













































































































































































































































































































































































































































































































































































































































































































Автор: Брукшир Дж. Гленн
Теги: компьютерные технологии информатика компьютерные науки
ISBN: 5-8459-0179-0
Год: 2001




Текст
Введение в
компьютерные
науки
Шестое издание
sixth edition
computer science
an overview
j. glenn brookshear
Marquette University
* ADDISON WESLEY
An imprint of Addison Wesley Longman, Inc.
Reading, Massachusetts • Menlo Park, California • New York • Harlow, England
Don Mills, Ontario • Sydney • Mexico City • Madrid • Amsterdam
Введение в
компьютерные
науки
Шестое издание *
Дж. Гленн Брукшир
(Под общей редакцией В. Н. Штонды)
Издательский дом "Вильяме"
Москва ♦ Санкт-Петербург ♦ Киев
2001
ББК 32.973.26-018.2.75
Б89
УДК 681.3.07
Издательский дом "Вильяме"
Перевод с английского канд.физ.-мат.наук ДА. Клюшина,
ААМомотюк, А.В. Назаренко,
канд.физ.-мат.наук АЛ. Орехова, А.В. Скилягина, А.В. Слепцова
Под редакцией А.В. Слепцова
Под общей редакцией В.Н. Штонды
По общим вопросам обращайтесь в Издательский дом "Вильяме"
по адресу: info@williamspublishing.com, http://www.williamspublishing.com
Брукшир, Дж., Гленн.
Б89 Введение в компьютерные науки. Общий обзор, 6-е издание. : Пер. с
англ. — М. : Издательский дом "Вильяме", 2001. — 688 с. : ил. — Парал.
тит. англ.
ISBN 5-8459-0179-0 (рус.)
Эта книга представляет собой базовый курс по компьютерным наукам, который
уже много лет читается в университетах США и других стран. Испытание
временем, которое она успешно выдержала, свидетельствует о широте охвгта и качестве
изложения представленного в ней материала. Несмотря на бурные темпы развития
этой области знаний, автор данного курса постоянно поддерживает его
актуальность, с каждым новым изданием обновляя излагаемый материал и пополняя
перечень освещаемых в нем аспектов компьютерных наук. Благодаря полноте и
доходчивости изложения материала, не требующего никакой специальной подготовки,
эта книга может быть полезна всем — как будущим профессионалам в области
вычислительной техники, так и самому широкому кругу иных специалистов,
нуждающихся в изучении основ компьютерной грамотности.
ББК 32.973.26-018.2.75
Все названия программных продуктов являются зарегистрированными торговыми
марками соответствующих фирм. . w x
Никакая часть настоящего издания ни в каких целях не может быть воспроизведена в
какой бы то ни было форме и какими бы то ни было средствами, будь то электронные или
механические, включая фотокопирование и запись на магнитный носитель, если на это нет
письменного разрешения издательства Addison-Wesley Publishing Company, Inc.
Authorized' translation from the English language edition published by Addison-Wesley
Publishing Company, Inc, Copyright © 2000
All rights reserved. No part of this book may be reproduced or transmitted in any form or by
any means, electronic or mechanical, including photocopying, recording or by any information
storage retrieval system, without permission from the Publisher.
Russian language edition published by Williams Publishing House according to the
Agreement with R&I Enterprises International, Copyright © 2001
ISBN 5-8459-0179-0 (рус.) © Издательский дом "Вильяме", 2001
ISBN 0-201-35747-Х (англ.) © Addison-Wesley Publishing Company, Inc, 2000
Оглавление
Глава нулевая. Введение 21
Архитектура машин 37
Глава первая. Хранение данных 39
Глава вторая. Обработка данных 109
Программное обеспечение 155
Глава третья. Операционные системы и сети 157
Глава четвертая. Алгоритмы 213
Глава пятая. Языки программирования 277
Глава шестая. Технология разработки
программного обеспечения 341
Организация данных 379
Глава седьмая. Структуры данных 381
Глава восьмая. Файловые структуры 433
Глава девятая. Структуры баз данных 463
Потенциал алгоритмических машин 505
Глава десятая. Искусственный интеллект 507
Глава одиннадцатая. Теория вычислений 563
Приложения 613
Приложение А. Код ASCII 615
Приложение Б. Электронные схемы обработки чисел
в двоичном дополнительном коде 617
Приложение В. Пример типичного машинного языка 621
Приложение Г. Примеры программ 625
Приложение Д. Эквивалентность итеративных
и рекурсивных структур 633
Приложение Е. Ответы на вопросы для самопроверки 635
Предметный указатель 679
Содержание
Глава нулевая. Введение 21
0.1. Знакомство с алгоритмами 22
0.2. Происхождение вычислительных машин 26
0.3. Эволюция компьютерных наук 30
0.4. Роль абстракции 32
0.5. Этические, социальные и правовые аспекты 33
Социальные и общественные вопросы 34
Рекомендуемая литература 36
Архитектура машин 37
Глава первая. Хранение данных 39
1.1. Хранение битов 40
1.2. Основная память 48
1.3. Массовая память 51
1.4. Представление информации в виде комбинации
двоичных разрядов 59
1.5. Двоичная система счисления 68
1.6. Представление целых чисел 71
1.7. Представление дробных значений 79
1.8. Сжатие данных 85
1.9. Ошибки при передаче информации 91
Упражнения 97
Общественные и социальные вопросы 106
Рекомендуемая литература 107
Дополнительная литература 108
Глава вторая. Обработка данных 109
2.1. Центральный процессор 110
2.2. Концепция хранимой программы 115
2.3. Выполнение программы 119
2.4. Арифметические и логические команды 127
2.5. Взаимодействие с другими устройствами 132
2.6. Другие типы архитектуры компьютеров 137
Упражнения 142
Социальные и общественные вопросы 151
Рекомендуемая литература 153
Дополнительная литература 153
Программное обеспечение 155
Глава третья. Операционные системы и сети 157
3.1. Эволюция операционных систем 158
3.2. Архитектура операционных систем 163
3.3. Координация действий машины 171
3.4. Организация конкуренции между процессами 176
3.5. Сети 182
6 Содержание
3.6. Сетевые протоколы 190
3.7. Безопасность 200
Упражнения 204
Общественные и социальные вопросы 209
Рекомендуемая литература 211
Дополнительная литература 211
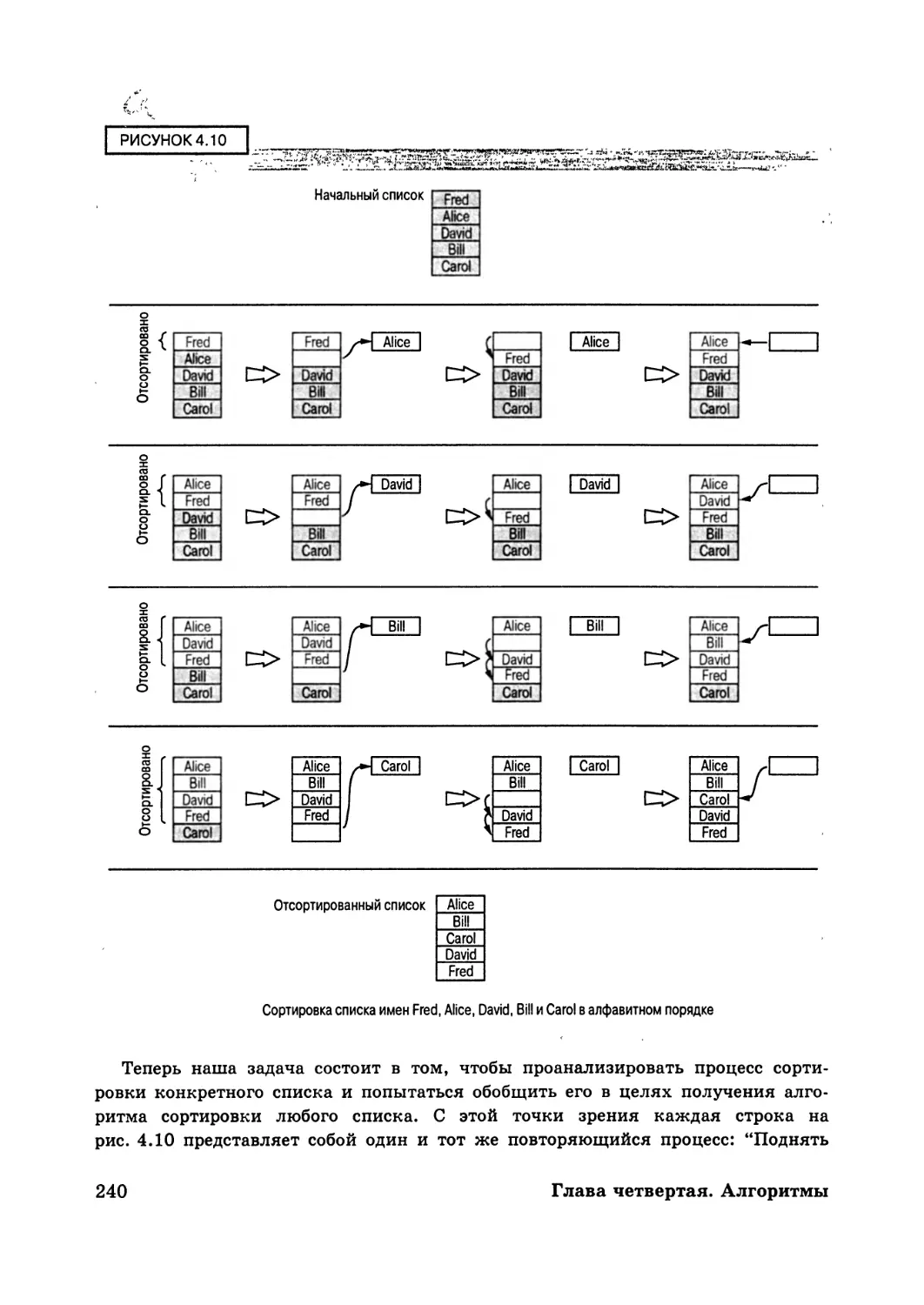
Глава четвертая. Алгоритмы 213
4.1. Понятие алгоритма 214
4.2. Представление алгоритма 217
4.3. Создание алгоритма 225
4.4. Итерационные структуры 232
4.5. Рекурсивные структуры 243
4.6. Эффективность и правильность 254
Упражнения 266
Общественные и социальные вопросы 274
Рекомендуемая литература 276
Глава пятая. Языки программирования 277
5.1. Исторический обзор 278
5.2. Концепции традиционного программирования 288
5.3. Процедуры и функции 300
5.4. Реализация языка 307
5.5. Объектно-ориентированное программирование 318
5.6. Программирование параллельных процессов 322
5.7. Декларативное программирование 325
Упражнения 331
Общественные и социальные вопросы 337
Рекомендуемая литература 339
Дополнительная литература 339
Глава шестая. Технология разработки
программного обеспечения 341
6.1. Предмет технологии разработки программного обеспечения 342
6.2. Жизненный цикл программного обеспечения 345
6.3. Модульность 351
6.4. Методы проектирования 358
6.5. Тестирование 366
6.6. Документирование 368
6.7. Право собственности и ответственность за создаваемое
программное обеспечение 370
Упражнения 373
Общественные и социальные вопросы 376
Рекомендуемая литература 377
Дополнительная литература 378
Организация данных 379
Глава седьмая. Структуры данных 381
7.1. Массивы 382
7.2. Списки 385
7.3. Стеки 393
7.4. Очереди 398
7.5. Древовидные структуры 402
Содержание 7
7.6. Специализированные типы данных 414
7.7. Указатели в машинном языке 421
Упражнения 422
Общественные и социальные вопросы 431
Рекомендуемая литература 432
Дополнительная литература 432
Глава восьмая. Файловые структуры 433
8.1. Роль операционной системы 434
8.2. Последовательные файлы 436
8.3. Текстовые файлы 442
8.4. Индексация 446
8.5. Хеширование 450
Упражнения 457
Общественные и социальные вопросы 461
Рекомендуемая литература 462
Глава девятая. Структуры баз данных 463
9.1. Общие понятия 464
9.2. Многоуровневый подход к реализации баз данных 467
9.3. Реляционная модель 470
9.4. Объектно-ориентированные базы данных 485
9.5. Обеспечение целостности баз данных 488
9.6. Влияние технологий баз данных на общество 493
Упражнения 496
Общественные и социальные вопросы 502
Рекомендуемая литература 503
Дополнительная литература 504
Потенциал алгоритмических машин 505
Глава десятая. Искусственный интеллект 507
10.1. Машины и интеллект 508
10.2. Распознавание изображений 512
10.3. Способность к рассуждению 515
10.4. Искусственные нейронные сети 528
10.5. Генетические алгоритмы 537
10.6. Приложения теории искусственного интеллекта 542
10.7. Осмысливание последствий 551
Упражнения 554
Общественные и социальные вопросы 560
Рекомендуемая литература 562
Дополнительная литература 562
Глава одиннадцатая. Теория вычислений 563
11.1. Простейший язык программирования 564
11.2. Машины Тьюринга 570
11.3. Вычислимые функции 575
11.4. Невычислимые функции 579
11.5. Сложность задач 586
11.6. Криптография с использованием открытых ключей 596
Упражнения 606
Содержание
Общественные и социальные вопросы 610
Рекомендуемая литература 612
Дополнительная литература 612
Приложения 613
Приложение А. Код ASCII 615
Приложение Б. Электронные схемы обработки чисел
в двоичном дополнительном коде 617
Приложение В. Пример типичного машинного языка 621
Архитектура машины 621
Машинный язык 621
Приложение Г. Примеры программ 625
Язык Ada 625
Язык С 626
Язык C++ 627
Язык FORTRAN 629
Язык JAVA 629
Язык PASCAL 630
Приложение Д. Эквивалентность итеративных
и рекурсивных структур 633
Приложение Е. Ответы на вопросы для самопроверки 635
Часть I 635
Часть II 644
Часть III 657
Часть IV 669
Предметный указатель 679
Содержание
О компьютерных науках
Компьютерные науки — это ядро теоретических и практических знаний, которые
используют в своей работе специалисты в области вычислительной техники,
программирования, информационных систем и технологий. Как научная дисциплина
компьютерные науки возникли в начале 40-х годов XX века в результате слияния
теории алгоритмов и математической логики, а также изобретения электронных
вычислительных машин. На протяжении полувековой истории компьютерных наук
неоднократно возникали и исчезали те или иные направления. Но одним из наиболее
важных разделов компьютерных наук остается теория, анализ, разработка, оценка
эффективности, реализация и практическое применение алгоритмов.
Чтобы применять основные результаты исследований в области
компьютерных наук, необходимо обладать навыками в четырех основных направлениях:
алгоритмическое мышление, представление информации, программирование и
проектирование систем. Предметная область компьютерных наук в целом может
быть разделена на две обширные подобласти. Первая из них включает изучение
конкретных процессов обработки информации и связанные с ними вопросы
представления данных. Вторая имеет отношение к структурам, механизмам и
схемам обработки информации.
Важнейшая цель обучения компьютерным наукам состоит в том, чтобы четко
понимать отношения, существующие между прикладными приложениями и
компьютерными системами. Компьютерные приложения делятся на две
категории: числовые и нечисловые. В числовых приложениях доминирующими
являются математические модели и числовые данные. В нечисловых приложениях
информация представляется в виде символов и правил. Традиционно
компьютерные науки имеют более тесные связи с математикой. Со своей стороны,
компьютерные науки оказывают сильное влияние на математику.
В настоящее время в области компьютерных наук обычно выделяют
двенадцать основных разделов.
■ Алгоритмы и структуры данных. Раздел теории алгоритмов включает
теорию вычислимости, теорию вычислительной сложности, теорию
параллельных вычислений (программирование параллельных процессов),
теорию дедуктивных и реляционных баз данных, теорию распознавания
образов, теорию алгоритмов, криптографию и многие другие направления.
■ Языки программирования. Этот раздел компьютерных наук изучает системы
обозначений, предназначенных для выполнения алгоритмов на виртуальных
машинах, а также способы формальной записи самих алгоритмов и данных.
Венцом достижений разработчиков стали программы, которые получают
описание языка и автоматически создают компилятор для перевода программ с
этого языка на машинный язык (например, программы YACC и LEX).
■ Архитектура компьютеров. Раздел теории архитектуры компьютеров
включает цифровую логику, булеву алгебру, теорию кодирования и тео-
0 компьютерных науках 11
рию конечных автоматов. К наиболее значительным достижениям в этой
области компьютерных наук относятся модули выполнения
арифметических операций, кэш-память, так называемые машины фон Неймана, RISC-
компьютеры и CISC-компьютеры. Были разработаны эффективные методы
записи и хранения информации, а также методы обнаружения и
исправления ошибок, включая средства восстановления после отказов.
Операционные системы и компьютерные сети. Этот раздел компьютерных
наук связан с исследованиями механизмов управления, позволяющих
эффективно координировать работу большого количества вычислительных
ресурсов при проведении вычислений, распределенных по многочисленным
компьютерным системам, объединенным в глобальные и локальные сети.
Разработка программного обеспечения. Данный раздел компьютерных наук
связан с созданием больших программных систем, которые должны
удовлетворять заданным программным спецификациям, быть безопасными,
защищенными, надежными и заслуживающими доверия пользователей.
Базы данных и информационно-поисковые системы. Этот раздел
компьютерных наук связан с организацией больших наборов постоянно
сохраняемых и совместно используемых данных, допускающих их обновление и
обеспечивающих эффективное выполнение запросов. Для изучения и
разработки баз данных и информационно-поисковых систем применяются
реляционная алгебра и реляционное исчисление, теория параллельной
обработки данных, выполняемых с помощью транзакций.
Искусственный интеллект и робототехника. Данный раздел компьютерных
наук включает моделирование процессов познания мира животными и
человеком с конечной целью создания компонентов машин, способных имитировать
или усиливать их. Основные объекты изучения в этой области включают
распознавание сенсорных сигналов, звуков, изображений и образов, обучение,
процессы рассуждения при решении задач и планирования, а также
понимание языков. Разработаны основные принципы проектирования систем
искусственного интеллекта: логическое программирование; экспертные системы;
методы и средства представления, хранения и использования знаний;
прикладные системы, использующие естественный язык; синтезаторы речи и
системы распознавания речи; роботы; генетические алгоритмы.
Компьютерная графика. Компьютерная графика связана с процессами
визуального представления реальных и виртуальных объектов, а также
имитации их движений на двухмерном экране компьютера или в трехмерной
голограмме. Она опирается на вычислительную геометрию и многие другие
области науки.
Взаимодействие человека и компьютера. Эта область компьютерных наук
изучает вопросы эффективной координации действий и передачи
информации между людьми и машинами (пользовательский интерфейс) с
помощью различных датчиков и устройств, имитирующих деятельность чело-
12 О компьютерных науках
века, а также информационные структуры, которые отражают
человеческие представления об окружающем мире.
■ Вычислительная математика. Эта область компьютерных наук связана с
проведением научных исследований, которые невозможно выполнить без
высокопроизводительных вычислений и обмена данными.
■ Деловая информатика. Данная область компьютерных наук изучает
вопросы обмена информацией и создания программных систем,
обеспечивающих работу организаций и координацию действий их сотрудников.
■ Биоинформатика. Эта новейшая область компьютерных наук возникла в
результате тесного взаимодействия вычислительной математики и
биологических наук.
Наиболее перспективные направления развития компьютерных наук
связываются с вычислительной математикой, теорией познания, библиотековедением,
деловой информатикой, биоинформатикой, организацией и управлением
промышленным производством, архитектурой.
Стать специалистом по современным информационным технологиям
возможно только при условии комплексного изучения всех составных частей
компьютерных наук. Прекрасным введением и хорошим источником информации о
современном состоянии компьютерных наук является эта книга, представляющая
собой популярный в США учебник для студентов высших учебных заведений и
тех, кто занимается самообразованием.
— Виктор Штонда
shtondaQwilliamspublishing.com
О компьютерных науках 13
Предисловие
Данная книга представляет собой введение в область компьютерных наук. В
ней сочетается необходимая широта обзора предмета с достаточно глубоким
проникновением в сущность излагаемого материала. Я писал эту книгу для двух
категорий читателей.
Для будущих специалистов по компьютерным наукам
и вычислительной технике
Первая категория читателей включает студентов начальных курсов, которые
по окончании учебного заведения станут специалистами в области
компьютерных наук и вычислительной техники. Как правило, на этом этапе обучения
студенты склонны отождествлять весь спектр компьютерных наук с
программированием и просмотром Web-страниц в Internet, поскольку это, в сущности,
именно то, что они видели раньше и с чем им приходилось сталкиваться. Однако
область компьютерных наук — это нечто существенно большее. Поэтому
студентам необходимо продемонстрировать всю глубину и обширность той области
знаний, к изучению которой они приступают и в которой планируют
специализироваться. В предоставлении этой, столь необходимой им информации и состоит
назначение данной книги. Она познакомит студентов с обзором всего спектра
компьютерных наук, что создаст основу для правильной оценки различных
курсов, которые им предстоит изучать впоследствии.
Для студентов других дисциплин
Кроме того, эта книга разработана с учетом интересов учащихся других
специальностей. Данный курс компьютерных наук позволит им заложить фундамент для
понимания основ этой области наук в целом. Подобная база необходима всем
студентам, чтобы научиться адаптироваться к тому техногенному обществу, в котором они
живут, и в случае необходимости самостоятельно продолжить изучение этих наук,
что на сегодняшний день очень важно. Поэтому данную книгу можно использовать в
качестве учебника для ознакомительного курса компьютерных наук, рассчитанного
на студентов различных естественных наук. После изучения данного курса студенты
получат необходимые знания обо всех направлениях компьютерных наук, которые
будут работать на них и в будущем.
Структура книги
Материал книги упорядочен в соответствии с восходящим подходом,
предусматривающим переход от конкретного к абстрактному. Именно такой способ
изложения обеспечивает ясную и доступную подачу материала, когда одна тема
плавно переходит в другую. Часть I включает обсуждение вопросов, связанных с
аппаратным обеспечением. Она начинается с объяснений, как информация
представляется и записывается в машинах и как выбранные способы представления
\
влияют на свойства этих машин (глава 1). Затем описывается, как машины
обрабатывают данные с помощью программ на машинных языках (глава 2).
В части II обсуждаются вопросы, связанные с программным обеспечением,
как функционирование машины координируется операционной системой и как
это координирование может быть распространено на всю компьютерную сеть, а
также на межсетевые взаимодействия (глава 3). На этой стадии обучения
студенты получают информацию, необходимую для понимания принципов
построения и функционирования типичной компьютерной системы. По сути, главы 1-3
могут использоваться как основа для краткого курса лекций "Что должен знать
каждый грамотный пользователь компьютера".
В последующих главах этой части рассматриваются вопросы разработки
программного обеспечения, включая разработку и анализ алгоритмов (глава 4),
применение языков программирования и используемые ими парадигмы
(глава 5), а также проектирование программного обеспечения (глава 6).
В части III детально рассматриваются темы, затронутые в предыдущей части,
и обсуждается взаимосвязь между алгоритмами и построением структур
хранения данных. В частности, здесь дано введение в теорию структур данных
(глава 7), приводятся элементарные сведения о методах файлового хранения
информации (глава 8) и представлен общий обзор систем баз данных (глава 9).
Курс достигает своей кульминации в части IV, включающей рассмотрение
наиболее впечатляющих достижений в области вычислительной техники. Эта часть
начинается с главы об искусственном интеллекте, в которой обсуждаются технологии
создания вычислительных машин, способных к восприятию и проведению
рассуждений (глава 10). Заканчивается данная часть рассмотрением ограничений, присущих
алгоритмическим системам, и тех пределов, которые эти ограничения устанавливают
в отношении возможностей вычислительных машин (глава 11).
Кроме того, существует ряд тем, которые красной нитью проходят через
всю книгу. Первая — это то, что компьютерные науки являются весьма
динамичной областью знания. Все рассматриваемые темы подаются в исторической
перспективе, обсуждается достигнутый на данный момент уровень развития и
указываются основные направления текущих исследований. Вторая тема
состоит в пояснении значения абстрактных методов и способов применения
различных абстрактных инструментов для управления уровнем сложности.
Фактически даже само построение книги отвечает раскрытию этой темы за счет
представления материала в порядке прогрессирующей абстракции —
аппаратное оборудование предоставляет абстрактные инструменты, используемые
системным программным обеспечением, а системное программное обеспечение, в
свою очередь, предоставляет абстрактные инструменты, используемые
прикладным программным обеспечением.
Студенту
Впервые я познакомился с областью компьютерных наук во время службы в
военно-морских силах США, в конце 60-х - начале 70-х годов. (Я сознаю, что
это признание старит меня в глазах читателя, однако и с вами это тоже когда-
нибудь произойдет.) Большую часть всего срока службы я занимался тем, что
Предисловие 15
содержал в исправности системное программное обеспечение компьютеров
военно-морского флота, установленных в Лондоне. По окончании службы я вернулся
к учебе и в 1975 году закончил аспирантуру. С тех пор я преподаю
компьютерные науки и математику.
Многое изменилось за эти годы в компьютерных науках, однако многое
осталось и неизменным. В частности, компьютерным наукам всегда была и по-
прежнему присуща некоторая притягательная сила. В этой области знаний
постоянно происходит множество увлекательных событий. Развитие и
повсеместное распространение Internet, прогресс в области искусственного интеллекта,
уникальные возможности сбора и распространения информации в неслыханных
размерах — это только некоторые из аспектов, способных воздействовать на
вашу жизнь. Вы живете в замечательном, изменяющемся мире, и вам
предоставляется реальная возможность стать участником происходящих событий.
Воспользуйтесь же ею! Чем больше вы узнаете, тем лучше будете подготовлены. Эта
книга позволит вам заложить основу, но это отнюдь не предел. Прочтите ее, а
потом совершенствуйтесь дальше и дальше. Одно из наиболее достойных
качеств, которое вы можете развить в себе, — это умение учиться самостоятельно.
Преподавателю
Объем материала этой книги превосходит тот, который может быть изучен за
один семестр, поэтому не бойтесь пропускать темы, которые не соответствуют
задачам вашего курса. Я написал книгу для того, чтобы она служила основой
для проведения курса обучения, а не определяла его содержание. Несмотря на то
что изложение материала следует определенной схеме, каждая из тем подается в
независимой манере, что позволит вам сделать выбор в соответствии с вашими
вкусами. В начале каждой из глав звездочками отмечены те разделы, которые я
считаю факультативными, однако желание навязать вам свое мнение не входило
в мои намерения. Я также предлагаю рассматривать некоторые темы как
задания для домашнего чтения. Мне кажется, что зачастую мы недооцениваем
студентов, когда считаем необходимым объяснять абсолютно все непосредственно на
занятиях. Я часто задаю моим студентам целую главу для чтения на дом, а
затем использую время занятий для того, чтобы разъяснить определенные вопросы
или подробно осветить некоторые части текста, исходя из собственного опыта.
Я уже указывал, что книга построена по восходящему принципу, от
конкретного к абстрактному, однако позвольте мне остановиться на этом подробнее. Как
ученые мы слишком часто полагаем, что студенты непременно оценят наш
подход к предмету, который вырабатывался нами на протяжении многих лет
работы в этой области. Однако как преподаватели мы поступим лучше, если будем
подавать материал, ориентируясь на точку зрения студента. Именно поэтому
книга начинается с освещения темы представления и хранения данных, которая
выбрана мною в качестве отправной точки для изложения последующего
материала. Современные студенты уже знакомы с магнитными дисками, модемами,
компакт-дисками, и я обнаружил, что они проявляют интерес к тому, как эти
устройства работают. Я часто наблюдал, как они находят ответы на многие свои
"почему?", после чего начинают воспринимать этот курс скорее как практиче-
16 Предисловие
ский, нежели как теоретический. После такого начала книга естественно
подходит к раскрытию вопросов о программном обеспечении, которое контролирует
эти устройства. Далее рассматривается, как можно разработать собственное
программное обеспечение. Затем обсуждение переходит к таким абстрактным
вопросам, как разработка алгоритмов, способ представления функций, а также
сложность, что и является основным содержанием большинства традиционных
вводных компьютерных курсов.
Всем нам известно, что студенты познают гораздо больше того, чему мы их
обучаем, и те знания, которые они получают окольным путем, зачастую
воспринимаются лучше, чем те, которые подаются им непосредственно. Эта особенность становится
особенно важной, когда приходит время "учить" решать задачи. Студенты не учатся
решать проблемы как отдельную дисциплину путем изучения методологий по
решению задач. Они учатся справляться с проблемами, решая их. Поэтому по всему
тексту книги я включил многочисленные задания. Я настоятельно рекомендую вам
использовать их и подробно пояснять методы их решения.
Еще одна тема, которую я отнес к этой же категории, — это профессионализм,
этика и социальная ответственность. Я не считаю, что подобный материал может
быть представлен как отдельный предмет. Напротив, он должен выходить на
поверхность там, где это уместно, и именно такой подход выбран в данной книге. В
частности, в разделы 0.5, 3.7, 6.1, 10.1 и 10.7 включены такие темы, как безопасность,
конфиденциальность, ответственность, социальные аспекты, обсуждаемые в
контексте работы в сети, использование баз данных, разработка программного обеспечения
и применение искусственного интеллекта. Кроме того, каждая глава включает ряд
вопросов (раздел "Общественные и социальные вопросы"), побуждающих студентов к
размышлениям об отношении представленного в книге материала к жизни того
общества, частью которого они являются.
Педагогические аспекты
Эта книга является плодом моей многолетней практики преподавания,
благодаря чему она богата разнообразным педагогическим материалом. В частности,
весьма существенным фактором является обилие поставленных задач, решение
которых требует активного участия обучающихся. Каждый раздел главы
заканчивается пунктом "Вопросы для самопроверки", назначение которого —
стимулировать обучающихся к самостоятельному мышлению. С помощью
предлагаемых задач закрепляется пройденный материал, приведенное выше обсуждение
расширяется дополнительными аспектами и даются ссылки на связанный
материал, рассмотрение которого будет проводиться позднее. Ответы на
предлагаемые вопросы вынесены в приложение Б.
Более того, каждая глава (за исключением вступительной) заканчивается
двумя группами задач. Первая включает подборку задач под заголовком
"Упражнения", разработанных для использования в качестве "домашнего
задания", поскольку они относятся к содержанию всей главы и в тексте прямо не
рассматриваются. Вторая группа содержит вопросы под заголовком
"Общественные и социальные вопросы", которые предназначены для
обдумывания и обсуждения. Многие из этих вопросов могут быть использованы в качестве
Предисловие 17
небольших заданий на проведение исследований, результаты которых должны
быть представлены в виде письменных или устных отчетов.
Каждая глава завершается списком рекомендуемой литературы, включающим
ссылки на материал, имеющий отношение к теме данной главы. Кроме того,
хорошим источником дополнительной информации по каждой теме является Web-
узел, речь о котором пойдет в следующем разделе.
Web-узел
Данная книга дополняется материалом, собранным на специальном Web-узле,
предназначенном для ее информационной поддержки. Его адрес http://
www.awlonline.com/brookshear. На этом узле представлен материал как для
студентов, так и преподавателей, включая вспомогательное программное
обеспечение, руководства к лабораторным работам по разнообразным языкам
программирования, ссылки на дополнительные темы по интересам, а также на
материалы, разработанные другими читателями этой книги.
Замечания к шестому изданию
Несмотря на то что это издание имеет ту же структуру построения по главам, что
и предыдущее, в него добавлены некоторые новые темы, а часть существовавших
ранее удалена. Большинство предлагаемого материала было переработано в целях
адекватного представления современного состояния в области компьютерных наук.
Ниже приведен обзор основных изменений, которые были внесены в данное издание.
Тема сжатия данных была перенесена из главы 2 в новый раздел 1.8. Этот
раздел также содержит сведения о программе LZ77 и методах представления
изображений, включая обсуждение форматов GIF и JPEG. Материал по анализу
алгоритмов, который раньше рассматривался в главе 11, был расширен и
перемещен в главу 4 "Алгоритмы". Глава 4 стала более доступной для понимания
после удаления обсуждения методов быстрой сортировки. В главу 5 "Языки
программирования" был добавлен раздел 5.5, посвященный объектно-
ориентированному программированию. Часть этого материала входила раньше в
главу 7. Большая часть главы 6 "Технология разработки программного
обеспечения" была полностью переписана. Теперь она включает введение в шаблоны
проектирования и новый раздел по тестированию. В главе 7 "Структуры
данных" появился новый раздел 7.7, содержащий сведения об использовании
косвенной адресации на уровне машинных языков. Глава 8 "Файловые
структуры" была полностью переписана в целях лучшего восприятия материала
(за счет удаления излишних примеров по конкретным языкам
программирования). Раздел 9.4 по объектно-ориентированным базам данных был переписан, и
появился новый раздел 9.6, посвященный социальным аспектам использования
технологии баз данных. В главу 10 "Искусственный интеллект" включены два
новых раздела — 10.5 "Генетические алгоритмы" и 10.7 "Осмысливание
последствий". Кроме того, прежние разделы 10.3, 10.4 и 10.5 были упрощены и
объединены. В главу 11 "Теория вычислений" был добавлен раздел 11.6
"Криптография с использованием открытых ключей".
Помимо упомянутых выше изменений, я добавил в книгу некоторую
изюминку, поместив в ее текст врезки, содержание которых позволяет лучше осоз-
18 Предисловие
нать связь излагаемого материала с реальным миром. Многие из этих врезок
содержат ссылки на источники в Internet, предоставляющие дополнительную
информацию по обсуждаемой теме.
Благодарности
Прежде всего я хотел бы поблагодарить тех, кто поддержал эту книгу тем,
что читал ее предыдущие издания и использовал их материал в своей работе* Вы
оказали мне этим большую честь.
С каждым новым изданием пополняется список тех, кто внес свой вклад в
создание этой книги. На сегодняшний день в этот список входят Дж. М. Адаме
(J. M. Adams), К. М. Аллен (СМ. Allen), Д. К. С. Эллисон (D. С. S. Allison), Б.
Ауернхеймер (В. Auernheimer), П. Бэнкстон (P. Bankston), М. Бернард (М.
Barnard), К. Боуер (К. Bowyer), П. У. Брешер (P. Brashear), К. М. Браун (С.
М. Brown), Б. Каллони (В. Calloni), М. Клэнси (М. Clancy), P. Т. Клоуз (R. Т.
Close), Д. X. Кули (D. H. Cooley), Ф. Дик (F. Deek), М. Дж. Дункан (М. J.
Duncan), С. Фокс (S. Fox), Н.Е. Гиббс (N. E. Gibbs), Дж. Д. Гаррис (J. D.
Harris), Д. Гэском (D. Hascom), Л. Хит (L. Heat), П. Хендерсон (P. Henderson),
Л. Хант (L. Hunt), Л. А. Джен (L. A. Jehn), К. Корб (К. Korb), Дж. Кренц (G.
Krenz), Дж. Лью (J. Liu), Т. Дж. Лонг (Т. J. Long), К. Мэй (С. May), С. Дж.
Меррил (S. J. Merrill), Дж. К. Мойер (J. С. Моуег), М. Мэрфи (М. Murphy),
Дж. П. Майерс (J. P. Myers), Дж. Д. С. Нунен (Jr. D. S. Noonan), С. Оларью
(S. Olariu), Дж. Райе (G. Rice), H. Риккерт (N. Rickert), К. Ридесел (С.
Riedesel), Дж. Б. Роджерс (J. В. Rodgers), Дж. Сайто (G. Saito), У. Савитч (W.
Savitch), Р. Шлефтли (R. Schlafly), Дж. К. Шлиммер (J. С. Schlimmer), С.
Селлс (S.Sells), Дж. К. Симмз (J. С. Simms), М. К. Слэттери (М. С. Slatterry),
Дж. Слимик (J. Slimick), Дж. А. Сломка (Slomka), Д. Смит (D. Smith), Дж.
Солдеритч (J. Solderitsch), P. Стейгервальд (R. Steigerwald), Л. Стайнберг (L.
Steinberg), У. Дж. Тэффе (W. J. Taffe), Дж. Толбарт (J. Talburt), П. Тромович
(P. Tromovitch), Э. Райт (Е. Wright) и М. Зиглер (М. Ziegler). Этим людям я
выражаю свою самую искреннюю благодарность.
Я также хочу поблагодарить своих друзей из издательства Addison-Wesley, чьи
усилия также нашли отражение на этих страницах. Они проделали большую работу,
превратив необработанную рукопись в отлично изданную книгу. В частности, Лисе
Кэлнер (Lisa Kalner) и Эми Роуз (Amy Rase) пришлось терпеливо работать со мной в
течение многих дней. Они могут поведать об этом множество историй.
Кроме того, я хотел бы поблагодарить мою жену Иэрлин за ту поддержку,
которую она оказывала мне на протяжении этих лет. Именно благодаря ей
утром 11 декабря 1998 года я был вовремя доставлен в больницу и смог
оправиться после инфаркта.
Сообщите нам ваше мнение
Вы, читатель этой книги, и есть главный ее критик. Мы ценим ваше мнение
и хотим знать, что было сделано нами правильно, что можно было сделать
лучше и что еще вы хотели бы увидеть изданным нами. Было бы интересно
услышать и другие замечания, которые вам хотелось бы высказать в наш адрес.
Предисловие 19
Мы ждем ваших комментариев и надеемся на них. Вы можете прислать
электронное письмо или просто посетить наш Web-узел, оставив свои замечания. Одним
словом, любым удобным для вас способом дайте нам знать, нравится ли вам эта
книга, а также выскажите свое мнение о том, какими бы вы хотели видеть наши книги.
Посылая письмо или сообщение, не забудьте указать название книги и ее
авторов, а также ваш факс или номер телефона. Мы внимательно ознакомимся с вашими
замечаниями и обязательно учтем их при подготовке последующих книг.
E-mail: inf o@williamspublishing. com
WWW: http: //www.williamspublishing.com
20 Предисловие
0.1. Знакомство с алгоритмами
0.2. Происхождение
вычислительных машин
0.3. Эволюция компьютерных наук
0.4. Роль абстракции
0.5. Этические, социальные и
правовые аспекты
глава
Введение
НУЛЕВАЯ
Компьютерные науки—это дисциплина, назначение которой состоит в
создании научной основы для таких предметов, как проектирование
электронно-вычислительных машин, разработха программного
обеспечения, обработка информации, алгоритмическое решение задач, а
также алгоритмический процесс сам по себе. Следовательно, она
представляет собой фундамент для успешного применения современных
вычислительных машин, а также закладывает основы, необходимые для
разработки новых прикладных программ. Это означает, что невозможно
стать специалистом в области компьютерных наук, изучив лишь
несколько тем как независимые предметы или же просто научившись
использовать уже существующие вычислительные инструменты. Для того
чтобы получить глубокие знания в области компьютерных наук, следует
охватить весь спектр разнообразных аспектов из широкого диапазона
динамически развивающихся тем.
Эта книга и создана в целях обеспечения такого фундамента. Здесь
дисциплина компьютерных наук представлена как комплексное
введение в ряд предметов, составляющих типичную университетскую учебную
программу для специалистов по вычислительной технике. Таким
образом, эта книга может использоваться как базовый курс для студентов
факультетов информатики и вычислительной техники или как основной
источник сведений для студентов других специальностей, которым
требуется изучить основы тех дисциплин, которые определяют развитие
современного компьютеризированного общества.
0.1. Знакомство с алгоритмами
Мы начнем с самого фундаментального понятия в области компьютерных наук —
алгоритма. Говоря неформально, алгоритм — это последовательность действий,
которая определяет способ решения некоторой задачи.1 Например, существуют
алгоритмы для конструирования моделей самолетов (представляемые в форме
пооперационных инструкций), для управления стиральными машинами (обычно
помещаемые на внутреннюю сторону крышки машины), для воспроизведения музыки
(изображаемые в виде музыкальных нот), а также для выполнения различных
фокусов. Пример алгоритма последнего типа приведен на рис. 0.1.
Прежде чем машина сможет выполнить некоторое задание, необходимо
определить алгоритм выполнения этого задания и предоставить его машине в том виде,
который будет с ней совместим. Представление алгоритма в таком виде называется
программой. Программы, представляющие эти алгоритмы, принято называть
программным обеспечением, в противоположность самой машине, которую принято
называть аппаратным обеспечением.
Изучение алгоритмов первоначально составляло один из разделов
математики. Поиск алгоритмов занимал математиков задолго до того, как появились
современные вычислительные машины. Основная цель этого поиска —
отыскать общий набор указаний, описывающих способ решения задачи
определенного типа. Одним из наиболее известных результатов ранних поисков является
алгоритм деления столбиком для определения частного двух многозначных
чисел. В качестве еще одного примера можно привести алгоритм Евклида,
предложенный древнегреческим математиком для определения общего
наибольшего делителя двух положительных целых чисел. Описание этого алгоритма
представлено на рис. 0.2.
Как только алгоритм решения задачи будет найден, само выполнение
предусмотренных этим алгоритмом действий уже не потребует понимания
законов, по которым данный алгоритм был построен. Напротив, решение задачи
сужается до простого выполнения установленной последовательности
инструкций. Мы можем применять алгоритм деления столбиком для поиска
частного двух многозначных чисел или Евклидов алгоритм определения
наибольшего общего делителя, даже не понимая тех принципов, на основании
которых эти алгоритмы работают. По сути, в алгоритме закодированы все
сведения, необходимые для решения поставленной задачи.
1 Если быть более точным, алгоритм — это упорядоченное множество однозначных,
выполнимых манипуляций, определяющих некоторое конечное действие. Подробнее эта
тема обсуждается в главе 4.
22 Глава нулевая. Введение
Описание фокуса. Исполнитель фокуса выкладывает на стол несколько карт из обычной игральной колоды,
помещая их лицевой стороной вниз. При этом колода карт постоянно тщательно перетасовывается. Затем
зрителям предоставляется право выбора, какого цвета должна быть масть очередной открываемой карты —
черного или красного, после чего исполнитель переворачивает на столе требуемую карту.
Секрет фокуса и последовательность его выполнения.
Этап 1. Из обычной колоды карт выберите десять карт красной масти и десять черной. Уложите их в две стопки,
согласно цвету масти, лицевой стороной вверх.
Этап 2. Объявите, что вы выбрали несколько карт черной масти и несколько красной.
Этап 3. Выберите карты красной масти. Под видом упорядочения в одну маленькую стопку возьмите карты в
левую руку лицевой стороной вниз, после чего большим и указательным пальцами правой руки отогните
один из концов этой стопки вниз так, чтобы каждая карта стала слегка выпуклой. Затем со словами: "В
этой стопке карты красной масти" положите колоду карт на стол лицевой стороной вниз.
Этап 4. Возьмите карты черной масти. Таким же образом, как и в предыдущем случае, отогните уголок стопки
вверх, что сделает карты слегка вогнутыми. Затем положите карты на стол лицевой стороной вниз со
словами: "А в этой стопке карты черной масти".
Этап 5. Сразу после того, как карты черной масти будут выложены на стол, перетасуйте обе стопки и приступайте
раскладывать их на столе (опять же, лицевой стороной вниз). Раскладывая карты, демонстрируйте
зрителям, как тщательно вы их перетасовываете.
Этап 6. Когда все карты будут разложены, выполните следующие действия.
6.1. Попросите зрителей выбрать карту красной или черной масти.
6.2. Если запрашиваемый цвет масти красный и есть карта с выпуклой поверхностью, переверните ее со
словами: "Вот карта красной масти".
6.3. Если запрашиваемый цвет черный и есть карта с вогнутой поверхностью, переверните ее со
словами: "Вот карта черной масти".
6.4. В противном случае заявите, что больше нет карт требуемого цвета, и переверните все оставшиеся
карты, чтобы доказать это.
Алгоритм для выполнения карточного фокуса
Именно благодаря такой возможности собирать и передавать информацию с
помощью алгоритмов мы можем создавать "разумные" машины. Следовательно,
уровень интеллекта, проявляемый определенной машиной, ограничен той информацией,
которая может быть ей передана через используемые алгоритмы. Только после того,
как будет найден алгоритм, позволяющий решить поставленную задачу, может быть
сконструировано некоторое устройство, предназначенное для ее решения. В свою
очередь, если не существует алгоритма выполнения определенного задания, то его
выполнение оказывается за пределами возможностей машин.
0.1. Знакомство с алгоритмами 23
РИСУНОК 0.2
Описание. В этом алгоритме предполагается, что входные данные представляют собой два целых положительных
числа, для которых требуется определить наибольший общий делитель. '\
Порядок выполнения.
Этап 1. Присвойте переменным М и N значения двух введенных чисел (большего и меньшего).
Этап 2. Разделите М на N и присвойте значение остатка переменной Р. >
Этап 3. Если значение Р не равняется 0, присвойте переменной М значение переменной N, затем переменной N
присвойте значение остатка Р и вернитесь к этапу 2. В противном случае наибольшим общим делителем
заданной пары чисел является значение, присвоенное в данный момент переменной N.
Алгоритм Евклида для поиска наибольшего общего делителя двух положительных целых чисел
Таким образом, важнейшая задача всей области компьютерных наук — это
разработка алгоритмов, поэтому существенная часть рассматриваемых этими
науками вопросов касается тех или иных аспектов данной задачи.
Следовательно, мы можем получить достаточно глубокие знания в области компьютерных
наук только путем изучения свойств алгоритмов. Один из важных аспектов,
касающийся вопроса о том, как алгоритмы разрабатываются впервые, тесно связан
с общей проблемой решения задач. Поиск алгоритма решения задачи в сущности
состоит в нахождении способа ее решения. Из этого следует, что исследования в
этой области компьютерных наук обязательно должны строиться на
достижениях в таких областях знания, как психология решения проблем и теория
обучения. С некоторыми идеями из этих областей мы познакомимся в главе 4.
После того как алгоритм решения задачи будет найден, необходимо
представить его в такой форме, которая может быть воспринята машиной или другим
человеком. Это означает, что мы должны преобразовать найденную
алгоритмическую концепцию в четкий набор инструкций, представленных в форме,
исключающей всякую неоднозначность. Проводимые по этому поводу
исследования основывались на наших знаниях в области языка и грамматики и привели к
созданию множества схем представления алгоритмов, известных как языки
программирования. В различных языках используются разные подходы к процессу
программирования, иначе называемые парадигмами программирования.
Некоторые из этих языков программирования и те парадигмы, на основе которых они
построены, будут рассмотрены в главе 5.
Разработка больших систем программного обеспечения предусматривает нечто
большее, чем просто определение независимых алгоритмов выполнения
необходимых действий. Дополнительно требуется разработать схему взаимодействия
отдельных компонентов системы. В результате трудности, с которыми
приходится сталкиваться при разработке больших систем программного обеспечения, су-
24 Глава нулевая. Введение
щественно превосходят те, которые имеют место при разработке небольших
программ. Поэтому в компьютерных науках существует отдельная обширная
прикладная область исследований, назначение которой состоит в поиске
инструментов для решения указанных проблем. Эта область компьютерных наук,
именуемая технологией разработки программного обеспечения, на сегодняшний
объединяет достижения различных сфер знания, таких как инженерное
искусство, управление проектами, управление персоналом, а также разработка языков
программирования. Так как наше общество становится все более зависимым от
больших программных систем, возрастает и необходимость совершенствования
инструментов и методов программирования. Поэтому вопросы технологии
разработки программного обеспечения являются важнейшим направлением в
современных исследованиях. Подробно эта тема будет рассматриваться в главе 6.
Другой, не менее важной задачей компьютерных наук является разработка и
конструирование машин. Подробно эта тема рассматривается в главах 1 и 2. Хотя
приведенное здесь описание архитектуры вычислительной машины включает
обсуждение некоторых технических вопросов, автор не ставил своей целью детальное
освещение методов реализации современной компьютерной архитектуры в виде
электронных схем. В противном случае потребовалось бы слишком углубиться в предмет
электроники. Более того, аналогично механическим калькуляторам, которые
уступили место электронным устройствам, современные электронные устройства могут
быть со временем заменены продуктами иных технологий, среди которых главный
кандидат — оптика. Наша цель состоит в получении знаний в области современных
технологий, необходимых для правильной оценки их влияния на современные
машины, а также на развитие компьютерных наук.
Конечно, хотелось, чтобы архитектура вычислительных машин определялась
исключительно нашими знаниями об алгоритмических процессах и не ограничивалась
возможностями существующих технологий. Другими словами, вместо того чтобы
позволять существующим технологиям определять принципы построения машин и,
следовательно, способы представления алгоритмов, нам бы хотелось, чтобы
существующие знания об алгоритмах стали той силой, которая устанавливала бы
требования к современной архитектуре машин. По мере совершенствования технологий эта
мечта становится все более реальной. На сегодняшний день стало возможным
создавать машины, которые воспринимают алгоритмы, выраженные в виде нескольких
последовательностей команд, выполняемых одновременно. В другом варианте они
представляются как схемы соединений между многочисленными обрабатывающими
устройствами, что очень похоже на то, как наш мозг представляет информацию в
виде связей между нейронами (глава 10).
Еще один контекст, в котором мы рассмотрим архитектуру вычислительных
машин, связан с хранением и поиском данных. Здесь внутренние свойства
машин часто отражаются в их внешних характеристиках. Сами эти свойства, а
также способы, позволяющие избежать их нежелательного влияния,
обсуждаются в главах 1, 7, 8 и 11.
С конструированием вычислительной техники тесно связаны проблемы
разработки интерфейса между машиной и внешним миром. Например, как алгоритмы
будут вводиться в машину и как указать машине, какой алгоритм следует вы-
0.1. Знакомство с алгоритмами 25
полнить? Решение этих задач в окружении, предполагающем предоставление
машиной множества различных услуг, требует разрешения многих проблем,
включая координацию действий и распределение ресурсов. Некоторые из таких
решений будут рассмотрены в главе 3, посвященной операционным системам.
По мере того как от машин требовалось выполнение все более и более
интеллектуальных заданий, в области компьютерных наук выделилось направление изучения
особенностей человеческого разума. Цель исследований состояла в том, что после
выявления механизмов, позволяющих нашему мозгу рассуждать и познавать, можно
будет разработать алгоритмы, имитирующие эти процессы, и, таким образом,
передать эти возможности машинам. Эта новая область компьютерных наук, именуемая
теорией искусственного интеллекта, в значительной степени основывается на
достижениях таких наук, как психология, биология и лингвистика. Некоторые аспекты
теории искусственного интеллекта обсуждаются в главе 10.
Поиски алгоритмов решения все более сложных задач сделали актуальными
исследования в области предельных ограничений самих процессов алгоритмизации.
Если не существует алгоритма выполнения задания, то это задание не может быть
выполнено машиной. Говорят, что задача, решение которой может быть описано с
помощью алгоритма, является алгоритмической. Из этого определения следует, что
машины способны выполнять только алгоритмические задания.
Такое понятие, как неалгоритмические задачи, появилось в математике в
начале двадцатого века после доказательства теоремы Курта Геделя о неполноте.
Коротко говоря, эта теорема утверждает, что в любой математической теории,
которая охватывает традиционную арифметическую систему, существуют
утверждения, которые невозможно ни доказать, ни опровергнуть. В результате любое
полное изучение нашей арифметической системы выходит за пределы
возможностей алгоритмических действий.
Стремление исследовать свойственные алгоритмическим методам ограничения,
вытекающие из сделанного Геделем открытия, привело математиков к разработке
понятия абстрактных машин, предназначенных для выполнения алгоритмов, и
изучению теоретических возможностей этих гипотетических машин. (Это было еще до
того, как технология позволила создать действующие машины для проведения
подобных исследований.) В настоящее время результаты подобных исследований
алгоритмов и машин представляют теоретические основы компьютерных наук.
Некоторые темы из этой области мы рассмотрим в главе 11.
0.2. Происхождение вычислительных машин
Абстрактные машины, созданные математиками в начале двадцатого века,
составляют важную ветвь в родословной современных компьютеров. Другие
ветви простираются в более далекое прошлое. В действительности поиск машин,
способных выполнять алгоритмические задачи, имеет весьма долгую историю.
Одним из первых вычислительных устройств является абак, т.е. счеты. Их
история восходит к периоду древнегреческой и древнеримской цивилизаций.
26 Глава нулевая. Введение
Само это устройство довольно простое и состоит из бусин, нанизанных на
прутья, которые вставлены в прямоугольную рамку. Перемещение бусин взад и
вперед по прутьям позволяет представлять сохраняемые значения. Именно
расположение бусин этот "компьютер" использует для представления и
суммирования данных. Управление выполнением требуемого алгоритма с помощью этой
машины возлагается на человека-оператора. Таким образом, сами счеты
являются просто системой хранения данных, и только сочетание человека и счет
образует полную вычислительную машину.
В относительно недалеком прошлом технология создания вычислительных
машин основывалась на использовании зубчатых колес. Среди создателей таких
механизмов были француз Блез Паскаль (1623-1662), немец Готфрид Вильгельм
Лейбниц (1646-1716) и англичанин Чарльз Бэббидж (1792-1871). Эти
устройства представляли данные с помощью расположения зубчатых колес, причем
данные вводились механически, посредством приведения колес в необходимое
положение. Результаты вычислений в машинах Паскаля и Лейбница определялись
путем считывания конечного положения колес, аналогично тому, как мы сейчас
определяем суммарный пробег автомобиля по показаниям спидометра. Однако
Бэббидж предвидел создание машин, которые будут печатать результаты
вычислений на бумаге, что позволит устранить возможность ошибок при считывании.
Что касается способности следовать алгоритму, то в этих машинах уже явно
виден определенный прогресс. Машина Паскаля могла выполнять только
алгоритм суммирования. Поэтому средства выполнения соответствующей
последовательности действий были встроены в саму машину. Аналогичным образом в
архитектуру машины Лейбница был встроен набор неизменных алгоритмов,
позволяющих выполнять множество арифметических действий по выбору оператора.
Машина Бэббиджа, в отличие от двух предыдущих машин, была
сконструирована таким образом, что последовательность выполняемых действий могла быть
передана с помощью пробивок в бумажных картах. Таким образом, машина
Бэббиджа была уже программируемой. Именно по этой причине ассистентка
Бэббиджа, Августа Ада Байрон, считается первым в мире программистом.
Передача алгоритма с помощью отверстий в бумажных картах не является
собственным открытием Бэббиджа. В 1801 году француз Джозеф Жаккард
применил подобную технологию для управления ткацкими станками (рис. 0.3). В
частности, он разработал ткацкий станок, процесс плетения которого
определялся узором из отверстий на бумажных картах. Благодаря этому алгоритм, по
которому работала машина, можно было легко изменить, что позволяло на одном
и том же станке производить множество различных типов тканей.
Позднее Герман Холлерит (1860-1929) использовал идею представления
информации с помощью отверстий в бумажных картах для ускорения составления
таблиц статистических сводок при переписи населения США в 1890 году.
Фактически именно эта разработка Холлерита привела к созданию корпорации IBM.
0.2. Происхождение вычислительных машин 27
РИСУНОК 0.3
Ткацкий станок Жаккарда (Показано с разрешения Международной коммерческой технической корпорации.
Несанкционированное использование запрещено)
Технологии тех времен не обеспечивали необходимого уровня точности,
который позволил бы сделать сложные шестеренчатые калькуляторы Паскаля,
Лейбница и Бэббиджа достаточно популярными. И до тех пор, пока электроника
не расширила возможности механических устройств, технология не позволяла
поддерживать те теоретические разработки, которые появлялись в
зарождающейся компьютерной науке того времени. Примерами такого прогресса могут
служить электромеханическая машина Джорджа Стибица, созданная в 1940 году
в лабораториях компании Bell, и машина Mark I, созданная в 1944 году в
Гарвардском университете Говардом Айкеном совместно с группой инженеров
корпорации IBM (рис. 0.4). В этих машинах широко использовались механические
реле, работой которых управляла электроника. В этом смысле они устарели
практически сразу же после создания, так как другие исследователи в это же
время уже использовали технологию электровакуумных приборов для
конструирования полностью электронных цифровых вычислительных машин. Первым
28
Глава нулевая. Введение
таким устройством была машина Атанасова-Берри, создаваемая с 1937 по 1941
гг. в колледже шт. Айова (сегодня университет шт. Айова). Создателями
машины были Джон Атанасов и его ассистент Клиффорд Берри. Другим аналогичным
устройством является машина COLLOSSUS, созданная в Англии в конце второй
мировой войны для расшифровки перехватываемых немецких шифрованных
сообщений. За ними вскоре последовали другие, более универсальные
компьютеры, например ENIAK (электронный цифровой интегратор и калькулятор),
разработанный Джоном Мочли и Дж. Преспером Экертом в электротехнической
школе Мура, университет шт. Пенсильвания.
Компьютер Mark I
С этого момента дальнейшая история вычислительных машин в большей
степени определялась прогрессом в области передовых технологий, включая
изобретение транзисторов и последующее развитие технологии интегральных схем,
создание спутниковых линий связи и новые достижения в оптической
технологии. Сегодня настольные вычислительные машины (как и их меньшие
переносные собратья, объединяемые ныне под названием "лэптоп") имеют большую
вычислительную мощность, чем огромные, размером с громадный зал, устройства
40-х годов, и способны осуществлять быстрый обмен информацией через
глобальные системы связи.
0.2. Происхождение вычислительных машин 29
Начало созданию таких малогабаритных машин положили те люди, для
которых компьютеры были предметом увлечения. Именно они начали
экспериментировать с машинами, сконструированными в домашних условиях, почти сразу
после появления в 40-х годах больших вычислительных машин для научных
исследований. Именно благодаря этой "подпольной" любительской деятельности
Стив Джобе (Steve Jobs) и Стефен Возняк (Stephen Wozniak) построили
коммерчески жизнеспособный домашний компьютер и в 1976 году основали компанию
Apple Computer, Inc., специализировавшуюся на изготовлении и продаже
подобных изделий. Несмотря на то что продукция компании Apple была популярной,
она не получила широкого признания в деловых кругах, которые продолжали
рассматривать респектабельную корпорацию IBM как главный источник
удовлетворения своих потребностей в вычислительной технике.
В 1981 году корпорация IBM представила свой первый настольный
персональный компьютер, который так и назывался Personal Computer (персональный
компьютер), для краткости PC (ПК). Базовое программное обеспечение для этого
компьютера было разработано молодой энергичной компанией, ныне известной
как Microsoft. Эта модель персонального компьютера очень быстро получила
признание и возвела настольный компьютер в ранг общепризнанного предмета
потребления для деловых кругов общества. Сегодня термин ПК широко
используется для обозначения всех тех устройств (изготовленных различными
производителями), базовые модели которых ведут свое начало от первоначального
настольного компьютера корпорации IBM. Большинство таких машин по-
прежнему выпускается на рынок с программным обеспечением от фирмы
Microsoft. Co временем термин ПК и исходный термин настольный компьютер
(desktop) стали практически взаимозаменяемыми.
Доступность настольных компьютеров выдвинула компьютерную технологию
на передний план в жизни современного техногенного общества. Действительно,
компьютерная технология сейчас получила настолько широкое распространение,
что умение пользоваться компьютером является обязательным условием для
каждого члена современного общества. Именно благодаря этой технологии
миллионы пользователей получили доступ к системе глобальной связи, известной
как Internet, которая оказывает и будет оказывать огромное влияние как на
коммерческий, так и частный сектор. Однако знание того, как можно
использовать современные продукты, вовсе не означает понимания тех научных основ, на
которых построена их работа. Назначение данной книги состоит в исследовании
этой относительно новой области науки в полном масштабе.
0.3. Эволюция компьютерных наук
Такие особенности ранних вычислительных машин, как ограниченные
возможности хранения данных и использование детального, требующего больших затрат
времени, программирования, ограничивали сложность алгоритмов, которые эти
машины могли выполнять. Однако по мере того как эти ограничения преодолевались,
30 Глава нулевая. Введение
компьютеры стали применяться к решению все более сложных задач. Когда
попытки выразить структуру этих задач в алгоритмической форме стали требовать
чрезмерных умственных усилий, все больше и больше исследований было направлено на
изучение самих алгоритмов и процесса программирования.
Именно тогда теоретическая работа математиков начала приносить свои
плоды. В результате появления теоремы Геделя о неполноте к моменту создания
первых вычислительных машин математики уже в достаточной степени
исследовали те аспекты алгоритмических процессов, которые были необходимы
развивающейся технологии. Этим была заложена основа для появления новой
дисциплины, ныне известной как компьютерные науки.
Сегодня эта дисциплина зарекомендовала себя как наука об алгоритмах. Как мы
уже убедились, границы этой науки достаточно широки, так как она использует
знания из таких дисциплин, как математика, инженерное искусство, психология,
биология, менеджмент и языкознание. В следующих главах мы рассмотрим многие
направления этой области науки. В каждом отдельном случае мы будем
представлять основные концепции, тематику современных исследований, а также некоторые
технологии, которые применялись к развитию этой области знаний. Например,
знакомство с программированием не имеет своей целью развитие у читателя навыков
программирования, а сосредоточено на тех принципах, которые были положены в
основу современных инструментов программирования (т.е. как эти инструменты
развивались), а также на проблемах, изучение и преодоление которых является
предметом последних научных исследований.
В процессе изучения отдельных тем будет непросто сохранить в памяти всю
полноту картины. Поэтому следует собраться с мыслями и сформулировать
некоторые вопросы, которые позволят охарактеризовать всю область
компьютерных наук в целом и обозначить метод ее изучения.
■ Какие проблемы могут быть решены с помощью алгоритмических процессов?
в Как можно упростить задачу поиска требуемого алгоритма?
■ Каким образом можно усовершенствовать технологию представления и
передачи алгоритмов?
■ Как наше знание алгоритмов и технологий может быть использовано для
создания лучших вычислительных машин?
■ Как можно анализировать и сравнивать свойства различных алгоритмов?
Обратите внимание, что общей темой во всех этих вопросах является понятие
алгоритма, что схематически представлено на рис. 0.5.
0.3. Эволюция компьютерных наук 31
Основная роль алгоритмов в информатике
0.4. Роль абстракции
Современные компьютерные системы чрезвычайно сложны, и изучение их во
всех деталях может показаться просто непреодолимой задачей. По этой причине
исследователями был выбран подход к изучению таких систем с различными
уровнями детализации. На каждом уровне мы представляем себе систему как
совокупность компонентов, внутренние свойства которых не принимаются во
внимание. Это позволяет сконцентрироваться на том, как отдельные компоненты
взаимодействуют с другими компонентами этого же уровня и как они
используются для построения компонентов более высокого уровня.
Разграничение внешних свойств компонента и внутренних деталей его
конструкции называется абстракцией. Абстракция является важным методом
упрощения, с помощью которого наше общество создало тот образ жизни, который
иначе создать было бы просто невозможно. Например, немногие из нас
понимают, как на самом деле реализуются различные удобства, которыми мы
пользуемся в повседневной жизни. Мы употребляем пищу и носим одежду, которую не
способны производить самостоятельно. Мы используем электроприборы, не
понимая принципов, положенных в основу их функционирования. Мы пользуемся
услугами других людей, не вникая в подробности их деятельности. С каждым
новым достижением лишь небольшая часть общества стремится профессионально
специализироваться в этой области, в то время как остальные лишь учатся
пользоваться достигнутыми результатами, воспринимаемыми как абстрактные
инструменты, внутреннее устройство которых нам понимать не нужно. В результате
накопленный объем абстрактных средств расширяется, повышая способность
общества к дальнейшему продвижению вперед.
32 Глава нулевая. Введение
Понятие абстракции широко применяется в различных областях
компьютерных наук. Именно благодаря методам абстракции были разработаны,
сконструированы и поддерживаются все существующие в настоящее время большие и
сложные системы аппаратного и программного обеспечения. Посредством
абстракции наука сохраняет способность к дальнейшему развитию. Фактически
наше изучение будет представлять собой иерархию последовательных абстракций,
начиная с глав 1 и 2, в которых обсуждаются вопросы выполнения машиной
отдельных алгоритмических шагов, и заканчивая главой 11, посвященной
рассмотрению свойств целых классов алгоритмов.
0.5. Этические, социальные и правовые аспекты
Развитие науки и техники привело к стиранию множества различий, исходя
из которых в нашем обществе ранее принимались те или иные решения. Более
того, это развитие даже бросает вызов некоторым принципам построения
общества. Какая разница между интеллигентным поведением и самой
интеллигентностью? Когда начинается жизнь? Когда она заканчивается? Какая разница между
животным и растением? Такие вопросы заставляют человека пересматривать
свои убеждения и часто даже перестраивать заново саму основу этих убеждений.
Компьютерные науки могут генерировать подобные вопросы в самых
различных контекстах. В правоведении возникают вопросы относительно того, в какой
степени возможно владение программным обеспечением, а также относительно
прав и обязанностей, накладываемых этим правом собственности. В этике люди
сталкиваются со множеством аспектов, бросающих вызов традиционным
принципам, на которых основано поведение человека. Что касается правительства, то
здесь возникают вопросы относительно допустимой степени регулирования
компьютерной технологии и ее применения.
Принятие разумных решений по таким дилеммам требует овладения
основными знаниями в данной области науки или технологии. Например, если
общество собирается вынести обоснованное решение по хранению и использованию
ядерных отходов, члены этого общества должны быть ознакомлены с влиянием
радиации, понимать, что требуется для защиты от этой опасности, и уметь
рассчитывать реальный период времени, в течение которого будет существовать
опасность воздействия радиации. Аналогичным образом, чтобы судить о том,
следует ли разрешать органам государственной власти или отдельным
компаниям создавать крупные, комплексные базы данных, содержащие информацию о
гражданах страны или клиентах компании, членам общества необходимо
понимать основные возможности, существующие ограничения и возможные
последствия от использования технологии баз данных.
Данная книга предоставит вам основную информацию, благодаря которой вы
сможете обоснованно обсуждать подобные вопросы. Некоторые разделы книги
непосредственно посвящены социальным, этическим и правовым вопросам.
Например, мы обсудим проблемы конфиденциальности в отношении использования
0.5. Этические, социальные и правовые аспекты 33
Internet и применения технологии баз данных, а также вопросы владения
программным обеспечением и прав собственности при разработке программного
обеспечения. Хотя данные вопросы не относятся к области компьютерных наук
как таковой, они имеют важное значение как для тех, кто не собирается
специализироваться в вычислительной технике, так и для тех, кто предполагает
сделать эту область сферой своих профессиональных интересов.
Конечно, само по себе знание фактического материала вовсе не обязательно
позволит легко решать многие вопросы, возникшие в результате современных
достижений в области компьютерных наук. Часто единого правильного ответа просто не
существует, и многие приемлемые решения являются компромиссами между
противоположными точками зрения. Таким образом, поиск решения часто требует умения
выслушивать и учитывать другие точки зрения, вести разумную дискуссию и
позволяет пополнить свои знания с учетом вновь возникших аспектов проблемы. Именно
по этой причине каждая глава данной книги завершается разделом "Социальные и
общественные вопросы". На предлагаемые здесь вопросы не требуется давать
немедленный ответ. Напротив, сначала их следует тщательно обдумать. Во многих
случаях тот ответ, который на первый взгляд казался вполне очевидным, перестанет вас
удовлетворять по мере исследования всех возможных вариантов. Я хочу завершить
это введение собранием таких вопросов, которые имеют отношение к общим
вопросам использования вычислительной техники.
Социальные и общественные вопросы
Следующие вопросы приводятся для того, чтобы помочь вам разобраться в
некоторых этических, общественных и юридических аспектах использования
вычислительной техники, а также в ваших собственных воззрениях и тех
принципах, на которых они основаны. Задача не сводится к тому, чтобы просто дать
ответ на предложенные вопросы. Вы должны также понять, почему вы ответили
именно так, а не иначе, и насколько ваши суждения по различным вопросам
согласуются друг с другом.
1. Предположение, что нынешнее общество отличается от того общества,
которое могло бы быть без компьютерной революции, как правило,
принимается большинством. Является ли наше общество лучше или
хуже некомпьютеризованного? Могли бы вы дать иной ответ на этот
вопрос, если бы занимали другое положение в обществе?
2i Возможно ли участие в жизни современного техногенного общества без
понимания основ этой технологии? Например, обязаны ли члены
демократического государства, чье решение на выборах часто определяет, как
технология будет поддерживаться и использоваться, осмыслить эту
технологию? Зависит ли ваш ответ от того, какая именно технология
имеется в виду? Например, будет ли ваш ответ на вопрос о ядерной технологии
таким же, как и при рассмотрении компьютерной технологии?
34 Глава нулевая. Введение
3. Используя наличные деньги, люди обычно имеют право проводить
финансовые операции без дополнительной оплаты за обслуживание.
Однако в процессе автоматизации экономики финансовые учреждения
сделали платными услуги за доступ к своим автоматизированным
системам. Верно ли утверждение, что эти доплаты несправедливо
ограничивают доступ частных лиц к экономике? Предположим, что
работодатель платит своим работникам только чеками, а все финансовые
учреждения ввели оплату за выдачу наличных денег по чеку или за
помещение их на счет. Справедливо ли это по отношению к
работникам? А как быть в том случае, если работодатель настаивает на оплате
труда только посредством помещения суммы на счет в банке?
4. Если интерактивные телепередачи или аналогичные явления станут
повседневной реальностью, в каких пределах можно разрешить компании
получать от детей информацию относительно состояния домашних дел
(возможно, через интерактивные игры). Например, можно ли разрешать
компаниям получать от ребенка информацию о покупках, сделанных им
или его родителями? А как насчет информации о самом ребенке?
5. В какой мере правительственные органы должны регулировать
развитие компьютерных технологий и их применение? Например, можно
еще раз вернуться к проблемам, упомянутым в вопросах 3 и 4. Чем
можно оправдать введение правительственного регулирования?
6. Как на наших внуков повлияют решения, принятые нами
относительно технологии в целом и компьютерной технологии в частности?
7. По мере развития технологии наша образовательная система
вынуждена постоянно пересматривать уровень абстракции, установленный в
отношении подачи отдельных тем. Многие вопросы касаются того,
действительно ли необходимо какое-либо умение или можно позволить
студентам пользоваться только абстрактным инструментом?
Студентов, изучающих тригонометрию, уже не учат определять значения
тригонометрических функций с помощью таблиц. Вместо этого они
используют калькуляторы как абстрактное средство определения этих
значений. Некоторые утверждают, что письменное деление чисел в
столбик также обеспечивает определенную абстракцию. Какие еще
есть дисциплины, характеризующиеся подобными разногласиями?
Может ли случиться так, что с использованием видеотехники когда-
нибудь отпадет потребность в чтении? И может ли наличие
автоматической проверки правописания устранить необходимость в грамотном
письме?
8. Предполагается, что концепция публичных библиотек построена в
основном на утверждении, что все граждане демократического общества
должны иметь доступ к информации. Так как все больше информации
сохраняется и распространяется с помощью компьютерных
технологий, является ли доступ к таким технологиям правом каждого чело-
Социальные и общественные вопросы 35
века? Если это так, то должны ли публичные библиотеки стать
средством, обеспечивающим этот доступ?
9. Какие вопросы этического характера возникают в обществе, которое
полагается на использование абстрактных средств? Есть ли такие
случаи, когда использование товара или услуги без знания того, как это
производится, является неэтичным?
Рекомендуемая литература
• Dejoie D., Fowler G., Paradice D. Ethical Issues in Information Systems. —
Boston: Boyd and Fraser, 1991.
• Edgar S. L. Morality and Machines. — Sudbury, MA: Jones and Barlett, 1997.
• Forester Т., Forrison P. Computer Ethics: Cautionary Tales and Ethical
Dilemmas. — Cambridge, MA: MIT Press, 1990.
• Goldstine J.J. The Computer from Pascal to von Neumann. — Princeton:
Princeton University Press, 1972.
• Jonson D.G. Computer Ethics, 2nd ed. — Englewood Cliffs, NJ: Prentice-Hall,
1994.
• Jonson D.G. Ethical Issues in Engineering. — Englewood Cliffs, NJ: Prentice-
Hall, 1991.
• Mollenhoff C. R. Atanasoff: Forgotten Father of the Computer. — Ames: Iowa
State University Press, 1988.
• Neumann P.G. Computer Related Risks. — Reading, MA: Addison-Wesley, 1995.
• Randell B. The Origins of Digital Computers. — New York: Springer-Verlag,
1973.
• Shurkin J. Engines of the Mind. — New York: Norton, 1984.
36 Глава нулевая. Введение
часть
первая
Архитектура машин
Основной принцип развития любой науки состоит в создании
теорий, которые либо доказываются, либо отрицаются в
результате проводимых исследований. Иногда доказательства
некоторых теорий откладываются на более длительный срок, пока
развитие технологии не предоставит средства, необходимые
для проверки их истинности. В других случаях возможности,
обеспечиваемые достигнутым на данный момент уровнем
развития технологий, способны оказать существенное влияние на
выбор направления развития науки.
На развитие компьютерных наук повлияли обе тенденции. Мы
уже убедились, что эти науки возникли из теорий, которые были
разработаны задолго до того, как технология смогла создать машины,
появление которых предсказывали еще первые исследователи. И
даже сегодня совершенствование наших знаний об алгоритмах
ведет к созданию новых конструкций машин, превосходящих
возможности современных технологий. В противоположность этому, другие
области компьютерных наук возникли в результате широкого
применения современных технологий. Говоря о компьютерных науках в
целом, заметим лишь, что в этой области знаний гармонично
сочетаются глубокие теоретические исследования и бурное развитие
технологии, оказывающие положительное влияние друг на друга.
Из этого следует, что если мы в полной мере хотим осознать
роль различных областей компьютерных наук, нам, прежде всего,
необходимо изучить основы современной компьютерной технологии
и понять, как она влияет на разработку и изготовление компьютеров
в наше время. Именно эти задачи преследуются в двух следующих
главах данной книги, назначение которых — познакомить читателя с
основами компьютерной технологии. В главе 1 освещены
различные методы представления и хранения информации, а в главе 2
читатель познакомится с различными способами обработки данных в
современных вычислительных машинах.
глава
Хранение данных
ПЕРВАЯ
Эта глава познакомит читателя с
представлением и хранением данных в компьютере.
Время от времени мы будем обращаться к
вопросам технологии, так как эти особенности часто
находят отражение во внешних
характеристиках современных машин. Помимо этого,
большая часть материала посвящена вопросам
проектирования ЭВМ, которые будут актуальны
даже после того, как будущие компьютерные
технологии займут место современных.
1.1. Хранение битов
Вентили и триггеры
Другие методы хранения данных
Шестнадцатеричная система
счисления
1.2. Основная память
1.3. Массовая память
Магнитные диски
Компакт-диски
Магнитная лента
Сохранение и считывание файлов
1.4. Представление информации
в виде комбинации двоичных
разрядов
Представление текста
Представление числовых значений
Представление изображений
*1.5. Двоичная система счисления
Двоичное сложение
Представление дробей в
двоичных кодах
*1.6. Представление целых чисел
Двоичный дополнительный код
Двоичная нотация с избытком
*1.7. Представление дробных
значений
Двоичная нотация с плавающей
точкой
Ошибки усечения значения
М.8. Универсальные методы
сжатия данных
Сжатие изображений
Т1.9. Ошибки при передаче
информации
Биты четности
Коды с исправлением ошибок
* Звездочкой отмечены
разделы, рекомендованные для
факультативного изучения.
\
1.1. Хранение битов
Информация в современных компьютерах представляется в виде
комбинации битов. Бит, или двоичный разряд, представляется одной из двух цифр
(нуль и единица), которые мы пока будем рассматривать как простые
символы, не имеющие числового значения. Далее мы увидим, что смысловое
значение бита изменяется от одного приложения к другому. Для запоминания
двоичных разрядов (или битов) машине требуется некоторое устройство,
которое может пребывать в одном из двух состояний. К таким устройствам
относятся переключатель (включен/выключен), реле (открыто/закрыто) или
флажок на флагштоке (поднят/опущен). Одно состояние представляет
значение 0, а другое — значение 1. Итак, вначале рассмотрим способы хранения
двоичных разрядов в современных машинах.
Вентили и триггеры
Начнем ознакомление с логических операций AND (И), OR (ИЛИ) и XOR
(исключающее ИЛИ), принципы выполнения которых показаны на рис. 1.1
Эти операции подобны арифметическим операциям умножения и сложения,
которые соответствующим образом комбинируют пару величин,
представляющих собой входные данные операции, в целях создания третьей
величины, являющейся выходными данными операции. Однако в отличие от
арифметических операций, единственными цифрами, которыми манипулируют
логические операции AND, OR и XOR, являются 0 и 1. В этом контексте мы
принимаем, что 0 представляет логическое значение ложь (false), а 1 —
логическое значение истина (true). Операции, которые манипулируют
значениями истина и ложь, называются логическими, или булевыми операциями
(последнее название присвоено в память о математике Джордже Буле (George
Boole, 1815-1864)).
Булева операция AND (И) была разработана для отражения истинности или
ложности высказываний, образованных в результате соединения двух меньших
высказываний с помощью союза и. В общем виде такие высказывания можно
представить следующим образом:
PANDQ
Здесь Р представляет одно высказывание, a Q — другое. Давайте рассмотрим
это на таком примере:
"Кермит — лягушка" AND "Мисс Пигги — актриса"
Входные данные для операции AND представляют истинность или ложность
компонентов, составляющих высказывание, а результат — истинность или
ложность самого высказывания. Поскольку высказывание, представленное в виде Р
AND Q, является истинным только тогда, когда оба его компонента истинны, мы
40 Глава первая. Хранение данных
можем сделать заключение, что выражение 1 AND 1 должно иметь значение 1,
тогда как во всех остальных случаях его результатом будет значение 0, как
показано на рис. 1.1, а.
Булевы операции AND, OR и XOR
Аналогичным образом операция OR (ИЛИ) основана на сложном
высказывании, имеющем следующий вид:
PORQ
Здесь также операнд Р представляет одно выражение, а операнд Q — другое.
Такие высказывания являются истинными в том случае, если хотя бы один из
их компонентов истинен, как изображено на рис. 1.1, б.
В английском языке нет отдельного союза, выражающего смысл операции XOR
(исключающее ИЛИ). Операция XOR дает в результате значение 1 (истина) только
тогда, когда один из входных операндов будет иметь значение 1 {истина), а
другой — значение 0 (ложь). Таким образом, утверждение, построенное по схеме Р XOR
Q, имеет следующий смысл: "либо Р, либо Q, но не оба одновременно".
Следующая булева операция выполняет действие NOT (HE). Она отличается
от операций AND, OR и XOR тем, что имеет только одно входное значение.
Результат этой операции имеет значение, противоположное входному значению.
Иначе говоря, если входным значением операции NOT является истина, то
результат будет иметь значение ложь, и наоборот. Например, пусть входное
значение операции NOT представляет истинность или ложность следующего
высказывания:
1.1. Хранение битов 41
"Фоззи — медведь"
Тогда результат выполнения этой операции будет представлять истинность
или ложность противоположного высказывания:
"Фоззи — не медведь"
Устройство, которое выдает результат булевой операции после введения входных
данных, называется вентилем. Существуют различные технологии конструирования
вентилей, например с использованием зубчатых колес, реле или оптических
устройств. Вентили, встроенные в современный компьютер, — это небольшие
электронные цепи, в которых цифры 0 и 1 представляются разными уровнями
электрического напряжения. Однако нам совсем не обязательно подробно обсуждать эту тему.
Вполне достаточно представить вентили в их символической форме, как это
показано на рис. 1.2. Обратите внимание, что вентили AND, OR, XOR и NOT изображаются
в виде различных схематических элементов, у которых входные данные поступают с
одной стороны, а выходной сигнал считывается с другой стороны.
РИСУНОК 1.2
Схематическое представление вентилей AND, OR, XOR и NOT и таблицы их входных и выходных данных
Вентили, подобные показанным на рис. 1.2, представляют собой
строительные блоки, из которых конструируются компьютеры. Один важный этап этого
направления представлен в электрической схеме, показанной на рис. 1.3. Это
42
Глава первая. Хранение данных
один из возможных вариантов схем определенного класса, называемых
триггерами. Триггер — это схема, которая постоянно выдает выходное значение О
или 1; оно не меняется до тех пор, пока одиночный импульс от другой схемы не
переведет ее в противоположное состояние. Другими словами, выходное
значение будет переключаться из одного состояния в другое только под воздействием
внешних стимулов. Пока оба входных значения в схеме, представленной на
рис. 1.3, равны нулю, выходное значение (0 или 1) будет неизменным. Однако
даже кратковременное появление значения 1 на верхнем входе схемы вызовет
установку на ее выходе значения 1, тогда как кратковременное появление
значения 1 на нижнем входе вызовет установку на выходе значения 0.
| РИСУНОК 1,3 |
Схема простого триггера
Теперь рассмотрим предыдущее утверждение более подробно. Мы не знаем
текущего выходного значения схемы, представленной на рис. 1.3, поэтому
предположим, что на верхний вход поступило значение 1, тогда как на нижнем входе
сохраняется значение 0 (рис. 1.4, а). Это приведет к тому, что выходное
значение вентиля OR станет равно 1, независимо от текущего значения на его втором
входе. В свою очередь, на обоих входах вентиля AND теперь будут значения 1,
поскольку на другом его входе уже присутствует значение 1 (оно появляется за
счет передачи значения 0 на нижнем входе триггера через вентиль NOT). В
результате выходное значение вентиля AND станет равно 1, а это значит, что на
втором входе вентиля OR также появится значение 1 (рис. 1.4, б). Это
гарантирует, что выходное значение вентиля OR останется равным 1 даже в том случае,
если значение на верхнем входе триггера вновь станет равно 0 (рис. 1.4, в).
Таким образом, выходное значение триггера теперь равно 1 и будет сохраняться
таким даже в том случае, если на верхний вход будет вновь подано значение 0.
Точно так же временное появление значения 1 на нижнем входе триггера
приведет к тому, что на его выходе установится значение 0, которое будет оставаться
неизменным даже после того, как на нижний вход вновь будет подано значение 0.
1.1. Хранение битов 43
РИСУНОК 1.4
ч
б) Это вызывает появление единицы на выходе вентиля OR,
что, в свою очередь, вызывает появление единицы
на выходе вентиля AND
в) Наличие единицы на выходе вентиля AND удерживает вентиль OR
от изменения его состояния и после снятия единичного сигнала
с верхнего входа
Установка выходного значения триггера равным 1
Для нас значение триггерной схемы состоит в том, что она является
идеальным механизмом для хранения двоичных данных (битов) внутри компьютера.
Величина, сохраняемая в триггере, определяется его выходным значением.
Другие схемы легко могут изменять это значение, посылая импульсы на входы
триггера. Подобным же образом другие схемы могут реагировать на хранимое в
44
Глава первая. Хранение данных
триггере значение посредством использования выходного значения триггера как
одного из своих входных значений.
Конечно, существуют и другие варианты построения триггеров. Один из них
изображен на рис. 1.5. Если поэкспериментировать с этой схемой, то можно
обнаружить, что, несмотря на совершенно иную внутреннюю структуру, ее внешние
свойства полностью аналогичны свойствам схемы, представленной на рис. 1.3. Это
первый пример большого значения абстрактных инструментов. При разработке
схемы триггера инженер рассматривает несколько альтернативных способов его
построения с использованием вентилей в качестве компоновочных блоков. Как
только триггеры и другие базовые схемы будут разработаны, инженер сможет
использовать их в качестве строительных блоков для создания более сложных схем.
Таким образом, разработка общей схемы компьютера приобретает иерархическую
структуру, в которой на каждом уровне в качестве абстрактных инструментов
используются компоненты, созданные на предыдущих уровнях.
РИСУНОК 1.5
Другие методы хранения данных
В 1960-х годах двоичные разряды запоминались в компьютерах с помощью
небольших колец, называемых сердечниками (своей формой они напоминали
бублики). Изготовлялись они из магнитного материала и нанизывались на
проволочные струны-провода. Когда электрический ток проходил по этим проводам,
каждый сердечник можно было намагнитить в одном из двух направлений.
Впоследствии направление магнитного поля определялось посредством оценки его
воздействия на электрический ток, проходящий через центр сердечника. Таким
образом, сердечник являлся средством хранения двоичных разрядов (битов):
единица представлялась магнитным полем, ориентированным в одном
направлении, а нуль — магнитным полем, ориентированным в другом направлении. В
настоящее время эти системы уже устарели из-за больших размеров и
значительных затрат электроэнергии.
1.1. Хранение битов 45
Конденсатор представляет собой более современное средство запоминания
битов. Он состоит из двух маленьких металлических пластин, расположенных
параллельно друг другу на небольшом расстоянии. Если положительный полюс
источника напряжения соединить с одной пластиной конденсатора, а
отрицательный — с другой, то электрические заряды из этого источника равномерно
распределятся по пластинам. Заряды сохранятся на пластинах конденсатора и
после отключения источника напряжения. Если впоследствии пластины
соединить проводником, то по нему потечет электрический ток и заряды
нейтрализуются. Таким образом, конденсатор может пребывать в заряженном или
разряженном состоянии; одно из них вполне может представлять значение 0, а
другое — значение 1. С помощью современных технологий на тонких пластинах,
называемых чипами, можно размещать миллионы крошечных конденсаторов
вместе с необходимыми схемами электрических соединений. Благодаря этому в
настоящее время конденсаторы широко используются для хранения битов в
вычислительных машинах.
Триггеры, сердечники и конденсаторы — это примеры запоминающих систем
с различной степенью продолжительности хранения информации. Сердечник
сохраняет свое магнитное поле даже после выключения машины, а триггер при
отключении от источника питания утрачивает помещенные в него данные.
Заряды же в крошечных конденсаторах настолько недолговечны, что способны
быстро исчезать сами по себе, даже если машина находится в рабочем состоянии.
Поэтому заряд конденсатора необходимо регулярно возобновлять с помощью
специальной схемы, называемой цепью регенерации. Принимая во внимание эту
кратковременность хранения данных, созданную по такой технологии
компьютерную память (раздел 1.2) именуют динамической памятью.
Шестнадцатеричная система счисления
При обсуждении внутренних процессов компьютера нам придется иметь дело
со строками битов, некоторые из которых могут оказаться достаточно
длинными. К сожалению, человек с трудом оперирует подобными величинами. Даже
простое воспроизведение комбинации 101101010011 кажется утомительной
задачей и подвержено ошибкам. Поэтому для упрощения представления комбинаций
двоичных разрядов обычно используется упрощенная система записи, которая
называется шестнадцатеричной нотацией, поскольку построена на шестнадцате-
ричной системе счисления. Особенность этой нотации состоит в том, что
двоичные комбинации в машине обычно представляются группами из двоичных
разрядов, длина которых кратна четырем. Это означает, что, поскольку в
шестнадцатеричной нотации каждый символ используется для представления четырех
битов, строку из двенадцати битов можно представить всего лишь тремя шестна-
дцатеричными символами.
На рис. 1.6 изображена схема шестнадцатеричной системы кодирования. В
левом столбце показаны все возможные комбинации битов для строк длиной
четыре двоичных разряда, а в правом приведен соответствующий символ, исполь-
46 Глава первая. Хранение данных
зуемый в шестнадцатеричной системе счисления для представления комбинации
битов из левого столбца. Согласно этой системе кодирования, двоичный код
10110101 может быть представлен как В5. Этот результат был получен путем
разделения исходной двоичной комбинации на подгруппы длиной четыре бита и
замены каждой такой группы ее шестнадцатеричным эквивалентом. Комбинация
1011 представлена буквой В, а комбинация 0101 — цифрой 5. Таким же способом
16-битовая строка 1010010011001000 может быть представлена в более удобной
форме: А4С8.
РИСУНОК 1.6
Шестнадцатеричная система кодирования
Подробнее об использовании шестнадцатеричной системы счисления мы
поговорим в следующей главе. Именно тогда у вас появится возможность оценить ее
эффективность.
Вопросы для самопроверки
1. При каких значениях на входах представленной ниже схемы на ее выходе
появится значение 1?
2. Выше утверждалось, что при поступлении значения 1 на нижний вход
триггера, показанного на рис. 1.3 (с сохранением при этом значения 0 на верхнем
1.1. Хранение битов 47
его входе), на его выходе установится значение 0. Опишите
последовательность событий, происходящих в этом случае в элементах триггера.
3. Предположим, что на оба входа триггера, показанного на рис. 1.5, подается
значение 0. Опишите последовательность событий, которые будут
происходить в элементах этого триггера при кратковременном поступлении на его
верхний вход значения 1.
4. Довольно часто необходимо согласовывать действия различных частей схемы.
Это достигается путем подачи импульсного сигнала (называемого сигналом
синхронизации) в те части схемы, работу которых требуется согласовать.
Изменение значения сигнала синхронизации с нуля на единицу вызывает
активизацию различных компонентов схемы. Ниже приведен пример одной из
частей подобной схемы, включающей триггер, изображенный на рис. 1.3.
При каких значениях сигнала синхронизации триггер будет защищен от
воздействия значений, поступающих на входы этой схемы? При каких
значениях сигнала синхронизации триггер будет реагировать на значения,
поступающие на входы этой схемы?
5. Используйте шестнадцатеричную систему счисления для представления
следующих комбинаций двоичных разрядов:
а) 0110101011110010 б) 111010000101010100010111
в) 01001000
6. Какие комбинации двоичных разрядов представлены следующими шестна-
дцатеричными кодами?
a) 5FD97 б) 610А в) ABCD г) 0100
1.2. Основная память
В компьютере для хранения данных используется большой набор схем,
каждая из которых способна запомнить один двоичный разряд (бит). Это хранилище
битов принято называть основной (или оперативной) памятью. Запоминающие
схемы основной памяти машины организованы в небольшие блоки (доступные
как единое целое), которые называются ячейками памяти (или машинными
словами). Как правило, размер ячейки памяти составляет восемь бит. Наборы из
48
Глава первая. Хранение данных
восьми бит получили такую популярность, что для их обозначения сейчас
широко используется специальный термин байт.
Микрокомпьютеры, используемые, например, в микроволновых печах, имеют
основную память, которая измеряется всего лишь несколькими сотнями ячеек,
тогда как компьютеры, предназначенные для хранения и обработки большого
количества информации, имеют миллиарды ячеек основной памяти. Размер
основной памяти машины часто измеряется единицами в 1 048 576 отдельных
ячеек. (Величина 1 048 576 — это число, равное 220, и это значение более удобно
в качестве единицы измерения в компьютере, чем число 1 000 000.) Для
обозначения этой единицы измерения используется термин мега. Аббревиатура Мбайт
обычно употребляется как сокращение для термина мегабайт. Следовательно,
память емкостью 4 Мбайт содержит 4 194 304 (4x1 048 576) ячейки, каждая
размером 1 байт. Другими единицами измерения памяти являются килобайт
(сокращенно Кбайт), который равен 1024 байт (210 байт), и гигабайт
(сокращенно Гбайт), который равен 1024 Мбайт, или 230 байт.
Для идентификации отдельных ячеек основной памяти машины каждой ячейке
присваивается уникальное имя, называемое адресом. Эта система аналогична
методу, используемому для поиска здания в городе по указанному адресу. Однако в
случае с ячейками памяти применяются исключительно цифровые адреса. Точнее
говоря, можно просто представить себе все эти ячейки помещенными в один ряд и
пронумерованными в восходящем порядке, начиная с нуля. Адреса ячеек в машине с
памятью 4 Мбайт будут представлены числами 0, 1, 2, ..., 4 194 304. Следует
отметить, что такая система адресации не только позволяет однозначно
идентифицировать каждую ячейку памяти (рис. 1.7), но и упорядочивает их, делая правомочными
такие выражения, как "следующая ячейка" или "предыдущая ячейка".
В состав основной памяти машины, помимо электрической цепи, фиксирующей
значения битов, входит и другая цепь, позволяющая остальным компонентам
машины записывать данные в ячейки памяти и извлекать их оттуда. Благодаря этому
другие схемы могут считывать информацию из памяти посредством электронного
запроса на извлечение содержимого ячейки с определенным адресом (это действие
называется операцией считывания) или записывать информацию в память, посылая
запрос на помещение определенной комбинации двоичных разрядов в ячейку с
указанным адресом (это действие называется операцией записи).
Поскольку основная память машины организована в виде небольших, прямо
адресуемых ячеек, это позволяет адресовать каждую ячейку памяти в
отдельности, т.е. данные, помещенные в основную память, могут обрабатываться в
произвольном порядке. Это поясняет, почему основную память машины часто
называют памятью с произвольной выборкой (random access memory, RAM).
Возможность произвольного доступа к небольшим блокам данных совершенно
противоположна принципам работы с устройствами массовой памяти, которые
будут обсуждаться в следующем разделе. В этих устройствах длинные строки
битов приходится обрабатывать как единый блок. Если память типа RAM
создается с использованием технологии динамической памяти, то в этом случае ее
называют DRAM (Dynamic RAM).
1.2. Основная память 49
РИСУНОК 1.7
®3g№£
;: Образное представление ячеек памяти, упорядоченных по адресам ;■
г" <о. _, ^ , .„ ( , .., .,.,.„, f.. n __ . ( ,. ,„, .,,.,.„,_,, i|
Биты в ячейке памяти можно представить себе размещенными в один ряд.
Один конец этого ряда называется старшим, а другой — младшим. Несмотря на
то что в машине нет ни правой, ни левой стороны, в нашем представлении биты
всегда выстроены в ряд слева направо, причем старший конец располагается
слева. Бит, находящийся на этом конце, обычно называют старшим, или битом с
наибольшим весом. Бит на другом конце именуют младшим, или битом с
наименьшим весом. Таким образом, содержимое ячейки памяти размером один байт
можно представить себе так, как показано на рис. 1.8.
Важным следствием упорядоченности ячеек в основной памяти и отдельных
битов в пределах каждой такой ячейки является то, что вся совокупность битов
50
Глава первая. Хранение данных
памяти машины, в сущности, располагается в один длинный ряд.
Следовательно, отдельные части этого длинного ряда могут использоваться для хранения
комбинаций двоичных разрядов, длина которых будет больше длины отдельной
ячейки. В частности, если память разделена на ячейки размером один байт, то
для сохранения строки из 16 бит можно просто воспользоваться двумя
последовательными ячейками памяти.
Вопросы для самопроверки
1. Если ячейка памяти с адресом 5 содержит число 8, то в чем состоит различие
между записью числа 5 в ячейку с номером 6 и пересылкой содержимого
ячейки с номером 5 в ячейку с номером 6?
2. Предположим, что требуется поменять местами значения, хранящиеся в
ячейках памяти с номерами 2 и 3. Найдите ошибку в следующей
последовательности действий.
Шаг 1. Переместите содержимое ячейки с номером 2 в ячейку с номером 3.
Шаг 2. Переместите содержимое ячейки с номером 3 в ячейку с номером 2.
Предложите последовательность действий, которая позволит корректно
поменять местами содержимое указанных ячеек.
3. Какое количество битов содержится в памяти компьютера, размер которой
равен 4 Кбайт?
1.3. Массовая память
В связи с невозможностью постоянного хранения данных и ограниченным
объемом основной памяти компьютера большинство машин обеспечивается
устройствами дополнительной памяти, которые называются массовой памятью, или
запоминающими устройствами большой емкости. В их число входят магнитные
диски, компакт-диски и магнитные ленты. Преимущества таких устройств, по
сравнению с основной памятью компьютера, состоят в долговременности
хранения данных, большей емкости и, в большинстве случаев, возможности,
извлечения носителя информации из машины в целях архивирования.
Термины постоянно подключенное и автономное часто используются для
описания устройств, которые можно присоединять к машине или отключать от
нее. Термин постоянно подключенное (on-line) означает, что устройство или
информация присоединены и могут быть доступны машине без вмешательства
человека. В отличие от этого, термин автономный (off-line) означает, ч;то прежде
чем устройство или информация смогут быть доступны машине, потребуется
вмешательство человека (требуется либо включить устройство, либо установить в
него носитель информации).
Основным недостатком устройств массовой памяти является то, что они
обычно требуют механических перемещений носителя или устройства
считывания. Поэтому время доступа к информации у этих устройств существенно боль-
1.3. Массовая память 51
ше по сравнению с основной памятью машины, в которой все необходимые
действия выполняются на уровне электрических сигналов.
Магнитные диски
Одним из наиболее распространенных типов массовой памяти, применяемых
в наше время, являются магнитные диски. В этих устройствах в качестве
носителя данных используется тонкий вращающийся диск с магнитным покрытием.
Головки чтения/записи размещаются над и/или под диском таким образом, что
во время вращения диска каждая головка описывает над ним круг, называемый
дорожкой, расположенной на верхней или нижней поверхности диска.
Перемещая головки чтения/записи над поверхностью диска, можно получить доступ к
различным концентрическим дорожкам. Чаще всего дисковая система памяти
состоит из нескольких дисков, смонтированных на общей оси и расположенных
друг над другом. Между дисками оставляется пространство, достаточное для
перемещения головок чтения/записи между пластинами. Все головки
чтения/записи в этом случае двигаются как единое целое. При каждом
перемещении головок становится доступной новая группа дорожек, которую принято
называть цилиндром.
Так как дорожка может содержать больше информации, чем обычно
требуется одновременно обрабатывать, все дорожки поделены на зоны, или секторы, в
которых информация записывается в виде непрерывной строки битов (рис. 1.9).
Каждая дорожка внутри дисковой системы содержит одинаковое количество
секторов, а каждый сектор, в свою очередь, — одинаковое число двоичных
разрядов. (Это означает, что в секторах, которые находятся ближе к центру диска,
биты данных размещаются более компактно, по сравнению с дорожками,
расположенными ближе к внешнему краю.)
Таким образом, мы выяснили, что дисковое запоминающее устройство
состоит из множества отдельных секторов, каждый из которых может быть
независимо считан как одна строка битов. Количество дорожек на поверхности диска, а
также количество секторов на дорожках могут значительно отличаться в разных
дисковых устройствах. Размеры секторов обычно не превышают нескольких
килобайт. Чаще всего размер сектора составляет 512 или 1024 байта.
Расположение дорожек и секторов не является постоянной характеристикой,
зафиксированной в физической структуре диска. На самом деле они
маркируются магнитным способом с помощью процесса, который называется
форматированием (или инициализацией) диска. Этот процесс обычно осуществляется той
фирмой, которая производит дисковые устройства, и на рынок поступают уже
отформатированные диски. Большинство компьютерных систем тоже могут
форматировать диски. Поэтому в случае повреждения формата диска он может
быть переформатирован, однако это приведет к уничтожению всей информации,
которая прежде была записана на данном устройстве.
52 Глава первая. Хранение данных
РИСУНОК 1.9
Емкость дисковых устройств зависит от числа используемых в нем дисковых
пластин, а также от плотности размещения дорожек и секторов на их
поверхности. Дисковые системы малой емкости состоят из единственного пластикового
диска, который называется дискетой, или гибким диском. (Современные гибкие
диски размером 3!/г дюйма имеют жесткие пластиковые корпуса, а не гибкие
упаковки, в отличие от своих более старых аналогов диаметром 51 /4 дюйма,
которые упаковывались в бумажные конверты.) Дискеты легко вставляются и
вынимаются из устройств, а также достаточно удобны в хранении. Поэтому они
часто используются как автономные хранилища информации. Универсальная
дискета размером З1 /2 дюйма имеет емкость, достаточную для хранения
1,44 Мбайт информации. Однако существуют и дискеты с существенно большей
емкостью. Примером может служить дисковое устройство типа Zip компании
Iomega Corporation, где на одной жесткой дискете может записываться
несколько сотен мегабайт информации.
Дисковые системы большой емкости способны хранить многие гигабайты
информации. Такие устройства включают от пяти до десяти жестких дисковых
пластин, смонтированных на общей оси. Поскольку используемые в таких
устройствах диски являются жесткими, их называют системами с жестким диском,
в отличие от гибких дисков, обсуждавшихся выше. Чтобы увеличить скорость
вращения дисков, головки чтения/записи в таких системах размещены так, что
они не соприкасаются с поверхностью диска, а как бы "плавают" над
поверхностью с магнитным покрытием. Расстояние между головкой и диском настолько
мало, что даже отдельная частица пыли может застрять между ними и вызвать
их повреждение (явление, известное как разрушение головки). Поэтому
устройства жестких дисков герметически упаковывают в коробки и запечатывают
непосредственно на том предприятии, где они изготовляются.
Для оценки производительности дисковой системы используется несколько
параметров: время установки (время, которое требуется для перемещения
головки чтения/записи с одной дорожки на другую); задержка вращения, или время
1.3. Массовая память 53
ожидания (половина времени, за которое совершается полный оборот диска, что
составляет среднее время, необходимое для того, чтобы нужные данные
появились под головкой чтения/записи после того, как она разместится над
выбранной дорожкой); время доступа (сумма времени установки и времени ожидания),
а также скорость передачи данных (скорость, с которой данные могут
передаваться дисковому устройству или считываться с него).
Устройства с жесткими дисками имеют намного лучшие характеристики в
сравнении с устройствами, использующими гибкие диски. Так как головки
чтения/записи не соприкасаются с поверхностью жесткого диска, скорость
вращения достигает от 3000 до 7000 оборотов в минуту, тогда как скорость вращения
гибких дисков составляет только 300 оборотов в минуту. Поэтому устройства с
жесткими дисками имеют более высокую скорость передачи, измеряемую
обычно в мегабайтах в секунду, тогда как скорость передачи данных гибких дисков
измеряется в килобайтах в секунду.
Поскольку работа дисковых устройств требует физического перемещения
носителя, жесткие и гибкие диски проигрывают в скорости по сравнению с
электронными схемами. Это неудивительно, так как задержки в электронных схемах
измеряются в наносекундах (миллиардная доля секунды) и меньше, тогда как
время установки, ожидания и доступа дисковых устройств измеряется в
миллисекундах (тысячная доля секунды). Таким образом, время, требуемое для
считывания информации с дисковых устройств, кажется просто вечностью в сравнении
со скоростью работы электронных схем.
Компакт-диски
Еще одной популярной технологией хранения данных является
использование компакт-дисков (CD). Это диски диаметром 12 сантиметров (около 5
дюймов), изготовленные из отражающего материала, покрытого прозрачным
защитным слоем. Информация записывается посредством создания изменений на
отражающей поверхности диска и считывается с помощью лазерного луча,
который отслеживает неравномерности на отражающей поверхности диска во
время его вращения.
Технология изготовления компакт-дисков изначально применялась в
производстве аудиозаписей с использованием формата, известного как CD-DA
(компакт-диск — цифровое аудио). Компакт-диски, используемые в настоящее
время для хранения компьютерных данных, похожи на своих аудиопредшест-
, венников, за исключением того, что для них применяется формат CD-ROM
(компакт-диск — постоянное запоминающее устройство). Различие между
форматами CD-DA и CD-ROM состоит в способе интерпретации полей данных.
Например, в формате CD-DA определенные поля предназначены для хранения
информации о времени воспроизведения, тогда как в формате CD-ROM это
пространство используется для хранения произвольных данных.
В отличие от устройств с магнитными дисками, где запись данных
осуществляется на концентрических дорожках, информация на компакт-дисках
записывается на единственной дорожке, которая закручивается спиралью на поверхно-
54 Глава первая. Хранение данных
сти диска подобно желобку на старых грампластинках. (Но в отличие от старых
грампластинок дорожка на компакт-диске записывается в направлении от
центра к краю.) Эта дорожка разделена на части, которые называют секторами. Все
секторы содержат одинаковое количество данных, и у каждого есть своя личная
маркировка. Сектор в формате CD-ROM содержит 2 Кбайт информации, а сектор
того же размера в формате CD-DA содержит данные, обеспечивающие
воспроизведение музыки в течение 1/75 секунды.
Обратите внимание, что длина одного оборота спиральной дорожки
увеличивается по направлению от внутренней части диска к внешней. Из соображений
увеличения емкости компакт-диска информация записывается с одной и той же
линейной плотностью по всей длине спиральной дорожки. Это означает* что на
витке во внешней части спирали хранится большее количество информации, чем
на витке в ее внутренней части. Поэтому за один оборот диска будет считываться
больше секторов, когда лазерный луч сканирует внешнюю часть спиральной
дорожки, и меньше секторов, когда луч будет сканировать внутреннюю часть
дорожки. В результате, чтобы получить равномерную скорость пересылки данных,
CD-плееры разрабатываются таким образом, чтобы можно было изменять
скорость вращения диска в зависимости от расположения лазерного луча.
Благодаря подобным конструктивным решениям запоминающие системы с
компакт-дисками имеют большую производительность при работе с длинными,
непрерывными строками данных, например при воспроизведении музыки.
Однако если прикладной программе требуется произвольный доступ к данным
(например, как в системе резервирования авиабилетов), подход, используемый в
устройствах магнитных дисков (отдельные концентрические дорожки, каждая из
которых содержит одинаковое количество секторов), оказывается эффективнее
спирального метода записи, используемого в компакт-дисках.
Емкость компакт-диска в формате CD-ROM составляет немного больше
600 Мбайт. Однако уже появились новые дисковые форматы, например DVD
(Digital Versatile Disk — цифровой универсальный диск). В этом формате
емкость каждого носителя составляет около 10 Гбайт. На таких компакт-
дисках можно хранить мультимедиа-презентации, в которых аудио- и
видеоинформация комбинируется в целях более интересной и содержательной
подачи материала. Главная задача разработки стандарта DVD состоит в
предоставлении инструментальных средств для записи на компакт-диски
полнометражных кинофильмов.
Еще одним вариантом в технологии компакт-дисков является формат CD-
WORM (Compact Disk -Write Once, Read Many — компакт-диск с однократной
записью и многократным считыванием). Он позволяет записывать данные на
компакт-диск после его изготовления, а не во время этого процесса. Эти
устройства чрезвычайно удобны для архивирования, а также для производства записей
на компакт-дисках в небольших количествах.
1.3. Массовая память 55
Магнитная лента
В более ранних типах запоминающих устройств большой емкости
используется магнитная лента (рис. 1.10). В этом случае информация записывается на
магнитное покрытие тонкой пластиковой ленты, которая для хранения
наматывается на бобину. Чтобы получить доступ к записанным на ней данным, магнитная
лента устанавливается на устройство, называемое лентопротяжным механизмом.
Это устройство позволяет считывать, записывать и перематывать магнитную
ленту под управлением компьютера. По своим размерам лентопротяжные
механизмы могут варьироваться от небольших кассетных блоков, называемых
стриммерами (в них применяются кассеты, подобные акустическим
стереокассетам), до более старых и громоздких катушечных устройств.
Направление движения ленты
Запоминающее устройство на магнитной ленте
В современных стриммерных устройствах лента разделена на сегменты,
которые маркируются магнитным способом в процессе форматирования (данный
способ подобен методу, применяемому для дисковых носителей информации).
Каждый из сегментов содержит несколько дорожек, расположенных вдоль ленты
параллельно друг другу. К каждой такой дорожке доступ можно получить
независимо от других. Это означает, что лента в сущности состоит из
совокупности отдельных строк битов, напоминающих секторы на диске.
Основным недостатком стриммерных устройств является то, что для
доступа к информации может потребоваться достаточно много времени,
поскольку это связано с перемоткой ленты с одной бобины на другую. Поэтому
лентопротяжные устройства характеризуются существенно большим
временем доступа к информации, чем устройства с магнитными дисками, в
которых для доступа к различным секторам достаточно короткого перемещения
головки чтения/записи. Именно по этой причине лентопротяжные устройства
не приобрели широкой популярности в качестве основных носителей
информации. Однако если речь идет об архивировании данных, то большая ем-
56 Глава первая. Хранение данных
кость, надежность и невысокая стоимость ленточных устройств позволяют
считать их хорошим выбором среди прочих современных устройств хранения
данных.
Сохранение и считывание файлов
Информация в массовой памяти хранится в виде больших блоков, которые
принято называть файлами. Типичный файл может содержать некоторый
текстовый документ, фотографию, программу или совокупность данных о персонале
какой-либо компании. Физические особенности устройств массовой памяти
требуют, чтобы файлы сохранялись и считывались отдельными блоками из
большого количества байтов. Например, каждый сектор на магнитном диске должен
обрабатываться как одна непрерывная строка битов. Блок данных,
соответствующий физическим характеристикам запоминающего устройства, называется
физической записью. Поэтому файл, записанный в массовую память, обычно
состоит из множества физических записей.
Помимо разделения на физические записи, любой файл обычно подразумевает
некоторое естественное разграничение представленной в нем информации.
Например, файл с информацией о персонале компании будет состоять из множества
элементов, каждый из которых содержит сведения об отдельном человеке. Такие
блоки данных, естественным образом образующиеся при создании файла,
называют логическими записями.
Размер логической записи редко совпадает с размером физической записи,
который определяется типом устройства массовой памяти. Поэтому несколько
логических записей могут помещаться в одну физическую запись, и наоборот,
логическая запись при необходимости может разделяться на несколько
физических (рис. 1.11). В результате считывание данных файла с устройства массовой
памяти обычно связано с восстановлением его логических записей из
физических. Типичный способ решения этой проблемы состоит в выделении некоторой
области основной памяти, достаточно большой для размещения нескольких
физических записей файла, и использовании ее в качестве промежуточного
хранилища для перегруппировки информации. В результате обмен данными между
этой промежуточной областью и устройством массовой памяти может
осуществляться блоками данных, соответствующими физическим записям, тогда как для
программ находящаяся в основной памяти информация может быть
представлена в виде логических записей. Используемая подобным образом область
основной памяти называется буфером.
Использование буфера поясняет относительную роль основной и массовой
памяти в системе. Основная память используется для хранения данных в целях их
обработки, тогда как массовая память является постоянным хранилищем
информации. Таким образом, обновление сохраняемой в массовой памяти
информации предполагает передачу информации в основную память, изменение ее, а
затем возврат обновленной информации в массовую память.
1.3. Массовая память 57
Размер физических записей соответствует размеру сектора
Представление логических и физических записей на диске
Можно сделать заключение, что основная память, магнитные диски,
компакт-диски и магнитная лента представляют различные уровни возможности
прямого доступа к данным в порядке ее уменьшения. Используемая в основной
памяти система адресации допускает быстрый произвольный доступ к
отдельным байтам данных. Магнитные диски обеспечивают прямой доступ только к
целым секторам данных. Кроме того, время, затрачиваемое на считывание
сектора, включает также время установки и время ожидания. Компакт-диски тоже
поддерживают произвольный доступ к отдельным секторам, однако величина
задержки для компакт-дисков значительно больше по сравнению с магнитными
дисками. Это обусловлено тем, что в этом случае требуется дополнительное
время для того, чтобы найти спиральную дорожку и настроить скорость вращения
диска. Наконец, устройства с магнитной лентой не позволяют получать прямой
доступ к информации. Современные лентопротяжные системы маркируют
фрагменты ленты, что позволяет ссылаться на различные сегменты по отдельности,
однако сама физическая организация данных обуславливает то, что поиск
сегмента потребует достаточно много времени.
Вопросы для самопроверки
1. Какие преимущества дает устройствам с жестким диском большая скорость
вращения диска по сравнению с гибким диском?
2. При записи информации на устройство дисковой памяти с несколькими
дисковыми пластинами, следует ли сначала использовать всю поверхность одной
дискорой пластины, прежде чем приступить к записи на поверхность другой
пластины, или же целесообразнее осуществить запись на всем цилиндре,
прежде чем переходить к следующему?
3. Почему информация в системе резервирования авиабилетов, которая
подвержена постоянному обновлению, должна храниться на магнитном диске, а не
на ленточном устройстве?
58 Глава первая. Хранение данных
4. Предположим, что логические записи длиной 450 байт должны храниться на
диске, размер секторов которого составляет 512 байт. Приведите аргументы в
защиту решения о размещении только одной логической записи в каждой
физической записи, даже несмотря на то, что 62 байта в каждом секторе
останутся свободными.
1.4. Представление информации в виде
комбинации двоичных разрядов
В этом разделе мы рассмотрим, как информация в машине представляется в
виде комбинации двоичных разрядов (битов). В частности, мы обсудим
популярные методы кодирования текста, представления цифровых данных и
изображений. Каждый из указанных методов имеет специфические особенности, с
которыми часто сталкивается типичный пользователь компьютера. Наша задача —
всецело ознакомиться с этими технологиями, чтобы потом можно было оценить
все их последствия.
Представление текста
Информация в форме текста обычно представляется с помощью кода, причем
каждому отличному от других символу (например, букве алфавита или знаку
пунктуации) присваивается уникальная комбинация двоичных разрядов. В этом
случае текст будет представлен как длинный ряд битов, в котором следующие
друг за другом комбинации битов отражают последовательность символов в
исходном тексте.
В ранний период развития компьютерной технологии было разработано много
подобных кодов, причем каждый из них использовался в различных элементах
оборудования. Это привело к появлению ряда проблем, связанных с передачей
информации. Во избежание этих проблем Американский национальный
институт стандартов (American National Standards Institute, ANSI) принял
американский стандартный код для обмена информацией (American Standard Code for
Information Interchange, ASCII — произносится как "эс-кии"), который приобрел
очень большую популярность. В этом коде комбинации двоичных разрядов
длиной семь бит используются для представления строчных и прописных букв
английского алфавита, знаков пунктуации, цифр от 0 до 9^ а также кодов
управления передачей информации (перевод строки, возврат каретки и табуляция). В
наше время код ASCII часто употребляется в расширенном восьмиразрядном
формате, который получается посредством добавления нуля в старший конец
каждого семиразрядного кода. Благодаря этому можно получить не только
коды, размер которых соответствует типичной однобайтовой ячейке памяти, но и
128 новых дополнительных комбинаций двоичных разрядов (которые
получаются в результате добавления в старший конец бита со значением 1). Это позволяет
представлять символы, не поддерживаемые исходной версией кода ASCII. К со-
1.4. Представление информации в виде комбинации двоичных разрядов 59
жалению, из-за того, что фирмы-разработчики широко использовали
собственные варианты толкования этих дополнительных кодов, данные, представленные
в этих кодах, оказалось не так-то просто переносить с одной программы в
другую, особенно если эти программы были разработаны разными фирмами.
Американский национальный институт стандартов
Американский национальный институт стандартов (ANSI) был основан в 1918 году небольшим
консорциумом машиностроительных ассоциаций и государственными агентствами как некоммерческое объединение.
Его задача - управление разработкой различных стандартов в частном секторе. В наше время число
членов ANSI достигло 1300 деловых организаций, профессиональных объединений, торгово-промышленных
ассоциаций и государственных агентств. Штаб-квартира этой организации расположена в Нью-Йорке.
Институт ANSI представляет США в международной организации ISO. Web-узел Американского национального
института стандартов расположен по адресу http: //www. ansi. org.
6 других странах также имеются подобные учреждения, среди которых Standards Australia (Австралия),
Standards Council of Canada (Канада), China State Bureau of Quality and Technical Supervision (Китай),
Deutsches Institur fur Normung (Германия), Japanese Industrial Standards Committee (Япония), Direccion
General de Normas (Мексика), State Committee of the Russian Federation for Standardization and Metrology
(Российская Федерация), Swiss Association for Standardization (Швейцария) и British Standards Institution
(Великобритания).
В приложении А представлена часть таблицы кода ASCII в восьмиразрядном
формате, а на рис. 1.12 показано, как в этой кодировке приветствие Hello,
представляется с помощью следующей комбинации битов:
01001000 01100101 01101100 01101100 01101111 00101110
Несмотря на то что ASCII — это один из наиболее широко используемых
кодов, сегодня растет популярность кодов с более широкими возможностями,
которые способны представлять документы на разных языках. Одним из них
является Unicode, который был разработан в результате объединенных
усилий нескольких ведущих фирм-производителей программного и аппаратного
обеспечения. В этом коде для представления каждого символа используется
уникальная комбинация из 16 двоичных разрядов. В результате кодировка
Unicode включает 65 536 различных двоичных кодов, что вполне достаточно
даже для представления всех широко употребляемых китайских и японских
символов. Международная организация по стандартизации (International
Organization for Standardization, часто именуемая ISO, от греческого isos —
одинаковый) разработала код, способный соперничать даже с кодировкой
Unicode. Здесь для выражения символов используются комбинации из 32
бит, в результате чего этот код позволяет представить более 17 миллионов
символов. Будущее покажет, какой из двух кодов приобретет большую
популярность.
60 Глава первая. Хранение данных
I РИСУНОК 1.12 | -^—^^ ^_
Представление слова Hello, в кодах ASCII
Международная организация по стандартизации
Международная организация по стандартизации (ISO) была основана в 1947 году как всемирная
федерация органов стандартизации, представляющая все страны, по одному представителю от каждой страны.
Сегодня эта федерация, штаб-квартира которой находится в Женеве (Швейцария), насчитывает более 100
организаций-членов, а также большое количество членов-корреспондентов. (Членами-корреспондентами
обычно являются организации из тех стран, которые не имеют своей организации по стандартизации. Они
не могут непосредственно участвовать в разработке стандартов, однако им предоставляется информация о
деятельности ISO.) Организация ISO поддерживает Web-узел, который находится по адресу
http//www.iso.ch.
Представление числовых значений
Несмотря на то что метод хранения информации в виде закодированных
символов достаточно удобен, он оказывается неэффективным при записи чисто
числовой информации. Попробуем разобраться, почему это так. Предположим, что
в память требуется записать число 25. Если воспользоваться символами в кодах
ASCII, то для записи этого числа потребуется один байт на каждый символ, а
всего — 16 бит. Более того, самое большое число, которое мы сможем
представить с помощью 16 битов, — это 99. В данном случае эффективнее будет
сохранить это число в его двоичном представлении.
Двоичная система счисления представляет собой способ выражения цифровых
величин с помощью только двух цифр (0 и 1), а не всех десяти (О, 1, 2, 3, 4, 5,
6, 7, 8, 9), как в традиционной десятичной системе счисления. Напомним, что в
десятичной системе счисления каждой цифровой позиции в представлении числа
приписывается определенное весовое значение. Например, в представлении числа
375 позиция цифры 5 имеет весовое значение единица, позиция цифры 7 —
весовое значение десять, а позиция цифры 3 — весовое значение сто
(рис. 1.13, а). В этом случае весовое значение каждой позиции в десять раз пре-
1.4. Представление информации в виде комбинации двоичных разрядов 61
восходит весовое значение следующей позиции. Представляемая величина
определяется посредством умножения каждой цифры на весовое значение
занимаемой ею позиции с последующим сложением полученных результатов. Таким
образом, комбинация цифр 375 представляет величину (3 х сто) + (7 х десять) +
(5 х один).
| РИСУНОК 1.13
Двоичная и десятичная системы счисления
В двоичной системе счисления позиция каждой цифры тоже связывается с
определенным весовым значением, однако в этом случае весовое значение
каждой позиции превосходит последующее только в два раза. Для большей
определенности скажем, что крайняя справа цифровая позиция в двоичном
представлении числа имеет весовое значение один (2°), следующая цифровая позиция
слева — весовое значение два (21), следующая позиция — весовое значение
четыре (22), а позиция за ней — весовое значение восемь (23) и т.д. Например, в
двоичном числе 1011 позиция крайней справа цифры 1 имеет весовое значение
один, позиция следующей единицы — весовое значение два, позиция цифры 0 —
весовое значение четыре, а позиция крайней слева единицы имеет весовое
значение восемь (рис. 1.13, б).
с
Для определения числового значения, представленного в двоичной
системе счисления, выполняются те же действия, что и при записи его в
десятичной системе счисления, — каждая его цифра умножается на весовое
значение занимаемой ею позиции, и полученные результаты суммируются.
Например, двоичное число 100101 имеет значение 37, как показано на
рис. 1.14. Более того, поскольку в двоичной системе счисления используются
только цифры 0 и 1, общая процедура умножения и суммирования
результатов сокращается до суммирования весовых значений позиций, в которых
находятся единицы. Например, двоичное число 1011 представляет значение 11,
так как единицы в нем расположены в позициях с весовыми значениями
один, два и восемь.
62
Глава первая. Хранение данных
! Расшифровка значения двоичного числа 100101
Обратите внимание на последовательность двоичных представлений чисел,
полученных в результате отсчета от нуля до восьми.
0
1
10
11
100
101
110
111
1000
Альтернативные системы счисления
В первых компьютерах двоичная система счисления еще не нашла своего применения. Способ
представления цифровых величин в вычислительных машинах был предметом острых дискуссий с конца 1930-х и на
протяжении всех 1940-х годов. Одним из предложенных вариантов была двоично-пятеричная система, в
которой каждая цифра десятичной системы заменялась двумя цифрами (одна — со значением 0,1,2,3
или 4, а другая - со значением 0 либо 5), чтобы сумма соответствовала требуемой десятичной цифре. Эта
система счисления использовалась в машине ENIAC. Другим потенциальным кандидатом являлась
восьмеричная система счисления. В статье "Binary Calculation" ("Двоичное счисление"), которая была напечатана в
журнале Journal of the Institute of Actuaries в 1936 году, Э.У. Филлипс (Е. W. Phillips) писал: "Первостепенная
задача — это убедить все цивилизованное общество отказаться от десятичного счисления и вместо этого
использовать восьмеричную систему; пора перестать считать десятками и перейти к восьмеркам".
Существует множество вариантов генерации этой последовательности. С
теоретической точки зрения они не являются достаточно убедительными, тем не менее
предлагают эффективный способ быстрого определения двоичного представления не-
1.4. Представление информации в виде комбинации двоичных разрядов 63
больших чисел. Представьте себе спидометр автомобиля, в котором колеса
индикатора пробега содержат только цифры 0 и 1. В начальной позиции стрелка
индикатора указывает на нуль и перемещается к единице, когда машина приходит в
движение. После этого при перемещении первого колеса от единицы обратно к нулю
появляется единица на соседнем колесе, расположенном левее, и на индикаторе
высвечивается число 10. Правая цифра 0 вновь перемещается к единице, и
показания индикатора будут уже равны 11. Затем правая крайняя единица перемещается к
нулю, и левая единица также переводится к нулю. В результате появляется единица
в третьей позиции, и на индикаторе мы видим число 100.
Для определения двоичного представления больших чисел можно
использовать более систематический подход, описанный в алгоритме,
представленном на рис. 1.15. Давайте применим этот алгоритм для определения
двоичного представления числа тринадцать (рис. 1.16). Сначала следует поделить
это число на два, в результате получим частное шесть и остаток единица.
Так как частное не равняется нулю, этап 2 предписывает поделить число
шесть на два, в результате будет получено частное три и остаток, равный
нулю. Поскольку новое частное тоже не равняется нулю, следует разделить его
на два, получив частное единица и остаток единица. Затем вновь следует
поделить очередное частное (единица) на два, и на этот раз частное
оказывается равным нулю, а остаток — единице. Теперь, когда мы получили частное,
равное нулю, можно перейти к этапу 3. В результате для исходного числа 13
будет получено двоичное представление 1101.
Этап 1. Поделите число на два и запишите остаток.
Этап 2. Пока не будет получено частное, равное нулю, выполняйте операцию деления предыдущего частного
на два и записывайте полученный при каждом делении остаток.
Этап 3. Как только будет получено частное, равное нулю, двоичное представление исходного числа можно
будет записать как последовательность всех полученных остатков отделения,
последовательно расположенных в направлении справа налево.
Алгоритм вычисления двоичного представления для произвольного положительного числа
А сейчас давайте вернемся к нашей исходной проблеме, связанной с
представлением числовых значений в памяти компьютера. Используя двоичную
систему счисления, можно в одном байте сохранить любое целое число в диапазоне
от 0 до 255 (от 00000000 до 11111111), а в двух байтах — уже любое целое
число в диапазоне от 0 до 65 535. Это намного лучше, нежели сохранять в двух
байтах только целые числа от 0 до 99, как при использовании для кодировки
числа однобайтовых символов в кодах ASCII.
64 Глава первая. Хранение данных
РИСУНОК 1.16
Применение алгоритма, представленного на рис. 1.15, для вычисления двоичного представления числа тринадцать
В силу этой и некоторых других причин принято сохранять цифровую
информацию представленной в той или иной двоичной форме, а не с помощью
символов кода. Мы говорим "в той или иной двоичной форме", поскольку
описанная выше двоичная система счисления является лишь фундаментом для
разработки разнообразных методов хранения цифровых данных, используемых в
вычислительных машинах. Некоторые варианты двоичного представления чисел
мы рассмотрим в последующих разделах этой главы. А сейчас мы лишь укажем,
что для представления целых чисел широко используется так называемый
двоичный дополнительный код числа; это наиболее удобный метод для
представления как отрицательных, так и положительных значений. Для представления
чисел с дробными частями, например 41/: или V4» используется метод, именуемый
форматом с плавающей точкой. Следовательно, определенное значение
(например, 25) может быть представлено с помощью нескольких различных
комбинаций двоичных разрядов (кодированных символов, в двоичном
дополнительном коде или в формате с плавающей точкой). И наоборот, определенная
комбинация битов может иметь несколько различных интерпретаций.
Здесь следует упомянуть о важнейшей проблеме, связанной с цифровыми
системами хранения данных; подробнее об этом мы поговорим чуть позже. Независимо от
того, какой размер битовой комбинации будет выделен в машине для представления
цифровых величин, всегда будут существовать значения, которые слишком велики
или же слишком малы для представления на отведенном для этого пространстве.
Поэтому всегда существует вероятность переполнения (слишком большие величины)
или потери значимости (слишком малые величины), что необходимо учитывать,
иначе ни о чем не подозревающий пользователь может неожиданно для себя
столкнуться с большим количеством ошибочных данных.
1.4. Представление информации в виде комбинации двоичных разрядов 65
Представление изображений
Современные компьютерные приложения способны обрабатывать не только
простейшие текстовые и цифровые данные. Помимо всего прочего, они позволяют
работать с изображениями, а также с аудио- и видеоинформацией. В отличие от методов
хранения символьной и числовой информации, способы представления данных в
этих дополнительных форматах находятся еще на ранней стадии своего развития, а
потому для них еще не существует общепризнанных стандартов.
Наиболее распространенные из существующих методов представления
изображений можно разделить на две большие категории: растровые методы и
векторные методы. При растровом методе изображение представляется как
совокупность точек, называемых пикселями (pixel, сокращение от picture element —
элемент изображения). Говоря упрощенно, изображение кодируется в виде
длинных строк битов, которые представляют ряды пикселей в изображении. При
этом каждый бит равен 0 или 1, в зависимости от того, является ли
соответствующий пиксель черным или белым. Включение информации о цвете
изображений лишь незначительно усложняет дело, поскольку в этом случае каждый
пиксель представляется комбинацией битов, определяющей его цвет. При растровом
методе полученную комбинацию битов часто называют битовой картой (bit
map), подчеркивая тот факт, что данная комбинация битов представляет собой
не более чем карту или схему исходного изображения.
Большинство периферийных устройств современных вычислительных машин,
например факсимильные аппараты, видеокамеры или сканеры, преобразует
цветные изображения в графические файлы с растровым форматом. Чаще всего
эти устройства записывают цвет каждого пикселя, раскладывая его на три
составляющие — красную, зеленую и синюю, соответствующие трем первичным
цветам. Для передачи интенсивности каждой компоненты обычно используется
один байт. Поэтому для представления каждого пикселя исходного изображения
требуются три байта.
Аналогичный трехкомпонентный пиксельный подход к передаче графической
информации используется и при выводе изображений на экраны мониторов
современных компьютеров. Экраны этих устройств содержат десятки тысяч
пикселей, каждый из которых состоит из трех компонентов (красного, зеленого и
синего), что можно заметить даже невооруженным глазом, если внимательно
посмотреть на экран. (Можно также воспользоваться увеличительным стеклом.)
Формат "три байта на пиксель" означает, что для хранения изображения, в
котором 1280 рядов по 1024 пикселя (фотография обычного размера),
потребуется несколько мегабайт памяти, что существенно превышает размер стандартной
дискеты. В разделе 1.8 будут рассмотрены два наиболее распространенных
формата для сжатия подобных изображений до более приемлемых размеров (это
форматы GIF и JPEG).
Одним из недостатков растровых методов является трудность пропорционального
изменения размеров изображения до произвольно выбранного значения. В сущности,
единственный способ увеличить изображение — это увеличить сами пиксели. Однако
66 Глава первая. Хранение данных
это приводит к появлению зернистости, что также часто встречается и при
фотографировании на пленку. Векторные методы позволяют избежать проблем
масштабирования, характерных для растровых методов. В этом случае изображение
представляется в виде совокупности линий и кривых. Вместо того чтобы заставлять устройство
воспроизводить заданную конфигурацию пикселей, составляющих изображение, ему
передается подробное описание того, как расположены образующие изображение
линии и кривые. На основе этих данных устройство, в конечном счете, и создает
готовое изображение. С помощью подобной технологии описываются различные
шрифты, поддерживаемые современными принтерами и мониторами. Они позволяют
изменять размер символов в широких пределах и по этой причине получили название
масштабируемых шрифтов. Например, технология True Type, разработанная
компаниями Microsoft и Apple Computer, описывает способ отображения символов в
тексте. Для подобных целей предназначена и технология PostScript (разработанная
компанией Adobe Systems), позволяющая описывать способ отображения символов, а
также других, более общих графических данных. Векторные методы также широко
применяются в автоматизированных системах проектирования (computer-aided
design, CAD), которые отображают на экране мониторов чертежи сложных
трехмерных объектов и предоставляют средства манипулирования ими. Однако векторная
технология не позволяет достичь фотографического качества изображений объектов,
как при использовании растровых методов. Именно поэтому в современных
цифровых фотокамерах используются растровые методы представления изображения.
Вопросы для самопроверки
1. Ниже приведено сообщение, представленное в виде символов ASCII с
использованием восьми битов на один символ. Какой текст этого сообщения?
01000011 01101111 01101101 01110000 01110101 01110100
01100101 01110010 00100000 01010011 01100011 01101001
01100101 01101110 01100011 01100101
2. Какая взаимосвязь между представлением строчных и соответствующих
прописных букв в кодировке ASCII?
3. Зашифруйте приведенные ниже предложения с помощью символов кода
ASCII.
a) Where are you?
б) "How" Cheryl asked.
в) 2 + 3 = 5
4. Опишите устройство, которое используется в повседневной жизни и может
пребывать в одном из двух состояний, подобно флажку на флагштоке,
который может быть поднят или опущен. Присвойте одному из состояний
значение 1, а другому — значение 0, а затем покажите, как будет выглядеть код
ASCII для буквы Ь, если представить ее таким способом.
5. Преобразуйте каждое из приведенных ниже двоичных значений в
эквивалентное десятичное представление.
1.4. Представление информации в виде комбинации двоичных разрядов 67
а) 0101 б) 1001 в) 1011 г) ОНО
д) 10000 е) 10010
6. Преобразуйте каждое из приведенных ниже десятичных значений в
эквивалентное двоичное представление.
а) 6 б) 13 в) 11 г) 18
Д) 27 е) 4
7. Какое наибольшее числовое значение может быть представлено в трех байтах
памяти, если каждая цифра будет зашифрована в виде символа кода ASCII?
Каким будет ответ при использовании двоичного представления числа?
8. Альтернативой шестнадцатеричной системе счисления в отношении
представления битовых комбинаций является десятичная нотация с точками, в
которой каждый байт битовой комбинации представляется эквивалентным
десятичным значением. Эти представления отдельных байтов, в свою очередь,
отделяются точками. Например, значение 12.5 представляет комбинацию
0000110000000101 (байт 00001100 представлен числом 12, а байт
00000101 — числом 5), а комбинация 10001000001000000000111 может быть
представлена как 136.16.7. Представьте приведенные ниже битовые
комбинации в десятичной нотации с точками.
а) 0000111100001111 б) 001100110000000010000000
в) 0000101010100000
1.5. Двоичная система счисления
Прежде чем рассматривать используемые в современных вычислительных
машинах методы сохранения информации, представленной в цифровом виде,
необходимо подробнее ознакомиться с двоичной системой счисления.
Двоичное сложение
Как и при изучении операции сложения десятичных чисел в начальной
школе, обсуждение операции суммирования двух чисел, представленных в двоичной
системе счисления, мы начнем с соответствующей таблицы правил двоичного
сложения, представленной на рис. 1.17. Приведенные на этом рисунке операции
демонстрируют основные правила сложения двух строк двоичных цифр. Вначале
необходимо сложить цифры в крайнем правом столбце, записать цифру
младшего разряда полученной суммы под этим столбцом, а цифру старшего разряда
полученной суммы (если таковая имеется) перенести в следующий слева столбец.
Для получения окончательного результата следует аналогичным образом
суммировать цифры во всех последующих столбцах.
68 Глава первая. Хранение данных
Правила двоичного сложения
В качестве примера рассмотрим решение следующей задачи:
00111010
+00011011
Начинаем с операции сложения крайних правых цифр 0 и 1, в результате
получим число 1 и запишем его под этим столбцом. Затем сложим цифры 1 и 1 в
следующем столбце и получим число 10. Цифру 0 этого числа запишем под
данным столбцом, а цифру 1 перенесем в следующий столбец и запишем над ним.
На данном этапе это будет выглядеть следующим образом:
1
00111010
+00011011
01
В следующем столбце сумма цифр 1, 0 и 0 будет равна числу 1, поэтому под
данным столбцом запишем цифру 1. Сумма цифр 1 и 1 в очередном столбце
составляет число 10. Запишем под данным столбцом цифру 0, а цифру 1
перенесем в следующий столбец, как показано ниже:
1
00111010
+00011011
0101
Сумма цифр 1, 1 и 1 в очередном столбце составит число 11, поэтому цифра 1
из младшего разряда записывается под данным столбцом, а цифра 1 из старшего
разряда переносится в следующий столбец. Суммируя цифры 1, 1 и 0 в
следующем столбце, получаем число 10. И вновь, цифра 0 из младшего разряда
записывается под данным столбцом, а цифра 1 из старшего разряда переносится в
следующий столбец, как показано ниже:
1
00111010
+00011011
010101
Далее останется просуммировать цифры 1, 0 и 0 в последнем столбце. Их
сумма равна числу 1, которое и записывается под данным столбцом. В этом слу-
1.5. Двоичная система счисления 69
чае нет никакой цифры, которая переносилась бы в следующий столбец.
Окончательное решение задачи выглядит следующим образом:
00111010
+00011011
01010101
Представление дробей в двоичных кодах
Чтобы иметь возможность работать с дробями в двоичной системе счисления,
мы применяем позиционную точку, подобную используемой в десятичных
дробях. Цифры слева от точки представляют целую часть числа (мантиссу) и
обрабатываются точно так, как целые числа, записанные в двоичной системе. Цифры
справа представляют дробную часть и обрабатываются аналогично любым
другим битам, за исключением того, что их позициям присвоены дробные весовые
значения. Это означает, что первая цифровая позиция справа от точки имеет
весовое значение 1/2, следующим позициям присваиваются весовые значения г/4,
Vs и т.д. Следует отметить, что описанный механизм является простым
расширением изложенного выше правила — каждой цифровой позиции присваивается
весовое значение в два раза большее, чем последующей в направлении слева
направо. Благодаря тому, что позиционным разрядам присваиваются указанные
выше весовые значения, процедура расшифровки двоичного представления с
точкой, отделяющей дробную часть от целой, аналогична той, которая
применяется к целым числам. Значение в каждом разряде просто умножается на весовое
значение, присвоенное его позиции в представлении числа, а затем полученные
результаты суммируются. Чтобы пояснить эту процедуру нагляднее, на рис. 1.18
показан пример расшифровки двоичного числа 101.101, десятичное
представление которого равно 55/8.
РИСУНОК 1.18
70 Глава первая. Хранение данных
В отношении операции сложения можно сказать, что для дробных двоичных
чисел используются те же методы, что и для десятичных дробей. Таким образом,
чтобы сложить два дробных двоичных числа, нужно их просто выровнять по
положению точки и после этого применить процедуру сложения, описанную выше.
Например, в результате сложения чисел 10.011 и 100.11 будет получен
результат 11.001.
10.011
+100.11
111.001
Вопросы для самопроверки
1. Преобразуйте каждое из приведенных ниже двоичных чисел в десятичный
формат.
а) 101010 б) 100001 в) 10111 г) ОНО
Д) 111Н
2. Преобразуйте каждое из приведенных ниже десятичных чисел в двоичный
формат.
а) 32 б) 64 в) 96 г) 15 д) 27
3. Преобразуйте каждое из приведенных ниже двоичных чисел в десятичный
формат.
а) 11.01 б) 101.111 в) 10.1 г) 110.011
д) 0.101
4. Преобразуйте каждое из приведенных ниже десятичных чисел в двоичный
формат.
а) 472 б) 23/4 в) lVs г) 5/i6 Д) 55/8
5. Выполните операцию сложения для следующих двоичных чисел.
а) 11011 б) 1010.001 в) 11111 г) 111.11
+ 1100 + 1.101 +1 + 0.01
1.6. Представление целых чисел
Математики долгое время занимались цифровыми системами счисления, и
многие выдвинутые ими идеи оказались весьма полезными для разработки
цифровых электронных схем. В этом разделе мы обсудим две такие системы
нотации, а именно двоичный дополнительный код и двоичную нотацию с избытком.
Эти системы построены на основе двоичной системы счисления, обсуждавшейся
в разделе 1.5, и имеют определенные преимущества, благодаря которым широко
используются при конструировании компьютеров. Однако эти преимущества
могут обернуться и недостатками. Наша задача — уяснить свойства этих систем и
понять, как они влияют на работу компьютеров.
1.6. Представление целых чисел 71
Двоичный дополнительный код
На сегодняшний день наиболее распространенной системой представления
целых чисел в компьютерах является двоичный дополнительный код, в котором
для представления каждого числа используется фиксированное количество
битов. В настоящее время данная система чаще всего реализуется с
использованием, для представления любого числа, 32-х двоичных разрядов. Подобное
решение позволяет предоставить широкий диапазон целых чисел, однако
демонстрация его работы вызывает определенные затруднения. Поэтому при изучении
свойств двоичного дополнительного кода мы будем оперировать числами
меньшей длины.
На рис. 1.19 показаны два варианта дополнительного двоичного кода, в
которых для представления чисел используются три и четыре бита соответственно.
Построение подобной системы начинается с записи строки нулей, количество
которых равно числу используемых двоичных разрядов. Далее ведется обычный
двоичный отсчет до тех пор, пока не будет получено значение, состоящее из
единственного нуля, за которым следуют лишь единицы. Полученные комбинации
будут представлять положительные числа 0, 1, 2, 3, ... . Для представления
отрицательных чисел выполняется обратный отсчет, начиная со строки из всех единиц
соответствующей длины. Обратный счет продолжается до тех пор, пока не будет
получена строка, состоящая из одной единицы, за которой будут следовать все
нули. Полученные комбинации будут представлять числа -1, -2, -3, ... . (Если вам
покажется трудным вести обратный отсчет в двоичной системе счисления, можно
отсчитывать комбинации в обратном порядке, начиная со строки с одной единицей
и всеми нулями и заканчивая строкой, состоящей из одних единиц.)
Обратите внимание, что в дополнительном двоичном коде крайний левый бит
в значении каждого числа определяет знак представляемой числовой величины,
поэтому этот бит принято называть знаковым разрядом. В этой нотации
отрицательные числа представляются комбинациями со знаковым битом, равным 1, а
положительные числа — комбинациями со знаковым битом, равным 0.
В двоичном дополнительном коде очень удобно представлена взаимосвязь
между комбинациями битов, представляющими положительные и
отрицательные значения, одинаковые по модулю. Последовательность битов оказывается
идентичной при чтении справа налево до первой единицы включительно. С этой
позиции и далее коды являются дополнительными друг другу. (Дополнением
двоичной комбинации называется такая комбинация, которая получается в
результате изменения всех нулей в исходном значении на единицы, а всех единиц
на нули. Например, двоичные комбинации ОНО и 1001 являются
дополнительными друг другу.) Например, в четырехразрядном коде (рис. 1.19) обе битовые
комбинации, представляющие числа 2 и -2, заканчиваются на 10, однако
комбинация, представляющая число 2, начинается с 00, тогда как комбинация,
представляющая число -2, начинается с 11. Данное наблюдение позволяет
сформулировать алгоритм взаимного преобразования битовых комбинаций,
представляющих положительные и отрицательные числа, имеющие одно и то же
72 Глава первая. Хранение данных
значение по модулю. Достаточно просто копировать исходную комбинацию
справа налево до тех пор, пока не будет встречена единица, а затем последовательно
заменять значения оставшихся битов их дополнениями (рис. 1.20).
РИСУНОК 1.19
а) Трехразрядный дополнительный код б) Четырехразрядный дополнительный код
Схемы кодирования в двои ином дополнительном коде
Ясное понимание описанных выше основных свойств двоичного
дополнительного кода позволяет также сформулировать алгоритм преобразования
значений этого кода в десятичное представление. Если битовая комбинация
имеет нулевой знаковый бит, то это значение рассматривается просто как
обычное двоичное число. Например, битовая комбинация ОНО представляет
число 6, поскольку комбинация битов 110 является двоичным
представлением числа 6. Если битовая комбинация содержит знаковый бит, равный
единице, то она представляет отрицательное число, и нам остается лишь
определить абсолютную величину этого числа. Это выполняется посредством
записи исходной комбинации справа налево, вплоть до первой встретившейся
единицы, после чего для оставшихся битов, в порядке их следования,
записываются дополнительные значения. Полученная комбинация битов
дешифруется как обычное двоичное число.
Например, чтобы определить десятичное значение комбинации 1010, мы,
прежде всего, отмечаем, что это значение является отрицательным, так как
исходная комбинация содержит единицу в знаковом бите. Затем исходная комби-
1.6. Представление целых чисел 73
нация преобразуется в комбинацию ОНО, которая представляет собой двоичное
число 6. Теперь можно сделать окончательное заключение, что исходная
двоичная комбинация представляет число -6.
РИСУНОК 1.20
Представление числа - 6 в четырехразрядном дополнительном коде
Сложение чисел в двоичном дополнительном коде
Чтобы сложить числа, представленные в двоичном дополнительном коде,
следует использовать тот же алгоритм, что и для сложения обычных двоичных
чисел. Однако нужно учесть тот факт, что в этом коде все представляемые числа,
включая и искомый результат, имеют одинаковую длину. Это означает, что, при
суммировании представленных в этом коде чисел, любой бит переноса,
появляющийся на левом конце результирующего значения при сложении самых
старших разрядов, должен отбрасываться. Например, при суммировании
битовых комбинаций 0101 и 0010 будет получен результат 0111, а при сложении
комбинаций 0111 и 1011 — результат 0010 (0111 + 1011 = 10010, после чего
результат усекается до 0010).
Учитывая сказанное выше, рассмотрим три примера сложения, показанные
на рис. 1.21. В каждом случае исходные числовые значения сначала
преобразовываются в четырехразрядный двоичный дополнительный код, а затем
выполняется операция суммирования, согласно описанному выше алгоритму.
Полученный результат вновь преобразуется в десятичное значение.
Обратите внимание, если бы при сложении использовался традиционный
метод, которому нас обучали еще в начальной школе, то для решения третьей
задачи потребовались бы совершенно иные действия (операция вычитания),
отличные от используемых в двух предыдущих задачах. Однако за счет
преобразования исходных данных в двоичные дополнительные коды можно вычислить
74
Глава первая. Хранение данных
результат с помощью одного и того же алгоритма сложения. Таким образом,
основным преимуществом двоичного дополнительного кода является то, что
операция сложения для любых целых чисел со знаком осуществляется с помощью
одного и того же алгоритма.
РИСУНОК 1.21
Сложение чисел в двоичном дополнительном коде
В отличие от учеников начальной школы, которые должны вначале освоить
операцию сложения, а затем операцию вычитания, машины, в которых используется
двоичный дополнительный код, должны уметь только суммировать числа и
изменять знак числа на обратный. Например, операция вычитания 7-5 аналогична
операции сложения 7 + (-5). Если машине потребуется вычесть число 5
(представленное битовой комбинацией 0101) из числа 7 (представленного битовой
комбинацией 0111), то она сначала поменяет знак числа 5 на -5 (представляемое
как битовая комбинация 1011), а затем выполнит операцию сложения для значений
0111 и 1011. В результате будет получено значение 0010, представляющее
десятичное число 2. Все это будет выглядеть следующим образом:
7 0111 0111
2_5 _> -0101 _> +1011
0010 _> 2
Из этого примера видно, что при использовании двоичного дополнительного кода
необходимо реализовать электронные схемы только для осуществления операций
сложения и отрицания. Этого будет достаточно для выполнения как операций
сложения, так и вычитания. (Описание построения подобных электронных схем и
объяснение принципов их работы можно найти в приложении Б.)
