нужных
коммуникационных сетей, являлись число линий связи и сложность коммутаторов.
Однако с ростом скорости срабатывания устройств наряду с этими
§23. СИСТОЛИЧЕСКИЕ МАССИВЫ
219
факторами стали иметь большое значение также и длины линий
связи.
В определенном отношении самой простой и эффективной
является коммуникационная сеть, в которой нет коммутаторов, все
устройства соединены непосредственно друг с другом и длины всех
линий связи минимальные, в некотором смысле, нулевые. С конца
семидесятых годов стали появляться работы, призывающие строить
специализированные вычислительные системы, получившие
название систолические массивы. Эти системы устроены предельно
просто и в то же время имеют предельно простую
коммуникационную сеть. Поэтому они являются исключительно эффективными по
быстродействию, но каждая из них ориентирована на решение
весьма узкого класса задач.
Общий подход к конструированию систолических массивов
основан на следующей идее. Пусть в нашем распоряжении имеется
достаточно большое число функциональных устройств (ФУ),
реализующих операции одного или нескольких типов. Будем называть
эти ФУ систолическими ячейками (процессорными элементами,
элементарными процессорами, чипами). Допустим, что
конструктивно каждое ФУ выполнено в виде некоторого плоского
многоугольника, причем входы и выходы ФУ выведены на его границу.
Будем считать, что однотипным ФУ соответствуют одинаковые
многоугольники. Теперь начнем складывать из многоугольников
различные фигуры, присоединяя без наложения последовательно
многоугольник за многоугольником и предполагая, что соседние
многоугольники соприкасаются друг с другом. Если в местах
соприкосновения соединить входы и выходы соседних ФУ, то
получится некоторая вычислительная система, которая при
некоторых дополнительных условиях и называется систолическим
массивом.
Прежде чем обсуждать различные аспекты конструирования
и функционирования систолических массивов, рассмотрим простой
пример. Предположим, что необходимо построить
специализированную вычислительную систему, на которой достаточно быстро
реализуется операция вычисления матрицы D=C+AB, где
Л =
011 Я12 0 1
#21 #22 #23
Д31 #32
Г) #42
С =
,. ,
Сц Οχ
С21 С2
c3i cz
с41 ·
0 ·■
' в=
1 о
2 ^13 CU 0
2 С2з ^
2
.
L2 &13
52 ...
12 ..·
•
0 1
220 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
Здесь все матрицы — ленточные, порядка п. Матрица А имеет
одну диагональ выше и две диагонали ниже главной. Матрица В
имеет одну диагональ ниже и две диагонали выше главной.
Матрица С имеет по три диагонали выше и ниже главной.
Пусть в нашем распоряжении имеется^ достаточно большое
число функциональных устройств, реализующих скалярную
операцию c+ab и осуществляющих одновременно передачу данных.
Ъ а с *
1 \ f 2 | з |
b а с а
Рис. 23.1
Точнее, каждое ФУ имеет три входа: а, 6, с и три выхода: а, й, с»
Входные (in) и выходные (out) данные в общем случае связаны
соотношениями
Cout = Cin + ainbin, boui = 6ln, aout = flifl. (23.1)
Если в момент выполнения операции какие-то данные не поступили,
то будем считать, что они доопределяются нулями. Предположим
далее, что конструктивно ФУ выполнено в виде правильного
шестиугольника, причем входы и выходы расположены на его
сторонах как показано на рис. 23.1—2. Точка указывает ориентацию
шестиугольника на плоскости.
На рис. 23.2 представлен систолический массив, реализующий
матричную операцию С+АВ, а также указаны расположение
и схема подачи входных данных. Сделаем по ней некоторые
пояснения.
Вся плоскость покрыта регулярной косоугольной решеткой,
образованной двумя семействами равноотстоящих параллельных
прямых, пересекающихся под углами соответственно 60° и 120°.
В узлах этой решетки размещены ФУ и входные данные. Система
работает по тактам. За каждый такт все данные перемещаются в
соседние узлы по направлениям, указанным стрелками.
На рисунке показано состояние в некоторый момент времени.
В следующий такт все данные переместятся на один узел и элементы
Яш Ь1Ъ Сц окажутся в одном ФУ, находящемся на пересечении
штриховых линий. Следовательно, будет вычислено выражение
Cu+ацЬц. В этот же такт, в частности, данные а12 и b2i
приблизятся вплотную к ФУ, находящемуся в вершине систолического
массива. В следующий такт все данные снова переместятся на
§ 23. СИСТОЛИЧЕСКИЕ МАССИВЫ
221
один узел в направлении стрелок и в верхнем ФУ окажутся
элементы αΐ2, &2i и результат предыдущего срабатывания ФУ,
находящегося снизу, т. е. Сп+ацЬц. Следовательно, будет вычислено
выражение c11+a11b11~\-a12b2i' Это есть элемент dxl матрицы D.
Рис. 23.2
Продолжая потактовое рассмотрение процесса, можно
убедиться, что на выходах ФУ, соответствующих верхней границе
систолического массива, периодически через три такта будут
выдаваться элементы матрицы D, причем на каждом выходе будут
появляться элементы одной и той же диагонали. Примерно через
Зп тактов будет закончено вычисление всей матрицы D. При этом
загруженность каждой систолической ячейки асимптотически
равна 1/3.
Трудно предположить, что после рассмотрения данного
примера у читателя сложилось четкое представление в отношении
возможностей систолических массивов как специализированных
вычислительных систем. Скорее всего возникло много вопросов.
222 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
В самом деле, этот пример показывает, что для данной задачи
систолический массив может быть построен. Но:
— Почему он выглядит именно таким?
— Существуют ли другие систолические массивы, позволяющие
решать ту же задачу?
— С чем связана шестиугольная форма систолических ячеек?
— Почему данные упорядочены именно так?
— С чем связана относительно низкая загруженность?
— Для каких алгоритмов можно построить систолические
массивы?
— Можно ли разработать общую методологию отображения
алгоритмов на систолические массивы?
Рассмотренный пример является одним из первых примеров
построения систолического массива для решения конкретной
задачи. В настоящее время построено много других систолических
массивов для решения различных задач, в основном матрично-
векторных. Тем не менее, мы не будем сейчас рассматривать новые
примеры. Это связано с тем, что анализ конкретных систолических
массивов не дает ответа на многие вопросы, касающиеся
потенциальных возможностей вычислительных систем данного типа. На
конкретных примерах легко объяснить, как заданный
систолический массив решает заданную задачу, 'но трудно понять, как
построить систолический массив, чтобы на нем можно было решать
нужную задачу.
Выполняя дальнейшие исследования, будем придерживаться
того же плана, который был реализован при изучении конвейерных
вычислителей. Во-первых, откажемся, по крайней* мере, на первом
этапе от рассмотрения смыслового содержания операций,
определяющих работу отдельных функциональных устройств. Затем на
основе анализа конкретных систолических массивов выберем
небольшое число общих характеристик, типичных для систем данного
типа. И, наконец, принимая во внимание именно эти
характеристики, будем исследовать наиболее важные для нас задачи.
Систолические ячейки всегда устроены очень просто и
выполняют, только простые операции. Самой существенной их
особенностью является отсутствие собственной памяти для хранения
результатов промежуточных вычислений, хотя они могут иметь
небольшую память, необходимую для выполнения операций.
Поэтому без большой потери общности можно считать, что
систолические ячейки представляют простые или конвейерные ФУ и
работают согласно правилам, описанным в § 7. По крайней мере,
такими они являются во всех систолических массивах. Если в
процессе исследований потребуется уточнить особенности их
строения и функционирования, то это будет оговорено дополнительно.
Входы и выходы отдельных систолических ячеек всегда
соединены друг с другом непосредственно, без использования каких-
либо коммутаторов или устройств передачи данных. К тому же
§ 23. СИСТОЛИЧЕСКИЕ МАССИВЫ
223
вся совокупность систолических ячеек обычно работает в общем
синхронном режиме. Поэтому в действительности систолический
массив является конвейерным вычислителем. Чаще всего это есть
безусловный конвейерный вычислитель с бесконечным индексом
расщепления. Следовательно, при изучении различных вопросов,
касающихся строения, функционирования или проектирования
систолических массивов, можно использовать любые подходящие
факты, установленные ранее относительно Б KB и KB общего
типа. Заметим сразу, что загрузка систолического массива как
конвейерного вычислителя не всегда осуществляется стандартным
способом.
Несмотря на то, что систолический массив является
конвейерным вычислителем, невозможно на основе лишь такого факта
выявить все особенности вычислительной системы данного типа.
Для этого необходимо принять во внимание специфические
характеристики структуры систолического массива и отразить их в
специфике графа конвейерного вычислителя, представляющего
систолический массив.
По-видимому, самой характерной особенностью систолических
массивов является отсутствие каких-либо дополнительных линий
связи при соединении входов и выходов систолических ячеек.
Соединение отдельных ячеек между собой лишь в местах
соприкосновения приводит к тому, что в систолических массивах все связи
имеют минимально возможные длины, и, следовательно,
оказываются минимальными временные затраты на передачу
информации от одних функциональных устройств к другим.
Подразумевая именно эту особенность, говорят, что в систолических
массивах реализуется принцип близкодействия.
Реализация принципа близкодействия влечет за собой
определенную особенность графа конвейерного вычислителя,
представляющего систолический массив. Как уже отмечалось, систолические
ячейки и весь массив принято изображать плоскими фигурами.
Поэтому, если в качестве вершин графа систолического массива
взять любые точки внутри соответствующих многоугольников,
то очевидно, что без ограничения общности можно считать граф
массива размещенным на плоскости.
Граф называется плоским, если он размещен на плоскости и
никакие его дуги (ребра) не пересекаются, т. е. не имеют общих
точек, кроме, возможно, концевых. Граф называется планарным,
если он изоморфен некоторому плоскому графу.
Утверждение 23.1. Пусть устройство и расположение
систолических ячеек таково, что ни в одной точке плоскости не
находятся входы или выходы более чем трех систолических ячеек.
Если на систолическом массиве реализуется принцип
близкодействия, то граф систолического массива является плоским.
Предположим, что граф систолического массива не плоский.
Так как он размещен на плоскости, то это означает, что сущест-
224 ГЛ. 4· ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ |
вуют, по крайней мере, две пересекающиеся дуги. Пересечение^
двух дуг возможно лишь в том случае, когда некоторая точка!
плоскости является общей для четырех систолических ячеек щ
служит к тому же точкой входа или выхода для каждой из них.1
В условиях утверждения эта ситуация невозможна. ;
Следствие. Пусть входы и выходы систолических ячеек;
расположены либо на сторонах многоугольников, либо в вершинах)
тупых углов. Если на систолическом массиве реализуется принцип^
близкодействия, то граф систолического массива является плоским^
Плоские графы обладают многими примечательными свойст-
вами. Очевидно, что любой такой граф делит плоскость на одно-
связные области, ограниченные дугами. Если граф конечный, то
среди этих областей одна будет не ограниченной, остальные —
ограниченными. Множество дуг, составляющих границу каждой
из областей, образует вектор-цикл. В плоском графе границы
различных конечных областей задают базис в пространстве векторов-
циклов. Если связный граф имеет η вершин, т дуг и делит
плоскость на / односвязных областей, то справедливо равенство
η—m+/ = 2,
называемое формулой Эйлера. Все эти особенности плоских графов
легко устанавливаются на основе рассмотренных ранее свойств
графов.
Граф любого систолического массива всегда тесно связан с
плоским графом. Рассмотрим произвольный систолический массив
и пусть на нем реализуется принцип близко действия. Исключим
временно из графа массива все дуги, имеющие пересечение с
другими. Полученный граф будет плоским, хотя и не обязательно
связным. Теперь очевидно, что любая исключенная дуга целиком
размещается внутри одной из областей плоского графа и
связывает граничные вершины области. Исключенные дуги могут
размещаться как в не ограниченной области, так и в ограниченных
областях.
Дальнейшее развитие принципа близкодействия позволяет
сделать новые выводы. Если многоугольники, представляющие
систолические ячейки, имеют произвольный вид, то в общем случае
при формировании систолического массива невозможно избежать
появления внутри него мест, не покрытых ни одной систолической
ячейкой. Это означает, что площадь систолического массива
используется не полностью. Можно предположить, что устранение
пустых мест приведет к более коротким связям. Пустых мест
заведомо не будет, если систолические ячейки задаются правильными
многоугольниками одинакового размера с числом сторон 3, 4, 6.
Такими многоугольниками можно без зазоров покрыть всю
плоскость. Заметим также, что при фиксированном числе сторон и
заданной площади правильные многоугольники имеют
наименьший диаметр.
§ 23. СИСТОЛИЧЕСКИЕ МАССИВЫ
225
В конечном счете, принцип близкодействия стал выражаться
наиболее ярко в том, что систолические ячейки почти всегда
изображают в виде правильных многоугольников одинакового размера.
Они могут быть, например, такими, как на рис. 23.1—1 или 23.1—2.
Расположение входов и выходов может отличаться от указанного.
Как правило, входы и выходы привязаны к серединам сторон или
вершинам углов. Ориентация ячеек с помощью точек задается не
всегда. В некоторых случаях отдельные систолические ячейки на
схемах выделяются для того, чтобы показать их специфические
особенности. Такие ячейки могут изображаться кружками, как на
рис. 23.1—3, или как-нибудь иначе. При этом число и расположение
связей остается таким, что принцип близкодействия в
действительности не нарушается. Чаще всего систолические ячейки
изображаются в виде правильных многоугольников с числом сторон
4 и 6. Использование правильных треугольников эквивалентно
использованию правильных 4- или 6-угольников, выполняющих
более крупную операцию.
Описанная конкретизация представления систолических
массивов, конечно, отражается на свойствах их графов. Если
систолические ячейки изображаются правильными многоугольниками
одинакового размера, то реализация принципа близкодействия
приводит к тому, что граф систолического массива оказывается
регулярным. На самом же деле даже свойство регулярности
является слишком общим для графов обычно рассматриваемых
систолических массивов. В регулярном графе пучок дуг, выходящий
из вершин, может быть произвольным. В графе систолического
массива все дуги пучка лежат в одной плоскости. Более того, среди
них можно выбрать такие базисные дуги, что все остальные будут
выражаться линейными комбинациями базисных с
коэффициентами 0, ±1.
Говоря об особенностях систолических массивов как
специализированных вычислительных систем, обычно выделяют
следующие:
— систолический массив состоит из однотипных или
небольшого числа различных типов функциональных устройств;
— систолические ячейки объединены в регулярную сеть;
— каждая ячейка связана только с соседними;
— каждый такт ячейка принимает данные, выполняет
определенную операцию и пересылает данные и результаты вычислений
другим ячейкам;
— систолический массив получает входные данные и выдает
результаты через граничные систолические ячейки;
— передача любой информации, в том числе рассылка по
систолическим ячейкам начальных данных осуществляется на фоне
выполнения операций.
Что касается двух последних особенностей, то к их
обсуждению мы еще вернемся. Сейчас же, подводя определенный итог
226 ГЛ. 4· ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
проведенным исследованиям, отметим, что наиболее важная
специфика систолических массивов может быть выражена следующим
образом: систолический массив есть конвейерный вычислитель с
регулярным графом.
Эта специфика настолько характерна, что ее описание можно
взять за определение систолического массива. Другие особенности
систолических массивов играют существенно меньшую роль и,
возможно, имеют преходящее значение. Действительно, почти не
имеет значения тип систолической ячейки и тип выполняемой ею
операции; значительно важнее количество входов и выходов.
Регулярность коммуникационной сети есть следствие регулярности
графа конвейерного вычислителя (KB). Регулярность графа KB
гарантирует в определенной мере и выполнение принципа близко-
действия, так как в таком KB отсутствуют длинные связи. По-
видимому, временным является требование плоской конфигурации
систолических массивов. Даже если систолические массивы не
станут объемными, они могут быть многослойными.
Утверждение 23.2. На конвейерном вычислителе с
регулярным графом в основном реализуются "только регулярные
алгоритмы.
Пусть вершины конвейерного вычислителя размещены в узлах
n-мерной решетки. Рассмотрим (п+1)-мерную решетку, добавив
ось времени /. Теперь построим развертку графа КВ. Однако в
отличие от развертки, описанной в § 18, будем считать, что при
каждом значении t все вершины развертки находятся не на прямой
линии, а в тех же узлах n-мерной решетки, что и вершины КВ.
При таком построении развертка будет регулярной, за
исключением, возможно, частей, соответствующих начальному и
заключительному этапам работы конвейерного вычислителя. Как
отмечалось ранее, на конвейерном вычислителе могут быть реализованы
лишь такие алгоритмы, графы которых являются подграфами
развертки, т. е. в основном регулярные алгоритмы.
Это утверждение позволяет сделать вывод, весьма важный,
по крайней мере в методологическом отношении. Как было
показано в § 17, любой направленный граф, и тем более регулярный
граф, с помощью подходящей замены вершин и специального
выбора системы координат можно преобразовать в координатный
решетчатый граф. Поэтому изучение различных аспектов,
связанных с проектированием конвейерных вычислителей, и в частности
систолических массивов, можно осуществлять без потери
принципиальных ограничений на примере алгоритмов, графы которых
не только регулярные, но и невырожденные координатные.
Прежде чем переходить к рассмотрению различных способов
построения конвейерных вычислителей для алгоритмов, заданных
координатными графами, обсудим подробнее две последние
особенности систолических массивов. Исследования, проведенные в
главе 3, показали, что координатные графы являются типичными
§ 23. СИСТОЛИЧЕСКИЕ МАССИВЫ
227
для многих вычислительных алгоритмов. Однако говоря о графах
алгоритмов, мы до сих пор почти не обсуждали вопросы, связанные
с рассылкой начальных данных по функциональным устройствам.
С формальной точки зрения можно поступить очень просто.
Введем в граф алгоритма дополнительные вершины и отождествим
их с фиктивными операциями, каждая из которых выдает одно
начальное данное. После этого с расширенным графом можно
поступать так же, как с графом алгоритма. Тем не менее, у нового
графа есть характерная особенность. В графе алгоритма обычно
имеется небольшое число вершин, из которых выходит много дуг.
Нередко таких вершин нет совсем. Что же касается фиктивных
вершин, то из них, как правило, выходит много дуг, так как очень
часто одно начальное данное используется в качестве аргумента
во многих операциях. Если граф алгоритма имеет вершины с
большим числом выходящих дуг, то реализация такого алгоритма,
например, на систолическом массиве должна вызывать какие-то
особенности, так как систолические ячейки всегда имеют небольшое
число выходов.
Не вызывает трудностей передача данных от одного ФУ к
другому одиночному ФУ. Но если некоторое данное должно
использоваться во многих ФУ, то необходимо применение специальных
способов его рассылки. Один из способов использует шинную связь.
Рассылаемое данное поступает на шину и одновременно
принимается несколькими функциональными устройствами. Для
систолических массивов такой способ неприемлем, так как не
обеспечивается выполнение принципа близкодействия. В подобных
вычислительных системах более подходящим является способ,
использующий транспортную связь. В этом случае данное поступает
в ФУ, используется в нем как операнд и, не изменяясь,
пересылается по транспортной магистрали в соседнее ФУ, где
используется, пересылается дальше и т. д.
Выбор способа рассылки данных зависит от многих факторов,
в первую очередь, от структуры алгоритма и используемых
технических средств. Какова бы ни была вычислительная система,
содержащая большое число одновременно работающих ФУ, каждая
реализация на ней любого алгоритма однозначно определяет
некоторую его параллельную форму. Очевидно, что все вершины,
находящиеся в разных ярусах параллельной формы, но имеющие
общую предшествующую вершину, могут быть связаны с этой
общей вершиной одной транспортной магистралью, причем данное
по магистрали должно передаваться от вершины к вершине по
возрастанию номеров ярусов. Если же в каком-то ярусе
находится более одной вершины, имеющих общую предшествующую,
то они, вообще говоря, должны быть связаны с общей вершиной
либо отдельными линиями связи, либо общей шинной связью.
Так как каждый алгоритм, как правило, имеет много параллельных
форм, то выбирая наиболее подходящую из них, можно в опреде-
228 гл· 4· ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
ленной мере выбирать и способы рассылки данных. В общем случае
для рассылки одного данного могут быть использованы несколько
транспортных магистралей, несколько шин или то и другое вместе.
Конвейерные вычислители и, в частности, систолические
массивы, могут потребовать для своей работы большого числа каналов
связи с памятью. Однако, как было показано в § 7, вообще говоря,
невозможно достичь необходимого уровня ускорения без
обеспечения достаточно большой пропускной способности этих каналов.
Тем не менее, в силу острой дефицитности данного вида
оборудования, минимизация числа каналов связи с памятью является
исключительно важной задачей. Шинные связи и в особенности
транспортные магистрали в конвейерных вычислителях помогают
ее решению. Вместо того, чтобы занимать канал связи и многократно
вводить одно и то же данное, достаточно подать его один раз на
шину или магистраль. При этом чем длиннее шины и магистрали,
тем меньше в общем случае будут заняты каналы связи
непроизводительными пересылками данных.
При конструировании конвейерных вычислителей границы шин
и транспортных магистралей, рассылающих начальные данные,
довольно часто выходят на границу графа КВ. Это является
отражением того факта, что в реальных вычислительных алгоритмах
операции, требующие одних и тех же начальных данных, довольно
часто соответствуют вершинам графа, лежащим на поверхности
или линии, пересекающей его границу. Поэтому особенность
конвейерных вычислителей, и в частности систолических массивов,
выражающаяся в том, что они получают входные данные и выдают
результаты через граничные функциональные устройства,
является, в основном, следствием свойств рассматриваемых
алгоритмов и в очень малой степени зависит от способа построения КВ.
Конечно, наличие такого свойства в алгоритмах может упростить
организацию связи конвейерных вычислителей с памятью, и этим
фактом не стоит пренебрегать.
Принимая во внимание сказанное, будем теперь поступать
следующим образом. Сначала зафиксируем в графе алгоритма те дуги,
которым заведомо должны соответствовать непосредственные
связи ФУ между собой. Затем попытаемся построить конвейерный
вычислитель с нужными свойствами, реализующий алгоритм с
выбранным подграфом. Если такое построение оказалось невозможно, то
оно тем более будет невозможно с учетом рассылки данных. Если
же построение удалось выполнить, то после этого выберем
подходящие способы рассылки данных, соответствующих оставшимся
дугам. И наконец, определим функции, выполняемые отдельными
устройствами. Говоря о том, что при изучении различных аспектов,
связанных с проектированием систолических массивов, можно
ограничиться рассмотрением алгоритмов с координатными графами,
мы в действительности подразумевали, что выбор способов
рассылки данных при необходимости может быть решен позднее.
§23. СИСТОЛИЧЕСКИЕ МАССИВЫ
229»
Итак, пусть алгоритм задан невырожденным координатным
решетчатым графом и ставится вопрос о проектировании
конвейерного вычислителя, реализующего данный алгоритм. Как было
показано в главе 2, эффективным средством построения по графу
алгоритма графа вычислительной системы является гомоморфная
свертка. В частности, для направленных графов эта свертка может
быть получена с помощью проектирования графа алгоритма на
гиперплоскость, перпендикулярную направляющему вектору. Для
координатного графа направляющим будет любой ненулевой
вектор с неотрицательными координатами.
Проектирование координатного графа на гиперплоскость,
перпендикулярную направляющему вектору, не только дает
возможность получить граф конвейерного вычислителя. При этом
определяется также режим работы отдельных ФУ.
Будем снова предполагать, что все ФУ выполняют свои
операции за одно и то же время, равное 1. Обозначим через χ вектор,,
характеризующий положение вершины координатного графа,
через еи · · ·, еп — координатные векторы, через t(x) — время
начала выполнения операции, соответствующей вектору х. Согласно
утверждению 8.2, для того чтобы функция t(x) являлась временной
разверткой, т. е. обеспечивала возможность реализации алгоритма,,
необходимо и достаточно выполнение неравенств t(x+ei)—t(x)^l
для всех i. Согласно утверждению 10.3 и его следствию выполнение
равенств ί(χ+βι)—t(x) = \ для всех > обеспечивает реализацию
алгоритма за минимально возможное время. Выбор функции t(x)
подсказывают следующие соображения.
Проведем через вершины координатного графа гиперплоскости,-
перпендикулярные некоторому неотрицательному вектору е. Если
вершины, лежащие в одной гиперплоскости, не связаны друг с
другом, то соответствующие операции могут выполняться
одновременно. Времена же выполнения операций, относящихся к разным
гиперплоскостям, вообще говоря, должны возрастать в
направлении вектора е. Поэтому кажется возможным искать временную
развертку в данном случае в виде t(x)=a(e, χ)+β, где α, β —- неко-*
торые константы.
Утверждение 23.3. Пусть граф алгоритма
координатный и все операции выполняются за одно и то же время, равное 1.
Тогда функции t(x)=a(e, χ)+β будут задавать временные
развертки, если только все координаты вектора ае не меньше 1.
Временные развертки т(х)=(е, х)+$, где все координаты вектора е
равны 1, α β — любое число, обеспечивают реализацию алгоритма
за минимально возможное время.
Действительно, t{x+et)—t(x)=a(e, et). Это выражение не
меньше 1 для всех i тогда и только тогда, когда все координаты вектора
ае не меньше 1, и равно 1, когда все координаты вектора ае равны 1.
Поэтому все указанные в утверждении функции 1{х) являются вре-
230 ГЛ 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
менными развертками и среди них только функции τ(χ)
обеспечивают реализацию алгоритма за минимально возможное время.
Теперь возьмем любой вектор а, не ортогональный вектору е[
•с единичными координатами, и спроектируем координатный граф;
на гиперплоскость, перпендикулярную вектору а. При этом в
одну точку спроектируются все вершины, лежащие на прямой
линии, проходящей через данную точку и имеющей направляющим:
вектор а. Легко проверить, что все такие вершины имеют различные
значения τ (л:). Несмотря на то, что выбранный вектор а не
обязательно будет направляющим для координатного графа, тем не менее
на построенном конвейерном вычислителе алгоритм,
представленный координатным графом, можно реализовать за минимальное
время.
Определение временных разверток t(x) и широкий произвол в
выборе направляющего вектора при конструировании
конвейерного вычислителя позволяют легко решить вопрос о рассылке
данных и построении транспортных магистралей. Пусть вершины,
положение которых задается векторами хи . . ., х3, имеют общую
предшествующую. Предположим, что временная развертка
задается вектором е. Если среди чисел (е, хл), . . ., (е, д:8) нет
одинаковых, то вершины можно связать транспортной магистралью и
передавать по ней информацию в соответствии с возрастанием этих
чисел. Шинной связью объединяются лишь вершины, соответст*
вующие равным числам из совокупности (е, хг)$ . . ., (et xs). В
случае, когда по каким-либо причинам шинная связь оказывается не-
лриемлемой, можно взять другой вектор е% определить другую
временную развертку, не обязательно оптимальную, и снова
проверить на совпадение числа (е, хх), . . ., (е, х8).
Таким образом, можно построить семейство конвейерных
вычислителей с максимальным быстродействием. Они отличаются
друг от друга конфигурацией связей, числом ФУ и выполняемыми
ФУ операциями, особенно в отношении рассылки данных. Число ФУ
в конвейерных вычислителях этого семейства колеблется в очень
значительных пределах. Для большинства направляющих векто-
•ров число ФУ в KB совпадает с числом вершин графа алгоритма.
Однако имеется немало направляющих векторов, для которых
число ФУ в KB существенно меньше. В общем случае минимальное
число ФУ в конвейерном вычислителе обеспечивает
проектирование вдоль координатных векторов. При этом обычно достигается
наибольшая загруженность. В этом же случае к каждому ФУ
присоединяется по одной ячейке памяти для хранения результата
одного срабатывания, передаваемого по направлению
проектирования. Следующие очевидные утверждения оказываются
полезными при выборе направления проектирования для получения из
координатного графа алгоритма графа конвейерного вычислителя.
Утверждение 23.4. При реализации алгоритма,
заданного координатным графом, каждое ФУ конвейерного вычислителя
§23. СИСТОЛИЧЕСКИЕ МАССИВЫ
23 Г
выполняет столько его операций, сколько вершин графа алгоритма
проектируется в вершину, соответствующую данному ФУ.
Утверждение 23.5. Пусть вектор а имеет
целочисленные координаты и на прямой линии с направляющим вектором а
есть хотя бы одна вершина бесконечного координатного графа. Тогда
все вершины этого графа, принадлежащие данной прямой, лежат на
одном пути и образуют равномерную сетку с шагом у~га, где γ
есть наибольший общий делитель модулей ненулевых координат
вектора а.
Утверждение 23.6. Пусть временная развертка задается
вектором е и граф конвейерного вычислителя получен из
координатного графа проектированием вдоль вектора а с целочисленными
координатами аи . . ., ап. Если все ФУ выполняют свои операции за
одно и то же время, равное 1, то каждое ФУ срабатывает не чаще,,
чем один раз в q тактов, где ^=γ""1| (е, а)\.
Общие принципы конструирования конвейерных вычислителей,
реализующих алгоритм с координатным графом, непосредственно·
переносятся на конструирование систолических массивов. По
существу осталось учесть только то, что граф систолического массива
размещен на плоскости или прямой линии. Мы ограничимся
рассмотрением случая плоского систолического массива как наиболее
интересного.
Проектирование трехмерного координатного графа на любую
плоскость дает граф, каждая вершина которого имеет либо 3, либо 2
входящих и выходящих дуги. Этот граф всегда является планар-
ным, что и объясняет использование систолических ячеек в виде
правильных 4- и 6-угольников. Всегда можно выбрать такие
плоскости, что при проектировании на них трехмерного графа
проекции никаких дуг не будут пересекаться. В частности, если взять
любую плоскость, направляющий вектор которой имеет
координаты, равные 0 или ±1, то проекция на нее координатного графа дает
плоский регулярный граф с дугами одинаковой длины.
Рассмотрим некоторые примеры. Пусть согласно алгоритму,
изложенному в §6, вычисляется выражение А+ВС для
квадратных матриц А, В, С порядка 3. Граф этого алгоритма представлен
на рис. 6.2. Легко проверить, что один и тот же элемент матрицы
А (В, С) требуется для выполнения операций, соответствующих
вершинам, лежащим на прямой, параллельной оси &(/, i). Если
спроектировать граф алгоритма на плоскость, перпендикулярную
оси k, то проекция будет состоять лишь из изолированных вершин.
В этом случае реализовать алгоритм за минимально возможное
время можно лишь при рассылке начальных данных β, С с
помощью шинных связей, параллельных осям /, i. Заметим, что в силу
специфики графа алгоритма и связей его вершин с начальными
данными никакая проекция не дает возможность построить
систолический массив без шинных связей, реализующий, к тому же,
режим максимального быстродействия.
232 ГЛ 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ |
Будем считать, что временная развертка определяется вектором
£=(1, 1, 1). Эта развертка увеличивает время реализации алгорит- ]
ма в три раза, но позволяет построить систолические массивы с \
транспортной рассылкой данных. Спроектируем теперь граф алго- j
ритма с учетом транспортных связей на плоскости, перпендикуляр- ]
ных осям /, / и вектору с координатами (1, 1, 1). Соответствующие |
трафы систолических массивов представлены на рис. 23.3—1, ]
23.3—3, 23.3—2. Сразу видны различия вершин и конфигурации ]
связей. Кроме этого, нетрудно заметить общность между графом |
:23.3—2 и структурой систолического массива на рис. 23.2. Жирными \
Рис. 23.3
«линиями на рис. 23.3 указаны проекции ребер куба, содержащего
вершины графа. Штриховыми линиями отмечено распространение
фронта вычислений. На рис. 23.3—1, 23.3—3 фронт
распространяется по диагонали квадрата, на рис. 23.3—2 от центра к границе.
Во всех трех случаях функции систолических ячеек описываются,
в основном, соотношениями (23.1) с переменой местами букв а п с.
Заметим, что при этой временной развертке можно получить граф
систолического массива с помощью проектирования и по
некоторым другим направлениям, в частности вдоль оси k.
Разные проекции приводят не только к различиям в числе
вершин и конфигурации связей, но и к различиям в организации
процессов. Так, в проекции 23.3—2 имеется достаточное число связей
для выполнения операций (23.1) без использования какой-либо
памяти. В проекциях 23.3—1, 23.3—3 связей меньше. Поэтому
здесь каждое ФУ должно иметь по одной ячейке памяти для
хранения соответственно элементов ckj, bik матриц С, В. Это
приводит, в свою очередь, к различиям в процессах загрузки и
разгрузки систолических массивов.
Следующий пример более содержателен. Пусть решается
система линейных алгебраических уравнений Ах=Ь методом Жордана
«без выбора ведущего элемента. Предположим, что входная инфор-
§23. СИСТОЛИЧЕСКИЕ МАССИВЫ
233
мация задана в виде матрицы А размера пХ (я+1), где правая часть
b расположена в (я+1)-м столбце. Алгоритм решения системы,
записанный в фортраноподобном виде, имеет такой вид:
DO 5 4=1, л
DO l i=l, k—l
DO 2 i = k+l, η
DO 5 j = k+l, n+l
DO 3 i=l, 4—1
3 a/t y = ai / + Vf/
DO 4 i = Λ + 1, η
5 aktJ = Uj
Решение системы после окончания вычислений будет расположено
в (я+1)-м столбце матрицы А.
Вообще говоря, можно записать алгоритм решения задачи,
используя для хранения результатов промежуточных вычислений
элементы массива А. Массивы / и и введены в чисто
иллюстративных целях для упрощения изложения дальнейших рассуждений,
ход которых одинаков в обоих случаях. Заметим, что
использование любого числа дополнительных переменных и массивов для
хранения результатов промежуточных вычислений никак не влияет на
граф алгоритма и, следовательно, не будет отражаться на структуре
систолического массива.