Проблема переполнения
В предыдущих примерах мы не упомянули об одной важной проблеме. Дело в
том, что любая обсуждаемая в этой книге система представления чисел
накладывает определенные ограничения на размер представляемых чисел. Например,
1.6. Представление целых чисел 75
при использовании четырехразрядного двоичного дополнительного кода не
существует битовой комбинации, представляющей число 9; это означает, что мы не
можем получить верный результат при решении задачи 5 + 4. Фактически при
сложении указанных чисел будет получен результат -7. Этот тип ошибок
называют переполнением. Они возникают в том случае, когда результат операции по
абсолютной величине превышает наибольшее представимое в выбранном
варианте кодировки значение. При использовании двоичного дополнительного кода
подобная ошибка может возникнуть при сложении двух положительных или
отрицательных чисел. В любом случае ошибку можно выявить путем проверки
значения знакового бита результата. Признаком переполнения является
отрицательный результат сложения двух положительных чисел или
положительный результат сложения двух отрицательных чисел.
Безусловно, реальные машины обычно работают с гораздо более длинными
битовыми комбинациями, чем те, которые были использованы в наших
примерах, и ошибка переполнения, даже при обработке относительно больших чисел,
возникает достаточно редко. В настоящее время для хранения чисел в двоичном
дополнительном коде обычно применяются битовые комбинации длиной 32 бита,
что позволяет без возникновения переполнения обрабатывать числа до
2 147 483 647. Если же требуется обработка чисел, превышающих это значение,
можно использовать более длинные битовые комбинации или же просто
изменить применяемую единицу измерения. Например, при обработке значений,
измеренных в километрах, а не сантиметрах, можно манипулировать меньшими
числами, что, возможно, позволит сохранить достаточную точность вычисления.
Из сказанного выше следует, что компьютеры также могут ошибаться.
Поэтому пользователи должны знать о существовании подобной опасности.
Зачастую программисты и пользователи созданных ими приложений бывают слишком
самоуверенны и забывают о том, что небольшие числовые значения могут
накапливаться, давая в результате очень большие величины. Раньше для
представления чисел в двоичном дополнительном коде широко использовались
шестнадцатиразрядные двоичные комбинации. Это означало, что переполнение возникало
при значениях, превышающих 215 = 32 768. Например, 19 сентября 1989 года
компьютер в одной из больниц выдал ошибку в расчетах, и это после долгих лет
безупречной работы. Была проведена тщательная проверка, которая показала,
что к этой дате, начиная с 1 января 1900 года, прошло ровно 32 768 дней. Как
вы полагаете, что оказалось причиной ошибки компьютера?
Двоичная нотация с избытком
Теперь давайте рассмотрим двоичную нотацию с избытком, которая является
еще одним способом представления целых чисел. Каждое число в этой нотации
представлено битовой комбинацией одной и той же длины. Чтобы сформировать
представление числа в двоичной нотации с избытком, сначала выбирается длина
битовой комбинации, а затем в порядке счета в обычной двоичной системе
последовательно записываются все возможные битовые комбинации, имеющие
установленную длину. При анализе полеченного результата можно заметить, что
76 Глава первая. Хранение данных
первая битовая комбинация с единицей в старшем разряде находится почти в
середине списка. Именно она выбирается в этой нотации для представления
числа 0. Все последующие комбинации с единицей в старшем разряде будут
представлять числа 1, 2, 3,... соответственно. Предыдущие комбинации в
обратном направлении используются для представления чисел -1, -2, -3,... .
Кодовые значения, получаемые при использовании четырехразрядных битовых
комбинаций, показаны на рис. 1.22. В частности, число 5 представлено
комбинацией 1101, а число -5 представлено комбинацией ООН. (Обратите внимание,
что различие между двоичной нотацией с избытком и двоичным
дополнительным кодом состоит только в противоположности значений знаковых битов.)
РИСУНОК 1.22
Значения четырехразрядных битовых комбинаций в двоичной нотации с избытком
Таблица значений, представленная на рис. 1.22, известна как двоичная
нотация с избытком восемь. Чтобы понять, почему она так называется, сначала
определим значения кодовых комбинаций как обычных двоичных значений, а
затем сравним полученный результат с тем значением, которое присвоено каждой
кодовой комбинации в двоичной нотации с избытком восемь. В результате мы
обнаружим, что соответствующее кодовой комбинации двоичное число
превышает представляемое этой комбинацией значение на 8. Например, комбинация
1100 обычно используется для представления числа 12, а в двоичной нотации с
избытком восемь эта же комбинация представляет число 4. Это же справедливо
и для комбинации 0000, которая обычно представляет число 0, а в данной нота-
1.6. Представление целых чисел 77
ции — число -8. Если же двоичная нотация с избытком создается для
комбинаций длиной пять битов, она будет называться двоичной нотацией с избытком 16.
В этом случае комбинация 10000 будет представлять число 0, а не 16, как в
обычной двоичной системе. Этот же принцип может быть использован для
именования любой конкретной схемы двоичной нотации с избытком. Например,
схему с тремя двоичными разрядами, представленную на рис. 1.23, можно
назвать двоичной нотацией с избытком четыре.
РИСУНОК 1.23
Значения трехразрядных битовых комбинаций в двоичной нотации с избытком
Вопросы для самопроверки
1. Преобразуйте каждое представленное ниже значение в двоичном
дополнительном коде в десятичный формат.
а) 00011 б) 01111 в) 11100
г) 11010 д) 00000 е) 10000
2. Преобразуйте каждое представленное ниже десятичное значение в двоичный
дополнительный код длиной восемь бит.
а) 6 б) 26 в) 217 г) 13 д) 21 е) О
3. Предположим, что приведенные ниже комбинации битов представляют числа
в двоичном дополнительном коде. Запишите представление обратных им
значений в этом же коде.
а) 00000001 б) 01010101 в) 11111100
г) 11111110 д) 00000000 е) 01111111
4. Предположим, что числа в машине сохраняются в двоичном дополнительном
коде. Какое наибольшее и наименьшее число может быть записано, если
используются битовые комбинации следующей длины.
а) четыре б) шесть в) восемь
78 Глава первая. Хранение данных
5. В следующих задачах каждая битовая комбинация представляет число,
записанное в двоичном дополнительном коде. Вычислите все операции сложения,
а затем проверьте ваши результаты посредством преобразования исходных
текстов задач в десятичную систему и вычисления их ответов.
а) 0101 б) ООН в) 0101 г) 1110 д) 1010
+0010 +0001 +1010 +0011 +1110
6. Решите следующие задачи с числами в двоичном дополнительном коде,
однако на этот раз следите за переполнением и укажите неверные ответы,
полученные в результате этой ошибки.
а) 0100 б) 0101 в) 1010 г) 1010 д) 0111
+0011 +0110 +1010 +0111 +0001
7. Переведите все приведенные ниже задачи из десятичного представления в
четырехразрядный двоичный дополнительный код, а затем преобразуйте их в
эквивалентные задачи сложения (как это сделала бы машина) и выполните
операции суммирования. Проверьте полученные ответы с помощью
преобразования их в десятичное представление.
а) б б) 3 в) 4 г) 2 д) 1
±1 zl zA ±1 zl
8. Может ли возникнуть ошибка переполнения при сложении двух чисел в
дополнительном коде, если одно из суммируемых чисел будет положительным,
а другое отрицательным? Поясните ваш ответ.
9. Преобразуйте приведенные ниже комбинации битов в двоичной нотации с
избытком восемь в десятичный формат, не прибегая к помощи приведенной
выше таблицы.
а) 1110 б) 0111 в) 1000
г) 0010 д) 0000 е) 1001
10. Преобразуйте приведенные ниже десятичные числа в коды двоичной нотации
с избытком восемь без помощи приведенной выше таблицы.
а) 5 б) -5 в) 3 г) 0 д) 7 е) -8
11. Можно ли представить число 9 в двоичной нотации с избытком восемь? А
что можно сказать по поводу представления числа 6 в двоичной нотации с
избытком четыре? Поясните ваш ответ.
1.7. Представление дробных значений
В отличие от методов представления целых чисел, задача представления
числовых значений с дробной частью требует не только сохранения комбинаций из
нулей и единиц, образующих его двоичное представление, но и запоминания
позиции точки, отделяющей целую часть от дробной. Наиболее распространенный
способ решения этой задачи, именуемый двоичной нотацией с плавающей
точкой, состоит в экспоненциальном представлении чисел.
1.7. Представление дробных значений 79
Двоичная нотация с плавающей точкой
Для пояснения принципа, положенного в основу двоичной нотации с плавающей
точкой, рассмотрим пример, в котором для хранения числа используется всего один
байт. Несмотря на то что в машинах обычно используются более длинные битовые
комбинации, восьмиразрядный формат достаточно наглядно демонстрирует
используемые принципы без ненужной избыточности длинных битовых комбинаций.
Для начала давайте условимся считать старший бит знаковым. Как и в
предыдущих примерах, значение нуль в знаковом бите означает, что представляемое число
неотрицательно, а значение единица, наоборот, указывает, что число является
отрицательным. Далее разделим оставшиеся биты байта на две группы, или поля, а
именно: поле порядка числа и поле мантиссы. Следующие три бита после знакового
бита будем считать полем порядка числа, а оставшиеся четыре бита — полем
мантиссы. Описанный выше способ разделения байта представлен на рис. 1.24.
Компоненты числа в двоичной нотации с плавающей точкой
Попробуем разобраться с назначением отдельных полей на конкретном примере.
Пусть байт содержит битовую комбинацию 01101011. При разложении этой
комбинации по элементам описанного выше формата оказывается, что знаковый бит
равен 0, поле порядка числа имеет значение 110, а поле мантиссы — значение 1011.
Для расшифровки представленного в этом байте значения, прежде всего, выделим
мантиссу и поместим плавающую точку слева от нее, как показано ниже:
.1011
Далее выделим значение в поле порядка числа (110) и интерпретируем его
как целое трехразрядное число, записанное в двоичной нотации с избытком (см.
рис. 1.20). Таким образом, в поле порядка числа закодировано целое число 2.
Это означает, что плавающую точку в полученном ранее значении следует
переместить на два бита вправо (при отрицательном порядке плавающая точка
перемещается влево), после чего будет получен окончательный результат:
10.11
Это значение является двоичным представлением числа 23/4. Наконец,
определяем, что представляемое число является положительным, поскольку знаковый бит
80 Глава первая. Хранение данных
имеет значение 0. Таким образом, мы установили, что битовая комбинация
01101011 в двоичной нотации с плавающей точкой представляет число 23/4.
Рассмотрим еще один пример, в котором байт содержит битовую комбинацию
10111100. Выделив мантиссу, получим следующее значение:
.1100
Теперь перенесем плавающую точку на один бит влево, так как в поле
порядка содержится значение 011, представляющее число -1. Поэтому окончательный
вид закодированного двоичного числа будет следующим:
0.01100
Это двоичное число имеет значение 3/8. Закодированное в значении байта
число является отрицательным, поскольку его знаковый бит равен 1. Из этого
следует, что битовая комбинация 10111100 в двоичной нотации с плавающей
точкой представляет число -а'/8.
Для представления чисел в двоичной нотации с плавающей точкой
необходимо следовать описанному выше процессу, но уже в обратном порядке. Например,
для определения представления в этой нотации числа lVs сначала необходимо
записать его двоичное представление: 1.001. Затем эта битовая комбинация
копируется в поле мантиссы слева направо, начиная с самой левой единицы в
двоичном представлении числа. Это будет выглядеть так:
10 0 1
Теперь остается заполнить поле порядка числа. Представим содержимое поля
мантиссы, слева от которого расположена плавающая точка, и определим число
разрядов, а также направление, в котором будет перемещаться плавающая точка
для получения исходного значения двоичного числа. Обратившись к нашему
примеру, можно увидеть, что точка в комбинации .01100 должна быть
перемещена на один бит вправо; в результате будет получено исходное значение 1.001.
Таким образом, порядок числа равен положительному числу 1, поэтому в
соответствующее поле следует поместить значение 101 (представляющее число +1 в
двоичной нотации с избытком четыре). Окончательное значение в байте будет
выглядеть следующим образом:
При заполнении поля мантиссы имеется один тонкий момент, на который вы
могли не обратить внимание. Правило требует копировать битовую комбинацию
двоичного представления числа в поле мантиссы слева направо, начиная с
крайней левой единицы. Чтобы прояснить для себя этот нюанс, рассмотрим процесс
кодирования числа 3/8, двоичным представлением которого является битовая
комбинация .011. В этом случае мантисса должна иметь следующее значение:
I ! oi о
Любой другой вариант, например представленный ниже, недопустим:
0 110
1.7. Представление дробных значений 81
Суть в том, что заполнение поля мантиссы всегда должно начинаться с
крайней левой единицы в двоичном представлении кодируемого числа. Данное
правило исключает возможность различного представления одного и того же
значения. Это также говорит о том, что в представлении всех чисел, отличных
от нуля, мантисса всегда будет содержать значение 1 в ее старшем разряде.
Такое представление чисел называется нормализированой формой. В связи с этим
заметим, что представление числа нуль является особым случаем, а
соответствующая битовая комбинация представляет собой строку из одних нулей.
Ошибки усечения значения
Давайте рассмотрим неприятную проблему, которая возникает при
попытке представить число 25/8 в виде однобайтового кода в двоичной нотации
с плавающей точкой. Прежде всего определим двоичное представление числа
25/8, которое имеет вид 10.101. Однако при копировании этого значения в
поле мантиссы имеющихся четырех разрядов оказывается недостаточно и
самая правая единица в двоичном представлении, имеющая весовое
значение Ve» теряется (рис. 1.25). Если не обратить на это внимание и продолжить
заполнение поля порядка числа и знакового бита, будет получена
комбинация 01101010, которая на самом деле представляет число 21/2, а не 25/8. Это
явление называется ошибкой усечения, или ошибкой округления. Оно
означает, что некоторая часть кодируемого числа теряется, поскольку размер
поля мантиссы оказывается недостаточным.
Во избежание подобных ошибок можно использовать поле мантиссы большего
размера. Как и в случае целых чисел, для представления значений в нотации с
плавающей точкой принято использовать комбинации не менее 32 бит, а не 8
бит, как в приведенных выше примерах. Одновременно это позволяет расширить
и размер поля порядка числа. Но даже при использовании более длинных полей,
достигаемая точность представления числовых значений в некоторых случаях
оказывается недостаточной.
Аналоговые и цифровые компьютеры
В ранний период развития компьютерной техники проводились многочисленные дискуссии в отношении того, на
какой основе должны создаваться будущие вычислительные устройства — на цифровой или аналоговой. В
цифровых системах данные представляются с помощью строго ограниченного количества различающихся цифровых
значений (например, нуль и единица). В аналоговых системах каждое значение представляется с помощью
единственного устройства, способного хранить любое значение из некоторого непрерывного диапазона.
Давайте сравним эти два подхода, применив в качестве примера ведра с водой. При использовании цифровой
системы договоримся, что пустое ведро представляет цифру 0, а полное— 1. В результате мы можем
представить любое числовое значение как ряд ведер, используя для их кодирования двоичную нотацию с
плавающей точкой. В отличие от этого, для представления чисел в аналоговой системе достаточно использовать все-
82 Глава первая. Хранение данных
го лишь одно ведро, частично наполняя его водой до той отметки, которая соответствует представляемому
числу. На первый взгляд аналоговая система может показаться более точной, так как здесь отсутствуют
ошибки усечения, неизбежные во всех цифровых системах. Однако любой случайный толчок ведра в аналоговой
системе вызовет ошибку в определении уровня воды, тогда как в цифровой системе легко можно будет
отличить пустое ведро от полного, даже если из него выльется значительное количество воды. Поэтому
вероятность возникновения случайных ошибок в цифровой системе существенно меньше, чем в аналоговой. Именно
зта устойчивость явилась основной причиной того, что многие исходно аналоговые технологии (например,
телефонная связь, аудиозаписи, телевидение) перешли на цифровую технологию.
РИСУНОК 1.25
Схема кодирования числа 25/8
Существует еще одна причина появления ошибок усечения, с которой
каждый из нас уже встречался при изучении десятичной системы счисления. Это
проблема бесконечного количества дробных знаков в представлении числа,
которая встречается, например, при выражении числа */з в виде десятичной дроби.
Дело в том, что некоторые числа невозможно точно выразить, сколько бы цифр
мы не использовали для их представления.
Различие между традиционной десятичной системой счисления и двоичной
системой состоит в том, что в двоичной системе больше чисел имеют бесконечное
представление, чем в десятичной. Например, даже такое число, как одна
десятая, имеет в двоичной системе бесконечное представление. Попробуйте
представить себе, какие могут возникнуть проблемы, если какой-либо неосторожный
человек решит использовать двоичные числа с плавающей точкой для хранения
и обработки данных, представляющих собой суммы в долларах и центах.
Например, если единицей измерения данных является доллар, то оказывается
невозможным точно представить даже обычную десятицентовую монету. Хорошее
решение в подобном случае — измерять данные в единицах центов, тогда все
значения окажутся целыми числами, и их можно будет представить с помощью
двоичного дополнительного кода.
1.7. Представление дробных значений 83
Ошибки усечения и все связанные с ними проблемы являются предметом
изучения тех, кто работает в области численного анализа. Эта отрасль математики
исследует проблемы, связанные с реальным выполнением вычислений,
отличающихся очень большим объемом и требующих повышенной точности результатов.
А сейчас мы рассмотрим пример, который порадует душу любого специалиста
по численному анализу. Предположим, что нам требуется сложить следующие
три числа, представленные в однобайтовых кодах двоичной нотации с
плавающей точкой (описанной выше):
272 + V8 + V8.
Если суммировать эти числа в указанном порядке, то сначала будет получено
промежуточное значение 25/8 (в результате сложения чисел 21/2 и Vg), двоичным
представлением которого является битовая комбинация 10.101. К сожалению, это
число не может быть представлено точно (в чем мы убедились раньше), поэтому в
результате сложения будет получено число 21/2 (т.е. первое из слагаемых). Если
теперь прибавить к полученному результату следующее число 1/8, то опять возникнет
та же ошибка усечения и вновь будет получен тот же неверный ответ — 2*/2.
А теперь попробуем сложить те же числа, но в обратном порядке. Сначала
сложим числа V8 и 1/8, в результате чего получим число V4, двоичным
представлением которого является битовая комбинация 0.01; соответствующий байт
результата будет иметь вид 00111000, отражающий точное значение. Теперь
прибавим число 1/4 к следующему числу в списке, 21/2. В результате будет
получено правильное значение 23/4, которое может быть точно представлено в байте в
виде кода 01101011. На этот раз мы получили правильный ответ.
Можно сделать заключение, что при сложении чисел большое значение может
иметь порядок, в котором они суммируются. Вся проблема состоит в том, что если
очень большое число прибавить к очень маленькому, то маленькое число может быть
утеряно в результате усечения. Поэтому общее правило суммирования большого
количества чисел требует начинать операцию сложения с самых малых чисел,
предполагая, что в результате будет получено достаточно большое промежуточное значение,
которое затем можно безопасно сложить с оставшимися большими числами. В
противном случае велика вероятность столкнуться с описанной выше проблемой.
Разработчики современного коммерческого программного обеспечения
прилагают значительные усилия, чтобы оградить пользователя от подобных проблем.
В типичном приложении электронных таблиц корректные результаты могут
быть достигнуты, если различия между суммируемыми значениями не
превосходят 1016 или меньше. Поэтому, если потребуется добавить единицу к числу
10 000 000 000 000 000,
то велика вероятность, что будет получен ответ
10 000 000 000 000 000
вместо предполагаемого значения
10 000 000 000 000 001.
84 Глава первая. Хранение данных
Такие проблемы имеют очень большое значение в приложениях, подобных
навигационным системам, где даже малейшие ошибки могут накапливаться в ходе
последующих вычислений, что может привести к весьма серьезным последствиям.
Вопросы для самопроверки
1. Декодируйте приведенные ниже битовые комбинации с помощью формата с
плавающей точкой, описанного в этом разделе.
а) 01001010 б) 01101101 в) 00111001 г) 11011100
д) 10101011
2. Представьте приведенные ниже числа в формате с плавающей точкой,
описанном выше в этом разделе. Укажите на случаи появления ошибок усечения.
а) 23/4 б) 574 в) 3/4 г) -372 Д) -43/s
3. При использовании формата с плавающей точкой, описанного выше в этом
разделе, какая из битовых комбинаций, 01001001 или 00111101,
представляет большее числовое значение? Опишите простейшую процедуру
определения, какое из двух представленных в этом формате чисел является большим.
4. Какое наибольшее число может быть представлено в формате с плавающей
точкой, описанном выше в этом разделе? Какое наименьшее положительное
число может быть представлено в этой системе?
1.8. Сжатие данных
При записи или передаче данных часто бывает полезно (а иногда просто
необходимо) сократить размер обрабатываемых данных. Технология, позволяющая
достичь этой цели, называется сжатием данных. В этом разделе мы сначала
рассмотрим некоторые общие методы сжатия данных, а затем обсудим несколько
конкретных приемов, разработанных специально для сжатия изображения.
Универсальные методы сжатия данных
Существует множество методов сжатия данных, каждый из которых
характеризуется собственной областью применения, в которой он дает наилучшие или,
наоборот, наихудшие результаты. Метод кодирования длины серий дает наилучшие
результаты, если сжимаемые данные состоят из длинных последовательностей
одних и тех же значений. В сущности, такой метод кодирования как раз и состоит в
замене подобных последовательностей кодовым значением, определяющим
повторяющееся значение и количество его повторений в данной серии. Например, для
записи кодированной информации о том, что битовая последовательность состоит
из 253 единиц, за которыми следуют 118 нулей и еще 87 единиц, потребуется
существенно меньше места, чем для перечисления всех этих 458 бит.
В некоторых случаях информация может состоять из блоков данных, каждый
из которых лишь немного отличается от предыдущего. Примером могут служить
1.8. Сжатие данных 85
последовательные кадры видеоизображения. Для таких случаев используется
метод относительного кодирования. Данный подход предполагает запись
отличий, существующих между последовательными блоками данных, вместо записи
самих этих блоков, т.е. каждый блок кодируется с точки зрения его взаимосвязи
с предыдущим блоком.
Еще один метод сжатия данных предполагает применение частотно-зависимого
кодирования, при котором длина битовой комбинации, представляющей элемент
данных, обратно пропорциональна частоте использования этого элемента. Такие
коды входят в группу кодов переменной длины, т.е. элементы данных в этих кодах
представляются битовыми комбинациями различной длины. Если взять английский
текст, закодированный с помощью частотно-зависимого метода, то чаще всего
встречающиеся символы (е, /, а, I) будут представлены короткими битовыми
комбинациями, а те знаки, которые встречаются реже (г, q, x), — более длинными битовыми
комбинациями. В результате мы получим более короткое представление всего
текста, чем при использовании обычного кода, подобного Unicode или ASCII.
Построение алгоритма, который обычно используется при разработке частотно-зависимых
кодов, приписывают Дэвиду Хоффману (David Huffman), поэтому такие коды часто
называются кодами Хоффмана. Большинство используемых сегодня частотно-
зависимых кодов является кодами Хоффмана.
Хотя обсуждавшиеся выше методы кодирования были представлены как
технологии сжатия данных общего назначения, тем не менее, каждый из них имеет
собственную сферу применения. В противоположность этому, системы,
основанные на использовании метода кодирования Lempel-Ziv (названного в честь его
создателей, Абрахама Лемпеля (Abraham Lempel) и Джэкоба Зива (Jacob Ziv)),
действительно являются системами сжатия данных общего назначения. Многие
пользователи Internet (глава 3), несомненно, уже встречали и даже использовали
такие универсальные программы сжатия данных произвольного типа, как zip и
unzip, в которых применяется технология Lempel-Ziv.
Системы кодирования по методу Lempel-Ziv используют технологию
кодирования с применением адаптивного словаря. В данном контексте термин словарь
означает набор строительных блоков, из которых создается сжатое сообщение.
Если сжатию подвергается английский текст, то строительными блоками могут
быть символы алфавита. Если потребуется уменьшить размер данных, которые
хранятся в компьютере, то компоновочными блоками могут стать нули и
единицы. В процессе адаптивного словарного кодирования содержание словаря может
изменяться. Например, при сжатии английского текста может оказаться
целесообразным добавить в словарь окончание ing и артикль the. В этом случае место,
занимаемое будущими копиями окончания ing и артикля the, может быть
уменьшено за счет записи их как одиночных ссылок вместо сочетания из трех
разных ссылок. Системы кодирования по методу Lempel-Ziv используют
изощренные и весьма эффективные методы адаптации словаря в процессе
кодирования (или сжатия). В частности, в любой момент процесса кодирования словарь
будет состоять из тех комбинаций, которые уже были закодированы (сжаты).
86 Глава первая. Хранение данных
В качестве примера давайте рассмотрим, как можно выполнить сжатие
сообщения с использованием конкретной системы метода Lempel-Ziv, известной как LZ77.
Процесс начинается практически с переписывания начальной части сообщения,
однако в определенный момент осуществляется переход к представлению будущих
сегментов с помощью триплетов, каждый из которых будет состоять из двух целых
чисел и следующего за ними одного символа текста. Каждый триплет описывает
способ построения следующей части сообщения. Например, пусть распакованный
текст имеет следующий вид (символы греческого алфавита здесь использованы для
того, чтобы данному примеру не придавался никакой определенный смысл):
ссРоссхРрР (5, 4, а)
Строка аРааРрр является уже распакованной частью сообщения. Для того
чтобы разархивировать остальной текст сообщения, необходимо сначала расширить
строку, присоединив к ней ту часть, которая в ней уже встречается (рис. 1.26).
Первый номер в триплете указывает, сколько символов необходимо отсчитать в
обратном направлении в строке, чтобы найти первый символ добавляемого
сегмента. В данном случае необходимо отсчитать в обратном направлении 5 символов, и
мы попадем на второй слева символ а уже распакованной строки. Второе число в
триплете задает количество последовательных символов справа от начального,
которые составляют добавляемый сегмент. В нашем примере это число 4, и это
означает, что добавляемым сегментом будет ассРр. Копируем его в конец строки и
получаем новое значение распакованной части сообщения:
осрааРрРааРр
Наконец, последний элемент (в нашем случае это символ а) должен быть
помещен в конец расширенной строки, в результате чего получаем полностью
распакованное сообщение:
аРссаРрРосаРра
Теперь предположим, что сжатая версия текста имеет такой вид:
аРааррр (5, 4, а) (0, 0, 5) (8, 6, р)
Вначале распакуем первый триплет, в результате чего получим сообщение
следующего вида:
араарррааррос (0, 0,5) (8, 6, р)
Теперь распакуем второй триплет и получим следующий результат:
аРаарррааРраб (8, 6, Р)
Обратите внимание, что второй триплет (0, 0, 5) использовался только потому,
что символ 5 еще не встречался в этом тексте. И наконец, распакуем третий
триплет и получим полностью распакованное сообщение:
арааррРааррабрРааРрр
1.8. Сжатие данных 87
РИСУНОК 1.26
а РАа а р р р
lf\ Л. .Л. Jk *K.,'
а) Отсчет 5-ти символов назад
а р и с р р р
б) Определение сегмента из 4-х символов, который должен быть
добавлен в конец строки
а р »; о fi с> р и !> \) р
в) Копирование сегмента из 4-х символов в конец сообщения
ссрасхррраарр!
г) Добавление в конец сообщения символа, указанного в триплете
Процесс распаковки сообщения abaabrb (5,4, а)
Чтобы запаковать сообщение с использованием системы LZ77, сначала
необходимо записать начальный сегмент текста, а затем искать в нем наиболее
длинный сегмент, соответствующий очередному фрагменту оставшейся части
сообщения. Это будет комбинация, описываемая первым триплетом. Все последующие
триплеты строятся по тому же методу.
Может показаться, что приведенные примеры не демонстрируют
значительного сжатия, поскольку все триплеты описывают лишь небольшие сегменты
сообщения. Однако при работе с длинными битовыми комбинациями есть основания
полагать, что достаточно длинные сегменты данных будут представлены
единственными триплетами, что приведет к значительному сжатию данных.
Сжатие изображений
В разделе 1.4 было показано, что растровый формат, используемый в
современных цифровых преобразователях изображений, предусматривает кодирование
изображения в формате по три байта на пиксель, что приводит к созданию
громоздких, неудобных в работе растровых файлов. Специально для этого формата было
разработано множество схем сжатия, предназначенных для уменьшения места,
занимаемого подобными файлами на диске. Одной из таких схем является формат
GIF (Graphic Interchange Format), разработанный компанией CompuServe.
Используемый в ней метод заключается в уменьшении количества цветовых оттенков
пикселя до 256, в результате чего цвет каждого пикселя может быть представлен
одним байтом вместо трех. С помощью таблицы, называемой цветовой палитрой,
каждый из допустимых цветовых оттенков пикселя ассоциируется с некоторой
комбинацией цветов "красный-зеленый-синий". Изменяя используемую палитру,
можно изменять цвета, появляющиеся в изображении.
88 Глава первая. Хранение данных
Обычно один из цветов палитры в формате GIF воспринимается как
обозначение "прозрачности". Это означает, что в закрашенных этим цветом участках
изображения отображается цвет того фона, на котором оно находится. Благодаря
этому и относительной простоте использования изображений формат GIF
получил широкое распространение в тех компьютерных играх, где множество
различных картинок перемещается по экрану.
Другим примером системы сжатия изображений является формат JPEG. Это
стандарт, разработанный ассоциацией Joint Photographic Experts Group (отсюда
и название этого стандарта) в рамках организации ISO. Формат JPEG показал
себя как эффективный метод представления цветных фотографий. Именно по
этой причине данный стандарт используется производителями современных
цифровых фотокамер. Следует ожидать, что он окажет немалое влияние на
область цифрового представления изображений и в будущем.
В действительности стандарт JPEG включает несколько способов
представления изображения, каждый из которых имеет собственное назначение. Например,
когда требуется максимальная точность представления изображения, формат
JPEG предлагает режим "без потерь", название которого прямо указывает, что
процедура кодирования изображения будет выполнена без каких-либо потерь
информации. В этом режиме экономия места достигается посредством
запоминания различий между последовательными пикселями, а не яркости каждого
пикселя в отдельности. Согласно теории, в большинстве случаев степень различия
между соседними пикселями может быть закодирована более короткими
битовыми комбинациями, чем собственно значения яркости отдельных пикселей.
Существующие различия кодируются с помощью кода переменной длины,
который применяется в целях дополнительного сокращения используемой памяти.
К сожалению, при использовании режима "без потерь" создаваемые файлы
растровых изображений настолько велики, что они с трудом обрабатываются
методами современной технологии, а потому и применяются на практике крайне редко.
Большинство существующих приложений использует другой стандартный метод
формата JPEG — режим "базовых строк". В этом режиме каждый из пикселей
также представляется тремя составляющими, но в данном случае это уже один
компонент яркости и два компонента цвета. Грубо говоря, если создать
изображение только из компонентов яркости, то мы увидим черно-белый вариант
изображения, так как эти компоненты отражают только уровень освещенности пикселя.
Смысл подобного разделения между цветом и яркостью объясняется тем, что
человеческий глаз более чувствителен к изменениям яркости, чем цвета.
Рассмотрим, например, два равномерно окрашенных синих прямоугольника,
которые абсолютно идентичны, за исключением того, что на один из них нанесена
маленькая яркая точка, тогда как на другой — маленькая зеленая точка той же
яркости, что и синий фон. Глазу проще будет обнаружить яркую точку, а не
зеленую. Режим "базовых строк" стандарта JPEG использует эту особенность,
кодируя компонент яркости каждого пикселя, но усредняя значение цветовых
компонентов для блоков, состоящих из четырех пикселей, и записывая цветовые
компоненты только для этих блоков. В результате окончательное представление
изображения сохраняет внезапные перепады яркости, однако оставляет размы-
1.8. Сжатие данных 89
тыми резкие изменения цвета. Преимущество этой схемы состоит в том, что
каждый блок из четырех пикселей представлен только шестью значениями (четыре
показателя яркости и два — цвета), а не двенадцатью, которые необходимы при
использовании схемы из трех показателей на каждый пиксель.
Кодирование и сжатие звука
Наиболее широко распространенным способом кодирования аудиоинформации (в целях ее сохранения и
обработки) является измерение значения амплитуды звуковой волны через регулярные интервалы времени
и запись последовательности полученных значений. Например, серия значений 0,1, 2, 1, 2, 3, 4, 2, 0
представляет звуковую волну, амплитуда которой сначала возрастает, затем незначительно уменьшается, вновь
возрастает выше достигнутого ранее уровня, а затем резко падает до уровня 0. Чтобы получить
необходимое качество звучания, на современных компакт-дисках музыка записывается с частотой выборки 44 100
значений в секунду. Каждое из значений записывается в 16-разрядном формате (для стереозаписей
используется 32-разрядный формат). Следовательно, для хранения звуковых данных с продолжительностью
звучания в одну секунду потребуется более миллиона битов памяти.
Подобные затраты памяти приемлемы для записи музыки на компакт-дисках, однако в сочетании с
видеозаписью (для получения движущихся озвученных изображений) эти требования превышают возможности
современной технологии. Поэтому ассоциация Motion Picture Experts Group (MPEG), входящая в состав ISO,
разработала методы сжатия аудиоинформации, позволяющие существенно снизить требования к
использованию памяти. Одним из таких форматов является МРЗ (MPEG-1, Audio Layer-3), позволяющий сжимать
аудиоинформацию в соотношении 12:1. При использовании этого формата музыкальные записи сжимаются
до таких размеров, которые позволяют эффективно пересылать их по Internet, а это может привести к
революционным изменениям в индустрии звукозаписи.
Дополнительной экономии места можно достичь с помощью записи
информации, определяющей изменения компонентов яркости и цвета, а не их
абсолютных значений. В этом случае, как и в режиме "без потерь" формата JPEG,
отправной точкой является тот факт, что при сканировании изображения уровень
различий между соседними пикселями может быть закодирован с
использованием меньшего количества битов, чем при записи самих характеристик отдельных
пикселей. (В действительности эти изменения кодируются с помощью
математического метода, называемого дискретным косинусным преобразованием и
применяемого к блокам размером 8x8 пикселей.) Полученная в результате битовая
комбинация дополнительно сжимается с использованием кодов переменной
длины. В результате применение режима "базовых строк" формата JPEG позволяет
получать цветные изображения приемлемого качества, размер которых
находится в соотношении 1:20 с размером растровых файлов, в которых для
представления каждого пикселя используется трехбайтовая схема, используемая в
большинстве существующих сканеров.
То, что режим "базовых строк" формата JPEG позволяет существенно
сократить размеры файлов за счет незначительного и практически незаметного сни-
90 Глава первая. Хранение данных
жения качества изображения, сделало этот формат очень популярным среди
пользователей. Однако в некоторых случаях использование других методов дает
лучшие результаты. Например, формат GIF позволяет лучше представлять
изображения, состоящие из блоков одного цвета с четкими границами (как,
например, в цветной мультипликации).
В заключение следует отметить, что сейчас в области сжатия данных
проводятся интенсивные и обширные исследования. Мы обсудили лишь два из
множества существующих методов сжатия изображений. А ведь, помимо них, имеются
еще многочисленные методы сжатия аудио- и видеоинформации. Например,
метод, подобный режиму "базовых строк" формата JPEG, был разработан
входящей в состав ISO ассоциацией Motion Picture Experts Group (MPEG) и принят в
качестве стандарта кодирования (или сжатия) аудио- и видеоинформации. Суть
этого стандарта состоит в записи начальной картинки последовательности
изображений с помощью метода, подобного режиму "базовых строк" формата JPEG,
после чего для кодирования оставшейся части изображений в их
последовательности применяются методы относительного кодирования.
Вопросы для самопроверки
1. Ниже представлен текст сообщения, сжатый с использованием метода LZ77.
Как будет выглядеть распакованное сообщение?
101101011 (7, 5, 0) (12, 10, 1) (18, 13, 0)
2. Несмотря на то что мы не очень подробно рассматривали алгоритм
кодирования данных по методу LZ77, все же попытайтесь выполнить сжатие
следующего сообщения:
РРа(ЗР(ЗааРа(ЗааРа(ЗааРа(Зааа
3. Выше утверждалось, что формат GIF позволяет лучше представлять цветные
мультипликационные изображения, чем формат JPEG. Объясните, почему это
действительно так.
4. Какое наибольшее количество байтов потребуется для представления
изображения размером 1024x1024 пикселей, если использовать формат GIF? Что
можно сказать относительно использования режима "базовых строк" формата
JPEG?
5. Какие особенности человеческого глаза используются в режиме "базовых
строк" формата JPEG?
1.9. Ошибки при передаче информации
Когда информация постоянно передается между различными частями
компьютера, пересылается от Земли к Луне и обратно либо просто сохраняется в устройстве
памяти, вероятнее всего, полученная в конце концов битовая комбинация будет
отличаться от исходной. Частички грязи или жира на магнитной записывающей
поверхности, случайная ошибка в работе электронной схемы — все это может вызвать
1.9. Ошибки при передаче информации 91
ошибки при записи или чтении данных. Более того, при использовании некоторых
технологий хранения данных фоновое радиационное излучение может изменять
битовые комбинации, записанные в основной памяти машины.
Для решения этих проблем было разработано множество технологий
кодирования данных, позволяющих обнаруживать и даже исправлять подобные
ошибки. В настоящее время эти технологии широко используются при создании
внутренних компонентов компьютеров, поэтому они остаются незаметными для
пользователей, работающих с машиной. Однако они чрезвычайно важны, и это
лишний раз подчеркивает значение результатов выполненных научных
исследований. В сущности, большую часть работы по созданию подобных технологий
выполнили математики-теоретики. Ниже мы рассмотрим некоторые из тех
методов, которые обеспечивают надежность функционирования современных
вычислительных машин.
Биты четности
Существует достаточно простой способ определения ошибок, построенный на
том принципе, что если каждая обрабатываемая битовая комбинация будет
состоять из нечетного количества единиц, то обнаружение комбинации с четным
количеством единиц будет свидетельствовать о возникновении ошибки.
Чтобы использовать этот принцип, необходимо создать систему, в которой
любая битовая комбинация будет содержать нечетное количество единиц.
Обычно это достигается путем добавления к уже существующему коду
дополнительного бита (который называется битом четности или контрольным битом), чаще
всего помещаемого в старший конец комбинации. В результате восьмиразрядный
код ASCII превращается в девятиразрядный, а шестнадцатиразрядная битовая
комбинация в двоичном дополнительном коде становится семнадцатиразрядной.
В каждом случае значение бита четности устанавливается равным 0 или 1,
исходя из требования, чтобы вся битовая комбинация в целом содержала нечетное
количество единиц. Как показано на рис. 1.27, символ А в коде ASCII будет
представлен как 101000001 (бит четности равен 1), тогда как символ F в этом
же коде будет иметь вид 001000110 (бит четности равен 0). Хотя исходная
восьмиразрядная комбинация, представляющая букву А, содержит четное
количество единиц, а аналогичная комбинация, представляющая букву F, — нечетное
количество единиц, оба девятиразрядных кода имеют нечетное количество
единиц. Если система будет построена указанным образом, то появление битовой
комбинации с четным количеством единиц будет свидетельствовать об ошибке и
сигнализировать, что обрабатываемые данные являются неверными.
Описанная выше система контроля четности называется проверкой на
нечетность, поскольку все обрабатываемые битовые комбинации должны содержать
нечетное количество единиц. Кроме того, существует способ, именуемый
проверкой на четность. В этом случае все обрабатываемые комбинации должны
содержать четное количество единиц, а показателем ошибки является нечетное
количество единиц в битовой комбинации.
92 Глава первая. Хранение данных
Вся битовая комбинация содержит нечетное
количество единиц
Представление символов А и F в коде ASCII с использованием контрольного бита
В наше время использование битов четности является типовым решением
для основной памяти машины. Хотя внешне создается впечатление, что
компьютеры используют восьмиразрядные ячейки памяти, в действительности
они являются девятиразрядными, причем девятый бит используется как
контрольный. Каждый раз, когда в память записывается некоторая
восьмибитовая комбинация, схема управления памятью автоматически добавляет к
ней требуемый контрольный бит для получения девятиразрядной
комбинации. При считывании информации схема управления памятью подсчитывает
количество единиц в полученной комбинации. Если ошибка не
обнаруживается, контрольный бит удаляется и образуется исходная восьмиразрядная
битовая комбинация. В противном случае схема управления памятью
возвращает считанное восьмиразрядное значение с указанием, что оно искажено
и может отличаться от исходного.
Длинные битовые комбинации часто дополняются группой контрольных
битов, образующих контрольный байт. Каждый бит в этом байте является
контрольным и относится к определенной группе битов, разбросанных по
основной битовой комбинации. Например, один контрольный бит может
относиться к каждому восьмому биту, начиная с первого, тогда как другой — к
каждому восьмому биту, начиная со второго, и т.д. В данном случае легче
выявить ошибки, сконцентрированные в одной области исходной
комбинации, поскольку их наличие будет контролироваться группой контрольных
битов. Различные варианты данного подхода к созданию схем контроля
называются методом контрольных сумм и методом использования кода
циклического контроля избыточности (CRC).
1.9. Ошибки при передаче информации 93
Коды с исправлением ошибок
Несмотря на то что бит четности является эффективным методом выявления
ошибок, он не дает информации, необходимой для исправления возникшей
ошибки. Многих удивляет сам факт, что можно разработать коды с
исправлением ошибок, позволяющие не только выявлять ошибки, но и исправлять их. В
конце концов, интуиция подсказывает, что мы не в состоянии исправить ошибку
в полученном сообщении, если заранее не знаем, о чем там идет речь. Тем не
менее существует довольно простой код, позволяющий исправлять возникающие
ошибки (рис. 1.28).
Для того чтобы понять принцип действия этого кода, сначала необходимо
определить дистанцию Хэмминга между двумя кодовыми комбинациями,
которая будет равна количеству битов, отличающихся в этих комбинациях.
(Понятие дистанция Хэмминга получило свое название в честь Р.В.
Хэмминга (R.W. Hamming), который провел первые исследования в области
разработки кодов с исправлением ошибок. Он обратился к этой проблеме в
1940-х годах по причине крайней ненадежности существовавших в то время
релейных вычислительных машин.) Например, дистанция Хэмминга между
кодами букв А и В (рис. 1.28) равна четырем, а дистанция Хэмминга между
кодами букв В и С равна трем. Важной особенностью этого кода является то,
что дистанция Хэмминга между любыми двумя комбинациями будет не
меньше трех. Если в результате сбоя в каком-либо отдельном бите появится
ошибочное значение, то ошибка будет легко установлена, так как
получившаяся комбинация не является допустимым кодовым значением. В любой
комбинации потребуется изменить не меньше трех битов, прежде чем она
вновь станет допустимой.
Если в любой комбинации, показанной на рис. 1.28, возникла одиночная
ошибка, то легко можно вычислить ее исходное значение. Дело в том, что
дистанция Хэмминга для измененной комбинации по отношению к исходной
форме будет равна единице, тогда как по отношению к другим разрешенным
комбинациям она будет равна не менее чем двум. При декодировании
некоторого сообщения достаточно просто сравнивать каждую полученную
битовую комбинацию с допустимыми комбинациями кода, пока не будет найдена
комбинация, находящаяся на дистанции, равной единице, от полученной
комбинации. Найденная допустимая кодовая комбинация принимается за
правильный символ, полученный в результате декодирования. Предположим,
что получена битовая комбинация 010100. Если сравнить ее с допустимыми
битовыми комбинациями кода, то будет получена таблица дистанций,
представленная на рис. 1.29. По содержанию этой таблицы можно сделать
заключение, что поступивший символ — это буква D, так как ее битовая
комбинация в наибольшей степени соответствует полученной.
94 Глава первая. Хранение данных
Код с исправлением ошибок
Как видите, при использовании кода, представленного на рис. 1.28,
действительно можно обнаружить до двух ошибок в одной комбинации и
исправить одну ошибку. Если использовать код, в котором дистанция Хэмминга
между комбинациями равняется как минимум пяти, то можно было бы
обнаруживать до четырех ошибок в одной комбинации и исправлять до двух
ошибок. Естественно, разработка эффективных кодов с достаточно длинными
дистанциями Хэмминга является непростой задачей. Для этого требуется
знание такой области математики, как алгебраическая теория кодирования,
которая является частью линейной алгебры и теории матриц.
Методы коррекции ошибок широко используются в целях повышения
надежности вычислительной техники. Например, они используются в
драйверах магнитных дисков большой емкости, чтобы снизить вероятность
искажения хранимой информации в результате дефектов поверхности диска. Более
того, главное отличие между форматом, используемым в звуковых компакт-
дисках, и форматом CD-ROM, предназначенным для записи компьютерных
данных, заключается именно в использовании кодов с исправлением ошибок.
Функция исправления ошибок в формате CD-DA позволяет устранять только
одну ошибку на два компакт-диска, и этого вполне достаточно для
аудиозаписей. Однако для компаний, поставляющих программное обеспечение,
наличие ошибок в 50% поставляемых ими компакт-дисков является
совершенно недопустимым. Поэтому в формат CD-ROM включены дополнительные
средства, позволяющие снизить вероятность возникновения ошибки до одной
на 20 000 компакт-дисков.
1.9. Ошибки при передаче информации 95
РИСУНОК 1.29
Декодирование битовой комбинации 010100 с помощью кода, представленного на рис. 1 28
Вопросы для самопроверки
1. Приведенные ниже битовые комбинации были закодированы с
использованием контроля по нечетности. Укажите комбинации с ошибками.
а) 10101101 б) 10000001 в) 00000000 г) 11100000
д) 11111111
2. Могли бы вы не заметить ошибки в байтах, представленных в первом
вопросе? Поясните свой ответ.
3. Какими бы были ваши ответы на вопросы 1 и 2, если бы в приведенных
байтах использовался контроль на четность?
4. Закодируйте эти предложения в коде ASCII с использованием контроля по
нечетности и помещением контрольного бита в старший конец кода каждого символа.
а) Where are you?
б) "How?" Cheryl asked.
в) 2 + 3 = 5.
5. Используйте представленный на рис. 1.28 код с исправлением ошибок для
декодирования следующих сообщений.
а) 001111 100100 001100
б) 010001 000000 001011
в) 011010 110110 100000 011100
6. Используя пятиразрядные битовые комбинации, разработайте для символов
А, В, С, D такой код, чтобы дистанция Хэмминга между любыми двумя
комбинациями составляла не меньше трех.
96 Глава первая. Хранение данных
Упражнения
(Упражнения, отмеченные звездочкой, относятся к разделам для
дополнительного чтения.)
1. Какое выходное значение будет иметь каждая из приведенных ниже
схем, если предположить, что на их верхний вход подано значение 1,
а на нижний — значение 0.
2. Для каждой из приведенных ниже схем укажите комбинации входных
значений, при которых их выходное значение будет равно 1.
Упражнения
97
3. В каждой из приведенных ниже схем прямоугольники представляют
вентили одного и того же типа. Основываясь на показанных входных и
выходных значениях этих схем, определите в каждом случае тип
используемого вентиля (AND, OR или XOR).
4. Предположим, что на оба входа приведенной ниже цепи поданы
значения 1. Опишите, что произойдет, если на верхний вход временно подать
значение 0. А что произойдет, если временно подать значение 0 на
нижний вход?
5. В приведенной ниже таблице представлены адреса и содержимое (в ше-
стнадцатеричной нотации) некоторых ячеек основной памяти машины.
Начиная с этого состояния, выполните приведенные инструкции и
запишите содержимое этих ячеек памяти после выполнения всех
указанных действий.
Адрес Содержимое
00 АВ
01 53
98
Глава первая. Хранение данных
02 D6
03 02
Этап 1. Переместите содержимое ячейки с адресом 03 в ячейку с
адресом 00.
Этап 2. Поместите число 01 в ячейку с адресом 02.
Этап 3. Переместите значение, сохраняемое по адресу 01, в ячейку с
адресом 03.
6. Сколько ячеек может содержаться в основной памяти компьютера,
если адрес каждой ячейки может быть представлен тремя шестнадцате-
ричными числами?
7. Какие комбинации битов представлены следующими шестнадцатерич-
ными обозначениями?
а) ВС б) 67 в) 9А г) 10 д) 3F
8. Определите значение старшего значащего бита в битовых комбинациях,
представленных следующими шестнадцатеричными обозначениями.
a) FF б) 7F в) 8F г) IF
9. Представьте следующие битовые комбинации в шестнадцатеричной
системе счисления.
а) 101010101010
б) 110010110111
в) 000011101011
10. Предположим, что на экране монитора отображено 24 строки,
содержащие по 80 символов каждая. Сколько байтов машинной памяти
потребуется, чтобы записать в нее все содержимое экрана, представив
каждый символ с помощью соответствующего кода ASCII (по одному
символу на байт)?
11. Предположим, что выводимое на экран монитора изображение
представляет собой прямоугольник, состоящий из 1024 столбцов и 768
строк пикселей. Если для кодирования цвета и яркости каждого
пикселя используется 8 бит, то сколько однобайтовых ячеек памяти
потребуется для сохранения всего выводимого изображения?
12.
а) Назовите два преимущества, которые имеет основная память
машины по отношению к дисковым носителям информации.
б) Назовите два преимущества, которые имеют дисковые носители
информации по отношению к основной памяти машины.
13. Предположим, вам необходимо подготовить на компьютере курсовую
работу объемом приблизительно 40 машинописных листов. В
компьютере имеется дисковое устройство чтения дискет диаметром З1/: дюй-
Упражнения 99
ма, емкость которых составляет 1,44 Мбайт. Поместится ли ваша
курсовая работа на одной такой дискете? Если да, то сколько таких
документов может поместиться на одной дискете? Если нет, то сколько
дискет потребуется для сохранения вашей курсовой работы?
14. Предположим, что на жестком диске вашего компьютера, емкость
которого составляет 5 Гбайт, осталось только 100 Мбайт дискового
пространства. Допустим, вы намерены заменить его жестким диском
большей емкости (10 Гбайт) и на время модернизации предполагаете
сохранить всю имеющуюся на жестком диске информацию на
дискетах размером Zl/2 дюйма. Разумно ли это? Поясните свой ответ.
15. Если каждый сектор диска содержит 512 байт, то сколько секторов
потребуется для записи одной печатной страницы текста, если для
хранения одного символа этого текста необходим один байт?
16. Обычная дискета диаметром 3*/г дюйма имеет емкость 1,44 Мбайт.
Достаточно ли одной такой дискеты для сохранения 400 страниц
текста, если каждая страница содержит 3500 символов?
17. Если дискета, которая содержит 16 секторов на каждой дорожке и 512
байт в каждом секторе, вращается со скоростью 300 оборотов в
минуту, то какой приблизительно будет скорость передачи данных через
головку чтения/записи устройства?
18. Если настольный компьютер содержит дисковод, описанный в
упражнении 17, и выполняет десять операций за одну микросекунду
(миллионную долю секунды), то сколько операций он может
выполнить между прохождением двух последовательных байтов данных
через головку чтения/записи дисковода?
19. Если дискета вращается со скоростью 300 оборотов в минуту, а
компьютер способен выполнить 100 операций в микросекунду
(миллионная доля секунды), то сколько операций сможет выполнить
этот компьютер за время ожидания доступа диска?
20. Сравните время ожидания доступа обычной дискеты, описанной в
упражнении 19, и время ожидания доступа жесткого диска со скоростью
вращения 60 оборотов в секунду.
21. Каким будет среднее время доступа жесткого диска, вращающегося со
скоростью 60 оборотов в секунду, если его время поиска равно
10 миллисекундам?
22. Предположим, что машинистка может непрерывно день за днем
печатать текст со скоростью 60 слов в минуту. Сколько времени
потребуется ей, чтобы заполнить компакт-диск емкостью 640 Мбайт? Будем
считать, что каждое слово состоит из пяти букв, а для сохранения
каждой буквы требуется один байт.
100 Глава первая. Хранение данных
23. Ниже приведен текст сообщения, представленного в кодах ASCII. О
чем говорится в этом сообщении?
01010111 01101000 01100001
01110100 00100000 01100100
01101111 01100101 01110011
00100000 01101001 01110100
00100000 01110011 00110001
01111001 00111111
24. Ниже приведен текст сообщения, представленного в кодах ASCII. В
этой кодировке на один символ приходится один байт, который в этом
упражнении представлен в шестнадцатеричной системе счисления.
Декодируйте этот текст.
68657861646563696D616C
25. Закодируйте приведенные ниже выражения в кодах ASCII, используя
один байт на один символ.
а) 100/5 = 20
б) То be or not to be?
в) The total cost is $7.25.
26. Представьте ответ из упражнения 25 в шестнадцатеричной системе
счисления.
27. Перечислите двоичные представления для целых чисел от б до 16.
28.
а) Запишите число 13, представив цифры 1 и 3 в коде ASCII.
б) Запишите число 13 в двоичной системе счисления.
29. В двоичном представлении каких чисел содержится только один
единичный бит? Приведите двоичные представления для шести
наименьших чисел такого вида.
*30. Закодируйте следующие выражения в кодах ASCII, используя один
байт на символ. Используйте старший бит каждого байта в качестве
контрольного бита (по нечету).
а) 100/5 = 20
б) То be or not to be?
в) The total cost is $7.25.
*31. Следующее сообщение было передано с использованием контрольного
бита (по нечету) в каждой короткой строке битов. В каких строках
имеются ошибки?
11011 01011 10110 00000 11111
10101 10001 00100 01110
*32. Предположим, что 24-разрядный код создан посредством
представления каждого символа с помощью трех последовательных копий его
Упражнения 101
ASCII-кода (например, символ А будет представлен строкой битов
010000010100000101000001). Какие возможности исправления
ошибок допускает этот код?
*33. Для декодирования приведенных ниже слов используйте код с
исправлением ошибок, представленный на рис. 1.28.
а) 111010 110110
б) 101000 100000 001100
в) 011101 000110 000000 010100
г) 010010 001000 001110 101111
д) 000000 110111 100110
е) 010011 000000 101001 100110
*34. Преобразуйте приведенные ниже двоичные числа в эквивалентные
десятичные значения.
а) 111 б) 0001 в) 11101
г) 10001 д) 10111 е) 000000
ж)100 з) 1000 и) 10000
к) 11001 л) 11010 * м) 11011
*35. Представьте следующие десятичные числа в двоичном представлении.
а) 7 б) 12 в) 16
г) 15 д) 33
*36. Преобразуйте приведенные ниже числа, представленные в двоичной
нотации с избытком шестнадцать, в десятичную форму.
а) 10000 б) 10011 в) 01101
г) 01111 д) 10111
*37. Представьте приведенные ниже десятичные числа в двоичной нотации
с избытком четыре.
а) 0 б) 3 в) -3
г) -1 д) 1
*38. Представьте в десятичной системе счисления приведенные ниже
числа, записанные в двоичном дополнительном коде.
а) 10000 б) 10011 в) 01101
г) 01111 д) 10111
*39. Представьте приведенные ниже десятичные числа в двоичном
дополнительном коде разрядностью 7 битов,
а) 12 б) -12 в) -1
г) 0 д) 8
*40. Выполните приведенные ниже операции сложения, полагая, что строки
битов представляют числа в двоичном дополнительном коде. Укажите,
когда полученный результат будет ошибочным из-за переполнения,
а) 00101 б) 01111 в) 11111
+01000 +00001 +00001
102 Глава первая. Хранение данных
г) 10111 д) 00111 е) 00111
+11010 +00111 +01100
ж) 11111 з) 01010 и) 01000
+11111 +10101 +01000
к) 01010
+00011
*41. Решите приведенные ниже задачи посредством перевода десятичных
чисел в двоичный дополнительный код (длиной 5 бит). Преобразуйте
операции вычитания в эквивалентные операции сложения, а затем
выполните суммирование. Проверьте полученные ответы,
преобразовав их в десятичную систему счисления (не забывайте о возможности
появления ошибок переполнения),
а) 7 б) 7 в) 12
±1 zl Zl
г) 8 д) 12 е) 4
ll ±1 +11
*42. Запишите в десятичной системе счисления приведенные ниже числа в
двоичном представлении.
а) 11.001 б) 100.1101 в) 0.0101
г) 1.0 д) 10.01
*43. Запишите приведенные ниже числа в двоичной системе счисления,
а) 5 3/4 б) V,6 в) 7 7/8
г) 1 V4 Д) 6 5/8
*44. Декодируйте следующие битовые комбинации в формате с плавающей
точкой, описанном в разделе 1.7.
а) 01011100 б) 11001000
в) 00101010 г) 10111001
*45. Закодируйте приведенные ниже числа, используя восьмиразрядный
формат с плавающей точкой, описанный в разделе 1.7. Укажите на
ошибки усечения.
a) V2 б) 7 V2 в) -3 3/4
г) 3/з2 Д) 31/з2
*46. Какое наилучшее приближение для значения квадратного корня из
числа 2 может быть представлено в восьмиразрядном формате с плавающей
точкой, описанном в разделе 1.7? Какое число мы получим, если это
приближенное представление корня будет возведено в квадрат в машине,
использующей указанный формат с плавающей точкой?
*47. Какое наилучшее приближение для значения числа 1/,0 может быть
достигнуто в восьмиразрядном формате с плавающей точкой,
описанном в разделе 1.7?
Упражнения 103
*48. Объясните, как могут возникнуть ошибки, если измерения,
выполненные с использованием метрической системы, сохраняются в
формате с плавающей точкой. Например, что произойдет, если значение
110 сантиметров будет записано в метрах?
*49. Используйте восьмиразрядный формат с плавающей точкой,
описанный в разделе 1.7, для вычисления следующей операции
суммирования: V8 + Vg + l/% + 2V2; при условии, что она выполняется слева
направо. Что изменится в полученном результате, если вычисления
производить справа налево?
*50. Какой ответ получит машина при вычислении приведенных ниже
примеров суммирования, если в ней используется восьмиразрядный
формат с плавающей точкой, описанный в разделе 1.7?
а) lV2 + 3/16 =
б) 31/4 + lVe =
в) 2V4 + lV8 =
*51. Для каждого приведенного ниже примера преобразуйте битовые
комбинации (интерпретируя их как числа в формате с плавающей
точкой, представленном в разделе 1.7) в десятичные значения,
выполните сложение, а затем закодируйте ответ в тот же формат с плавающей
точкой. Укажите на ошибки усечения,
а) 01011100 б) 01101010
+01101000 +00111000
в) 01111000 г) 01011000
+00011000 +01011000
*52. Одна из двух битовых комбинаций 01011 и 11011 представляет
некоторое число в двоичной нотации с избытком шестнадцать, а другая —
это же число в двоичном дополнительном коде.
а) Что можно сказать относительно этого закодированного значения?
б) Какая взаимосвязь существует между комбинацией битов,
представляющей число в двоичном дополнительном коде, и
комбинацией битов, представляющей это же число в двоичной нотации с
избытком, если в обоих случаях используется один и тот же
размер комбинации?
*53. Три битовые комбинации 01101000, 10000010 и 00000010
представляют одно и то же число, записанное в разных форматах: двоичном
дополнительном коде, двоичной нотации с избытком и
восьмиразрядном формате с плавающей точкой, описанном в разделе 1.7; однако не
обязательно в указанном порядке. Определите это число и укажите,
какая из битовых комбинаций принадлежит к каждому из
перечисленных форматов.
*54. Каждая из приведенных ниже строк битов представляет одно и то же
число, записанное в различных системах кодирования, обсуждавших-
104 Глава первая. Хранение данных
ся нами выше. Определите каждое из чисел и укажите
использованную в каждом случае систему кодирования.
а) 11111010 ООН 1011
б) 11111101 01111101 11101100
в) 1010 0010 01101000
*55. Какие из перечисленных ниже битовых комбинаций не являются
допустимыми значениями в двоичной нотации с избытком
шестнадцать?
а) 01001 б) 101 в) 010101
г) 00000 д) 1000 е) 000000
ж)1111
*56. Какие из приведенных ниже чисел невозможно точно представить в
формате с плавающей точкой, описанном в разделе 1.7?
а) б V2 б) 9 в) 1 3/,б
Г) 1?/з2 Д) 15/16
*57. Если увеличить длину битовой строки, используемой для
представления целых чисел в двоичной системе, от четырех до восьми бит, то
какие изменения вызовет это действие в значении наибольшего
целого числа, которое может быть представлено этой строкой? Каков
будет ответ при использовании двоичного дополнительного кода?
*58. Каким будет шестнадцатеричное представление наибольшего адреса
памяти, если размер этой памяти составляет 4 Мбайт и каждая
ячейка имеет длину один байт.
*59. Используя вентили, разработайте такую схему с четырьмя входами и
одним выходом, чтобы значение на выходе было равно нулю или
единице, в зависимости от того, является ли четырехразрядная
комбинация на входах этой схемы четной или нечетной.
*60. Приведенное ниже сообщение было сжато по методу LZ77. Распакуйте
это сообщение.
0100101 (4, 3, 0) (8, 7, 1) (17, 9, 1) (8, 6, 1)
*61. Ниже приведена часть сообщения, закодированного по методу LZ77.
Исходя из содержащейся в данном представлении информации,
определите длину исходного сообщения.
<xPYL,3,P)(_.6,Y)
*62. Запишите последовательность инструкций, поясняющих способ
сжатия сообщений по методу LZ77.
*63. Запишите последовательность инструкций, поясняющих способ
распаковки сообщений, сжатых по методу LZ77.
Упражнения 105
Общественные и социальные вопросы
Следующие вопросы приводятся для того, чтобы помочь вам разобраться в
некоторых этических, общественных и юридических аспектах использования
вычислительной техники, а также в ваших собственных воззрениях и тех
принципах, на которых они основаны. Задача не сводится к тому, чтобы просто дать
ответы на предложенные вопросы. Вы должны также понять, почему вы
ответили именно так, а не иначе, и насколько ваши суждения по различным вопросам
согласуются друг с другом.
1. Предположим, что ошибка усечения возникла в критической ситуации
и послужила причиной обширных разрушений и гибели людей. Должен
ли кто-то за это ответить, и если да — кто именно? Разработчик
аппаратного обеспечения? Создатель программного обеспечения?
Программист, который написал именно эту часть программы? Человек, который
принял решение об использовании этой программы в данном
приложении? Как поступить, если данная программа была исправлена
компанией-разработчиком программного обеспечения, однако новый вариант не
был закуплен и установлен в данном ответственном приложении? Как
быть, если используемая программа является пиратской копией?
2. Допустимо ли частному пользователю игнорировать возможность
возникновения ошибок усечения и их последствий при разработке
прикладных программ для своего собственного компьютера?
3. Как вы считаете, этично ли было при разработке программ в 1970-х годах
использовать всего лишь две цифры для представления года (например,
цифры 76 представляют 1976 год) и игнорировать тот факт, что при смене
столетия в системе могут возникнуть ошибки? Этично ли сегодня
использовать только три цифры для представления года (например, цифры 982
представляют 1982 год, а цифры 015 представляют 2015 год)? Что можно
сказать об использовании только четырех цифр?
4. Много споров ведется относительно того, что кодирование так или
иначе лишает информацию выразительности или даже разрушает ее,
поскольку требует представления данных в количественной форме.
Как пример такого отрицательного воздействия кодирования
приводится анкета, в которой респондент должен выразить свое мнение
посредством указания оценки в диапазоне от одного до пяти, что
приводит к определенным изъянам или ошибкам. Так в какой же мере
информация поддается количественному измерению? Можно ли
представить в количественном виде все за и против относительно
размещения опасного для окружающей среды предприятия? Можно ли
количественно выразить споры вокруг ядерной энергетики и
связанной с ней опасности радиационного заражения? Опасно ли принимать
106 Глава первая. Хранение данных
решения, исходя из результатов усреднения и других типов
статистического анализа? Этично ли поступают информационные агентства,
сообщая результаты опроса без указания точной словесной
формулировки вопроса? Можно ли представить ценность человеческой жизни в
количественной форме? Является ли приемлемым для компании
запретить вложение инвестиций для повышения качества продукции,
если эти вложения помогут снизить риск фатальных случаев при ее
использовании?
5. С появлением цифровых фотокамер возможность подделки
фотографий стала общедоступной. Какие изменения это может внести в жизнь
общества? Какие новые проблемы морального или юридического
характера могут возникнуть в связи с этим?
6. Должны ли существовать различия в правах сбора и распространения
данных в зависимости от их особенностей? Другими словами, должно
ли право сбора и распространения фотографии, аудио- и
видеоинформации быть таким же, как и право сбора и распространения текстовой
информации?
7. Любое выступление журналиста, как правило, умышленно или
ненамеренно, содержит какой-то определенный элемент пристрастного
отношения к излагаемой информации. Часто достаточно изменить лишь
пару слов, чтобы придать сообщению положительную или
отрицательную окраску. (Сравните: "Большинство опрашиваемых не верят в то,
что..." и "Значительная часть опрашиваемых согласились с тем, что
...".) Существует ли различие между изменением излагаемого
материала (путем ухода от острых вопросов или тщательного подбора слов) и
изменением фотографии?
8. Предположим, что сжатие данных привело к потере небольшой, но
достаточно важной части информации. Какие могут возникнуть
проблемы, связанные с ответственностью за это происшествие? Как эти
проблемы могут быть решены?
Рекомендуемая литература
• Gibbs S.J., Tsichritzis D.C. Multimedia Programming. — Reading, MA:
Addison-Wesley, 1995.
• Hamacher V.C., Vranesic Z.G., Zaky S.G. Computer Organisation, 4th ed. —
New York: McGraw-Hill, 1996.
• Kay D.C, Levine J.R. Graphics File Formats, 2nd ed. — New York: McGraw-
Hill, 1995.
• Knuth D.E. The Art of Computer Programming. Vol. 2, 3rd ed. — Reading, MA:
Addison-Wesley Longman, 1998. (Имеется русский вариант этой книги: Кнут
Рекомендуемая литература 107
Д. Э. Искусство программирования. Т.2. Получисленные алгоритмы, 3-е
изд. — М.: Издательский дом "Вильяме", 2000.)
Patterson D.A., Hennessy J.L. Computer organization and Design. — San
Francisco: Morgan Kaufmann, 1994.
Sayood K. Introduction to Data Compression. — San Francisco: Morgan
Kaufmann
Дополнительная литература
Столлингс В. Устройство и архитектура компьютеров, 5-е изд. — М.:
Издательский дом "Вильяме", готовится к выпуску в 2001 г.
108 Глава первая. Хранение данных
глава
Обработка данных
вторая
В главе 1 рассматривались общие концепции
методов хранения данных и организации
компьютерной памяти. Однако, помимо хранения данных,
алгоритмическая машина должна также уметь
обрабатывать информацию в соответствии с
некоторым алгоритмом. Для манипуляции данными
требуется наличие в машине некоторого
механизма выполнения отдельных операций обработки
данных, а также управления последовательностью
их выполнения. В типичной вычислительной
машине подобное устройство обычно называется
центральным процессором. Данная глава посвящена
обсуждению именно этого устройства. Здесь мы
также рассмотрим все вопросы, связанные с
работой центрального процессора.
2.1. Центральный процессор
Регистры
Интерфейс между ЦП и основной
памятью
Машинные команды
2.2. Концепция хранимой
программы
Представление машинных
команд в виде битовых комбинаций
Машинный язык
2.3. Выполнение программы
Пример выполнения программы
Программы и данные
*2.4. Арифметические и
логические команды
Логические операции
Операции сдвига
Арифметические операции
*2.5. Взаимодействие с другими
устройствами
Взаимодействие через
управляющее устройство
Скорость передачи данных
*2.6. Другие типы архитектуры
компьютеров
CISC- и RISC-архитектура
компьютеров
Конвейерная обработка
Многопроцессорные машины
* Звездочкой отмечены
разделы, рекомендованные для
факультативного изучения.
2.1. Центральный процессор
Электронные цепи типичного компьютера, предназначенные для выполнения
различных операций с данными (например, сложения или вычитания), обычно
не связаны с ячейками основной памяти напрямую. Все эти цепи размещаются в
изолированной части компьютера, которая называется центральным
процессором, или ЦП. Данное устройство состоит из двух частей: арифметико-
логического блока, включающего схемы для обработки данных, и блока
управления, который содержит схемы, координирующие деятельность всей машины.
Регистры
Для временного запоминания информации в ЦП имеются ячейки,
называемые регистрами, которые похожи на ячейки основной памяти. Их можно
разделить на регистры общего назначения и специализированные регистры.
Обсуждение специализированных регистров приводится в разделе 2.3; в этом разделе
мы ограничимся изучением работы регистров общего назначения.
Регистры общего назначения используются для временного хранения данных,
обрабатываемых в ЦП. В них сохраняются входные данные для схем
арифметико-логического блока. Кроме того, эти регистры используются для размещения
результатов, полученных при выполнении операций. Для обработки
информации, сохраняемой в основной памяти машины, блок управления должен
организовать передачу данных из памяти в регистры общего назначения, а также
указать арифметико-логическому блоку, в каких регистрах содержатся
необходимые входные данные, активизировать соответствующие электронные цепи в этом
блоке, а также указать арифметико-логическому блоку тот регистр, в который
должен быть помещен результат.
Наиболее распространенные типы ЦП
Сегодня самыми распространенными типами центральных процессоров являются процессоры серии
Pentium, разработанные фирмой Intel, и процессоры серии PowerPC, совместно разработанные
компаниями Motorola и IBM. Процессоры Pentium нашли наиболее широкое применение в настольных ПК, а
процессоры PowerPC используются в разработках Apple Computer Corporation. Эти ЦП выпускаются обычно в виде
небольших плоских прямоугольных пластин с игольчатыми контактами, совместимыми с конструкциями
современных плат. Для повышения производительности эти процессоры за одно обращение могут считывать
из основной памяти блоки из многих байтов. В частности, они обычно выбирают из памяти сразу несколько
команд и во многих случаях оказываются способны выполнять больше одной команды одновременно.
110 Глава вторая. Обработка данных
В разделе 2.6 будет показано, что процессоры Pentium и PowerPC представляют два различных подхода к
конструированию центральных процессоров. В частности, процессоры Pentium имеют CISC-архитектуру,
тогда как процессоры PowerPC являются примером использования RISC-архитектуры.
Полезно будет рассмотреть назначение регистров с точки зрения общих
функций памяти компьютера. Регистры предназначены для хранения тех
данных, с которыми машине необходимо работать непосредственно сейчас; основная
память используется для хранения тех данных, которые понадобятся для работы
в ближайшем будущем; а массовая память применяется для хранения данных, с
которыми в ближайшее время вряд ли потребуется работать.
Во многих машинах к этой иерархической структуре присоединен
дополнительный уровень, который называется сверхоперативной памятью (кэш). Кэш —
это раздел высокоскоростной памяти с временем доступа, сравнимым со
временем доступа к регистрам центрального процессора. Часто кэш непосредственно
входит в состав ЦП. В эту специальную область памяти машина стремится
скопировать именно ту часть основной памяти, в которой содержатся данные,
необходимые для работы на данный момент. В этом случае обмен данными будет
осуществляться не между регистрами и основной памятью, как это обычно
бывает, а между регистрами и кэшем. Затем, в подходящий момент, все
выполненные изменения одновременно передаются в основную память машины.
Интерфейс между ЦП и основной памятью
Для передачи битовых комбинаций между ЦП и основной памятью машины
эти устройства соединяются группой проводов, которая называется шиной
(рис. 2.2). Именно через эту шину центральный процессор извлекает (или
считывает) данные из основной памяти, направляя в нее адрес необходимой ячейки
памяти вместе с сигналом считывания. Аналогичным образом ЦП помещает
(или записывает) данные в память, указав адрес ячейки назначения и
записываемую информацию, сопровождаемые сигналом записи.
Соединение центрального процессора и основной памяти с помощью шины
2.1. Центральный процессор 111
Получив представление об этом механизме, можно понять, что даже такая
простая операция, как сложение данных, сохраняемых в основной памяти
машины, включает гораздо больше действий, чем собственно выполнение операции
сложения. Такая процедура требует согласованных совместных действий как
блока управления, координирующего передачу информации между регистрами и
основной памятью, так и арифметико-логического блока, выполняющего
собственно операцию сложения по команде, поступающей от блока управления. Весь
процесс сложения двух сохраняемых в основной памяти чисел можно разделить
на пять этапов, как показано на рис. 2.2.
а.
I РИСУНОК 2.2
Этап 1. Выбрать первое слагаемое из основной памяти и поместить его в регистр.
Этап 2. Выбрать второе слагаемое из основной памяти и поместить его в другой регистр.
Этап 3. Активизировать электронную схему суммирования, указав используемые на этапах
1 и 2 регистры в качестве входных и задав еще один регистр в качестве выходного,
предназначенного для размещения результата.
Этап 4. Сохранить результат выполнения операции в основной памяти.
Этап 5. Завершить выполнение операции.
Сложение двух чисел, сохраняемых в основной памяти машины
Машинные команды
Показанная на рис. 2.2 последовательность этапов представляет собой пример
команды, которую должен уметь выполнять центральный процессор любой машины.
Такие команды называются машинными командами. Вас, вероятно, удивит тот
факт, что полный список машинных команд относительно невелик. Одной из
наиболее удивительных особенностей компьютерных наук является то, что если машина
способна выполнять определенный тщательно продуманный набор элементарных
операций, то дальнейшее расширение набора команд машины не приведет к
увеличению ее теоретических функциональных возможностей. Другими словами, после
какого-то момента добавление новых функций позволяет повысить лишь
комфортность эксплуатации машины или скорость ее работы, однако никак не влияет на
основные ее свойства. Подробнее об этом речь пойдет в главе 11.
При изучении системы машинных команд полезно будет разделить их на три
категории: команды передачи данных, арифметические и логические команды, а
также команды управления.
112 Глава вторая. Обработка данных
Команды передачи данных
Первая группа команд этой категории включает те команды, при выполнении
которых происходит перемещение данных из одного места в другое. На рис. 2.2 к этой
группе относятся действия, выполняемые на этапах 1, 2 и 4. Как и в случае с
основной памятью, наиболее типичной является ситуация, когда перемещаемые данные
сохраняются и в месте их исходного расположения. Процедура выполнения команд
передачи данных больше напоминает копирование информации с одного места в
другое, а не обычное их перемещение. Поэтому чаще всего употребляемые названия
команд пересылка или перемещение следует считать выбранными неверно. Более
подходящими названиями для этих команд можно считать копирование или
дублирование. Поскольку мы коснулись терминологии, то следует указать, что для
передачи данных между ЦП и основной памятью существуют специальные термины.
Запрос на заполнение регистра общего назначения содержимым ячейки памяти обычно
называют командой загрузки (LOAD), а запрос на передачу содержимого регистра в
ячейку основной памяти — командой сохранения (STORE).
Вторую, очень важную группу команд этой категории составляют команды
связи с устройствами, выходящими за рамки интерфейса ЦП-основная память.
Поскольку эти команды отвечают за выполнение в машине операций
ввода/вывода, они обычно называются командами ввода/вывода и в некоторых
случаях помещаются в отдельную категорию. Однако в разделе 2.6 будет показано,
что для выполнения операций ввода/вывода обычно используются те же
команды, с помощью которых выполняется передача данных между ЦП и основной
памятью машины. А это означает, что выделение данных команд в отдельную
категорию следует считать неправомерным.
Арифметические и логические команды
Ко второй категории относятся те команды, которые указывают блоку
управления на необходимость запросить выполнение определенных действий
арифметико-логического блока. На рис. 2.2 к этой категории относятся действия,
выполняемые на этапе 3. Как следует из самого названия арифметико-логического
блока, он также предусматривает выполнение группы операций, отличающихся
от основных арифметических действий. К ним относятся обычные логические
операции AND (И), OR (ИЛИ) и XOR (исключающее ИЛИ), которые мы уже
рассматривали в главе 1. В этой главе мы обсудим эти операции более подробно. В
основном они используются для манипуляции отдельными битами некоторого
регистра общего назначения; при этом состояние остальных регистров остается
неизменным. Другая группа операций, реализованная в большинстве типов
арифметико-логических блоков, состоит из команд, позволяющих перемещать
содержимое регистров влево или вправо в пределах самих этих регистров. Такие
операции называются операциями сдвига (SHIFT) или вращения (ROTATE), в
зависимости от того, что происходит с битами, выходящими при перемещении
содержимого регистра за его пределы. При операции сдвига эти биты просто
отбрасываются, а при операции вращения — биты, покидающие пределы регистра
с одного конца, помещаются во вновь вставляемые позиции на другом конце
регистра. (Иногда последняя операция называется циклическим сдвигом.)
2.1. Центральный процессор 113
Команды управления
Третья категория состоит из команд, предназначенных для управления ходом
выполнения программы, а не обработки каких-либо данных. На рис. 2.2 к этой
категории относятся действия, выполняемые на этапе 5, однако это очень простой
пример. Данная категория включает много интересных команд, например группа
команд перехода (JUMP) или ветвления (BRANCH). Они используются для
перенаправления управляющего блока на выполнение команды, отличной от той, которая
является очередной в выполняемой последовательности. Команды перехода
реализуются в двух вариантах: команды безусловного перехода и команды условного
перехода. К первому варианту относится команда типа "Пропустите все команды до
этапа 5м, а ко второму — команда типа "Если полученное число равно 0, то
перейдите к этапу 5". Разница между ними состоит в том, что при выполнении команды
условного перехода изменение последовательности произойдет только при
выполнении указанного условия. В качестве примера можно привести последовательность
команд (рис. 2.3), которая представляет собой реализацию алгоритма деления двух
чисел. В этом примере этап 3 содержит команду условного перехода,
предназначенную для предотвращения операции деления на нуль.
Этап 1. Загрузить в регистр число из основной памяти
Этап 2. Загрузить в другой регистр еще одно число из основной памяти
Этап 3. Если второе число равно нулю, перейти к этапу 6
Этап 4. Разделить содержимое первого регистра на содержимое второго и записать
результат в третий регистр
Этап 5. Запомнить содержимое третьего регистра в основной памяти
Этап 6. Завершить выполнение операции
Деление чисел, сохраняемых в основной памяти
Вопросы для самопроверки
1. Как вы думаете, какая последовательность действий должна быть выполнена
машиной для перемещения содержимого одной ячейки основной памяти в
другую?
2. Какую информацию должен представить центральный процессор в
электронные схемы основной памяти для сохранения числа в одной из ее ячеек?
3. Почему термин "перемещение" следует считать неправильным для
обозначения операции перемещения данных из одного места в другое?
114 Глава вторая. Обработка данных
4. В тексте команда перехода была записана так, что требуемое место передачи
управления явно указывалось в ней с помощью имени (или номера этапа),
например "Перейдите к этапу 6". Недостатком данного способа записи
является то, что если имя (или номер) адресуемой команды позднее будет
изменено, потребуется найти и исправить все команды перехода на эту команду.
Предложите другой способ записи команд перехода, не содержащий явного
указания имени адресуемой команды.
5. Как вы считаете, команда "Если 0 равен 0, то перейдите к этапу 7" является
условным или безусловным переходом? Поясните ваш ответ.
2.2. Концепция хранимой программы
Ранние модели вычислительных устройств не отличались особой гибкостью,
так как программы их работы встраивались непосредственно в блок управления
как неотъемлемая часть данной машины. Подобную систему можно сравнить с
музыкальной шкатулкой, которая всегда играет одну и ту же мелодию. Однако
нам необходимо устройство, которое должно обладать гибкостью, не уступающей
возможностям плейера компакт-дисков. Один из подходов к достижению
необходимой гибкости в ранних электронных машинах состоял в том, что блок
управления машиной конструировался с учетом возможности его
перекоммутации. В этом случае в блок управления входила коммутационная панель,
напоминающая коммутаторы старинных телефонных станций. Концы
коммутируемых линий выводились на штекеры, которые требовалось вставлять в
соответствующие контактные гнезда.
Представление машинных команд в виде битовых комбинаций
Значительный шаг вперед (приписываемый, возможно, несправедливо Джону фон
Нейману (John von Neuman ))1 состоял в осознании того, что программа, как и
данные, может быть закодирована и сохранена в основной памяти машины. Если
разработать блок управления таким образом, чтобы он был способен извлекать программу
из памяти, расшифровывать команды, а затем выполнять их, то программу работы
компьютера можно было бы изменять посредством изменения содержимого ячеек его
основной памяти, вместо того чтобы перекоммутировать схемы блока управления. С
тех пор эта концепция хранимой программы считается стандартным подходом к
решению данной проблемы, применяемым и в настоящее время. Для реализации
этой идеи машина разрабатывается так, чтобы распознавать определенные битовые
комбинации как представления конкретных команд. Весь набор выполняемых
операций вместе с системой их кодирования называют машинным языком, поскольку
он представляет собой средство передачи алгоритмов машине.
1 Многие утверждают, что концепция хранимых программ в действительности
принадлежит Дж. П. Эккерту-младшему (J.P. Eckert, Jr.) из школы Мура, которую посещал
Джон фон Нейман.
2.2. Концепция хранимой программы 115
Кодированное представление машинной команды обычно состоит из двух частей:
поля кода операции (op-code — сокращение от operation code) и поля операндов.
Битовая комбинация, помещаемая в поле кода операции, определяет ту элементарную
операцию (например, STORE, SHIFT, XOR и JUMP), выполнение которой
предусматривается данной командой. Битовые комбинации в поле операндов предоставляют
более детальную информацию о той операции, которая задана в поле кода операции.
Например, при выполнении операции STORE информация в поле операндов
указывает регистр, в котором содержатся предназначенные для сохранения данные, а также
ту ячейку основной памяти, в которую эти данные должны быть записаны.
Концепция хранения программы в памяти машины совсем проста. Прежде
эта идея считалась сложной, поскольку многие относили данные и программы к
совершенно разным категориям. Данные хранились в памяти, а программы
являлись частью блока управления. Это как раз тот случай, когда за деревьями не
удавалось увидеть леса. В подобные сети очень легко попасться, и развитие
компьютерных наук во многом еще зависит от таких несоответствий, хоть мы об
этом иногда и не догадываемся. Одной из самых замечательных особенностей
науки следует считать то, что каждый новый взгляд на проблему открывает
пути к новым теориям и возможностям их применения.
Машинный язык
Теперь давайте посмотрим, как можно закодировать команды в типичной
вычислительной машине. Машина, которая используется в нашем примере, подробно
описана в приложении В и схематично показана на рис. 2.4. Она состоит из 16
регистров общего назначения и 256 ячеек основной памяти, каждая из которых
имеет длину восемь битов. Для целей адресации присвоим регистрам номера от О
до 15, а адреса ячеек основной памяти установим равными от 0 до 255, исключая
те случаи, когда мы будем работать с этими числами, представленными в
двоичной системе. В последнем случае битовые комбинации будем представлять в шест-
надцатеричной системе счисления, поэтому регистры общего назначения будут
иметь номера от 0 до F, а ячейки памяти — адреса от 00 до FF.
Коды операций
Если мы обратимся к машинному языку, описанному в приложении В, то
заметим, что любая команда кодируется в 16 битах, представляемых в листингах
четырьмя шестнадцатеричными цифрами (рис. 2.5). Код операции для каждой
команды размещается в первых ее четырех битах и представляется одной шестнадцате-
ричной цифрой. Весь перечень команд включает только двенадцать базовых команд,
коды операций которых представляются шестнадцатеричными цифрами от 1 до С.
Таким образом, любой код команды, который начинается с шестнадцатеричной
цифры 3 (битовая комбинация ООН), относится к команде сохранения STORE, а
каждая команда, код которой начинается с шестнадцатеричного символа А, является
командой циклического сдвига ROTATE.
116 Глава вторая. Обработка данных
/''>
РИСУНОК 2.4
Архитектура машины, описанной в приложении В
РИСУНОК 2.5
Формат команды вычислительной машины, описанной в приложении В
2.2. Концепция хранимой программы
117
В машине есть две команды сложения ADD: одна — для сложения чисел в
двоичном дополнительном коде, а другая — для сложения чисел в формате с
плавающей точкой. Такое разделение обусловлено тем, что сложение чисел в
двоичном дополнительном коде потребует от арифметико-логического блока
выполнения совершенно иных действий, чем в случае сложения чисел в формате с
плавающей точкой.
Операнды
А теперь рассмотрим формат поля операндов. Это поле состоит из трех шестна-
дцатеричных цифр (12 бит) и во всех случаях (кроме команды остановки HALT,
для которой не требуется никаких уточнений) содержит дополнительные сведения
о команде, заданной кодом операции. Например, если первая шестнадцатеричная
цифра команды равна 1 (код операции считывания ячейки памяти LOAD), то
следующая шестнадцатеричная цифра команды указывает общий регистр, в который
требуется загрузить считанное из основной памяти значение, а последние две ше-
стнадцатеричные цифры задают адрес ячейки памяти, из которой требуется
считать данные. Например, команда 1347 (шестнадцатеричное число) воспринимается
машиной как "Загрузить в регистр 3 содержимое ячейки памяти с адресом 47".
Если код операции представлен шестнадцатеричной цифрой 7 (операция OR над
содержимым двух регистров общего назначения), то следующая
шестнадцатеричная цифра указывает номер регистра, в который следует поместить результат
операции, а две последние шестнадцатеричные цифры поля операндов задают номера
тех регистров, над содержимым которых необходимо выполнить операцию OR. В
результате команда 70С5 понимается как инструкция "Выполнить операцию OR с
содержимым регистров С и 5, а результат поместить в регистр О".
В нашей машине небольшое отличие существует и между двумя командами
загрузки LOAD. Возможно, вы уже заметили, что код операции 1
(шестнадцатеричный) относится к команде загрузки регистра общего назначения
содержимым ячейки основной памяти, тогда как код операции 2
(шестнадцатеричный) — к команде загрузки регистра общего назначения
указанным числовым значением. Различие заключается в том, что поле операндов в
команде первого типа содержит адрес, тогда как в команде второго типа поле
операндов содержит ту битовую комбинацию, которую требуется загрузить в регистр.
Интересное решение принято в отношении команды перехода JUMP (код
операции — шестнадцатеричная цифра В). Первая шестнадцатеричная цифра поля
операндов указывает, какой регистр общего назначения следует сравнить с регистром 0.
Если указанный регистр содержит ту же битовую комбинацию, что и регистр 0, то
машина выполняет переход посредством выбора следующей команды по тому адресу,
который указан в двух последних шестнадцатеричных цифрах поля операндов. В
противном случае программа продолжает нормальную последовательность
выполнения команд. По сути, это пример команды условного перехода. Однако если первая
шестнадцатеричная цифра поля операндов будет равна 0, то данная команда
запрашивает сравнить регистр 0 с регистром 0. Так как содержимое любого регистра
всегда равно самому себе, то в этом случае переход всегда выполняется. Следовательно,
118 Глава вторая. Обработка данных
команда, код которой начинается с шестнадцатеричных цифр ВО, воспринимается
как команда безусловного перехода.
Пример программы
Закончим этот раздел примером закодированной последовательности команд,
приведенной на рис. 2.2. Предположим, что суммируемые числа представлены в
дополнительном двоичном коде и хранятся в ячейках памяти с адресами 6С и
6D, а сумму этих чисел необходимо поместить в ячейку памяти с адресом 6Е.
Этап1 156С
Этап 2 166D
ЭтапЗ 5056
Этап 4 306Е
Этап 5 С000
Вопросы для самопроверки
1. Запишите программу, приведенную как пример в конце данного раздела, в
виде собственно битовых комбинаций.
2. Ниже представлены команды, записанные на машинном языке, который
описан в приложении В. Приведите текстовую формулировку этих команд.
а) 368А б) BADE в) 803С г) 40F4
3. В чем состоит различие между командами 15АВ и 25АВ, записанными на
машинном языке, представленном в приложении В?
4. Ниже дано текстовое представление нескольких машинных команд.
Запишите эти команды на машинном языке, представленном в приложении В.
а) Загрузить в регистр 3 шестнадцатеричное число 56.
б) Сдвинуть содержимое регистра 5 на три бита вправо.
в) Передать управление команде, расположенной по адресу F3, если
содержимое регистра 7 равно содержимому регистра 0.
г) Выполнить операцию AND над содержимым регистров А и 5 и поместить
ее результат в регистр 0.
2.3. Выполнение программы
Компьютер выполняет хранимую в его памяти программу посредством
копирования команд из основной памяти в блок управления (по мере необходимости).
Как только команда попадает в блок управления, она декодируется, после чего
выполняется. Порядок, в котором команды выбираются из памяти,
соответствует порядку их размещения в памяти, за исключением случаев выполнения
команды перехода JUMP. Чтобы представить себе общий процесс выполнения
команд, необходимо познакомиться с тем, как блок управления функционирует
2.3. Выполнение программы 119
внутри процессора. Этот блок включает два специализированных регистра:
счетчик адреса и регистр команд (см. рис. 2.4). Счетчик адреса содержит адрес
следующей выполняемой команды, т.е. он предназначен для наблюдения за ходом
выполнения программы. Регистр команды используется для хранения кода
выполняемой команды.
Блок управления работает в режиме постоянного повторения алгоритма,
называемого машинным циклом, который состоит из трех этапов: выборки,
декодирования и выполнения (рис. 2.6). На этапе выборки блок управления
извлекает из основной памяти ту команду, которая должна выполняться следующей.
Блок управления знает, где именно в памяти находится требуемая команда,
поскольку ее адрес содержится в счетчике адреса. Блок управления помещает
считанную команду в регистр команд, а затем увеличивает значение в счетчике
адреса так, чтобы он содержал адрес следующей команды.
| РИСУНОК 2.6
1. Выборка следующей команды
из памяти
(по значению счетчика адреса)
и увеличение значения
счетчика адреса
2. Декодирование битовой
комбинации в регистре
команд
3. Выполнение действий,
предусматриваемых
командой, находящейся
в регистре команд
Схема машинного цикла
Когда команда поступает в регистр команды, блок управления декодирует ее.
Эта процедура включает и разбиение поля операндов на соответствующие
составляющие части, исходя из кода операции данной команды.
Затем блок управления выполняет команду посредством активизации
соответствующей схемы, предназначенной для выполнения поставленной задачи.
Например, если команда представляет собой операцию загрузки данных из
основной памяти, блок управления выполняет загрузку требуемых данных; если
же команда предусматривает выполнение арифметической операции, то блок
120
Глава вторая. Обработка данных
управления активизирует соответствующую схему в арифметико-логическом
блоке, указывая в качестве входных регистры, заданные в команде.
Когда обработка команды будет завершена, блок управления вновь начинает
выполнение алгоритма машинного цикла с первого этапа. Напомним, поскольку
в конце предыдущего этапа выборки счетчик адреса был увеличен, он по-
прежнему предоставляет блоку управления корректный адрес следующей
выполняемой команды.
Особым случаем является команда перехода JUMP. Давайте рассмотрим
выполнение команды с кодом В258, которая имеет следующий смысл: "Выполнить
переход к команде, сохраняемой по адресу 58, если содержимое регистра 2
идентично содержимому регистра О". В этом случае этап выполнения в машинном
цикле начинается со сравнения содержимого регистров 2 и 0. Если оно
различно, то этап выполнения этой команды завершается и начинается выполнение
нового машинного цикла. Если же содержимое указанных регистров одинаково, то
машина на этом этапе поместит в счетчик адреса значение 58. Теперь на этапе
выборки следующего машинного цикла блок управления обнаружит в счетчике
адреса значение 58, поэтому следующей будет выполнена команда,
расположенная по этому адресу.
Для координации действий, выполняемых на протяжении машинного цикла,
необходимо обеспечить синхронизацию работы различных схем машины. С этой
целью на соответствующие электронные схемы подается импульсный сигнал,
который называется сигналом синхронизации. Амплитуда этого сигнала
изменяется между уровнями 0 и 1, а различные электронные схемы машины
разрабатываются таким образом, чтобы они приводились в действие тем или иным
фронтом импульса синхронизирующего сигнала. В результате тактовая частота этого
сигнала фактически определяет ту скорость, с которой центральный процессор
выполняет свой машинный цикл.
Сравнение производительности компьютеров
Приступив к поиску подходящего персонального компьютера, вы обнаружите, что зачастую частота сигнала
синхронизации (тактовая частота компьютера) используется для сравнения производительности различных
вычислительных машин. Частота синхронизации задается компьютерными часами, которые представляют
собой генератор электрических колебаний. Импульсы сигнала синхронизации предназначены для
согласования всех действий в компьютере: чем выше частота импульсов синхронизации, тем быстрее машина
выполняет введенные в нее задания. Частота сигналов синхронизации измеряется в герцах (сокращенно Гц);
1 Гц соответствует выполнению одного цикла (или появлению одного импульса) за секунду. Частота
синхронизирующего сигнала в обычном компьютере колеблется в диапазоне от единиц до сотен и тысяч
мегагерц (МГц); 1 МГц равен одному миллиону герц.
К сожалению, центральные процессоры производятся многими фирмами, каждая из которых устанавливает
собственный объем работы, выполняемой за один цикл синхронизации. По этой причине сравнение произ-
2.3. Выполнение программы 121
водительности работы по частоте синхронизации для центральных процессоров, имеющих разные
конструкции, следует считать неадекватным. Если необходимо сравнить производительность компьютера, в
котором установлен процессор типа PowerPC, с компьютером, имеющим ЦП типа Pentium, то разумнее будет
выполнить измерение показателей производительности с помощью специальных тестовых заданий
(benchmark). В этом случае сравнивается реальная скорость выполнения каждым из компьютеров одного и
того же задания, называемого тестовым. Подобрав тестовое задание, которое может служить эталоном
для некоторого типа приложений, мы получим инструмент сравнения, позволяющий получить осмысленную
оценку коммерческих продуктов, представленных в некотором сегменте рынка. Следует отметить, что
очень часто компьютер, демонстрирующий наилучшую производительность для одного класса приложений,
не является таковым для приложений иного типа.
Пример выполнения программы
Давайте проследим за выполнением всех машинных циклов,
предусматриваемых программой, текст которой представлен в конце раздела 2.2. Вначале
необходимо разместить программу в какой-либо области памяти машины. Например,
будем считать, что текст нашей программы занесен в последовательные ячейки
памяти, начиная с адреса АО (шестнадцатеричное представление). На рис. 2.7
представлена таблица, отражающая содержимое этой области памяти. Если
записать программу таким способом, можно заставить машину выполнить нашу
программу, поместив адрес ее первой команды (АО) в счетчик адреса и запустив
машину в работу.
РИСУНОК 2.7
Программа сложения чисел, записанная в память машины, начиная с адреса АО
Блок управления начинает с извлечения из основной памяти команды,
записанной по адресу АО, и помещает ее (156С) в регистр команды, выполнив тем
самым этап выборки первого машинного цикла. Обратите внимание, что длина
команды составляет шестнадцать разрядов (2 байта). Поэтому выбираемая ко-
122 Глава вторая. Обработка данных
манда должна занимать две ячейки памяти с адресами АО и А1. Конструкция
блока управления разработана с учетом этой особенности, поэтому он выбирает
содержимое обеих ячеек и помещает данные в регистр команды, размер которого
составляет 16 бит. Затем блок управления добавляет число 2 к значению в
счетчике адреса, чтобы содержимое этого регистра представляло собой адрес
следующей команды. По завершении этапа выборки первого машинного цикла в
счетчике адреса и регистре команд будут содержаться следующие данные:
Счетчик адреса: А2
Регистр команд: 156С
На следующем этапе блок управления анализирует команду, помещенную в
регистр команд, и приходит к заключению, что это команда загрузки в
регистр 5 содержимого ячейки памяти с адресом 6С. Загрузка осуществляется на
этапе выполнения данного машинного цикла, после чего блок управления начнет
новый машинный цикл.
Новый цикл начинается с выборки команды 166D из ячеек памяти с
адресами А2 и A3. Блок управления помещает эту команду в регистр команд и
увеличивает значение счетчика адреса, после чего оно становится равным А4. После
завершения очередного этапа выборки в счетчике адреса и регистре команд
будут следующие данные:
Счетчик адреса: А4
Регистр команд: 166D
Блок управления декодирует команду 166D и определяет, что в регистр б
необходимо загрузить содержимое ячейки памяти с адресом 6D, после чего
выполняет команду, и в регистр б действительно загружается требуемое значение.
Поскольку в данный момент счетчик адреса имеет значение А4, блок
управления считывает следующую команду, которая начинается с указанного адреса.
В результате в регистр команд помещается значение 5056, а счетчик адреса
получает новое значение А6. Блок управления декодирует содержимое очередной
команды и выполняет ее посредством активизации электронной схемы сложения
чисел в дополнительном двоичном коде, указав этой схеме использовать как
входные регистры 5 и б.
На этапе выполнения данной команды арифметико-логический блок
выполняет сложение и записывает результат в регистр 0 (как было указано блоком
управления), после чего сообщает блоку управления о том, что требуемые
действия выполнены. После этого блок управления начинает следующий машинный
цикл. И вновь, используя текущее значение в счетчике адреса, он выбирает
следующую команду из двух смежных ячеек памяти с адресами А б и А7 (теперь это
команда 306Е) и модифицирует значение счетчика адреса, установив его
равным А8. Затем считанная из памяти команда декодируется и выполняется. В
результате сумма двух чисел помещается в ячейку памяти с адресом 6Е.
Следующая выбираемая команда расположена в памяти, начиная с адреса А8.
После ее извлечения значение счетчика адреса увеличивается до АА. Содержимое
2.3. Выполнение программы 123
регистра команд равно СО00 и расшифровывается как команда останова. В
результате работа машины останавливается на этапе выполнения, и это означает,
что выполнение нашей программы завершено.
В заключение скажем, что выполнение хранимой в памяти программы не
отличается от того процесса, к которому мог бы прибегнуть любой человек, перед
которым поставлена задача четко следовать определенному списку инструкций.
Обычно человек отмечает в списке выполненные им инструкции галочками —
машина же для этого использует счетчик адреса. Определив, какая из
инструкций должна выполняться следующей, человек знакомится с ней и принимает
решение, что именно нужно сделать. Затем он выполняет требуемые действия и
переходит к следующей инструкции. Аналогичным образом поступает и
машина — она выполняет очередную команду, помещенную в регистре команд, и
запускает следующий цикл выборки.
Программы и данные
В основной памяти компьютера можно разместить множество программ
одновременно, выделив для каждой различные области памяти. Тем, какая
из этих программ начнет выполняться при запуске машины, можно легко
управлять, просто соответствующим образом установив исходное значение
счетчика адреса.
Однако не следует забывать, что данные также содержатся в основной
памяти и кодируются с помощью нулей и единиц, поэтому машина сама по
себе не может установить, что именно является данными, что — программой.
Если в счетчике адреса, вместо адреса требуемой программы, будет
установлен адрес данных, то компьютер не сможет предпринять никаких иных
действий, кроме как считать битовые комбинации данных так, как если бы они
были командами, и попытаться выполнить их. Полученный результат
непредсказуем и будет зависеть от того, с какими именно данными работала
машина.
Тем не менее нельзя сказать, что мы поступаем неверно, придавая и
программам и данным одинаковую форму. Благодаря этому одна программа может
работать с другими программами (и даже с самой собой) как с обычными
данными. Например, можно представить себе программу, которая в результате
взаимодействия с окружающей средой изменяет саму себя, получая, таким
образом, возможность обучаться. Или другой пример — программа, кг орая пишет и
выполняет другие программы, используя их как средства решения поставленной
перед ней задачи.
Вопросы для самопроверки
1. Предположим, что в памяти машины, описанной в приложении В, в ячейках
с адресами от 00 до 05 содержатся битовые комбинации, приведенные ниже
(шестнадцатеричное представление).
124 Глава вторая. Обработка данных
Адрес Содержимое
00 14
01 02
02 34
03 17
04 СО
05 00
Если запустить машину, предварительно установив в счетчике адреса
значение 00, то какая битовая комбинация окажется в ячейке памяти с адресом 17
(шестнадцатеричное представление), когда работа машины будет остановлена?
2. Предположим, что в памяти машины, описанной в приложении В, в ячейках
с адресами от ВО до В8 содержатся битовые комбинации, приведенные ниже
(шестнадцатеричное представление).
Адрес Содержимое
ВО 13
Bl B8
82 A3
83 02
84 33
85 В8
86 СО
87 00
88 0F
а) Если в начале работы в счетчик адреса помещается значение ВО, то какая
битовая комбинация будет содержаться в регистре 3 после выполнения
первой команды?
б) Какая битовая комбинация будет находиться в ячейке памяти с
адресом В 8 после выполнения команды останова?
3. Предположим, что в памяти машины, описанной в приложении В, в ячейках
с адресами от А4 до В1 содержатся битовые комбинации, приведенные ниже
(шестнадцатеричное представление).
Адрес
А4
А5
А6
А7
А8
Содержимое
20
00
21
03
22
2.3. Выполнение программы 125
А9 01
АА ВЗ
АВ ВО
АС 50
AD 02
АЕ ВО
AF АА
80 СО
81 00
Отвечая на следующие вопросы, исходите из того, что в начале работы
счетчик адреса содержит значение А4.
а) Какое значение будет находиться в регистре 0 после первого выполнения
команды, расположенной в ячейке с адресом АА?
б) Что будет находиться в регистре 0 после второго выполнения команды,
расположенной в ячейке с адресом АА?
в) Сколько раз должна быть выполнена команда, расположенная в ячейке с
адресом АА, прежде чем машина остановится?
4. Предположим, что в памяти машины, описанной в приложении В, в ячейках
с адресами от F0 до F9 содержатся битовые комбинации, приведенные ниже
(шестнадцатеричное представление).
Адрес
F0
F1
F2
F3
F4
F5
F6
F7
F8
F9
Содержимое
20
СО
30
F8
20
00
30
F9
FF
FF
Если в начале работы машины счетчик адреса содержит значение F0, то
какими будут действия машины, если она дойдет до команды, записанной в
ячейке с адресом F8?
126 Глава вторая. Обработка данных
2.4. Арифметические и логические команды
Как мы уже говорили ранее, группа арифметических и логических команд
состоит из таких команд, которые требуют выполнения некоторых
арифметических операций, логических или операций сдвига. В этом разделе мы
познакомимся с этими командами более подробно.
Логические операции
В первой главе логические операции AND (И), OR (ИЛИ) и XOR
(исключающее ИЛИ) были представлены как операции, которые комбинируют
значения двух входных двоичных разрядов в целях получения одного двоичного
разряда на выходе. Эти операции могут быть расширены, т.е. они могут
рассматриваться как операции, комбинирующие значения двух строк битов для
получения одной строки битов на выходе, что достигается посредством применения
соответствующей базовой операции к отдельным позициям в строках. Например,
результат применения операции AND к строкам битов 10011010 и 11001001
будет следующим.
10011010
AND 11001001
10001000
Другими словами, при выполнении этой строковой операции результат
операции AND для двух битов в каждой позиции исходных строк просто
записывается в этой же позиции строки результата. Аналогичным образом при
выполнении операций OR и XOR с теми же входными строками битов будут получены
следующие результаты.
10011010 10011010
OR 11001001 XOR 11001001
11011011 01010011
Операции AND чаще всего используются для помещения нулей в некоторую часть
битовой комбинации (не затрагивая при этом другую ее часть). Например, давайте
посмотрим, что произойдет, если байт 00001111 использовать в качестве первого
операнда логической операции AND. Даже не имея никакой информации о втором
операнде, можем сразу же сделать вывод, что четыре старших бита строки
результата всегда будут равны 0. Более того, можно также заранее утверждать, что четыре
младших бита строки результата будут копиями соответствующих битов второго
операнда, что непосредственно подтверждается следующим примером.
00001111
AND 10101010
00001010
Подобное применение операции AND является примером процедуры, называемой
маскированием. Первый операнд, или маска, определяет ту часть второго операнда,
2.4. Арифметические и логические команды 127
которая будет способна оказать воздействие на результат операции. В случае
операции AND результатом маскирования будет частичная копия второго операнда, в
которой нули заполняют те позиции, которые не подлежат дублированию.
Такая операция полезна при работе с битовыми отображениями, т.е. строкой
битов, в которой каждый бит представляет наличие или отсутствие
определенного объекта. Мы уже встречались с битовыми отображениями при изучении
растрового представления изображений, в котором каждый бит ассоциируется с
отдельным пикселем. Другим примером может служить 52-разрядная битовая
строка, в которой каждый бит ассоциируется с некоторой игральной картой.
Данное представление может использоваться для описания карт, которые были
сданы игроку в покер. В этой строке битов в единичном состоянии будут
находиться только те пять битов, которые ассоциируются с картами, полученными
игроком при раздаче, все остальные биты будут иметь значения 0. Аналогичная
52-разрядная битовая строка, в которой уже 13 битов будут равны 1, может
представлять отдельного игрока в бридж, тогда как 32-разрядная битовая строка
может представлять 32 вида мороженого, выпускаемого изготовителем.
Предположим, что восьмиразрядная ячейка памяти используется как битовое
отображение и мы хотим убедиться, что объект, представленный третьим битом со
старшего конца, имеется в наличии. Для этого достаточно выполнить операцию
AND, использовав в качестве операндов весь байт битового отображения и маску
00100000. В результате будет получен байт, содержащий все нули тогда и только
тогда, когда третий со старшего конца бит исходного отображения равен 0. В этом
случае в программе можно предпринять необходимые действия посредством
помещения после данной команды AND соответствующей команды условного перехода.
Если же третий со старшего конца бит растрового изображения равен 1, а нам
требуется изменить его значение на 0 без изменения состояния других битов, достаточно
выполнить операцию AND, используя в качестве операндов весь байт с битовым
отображением и маску 11011111, а затем записать результат в ту ячейку, где хранился
исходный байт битового отображения.
Если операция AND может использоваться для дублирования части битовой
строки с помещением нулей во все биты другой ее части, то операция OR может
применяться для дублирования части строки с помещением во все ее оставшиеся биты
единиц. Для этого также используется определенная маска, но на этот раз те
позиции, значения которых должны быть продублированы, отмечаются в ней нулями, а
единицами заполняются все остальные позиции, не подлежащие дублированию.
Приведем пример. При выполнении операции OR с любым байтом и битовой
комбинацией 11110000 будет получен результат, в котором четыре старших бита всегда
будут содержать единицы, тогда как младшие биты будут просто копиями битов
исходного операнда, что демонстрируется следующим примером.
11110000
OR 10101010
11111010
Таким образом, если операция AND с маской 11011111 может использоваться
для того, чтобы поместить значение 0 в третий со старшего конца бит некоторо-
128 Глава вторая. Обработка данных
го восьмиразрядного битового отображения, то операция OR с маской 00100000
может применяться для установки этого же бита в единицу.
Операция XOR чаще всего используется для создания строки дополнения к
некоторой строке битов. Например, обратите внимание на взаимосвязь между
вторым операндом и строкой результата.
11111111
XOR 10101010
01010101
Операция XOR между любым байтом и байтом, содержащим все 1, дает в
результате байт дополнения к исходному байту.
Операции сдвига
Операции сдвига и вращения (циклического сдвига) позволяют перемещать
биты в регистре и часто используются для решения проблем выравнивания,
например при подготовке значения байта к последующим операциям маскирования
или манипулирования значением мантиссы в представлениях с плавающей
точкой. Классификация этих операций производится по направлению движения
(вправо или влево), а также с учетом того, является сдвиг циклическим или нет.
В рамках этой классификации существует множество различных вариантов, для
обозначения которых используется смешанная терминология. Давайте бегло
ознакомимся с основными принципами, положенными в ее основу.
Возьмем для примера некоторый байт и сдвинем его содержимое на один бит
вправо или влево. На том конце байта, в направлении которого происходит сдвиг,
крайний бит выйдет за его пределы и будет потерян, на другом конце образуется
пустое место, в которое потребуется ввести некоторое значение. Что произойдет с
удаляемым битом и что будет вставлено в освободившуюся позицию — именно это и
определяет отличия между множеством разнообразных операций сдвига. Одним из
возможных решений является помещение бита, удаляемого с одного конца байта, в
пустую позицию на другом его конце. В результате мы получим циклический сдвиг,
который также иногда называют вращением. Если выполнить циклический сдвиг
байта вправо восемь раз подряд, то получим ту же битовую комбинацию, которая
существовала вначале, тогда как семь циклических сдвигов вправо идентичны
одному циклическому сдвигу влево.
Другим вариантом решения является удаление бита, выходящего за пределы
байта, и помещение в освобождающиеся позиции исключительно значения 0.
Подобный вариант называют логическим сдвигом. Этот вариант сдвига влево
можно использовать для умножения значения байта в дополнительном двоичном
коде на число 2. В любом случае сдвиг двоичных цифр влево означает
умножение значения на 2, подобно тому как и аналогичный сдвиг десятичных цифр
означает умножение на десять. Кроме того, сдвинув двоичную строку вправо,
можно выполнить деление ее значения на два. Однако в этом случае нужно
обязательно сохранить тот знаковый бит, который используется в данной нотации.
Для этого часто используется такой вариант сдвига вправо, при котором освобо-
2.4. Арифметические и логические команды 129
ждающаяся позиция (а это, чаще всего, и будет знаковый бит) всегда
заполняется тем значением, которое в ней находилось до операции сдвига. Сдвиги,
которые не изменяют значения знакового бита, иногда называют арифметическими.
Арифметические операции
Несмотря на то что выше уже шла речь об арифметических операциях
сложения, вычитания, умножения и деления, все же необходимо расставить все
точки над i. Как уже говорилось, все операции этой группы чаще всего могут
быть реализованы с помощью единственной операции сложения и действия
отрицания. Поэтому некоторые малогабаритные компьютеры содержат в своем
наборе команд только операции сложения или сложения и вычитания.
Кроме того, следует напомнить, что существует множество различных
вариантов любой арифметической операции. Речь об этом уже шла выше в связи с
операциями сложения, которые включены в набор команд гипотетической
машины, описанной в приложении В. При операциях сложения операнды могут
быть представлены в двоичном дополнительном коде, и тогда операция их
сложения будет выполняться как обычное двоичное суммирование. Если же
операнды будут представлены как числа в формате с плавающей точкой, то при
суммировании потребуется выделить мантиссу каждого из чисел. После этого
эти значения должны быть сдвинуты вправо или влево в зависимости от
значения в поле порядка. Затем проверяются знаковые биты и выполняется операция
сложения. Полученный результат вновь переводится в формат с плавающей
точкой. Как видите, хотя обе описанные выше операции считаются операциями
сложения, действия машины по их выполнению будут существенно отличаться.
Более того, с точки зрения самой машины, между этими двумя операциями
вообще нет никакой связи.
Вопросы для самопроверки
1. Выполните приведенные ниже операции.
2. Предположим, что требуется выделить средние три бита в семиразрядной
строке посредством помещения нулей в оставшиеся ее четыре бита, не
изменяя значения трех выделяемых битов. Какую маску и операцию следует
использовать в этом случае?
3. Предположим, что нужно заменить значение средних трех битов в
семиразрядной строке на обратное, не изменяя при этом значения оставшихся
четырех битов. Какую маску и операцию следует использовать в этом случае?
130 Глава вторая. Обработка данных
4. а) Предположим, что была выполнена операция XOR с первыми двумя
битами некоторой строки битов, а затем эта операция последовательно
выполнялась с очередным результатом и следующим битом строки. Как общий
результат связан с количеством единиц в исходной строке битов?
б) Какое отношение приведенная выше задача имеет к определению
требуемого значения бита четности при кодировании сообщения?
5. Иногда удобнее использовать логическую операцию вместо цифровой.
Например, логическая операция AND комбинирует значения двух битов по тому же
принципу, что и операция умножения. Какая логическая операция почти
идентична операции сложения двух битов? Какие отличия существуют между
этими операциями?
6. Какую логическую операцию и в сочетании с какой маской следует
использовать для преобразования строчных букв в прописные в коде ASCII?
7. Каков будет результат при выполнении циклического сдвига вправо на три
позиции для каждой из следующих битовых комбинаций.
а) 01101010 б) 00001111 в) 01111111
8. Каков будет результат при циклическом сдвиге влево на одну позицию для
каждой из следующих битовых комбинаций, представленных в шестнадцате-
ричной системе счисления.
а) АВ б) 5С в) В7 г) 35
9. На сколько разрядов влево нужно сдвинуть восьмиразрядную строку, чтобы
результат был эквивалентен циклическому сдвигу этой же строки вправо на
три бита?
10. Какая комбинация битов будет представлять сумму значений 01101010 и
11001100, если считать, что эти значения представляют числа в формате с
плавающей точкой, речь о котором шла в главе 1?
11.Используя машинный язык, описываемый в приложении В, напишите
программу, которая поместит единицу в старший бит ячейки памяти с
адресом А7, оставив значения всех остальных битов этой ячейки без изменения.
12.Используя машинный язык, описываемый в приложении В, напишите
программу, которая скопирует значения четырех средних битов ячейки памяти с
адресом Е0 в младшие четыре бита ячейки памяти с адресом Е1, при этом в
старшие четыре бита этой ячейки должны быть занесены нули.
2.4. Арифметические и логические команды 131
2.5. Взаимодействие с другими устройствами
Основная память и центральный процессор образуют центральное звено
компьютера. В этом разделе мы рассмотрим, как это центральное звено
взаимодействует с различными периферийными устройствами, такими как дисковые
накопители, принтеры, а также другими компьютерами.
Взаимодействие через управляющее устройство
Взаимодействие между машиной и другими устройствами обычно
осуществляется через промежуточное устройство, называемое контроллером. Если в
качестве примера взять персональный компьютер, то контроллер будет представлять
собой ту монтажную плату, которая вставляется в разъем на основной плате
компьютера (материнской плате). С помощью кабелей платы контроллеров
соединяются с периферийными устройствами, установленными в самом
компьютере, а соединение с внешними устройствами осуществляется через
промежуточные разъемы, установленные на задней стенке корпуса компьютера.
Каждый контроллер обеспечивает взаимодействие с определенным видом
устройства. Некоторые из них разработаны для взаимодействия с монитором,
другие отвечают за взаимодействие с дисководами, а есть контроллеры,
поддерживающие взаимодействие компьютера с устройствами чтения компакт-дисков.
Поэтому иногда вместе с новым периферийным устройством приходится покупать и
новый контроллер. Задача контроллера состоит в преобразовании сообщений и
данных, которыми обмениваются компьютер и периферийное устройство, в тот
формат, который будет совместим с внутренними характеристиками самого
компьютера и подключенного к нему устройства. Подобные контроллеры часто
представляют собой небольшие специализированные компьютеры с собственной
основной памятью и центральным процессором, который выполняет программу,
управляющую всеми действиями данного контроллера.
Когда контроллер вставляется в один из разъемов на материнской плате
компьютера, он электрически подключается к шине, соединяющей ЦП компьютера
и его основную память (рис. 2.8). В месте своего подключения каждый
контроллер осуществляет непрерывное наблюдение за сигналами, посылаемыми из ЦП
машины, и отвечает на те, которые адресованы непосредственно ему. Более того,
когда контроллер подключен к шине компьютера, он может посылать сигналы
чтения и записи непосредственно в основную память машины, используя для
этого те микросекунды, когда ЦП не обращается к шине.
Подобный тип доступа контроллера к основной памяти называется прямым
доступом к памяти (DMA — direct memory access) и является важным средством
повышения производительности компьютера. Если в компьютере контроллер дисковых
устройств обладает прямым доступом к памяти, то ЦП может посылать ему
представленные в виде битовых комбинаций запросы, требующие считать с диска
определенный сектор и поместить прочитанные данные в указанный блок ячеек основной
132 Глава вторая. Обработка данных
памяти. Такой блок ячеек называется буфером. В общем случае буфер представляет
такое местоположение, где одна система может оставить данные, к которым позднее
сможет получить доступ другая система. Пока контроллер будет выполнять
затребованную операцию считывания данных, ЦП может продолжать обработку других
заданий. Это означает, что в одно и то же время будут выполняться два разных
действия. ЦП будет выполнять программу, а контроллер в это время будет обеспечивать
передачу данных между дисковым устройством и основной памятью компьютера.
Такой подход позволяет избежать простоя вычислительных ресурсов во время
выполнения относительно медленного процесса передачи данных.
РИСУНОК 2.8
Подключение контроллеров к шине компьютера
Однако механизм DMA оказывает и определенный отрицательный эффект,
поскольку при этом увеличивается количество взаимодействий, осуществляемых через
шину компьютера. Битовые комбинации должны перемещаться между ЦП и
основной памятью, между ЦП и каждым из контроллеров, а также между каждым из
контроллеров и основной памятью компьютера. Координация всей этой
деятельности, осуществляемой через шину компьютера, является важнейшей задачей
конструирования. Даже в самых лучших проектных решениях центральная шина может
превратиться в источник помех в работе компьютера, возникающих из-за того, что
ЦП и контроллеры соревнуются между собой за доступ к шине.
Взаимодействие центрального процессора компьютера и каждого из контроллеров
осуществляется по тем же принципам, что и взаимодействие ЦП и основной памяти.
Чтобы послать некоторую битовую комбинацию контроллеру, эта комбинация
должна быть сначала создана в одном из регистров общего назначения процессора.
Затем ЦП выполняет команду, подобную STORE, которая позволяет "записать" эту
комбинацию в контроллер. Следовательно, единственное отличие между записью би-
2.5. Взаимодействие с другими устройствами
133
товой комбинации в основную память и пересылкой битовой комбинации в
контроллер заключается только в месте назначения для доставки комбинации. И
действительно, в машинном языке многих компьютеров выполняемая в обоих этих случаях
операция имеет один и тот же код. Как правило, при этом схемы основной памяти
машины разрабатываются таким образом, чтобы игнорировать ссылки на
определенные ячейки памяти, тогда как контроллеры конструируются так, чтобы реагировать
только на ссылки к этим ячейкам. Поэтому когда ЦП посылает сообщение на шину
для записи данных в эти особые ячейки памяти, их получает соответствующий
контроллер, а не основная память компьютера. Аналогичным образом, когда ЦП
пытается считать данные из этих ячеек памяти, например с помощью команды LOAD, он
получит битовую комбинацию не из основной памяти, а из соответствующего
контроллера. Такая схема взаимодействия называется отображением ввода/вывода в
память, поскольку различные устройства ввода/вывода компьютера представлены
для ЦП как определенные ячейки памяти. Адреса памяти, выделенные
контроллерам при использовании подобной схемы, называются портами, каждый из которых
представляет определенное "местоположение", через которое информация попадает в
машину или выводится из нее (рис. 2.9).
РИСУНОК 2.9
Концептуальная схема метода отображения ввода/вывода в память
Передача данных между двумя компонентами компьютера редко бывает
односторонним действием. На первый взгляд может показаться, что принтер является
устройством, которое способно только получать данные, однако в действительности оно
способно посылать данные обратно в компьютер. В самом деле, компьютер способен
подготавливать символы и передавать их принтеру намного быстрее, чем принтер
сможет их печатать. Если компьютер будет передавать данные на принтер вслепую,
то принтер быстро начнет отставать, что может привести к потере данных. Поэтому
такой процесс, как печать документа, предусматривает постоянный двусторонний
диалог, в процессе которого компьютер и периферийное устройство обмениваются
информацией о текущем состоянии устройства.
Такой диалог часто предусматривает использование слова состояния
устройства, т.е. определенной битовой комбинации, которая генерируется
периферийным устройством и посылается его контроллеру. Биты в слове состояния
134
Глава вторая. Обработка данных
отражают текущее состояние устройства. Если вернуться к примеру с
принтером, то значение младшего бита слова состояния может указывать, что в
принтере закончилась бумага, тогда как следующий бит в этом слове указывает,
готов ли принтер к приему очередной порции информации. В зависимости от
выбранной системы, контроллер либо сам реагирует на подобную информацию о
состоянии устройства, либо передает ее на обработку в ЦП. В каждом случае
либо программа в контроллере, либо программа, выполняемая центральным
процессором, должна быть разработана так, чтобы задержать пересылку данных на
принтер до тех пор, пока от него не будет получена соответствующая
информация о состоянии.
Скорость передачи данных
Скорость, с которой биты передаются от одного вычислительного компонента
к другому, измеряется в битах в секунду (бит/с). Широкое распространение
также получили такие единицы измерения, как Кбит/с (килобит в секунду,
равный 1000 бит/с), Мбит/с (мегабит в секунду, равный миллиону бит/с) и Гбит/с
(гигабит в секунду, равный миллиарду бит/с). В каждом случае максимальная
скорость передачи данных зависит от типа используемой линии связи и
технологии, примененной для ее реализации.
Существуют два основных типа соединений: параллельный и
последовательный. Указанные термины определяют способ, который используется для
передачи отдельных битов в комбинации по отношению друг к другу. При
параллельной передаче несколько битов передаются одновременно, каждый по отдельной
линии связи. Такой способ позволяет повысить скорость передачи данных,
однако требует использования относительно сложных соединений. В качестве
примеров таких соединений можно привести внутреннюю шину компьютера и
большинство соединений между компьютером и его периферийными устройствами,
например устройствами массовой памяти или принтерами. В этих случаях
скорость передачи данных измеряется обычно в Мбит/с и даже выше.
Конструкция шины
Конструирование шины компьютера всегда было очень сложной задачей. Например, проводники в плохо
разработанной шине способны вести себя как небольшие антенны и ловить сигналы различных передач
(радио, телевидение и т.д.), что вызывает нарушения во взаимодействиях центрального процессора
компьютера, его основной памяти и периферийных устройств. Более того, длина шины (у настольного
компьютера она равна примерно пятнадцати сантиметрам) намного превышает длину "проводников" внутри
центрального процессора (длина которых измеряется в микронах). Поэтому прохождение сигналов через шину
занимает существенно больше времени, чем требуется для передачи сигналов внутри центрального
процессора. В результате технология изготовления шин находится в постоянной погоне за бурно
развивающимися технологиями центральных процессоров. В современных компьютерах используется ряд различных
2.5. Взаимодействие с другими устройствами 135
конструкций шин. Основные отличия этих шин заключаются в объеме передаваемой одновременно
информации, скорости изменения сигналов в шине, а также в физических свойствах соединений между шиной и
платами контроллеров. Важнейшими типами используемых в настоящее время шин являются ISA (Industrial
Standard Architecture— стандартная промышленная архитектура), EISA (Extended Industrial Standard
Architecture - усовершенствованная стандартная промышленная архитектура) и PCI (Peripheral Component
Interconnect — соединение периферийных компонентов).
В противоположность этому, при последовательной передаче в каждый
момент по соединению передается только один бит данных. В результате передача
данных происходит медленнее, однако соединение более простое, так как все
биты последовательно, один за другим, передаются по одной и той же линии
связи. Последовательные соединения чаще всего используются для связи между
разными компьютерами, где простота соединений позволяет достичь
существенной экономии ресурсов.
Например, существующие телефонные линии, как раньше, так и сейчас,
представляют собой основное средство обеспечения связи между компьютерами.
Используемые для этого средства унаследовали от телефонных сетей принцип
последовательной передачи данных с помощью звуковых сигналов.
Взаимодействие компьютеров через подобные линии связи осуществляется посредством
преобразования исходных битовых комбинаций в звуковые сигналы с помощью
специальных устройств, называемых модемами (сокращение от модулятор-
демодулятор). Затем полученные звуковые сигналы последовательно, один за
другим, посылаются по телефонным линиям, после чего на приемной стороне
вновь преобразуются другим модемом в битовые комбинации.
На практике простое представление битовых комбинаций в виде звуковых
сигналов различной частоты (что называется частотной манипуляцией)
используется только при низкоскоростных передачах со скоростью до 1200 бит/с. Для
того чтобы добиться скорости 2400 бит/с, 9600 бит/с и выше, модем
комбинирует изменения частоты тона, его амплитуды (громкости) и фазы (степени
задержки передачи сигнала). А для достижения еще более высоких скоростей передачи
данных часто применяются способы сжатия данных, что позволяет получить
скорость передачи до 57,6 Кбит/с.
Такая скорость передачи данных является предельной для обычных телефонных
линий, хотя этот уровень уже не удовлетворяет запросы современных пользователей.
Время, необходимое для передачи обычной фотографии (файл, размером
приблизительно в один мегабайт), при скорости 57,6 Кбит/с измеряется в минутах. В
результате передача видеоинформации со скоростью, соответствующей скорости ее
просмотра, оказывается практически невозможной. Поэтому разработка новых
технологий межкомпьютерной связи имеет весьма важное значение. В качестве примера
можно привести разработку оптоволоконного кабеля, допускающего передачу
данных со скоростью, измеряемой в сотнях Мбит/с и даже Гбит/с.
136 Глава вторая. Обработка данных
Вопросы для самопроверки
1. Предположим, машина, описанная в приложении В, использует механизм
отображения ввода/вывода в память, а адрес В5 определяет местоположение порта
принтера, в который должны передаваться данные для вывода на печать.
а) Если регистр 7 содержит код ASCII буквы А, какая команда машинного
языка может быть использована для вывода этой буквы на печать?
б) Если наша машина способна выполнять миллион операций в секунду, то
сколько раз за одну секунду этот символ может быть послан принтеру для
вывода на печать?
в) Если принтер может напечатать пять стандартных страниц текста в
минуту, то успеет ли он вывести на печать все символы, посланные ему при
условиях, указанных в предыдущем пункте?
2. Предположим, что жесткий диск персонального компьютера вращается со
скоростью 3000 оборотов в минуту. Каждая дорожка этого диска содержит
16 секторов, а каждый сектор — 1024 байта информации. Какая
приблизительно скорость передачи данных потребуется для линии связи между
дисководом и контроллером диска, если контроллер будет получать с дисковода
биты непосредственно после их считывания по мере вращения диска?
3. Сколько времени займет передача рассказа, занимающего 300 страниц
печатного текста, представленного символами в коде ASCII, если передача данных
будет осуществляться со скоростью 57600 бит/с?
2.6. Другие типы архитектуры компьютеров
Для расширения кругозора целесообразно рассмотреть некоторые варианты
архитектуры построения компьютеров, отличающиеся от той архитектуры, речь
о которой шла в предыдущих разделах этой главы.
CISC- и RISC-архитектура компьютеров
Разработка машинного языка требует предварительного принятия многих
решений. Одно из них состоит в выборе между построением сложной машины,
способной декодировать и выполнять широкий спектр разнообразных команд, и
созданием более простой машины, которая будет иметь ограниченный набор
команд. К первому варианту относятся компьютеры с CISC-архитектурой (Complex
Instruction Set Computer — компьютер со сложным набором команд), а ко
второму — компьютеры с RISC-архитектурой (Reduced Instruction Set Computer —
компьютер с ограниченным набором команд). CISC-компьютер проще
программировать, поскольку единственная его команда позволяет решить задачу,
выполнение которой в RISC-компьютере потребует длинной последовательности
более простых команд. Однако CISC-компьютер сложнее сконструировать, и он
обходится дороже как при создании, так и при эксплуатации. Более того, многие
2.6. Другие типы архитектуры компьютеров 137
сложные команды найдут лишь ограниченное применение, вследствие чего могут
оказаться просто балластом, создающим дополнительную бесполезную нагрузку.
Для уменьшения числа используемых электронных цепей CISC-процессоры
обычно конструируются по двухуровневой схеме, при которой каждая машинная
команда в действительности выполняется как последовательность простейших
операций. В такие процессоры обычно встроен блок специальных ячеек памяти,
называемых памятью микрокоманд, в которых записана программа, именуемая
микропрограммой. Именно эта микропрограмма управляет выполнением
сложных команд машинного языка. Кроме того, в микропрограмму можно вносить
коррективы и тем самым изменять смысл команд машинного языка. Таким
образом, помимо поддержки расширенного набора команд CISC-процессоров,
реализуемой без использования сложных электронных схем, наличие
микропрограммы позволяет настраивать один и тот же тип центрального процессора на
поддержку различных специализированных команд машинного языка просто
посредством внесения необходимых изменений в микропрограмму.
Сторонники RISC-архитектуры заявляют, что все эти преимущества не
оправдывают издержки, связанные с поддержкой микропрограммирования. Они
утверждают, что лучше спроектировать более простую машину с небольшим, но тщательно
продуманным набором команд. Такой подход позволяет избежать усложнения
конструкции, связанного с поддержкой памяти микропрограмм, что приводит к
упрощению проектирования центрального процессора. Однако это означает, что
программы на машинном языке для RISC компьютеров будут значительно длиннее
программ для CISC-компьютеров, так как для выполнения сложных операций
потребуется несколько отдельных машинных команд, тогда как в CISC-архитектуре
тот же результат достигается с помощью единственной команды.
В настоящее время на рынке представлены оба вида процессоров — как с
CISC-, так и с RISC-архитектурой. Процессоры серии Pentium, выпускаемые
компанией Intel, являются примером центральных процессоров с CISC-
архитектурой, тогда как процессоры серии PowerPC, выпускаемые компаниями
Apple Computer, IBM и Motorola, имеют RISC-архитектуру.
Конвейерная обработка
Скорость прохождения электронных импульсов по проводам не превышает
скорости света. Поскольку скорость света составляет около 30 см в наносекунду
(одна миллиардная часть секунды), потребуется не менее двух наносекунд,
чтобы блок управления центрального процессора выбрал команду из ячейки
памяти, которая находится от него на расстоянии около 30 см. Запрос на считывание
должен поступить в схемы основной памяти, для чего потребуется не менее
одной наносекунды. После этого выбранная команда должна быть доставлена в
блок управления, что также потребует не менее одной наносекунды.
Следовательно, чтобы выбрать и выполнить команду, машине потребуется несколько
наносекунд, а это означает, что увеличение скорости выполнения команд прямо
связано с проблемой его миниатюризации. Несмотря на фантастический прогресс
в этой области, все же рано или поздно будет достигнут теоретический предел.
138 Глава вторая. Обработка данных
Попытки решить эту проблему привели к тому, что конструкторы
вычислительных машин заменили исходную концепцию скорости выполнения команд
принципом пропускной способности. Этот термин означает общее количество работы,
которое машина способна выполнить за определенный период времени, при этом
продолжительность выполнения отдельного задания в расчет не принимается.
Приведем пример того, как можно повысить пропускную способность
компьютера без увеличения скорости выполнения команд. В данном случае
используется подход, называемый конвейерной обработкой, согласно которому
выполнение этапов машинного цикла может перекрываться во времени. Например, во
время этапа выполнения одной из команд для следующей команды уже может
выполняться этап выборки, а это означает, что выполнение более одной команды
одновременно осуществляется по принципу "конвейера", т.е. каждая из них
будет находиться на разной стадии выполнения. В результате общая пропускная
способность компьютера увеличится, причем без повышения скорости выборки и
выполнения каждой отдельной команды. Естественно, когда машина достигнет
команды перехода, все преимущества от предварительной выборки и
выполнения последующих команд будут утрачены, так как в действительности
потребуется выполнение совершенно других команд, которых в данное время на
"конвейере" нет.
Конструкции современных процессоров оставляют далеко позади
рассмотренный выше простейший пример конвейерной обработки. Современные процессоры
способны выбирать сразу несколько команд за одно и то же время, а также
реально выполнять больше одной команды одновременно, если только их действия
не являются взаимозависимыми.
Многопроцессорные машины
Использование конвейерного режима можно рассматривать как первый шаг в
направлении реализации параллельной обработки, предусматривающей
одновременное выполнение сразу нескольких действий. Однако параллельная
обработка требует использования нескольких устройств обработки данных, что
приводит к необходимости создания многопроцессорных машин.
Аргументом в пользу создания многопроцессорных машин может стать не что
иное, как модель работы человеческого мозга. Современные технологии уже
позволяют создавать электронные схемы, в которых есть столько же
переключающих цепей, сколько нейронов в мозге человека (нейроны можно рассматривать как
живые переключающие схемы). Несмотря на это, возможности современных
компьютеров все еще значительно уступают возможностям человеческого мозга.
Считается, что это происходит из-за неэффективного использования компонентов
машин, вызванного недостатками архитектуры компьютеров. Действительно, если в
компьютере установлено множество схем памяти и всего один центральный
процессор, то большинство схем памяти в любой момент времени просто не
используется. В противоположность этому, большая часть человеческого мозга в любой
момент времени пребывает в активном состоянии. По этой причине сторонники
параллельной обработки выступают в защиту машин, имеющих несколько устройств
2.6. Другие типы архитектуры компьютеров 139
обработки данных. Они заявляют, что такое решение способствует созданию
конфигурации с более высокой степенью использования элементов.
По этому принципу было разработано большое количество машин. Один
подход предусматривает подключение к одним и тем же ячейкам основной памяти
нескольких устройств обработки данных, каждое из которых напоминает
обычный центральный процессор однопроцессорной машины. В такой конфигурации
процессоры могут работать независимо, координируя свои действия посредством
обмена сообщениями через общие ячейки памяти. Например, когда один
процессор получает большое и сложное задание, он может записать программу для
выполнения части этого задания в общем поле памяти, а затем послать другому
процессору запрос на ее выполнение. В результате мы получим машину, в
которой разные последовательности команд выполняют обработку разных наборов
данных. Подобная архитектура носит название MIMD (multiple instruction
stream, multiple-data stream — множество потоков команд с множеством потоков
данных). Очевидно, что она является противоположной по отношению к
традиционной архитектуре компьютеров, называемой SISD (single instruction stream,
single-data stream — один поток команд и один поток данных).
Еще одним вариантом архитектуры многопроцессорных компьютеров
является такое соединение процессоров между собой, которое позволит им
одновременно выполнять одну и ту же последовательность команд, но с разными наборами
данных. Этот вариант носит название архитектуры SIMD (single instruction
stream, multiple-data stream — один поток команд и множество потоков
данных). Машины этого типа больше всего подходят для выполнения таких
приложений, в которых один и тот же алгоритм обработки применяется к отдельным
наборам схожих элементов, составляющих один большой блок данных.
Еще один подход к реализации параллельной обработки заключается в
конструировании больших машин как некоего конгломерата из машин меньшего размера,
каждая из которых имеет собственную памятью и центральный процессор. В
подобной архитектуре каждая машина связана со своими соседями; в результате задача,
поставленная перед всей системой, может быть разделена на элементарные задания,
распределяемые между отдельными машинами. Таким образом, если задача,
поставленная перед одной внутренней машиной, может быть разделена на несколько
подзадач, то эта машина может "попросить" соседние машины выполнить все подзадачи
параллельно. В результате вся задача в целом может быть выполнена в
многопроцессорной машине намного быстрее, чем в однопроцессорной.
При разработке и использовании многопроцессорных машин мы сталкиваемся
с проблемой баланса нагрузки, т.е. динамического распределения задач между
различными процессорами в целях повышения эффективности их работы. Эта
проблема тесно связана с проблемой масштабирования, или разделения текущей
задачи на несколько подзадач, количество которых совместимо с количеством
доступных процессоров. Еще одна проблема заключается в сложности
распределения выделенных задач. Действительно, если количество задач возрастает, то
объем работы, связанной с их распределением и координацией взаимодействия
между отдельными подзадачами, растет экспоненциально. Если имеется четыре
задачи, то можно выделить шесть потенциальных пар задач, которым потребует-
140 Глава вторая. Обработка данных
ся взаимодействовать друг с другом. Если имеется пять задач, то количество
потенциальных каналов взаимодействия возрастает до десяти, а в случае с шестью
задачами это количество увеличится до пятнадцати.
В главе 10 мы познакомимся с искусственными нейронными сетями,
конструкция которых основана на наших знаниях о структуре человеческого мозга.
Подобные конструкции представляют собой еще один тип многопроцессорной
архитектуры, так как они состоят из множества элементарных процессоров или
устройств обработки информации, выходные данные которых — это просто
реакция такого устройства на поступившие входные данные. Все эти простые
процессоры соединены между собой и образуют сеть, в которой выходные данные
одних процессоров являются входными данными для других процессоров. Такая
машина программируется посредством настройки степени влияния выходных
данных каждого процессора на реакцию соединенных с ним процессоров. В
какой-то степени этот подход имитирует способ, в соответствии с которым, как
считается, происходит обучение нашего мозга. Точнее говоря, биологические
сети нейронов головного мозга человека учатся реагировать определенным образом
на заданные стимулы посредством управления химическим составом соединений
(синапсов) между отдельными нейронами, что, в свою очередь, контролирует
способность одного нейрона влиять на действия других нейронов.
Вопросы для самопроверки
1. Почему для работы машины с микропрограммным управлением требуются
два счетчика адреса и два регистра команд?
2. Еще раз вернемся к вопросу 3 из раздела 2.3. Если в машине будет
применяться обсуждавшаяся выше технология конвейерной обработки, то какая
команда попадет на "конвейер", когда будет выполняться команда,
расположенная в ячейке с адресом АА? При каких условиях конвейерная обработка
на данном этапе программы не будет давать никаких преимуществ?
3. Какие противоречия должны быть разрешены при запуске программы,
приведенной в вопросе 4 из раздела 2.3, в машине с конвейерной обработкой
данных?
4. Предположим, что два "центральных" процессора подсоединены к одному и
тому же полю основной памяти и выполняют различные программы. Более
того, в одно и то же время одному из процессоров требуется прибавить
единицу к содержимому некоторой ячейки памяти, а другому необходимо отнять
единицу от содержимого этой же ячейки. (Общий результат этих действий
должен быть таким, что содержимое данной ячейки останется неизменным.)
а) Опишите последовательность действий, которая приведет к тому, что в
результате их выполнения содержимое данной ячейки будет на единицу
меньше исходного значения.
б) Опишите, какая последовательность действий приведет к тому, что в
результате их выполнения содержимое данной ячейки будет на единицу
больше исходного значения.
2.6. Другие типы архитектуры компьютеров 141
Упражнения
(Упражнения, отмеченные звездочкой, относятся к разделам для
дополнительного чтения.)
1. Дайте краткое определение следующим понятиям,
а) Регистр б) Кэш-память
в) Основная память г) Массовая память
2. Предположим, что в ячейках памяти машины, описанной в
приложении В, записан блок данных с адресами от В9 и до С1 включительно.
Сколько ячеек памяти содержит этот блок? Перечислите их адреса.
3. Каким будет значение в счетчике адреса машины, описанной в
приложении В, непосредственно после выполнения команды с кодом ВОВА?
4. Предположим, что ячейки памяти с адресами от 00 до 05 в машине,
описанной в приложении В, содержат следующие битовые комбинации.
Адрес Содержимое
00 21
01 04
02 31
03 00
04 СО
05 00
Исходя из предположения, что исходно счетчик адреса содержал
значение 00, запишите содержимое счетчика адреса, регистра команд и
ячейки памяти по адресу 00 в конце фазы выборки каждого
машинного цикла до тех пор, пока машина не остановится.
5. Предположим, что в машинной памяти записаны три числа (х, у и г).
Опишите последовательность действий (загрузка значений из памяти в
регистры, сохранение результатов в памяти и т.д.), необходимых для
вычисления суммы х + у + z. А какая последовательность действий
потребуется для вычисления значения выражения (2х) + у?
6. Ниже приведено несколько команд на машинном языке, описанном в
приложении В. Дайте текстовое описание этих команд,
а) 407Е б) -9028 в) А302
г) B3AD д) 2835
7. Предположим, что в некотором машинном языке поле кода операции
имеет длину четыре бита. Сколько различных типов команд может
существовать в этом языке? Что можно сказать по этому поводу, если
длина поля кода операции будет увеличена до 8 бит?
142 Глава вторая. Обработка данных
8. Запишите приведенные ниже команды на машинном языке,
описанном в приложении В.
а) Загрузить в регистр 8 содержимое ячейки памяти с адресом 55.
б) Загрузить в регистр 8 шестнадцатеричное число 55.
в) Выполнить циклический сдвиг содержимого регистра 4 на три бита
вправо.
г) Выполнить операцию AND над содержимым регистров F и 2,
поместив результат операции в регистр 0.
д) Выполнить переход к команде, расположенной по адресу 31, если
содержимое регистра 0 будет равно содержимому регистра В.
9. Распределите на три категории приведенные ниже команды
(записанные на машинном языке, описанном в приложении В), исходя
из того, изменит ли выполнение команды содержимое ячейки памяти
с адресом ЗВ, позволит ли выполнение команды считать содержимое
ячейки памяти с адресом ЗВ или же данная команда никак не зависит
от содержимого ячейки памяти с адресом ЗВ.
а) 153В б) 253В в) 353В
г) ЗВЗВ д) 403В
10. Предположим, что в машине, описанной в приложении В, ячейки памяти
с адресами от 00 до 03 содержат следующие битовые комбинации.
Адрес Содержимое
00 23
а) Дайте текстовую формулировку первой команды.
б) Если в начале работы машины содержимое счетчика адреса будет
равно 00, какая битовая комбинация окажется в регистре 3, когда
машина выполнит команду останова?
11. Предположим, что в машине, описанной в приложении В, ячейки памяти
с адресами от 00 до 05 содержат следующие битовые комбинации.
Адрес Содержимое
00 10
Дайте ответ на поставленные ниже вопросы, полагая, что машина
начинает работу со счетчиком адреса, равным 00.
а) Сформулируйте текстовое описание каждой команды.
б) Какая битовая комбинация будет находиться в ячейке памяти с
адресом 45, после того как машина выполнит команду останова?
в) Какая битовая комбинация будет находиться в счетчике адреса,
когда машина выполнит команду останова?
12. Предположим, что в машине, описанной в приложении В, ячейки памяти
с адресами от 00 до 09 содержат следующие битовые комбинации.
Адрес Содержимое
00 1А
01 02
Будем считать, что машина начинает работу со счетчиком адреса,
равным 00.
а) Какое значение будет находиться в ячейке памяти с адресом 00,
когда машина выполнит команду останова?
б) Какая битовая комбинация будет находиться в счетчике адреса,
когда машина выполнит команду останова?
13. Предположим, что в машине, описанной в приложении В, ячейки памяти
с адресами от 00 до 0D содержат следующие битовые комбинации.
144 Глава вторая. Обработка данных
07 12
08 Bl
09 ОС
OA ВО
OB Об
ОС СО
0D 00
Будем считать, что машина начинает работу со счетчиком адреса,
равным 00.
а) Какая битовая комбинация будет находиться в регистре 1, когда
машина выполнит команду останова?
б) Какая битовая комбинация будет находиться в регистре 0, когда
машина выполнит команду останова?
в) Какая битовая комбинация будет находиться в счетчике адреса,
когда машина выполнит команду останова?
14. Предположим, что в машине, описанной в приложении В, ячейки
памяти с адресами от F0 до FD содержат следующие битовые
комбинации (шестнадцатеричные).
Если машина начнет работу со счетчиком адреса, имеющим
значение F0, какое значение будет находиться в регистре 0, когда машина
выполнит команду останова, расположенную в ячейке с адресом FC?
Упражнения 145
15. Если машина, описанная в приложении В, выполняет каждую
команду за одну микросекунду (миллионная доля секунды), сколько
времени займет выполнение программы, приведенной в задаче 14?
16. Предположим, что в машине, описанной в приложении В, в ячейках
памяти с адресами от 00 до 05 содержатся следующие битовые
комбинации (шестнадцатеричные).
Адрес Содержимое
00 25
01 ВО
02 35
03 04
04 СО
05 00
Когда машина выполнит команду останова, если она начнет работу
при содержимом счетчика адреса 00?
17. Для каждого приведенного ниже задания напишите небольшую
программу на машинном языке, описанном в приложении В,
предназначенную для его выполнения. Исходите из того, что каждая программа
будет записана в памяти, начиная с адреса 00.
а) Переместите значение, сохраняемое в ячейке памяти с адресом 8D,
в ячейку с адресом ВЗ.
б) Поменяйте местами значения, записанные в ячейках с адресами 8D
и ВЗ.
в) Если значение, записанное в ячейке памяти с адресом 45, равно 00,
запишите значение СС в ячейку памяти с адресом 88, в противном
случае запишите значение DD в ячейку памяти с адресом 88.
18. Одной из популярных среди любителей компьютеров игр является core
wars (война сердечников). (Термин core использовался в устаревших
технологиях создания основной памяти, где нули и единицы представлялись
магнитными полями в небольших кольцевых сердечниках из магнитного
материала.) Игра проводится между двумя программами, выступающими
друг против друга, которые записаны по разным адресам общей памяти
компьютера. Предполагается, что компьютер постоянно переключается с
одной программы на другую, т.е. выполняет одну команду первой
программы, после чего немедленно выполняет одну команду второй
программы и т.д. Цель каждой программы — уничтожение другой программы
посредством записи посторонних данных поверх ее текста, сохраняемого в
основной памяти. Однако ни одна из программ не знает места
расположения другой программы.
146 Глава вторая. Обработка данных
а) Напишите игровую программу на машинном языке (описанном в
приложении В), реализующую стратегию обороны, т.е. имеющую
минимально возможный размер.
б) Напишите игровую программу на машинном языке, описанном в
приложении В, стратегия которой будет построена на стремлении
избежать любых нападений другой программы посредством перемещения
самой себя по различным адресам основной памяти. Точнее говоря,
напишите программу, начинающуюся с адреса 00, которая при
выполнении должна копировать себя в ячейки памяти, начиная с адреса 70,
а затем передавать управление этой новой копии.
в) Модернизируйте программу из пункта б), чтобы она продолжала
свое перемещение по новым адресам. В частности, пусть программа
переместит себя по адресу 70, затем по адресу Е0 (70 + 70), а
затем по адресу 60 (70 + 70 + 70) и т.д.
19. Напишите программу на машинном языке, описанном в
приложении В, которая будет вычислять сумму чисел, представленных в
двоичном дополнительном коде и сохраняемых в ячейках с адресами А1,
А2, A3, А4. Результат должен быть записан в ячейку с адресом А5.