Можно "было бы провести анализ именно приведенной формы
записи алгоритма. Однако легко видеть, что основная доля
вычислений приходится на опорные гнезда размерности 3 с операторами 3,
4. Эти гнезда почти одинаковы. Различие заключается лишь в том,
что одно гнездо описывается значениями параметра i от 1 до k—1,
а другое — значениями i от k+l до п. Поэтому в решетчатом графе
не будет'вершин, лежащих на плоскости i=k. Отсюда вытекает, что
граф алгоритма по существу состоит из двух подграфов и
необходимо либо строить систолические массивы для каждого подграфа
в отдельности, либо объединить их. Второе предпочтительнее,
причем объединение можно осуществить как на уровне
модификации формы записи, так и на уровне «стыковки» систолических
массивов. Подграфы объединяются, например, следующим
изменением записи:
DO 5 k=l, n
1 /ι =1/0ι*
DO 2 ί = 2, η
8 В. В. Воеводин
234 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
2
3
4
5
h = — Ωί.*
DO 5 i = k+T, n+l
"/=%/l
DO 4 t = 2, η
ai-i.y = ai.y + 'i«/
««,/ = "/
Согласно исследованиям, проведенным в главе 3, можно
утверждать, что решетчатый граф этого алгоритма должен состоять и$
связанных между собой решетчатых графов пяти опорных гнезд
циклов, соответствующих операторам 1—5. Формальный анализ
показывает, что графы гнезд 1—3, 5 пустые. Это объясняется
отсутствием элементов пересекающихся массивов в левых и правых
частях строк записи алгоритмов, метки которых имеют данные
номера. В строке с меткой 4 есть только одна пара элементов а{_1%/
и ui,j, относящихся к одному массиву. Поэтому в опорном гнезде
4 могут быть дуги. Они определяются решением задачи (15.1).
Соответствующий анализ позволяет установить, что из каждой
вершины опорного гнезда 4 с координатами (к, /, i) действительно выходит
одна дуга и достигает вершины с координатами (k+l, /, i—1).
В этом гнезде заведомо есть путь длиной η—1. Следовательно, нель-·
зя рассчитывать на то, что высота алгоритма будет меньше п. Как
показано в главе 3, вершины разных опорных гнезд могут быть
связаны между собой дугами. В данном случае эти связи таковы:
— для гнезда 1 дуги
заходят из гнезда 4 и выходят в
гнездо 3;
— для гнезда 2 дуги
заходят из гнезда 4 и выходят в
гнездо 4;
— для гнезда 3 дуги заходят
из гнезд 1, 4 и выходят в
гнездо 4;
— для гнезда 4 дуги
заходят из гнезд 2—5 и выходят в
гнезда 1—4;
— для гнезда 5 дуги заходят из гнезда 3 и выходят в гнездо 4.
Связи из гнезда 1 в гнездо 3, из гнезда 2 в гнездо 4, а также из
гнезда 3 в гнездо 4 — множественные. Поэтому здесь придется
организовать транспортные магистрали.
Суммируя сказанное, разместим вершины опорных гнезд 1—3, 5
вокруг опорного гнезда 4. Область, занимаемая вершинами
решетчатого графа рассматриваемого алгоритма, изображена на
рис. 23.4. Она представляет призму, из которой исключено ребро 6.
Вершины опорного гнезда 1 размещены на ребре 1, гнезда 2 — на
грани 2, гнезда 3 — на грани 3, гнезда 5 — на грани 5, вершины
опорного гнезда 4 размешены в остальной части призмы.
(W)
(/7, Я + 1,/7-И )
(/7,/7,/7-М)
J
(1;/7+1;/Ж)
б'
Рис. 23.4
§23. СИСТОЛИЧЕСКИЕ МАССИВЫ
235
Основной объем вычислений приходится на оператор 4, который
является телом тройного цикла. Неоднородности вычислений,
связанные с операторами 1—3, 5, локализованы на границе.
Структура связей в решетчатом графе вместе с транспортными связями
показана на рис. 23.5. В каждую вершину графа входят и выходят
дуги, определяемые векторами (1, 0, —1), (0, 1, 0), (0, 0, 1). В
вершинах, лежащих на границе призмы 23.4, отсутствуют дуги, свя-
*+1„/+1,£-2
*ЧУ-У-2
/ ' N
Ж ' χι
1χ n1 ίΧ
ι/ Ν/
—*Vfv.
/ι
Κ ι
/ *" ^ч
ι ν
Ν Ι /
—3»Ж
—ύκ~~?
^ΛΧι Λ N1
4W
^Ν Ι /
ν!/
Ar+1J+1fA+1
Рис. 23.5
занные с внешним объемом. Транспортные магистрали для
рассылки элементов щ расположены на прямых, параллельных оси i.
Они начинаются на грани 3 и заканчиваются на грани 5, проходя
через соответствующие точки призмы. Транспортные магистрали для
рассылки элементов lt начинаются на грани 2 и ребре 1 и проходят
через соответствующие точки призмы на прямых, параллельных
оси /. Входные данные, т. е. элементы массива Л, поступают через
нижнюю грань.
Решетчатый граф алгоритма с учетом введенных транспортных
связей легко сводится к координатному с помощью линейного
преобразования
k' = k, ./' = /, i' = i + k— l.
Область, занимаемая графом в пространстве (&', /', Г), изображена
на рис. 23.6. Соответствие между операторами и вершинами
координатного графа остается ана -
ЛОГИЧНЫМ рассмотренному ВЫ - л —/(η,η + ϊ,Ίη)
ше. Все неоднородности вы- У/ /у (п>п>?-п)
числений в новом графе также
локализованы на границе.
Рассмотрим две
проекции координатного решет- j.i,i
чатого графа для я=4.
Проекция по направлению (1,
1, 1) представлена на рис.
23.7. В новых координатах ξ=/—k, η = /—k ребро 1 перешло в
точку (0, 0), грань 2 — в линию (1,0) — (п—1, 0), грань 3 — в
линию (0, 1) — (0, я), грань 5 — в линию (я, 1) — (/г, п). При этом
проектировании все неоднородности снова остались на границе.
в*
236 гл· 4· ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
В координатах k, /, i оптимальная развертка с точностью до
момента начала работы есть функция k+j+i- В новых координатах она
равна ξ+η+3/г, т. е. каждая ячейка систолического массива будет
срабатывать один раз в три такта.
Функции систолических ячеек определяются содержанием
операторов, которым они соответствуют, а также необходимостью
Рис. 23.7
пересылки элементов щ-, Ιχ и входных данных. Ячейки
осуществляют полностью или частично операции типа (23.1). Именно,
— ячейка (0, 0): /out=1^in> аот=а1п>
— ячейки (1,0) — (η—1, 0): /out=—α1η,
— ячейки (0, 1) — (0, η): uoui=ainlm, Ιοηί=1·ϊη,
— ячейки (η, 1) — (η, η): αοαί=α·ιη+ιιϊη,
— остальные ячейки: aoui=am+ulnl{n, иот=Щ^ lout=hn-
Всю совокупность ячеек можно свести к устройствам двух типов.
Ячейка (0, 0) изображена на рис. 23.1—3 и ее функции таковы:
#out = ain> ^out = l/flin» ^out = ^in» ^in = 1 ·
Остальные ячейки можно взять, согласно рис. 23.1—2, с функциями
£out = £in"T"fliiAn> ^out = ^in> ^out^^in*
Обозначения входов и выходов не играют никакой роли.
Предполагается, что недостающие операнды всегда доопределяются нулями,
а на вход bin ячейки (я, 1) всегда подается —1.
Схема систолического массива и порядок подачи данных и
выдачи результатов для η = 4 приведены на рис. 23.8. Общее время
решения системы порядка η приблизительно равно 5я. При этом
загруженность систолического массива при решении одиночной
задачи приблизительно равна 0,1.
Рассмотрим теперь проекцию координатного решетчатого
графа также для η = 4 по направлению (0, 0, 1). Она представлена на
рис. 23.9. В новых координатах ξ=/, r\=k ребро 1 и грань 2 перешли
в линию (1, 1) — (я, я), грани 3, 5 и внутренность призмы перешли
на всю область, за исключением этой линии. В новых координатак
оптимальная развертка равна ξ+η+t, τ. е. каждая ячейка систоли-
§ 23. СИСТОЛИЧЕСКИЕ МАССИВЫ
237
JC^ Л?ъ ι2Γζ αΤ-,
\ \ \ \
- - - α,ι
— — ff21 ~ #12 — — —
Λ
31
β.
13
~ ~~ ^32 *~* &23 -"
#41 "" "~ ^33 ~~ ~ °-\Л "
а4г - - ~ Д-24 - -
Ячз ~ β34 - - А
/и
Рис. 23.8
с/7, л/; {п + \,/?)
- ^
I A
* ΐ*->
• 2*Л ^и
f Ж А
^-t *-
LL I
7 к
^ηυ
Рис· 23.9
238 ГЛ· 4· ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
ЕГ
ЕГ
ЕГ
ЕГ
ЕГ
13
ЕГ
ЕГ
EJ
ЕТ
ЕГ
EJ
Щ
Щ
Г Τ Τ Τ 1
ческого массива будет срабатывать каждый такт после начала
функционирования.
Схема систолического массива и порядок подачи данных и
выдачи результатов приведены на рис. 23.10. Результаты вычислений
х будут выдаваться из ячейки
φ, (η+1, ή) в последовательные
%* моменты, начиная с t=3n+2.
} Все ячейки массива меняют
выполняемые ими функции во
время счета, хотя в целом
они делают примерно то же,
что и в предыдущем
примере. Загруженность
систолического массива при решении
одиночной задачи
приблизительно равна 0,25
Эти примеры показывают,
что на одиночной задаче
загруженность систолических
массивов оказывается не очень
высокой. Особенно заметно
она уменьшается из-за
достаточно длинных этапов
загрузки и разгрузки массивов. Как
и в любом конвейерном
вычислителе, загруженность
можно повысить, решая
одновременно несколько задач.
ь_ В заключение отметим,
что большинство
систолических массивов являются
безусловными конвейерными
вычислителями. Такие
систолические массивы без
существенной потери своих качеств
могут успешно функционировать не только в общем синхронном, но
и в асинхронном режиме. Управление процессом легко
осуществляется, например, с помощью тегирования. Систолические массивы с
малой загруженностью нередко удается свернуть з массив с
большей загруженностью при одновременном уменьшении числа ячеек
и индекса расщепления.
§ 24. Алгебраический вычислитель
Проведенные исследования конвейерных [и,^"частности,
векторных вычислителей, а также систолических массивов, позволяют
высказать некоторые соображениям построении моделей, специали-
«11
#21
*31
«41
—.
aiZ
Чг
# 32
а42
~
~
013
&гз
•Язз
%
—
-
~
ац
#-24
#34
#44
~
—
-
—
А
Рис. 23.10
§ 24. АЛГЕБРАИЧЕСКИЙ ВЫЧИСЛИТЕЛЬ
239
зированных для решения классов задач. Мы рассмотрим в качестве
примера одну из возможных моделей для решения задач линейной
алгебры с плотными матрицами.
Для задач данного класса характерным является
исключительно большая их трудоемкость. В общем случае решение практически
любой из них требует выполнения порядка п? арифметических
операций, где η есть параметр, определяющий порядок используемых
матриц или размерность векторов. В настоящее время нередко
возникает необходимость в решении задач линейной алгебры с
плотными матрицами порядка 10?—105. По существу единственный путь
быстрого их решения связан с применением специализированных
вычислительных систем с большим числом одновременно
работающих функциональных устройств.
Чтобы вычислительная система могла работать наиболее
эффективно, недостаточно лишь наличие в ней большого числа ФУ. Столь
же важно иметь подходящие алгоритмы, которые позволили бы
обеспечить необходимый уровень загруженности всех или, по
крайней мере, большей части ФУ системы. Для повышения общего
быстродействия существенно также, чтобы структура алгоритмов
не требовала от вычислительной системы сложной
коммуникационной сети.
Одним из самых эффективных типов вычислительных систем с
многими ФУ являются систолические массивы. Весьма заманчиво
сконструировать один или несколько массивов, с помощью которых
можно решать различные задачи линейной алгебры с плотными
матрицами. На первый взгляд, эта задача не кажется такой уж
нереальной, так как опыт создания систолических массивов,
реализующих различные алгоритмы решения задач линейной алгебры,
говорит о том, что в подобных массивах есть много общего. Более того,
иногда один и тот же массив может решать различные задачи всего
лишь после незначительного изменения функций систолических
ячеек или способа подачи данных. Тем не менее, по-видимому,
нецелесообразно идти непосредственно по этому пути.
Число ячеек систолического массива, предназначенного для
решения конкретной задачи линейной алгебры с матрицей порядка я,
обычно имеет порядок я2. Хотя в теоретическом плане систоличе-
ские массивы легко наращиваются, зависимость числа ячеек от л
не дает возможность эффективно использовать все функциональные
устройства при фиксированном п. К тому же, при больших η общее
число систолических ячеек оказывается настолько значительным,
что начинают возникать серьезные технические трудности. В
частности, требуется очень большое число каналов связи с памятью для
обеспечения режима максимального быстродействия. К
сожалению, нет никаких оснований рассчитывать на существование
систолических массивов с фиксированным числом ячеек, обеспечивающих
решение сколько-нибудь сложной задачи линейной алгебры с
матрицей произвольного порядка без многократного обращения к па-
240 · ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
мяти для записи и считывания результатов промежуточных
вычислений. Созданию унифицированных систолических массивов мешает
и то обстоятельство, что массивы для разных задач все-таки
отличаются друг от друга. Суммарный объем этих различий весьма
велик и затрагивает не только функции систолических ячеек, но и
коммуникационную сеть.
Модель специализированной вычислительной системы для
решения задач линейной алгебры с плотными матрицами может быть
предложена, если ориентироваться на использование клеточных
методов. Основанием к этому предложению служат следующие
факты:
— разработаны клеточные аналоги для всех основных
численных методов линейной алгебры;
— основная часть вычислений в клеточных методах приходится
на выполнение операций сложения и умножения матриц
небольшого фиксированного размера;
— клеточные методы являются экономичными с точки зрения
числа и времени обменов с памятью;
— для реализации матричных операций с матрицами
небольшого фиксированного размера можно построить систолические
массивы.
Детальный анализ различных клеточных методов показывает,
что основная часть вычислений приходится в действительности на
выполнение матричных операций вида
s
D = A+ 2 Bfir (24.1)
В некоторых методах s равно 1 или 2, в отдельных методах
величина s является переменной. Во всех методах матрицы Л, Bh С ι
квадратные и имеют такой же размер, как клетки, на которые
разбиваются входные, выходные и промежуточные данные. Остальные
матричные операции, необходимые для реализации клеточных
методов, так же разнообразны, как разнообразна вся совокупность
численных методов линейной алгебры. Однако общий объем
приходящихся на них вычислений относительно невелик и все
нестандартные операции, как правило, относятся к матрицам размера одной
клетки.
Общая схема предлагаемой вычислительной системы показана на
рис. 24.1. Систолический массив предназначен для быстрого
выполнений операций вида (24.1) при фиксированном порядке матриц.
Быстрая память предназначена, в основном, для подачи данных на
систолический массив и считывания результатов его работы. Она
может быть организована по такому же принципу, как в векторном
вычислителе, или как-нибудь иначе. Универсальный процессор
предназначен для выполнения всех остальных операций, кроме
операций (24.1). Он не обязательно должен обладать большим
§24. АЛГЕБРАИЧЕСКИЙ ВЫЧИСЛИТЕЛЬ
241
Универсальный
не очень быстрый
процессор
А
1
Небольшая
быстрая память
А
Систолический
массив
1 С+АВ^С
1
Массовая
память
Рис. 24.1
быстродействием. Вся его работа может осуществляться
параллельно с работой систолического массива. Общий объем выполняемой
им работы относительно невелик. Нетрудно вывести различные
соотношения, связывающие общее время решения задачи со
скоростью выполнения операций универсальным процессором,
числом ячеек систолического массива, скоростью их срабатывания,
размером быстрой памяти
и числом каналов связи с
массовой памятью.
Рассмотрим несколько
подробнее систолический
массив, предназначенный
для выполнения операций
(24.1). Пусть порядок всех
матриц из (24.1) равен т.
Обозначим 5=(5i,..., Bs),
С'=(С'1У . . .,Q. Матрицы
В, С имеют размеры mXms
и очевидно, 4toD=A-\-BC.
Поэтому в
действительности систолический массив.
должен реализовывать
матричную операцию *' А +ВС
для прямоугольных матриц В, С и квадратной матрицы А. При
этом число столбцов (строк) матрицы В (С) кратно числу ее строк
(столбцов) и с учетом данного ограничения может быть
произвольным.
Предположим, что матричная функция Α+BC вычисляется
стандартным способом, и пусть s фиксировано. В этом случае граф
алгоритма аналогичен представленному на рис. 6.2. Вершины
графа заполняют прямоугольный параллелепипед, содержащий по т
вершин вдоль осей i, / и ms вершин вдоль оси k. Для построения
графа систолического массива спроектируем граф алгоритма на
гиперплоскость, перпендикулярную оси i. Полученный граф
аналогичен представленному на рис. 23.3—1, Его вершины будут
заполнять прямоугольник, содержащий т вершин вдоль оси / и ms
вершин вдоль оси k.
Систолический массив с таким графом будет работать не очень
эффективно даже при наличии длинных шинных связей. В самом
деле, число ФУ в массиве равно m2s и они выполняют тЧ скалярных
операций вида α+bc. На критическом пути графа алгоритма
находится ms вершин. Поэтому согласно утверждению 7.5 время
вычисления матричной функции А+ВС на систолическом массиве при
любом режиме включения его ячеек будет не меньше ms, если,
конечно, считать равным 1 время выполнения отдельных операций
α+bc. Теперь из соотношения (7.2) вытекает, что средняя
загруженность ячеек не будет превышать s*1. Этот вывод нельзя рассматри-
242 ГЛ. 4. ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ ОБРАБОТКИ ИНФОРМАЦИИ
вать как удовлетворительный, так как s может быть достаточно
большим.
Чтобы разобраться в данной ситуации и понять причины
снижения загруженности систолического массива, изучим детальнее
процесс вычисления матричной функции А+ВС. Пусть для
определенности Л=0 и временная развертка задана вектором θ=(1, 1, 1).
Легко заметить, что фронт вычислений описывается прямыми,
перпендикулярными биссектрисе угла между осями j,k на рис. 23.3—1
и перемещается каждый такт параллельно. Если среди ячеек
систолического массива, выполняющих в какой-то момент операции
алгоритма, выбрать те, которые находятся на любой прямой,
параллельной оси k, то все они будут расположены подряд за ячейкой
фронта и их число превосходит т.
Таким образом, малая загруженность систолического массива
объясняется тем, что в каждый момент времени работает малая часть
его ячеек. Следовательно, единственный путь повышения
загруженности заключается в построении для вычисления матричной
функции А+ВС систолического массива, содержащего существенно
меньшее число ФУ.
Среди различных проекций графа алгоритма только проекция
на гиперплоскость, перпендикулярную оси k, содержит
существенно меньшее число вершин. В этом случае, как, впрочем, и во всех
других, нельзя реализовать алгоритм за минимально возможное
время, используя транспортные магистрали для рассылки данных.
Снова рассмотрим временную развертку, заданную вектором е=
=(1, 1, 1). Она увеличивает время реализации алгоритма не более,
чем на 2 т тактов. Это увеличение вполне приемлемо при всех s
и не очень существенно при больших s. Однако теперь
систолический массив может быть построен. В целом он аналогичен массиву,
граф которого представлен на рис. 23.3—1. Имеются лишь
некоторые отличия в процессах загрузки и разгрузки.
Мы не будем подробно обсуждать модель предлагаемой
вычислительной системы для решения задач линейной алгебры с плотными
матрицами, так как это обсуждение зависит от многих конкретных
деталей. Заметим только, что при подходящем согласовании
всех ее узлов на ней можно решать задачи со скоростью,
пропорциональной скорости реализации матричной операции А +ВС на
систолическом массиве. Если по каким-либо причинам
сдерживающим фактором является время выполнения нестандартных
операций на универсальном процессоре, то для повышения общего
быстродействия в его состав также можно ввести систолические массивы,
но уже существенно меньших размеров. Конечно, для быстрого
выполнения матричной операции А+ВС можно использовать и
другие систолические массивы, а также и принципиально другие
устройства.
БИБЛИОГРАФИЧЕСКИЕ УКАЗАНИЯ
В настоящее время опубликовано очень большое число работ, связанных
с параллельными вычислительными системами и параллельными численными
методами. Значительный список соответствующей литературы приведен в конце
книги. Он дается в алфавитном порядке. Для облегчения работы с литературой
приведено разбиение публикаций по их принадлежности к более узким областям.
На формирование списка литературы, выбор узких областей и отнесение
конкретной работы к той или иной области оказали влияние многие факторы, в
первую очередь, поставленная автором цель написания книги и его точка зрения·
Поэтому автор заранее приносит свои извинения тем читателям, которые сочтут
принятые решения в отношении литературы не совсем удачными. Вместе с тем,
автор надеется, что в приведенном списке литературы даже искушенный читатель
найдет для себя что-нибудь интересное.
Общие вопросы
[5, 20, 85,98, 100, 105, 106, 154, 204, 235, 245, 246, 276—279, 320, 323, 345,
377, 379, 428, 492, 564, 609, 628, 629, 631, 636, 648, 709, 715, 768, 769, 834, 840—
845, 914, 958, 959, 1000].
Архитектура вычислительных систем
[2, 4, 22, 23, 43, 62, 67, 68, 71, 74, 75, 88у 99, 144, 149, 150, 152, 154,
167, 203, 207, 211, 214, 215, 219, 220, 222, 231, 235, 245, 248, 273, 275, 300,
327, 332, 344, 345, 358, 359, 366, 371, 378, 379, 381, 382, 399, 405, 432, 473,
475, 486, 492, 500, 502, 508—516, 523, 547, 554, 555, 564, 591, 594, 609—613, 634,
636, 644, 645, 648, 655, 686, 697, 759—761, 790, 818, 823, 830, 839, 849, 884, 911,
926, 954, 972—974, 976, 984, 995, 1019].
Взаимосвязь архитектуры и численных методов
[5, 10, 13, 17, 71, 74, 172, 174, 219, 220, 231, 239, 240, 302, 360, 415, 417,
447, 479, 484, 485, 517, 520, 531, 574, 593, 637, 681, 701, 723, 725, 779, 831,
836, 857, 872, 997].
Распараллеливаниеу конвейеризация и векторизация алгоритмов
[1, 9, 42, 49, 72, 73, 77, 94—96, 103, 104, 108, 121, 127, 128, 147, 168, 205,
224, 226, 306, 317, 318, 339, 454, 590, 667, 675, 731, 756, 762, 859, 878, 910, 999].
Распараллеливаниеу конвейеризация и векторизация программ.
Автоматизация процесса распараллеливания
[8, 14, 18, 48, 49, 50-59, 64, 77, 78, 90, 114, 138, 139, 146, 155, 162, 169,
193, 196—198, 206, 210, 229, 263, 269, 270, 297, 303, 315, 316, 335, 340, 368,
369, 388, 389, 444, 504, 505, 526, 710, 714, 716, 718, 744—746, 751, 822, 867,
886, 912, 913, 932, 986, 1010].
244
БИБЛИОГРАФИЧЕСКИЕ УКАЗАНИЯ
Параллельные языки, трансляторы, программирование.
Модели параллельных вычислений
[12, 19, 39, 40, 54, 87, 148, 157, 161, 162, 171, 175—177, 188, 192, 213, 223,
228, 255, 316, 345, 346, 353, 380, 383—385, 409, 444, 462, 554, 561—563, 605,
662, 682, 693, 700, 711, 719, 777, 794, 816, 837, 846, 858, 871, 977, 1011, 1025].
Планирование, организация и оптимизация параллельных процессов
[26, 27, 40, 81, 91—93, 101, 125, 126, 131, 145, 230, 250, 305, 317, 325,
338, 341, 390, 525, 749].
Различные оценки эффективности алгоритмов, программ
' и вычислительных систем
[И, 161, 181, 190, 355, 367, 376, 386, 387, 391, 395, 402, 421, 431, 455,
473, 497, 507, 551, 571, 583, 625, 633, 635, 655, 670, 671, 673, 679, 685, 687,
713, 723, 730, 752, 786, 848,·881, 885, 891, 922, 934, 940, 941, 950, 952, 1017].
Параллельные алгоритмы алгебры
[6, 7, 30, 31,35, 36, 41, 46, 61, 70, 76, 79, 123, 124, 129, 133, 153, 180, 181,
185—187, 195, 199'208, 216, 217, 225, 242, 243, 251—254, 259, 262, 266, 284—286,
291—293, 301, 307—309, 313, 323, 330, 354, 370, 375, 396—398, 400, 401, 403, 407,
408, 410, 413, 414, 416, 421—425, 443, 451, 456, 461, 463, 464, 466—468, 470, 472,
477, 478, 481—483, 487, 488, 490, 493, 496, 506, 528—530, 532—538, 544, 545, 558,
559, 565—569, 578, 581, 584, 587, 588, 595, 602, 604, 607, 608, 614, 706, 717, 722,
726, 739, 743, 750, 758, 764, 767, 771—773, 788, 789, 795—797, 799, 800, 802—804,
808, 809, 811, 819, 850—854, 856, 863, 877, 882, 892, 896-906, 919, 928, 930, 931,
933, 935, 939, 942—944, 951, 953, 956, 961—964, 968, 969, 975, 979, 980, 987, 992,
998, 1001, 1002, 1004—1007, 1009, 1013—1015, 1018, 1028].
Параллельные алгоритмы математической физики
[10, 13, 84, 97, 110, 112, 122, 134—137, 159, 160, 165, 183, 184, 189, 194, 195,
199, 209, 217, 218, 234, 240, 241, 258, 260, 261, 267, 274, 283, 287, 289, 312, 326,
347—351, 356, 357, 361, 364, 372, 392—394, 411, 412, 420, 433, 448—450, 453,
457, 518, 527, 556, 557, 560, 572, 573, 575, 577, 579, 580, 586, 763, 766, 776, 781,
791, 826—829, 833, 835, 838, 855, 860, 887—889, 893, 895, 902, 915, 917, 918, 920,
921, 927, 966, 967, 988—991, 1023, 1030].
Параллельные алгоритмы для вычисления простых выражений,
функций, рекурсий и т. п.
[28, 191, 247, 271, 310, 322, 333, 343, 383, 434, 435, 437, 469, 521, 522, 526,
546, 583, 597, 619, 652, 653, 707, 708, 721, 727, 774, 778, 815, 817, 825, 832, 847,
883, 945, 993, 1016].
Параллельные алгоритмы для других задач
[34, 60, 63, 65, 120, 131, 156, 182, 221, 244, 281, 282, 294, 295, 298, 299, 328,
336, 337, 342, 418, 428, 446, 465, 585, 638, 640, 741, 754, 780, 782, 798, 812, 813,
1020].
■'.. Асинхронные вычисления
[61, 68, 102, 103, 179, 219, 257, 304, 305, 402, 692, 730, 885].
БИБЛИОГРАФИЧЕСКИЕ УКАЗАНИЯ
245
Теория графов и расписаний
[32, 80, 132, 158, 268, 290, 311, 334, 404, 494, 656].
С БИС у систолические массивы и алгоритмы
[36, 49, 74, 78, 107, 173, 184, 185, 232, 238, 314, 331, 352, 363, 374, 391, 419,
436, 438—442, 445, 459, 480, 491, 495, 503, 524, 540, 541, 550, 552, 553, 582, 598,
617, 639, 649, 650, 654, 657, 661, 668, 669, 689, 695, 696, 728, 729, 732—739, 753,
755, 757, 765, 770, 783—785, 787, 792, 793, 805—807, 820, 862, 864, 865, 868—870,
873, 874, 880, 890, 907—909, 923—925, 929, 946, 947, 960, 970, 971, 978, 981, 982,
985, 994—996, 1008, 1012, 1027].
Ассоциативные у векторные, конвейер ныеу перестраиваемые,
потоковые, программируемые вычислительные системы
[3, 7, 24, 38, 45, 69, 109, 111, ИЗ, 115—119, 125, 140—144, 163, 164, 166,
200—202, 212, 216, 227, 233, 236, 264, 272, 286, 288, 324, 329, 351, 458, 476, 498,
499, 570, 588, 600, 601, 651, 688, 697, 703, 875, 879, 947, 965, 974, 1026].
Специализированные вычислительные системы
[21, 25, 69, 70, 79, 130, 134, 135, 137, 260, 262, 362, 365, 460, 501, 518, 549,
559, 576, 814, 918, 949, 1024].
Конкретные вычислительные системы
[11, 13, 15, 16, 33, 37, 44, 66—68, 89, 151, 178, 237, 250, 280, 296, 373, 406,
427, 430, 471, 472, 519, 539, 542, 543, 606, 659, 672, 685, 712, 724, 801, 810, 876,
894, 941, 950, 1022].
v Коммутационные сети
[29, 548, 596, 748, 775, 861, 866, 936—938, 948, 955, 1021].
Другие вопросы
[47, 82, 83, 92, 170, 249, 256, 321, 426, 474, 489, 592, 616, 624, 627, 643, 657,
691, 740, 747, 821, 957, 983, 1003, 1029].
СПИСОК ЛИТЕРАТУРЫ
1. Абрамов В. Μ. Анализ алгоритмов в целях распараллеливания
вычислений.— В кн.: Вычислительные системы и автоматизация научных
исследований. М.: МФТИ, 1980, с. 53—63.
2. Авдошин С. М., Б е л о в В. В., Μ а с л о в В. П. Математические
аспекты синтеза вычислительных сред.— М.: МИЭМ, 1984.—127 с.
3. Аксенов В. П. Ассоциативные процессоры и области их применения.—
Зарубежная радиоэлектроника, 1977, № 1, с. 52—80.
4. А к с е н о в В. П., Б о ч к о в С. В., Μ о ш к о в А. А. Структура и
характеристики высокопроизводительных ЭВМ и систем.— Зарубежная
радиоэлектроника, 1982, № 3, с. 35—53; № 4, с. 33—57.
5. Алгоритмы, математическое обеспечение и архитектура многопроцессорных
вычислительных систем / Под ред. В. Е. Котова, И. Миклошко.— М.:
Наука, 1982.—336 с.
6. Алеева В. Н. Распараллеливание некоторых итерационных методов
решения систем линейных уравнений.— В кн.: Высокопроизводительные
системы обработки больших массивов данных. Новосибирск: ВЦ СО АН СССР,
1982, с. 72—84.
7. Алеева В. Н. Решение задач линейной алгебры на ассоциативном
процессоре.— В кн.: Оптимизация. Вып. 18(35). Новосибирск: ИМ СО АН
СССР, 1976, с. 146—159.
8. АлимовВ. В. О преобразовании последовательных программ к
конвейеризуемому виду.— В кн.: Архитектура ЭВМ и численные методы. Μ.: ΟΒΜ
АН СССР, 1984, с. 3—14.
9. АмербаевВ. М., Пак И. Т. Параллельные вычисления в комплексной
плоскости.— Алма-Ата: Наука, 1984.—184 с.
10. А н д ρ и а н о в А. Н., Б а б е н к о К. И., 3 а б ρ о д и н А. В., 3 а д ы-
хайлоИ. Б., КотовЕ.И.,МямлинА. Н.,ПоддерюгинаН.В.,
Поздняков Л. А. О структуре вычислителя для решения задач
обтекания. Комплексный подход к проектированию.— В кн.: Вычислительные
процессы и системы. Вып. 2. М.: Наука, 1985, с. 13—62.
И.Андрианов А. Н., Задыхайло И. Б. Некоторые особенности
программирования на ЭВМ CRAY-1.— М., 1982.—24 с. (Препринт/ИПМ АН
СССР: № 77.)
12. Α ρ е φ ь е в Α. Α., К о ρ а б л и н Ю. П., К у τ е π о в В. П. Язык граф-
схем параллельных алгоритмов и его расширения.— Программирование,
1981, № 4, с. 14—25.
13. Асриэли В. Д., Борисов П. В. Опыт программирования для
векторного процессора решения уравнения Навье — Стокса в трехмерной
области.— В кн.: Вычислительные процессы и системы. Вып. 2. М.: Наука,
1985, с. .84—90.
14. Афанасьева Т. Ф. Некоторые вопросы адаптации Фортран-программы
на ЭВМ типа SIMD.— В кн.: Многопроцессорные вычислительные
структуры. Вып. 4(13). Таганрог: ТРТИ, 1982, с. 40—43.
15. Бабаян Б. А. Основные принципы программного обеспечения MB К
«Эльбрус».— М., 1977.— 11 с. (Препринт/ИТМ и ВТ АН СССР: № 5.)
СПИСОК ЛИТЕРАТУРЫ
247
16. Бабаян Б. Α., Сахин Ю. X. Система «Эльбрус».—
Программирование, 1980, № 6, с. 72—86.
17. Б а б е н к о К. И., 3 а б ρ о д и н А. В., 3 а д ы χ а й л о И. Б., Мям-
л и н А. Н. Некоторые вопросы анализа математических алгоритмов
решения задач и архитектуры ЭВМ.—М., 1981.—19 с. (Препринт/ОВМ АН
СССР: № 7.)
18. Бабичев А. В., Лебедев В. Г. Распараллеливание программных
циклов.— Программирование, 1983, № 5, с. 52—63.
19. Бабичев А. В., Лебедев В. Г., Π а р ш е н ц е в В. В.,
Пронина В. Α., ТрахтенгерцЭ. А. Построение транслятора для
многопроцессорных вычислительных систем.— Кибернетика, 1984, № 6, с. 18—22.
20. Б а з б и Б. Л. Супер-ЭВМ — мощный инструмент познания.— Труды ИИЭР,
1984, 72, № 1, с. 27—30.
21. Байков В. Д., Смолов В. Б. Специализированные процессоры:
итерационные алгоритмы и структуры.— М.: Радио и связь, 1985.— 288 с.
22. Б а й ц е ρ Б. Архитектура вычислительных комплексов. Том 1, 2.— М.:
Мир, 1974.—498 с, 566 с.
23. Балабанов А. С. Многопроцессорные системы. Основные принципы
организации (обзор).— Управл. системы и машины, 1983, № 3, с. 3—10.
24. Б а н д м а н О. Л., Ε в ρ е и н о в Э. В., К о ρ н е е в В. В., Χ ο ρ о ш е в-
с к и й В. Г. Однородные вычислительные системы на базе
микропроцессорных больших интегральных схем.— В кн.: Вычислительные системы.
Вып. 70. Новосибирск: ИМ СО АН СССР, 1977, с. 3—28.
25. Б а н д м а н О. Л., Π и с к у н о в С. В., Сергееве. Н. Применение
методов параллельного микропрограммирования для синтеза структуры
специализированных вычислителей.— Новосибирск, 1983.— 32 с. (Пре-
принт/ИМ СО АН СССР: ОВС-18.)
26. Барский А. Б. Планирование параллельных вычислительных
процессов.— М.: Машиностроение, 1980.— 191 с.