20. Предположим, что в машине, описанной в приложении В, ячейки
памяти с адресами от 00 до 05 содержат следующие битовые
комбинации (шестнадцатеричное представление).
Что произойдет, если машина начнет работу со счетчиком адреса,
имеющим значение 00?
21. Что произойдет, если в машине, описанной в приложении В, ячейки
памяти с адресами Об и 07 будут содержать битовые комбинации ВО
и Об и машина начнет работу со счетчиком адреса, имеющим
значение 06?
22. Предположим, что приведенная ниже программа написана на
машинном языке, описанном в приложении В, и записана в память машины,
начиная с ячейки с адресом 30 (шестнадцатеричное представление).
Какое задание будет выполнено программой после ее завершения?
2003
2101
Упражнения 147
2200
2310
1400
3410
5221
5331
3239
333В
В248
В038
С000
23. Опишите этапы выполнения машиной, описанной в приложении В,
команды с кодом операции В. Представьте свой ответ в виде набора инструкций,
указывающих центральному процессору, что и как нужно делать.
*24. Опишите этапы выполнения машиной, описанной в приложении В,
команды с кодом операции 5. Представьте свой ответ в виде набора инструкций,
указывающих центральному процессору, что и как нужно делать.
*25. Опишите этапы выполнения машиной, описанной в приложении В,
команды с кодом операции 6. Представьте свой ответ в виде набора инструкций,
указывающих центральному процессору, что и как нужно делать.
*26. Предположим, что регистры 4 и 5 в машине, описанной в приложении В,
содержат битовые комбинации ЗС и С8 соответственно. Какая комбинация
окажется в регистре 0 после выполнения следующих команд,
а) 5045 б) 6045 в) 7045
г) 8045 д) 9045
*27. Используя машинный язык, описанный в приложении В, напишите
программы для выполнения приведенных ниже заданий.
а) Скопируйте битовую комбинацию, записанную в ячейке памяти с
адресом 66, в ячейку с адресом ВВ.
б) Присвойте четырем младшим битам ячейки памяти с адресом 34
значение 0, не изменяя при этом значения остальных ее битов.
в) Скопируйте четыре младших бита из ячейки памяти с адресом А5 в
четыре младших бита ячейки с адресом А6, не изменяя при этом
значения остальных битов ячейки с адресом Аб.
г) Скопируйте четыре младших бита из ячейки памяти с адресом А5 в
четыре старших бита этой же ячейки. (В результате первые четыре бита в
ячейке с адресом А5 будут идентичны ее последним четырем битам.)
*28. Выполните указанные операции.
а) 111000 б) 000100
AND 101001 AND 101010
48 Глава вторая. Обработка данных
*29. Укажите значение маски и тип логической операции, необходимые для
выполнения указанных ниже действий.
а) Поместите значение 0 в четыре средних бита восьмибитовой
комбинации, не изменяя состояния других ее битов.
б) Получите двоичное дополнение для комбинации из восьми битов.
в) Определите двоичное дополнение для старшего бита восьмибитовой
ячейки памяти без изменения состояния остальных ее битов.
г) Поместите значение 1 в старший бит восьмибитовой комбинации, не
изменяя состояния остальных ее битов.
д) Поместите значение 1 во все биты восьмибитовой комбинации,
кроме самого старшего, оставив его значение неизменным.
*30. Укажите тип логической операции (вместе с соответствующей маской),
которая при применении к входной восьмибитовой строке даст на
выходе строку из всех нулей тогда и только тогда, когда входная строка
будет иметь значение 10000001.
*31. Укажите последовательность логических операций (вместе с
соответствующими масками), которые при применении ее к входной
восьмибитовой строке дадут на выходе строку из всех нулей тогда и только тогда,
когда входная строка будет начинаться и заканчиваться битом со
значением 1. Во всех остальных случаях выходная строка должна будет
содержать по крайней мере один единичный бит.
*32. Каков будет результат выполнения операции циклического сдвига на
четыре бита влево для следующих битовых комбинаций,
а) 10101 б) 11110000 в) 001
г) 101000 д) 00001
*33. Каким будет результат выполнения циклического сдвига на один бит
вправо для следующих байтов, представленных в шестнадцатеричной
системе? Ответы также должны быть представлены в
шестнадцатеричной системе,
a) 3F б) 0D в) FF г) 77
*34. Напишите программу на машинном языке, описанном в приложении В,
которая изменит содержимое ячейки памяти с адресом 8С на обратное.
Упражнения 149
*35. Успеет ли принтер, печатающий 40 знаков в секунду, вывести строку
из символов кода ASCII (каждый имеет бит четности), последовательно
поступающих со скоростью 300 бит/с? А если скорость передачи будет
1200 бит/с?
*36. Предположим, что человек вводит с клавиатуры по 30 слов в минуту,
причем каждое слово состоит из пяти символов. Если считать, что
машина каждую микросекунду (миллионная доля секунды) выполняет
одну команду, то сколько команд выполнит эта машина, пока с
клавиатуры будут введены два символа?
*37. Сколько битов в секунду должна передавать клавиатура в компьютер,
чтобы успевать за пользователем, выполняющим ввод со скоростью 30
слов в минуту? (Предположим, что каждый символ шифруется в коде
ASCII и имеет бит четности, а каждое слово состоит из пяти символов.)
*38. Какую скорость передачи информации, выраженную в битах в секунду,
будет иметь система связи, способная передавать любую
последовательность из восьми различных состояний с максимальной скоростью
300 состояний в секунду?
*39. Предположим, что машина, описанная в приложении В, для работы с
принтером использует метод отображения ввода/вывода в память.
Также предположим, что адрес FF используется для передачи символов
в принтер, а адрес FE — для получения информации о состоянии
принтера. В частности, будем считать, что младший бит ячейки с
адресом FE определяет готовность принтера получить еще один символ
(значение 0 означает неготовность, а значение 1 — готовность получить
очередной символ). Напишите на машинном языке программу,
начинающуюся с адреса 00, которая будет ожидать, пока принтер сообщит
о готовности принять очередной символ, а затем отправит ему символ,
представленный битовой комбинацией в регистре 5.
*40. Напишите программу на машинном языке, описанном в
приложении В, которая будет помещать значения 00 во все ячейки основной
памяти с адресами от АО до СО и одновременно будет достаточно
небольшого размера, чтобы помещаться в ячейках памяти с адресами
от 00 до 13 (шестнадцатеричными).
*41. Предположим, что машина, имеющая на жестком диске 500 Мбайт
свободной памяти, принимает данные по телефонной линии связи со
скоростью 14 400 бит/с. Сколько времени ей понадобится, чтобы
заполнить данными все свободное место на жестком диске?
*42. Предположим, что линия связи используется для последовательной
передачи данных со скоростью 14 400 бит/с. Сколько битов данных будет
искажено, если возникнет радиопомеха общей длительностью
0,01 секунды?
150 Глава вторая. Обработка данных
*43. Предположим, что имеется 32 процессора, каждый из которых
способен определить сумму двух многозначных чисел за миллионную долю
секунды. Опишите, как применить методы параллельной обработки,
чтобы обеспечить вычисление суммы 64 чисел всего за шесть
миллионных долей секунды. Сколько времени потребуется одному процессору
для определения этой суммы?
*44. Кратко опишите основные отличия между CISC- и RISC-
архитектурами.
*45. Кратко опишите отличия между основной памятью и памятью
микропрограмм.
*46. Опишите два подхода к увеличению пропускной способности машины.
*47. Объясните, как среднее значение для некоторого набора чисел может
быть вычислено быстрее в многопроцессорной машине, чем в машине,
имеющей только один процессор.
|;^ Социальные и общественные вопросы
Следующие вопросы приводятся для того, чтобы помочь вам разобраться в
некоторых этических, общественных и юридических аспектах использования
вычислительной техники, а также в ваших собственных воззрениях и тех
принципах, на которых они основаны. Задача не сводится к тому, чтобы просто дать
ответы на предложенные вопросы. Вы должны разобраться, почему вы ответили
именно так, а не иначе, и насколько ваши суждения по различным вопросам
согласуются друг с другом.
1. Предположим, что фирма-производитель вычислительных машин
разработала новую архитектуру машины. В какой степени данной фирме
может быть позволено обладать правом собственности на эту
архитектуру? Какая политика в подобных случаях будет оптимальной с точки
зрения общества?
2. В какой-то мере 1923 год можно считать годом рождения так
называемой модели планируемого устаревания. Именно в этом году
компания General Motors, возглавляемая Альфредом Слоэном (Alfred
Sloan), ввела в автомобильной индустрии понятие модели года. Идея
состояла в том, чтобы повысить уровень продаж посредством
изменения моды, а не изготовления лучшей машины. Часто цитируется
следующее высказывание Слоэна: "Мы хотим заставить вас быть
неудовлетворенными имеющейся у вас сейчас моделью машины, чтобы вы
покупали новые". В какой мере эта коммерческая уловка применяется
в современной компьютерной индустрии? Можно ли действительно
считать устаревшей машину, бывшую наиболее мощной всего шесть
месяцев назад?
Социальные и общественные вопросы 151
3. Мы часто думаем о том, как компьютерная технология изменила наше
общество. Однако многие считают, что эта технология часто была
сдерживающим фактором для распространения многих нововведений
только потому, что поддерживала старые системы и позволяла им не
только выжить, но и укрепить свои позиции. Как вы думаете,
сохранилось бы господство нью-йоркской фондовой биржи и осталось бы
неизменным влияние правительства США на жизнь общества, если бы
компьютерных технологий не существовало? Какую степень влияния
имела бы сейчас централизованная власть, если бы компьютерные
технологии были для нее недоступны? Как бы мы жили, лучше или
хуже, при отсутствии компьютерных технологий?
4. Можно ли считать этичным для личности утверждение, что ей не
нужно знать какие-либо подробности об устройстве и принципах
работы машины, поскольку есть люди, которые занимаются разработкой
таких машин, их обслуживанием и решением всех проблем,
возникающих при их эксплуатации? Будет ли предоставленный вами ответ
отличаться, если речь идет о компьютере, автомобиле, атомной
станции или тостере?
5. Предположим, что фирма-изготовитель выпустила компьютерную
микросхему на рынок, а позднее обнаружила в ее конструкции
недоработку. В результате она решает не отзывать уже выпущенные схемы
и сохраняет сведения о дефекте в секрете, мотивируя это тем, что ни
одна из выпущенных микросхем не используется в таких
приложениях, где это может иметь какие-либо последствия. Принесло ли кому-
либо вред такое решение фирмы?
6. Помогает ли развитие технологии лечить заболевания сердца или,
наоборот, ведет к сидячему образу жизни, который является важной
причиной сердечно-сосудистых заболеваний?
7. В журнале Walden напечатана статья Гэнри Дэвида Тореау (Henry
David Thoreau), в которой он заявляет, что мы стали орудиями своих
собственных орудий. Он считает, что, вместо того чтобы получать от
них пользу, мы тратим все свое время на приобретение и
обслуживание этих инструментов. В какой мере это утверждение справедливо по
отношению к компьютерам? Например, если у вас есть собственный
персональный компьютер, соизмеримо ли время, потраченное на то,
чтобы заработать средства на его покупку, обучение тому, как им
пользоваться, на его обслуживание, усовершенствование и ремонт со
временем, которое вы провели, получая пользу от своего
приобретения? Когда вы пользуетесь компьютером, то считаете ли вы, что
хорошо проводите время? Зависит ли степень вашей социальной
активности от наличия собственного компьютера?
8. Легко представить себе те финансовые или навигационные
катастрофы, которые могут произойти в результате арифметических просчетов,
152 Глава вторая. Обработка данных
вызванных ошибками при усечении или переполнении. А какими, по
вашему мнению, будут последствия ошибок в системах запоминания
изображений (например, тех, которые используются при зондировании
или определении медицинского диагноза)?
Рекомендуемая литература
Hamacher V.C., Vranesic Z.G., Zaky S.G. Computer Organisation, 4th ed. — New
York: McGraw-Hill, 1996.
Knuth D.E. The Art of Computer Programming. Vol. 1, 3rd ed. — Reading, MA:
Addison-Wesley Longman, 1998. (Имеется русский вариант этой книги: Кнут
Д. Э. Искусство программирования. Т.1. Полу численные алгоритмы, 3-е
изд. — М.: Издательский дом "Вильяме", 2000.)
Patterson D.A., Hennessy J.L. Computer organization and Design.— San
Francisco: Morgan Kaufmann, 1994.
Дополнительная литература
Столлингс В. Устройство и архитектура компьютеров, 5-е изд. — М.:
Издательский дом "Вильяме", готовится к выпуску в 2001 г.
Stallings W. Computer Organization and Architecture. 5-th ed. — Upper Saddle
River, NJ: Prentice Hall Inc, 2000. (Русский вариант этой книги: Столлингс В.
Устройство и архитектура компьютеров, 5-е изд. — М.: Издательский дом
"Вильяме", готовится к выпуску в 2001 г.)
Рекомендуемая литература 153
Часть
Программное обеспечение
В части I мы рассмотрели основные компоненты компьютера —
осязаемые, вещественные элементы, которые принято называть
аппаратным обеспечением. В отличие от аппаратного
обеспечения, программы, которые выполняются на нем, неосязаемы и
классифицируются как программное обеспечение. В части II мы
сосредоточим внимание на вопросах, связанных именно с
программным обеспечением, что подведет нас к самому сердцу
компьютерных наук— изучению алгоритмов. В частности, мы
подробно познакомимся с созданием, способами
представления и взаимодействием алгоритмов.
Начнем с изучения операционных систем, описываемых в
главе 3. Эти системы представляют собой сложные пакеты
программ, контролирующие всю деятельность машины или группы
машин, объединенных в сеть. Затем, закончив знакомство с
операционными системами, мы естественным образом
перейдем к изучению сетей. Глава 4 посвящена алгоритмам, причем
главное внимание уделяется их разработке и представлению. В
главе 5 мы обсудим, как с помощью процесса
программирования алгоритмы преобразуются в форму, понятную машинам, и
рассмотрим свойства наиболее популярных языков
программирования. В главе 6 обсуждается весь процесс разработки
программного обеспечения в контексте принятой технологии
создания программных продуктов.
глава
Операционные
системы и сети
ТРЕТЬЯ
В настоящее время в компьютерных приложениях зачастую
требуется, чтобы на одной машине одновременно выполнялся ряд
действий, которые могут конкурировать друг с другом за
машинные ресурсы. Например, машина может быть соединена с
несколькими терминалами или рабочими станциями, с которых
различные пользователи смогут одновременно обращаться к
машине. Даже в конфигурации с единственным пользователем
может потребоваться выполнение нескольких взаимно
пересекающихся действий, таких как печать документа, модификация
другого документа и создание графического изображения,
предназначенного для включения в документ. Для выполнения
этих требований нужна высокая степень координации,
гарантирующая, что независимые действия не будут оказывать влияние
друг на друга, а взаимодействие взаимосвязанных заданий
будет эффективным и надежным. Эта координация
осуществляется с помощью программного комплекса, называемого
операционной системой.
Аналогичные проблемы координации и взаимодействия
возникают и в том случае, когда различные машины объединяются
в целях образования компьютерной сети. Решение этих
проблем — естественное расширение области применения
операционных систем. В этой главе мы обсудим основные понятия,
относящиеся к операционным системам и сетям.
3.1. Эволюция операционных систем
Однопроцессорные системы
Многопроцессорные системы
3.2. Архитектура операционных
систем
Обзор программного обеспечения
Компоненты операционной системы
Запуск операционной системы
3.3. Координация действий машины
Понятие процесса
Управление процессами
Модель "клиент/сервер"
*3.4. Организация конкуренции
между процессами
Семафоры
Взаимная блокировка
3.5. Сети
Классификация сетей
Internet
*3.6. Сетевые протоколы
Управление правом передачи данных
Многоуровневый подход
к организации сетевого
программного обеспечения
Семейство протоколов TCP/IP
3.7. Безопасность
* Звездочкой отмечены разделы,
рекомендованные для
факультативного изучения.
3.1. Эволюция операционных систем
Изучение операционных систем и сетей мы проведем в порядке их
возникновения и развития: от ранних однопроцессорных к более поздним
многопроцессорным системам.
Однопроцессорные системы
В 1940-1950 гг. однопроцессорные машины были недостаточно гибкими и
эффективными. Выполнение программ требовало определенной
предварительной подготовки оборудования: установки лент, загрузки перфокарт в
устройство чтения перфокарт, установки переключателей и т.д. Запуск
каждой программы, называемый заданием (job), производился по отдельности.
Если нескольким пользователям требовалось работать на одной и той же
машине, то предварительно составлялось специальное расписание,
позволяющее им зарезервировать машинное время. На протяжении отведенного
времени машина находилась полностью в распоряжении пользователя. Сеанс
обычно начинался с подготовки машины, после чего следовало выполнение
самой программы. Чаще всего сеанс заканчивался лихорадочными усилиями
пользователя сделать что-то еще ("Это займет только одну минуту!"), в то
время как следующий пользователь с нетерпением ожидал, когда он сможет
приступить к подготовке машины для своей задачи.
В подобной ситуации операционные системы создавались как средство для
упрощения подготовки программ и ускорения перехода от одного задания к
другому. Первой целью создания таких систем было отделение пользователя
от оборудования, что позволяло избавиться от постоянного потока людей,
входящих и выходящих из помещения, в котором находилась машина.
Дополнительно была введена должность оператора компьютера, задача которого
заключалась в выполнении всех операций непосредственно на оборудовании.
Каждый пользователь должен был предоставить оператору программу вместе
с необходимыми данными и специальными указаниями о ее требованиях, а
затем вернуться за результатами. Оператор загружал полученные материалы
в массовую память машины, откуда операционная система могла отправить
их на выполнение. Это было началом пакетной обработки — метода
выполнения заданий посредством предварительного объединения их в единый
пакет, который затем выполнялся без дальнейшего взаимодействия с
пользователем. Задания, ожидающие своего выполнения в массовой памяти, образуют
очередь заданий (рис. 3.1).
Очередь — это способ организации памяти, когда сохраняемые в ней объекты
(в нашем случае — задания) упорядочены по принципу "Первым вошел —
первым вышел" (FIFO, First-in, First-out), т.е. объекты покидают очередь в том же
порядке, в котором они в нее поступают. На самом деле большинство очередей
задач не следует в точности принципу FIFO, так как большая часть операцион-
158 Глава третья. Операционные системы и сети
ных систем поддерживает установку приоритетов задач. В результате
выполнение находящегося в очереди задания может быть отодвинуто на более поздний
срок заданием с более высоким приоритетом.
РИСУНОК 3.1
Пакетная обработка
В ранних системах пакетной обработки каждое задание сопровождалось
рядом инструкций, описывающих шаги, необходимые для подготовки машины к
выполнению этого конкретного задания. Эти инструкции кодировались на языке
управления заданиями (JCL, Job Control Language) и помещались вместе с
заданием в очередь задач. Когда задание выбиралось для выполнения, операционная
система распечатывала эти инструкции на принтере, чтобы оператор мог их
прочитать и выполнить. Инструкции, требовавшие вмешательства оператора,
касались главным образом управления неинтерактивным периферийным
оборудованием. Поскольку в настоящее время эти действия сведены к минимуму, язык
управления заданиями превратился, скорее, в язык общения с операционной
системой, а не с оператором компьютера. И действительно, должность оператора
компьютера стала практически ненужной. Теперь организации нанимают для
управления вычислительной системой системных администраторов. В их задачу,
вместо управления вычислительными системами в прежнем понимании этого
слова, входит получение нового оборудования и программного обеспечения,
наблюдение за его установкой, осуществление локального руководства,
включающего ведение учетных записей пользователей, определение лимитов дискового
пространства для отдельных пользователей и координацию усилий по решению
возникающих в системе проблем.
Главным недостатком традиционной пакетной обработки является то, что
пользователь лишен возможности взаимодействовать с программой с того
момента, как она поставлена в очередь. Такой подход допустим для приложений, в
которых все данные и процедуры определены заранее (например, при подготовке
платежных ведомостей). Однако он неприемлем, если пользователю необходимо
взаимодействовать с программой в процессе ее выполнения. Примером могут
3.1. Эволюция операционных систем
159
служить системы резервирования (мест, билетов), в которых информация о
резервировании и отказах должна быть доступна сразу же после поступления;
системы обработки текстов, поддерживающие интерактивное создание и обновление
документов; а также компьютерные игры, в которых взаимодействие с машиной
является основным элементом игры.
Для решения этих проблем были созданы новые операционные системы,
которые позволяют выполнять программы, ведущие диалог с пользователем,
работающим за удаленным терминалом или рабочей станцией. Такой режим
функционирования называется интерактивной обработкой (рис. 3.2). Для работы
интерактивных систем требуется, чтобы выполняемые машиной действия
координировались с происходящими в ее среде событиями. Эта координация
действий машины и среды именуется обработкой в реальном времени.
РИСУНОК 3.2
Интерактивная обработка
Если бы от интерактивных систем требовалось обслуживать в каждый момент
времени только одного пользователя, то обработка в реальном времени не
вызывала бы никаких проблем. Однако вычислительные машины стоили дорого,
поэтому каждая машина должна была обслуживать несколько пользователей.
Вполне типичной являлась ситуация, когда нескольким пользователям
одновременно требовалось получить доступ к машине в интерактивном режиме, поэтому
выполнение работы в реальном времени оказывалось затруднительным. Если в
такой многопользовательской среде операционная система будет придерживаться
строго поочередного выполнения заданий, то только один из пользователей
сможет получить удовлетворительное обслуживание в реальном времени.
Решение этой проблемы состоит в разработке операционной системы,
способной организовать постоянное чередование выполнения частей различных
заданий с помощью процесса разделения времени. Этот метод заключается в
разделении машинного времени на интервалы, или кванты, с последующим
ограничением времени непрерывного выполнения каждой программы одним квантом
времени за один раз. В конце каждого интервала текущее задание выгружается,
160
Глава третья. Операционные системы и сети
а во время следующего кванта выполняется новое. При быстром чередовании
заданий подобным образом создается иллюзия, что несколько заданий
выполняется в машине одновременно. В зависимости от типа выполняемых заданий,
ранние системы разделения времени позволяли обслуживать в реальном времени
одновременно до 30 пользователей.
Сегодня разделение времени активно используется как в
многопользовательских системах, так и в системах с одним пользователем, хотя раньше этот
режим назывался многозадачным, поскольку создавалась полная иллюзия
одновременного выполнения нескольких задач. Независимо от того, одно- или
многопользовательской является данная вычислительная среда, было установлено,
что применение режима разделения времени повышает эффективность работы
машины. Конечно, вас это может удивить, особенно если принять во внимание,
что процесс переключения заданий, обязательный при разделении времени,
требует немалых дополнительных затрат времени. Действительно, время,
потраченное на переключения между задачами, непродуктивно. Однако без
использования такого режима разделения времени компьютер большую часть своего
рабочего времени будет проводить в ожидании того, когда завершат работу
периферийные устройства или пользователь введет свой следующий запрос.
Режим разделения времени позволяет использовать это бесполезно теряемое время
на решение других задач. В результате пока одно задание ожидает какое-либо
событие, выполняется другое задание. В конечном итоге при использовании
режима разделения времени вся группа одновременно запущенных заданий будет
выполнена быстрее, чем в случае их последовательного выполнения.
Многопроцессорные системы
В последние годы необходимость в совместном использовании информации и
ресурсов различными машинами породила потребность соединить компьютеры
для обмена информацией. Для этого были созданы ставшие популярными
объединенные компьютерные системы, называемые сетями. Сегодня концепция
большой центральной машины, обслуживающей многих пользователей, в
основном уступила место концепции множества маленьких машин, объединенных в
сеть, в которой пользователи совместно используют ресурсы, рассредоточенные
по всей системе, — устройства печати, программные пакеты, устройства памяти
и информацию. Основной пример — это Internet, глобальная сеть сетей, которая
сегодня объединяет миллионы компьютеров во всем мире. Мы познакомимся с
Internet подробнее в разделах 3.5 и 3.6.
Большинство проблем координации действий, возникающих при создании
сетей, очень похожи на проблемы, с которыми пришлось столкнуться при
разработке операционных систем. Фактически программное обеспечение для
управления сетью может рассматриваться как сетевая операционная система. В этом
свете разработка сетевого программного обеспечения является естественным
расширением концепции операционной системы. Хотя первые сети создавались
как свободно соединяемые между собой отдельные машины, каждая из которых
управлялась собственной операционной системой, дальнейшие исследования в
3.1. Эволюция операционных систем 161
области сетевой технологии привели к появлению сетевых систем,
обеспечивающих совместное использование имеющихся ресурсов всеми выполняемыми в сети
задачами. Различные ресурсы поочередно выделяются выполняемым в сети
задачам согласно их потребностям, невзирая на физическое местонахождение этих
ресурсов. Примером может служить система серверов имен, существующая в
Internet, которую мы подробнее рассмотрим в разделе 3.5. Эта система позволяет
множеству машин, разбросанных по всему миру, работать совместно, решая
задачу перевода Internet-адресов из мнемонической формы, понятной человеку, в
цифровую, понятную установленному в сети оборудованию.
Выгодное единообразие или ограничивающая монополия?
Поскольку операционная система определяет основные принципы общения человека с компьютером,
представляется разумным утверждение, что использование стандартной операционной системы для
самого широкого класса машин — это хорошая идея. Подобная стандартизация означала бы, что операторские
навыки, приобретенные на одной машине, могут быть легко перенесены на другие машины. Более того,
разработчики прикладных программ избавились бы от необходимости создавать версии своих продуктов,
предназначенные для разных типов операционных систем. Однако эти аргументы не учитывают многих
реалий современного общества. В частности, производитель универсальной операционной системы
получил бы огромную власть на рынке, что может принести пользователям больше вреда, чем пользы. Многие
из этих вопросов поднимались противоборствующими сторонами в антимонопольном процессе, начатом
правительством США против корпорации Microsoft в 1998 г. Чтобы подробнее узнать об этом и других
подобных процессах, воспользуйтесь прекрасными возможностями изучения архивов, которые предоставляет
Web. По упомянутым выше вопросам материал можно найти на следующих Web-узлах:
http://newsweek.com, http://www.npr.org, http://www.nytimes.com,
http://washingtonpost.com.
Сети представляют собой только один из типов многопроцессорных
проектных решений, используемых при разработке современных операционных систем.
В то время как в сетях многопроцессорная система создается посредством
объединения отдельных машин, каждая из которых имеет только один центральный
процессор (ЦП), другие многопроцессорные системы разрабатываются как одна
машина с несколькими процессорами. Операционная система в такой машине
должна не только координировать взаимодействие между различными видами
деятельности, которые действительно выполняются одновременно, но и
контролировать процесс распределения действий по отдельным процессорам в машине.
В связи с этим возникают проблемы баланса загрузки (получение гарантий, что
все процессоры в системе используются одинаково эффективно), а также
масштабирования (разбиение задач на количество подзадач, совместимое с числом
процессоров в машине).
162 Глава третья. Операционные системы и сети
Мы видим, что появление многопроцессорных систем добавило много новых
направлений исследований в области операционных систем. Эти исследования,
несомненно, будут продолжаться и в будущем.
Вопросы для самопроверки
1. Приведите примеры очередей. В каждом случае укажите любые ситуации,
способные нарушить FIFO-структуру очереди.
2. Какие из приведенных ниже ситуаций требуют обработки в реальном времени.
а) Печать почтовых этикеток с адресами.
б) Компьютерная игра.
в) Отображение букв на экране монитора по мере их набора на клавиатуре.
д) Выполнение программы, предсказывающей состояние экономики в
будущем году.
3. Каковы различия между обработкой в реальном времени и интерактивной
обработкой?
4. Каковы отличия между режимом с разделением времени и многозадачностью?
3.2. Архитектура операционных систем
Для понимания архитектуры типичной операционной системы полезно
представлять себе полный спектр программного обеспечения, используемого в
стандартной вычислительной системе. Мы начнем обсуждение с обзора программного
обеспечения, включающего общую схему его классификации. В подобных
классификациях близкие элементы программного обеспечения зачастую помещаются
в различные классы, подобно тому как введение часовых поясов заставляет
близких соседей устанавливать свои часы с разницей в час, хотя моменты заката
и восхода у них почти совпадают. Более того, в случае с классификацией
программного обеспечения динамичность самого предмета и отсутствие признанных
авторитетов в этой области часто имеют следствием противоречивость
используемой терминологии. Например, в операционной системе Windows 98 фирмы
Microsoft имеется группа так называемых "вспомогательных программ",
содержащая по нашей классификации как программы из класса прикладных, так и
программы из класса утилит. Поэтому приводимую ниже классификацию
следует рассматривать скорее как средство, дающее некоторую точку опоры в
сложном предмете, а не как констатацию всеми признанного факта.
Обзор программного обеспечения
Первым делом разделим программное обеспечение на две общие категории:
прикладное программное обеспечение и системное программное обеспечение
(рис. 3.3.). Прикладное программное обеспечение включает программы,
предназначенные для решения задач, вытекающих из специфических особенностей ис-
3.2. Архитектура операционных систем 163
пользования данной машины. Машина, используемая при инвентаризации в
промышленной компании, будет иметь набор прикладных программ,
существенно отличающийся от того, который будет иметь машина, используемая в работе
инженером-электриком. Примером прикладного программного обеспечения
являются электронные таблицы, системы баз данных, настольные издательские
системы, системы разработки программ и игры.
В отличие от прикладного программного обеспечения, системное программное
обеспечение выполняет задачи, общие для всех вычислительных систем в целом.
Фактически системное программное обеспечение формирует среду, в которой
функционирует прикладное программное обеспечение, аналогично тому, как
государственная инфраструктура создает фундамент, на котором ее граждане
основывают свой индивидуальный стиль жизни.
| РИСУНОК 3.3
Программное обеспечение
Прикладное программное обеспечение Системное программное обеспечение
Служебная программа (утилита) Операционная система
Оболочка Ядро
Классификация программного обеспечения
Внутри класса системного программного обеспечения также есть две
категории: одна — собственно операционная система, вторая — элементы
программного обеспечения, объединяемые понятием обслуживающие программы,
или утилиты. Большую часть установленных в системе обслуживающих
программ составляют программы, предназначенные для выполнения действий,
необходимых для успешного функционирования компьютера, но еще не
включенные в операционную систему. В некотором смысле обслуживающие
программы объединяют элементы программного обеспечения, расширяющие
возможности операционной системы. Например, обычно операционная система
сама по себе не предоставляет средств форматирования диска или копирования
файлов, поэтому данные функции обеспечиваются обслуживающими
программами. К другим видам обслуживающих программ относятся программы для
установки соединений по телефонным линиям с использованием модема,
программы сжатия и распаковки данных, программное обеспечение для
осуществления сетевых соединений.
164 Глава третья. Операционные системы и сети
Предоставление определенных функциональных возможностей с помощью
обслуживающих программ существенно упрощает разработку операционной
системы. Более того, выполнение рутинных операций, реализуемых с помощью
утилит, легче настроить в соответствии с требованиями конкретной установки.
Действительно, вовсе не являются исключением компании или ' независимые
пользователи, модифицирующие или расширяющие возможности утилит,
поставляемых вместе с операционной системой.
Различие между прикладным и обслуживающим программным обеспечением
весьма условно. С нашей точки зрения различие заключается в том, является ли
пакет частью инфраструктуры программного обеспечения. Таким образом, новое
приложение может превратиться в утилиту, если оно становится одной из
основных сервисных программ. Различие между обслуживающими программами и
операционной системой также условно. В некоторых системах такая основная
функция, как ведение списка файлов в массовой памяти, представлена в виде
обслуживающих программ, в то время как другие системы встраивают ее в
операционную систему.
Компоненты операционной системы
Часть операционной системы, которая обеспечивает интерфейс операционной
системы с пользователями, часто называют оболочкой. Назначение оболочки —
организация взаимодействия с пользователем (или пользователями) системы.
Современные оболочки выполняют эту задачу с помощью графического
интерфейса пользователя (Graphical User Interface, GUI), в котором объекты
манипуляции, подобные файлам и программам, представлены на экране монитора в
виде небольших рисунков — пиктограмм. Подобные системы позволяют
пользователям вводить команды, указывая на эти пиктограммы и щелкая на них с
помощью управляемого рукой приспособления, называемого мышью. Прежние
оболочки поддерживали общение с пользователями посредством текстовых
сообщений, вводимых с клавиатуры и отображаемых на экране монитора.
Хотя оболочка операционной системы играет важную роль в определении
доступной на данной машине функциональности, она, тем не менее, является
всего лишь интерфейсом между пользователем и сердцем самой операционной
системы (рис. 3.4). Различие между оболочкой и внутренними частями
операционной системы подчеркивается тем фактом, что некоторые операционные
системы разрешают пользователю выбрать наиболее удобный для него тип оболочки.
Например, пользователи операционной системы UNIX могут выбрать одну из
оболочек, включая Borne, С или Когп. Ранние версии Windows также
представляли собой всего лишь оболочки для операционной системы MS-DOS. Во всех
этих случаях сама операционная система остается прежней — меняется лишь
способ ее общения с пользователями.
Главным компонентом современных графических оболочек является программа
управления окнами, которая распределяет отдельные блоки пространства экрана,
называемые окнами, и отслеживает, какое приложение ассоциируется с каждым из
этих окон. Когда приложение намеревается отобразить что-нибудь на экране, оно со-
3.2. Архитектура операционных систем 165
общает об этом программе управления окнами. В результате программа размещает
предоставленный трафарет в окне, соответствующем данному приложению. В свою
очередь, когда пользователь нажимает кнопку мыши, именно программа управления
окнами определяет положение указателя мыши на экране и уведомляет
соответствующее приложение об этом действии пользователя.
Оболочка как интерфейс между пользователями и операционной системой
Linux
Для энтузиастов, желающих поэкспериментировать с внутренними компонентами операционной системы,
существует ОС Linux. Эта операционная система была разработана Линусом Торвальдсом (Linus Torvalds),
в то время когда он был еще студентом университета в городе Хельсинки. Это некоммерческий продукт, и
потому данную операционную систему можно получить бесплатно вместе с документацией и исходным
текстом программ (подробности — в главе 5). Благодаря свободе доступа к предоставляемому исходному
коду, она стала весьма популярна среди тех, для кого компьютер — хобби, а также среди студентов,
изучающих операционные системы, и программистов вообще. Она приобрела большую популярность и в
качестве альтернативы коммерческим операционным системам, предлагаемым на рынке. Однако установка
Linux обычно требует более высокого уровня профессионализма, чем установка коммерческих продуктов
типа Microsoft Windows, которые чаще всего устанавливаются на персональных компьютерах
непосредственно в процессе их сборки на заводе-изготовителе. Дополнительные сведения о Linux можно найти на
Web-узле по адресу http: //www. linux. org.
166 Глава третья. Операционные системы и сети
В отличие от оболочки операционной системы, ее внутренняя часть обычно
называется ядром, которое включает компоненты программного обеспечения,
выполняющие основные функции в процессе приведения компьютера в рабочее
состояние. Одним из этих компонентов является программа управления
файлами, в задачу которой входит координация использования устройств массовой
памяти машины. Точнее говоря, эта программа поддерживает записи обо всех
файлах, содержащихся в массовой памяти, включая информацию о том, где
каждый из файлов находится, каким пользователям разрешен доступ к различным
файлам и какой объем массовой памяти может быть использован для записи
новых и расширения уже имеющихся файлов.
Для удобства пользователей большинство программ управления файлами
разрешает группировать файлы в группы, называемые каталогами, или папками.
Такой подход позволяет пользователям размещать свои файлы так, как им это
удобно, помещая связанные друг с другом файлы в один каталог. Более того,
каталоги могут содержать в себе другие каталоги, называемые подкаталогами, что
позволяет создавать из файлов иерархические структуры. Например,
пользователь может создать каталог Записи, который будет включать подкаталоги
Финансы, Медицина и Хозяйство. В каждом подкаталоге будут размещаться
файлы, относящиеся к соответствующей категории. Цепочка каталогов внутри
каталогов называется путем доступа.
Любой доступ к файлу со стороны других компонентов программного
обеспечения предоставляется и контролируется программой управления файлами.
Процедура получения доступа к файлу начинается с запроса к программе
управления файлами (этот запрос выполняется в рамках процедуры открытия файла).
Если программа управления файлами разрешает доступ, то она предоставляет
информацию, необходимую для поиска файла и работы с ним. Эта информация
записывается в область основной памяти, называемую дескриптором файла.
Любые действия с файлом осуществляются посредством обращения к информации,
содержащейся в дескрипторе файла.
Другой компонент ядра операционной системы представляет собой набор
драйверов устройств, т.е. элементов программного обеспечения,
взаимодействующих с контроллерами устройств (или же непосредственно с устройствами) в
целях выполнения различных операций в периферийных устройствах машины.
Каждый драйвер устройства специально разрабатывается для конкретного типа
устройства (например, принтера, дисковода, накопителя на магнитных лентах
или монитора). Он преобразует поступающие запросы в последовательность
команд выполнения отдельных физических операций, которые требуется
выполнить устройству, связанному с этим драйвером. В результате разработка других
элементов программного обеспечения может вестись независимо от
специфических особенностей конкретных устройств. Все это позволяет создать обобщенную
операционную систему, которая будет настраиваться на использование
определенных периферийных устройств с помощью простой установки
соответствующих драйверов.
Еще один компонент ядра операционной системы — программа управления
памятью, которая решает задачу координации использования машиной ее ос-
3.2. Архитектура операционных систем 167
новной памяти. В среде, где машина выполняет только одно задание в каждый
момент времени, обязанности этой программы минимальны. В этом случае
необходимая текущему заданию программа помещается в основную память,
выполняется, а затем заменяется программой для последующего задания. Однако в
многопользовательской среде или в среде со многими задачами, когда машина
должна обрабатывать множество запросов, поступающих в одно и то же время, у
программы управления памятью обширные обязанности. В этой ситуации в
основной памяти одновременно должно находиться множество программ и блоков
данных, причем каждая из программ занимает собственную область памяти,
отведенную ей программой управления памятью. По мере того как возникает
необходимость в выполнении различных действий и после их окончания,
программа управления памятью должна находить области памяти для удовлетворения
возникающих потребностей в памяти, а также отслеживать информацию о тех
участках памяти, которые уже освободились.
Задача программы управления памятью еще больше усложняется, когда
требуемый объем основной памяти превышает реально существующий объем. В
этом случае программа управления памятью может создать иллюзию увеличения
объема памяти путем перемещения программ и данных из основной памяти в
массовую и обратно. Этот иллюзорный объем памяти называется виртуальной
памятью. Предположим, что выполняемым программам требуется 64 Мбайт
основной памяти, а в наличии имеется только 32. Чтобы создать иллюзию
большего объема памяти, программа управления памятью делит требуемый объем на
элементы, называемые страницами, и хранит содержимое этих страниц в
массовой памяти. Типичный объем страницы — не больше 4 Кбайт. Программа
управления памятью помещает в основную память те страницы, которые в
данный момент должны там находиться, замещая ими те, в которых больше нет
потребности. Таким образом, остальные компоненты программного обеспечения
могут работать так, как если бы объем основной памяти машины действительно
составлял 64 Мбайт.
Кроме того, в состав ядра операционной системы входят планировщик и
диспетчер, о которых речь пойдет в следующем разделе. Сейчас мы только отметим,
что в системах с разделением времени планировщик определяет
последовательность выполняемых действий, а диспетчер контролирует распределение
временных квантов для них.
г"' ■::" *т*"ч
Запуск операционной системы
Мы уже обсудили, как операционная система взаимодействует с пользователями
и как компоненты операционной системы совместно осуществляют координацию
действий внутри машины. Однако еще не было сказано ни слова о том, как же
запускается сама операционная система. Запуск операционной системы
осуществляется с помощью процесса, называемого самозагрузкой (booting), который выполняется
при каждом включении машины. Первым шагом к пониманию этого процесса есть
осознание того, почему его необходимо выполнять на первом этапе.
168 Глава третья. Операционные системы и сети
Центральный процессор машины (ЦП) разработан таким образом, что при его
включении выполняемая им программа каждый раз стартует с определенного,
наперед заданного адреса. Следовательно, именно в этом месте основной памяти
ЦП ожидает найти первую команду, которую требуется выполнить. Чтобы
гарантировать, что требуемая программа всегда будет присутствовать на указанном
месте, этот участок памяти обычно конструируется так, чтобы его содержание
было неизменным. Такая память носит название постоянной памяти (постоянное
запоминающее устройство, ПЗУ). Последовательность битов, однажды
помещенная в ПЗУ с помощью специального процесса, аналогичного напылению
проводников на подложку чипа, находится там постоянно, независимо от того,
включена машина или выключена.
В маленьких компьютерах, используемых в качестве управляющих приборов
в микроволновых печах, автомобильных системах зажигания и стереоприемни-
ках, представляется удобным выделить значительный объем основной памяти
под ПЗУ, так как гибкость в таких системах не нужна. При каждом включении
выполняется одна и та же программа. Но в случае с универсальными
компьютерами ситуация другая и в них не практикуется отведение большого объема
основной памяти под постоянные программы. Содержимое памяти таких машин
должно быть изменяемым. Фактически большая часть памяти универсальных
компьютеров в настоящее время сконструирована так, что ее содержимое может
не только изменяться, но и теряться при выключении машины. Такая память
называется энергозависимой.
Поэтому для начальной загрузки в компьютерах общего назначения лишь
малая часть основной памяти строится из микросхем ПЗУ. Эта область содержит
ячейки памяти, в которых ЦП ожидает найти команды, выполняемые при
включении машины. Небольшая программа, которая постоянно находится в этой
области памяти, называется программой первоначальной загрузки (bootstrap).
Эта программа выполняется автоматически при каждом включении компьютера.
Она предписывает ЦП считать данные из заранее определенного участка
массовой памяти в энергозависимую основную память (рис. 3.5). В большинстве
случаев этими данными является программный код операционной системы. Как
только программы операционной системы будут помещены в основную память,
программа первоначальной загрузки потребует от ЦП выполнить команду
перехода в данную область памяти. В результате стартуют программы ядра, и
операционная система начинает контролировать дальнейшую деятельность машины.
В большинстве современных персональных компьютеров программа
первоначальной загрузки разработана так, что прежде всего она пытается отыскать
операционную систему на гибком диске (дискете). Если дискета в машину не
вставлена, программа загрузки автоматически приступает к считыванию
операционной системы с жесткого диска. Однако если дискета вставлена в устройство, но
не содержит копии операционной системы, программа загрузки приостановится
и выдаст сообщение об ошибке оператору. Вы, вероятно, сталкивались с этим,
когда включали персональный компьютер, забыв предварительно вынуть
несистемную дискету из дисковода.
3.2. Архитектура операционных систем 169
РИСУНОК 3.5
Этап 1. Машина начинает выполнять программу начальной загрузки,
находящуюся в памяти. Операционная система находится
в массовой (внешней) памяти
Этап 2. Программа начальной загрузки выдает указание поместить
операционную систему в оперативную память,
а затем передает ей управление
Процесс первоначальной загрузки
Вопросы для самопроверки
1. Перечислите компоненты типичной операционной системы и охарактеризуйте
роль каждого из них одной фразой.
2. В чем заключаются различия между прикладным программным обеспечением
и обслуживающими программами?
3. Что такое виртуальная память?
4. Опишите процедуру начальной загрузки.
170
Глава третья. Операционные системы и сети
3.3. Координация действий машины
В этом разделе мы рассмотрим, как операционная система координирует
выполнение прикладных программ, утилит и собственных программных элементов.
Начнем обсуждение с введения понятия процесса.
Понятие процесса
Одной из наиболее фундаментальных концепций в современных
операционных системах является разграничение между самой программой и
деятельностью, связанной с ее выполнением. Первое представляет собой
статический набор инструкций, в то время как второе — это динамическая
деятельность, свойства которой меняются во времени. Эта деятельность и
получила название процесса. Процесс охватывает текущее состояние работы,
называемое состоянием процесса. Это состояние включает текущую позицию
выполняемой программы (значение счетчика адреса), а также значения
прочих регистров центрального процессора и тех ячеек памяти, к которым
производится обращение. Говоря упрощенно, состояние процесса — это
моментальный снимок состояния машины в определенный момент времени. В
различные моменты выполнения программы (процесса) будут получаться
различные моментальные снимки (состояния процесса).
Чтобы подчеркнуть различие между программой и процессом, заметим, что
одна программа может быть связана одновременно с несколькими процессами.
Например, в многопользовательской системе с разделением времени двум
пользователям может одновременно потребоваться редактировать различные
документы. Оба могут использовать одну и ту же программу редактирования, но в
каждом случае это будет самостоятельный процесс, со своим набором данных и
относительной скоростью выполнения. В такой ситуации операционная система
может хранить в основной памяти только одну копию программы
редактирования и разрешить каждому из процессов пользоваться ею на время выделенного
ему кванта времени.
В типичной компьютерной установке с разделением времени в состязании за
кванты времени обычно принимает участие множество процессов. Эти процессы
включают выполнение прикладных программ, утилит и программных элементов
операционной системы. Задача операционной системы состоит в координации
выполнения всех этих процессов. Координация подразумевает получение
гарантий в том, что каждый процесс получит все необходимые ему ресурсы (доступ к
периферийным устройствам, место в основной памяти, доступ к данным и
центральному процессору); что независимые процессы не влияют друг на друга; а
процессы, которым необходимо обмениваться информацией, имеют возможность
делать это. Взаимодействие между процессами называется межпроцессным
взаимодействием.
3.3. Координация действий машины 171
Управление процессами
Задачи, связанные с координацией процессов, решаются планировщиком и
диспетчером, входящими в состав ядра операционной системы. Планировщик
ведет пул записей о процессах, присутствующих в вычислительной системе,
вводит в него сведения о новых процессах и удаляет информацию о
завершившихся. Для отслеживания состояния всех процессов планировщик организует в
основной памяти блок информации, называемый таблицей процессов. Каждый
раз, когда машине дается новое задание, планировщик создает процесс для этого
задания посредством занесения новой записи в таблицу процессов. Эта запись
содержит сведения об объеме выделенной процессу памяти (эта информация
поступает от модуля управления памятью), о присвоенном ему приоритете, а также
о том, находится процесс в состоянии готовности или ожидания. Процесс
находится в состоянии готовности, если его развитие может продолжаться, и
переводится в состояние ожидания, когда его развитие приостанавливается до тех пор,
пока не произойдут некоторые внешние события, например завершится
процедура доступа к диску или поступит сообщение от другого процесса.
Диспетчер — это компонент ядра, отвечающий за то, чтобы запланированные
процессы действительно выполнялись. В системе с разделением времени эта
задача решается посредством разбиения времени процессора на короткие
интервалы, называемые квантами (обычно продолжительностью около 50 миллисекунд).
По истечении этого времени происходит принудительное переключение
центрального процессора от одного процесса к другому; так что каждому процессу
предоставляется возможность непрерывного выполнения лишь в течение одного
кванта времени (рис. 3.6). Процедура смены одного процесса другим называется
переключением процессов.
Каждый раз, когда процессу предоставляется очередной квант времени,
диспетчер инициирует цепь таймера, подготавливая его к измерению продолжительности
следующего кванта. По окончании установленного кванта цепь таймера генерирует
сигнал, называемый прерыванием. Центральный процессор реагирует на этот
сигнал так же, как и человек, которого останавливают во время выполнения
определенного задания. Человек прекращает свою работу, записывает текущее состояние
задачи и обращает внимание на то, что его отвлекло. При получении сигнала
прерывания центральный процессор завершает текущий машинный цикл, сохраняет
свое положение в текущем процессе (подробнее мы обсудим это чуть ниже) и
начинает выполнять программу, называемую обработчиком прерываний,
помещенную в заранее определенное место в основной памяти.
В нашем сценарии разделения времени обработчик прерываний — это часть
диспетчера. Таким образом, результатом поступления сигнала прерывания
является приостановка текущего процесса и передача управления диспетчеру. В этот
момент диспетчер разрешает планировщику обновить состояние таблицы
процессов (например, возможно, что приоритет только что отработавшего свой квант
времени процесса следует понизить, а приоритеты других процессов —
повысить). Затем из таблицы процессов диспетчер выбирает процесс с наивысшим
172 Глава третья. Операционные системы и сети
приоритетом из числа процессов, находящихся в состоянии готовности, заново
инициализирует цепь таймера, после чего разрешает выбранному процессу
использовать новый квант времени.
РИСУНОК 3.6
Квант времени Квант времени Квант времени Квант времени
Разделение времени между процессами А и В
Главным условием успешной работы системы с разделением времени
является ее способность остановить, а затем повторно запустить процесс. Если
вас прерывают во время чтения книги, то возможность продолжить чтение
позднее зависит от вашей способности вспомнить, на чем вы остановились и что
прочли до этого момента. Короче говоря, вы должны иметь возможность воссоздать
ситуацию такой, какой она была непосредственно в момент прерывания. В
отношении процесса эта ситуация есть его состояние. Напомним, что состояние
процесса включает в себя значение счетчика адреса, а также содержимое
регистров ЦП и ячеек памяти, к которым выполняется обращение. Машины,
разработанные для систем с разделением времени, включают средства, позволяющие
сохранять эту информацию как реакцию центрального процессора на сигнал
прерывания. Кроме того, машинный язык таких процессоров обычно включает
специальные команды для перезагрузки ранее сохраненной информации о
состоянии. Подобные функциональные возможности вычислительных машин
упрощают задачу диспетчера по переключению процессов и служат примером того,
как потребности современных операционных систем оказывают влияние на
разработку компьютеров.
Иногда использование процессом предоставленного ему кванта времени
заканчивается раньше, чем истекает интервал, установленный на таймере.
Например, если процесс выдает запрос на выполнение операции ввода/вывода, скажем
запрос на получение данных с диска, выделенный процессу квант времени будет
принудительно завершен, так как в противном случае процесс бесполезно потра-
3.3. Координация действий машины
173
тит оставшееся время на ожидание, когда контроллер выполнит запрос. В этом
случае планировщик обновит таблицу процессов, отразив в ней переход данного
процесса в состояние ожидания, а диспетчер предоставит очередной квант
времени процессу, находящемуся в состоянии готовности. Позднее (возможно, через
несколько сотен миллисекунд), когда контроллер сообщит о том, что
поступивший запрос на операцию ввода/вывода уже выполнен, планировщик вновь
отметит данный процесс, как готовый к выполнению, и этот процесс сможет
конкурировать за получение очередного кванта времени ЦП.
Модель „клиент/сервер"
Различные составляющие операционной системы обычно выполняются как
отдельные процессы, конкурирующие в системе с разделением времени за
получение от диспетчера квантов времени ЦП. Для координации своих действий
этим процессам необходимо взаимодействовать друг с другом. Например, чтобы
запланировать новый процесс, планировщик должен получить для него место в
памяти от программы управления памятью, а чтобы получить доступ к файлу в
массовой памяти, любой процесс должен сначала получить информацию об этом
файле от программы управления файлами.
Для упрощения взаимодействия процессов компоненты операционной системы
обычно разрабатываются в соответствии с моделью "клиент/сервер" (рис. 3.7).
Согласно этой модели, каждый компонент выступает в роли клиента, посылающего
запросы другим компонентам, или же в роли сервера, отвечающего на запросы,
поступившие от клиентов. Например, программа управления файлами функционирует
как сервер, предоставляющий доступ к файлам в соответствии с запросами,
поступающими от различных клиентов. Построенное в соответствии с этой моделью
взаимодействие между процессами внутри операционной системы предусматривает
поступление запросов от процессов, выполняющих роль клиентов, и предоставление
ответов на них другими процессами, играющими роль серверов.
Обслуживание
Модель "клиент/сервер"
При разработке программного обеспечения соблюдение принципов модели
"клиент/сервер" позволяет четко определить роли отдельных его элементов.
Клиент просто посылает запросы серверам и ожидает поступления ответов, а
174 Глава третья. Операционные системы и сети
сервер, выполняет обслуживание поступивших запросов и посылает ответы
клиентам. Роль сервера не зависит от того, функционирует ли клиент на этой же
машине или на удаленной, соединенной с данной машиной через сеть. Различия
существуют в программном обеспечении, используемом для их взаимодействия,
но не в клиенте или сервере. В результате, если компоненты некоторой
программной системы будут организованы как клиенты и серверы, то они смогут
выполнять свои функции независимо от того, функционируют ли они на одной
машине или на различных машинах, разделенных огромным расстоянием
(рис. 3.8). Поэтому, если программное обеспечение, образующее нижний уровень
системы, предоставляет средства обмена запросами и ответами на них, серверы и
клиенты могут быть распределены по машинам в любой конфигурации, как это
будет удобнее в данной сети.
Идентичность схемы взаимодействия клиентов и серверов, функционирующих
на одной и той же машине и на разных машинах
Желание установить единообразную систему отправки сообщений, которая
сможет поддерживать такую распределенную систему в компьютерной сети,
является основополагающей целью ряда стандартов и спецификаций, известных
как CORBA (Common Object Request Broker Architecture — архитектура
брокеров запросов общих объектов). Спецификация CORBA включает систему
стандартов, регламентирующих сетевые взаимодействия элементов программного
обеспечения, называемых объектами (такими как клиенты или серверы). Она
была разработана группой OMG (Object Management Group — группа по
управлению объектами), представляющей собой консорциум фирм-производителей
аппаратного и программного обеспечения, а также пользователей,
заинтересованных в расширении сферы применения объектно-ориентированной технологии, с
которой мы познакомимся в главе 5 и к которой будем неоднократно
возвращаться в последующих главах.
3.3. Координация действий машины 175
Вопросы для самопроверки
1. Кратко опишите различия между программой и процессом.
2. Кратко опишите действия, предпринимаемые центральным процессором при
возникновении прерывания.
3. Каким образом в системе с разделением времени процесс с высоким
приоритетом может выполняться быстрее других?
4. В системе с разделением времени каждый квант времени равен 50
миллисекундам, а на каждое переключение между процессами затрачивается 5
миллисекунд. Сколько процессов может обслужить машина за одну секунду?
5. Если каждый процесс в машине с характеристиками, указанными в
предыдущем вопросе, использует свой квант времени полностью, какая часть
машинного времени используется для реального выполнения процессов? Какой
будет эта часть в случае, если каждый процесс выполняет запрос на
ввод/вывод по истечении 5 миллисекунд от начала каждого выделенного ему
кванта времени?
6. Определите, какие взаимосвязи в обществе отвечают модели "клиент/сервер"?
- 'ijgrS^asfrrf
3.4. Организация конкуренции между процессами
Общей задачей всех компонентов ядра операционной системы является
распределение машинных ресурсов между процессами в системе. Здесь понятие ресурсы
используется в широком смысле и включает как периферийные устройства, так и
ресурсы самой машины. Программа управления файлами отвечает как за организацию
доступа к уже существующим файлам, так и за распределение места на диске при
создании новых файлов. Программа управления памятью распределяет свободные
области памяти. Планировщик распределяет место в таблице процессов, а
диспетчер — кванты времени. На первый взгляд задача распределения может показаться
несложной. Однако если присмотреться, можно обнаружить несколько проблем,
способных привести к сбоям в недостаточно тщательно разработанной системе. Не
забывайте, что сама по себе машина не думает, а лишь следует имеющимся
инструкциям. Поэтому для создания надежной операционной системы следует разработать
алгоритмы, учитывающие все существующие аспекты выполняемой работы, какими
бы незначительными они не казались.
Семафоры
Представим себе операционную систему с разделением времени,
управляющую работой машины с одним принтером. Если процессу требуется напечатать
полученные результаты, он должен запросить у операционной системы доступ к
драйверу принтера. Получив запрос, операционная система должна решить,
следует ли его удовлетворять, исходя из того, используется ли принтер в данный
момент другим процессом. Если принтер свободен, операционная система может
176 Глава третья. Операционные системы и сети
удовлетворить запрос и разрешить процессу продолжить свою работу; в
противном случае она должна ответить на запрос отказом и, возможно, перевести
процесс в состояние ожидания, которое будет продолжаться до тех пор, пока
принтер вновь не будет доступен. Если доступ к принтеру будет предоставлен двум
процессам одновременно, полученные результаты будут неудовлетворительны
для каждого из них.
Чтобы управлять доступом к принтеру, операционная система должна
следить, занят ли принтер в данный момент или нет. Одним из возможных
решений может быть использование флажка, который в данном контексте будет
представлять собой бит памяти, состояние которого будет означать занят или
свободен, а не лросто1 или 0. Если значение флажка "свободен", то это означает,
что принтер доступен, а если "занят", это указывает на то, что принтер уже
предоставлен некоторому процессу. На первый взгляд использование такого подхода
не должно вызывать каких-либо непредвиденных проблем. Операционная
система просто проверяет состояние флажка при каждом поступлении запроса на
предоставление доступа к принтеру. Если флажок находится в состоянии
"свободен", то запрос удовлетворяется и операционная система изменяет
значение флажка на "занят". Если текущее значение флажка "занят", то
операционная система переводит процесс, направивший запрос, в состояние ожидания.
Каждый раз, когда очередной процесс заканчивает работу с принтером,
операционная система или предоставляет принтер ожидающему процессу, или, если
ожидающих процессов нет, просто изменяет значение флажка на "свободен".
Хотя это решение выглядит вполне удовлетворительным, оно заключает в
себе проблему. Задача проверки и, возможно, установки состояния флажка
решается операционной системой за несколько машинных шагов. Следовательно,
вполне возможно, что выполнение этой задачи будет прервано после того, как
будет установлено, что флажок в состоянии "свободен", но еще до того, как его
состояние будет изменено на "занят". В результате возможно возникновение
следующей последовательности событий.
Предположим, что в данный момент времени принтер доступен и некоторый
процесс запрашивает его использование. Система проверяет соответствующий
флажок и обнаруживает, что он находится в состоянии "свободен", т.е. принтер
доступен. Однако в этот момент выполнение процесса прерывается, и другой
процесс начинает использовать выделенный ему квант времени. Он также
запрашивает обращение к принтеру. Состояние флажка еще раз проверяется и
обнаруживается, что он по-прежнему имеет значение "свободен", так как
выполнение предыдущего процесса было прервано прежде, чем операционная система
успела изменить значение флажка. В результате операционная система
разрешает использовать принтер и второму процессу. Через некоторое время первый
процесс возобновляет свою работу с того места, где он был приостановлен, т.е.
непосредственно после того, как операционная система обнаружила, что флажок
имеет значение "свободен". В результате операционная система разрешит
первому процессу продолжить работу и предоставит ему доступ к принтеру. В итоге
два процесса одновременно будут использовать один и тот же принтер.
3.4. Организация конкуренции между процессами 177
Проблема состоит в том, что задача проверки и, возможно, установки
значения флажка должна выполняться без прерываний. Одним из решений может
быть использование команд запрета прерываний и команд разрешения
прерываний, имеющихся в большинстве машинных языков. Если операционная система
начнет процедуру проверки состояния флажка с команды, запрещающей выдачу
прерываний в системе, и закончит ее командой, вновь разрешающей
прерывания, то как только эта процедура будет начата, выполнение ее уже никогда не
сможет быть прервано каким-либо другим процессом.
Другой подход к решению этой проблемы состоит в использовании команды
test-and-set (проверить и установить), имеющейся во многих машинных языках.
По этой команде центральному процессору предписывается считать значение
флажка, проанализировать полученное значение, а затем при необходимости
установить новое значение — и все это в пределах одной машинной команды.
Преимущество этого варианта заключается в том, что центральный процессор,
прежде чем проанализировать наличие прерывания, всегда завершает выполнение
текущей команды, и выполнение задачи проверки и установки флажка не может
быть прервано, если она реализована в виде одной команды.
Реализованный таким образом флажок называется семафором. Это
напоминает железнодорожное сигнальное устройство, используемое для управления
доступом к определенному участку пути. Фактически в системах программного
обеспечения семафоры используются почти так же, как и на железнодорожных
линиях. Участку пути, на котором может находиться только один состав,
соответствует последовательность команд, которая может выполняться одновременно
только одним процессом. Такая последовательность команд называется
критической областью. Требование о том, что в любой заданный момент только один
процесс может выполнять команды критической области, называют взаимным
исключением. Типичным способом реализации взаимного исключения для
некоторой критической области является защита этой области с помощью семафора.
Чтобы войти в критическую область, процесс должен удостовериться, что
семафор открыт, и затем изменить его значение на "закрыт" еще до того, как войдет
в критическую область. При выходе из критической области процесс должен
вновь открыть семафор.
Взаимная блокировка
Другой проблемой, которая может иметь место при распределении ресурсов,
является взаимная блокировка. Это состояние, при котором дальнейшая работа
двух или нескольких процессов взаимно заблокирована, так как каждый из них
ожидает доступа к ресурсам, которые уже предоставлены другому. Например,
один процесс может иметь доступ к принтеру, но ожидать доступа к накопителю
на магнитных лентах, в то время как другой уже получил доступ к накопителю
на магнитных лентах, но ожидает освобождения принтера. Другим примером
является ситуация, когда процессы создают новые процессы, предназначенные
для выполнения подзадач. Если у планировщика уже нет свободного места в
таблице процессов, а каждому из процессов в системе для завершения своей за-
178 Глава третья. Операционные системы и сети
дачи необходимо создать дополнительный процесс, то ни один из процессов не
сможет продолжить свою работу. Эта и подобные ситуации (рис. 3.9) могут
серьезно нарушить работу системы.
Взаимная блокировка, возникшая в результате конкуренции за использование неразделяемых
пересечений железнодорожных путей
Анализ причин появления взаимных блокировок показывает, что такие
ситуации возможны только тогда, когда удовлетворены следующие три условия.
1. В системе имеет место конкуренция за использование неразделяемых
ресурсов.
2. Ресурсы запрашиваются частями — процесс, уже получив некоторые
ресурсы, продолжает запрашивать другие.
3. Предоставленный ресурс не может быть отобран принудительно.
Смысл выделения этих трех условий состоит в том, что проблема
возникновения взаимной блокировки может быть решена посредством устранения любого
из них. В общем случае методы, предназначенные для подавления третьего
условия, относятся к категории схем обнаружения взаимных блокировок с
последующей коррекцией. При данном подходе считается, что тупиковые ситуации
возникают настолько редко, что не стоит тратить усилия на предотвращение
этой проблемы. Суть метода состоит в обнаружении ситуации взаимной блоки-
3.4. Организация конкуренции между процессами 179
ровки, когда она уже возникла, и устранении ее посредством отбора некоторых
предоставленных ресурсов. Приведенный выше пример с заполненной до отказа
таблицей процессов можно отнести к этому классу. Как правило, системный
администратор устанавливает размер таблицы процессов достаточно большим для
данной конкретной системы. Если взаимная блокировка по причине
переполнения таблицы процессов все же возникнет, то администратор просто использует
свое право "суперпользователя", чтобы удалить (технический термин — убить)
некоторые из процессов. В результате освобождается место в таблице процессов,
после чего оставшиеся процессы смогут продолжить выполнение своих задний.
Методики, нацеленные на устранение двух первых условий, относятся к
схемам исключения тупиковых ситуаций. Одна из них, например, позволяет
исключить второе условие за счет того, что каждый процесс должен запрашивать
все необходимые ему ресурсы сразу. Другая, возможно более утонченная
методика, направлена на устранение первого условия, но не за счет простого запрета
конкуренции, а за счет превращения неделимых ресурсов в разделяемые.
Например, предположим, что рассматриваемым ресурсом является принтер и
множество процессов запрашивают доступ к нему. Каждый раз, когда процесс
запрашивает доступ к принтеру, система предоставляет ему этот доступ. Но вместо
того чтобы подключить процесс непосредственно к драйверу принтера,
операционная система подключает его к драйверу логического устройства,
записывающего предназначенную для печати информацию на диск, вместо того чтобы
отправить ее непосредственно на принтер. В результате каждый процесс
выполняется нормальным образом, полагая, что он имеет доступ к принтеру. Позднее,
когда принтер освободится, операционная система может переслать данные с
диска на принтер. В этом случае операционная система придала неразделяемому
ресурсу вид разделяемого, создав иллюзию наличия в системе более чем одного
принтера. Подобная методика предварительного сохранения выводимых данных
в целях ожидания подходящего момента для их действительного вывода
получила название спулинга (spooling). В настоящее время она весьма
распространена в операционных системах для любых платформ.
Безусловно, при конкуренции процессов за машинные ресурсы возникают и
другие проблемы. Например, программа управления файлами должна
предоставлять доступ к одному и тому же файлу сразу нескольким процессам, если они
только считывают данные этого файла. Однако если нескольким процессам в
одно и то же время потребуется изменить содержимое файла, это может привести
к конфликтной ситуации. Поэтому программа управления файлами должна
предоставлять доступ к файлам с учетом конкретных потребностей процессов, в
каждый момент позволяя сразу нескольким процессам иметь доступ для чтения
файла, но разрешая только одному процессу иметь доступ для записи в файл.
Некоторые системы допускают разделение файла на части, в результате чего
различные процессы получают возможность одновременно изменять различные
части одного файла. Кроме того, могут возникать и другие проблемы,
требующие своего решения. Например, как проинформировать процессы, получившие
доступ для чтения, о том, что процесс с доступом для записи изменяет файл?
180 Глава третья. Операционные системы и сети
Вопросы для самопроверки
1. Предположим, что процессы А и В функционируют в системе с разделением
времени и что каждый из них нуждается в одном и том же неделимом
ресурсе на короткий период времени. (Например, каждый процесс может печатать
ряд независимых коротких сообщений.) В этой ситуации каждый процесс
может многократно запрашивать доступ к ресурсу, освобождать его, а затем
вновь запрашивать доступ. Какой недостаток существует в схеме контроля
доступа к этому ресурсу, построенной по приведенному ниже принципу?
Исходно флажку присваивается значение 0. Если процесс А запрашивает
ресурс и значение флажка равно 0, следует удовлетворить этот запрос. В
противном случае необходимо перевести процесс А в состояние ожидания. Если
процесс В запрашивает ресурс и флажок имеет значение 1, следует
удовлетворить этот запрос. В противном случае необходимо перевести процесс В в
состояние ожидания. Каждый раз, когда процесс А заканчивает работу с
ресурсом, значение флажка следует изменить на 1. Каждый раз, когда процесс В
заканчивает работу с ресурсом, следует изменить значение флажка на 0.
2. Предположим, что дорога имеет двустороннее движение, которое переходит в
одностороннее при прохождении через туннель. Для координации
использования туннеля была применена следующая система сигналов.
Когда машина въезжает в туннель с любого его конца, над обоими
входами загорается красный свет. Когда автомобиль выезжает, свет гаснет. Если
при подъезде машины красный свет включен, она ожидает, пока он не
будет выключен, и только после этого въезжает в туннель.
Какой недостаток в этой системе?
3. Предположим, что предложено несколько решений для устранения
возможности взаимной блокировки при встрече двух автомобилей на мосту с
односторонним движением. Определите, какое из трех условий, упомянутых выше
в данном разделе, снимается каждым из следующих решений.
а) Автомобиль не заезжает на мост до тех пор, пока он не освободится.
б) Если на мосту встречаются две машины, одна из них едет назад.
в) Добавляется вторая полоса движения.
4. Предположим, что каждый процесс в системе с разделением времени
будет представлен точкой; дополнительно рисуется стрелка от одной точки к
другой, если процесс, представленный первой точкой, ожидает
освобождения ресурса, который используется вторым процессом. Математики
называют этот чертеж ориентированным графом. Какая особенность в
структуре ориентированного графа будет указывать на наличие в системе
ситуации взаимной блокировки?
3.4. Организация конкуренции между процессами 181
3.5. Сети
В прежние времена компьютерная сеть состояла из отдельных машин,
которые вряд ли были способны на большее, чем просто передавать файлы по
временным телефонным соединениям, используя программное обеспечение,
добавленное к их операционным системам в форме утилит. Сегодня сетевое
взаимодействие машин имеет гораздо более широкий спектр, и современные
операционные системы, разработанные с ориентацией на сетевое применение,
включают многие функции, необходимые для работы в сети. Например,
программное обеспечение, реализующее семейство протоколов TCP/IP (с которым
мы подробно познакомимся чуть позже), поставляется как часть многих
современных операционных систем. В этом и следующем разделе будут рассмотрены
некоторые темы, связанные с подобным расширением функциональных
возможностей операционных систем.
Классификация сетей
Каждая компьютерная сеть принадлежит к одной из следующих обширных
категорий: локальные вычислительные сети, или ЛВС (Local Area Networks, LAN), и
глобальные вычислительные сети, или ГВС (Wide Area Networks, WAN). Локальная
сеть, как правило, состоит из нескольких компьютеров, находящихся в одном
здании или комплексе зданий. Например, компьютеры, используемые в
университетском городке или на одном заводе, могут быть соединены единой локальной сетью.
Глобальная сеть соединяет машины, которые могут находиться в противоположных
концах города или света. Основное различие между локальными и глобальными
сетями заключается в технологиях, используемых для установления путей
соединения. (Например, использование спутниковых линий связи характерно для
глобальных сетей, но не для локальных.) В связи с этим сегодня программное обеспечение
обычно заключается в небольшой изолированной части всего пакета сетевого
программного обеспечения, а это означает, что с точки зрения перспектив развития
программного обеспечения различие между локальными и глобальными сетями
становится все менее и менее важным.
Другой принцип классификации сетей базируется на том, является ли право
собственности на проект внутреннего устройства сети общественным достоянием
или же принадлежит отдельной корпорации. Сеть первого типа называется
открытой сетью, а второго типа — закрытой, или частной сетью. Сеть Internet
является открытой системой. Связь через Internet регулируется открытой
системой стандартов, известной как семейство протоколов TCP/IP, которое мы
рассмотрим в следующем разделе. В противоположность этому, компания
Novell Inc. является главным поставщиком сетевого программного обеспечения,
которое было разработано ею и является ее частной собственностью. Таким
образом, сетевые системы, устанавливаемые и поддерживаемые с помощью
программного обеспечения компании Novell, являются закрытыми.
182 Глава третья. Операционные системы и сети
Еще один способ классификации основывается на конфигурации сетей, т.е. на
физической схеме соединения входящих в них машин. На рис. 3.10
представлены четыре наиболее распространенные конфигурации: а) "кольцо", в этом случае
машины соединены по замкнутому кругу; б) "шина", здесь все машины
соединены с общей линией связи, называемой шиной; в) "звезда", в этой конфигурации
одна машина служит концентратором (hub), к которому подключаются все
остальные машины; г) неупорядоченная, когда машины соединяются случайным
образом. Неупорядоченная конфигурация характерна для глобальных сетей,
тогда как при создании локальных обычно используется конфигурация "кольцо"
или "шина", поскольку в этом случае работа по созданию сети чаще всего
ведется под единым руководством.
РИСУНОК 3.10
в) Звезда г) Неупорядоченная структура
Типы конфигурации сетей
3.5. Сети 183
Internet
Если мы соединим несколько уже существующих независимых сетей, то
получим сеть из сетей. Наиболее известный пример такой структуры — глобальная
суперсеть Internet (пишется всегда с прописной буквы), которая возникла в 1973
году в ходе программы, начатой американским агентством DARPA для
проведения различных исследований в интересах министерства обороны США. Целью
этой программы была разработка средств соединения разнообразных
компьютерных сетей, позволяющих им функционировать как единая надежная сеть. В
настоящее время Internet является глобальным объединением множества
локальных и глобальных сетей, включающим миллионы машин. Сети в Internet
соединены с помощью специальной машины, называемой маршрутизатором.
Маршрутизатор — это машина, принадлежащая к обеим сетям и передающая
сообщения из одной сети в другую.1
Internet-адресация
Концептуально Internet может рассматриваться как объединение сетевых
кластеров, называемых доменами (рис. 3.11); каждый из доменов обычно
состоит из сетей, принадлежащих к одной организации, например университету,
компании или государственному учреждению. Каждый домен является
автономной системой, конфигурация которой может быть выбрана местным
руководством произвольно, вплоть до объединения из нескольких глобальных сетей.
Адрес каждой машины в Internet представляет собой строку из 32 бит,
состоящую из двух частей: первая задает домен, в котором находится машина, а
вторая определяет конкретную машину внутри домена. Часть адреса,
определяющая домен, называется сетевым идентификатором и присваивается домену
организацией InterNIC (Internet Network Information Center — Центр сетевой
информации Internet) в процессе создания домена, при регистрации его в
InterNIC. Именно эта процедура регистрации гарантирует, что каждый домен в
Internet будет иметь уникальный сетевой идентификатор. Часть адреса,
определяющая конкретную машину в домене, называется адресом узла. (Термин узел
(host) часто используется по отношению к машине в сети с целью подчеркнуть ее
роль как пункта назначения для запросов, поступающих от других машин.)
Адрес узла устанавливается локальной администрацией домена; обычно это
администратор сети или системный администратор. Например, сетевой
идентификатор издательской компании Addison Wesley Longman— 192.207.177 (сетевые
идентификаторы традиционно записывают в десятичной нотации с точками (см.
упр. 8 в конце раздела 1.4). Машина в этом домене будет иметь адрес, подобный
следующему: 192.207.177.133. Последний байт здесь является адресом узла.
1 Иногда вместо термина маршрутизатор используется термин шлюз. Однако шлюзами
обычно называют более сложные соединения, чем типичные маршрутизаторы. Например,
"шлюз" чаще всего используется по отношению к машине, соединяющей две надсети из сетей,
причем в каждой надсети используется разный межсетевой протокол. В частности, шлюзом
будет называться машина, соединяющая локальную корпоративную сеть с Internet.
184 Глава третья. Операционные системы и сети
I РИСУНОК 3.11
Группировка отдельных локальных сетей в домены Internet
Представление адресов в битовой форме неудобно для нашего восприятия.
Поэтому организация InterNIC присваивает каждому домену также уникальный
мнемонический адрес, называемый именем домена. Каждый локальный
администратор имеет право расширить это имя домена, чтобы получить мнемоническое
имя для машины внутри домена. Например, имя домена издательской компании
Addison Wesley Longman — awl. com. Отдельная машина в этом домене может
иметь мнемоническое имя ssenterprise.awl.com.
Нотация с точками, используемая в мнемоническом адресе, никак не связана
с десятичной нотацией с точками, используемой для представления адресов в
битовой форме. Напротив, элементы мнемонического адреса определяют
местонахождение машины внутри иерархической системы классификации. В
частности, адрес ssenterprise.awl.com определяет машину, которой присвоено имя
ssenterprise в пределах организации awl, относящейся к классу коммерческих
организаций, входящих в домен com. (Помимо домена com существует
множество других доменов классов, например edu — для образовательных учреждений,
gov — для правительственных учреждений и org — для организаций более об-
3.5. Сети 185
щего типа.) Если домен очень большой, локальная администрация может
разделить его на поддомены, и тогда мнемонические адреса машин внутри домена
станут длиннее. Например, пусть домену университета присвоено имя nu. edu и
пусть принято решение о разделении его на поддомены. Тогда адрес машины в
университете может иметь вид r2d2 .compsc.nu.edu; это означает, что машина с
сетевым именем r2d2 находится в поддомене compsc домена пи, относящегося к
классу доменов образовательных организаций edu.
Организация InterNIC (Центр сетевой информации Internet)
Центр сетевой информации InterNIC был создан в 1993 году, когда Национальный научный фонд США
заключил контракт с тремя компаниями (AT&T, General Atomics и Network Solutions). Этот центр должен был
взять на себя ответственность за функционирование Internet, включая регистрацию доменов и поддержку
баз данных, необходимых для идентификации доменных имен серверов в Internet. До этого момента
регистрация доменов осуществлялась Центром сетевой информации Агентства оборонных информационных
систем США (DISA NIC). Срок действия заключенных тогда контрактов уже истек, и будущая структура
"правящего органа" Internet сейчас активно обсуждается. Выдвигается аргумент, что Internet больше уже не
является местом для проведения научно-исследовательской деятельности и, следовательно, не подпадает
под покровительство Национального научного фонда США. Фактически Национальный научный фонд США
сегодня поддерживает разработку Internet 2 — новой системы, предназначенной для сообщества ученых и
исследователей. В настоящее время регистрацию доменов internet по-прежнему осуществляет компания
Network Solutions. Дополнительную информацию о процессе регистрации можно найти на Web-узеле,
расположенном по адресу http://internic/net.
Для обмена сообщениями между отдельными пользователями Internet (такую
систему называют "электронной почтой", или e-mail) каждая локальная
администрация присваивает всем зарегистрированным пользователям адреса электронной
почты, выделяемые в рамках, определенных именем соответствующего домена.
Почтовый адрес Internet состоит из строки символов, идентифицирующей отдельного
пользователя, за которой следует символ @, отделяющий имя домена той машины,
которой предписано обслуживать работу электронной почты в этом домене. Поэтому
адрес электронной почты работника издательства Addison Wesley Longman будет
иметь примерно такой вид: wshakespeare@mailroom.awl.com. Этот адрес можно
интерпретировать следующим образом: машина под именем mailroom внутри домена
awl.com обрабатывает электронную почту для пользователя с идентификатором
wshakespeare.
Локальная администрация каждого домена ответственна за ведение каталога,
содержащего мнемонические адреса и соответствующие цифровые Internet-
адреса машин данного домена. Каталог поддерживается на специально
выделенной для этих целей машине данного домена, которая играет роль сервера,
именуемого сервером имен. Назначение этого сервера состоит в предоставлении от-
186 Глава третья. Операционные системы и сети
ветов на запросы, касающиеся адресов. Все серверы имен образуют
распределенную в Internet систему каталогов, предназначенную для перевода адресов из
мнемонической в эквивалентную цифровую форму. В частности, если
пользователь хочет послать сообщение, причем адрес места назначения указан им в
мнемонической форме, система серверов имен используется для перевода этого
адреса в эквивалентную последовательность битов, совместимую с программным
обеспечением Internet. Обычно эта задача выполняется за доли секунды.
Если организация принимает решение подключиться к Internet, она может
стать частью уже существующего домена или найти в Internet точку, к которой
можно будет подсоединить маршрутизатор и создать собственный домен.
Преимущество создания нового домена состоит в том, что организация сама
контролирует свое поведение, а не подчиняется администрации другой организации.
Чтобы создать новый домен, организация должна зарегистрироваться в InterNIC
и получить собственный сетевой идентификатор и имя домена.
Отдельный пользователь обычно получает доступ к Internet как член
некоторой организации, имеющей свой домен. Некоторые компании, называемые
провайдерами услуг Internet, предлагают отдельным пользователям доступ к
Internet на коммерческой основе. Эти компании, которые, как правило, имеют в
Internet собственный домен, устанавливают на своих машинах программное
обеспечение, позволяющее им устанавливать телефонные соединения с
удаленными пользователям. С помощью такого соединения пользователь может
получить доступ к тем службам Internet, на которые он подписался. Многие
провайдеры услуг Internet также разрешают подключаться к Internet организациям,
желающим создать собственные домены.
World Wide Web (WWW)
Помимо предоставления услуг электронной почты, суперсеть Internet в
настоящее время стала также и средством публикации мультимедиа-документов,
содержащих гипертекст, т.е. текст со словами, фразами и графическими
изображениями, связанными с другими документами. Читатель такого текста может при
необходимости получить доступ к связанным с ним документам. Для этого ему
достаточно просто указать на соответствующую ссылку и щелкнуть мышью или
выбрать эту ссылку с помощью клавиш со стрелками. Предположим, что в
гипертекстовом документе есть следующее предложение: "Исполнение симфоническим
оркестром "Болеро" Мориса Равеля было просто выдающимся", причем имя Морис
Равель связано с другим документом, возможно, содержащим информацию об
этом композиторе. Пользователь может просмотреть этот материал, поместив на
имя Морис Равель указатель мыши и нажав кнопку мыши. Более того, если
установлены соответствующие ссылки, читатель сможет прослушать аудиозапись
указанного произведения, выбрав слово Болеро.
Таким способом читатель гипертекстового документа может изучать
связанные с ним документы или следовать развитию мысли, переходя от документа к
документу. По мере того как возрастает количество документов, связанных
ссылками с другими документами, образуется некое подобие паутины из
взаимосвязанной информации. В компьютерной сети документы, образующие эту ин-
3.5. Сети 187
формационную паутину, могут находиться на различных машинах, охватывая
ссылками всю сеть. Подобная информационная паутина, развернутая в Internet,
охватывает весь земной шар и поэтому получила название всемирной паутины
(World Wide Web, WWW, или просто Web).
Пакеты программ, помогающие пользователям работать с гипертекстовыми
документами, относятся к одной из двух категорий: программы, выполняющие
роль клиента, и программы-серверы. Программа-клиент выполняется на машине
пользователя и имеет своей целью получение запрошенных пользователем
материалов и представление их в подобающем виде. Именно программа-клиент
предоставляет пользователю интерфейс, позволяющий этому пользователю получать
доступ и просматривать информацию, размещенную в Web. Поэтому такую
программу-клиент часто называют броузером, или Web-броузером. Сервер
гипертекста функционирует на машине, содержащей те документы, к которым запрошен
доступ. Задача сервера — предоставить доступ к размещенным на его машине
документам в соответствии с запросами, поступающими от клиентов. Короче
говоря, пользователь получает доступ к гипертекстовым документам, пользуясь
услугами функционирующего на его машине броузера, а этот броузер выполняет
требования пользователя, обращаясь с запросами к службам гипертекстовых
серверов, размещенных в Internet.
Поисковые системы Internet
Для помощи в поиске размещенной в WWW информации некоторые организации создали Web-узлы,
известные как "поисковые системы". С их помощью пользователи Internet могут выполнять поиск в больших
базах данных, содержащих ссылки на Web-страницы в масштабе всей Internet. В этих базах данных
документы классифицируются с использованием ключевых слов. Поэтому, чтобы найти в Internet информацию
об автомобиле Ford модели Т, пользователь просит поисковую систему отыскать в ее базе данных
документы, содержащие такие ключевые слова, как "Ford" "модель Г, "старинные автомобили",
"коллекционные автомобили" и т.д.
Информация в базу данных поисковой системы собирается двумя способами. Первый способ состоит в
том, что программы (иногда называемые пауками (spiders)) просто передвигаются по Web, следуя ссылкам
от одной Web-страницы к другой, и собирают сведения о найденных документах. Второй способ
заключается в прямом уведомлении, т.е. разработчик Web-страницы может уведомить менеджера поисковой
системы и потребовать включить сведения о его странице в базу данных. Вот имена некоторых (но не всех)
наиболее известных поисковых систем: Alta Vista— http://www.altavista.com; Infoseek —
http://infoseek.go.com; Webcrawler-http://www.webcrawler. com. Среди
российских поисковых систем можно упомянуть flndex- http://www.yandex.ru/ и Апорт -
http://aport.ru.
Набор доступных на сегодняшний день броузеров включает разнообразные
продукты конкурирующих фирм. Эти программы способны работать с
документами, включающими звукозаписи, фотографии и видеозаписи. Такие документы
188 Глава третья. Операционные системы и сети
иногда называют гипермедиа, чтобы подчеркнуть их отличие от традиционного
гипертекста.
Для создания гипертекста необходимо иметь средства установки ссылок
между документами. Для этих целей каждый документ идентифицируется
уникальным адресом, который называется URL-адресом (Uniform Resource Locator —
универсальный адрес ресурса). Содержащаяся в URL информация позволяет
броузеру связаться с соответствующим сервером и запросить требуемый
документ. Общий вид типичного URL-адреса представлен на рис. 3.12. Иногда URL-
адрес не указывает явным образом на конкретный документ, а состоит лишь из
имени используемого протокола и мнемонического имени машины. В подобных
случаях сервер этой машины возвращает определенный документ (обычно
называемый основной страницей (home page)), кратко описывающий информацию,
доступную на этой машине. Такие сокращенные URL-адреса являются средством
установления контакта с организациями. Например, URL-адрес
http://www.awl.com указывает на основную страницу компании Addison
Wesley Longman , содержащую ссылки на многие документы, связанные с этой
компанией и ее продукцией.
РИСУНОК 3.12
' Мнемоническое имя узла, на котором хранится документ
• Протокол, который нужно использовать для доступа к документу.
В данном случае это протокол передачи гипертекста (http)
Общий вид и структура типичного URL-адреса
Гипертекстовый документ похож на традиционный текстовый тем, что его
содержание также символ за символом закодировано с использованием таблицы
символов стандарта ASCII или Unicode. Различие же состоит в том, что
гипертекстовый документ дополнительно содержит специальные маркеры, подробно
описывающие, как этот документ должен выглядеть на экране компьютера и
какие элементы этого документа должны быть связаны с другими документами.
Данная система маркеров получила название языка разметки гипертекстов,
3.5. Сети
189
HTML (Hyper Text Markup Language). Таким образом, при создании Web-
страницы автор помещает в нее информацию, необходимую броузеру клиента
для выполнения его задач, записывая ее на языке HTML.
Вопросы для самопроверки
1. Что такое открытая сеть?
2. Что представляет собой маршрутизатор?
3. Что является компонентами полного Internet-адреса машины?
4. Что такое URL-адрес? Что такое броузер?
5. Пусть локальная сеть имеет кольцевую конфигурацию. В чем состоит
основной недостаток ограничения, разрешающего передачу сообщений только в
одном направлении?
3.6. Сетевые протоколы
Правила, регулирующие взаимодействие различных компонентов
вычислительной системы, называются протоколами. Этот термин возник по аналогии с
протоколом, регулирующим взаимоотношения между людьми в обществе. В
компьютерной сети протоколы определяют детали каждого действия, включая
то, как адресуются сообщения, как между машинами передается право передачи
сообщения, как должны решаться задачи упаковки сообщений для передачи и
дальнейшей обработки уже распакованных поступивших сообщений. Давайте
начнем с рассмотрения протоколов, в задачу которых входит управление правом
машины передать по сети собственное сообщение.
Управление правом передачи данных
Одним из подходов к координации распределения прав на отправку
сообщений является протокол с передачей маркера по сети с кольцевой
конфигурацией. Согласно этому протоколу, каждая машина передает сообщения
только "направо", а получает их только "слева", как показано на рис. 3.13.
Следовательно, сообщение от одной машины к другой передвигается по сети
против часовой стрелки до тех пор, пока не достигнет своего места
назначения. Когда сообщение поступает по назначению, машина-получатель
сохраняет его копию и отправляет ее дальше по сети. Когда отправленная копия
достигает машины-отправителя, эта машина определяет, что ее сообщение
получено, и удаляет его из кольца. Конечно, такая система зависит от
четкого взаимодействия всех машин. Если каждая машина постоянно будет
отправлять только свои сообщения, а не пересылать сообщения других машин,
то ничего не получится.
Чтобы разрешить эту проблему, по кольцу посылается определенная
последовательность битов, называемая маркером (token). Обладание этим маркером дает
190 Глава третья. Операционные системы и сети
машине право послать собственное сообщение; в противном случае ей разрешено
передавать только чужие сообщения. В обычной ситуации каждая машина
просто передает маркер слева направо, точно так же как она передает сообщения.
Если машина, получившая маркер, имеет собственные сообщения, которые
нужно передать по сети, она посылает одно сообщение, удерживая маркер у себя.
Когда это сообщение завершит свой кольцевой цикл, машина передаст маркер
следующей машине в кольце. Аналогично, когда следующая машина получает
маркер, она может или сразу передать маркер дальше, или послать собственное
сообщение, перед тем как передать маркер следующей машине. Таким образом,
машины в сети имеют равные возможности вводить свои сообщения по мере
циркуляции маркера в сети.
РИСУНОК 3.13
Обмен информацией в сети с кольцевой конфигурацией
Другой протокол для координации распределения прав отправки сообщений
применен в сетях Ethernet — популярной версии сети с шинной конфигурацией.
В таких сетях право передачи сообщений регулируется протоколом CSMA/CD
(Carrier Sence, Multiple Access with Collision Detection — множественный доступ
с опросом несущей и разрешением конфликтов). Этот протокол предусматривает,
что каждое посланное сообщение будет передано всем машинам, соединенным
шиной (рис. 3.14). Каждая машина просматривает все поступающие сообщения,
но отбирает только те, которые адресованы именно ей. Чтобы отправить
собственное сообщение, машина ожидает, пока в шине наступит тишина, затем
начинает отправку, одновременно продолжая наблюдать за шиной. Если в этот
момент и другая машина пытается отправить свое сообщение, обе обнаруживают
конфликт и делают паузу на произвольно короткий промежуток времени, а
затем предпринимают попытку вновь начать отправку. В результате складывается
ситуация, аналогичная той, которая возникает при разговоре в небольшой груп-
3.6. Сетевые протоколы
191
пе людей. Если два человека начинают говорить одновременно, оба замолкают.
Различие состоит в том, что люди могут выйти из ситуации таким образом:
"Простите, что вы хотели сказать?", "Нет, нет, говорите вы первым"; в то время
как по протоколу CSMA/CD каждая машина просто делает следующую попытку.
РИСУНОК 3.14
Обмен информацией в сети с шинной конфигурацией
Многоуровневый подход
к организации сетевого программного обеспечения
Главной задачей сетевого программного обеспечения является
предоставление абстрактных механизмов для передачи сообщений по сети. В случае с
Internet эта задача также включает передачу сообщений между сетями.
Процесс передачи сообщений аналогичен процедуре, к которой мы прибегаем,
если необходимо отослать некоторую запчасть к автомобилю заказчику,
проживающему в другом городе. Прежде всего запчасть упаковывают и на
пакете пишут адрес получателя. Затем пакет доставляют в компанию по
перевозке грузов. Работники компании помещают его в большой контейнер
вместе с другими пакетами и отправляют в агентство некоторой авиалинии.
Служащие авиалинии грузят контейнер в самолет, который отправится в
нужный город, возможно, с промежуточными остановками по пути. В месте
назначения служащие авиалинии выгружают контейнер из самолета и
отправляют в контору компании по перевозке грузов. Наконец, работники
компании извлекают наш пакет из контейнера и доставляют его адресату.
Говоря коротко, транспортировка запасных частей производится с
помощью трехуровневой иерархии служб доставки (рис. 3.15). Первый уровень —
это уровень пользователя, он состоит из отправителя и получателя. Второй
уровень представлен компанией по перевозке грузов, а третий —
авиалинией. Каждый из уровней рассматривает следующий более низкий уровень как
некий абстрактный механизм доставки. (Отправитель не вникает в детали
192 Глава третья. Операционные системы и сети
работы компании по перевозке грузов, а эта компания не интересуется
внутренними делами авиалинии.) На каждом уровне имеются и отправители, и
получатели, причем действия получателей противоположны действиям
соответствующих отправителей. Сходным образом организовано и программное
обеспечение, управляющее взаимодействиями через Internet; только в нем
имеется четыре уровня вместо трех, и каждый уровень представляет собой
набор стандартных программ, а не людей и организаций.
Пример доставки посылки
Четыре уровня программного обеспечения Internet (прикладной,
транспортный, сетевой и канальный) представлены на рис. 3.16. Левый столбец
представляет уровни программного обеспечения, используемые машиной для отправки
исходного сообщения, а правый — уровни, используемые машиной при
обработке поступившего сообщения. Как и в примере с доставкой груза, уровни
программного обеспечения при обработке отправляемого и получаемого сообщения
одни и те же.
На рис. 3.16 стрелки обозначают путь, который проходит сообщение. Обычно
сообщение порождается на прикладном уровне. Оттуда оно последовательно
передается от уровня к уровню по мере подготовки к отправке, спускаясь по
левому столбцу, как показано на рисунке. Наконец, оно покидает канальный
уровень породившей его машины и поступает на канальный уровень машины-
получателя. Здесь сообщение продвигается вверх по той же иерархии уровней,
пока не достигнет прикладного уровня машины-получателя.
3.6. Сетевые протоколы
193
Место отправки сообщения Место назначения
Уровни сетевого программного обеспечения в Internet
Самым верхним уровнем в иерархии программного обеспечения Internet
является прикладной уровень, который, несмотря на схожесть названий, не
следует путать с прикладным программным обеспечением в классификации,
приведенной в разделе 3.2. (В действительности мы скоро увидим, что большая часть
программного обеспечения прикладного уровня в иерархии программного
обеспечения Internet относится к категории обслуживающих программ.) Этот
уровень иерархии состоит из элементов программного обеспечения, которые должны
взаимодействовать друг с другом через Internet. Традиционный пример — набор
стандартных утилит для передачи файлов по Internet с использованием
протокола передачи файлов FTP (File Transfer Protocol). Этот набор стандартных
утилит часто оформляется в виде единой прикладной программы с именем FTP,
название которой отражает лежащий в ее основе протокол. Другой пример —
пакет утилит под именем telnet, который был разработан в целях предоставления
пользователям доступа к любой машине в Internet в таком режиме, как если бы
они были локальными пользователями этой машины. Как программа FTP, так и
194 Глава третья. Операционные системы и сети
пакет telnet первоначально создавались как прикладное программное
обеспечение в соответствии с классификацией, приведенной в разделе 3.2. Однако
сегодня они стали частью инфраструктуры операционных систем большинства
персональных компьютеров. Действительно, эти элементы системного программного
обеспечения используются как абстрактные механизмы для конструирования
более крупных приложений, подобных Web-броузерам. В этом смысле они
превратились теперь в типичные программы класса утилит.
Традиционные прикладные программы Internet
Здесь представлено краткое введение в традиционное прикладное программное обеспечение Internet,
telnet. В персональном компьютере единственный пользователь взаимодействует с ним посредством
монитора, клавиатуры и мыши, непосредственно соединенных с машиной, однако многие пользователи
нуждаются в получении доступа к машинам из удаленных мест. Протокол telnet был разработан как средство
для получения такого удаленного доступа через Internet. Используя программное обеспечение протокола
telnet, человек, находящийся в одной части света, может зарегистрироваться как пользователь машины,
расположенной в другой части света, с такой же легкостью, как если бы эта машина находилась в
соседней комнате. В большинстве случаев пользователю достаточно просто сообщить программе telnet
мнемоническое имя машины, к которой он желает подключиться, а затем действовать так, как и при наличии
прямого доступа к этой машине; как правило, с предварительным указанием имени пользователя и пароля.
FTP (Протокол передачи файлов) был разработан как средство передачи файлов по Internet. Чтобы
воспользоваться средствами FTP, пользователь обычно сообщает программе FTP на своем компьютере
мнемоническое имя интересующей его удаленной машины. Затем эта программа устанавливает связь с FTP-
программой удаленной машины, и пользователь регистрируется на ней, используя установленные имя и
пароль. После этого обе машины могут пересылать друг другу файлы с использованием команд get (для
получения файла) и put (для отправки файла). При использовании протокола FTP доступ к файлам
контролируется системой имен и паролей. Если нужно сделать файл доступным в Internet, администратор
машины может объявить его доступным для любого пользователя, зарегистрировавшегося под именем
anonymous. О таких файлах говорят, что они доступны по анонимному FTP. При передаче файлов
средствами FTP важно указать, каким является данный файл - двоичным или текстовым. Дело в том, что
разные операционные системы указывают конец текстовой строки различными способами (подробнее об этом
речь пойдет в разделе 8.2). Следовательно, при передаче текстовых файлов с машины на машину могут
потребоваться определенные преобразования.
Транспортный уровень программного обеспечения Internet рассматривает
прикладной уровень как источник отправляемых сообщений. Это означает, что
прикладной уровень передает сообщения, которые нужно отправить,
транспортному уровню аналогично тому, как посылку сдают в компанию грузоперевозок.
И так же, как в обязанности отправителя посылки входит написание адреса
получателя в форме, соответствующей требованиям компании грузоперевозок,
обязанностью прикладного уровня является предоставление адреса доставки в
формате, отвечающем требованиям транспортного уровня. Именно для решения этой
3.6. Сетевые протоколы 195
задачи прикладной уровень нуждается в услугах серверов имен Internet, к
которым он обращается в целях перевода мнемонических адресов, понятных людям,
в двоичные адреса, совместимые с программным обеспечением сети.
Задача транспортного уровня машины-отправителя сообщения — проследить
за тем, чтобы сообщение было успешно доставлено транспортному уровню
компьютера-получателя, где оно будет вновь преобразовано в форму,
соответствующую прикладному уровню. Таким образом, обязанности транспортного уровня
состоят в выполнении тех действий, которые должны производиться в месте
отправления сообщения и в месте его получения, без учета возможных
промежуточных остановок по пути следования. В частности, в задачу транспортного
уровня входит разбиение длинных сообщений на сегменты, размеры которых
совместимы с требованиями лежащего ниже сетевого уровня. Отдельные сегменты
последовательно нумеруются, что позволяет машине-получателю воссоздать
первоначальное сообщение после пересылки. Затем транспортный уровень
присоединяет к каждому сегменту адрес места назначения и передает сформированные
блоки данных, называемые пакетами, на сетевой уровень.
Как видите, сообщения путешествуют по Internet в виде небольших пакетов,
каждый из которых содержит фрагмент исходного сообщения и дополнительную
"упаковку", содержащую информацию, необходимую для передачи сообщения.
Нередко бывает так, что размеры упаковки пакета превышают размеры
находящегося внутри элемента сообщения. Достаточно часто встречаются элементы
сообщений, состоящие из одного байта, в то время как каждый пакет содержит
более 50 байтов упаковки. Хотя это и кажется неэффективным, тем не менее,
вся система работает достаточно хорошо.
В обязанности сетевого уровня входит наблюдение за тем, чтобы полученные
им пакеты надлежащим образом передавались от одной сети в составе Internet к
другой, прка они не достигнут места назначения. Таким образом, в отличие от
транспортного уровня, имеющего дело только с исходным и конечным пунктами
пересылки сообщения, сетевой уровень контролирует промежуточные этапы
прохождения пакетов через Internet. Он решает эту задачу посредством
прикрепления к каждому пакету адреса промежуточного пункта назначения. Адрес
промежуточного пункта назначения определяется следующим образом. Если
конечное место назначения находится в данной сети, то прикрепляемый адрес
будет простым повторением адреса пункта конечного назначения. В противном
случае это будет адрес маршрутизатора, установленного в данной сети. Таким
образом, пакет, предназначенный машине внутри данной сети, будет послан
непосредственно этой машине, а пакет, предназначенный машине за пределами
сети, будет отправлен маршрутизатору, через который он попадет в смежную сеть.
Для достижения указанной цели сетевой уровень снабжает пакеты, полученные
от транспортного уровня, дополнительной упаковкой, содержащей, как правило,
промежуточный адрес, а не конечный. Эти расширенные пакеты передаются на
канальный уровень.
В обязанности канального уровня входит учет всех деталей установки
соединений, присущих той сети, где находится данная машина. Если это кольцевая
сеть с передачей маркера, канальный уровень должен дождаться получения
196 Глава третья. Операционные системы и сети
маркера, прежде чем начать передачу поступившего пакета. Если сеть
использует протокол CSMA/CD, канальный уровень, прежде чем начать передачу, должен
дождаться тишины в шине. Кроме того, каждая отдельная сеть в составе
Internet имеет собственную систему адресации, независимую от общей системы
адресации в Internet. Следует учитывать, что многие из входящих в Internet
сетей самостоятельно функционировали задолго до того, как их владельцы
приняли решение подключить их к Internet. Поэтому канальный уровень должен
перевести Internet-адреса, указанные во внешней оболочке пакета, в адреса,
соответствующие локальной адресной системе, после чего добавить их к пакетам в
виде дополнительного слоя упаковки.
Каждый уровень в иерархии программного обеспечения Internet играет
определенную роль и в процессе получения сообщений, которая в общих чертах
противоположна задаче, выполняемой на данном уровне при отправке сообщения. Так,
канальный уровень получает пакеты из сетевых линий связи, удаляет внешнюю
упаковку (адрес данной машины в форме, совместимой с этой локальной сетью), в
которую поместил данный пакет канальный уровень той машины, откуда этот пакет
поступил, а затем передает обработанный пакет своему сетевому уровню.
Каждый раз, когда сетевой уровень получает пакет от своего канального уровня,
он удаляет из него промежуточный Internet-адрес, прикрепленный сетевым уровнем
последней машины-отправителя, и изучает адрес конечного места назначения
пакета, находящийся под ним. Если это собственный адрес данной машины, сетевой
уровень передает обработанный пакет своему транспортному уровню. В противном
случае сетевой уровень решает, что пакет должен быть передан по Internet дальше. Для
этого он должен снова "упаковать" пакет, снабдив его новым промежуточным
адресом, и вернуть его на свой канальный уровень для дальнейшей передачи. Таким
способом пакеты "перепрыгивают" с машины на машину, пока не достигнут конечного
места назначения. На каждом промежуточном этапе именно сетевой уровень
определяет место назначения следующего прыжка.
Чтобы упростить процесс переадресации, сетевой уровень поддерживает таблицу
маршрутизации, содержащую конечные адреса, с которыми ему приходилось
сталкиваться в недавнем прошлом, и промежуточные адреса, куда он направил каждый
из этих пакетов. Сетевые уровни различных машин в Internet постоянно
обмениваются данными из своих таблиц маршрутизации, в результате чего информация об
адресах пересылки распространяется по Internet. Сетевой уровень каждой машины
хранит только ту информацию, которая, по его мнению, может ему пригодиться, и
постоянно удаляет устаревшие сведения из своей таблицы маршрутизации; в
результате таблицы не разрастаются до недопустимо больших размеров. Следовательно,
содержание таблиц маршрутизации в Internet является динамическим, и вполне
возможно, что пакеты, представляющие разные части одного и того же сообщения,
пройдут через Internet различными путями.
Заметим, что сетевой уровень передает транспортному уровню только те
пакеты, которые адресованы данной локальной машине. Таким образом, в пересылке
пакетов, предназначенных другим машинам, участвуют только канальный и
сетевой уровни. Транспортный и прикладной избавлены от этой обязанности и
обрабатывают только те пакеты, которые предназначены их собственной машине
3.6. Сетевые протоколы 197
(рис. 3.17). Когда транспортный уровень получает пакеты от сетевого уровня, он
выделяет из них сегменты сообщения и воссоздает первоначальное сообщение,
используя последовательную нумерацию фрагментов, выполненную
транспортным уровнем в месте отправления сообщения. Как только сообщение будет
готово, транспортный уровень передает его прикладному уровню, завершая таким
образом процесс передачи сообщения.
| РИСУНОКЗ/17 I
;; Путь прохождения данных no Internet, включающий две промежуточные машины
В заключение отметим, что передача данных через Internet предусматривает
взаимодействие нескольких уровней программного обеспечения, расположенных
на многих машинах этой глобальной системы. Учитывая все это, кажется
совершенно невероятным, что среднее время ответа в Internet измеряется в
миллисекундах. И действительно, большинство описанных действий происходит
фактически мгновенно.
Семейство протоколов TCP/IP
Спрос на открытые сети вызвал потребность в разработке открытых
стандартов. Следуя этим стандартам, производители могли бы выпускать оборудование
и программное обеспечение, корректно взаимодействующее с продуктами других
фирм-производителей. Одним из таких стандартов является модель OSI (Open
System Interconnection — взаимодействие открытых систем), разработанная
Международной организацией по стандартизации (ISO). Этот стандарт
предусматривает иерархию из семи уровней, в отличие от четырехуровневой системы,
198 Глава третья. Операционные системы и сети
принятой в Internet. На модель OSI часто ссылаются, так как ее поддерживает
авторитет международной организации. Но она так и не была окончательно
внедрена, главным образом из-за того, что появилась уже после того, как семейство
протоколов TCP/IP получило широкое распространение в Internet.
Семейство протоколов TCP/IP представляет собой набор протоколов,
определяющих четырехуровневую иерархию, используемую в Internet. В действительности
TCP/IP — это название только двух протоколов: TCP (Transmission Control
Protocol — протокол управления передачей) и IP (Internet Protocol); так что по
отношению ко всему семейству такое название несколько неточно. Говоря точнее,
протокол TCP определяет одну из версий транспортного уровня. Мы употребили слово
версия, так как в семействе протоколов TCP/IP для представления транспортного
уровня существуют два способа; второй определяется протоколом UDP (User
Datagram Protocol — протокол датаграмм пользователя). Это напоминает ситуацию,
когда при отправке запчастей отправитель имеет возможность выбора среди
различных компаний по доставке грузов, каждая из которых предлагает одинаковый набор
основных услуг, но имеет собственные характеристики. Таким образом, в
зависимости от специфики требуемого обслуживания программное обеспечение прикладного
уровня может выбирать, с помощью какой версии транспортного уровня, протокола
TCP или UDP, будут отправлены данные.
Между протоколами TCP и UDP существуют два основных различия.
Первое состоит в том, что, перед тем как передать данные на транспортный
уровень, базирующийся на протоколе TCP, посылается сообщение
транспортному уровню машины-получателя, уведомляющее о том, что предназначенные
ему данные готовы к отправке, и извещающее, какое именно программное
обеспечение прикладного уровня должно их принять. Затем транспортный
уровень машины-отправителя ожидает уведомления о получении адресатом
этого предварительного сообщения, и только после его прихода он
приступает к передаче сегментов данных. Говорят, что транспортный уровень с
протоколом TCP сначала устанавливает соединение, а затем посылает данные.
Транспортный уровень, основанный на UDP, не устанавливает никакие
соединения, прежде чем послать данные. Он просто посылает данные по
указанному адресу и забывает о них. Для него не имеет значения, работает ли
вообще в данный момент машина, указанная как получатель. Поэтому
протокол UDP называют протоколом без установки соединения.
Второе существенное отличие между протоколами TCP и UDP заключается в
том, что транспортные уровни отправителя и получателя, использующие
протокол TCP, совместно работают над обеспечением целостности передаваемых
сообщений. Для этой цели используется механизм уведомлений и повторных передач
сегментов, выполняемых до тех пор, пока не появится уверенность в том, что
все сегменты сообщения были успешно переданы. Поэтому протокол TCP
называют надежным, в то время как о протоколе UDP, который не предоставляет
услуг по повторной передаче сегментов, говорят как о ненадежном. Это не
означает, что протокол UDP вообще плох. В действительности, транспортный уровень,
основанный на UDP, работает существенно быстрее, и если прикладной уровень
3.6. Сетевые протоколы 199
готов к устранению возможных последствий использования протокола UDP, то
последний может оказаться лучшим выбором.
Протокол IP — это стандарт Internet для сетевого уровня. Одна из его
функций состоит в том, что каждый раз, когда использующий протокол IP
сетевой уровень с протоколом IP подготавливает пакет к передаче на
канальный уровень, он прикрепляет к пакету некоторое значение, называемое
счетчиком переходов по сети, или временем жизни пакета. Это значение
указывает, сколько раз пакет может пересылаться между машинами в попытках
проложить свой путь через Internet. Каждый раз, когда использующий
протокол IP сетевой уровень пересылает некоторый пакет, он уменьшает
значение его счетчика переходов на единицу. С помощью этого механизма сетевой
уровень защищает Internet от бесконечной циркуляции пакетов в системе.
Хотя размеры Internet продолжают расти с каждым днем, начальное
значение счетчика переходов по сети, равное 64, остается более чем достаточным
для того, чтобы позволить пакету найти свой путь в лабиринте локальных и
глобальных сетей и маршрутизаторов.
Вопросы для самопроверки
1. Какие уровни иерархии программного обеспечения Internet используются для
пересылки исходящего сообщения в адрес другой машины?
2. Каковы различия между транспортным уровнем, основанным на протоколе
TCP, и транспортным уровнем, основанным на UDP?
3. Как программное обеспечение Internet гарантирует, что сообщения не будут
вечно блуждать по Internet?
4. Что удерживает подключенную к Internet машину от записи копий всех
проходящих через нее сообщений?
3.7. Безопасность
Когда машина подключена к сети, она доступна многим потенциальным
пользователям. В связи с этим возникают проблемы, которые можно отнести
к двум категориям: несанкционированный доступ к информации и
вандализм. Одним из решений проблемы несанкционированного доступа является
использование паролей, контролирующих или доступ к самой машине, или
доступ к отдельным элементам данных. К сожалению, пароли можно узнать
многими способами. Некоторые просто сообщают свои пароли друзьям, что
является достаточно сомнительным в этическом отношении. В других
случаях пароли похищаются. Один из способов состоит в использовании слабых
мест в операционной системе для получения информации о паролях. Другой
способ заключается в написании программы, имитирующей процесс
регистрации в локальной системе; пользователи, полагающие, что они общаются с
операционной системой, вводят свои пароли, которые затем записываются
этой программой. Еще один способ получения паролей — поочередно вводить
200 Глава третья. Операционные системы и сети
наиболее очевидные пароли и наблюдать, что из этого получится. Например,
пользователи, которые боятся забыть свой пароль, могут в качестве
последнего использовать собственное имя. Кроме того, некоторые даты, например
дни рождения, также весьма популярны в качестве паролей.
Группа быстрого реагирования на инциденты
в компьютерной системе
В ноябре 1988 года запущенная в Internet программа-"червь" вызвала серьезные сбои в работе сети. Как
следствие, агентство DARPA министерства обороны США создало группу быстрого реагирования на
инциденты в этой компьютерной системе (Computer Emergency Response Team, CERT), размещенную в
координационном центре CERT университета Карнеги-Меллона. Группа CERT выступает в роли наблюдателя за
безопасностью в Internet. В ее обязанности входит изучение проблем безопасности, распространение
предупреждений о возможной угрозе, проведение кампаний по повышению доверия пользователей к
безопасности работы в Internet и т.д. Координационный центр CERT поддерживает Web-узел
(http: //www. cert. org), на котором он размещает сообщения о своих действиях.
Чтобы помешать тем, кто пытается сыграть в игру с угадыванием пароля, в
операционные системы можно включить средства, сообщающие о лавине
неправильных паролей. Многие операционные системы также предусматривают
возможность предоставления отчета о времени, когда учетная запись
использовалась в последний раз, и о времени начала нового сеанса работы с ней. Это
позволяет обнаружить любое несанкционированное использование их учетных
записей. Более сложный способ борьбы с хакерами состоит в создании иллюзии
успеха при введении неправильного пароля (так называемый "вход-ловушка");
при этом нарушителю предоставляется ложная информация и одновременно
осуществляется попытка установить его местонахождение.
Другой подход к защите данных от несанкционированного доступа
заключается в шифровании данных. Даже если похититель получит данные,
заключенная в них информация будет ему недоступна. Для этого разработано множество
методов шифрования. Одним из наиболее популярных методов шифрования
сообщений, посылаемых через Internet, является шифрование с открытым
ключом. Он позволяет посылать сообщения, недоступные посторонним. При
шифровании с открытым ключом используются два значения, называемые ключами.
Так называемый открытый ключ используется для кодирования сообщений и
известен всем, кому разрешено создавать сообщения. Закрытый ключ требуется
для декодирования сообщения и известен только тому, кто должен получать
сообщения. Знание открытого ключа не позволяет декодировать сообщения. Так
что большого вреда не будет, даже если он попадет в чужие руки; пользователь,
получивший несанкционированный доступ, сможет посылать шифрованные
сообщения, но не будет иметь возможности декодировать перехваченные сообще-
3.7. Безопасность 201
ния. Знание закрытого ключа, безусловно, более существенно, но узнать его
сложней, чем открытый, так как им владеет только один человек. Мы
познакомимся с некоторыми системами кодирования с открытым ключом в главе 11.
Существует также множество правовых вопросов, касающихся
несанкционированного доступа к информации. Некоторые из них имеют отношение к тому, что
именно считать санкционированным и несанкционированным доступом. Например,
может ли работодатель контролировать обмен информацией, осуществляемый его
работником? В каких пределах провайдеру услуг Internet разрешается доступ к
информации, которой обмениваются его клиенты? Какую ответственность он несет за
содержание информации, которой обмениваются его клиенты? Эти и другие
подобные вопросы беспокоят сегодня юридическое сообщество.
В Соединенных Штатах Америки многие из этих вопросов регулируются
законом о тайне обмена электронной информацией (Electronic Communication Privacy
Act, ECPA), принятым в 1986 году. В качестве его основы использовалось
законодательство о перехвате информации. Хотя этот документ достаточно объемный, его
содержание можно передать несколькими короткими выдержками.
За исключением особо оговоренных случаев, любое лицо, которое
намеренно перехватывает, пытается перехватить или склоняет другое
лицо к перехвату или попытке перехвата любой информации по
проводам, в устной форме или в виде электронного сообщения,., будет
наказано в соответствии с подразделом 4 или подвергнуто судебному
преследованию в соответствии с подразделом 5.
Вот еще одна выдержка.
...любому лицу или организации, предоставляющим услуги электронного
сообщения для общественного пользования, запрещается намеренное
раскрытие содержания любого обмена информацией... любому иному
лицу или организации, кроме получателя, которому эта информация
предназначена, или его официального представителя.
В целом закон ЕСРА подтверждает право индивидуума на тайну общения;
службы, не уполномоченные на то специально, не имеют права прослушивать
информацию, которой обмениваются третьи лица. Также незаконными
считаются действия провайдера сетевых услуг, связанные с распространением сведений о
содержании информации, которой обмениваются его клиенты. Однако законом
также устанавливается следующее.
Не будет незаконным... если должностное лицо, наемный работник или
агент Федеральной комиссии по связи по долгу службы и при
исполнении своих обязанностей по наблюдению, осуществляемому федеральной
комиссией согласно положениям главы 5 статьи 47 Кодекса
Соединенных Штатов Америки, перехватывает информацию,
распространяемую по проводам или электронным коммуникациям, устные переговоры
по радио, а также раскрывает или использует информацию,
полученную таким путем.
Таким образом, закон ЕСРА в явном виде предоставляет Федеральной
комиссии по связи (FCC) США право контролировать электронные средства связи с
202 Глава третья. Операционные системы и сети
некоторыми ограничениями. Это приводит к определенным и довольно сложным
проблемам. Чтобы комиссия FCC могла воспользоваться предоставленными ей
законом ЕСРА правами, системы связи должны быть разработаны и
запрограммированы так, чтобы наблюдение за ними было возможно. Для обеспечения этой
возможности был принят акт о содействии средств связи выполнению закона
(Communications Assistance for Law Enforcement Act, CALEA). Он требует от
владельцев средств телекоммуникации модифицировать их оборудование таким
образом, чтобы оно допускало перехваты, требуемые по закону. Однако
практическая реализация этого закона оказалась делом настолько сложным и
дорогостоящим, что это привело к определенному смягчению требований.
Еще более спорная проблема заключается в конфликте между правом
комиссии FCC осуществлять контроль за информацией и правом пользователей
использовать шифрование. Ведь если контролируемые сообщения хорошо
зашифрованы, то простой их перехват в линиях связи практически бесполезен для
служителей закона. Поэтому правительство США пошло по пути создания
системы регистрации, требующей обязательной регистрации ключей шифрования
(или, возможно, ключей к ключам). Но мы живем в мире, где промышленный
шпионаж получил столь же широкое распространение, как и военный. Отсюда
понятно, что требование регистрации ключей шифрования ставит многих
законопослушных граждан в затруднительное положение. Насколько надежной будет
сама регистрирующая система? Этот вопрос важен не только для США.
Возможность создания аналогичных систем регистрации рассматривалась также в
Канаде и странах Европы.
Проблема вандализма иллюстрируется появлением таких неприятных явлений,
как компьютерные вирусы и сетевые черви. В общем случае вирус представляет
собой сегмент программы, который сам прикрепляет себя к другим программам
компьютерной системы. Например, вирус может внедриться в начало некоторой
присутствующей в системе программы, так что каждый раз при выполнении программы-
хозяина сначала будет выполняться программа-вирус. Она может осуществлять
злонамеренные действия, которые будут заметны пользователю, или просто искать
другие программы, к которым сможет прикрепить свою копию. Если пораженная
вирусом программа переносится на новую машину (неважно, с помощью сети или
гибкого диска), вирус начнет поражать программы на новой машине, как только
перенесенная программа будет запущена на выполнение. Именно таким способом
вирусы перемещаются с машины на машину. В некоторых случаях вирусы
разрабатываются так, чтобы просто заражать другие программы до тех пор, пока не будет
выполнено определенное условие, например до определенной даты, и лишь затем
программа-вирус начнет свои разрушительные действия. В этом случае существенно
повышается вероятность того, что, прежде чем его обнаружат, вирус сможет
распространиться на множество машин.
Такое понятие, как червь, обычно применяют к автономной программе, которая
сама распространяется по сети, резидентно загружаясь в машины и рассылая свои
копии. Как и в случае с вирусами, такие программы создаются и для того, чтобы
просто рассылать свои копии, и для нанесения определенного ущерба.
3.7. Безопасность 203
С ростом популярности сетей увеличивается и вероятность нанесения ущерба
от несанкционированного доступа к информации и вандализма. В связи с этим
возникает множество вопросов, касающихся благоразумного размещения важной
информации на сетевой машине, ответственности за распространение
неадекватно защищенной информации, а также ответственности за вандализм. В свою
очередь, в ближайшем будущем можно ожидать проведения обширных дебатов
по этическим и юридическим вопросам, связанным с этими проблемами.
Вопросы для самопроверки
1. С технической точки зрения термин данные означает некоторое
представление информации, а информация — содержимое данных. Что защищает
пароль — данные или информацию? Что из них защищает шифрование?
2. Каковы основные положения закона ЕСРА?
3. На примере закона CALEA покажите, что принятие требующего
определенных действий закона может и не привести к выполнению этих требований на
практике.
Упражнения
(Упражнения, отмеченные звездочкой, относятся к разделам для
дополнительного чтения.)
1. Перечислите четыре вида действий, выполняемых типичной
операционной системой.
2. Кратко охарактеризуйте различия между пакетной и интерактивной
обработкой.
3. В чем состоит различие между интерактивной обработкой и
обработкой в реальном масштабе времени?
4. Что такое многозадачная операционная система?
5. Какая информация содержится в таблице процессов, поддерживаемой
операционной системой?
6. В чем различие между процессом, готовым к выполнению, и
ожидающим процессом?
7. В чем заключается различие между виртуальной и основной памятью?
8. Какие сложности могут возникнуть в системе с разделением времени,
если два процесса одновременно запрашивают доступ к одному и тому
же файлу? Существуют ли ситуации, при которых программа
управления файлами предоставит такой доступ? В каких случаях
программа управления файлами ответит отказом?
9. Дайте определение понятий балансировки загрузки и
масштабирования в контексте многопроцессорной архитектуры.
10. Кратко опишите процесс первоначальной загрузки.
204 Глава третья. Операционные системы и сети
11. Предположим, что операционная система с разделением времени
использует кванты времени длительностью 50 миллисекунд. Если
обычно процедура позиционирования головки чтения/записи диска над
нужной дорожкой занимает 8 миллисекунд и еще 17 миллисекунд
будет затрачено, пока требуемые данные пройдут под головкой
чтения/записи, то какую часть кванта времени программа проведет в
ожидании выполнения операции чтения с диска? Если машина
способна выполнять по одной команде за каждую миллисекунду, сколько
команд она смогла бы выполнить за время этого ожидания? (Именно
по этой причине системы с разделением времени обычно позволяют
выполняться другим процессам, в то время как первый процесс будет
ожидать окончания обслуживания периферийным устройством.)
12. Назовите пять ресурсов, доступ к которым должна координировать
многозадачная операционная система.
13. Говорят, что процесс зависит от ввода/вывода, если ему требуется
выполнить много операций ввода/вывода. Процесс, преимущественно
выполняющий вычисления в пределах системы "ЦП-память",
называют вычислительно зависимым. Если вычислительно зависимый
процесс и процесс, зависимый от ввода/вывода, ожидают предоставления
кванта времени, кому должен быть предоставлен приоритет и почему?
14. Какая система достигнет большей производительности — система,
выполняющая два процесса, зависимых от ввода/вывода (см. вопрос 13),
или система с одним процессом, зависимым от ввода/вывода, и
вычислительно зависимым процессом? Почему?
15. Разработайте набор инструкций, который будет определять действия
программы-диспетчера операционной системы по истечении кванта
времени, выделенного выполняющемуся процессу.
16. Назовите компоненты информации о состоянии процесса.
17. Приведите пример ситуации в системе с разделением времени, при
которой процесс не использует весь предоставленный ему квант времени.
18. Перечислите в хронологическом порядке основные события, которые
происходят при прерывании процесса.
19. Опишите модель "клиент/сервер".
20. Что такое CORBA?
21. Опишите два способа классификации компьютерных сетей.
22. Укажите и опишите назначение составных частей следующего адреса
электронной почты:
kermit@fгод.animals.com
23. Дайте определение следующих понятий.
а) Сервер имен.
Упражнения 205
б) Домен.
в) Маршрутизатор.
г) Узел.
24. Предположим, что адрес узла в Internet задан как 134.48.4.123.
Каков будет его 32-битовый адрес в шестнадцатеричном представлении?
25. В чем состоит различие между открытой и закрытой сетью?
26. Дайте определение для каждого из следующих понятий.
а) Гипертекст.
б) HTML.
в) Броузер.
27. Что такое World Wide Web?
28. Укажите компоненты следующего URL-адреса и объясните их значение:
http://frogs.animals.com/animals/moviestars/kermit.html.
29. В чем состоит разница между червем и вирусом в контексте
компьютерных сетей?
30. Что вызывает беспокойство в отношении безопасности и секретности
работы в Internet?
31. Что такое ЕСРА и CALEA?
*32. Объясните назначение команды "проверить и установить",
присутствующей во многих машинных языках. Почему важно, чтобы весь процесс
"проверки и установки" был реализован в виде одной команды?
*33. Банкир, который имеет всего $100 000, дает взаймы по $50 000 двум
клиентам. Позже оба клиента снова обращаются к нему с уверениями о
том, что, прежде чем они смогут вернуть долг, им нужно еще по $10 000
для завершения тех сделок, в которых задействованы кредиты. Банкир
решает проблему путем заимствования дополнительных сумм у внешнего
источника и дает своим клиентам дополнительный кредит (под более
высокий процент). Какое из трех условий тупиковой ситуации (ситуации
взаимной блокировки) устранил банкир в данном случае?
*34. Студенты, желающие записаться на курс "Моделирование железных
дорог" в местном университете, должны получить разрешение от
преподавателя и внести плату за работу в лаборатории. Эти два
требования могут выполняться независимо и в любом порядке, причем в
различных точках студенческого городка. Количество слушателей
ограничено 20 студентами. Это ограничение отслеживает как
преподаватель, который выдаст разрешение только 20 студентам, так
и финансовый отдел, который разрешит внести плату также только 20
студентам. Предположим, что 19 студентов уже зачислены на этот
курс, а на последнее место претендуют два студента — один уже
получил разрешение от преподавателя, а второй — уже внес плату. Какое
206 Глава третья. Операционные системы и сети
условие возникновения тупиковой ситуации устраняется каждым из
следующих возможных решений проблемы.
а) Обоим студентам разрешено посещать курс.
б) Группа уменьшена до 19 человек, так что ни одному из студентов
не разрешено записаться на курс.
в) Ни одному из двух претендентов не разрешено участвовать в
занятиях, а разрешение выдано третьему студенту.
г) Принято решение о том, что единственным требованием для
зачисления на курс является внесение платы. Таким образом, студент, уже
внесший плату, записывается на курс, а второй получает отказ.
*35. Объясните, как может возникнуть ситуация взаимной блокировки при
игре в шахматы, когда пешки вплотную подходят друг к другу. Что
выступает здесь в роли неделимого ресурса? Каким образом эта
ситуация обычно преодолевается?
*36. Предположим, что неразделяемые ресурсы в компьютерной системе
классифицированы как ресурсы первого, второго и третьего уровней.
Также предположим, что каждому процессу в системе предписано
запрашивать нужные ему ресурсы согласно этой классификации.
Сначала он должен запросить все необходимые ему ресурсы первого уровня,
прежде чем он сможет запрашивать какой-либо ресурс второго уровня.
После того как все требуемые ресурсы первого уровня будут получены,
процесс может запросить все необходимые ему ресурсы второго уровня
и т.д. Может ли в этой схеме возникнуть ситуация взаимной
блокировки и почему?
*37. Каждая из двух рук робота запрограммирована поднимать детали с
конвейерной ленты, проверять их на допуски и класть в один из двух
контейнеров в зависимости от результатов проверки. Детали поступают
по одной с нерегулярным интервалом между поступлениями. Чтобы
избежать ситуации, когда обе руки робота попытаются взять одну и ту
же деталь, компьютеры, управляющие руками, используют общую
ячейку памяти. Если в момент приближения детали рука свободна,
управляющий ею компьютер считывает значение общей ячейки. Если
оно отлично от нуля, рука пропускает деталь. В противном случае
компьютер помещает ненулевое значение в ячейку памяти и
направляет руку, чтобы поднять деталь. После того как это действие будет
завершено, компьютер вновь помещает в ячейку памяти значение 0.
Какая последовательность действий может привести к конфликту между
двумя руками?
*38. Предположим, что каждый компьютер в сети с кольцевой
конфигурацией запрограммирован так, чтобы передавать сразу в обоих
направлениях те сообщения, которые создаются на нем и предназначены всем
остальным компьютерам в сети. Также предположим, что сначала
устанавливается соединение с машиной слева, которое удерживается до
Упражнения 207
тех пор, пока не будет установлено соединение с машиной справа,
после чего осуществляется собственно передача сообщения. Поясните,
как в этой сети может возникнуть ситуация взаимной блокировки,
если всем ее машинам одновременно потребуется отправить подобные
сообщения.
*39. Опишите, как можно использовать механизм очереди в процессе спу-
линга выводимой на принтер информации.
*40. Участок дороги в центре перекрестка можно рассматривать как
неделимый ресурс, на который претендуют все приближающиеся к
перекрестку автомобили. Для распределения права доступа к этому ресурсу
используется не операционная система, а светофор. Если светофор
способен учитывать интенсивность дорожного движения в каждом из
направлений и запрограммирован так, чтобы давать зеленый свет
наибольшему из потоков, то автомобили из меньшего потока могут
подолгу простаивать под этим светофором (поток зависает). Что в данном
случае означает это зависание? Что будет происходить в
многопользовательской компьютерной системе, в которой всем выполняющимся
процедурам присвоены приоритеты и ресурсы распределяются согласно
этим приоритетам?
*41. По какой причине может зависнуть процесс, если диспетчер всегда
выделяет кванты времени согласно системе приоритетов, в которой
приоритет каждого процесса остается постоянным? (Подсказка, Какой
приоритет у процесса, который только что завершил использование
своего кванта времени по сравнению с ожидающими процессами, и,
как следствие, какому процессу будет предоставлен следующий квант
времени?)
*42. В чем сходство между ситуацией взаимной блокировки и зависанием
(см. вопрос 41)? В чем отличие между ними?
*43. Какая проблема возникнет, если в системе с разделением времени
размер кванта времени делать все меньше и меньше? Что будет
происходить, если делать эти кванты все больше и больше?
*44. Что представляет собой модель OSI, рекомендованная международным
комитетом стандартов (OSI)?
*45. В сети с шинной конфигурацией сама шина является неделимым
ресурсом, за доступ к которому машины должны соревноваться при
необходимости передать сообщение. Как решается проблема тупиковых
ситуаций в этом контексте?
*46. Протоколы, основанные на использовании маркеров, можно применять
для управления правом передачи и в сетях, не имеющих кольцевой
конфигурации. Разработайте протокол, построенный на использовании
маркера и предназначенный для управления правом передачи в
локальной сети с шинной конфигурацией.
208 Глава третья. Операционные системы и сети
*47. Опишите действия, выполняемые машиной при необходимости
отправить сообщение по сети, работа которой регулируется протоколом
CSMA/CD.
*48. Перечислите четыре уровня иерархии программного обеспечения
Internet и опишите задачи, выполняемые каждым уровнем.
*49. С какой точки зрения протокол TCP представляется более удачным
протоколом транспортного уровня, чем протокол UDP? В чем
преимущества протокола UDP?
*50. Что означает утверждение о том, что UDP является протоколом, не
устанавливающим соединения?
Общественные и социальные вопросы
Следующие вопросы приводятся для того, чтобы помочь вам разобраться в
некоторых этических, общественных и юридических аспектах использования
вычислительной техники, а также в ваших собственных воззрениях и тех
принципах, на которых они основаны. Задача не сводится к тому, чтобы просто дать
ответ на предложенный вопрос. Вы должны также разобраться, почему вы
ответили именно так, а не иначе, и насколько ваши суждения по различным
вопросам согласуются друг с другом.
1. Предположим, что вы работаете в многопользовательской
операционной системе, которая позволяет просматривать имена файлов,
принадлежащих другим пользователям, а также содержимое этих файлов,
если оно не защищено паролем. Будет ли просмотр этой информации
выглядеть так, как будто вы рыщете по чужому незапертому дому,
или же это похоже на чтение журналов, предлагаемых пациентам,
ожидающим приема у стоматолога?
2. Если вы имеете доступ к многопользовательской вычислительной
системе, то в чем заключаются ваши обязанности при выборе пароля?
3. Возможность объединять компьютеры в сети привела к росту
популярности концепции работы на дому. В чем состоят преимущества и
недостатки этой идеи? Влияет ли она на уровень потребления
природных ресурсов? Способствует ли она укреплению семей? Станет ли
меньше "служебных интриг"? Будут ли работающие на дому обладать
теми же возможностями продвижения по службе, что и те
сотрудники, которые ежедневно ходят на работу? Ослабнут ли общественные
связи? Какой эффект — положительный или отрицательный — будет
иметь уменьшение контактов работников и работодателей?
4. Internet стоит на пороге того, чтобы стать альтернативой
традиционному "собственноручному" способу делать покупки. Какое влияние это
окажет на привычки в обществе, связанные с процессом покупок? Что
Общественные и социальные вопросы 209
произойдет с супермаркетами? Что произойдет с маленькими
магазинами, например книжными или магазинами одежды, по которым вы
любите побродить, не делая покупок? Хорошо или плохо покупать
товары по минимально возможным ценам? Существуют ли какие-то
моральные обязательства платить больше за предмет с целью поддержать
местный бизнес? Этично ли осматривать товары в местном магазине,
выбирая понравившиеся, а потом заказывать их по более низкой цене
через Internet? Каковы отдаленные последствия такого поведения?
5. В какой степени правительство может контролировать доступ граждан
к Internet (или другой международной сети), исходя из соображений
национальной безопасности? Какие вопросы, связанные с
безопасностью, могут при этом возникнуть?
6. Электронные доски объявлений позволяют пользователям сетей
помещать свои объявления (часто анонимно), а также читать сообщения,
помещенные другими. Следует ли администратора такой доски
объявлений считать ответственным за ее содержание? Должна ли
телефонная компания нести ответственность за содержание телефонных
переговоров? Должен ли управляющий овощным магазином нести
ответственность за содержание местной доски объявлений, которая висит на
стене магазина?
7. Следует ли контролировать использование Internet? Следует ли это
использование регулировать законодательно? Если да, кто должен
этим заниматься?
8. Сколько времени вы тратите на работу в Internet? С пользой ли вы
проводите это время? Изменила ли возможность работы в Internet ваш
образ жизни и поведение в обществе? Как вам легче общаться с
людьми: по Internet или лично?
9. Когда вы приобретаете пакет программного обеспечения для
персонального компьютера, разработчик обычно предлагает вам
зарегистрироваться, чтобы ставить вас в известность о возможных
усовершенствованиях. Этот процесс регистрации все чаще осуществляется через
Internet. Вас обычно просят ввести такие данные, как имя, адрес и,
возможно, сведения о том, откуда вы узнали о продукте, после чего
программное обеспечение разработчика автоматически передает ему
эти данные. Какие этические проблемы возникнут, если разработчик
так сконструирует программу регистрации, что во время
регистрационного процесса она будет посылать разработчику некоторую
дополнительную информацию? Например, эта программа может сканировать
содержимое вашей системы и сообщать о других имеющихся пакетах
программного обеспечения.
210 Глава третья. Операционные системы и сети
Рекомендуемая литература
• Denning D. Е., Denning P.J. Internet Besieged. — Reading, MA: Addison
Wesley Longman, 1998.
• Dietel H. M. An Introduction to Operating Systems, 3rd ed. — Reading, MA:
Addison-Wesley, 1994.
• Shay W. A. Undertaking Data Communications and Networks. — Boston: PWS,
1994.
• Silberchatz A., Galvin P. B. Operating System Concepts, 5th ed. — Reading,
MA: Addison-Wesley, 1998.
• Stein L. D. How to Set Up and Maintain a Web Site. — Reading, MA: Addison-
Wesley, 1997.
• Stevens W. R. TCP/IP Illustrated, Vol. 1. — Reading, MA: Addison-Wesley,
1994.
Дополнительная литература
• Столлингс В. Операционные системы. Основные принципы построения и
проектирования, 4-е изд. — М.: Издательский дом "Вильяме", готовится к
выпуску в 2002 г.
• Камер Д.Э. Компьютерные сети и Internet, 3-е изд. М.: Издательский дом
"Вильяме", готовится к выпуску в 2002 г.
Рекомендуемая литература 211
глава
Алгоритмы
ЧЕТВЕРТАЯ
Как уже было сказано выше, прежде чем компьютер
сможет выполнить задачу, ему необходимо предоставить
алгоритм ее решения, в точности описывающий, что и как надо
делать. Следовательно, изучение алгоритмов является
краеугольным камнем компьютерных наук. В этой главе мы
обсудим многие фундаментальные понятия этой области
знаний, включая разработку и представление алгоритмов, а
также важнейшие управляющие концепции — итерацию и
рекурсию. В процессе обсуждения мы рассмотрим
некоторые хорошо известные алгоритмы поиска и сортировки.
4.1. Понятие алгоритма
4.2. Представление алгоритма
Примитивы
Псевдокод
4.3. Создание алгоритма
Теория решения задач
С чего начать
4.4. Итерационные структуры
Алгоритм последовательного
поиска
Управление циклами
Алгоритм сортировки методом
вставки
4.5. Рекурсивные структуры
Алгоритм двоичного поиска
Управление рекурсией
4.6. Эффективность и
правильность
Эффективность алгоритма
Верификация программ
4.1. Понятие алгоритма
Во введении этой книги алгоритм был неформально определен как
последовательность этапов, описывающая способ решения поставленной задачи. В данном
разделе мы рассмотрим это основополагающее понятие более детально. Вначале
подчеркнем различие между алгоритмом и его представлением, что аналогично
различию между сюжетом и книгой. Сюжет абстрактен или концептуален по
своей природе, а книга является его физическим представлением. Если книгу
перевести на другой язык или опубликовать в другом формате, изменится
только представление сюжета, сам по себе сюжет останется прежним.
Точно так же алгоритм является абстракцией и отличается от своего
конкретного представления. Существует много способов представления одного и того
же алгоритма. Например, алгоритм для перевода показаний температуры по
шкале Цельсия в показания по шкале Фаренгейта традиционно представляется в
виде алгебраической формулы
F = (9/5)С + 32.
Однако его можно представить и в виде инструкции:
Умножить значение температуры в градусах Цельсия на 9/5, а затем к полученному
произведению прибавить 32.
Эту последовательность действий можно представить даже в виде
электронной схемы. В каждом случае лежащий в основе алгоритм остается прежним,
отличаются только методы его представления.
В контексте обсуждения различий между алгоритмами и их представлениями
следует также прояснить различие между двумя другими, связанными с ними
понятиями: программами и процессами. Программа является представлением
алгоритма. По сути, специалисты в области компьютерных наук используют
термин программа по отношению к формальному представлению алгоритма,
разработанного для некоторого компьютерного приложения. В главе 3 мы
определили процесс как деятельность, связанную с выполнением программы. Однако
следует заметить, что выполнить программу — означает также и выполнить
алгоритм, представленный этой программой; поэтому процесс можно эквивалентно
определить как деятельность по выполнению алгоритма. Из сказанного можно
сделать заключение, что процессы, алгоритмы и программы — это различные,
хотя и взаимосвязанные понятия.
Рассмотрим теперь формальное определение алгоритма, приведенное на
рис. 4.1. Требование упорядоченности этапов алгоритма указывает, что
отдельные этапы алгоритма должны составлять четко определенную структуру в
смысле порядка их выполнения. Однако это не означает, что этапы должны
выполняться в строгой последовательности: первый, второй и т.д. Например,
некоторые алгоритмы, называемые параллельными, содержат больше одной
последовательности этапов, каждая из которых разработана так, что может
выполняться отдельным процессором многопроцессорной машины. В таких случаях
214 Глава четвертая. Алгоритмы
алгоритм в целом не представляет собой единую последовательность этапов,
соответствующую сценарию "первый этап, второй этап". Он содержит множество
последовательностей, которые разветвляются и вновь объединяются, по мере
того как разные процессоры выполняют различные части задачи. Другими
примерами могут служить алгоритмы, выполняемые такими электронными схемами,
как триггеры (см. раздел 1.1), в которых каждый вентиль реализует отдельный
этап всего алгоритма. В этом случае этапы упорядочены как причина и
следствие, так как действие каждого вентиля распространяется на всю схему.
Определение алгоритма
Теперь рассмотрим требование, по которому алгоритм должен состоять из
выполнимых этапов. Чтобы оценить важность этого условия, рассмотрим
последовательность инструкций.
Этап 1. Составить список всех целых положительных чисел.
Этап 2. Упорядочить этот список в убывающем порядке (от большего
значения к меньшему).
Этап 3. Выбрать первое число из отсортированного списка.
Этот набор инструкций не является алгоритмом, так как этапы 1 и 2
выполнить невозможно. Никто не в состоянии составить список всех целых
положительных чисел, и целые положительные числа невозможно упорядочить,
начиная с "наибольшего". Для понятия "выполнимый" специалисты в области
компьютерных наук используют термин эффективный. Таким образом, если
говорится, что данный этап эффективен, то, значит, он осуществим.
Еще одним требованием, налагаемым определением, приведенным на
рис. 4.1, является недвусмысленность этапов алгоритма. Это означает, что во
время выполнения алгоритма, при любом состоянии процесса, информации
должно быть достаточно, чтобы полностью и однозначно определить действия,
которые требуется осуществить на каждом его этапе. Другими словами,
выполнение любого этапа алгоритма не потребует каких-либо творческих способностей.
Наоборот, единственное требование состоит в способности следовать имеющимся
инструкциям.
При обсуждении проблемы неоднозначности важно различать алгоритм и его
представление. Неоднозначность конкретного представления алгоритма часто не-
4.1. Понятие алгоритма 215
правильно интерпретируется как неоднозначность, присущая самому алгоритму.
Распространенным примером является степень детализации в описании
алгоритма. Для метеорологов инструкция "Перевести показания в градусах Цельсия
в эквивалентные им показания по шкале Фаренгейта" будет вполне
удовлетворительной, но непрофессионалы, нуждающиеся в детальных инструкциях,
сочтут ее неоднозначной. Обратите внимание, что проблема заключается не в том,
что неоднозначен лежащий в основе алгоритм, а в том, что с точки зрения
непрофессионалов он представлен недостаточно подробно. Таким образом,
неоднозначность скорее присуща представлению алгоритма, а не самому алгоритму. В
следующем разделе мы увидим, как во избежание проблем неоднозначности в
представлении алгоритма может использоваться концепция примитивов.
Требование, утверждающее, что алгоритм должен определять конечный
процесс, означает, что выполнение алгоритма обязательно должно приводить к его
завершению. Это требование происходит из теории вычислений, в задачи
которой входит получение ответа на вопросы типа: "Что является предельным
ограничением алгоритмов и машин?". В данном случае теория вычислений пытается
разграничить вопросы, ответы на которые могут быть получены
алгоритмическим путем, и вопросы, ответы на которые лежат за пределами возможностей
алгоритмических систем. В этом контексте грань проводится между процессами,
которые приводят к конечному результату, и процессами, которые выполняются
бесконечно, не приводя к окончательному результату.
На практике требование конечности определяемого алгоритмом процесса
полезно тем, что исключает бесконечные процессы, которые никогда не приведут к
получению каких-либо содержательных результатов. Например, прямое
следование инструкции "Выполнить этот этап еще раз" лишено смысла. Однако в
действительности существуют примеры содержательных приложений, использующих
бесконечные процессы, например контроль показателей жизнедеятельности
пациента в больнице или поддержание установленной высоты полета авиалайнера.
Можно возразить, что на самом деле в этих приложениях многократно
повторяются конечные алгоритмы, каждый из которых доходит до своего завершения, а
затем автоматически начинается вновь. Тем не менее трудно возразить
утверждению, что такие аргументы являются лишь попытками остаться верными
ограничительному формальному определению.
Независимо от того, какую точку зрения считать правильной, на практике
термин алгоритм часто неформально используется по отношению к
последовательностям этапов, не обязательно определяющим конечные процессы.
Примером может служить известный нам еще со школьной скамьи алгоритм деления в
столбик, который не определяет конечный процесс в случае деления 1 на 3.
Вопросы для самопроверки
1. Охарактеризуйте различия между процессом, алгоритмом и программой.
2. Приведите примеры алгоритмов, с которыми вы знакомы. Действительно ли
они являются алгоритмами в строгом смысле этого слова?
216 Глава четвертая. Алгоритмы
3. Укажите элементы неопределенности в том неформальном определении
алгоритма, которое было предложено в разделе 0.1.
4. Каким пунктам в определении алгоритма не соответствует приведенная ниже
последовательность инструкций?
Этап 1. Возьмите монету из вашего кармана и положите ее на стол.
Этап 2. Возвратитесь к этапу 1.
4.2. Представление алгоритма
В этом разделе мы рассмотрим вопросы, относящиеся к представлению
алгоритмов. Наша задача — ввести основные понятия примитивов и псевдокода, а также
разработать некоторую систему представления для собственного использования.
Примитивы
Для представления алгоритмов необходимо использовать некоторую
форму языка. Если с алгоритмом работает человек, то это может быть и
традиционный язык (английский, русский, японский), и язык картинок,
представленный на рис. 4.2. (На этом рисунке приведен алгоритм изготовления
игрушечной птички из квадратного листа бумаги.) Однако зачастую
использование этих естественных средств общения ведет к неправильному
пониманию. Иногда причина состоит в неоднозначности используемой
терминологии. Например, предложение Посещение внуков — это большая нагрузка на
нервную систему может иметь двоякий смысл: либо приезд внуков вызывает
массу хлопот, либо поездка к ним является серьезным испытанием для
пожилого человека. Другой источник проблем — это неправильное понимание
алгоритма, вызванное недостаточной детализацией его описания. Мало кто
из читателей сможет успешно сделать птичку, пользуясь лишь указаниями,
приведенными на рис. 4.2, тогда как для тех, кто уже изучал искусство
оригами, это, вероятно, будет несложно. Короче говоря, проблемы восприятия
возникают в тех случаях, когда выбранный для представления алгоритма
язык неточно определен или представленная в описании алгоритма
информация недостаточно детальна.
В компьютерных науках эти проблемы решают путем создания четко
определенного набора составных блоков, из которых могут конструироваться
представления алгоритмов. Такие блоки называются примитивами. То, что примитивам
даются точные определения, устраняет многие проблемы неоднозначности и
одновременно требует одинакового уровня детализации для всех описываемых с их
помощью алгоритмов. Набор примитивов вместе с набором правил,
устанавливающих, как эти примитивы могут комбинироваться для представления более
сложных идей, образуют язык программирования.
4.2. Представление алгоритма 217
Как сложить птичку из квадратного листа бумаги
Каждый примитив состоит из двух частей: синтаксической и семантической.
Синтаксис относится к символьному представлению примитива, а семантика — к
представляемой концепции, т.е. к значению примитива. Например, синтаксис слова
воздух включает шесть соответствующих символов, тогда как семантически — это
окружающая нас газовая субстанция. В качестве примера на рис. 4.3 представлены
некоторые примитивы, используемые в искусстве оригами.
218
Глава четвертая. Алгоритмы
I РИСУНОК 4.3 I
Примитивы, используемые в оригами
Чтобы получить набор примитивов, пригодных для представления
выполняемых машиной алгоритмов, мы можем обратиться к отдельным командам,
которые эта машина способна выполнять благодаря ее конструкции. Если алгоритм
будет описан с подобным уровнем детализации, то, несомненно, это будет
программа, пригодная для выполнения машиной. Однако описание алгоритма на
таком уровне детализации весьма утомительно, поэтому обычно используется
4.2. Представление алгоритма
219
набор примитивов более высокого уровня; каждый из них является абстрактным
инструментом, сконструированным из примитивов более низкого уровня,
представляемых машинным языком. В результате будет получен формальный язык
программирования, позволяющий описывать алгоритмы на более высоком
концептуальном уровне, чем это возможно в собственно машинном языке. Такие
языки программирования мы подробно обсудим в следующей главе.
Псевдокод
Начиная с этого момента мы отказываемся от использования команд
формального языка программирования в пользу менее формальной и более
интуитивной системы обозначений, известной как псевдокод. В общем случае
псевдокод — это система обозначений, предназначенная для неформального
представления идей в процессе разработки алгоритмов.
Один из путей создания псевдокода состоит в простом ослаблении правил того
формального языка программирования, на котором требуется записать
окончательную версию алгоритма. Этот подход обычно используется, когда целевой
язык программирования известен заранее. В подобной ситуации псевдокод,
используемый на ранних стадиях разработки программы, может состоять из
синтаксических и семантических структур, аналогичных структурам целевого
языка программирования, но не столь формализованных.
Представление алгоритма во время его разработки
При разработке алгоритма разработчик должен сохранить в памяти множество взаимосвязанных понятий, объем
которых в некоторых случаях просто превосходит возможности человеческого мышления. (В своей статье в
журнале Psychological Review за 1956 год Джордж Миллер (George A. Miller) описывает исследования, результаты
которых свидетельствуют о том, что человеческое мышление способно одновременно оперировать лишь
приблизительно семью деталями.) Поэтому разработчик сложных алгоритмов нуадается в средствах записи, которые
позволят ему при необходимости вспомнить особенности любой части разрабатываемого им алгоритма.
На протяжении 1950-1960-х гг. самым совершенным инструментом проектирования являлись блок-схемы (в
которых алгоритмы представлялись в виде геометрических фигур, соединенных стрелками). Однако зачастую они
превращались в запутанную паутину пересекающихся стрелок, что затрудняло понимание структуры
разрабатываемого алгоритма. Поэтому со временем блок-схемы уступили свое место другим методам представления. Примером
может служить используемый в этом разделе псевдокод, в котором алгоритмы описываются посредством точно
определенных текстовых структур. Тем не менее блок-схемам по-прежнему отдают предпочтение при проведении
презентаций. Например, на рис. 4.8 и 4.9 они используются для демонстрации алгоритмической структуры,
присущей распространенным управляющим операторам.
Поиск более удачных средств проектирования продолжается и поныне. В главе 6 мы увидим, что
существующие тенденции заключаются в использовании графических методов для задач глобального
проектирования больших программных систем, в то время как псевдокод остается популярным при разработке
процедурных компонентов меньшего размера, входящих в состав системы.
220 Глава четвертая. Алгоритмы
Однако наша задача — рассмотреть проблемы разработки и представления
алгоритмов, не концентрируя внимание на каком-либо определенном языке
программирования. Поэтому выбранный здесь подход к созданию псевдокода состоит в
разработке непротиворечивой и краткой системы обозначений для представления
рекуррентных семантических структур. В свою очередь, эти структуры станут
примитивами, с помощью которых мы попытаемся выразить дальнейшие идеи.
Например, необходимость выбрать одно из двух возможных действий, в
зависимости от истинности или ложности некоторого условия, является типичной и
широко распространенной алгоритмической структурой. Вот примеры ее использования.
Если валовой внутренний продукт растет, покупать обыкновенные акции; в противном случае
продавать обыкновенные акции.
Покупать обыкновенные акции, если валовой внутренний продукт растет, и продавать их в
противном случае.
Покупать или продавать обыкновенные акции в зависимости от того, растет или уменьшается
валовой внутренний продукт.
Каждое из этих предложений можно переписать так, чтобы оно
соответствовало следующей структуре:
if {условие) then (действие)
else (действие)
В этой структуре ключевые слова if (если), then (то) и else (иначе)
используются для того, чтобы объявить различные подструктуры внутри основной
структуры, а скобки позволяют обозначить границы этих подструктур. Включив
такую синтаксическую структуру в наш псевдокод, мы получаем универсальный
способ описания указанной общей семантической структуры. Это и есть то, что
требовалось сделать.
Рассмотрим приведенное ниже предложение.
В зависимости от того, является год високосным или нет, разделить итог на 366 или
365 соответственно.
Хотя приведенный выше вариант больше отвечает литературному стилю, мы
будем использовать следующую его версию:
if (год високосный)
then(разделить итог на 366)
else (разделить итог на 365)
Мы также примем сокращенный синтаксис этого конструкта:
if (условие) then (действие)
Он будет использоваться в случаях, когда не предусмотрено действие для
варианта else. Используем эту схему для следующего предложения:
В случае уменьшения объема продаж снизить цену на 5%.
Применение ее позволяет сократить исходный вариант следующим образом:
if (продажи сократились) then (снизить цену на 5%)
Другая универсальная алгоритмическая структура заключается в
необходимости продолжать выполнение последовательности инструкций до тех пор, пока
4.2. Представление алгоритма 221
некоторое условие остается верным. Ниже приведено несколько неформальных
примеров этой структуры.
До тех пор, пока есть билеты для продажи, продолжать продавать билеты.
Пока есть билеты для продажи, продолжать продажу билетов.
Для подобных случаев в нашем псевдокоде будет применяться следующий
универсальный шаблон:
while {условие) do {действие)
Коротко говоря, эта инструкция предписывает проверить условие и, если оно
верно, выполнить действие, а затем вновь проверить условие. Если при
очередной проверке условие оказывается неверным, следует перейти к инструкции,
следующей за данной структурой. Таким образом, оба предшествующих примера
при записи на псевдокоде будут выглядеть следующим образом:
while (имеются билеты, которые можно продать) do (продавать билеты)
Часто желательно ссылаться на некоторые значения с помощью описательных
имен. Для установки подобных связей будет использоваться следующая
конструкция:
assign имя the value выражение
Здесь параметр имя — это описательное имя, а параметр выражение описывает
значение, связываемое с этим именем. Например, рассмотрим следующую
инструкцию:
assign Итог the value Цена + Налог
При ее выполнении результат суммирования значений переменных Цена и
Налог будет связан с именем Итог.
Использование отступов при размещении текста позволяет повысить
читабельность программы:
if (товар налогооблагаемый)
then (if (цена > минимум)
then платить х)
else (платить у)
)
else (платить z)
Эта конструкция воспринимается легче, чем ее эквивалент, приведенный ниже.
if (товар налогооблагаемый) then (if (цена > минимум) then (платить х)
else (платить у)) else (платить z)
Поэтому мы договоримся использовать отступы для отражения структуры текста
в нашем псевдокоде. (Заметим, что мы даже будем выравнивать скобки, связанные с
внешней конструкцией then, чтобы отметить начало и окончание этой структуры.)
Мы собираемся использовать наш псевдокод для описания действий, которые
могут выступать в роли абстрактных вспомогательных программ в других
приложениях. В компьютерных науках такие программные элементы имеют
несколько различных названий, а именно: подпрограммы, процедуры, модули и
функции (значение каждого из них имеет свой смысловой оттенок). Договоримся
применять к нашему псевдокоду термин процедура (procedure), используя его
222 Глава четвертая. Алгоритмы
для обозначения заголовка, по которому можно будет распознать данный блок
псевдокода. Точнее говоря, мы будем начинать каждый блок псевдокода со
следующей инструкции:
procedure имя
Здесь имя — это конкретное название, присвоенное данному блоку. Ниже будут
следовать инструкции, определяющие выполняемые в этом блоке действия.
Например, на рис. 4.4 представлен псевдокод процедуры с именем Приветствие, в
которой трижды печатается сообщение "Привет".
| РИСУНОК4.4 | .«__- _ _
procedure Приветствие
assign Счетчик the value 3;
while (Счетчик > 0) do
(напечатать сообщение "Привет" и
assign Счетчик the value (Счетчик — 1))
Процедура "Приветствие", записанная на псевдокоде
Когда где-либо в псевдокоде потребуется выполнить действия, реализованные
в некоторой процедуре, эта процедура будет просто вызываться по имени.
Например, пусть две процедуры имеют имена Предоставление_3айма и Отклоне-
ние_3аявки соответственно. Тогда мы сможем включить их выполнение в
структуру if-then-else, написав следующую инструкцию:
if (...) then (выполнить процедуру Предоставление_3айма)
else(выполнить процедуру 0тклонение_3аявки)
В результате процедура Предоставление_3айма будет выполняться, если
проверяемое условие истинно, а процедура Отклонение_3аявки — если это
условие ложно.
Процедуры разрабатываются так, чтобы быть как можно более общими.
Процедура сортировки списков имен должна быть способна сортировать любой
список, а не какой-то один определенный. Поэтому она должна быть написана
таким способом, чтобы подлежащий сортировке список не определялся в самой
процедуре. Вместо этого список в процедуре должен быть представлен
некоторым обобщенным именем.
В нашем псевдокоде условимся выделять эти обобщенные имена угловыми
скобками и указывать их в круглых скобках в той же строке, в которой
определяется имя данной процедуры. В частности, процедура с именем Сортировка,
предназначенная для сортировки произвольных списков имен, будет начинаться
следующей инструкцией:
procedure Сортировка {<список>)
4.2. Представление алгоритма 223
Далее в представлении, где потребуется ссылка на подлежащий сортировке
список, будет использовано обобщенное имя <список>. Когда потребуется
обращение к процедуре Сортировка, мы определим, какой именно список имен
должен быть передан в процедуру Сортировка под именем <список>. Для этого
можно использовать, например, следующий синтаксис:
Применить процедуру Сортировка к списку членов организации.
В зависимости от наших потребностей, мы можем применить другой вариант
синтаксиса:
Применить процедуру Сортировка к списку гостей на свадьбе.
Не забывайте, что назначение нашего псевдокода состоит в
предоставлении средств, позволяющих записывать схемы алгоритмов лишь в общих
чертах, а не в написании законченных формальных программ. Поэтому мы не
связаны запретом использования неформальных фраз, запрашивающих такие
действия, детали которых не определены достаточно строго. (Как именно
будут разрешены эти детали, не столь уж важно для описания алгоритма,
поскольку это касается только свойств языка, на котором будет написана
формальная программа.) В то же время, если позже мы обнаружим, что
определенная идея повторяется в обсуждаемых нами схемах, то мы примем
соответствующий синтаксис для ее представления и этим расширим наш
псевдокод.
Вопросы для самопроверки
1. То, что является примитивом в одном контексте, может, в свою очередь, быть
составлено из примитивов другого контекста. Например, инструкция while
является примитивом в нашем псевдокоде, хотя она является сложной
конструкцией из нескольких команд машинного языка. Приведите два примера
подобных явлений из области, не связанной с компьютерами.
2. В каком смысле построение процедур является построением примитивов?
3. Алгоритм Евклида позволяет найти наибольший общий делитель двух
положительных целых чисел X и Y с помощью следующего процесса:
до тех пор, пока значения X и Y отличны от нуля, выполнять деление
большей величины на меньшую и присваивать переменным X и Y значения
делителя и остатка соответственно. (Конечное значение X является наибольшим
общим делителем.)
Запишите этот алгоритм с помощью нашего псевдокода.
4. Опишите набор примитивов, используемых в некотором предмете, отличном
от компьютерного программирования.
224 Глава четвертая. Алгоритмы
4.3. Создание алгоритма
Разработка программы состоит из двух различных действий — создания
алгоритма ее работы и представления этого алгоритма в виде программы. До
настоящего момента мы рассматривали только способы представления алгоритмов
и не касались вопроса, как, собственно, эти алгоритмы создаются. Однако
создание алгоритма — это, как правило, наиболее сложный этап в процессе
разработки программного обеспечения. В конце концов, создать алгоритм — означает
найти метод решения задачи, в решении которой и состоит назначение этого
алгоритма. Поэтому, чтобы понять, как создаются алгоритмы, необходимо понять
процесс решения задач.
Теория решения задач
Рассмотрение методов решения задач и их подробное изучение не являются
аспектами, специфическими только для компьютерных наук. Напротив, это
важно практически для любой области науки. Тесная связь между процессом
создания алгоритмов и общей проблемой поиска решения задач привела к
сотрудничеству специалистов в области компьютерных систем и ученых из других
областей науки в поисках лучших методов решения задач. В конечном счете
желательно было бы свести проблему решения задач к алгоритмам как таковым,
но это оказалось невозможным. (В главе 11 будет показано, что существуют
задачи, не имеющие алгоритмических решений.) Таким образом, способность
решать задачи в значительной степени является профессиональным навыком,
который необходимо развивать, а не точной наукой, которую можно изучить.
Решение задач является скорее искусством, чем наукой. Доказательством
этого может служить тот факт, что представленные ниже, весьма расплывчато
определенные фазы решения задач, предложенные математиком Дж. Полна (G.
Polya) в 1945 году, остаются теми основными принципами, на которых и
сегодня базируется обучение навыкам решения задач.
Фаза 1. Понять существо задачи.
Фаза 2. Разработать план решения задачи.
Фаза 3. Выполнить план.
Фаза 4. Оценить точность решения, а также его потенциал в качестве
средства для решения других задач.
Применительно к процессу разработки программ эти фазы выглядят
следующим образом:
Фаза 1. Понять существо задачи.
Фаза 2. Предложить идею, какая алгоритмическая процедура позволила бы
решить задачу.
Фаза 3. Сформулировать алгоритм и представить его в виде программы.
Фаза 4. Оценить точность программы и ее потенциал в качестве средства для
решения других задач.
4.3. Создание алгоритма 225
Необходимо подчеркнуть, что предложенные математиком Полна фазы не
являются этапами, которым надо следовать при решении задачи. Скорее это те
фазы, которые должны быть когда-либо выполнены в процессе ее решения.
Здесь ключевое слово — следовать, т.е. просто "следуя", вы не сможете решить
задачу. Напротив, чтобы решить задачу, необходимо проявлять инициативу и
двигаться вперед. Если подходить к решению задачи по принципу: "Ну вот, я
закончил фазу 1, пора переходить к фазе 2", то вряд ли вам будет сопутствовать
успех. Однако если вы с головой окунетесь в решение задачи и в конечном счете
решите ее, то, оглянувшись назад, обязательно увидите, что выполнили все
четыре фазы, предложенные математиком Полна.
Кроме того, необходимо заметить, что эти четыре фазы не обязательно
выполняются в указанном порядке. Как отмечают многие авторы, те, кто успешно
решает задачи, часто начинают формулировать стратегию решения (фаза 2) еще
до того, как полностью смогут понять существо задачи (фаза 1). Впоследствии,
если выбранные стратегии так и не приведут к успеху (что проявится во время
фазы 3 или 4), решающий задачу человек все же приобретет более глубокое
понимание сути задачи и, основываясь на этом понимании, сможет вновь
вернуться к формулированию других, возможно, более успешных стратегий.
Не забывайте, что здесь мы обсуждаем, как задачи решаются, а не то, как бы
нам хотелось, чтобы они решались. В идеале хотелось бы полностью исключить
изнурительный по своей сути процесс проб и ошибок, описанный выше. При
разработке крупной системы программного обеспечения обнаружение
неправильного понимания лишь на фазе 4 может привести к огромным потерям
ресурсов. Избежать таких катастроф — основная задача разработчиков
программного обеспечения (глава 6), которые традиционно настаивают на том, что полное
осмысление задачи должно предшествовать ее решению. Можно возразить, что
истинное понимание задачи невозможно, пока не будет найдено ее решение. Тот
факт, что решить задачу не удается, подразумевает недостаток ее понимания.
Следовательно, настаивать на том, что нужно вначале полностью осознать
задачу, прежде чем предлагать какое-либо ее решение, — это чистый идеализм.
В качестве примера рассмотрим следующую задачу.
Предположим, что некто А хочет определить возраст трех детей некоего В. Этот В сообщает А,
что произведение возрастов его детей равно 36. Обдумав эту подсказку, А отвечает, что
необходима еще подсказка, и В сообщает ему сумму возрастов его детей. Затем А отвечает, что
требуется еще подсказка, и В говорит ему, что старший из детей играет на пианино. Услышав эту
подсказку, А сообщает В возраст всех трех его детей. Сколько лет детям?
На первый взгляд может показаться, что последняя подсказка совсем не
имеет отношения к задаче, хотя именно она позволила А окончательно
определить возраст детей. Как это может быть? Давайте двигаться вперед,
формулируя план и следуя ему, несмотря на то, что у нас еще остается много вопросов
по поводу этой задачи. Наш план будет состоять в том, чтобы отслеживать
этапы, описанные в условии задачи, учитывая информацию, доступную А по
мере развития событий.
226 Глава четвертая. Алгоритмы
В первой подсказке сообщалось, что произведение возрастов детей равно 36. Это
означает, что искомые значения образуют одну из троек, перечисленных на
рис. 4.5, а. Следующая подсказка указывала сумму искомых значений. Нам
неизвестно, чему именно равна эта сумма, но мы знаем, что этой информации оказалось
недостаточно, чтобы А смог выбрать правильную тройку. Следовательно, искомая
тройка должна быть одной из тех, которые имеют одинаковые суммы в списке на
рис. 4.5, б. Таких троек на рисунке две: (1, 6, 6) и (2, 2, 9); сумма членов каждой из
них равна 13. Это та информация, которая была известна А на момент, когда он
получил последнюю подсказку. Именно на данном этапе мы осознаем важность
последней подсказки. Собственно умение играть на пианино не имеет никакого
значения, важен тот факт, что в семье есть старший ребенок. Это позволяет отбросить
тройку (1,6,6) и заключить, что одному ребенку 9 лет, а двум — по 2 года.
(1,1,36) (1,6,6) 1 + 1+36 = 38 1+6 + 6=13
(1,2,18) (2,2,9) 1+2+18 = 21 2 + 2 + 9=13
(1,3,12) (2,3,6) 1+3+12=16 2 + 3 + 6=11
(1,4,9) (3,3,4) 1+4 + 9=14 3 + 3 + 4=10
а) Тройки чисел, произведение которых равно 36 б) Суммы троек чисел, приведенных в а)
Это именно тот случай, когда, не попытавшись реализовать выбранный план
решения (фаза 3), невозможно достичь полного понимания задачи (фаза 1). Если
бы мы настаивали на завершении фазы 1, вместо того чтобы двигаться дальше,
то, возможно, так и не смогли бы определить возраст детей. Такая
неупорядоченность процесса решения задач является основной причиной трудностей,
связанных с разработкой систематического подхода к решению задач.
Кроме того, существует и некое мистическое вдохновение, посещающее человека,
решающего задачу. Оно проявляется в том, что, работая какое-то время над задачей
без видимого успеха, позднее он неожиданно может найти ее решение при
выполнении совершенно другого задания. Этот феномен был обнаружен ученым Г. фон
Гельмгольцем (Н. von Helmholtz) еще в 1896 году, а математик Анри Пуанкаре
(Henri Poincare) говорил о нем в своей лекции, прочитанной Психологическому
обществу в Париже. Пуанкаре описал свой опыт, связанный с неожиданным
осознанием способа решения задачи, которой он безуспешно занимался некоторое время, а
затем отложил, обратившись к другим проблемам. Этот феномен отражает процесс, в
котором подсознание осуществляет непрерывную работу над решением задачи и в
случае успеха выталкивает найденный результат в сознание человека. В наши дни
промежуток времени между процессом сознательного решения задачи и внезапным
озарением получил название инкубационного периода. Исследования этого явления
продолжаются и в настоящее время.
4.3. Создание алгоритма 227
С чего начать
Мы обсудили решение проблем с философской точки зрения, пока не
затрагивая вопрос, как следует действовать при попытке решить некоторую задачу.
Безусловно, существует множество подходов к решению задач, каждый из
которых приводит к успеху в определенных ситуациях. Ниже мы кратко обсудим
некоторые из них. Сейчас же просто отметим, что существует нечто общее,
присущее всем этим методам. Это можно охарактеризовать как выбор оптимальной
позиции для дальнейших действий. В качестве примера рассмотрим следующую
простую задачу.
Перед соревнованиями участники А, В, С и D сделали следующие прогнозы:
Участник А предсказал, что победит участник В.
Участник В предсказал, что участник D будет последним.
Участник С предсказал, что участник А будет третьим.
Участник D предсказал, что сбудется предсказание участника А.
Только один из этих прогнозов оказался верным, и это был прогноз победителя. В каком порядке
участники А, В, С и D закончили соревнования?
Ознакомившись с задачей и проанализировав приведенные в ее условии
сведения, нетрудно заметить, что, поскольку прогнозы участников А и D
эквивалентны, а верным оказался только один прогноз, прогнозы участников А и D
неверны. Следовательно, ни участник А, ни участник D не являются победителями
соревнования. Теперь можно считать, что первый шаг сделан. Для получения
окончательного решения надо просто продолжить наши рассуждения. Поскольку
прогноз участника А оказался неверным, значит, участник В также не стал
победителем. Остается единственный возможный вариант, в котором победителем
стал участник С. Итак, участник С выиграл соревнования, и его прогноз
оказался верным. Отсюда можно сделать вывод, что участник А занял третье место.
Это означает, что участники финишировали либо в порядке CBAD, либо в
порядке CDAB. Но первый вариант нужно отбросить, так как прогноз участника В
не оправдался. Следовательно, участники финишировали в порядке CDAB.
Конечно, сказать, что нужно сделать первый шаг и занять оптимальную
позицию, — совсем не то же самое, что сказать, как это сделать. Первоначальный
прорыв, а затем осознание того, как закрепить полученный успех, чтобы суметь
найти окончательное решение задачи, потребуют значительных усилий от того,
кто ее решает. Однако существует несколько общих подходов, предложенных
математиком Полна и другими исследователями, подсказывающими, как можно
осуществить этот первоначальный прорыв. Один из подходов состоит в том,
чтобы работать с задачей в обратном порядке. Например, если задача заключается в
том, чтобы найти способ получения определенного конечного результата из
заданного начального, можно начать поиск с конечного результата и попытаться
пройти путь к заданному начальному. Этот подход будет полезен, если
потребуется найти алгоритм складывания бумажной птички, упомянутый в предыдущем
228 Глава четвертая. Алгоритмы
разделе. Логично начать с попытки развернуть сложенную птичку с целью
понять, как она была сделана.
Другой общий подход к решению задачи состоит в поиске связанных с ней
проблем, которые или легче решаются, или уже были решены раньше. Позже
предпринимается попытка применить способ их решения к данной задаче. Этот
метод особенно важен в контексте разработки программ. Часто при разработке
программы основная трудность заключается в создании общего алгоритма для
решения всех разновидностей данной задачи. Другими словами, если нам
необходимо разработать программу для упорядочения списка имен в алфавитном
порядке, наша задача не сводится к сортировке отдельного списка, а заключается в
нахождении алгоритма, пригодного для сортировки любого списка имен.
Рассмотрим следующий набор инструкций.
Поменять местами имена David и Alice.
Поместить имя Carol между именами Alice и David.
Поместить имя Bob между именами Alice и Carol.
Этот набор позволяет правильно выполнить сортировку списка, состоящего из
имен David, Alice, Carol и Bob, но он не является тем общим алгоритмом, который
мы ищем. Нам же нужен алгоритм, который в состоянии выполнить сортировку
как данного списка, так и любого другого, который может встретиться. Однако
найденное решение сортировки конкретного списка не является совершенно
бесполезным для разработки общего алгоритма. Мы можем, например,
продвинуться в решении, рассматривая такие частные случаи, как попытки найти общий
принцип, которые, в свою очередь, послужат основой для создания искомого
общего алгоритма. В этом случае искомое решение в конце концов будет найдено
с помощью метода решения набора взаимосвязанных частных задач.
Еще один подход к проблеме "с чего начинать" заключается в применении
метода поэтапного уточнения, который предполагает, что задачу не следует
пытаться решить сразу же и целиком во всех ее деталях. Согласно этому методу,
исследователь должен разбить задачу на ряд подзадач. Идея заключается в том,
что при разбиении исходной задачи на подзадачи появляется возможность найти
общее решение как последовательность этапов, на каждом из которых решается
задача, более простая по сравнению с исходной. Поэтапное уточнение
подразумевает также, что каждый из этапов, в свою очередь, можно разбить на меньшие,
а те — на еще меньшие, так что в конце концов вся задача сводится к набору
легко разрешимых подзадач.
Поэтапное уточнение является нисходящим методом, так как его развитие
происходит в направлении от общего к частному. В противоположность этому,
восходящие методы предусматривают развитие от частного к общему. Хотя в
теории эти подходы противоположны, на практике они просто дополняют друг
друга. Например, разбиение задачи, предлагаемое нисходящим методом
поэтапного уточнения, обычно осуществляется интуитивно с использованием
восходящей модели.
Решениям, полученным с помощью метода поэтапного уточнения,
свойственна естественная модульная структура. Именно в этом кроется основная причина
4.3. Создание алгоритма 229
популярности этого метода при разработке алгоритмов. Если алгоритм имеет
естественную модульную структуру, то он легко реализуется в модульном
представлении, способствующем созданию удобных в сопровождении программ.
Более того, модульная структура, создаваемая в процессе поэтапного уточнения,
легко совмещается с концепцией коллективного программирования, в
соответствии с которой несколько человек объединяются в команду, имеющую своей
задачей разработку определенного программного продукта. После того как
исходная задача будет разбита на подзадачи (потенциальные модули), члены команды
смогут работать над ними независимо, не мешая друг другу.
Метод поэтапного уточнения пользуется широкой популярностью при
разработке программного обеспечения. Однако несмотря на все его преимущества,
этот метод отнюдь не является последним словом науки в отношении создания
алгоритмов. В сущности, он представляет собой только средство организации
работы, и все его возможности по решению задач являются лишь следствием этой
организации. Вполне естественно использовать метод поэтапного уточнения при
организации общенациональной политической кампании, написании курсовой
работы или заключении торгового соглашения. Аналогичным образом для
большинства проектов разработки программного обеспечения из области обработки
данных характерна большая роль организационного компонента. Задача этих
проектов состоит не столько в создании нового сенсационного алгоритма,
сколько в представлении решаемых задач таким образом, чтобы их можно было
реализовать в виде согласованно функционирующего пакета программ. Поэтому
метод поэтапного уточнения по праву стал основой всей методологии
проектирования в области обработки данных.
Однако поэтапное уточнение остается всего лишь одной из многих
методологий проектирования, представляющих интерес для специалистов в области
компьютерных наук. Поэтому не следует впадать в заблуждение, полагая, что все
алгоритмы могут быть созданы с помощью этого метода. Фактически
применение при решении задач предвзятых представлений и заранее выбранных схем в
некоторых случаях может даже усложнить изначально простое задание.
Рассмотрим следующую задачу.
Когда вы садились в лодку, ваша шляпа упала в воду, но вы этого не заметили. Скорость течения
реки 2,5 мили в час, и ваша шляпа поплыла вниз по течению. Тем временем вы поплыли в лодке
вверх против течения со скоростью 4,75 мили в час (относительно воды). Спустя 10 минут вы
заметили пропажу шляпы, развернули лодку и поплыли вниз по реке догонять вашу шляпу. Через
какое время вы поймаете свою шляпу?
Большинство студентов, изучающих алгебру в высшей школе, а также
любителей карманных калькуляторов начнут решение этой задачи с определения,
какое расстояние прошла лодка за 10 минут вверх по течению и какое расстояние
за это время проплыла шляпа вниз по течению. Затем они попытаются
вычислить, сколько времени понадобится лодке, чтобы пройти вниз по течению до той
точки, где находится шляпа. Но ведь пока лодка будет идти к этой точке, шляпа
будет уплывать дальше вниз по течению! Таким образом, они, весьма вероятно,
попадут в цикл вычислений, где будет находиться шляпа в тот момент, когда
лодка достигнет того места, где шляпа была на предыдущем этапе расчета.
230 Глава четвертая. Алгоритмы
На самом же деле задача гораздо проще. Весь фокус состоит в том, чтобы суметь
противостоять стремлению писать формулы и делать вычисления. Необходимо
просто отложить эти навыки в сторону и взглянуть на задачу в ее истинном свете. Суть
всей проблемы в реке. В данном случае тот факт, что вода движется относительно
берегов, не имеет никакого значения. Представьте себе ту же задачу на длинной
конвейерной ленте. Сначала решим поставленную задачу, когда лента неподвижна.
Если вы, стоя на ленте, положите шляпу у своих ног, а затем будете идти вдоль
ленты в течение 10 минут, то вернуться к шляпе вы сможете за те же 10 минут. Теперь
включим конвейер. Это будет означать, что сначала вы пойдете против движения
ленты. Но поскольку вы, как и шляпа, находитесь на ленте, это не изменит ваших
взаимоотношений с лентой и шляпой. Вам по-прежнему потребуется 10 минут,
чтобы вернуться к оставленной шляпе.
В результате можно прийти к заключению, что создание алгоритмов является
сложным искусством, которое необходимо постоянно совершенствовать, а не изучать
как предмет, состоящий из хорошо определенных методологий. Учить решать
задачи, следуя четко определенным методологиям, — значит "загубить" творческие
способности учащихся, которые, напротив, нужно всемерно развивать.
Вопросы для самопроверки
1. Найдите алгоритм решения следующей задачи и ответьте на дополнительные
вопросы.
а) Для заданного положительного числа п найдите такую комбинацию целых
положительных чисел, произведение которых максимально среди всех
возможных комбинаций целых положительных чисел, сумма которых
равна п. Например, если п равно 4, то искомый список есть (2, 2), так как
2*2 больше, чем 1*1*1*1, 2*1*1 и 3*1. Для п, равного 5, искомая
комбинация будет (2, 3).
б) Какова искомая комбинация для п =2001?
в) Объясните, как вам удалось продвинуться в решении этой задачи.
2. Найдите алгоритм решения следующей задачи и ответьте на дополнительные
вопросы.
а) Пусть дана квадратная шахматная доска размером 2П х 2П, где п — целое
положительное число, и коробка с L-образными фишками, каждая из
которых может закрыть в точности три квадрата на доске. Если вырезать из
доски один какой-либо квадрат, сможем ли мы покрыть оставшуюся
часть доски фишками таким образом, чтобы они не перекрывались и не
выступали за край доски?
б) Объясните, как предложенное решение этой задачи может быть использовано,
чтобы показать, что 2п-1 делится на 3 для любых целых положительных п.
в) Как ответы на два предыдущих вопроса связаны с фазами решения задач,
предложенными математиком Полна?
4.3. Создание алгоритма 231
3. Декодируйте следующее сообщение и объясните, как вам удалось сделать
первый шаг в поисках решения:
Pdeo eo pda yknnayp wjosan.
4.4. Итерационные структуры
Теперь нашей задачей является изучение некоторых повторяющихся структур,
используемых при описании алгоритмических процессов. В этом разделе мы обсудим
итерационные структуры, в которых выполнение набора инструкций повторяется в
циклическом режиме. В следующем разделе рассматривается метод рекурсии.
Читатель также сможет познакомиться с некоторыми популярными алгоритмами —
последовательного и двоичного поиска, а также с алгоритмом сортировки методом
вставки. ^Начнем с рассмотрения алгоритма последовательного поиска.
Алгоритм последовательного поиска
Рассмотрим задачу поиска в списке некоторого заданного значения. Необходимо
разработать алгоритм, позволяющий установить, есть ли заданное значение в списке.
Если это значение в списке присутствует, поиск будет считаться успешным, в
противном случае будем считать его завершившимся неудачей. Будем считать, что
список отсортирован согласно некоторому правилу, позволяющему упорядочить его
элементы. Например, если это список имен, будем считать, что имена в нем
расположены в алфавитном порядке. Если же это список числовых значений, будем полагать,
что его элементы расположены в порядке возрастания.
Давайте попробуем представить, как бы мы действовали при поиске
определенного имени в списке гостей, содержащем около 20 фамилий. В данном случае можно
было бы просмотреть весь список от начала и до конца, сравнивая каждый его
элемент с искомым именем. Если требуемое имя будет найдено, поиск завершится
успешно. Однако, если будет достигнут конец списка или обнаружено имя,
расположенное по алфавиту после искомого, поиск завершится неудачей. (Не забывайте, что
список упорядочен в алфавитном порядке, поэтому если будет найдено имя,
расположенное по алфавиту после требуемого, то это означает, что нужного нам имени в
списке нет.) Таким образом, наша задача — выполнять последовательный просмотр
элементов списка в направлении сверху вниз до тех пор, пока не будут проверены
все имена или нужное нам имя не будет найдено.
С помощью нашего псевдокода этот процесс можно представить следующим
образом:
Выбрать как <проверяемое значеиие> первый элемент списка.
while {<искомое значение> > <проверяемое значение> и есть
непроверенные элементы)
do (выбрать следующий элемент списка как <проверяемое значение>)
По окончании выполнения структуры while искомое значение либо будет
найдено, либо выяснится, что его нет в списке. В любом случае успешность по-
232 Глава четвертая. Алгоритмы
иска можно установить, сравнивая искомое значение с проверяемым. Если они
эквивалентны, поиск успешен. Таким образом, в конец приведенной выше
программы необходимо добавить следующую инструкцию:
if {<искомое значение> = <проверяемое значение>)
then (объявить поиск успешным)
else (объявить поиск неудачным)
Наконец, в нашей программе предполагается, что первая инструкция, где в
качестве проверяемого значения явно указан первый элемент списка, содержит, как
минимум, один элемент. Конечно же, это условие могло бы выполняться всегда, однако
для полной уверенности в правильности программы следует поместить составленную
выше программу в предложение else следующей инструкции if:
if (список пуст)
then (объявить поиск неудачным)
else (...)
В результате получается процедура, текст которой приведен на рис. 4.6.
Заметим, что для поиска некоторых значений в списке другие процедуры вполне
могут использовать ее с помощью следующей инструкции:
Применить процедуру Поиск к списку пассажиров в целях
нахождения в нем имени "Даррел Бейкер"
Эта инструкция позволяет установить, является ли Даррел Бейкер
пассажиром некоторого рейса. Вот еще один пример:
Применить процедуру Поиск к списку ингредиентов,
используя в качестве искомого значения "мускатный орех"
Данная инструкция позволит установить, входит ли мускатный орех в
перечень ингредиентов некоторого блюда.
procedure Поиск (<список>, <искомое значение>)
if (список пуст)
then (объявить поиск неудачным)
else
[выбрать как Проверяемое значение> первый элемент списка.
while (<искомое значение> > < проверяемое значение>
и есть непроверенные элементы)
do (выбрать следующий элемент списка
как Проверяемое значение>)
if (<искомое значение> = Проверяемое значение>)
then (объявить поиск успешным)
etse (объявить поиск неудачным)
]
Алгоритм последовательного поиска, сформулированный с помощью псевдокода
Итак, можно сказать, что представленный на рис. 4.6 алгоритм
последовательно рассматривает все элементы списка. По этой причине данный алгоритм
4.4. Итерационные структуры 233
называется алгоритмом последовательного поиска. 6 силу своей простоты он
часто применяется к коротким спискам либо когда это необходимо по каким-то
иным соображениям. Однако в случае длинных списков этот метод оказывается
менее эффективным, чем другие (в чем мы скоро убедимся).
Управление циклами
Неоднократное использование инструкции или последовательности инструкций
представляет собой важную алгоритмическую концепцию. Одним из методов
организации такого повторения является итеративная структура, известная как цикл; здесь
последовательность инструкций, называемая телом цикла, многократно выполняется
под контролем некоторого управляющего процесса. Типичный пример цикла можно
найти в алгоритме последовательного поиска, представленном на рис. 4.6. Здесь
инструкция while используется в целях управления повторным выполнением
единственной инструкции "выбрать следующий элемент списка как <проверяемое
значение>". Общий синтаксис инструкции while имеет такой вид:
while {условие) do {тело цикла)
Эта инструкция представляет собой типичный образец циклической
структуры, т.е. при ее выполнении циклически совершаются следующие действия:
проверить условие
выполнить тело цикла
проверить условие
выполнить тело цикла
проверить условие
Эти действия будут продолжаться до тех пор, пока заданное условие будет
выполняться.
Итеративные структуры в музыке
В музыке итеративные структуры использовали и программировали за много столетий до того, как это
стали делать специалисты в области компьютерных наук. Действительно, структура песни (состоящая из
нескольких куплетов, за каждым из которых следует припев) может быть представлена с помощью
следующей инструкции while:
while (остались куплеты) do
(исполнить следующий куплет;
исполнить припев)
Более того, запись
234 Глава четвертая. Алгоритмы
представляет собой способ описания композитором такой структуры:
assign N the value 1/
while (N<3) do
(играть пассаж;
играть концовку N;
assign N the value N+l)
Как правило, использование циклических структур придает алгоритму
большую гибкость по сравнению с явным многократным написанием тела цикла.
Рассмотрим такой пример:
Выполнить инструкцию "Добавить каплю серной кислоты" три раза.
Эта циклическая структура эквивалентна такой последовательности инструкций:
Добавить каплю серной кислоты.
Добавить каплю серной кислоты.
Добавить каплю серной кислоты.
Однако невозможно написать аналогичную последовательность,
эквивалентную следующему циклу:
while (уровень рН больше, чем 4) do
(добавить каплю серной кислоты)
Суть в том, что мы не знаем заранее, сколько капель серной кислоты
понадобится в каждом конкретном случае.
А теперь давайте подробно рассмотрим, как осуществляется управление
циклом. Может показаться, что эта часть структуры цикла менее важна. Ведь
именно в теле цикла непосредственно выполняются требуемые действия (например,
добавляются капли кислоты). Поэтому управляющие действия можно
рассматривать просто как надстройку, появившуюся только из-за того, что мы решили
повторять выполнение тела цикла. Однако опыт показывает, что именно
управление циклом чаще всего служит источником ошибок в циклических структурах
и, следовательно, требует особого внимания.
Управление циклом состоит из трех операций: инициализации, проверки и
модификации (рис. 4.7), причем все они обязательны для успешного управления
циклом. Назначение операции проверки состоит в обеспечении своевременного
окончания циклического процесса за счет отслеживания возникновения условия,
указывающего, что цикл пора заканчивать. Это условие называют условием
окончания цикла. Именно для выполнения операции проверки некоторое
условие обязательно указывается при записи каждой инструкции while нашего
псевдокода. Однако условие, задаваемое в инструкции while, — это то условие,
при котором тело цикла должно выполняться, а условие окончания — это отри-
4.4. Итерационные структуры 235
цание условия, заданного в инструкции while. Поэтому в инструкции while,
показанной на рис. 4.6, условие окончания выглядит следующим образом:
(<искомое значение> =< <проверяемое значение> и есть непроверенные
элементы)
/Л
Инициализация: Установить начальное состояние, которое будет модифицироваться
до тех пор, пока не будет выполнено условие окончания
Проверка: Сравнить текущее состояние с условием завершения и прекратить повторение
тела цикла, если состояние соответствует условию окончания
Модификация: Изменить состояние таким образом, чтобы приблизиться к ситуации,
в которой будет выполнено условие окончания
Операции процедуры управления повторяющимся действием
Остальные две операции управления циклом гарантируют, что условие
окончания обязательно возникнет. Операция инициализации устанавливает
начальное условие, а операция модификации изменяет его в направлении достижения
условия окончания. Например, на рис. 4.6 операция инициализации
выполняется инструкцией, предшествующей инструкции while. В этой операции первый
элемент списка устанавливается в качестве текущего проверяемого. Операция
модификации в этом случае реализуется в теле цикла, когда интересующая нас
позиция (проверяемый элемент) перемещается к концу списка. Таким образом,
выполнение операции инициализации и многократное выполнение операции
модификации приводят к тому, что условие окончания обязательно будет
достигнуто. (Или обнаружится проверяемый элемент, больший либо равный искомому,
или будет достигнут конец списка.)
Следует подчеркнуть, что операции инициализации и модификации
обязательно должны приводить к заданному условию окончания. Это является
важнейшим требованием организации надлежащего управления циклом, поэтому
при разработке циклической структуры следует, как минимум, дважды
убедиться в том, что оно выполняется. Если пренебречь подобной проверкой, то это
может привести к ошибкам даже в простейших случаях. Типичным примером
могут служить следующие инструкции:
assign число the value I
while (число Ф б) do
(assign число the value число + 2)
В данном случае условием окончания является выражение число = 6. Однако
переменная число инициализируется значением 1, а затем увеличивается на 2 на
каждом этапе модификации. Таким образом, при выполнении цикла переменной
236 Глава четвертая. Алгоритмы
число будут присваиваться значения 1, 3, 5, 7, 9,..., и ее значение никогда не
будет равно 6. В результате выполнение данного цикла никогда не закончится.
Существуют два варианта широко распространенных циклических структур,
которые отличаются только порядком выполнения операций управления
циклом. Первая представлена инструкцией нашего псевдокода:
while {условие) do {действие)
Семантика этой циклической структуры представлена на рис. 4.8 в виде
блок-схемы. На подобных схемах для представления отдельных этапов
выполнения используются различные геометрические фигуры, а стрелки
указывают порядок выполнения этих этапов. Различные фигуры отражают
отдельные типы деятельности, выполняемой на соответствующем этапе. Ромб
указывает на принятие решения, а прямоугольник представляет
произвольную инструкцию или последовательность инструкций. Обратите внимание,
что в данной циклической структуре проверка условия окончания
производится до того, как выполняется тело цикла.
РИСУНОК 4.8
Структура цикла типа while-do
В противоположность этому, в структуре, представленной на рис. 4.9,
указывается, что тело цикла должно выполняться до проверки условия окончания. В
результате тело цикла всегда выполняется хотя бы один раз, в то время как в
структуре типа while тело цикла может не выполниться ни разу (если условие
окончания будет выполнено при первой же его проверке).
4.4. Итерационные структуры
237
РИСУНОК 4.9
Структура цикла типа repeat-until
В нашем псевдокоде общий синтаксис цикла этого типа имеет следующий вид:
repeat {действие) until {условие)
Рассмотрим конкретный пример:
repeat (взять монету из кармана)
until (в кармане нет монет)
Когда выполнение алгоритма доходит до этой инструкции, подразумевается,
что в кармане есть хотя бы одна монета. Это предположение не является
обязательным при использовании следующей инструкции:
while (в кармане есть монета) do
(взять монету из кармана)
Алгоритм сортировки методом вставки
В качестве дополнительного примера итеративной структуры рассмотрим
задачу сортировки списка имен в алфавитном порядке. Прежде чем приступить к
обсуждению, следует установить некоторые ограничения, которые необходимо
будет учитывать. Попросту говоря, наша задача — отсортировать список "внутри
его самого". Другими словами, мы хотим отсортировать список, просто
переставляя его элементы, а не перемещая весь список в другое место. Это
аналогично сортировке списка, элементы которого записаны на отдельных карточках,
разложенных на переполненном рабочем столе. На столе достаточно места для
всех карточек, однако запрещается отодвигать другие находящиеся на столе
материалы, чтобы освободить дополнительное пространство. Подобное ограничение
238
Глава четвертая. Алгоритмы
типично для компьютерных приложений, но не потому, что рабочее
пространство в машине обязательно переполнено, как наш рабочий стол, а потому, что мы
стремимся использовать доступный объем памяти самым эффективным образом.
Попробуем сделать первый шаг в поисках решения задачи. Рассмотрим, как
можно .было бы отсортировать карточки с именами, расположенные на рабочем
столе. Пусть исходный список имен выглядит следующим образом:
Fred
Alice
David
Bill
Carol
Один из подходов к сортировке этого списка заключается в следующем.
Обратите внимание, что подсписок, состоящий из единственного верхнего имени,
Fred, уже отсортирован, а подсписок из двух верхних имен, Fred и Alice, — еще
нет. Поэтому подымем карточку с именем Alice, поместим карточку с именем
Fred вниз, туда, где раньше была карточка с именем Alice, а затем положим
карточку с именем Alice в самое верхнее положение, как показано в первой строке
на рис. 4.10. Теперь список будет иметь такой вид:
Alice
Fred
David
Bill
Carol
В этом варианте два верхних имени образуют отсортированный подсписок, а
три верхних — нет. Подымем третью карточку с именем David, опустим
карточку с именем Fred вниз, туда, где только что была карточка с именем David, а
затем поместим карточку с именем David в ту позицию, которую раньше занимала
карточка с именем Fred, как показано во второй строке на рис. 4.10. Теперь три
верхних элемента списка образуют отсортированный подсписок. Продолжая
действовать таким способом, мы можем получить список, в котором будут
отсортированы четыре верхних элемента. Для этого нужно поднять четвертую карточку
с именем Bill, опустить вниз карточки с именами Fred и David, а затем поместить
карточку с именем Bill в освободившуюся позицию (третья строка на рис. 4.10).
И, наконец, чтобы завершить процесс сортировки, необходимо поднять карточку
с именем Carol, опустить вниз карточки с именами Fred и David, а затем
поместить карточку с именем Carol в освободившуюся позицию — как показано в
четвертой строке на рис. 4.10.
4.4. Итерационные структуры 239
РИСУНОК 4.10
Сортировка списка имен Fred, Alice, David, Bill и Carol в алфавитном порядке
Теперь наша задача состоит в том, чтобы проанализировать процесс
сортировки конкретного списка и попытаться обобщить его в целях получения
алгоритма сортировки любого списка. С этой точки зрения каждая строка на
рис. 4.10 представляет собой один и тот же повторяющийся процесс: "Поднять
240
Глава четвертая. Алгоритмы
карточку с именем, первую в неотсортированной части списка, сдвинуть вниз
карточки с именами, которые находятся ниже по алфавиту, чем имя на взятой
нами карточке, а затем поместить эту взятую карточку на освободившееся место
в списке". Если назвать выбранное имя опорным элементом, то с помощью
нашего псевдокода данный процесс можно описать следующим образом:
Переместить опорный элемент во временное хранилище,
оставив в списке пустое место;
while (над пустым местом есть имя, и оно по алфавиту размещается
ниже, чем опорный элемент) do
(переместить имя, находящееся над пустым местом, вниз,
оставив в его прежней позиции пустое место)
Поместить опорный элемент на пустое место в списке
Обратите внимание, что этот процесс должен выполняться многократно.
Чтобы начать процедуру сортировки, в качестве опорного элемента должен быть
выбран второй элемент списка. Затем, перед каждым последующим выполнением
описанной процедуры, должен выбираться новый опорный элемент,
находящийся на одну позицию ниже предыдущего, и так до тех пор, пока не будет
достигнут конец списка, т.е. положение опорного элемента должно перемещаться от
второго элемента к третьему, затем к четвертому и т.д. Следуя этому, мы можем
организовать требуемое управление путем повторения процедуры с помощью
следующей последовательности инструкций:
assign N the value 2;
while (значение N не превышает <длина списка>) do
(выбрать N-й элемент списка в качестве опорного элемента;
assign N the value N + 1)
Здесь N — счетчик, параметр <длина списка> — количество элементов в
списке, а точки указывают место, где должна располагаться составленная нами
выше процедура.
Полный текст программы сортировки на языке псевдокода приведен на
рис. 4.11. Не вдаваясь в подробности, можно сказать, что эта программа
сортирует список, многократно повторяя следующие действия: "Элемент извлекается
из списка, а затем вставляется на надлежащее ему место". Именно по причине
многократного повторения вставки элементов в список данный алгоритм
получил название сортировки методом вставки.
Обратите внимание, что представленная на рис. 4.11 структура содержит
цикл, помещенный внутрь другого цикла. Внешний цикл представлен первой
инструкцией while, а внутренний цикл — второй инструкцией while. Каждое
выполнение тела внешнего цикла приводит к тому, что внутренний цикл
инициализируется и выполняется до тех пор, пока не будет выполнено условие его
окончания. Таким образом, однократное выполнение тела внешнего цикла будет
сопровождаться многократным выполнением тела внутреннего цикла.
4.4. Итерационные структуры 241
procedure Сортировка (<список>)
assign N the value 2,
while (значение N не превышает <длина списка>) do
(Выбрать N-й элемент списка в качестве опорного элемента;
Переместить опорный элемент во временное хранилише,
оставив в списке пустое место;
while (над пустым местом есть имя, которое по алфавиту
размещается ниже, чем опорный элемент) do
(переместить имя, находящееся над пустым местом вниз,
оставив в его прежней позиции пустое место) ;
Поместить опорный элемент на пустое место в списке *;
assign Ы the value H+) ,
Алгоритм сортировки методом вставки, написанный на псевдокоде
При инициализации управления внешним циклом начальное значение
счетчика N устанавливается с помощью инструкции
assign N the value 2;
Операция модификации этого цикла включает увеличение значения счетчика
N в конце тела цикла с помощью инструкции
assign N the value N+l.
Условие окончания внешнего цикла выполняется, когда значение счетчика N
превысит длину сортируемого списка.
Управление внутренним циклом инициализируется, когда опорный элемент
извлекается из списка и в нем образуется пустое место. Операция модификации
включает перемещение расположенных выше элементов на пустое место вниз, в
результате чего свободное место перемещается вверх по списку. Условие
окончания выполняется, когда пустое место или находится непосредственно под
именем, которое по алфавиту размещается выше опорного значения, или же
достигает верхней позиции списка.
Вопросы для самопроверки
1. Преобразуйте показанную на рис. 4.6 процедуру последовательного поиска
так, чтобы она могла работать с неотсортированными списками.
2. Перепишите приведенную ниже программу на псевдокоде так, чтобы в ней
использовались повторяющиеся инструкции.
assign Z the value 0;
assign X the value 1;
while (X < 6) do
(assign Z the value Z + X;
assign X the value X + 1)
242 Глава четвертая. Алгоритмы
3. Предположим, что процедура сортировки методом вставки, представленная
на рис. 4.11, была применена к списку George, Cheryl, Alice и Bob. Опишите,
как будет выглядеть список каждый раз по окончании выполнения тела
внешней структуры while.
4. Почему не следует заменять фразу "по алфавиту размещается ниже" в
инструкции while на рис. 4.11 на фразу "по алфавиту размещается ниже или
эквивалентно"?
5. Вариантом алгоритма сортировки методом вставки является выборочная
сортировка. Каждый раз выбирается наименьший элемент списка и помещается
на первое место. Затем выбирается наименьший элемент из оставшихся
элементов списка и помещается на второе место в списке. Многократно выбирая
наименьший элемент из оставшейся части списка и перемещая его вперед, мы
увеличиваем отсортированную часть списка, находящуюся в начале, тогда
как его конечная часть, состоящая из неотсортированных элементов,
сжимается. С помощью нашего псевдокода напишите процедуру сортировки списка
с использованием алгоритма выборочной сортировки, аналогичную
процедуре, представленной на рис. 4.11.
6. Другой известный алгоритм сортировки — сортировка методом пузырька. Он
основан на процессе повторяющегося сравнения двух стоящих рядом имен и
перестановки их местами, если они находились относительно друг друга в
порядке, отличном от требуемого. Предположим, что сортируемый список
состоит из п элементов. Сортировка методом пузырька начнется сравнением (и,
возможно, перестановкой) элементов, стоящих на местах п и п-1. Затем
сравниваются элементы, стоящие на местах п-1 и п-2, и так далее в направлении к
началу списка, пока не будет выполнено сравнение (и, возможно,
перестановка) первого и второго элементов списка. В результате прохождения по всему
списку его наименьший элемент будет вынесен на первое место. Аналогичным
образом, после второго прохождения списка следующий по величине элемент
будет вынесен на второе место и т.д. Таким образом, пройдя список п-1 раз,
мы отсортируем его целиком. (Если визуально представить себе работу
данного алгоритма, то создается впечатление, что наименьшие из оставшихся
неупорядоченных элементов списка последовательно всплывают к его вершине
как пузырьки, — отсюда и название алгоритма.) Используя наш псевдокод,
напишите процедуру сортировки списка методом пузырька по аналогии с
процедурой, представленной на рис. 4.11.
4.5. Рекурсивные структуры
Рекурсивные структуры также представляют собой тип повторяющихся
действий, но иной, отличный от циклического. Чтобы ввести понятие рекурсии,
рассмотрим алгоритм двоичного поиска, в котором к процессу поиска
применяется известный принцип "разделяй и властвуй".
4.5. Рекурсивные структуры 243
Поиск и сортировка
Алгоритмы последовательного и двоичного поиска — это всего лишь два представителя из большого
семейства алгоритмов, осуществляющих поисковый процесс. (Использование для этой цели индексов и
механизм перемешивания будет рассматриваться в главе 8.) Аналогично, сортировка методом вставки — это
лишь один из многих существующих алгоритмов сортировки. Другими классическими алгоритмами
являются сортировка слиянием (обсуждается в главе 11), выборочная сортировка (ее описание можно найти в
подразделе "Вопросы для самопроверки", п. 5, раздела 4.4), сортировка методом пузырька (см. подраздел
"Вопросы для самопроверки", п. 6, раздела 4.4), быстрая сортировка (применяющая к процессу
сортировки принцип "разделяй и властвуй") и древовидная сортировка (использующая искусную методику для
нахождения элементов, которые следует переместить вверх по списку).
Описание этих алгоритмов вы сможете найти в книгах, указанных в списке дополнительной литературы в
конце главы. Третий том книги Дональда Кнута "Искусство программирования", хотя и сложен для
восприятия начинающими, в целом может считаться последним словом в области методик поиска и сортировки. В
своем многотомном труде (который со временем может составить семь томов) Кнут собрал невероятное
количество информации, относящейся к фундаментальным алгоритмам вычислений, и тем самым внес
значительный вклад в библиотеки специалистов в области компьютерных наук и обработки данных.
Алгоритм двоичного поиска
Давайте вновь рассмотрим задачу поиска заданного элемента в
отсортированном списке. Но на этот раз подойдем к этому несколько иначе. Попытаемся
использовать процедуру, которой мы обычно следуем при поиске имени в
телефонном справочнике. Человек никогда не просматривает справочник
последовательно, элемент за элементом или даже страница за страницей. Мы просто
открываем его примерно в том месте, где, как мы думаем, может находиться
нужное имя. Если повезет, оно окажется именно там, в противном случае поиск
придется продолжить. Однако в этой точке мы уже сузим область поиска либо
до начальной части справочника, предшествующей нашей текущей позиции,
либо до остальной части справочника, следующей за ней.
На рис. 4.12 этот подход, применяемый к произвольному отсортированному
списку, описан с помощью псевдокода. В данном случае мы не знаем примерного
места расположения элементов, поэтому инструкции на рисунке предписывают
начинать работу с открытия списка на "среднем" элементе. Слово средний
заключено в кавычки, поскольку вполне возможно, что число элементов в списке
будет четным, и тогда среднего элемента в строгом смысле этого слова просто не
существует. В этом случае условимся, что средним считается первый элемент
второй половины списка.
244 Глава четвертая. Алгоритмы
I РИСУНОК 4,12
Выбрать "средний" элемент в <список> в качестве
<проверяемый_элемент>;
Выполнить один из следующих трех блоков инструкций,
в зависимости от того, является ли <искомое_значение>
равным, меньшим или большим, чем <проверяемый_элемент>
Case 1: <искомое_значение> = <проверяемый_элемент>
(Объявить поиск успешным)
Case 2: <искомое_значение> < <проверяемый_элемент>
[Применить процедуру Search, чтобы определить, есть
ли в части списка, предшествующей элементу
<проверяемый_элемент>, элемент <искомое_значение>, и
if (тот поиск успешен)
then (Объявить этот поиск успешным)
else (Объявить этот поиск неудачным)
1
Case 3: <искомое_значение> > <проверяемый_элемент>
[Применить процедуру Search, чтобы определить, есть
ли в части списка, следующей за элементом
<проверяемый_элемент>, элемент <искомое_значение>, и
if (тот поиск успешен)
then (Объявить этот поиск успешным)
else (Объявить этот поиск неудачным)
]
Принцип двоичного поиска
Если выбранный элемент не является искомым, то программа, приведенная на
рис. 4.12, предлагает два варианта дальнейших действий (поиск или в начальной
или конечной половине списка). В каждом из них предусматривается выполнение
вторичного поиска, осуществляемого процедурой с именем Search. Следовательно,
чтобы завершить нашу программу, необходимо создать подобную процедуру,
описывающую, как осуществляется этот вторичный поиск. Заметим, что эта процедура
должна быть в состоянии удовлетворить запрос на поиск в пустом списке. Например,
если показанной на рис. 4.12 программе будет передан список, состоящий из одного
элемента, который не является искомым, то процедура Search будет вызвана для
поиска либо в подсписке, находящемся выше этого единственного значения, либо в
подсписке, находящемся ниже его, однако оба эти списка пусты.
В качестве искомой процедуры Search можно было бы использовать процедуру
последовательного поиска, созданную нами в предыдущем разделе, но это совсем не
тот метод, который выбрал бы человек при поиске в телефонном справочнике.
Вероятно, он просто применил бы к оставшейся части справочника тут же процедуру,
которой только что воспользовался для всего справочника в целом. Другими словами,
выбрал бы какой-то элемент, достаточно близкий к середине оставшейся части
списка, и использовал его для дальнейшего сужения области поиска.
Подобный подход к процедуре поиска представлен на рис. 4.13. Здесь
демонстрируется способ решения задачи, заключающейся в определении присутствия
4.5. Рекурсивные структуры 245
имени John в списке, приведенном в левой части рисунка. Прежде всего,
анализируется средний элемент Harry. Так как имя, которое мы ищем, по алфавиту
располагается после данного имени, поиск продолжается в нижней части
исходного списка. Средним элементом этой части является имя Larry. Поскольку по
алфавиту искомое имя предшествует данному, поиск следует продолжать в
верхней части текущего подсписка. Обратившись к среднему элементу этого
вторичного подсписка, обнаруживаем искомое имя John и объявляем поиск успешным.
Короче говоря, наша стратегия состоит в последовательном делении
анализируемого списка на меньшие по размеру сегменты до тех пор, пока либо будет
найдено искомое значение, либо поиск сузится до пустого сегмента.
Применение стратегии, представленной на рис. 4.12, для поиска имени John в упорядоченном списке
Можно реализовать эту стратегию с помощью нашего псевдокода,
модифицировав приведенную на рис. 4.12 программу так, чтобы учесть возможность
получения пустого списка. Модифицированная соответствующим образом программа
на псевдокоде, которой присвоено имя Search, показана на рис. 4.14. При
выполнении этой процедуры и при достижении инструкции "Применить
процедуру Search, чтобы ...", мы будем просто применять этот же метод поиска к
меньшему списку, который является частью исходного списка. Если этот
вторичный поиск завершится успешно, мы вернемся в исходную процедуру, чтобы
объявить выполняемый в ней поиск успешным. Если же вторичный поиск
окончится неудачей, мы объявим неудачным и исходный поиск.
246 Глава четвертая. Алгоритмы
I РИСУНОК4.14 | _„_ .,____^,..^^.,_Wf-_ _
procedure Search (<список> <искомое_значение>)
#(<список>пуст)
then
(Объявить поиск неудачным)
else
Выбрать "средний" элемент в <список> в качестве
<проверяемый_элемент>;
Выполнить один из следующих трех блоков инструкций,
в зависимости от того, является ли <искомое_значение>
равным, меньшим или большим, чем <проверяемый_элемент>
Case 1: <искомое_значение> = <проверяемый_элемент>
(Объявить поиск успешным)
Case 2: <искомое_значение> < <проверяемый_элемент>
[Применить процедуру Search, чтобы определить, есть
ли в части списка, предшествующей элементу
<проверяемый_элемент>, элемент <искомое_значение>, и
if (тот поиск успешен)
then (Объявить этот поиск успешным)
else (Объявить этот поиск неудачным)
]
Case 3: <искомое_значение> > <проверяемый_элемент>
[Применить процедуру Search, чтобы определить, есть
ли в части списка, следующей за элементом
<проверяемый_элемент>, элемент <искомое_значение>, и
if (тот поиск успешен)
then (Объявить этот поиск успешным)
else (Объявить этот поиск неудачным)
]
Алгоритм двоичного поиска, написанный на псевдокоде
Чтобы увидеть, как представленная на рис. 4.14 процедура выполняет свою
задачу, попробуем с ее помощью определить, содержится ли значение Bill в
списке имен Alice, Bill, Carol, David, Evelyn, Fred, George. Поиск начинается с выбора в
качестве проверяемого элемента имени David (среднего элемента списка). Так как
искомое значение (Bill) по алфавиту предшествует проверяемому, следует
применить процедуру Search к списку элементов, предшествующих имени David, т.е. к
списку Alice, Bill, Carol. Для этого нам потребуется создать вторую копию
процедуры Search, предназначенную для решения данной промежуточной задачи.
Теперь мы имеем две выполняющиеся копии нашей процедуры поиска, как
показано на рис. 4.15. Дальнейшее выполнение исходной копии процедуры
временно приостановлено на следующей инструкции:
Применить процедуру Search, чтобы определить, есть
ли в части списка, предшествующей элементу
<проверяемый_элемент>, элемент <искомое_значение>
4.5. Рекурсивные структуры 247
Вторая копия процедуры используется для поиска имени Bill в списке Alice,
Bill, Carol. Завершив вторую процедуру двоичного поиска, мы аннулируем ее
копию и сообщим полученные в ней результаты исходной копии, после чего
выполнение исходной копии будет продолжено с указанного места. Таким образом,
вторая копия процедуры функционирует как подчиненная исходной, выполняя
задачу, запрошенную исходной копией, а затем исчезая.
РИСУНОК 4.15
Вызов вторичной копии процедуры из ее исходной копии
248
Глава четвертая. Алгоритмы
Вторичная процедура поиска выбирает имя Bill в качестве проверяемого
значения, так как это средний элемент в списке Alice, Bill, Carol. Поскольку он
совпадает с искомым значением, поиск объявляется успешным и вторичная
процедура завершает свою работу.
Теперь вторичный поиск, запрошенный исходной копией процедуры,
завершен, и выполнение этой исходной копии может быть продолжено. В очередной
инструкции указано, что, поскольку вторичный поиск был успешным, следует
объявить успешным и исходный поиск. В результате выполнения всего процесса
было совершенно справедливо установлено, что имя Bill присутствует в списке
имен Alice, Bill, Carol, David, Evelyn, Fred, George.
Теперь давайте посмотрим, что произойдет, если перед представленной на
рис. 4.14 процедурой поставить задачу определить наличие в списке Alice, Carol,
Evelyn, Fred, George элемента David. На этот раз исходная копия процедуры
выбирает в качестве проверяемого значения имя Evelyn и определяет, что искомое
значение должно находиться в предшествующей части списка. Поэтому она
вызывает еще одну копию процедуры для поиска в списке тех элементов, которые
стоят перед именем Evelyn, т.е. в двухэлементном списке, состоящем из имен
Alice и Carol. Ситуация на этой стадии выполнения алгоритма представлен на
рис. 4.16.
Вторая копия процедуры выберет в качестве проверяемого элемента имя Carol
и определит, что искомое значение должно находиться после него. Процедура
вызовет третью копию процедуры Search для поиска требуемого элемента в
списке имен, следующих за именем Carol в списке Alice, Carol. Однако этот список
пуст и перед третьей копией процедуры стоит задача поиска искомого значения
David в пустом списке. Ситуация, сложившаяся на этом этапе, представлена на
рис. 4.17. Исходная копия процедуры осуществляет поиск требуемого элемента в
списке Alice, Carol, Evelyn, Fred, George, выбрав в качестве проверяемого имя
Evelyn; вторая копия процедуры занята поиском требуемого элемента в списке
Alice, Carol, выбрав в качестве проверяемого элемент Carol; а третья начинает
поиск в пустом списке.
Конечно же, третья копия процедуры тут же объявляет свой поиск
неудачным и завершается. После этого вторая копия может продолжить свою работу.
Она обнаруживает, что запрошенный поиск оказался неуспешным, поэтому
также объявляет свой поиск неудачным и завершается. Исходная копия процедуры,
ожидавшая поступления сообщения от второй копии, теперь может продолжить
свою работу. Так как запрошенный поиск оказался неудачным, она тоже
объявляет свой поиск неудачным, после чего завершается. Таким образом, наша
программа пришла к правильному заключению, что имя David не содержится в
списке имен Alice, Carol, Evelyn, Fred, George.
4.5. Рекурсивные структуры 249
I РИСУНОК 4.16
Еще один пример двоичного поиска
Если еще раз просмотреть приведенные выше примеры, можно увидеть, что в
процессе, осуществляемом представленным на рис. 4.14 алгоритмом, необходимо
многократно разделять рассматриваемый список на две примерно равные части,
после чего область дальнейшего поиска ограничивается лишь одной из этих
частей. Именно это повторяющееся деление на два послужило причиной того, что
данный алгоритм был назван двоичным поиском.
250
Глава четвертая. Алгоритмы
Поиск привел к получению пустого списка
Управление рекурсией
Алгоритм двоичного поиска похож на алгоритм последовательного поиска,
так как каждый из них предусматривает выполнение повторяющегося процесса.
Однако реализация этого повторения в каждом случае существенно отличается.
При последовательном поиске повторение организуется с помощью цикла, в
случае двоичного поиска каждая стадия повторения реализуется как подзадача
предыдущей стадии. Этот метод повторения известен как рекурсия.
Рекурсивные структуры в изобразительном искусстве
С помощью приведенной ниже рекурсивной процедуры на прямоугольном холсте можно создавать картины
в стиле нидерландского живописца Пита Мондриана (Piet Mondrian, 1872-1944). (На его картинах
прямоугольный холст разделен на последовательно уменьшающиеся прямоугольники.) Следуя данной
процедуре, попытайтесь самостоятельно создать картины, аналогичные изображенной на рисунке. Начните с
прямоугольника, представляющего весь холст, на котором вы работаете.
4.5. Рекурсивные структуры
251
procedure Mondrian (<прямоугольиик>)
if (<прямоугольник> имеет размеры, слишком большие для
вашего художественного восприятия)
then (разделить <прямоугольник> на два меньших
прямоугольника;
применить процедуру Mondrian к первому из
полученных меньших прямоугольников;
применить процедуру Mondrian ко второму меньшему
прямоуголь нику)
При выполнении рекурсивного алгоритма создается иллюзия существования
множества его копий, называемых активациями, которые появляются и
исчезают по мере выполнения алгоритма. Из всех активаций, существующих в
заданный момент времени, активно функционирует только одна. Все остальные
фактически остановлены, поскольку каждая из них ожидает, пока завершится
следующая, запущенная ею активация, и только после этого она сможет
продолжить свою работу.
Будучи повторяющимися процессами, рекурсивные структуры почти так же
зависят от корректного управления, как и циклические структуры. Как и в
случае управления циклами, рекурсивные системы зависят от проверки условия
окончания и должны разрабатываться так, чтобы иметь гарантии, что это
условие будет обязательно выполнено. Фактически правильно организованное
управление рекурсией включает те же три операции, что и управление циклом, —
инициализация, модификация и проверка условия окончания.
Разработка рекурсивных процедур
При создании рекурсивных процедур основным условием является выбор способа, с помощью которого
исходную задачу можно разделить на меньшие задачи того же типа, а также определить, как результаты
решения этих меньших задач могут быть использованы в качестве абстрактных инструментов нахождения
решения исходной задачи. Давайте применим этот подход к поиску выхода из лабиринта, подобного
приведенному на этом рисунке. Будем продвигаться вперед до тех пор, пока не подойдем к первому разветв-
252 Глава четвертая. Алгоритмы
лению. В этой точке мы будем считать, что каждый вариант дальнейшего движения представляет собой
вход в новый лабиринт меньшего размера. Если в любом из этих меньших лабиринтов выход будет найден,
наша задача решена. Такой способ рассуждений приводит к построению следующей процедуры:
procedure FindExit (<лабиринт>)
Продвигаться по лабиринту до развилки, тупика или выхода;
В каждом из указанных случаев выполнить соответствующие
инструкции из числа приведенных ниже:
case 1: достигнут выход: (сообщить "выход найден")
case 2: достигнут тупик: (сообщить "неудача")
case 3: достигнута развилка:
(while (есть ветвь, ведущая к неисследованной
территории, и выход еще не найден) do
(применить процедуру FindExit к лабиринту,
представленному одной из неисследованных ветвей;
if (эта процедура сообщила, что выход найден)
then (сообщить "выход найден".)
)
if (все варианты этой развилки неудачны) then
(сообщить "неудача")
Обычно рекурсивная программа разрабатывается так, чтобы проверять
условие окончания (часто называемое граничным условием, или условием
вырождения) до того, как будут вызваны последующие активации. Если условие
окончания еще не достигнуто, то программа создает следующую свою активацию,
задача которой — найти решение сокращенной версии задачи текущей активации.
Подразумевается, что эта сокращенная версия находится ближе к условию
окончания, чем задача, которой занимается текущая активация. Как только условие
окончания будет обнаружено, выбирается путь, вызывающий завершение
текущей активации без создания дополнительных активаций. Это означает, что
одной из остановленных активаций разрешается продолжить свое выполнение,
завершить ее задачу и, в свою очередь, позволить следующей остановленной
активации возобновить свои действия. Таким образом, все порожденные активации в
конечном счете будут завершены, что приведет к завершению исходной задачи.
4.5. Рекурсивные структуры
253
Теперь посмотрим, как операции инициализации и модификации механизма
управления повторением реализованы в рекурсивной программе двоичного поиска,
представленной на рис. 4.14. В этом случае создание дополнительных активаций
прекращается, когда обнаруживается искомое значение или задача сужается до
поиска в пустом списке. Процесс инициализируется неявно, посредством задания
исходного списка и искомого значения. Начиная с этой конфигурации, программа
модифицирует свою задачу, что приводит к поиску во все уменьшающемся списке.
Поскольку длина исходного списка конечна, а каждый этап модификации уменьшает
длину рассматриваемого списка, можно гарантировать, что либо искомое значение
будет найдено, либо задача сузится до поиска в пустом списке. Следовательно,
можно сделать заключение, что процесс повторения гарантированно прекратится.
Рассматривая структуры управления рекурсией и итерациями, можно
попробовать установить, одинаковы ли их возможности. То есть, если некоторый алгоритм
разработан с использованием циклической структуры, то можно ли для решения
этой же задачи разработать другой алгоритм, применяющий только рекурсивные
методы, и наоборот. Такие вопросы важны с точки зрения компьютерных наук, так
как ответы на них позволяют понять, какие функции необходимо реализовать в
языке программирования, чтобы получить как можно более мощную систему
разработки программ. Мы вернемся к этой проблеме в главе 11, где будут
рассматриваться некоторые теоретические аспекты компьютерных наук и их математических
основ. Опираясь на сделанные в этой главе выводы, в приложении Д будет доказана
эквивалентность итеративных и рекурсивных структур.
Вопросы для самопроверки
1. Какие имена будут проверены программой двоичного поиска (рис. 4.14) при
поиске имени Joe в списке имен Alice, Bob, Carol, David, Evelyn, Fred, George,
Henry, Irene, Joe, Karl, Larry, Mary, Nancy и Oliver?
2. Какое максимальное количество элементов может потребоваться проверить
при выполнении двоичного поиска в списке из 200 элементов? А в списке из
100 000 элементов?
4.6. Эффективность и правильность
В этом разделе мы обсудим понятия, которые являются частью данного
формального введения в теорию алгоритмов. О них всегда нужно помнить при
самостоятельной разработке алгоритмов. Первое из них — эффективность, а
второе — правильность.
Эффективность алгоритма
Хотя современные машины способны выполнять миллионы операций в
секунду, эффективность по-прежнему остается важнейшим аспектом разработки
алгоритмов. Зачастую выбор между эффективным и неэффективным решением
254 Глава четвертая. Алгоритмы
задачи может на самом деле означать выбор между реализуемым и
нереализуемым способом ее решения.
Рассмотрим задачу, с которой сталкивается секретарь университета при поиске
личных дел студентов и их заполнении. Хотя в университете на протяжении любого
семестра фактически числится около 10 000 студентов, секретарю в
действительности приходится иметь дело с более чем 30 000 личных дел, поскольку за несколько
предыдущих лет многие из студентов зарегистрировались для изучения хотя бы
одной из преподаваемых в университете дисциплин, но не смогли закончить цикл
обучения. Теперь предположим, что все личные дела хранятся в компьютере секретаря
в виде списка, упорядоченного по идентификационным номерам каждого из
студентов. Чтобы найти личное дело некоторого студента, секретарь должен выполнить
поиск по его идентификационному номеру в общем списке.
Мы уже познакомились с двумя алгоритмами поиска в подобных списках —
последовательным и двоичным поиском. Сейчас нам нужно дать ответ на вопрос,
почувствует ли секретарь разницу между этими двумя алгоритмами? Начнем с
рассмотрения последовательного поиска.
При заданном идентификационном номере студента алгоритм последовательного
поиска начинает работу с начала списка и последовательно сравнивает каждый
выбираемый элемент с искомым числом. Не зная, что представляет собой искомое
число, мы не можем определить, насколько далеко потребуется просматривать список.
Все же можно утверждать, что для множества выполненных операций поиска их
средняя глубина будет равна приблизительно половине длины списка, хотя в
отдельных случаях поиск потребует меньшего числа операций, а в других — большего.
Можно сделать вывод, что при многократном выполнении последовательного поиска
на каждый случай в среднем приходится приблизительно 15 000 просмотренных
личных дел. Если выборка каждого личного дела из памяти и сравнение его номера
с искомым выполняется за десять миллисекунд (десять тысячных долей секунды), то
среднее время поиска будет составлять 150 секунд или две с половиной минуты.
Если секретарю придется так долго ожидать появления на экране монитора личного
дела интересующего его студента, несомненно, что этот вариант совершенно
неприемлем. Даже если время выборки и проверки каждой записи сократить до одной
миллисекунды, на поиск личного дела студента все равно потребуется в среднем
около 15 секунд — все еще слишком много для среднего времени ожидания ответа,
которое можно считать приемлемым.
В противоположность этому, алгоритм двоичного поиска начинает работу со
сравнения искомого значения со средним элементом списка. Если это не искомый
элемент, то область поиска сразу же сужается до половины исходного списка, т.е.
после проверки среднего элемента списка из 30000 личных дел алгоритм двоичного
поиска в большинстве случаев выберет для дальнейшего рассмотрения только 15000
дел. После второго этапа область поиска в большинстве случаев сократится до 7500
дел, после третьего — до 3750 и т.д. В результате искомое значение будет найдено
при выборе, самое большее, 15 элементов списка, состоящего из 30000 дел. Таким
образом, если каждое выбранное значение обрабатывается за 10 миллисекунд,
процесс поиска нужного личного дела потребует не более 0,15 секунды, а это означает,
что с точки зрения секретаря личное дело любого студента будет появляться на эк-
4.6. Эффективность и правильность 255
ране практически мгновенно. Можно сделать обоснованное заключение, что выбор
между алгоритмом последовательного поиска и алгоритмом двоичного поиска в
данном случае имеет большое значение.1
Этот пример иллюстрирует важность той области компьютерных наук,
которую называют анализом алгоритмов. Эта область связана с изучением
необходимых алгоритмам ресурсов, таких как время или используемый объем памяти.
Основным практическим применением результатов подобных исследований
является оценка относительных достоинств альтернативных алгоритмов. В нашем
случае мы проанализировали время, требующееся алгоритмам последовательного
и двоичного поиска, что позволило нам определить, какой из них больше
подходит в данном конкретном случае. В общем случае такой анализ осуществляется в
более широком контексте. Это означает, что при рассмотрении алгоритмов,
выполняющих поиск в списке, мы не ограничимся списком фиксированной длины,
но пытаемся вывести формулу эффективности алгоритма для списков
произвольной длины. Такой анализ включает изучение ситуаций, в которых алгоритм
демонстрирует свои наилучшие свойства, ситуаций, когда его эффективность
минимальна, а также оценку его средней производительности.
В предыдущем случае выполненный нами анализ заключался в оценке средней
производительности алгоритма последовательного поиска, а также определении той
производительности, которую алгоритм двоичного поиска продемонстрирует в
наихудшем случае. Хотя мы рассматривали список определенной длины, несложно
обобщить наши рассуждения на случай списка произвольной длины. В частности,
при применении к списку из п элементов алгоритму последовательного поиска в
среднем потребуется проверить п/2 элементов, тогда как алгоритму двоичного поиска
в самом худшем случае потребуется проверить только log2n элементов. (В данном
случае выражение log2n представляет логарифм числа п по основанию 2, который
показывает, сколько раз число п можно разделить на два.)
Давайте попробуем проанализировать аналогичным образом алгоритм
сортировки методом вставки (см. рис. 4.11). Поскольку основным действием в
реализации данного алгоритма является сравнение двух имен, наш подход будет
состоять в подсчете количества таких сравнений, которые потребуется выполнить
при сортировке списка длиной п элементов.
Вспомним, что при сортировке методом вставки осуществляется выбор
некоторого элемента, называемого опорным; после этого он сравнивается с предшествующими
ему элементами, пока для него не будет найдено надлежащее место, после чего
опорный элемент вставляется в соответствующую позицию. Алгоритм начинается с
выбора второго элемента списка в качестве опорного. По мере его выполнения в ка-
1 Чтобы воспользоваться преимуществами алгоритма двоичного поиска, личные дела
студентов должны располагаться в памяти машины таким образом, чтобы можно было
извлекать средние записи последовательно уменьшающихся подсписков без чрезмерных
усилий. Это можно осуществить, запоминая личные дела в индексированных файлах —
структурах, которые будут обсуждаться в главе 8. Кроме того, тех же результатов можно
достичь и с использованием хешированных файловых структур, которые также
описываются в главе 8.
256 Глава четвертая. Алгоритмы
честве опорных выбираются следующие элементы — пока не будет достигнут конец
списка. В самом лучшем случае каждый опорный элемент уже находится на
положенном ему месте. Следовательно, чтобы это было обнаружено, его потребуется
сравнить только с одним именем. Поэтому в наилучшем случае применение
алгоритма сортировки методом вставки к списку из п элементов потребует выполнения
п -1 сравнений. (Второй элемент сравнивается с одним элементом (первым), третий
элемент — с одним элементом (вторым) и т.д.)
И наоборот, наихудший сценарий имеет место в том случае, когда
каждый опорный элемент потребуется сравнивать со всеми впереди стоящими
элементами, прежде чем удастся найти правильное место его расположения.
Очевидно, что в этом случае исходный список упорядочен в обратном
порядке. Первый опорный элемент (второй элемент списка) сравнивается с одним
элементом, второй опорный элемент (третий элемент списка) — с двумя
элементами и т.д. (рис. 4.18). Следовательно, общее количество сравнений при
сортировке списка из п элементов составит 1 + 2+3 + ... + (л-1), что
эквивалентно п(п - 1)/2 или (1/2)(л2 - п). В частности, для списка из 10 элементов
алгоритму сортировки методом вставки в наихудшем случае потребуется
выполнить 45 сравнений.
Сравнения, выполняемые для каждого опорного элемента
Работа алгоритма сортировки методом вставки в наихудшем случае
В среднем при сортировке методом вставки можно ожидать, что каждый
опорный элемент потребуется сравнить с половиной предшествующих ему
элементов. В этом случае общее количество выполненных сравнений будет вдвое
меньше, чем в наихудшем случае, т.е. (\/4)(п2-п) сравнений для списка длины п.
Например, если использовать сортировку методом вставки для упорядочения
множества списков из 10 элементов, то среднее число производимых в каждом
случае сравнений будет равно 22,5.
Важность полученного выше результата состоит в том, что количество
сравнений, выполненных алгоритмом сортировки методом вставки, позволя-
4.6. Эффективность и правильность 257
ет оценить время, которое потребуется для выполнения сортировки. Эта
оценка была использована для построения графика, представленного на
рис. 4.19. Он показывает, как будет возрастать время, необходимое для
выполнения сортировки методом вставки, при увеличении длины сортируемого
списка. Данный график построен по оценкам работы алгоритма в наихудшем
случае, когда, исходя из результатов наших исследований, для списка
длиной п требуется выполнить не менее (1/2)(я2 -п) сравнений элементов. На
графике отмечено несколько конкретных значений длины списка и указано
время, необходимое в каждом случае. Обратите внимание, при увеличении
длины списка на одно и то же количество элементов время, необходимое для
сортировки списка, все больше и больше возрастает. Таким образом, с
увеличением длины списка эффективность данного алгоритма уменьшается.
С4„
РИСУНОК 4.19
Работа алгоритма сортировки методом вставки в наихудшем случае с
Выполним аналогичный анализ работы алгоритма двоичного поиска в
наихудшем случае. Как было установлено выше, при использовании этого
алгоритма для поиска в списке из п элементов потребуется проанализировать
не более log2 n элементов. Это позволяет оценить время, необходимое для
выполнения алгоритма при различной длине сортируемого списка. На рис. 4.20
представлен график, построенный по результатам данного анализа. На этом
графике также отмечены конкретные значения длины списка, возрастающие
на одну и ту же величину, и указано соответствующее время выполнения ал-
258 Глава четвертая. Алгоритмы
горитма. Обратите внимание, что темпы роста времени выполнения
алгоритма снижаются по мере увеличения длины списка, т.е. эффективность
алгоритма двоичного поиска возрастает с увеличением длины списка.
РИСУНОК 4.20
График продолжительности работы алгоритма двоичного поиска для наихудшего случая
Основным отличием между графиками, представленными на рис. 4.19 и 4.20,
безусловно, является их общая форма. Именно форма графика, а не его
индивидуальные особенности, демонстрирует, насколько хорошо данный алгоритм будет
справляться со все возрастающими объемами данных. Заметим, что общая
форма графика определяется типом отображаемого выражения, а не его
конкретными особенностями: все линейные выражения изображаются прямой линией, все
квадратичные выражения — параболической кривой, а все логарифмические
выражения порождают логарифмическую кривую, подобную представленной на
рис. 4.20. Общую форму кривой принято определять простейшим выражением,
порождающим кривую данной формы. В частности, параболическая форма
обычно определяется выражением л2, а логарифмическая — выражением lg п.
Выше было показано, что форма графика, представляющего зависимость
времени выполнения алгоритма от объема входных данных, отражает общие
характеристики эффективности алгоритма. Поэтому принято классифицировать
алгоритмы согласно форме их графиков, построенных для самого неблагоприятного
случая. Способ обозначения, используемый для определения этих классов,
иногда называют тета-классами. Алгоритмы, графики которых имеют
параболическую форму (например, сортировка методом вставки), относятся к классу О(я2),
4.6. Эффективность и правильность
259
алгоритмы, графики которых имеют логарифмическую форму (например,
двоичный поиск), — к классу 0(lg n). Любой алгоритм из тета-класса 6(lg n) по самой
свой сути всегда более эффективен, чем алгоритм из тета-класса 0(я2).
Верификация программ
Вспомним, что четвертая фаза процедуры решения задачи, согласно схеме,
предложенной математиком Полна (см. раздел 4.3), заключается в оценке
точности найденного решения и определении его потенциала как инструмента для
решения других задач. Важность первой части этой фазы мы проиллюстрируем
следующим примером.
Путешественник, у которого есть золотая цепочка из семи звеньев, должен остановиться в
уединенном отеле на семь ночей. Плата за кавдую проведенную в отеле ночь составляет одно звено
его цепочки. Какое наименьшее число звеньев необходимо разрезать, чтобы путешественник мог
платить владельцу отеля одно звено каждое утро, не внося плату заранее?
Первым делом уясним себе, что нет необходимости разрезать все звенья. Если
мы разрежем только второе звено, то и первое, и второе будут отделены от
остальных пяти звеньев. Следуя этому, можно прийти к решению разрезать только
второе, четвертое и шестое звенья цепочки. В результате все звенья окажутся
свободными, причем только три из них будут разрезанными (рис. 4.21). Более
того, любое меньшее число разрезов оставит два звена соединенными, поэтому
мы заключаем, что правильный ответ для этой задачи — три звена.
РИСУНОК 4.21 ]
Разъединение всех звеньев цепочки с помощью всего лишь трех разрезов
Однако рассмотрев задачу более внимательно, можно заметить, что если
разрезать только третье звено, то получится три фрагмента цепочки, состоящие из
260
Глава четвертая. Алгоритмы
одного, двух и четырех звеньев (рис. 4.22). С этими фрагментами мы можем
поступить следующим образом.
Первое утро. Отдать владельцу отеля одно звено.
Второе утро. Забрать у владельца отеля одно звено и отдать ему
фрагмент цепочки из двух звеньев.
Третье утро. Отдать владельцу отеля одно звено.
Четвертое утро. Забрать у владельца отеля три отданные ему ранее звена
и отдать ему фрагмент цепочки из четырех звеньев.
Пятое утро. Отдать владельцу отеля одно звено.
Шестое утро. Забрать у владельца отеля одно звено и отдать ему
фрагмент цепочки из двух звеньев.
Седьмое утро. Отдать владельцу отеля одно звено.
Решение задачи с помощью всего лишь одного разреза
Следовательно, тот ответ, который мы считали правильным, на самом деле
неверен. Как же убедиться, что новое решение действительно правильно? В качестве
доказательства можно привести следующее рассуждение. Поскольку в первое утро
необходимо отдать владельцу отеля одно звено, придется разрезать, по крайней мере,
одно звено цепочки. Но так как в новом варианте решения требуется разрезать
только одно звено, то это решение должно быть оптимальным.
Применительно к программированию этот пример демонстрирует различия
между программой, которая выглядит правильной, и программой, которая
действительно является правильной. Это не всегда одно и то же. Специалистам в
области обработки данных известно множество ужасных историй о том, как
программное обеспечение, которое считалось безусловно правильным, все же
отказывало в критический момент, поскольку возникшая ситуация оказывалась для
4.6. Эффективность и правильность 261
него совершенно непредвиденной. Следовательно, верификация программного
обеспечения — это важное и необходимое дело, а поиск эффективных методов
верификации является активным направлением исследований в области
компьютерных наук.
Одно из самых современных направлений в этой области заключается в
использовании методов формальной логики для доказательства корректности программ. Это
означает, что цель проводимых исследований состоит в применении формальной
логики для доказательства того факта, что реализованный данной программой
алгоритм делает именно то, для чего он предназначен. Основополагающий тезис
заключается в том, что при сведении процесса верификации к формальной процедуре мы
застрахованы от некорректных умозаключений, вытекающих из интуитивной
аргументации, как это было в случае с задачей о золотой цепочке. Давайте рассмотрим
данный подход к верификации программ более подробно.
Подобно тому, как формальное математическое доказательство основывается
на аксиомах (геометрические доказательства часто базируются на аксиомах
Евклидовой геометрии, тогда как доказательства других утверждений — на
аксиомах теории множеств), формальное доказательство правильности программы
основывается на спецификациях, в соответствии с которыми эта программа
разрабатывалась. Чтобы доказать, что программа правильно сортирует списки имен,
мы можем начать с предположения о том, что на вход программы подается
список имен. Если программа создана для вычисления среднего значения одного
или более положительных чисел, мы можем предположить, что исходными
данными для программы является одно или несколько положительных чисел.
Короче говоря, доказательство корректности начинается с предположения о том,
что в начале работы программы удовлетворены некоторые условия, называемые
предварительными условиями, или предусловиями.
Следующий этап доказательства корректности заключается в рассмотрении
того, как следствия из этих предусловий распространяются по программе. С этой
целью исследователи изучили различные программные структуры, пытаясь
установить, как выполнение данной структуры влияет на утверждение, о котором
до выполнения этой структуры было известно, что оно истинно. Например, пусть
определенное утверждение о значении переменной Y перед выполнением
приведенной ниже инструкции было истинно:
assign X the value of Y
После выполнения этой инструкции то же утверждение можно сделать о
значении переменной X. Например, если перед выполнением инструкции значение
переменной Y отличалось от 0, то можно сделать заключение, что после
выполнения этой инструкции значение переменной X также будет отличаться от 0.
Несколько более сложным случаем является выполнение оператора if-then-
else, например, следующего вида:
if (условие) then {инструкция 1)
else (инструкция 2).
Если в этом примере известно, что некоторое утверждение было истинно перед
выполнением данной структуры, то непосредственно перед выполнением инструкции
262 Глава четвертая. Алгоритмы
1 мы знаем, что истинны как это утверждение, так и проверяемое условие. В то же
время, если должна выполняться инструкция 2, мы знаем, что должны быть
истинны исходное утверждение и отрицание проверяемого условия.
Верификация требуется не только программному обеспечению
Обсуждаемые в тексте проблемы верификации касаются не только программного обеспечения. Столь же
важно получить гарантии, что выполняющая программу аппаратура также не содержит ошибок. Это
подразумевает верификацию как разрабатываемых схем, так и конструкции всей машины. И в этом случае
полученные результаты в значительной степени зависят от тестирования, задача которого, как и в случае с
программным обеспечением, — выявить скрытые ошибки. Показателен пример машины Mark 1, созданной в
Гарвардском университете в 1940 году, монтажные ошибки в которой оставались необнаруженными в
течение многих лет. Более "свежий" пример — ошибки в блоке выполнения операций с плавающей точкой,
имевшие место в первых микропроцессорах типа Pentium. В обоих случаях существующие ошибки были
выявлены до каких-либо серьезных последствий.
Если следовать правилам, приведенным выше, доказательство корректности
программы осуществляется путем определения положений, называемых
утверждениями, которые устанавливаются в различных точках программы. В
результате получается набор утверждений, каждое из которых является следствием
предусловий программы и последовательности инструкций, приводящей к той
точке программы, где установлено данное утверждение. Если утверждение,
установленное подобным образом в конце программы, соответствует спецификациям
того, что требуется получить на ее выходе, то можно сделать заключение о
правильности программы.
В качестве примера рассмотрим типичную циклическую структуру while-
do, представленную на рис. 4.23. Предположим, как следствие предусловий,
заданных в точке А, мы можем установить, что определенное утверждение
истинно при каждой проверке условия окончания цикла (точка В) на
протяжении всего процесса повторения. (Такое утверждение внутри цикла
называется инвариантом цикла.) Как только повторение завершается, выполнение
переходит к точке С, где мы можем заключить, что истинны как инвариант
цикла, так и условие его окончания. (Инвариант цикла остается истинным,
поскольку проверка условия окончания не изменяет никаких величин в
программе, а условие окончания истинно, поскольку в противном случае цикл
бы просто не завершился.) Если комбинация этих положений означает то,
что мы хотим видеть на выходе, наше доказательство корректности можно
завершить, просто показав, что компоненты инициализации и модификации
цикла в конечном счете приводят к условию окончания.
4.6. Эффективность и правильность 263
Утверждения, относящиеся к типичной структуре while-do
Этот метод анализа можно применить к приведенному выше алгоритму
сортировки методом вставки (см. рис. 4.11). Внешний цикл в этой программе
основан на следующем инварианте цикла:
Каждый раз при выполнении проверки условия окончания цикла имена, предшествующие N-му
элементу, образуют отсортированный список.
Условие окончания этого цикла формулируется следующим образом:
Значение N больше, чем длина списка.
Таким образом, как только цикл завершится, мы будем знать, что оба условия
должны быть выполнены, а это означает, что весь список будет отсортирован.
К сожалению, методы формальной верификации программ не настолько
хорошо разработаны, чтобы их можно было использовать в приложениях общего
типа. Сегодня в большинстве случаев "верификация" программного обеспечения
производится посредством его тестирования при различных исходных условиях,
что весьма ненадежно. Верификация с помощью тестирования не доказывает
ничего иного, кроме того, что программа правильно работает в тех условиях, в
которых ее проверяли. Любые дополнительные заключения — это всего лишь
предположения. Ошибки, содержащиеся в программе, чаще всего являются
следствием оплошности и недосмотра, что может произойти и при тестировании.
В результате ошибки в программе, такие как в задаче с золотой цепочкой, могут
264 Глава четвертая. Алгоритмы
остаться и часто остаются незамеченными, хотя были потрачены значительные
усилия, чтобы этого избежать. Драматический случай произошел в компании
AT&T. Ошибка в программном обеспечении, управляющем 114 телефонными
станциями, оставалась незамеченной с момента его установки в декабре 1989
года и вплоть до 15 января 1990 года, когда исключительное стечение
обстоятельств привело к тому, что за девять часов было беспричинно заблокировано
примерно 5 миллионов телефонных звонков.
Вопросы для самопроверки
1. Предположим, было установлено, что при использовании алгоритма
сортировки методом вставки машине требуется в среднем одна секунда для
сортировки списка из 100 элементов. Оцените, сколько времени ей понадобится
для сортировки списков из 1000 и 10 000 элементов?
2. Приведите примеры алгоритмов, относящихся к каждому из следующих
классов: 0(lg л), 0(л), 0(л2).
3. Перечислите следующие классы в порядке убывания их эффективности: 0(л2),
0(lg/7), 0(л), 0(А73).
4. Проанализируйте следующую задачу и предлагаемый ответ. Является ли этот
ответ правильным? Поясните свои выводы.
Задача. Предположим, что в коробке находятся три карточки. У одной из
них обе стороны черного цвета, у второй обе стороны красного цвета, а у
третьей одна сторона черного цвета, а другая — красного. Из коробки
вынимают одну карточку, и вам разрешается посмотреть на одну из ее сторон.
Какова вероятность того, что вторая сторона этой карточки того же цвета, что и
та, которую вам показали?
Предлагаемый ответ. Одна вторая. Предположим, что показанная вам сторона
карточки была красного цвета. (Рассуждения будут аналогичны и в том случае,
если она будет черного цвета, так как задача симметрична.) Из трех карточек
только у двух есть красная сторона. Следовательно, карточка, которую вы
увидели, — одна из этих двух. У одной из этой пары карточек вторая сторона красная,
а у другой — черная. Следовательно, вторая сторона у выбранной из коробки
карточки с равной вероятностью может быть как черной, так и красной.
5. Приведенный ниже программный сегмент используется, чтобы вычислить
частное (не принимая во внимание остаток) двух целых положительных чисел
(делимого и делителя) путем подсчета, сколько раз делитель можно вычесть
из делимого, пока оставшаяся часть станет меньше делителя. Например, при
делении по этому методу числа 7 на 3 получится 2, так как число 3 можно
вычесть из 7 дважды. Правильно ли составлена эта программа? Обоснуйте
свои выводы.
assign Счетчик the value 0;
assign Остаток the value <делимое>;
repeat (assign Остаток the value Остаток - <делитель>;
4.6. Эффективность и правильность 265
assign Счетчик the value Счетчик + 1)
until (Остаток < <делитель>)
assign Частное the value Счетчик
6. Приведенный ниже программный сегмент предназначен для определения
произведения двух неотрицательных целых чисел X и Y посредством
вычисления суммы X копий числа Y. Другими словами, выражение 3x4
вычисляется как сумма трех четверок. Правильно ли составлена эта программа?
Обоснуйте это.
assign Произведение the value Y;
assign Счетчик the value 1;
while (Счетчик < X) do
(assign Произведение the value Произведение + Y;
assign Счетчик the value Счетчик + 1)
7. Приняв как предусловие, что значение N — целое положительное число,
установите инвариант цикла, который приводит к заключению, что по
окончании приведенной ниже программы переменной Сумма будет присвоено
значение, равное 0 + 1 + ... + N.
assign Сумма the value 0;
assign I the value 0;
while (I < N) do
(assign I the value I + 1;
assign Сумма the value Сумма + I)
Приведите аргументы в пользу того, что эта программа действительно
завершится.
8. Предположим, что программа и выполняющая ее аппаратура были
формально проверены на корректность. Гарантирует ли это правильность их работы?
Упражнения
1. Приведите примеры последовательности этапов, удовлетворяющей
неформальному определению алгоритма, приведенному во введении к
разделу 4.1, но не удовлетворяющей определению, приведенному на рис. 4.1.
2. Объясните различие между неоднозначностью в предложенном
алгоритме и неоднозначностью в представлении алгоритма.
3. Поясните, как использование примитивов помогает устранить
неоднозначность в представлении алгоритмов?
4. Представляет ли следующая программа алгоритм в строгом смысле
этого слова? Поясните свой ответ.
assign Счетчик the value 0;
while (Счетчик не равен 5) do
(assign Счетчик the value Счетчик + 2)
266 Глава четвертая. Алгоритмы
5. По какой причине приведенная ниже последовательность этапов не
образует алгоритм?
Этап 1. Провести отрезок прямой линии, соединяющий точки с
координатами (2, 5) и (6, 11).
Этап 2. Провести отрезок прямой линии, соединяющий точки с
координатами (1, 3) и (3, 6).
Этап 3. Провести окружность с радиусом 2 и центром в точке
пересечения проведенных отрезков.
6. Перепишите следующий сегмент программы, используя структуру
repeat-until вместо while-do. Убедитесь, что новая версия
программы печатает те же значения, что и исходная.
assign Счетчик the value 2;
while (Счетчик < 7) do
(напечатать текущее значение переменной Счетчик и
assign Счетчик the value Счетчик + 1)
7. Перепишите следующий фрагмент программы, используя структуру
while-do вместо repeat-until. Убедитесь, что новая версия печатает
те же значения, что и исходная.
assign Счетчик the value 1;
repeat (напечатать текущее значение переменной Счетчик и
assign Счетчик the value Счетчик + 1)
until (Счетчик = 5)
8. Разработайте алгоритм, который получает на входе некую
конфигурацию из цифр 0, 1,2, 3, 4, 5, 6, 7, 8, 9 и переставляет полученные
цифры таким образом, чтобы новая конфигурация представляла собой
значение, следующее по величине за исходным, из числа тех, которые
могут быть составлены из этих цифр (или сообщает, что такой
перестановки не существует, если никакие перестановки не приводят к
большему значению). Например, для исходной конфигурации
5 647 382 901 таким числом будет 5 647 382 910.
9. В чем отличие формального языка программирования от псевдокода?
10. В чем отличие между синтаксисом и семантикой?
11. Четыре шахтера, которые имеют один фонарь, должны пройти через
шахту. Одновременно по шахте могут двигаться не больше двух человек,
и каждый шахтер, двигаясь в шахте, должен иметь фонарь. Шахтеры,
имена которых Эндрю, Блэйк, Джонсон и Келли, могут пройти шахту за
одну, две, три и четыре минуты соответственно. Когда два шахтера идут
вместе, они движутся со скоростью более медленного из них. Каким
образом шахтеры могут пройти через шахту за 15 минут? После того как вы
решите задачу, объясните, с чего вы начали решение.
Упражнения 267
12. Допустим, у нас есть большой и маленький стаканчики для вина.
Сначала наполним вином маленький стаканчик и перельем его в
большой стакан. Затем наполним водой маленький стакан, перельем
некоторое количество воды в большой стакан и смешаем его с вином.
Теперь будем переливать смесь обратно в маленький стакан, пока он
не наполнится. Чего теперь больше в маленьком стакане — воды в
вине или вина в воде? После того как вы решите задачу, объясните ход
ваших рассуждений.
13. Две пчелы, Ромео и Джульетта, живут в разных ульях, но они
встретились и полюбили друг друга. Однажды безветренным весенним
утром они одновременно вылетели из своих ульев, чтобы слетать друг к
другу в гости. В 50-ти метрах от ближайшего улья они встретились,
но не заметили друг друга и полетели дальше. Прибыв к месту своего
назначения, они потратили одинаковое время, чтобы выяснить, что
того, к кому они прилетели, нет дома, и повернуть назад. На обратном
пути они встретились в точке, находящейся на расстоянии 20 метров
от ближайшего улья. На этот раз они увидели друг друга и устроили
пикник, прежде чем возвратиться домой. На каком расстоянии друг от
друга расположены их улья? Решив задачу, объясните, с чего вы
начали свои рассуждения.
14. Разработайте алгоритм, который получает на вход две строки
символов и проверяет, является ли первая строка частью второй.
15. Следующий алгоритм разработан для того, чтобы напечатать
несколько первых чисел Фибоначчи. Определите, что является телом цикла.
Где выполняется операция инициализации управления циклом? Где
выполняется операция модификации? Какая инструкция реализует
операцию проверки? Какой список чисел получится в результате
работы алгоритма?
assign Последнее the value 0;
assign Текущее the value 1;
while (Текущее < 100) do
(напечатать значение переменной Текущее;
assign Временное the value Последнее;
assign Последнее the value Текущее; и
assign Текущее the value Последнее + Временное)
16. Какую последовательность чисел напечатает следующий алгоритм,
если на входе задать значения 0 и 1?
procedure MysteryWrite [<последний>, <текущий>)
if {<текущий> < 100) then
(напечатать значение, присвоенное параметру <текущий>;
assign Временный the value <текущий> + <последиий>;
268 Глава четвертая. Алгоритмы
применить процедуру MysteryWrite к значениям
<Текущий> и Временный)
17. Преобразуйте процедуру MysteryWrite из предыдущего задания так,
чтобы она печатала числа в обратном порядке.
18. Какие буквы будут проверяться, если применить двоичный поиск (см.
рис. 4.13) для поиска значения J в списке А, В, С, D, E, F, G, H, I, J, К,
L, M, N, О? А в случае поиска значения Z?
19. Сколько раз в среднем потребуется сравнивать между собой два
элемента при поиске значения в списке из 6000 элементов с помощью
метода последовательного поиска? А что можно сказать о методе
двоичного поиска?
20. Определите тело цикла в следующей структуре и подсчитайте, сколько
раз оно будет выполнено. Что произойдет, если проверяемое условие
заменить на выражение "while (Счетчик не равен 6)"?
assign Счетчик the value 1;
while (Счетчик не равен 7) do
(напечатать присвоенное счетчику значение, и
assign Счетчик the value Счетчик + 3)
21. Какие проблемы могут возникнуть при реализации на компьютере
следующей программы? (Подсказка. Вспомните об ошибках
округления при выполнении арифметических операций с плавающей точкой.)
assign Счетчик the value 0.1;
repeat
(напечатать текущее значение переменной Счетчик и
assign Счетчик the value Счетчик + 0.1)
until (Счетчик = 1)
22. Разработайте рекурсивную версию алгоритма Евклида (вопрос 3 к
разделу 4.2).
23. Предположим, что на вход процедур Testl и Test2, приведенных
ниже, передано значение 1. Чем будут отличаться напечатанные этими
процедурами результаты?
procedure Testl(<счетчик>)
if (<счетчик> не равен 5)
then (напечатать текущее значение параметра <счетчик>
и
выполнить процедуру Testl для значения <счетчик> +
1)
procedure Test2[<счетчик>)
if{<счетчик> не равен 5)
Упражнения 269
then (выполнить процедуру Test2 для значения
<счетчик> + 1
и напечатать текущее значение параметра <счетчик>)
24. Определите основные составляющие механизма управления в
предыдущей задаче. В частности, какое условие вызывает окончание
процесса? Где происходит модификация состояния процесса, приближающая
его к условию завершения? Где инициализируется состояние
управляющего процесса?
25. Разработайте алгоритм генерации последовательности целых
положительных чисел (в возрастающем порядке), которые имеют только два
простых множителя — 2 и 3, т.е. программа должна генерировать
последовательность чисел 2, 3, 4, 6, 8, 9, 12, 16, 18, 24, 27, ... .
Представляет ли эта программа алгоритм в строгом смысле этого слова?
26. Ответьте на следующие вопросы применительно к списку имен Alice,
Byron, Carol, Duane, Elaine, Floyd, Gene, Henry, Iris.
а) Какой алгоритм поиска (последовательный или двоичный)
позволит быстрее найти имя Gene?
б) Какой алгоритм поиска (последовательный или двоичный)
позволит быстрее найти имя Alice?
в) Какой алгоритм поиска (последовательный или двоичный)
позволит быстрее обнаружить отсутствие в списке имени Bruce?
г) Какой алгоритм поиска (последовательный или двоичный)
позволит быстрее обнаружить отсутствие в списке имени Sue?
д) Сколько элементов будет рассмотрено при поиске имени Elaine с
использованием метода последовательного поиска? Сколько
элементов будет рассмотрено при поиске этого имени с
использованием метода двоичного поиска?
27. По определению факториал числа 0 равен 1. Факториал целого
положительного числа — это произведение данного целого положительного
числа и факториала предшествующего ему целого положительного
числа. Для обозначения факториала целого положительного числа п
используется запись п\. Таким образом, факториал числа 3
(обозначается как 3!)— это 3!= 3*(2!) = 3*(2*(1!)) = 3*(2*(1*(0!))) =
3*(2*(1*(1))) = 6. Разработайте рекурсивный алгоритм вычисления
факториала заданного числа.
28.
а) Предположим, что вам необходимо отсортировать список из пяти
имен и что вы уже разработали раньше алгоритм для сортировки
списка из четырех имен. Разработайте алгоритм сортировки списка
из пяти имен, использующий ранее разработанный алгоритм.
270 Глава четвертая. Алгоритмы
б) Разработайте рекурсивный алгоритм сортировки списка
произвольной длины, основанный на методе, используемом для решения
предыдущей задачи.
29. Головоломка "Ханойская башня" состоит из трех вертикальных
стержней, на один из которых надето несколько колец
последовательно уменьшающихся (в направлении снизу вверх) размеров.
Задача состоит в том, чтобы переместить набор колец на другой
стержень. Разрешается перемещать только одно кольцо за один
ход, причем нельзя надевать большее кольцо поверх меньшего.
Заметим, что головоломка с одним кольцом решается предельно
просто. Если колец несколько, то, переместив на другой стержень все
кольца, кроме наибольшего, наибольшее кольцо можно было бы
перенести на третий стержень. После этого задача была бы сведена
к перемещению всех остальных колец на наибольшее. Исходя из
этого, разработайте рекурсивный алгоритм для решения
головоломки "Ханойская башня" с произвольным числом колец.
30. Еще один подход к решению головоломки "Ханойская башня"
(упр. 29) состоит в следующем. Представьте себе, что стержни
расставлены по кругу в положениях, соответствующих отметкам 4, 8
и 12 часов на циферблате. Кольца, находящиеся исходно на одном
из стержней, нумеруются числами 1, 2, 3 и т.д., начиная с
верхнего. Кольца с нечетными номерами, находящиеся сверху набора,
разрешается перемещать только на стержень, следующий по
часовой стрелке, кольца с четными номерами можно перемещать
только против часовой стрелки (при условии, что такое перемещение не
приведет к помещению большего кольца над меньшим). Учитывая
вышеизложенные требования, вы всегда должны выбирать кольцо
с наибольшим номером из числа тех, которые доступны для
перемещения. Используя такой подход, разработайте нерекурсивный
алгоритм решения головоломки "Ханойская башня".
Упражнения
271
31. Разработайте циклический и рекурсивный алгоритмы для распечатки
дневной заработной платы рабочего, который в каждый последующий
день получает вдвое больше, чем в предыдущий (первый платеж равен
одному пенни), за 30 дней работы. С какими проблемами,
касающимися хранения данных, вам придется столкнуться при реализации
вашего решения на реальной машине?
32. Разработайте алгоритм для нахождения значения квадратного
корня из положительного числа с помощью следующего метода. В
качестве первого приближения выбирается само это число, а
последующие приближения получаются из предыдущих путем
вычисления среднего арифметического для предыдущего приближения и
числа, полученного при делении исходного числа на предыдущее
приближение. Проанализируйте возможности управления этим
повторяющимся процессом. В частности, какое условие должно
использоваться для его окончания?
33. Разработайте алгоритм, который печатает все возможные варианты
перестановки символов в строке из пяти различных символов.
34. Разработайте алгоритм, который в заданном списке имен находит
самое длинное имя. Определите, как поведет себя алгоритм,
предложенный вами в качестве решения, если "самых длинных" имен в списке
будет несколько. В частности, как поведет себя ваш алгоритм, если
все имена в списке будут одной длины?
35. Разработайте алгоритм, который в заданном списке из пяти или более
чисел находит пять наименьших и пять наибольших чисел, не
сортируя полностью весь список.
36. Расположите имена Brenda, Doris, Raymond, Steve, Timothy и William в таком
порядке, который при использовании алгоритма сортировки методом
вставки потребует выполнения наименьшего числа сравнений (рис. 4.11).
37. Какое максимальное количество элементов может быть проверено при
применении алгоритма двоичного поиска (рис. 4.13) к списку,
содержащему 4000 строк? Как оно соотносится с аналогичным значением
для метода последовательного поиска (рис. 4.6)?
38. Используя нотацию тета-классов, классифицируйте традиционные
школьные алгоритмы для сложения и умножения в столбик. Другими
словами, определите, сколько отдельных операций сложения
необходимо выполнить при суммировании двух чисел значностью п и сколько
отдельных операций умножения потребуется для их перемножения.
39. Иногда небольшое изменение условия задачи может вызвать
существенные изменения в способе ее решения. Например, найдите простой
алгоритм решения следующей задачи и определите его тета-класс.
272 Глава четвертая. Алгоритмы
Разделите группу людей на две непересекающиеся подгруппы
(произвольных размеров), такие, чтобы разность между суммами
возрастов членов этих подгрупп была максимальной.
Теперь измените условие задачи так, чтобы требуемая разность была
минимальной, и вновь классифицируйте ваше решение.
40. Из следующего списка выделите несколько чисел, сумма которых
равна 3165. Насколько эффективен ваш метод решения задачи?
26, 39, 104, 195, 403, 504, 793, 995, 1156, 1673
41. Завершится ли цикл в следующей программе? Поясните свой ответ.
Объясните, что могло бы случиться, если бы эта программа в
действительности выполнялась машиной (см. раздел 1.7)
assign X the value 0;
assign Y the value 1/2;
while (X не равно 1) do
(assign X the value X + Y;
assign Y the value Y - 2)
42. Следующий фрагмент программы разработан для вычисления
произведения двух неотрицательных целых чисел X и Y путем вычисления
суммы X копий числа Y. Выражение 3x4 вычисляется посредством
нахождения суммы трех четверок. Правильно ли составлен данный
фрагмент? Поясните свой ответ.
assign Произведение the value 0;
assign Счетчик the value 0;
repeat (assign Произведение the value Произведение + Y,
assign Счетчик the value Счетчик + 1)
until (Счетчик = X)
43. Следующий фрагмент программы составлен для определения, какое из
двух целых чисел X и Y является большим. Является ли этот
фрагмент правильным? Поясните свой ответ.
assign Разность the value X — Y;
if (Разность положительна)
then (напечатать "X больше Y")
else (напечатать "Y больше Xй)
44. Следующий фрагмент программы должен находить наибольший
элемент в непустом списке целых чисел. Правильно ли он составлен?
Поясните свой ответ.
assign Значение the value значение первого элемента списка
assign Текущий the value значение первого элемента списка
while (Текущий не равен последнему элементу списка) do
(if (Текущий > Значение)
Упражнения 273
then (assign Значение the value Текущий)
assign Текущий the value значение следующего
элемента списка)
45.
а) Определите предусловия для алгоритма последовательного поиска,
представленного на рис. 4.6. Установите инвариант цикла для
структуры while в этой программе, который, будучи объединен с
условием окончания цикла, предполагает, что по окончании этого
цикла алгоритм правильно сообщит об успехе или неудаче.
б) Приведите аргументы в пользу того, что цикл while на рис. 4.6
действительно завершается.
46. Опираясь на предусловие для приведенной ниже программы,
утверждающее, что параметрам X и Y присвоены неотрицательные целые
значения, определите инвариант цикла ее структуры while, который,
будучи объединен с указанным условием окончания, предполагает, что
значение переменной Z по завершении цикла будет X - Y.
assign Z the value X;
assign J the value 0;
while (J < Y) do
(assign Z the value Z — 1;
assign J the value J+l)
Общественные и социальные вопросы
Следующие вопросы приводятся для того, чтобы помочь вам разобраться в
некоторых этических, общественных и юридических аспектах использования
вычислительной техники, а также в ваших собственных воззрениях и тех
принципах, на которых они основаны. Задача не сводится к тому, чтобы просто дать
ответы на предложенные вопросы. Вы должны также разобраться, почему вы
ответили именно так, а не иначе, и насколько ваши суждения по различным
вопросам согласуются друг с другом.
1. Поскольку сегодня невозможно осуществить всеобъемлющую
верификацию сложных программ, при каких обстоятельствах (если таковые
вообще существуют) создатель программы должен нести
ответственность за имеющиеся в ней ошибки?
2. Предположим, у вас есть идея, которую вы воплощаете в некоем
продукте, пригодном для использования множеством людей. Более того,
чтобы ваша идея обрела форму, в которой она становится полезной
большинству людей, потребовалось потратить год работы и 50000
долларов. Однако большинство людей могут использовать продукт в его
окончательном виде без того, чтобы приобретать у вас что-нибудь.
274 Глава четвертая. Алгоритмы
Есть ли у вас право потребовать компенсации? Является ли этичным
использование пиратских копий программ?
3. Предположим, что пакет программ стоит настолько дорого, что вам он
совершенно не по карману. Этично ли скопировать его для личного
пользования? (В конце концов, вы же не лишаете поставщика
программы заработка, поскольку вы бы ее все равно не купили.)
4. Право собственности на "вещи" всегда было предметом обсуждения.
Имело место множество дебатов о том, кому принадлежат реки, леса,
океаны и т.п. В каком смысле правомочно говорить о передаче
какому-то лицу или организации права собственности на алгоритм?
5. Предположим, что некто изобретает алгоритм для взлома системы
защиты в многопользовательской операционной системе. Следует ли
предоставить данному лицу право собственности на этот алгоритм?
Если да, то какими правами должно быть наделено данное лицо?
Следует ли предоставление права собственности на алгоритм поставить в
зависимость от назначения данного алгоритма? Является ли этичным
рекламировать и распространять методы взлома систем защиты?
Имеет ли значение, что именно подвергается взлому?
6. Некоторые полагают, что новые алгоритмы открываются, тогда как
другие считают, что они создаются. А как думаете вы? Может ли это
привести к различным заключениям в отношении владения
алгоритмами и прав собственности на алгоритмы?
7. Этично ли разработать алгоритм для незаконного действия? Имеет ли
значение, был ли этот алгоритм когда-либо действительно применен
на практике?
8. Писателю платят за право экранизации его произведения, хотя очень
часто при этом в сюжет вносятся те или иные изменения. До какой
степени допустимо изменять сюжет произведения, чтобы новая версия
не превратилась в другое произведение? Какие изменения должны
быть внесены в алгоритм, чтобы он превратился в другой алгоритм?
9. В настоящее время на рынке имеется образовательное программное
обеспечение для детей в возрасте 18 месяцев и даже младше.
Сторонники этих продуктов заявляют, что данное программное
обеспечение воспроизводит изображения и звуки, которые многие дети
иначе никогда не смогли бы увидеть или услышать. Противники
же утверждают, что подобные программы являют собой очень
слабую замену личному общению ребенка с его родителями. Каково
ваше мнение по этому вопросу? Можете ли вы выбрать одну из
указанных точек зрения, не имея никаких дополнительных
сведений об этих программных продуктах?
Общественные и социальные вопросы 275
Рекомендуемая литература
• Brassard G., Bratley P. Fundamentals of Algorithmics. — Englewood Cliff, NJ:
Prentice-Hall, 1996.
• Cormen T. H., Leiserson С E., Rivest R. L. Introduction to Algorithms. — New
York: McGraw-Hill, 1990.
• Gries D. The Science of Programming. — New York: Springer-Verlag, 1981.
• Harbin R. Origami — the Art of Paper Folding. London: Hodder Paperbacks,
1973.
• Knuth D. E. The Art of Computer Programming, vol3, 2-rd ed. — Reading, MA:
Addison Wesley Longman, 1998. (Имеется русский вариант этой книги: Кнут
Д.Э. Искусство программирования. Т.З. Сортировка и поиск, 2-е изд.: Уч.
пос. — М.: Издательский дом "Вильяме", 2000.)
• Kruse R. L., Ryba A. J. Data Structures and Program Design in C++. — Upper
Saddle River, NJ: Prentice Hall, 1999.
• Polya G. How to Solve It. — Princeton, NJ: Princeton University Press, 1973.
• Rawlins G. J. E. Compared to What? An Introduction to the Analysis of
Algorithms. — New York: Computer Science Press, 1992.
• Roberts E. S. Thinking Recursively. — New York: Wiley, 1986.
• Sedgewick R., Flajolet P. An Introduction to the Analysis of Algorithms. —
Reading, Ma: Addison-Wesley, 1996.
276 Глава четвертая. Алгоритмы
глава
Языки
программирования
ПЯТАЯ
Разработка сложных систем программного обеспечения,
например операционных систем или сетевого программного
обеспечения, была бы практически невозможна, если бы люди
вынуждены были выражать требуемые алгоритмы на
машинном языке. Было бы, мягко говоря, очень неудобно работать с
огромным количеством запутанных деталей. В результате
были разработаны языки программирования, подобные
использованному нами выше псевдокоду. С помощью этих языков
можно выражать алгоритмы в форме, доступной для людей и
в тоже время достаточно удобной для преобразования в
инструкции машинного кода. Эти языки позволяют избежать
блуждания в лабиринтах регистров, адресов памяти и
машинных циклов при разработке программ и помогают
сконцентрироваться на особенностях решаемой задачи. В этой главе
мы подробно познакомимся с научной областью разработки и
использования языков программирования.
5.1. Исторический обзор
Ранние поколения
Машинная независимость
Парадигмы программирования
5.2. Концепции традиционного
программирования
Переменные, константы и
литералы
Типы данных
Структура данных
Операторы присваивания
Управляющие операторы
Комментарии
5.3. Процедуры и функции
Процедуры
Параметры
Функции
Операторы ввода/вывода
5.4. Реализация языка
Процесс перевода
Связывание и загрузка
Пакеты для разработки программ
*5.5. Объектно-ориентированное
программирование
*5.6. Программирование
параллельных процессов
*5.7. Декларативное
программирование
Логический вывод
Язык Prolog
* Звездочкой отмечены
разделы, рекомендованные для
факультативного изучения.
5.1. Исторический обзор
Давайте проследим общую историю развития языков программирования.
Ранние поколения
Первоначально процесс программирования предусматривал запись
программистом всех алгоритмов непосредственно на машинном языке. Такой подход усугублял
и без того трудную задачу разработки алгоритмов и слишком часто приводил к
ошибкам, которые необходимо было обнаружить и исправить (процесс, известный
как отладка) до того, как работу можно было считать законченной.
Первым шагом на пути к облегчению задачи программирования был отказ от
использования цифр для записи команд и операндов непосредственно в той
форме, в которой они используются в машине. С этой целью при разработке
программ стали широко применять мнемоническую запись различных команд
вместо их шестнадцатеричного представления. Например, вместо цифрового кода
команды загрузки регистра программист мог теперь написать LD, а вместо кода
команды копирования содержимого регистра в память мог использовать
мнемоническое обозначение ST. Для записи операндов были разработаны правила, в
соответствии с которыми программист мог присваивать некоторым областям
памяти описательные имена (их часто называют идентификаторами) и
использовать их при записи команд программы вместо адресов соответствующих ячеек
памяти. Одним из специфических вариантов является присвоение
мнемонических имен регистрам центрального процессора, например RO, Rl, R2,... .
Используя идентификаторы для ячеек памяти и мнемонические обозначения
для команд, программисты смогли значительно повысить читабельность
написанных ими последовательностей машинных команд. Давайте вернемся,
например, к программе на машинном языке, приведенной в конце раздела 2.2. Эта
программа суммировала содержимое ячеек с адресами '6С и f6Df, после чего
помещала результат в ячейку с адресом f 6Ef. Напомним, что в шестнадцатерич-
ном виде соответствующая последовательность команд имеет следующий вид:
156С
166D
5056
306Е
С000
Если мы присвоим имя PRICE ячейке с адресом '6С1, имя TAX — ячейке с
адресом f6D' и имя TOTAL — ячейке с адресом '6Е', то сможем переписать ту
же самую программу с использованием мнемонических записей команд так, как
показано ниже:
LD R5,PRICE
LD R6,TAX
ADDI R0,R5,R6
278 Глава пятая. Языки программирования
ST RO,TOTAL
HLT
Большинство читателей, вероятно, согласятся, что второй способ записи
текста программы намного лучше отражает ее смысл, чем первый (оставаясь,
впрочем, также не вполне понятным). Заметим, что мнемоническая запись ADDI
здесь использована для команды сложения двух целых чисел, в то время как
команду сложения двух чисел с плавающей точкой можно мнемонически
обозначить как ADDF.
Вначале программисты использовали такие обозначения при разработке программ
на бумаге, а затем переводили их на машинный язык. Однако вскоре стало понятно,
что такой перевод может выполнить и сама машина. В результате были разработаны
программы, названные ассемблерами и предназначенные для перевода записанных в
мнемоническом виде программ на машинный язык. Название "ассемблер"
(assembler — сборщик) эти программы получили потому, что их назначение
заключалось в сборке машинных команд из кодов команд и операндов, полученных в
результате перевода мнемонических обозначений и идентификаторов. Мнемонические
системы записи программ стали, в свою очередь, рассматриваться как особые языки
программирования, именуемые языками ассемблера.
В свое время разработка языков ассемблера считалась гигантским шагом вперед в
поисках более совершенных технологий программирования. Многие считали, что
они представляют собой совершенно новое поколение языков программирования. Со
временем языки ассемблера стали называть языками программирования второго
поколения, а к первому поколению были отнесены сами машинные языки.
Хотя языки второго поколения имели много преимуществ по сравнению с
машинными языками, они все же не могли обеспечить завершенную среду
программирования. Помимо всего прочего, применяемые в языке ассемблера языковые
конструкции, по существу, совпадают с конструкциями соответствующих машинных
языков. Разница заключается лишь в синтаксическом способе их выражения. По этой
причине программы, написанные на языке ассемблера, являются принципиально
машинно-зависимыми, т.е. команды в этих программах выражаются в терминах
определенных машинных атрибутов. Программу на языке ассемблера достаточно
сложно выполнить на другой машине, поскольку для этого ее нужно переписать с
учетом новой конфигурации регистров и набора команд.
Кроссплатформенное программное обеспечение
При решении многих задач типичная прикладная программа вынуждена полагаться на операционную
систему. Например, она может обратиться к диспетчеру окна для организации взаимодействия с
пользователем или диспетчеру файлов для считывания данных с устройств массовой памяти. К сожалению, различные
операционные системы выполняют такие запросы по-разному. Поэтому если программа предназначена для
рассылки и выполнения в сети, объединяющей машины разного типа, которые имеют различные операци-
5.1. Исторический обзор 279
онные системы, то она должна быть независимой как от операционных систем, так и от типа используемых
машин. Чтобы отметить этот уровень независимости, используется термин кроссплатформенное
программное обеспечение. Иными словами, кроссплатформенное программное обеспечение— это
программы, которые не зависят ни от операционной системы, ни от аппаратного обеспечения, а значит, могут
выполняться на разных компьютерах, объединенных в сеть.
Кроме того, хотя программист и не обязан больше кодировать программу с
помощью нулей и единиц, он все еще вынужден мыслить в терминах пошагового
выполнения команд машинного языка. Это аналогично проектированию дома из досок,
гвоздей, кирпичей и других материалов. Конечно, реальная конструкция дома
состоит именно из этих элементарных вещей, но проектировать его все же легче, имея
дело с комнатами, окнами, дверьми и прочими подобными понятиями.
Короче говоря, элементарные примитивы, из которых в конечном счете должен
быть сконструирован продукт, вовсе не обязательно должны использоваться и при
разработке проекта этого продукта. При проектировании удобнее пользоваться
примитивами более высокого уровня, каждый из которых представляет концепцию,
связанную с некоторой функцией конечного продукта достаточно высокого уровня.
По окончании проектирования эти примитивы могут быть выражены с помощью
концепций более низкого уровня, относящихся к деталям их реализации.
Следуя такому подходу, специалисты по компьютерам стали разрабатывать
языки программирования, которые больше подходили для целей разработки
программного обеспечения, чем низкоуровневые языки ассемблера. В результате
появились языки программирования третьего поколения, которые отличались от
предыдущих поколений тем, что их языковые конструкции имели более
высокий уровень и были машинно-независимыми. Наиболее известными примерами
ранних языков третьего поколения являются FORTRAN (FORmula
TRANslator — переводчик формул), который был предназначен для научных и
инженерных расчетов, и COBOL (COmmon Business-Oriented Language — язык
общего назначения деловой ориентации), разработанный специалистами военно-
морского флота США для решения экономических задач.
В общем случае язык программирования третьего поколения представляет собой
определенный набор языковых конструкций достаточно высокого уровня,
предназначенный для разработки программного обеспечения. По существу, точно так же
был разработан и наш псевдокод, описанный в главе 4. Каждая из языковых
конструкций была разработана так, чтобы ее можно было реализовать в виде
последовательности низкоуровневых примитивов, существующих в машинных языках.
Рассмотрим следующий оператор:
assign Total the value Price + Tax
Он представляет собой выражение высокого уровня, в котором совершенно
отсутствуют указания, как именно определенная машина должна выполнять
поставленную задачу. Однако этот оператор вполне можно реализовать в виде
последовательности машинных команд, которые мы обсуждали выше. Таким
образом, показанная ниже структура потенциально является языковой конструкцией
высокого уровня:
assign <идентификатор> the value <выражение>
280 Глава пятая. Языки программирования
После того как необходимый набор примитивов высокого уровня будет определен,
пишется программа, называемая транслятором (translator — переводчик). Она
предназначена для перевода программ, записанных с использованием примитивов языка
высокого уровня, на машинный язык. Подобный транслятор похож на программу-
ассемблер второго поколения, за исключением того, что ему часто приходится
объединять (или компилировать, от англ. compile) несколько машинных инструкций в
короткие последовательности команд, предназначенные для имитации выполнения
отдельных примитивов высокого уровня. Именно поэтому подобные программы-
переводчики часто называют компиляторами. Разработку первого компилятора
приписывают Грейс Хоппер (Grace Hopper), которая играла ведущую роль в
продвижении концепции языков программирования высокого уровня. Действительно, идея
писать программы в форме, близкой к естественному языку, была настолько
революционной, что многие руководители поначалу отвергали ее.
Популярной альтернативой трансляторам являются интерпретаторы,
предложенные как еще один способ выполнения программ, написанных на языках
программирования третьего поколения. Эти программы подобны трансляторам, однако они
выполняют команды программы непосредственно после их перевода, а не записывают,
подобно трансляторам, переведенный код в виде выполняемого модуля,
предназначенного для последующего использования. Это означает, что вместо создания копии
программы на машинном языке, которую необходимо будет выполнить позже,
интерпретатор немедленно выполняет все переведенные им инструкции.
Машинная независимость
С появлением языков программирования третьего поколения цель обеспечения
машинной независимости программ была в основном достигнута. Поскольку
операторы в языках третьего поколения не привязаны к особенностям какой-то
конкретной машины, они легко могут быть скомпилированы на любом компьютере.
Теоретически программа, написанная на языке третьего поколения, может быть
выполнена на любой машине за счет использования соответствующего компилятора.
В действительности не все так просто. При разработке самого компилятора
приходится учитывать определенные ограничения, накладываемые той
машиной, для которой он предназначен. В результате эти ограничения отражаются на
языке программирования, который подлежит переводу на машинный язык.
Например, размер машинных регистров и ячеек памяти влияет на максимальный
размер значений целых переменных, которыми может непосредственно
оперировать программа. Такие ограничения приводят к тому, что один и тот же язык
программирования на разных машинах имеет свои особенности, или диалекты.
Вследствие этого программистам часто приходится выполнять, как минимум,
легкую модификацию программы при переносе ее с одной машины на другую.
Проблема переноса программ с одной машины на другую заключается в
отсутствии общей точки зрения на то, что именно считать стандартом данного
языка программирования. В связи с этим Американский национальный
институт стандартов (ANSI) и Международная организация по стандартизации (ISO)
приняли и опубликовали стандарты для многих популярных языков программи-
5.1. Исторический обзор 281
рования. В других случаях применяются неформальные стандарты, которые
являются следствием популярности того или иного диалекта языка, а также
желания многих разработчиков компиляторов создавать продукты, совместимые с
другими, подобными им.
Тот факт, что языки третьего поколения не достигли истинной машинной
независимости, на самом деле не имеет большого значения по двум причинам. Во-
первых, они все же являются достаточно машинно-независимыми, для того
чтобы можно было относительно легко переносить программное обеспечение с одной
машины на другую. Во-вторых, машинная независимость — это лишь
промежуточная ступень на пути к достижению более важных целей. Со временем
машинная независимость стала вполне достижимой, однако она стала менее
важной по сравнению с другими велениями времени. Действительно, понимание
того, что машина могла бы выполнять такие операторы высокого уровня, как
assign Total the value Price + Tax,
породило среди ученых в области компьютерных наук мечту о создании среды
программирования, которая позволила бы людям общаться с машиной в
терминах абстрактных понятий, а не заставляла их переводить эти понятия в
машинно-совместимую форму. Более того, ученым понадобились машины, способные
самостоятельно выбирать алгоритмы, а не просто выполнять действия,
описанные с помощью набора инструкций. В результате спектр языков
программирования заметно расширился, что в конечном счете привело к усложнению их
прежней классификации в терминах простого разделения на поколения.
Парадигмы программирования
Классификация языков программирования по поколениям требует
распределения их по линейной шкале (рис. 5.1) в соответствии с той степенью свободы от
компьютерной тарабарщины, которую данный язык предоставляет
программисту. Это позволяет ему мыслить понятиями, связанными непосредственно с
решаемой задачей. В действительности развитие языков программирования
происходило несколько иначе. Оно протекало по разным направлениям, связанным с
альтернативными подходами к процессу программирования (называемыми
парадигмами программирования). Таким образом, историческую схему развития
языков программирования наиболее точно можно изобразить составной
диаграммой, показанной на рис. 5.2, на которой отдельные линии,
символизирующие различные парадигмы программирования, появляются и развиваются
независимо друг от друга. В частности, на рисунке показаны четыре независимых
направления, соответствующие функциональной, объектно-ориентированной,
императивной и декларативной парадигмам программирования, а также
представлены различные относящиеся к ним языки. Месторасположение названия
языка на линии соответствует времени его появления относительно других
языков. Однако это вовсе не означает, что каждый последующий язык обязательно
является наследником предыдущего.
282 Глава пятая. Языки программирования
РИСУНОК 5.1
W&4
Схематическое представление поколений языков программирования
| РИСУНОК 5,2 |
Эволюция парадигм программирования
Императивная, или процедурная парадигма, представляет традиционный
подход к процессу программирования. Действительно, именно в соответствии с
этой парадигмой построен цикл обработки команды центрального процессора:
"извлечь-декодировать-выполнить". Как следует из названия, императивная
парадигма определяет процесс программирования как запись последовательности
команд, которая при выполнении выполнит обработку данных, необходимую для
получения желаемого результата. Таким образом, для решения задачи
императивная парадигма предлагает попытаться найти алгоритм ее решения.
В противоположность этому, декларативная парадигма во главу угла ставит
вопрос "Что представляет собой задача?", а не "Какой алгоритм нужен для
решения задачи?" Основная проблема здесь состоит в том, чтобы создать и
реализовать общий алгоритм решения задач. После этого задачи можно
формулировать в виде, совместимом с этим алгоритмом, а затем применять его. В этом слу-
5.1. Исторический обзор
283
чае роль программиста заключается в точной формулировке задачи, а не в
поисках и реализации алгоритма ее решения.
Основной трудностью в разработке декларативных языков программирования
является выбор базового алгоритма решения задач. По этой причине ранние
декларативные языки были узкоспециализированными по своей природе и
ориентированными на специфические приложения. Например, декларативный
подход уже многие годы применяется для моделирования систем (экономических,
физических, политических и т.п.) в целях проверки выдвинутых гипотез. В этом
случае базовый алгоритм, в сущности, является процессом моделирования
течения времени посредством многократно повторяющегося вычисления значений
параметров (роста внутреннего продукта, торгового дефицита и т.д.) исходя из
вычисленных ранее значений. Использование декларативного языка для
выполнения такого моделирования сводится, прежде всего, к реализации алгоритма,
выполняющего указанную повторяющуюся процедуру. В результате
программисту остается лишь описать взаимоотношения моделируемых параметров. Далее
базовый алгоритм моделирования просто имитирует течение времени, используя
указанные соотношения для выполнения требуемых вычислений.
Не так давно декларативная парадигма нашла свое новое применение —
благодаря осознанию того факта, что применение методов математической
формальной логики позволяет создавать простые алгоритмы решения задач,
подходящие для использования в системах декларативного программирования общего
назначения. Результатом пристального внимания ученых к декларативной
парадигме явилось появление дисциплины логического программирования, которое
будет обсуждаться в разделе 5.7.
Функциональная парадигма рассматривает процесс разработки программ как
конструирование ее из неких "черных ящиков", каждый из которых получает
некоторые исходные данные (на входе) и вырабатывает соответствующий
результат (на выходе). Математики называют такие "ящики" функциями, поэтому этот
подход называется функциональной парадигмой. Языковые конструкции
функциональных языков программирования состоят из элементарных функций, на
основе которых программист должен создавать более сложные функции,
необходимые для решения поставленной задачи. Таким образом, согласно
функциональной парадигме, программист решает задачу, рассматривая исходные данные,
требуемые результаты и преобразование, которое необходимо выполнить, чтобы
получить результаты из исходных данных. Решение требуемой задачи, вероятнее
всего, можно получить, разбивая исходное преобразование на более простые
преобразования, порождающие промежуточные результаты, служащие, в свою
очередь, исходными данными для других простых преобразований. Короче говоря, в
соответствии с функциональной парадигмой процесс программирования
заключается в конструировании требуемых функций в виде вложенных друг в друга
совокупностей более простых функций.
Например, на рис. 5.3 показано, как можно построить функцию вычисления
среднеарифметического нескольких чисел из трех более простых функций.
Первая из них — Sum — получает на вход список чисел и вычисляет их сумму;
вторая — Count — получает список чисел и подсчитывает их количество; третья —
284 Глава пятая. Языки программирования
Divide — получает на вход два числа и вычисляет их частное. На языке LISP
(популярном функциональном языке программирования) эта конструкция может
быть записана в виде следующего выражения:
(Divide (Sum Numbers) (Count Numbers))
Использование в этом выражении вложенных структур отражает, что
исходные данные для функции Divide являются результатами выполнения функций
Sum и Count. В качестве другого примера предположим, что у нас есть функция
Sort, которая сортирует список чисел, и функция First, которая находит
первое число в этом списке. В этом случае приведенное ниже выражение позволяет
извлечь из списка List наименьшее из чисел:
(First (Sort List))
В данном случае использование вложенных структур означает, что результат
функции Sort является исходной информацией для функции First. Таким
образом, список сначала сортируется, а затем из отсортированного списка
извлекается первое число.
РИСУНОК 5.3
Функция вычисления среднеарифметического для списка чисел, построенная из более
простых функций Sum, Count и Divide
5.1. Исторический обзор
285
Превосходство функциональной парадигмы программирования над
императивной проявляется в том, что она стимулирует модульный подход к
конструированию программ. Действительно, то, что программы рассматриваются как
функции, которые, в свою очередь, должны состоять из других функций,
вынуждает программиста думать в терминах модулей. По этой причине сторонники
функционального программирования утверждают, что этот подход приводит к
созданию более высокоорганизованных программ, чем в случае применения
императивной парадигмы. Более того, многие утверждают, что функциональная
парадигма является естественной средой для метода, предусматривающего
построение программ из "строительных блоков". Данный подход напоминает
скорее конструирование программ из заранее подготовленных блоков, нежели
выполнение всей работы с нуля. Такому способу программирования отдают
предпочтение в основном специалисты по разработке больших пакетов программ. Эти
же аргументы приводятся и в защиту объектно-ориентированной парадигмы.
Объектно-ориентированная парадигма, которая предполагает применение
методов объектно-ориентированного программирования (ООП), — это еще один
подход к процессу разработки программного обеспечения. В рамках этого
подхода элемент данных рассматривается как активный "объект", а не как пассивный
элемент, как это принято в традиционной императивной парадигме. Поясним это
на примере списка имен. В традиционной императивной парадигме этот список
рассматривается просто как совокупность некоторых данных. Любая программа,
получающая на вход этот список, должна содержать алгоритм выполнения над
ним требуемых действий. Таким образом, список является пассивным объектом,
поскольку он обрабатывается управляющей программой, а не обрабатывает себя
сам. Однако при объектно-ориентированном подходе список рассматривается как
объект, содержащий некоторую совокупность данных вместе с набором процедур
для их обработки. Этот набор может включать процедуры для вставки в список
нового элемента, удаления элемента из списка или сортировки списка. Поэтому
программа, получающая доступ к списку для его обработки, не обязана
содержать алгоритм для выполнения указанных действий. При необходимости она
просто выполняет процедуры, предоставляемые самим объектом. В этом смысле
объектно-ориентированная программа вместо сортировки списка (как при
императивной парадигме) скорее просит список отсортировать самого себя.
Язык Visual Basic
Visual Basic — это объектно-ориентированный язык программирования, разработанный компанией Microsoft в
качестве инструмента, с помощью которого пользователи операционной системы Microsoft Windows могли бы
создавать собственные графические интерфейсы пользователя (GUI). В действительности Visual Basic — это нечто
больше, чем просто язык программирования. Это — мощный интегрированный пакет разработки программного
обеспечения, позволяющий программисту создавать графический интерфейс пользователя из заранее опреде-
286 Глава пятая. Языки программирования
ленных компонентов (таких как кнопки, флажки опций, текстовые поля, полосы прокрутки и т.п.) и настраивать
работу этих компонентов в приложении, описывая их реакцию на различные события. Например, если речь идет о
кнопке, программист должен описать, что должно случиться, если пользователь щелкнет на ней. В главе б мы
увидим, что эта стратегия создания программ из готовых компонентов представляет собой важнейшую современную
тенденцию в области разработки программного обеспечения.
Популярность операционной системы Windows и удобство пакета для разработки программ Visual Basic
способствовали тому, что язык Visual Basic в настоящее время стал одним из наиболее известных и
широко используемых языков программирования.
В качестве другого примера использования объектно-ориентированного
подхода рассмотрим задачу разработки графического интерфейса пользователя. В
этом случае все отображаемые на экране графические элементы реализуются как
объекты. Каждый из этих объектов включает собственный набор процедур,
определяющих реакцию объекта на возникновение различных событий, — выбор
этого объекта, щелчок на нем кнопкой мыши или перетаскивание его по экрану.
Таким образом, вся система в целом выглядит как совокупность объектов,
каждый из которых знает, как реагировать на определенное событие.
Многие из преимуществ объектно-ориентированного проектирования являются
следствием модульной структуры, которая возникает как естественный побочный
эффект от применения объектно-ориентированного подхода. В рамках этого подхода
каждый объект реализуется в виде отдельного, точно определенного элемента. После
того как свойства некоторой сущности будут определены подобным образом,
полученное определение можно повторно использовать всякий раз, когда возникнет
потребность в этой сущности. По этой причине сторонники объектно-ориентированного
программирования утверждают, что объектно-ориентированная парадигма
предоставляет естественную среду для конструирования программного обеспечения из
"строительных блоков". Они предсказывают появление программных библиотек,
содержащих определения различных объектов, с помощью которых новое
программное обеспечение можно будет собирать точно так же, как обычные промышленные
изделия собирают из готовых компонентов.
Еще одним преимуществом модульной структуры, полученной в результате
применения объектно-ориентированной парадигмы, является то, что все взаимодействия
модулей осуществляются посредством пересылки сообщений — основного способа
взаимодействия машин в компьютерных сетях. Таким образом, концепция объектов,
посылающих друг другу сообщения, — это естественный подход к разработке
программного обеспечения, распределенного по сети. Реализация такой сетевой системы
объектов является целью технологии CORBA (Common Object Request Broker
Architecture — архитектура с брокерами запросов к общим объектам) — открытой
системы спецификаций для реализации механизмов передачи сообщений между
объектами в сети. Мы уже сталкивались с этим явлением в контексте обсуждения
модели "клиент/сервер" (раздел 3.3). Действительно, модель "клиент/сервер" идеально
соответствует объектно-ориентированной парадигме.
Объектно-ориентированная парадигма оказывает все большее влияние на область
компьютерных наук, поэтому в разделе 5.5 мы детально обсудим ее особенности.
Кроме того, в последующих главах мы вновь и вновь будем встречаться с проявле-
5.1. Исторический обзор 287
ниями этой парадигмы. В частности, будет показано, какое влияние оказала
объектно-ориентированная парадигма на методы разработки программного обеспечения
(глава 6) и проектирования баз данных (глава 9), а в главе 7 мы увидим, как
объектно-ориентированный подход к разработке программного обеспечения
естественным образом обобщает результаты исследований в области структур данных.
В заключение следует заметить, что хотя мы называем рассмотренные выше
концепции парадигмами программирования, они имеют ответвления и за
рамками собственно процесса программирования. Эти парадигмы представляют
совершенно разные подходы к методам решения задач вообще и потому оказывают
влияние на всю область разработки программного обеспечения. В этом смысле
термин парадигма программирования является неверным. Правильно было бы
назвать эти понятия парадигмами разработки программного обеспечения.
Вопросы для самопроверки
1. В каком смысле программа на языке третьего поколения является машинно-
независимой? В каком смысле она остается машинно-зависимой?
2. Какая разница между ассемблером и компилятором?
3. Императивную парадигму программирования мо*жно кратко
охарактеризовать, просто сказав, что она делает акцент на описании процесса, который
ведет к решению поставленной задачи. Дайте аналогичное краткое описание
декларативной, функциональной и объектно-ориентированной парадигм
программирования.
4. В каком смысле языки программирования третьего поколения являются
языками более высокого уровня, чем языки предыдущих поколений?
5.2. Концепции традиционного программирования
В этом разделе мы рассмотрим некоторые основные концепции, положенные в
основу императивных и объектно-ориентированных языков программирования.
Для этого рассмотрим примеры программ на языках Ada, С, C++, FORTRAN, Java
и Pascal. FORTRAN, Pascal и С — императивные языки программирования
третьего поколения, тогда как C++ — объектно-ориентированный язык, который
является расширением языка С. Java — это объектно-ориентированный язык,
производный от С и C++. Язык Ada изначально был разработан как императивный язык
третьего поколения, обладающий многими объектно-ориентированными
свойствами. Однако более поздние версии этого языка больше соответствуют объектно-
ориентированной парадигме, чем императивной.
В приложении Г содержится краткое описание каждого из этих языков
программирования, дополненное примером того, как алгоритм сортировки по методу
вставки может быть реализован в каждом из них. Вы можете обращаться к этому
приложению по мере чтения данного раздела. Помните, однако, что в данном
случае наша цель — понять основные свойства языков программирования.
Приводимые здесь примеры предназначены просто для иллюстрации того, как обсуждае-
288 Глава пятая. Языки программирования
мые функции практически реализуются в существующих языках
программирования, поэтому вам не следует слишком углубляться в их рассмотрение.
Операторы в языках программирования обычно подразделяются на три
категории: операторы объявления, выполняемые операторы и комментарии.
Операторы объявления вводят терминологию, которая в дальнейшем будет
использоваться в программе, например имена для обозначения отдельных элементов
данных. Выполняемые операторы описывают шаги применяемого алгоритма, а
комментарии повышают читабельность программы, поясняя ее специфические
особенности в более удобной для пользователя форме. Этот раздел мы начнем с
изучения понятий, связанных с операторами объявления, затем перейдем к
обсуждению выполняемых операторов и закончим рассмотрением примера
документирования программы.
Переменные, константы и литералы
В разделе 5.1 мы убедились в несомненном преимуществе идентификации
участков памяти с помощью имен по сравнению с цифровой адресацией. Такие
идентификаторы обычно называют переменными. Это подчеркивает, что, изменяя значение,
размещенное в данном участке памяти, мы изменяем значение, связанное с
идентификатором, присвоенным этому участку по ходу выполнения программы.
Однако иногда в программе необходимо использовать фиксированное, заранее
определенное значение. Например, программа управления воздушными
полетами в окрестности некоторого аэропорта может содержать многочисленные
ссылки на высоту аэропорта над уровнем моря. При создании подобной программы
можно конкретно указывать это значение (скажем, 645 футов), когда оно
потребуется. Такое явное указание конкретного значения называется литералом.
Использование литералов приводит к появлению в программах операторов,
подобных приведенному ниже:
assign EffectiveAlt the value Altimeter+64 5,
где EffectiveAlt и Altimeter являются переменными, а значение 645 —
литералом.
Как правило, применение литералов не считается лучшим стилем
программирования, поскольку они затрудняют понимание тех выражений, в которых
используются» Например, как читающий программу сможет узнать, что именно
означает число 645? Кроме того, литералы могут усложнить модификацию
программы, когда это станет необходимым. Если потребуется использовать данную
программу управления воздушным движением для другого аэропорта, то
значение высоты аэропорта над уровнем моря придется изменить. Если в программе
для ссылки на эту высоту используется литерал 645, то каждую такую ссылку в
программе нужно найти и изменить. Задача еще более усложнится, если
окажется, что литерал 645 в некоторых случаях представляет также и другую
величину, а не только высоту аэропорта над уровнем моря. Как тогда узнать, какой из
литералов следует изменить, а какой оставить неизменным?
5.2. Концепции традиционного программирования 289
Традиции в языках программирования
Как и при использовании естественных языков, пользователи различных языков программирования
стремятся выработать собственные традиции, отличающие их от остальных программистов, и часто вступают в
дебаты по поводу преимуществ, присущих, по их мнению, тем воззрениям, которых они придерживаются.
Иногда отличия могут быть очень существенными, особенно при использовании различных парадигм, в
других же случаях они оказываются совершенно незначительными. Например, несмотря на различия,
существующие между процедурами и функциями (подробно о них рассказывается в разделе 5.3),
пользователи языка С называют оба конструкта функциями. Происходит это по той причине, что в языке С
процедура рассматривается как функция, не возвращающая никакого значения. Аналогичный пример можно
привести в отношении пользователей языка C++, которые ссылаются на функции, входящие в состав
объектов, как на функции-члены, тогда как в объектно-ориентированной парадигме для них используется
термин "метод". Это расхождение имеет место по той причине, что C++ был разработан как расширение
языка С. Другим примером подобных расхождений является то, что в программах на языках Pascal и Ada
зарезервированные слова принято выделять полужирным шрифтом, тогда как пользователи языков С, C++,
Fortran и Java не придерживаются этой традиции.
Текст этой книги выдержан в нейтральном стиле благодаря использованию классической терминологии,
применяемой теоретиками. Однако каждый конкретный пример представлен в форме, совместимой с
традициями данного языка. Встретив подобный пример, читатель должен помнить, что это всего лишь
образец того, как теоретические идеи реализованы в реальном языке программирования, и он вовсе не
предназначен для обучения читателя особенностям работы с тем или иным языком программирования.
Постарайтесь увидеть лес за отдельными деревьями.
Для решения подобных проблем языки программирования позволяют давать
описательные имена конкретным постоянным величинам. Такое имя называется
константой. Например, рассмотрим следующий оператор объявления языка Pascal:
const AirportAlt = 645;
Этот оператор связывает идентификатор Airport Alt с фиксированным
значением, равным 645. Аналогичные действия в языке Java записываются в виде
следующего оператора:
final int AirportAlt = 645;
В результате подобного объявления имя AirportAlt можно будет
использовать вместо литерала 645. Используя такую константу в нашем псевдокоде, мы
можем переписать оператор
assign EffectiveAlt the value Altimeter +64 5
в виде
assign EffectiveAlt the value Altimeter + AirportAlt.
Последний вариант лучше представляет смысл программы. Кроме того, если
в программе вместо литералов используются подобные именованные константы и
эту программу потребуется перенести в другой аэропорт, расположенный на вы-
290 Глава пятая. Языки программирования
соте 267 футов над уровнем моря, то все, что нужно сделать, для того чтобы
присвоить всем ссылкам на высоту аэропорта новые значения, — это изменить
одно-единственное объявление следующим образом:
const AirportAlt = 267;
Типы данных
Операторы объявления, с помощью которых данным присваиваются имена,
обычно одновременно определяют и их тип. Тип данных определяет как
интерпретацию конкретных данных, так и операции, которые можно с ними выполнять. К
основным типам данных относятся integer (целый), real (действительный),
character (символьный) и Boolean (логический, или булев). Тип integer
используется для обозначения числовых данных, являющихся целыми числами. В памяти
они чаще всего представляются с помощью двоичной нотации с дополнением. С
данными типа integer можно выполнять обычные арифметические операции и
операции сравнения. Тип real предназначен для представления числовых данных,
которые могут содержать нецелые величины. В памяти они обычно хранятся как
двоичные числа с плавающей точкой. Операции, которые можно выполнять с данными
типа real, аналогичны операциям, выполняемым с данными типа integer. Однако
заметим, что манипуляции, которые следует выполнить, чтобы сложить два
элемента данных типа real, отличаются от манипуляций, необходимых для выполнения
аналогичных действий с переменными типа integer.