27. Б а р с к и й А. Б. Потоковая обработка информации в ВС на
асинхронном решающем поле.— В кн.: Вопросы кибернетики. Вып. 97. М.:
Научный совет по комплексной проблеме «Кибернетика» АН СССР, 1984,
с. 119—141.
28. БаскинН. В., ШурайцЮ. М. Распараллеливание линейных
рекурсий с переменными коэффициентами путем вычисления матричных
полиномов.— В кн.: Многопроцессорные вычислительные системы и их
математическое обеспечение. Новосибирск: ВЦ СО АН СССР, 1982, с. 28—39.
29. Б а ш и ρ о в Р. Э. Об универсальности тасовочной коммутационной сети.—
В кн: Архитектура ЭВМ и численные методы. Μ.: ΟΒΜ АН СССР,
1985, с. 3—15.
30. Белецкий В. Н. Об условиях сходимости итерационного процесса
решения систем линейных алгебраических уравнений в многопроцессорных
структурах.—Электрон, моделир., 1982, № 5, с. 21—23.
31. Белецкий В. Н. О необходимых и достаточных условиях сходимости
асинхронных итерационных вычислительных процессов при решении
систем линейных алгебраических уравнений.— Электрон, моделир., 1983,
№ 4, с. 8—14.
32. Берж X. Теория графов и ее применения.— М.: Изд-во иностр. Лит.,
1962.— 319 с.
33. Б е ρ нсГ. X., Б ρ а у нР.М., КатоМ. Α., КукД. Д., Слотн икД. Л.,
Сто к с Р. А. Многопроцессорная вычислительная система ИЛЛИАК III.—
Зарубежная радиоэлектроника, 1972, № 5, с. 53—67.
34. Б е с а р а б П. Н., Л ю д в и ч е н к о В. А. Об алгоритмах численной
реализации одного класса динамических моделей на многопроцессорных
вычислительных системах.— В кн.: Эффективная организация вычислений
и численные методы. Киев: ИК АН УССР, 1983, с. 39—46.
35. Бондарен.ко Е. В. Распараллеливание методов модификации
матричных факторизации.— В кн.: Вычислительные процессы и системы.
Вып. 2. М.: Наука, 1985, с 228—264.
248
СПИСОК ЛИТЕРАТУРЫ
36. Бондаренко Е. В. Систолические массивы для некоторых методов
решения задач с малоранговыми модификациями.— В кн.: Архитектура
ЭВМ и численные методы. Μ.: ОВМ АН СССР, 1984, с. 15—57.
37. БоунайтВ. Д., Диненберг С. Α., Μ а к и н τ а й ρ Д. Ε., Ρ э н-
д е л л Д. М., С а м е χ А. Н., С л о τ н и к Д. Л. Система ILLIAC IV.—
Труды ИИЭР, 1972, 60, № 4, с. 36—62.
38. Б ρ и н τ о н Д. Б. Новая компьютерная архитектура, основанная на
потоке данных.— Электроника, 1979, № 9, с. 88—90.
39. Бронштейн И. И. Достаточные условия построения явного решения
в задачах оптимального управления ресурсами многопроцессорных
систем.— В кн.: Организация вычислений на многопроцессорных ЭВМ. Сб.
трудов, вып. 26. М.: ИПУ, 1981, с. 110—116.
40. БронштейнИ. И., Панкова Л. А. Оптимальное разбиение
ресурсов в вычислительных системах.— В кн.: Организация вычислений на
многопроцессорных ЭВМ. Сб. трудов, вып. 26. М.: ИПУ, 1981, с. 106—109.
41. Б у г ρ о в А. Н., Коновалов А. Н. Об устойчивости алгоритма
распараллеливания прогонки.— Числ. методы мех. сплошн. среды, 1979, 10,
№ 6, с. 27—32.
42. Б у ρ г и н М. С. Композиции операторов в многомерной структурно-
ориентированной модели параллельных вычислений и систем.—
Кибернетика, 1983, № 3, с. 38—46.
43. Б у ρ ц е в В. С. Перспективы создания ЭВМ высокой производительности.—
Вестн. АН СССР, 1975, № 3, с. 25—31.
44. Бурцев В. С. Принципы построения многопроцессорных
вычислительных комплексов «Эльбрус».— М., 1977.— 53 с. (Препринт/ИТМ и ВТ АН
СССР: № 1.)
45. Б у ρ ц е в В. С, К ρ и в о ш е е в Ε. Α., А с ρ и э л и В. Д.,
Борисов П. В., Трегубов К. Я. Векторный процессор с программируемой
структурой.— В кн.: Вычислительные процессы и системы. Вып. 2. М.:
Наука, 1985, с. 63—72.
46. В а а р м а н н О. О некоторых параллельных итерационных методах для
решения нелинейных уравнений.— Изв. АН Эст. ССР. Физика —
математика, 1983, 32, № 1, с. 1—5.
47. В а д о в а 3. Α., С е й φ у л и н а Г. Ф. Микропроцессорные системы для
реализации параллельных поточных алгоритмов.— М.: ВЦ АН СССР,
1984.—39 с.
48. Вальковский В. А. Автоматический синтез параллельных
алгоритмов.— В кн.: Вычислительные процессы и системы. Вып. 2. М.: Наука,
1985, с. 109—120.
49. Вальковский В. А. К проблеме автоматизации разработки
систолических систем.— В кн.: Вычислительные системы. Вып. 104. Новосибирск:
ИМ СО АН СССР, 1984, с. 87—100.
50. В а л ь к о в с к и й В. А. Некоторые методы параллельной организации
массовых вычислений.— Электрон, моделир., 1983, № 3, с. 13—20.
51. Вальковский В. А. Параллельное выполнение циклов. Метод
параллелепипедов.— Кибернетика, 1982, № 2, с. 51—62.
52. Вальковский В. А. Параллельное выполнение циклов. Метод
пирамид.— Кибернетика, 1983, № 5, с. 51—55.
53. Вальковский В. А. Параллельные операторные схемы над
массивами и проблема максимального распараллеливания.— Кибернетика, 1979,
№ 5, с. 52—63.
54. Вальковский В. А. Формальные модели параллельных программ
и вычислений.— Новосибирск: Изд-во НГУ, 1984.— 88 с.
55. Вальковский В. Α., Касьянов В. Н. Крупноблочная
сегментация и распараллеливание схем программ.— Программирование, 1976,
№ 1, с. 16—26.
56. Вальковский В. Α., Кондрацкий В. Л. Максимальное
распараллеливание простых циклов.— В кн.: Параллельные вычислительные
и программные системы. Новосибирск: ВЦ СО АН СССР, 1981, с. 29—36.
СПИСОК ЛИТЕРАТУРЫ
249»
57. ВальковскийВ.А., Константинов В. И.,МиренковН.Н.
Теория и практика параллельной обработки.— Зарубежная
радиоэлектроника, 1976, № 5, с. 72—89.
58. В а л ь к о в с к и й В. Α., Котов В. Е. Автоматическое построение
параллельных программ. Распараллеливание выражений и циклов.—
Новосибирск, 1979.—41 с. (Препринт/ВЦ СО АН СССР: № 146.)
59. В а л ь к о в с к и й В. Α., Л е б е д е в В. Г., Ш у ρ а й ц Ю. М. О
распараллеливании циклов с переменными границами.— В кн.:
Многопроцессорные вычислительные системы и их математическое обеспечение.
Новосибирск: ВЦ СО АН СССР, 1982, с. 24—27.
60. Василенко В. А. Параллельные вычисления в задаче гладкого
восполнения сеточной функции.— В кн.: Параллельные вычислительные и
программные системы. Новосибирск: ВЦ СО АН СССР, 1981, с. 110—115.
61. В а с и л е н к о В. Α., Л ю л я к о в А. В., Русских А. В.
Моделирование асинхронных вычислений в некоторых задачах линейной алгебры.—
В кн.: Архитектура ЭВМ и численные методы. Μ.: ΟΒΜ АН СССР, 1983,
с. 75—83.
62. В е й ц м а н К. Распределенные системы мини- и микро-ЭВМ.— М.:
Финансы и статистика, 1983.— 384 с.
63. В е ρ е в к а О. В. Вопросы решения задач спектрального анализа
временных рядов на ЭВМ с параллельной организацией вычислений.—
Кибернетика, 1983, № 2, с. 110—113.
64. В е ρ л а н ь А. Ф., Горячев В. Φ., Ε φ и м о в И. Е. Об одной
реализации метода автоматического распараллеливания алгоритмов и программ.—
Электрон, моделир., 1981, № 2, с 23—25.
65. Виленкин С. Я-, Комаровский А. А. Параллельный метод
решения обыкновенных дифференциальных уравнений на
многопроцессорной ЭВМ с единым потоком команд.— Вопросы кибернетики. Вып. 43. М.:
Научный совет по комплексной проблеме «Кибернетика» АН СССР, 1978,
с. 75—78.
66. В и ш н е в с к и й Ю. Л. Архитектурные особенности процессора Мини-
МАРС.— В кн.: Высокопроизводительные системы обработки больших
массивов данных. Новосибирск: ВЦ СО АН СССР, 1982, с. 5—33.
67. Вишневский Ю. Л., Котов В. Ε., Μ а р ч у к А. Г. Архитектура
и принципы параллельного процессора для числовой обработки.— В кн.:
Высокопроизводительные вычислительные средства для обработки
данных. Новосибирск: ВЦ СО АН СССР, 1981, с. 5—13.
68. В и ш н е в с к и й Ю. Л., К о τ о в В. Ε., Μ а р ч у к А. Г. Модульная
асинхронная развиваемая система.— Кибернетика, 1984, № 3, с. 22—29.
69. В о е в о д и н А. В. Некоторые вопросы исследования конвейерных систем
с перестраиваемой коммутацией.— В кн.: Архитектура ЭВМ и численные
методы. Μ.: ΟΒΜ АН СССР, 1983, с. 53—74.
70. Воеводин А. В.О математической модели спецпроцессора для решения
задач линейной алгебры.— В кн.: Численные методы алгебры. М.: Изд-ва
МГУ, 1981, с. 69—111.
71. Воеводин В. В. Вычислительные алгоритмы и вычислительные
системы.— В кн.: Актуальные проблемы вычислительной математики и
математического моделирования. Новосибирск: Наука, 1985, с. 163—178.
72. В о е в о д и н В. В. Конвейерные вычисления на потоках алгорифмов.—
М., 1983.— 18 с. (Препринт/ОВМ АН СССР: № 48.)
73. Воеводин В. В. Математическая модель конвейерных вычислений.—
М., 1982.— 34 с. (Препринт/ОВМ АН СССР: № 42.)
74. Воеводин В. В. Математические вопросы отображения алгоритмов на
параллельные системы.— М., 1985.— 64 с. (Препринт/ОВМ АН СССР: № 94.)
75. Воеводин В. В. Математические проблемы освоения супер-ЭВМ.—
В кн.: Вычислительные процессы и системы. Вып. 2. М.: Наука, 1985, с. 3—
12.
76. В о е в о д и н В. В. Некоторые машинные аспекты распараллеливания
вычислений.—М., 1981.— 10_с. (Препринт/ОВМ АН СССР: № 22.)
250
СПИСОК ЛИТЕРАТУРЫ
77. Воеводин В. В. Параллельные структуры алгоритмов и программ.—
М., 1985.— 24 с. (Препринт/ОВМ АН СССР: № 73.)
78. Воеводин В. В., Краснов С. А. Математические вопросы
проектирования систолических массивов.— М., 1985.— 26 с. (Препринт/ОВМ АН
СССР: № 80.)
79. Войтенков И. Н. Об одном подходе к организации
специализированных вычислительных структур для решения систем линейных
алгебраических уравнений.— Электрон, моделир., 1982, № 2, с. 39—45.
$0. Воробьев В. А. Относительная адресация элементов циклического
графа.— В кн.: Вычислительные системы. Вып. 97. Новосибирск: ИМ СО АН
СССР, 1983, с. 87—103.
-81. Воронов А. В., Пастушков В. И. Использование циклических
методов для организации параллельных вычислений.— В кн.: Комплексы
программ математической физики. Материалы VII Всесоюзн. совещания,
Горький, 1981. Новосибирск: ИТПМ СО АН СССР, 1982, с. 136—142.
82. Вышинский В. Α., Ρ а б и н о в и ч 3. Л. Об одной возможности
повышения производительности ЭВМ путем ускорения матрично-векторных
операций.— Кибернетика, 1979, № 1, с. 120—123.
S3. Вышинский В. Α., Рабинович 3. Л. О создании
высокопроизводительных универсальных ЭВМ, работающих в алгебре матриц.—
Автоматика, 1983, № 5, с. 80—84.
84. Г а л б а Е. Ф., Степанец Н.И. Алгоритмы параллельных вычислений
для неявной итерационной схемы.— В кн.: Эффективная организация
вычислений и численные методы. Киев: ИК АН УССР, 1983, с. 54—60.
85. Г е ρ и М„ Джонсон Д. Вычислительные машины и труднорешаемые
задачи.—М.: Мир, 1982.—416 с.
86. Г л и в е н к о Е. В. Об одной системе параллельных вычислений..—
Программирование, 1977, № 1, с. 3—9.
•87. ГливенкоЕ. В., Жукова Т. М., Шевченко СВ.
Многопроцессорная машина функционально-операторного типа и проблема
распараллеливания алгоритмов.— Программирование, 1980, № 5, с. 34—39.
88. Г л у ш к о в В. М. Об архитектуре высокопроизводительных ЭВМ.— Киев,
1978.— 41 с. (Препринт/ИК АН УССР: № 78—65.)
•89. Глушков В. М., Игнатьев М. Б., Мясников В. Α., Τ ο ρ-
г а ш е в В. А. Рекурсивные машины и вычислительная техника.— Киев,
1974.—36 с. (Препринт/ИК АН УССР: № 74—57.)
90. Глушков В. М., Капитонова Ю. В., Летичевский А. А.
Алгебра алгоритмов и динамическое распараллеливание последовательных
программ.— Кибернетика, 1982, № 5, с. 4—10.
"91. Глушков В. М., К а п и τ о н о ва Ю. В., Летичевский А. А.
Об одном подходе к реализации параллельных вычислений в
многопроцессорных вычислительных системах.— В кн.: Параллельное
программирование и высокопроизводительные системы. Часть I. Новосибирск: ВЦ СО
АН СССР, 1980, с. 5—20.
92. Глушков В. М., Капитонова Ю. В., Летичевский А. А.
Теория структур данных и синхронные вычисления.— Кибернетика, 1976,
№ 6, с. 2—15.
93. Г л у ш к о в В.М., Капитонова Ю. В., Л е τ и ч е в с к и й А. А.
Эффективность параллельных вычислений при ограниченных ресурсах.—
Докл. АН СССР, 1980, 254, № 3, с. 527—530.
94. Глушков В. М., Капитонова Ю. В., Летичевский Α. Α.,
Горлач СП. Макроконвейерные вычисления над структурами данных.—
Кибернетика, 1981, № 4, с. 13—21.
95. Глушков В. М., Молчанов И. Н. Макроконвейерный способ
организации вычислений.— В кн.: Актуальные проблемы математической
физики и вычислительной математики. М.: Наука, 1984, с. 49—67.
96. Глушков В. М.,Молчанов И. Н.О некоторых проблемах решения
задач на ЭВМ с параллельной организацией вычислений.— Кибернетика,
1981, № 4, с. 82—88.
СПИСОК ЛИТЕРАТУРЫ
251
97. Г л у ш к о в В. М., Пшеничный Б. Н., Буланый А. П.
Параллельный алгоритм решения краевых задач для систем дифференциальных:
уравнений.— Кибернетика, 1980, № 6, с. 68—71.
98. Головкин Б. А. Методы и средства параллельной обработки
информации.— В кн.: Итоги науки и техники: Теория вероятностей.
Математическая статистика. Теоретическая кибернетика. Том 17. М.: ВИНИТИ, 1979,
с. 85—193.
99. Г о л о в к и н Б. А. Параллельные вычислительные системы.— М.: Наукаг
1980.— 520 с.
100. Головкин Б. А. Параллельная обработка информации.
Программирование, вычислительные методы, вычислительные системы.— Изв. АН
СССР. Техн. кибернетика, 1979, № 2, с. 116—151.
101. Г о л о в к и н Б. А. Расчет характеристик и планирование
вычислительных процессов.— М.: Радио и связь, 1983.— 272 с.
102. ГончаренкоЮ. В., Нестеренко Б. Б. Асинхронные принципы
в параллельных вычислениях. Часть 1,2.— Киев, 1981.— 47 с, 63 с. (Пре-
принт/ИМ АН УССР: № 81.56, 82.38.)
103. Горлач С. П. О макроконвейерных асинхронных вычислениях
структурных функций.— Кибернетика, 1983, № 5, с. 41—46.
104. Горлач СП. Средства проектирования макроконвейерных алгоритмов-
и программ.— Кибернетика, 1984, № 3, с. 111—ИЗ.
105. Грицик В. В. Распараллеливание алгоритмов обработки информации
в системах реального времени.— Киев: Наукова думка, 1981.— 216 с.
106. Грицик В.В., Златогурский Э. Р., Михайловский В.Н.
Распараллеливание алгоритмов обработки информации.— Киев: Наукова
думка, 1977.— 123 с.
107. Г у н С. Систолические и волновые процессоры для
высокопроизводительных вычислений.— Труды ИИЭР, 1984, 72, № 7, с. 133—153.
108. Давыдова И. М., Давыдов Ю. М. Об особенностях решения
вычислительных задач на современных и перспективных
высокопроизводительных системах.— В кн.: Вычислительные процессы и системы. Вып. 2,
М.: Наука, 1985, с. 162—172.
109. Деннис Д. Б., Фоссин Д. Б., Линдерман Д. П. Схемы потока
данных.— В кн.: Теория программирования. Часть 2. Новосибирск: ВЦ СО
АН СССР, 1972, с. 7—43.
110. Д ж о н с о н О. Г. Численное решение трехмерного волнового уравнения
на векторных ЭВМ.—Труды ИИЭР, 1984, 72, № 1, с. 109—112.
Ш.Джордан X. Ф. Конвейерная ЭВМ с несколькими потоками команд.—
Труды ИИЭР, 1984, 72, № 1, с. 135—147.
112. Дидовик А. А. Распараллеливание итерационных процессов для
монотонных операторов.— В кн.: Модели и системы обработки информации.
Вып. 2. Киев, 1983, с 23—25.
ИЗ. Димитриев Ю. К., Хорошевский В. Г. Однородные
вычислительные системы из мини-ЭВМ.— М.: Радио и связь, 1982.— 304 с.
114. Д о ρ о ш е н к о А. Е. О преобразованиях циклических операторов к
параллельному виду.— Кибернетика, 1982, № 4, с. 22—28.
115. Евреинов Э. В. Однородные вычислительные системы, структуры и
среды.— М.: Радио и связь, 1981.— 208 с.
116. Ε в ρ е и н о в Э. В., К о с а р е в Ю. Г. Однородные универсальные
вычислительные системы высокой производительности.— Новосибирск: Наукаг
1966.—308 с.
117. Евреинов Э. В., Прангишвили И. В. Цифровые автоматы с
перестраиваемой структурой (Однородные среды).— М.: Энергия, 1974. —
240 с.
118. Евреинов Э. В., Хорошевский В. Г. Вычислительные системы
с программируемой структурой.— В "кн.: Параллельное программирование
и высокопроизводительные системы. Часть 1. Новосибирск: ВЦ СО АН
СССР, 1980, с. 64—86.
252
СПИСОК ЛИТЕРАТУРЫ
119. Евреинов Э. В., Хорошевский В. Г. Однородные
вычислительные системы.— Новосибирск: Наука, 1978.— 319 с.
120. Егоров Η. Α., Ш у ρ а й ц Ю. М. Параллельный метод решения
обыкновенных дифференциальных уравнений, основанный на экстраполяции
Ричардсона.— В кн.: Организация вычислений на многопроцессорных ЭВМ.
Сб. трудов, вып. 26. М.: ИПУ, 1981, с. 129—132.
121. Ε л ь к и н Ю. Г., К о н о ш е н к о М. П. Исследование структуры
алгоритма для выявления возможности его распараллеливания.—
Кибернетика, 1983, № 2, с. 29—36.
122. Елькин Ю. Г., Коношенко М. П. Особенности решения
физических задач на вычислительной машине с параллельными процессорами.—
Программирование, 1980, № 1, с. 24—29.
123. Ж а б и н Б. И., К о ρ н е й ч у к В. И., Τ а р а с е н к о В. П., Щ е р-
б и н а А. Л. Структурный способ быстрого решения систем
алгебраических уравнений с трехдиагональной матрицей.— Автомат, и вычисл. техн.,
1979, № 6, с. 73—80.
124. 3 а г у с к и н В. Л., Μ а н ж и ρ о в а Т. В. Параллельный вариант
метода продольно-поперечной прогонки.— В кн.: Организация вычислений
на многопроцессорных ЭВМ. Сб. трудов, вып. 26. М.: ИПУ, 1981, с. 99—
105.
125. Зады хайло И. Б., Поддерюгина Н. В. Совмещение
арифметических операций в неоднородной мультипроцессорной конвейерной
системе.— Программирование, 1983, № 5, с. 23—35.
126. Засыпкин А. В., Малышкин В. Э. Параллельный алгоритм
планирования вычислений на вычислительных моделях.— В кн.:
Многопроцессорные вычислительные системы и их математическое обеспечение.
Новосибирск: ВЦ СО АН СССР, 1982, с. 51—58.
127. Затуливетер Ю. С. Метод группового распараллеливания
вычислений в многопроцессорной системе с общим потоком команд.— В кн.:
Многопроцессорные системы с общим потоком команд. Сб. трудов, вып. 19. М.: ИПУ,
1978, с. 46—59.
128. Затуливетер Ю. С, Медведев И. Л. О групповом
параллелизме и двойственной реализации параллельных вычислений.— В кн.:
Вопросы кибернетики. Вып. 43. М.: Научный совет по комплексной
проблеме «Кибернетика» АН СССР, 1978, с. 44—64.
129. Золотарев А. М., Михайлова Е. Д. Распараллеливание
вычислений при решении систем нелинейных алгебраических уравнений методом
результантов.— Электрон, моделир., 1984, № 4, с. 108—110.
130. Золотовский В. Е. Микропроцессорные вычислительные структуры
для решения уравнений в частных производных.— Автомат, и вычисл.
техн., 1984, № 3, с. 62—68.
131. 3 у е н к о в М. А. Организация вычислений при решении
последовательности задач линейного программирования.— В кн.: Вопросы кибернетики.
Вып. 92. М.: Научный совет по комплексной проблеме «Кибернетика» АН
СССР, 1983, с. 57—69.
132. Иванов Ε. Α., Шевченко В. П. О параллельных вычислениях на
графах. Кибернетика, 1984, № 3, с. 89—94.
133. Игнатьев М. Б., Фильчаков В. В. Организация параллельного
вычислительного процесса при использовании декомпозиции для решения
системы линейных алгебраических уравнений с трехдиагональной
матрицей.— В кн.: Вычислительные процессы и структуры. Сб. трудов, вып. 148.
Л.: ЛИАП, 1981, с. 3—14.
134. Ильин В. П., Фет Я. И. Параллельный процессор для решения задач
математической физики.— Новосибирск, 1979.— 36 с. (Препринт/ВЦ СО
АН СССР: № 217.)
135. Ильин В. П., Фет Я. И. Параллельный процессор для решения
разностных уравнений Пуассона.— Изв. АН СССР. Техн. кибернетика, 1979,
№ 5, с. 200—204.
136. Ильин В. П., Φ е τ Я. И. Распараллеливание неявных сеточных мето-
СПИСОК ЛИТЕРАТУРЫ
253
дов на универсальном матричном процессоре.— М., 1982.— 16 с. (Препринт/
ОВМ АН СССР: № 27.)
137. Ильин В. П., Φ е τ Я. И. Семейство параллельных процессоров для
задач математической физики.— В кн.: Вычислительные процессы и
системы. Вып. 1. М.: Наука, 1983, с. 81—99.
138. И τ к и н В. Э. Алгебра распараллеливания программ.— В кн.:
Теоретические и прикладные вопросы параллельной обработки. Новосибирск: ВЦ
СО АН СССР, 1984, с. 3—24.
139. Иткин В. Э. Динамическое распараллеливание программ методом
смешанных вычислений.— В кн.: Теоретические вопросы параллельного
программирования и многопроцессорные ЭВМ. Новосибирск: ВЦ СО АН СССР,
1983, с. 110—128.
440. Каляев А. В. Микропроцессоры с программируемой структурой и
многопроцессорные системы с универсальной коммутацией и распределенной
памятью.— В кн.: Параллельное программирование и
высокопроизводительные системы. Часть 1. Новосибирск: ВЦ СО АН СССР, 1980, с. 87—117.
141. Каляев А. В. Многопроцессорные однородные вычислительные
структуры.— Изв. вузов СССР. Радиотехника, 1978, № 12, с. 5—17.
142. Каляев А. В. Многопроцессорные системы с программируемой
архитектурой.— М.: Радио и связь, 1984.— 240 с.
143. Каляев А. В. Многопроцессорные суперсистемы с программируемой
архитектурой, основанные на принципе потока данных.— В кн.:
Вычислительные процессы и системы. Вып. 2. М.: Наука, 1985, с. 140—153.
144. Каляев А. В. Принципы организации многопроцессорных систем
сверхвысокой производительности.— Микропроцессорные средства и системы,
1984, № 2, с. 31—35.
145. Капитонова Ю. В., Кляус П. С, Коваленко Н. С. Об
оптимальной организации одного класса параллельных процессов.—
Программирование, 1984, № 4, с. 48—56.
146. Капитонова Ю. В., Коляда С. В.К проблеме распараллеливания
циклических операторов.— В кн.: Математическое обеспечение систем
логического вывода и дедуктивных построений на ЭВМ. Киев: ИК АН УССР,
1983, с. 3—17.
147. Капитонова Ю. В., Летичевский А. А. О построении теории
макроконвейерных вычислений.— В кн.: Актуальные проблемы развития
архитектуры ЭВМ и вычислительных систем. Новосибирск: ВЦ СО АН СССР,
1983, с. 107—120.
148. Карп Р. М., Миллер Р. Е. Параллельные схемы программ.— В кн.:
Кибернетический сборник (Новая сер.). Вып. 13. М.: Мир, 1975, с. 5—61.
149. Карцев М. А. Архитектура цифровых вычислительных машин.— М.:
Наука, 1978.—296 с.
150. Карцев М. А. Вопросы построения многопроцессорных вычислительных
систем.— Вопросы радиоэлектроники. Серия ЭВТ, 1970, вып. 5/6, с. 3—19.
151. Карцев М. А. Вычислительная машина М-10.— Докл. АН СССР, 1979,
245, № 2, с. 309—312.
152. Карцев М. А. Принципы организации параллельных вычислений,
структуры вычислительных систем и их реализация.— Кибернетика, 1981,
№ 2, с. 68—74.
153. Карцев М. А. Распараллеливание алгоритмов итерационного типа.—
Вопросы радиоэлектроники. Серия ЭВТ, 1971, вып. 9, с. 36—39.
154. Карцев Μ. Α., Б ρ и к В. А. Вычислительные системы и синхронная
арифметика. М.: Радио и связь, 1981.—360 с.
155. К е ρ б е л ь В. Г., Μ и ρ е н к о в Η. Η. Автоматическое
распараллеливание алгоритмов специального типа. В кн.: Вычислительные системы.
Вып. 63. Новосибирск: ИМ СО АН СССР, 1975, с. 149—158.
156. Климова О. В. Параллельный алгоритм вычисления двумерной
корреляционной функции с помощью теоретико-числовых преобразований.— В кн.:
Вычислительные системы. Вып. 104. Новосибирск: ИМ СО АН СССР, 1984,
с. 109—120.
254
СПИСОК ЛИТЕРАТУРЫ
157. К о в а л е н к о Н. С. Об одной модели системы параллельных
вычислений.— В кн.: Параллельное программирование и высокопроизводительные
системы. Часть 2. Новосибирск: ВЦ СО АН СССР, 1980, с. 145—151.
158. Конвей Р. В., Максвелл В. Л., Миллер Л. В. Теория
расписаний.— М.: Наука, 1975.— 359 с.
159. Коновалов А. Н., Бугров А. Н., Блинов В. Д. Алгоритмы
распараллеливания сеточных задач.— В кн.: Актуальные проблемы
вычислительной и прикладной математики. Новосибирск: Наука, 1983, с. 95—99.
160. Коновалов А. Н., Я н е н к о Η. Η. Некоторые вопросы теории
модульного анализа и параллельного, программирования для задач
математической физики и механики сплошной среды.— В кн.: Современные
проблемы математической физики и вычислительной математики. М.: Наука,
1982, с. 200—207.
161. К о н о ш е н к о М. П. Оценка эффективности решения задачи в
параллельном режиме.— Программирование, 1982, № 5, с. 80—86.
162. Копнинский Е. А. Алгоритм параллельного выполнения
программы.— Журн. вычисл. мат. и мат. физ., 1969, 9, № 5, с. 1137—1144.
163. Корнеев В. В. Архитектура вычислительных систем с
программируемой структурой.— Новосибирск: Наука, 1985.— 167 с.
164. Корнеев В. В. Параллельные вычисления в вычислительных системах
с программируемой структурой.— Программирование, 1984, № 3, с. 21—28.
165. Корнеев В. В., Тар ков М. С. Организация параллельных
вычислений при. решении задач механики сплошной среды с использованием
неявных схем расщепления.— В кн.: Комплексы программ математической
физики. Материалы VIII Всесоюзн. семинара, Ташкент, 1983. Новосибирск:
ИТПМ СО АН СССР, 1984, с. 94—99.
166. Корнеев В. В., Хорошевский В. Г. Вычислительные системы с
программируемой структурой.— Электрон, моделир., 1979, № 1, с. 42—52.
167. Королев Л. Н. Структуры ЭВМ и их математическое обеспечение.—
М.: Наука, 1978.— 352 с.
168. Косарев Ю. Г. Об информационных и пространственно-временных
преобразованиях алгоритма.— В кн.: Вычислительные системы. Вып. 57.
Новосибирск: ИМ СО АН СССР, 1973, с. 149—160.
169. Косарев Ю. Г. Распараллеливание по циклам.— В кн.:
Вычислительные системы. Вып. 24. Новосибирск: ИМ СО АН СССР, 1967, с. 3—20.
170. Котов В. Е. Новая технология математического моделирования и
средства ее реализации.— В кн.: Актуальные проблемы вычислительной
математики и математического моделирования. Новосибирск: Наука, 1985, с.
201—207.
171. Котов В. Е. О параллельных языках.— Кибернетика, 1980, № 3, с. 1—
12; № 4, с. 1—10.
172. Котов В. Е. О связи алгоритмических и архитектурных аспектов
параллельных вычислений.— В кн.: Вычислительные процессы и системы.
Вып. 1. М.: Наука, 1983, с. 54—80.
173. Котов В. Е. Перспективы и проблемы создания ЭВМ на сверхбольших
интегральных схемах.— В кн.: Теоретические вопросы параллельного
программирования и многопроцессорные ЭВМ. Новосибирск: ВЦ СО АН СССР,
1983, с. 6—30.
174. Котов В. Е. Распараллеливание программ и алгоритмов и архитектура
ЭВМ.—М., 1981.— 12 с. (Препринт/ОВМ АН СССР: № 5.)
175. Котов В. Е. Сети Петри.—М.: Наука, 1984.— 159 с.
176. Котов В. Е. Теория параллельного программирования. Прикладные
аспекты.— Кибернетика, 1974, № 1, с. 1—16; № 2, с. 1—18.
177. Котов В. Е. Формальные модели параллельных вычислений.—
Новосибирск, 1979.— 56 с. (Препринт/ВЦ СО АН СССР: № 165.)
178. Котов В. Е., Map чук А. Г. Некоторые итоги и перспективы развития
проекта МАРС.— В кн.: Актуальные проблемы развития архитектуры и
программного обеспечения ЭВМ и вычислительных систем. Новосибирск:
ВЦ СО АН СССР, 1983, с. 13—23.
СПИСОК ЛИТЕРАТУРЫ
255
179. Котов В.Е.,Нариньяни А. С. Асинхронные вычислительные
процессы над памятью.— Кибернетика, 1966, № 3, с. 64—71.
180. К о φ τ ο Α. Γ. Алгоритмы распараллеливания решения систем уравнений
большой размерности, имеющих блочно-диагональные с окаймлением
матрицы коэффициентов, на многопроцессорных вычислительных системах.—
Электрон, моделир., 1982, № 2, с. 90—92.
181. Кофто А. Г. Об оценке быстродействия при решении систем линейных
уравнений прямыми методами на многопроцессорных структурах.—
Электрон, моделир., 1982, № 4, с. 111—113.
182. Кравченко И. В. Реализация симплекс-метода в управляющих
пространствах.— В кн.: Модели и системы обработки информации. Вып. 3.
Киев, 1984, с. 8—15.
183. Краснов С. А. Конвейеризация некоторых итерационных методов
решения эллиптических дифференциальных уравнений.— В кн.: Архитектура
ЭВМ и численные методы. Μ.: ΟΒΜ АН СССР, 1983, с. 11—28.
184. Краснов С. А. Некоторые итерационные методы на систолических
массивах.— В кн.: Архитектура ЭВМ и численные методы. Μ.: ΟΒΜ АН
СССР, 1984, с. 58—72.
185. Краснов С. Α., ТыртышниковЕ. Е. Векторизованные алгоритмы
и систолические массивы для теплицевых систем.— В кн.: Архитектура
ЭВМ и численные методы. Μ.: ΟΒΜ АН СССР, 1985, с. 33—56.
186. Красносельский Μ. Α., Лифшиц Е. А. Распараллеленный
вариант метода Зейделя — Некрасова решения систем алгебраических
уравнений.— Автомат, и телемех., 1981, № 9, с 178—185.
187. Крат С. П., Родимин С. П., Юрчишин В. В. Некоторые
параллельные алгоритмы линейной алгебры.— В кн.: Модели и системы
обработки информации. Вып. 1. Киев, 1982, с. 25—31.
188. КриницкийН. А. О параллельных алгоритмах.— Программирование,
1983, № 4, с. 9—15.
189. Кузнецов И. Б. Параллельный комбинированный метод быстрого
преобразования Фурье и редукции.— Новосибирск, 1983.— 16 с. (Препринт/
ВЦ СО АН СССР: № 101.)