Тип character используется для данных, состоящих из символов, которые
хранятся в памяти в виде кодов ASCII или UNICODE. Данные этого типа можно
сравнивать друг с другом (определять, какой из двух символов предшествует
другому в алфавитном порядке); проверять, является ли одна строка символов
частью другой, а также объединять две строки в одну, более длинную строку,
дописывая одну из них после другой (операция конкатенации).
Тип Boolean относится к данным, которые могут принимать только два
значения: true (истина) и false (ложь). Примером таких данных может служить результат
выполнения операции сравнения двух чисел. Операции с данными типа Boolean
включают проверку, является ли текущее значение переменной true или false.
Другие типы данных, которым пока не соответствуют какие-либо
общепринятые элементарные конструкции в основных языках программирования, — это
аудио- и видеоданные. Встроенные средства для обработки таких данных
имеются в среде программирования языка Java.
В большинстве языков программирования требуется, чтобы операторы
объявления не только вводили новую переменную в программу, но и определяли ее
тип. На рис. 5.4 приведены примеры таких объявлений в языках Pascal, С, C++,
Java и FORTRAN. В каждом случае переменным Length и Width присвоен тип
real, а переменным Price, Tax и Total — тип integer. Обратите внимание,
что в языках С, C++ и Java для ссылки на тип данных real используется
ключевое слово float, поскольку данные этого типа представляются в машине как
числа с плавающей точкой.
5.2. Концепции традиционного программирования 291
а) Объявление переменных в языке Pascal
var :
Length, Width: real;
Price, Tax, Total: integer;
б) Объявление переменных в языках С, C++ и Java *
float Length, Width;
int Price, Tax, Total;
в) Объявление переменных в языке FORTRAN
REAL Length, Width
INTEGER Price, Tax, Total
Объявление переменных в языках Pascal, С, C++, Java и FORTRAN
В разделе 5.5 мы увидим, как транслятор использует сведения о типах данных
при переводе программы с языка высокого уровня на машинный. Заметим, что эту
информацию можно использовать и для обнаружения ошибок. Например, попытка
сложить два значения типа character или выполнить операцию, манипулирующую
данными разных типов, может вызвать у транслятора подозрение.
Структура данных
Другим понятием, связанным с операторами объявления, является структура
данных, определяющая общую форму представления данных. Например, текст
обычно рассматривается как длинная строка символов, тогда как информация о
продажах может рассматриваться как прямоугольная таблица с числовыми
значениями, каждое из которых представляет число сделок, заключенных
определенным работником в определенный день.
Одной из общих структур данных является однородный массив, который
представляет собой блок значений одного типа, например линейный список,
двухмерную таблицу из строк и столбцов или таблицу более высокой
размерности. Для объявления такого массива в большинстве языков программирования
используются специальные операторы объявления, содержащие указания о
длине каждой размерности массива. Например, на рис. 5.5 представлены операторы
языков С, Java и Pascal, объявляющие переменную Scores как двухмерный
массив целых чисел из двух строк и девяти столбцов.
Объявив однородный массив, мы можем ссылаться на него по имени в любом
месте программы, а доступ к отдельным элементам массива можно получить с
помощью индексов, указывающих номер нужной строки, столбца и т.д.
Например, в программе на языке Pascal элемент, находящийся на пересечении второй
строки и четвертого столбца массива Scores, обозначается как Scores [2,4];
тогда как в языках С, C++ и Java этот же элемент массива будет обозначаться как
292 Глава пятая. Языки программирования
Scores [1] [3]. (В этих языках нумерация строк и столбцов начинается с нуля,
т.е. элемент, находящийся на пересечении первой строки и первого столбца
массива, обозначается как Scores [0] [0].)
РИСУНОК 5.5
г) Вид структуры, объявляемой в каждом из приведенных выше примеров
Объявление двухмерного массива с именем Scores ;
В противоположность однородному массиву, в котором все элементы имеют один
и тот же тип, неоднородный массив представляет собой блок данных, в котором
отдельные элементы могут иметь разный тип. Например, блок данных, относящийся к
некоторому работнику, может содержать элемент Name типа character, элемент Age
типа integer, а также элемент SkillRating типа real. На рис. 5.6 показано, как
можно объявить такой массив в языках С и Pascal.
При ссылке на компоненты неоднородного массива обычно указывают имя
массива и имя элемента, разделенные точкой. Например, в языках С, C++, Java
и Pascal для доступа к элементу Age массива Employee, показанного на рис. 5.6,
можно использовать имя Employee.Age.
В главе 7 мы увидим, как концептуальные структуры, подобные массивам,
реализуются в компьютерах. В частности, будет показано, что относящиеся к
массиву данные могут быть распределены по большой области основной памяти
или внешнего запоминающего устройства. Вот почему мы рассматриваем
структуры данных как концептуальные формы их представления. В действительности
же "реальная" форма представления данных в запоминающих устройствах
машины может совершенно отличаться от теоретической формы.
5.2. Концепции традиционного программирования
293
I РИСУНОК 5.6 I
а) Объявление массива в языке Pascal
var
Employee: record
Name: packed array[1. . 8] of char;
Age: integer;
SkillRating: real
end
б) Объявление массива в языке С
struct *
{char Name [8];
int Age;
float SkillRating;
Employee;
}
в) Вид структуры, объявляемой в каждом из приведенных выше примеров
Employee
Name Age Skill
Rating
Объявление неоднородных массивов в языках Pascal и С
Операторы присваивания
Наиболее важным выполняемым оператором является оператор
присваивания, предназначенный для присвоения переменной некоторого значения.
Синтаксически форма этого оператора обычно состоит из имени переменной,
символа операции присваивания и выражения, определяющего то значение, которое
должно быть присвоено переменной. Семантика этого оператора заключается в
вычислении выражения, стоящего в его правой части, и присвоении полученного
результата переменной, указанной в левой части оператора. Например, в языках
С, C++ и Java в результате выполнения приведенного ниже оператора,
переменной Total присваивается сумма значений переменных Price и Tax:
Total = Price + Tax;
В языках Ada и Pascal эквивалентный оператор записывается в следующем виде:
Total := Price + Tax;
Обратите внимание, что эти операторы отличаются только синтаксисом операции
присваивания, которая в языках С, C++ и Java обозначается просто знаком
равенства, а в языках Ada и Pascal перед знаком равенства ставится двоеточие. Возможно,
294 Глава пятая. Языки программирования
более удачное обозначение операции присваивания используется в языке APL (А
Programming Language — язык программирования), разработанном Кеннетом Ивер-
сеном (Kenneth E. Iverson) в 1962 году. В этом языке для представления операции
присваивания используется стрелка. Таким образом, предыдущий оператор
присваивания в языке APL будет записан следующим образом:
Total <r- Price + Tax
"Мощь" оператора присваивания определяется диапазоном выражений,
допустимых в правой части оператора. Как правило, разрешается использовать
любые алгебраические выражения с арифметическими операциями сложения,
вычитания, умножения и деления, обычно обозначаемые символами +, -, * и /
соответственно. Однако языки программирования по-разному интерпретируют
подобные выражения. Например, при вычислении выражения 2 * 4 + б / 2
справа налево получим результат 14, а слева направо — значение 7. Во
избежание таких неоднозначностей обычно устанавливаются приоритеты операций,
определяющие порядок выполнения операций в выражениях. Традиционно
умножение и деление имеют более высокий приоритет, чем сложение и вычитание.
Таким образом, операции умножения и деления должны выполняться до
сложения и вычитания. В соответствии с этим при вычислении приведенного выше
выражения получим результат 11. В большинстве языков программирования
для изменения порядка выполнения операций используются скобки. В этом
случае вычисление выражения 2 * (4 + 6) /2 даст результат 10.
Выражения в операторах присваивания могут содержать не только обычные
алгебраические операции. Например, пусть First и Last — переменные,
имеющие тип строки символов. Рассмотрим следующий оператор языка FORTRAN:
Both = First // Last
В результате его выполнения переменной Both в качестве значения будет
присвоена строка символов, полученная посредством конкатенации строк из
переменных First и Last. Таким образом, если переменные First и Last
содержат строки abra и cadabra соответственно, то переменная Both будет иметь
значение abracadabra.
Многие языки программирования позволяют использовать один и тот же
символ для обозначения нескольких типов операций. В таких случаях значение
символа определяется типом операндов. Например, символ + обычно означает
операцию сложения, если операнды являются числами, но в некоторых случаях,
например в языке Java, этот символ означает операцию конкатенации, если
операндами являются строки символов. Такое многозначное использование
символов операций называется перегрузкой.
Управляющие операторы
Управляющие операторы предназначены для изменения порядка выполнения
программы. Из всех операторов именно они привлекают к себе наибольшее
внимание и порождают большинство споров. Главным виновником этого является
самый простой из всех управляющих операторов — оператор goto. Он позволяет
5.2. Концепции традиционного программирования 295
изменить порядок выполнения программы путем перехода к другому месту
программы, обозначенному специально для этой цели именем или числом. Таким
образом, этот оператор является не чем иным, как прямым применением
машинной команды передачи управления в другое место программы. Проблема
оператора goto заключается в том, что в языках программирования высокого
уровня он позволяет программисту писать очень запутанные тексты,
пронизанные операциями перехода, как крысиными норами:
goto 40
20 Total = Price + 10
goto 70
40 if Price <50 then goto 60
goto 20
60 Total = Price + 5
70 stop
Однако эти же действия можно выполнить с помощью буквально двух
следующих операторов:
if (Price < 50)
then Total = Price + 5
else Total = Price + 10
stop
Чтобы избежать подобных ситуаций, современные языки программирования
включают более продуманный набор управляющих операторов, позволяющий
представлять разветвленные структуры с помощью единственного оператора. На рис. 5.7
показаны некоторые наиболее распространенные структуры ветвления и
соответствующие управляющие операторы, используемые в различных языках
программирования для их представления. Заметим, что первые два типа структур уже
упоминались в главе 4. В нашем псевдокоде они представляются операторами if-then-else
и while. Третью структуру, известную под названием "оператор case", можно
рассматривать как обобщение структуры if-then-else. В то время как структура if-
then-else допускает выбор только из двух возможностей, оператор case позволяет
сделать выбор одного из многих описанных вариантов.
Другие широко распространенные типы структур, часто называемые
структурами типа for, реализуются в разных языках программирования так, как
показано на рис. 5.8. Эти циклические структуры похожи на оператор while нашего
псевдокода. Разница лишь в том, что в структуре цикла инициализация и
модификация счетчика цикла, а также проверка условия выхода выполняются
единственным оператором. Такой оператор удобен, когда тело цикла выполняется
один раз для каждого значения переменной из заданного диапазона. В
частности, представленные на рис. 5.8 операторы указывают, что тело цикла должно
выполняться несколько раз — сначала со значением переменной Const, равным
1, затем со значением переменной Const, равным 2, и еще раз со значением
переменной Const, равным 3.
296 Глава пятая. Языки программирования
РИСУНОК 5.7
Управляющие структуры и их представление в языках С, C++, Java и Ada
Назначение этих примеров — продемонстрировать, что типичные структуры
ветвления программы присутствуют (с незначительными отличиями) во всех
существующих императивных и объектно-ориентированных языках
программирования. Однако, хотя это может показаться несколько неожиданным, с
теоретической точки зрения компьютерной науки лишь немногие из этих структур
являются действительно необходимыми для записи алгоритма решения любой
задачи на некотором языке программирования. Мы обсудим это позже, в гла-
5.2. Концепции традиционного программирования
297
ве 11. Пока же просто отметим, что изучение языка программирования не
сводится к бесконечному изучению различных управляющих операторов. В
действительности большинство управляющих структур, имеющихся в современных
языках программирования, по сути, являются лишь вариантами тех структур,
которые мы уже рассмотрели здесь.
РИСУНОК 5.8
Выбор набора управляющих структур, предназначенных для включения в
язык программирования, является одним из аспектов его разработки. Задача
состоит не только в том, чтобы обеспечить язык средствами выражения
алгоритмов в наиболее удобной форме, но и в том, чтобы помочь программисту
действительно достичь этого. Для достижения этой цели необходимо отказаться от
использования тех языковых конструкций, которые допускают небрежное
программирование, и поощрить применение более продуманных проектных
решений. Результатом такого подхода стала разработка часто неверно трактуемой
методологии, известной как структурное программирование. Она объединяет в
себе строгие требования к организации проектирования с соответствующим
использованием управляющих структур языка программирования. Назначение
этого подхода заключается в создании понятных и хорошо организованных
программ, полностью отвечающих требованиям своих спецификаций.
298
Глава пятая. Языки программирования
Комментарии
Как показывает практика, независимо от того, насколько хорошо разработан
язык программирования и насколько правильно использованы его возможности,
всякий раз, когда человек пытается разобраться в программе сколько-нибудь
значительного размера, дополнительная информация о ней оказывается либо
полезной, либо просто необходимой. Поэтому в языках программирования
предусмотрены синтаксические конструкции для вставки в программу поясняющих
операторов, называемых комментариями. Документация, составленная из таких
комментариев, называется внутренней, поскольку она заключена внутри
программы, а не в отдельном документе.
Транслятор игнорирует внутреннюю документацию, поэтому ее наличие или
отсутствие с машинной точки зрения никак не влияет на саму программу.
Машинная версия программы, созданная транслятором, будет одной и той же,
независимо от того, содержит исходный код комментарии или нет. Однако
содержащаяся в этих комментариях информация является важной частью программы
с точки зрения человека. Без такого документирования большие и сложные
программы часто превышают пределы понимания программиста.
Существуют два способа выделения комментариев из остального текста
программы. Первый состоит в том, чтобы пометить весь комментарий
специальными маркерами, поставив один из них в начале, а второй — в конце текста
комментария. Другой способ — отметить начало комментария и считать, что он
занимает всю оставшуюся часть строки справа от маркера. Оба способа
применяются в языках C++ и Java. В общем случае комментарий должен
размещаться между парами символов /* и */, однако в этих языках комментарий
может также начинаться символами //и продолжаться до конца текущей
строки. Таким образом, в языках C++ и Java оба приведенные ниже варианта
оператора комментария являются правильными:
/* Это комментарий. */
// Это тоже комментарий.
Скажем несколько слов о том, что следует считать осмысленным
комментарием. Начинающие программисты при внесении комментариев в целях создания
внутренней документации обычно делают это следующим образом:
Total := Price + Tax; // Вычисляем Total, складывая Price и Tax
Подобные комментарии совершенно излишни и скорее просто увеличивают
размер программы, нежели проясняют ее суть. Запомните, что задача
внутренней документации — объяснить другому программисту смысл программы, а не
просто перифразировать выполняемые в ней действия. Более приемлемым
комментарием для приведенного выше оператора было бы краткое пояснение, зачем
вычисляется значение Total, если это не очевидно из предыдущего текста.
Например, комментарий "Переменная Total используется ниже при вычислении
значения переменной GrandTotal и после этого будет не нужна" будет более
полезен, чем предыдущий.
5.2. Концепции традиционного программирования 299
Кроме того, программа, в которой комментарии беспорядочно разбросаны
среди выполняемых операторов, может быть еще более непонятной, чем
программа вовсе без комментариев. Лучше собрать все относящиеся к некоторому
модулю программы комментарии в одном месте, например в начале модуля, где
читатель программы сможет найти объяснения. Здесь также целесообразно будет
описать задачу и общие свойства данного программного модуля. Если это
принять для всех модулей, то получится единообразно выполненная программа,
каждая часть которой будет состоять из блока поясняющих комментариев и
следующих за ними выполняемых операторов. Такое единообразие программы
существенно улучшает ее читабельность.
Вопросы для самопроверки
1. Почему использование констант вместо литералов считается лучшим стилем
программирования?
2. В чем разница между оператором объявления и выполняемым оператором?
3. Перечислите некоторые из наиболее распространенных типов данных.
4. Назовите некоторые из наиболее распространенных управляющих структур,
существующих в императивных и объектно-ориентированных языках
программирования.
5. Чем отличаются однородные и неоднородные массивы?
5.3. Процедуры и функции
В предыдущих главах мы убедились в преимуществах разделения больших
программ на более мелкие и удобные в работе модули. Для выполнения такой
декомпозиции языки программирования предоставляют много различных
средств. Языки, поддерживающие функциональную парадигму, естественным
образом требуют разделения программы на отдельные функции. Языки,
поддерживающие объектно-ориентированную парадигму, позволяют создавать
программные модули, представляющие отдельные объекты.
В этом разделе мы сосредоточим внимание на методах модульного
представления алгоритмов. Этот подход состоит в объединении шагов алгоритма в
короткие, простые фрагменты с последующим их применением в качестве
абстрактных инструментов для достижения желаемой цели. В результате образуется
некоторая структура из подпрограмм, каждая из которых кодируется на нашем
псевдокоде как отдельная процедура.
Процедуры
Процедура — это модуль программы, написанный независимо от других
модулей и связанный с ними с помощью процедуры передачи и возврата
управления (рис. 5.9). Управление передается процедуре (посредством команды
машинного языка JUMP) в тот момент, когда возникает необходимость в получении
300 Глава пятая. Языки программирования
предоставляемых ей услуг, и возвращается в модуль вызывающей программы
после завершения работы процедуры. Процесс передачи управления часто
называют вызовом процедуры. Мы будем называть модуль программы, который
обращается к процедуре, вызывающим.
РИСУНОК 5.9
Передача и возврат управления при вызове процедуры
В рассматриваемых языках программирования процедуры определяются
почти так же, как и в нашем псевдокоде, обсуждавшемся в главе 4. Определение
процедуры начинается с оператора, называемого заголовком процедуры,
который, помимо всего прочего, содержит ее имя. За заголовком следуют операторы,
детально описывающие данную процедуру. Во многих отношениях процедура —
это миниатюрная программа. Она содержит как объявления используемых
переменных и констант, так и выполняемые операторы, описывающие шаги
алгоритма, для реализации которого эта процедура предназначена.
Как правило, переменные, объявленные в процедуре, являются
локальными. Это означает, что на них можно ссылаться только внутри данной
процедуры. Подобный подход исключает возможные недоразумения, которые
могут возникнуть, когда две процедуры, написанные независимо друг от
друга, используют переменные с одинаковыми именами. Однако иногда
требуется, чтобы некоторые данные были доступны всем модулям внутри
программы. Переменные, представляющие собой такие данные, называются
глобальными. Многие языки программирования имеют средства для описания
как локальных, так и глобальных переменных.
5.3. Процедуры и функции
301
Событийно-управляемое программное обеспечение
В этой главе рассматриваются случаи, когда процедуры явно вызываются операторами, расположенными в
различных местах программы. Однако иногда процедуры должны активизироваться неявно, при
наступлении какого-то события. Например, в графическом интерфейсе пользователя (GUI) процедура,
описывающая реакцию программы на щелчок на командной кнопке, вызывается не из другого программного модуля,
а активизируется непосредственно в ответ на щелчок мышью на данном элементе. Программное
обеспечение, содержащее подобные процедуры, называется событийно-управляемым. Короче говоря, такое
программное обеспечение состоит из процедур, описывающих реакцию системы на различные события. При
функционировании системы эти процедуры бездействуют, пока не наступит требуемое событие; после
этого они активизируются, выполняют свою задачу и вновь возвращаются в состояние покоя.
Синтаксические конструкции, используемые для вызова процедур из другой
части программы, в разных языках несколько отличаются. В языке FORTRAN
используется оператор CALL. В языках Ada, С, C++, Java и Pascal просто
указывается имя процедуры. Таким образом, если GetNames, SortNames и
WriteNames — это процедуры для получения, сортировки и печати списка имен
(определенного как глобальная переменная), то мы могли бы использовать их
при написании приведенной ниже программы на языке FORTRAN,
предназначенной для получения, сортировки и печати списков.
CALL GetNames
CALL SortNames
CALL WriteNames
В языках Ada, С, C++, Java и Pascal эта же программа выглядит следующим
образом:
GetNames;
SortNames;
WriteNames;
Обратите внимание, что в этом случае программа состоит из трех команд,
каждая из которых обращается к абстрактной процедуре. Детали того, как именно
каждая процедура выполняет свою задачу, скрыты от главной программы.
Параметры
Обычно не рекомендуется предоставлять информацию для совместного
использования с помощью глобальных переменных, поскольку при этом трудно
определить, какая часть программы использует эти данные. Лучше всего в
явном виде определить, какие данные используются в каждом модуле программы.
Для этого нужно перечислить данные, которые передаются процедуре
оператором вызова. В свою очередь, заголовок процедуры содержит список переменных,
которым будут присвоены значения, полученные при вызове процедуры, как и в
302 Глава пятая. Языки программирования
нашем псевдокоде, описанном в главе 4. Элементы обоих списков называют
параметрами.
При вызове процедуры параметры, перечисленные в вызывающем программном
модуле, ставятся в однозначное соответствие параметрам, перечисленным в
заголовке процедуры; первый параметр в вызывающем модуле соответствует первому
параметру в заголовке процедуры и так далее. Затем значения параметров из
вызывающего модуля присваиваются соответствующим параметрам процедуры, и процедура
выполняется. Таким образом, как и в нашем псевдокоде, параметры, перечисленные
в заголовке процедуры, указывают, где будут размещены конкретные данные при
вызове процедуры. Поэтому такие параметры часто называют формальными, тогда
как параметры, перечисленные в вызывающем модуле, именуют фактическими,
поскольку они представляют реальные данные.
В некоторых языках программирования передача данных от фактических
параметров к формальным осуществляется посредством копирования. При этом
процедура может манипулировать лишь предоставленными ей копиями.
Говорят, что такие параметры передаются по значению. Передача данных по
значению защищает переменные в вызывающем модуле от ошибочного изменения
плохо разработанной процедурой. Например, если вызывающий модуль передает
процедуре номер социального страхования работника, то крайне нежелательно,
чтобы она этот номер изменила.
К сожалению, передача параметров по значению неэффективна, особенно
когда параметрами являются большие блоки данных. Более эффективный способ
передачи параметров процедуре состоит в предоставлении ей прямого доступа к
фактическим параметрам посредством указания их адресов. В этом случае
говорят, что параметры передаются по ссылке. Напомним, что передача параметров
по ссылке позволяет вызываемой процедуре модифицировать данные в
вызывающем модуле. Такой подход был бы желателен, например, при сортировке
списка. И действительно, в этом случае вызов процедуры сортировки имел бы
результатом переупорядочивание исходного списка.
Например, пусть процедура Demo описана так, как показано ниже:
procedure Demo(Fo rma1)
assign Formal the value Forma1+1;
Кроме того, предположим, что переменной Actual присвоено значение 5,
после чего процедура Demo вызывается с помощью следующего оператора:
Demo (Actual)
(Здесь использована синтаксическая конструкция, более характерная для
языков программирования, чем для нашего псевдокода, в котором этот оператор
имел бы вид "apply Demo to Actual".) В этом случае, если параметры
передаются по значению, то изменения, внесенные в переменную Formal при
выполнении процедуры Demo, не отразятся на значении переменной Actual (рис. 5.10).
Однако если параметры передаются по ссылке, значение переменной Actual
увеличится на единицу (рис. 5.11).
5.3. Процедуры и функции 303
РИСУНОК 5.10 |
В разных языках программирования передача параметров осуществляется
различными методами, но в любом случае использование параметров позволяет
писать процедуры в абстрактном виде и применять их к конкретным данным в
нужный момент.
304
Глава пятая. Языки программирования
РИСУНОК 5.11
Выполнение процедуры Demo с передачей параметров по ссылке
Функции
Обычно назначение программного модуля состоит в выполнении действия
и/или вычислении значения. Когда упор делается на вычислении значения,
программный модуль может быть реализован в виде функции. В данном случае
термин функция относится к программному модулю, который во всем похож на
процедуру, за исключением того, что он возвращает в вызывающий модуль не
список параметров, а единственное значение, которое называется "значением
функции". Значение функции связано с именем функции так же, как значение
переменной связано с именем переменной. Отличие заключается лишь в
усилиях, которые нужно приложить, чтобы получить значение. При ссылке на
переменную соответствующее значение извлекается из основной памяти, при исполь-
5.3. Процедуры и функции
305
зовании функции значение вычисляется путем выполнения инструкций,
содержащихся в теле функции.
Например, если Total — это переменная, которой присвоена общая
стоимость единицы продукции (цена плюс налог на продажу), то стоимость двух
таких единиц можно найти, вычислив следующее выражение:
2 * Total
В противоположность этому, если TotalCost — функция, которая вычисляет
стоимость единицы продукции на основе ее цены и установленного налога на
продажу, то стоимость двух единиц продукции можно найти, вычислив такое
выражение:
2 * TotalCost(Price, TaxRate)
В первом случае значение переменной Total просто извлекается из памяти и
умножается на число 2. Во втором случае функция TotalCost выполняется для
переданных ей на вход значений Price и TaxRate, после чего полученное
значение умножается на 2.
Операторы ввода/вывода
Процедуры и функции расширяют возможности языков программирования.
Если язык не предусматривает некоторую операцию в качестве
предопределенной языковой конструкции, для выполнения этой задачи можно написать
процедуру или функцию, а затем вызвать ее из того программного модуля, где эта
операция потребуется. Подобным же образом во многих языках
программирования осуществляются и операции ввода/вывода, но за исключением того, что
вызываемые процедуры и функции в конечном счете представляют собой
подпрограммы, выполняемые операционной системой компьютера.
Например, чтобы ввести значение с клавиатуры и присвоить его переменной
под именем Value, в языке Pascal необходимо использовать оператор
readln(Value);
Для вывода переменной Value на экран дисплея используется другой оператор:
writeln(Value);
Заметим, что синтаксис этих операторов не отличается от вызова процедуры
со списком параметров.
Аналогично в языке С для выполнения операций ввода и вывода предназначены
функции scanf и printf соответственно. Эти функции используют параметры как
для определения вводимых данных, так и для определения вида этих данных в
напечатанном виде. Этот подход называется форматным вводом и выводом. Например,
чтобы напечатать в отдельной строке значения переменных Value 1 и Value2 в
десятичном виде, в языке С можно использовать следующий оператор:
printf("%d %d \n", Valuel, Value2);
Здесь строка в кавычках определяет формат данных, а остальные параметры
задают выводимые значения. Каждая пара символов "%d" определяет позицию,
которая должна быть заполнена очередным значением в десятичной нотации, задавае-
306 Глава пятая. Языки программирования
мым соответствующим параметром. Пара символов "\п" означает, что после вывода
значений следует перейти на новую строку. Предположим, что значения переменных
Agel и Age2 равны 16 и 25 соответственно и что выполняется оператор
printf("The ages are %d and %d. \n", Agel, Age2);
В этом случае на экран дисплея будет выведено следующее сообщение:
The ages are 16 and 25
Поскольку языки C++ и Java являются объектно-ориентированными, они
трактуют операции ввода/вывода как передачу данных от объекта к объекту. В
частности, в язык C++ встроены готовые объекты с именами cin и cout,
предназначенные для представления стандартных устройств ввода (возможно,
клавиатуры) и вывода (возможно, экрана дисплея) соответственно. Данные, которые
вводятся с клавиатуры или выводятся на экран дисплея, передаются этим
объектам или поступают от них в виде сообщений. Например, с помощью
следующего оператора можно ввести с клавиатуры некоторое значение и присвоить его
переменной Value:
cin >> Value;
Для того чтобы вывести значение переменной Value на экран, следует
послать его на устройство вывода с помощью следующего оператора:
cout << Value;
Вопросы для самопроверки
1. Чем отличаются локальные переменные от глобальных?
2. Чем отличается процедура от функции?
3. Почему многие языки программирования реализуют операторы ввода/вывода
так, будто они представляют собой вызов процедуры?
4. Чем отличаются формальные параметры от фактических?
.j&B
5.4. Реализация языка
В этом разделе мы познакомимся с процессом перевода программы с языка
высокого уровня в такую форму, которая может быть выполнена машиной.
Процесс перевода
Процесс перевода программы с одного языка на другой называется
трансляцией. Программа в своем оригинальном виде называется исходной
программой; а оттранслированная ее версия называется объектным кодом. Процесс
трансляции состоит из трех этапов — лексического анализа, синтаксического
разбора и генерации кода, которые выполняются элементами транслятора,
называемыми лексическим анализатором, синтаксическим анализатором и
генератором кода (рис. 5.12).
5.4. Реализация языка 307
РИСУНОК 5.12 |
Процесс трансляции программы
Лексический анализ — это процесс выделения отдельных символьных строк
из текста исходной программы. Например, символы f153f должны
интерпретироваться транслятором не как совокупность цифр, состоящая из единицы,
пятерки и тройки, а как единое числовое значение, равное ста пятидесяти трем.
Аналогично этому, слова в программе представляют собой самостоятельные и
неразделимые единицы текста, хотя и состоят из отдельных символов.
Большинство людей выполняют лексический анализ без каких-либо видимых усилий. И
действительно, когда нас просят прочитать текст вслух, мы произносим целые
слова, а не те отдельные буквы, из которых они состоят.
Таким образом, лексический анализатор символ за символом считывает текст
исходной программы, определяя, какие группы символов образуют
самостоятельные единицы текста. Затем эти единицы классифицируются, чтобы
выяснить, что они собой представляют — числа, слова, арифметические операторы и
т.д. Как только единица текста классифицирована, лексический анализатор
генерирует ее битовый образ, называемый лексемой (token), и передает его
синтаксическому анализатору. При выполнении этого процесса лексический
анализатор игнорирует все комментарии, содержащиеся в тексте исходной программы.
Реализация языка Java
При использовании анимированной Web-страницы управляющее анимацией программное обеспечение
передается через Internet вместе с самой страницей. Если программное обеспечение представляет собой
исходный текст программы, то при просмотре страницы возникает дополнительная задержка, связанная с
трансляцией программы в соответствующий машинный язык. Однако если это программное обеспечение
308
Глава пятая. Языки программирования
пересылать сразу на машинном языке, то может оказаться, что для разных типов машин потребуются
различные версии программы.
Фирма Sun Microsystems решила эту проблему, разработав универсальный "машинный язык", названный
байт-кодом, на который переводятся исходные тексты программ, написанные на языке Java. Хотя байт-код
не является настоящим машинным языком, подходящий интерпретатор сможет выполнить его достаточно
быстро. В настоящее время такие интерпретаторы уже стали стандартной частью любых Web-броузеров.
Поэтому, если управляющее Web-страницей программное обеспечение написано на языке Java и
переведено в байт-код, то эту байт-кодовую версию программы можно передавать любому броузеру, что
гарантирует эффективную анимацию изображений при просмотре данной Web-страницы.
Из сказанного выше можно прийти к заключению, что синтаксический
анализатор (parser) анализирует программу в терминах лексических единиц
(лексем), а не отдельных символов. Задачей синтаксического анализатора
является объединение этих единиц в операторы. Действительно, синтаксический
анализ — это процесс идентификации грамматической структуры программы и
распознавания роли каждого ее компонента. Это — техническая сторона
синтаксического разбора, которая может привести к некоторой задержке при чтении
следующего предложения.
Человек, которого лошадь, проигравшая скачки, сбросила, не был ранен.
Чтобы упростить процесс синтаксического разбора, ранние языки
программирования требовали, чтобы каждый оператор программы размещался в
определенном месте бланка исходного текста. Такие языки называются языками с
фиксированным форматом. В настоящее время большинство языков
программирования являются языками со свободным форматом. Это означает, что
расположение операторов в тексте не имеет значения. Преимущество свободного
формата состоит в том, что программист теперь может писать программу так, чтобы
человеку было легко ее читать. В таких программах принято использовать
отступы, чтобы помочь читателю понять внутреннюю структуру оператора.
Например, рассмотрим следующий оператор:
if Cost < Cash on hand then pay with cash else use credit card
При использовании свободного формата программист может записать этот же
оператор в более удобном виде:
if Cost<Cash on hand
then pay with cash
else use credit card
Для того чтобы машина могла выполнять синтаксический анализ программы,
написанной на языке со свободным форматом, синтаксис языка следует
разрабатывать таким образом, чтобы структуру программы можно было
идентифицировать, не обращая внимания на пробелы в исходном тексте программы. По этой
причине во многих языках со свободным форматом для обозначения конца
оператора используются знаки пунктуации (например, точка с запятой), а также
ключевые слова, такие как if, then и else, предназначенные для выделения
начала отдельных фраз. Эти ключевые слова обычно называют зарезервирован-
5.4. Реализация языка 309
ными словами, чтобы подчеркнуть, что программист не может использовать их
в своей программе для иных целей.
Процесс синтаксического анализа базируется на совокупности правил,
определяющих синтаксис языка программирования. Один из способов
представления этих правил состоит в использовании синтаксических диаграмм,
наглядно иллюстрирующих грамматическую структуру программы. На
рис. 5.13 представлена синтаксическая диаграмма оператора if-then-else
для нашего псевдокода, описанного в главе 4. Эта диаграмма показывает, что
структурно оператор if-then-else начинается с ключевого слова if, за
которым следует Логическое выражение. Затем указывается ключевое слово
then, после которого должен присутствовать выполняемый Оператор. Эта
комбинация ключевых слов может дополняться (но необязательно)
ключевым словом else и еще одним элементом Оператор. Обратите внимание, что
члены выражения, или термы, которые действительно присутствуют в
операторе if-then-else, заключены в овалы, а те термы, которые подлежат
дальнейшему уточнению, например Логическое выражение или Оператор,
помещены в прямоугольники. Термы, подлежащие дальнейшему уточнению
(т.е. те, которые заключены в прямоугольники), называются
нетерминальными, а термы, окруженные овалами, — терминальными. В полном
описании синтаксиса языка программирования нетерминальные термы
описываются дополнительными диаграммами.
РИСУНОК 5.13 |
5' Синтаксическая диаграмма оператора if-then-else нашего псевдокода
На рис. 5.14 представлен набор синтаксических диаграмм, описывающих
синтаксис структуры Выражение, являющейся структурой простого
арифметического выражения. Первая диаграмма описывает структуру Выражение как
состоящую из компонента Терм, за которым могут вначале следовать (но
необязательно) символы + или -, а затем другой компонент Выражение. Вторая
диаграмма описывает структуру компонента Терм как состоящую из
отдельных символов х, у и z или другого компонента Терм, за которым следует один
из символов * или /, а потом идет некоторый компонент Выражение.
310
Глава пятая. Языки программирования
РИСУНОК 5.14
Синтаксическая диаграмма, описывающая структуру простого алгебраического выражения
Метод, с помощью которого отдельная строка программы проверяется на
соответствие некоторой совокупности синтаксических диаграмм, можно наглядно
представить с помощью дерева синтаксического анализа (рис. 5.15). На нем
приведено дерево синтаксического анализа следующей строки:
х + у * z
Это дерево построено на совокупности диаграмм, представленных на рис. 5.14.
Заметим, что данное дерево анализа начинается расположенным вверху
нетерминальным термом Выражение и на каждом очередном уровне дерева показано, как
нетерминальные термы этого уровня раскладываются на составные части, вплоть
до отдельных символов, из которых и состоит исходная строка.
Процесс синтаксического анализа программы, по сути, сводится к построению
дерева синтаксического анализа для ее исходного текста. Фактически дерево
синтаксического анализа отражает, как синтаксический анализатор понял грамматическую
структуру программы. По этой причине синтаксические правила, описывающие эту
грамматическую структуру, не должны допускать построения двух разных деревьев
синтаксического анализа для одной и той же строки, поскольку это приведет к
неоднозначности. Такие неточности могут быть практически незаметными. И
действительно, показанное на рис. 5.13 синтаксическое правило содержит подобную
неточность. Оно допускает построение двух разных деревьев синтаксического анализа для
одного и того же оператора, показанного ниже, что отражено на рис. 5.16:
if Bl then if В2 then SI else S2
5.4. Реализация языка
311
Дерево синтаксического анализа строки х + у * z, выполняемого на основании синтаксических диаграмм,
, представленных на рис. 5.14
Заметим, что эти интерпретации существенно отличаются друг от друга.
Первая предполагает, что оператор S2 будет выполнен, если выражение В1 окажется
ложным. Из второй интерпретации следует, что оператор S2 должен
выполняться только тогда, когда выражение В1 истинно, а выражение В2 ложно.
Синтаксические определения формальных языков программирования
разрабатываются так, чтобы избежать подобных неоднозначностей. В нашем
псевдокоде этой проблемы можно избежать за счет применения скобок. В частности,
этот оператор следовало бы записать следующим образом:
if B1
then (if B2 then SI)
else S2
Возможен и другой вариант записи этого выражения:
if B1
then (if B2 then SI
else S2)
В результате можно будет четко различать обе возможные интерпретации
исходного оператора.
312
Глава пятая. Языки программирования
РИСУНОК 5.16
Два различных дерева синтаксического анализа для оператора If В1 than If В2 then S1 else S2 j
' i r 4 ( S !
При синтаксическом анализе операторов объявления содержащаяся в них
информация записывается в таблицу символов. В результате таблица символов
будет содержать информацию о том, какие переменные были описаны в
программе и какие типы и структуры данных связаны с этими переменными. В
дальнейшем синтаксический анализатор использует эту информацию при
анализе выполняемых операторов. Ниже представлен один из таких операторов:
5.4. Реализация языка
313
assign Total the value Price + Tax;
Действительно, чтобы определить значение символа +, синтаксический
анализатор должен знать, какой тип данных связан с переменными Price и Tax. Если
переменная Price имеет тип real, а переменная Tax — тип character, то
операция суммирования переменных Price и Tax не имеет смысла; ее появление
должно рассматриваться как ошибка. Если обе переменные Price и Tax имеют
тип integer, то синтаксический анализатор потребует от генератора кода
создать на машинном языке команду с кодом операции сложения двух целых
чисел. Если эти переменные имеют тип real, то синтаксический анализатор
потребует использовать операцию сложения двух чисел с плавающей точкой.
Предыдущий оператор имеет смысл и в некоторых из тех случаев, когда
входящие в него переменные имеют разный тип. Например, если переменная Price
имеет тип integer, а переменная Tax — тип real, то вполне возможно
применить операцию сложения. В этом случае синтаксический анализатор может
предложить генератору кода предварительно преобразовать одну из переменных
в другой тип и после этого выполнить требуемое сложение. Такое неявное
преобразование типов называется приведением типов (coercion).
Неявное приведение типов не одобряется многими разработчиками языков.
Они считают, что неявное приведение типов свидетельствует о неправильной
разработке программы и что синтаксический анализатор ни в коем случае не
должен покрывать эти недостатки. В результате большинство современных
языков программирования являются строго типизированными, т.е. они требуют,
чтобы все операции в программе выполнялись над данными согласованных
типов без необходимости неявного приведения типов. Синтаксические анализаторы
этих языков рассматривают любые несоответствия типов как ошибку.
Последним этапом трансляции является генерация кодов — процесс создания
команд машинного языка, имитирующих выполнение операторов, опознанных
синтаксическим анализатором. Этот процесс включает множество различных аспектов,
один из которых — повышение эффективности генерируемого кода. Например,
рассмотрим задачу трансляции последовательности из двух следующих операторов:
assign x the value у + z;
assign w the value x + z;
Эти операторы могут быть оттранслированы по отдельности. Однако это не
позволит достичь высокой эффективности результата. Генератор кода должен суметь
распознать, что, когда первый оператор будет выполнен, переменные х и z уже будут
находиться в регистрах общего назначения центрального процессора и,
следовательно, нет необходимости снова загружать их из памяти перед выполнением второго
оператора. Реализация подобных нюансов в построении программы называется
оптимизацией кода и является важной задачей генератора кода.
Этапы лексического анализа, синтаксического анализа и генерации кода
никогда не выполняются в указанной строгой последовательности. На самом деле
они тесно переплетаются между собой. Лексический анализатор начинает с
чтения символов текста исходной программы и идентификации первых лексем.
Затем он передает эти лексемы синтаксическому анализатору. Каждый раз, когда
314 Глава пятая. Языки программирования
синтаксический анализатор получает очередную лексему, он анализирует
считываемую в данный момент грамматическую структуру. В результате он может
запросить у лексического анализатора следующую лексему либо, если он
распознал законченную фразу или оператор, обратиться к генератору кода для
порождения соответствующих машинных инструкций. Каждый поступивший запрос
вынуждает генератор кода строить соответствующие машинные команды и
добавлять их к объектному коду программы. Как можно заметить, задача перевода
программы с одного языка на другой естественно согласуется с объектно-
ориентированной парадигмой. Поэтому исходный текст программы, лексический
анализатор, синтаксический анализатор, генератор кода и объектный код могут
рассматриваться как объекты, которые взаимодействуют, посылая друг другу
сообщения по мере выполнения своих функций (рис. 5.17).
РИСУНОК 5.17
Объектно-ориентированный подход к процессу трансляции программ
Связывание и загрузка
Объектный код программы, полученный в результате ее трансляции, хотя
и записан на машинном языке, но чаще всего еще не имеет той формы,
которая необходима для выполнения машиной. Одной из причин этого
является то, что многие средства программирования позволяют разрабатывать
программы в виде отдельных модулей, транслируемых в разное время (это
способствует приданию программному обеспечению модульной структуры).
Поэтому объектный код, полученный в результате отдельного процесса
трансляции, чаще всего представляет собой всего лишь некоторую составную
часть программы, которая должна быть связана с другими ее частями для
решения задач, стоящих перед всей системой в целом. Даже если вся
программа разработана и оттранслирована в виде единственного модуля, ее
объектный код все же не готов для выполнения машиной, поскольку любой
программе, как правило, требуются функции, выполняемые другими програм-
5.4. Реализация языка
315
мами или же операционной системой. Поэтому объектный код программы в
действительности представляет собой программу на машинном языке,
обычно содержащую несколько неразрешенных ссылок; эту программу
необходимо связать с другими программами, прежде чем можно будет получить
полноценный выполняемый модуль.
Связывание объектного кода программы с другими модулями выполняет
программа, называемая редактором связей (linker). Ее задача — связать между
собой несколько объектных модулей (полученных в результате предшествующих
независимо выполненных процедур трансляций), программ операционной
системы и другое программное обеспечение в целях получения завершенного
выполняемого модуля (иногда называемого загрузочным модулем), который
представляет собой файл, размещаемый во внешней памяти машины.
Наконец, чтобы выполнить оттранслированную программу, ее
загрузочный модуль должен быть размещен в основной памяти машины с помощью
специальной программы, называемой загрузчиком (loader). Загрузчик
обычно является частью программы-планировщика операционной системы (см.
раздел 3.3). Важность этого этапа особенно велика в многозадачных
системах. В подобных системах любая программа вынуждена использовать память
совместно с другими параллельно выполняемыми процессами, причем набор
параллельно выполняемых процессов изменяется при каждом выполнении
программы. Поэтому точное расположение выделяемого для некоторой
программы участка памяти остается неизвестным, вплоть до ее вызова на
выполнение. Таким образом, задачей загрузчика является считывание
программы в указанную операционной системой область памяти и выполнение в
ней всех необходимых настроек, которые невозможно осуществить, пока не
будет известно точное расположение данной программы в памяти. (Команды
перехода в программе должны выполнять переход на правильные адреса
внутри программы.) Желание минимизировать объем выполняемой
загрузчиком окончательной настройки привело к разработке таких способов
программирования, в которых запрещается использовать явные ссылки на
адреса памяти в программе. Это позволяет создавать программные модули
(называемые переместимыми модулями), которые правильно работают без
каких-либо изменений в их тексте, независимо от того, в какую область
памяти они загружены.
Итак, подготовка программы на языке программирования высокого уровня
состоит из трех последовательных этапов: трансляции, связывания и загрузки,
как показано на рис. 5.18. После выполнения трансляции и связывания
программу можно повторно загружать и выполнять без обращения к ее исходному
тексту. Однако если в программу потребуется внести изменения, то их придется
ввести в исходный текст, а затем вновь оттранслировать и заново связать
модифицированную версию исходного текста программы, чтобы создать новый
вариант ее загрузочного модуля.
316 Глава пятая. Языки программирования
РИСУНОК 5.18
Полный цикл подготовки программы к выполнению
Пакеты для разработки программ
В настоящее время прочно укрепилась тенденция объединять транслятор с
другими элементами программного обеспечения в общий пакет,
функционирующий как единая интегрированная программная система. В соответствии со
схемой классификации, предложенной в разделе 3.2, такую систему следует отнести
к прикладному программному обеспечению. Используя такой программный
пакет, программист получает удобный доступ к текстовому редактору,
предназначенному для написания программ, транслятору, необходимому для перевода
программы на машинный язык, и разнообразным инструментам отладки
программ, позволяющим отслеживать выполнение неправильно работающих
программ и обнаруживать имеющиеся в них ошибки.
Такая интегрированная система имеет много достоинств. Вероятно, наиболее
важное из них — возможность легко переходить от текстового редактора к
отладчику и обратно при написании и проверке программ. Более того, многие
пакеты разработки программ позволяют связывать разрабатываемые программные
модули таким образом, что доступ к ним заметно упрощается. Некоторые
пакеты обеспечивают ведение записей, относящихся к тем программным единицам в
группе взаимосвязанных модулей, которые были изменены со времени
последнего сеанса проверки их функционирования. Подобные средства очень удобны при
разработке больших программных систем, в состав которых входит множество
отдельных модулей, разрабатываемых разными программистами.
Кроме того, текстовые редакторы обычно настроены для работы с тем
языком программирования, который используется в данном пакете. Например,
текстовые редакторы в пакетах для разработки программного обеспечения
обычно позволяют автоматически применять отступы строк, что фактически
уже стало стандартом для большинства языков программирования. В
некоторых случаях текстовый редактор способен распознавать и автоматически
дописывать ключевые слова сразу же после того, как программист введет лишь
несколько их первых букв.
5.4. Реализация языка
317
Во многих пакетах для разработки программ используют графический
интерфейс, что позволяет программистам создавать программы из заранее написанных
блоков, представленных на экране пиктограммами. Отдельные блоки могут
дополнительно настраиваться в среде текстового редактора. Разработка подобных
пакетов отражает общую тенденцию к созданию программ из больших, заранее
заготовленных блоков, вместо обычного покомандного программирования.
Вопросы для самопроверки
1. Опишите три основных этапа процесса трансляции.
2. Что такое таблица символов?
3. Исходя из синтаксических диаграмм, представленных на рис. 5.14, нарисуйте
дерево синтаксического разбора для выражения
х * у + х + z.
4. Напишите несколько строк, формат которых будет соответствовать структуре
Ча-ча-ча, определенной с помощью следующих синтаксических диаграмм.
Ча-Ча-Ча
5.5. Объектно-ориентированное программирование
В разделе 5.1 уже говорилось, что объектно-ориентированная парадигма
предусматривает разработку активных программных модулей, называемых объектами,
каждый из которых содержит процедуры, описывающие реакцию объекта на раз-
318
Глава пятая. Языки программирования
личные входные сигналы. Эти внутренние процедуры называются методами (или
функциями-членами — в терминологии языка C++). Объектно-ориентированный
подход к решению задачи состоит в выявлении и описании необходимых объектов, а
также связанных с ними методов в виде самодостаточного отдельного программного
модуля. В соответствии с этим, объектно-ориентированные языки программирования
предоставляют операторы и другие средства для реализации этих идей. Некоторые
из них мы рассмотрим в данном разделе.
Для упрощения в этом разделе описывается процедура разработки
программы, моделирующей функционирование малого предприятия. Под малым
предприятием подразумевается частное предприятие, на котором работает не более
25 сотрудников. Наша задача — создать программу для исследования влияния,
которое могут оказывать на подобные предприятия различные изменения,
происходящие в экономике. Следовательно, необходимо разработать программу,
которая будет моделировать деятельность нескольких таких предприятий и
отслеживать, как они взаимодействуют друг с другом и внешним окружением.
Используя объектно-ориентированный язык, мы могли бы описать каждое такое
предприятие как объект с внутренними методами, определяющими его реакцию
на воздействия внешнего мира.
В языках C++ и Java для объявления, что имя BusinessX будет
использоваться для ссылки на объект "типа" SmallBusiness, мы могли бы применить
следующий оператор:
SmallBusiness BusinessX;
Обратите внимание, что этот оператор ничем не отличается от используемого
в языке программирования С для объявления, что Cost является переменной
типа integer:
int Cost;
Несмотря на общее сходство, эти операторы имеют несколько существенных
отличий. Одно из них состоит в том, что "тип" объекта принято называть
классом. Таким образом, класс — это описание структуры объекта. В некотором
смысле класс представляет собой шаблон, который используется для создания
объекта. Другое отличие заключается в том, что тип integer является
встроенным типом языка программирования, тогда как класс SmallBusiness — это
"тип", который должен быть описан в каком-то месте программы.
Для описания классов многие объектно-ориентированные языки
программирования включают специальные операторы, подобные представленному ниже:
class SmallBusiness
{
};
Первая строка этого объявления означает, что блок операторов внутри
фигурных скобок определяет класс под названием SmallBusiness. Внутри
фигурных скобок объявляются разнообразные методы, описывающие, как объект типа
5.5. Объектно-ориентированное программирование 319
SmallBusiness должен реагировать на различные внешние воздействия.
Объявления методов напоминают описание обычных процедур и функций.
Обобщая сказанное, можно сделать вывод, что в нашей моделирующей
программе сначала следует воспользоваться оператором class для описания класса
с именем SmallBusiness, а затем поместить операторы объявления
приведенного выше типа для указания, что в программе будут использоваться объекты
BusinessX, BusinessY и BusinessZ "типа" SmallBusiness.
К сожалению, многие малые предприятия, работу которых мы собираемся
моделировать, имеют разные особенности. Предприятие, принимающее заказы на
доставку товаров по почте, должно отвечать на поступающие заявки и пополнять свой
запас товаров на складе. Тогда как небольшое предприятие, занимающееся
консалтингом, взаимодействует со своими клиентами совершенно иным образом. Однако
между этими предприятиями достаточно много общего. Например, все они
подчиняются одним и тем же законам налогообложения, одинаково обрабатывают
платежные ведомости и сходным образом пополняют запасы канцелярских товаров.
Для того чтобы упростить описание объектов, имеющих больше одинаковых
свойств, чем разных, многие объектно-ориентированные языки
программирования позволяют одному классу включать свойства другого посредством
механизма, называемого наследованием. Предположим, что для разработки нашей
программы моделирования будет использоваться язык Java. В этом случае сначала
можно было бы применить приведенный выше оператор объявления для
описания класса SmallBusiness, содержащего те методы, которые являются общими
для всех малых предприятий в данном приложении. А затем использовать
приведенный ниже оператор для описания другого класса, например, с именем
MailOrderBusiness:
class MailOrderBusiness extends SmallBusiness
{
}
Здесь ключевое слово extends означает, что данный класс наследует все свойства
класса SmallBusiness, а также дополнительно имеет свойства, указанные внутри
фигурных скобок. Аналогично можно было бы описать и другой класс под
названием ConsultingBusiness, который также наследует свойства класса SmallBusiness
и одновременно обладает свойствами, характерными только для предприятий,
занимающихся консалтингом. После того как указанные выше классы будут описаны,
появится возможность использовать следующие операторы:
MailOrderBusiness BusinessX;
ConsultingBusiness BusinessY;
Эти операторы указывают, что переменная BusinessX является объектом,
описывающим малое предприятие, принимающее заказы по почте, а
переменная BusinessY — это объект, описывающий малое предприятие,
занимающееся консалтингом.
320 Глава пятая. Языки программирования
Существование множества объектов, имеющих сходные, но все же отличающиеся
характеристики, приводит к явлению, напоминающему перегрузку, речь о которой
шла в разделе 5.2. (Напомним, что понятие перегрузки означает использование
одного и того же символа, например знака +, для представления разных операций в
зависимости от типа указанных операндов.) Предположим, что объектно-
ориентированный графический пакет состоит из разнообразных объектов, каждый из
которых описывает некоторую фигуру (окружность, прямоугольник, треугольник и
т.п.). Каждое изображение состоит из совокупности таких объектов. Для каждого
объекта известны его размер, положение и цвет, а также то, как он реагирует на
сообщения, требующие от него определенных действий, например перемещение в новое
положение или отображение самого себя на экране. Для того чтобы нарисовать
изображение в целом, мы просто посылаем сообщение "нарисуй себя" каждому из
объектов, образующих это изображение. Однако программы, рисующие отдельные
объекты, изменяются в зависимости от их формы — процесс рисования квадрата
отличается от процесса рисования окружности. Данный механизм специфической
интерпретации одного и того же сообщения называется полиморфизмом, а
соответствующее сообщение — полиморфным.
Другим свойством, связанным с объектно-ориентированным
программированием, является инкапсуляция, которая означает ограничение доступа к
внутренним свойствам объекта. Если сказать, что некоторое свойство объекта
является инкапсулированным, это будет равноценно утверждению, что доступ к
этому свойству может иметь только сам объект. Инкапсулированные свойства
называются закрытыми (private), а свойства, доступные извне объекта, —
открытыми (public). Например, рассмотрим объект нашей программы для
моделирования бизнеса, имеющий "тип" MailOrderBusiness. Следует ожидать, что
этот объект будет содержать метод, описывающий его реакцию на поступление
заказа. Прочим объектам потребуется обращаться к данному методу в целях
передачи некоторого заказа. Следовательно, доступ к этому методу должен быть
открытым. Однако детальные сведения о том, как именно данное предприятие
выполняет заказ, должны быть доступны только внутри объекта. Это означает,
что все эти детали должны быть закрытыми. Большинство объектно-
ориентированных языков программирования позволяет программисту
определять непосредственно в описании класса, какие части объекта являются
открытыми, а какие — закрытыми. Например, описание класса MailOrderBusiness
на языке Java может выглядеть следующим образом:
class MailOrderBusiness extends SmallBusiness
{
public
private ...
private ...
public ...
}
Здесь ключевые слова public и private в начале описания каждого
компонента используются для того, чтобы указать вид доступа к ним.
5.5. Объектно-ориентированное программирование 321
Вопросы для самопроверки
1. В чем заключается отличие между объектом и классом?
2. Предположим, что классы PartTimeEmployee (Временный работник) и
FullTimeEmployee (Постоянный работник) наследуют свойства класса
Employee (Работник). Укажите, какими свойствами, по вашему мнению,
должен обладать каждый из этих классов.
3. Что такое инкапсуляция?
5.6. Программирование параллельных процессов
Предположим, что нам поручили разработать программу для анимации
объектов в компьютерной игре, включающей в себя бегущее стадо антилоп,
марширующую колонну муравьев или, например, множество атакующих вражеских
космических кораблей. Один из подходов к решению этой задачи — создание
единой программы, которая управляла бы всей анимацией на экране дисплея. В
задачу такой программы входило бы рисование каждой антилопы, которое (если
требуется достаточно реалистичная анимация) предполагало бы, что программа
должна непрерывно вычислять индивидуальные параметры для каждого из ста
животных. Альтернативный подход состоит в разработке программы,
управляющей анимацией отдельной антилопы, характеристики которой определяются
параметрами, задаваемыми при запуске этой программы. Теперь анимацию на
всем экране можно было бы создать посредством выполнения ста запусков этой
программы и использования в каждом случае собственного набора параметров.
Выполнив эти запуски одновременно, можно получить иллюзию, что сто
отдельных антилоп бегут на экране в одно и то же время. (Хотя, строго говоря,
одновременное выполнение ста запусков такой программы и превосходит
возможности современных компьютеров, тем не менее, пять запусков программы,
имитирующей атаку космического корабля, не должны составить проблемы; на
практике этот прием применяется довольно часто.)
Одновременное выполнение нескольких запусков программы называется
параллельной обработкой. Для действительно параллельной обработки данных
необходимо несколько центральных процессоров, каждый из которых будет
выполнять отдельную запущенную копию программы. Когда в наличии есть только
один центральный процессор, для создания иллюзии параллельной обработки
можно разрешить нескольким процессам совместно использовать время
единственного процессора (этот вопрос обсуждался в главе 3).
Языки программирования для написания программ, выполняющих
параллельную обработку данных, первоначально предназначались для разработки
операционных систем. Однако, как показывает приведенный в начале раздела
пример, многие современные компьютерные приложения легче реализовать с
использованием параллельной обработки, чем традиционным способом,
предусматривающим запуск единственной программы. В свою очередь, совре-
322 Глава пятая. Языки программирования
менные языки программирования имеют синтаксические конструкции,
предназначенные для выражения семантических структур, необходимых при
параллельной обработке данных. Разработка таких языков требует выявления
подобных синтаксических структур и определения синтаксиса для их выражения.
Анимация в кинофильмах
Конечно, было бы неверным связывать начало современной анимации с одним-единственным кинофильмом,
однако многие считают фильм Звездные войны (Lucasfilm, 1977) началом современной волны компьютерной
анимации в кинематографе. В настоящее время технология, использовавшаяся при создании таких классических
мультфильмов Уолта Диснея, как Спящая красавица и Фантазия, и предусматривающая создание многочисленных,
сделанных вручную кадров, заменена технологиями компьютерной анимации, требующими применения современных
многопроцессорных компьютерных систем. Кинозритель может согласиться, что примеры, описанные в начале
этого раздела (бегущие антилопы и марширующие полчища муравьев), вовсе не являются надуманными. Это —
примеры из реальных кинофильмов, которые созданы с использованием компьютерных технологий (хотя и не
обязательно так, как это описано в тексте, поскольку, в отличие от компьютерных игр, анимация в кинофильмах может
быть разработана прежде, чем будет выполнена). Существуют ссылки на Web-страницы, посвященные анимации в
кинофильмах. В частности, заинтересованный читатель может посетить следующие Web-узлы:
http://www.lucasfilm.com, http://www.disney.go.com, http://www.pixar.comH
http://www.pdi.com. Особенный интерес представляют Web-узлы http://www.antz.com и
http: //www.dreamworksgames.com.
Каждый из языков программирования стремится реализовать парадигму
параллельной обработки со своей точки зрения, выраженной с помощью
собственной терминологии. Например, то, что мы неформально называем запуском, в
языке Ada именуется задачей (task), а в языке Java — потоком (thread). Таким
образом, в программе на языке Ada одновременные действия осуществляются
путем создания нескольких задач, тогда как программа на языке Java создает
несколько потоков. В любом случае результатом является порождение
нескольких процессов, которые выполняются так же, как и процессы под управлением
многозадачной операционной системы. Поэтому далее мы договоримся ссылаться
и на запущенную программу, и на задачу, и на поток как на процесс.
Возможно, наиболее важным действием, которое потребуется описывать в
программе, выполняющей параллельную обработку данных, является создание
новых процессов. Если мы хотим осуществить одновременно сто запусков
программы анимации движения антилопы, нам потребуется синтаксическая
конструкция, позволяющая выполнить эти действия. Запуск новых процессов обычно
выполняется способом, очень напоминающим традиционный вызов процедуры.
Разница лишь в том, что в традиционном способе вызывающий процедуру
программный модуль приостанавливает свою работу, пока вызываемая процедура
не закончит свое выполнение, тогда как при параллельной обработке вызываю-
5.6. Программирование параллельных процессов 323
щий программный модуль продолжает свою работу одновременно с вызванной
процедурой. Таким образом, чтобы воспроизвести бег ста антилоп на экране, нам
нужно написать основную программу, которая просто генерирует сто запусков
программы, имитирующей бег антилопы; причем каждый запуск выполняется со
своим набором параметров, описывающим отличия одной антилопы от другой.
Более сложный вопрос связан с параллельной обработкой данных, которая
предусматривает обмен данными между процессами. Например, при имитации бега
антилоп вычислительные процессы, соответствующие отдельным антилопам, должны
согласовывать между собой их взаимное расположение, что необходимо для
координации движения отдельных антилоп. В случае компьютерной игры процесс,
управляющий полетом ракеты, должен быть связан с процессом, управляющим
другими объектами на экране, например, чтобы определить, какой из существующих
объектов следует взорвать. В иных случаях один процесс должен ожидать, пока
другой не достигнет определенной точки в своих вычислениях. Кроме того, один
процесс, выполнив собственную задачу, может остановить другой процесс.
Необходимые виды взаимодействия процессов долгое время тщательно изучались
специалистами по компьютерным наукам, и многие современные языки
программирования отражают различные подходы к проблеме организации взаимосвязи между
процессами, выработанные учеными. В качестве примера рассмотрим проблему
взаимосвязи, возникающую в том случае, когда два процесса обрабатывают один и
тот же набор данных. (Этот пример детально освещается в разделе 3.4.) В частности,
если каждый из двух параллельных процессов должен добавить число 3 к общему
элементу данных, требуется найти метод, гарантирующий, что один процесс сможет
беспрепятственно завершить начатую им операцию, прежде чем другой получит
право на выполнение своей задачи. В противном случае оба процесса могут начать
собственную обработку с одного и того же исходного значения. В результате исходное
значение будет увеличено только на три, а не на шесть. О данных, которые в
каждый момент времени могут быть доступны только одному процессу, говорят, что они
нуждаются во взаимно исключающем доступе.
Один из способов решения этой проблемы заключается в описании подобных
процессов в программе таким образом, что возможность их доступа к совместно
используемым данным исключается до тех пор, пока работа с ними не станет
безопасной. (Этот подход описан в разделе 3.4, где та часть процесса, которая имеет доступ
к совместно используемым данным, была названа критической областью.) Опыт
показал, что этот подход имеет недостаток, связанный с распределением задачи
организации взаимно исключающего доступа между различными частями программы. В
этом случае ошибка в описании любого из процессов, имеющих доступ к совместно
используемым данным, способна вызвать повреждение всей системы в целом. По
этой причине многие считают, что лучше объединять сами данные и средства
контроля доступа к ним в единое целое. Такой управляющий механизм часто называют
монитором. Коротко говоря, в этом случае ответственность за исключение
множественного доступа к данным налагается не на процесс, который стремится получить
доступ, а на те данные, к которым необходим доступ. В результате контроль над
324 Глава пятая. Языки программирования
доступом к данным сосредоточивается в одном месте программы, а не распыляется
среди множества ее сегментов1.
Таким образом, проектирование языков программирования для параллельной
обработки данных включает разработку способов выражения таких действий,
как активизация процесса, приостановка и повторный запуск процесса,
идентификация критических областей и создание мониторов.
В заключение следует отметить, что хотя анимация и представляет собой
интересный пример для исследования различных аспектов проблемы параллельных
вычислений, это всего лишь одна из многих областей применения,
нуждающихся в организации параллельной обработки данных. К таким областям следует
отнести составление прогнозов погоды, управление потоками авиаперевозок,
моделирование сложных систем (от ядерных реакторов до пешеходных потоков),
организацию работы компьютерных сетей и сопровождение баз данных.
Вопросы для самопроверки
1. Какие свойства характерны для языков программирования, поддерживающих
параллельную обработку данных, и какие характеристики отсутствуют в
традиционных языках программирования?
2. Опишите два метода организации взаимно исключающего доступа к данным.
5.7. Декларативное программирование
Выше мы утверждали, что формальная логика позволяет создать общий
алгоритм решения задач, на основе которого можно построить систему
декларативного программирования. В данном разделе мы исследуем это утверждение,
создав сначала некоторый упрощенный алгоритм, а затем кратко обсудив
возможности основанного на нем языка декларативного программирования.
Логический вывод
Предположим, мы знаем, что лягушонок Кермит либо играет в спектакле,
либо болен, и нам сказали, что сейчас лягушонок Кермит не играет в спектакле.
Тогда мы можем сделать вывод, что лягушонок Кермит, должно быть, болен.
Это — пример дедуктивного рассуждения, которое называется резолюцией.
Чтобы лучше понять этот принцип, примем сначала соглашение представлять
простые высказывания отдельными буквами, а отрицание высказывания —
символом -п. Например, мы можем представить высказывание "Кермит — принц" буквой
А, а высказывание "Мисс Пигги — актриса" — буквой В. Тогда выражение
1 Эта задача имеет вполне естественное решение в объектно-ориентированных языках
программирования, где и данные, и получающие к ним доступ процессы собраны в
пределах одного объекта. В частности, для читателя может представлять определенный интерес
использование команды synchronize в языке Java
5.7. Декларативное программирование 325
A OR В
означает "Кермит — принц или мисс Пигги — актриса", а выражение
В AND -, А
означает "Мисс Пигги — актриса, а Кермит — не принц". Для обозначения
отношения "следует" мы будем использовать стрелку. Например, выражение
А->В
означает "Если Кермит — принц, то мисс Пигги — актриса".
В общем виде принцип резолюции утверждает, что из двух высказываний
Р OR Q и R OR -, Q
мы можем вывести высказывание
RORQ.
В этом случае мы говорим, что два исходных высказывания сводятся к
третьему, которое называется резольвентой. Важно подчеркнуть, что резольвента —
это логическое следствие исходных высказываний. Если исходные высказывания
истинны, то резольвента также должна быть истинной. (Если Q — истинно, то R
должно быть истинно, но если Q — ложно, то Р должно быть истинным.
Следовательно, независимо от того, является Q истинным или ложным, либо Р, либо R
должно быть истинным.)
Графически мы будем представлять резолюцию двух высказываний так, как
показано на рис. 5.19, где мы написали исходные высказывания и изобразили
линии, соединяющие их со своей резольвентой. Заметим, что резолюцию можно
применять только к парам высказываний, которые выражаются в форме
предложения, т.е. к высказываниям, элементарные компоненты которых можно
соединять булевой операцией OR (ИЛИ). Таким образом, высказывание
PORQ
выражено в форме предложения, в то время как для высказывания
P->Q
это не так. Эта потенциальная проблема не очень серьезна. В математической
логике существует теорема, утверждающая, что любое высказывание,
записанное средствами логики предикатов первого порядка (системы для представления
высказываний, имеющей очень большие выразительные возможности), можно
сформулировать в форме предложения. Мы не будем обсуждать здесь эту
важную теорему, но для дальнейших ссылок заметим, что высказывание
P->Q
эквивалентно высказыванию в форме предложения
QOR-yP
326 Глава пятая. Языки программирования
РИСУНОК 5,19 | __ _„_
PORR
Резолюция высказываний (P OR Q) и (R OR - Q) с получением высказывания (Р OR R)
Совокупность высказываний является противоречивой, если все они не могут
быть истинными одновременно. Другими словами, такая совокупность
высказываний состоит из противоречащих друг другу высказываний. Простой пример
такой совокупности — объединение высказывания Р и его отрицания —\Р.
Специалисты-логики доказали, что повторное применение резолюции — это
систематический метод проверки непротиворечивости множества предложений. Если
повторный метод резолюции приводит к пустому предложению (результату
резолюции предложения Р с предложением -ъР), то исходная совокупность
высказываний является противоречивой. Например, на рис. 5.20 показано, что
совокупность высказываний
PORQ ROK-iQ -Л 4Q
является противоречивой.
Пустое предложение
Резолюция высказываний (Р OR Q), (R OR -»Q), - R и - Q
5.7. Декларативное программирование 327
Предположим, нам необходимо проверить, что из некоторой совокупности
высказываний действительно следует высказывание Р. Высказывание Р
эквивалентно отрицанию высказывания -тР. Следовательно, чтобы показать, что из
исходной совокупности высказываний следует высказывание Р, нам нужно лишь
применять процедуру резолюции к исходным высказываниям и высказыванию
-тР до тех пор, пока мы не получим пустое предложение. Получив пустое
предложение, мы можем прийти к выводу, что высказывание -тР противоречит
исходным высказываниям, а значит, из исходных высказываний следует
высказывание Р.
Остается решить всего одну проблему, и мы будем готовы к применению
процедуры резолюции в реальной программной среде. Предположим, что имеются
два высказывания:
(Маша находится в X) -» (Машин ягненок находится в X),
где X означает произвольное местоположение и еще одно высказывание
(Маша находится дома).
В форме предложения эти высказывания принимают следующий вид:
(Машин ягненок находится в X) OR -{Маша находится в X)
и
(Маша находится дома).
На первый взгляд может показаться, что эти предложения не имеют
компонентов, которые можно подвергнуть резолюции. Однако компоненты (Маша находится
дома) и -)(Маша находится в X) почти противоречат друг другу. Задача заключается в
том, чтобы установить истинность высказывания (Маша находится в Л), которое
является высказыванием о местонахождении вообще и о доме в частности.
Таким образом, частный случай первого высказывания имеет вид
(Машин ягненок находится дома) OR -«(Маша находится дома)
который может быть сведен путем резолюции с высказыванием
(Маша находится дома)
к высказыванию вида
(Машин ягненок находится дома)
Процесс присваивания значений переменным (например, присвоение значения
"дом" переменной А), который делает возможным выполнение резолюции,
называется унификацией. Это — процесс, который позволяет применять общие
высказывания к частным приложениям в дедуктивной системе.
Язык Prolog
Prolog (PROgramming in LOGic — программирование в логике) — это
декларативный язык программирования, базовый алгоритм решения задач которого
основан на методе повторной резолюции. Программа на языке Prolog состоит из
328 Глава пятая. Языки программирования
совокупности исходных высказываний, с помощью которых базовый алгоритм
выполняет свои дедуктивные рассуждения. Компоненты, из которых состоят эти
высказывания, называются предикатами. Предикат состоит из идентификатора
предиката, за которым в скобках следуют аргументы предиката. Отдельный
предикат представляет собой некоторый факт в отношении его аргументов, а
идентификатор предиката обычно выбирается так, чтобы отразить его семантику.
Таким образом, если мы хотим выразить тот факт, что Билл — отец Мери, мы
можем использовать следующую предикатную форму:
parent(bill, тагу).
Обратите внимание, что аргументы в этом предикате начинаются со строчных
букв, даже если речь идет об именах собственных. Это происходит потому, что
язык Prolog различает константы и переменные и требует, чтобы константы
начинались со строчных букв, а переменные — с прописных.
Операторы в языке Prolog являются либо фактами, либо правилами. Каждый
из операторов заканчивается точкой. Факт состоит из отдельного предиката.
Например, тот факт, что черепаха (turtle) двигается быстрее улитки (snail),
выражается оператором языка Prolog следующего вида:
faster(turtle, snail).
А тот факт, что кролик (rabbit) бегает быстрее черепахи, выражается оператором
faster(rabbit, turtle).
Правило в языке Prolog — это оператор импликации (следования). Вместо
записи оператора в виде X —> Y программист на языке Prolog пишет "Y, если
X", используя вместо слова "если" символы : -. Таким образом, правило "из
того, что X быстрее (faster) Y, a Y быстрее Z, следует, что X быстрее Z" может быть
выражено специалистом-логиком в следующем виде:
(faster(X, Y) AND faster(Y, Z)) -> faster(X, Z)
На языке Prolog это же правило выражается следующим образом:
faster(X, Z) :- faster(X, Y), faster(Y, Z).
Запятая, разделяющая термы faster (X, Y) и faster (Y, Z), представляет
оператор конъюнкции AND (И). Такие правила легко могут быть преобразованы
программным обеспечением языка Prolog в форму предложения.
Учтите, что система языка Prolog ничего не знает о значении предикатов в
программе, она просто манипулирует высказываниями, формально применяя
правило резолюции. Таким образом, описание всех относящихся к делу свойств
предикатов в терминах фактов и правил входит в обязанности программиста. В
этом смысле факты в языке Prolog обычно используются для конкретизации
примеров предиката, а правила — для описания общих принципов. Этому
подходу соответствуют предыдущие операторы, относящиеся к предикату faster.
Два факта описывают конкретные примеры свойства "двигаться быстрее", а
правило — некое общее свойство. Заметим, что факт "кролик двигается быстрее
улитки", хотя и не высказан явно, является следствием двух фактов,
объединенных в соответствии с существующим правилом.
5.7. Декларативное программирование 329
Большинство реализаций языка Prolog разработано для интерактивного
применения. В этом смысле задача программиста — разработать совокупность
фактов и правил, которые образуют множество исходных высказываний,
используемых затем в дедуктивной системе. Установив такую совокупность
высказываний, можно ввести с клавиатуры предложение (называемое в терминологии
языка Prolog целью), которое система должна проверить. Как только перед
дедуктивной системой языка Prolog будет поставлена некоторая цель, она
применит операцию резолюции, пытаясь найти подтверждение того, что указанная
цель следует из исходных высказываний. С помощью нашего набора
высказываний, описывающих отношение faster, приведенные ниже предложения
faster(turtle, snail).
faster(rabbit, turtle).
faster(rabbit, snail).
будет подтверждены, поскольку каждое из них является логическим следствием
исходных высказываний. Первые два факта идентичны фактам приведенным в
исходных высказываниях, а третий является результатом дедукции.
Более интересные результаты получаются, если в задачах используются не
константы, а переменные. В этих случаях программа на языке Prolog пытается
вывести цель из исходных высказываний, отслеживая требуемые унификации.
Затем, если цель достигнута, программа указывает эти унификации. Например,
рассмотрим цель
faster{W, snail).
В результате программа сообщает
faster(turtle, snail).
Действительно, это — следствие исходных высказываний, которое согласуется с
поставленной целью с помощью унификации. Далее, если мы попросим программу
сообщить нам больше фактов, она найдет и выведет на печать следующее следствие:
faster(rabbit, snail).
И наоборот, мы можем попросить программу найти примеры животных,
которые более медлительны, чем кролик, поставив программе цель
faster(rabbit, W) .
Поэтому, если мы поставим задачу
faster {V, W) .
то программа в конце концов найдет все отношения faster, которые могут
быть выведены из исходных высказываний. Таким образом, единственная
программа на языке Prolog может быть использована для подтверждения,
что одно конкретное животное быстрее другого; для поиска всех тех
животных, которые быстрее указанного животного; для поиска животных, которые
медленнее указанного животного; а также для поиска всех отношений
"быстрее/медленнее" между животными. Подобная гибкость просто
захватывает воображение специалистов в области компьютерных наук.
330 Глава пятая. Языки программирования
Вопросы для самопроверки
1. Какие из высказываний R> S> T, U и V являются логическим следствием
совокупности высказываний (-.Я OR T OR 5), (^5 OR F), (-.F OR Я), (U OR -т£), (Г
OR -лЦ) и (5 OR F)?
2. Является ли следующая совокупность высказываний непротиворечивой?
Обоснуйте свой ответ.
Р OR О OR Л -лЯ OR 0 ROR-^P -^Q
3. Предположим, что программа на языке Prolog состоит из операторов,
выражающих отношение "экономнее" (thriftier):
thriftier(carol, John).
thriftier(bill, sue).
thriftier(sue, carol).
thriftier(X,Z) :- thriftier(x, Y), thriftier(Y,Z).
Перечислите результаты, которые можно получить для каждой из следующих
целей:
а) thriftier (sue, V).
б) thriftier(U, carol).
в) thriftier (U, V) .
Упражнения
(Упражнения, отмеченные звездочкой, относятся к разделам для
дополнительного чтения.)
1. Что означает высказывание "язык программирования является
машинно-независимым"?
2. Переведите следующую программу с псевдокода на машинный язык,
описанный в приложении В.
assign x the value 0;
while (x*3) do
(assign x the value x+1)
3. Переведите приведенный ниже оператор на машинный язык,
описанный в приложении В, предполагая, что переменные Length, Width и
Halfway представлены как числа с плавающей точкой:
assign Halfway the value Length + Width
4. Переведите следующий оператор языка высокого уровня на машинный
язык, описанный в приложении В, предполагая, что числа W, X, Y и Z
представлены в двоичном коде и занимают в основной памяти один байт:
Упражнения 331
if(X equals 0)
then assign Z the value Y+W
else assign Z the value Y+X
5. Для чего при трансляции операторов необходимо указывать тип
данных, связанный с переменными в задаче 4? Почему многие языки
высокого уровня требуют от программистов указывать тип каждой
переменной в начале программы?
6. Назовите и опишите четыре существующие парадигмы
программирования.
7. Предположим, что функция f получает два числа в качестве
параметров и возвращает меньшее из них в качестве результата. Если
переменные w, х, у и z представляют собой числа, то какой результат
будет возвращен этой функцией при вычислении выражения f(f(w,
х), f(y, z))?
8. Предположим, что f — это функция, возвращающая в качестве
результата строку, в которой все символы из входной строки
переставлены в обратном порядке, ад — это функция, осуществляющая
конкатенацию двух входных строк. Если х — строка "abed", что вернет
функция g (f (х) , х) ?
9. Предположим, что вы собираетесь написать объектно-
ориентированную программу для ведения своих финансовых записей.
Какие данные нужно хранить в объекте, представляющем ваш
текущий счет в банке? На какие сообщения должен реагировать этот
объект? Какие еще объекты следует использовать в программе?
10. Опишите отличия, существующие между машинным языком и языком
ассемблера.
11. Разработайте язык ассемблера для машины, описанной в
приложении В.
12. Некий Джон Программер утверждает, что возможность объявления
констант в программе является излишней, поскольку вместо них
можно использовать переменные. Например, в разделе 5.2 можно
описать переменную Airport Alt, а потом присвоить ей нужное значение
в начале программы. Почему это решение хуже, чем вариант с
использованием константы?
13. Опишите отличия, существующие между операторами объявления и
выполняемыми операторами.
14. Объясните разницу между литералом, константой и переменной.
15. Что такое приоритет оператора?
16. Что такое структурное программирование?
17. Чем отличается смысл символа равенства в операторе
332 Глава пятая. Языки программирования
if(X = 5) then (...)
от смысла этого же символа в следующем операторе присваивания?
X = Z + Y
18. Начертите блок-схему структуры, выраженной следующими
операторами языков C++ и Java:
for(x = 0; х < 8; ++х)
{...}
19. Начертите блок-схему структуры, выраженной следующими
операторами языков С, C++ и Java:
switch(suit)
{case "clubs": bid(l);
case "diamonds": bid(2);
case "hearts": bid(3);
case "spades": bid(4);
}
20. Если вы знакомы с нотной записью, проанализируйте принятый
принцип записи нот с точки зрения языка программирования. Что
здесь является управляющими структурами? Какой предусмотрен
синтаксис для вставки комментариев? Какие музыкальные обозначения
похожи на операторы for, представленные на рис. 5.8?
21. Перепишите следующий фрагмент программы, используя один
оператор case вместо серии вложенных операторов if-then-else.
if (W = 5)
then (assign Z the value 7)
else (if (W = 6)
then (assign Y the value 7)
else (if (W = 7)
then (assign X the value 7)
)
)
22. Выразите приведенную ниже запутанную последовательность
операторов с помощью единственного оператора if-then-else.
23. Опишите отличия между транслятором и интерпретатором.
Упражнения 333
24. Предположим, что переменная X в программе описана как переменная
типа integer. Какая ошибка будет обнаружена транслятором при
выполнении следующего оператора?
assign X the value 2.5
25. Что означает выражение "язык программирования со строгой
типизацией"?
26. Почему большой массив не всегда можно передать в вызываемую
процедуру по значению?
27. Предположим, что процедура modify определена следующим образом:
procefure modi fу(Y)
assign Y the value 7;
print the value of Y;
Если параметры передаются по значению, что будет напечатано при
выполнении следующего фрагмента программы? Что будет
напечатано, если параметры передаются по ссылке?
assign X the value 5;
apply modify to X;
print the value of X;
28. Предположим, что процедура modify определена следующим образом:
procefure modify(Y)
assign Y the value 9;
print the value of X;
print the value of Y;
Допустим также, что X — это глобальная переменная. Если параметры
передаются по значению, что будет напечатано при выполнении
следующего фрагмента программы? Что будет напечатано, если
параметры передаются по ссылке?
assign X the value 5;
apply modify to X;
print the value of X;
29. Иногда фактический параметр передается в процедуру путем создания
его копии, предназначенной для использования в процедуре (как если
бы параметр передавался по значению), но после выполнения
процедуры значение копии присваивается фактическому параметру перед
тем, как будет продолжено выполнение вызывающей процедуры. В
таких случаях говорят, что параметр передается по значению-
результату. Что будет напечатано фрагментом программы из
упражнения 28, если параметры передаются по значению-результату?
30. Какая неоднозначность кроется в следующем операторе?
334 Глава пятая. Языки программирования
assign X the value 3+2*5
31. Предположим, что небольшая компания имеет пять сотрудников и
планирует увеличить их число до шести. Ниже приведены фрагменты
из двух эквивалентных программ (используемых компанией), которые
нужно изменить, чтобы отобразить изменение количества
сотрудников. Обе программы написаны на языке, напоминающем Pascal.
Укажите, какие изменения следует произвести в каждой программе.
Какие осложнения возникают в первой программе и не возникают при
использовании констант во второй программе?
Программа 1
32. Нарисуйте синтаксическую диаграмму, представляющую структуру
оператора while из псевдокода, описанного в главе 4.
33. Разработайте совокупность синтаксических диаграмм для описания
синтаксиса телефонных номеров, написанных в формате (044) 555-
1234.
Упражнения 335
34. Разработайте совокупность синтаксических диаграмм для описания
простого предложения на английском языке.
35. Напишите предложение, описывающее структуру строки, в
соответствии с приведённой ниже синтаксической диаграммой. Затем нарисуйте
дерево синтаксического анализа строки ххухх.
Строка
36. Добавьте синтаксические диаграммы к диаграммам из вопроса 4 в
разделе 5.4, чтобы получить совокупность диаграмм, определяющих
структуру Танец, которая может быть структурой Ча-ча-ча или
Вальс, где Вальс состоит из одной или более копий типа
вперед по_диагонали каданс
или
назад по_диагонали каданс.
37. Нарисуйте дерево синтаксического анализа приведенного ниже
выражения, используя синтаксические диаграммы, представленные на
рис. 5.14.
х * у + у / х
38. Какую оптимизацию кода может выполнить генератор кода при
создании машинного кода для следующего оператора?
if (X = 5) then (assign Z the value X + 2)
else (assign Z the value X + 4)
39. Упростите следующий фрагмент программы:
assign Y the value 5;
if (Y = 7)
then (assign Z the value 8)
else (assign Z the value 9)
40. Упростите следующий фрагмент программы:
while(X not equal to 5) do
(assign X the value 5)
*41. Нарисуйте диаграмму (подобную диаграмме, показанной на рис. 5.20),
представляющую последовательность операций резолюции, необходимых для того, чтобы
показать, что совокупность высказываний (Q OR -iR), (T OR R), -iP, (P OR -ГГ)
и (R OR —iP) противоречива.
336
Глава пятая. Языки программирования
*42. Является ли совокупность высказываний -.R, (T OR R), (P OR -iQ), (Q
OR —iT) и (R OR -iP) противоречивой? Обоснуйте свой ответ.
*43. К каким выводам может прийти программа на языке Prolog, если
поставить ей цель
bigger(X, Lassie).
Исходными высказываниями являются следующие:
bigger(rex, lessie).
bigger(fido, rex).
bigger(spot, rex).
bigger(X,Z) :- bigger(X,Y), bigger(Y,Z).
*44. К каким выводам придет программа на языке Prolog, если поставить
ей цель
eq(X, Y) .
Исходными высказываниями являются следующие:
qrteq(a b).
qrteq(b, с).
qrteq(c, a).
qrteq(U, W :- qrteq(Uf V), qrteq(V, W).
eq(X, Y) :- qrteq(X, Y), qrteq(Y, X).
*45. Какие проблемы могут возникнуть при выполнении машиной
следующего фрагмента программы (описанной в разделе 1.7), в которой
числа хранятся в 8-битовом формате с плавающей точкой?
assign X the value 0.01;
while(X not equal to 1.00) do
(print the value of X;
assign X the value X + 0.01)
Общественные и социальные вопросы
Следующие вопросы приводятся для того, чтобы помочь вам разобраться в
некоторых этических, общественных и юридических аспектах использования
вычислительной техники, а также в ваших собственных воззрениях и тех
принципах, на которых они основаны. Задача не сводится к тому, чтобы просто дать
ответы на предложенные вопросы. Вы должны также разобраться, почему вы
ответили именно так, а не иначе, и насколько ваши суждения по различным
вопросам согласуются друг с другом.
1. Закон об авторском праве допускает присвоение права собственности на
способ выражения идеи, но не на саму идею. В результате на текст
параграфа в книге авторские права распространяются, а на изложенную в этом
Общественные и социальные вопросы 337
параграфе идею — нет. Как распространить это право на исходные тексты
программ и алгоритмы, которые они выражают? В какой степени можно
разрешать людям, которые знают алгоритмы, лежащие в основе
коммерческих программ, писать собственные программы, выражающие те же
алгоритмы, и продавать эти версии программного обеспечения на рынке?
2. Должен ли человек, который разработал новый и полезный язык
программирования, иметь право на доход от использования этого языка?
Если да, то как можно защитить это право? До какой степени язык
программирования может быть чьей-то собственностью?
3. В какой степени программист, разработавший жестокую
компьютерную игру, несет ответственность за любые последствия от ее создания?
Следует ли ограничивать доступ детей к таким компьютерным играм?
Если да, как и кто должен этим заниматься? Что вы скажете по этому
поводу в отношении других общественных групп, например
преступников, находящихся в местах заключения?
4. В какой степени профессионал в компьютерных науках должен
разбираться в различных парадигмах программирования? Некоторые компании
настаивают, чтобы все программное обеспечение, разрабатываемое их
сотрудниками, было написано на одном и том же заранее определенном
языке программирования. Изменится ли ваш первоначальный ответ, если
профессионал работает в такой компании?
5. В случае угрозы срыва установленных сроков разработки, считаете ли
вы приемлемым для программиста отказаться от документирования
программы с помощью комментариев, если это позволит ему получить
работающую программу вовремя? (Студенты часто удивляются,
насколько серьезно профессиональные разработчики программного
обеспечения относятся к программной документации.)
6. Множество исследований в области языков программирования посвящено
языкам, позволяющим программистам писать программы, которые
удобочитаемы и понятны человеку. Насколько программист нуждается в
таких возможностях? Достаточно ли, чтобы программа работала правильно,
будучи даже не очень хорошо написанной с точки зрения человека?
7. Предположим, что программист-любитель пишет программу для себя и
при этом относится к ее разработке достаточно небрежно. В результате в
программе не используются возможности языка программирования,
способные сделать ее более читабельной; программа работает неэффективно;
текст содержит упрощения и специфические приемы, ориентированные на
данный конкретный случай, для которого программист и написал свою
программу. Со временем программист делает копии этой программы для
своих друзей, которые хотят использовать ее в собственных целях, а эти,
в свою очередь, передают ее своим знакомым. Какую ответственность
несет программист за проблемы с этой программой, которые могут
возникнуть у ее пользователей?
338 Глава пятая. Языки программирования
Рекомендуемая литература
• Aho A.V., Sethi R., Illman I.D. Compilers: Principles, Techniques, and Tools.—
Reading, MA: Addison-Wesley, 1986. (Русский вариант этой книги: Ахо А.В.,
Рави С, Ульман Дж.Д. Компиляторы: принципы, технологии и
инструментарий — М.: Издательский дом "Вильяме", готовится к выпуску в 2001 г.)
• Barnes J. Programming in Ada 95. — Reading, MA: Addison-Wesley, 1996.
• Bergin T.J., Gibson R.G. History of Programming Languages.— New York:
ACM Press, 1996.
• Clocksin W.F., Mellish C.S. Programming in Prolog, 3rd ed.— New York:
Springer-Verlag, 1987.
• Fisher C.N., LeBlanc R.J. Jr. Crafting Compiler with С— Menlo Park, CA:
Benjamin/Cummings, 1991.
• Graham P. ANSI Common Lisp. — Englewood Cliffs, NJ: Prentice-Hall, 1996.
• Jackson I.R., McClellan A.L. Java Example.— Palo-Alto, CA: Sun
Microsystems, 1999.
• Metcalf M., Reid J. Fortran 90 Explained.— Oxford, England: Oxford
University Press, 1990.
• Pohl I., Kelley A. A Book on C, 2nd ed. — Redwood City, CA:
Benjamin/Cummings, 1990.
• Pratt T.W., Zelkowitz M.V. Programming Languages, Design and
Implementation, 3rd ed. — Englewood Cliiffs, NJ: Prentice-Hall, 1996.
• Savitch W. Problem Solving with C++. — Reading, MA: Addison-Wesley, 1996.
(Русский вариант 3-го издания этой книги: Сэвитч У. Язык C++. Курс
объектно-ориентированного программирования, 3-е изд. — М.: Издательский
дом "Вильяме", готовится к выпуску в 2002 г.)
• Sebesta R.W. Concepts of Programming Languages, 4th ed. — Reading, MA:
Addison-Wesley, 1999. (Русский вариант этой книги: Себеста Р. Языки
программирования. Основные концепции, 4-е изд. — М.: Издательский дом
"Вильяме", готовится к выпуску в 2001 г.)
Дополнительная литература
• Арнолд К., Гослинг Дж., Холмс Д. Язык программирования Java, 3-е изд.—
М.: Издательский дом "Вильяме", 2001 г.
• Сэвитч У. Язык Java. Курс программирования, 2-е изд. 4-е изд. — М.:
Издательский дом "Вильяме", готовится к выпуску в 2002 г.
Рекомендуемая литература 339
глава
Технология
разработки
программного обеспечения
ШЕСТАЯ
В этой главе мы обсудим вопросы, связанные с общими
процессами разработки и сопровождения программного
обеспечения. Глава получила название "Технология разработки
программного обеспечения", поскольку процесс разработки
программного обеспечения вполне обоснованно считается
техническим процессом. Однако позже мы увидим, что
технология создания программного обеспечения имеет много
особенностей, которые отличают ее от других технических дисциплин.
Мы рассмотрим создание крупномасштабных систем
программного обеспечения, которые слишком велики для
человеческого восприятия. Примерами могут служить системы
складского и бухгалтерского учета, распределенные банковские
системы, системы контроля и безопасности в офисных зданиях,
системное программное обеспечение и даже компьютерные
игры. Проблемы, с которыми приходится сталкиваться при
разработке таких систем, представляют собой не просто
расширенные версии вопросов, возникающих при написании небольших
программ. В частности, разработка подобных систем, как
правило, требует усилий многих людей на протяжении длительного
времени, причем за этот период могут меняться как требования
к создаваемой системе, так и состав персонала,
занимающегося ее разработкой. Поэтому предмет технологии разработки
программного обеспечения включает и такие аспекты, как
управление проектом и персоналом, которые обычно
ассоциируются с менеджментом, а не с областью компьютерных наук.
Однако в этой главе мы сконцентрируем наше внимание только
на вопросах, относящихся к компьютерным наукам.
6.1. Предмет технологии
разработки программного обеспечения
6.2. Жизненный цикл
программного обеспечения
Жизненный цикл в целом
Традиционные этапы разработки
программ
Современные тенденции
6.3. Модульность
Реализация модулей
Связанность модулей
Связность элементов модуля
6.4. Методы проектирования
Нисходящие и восходящие
методы разработки
Общие инструменты разработки
Шаблоны проектирования
6.5. Тестирование
6.6. Документирование
6.7. Право собственности и
ответственность за создаваемое
программное обеспечение
6.1. Предмет технологии разработки программного
обеспечения
Чтобы иметь представление о проблемах, возникающих при проектировании
программного обеспечения, рассмотрим любой достаточно большой и сложный объект
(автомобиль, многоэтажное офисное здание или кафедральный собор), а затем
представим себе, что в наши обязанности входит как разработка его проекта, так и
управление процессом его сооружения. Как оценить время, деньги и другие ресурсы,
которые потребуются для выполнения проекта? Как разделить проект на
управляемые части? Как убедиться, что созданные части совместимы? Как обеспечить
взаимодействие сотрудников, работающих над разными частями проекта? Как оценить
скорость выполнения работы? Как справиться с обилием всевозможных деталей
(выбором дверных ручек, проектированием скульптурных украшений, поисками
голубого стекла для витражей, расчетом прочности колонн, планированием работ по
монтажу системы отопления)? На подобные вопросы приходится отвечать и в
процессе разработки крупной системы программного обеспечения.
Поскольку проектирование является хорошо разработанной областью, можно
полагать, что уже существует множество разработанных методов
проектирования, предоставляющих ответы на такие вопросы. Однако в этих рассуждениях
не учитываются различия в свойствах программного обеспечения и объектов
проектирования из других областей науки и техники.
Ассоциация по вычислительной технике
Основанная в 1947 году, Ассоциация по вычислительной технике (ACM- Association for Computing
machinery) является международной научной и образовательной организацией, задача которой —
распространение навыков, теорий и приложений из области информационных технологий. Штаб-квартира этой
организации, расположенная в Нью-Йорке, руководит деятельностью множества групп по различным
направлениям (SIG — Special Interest Group), занимающихся такими проблемами, как архитектура
компьютеров, искусственный интеллект, применение компьютеров в биомедицинских исследованиях, компьютеры и
общество, обучение в области компьютерных наук, компьютерная графика, гипертекст/гипермедиа,
операционные системы, языки программирования, имитация и моделирование, а также разработка
программного обеспечения. Web-узел этой ассоциации размещен по адресу http://www.acm.org/
constitution/code/html.
Одно из этих различий связано с возможностью создания системы из
предварительно изготовленных компонентов общего назначения. Уже многие годы при
создании сложных объектов в традиционных областях проектирования значи-
342 Глава шестая. Технология разработки программного обеспечения
тельные преимущества достигаются просто за счет использования в качестве
строительных блоков некоторых готовых компонентов. Конструктору
автомобиля не нужно конструировать для него мотор, радиоприемник, кондиционер или
дверные замки. Вместо этого он может воспользоваться уже созданными
версиями необходимых ему компонентов. Однако в области программного обеспечения
ранее разработанные компоненты, как правило, не являются универсальными,
т.е. их внутренняя конструкция зависит от характерных особенностей
конкретного приложения. Следовательно, попытка повторно использовать подобный
компонент потребует его перепроектирования. В результате исторически
сложилось так, что достаточно сложные системы программного обеспечения чаще всего
создавались практически с нуля.
Другое различие между разработкой программного обеспечения и традиционным
инженерным проектированием связано с наличием допусков. В традиционных
областях проектирования разрабатываемые изделия обычно считаются приемлемыми,
если они успешно выполняют поставленную задачу в определенных рамках.
Стиральная машина, выполняющая цикл стирки, полоскания и отжима за
установленное время, с учетом двухпроцентного допуска, будет совершенно приемлемой. В
противоположность этому, программное обеспечение работает или правильно, или
неправильно. Бухгалтерская система, точность расчетов в которой гарантируется в
пределах двухпроцентного допуска, является совершенно неприемлемой.
IEEE
IEEE (Institute of Electrical and Electronics Engineers — институт инженеров по электротехнике и
радиоэлектронике) был создан в 1963 году в результате слияния американских обществ IAEE (основанного в 1884
году 25-ю инженерами-электротехниками, среди которых был и Томас Эдисон) и IRE (основанного в 1912
году). IEEE — всемирная организация инженеров в области электротехники, радиоэлектроники и
радиоэлектронной промышленности со штаб-квартирой в Лондоне. Она направляет деятельность 36-ти технических
обществ, таких как общество инженеров аэрокосмических и электронных систем, общество специалистов в
области лазеров и электрооптики, общество инженеров по робототехнике и автоматике, общество
специалистов по самоходной технике, а также компьютерное общество (представляющее для нас наибольший
интерес). Наряду с другими видами деятельности, IEEE участвует в разработке стандартов. В частности,
именно усилия этой организации позволили принять стандарты на форматы чисел с плавающей точкой.
Web-узел IEEE размещен по адресу http://www.ieee.org; Web-узел компьютерного общества —
http: //www. computer. org; а документ, содержащий кодекс этики организации IEEE, можно
найти по адресу http: //www. ieee .org/about/whatis/code .html.
Еще одно отличие связано с нехваткой количественных систем, называемых
метриками, которые можно было бы использовать для измерения свойств программного
обеспечения. Качество механического прибора часто определяется средним временем
между поломками, поэтому именно это время характеризует, насколько качественно
6.1. Предмет технологии разработки программного обеспечения 343
сделан прибор. В противоположность этому, программное обеспечение не
изнашивается, поэтому данный метод не подходит для оценки его качества.
Невозможность количественно измерить свойства программного обеспечения
является одной из основных причин того, что проектирование программного
обеспечения до сих пор не нашло строгого обоснования в том смысле, как это
имеет место при проектировании в области механики или электротехники. В то
время как эти предметы опираются на законы физики, технология разработки
программного обеспечения все еще находится на стадии поиска необходимых
теоретических оснований. Фактически современное состояние технологии
разработки программного обеспечения напоминает нам состояние физики в начале
семнадцатого столетия, до того как Исаак Ньютон и другие ученые открыли, что
такие фундаментальные свойства, как масса, ускорение и сила, могут быть
измерены и что между ними существует строгая математическая зависимость.
Поэтому в настоящее время исследования в области технологии разработки
программного обеспечения разворачиваются на двух уровнях. Исследователи-практики
работают над развитием методов разработки, предназначенных для
непосредственного применения, тогда как исследователи-теоретики ведут поиск таких принципов и
теорий, которые могут быть положены в основу будущей разработки более
надежных технологических методов. Основанные на субъективных представлениях,
многие разработанные (и применяемые) в прошлом практиками методы были заменены
другими подходами, которые со временем также могут устареть. Между тем, успехи
теоретиков остаются весьма относительными.
Прогресс в исследованиях как практиков, так и теоретиков имеет огромное
значение. Жизнь нашего общества уже невозможна без использования компьютерных
систем и связанного с ними программного обеспечения. Экономика,
здравоохранение, государственные учреждения, законодательство, транспорт и оборона любого
современного государства зависят от больших систем программного обеспечения. Тем
не менее надежность этих систем по-прежнему оставляет желать лучшего. Ошибки в
программном обеспечении приводили к таким катастрофическим (или почти
катастрофическим) последствиям: принятие растущей луны за ядерную атаку, потеря 5
миллионов долларов банком Нью-Йорка только за один день, потеря космическим
кораблем "Маринер-18" сведений о пробах космического пространства, радиационное
облучение людей, вызвавшее их смерть или паралич, или же нарушение работы
телефонных линий в обширном географическом регионе.
В то время как наука продолжает поиск методов разработки качественного
программного обеспечения, профессиональные организации пропагандируют
высокие стандарты этики и профессионального поведения среди своих членов.
Например, Ассоциация по вычислительной технике (АСМ) и IEEE приняли кодекс
профессионального поведения и этики, который направлен на повышение
профессионализма разработчиков программного обеспечения и предупреждение
случаев их беспечного отношения к собственным разработкам.
В этой главе мы приводим некоторые результаты исследований в области
технологии разработки программного обеспечения, включающие как основные
принципы (жизненный цикл программного обеспечения, модульность, шаблоны
844 Глава шестая. Технология разработки программного обеспечения
проектирования), так и наиболее эффективные средства и методы разработки,
используемые сегодня.
Вопросы для самопроверки
1. Почему количество строк в программе не определяет ее сложность?
2. С помощью какого метода можно определить, сколько ошибок содержится в
определенной части программного обеспечения?
3. Предложите метрику для оценки качества программного обеспечения. Какие
слабые места она имеет?
6.2. Жизненный цикл программного обеспечения
Важнейшим понятием в технологии разработки программного обеспечения
является жизненный цикл программы.
Жизненный цикл в целом
Жизненный цикл программы представлен на рис. 6.1. Здесь отражен тот
факт, что, будучи однажды созданной, программа входит в цикл, включающий
ее использование и модификацию; продолжительность этого цикла
распространяется на все время жизни программы. Такая картина характерна и для многих
промышленных изделий. Отличие заключается лишь в том, что для таких
изделий фазу модификации точнее было бы назвать ремонтом или техническим
обслуживанием, поскольку они модифицируются по мере износа их частей.
Жизненный цикл программы
Однако программы не подвержены износу. Поэтому они проходят фазу
модификации из-за обнаружения ошибок, возникновения изменений в области их
применения, требующих внесения соответствующих корректировок в
программы, или из-за того, что прежняя модификация вызвала появление проблем в
других частях программы. Например, изменения в налоговом законодательстве
6.2. Жизненный цикл программного обеспечения 345
могут потребовать внесения корректировок в программы подготовки платежных
ведомостей, связанные с расчетом удерживаемого налога. Однако внесенные
изменения, в свою очередь, могут неблагоприятно повлиять на другие части
программы, причем это может быть замечено не сразу.
Независимо от того, почему программа модифицируется, необходимо, чтобы
некто (как правило, не автор ее исходной версии) изучил и понял программу и
ее документацию; если не всю программу, то хотя бы ту часть, которая
относится к делу. Любая модификация алгоритма программы может вызвать намного
больше проблем, чем она предназначена решить. Достижение необходимой
степени понимания является сложной задачей, даже если программа правильно
разработана и документирована. Фактически именно на этой стадии отдельные
фрагменты программного обеспечения просто отбрасывают, исходя из
утверждений (часто вполне справедливых), что проще разработать новую систему с нуля,
чем успешно модифицировать уже существующий пакет.
Опыт показывает, что незначительные дополнительные усилия, затраченные
при разработке программы, впоследствии могут существенно изменить
ситуацию, когда потребуется внести в нее изменения. Например, при обсуждении
операторов описания данных в главе 5 было показано, как вместо безличного
числового значения 645 в программе может использоваться символическое имя
AirportAlt. В дальнейшем обсуждении разъяснялось, что если возникнет
необходимость в изменениях, гораздо легче изменить значение, связанное с
некоторым символическим именем, чем осуществить поиск и изменение множества
вхождений безличного арифметического значения 645. Как следствие, большая
часть исследований в области технологии разработки программного обеспечения
концентрирует свое внимание именно на фазе разработки в жизненном цикле
программы. Их задача — найти способы эффективного использования тех
преимуществ, которые достигаются за счет дополнительных усилий на данной
стадии, понимаемых как выгодное средство достижения цели.
Традиционные этапы разработки программ
Фаза разработки в жизненном цикле программы традиционно включает
следующие этапы: анализ, проектирование, реализацию и тестирование (рис. 6.2).
Анализ
Фаза разработки в жизненном цикле программы начинается с анализа, основная
задача которого состоит в определении нужд пользователей предлагаемой системы.
Если система должна быть продуктом общего назначения, продаваемым на рынке в
условиях свободной конкуренции, анализ, вероятно, будет включать
широкомасштабные исследования в целях определения потребностей потенциальных
пользователей. Однако если система разрабатывается для нужд конкретного пользователя,
исследования будут носить более целенаправленный характер.
По мере того как выясняются потребности потенциального пользователя, они
преобразуются в ряд требований, которым должна удовлетворять новг.я система.
Эти требования формулируются в терминах, принятых в сфере приложения, без
346 Глава шестая. Технология разработки программного обеспечения
использования специальной терминологии, принятой среди специалистов по
обработке данных. Одно из требований может состоять в том, что доступ к данным
должен предоставляться только зарегистрированным пользователям. Другое
требование может заключаться в том, чтобы данные отражали текущее состояние
товарных запасов на конец последнего рабочего дня или чтобы организация
данных на экране компьютера соответствовала формату используемых в настоящее
время бумажных документов.
Фаза разработки в жизненном цикле программного обеспечения
После того как требования к создаваемой системе будут определены, их
преобразуют в систему спецификаций, имеющих более технически организованный
вид. Например, разрешение доступа к данным только зарегистрированным в
системе пользователям должно быть представлено отдельным пунктом
спецификаций; в нем указывается, что система не должна отвечать на какие-либо
запросы, пока с клавиатуры не будет введен соответствующий пароль из восьми цифр,
или же данные будут отображаться на экране в закодированной форме и примут
осмысленный вид только после обработки некоторой стандартной программой,
имя которой должно быть известно лишь зарегистрированным пользователям.
Проектирование
В то время как анализ определяет, что должна делать предлагаемая система,
проектирование определяет, как она будет выполнять эти задачи. Именно на
этом этапе определяется структура системы программного обеспечения.
Не вызывает сомнения то, что наилучшей структурой для крупной системы
программного обеспечения является модульная. Именно благодаря разбиению
больших систем на модули становится возможной их практическая реализация.
Без этого разбиения технические детали, необходимые при реализации большой
системы, превысили бы возможности человеческого восприятия. При
использовании модульной конструкции разработчик может ограничиться изучением
только тех деталей, которые относятся к рассматриваемому модулю. Модульная
конструкция также удобна при дальнейшем сопровождении программы, по-
6.2. Жизненный цикл программного обеспечения 347
скольку позволяет вносить изменения на модульной основе. (Если изменение
нужно внести в способ выполнения расчетов по больничным листам работников,
то потребуется рассматривать только те модули, которые непосредственно
связаны с оплатой больничных листов.)
Однако понятие модуля может трактоваться по-разному. Если подходить к задаче
конструирования, используя парадигму традиционного императивного
программирования, то модули будут состоят из отдельных процедур и разработка модульной
структуры примет форму выявления различных заданий, которые создаваемая
система должна будет выполнять. В противоположность этому, если предполагается
использовать объектно-ориентированный подход, то в качестве модулей будут
выступать отдельные объекты, а процесс конструирования модульной структуры
превратится в процесс выявления имеющихся в предметной области сущностей (объектов)
и определения их поведения в предлагаемой системе.
Реализация
Реализация включает собственно написание программ, создание файлов
данных и разработку баз данных.
Тестирование
Тестирование тесно связано с реализацией, так как каждый модуль
системы, как правило, должен подвергаться тестированию как только он будет
написан. Действительно, в правильно сконструированной системе каждый
модуль может и должен быть проверен либо независимо от других модулей, либо
с использованием упрощенных версий других модулей, называемых
заглушками. Назначение заглушек состоит в том, чтобы имитировать взаимодействие
тестируемых модулей и остальной части системы. Аналогичным образом
можно тестировать и систему в целом, по мере завершения создания отдельных
модулей и их объединения в единое целое.
К сожалению, этап тестирования и устранения обнаруженных в системе
неполадок чрезвычайно сложно довести до успешного завершения. Опыт
показывает, что большие системы программного обеспечения могут содержать
множество ошибок даже после продолжительного тестирования. Многие из этих
ошибок могут оставаться незамеченными на протяжении всего жизненного
цикла системы, в то время как другие могут стать причиной весьма опасных
ошибок. Устранение таких ошибок является одной из важнейших задач
технологии разработки программных систем. Тот факт, что количество
обнаруживаемых ошибок все еще весьма значительно, говорит о том, что исследования в
этой области необходимо продолжать.
Современные тенденции
Ранние подходы к проектированию программного обеспечения предполагали
строго последовательное выполнение этапов анализа, проектирования,
реализации и тестирования. Предполагалось, что риск, связанный с использованием
метода проб и ошибок при разработке больших систем программного обеспечения,
слишком велик. В результате разработчики программного обеспечения настаива-
348 Глава шестая. Технология разработки программного обеспечения
ли на полном завершении общего анализа системы до начала ее проектирования.
Точно так же необходимо полностью завершить этап проектирования системы до
начала ее реализации. Подобная схема процесса разработки получила название
модели водопада (по аналогии с движением потока падающей воды, поскольку
процесс разработки должен был двигаться только в одном направлении).
Разработка программных систем в реальном мире
Следующий сценарий типичен в отношении тех задач, с которыми сталкиваются разработчики программного
обеспечения в реальности. Допустим, компания XYZ заказывает фирме, занимающейся созданием
программного обеспечения, разработать и установить интегрированную систему программного обеспечения для
обработки данных в масштабах этой компании. При развертывании этой системы каждому работнику выделяется
персональный компьютер, подключенный к сети, общей для всей компании. Эти персональные компьютеры не
только обеспечивают доступ к установленной в компании системе обработки данных, но и могут
использоваться в качестве некоторого настраиваемого инструмента, с помощью которого каждый работник компании
стремится повысить производительность своего труда. Например, какой-либо работник разрабатывает
электронную таблицу, упрощающую или ускоряющую выполнение стоящих перед ним задач. К сожалению, подобные
разработанные пользователями приложения очень часто оказываются неправильно спроектированными и
недостаточно тщательно протестированными, а также включают функции, работа которых была понята
работником неправильно или же лишь частично. Со временем эти самодельные приложения включаются в процедуры
производственной деятельности компании. В результате то, что исходно представляло собой правильно
спроектированную систему, оказывается погребенным под беспорядочным нагромождением из плохо
спроектированных, недокументированных, содержащих множество ошибок приложений.
Можно отметить сходство между четырьмя этапами решения задач,
определенными математиком Полна (см. раздел 4.3), и этапами анализа, проектирования,
реализации и тестирования, входящими в фазу разработки программного
обеспечения. В конце концов, разработать большую систему программного обеспечения
действительно означает решить сложную задачу. Однако традиционный подход к
разработке программного обеспечения, соответствующий модели водопада,
полностью противоположен свободно развивающемуся методу проб и ошибок,
присущему творческому решению задач. В то время как подход, соответствующий модели
водопада, стремится к организации четко структурированной среды, в которой
разработка программного обеспечения будет происходить в строгой
последовательности, творческий подход к решению задач предполагает неструктурированную
среду, в которой можно отказаться от работы по предварительно намеченному
плану, следуя интуиции, не требующей пояснения, почему это происходит.
С недавних пор в методах проектирования программного обеспечения стало
учитываться это основополагающее противоречие, что выразилось в появлении
пошаговой модели разработки программного обеспечения. В соответствии с этой
моделью, требуемая система программного обеспечения создается поэтапно.
Первый вариант является некоторой упрощенной версией требуемой системы с огра-
6.2. Жизненный цикл программного обеспечения 349
ничейным набором функций. После того как эта версия будет протестирована и,
возможно, оценена будущим пользователем, к ней последовательно добавляют и
тестируют другие функции, и так до тех пор, пока система не приобретет
законченный вид. Например, если разрабатываемая система является приложением
для ведения личных дел студентов, предназначенным для секретаря
университета, то ее первое приближение может включать только функцию просмотра
личных дел студентов. После того как эта версия окажется работоспособной, в ней
поэтапно будут реализованы дополнительные функции, такие как добавление
новых записей и обновление уже существующих.
Пошаговая модель является примером использования в технологии разработки
программного обеспечения метода создания прототипов, который заключается в
создании и последующей оценке неполных версий разрабатываемой системы,
называемых прототипами. В пошаговой модели прототип развивается в конечную
версию системы, поэтому данный вариант метода создания прототипов именуется
эволюционным. В других случаях прототипы могут отбрасываться, уступая место
новым реализациям конечного проекта. Такой вариант метода создания
прототипов называется методом с отбрасыванием прототипов. Примером использования
этого варианта может служить быстрое создание прототипов, при котором на
ранних стадиях разработки очень быстро создается серия упрощенных вариантов
разрабатываемой системы. Такой прототип может состоять всего лишь из нескольких
эскизов компоновки экрана, показывающих, как система будет взаимодействовать
с пользователем и каковы будут ее возможности. В данном случае задача состоит
не в создании рабочей версии продукта, а в получении средства демонстрации,
предназначенного для углубления взаимопонимания между участвующими в
разработке сторонами. В частности, метод быстрого создания прототипов доказал
свою эффективность в отношении систематизации требований к системе,
выдвинутых на этапе анализа, а также в качестве средства для проведения презентаций
возможностей системы ее потенциальным заказчикам.
Другое усовершенствование методов проектирования программных систем
предусматривает применение компьютерных технологий к самому процессу разработки
программного обеспечения, что привело к появлению CASE-технологий (CASE —
Computed-Aided Software Engineering). Эти компьютеризованные системы, известные
как CASE-инструменты, включают средства планирования проекта
(предназначенные для оценки стоимости календарного планирования и
распределения исполнителей), средства управления проектом (для контроля за процессом
разработки проекта), средства документирования (для написания и систематизации
проектной документации), средства создания прототипов и имитации (для создания
прототипов), средства разработки интерфейсов (для разработки графических
интерфейсов пользователя), а также средства программирования (для написания и
отладки программ). Некоторые из этих инструментов немногим отличаются от обычных
текстовых редакторов, приложений электронных таблиц и систем электронной
почты, используемых в других приложениях. Однако другие представляют собой
достаточно сложные пакеты, предназначенные преимущественно для использования при
разработке систем программного обеспечения. Например, некоторые CASE-
инструменты включают генераторы кода, которые по заданной спецификации на не-
350 Глава шестая. Технология разработки программного обеспечения
которую часть системы генерируют программу на языке высокого уровня,
представляющую собой реализацию этой части системы.
Вопросы для самопроверки
1. В чем состоит отличие между требованиями к системе и спецификацией на
систему?
2. Кратко охарактеризуйте каждый из четырех этапов (анализ, проектирование,
реализация и тестирование) фазы разработки в жизненном цикле
программного обеспечения.
3. Охарактеризуйте различия между традиционной моделью разработки
программного обеспечения (модель водопада) и новым подходом,
предусматривающим создание прототипов.
6.3. Модульность
Одним из ключевых положений в разделе 6.2 было утверждение о том, что
для модификации программы необходимо разобраться в принципах ее работы
или, по крайней мере, тех ее частей, которые относятся к делу. Зачастую этого
нелегко достичь даже в небольших программах, а в крупных системах
программного обеспечения это было бы практически невозможно, если бы не
принцип модульности, предполагающий разделение программного обеспечения на
поддающиеся осмыслению элементы, каждый из которых сконструирован так,
чтобы выполнять только определенную часть общей задачи.
Реализация модулей
Модульности можно достичь многими способами. В главах 4 и 5 было
показано, как можно реализовать модули в виде отдельных процедур, которые
впоследствии используются в качестве конструкционных элементов для построения
систем большего размера. В главе 5 модульность также обсуждалась в контексте
объектно-ориентированного подхода. В этом случае модули принимали форму
объектов, каждый из которых имел собственную внутреннюю организацию, не
зависящую от содержимого других объектов. Фактически рост популярности
объектно-ориентированного подхода к разработке программного обеспечения в
значительной степени можно объяснить именно модульной структурой,
изначально присущей этому методу.
Структурная схема — это традиционное средство представления модульной
структуры, достигаемой за счет создания процедур. На этой схеме каждый
модуль (процедура) представляется прямоугольником, а связи между ними —
стрелками, соединяющими эти прямоугольники. Структурная схема,
представленная на рис. 6.3, отображает модульную структуру простой ролевой игры в
жанре фантази, в которой игрок должен передвигаться по комнатам
средневекового замка, решая в каждой некоторую задачу, прежде чем ему будет позволено
6.3. Модульность 351
перейти в следующее помещение. На схеме показано, что модуль с именем
CoordinateGame (Координировать игру) использует модули InitializeGame
(Инициализировать игру), SimulateGreatHall (Имитация большого зала),
SimulateDungeon (Имитация темницы) и SimulateTurret (Имитация башни) в
качестве абстрактных средств решения задачи. Точнее говоря, процедура
CoordinateGame вызывает процедуру InitializeGame для организации начала
игры (узнать имя игрока, установить уровень сложности игры — начинающий,
средний или сложный — и т.д.). После каждого перехода игрока на новый
уровень (т.е. перехода в следующую комнату) процедура CoordinateGame вызывает
другую процедуру, выполняющую имитацию требуемой комнаты, чтобы
организовать выполнение происходящих в этой комнате событий. Кроме того, на схеме
показано, что каждый из модулей имитации комнаты обращается к процедуре
UpdateScore (Обновление счета), чтобы записать результаты, достигнутые
игроком в данной комнате.
РИСУНОК 6.3
Структурная схема простой ролевой игры
В то время как структурные схемы используются для представления
внутренней структуры программного обеспечения с процедурной организацией,
диаграммы классов применяются для представления структуры систем с объектно-
ориентированной организацией. Диаграмма классов определяет набор
существующих в системе классов объектов и описывает взаимоотношения этих классов.
На рис. 6.4 представлена простая диаграмма классов для упомянутой выше
ролевой игры. На этой диаграмме показано, что система состоит из объектов двух
типов, PlayRecord (Запись игрока) и Room (Комната), связанных отношением
352
Глава шестая. Технология разработки программного обеспечения
IsCurrentlyln (В данный момент внутри). Здесь объект типа PlayRecord
содержит данные и процедуры, относящиеся к конкретному игроку (имя, уровень,
результат), а объект типа Room — данные и процедуры, относящиеся к
определенной комнате (образ комнаты, возникающий на экране, и связанные с этой
комнатой задачи). Отношение IsCurrentlyln представляет связи,
существующие между комнатами и игроками, т.е. запись игрока связывается с комнатой, в
которой он в данный момент находится. Числа, указанные на концах линий,
представляющих данное отношение, показывают, что один игрок в конкретный
момент времени может быть связан только с одной комнатой. Такая связь типа
"один к одному" отличается от связи "один ко многим", примером которой
может служить связь "обучать", когда один преподаватель ведет на протяжении
семестра сразу несколько курсов.
Диаграмма классов для простой ролевой игры
В последние годы был достигнут значительный прогресс в разработке
стандартной системы обозначений для представления элементов в процессе объектно-
ориентированного проектирования. Наиболее ярким примером является язык
UML (Unified Modeling Language — унифицированный язык моделирования),
представляющий собой унифицированную систему для представления множества
объектно-ориентированных понятий. Обозначения, используемые на рис. 6.4,
основаны на стандартах языка UML.
Связанность модулей
Выше в этой главе модульность была предложена как способ получения
управляемого программного обеспечения. Идея состоит в том, что каждая последующая
модификация, вероятнее всего, коснется относительно небольшого числа модулей,
так что в процессе ее выполнения достаточно будет ограничиться рассмотрением
только этой части системы. Данное утверждение, безусловно, основывается на
предположении, что внесение изменений в один из модулей не окажет непредвиденного
влияния на работу других модулей системы. Соответственно при проектировании
модульной системы задача состоит в обеспечении максимальной независимости
отдельных модулей. Однако некоторые взаимосвязи между модулями все-таки
необходимы, поскольку данные модули должны образовать согласованно функционирую-
6.3. Модульность 353
щую систему. Наличие подобных связей между модулями системы называют
связанностью. Следовательно, задача достижения максимальной независимости
модулей соответствует минимизации их связанности.
Связанность модулей системы может существовать в нескольких различных
формах. Одна из них — это связанность по управлению. В этом случае один
модуль передает управление другому так, как это происходит при возврате и
передаче управления между отдельными процедурами в программе. Другая форма —
это связанность по данным, т.е. совместное использование одних и тех же
данных несколькими модулями.
Структурная схема, представленная на рис. 6.3, отражает связанность модулей по
управлению при процедурном подходе к построению упоминаемой выше ролевой
игры. На структурной схеме связанность по данным обычно представляется с помощью
дополнительных стрелок (рис. 6.5). На этой схеме изображено, какие элементы
данных передаются модулю при обращении к предоставляемым им сервисам и какие
возвращаются вызывающему модулю при завершении выполнения запрошенной
функции. В частности, на данной схеме показано, что модуль CoordinateGame при
обращении к процедуре SimulateGreatHall передает ей значение уровня игрока.
Обратите внимание, что модуль CoordinateGame, в свою очередь, получает значение
уровня игрока от процедуры InitializeGame. Кроме того, на схеме показано, что
когда любой из модулей имитации помещения обращается с запросом к процедуре
UpdateScore, он передает ей данные о количестве очков, уже набранных игроком.
Структурная схема, содержащая сведения о связанности поданным
354
Глава шестая. Технология разработки программного обеспечения
Минимизация связанности по данным является одним из главных
преимуществ объектно-ориентированного подхода. Побудительным мотивом при
создании концепции объекта было желание собрать в единый модуль программы,
работающие с определенным элементом данных. Поэтому в объектно-
ориентированной системе большинство межмодульных связей имеет форму
связей, устанавливаемых между объектами, которые, как правило, реализуются
как связи по управлению. Таким образом, обращение к объекту с запросом о
выполнении некоторого задания является, по существу, запросом о выполнении
некоторого метода (процедуры) внутри объекта. Поэтому такой запрос вызывает
передачу управления объекту аналогично тому, как управление передается
вызываемой процедуре при императивном подходе.
Один из способов представления связей между объектами в объектно-
ориентированном проектировании состоит во внесении информации в диаграмму
классов в целях построения диаграммы взаимодействий, которая, по существу,
является диаграммой классов, показывающей, как различные объекты системы
взаимодействуют друг с другом. Простая диаграмма взаимодействий для нашей
ролевой игры (с использованием обозначений языка UML) представлена на
рис. 6.6. На ней показано, что объект класса Room может послать сообщение
объекту класса PlayerRecord, предлагая ему обновить значение счета, а объект
класса PlayerRecord может послать сообщение объекту класса Room,
запрашивая у него сведения об очередном помещении.
Диаграмма взаимодействий для простой ролевой игры
Независимо от типа связей, программисту следует стремиться к тому, чтобы
они были явно видны в конечной версии программы. Скрытая связанность
называется неявной и приводит ко множеству ошибок в программном обеспечении.
Обычно образование неявных связей происходит при использовании глобальных
данных — элементов данных, которые автоматически доступны всем модулям
системы. В отличие от них, локальные данные доступны только внутри
определенного модуля, если они не пересылались другому в явной форме. В
большинстве языков высокого уровня существуют методы реализации как глобальных,
так и локальных данных.
6.3. Модульность
355
Связность элементов модуля
Почти столь же важной задачей, как минимизация связей между модулями,
является достижение максимальной внутренней связности элементов внутри
каждого модуля. Термин связность (cohesion) относится именно к этим внутренним
связям или, другими словами, к степени взаимосвязанности внутренних частей
модуля. Чтобы убедиться в важности понятия связности, необходимо выйти за
рамки процесса первоначальной разработки системы и обратиться ко всему
жизненному циклу программного обеспечения. Если возникает необходимость
внести изменения в модуль, то существование множества разнообразных действий
внутри него может существенно усложнить процесс, который в противном
случае мог бы оказаться совсем простым. Следовательно, помимо поиска любых
возможностей уменьшить связывание отдельных модулей, разработчики
программного обеспечения должны стремиться к достижению самого высокого
уровня связности элементов внутри каждого модуля.
Самая слабая форма связности — логическая связность. Этот тип связности
внутри модуля строится на том, что его внутренние элементы выполняют
действия, сходные по своей логической природе. Например, рассмотрим модуль,
осуществляющий все связи системы с внешним миром. "Клеем", скрепляющим
элементы такого модуля, является то, что все действия внутри этого модуля так
или иначе относятся к обмену информацией с внешним миром. Однако
назначение такого обмена в каждом конкретном случае может сильно отличаться.
Например, одни действия могут быть связаны с получением данных, а другие — с
выдачей сообщений об ошибках.
Более сильная форма связности — функциональная связность; она означает,
что все части модуля собраны вместе для выполнения одних и тех же действий.
Модуль SimulateGreatHall, показанный на рис. 6.3, нельзя считать
функционально связным, если он содержит сведения, необходимые для создания
изображения на экране большого зала замка, представления всех связанных с этим
залом задач и обработки ответных действий игрока. Однако если эти детали
локализованы в других модулях и используются модулем SimulateGreatHall в
качестве абстрактных инструментов, то каждый этап работы этого модуля
можно рассматривать в общем контексте наблюдения за действиями игрока,
связанными с большим залом замка. В этом случае модуль SimulateGreatHall
выглядит более функционально связным.
В объектно-ориентированном проектировании объекты в целом обычно
являются только логически связными, так как методы внутри объектов зачастую
выполняют слабо связанные действия. Единственное, что объединяет все методы
объекта, — это то, что они выполняют эти действия с одним и тем же объектом.
Например, в нашей ролевой игре каждый объект помещения будет, вероятно,
содержать метод для создания изображения этого помещения наряду с
методами, необходимыми для представления связанных с ним задач и получения
ответа игрока. Следовательно, каждый такой объект представляет собой лишь
логически связный модуль. Однако разработчики программного обеспечения должны
356 Глава шестая. Технология разработки программного обеспечения
стремиться делать каждый метод внутри объекта функционально связным.
Другими словами, даже если объект в целом является всего лишь логически
связным, каждый метод внутри объекта должен выполнять всего лишь одну
функционально связную задачу (показано на рис. 6.7).
Логическая и функциональная связность внутри объекта, представляющего отдельную комнату
в простой ролевой игре
Вопросы для самопроверки
1. Чем роман отличается от энциклопедии в смысле степени связанности,
существующей между его элементами, такими как главы, разделы или отдельные
записи? Что можно сказать о связности этих элементов?
2. Игра в бридж состоит из двух этапов: торг и розыгрыш. Проанализируйте
связанность этих фаз, предварительно определив, какая информация
передается из первой фазы во вторую в явной форме. Какая информация передается
в этом случае неявно?
3. Совместимы ли задачи максимизации связности и минимизации связанности?
Другими словами, будет ли естественным образом уменьшаться связанность
при возрастании связности?
4. Расширьте диаграмму взаимодействий, представленную на рис. 6.6, включив
в нее другие сообщения, которые должны передаваться между объектами
классов Room и PlayerRecord.
6.3. Модульность 357
6.4. Методы проектирования
Разработка методов проектирования систем программного обеспечения
является основным предметом поиска в области технологии разработки программного
обеспечения. В этом разделе мы рассмотрим несколько разработанных ранее
методов и познакомимся с направлениями текущих исследований.
Нисходящие и восходящие методы разработки
Возможно, наиболее известной стратегией проектирования программных
систем является нисходящая методология. Суть ее состоит в том, что не следует
пытаться решить сложную задачу за один этап. Приступая к решению
поставленной задачи, необходимо сначала разбить ее на меньшие, более простые
подзадачи, которые, в свою очередь, следует разбить на еще меньшие. В результате
сложная задача будет сведена к набору более простых задач, решение которых
приведет к выполнению и самой исходной задачи.
При использовании нисходящей технологии проектирования обычно
образуется иерархическая система последовательных уточнений, которая, как
правило, может быть прямо отображена в модульную структуру,
совместимую с парадигмой императивного программирования. Решение задач самого
нижнего уровня этой иерархии обеспечивается процедурными модулями,
выполняющими элементарные задания. В системе эти модули используются в
качестве абстрактных инструментов модулями более высоких уровней,
предназначенными для решения сложных задач.
В противоположность этому методу проектирования, при восходящем
методе проектирование системы начинается с определения отдельных задач
внутри системы. Затем изучается, как решение этих задач может
использоваться в качестве абстрактных инструментов для решения более общих
задач. Многие годы этот подход считался хуже нисходящего метода
проектирования. Однако в настоящее время методология восходящего
проектирования получила мощную поддержку. Одна из причин этого заключается в том,
что нисходящая методология ищет решение, в котором основной модуль
использует подмодули, каждый из которых основывается на подмодулях, и т.д.
Однако для многих систем наилучший вариант решения лишен подобной
иерархической природы. Действительно, при построении приложения по
принципам архитектуры "клиент/сервер" или использовании методов
параллельной обработки проектное решение, в котором два или несколько модулей
взаимодействуют как равноправные партнеры, может оказаться более
удачным, чем проект, состоящий из управляющего модуля, обращающегося к
модулям подпрограмм для решения стоящих перед ним задач.
Другой причиной такого интереса к восходящему проектированию является
то, что оно лучше соответствует задачам построения сложных систем
программного обеспечения из предварительно созданных, стандартных, свободно прода-
358 Глава шестая. Технология разработки программного обеспечения
ваемых компонентов. Однако именно этот подход является наиболее
современной тенденцией в технологии разработки программного обеспечения. Подробно
мы рассмотрим эту стратегию ниже.
Общие инструменты разработки
В технологии разработки программного обеспечения создано множество
систем обозначения, предназначенных для анализа и проектирования систем. Мы
уже встречались с некоторыми из них, например структурными схемами,
диаграммами классов и диаграммами взаимодействия. Еще одна разновидность
подобных инструментов — диаграмма потоков данных, содержащая графическое
представление путей перемещения данных в системе. На диаграмме потоков
данных указываются места происхождения, конечного назначения и
промежуточной обработки данных в системе. Каждый из символов, который указывается
на такой диаграмме, имеет специальное значение: стрелки представляют потоки
данных; сплошные линии — источники и приемники данных; кружки
указывают, где с данными производятся некоторые действия; а жирные прямые линии
отмечают места сохранения данных. В каждом случае символ помечается
именем представляемого объекта. Схема потоков данных для нашей простой
ролевой игры представлена на рис. 6.8.
Метод разработки систем программного обеспечения, основанный на
анализе потоков данных, возник в среде императивного программирования.
Изначально задача состояла в том, что, отслеживая пути данных в предлагаемой
системе, можно обнаружить, где элементы данных сливаются, разделяются
или изменяются каким-либо другим образом. В таких местах системы
обязательно потребуются те или иные вычислительные действия, которые (взятые
по отдельности или сгруппированные) позволят образовать процедурные
модули системы. Следовательно, изучение потоков данных поможет определить
модульную структуру системы.
Хотя разработка метода анализа потоков данных происходила в рамках
императивной парадигмы программирования, он нашел широкое применение и в
объектно-ориентированной среде. В частности, определение элементов данных
в системе помогает выявить необходимые объекты, а определение
происходящих с данными изменений — уточнить действия, которые эти объекты
должны выполнять.
Еще одним инструментом анализа и проектирования систем программного
обеспечения является диаграмма "сущность-связь", на которой наглядно
представляются присутствующие в системе элементы информации (сущности),
а также существующие между этими элементами отношения. В качестве
примера рассмотрим часть диаграммы "сущность-связь" для системы
программного обеспечения, предназначенной для сбора информации о преподавателях,
студентах и занятиях.
6.4. Методы проектирования 359
РИСУНОК 6.8
Диаграмма потоков данных в простой ролевой игре
Прежде всего определим те сущности, которые должны содержаться в системе.
Сущность Professor (Профессор) представляет отдельного преподавателя
университета; сущность Student (Студент) — отдельного студента и сущность Class (Занятие) —
раздел определенного курса. С каждым экземпляром сущности Professor связывается
фамилия, адрес, идентификационный номер, оклад и т.д., с каждым экземпляром
сущности Student — фамилия, адрес, идентификационный номер, средний балл и
т.д., с каждым экземпляром сущности Class — название курса (История 101),
семестр и год, аудитория, время проведения и т. д.
Определив присутствующие в создаваемой системе сущности, следует рассмотреть
связи, существующие между ними. Прежде всего, заметим, что каждый
преподаватель ведет занятия, а каждый студент посещает их. Следовательно, связь между
сущностями Professor и Class можно определить как Teaches (Проводит), а
между сущностями Student и Class — как Attends (Посещает). (Обратите внимание,
что сущности обозначаются существительными, а связи между ними — глаголами.)
360
Глава шестая. Технология разработки программного обеспечения
Для отображения этих сущностей и связей составляют диаграмму "сущность-
связь", показанная на рис. 6.9, где каждая сущность представлена
прямоугольником, а каждая связь — ромбом. Из этой диаграммы следует, что
преподаватели связаны с занятиями посредством связи Teaches, а студенты — посредством
связи Attends.
РИСУНОК 6.9
Пример диаграммы "сущность - связь"
Однако для двух существующих в данном примере связей характерна различная
структура. Связь между сущностями Professor и Class имеет тип "один ко
многим", поскольку каждый преподаватель проводит несколько различных занятий,
однако каждое занятие проводится только одним преподавателем. В
противоположность этому, связь между сущностями Student и Class имеет тип "многие ко
многим", так как каждый студент посещает несколько занятий и каждое занятие
посещают несколько студентов. Эта дополнительная информация представлена на
рис. 6.9 с помощью стрелок, соединяющих сущности и связи. В частности,
одинарная стрелка, направленная в сторону сущности, указывает, что только одна
сущность данного вида входит в каждую связь этого типа, тогда как двойная стрелка
означает, что в этой связи может участвовать несколько экземпляров данной
сущности. Например, одинарная стрелка, направленная на рис. 6.9 в сторону сущности
Professor, означает, что каждое занятие проводит только один преподаватель, в то
время как двойная, направленная в сторону сущности Class от связи Teaches,
показывает, что каждый преподаватель может проводить более чем одно занятие.
Можно предположить, что среди различных средств, используемых
разработчиками программного обеспечения в прошлом, диаграммы "сущность-связь"
имели больше шансов выжить при переходе к объектно-ориентированным
методам. Действительно, определение сущностей является, по сути, определением
объектов системы, а классификация связей между ними — первый шаг на пути
к определению необходимых связей и взаимодействий этих объектов. Поэтому в
традиционной диаграмме "сущность-связь" легко распознать предшественницу
диаграммы классов языка UML (рис. 6.4), которая используется в объектно-
ориентированной среде проектирования.
Существует также такой полезный инструмент разработки систем
программного обеспечения, как словарь данных. Он представляет собой центральное
хранилище информации обо всех элементах данных из всех частей системы. Сюда
6.4. Методы проектирования
361
входят идентификатор, используемый для обращения к каждому элементу;
сведения о том, из каких символов может состоять каждый элемент (Будет ли
элемент состоять только из цифр или, возможно, только из букв? Каким будет
диапазон значений, которые могут присваиваться данному элементу?); данные о
том, где хранится этот элемент данных (Будет элемент записан в файл или базу
данных; если да, то в какую именно?); а также указания, где именно в
программе осуществляются обращения к элементу (Каким модулям требуется
информация из данного элемента данных?).
Разработка словаря данных преследует сразу несколько целей. Одна из них
состоит в расширении взаимодействия потенциальных пользователей системы и
аналитика, перед которым поставлена задача превращения пожеланий
пользователя в требования и спецификации. Было бы весьма досадно обнаружить уже
после завершения реализации системы, что номера деталей в действительности
не являются числовыми или размер инвентаризационной ведомости превышает
допустимый в системе. Процесс создания словаря данных помогает избежать
подобных недоразумений.
Другая цель создания словаря данных — установить в системе необходимое
единообразие. Обычно именно за счет создания словаря можно избежать
избыточности и противоречивости данных. Например, элемент данных, который в
записи складского учета был назван PartNumber, в записях о продажах может
получить имя Partld. Кроме того, отдел кадров может использовать элемент
Name (Имя) по отношению к сотруднику, в то время как в записи складского
учета элемент Name (Название) может входить в описание детали.
Наконец, следует упомянуть и CRC (Class-Responsibility-Collaboration —
карты взаимодействия классов), которые могут оказаться полезными при
проектировании объектно-ориентированных систем. Карта CRC является, в сущности,
традиционной индексной картой, содержащей описание объекта. Метод
использования карт CRC состоит в том, что проектировщик создает карту CRC для
каждого объекта предлагаемой системы, а затем использует эти карты для
моделирования действий в системе — например, на поверхности рабочего стола или с
помощью "театрализованного" эксперимента, в котором каждый член команды
проектировщиков играет роль объекта, выполняя все действия именно так, как
это предписывается соответствующей картой. Такое моделирование используется
для обнаружения недостатков в проекте.
Шаблоны проектирования
В своих поисках, предпринимаемых с целью найти способы создания
программного обеспечения из готовых компонентов, разработчики программного
обеспечения обратились и к области архитектуры. Особый интерес здесь
представляет книга Кристофера Александера (Christopher Alexander) и др. A Pattern
Language, в которой описывается набор шаблонов для сообщества архитекторов-
проектировщиков. Каждый шаблон состоит из постановки задачи, за которой
следует предлагаемое решение. Приведенные задачи в основном универсальны, а
362 Глава шестая. Технология разработки программного обеспечения
предлагаемое решение является обобщенным в том смысле, что оно относится к
общей природе задачи, а не к конкретному случаю.
Например, один из шаблонов, названный "Quiet Backs" ("тихие уголки"),
предназначен для создания в деловом центре тихих местечек для отдыха.
Предлагаемое решение заключается в том, чтобы спроектировать в деловых районах
"тихие уголки". В некоторых случаях следует проектировать район вокруг
главной улицы, к которой все здания повернуты фасадами, обеспечивая, таким
образом, тихую сторону на улицах, проходящих позади этих зданий. В других
случаях "тихие уголки" могут быть получены с помощью парков, рек или соборов.
Важным для нашего обсуждения является то, что в данной работе Алексан-
дера сделана попытка определить общие задачи и предложить типовые шаблоны
их решения. Сегодня многие разработчики программного обеспечения пытаются
применить аналогичный подход к проектированию больших систем
программного обеспечения. В частности, исследователи используют шаблоны
проектирования в качестве средств создания обобщенных строительных блоков, из которых
можно конструировать системы программного обеспечения.
Среда программирования языка Java
Java был бы просто еще одним объектно-ориентированным языком программирования, если бы не имел
набора структур, разработанных специально для упрощения процесса программирования на этом языке.
Набор этих структур получил общее название "Прикладной программный интерфейс", или API (Application
Program Interface), и является частью набора инструментальных средств языка Java (JDK— Java
Development Kit), разработанного компанией Sun Microsystems. Структуры API языка Java включают
шаблоны для решения таких задач, как разработка графических интерфейсов пользователя (GUI), работа с аудио-
и видеоданными, передача данных через Internet или разработка анимированных Web-страниц. Таким
образом, среда программирования языка Java — это прогресс в направлении конструирования программного
обеспечения из готовых компонентов.
Примером такого шаблона является Publisher-Subscriber (Издатель-
Подписчик), состоящий из модуля (издателя), который должен посылать копии
своих "публикаций" другим модулям (подписчикам), как показано на рис. 6.10.
Как частный случай рассмотрим группу данных, которые изображаются на
экране компьютера одновременно в нескольких форматах, например в виде
круговой диаграммы и гистограммы. В этом случае любое изменение данных должно
быть отражено сразу в обоих форматах. Следовательно, модули программного
обеспечения, отвечающие за построение диаграмм, должны оповещаться об
изменении данных. В данном случае модуль программного обеспечения,
управляющий данными, выполняет роль издателя, посылающего сообщения о
произошедших изменениях сразу всем его подписчикам, т.е. модулям, отвечающим
за построение диаграмм.
6.4. Методы проектирования 363
РИСУНОК 6.10
Шаблон Publisher-Subscriber
Еще одним примером шаблона проектирования программного обеспечения
является Container-Component (Контейнер-Компонент). Он воплощает
обобщенную концепцию контейнера, содержащего компоненты, которые, в свою
очередь, также могут быть контейнерами (рис. 6.11). Примером использования
этого шаблона может служить иерархия каталогов или папок, создаваемая
программой управления файлами операционной системы. Каждый из этих
каталогов обычно содержит другие каталоги, которые также могут содержать
каталоги, и т.д. Короче говоря, шаблон Container-Component служит для
описания рекурсивной концепции контейнеров, содержащих такие же контейнеры.
После того как структура шаблонов, подобных Publisher-Subscriber или
Container-Component, будет определена, разработчики программного обеспечения
выполняют разработку каркасных программных элементов, называемых
структурами, в которых реализуются основные особенности решений, предлагаемых
шаблонами. Тогда как реализация специфических функций, присущих конкретным
приложениям, откладывается на более поздний срок за счет организации соответствующих
слотов, подлежащих заполнению конкретными значениями. Как дополнение к
структурам, разработчики программного обеспечения обычно предлагают
документацию, описывающую как следует заполнять эти структуры в целях получения
завершенной реализации положенного в ее основу шаблона в рамках конкретной
разработки. Такую документацию называют рецептом, поэтому подборки структур
вместе с их рецептами шутливо именуют кулинарными книгами.
Исследователи надеются, что с помощью кулинарных книг разработчики
программного обеспечения получат, наконец, возможность конструировать большие
сложные системы программного обеспечения из готовых компонентов, таких как
структуры. Первые результаты показали, что при разработке новой системы такой
подход позволяет значительно уменьшить необходимый объем программирования.
364
Глава шестая. Технология разработки программного обеспечения
РИСУНОК 6.11
Шаблон Container-Component
Несмотря на ажиотаж, вызванный в сообществе разработчиков программного
обеспечения вокруг шаблонов проектирования, интересно отметить, что сам
Александер не был удовлетворен результатами использования его шаблонов в
архитектуре. Он обнаружил, что системам, разработанным на основе его
шаблонов, недостает индивидуальности, и поэтому с начала 80-х направил все свои
усилия на поиск путей включения в новые разработки этого ускользающего
качества. Однако разработчики программного обеспечения сходятся на том, что
при разработке программного обеспечения важна не красота и
индивидуальность, а, прежде всего, точность и эффективность. Поэтому, считают они,
применение шаблонов проектирования в области создания программного
обеспечения окажется более успешным, чем в архитектуре.
Вопросы для самопроверки
1. Предположим, что секретарь получает просьбы о предоставлении встреч с его
боссом. Действия секретаря заключаются или в назначении встречи на
ближайшие дни, или в немедленном предоставлении желаемой встречи.
Нарисуйте схему потоков данных, представляющую эту часть работы секретаря.
2. Нарисуйте диаграмму "сущность-связь", представляющую авиационные
компании; полеты, выполняемые каждой компанией; и пассажиров различных рейсов.
6.4. Методы проектирования 365
3. Приведите примеры некоторых программных структур, обсуждаемых в
предыдущих главах, которые можно рассматривать в качестве шаблонов
проектирования.
4. Какую роль, как надеются исследователи, будут играть структуры в процессе
создания программного обеспечения в будущем?
6.5. Тестирование
В разделе 4.6 рассматривались методы верификации алгоритмов в строгом
математическом смысле. Однако было сделано заключение, что большая часть
создаваемого сегодня программного обеспечения "верифицируется" посредством
тестирования. К сожалению, тестирование в лучшем случае можно расценивать
как неточную науку. Выполнив тестирование, мы не можем утверждать, что
некоторая часть программы правильна, если не были выполнены все проверки,
исчерпывающие возможные сценарии. Но даже для простой структуры цикла,
содержащей единственную инструкцию if-then-else, существует более 1000
различных пересекающихся путей выполнения, если цикл повторяется всего лишь
десять раз. Следовательно, проверить все возможные пути выполнения в
сложной программе — просто невыполнимая задача.
С другой стороны, создатели программного обеспечения разработали методы
тестирования программ, повышающие вероятность обнаружения существующих
в них ошибок. Один из таких методов основан на наблюдении, что ошибки в
программном обеспечении имеют тенденцию к группированию. (Это часто
называют принципом Парето, в честь Вильфредо Парето (Vilfredo Pareto), который
заметил, что малая часть населения Италии контролирует большую часть
богатств этой страны.) Как показывает опыт, в крупной системе программного
обеспечения всегда существует определенное число модулей, являющихся более
проблематичными, чем остальные. Следовательно, обнаружив эти модули и
проверив их более тщательно, можно выявить большую часть существующих в
системе ошибок, даже если все остальные модули будут протестированы обычным,
менее тщательным образом. Задача, таким образом, заключается в обнаружении
таких проблематичных модулей.
Еще один метод, называемый тестированием основных путей, состоит в
разработке набора контрольных данных, гарантирующего, что каждая инструкция
в программе будет выполнена хотя бы один раз. Для подготовки таких наборов
были разработаны методы, построенные на основе математической теории
графов. Поэтому, хотя и нельзя будет утверждать, что все возможные пути
выполнения в системе программного обеспечения будут проверены, можно
гарантировать, что в процессе тестирования каждая инструкция в программном коде
системы будет выполнена, как минимум, один раз.
Методы, основанные на принципе Парето, и способ тестирования основных
путей предполагают знание внутренней структуры тестируемого программного
обеспечения. Следовательно, они относятся к категории тестирования по прин-
366 Глава шестая. Технология разработки программного обеспечения
ципу "прозрачного ящика", при котором подразумевается, что внутреннее
устройство программного обеспечения известно тестирующему. В
противоположность этому, при тестировании по принципу "черного ящика" выполняемая
проверка не может основываться на знании внутренней структуры тестируемого
программного обеспечения. Короче говоря, тестирование по принципу "черного
ящика" выполняется с точки зрения пользователя системы. В этом случае
анализируется не то, как именно программа функционирует при решении задачи, а
исключительно то, насколько правильно она работает в смысле точности
достигнутых результатов и скорости ее выполнения.
Один из методов, который обычно относится к концепции тестирования по
принципу "черного ящика", именуется анализом граничных условий. Этот метод
заключается в определении граничных условий, указанных в спецификации
программного обеспечения, с последующей проверкой функционирования
программы при этих условиях. Например, если предполагается, что в программе
допускается введение исходных значений только из конкретно заданного
диапазона, то работу программы следует проверить при вводе наименьшего и
наибольшего значений из допустимого диапазона. Если же программное обеспечение
должно координировать множество различных действий, то его работу следует
проверять с использованием множества действий, имеющих максимальные
требования к системе.
Therac-25
Необходимость жестких требований к качеству проектных работ подтверждается проблемами, возникшими при
использовании Therac-25, — системы радиационной терапии, включающей управляемый компьютером ускоритель
электронов. Эта система применялась медиками в середине 80-х годов. Недостатки, присущие этому проекту,
вызвали шесть случаев передозировки радиационного облучения, три из которых привели к смертельному исходу. К
недостаткам системы можно отнести неудачный проект интерфейса пользователя, позволявший оператору
начинать облучение до того, как машине будет задана соответствующая дозировка, а также плохую координацию
взаимодействия аппаратного и программного обеспечения, вызвавшую снижение необходимого уровня
безопасности. Более подробно познакомиться с данным вопросом можно в форуме Risks на Web-узле
http: //catless. ncl. as. uk/, посвященном вопросам возникновения рисков.
Еще одним методом тестирования по принципу "черного ящика" является
применение избыточности. В данном случае две системы для выполнения одной
и той же задачи разрабатываются независимо различными группами или даже
компаниями. Затем обе системы проверяют путем задания им одинаковых
данных и сравнения результатов. Ошибки проявляются при расхождении в
полученных результатах. Такие методы часто применяются в космических
исследовательских системах.
6.5. Тестирование 367
Следующим методом тестирования по принципу "черного ящика" является метод
"упрощенных версий", который все шире используется разработчиками
программных средств, предназначенных для рынка персональных компьютеров. Он
заключается в представлении части предполагаемой аудитории предварительной версии
программного обеспечения, называемой бета-версией. Основная задача — изучить, как
программное обеспечение функционирует в реальных условиях, перед тем как
конечная версия продукта будет утверждена и выпущена на рынок.
Достоинства подобного тестирования опытного образца превышают рамки
традиционного обнаружения ошибок. Получение отзывов потребителей (как
положительных, так и отрицательных) может существенно помочь в уточнении
рыночных стратегий. Более того, раннее распространение бета-версий
программного обеспечения помогает другим производителям программного обеспечения в
разработке совместимых продуктов. Например, распространение бета-версии
новой операционной системы ускорит разработку совместимых с ней
обслуживающих программ, в результате окончательная версия операционной системы
окажется на полке магазина сразу в окружении сопутствующих программных
продуктов. Наконец, существование бета-версий программного обеспечения
помогает создать на рынке атмосферу предвкушения, которая повышает
популярность продукта, а значит, и увеличивает объем его продаж.
Вопросы для самопроверки
1. Какая проверка при тестировании программного обеспечения является
успешной, нашедшая или не нашедшая ошибки?
2. Какие методы можно предложить для обнаружения в системе модулей,
которые необходимо тестировать более тщательно, чем все остальные?
3. Что можно считать хорошим тестом для проверки работы пакета
программного обеспечения, разработанного для сортировки списка, содержащего не
более 100 элементов?
6.6. Документирование
Чтобы успешно пользоваться и управлять работой системы программного
обеспечения, люди должны иметь возможность изучить ее. Следовательно, важной частью
пакета программного обеспечения является документация, а ее разработка — не
менее важная тема в технологии разработки программного обеспечения.
При создании документации к пакетам программного обеспечения обычно
преследуются две задачи. Одна из них — описание функций программного
обеспечения и методов его использования. Эта часть называется документацией
пользователя, так как она предназначена для нужд пользователей данного
программного обеспечения. Следовательно, документация пользователя должна
носить нетехнический характер.
Сегодня документация пользователя считается важным средством маркетинга.
Хорошая документация (в сочетании с хорошо разработанным интерфейсом пользо-
368 Глава шестая. Технология разработки программного обеспечения
вателя) делает программный пакет более доступным и способствует увеличению
объема его продаж. Осознавая это, многие разработчики программного обеспечения для
выполнения данной части проекта нанимают известных авторов технической
литературы или представляют предварительные версии своих продуктов независимым
авторам в надежде, что соответствующие книги уже поступят в продажу к тому
моменту, когда само программное обеспечение появится на рынке.
Документация пользователя традиционно имеет форму учебного руководства,
в котором представлен вводный материал о наиболее часто используемых
функциях программного обеспечения (часто в форме учебника), специальный раздел,
объясняющий, как установить данное программное обеспечение, а также
справочный раздел, содержащий подробное описание каждой его функции. Это
руководство, как правило, издается в виде книги, но во многих случаях эта же
информация входит в само программное обеспечение. Такое решение предоставляет
пользователю возможность обращаться к документации при работе с
программным обеспечением. В этом случае информация может быть разбита на небольшие
элементы, иногда называемые модулями справочной информации, которые
могут автоматически появляться на экране, если пауза между командами
пользователя становится слишком долгой.
Другая задача программной документации состоит в описании внутренней
структуры программного обеспечения для поддержки последующего сопровождения
системы на протяжении всего ее жизненного цикла. Данная часть документации
называется системной и по своей сути является более технической, чем документация
пользователя. Основным компонентом системной документации является исходная
версия всех программ системы. Очень важно, чтобы эти программы были
представлены в читабельном виде, поэтому разработчики программного обеспечения
используют хорошо разработанные языки программирования высокого уровня,
сопровождают текст программы комментариями, а также применяют технологию модульного
проектирования, что позволяет представить каждый модуль как отдельный,
согласованно работающий элемент. На практике многие компании, выпускающие
программное обеспечение, приняли ряд правил, которым должны следовать их
работники при написании программ. Сюда входят соглашения об использовании отступов
в исходных текстах программ; соглашения о присвоении имен, устанавливающие
различия между именами переменных, констант, объектов, классов и т.д.; и
соглашения по документированию, гарантирующие, что все написанные программы будут
достаточно документированы. Подобные соглашения обеспечивают единообразие
создаваемого программного обеспечения в рамках всей компании, что существенно
упрощает процесс его сопровождения.
Другим компонентом является проектная документация, описывающая
спецификации системы и то, как они были получены. Создание этой документации —
длительный процесс, начинающийся с проведения начального анализа. Из-за
длительности процесса при создании подобной документации часто возникает конфликт между
задачами проектирования программного обеспечения и особенностями человеческой
натуры. Весьма вероятно, что начальные спецификации и начальный проект
программного обеспечения будут изменены в процессе разработки. Появляется
искушение выполнить эти изменения, не обновляя созданные раньше проектные докумен-
6.6. Документирование 369
ты. В результате возникает большая вероятность того, что эти документы к моменту
завершения разработки окажутся неправильными и их использование в конечной
документации приведет к заблуждениям.
Все сказанное выше является еще одним аргументом в пользу широкого
использования инструментов CASE-технологии. Они существенно упрощают задачи
повторного составления разнообразных диаграмм и обновления словарей данных
в сравнении с традиционными ручными методами. Следовательно, при
использовании CASE-инструментов более вероятно, что требуемые изменения
действительно будут внесены и конечная документация будет точной.
В завершение подчеркнем, что пример с обновлением документации — всего
лишь один из многих случаев, когда при проектировании программного
обеспечения приходится бороться с недостатками, присущими человеческой натуре.
Другими примерами могут служить возникновение неизбежных конфликтов
персонала, проявление зависти, столкновение эгоистических интересов и прочие
негативные явления, почти всегда возникающие в тех случаях, когда люди
работают вместе. Поэтому, как мы отмечали раньше, проектирование программных
систем (в широком смысле) включает не только те аспекты, которые
непосредственно связаны с информатикой.
Вопросы для самопроверки
1. Какие существуют формы документации на программное обеспечение?
2. На какой фазе (или фазах) жизненного цикла программного обеспечения
создают его документацию?
3. Что важнее, программа или ее документация?
6.7. Право собственности и ответственность за
создаваемое программное обеспечение
Не вызывает сомнения, что компания или отдельный человек должны иметь
возможность возмещать затраты и получать прибыль от тех инвестиций,
которые потребовались для разработки качественного программного обеспечения. Без
средств защиты этих инвестиций мало кто захочет взять на себя задачу
производства программного обеспечения, необходимого обществу. Но вопросы,
касающиеся прав собственности на программное обеспечение и прав его владельцев,
часто попадают в "провалы", существующие между хорошо разработанными
законами об авторских правах и патентах. Эти законы были разработаны для того,
чтобы дать возможность производителю "продукта" представить его
общественности и защитить при этом его право собственности, однако особенности
программного обеспечения неоднократно мешали судам в их попытках применить
принципы закона об авторском праве и патентах к разрешению споров о праве
собственности на программное обеспечение.
370 Глава шестая. Технология разработки программного обеспечения
Законы об авторском праве были первоначально сформулированы для защиты
авторских прав на литературные работы. В этом случае ценность произведения
состоит в том, как идеи описаны, а не в идеях самих по себе. Ценность поэмы в
ее рифмах, стиле и стихотворном размере, а сам предмет поэмы — далеко не
главное. Ценность романа состоит в авторском представлении сюжета, а не в
самом сюжете. Таким образом, труд поэта или писателя может быть защищен,
если ему дается право собственности на определенное описание идеи, но не на саму
идею. Другой человек имеет право описывать ту же идею, пока его описание не
является "фактическим подобием" оригинала.
В противоположность поэме или роману, ценность программного обеспечения
обычно состоит не в способе написания программы. Напротив, она заключается в
представленном в ней алгоритме (идее). Следовательно, прямое применение законов
об авторском праве не защитит инвестиции разработчика программного обеспечения.
Действительно, ничто не помешает конкуренту использовать тот алгоритм, на
создание которого разработчик мог затратить значительные средства, если только это
представление не является "фактическим подобием" оригинала.
Коротко говоря, законы об авторском праве защищают скорее форму, а не
функцию, но ценность программы чаще всего состоит в ее функции, а не в
форме. В результате закон об авторском праве защищает скорее программы,
реализующие широко известные, неоригинальные алгоритмы, чем инвестиции,
вложенные в создание новых алгоритмов. Если алгоритм хорошо известен,
единственную ценность представляет текст программы; однако если описываемый
алгоритм новый и творческий, главной ценностью программы является именно
алгоритм, который не защищается авторским правом. В этом есть что-то
парадоксальное — чем больше творческих усилий затрачено на производство
программы, тем менее вероятно, что закон об авторском праве сможет защитить
вложенные в это инвестиции.
С целью применить закон об авторском праве к программному обеспечению
были сделаны попытки обратиться к концепции сценария диалога с
пользователем (look and feel) в системе программного обеспечения. Хотя сама фраза look
and feel не использовалась до 1985 года, данная концепция уходит своими
корнями в начало 1960-х годов, когда компания IBM выпустила новую серию
машин System/ЗбО. Эта серия состояла из нескольких машин, предназначенных
для удовлетворения самых разнообразных потребностей, — от приложений
мелкого бизнеса до мощных корпоративных систем. Все эти машины поставлялись с
операционными системами, которые общались с окружающей средой
аналогичным образом. Иными словами, машины этой серии имели стандартизованный
интерфейс пользователя. По мере роста бизнеса можно было заменить
используемую машину на более мощную из той же серии, не затрачивая усилий на
переделку программ и переобучение персонала. Действительно, внешний вид (look)
(оформление, поддерживаемое системным программным обеспечением) и
способы работы (feel) (то, как пользователь взаимодействует с системным
программным обеспечением) были одинаковы для всех машин этой серии.
Сегодня преимущества стандартизованного интерфейса очевидны, и
разработчики стараются добиться его во всех сферах программного обеспечения. Когда
6.7. Право собственности и ответственность за создаваемое... 371
интерфейс, разработанный одной компанией, становится популярным,
конкурирующим компаниям выгодно разрабатывать свои системы с аналогичным
сценарием диалога с пользователем. Это упрощает пользователям хорошо известной
системы переход к системе конкурента даже в том случае, если внутренние
проекты двух систем значительно отличаются. Компании, столкнувшиеся с такими
действиями конкурентов, стали искать защиты в законах об авторском праве,
объявив своей собственностью сценарий диалога с пользователем исходной
системы. В конце концов, сценарий диалога с пользователем в пакете программного
обеспечения имеет много особенностей, характерных для собственности,
защищаемой законом об авторском праве.
Первую проверку аргумент схожести сценариев диалога с пользователем
прошел в 1987 году, когда корпорация Lotus Development Corporation судилась с
компанией Mosaic Software, заявив, что последняя скопировала сценарий
диалога с пользователем системы электронных таблиц Lotus 1-2-3. Дело было
выиграно. Однако в дальнейшем аргументы схожести сценариев диалога с
пользователем имели переменный успех.
Попытка применить патентное право для защиты прав владельцев
программного обеспечения тоже приводит к определенным проблемам. Одним из
препятствий является давнишний принцип, что никто не может быть собственником
таких явлений природы, как законы физики, математические формулы и
мысли. Суды обычно считали, что алгоритмы попадают в эту же категорию. Таким
образом, как и авторское право, патентное право не может защитить главную
ценность программы — ее алгоритм. Кроме того, получение патента —
дорогостоящий и длительный процесс, часто занимающий несколько лет. За это время
программный продукт может устареть; пока патент еще не выдан, претендент на
его получение имеет весьма спорное право препятствовать другим присваивать
его продукт. Однако существуют и прецеденты выдачи патентов на алгоритмы.
Примером может служить алгоритм кодирования RSA, активно используемый
во множестве современных систем кодирования с открытым ключом.
Закон об авторском праве и патентное право разработаны с той целью, чтобы
помочь распространению изобретений и расширить свободный обмен идеями на пользу
обществу. Когда права собственности защищены, более вероятно, что творцы и
изобретатели сделают свои достижения достоянием гласности. Напротив, закон о
коммерческой тайне является средством ограничения распространения идей.
Разработанный для поддержания этики взаимоотношений между конкурентами, этот закон
противодействует неуместному разглашению и незаконному присвоению внутренних
достижений компании. Часто компании пытаются защитить свои коммерческие
секреты путем подписания закрытых соглашений, в которых персонал, имеющий
доступ к секретам компании, обязуется не раскрывать их другим. Суды в основном
принимают во внимание такие соглашения.
Чтобы избежать ответственности, разработчики программного обеспечения
зачастую сопровождают свои продукты оговорками, ограничивающими уровень
их ответственности. Часто можно встретить предложения следующего вида:
"Компания X не несет никакой ответственности за ущерб, нанесенный в связи с
использованием этого программного обеспечения". Суды, однако, редко прини-
372 Глава шестая. Технология разработки программного обеспечения
мают во внимание такие оговорки, если истец может указать на небрежное
отношение со стороны ответчика. Следовательно, при разрешении вопроса об
ответственности исходят из того, насколько тщательно был разработан продукт и
соответствует ли он предполагаемому использованию. Уровень тщательности,
приемлемый при разработке редакторской системы, может считаться
недостаточным, если речь идет о программном обеспечении для управления ядерным
реактором. Поэтому при разработке программного обеспечения лучшей защитой
против исков о возмещении убытков является выбор общего с заказчиком
подхода к процессу разработки.
Вопросы для самопроверки
1. Какой тест можно использовать для определения того, является ли одна
программа фактическим подобием другой?
2. Каким образом закон об авторском праве, патентное право и закон о
коммерческой тайне служат на благо обществу?
3. В каких случаях оговорки об отказе от ответственности не принимаются во
внимание судами?
Упражнения
1. Приведите пример, каким образом усилия, затраченные при
разработке программного обеспечения, могут окупиться позднее при
сопровождении программы.
2. Что такое пошаговая модель?
3. Охарактеризуйте, как изменило использование инструментов CASE-
технологии процесс разработки программного обеспечения.
4. Объясните, как влияет на технологию разработки программного
обеспечения отсутствие метрик для измерения точных характеристик
программного обеспечения.
5. Чем отличаются технологии разработки программного обеспечения от
традиционных технических дисциплин?
6.
а) В чем заключаются недостатки использования традиционной
модели водопада при разработке программного обеспечения?
б) В чем заключаются преимущества использования традиционной
модели водопада при разработке программного обеспечения?
7. Как помогает в разработке высококачественного программного
обеспечения принятие кодексов о профессиональной этике?
8. Опишите, как может упростить модификацию программного
обеспечения использование констант вместо литералов?
9. В чем заключается различие между связанностью и связностью
модулей? Что следует минимизировать, а что — максимизировать?
Упражнения 373
10. Какое из следующих предложений является аргументом в пользу
связанности, а какое — в пользу связности?
а) При изучении предмета студентами материал должен быть
представлен в виде хорошо организованных разделов, имеющих
конкретные задачи.
б) Студенты не поймут предмет по-настоящему, пока не овладеют
всем материалом в целом и не изучат его связи с другими
предметами.
11. В тексте упоминалось понятие связанности по управлению, но эта
тема не получила достаточного развития. Сравните связанность между
двумя программными единицами, достигаемую с помощью команды
goto, со связанностью, получаемой при использовании механизма
вызова процедур.
12. Ответьте на следующие вопросы, пользуясь приведенной ниже
структурной схемой.
а) Какому модулю возвращает
управление модуль Y?
б) Какому модулю возвращает
управление модуль Z?
в) Являются ли модули W и X
связанными по управлению?
г) Связаны ли модули W и X данными?
д) Какие данные совместно используются
модулями W и Y?
е) В каких отношениях находятся
модули Y и X?
13. Используя структурную схему из
предыдущей задачи, определите, какие заглушки необходимы для
тестирования модуля V? Какие характеристики должны иметь эти модули
заглушек?
14. Ответьте на следующие вопросы, пользуясь прилагаемой ниже схемой.
а) Чем отличаются способы
использования модулями А и В элементов
данных х и у?
б) Если один из модулей отвечает за
получение элемента данных z от
пользователя удаленного терминала,
то какой именно?
15. Начертите простую диаграмму классов, представляющую
взаимоотношения между издателями, журналами и подписчиками.
16. Расширьте предыдущую диаграмму классов до диаграммы совместно
выполняемых действий.
374
Глава шестая. Технология разработки программного обеспечения
17. Чем диаграмма классов отличается от диаграммы взаимодействий?
18. Что такое UML?
19. Воспользовавшись структурной схемой, представьте структуру процедур
системы реального времени для обработки заказов и учета клиентов
компании по доставке товаров почтой. Какие модули этой системы
потребуется изменить в случае внесения изменений в закон о налогах на продажи?
Что произойдет в случае изменения длины почтового индекса?
20. Разработайте решение для предыдущей задачи с использованием
объектно-ориентированной парадигмы и представьте его в виде
диаграммы классов.
21. Приведите несколько примеров шаблонов проектирования в областях,
отличных от архитектуры и программирования.
22. Охарактеризуйте роль шаблонов проектирования в технологии
разработки программного обеспечения.
23. Начертите схему потоков данных, наглядно отображающую процесс
регистрации студента в университете.
24. Сравните информацию, представленную на схеме потоков данных, с
информацией, отображаемой на структурной схеме.
25. Чем отличаются связи типов "один ко многим" и "многие ко многим"?
26. Начертите диаграмму "сущность-связь" для отношений между
поварами, официантами, посетителями и кассирами в ресторане.
27. Начертите диаграмму "сущность-связь", представляющую отношения
между журналами, издателями и подписчиками.
28. В каждом из следующих случаев определите, о чем идет речь — о
структурной схеме, схеме потоков данных, диаграмме "сущность-
связь" или словаре данных.
а) Определяет данные, относящиеся к разрабатываемой системе.
б) Определяет взаимоотношения между различными элементами
данных, существующими в системе.
в) Определяет характеристики каждого элемента данных в системе.
г) Определяет, какие элементы данных совместно используются
различными частями системы.
29. В чем отличие между диаграммой классов и диаграммой "сущность-
связь"?
30. Охарактеризуйте различие между нисходящей и восходящей
стратегиями проектирования.
Упражнения 375
31. В чем отличие между тестированиями по принципам "черного ящика"
и "прозрачного" ящика?
32. Предположим, что перед окончательным тестированием крупной
системы программного обеспечения в нее было намеренно внесено 100
ошибок. Допустим, во время этого тестирования было обнаружено и
исправлено 200 ошибок, из которых 50 оказались из группы
намеренно помещенных в систему. Если исправить оставшиеся 50 известных
ошибок, сколько не выявленных ошибок, по-вашему, еще останется в
системе? Объясните, почему.
33. В каких случаях закон о защите авторских прав не может защитить
инвестиции разработчиков программного обеспечения?
34. По каким причинам патентное право не может защитить инвестиции
разработчиков программного обеспечения?
Общественные и социальные вопросы
Следующие вопросы приводятся для того, чтобы помочь вам разобраться в
некоторых этических, общественных и юридических аспектах использования
вычислительной техники, а также в ваших собственных воззрениях и тех
принципах, на которых они основаны. Задача не сводится к тому, чтобы просто дать
ответы на предложенные вопросы. Вы должны также разобраться, почему вы
ответили именно так, а не иначе, и насколько ваши суждения по различным
вопросам согласуются друг с другом.
1.
а) Исполнителю была поставлена задача разработать систему для
занесения медицинских записей в машину, соединенную с большой
сетью. Его предложения относительно требований безопасности
были отклонены по финансовым соображениям, и исполнителю было
приказано продолжить работу над проектом, применяя систему
безопасности, которую он считал недостаточной. Что ему следует
делать и почему?
б) Предположим, что упомянутый выше исполнитель разработал
систему так, как ему было приказано, и теперь опасается, что
медицинские записи могут подвергаться несанкционированному
просмотру. Что ему следует делать? В какой степени он несет
ответственность за возможные нарушения безопасности?
в) Допустим, вместо того чтобы подчиниться руководству,
исполнитель отказывается от работы с системой и поднимает шум,
разглашая недостатки проекта, что приводит к финансовым затруднениям
в компании и потере работы многими ни в чем не повинными
сотрудниками. Корректны ли действия этого исполнителя? Что если,
будучи всего лишь одним из рядовых членов группы разработчи-
376 Глава шестая. Технология разработки программного обеспечения
ков, он не знал о том, что в другом подразделении компании
предпринимались усилия по разработке действенной системы
безопасности, которую предполагалось применить и к его системе. Как это
изменит ваше отношение к действиям данного исполнителя?
(Помните, что взгляд исполнителя на ситуацию остается таким же,
как и раньше.)
2. Как должна распределяться ответственность, если крупная система
программного обеспечения разрабатывается многими людьми?
Существует ли иерархия ответственности? Существуют ли степени
юридической ответственности?
3. Как мы знаем, крупные и сложные системы программного
обеспечения часто разрабатываются многими людьми, однако лишь некоторые
из них имеют полное представление о существе проекта. Допустимо ли
работнику принимать участие в проекте, не имея полных знаний о его
назначении и свойствах?
4. До какой степени каждый несет ответственность за то, как его
достижения в конечном счете применяются другими людьми?
5. Должен ли профессионал в области компьютеров просто реализовы-
вать желания клиента или же скорее направлять его желания? Что
если профессионал предвидит, что желания клиента могут привести к
неэтичным последствиям? Например, клиент может пожелать внести в
систему некоторые упрощения для повышения ее эффективности, но
специалист может предвидеть, что такие упрощения могут стать
потенциальным источником появления ошибочных данных или
злоупотреблений в системе. Если клиент все же настаивает на своем решении,
может ли специалист считать себя свободным от ответственности?
Рекомендуемая литература
• Booch G. Objec-Oriented Analysis and Design with Applications, 2nd ed. —
Redwood City, CA: Benjamin/Cummings, 1994.
• Fenton N. E., Pfleeger S. L. Software Metrics: A Rigorous and Practical
Approach, 2nd ed.—Boston, MA: PWS, 1997.
• Pooley R., Stevens P. Using UML: Software Engineering with Objects and
Components. — Reading, MA: Addison-Wesley, 1999.
• Pressman R. S. Software Engineering: A Practioner's Approach, 4th ed. — New
York: McGraw-Hill, 1997.
• Schach S. R. Classical and Object-Oriented Software Engineering, 4th ed. — New
York: McGraw-Hill, 1999.
Рекомендуемая литература 377
Sommerville I. Software Engineering, 5th ed. — Reading, MA: Addison-Wesley,
1995. (Русский вариант 6-го изд. этой книги: Соммервиль Я. Разработка
программного обеспечения, 6-е изд. — М.: Издательский дом "Вильяме",
готовится к выпуску в 2002 г.)
Дополнительная литература
Ларман К. Применение UML и шаблонов проектирования.— М.:
Издательский дом "Вильяме", 2000 г.
Элиенс А. Принципы разработки объектно-ориентированных программ, 2-е
изд. — М.: Издательский дом "Вильяме", 2001 г.
Грехэм Я. Объектно-ориентированные методы. Принципы и практика, 3-е
изд. — М.: Издательский дом "Вильяме", готовится к выпуску в 2002 г.
378 Глава шестая. Технология разработки программного обеспечения
часть
третья
Организация данных
Выше уже говорилось, что хранящаяся внутри машины
информация представлена в кодированной форме и организована
способом, который совместим с соответствующей технологией
хранения, такой как индивидуально адресуемые ячейки памяти
или секторы на диске. Этот способ редко совпадает с тем
представлением информации, с которым имеет дело
пользователь данных. Например, данные об объеме продаж,
произведенных отделом сбыта компании за неделю, визуально могут
быть представлены в виде таблицы, в которой отдельные
столбцы содержат сведения по дням недели, а каждая строка
включает данные о результатах работы некоторого сотрудника
отдела. Другой пример — это визуальное представление фамилий и
должностей работников компании в виде структурной схемы
данной организации. Более того, компания может представить
сведения о наличных запасах на складах путем упорядочения
деталей либо по названиям, либо по стоимости.
В части III вы познакомитесь с тем, как запрограммировать
машину, чтобы она представляла пользователю данные так, как
будто они хранятся в наиболее удобной для него
концептуальной форме, и узнаете, как это может повлиять на выбор
формата, используемого при сохранении данных в машине. В главе 7
мы рассмотрим вопросы хранения данных в основной памяти
машины; в главе 8 — вопросы хранения данных в массовой
памяти, а глава 9 посвящена обсуждению систем баз данных.
глава
Структуры данных
СЕДЬМАЯ
Основная память машины организована в виде отдельных
ячеек с последовательно увеличивающимися адресами.
Однако часто эти ячейки используются как основа для
реализации иных способов размещения данных. Например,
записи об объемах продаж на протяжении недели удобнее
представить в виде таблицы, в которой сведения о реализации
различных товаров в разные дни недели располагаются в
отдельных строках и столбцах. В этой главе мы
познакомимся с тем, как смоделировать такие абстрактные
структуры данных в памяти машины. Задача состоит в том, чтобы
предоставить пользователю средства, позволяющие
оперировать подобными абстрактными структурами, вместо того
чтобы вникать в детали истинной организации данных в
основной памяти машины.
7.1. Массивы
7.2. Списки
Указатели
Непрерывные списки
Связанные списки
Поддержка концептуального списка
7.3. Стеки
Механизм возврата
Реализация стеков
7.4. Очереди
7.5. Древовидные структуры
Реализация древовидной
структуры
Пакет реализации бинарных
деревьев
*7.б. Специализированные типы
данных
Типы данных, определяемые
пользователем
Абстрактные типы данных
Инкапсуляция
Классы
*7.7. Указатели в машинном языке
* Звездочкой отмечены
разделы, рекомендованные для
факультативного изучения.
7.1. Массивы
В главе 5 уже говорилось о том, что многие языки высокого уровня
позволяют программисту писать алгоритмы так, как будто данные, с которыми он
работает, хранятся в виде прямоугольной структуры, называемой однородным
массивом. Здесь термин однородный указывает на то, что все элементы массива
имеют один и тот же тип. В этом разделе мы обсудим, как в действительности
реализуются такие массивы и как транслятор преобразует ссылки на массивы,
находящиеся в исходной программе, в термины ячеек памяти и их адресов.
Предположим, что алгоритм работы с 24 показаниями температуры,
снимаемыми через каждый час, написан на языке высокого уровня.
Программисту, вероятно, будет удобно представить эти показания в виде одномерного
массива с именем Readings (Показания), обращение к различным элементам
которого осуществляется по их позиции в списке, которая называется
индексом. Следовательно, первый элемент обозначается как Readings [1],
второй — Readings [2] и т.д.
Переход от этой концептуальной организации в виде одномерного массива
к действительной организации данных внутри машинной памяти вполне
очевиден, так как данные могут быть записаны в виде последовательности из 24
ячеек памяти с последовательно возрастающими адресами, значения в
которых будут упорядочены точно так, как предполагалось программистом. Зная
адрес первой ячейки в этой последовательности, транслятор легко сможет
преобразовать ссылки вида Readings [4] в соответствующие термины на
машинном языке. Для этого ему достаточно просто вычесть единицу из индекса
требуемого элемента, а затем прибавить полученный результат к адресу
ячейки памяти, хранящей первое показание температуры. Если первое
показание находится по адресу х, то четвертое будет расположено по адресу х +
(4- 1), как показано на рис. 7.1.
Теперь предположим, что программисту требуется написать программу
обработки данных о продажах, произведенных отделом сбыта в течение недели.
Такие данные обычно представляются в виде таблицы; в крайнем левом столбце
(сверху вниз) указываются фамилии работников отдела, а в верхней строке
(слева направо) — дни недели. Логично предположить, что программист,
вероятнее всего, будет писать программу, полагая, что данные организованы в виде
двухмерного массива, в котором значения в каждой строке означают объем
продаж, произведенных определенным работником, а значения в каждом столбце —
объем продаж, произведенных в определенный день недели.
Однако машинная память организована не в виде подобного
прямоугольника, а в виде отдельных ячеек с последовательными адресами. Поэтому
требуемую прямоугольную структуру массива необходимо смоделировать тем
или иным образом. Первым делом примем решение, что размер массива не
должен изменяться при внесении или обновлении данных. Это позволит
заранее определить количество памяти, необходимое для размещения всех
382 Глава седьмая. Структуры данных
элементов массива, и зарезервировать непрерывный участок ячеек памяти
соответствующего размера. Теперь можно выполнить запись данных в
массив, последовательно размещая их в памяти, строка за строкой. Иными
словами, начав работу с первой ячейки зарезервированного блока, будем
записывать значения из первой строки массива данных в последовательные
ячейки памяти. Затем, когда первая строка будет закончена, таким же образом
запишем вторую строку данных и т.д. (рис. 7.2). О таком методе хранения
данных говорят, что в нем используется развертка по строкам; в
противоположность этому методу, существует и развертка по столбцам, при которой
массив запоминается в памяти столбец за столбцом.
РИСУНОК 7.1
Массив Readings, хранящийся в памяти, начиная с ячейки памяти с адресом х
Давайте рассмотрим, как при таком методе хранения данных можно найти
ячейку памяти, содержащую значение из третьей строки четвертого столбца
нашего массива. Представим, что мы находимся в первой ячейке
зарезервированного блока памяти. Начиная с этой ячейки расположены данные первой
строки массива, затем второй, третьей и т.д. Чтобы добраться до данных
третьей строки, необходимо пропустить данные первой и второй строк.
Поскольку каждая строка содержит пять элементов данных (по одному на
каждый рабочий день — с понедельника по пятницу), то следует пропустить
десять элементов данных, чтобы попасть к первому элементу третьей строки.
Чтобы от начала третьей строки добраться до значения четвертого столбца
массива, следует продвинуться еще на три элемента. Таким образом, чтобы
попасть к элементу третьей строки четвертого столбца, в сумме потребуется
продвинуться на 13 элементов от начала блока.
7.1. Массивы
383
РИСУНОК 7.2
Память машины ч Значение в 4-м столбце 3-й строки
Двухмерный массив с четырьмя строками и пятью столбцами, записанный в памяти с разверткой по строкам
Предыдущие вычисления можно обобщить, что позволит получить общий
алгоритм, который может быть использован транслятором для преобразования
ссылок в формате с указанием номеров строк и столбцов в реальные адреса в
машинной памяти. В частности, если с является числом столбцов в массиве (т.е.
числом элементов в каждой строке), то адрес элемента i-й строки j-ro столбца
будет выглядеть следующим образом:
x + (cx(i-l)) + G-l)
Здесь х — это адрес ячейки, содержащей элемент из первой строки первого
столбца. Другими словами, чтобы дойти до i-й строки, необходимо продвинуться
на i -1 строки, каждая из которых содержит с элементов, а затем, чтобы дойти
до j-ro элемента этой строки, необходимо продвинуться еще на j - 1 элемент. В
нашем примере с = 5, i = 3,j=4, так что если массив записан в памяти, начиная с
адреса х, то элемент третьей строки четвертого столбца будет находиться по
адресу х + (5 х (3 - 1)) + (4 - 1) = х + 13. (Выражение (с х (i - 1)) + (j - 1) иногда называют
адресным полиномом.)
Исходя из приведенной выше информации, можно написать стандартные
программы преобразования запросов в формате строк и столбцов в формат
местонахождения затребованных данных внутри блоков памяти, содержащих массив.
Транслятор, например, использует этот метод при преобразовании ссылок вида
Sales [2,4] в действительный адрес памяти. Следовательно, программист со
своей точки зрения вполне может полагать, что данные организованы в виде
384 Глава седьмая. Структуры данных
таблицы (концептуальная структура), даже если в действительности они
хранятся в памяти в виде единой строки (действительная структура).
Вопросы для самопроверки
1. Покажите, как приведенный справа массив может быть
записан в основной памяти с разверткой по строкам.
2. Приведите формулу для нахождения элемента i-й строки j-
го столбца двухмерного массива, записанного в основной
памяти с разверткой по столбцам, а не по строкам.
3. Двухмерный массив из 8 строк и 11 столбцов записан в
памяти с разверткой по строкам, начиная с адреса 25. Каким будет адрес
элемента, содержащегося в третьей строке шестого столбца массива, если
каждый элемент массива занимает две ячейки памяти?
4. В языках программирования С, C++ и Java индексы массивов начинаются
с 0, а не 1, поэтому элемент, содержащийся в первой строке четвертого
столбца, обозначается как Аггау[0][3]. Какой адресный полином
используется в этом случае для преобразования ссылок из формы
Array [i] [j] в адреса памяти?
7.2. Списки
Важным свойством массивов является то, что их размер и форма постоянны.
Поэтому моделирование массивов в машинной памяти, по сути, является
процессом преобразования концептуального места расположения элемента в его
действительное местонахождение. Совсем по-другому обстоит дело с динамическими
структурами, форма и размер которых могут изменяться. Примером такой
структуры является список членов организации, который увеличивается по мере
вступления новых членов и сокращается, когда старые члены покидают
организацию. Моделирование таких концептуальных структур требует наличия
механизма самонастройки в пределах самих этих структур.
В этом разделе мы рассмотрим два способа реализации динамической
структуры, известной как список. Но сначала нам следует ввести понятие
указателя, которое является основным средством для реализации множества
динамических структур.
Указатели
Вспомним, что различные месторасположения данных в основной памяти
машины определяются числовыми адресами. Если известен адрес некоторого
элемента данных, то найти этот элемент не составляет труда. Будучи просто
числовыми величинами, эти адреса сами по себе легко могут сохраняться в
машинной памяти. Таким образом, записывая элемент данных в одну ячейку
памяти, мы можем записать адрес этого элемента данных в другую ячейку
7.2. Списки 385
памяти, а позднее использовать эту ячейку памяти в качестве средства
доступа к соответствующему элементу данных. Иными словами, значение в этой
ячейке сообщает нам, где искать данные.
В этом смысле ячейку памяти, содержащую адрес другой ячейки, можно
рассматривать как способ указания на расположение другой ячейки памяти.
Поэтому такие ячейки называют указателями. Понятие указателя уже
использовалось при обсуждении машинного цикла обработки команды,
включающего этапы выборки, декодирования и выполнения. В этом случае для
хранения адреса команды, которую требуется выполнять следующей,
используется счетчик адреса. В действительности существовало и другое, уже
устаревшее название этого регистра — указатель команд. URL-указатели,
используемые для связывания фрагментов гипертекстовых документов, также
являются примерами концепции указателя, но с той лишь разницей, что они
указывают на месторасположение элемента данных в Internet, а не в
основной памяти компьютера.
Сегодня многие языки программирования позволяют объявлять и размещать
указатели, а также манипулировать ими подобно тому, как это происходит с целыми
числами или строками символов. С помощью таких языков программист может
создавать в памяти машины сложные сети из элементов данных. Предположим, что
названия имеющихся в библиотеке изданий сохраняются в машинной памяти в
алфавитном порядке. Во многих случаях такая организация информации достаточно
удобна, однако в этом случае будет затруднительно найти все книги заданного
автора, поскольку сведения о них разбросаны по разным местам каталога в соответствии
с названиями. Для решения этой проблемы можно зарезервировать дополнительную
ячейку памяти для указателя в блоке ячеек памяти, представляющих каждую
книгу. Затем в каждую из ячеек-указателей можно поместить адрес другого блока,
представляющего книгу этого же автора. В результате все книги одного автора окажутся
объединенными в некоторое подобие кольца (рис. 7.3). Если вы найдете одну книгу
некоторого автора, то без труда сможете найти и все другие его книги — просто
следуя по указателям от одной книги к другой.
Непрерывные списки
Теперь давайте рассмотрим методы, которые можно использовать для
хранения списка имен в основной памяти машины. Одна из стратегий заключается в
том, чтобы хранить содержимое списка в едином блоке ячеек памяти с
последовательными адресами. Если предположить, что каждое имя будет состоять не
более чем из восьми букв, то можно разделить этот большой блок ячеек на
множество подблоков, каждый из которых будет состоять из восьми ячеек. В
каждом таком подблоке можно хранить отдельное имя, записанное с помощью
символов кода ASCII, — по одной ячейке памяти на каждую букву (рис. 7.4). Если
имя не заполняет все ячейки выделенного для него подблока, можно просто
заполнить оставшиеся ячейки ASCII-кодом символа "пробел". При использовании
такой системы для хранения списка из десяти имен понадобится блок из
восьмидесяти последовательно расположенных ячеек памяти.
386 Глава седьмая. Структуры данных
I РИСУНОК 7.3 I
Хранение библиотечной информации посредством упорядочения по названиям книг
и авторам
7.2. Списки
387
РИСУНОК 7.4
: Список имен, сохраняемый в памяти в виде непрерывного списка
Такая структура называется непрерывным списком и является типичной для
системы хранения, получаемой, когда программист хранит список в виде
массива. Например, если допустить, что каждое имя состоит не более чем из восьми
символов, то в данном случае программист сможет организовать список из
десяти имен в виде массива символов из десяти строк и восьми столбцов. В
результате образуется структура, представленная на рис. 7.4 (предполагается, что массив
записывается в памяти с разверткой по строкам).
Непрерывный список прост в применении, однако имеет некоторые существенные
недостатки. Предположим, что необходимо удалить одно из имен в списке. Если это
имя в настоящий момент расположено близко к началу списка и требуется
сохранить в списке тот же (допустим, алфавитный) порядок, понадобится переместить все
имена, находящиеся дальше по списку, вперед, чтобы заполнить пустое место в
памяти, образовавшееся после удаления. Более серьезная проблема возникнет, если
потребуется добавить имена, поскольку при этом может понадобиться переместить весь
список в другое место, так как придется получить новый блок непрерывной памяти,
достаточный для размещения расширенного списка.
Связанные списки
Во избежание указанных выше проблем можно позволить хранить
отдельные имена из одного списка в различных местах памяти, вместо того чтобы
хранить их все вместе в одном большом блоке непрерывной памяти. Для
этого потребуется хранить каждое имя в блоке из девяти непрерывных ячеек
памяти. Первые восемь предназначены для хранения самого имени, а
девятая используется в качестве указателя на следующий элемент списка. При
таком способе хранения элементы списка могут быть разбросаны по
множеству маленьких блоков памяти из девяти ячеек, объединяемых в единый
список указателями. В соответствии с используемым методом объединения,
такая структура называется связанным списком.
388
Глава седьмая. Структуры данных
Чтобы знать о местонахождении первого элемента списка, обычно
используется отдельная ячейка памяти, предназначенная для хранения адреса этого
элемента. Так как эта ячейка указывает на начало (или голову) списка, она
называется указателем головного элемента. Чтобы прочитать весь список, обработку
следует начать с того места, на которое ссылается указатель головного элемента.
Именно там можно найти первый элемент списка вместе с указателем на
следующий его элемент. Следуя этому указателю, можно найти второй элемент (и
так по всему списку). Таким образом, существует возможность перемещаться по
списку от одного его элемента к следующему.
Конец связанного списка отмечается специальным нулевым указателем
(NIL), представляющим собой специальный двоичный код, который находится в
ячейке указателя последнего элемента и означает, что больше элементов в
списке нет. Например, если мы условимся никогда не хранить элементы списка по
адресу 0, то нулевое значение никогда не будет значением обычного указателя и,
следовательно, может быть использовано в качестве нулевого указателя (NIL). В
этом случае перемещение по списку будет выполняться в соответствии с
системой указателей от одного элемента к следующему, пока не будет достигнут
указатель с нулевым значением.
Структура связанного списка представлена на схеме, показанной на рис. 7.5.
Здесь раздельные блоки памяти, используемые для хранения элементов списка,
изображены как отдельные прямоугольники. Надписи над каждым из
прямоугольников отражают структуру данного блока. Каждый указатель представлен
стрелкой, ведущей от самого указателя к адресуемому им элементу.
Уу
РИСУНОК 7.5
Структура связанного списка
7.2. Списки
389
Вернемся теперь к удалению и включению элементов списка. Наша задача
состоит в том, чтобы показать, как с помощью указателей можно исключить
перемещение элементов списка, что неизбежно при хранении его в одном
непрерывном блоке памяти. Обратите внимание, что удалить имя из списка можно
посредством изменения значения одного указателя: указатель, который прежде
указывал на удаляемое имя, изменяется так, чтобы указывать на имя,
следующее за удаляемым (рис. 7.6). Теперь при просмотре измененного списка
удаленное имя будет пропущено, так как оно больше не является частью цепочки
элементов данного списка.
РИСУНОК 7.6
Удаление элемента из связанного списка ;
Операция включения нового элемента в список не намного сложнее. Прежде
всего следует найти неиспользуемый блок из девяти ячеек памяти и записать
новое имя в его первые восемь ячеек. В девятую ячейку заносится адрес
элемента списка, который должен следовать за новым элементом. Наконец, значение
указателя элемента списка, который будет предшествовать новому элементу,
изменяется таким образом, чтобы он указывал на этот новый элемент (рис. 7.7).
После выполнения указанных манипуляций при каждом просмотре списка вновь
вставленный элемент будет находиться на положенном ему месте.
390
Глава седьмая. Структуры данных
Включение элемента в связанный список
Поддержка концептуального списка
. При написании программы программисту часто приходится выбирать, как
реализовать список — в виде непрерывной структуры или связанного списка. Но
когда решение принято и структура списка определена, программисту следует
обратить внимание на другие детали. Другими словами, программа должна быть
сконструирована так, чтобы данный список мог использоваться другими частями
программы как некоторый абстрактный инструмент.
Например, рассмотрим задачу разработки пакета программ для поддержки
процедуры регистрации слушателей курса, выполняемой секретарем
университета. Программист, разрабатывающий такой пакет, при решении данной задачи
может выбрать вариант создания отдельной списочной структуры для каждого
читаемого курса. При этом каждый список будет содержать фамилии
слушателей данного курса в алфавитном порядке. После того как этот механизм будет
реализован, программист сможет перенести свое внимание на более общие
аспекты задачи, вместо того чтобы вновь и вновь возвращаться к тому, как в
случае необходимости будут перемещаться элементы в непрерывном списке или
меняться указатели в связанном списке.
Для этого программист может написать набор процедур для выполнения
таких действий, как включение нового элемента, удаление старого элемента, поиск
элемента или распечатка списка, а затем использовать эти процедуры в
создаваемом им пакете программ для работы со списками слушателей в системе
регистрации. Например, чтобы зарегистрировать студента Дж. У. Брауна в качестве
7.2. Списки
391
слушателя курса "Физика 208", программист может использовать следующую
инструкцию:
Insert ("Браун Дж. У.", "Физика 208")
В этом случае предполагается, что процедура Insert (Вставить) выполнит все
действия, необходимые для включения в список нового элемента. Тот же способ
программист может применить и для разработки других частей программы, не
вдаваясь в детали, как на самом деле реализован список.
Проблема указателей
Известно, что использование блок-схем может привести к путанице при разработке алгоритмов (см.
главу 4), а беспорядочное использование команд безусловного перехода goto ведет к созданию плохо
спроектированных программ (см. главу 5). Точно так же бессистемное использование указателей, как
оказалось, может привести к созданию необоснованно сложных и потенциально приводящих к ошибкам
структур данных. Чтобы внести некоторый порядок в этот хаос, многие языки программирования ограничивают
допустимую гибкость использования указателей. Например, в языке Java не разрешается использовать
указатели общего вида. Допускается применение только ограниченных типов указателей — так называемых
ссылок. Одно из отличий между ссылками и указателями состоит в том, что значение ссылки нельзя
модифицировать с помощью арифметических операций. Например, если программист, работающий на языке
Java, хочет переместить ссылку Next к следующему элементу непрерывного списка, он должен
использовать инструкцию, эквивалентную следующему выражению:
переадресовать ссылку Next к следующему элементу списка
Тогда как программист, работающий на языке С, может использовать инструкцию, эквивалентную следующей:
присвоить ссылке Next значение Next + 1
Заметим, что инструкция на языке Java лучше отражает назначение производимого действия. Более того,
для выполнения инструкции языка Java необходимо, чтобы существовал еще один элемент списка. Однако
если ссылка Next уже указывает на последний элемент списка, то выполнение инструкции языка С
приведет к тому, что она будет указывать на нечто, находящееся вне списка, — распространенная ошибка
начинающих (и не только начинающих) программистов.
Примером реализации данного подхода может служить процедура PrintList
(Печать списка), предназначенная для распечатки связанного списка имен
(рис. 7.8). Вспомним, что на первый элемент списка указывает специальный
указатель, называемый указателем головного элемента, и что каждый элемент
списка состоит из двух частей: имени и указателя. После того как эта процедура
будет разработана, она может использоваться в качестве абстрактного
инструмента печати списка, и при этом уже не потребуется вникать в то, как список
организован на самом деле. Например, чтобы напечатать список слушателей
курса "Экономика 301", программисту потребуется написать только следующую
директиву: PrintList("Экономика 301").
392 Глава седьмая. Структуры данных
I РИСУНОК 7,8 | _
procedure PrintList (<список>)
Assign <текущий указатель> the value значение указателя на
головной элемент списка <список>.
while (<текущий указатель> не равен NIL) do
(Печатать поле имени из элемента списка <список>, на
который указывает <текущий указатель>;
получить значение из поля указателя элемента списка
<список>, на который указывает <текущий указатель>,
и присвоить это значение переменной <текущий указатель>.)
Процедура распечатки связанного списка
Вопросы для самопроверки
1. Если вам известен адрес первого элемента непрерывного списка, то как
узнать адрес пятого элемента? Что нужно делать в случае связанного списка?
2. Какое условие показывает, что связанный список пуст?
3. Преобразуйте процедуру на рис. 7.8 так, чтобы она прекращала печать, как
только будет напечатано определенное имя.
4. Разработайте процедуру нахождения определенного элемента в связанном
списке с последующим его удалением.
7.3. Стеки
Одно из свойств списков, которое делает связанную структуру более
привлекательной, чем непрерывная, состоит в необходимости включения и
удаления элементов. Вспомним, что в случае непрерывного списка подобные
операции могут потребовать широкомасштабных перемещений элементов,
необходимых для заполнения или создания в списке свободных мест. Если
ограничить область применения операций вставки и удаления только
концами списка, использование непрерывной структуры окажется более удобным.
Примером подобной структуры является стек — список, в котором все
включения и исключения элементов выполняются только на одном конце
структуры. Следствием такого ограничения является то, что элемент, включенный
в список последним, всегда будет первым удаляемым, что послужило
основанием называть стеки структурами типа LIFO (Last In, First Out —
последним пришел, первым ушел).
Конец стека, на котором осуществляются включения и исключения
элементов, называется вершиной. Другой конец стека иногда называют его
основанием. Чтобы отразить тот факт, что доступ к стеку ограничен элементом на его
7.3. Стеки 393
вершине, по отношению к операциям включения и исключения используется
специальная терминология. Процесс включения объекта в стек называется
операцией вставки, а процесс удаления — операцией извлечения. Таким
образом, мы говорим о вставке элемента в стек и извлечении его из стека.
Механизм возврата
Классическим приложением стеков является выполнение программ,
содержащих процедуры, с которыми мы встречались при обсуждении нашего
псевдокода. Когда запрашивается выполнение процедуры, машина должна
переключить свое внимание на процедуру, а позднее, когда процедура завершится,
вернуться к точке вызова для продолжения работы. Это означает, что при
переключении должен использоваться некоторый механизм запоминания адреса,
к которому нужно будет вернуться после завершения процедуры.
Ситуация усложняется тем, что процедура может и сама потребовать
выполнения другой процедуры, которая, в свою очередь, также может потребовать
вызова еще одной и т.д. (рис. 7.9). Как следствие, запомненных адресов возврата
становится все больше. Позднее, по мере того как каждая из запущенных
процедур будет завершена, выполнение должно возвращаться к соответствующей
позиции в той части программы, которая вызывала завершившуюся процедуру.
Следовательно, системе нужно запоминать адреса возврата, а позднее извлекать
их в правильном порядке.
| РИСУНОК 7.9 | _
Завершение работы вложенных процедур происходит в порядке, обратном порядку их вызова
394
Глава седьмая. Структуры данных
Стек является идеальной структурой для организации такой системы. При
вызове каждой процедуры указатель на соответствующий адрес возврата
вставляется в стек, а по окончании каждой процедуры очередной элемент извлекается
из вершины стека. Этот механизм гарантирует получение указателя на
правильный адрес возврата. Данный пример показателен для общего типа применения
стеков, поскольку он демонстрирует взаимосвязь структуры стека и организации
процессов возврата. Действительно, концепция стека является совершенно
органичной для любого процесса, связанного с выходом из системы в порядке,
обратном порядку входа в нее.
В качестве другого примера механизма возврата рассмотрим следующее.
Предположим, что имена, сохраняемые в связанном списке (того же типа, что
описан в разделе 7.2), необходимо распечатать в обратном порядке, т.е.
последнее имя должно стать первым. Проблема заключается в том, что единственный
способ доступа к именам в данном списке — это следование существующей
структуре ссылок. Таким образом, необходимо найти способ сохранения каждого
выбранного из списка имени до тех пор, пока не будут выбраны и напечатаны
все имена, следующие за ним. Наше решение заключается в том, чтобы
просмотреть список от начала до конца, одновременно вставляя все найденные
имена в стек. После того как будет достигнут конец списка, следует выполнить
печать имен, последовательно извлекаемых из стека (рис. 7.10). Текст процедуры,
реализующей этот процесс, представлен на рис. 7.11.
Реализация стеков
Для реализации стековой структуры в памяти компьютера обычно
резервируется блок непрерывно расположенных ячеек памяти, достаточно большой, чтобы
стек мог разместиться там при его расширении и сокращении. (Определение
размера такого блока всегда является ответственным решением. Если
зарезервировать слишком мало места, стек в конце концов превысит отведенное ему
пространство, если же зарезервировать слишком большой участок, это приведет к
нерациональному использованию памяти.) Один из концов этого блока
отмечается как основание стека. Именно сюда помещается первый вставляемый в стек
элемент. По мере поступления каждый последующий элемент вставляется вслед
за его предшественником, при этом стек увеличивается в сторону другого конца
зарезервированного блока.
Таким образом, при вставке и извлечении элементов вершина стека
перемещается вперед и назад внутри зарезервированного блока ячеек памяти.
Следовательно, необходим какой-то механизм запоминания информации о текущем
адресе вершины стека. Для этого адрес элемента, являющегося в настоящее время
вершиной стека, записывается в дополнительную ячейку памяти, называемую
указателем вершины стека. Таким образом, указатель вершины стека всегда
определяет текущее положение вершины стека.
7.3. Стеки 395
РИСУНОК 7.10
Использование стека для печати элементов связанного списка в обратном порядке
396
Глава седьмая. Структуры данных
I РИСУНОК 7.11 I
procedure Обратная_Печать (<список>)
Assign <текущий указатель> the value значение указателя на
головной элемент списка <список>.
while (<текущий указателе не равен NIL) do
(Вставить в стек поле имени из элемента списка <список>, на
который указывает <текущий указатель>;
получить значение из поля указателя элемента списка
<список>, на который указывает <текущий указатель>,
и присвоить это значение переменной <текущий указатель>.)
while (стек не пуст) do
(Извлечь из стека значение имени и напечатать его.)
Процедура печати связанного списка в обратном порядке, использующая дополнительный стек
Вся система в целом представлена на рис. 7.12 и работает следующим
образом. Чтобы вставить элемент в стек, прежде всего следует так изменить текущее
значение указателя вершины стека, чтобы оно указывало на свободную
позицию, следующую за тем элементом, который является текущей вершиной стека,
а затем поместить в эту позицию новый элемент. Чтобы извлечь элемент из
стека, считываются те данные, на которые указывает указатель вершины стека, а
затем текущее значение указателя вершины стека корректируется таким
образом, чтобы оно указывало на следующий (ниже) расположенный элемент стека.
Организация стека в памяти компьютера
Как и в случае со списками, программист, вероятно, сочтет более удобным
написать специальные процедуры, выполняющие операции вставки и
извлечения элементов стека, что позволит ему использовать стеки в качестве
абстрактных инструментов. Заметим, что эти процедуры должны корректно
обрабатывать такие особые ситуации, как попытку извлечь элемент из пустого стека или
7.3. Стеки 397
вставить новый в полностью заполненный. В частности, полная система работы
со стеком будет, вероятно, содержать процедуры для вставки и извлечения
элементов, а также для проверки, не является ли стек пустым или заполненным.
При организации стека в непрерывном блоке ячеек памяти различие между его
концептуальной и реальной структурами в основной памяти невелико.
Предположим, однако, что невозможно зарезервировать фиксированный блок памяти и
гарантировать, что указанного объема будет достаточно на все случаи жизни. Решение
состоит в реализации стека в виде связанной структуры, аналогичной той, которая
обсуждалась в разделе 7.2. Это позволит избежать ограничения размера стека блоком
фиксированного размера, так как при такой реализации элементы стека могут быть
разбросаны по небольшим участкам свободного пространства в любых доступных
областях памяти. В этом случае концептуальная структура стека будет значительно
отличаться от реальной организации данных в памяти.
Вопросы для самопроверки
1. Перечислите некоторые дополнительные примеры применения стеков в
повседневной жизни.
2. Предположим, что основная программа вызывает процедуру А, которая
вызывает процедуру В, а после завершения процедуры В процедура А вызывает
процедуру С. Следуя этому сценарию, продемонстрируйте динамику
заполнения данными стека адресов возврата.
3. Какое условие будет означать, что стек пуст, если использовать описанный
метод реализации стека в непрерывном блоке ячеек памяти?
4. Разработайте процедуру для извлечения элемента из стека, реализованного с
использованием указателя вершины стека. Если стек пуст, процедура должна
печатать сообщение об ошибке.
5. Опишите, как стек может быть реализован на языке высокого уровня в
терминах одномерного массива.
7.4. Очереди
В противоположность стеку, в котором включение и исключение элементов
производится на одном и том же конце, очередь представляет собой такой
список, в котором включение элементов выполняется на одном конце, а
исключение — на другом. Мы уже встречались с подобными структурами в главе 3 при
обсуждении механизма перевода программ в режим ожидания. В частности, там
отмечалось, что подобные структуры относятся к системам хранения,
действующим по принципу FIFO (First In, First Out — первым вошел, первым вышел).
Действительно, концепция очереди органична для любой системы, в которой
объекты обслуживаются в порядке их поступления. Концы очереди получили
свое название в соответствии с их ролью. Конец, на котором производится
удаление элементов из очереди, называется началом (иногда головой), аналогично
398 Глава седьмая. Структуры данных
тому, как о человеке, которого должны обслужить в кафетерии следующим,
говорят, что он находится в начале (в голове) очереди. Соответственно, тот конец
очереди, на котором происходит включение в нее новых элементов, называют ее
концом (или хвостом).
Мы можем реализовать очередь в машинной памяти в блоке непрерывных
ячеек способом, аналогичным организации стека. Поскольку потребуется выполнять
операции на обоих концах структуры, для использования в качестве указателей
понадобится выделить две отдельные ячейки памяти вместо одной, как это
делалось при использовании стека. Один из этих указателей, указатель начала,
отслеживает положение начала очереди, а другой, указатель конца, — положение
конца очереди. Когда очередь пуста, оба указателя указывают на один и тот же адрес
памяти (рис. 7.13). Каждый раз при включении в очередь новый элемент
помещается в позицию, определяемую указателем конца очереди, после чего значение
этого указателя корректируется таким образом, чтобы он указывал на следующую
свободную позицию. Таким образом, указатель конца очереди всегда указывает на
первую свободную позицию в конце очереди. Удаление элемента из очереди
означает извлечение элемента, на который указывает указатель начала очереди, с
последующим изменением значения этого указателя таким образом, чтобы он
указывал на элемент очереди, следующий за только что удаленным.
| РИСУНОК 7.13 | _^
Реализация очереди с использованием указателей ее начала и конца
7.4. Очереди
399
Однако описанный выше механизм хранения связан с некоторой проблемой.
Если оставить его работу без контроля, то очередь будет ползти по памяти как
ледник, разрушая все данные на своем пути (рис. 7.14). Это движение —
результат весьма эгоистической политики включения каждого нового элемента в
очередь путем простого помещения его в память непосредственно после
предыдущего и соответствующей переустановки указателя конца очереди. Если добавить в
очередь достаточно много элементов, то в конце концов хвост очереди дотянется
до конца машинной памяти.
РИСУНОК 7.14
Очередь, "ползущая" по памяти (сначала она содержит элементы А, В, С, а позднее — элементы С, D, Е и F)
Это чрезмерное использование памяти является следствием не размеров
самой очереди, а побочным эффектом способа доступа к ней. (Небольшая, но
активная очередь вполне может потребовать существенно больше ресурсов
машинной памяти, чем очередь большая, но неактивная.) Одно из решений состоит в
перемещении элементов очереди вперед по мере удаления впередистоящих
элементов; это подобно очереди за театральными билетами, когда люди делают шаг
вперед каждый раз, как будет обслужен очередной человек. Однако такое
массовое перемещение данных весьма неэффективно. Единственное, что нам
требуется, — это ограничить используемую очередью область памяти, не прибегая к
массовому переупорядочению ее элементов.
Наиболее распространенное решение — выделить очереди отдельный блок
памяти и организовать заполнение очереди с одного конца блока, разрешив ей
свободное перемещение к другому концу этого блока. Затем, когда конец
очереди достигнет конца блока, следующие поступающие элементы снова помещаются
в начальный конец блока, который к этому времени уже освободится.
Аналогичным образом, когда последний элемент блока, в конце концов, станет
начальным в очереди и будет удален, указатель начала очереди вновь будет
установлен на начало блока, где и расположены оставшиеся элементы очереди, кото-
400
Глава седьмая. Структуры данных
рые находились до этого момента в ожидании. Таким образом, очередь, вместо
того чтобы "бродить" по всей памяти, преследует саму себя по кругу внутри
выделенного ей блока памяти.
Такой метод реализации приводит к созданию структуры, называемой
циклической очередью, поскольку в отведенном для очереди блоке памяти образуется
циклическая структура из ячеек памяти (рис. 7.15). С точки зрения механизма
управления очередью, последняя ячейка блока непосредственно примыкает к первой.
Циклическая очередь, содержащая буквы от F до 0:
а) действительное расположение элементов очереди в памяти;
б) концептуальное представление очереди, в котором ее последняя ячейка непосредственно примыкает к первой
7.4. Очереди
401
И вновь следует подчеркнуть отличие между концептуальной структурой, как
ее представляет себе пользователь очереди, и реальной циклической,
реализованной в машинной памяти. Как и в случае рассмотренных раньше типов
структур, это различие обычно преодолевается с помощью специального программного
обеспечения. Иными словами, помимо набора ячеек памяти, используемых для
хранения данных, реализация очереди должна включать и набор процедур для
включения и исключения элементов очереди, а также для определения того,
является ли очередь пустой или заполненной до предела. В этом случае
программист, работающий над другой частью программного обеспечения, сможет
выполнять в очереди включение и исключение элементов с помощью вызова
соответствующих процедур, не вдаваясь в детали того, как данная очередь реализована в
памяти на самом деле.
Вопросы для самопроверки
1. Используя карандаш и бумагу, запишите, как будет выглядеть описанная в
этом разделе циклическая очередь при следующем сценарии ее
использования. (Предполагается, что зарезервированный для очереди блок памяти
может содержать только четыре элемента.)
Включить элемент А.
Включить элемент В.
Включить элемент С.
Исключить элемент.
Исключить элемент.
Включить элемент D.
Включить элемент Е.
Исключить элемент.
Включить элемент F.
Исключить элемент.
2. Пусть очередь реализована в виде циклической структуры, как описано в
данном разделе. Каково взаимоотношение указателей начала и конца
очереди, когда очередь пуста и когда очередь полностью заполнена? Как можно
определить, является очередь пустой или полностью заполненной?
3. Разработайте процедуру включения элемента в циклическую очередь.
7.5. Древовидные структуры
Последним типом структуры, который мы рассмотрим в этой главе, является
древовидная. Такой тип обычно имеет схема организации типовой компании
(рис. 7.16). На этой схеме президент компании представлен главной вершиной,
от которой линии ведут к вице-президентам, за которыми следуют региональные
менеджеры, и т.д. На это интуитивное определение древовидной структуры мы
наложим одно дополнительное ограничение, которое (в терминах схемы органи-
402 Глава седьмая. Структуры данных
зации компании) состоит в том, что ни один сотрудник компании не может быть
в непосредственном подчинении у двух различных людей. Другими словами,
ветви организации не могут пересекаться на находящихся ниже уровнях.
РИСУНОК 7.16
Пример схемы организации типовой компании ;'
Каждый элемент дерева называется вершиной, или узлом. Самая верхняя
точка именуется корневой вершиной (если перевернуть рисунок вверх ногами,
этот узел будет представлять собой основание, или корень дерева). Вершины
на противоположной стороне дерева называются конечными (или листами).
Выбрав некоторую вершину дерева, можно заметить, что эта вершина вместе с
расположенными ниже ее вершинами также образует некоторую древовидную
структуру. Эту меньшую структуру принято называть поддеревом. При
обсуждении древовидной структуры говорят, что каждая вершина порождает те
вершины, которые находятся непосредственно ниже ее. В этом смысле могут
употребляться ссылки на предков и потомков данной вершины.
Непосредственных потомков некоторой вершины называют ее дочерними вершинами, а ее
непосредственного предка — родительской вершиной. Кроме того, вершины,
имеющие общую родительскую вершину, называют близнецами. Наконец,
существует понятие глубины дерева, которая определяется количеством узлов на
самом длинном пути от корня к листу. Другими словами, глубина дерева —
это число горизонтальных уровней в нем.
В последующих главах мы неоднократно будем встречаться с древовидными
структурами, поэтому сейчас не будем утруждать себя примерами. Ниже в этом
разделе, а также при обсуждении индексной организации данных в главе 8 будет
показано, что чаще всего информация организовывается в виде дерева с целью
быстрого нахождения данных. Кроме того, в главе 10 мы обсудим, как с
помощью деревьев можно анализировать игровые алгоритмы.
7.5. Древовидные структуры
403
Реализация древовидной структуры
При обсуждении методов представления деревьев в памяти мы ограничимся
только бинарными деревьями, т.е. такими, в которых каждая вершина имеет не
больше двух дочерних вершин. Такие деревья обычно хранятся в памяти с
использованием связанных структур, аналогичных связанным спискам. Однако вместо двух
компонентов (значение данных, за которым следует указатель) каждый элемент (или
вершина) бинарного дерева состоит из трех компонентов: значения данных,
указателя первой дочерней вершины и указателя второй дочерней вершины. Хотя в
пределах памяти машины не существует понятий "левый" или "правый", исходя из
способа изображения дерева на бумаге, удобно считать первый указатель указывающим
на левую дочернюю вершину, а второй — на правую дочернюю. Таким образом,
каждая вершина дерева представляется коротким непрерывным блоком ячеек памяти,
формат которого представлен на рис. 7.17.
РИСУНОК 7.17
Представление вершины бинарного дерева в памяти машины
Для сохранения дерева в памяти необходимо найти доступные блоки
ячеек, достаточные для сохранения отдельных вершин, и связать эти вершины в
соответствии с желаемой структурой данного дерева. Это означает, что
каждый указатель надо установить так, чтобы он указывал на левую или правую
дочернюю вершину для данной вершины, или присвоить ему значение NIL,
если в этом направлении у дерева больше нет вершин. Отсюда следует, что у
листовых вершин дерева оба указателя имеют значение NIL. Наконец,
отдельно от дерева необходимо выделить специальную ячейку памяти,
называемую указателем корневой вершины, в которой будет храниться адрес
корневой вершины дерева. Наличие указателя корневой вершины
обеспечивает первоначальный доступ к дереву.
Пример такой связанной системы хранения представлен на рис. 7.18. Здесь
изображена концептуальная структура бинарного дерева вместе с реальным
представлением этого дерева в памяти машины. В этой системе хранения с
помощью указателя корневой вершины всегда можно получить доступ к корневой
вершине дерева, а затем осуществить обход вниз по дереву, следуя от вершины к
вершине по соответствующим указателям.
404 Глава седьмая. Структуры данных
РИСУНОК 7.18 |_
Концептуальная и реальная организации бинарного дерева с использованием связанной системы хранения
Альтернативой связанной системе хранения бинарных деревьев является
метод, предусматривающий выделение непрерывного блока ячеек памяти. В
первой из этих ячеек записывается корневая вершина (для простоты
предположим, что каждая вершина дерева занимает одну ячейку), во второй —
левый дочерний элемент корневой вершины, в третьей — правый дочерний
элемент и т.д. В общем случае левый и правый дочерние элементы вершины
п находятся в ячейках 2п и 2п + 1 соответственно. В пределах блока ячейки,
не используемые в данной древовидной структуре, отмечаются специальным
двоичным кодом, означающим отсутствие данных. В результате
концептуальная древовидная структура, изображенная на рис. 7.18, будет сохранена в
памяти в виде, представленном на рис. 7.19. Отметим, что, в сущности, при
этой системе хранения вершины, находящиеся на последовательно
понижающихся уровнях дерева, сохраняются в виде непрерывных сегментов,
следующих друг за другом. Иначе говоря, первый элемент блока является
корневой вершиной дерева, за ним следуют дочерние вершины корневой
вершины, затем — вершины-"внуки" корневой вершины и т.д.
7.5. Древовидные структуры
405
РИСУНОК 7.19
Древовидная структура (рис. 7.18), сохраненная в памяти без использования указателей
В отличие от связанных структур, описанных выше, эта альтернативная
система хранения обеспечивает удобный метод нахождения для любой вершины
дерева ее родительской вершины или вершины, имеющей с данной общую
родительскую вершину. (Конечно, это можно реализовать и в связанной структуре
путем введения дополнительных указателей.) Местонахождение родительской
вершины для данной вершины можно найти, разделив позицию данной
вершины в блоке на 2 и отбросив остаток (например, родительской вершиной для
вершины, находящейся на 7-й позиции в блоке, будет вершина в позиции 3).
Местоположение вершины, имеющей общего родителя с данной, можно найти,
прибавив 1 к местоположению данной вершины, если оно четно, и отняв 1, если
данная вершина находится на нечетной позиции в блоке (например, вершина,
имеющая общего родителя с вершиной в позиции 4, находится в позиции 5, а
вершина, имеющая общего родителя с вершиной в позиции 3, — в позиции 2).
Кроме того, эта система хранения эффективно использует область памяти в
случае бинарных деревьев, структура которых практически сбалансирована (оба
поддерева, находящиеся ниже корневой вершины, имеют одинаковую глубину) и
является полной (дерево не имеет длинных тонких ветвей). Для деревьев, не
обладающих указанными характеристиками, данная система хранения может
оказаться неэффективной, как показано на рис. 7.20.
Пакет реализации бинарных деревьев
Как и для других структур, которые уже обсуждались нами выше, удобно
отделить методы реализации деревьев от других частей создаваемой системы
программного обеспечения. Следуя этой схеме, программист обычно определяет,
какие действия будут выполняться с деревом, пишет процедуры для них, а затем
использует созданные процедуры для доступа к дереву из других частей
программы. Таким образом, подготовленные процедуры обработки вместе с
областью хранения образуют программный пакет, используемый в качестве
абстрактного инструмента.
Чтобы наглядно продемонстрировать пример такого пакета, давайте вернемся
к задаче хранения списка имен в алфавитном порядке. Предположим, что с этим
списком будут выполняться следующие операции: i
406 Глава седьмая. Структуры данных
Поиск определенного элемента.
Распечатка списка в алфавитном порядке.
Включение нового элемента.
Наша задача — разработать систему хранения данных вместе с набором
процедур, выполняющих указанные операции.
РИСУНОК 7.20
^"^^ !":
Пример неполного и несбалансированного дерева в концептуальной форме и схема его размещения
в памяти в системе без указателей
Мы начнем с рассмотрения возможностей, касающихся процедуры поиска в
списке. Если список хранится в соответствии с моделью связанного списка,
описанной в разделе 7.2, поиск придется осуществлять методом последовательного
перебора, что, как уже указывалось в главе 4, может оказаться весьма
неэффективным, если список достаточно длинен. Следовательно, для списка необходимо
выбрать реализацию, позволяющую применить алгоритм двоичного поиска (см.
главу 4). Чтобы можно было применить указанный алгоритм, система хранения
должна позволять находить средний элемент последовательно уменьшающихся
частей списка. Такая операция возможна при использовании схемы
непрерывного списка, поскольку всегда можно вычислить адрес среднего элемента тем же
способом, который применяется для вычисления адресов элементов массива.
Однако использование схемы непрерывного списка связано с проблемой включения
новых элементов, речь о которой шла в разделе 7.2.
Для решения поставленной задачи необходимо хранить список в виде
связанного бинарного дерева, вместо того чтобы использовать одну из традиционных
систем хранения списков. Можно сделать средний элемент списка его корневой
вершиной, средний элемент оставшейся первой части списка — ее левой дочер-
7.5. Древовидные структуры
407
ней вершиной, а средний элемент второй части списка — ее правой дочерней
вершиной. Средние элементы оставшихся четвертей списка будут дочерними
вершинами дочерних вершин корневой вершины и т.д. Например, дерево,
показанное на рис. 7.21, представляет собой список, состоящий из букв А, В, С, D,
Е, F, G, H, I, L, К, L, М. (Если рассматриваемая часть списка содержит четное
число элементов, будем считать средним больший из двух элементов.)
Латинские буквы от А до М, организованные в виде упорядоченного дерева
Сборка мусора
При расширении и сжатии динамических структур данных, таких как связанные списки и деревья,
происходит распределение и освобождение пространства памяти. Процесс поиска и восстановления
неиспользуемого пространства памяти с целью его утилизации известен как сборка мусора. Сборка мусора требуется
во многих ситуациях. Программа управления памятью, имеющаяся в составе операционной системы,
должна осуществлять сборку мусора при распределении и освобождении памяти. Программа управления
файлами выполняет сборку мусора при размещении файлов в массовой памяти машины и удалении их
оттуда. Кроме того, каждому процессу, работающему под управлением диспетчера, может понадобится
осуществить сборку мусора в пределах выделенного ему пространства памяти.
Процедура сборки мусора содержит скрытые проблемы. В случае связанных структур при каждом
изменении указателя на элемент данных сборщик мусора должен решить, освобождается ли та область в памяти,
на которую исходно указывал указатель. Проблема становится особенно сложной в переплетающихся
структурах данных, содержащих множество ветвей указателей. Неточности в процедурах сборки мусора
могут привести к потере данных или неэффективному использованию пространства памяти. В частности,
если сборка мусора не в состоянии восстанавливать пространство памяти, объем доступного пространства
будет медленно сокращаться — явление, известное как утечка памяти.
Для поиска в списке, хранящемся в таком виде, следует начать со сравнения
искомого значения с корневой вершиной. Если они эквивалентны, поиск успеш-
408 Глава седьмая. Структуры данных
но завершается. Если они не равны, выполняется переход к левой или правой
дочерней вершине, в зависимости от того, является ли искомое значение
меньшим или большим корневого. Там находится средний элемент оставшейся части
списка, необходимый для продолжения поиска. Этот процесс сравнения и
перемещения к дочерним элементам продолжается до тех пор, пока не будет найдено
искомое значение (это означает, что поиск был успешным) или не будет
достигнут листовой узел дерева, без нахождения нужного нам значения (это означает,
что поиск завершился неудачей). На рис. 7.22 показано, как этот процесс поиска
можно сформулировать для связанной древовидной структуры. (Поясняющие
комментарии отмечены звездочками.)
** Переменная <текущий указатель> используется для хранения **
; "указателя на текущую позицию в дереве. Вершина в этой **
"позиции называется текущей вершиной. **
: procedure BinarySearch (<дерево>, <искомое значение>)
assign <текущий указателе the value значение корневого
указателя дерева <дерево;
assign <найдено> the value "ложь";
.. while (<найдено> равно "ложь" и <текущий указатель> не NIL) do
, ' [Выбрать подходящий вариант (case) из перечисленных ниже и
выполнить предусмотренные в нем действия;
case 1, <искомое значение> = значение из текущей вершины:
(assign <найдено> the value "истина")
case 2, <искомое значение> < значения из текущей вершины:
(assign <текущий указатель> the value указатель на левую
дочернюю вершину текущей вершины)
case 3, <искомое значение> > значения из текущей вершины:
(assign <текущий указатель> the value указатель на правую
дочернюю вершину текущей вершины)
:. ]
if (<найдено> = "ложь") then (объявить поиск неудачным) ;
else (объявить поиск успешным)
i[ >>
' Процедура двоичного поиска в связанном бинарном дереве ;
Можно предположить, что изменение естественного последовательного
порядка хранения списка для обеспечения эффективности поиска приведет к
возникновению трудностей при распечатке списка в алфавитном порядке. Однако это
не так. Поскольку левое поддерево содержит все элементы, меньшие корневой
вершины, а правое — все элементы, большие ее, для того чтобы распечатать
список в алфавитном порядке, нам просто надо распечатать левое поддерево в
алфавитном порядке, корневую вершину, а затем печатать в алфавитном
порядке правое поддерево (рис. 7.23). Предварительный вариант процедуры,
осуществляющей печать списка, выглядит следующим образом:
7.5. Древовидные структуры 409
if (дерево не пусто)
then (печатать левое поддерево в алфавитном порядке;
печатать корневую вершину;
печатать правое поддерево в алфавитном порядке)
I РИСУНОК 7.23
Р! Печать связанного бинарного дерева в алфавитном порядке I
щ
Можно возразить, что эта процедура мало чем поможет при разработке
полной процедуры печати, поскольку здесь остаются нерешенными задачи печати
левого и правого поддеревьев в алфавитном порядке. Однако, по существу, обе
эти задачи совершенно эквивалентны исходной, просто объем печати каждого из
поддеревьев меньше объема печати всего дерева. Таким образом, для задачи
печати дерева необходимо решить меньшую задачу печати поддеревьев, что
предполагает рекурсивный подход к решению всей проблемы.
Следуя этому подходу, можно привести наш предварительный вариант к
полному тексту процедуры печати дерева, написанной на псевдокоде (рис. 7.24).
Процедуре присвоено имя Печать_Дерева, и она обращается к самой себе для
печати левого и правого поддеревьев. Обратите внимание, что условие окончания
рекурсивного процесса (процесс доходит до пустого дерева) обязательно будет
достигнуто, так как каждая из активаций процедуры работает с меньшим
деревом, чем вызвавшая ее процедура.
Задача включения в дерево нового элемента намного проще, чем может
показаться на первый взгляд. Можно подумать, что такое включение потребует
полного разрезания связей в дереве с целью нахождения подходящего места для
нового элемента, но на самом деле добавляемую вершину всегда можно
присоединить к основанию дерева в качестве листа, независимо от ее значения. Чтобы
410 Глава седьмая. Структуры данных
найти надлежащее место для нового элемента, следует перемещаться по дереву
точно так, как при поиске данного элемента. Поскольку такого элемента в
дереве нет, поиск обязательно приведет нас к основанию дерева. В данной точке и
будет размещаться новая вершина (рис. 7.25), поскольку была найдена именно
та позиция, к которой привел бы поиск этих новых данных.
/>
РИСУНОК 7.24
procedure Печать_Дерева (<дерево>)
if (<дерево не пусто)
then (применить процедуру ПечатьЛерева к поддереву,
являющемуся левой ветвью структуры <дерево>;
печатать корневую вершину структуры <дерево>;
применить процедуру Печать_Дерева к поддереву,
являющемуся правой ветвью структуры <дерево>)
Процедура печати связанного бинарного дерева в алфавитном порядке
ШЗ^^^^^^^^^^^^1^
а) Поиск нового элемента, пока не будет устновлено его отсутствие
б) Позиция, к которой нужно прикрепить новый элемент
Включение элемента М в список В, Е, G, Y, J, К, N, Р, хранящийся в виде бинарного дерева
7.5. Древовидные структуры
411
** Переменная <текущий указатель> используется для хранения **
** указателя на текущую позицию в дереве. Вершина, **
** находящаяся на этой позиции, называется текущей. **
** Переменная Предыдущий указателе содержит указатель на **
** родительскую вершину текущей вершины, которая называется **
** предшествующей. **
procedure Включение (<дерево>, вставляемый элемент>)
** Прежде всего найдем место вставки новой вершины **
assign <текущий указателе the value значение корневого
указателя структуры <дерево>;
assign <найдено> the value "ложь";
while (<найдено> есть "ложь" и <текущий указатель> не NIL) do
[Выбрать подходящий вариант (case) из перечисленных ниже и
выполнить предусмотренные в нем действия;
case 1, вставляемый элемент> = значение в текущей вершине:
(assign <найдено> the value "истина")
case 2, вставляемый элемент> < значения в текущей вершине:
(assign Предыдущий указателе the value <текущий указатель>;
assign <текущий указатель> the value указатель на левую
дочернюю вершину текущей вершины)
case 3, <вставляемый элемент> > значения в текущей вершине:
(assign Предыдущий указатель> the value <текущий указатель>;
assign <текущий указателе the value указатель на правую
дочернюю вершину текущей вершины)
]
*" Теперь следует добавить новый элемент как дочернюю **
** вершину текущей вершины. Заметим, что если переменная **
** <текущий указатель> по-прежнему равна значению корневого **
** указателя, то исходное дерево пусто **
И(<найдено> = "ложь")
then (Создать новую вершину, содержащую вставляемый элемент>;
Выбрать подходящий вариант (case) из перечисленных
ниже и выполнить предусмотренные в нем действия;
case 1, <текущий указатель> = <корневой указатель>:
(включить новую вершину в качестве корневой)
case 2, вставляемый элемент> < значения в предыдущей вершине:
(включить новую вершину в качестве левой дочерней
вершины предыдущей вершины)
case 3, вставляемый элемент> > значения в предыдущей вершине:
(включить новую вершину в качестве правой дочерней
вершины предыдущей вершины)
)
Процедура включения элемента в связанное упорядоченное бинарное дерево
412 Глава седьмая. Структуры данных
Процедура, осуществляющая этот процесс при использовании связанной
древовидной структуры, представлена на рис. 7.26. Сначала осуществляется поиск в
дереве включаемого значения, а затем новая вершина помещается в
соответствующую позицию. Заметим, что существует особый случай, когда дерево
оказывается пустым в первой же позиции. Это выявляется посредством проверки
условия, что значение переменной <текущий указатель> после завершения
поиска остается равным значению указателя корневой вершины. Если же в процессе
поиска выясняется, что включаемый элемент в действительности уже
присутствует в дереве, то никакого включения не выполняется.
Итак, можно сделать заключение, что пакет программного обеспечения,
состоящий из связанной древовидной структуры и процедур поиска, печати и
включения данных в нее, образует полный пакет, который может
использоваться в качестве абстрактного инструмента в других создаваемых приложениях.
Вопросы для самопроверки
1. Укажите корневую вершину и листья в приведенной ниже древовидной
структуре. Укажите поддеревья, находящиеся ниже вершины 9. Укажите в
этом дереве группы элементов, имеющих общего родителя.
2. Какое условие показывает, что связанное дерево в машинной памяти пусто?
3. Нарисуйте схему, представляющую, как выглядит
приведенное ниже дерево в машинной памяти, если оно хранится по
схеме с использованием левых и правых дочерних указателей,
описанной в этом разделе. Затем нарисуйте другую схему,
показывающую, как это дерево будет выглядеть в схеме с
использованием непрерывного блока памяти, также описанной в
данном разделе.
4. Нарисуйте бинарное дерево, которое можно использовать для хранения и
поиска в списке следующих элементов: R, S, T, U, V, W, X, Y, Z.
5. Укажите, по какому пути будет следовать алгоритм двоичного поиска, текст
которого приведен на рис. 7.22, если его использовать для поиска элемента J
в бинарном дереве, изображенном на рис. 7.21. Укажите путь следования
этого алгоритма при поиске элемента Р.
6. Нарисуйте схему, представляющую состояние активаций рекурсивного
алгоритма печати бинарного дерева (см. рис. 7.24) во время печати элемента К
упорядоченного бинарного дерева, представленного на рис. 7.21.
7.5. Древовидные структуры 413
7.6. Специализированные типы данных
В главе 5 было введено понятие типа данных и рассмотрены такие элементарные
типы данных, как целый, действительный, символьный и логический, являющиеся
базовыми в большинстве языков программирования. В этом разделе мы рассмотрим
методы, с помощью которых пользователь сможет определять собственные типы
данных, более точно отвечающие нуждам конкретного приложения.
Типы данных, определяемые пользователем
Часто удобнее описывать алгоритм, если используемые в нем типы данных
отличаются от базовых типов данного языка программирования. Поэтому
большинство современных языков программирования предоставляет пользователю
возможность определять дополнительные типы данных, используя в качестве
строительных блоков базовые типы и структуры. Такие "самодельные" типы
данных принято называть типами, определяемыми пользователем.
В качестве примера рассмотрим разработку программы, в которой будет
использоваться множество переменных, имеющих одинаковую смешанную
структуру, состоящую из имени, возраста и показателя квалификации некоторого
работника. Один из подходов может состоять в повторном объявлении состава этой
структуры при каждом обращении к ней. Например, для создания переменной
Emhloyee, имеющей указанную смешанную структуру, работающий на языке С
программист мог бы написать следующий оператор (см. рис. 5.6 в главе 5):
struct
(char Name [8]; // Имя
int Age; // Возраст
float SkillRating; // Показатель квалификации
) Employee; // Структура "Работник"
При таком подходе проблема состоит в том, что если описание структуры
повторяется слишком часто, то программа увеличивается в размерах и чтение ее
становится затруднительным. Лучше было бы описать структуру лишь однажды
и присвоить ей описательное имя, а затем использовать его каждый раз при
ссылке на данную структуру. Язык С позволяет программисту сделать это с
помощью следующего оператора:
typedef struct
(char Name [8]; // Имя
int Age; // Возраст
float SkillRating; // Показатель квалификации
) EmployeeType; // Тип данных "Работник"
Этот оператор определяет новый тип данных, EmployeeType, который можно
использовать при объявлении переменных наряду с базовыми типами языка.
Например, переменная Employee теперь может быть объявлена с помощью
следующего оператора:
414 Глава седьмая. Структуры данных
EmployeeType Employee;
Преимущество использования таких пользовательских типов очевидно при
объявлении множества переменных этого типа. С помощью приведенного ниже
оператора программист на языке С может объявить, что переменные Sleeve,
Waist и Neck относятся к базовому типу "действительный":
float Sleeve, Waist, Neck;
Аналогично этому, после определения пользовательского типа EmployeeType,
с помощью следующего оператора можно объявить, что переменные
DistManager, SalesRepl и SalesRep2 относятся к данному типу:
EmployeeType DistManager, SalesRepl, SalesRep2;
Важно отличать определенные пользователем типы данных и сами элементы
данных этих типов. Последние рассматриваются как реализации данного типа. Тип,
определенный пользователем, по сути, является шаблоном, используемым при
создании экземпляров данных этого типа. Он описывает свойства, которые имеют все
реализации данного типа, но сам не является реальным представителем этого типа. В
предыдущем примере тип пользователя EmployeeType использовался для создания
трех реализаций этого типа: DistManager, SalesRepl и SalesRep2.
Абстрактные типы данных
Хотя концепция типов данных, определяемых пользователем, и привлекательна,
она является лишь частью всех существующих возможностей создания новых типов
данных в широком смысле этого понятия. Вспомним, что тип данных состоит из
двух частей: предварительно определенной системы хранения (например,
использование дополнительного двоичного кода для представления данных целого типа и
формата с плавающей точкой для представления данных действительного типа) и
набора предварительно определенных операций (таких как сложение и вычитание).
Однако традиционные типы пользователя позволяют программисту определять
только новые системы хранения. Они не являются средством определения операций,
которые могут выполняться с данными этой структуры.
Абстрактные типы данных являются более общим средством расширения типов
данных, доступных в языке программирования. Как и тип, определяемый
пользователем, абстрактный тип данных является шаблоном, отличным от реализаций
данного типа. Но абстрактный тип данных определяет как систему хранения данных,
так и выполняемые над ними операции. Поэтому абстрактный тип данных состоит
из описания системы хранения элементов данных, а также набора процедур,
определяющих операции, которые могут выполняться с реализациями этого типа.
На рис. 7.27 показано, как абстрактный тип данных StackOf Integers может
быть определен в языке программирования Ada. На рисунке представлен
фрагмент программы StackOf Integers (в терминологии языка Ada — пакет),
содержащий определение нового типа данных, названного StackOf Integers, и
определяющий две процедуры — push и pop. Тип StackOf Integers описан как
массив (названный StackEntries) из 25 целых чисел и еще одной целой
переменной StackPointer, используемой для хранения сведений о положении вер-
7.6. Специализированные типы данных 415
шины стека в массиве (см. упр. 5 к разделу 7.3). Детальное описание процедур
push и pop должно находиться в другом фрагменте программы, называемом
телом пакета. Именно там находятся операторы, необходимые для действительной
вставки и извлечения элементов (а также для инициализации значения
переменной StackPointer).
package StackPackage is
type StackOfIntegers is
record
StackEntries: array (1...25) of integer;
; StackPointer: integer;
end record;
procedure push(Value: in integer; Stack: in out StackOfIntegers);
;'' procedure pop(Value: out integer; Stack: in out StackOflntegers); '*
end StackPackage;
Определение абстрактного типа данных на языке Ada
Используя этот пакет в качестве шаблона, можно объявлять реальные стеки
целых чисел (реализации типа StackOf Integer) с помощью следующих инструкций:
StackOne: StackOfInteger;
StackTwo: StackOfInteger;
В этом примере объявляется, что переменные StackOne и StackTwo
принадлежат к типу StackOf Integer. Теперь с этими переменными можно выполнять
различные манипуляции, например вставить значение 106 в стек StackOne:
push (106, StackOne);
Рассмотрим еще один пример — присвоение переменной OldValue значения
из вершины стека StackTwo:
pop (OldValue, StackTwo);
Инкапсуляция
В этой главе неоднократно демонстрировалось, как пакеты программного
обеспечения, состоящие из структуры (или структур) данных и набора процедур,
работающих с этими структурами, могут использоваться для представления
абстрактных структур организации данных, таких как стек, очередь, список или
дерево. Однако нигде пока не подчеркивалась важность того требования, чтобы
все операции со структурой, находящейся внутри пакета, производились только
с помощью включенных в него процедур. Обеспечить это требование — очень
важная задача, так как разрешение прямого доступа к внутренней структуре
пакета зачастую приводит к непредсказуемым осложнениям.
416 Глава седьмая. Структуры данных
Предположим, что программисту нужно обратиться к третьему элементу
стека типа StackOf Integers (рис. 7.27). Программист, знающий, как в
действительности реализован стек, может попытаться нарушить целостность стека
посредством прямого обращения к массиву StackEntry, вместо того чтобы
действовать с помощью формального процесса извлечения двух его первых
элементов. Такая тактика часто приводит к осложнениям на протяжении
жизненного цикла программы и рассматривается разработчиками программного
обеспечения как худшее из зол.
Проблема состоит в том, что при последующих модернизациях программы
программисты могут внести в нее изменения, не совместимые с
"упрощением", скрытым где-либо в тексте программы. Например, в целях
увеличения размера стека внутренняя структура типа данных
StackOf Integers впоследствии может быть изменена с отказом от
использования массива и переходом к использованию связанной структуры.
Очевидно, что новый вариант будет не совместим с "упрощением",
предполагающим, что стек реализован в виде массива.
Чтобы избежать таких ситуаций при работе с абстрактными типами данных,
новые языки программирования предоставляют методы, с помощью которых в
пакетах программного обеспечения может быть реализована инкапсуляция, что
гарантирует доступ к их внутренней структуре только посредством
использования процедур самого этого пакета. Если экземпляры имеющихся в программе
абстрактных типов данных будут инкапсулированы, целостность их данных
будет защищена от любых плохо продуманных модификаций.
На рис. 7.28 представлена модифицированная версия абстрактного типа
данных StackOf Integers, исходная версия которого приведена на рис. 7.27.
Разница состоит в том, что новая версия использует преимущества функции
инкапсуляции языка Ada. Обратите внимание, что в новой версии подробное описание
структуры стека помещено в закрытую часть объявления (следующую за
ключевым словом private) нашего пакета. Извне пакета доступна только информация
из открытой части пакета (той части, которая предшествует ключевому слову
private). Информация из закрытой части пакета является локальной для этого
пакета. Следовательно, в нашем примере вне пакета известно только о
существовании типа, именуемого StackOf Integers, и процедур push и pop. Тот факт,
что данный стек реализован в виде массива, именуемого StackEntries, скрыт
(инкапсулирован) внутри пакета. В результате приведенные ниже операторы по-
прежнему могут использоваться вне пакета:
StackOne: StackOfInteger;
StackTwo: StackOfInteger;
push (106, StackOne);
pop (OldValue, StackTwo);1
Однако прямые обращения к массиву StackEntries и целому StackPointer
из текста программы уже невозможны.
7.6. Специализированные типы данных 417
РИСУНОК 7.28
package StackPackage is
type StackOfIntegers is private;
procedure push(Value: in integer; Stack: in out StackOfIntegers);
procedure pop(Value: out integer; Stack: in out StackOfIntegers);
private
end StackPackage;
Абстрактный тип данных на языке Ada, определенный с использованием механизма инкапсуляции
В заключение отметим, что использование абстрактных типов данных и
инкапсуляции позволяет приспособить универсальные языки программирования к
нуждам конкретных приложений. Биологи, изучающие нервную систему, могут
разработать и инкапсулировать пакет, в котором внутренние структуры данных
и процедуры моделируют соответствующие характеристики отдельного нейрона.
Определив такой абстрактный тип, биолог может использовать его так же, как и
базовые типы языка программирования. В этом смысле биолог расширяет
универсальный язык программирования до специализированного языка,
содержащего примитивы, наиболее подходящие для решения его задач.
Классы
Абстрактные типы данных и реализаций этих типов очень близки классам и
объектам в объектно-ориентированных языках программирования (см. раздел 5.5).
Концепции как абстрактных типов данных, так и классов основаны на построении
структур данных, объединяемых с процедурами манипулирования этими
структурами с образованием программных пакетов, которые затем могут использоваться в
качестве абстрактных инструментов повсюду в программе. Основное отличие состоит в
том, что класс является более гибкой структурой. Он может содержать или
процедуры, или структуры данных, или же и то и другое одновременно, или вовсе ничего.
Поэтому классы могут использоваться для описания компонентов программы,
возможности которых выходят за пределы возможностей абстрактных типов данных.
Кроме того, объектно-ориентированные языки программирования предоставляют
способы определения классов через другие классы посредством механизма
наследования (см. раздел 5.5).
Шаблонная природа классов в сочетании с гибкостью их содержимого и
возможностью наследовать свойства других классов делает их важнейшими кандидатами
для использования разработчиками программного обеспечения, ищущими способы
418 Глава седьмая. Структуры данных
реализации шаблонов проектирования. Действительно, большинство структур,
разрабатываемых сегодня, по существу, является определениями классов. Рано или
поздно 'объектно-ориентированная парадигма программирования предоставит
разработчикам программного обеспечения такие средства, с помощью которых они смогут
создавать большие системы программного обеспечения из предварительно
изготовленных компонентов, и этими компонентами будут именно классы.
Библиотека стандартных шаблонов
Структуры данных, обсуждаемые в этой главе, уже стали стандартными структурами программирования,
причем настолько стандартными, что во многих средах программирования они трактуются как примитивы.
Один из примеров этому можно найти в типичной среде разработки языка программирования C++, которая
часто дополняется библиотекой стандартных шаблонов (STL— Standard Template Library). Библиотека STL
представляет набор предварительно определенных классов (во многом схожих с классом
StackOf Integers, определение которого представлено на рис. 7.29), описывающих наиболее
популярные структуры данных. Следовательно, в результате включения библиотеки STL в программу на языке
C++ программист избавляется от необходимости подробного описания этих структур. Он просто
объявляет, что те или иные идентификаторы принадлежат к тем или иным типам библиотеки STL, — подобно тому,
как в разделе 7.6 декларируется, что переменные StackOne и stackTwo принадлежат к типу
StackOfIntegers.
В заключение рассмотрим программы, представленные на рис. 7.29, чтобы
продемонстрировать, как стек целых чисел может быть реализован в объектно-
ориентированных языках C++ и Java. Обратите внимание, что здесь тип
данных StackOf Integers определен как класс, а это означает, что в данном месте
определяются только свойства типа StackOf Integers, а реальные экземпляры
этого типа должны определяться в других местах программы — там, где в них
возникает потребность. Процедура StackOf Integers, имеющая такое же имя,
как и сам класс, называется конструктором этого класса. Конструктор класса
автоматически выполняется при каждом создании нового экземпляра данного
класса. В нашем примере конструктор выполняет действия, связанные с
созданием нового стека, например установку указателя вершины стека с целью
отразить тот факт, что стек пока еще пуст.
Обратите внимание, что в этих примерах для защиты целостности
внутренних характеристик класса используется механизм инкапсуляции. Только к той
части класса, которая объявлена как открытая, можно обращаться извне
любого экземпляра класса. Так, в обоих примерах тот массив, в котором стек
хранится в пределах объекта, доступен только изнутри этого объекта. Любые
действия с этим массивом должны выполняться посредством методов,
объявленных как открытые.
7.6. Специализированные типы данных 419
| РИСУНОК7.29 | u п^.п^ш«Шоишии^. г-
а) Описание стека целых чисел на языке C++
; const int MaxStack =25;
class StackOflntegers
{int StackPointer; // Все структуры данных закрытые
int StackEntries[MaxStack];
public: // Открытые методы доступа
void push(int Entry)
{if {StackPointer < MaxStack)
Stackentries[StackPointer++] = Entry;
}
int pop(void)
{if (StackPointer > 0) return StackEntries[--StackPointer];
else return 0;
}
6) Описание стека целых чисел на языке Java
class StackOflntegers
{private final int MaxStack = 25; // Все структуры данных закрытые
private int StackPointer;
private int[] StackEntries;
public void push(int Entry)
{if (StackPointer < MaxStack)
StackEntries[StackPointer++] = Entry;
}
public int pop()
{if (StackPointer > 0) return StackEntries[--StackPointer];
else return 0;
}
}
Описание стека целых чисел на языках C++ и Java
Вопросы для самопроверки
1. Каким способом в банке инкапсулируется чековый счет?
2. В чем отличие между абстрактным типом данных и реализацией этого типа?
420 Глава седьмая. Структуры данных
3. В чем сходство между абстрактными типами данных и классами? В чем их
отличие?
4. Опишите две структуры, которые могут быть использованы для реализации
объекта типа очереди из целочисленных значений.
7.7. Указатели в машинном языке
В этой главе было введено понятие указателей и показано, как они
используются при конструировании структур данных. В данном разделе мы обсудим, как
работа с указателями реализуется в машинном языке.
Предположим, что на машинном языке требуется написать программу,
описанную в приложении В и предназначенную для извлечения элемента из стека,
описанного на рис. 7.12, с помещением его в регистр общего назначения. Другими словами,
требуется загрузить регистр содержимым той ячейки памяти, в которой сохранен
элемент, представляющий собой вершину стека. В нашем машинном языке есть две
инструкции для загрузки регистра: одна с кодом операции 2, а другая с кодом
операции 1. Вспомним, что если код операции равен 2, то поле операнда содержит сами
загружаемые данные, а если код операции равен 1, то поле операнда содержит адрес
загружаемых в регистр данных.
Поскольку мы не знаем, каким будет содержимое ячейки, мы не можем
использовать для наших целей операцию с кодом 2. Более того, мы не можем использовать
и операцию с кодом 1, так как не знаем адреса требуемой ячейки, поскольку адрес
вершины стека может меняться в процессе выполнения программы. Что мы
действительно знаем, так это адрес указателя вершины стека, т.е. мы знаем
местонахождение адреса данных, которые требуется загрузить. Поэтому необходимо иметь
третий тип операции загрузки регистра, для которой поле операндов будет содержать
адрес указателя на данные, которые надо загрузить.
Разработчик машины, описанной в приложении В, мог бы присвоить
подобной операции код D. В этом случае машинный язык следовало разработать так,
чтобы инструкция вида DRXY означала загрузку регистра R содержимым ячейки
памяти, адрес которой находится по адресу XY. Следовательно, если указатель
вершины стека находится в ячейке памяти с адресом F0, инструкция D4F0 будет
приводить к загрузке данных из вершины стека в регистр 4.
Однако эта машинная команда не реализует всю операцию извлечения.
Требуется также вычесть единицу из значения указателя вершины стека, чтобы он
указывал на новую вершину стека. Это означает, что в программе на машинном
языке за командой загрузки вершины стека в регистр должны следовать
команды загрузки в регистр указателя вершины стека, вычитания из него единицы и
записи результата обратно в память.
Если в качестве указателя вершины стека использовать не ячейку памяти, а
один из регистров, можно уменьшить число необходимых перемещений
указателя вершины стека из памяти в регистр и обратно. Но для этого потребуется
переделать и новую команду загрузки, чтобы учесть тот факт, что указатель нахо-
7.7. Указатели в машинном языке 421
дится в регистре, а не в ячейке основной памяти. Следовательно, в этом случае
разработчик машины должен определить машинную команду с кодом операции
D в виде DR0S, что означает загрузить регистр R содержимым той ячейки
памяти, на которую указывает регистр S.
Отметим, что аналогичная команда необходима и для реализации операции
вставки. Разработчик машины может еще раз расширить ее машинный язык,
описанный в приложении В, добавив машинную команду с кодом операции Е,
которая будет иметь вид EROS и осуществлять запись содержимого регистра R в
ту ячейку памяти, адрес которой содержит регистр S.
В результате указанных дополнений, машинный язык, описанный в
приложении В, будет поддерживать три различных метода адресации. В первом методе
сама команда содержит используемые данные, что демонстрируется операцией с
кодом 2. Во втором — команда содержит адрес используемых данных, как при
операциях с кодами 1 и 3. В третьем — команда содержит сведения о
местоположении адреса обрабатываемых данных, как при операциях с кодами D и Е.
Эти методы известны как непосредственная адресация, прямая адресация и
косвенная адресация соответственно. Все три типа адресации широко
используются в современных машинных языках.
Вопросы для самопроверки
1. Предположим, что машинный язык, описанный в приложении В, дополнен
теми командами, которые были предложены в конце этого раздела.
Допустим, что регистр 8 содержит комбинацию DB, ячейка памяти с адресом DB —
комбинацию СА, а ячейка с адресом СА — комбинацию А5. Какая комбинация
будет в регистре 5 непосредственно после выполнения каждой из следующих
машинных команд?
а) 25А5 б) 15СА в) D508
2. Используя дополнительные команды, описанные в конце данного раздела,
напишите на машинном языке полную процедуру выполнения операции
извлечения элемента из стека. Предполагается, что стек реализован так, как
показано на рис. 7.12: указатель вершины стека находится в регистре F, а
вершина стека помещается в регистр 5.
3. С помощью дополнительных команд, описанных в конце данного раздела,
напишите на машинном языке программу копирования содержимого пяти
последовательно расположенных ячеек памяти, начиная с адреса АО, в пять ячеек памяти,
начиная с адреса ВО. Исходите из того, что программа начинается с адреса 00.
Упражнения
(Упражнения, отмеченные звездочкой, относятся к разделам для
дополнительного чтения.)
1. Изобразите, как приведенный ниже массив будет выглядеть в
машинной памяти, если записать его с разверткой по строкам и столбцам.
422 Глава седьмая. Структуры данных
А В С D
Е F G Н
I J К L
2. Предположим, что массив из 6 строк и 8 столбцов записан в память с
разверткой по строкам, начиная с адреса 20 (десятичное). Если для
каждого элемента массива требуется одна ячейка памяти, каким будет
адрес элемента из третьей строки четвертого столбца? Каков будет
этот адрес, когда каждый элемент занимает две ячейки?
3. Решите предыдущую задачу, предполагая, что массив записан с
разверткой по столбцам.
4. Предположим, что список из букв А, В, С, Е, F и G записан в
непрерывном блоке ячеек памяти. Какие действия потребуется выполнить, чтобы
включить букву D в этот список, сохранив его алфавитный порядок?
5. Приведенная ниже таблица представляет адреса и содержимое
некоторых ячеек основной памяти машины. Обратите внимание, что
некоторые из этих ячеек содержат буквы алфавита и что за каждой такой
ячейкой следует пустая. Поместите в пустые ячейки адреса, причем
так, чтобы каждая содержащая букву ячейка вместе с последующей
образовали элемент связанного списка, в котором буквы следуют в
алфавитном порядке. (Для указателя NIL используйте значение 0.)
Какой адрес будет содержать указатель головы списка?
Адрес Содержимое
11 С
12
13 G
14
15 Е
16
17 В
18
19 U
20
21 F
22
6. Приведенная ниже таблица представляет собой часть связанного
списка, размещенного в основной памяти машины. Каждый элемент этого
списка состоит из двух ячеек: первая содержит букву алфавита, а вто-
Упражнения
423
рая — указатель на следующий элемент списка. Измените указатели
так, чтобы буква N больше не находилась в этом списке. Затем
замените букву N на G и измените указатели так, чтобы новая буква
размещалась в списке на положенном ей месте в алфавитном порядке.
Адрес Содержимое
30 J
31 38
32 В
33 30
34 X
35 46
36 N
37 40
38 К
39 36
40 Р
41 34
7. Приведенная ниже таблица представляет собой связанный список,
имеющий тот же формат, что и в предыдущем упражнении. Если указатель
головы списка содержит значение 44, какое имя представляется этим
списком? Измените указатели так, чтобы список содержал имя Jean.
Адрес Содержимое
40 N
41 46
42 I
43 40
44 J
45 50
46 Е
47 00
48 М
49 42
50 А
51 40
424 Глава седьмая. Структуры данных
8. Какая из следующих процедур правильно включает в связанный
список элемент NewEntry непосредственно после элемента
PreviousEntry? Что именно неправильно в другой процедуре?
Процедура 1
1. Скопировать значение из поля указателя элемента PreviousEntry
в поле указателя элемента NewEntry.
2. Изменить значение в поле указателя элемента PreviousEntry
на адрес элемента NewEntry.
Процедура 2
1. Изменить значение в поле указателя элемента PreviousEntry
на адрес элемента NewEntry.
2. Скопировать значение из поля указателя элемента PreviousEntry
в поле указателя элемента NewEntry.
9. Разработайте процедуру для конкатенации двух связанных списков
(т.е. размещения одного списка вслед за другим с образованием
единого списка).
10. Разработайте процедуру объединения двух отсортированных списков в
формате непрерывного блока ячеек памяти в один непрерывный
отсортированный список. Как изменится эта процедура, если списки
будут иметь связанный формат?
11. Разработайте процедуру изменения порядка элементов связанного
списка на обратный.
12. На рис. 7.11 представлен алгоритм печати связанного списка в обратном
порядке с использованием стека в качестве дополнительной структуры
памяти. Разработайте рекурсивную процедуру, позволяющую решить эту
задачу без явного использования стека. В какой форме стек все же будет
использоваться в новом рекурсивном варианте решения?
13. Иногда один и тот же связанный список представляется упорядоченным в
двух направлениях посредством присоединения к каждому элементу двух
указателей вместо одного. Заполните приведенную ниже таблицу так,
чтобы следуя первым указателям, помещаемым непосредственно после
каждой буквы, получалось имя Carol, а следуя вторым указателям,
буквы были упорядочены в алфавитном порядке. Какие значения находятся
в указателе головного элемента каждого из этих представлений?
Адрес Содержимое
60 О
61
62
63 С
Упражнения 425
Адрес Содержимое
64
65
66 А
67
68
69 L
70
71
72 R
73
74
14. Приведенная ниже таблица представляет собой стек, записанный в
непрерывном блоке ячеек памяти, в формате, описанном выше в тексте
главы. Если база стека находится по адресу 10, а указатель вершины
стека содержит значение 12, какой символ будет получен с помощью
операции извлечения? Какое значение после этой операции будет
иметь указатель вершины стека?
Адрес Содержимое
10 F
11 С
12 А
13 В
14 Е
15. Начертите таблицу, показывающую конечное содержимое ячеек
памяти, заменив в предыдущей задаче операцию извлечения элемента из
стека на операцию вставки в него буквы D. Каким будет значение
указателя вершины стека после выполнения операции вставки?
16. Разработайте процедуру удаления нижнего элемента стека.
17. Разработайте процедуру сравнения содержимого двух стеков.
18. Предположим, что требуется создать стек имен различной длины.
Почему в этом случае выгоднее сохранять имена в отдельных областях
памяти, а затем построить стек из указателей на эти имена, чем
просто помещать в стек сами имена?
19. В каком направлении очередь дрейфует по памяти — в направлении ее
головы или хвоста?
426 Глава седьмая. Структуры данных
20. Предположим, что каждый элемент очереди занимает одну ячейку
памяти, указатель начала очереди содержит значение 11, а указатель
конца очереди — значение 17. Какими будут значения этих указателей
после того, как один элемент будет включен в очередь, а два — удалены?
21.
а) Предположим, что очередь, реализованная как циклическая
структура, находится в изображенном ниже состоянии. Начертите схему,
показывающую ее структуру после того, как в очередь будут включены
буквы G и R, три буквы — удалены, а потом включены буквы D и Р.
б) Какая ошибка возникнет при выполнении задания из предыдущего
пункта, если буквы G, R, D и Р будут включены до того, как и*
очереди будут удалены какие-либо буквы?
22. Опишите, как массив может быть использован для реализации
очереди средствами языка высокого уровня.
23. Приведенная ниже таблица представляет дерево, записанное в
машинной памяти. Каждая вершина дерева состоит из трех ячеек. Первая
ячейка содержит данные (букву), вторая — указатель левой дочерней
вершины данной вершины, а третья — указатель правой дочерней
вершины. Значение 0 представляет указатель NIL. Нарисуйте это
дерево, если значение указателя корневой вершины равно 55.
Адрес Содержимое
40 G
41 0
42 О
43 X
44 0
45 0
46 J
47 49
48 О
49 М
50 0
51 0
Упражнения
427
Адрес Содержимое
52 F
53 43
54 40
55 W
56 46
57 52
24. Приведенная ниже таблица представляет содержимое блока ячеек
основной памяти машины. Обратите внимание, что некоторые ячейки
содержат буквы алфавита и что за каждой такой ячейкой следуют две
пустые ячейки. Заполните пустые ячейки таким образом, чтобы этот
блок памяти представлял дерево, организованное следующим образом:
первая ячейка, следующая за каждой буквой, содержит указатель
левой дочерней вершины данной вершины, а вторая — указатель правой
дочерней вершины. Для представления указателя NIL используйте
значение 0. Каким будет значение указателя корневой вершины?
Адрес Содержимое
30 С
31
32
33 Н
34
35
36 К
37
38
39 Е
40
41
42 G
43
44
45 Р
46
47
428 Глава седьмая. Структуры данных
с к
\ /\
Е Н Р
25. Разработайте нерекурсивный алгоритм распечатки дерева вместо
рекурсивного алгоритма, представленного на рис. 7.24. Для управления
возвратами управления, которые могут потребоваться, используйте стек.
26. Примените рекурсивный алгоритм распечатки дерева, приведенный на
рис. 7.24, к дереву, описанному в упражнении 23. Начертите схему
вложенных активаций алгоритма (и текущую позицию в каждой из
них) для печати вершины X.
27. Оставив прежней корневую вершину и не меняя физического
расположения элементов данных в дереве, описанном в упражнении 23,
измените указатели так, чтобы алгоритм печати дерева (см. рис. 7.24)
печатал его вершины в алфавитном порядке.
28. Начертите схему, показывающую, как выглядит в основной памяти
приведенное ниже бинарное дерево, если оно сохранено без
использования указателей в блоке непрерывно расположенных ячеек памяти,
как было описано в разделе 7.5.
29. Предположим, что непрерывно расположенные ячейки,
представляющие бинарное дерево в формате, описанном в разделе 7.5, содержат
значения А, В, С, D, E, F и G соответственно. Нарисуйте это дерево.
30. Опишите структуру данных, пр* ^одную для представления позиции на
шахматной доске во время игры.
31. Укажите, для какого из представленных ниже деревьев алгоритм печати
дерева (см. рис. 7.24) напечатает вершины в алфавитном порядке.
Упражнения 429
32. Модифицируйте представленную на рис. 7.24 процедуру так, чтобы
"список" печатался в обратном порядке.
33. Опишите структуру дерева, которое можно было бы использовать для
записи сведений о генеалогии семьи. Какие операции могут
выполняться с этим деревом? Если это дерево необходимо реализовать в
виде связанной структуры, то какие указатели должны быть связаны с
каждой из его вершин? Разработайте процедуры, выполняющие
установленные вами выше операции, полагая, что дерево реализовано в
виде связанной структуры с определенными вами указателями.
34. Разработайте процедуру поиска и удаления заданного значения из
дерева, упорядоченного так, как показано на рис. 7.21.
35. В чем отличие между типом данных, определяемым пользователем, и
абстрактным типом данных?
36. В чем заключается отличие между абстрактным типом данных и его
реализацией?
37. Дайте определение механизма инкапсуляции.
38. В чем отличие между открытой и закрытой частями абстрактного
типа данных?
39. Укажите структуры данных и процедуры их обработки, которые
могут использоваться в абстрактном типе данных, представляющем
адресную книгу.
40. Укажите структуры данных и процедуры их обработки, которые
могут использоваться в абстрактном типе данных, представляющем в
компьютерной игре космический корабль.
41. Используя расширения машинного языка, описанные в конце
раздела 7.7, напишите на машинном языке полную процедуру для вставки
элемента в стек, реализованный по схеме, представленной на
рис. 7.12. Предполагается, что указатель вершины стека находится в
регистре F, а вставляемые данные — в регистре 5.
42. Предположим, что каждый элемент связанного списка состоит из
одной ячейки памяти с данными, за которой следует указатель
следующего элемента списка. Кроме того, новый элемент,
расположенный в ячейке памяти с адресом АО, должен быть включен
между элементами, размещенными в ячейках с адресами В5 и С4.
Используя машинный язык, описанный в приложении В, и
дополнительные машинные команды с кодами операции D и Е,
описанные в конце раздела 7.7, напишите процедуру, выполняющую
требуемое включение элемента.
430 Глава седьмая. Структуры данных
Общественные и социальные вопросы
Следующие вопросы приводятся для того, чтобы помочь вам разобраться в
некоторых этических, общественных и юридических аспектах использования
вычислительной техники, а также в ваших собственных воззрениях и тех
принципах, на которых они основаны. Задача не сводится к тому, чтобы просто дать
ответы на предложенные вопросы. Вы должны также понять, почему вы
ответили именно так, а не иначе, и насколько ваши суждения по различным вопросам
согласуются друг с другом.
1. Предположим, что программист-аналитик, работающий на
определенную компанию, разрабатывает способ организации данных,
обеспечивающий их эффективную обработку в конкретном приложении. Затем
его нанимает другая компания и предлагает выполнить аналогичный
проект. Может ли этот аналитик использовать ту же организацию
данных в разработках, выполняемых для второй компании? Как
компания может защитить себя от конкурентов в таких разработках?
2. До какой степени можно считать, что неверная информация хуже, чем
отсутствие информации?
3. Во многих прикладных программах пределы роста стека определяются
количеством доступной памяти. Обычно программы разрабатываются
так, что если доступная память закончится, они выдают сообщение о
переполнении стека с последующим завершением работы. В
большинстве случаев такая ошибка никогда не возникает и пользователю
ничего не известно о ее существовании. Кто должен нести
ответственность, если в результате возникновения подобной ошибки будут
утрачены важные данные? Как разработчик программного обеспечения
может минимизировать свою ответственность?
4. В структуре данных, построенной на использовании указателей,
удаление данных обычно заключается в изменении указателя, а не в
освобождении ячеек памяти. Следовательно, при удалении элемента из
связанного списка он на самом деле остается в памяти до тех пор,
пока занимаемое им место не понадобится для других данных. Какие
этические проблемы и проблемы безопасности могут иметь место в
результате такой "живучести" удаляемых данных?
5. Перенести данные и программы с одного компьютера на другой
достаточно легко. Следовательно, знания, хранящиеся в одной машине,
легко перенести на многие другие. Человеку, напротив, иногда трудно
передать свои знания другому. Например, чтобы научить одного
человека какому-то языку, другому понадобится достаточно много
времени. Каковы могут быть последствия подобных отличий в скорости пе-
Общественные и социальные вопросы 431
редачи знаний, если возможности машин станут сравнимы с
возможностями человека?
6. Имеет ли право разработчик защищать авторским правом свои разработки
удачных структур данных? Что можно сказать о патентном праве?
Рекомендуемая литература
• Carrano F.M., Helman P., Veroff R. Data Abstraction and Problem Solving with
C++, 2nd ed. —Reading, MA: Addison-Wesley, 1997.
• Kruze R.L., Ryba A.J. Data Structures and Program Design in C++.— Upper
Saddle River, NJ: Prentice Hall, 1999.
• Weiss M.A. Data Structures and Problem Solving Using Java. — Reading, MA:
Addison-Wesley, 1997.
Дополнительная литература
Ахо А.В., Хопкрофт Д., Ульман Д.Д. Структуры данных и алгоритмы. —
М.: Издательский дом "Вильяме", 2000.
432 Глава седьмая. Структуры данных
глава
Файловые
структуры
ВОСЬМАЯ
В главе 7 мы рассмотрели способы организации данных в
основной памяти машины. В этой главе мы остановимся на
методах хранения данных в массовой памяти. Важнейшим
здесь является то, что требуемый способ доступа к данным
играет важную роль при определении того, как эти данные
должны храниться. Как и при изучении структур данных, мы
увидим, что формат, в котором данные в конечном счете
представляются пользователю, может не совпадать с
форматом, в действительности использующимся в системе
хранения. Поэтому, как и в главе 7, по ходу обсуждения мы
постоянно будем сравнивать концептуальную и реальную
организации данных.
8.1. Роль операционной системы
8.2. Последовательные файлы
Обработка последовательных
файлов
Особенности программирования
8.3. Текстовые файлы
Состав текстовых файлов
Особенности программирования
8.4. Индексация
Принципы индексации
Особенности программирования
8.5. Хеширование
Пример системы хеширования
Проблемы распределения
Особенности программирования
8.1. Роль операционной системы
Как было указано в конце раздела 1.3, для сохранения файла в массовой
памяти необходимо разделить его на блоки (физические записи),
совместимые с устройством, используемым для хранения. Например, при работе с
файлами, хранящимися на дисках, оперируют блоками данных,
соответствующими размеру сектора. Вся обработка, связанная с разделением файлов
на блоки, осуществляется операционной системой. Если прикладной
программе требуется считать часть данных файла, она обращается к
операционной системе с запросом выполнить операцию чтения. Обычно операционная
система обрабатывает подобные запросы следующим образом: считывает
достаточное для его выполнения количество физических записей, помещает
полученные данные в область основной памяти, называемую буфером, а затем
делает этот буфер доступным прикладной программе. Аналогично при записи
информации в файл прикладная программа передает требуемые данные
операционной системе. Операционная система помещает эти данные в буфер,
пока не будет сформирована полная физическая запись, а затем пересылает
содержимое всей этой физической записи в массовую память.
Прикладное программное обеспечение обычно пишется на одном из языков
программирования третьего поколения, в котором подобные обращения к
операционной системе реализованы в виде примитивов. В этой главе мы ознакомимся
со многими из них. Будет показано, что иногда операторы манипулируют
данными в терминах логической записи в целом, а в других случаях — элементами
данных меньшего размера, называемыми полями. Например, логическая запись,
содержащая информацию о работнике, состоит из таких полей, как фамилия,
адрес, его идентификационный номер и т. д.
Для выполнения своих обязанностей по доступу к файлам операционная
система должна хранить информацию о тех файлах, с которыми она в
данный момент работает. Например, она должна знать, на каком устройстве
хранится некоторый файл, имя этого файла, расположение в памяти его
буфера, используемого для передачи данных прикладной программе, а также
следует ли сохранять файл после завершения работающей с ним прикладной
программы. Такая информация хранится в таблице, называемой
дескриптором файла, или управляющим блоком файла. Процедура создания
дескриптора файла называется открытием файла.
Прежде чем прикладная программа с помощью операционной системы
получит доступ к файлу, она должна попросить операционную систему открыть его.
При использовании императивной парадигмы программирования это обычно
делается с помощью оператора на языке высокого уровня, эквивалентного
следующей инструкции псевдокода:
Открыть файл document.txt как DocFile для ввода информации
Эта инструкция представляет собой запрос на открытие файла document.txt.
Из текста этой инструкции следует, что файл должен уже существовать в массо-
434 Глава восьмая. Файловые структуры
вой памяти ("для ввода", а не "для вывода") и что в других местах программы
на этот файл мы будем ссылаться как на файл DocFile. Причина, по которой в
программе используется альтернативное имя (DocFile), состоит в том, что
реальное имя файла (document.txt), указанное операционной системе, может
быть несовместимо с синтаксическими правилами по определению имен,
принятыми в языке программирования высокого уровня.
В объектно-ориентированных языках программирования файлы трактуются
как объекты. Поэтому открытие файлов осуществляется как создание объекта,
который будет играть роль файла. Следовательно, в объектно-ориентированной
среде оператор создания дескриптора файла будет иметь вид, эквивалентный
следующей инструкции псевдокода:
Создать объект DocFile, представляющий входной файл document.txt
В результате выполнения этого оператора будет создан объект DocFile, с
помощью которого можно получать доступ к файлу document.txt как к входному.
Далее в программе данные из этого файла можно будет считывать, просто
посылая объекту DocFile соответствующее сообщение:
Послать сообщение GetCharacter объекту DocFile с целью считать
объект Symbol.
Потребовав от операционной системы создать дескриптор некоторого файла,
программа также должна поставить ее в известность о том, что этот дескриптор
больше не нужен. Эту процедуру называют закрытием файла. Обычно закрытие
осуществляется оператором, эквивалентным следующей инструкции псевдокода:
Закрыть файл DocFile
Подобный оператор информирует операционную систему, что доступ к файлу
DocFile больше не требуется и, следовательно, место в памяти, используемое для
дескриптора этого файла, может быть применено для чего-то другого. Однако в
некоторых ситуациях использование данного оператора вызывает не только
освобождение места в памяти. Например, если в файле есть частично заполненная физическая
запись, содержащая данные, которые должны быть сохранены, операционная
система дополнит ее (возможно, двоичными нулями) и перешлет в массовую память.
Закрытие файла в объектно-ориентированной среде осуществляется путем
посылки соответствующему объекту сообщения, предписывающего закрыть его файл:
Послать сообщение Close объекту DocFile
Эта инструкция требует послать объекту DocFile сообщение о необходимости
закрыть его файл.
Вопросы для самопроверки
1. Опишите буферную систему, используемую для пересылки данных файла
прикладной программе.
2. Что такое дескриптор файла?
3. Какую роль играет система управления файлами операционной системы в
процедуре открытия файла?
8.1. Роль операционной системы 435
8.2. Последовательные файлы
Последовательным является такой файл, доступ к которому осуществляется
последовательно, от начала до конца, как будто его данные представляют собой одну
длинную строку. Примерами могут служить аудиофайлы, файлы, содержащие
программы или текстовые документы. Фактически большинство файлов, создаваемых
обычным пользователем персонального компьютера, являются последовательными.
Обработка последовательных файлов
Для изучения методов обработки последовательных файлов мы рассмотрим
классический пример из области обработки данных, когда файл содержит
информацию о сотрудниках компании. Этот файл состоит из логических записей,
каждая из которых содержит информацию об одном сотруднике. В свою очередь,
каждая из логических записей разделена на поля, такие как фамилия, адрес,
идентификационный код, номер полиса социального страхования и т.д.
Таблицы размещения файлов
Как следует из текста, для организации доступа к файлам, записанным на магнитных дисках, операционная
система создает список секторов, выделенных каждому файлу. В действительности дисковое пространство обычно
выделяется файлам блоками из нескольких секторов, называемых кластерами. В персональном компьютере
каждый кластер чаще всего содержит от 4 до 16 секторов, а жесткий диск большой емкости — тысячи подобных
кластеров. Для хранения сведений о том, какие кластеры и какому файлу выделены, операционная система ведет на
каждом диске так называемую таблицу размещения файлов (FAT, File Allocate Table). В этой таблице содержится
по одному элементу для каждого кластера диска. Когда файл записывается на диск, операционная система
записывает номер первого кластера, выделенного файлу, в том каталоге, в котором этот файл создается. Затем в
представляющий этот кластер элемент FAT операционная система записывает номер следующего кластера,
выделенного файлу; в элемент, представляющий тот кластер, операционная система записывает номер следующего
и т.д. Таким образом, начиная поиск с каталога файла и следуя указателям в FAT, операционная система может
осуществить выборку относящихся к файлу кластеров в соответствующем порядке, кластер за кластером.
Ранние версии операционной системы Windows компании Microsoft использовали таблицы размещения
файлов с 16-битовыми элементами, а это означало, что в этой таблице можно было представить номера
только 64 Кбайт различных кластеров. Поскольку каждый кластер содержит около 2 Кбайт данных, одна
таблица FAT позволяла описать только 128 Мбайт дискового пространства— максимальное значение,
вполне разумное в те времена, когда устройства с жесткими дисками имели емкость всего лишь от 10 до
40 Мбайт. В настоящее время в таблице FAT используются 32-битовые элементы; это означает, что FAT
можно использовать для записи информации о размещении файлов на дисках, емкость которых
измеряется в терабайтах, что эквивалентно 240 байт.
436 Глава восьмая. Файловые структуры
Предположим, что этот файл, содержащий информацию о сотрудниках,
используется для создания платежных ведомостей. Для этого весь файл обрабатывается при
каждом начислении зарплаты: считывается запись для каждого сотрудника,
рассчитывается его зарплата и генерируется соответствующий расчетный листок.
Поскольку обрабатываются все записи, не важно, какие из них будут обработаны первыми.
Поэтому самый простой метод состоит в том, чтобы реализовать этот файл в виде
последовательного файла, представляющего собой длинный список записей, и
обрабатывать эти записи по одной, от начала до конца файла.
Действия по обработке такого последовательного файла можно описать с
помощью следующей инструкции:
while (конец файла не достигнут) do
(считать следующую запись файла и обработать ее)
Чтобы подобный процесс последовательной обработки был возможен,
записи файла должны храниться в упорядоченном виде, что позволит
извлекать их согласно этому порядку. Если в качестве носителя массовой памяти
используется магнитная лента, то решение совершенно очевидно. Поскольку
сама система хранения в этом случае изначально последовательна,
достаточно просто помещать записи на магнитную ленту одну за другой. Обработка
подобного файла сводится к прочтению ленты и последовательной обработке
записей в порядке их считывания.
Однако, если используется дисковая память, содержимое файла будет
распределено по различным секторам, которые, в принципе, можно
считывать в различном порядке. Чтобы сохранить требуемый порядок,
большинство операционных систем создает и поддерживает список секторов, в которых
хранится каждый файл (рис. 8.1). Данный список хранится как часть
системы каталогов диска на том же дисковом устройстве, что и сам файл. С
помощью этого списка операционная система может считывать секторы в
требуемом порядке, что позволяет писать прикладные программы так, как
будто данные файла хранятся последовательно, хотя в действительности они
разбросаны по разным участкам диска.
При обработке последовательного файла необходимо контролировать
достижение конца этого файла. В общем случае конец последовательного файла
принято обозначать как EOF (End Of File). Существует множество способов
определения EOF. Один из них состоит в размещении в конце файла специальной
записи, называемой меткой конца файла (sentinel). Во избежание ошибок поля
метки конца файла должны содержать значения, которые никогда не появятся
среди значений данных этой прикладной программы. При использовании этого
метода программа на языке программирования третьего поколения может
осуществлять обработку файла с последовательным доступом с помощью следующей
инструкции:
считать первую запись файла;
while (считанная запись не является меткой конца файла) do
(обработать запись и
считать следующую запись файла)
8.2. Последовательные файлы 437
РИСУНОК 8.1
Организация упорядоченности данных в последовательном файле с помощью таблицы размещения файлов
Другой подход состоит в том, чтобы оставить задачу определения EOF
операционной системе. Например, если файл хранится на диске и операционная
система находит его записи с помощью списка секторов, то она всегда знает, когда
обработка доходит до конца файла. Следовательно, она может сообщить это
прикладной программе с помощью переменной, называемой EOF, которой
присваивается значение истина или ложь, в зависимости от того, достигнут ли конец
файла. При использовании этой стратегии прикладная программа будет
содержать следующую инструкцию:
while (не EOF) do
(считать запись файла и обработать ее)
Во многих случаях необходимо поддержание упорядоченности записей в
файле с последовательным доступом. Аудио- или видеофайл будет испорчен, если
порядок его записей будет нарушен. Однако в других случаях упорядоченность
используется лишь для удобства обработки. Классическим примером может
служить обсуждавшийся выше файл с записями о служащих, в котором для
идентификации каждой отдельной записи используется значение определенного
поля, называемого полем ключа. В частности, в файле с информацией о
служащих это может быть поле, содержащее номер полиса социального страхования
или идентификационный номер служащего.
Упорядочивая подобные файлы по полю ключа, мы можем значительно
сократить время их обработки. Предположим, что при создании платежных ведомостей
требуется обновлять каждую запись работника, чтобы отразить информацию о
табельном учете для данного работника. Если файл, содержащий сведения о табельном
438 Глава восьмая. Файловые структуры
учете за расчетный период, упорядочен по тому же полю ключа, что и файл с
записями о служащих, то процесс обновления может быть выполнен посредством
последовательного доступа к данным обоих файлов и использования сведений о табельном
учете, полученных из записи одного файла для обновления соответствующей записи
другого. Если же эти файлы не будут упорядочены по общему полю ключа, то для
обновления потребуется последовательно считывать записи одного файла с
выполнением для каждой из них поиска соответствующей записи в другом файле.
Поэтому классический способ обновления последовательных файлов обычно
предусматривает выполнение нескольких этапов. Прежде всего, новая информация
(например, пачка ведомостей табельного учета) записывается в файл с
последовательным доступом, называемый файлом изменений, и этот файл сортируется так,
чтобы информация в нем была упорядочена так же, как и в обновляемом файле,
который в этом случае называется основным. Затем записи основного файла
обновляются в процессе последовательного считывания записей обоих файлов.
Иным классическим примером последовательной обработки является слияние
двух файлов для создания нового файла, содержащего записи исходных.
Предполагается, что записи входных файлов организованы в порядке возрастания
значений общего поля ключа и что выходной файл должен обладать тем же
свойством. Классический алгоритм слияния файлов представлен на рис. 8.2. В
этом случае задача заключается в построении выходного файла по мере
последовательного сканирования двух входных файлов, как показано на рис. 8.3.
РИСУНОК 8.2
procedure Слияние_Файлов (<входной файл А>, <входной файл В>
<выходнойфайл>)
if (в обоих входных файлах достигнут EOF) then (завершить работу,
причем <выходной файл> пуст)
if (для <входной файл А> EOF не достигнут) then (объявить его первую
запись текущей записью этого файла)
if (для <входной файл В> EOF не достигнут) then (объявить его первую
запись текущей записью этого файла)
while (EOF не достигнут ни в одном из входных файлов) do
(поместить в <выходной файл> текущую запись с "меньшим" значением
поля ключа;
if (эта текущая запись является последней в соответствующем
входном файле)
then (считать этот входной файл достигшим EOF)
else (объявить следующую запись этого входного файла его
текущей записью)
)
Начиная с текущей записи файла, не достигшего EOF, копировать
его оставшиеся записи в <выходной файл>.
Процедура слияния двух файлов с последовательным доступом
8.2. Последовательные файлы 439
Применение алгоритма слияния (буквы использованы для представления содержимого записей,
каждая буква представляет собой значение поля ключа соответствующей записи)
Особенности программирования
Для представления алгоритмов, используемых при работе с
последовательными файлами, в большинстве языков программирования высокого уровня
имеются операторы, предназначенные для помещения записей в файл с
последовательным доступом и извлечения их из него. Если это императивный язык про-
440 Глава восьмая. Файловые структуры
граммирования, то данные инструкции имеют форму вызова предварительно
написанной процедуры, выполняющей желаемые операции. Например, эти
операторы могут быть эквивалентны следующей инструкции псевдокода:
Применить процедуру ReadFile для считывания записи MailRecord из
файла MailList
По этой инструкции из файла MailList будет извлечена следующая
логическая запись и помещена в переменную MailRecord. Как и в случае этой
инструкции, некоторые языки разрешают пересылать содержимое записей как
неоднородные массивы. В других случаях записи приходится пересылать поле за
полем способом, аналогичным следующей инструкции псевдокода:
Применить процедуру ReadFile для извлечения полей Name, Address и
EmpNum из файла MailList
В объектно-ориентированных языках программирования файлы трактуются
как объекты. Как следствие, инструкции для пересылки записей в файл с
последовательным доступом и из него имеют форму сообщений, направляемых
соответствующим объектам. Например, программист может написать инструкции,
эквивалентные следующей инструкции псевдокода:
Послать сообщение ReadFile объекту MailList для считывания объекта
MailRecord
Большинство языков программирования высокого уровня рассматривает
периферийные устройства как последовательные файлы. Например,
клавиатура компьютера обычно рассматривается как последовательный файл, из
которого поступают вводимые пользователем данные, а монитор и принтер
считаются последовательными файлами, данные в которые выводятся
системой. Таким образом, чтобы получить данные, введенные пользователем с
клавиатуры, программист может использовать следующую инструкцию:
Применить процедуру ReadFile, чтобы считать переменную Name из файла
KeyBoard
Здесь Name — переменная с типом "строка символов".
Вопросы для самопроверки
1. Выполните слияние файлов, следуя алгоритму, представленному на рис. 8.2.
Предположим, что один входной файл содержит записи со значениями поля
ключа, эквивалентными В и Б, а второй — со значениями, эквивалентными
А, С, D, и F.
2. Алгоритм слияния является основой популярного алгоритма сортировки,
называемого сортировкой слиянием. Можете ли вы записать этот алгоритм?
(Подсказка. Любой непустой файл может рассматриваться как набор
одноэлементных файлов.)
8.2. Последовательные файлы 441
8.3. Текстовые файлы
Иногда размеры логических записей в файле с последовательным доступом
могут быть малы. Примером является текстовый файл, представляющий собой
последовательный файл, в котором каждая логическая запись состоит из
одного "печатаемого" символа. Мы заключили слово печатаемого в кавычки,
поскольку в это понятие включаются не только буквы алфавита, цифры и знаки
пунктуации, но и управляющие коды, например символ возврата каретки или
перевода строки. В свободной трактовке каждая логическая запись текстового
файла является двоичной битовой комбинацией, представляющей клавишу
традиционной клавиатуры.
'Л' /л <
Состав текстовых файлов
На протяжении многих лет текстовые файлы создавались с
использованием кода ASCII (American Standard Code for Information Interchange —
американский стандартный код для обмена информацией). Это означало, что на
практике стандартным форматом для представления текстовых файлов стало
использование одного байта на символ, причем каждый байт представляет
один печатаемый символ кода ASCII. Действительно, термин файл ASCII
часто использовался как синоним текстового файла. В настоящее время все
еще не ясно, сможет ли растущая популярность кода Unicode изменить
сложившуюся терминологию. Может оказаться, что термины, позволяющие
отличать лежащий в основе код (например, файл Unicode от файла ASCII),
станут общепринятыми. Однако для наших задач это различие не столь важно.
Термин двоичный файл обычно используется по отношению к любому
файлу, не являющемуся текстовым. Это отличие является существенным при
передаче файлов из одной системы в другую. Например, в текстовых файлах
многие операционные системы (большинство операционных систем
персональных компьютеров) для обозначения конца строки текста используют код
символа перевода строки, в то время как другие (например, различные
версии операционной системы UNIX) применяют сразу два символа — возврата
каретки и перевода строки. Кроме того, операционные системы компании
Apple Computer, Inc. используют только символ возврата каретки. (В строгом
смысле перевод строки — это вертикальное перемещение бумаги, а возврат
каретки — горизонтальное.) Поэтому при передаче текстового файла между
такими системами его требуется дополнительно преобразовать, в чем нет
необходимости при передаче обычного двоичного файла.
442 Глава восьмая. Файловые структуры
Размещение файлов на дисках
Предположим, на диске необходимо сохранить файл с последовательным доступом, текстовый файл или
графическое изображение. Важным моментом является то, что хранимые данные будут занимать больше
одного сектора, а это означает, что при каждом извлечении данных потребуется последовательно
считывать несколько секторов. Учитывая это, желательно по возможности записывать весь файл на одну и ту же
дорожку (или же на один цилиндр). В противном случае при извлечении данных потребуется выполнять
перемещение головок чтения/записи. Однако другая особенность, уже не столь очевидная, состоит в том, что
нецелесообразно размещать данные в последовательных секторах одной дорожки. Лучше заполнить
данными один сектор, а несколько следующих пропустить.
Суть этих действий в том, что после чтения одного сектора система затратит какое-то время на подготовку
к чтению следующего, прежде чем будет готова считать его. Если очередная часть файла будет записана в
следующий сектор дорожки, то этот сектор сместится относительно головки чтения/записи за то время,
которое система затратит на подготовку к его чтению. В результате придется ждать следующего оборота
диска, чтобы этот сектор вновь оказался под головкой чтения. Если же между последним прочитанным
сектором и следующим, нужным нам сектором будет находиться несколько секторов, у системы будет
достаточно времени на подготовку к чтению, прежде чем нужный сектор окажется под головками чтения/записи.
Для дорожки с 16-ю секторами последовательный файл следует записывать в секторы 5, 10, 15, 1, 6, 11,
16, 2, 7 и т.д. В результате, когда будут использованы все секторы, извлечь данные из всей дорожки
можно будет всего лишь за пять оборотов диска.
Следует подчеркнуть отличия, существующие между классическими
обслуживающими программами, именуемыми текстовыми редакторами, и более сложными
прикладными программами, называемыми текстовыми процессорами. Основные
отличия заключаются в производимых ими "текстовых файлах". Как те, так и другие
используются для создания и модификации текстовых документов путем
отображения их на экране компьютера и предоставления пользователю средств, необходимых
для изменения этих документов с помощью клавиатуры и мыши. Отличие состоит в
том, что редактор создает и модифицирует текстовые файлы, формат которых строго
соответствует данному выше определению, тогда как текстовый процессор включает
в создаваемый файл непечатаемые коды, предназначенные для сохранения сведений
об используемых шрифтах, информации о выравнивании текста абзацев и т.д.
Поэтому документы, с которыми работают текстовые процессоры, следует считать
"расширенными текстовыми файлами", но не текстовыми файлами в строгом смысле
данного выше определения.
Именно из-за указанных отличий файлы, создаваемые с помощью текстовых
процессоров, должны пересылаться по электронной почте как файлы-вложения, а не
как часть самого сообщения электронной почты. Поскольку существующие системы
электронной почты разрабатывались для работы с текстовыми файлами, они не
совместимы с расширенными функциями документов текстовых процессоров.
Обратите внимание, как редакторы, так и текстовые процессоры обычно
скрывают строго последовательную природу тех файлов, с которыми они рабо-
8.3. Текстовые файлы 443
тают. Например, они обычно считывают значительную часть файла в основную
память и предоставляют пользователю возможность перемещаться по документу
вперед и назад, внося необходимые изменения. Как правило, в основной памяти
содержится весь файл. Однако иногда новые части файла извлекаются из
массовой памяти по мере того, как пользователь продвигается по тексту, тогда как
ранее обновленные части пересылаются обратно в массовую память (рис. 8.4). В
результате текстовый редактор или текстовый процессор может предоставить
пользователю произвольный доступ к той части файла, которая в данный
момент находится в основной памяти. Однако в этом случае определенные
сложности возникают, когда пользователю необходимо вернуться к уже обновленным
частям файла, которые были перемещены в массовую память. Поэтому при
работе с большими документами простой редактор или недорогой текстовый
процессор может испытывать определенные проблемы.
| РИСУНОК 8.4 |
Обновление текстового файла
Особенности программирования
Текстовые файлы являются наиболее распространенными файловыми
структурами, поддерживаемыми языками программирования высокого уровня. В
большинстве этих языков имеются операторы посимвольной пересылки данных
444
Глава восьмая. Файловые структуры
в текстовый файл или из него. Кроме того, в некоторых языках реализована
возможность пересылки данных текстовых файлов построчно, где строкой
считаются символы, находящиеся между двумя маркерами "новой строки". (Не
забывайте, что формат маркеров "новой строки" меняется от системы к системе.)
Таким образом, императивный язык высокого уровня может содержать
операторы, эквивалентные следующей инструкции псевдокода:
Применить процедуру GetCharacter для считывания в переменную Symbol
символа из файла Text
Здесь переменная Symbol представляет собой переменную символьного типа. При
работе со строками операторы будут эквивалентны другой инструкции псевдокода:
Применить процедуру ReadLine для считывания в переменную TextLine
строки из файла Text
Здесь переменная TextLine является переменной типа "строка символов". В
объектно-ориентированном языке подобные инструкции будут выглядеть
следующим образом:
Послать сообщение GetCharacter объекту Text для считывания значения
в переменную Symbol
Послать сообщение ReadLine объекту Text для считывания значения
в переменную TextLine
Во многих случаях процесс пересылки данных текстовому файлу или из него
включает не только передачу, но и преобразование данных. Например,
рассмотрим следующую инструкцию псевдокода:
Применить процедуру Write для помещения значения переменной Length
в файл Text
Здесь переменная Length является переменной целого типа, а файл Text
представляет собой текстовый ASCII-файл. В этом случае текущее значение
переменной Length, прежде чем его можно будет записать в указанный файл,
должно быть преобразовано из двоичного дополнительного кода в символы кода
ASCII. Уточним нашу задачу, предположив, что целые числа представляются в
двоичном дополнительном коде с использованием 16 бит на каждое значение и
что текущее значение переменной Length равно 134. Тогда двоичная
комбинация, сохраняемая в данный момент в этой переменной, будет такой:
0000000010000110
(Это представление числа 134 в двоичном дополнительном коде.) Однако в
файл Text следует записать следующий двоичный код:
001100010011001100110100
(Это ASCII-код для символа 1, за которым следует ASCII-код для символа 3,
за которым следует ASCII-код для символа 4.)
Рассмотрим теперь обратный процесс извлечения значения переменной
Length из файла Text с помощью следующей инструкции:
Применить процедуру ReadFile для считывания значения в переменную
Length из файла Text
8.3. Текстовые файлы 445
Эта операция предусматривает извлечение символов из файла Text, которое
будет продолжаться до тех пор, пока не будут считаны все цифры,
представляющие требуемое значение. Далее считанные цифры необходимо преобразовать
в соответствующее значение в двоичном дополнительном коде, которое и будет
присвоено переменной Length.
Такие операции преобразования данных широко используются при
пересылке данных в периферийные устройства компьютера и от них. Как уже
отмечалось в конце предыдущего раздела, в большинстве языков
программирования высокого уровня периферийные устройства компьютера
рассматриваются как последовательные файлы. На практике эти файлы часто
являются текстовыми. Например, клавиатура обычно рассматривается как
текстовый файл, из которого машина получает данные в посимвольном формате.
Рассмотрим процесс, происходящий при выполнении следующей инструкции
псевдокода:
Выполнить процедуру ReadFile для считывания значения в переменную
Age из файла Keyboard
Здесь переменная Age является переменной целого типа. Если пользователь
вводит с клавиатуры значение 34, то клавиатура передает в компьютер код
символа 3, а затем код символа 4. Эти текстовые данные необходимо преобразовать
в двоичный дополнительный код числа 34, прежде чем можно будет присвоить
соответствующее значение переменной Age.
Вопросы для самопроверки
1. В каком смысле текстовый файл является особым случаем последовательного
файла?
2. Опишите два приложения, в которых целесообразно использование текстовых
файлов.
3. Какие проблемы могут возникнуть, если текстовому процессору придется
осуществлять возврат на большое расстояние в уже обновленном документе?
4. Рассмотрим последний пример этого раздела. Предположим, что на
клавиатуре одна за другой были нажаты клавиши 2 и 4. Предположим также, что
клавиатура генерирует ASCII-коды символов, а целые величины
представляются в компьютере в двоичном дополнительном коде с использованием 16 бит
на каждое значение. Какой двоичный код будет получен от клавиатуры?
Какой двоичный код будет помещен в переменную Age?
8.4. Индексация
Основным недостатком последовательных файлов является то, что они не
подходят для приложений, требующих произвольного доступа к записям. Для
извлечения из последовательного файла единственной записи необходимо
осуществить в нем последовательный поиск, а это, как уже отмечалось раньше (см.
446 Глава восьмая. Файловые структуры
раздел 4.6), требует больших затрат времени. Одним из решений проблемы
является создание для последовательного файла индекса, в результате чего мы
получим индексированный файл. Для нахождения записи в таком файле
необходимо сначала найти соответствующий элемент в файле индекса. Этот элемент
будет содержать сведения о местоположении нужной записи. Наглядным
примером являются музыкальные компакт-диски, в которых для обеспечения доступа
к отдельным произведениям используются соответствующие индексы.
Принципы индексации
Индекс файла состоит из списка элементов, каждый из которых содержит
значение идентифицирующего свойства записи (возможно, значение поля
ключа), за которым следует указание о местоположении данной записи. Подобный
индекс обычно хранится на том же устройстве массовой памяти, что и сам файл.
Для извлечения записи из файла индекс файла предварительно пересылается в
основную память, где в нем производится поиск соответствующего элемента. Как
только требуемый элемент будет найден, нужную запись можно будет считать с
устройства массовой памяти. Таким образом, индекс обеспечивает прямой доступ
к отдельным записям файла, т.е. определенная запись может быть считана без
просмотра других записей файла.
Классическим примером является задача ведения записей о служащих. В
этом случае индекс можно использовать во избежание продолжительных
последовательных просмотров при извлечении отдельных записей. В частности,
если файл записей о служащих будет индексирован по их идентификационным
номерам, то можно быстро считать запись любого служащего, зная его
идентификационный номер.
Эта же задача может служить примером удобства создания системы с
несколькими индексами. Например, может понадобиться извлекать записи
служащих не только по идентификационным номерам, но и по номерам полисов
социального страхования. Эту проблему можно решить с помощью дополнительного
индекса, созданного но основе значений номеров социального страхования
работников, вместо их идентификационных номеров (рис. 8.5). В этом случае
можно быстро получать доступ к нужной записи служащего посредством опроса
соответствующего индекса, независимо от того, проводится ли поиск сотрудника
по идентификационному номеру или по номеру социального страхования.
(Иногда такие файлы называют инвертированными, причем одно поле ключа
называют первичным ключом, а другое — вторичным.)
Иногда удобно создавать индекс, указывающий только приблизительное, а
не точное местоположение нужной записи. Этот вариант индекса можно
реализовать посредством хранения отсортированного последовательного файла в
виде нескольких сегментов, состоящих из некоторого количества записей.
Каждый сегмент представляется в индексе одним элементом, который, как
правило, является последним значением поля ключа в сегменте. В результате
получается частичный индекс, содержащий только часть значений поля
ключа, имеющихся в файле.
8.4. Индексация 447
РИСУНОК 8.5
Индекс для поля идентификационного Индекс для поля номера
номера работника социального страхования
Расположение Расположение
ПолеЕтр1# записи ПолеББ* записи
Записи, хранящиеся на диске
Инвертированный файл
Структура с использованием частичного индекса схематически
представлена на рис. 8.6, где в каждой записи показан только элемент поля ключа,
причем предполагается, что эти элементы являются отдельными буквами
алфавита. Процесс извлечения записи из такого файла начинается с
нахождения первого элемента индекса, который равен или больше нужного нам
значения, а затем методом последовательного перебора осуществляется поиск
искомой записи в соответствующем сегменте. Например, чтобы в файле,
представленном на рис. 8.6, найти запись со значением поля ключа, равным
Е, из файла выполняется считывание сегмента по указателю, связанному с
элементом индекса F, а затем в этом сегменте нужной записи осуществляется
поиск требуемой записи.
Другой подход к индексации файлов — создание индекса по
иерархическому принципу, когда общий индекс файла представляет собой
многоуровневую или древовидную структуру. Ярким примером такой индексной
структуры является иерархическая система каталогов, используемая
большинством операционных систем для управления файлами. В этом случае каталоги
или папки выполняют роль индексов, каждый из которых содержит ссылки
на свои подкаталоги. С этой точки зрения вся файловая система компьютера
в целом представляет собой один большой индексированный файл.
448 Глава восьмая. Файловые структуры
РИСУНОК 8.6
Файл с частичным индексом
Особенности программирования
Некоторые прикладные программы для персональных компьютеров (включая
приложения электронных таблиц и системы баз данных) создают
индексированные файлы непосредственно в процессе своей деятельности. Для разработки
таких прикладных программ многие языки программирования третьего поколения
предлагают специализированные строительные блоки, предназначенные для
создания индексированных файлов и работы с ними. В этом разделе мы рассмотрим
возможности языка С.
Такие функции языка С, как fgetpos (file get position — определить
текущую позицию в файле) и fsetpos (file set position — установить текущую
позицию в файле), идеально подходят для создания и использования индексов. В
частности, функция fgetpos может быть использована, чтобы узнать текущую
координату в файле. Например, рассмотрим следующий оператор:
fgetpos(Personnel, &Position);
При его выполнении текущее значение координаты в файле Personnel
присваивается переменной Position. (Как именно кодируется значение этой
координаты, зависит от конкретной операционной системы.) "Текущая координа-
8.4. Индексация
449
та" — это позиция в файле, в которой будет осуществляться следующая
операция чтения или записи для данного файла. Поэтому данную позицию можно
использовать при создании индекса как указатель места хранения записи в файле.
Иными словами, если получить и сохранить текущие координаты в файле перед
каждым помещением в него новой записи, то будет сформирован индекс,
содержащий сведения о местоположении записей файла.