190. Кузнецов Н. Ю., Ш у м с к а я Α. Α., Γ ο ρ л а ч С. П. Об одном
подходе к построению оценок эффективности работы многопроцессорных
систем.— Кибернетика, 1983, № 6, с. 45—49.
191. Кузюрин Н. Н., Шокуров А. В. Особенности алгоритмической
и программной реализации математических функций на векторно-конвей-
ерной ЭВМ.— В кн.: Вопросы кибернетики. Вып. 97. М.: Научный совет
по комплексной проблеме «Кибернетика» АН СССР, 1984, с. 6—23.
192. Кутепов В. П. Исчисление функциональных схем и параллельные
алгоритмы.— Программирование, 1975, № 4, с. 3—11; 1976, № 6, с. 3—15.
193. Кутьин А. Б., Лебедев В. Г., ТрахтенгерцЭ. Α.,
Шура й ц Ю. Μ. Алгоритмы и анализ распараллеливания программ.для
параллельных машин с множественным потоком команд.— В кн.: Вопросы
кибернетики. Вып. 79. М.: Научный совет по комплексной проблеме
«Кибернетика» АН СССР, 1981, с. 28—46.
194. Кучеров А. Б., Николаев Е. С. Параллельные алгоритмы
итерационных методов с факторизованным оператором для решения
эллиптических краевых задач.— Дифференц. уравнения, 1984, 20, № 7, с. 1230—
1237.
195. Кучеров А. Б., Николаев Е. С. Параллельные и конвейерные
алгоритмы попеременно-треугольного итерационного метода.— В кн.:
Разностные методы математической физики. М.: Изд-во МГУ, 1984, с. 66—83.
196. Лебедев В. Г., Митяева С. А. Реализация алгоритма
распараллеливания последовательной программы.— В кн.: Вопросы кибернетики.
Вып. 43. М.: Научный совет по комплексной проблеме «Кибернетика» АН
СССР, 1978, с. 98—107.
197. Лебедев В. Г., Петрова Е. Ю. Представление программы в виде
линейных структур для распараллеливания.— В кн.: Организация вычис-
256
СПИСОК ЛИТЕРАТУРЫ
лений на многопроцессорных ЭВМ. Сб. трудов, вып. 26. М.: ИПУ, 1981,
с. 29—36.
198. Лебедев В. Г., Ш у ρ а й ц Ю. М. Распараллеливание циклов с
произвольным шагом.— Автомат, и телемех., 1979, № 9, с. 158—167.
199. Лебедев В. И., Бахвалов Н. С, Агошков В. И.,
Бабурин О. В., К н я з е в А. В., Ш у τ я е в В. П. Параллельные алгоритмы
решения некоторых стационарных задач математической физики.— Μ.: ΟΒΜ
АН СССР, 1984.— 142 с.
200. Лебединский Μ. Μ. Ассоциативные процессоры как средство
максимального распараллеливания задач.— Кибернетика, 1983, № 2, с. 37—42.
201. Лебединский Μ. Μ. О возможностях выполнения параллельных
вычислений на трехмерном ассоциативном параллельном процессоре.—
В кн.: Записки научных семинаров ЛОМИ АН СССР. Том 70. Ленинград:
Наука, 1977, с. 140—160.
202. Лебединский Μ. Μ. О возможности максимального
распараллеливания задач на ассоциативных процессорах.— В кн.: Записки научных
семинаров ЛОМИ АН СССР. Том 90. Ленинград: Наука, 1979, с. 83—149.
203. Л е в а й н Р. Д. Суперкомпьютеры.— В мире науки, 1983, № 1, с. 16—29.
204. Л е м а н М. Параллельная обработка и параллельные устройства
обработки. Обзор проблем и предварительные результаты.— Труды ИИЭР,
1966, 54, № 12, с. 297—311.
205. Летичевский А. А. Математическое обеспечение макроконвейерного
вычислительного комплекса.— В кн.: Вычислительные процессы и системы.
Вып. 2. М.: Наука, 1985, с. 91—95.
206. Летичевский А. А. О максимальной десеквенции циклических
операторов.—Докл. АН СССР, 1978, 242, № 4, с. 761—764.
207. Л о ρ и н Г. Распределенные вычислительные системы. М.: Радио и связь,
1984.— 296 с.
208. Лучка А. Ю., НощенкоО. Э., СергиенкоИ. В., Тукалев-
с к а я Н. И. Параллельная организация вычислений при решении
линейных уравнений методами проекционно-итерационного типа.—
Кибернетика, 1984, № 3, с. 38—47.
209. Люляков А. В., Василенко В. А. Потоковые вычисления в
методе конечных элементов.— Новосибирск, 1983.— 18 с. (Препринт/ВЦ СО
АН СССР: № 456.)
210. Μ а з у ρ Т. В., Нестеренко Б. Б. Некоторые вопросы
автоматического построения параллельных программ.— Киев, 1983.— 54 с. (Препринт/
ИМ АН УССР: 83.61.)
211. Μ а й е ρ с Г. Архитектура современных ЭВМ. Том 1, 2.— М.: Мир, 1985.—
365 с, 310 с.
212. Макаревич О. Б. Микропроцессоры с набором крупных операций и с
программируемой структурой.— В кн.: Параллельное программирование
и высокопроизводительные системы. Часть 2. Новосибирск: ВЦ СО АН
СССР, 1980, с. 53—63.
213. Μ а л ы ш к и н В. Э. Система синтеза параллельных программ на основе
вычислительных моделей с массивами.— Новосибирск, 1984.— 45 с.
(Препринт/ВЦ СО АН СССР: № 505.)
214. Мамзелев И. А. Архитектура параллельных вычислительных систем
и тенденции их развития.— Зарубежная радиоэлектроника, 1980, № 11,
с. 3—28.
215. Μ а н о М. Архитектура вычислительных систем.— М.: Стройиздат, 1980.—
448 с.
216. Маркова В. П. Параллельные микропрограммные структуры для
ортогональных преобразований.— В кн.: Вычислительные системы. Вып. 104.
Новосибирск: ИМ СО АН СССР, 1984, с. 61—74.
217. Марчук В. Α., Нестеренко Б. Б. Итерационные алгоритмы
параллельных вычислений.— Киев, 1982.— 66 с. (Препринт/ИМ АН УССР:
№ 82.12.)
218. Марчук Г. И., Ильин В. П. Параллельные вычисления в сеточных
СПИСОК ЛИТЕРАТУРЫ
257
методах решения задач математической физики.— Новосибирск, 1979.—
23 с. (Препринт/ВЦ СО АН СССР: № 220.)
219. Μ а р ч у к Г. И., Котов В. Е. Модульная асинхронная развиваемая
система (Концепция). Часть 1. Предпосылки и направления развития
архитектуры вычислительных систем. Часть 2. Основные принципы и
особенности.— Новосибирск, 1978.— 48 с, 51 с. (Препринты/ВЦ СО АН СССР:
№ 86, 87.)
220. Map чу к Г. И., Котов В. Е. Проблемы вычислительной техники и
фундаментальные исследования.— Автомат, и вычисл. техн., 1979, № 2,
с. 3—14.
221. Мацук Т. В. Быстрое матричное умножение на многопроцессорных ЭВМ
с общим потоком команд.— В кн.: Программное обеспечение
многопроцессорных систем с общим потоком команд. М.: ИПУ, 1984, с. 53—64.
222. Медведев И. Л. Принципы построения многопроцессорных
вычислительных систем с общим потоком команд.— В кн.: Многопроцессорные
вычислительные системы с общим потоком команд. Сб. трудов, вып. 19.
М.: ИПУ, 1978, с. 5—21.
223. Методы параллельного микропрограммирования / Под ред. О. Л. Банд-
ман.— Новосибирск: Наука, 1981.— 181 с.
224. Миренков Н. Н. Иерархические параллельные алгоритмы.— В кн.:
Вычислительные процессы и системы. Вып. 2. М.: Наука, 1985, с. 121—128.
225. Миренков Н. Н. К решению системы линейных уравнений на ВС.—
В кн.: Вычислительные системы. Вып. 30. Новосибирск: ИМ СО АН СССР,
1968, с. 8—11.
226. Миренков Η. Η. Об одном методе построения параллельных
алгоритмов.— Кибернетика, 1980, № 5, с. 19—23.
227. Миренков Η. Η. Параллельные алгоритмы для решения задач на
однородных вычислительных системах.— В кн.: Вычислительные системы.
Вып. 57. Новосибирск: ИМ СО АН СССР, 1973, с. 3—32.
228. Миренков Η. Η. Параллельные алгоритмы и корректность
параллельных программ.— Новосибирск, 1983.— 16 с. (Препринт/ИМ СО АН СССР:
ОВС-17.)
229. Миренков Η. Η., Симонов С. А. Выявление параллелизма в
циклах методом имитации их выполнения.— Кибернетика, 1981, № 3, с. 28—33.
230. МихалевичВ. С, Капитонова Ю. В.,ЛетичевскийА. Α.,
Молчанов И. Н., Погребинский С. Б. Организация
вычислений в многопроцессорных вычислительных системах.— Кибернетика,
1984, № 3, с. 1—10.
231. Михалевич В. С, Молчанов И. Н. Тенденции развития
суперЭВМ и проблемы, ими порождаемые.— Киев, 1984.— 38 с. (Препринт/ИК
АН УССР: № 84-6.)
232. Мишин А. И., С е д у х и н С. Г. Вычислительные системы и
параллельные вычисления с локальными взаимодействиями.— В кн.: Вычислительные
системы. Вып. 78. Новосибирск: ИМ СО АН СССР, 1979, с. 90—103.
233. Мишин А. И., Седухин С. Г. Однородные вычислительные системы
и параллельные вычисления.— Автомат, и вычисл. техн., 1981, № 1,
с. 20—24.
234. Мишнева А. П. Параллельные алгоритмы для решения некоторых
задач теории переноса.—М., 1983.— 24 с. (Препринт/ОВМ АН СССР: № 58.)
235. Многопроцессорные вычислительные системы.— М.: Наука, 1975.— 143 с.
236. Многофункциональные регулярные вычислительные структуры.— М.:
Советское радио, 1978.— 288 с.
237. Моисеев Н. В. Некоторые вопросы оптимизации объектного кода для
векторно-конвейерных ЭВМ.— Вопросы кибернетики. Вып. 97. М.:
Научный совет по комплексной проблеме «Кибернетика» АН СССР, 1984,
с. 24—40.
238. Молдован Д. И. О разработке алгоритмов для систолических матриц,
СБИС—Труды ИИЭР, 1983, 71, № 1, с. 140—149.
239. Молчанов, И. Н. Прикладное программное обеспечение многопроцес-
258
СПИСОК ЛИТЕРАТ* Ы
сорного вычислительного комплекса ЕС.— В кн.: Вычислительные про-1
цессы и системы. Вып. 2. М.: Наука, 1985, с. 99—108. 1
240. Молчанов И. Н., Г а л б а Е. Ф., Степанец Н. И. Алгоритмы!
параллельных вычислений для решения сеточных уравнений на многопро-1
цессорной ЭВМ.— В кн.: Комплексы программ математической физики.1
Материалы VII Всесоюзн. семинара, Горький, 1981. Новосибирск: ИТПМ?
СО АН СССР, 1982, с. 143—147. ;
241. Μ о л ч а н о в И. Н., Г а л б а Е. Ф., Степанец Н. И. Реализация;
итерационных методов на многопроцессорной ЭВМ с параллельной
организацией вычислений.— Кибернетика, 1983, № 4, с. 18—23.
242. Молчанов И. Η., Ρ я б ц е в В. Е. Об организации вычислений при
решении больших систем линейных алгебраических уравнений методом:
отражений.— Кибернетика, 1983, № 2, с. 24—28.
243. Молчанов И. Н., ХимичА. Н. Некоторые алгоритмы решения
симметричной проблемы собственных значений на многопроцессорной
электронной вычислительной машине.— Кибернетика, 1983, № 6, с. 36—38.
244.. Молчанов И. Н., Яковлев М. Ф., Г е е ц Е. Г. Некоторые методы
интегрирования обыкновенных дифференциальных уравнений на
многопроцессорной ЭВМ.— Кибернетика, 1983, № 5, с. 10—21.
245. Мультипроцессорные вычислительные системы / Под ред. Я. А. Хетагу-
рова.—М.: Энергия, 1971.—320 с.
246. Мультипроцессорные системы и параллельные вычисления / Под ред.
Ф. Г. Энслоу.— М.: Мир, 1976.— 384 с.
247. Мюллер Д. Е., Препарата Ф. П. Перестроение арифметических
выражений для параллельного вычисления.— В кн.: Кибернетический
сборник (Новая сер.). Вып. 16. М.: Мир, 1979, с. 5—22.
248. Μ я м л и н А. Н., С о с н и н А. А. Супер-ЭВМ: архитектура и области
применения. М., 1977.—49 с. (Препринт/ИПМ АН СССР: № 15.)
249. Мясников В. Α., Игнатьев М. Б., Торгашев В. А.
Рекурсивные вычислительные машины.—М., 1977.— 36 с. (Препринт/ИТМ и
ВТ АН СССР: № 12.)
250. Мясников В. Α., Игнатьев М. Б., Фильчаков В. В.
Организация вычислительного процесса при решении прикладных задач на
многомикропроцессорной системе с рекурсивной организацией.—
Кибернетика, 1984, № 3, с. 30—37.
251. Нагорный Л. Я- Методы распараллеливания систем уравнений
большой размерности для решения их на многопроцессорных структурах.—
Электрон, моделир., 1980, № 1, с. 28—32.
252. Нагорный Л. Я-, Кофт о А. Г. Оценка эффективности решения
систем линейных уравнений большой размерности на одно- и
многопроцессорных вычислительных системах.— Электрон, моделир., 1981, № 2,
с. 31—35.
253. Нагорный Л. Я-, К о φ τ ο Α. Γ. Распараллеливание алгоритмов
моделирования нелинейных систем большой размерности.— Электрон,
моделир., 1983, №4, с. 45—51.
254. Нагорный Л. Я., Л у ц к и й Г. М., ДолголенкоА. Η.,
Κοφτό А. Г. Организация решения систем уравнений большой размерности с
разреженными матрицами коэффициентов в конвейерной вычислительной
системе.— Электрон, моделир., 1984, № 1, с. 12—15.
255. Нариньяни А. С. Теория параллельного программирования.
Формальные модели.— Кибернетика, 1974, № 3, с. 1—15; № 5, с 1—14.
256. Нестеренко Б. Б. Некоторые аспекты параллельных вычислений.—
Киев, 1980.—35 с. (Препринт/ИМ АН УССР: № 80.11.)
257. Нестеренко Б. Б., Новотарский М. А. Принципы организации
синхронных мультипроцессорных систем MIMD и их структур.— Киев,
1982.—61 с. (Препринт/ИМ АН УССР: № 82.17.)
258. Нестеренко Б. Б., Хрузин А. Н. Ассоциативная постановка
краевых задач в параллельных системах MIMD структуры.— Киев, 1981.—
37 с. (Препринт/ИМ АН УССР: № 81.57.)
СПИСОК ЛИТЕРАТУРЫ
259
259. НечепуренкоЮ. М. Новый параллельный алгоритм для трехдиаго-
нальной системы.— В кн.: Архитектура ЭВМ и численные методы. М.:
ОВМ АН СССР, 1983, с. 29—45.
260. Николаев И. А. Многопроцессорные цифровые однородные сетки для
решения задач математической физики.— В кн.: Параллельное
программирование и высокопроизводительные системы. Часть 2. Новосибирск:
ВЦ СО АН СССР, 1980, с. 84—91.
261. Η и к о л а е в И. Α., Б а б е н к о Л. К., С у χ и н о в А. И. Алгоритм
решения многомерных параболических уравнений на многопроцессорных
вычислительных системах матричного типа.— В кн.: Вычислительные
системы и алгоритмы. Ростов н/Д: Изд-во Ростовского ун-та, 1983, с. 8—17.
262. Николаев И. Α., Фрадкин Б. Г., Μ а к а р е в и ч О. Б. Об одном
способе аппаратурной реализации параллельного решения системы
алгебраических уравнений с ленточной матрицей.— В кн.: Цепные дроби и их
применения. Киев: ИМ АН УССР, 1976, с. 79—81.
263. Нуриев P.M. Необходимые и достаточные условия существенной ρ ас-
пар аллеливаемости программ по циклам.— Изв. АН СССР. Техн.
кибернетика, 1976, № 2, с. 105—111.
264. Однородные микроэлектронные ассоциативные процессоры/ Под ред.
И. В. Прангишвили.— М.: Советское радио, 1973.— 280 с.
265. Оленин А. С. Векторные процессы в линейных алгебраических задачах
с плотными матрицами.—М., 1983.— 38 с. (Препринт/ИТМ и ВТ АН СССР:
№ 17.)
266. Оленин А. С. Организация скалярно-векторных вычислений в алгебре
ленточных и блочных матриц.— М., 1984.— 44 с. (Препринт/ИТМ и ВТ
АН СССР: № 8.)
267. Оленин А. С. Параллельные вычисления в некоторых разностных
задачах.—М., 1983.—25 с. (Препринт/ИТМ и ВТ АН СССР: № 3.)
268. О ρ е О. Теория графов. М.: Наука, 1980.— 336 с.
269. Петрова Г. Б. Анализ параллелизма при распараллеливании циклов
единичной вложенности.— В кн.: Программное обеспечение
многопроцессорных вычислительных систем с общим потоком команд. М.: ИПУ, 1984,
с. 40—46.
270. Петрова Г. Б. О распараллеливании циклов с регулярной информа-
. ционной зависимостью операторов.— В кн.: Управление в сложных
нелинейных системах. М.: Наука, 1984, с. 60—63.
271. Поддерюгина Н. В. Об одной задаче программирования
арифметических выражений, связанной с параллельными вычислениями.— М.,
1982.— 28 с. (Препринт/ИПМ АН СССР: № 40.)
272. Пономарев В. М., Плюснин В. У., ТоргашевВ. А.
Распределенные вычисления и машины с динамической архитектурой.— В кн.:
Актуальные проблемы развития архитектуры и программного обеспечения
ЭВМ вычислительных систем. Новосибирск: ВЦ СО АН СССР, 1983, с. 37—59.
273. Поспелов Д. А. Введение в теорию вычислительных систем.— М.:
Советское радио, 1972.— 280 с.
274. Потапов В. Н., Сухов Е. Г. Численное решение уравнения
Пуассона на многопроцессорной вычислительной системе с общим потоком
команд.— В кн.: Многопроцессорные вычислительные системы с общим
потоком команд. Сб. трудов, вып. 19. М.: ИПУ, 1978, с. 54—64.
275. Прангишвили И. В. Архитектурные концепции
высокопроизводительных параллельных вычислительных систем 80-х годов.— В кн.:
Вопросы кибернетики. Вып. 79. М.: Научный совет по комплексной проблеме
«Кибернетика» АН СССР, 1981, с. 3—14.
276. Прангишвили И. В. Микропроцессорные и локальные сети микро-
ЭВМ в распределенных системах управления.— М.: Энергоатомиздат,
1985.—272 с.
277. Прангишвили И. В., Виленкин С. Я-, Медведев И. Л.
Параллельные вычислительные системы с общим управлением.— М.:
Энергоатомиздат, 1983.— 312 с.
260
СПИСОК ЛИТЕРАТУРЫ
278. Прангишвили И. В., Подлазов В. С, Стецюра Г. Г.
Локальные микропроцессорные вычислительные сети.— М.: Наука, 1984.—
176 с.
279. Прангишвили И. В., Стецюра Г. Г. Микропроцессорные
системы.—М.: Наука, 1980.—237 с.
280. Пшеничников Л. Е., Сахин Ю. X. Архитектура
многопроцессорного вычислительного комплекса «Эльбрус».— М., 1977.— 40 с. (Пре-
принт/ИТМ и ВТ АН СССР: № 7.)
281. ПьявченкоО. Н., Ромм Я. Е., С у ρ ж е н к о И. Ф. О реализации
параллельной полиномиальной аппроксимации в многопроцессорной
структуре.— Автомат, и вычисл. техн., 1981, № 4, с. 33—40.
282. Пьявченко О. Н., Сурженко И. Ф., Ромм Я- Е. Метод
распараллеливания схемы Горнера и его приложение к цифровым
вычислительным | устройствам.— Автомат, и вычисл. техн., 1978, № 5, с. 73—
78.
283. РезницкийЛ. И. Принципы автоматического выбора сеточного метода
счета на многопроцессорной ЭВМ ПС-3000.— Автомат, и телемехан., 1983,
№ 3, с. 170—176.
284. Решетуха И. В. Решение систем линейных алгебраических уравнений
с разреженными матрицами на многопроцессорной машине.— В кн.:
Методы прикладного программирования. Киев, 1981, с. 75—84.
285. Ромм Я. Е. Об ускорении линейных стационарных итерационных
процессов в многопроцессорных ЭВМ.— Кибернетика, 1982, № 1, с. 47—54;
№ 3, с. 64—67.
286. Ρ о о з е А. К параллельным методам решения систем нелинейных
уравнений.— Изв. АН Эст. ССР. Физика — математика, 1981, 30, № 2, с. 160—
163.
287. Русанов В. В., Четверушкин Б. Н. Структурная модель одного
класса численных алгоритмов.— М., 1983.— 13 с. (Препринт/ИПМ АН
СССР: № И.)
288. Самофалов К. Г., Л у ц к и й Г. М. Основы построения конвейерных
ЭВМ.—Киев: Вища школа, 1981.—223 с.
289. Саульев В. К. Об одном явном параллельном разностном методе
решения нелинейных уравнений параболического типа.— М., 1981.— 10 с.
(Препринт/ОВМ АН СССР: № И.)
290. С в а м и М., Тхуласираман К. Графы, сети и алгоритмы.—М.:
Мир, 1984.—454 с.
291. С еду хин С. Г. Параллельная интерпретация прямых методов
линейной алгебры.— Программирование, 1984, № 4, с. 57—68.
292. Седухин С. Г. Параллельно-поточная интерпретация мет 0да Холец-
кого.— Электрон, моделир., 1984, № 6, с. 3—6.
293. Седухин С. Г. Параллельно-поточная интерпретация метода Гаусса.—
В кн.: Вычислительные системы. Вып. 94. Новосибирск: ИМ СО Ан СССР,
1982, с. 70—80.
294. Седухина Л. А. Параллельные алгоритмы в линейном прогр аммиро-
вании.— В кн.: Вычислительные системы. Вып. 97. Новосибирск: ИМ СО
АН СССР, 1983, с. 10—27.
295. Седухина Л. А. Параллельная интерпретация одной задачи ди нами-
ческого программирования.— В кн.: Вычислительные системы. Вып. 104.
Новосибирск: ИМ СО АН СССР, 1984, с. 101—108.
296. Семерджан Μ. Α., Налбандян Ж- С. Матричный процессор ЕС-
2345: Принципы работы и программное обеспечение.— М.: Финансы и
статистика, 1984.— 133 с.
297. Семик В. П., Сплетухов Ю. А. Приведение вычислительных
схем к виду, удобному для конвейерной реализации.— Программирование,
1983, № 5, с. 36—39. * '
298. СергиенкоИ. В., Гуляницкий Л. Ф. Фронтальные алгоритмы
оптимизации для многопроцессорных ЭВМ.— Кибернетика,1 1981,5 № 6,
с. 1—4.
СПИСОК ЛИТЕРАТУРЫ
261
299. СергиенкоИ. В., Червак Ю. Ю., Гренджа В. И.
Распараллеливание в лексикографических алгоритмах дискретной оптимизации.—
Кибернетика, 1984, № 5, с. 82—85.
300. Соболевский М. И. Анализ и оптимизация структур матричных
вычислительных систем.— М.: Энергия, 1979.— 168 с.
301. Солодовников В. И. Верхние оценки сложности решения систем
линейных уравнений.— В кн.: Записки научных семинаров ЛОМИ АН
СССР. Том 118. Л.: Наука, 1982, с. 159—187.
302. Софронов И. Д. Оценка параметров вычислительной машины,
предназначенной для решения задач механики сплошной среды.— Числ. методы
мех. сплошн. среды, 1975, 6, № 3, с. 98—147.
303. Сохранская В. С, Тушкина Т. А. О распараллеливании
вычислительных процессов с циклами и ветвлениями.— В кн.: Записки
научных семинаров ЛОМИ АН СССР. Том 90. Л.: Наука, 1979, с 210—226.
304. Стародубцев Н. А. Синтез схем управления параллельных
вычислительных систем.— Л.: Наука, 1984.— 192 с.
305. Стародубцев Н. А. Перспективы схемотехники
высокопроизводительных ВС и ее влияние на архитектуру.— В кн.: Архитектура ЭВМ и*
численные методы. Μ.: ΟΒΜ АН СССР, 1985, с. 108—137.
306. Столяров Л. Н. Структурный анализ алгоритмов для эффективной
организации вычислений.— В кн.: Вычислительные системы и
автоматизация научных исследований. М.: МФТИ, 1980, с. 23—45.
307. Сухов Е. Г. Решение линейных и нелинейных систем алгебраических
уравнений на многопроцессорных ЭВМ с общим потоком команд.— В кн.:
Программное обеспечение многопроцессорных вычислительных систем с
общим потоком команд. М.: ИПУ, 1984, с. 65—73.
308. Сухов Е. Г. Решение линейных систем алгебраических уравнений
большого порядка на многопроцессорных ЭВМ с общим потоком команд.—
Программирование, 1984, № 2, с. 23—30.
309. Сухов Е. Г. Матричные вычисления на многопроцессорных ЭВМ с общим
потоком команд.— Программирование, 1981, № 4, с. 40—49.
310. Τ а у τ с А. Распараллеливание рекурсивных вычислений.— Изв. АН Эст.
ССР. Физика — математика, 1983, 32, № 2, с. 121—127.
311. Теория расписаний и вычислительные машины / Под ред. Э. Г. Коффмана.—
М.: Наука, 1984.—334 с.
312. ТеренковВ. И. О реализации прямых методов решения сеточных
уравнений на многопроцессорных вычислительных системах.— В кн.:
Разностные методы математической физики. М.: Изд-во МГУ, 1984, с. 97—105.
313. Тищенко А. Г. Структурная реализация крупных операций в
параллельно-последовательных алгоритмах базовых задач линейной алгебры на*
примере метода полной редукции.— В кн.: Разностные методы
математической физики. М.: Изд-во МГУ, 1984, с. 106—115.
314. Тищенко Т. П. Систолические структуры для реализации дискретных
бинарных преобразований сигналов.— Новосибирск, 1984.— 18 с.
(Препринт/ВЦ СО АН СССР: № 526.)
315. Тодоров Г. А. Анализ параллелизма вычислительных процессов в-
циклических программных структурах.— Программирование, 1980, № 1,
с. 11—23.
316. ТрахтенгерцЭ. А. Введение в теорию анализа и распараллеливания
программ ЭВМ в процессе трансляций.— М.: Наука, 1981.— 255 с.
317. Τ ы ρ τ ы ш н и к о в Ε. Ε. О конвейерных вычислениях.— В кн.:
Архитектура ЭВМ и численные методы. Μ.: ΟΒΜ АН СССР, 1983, с. 4—10.
318. Тыртышников Е.Е.О некоторых оптимизационных задачах,
связанных с реализацией алгоритмов.— В кн.: Архитектура ЭВМ и численные
методы. Μ.: ΟΒΜ АН СССР, 1985, с. 138—148.
319. Тыртышников Ε. Ε. О формах записи алгоритмов.— В кн.:
Архитектура ЭВМ и численные методы. Μ.: ΟΒΜ АН СССР, 1984, с. 137—144.
320. Τ ы у г у Э. X. Концептуальное программирование.— М.: Наука, 1984.—
255 с.
262
СПИСОК ЛИТЕРАТУРЫ
.321. Τ ы у г у Э. X. Решение задач на вычислительных моделях.— Журн. вы- 1
числ. мат. и мат. физ., 1970, 10, № 3, с. 716—733. j
322. Уваров СИ. Вычисление арифметических выражений на многопроцес- ι
сорной вычислительной системе с общим потоком команд.— В кн.: Много- |
процессорные вычислительные системы с общим потоком команд. Сб. трудов, ]
вып. 19. М.: ИПУ, 1978, с. 67—78. |
323. Фаддеева В. Н., Фаддеев Д. К. Параллельные вычисления в ли-,
нейной алгебре. 1, 2.—Кибернетика, 1977, № 6, с. 28—40; 1982, № 3, \
с. 18—31, 44.
324. Фет Я. И. Массовая обработка информации в специализированных одно- ]
родных процессорах.— Новосибирск: Наука, 1976.— 200 с. I
.325. Фет Я. И. Параллельные процессоры для управляющих систем.—М.:
Энергоиздат, 1981.—158 с. ]
-326. Фильчаков В. В. Организация параллельного вычислительного про- 1
цесса и структуры данных для решения сеточных уравнений методом Монте- ]
Карло.— В кн.: Вычислительные процессы и структуры. Сб. трудов, вып. j
154. Ленинград: ЛИАП, 1982, с. 17—22. -j
•327. Φ л и н М. Сверхбыстродействующие вычислительные системы.— Труды !
ИИЭР, 1966, 54, № 12, с. 311—320.
-328. Фомин Ю. Т., Черкасов А. А. Параллельные методы решения
задачи Коши для обыкновенных дифференциальных уравнений в
интервальном исполнении.— В кн. Комплексы программ математической физики.
Материалы VII Всесоюзн. семинара. Ташкент, 1983. Новосибирск: ИТПМ
СО АН СССР, 1984, с. 62—69.
329. Φ остер К. Ассоциативные параллельные процессоры.— М.:
Энергоиздат, 1981.—240 с.
.330. Фрумкин М. А. Конвейерные алгоритмы решения некоторых задач
линейной алгебры.— В кн.: Вопросы кибернетики. Вып. 103. М.:
Научный совет по комплексной проблеме «Кибернетика» АН СССР, 1984,
с. 96—111.
-331. Фрумкин М. А. О приведении алгоритмов к систолической форме.—
В кн.: Вопросы кибернетики. Вып. 97. М.: Научный совет по комплексной
проблеме «Кибернетика» АН СССР, 1984, с. 111—118.
332. ФуллерС. X., УстерхутД. К-, Раскин Л., Рубенфельд
П. Α., С и н д χ у П. Д., С τ у о н Р. Д. Мультимикропроцессорные
системы: Обзор и пример практической реализации.— Труды ИИЭР, 1978,
66, № 2, с. 135—150.
333. Халилов А. И. Распараллеливание арифметических выражений
методом последовательного углубления.— Программирование, 1979, № 2,
с. 34—40.
-334. X ар ар и Ф. Теория графов.—М.: Мир, 1973.—300 с.
335. Хорошавина Г. Ф. Об одном практическом методе анализа и
преобразования последовательных программ к параллельному виду.—
Программирование, 1981, № 1, с. 42—47.
-336. Χ ο χ л ю к В. И.чО параллелизме в целочисленной оптимизации.— В кн.:
Вычислительные системы. Вып. 89. Новосибирск: ИН СО АН СССР, 1981,
с. 3—22.
337. Шавловская С. А. О распараллеливании при вычислении
определенных интегралов.— Вопросы радиоэлектроники. Серия ЭВТ, 1973, вып. 7,
с. 3—10.
.338. Шахбазян К. В., Тушкина Т. А. Обзор методов составления
расписаний для многопроцессорных систем.— В кн.: Записки научных
семинаров ЛОМИ АН СССР. Том 54. Ленинград: Наука, 1975, с. 229—258.
339. Шахбазян К. В., Тушкина Т. А. О максимальном количестве
потоков в конвейере.— В кн.: Записки научных семинаров ЛОМИ АН СССР.
Том 139. Л.: Наука, 1984, с. 22—40.
«340. Ш е л е в а А. С. Некоторые свойства алгоритмов, представленных гнездом
циклов.— В кн.: Методы вычислительной и прикладной математики. М.:
ОВМ АН СССР, 1985, с. 163—172.
СПИСОК ЛИТЕРАТУРЫ
26$
341. Шелева А. С. Построение расписаний, близких к оптимальным, для
одного класса алгоритмов.— В кн.: Архитектура ЭВМ и численные
методы. Μ.: ΟΒΜ АН СССР, 1985, с. 149—168.
342. Шелева А. С. Решение задач линейного программирования на ЭВМ
конвейерного типа.— В кн.: Архитектура ЭВМ и численные методы. М.:
ОВМ АН СССР, 1983, с. 46—52.
343. Ш у ρ а й ц Ю. М. Алгоритмы распараллеливания вычисления
алгебраических полиномов на многопроцессорной вычислительной системе.— В кн.;
Организаций вычислений на многопроцессорных ЭВМ. Сб. трудов, вып. 26.
М.: ИПУ, 1981, с. 37—43.
344. ЭВМ пятого поколения: концепции, проблемы, перспективы / Под ред.
Т. Мото-ока.— М.: Финансы и статистика, 1984.— 112 с.
345. Элементы параллельного программирования / В. А. Вальковский, В. Е.
Котов, А. Г. Марчук, Н. Н. Миренков. Под ред. В Е. Котова.— М.: Радио и
связь, 1983.— 240 с.
346. Ющенко Е. Л. Структурное программирование и параллельные
вычисления.— В кн.: Параллельное программирование и параллельные
вычисления. Часть 1. Новосибирск: ВЦ СО АН СССР, 1980, с. 21—35.
347. Яковлев Μ. Φ. О решении систем уравнений с частными производными
на многопроцессорном вычислительном комплексе.— Кибернетика, 1984,
№ 4, с. 112—114.
348. Я н е н к о Η. Η. Вопросы модульного анализа и параллельных вычислений
в задачах математической физики.— В кн.: Параллельное
программирование и высокопроизводительные системы. Часть 1. Новосибирск: ВЦ СО
АН СССР, 1980, с. 135—144.
349. Я ненко Η. Η. Эффективность алгоритмов и принципы их декомпозиции
для современных ЭВМ.— В кн.: Комплексы программ математической
физики. Материалы VII Всесоюзн. семинара. Ташкент, 1983. Новосибирск:
ИТПМ СО АН СССР, 1984, с. 3—17.
350. Я н е н к о Н. Н., К о н о в а л о в А. Н., Б у г ρ о в А. Н., Ш у с τ о в Г. В,
Об организации параллельных вычислений и «распараллеливании»
прогонки.— Числ. методы мех. сплошн. среды, 1978, 9, № 7, с. 139—146.
351. Я н е н к о Н. Н., Хорошевский В. Г., Ρ ычков А. Д.
Параллельные вычисления в задачах математической физики на вычислительных
системах с программируемой архитектурой.— Электрон, моделир., 1984,
' № 1, с. 3—8.
352. Abelson Η., Andreae P. Information transfer and area-time
tradeoffs for VLSI multiplication.—Commun. ACM, 1980, 23, № 1, p. 20—23.
353. Adams D. A. A model for parallel computations.— In: Parallel processor
systems, technolgies and applications. N. Y.: Spartan Boocs, 1970, p, 311—333.
354. Adams L. An M-step preconditioned conjugate gradient method for parallel
computation.— Proc. 1983 Int. Conf. Parallel Process.. N. Y.: IEEE, 1983,
p. 36—43.
355. Adams L., Crockett T. W. Modeling algorithm execution time on,
processor arrays.—Computer, 1984, 17, №7, p. 38—43.
356. Adams L., Ortega J. A multi-color SOR method for parallel
computation.— Proc. 1982 Int. Conf. Parallel Process.. N. Y.: IEEE, 1982, p. 53—56.
357. Adams L., Voigt R. G. A methodology for exploiting parallelism
in the finite element process.— In: High-speed computation. Berlin: Springer-
Verlag, 1984, p. 373—392.
358. A d e 1 a n t a g о М., С о m t e D., S i г о η P., S у г e J. С. A MIMD
supercomputer system for large numerical applications.— Proc. IFIP Congr.
83, Paris, 1983. Amsterdam: North-Holland, 1983, p. 821—826.
359. Ae Т., Aibara R., EtohM. Design and realization of many processor
system using parallel flow graph.— Proc. 1984 IEEE Workshop Lang. Autom.r
New Orleans, 1984. N. Y.: IEEE, 1984, p. 7—12.
360. Agerwala Т., Lint B. Communication issues in parallel algorithms
and systems.— Proc. IEEE 2th Int. Comput. Sof tw. and Appl. Conf., Chicago,
1978. N. Y.: IEEE, 1978, p. 583—588.
264
СПИСОК ЛИТЕРАТУРЫ
.361. Ahlberg R., Gustafsson В., Olsmats Μ., Schneider W.,
Tap ia M., Wiren A. A note on parallel algorithms for partial
differential equations.— In: Parallel computing 83. Amsterdam: North-Holland,
1984, p. 93—98.
-362. Ahmed H. M., D e 1 о s m e J.-M., Μ о г f M. Highly concurrent
computing structures for matrix arithmetic and signal processing.— Computer,
1982, 15, № 1, p. 65—82.
-363. Alia G. VLSI syslotic arays for band matrix multiplication.— Integration,
1983, 1, №2/3, p. 233—249.
364. Alvarado F. L. Parallel solution of transient problems by trapezoidal
integration.— IEEE Trans. Power Appar. and Syst., 1979, PAS-98, № 3,
p. 1080—1088.
365. A m a η ο Η., Υ ο s h i d а Т., A i s ο Η. (SM)2: Sparse matrix solving
machine.— Proc. 10th Annu. Int. Symp. Comput. Archit., Stockholm, 1983.
N. Y.: IEEE, 1983, p. 213-220.
366. A m e 1 i η g W. Parallelism in computer architecture.— In: Parallel and
large-scale computers: performance, architecture, applications. Amsterdam:
North-Holland, 1983, p. 251—260.
367. Arjomandi E., Fischer M. J., Lynch N. A. Efficiency o!
synchronous versus asynchronous distributed systems.— J. Assoc. Comput.
Mach., 1983, 30, №3, p. 449—456.
*368. Arnold С N. Performance evaluation of three automatic vectorizer
packages.— Proc. 1982 Int. Conf. Parallel Process.. N. Y.: IEEE, 1982,
p. 235—242.
.369. Arnold С N. Vector optimization on the CYBER 205.— Proc. 1983 Int.
Conf. Parallel Process.. N. Y.: IEEE, 1983, p. 530—536.
370. A r η ο 1 d C. P., Parr M. I., Dewe Μ. Β. An efficient parallel
algorithm for the solution of large sparse linear matrix equations.— IEEE Trans.
Comput., 1983, C-32, №3, p. 265—273.
371. Arnold R. G., Berg R. O., Thomas J. W. A modular approach
to realtime supersystems.— IEEE Trans. Comput., 1982, C-31, № 5, p. 385—
398.
*372. Askew S. L., Walkden F. On the design and implementation of a
package for solving a class of partial differential equations on the ICL
distributed array processor.— In: Supercomputers and parallel computation.
Oxford: Clarendon Press, 1984, p. 107—114.
■373. Austin J. H. The Burroughs Scientific Processor.— In: Supercomputers,
2. Maidenhead: Infotech Int., 1979, p. 1—31.
374. Avila J., Kuekes P. One-gigaflop VLSI systolic processor.— In:
Real-time signal processing VI. Proc. SPIE, 431. Bellingnam, Wash: SPIE,
1983, p. 159—165.
,375. Avila J., Tomlin J. A. Solution of very large least squares problems
by nested dissection on a parallel processor.— Proc. 12th Sump. Interface
Comput. Sci. and Stat., Ontario, 1979, p. 9—14.
376. Axelrod Т., Dubois P., Eltgroth P. A simulator for MIMD
performance prediction: application to the S-l Mklla multiprocessor.—
Parallel. Comput., 1984, 1, №3/4, p. 237—274.
377. Baer J.-L. A survey of some theoretical aspects of multiprocessing.—
Comput. Surv., 1973, 5, № 1, p. 31—80.
378. Baer J.-L. Computer architecture.—Computer, 1984, 17, № 10, p. 77—87.
379. В a e r J.-L. Computer systems architecture.— London: Pitman, 1980.—
626 p.
380. Ba&r J.-L. Modeling for parallel computation: a case study.—Proc. 1973
Sagamore Comput. Conf. Parallel Process.. N. Y.: IEEE, 1973, p. 13—22.
381. Baer J.-L. Multiprocessing systems.—IEEE Trans. Comput., 1976, C-25,
№ 12, p. 1272—1277.
382. Baer J.-L. Techniques to exploit parallelism.—In: Parallel processing
systems. Cambridge Univ. Press, 1982, p. 75—100.
383. Baer J.-L., Bovet D. P. Compilation of arithmetic expressions for
СПИСОК ЛИТЕРАТУРЫ
265
parallel computations.— Proc. IFIP Congr. 68, Edinburg, 1968. Amsterdam :
North-Holland, 1968, p. 340—346.
384. В a e r J.-L., Β ο ν e t D. P., Ε s t r i η G. Legality and other properties
of graph models of computations.—J. Assoc. Comput. Mach., 1970, 17, №3,
p. 543—552.
385. В a e r J.-L., Ellis С S. Model, design and evaluation of compiler for
a parallel environment.— IEEE Trans. Softw. Eng., 1977, SE-3, № 6, p. 394—
405.
386. Banatre J. P., Banatre M. Parallel structures for vector
processing.—CONPAR 81 Conf. Proc, Nuremberg, 1981. Lect. Notes Comput. Sci.,
III. Berlin: Springer-Verlag, 1981, p. 101—114.
387. Banerjee U. Bounds on the parallel processor speedup.— Proc. 19th
Annu. Allerton Conf. Commun., Contr. and Comput., Monticello, 111., 1981,
• p. 514—523.
388. Banerjee U., Chen S.-C, К u с k D. J., Τ ο w t e R. A. Time
and parallel processor bounds for FORTRAN-like loops.— IEEE Trans.
Comput., 1979, C-28, №9, p. 660—670.
389. Banerjee U., Gajski D. Fast execution of loops with IF statements.—
IEEE Trans. Comput., 1984, C-33, № 11, p. 1030—1033.
390. Banerjee U., Gajski D., К u с k D.J. Accessing sparse arrays in
parallel memories.—J. VLSI and Comput. Syst., 1983, 1, № 1, p. 69—100.
391. Bannister J. Α., Clary J. B. Performance analysis of systolic array
• architectures.— In: Real-time signal processing V. Proc. SPIE, 341. Belling-
ham, Wash.: SPIE, 1982, p. 269—277.
392. Barkai D., Brandt A. Vectorized multigrid Poisson solver for the
CDC CYBER 205.— Appl. Math, and Comput., 1983, 13, № 3/4, p. 215—227.
393. Barkai D., Moriarty K. J. M. Vectorizing the Monte Carlo algo-
rihm for lattice gauge theory calculations on the CDC CYBER 205.— Comput.
Phys. Commun. 1982, 25, №1, p. 57—62.
394. Barkai D., Moriarty K- J. M., R e b b i С A highly optimized
vectorized code for Monte Carlo simulations of SU (3) lattice gauge theories.—
Comput. Phys. Commun., 1984, 32, №1, p. 1—9.
395. Barlow R. H. Performance measures for parallel algorithms.— In:
Parallel processing systems. Cambridge Univ. Press, 1982, p. 179—192.
396i Barlow R. H., Evans D.J. Parallel organization of the bisection
algorithm.—Comput. J., 1979, 22, №3, p. 267—269.
397. Barlow R. H., Evans D. J. Parallel algorithms for the iterative
solution to linear systems.—Comput. J., 1982, 25, №1, p. 56—60.
398. Barlow R. H., Evans D. J., S h a n e h с h i J. An asynchronous
parallel version of the power method.— Int. J. Comput. Math., 1982, 11,
№2, p. 143—154.
399. Barlow R. H., Evans D. J., Shanehchi J. Comparative study
of the exploitation of different levels of parallelism on different parallel
architectures.— Proc. 1982 Int. Conf. Parallel Process.. N. Y.: IEEE, 1982, p. 34—
40.
400. Barlow R. H., Evans D. J., Shanehchi J. Parallel
multisections applied to the eigenvalue problem.— Comput. J., 1983, 26, № 1, p. 6—9.
401. Barlow R. H., Evans D. J., Shanehchi J. Parallel
multisection for the determination of the eigenvalues of symmetric quindiagonal
matrices.—Inf. Process. Lett., 1982, 14, №3, p. 117—118.
402. Barlow R. H., Evans D. J., Shanehchi J. Performance
analysis of algorithms on asynchronius parallel processors.— Proc. Int. Conf.
Vector and Parallel Process. Comput. Sci., Chester, 1981. Comput. Phys. Com*
num., 1982, 26, №3/4, p. 233—236.
403. Barlow R. H., Evans D. J., Shanehchi J. Programming expi-
rience on parallel algorithms for the eigenvalue problem.— Proc. 1st Int.
Colloq. Vector and Parallel Comput. in Sci. Appl., Paris, 1983. EDF Bull.
Dir. Etud. et Rech., 1983, C, № 1, p. 31—38.
404. Barnwell III T. P., Schwartz D. A. Optimal implementation of
9 В. В. Вооводин
266
СПИСОК ЛИТЕРАТУРЫ
flow graphs on synchronous multiprocessors.— Proc. 17th Asilomar Conf.
Circuits, Syst. and Comput., Santa Clara, Cal., 1983. N. Y.: IEEE, 1983,
p. 188—193.
405. В a s u A. A classification of parallel processing systems.— Proc. 1984 IEEE
Int. Conf. Comput. Design, Port Chester, N. Y., 1984. N. Y.: IEEE, 1984,
p. 222—226.
406. Batcher К. Е. The STAR AN computer.— In: Supercomputers, 2.
Maidenhead: Infotech Int., 1979, p. 33—49.
407. В a u d e t G. M. Asynchronous iterative methods for multiprocessors.—
J.Assoc. Comput. Mach., 1978, 25, №2, p. 226—244.
408. В е е с k H. Parallel algorithms for linear equations with not sharply defined
data.— In: Parallel computers — parallel mathematics. Amsterdam: North-
Holland, 1977, p. 257—261.
409. Ben-Ari M. Principles of concurrent programming.— Englewood Cliffs,
N.J.: Prentice Hall Int., 1982.—172 p.
410. Benson M., Krettmann J., Wright M. Parallel algorithm for
the solution of certain large sparse linear systems.— Int. J. Comput. Math.,
1984, 16, №3/4, p. 245—260.
411. Berger M., Oliger J., Rodrigue G. Predictor-corrector methods
for the solution of time-dependent parabolic problems on a parallel
processors.—In: Elliptic problem solvers. N. Y.: Acad. Press, 1981, p. 197—201.
412. Berger P., Brouaye P., Syre J. С A mesh coloring method for
efficient MIMD processing in finite element problems.— Proc. 1982 Int. Conf.
Parallel Process.. N. Y.: IEEE, 1982, p. 41—46.
413. Bergland G. D. A. parallel implementation of the fast Fourier transform
algorithm.— IEEE Trans. Comput., 1972, C-21, №4, p. 366—370.
414. Berkowitz S. J. On computing the determinant im small parallel
time using a small number of processors.— Inf. Process. Lett., 1984, 18, № 3,
p. 147—150.
415. В e r m a n F., Snyder L. On mapping parallel algorithms into parallel
architectures.— Proc. 1984 Int. Conf. Parallel Process.. N. Y.: IEEE, 1984, p. 307—
309.
416. Bernard L. C, Helton F. J. A vectorizable eigenvalue solver for
sparse matrices.—Comput. Phys. Commun., 1982, 25, № 1, p. 73—80.
417. Bernhart R. More hardware means less software.—IEEE Spectrum,
1981, 18, № 12, p. 30—37.
418. Bejnutat-Buchmann U., Krieger J. Evolution strategies in
numerical optimization on vector computers.— In: Parallel computing 83.
Amsterdam: North-Holland, 1984, p. 99—105.
419. В e r ζ i η s M., Buckley T. F., Dew P. M. Systolic matrix iterative
algorithms.— In: Parallel computing 83. Amsterdam: North-Holland, 1984,
p. 483—488.
420. Bhavsar V. С Some parallel algorithms for Monte Carlo solution of
partial differential equations.— In: Advances in computer methods for partial
differential equations-IV. New Brunswich, N. J.: IMACS, 1981, p. 135—143.
421. В h u у a n L. Ν., A g r a w a 1 D. P. Performance analysis of FFT
algorithms on multiprocessor systems.-1- IEEE Trans. Softw. Eng., 1983, SE-9,
№4, p. 512—521.
422. В i η i D. Parallel solution of certain Teoplitz linear systems.—SI AM 1.
Comput., 1984, 13, № 2, p. 268—276.
423. Bini D., Capovani M. Fast parallel and sequential computations and
spectral properties concerning band Toeplitz matrices.— Calcolo, 1983, 20,
№2, p. 177—189.
424. Blumenfeld M. Preconditioning conjugate gradient methods on vector
computers.— In: Parallel computing 83. Amsterdam: North-Holland, 1984,
' p. 107—113.
425. Bojanczyk Α., Brent R. P., К u η g Η. Τ. Numerically stable
solution of dense systems of linear equations using mesh-connected
processors.— SIAM J. Sci. and Stat. Comput., 1984, 5, № 1, p. 95—104.
СПИСОК ЛИТЕРАТУРЫ
267
426. В о k h а г i Η. S. On the mapping problem.— IEEE Trans. Comput., 1981,
C-30, №3, p. 207—214.
427. Bond A. H. Self-broadcasting arrays — a new computer architecture
suitable for easy fabrication.— In: Parallel computing 83. Amsterdam: North-
Holland, 1984, p. 489—494.
428. Borodin Α., Gathen J., Hopcroft J. Fast parallel matrix and
GCD computations.— Proc. 23th Annu. Symp. Found. Comput. Sci., N. Y.:
IEEE, 1982, p. 65—71.
429. Borodin Α., Munro I. The computational complexity of algebraic
and numeric problems.— N. Y.: American Elsevier, 1975.— 173 p.
430. Bossavit A. The «Vector machine»: An approach to simple programming
on CRAY-1 and other computers.— In: PDE software: modules, interfaces and
systems. Amsterdam: North-Holland, 1984, p. 103—121.
431. Bo vet D. P., Vanneschi M. Models and evaluation of pipeline
systems.— In: Computer architecture and networks: modeling and evaluation.
Amsterdam: North-Holland; N. Y.: American Elsevier, 1974, p. 99—111.
432. Bohm C, Dezani-Ciancagling M. To what extent can or must
computation be parallelized.— In: New concepts and technologies in parallel
information processing. Leyden: Noordhoff, 1975, p. 137—154.
433. Brandt A. Muligrid solvers on parallel computers.— In: Elliptic problem
solvers. N. Y.: Acad. Press, 1981, p. 39—83.
434. Brent R. P. The parallel evaluation of arithmetic expressions in
logarithmic time.— In: Complexity of sequential and parallel numerical algorithms.
N. Y.: Acad. Press, 1973, p. 83—102.
435. Brent R. P. The parallel evaluation of general arithmetic expressions.—
J.'Assoc. Comput. Mach., 1974, 21, №2, p. 201—206.
436. Brent R. P., Coldschlager L. M. Some area-time tradeoffs for VLSI.—
SIAM J. Comput., 1982, И №4, p. 737—747.
437. Brent R. P., Kuck D. J., Maruyama K. The parallel evaluation
of arithmetic expressions without division.— IEEE Trans. Comput., 1973,
C-22, №5, p. 532—534.
438. Brent R. P., К u η g Η. Τ. Systolic VLSI arrays for polynomial GCD
computation.— IEEE Trans. Comput., 1984, C-33, № 8, p. 731—736.
439. Brent R. P., Kung H. Т., Luk F. T. Some linear-time algorithms
for systolic arrays.— Proc. IFIP Congr. 83, Paris, 1983. Amsterdam: North-
Holland, 1983, p. 865—876.
440. Brent R. P., Luk F. T. A systolic array for the linear-time solution of
Toeplitz systems of equations.—J. VLSI and Comput. Syst., 1983, 1, № 1,
p. 1—22.
441. Brent R. P., Luk F. T. Computing the Cholesky factorization using
a systolic architecture.— Proc. 6th Australian Comput Sci. Conf., Sydney,
1983, p. 295—302.
442. Brent R. P., Luk F. Т., van Loan С Computation of the generelized
singular value decomposition using mesh-connected processors.— In: Real-time
signal processing VI. Proc. SPIE, 431. Bellingham, Wash.: SPIE, 1983, p. 66—
71.
443. Briggs F. Α., Dubois M. Modeling of synchronized iterative
algorithms for multiprocessors.— Proc. 18th Annu. Allerton Conf. Commun.,
Control and Comput., Monticello, 111., 1980, p. 554—563.
444. В г о d e B. Precompilation of FORTRAN, programs to facilitate array
processing.—Computer, 1981, 14, №9, p. 46—51.
445. В г о m 1 e у К., Symanski J. J., Speiser J. M., White-
house H. J. Systolic array processor developments.— In: VLSI systems
and computations. Rocville, Md.: Comput. Sci. Press., 1981, p. 273—284.
446. Bucu S. R., Senne K- D. Nonlinear filtering algorithms for vector
processing machines.—Comput. and Mth. Appl., 1980, 6, №3, p. 317—338.
447. Budnik P., Oliger J. Algorithms and architecture.— In: High speed
computer and algorithm organization. N. Y.: Acad. Press, 1977, p. 355—
370.
268
СПИСОК ЛИТЕРАТУРЫ
448. В u z b е е В. L. A fast Poisson solver anable to parallel computation.—
IEEE Trans, Comput., 1973, C-22, №8, p. 793—796.
449. Buzbee B. L. Implementing techniques for elliptic problems on vector
processors.— In: Elliptic problem solvers. N. Y.: Acad. Press, 1981, p. 85—98.
450. Buzbee B. L., G о 1 u b G. H., Howell J. A. Vectorization for
the CRAY-1 of some methods for solving elliptic difference equations.— In:
High speed computer and algorithm organization. N. Y.: Acad. Press, 1977,
p. 255—271.
451. С a 1 a h a n D. A. A block-oriented sparse equation solver for the CRAY-1.—
Proc. 1979 Int. Conf. Parallel Process.. N. Y.: IEEE, 1979, p. 116—123.
452. Calahan D. A. Algorithmic and architectural issues related to vector
processing.— Proc. Int. Symp. Large Eng. Syst., Winnipeg, 1976. Oxford:
Pergamon Press, 1977, p. 327—339.
453. Calahan D. A. Complexity of vectorized solution of two-dimensional
finite element grids.— Proc. Int. Symp. Large Eng. Syst., Winnipeg, 1976.
Oxford: Pergamon Press, 1977, p. 38—50.
454. Calahan D. A. Exploiting parallelism in design algorithms.— In: Basic
quetions in design thecry. Amsterdam: Ncrth-Holland; N. Y.: American
Elsevier, 1974, p. 285—302.
455. Calahan D. A. Influence of task granularity on vector multiprocessor
performance.—Proc. 1984 Int. Conf. Parallel Process.. N. Y.: IEEE, 1984,
p. 278—284.
456. Calahan D. A. Parallel solution4 of sparse simultaneous linear
equations.— Proc. 11th Annu. Allerton Conf. Circuits and Syst. Theory, 1973, p. 729—
735.
457. Calahan D. A. Sparse vectorized direct solution of elliptic problems.—
In: Elliptic problem solvers. N. Y.: Acad. Press, 1981, p. 241—245.
458. Calahan D. Α., Ames W. G. Vector processors: models and appli-
. cations.— IEEE Trans. Circuits and Syst., 1979, CAS-26, №9, p. 715—726.
459. Cappello P. R., Steiglitz K. Unifying VLSI array designs with
geometric transformations.— Proc. 1983 Int. Conf. Parallel Process.. N. Y.:
IEEE, 1983, p. 448—457.
460. Carey G. F. High-speed processors and implication for algorithms and
methods.— In: Nonlinear finite element analysis in structural mechanics.
Berlin: Springer-Verlag, 1981, p. 758—777.
461. С a r 1 s ο η D. Α., S u g 1 a B. Time and processor efficient parallel
algorithms for recurrence equations and related problems.— Proc. 1984 Int. Conf.
Pcrallel Process.. N. Y.: IEEE, 1984, p. 310—314.
462. Casti J., Richardson M., Larson R. Dynamic programming
and parallel computing.— J. Optim. Theory Appl., 1973, 12, № 4, p. 423—438.
463. Casulli V., Trigiante D. Multipoint iterative parallel methods for
solving equations.—Calcolo, 1978, 15, № 2, p. 147—160.
464. С e i S., G a 1 1 i M., S о с с i ο Μ., Ζ е 1 1 i η i P. On some parallel
algorithms for inverting tridiagonal and pentadicgcnal matrices.—Calcolo, 1981,
18, №4, p. 303—319.
465. Chazan D., Miranker W. L. A nongradient and parallel algorithm
for unconstrained minimization.— SIAM J . Control, 1970, 8, № 2, p. 207—217.
466. Chazan D., Miranker W. L. Chaotic relaxation.— Linear Alg.
Appl., 1969, 2, p. 199—222.
467. Chen A. C, Wu C—. 1, Optimal solution to dense linear systems of
equations.— Proc. 1984 Int. Conf. Parallel Process.. N. Y.: IEEE, 1984,
p. 417—424.
468. Chen K.-W., Irani К. В. A Jacobi algorithm and its implementation
on parallel computers.— Free. 18th Annu. Allerton Conf. Commun., Control
and Ccmput., Monticello, 111., 1980, p. 564,—573.
469. Chen S.-C., К u с k D. J. Time and parallel processor bounds for linear
recurrence systems.—IEEE Trans. Ccmput., 1975, C-24, №7, p. 701—717.
470. Chen S.-C, Kuck D.J, Sameh A. H. Practical parallel band
triangular system solvers.— ACM Trans. Math. Softw., 1978, 4, №4, p. 270—277.
СПИСОК ЛИТЕРАТУРЫ
269
471. С h e n S. S. Large-scale and high-speed multiprocessor system for scientific
applications: CRAY X-MP series.— In: High-speed computation. Berlin:
Springer-Verlag, 1984, p. 59—67.
472. С h e η S. S., D ο η g a r r a J. J., Hsiung C. Multiprocessing linear
algebra algorithms on the CRAY X-MP-2: Experiences with small
granularity.—J. Parallel and Distibuted Comput., 1984, 1, № 1, p. 22—31.
473. Chen Т. С Parallelism, pipelining and computer efficiency.— Comput.
Design, 1971, 10, № 1, P. 69—76.
474. Chen Т. С Overlap and pipeline processing.— In: Introduction to computer
architecture. Palo Alto, Cal.: Sci. Research Assoc, 1975, p. 375—431.
475. Chen Т. С Unconventional superspeed computer systems.— AFIPS Conf.
Proc, 28. 1971 SJCC, p. 365—371.
476. Cheng W.-T., Feng T.-Y. Solving some mathematical problems by
associative processing.— Proc 1972 Sagamcre Comput. Conf. RADCAP and
Appl., 1972, p. 169—206.
477. Chern M.-Y., Murata T. A fast algorithm for concurrent LU
decomposition and matrix inversion.— Proc. 1983 Int. Conf. Parallel Process...
N. Y.: IEEE, 1983, p. 79—86.
478. Chern M.-Y., Murata T. Efficient matrix multiplications on a
concurrent data-loading array processor.— Proc. 1983 Int. Conf. Parallel Process..
N. Y.: IEEE, 1983, p. 90—94.
479. Chiang Y. P., F u K-S. Matching parallel algorithm and architecture.—
Proc. 1983 Int. Conf. Parallel Process.. N. Y.: IEEE, 1983, p. 374—380.
480. С h u a η g Η. Υ. Η., Η e G. Design of problem-size indedendent systolic
array systems.— Proc. 1984 IEEE Int. Conf. Ccmput. Design, Port Chester,
N. Y., 1984. N.Y.: IEEE, 1984, p. 152—157.
481. Clint M. A vectcr-multiplication dominated parallel algorithm for the
computation of real eigenvalue spectra.— Proc. Int. Conf. Vector and Parallel
Process. Ccmput. Sci., Chester, 1981. Ccmput. Phys. Ccmmun., 1982, 26,
№3/4, p. 373—376.
482. Clint M., Holt C, Ρ e г г о t t R., Stewart A. A comparison
of two parallel agcrithms for the symmetric eigenproblem.— Int. J. Comput.
Math., 1984, 15, №3/4, p. 291—302.
483. Clint M., Holt C, Ρ e г г о t t R., Stewart A. Algorithms for
the parallel computation of eigensystems.— In: Parallel computing 83.
Amsterdam: Ncrth-Holland, 1984, p. 123—130.
484. Clint M., Holt C, Ρ e г г о t t R., Stewart A. The influence of
hardware and software considerations on the design of synchronous parallel
algorithms.— Softw.— Pract. and Exper., 1983, 13, № 10, p. 961—974.
485. Cody W. Desirable hardware characteristics fcr scientific ccmputaton.—
SIGNUM Newslet., 1971, 6, № 1, p. 16—31.
486. Computer architecture and netwcrks: modelling and evaluation (Proc. Int.
Workshop Ccmput. Archit. and Netwcrks, Rocquencourt, France, 1974.) / Eds.
E. Gelenbe, R.Mahl.— Amsterdam: Ncrth-Holland: N. Y.: American
Elsevier, 1974.— 527 p.
487. Conrad V., Wallach Y. Iterative solution of linear equations on
a parallel prccesscr system.—IEEE Trans. Comput., 1977, C-26, №9,
p. 838—847.
488. Conrad V., Wallach Y. Parallel optimally crdered factcrisation.—
Proc. 1977 Fewer Ind. Ccmput. Appl. Conf., Tcronto, 1977. N. Y.: IEEE,
1977, p. 302-306.
489. Cook S. A. The classificaticn of prcblems which have fast parallel
algorithms.— Free. 1983 Int. Fctnd. Ccmput. Thecry Conf., Bcrgholm, 1983.
Lect. Notes Ccrrput. Sci., Vol. 158. Berlin: Springer-Verlag, 1983, p. 7Й—93.
490. С s a n k у L. Fast parallel matrix imersicn algorithms.— SIAM J. Ccmput.„
1976, 5, №4, p. 618—623.
491. С u 1 i k II K., Gruska J., Salomaa A. Systolic trellis automata
(Part 1, 2).— Int. J. Ccmput. Math., 1984, 15, №3/4, p. 195—212; 16, № lr
p. 3—22.
270
СПИСОК ЛИТЕРАТУРЫ
492. Dasgupta S. The design and description of computer architecture.—
N. Y.: John Wiley and Sons, 1984.—300p.
493. D a v i e s S. T. The implementation of the FFT on the DAP.— In:
Supercomputers and parallel computation. Oxford: Clarendon Press, 1984, p. 195—
208.
494. D e k e 1 Ε., Ν a s s i m i D., S a h η i S. Parallel matrix and graph
algorithms.— SIДМ J. Comput., 1981, 10, №4, p. 657—675.
495. D e 1 о s e J.-M., Μ о г f M. Scattering arrays for matrix computations.—
In: Real-time signal processing IV. Proc. SPIE, 298. Bellingham, Wash.:
SPIE, 1981, p. 74—83.
496. Delves L. M., Samba A. S., Hendry J. A. Band matrices on
the DAP.— In: Supercomputers and parallel computation. Oxford: Clarendon
Press, 1984, p. 167—184.
497. D e m i η e t J. Experience with multiprocessor algorithms.— IEEE Trans.
Comput., 1982, C-31, №4, p. 278—288.
498. Dennis J. B. Data flow supercomputers.—Computer, 1980, 13, №11,
p. 48—56.
499. Dennis J. B. The varieties of data flow computers.— Proc. 1th Int. Conf.
Distributed Comput. Syst., Houstville, ΑΙ., 1979. Ν. Υ.: IEEE, 1979, p. 430-
439.
500. D e s ρ a i η Α. Μ. Notes on computer architecture for high performance.—
In: New computer architecture. N. Y.: Acad. Press, 1984, p. 59—138.
501. Despain A. M. Very fast Fourier transform algorithms for hardware
implementation.—IEEE Trans. Comput., 1979, C-28, №5, p. 333—341.
502. Despain A. M., Patterson D. A X-tree: a tree structured
multiprocessor computer architecture.— Proc. 5th Annu. Symp. Comput. Archit.,
1978. N. Y.: IEEE, 1978, p. 144—151.
503. Dew P. M. VLSI architectures for problems in numerical computation.—
In: Supercomputers and parallel computation. Oxford: Clarendon Press, 1984,
p. 1—24.
504. D i Μ a n ζ ο Μ., F r i s i a η i A. L., О 1 i m ρ ο G. Loop optimization
for parallel processing.—Comput. J., 1979, 22, №3, p. 324—239.
505. D ο η e g a n Μ. Κ·, Κ a t ζ k e S. W. Lexical analysis and parsing
techniques for a vector machine.—SIGPLAN Not., 1975, 10, №3, p. 138—145.
506. Dongarra J. J. Redisigning linear algebra algorithms.— Proc. 1st Int.
Colloq. Vector and Parallel Comput. in Sci. Appl., Paris, 1983. EDF Bull.
Dir. Etud. et Rech., 1983, C, № 1, p. 51—50.
507. Dongarra J. J., Eisenstat S. С Squeezing the most out of an
algorithm in CRAY FORTRAN.— ACM Trans. Math. Softw., 1984, 10, №3,
p. 219—230.
508. Dongarra J. J., Gustavson F. G., Karp A. Implementing
linear algebra algorithms for dense matrices on a vector pipeline machine.—
SIAM Rev., 1984, 26, №1, p. 91 — 112.
509. Dongarra J. J., Hiromoto R.E. A collection of parallel linear
equations routines for the Denelcor HEP.— Parallel Comput., 1984, 1, № 2,
p. 133—142.
510. Dongarra J. J., Sameh A. H. On some parallel banded system
solvers.—Parallel Comput., 1984, 1, №3/4, p. 223—235.
511. Donnelly J. D. P. Periodic chaotic relaxation.— Linear Alg. Appl.,
1971, 4, p. 117—128.
512.. D u b о i s M., В г i g g s F. A. Performance of synchronized iterative
processes in multiprocessor systems.— IEEE Trans. Softw. Eng., 1982, SE-8,
№4, p. 419—431.
513. Dubois P. F., Greenbaum Α., Rodrique G. H.
Approximating the inverse of a matrix for use in iterative algorithms on vector
processors.—Computing, 1977, 22, №3, p. 257—268.
514. D u b о i s P. F., Rodrigue G. H. An analysis of the recursive
doubling algorithm.— In: High speed computer and algorithm organization. N. Y.:
Acad. Press, 1977, p. 299—305.
СПИСОК ЛИТЕРАТУРЫ
271
515. Duff I. S. The solution of sparse linear equations on the CRAY-1.— In:
High-speed computation. Berlin: Springer-Verlag, 1984, p. 293—309.
516. Duff I. S., R e i d J. К- Experience of sparse matrix codes on the
CRAY-1.— Proc. Int. Conf. Vector and Parallel Process. Comput. Sci.,
Chester, 1981., Comput. Phys. Commun., 1982, 26, №3/4, p. 293—302.
517. Duff M. J. B. Parallel algorithms and their influence on the specification
of application problem.— In: Multicomputer and image processing: Algorithms
and programs. N. Y.: Acad. Press, 1982, p. 261—274.
518. Duller A. W. G., Ρ a d d ο η D.J. Processor arrays and the finite
element method.— In: Parallel computing 83. Amsterdam: North-Holland,
1984, p. 131—136.
519. Dungworth M. The CRAY-1 computer system.— In: Supercomputers, 2.
, Maidenhead: Infotech Int., 1979, p. 51—76.
520. D у m ο η P. W., Cook S. A. Hardware complexity and parallel compu-,
tation.— Proc. 21th Annu. Symp. Found. Comput. Sci., Syracuse, 1980. N. Y.:
IEEE, 1980, p. 360—372.
521. Eberly W. Very Fast parallel matrix and polynomial arithmetic.—
Proc. 25th Annu. Symp. Found. Comput. Sci., Singer Island, Fla., 1984. N. Y.:
IEEE, 1984, p. 21-30.
522. Ellis G. H., Watson L. T. A parallel algorithm for simple roots of
polynomials.—Comput. and Math. Appl., 1984, 10, №2, p. 107—121.
523. Ε η s 1 о w P. Η. Multiprocessor organization — a survey.— Ccmput. Surv.,
1977, 9, № 1, p. 103—129.
524. Erbilgin В., Peterson A. M. VLSI structures for iterative
computations.— Proc. 17th Asilomar Conf. Circuits, Syst. and Comput., Santa Clara;
Cal., 1983. N. Y.: IEEE, 1983, p. 128—134.
525. Erickson D. B. Array processing on an array processor.— SIGPLAN
Not., 1975, 10, №3, p. 17—24.
526. Eriksen O., Staunstrup J. Concurrent algorithms for root
searching.—Acta Inf., 1983, 18, №4, p. 361—376.