Функция f setpos предназначена для установки новой позиции в файле.
Например, рассмотрим следующий оператор:
fsetpos (Personnel, &Position);
В результате его выполнения текущая координата в файле Personnel будет
установлена в то место, которое определяется текущим значением переменной Position.
Предположим, что за этим оператором находится следующий оператор:
fscanf (Personnel, "Is", Name);
В результате его выполнения переменной Name будут присвоены данные,
считанные из позиции файла, установленной предыдущим оператором. Таким
образом, функция fsetpos предоставляет программисту средство извлечения
определенной записи с использованием информации, хранящейся в индексе.
Вопросы для самопроверки
1. Какие действия будет выполнять операционная система при извлечении
записи из индексированного файла?
2. Что можно добавить к вашему ответу на первый вопрос, если операционная
система использует механизм разделения времени?
8.5. Хеширование
Хотя индексация и обеспечивает прямой доступ к записям файла, это
делается за счет организации и ведения индекса. Хеширование — это метод,
обеспечивающий прямой доступ к записям без использования каких-либо
дополнительных структур. Процесс можно кратко описать следующим образом.
Пространство, где хранится файл, делится на несколько секторов, каждый из которых
называется сегментом (bucket) (участок памяти, адресуемый как единое целое).
Записи распределяются по этим сегментам согласно некоторому алгоритму
(называемому алгоритмом хеширования), преобразующему значение поля ключа
в номер сегмента. Каждая запись хранится в сегменте, определяемом этим
процессом. Следовательно, запись можно извлечь, применив алгоритм хеширования
к значению ее поля ключа и считав записи соответствующего сегмента. Файл,
сконструированный таким способом, называется хешированным.
Пример системы хеширования
Применим концепцию хеширования к классическому файлу с информацией о
служащих. Прежде всего создадим несколько пустых последовательных файлов,
450 Глава восьмая. Файловые структуры
которые будут играть роль отдельных сегментов. (Подход с использованием
отдельных файлов для размещения сегментов имеет нежелательные последствия,
которые мы рассмотрим позже при обсуждении вопросов программирования.
Количество используемых сегментов является вопросом проектирования, и к
нему мы еще вернемся.) Предположим, что создано 40 сегментов, которые мы
будем называть сегмент 0, сегмент 1, ..., сегмент 39. В качестве поля ключа будем
использовать идентификационный номер работника.
Наша следующая задача — разработать алгоритм хеширования,
позволяющий преобразовать любое значение поля ключа в номер сегмента. Вспомним, что
идентификационные номера работников хранятся в виде битовых комбинаций,
каждая из которых может интерпретироваться как числовое значение в
двоичном представлении. Таким образом, хотя сами идентификационные "номера"
могут иметь вид 25X3Z или J2-X35, мы всегда можем интерпретировать
соответствующие битовые комбинации как двоичные числа. В результате можно
поделить любое хранящееся в памяти значение поля ключа на количество сегментов,
которое в нашем случае равно 40. При делении получим целое число,
называемое частным, и другое целое число — остаток. Важно отметить, что остаток
всегда будет находиться в пределах от 0 до 39, т.е. если учитывать только остаток
от деления, всегда получится одно из 40 возможных значений: 0, 1, 2, 3, ..., 39.
Таким образом, каждому возможному остатку от деления мы можем однозначно
поставить в соответствие один из 40 сегментов (рис. 8.7).
РИСУНОК 8.7
Фрагменты системы хеширования, в которой каждый сегмент содержит те записи,
которым алгоритм хеширования поставил в соответствие номер этого сегмента
8.5. Хеширование
451
Хеширование как общий метод
Хотя мы ввели методы хеширования в их традиционном файловом контексте, хеширование не
ограничивается этой средой. Сегодня хеширование часто используется для размещения и последующего нахождения
данных в основной памяти. Например, таблица символов в трансляторе часто реализуется в виде набора
связанных списков, а принцип хеширования используется для определения списка, содержащего заданный
идентификатор. Кроме того, хеширование используется как средство аутентификации сообщений,
передаваемых через Internet. Идея состоит в том, чтобы хешировать сообщение (секретным способом) и
закодировать полученное значение. Это значение затем передается вместе с сообщением. Чтобы установить
подлинность поступившего сообщения, получатель хеширует его по тому же алгоритму и сравнивает
значение результата с исходным значением.
С помощью этой системы мы можем преобразовать любое значение поля
ключа в целое число (точнее, остаток от деления), определяющее один из
сегментов. Поэтому данную систему можно использовать для определения, в
какой именно сегмент следует поместить ту или иную запись. Другими словами,
каждая запись должна рассматриваться отдельно, при этом значение ее поля
ключа понимается как целое число, к которому применяется описанный выше
алгоритм хеширования, позволяющий определить сегмент, в котором данная
запись должна быть сохранена. Эта последовательность действий схематически
представлена на рис. 8.8. Позднее, если потребуется извлечь запись с
определенным значением поля ключа, можно аналогичным образом преобразовать
это значение в номер сегмента, а затем выполнить в этом сегменте поиск
нужной нам записи.
РИСУНОК 8.8 1
Значение поля ключа 25X3Z
Представление ключа в кодах ASCII 0011001000110101010110000011001101011010
{
Эквивалентное десятичное число 215,643,337,562
Остаток от деления на 40 2
Номер сегмента 2
Хеширование записи, у которой значение в поле ключа равно 25X3Z, в один из 40 сегментов файла
452 Глава восьмая. Файловые структуры
Проблемы распределения
Описанная выше простая система хеширования имеет несколько недостатков.
Выбрав однажды алгоритм хеширования, мы больше уже не сможем управлять
распределением записей по сегментам. Например, если использовать описанный
выше алгоритм с делением на 40, а числовая интерпретация значений в поле
ключа будет, как правило, кратна числу 40, то непропорционально большое
количество записей окажется помещенным в сегмент, соответствующий остатку 0.
В результате поиск в этом сегменте будет практически эквивалентен поиску во
всем файле, так что преимущество использования этой схемы в сравнении с
последовательным файлом практически утрачивается.
Следовательно, любые преимущества возможны только при условии выбора
такого алгоритма хеширования, который обеспечит равномерное распределение записей
файла по сегментам массовой памяти. Однако процесс выбора осложняется тем, что
мы, как правило, точно не знаем наперед, какими именно будут значения в поле
ключа, например по причине текучести кадров; идентификационные номера
работников, используемые сегодня, не совпадают с теми, которые будут применяться
завтра. Поэтому выбор алгоритма хеширования должен основываться на некоторых
эвристических предположениях, статистическом анализе и общих рекомендациях.
Одна из общих рекомендаций относится к принятому нами решению
использовать для построения файла 40 отдельных сегментов, что в целом было не лучшим
выбором. Чтобы понять, почему это так, напомним, что если делимое и делитель
имеют в разложении общий множитель, то он будет присутствовать в остатке. Как
следствие, остатки, полученные в процессе деления, будут кратными этому общему
множителю, а другие значения получаться не будут. Частный случай такой
ситуации мы рассматривали, рассуждая о вероятности того, что величины поля ключа
будут кратны 40, что приведет к получению нулевых остатков. Аналогичная проблема
существует, если поля ключа будут преимущественно кратны пяти. Поскольку число
40 тоже кратно пяти, множитель 5 будет присутствовать в большинстве остатков
деления и записи файла будут в подавляющем случае попадать в сегменты,
соответствующие остаткам 0, 5, 10, 15, 20, 25, 30 и 35.
Аналогичные ситуации возникают и в тех случаях, когда величины поля
ключа кратны 2, 4, 8, 10 и 20, поскольку все эти числа являются делителями
числа 40. Данное наблюдение позволяет найти частичное решение проблемы.
Вероятность группировки записей, возникающей вследствие такого явления,
можно минимизировать, выбирая такое число сегментов для файла, которое
будет иметь минимально возможное количество простых делителей. Поэтому
обычно в качестве количества сегментов выбирается некоторое простое число.
Например, вероятность группировки записей в примере с файлом записей о
служащих значительно уменьшится, если разделить массовую память на 41 сегмент
вместо 40, поскольку число 41 имеет только два делителя, 1 и 41.
Иногда группировки записей удается избежать, выбирая алгоритм
хеширования, построенный на принципах, отличных от деления. Один из предлагаемых
методов, называемый методом середины квадрата (midsquare), заключается в
8.5. Хеширование 453
умножении значения поля ключа самого на себя и выборе для представления
номера сегмента средних цифр из полученного произведения. Другой метод,
называемый методом выделения, состоит в выборе цифр, находящихся на
определенных позициях в поле ключа, и составлении номера сегмента путем
построения комбинации этих цифр с помощью заранее определенного процесса. В любом
случае, прежде чем сделать окончательный выбор, функционирование
различных алгоритмов хеширования должно быть проверено на образцах записей.
К сожалению, независимо от того, каким алгоритмом хеширования мы
воспользуемся, группировка записей все-таки будет иметь место со временем, по
мере модификации файла. Можно получить достаточно ясное представление о
том, насколько быстро это может происходить, если рассмотреть, что происходит
при первоначальном помещении записей в модифицируемый файл информации о
служащих, состоящий из 41 сегмента.
Предположим, что был найден некоторый алгоритм хеширования, произвольно
распределяющий записи по всем сегментам, что исходно файл пуст и записи в него
помещаются по одной. При помещении первой записи она обязательно попадает в
пустой сегмент. Однако при помещении в файл второй записи, только 40 из 41
сегмента являются пустыми, следовательно, вероятность того, что вторая запись будет
помещена в пустой сегмент, составляет 40/41. Если предположить, что вторая
запись также была помещена в пустой сегмент, то для третьей записи найдется только
39 пустых сегментов и вероятность ее помещения в пустой сегмент составит 39/41.
Продолжая этот процесс, можно обнаружить, что если первые семь записей файла
помещены в пустые сегменты, то вероятность помещения восьмой записи в один из
оставшихся пустых сегментов составит лишь 34/41.
Приведенный выше анализ позволяет вычислить вероятность того, что
первые восемь записей будут помещены в пустые сегменты, как произведение
вероятностей того, что каждая из этих записей помещена в пустой сегмент в
предположении, что предыдущие также были помещены в пустые сегменты.
Следовательно, эта вероятность вычисляется следующим образом:
(41/41 )(40/41 )(39/41 )(3 8/41)... (34/41) = 0,482.
Полученный результат меньше одной второй! Поэтому весьма вероятно, что,
по крайней мере, две из первых восьми записей будут распределены в один
сегмент. Ситуация, когда несколько записей попадает в один и тот же сегмент,
получила название коллизии. Таким образом, весьма вероятно, что эта ситуация
будет иметь место уже при помещении всего лишь восьми записей в файл,
разделенный на 41 сегмент.
Высокая вероятность возникновения коллизий показывает, что невозможно
реализовать систему хеширования так, чтобы группировка записей файла была
невозможна. В нашем примере с записями о служащих каждый сегмент, являющийся
отдельным файлом, можно расширять без ограничений. Поэтому единственным
следствием неконтролируемой группировки записей является возрастание времени их
извлечения. Однако в других случаях хеширование может применяться при
фиксированных размерах сегментов файла. В результате при добавлении данных сегменты
могут переполняться, что приведет к потере данных.
454 Глава восьмая. Файловые структуры
Классическим решением, позволяющим справиться с указанной проблемой,
является резервирование дополнительной области памяти для хранения
избыточных данных. Тогда, если сегмент заполнен, записи, которые должны были бы
добавляться в него, помещаются в область переполнения и связываются с
соответствующим сегментом с помощью структуры, аналогичной связанному списку.
В такой системе файл, хранящийся в пяти сегментах, может иметь структуру,
представленную на рис. 8.9. На этом рисунке область памяти, занятая данными,
заштрихована. (Обратите внимание, что сегменты 1 и 4 переполнены и что часть
их записей находится в области переполнения, а добавление еще одной
дополнительной записи в сегмент 2 также вызовет его переполнение.)
РИСУНОК 8.9
Обработка переполнения сегментов файла
При попытке извлечь запись из такого файла прежде всего необходимо с
помощью алгоритма хеширования определить соответствующий сегмент, а затем
выполнить поиск требуемой записи в этом сегменте. Если искомая запись не
будет обнаружена, следует выполнить поиск в области переполнения, связанной с
этим сегментом. Отметим, что если число переполнений сегментов велико,
эффективность доступа к файлу резко снижается. Таким образом, проектирование
хешированного файла требует тщательного анализа его данных, по результатам
которого выбирается алгоритм хеширования, устанавливается количество и
размер сегментов файла, а также размер и структура области переполнения.
Особенности программирования
Предположим, что мы пишем программу на языке программирования третьего
поколения, в которой необходимо реализовать систему хеширования файла. Прежде
всего отметим, что стратегия использования отдельного файла для каждого сегмента,
которая предлагалась раньше в этом разделе, может оказаться несовместимой с тре-
8.5. Хеширование 455
бованиями операционной системы. Суть в том, что обычно существуют ограничения
на количество файлов, которые прикладная программа может держать открытыми
одновременно, а число сегментов, необходимое для обеспечения эффективного
доступа к записям, вполне может превысить это ограничение.
Более практичный подход состоит в резервировании достаточного пространства
массовой памяти посредством создания единственного большого пустого файла.
Впоследствии части этого файла можно использовать в качестве сегментов создаваемой
системы хеширования. Некоторые языки программирования поддерживают такой
подход с помощью встроенных функций. Например, язык COBOL позволяет
программисту создавать большой пустой файл, доступ к которому осуществляется
аналогично доступу к массиву. Другими словами, местоположение записи в таком
файле может задаваться индексами. Следовательно, программист может создать такой
файл и использовать различные его блоки как сегменты хешированного файла
(рис. 8.10). Например, места с 1 по 20 используются в качестве первого сегмента, с
21 по 40 — в качестве второго и т.д. В результате при необходимости можно прямо
обращаться к содержимому отдельных сегментов файла.
| РИСУНОК 8.10
Большой файл, разделенный на сегменты, доступ к которым осуществляется
с помощью механизма хеширования
Аналогичная система может быть реализована в программе на языке С с
использованием функций fgetpos и fsetpos, описанных в предыдущем разделе. Эти
функции могут применяться для организации доступа к различным частям файла.
Вопросы для самопроверки
1. Предположим, что система записей о служащих реализована в виде
хешированного файла с использованием 1000 сегментов массовой памяти, причем в
качестве поля ключа выбрано поле номера социального страхования.
Установлено, что один из возможных алгоритмов хеширования состоит в выборе
первых трех цифр из номера социального страхования работника, поскольку
это всегда будет значение в пределах от 0 до 999 включительно. Почему этот
вариант нельзя считать приемлемым?
456
Глава восьмая. Файловые структуры
2. Объясните, как неудачный выбор алгоритма хеширования может привести к
тому, что работа с хешированным файлом будет мало чем отличаться от
использования обычного последовательного файла.
3. Предположим, что хешированный файл создается с помощью описанного в тексте
алгоритма хеширования, основанного на операции деления, но с выделением
шести сегментов. Для каждого из приведенных ниже значений поля ключа
определите номер сегмента, в который будет помещена запись с этим значением поля
ключа. Что будет происходить не так, как хотелось бы, и почему?
а) 24 б) 30 в) 3 г) 18 д) 15
е) 21 ж) 9 з) 39 и) 27 к) 0
4. Сколько людей нужно собрать вместе, чтобы вероятность того, что у двух
членов этой группы совпадают дни рождения превысила одну вторую?
Упражнения
1. Предположим, что последовательный файл содержит 50 000 записей и
для просмотра одной записи требуется 5 миллисекунд. Сколько
времени потребуется для доступа к записи в середине файла?
2. Какие преобразования могут потребоваться при передаче через
Internet текстового файла и какие будут не нужны при передаче файла
графического изображения в формате JPEG?
3. Перечислите этапы выполнения алгоритма слияния, приведенного на
рис. 8.2, если в исходном состоянии один из входных файлов будет пуст.
4. Модифицируйте алгоритм, приведенный на рис. 8.2, так, чтобы он
позволял обрабатывать случаи, когда оба входных файла содержат
запись с одинаковым значением в поле ключа. Исходите из того, что эти
записи идентичны и только одна из них должна присутствовать в
выходном файле.
5. Разработайте систему, с помощью которой хранящийся на диске файл
можно будет обрабатывать как последовательный файл, имеющий
одну из двух различных упорядоченностей.
6. Почему в качестве поля ключа лучше выбрать присвоенный
компанией идентификационный номер работника, а не его фамилию?
7. В каком смысле преимущества индексирования в частично-
индексированной системе утрачиваются, когда в стремлении
уменьшить размеры индекса выбирают слишком большой размер
используемых сегментов?
8. В приведенной ниже таблице представлено содержимое частичного
индекса файла. Определите, какой именно сегмент нужно извлечь для
поиска записи с каждым из следующих значений поля ключа:
а) 24X17 б) 12N67
в) 32Е75 г) 26X28
Упражнения 457
Поле ключа Номер сегмента
13С08 1
23G19 2
26X28 3
36Z05 4
9. Исходя из индекса файла, приведенного в предыдущем упражнении,
определите, какое наибольшее значение поля ключа присутствует в
файле? Что можно сказать о наименьшем значении?
10. Чем отличается файл, созданный с помощью текстового редактора, от
файла, созданного с помощью текстового процессора?
11. Что такое таблица размещения файлов (FAT)?
12. Какие преимущества имеет индексированный файл по сравнению с
хешированным? Каковы преимущества хешированного файла перед
индексированным?
13. В тексте главы проведена параллель между традиционным индексом
файла и системой каталогов файлов, которую ведет операционная
система. Чем отличается система каталогов файлов операционной
системы от традиционного индекса?
14. Какую структуру вы порекомендовали бы выбрать для файла,
содержащего описания библиотечных фондов, если предположить, что
запись о книге должна содержать имя автора, название книги и ее тему.
Обоснуйте ваше предложение.
15. Какая информация необходима для получения полного перечня всех
записей, если единственным способом получения информации из
хешированного файла является явное хеширование значения поля
ключа каждой записи?
16. Если хешированный файл разделен на 10 сегментов, то какова
вероятность того, что, по крайней мере, две из трех произвольно взятых
записей будут помещены в один и тот же сегмент? (Предполагается, что
в алгоритме хеширования ни один из сегментов не имеет приоритета.)
Сколько записей должно быть помещено в файл, чтобы вероятность
возникновения коллизии превысила половину?
17. Решите предыдущую задачу, предполагая, что файл разделен на 100
сегментов вместо 10.
18. В каком сегменте следует искать запись, у которой двоичное значение
в поле ключа интерпретируется как число 124, если в качестве
алгоритма хеширования используется метод деления, описанный в этой
главе, а пространство хранения файла разделено на 23 сегмента.
458 Глава восьмая. Файловые структуры
19. Сравните реализацию хешированного файла с организацией
однородного массива. В чем сходство хеш-функции и адресного полинома?
20. Разработайте хешированный файл слов, предназначенный для
использования программой проверки орфографии. Что будет использоваться
в качестве хеш-функции? Зависит ли выбор хеш-функции от языка,
для которого выбираются слова? Почему такой файл не следует
хранить в виде файла с последовательным доступом?
21. Оцените размер файла в предыдущем упражнении, предполагая, что
он содержит 50000 слов. Можно ли такой файл поместить в блоке
основной памяти размером 8 Мбайт? Если да, то почему при работе
предпочтительнее поместить весь файл в основную память?
22. Разработайте индексированный файл слов, предназначенный для
использования программой проверки орфографии. Почему его не следует
хранить в виде файла с последовательным доступом?
23. Почему при использовании приведенного в тексте алгоритма
хеширования, основанного на операции деления, возникновение группировки
записей более вероятно, если пространство хранения файла разделить
на 60 сегментов, а не на 61?
24. Почему предпочтительнее упорядочить список записей переполнения (для
сегмента хешированного файла) согласно значениям в поле ключа?
25. Если разделить область хранения хешированного файла на 41 сегмент,
каждый из которых может содержать ровно одну запись, то весьма
вероятно (с вероятностью более 1/2), что, по крайней мере, один сегмент
будет переполнен уже после внесения восьми записей. Если же
объединить эту область памяти в один сегмент, который может содержать
41 запись, всегда сможем внести 41 запись, мы прежде чем возникнет
переполнение. Что удерживает нас от решения реализовать хеширо-
ванные файлы, используя последний вариант его структуры?
26. Предположим, что значение в поле ключа записи равно XY. Используя
для хеширования обсуждавшийся в тексте метод деления,
преобразуйте это значение в номер сегмента, который будет содержать данную
запись в хешированном файле, состоящем из 41 сегмента.
(Предполагается, что символы кодируются в коде ASCII с
использованием одного байта на символ.)
27. Предположим, что требуется создать хешированный файл,
содержащий информацию о жителях некой местности США. Если поле ключа
данного файла будет состоять из семизначных телефонных номеров, то
почему нельзя признать удачным выбор алгоритма хеширования,
построенного на использовании первых трех цифр этого номера?
28. Хешированный файл, использующий описанный в тексте алгоритм
хеширования, основанный на делении, может быть создан с использо-
Упражнения 459
ванием 50, 51, 52 или 53 сегментов. Какое решение является
наилучшим и почему?
29. Предположим, что хешированный файл создается с использованием
описанного в этой главе алгоритма хеширования, основанного на
методе деления. Кроме того, предположим, что запись из третьего
сегмента имеет в поле ключа двоичное значение, которое можно
интерпретировать как целое число 26. На сколько сегментов поделена
отведенная этому файлу область массовой памяти?
30. Охарактеризуйте преимущества:
а) последовательного файла по сравнению с индексированным;
б) последовательного файла по сравнению с хешированным;
в) индексированного файла по сравнению с последовательным;
г) индексированного файла по сравнению с хешированным;
д) хешированного файла по сравнению с последовательным;
е) хешированного файла по сравнению с индексированным.
31. Какую структуру файла (последовательную, текстовую,
индексированную или хешированную) вы порекомендуете использовать в каждом из
приведенных ниже случаев (обоснуйте свои рекомендации):
а) черновой набросок доклада;
б) файл записей о пациентах стоматолога;
в) список почтовой рассылки;
г) справочный файл из 50 000 слов и их определений.
32. Предположим, что магнитный диск разделен на секторы размером в
512 байт. Сколько приблизительно секторов понадобится для
сохранения текстового документа, состоящего из 20 страниц, для
представления которого используются символы кода ASCII? Что произойдет,
если документ будет сохранятся с использованием кода Unicode?
33. В каком смысле последовательный файл аналогичен связанному списку?
34. Укажите два метода, которые можно использовать для определения
конца текстового файла.
35. Объясните, как последовательный файл, содержащий записи о
служащих, можно реализовать, используя примитивы языка
программирования, предназначенные для работы с текстовыми файлами.
36. Дайте определение каждой из следующих структур.
а) Текстовый файл.
б) Индексированный файл.
в) Хешированный файл.
37. Почему программисту при написании программы может потребоваться
использовать для обращения к файлу некоторый внутренний
идентификатор, а не действительное внешнее имя файла?
460 Глава восьмая. Файловые структуры
38. Укажите три элемента информации, которые могут находиться в
дескрипторе файла.
39. Каково назначение процедуры открытия файла? В чем состоит
назначение процедуры закрытия файла?
40. Чем будет отличаться реализация последовательного файла при
сохранении его на магнитной ленте, а не на диске?
41. Предположим, что последовательный файл содержит 2000 записей.
Если на протяжении достаточно длительного периода эксплуатации из
файла будут считываться различные записи, то каким, по вашему
мнению, будет среднее число записей, просматриваемых при каждом
извлечении? Поясните ваш ответ.
42. Оцените объем массовой памяти, необходимый для хранения
договора, состоящего из 40 страниц текста, сохраненного в формате
текстового файла.
Общественные и социальные вопросы
Следующие вопросы приводятся для того, чтобы помочь вам разобраться в
некоторых этических, общественных и юридических аспектах использования
вычислительной техники, а также в ваших собственных воззрениях и тех
принципах, на которых они основаны. Задача не сводится к тому, чтобы просто дать
ответы на предложенные вопросы. Вы должны также понять, почему вы
ответили именно так, а не иначе, и насколько ваши суждения по различным вопросам
согласуются друг с другом.
1. В какой степени организациям можно позволить объединять файлы
для получения информации, которая в противном случае была бы
недоступна? Например, допустимо ли совместно обрабатывать записи о
подоходном налоге с записями о благосостоянии? Следует ли
разрешить совместную обработку медицинских записей и записей с
данными по страхованию?
2. Из-за большой загруженности социальный работник копирует
некоторые файлы, относящиеся к рассматриваемым в настоящий момент
случаям, на дискеты и забирает их домой, чтобы поработать вечером.
Допустимы ли такие действия? Изменится ли ваш ответ, если взятые
им материалы являются печатными документами, а не файлами,
записями на магнитных носителях? Изменится ли ваш ответ, если речь
идет о сотруднике университета, а записи содержат сведения о
студентах? Изменится ли ваш ответ, если сотрудник, работая дома, получает
доступ к тем же записям посредством телефонных линий?
3. Предположим, что в качестве шутки программист добавляет
дополнительное поле к каждой записи файла с информацией о персонале и
Общественные и социальные вопросы 461
пишет соответствующую программу, которая помещает в это поле
шутливые комментарии. Если только один этот программист знает,
как получить доступ к данной дополнительной информации, то
нанесен ли работникам какой-либо ущерб?
4. Когда файл удаляется с диска, он обычно не стирается, а просто
отмечается как удаленный. Информация, содержащаяся в файле, может
сохраняться на диске в течение некоторого времени, пока эта часть
диска не будет повторно использована для размещения данных
другого файла. Этично ли восстанавливать файлы, находящиеся на диске,
который раньше использовали другие люди?
5. Каковы могут быть этические последствия, если большинство
создателей программного обеспечения разработают программные продукты
таким образом, что все создаваемые файлы тайным образом будут
снабжаться информацией о создателе файла? Например, разработчик
программного обеспечения персональных компьютеров может
разработать программное обеспечение так, что имя владельца персонального
компьютера будет секретным образом прикреплено ко всем файлам,
созданным на этой машине, и эта информация будет передаваться
вместе с файлом при пересылке по Internet.
Рекомендуемая литература
• Folk M. J., Zoellick В., Riccardi G. File Structures — An Object-Oriented
Approach in C++, 3rd ed. —Reading, MA: Addison-Wesley, 1998.
• Kay D.C., Levine R. Graphic File Formats, 2nd ed. — New York: McGraw-Hill,
1995.
• McFedries P. Windows 98 Unleashed, — Indianapolis, IN: Sams, 1998. (Имеется
русский вариант этой книги: Мак-Федрис П. Руководство Пола Мак-Федриса
по Windows 98. Издание для профессионалов. — М.: Издательский дом
"Вильяме", 1998.)
• Miller N. Е., Petersen С. G. File Structures with Ada.— Redwood City, CA:
Benjamin/Cummings, 1990.
• Shaffer С A. A Practical Introduction to Data Structures and Algorithm
Analysis. — Upper Saddle River, NJ: Prentice-Hall, 1998.
462 Глава восьмая. Файловые структуры
глава
Структуры баз
данных
ДЕВЯТАЯ
Технология баз данных представляет собой синтез структур
данных и файловых структур. В современных базах данных
используются методы из обеих этих областей для создания
единых систем массового хранения данных, которые нашли
применение в обслуживании самых разнообразных приложений. Такие
структуры исключают дублирование информации, что
характерно для подхода, ориентированного на использование файлов, и
тем самым предоставляют отдельные системы данных для
каждого приложения. В этой главе мы обсудим состав систем баз
данных и познакомимся с основными направлениями
современных исследований в этой области.
9.1. Общие понятия
9.2. Многоуровневый подход к
реализации баз данных
9.3. Реляционная модель
Реляционное проектирование
Реляционные операции
Язык SQL
*9.4. Объектно-ориентированные
базы данных
*9.5. Обеспечение целостности
баз данных
Протокол фиксации/отката
изменений
Механизм блокировок
9.6. Влияние технологий баз
данных на общество
* Звездочкой отмечены разде-
лы, рекомендованные для
факультативного изучения.
9.1. Общие понятия
Чтобы подчеркнуть отличие между традиционной файловой системой и
системой базы данных, иногда используется понятие плоский файл. Такой файл
может рассматриваться как одномерная система хранения информации,
представленной с какой-либо одной точки зрения. Понятие база данных
подразумевает набор данных, многомерный в смысле наличия внутренних связей
между отдельными его элементами, что позволяет получать доступ к
информации, исходя из различных точек зрения. В то время как плоский файл,
содержащий информацию о композиторах и их произведениях, позволяет получить
только список произведений, упорядоченный по авторам, база данных с той же
информацией позволяет отыскать все произведения одного композитора, всех
композиторов, работавших в некотором музыкальном направлении, или,
например, авторов, написавших вариации на произведения других композиторов.
Исторически базы данных развивались как средство интеграции систем
хранения данных. Хотя вычислительная техника находила все более и более
широкое применение в информационных системах управления, первоначально
преобладала тенденция создания приложений в виде отдельных систем,
использующих собственный набор данных. Весьма характерно, что необходимость в
обработке платежных документов послужила причиной появления
последовательных файлов, а позднее необходимость в интерактивном доступе к данным
привела к разработке систем с совершенно иной архитектурой, построенной на
использовании индексированных файлов. Несмотря на то что каждая из этих
систем предоставляла определенные улучшения в сравнении с ранее
используемыми ручными технологиями, взятый как единое целое набор отдельных
автоматизированных систем по-прежнему характеризовался ограниченностью и
неэффективностью использования ресурсов в отличие от возможностей
интегрированных систем баз данных. Например, различные подразделения не могли
совместно использовать общие данные, поэтому значительный объем
необходимой информации дублировался на внешних носителях. В результате, когда
работник менял свое местожительство, ему следовало посетить множество
подразделений предприятия, чтобы заполнить карточку-извещение об изменении
адреса. Типографские ошибки, потерянные карточки и нерадивость сотрудников в
конечном счете приводили к появлению ошибочных и противоречивых данных в
информационных системах подразделений. Например, после переезда работника
корреспонденция на его имя могла доставляться по новому адресу, но с
указанием неверного имени получателя, в то время как платежные записи могли по-
прежнему печататься с указанием старого адреса. Поэтому системы базы данных
были просто необходимы как средство интеграции всей хранимой и
обрабатываемой внутри организации информации (рис. 9.1). В такой системе при
составлении платежной ведомости и при пересылке почтовой корреспонденции может
использоваться одна и та же адресная информация, хранимая в единой
интегрированной базе данных.
464 Глава девятая. Структуры баз данных
РИСУНОК 9.1
Построение обычной файловой системы и системы базы данных
Кроме того, еще одно преимущество интегрированной системы данных состоит в
расширении возможностей контроля, что достигается посредством хранения
информации в общем "котле". До тех пор, пока каждое подразделение располагает
собственными независимыми данными, эти данные в большей степени служат
подразделению, нежели организации в целом. Если на предприятии внедрена
интегрированная база данных, управление информацией обычно возлагается на администратора
базы данных (АБД), обязанности которого могут выполнять один или несколько
сотрудников. Этот администратор должен быть компетентен как в отношении
существующих на предприятии данных, так и информационных потребностей различных
подразделений. Централизованная структура позволяет ему принимать любые
решения, связанные с организацией и доступом к данным, с учетом интересов всей
организации в целом, а не отдельных ее подразделений
Однако наряду с преимуществами интеграция данных имеет и определенные
недостатки. Один из них состоит в необходимости контроля доступа к важной
9.1. Общие понятия
465
информации. Например, сотрудник, работающий с корреспонденцией
организации, по понятным причинам должен иметь доступ к информации об именах и
адресах сотрудников, но не должен иметь права доступа к данным о выплате
зарплаты. Точно так же сотрудник, отвечающий за начисление заработной
платы, не должен иметь доступ к прочей информации, касающейся финансовых дел
корпорации. Поэтому возможность контролировать доступ к информации в базе
данных часто имеет не меньшее значение, чем возможность предоставлять
совместный доступ к ним.
Для предоставления различных прав доступа к данным в системах баз данных
часто применяются схемы и подсхемы. Схема представляет собой полное описание
структуры базы данных, которое используется ее программным обеспечением для
обслуживания базы данных в целом. Подсхема — это описание части базы данных,
соответствующей нуждам отдельного пользователя. Рассмотрим в качестве примера
схему базы данных университета, которая указывает, что запись о каждом из
студентов, помимо информации об успеваемости, содержит его телефон и адрес места
жительства. Более того, схема указывает, что запись о каждом студенте связана с
записью его куратора. В свою очередь, запись о каждом сотруднике факультета
включает его адрес, послужной список и т.п. Исходя из этой схемы, в базе данных
поддерживается система указателей, которая необходимым образом связывает
информацию о студенте с послужным списком его куратора.
Чтобы воспрепятствовать использованию подобных связей для получения
конфиденциальной информации о факультете, права доступа к базе данных для
рядового делопроизводителя должны быть ограничены с помощью некоторой
подсхемы, в которой описание информации о факультете не включает
послужные списки сотрудников. Согласно этой подсхеме, пользователь сможет
определить, кто из сотрудников факультета является куратором определенного
студента, но не сможет получить доступ к дополнительной информации об этом
сотруднике. И наоборот, подсхема для работника бухгалтерии должна включать
доступ к послужному списку сотрудника, но не должна устанавливать никакой
связи между записями сотрудников и студентов. В результате бухгалтер сможет
изменить заработную плату сотрудника, но не будет иметь возможности узнать
имена студентов, курируемых этим сотрудником.
Помимо этого, существуют и другие недостатки, связанные с особенностями
развития технологии баз данных. Существующие базы данных стремительно
растут, а область их применения постоянно расширяется. В настоящее время
чрезвычайно большие объемы данных, распределенных по всему миру, могут
быть собраны и доставлены пользователю по единственному запросу, составление
которого потребует минимальных усилий. Однако это влечет за собой и
увеличение объемов недостоверной и неправильно применяемой информации. История
изобилует всевозможными недоразумениями, возникшими вследствие
неточностей в налоговых декларациях и ошибок в записях о совершенных
преступлениях, а также случаями неэтичного использования личной информации,
полученной посредством неправомерного доступа.
Иногда на первый план выходят проблемы, связанные с правом сбора и
хранения информации. Какую информацию о своих клиентах имеет право собирать
466 Глава девятая. Структуры баз данных
страховая компания? Имеет ли правительство право вести учет результатов
голосования отдельных граждан? Имеет ли право компания, специализирующаяся
в области распространения и обслуживания кредитных карточек, продавать
маркетинговым фирмам информацию о покупательских предпочтениях своих
клиентов? Эти вопросы характеризуют лишь некоторые правовые и этические
аспекты, с которыми пришлось столкнуться обществу в результате бурного
развития технологий баз данных.
Вопросы для самопроверки
1. Назовите два подразделения одного производственного предприятия, которые по-
разному используют одну и ту же или сходную информацию о складских запасах.
2. Укажите различные наборы данных, существующие в университетской среде,
которые можно было бы объединить в единую интегрированную базу данных.
3. Опишите, чем будут отличаться подсхемы базы данных для двух
подразделений, упоминаемых в первом вопросе.
9.2. Многоуровневый подход к реализации баз данных
Чтобы скрыть сложности реализации базы данных, система базы данных
конструируется из нескольких уровней абстракции (рис. 9.2). Представление о данных,
возникающее у пользователя базы данных, определяется прикладным программным
обеспечением, с которым этот пользователь интерактивно взаимодействует, а также
терминологией, используемой в приложениях. В больших компаниях это
программное обеспечение может быть разработано собственными программистами. В
персональной вычислительной среде это программное обеспечение обычно приобретается в
виде программного продукта четвертого поколения, предусматривающего
сравнительно простые (как правило, визуальные) средства настройки в соответствии с
индивидуальными нуждами. Именно дизайн этой части программного комплекса
придает всей системе ее неповторимую индивидуальность. Например, приложение
может взаимодействовать с пользователем посредством ведения диалога или же с
использованием сценария, предусматривающего заполнение форм. Независимо от
выбранного в приложении интерфейса пользователя, прикладное программное
обеспечение должно взаимодействовать с пользователем в целях определения
необходимой ему информации. После получения запрошенной информации она должна быть
представлена пользователю в каком-либо осмысленном виде.
Отметим, что выше нигде не утверждалось, что прикладное программное
обеспечение манипулирует информацией в базе данных. В действительности манипуляция
данными осуществляется программным обеспечением следующего уровня,
называемым системой управления базой данных (СУБД). Такое разделение на
функционально непересекающиеся модули имеет несколько преимуществ. Одно из них
состоит в том, что разделение обязанностей упрощает процесс разработки. Аналогично
тому, как обязанности пользователя только усложнились бы при рассмотрении
компьютерных концепций одновременно с методами решения проблемы из предметной
9.2. Многоуровневый подход к реализации баз данных 467
области, задачи, стоящие перед разработчиком прикладного программного
обеспечения, оказались бы существенно более сложными, если бы действительное управление
данными составляло часть прикладного программного обеспечения. Это особенно
справедливо для распределенной базы данных (базы данных, развернутой на
нескольких компьютерах в сети). Без предоставляемых СУБД сервисов прикладное
программное обеспечение должно было бы включать все средства, необходимые для
учета действительного расположения различных частей базы данных на
компьютерах в сети. Однако при использовании хорошо спроектированной СУБД программное
обеспечение приложения может быть написано так, как будто база данных хранится
на одном компьютере.
с/
РИСУНОК 9.2
Концептуальные уровни системы базы данных
Распределенные базы данных
Как подразумевается в тексте, базы данных изначально конструировались как средства консолидации или
централизации информации. Между тем, более современный взгляд состоит в рассмотрении баз данных
как средства интеграции информации, которая может храниться на разных компьютерах в локальной сети
или Internet. Например, международная корпорация может хранить и обслуживать записи о местных
сотрудниках на локальных сайтах, одновременно связывая эти записи через сеть с построением
распределенной базы данных — единой интегрированной базы данных, состоящей из нескольких фрагментов,
находящихся на различных компьютерах.
Распределенная база данных может содержать фрагментированные и/или реплицированные данные. Предыдущий
пример с записями о сотрудниках служит образцом для первого случая, когда различные фрагменты базы данных
хранятся в разных местах. Во втором случае дубликаты одного и того же компонента базы данных хранятся в
различных местах. Подобная репликация может быть полезна в тех случаях, когда необходимо уменьшить время
доступа к требуемой информации. В обоих случаях возникают вопросы, не характерные для более традиционных
централизованных систем, — как скрыть распределенную природу базы данных, чтобы она функционировала как
468 Глава девятая. Структуры баз данных
связная система, или как обеспечить точное соответствие реплицированных частей базы данных при обновлении
данных. По этой причине распределенные базы данных являются одной из наиболее интенсивно исследуемых в
настоящее время областей компьютерных наук.
Другое преимущество подобного распределения функций между программным
обеспечением приложения и СУБД состоит в том, что такая организация
предоставляет удобные средства для управления доступом к базе данных. Потребовав,
чтобы весь доступ к базе данных осуществлялся посредством единственной
СУБД, мы тем самым четко определяем, что именно она должна реализовывать
все ограничения, накладываемые на различные подсхемы. В частности, СУБД
может использовать схему всей базы данных для своих внутренних потребностей
и при этом наблюдать, чтобы каждый из пользователей имел доступ только к
данным, описанным соответствующей его полномочиям подсхемой.
Еще одной причиной, по которой функции пользовательского интерфейса и
функции собственно манипуляции данными следует разместить в двух
различных программных модулях, является необходимость достичь независимости
данных, т.е. возможности вносить изменения в организацию базы данных без
изменений программного обеспечения приложения. Например, отделу кадров
может потребоваться добавить к записи сотрудника новое поле, предназначенное
для учета его участия в новой программе медицинского страхования. Если
программное обеспечение приложения напрямую взаимодействует с базой данных,
подобное изменение формата данных может потребовать модификации всех
программных модулей, взаимодействующих с этой базой данных. В результате
внесение изменений по требованию отдела кадров повлечет за собой изменения в
программном обеспечении расчетного отдела или, скажем, в программном
обеспечении печати почтовых наклеек для исходящей корреспонденции.
Распределение функций между программным обеспечением приложения и
СУБД устраняет всякую необходимость в подобном перепрограммировании. Для
внесения изменений, необходимых для одного пользователя, потребуется лишь
изменить общую схему и подсхемы тех пользователей, которые заинтересованы
или нуждаются в подобной модификации. Все остальные подсхемы при этом
остаются неизменными, и программное обеспечение приложений продолжает
функционировать точно так же, как и до внесения изменений.
И последнее преимущество такого распределения функций состоит в том, что
подобная архитектура позволяет создавать прикладное программное обеспечение,
используя упрощенное, концептуальное представление о базе данных, не задумываясь
о ее действительной, весьма сложной структуре, включающей дисковые дорожки,
указатели и области переполнения данных. Ранее, при рассмотрении структур
данных, мы говорили, что программное обеспечение может содержать процедуры
преобразования запросов (сформулированных в терминах концептуальной теоретико-
множественной модели) в соответствующие операции в реальном хранилище
информации. СУБД также содержит процедуры, которые используются программным
обеспечением приложения как абстрактные средства преобразования
сформулированных в понятиях концептуальной модели данных команд в действия,
выполняемые непосредственно в самом хранилище базы данных.
9.2. Многоуровневый подход к реализации баз данных 469
Если быть точнее, то прикладное программное обеспечение часто разрабатывается
с использованием языков программирования общего назначения, подобных тем,
которые обсуждались в главе 5. Эти языки предоставляют базовые элементы для
реализации алгоритма, но не включают операторы, которые позволяют удобно
манипулировать содержимым базы данных. Как мы увидим в последующих разделах,
предоставляемые СУБД средства и инструменты расширяют возможности используемого
языка программирования, обеспечивая поддержку концептуальной модели базы
данных. Согласно этой концепции, положенный в основу общецелевой язык
программирования высокого уровня, расширяемый за счет добавления возможностей
СУБД, принято называть базовым языком (host language). Многие современные
коммерческие СУБД в действительности представляют собой системы,
объединяющие традиционную базу данных с программным интерфейсом базового языка. В
некоторых случаях внешне оба элемента можно принять за единое целое, однако
внутренне различия между ними сохраняются.
Для успешной разработки прикладного программного обеспечения,
работающего с базой данных, программист должен овладеть теми абстрактными
средствами, которые предоставляются ему используемой СУБД. В следующем разделе
мы посмотрим на реляционную модель данных, представляющую собой пример
подобной абстракции, глазами прикладного программиста. Эта модель лежит в
основе большинства современных коммерческих СУБД и позволяет при
разработке прикладного программного обеспечения рассматривать базу данных как
простой набор таблиц, состоящих из строк и столбцов.
Процесс поиска новых, улучшенных моделей баз данных не прекращается. Цель
этих поисков — найти модель, которая позволит простым способом формализовать
сложные структуры данных и предоставит более удобные средства формулирования
запросов к информации, т.е. позволит создавать более эффективные СУБД.
Вопросы для самопроверки
1. Обеспечивается ли независимость данных при использовании общего
индексного файла для пакетной обработки финансовой информации и
интерактивного извлечения данных?
2. Следуя образцу, представленному на рис. 9.2, нарисуйте диаграмму,
представляющую взаимосвязь компьютера с машинным языком, языком высокого
уровня и представлением программиста о компьютере.
3. Охарактеризуйте роль прикладного программного обеспечения, программ
СУБД и процедур, непосредственно манипулирующих данными, в общем
процессе получения информации из базы данных.
9.3. Реляционная модель
В этом разделе мы познакомимся с реляционной моделью данных — наиболее
популярным в наши дни способом представления внутренней организации базы
данных. Популярность этой модели обусловлена ее простотой. Данные в реляционной
470 Глава девятая. Структуры баз данных
модели отображаются в виде обыкновенных прямоугольных таблиц, называемых
отношениями (relation), которые похожи на формат отображения данных в
электронных таблицах. Например, информацию о сотрудниках некоторой фирмы можно
представить в виде отношения, приведенного на рис. 9.3.
РИСУНОК 9.3
Отношение, содержащее сведения о сотрудниках
Строка в отношении называется кортежем (tuple). В отношении,
представленном на рис. 9.3, каждый кортеж содержит информацию об одном сотруднике.
Столбцы в отношении именуются атрибутами (attribute), поскольку каждый
элемент столбца описывает некоторую характеристику (или атрибут) одной
сущности, представленной соответствующим кортежем. В нашем примере каждый
кортеж содержит атрибуты Emplld (Личный номер работника), Name (Имя и
фамилия), Address (Адрес) и SSNum (Номер полиса социального страхования).
Реляционное проектирование
Проектирование базы данных в терминах реляционной модели сводится к
разработке отношений, входящих в эту базу данных. Невзирая на кажущуюся
простоту этой задачи, неискушенного разработчика поджидает множество
коварных ловушек — источников широко распространенных ошибок.
Предположим, что в дополнение к информации, содержащейся в представленном
на рис. 9.3 отношении, мы хотим включить сведения о должностях, которые
занимали сотрудники. Поэтому для каждого из сотрудников потребуется ввести
информацию о должностных перемещениях, включающую следующие атрибуты:
JobTitle — название должности (секретарь, начальник группы, начальник отдела),
Job Id — идентификационный код должности (уникальный для каждой должности),
SkillCode — код требуемого уровня навыков (связанный с каждой должностью),
Dept — подразделение, в котором работник занимал эту должность, начальная
(StartDate) и конечная (TermDate) даты периода, в течение которого сотрудник
занимал данную должность. Если сотрудник занимает данную должность и в
настоящий момент, то вместо конечной даты должен указываться символ "звездочка".
9.3. Реляционная модель
471
Один из подходов к решению этой задачи состоит в расширении
представленного на рис. 9.3 отношения путем добавления новых столбцов для
дополнительных атрибутов. Результат применения этого подхода показан на
рис. 9.4. Однако при более пристальном взгляде на полученное отношение
можно заметить определенные осложнения. Одно из них заключается в
потере эффективности. В самом деле, полученное отношение уже не содержит по
одному кортежу для каждого сотрудника. Теперь один кортеж соответствует
отдельному назначению определенного сотрудника на некоторую должность.
Если работа сотрудника в компании сопровождалась его продвижением по
службе, то в новом отношении ему будет соответствовать уже несколько
кортежей. Проблема состоит в том, что в исходном отношении информация о
сотруднике (имя, адрес, идентификационный код и номер полиса
социального страхования) в новом отношении будет многократно дублироваться. (В
приведенном примере дублируется информация о сотрудниках Бейкер и
Смит, поскольку каждый из них занимал в компании больше одного поста.)
Более того, если какую-либо должность одновременно занимают несколько
сотрудников подразделения, то название подразделения и код уровня
необходимых навыков будут повторяться в каждом кортеже, соответствующем
назначению отдельных работников на эту должность. (В нашем примере
описание должности начальника группы повторяется в отношении несколько
раз, поскольку эту должность в компании занимает более одного работника.)
[РИСУНОК 9.4
Отношение, содержащее избыточную информацию
Другая, возможно, более серьезная проблема, связанная с использованием
расширенного подобным образом отношения, возникает при удалении
информации из базы данных. Предположим, что единственным сотрудником,
занимавшим должность с кодом "D7", был Джо Бейкер. Если он покинет
компанию и информация о нем будет удалена из базы данных, показанной
472
Глава девятая. Структуры баз данных
на рис. 9.4, то будут утеряны и все сведения о должности с кодом "D7".
Действительно, единственным кортежем, содержащим сведения о том, что
для должности с кодом ffD7" требуется уровень навыков с кодом "D2",
является кортеж, содержащий сведения о Джо Бейкере. Следовательно, если мы
удалим из базы данных все ссылки на Джо Бейкера, а затем попытаемся
извлечь из нее сведения о должности с кодом "D7", то требуемых данных в
базе не окажется.
Вы можете возразить, что подобную проблему можно устранить путем
удаления не всего кортежа, а только его части, но это может повлечь за собой другие
осложнения. (В частности, следует ли при удалении информации о Джо Бейкере
сохранить частично стертый кортеж со сведениями о должности с кодом "F5"
или в каком-либо другом кортеже отношения так же содержатся сведения о
ней?) Более того, сама попытка использовать частично заполненные кортежи
является верным признаком несовместимости выбранной структуры отношения и
требований приложения.
Источником подобных проблем является попытка использовать одно
отношение для представления информации о более чем одном понятии
предметной области. Предложенный выше вариант расширенного отношения
содержит информацию о сотрудниках (имя, идентификационный номер, адрес,
номер полиса социального страхования), штатном расписании компании
(идентификационный код должности, ее название, подразделение, код
необходимого уровня навыков) и хронологические данные о взаимосвязи
сотрудников и должностей (начальная и конечная даты периода выполнения
определенных должностных обязанностей). Исходя из этих соображений, можно
решить возникшие проблемы за счет изменения структуры базы данных и
включения в ее состав уже трех отношений: по одному отношению для
каждого из перечисленных выше понятий. Исходное отношение EMPLOYEE
(Сотрудники) можно оставить без изменений, а для хранения
дополнительной информации нужно создать два новых отношения, JOB (Штатное
расписание) и ASSIGNMENT (Назначения), как показано на рис. 9.5.
База данных, состоящая из трех отношений, содержит необходимую
информацию о сотрудниках (в отношении EMPLOYEE), штатном расписании (в
отношении JOB) и должностном продвижении (в отношении ASSIGNMENT).
Дополнительная информация может быть получена косвенно, за счет
комбинирования данных из различных отношений. Например, мы можем
установить все подразделения, в которых работал некоторый сотрудник, выбрав
сначала из отношения ASSIGNMENT сведения обо всех должностях, которые
он занимал, а затем получив из отношения JOB наименования
соответствующих подразделений. Посредством процедур, подобных только что описанной,
из базы данных, состоящей из трех отношений, можно извлечь любую
информацию, которая могла быть доступна из единственного избыточного
отношения, но уже без упомянутых ранее осложнений.
9.3. Реляционная модель 473
Emplld
База данных с информацией о сотрудниках, состоящая из трех отношений
К сожалению, процесс разделения информации на несколько отношений не
всегда носит столь безобидный характер. Например, сравните отношение с
атрибутами Emplld, JobTitle и Dept, представленное на рис. 9.6, с его
декомпозицией на два отношения, показанные на рис. 9.7.
На первый взгляд кажется, что система из двух отношений содержит ту же
информацию, что и система из одного отношения, но в действительности это не
так. Например, рассмотрим задачу определения подразделения, в котором
работает некоторый сотрудник. При использовании системы с одним отношением эта
задача сводится к извлечению информации из атрибута Dept того кортежа
отношения, у которого значение в атрибуте Emplld совпадает с личным номером
474
Глава девятая. Структуры баз данных
указанного сотрудника. Однако для системы из двух отношений эта информация
далеко не всегда может быть определена однозначно. Всегда можно установить
название занимаемой некоторым сотрудником должности, а также выяснить, в
каких подразделениях имеется эта должность. Но это не означает, что будут
получены сведения о том, где работает указанный сотрудник, поскольку
занимаемая им должность может существовать сразу в нескольких подразделениях.
РИСУНОК 9.6
Два отношения, содержащие атрибуты Emplld, JobTitle и JobTitle, Dept
В некоторых случаях отношение может быть подвергнуто декомпозиции на
несколько меньших отношений без утраты информации (это называется
декомпозицией без потерь), в других случаях декомпозиция неизбежно будет
сопровождаться потерей информации. Изучение подобных реляционных
характеристик было и остается важной областью исследований в компьютерных науках.
Результатом исследований в этом направлении явилось выделение целой
иерархии классов отношений, называемых первой нормальной формой (1НФ), второй
нормальной формой (2НФ), третьей нормальной формой (ЗНФ) и т.д. При этом
приведение набора составляющих базу данных отношений к очередной
нормальной форме позволяет сделать базу данных более удобной в использовании.
Реляционные операции
Теперь, когда читатель уже получил общее представление о применяемой в
реляционной модели структуре данных, пришло время обсудить, как эта
структура может использоваться при разработке программ. Мы начнем наше
обсуждение с рассмотрения нескольких операций над отношениями, которые могут
оказаться полезными в этом смысле.
9.3. Реляционная модель
475
В некоторых случаях возникает потребность в простом извлечении кортежей из
отношений. Для получения информации о сотруднике нам необходимо выбрать из
отношения EMPLOYEE кортеж с соответствующим значением атрибута EmplID, а для
получения списка существующих в некотором подразделении должностей следует
выбрать из отношения JOB все кортежи с соответствующим значением атрибута
Dept. В результате выполнения операции выборки (SELECT) будет создано новое
отношение (новая таблица), состоящее из отобранных кортежей исходного отношения.
В случае выбора информации о сотруднике новое отношение будет содержать только
один кортеж из отношения EMPLOYEE. При определении существующих в некотором
подразделении должностей результирующее отношение, вероятно, будет содержать
несколько кортежей из исходного отношения JOB.
Таким образом, одной из операций, которую нам может потребоваться
выполнить над некоторым отношением, является выборка кортежей, обладающих
некоторыми характеристиками, и помещение выбранных кортежей в новое
отношение. Для формального представления этой операции мы будем использовать
следующий синтаксис:
NEW <- SELECT from EMPLOYEE where Emplld = "34Y70"
Семантика этого выражения — создать новое отношение с именем NEW,
содержащее те кортежи (в приведенном случае он будет единственным) отношения
EMPLOYEE, в которых значение атрибута Emplld равно "34Y70" (рис. 9.8).
| РИСУНОК О8
Операция SELECT
476
Глава девятая. Структуры баз данных
В противоположность операции выборки SELECT, которая извлекает из
отношения строки, операция проекции PROJECT предназначена для извлечения
столбцов. Предположим, что при определении списка существующих в
некотором подразделении должностей уже была выполнена операция SELECT,
извлекающая из отношения JOB все кортежи, относящиеся к указанному
подразделению. Выбранные кортежи были помещены в новое отношение NEW1. Требуемый
список наименований должностей содержится в столбце JobTitle нового
отношения. Операция PROJECT позволяет извлечь этот столбец (или несколько
столбцов) и поместить результат в новое отношение. Эту операцию можно
представить следующим образом:
NEW2 <- PROJECT JobTitle from NEW1
В результате будет создано еще одно новое отношение (с именем NEW2),
состоящее из единственного столбца значений, выбранных из столбца JobTitle
отношения NEW1.
Ниже приведен еще один пример использования операции PROJECT:
MAIL <- PROJECT Name, Address from EMPLOYEE
Эта операция позволяет получить список имен и адресов всех сотрудников
компании. Искомый список содержится во вновь созданном отношении с именем
MAIL, с двумя атрибутами Name и Address (рис. 9.9).
Третьей операцией, с которой мы здесь познакомимся, является операция
соединения JOIN. Она предназначена для объединения данных из двух
разных отношений. Соединение двух отношений посредством операции JOIN
приводит к созданию нового отношения, набор атрибутов которого включает
все атрибуты исходных отношений (рис. 9.10). Имена атрибутов нового
отношения не отличаются от имен атрибутов исходных отношений, за
исключением того, что перед каждым из них в качестве префикса, отделяемого
точкой, указывается имя исходного отношения. (Если отношение А содержит
атрибуты V и W, а отношение В — атрибуты X, Y и Z, то полученное в
результате их соединения отношение будет содержать атрибуты A.V, A.W, B.X, B.Y
и B.Z.) Такой принцип именования атрибутов гарантирует уникальность
имен атрибутов нового отношения даже в том случае, когда исходные
отношения содержат одноименные атрибуты.
Кортежи (строки) нового отношения образуются посредством конкатенации
кортежей двух исходных отношений (рис. 9.10). Для того чтобы определить,
какие именно строки из исходных отношений должны быть объединены, в
операции JOIN задается некоторое условие. Одним из вариантов такого условия
является задание пары атрибутов исходных отношений, значения в которых должны
совпадать. Именно этот вариант условия представлен на рис. 9.10, который
демонстрирует механизм выполнения следующего оператора:
С <- JOIN A and В where A.W = B.X
9.3. Реляционная модель 477
РИСУНОК 9.9
Операция PROJECT
В данном примере кортеж из отношения А должен быть объединен с
кортежем из отношения В только при совпадении в этих кортежах значений
атрибутов W и X. Таким образом, конкатенация кортежа (г, 2) из отношения А и
кортежа (2, m, q) из отношения В присутствует в результирующей таблице в
результате равенства в них значений атрибута W из отношения А и атрибута X из
отношения В. И наоборот, в результирующем отношении отсутствует
конкатенация кортежа (г, 2) из отношения А и кортежа (5, д, р) из отношения В,
поскольку значения атрибутов W и X в этих кортежах различны.
478
Глава девятая. Структуры баз данных
I РИСУНОК 9.10
Операция JOIN
Еще один пример приведен на рис. 9.11, где представлен результат
выполнения следующего оператора:
С <г- JOIN A and В where A.W < В.Х
Обратите внимание, что в результирующее отношение помещены только те
кортежи из отношения А, в которых значение атрибута W меньше значения
атрибута X из отношения В.
Теперь рассмотрим, как операция JOIN может быть использована для получения
из представленной на рис. 9.5 базы данных списка личных номеров всех работников
с указанием подразделений, где они работают в настоящее время. При первом же
взгляде на эту базу данных становится ясно, что требуемая информация размещена
более чем в одном отношении, поэтому для получения желаемого результата будет
недостаточно одних только операций SELECT и PROJECT. В действительности в этом
случае необходимо выполнить такую операцию:
NEW1 <- JOIN ASSIGNMENT and JOB
where ASSIGNMENT.Jobld = JOB.Jobld
9.3. Реляционная модель
479
РИСУНОК 9.11
Еще один пример выполнения операции JOIN
В результате будет создано отношение с именем NEW1 (рис. 9.12). Далее с
помощью операции SELECT из нового отношения извлекаются те кортежи, в
которых атрибут ASSIGNMENT.TermDate имеет значение "*" (это признак того, что
сотрудник занимает данную должность и в настоящее время). После этого к
полученному результату применяется операция PROJECT для извлечения атрибутов
ASSIGNMENT.Emplid и JOB.Dept. Ниже приведена последовательность всех
операций, которые следует выполнить для извлечения требуемой информации из
базы данных, представленной на рис. 9.5.
NEW1 <г- JOIN ASSIGNMENT and JOB
where ASSIGNMENT.Jobld = JOB.Jobld
NEW2 <r- SELECT from NEW1 where ASSIGNMENT .TermDate = "*"
LIST <- PROJECT ASSIGNMENT.Emplld, JOB.Dept from NEW2
Теперь, ознакомившись с основными реляционными операциями, давайте
вновь обратимся к общей структуре системы базы данных. Напомним, что в
действительности физический способ хранения информации в базе данных
описывается в терминах систем массовой памяти. Чтобы оградить прикладного
программиста от подобных забот, СУБД должна позволять ему создавать при-
480
Глава девятая. Структуры баз данных
кладное программное обеспечение в терминах принятой модели базы данных,
подобной обсуждавшейся нами раньше. Поэтому реляционная СУБД должна
принимать команды, сформулированные в терминах реляционной модели, а
затем неявно преобразовывать их в последовательность действий, необходимых
для доступа к реальным структурам хранения информации. Подобная задача
обычно решается с помощью набора процедур, которые могут использоваться в
прикладном программном обеспечении как абстрактные инструменты.
Следовательно, СУБД, использующие реляционную модель, должны включать
процедуры для выполнения реляционных операций SELECT, PROJECT и JOIN,
которые могли бы вызываться из прикладного программного обеспечения с
использованием синтаксических структур, совместимых с базовым языком. В
этом случае прикладное программное обеспечение можно было бы
разрабатывать так, как если бы данные действительно хранились в виде тех простых
таблиц, которыми оперирует реляционная модель.
РИСУНОК 9.12
Пример использования операции JOIN
9.3. Реляционная модель
481
Системы баз данных для персональных компьютеров
Для персональных компьютеров разработано множество программ разной степени сложности. Простейшие
из баз данных для ПК (учет рекордов в кегельбане или ведение списка рассылки новогодних открыток)
требуют, как правило, лишь инструментов хранения, печати и сортировки данных, поэтому вполне могут
быть реализованы с помощью электронных таблиц. Между тем, существуют и достаточно мощные СУБД
для ПК, например Microsoft Access. Это полнофункциональная реляционная СУБД, включающая все
функциональные возможности, описанные в разделе 9.3, а также ряд дополнительных инструментов (генератор
отчетов, мастер построения диаграмм и пр.). Существенным преимуществом СУБД Access с точки зрения
рядового пользователя является наличие в ней графического интерфейса для построения запросов (QBE),
позволяющего формулировать запросы графическими средствами, вместо использования языка SQL,
синтаксис которого будет рассмотрен ниже. Кроме того, новейшие версии СУБД Access предоставляют
некоторые средства работы в Internet, в частности возможность хранить в поле кортежа адрес URL
определенного ресурса, что делает его легкодоступным непосредственно из базы данных.
Полезно было бы рассмотреть, каким образом СУБД хранит информацию в базе
данных и как способ хранения может влиять на ее работу. Для СУБД простейшим
способом реализации отношения является его представление в виде
последовательного файла, в котором каждый кортеж представляется отдельной логической записью.
Однако при использовании этого метода выполнение операции SELECT потребует
последовательного просмотра записей файла, и для достаточно большого отношения
этот процесс может оказаться слишком длительным. Поэтому, более вероятно, что
для представления большого отношения СУБД использует индексированный файл.
Например, если отношение EMPLOYEE, представленное на рис. 9.5, будет
проиндексировано по атрибуту Emplld, то выборка кортежа для сотрудника, указанного своим
личным номером, будет выполнена существенно быстрее.
В заключение следует отметить, что вместо реляционных операций SELECT,
PROJECT и JOIN, представленных нами в простейшем виде, многие современные
СУБД предоставляют наборы операторов, являющихся комбинациями из этих
базовых операций. Одним из наиболее популярных инструментов этого типа
является язык SQL.
Язык SQL
SQL (Structured Query Language — язык структурированных запросов)
является наиболее распространенным языком манипулирования данными в СУБД, в
той или иной степени построенных на основе реляционной модели данных.
Одной из причин такой популярности SQL является издание стандарта этого языка
институтом ANSI (Американский национальный институт стандартов). Другая
причина состоит в том, что SQL был разработан и впервые реализован в фирме
IBM, авторитет которой на рынке информационных технологий несомненен. В
482 Глава девятая. Структуры баз данных
этом разделе мы рассмотрим, как запросы к реляционной базе данных могут
быть сформулированы средствами языка SQL.
Прежде всего, следует заметить, что запрос, включающий последовательность
операций SELECT, PROJECT и JOIN, в языке SQL может быть представлен с
помощью единственного оператора. Однако еще более существенно то, что
выражения языка SQL не задают никакой определенной последовательности операций.
Хотя запросы в языке SQL формулируются в повелительной форме, на самом
деле они являются сугубо декларативными операторами. Это освобождает
пользователей базы данных от бремени разработки конкретной последовательности
действий, необходимых для получения требуемой информации. Единственное,
что от них требуется, — это описать интересующую их информацию. Например,
сформулированный в предыдущем разделе запрос на получение списка всех
работающих сотрудников, включающий три последовательно выполняемых этапа,
в языке SQL может быть сформулирован с помощью единственного оператора:
select Emplld, Dept
from ASSIGNMENT, JOB
where ASSIGNMENT.Jobld = JOB.Jobld
and ASSIGNMENT.TermDate = •*•
Как видно из приведенного примера, каждое SQL-выражение может
содержать три отдельных предложения — select, from и where. Грубо говоря,
подобный оператор представляет собой запрос на получение результатов операции
JOIN для всех отношений, перечисленных в предложении from, с последующей
выборкой из этого результата всех кортежей, которые удовлетворяют условию,
заданному в предложении where. Выполнение запроса должно завершаться
операцией PROJECT для всех атрибутов, перечисленных в предложении select.
(Обратите внимание, что терминология, используемая в языке SQL, в некотором
смысле противоположна употреблявшейся нами ранее, т.е. предложение select
в SQL-выражении определяет атрибуты, которые должны использоваться в
операции PROJECT.) Ниже рассмотрено несколько простых примеров:
select Name, Address
from EMPLOYEE
С помощью этого SQL-оператора создается список имен и адресов всех
сотрудников, описанных в отношении EMPLOYEE. Обратите внимание, что это всего
лишь операция PROJECT:
select Emplld, Name, Address, SSNum
from EMPLOYEE
where Name = 'Шери Кларк1
С помощью данного SQL-оператора извлекается вся информация из кортежа
отношения EMPLOYEE, относящегося к работнику по имени Шери Кларк. По
существу, это просто операция SELECT:
select Name, Address
from EMPLOYEE
where Name = 'Шери Кларк1
9.3. Реляционная модель 483
С помощью этого SQL-оператора из таблицы EMPLOYEE извлекаются только
имя и адрес работника по имени Шери Кларк. Это пример комбинации операций
SELECT и PROJECT:
select EMPLOYEE.Name, ASSIGNMENT.StartDate
from EMPLOYEE, ASSIGNMENT
where EMPLOYEE.EmplId = ASSIGNMENT.EmplId
С помощью данного SQL-оператора извлекается список имен и дат поступления
на работу всех сотрудников организации. Отметим, что фактически это результат
применения операции JOIN к отношениям EMPLOYEE и ASSIGNMENT с последующим
выполнением операций SELECT для кортежей, определенных в предложении where,
и операции PROJECT для атрибутов, определенных в предложении select.
В завершение следует сказать, что, помимо операторов для выполнения запросов,
язык SQL располагает также операторами для определения структуры отношений,
создания отношений и изменения содержимого отношений. Ниже приведены
примеры применения операторов insert into, delete from и update:
insert to EMPLOYEE
values ('42Z12', 'Сью Барт1, 'ул. Южная, 33f, M446611111)
С помощью этого SQL-оператора в отношение EMPLOYEE помещается новый
кортеж с указанными значениями атрибутов:
delete from EMPLOYEE
where Name = 'Джерри Смит'
С помощью приведенного SQL-оператора из таблицы EMPLOYEE удаляется
кортеж, содержащий информацию о работнике Джерри Смите:
update EMPLOYEE
set Address = 'ул. Северная, 18'
Where Name = 'Джо Бейкер'
С помощью данного оператора изменяется значение атрибута ADDRESS того
кортежа таблицы EMPLOYEE, который содержит информацию о работнике Джо Бейкере.
Вопросы для самопроверки
1. На основании информации из отношений EMPLOYEE, JOB и ASSIGNMENT (см.
рис. 9.5) дайте ответы на следующие вопросы:
а) Кто из секретарей, работающих в бухгалтерии, имеет опыт работы в
отделе кадров?
б) Кто занимает должность начальника группы в отделе сбыта?
в) Какую должность занимает сейчас Джерри Смит?
2. Используя информацию из отношений EMPLOYEE, JOB и ASSIGNMENT (см.
рис. 9.5), напишите последовательность реляционных операций для
получения списка всех должностей, имеющихся в отделе кадров.
3. На основании информации из отношений EMPLOYEE, JOB и ASSIGNMENT
(см. рис. 9.5) напишите последовательность реляционных операций для
484 Глава девятая. Структуры баз данных
получения списка имен сотрудников с указанием подразделений, в
которых они работают.
4. Преобразуйте ваши ответы на вопросы 2 и 3 в форму операторов языка SQL.
5. Как в реляционной модели обеспечивается независимость данных?
6. Каким образом различные отношения связываются между собой в
реляционной модели данных?
9.4. Объектно-ориентированные базы данных
Одним из новейших направлений исследований в области технологии баз
данных является применение объектно-ориентированной парадигмы к
построению баз данных. Результатом этих исследований явилась разработка технологии
объектно-ориентированных баз данных, состоящих из объектов, содержащих
взаимные ссылки, которые представляют связи между этими объектами.
Например, объектно-ориентированная реализация базы данных со сведениями о
работниках из предыдущего раздела могла бы включать три класса (три типа
объектов): EMPLOYEE, JOB и ASSIGNMENT. Объект (экземпляр) класса EMPLOYEE мог
бы содержать свойства Emplld, Name, Address и SSNum; объект класса JOB —
свойства Jobld, JobTitle, SkillCode и Dept; а каждый объект класса
ASSIGNMENT — свойства StartDate и TermDate.
Каждый из этих объектов также должен включать методы, описывающие его
реакцию на сообщения, касающиеся его содержимого и связей с другими
объектами. Например, каждый объект класса EMPLOYEE должен иметь методы
извлечения и обновления информации о сотруднике, метод извлечения информации о
послужном списке сотрудника и, возможно, метод изменения должности,
занимаемой сотрудником. Подобно этому, любой объект класса JOB должен включать
методы для извлечения описания должности и, возможно, для выдачи списка
всех сотрудников, занимавших данную должность. Таким образом, для
получения послужного списка сотрудника нам, вместо того чтобы писать внешнюю
процедуру, описывающую, как может быть получена требуемая информация,
достаточно просто обратиться к соответствующему методу объекта класса
EMPLOYEE.
Такая организация базы данных концептуально может быть представлена в
виде схемы, показанной на рис. 9.13, в которой для отображения существующих
между различными объектами связей используются соединяющие их линии.
Взглянув на объект класса EMPLOYEE, можно заметить, что он связан с
коллекцией, состоящей из нескольких объектов класса ASSIGNMENT, представляющих
различные назначения, которые получал конкретный сотрудник. В свою
очередь, каждый из членов этой коллекции объектов класса ASSIGNMENT связан с
некоторым объектом класса JOB, описывающим должность, которую занимал
данный работник. Таким образом, все назначения сотрудника могут быть
прослежены по ссылкам, присутствующим в объекте, представляющем этого со-
9.4. Объектно-ориентированные базы данных 485
трудника. Аналогичным образом по ссылкам, присутствующим в объекте,
представляющем некоторую должность, можно установить всех сотрудников, когда-
либо занимавших ее.
РИСУНОК 9.13 |
Связи между объектами в объектно-ориентированной базе данных
В объектно-ориентированной базе данных связи между объектами, как
правило, поддерживаются средствами СУБД, поэтому детали реализации этого
процесса не должны занимать прикладного программиста. В прикладной программе
просто указывается, с какими именно объектами должны быть установлены
связи при создании нового объекта некоторого класса. Далее СУБД сама создает
такую систему указателей, которая необходима для представления заданных
связей. Например, объекты, представляющие последовательность назначений
некоторого сотрудника на различные должности, могут быть реализованы в СУБД
посредством связанного списка.
Другая задача, которую должна решать объектно-ориентированная СУБД,
состоит в обеспечении постоянного хранения вверенных ей объектов. Это
требование кажется совершенно естественным, однако на самом деле оно существенно
отличается от обычных методов работы с объектами. Объекты, созданные в
процессе выполнения объектно-ориентированной программы, обычно разрушаются
при ее завершении. В этом смысле объекты в ООП рассматриваются как
временные конструкции. Однако объекты, созданные и помещенные в базу данных в
процессе выполнения объектно-ориентированной программы, должны быть со-
486
Глава девятая. Структуры баз данных
хранены в ней и после завершения программы. Отсюда можно сделать вывод,
что требование постоянного хранения объектов является существенным
отклонением от норм, принятых в ООП.
Важнейшим преимуществом объектно-ориентированных баз данных является то,
что они позволяют разрабатывать все программное обеспечение некоторой системы в
рамках одной и той же парадигмы, т.е. взаимодействующее с базой данных
прикладное программное обеспечение и сама база данных могут быть разработаны с
использованием одной и той же парадигмы ООП. Это существенно отличает данную
технологию от общепринятой практики применения императивных языков
программирования для разработки прикладного программного обеспечения,
взаимодействующего с реляционной базой данных. Неизбежные различия между
императивной парадигмой языка высокого уровня и реляционной парадигмой базы данных
служат, как показало время, источником множества ошибок в программном
обеспечении. Поэтому устранение различия в используемых парадигмах является
важнейшим преимуществом объектно-ориентированных баз данных.
Чтобы проиллюстрировать другое преимущество объектно-ориентированных
СУБД, рассмотрим задачу хранения имен сотрудников в реляционной базе данных.
Если полное имя сотрудника хранится в одном поле, то создание запросов на
извлечение только его фамилии существенно усложняется. Тем не менее, если для
хранения имени использовать три отдельных атрибута (для имени, отчества и фамилии),
то это осложняет обработку имен, которые не могут быть разделены на три части
согласно этому шаблону. В объектно-ориентированной базе данных все эти проблемы
могут быть скрыты внутри объекта, содержащего имя сотрудника. Имя любого
сотрудника может храниться в достаточно "интеллектуальном" объекте, обладающем
внутренней способностью предоставлять имя сотрудника в различных форматах.
Поэтому извне этого объекта доступ к полному имени или к фамилии, имени, отчеству
по отдельности одинаково прост. Детали реализации в каждом конкретном случае
инкапсулируются в рамках самих объектов.
Подобная возможность инкапсулировать особенности представления
различных форматов данных также выгодна и в других случаях. В реляционной базе
данных атрибуты отношения являются частью общей структуры базы данных,
поэтому типы данных, связанные с этими атрибутами, распространяются на всю
базу данных в целом. Такая структура оправдывает себя при работе с данными
только строковых и численных типов. Однако расширение реляционной базы
данных путем создания нового отношения, содержащего атрибуты аудио- и
видеотипов, может быть весьма проблематичной задачей. Чтобы обрабатывать
данные этих типов, может потребоваться изменить многие уже существующие
процедуры. Однако вследствие того, что отличия в типах скрыты внутри объектов,
в объектно-ориентированной базе данных те процедуры, которые используются
для обработки объектов, представляющих имя работника, могут применяться и
для обработки объектов, представляющих видеозапись. По этой причине
объектно-ориентированный подход представляется более удобным при разработке
мультимедийных баз данных — особенность, которую можно расценивать как
большое преимущество в сравнении с другими типами базами данных.
9.4. Объектно-ориентированные базы данных 487
Вопросы для самопроверки
1. Какие методы должен содержать каждый экземпляр объекта класса
ASSIGNMENT в обсуждавшейся в этом разделе базе данных сотрудников?
2. Определите несколько классов, которые могли бы использоваться в объектно-
ориентированной базе данных складского учета, и укажите некоторые из их
необходимых внутренних характеристик.
3. Назовите преимущества объектно-ориентированных баз данных в сравнении с
реляционными.
9.5. Обеспечение целостности баз данных
Недорогие СУБД для индивидуального использования являются относительно
простыми и создаются с единственной целью — оградить пользователя от
технических подробностей реализации базы данных. Поддерживаемые подобными
системами базы данных относительно невелики и обычно содержат информацию, потеря
которой скорее доставит неудобства, нежели приведет к катастрофическим
последствиям. При возникновении проблемы пользователь, как правило, может либо
непосредственно внести исправления в ошибочные данные, либо восстановить базу
данных из резервной копии, а затем вручную внести все изменения, имевшие место
с момента создания этой копии. Подобный процесс, безусловно, неудобен, но
стоимость модернизации программного обеспечения значительно превышает неудобства.
К тому же, подобные неудобства касаются лишь нескольких человек, а финансовые
потери от возникших проблем чаще всего весьма ограничены.
В случае больших многопользовательских коммерческих баз данных уровень
риска значительно выше. Цена, которую придется платить за некорректные или
утраченные данные, может оказаться огромной, а последствия
катастрофическими. В подобной ситуации важнейшая роль СУБД заключается в обеспечении
целостности данных, которая достигается в результате предупреждения проблем,
возможных при частичном завершении операций, а также посредством
исключения возможности взаимного влияния независимо выполняемых операций, что
может привести к нарушению достоверности хранящейся в базе данных
информации. Именно эту функцию СУБД мы обсудим в этом разделе.
Протокол фиксации/отката изменений
Единичная транзакция, примерами которой могут служить перевод денежных
средств с одного банковского счета на другой, отмена резервирования
авиабилетов или регистрация студента как слушателя университетского курса, на уровне
базы данных может выполняться в несколько шагов. Например, перевод
денежных средств между банковскими счетами требует уменьшения остатка на одном
счете и увеличения на другом. Между этими двумя шагами информация в базе
данных оказывается несогласованной. Действительно, на протяжении короткого
периода времени, между уменьшением остатка на одном счете и увеличением на
488 Глава девятая. Структуры баз данных
другом, снятая сумма денег просто отсутствует. Подобным же образом при
переопределении места пассажира некоторого авиарейса какое-то время у пассажира
вообще нет места, т.е. в списке пассажиров на одного человека больше, чем в
действительности имеется распределенных мест.
При использовании больших баз данных, подвергающихся интенсивной
обработке со множеством выполняемых транзакций, весьма вероятно, что в любой
произвольно выбранный момент несколько транзакций в базе данных находится
в процессе выполнения. Это означает, что запрос на выполнение новой
транзакции или сбой оборудования, как правило, происходят в тот момент, когда база
данных находится в противоречивом состоянии.
Хронологические базы данных
Традиционные базы данных разрабатываются для обработки текущих записей. Например, традиционная
база данных складского учета используется для определения текущих товарных остатков в целях
поддержания соответствующих запасов. В таких случаях, если потребуются прошлогодние записи о состоянии
запасов, они часто доступны только через архивные копии базы данных или же за счет явного включения в
данные информации о дате. Однако для множества приложений было бы намного предпочтительней иметь
более удобный способ доступа к информации, касающейся как прошлого состояния дел, так и возможного
их состояния в будущем. Так, в обязанности секретаря университета входит составление расписаний,
определение состава групп, распределение учебных помещений, фиксация сведений о преподавателях,
читающих различные курсы лекций, и т.д. Секретарь должен работать с данными как по текущему семестру,
так и по прошлым и будущим. Хронологические базы данных создаются именно для таких приложений. При
внесении в хронологическую базу данных новой информации старая не удаляется. Новые данные
становятся последними элементами в исторической записи, каждая часть которой легко доступна.
Хронологические базы данных — это одно из наиболее активно разрабатываемых сегодня направлений
исследований. Цель этих исследований — найти эффективные способы хранения и сопровождения
информации, касающейся прошлого, настоящего и будущего состояний дел, разработать методы поиска такой
информации по запросу, а также создать языки запросов к хронологическим базам данных.
Рассмотрим случай возникновения сбоев. Задача СУБД заключается в том,
чтобы предотвратить переход системы в противоречивое состояние при
возникновении сбоя. Чаще всего эта задача решается с помощью ведения журнала, в
котором фиксируются сведения о каждом выполненном шаге транзакции,
завершившемся физической записью информации на постоянное устройство
хранения (например, жесткий диск). Прежде чем транзакции будет позволено
внести изменения в базу данных, характер предполагаемых изменений заносится в
журнал в виде соответствующей записи. Таким образом, журнал содержит
сведения о каждом действии выполняемой транзакции.
Момент, когда все шаги выполняемой транзакции оказываются записаны в
журнал, называется точкой фиксации. Именно с этого момента СУБД получает в
свое распоряжение всю информацию, необходимую для восстановления резуль-
9.5. Обеспечение целостности баз данных 489
татов выполнения транзакции, если это понадобится. И только с этого момента
СУБД может ответственно гарантировать, что все выполненные транзакцией
действия действительно отражены в базе данных. При сбое в работе
оборудования СУБД сможет использовать находящуюся в журнале информацию для
восстановления результатов выполнения всех транзакций, имевших место с
момента последнего резервного копирования базы данных.
Если проблема возникла до достижения точки фиксации, СУБД легко сможет
обнаружить эту частично выполненную транзакцию. В этом случае данные
журнала могут быть использованы СУБД для отката (отмены) всех выполненных в
транзакции действий. Например, при аппаратном сбое СУБД сможет вернуть
базу данных в согласованное состояния за счет отката результатов выполнения
всех транзакций, которые не достигли точки фиксации к моменту сбоя.
Применение процедуры отката транзакций не ограничивается лишь процессом
восстановления системы после сбоев. Очень часто откат транзакции является
элементом нормальной работы СУБД. Например, транзакция может быть прервана до
ее завершения из-за обнаружения системой попытки несанкционированного доступа
к защищенной информации. Откат транзакции может потребоваться и для вывода
системы из состояния взаимной блокировки, когда каждая из пары конкурирующих
за доступ к одним и тем же данным транзакций находится в состоянии бесконечного
ожидания получения доступа к данным, используемым другой транзакцией этой
пары. При обнаружении подобной ситуации СУБД использует данные журнала для
отката транзакции и предотвращения перехода базы данных в противоречивое
состояние вследствие незавершенности транзакций.
Чтобы подчеркнуть сложность задач, решаемых при разработке СУБД,
следует отметить, что существуют некоторые, не вполне очевидные проблемы,
связанные с процедурой отката транзакции. Отмена одной транзакции может
затрагивать данные, которые уже были использованы другой транзакцией. Например,
возвращаемая транзакция может восстановить прежнее значение баланса
некоторого счета, в то время как другая уже использовала новое значение. Это
означает, что эти дополнительные транзакции также должны быть отменены, что, в
свою очередь, может потребовать отмены других транзакций. Данная проблема
получила название каскадного отката транзакций.
Механизм блокировок
Теперь давайте рассмотрим ситуацию, при которой транзакция начинается в
тот момент, когда база данных находится в промежуточном состоянии
вследствие выполнения другой транзакции. Очевидно, что подобная ситуация может
привести к ошибочным результатам, возникающим из-за неправильного
взаимодействия транзакций. Например, может иметь место так называемая проблема
недостоверных итогов, которая возникает, когда одна транзакция выполняет
перевод средств с одного счета на другой, а другая подсчитывает общую сумму
всех банковских вкладов. В зависимости от порядка выполнения отдельных
шагов транзакции перевода, результат суммирования может оказаться меньше или
больше действительного значения. Другой тип возможных ошибок связан с про-
490 Глава девятая. Структуры баз данных
блемой потерянного обновления; когда две транзакции одновременно обновляют
текущее значение одного и того же счета. Если одна транзакция считывает
текущее значение остатка на счете в тот момент, когда другая уже прочла его, но
еще не изменила, то обе транзакции будут выполнять обновление значения на
счете, исходя из одного и того же начального значения. В результате одно
значение остатка будет перекрыто значением, вычисленным другой транзакцией.
Для разрешения подобных проблем СУБД должна обеспечить режим
поочередного выполнения транзакций во всей ее полноте посредством помещения
каждой из них в очередь до тех пор, пока предыдущая транзакция не будет
полностью завершена. Однако транзакции обычно долго ожидают завершения
дисковых операций ввода/вывода. Чередуя выполнение этапов различных транзакций,
можно организовать работу так, что время ожидания доступа к данным в одной
транзакции может быть использовано для обработки данных в другой
транзакции, уже получившей всю необходимую информацию. Поэтому более мощные
СУБД для координации разделения времени между транзакциями используют
специальную программу-планировщик, функционирующую во многом
аналогично планировщику задач в многозадачных операционных системах.
Во избежание аномалий, подобных проблеме недостоверных итогов или проблеме
потерянного обновления, планировщик использует механизм, называемый
протоколом блокировки, который требует, чтобы каждый используемый транзакцией
элемент базы данных помечался специальным образом. Эти метки называются
блокировками, а отмеченные подобным образом элементы базы данных являются
заблокированными. Существуют два типа блокировок — разделяемая и эксклюзивная,
которые соответствуют, в свою очередь, двум типам доступа к данным, необходимым
транзакциям, — совместному и эксклюзивному. Если в процессе выполнения
транзакции используемый ею элемент данных изменяться не будет, то доступ к нему
может быть разделяемым. Это означает, что другим транзакциям также будет
разрешено считывать этот элемент данных. Однако если транзакция намеревается
вносить изменения в элемент данных, то ей необходимо получить к нему эксклюзивный
доступ, означающий, что никакая другая транзакция не сможет в этот момент
получить доступ к этому элементу данных.
В соответствии с протоколом блокировки, любая транзакция при каждом запросе
на получение доступа к некоторому элементу данных должна указывать СУБД тип
необходимого ей доступа. Если транзакция запрашивает разделяемый доступ к
элементу данных, который в данный момент не заблокирован или заблокирован
разделяемой блокировкой, то требуемый доступ предоставляется и этот элемент данных
отмечается как заблокированный разделяемой блокировкой. Однако если требуемый
элемент данных помечен как заблокированный эксклюзивной блокировкой, то
разделяемый доступ к данным не предоставляется. Если транзакция требует получения
эксклюзивного доступа к данным, то он может быть предоставлен только в том
случае, если требуемый элемент данных не отмечен как заблокированный. В результате
транзакция, намеревающаяся изменить некоторый элемент данных, сможет
предотвратить доступ к нему со стороны других транзакций посредством получения
эксклюзивного доступа к этому элементу. В то же время несколько транзакций смогут
получить совместный доступ к данным, если ни одна из них не намеревается вносить
9.5. Обеспечение целостности баз данных 491
в них изменения. Безусловно, как только транзакция завершит работу с некоторым
элементом данных, она должна уведомить об этом СУБД, и блокировка с этого
элемента данных будет снята.
Для обработки ситуации отказа транзакции в доступе к требуемому ей элементу
данных используются самые разнообразные алгоритмы. В соответствии с одним из
них выполнение транзакции приостанавливается до тех пор, пока требуемые данные
не станут доступными. Однако такой подход способен привести к ситуации взаимной
блокировки, когда две транзакции, требующие эксклюзивного доступа к одной паре
элементов данных, блокируют выполнение друг друга за счет того, что одна
транзакция блокирует первый элемент данных и ожидает, пока другая освободит второй,
уже заблокированный этой транзакцией элемент данных. Во избежание подобных
ситуаций некоторые СУБД предоставляют больший приоритет тем транзакциям,
которые начали свое выполнение раньше. Если более ранней транзакции потребуется
доступ к данным, заблокированным более поздней транзакцией, выполнение
последней прекратится, все заблокированные ею элементы данных разблокируются и для
этой транзакции будет выполнен принудительный откат (с использованием данных
журнала). В результате более ранняя транзакция получает доступ к необходимым ей
данным, а отмененная вновь запускается с начальной точки. Если более поздняя
транзакция будет перезапускаться несколько раз подряд, то в итоге она непременно
окажется более ранней в сравнении с другими выполняющимися транзакциями.
Этот протокол, называемый протоколом принудительной отмены-ожидания (более
ранние транзакции принудительно отменяют более поздние, а более поздние просто
дожидаются окончания более ранних), гарантирует, что каждая транзакция, в конце
концов, сможет завершить свою работу.
Вопросы для самопроверки
1. В чем состоит отличие между транзакцией, достигшей точки фиксации, и
транзакцией, не достигшей этой точки?
2. Каким образом СУБД может предупреждать возникновение обширных
каскадных откатов транзакций?
3. Покажите, каким образом неконтролируемое чередование этапов двух
одновременно выполняемых транзакций, одна из которых уменьшает значение
остатка на счете на 100 долларов, а другая — на 200 долларов, может привести
к конечному значению 100, 200 или 300 долларов, если принять исходное
значение остатка равным 400 долларам?
4. Предположим, что в СУБД используется механизм блокировок.
а) Перечислите возможные варианты ответов СУБД на запрос транзакции о
получении разделяемого доступа к элементу данных в базе.
б) Перечислите возможные варианты ответов СУБД на запрос транзакции о
получении эксклюзивного доступа к элементу данных в базе.
5. Опишите последовательность событий, которая может привести к
возникновению ситуации взаимной блокировки между двумя транзакциями,
выполняющимися в базе данных.
492 Глава девятая. Структуры баз данных
6. Предложите способ предотвращения возникновения той ситуации взаимной
блокировки, которая была описана вами в ответе на предыдущий вопрос.
Требует ли предложенное вами решение использования журнала СУБД?
Поясните ваш ответ.
9.6. Влияние технологий баз данных на общество
В прошлом наборы данных рассматривались как нечто неподвижное и
пассивное. Каждый набор данных разрабатывался и использовался для
определенной цели. Например, в местной библиотеке составляли и поддерживали список
имен и адресов читателей. В каждую книгу вкладывали библиотечную карточку
с названием книги. Когда кто-либо брал книгу, в эту карточку заносили имя
читателя и она оставалась в библиотеке. При возврате книги карточку вновь
помещали в книгу. Если книгу не возвращали в срок, библиотекарь мог связаться
с человеком, взявшим эту книгу, пользуясь информацией из списка читателей.
В принципе, используя подобную систему, можно было бы получить список
всех прочитанных некоторым читателем книг. Однако для этого потребовалось
бы пересмотреть карточки всех книг, чтобы обнаружить в них имя
интересующего читателя. Понятно, что подобное мероприятие потребует слишком много
времени и что выполнение такого поиска будет просто непрактичным. В
результате, хотя в библиотеке и имелись некоторые личные сведения о ее читателях,
которые можно было бы использовать для целей, отличных от тех, для которых
они предназначались, читатель мог быть уверен, что подобное не произойдет в
силу вышеуказанных причин. Однако в настоящее время ведение
регистрационных записей в большинстве библиотек автоматизировано, поэтому определение
читательских предпочтений любого ее абонента уже не потребует особых
временных затрат. Поэтому вполне возможно, что теперь библиотеки смогут
предоставлять подобную информацию маркетинговым компаниям, юридическим
конторам, политическим партиям, работодателям и частным лицам.
Последствия этих действий просто трудно оценить адекватно.
Приведенный выше простой пример с библиотекой демонстрирует весь спектр
типичных потенциальных возможностей, которыми обладают приложения баз
данных. Эта технология делает весьма простой задачу сбора и накопления
информации, а также обобщения и сравнения различных наборов данных в целях
выявления некоторых взаимосвязей, которые при прежнем уровне технологии
обработки информации были погребены в груде фактов.
Сбор данных сейчас производится в огромных масштабах. В одних случаях
этот процесс очевиден; в других — скрыт. Открытый сбор данных состоит в
явном обращении за информацией к кому-либо. При проведении опросов
населения этот сбор данных проходит на добровольной основе, однако на основании
решений правительственных органов могут проводиться и принудительные
сборы данных. Ответ на вопрос, носит ли сбор данных принудительный или
добровольный характер, часто зависит лишь от точки зрения индивидуума. Скажем,
ответ на вопрос, является ли требование предоставить информацию личного ха-
9.6. Влияние технологий баз данных на общество 493
рактера при предоставлении займа добровольным или принудительным, зависит
от цели, для которой требуется этот кредит. При оплате покупки с помощью
кредитной карточки некоторые торговые предприятия требуют сейчас согласия
покупателя на представление его личной подписи в оцифрованном виде.
Является ли это обязательным требованием или только пожеланием — зависит от
характера приобретения.
При более скрытом сборе данных прямого контакта с объектом избегают.
Примерами могут служить кредитные компании, осуществляющие сбор данных
о покупках, совершенных владельцами их кредитных карточек; организации,
собирающие информацию о посетителях принадлежащих им Web-узлов;
сотрудники правоохранительных органов, записывающие номерные знаки
автомобилей, припаркованных у стен некоторого учреждения. В этих случаях объект
опроса может быть вообще не осведомлен о сборе информации и, тем более, о
существовании базы данных, хранящей его личные данные. Иногда это становится
вполне очевидным, если просто остановиться и подумать. Например,
продуктовый магазин может предлагать скидки тем постоянным покупателям, которые в
нем предварительно зарегистрируются. В процессе регистрации клиенту выдают
личную дисконтную карточку, которую он должен предъявлять при покупке для
получения скидки. В результате магазин получает возможность вести запись
всех покупок клиента, а ценность этой информации может быть значительно
выше размера предоставленных ему скидок.
Интерес к сбору информации был вызван той значимостью данных, которую
они приобрели вследствие бурного развития технологии баз данных. С помощью
этой технологии можно связывать и обрабатывать исходные данные таким
образом, чтобы вскрыть невидимые ранее закономерности. Это приводит к
появлению новых обобщенных данных, ценность которых превышает простую сумму
их исходных составляющих. Так, покупательские предпочтения владельцев
кредитных карточек могут быть классифицированы и упорядочены в целях
получения потребительских профилей огромного маркетингового значения. На
основании этих профилей предложение подписаться на журнал по бодибилдингу может
рассылаться лицам, ранее приобретавшим тренажеры, а подписка на журналы
по дрессировке собак — лицам, ранее покупавшим корм для собак. Способы
альтернативного использования информации могут быть весьма изощренными.
Записи об уровне благосостояния сравнивались с записями о криминальных
преступлениях в целях обнаружения и задержания нарушителей правил условного
освобождения от тюремного заключения, а в 1984 году призывная комиссия
США использовала список дней рождения граждан, полученный от фирмы —
популярного поставщика мороженого, для определения лиц, уклонившихся от
регистрации в ходе призывной кампании.
В последнем случае фирма-поставщик заявила, что список ее клиентов был
продан по ошибке. Список был возвращен поставщику мороженого, но, тем не
менее, данные были использованы. К сожалению, использование данных не по
назначению происходит вновь и вновь. Вскрываются все новые и новые факты
злоупотребления служебной информацией, полученной из баз данных
организаций, от работников государственных и частных учреждений.
494 Глава девятая. Структуры баз данных
Продажа списка дней рождения клиентов поднимает вопросы, касающиеся
права собственности на информацию. Следует ли считать, что лицо, собравшее
информацию, автоматически становится ее владельцем? Насколько широко
простирается наше право на владение информацией о самих себе? До каких
пределов простирается право третьих лиц на владение информацией о нас?
Существует несколько подходов к защите общества от злоупотреблений при
использовании баз данных. Один из них состоит в применении ограничений правового
характера. К сожалению, принятие закона не исключает возможности определенного
действия; чаще всего такое действие просто переходит в разряд нелегальных. Одним
из ярких примеров является принятие в 1974 году закона США о защите частной
жизни, призванного, в частности, защитить граждан от злоупотреблений
информацией из государственных баз данных. В этом законе говорится, что государственные
агентства должны сообщать о существовании таких баз данных в едином
федеральном регистре, чтобы каждый гражданин имел возможность доступа к информации о
самом себе и проверки ее достоверности. Однако государственные агентства медлили
с исполнением этого требования. Во многих случаях это было скорее следствием
бюрократичности, нежели злонамеренности. Однако сам факт, что бюрократия
способна создавать базы данных с личными данными, о существовании которых ничего
неизвестно, не успокаивает.
Другим, может быть, более действенным, средством контроля за
злоупотреблениями при использовании баз данных является общественное мнение. Базы
данных не будут использоваться недопустимым образом, если потери от этого
превзойдут возможный выигрыш. Для большинства компаний не существует
более страшного наказания, чем неблагоприятное общественное мнение. В начале
90-х годов именно общественное мнение положило конец продаже крупными
кредитными компаниями списков адресов своих клиентов для целей маркетинга.
Еще раньше компания America Online (крупнейший провайдер Internet)
подверглась давлению со стороны общественности в связи с продажей ею информации о
своих клиентах он-лайновым маркетинговым компаниям. Даже
государственным учреждениям приходилось сгибаться под давлением общественного мнения.
В 1997 году Министерство социальной защиты США изменило свой план сделать
доступными в Internet записи о социальной защите граждан, после того как
общественное мнение выразило озабоченность по поводу защиты этих данных. В
описанных случаях результат был получен в течение считанных дней, хотя для
правового урегулирования проблемы необходимо существенно больше времени.
Безусловно, в большинстве случаев приложения баз данных приносят выгоду
как держателю, так и источнику информации, однако здесь существует
определенная потеря конфиденциальности, которую не следует оставлять без
внимания. Если данные верны, то подобная потеря конфиденциальности частной
информации является, конечно же, серьезной проблемой, однако если информация
ошибочна, последствия могут иметь просто катастрофический характер.
Представьте себе, что должен чувствовать человек, узнавший о неблагоприятном
изменении его кредитного рейтинга из-за ошибки при вводе информации.
Подумайте, насколько осложнится стоящая перед этим человеком проблема, если эта
9.6. Влияние технологий баз данных на общество 495
ошибочная информация была открыта для совместного доступа и со стороны
других учреждений.
Проблемы конфиденциальности данных есть и будут в будущем важнейшим
побочным эффектом развития технологии в целом и технологии баз данных в
частности. Решение этих проблем требует продуманных, сознательных и
активных действий со стороны всего общества.
Вопросы для самопроверки
1. Должны ли правоохранительные органы обладать правом доступа к базам
данных для определения лиц с преступными наклонностями, даже если ранее
они не совершали каких-либо преступлений?
2. Должны ли страховые компании иметь доступ к данным о возможных
потенциальных проблемах со здоровьем своих клиентов, если клиенты внешне не
проявляют каких-либо симптомов заболеваний?
3. Предположим, что в финансовом отношении вы преуспеваете. Какие позитивные
для вас последствия могут иметь место, если информация об этом будет доступна
самому широкому кругу организаций? Какие негативные последствия может
иметь распространение подобной информации? А что вы обо всем этом скажете,
если ваше финансовое положение оставляет желать лучшего?
4. Какова роль независимых средств массовой информации в контроле над
использованием баз данных не по прямому назначению? (Например, в какой
степени пресса может воздействовать на общественное мнение?)
Упражнения
(Упражнения, отмеченные звездочкой, относятся к разделам для
дополнительного чтения.)
1. Перечислите отличия между плоским файлом и базой данных.
2. Что подразумевается под независимостью данных?
3. Какова роль СУБД в многоуровневом подходе к реализации базы данных?
4. В чем состоят различия между схемой и подсхемой?
5. Опишите основные преимущества разделения функций прикладного
программного обеспечения и СУБД.
6. Определите, в чью компетенцию (пользователя, прикладного
программиста, разработчика СУБД) входят следующие вопросы:
а) Как обеспечить наиболее эффективное хранение данных на диске?
б) Есть ли свободные места на рейс № 243?
в) Можно ли хранить отношение в виде последовательного файла?
г) Сколько раз следует разрешить пользователю ошибаться при
вводе пароля, прежде чем система должна будет отказаться от
работы с ним?
д) Каким образом может быть реализована операция PROJECT?
496 Глава девятая. Структуры баз данных
7. Опишите, каким образом приведенная ниже информация об
авиакомпаниях, рейсах (на конкретный день) и пассажирах может быть
представлена в реляционной базе данных.
Авиалинии: "Clear Sky", "Long Hop", "Tree Top"
Рейсы компании Clear Sky: "CS205", "CS37", "CS102"
Рейсы компании Long Hop: "LH67", "LH89"
Рейсы компании Tree Top: "TT331", "TT809"
Пассажир "Smith" зарезервировал билеты на рейс CS205 (место
"12В"), рейс CS37 (место "18С") и рейс LH89 (место "14А")
Пассажир "Baker" зарезервировал билеты на рейс CS37 (место
"18В") и рейс LH89 (место "14В")
Пассажир "Clark" зарезервировал билеты на рейс LH67 (место
"5А") и рейс ТТ331 (место "4В").
8. Исходя из представленных ниже отношений, покажите, как будет
выглядеть отношение RESULT после следующих операций:
Отношение X
а) RESULT <- PROJECT W from X
б) RESULT <- SELECT from X where W = 5
в) RESULT <r- PROJECT S from Y
r) RESULT <- JOIN X and Y where X.W > Y.R
9. Исходя из представленных ниже отношений PART (Деталь) и
MANUFACTURER (Изготовитель) с помощью команд SELECT, PROJECT и
JOIN напишите последовательность операций, необходимых для
получения ответа на каждый из приведенных ниже вопросов о деталях и
их изготовителях.
Отношение PART
PartName Weight
Bolt 2X | 1
BOLT 2Z ГТ5
Nut V5 0T5
Упражнения
497
Отношение MANUFACTURER
CompanyName PartName Cost
Company X | BOLT 2Z | 0.03
Company X Nut V5 0.01
Company Y Bolt 2X 0.02
Company Y Nut V5 0.01
Company Y BOLT 2Z 0.04
Company Z Nut V5 0.01
а) Какие компании производят деталь "BOLT 2Z"?
б) Получите список деталей, производимых компанией "Company X",
с указанием их стоимости (атрибут Cost).
в) Какие компании выпускают детали, вес которых (атрибут Weight)
равен 1?
10. Выполните упражнение 9, используя язык SQL.
11. Какая избыточная информация будет внесена в базу данных при
объединении данных из отношений PART и MANUFACTURER в упражнении 9?
12. Используя команды SELECT, PROJECT и JOIN, напишите
последовательности операций, необходимые для получения ответа на вопросы,
касающиеся отношений EMPLOYEE, JOB, ASSIGNMENT, представленных
на рис. 9.5.
а) Получите список имен и адресов сотрудников компании.
б) Получите список имен и адресов тех, кто работал и работает в
отделе кадров.
в) Получите список имен и адресов тех, кто работает в отделе кадров.
13. Выполните упражнение 12, используя язык SQL.
14. Разработайте структуру реляционной базы данных, предназначенной
для хранения информации о композиторах, их биографиях и списках
созданных ими произведений.
15. Разработайте структуру реляционной базы данных, предназначенной
для хранения информации о музыкальных исполнителях, записях в
их исполнении и тех композиторах, произведения которых были
записаны в их исполнении.
16. Разработайте структуру реляционной базы данных, предназначенной
для хранения информации о производителях компьютерного
оборудования и выпускаемой ими продукции.
17. Разработайте структуру реляционной базы данных, предназначенной
для хранения информации об издательствах, журналах и
подписчиках, в которой отношения между указанными сущностями будут
соответствовать следующей диаграмме "сущность-связь".
498
Глава девятая. Структуры баз данных
18. Разработайте структуру реляционной базы данных, содержащей
информацию о деталях, поставщиках и заказчиках. Предусмотрите, что
каждая деталь может поставляться несколькими поставщиками и
заказываться несколькими заказчиками. Каждый поставщик может
поставлять множество деталей и обслуживать нескольких заказчиков.
Наконец, каждый заказчик может заказывать множество деталей у
разных поставщиков, причем одну и ту же деталь можно заказывать у
разных поставщиков.
19. Какие изменения должны быть внесены в структуру базы данных,
представленной на рис. 9.5, чтобы получить список всех сотрудников
по фамилии "Смит" с использованием одной лишь операции SELECT?
20. Какие неудобства могут возникнуть вследствие объединения в одном
атрибуте реляционной базы данных сразу трех элементов данных:
месяц, день и год (см. рис. 9.5)?
21. Составьте последовательность операторов, используя операции SELECT,
PROJECT и JOIN, чтобы получить значения полей Jobld, StartDate и
TermDate для каждой из должностей в бухгалтерии (см. рис. 9.5).
22. Подготовьте ответ к упражнению 21, используя язык SQL.
23. Составьте последовательность операторов, используя операции SELECT,
PROJECT и JOIN, чтобы получить информацию о значениях полей
Name, Address, JobTitle и Dept для каждого работающего в
настоящий момент сотрудника (см. рис. 9.5).
24. Подготовьте ответ к упражнению 23, используя язык SQL.
25. Составьте последовательность операторов, используя операции SELECT,
PROJECT и JOIN, чтобы получить информацию о значениях полей Name
и JobTitle для каждого работающего в настоящий момент
сотрудника (см. рис. 9.5).
26. Подготовьте ответ к упражнению 25, используя язык SQL.
27. Чем отличается информация в первой из представленных ниже таблиц
от информации в двух других таблицах?
Упражнения
499
Name Department TelephoneNumber
Jones | Sales | 111-2222
Smith Sales 111-3333
Baker Personnel 111-4444
Name Department
Jones Sales
Smith Sales
Baker Personnel
Departmen TelephoneNumbe
t r
Sales | 111-2222
Sales 111-3333
Personnel 111-4444
28. Разработайте реляционную базу данных, содержащую информацию об
автомобильных узлах и входящих в них деталях. Предусмотрите
возможность того, что каждый узел может не только состоять из меньших узлов
и деталей, но в то же время являться составной частью большего узла.
29. Исходя из информации в базе данных, представленной на рис. 9.5,
сформулируйте запрос, ответ на который дает следующий фрагмент
программного кода:
TEMP <- SELECT from ASSIGNMENT
where TermDate="*"
RESULT <- PROJECT Jobld, StartDate from Temp
30. Запишите сформулированный в упражнении 29 запрос средствами
языка SQL.
31. Исходя из информации в базе данных, представленной на рис. 9.5,
сформулируйте запрос, ответ на который дает следующий фрагмент
программного кода:
TEMPI <- JOIN EMPLOYEE and ASSIGNMENT
where EMPLOYEE.Emplid = ASSIGNMENT.EmplId
TEMP2 <- SELECT from TEMPI
where TermDate = "*"
RESULT <- PROJECT name, StartDate
from TEMP2
32. Запишите сформулированный в упражнении 31 запрос средствами
языка SQL.
33. Исходя из информации в базе данных, представленной на рис. 9.5,
сформулируйте запрос, ответ на который дает следующий фрагмент
программного кода:
TEMPI ^- JOIN EMPLOYEE and ASSIGNMENT
where EMPLOYEE.EmplId = ASSIGNMENT.EmplId
500
Глава девятая. Структуры баз данных
ТЕМР2 <- JOIN TEMPI and JOB
where TEMPI.Jobld = JOB.Jobld
TEMP3 <- SELECT from TEMP2
where Dept = "Бухгалтерия"
RESULT <- PROJECT Name from TEMP3
34. Запишите сформулированный в упражнении 33 запрос средствами
языка SQL.
35. Преобразуйте следующий SQL-запрос в последовательность операций
SELECT, PROJECT и JOIN:
select JOB.JobTitle
from ASSIGNMENT, JOB
where ASSIGNMENT.Jobld = JOB.Jobld
and ASSIGNMENT.EmplId = '34Y701
36. Преобразуйте следующий SQL-запрос в последовательность операций
SELECT, PROJECT и JOIN:
select ASSIGNMENT.StartDate
from ASSIGNMENT, EMPLOYEE
where ASSIGNMENT.EmplId = EMPLOYEE.EmplId
and EMPLOYEE.Name = 'Джо Бейкер'
37. Какой эффект окажет на базу данных из упражнения 9 выполнение
следующего SQL-оператора:
insert into MANUFACTURER
values ('Company Z', 'Bolt 2X' , 0.03)
38. Какой эффект окажет на базу данных из упражнения 9 выполнение
следующего SQL-оператора:
update MANUFACTURER
set Cost =0.03
where CompanyName = 'Company Y1
and PartName = 'Bolt 2X'
39. В чем преимущество хранения отношения в виде индексированного
файла в сравнении с простым последовательным файлом?
*40. Назовите несколько объектов, которые можно использовать в объектно-
ориентированной базе данных для ведения учета товаров на складе
продуктового магазина. Какие методы могут понадобиться этим объектам?
*41. Назовите несколько объектов, которые можно использовать в
объектно-ориентированной базе данных для ведения картотеки читателей
библиотеки. Какие методы могут понадобиться этим объектам?
*42. Сравните взаимоотношения между классом и объектом в объектно-
ориентированной базе данных с взаимоотношениями между схемой
реляционной базы данных и самой базой данных.
Упражнения 501
*43. Какие ошибки будут внесены в информацию при следующем
выполнении транзакций Т1 и Т2.
*44. Транзакция Т1 предназначена для вычисления суммы остатка на
счетах А и В, а транзакция Т2 — для перечисления 100 долларов со
счета А на счет В. Транзакция Т1 начинает свое выполнение первой и
считывает значение остатка на счете А. Затем запускается транзакция
Т2 и выполняет соответствующие перечисления. Наконец, транзакция
Т1 считывает остаток на счете В и вычисляет итоговое значение.
*45. Объясните, каким образом описанный в этой главе протокол
блокировки может разрешить проблему, возникшую в сценарии,
предложенном в упражнении 43?
*46. Объясните, какое значение мог бы иметь описанный в этой главе
протокол принудительной отмены/ожидания для изложенной в
упражнении 43 последовательности событий, если предположить, что
транзакция Т1 запущена после транзакции Т2? А если транзакция Т2 будет
запущена после транзакции Т1?
*47. Предположим, что одна транзакция предпринимает попытку
увеличить на 100 долларов сумму счета, остаток на котором составляет 200
долларов, а другая — уменьшить значение этого счета на 100
долларов. Покажите, какой вариант чередования отдельных этапов этих
транзакций может привести к получению остатка, равного 100
долларам? А какой вариант чередования отдельных этапов этих транзакций
может привести к получению остатка, равного 300 долларам?
Общественные и социальные вопросы
Следующие вопросы приводятся для того, чтобы помочь вам разобраться в
некоторых этических, общественных и юридических аспектах использования
вычислительной техники, а также в ваших собственных воззрениях и тех
принципах, на которых они основаны. Задача не сводится к тому, чтобы просто дать
ответы на предложенные вопросы. Вы должны также разобраться, почему вы
ответили именно так, а не иначе, и насколько ваши суждения по различным
вопросам согласуются друг с другом.
1. В США записи о всех федеральных заключенных сохраняются в
единой базе данных в целях проведения криминальных расследований.
Этично ли использовать эту информацию в других целях, скажем для
генетических исследований? Если да, то для каких целей? Если нет,
то почему? Каковы за и против в обоих случаях?
2. В какой степени университеты обладают правом распространять
информацию о своих студентах? Допустимо ли это в отношении имен и
адресов студентов? Можно ли распространять данные о показателях
502 Глава девятая. Структуры баз данных
успеваемости в университете без указания имен студентов?
Согласуется ли ваш ответ с ответом на вопрос 1?
3. Какие ограничения могут применяться при разработке структуры базы
данных для хранения персональной информации о людях? Какую
информацию о гражданах своей страны имеют право хранить
государственные органы? Какую информацию о своих клиентах имеет право
хранить страховая компания? Какую информацию о своих
сотрудниках имеет право хранить любая компания? Должен ли в этих областях
осуществляться контроль; если да, то как?
4. Имеет ли право кредитная компания продавать маркетинговым фирмам
информацию о покупательских предпочтениях владельцев выпущенных
ею кредитных карточек? Может ли фирма, специализирующаяся на
заказах спортивных автомобилей по почте, продавать список почтовых
адресов своих клиентов журналам, освещающим ту же тематику? Допустимо
ли, чтобы налоговая администрация продавала биржевым брокерам
адреса и имена состоятельных налогоплательщиков?
5. В какой мере разработчик базы данных ответствен за возможное
использование информации не по прямому назначению?
6. Предположим, что вследствие ошибки СУБД злоумышленник смог
получить несанкционированный доступ к базе данных. Если в результате
этого некоторая информация была извлечена и использована
неблагоприятным образом, то в какой степени разработчики базы данных
должны разделять ответственность за это? Зависит ли ответ на этот
вопрос от тех усилий, которые злоумышленник вынужден был
предпринять для обнаружения в конструкции базы данных той бреши,
которая позволила ему осуществить это проникновение?
Рекомендуемая литература
Date С.J. An Introduction to Datebase Systems, 6th ed. — Reading, MA:
Addison-Wesley, 1995. (Имеется русский перевод этой книги: Дейт К.Дж.
Введение в системы баз данных, 6-е изд. — М.: Издательский дом
"Вильяме", 2000.)
Elmasri R., Navathe S.B. Fundamentals of Datebase Systems, 2nd ed.—
Redwood City, CA : Benjamin/Cumming, 1994.
Ozsu M.T., Valduriez P. Principles of Distributed Database Systems. — Upper
Saddle River, NJ: Prentice Hall, 1999.
Ramakrishnan R. Database Management Systems. — New York : McGraw-Hill,
1998.
Рекомендуемая литература 503
Дополнительная литература
Коннолли Т., Бегг К., Страчан А. Базы данных: проектирование, реализация
и сопровождение. Теория и практика, 2-е изд.: Пер. с англ. — М.:
Издательский дом "Вильяме", 2000.
Дейт К. Дж. Введение в системы баз данных, 7-е изд.: Пер. с англ. — М.:
Издательский дом "Вильяме", 2001.
Джордан Д. Обработка объектных баз данных в C++. Программирование с
использованием стандарта ODMG.: Пер. с англ. — М.: Издательский дом
"Вильяме", 2001.
Риккарди Г. Системы баз данных. Теория и практика использования в Internet
и среде Java.: Пер. с англ. — М.: Издательский дом "Вильяме", 2001.
504 Глава девятая. Структуры баз данных
часть
четвертая
Потенциал алгоритмических машин
В этой части мы рассмотрим потенциальные возможности
алгоритмических машин. Начнем с изучения искусственного
интеллекта. В главе 10 мы выясним, какие главные достижения были
сделаны при создании машин, имитирующих человеческую
деятельность и демонстрирующих, таким образом, видимость
разумного поведения. Развитие подобных технологий
стимулировало поиски ответа на вопрос, чем ограничена деятельность
машин и существуют ли эти границы вообще.
Этот вопрос будет подробно рассмотрен в главе 11, где
обсуждается теория вычислений. Из этой главы вы узнаете, что
пределы для задач, которые способна решать машина,
действительно существуют. Кроме того, будет показано, что соображения
практичности еще более ограничивают круг этих задач.
Оказывается, существуют задачи, решение которых займет слишком
много времени даже с учетом теоретически возможной
мощности компьютеров.
глава
Искусственный
интеллект
ДЕСЯТАЯ
Главной целью специалистов по компьютерным наукам
является создание машин, способных общаться с окружающей
средой посредством присущих человеку органов чувств и
поддерживать осмысленную деятельность без вмешательства
человека. Это подразумевает, что машина должна "понимать" или
"осознавать" получаемые данные и уметь делать из них выводы
посредством некоего процесса рассуждения.
И восприятие, и рассуждение подпадают под категорию
той деятельности, которую мы привыкли называть здравым
смыслом, явлением, совершенно естественным для
человеческого разума, но, несомненно, весьма трудно
достижимым для машин. Результатом является то, что связанная
с этими проблемами область исследований, известная как
создание искусственного интеллекта, все еще находится в
периоде становления, с точки зрения поставленных целей
и достигнутых результатов.
10.1. Машины и интеллект
10.2. Распознавание изображений
10.3. Способность к рассуждению
Порождающие системы
Дерево поиска
Эвристические методы
10.4. Искусственные нейронные
сети
Основные свойства
Конкретное приложение
10.5. Генетические алгоритмы
10.6. Приложения теории
искусственного интеллекта
Обработка языка
Робототехника
Системы баз данных
Экспертные системы
10.7. Осмысливание последствий
10.1. Машины и интеллект
Считается, что компьютер обладает индивидуальностью, но нельзя забывать,
что между ним и человеческим разумом все же имеются существенные
различия. Конечно, современные машины способны быстро и точно выполнять строго
определенные задания, но компьютер не обладает здравым смыслом. При
возникновении ситуации, не предусмотренной программистом, деятельность
машины становится непредсказуемой. Разум же человека, наоборот, часто путается в
сложных вычислениях, но способен к пониманию и рассуждению.
Следовательно, если машина превосходит человека по быстродействию при решении задач
ядерной физики, человек имеет больше шансов понять полученные результаты и
определить направление последующих вычислений.
Если мы хотим создать машину, не требующую вмешательства человека при
возникновении непредвиденной ситуации, она должна стать более
человекоподобной, т.е. должна иметь (или, по крайней мере, имитировать) способность
рассуждать. Учитывая это требование, специалисты по искусственному интеллекту
обратились к психологии и ее модели человеческого разума в надежде найти и
понять те принципы, которые можно было бы положить в основу создания более
гибких машин и программ. В результате часто оказывается довольно трудно
провести четкое разграничение между исследованиями психолога и специалиста
по компьютерной технике. Различие здесь заключается не в методах
исследований, а в целях, которые эти ученые преследуют. Психолог пытается полнее
изучить человеческое сознание и происходящие в нем мыслительные процессы,
тогда как специалист по вычислительной технике стремится к созданию все более
полезных машин. Подобным же образом деятельность специалиста по
компьютерам можно сравнить и с исследованиями, проводимыми в других областях
науки. Например, лингвиста интересует, как человек оперирует языком, а
программист заинтересован в создании механизма, который мог бы обрабатывать
языковые выражения, и т. п. Таким образом, исследования по искусственному
интеллекту охватывают целый спектр различных дисциплин.
Происхождение искусственного интеллекта
Исследования по созданию машин, имитирующих человеческое поведение, имеют долгую историю.
Большинство авторов соглашаются с тем, что современный этап в исследованиях искусственного интеллекта
начался в 1950 году, с момента публикации книги Алана Тьюринга Computing Machinery and Intelligence.
Именно в ней Тьюринг впервые предположил, что возможно создание машин, запрограммированных для
демонстрации разумного поведения. Однако название данной области науки — искусственный интеллект—
впервые было употреблено несколько лет спустя, в теперь уже ставшем легендарном проекте Джона Мак-
Карти (John McCarthy). В нем говорилось о том, что "изучение искусственного интеллекта будет осуществ-
508 Глава десятая. Искусственный интеллект
лено в течение лета 1956-го года в Дартмутском колледже" с целью проверить "гипотезу о том, что каждый
аспект механизма обучения или любой другой функции сознания может быть описан настолько точно, что
это позволит создать машину для его воспроизведения".
Одним из следствий такой обширности области исследования является то, что
специалисты по искусственному интеллекту склонны к принятию двух
различных парадигм. Для пояснения этой мысли предположим, что специалист по
компьютерам и психолог независимо взялись за создание программы для игры в
покер. Вероятнее всего, специалист по компьютерам в основу стратегии своей
программы положит теорию вероятности и статистику. В результате он создаст
программу, стремящуюся использовать любой доступный шанс, блефующую
случайным образом, не проявляющую никаких эмоций и, как следствие,
имеющую максимальные шансы на победу. Психолог же, напротив, построит
стратегию своей программы на теории человеческого мышления и поведения. В общем
случае результатом работы психолога может быть даже несколько различных
программ: одна, например, будет играть весьма агрессивно, тогда как другую
будет очень легко запугать. В противоположность программе компьютерного
специалиста, программа психолога во время игры может оказаться "в плену
эмоций" и в результате "проиграться до нитки".
Подведем итог этого маленького мысленного эксперимента. Для специалиста по
компьютерам наибольшее значение в его работе имеет, вероятнее всего, конечный
результат деятельности его программы. Такой подход называют результативно-
ориентированным. В противоположность этому, психолог более заинтересован в
понимании процессов, происходящих в естественном интеллекте, и, следует полагать,
использовал бы данный проект для проверки своих теорий посредством построения
их компьютерной модели. С подобной точки зрения разработка "интеллектуальной"
программы фактически является лишь побочным эффектом от преследования совсем
иной цели — получения новых знаний о человеческом мышлении и поведении.
Такой подход назвали имитационно-ориентированным.
Оба подхода действенны и способны внести существенный вклад в разработку
искусственного интеллекта. Однако в связи с этим возникают и определенные
философские проблемы. В качестве примера можно привести дискуссию, которая могла
бы иметь место в группе специалистов, перед которыми поставлена задача
установить, действительно ли созданные программистом и психологом программы
обладают интеллектом; если да, то какая из двух программ умнее. Что есть мера
интеллекта — способность выигрывать или человекоподобное поведение?
Вариант ответа на последний вопрос предложил в 1950 году Алан Тьюринг в
своем тесте для оценки интеллектуальных возможностей машины (сейчас он известен
как тест Тьюринга). Суть теста состоит в следующем: позволить человеку (назовем
его опросчиком) общаться с тестируемым субъектом посредством терминала, не
уточняя при этом, кем является субъект — человеком или машиной. В данной
ситуации поведение машины будет считаться интеллектуальным, если она будет
высказываться о событиях настолько разумно, что опросчик не сможет отличить ее от
человека. Очевидно, что тест Тьюринга оценивает уровень соответствия поведения
машины по отношению к поведению человека. Тьюринг предполагал, что к 2000 го-
10.1. Машины и интеллект 509
ду машины смогут с 30-процентной вероятностью продержаться пять минут. Как
показало время, эта догадка оказалась на удивление точной.
Хорошо известный пример применения сценария теста Тьюринга связан с
испытаниями программы DOCTOR (версия более общей системы с названием
ELIZA), разработанной в середине 1960-х годов Джозефом Уэйзенбаумом (Joseph
Weizenbaum). Эта интерактивная программа была сконструирована для
имитации поведения психиатра Рогерианской (Rogerian) школы психоанализа,
проводящего психологический опрос. Компьютер играл роль психиатра, а роль
пациента была отведена пользователю. В сущности, все выполняемые программой
DOCTOR действия сводились к реструктуризации получаемых от собеседника
выражений, проводимой по нескольким хорошо известным правилам.
Измененные выражения возвращались на экран пользователя в виде ответных реплик.
Например, в ответ на выражение "Я сегодня устал" программа DOCTOR
выдавала пользователю следующее сообщение: "Как вы думаете, из-за чего вы сегодня
устали?" Если программа не могла распознать структуру полученного
сообщения, она просто выводила пользователю малозначащую общую фразу, например
"Продолжайте, продолжайте..." или "Очень интересно".
Первоначальная цель Уэйзенбаума при разработке программы DOCTOR
состояла в проведении исследований природы языкового общения. С этой точки
зрения выбор психотерапии играл второстепенную роль как средства создания
нужной окружающей обстановки (или предмета беседы), в которой программа
могла бы функционировать. К удивлению Уэйзенбаума, несколько психологов
предложили использовать его программу для проведения реальной
психотерапии. (Главным тезисом Рогерианской школы является утверждение, что не
психиатр, а пациент должен задавать направление беседы в течение
терапевтического сеанса. Именно поэтому, как утверждали психологи, компьютер будет вполне
способен поддерживать беседу так же хорошо, как и профессиональный
терапевт.) Кроме того, программа DOCTOR настолько хорошо имитировала
понимание ситуации, что многие "общавшиеся" с ней пациенты чувствовали себя
установившими контакт с личностью, имеющей родственные мысли и чувства, и в
большинстве случаев, как ни странно, подчинялись машинному диалогу,
состоящему из вопросов и ответов. В этом смысле программа DOCTOR прошла тест
Тьюринга. В результате возникли новые этические и технические проблемы.
Даже если машина и прошла тест Тьюринга, обладает ли она интеллектом? В
конечном счете главная трудность в нахождении ответа на этот вопрос упирается в
сложность различения чисто внешних проявлений интеллекта и его подлинной
сущности. Интеллект — это внутренняя характеристика, существование которой
определяется снаружи только косвенно, в контексте диалога по принципу "раздражитель-
реакция". Но предполагают ли умные реакции действительное наличие интеллекта?
Подобные философские вопросы касаются самых основ проблемы
искусственного интеллекта. Не удивительно, что этот предмет окружен аурой
таинственности, часто эксплуатируемой как средствами массовой информации, так и
писателями-фантастами. К счастью, нашей задачей является не решение подобных
спорных вопросов, а исследование того, как можно запрограммировать
поведение машины, чтобы окружающим оно казалось разумным. Мы приступим к по-
510 Глава десятая. Искусственный интеллект
искам решения этой задачи с рассмотрения проекта машины, имеющей
элементарные интеллектуальные характеристики.
Наша машина будет иметь вид металлической коробки, снабженной
зажимом, видеокамерой и манипулятором с резиновым наконечником, необходимым
для того, чтобы манипулятор не проскальзывал при толкании чего-либо
(рис. 10.1). Представьте, что подобный механизм помещен на стол, на котором
находится и головоломка. Имеется в виду вариант хорошо известной игры "В
пятнадцать". Данный вариант игры (назовем его "Восьмерка") состоит из восьми
квадратных фишек, помеченных цифрами от 1 до 8. Фишки помещены в рамку,
способную вместить девять таких фишек, расположенных в три ряда по три
штуки. Девятое место в рамке свободно, и на него может быть перемещена
любая из расположенных рядом фишек. В настоящее время фишки упорядочены
так, как показано на рис. 10.2.
Машина для решения головоломки "Восьмерка"
Начнем с того, что подымем рамку с головоломкой со стола и многократно
произвольно переместим случайно выбранные фишки на свободные места. Затем
включим нашу машину, и ее зажим начнет открываться и закрываться, как бы требуя
предоставить ему головоломку. Поместим рамку с головоломкой в зажим, который
тут же захватит ее. Очень скоро манипулятор машины опустится вниз и начнет
методично перемещать фишки внутри рамки до тех пор, пока они не вернутся в изна-
10.1. Машины и интеллект 511
чальное положение. Как только цель будет достигнута, машина отпустит рамку с
головоломкой и выключится. Поскольку действия такой машины включают в себя как
элементарное восприятие, так и необходимость проведения определенных
рассуждений, ее устройство представляет собой фундамент, вполне достаточный для
проведения необходимых рассуждений в последующих двух разделах.
РИСУНОК 10.2
Головоломка "Восьмерка" с расположением фишек, соответствующим правильному решению
Вопросы для самопроверки
1. Растение, помещенное в темную комнату с единственным источником света,
растет по направлению к нему. Является ли такое поведение разумным?
Обладает ли растение интеллектом?
2. Предположим, что торговый автомат предназначен для отпуска различных
товаров, в зависимости от того, какая кнопка нажата. Как вы считаете,
можно ли сказать, что этот автомат "осознает", какая кнопка была нажата?
3. Если машина прошла тест Тьюринга, согласитесь ли вы с тем, что она
разумна? Если нет, то согласитесь ли вы признать, что она кажется разумной?
10.2. Распознавание изображений
Открытие и закрытие зажима нашей машины не представляет собой
серьезной проблемы. Обнаружить в зажиме рамку с головоломкой по ходу этого
процесса также достаточно просто, поскольку эта прикладная задача не требует
большой точности. (Например, устройство для автоматического открытия дверей
гаража способно обнаружить и отреагировать на препятствия в дверном проеме в
момент их закрытия.) С проблемой фокусировки камеры на головоломке также
легко можно справиться, сконструировав зажим таким образом, чтобы рамка с
головоломкой всегда находилась по отношению к камере под определенным
углом зрения. Следовательно, первым проявлением разумного поведения,
необходимым для нашей машины, является способность получения информации
посредством оптических средств.
512 Глава десятая. Искусственный интеллект
Кроме того, важно понимать, что проблема, с которой сталкивается машина
при взгляде на головоломку, это не просто воспроизведение и запоминание
изображения. Технически решение подобных задач возможно уже многие годы,
например с помощью фотографии или телевидения. Фактически проблема
заключается в понимании изображения, причем на таком уровне, который позволит
извлечь из него сведения о текущем состоянии головоломки (а позднее
контролировать перемещение фишек). Это существенно отличается от телевизионного
приемника, который просто переносит изображение из одной среды в другую,
без какого-либо понимания передаваемых образов. Короче говоря, наша машина
должна демонстрировать способность осознавать смысл образов.
В случае нашего автомата для решения головоломок существует относительно
немного вариантов возможных изображений. Мы предполагаем, что в поле
зрения машины всегда находится изображение головоломки, содержащей целые
числа от 1 до 8, причем в виде хорошо организованной структуры. Проблема, по
сути, состоит только в том, чтобы установить взаимное расположение этих
чисел. Для решения поставленной задачи представим себе, что изображение
головоломки передается машине в закодированном виде — как состояние битов
компьютерной памяти. Здесь каждый бит, называемый пикселем, определяет
уровень яркости отдельной части картины. Если предположить, что изображение
всегда имеет один и тот же размер (головоломка помещается в одно и то же
место непосредственно перед камерой), то наша машина сможет определить, какую
позицию занимает каждая из фишек головоломки, сравнивая различные участки
изображения с предварительно записанными шаблонами. Эти шаблоны
представляют собой комбинации битов, соответствующие отдельным нумерованным
фишкам головоломки. Как только соответствие между изображением и эталоном
будет установлено, состояние головоломки считается определенным.
Этот метод распознавания изображений является одним из тех, которые
используются в оптических считывающих устройствах. Однако он имеет существенный
недостаток, заключающийся в требовании определенного единообразия в стиле
представления, размере и ориентации символов по отношению к считывающему
устройству. В частности, битовый образ физически большего по размеру символа будет
отличаться от битового образа того же символа, но меньшего размера, даже если
символы имеют в точности одну и ту же форму. А теперь представьте себе,
насколько усложняется проблема при обработке рукописного текста.
Другой подход к проблеме распознавания символов основан на определении
соответствий в геометрических характеристиках, а не на сравнении образа с
точным представлением символа. В этом случае характерной особенностью числа 1
будет одна вертикальная линия, число 2 может характеризоваться незамкнутой
изогнутой линией, соединенной внизу с прямой горизонтальной линией, и т.д.
Этот метод распознавания символов включает два этапа: первый состоит в
определении характерных особенностей изображения, а второй — в сравнении
найденных особенностей с характеристиками эталонных изображений. По
отношению к методу сравнения шаблонов этот метод распознавания символов
значительно сложнее. Даже незначительные ошибки в изображении символов могут
привести к получению набора совершенно различных геометрических показате-
10.2. Распознавание изображений 513
лей, что весьма затрудняет распознавание близких по начертанию символов,
например О и С или, как в случае с нашей головоломкой, цифры 3 и 8.
Можно считать, что нам еще повезло с нашей головоломкой, поскольку здесь не
требуется распознавание изображений в общей трехмерной картине. Действительно,
то, что образы, которые необходимо распознать (числа от 1 до 8), изолированы в
различных частях общей картины, существенно упрощает дело, поскольку это
позволяет исключить из рассмотрения возможность появления перекрывающихся
изображений, что достаточно типично в случае трехмерных изображений. На обычной
фотографии, например, машина сталкивается не только с проблемой распознавания
объекта, вид которого может быть показан с различных точек зрения, но и с тем
фактом, что некоторые части предмета могут быть вообще скрыты от глаз.
Задача распознавания произвольных изображений обычно решается в два
этапа. На первом выполняется обработка изображения, направленная на
идентификацию характерных особенностей изображения, а на втором проводится
анализ изображения, т.е. предпринимаются попытки понять, что эти
особенности означают. Выше мы уже рассматривали это противопоставление в контексте
распознавания символов через особенности их графического воспроизведения.
Можно сказать, что в этом случае обработка изображения представлена
процессом идентификации геометрических особенностей изображения, а анализ
изображения — процессом идентификации смысла найденных особенностей.
Процесс обработки изображения состоит из многочисленных составляющих.
Одной из них является усиление контуров, т.е. применение математических
методов для уточнения границ между отдельными частями изображения. Конечно
же, в каком-то смысле усиление контуров — это попытка превращения
фотографии в чертеж. Другая составляющая процесса анализа изображения состоит в
нахождении областей, т.е. определении тех областей изображения, которые
имеют такие общие свойства, как яркость, цвет или текстуру. Эти области, как
правило, представляют часть изображения, принадлежащую одному и тому же
объекту. С помощью метода распознавания областей компьютер может
раскрашивать мультфильмы и старые черно-белые фильмы. Еще одной процедурой в
процессе обработки изображения является сглаживание, представляющее собой
удаление мелких дефектов изображения. Сглаживание не позволяет мелким
дефектам изображения оказывать нежелательное влияние на выполнение других
процедур обработки изображения. Однако слишком сильное сглаживание может
привести к уничтожению важной информации об объектах.
Сглаживание, усиление контуров и нахождение областей — это отдельные
этапы процесса идентификации различных частей изображения, тогда как
анализ изображения позволяет определить, что представляют собой данные части и,
в конечном счете, что означает все изображение в целом. Здесь мы сталкиваемся
с задачей распознавания частично заслоненных объектов, показанных с
различных точек зрения. Один из методов анализа изображений заключается в выборе
некоторого исходного предположения, чем должен оказаться изображенный
объект, с последующей попыткой связать части изображения с предполагаемым
объектом. Похоже, что именно так подходит к данной проблеме сам человек.
Например, мы часто не в состоянии определить незнакомый предмет в условиях
514 Глава десятая. Искусственный интеллект
плохой видимости, но стоит нам получить подсказку, на что этот объект может
быть похож, как мы легко его распознаем.
Распознавание произвольных изображений связано со многими сложнейшими
проблемами, и множество из них еще ждет своего решения, несмотря на
непрекращающиеся обширные исследования в этой области. Решение многих задач, с
которыми человеческий мозг справляется быстро и внешне без особых затруднений, по-
прежнему остается за пределами возможностей машин. Хотя существует вероятность
того, что использование машин с альтернативной архитектурой позволит преодолеть
проблемы, которые сегодня кажутся нам непреодолимыми (раздел 10.4).
Вопросы для самопроверки
1. Как изменятся требования к видеосистеме робота, если изображения,
используемые им для самоконтроля, потребуется посылать человеку, удаленно
контролирующему поведение робота?
2. Что подсказывает вам, что следующий рисунок не имеет смысла? Как
понимание этого факта может быть запрограммировано в машине?
3. Сколько кубиков изображено на рисунке? Как запрограммировать машину
для получения точного ответа на подобный вопрос?
10-3. Способность к рассуждению
После того как наша машина для разгадывания головоломок разберется с
расположением фишек на полученном изображении, она должна определить, какие
фишки следует переместить для решения задачи. Первое приходящее на ум решение этой
проблемы состоит в предварительном программировании отдельных решений задачи
для всех возможных случаев взаимного расположения фишек. В этом случае
машине потребуется просто выбрать нужную программу. Однако для этой головоломки
существует 181 440 различных возможных конфигураций фишек, поэтому идея
предоставления конкретного решения для каждого из этих случаев, безусловно, мало
привлекательна и даже, вероятно, просто невозможна, если учесть время,
необходимое для ее решения, и объем машинной памяти.
10.3. Способность к рассуждению 515
Таким образом, мы вынуждены запрограммировать машину так, чтобы она
смогла сама найти решение этой головоломки, т.е. она должна быть способна принимать
решения, делать выводы, короче говоря, выполнять простейшие рассуждения.
Порождающие системы
Развитие у машин способности к рассуждению уже долгие годы является
темой различных исследовательских работ. Одним из результатов подобных
исследований есть осознание того, что большой класс проблем, связанных с
рассуждениями, имеет общие характеристики, которые выделены в порождающую
систему, состоящую из трех основных элементов.
1. Набор состояний. Каждое состояние — это ситуация, которая может
возникнуть в прикладной среде. Начальное состояние называется
стартовым (или исходным). Желаемое состояние (или состояния)
именуется целевым. (В нашем случае состояние — это конфигурация
головоломки, стартовое состояние — это конфигурация головоломки в
момент передачи ее машине, а целевое состояние — это конфигурация
решенной головоломки, показанная на рис. 10.2.)
2. Набор порождений (правил, или ходов). Порождение — это операция,
которую можно выполнить в прикладной среде для перевода системы
из одного состояния в другое. Каждое порождение может быть связано
с необходимыми условиями, т.е. могут существовать условия, которые
должны быть удовлетворены, прежде чем данное порождение может
быть выполнено. (В нашем случае порождениями являются
перемещения фишек. Каждое такое перемещение имеет необходимым условием
существование свободной позиции для перемещаемой фишки.)
3. Система контроля. Система контроля состоит из логики, способной
решить проблему продвижения системы от стартового состояния до
целевого. На каждом этапе процесса система контроля должна
решить, какое из порождений, удовлетворяющих необходимым
условиям, будет применено следующим. (Для примера приведем некоторое
состояние нашей головоломки, когда рядом со свободной вакансией
находится несколько фишек. Так вот, система контроля должна
решить, какую из них следует перемещать.)
Таким образом, мы видим, что система контроля — это помещенная в машину
программа поведения. Эта программа обследует текущее состояние управляемой ею
системы, определяет последовательность действий, которые должны привести
систему к заданному состоянию, а также выполняет эту последовательность.
Важным понятием при разработке систем контроля является граф состояний,
который представляет собой наиболее удобный способ представления (по крайней мере,
на концептуальном уровне) всех возможных состояний, порождений и необходимых
условий в порождающей системе. Здесь термин граф мы будем использовать в
математическом смысле, что означает набор точек, т.е. узлов, соединенных стрелками,
или дугами. Граф состояний — это набор узлов (представляющих состояния систе-
516 Глава десятая. Искусственный интеллект
мы), соединенных дугами (представляющими порождения, переводящие систему из
одного состояния в другое). Два узла связываются на графе состояний дугой тогда и
только тогда, когда существует порождение, переводящее по этой дуге систему из
одного состояния в другое. Необходимые условия, по смыслу, представлены
отсутствием дуги между определенными узлами.
Следует отметить, что подобно тому, как слишком большое количество
возможных исходных состояний головоломки не допускает явного
предварительного расчета всех возможных вариантов ее решения, эта же проблема размера не
позволяет создать и явного представления всего ее графа состояний. Поэтому
граф состояний является подходящим способом осмысления проблемы, но он не
позволяет выразить ее во всей полноте. Как бы там ни было, полезно будет
рассмотреть (а возможно, и расширить) часть графа состояний нашей головоломки,
изображенную на рис. 10.3.
РИСУНОК 10.3
Небольшая часть графа состояний для головоломки "Восьмерка"
Стоящая перед системой контроля проблема, рассмотренная в терминах графа
состояний, сводится к нахождению последовательности дуг, по которой система
могла бы перейти из начального состояния в требуемое. Действительно, подоб-
10.3. Способность к рассуждению
517
ная последовательность дуг будет представлять ту последовательность
порождений, которая позволит решить исходную проблему. Следовательно, независимо
от конкретного приложения, задача системы контроля состоит в нахождении
пути по графу состояний. Подобная универсальная точка зрения на систему
контроля — важное достижение, полученное нами благодаря выполненному в
терминах порождающих систем анализу проблем, требующих для своего решения
проведения рассуждений. Чтобы развить достигнутый нами успех, рассмотрим,
как другие задачи могут быть выражены в терминах порождающих систем и,
следовательно, как система контроля сможет найти путь через граф состояний.
Одной из групп классических проблем, изучаемых в области искусственного
интеллекта, являются игры, например шахматы. Эти игры предполагают
некоторые действия умеренной сложности, выполняемые в строго определенном
контексте, и поэтому предоставляют собой идеальную среду для тестирования
различных теорий. В шахматах состояния соответствующей порождающей
системы — это возможные положения фигур на доске, порождения — это
перемещения фигур, а система контроля воплощена в игроке (человеке или
машине). Начальный узел графа состояний представлен доской с фигурами,
расположенными на исходных позициях. Разветвлениями этого узла являются дуги,
ведущие к тем положениям фигур на доске, которые могут быть получены после
выполнения первого хода. Разветвления, выходящие из каждого из этих
узлов, — позиция после ответного хода и т.д. При такой формулировке мы можем
представить себе игру в шахматы как состязание двух игроков, каждый из
которых пытается найти путь через огромнейший граф состояний к конечной
вершине, выбранной каждым из них.
Возможно, менее очевидным примером порождающих систем является
проблема получения логического заключения из имеющихся фактов. В данной
ситуации порождения — это правила логики, позволяющие создавать новые
утверждения из уже имеющихся. Например, утверждения "Все студенты
старательно учатся" и "Джон является студентом" могут быть скомбинированы, и в
результате мы получим утверждение "Джон старательно учится". Точно так же
утверждение "Мери и Джордж — умные" может быть выражено в ином виде:
"Ни Мери, ни Джордж не являются неумными". В такой системе состояния —
это набор утверждений, которые полагаются верными на данный момент
процесса дедукции. Начальным же состоянием системы является набор базовых
утверждений (иначе называемых аксиомами), на основании которых делаются
дальнейшие выводы. Целью является любой набор утверждений, включающий
предложенное умозаключение.
К примеру, на рис. 10.4 показана часть графа состояний, по которому можно
проследить вывод утверждения "Сократ смертен" из набора таких утверждений,
как "Сократ — мужчина", "Все мужчины — люди" и "Все люди смертны". По
сути, это база знаний, переходящая из одного состояния в другое по ходу
процесса умозаключений, в котором соответствующие порождения используются
для генерации дополнительных утверждений.
518 Глава десятая. Искусственный интеллект
РИСУНОК 10.4
Дедуктивные рассуждения, представленные в контексте порождающей системы
Дерево поиска
Мы видим, что работа системы контроля включает анализ графа
состояний в целях нахождения пути от стартового узла к цели. Простейший метод
этого поиска состоит в проходе каждой дуги, связанной с начальным узлом и
записью достигнутого в каждом случае состояния, с последующим проходом
всех дуг новых состояний, также сопровождающихся записью результата, и
т.д. Таким образом, поиск пути к цели "расходится" от начального
состояния во всех направлениях, как круги на воде от падающей капли. Этот
процесс продолжается, пока одно из полученных состояний не окажется
искомой целью. В результате решение считается найденным, и системе контроля
остается просто реализовать порождения, следуя обнаруженному пути от
начального состояния к целевому.
Результатом применения этой стратегии является построение дерева, называемого
деревом поиска, состоящим из части графа состояний, исследованной системой
контроля. Корневой узел дерева поиска — это начальное состояние, а дочерние состоя-
10.3. Способность к рассуждению
519
ния каждого узла — это состояния, которые могут быть достигнуты из
родительского узла за одно порождение. Каждая дуга между узлами дерева поиска представляет
реализацию отдельного порождения, а каждая часть от корня до листового узла —
путь между соответствующими состояниями на графе состояний.
На рис. 10.6 представлено дерево поиска, которое может быть построено при
решении нашей головоломки с начальной конфигурацией, показанной на
рис. 10.5. Левая ветвь этого дерева предлагает решить проблему путем
перемещения на первом шаге фишки 6 вверх, центральная ветвь представляет вариант
с перемещением на первом шаге фишки 2 вправо, а правая отражает ситуацию
после перемещения на первом шаге фишки 5 вниз. Более того, дерево поиска
показывает, что если мы начнем с перемещения фишки 6 вверх, то
единственной доступный следующий ход — это перемещение фишки 8 вправо. (В
действительности мы можем вновь переместить фишку 6 вниз, но это вернет систему в
первоначальное положение, поэтому мы будем считать такой ход ненужным и в
дальнейшем подобные ходы рассматривать не будем.)
РИСУНОК 10.5
Головоломка в промежуточном состоянии
Конечное состояние достигается на листовом уровне дерева поиска,
изображенного на рис. 10.6. Поскольку это означает завершение процедуры
поиска, система контроля завершает поиск пути и приступает к созданию
набора пошаговых инструкций, которые будут применены к решению
головоломки во внешней среде. Данный процесс состоит в простом прохождении
вверх по дереву поиска, начиная с найденного целевого узла. При этом
сведения обо всех порождениях, соединяющих узлы в ветвях дерева,
записываются в стек в том же порядке, в каком они встречаются. Применение этого
метода к дереву поиска (рис. 10.6) приведет к последовательности
порождений, показанной на рис. 10.7. Отметим, что система контроля сможет теперь
решить головоломку во внешнем мире, просто следуя инструкциям,
извлеченным из стека.
Итак, вспомним, что для построения деревьев, которые мы обсуждали в
главе 7, используется система указателей, показывающая путь вниз по дереву. Это
позволяет нам двигаться от родительского узла к дочерним. Однако в данном
случае системе контроля требуется передвигаться от потомков к их родителям,
так как она движется вверх по дереву от конечного состояния системы к на-
520
Глава десятая. Искусственный интеллект
чальному. Такие деревья создаются с собственной системой указателей,
показывающей чаще вверх, чем вниз (или в некоторых случаях с двумя наборами
указателей, что позволяет двигаться в обоих направлениях).
РИСУНОК 10.6
РИСУНОК 10.7
Последовательность порождений, записанная в стек для последующего выполнения
10.3. Способность к рассуждению
521
Эвристические методы
В нашем примере (рис. 10.6) мы выбрали начальную конфигурацию, которая
породила вполне обозримое дерево поиска. Однако деревья поиска, порожденные
при попытке решить более сложную проблему, могут расти намного быстрее.
Например, при игре в шахматы возможно 20 вариантов только первого хода, т.е.
корневой узел дерева поиска будет иметь 20 ветвей, в отличие от 3 в случае с
головоломкой "Восьмерка". Более того, средняя партия в шахматы состоит из
30-35 пар ходов, в отличие от предыдущего примера, где всего 5 вполне
очевидных ходов. Однако даже в случае с головоломкой "Восьмерка" дерево вариантов
может стать достаточно большим, если решение не будет найдено достаточно
быстро. В результате расчет всего дерева вариантов может оказаться таким же
непрактичным решением, как и представление всего графа состояний, исходя из
соображений как времени, так и объема занимаемой памяти. Поэтому
желательно найти более экономичные методы манипулирования деревом поиска.
Наша стратегия будет заключаться в изменении порядка, в котором создается
дерево поиска. Вместо того чтобы строить дерево посредством горизонтального
поиска (или поиска в ширину — breadth-first search), что означает построение
дерева за счет последовательного добавления уровней, мы можем рассмотреть
более обещающий путь в глубину и принять во внимание остальные
альтернативы только в том случае, если выбранный путь приведет к провалу.
Образующаяся вертикальная конструкция дерева поиска (поиск в глубину — depth-first
search) означает, что дерево строится прежде по вертикальным связям, а лишь
затем по горизонтальным.
Вертикальный подход более похож на ту стратегию, которой мы, будучи людьми,
руководствуемся при решении головоломки "Восьмерка". Мы редко рассматриваем
сразу несколько альтернатив, как при горизонтальном методе. Сталкиваясь с
необходимостью выбора, мы, вероятнее всего, предпочтем тот вариант, который
покажется нам наиболее обещающим, и последуем ему. Подчеркнем, что было сказано
"покажется наиболее обещающим". Мы обычно не уверены в том, какой из
вариантов действительно лучший, и следуем нашей интуиции, которая, безусловно, может
и подвести. Несмотря на это, использование такой интуитивной информации,
похоже, дает человеку преимущество над методом решения "в лоб", в котором каждому
варианту уделяется одинаковое внимание.
Первый шаг на пути к использованию этого подхода в автоматизированных
системах контроля — определение тех характеристик, которые мы, как люди,
используем при выборе рассматриваемых вариантов. В общем случае люди склонны
держать конечный результат в уме и подбирать вариант, который, по их мнению, ведет
к достижению этой цели. В случае с головоломкой "Восьмерка" это означает, что
человек, делая выбор хода, стремится выбрать вариант, который переместит
некоторую фишку в направлении ее конечного положения.