527. Evans D.J. New parallel algorithms for partial differential equations.—
In: Parallel computing 83. Amsterdam: North-Holland, 1984, p. 3—56.
528. Evans D. J. New parallel algorithms in numerical algebra.—Proc.
1st Int. Colloq. Vector and Parallel Comput. in Sci. Appl., Paris, 1983. EDF
Bull. Dir. Etud. et Rech., 1983, C, № 1, p. 61—70.
529. Evans D. J. Parallel numerical algorithms for linear systems.— In:
Parallel processing systems. Cambridge Univ. Press, 1982, p. 357—383.
530. Evans D.J. Parallel S. O. R. iterative methods.—Parallel
Comput., 1984, 1, № 1, p. 3—18.
531. Evans D. J. Problem formulation using array processing techniques.—
* SIGPLAN Not., 1975, 10, №3, p. 153—163.
532. Evans D.J., Hadjidimos A. A modification of the quadrant
interlocking factorisation parallel method.— Int. J. Comput. Math., 1980, 8,
№2, p. 149—166.
533. Evans D. J., Hadjidimos Α., Ν ο u t s о s D. Parallel solution
of linear systems by quadrant interlocking factorisation methods.— Comput.
Meth. Appl. Mech. and Eng., 1981, 29, № 1, p. 97—107.
534. Evans D. J., Hadjidimos Α., Ν ο u t s о s D. The parallel
solution of banded linear equations by the new quadrant interlocking
factorisation (Q. I. F.) method.— Int. J. Comput. Math., 1981, 9, № 2, p. 151—161.
535. Evans D. J., Hatzopoulos M. A parallel linear system solver.—
Int. J. Comput. Math., 1979, 7, №3, p. 227—238.
536. Evans D. J., Hatzopoulos M. The parallel calculation of the
eigenvalues of a real matrix Α.— Comput. and Math. Appl., 1978, 4, № 3,
p. 211—218.
537. Evans D. J., Shanehchi J., Barlow R. H. Implementation of
the conjugate gradient and Lanczos algorithms for large sparse banded matrices
on the ICL-DAP.— In: Parallel computing 83. Amsterdam: North-Holland,
1984, p. 143—151.
272
СПИСОК ЛИТЕРАТУРЫ
538. Evans D. J., Sojoodi-Haghighi R. Parallel iterative methods
for solving linear equations.— Int. J. Comput. Math., 1982, 11, № 3/4, p. 247—
284.
539. Farmwald P. M. The S-l Mark IIA supercomputer.— In: High-speed
computation. Berlin: Springer-Verlag, 1984, p. 145—155.
540. Fawcett J. Partitioning and tearing applied to cellular array
processing.— In: Real-time signal processing V. Proc. SPIE, 341. Bellingham, Wash.:
SPIE, 1982, p. 118—125.
541. Fawcett J., Bickart T. A. Cellular arrays in the solution of large
sets of linear equations.— Proc. IEEE Int. Conf. Circuits and Comput., Port
Chester, N. Y., 1980. N. Y.: IEEE, 1980, p. 984—987.
542. Feierbach G., Stevenson D. The ILLIAC IV.— In:
Supercomputers, Vol. 2. Maidenhead: Infotech Int., 1979, p. 77—92.
543. Fe i er b ach G., Stevenson D. The PHOENIX project.— In:
Supercomputers, 2. Maidenhead: Infotech Int., 1979, p. 93—115.
544. F e i 1 m e i e r M. Parallel numerical algorithms.— In: Parallel processing
systems. Cambridge Univ. Press, 1982, p. 285—338.
545. F e i 1 m e i e г Μ., R ο η s с h W. Parallel non-linear algorithm.— Proc.
Int. Conf. Vector and Parallel Process. Comput. Sci., Chester, 1981. Comput.
Phys. Commun., 1982, 26, №3/4, p. 335—348.
546. F e i 1 m e i e r M., Segerer G. Numerical stability in parallel
evaluation of arithmetic expressions.— In: Parallel computers — parallel
mathematics. Amsterdam: North-Holland, 1977, p. 107—112.
547. Feller M., Ercegovac M. D. Queue machines: an organization for
parallel computation.—CONPAR 81 Conf. Proc, Nuremberg, 1981. Lect.
Notes Comput. Sci., 111. Berlin: Springer-Verlag, 1981, p. 37—47.
548. Feng T.-Y. A survey of interconnection networks.—Computer, 1981, 14,
№ 12, p. 12—27.
549. F i 1 о t t i I. Parallel general-purpose architecture.— In: VLSI architecture.
Englewood Cliffs, N. J.: Prentice Hall Int., 1983, p. 327—347.
550. Finn A. M., L u к F. Т., Pottle С Systolic array computation of the
singular value decomposition.— In: Real-time signal processing V. Proc.
SPIE, 341. Bellingham, Wash.: SPIE, 1982, p. 35—43.
551. Fishburn J. P. Analysis of speedup in distributed algorithms.— Ann
Arbor: UMI Research Press, 1984.—115 p.
552. Fisher A. L., Kung Η. Τ. Synchronizing large systolic arrays.—
In: Real-time signal processing V. Proc. SPIE, 341. Bellingham, Wash.: SPIE,
1982, p. 44—52.
553. Fisher A. L., Kung H. Т., Μ ο η i e r L. Μ., D о h i Υ. The
architecture of a programmable systolic chip.— J. VLSI and Comput. Syst., 1984,
1, №2, p. 153—169.
554. Flynn M. J. Directions and issues in architecture and language.—
Computer, 1980, 13, № 10, p. 5—22.
555. Flynn M. J. Soms computer organizations and their effectiveness.—
IEEE Trans. Comput., 1972, C-21, №9, p. 948—960.
555. Fong J., Pottle C. Parallel processing of power system analysis
problems via simple parallel microcomputer structures.— IEEE Trans. Power
Appar. and Syst., 1978, PAS-97, № 5, p. 1834—1841.
557. Forestier C. On the use of a multimicroprocessor systems for the
resolution of eigenvalue problems in partial differential equations.— In: Advances
in computer methods for partial differential equations IV. New Brunswich,
N. J.: IMACS, 1981, p. 281—285.
558. Fornberg B. A vector implementation of the fast Fourier transform algo-
ritm.—Math. Comput., 1981, 36, №153, p. 189—191.
559. F r a g η e 1 1 i V. Architectures for sparse band matrix dense vector
multiplication.— In: Parallel computing 83. Amsterdam: North-Holland, 1984,
p. 507—514.
560. Frailong J.M., Ρ а к 1 e ζ a J. Resolution of general partial different
tial equations on a fixed size SIMD/MIMD large cellular processor.— In:
СПИСОК ЛИТЕРАТУРЫ
273*
Simulation of systems'79. Amsterdam: North-Holland, 1980, p. 199—
204.
561. Franklin M. A. Parallel solution of ordinary differential equations.—
IEEE Trans. Comput., 1978, C-27, № 5, p. 413—419.
562. Franklin Μ. Α., Soong N. L. One-dimensional optimization onr«
multiprocessor systems.— IEEE Trans. Comput., 1981, C-30, № 1, p. 61—66.
563. Fritsch G., Muller H. Parallelization of a mimnimization problem-
for multiprocessor systems.—CONPAR 81 Conf. Proc, Nuremberg, 198L
Lect. Notes Comput. Sci., 111. Berlin: Springer-Verlag, 1981, p. 453—463.·
564. Future systems. 1, 2 / Ed. С. Н. White.— Maidenhead: Infotech Int., 1977.—
286 p., 420 p.
565. G a j s k i D. D. An algorithm fcr solving linear recurrence systems on
parallel and pipelined machines.—IEEE trans. Ccmput., 1981, C-30, № 3,
p. 190—206.
566. G a j s k i D. D. Processor arrays for computing linear recurrence systems.—
Proc. 1978 Int. Conf. Parallel Process.. N. Y.: IEEE, 1978, p. 246—256.
567. G a j s k i D. D. Recurrence semigroups and their relation to data storage
in fast recurrence solvers on parallel machines.— CONPAR 81 Conf. Proc.,
Nuremberg, 1981. Lect. Notes Ccmput. Sci., 111. Berlin: Springer-Verlag*
1981, p. 343—357.
568. G a j s k i D. D. Solving banded triagular systems on pipelined machines.—
Proc. 1979 Int. Conf. Parallel Process.. N. Y.: IEEE, 1979, p. 308—319.
569. G a j s k i D. D., S a m e h A. H., Wisniewski J. A. Iterative
algorithms for tridiagonal matrices on a WSI-multiprocessor.— Proc. 1982
Int. Conf. Parallel Process.. N. Y.: IEEE, 1982, p. 82—89.
570. Galli L., Resta G. Implementation of a data flow algorithm for
linear programming.— In: Parallel computing 83. Amsterdam: North- Ho Hand,.
1984, p. 153—158.
571. G a 1 1 ο ρ о u 1 о s Ε. J., Μ с Ε w a n S. D. Numerical experiments with
the massively parallel processor.— Proc. 1983 Int. Conf. Parallel Process.. ·
N. Y.: IEEE, 1983, p. 29—35.
572. Gannon D. B. A note on pipelining a mesh connected multiprocessor
for finite element problems by nested dissection.— Proc. 1980 Int. Conf.
Parallel Process.. N. Y.: IEEE, 1980, p. 197—204.
573. Gannon D. B. On mapping non-uniform P. D. E. structures' and
algorithms onto uniform array architectures.— Proc. 1981 Int. Conf. Parallel
Process.. N. Y.: IEEE, 1981, p. 100—105.
574. Gannon D. В., van Rosendale J. On the impact of communica-
tional complexity on the design of parallel numerical algorithms.— IEEE
Trans. Comput., 1984, C-33, № 12, p. 1180—1194.
575. Gannon D. В., Snyder L., van Rosendale J.
Programming substructure computations for elliptic problems on the CHiP system.—.
In: Impact of new computing systems on computational mechanics, AmeF~
Soc. Mech. Eng., 1983, p. 65—80.
576. G а о Q.-S;, Wang Q.-O. Vector computer for sparse matrix operations.—
Proc. 1983.Int. Conf. Parallel Process.. N. Y.: IEEE, 1983, p. 87—89.
577. Gary J., McCormick S., Sweet R. Successive overrelaxationy
multigrid and preconditioned conjugate gradients algorithms for solving a
diffusion problem on a vector computer.— Appl. Math, and Comput., 1983».
13, №3/4, p. 285—309.
578. von zur Gathen J. Parallel algorithms for algebraic problems.—
SIAM J. Comput., 1984, 13, №4, p. 802—824.
579. Gelen.be E. Parallel computation of partial differential equations: a
modelling approach.— Proc. 19th IEEE Conf. Decision and Control,
Albuquerque, N. Мех., 1980. Ν. Υ.: IEEE, 1980, 1, p. 755—760.
580. Gelenbe E., Lichnewsky Α., Staphylopatis A.
Experience with the parallel solution of partial differential equations on a distributed
computing system.—IEEE Trans. Comput., 1982, C-31, № 12, p. 1157—
1164.
274
СПИСОК ЛИТЕРАТУРЫ
581. G e n t-e 1 m a n W. M. Some complexity results for matrix computatios on
parallel processors.—J. Assoc. Comput. Mach., 1978, 25, № 1, p. 112—115.
582. Gentleman W. Μ., Κ u η g Η. Τ. Matrix triangularization by
systolic arrays.— In: Real-time signal processing IV. Proc. SPIE, 298. Belling-
ham, Wash.: SPIE, 1981, p. 19—26.
583. Gentzsch W. How to maintain the efficiency of highly serial algorithms
involving recursions on vector computers.— Proc. 1st Int. Colloq. Vector and
Parallel Comput. in Sci. Appl., Paris, 1983. EDF Bull. Dir. Etud. et Rech.,
1983, C, № 1, p. 79—86.
584. Gentzsch W., Schafer G. Solution of large linear systems on vector
computers.— In: Parallel computing 83. Amsterdam: North-Holland, 1984,
p. 159—166.
585. G e η ζ A. Numerical multiple integration on parallel computers.— Proc.
Int. Conf. Vector and Parallel Process. Comput. Sci., Chester, 1981. Comput.
Phys. Commun., 1982, 26, №3/4, p. 349—352.
586. G e η ζ Α., Swayne D. A. Parallel implementation of ALOD methods
for partial differential equations.— In: Parallel computing 83. Amsterdam:
North-Holland, 1984, p. 167—172.
587. George Α., Poole W. G., V о i g h t R. G. Analysis of dissection
algorithms for vector computers.— Comput. and Math. Appl., 1978, 4, № 4,
p. 287—304.
588. G i 1 m о r e P. A. Matrix computations on an associative processor.— Proc.
1974 Sagamore Comput Conf. Parallel Process.. Lect. Notes Comput. Sci., 24.
Berlin: Springer-Verlag, 1975, p. 272—290.
589. G i 1 m о г е P. A. Numerical solution of partial differential equations by
associative processing.—AFIPS Conf. Proc, 39, 1971 FJCC, p. 411—418.
590. G i 1 m о r e P. A. Structuring of parallel algorithms.— J. Assoc. Comput.
Mach., 1968, 15, p. 176—192.
591. Ginsberg M. Some observations on supercomputer computational en-
viroments.— In: Parallel and large-scale computers: performance, architecture,
applications. Amsterdam: North-Holland, 1983, p. 173—184.
592. Gostick R. W. Software and algorithms for the distributed array
processor.—ICL Tech. J., 1979, 1, №2, p. 116—135.
593. Gottlieb Α., Schwartz J. T. Networks and algorithms for very-
' large-scale parallel computation.—Computer, 1982, 15, № 1, p. 27—36.
594. Graham W. R. A review of capabilities and limitation of parallel and
pipeline computers.— In: Numerical and computer methods in structural me-
• chanics. N. Y.: Acad. Press, 1973, p. 479—495.
595. Grcar J.,Sameh A. On certan parallel Toeplitz linear system solvers.—
SIAM J. Sci. and Stat. Comput., 1981, 2, №2, p. 238—256.
596. Greene W., Pooch V. W. A review of classification schemes for
computer communication network.— Computer, 1977, 10, №11, p. 12—21.
597. G.reenberg A. C, Ladner R. E, Paterson M. S, G a-
1 i 1 Z. Efficient parallel algorithms for linear recurrence computation.—
Inf. Process. Lett., 1982, 15, № 1, p. 31—35.
598. Gremers А. В., К u η g S. Y. On programming VLSI concurrent array
• processors.— Integration, 1984, 2, № 1, p. 15—26.
599. G'г о s с h С. Е. Performance analysis of Poisson solvers on array
computers.— In: Supercomputers, 2. Maidenhead: Infotech Int., 1979, p. 147—180.
600. Gurd J., Watson I. Data driven system for high speed parallel
computing. Part 1: Structuring software for parallel execution.— Comput. Design,
1930, №6, p. 91 — 100.
601. Gurd J., Watson I. Data driven system for high speed parallel
computing. Part 2: Hardware design.— Comput. Design, 1980, 19, № 7, p. 97—106.
602. Η a 1 a d a L. A parallel algorithm for solving band systems and matrix
inversion.—CONPAR 81 Conf. Proc, Nuremberg, 1981. Lect. Notes Comput.
Sci., HI. Berlin: Springer-Verlag, 1981, p. 433—440.
603. Η a 1 i η J., Burer R., Halg W. Software development for the ETN-
multiprocessor project: parallel integration of ordinary and partial differential
СПИСОК ЛИТЕРАТУРЫ
27S
equations by means of power series.— In: Advances in computer methods for
partial differential equations-II. New Brunswich, N. J.: IMACS, 1977, p. 189—
194.
604. Η a n η a W. A. Parallel algorithms for solving matrix-oriented problems
on the three-dimensial computer.— Euromicro J., 1978, 4, № 4, p. 227—231.
605. Hansen P. B. The architecture of concurrent programs.— Englewood
Cliffs, N.J.: Prentice-Hall, 1977.—317 p.
606. Η arte J. The FPS AP-120B array processor.— In: Supercomputers, 2..
Maidenhead: Infotech Int., 1979, p. 183—203.
607. Hatzopoulos M. A symmetric parallel linear system solver.— Int.
J. Comput. Math., 1983, 13, p. 133—141.
608. Hatzopoulos M. Parallel linear system solvers for tridiagonal
systems.— In: Parallel processing systems. Cambridge Univ. Press, 1982, p. 385—
393
609. Hay nes L. S., L a u R. L., Siewiorek D. P., Μ i ζ e 1 1 D. W.
A survey of highly parallel computing.— Computer, 1982, 15, № 1, p. 9—24.
610. Handler W. Aspects of parallelism in computer architecture.— Math,
and Comput. Simul., 1977, 19, №4, p. 278—283.
611. Η a n d 1 e г W. Innovative computer architecture — how to increase
parallelism but not complexity.— In: Parallel processing systems. Cambridge Univ.
Press, 1982, p. 1—42.
612. Handler W. Simplicity and flexibility in concurrent computer
architecture.— In: High-speed computation. Berlin: Springer-Verlag, 1984, p. 69—
88.
613. Handler W., Schreiber H., S i g m u η d V. Computation
structures reflected in general purpose and special purpose
multi-micro-processor systems.— Proc. 1979 Int. Conf. Parallel Process.. N. Y.: IEEE, 1979,
p. 95—102.
614. Heller D. A determinant theorem with applications to parallel
algorithms.—SIAM J. Numer. Anal., 1974, 11, №3, p. 559—568.
615. Heller D. A survey of parallel algorithms in numerical linear algebra.—
SIAM Rev., 1978, 20, №4, p. 740—777.
616. Η e 1 1 e r D. Minimal parallelism for computations under time constraints.—
In: High speed computer and algorithm organization. N. Y.: Acad. Press, 1977,
p. 321—322.
617. Heller D., Ipsen I.C.F. Systolic networks for orthogonal
decompositions.— SIAM J. Sci. and Stat. Comput., 1983, 4, № 2, p. 261—269.
618. Heller D., Stevenson D. K., Traub J. F. Accelerated
iterative methods fcr the solution of tridiagonal systems on parallel computers.—
J. Assoc. Comput. Mach., 1976, 23, №4, p. 636—654.
619. Hellerman H. Parallel processing of algebraic expressions.— IEEE
Trans. Electr. Comput., 1966, EC-15, № 1, p. 82—91.
620. Η e 1 1 i e r R. L. DAP implementation of the WZ algorithm.— Proc. Int.
Conf. Vector and Parallel Process. Comput. Sci., Chester, 1981. Comput. Phys.
Commun., 1982, 26, №3/4, p. 321—324.
621. Helmbrecht U., Zabolitzky J. G. Greens-function Monte
Carlo on the CYBER 205.— In: Parallel computing 83. Amsterdam: North-Holland,
1984, p. 319—324.
622. Hemker P. W. Multigrid algcrithms run on supercomputers.— CWI
Newslett., 1984, №3, p. 25—30.
623. Hemker P. W., Wesseling P., de Zeeuw P. M. A portable
vector-code for autoncmous multigrid modules.— In: PDE software: modules,,
interfaces and systems. Amsterdam: North-Holland, 1984, p. 29—40. -
624. Hendry J. Α., Delves L. M. GEM calculations on the DAP.— In:
Supercomputers and parallel ccmputation. Oxford: Clarendon Press, 1984,
p. 185—194.
625. Η e r ζ ο g U. Performance modelling and evaluation for concurrent computer
architectures.— In: High-speed computation. Berlin: Springer-Verlag, 1984„
p. 177—189.
276
СПИСОК ЛИТЕРАТУРЫ
626. Η е u f t R. W., Little W. D. Improved time and parallel processor
bounds for FORTRAN-like loops.— IEEE Trans. Comput., 1982, C-31, № 1,
p. 78—81.
627. Η i g b i e L. Applications of vector processing.— Comput. Design, 1978,
17, №4, p. 139—145.
628. High-speed computation (Proc. NATO Advanced Research Workshop High-
Speed Comput.. Julich, FRG, 1980.) / Ed. J. S. Kowalik.— Berlin: Springer-
Verlag, 1984.— 441 p.
629. High speed computer and algorithm organization (Proc. Symp. High Speed
Comput. and Algorithm organization. Urbana, 111., 1977.) / Eds. D.J. Kuck,
D. H. Lawrie, A. H. Sameh.— N. Y.: Acad. Press, 1977.— 468 p.
630. Η i r a i w a K. A new parallel algorithm for the fast Fourier transform on
pipeline computer with bit-and-indirect-vector-facilities.— FUJITSU Sci.
Tech. J., 1983, 19, №2, p. 177—198.
631. Hockney R.W. Characterization of parallel computers and algorithms.—
Proc. Int. Conf. Vector and Parallel Process. Comput. Sci., Chester, 1981.
Comput. Phys. Commun., 1982, 26, №3/4, p. 285—292.
632. Hockney R. W. Characterizing computers and optimizing the FACR (1)
Poisson-solver on parallel unicomputers.— IEEE Trans. Comput., 1983,
C-32, № 10, p. 933—941.
633. Hockney R.W. Performance of parallel computers.—In: High-speed
computation. Berlin: Springer-Verlag, 1984, p. 159—175.
634. Hockney R.W. Super-computer architecture.— In: Future systems, 2,
Maidenhead: Infotech Int., 1977, p. 277—305.
635. Hockney R. W. The n1/2 method of algorithm analysis.— In: PDE
software: modules, interfaces and systems. Amsterdam: North-Holland, 1984,
p. 429—444.
636. Hockney R. W., Jesshope C. R. Parallel computers: Architec-
/: ture, programming and algorithms.— Bristol: Adam Hilger, 1981.— 423 p.
637. Hon R. W., Reddy D. R. The effect of computer architecture on
algorithm decomposition and performance.— In: High speed computer and
algorithm organization. N. Y.: Acad. Press, 1977, p. 411—422.
638. Horiguchi S., Kawazoe Y., Nara H. A parallel algorithm for
the integration of ordinary differential equations.— Proc. 1984 Int. Conf.
Parallel Process.. N. Y.: IEEE, 1984, p. 465—469.
639. Horowitz E. VLSI architecture for matrix computations.— Proc. 1979
Int. Conf. Parallel Process.. N. Y.: IEEE, 1979, p. 124—127.
640. Η ο u s о s E. C, Wing O. Parallel nonlinear minimization by conjugate
directions.—Proc. 1980 Int. Conf. Parallel Process.. N. Y.: IEEE, 1980,
p. 157—158.
641. Houstis С E., Houstis E. N., R i с e J. R. Partitioning and
allocation of the PDE computations in distributed systems.— In: PDE
software: modules, interfaces and systems. Amsterdam: North-Holland, 1984,
p. 67—87.
642. Huang J. W., Wing O. Optimal parallel triangulation of a sparse
matrix.— IEEE Trans. Circuits and Syst., 1979, CAS-26, №9, p. 726—732.
643. Huang K.-H., Abraham J. A. Efficient parallel algorithms for
processor arrays.— Proc. 1982 Int. Conf. Parallel Process.. N. Y.: IEEE, 1982,
p. 271—279.
644. Huck J. C, Flynn M. J. Comparative analysis of computer
architectures.— Proc. IFIP Congr. 83, Paris, 1983. Amsterdam: North-Holland, 1983,
p. 699—703.
645. Hunt D.J. Application techniques for parallel hardware.— In:
Supercomputers, 2. Maidenhead: Infotech Int., 1979, p. 205—219.
646. Hunt D.J., Webb S. J., Wilson A. Application of a parallel
processor to the solution of finite difference problems.—,'ln: Elliptic problem
solvers. N. Y.: Acad. Press, 1981, p. 339—344.
647. Η u b 1 e г Α., Klette R. On parallel realization of the fast Fourier
СПИСОК ЛИТЕРАТУРЫ
277
transformation of NxN matrices.— Elektr. Inf. und Kuber., 1979 15, № 12,
p. 599—609.
648. Hwang K,., В г i g g s F. Computer architectures and parallel
processing.— N. Y.: McGraw-Hill, 1984.
649. Hwang К-, Cheng Y.-H. Partitioned matrix algorithms for VLSI
arithmetic systems.—IEEE Trans. Comput., 1982, C-31, №12, p. 1215—
1224.
650. Hwang K., Cheng Y.-H. VLSI computing structures for solving large-
scale linear systems of equations.— Proc. 1980 Int. Conf. Parallel Process..
N. Y.: IEEE, 1930, p. 217—230.
651. Hwang K·, Su S.-P., Ni L. M. Vector computer architecture and
processing techniques.— In: Advances in computers, 20. N. Y.: Acad. Press,
1981, p. 116—199.
652. Η у a f i 1 L. On the parallel evaluation of multivariate polynomials.—
Proc. 10th Annu. ACM Symp. Theory Comput., San Diego, Cal., 1978, p. 193—
195.
653. Η у a f i 1 L., К u η g Η. Τ. The complexity of parallel evaluation of
linear recurrences.— J. Assoc. Comput. Mach., 1977, 24, №3, p. 513—521.
654. Ibarra Ο. Η., Ρ a 1 i s Μ. Α., Κ i m S. Μ. Designing systolic
algorithms using sequentional machines.— Proc. 25th Annu. Symp. Found.
Comput. Sci., Singer Island, Fla., 1984. N. Y.: IEEE, 1984, p. 46—55.
655. I g η i ζ i о J. P., Palmer D. F., Murphy С Μ. A multicriteria
approach to supersystem architecture definition.— IEEE Trans. Comput.,
1982, C-31, №5, p. 410—418.
656. I i ζ a w a Α., Κ u η i i T. L. Graph-based design specification of parallel
computation.— In: VLSI Engineering. Lect. Notes Comput. Sci., 163. Berlin:
Springer-Verlag, 1984, p. 132—160.
657. J a'J a J., Kumar P. Information transfer in distributed computing
with application to VLSI.— J. Assoc. Comput. Mach., 1984, 31, № 1, p. 150—
162.
658. Jensen С Taking another approach to supercomputing.— Datamation,
1978, 24, №2, p. 159-172.
€59. Jensen E. D. The Honeywell experimental distributed processor: an
overview.—Computer, 1978, U, №1, p. 28—38.
660. J e s s J. A. G., К e e s H. G. M. A data structure for parallel L/U
decomposition.—IEEE Trans. Comput., 1982, C-31, №3, p. 231—239.
661. Jesshope С R. A reconfigurable processor array for VLSI.— In:
Supercomputers and parallel computation. Oxford: Clarendon Press, 1984, p. 35—
40.
662. Jesshope C. R. Programming with a high degree of parallelism in
FORTRAN.—Proc. Int. Conf. Vector and Parallel Process. Comput. Sci.,
Chester, 1981. Comput. Phys. Commun., 1982, 26, № 3/4, p. 237—246.
663. Jesshope С R., Craigie J. A. I. Some principles of parallelism
in particle and mesh modelling.— In: Supercomputers, 2. Maidenhead: Info-
tech Int., 1979, p. 221—235.
664. Johnson O. G. On the use an array processor in the solution of partial
differential equations.— Trans. Amer. Nucl. Soc, 1970, 13, № 1, p. 181—182.
665. Johnson O. G. Vector function chainer software for banded
preconditioned conjugate gradient calculations.— In: Advances in computer methods
for partial differential equations-IV. New Brunswich, N. J.: IMACS, 1981,
p. 243—245.
666. Johnson O. G., Paul G. Vector algorithms for elliptic partial
differential equations based on the Jacobi method.— In: Elliptic Problem Solvers.
N. Y.: Acad. Press, 1981, p. 345—351.
667. Johnson P. M. An introduction to vector processing.— Comput. Design,
1978, 17, № 2, p. 89—97.
668. Johnsson L. A computational array for the QR-method.— Proc. Conf.
Advanc. Res. VLSI, Cambrige, 1981; Dedham, Ma.: Artech, 1982, p. 123—129.
669. Johnsson L. VLSI algorithms for Doolittle's, Crout's and Cholesky's
278
СПИСОК ЛИТЕРАТУРЫ
methods.— Proc. IEEE Int. Conf. Circuits and Comput., 1982. N. Y.: IEEEr
1982, p. 372—376.
670. Jones A. K-, Schwarz P. Experience uzing multiprocessor
systems. — A statut report.— Comput. Surv., 1980, 12, № 2, p. 121—165.
671. J о r d a η Η. F., Scalabr-in M., С a 1 ν e r t W. A comparison of
three types of multiprocessor algorithms.— Proc. 1979 Int. Conf. Parallel
Process.. N. Y.: IEEE, 1979, p. 231—238.
672. Jordan T. L. A guide to parallel computation and some CRAY-1
experiences.— In: Parallel computations. N. Y. : Acad. Press, 1982, p. 1—50.
673. Jordan T. L.A performance evaluation of linear algebra software in
parallel architectures.— In: Performance evaluation of numerical software.
Amsterdam: Ncrth-Holland, 1979, p. 59—76.
674. К a m e 1 Η. Α., Τ'a n J. Μ. Performance of finite element algorithms on
an array processor-minicomputer based system.— In: Nonlmear finite elenent
analysis in structutral mecanics. Berlin: Springer-Verlag, 1981, p. 742—757.
675. Kamiya S., Isobe F., Takashima H., Takiuchi M.
Practical vectorization techniques for the «FACOM VP».— Proc. IFIP Congn
83, Paris, 1983. Amsterdam: North-Holland, 1983, p. 389—394.
676. Kaneda Y., Kohata M. Highly parallel computing of linear
equations on the matrix-broadcast-memory connected array processor system.— In:
Parallel and large-scale computers: performance, architecture, applications.
Amsterdam: North-Holland, 1983, p. 221—226.
677. Kaneda Y., Kohata M. Parallel algorithm for transformation of a
symmetric band matrix to tridiagonal form on ring-shaped processor array.—
J. Inf. Process., 1984, 6, №4, p. 242—243.
678. Kant R. Μ., Κ i m u r a T. Decentralized parallel algorithms for matrix
computation.— Proc. 5th Annu. Symp. Comput. Archit., 1978. N. Y.: IEEE,
1978, p. 96—100.
679. К a p a u a η Α., W a n g Κ. Υ., Gannon D, С u η у J.,
Snyder L. The Pringle: am experimental system for parallel algorithm and
software testing.— Proc. 1984 Int. Conf. Parallel Process.. N. Y. : IEEE, 1984,
p. 1—6.
680. Kapur R. N., Browne J. С Techniques for solving block tridiagonaf
systems on reconfigurable zrray computers.— SIAM J. Sci. and Stat. Comput,
1984, 5, №3, p. 701—719.
681. К a s a b ο ν Ν. Κ·, Β i j e ν G. Т., J e с h e ν Β. J. Hierarchical
discrete systems and realisation of parallel algorithms.— CONPAR 81 Conf.
Proc, Nuremberg, 1981. Lect. Notes Comput. Sci., 111. Berlin: Springer-
Verlag, 1981, p. 414—422.
682. К a s a i Т., Miller R. E. Hcmomorphisms between models of parallel
computation.—J. Comput. and Syst. Sci., 1982, 25, №3, p. 285—331.
683. К a sci с Μ. J. Anatomy of a Poisson solver.—In: Parallel computing
83. Amsterdam: North-Holland, 1984, p. 173—179.
684. К a sci с Μ. J. A performance survey of the CYBER 205.—In:
Highspeed computation. Berlin: Sprirger-Verlag, 1984, p. 191—209.
685. Kascic M. J. Vector processing on the CYBER 200.— In: Supercomputers,
2. Maidenhead: Infotech Int., 1979, p. 237—270.
686. Kashiwagi H. Japanese super-speed computer project.— In:
Highspeed computation. Berlin: Springer-Verlag, 1984, p. 117—125.
687. К a t ζ Ι. Ν., Franklin Μ. Α., Sen A. Optimaly stable parallel
predictors for Adams-Moulton correctors.— Comput. and Math. Appl., 1977, 3,
№3, p. 217—233.
688. К a t ζ J. Η. Matrix computations on an associative processor.— In: Parallel
processor systems, technologies and applications. N. Y.: Spartan Bocks, 1970,
p. 131 — 149.
689. Katz R., Scacchi W., Subrahmayam P. Environments for
VLSI and software engeneering.—J. Syst. Softw., 1984, 4, № ί, ρ. 13—26.
€90. Kaufman L. Banded eigenvalue solvers on vector machines.— ACM
Trans. Math. Softw., 1984, 10, № 1, p. 73—85.
СПИСОК ЛИТЕРАТУРЫ
279
691. Kees H. G. M. A study on the parallel organization of the solution of
a 1600-node network.— Proc. IEEE Int. Conf. Circuits and Comput., Port
Chester, N. Y., 1980. N. Y.: IEEE, 1980, p. 988—991.
692. Keller R. M. A fundamental theorem of asynchronous parallel
computation.— Proc. 1974 Sagamore Comput. Conf. Parallel Process.. Lect. Notes
Comput. Sci., 24. Berlin: Springer-Verlag, 1975, p. 102—112.
693. Keller R. M. Parallel program schemata and maximal parallelism.
1, 2.— J. Assoc. Comput. Mach., 1973, 20, № 3, p. 514—537; № 4, p. 686—710.
694. Kershaw D. Solution of single tridiagonal linear systems and vectoriza-
tion of the ICCG algorithm on the CRAY-1.— In: Parallel computations.
N. Y.: Acad. Press, 1982, p. 85—99.
695. Khurshid Α., Fisher P. D. Design of a reconfigurable systolic
array using LSSD techniques.—Proc. 1984 IEEE Int. Conf. Comput. Design,
Port Chester, N. Y., 1984. N. Y.: IEEE, 1984, p. 171 — 176.
696. К i m u r a T. Gauss-Jordan elimination by VLSI mesh-connected
processors.— In: Supercomputers, 2. Maidenhead: Infotech Int., 1979, p. 271—290.
697. К о gge P. Μ. The architecture of pipelined computers.— N. Y.: McGraw-
Hill, 1981.—334 p.
698. К о gge P. M., Stone H. S. A parallel algorithm for the efficient
solution of a general class of recurrence equations.— IEEE Trans. Comput.,
1973, C-22, №8, p. 786—793.
699.· К orn D. G., Lambiotte J.J. Computing the fast Fourier transform
on a vector computer.—Math. Comput., 1979, 33, № 147, p. 977—992.
700. К о t o.v V. E. An algebra for parallelism based on Petri nets.— Proc.
7th Symp. Math. Found. Comput. Sci., Zakopane, 1978. Lect. Notes Comput.
Sci., 64. Berlin: Springer-Verlag, 1978, p. 39—55. .
701. К о w a 1 i k J. S., Kumar S. P. An efficient parallel block conjugate
gradient method for linear equations.— Proc. 1982 Int. Conf. Parallel
Process.. N. Y.: IEEE, 1982, p. 47—52.
702. К о w a 1 i k J. S., Lord R. E., Kumar S. P. Design and
performance of algoritms for MIMD parallel computers.— In: High-speed computation.
Berlin: Springer-Verlag, 1984, p. 257—276.
703. Kozdrowicki E. W., Τ h e i s D. J. Second generation of vector
supercomputers.—Computer, 1980, 13, №11, p. 71—83.
704. Kransky V., Giroux D., Long G. Parallel implementation of a
twodimensional model.— Proc. 1973 Sagamore Comput. Conf. Parallel
Process.. N. Y.: IEEE, 1973, p. 69—77.
705. К r a t ζ Μ. Vectorized finite-element stiffness generation: Tuning the Noor-
Lambiotte algorithm.—Parallel Comput., 1984, 1, №2, p. 121 — 132.
706. Krishnamurthy E. V. Fast parallel exact computation of the Moore-
Penrose inverse and rank of a matrix.— Elektr. Inf. und Kyber., 1983, 19,
№ 1/2, p. 95—98.
707. Krishnamurthy E. V., Klette R. Fast parallel realization of
matrix multiplication.— Elektr. Inf. und Kyber., 1981, 17, № 4/6, p. 279—292.
708. Krishnamurthy E. V., Venkateswaran H. A parallel Wilf
algorithm for complex zeros of a polynomial.— BIT, 1981, 21, № I, p. 104—
111.
709. К u с k D. J. A survey of parallel machine organization and programming.—
Comput. Siirv., 1977, 9, № 1, p. 29—59.
710. Kuck D. J. Automatic program restructuring for high-speed
computation.—CONPAR 81 Conf. Proc, Nuremberg, 1981. Lect. Notes Comput. Sci.,
111. Berlin: Springer-Verlag, 1981, p. 66—84.
711. Kuck D. J. High-speed machines and their compilers.—In: Parallel
processing systems. Cambridge Univ. Press, 1982, p. 193—214.
712. Kuck D. J. ILLIAC IV software and application programming.—IEEE
Trans. Comput., 1968, C-17, №8, p. 758—770.
71 3. К U с k D. J. Multioperation machine computational complexity.—- In:
Complexity of sequential and parallel numerical algorithms. N. Y.: Acad. Press,
1973, p. 17—47.
280
СПИСОК ЛИТЕРАТУРЫ
714. К иск D. J. Parallel processing of ordinary programs.— In: Advances in
computers, 15. N. Y.: Acad. Press, 1976, p. 119—179.
715. К и с к D. J. The structure of computers and computations, 1. N. Y.: John
Wiley and Sons, 1978.—611 p.
716. К и с к D. J., В и d η i с P. P., Ρ а и 1 P., Chen S.-C, L a w-
rie D. H., Towle R. Α., Strebendt R. E., Davis E. W.,
Han J., Kraska P. W., Muraoka Y. Measurements of
parallelism in ordinary FORTRAN programs.—Computer, 1974, 7, № 1, p. 37—46.
717. К и с к D. J., G a j s к i D. D. Parallel processing of sparse structures.—
In: High-speed computation. Berlin: Springer-Verlag, 1984, p. 229—244.
718. К иск D. J., К и hn R. Η., Lea sure В., Wolfe M. The
structure of an advanced vectorizer for pipelined processors.— Proc. 5th Int. Corn-
put. Softw. and Appl. Conf., Chicago, 1980. N. Y.: IEEE, 1980, p. 709—715.
719.Kuck D. J., Kuhn R. H., Padua D. Α., Leasure В.,
Wolfe M. Dependence graphs and compiler organizations.— Proc. 8th
Annu. ACM Symp. Princip. Progr. Lang., Williamsburg, Va., 1981, p. 207—
218.
720. Kuck D. J., Muraoka Y., Chen S.-C. On the number of
operations simultaneously executable in FORTRAN-like programs and their resulting
speedup.— IEEE Trans. Comput., 1972, C-21, № 12, p. 1293—1310.
721. Kuck D. J., Maruyama K. Time bounds on the parallel evaluation
of arithmetic expressions.—SГАМ J. Comput., 1975, 4, №2, p. 147—162.
722. Kuck D. J., S a m e h A. H. Parallel computation of eigenvalues of
real matrices.—Proc. IFIP Congr. 71, Ljubljana, 1971. Amsterdam: North-
Holland, 1972, 2, p. 1266—1272.
723. Kuck D. J., Sam eh A. H., Cytron R., Vei denbaum A.V.,
Polychronopoulos C. D., Lee G., Μ с D a n i e 1 Т., Lea-
sure B. R., Beckman C, Davies J. R. В., Kruskal С
The effects of program restructuring, algorithm change, and architecture choice
on program performance.—Proc. 1984 Int. Conf. Parallel Process.. N. Y.:
IEEE, 1984, p. 129—138.
724. К и с к D. J., Stokes R. A. The Burroughs Scientific Processor
(BSP).— IEEE Trans. Comput., 1982, C-31, № 5, p. 363—376.
725. Kuhn R. H. Efficien mapping of algorithms to single-state
interconnections.— Proc. 7th Annu. Symp. Comput. Archit., 1980. N. Y.: IEEE, p. 182—
189.
726. Kumar S. P., К о w a 1 i к J. S. Parallel factorization of a positive
definite matrix on a MIMD computer.— Proc. 1984 Int. Conf. Parallel
Process.. N. Y.: IEEE, 1984, p. 410—416.
727. К и η g Η. Τ. New algorithms and lower bounds for the parallel evaluation
of certain rational expressions and recurrences.—J. Assoc. Comput. Mach.T
1976, 23, №2, p. 252—261.
728. К и η g Η. Τ. Notes on VLSI computation.— In: Parallel processing
systems. Cambridge Univ. Press, 1982, p. 339—356.
729. К и η g Η. Τ. Putting inner loops automatically in silicon.— In: VLSI
Engineering. Lect. Notes Comput. Sci., 163. Berlin: Springer-Verlag, 1984,
p. 70—104.
730. К и η g Η. Τ. Synchronized and asynchronous parallel algorithms for
multiprocessors.— In: Algorithms and complexity: new directions and recent
results. N. Y.: Acad. Press, 1976, p. 153—200.
731. Kung H. T. The structure of parallel algorithms.— In: Advances in
computers, 19. N. Y.: Acad. Press, 1980, p. 65—112.
732. Kung H. T. Use of VLSI in algebraic computation: some suggestions.—
Proc. 1981 ACM Symp. Symbol, and Algebr. Comput., Snowbirg, Ut., 1981,
p. 218—222.
733. Kung H. T. Why systolic architecture? — Computer, 1982, 15, № I,
p. 37—46.
734. Kung H. Т., Leiserson С. Е. Systolic arrays (for VLSI).—In
Sparse matrix processings 1978. Philadelphia: SIAM, 1979, p. 256—282.
СПИСОК ЛИТЕРАТУРЫ
28 Г
735. К ύ η g Η. Т., Υ ο S. Q. Integrating high-performance special-purpcse
devices into system.— In: VLSI architecture, Englewood Cliffs, N. J.: Prentice
Hall Int., 1983, p. 205—211.
736. Kung S. Y., A.run K. S., G a 1 - Ε ζ e r R. J., Bhaskar
Rao D. V. Wevefront array processor: Language, architecture and
applications.— IEEE Trans. Comput., 1982, C-31, № 11, p. 1054—1066.
737. Kung S. Y., Bhaskar Rao D. V. Highly parallel architectures
for solving linear equations.— Proc. 1981 Int. Conf. Acoustics, Speech and
Signal Process., Atlanta, 1981. N. Y.: IEEE, 1981, p. 39—42.
738. Kung S. Y., Gal-Ezer R.J. Synchronous versus asynchronous
computation in very large scale integrated (VLSI) array processors.— In: Real-time
signal processing V. Proc. SPIE, 341. Bellingham, Wash.: SPIE, 1982, p. 53—
65.
739. Kung S. Υ., Η u Y. I* Fast and parallel algorithms for solving Teoplitz
systems.— Proc. Int. Symp. Mini- and Micro-comput. in Conrol and
Measurement, San Francisco, Cal., 1981, p. 163—168.
740. L a i T.-H., S a h η i S. Anomalies in parallel branch-and-bound
algorithms.—Commun. ACM, 1984, 27, №6, p. 594—602.
741. L a ks hm i ν ar a h a n S., D h a 1 1 S. K., Miller L. L. Parallel
sorting algorithms.— In: Advances in computers, 23. N. Y.: Acad. Press, 1984,
p. 295—354.
742. L a m b i о t t e J. J., В о k h a r i S. Η., Η u s s a i η i M. Y., О г s-
z a g S. A. Navier-Stokes solution on the CYBER 203 by a pseudcspectral
technique.— In: Parallel and large-scale computers: performance, architecture,
applications. Amsterdam: North-Holland, 1983, p. 207—212.
743. Lambiotte J. J., Voigt R. G. The solution of tridiagonal .linear
systems on the CDC STAR-100 computer.— ACM Trans. Math. Softw., 1975,
1, № 4, p. 308—329.
744. Lamport L. The coordinate method for parallel exutation of DO loops.—
Proc. 1973 Sagamore Comput. Conf. Parallel Process.. N. Y.: IEEE, 1973,
p. 1—12.
745. Lamport L. The hyperplane method for an array computer.— Proc. 1974
Sagamore Comput. Conf. Parallel Process.. Lect. Notes Comput. Sci., 24.
Berlin: Springer-Verlag, 1975, p. 113—131.
746. Lamport L. The parallel execution of DO loops.— Commun. ACM,
1974, 17, №2, p. 83—93.
747. Lander R. E., Fischer M. J. Parallel prefix computations.—J.
Assoc. Comput. Mach., 1980, 27, №4, p. 831—838.
748. Lang Т., Stone H. S. A shuffle-exchange network with simplified,
control.— IEEE Trans. Comput., 1976, C-25, № 1, p. 55—65.
749. L a w r i e D. H. Access and alignment of data in an array processcr.— IEEE
Trans. Comput., 1975, C-24, №12, p. 1145—1155.
750. L a w r i e D. H., S a m e h A. H. The computation and communication
complexity of a parallel banded system solver.— ACM Trans. Math. Softw.,
1984, 10, №2, p. 185—195.
751. Lecouffe P. SAUGE: How to use the parallelism of sequential
programs.—CONPAR 81 Conf. Proc, Nuremberg, 1981. Lect. Notes Comput.
Sci., 111. Berlin: Springer-Verlag, 1981, p. 231—244.
752. Lee K. Y., Abu-Suvah W., Kuck D.J. On modeling perf or-
mance degradation due to data moverment in vector machines.— Proc. 1984
Int. Conf. Parallel Process.. N. Y.: IEEE, 1984, p. 269—277.
753. Leiserson С Ε., Saxe J. В. Optimizing synchronous systems.— J.
VLSI and Comput. Syst., 1983, 1, № 1, p. 41—67.
754. L e m m e J. M., Rice J. R. Speedup in parallel algorithms for adaptive
quadrature.—J. Assoc. Comput. Mach., 1976, 26, № 1, p. 65—71.
755. Lengauer Т., Mehlhorn K. On the complexity of VLSI
Computations.— In: VLSI systems and computations. Rockville, Md.: Comput. Sci.
Press, 1981, p. 89—99.
282
СПИСОК ЛИТЕРАТУРЫ
756. Letichevsky A. Algebra of algorithms, data structures and parallel
computation.— Proc. IFIP Congr., Paris, 1983. Amsterdam: North-Holland,
1983, p. 859—864.
757. L i G.-J., W a h B. W. The design of optimal systolic algorithms.— Proc.
IEEE 7th Int. Comput. Softw. and Appl. Conf., Chicago, 1983. N. Y.: IEEE,
1983, p. 310—319.
758. Lichnewsky A. Some vector and parallel implementations for
preconditioned conjugate gradient algorithms.— In: High-speed computation.
Berlin: Springer-Verlag, 1984, p. 343—359.
759. Lincoln N. R. It's really not as much fun building a supercomputer as
it is simply inventing one.— In: High speed computer and algorithm
organization. N.Y.: Acad. Press, 1977, p. 3—11.
760.^L i η с о 1 η Ν. R. Supercomputers = colossal computations + enormous
expectations + renowned risk.—Computer, 19£3, 16, №5, p. 38—47.
761. Lincoln N. R. Technology and design tradeoffs in the creation of a mor-
den supercomputer.—IEEE Trans. Comput., 1982, C-31, №5, p. 349—362.
762. Lint В., Agerwala T. Communication issues in the design and
analysis of parallel algorithms.—IEEE Trans. Softw. Eng., 1981, SE-7, №2,
P. 174—188.
763. L i ρ i t a k i s E. A. Solving elliptic boundary-value problems on parallel
processors by approximate inverse matrix semi-direct methods based on the
multiple explicit Jacobi iteration.— Comput. and Math. Appl., 1984, 10,
№2, p. 171 — 184.
764. L i ρ i t a k i s Ε. Α., Evans D. J. An approximate QIF method for
parallel computers.— In: Preconditioning methods: analysis and'applications.
N. Y.: Cordon and Breach, 1982, p. 537—552.
765. Liu P. S., Young Τ. Υ. VLSI array design under constraint of
limited I/O bandwidth.—IEEE Trans. Comput., 1983, C-32, №12, p. 1160—
1170.
766. L о m a χ Η., Ρ u 1 1 i a m Т. Н. A fully implicit, factored code for
computing three-dimensional flows on the ILLIAC IV.— In: Parallel
computations. N. Y.: Acad. Press, 1982, p. 217—250.
767. Lord R. Ε., Κ ο w a 1 i k J. S., Kumar S. P. Solving linear
algebraic equations on a MIMD computer.— Proc. 1980 Int. Conf. Parallel Process..
N. Y.: IEEE, 1980, p. 205—210.
768. L о r i η Η. Introduction to computer architecture and organization.—
N. Y.: John Wiley and Sons, 1982.—311 p.
769. L о r i η Η. Parallelism in hardware and software — real and apparent
concurrency.—Englewood Cliffs, N. J.: Prentice Hall, 1972.—508 p.
770. L о t t i G. Area-time tradeoff for rectangular matrix multiplication in
VLSI models.—Inf. Process. Lett., 1984, 19, №2, p. 95—98.
771. L u b а с h e ν s k у В., Mitra D. Chaotic parallel computations of
fixed points of nonnegative matrices of unit spectral radius.— Proc. 1984 Int.
Conf. Parallel Process.. N. Y.: IEEE, 1984, p. 109—116.
772. L u k F. T. Computing the singular-value decomposition on the ILLIAC
IV.—ACM Trans. Math. Softw, 1980, 6, №4, p. 524—539.
773. Madsen N. K-, Rodrigue G. Odd-even reduction of pentadiagonal
matrices.— In: Parallel computers — parallel mathematics. Amsterdam:
North-Holland, 1977, p. 103—106.
774. Madsen N. K., Rodrigue G., Karush J.I. Matrix
multiplication by diagonals on a vector/parallel processor.— Inf. Process. Lett., 1976,
5, №2, p. 41—45.
775. Maekawa M. Optimal processor interconnection topologies.— Proc. 8th
Anmi. Symp. Comput. Archit., Minneapolis, Minn., 1981. N. Y„: IEEE,
1981, p. 171 — 185.
776. Μ a g ό G. Α., Ρ a r g a s R. P. Solving partial differential equations on
a celluar tree machine.— In: Parallel and large-scale computers^
performance, architecture, applications. Amsterdam: North-Holland, 1983, p. 235—
242. .<·"-·
СПИСОК ЛИТЕРАТУРЫ
283
777. Marsh J. M. Program development software for array processors.— In.
Supercomputers and parallel computation. Oxford: Clarendon Press, 1984,
p. 67—72.
778. Μ a r u у a m a K. On the parallel evaluation of polynomials.—IEEE
Trans. Comput., 1973, C-22, № 1, p. 2—5.
779. Matsuura Т., Kamiya S., Takiuchi M. Design concept of
the FACOM VP based on extensive analyses of applications.— Proc. 1984
IEEE Int. Conf. Comput. Design, Port Chester, N. Y., 1984. N. Y.: IEEEr
1984, p. 232—237.
780. Μ a t t i ο η e R. P., К a t ζ Ι. Ν., Franklin M. A. A partitioned
parallel Runge-Kutta method for weakly coupled ordinary differential
equations.—Int. J. Numer. Meth. Eng., 1978, 12, №2, p. 267—278.
781. McDonald Β. Ε. Explicit Chebychev-iterative solution of nonself-
adjoint elliptic equations on a vector computer.— In: Advances in computer
methods for pertial differential equations-II. New Brunswich, N. J.: IMACS,
1977, p. 181 — 188.
782. McKeown J.J. Aspects of parallel computation in numerical
optimization.— In: Numerical techniques for stochastic systems. Amsterdam: North-
Holland, 1980, p. 297—372.
783. Mead C. A. VLSI and the foundations of computation.— Proc. IFIP
Congr. 83, Paris, 1983. Amsterdam: North-Holland, 1983, p. 271—274.
784. Mead С Α., Conway L. A. Introduction to VLSI systems.—
Reading, Mass.: Addison-Wesley, 1980.—396 p.
785. Μ e a d С Α., R e m Μ. Cost and performance of VLSI computing
structures.—IEEE J. Solid-State Circuits, 1979, SC-14, №2, p. 455—462.
786. Mehlhorn K., Vishkin U. Randomized and deterministic
simulations of PRAMs by parallel machines with restricted granularity of parallel
memories.—Acta Inf., 1984, 21, №4, p. 339—374.
787. Μ e 1 h e 1 R. G., R h e i η b о 1 d t W. С A mathematical model for the
verification of systolic networks.— SIAM J. Comput., 1984, 13, № 3, p. 541 —
565.
788. Meurant G. The block preconditioned conjugate gradient method on
vector computer.— BIT, 1984, 24, № 4, p. 623—633.
789. Meurant G. Vector preconditioning for the conjugate gradient on CRAY-1
and CDC CYBER 205.— In: Computing methods in applied sciences and
engineering, IV. Amsterdam: North-Holland, 1984, p. 255—271.
790. Μ e у e r auf der Heide F., Reischuk R. On the limits to
speed up parallel machines by large hardware and unbounded communication.—
Proc. 25th Annu. Symp. Found. Ccmput. Sci., Singer Island, Fla., 1984. N. Y.:
IEEE, 1984, p. 56—64.
791. Meyer G. G. L. Effectiveness of multi-microprocessor networks for
solving the nonlinear Poisson equation.— In: High speed computer anct algorithm
organization. N. Y.: Acad. Press, 1977, p. 323—326.
792. Μ i k 1 о s k о J. Systolic system for linear equation system and matrix
inverstion.— Comput. vand Artif. Intell., 1983, 2, №4, p. 361—372.
793. Miklosko J., Zatko B. Universal systolic array for fast matrix
operations.— In: Artifical intelligence and information-control systems of
robots. Amsterdam: North-Holland, 1984, p. 259—263.
794. Miller R. E. A comparison of some theoretical models of parallel ccmru~
tation.— IEEE Trans. Comput., 1973, C-22, №8, p. 710—717.
795. Miranker W. L. A survey of parallelism in numerical analysis.—
SIAM Rev., 1971, 13, №4, p. 524—527.
796. Miranker W. L. Hierarchical relaxation.—Computing, 1979, 23, № 3,
p. 267—285.
797. Miranker W. L. Parallel methods for solving equations.— Math, гпа
Comput. Simulat., 1978, 20, №2, p. 93—101.
798. Miranker W. L., L i η i g e r W. M. Parallel methods for the
numerical integration of ordinary differential equations.— Math. Comput., 1967.
21, №99, p. 303—320.
:284
СПИСОК ЛИТЕРАТУРЫ
799. Μ i s s i r 1 i s N. M. A parallel iterative method for solving a class of linea,
systems.— In: Parallel computing 83. Amsterdam: North-Holland, 1984r
p. 181 — 189.
300. Μ i s s i r 1 i s N. M. Convergence of a parallel Jacobi-type method.— Int.
J. Comput. Math., 1983, 14, №3/4, p. 371—384.
$01. Μ i u r a K-, Uchida K. FACOM vector processor VP-100/VP-200.—
In: High-speed computation. Berlin: Springer-Verlag, 1984, p. 127—
138.
802. Modi J. J., Bowgen G. S. J. QU factorisation and singular value
decomposition on the DAP.— In: Supercomputers and parallel computation.
Oxford: Clarendon Press, 1984, p. 209—228.
.803. Modi J. J., Davies R. O., Parkinson D. Extention of the
parallel Jacobi method to the generalised eigenvalue problem.— In: Parallel
computing 83. Amsterdam: North-Holland, 1984, p. 191—197.
£04. Modi J. J., Parkinson D. Study of Jacobi methods for eigenvalues
and singular value decomposition on DAP.— Proc. Int. Conf. Vector and
Parallel Process. Comput. Sci., Chester, 1981. Comput. Phys. Commun., 1982,
26, №3/4, p. 317—320.
•805. Moldovan D. I. ADVIS: A software package for the design of systolic
arrays.— Proc. 1984 IEEE Int. Conf. Comput. Design, Port Chester, N. Y.,
1984. N. Y.: IEEE, 1984, p. 152—157.
-806. Moldovan D. I., Varma A. Design of algorithmically-specialized
VLSI devices.— Proc. 1983 IEEE Int. Conf. Comput. Design, Port Chester,
N. Y., 1983. N. Y.: IEEE, 1983, p. 88—92.
$07. Moldovan D. I., W u С I., F о r t e s A. B. Mapping an arbitrarily
large QR algorithm into a fixed size VLSI array.— Proc. 1984 Int. Conf.
Parallel Process. N. Y.: IEEE, 1984, p. 365-373.
$08. Montoye R. K-, Lawrie D. H. A practical algorithm for the
solution of lower triangular systems on a parallel processing system.— IEEE
Trans. Comput., 1982, C-31, № 11, p. 1076—1082.
.809. Morjaria M., Makinson G. J. Unstructured sparse matrix vector
multiplication on the DAP.— In: Supercomputers and parallel computation.
Oxford: Clarendon Press, 1984, p. 157—166.
•810. Μ ο t e g i M., Uchida K., Tsuchimoto T. The architecture of
the FACOM vector processor.— In: Parallel computing 83. Amsterdam: North-
Holland, 1984, p. 541—546.
.811. Mueller P. Т., Siegel L. J., Siegel H. J. Parallel algorithms
for the two-dimensional FFT.— Proc. 5th Int. Conf. Pattern Recognition,
.1980, p. 497—503.
812. Μ u к a i H. Parallel algorithms for unconstrained optimization.— Proc.
18th IEEE Conf. Decision and Control, Fort Lauderdale, Fla., 1979. N. Y.:
IEEE, 1979, 1, p. 451—454.
313. Μ u к a i H. Parallel optimization algorithms using sparsity.— Proc. 19th
IEEE Conf. Decision and Control, Albuquerque, N. Мех, 1980. Ν. Υ.: IEEE,
1930, 1, p. 242—243.
814. Multicomputer and image processing: Algorithms and programs / Eds. K.
Preston, L. Uhr.— N. Y.: Acad. Press, 1982.— 470 p.
$15. Μ u η г о I., Paterson M. Optimal algorithms for parallel polynomial
evaluation.—J. Comput. and Syst. Sci., 1973, 7, №2, p. 189—198.
$16. Μ u η t ζ С. A. The ILLIAC IV FORTRAN compiler.— SIGPLAN Not.,
1975, 10, №3, p. 1—8.
$17. Μ u г а о к a Y., К u с к D. J. On the time required for a sequence of
matrix products.—Commun. ACM, 1973, 16, №1, p. 22—26.
$18. Nagashima S., Inagami Y., Odaka Т., Kawaba S.
Design consideration for a high-speed vector processor: The Hitachi S-810.— Proc.
1984 IEEE Int. Conf. Comput. Design, Port Chester, N. Y., 1984. N. Y.:
IEEE, 1984, p. '238—244.
$19. N a g e 1 K. Solving linear equations with the SMS 201 parallel processor.—
Euromicro J., 1979, 5, № 1, p. 53—54.
СПИСОК ЛИТЕРАТУРЫ
285
820. Nash J. G., Hansen S„ Nudd G. R. VLSI processor arrays foi
matrix manipulation.— In: VLSI systems and computations. Rockville, Md.:
Comput. Sci. Press, 1981, p. 367—378.
821. Neves K. W. Mathematical software libraries for vector computers.—
Proc. Int. Conf. Vector and Parallel Process. Comput. Sci., Chester, 1981.
Comput. Phys. Commun., 1982, 26, №3/4, p. 303—310.
822. Neves K. W. Vectorization of scientific software.— In: High-speed
computation. Berlin: Springer-Veriag, 1984, p. 277—291.
823. New computer architecture / Ed. J. Tiberghien.— N. Y.: Acad. Press, 1984.—
289 p.
824. Newman I. A. The organisation and use of parallel processing systems.—
In: Parallel processing systems. Cambridge Univ. Press, 1982, p. 143—160.
825. N i L. M., Hwang K. Pipelined evaluation of first-order recurrence
systems.— Proc. 1983 Int. Conf. Parallel Process.. N. Y.: IEEE, 1983, p. 537—543.
826. Nikolaev Ι. Α., Sukhinov A. I. Symmetrized difference scheme
for solving multidimensional differential equations on array computers.—
In: Advances in computer methods for partial differential equations-IV. New
Brunswich, N. J.: IMACS, 1981, p. 239—241.
827. N о о r Α. Κ., Η a r t 1 e у S. J. Evaluation of element stiffness matrices on
CDC STAR-100 computer.—Comput. and Struct., 1978,9, №2, p. 151 — 161.
828. Noor A. K-, Lambiotte J.J. Finite element dynamic analysis on
CDC STAR-100 computer.—Comput. and Struct., 1979, 10, № 1, p. 7—19.
82Э. Noor A. K., V о i g t S. J. Hypermatrix scheme for finite element
systems on CDC STAR-ЮЗ computer.—Comput. and Struct., 1975, 5, №5/6,
p. 287—296.
830. Ν ο r r i e С Supercomputers for superproblems: An architectural
introduction.—Computer, 1984, 17, №3, p. 62—74.
831. Ν ο r r i e D. Η., Ν ο r r i e С W. Architecture aad program structures
for a special purpose finite element computer.— Proc. 1st Int. Colloq. Vector
and Parallel Comput. in Sci. Appl., Paris, 1933. EDF Bull. Dir. Etud. et Recti.,
1983, C, №1, p. 103—108.
832. Oed W., Lange O. Transforming linear recurrence relations for vector
processors.—In: Parallel comouting 83. Amsterdam: North-Holland, 1984,
p. 211—216.
833. O'Leary D. P. Ordering schemes for parallel processing of certain mash
problems.—SIAM J. Sci. and Stat. Comput., 1984, 5, №3, p. 620-632.
834. О 1 e i η i с k P. N. Parallel algorithms on a multiprocessor.— Ann Arbor:
UMI Research Press, 1932.—110 p.
835. Ortega J. M., V о i g t R. G. Solution of partial differential equations
on vector computers.—Proc. 1977 Army Numer. Anal. Conf., p. 475—526.
835. Owens J. L. The influence of machine organization on algorithms.— In:
Complexity of sequential and parallel numerical algorithms. N. Y.: Acad.
Press, 1973, p. 111 — 130.
837. Padua D. Α., Κ u с k D. J., L a w r i e D. H. High-speed
multiprocessors and compilation techniques.— IEEE Trans. Comput., 1930, C-29,
№9, p. 763—776.
838. Paker Y. Auplication of microprocessor networks for the solution of
diffusion equation.—Math, and Comput. Simulat., 1977, 19, № 1, p. 23-27.
£39. Ρ a k e г Υ. Multi-microprocessor systems.—Ν. Υ.: Acad. Press, 1983.—
204 p.
840. Parallel and large-scale computers: performance, architecture, applications
(Proc. 10th IMACS World Congr. Syst. Simulat. and Sci. Comput., Montreal,
1982.) / Ed. M. Ruschitzka.— Amsterdam: North-Holland, 1983.— 329 p.
841. Parallel computations / Ed. G. Rodrigue.— N. Y.: Acad. Press, 1932.— 403 p.
842. Parallel computers — parallel mathematics / Ed. M. Feilmeier.— Amsterdam:
North-Holland, 1977.
843. Parallel computing 83 (Proc. Int. Conf. Parallel Comput., Berlin, 1933.) / Ed.
M. Feilmeier, G. Joubert, U. Schendel.— Amsterdam: North-Holland, 1984.—
566 p.
286
СПИСОК ЛИТЕРАТУРЫ
844. Parallel processing systems / Ed. D. J. Evans.—Cambridge Univ. Press,.
1982.—399 p.
845. Parallel processor systems, technologies and applications / Eds. L. С Hobbsr
D.J.Theis, J.Trimble, H.Titus, I. Highberg.— N. Y.: Spartan Books,
1970.—438 p.
846. Parallel programming — a bibliography.—N. Y.: John Wiley and Sons,.
1983.—68 p.
847. Parker D. S. Nonlinear recurrences and parallel computation.— In:
High speed computer and algorithm organization. N. Y.: Acad. Press, 1977,
p. 317—320.
848. Parkinson D. Experience in exploiting large scale parallelism.— In::
High-speed computation. Berlin: Springer-Verlag, 1984, p. 247—255.
849. Parkinson D. Practical parallel processors and their uses.— In: Parallel
processing systems. Cambridge Univ. Press, 1982, p. 215—238.
850. Parkinson D. The solution of N linear equations using Ρ processors.—
In: Parallel computing 83. Amsterdam: North-Holland, 1984, p. 81—87.
851. Parkinson D., Wunderlich M. A compact algorithm for
Gaussian elimination over GF (2) implemented on highly parallel computers.—
Parallel Comput., 1984, 1, № 1, p. 65—73.
852. Patel N. R., Jordan H. F. A parallelized point rowwise succesive
over-relaxation method on a multiprocessor.— Parallel Ccmput., 1984, U
№3/4, p. 207—222.
853. Pease M. C. An adaptation of the fast Fourier transform for parallel
processing.—J. Assoc. Comput. Mach., 1968, 15, №2, p. 252—264.
854. Pease M. C. Matrix inversion using parallel processing.— J. Assoc.
Comput. Mach., 1967, 14, №4, p. 757—764.
855. Peters F. J. Parallel large scale finite element computations.— Proc.
IEEE Int. Conf. Circuits and Comput., Pert Chester, N. Y., 1980. N. Y.:
IEEE, 1980, p. 992—995.
856. Peters F. J. Parallel pivoting algorithms for sparse symmetric matrices.—
Parallel Comput., 1984, 1, №1, p. 99—110.
857. Peters F. J. Tree machines and divide-and-conquer algorithms.— COMP-
CON 81 Conf. Proc, Nuremberg, 1981. Lect. Notes Comput. Sci., 111. Berlin:
Springer-Verlag, 1981, p. 25—36.
858. Peterson W. P. Vector FORTRAN for numerical problems on CRAY-1.—
Commun. ACM, 1983, 26, № 11, p. 1008—1021.
859. Poole W. G., Voigt R. G. Numerical algorithms fcr parallel and
vector cemputers: an annotated bibliography.— Comput. Rev., 1974, 15,
№ 10, p. 379-388.
860. Pottle C. Solution of sparse linear equations arising from power system
similation on vector and parallel processors.— ISA Trans., 1979, 18, № 3,
p. 81—88.
861. Pradhan D. K., Kodandapahi K. L. A uniform representation
of single- and multistage interconnection networks used in SIMD machines.—
IEEE Trans. Comput., 1980, C-29, №9, p. 777—791.
862. Preparata F. P. VLSI algorithms and architectures.— Prcc. 11th
Semp. Math. Found. Ccmput. Sci., Praha, 1984. Lect. Notes Comput. Sci., 176.
Berlin: Springer-Verlag, 1984, p. 149—161.
863. Preparata F. P., S a r w a t e D. V. An improved processor bound
in fast matrix inversion.—Inf. Process. Lett., 1978, 7, №3, p. 148—150.
864. Preparata F. P., Vuillemin J. Area-time optimal VLSI
networks for multiplying matrices.— Inf. Process. Lett., 1980, 11, № 2, p.
77—80.
865. Preparata F. P., Vuillemin J. Optimal integrated-circuit
implementation of triangular matrix inversion.— Free. 1980 Int. Conf. Parallel
Process.. N.Y.: IEEE, 1980, p. 211—216.
866. Preparata F. P., Vuillemin J. The cube-connected cycles:
A versatile netwerk for parallel computation.— Commun. ACM, 1981, 24,
№5, p. 300—309.
СПИСОК ЛИТЕРАТУРЫ
287
867. Ρ res berg D. L., Johnson N. W. The Parallyzer: IVTRAN's
parallelism analyzer and synthesizer.— SIGPLAN Not., 1975, 10, № 3, p. 9—
16.
868. Pries ter R. W., Whitehouse H. J., Bromley K-,
Clary J. B. Problem adaptation to systolic arrays.— In: Real-time signal
processing IV. Proc. SPIE, 298. Bellingham, Wash.: SPIE, 1981, p. 33—39.
869. Pries ter R. W., Whitehouse H. J., Bromley K.,
Clary J. B. Signal processing with systolic arrays.—Proc. 1981 Int. Conf.
Parallel Process.. N. Y.: IEEE, 1981, p. 207—215.
£70. Q u i η t ο η P. Automatic synthesis of systolic arrays from uniform recurrent
equations.— Proc. 11th Annu. Int. Symp. Comput. Archit., Ann Arbor, Mich.,
1984. N.Y.: IEEE, 1984, p. 208—214.
871. Ramakrishnan I. V., Browne J. С A paradigm for the design
of parallel algorithms with applications.— IEEE Trans. Softw. Eng., 1983,
SE-9, №4, p. 411—415.
872. R a m a k r i s h η a n I. V., Fussell D. S., Silberschatz A.
On mapping homogeneous graphs on a linear array-processor model.— Proc.
1983 Int. Conf. Parallel Process.. N. Y.: IEEE, 1983, p. 4^0—447.
873. Ramakrishnan I. V., Varman P. J. Modular matrix mutipli-
cation on a linear array.— IEEE Trans. Comput., 1984, C-33, № 11, p. 952—
958.
874. Ramakrishnan I. V., Varman P. J. On mapping cube graphs
onto VLSI arrays.— Proc. 4th Conf. Found. Softw. Techn. and Theor. Comput.
Sci., Bangalore, India, 1984. Lect. Notes Comput. Sci., 181. Berlin: Springer-
Verlag, 1984, p. 296—316.
875. R a m a m о о Г t h у С. V., Li Η. F. Pipeline architecture.— Comput.
Surv., 1977, 9, № 1, p. 61 — 102.
876. Reddaway S. F. The DAP approach.— In: Supercomputers, 2.
Maidenhead: Infotech Int., 1979, p. 309—329.
877. Reed D. D., Patrick M. L. A model of asyncronous iterative
algorithms for solving large, sparse, linear systems.— Proc. 1984 Int. Conf. Parallel
Process.. N.Y. : IEEE, 1984, p. 402—409.
878. Remund R. N., Taggart K. A. To vectorize or to «Vectorize»: that
is the quastion.— In: High speed computer and algorithm organization. N. Y.:
Acad. Press, 1977, p. 399—410.
879. Requa J.E., McGraw J.R. The piecewise data flow architecture:
Architectural consepts.— IEEE Trans. Comput., 1983, C-32, № 5, p. 425—438.
880. Reynolds R. G., Chang T. L. The PAL system — a parallel
algorithm design system for VLSI based array architectures.— In: Parallel and
large-scale computers: performance, architecture, applications. Amsterdam:
North-Holland, 1983, p. 243—250.
881. Reynolds R. G., Cichanowski G. W. Metrics for the
comparison of parallel algorithms and their design methodologies.— Inf. Process.
Manag., 1984, 20, № 1/2, p. 317—332.
882. Rice J. Matrix representations of nonlinear equation
iterations-applications to parallel computation.— Math. Comput., 1971, 25, p. 639—647.
883. Rice Τ. Α., S i e g e 1 L. J. A parallel algorithm for finding the roots of
a polynomial.—Proc. 1932 Int. Conf. Parallel Process.. N. Y.: IEEE, 1982,
p. 57—61.
884. Riganati J. P., Schneck P. B. Supercomputing.»— Computer,
1984, 17, №10, p. 97—113.
885. Robinson J.T. Some analysis techniques for asynchronous
multiprocessor algorithms.— IEEE Trans. Softw. Eng., 1-979, SE-5, № 1, p. 24—31.
886. Rodeheffer T. L., Hibbard P. G. Automatic explotation of
parallelism on a homogenous asynchronous multiprocessor.— Proc. 1980 Int.
Conf. Parallel. Process.. N. Y.: IEEE, 1980, p. 15—18.
887. Rodrigue G. A parallel first-order method for parabolic partial
differential equations.— In: High-speed computation. Berlin: Springer-Verlag,
1984, p. 329—342.
288
СПИСОК ЛИТЕРАТУРЫ
888. Rodrigue G., Hendrickson С, Pratt Μ. An implicit nume-
. rical scluticn on of the two-dimentional diffusion equation and vectorization
experiments.— In: Parallel ccmputations. N. Y.: Acad. Press, 1982, p. 101—
128.
889. Rodrigue G., Simon J. A generalization of the Schwarz algorithm.—
In: Ccmputing methods in applied sciences and engineering, VI. Amsterdam:.
North-Holland, 1984, p. 273—283.
890. Rogers Μ. Η. Specification of algorithms for systolic array elements.-—
In: VLSI architecture. Englewood Cliffs, N. J.: Prentice Hall Int., 1983,
p. 212—224.
891. Rons с h W. Stability aspects in using parallel algorithms,—Parallel
Comput., 1984, 1, № 1, p. 75—98.
892. van Rosendale J. Minimizing inner product data dependencies in
conjugate gradient iteration.— Proc. 1983 Int. Conf. Parallel Process.. N. Y.:
IEEE, 1983, p. 44—46.
893. R о s e η f e 1 d J. L., D r i s с о 1 1 G. С. Solution of the Dirichlet
problem on a simulated parallel processing system.— Proc. IFIP Congr. 68,
Edinburgh, 1968. Amsterdam: North-Holland, 1968, p. 499—507.
894. Russell R. M. The CRAY-1 computer system.—Commun. ACM, 1978,
21, № l,cp. 63—72.
895. S a a d Y., S a m e h A. H. Iterative methods for the solution of elliptic
difference equations on multiprocessors.— CONPAR 81 Conf. Proc,
Nuremberg, 1981. Lect. Notes Comput. Sci., 111. Berlin: Springer-Verlag, 1981,
p. 395—413.
896. Sack R. A. Relative pivoting fcr systems cf linear equations.— In: Parallel
computing 83. Amsterdam: North-Holland, 1984, p. 233—237.
897. S a m e h A. H. An overview of parallel algorithms in numerial algebra.—
Proc. 1st Int. Colloq. Vector and Parallel Comput. in Sci. Appl., Paris, 1983.
EDF Bull. Dir. Etud. et Recti., 1983, C, № 1, p. 129—134.
898. S a m e h A. H. Numerical parallel algorithms — a survey.— In: High
speed computer and algorithm organization. N. Y.: Acad. Press, 1977, p. 207—
228.,
899. S a m e h A. H. On Jacobi and Jacobi-lil^e algorithms for a parallel
computer.—Math. Comput., 25, № 115, p. 579—590.
900. S a m e h A. H. On two numerical algorithms for multiprocessors.— In:
High-speed computations. Berlin: Springer-Verlag, 1984, p. 311—328.
901. S a m e h A. H., Brent R. P. Solving triangular systems on a parallel
computer.—SIAM J. Numer. Anal., 1977, 14, №6, p. 1101—1113.
902. Sam eh A. H., Chen S.-C, Kuck D. J. Parallel Poisson and
biharmonic solvers.—Computing, 1976, 17, №3, p. 219—230.
903. S a m e h Α. Η., Κ u с k D. J. A parallel QR algorithm for symmetric
tridiagonal matrices.— IEEE Trans. Comput., 1977, C-26, № 2, p. 147—153.
904..S a m e h A. H., Kuck D. J. On stable parallel linear system solvers.—
J. Assoc. Comput. Mach., 1978, 25, № 1, p. 81—91.
905. Sam eh A. H., Kuck D. J. Parallel direct linear system solvers- a
survey.—Math, and Comput. Simulat., 1977, 19, №4, p. 272—277.
906. Sasaki Т., Kanada Y. Parallelism in algebraic computation and
parallel algorithms for symbolic linear systems.— Proc. 1981 ACM Symp.
Symbol, and Alg. Comput., Snowbird, Ut., 1981, p. 160—167.
907. Savage J. E. Area-time tradeoffs for matrix multipication and related
problems in VLSI models.— J. Comput. and Syst. Sci., 1981, 22, № 2, p. 230—
242.
908. Savage J. E. Sparse-time tradeoffs for banded matrix problems.— J.
Assoc. Comput. Mach., 1984, 31, №2, p. 422—437.
909. Savage J. E. The performance of multilective VLSI algorithms.—J.
Comput. and Syst. Sci., 1984, 29, №2, p. 243—473.
910. Sehendel U. On basic concepts in parallel numerical mathematics.—
CONPAR 81 Conf. Proc, Nuremberg, 1981. Lect. Notes Ccmput. Sci., 11L
Berlin: Springer-Verlag, 1981, p. 373—394.
СПИСОК ЛИТЕРАТУРЫ^
28Э
911. Schlansker M., Atkins D. Ε. A complexity result on a pipeline
processor design problem.— In: High speed computer and algorithm
organization. N. Y.: Acad. Press, 1977, p. 129—142.
912. Schneck P. B. Automatic recognition of vector and parallel operations
in a higher level language.—SIGPLAN Not., 1972, 7, p. 45—52.
913. Schneck P. B. Moverment of implicit parallel and vector expressions
out of program loops.—SIGPLAN Not., 1975, 10, №3, p. 103—106.
914. Schnendel U. Introduction to numerical methods for parallel
computers.—N. Y.: John Wiley and Sons; 1984.— 151 p.
915. Schnepf E., Schonauer W. Parallelization of PDE software for vector
computers.— In: Parallel computing 83. Amsterdam: North-Holland, 1984, p.. 239—
244.
916. S с h о m b e r g H. A special purpose computer for partial differential
equations.— In: Advances in computer methods for partial differential
equations. New Brunswich, N.J.: IMACS, 1975, p. 187—191.
917. Schomberg H. Parallel solution of a nonlinear elliptic boundary value
problem.— In: Simulation of Systems. Amsterdam: North-Holland* 1976,
p. 461—470.
918. Schonauer W. The efficient solution of large linear systems, resulting
from the FDM for 3-D PDE's on vector computers.— Proc. 1st Int. Colloq.
Vector and Parallel Comput. in Sci. Appl., Paris, 1983. EDF Bull. Dir. Etud.
.et Recti., 1983, C, № 1, p. 135—142.
919. Schonauer W., R a i t h K. A polyalgorithm with diagonal storing
for the solution of very large indefinite linear banded systems on a vector
computer.— In: Parallel and large-scale computers: performance, architecture,
applications. Amsterdam: North-Holland, 1983, p. 213—220.
920. Schonauer W., Schnepf E., Raith K. Modularization of
PDE software for vector computers.— Z. Angew. Math, und Mech., 1984, 64,
№5, p. 309—312.
921. Schonauer W., Schnepf E., Raith K. The redesign and vec-
torization of the SLDGL-program package for the selfadaptive solution of
' nonlinear systems of elliptic and parabolic PDE's.— In: PDE software:
modules, interfaces and systems. Amsterdam: North-Holland, 1984, p. 41—66.
922. Schrage Μ. Η. Architectural barriers to array processor efficiency and
their analysis.— Proc. Int. Conf. Vector and Parallel Process. Comput. Sci.,
Chester, 1981. Comput. Phys. Commun., 1982, 26, №3/4, p. 353—357.
923. Schreiber R.A systolic architecture for singular valie decomposition.—
Proc. 1st Int. Colloq. Vector and Parallel Comput. in Sci. Appl., Paris, 1983.
EDF Bull. Dir. Etud. et Rech., 1983, C, № 1, p. 143—148.
924. Schreiber R. Computing generalized inverses and eigenvalues of
symmetric matrices using systolic arrays.— In: Computing Methods in applied
sciences and engineering, VI. Amsterdam: North-Holland, 1984, p. 285—295:
925. Schreiber R. Systolic arrays for eigenvalue computation.— In:
Realtime signal processing V. Proc. SPIE, 341. Bellingham, Wash.: SPIE, 1982,
p. 27—34.
926. Schwartz J.T. Ultracomputers.— ACM Trans. Progr. Lang, and Syst.,
1980, 2, №4, p. 484—521.
927. Scott L. R. On the choice of discretization for solving P. D. E.'s on a
multi-processor.— In: Elliptic problem solvers. N. Y.: Acad. Press, 1981,
p. 419—422.
928. Sedukhin S. G. Highly parallel algorithms and the architecture of
a computer system for solving large matrix problems.— In: Artifical
intelligence and information —control systems of robots. Amsterdam: Horth-Holland,
1984, p. 319—323.
929. S e i t ζ С. L. Concurrent VLSI architectures.— IEEE Trans. Comput.,
1984, C-33, № 12, p. 1247—1265.
930. Shanehchi J., Evans D. J. Further analysis of the quadrant
interlocking factorisation (Q. I.F.) method.—Int. J. Comput. Math., 1982, \\r
№ 1, p. 49—72.
^90
СПИСОК ЛИТЕРАТУРЫ
931. Shanehchi J., Evans D. J. New variants of the quadrant inteno-
cking factorisation (Q. I. F.) method.— CONPAR.81 Conf. Proc, Nuremberg,
1981. Lect. Notes Comput. Sci., 111. Berlin: Springer-Verlag, 1981, p. 493—
507.
932. Shapiro H. A comparison of various methods for detecting and utilizing
parallelism in a single instruction stream.— Proc. 1977 Int. Conf. Parallel
Process.. N. Y.: IEEE, 1977, p. 67—76.
933. Shedler G. S. Parallel numerical methods fcr the solution of equations.—
Commun. ACM, 1967, 10, p. 286—291.
934. Shedler G. S., Lehrman Μ. Μ. Evaluation of redundancy in a
parallel algorithm.— IBM Systems J., 1967, 6, p. 142—149.
935. Shensa M. J., С a r 1 s s ο η G. С, S e χ t ο η Η. В., W r i g h t С G.
Matrix tridiagonalization by concurrent Givens rotations.— Proc. 17th Asilomar
Conf. Circuits, Syst. and Ccmput., Santa Clara, Cal., 1983. N. Y.: IEEE, 1983,
p. 204—207.
936. S i e ge 1 H. J. A model of SIMD machines and a comparison of various
interconnection networks.— IEEE Trans. Comput., 1979, C-28, № 12, p. 907—
917.
937. S i ege 1 H. J. Interconnection networks for SIMD machines.—Computer,
1979, 12, №6, p. 57—65.
938. S i e g e 1 H. J., Smith S. D. Study of multistage SIMD interconnection
networks.— Proc. 5th Annu. Symp. Comput. Archit., 1978. N. Y.: IEEE,
1978 d 223 229
939. Sie'gel L. J., Mueller P. Т., Siegel H. J. FFT algorithms for
SIMD machines.— Proc. 17th Annu. Allerton Conf. Commun., Contr. and
Comput., Monticello, 111, 1979, p. 1006—1015.
940. Siegel L. J., Siegel H. J., Swain P. H. Performance measures
for evaluating algorithms fcr SIMD machines.— IEEE Trans. Softw. Eng.,
1982, SE-8, №4, p. 319—330.
941. Sites R. L. An analysis of the CRAY-1 computer.—Proc. 5th Annu.
Symp. Comput. Archit., 1978. N. Y.: IEEE, 1978, p. 101—106.
942. Sloboda F. A parallel projection method for linear algebraic systems.—
Apl. Mat., 1978, 23, №3, p. 185—198.
943. Sloboda F. Nonlinear iterative methods and parallel computation.—
Apl. Mat., 1976, 21, №4, p. 252—262.
944. Sloboda F. Parallel method of conjugate directions for minimization.—
Apl. Mat., 1975, 20, №6, p. 436—446.
945. S η i r M., Barak A. B. A direct approach to the parallel evaluation of
rational expressions with a small number of processors.— IEEE Trans. Corn-
put., 1977, C-26, № 10, p. 933—937.
946. Snyder L. Supercomputers and VLSI: The effect of large-scale integration
on computer architecture.— In: Advances in computers, 23. N. Y.: Acad.
Press, 1984, p. 2—33.
947. Snyder L. Introduction to the configurable, highly parallel computer.—
Computer, 1982, 15, № 1, p. 47—56.
948. Sovis F. Uniform theory of the shuffle-exchange type permutation
networks.—Proc. 10th Annu. Int. Symp. Comput. Archit., Stockholm, 1983.
N. Y.: IEEE, 1983, p. 185—193.
949. Speiser J.M., Whitehouse H.J. Parallel processing algorithms
and architectures for real-time signal processing.— In: Real-time signal
processing IV. Proc. SPIE, Vol. 298. Bellingham, Wash.: SPIE, 1981, p. 2—9.
950. S r i η i V. P., A s e η j о J. F. Analysis of CRAY-IS architecture.— Proc.
10th Annu. Int. Symp. Comput. Archit., Stockholm, 1983. N. Y.: IEEE, 1983,
p. 194—206.
951. S r i η i ν a s M. A. Optimal parallel scheduling of Gaussian elimination
DAG's.—IEEE Trans. Comput., 1983, C-32, №12, p. 1109—1117.
952. Staunstrup J. Analysis of concurrent algorithms.— CONPAR 81 Conf.
Proc, Nuremberg, 1981. Lect. Notes Ccmput. Sci., 111. Berlin:
Springer-Verlag, 1981, p. 217—230.
СПИСОК ЛИТЕРАТУРЫ
291
-953. Stone Η. S. An efficient parallel algorithm for the solution of a tridiagonal
linear system of equations.— J. Assoc. Comput. Mach., 1973, 20, № 1, p. 27—
38.
954. Stone H. S. Parallel computers.— In: Introduction in computer
architecture. Palo Alto, Cal.: Sci. Research Assoc, 1975, p. 318—374.
955. S t ο η e H. S. Parallel processing with perfect shufle.—IEEE Trans.
Comput., 1971, C-20, №2, p. 153—161.
956. Stone H. S. Parallel tridiagonal equation solver.— ACM Trans. Math.
Softw., 1975, 1, №4, p. 289—307.
957. Stone H. S. Problems of parallel computation.— In: Complexity of
sequential and parallel numerical algorithms. N. Y.: Acad. Press, 1973, p. 1 —16.
958. Supercomputers. 1, 2 / Eds. R. W. Hockney, С R. Jesshope.—Maidenhead:
Infotech Int., 1979.—297 p., 400 p.
959. Supercomputers and parallel computation (Based on Proc. Workshop Progress
in Use Vector And Array Processors, Bristol, 1982.) / Ed. D. J. Paddon.—
Oxford: Clarendon Press, 1984.— 258 p.
960. Swartzlander E. E. VLSI architecture.— In: Very large scale
integration (VLSI): fundam2ntals and applications. Berlin: Springer-Verlag,
1980, p. 178—221.
951. Swarztrauber P. N. A parallel algorithm for solving general
tridiagonal equations.—Math. Comput., 1979, 33, №145, p. 185—199.
952. Swarztrauber· P. N. FFT algorithms for vector computers.— Parallel
Comput., 1984, 1, № 1, p. 45—63.
963. Swarztrauber P. N. The solution- of tridiagonal systems on the
CRAY-1.— In: Supercomputers, 2. Maidenhead: Infotech Int., 1979, p. 343—
357.
954. Swarztrauber P.N. Vectorization the FFT's.— In: Parallel
computations. N.Y.: Acad. Press, 1932, p. 51—83.
965. Syre J.-C. Тпэ data flow арргэасй for MiMD multiprocessor systems.—
In: Parallel processing systems. Cambridge Univ. Press, 1982, p. 239—
274.
966. Temperton С Fast Fourier transforms and Poiss^n solvers on CRAY-1.—
In: Supercomputers, 2. Maidenhead: Infotech Int., 1979, p. 359—378.
967. Temperton С Fast Fourier transform for numerical weather prediction
. models on vector comouters.— Proc. 1st Int. Colloq. Vector and Parallel
Comput. in Sci. Appl., Paris, 1983. EDF Bull. Dir. Etud. et Rech., 1983, C,
№ 1, p. 159—162.
968. Temperton C. Fast Fourier transforms on the CYBER 205.— In:
High-speed computations. Berlin: Springer-Verlag, 1984, p. 403—416.
969. Temperton С Fast mathods on parallel and vector machines.— Proc.
Int. Conf. Vector and Parallel Process. Comput. Sci., Chaster, 1931. Comput.
Phys. Commun., 1982, 26, №3/4, p. 331—334.
970. Thompson CD. Area-time complexity for VLSI.—Proc. 11th Annu.
ACM Symp. Theory of Comput., Atlanta, 1979, p. 81—88.
971. Τ h о m ρ s ο η CD. Fourier transforms in VLSI.— IEEE Trans. Comput.,
1983, C-32, №11, p. 1047—1057.
972. Thurber K. J. Large-scale computer architecture: Parallel and
associative processors.— Rochelle Park: Heyden Book, 1976.— 324 p.
973. Thurber K. J., Masson G. M. Distributed-processor comunication
architecture.— Lexington, Ma.: Healh, 1979.— 252 p.
974. Thurber K. J., Wald L. D. Associative and parallel processors.—
Comput. Surv., 1975, 7, №4, p. 215—255.
975. Τ r a u b J. F. Iterative solution of tridiagonal systems on parallel or vector
computers.— In: Complexity of sequential and parallel numerical algorithms.
N. Y.: Acad. Press, 1973, p. 49—82.
976. Treleaven P. С Decentrelised computer architecture.— In: New
computer architecture. N. Y.: Acad. Press, 1984, p. 1—58.
977. Treleaven P. С Parallel models of computation.— In: Parallel
processing systems. Cambridge Univ. Press, 1982, p. 275—284.
292
СПИСОК ЛИТЕРАТУРЫ
978. Treleaven P. С. VLSI processor architectures.— Computer, 1982, 15,
№6, p. 33—45.
979. Τ s a i R. Y., Huang T. S. A new parallel algorithm fcr eigencomputa-
tion of large scale banded circulant and block circulant matrices.— Proc. 1981
IEEE Workshop Comput. Archit. for Pattern Anal, and Image Database Manag ,.
Hot Springs, Va., 1981. N. Y.: IEEE, 1981, p. 323—328. -
980. Tylavsky D. J. Parallel processing of the sparse matrix equations
encountered in large scale systems analysis.— Proc. 17th Asilomar Conf.
Circuits, Syst. and Comput., Santa Clara, Cal., 1983. N. Y.: IEEE, 1983, p. 113—
117.
981. U 1 1 m a n J. D. Ccmputatinal aspects of VLSI.— Rockwille, Md.: Ccmput.
ScL Press, 1984.—495 p. ^
982. U m e о Н. A class of SIMD algorithms implemented on systolic VLSI
arrays.— Proc. 1984 Int. Conf. Parallel Process.. N. Y.: IEEE, 1984, p. 374—376.
983. U ρ f a 1 E. Efficient schemes for parallel communication.— J. Assoc.
Comput. Mach., 1984, 31, №3, p. 507—517.
984. U r h L. Algorithm-structured computer arrays and networks,— N. Y::»
Acad. Press, 1984.— 413 p.
985. Urquhart R. В., Wood D. Systolic matrix and vector multiplica-
' tion methods for signal processing.— IEE Proc.-F, 1984, 131, № 6, p. 623—631.
986. Urschler G. The transformation of flow diagrams into maximally
parallel form.— Proc. 1973 Sagamore Comput. Conf. Parallel Process.. N. Y.:
IEEE, 1973, p. 38—46.
987. Vajtersic M. A fast SVD image restoration on an associative parallel
computer.— In: Artifical intelligence and informationcontrol systems of
robots. Amsterdam: North-Holland, 1984, p. 383—387.
988. Vajtersic M. An elimination approach for fast parallel solution of the
model fourth-crder elliptic problem.— Proc. Int. Ccnf. Vector and Parallel
Process. Comput. Sci., Chester, 1981. Ccmput. Phys. Ccmmun., 1982, 26,
№3/4, p. 357—361.
989. Vajtersic M. Parallel marching Poisson solvers.— Parallel Ccmput.,
1984, 1, №3/4, p. 325—330.
990. Vajtersic M. Parallel Poisson and biharmcnic sobers implemented on
the EGPA multiprocessor.— Prcc. 1982 Int. Conf. ParalleKPrccess.. N. Y,:
IEEE,, 1982, p. 72—81.
991. Vajtersic M. Solving two modified discret Poisson equation in 7 log η
steps on η processors.— CONPAR 81 Conf. Proc, Nuremberg, 1981. Lect. Notes
Comput. Sci., 111. Berlin: Springer-Verlag, 1981, p. 423—432.
992. Vajtersic M. Seme algorithms of linear algebra for the EGPA
multiprocessor.—Ccmput. and Artif. Intell., 1983, 2, №4, p. 385—394.
993.. V a 1 i a n t L. G., Skyum S., Berkowitz S., R а с к о f f С.
Fast parallel computation of polynomials using few processors.— SIAM J.
Comput., 1983, 12, № 4, p. 641—644.
994. Varman P. J., Fussell D. S. Design of robust systolic algorithms.—
Proc. 1983 Int. Conf. Parallel Process.. N. Y.: IEEE, 1983, p. 458—460.
995. VLSI architecture / Eds. B. Randell, P. С Treleaven.— Englewood Cliffs,
N. J.: Prentice Hall Int., 1983.—426 p.
996. VLSI systems and computations / Eds. H. T. Kung, B. Sproull, G. Steele.—
Rockville, Md. Comput. Sci. Press, 1981.—415 p.
997. V о i g t R. G. The influence of vector computer architecture on numerical
algorithms.— In: High speed computer and algorithm organization. N. Y.:
Acad. Press, 1977, p. 229—244.
998. van derVorstH. A vectorizable variant of seme ICCG methods.—
SIAM J. Sci. and Stat. Ccmput., 1982, 3, № 3, p. 350—356.
999. Waidner P., Habfeld F. Parallel algorithms- theory and
limitations.— Proc. Workshop Parallel Process.: Logic, Organiz. and Techn., Minich,
1983. Lect. Notes Phys., 196. Berlin: Springer-Verlag, 1984, p. 98—109.
iOOO. W a 1 1 а с h Y. Alternating sequential/parallel processing.—Lect. Notes
Comput. Sci., 127. Berlin: Springer-Verlag, 1982.— 327 p.
СПИСОК ЛИТЕРАТУРЫ
293'
1001. W а 1 1 а с h Υ., К о η г a d V. On block-parallel methods for solving
linear equations.— IEEE Trans. Comput., 1980, C-29, № 5, p. 354—359.
1002. Wallach Y., Shimar A. Alternating sequential/parallel vertions
of FFT.— IEEE Trans. Acoust., Speech and Sign. Process., 1980, ASSP-28,
№2, p. 236—242.
1003. Wallis J. R., Grisham J.R. Petroleum reservoir simulation on.
the CRAY-1 and the ESP-164.— In: Parallel and large-scale computers:
performance, architecture, applications. Amsterdam: North-Holland, 1983,.
p. 191—200.
1004. Wang Η. Η. A parallel method for tridiagonal equations.— ACM Trans.
Math. Softw., 1981, 7, № 2, 170—183.
1005. Wang Η. Η. On vectorizing the fast Fourier transform.— BIT, 1980, 20,
№ 2, p. 233—243.
1006. Ward R. С The QR algorithms and Hyman's method on vector
computers.—Math. Comput., 1976, 30, №133, p. 132—142.
1007. We-bb S.J., McKeown J.J, Η u η t D. J. The solution of
linear equations on a SIMD computer using a parallel iterative algorithm.—
Proc. Int. Conf. Vector and Parallel Process. Comput. Sci., Chester, 1981.
Comput. Phys. Commun., 1982, 26, №3/4, p. 325—330.
1008. Weiser U., Davis A. A wavefront notation tool for VLSI array
design.— In: VLSI systems and computations. Rockville, Md.: Comput. Sci.
Press, 1981, p. 226—234.
1009. W h i t e s i d e R. Α., Ostlund N. S., Η i b b a r d P. G. A
parallel Jacobi diagonalization algorithms for a loop multiple processor system.—
IEEE Trans. Comput., 1984, C-33, №5, p. 409—413.
1010. Williams S. Α., Evans D. J. An implicit approach to the
determination of parallelism.— Int. J. Comput. Math., 1980, 8, № 1, p. 51—59.
1011. W i 1 s ο η A. Examples of array processing in the next FORTRAN.— In:
Supercomputers and parallel computation. Oxford: Clarendon Press, 1984,
p. 41—44.
1012. Wing O. A content addressable systolic array for sparse matrix
computation.— Proc. 1983 IEEE Int. Conf. Comput. Design, Port Chester, N. Y.,
1983. N. Y.: IEEE, 1983, p. 247—250.
1013. Wing O., Huang J.W. A computation model of parallel solution of
linear equations.—IEEE Trans. Comput., 1980, C-29, №7, p. 632—
638.
1014. Wing O., Huang J. W. An experiment in parallel processing of
Gaussian elimination of a sparse matrix.— Proc. Int. Symp. Circuits and Syst.,
Munich, 1976. N. Y.: IEEE, 1976, p. 263—266.,
1015. Wing Ο., Η u a ng J. W. A parallel triangulation process for sparse
matrices.— Proc. 1977 Int. Conf. Parallel Process.. N. Y.: IEEE, 1977,
p. 207—214.
1016. W i η ο g r a d S. On the parallel evaluation of certain arithmetic
expressions.—J. Assoc. Comput. Mach., 1975, 22, №4, p. 477—492.
1017. Winograd S. On the speed gained in parallel methods.—In: New
concepts in parallel information processing. Leuden: Noordhoff, 1975, p. 155—
166.
1018. Winograd S. Parallel iteration methods.— In: Complexity of computer
computations. N. Y.: Plenum Press, 1972, p. 53—60.
1019. Wood A. M. The organization of parallel processing machines.— Proc.
Workshop Parallel Process.: Logic, Organiz. and Techn., Minich, 1983. Lect.
Notes Phys., 196. Berlin: Springer-Verlag, 1984, p. 132—144.
1020. Worland P. B. Parallel methods for the numerical solution ordinary
differential equations.— IEEE Trans. Comput., 1976, C-25, № 10, p. 1045—
1048.
1021. W u C, Feng T.-Y. The universality of the shuffle — exchange
network.—IEEE Trans. Comput., 1981, C-30, №5, p. 324--332.
1022. W u 1 f W. Α., Β e 1 1 С. G. C.mmp — a multi-mini-processor.— AFIPS
Conf. Proc, 41. FJCC 1972, Part 2, p. 765—777.
294
СПИСОК ЛИТЕРАТУРЫ
.1023. Yanenko N.N. Efficiency of the numerical algorithms and the
decomposition principle for morden computers.— In: PDE software: modules,
interfaces and systems. Amsterdam: North-Holland, 1984, p. 291—308.
1024. Yasrebi M., Lipovski G. J. A state-of-the-art SIMD
two-dimensional FFT array processor.— In: Proc. 11th Annu. Int. Symp. Comput.
- Archit., Ann Arbor, 1984. N. Y.: IEEE, 1984, p. 21—29.
1025. Yasumura M., Tanaka Y., Kanada Y. Compiling algorithms
and techniques for the S-810 vector processor.— Proc. 1984 Int. Conf. Parallel
Process.. N.Y.: IEEE, 1984, p. 285—290.
.1026. Υ a u S. S., Fung H. S. Associative processor architecture — a
survey.—Comput. Surv., 1977, 9, №1, p. 3—27.
1027. Zhang C. Ν., Υ u η D. Υ. Υ. Multi-dimensional systolic networks for
discrete Fourier transform.— Proc. 11th Annu. Int. Symp. Comput. Archit.,
Ann Arbor, Mich., 1984. N. Y.: IEEE, p. 215—223.
.1028. Zhou Y. F. Optimal parallel triangulation of a sparse matrix- a graphical
approach.— Proc. Int. Symp. Circuits and Syst., Houston, Tex., 1981. N. Y.:
IEEE, 1981, p. 624—627.
1029. Zuczek R. A new approach to parallel computing.— Acta Inf., 1976, 7,
№ 1, p. 1—13.
1030. Ζ u ν e P., Cole G. E. A quantitative evaluation of the feasibility of,
and suitable hardware architectures for, an adaptive, parallel finite-element
system.—ACM Trans. Math. Softw., 1983, 9, №3, p. 271—292.
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Алгоритм безусловный 125
— простой 137
— условный 125
— элементарный 138
Алгоритма высота 66
— ширина 66
Базовая операция 65
— переменная 65
— программа 84
Базовый вектор 164
— параллелепипед 165
Близкодействия принцип 223
Ведущая координата 150
Векторная память 211
Вектор-цикл 107
— элементарный 107
Вершина 58
— висячая 59
— изолированная 59
— конечная 59
— начальная 59
Вершины концевые 59
— смежные 59
— степень 59
Временная развгртка 84
Время цикла 71
Вычислитель векторный 211
— конвейерный 178
— — безусловный 179
— — — полностью синхронный 202
— — — почти синхронный 202
— — смежный 204
Вычислительная система асинхронная 27
— — базовая 84
— — — синхронизированная 99
— — — уравновешенная 99
— — параллельная 5
— — синхронная 27
Граф периодический основной 189
— планарный 223
— плоский 223
— помеченный 60
—, преобразование 64
—, проекция 64
— простой 59
— пустой 59
— регулярный 164
— — бесконечный 164
— решетчатый 69, 125
— — простой 137
— — элементарный 138
—, свертка 63
— связный 59
— — сильно 60
— сопровождающий БКВ 192
— частично упорядоченный 59
Графа гомоморфный образ 63
Графы, гомоморфизм 63
— независимый 63
— простой 63
— связный 63
— элементарный 62
изоморфизм 62
объединение 62
пересечение 62
Дуга 59
—, направление отрицательное 107
—, — положительное 107
— связующая 190
Загруженность 73
— асимптотическая 73
Зацепление 214
Избыточные вычисления 154
Индекс расщепления 198
Гнездо циклов 124
— — нормальное 150
— — опорное 126
— —, размерность 124
— — составное 124
Граф 58
— алгоритма 65
— — вычислительный 79
— ациклический 60
— информационно значимый 154
—, инцидентность 59
— конвейера 179
— направленный 68
— — строго 68
—, направляющий вектор 68
— ориентированный 59
— периодический бесконечный 185
Канал 18
Классификация вычислительных систем 25*-
Коммуникационная сеть 20
Конвейер 22
Контур 60
Концепция неограниченного параллелизма
41
Максимальная последовательность 96
Максимального быстродействия режим 100*
Массив 121
—, размерность 122
Матрица инциденций 103
— смежностей 103
Метка 123
Мультиграф 59
- Ь2Э6
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Оператор цикла 123
—, обратимый на множестве 146
Операторы последовательного дейст]
157
Операция безусловная 122
— пустая 124
— условная 124
Опорная гиперплоскость 146
Опорный вектор 165
— функционал 129
Орграф 59
Отношение предшествования 60
— частичной упорядоченности 60
Память 18
Параллельная форма 31, 66
— —, высота 31, 66
— — каноническая 66
— — максимальная 66
— — последовательная 66
— —, ширина 31, 66
— —, ярус 31, 66
Переменная с индексом 121
Петля 59
Подграф 62
— базовый 190
— главный 187
— — регулярный 165
— опорный регулярный 166
— остовный 62
Порядок лексикографический 125
Последовательная ЭВМ 19
Программа 124
Производительность номинальная 74
Процессор 18
Псевдограф 59
Путь 60
—, длина 60
— критический 60
Развертка БКВ 183
Ребро 58
я — ориентированное 59
Рёбра кратные 59
— параллельные 59
— различные 59
Связь транспортная 227
— шинная 227
Сдваивания процесс 34
Систолическая ячейка 219
Систолический массив 219
Стоимость операции 73
— работы 73
Такт 71
Топологическая сортировка 61
— — линейная 61
Универсальная задача 115
Ускорение 78
Устройство управления 18
— функциональное конвейерное~!71
— — простое 71
Формула Эйлера 224
Фронт вычислений 148
Цепь 59
— простая 59
— составная 59
Цикл 59
— неуравновешенный 182
—, ориентированная длина 195
— простой 59
— составной 59
— элементарный 59