Таким образом, нашей стратегией является разработка эвристического
метода — количественной меры, которой программа будет руководствоваться при
выборе состояния, ближайшего к цели. В случае головоломки "Восьмерка" про-
522 Глава десятая. Искусственный интеллект
стой эвристический метод может предусматривать использование (как
характеристики каждого состояния) того количества фишек, которое находится не на
своей позиции. Следующим будет рассматриваться состояние с наименьшим
показателем (т.е. ближайшее к цели). Однако это число никак не учитывает,
насколько далеко от нужной позиции находятся фишки. Несколько более сложный
способ вычисления показателей учитывает, на каком расстоянии находится
каждая фишка от своего места назначения, и прибавляет это значение к
предыдущей мере. За расстояние в этом случае принимается минимальное количество
перемещений, необходимых для установки данной фишки на свою позицию; при
этом положения остальных фишек в расчет не принимаются. Таким образом,
фишка, расположенная непосредственно рядом со своей конечной позицией,
характеризуется расстоянием 1, тогда как фишка, касающаяся этой позиции
углом,— расстоянием 2 (поскольку ей требуется выполнить, как минимум, одно
перемещение по вертикали и одно — по горизонтали).
РИСУНОК 10.8
Еще один вариант смешанного состояния головоломки
РИСУНОК 10.9
Принимаем начальный узел графа состояний в качестве корня
дерева поиска и записываем его предполагаемую стоимость
while (цель не достигнута) do
[Выбрать самый левый из листовых узлов с наименьшей предполагаемой
стоимостью и присоединить к нему в качестве дочерних все узлы,
достигаемые от него за одно порождение
Записать предполагаемую стоимость для каждого из этих новых узлов.
]
Пройти по дереву поиска вверх от целевого узла к корню дерева,
помещая в стек сведения обо всех порождениях, представленных
последовательно проходимыми дугами графа.
Решить поставленную задачу посредством выполнения последовательности
порождений, сведения о которых записаны в стеке.
Алгоритм работы системы контроля, использующий эвристический метод
10.3. Способность к рассуждению
523
При использовании этого эвристического метода показатель, связанный с
каждым возможным состоянием, в действительности приблизительно соответствует
числу перемещений, которые потребуется выполнить для достижения конечной
цели. Назовем эту величину предполагаемой стоимостью. Например, общая
предполагаемая стоимость для конфигурации фишек, показанной на рис. 10.8,
равна семи. (Здесь фишки 2, 5 и 8 находятся на расстоянии 1 от своих конечных
позиций, а фишки 3 и 6 — на расстоянии 2.) И действительно, возврат
головоломки в ее собранное состояние потребует семи ходов.
Предполагаемая стоимость имеет две важные характеристики. Во-первых, как
только что было замечено, она дает разумную оценку объему работы, которую
необходимо выполнить для достижения цели. Это означает, что данные показатели могут
быть полезны для принятия решения. Во-вторых, эти характеристики достаточно
легко вычисляются. Это значит, что использование показателей предполагаемой
стоимости при поиске решения, вероятнее всего, принесет выигрыш во времени и не
окажется чрезмерно обременительным. (В противоположность этому, хотя точные
сведения о количестве перемещений, необходимых для достижения цели,
безусловно, полезны для принятия решения, тем не менее, вычисление этих показателей
требует предварительного решения всей задачи.)
РИСУНОК 10.10
Начало эвристического поиска
Теперь, когда найден эвристический метод решения головоломки, следующим
шагом будет включение его в процесс принятия решений. Напомним, что
человек, сталкиваясь с необходимостью принятия решения, предпочитает вариант,
быстрее всего приводящий к достижению цели. Поэтому наша процедура поиска
должна оценивать предполагаемую стоимость всех вариантов при каждом раз-
524
Глава десятая. Искусственный интеллект
ветвлении процесса и в каждом случае выбирать альтернативу с наименьшей
предполагаемой стоимостью. Применение подобной стратегии демонстрируется
на рис. 10.9, где представлен алгоритм расчета дерева поиска и выполнения
найденного решения.
Применим этот алгоритм для нашей головоломки, выбрав в качестве
стартовой конфигурацию, показанную на рис. 10.5. Прежде всего определим это
состояние как корень дерева поиска и запишем его предполагаемую стоимость
равной пяти. Затем выполним первый проход по телу цикла while-do, в
результате чего будут порождены три новых узла, показанных на рис. 10.10. Обратите
внимание, что для каждого из этих узлов в круглых скобках показана
вычисленная предполагаемая стоимость.
Конечный узел еще не достигнут, поэтому цикл while-do выполняется еще
раз — для узла, расположенного слева ("выбрать самый левый из листовых
узлов с наименьшей предполагаемой стоимостью"). Полученное в результате дерево
поиска представлено на рис. 10.11.
РИСУНОК 10.11
Дерево поиска после двух проходов цикла
Обратите внимание, что теперь предполагаемая стоимость для левого узла
будет равна пяти, а это указывает, что данный узел уже не является лучшим
вариантом продолжения поиска. Алгоритм учитывает это и при следующем прохо-
10.3. Способность к рассуждению
525
де цикла while-do требует раскрыть правый узел (именно он теперь является
"самым левым из листовых узлов с наименьшей предполагаемой стоимостью").
Расширенное подобным образом дерево поиска показано на рис. 10.12.
РИСУНОК 10.12
Дерево поиска после трех проходов цикла
Похоже, что наш алгоритм на правильном пути. Поскольку предполагаемая
стоимость вновь раскрытого узла равна всего лишь трем, цикл while-do
предписывает нам продолжать путь с этого узла и в конце концов достигает цели с
построением дерева поиска, показанного на рис. 10.13. Сравнив это дерево с
деревом, представленным на рис. 10.6, можно увидеть, что, даже с учетом неудачно
выбранного вначале направления, использование эвристической информации
значительно уменьшило размер дерева поиска и позволило реализовать намного
более эффективный процесс.
По достижении конечного состояния цикл while-do прекращается, и алгоритм
переходит к прохождению дерева от пункта назначения до начального
состояния, помещая в стек сведения обо всех встреченных порождениях. Полученный
стек выглядит точно так же, как и на рис. 10.7.
526
Глава десятая. Искусственный интеллект
РИСУНОК 10.13
Полное дерево поиска, созданное нашей эвристической системой
И наконец, алгоритм требует выполнить все порождения строго в порядке их
расположения в стеке. В этот момент мы увидим, как машина опустит
манипулятор и начнет перемещать фишки.
Вопросы для самопроверки
1. Каково значение порождающих систем для теории искусственного
интеллекта?
2. Нарисуйте часть графа состояний, окружающую представленный на рисунке
узел головоломки "Восьмерка".
10.3. Способность к рассуждению
527
3. Используя горизонтальный подход, нарисуйте дерево поиска, которое могла
бы создать система контроля машины при решении головоломки "Восьмерка"
с указанным начальным состоянием.
4. С помощью карандаша, бумаги, применив горизонтальный подход,
попытайтесь построить дерево поиска решения головоломки со следующим начальным
состоянием (успеха вы не добьетесь). С какой проблемой вы столкнулись?
5. Какая аналогия может быть прослежена между нашей эвристической
системой для решения головоломки "Восьмерка" и пытающимся достигнуть
вершины альпинистом, осматривающим только доступную ему часть ландшафта
и всегда направляющимся в сторону наиболее крутого подъема.
6. Используя описанный в данном разделе эвристический подход, примените
алгоритм системы контроля (см. рис. 10.9) к проблеме поиска решения
следующей исходной позиции в головоломке "Восьмерка".
7. Уточните метод вычисления предполагаемой стоимости так, чтобы алгоритм
поиска решения, представленный на рис. 10.9, не допускал неправильных
выборов, как это имело место в примере, приведенном в тексте раздела.
Можете ли вы найти пример, в котором преложенная вами система все-таки
сбивалась бы с правильного пути?
10.4. Искусственные нейронные сети
Несмотря на прогресс, достигнутый в теории искусственного интеллекта,
решение многих проблем в этой области по-прежнему требует затрат ресурсов,
превосходящих возможности обычных компьютеров. Центральные процессоры,
выполняющие единственную последовательность команд, похоже, никогда не
смогут обрести способность ощущать и рассуждать на уровне, сравнимом с рабо-
528
Глава десятая. Искусственный интеллект
той многопроцессорного человеческого мозга. По этой причине многие ученые
склонны к созданию машин с многопроцессорной структурой. Одним из типов
таких машин является искусственная нейронная сеть.
Основные свойства
Как уже говорилось в главе 2, искусственные нейронные сети создаются
из множества отдельных процессоров, которые мы называем блоками
обработки (или просто блоками, для краткости); они соединяются по схеме,
моделирующей нейронную сеть живых биологических систем. Биологический
нейрон — это отдельная клетка с входящими отростками, называемыми ден-
дритами, и исходящими отростками, именуемыми аксонами (рис. 10.14).
Сигнал, передаваемый по аксону клетки, отражает состояние этой клетки,
которое может быть заторможенным или возбужденным. Состояние клетки
определяется комбинацией сигналов, поступающих через дендриты клетки,
которые передают клетке сигналы от аксонов других клеток через небольшие
промежутки, называемые синапсами. Исследователи полагают, что
проводимость через отдельные синапсы контролируется их химическим составом.
Поэтому именно химическим составом синапса определяется, окажет ли
отдельный входной сигнал возбуждающее или тормозящее действие на данный
нейрон. Таким образом, считается, что биологическая нейронная сеть
собирает информацию (т.е. обучается) посредством регулирования этих
химических соединений между нейронами.
РИСУНОК 10.14
Нейрон живой биологической системы
Блок обработки в искусственной нейронной сети — это простейшее
устройство, имитирующее описанные выше элементарные представления о
поведении биологического нейрона. Блок выдает на выход значение 1 или 0, в
10.4. Искусственные нейронные сети
529
зависимости от того, превышает ли входной сигнал заданное пороговое
значение. Действующий входной сигнал — это взвешенная сумма
действительных входных сигналов, как показано на рис. 10.15. На этом рисунке
выходные сигналы трех блоков (отмеченных как V\9 v2, и i>3) являются входными
сигналами для четвертого блока. Каждому входному сигналу этого блока
поставлено в соответствие значение, называемое весовым коэффициентом (w\,
w2, и м;3). Действующий входной сигнал образуется как сумма значений,
получаемых после перемножения каждого входного сигнала на
соответствующий весовой коэффициент (V\W\ + v2w2 + v^Wy). Если общая сумма превышает
пороговое значение данного блока, то на его выходе получим значение 1, в
противном случае — 0.
РИСУНОК 10.15
Процессы, происходящие внутри блока обработки
Исходя из рис. 10.15, условимся представлять блоки обработки
прямоугольниками. На входящей стороне блока рисуются прямоугольники меньшего
размера, по одному для каждого входного сигнала, в которых указывается
присвоенный этому сигналу весовой коэффициент. В центре большого прямоугольника
указывается пороговое значение данного блока. В качестве примера на
рис. 10.16 представлен блок обработки с тремя входными сигналами и
пороговым значением, равным 1,5. Весовой множитель для первого сигнала равен -2,
для второго — 3, а для третьего — -1. Следовательно, если в блок поступают
входные сигналы 1, 1 и 0, то его эффективный входной сигнал будет равен 1*(-
2) + 1*3 4- 0*(-1) = 1, а на выходе блока будет получено значение 0. Однако если
в блок поступят сигналы 0, 1 и 1, то его эффективный входной сигнал будет
равен уже 0*(-2) + 1*3 + 1*(-1) = 2, что превышает пороговое значение. В этом
случае на выходе будет представлено значение 1.
530
Глава десятая. Искусственный интеллект
РИСУНОК 10.16
Графическое представление блока обработки
Весовые значения могут быть как положительными, так и отрицательными, т.е.
соответствующие входные сигналы оказывают либо возбуждающее, либо тормозящее
действие на принимающий блок. (Если весовой коэффициент отрицателен, то
значение 1 на этом входе уменьшает общую сумму, что удерживает эффективный входной
сигнал ниже порогового значения. И наоборот, положительный весовой
коэффициент способствует повышению данным входным сигналом общей суммы и, как
следствие, увеличивает шансы на превышение порогового значения.) Сама абсолютная
величина весового коэффициента определяет степень, с которой данный входящий
сигнал способен возбуждать или тормозить принимающий блок. Следовательно,
посредством регулирования величин весовых коэффициентов во всей искусственной
нейронной сети можно запрограммировать эту сеть так, чтобы она реагировала на
входящие сигналы определенным образом.
Например, простейшая нейронная сеть, представленная на рис. 10.17, а,
запрограммирована выдавать значение 1, если ее входные сигналы различны, и
значение 0 — в противном случае. Однако если изменить весовые функции так, как
показано на рис. 10.17, б у получим сеть, которая представляет на выходе значение 1,
если оба входных сигнала равны 1, и значение 0 — в любом другом случае.
Следует отметить, что представленная на рис. 10.17 искусственная сеть
значительно проще, чем реальная биологическая сеть. Человеческий мозг состоит
приблизительно из 1011 нейронов, на каждый из которых приходится около 104
синапсов. На самом деле дендриты биологического нейрона настолько
многочисленны, что больше похожи на запутанные клубки нитей, чем на аккуратные
линии, изображенные на нашем рисунке.
Конкретное приложение
Для оценки потенциала искусственной нейронной сети рассмотрим конкретную
задачу из области распознавания символов, а именно: различение прописных букв С
и Т, показанных на рис. 10.18. Задача заключается в идентификации каждой из
букв независимо от ее ориентации в поле зрения. Все образцы, представленные на
рис. 10.19, а, должны быть идентифицированы как буква С, тогда как все остальные
образцы, показанные на рис. 10.19, б, должны быть опознаны как буква Т.
10.4. Искусственные нейронные сети 531
I РИСУНОК 10.17 I
Нейронная сеть с двумя различными программами
РИСУНОК 10.18
Формат прописных букв С и Т
532
Глава десятая. Искусственный интеллект
РИСУНОК 10.19
Различные варианты ориентации букв С и Т
Предположим, что поле зрения состоит из квадратных пикселей, размер
каждого из которых равен размеру структурных частей наших букв. Каждый из
этих пикселей прикреплен к сенсору, генерирующему значение 1, если пиксель
принадлежит некоторой букве, и значение 0 — в противном случае. В
дальнейшем выходящие из этих сенсоров сигналы мы будем рассматривать как входные
сигналы для искусственной нейронной сети.
Эта сеть состоит из двух уровней блоков обработки. Первый уровень содержит
большое количество блоков — по одному на каждый участок, размером 3x3
пикселя (рис. 10.20). Каждый из таких блоков имеет 9 входов с присоединенными к
ним сенсорами, регистрирующими состояние соответствующих пикселей.
(Отметим, что участки размером 3x3 пикселя, связанные с блоками первого
уровня, взаимно перекрываются. Поэтому каждый сенсор обеспечивает
информацией 9 таких блоков.)
Второй уровень нашей сети состоит из единственного блока обработки с
отдельным каналом ввода от каждого из блоков первого уровня. Пороговое значение для
блока второго уровня составляет 0,5, а весовые коэффициенты для каждого
входящего сигнала равны 1. Следовательно, этот блок выдаст на выходе значение 1 только
в том случае, если хотя бы один из входящих сигналов равен 1.
Каждый блок первого уровня имеет пороговое значение 0,5. Каждый сигнал
входит с весовым коэффициентом -1, за исключением сигнала от центрального
пикселя участка, входящего с весовым коэффициентом 2. Таким образом,
необходимым условием выдачи значения 1 блоком первого уровня является
наличие сигнала от сенсора, связанного с центральным пикселем участка
размером 3x3 пикселя.
10.4. Искусственные нейронные сети 533
РИСУНОК 10.20
Структура системы распознавания символов
Теперь, если в поле зрения расположена буква С (рис. 10.21), все блоки
первого уровня будут выдавать на выходе значение 0. Это происходит
потому, что блок, центральный пиксель которого закрыт буквой, имеет как
минимум два других пикселя в этом же блоке, накрытых той же буквой, и
сигналы от этих двух пикселей компенсируют вклад центрального пикселя.
Следовательно, если в поле зрения находится буква С, все сигналы,
входящие в блок второго уровня, имеют значение 0, что означает присутствие на
выходе нашей сети сигнала 0.
Теперь предположим, что в поле зрения находится буква Т. Рассмотрим
участок 3x3, на центр которого приходится основание ножки буквы Т (рис. 10.22).
Блок обработки информации, отвечающий за этот участок, выдаст на выходе
значение 1 (на него поступают значение 2 от центрального пикселя и значение -
1 — от пикселя, содержащего середину ножки буквы Т). В результате пороговое
значение данного блока будет превышено и на верхний уровень поступит
значение 1, что, в свою очередь, вызовет выдачу сигнала 1 блоком второго уровня.
534
Глава десятая. Искусственный интеллект
РИСУНОК 10.21
В поле зрения нейронной сети находится буква С
В итоге мы имеем искусственную нейронную сеть, способную различать
буквы С и Т независимо от их ориентации в поле зрения. Если это буква С, сеть
выдает сигнал 0, если же это буква Т — то 1.
Конечно, способность этой искусственной сети различать всего лишь две
буквы не идет ни в какое сравнение с возможностями обработки изображений,
свойственными человеческому сознанию. Однако продемонстрированное
элегантное решение свидетельствует о том, что дальнейшие исследования в этой
области, безусловно, оправданы.
В настоящее время в области искусственных нейронных сетей ведутся
активные научные исследования. Основные трудности связаны с разработкой и
программированием подобных сетей. Типичные задачи, относящиеся к
разработке сетей, включают определение необходимого количества блоков обработки
и уровней размещениях этих блоков, требуемых для решения определенной
проблемы, а также выбор структуры связей между блоками, позволяющими
достичь наибольшей эффективности.
10.4. Искусственные нейронные сети 535
В поле зрения нейронной сети находится буква Т
Следует сказать несколько слов и относительно предмета сетевого
программирования. Мы уже видели, что задача программирования искусственной
нейронной сети состоит в назначении различным блокам системы подходящих
весовых коэффициентов. В настоящий момент наиболее популярным методом
выполнения этой задачи является тренировка сети, заключающаяся в
многократно повторяющемся процессе запуска в нее одиночного сигнала с
последующим плавным повышением величины весовых коэффициентов до
достижения желаемого сигнала на выходе. По мере повторения этого процесса для
различных образцов сигналов можно надеяться, что значения весовых
коэффициентов будут требовать все меньшей и меньшей корректировки, пока сеть
не начнет корректно работать с необходимым набором различных сигналов.
Самое важное в этом процессе — правильная стратегия подбора весовых
коэффициентов, гарантирующая, что каждая последующая регулировка весовых
коэффициентов действительно будет приближать нас к цели, а не разрушать
результаты, достигнутые на предыдущих этапах.
536 Глава десятая. Искусственный интеллект
Вопросы для самопроверки
1. Какой сигнал будет на выходе приведенного ниже блока обработки, если оба
входных сигнала будут равны 1? А если сигналы будут иметь значения 0:0,
0:1 или 1:0?
2. Подберите весовые коэффициенты и пороговый уровень так, чтобы на выходе
показанного ниже блока значение 1 появлялось только в том случае, когда
хотя бы два из входных сигналов равны 1.
3. Разработайте искусственную нейронную сеть, которая могла бы различать,
какой из двух приведенных ниже рисунков находится в поле ее зрения.
4. Разработайте искусственную нейронную сеть, которая могла бы различать,
какой из двух приведенных ниже рисунков находится в поле ее зрения.
10.5. Генетические алгоритмы
Область генетических алгоритмов связана с попытками исследователей найти
применение нашим знаниям о естественной эволюции к методам решения
различных задач. Данный подход заключается в попытке перемешать наиболее
перспективные варианты из набора предложенных решений для генерации их
нового поколения. Возможно, они окажутся лучше исходных. Многократное
повторение этого процесса можно рассматривать как имитацию процесса эволюции,
что в конечном счете, как надеются исследователи, позволит найти подходящее
решение изучаемой проблемы.
В качестве примера предположим, что вы каждую среду вечером играете в
покер с одной и той же группой людей и хотите разработать для себя стратегию
получения максимально возможного выигрыша. Эволюционный подход к
решению этой проблемы мы начнем с определения различных ситуаций, возникаю-
10.5. Генетические алгоритмы
537
щих при игре в покер, и вашей возможной реакции на каждую из них. Конечно,
все это предполагает огромный объем работы, поскольку существует очень много
ситуаций, требующих рассмотрения. Как только данный анализ будет выполнен,
можно будет приступить к разработке желаемой стратегии игры; для этого
потребуется определить вашу ответную реакцию на каждую выделенную ситуацию.
Каждую возможную стратегию игры можно представить как список вида S,Rb
S2R2, ..., SnRn, где S — одна из возможных ситуаций, а соответствующее R — это
ваша реакция на нее. Представления различных стратегий будут содержать одни
и те же ситуации, но будут отличаться способами реагирования на них. Для
применения некоторой стратегии необходимо просто найти в ее списке
соответствующую ситуацию и выполнить указанное для нее ответное действие.
Следующим этапом в решении нашей покерной проблемы будет выбор
исходного набора стратегий и применение их в игре на протяжении всего
вечера. Дополнительно потребуется записывать сведения о выигрыше,
полученном при применении данной стратегии. Позднее, основываясь на собранной
информации, следует выбрать лучшие из исходных стратегий и
скомбинировать их в пары. Из каждой такой пары создаются две новые стратегии —
посредством разбиения списка, представляющего эту пару стратегий, и
соединения начала одной стратегии с концом другой, как показано на рис. 10.23.
Все полученные таким образом стратегии составят тот набор стратегий,
который будет проверяться во время следующего игрового вечера. Каждую
неделю необходимо снова и снова выбирать лучшие стратегии и использовать
их для создания очередного поколения стратегий, которое будет
тестироваться на следующей неделе. Таким образом, неделя за неделей наш процесс
будет моделировать естественный эволюционный процесс, в котором выжившие
в одном поколении порождают следующее поколение. К тому же, время от
времени мы даже можем моделировать мутации путем случайного изменения
отдельной ответной реакции на какую-нибудь ситуацию.
К сожалению, наш пример с игрой в покер относится к разряду
нереалистичных, поскольку невозможно в течение одного вечера протестировать
достаточно большое поколение новых стратегий. Но если процесс тестирования
игры может быть автоматизирован, что имеет место в большинстве
приложений, эволюционный подход вполне реален. Это процесс, предложенный в
результате проведения исследований в области генетических алгоритмов.
Прежде всего необходимо найти способ представления возможных решений в
виде строк символов. Затем генерируется и тестируется исходный набор
возможных решений. Лучшие варианты этого набора "скрещиваются" и
порождают новое поколение возможных решений, которые вновь тестируются
и формируют следующее поколение. Иногда в процесс скрещивания могут
вводиться случайные мутации.
538 Глава десятая. Искусственный интеллект
От малого до великого
При разработке и проверке теорий переход от незначительного эксперимента к более масштабным
приложениям является обязательным и многократно повторяющимся этапом. Исходная экспериментальная
проверка новой теории обычно проводится на небольших и очень простых системах. В случае успеха рамки
эксперимента расширяются до более реалистичных и масштабных систем. При этом переходе одни теории
"выживают", а другие — нет. Иногда успех эксперимента малого масштаба настолько ободряет
сторонников обсуждаемой теории, что они упорствуют в ней даже тогда, когда неудачи в крупномасштабных
системах заставляют других исследователей отвернуться от нее. В некоторых случаях подобное упорство
окупается сполна, в других — это напрасная трата усилий.
Подобное случается и в области искусственного интеллекта. Одним из примеров является область
обработки естественного языка, где ранние успехи в ограниченных средах посеяли во многих
исследователях убеждение, что понимание машинами обычного естественного языка уже не за горами. К
сожалению, распространение достигнутых результатов на системы большего масштаба оказалось намного
более трудным делом, и успех здесь достигается очень медленно, ценой значительных усилий. Другим
примером являются искусственные нейронные сети, которые вышли на сцену под звуки фанфар.
Однако со временем интерес к ним угас, а возможность крупномасштабного применения была поставлена
под сомнение. Сейчас популярность этого направления вновь растет, однако уже без прежнего
ажиотажа. Как отмечено в тексте, область генетических алгоритмов сейчас как раз подвергается подобному
испытанию, она переходит в новое качество. Докажет ли эволюционный подход свою полезность в
качестве надежного инструмента, покажет время.
10.5. Генетические алгоритмы 539
Эволюционный подход применялся в разнообразных областях в целях получения
многообещающих результатов. В одном из исследований этот подход применялся
для разработки конфигурации искусственных нейронных сетей. Предположим,
требуется решить некоторую проблему посредством создания искусственной нейронной
сети, состоящей из заранее заданного количества блоков обработки. Прежде чем
приступать к обучению сети, следует решить, как ее блоки будут связаны между
собой. С этой целью условимся описывать искусственную нейронную сеть в виде
строки нулей и единиц по следующему правилу (рис. 10.24). Например, количество
используемых в сети блоков обработки равно п. Пронумеруем все блоки от 1 до п и
построим квадратную таблицу, состоящую из п столбцов и п строк. Будем помещать
значение 1 в i-ю строку j-ro столбца таблицы в том случае, если кодируемая сеть
имеет связь с выхода i-ro блока на вход j-ro. Все остальные позиции таблицы
заполняются нулями. Далее запишем содержимое таблицы в виде одной строки,
последовательно помещая строки таблицы одну за другой.
РИСУНОК 10.24
а) Конфигурация искусственной нейронной сети
б) Таблица, представляющая способ
соединения блоков в сети
0011000110000010000100000
Кодирование топологии искусственной нейронной сети
Для нахождения подходящей конфигурации нейронной сети,
предназначенной для решения нашей частной проблемы, выберем ряд возможных
конфигураций и начнем процесс обучения для каждой из них. После краткого периода
540
Глава десятая. Искусственный интеллект
обучения выберем конфигурации, кажущиеся наиболее перспективными, и с
помощью описанного выше метода представим их в виде цепочек, состоящих из
нулей и единиц. Затем методом скрещивания представленных цепочек получим
новое поколение возможных конфигураций. В свою очередь, новое поколение
будет подвергнуто обучению, после чего будут отобраны лучшие варианты для
генерации следующего поколения, и т.д. Подобный подход оказался весьма
успешным при проектировании простых искусственных нейронных сетей.
Метод генетического алгоритма также использовался для решения задачи
разработки программ по технологии, называемой эволюционным
программированием. Суть этой технологии состоит в таком подходе, который позволяет
программам развиваться самостоятельно, исключая явное их программирование.
Важным шагом в этом направлении является нахождение способа, посредством
которого программы могли бы обмениваться собственными частями для
получения новых осмысленных программ. В этом контексте доказала свою полезность
парадигма функционального программирования. Действительно, программа,
написанная в соответствии с требованиями парадигмы функционального
программирования, состоит из вложенных функций, где выходное значение одной
функции используется как входное значение для другой. Таким образом, вполне
возможен обмен функциями между программами без разрушения их структуры.
Следуя подобным рассуждениям, ученые-исследователи применили технику
эволюционного программирования к процессу разработки программ на языках
функционального программирования. Выбранный подход состоял в том, чтобы
начать с набора программ, содержащих множество различных функций. В
результате функции этого стартового набора сформировали исходный "генофонд",
из которого впоследствии должны были конструироваться будущие поколения
программ. После этого эволюционный процесс многократно повторили в
надежде, что при создании следующего поколения программ из лучших
представителей предыдущего обязательно будет найдено решение поставленной задачи.
Область эволюционного программирования находится еще на ранней стадии
развития. Пока что успеха удалось достичь только в простых случаях.
Например, эволюционная технология использовалась для получения программ,
вычисляющих такие свойства простых геометрических фигур, как площадь квадрата
или длина окружности. Главной проблемой является определение "лучших
представителей" в группе программ, в которой ни одна не кажется сколько-нибудь
близкой к желаемой цели. Как и в других областях применения генетических
алгоритмов, остается открытым вопрос: будет ли данная технология успешно
развита для разрешения существенных и имеющих реальный смысл проблем. В
любом случае область генетических алгоритмов — это яркий пример
приложения человеческого творчества и воображения к области современных
компьютерных исследований.
Вопросы для самопроверки
1. Закодируйте конфигурацию искусственной нейронной сети по описанному в
этом разделе методу.
10.5. Генетические алгоритмы 541
2. Выберите проблему, пригодную, по вашему мнению, для эволюционного
подхода, и опишите, как возможные решения могут быть закодированы одной
строкой. Затем предложите подходящий механизм скрещивания этих строк
для формирования будущих поколений.
3. Приведите аргументы в пользу утверждения о том, что парадигма
функционального программирования более совместима с эволюционным
программированием, чем парадигма объектно-ориентированного программирования.
10.6. Приложения теории искусственного интеллекта
После рассмотрения некоторых технологий, разработанных в области
искусственного интеллекта, перейдем к обсуждению тех областей науки и техники, в
которых они уже нашли применение.
Обработка языка
Начнем с рассмотрения задачи перевода выражений с одного языка на другой.
Здесь могут использоваться как традиционные системы, так и системы
искусственного интеллекта, в зависимости от обрабатываемых языков. Различие заключено в
том, должна ли при переводе рассматриваться семантика исходного выражения.
Например, традиционные языки программирования сконструированы так, что процесс
перевода, по существу, заключается в простом нахождении исходного выражения
(или его части) в определенной таблице, в которой и находится его переведенный
эквивалент. Поэтому машина никогда не задумывается над смыслом переводимого
выражения — она просто распознает его синтаксис, ищет его в таблице и извлекает
перевод. По этой причине подобные приложения вполне укладываются в диапазон
возможностей традиционных компьютерных приложений.
В противоположность этому, проблема перевода таких естественных языков,
как английский, немецкий или латинский, часто требует понимания семантики
предложения, поскольку только в этом случае можно сделать его правильный
перевод. Например, рассмотрим задачу перевода следующих двух выражений:
Норман Роквелл изображал людей.
У Золушки есть коса.
В обоих случаях корректный перевод не может быть выполнен простым
переводом каждого отдельного слова. Точный перевод этих предложений требует
понимания их смысла.
542
Глава десятая. Искусственный интеллект
Разработка компьютеров, способных понимать естественные языки, является
важнейшим направлением исследований в области искусственного интеллекта.
Именно это направление демонстрирует, насколько сложными могут оказаться
исследования в области искусственного интеллекта.
Одна из проблем обработки естественных языков заключается в том, что речь
человека не всегда соответствует существующим правилам. В некоторых случаях
люди говорят совсем не то, что они в действительности подразумевают.
Например, рассмотрим следующую фразу:
Ты знаешь, который час?
Чаще всего она означает: "Скажите, пожалуйста, который час?" Однако если
говорящий к этому моменту уже достаточно долго ожидал того, кому адресован этот
вопрос, то данная фраза может означать совсем другое: "Ты сильно опоздал!"
Таким образом, определение смысла высказывания на естественном языке
требует нескольких уровней анализа. Первый — это синтаксический анализ,
основной составляющей которого является грамматический разбор. Он покажет,
что в следующем предложении подлежащим является слово Мери:
Мери подарила Джону открытку ко дню рождения.
Тогда как подлежащим предложения, приведенного ниже, является слово Джон.
Джон получил от Мери открытку ко дню рождения.
Второй уровень анализа высказываний называется семантическим. В отличие
от грамматического разбора, при котором просто определяется грамматическая
роль каждого слова в предложении, в результате семантического анализа
требуется установить семантическую роль каждого слова. Цель семантического
анализа — определение описываемого действия, агента действия (которым может
быть, а может и не быть подлежащее этого предложения) и объекта действия. В
результате семантического анализа может быть установлено, что предложения
"Мери подарила Джону открытку ко дню рождения" и "Джон получил от Мери
открытку ко дню рождения" сообщают об одном и том же.
Третьим уровнем анализа высказываний является контекстный. Именно на этом
уровне выявляется действительный смысл высказывания. Например, достаточно
просто определить грамматическую роль каждого слова в следующем предложении:
Он прикоснулся к бабочке.
Мы даже можем выполнить его семантический анализ, определив действие —
прикосновение, агента действия — бабочку и т.д. Но пока мы не знаем контекста
этого высказывания, его действительный смысл остается неясным.
Действительно, данное высказывание может иметь совершенно разный смысл в контексте
сборов на званый ужин и в контексте прогулки на природе. Точно так же,
только на контекстном уровне можно установить истинное значение вопроса "Ты
знаешь, который час?"
Мы должны отметить, что различные уровни анализа (синтаксический,
семантический и контекстный) не обязательно являются независимыми.
Рассмотрим следующее предложение на английском языке:
10.6. Приложения теории искусственного интеллекта 543
Stampeding cattle can be dangerous.
(Паникующий крупный рогатый скот может быть опасен, или
Пугать крупный рогатый скот может быть опасно.)
Подлежащим этого предложения является существительное cattle (скот),
уточненное прилагательным stampeding (паникующий), если речь идет о стаде, по какой-
то причине впавшем в панику. Но в этом же предложении подлежащим может быть
и отглагольное существительное (герундий) stampeding (пугающий, т.е. тот, кто
пугает) с объектом действия cattle (скот), если разговор идет о нарушителе спокойствия
стада, в результате действий которого оно впадает в панику.
Помимо проблем перевода, важными направлениями исследований в области
понимания естественного языка являются информационный поиск и извлечение
информации. Информационный поиск — это задача идентификации документов,
имеющих отношение к поставленной проблеме. Например, проблема (цель
поиска) может быть поставлена адвокатом, пытающимся найти все прецеденты,
связанные с текущим судебным разбирательством. Мы еще вернемся к этому
примеру при рассмотрении поиска в базах данных.
Рекурсия в естественном языке
Рекурсивное вложение одних предложений в другие — довольно обычное явление для английского языка
(так же, как и для других), где предложение, являющееся частью другого предложения, называется clause.
Поиск методов выявления подобных структур был одной из первых задач исследований в области создания
компьютерных систем обработки естественного языка.
Иногда подобные структуры включают несколько уровней вложения, что весьма затрудняет определение
общего значения предложения даже в случае, когда оно имеет абсолютно правильную грамматическую
структуру. Например, рассмотрим следующее предложение:
Человек, которого лошадь, проигравшая забег, сбросила, не пострадал.
Данное выражение включает три предложения — одно в другом. Внешним является предложение "Человек
не пострадал". Следующая внутренняя структура определяет этого человека как сброшенного лошадью.
Внутри этой структуры находится еще одна, определяющая лошадь как ту, которая проиграла забег.
Приведенные ниже предложения представляют несколько иные конструкции:
Картина, повешенная человеком, которого женщина, живущая рядом, наняла, упала.
Новый повар, которого шеф, поверив его заверениям, нанял, но который не умел готовить
соте, был уволен.1
Извлечение информации заключается в выборке из документов данных с
приданием им такой формы, которая сделает их полезными и для использования
1 Большим преимуществом русского языка, в сравнении с английским, является
обязательное выделение встроенных структур запятыми. В тексте оригинала во всех
приведенных здесь примерах знаки препинания отсутствуют. —Прим. перев.
544 Глава десятая. Искусственный интеллект
в других приложениях. Это может означать поиск ответа на конкретный вопрос
или запись информации в такой форме, которая позже позволит ответить на
различные вопросы. Одним из типов подобных форм являются шаблоны. По
сути, это просто анкета, в которой фиксируются некоторые характеристики.
Например, рассмотрим систему для чтения газет. Эта система может использовать
набор шаблонов, по одному для каждого из возможных типов газетных статей.
Если система опознает статью как сообщение о грабеже, она попытается
заполнить строки шаблона, относящегося к грабежам. Данный шаблон, вероятно,
будет запрашивать информацию о месте, времени и дате грабежа, о взятых вещах
и т. п. В то же время, если система определит статью как сообщение о
стихийном бедствии, она будет заполнять соответствующий шаблон, который заставит
систему определить тип стихийного бедствия, причиненный ущерб и т. п.
Другой тип формы, в которую может записываться информация,
предназначенная для последующего извлечения, называется семантической сетью. В
сущности, это большая взаимосвязанная структура данных, в которой для
представления взаимосвязей между элементами данных используются указатели. На
рис. 10.25 приведена часть семантической сети, в которой выделена
информация, полученная из следующего высказывания:
Мери ударила Джона.
Робототехника
Другим обширным полем приложения методов искусственного интеллекта
является область робототехники, или, в менее претенциозной интерпретации,
управление машинами. В этой области традиционные технологии применяются в
тех случаях, когда машина выполняет свою работу в полностью контролируемой
среде. Рассмотрим, например, использование автоматизированных
компьютерных систем на фабричном сборочном конвейере. В подобной среде от машины
чаще всего требуется лишь многократное повторение однотипных действий.
Например, задача может заключаться в подъеме готовых узлов и помещении их в
коробки, причем узлы прибывают по конвейеру через одинаковые промежутки
времени, а заполненные коробки непрерывно заменяются пустыми в одном и
том же месте. В этом случае машина, по сути, не поднимает узлы, а просто
закрывает свой зажим в определенный момент в определенном месте и перемещает
манипулятор в другое положение, где, вместо того чтобы поместить узел в
коробку, просто открывает зажим. Большинство из вас согласятся, что в подобных
случаях интеллект не требуется.
Однако случай, когда машина должна выполнять свою работу в
неконтролируемой среде, существенно отличается от приведенного выше примера. Наиболее ярким
примером является работа в безжизненной и неизвестной среде, например при
исследовании космического пространства. Но даже для фабричного сборочного
конвейера можно найти применение искусственному интеллекту. Действительно, даже
небольшое изменение условий описанной выше задачи по перемещению узлов может
потребовать от машины демонстрации "интеллектуального" поведения. Предполо-
10.6. Приложения теории искусственного интеллекта 545
жим, что нужные узлы не просто по отдельности выложены на конвейерной ленте, а
доставляются в коробке, содержащей и другие детали. В таком случае машине
потребуется распознать нужный узел, отодвинуть другие мешающие детали и поднять
необходимый узел. Предположим также, что предметы расположены в коробке
произвольным образом и поиск нужной детали в каждом случае будет требовать
уникальной последовательности шагов, которые должна определить сама машина. Более
того, машина должна будет постоянно контролировать текущую ситуацию и уметь
правильно ее понимать, поскольку предметы в коробке могут перемешиваться.
Процесс разрешения подобных проблем продолжается в исследованиях по
искусственному интеллекту и по сей день.
РИСУНОК 10.25
Семантическая сеть
Системы баз данных
Теперь мы рассмотрим хранилища данных и системы поиска,
представляющие собой основное место приложения для систем обработки естественного
языка. Цель их применения — возможность получения требуемой информации
посредством использования обычного языка, а не специального языка запросов.
546
Глава десятая. Искусственный интеллект
Большую пользу можно было бы извлечь из систем, способных давать
разумные ответы на поставленные вопросы. Традиционные хранилища данных и
системы поиска могут только извлекать из памяти явно запрошенные факты. В
противоположность этому, целью использования методов искусственного
интеллекта является разработка систем, способных выдавать не только прямо
запрошенную информацию, но и в той или иной степени связанные с ней данные.
Потребность в такой системе острее всего ощущается в юридических кругах. Юрист
может нуждаться в получении информации обо всех предыдущих случаях,
имеющих отношение к текущему судебному разбирательству. Однако для
понимания того, какой случай действительно имеет отношение к делу, необходимы
специальные юридические знания. Таким образом, юрист более заинтересован в
интеллектуальной системе поиска близких по теме материалов, чем в системе с
простой выдачей затребованных данных. Точнее говоря, традиционный подход к
данной проблеме требует от юриста указания ключевых слов и фраз, имеющих
какое-либо отношение к рассматриваемому случаю. Затем система
просматривает все свои досье и извлекает те из них, которые содержат ключевые слова и
выражения. Такая система просто просеивает данные, уменьшая, таким образом,
количество материалов, которые должен будет просмотреть юрист, и вполне
может пропустить действительно важные материалы из-за поиска "подростков", а
не "несовершеннолетних". Более "разумная" система, тем не менее, сможет
осуществлять более надежный отбор.
В качестве другого примера предположим, что имеется база данных,
содержащая сведения обо всех курсах, читаемых профессорами университета, с оценками,
выставленными студентам. Представим следующую цепочку событий. В базу
данных посылается запрос, сколько оценок "отлично" выставил профессор Джонсон в
прошлом семестре. Из базы данных поступает ответ: "Ни одной". Можно прийти к
заключению, что профессор Джонсон, должно быть, очень требователен к своим
студентам, и поинтересоваться количеством двоек, выставленных им в том же
семестре. И снова из базы данных поступает ответ: "Ни одной". Остается
предположить, что профессор Джонсон полагает, что все его студенты имеют средние
знания, и спросить о количестве выставленных троек. И опять получаем тот же ответ:
"Ни одной". В этот момент мы начинаем понимать, что происходит, и
спрашиваем, вел ли вообще профессор Джонсон занятия в прошлом семестре. База данных
отвечает: "Нет". Если бы она ответила так сразу!
Другой проблемой, связанной с традиционными системами накопления и
поиска данных, является то, что они могут выдавать только ту информацию,
которая записана в них явно. Однако мы нуждаемся в системах, способных делать
выводы и снабжать нас информацией, которая непосредственно следует из
данных, находящихся в базе. Рассмотрим, например, базу данных, содержащую
информацию обо всех президентах США. На вопрос, был ли среди президентов
человек трехметрового роста, традиционная система поиска ответить не сможет,
если, конечно, в ней не хранится информация о росте всех президентов. Однако
разумная система может ответить правильно и при отсутствии информации о
росте всех президентов. Ее цепочка рассуждений может выглядеть следующим
образом. Если бы существовал президент трехметрового роста, это был бы важ-
10.6. Приложения теории искусственного интеллекта 547
ный факт, который обязательно был бы помещен в базу данных. Поскольку
этого факта в базе нет, то и такого президента не существовало.
Умозаключение о том, что президента, который был бы ростом три метра, не
существовало, содержит очень ценную концепцию для теории проектирования
баз данных — различие между базами данных, реализованных в предположении
о замкнутости мира, и базами данных, исходящих из концепции открытости
мира. Грубо говоря, для базы данных первого типа (замкнутой) предполагается,
что она содержит все истинные факты по данной теме, тогда как для базы
данных второго типа (открытой) такого допущения не делается. В приведенном
выше примере способность отвергнуть гипотезу о существовании президента
трехметрового роста основана на предположении системы управления базой данных о
замкнутости мира, т.е. если факт не внесен в ее базу данных, то он неверен.
Хотя на первый взгляд допущение о замкнутости мира может показаться вполне
обоснованным, тем не менее, оно может послужить источником определенных
трудностей. Рассмотрим базу данных, состоящую из единственного выражения:
Или изделий А имеется в избытке, или изделий Б имеется в избытке.
Исходя из этого утверждения, нельзя с уверенностью сказать, что изделий А
действительно имеется в избытке. Таким образом, база данных, использующая
предположение о замкнутости мира, вынудит нас предположить следующее:
Изделий А имеется не в избытке.
Подобным же образом можно получить и другое утверждение:
Изделий Б имеется не в избытке.
Таким образом, очевидно, что использование в базе данных предположения о
замкнутости мира может привести к получению противоречивых результатов:
"Хотя или изделия А, или изделия Б имеются в избытке, ни одного из них в
избытке нет". Понимание ограниченности, свойственной подобным внешне вполне
безобидным принципам рассуждений, является одной из задач текущих
исследований в области искусственного интеллекта.
Другой задачей исследований в области искусственного интеллекта в
применении к базам данных является выяснение, что же действительно хочет знать
пользователь системы или что он хотел бы получить вместо буквального ответа
на поставленный им вопрос.
Экспертные системы
Важным расширением понятия разумных баз данных является концепция
экспертных систем — программных пакетов, предназначенных для оказания
помощи человеку в тех случаях, когда он нуждается в совете специалиста по
какому-либо вопросу. Эти системы сконструированы для имитации причинно-
следственных рассуждений, которые мог бы провести эксперт, столкнувшийся с
той же проблемой. Так, медицинская экспертная система предложила бы те же
процедуры, что и врач-специалист, знающий, что биопсия проводится при
обнаружении аномалий, которые подтверждены рентгеновским снимком.
548 Глава десятая. Искусственный интеллект
Следовательно, главной задачей при конструировании экспертных систем
является получение необходимой информации от специалиста. Вопрос, как это
можно сделать, стал темой независимых важных исследований. Эта проблема в
действительности двойственная. Во-первых, это установление и поддержка
взаимодействия с экспертами — предприятие, которое может оказаться нелегким,
поскольку требуемый опрос, вероятнее всего, окажется долгим и утомительным.
Кроме того, эксперт может просто не захотеть передавать знания машине,
способной впоследствии занять его место. Во-вторых, сами эксперты часто не
отдают себе отчета в том, каким образом они делают свои выводы. На вопрос:
"Почему вы уверены, что нужно сделать так?" они часто отвечают: "Не знаю".
После того как указанные проблемы будут успешно преодолены, полученные
от эксперта знания должны быть представлены в форме, совместимой с
выбранной программной системой. Это требование чаще всего удовлетворяется
посредством выражения полученных знаний в качестве набора правил, представленных
в виде выражений типа если-то. Например, правило о том, что аномалия,
подтвержденная рентгеновским снимком, требует применения биопсии, может быть
выражено следующим образом:
(аномалия обнаружена и рентгеновский снимок показывает присутствие массы)
(предполагает выполнение биопсии)
(Те, кто прочитал необязательный раздел по декларативному
программированию в главе 5, обнаружат определенное сходство между структурой
экспертной системы и программой на языке Prolog. Это сходство является
основной причиной популярности этого языка в области искусственного
интеллекта. И действительно, язык Prolog — это прекрасный инструмент для
разработки экспертных систем.)
Отметим также определенное сходство между правилами экспертных систем и
порождениями в порождающих системах. Первая часть правила, по существу,
задает необходимые условия для выполнения или выведения утверждений,
находящихся во второй его части. И действительно, многие экспертные системы,
по сути, являются порождающими системами, в которых правила, полученные
от человека-эксперта, играют роль порождений, а выполнение основанных на
этих правилах рассуждений имитируется системой контроля. В таком контексте
набор порождений часто называют базой знаний системы, а на систему контроля
ссылаются как на механизм логического вывода.
Однако не впадите в заблуждение, полагая, что экспертная система — это
просто очень большая версия обсуждавшейся раньше системы для решения
головоломок. Некоторые экспертные системы сформированы как
совокупность порождающих систем, объединяющих свои усилия для решения
поставленной задачи. Примером являются экспертные системы, построенные по
принципу "классной доски", в соответствии с которым несколько систем
поиска решений, называемых источниками знаний, делят общую область
памяти, называемую "классной доской". Эта "классная доска" отражает текущее
состояние решаемой проблемы и, так как она поделена между всеми
источниками знаний, образует среду, с помощью которой отдельные источники
10.6. Приложения теории искусственного интеллекта 549
знаний могут вносить свой вклад в решение проблемы. Для координации
деятельности источников знаний создается управляющий модуль, задачей
которого является включение нужного источника в нужное время. В
терминах модели классной доски этот управляющий модуль определяет положение
"фокуса внимания" всей системы.
Еще одно различие между экспертной системой и простой порождающей
системой состоит в том, что экспертная система не обязательно должна
достичь заранее определенной цели, а, скорее, должна предоставить
убедительный совет. Например, предположим, что экспертная система поставлена
перед проблемой диагностики заболевания. В идеале хотелось бы получить от
системы окончательный ответ: "Это болезнь X", где в место X будет указано
название данной болезни. К сожалению, такая точность не всегда достижима
на практике. Вместо этого лучшим возможным ответом может быть такой:
"Наиболее вероятно, что это болезнь X" или же "Это болезнь X или Y.
Пожалуйста, пройдите следующий тест для определения наиболее вероятного из
этих двух вариантов". Из-за такой двусмысленности система контроля
экспертной системы может выбрать вариант исследования нескольких путей в
графе состояний и сообщить пользователю о результатах каждого из них. В
то же время, если порождение, достигнутое в одном из состояний, будет
иметь вид
(ревматоидный фактор присутствует, и больной жалуется на боли в суставах)
(с вероятностью 80% предполагается ревматоидный артрит),
то все дальнейшие рассуждения о том, что это ревматоидный артрит,
потенциально могут оказаться неверными.
Как и в других исследованиях, ранние приложения экспертных систем
были ограничены лишь несколькими областями. Однако сейчас число
областей, в которых экспертные системы находят применение, существенно
возросло. Одним из катализаторов для подобной экспансии оказалось
утвердившееся понимание, что экспертные системы могут быть разделены на
рассуждающий компонент и компонент знаний. Удалив из существующей
экспертной системы ее базу знаний, можно выделить из нее только
подсистему логических рассуждений, которая вполне может быть применена и к
другой среде. Таким образом, экспертные системы для новых областей могут
быть созданы всего лишь посредством присоединения новой базы знаний к
уже существующей рассуждающей системе. Это наблюдение, в сущности,
говорит о том, что система контроля, разработанная нами для решения
головоломки "Восьмерка", может быть использована и для решения других
проблем — посредством простой замены порождений этой головоломки на
порождения, связанные с новой проблемой.
Вопросы для самопроверки
1. Определите двусмысленность, имеющую место при переводе фразы "Они —
гоночные лошади".
550 Глава десятая. Искусственный интеллект
2. Сравните результаты грамматического разбора следующих двух предложений
и объясните, чем они отличаются семантически.
Фермер построил изгородь на поле.
Фермер построил изгородь зимой.
3. Исходя из информации в семантической сети, представленной на рис. 10.25,
определите степень родства между Мери и Джоном.
4. База данных о подписке на журналы обычно содержит список подписчиков
на каждый журнал, но не содержит список тех людей, которые не
подписались на него. Каким образом подобная база данных может определить, что
некоторый человек не подписался на данный журнал?
5. Каковы различия между традиционной базой данных и базой знаний
экспертной системы?
10.7. Осмысливание последствий
Несомненно, что прогресс, достигнутый в области исследований
искусственного интеллекта, предполагает значительную потенциальную возможность
принести пользу человечеству, поэтому очень легко поддаться энтузиазму,
вызванному этой возможностью. Но нельзя забывать и о таящейся в
будущем потенциальной угрозе, последствия которой могут быть столь же
разрушительными, как и размеры полученной выгоды. Различие довольно часто
заключается всего лишь в точке зрения или в положении, занимаемом
человеком в обществе: что для одного выгодно, для другого может оказаться
губительным. Будет весьма полезно остановиться на некоторое время и
взглянуть на успехи технологии с противоположной точки зрения.
Одни смотрят на бурное развитие технологий как на подарок
человечеству, подразумевая освобождение человека от утомительных, традиционных
обязанностей и прокладывание пути к более удобному и приятному образу
жизни. Однако другие рассматривают это же явление как проклятье,
лишающее граждан ремесел и перераспределяющее доходы в пользу сильных
мира сего. Приблизительно так звучало письмо истинного гуманиста
Махатмы Ганди, имевшего огромное влияние во время борьбы Индии за
независимость от Британии. Он неоднократно приводил доводы в пользу того, что для
Индии будет лучше, если заменить большие текстильные фабрики на
прялки, расположенные в домах сельских жителей. Таким образом, утверждал
он, централизованное серийное производство, предоставляющее работу лишь
избранным, будет заменено рассредоточенной системой массового
производства, приносящей выгоду большему количеству людей.
История полна революций, причиной которых являлись диспропорции в
распределении богатств и привилегий. Если нынешняя, бурно развивающаяся
технология будет способствовать усилению подобных различий, последствия могут
оказаться катастрофическими.
10.7. Осмысливание последствий 551
Сильный ИИ против слабого ИИ
Предположение о том, что машины могут быть запрограммированы для демонстрации разумного поведения,
известно как слабый ИИ (ИИ — искусственный интеллект) и в той или иной степени уже принято широкой
аудиторией. Однако предположение, что машина может быть запрограммирована на обладание разумом и фактически
искусственным сознанием, известное как сильный ИИ, все еще активно дискутируется. Противники сильного ИИ
приводят доводы, что машина радикально отличается от человека и, таким образом, никогда не испытает любви,
не отличит правду от лжи и не будет думать о себе так, как это делает человек. Сторонники сильного ИИ
возражают, что человеческий мозг состоит из мельчайших элементов, каждый из которых по отдельности человеком не
является и таковым себя не осознает, но все вместе те же элементы формируют личность. Почему же,
спрашивают они, то же явление не может происходить и с машинами?
Проблема разрешения споров по проблеме сильного ИИ состоит, как уже отмечалось выше, в том, что
вещи, подобные разуму и сознанию, являются внутренними характеристиками и не могут быть прямо
определены. Как указал еще Алан Тьюринг, мы верим, что люди обладают разумом, поскольку они ведут себя
разумно, хотя мы и не можем наблюдать их внутреннее умственное состояние. Готовы ли мы
проиллюстрировать подобный подход и по отношению к машине, если она продемонстрирует внешние признаки
сознания? Почему да или почему нет?
Но последствия построения все более и более "разумных" машин существенно
глубже (и более фундаментальны), чем последствия борьбы классов и различных
группировок в обществе. Эта проблема поразила человеческое самомнение в
самое сердце. В XIX веке общество было приведено в смятение теорией Чарльза
Дарвина об эволюции и мыслью о том, что человек мог произойти от низших
форм жизни. И как должно реагировать общество, поставленное перед фактом
возможности неудержимой атаки со стороны машин, умственные способности
которых бросают вызов человеку?
В прошлом технологии развивались медленно, давая время на сохранение
нашего самомнения за счет пересмотра существовавших понятий об интеллекте.
До известной степени мы привыкли определять способность человека к
пониманию как "то, чего машина делать не умеет". Наши древние предки наделили бы
механические устройства XIX века сверхъестественным интеллектом, а мы
сейчас отказываем этим машинам в каких бы то ни было признаках сознания. Но
как же отреагирует человечество, если машины действительно бросят вызов
интеллекту человека или, что более вероятно, если возможности машин будут
развиваться быстрее, чем наши способности приспосабливаться?
Вы можете возразить, что такая постановка вопроса граничит скорее с
областью научной фантастики, чем с вычислительной техникой. Однако не так давно
многие отмахивались от вопроса "Как поведет себя человечество, если
компьютеры подчинят себе всю жизнь общества?", считая, что "этого никогда не
случится". Однако во многих отношениях следует признать, что этот день уже
наступил. Если компьютеризированная база данных ошибочно сообщает о вашей
552 Глава десятая. Искусственный интеллект
некредитоспособности, о наличии судимости или превышает при расчетах сумму
остатка на счету в банке, является ли это простой ошибкой компьютера или
должно расцениваться как посягательство на вашу невиновность и честное имя?
Если неисправная навигационная система показывает, что скрытая туманом
взлетно-посадочная полоса находится совсем не там, где она действительно
расположена, куда приземлится самолет? Если машина будет использоваться для
предсказания реакции народа на различные политические решения, какое
решение примет политик? Кто (или что) тогда будет ответственным за принятие этого
решения? Разве мы уже не подчинили общество машинам? Изменится ли наш
уровень жизни в зависимости от того, будем ли мы считать машины,
оказывающие влияние на нашу жизнь, как принимающие сознательные решения,
основанные на разуме, или просто как воспроизводящие запрограммированные
реакции, даже если решение остается тем же?
Мы можем попытаться представить себе, как человечество отнесется к
появлению машин, бросающих вызов нашему интеллекту, рассмотрев реакцию общества
на введение тестов по определению коэффициента интеллекта (IQ), имевшее место
в середине XX столетия. Эти тесты были предназначены для определения уровня
интеллекта ребенка. Дети в США часто классифицировались по результатам,
показанным при выполнении этих тестов, и затем распределялись по
соответствующим учебным программам. Так, благоприятные возможности для обучения
предоставлялись прежде всего тем детям, чьи успехи в выполнении тестов были
значительными. Если же ребенок справлялся с тестами плохо, то и учился он, как
правило, по упрощенной программе. Обобщая сказанное, можно утверждать, что
когда установлена шкала для измерения индивидуального интеллекта, общество
стремится пренебречь возможностями тех своих членов, которые находятся на
нижних уровнях этой шкалы. Что же будет делать общество, если "разумные"
возможности машины станут сравнимы (или даже будут казаться сравнимыми) с
соответствующими возможностями человека? Откажется ли общество от тех, чьи
способности будут оцениваться "ниже" способностей машин? Если да, то каковы
будут последствия для этих членов общества? Должно ли достоинство человека
подчиняться тому, насколько он или она сравнимы с машиной?
Мы уже видим, как в некоторых областях интеллектуальная мощь человека
ставится машинами под сомнение. Машины уже способны обыграть мастеров
игры в шахматы, компьютеризированные экспертные системы способны давать
медицинские советы, а управление инвестициями некоторым программам
удается даже лучше, чем профессиональным брокерам. Как повлияют подобные
системы на вовлеченных в эти занятия людей и их представление о самих себе? Как
влияет на человеческое чувство собственного достоинства тот факт, что во все
большем количестве отраслей машина уже превосходит человека?
Многие возражают, что интеллект, которым обладают машины, всегда будет
радикально отличаться от человеческого, поскольку человек имеет
биологическое происхождение, а машина — нет. Поэтому, утверждают они, машина
никогда не сможет воспроизвести процесс принятия решений человеком. Машины
могут прийти к тем же выводам, что и человек, но эти умозаключения будут
сделаны не на том основании, на котором их делает человек. Но тогда, как оце-
10.7. Осмысливание последствий 553
нить, до какой степени отличаются эти два интеллекта, и будет ли этично для
общества следовать по пути, указанному нечеловеческим интеллектом?
Мы закончим наше обсуждение цитатой из книги Джозефа Уэйзенбаума
(Joseph Weizenbaum) Computer Power and Human Reason, в которой он
возражает против неконтролируемого применения компьютерных технологий.
Компьютеры могут выносить судебные вердикты, компьютеры могут
принимать решения в отношении психиатрических диагнозов. Они
могут подбрасывать в воздух монеты более изощренно, чем самые упорные
из людей. Все дело в том, что им нельзя давать такие задания. Они
даже могут прийти к "правильному" выводу в некоторых случаях, но
всегда и непременно на таких основаниях, которые человек не пожелал
бы принять во внимание.
В прошлом уже имело место множество дебатов относительно
проблемы "компьютер и мозг". Главный вывод, который я сделал, состоит в
том, что соответствующая проблема не является ни технологической,
ни даже математической — она этическая. Она не может быть
устранена с помощью вопросов, начинающихся со слов "Может ли...". Пределы
области применения компьютеров в итоге могут быть установлены
исключительно в терминах долженствования. Наиболее простое
понимание проблемы заключается в том, что поскольку мы не имеем на
данный момент возможности сделать компьютер мудрым, то мы и не
должны давать ему заданий, требующих наличия мудрости.
Вопросы для самопроверки
1. Какая часть современного общества выживет, если убрать все механизмы,
появившиеся за последние 100, 50, 20 лет? Где будут жить такие люди?
2. В какой степени вашу жизнь контролируют машины? Кто контролирует
машины, воздействующие на вашу жизнь?
3. Откуда поступает информация, на которой основываются ваши ежедневные
решения? Основные решения? Насколько вы доверяете точности этой
информации? Почему?
Упражнения
1. Иногда способность ответить на вопрос зависит от знания пределов
осведомленности, поскольку это само по себе является дополнительным
фактом. Например, предположим, что существуют две базы данных — А и Б.
Обе содержат полный список работников, принимающих участие в
программе страхования здоровья компании, но только в базе А есть сведения
о том, что этот список полный. Какой вывод может сделать база А (и не
может сделать база Б) относительно человека, не внесенного в список?
2. В тексте этой главы мы кратко обсудили проблему понимания
естественных языков в сравнении с формальными языками программирова-
554 Глава десятая. Искусственный интеллект
ния. В качестве примера сложностей, возникающих при работе с
естественным языком, укажите ситуации, в которых один и тот же вопрос
"Ты знаешь, который час?" будет иметь различные значения.
3. Как было продемонстрировано в предыдущем упражнении, люди
могут употреблять вопросы для целей, отличных от опрашивания. Вот
один из подобных вопросов: "Вы знаете, что у вас шина спустила?"
Обычно его целью является информирование человека, а не пустое
любопытство. Приведите примеры вопросов, используемых для
убеждения, предостережения, осуждения.
4. Сравните значения предложных оборотов в следующих двух
предложениях (они отличаются всего лишь одним словом):
The pigpen was built by the barn (Хлев был выстроен рядом с сараем.)
The pigpen was built by the farmer (Хлев был выстроен фермером.)
5. Если исследователь использует компьютерную модель для изучения
способностей и процессов запоминания в человеческом мозге, всегда
ли будут соответствующие программы использовать память
компьютера на пределе его возможностей? Объясните свою точку зрения.
6. Какие из следующих видов деятельности относятся к деятельно-
ориентированным, а какие — к объектно-ориентированным?
а) Разработка имитатора полетов.
б) Разработка автопилота.
в) Разработка базы данных, предназначенной для библиотечных
материалов.
г) Разработка модели экономики государства для проверки
экономических теорий.
д) Разработка программы слежения за основными показателями
состояния больного.
7. Определите небольшой набор геометрических свойств, которые могут
быть использованы для различения символов О, G, С и Q.
8. Опишите сходство между технологией идентификации символов
посредством сравнения их с образцом и кодом с исправлением ошибок,
обсуждавшимся в главе 1.
9. Опишите две трактовки приведенного ниже чертежа, основанные на том,
является ли обозначенный буквой А угол выпуклым или вогнутым.
Упражнения 555
10. Какие различия существуют между графом состояний и деревом
поиска в контексте порождающих систем?
11. Охарактеризуйте задачу сборки кубика Рубика в терминах порождающих
систем. (Что здесь является состоянием, порождением, и т. д.?)
12. В тексте мы упоминали, что порождающая система часто используется
как технологический прием для того, чтобы делать выводы из
известных фактов. Состояния системы — это факты, гарантированно
истинные на каждом этапе процесса рассуждения, а порождения — это
правила логики для оперирования известными фактами. Определите
несколько правил логики, необходимых для вывода утверждения
"Джон — высокий" из известных фактов "Джон — баскетболист,"
"Баскетболисты не низкие," "Джон либо высокий, либо низкий".
13. Приведенное ниже дерево представляет возможные ходы в игре с
противником и показывает, что игрок X в настоящий момент имеет выбор
между ходами А и Б. После хода игрока X игрок Y выбирает свой
ход, после чего игрок X делает последний ход в игре. Листовые узлы
дерева помечены буквами В, П и Н, в зависимости от того,
заканчивается игра выигрышем, проигрышем или ничьей для игрока X. Какой
ход выберет игрок X — А или Б? Почему? Чем выбор порождения в
игре с противником отличается от подобного выбора в одиночной игре,
такой как головоломка "Восьмерка"?
14. Если рассматривать манипуляционные правила алгебры как
порождения, то проблема упрощения алгебраических выражений может быть
автоматизирована в контексте порождающих систем. Определите
набор алгебраических порождений, которые позволили бы упростить
исходное уравнение 3/(2х+ 1) = 2/(2х-2) к виду х = 4. Какие эмпирические
(эвристические) правила необходимо использовать для выполнения
подобного алгебраического упрощения?
15. Нарисуйте дерево поиска, порожденное горизонтальным поиском при
попытке решить головоломку "Восьмерка", для приведенного ниже
исходного состояния, причем без использования какой бы то ни было
эвристической информации.
556 Глава десятая. Искусственный интеллект
16. Нарисуйте дерево поиска, которое будет порождено алгоритмом,
представленным на рис. 10.9, при попытке решить головоломку
"Восьмерка" для начального состояния, показанного в упражнении 15,
считая эвристической величиной количество фишек, находящихся не
на своих местах.
17. Нарисуйте дерево поиска, которое будет порождено алгоритмом,
представленным на рис. 10.9, при попытке решить головоломку
"Восьмерка" для показанного ниже начального состояния, используя
эвристическую величину, описанную в разделе 10.3.
18. Почему при решении головоломки "Восьмерка" лучше в качестве
эвристической величины использовать параметр, описанный в
разделе 10.3, а не число фишек, находящихся не на своих местах?
19. Каковы различия между методом принятия решения о том, какую из
частей списка следует рассматривать при выполнении двоичного поиска (см.
раздел 4.5), и методом выбора ветви при эвристическом поиске?
20. Отметим, что если состояние на графе состояний порождающей
системы имеет очень малую эвристическую величину по сравнению с
остальными состояниями и существует порождение, переводящее это
состояние само в себя, то приведенный на рис. 10.9 алгоритм может
попасть в бесконечный цикл и рассматривать это состояние снова и
снова. Покажите, что бесконечного зацикливания процесса поиска
можно избежать, если установить стоимость выполнения любого
порождения в системе равным единице. При этом предполагаемую
стоимость следует вычислять как сумму эвристической величины и
стоимости достижения данного состояния по всему пройденному пути.
21. Какие эвристические показатели вы используете при поиске маршрута
между двумя городами на большой карте дорог?
22. Укажите два свойства, которыми должны обладать эвристические
показатели, чтобы они могли оказаться полезными в порождающих системах.
23. Предположим, что у вас есть два ведра: одно емкостью 3 литра,
другое — 5 литров. Вы можете переливать воду из одного ведра в другое,
опорожнять ведро или наполнять его. Ваша задача — налить 4 литра
воды в 5-литровое ведро. Опишите, как решение этой задачи может
быть представлено в виде порождающей системы.
Упражнения
557
24. Предположим, что вашей обязанностью является наблюдение за
погрузкой двух грузовиков, каждый из которых может перевозить до
14 т груза. Груз состоит из набора ящиков массой 28 т, но масса груза
каждого ящика — различна (она указана на нем). Какой
эвристический показатель можно было бы использовать при распределении
ящиков между машинами?
25. Разработайте схему искусственной нейронной сети, способной
распознавать, какая из показанных ниже двух фигур находится в поле ее зрения.
26. Разработайте схему искусственной нейронной сети, способной
распознавать, какая из показанных ниже двух фигур находится в поле ее
зрения.
27. Разработайте схему искусственной нейронной сети, способной
распознавать, какая из показанных ниже четырех фигур находится в поле
ее зрения.
28. Чем будут отличаться результаты грамматического разбора двух
приведенных ниже предложений? Чем будут отличаться результаты их
семантического анализа?
Теодору удалось объездить зебру.
Зебра была объезжена Теодором.
29. Чем отличаются результаты грамматического разбора двух
приведенных ниже предложений? Чем отличаются результаты их
семантического анализа?
558 Глава десятая. Искусственный интеллект
Если X = 5, то прибавить1 к X, иначе вычесть 1 из X.
Если X Ф 5, то вычесть 1 из X, иначе прибавить 1 к X.
30. Приведите пример, в котором база данных, использующая
предположение о замкнутости мира, приходит к противоречию.
31. Приведите два примера приложений, в которых обычно применяется
база данных, использующая предположение о замкнутости мира.
32. Подберите для искусственной нейронной сети, приведенной на
рис. 10.17, такие значения весовых коэффициентов и пороговой
величины, чтобы она давала на выходе значение 1, когда оба входных
сигнала одинаковы (два 0 или две 1), и значение 0, когда они различны
(один сигнал равен 1, другой — 0).
33. Начертите диаграмму, подобную изображенной на рис. 10.4 и
представляющую процесс упрощения алгебраического выражения 7х + 3 =
Зх-5 к виду х = -2.
34. Дополните ваш ответ на предыдущий вопрос в целях представления
других путей, которыми сможет следовать система контроля при
попытках решить поставленную задачу.
35. Начертите диаграмму, подобную изображенной на рис. 10.4 и
представляющую процесс рассуждений, которые позволяют сделать
заключение "Полли может летать", исходя из следующих известных фактов:
"Полли — попугай," "Попугай — птица" и "Все птицы умеют летать".
36. В противовес принятому в предыдущем упражнении утверждению,
некоторые птицы, такие как страус или скворец с перебитым крылом,
не могут летать. Однако идея создания дедуктивной системы, в
которой будут явно перечислены все исключения из утверждения "Все
птицы умеют летать", не кажется нам разумной. Как же тогда человек
принимает решение, может ли определенная птица летать или нет?
37. Объясните, как семантическое значение выражения "Я представил
мужа тучной леди" может зависеть от контекста.
38. Объясните, как проблема путешествия из одного города в другой
может быть описана в терминах порождающей системы. Что здесь
является состояниями, а что — порождениями?
39. Предположим, что вы должны в произвольном порядке, но не
одновременно выполнить три задания — А, Б и В. Опишите эту проблему в
терминах порождающей системы и начертите для нее граф состояний.
40. Как изменится граф состояний из предыдущего упражнения, если
задание В должно быть выполнено раньше, чем задание А?
41. Объясните, как стратегия игры в крестики-нолики может
совершенствоваться с использованием метода генетического алгоритма.
Упражнения 559
42. Метод скрещивания стратегий, описанный в разделе 10.5 называют
одноточечным. Существует и альтернативный метод, именуемый
двухточечным скрещиванием, в котором две стратегии обмениваются
"центральными" сегментами. Покажите, что любая стратегия,
которую можно получить с помощью одноточечного скрещивания, также
может быть получена и с помощью двухточечного, и наоборот.
43.
а) Пусть запись (i,j), где i и j — целые положительные числа,
используется для обозначения правила: "если число, находящееся на i-й позиции
списка, больше, чем находящееся на j-й, то следует поменять их
местами". Какая из следующих двух последовательностей действий лучше
справится с задачей сортировки списка из трех чисел?
(1,3) (3,2)
(1,2) (2,3) (1,2)
б) Используя данную систему записи, разработайте генетический
алгоритм для создания программы, сортирующей список из десяти
чисел.
44. Изменения в контексте выражения могут изменить как его смысл, так
и значимость. Исходя из контекста, представленного на рис. 10.25,
покажите, как изменится значимость предложения "Мери ударила
Джона" при изменении дат рождения с 1990-х на 1960-е. А если одну
дату изменить на 1960-е, а другую оставить в 1990-х?
45. Нарисуйте семантическую сеть, представляющую информацию из
следующего абзаца.
"Дон бросил мяч Джеку, который послал его в центр поля.
Центральный полевой игрок попытался поймать его, но мяч отскочил
рикошетом от стенки".
Общественные и социальные вопросы
Следующие вопросы приводятся для того, чтобы помочь вам разобраться в
некоторых этических, общественных и юридических аспектах использования
вычислительной техники, а также в ваших собственных воззрениях и тех
принципах, на которых они основаны. Задача не сводится к тому, чтобы просто дать
ответы на предложенные вопросы. Вы должны также разобраться, почему вы
ответили именно так, а не иначе, и насколько ваши суждения по различным
вопросам согласуются друг с другом.
1. Насколько исследователи в области ядерной энергетики, генной
инженерии и искусственного интеллекта ответственны за использование
результатов их работы?
560 Глава десятая. Искусственный интеллект
2. Как бы вы определили различие между интеллектом и кажущимся
интеллектом? Вы уверены, что это разные вещи?
3. Предположим, что компьютеризированная медицинская экспертная
система приобрела в медицинском сообществе хорошую репутацию
благодаря высокому качеству даваемых ею советов. До какой степени
врач может позволить этой системе изменять его решение
относительно методов лечения его пациентов? (Если врач выберет метод лечения,
противоположный рекомендациям системы, а впоследствии окажется,
что права была система, виновен ли человек в злоупотреблении
доверием больного?) И вообще, если экспертная система становится
широко известной в своей области, то до какой степени она будет скорее
повышать, чем снижать возможности человеческих экспертов, когда
те выносят собственное суждение?
4. Многие согласятся с тем, что действия компьютера — это просто
последствия того, как он был запрограммирован, следовательно,
компьютер не имеет свободы воли. А это значит, что компьютер не несет
ответственности за совершаемые им действия. Является ли компьютером
человеческий мозг? Заложена ли в него программа уже при рождении
человека? Программируются ли люди окружающей их средой?
Ответственны ли люди за свои действия?
5. Имеются ли области, в которых наука не должна работать, даже если
и есть такая возможность? Например, если станет возможным
создание машины, ощущения и мыслительные возможности которой
сравнимы с человеческими, будет ли уместным создание такой машины?
Какие предметы для спора вызовет возможность существования такой
машины? Какие споры кипят уже сейчас в отношении достижений в
других областях науки?
6. Истории известны многочисленные примеры влияния на работу
ученых и художников политических, религиозных и других
общественных институтов того времени. Какими способами сейчас оказывается
подобное влияние на работу ученых и на работу специалистов по
программированию в частности?
7. Сегодня многие организации берут на себя хотя бы часть
ответственности за переобучение тех, чье поле деятельности было сокращено в
связи с развитием технологии. Что должно и что может сделать
общество, если технологии все больше и больше будут выходить за пределы
наших возможностей?
8. Предположим, что вы получили счет на $0.00. Что вы будете делать?
Предположим, что вы ничего не сделали и через 30 дней получили
второе извещение на $0.00. Что вы теперь будете делать?
Предположим, что вы опять ничего не сделали и через 30 дней получили новое
извещение на $0.00 с примечанием, что если вы немедленно не
оплатите счет, будут приняты меры. Кто ответствен за подобное?
Общественные и социальные вопросы 561
Рекомендуемая литература
• Allen J. Natural Language Understanding, 2nd ed. Reading. —- MA: Addison-
Wesley, 1995.
• Banzhaf W., Nordin P., Deller R. E., Francone F. D. Genetic Programming: An
Introduction, — San Francisco, CA: Morgan Kaufmann, 1998.
• Mitchell M. An Introduction to Genetic Algorithms. — Cambridge, MA: MIT
Press, 1998.
• Mitchell Т. М. Machine Learning. — New York: McGraw-Hill, 1997.
• Nilsson N. Artificial Intelligence: A New Synthesis. — San Francisco, CA:
Morgan Kaufmann, 1998.
• Rumelhart D. E., McClelland J. L. Parallel Distibuted Processing. — Cambridge,
MA: MIT Press, 1986.
• Russell S., Norvig P. Artificial Intelligence: A Modern Approach. — Englewood
Cliffs, NJ: Prentice-Hall, 1995. (Русский вариант этой книги: Рассел С, Нор-
виг П. Искусственный интелект: совеременный подход. — М.:
Издательский дом "Вильяме", готовится к выпуску в 2002 г.)
• Tanimoto S. L. The Elements of Artificial Intelligence Using Common Lisp, 2nd
ed — New York: Computer Science Press, 1995.
• Weizenbaum J. Computer Power and Human Reason. — New York: W. H.
Freeman, 1979.
• Zurada J. M. Introduction to Artificial Neural Systems. — St. Paul, MN: West,
1992.
Дополнительная литература
Джексон П. Введение в экспертные системы, 3-е изд. — М.: Издательский
дом "Вильяме", 2001.
562 Глава десятая. Искусственный интеллект
глава
Теория
вычислений
ОДИННАДЦАТАЯ
В этой главе мы обсудим некоторые теоретические идеи,
выдвинутые при рассмотрении вопроса о том, что могут и чего не могут
машины. Обсуадение начинается со знакомства с очень простым
языком программирования, Далее будет продемонстрировано,
что любая проблема, решаемая с помощью современных
компьютеров, обязательно имеет решение и в терминах этого простого
языка. Таким образом, если некоторый язык программирования
охватывает все функции данного простого языка, то это
гарантирует наличие в некотором языке средств, необходимых для
представления решения любой проблемы, которую способна решить
машина. Затем на примере нашего простейшего языка будет
показано, что существуют задачи, которые современные машины
решить не в состоянии, и, вероятнее всего, компьютеры
будущего тоже не смогут этого сделать. Более того, мы узнаем, что даже
среди потенциально решаемых задач существуют такие, решение
которых настолько сложно, что они являются фактически
неразрешимыми с чисто практической точки зрения.
11.1. Простейший язык
программирования
Операторы описания данных
Императивные операторы
Возможности программ,
написанных на простейшем языке
11.2. Машины Тьюринга
Понятие машины Тьюринга
Конкретный пример машины
Тьюринга
11.3. Вычислимые функции
Функции и их вычисление
Тезис Черча-Тьюринга
Универсальность простейшего
языка
11.4. Невычислимые функции
Небольшое вступление
Проблема остановки
11.5. Сложность задач
Измерение сложности задачи
Задачи полиномиального и
неполиномиального типов
НП-задачи
11.6. Криптография с
использованием открытых ключей
Шифрование с использованием
алгоритма задачи о рюкзаке
Модульная арифметика
Возвращаясь к шифрованию
11.1. Простейший язык программирования
Предположим, что нам необходимо разработать новый императивный язык
программирования, который можно будет использовать как язык
программирования общего назначения на протяжении многих лет. Наша задача усложняется
тем, что мы не можем предвидеть, какие функции для данного языка
понадобятся в будущем. Однако как в этом случае можно было бы гарантировать, что
создаваемый язык будет содержать все те функции, которые могут
потребоваться при решении любой проблемы в будущем?
Решение проблемы заключается в создании языка, мощность которого не
будет уступать мощности самих алгоритмических процессов. Иными словами, если
некоторая задача может быть решена алгоритмически, то алгоритм ее решения
всегда можно будет выразить на нашем языке. Следовательно, если
впоследствии программист обнаружит, что некоторая задача не может быть решена с
помощью нашего языка, то причины этого следует искать не в нашем языке. Язык
программирования с подобными свойствами называется универсальным языком
программирования.
Предположим, что из-за ограниченности бюджета мы не можем позволить
себе реализовать избыток функций, которые просто повышают удобство работы с
языком. Наша задача состоит в разработке мощного, но исключительно
компактного языка программирования.
В этом разделе описывается императивный язык программирования,
удовлетворяющий всем указанным выше требованиям. Поскольку рассматриваемый
язык имеет совсем немного дополнительных функций, характерных для других
языков программирования, мы соответственно будем называть его простейшим.
В самом деле этот язык отвечает лишь минимальному набору требований,
предъявляемых к любому универсальному языку программирования.
Операторы описания данных
Как было сказано выше, операторы описания данных, присутствующие в
современных языках программирования высокого уровня, позволяют программистам
мыслить непосредственно в терминах массивов числовых величин и строк буквенных
символов, даже несмотря на то, что сама машина не ассоциирует такую трактовку с
теми наборами двоичных разрядов, которые представляют эти объекты. Машина
просто манипулирует битовыми комбинациями так, как это предписывается
выполняемой инструкцией. Прежде чем представить машине для выполнения команду
высокого уровня, требующую поменять местами два символа в строке, необходимо
преобразовать ее (оттранслировать) в набор машинных команд, с помощью которых
можно поменять местами две комбинации двоичных разрядов.
Следовательно, разработка языка программирования может быть существенно
упрощена, прежде всего, за счет принуждения программиста выражать все
выполняемые операции в терминах комбинаций двоичных разрядов. Такой язык
564 Глава одиннадцатая. Теория вычислений
будет иметь единственный тип данных и структуру данных, поэтому ему вообще
не потребуются какие-либо операторы описания данных.
Для упрощения в нашем простейшем языке будет использован именно такой
подход. Здесь будут рассматриваться переменные типа "комбинация двоичных
разрядов произвольной длины". Поэтому в программе на этом простейшем языке
не нужны декларативные операторы описания имен переменных и связанных с
ними свойств. При необходимости достаточно просто начать использование
нового имени переменной, подразумевая, что оно ссылается на последовательность
битов произвольной длины.
Конечно, транслятор нашего простейшего языка должен уметь отличать
имена переменных от других выражений. Для этого необходимо разработать такой
синтаксис языка, чтобы роль каждого терма была понятна из его контекста.
Установим, что имена переменных состоят только из латинских букв. Поэтому
строки XYZ, Bill и abcdefghi могут использоваться в качестве имен
переменных, тогда как строки 2G5, %о или х.у. — нет. Более того, мы примем за
правило ограничивать каждый оператор языка точкой с запятой, что позволит
транслятору легко отделять операторы друг от друга.
Императивные операторы
Наш простейший язык включает всего три оператора присваивания, каждый
из которых тем или иным образом модифицирует значение указанной в этом
операторе переменной. Первый оператор позволяет связать с именем переменной
строку двоичных нулей. Он имеет следующий синтаксис:
clear <имя>;
Здесь параметр <имя> может быть любым допустимым именем переменной.
Оставшиеся два оператора присваивания взаимно противоположны по
выполняемым действиям и имеют следующий синтаксис:
incr <имя>;
deer <имя>;
И в этом случае параметр <имя> представляет собой любое допустимое имя
переменной. Первый из представленных операторов выполняет увеличение
связанного с указанной переменной значения. Здесь термин увеличение (increment)
предполагает представление комбинации двоичных разрядов как числового
значения в двоичной системе счисления и означает замену этого значения другой
комбинацией битов, представляющей следующее по величине число. Например,
рассмотрим выполнение приведенного ниже оператора, полагая, что исходным
значением переменной Y является комбинация битов 101.
incr Y;
Поскольку к исходному значению переменной Y прибавляется единица, после
выполнения этого оператора с переменной Y будет связана комбинация битов 110.
В противоположность этому, оператор deer (decrement) используется для
уменьшения значения, связанного с указанной переменной, или, другими
словами, для уменьшения представленного ей значения на единицу. Исключением
11.1. Простейший язык программирования 565
является случай, когда связанное с переменной значение уже равно нулю. В
этом случае данный оператор не изменяет значения переменной. Рассмотрим
выполнение следующего оператора.
deer Y;
Если исходным значением переменной Y является комбинация битов 101, то
после выполнения данного оператора с переменной Y будет связана комбинация
битов 100. Если же до выполнения этого оператора с переменной Y было связано
нулевое значение, то оно останется неизменным и после его выполнения.
Наш простейший язык содержит всего одну управляющую структуру,
представленную парой операторов while-end, имеющей следующий синтаксис:
while <имя> not 0 do;
end;
Здесь параметр <имя> представляет собой любое допустимое имя переменной.
Указанная выше синтаксическая конструкция будет вызывать повторение любой
последовательности операторов, помещенных между операторами while и end, пока
значение переменной <имя> не станет равным нулю. Точнее говоря, когда в процессе
выполнения программы встречается структура while-end, то, прежде всего,
проверяется, равно ли нулю текущее значение переменной <имя>. Если это так, то вся
структура пропускается и начинается выполнение команд, следующих за оператором
end. Если же значение данной переменной отлично от нуля, то выполняется
последовательность операторов внутри блока while-end, после чего управление
возвращается оператору while, где вновь выполняется указанное сравнение. Отметим, что
ответственность за предупреждение зацикливания программы возлагается
исключительно на программиста, который в теле цикла должен явно описать действия,
необходимые для изменения значения его управляющей переменной. Например,
рассмотрим следующую последовательность операторов:
incr X;
while X not 0 do;
incr Z;
end;
Этот цикл будет выполняться бесконечно, поскольку значение переменной X
никогда не будет равно нулю. Этого нельзя сказать о следующей
последовательности операторов:
clear Z;
while X not 0 do;
incr Z;
deer X;
end;
Выполнение данного цикла обязательно завершится, причем в переменную Z
будет помещено исходное значение переменной X.
566 Глава одиннадцатая. Теория вычислений
Отметим, что операторы while и end всегда должны появляться парами,
причем оператор while должен предшествовать оператору end. Однако пара
операторов while-end может появиться и среди операторов, заключенных между
другой парой операторов while-end. В подобных случаях пары операторов
while-end формируются посредством просмотра текста программы от начала до
конца в том виде, как она написана. При этом каждый найденный оператор end
связывается с ближайшим предшествующим свободным оператором while.
Кроме того, хотя это и не является синтаксически необходимым, для улучшения
читабельности подобных структур обычно будут использоваться отступы.
Наконец, рассмотрим последовательность команд, представленную на
рис. 11.1. Она предназначена для вычисления произведения значений
переменных X на Y, которое присваивается переменной Z. Эта программа имеет
побочный эффект, заключающийся в уничтожении любого исходного значения
переменной X, отличного от нуля. (Исходное значение переменной Y
восстанавливается в структуре while-end, управляемой переменной W.)
РИСУНОК 11.1
- ^^ШШ'^рШ^^^^'Г^^- / :}< ;:"":"*?" Г' •-•-•• -—
clear Z;
while X not 0 do;
clear W;
while Y not 0 do;
incrZ;
incrW;
decrY;
end;
while W not 0 do;
incrY;
decrW;
end;
decrX;
end;
Программа перемножения значений переменных X и Y, написанная на простейшем языке
В заключение отметим, что программы, написанные на простейшем языке,
завершаются при достижении конца списка команд.
Возможности программ, написанных на простейшем языке
Хотя данный раздел посвящен созданию удобного языка программирования,
в действительности наша задача состоит в изучении того, что возможно, а не
того, что удобно. Использование нашего простейшего языка для каких-либо
прикладных целей, вероятно, весьма затруднительно. Однако в разделах 11.2 и 11.3
11.1. Простейший язык программирования 567
будет доказано, что этот простой язык вполне отвечает поставленной задаче —
реализации универсального языка программирования.
Языки, подобные нашему простейшему языку, хотя и непрактичны в
отношении создания прикладного программного обеспечения, но, тем не менее,
находят применение в теории вычислительных машин. Например, в приложении Д
данный простейший язык программирования использован в качестве
инструмента для решения рассмотренного в главе 4 вопроса об эквивалентности
итеративных и рекурсивных структур. В этом же приложении показано, что наше
исходное предположение об их эквивалентности является обоснованным.
А сейчас сказанное выше в отношении мощности простейшего языка мы
подкрепим демонстрацией его пригодности для выражения некоторых элементарных
операций. Прежде всего отметим, что посредством комбинирования выражений
присвоения с заданной переменной может быть связано практически любое значение
(любая битовая комбинация). Например, следующая последовательность операторов
присваивает битовую комбинацию 11 (двоичное представление числа 3) в качестве
значения переменной X, что достигается посредством обнуления ее предыдущего
значения и последующего троекратного увеличения:
clear X;
incr X;
incr X;
incr X;
Кроме того, еще одним типичным действием в программах является
перемещение данных из одного места в другое. В терминах простейшего языка это
означает возможность присвоения одной переменной значения, ранее присвоенного
другой. Эта операция может быть выполнена посредством предварительного
обнуления переменной назначения и последующего увеличения ее значения
соответствующее число раз. Фактически эти действия уже были реализованы в
рассмотренном выше примере:
clear Z;
while X not 0 do;
incr Z;
deer X;
end;
В результате выполнения данной последовательности операторов
переменной Z присваивается значение переменной X. Однако выполнение этой
последовательности операторов имеет побочный эффект, заключающийся в
уничтожении исходного значения переменной X. Во избежание этого введем
промежуточную переменную, в которую предварительно переместим пересылаемое значение
из его исходного положения. Затем используем эту промежуточную переменную
как источник данных для восстановления исходного значения с одновременным
присвоением того же значения целевой переменной. С помощью данного метода
перемещение значения переменной Tax (Налог) в переменную Extra (Наценка)
может быть выполнено с помощью последовательности операторов,
представленной на рис. 11.2.
568 Глава одиннадцатая. Теория вычислений
РИСУНОК 11.2 | . _^ _ w.y w ^^vtW№W_ ,..-,„,, . - „^
clear Aux;
clear Extra;
while Tax not 0 do;
incrAux;
deer Tax;
end;
while Aux not 0 do;
incrTax;
incr Extra;
deer Aux;
end;
Реализация на простейшем языке команды move Tax to Extra
Для сокращенного представления показанной на рис. 11.2
последовательности операторов мы можем принять следующий синтаксис:
move <имя 1> to <имя 2>;
Здесь параметры <имя 1> и <имя 2> представляют имена соответствующих
переменных. Таким образом, хотя простейший язык сам по себе и не имеет
явной команды присвоения, мы часто будем писать программы, полагая, что он
допускает подобные действия. При этом следует помнить, что для
преобразования подобной программы в текст на действительном простейшем языке следует
повсеместно заменить оператор move на эквивалентную структуру while-end,
обратив внимание на то, чтобы используемая в ней промежуточная переменная
больше нигде в программе не употреблялась.
Вопросы для самопроверки
1. Покажите, что оператор invert X; (устанавливающий значение переменной X
в нуль, если ее исходное значение отличалось от 0, или присваивающий ей
значение 1 в противном случае) может быть смоделирован программой на
простейшем языке.
2. Покажите, что даже наш простейший язык содержит больше операторов,
чем это действительно необходимо, продемонстрировав это на примере
замены команды clear комбинацией других операторов языка.
3. Покажите, что структура if-then-else может быть смоделирована на
простейшем языке, т.е. напишите программу, воспроизводящую действие
следующего выражения:
if X not 0 then <S1> else <S2>;
Здесь параметры <S1> и <S2> — произвольные последовательности операторов.
11.1. Простейший язык программирования 569
4. Покажите, что каждый из операторов простейшего языка может быть
выражен в терминах машинного языка, описанного в приложении В.
(Следовательно, наш простейший язык может быть использован в качестве
языка программирования для подобной машины.)
11.2. Машины Тьюринга
В разделе 11.1 утверждалось, что простейший язык программирования
является универсальным в том смысле, что с его помощью можно выразить решение
любой проблемы, которую способна решить машина. Более детально мы
поговорим об этом в разделе 11.3, а вначале ознакомимся с теми возможностями,
которые свойственны самим машинам.
Понятие машины Тьюринга
Рассмотрим класс вычислительных машин, известных как машины
Тьюринга. Впервые эти машины были введены в 1936 году Аланом Тьюрингом (Alan
Turing) как инструмент для изучения мощности алгоритмических процессов;
для этой цели они используются и по сей день. Отметим, что Тьюринг "изобрел"
данные машины еще до того, как развитие технологии позволило реализовать их
на практике. Таким образом, машина Тьюринга является скорее абстрактным
устройством, чем реальной машиной.
Машина Тьюринга состоит из блока управления, который считывает и
записывает символы на ленте с помощью головки считывания/записи (рис. 11.3).
Лента неограниченно простирается в обоих направлениях; она поделена на
ячейки, каждая из которых может содержать один произвольный символ из
конечного набора. Этот набор символов называется машинным алфавитом.
РИСУНОК 11.3
Компоненты машины Тьюринга
570
Глава одиннадцатая. Теория вычислений
В любой момент вычислений машина Тьюринга должна находиться в одном
из возможных положений (число которых конечно), называемых состояниями.
Вычисления машины Тьюринга начинаются в специальном состоянии,
называемом стартовым, и прекращаются, когда машина переходит в другое специальное
состояние, называемое состоянием останова.
Вычисления машины Тьюринга состоят из последовательности шагов,
выполняемых блоком управления. Каждый шаг включает считывание символа в
текущей ячейке ленты (находящегося под считывающей головкой), запись символа
в ту же ячейку, возможное перемещение головки в соседнюю ячейку слева или
справа с последующим изменением состояния. Конкретное выполняемое
действие зависит от программы, сообщающей блоку управления, что делать, исходя
из состояния машины и содержания текущей ячейки ленты.
Происхождение машин Тьюринга
Алан Тьюринг разработал модель своей машины еще в 1930-х годах — задолго до того, как развитие технологии
позволило изготовить те вычислительные машины, с которыми мы имеем дело сегодня. Фактически исходной
концепцией Тьюринга явилось представление о выполнении человеком вычислений с помощью карандаша и
бумаги. Целью работы Тьюринга являлась разработка модели, которая позволила бы изучать предельные возможности
"вычислительных процессов". Машина Тьюринга появилась вскоре после публикации в 1931 году знаменитой
статьи Геделя (Godel), демонстрирующей ограниченность вычислительных систем. В это время все усилия ученых-
исследователей были направлены на понимание этих ограничений. В том же 1936 году, когда Тьюринг представил
свою модель, Эмиль Пост (Emil Post) создал другую модель (в настоящее время известную как порождающая
система Поста), имеющую те же возможности, что и машина Тьюринга. Обе модели до сих пор используются в
качестве инструментов для изучения возможностей современной вычислительной техники, что служит доказательством
проницательности упомянутых исследователей.
Будучи по своей природе абстрактной, машина Тьюринга может быть
воплощена в разнообразных формах. Фактически все современные универсальные
вычислительные машины являются машинами Тьюринга (за исключением
конечности их памяти, в отличие от бесконечного запаса ленты в машине Тьюринга).
Центральный процессор таких машин — это блок управления, состояниями
которого являются различные битовые комбинации, назначаемые его регистрам.
Машинная память заменяет исходную ленточную систему хранения
информации, а алфавит компьютеров состоит из символов 0 и 1.
Подобное сходство между машинами Тьюринга и современными компьютерами
совсем не случайно. Целью Тьюринга было создание абстрактной машины,
представляющей самую суть вычислительного процесса. Именно по этой причине
современные компьютеры реализуют основные функции, определенные Тьюрингом.
Значение машин Тьюринга для современной теории вычислительных систем
состоит в предположении, что (согласно тезису Черча-Тьюринга, речь о котором
пойдет далее) вычислительная мощность машины Тьюринга выше, чем у любой
11.2. Машины Тьюринга 571
алгоритмической системы. Таким образом, хотя машина Тьюринга и предельно
проста в конструкции, она представляет теоретический предел возможностей
машин, существующих на практике. Следовательно, машина Тьюринга может
быть полезна в качестве инструмента для исследования ограничений,
свойственных как машинам, так и самим алгоритмическим процессам.
Конкретный пример машины Тьюринга
Давайте рассмотрим какой-либо конкретный пример машины Тьюринга. Для
этого представим ее машинную ленту как длинную полоску, поделенную на
ячейки, в которые можно записывать символы машинного алфавита. Текущее
положение машины будем отмечать специальным указателем над текущей
ячейкой. В нашем примере машинный алфавит будет состоять из символов 0, 1 и *.
Лента нашей машины может выглядеть следующим образом:
Интерпретируя строку символов на ленте машины как двоичное
представление чисел, разделенных звездочками, можно прийти к заключению, что данная
часть ленты содержит число 5. Назначение нашей машины Тьюринга состоит в
увеличении числа на ленте на единицу. Точнее говоря, предполагается, что в
стартовом положении головка находится над звездочкой, расположенной справа
от строки из нулей и единиц, а задача заключается в том, чтобы изменить
комбинацию битов, расположенную левее, так, чтобы она представляла собой
следующее по величине целое число.
Состояниями нашей машины являются START (Старт), ADD (Прибавить),
CARRY (Перенести), NO CARRY (He переносить), OVERFLOW (Переполнение),
RETURN (Возврат), HALT (Останов). Действия, относящиеся к каждому из этих
состояний, и содержание текущей ячейки описаны в таблице,
представленной на рис. 11.4. Будем предполагать, что в начале работы машина всегда
находится в состоянии START.
Запустим машину, установив на нее изображенную выше ленту, содержащую
число 5. Обратите внимание, когда в состоянии START текущая ячейка содержит
звездочку, инструкция в таблице требует записать в эту ячейку символ *,
переместить ленту на одну ячейку влево, а затем перевести машину в состояние ADD.
В результате возникает следующая ситуация:
572 Глава одиннадцатая. Теория вычислений
Состояния машины Тьюринга, предназначенной для увеличения числа
Для продолжения работы вновь заглянем в таблицу, чтобы узнать, что нужно
делать, когда машина находится в состоянии ADD, а в ячейке содержится
символ 1. Таблица указывает, что необходимо заменить символ 1 на 0, переместить
ленту на одну ячейку влево, а затем перевести машину в состояние CARRY.
Новая ситуация выглядит следующим образом:
Вновь обращаемся к таблице, чтобы узнать, что нужно делать, когда машина
находится в состоянии CARRY, а в текущей ячейке содержится символ 0.
Оказывается, что следует заменить символ 0 на 1, переместить ленту на одну ячейку
влево, а затем перевести машину в состояние NO CARRY. После выполнения
указанной последовательности действий получаем следующее состояние машины.
Далее, согласно таблице, следует заменить символ 1 в текущей ячейке на тот
же символ 1, после чего переместить ленту на одну ячейку влево, оставив
машину в прежнем состоянии NO CARRY. В результате мы получаем ситуацию,
показанную ниже:
11.2. Машины Тьюринга
573
В этом случае, согласно таблице, требуется перезаписать символ звездочки в
текущей ячейке, переместить ленту на один символ вправо и перевести машину
в состояние RETURN. Продолжая действовать аналогичным образом, мы на
каждом этапе оставляем машину в состоянии RETURN и перемещаем ленту вправо до
тех пор, пока не будет достигнуто следующее положение:
Согласно таблице, в этом положении следует перезаписать символ звездочки в
текущей ячейке и перевести машину в состояние HALT. В результате машина
завершает работу в следующем положении (теперь совокупность символов на ленте
представляет число б, что и требовалось получить):
В заключение отметим, что данный пример показывает, как машина
Тьюринга может выполнить действие, описываемое следующим оператором прЛ^ейшего
языка, описанного в разделе 11.1:
incr X;
Вопросы для самопроверки
1. Запустите в работу описанную выше машину Тьюринга, поместив ее ленту в
следующее исходное состояние:
2. Опишите машину Тьюринга, заменяющую строку нулей и единиц
единственным нулем.
3. Опишите машину Тьюринга, уменьшающую ненулевое значение на 1 и не
изменяющую значение, равное нулю.
4. Приведите примеры типичных ситуаций из повседневной жизни, в которых
требуется выполнение вычислений. Какую аналогию можно провести между
этими ситуациями и машиной Тьюринга?
574 Глава одиннадцатая. Теория вычислений
11.3. Вычислимые функции
Наша задача состоит в использовании машин Тьюринга для исследования
мощности описанного выше простейшего языка программирования. Однако
вначале требуется найти метод измерения вычислительной мощности. Понятие
вычислимых функций поможет нам в этом.
Функции и их вычисление
Рассмотрим действия компьютера на самом фундаментальном уровне. Если
можно было бы сделать снимки состояния памяти компьютера до и после
выполнения программы, то мы бы увидели один набор двоичных разрядов,
соответствующий состоянию памяти до ее выполнения, а другой — после ее
выполнения. Таким образом, фактически программа выполняет единственное
действие: управляет преобразованием некоторого исходного набора двоичных
разрядов, который будем называть входным, в другой набор двоичных разрядов,
именуемый выходным. Связь, существующая между этими наборами,
называется функцией. Многие функции употребляются настолько часто, что им даны
собственные названия, например сложение (эта функция связывает каждую
входную пару значений с выходным значением, равным их сумме), умножение
(также имеет дело с парой входных величин, но выходное значение в этом
случае равно их произведению) или функция следования (на выход передается
значение, на единицу большее входного).
Процесс определения выходной величины функции на основе значения ее
входной величины называется вычислением функции. Следовательно, действия
компьютера при выполнении программы могут рассматриваться как вычисление
функции. Такое понимание процесса вычислений предоставляет нам средство
для измерения вычислительной мощности машины или, в итоге, любой
вычислительной системы. Необходимо просто определить набор функций, которые
данная система способна вычислить, и использовать объем этого набора в
качестве меры. Если некоторая машина или алгоритмическая система способна
вычислять больше функций, нежели другая, то мы будем считать ее более мощной.
Например, рассмотрим систему, в которой выходные значения функции
определены заранее и записаны в таблицу вместе с соответствующими им входными
значениями. Всякий раз, когда требуется найти значение функции, мы просто
находим входную величину в таблице и определяем соответствующее ей
выходное значение. Подобные системы удобны, но их возможности ограничены,
поскольку множество функций не может быть представлено в табличном виде.
Пример подобной функции приведен на рис. 11.5, где сделана попытка
отобразить функцию следования. Поскольку ограничений для списка возможных пар
значений на входе и выходе не существует, то и закончить заполнение таблицы
невозможно. Функцию сложения ожидает та же участь — невозможно
отобразить в таблице все ее допустимые входные и выходные значения.
11.3. Вычислимые функции 575
РИСУНОК 11.5
Функция следования
Иной подход к определению выходных значений функций заключается в
описании способа вычисления выходного значения, а не в попытке отображения
всех возможных комбинаций ввода/вывода в таблице. Например, для описания
связи между входными и выходными значениями многих функций могут
использоваться алгебраические формулы. Для описания функции, выходное
значение которой определяет доход за п лет от вложения суммы Р при процентной
ставке г, можно использовать следующую формулу:
V = P(l+r)n
Вместо представления всех возможных результатов в табличной форме эта
формула описывает, как можно вычислить интересующее значение. Подобным
образом можно описать и функцию следования:
Выход = Вход + 1
Однако выразительная мощность алгебраических формул также имеет свой
предел. Существуют функции, в которых взаимосвязь между входными и выходными
значениями настолько сложна, что не может быть описана посредством
алгебраических манипуляций с входными значениями. Типичным примером являются
тригонометрические функции, такие как синус и косинус. Если требуется вычислить
синус угла в 38 градусов, то следует нарисовать соответствующий треугольник,
измерить его стороны и вычислить требуемое отношение; это процесс, не имеющий
выражения в терминах алгебраических действий с числом 38. Тем не менее любой
карманный калькулятор успешно решает проблему вычисления синуса угла в 38
градусов. Однако фактически в этом случае изощренные математические методы
применяются для получения лишь очень хорошего приближения к значению синуса
угла в 38 градусов, которое и выдается в качестве ответа.
Как видите, по мере рассмотрения функций, в которых соотношения между
входными и выходными величинами становятся все более и более сложными, необ-
576 Глава одиннадцатая. Теория вычислений
ходимо применять все более и более сложные алгоритмы вычисления этих
отношений и соответственно искать все более мощные методы описания этих алгоритмов.
Поразительным результатом математических исследований является
обнаружение существования такого класса функций, в которых отношения между
входными и выходными величинами настолько сложны, что не существует
четкого пошагового процесса определения значения функции по значению заданной
входной величины. Таким образом, существуют функции, для которых
отношения между входными и выходными величинами не могут быть определены
никаким алгоритмическим методом. Эти функции называются невычислимыми, в
отличие от вычислимых, выходные значения которых могут быть
алгоритмически определены на основании их входных значений.
Поскольку не существует алгоритмического метода для нахождения
выходных значений невычислимых функций, то эти функции находятся вне пределов
возможностей как современных, так и будущих компьютеров. Вспомните,
прежде чем машина сможет выполнить задание, необходимо найти алгоритм его
выполнения. Следовательно, понимание границы между вычислимыми и
невычислимыми функциями равнозначно пониманию ограничений, свойственных любым
компьютерам в принципе. Тезис Черча-Тьюринга представляет собой важный
шаг в направлении определения этих границ.
Тезис Черча-Тьюринга
Выше было показано, что для описания отношений между входными и
выходными величинами всех вычислимых функций недостаточно конечных по
размеру таблиц и алгебраических формул. Например, утверждалось, что
тригонометрические функции не могут быть описаны ни одним из этих двух методов.
Алан Тьюринг разработал концепцию своей машины для определения
простейшей среды, в которой могут быть описаны все вычислимые функции.
Еще раз обратимся к примеру машины Тьюринга, описанному в разделе 11.2. Эта
машина может быть использована для определения значения функции следования.
Для этого достаточно поместить на ленту входное значение, представленное в
двоичной форме, запустить машину в работу и, дождавшись ее останова, считать с ленты
полученное выходное значение. Другими словами, описанная в разделе 11.2 машина
Тьюринга позволяет вычислять выходные значения функции следования. Функция,
выходные значения которой могут быть вычислены с помощью подобной машины
Тьюринга, называется вычислимой по Тьюрингу.
Гипотеза Тьюринга заключалась в тождественности понятий функции,
вычислимой по Тьюрингу, и просто вычислимой функции. Иными словами, он
предположил, что вычислительная мощность машин Тьюринга не уступает
мощности любых алгоритмических систем. Это эквивалентно тому, что (в отличие от
подходов, использующих таблицы или алгебраические формулы) концепция
машины Тьюринга предоставляет среду, в которой могут быть описаны все
вычислимые функции. В наше время эта гипотеза обычно упоминается как тезис
Черча-Тьюринга, в честь Алана Тьюринга и Алонзо Черча (Alonzo Church). С
момента выхода основополагающей работы Тьюринга было собрано множество
11.3. Вычислимые функции 577
фактов в поддержку этого тезиса, и сейчас тезис Черча-Тьюринга можно считать
принятым широкими научными кругами. Поэтому мы можем утверждать, что
вычислимые функции и функции, вычислимые по Тьюрингу, следует
рассматривать как эквивалентные понятия.
Важность этой гипотезы состоит в том, что она предоставляет конкретный
подход к оценке возможностей и ограничений, свойственных вычислительной
технике. Более точно, она устанавливает набор вычислимых по Тьюрингу
функций в качестве пробного набора, с помощью которого сравнивается
вычислительная мощность различных вычислительных систем. Если вычислительная
система способна вычислить все вычислимые по Тьюрингу функции, то она
рассматривается как универсальная система.
Универсальность простейшего языка
В качестве примера значения тезиса Черча-Тьюрига применим его для
подтверждения сделанного выше заявления о том, что наш простейший язык является
универсальным языком программирования. Прежде всего отметим, что любая
программа, написанная на этом языке, может рассматриваться как вычисление значений
функции. Входные значения функции представляют собой те числовые величины,
которые были присвоены определенным переменным до выполнения программы, а
выходными значениями являются числовые значения определенных переменных
программы после завершения ее выполнения. Для вычисления функции мы просто
выполняем программу, предварительно позаботившись о том, чтобы входные
переменные содержали требуемые значения, а затем считываем значения выходных
переменных, которые они будут иметь после останова программы.
Рассмотрим в этом контексте следующую программу:
incr X;
Ее выполнение приводит к вычислению той же функции (функции
следования), которая вычисляется машиной Тьюринга, описанной в разделе 11.2.
Действительно, она увеличивает помещенное в переменную X значение на единицу.
Аналогичным образом мы можем рассматривать содержимое переменных X и Y в
качестве входных значений, а конечное содержимое переменной Z — как
выходное значение для следующей программы:
move Y to Z;
while X not 0 do;
incr Z;
deer X;
end;
Нетрудно убедиться, что эта программа реализует функцию сложения.
Таким образом, мы видим, что наш простейший язык программирования может
быть использован для описания связи между входными и выходными значениями
функций. В действительности проведенные исследования показали, что этот
простейший язык программирования может быть использован для описания абсолютно
всех функций, значения которых могут быть вычислены машинами Тьюринга.
578 Глава одиннадцатая. Теория вычислений
Данная эквивалентность — это именно то, что нужно для полного
решения поставленной в разделе 11.1 проблемы создания простого, но мощного
языка программирования. Поскольку любая вычислимая по Тьюрингу
функция может быть вычислена с помощью программы, написанной на нашем
простейшем языке, то (согласно тезису Черча-Тьюринга) с помощью
написанной на этом языке программы может быть вычислена любая вычислимая
функция. Таким образом, наш простейший язык программирования является
универсальным в том смысле, что если алгоритм для решения задачи
существует, то эта задача может быть решена с помощью программы на
простейшем языке. Иными словами, теоретически наш простейший язык может
служить в качестве универсального языка программирования.
Мы говорим теоретически, поскольку данный язык, безусловно, не
настолько удобен, как языки высокого уровня, описанные в главе 5. Тем не менее
каждый из этих языков в качестве своего ядра непременно содержит все функции,
входящие в состав нашего простейшего языка. Фактически именно это ядро
обеспечивает универсальность каждого языка, все же прочие функции
различных языков включены в них исключительно для удобства.
Вопросы для самопроверки
1. Приведите несколько функций, выходное значение которых может быть
описано как алгебраическое преобразование их входного значения.
2. Приведите пример функции, которая не может быть описана в терминах
алгебраических формул. Является ли ваша функция вычислимой?
3. Охарактеризуйте функцию, вычисляемую приведенной ниже программой на
простейшем языке, предполагая, что входным значением является
переменная X, а выходным — переменная Z.
clear Z;
while X not 0 do;
incr Z;
incr Z;
deer X;
end;
4. Опишите машину Тьюринга, которая обязательно завершит свою работу для
одних входных значений, но никогда не остановится при других входных
значениях.
11.4. Невычислимые функции
В этом разделе мы ознакомимся с функцией, невычислимой по Тьюрингу,
которая, согласно тезису Черча-Тьюринга, является невычислимой и в общем смысле.
11.4. Невычислимые функции 579
Небольшое вступление
Предстоящее знакомство с невычислимой функцией требует предварительного
введения двух дополнительных понятий. Первым является геделевская
нумерация, представляющая собой метод, первоначально используемый Куртом Геде-
лем (Kurt Godel) для назначения уникальных неотрицательных целых чисел
каждому из объектов набора. В работе Геделя объектами были формулы и
доказательства. В нашем случае объектами будут программы, написанные на
простейшем языке. Система Геделя базируется на особенностях простых чисел и
является более сложной, чем та, которая нам сейчас необходима. Для наших целей
достаточно процесса, обобщенно представленного на рис. 11.6. Любую
программу, написанную на нашем простейшем языке, мы прежде всего будем
рассматривать как одну большую строку символов (в которой команды разделяются
точкой с запятой). Далее представим каждый символ как комбинацию битов,
соответствующую его ASCII-коду. В результате каждая программа будет иметь вид
длинной строки из нулей и единиц, что может быть интерпретировано как
(достаточно большое) число в двоичной системе счисления.
| РИСУНОК 11.6 | _
Программа на ?.
Clear X ; простейшем языке '<
oiioooii 01101Ю0 01100Ю1 oiiooooi ошоою ооюоооо 0101Ю00 00Ш011 Программа
в кодах ASCII
2,114,075,508,630,810,683 Эквивалентное представление
: в десятичной системе счисления :
Вычисление геделевского номера программы на простейшем языке
В нашем случае не имеет значения, как именно были получены
положительные числа, связанные с конкретными программами на простейшем языке, — с
помощью описанного выше процесса или посредством метода самого Геделя.
Важным является сама возможность подобной связи между числами и
программами. Определив эту возможность, продолжим наши рассуждения, полагая, что
требуемое соответствие было установлено. Более того, мы будем называть
связанное с данной программой число ее геделевским номером.
Второй необходимой нам концепцией является понятие
самоостанавливающейся программы. Для введения этого понятия рассмотрим следующую
программу на простейшем языке:
580 Глава одиннадцатая. Теория вычислений
while X not 0 do;
incr X;
end;
Если мы начнем выполнение этой программы с исходным значением
переменной X, равным 0, то цикл выполняться не будет и программа сразу же
остановится. Однако если мы начнем выполнение программы при любом другом
исходном значении переменной X, то цикл будет выполняться вечно и эта
программа никогда не остановится.
Теперь отметим, что написанная на простейшем языке программа должна
содержать имя хотя бы одной переменной. Поскольку имя каждой
переменной представляет собой строку из буквенных символов, все переменные
данной программы всегда могут быть упорядочены по алфавиту. В соответствии
с этим, мы можем говорить о первой переменной программы. Будем считать,
что программа является самоостанавливающейся, если она обязательно
остановится в случае ее запуска с исходным значением в первой переменной,
равным значению геделевского номера этой программы, а все ее остальные
переменные будут иметь исходное значение 0. (Отметим, что подобное
использование программы, вероятно, не имеет никакого отношения к задаче,
для решения которой она писалась.) Любая написанная на простейшем
языке программа является либо самоостанавливающейся, либо не
самоостанавливающейся.
Например, приведенная выше программа не является
самоостанавливающейся. Мы точно знаем, что геделевский номер этой программы не равен
нулю. Поэтому если переменной X присвоить значение геделевского номера
данной программы, то выполнение входящего в нее цикла никогда не
прекратится.
В сущности, программа будет самоостанавливающейся тогда и только
тогда, когда она обязательно остановится при запуске с использованием в
качестве входной величины самой себя. Таким образом, понятие
самоостанавливающейся программы включает в себя концепцию самоотносимости, когда
объект ссылается на самого себя. Эта уловка часто приводила к
поразительным результатам в математике, начиная с информационных курьезов,
подобных выражению "Это утверждение неверно", до более серьезных
парадоксов, представленных вопросом "Содержит ли набор всех наборов сам себя?".
Таким образом, то, чего мы достигли благодаря введению концепции
самоостанавливающихся программ, заключается в создании фундамента для
следующей логической цепочки: "Если это верно, то это неверно; но если это
неверно, то это верно", речь о которой пойдет чуть ниже.
Проблема остановки
Теперь мы вплотную подошли к определению функции, которая является
невычислимой. Эта функция связывает с геделевским номером программы на
простейшем языке (входная величина) значение 1 или 0 (выходная величина
функции), в зависимости от того, является ли данная программа самооста-
11.4. Невычислимые функции 581
навливающейся или нет. Точнее говоря, мы определяем эту функцию так,
что геделевский номер самоостанавливающейся программы дает на выходе
значение 1, а геделевский номер несамоостанавливающейся программы —
значение 0. Проблема вычисления данной функции фактически представляет
собой проблему определения, остановится ли данная программа после ее
запуска из некоторого конкретного начального состояния. Поэтому обычно она
упоминается как проблема остановки.
Наша задача состоит в том, чтобы показать, что представленная выше
функция является невычислимой. Доказательство проведем методом от противного,
т.е. покажем, что исходное предположение о вычислимости данной функции
приводит к противоречию, вследствие чего мы будем вынуждены сделать вывод
о ее невычислимости.
В соответствии с процедурой, представленной на рис. 11.7, предположим,
что данная функция является вычислимой. А это означает, что должна
существовать написанная на простейшем языке программа, которая позволяет
вычислять значения данной функции. Другими словами, должна
существовать программа, которая останавливается с выходным значением 1, если ее
входное значение равно геделевскому номеру самоостанавливающейся
программы, и выходным значением 0 в противном случае. Предположим, что
переменные в этой программе названы так, что входная переменная является
первой по алфавиту; иначе мы сможем просто переименовать переменные
программы для достижения этого свойства.
Теперь изменим эту программу посредством добавления в ее конец
следующих операторов:
while X not 0 do;
end;
В результате будет получена новая программа, которая должна быть или
самоостанавливающейся, или не самоостанавливающейся. Однако в
действительности, как мы скоро увидим, она не может быть ни той ни другой. В
частности, если эта новая программа самоостанавливающаяся и мы запустим ее
с ее собственным геделевским номером в качестве входного значения, то
выполнение этой программы дойдет до добавленной нами команды while со
значением переменной X, равным 1. (До этого момента новая версия
программы идентична исходной программе, которая выдавала 1 в том случае,
если в качестве входного значения ей указывался геделевский номер любой
самоостанавливающейся программы.) Но в этой точке выполнение
программы зациклится, поскольку структура while-end не позволяет уменьшать
значение переменной X в теле цикла. Однако это противоречит нашему
исходному предположению о том, что новая программа является
самоостанавливающейся. Следовательно, мы приходим к заключению, что данная
программа не является таковой.
582 Глава одиннадцатая. Теория вычислений
В то же время, если новая версия программы не является
самоостанавливающейся и мы начнем ее выполнение с ввода ее собственного геделевского
номера, она подойдет к добавленному нами оператору while со значением
переменной X, равным 0. (Это произойдет вследствие того, что команды,
предшествующие оператору while, составляют исходную программу, которая даст на
выходе 0 только в том случае, если данная программа не является
самоостанавливающейся.) В этом случае цикл while-end будет просто проигнорирован, и
программа завершит свое выполнение. Но это является свойством
самоостанавливающихся программ, и мы вынуждены заключить, что наша новая программа
самоостанавливающаяся, подобно тому, как ранее мы были вынуждены
признать ее не самоостанавливающейся.
Подведем итоги. Мы видим, что имеет место невозможная ситуация, когда, с
одной стороны, программа должна быть или самоостанавливающейся, или нет, а
с другой стороны, она не может быть ни той ни другой. Следовательно, наше
исходное предположение привело к противоречию. Другими словами,
рассматриваемая функция является невычислимой.
В результате мы показали, что существует функция, не являющаяся
вычислимой по Тьюрингу и, следовательно (согласно тезису Черча-Тьюринга),
являющаяся невычислимой вообще. В заключение можно сказать, что проблема
остановки является примером неразрешимой задачи, а это означает, что ее
решение требует нахождения выходных значений невычислимой функции и, как
следствие, находится за пределами возможностей вычислительной техники.
И наконец, рассмотрим вопрос, уже обсуждавшийся в главе 10. Это главный
основополагающий вопрос о том, достаточно ли мощности вычислительных машин для
удовлетворения требований, выдвигаемых задачей создания искусственного
интеллекта. Теперь мы видим, что возможности вычислительных машин ограничены и
что это не может быть устранено чисто технологическими методами. Машины
способны решать только такие задачи, которые имеют алгоритмическое решение.
Следовательно, вопрос сводится к тому, воплощает ли естественный интеллект нечто
большее, нежели просто выполнение исключительно алгоритмических процессов.
Излишне говорить, что сейчас эта проблема обсуждается достаточно интенсивно,
причем в некоторых случаях даже весьма эмоционально.
Вопросы для самопроверки
1. Какой геделевский номер, согласно описанной выше технологии, должен
быть связан со следующей программой на простейшем языке?
incr X;
2. Является ли программа "incr X; deer Y;" самоостанавливающейся?
3. Что неверно в следующем сценарии?
В некотором государстве каждый имеет собственный дом. Маляр государства должен покрасить
все те и только те дома, которые не выкрашены их хозяевами.
(Подсказка. Кто покрасит дом самого маляра?)
11.4. Невычислимые функции 583
Доказательство неразрешимости проблемы остановки программным путем
584
Глава одиннадцатая. Теория вычислений
РИСУНОК 11.7, б
Доказательство неразрешимости проблемы остановки программным путем (продолжение)
11.4. Невычислимые функции
585
11.5- Сложность задач
В разделе 11.4 мы исследовали проблемы в терминах их разрешимости. В
данном разделе мы остановимся на вопросе, всегда ли разрешимая задача имеет
практическое решение. Ниже будет показано, что некоторые проблемы,
теоретически имеющие решение, оказываются настолько сложными, что фактически
являются неразрешимыми с практической точки зрения.
Измерение сложности задачи
Начнем с повторного рассмотрения проблемы эффективности алгоритмов,
поднятой в разделе 4.6. В этом разделе для классификации алгоритмов в зависимости от
времени, необходимого для их выполнения, мы ввели нотацию с использованием
прописной буквы тета (0). Там же было обнаружено, что алгоритм сортировки
вставками относится к классу 0(п2), алгоритм последовательного поиска — к классу
0(п), а алгоритм двоичного поиска — к классу 0(lg n). Здесь мы будем использовать
эту систему классификации как средство, которое поможет нам при определении
сложности задач. В данном случае мы должны построить систему классификации,
которая укажет нам, какая задача является более сложной, и, в конце концов,
поможет установить, что решение определенной задачи настолько сложно, что
находится за пределами имеющихся практических возможностей.
Причина того, что данное исследование основывается на наших знаниях об
эффективности алгоритмов, заключается в намерении измерять сложность
задачи в терминах сложности ее решения. Будем считать задачу простой, если она
имеет простое решение, а сложной будем называть такую задачу, для которой
простого решения не существует. Отметим, что сам факт существования
сложного решения некоторой задачи не означает, что эта задача обязательно сложная.
В конце концов, для одной и той же задачи, как правило, существует много
решений. Поэтому, чтобы прийти к заключению, что некоторая задача является
сложной, необходимо доказать, что для нее не существует простых решений.
В область интересов компьютерных наук попадают только те задачи, которые
могут быть решены с помощью машин. Решения подобных задач
формулируются как алгоритмы. Поэтому сложность задачи определяется свойствами
алгоритма, позволяющего найти ее решение. Точнее говоря, сложность простейшего
алгоритма решения некоторой задачи определяет сложность этой задачи.
Но как можно измерить сложность алгоритма? К сожалению, термин сложность
может трактоваться по-разному. Сложность может определяться количеством
принятых решений и разветвлений алгоритма. В данном случае сложным будет считаться
алгоритм, представляющий собой набор запутанных и переплетающихся между
собой указаний. Подобная трактовка может быть совместима с точкой зрения
разработчика программного обеспечения, для которого наибольший интерес представляют
вопросы разработки и отображения алгоритмов. Однако это не отражает понятия
сложности с точки зрения машины. На самом деле при выборе следующей выпол-
586 Глава одиннадцатая. Теория вычислений
няемой инструкции машина не принимает никаких решений, а просто повторяет
свой машинный цикл снова и снова, каждый раз выполняя инструкцию, указанную
значением счетчика адреса. Поэтому машина может выполнять самый запутанный
набор инструкций с той же легкостью, что и серию последовательно расположенных
команд. Следовательно, данная интерпретация оценивает скорее уровень сложности,
с которым приходится сталкиваться при разработке алгоритма, а не уровень
сложности алгоритма самого по себе.
Пространственная сложность
Сложность задачи может определяться не только с помощью оценки времени, необходимого для ее решения, но и
с помощью оценки объема требуемой машинной памяти. Данный метод носит название пространственной
сложности. В тексте раздела мы видели, что временная сложность упорядочения списка из п наименований
равна O(n lgn). Пространственная сложность этой же задачи не больше О(п+1)=О(п). Действительно, если для
упорядочения такого списка применяется сортировка методом вставки, то это потребует пространства, равного
объему списка, плюс пространство для временного хранения одной строки. Таким образом, если последовательно
сортировать все большие и большие по размеру списки, можно обнаружить, что время, требуемое для
выполнения кавдого следующего задания, растет намного быстрее, чем объем требуемого для его выполнения
пространства. В действительности это вполне закономерное явление. Поскольку на использование пространства требуется
некоторое время, то пространственная сложность никогда не будет расти быстрее временной.
Обычно используется компромисс между временной и пространственной сложностью. В некоторых
приложениях может оказаться полезным предварительное выполнение определенных вычислений и запоминание их
результатов в таблице, из которой впоследствии, при необходимости, они могут быть быстро извлечены.
Подобная техника "табличного поиска" сокращает время, необходимое для решения задач, за счет увеличения
пространства, необходимого для размещения таблицы. Однако для уменьшения объема используемой памяти
часто применяется сжатие данных, что всегда связано с дополнительными затратами времени.
Трактовка, более точно отражающая сложность алгоритма, может быть получена
при анализе свойств алгоритмов с машинной точки зрения. В этом контексте
сложность алгоритма измеряется в терминах необходимого для его выполнения времени,
которое, в свою очередь, пропорционально количеству действий, совершаемых
машиной. Отметим, что это количество действий вовсе не равно числу инструкций,
записанных в тексте программы. Например, цикл, тело которого в распечатке состоит
из единственной инструкции вывода на печать, а выполнение которого стократно
повторяется, при работе программы равносилен сотне отдельных инструкций вывода
на печать. Значит, подобная программа будет считаться более сложной, чем набор из
50 отдельных операторов вывода на печать, хотя в последнем случае текст
программы будет существенно длиннее. В конечном итоге данный подход к измерению
сложности задачи связан со временем, затрачиваемым машиной на ее решение, а не
с объемом программы, представляющей это решение. Задача считается сложной,
если все ее существующие решения требуют больших затрат времени. Данное понятие
сложности обычно называют временной сложностью.
11.5. Сложность задач 587
Именно на этом этапе приобретают важность результаты анализа
эффективности алгоритмов, проведенного нами ранее. Изучение эффективности
алгоритмов представляет собой анализ их временной сложности, однако результаты
обоих процессов абсолютно противоположны. Если алгоритм класса 0(lgn) более
эффективен, чем алгоритм класса 0(п), то алгоритм класса 0(п) является более
сложным, чем алгоритм класса 0(lgn). Так, в терминах временной сложности
последовательный алгоритм поиска является более сложным решением задачи
поиска значения в списке, чем двоичный поиск, хотя студенты часто находят
последний более трудным для понимания.
Теперь рассмотрим классификацию задач соответственно их временной
сложности. Определим, что (временная) сложность задачи равна 0(f(n)), где f(n) — некоторое
математическое выражение, зависящее от п, если существует алгоритм решения
задачи с временной сложностью 0(f(n)) и не существует алгоритма для решения этой
задачи с большей временной эффективностью. Иными словами, (временная)
сложность задачи определяется как (временная) сложность лучшего из ее решений. К
сожалению, нахождение лучшего решения и доказательство, что найденное решение
действительно является лучшим, само по себе является сложной задачей. В
подобной ситуации для представления известных сведений о сложности задачи часто
используется О-нотация (разновидность 0-нотации). Точнее говоря, если f(n) является
математическим выражением, зависящим от п, и задача может быть решена с
помощью алгоритма класса 0(f(n)), то мы говорим, что наша задача есть "о большое от
f(n)", что записывается как O(f(n)). Таким образом, то, что задача принадлежит к
классу O(f(n)), равносильно утверждению о существовании ее решения (не
обязательно лучшего), сложность которого равна 0(f(n)).
Выполненные нами ранее исследования задач поиска и сортировки
показывают, что задача поиска в списке из п строк (при этом наши знания о списке
исчерпываются тем, что он был предварительно упорядочен) имеет сложность
O(lg n), поскольку алгоритм двоичного поиска позволяет решить данную
проблему. Более того, эти исследования показали, что проблема поиска действительно
принадлежит к классу 0(lg n), так что алгоритм двоичного поиска представляет
собой оптимальное решение данной проблемы. В то же время мы знаем, что
проблема упорядочения такого списка (когда мы не имеем никакой информации о
расположении его элементов) имеет сложность не более О(п2), поскольку
алгоритм сортировки методом вставки позволяет решить данную задачу. Однако, как
показывают исследования, проблема сортировки в действительности относится к
классу 0(n lg n), а отсюда следует, что алгоритм сортировки методом вставки не
является лучшим решением этой задачи (в терминах временной сложности).
Примером лучшего решения данной проблемы является алгоритм сортировки
слиянием. Данный подход заключается в многократном слиянии маленьких
упорядоченных частей списка (при этом каждый раз образуются упорядоченные списки
большего размера) до тех пор, пока весь список не будет правильно отсортирован. В
каждом отдельном процессе слияния используется алгоритм слияния, с которым мы
познакомились при обсуждении обработки последовательных файлов (см. рис. 8.2).
588 Глава одиннадцатая. Теория вычислений
Для удобства мы вновь приводим этот алгоритм (рис. 11.8), но теперь уже в
контексте слияния двух списков. Полный (рекурсивный) алгоритм сортировки методом
слияния представлен на рис. 11.9 как процедура MergeSort. При вызове этой
процедуры для упорядочения некоторого списка она сначала проверяет, сколько
позиций имеет список. Если меньше двух, то задача процедуры считается выполненной.
В противном случае список делится на две части и вызываются копии этой же
процедуры MergeSort для сортировки полученных частей, после чего отсортированные
части сливаются для получения полностью упорядоченного списка.
I РИСУНОК 11.8
procedure MergeUsts (<входной список А>, <входной список В>,
<выходной список >)
if (оба входных списка пусты) then (завершить работу, причем <выходной список> пуст)
if (<входной список А> пуст)
then (объявить его оконченным)
else (объявить его первый элемент текущим)
if (<входной список В> пуст)
then (объявить его оконченным)
else (объявить его первый элемент текущим)
while (ни один из входных списков не окончен) do
(поместить в <выходной список> текущую запись с "меньшим" значением
поля ключа;
if (эта текущая запись является последней в соответствующем
входном списке)
then (объявить этот входной список оконченным)
else (объявить следующую запись этого входного списка текущей)
)
Начиная с текущей записи списка, который еще не окончен, копировать
оставшиеся записи в <выходной список>.
Процедура MergeLJst для слияния двух списков
Для анализа сложности представленного алгоритма рассмотрим, сколько
сравнений необходимо провести между элементами при слиянии списков длиной
гиб. Процесс слияния происходит путем сравнения элемента из одного списка с
элементом из другого и помещения в выходной список меньшего из них.
Поскольку на каждом этапе выполняется одно сравнение, общее число еще не
рассмотренных элементов каждый раз уменьшается на единицу. Так как в двух
списках имеется всего г + s элементов, то можно сделать вывод, что для слияния
этих двух списков потребуется не более г + s сравнений.
Теперь рассмотрим алгоритм сортировки методом слияния в целом. В нем задача
сортировки списка длиной п решается таким образом, что исходная задача
распадается на две меньшие, каждая из которых заключается в упорядочении списка
длиной приблизительно п/2. Эти две задачи, в свою очередь, разбиваются на четыре
задачи сортировки списков длиной приблизительно п/4. Подобный процесс разделения
11.5. Сложность задач 589
может быть обобщен в виде древовидной структуры (рис. 11.10). Здесь каждый узел
дерева представляет собой отдельную задачу рекурсивного процесса, а отходящие от
узла ветви — меньшие задачи, порожденные родительской. Эта структура позволяет
нам определить общее число сравнений, необходимых для процесса сортировки
полного списка. Очевидно, что эта величина представляет собой сумму всех сравнений,
выполняемых в каждом узле дерева.
| РИСУНОК 11,9
РИСУНОК 11.10
Иерархическое представление множества задач, порожденных алгоритмом сортировки методом слияния
Прежде всего определим число сравнений, выполняемых на каждом уровне
дерева. Отметим, что каждый узел дерева представляет собой задачу
упорядочения уникальной части исходного списка. Эта операция выполняется с помощью
500
Глава одиннадцатая. Теория вычислений
процедуры слияния уже упорядоченных списков и, следовательно, требует не
больше операций сравнения, чем имеется строк в объединяемых списках, как
было показано выше. Таким образом, выполнение операций слияния на каждом
уровне дерева не требует больше операций сравнения, чем общее количество
строк во всех частях списках. Но поскольку каждый уровень состоит из
процедур сортировки частей расчлененного исходного списка, общее число сравнений
будет не больше полной длины исходного списка. Поэтому на каждом уровне
дерева выполняется не более п сравнений. (Кроме того, следует учесть, что самый
нижний уровень дерева связан с обработкой списков, длина которых составляет
одну или нуль строк, а потому вообще не требует выполнения сравнений.)
Теперь определим число уровней дерева. Предварительно отметим, что
процесс разделения задач на меньшие составляющие будет продолжаться до тех
пор, пока не будут получены списки длиной меньше двух элементов. Таким
образом, количество уровней дерева определяется числом операций деления списка
на два подсписка, выполняемых до тех пор, пока список начальной длины п не
превратится в величину, не превосходящую 1. Количество таких операций равно
lg n, или, более точно, [lgn], где запись [lgn] означает округление точного
значения lg n до следующего целого числа.
В результате общее число операций сравнения, выполняемых алгоритмом
сортировки методом слияния при упорядочении списка длиной п, определяется как
результат умножения числа сравнений, производимых на каждом уровне дерева, на
общее количество уровней. Таким образом, можно заключить, что это число
сравнений будет не больше n[lgn]. Поскольку график n[lgn] имеет такое же поведение, как
и n lg п, можно принять окончательное решение, что алгоритм сортировки методом
слияния относится к классу O(n lg n). Сравнив полученный результат с доказанным
математиками утверждением о том, что задача сортировки списка относится к
классу 0(n lg n), можем сказать, что алгоритм сортировки методом слияния представляет
собой оптимальное решение задачи сортировки.
Задачи полиномиального и неполиномиального типов
Предположим, что f(n) и g(n) — это математические выражения. Тогда
утверждение, что функция g(n) ограничивает функцию fl(n), означает, что при
возрастании аргумента п значение функции f(n) непременно окажется больше значения
функции g(n) и будет оставаться большим при дальнейшем возрастании
аргумента п. Другими словами, выражение "функция g(n) ограничивает функцию f(n)"
означает, что график функции f(n) для больших значений п находится над
графиком функции g(n). Например, функция lgn ограничена функцией п
(рис. 11.11, а), а функция nlgn — функцией п2 (рис. 11.11, б). Будем говорить,
что задача относится к полиномиальному типу, если она принадлежит классу
O(f(n)), где функция f(n) либо сама является полиномом, либо ограничивается
некоторым полиномом. Совокупность всех задач полиномиального типа тради-
11.5. Сложность задач 591
ционно обозначается как Р. Отметим, что выполненные нами выше исследования
показывают, что задачи поиска в списке и упорядочения списка относятся к Р.
| РИСУНОК 11,11 |
Графики основных типов математических функций -
Утверждение о том, что задача относится к полиномиальному типу, связано
со временем, необходимым на ее решение. Часто говорится, что задача,
принадлежащая Р, может быть решена за полиномиальное время, или же, что то же
самое, имеет полиномиальное временное решение.
Определение принадлежности задачи к множеству Р является достаточно важным
моментом в программировании, поскольку это тесно связано с существованием
практического решения задачи. И действительно, задачи, не принадлежащие к
множеству Р, характеризуются крайне высоким временем выполнения даже при обработке
умеренного объема входных данных. Например, рассмотрим задачу, решение
которой состоит из 2П шагов. Степенная функция 2П не ограничивается никаким
полиномом; если f(n) является полиномом, то при увеличении значения аргумента п мы
обнаружим, что значение функции 2П всегда больше соответствующего значения
функции f(n). Это означает, что алгоритм сложности 0(2П) будет менее эффективным и,
следовательно, потребует больше времени, чем алгоритм сложности 0(f(n)). Принято
говорить, что алгоритм, сложность которого определяется степенной или
экспоненциальной функцией, требует экспоненциального времени выполнения.
В качестве примера рассмотрим задачу определения состава всех возможных
подкомиссий, которые могут быть сформированы из группы, содержащий п человек.
Поскольку существует 2П-1 подобных подкомиссий (мы допускаем, что подкомиссия
может состоять из всей группы, но не рассматриваем подкомиссию, не содержащую
ни одного человека), любой алгоритм решения данной задачи должен включать не
менее 2п-1 шагов. Следовательно, его сложность не менее 0(2п-1). Однако
выражение 2п-1 относится к экспоненциальному классу и не ограничивается никаким по-
592
Глава одиннадцатая. Теория вычислений
линомом. Таким образом, при увеличении размера группы, из которой производится
выборка, решение данной задачи становится чрезвычайно трудоемким.
В отличие от предыдущего примера, в котором сложность определялась
объемом выходной информации, существуют еще более сложные задачи, несмотря на
то, что от них требуется лишь выдача простого ответа "да" или "нет". Примером
такой задачи является определение истинности выражений, касающихся
сложения действительных чисел. Например, мы легко можем определить, что на
вопрос "Правда ли, что существует действительное число, которое, будучи
прибавленным к самому себе, даст в результате 6?" последует ответ "да", а на вопрос
"Правда ли, что имеется ненулевое действительное число, которое, будучи
прибавленным к самому себе, даст в результате 0?" — последует ответ "нет". В то
же время с повышением сложности таких вопросов наши возможности дать на
них ответы резко снижаются. Если потребуется дать ответы на большое
количество подобных вопросов, может возникнуть соблазн обратиться за помощью к
компьютеру. К сожалению, было доказано, что поиск ответов на такие вопросы
требует экспоненциального времени. Таким образом, при повышении сложности
вопросов компьютер не сможет выдавать ответы с требуемой скоростью.
То, что теоретически разрешимые, но не принадлежащие к множеству Р
задачи имеют столь огромную временную сложность, свидетельствует о том, что с
практической точки зрения они являются неразрешимыми. В то же время
задачи, имеющие практическое решение, обычно относятся к множеству Р. Таким
образом, определение границ множества Р можно считать важным направлением
исследований в области компьютерных наук.
НП-задачи
Рассмотрим задачу коммивояжера, заключающуюся в том, что он должен
посетить всех покупателей, проживающих в различных городах, не превысив при
этом установленной сметы. Таким образом, данная задача сводится к
нахождению пути (от его дома, соединяющего все требуемые города, и до его дома),
суммарная протяженность которого не превысит определенной величины.
Традиционное решение данной задачи заключается в систематическом
рассмотрении возможных путей, сравнении их протяженности с некоторым пределом, пока не
будет найден приемлемый вариант или не будут рассмотрены все возможности.
Однако данный подход не имеет полиномиального временного решения. По мере
увеличения числа городов количество перебираемых возможных путей растет намного
быстрее, чем любой полином. Следовательно, данное решение задачи коммивояжера
является непрактичным, особенно если необходимо посетить много городов.
Итак, приходим к выводу, что для решения данной задачи за разумное время
необходимо найти более быстрый алгоритм. Наш интерес подогревается тем, что
если удовлетворяющий условиям задачи путь существует и если нам
посчастливится выбрать его с первой же попытки, то описанный выше продолжительный
алгоритм на самом деле завершится очень быстро. В частности, приведенный
ниже набор операторов может быть выполнен очень быстро и потенциально
позволяет найти решение поставленной задачи.
11.5. Сложность задач 593
Выбрать один из возможных путей и вычислить его протяженность.
If эта протяженность не больше заданной,
then объявить об успехе
else не объявлять ни о чем
Однако данная последовательность команд не является алгоритмом в
техническом смысле. Его первая команда не определена в том смысле, что она не
указывает, какой именно путь следует выбирать, т.е. результат ее выполнения не
может быть определен до момента выполнения. Говорят, что подобные команды
не детерминированы, поэтому содержащий подобные указания "алгоритм" мы
будем называть недетерминированным алгоритмом.
Отметим, что при увеличении числа городов время, затрачиваемое на
недетерминированный алгоритм, увеличивается относительно медленно. Процесс
выбора произвольного пути состоит в простом составлении списка всех городов, что
может быть выполнено за время, пропорциональное их количеству. Более того,
время, требуемое на вычисление общей протяженности проложенного пути,
также пропорционально количеству посещаемых городов, а время, необходимое
для сравнения его длины с заданным пределом, вообще не зависит от числа
городов. Следовательно, время, необходимое на выполнение недетерминированного
алгоритма, ограничено какой-то полиномиальной функцией. Таким образом, при
использовании недетерминированного алгоритма появляется возможность
решения задачи коммивояжера за полиномиальное время.
Конечно, подобное недетерминированное решение нельзя считать полностью
удовлетворительным. Фактически оно полагается на удачу. Однако этого вполне
достаточно, чтобы предположить о существовании детерминированного решения
задачи коммивояжера, которое выполнялось бы за полиномиальное время.
Вопрос об истинности данного предположения остается открытым. В
действительности задача коммивояжера является лишь одним из представителей большого
класса задач, имеющих недетерминированное решение, выполнение которого
требует полиномиального времени. Однако для этих задач еще не найдено
детерминированное решение, имеющее полиномиальное время выполнения.
Дразнящая эффективность недетерминированных решений указанных задач
вызывает у некоторых надежду, что когда-нибудь будут найдены эффективные
детерминированные решения поставленных проблем, но большинство уверены в том,
что данные задачи настолько сложны, что их решение невозможно
сформулировать в рамках эффективных детерминированных алгоритмов.
Задача, имеющая недетерминированное решение с полиномиальным
затрачиваемым временем, называется недетерминированной полиномиальной задачей, или,
для краткости, НП-задачей. Для обозначения множества НП-задач обычно
употребляется обозначение NP. Отметим, что все задачи множества Р также принадлежат и
множеству NP, поскольку к любому (детерминированному) алгоритму можно
добавить недетерминированную команду, не нарушив при этом его функционирования.
Вопрос о принадлежности всех НП-задач множеству Р остается открытым,
как мы только что убедились на примере задачи коммивояжера. Можно
считать, что это наиболее известная проблема из числа еще не решенных в
современной теории вычислительных систем. Ее успешное решение может
594 Глава одиннадцатая. Теория вычислений
иметь значительные последствия. Например, в следующем разделе
рассказывается о существовании шифровальных систем, надежность которых
основывается на нереальном количестве времени, затрачиваемом на решение задач,
подобных представленной выше (о коммивояжере). Если будет доказано
существование эффективных методов решения подобных задач, то данные
шифровальные системы будут скомпрометированы.
Попытки разрешения вопроса о тождественности множеств Р и NP
привели к открытию класса задач, принадлежащих множеству NP и известных
как полные НП-задачи. Эти задачи имеют следующую особенность: из их
полиномиального временного решения могут быть выведены
полиномиальные временные решения всех задач, принадлежащих множеству NP. Поэтому
если может быть найден (детерминированный) алгоритм для решения одной
из полных НП-задач за полиномиальное время, то данный алгоритм может
быть расширен для решения любой НП-задачи за полиномиальное время. А
значит, множество NP окажется тождественным множеству Р. Задача
коммивояжера относится именно к классу полных НП-задач.
Итак, в этом разделе мы обнаружили, что задачи могут быть
классифицированы как разрешимые (имеющие алгоритмическое решение) и неразрешимые (не
имеющие такого решения), как показано на рис. 11.12. Более того, множество
разрешимых задач включает два подмножества. Одно состоит из задач
полиномиального типа, имеющих практическое решение, а второе подмножество
включает задачи неполиномиального типа, имеющие практически реализуемые
решения только в определенных случаях или только при тщательно подобранных
входных данных. Кроме того, существуют некие загадочные НП-задачи, которые
пока еще не поддаются точной классификации.
Графическое обобщение классификации задач
11.5. Сложность задач 595
Вопросы для самопроверки
1. Предположим, что задача может быть решена с помощью алгоритма класса
0(2П). Что можно сказать о сложности данной задачи?
2. Предположим, что задача может быть решена как с помощью алгоритма
класса 0(п2), так и алгоритма класса 0(2П). Всегда ли один алгоритм будет
превосходить другой?
3. Выпишите все подгруппы, которые можно сформировать из группы, в
которую входят два человека: Алиса и Билл. Выпишите все подгруппы, которые
можно сформировать из группы, в которую входят Алиса, Билл и Кэрол. Что
можно сказать о подгруппах для группы, состоящей из четырех человек:
Алисы, Билла, Кэрол и Девида?
4. Приведите пример задачи полиномиального типа. Приведите пример задачи
неполиномиального типа. Приведите пример НП-задачи, о принадлежности
которой к полиномиальному типу ничего не известно.
11.6. Криптография с использованием
открытых ключей
Тот факт, что эффективного решения полной НП-задачи пока не существует,
находит много интересных применений, одно из которых связано с шифрованием
секретной информации. В данном разделе мы рассмотрим подобную технику
шифрования. Она предусматривает применение числовых значений, называемых ключами,
которые используются для кодирования и декодирования зашифрованных данных.
Однако ключи, используемые для зашифровки данных, не идентичны ключам,
используемым для их расшифровки. Для декодирования сообщения требуется знание
дешифровочных ключей. Поэтому ключи шифрования можно широко
распространять, не нарушая при этом безопасность системы. Люди, знающие ключи
шифрования, смогут закодировать свои сообщения, но не смогут расшифровать сообщения,
закодированные другими, даже если при этом использовался тот же ключ
шифрования. С помощью подобной шифровальной системы множество людей смогут
посылать засекреченные сообщения одному адресату, и только этот адресат будет иметь
ключ для дешифровки всех поступающих к нему шифрованных сообщений.
Подобная техника шифрования составляет отрасль исследований, известную как
криптография с использованием открытых ключей. Последний термин отражает тот факт,
что используемые для шифровки сообщений ключи являются общедоступными.
Шифрование с использованием алгоритма задачи о рюкзаке
Прежде чем начать обсуждение конкретной системы шифрования с открытым
ключом, предварительно следует рассмотреть НП-задачу, известную как задача о
рюкзаке. Данная задача заключается в выборе чисел из предложенного набора,
сумма которых равнялась бы заданному числу. Название задачи отражает ее схо-
596 Глава одиннадцатая. Теория вычислений
жесть с практической проблемой полного заполнения рюкзака некоторым набором
вещей. Конкретным примером задачи о рюкзаке является задача выбора
нескольких чисел из приведенного ниже набора так, чтобы их сумма равнялась 2063:
191 691 573 337 365 730 651 493 177 354
Наиболее известным методом решения задачи о рюкзаке является перебор всех
возможных комбинаций, пока не будет найдено подходящее решение. Но если
количество предложенных чисел будет равно п, то число их возможных комбинаций
будет равно 2П. Таким образом, если исключить из рассмотрения возможность
случайной удачи, то время, необходимое для поиска решения, будет достаточно большим.
Чтобы убедиться в этом, попробуйте решить предложенную выше задачу. Вы
убедитесь, что она окажется довольно трудоемкой, даже если для выбора будет
предложено всего десять чисел. Представьте, как возрастет трудоемкость этой задачи, если
для выбора будет предложено 20 чисел; возможных вариантов в этом случае будет
существовать уже больше миллиона.
Предложенную выше задачу о рюкзаке можно использовать в качестве
средства для шифровки сообщений. Вначале представим сообщение в виде строки
двоичных разрядов, используя, например, для представления его символов код
ASCII или Unicode. Затем разобьем полученную строку на сегменты по десять
бит и представим каждый сегмент как некоторое число. Это число получается в
результате сложения чисел, находящихся в тех позициях списка нашей задачи о
рюкзаке, которые соответствуют единицам в двоичной записи шифруемого
числа. Например, комбинация битов 1001100001 будет представлена числом 1247, так
как единицы в записи шифруемого набора находятся на первой, четвертой,
пятой и десятой позициях, а сумма соответствующих чисел из списка нашей
задачи о рюкзаке (191, 337, 365 и 354) равна именно 1247 (рис. 11.13). Точно так же
битовая комбинация 0010011010 будет представлена числом 2131 (равным сумме
573 + 730 + 651 + 177). Поэтому сообщение 10011000010010011010 будет зашифровано
как число 1247, за которым будет следовать число 2131.
Популярные системы шифрования
Одной из наиболее популярных систем шифрования, используемых частными лицами для обеспечения тайности
общения через Internet, является PGP (Pretty Good Privacy — весьма хорошая секретность), разработанная в 1991
году Филиппом Циммерманом (Philip Zimmermann). Она является универсальной и простой в употреблении
системой шифрования с открытым ключом, бесплатно распространяемой (для некоммерческого использования) на
многих ресурсах в Internet. Система PGP основана на алгоритме RSA, который был назван в честь его создателей:
Рона Ривеста (Ron Rrvest), Ади Шамира (Adi Shamir) и Леонарда Эдлмана (Leonard Adleman). В то время как
описываемая в тексте система шифрования строится на трудности решения задачи о рюкзаке при большой длине
списка, алгоритм RSA исходит из трудности нахождения делителей больших чисел. Алгоритм RSA принадлежит
компании RSA Data Security, которая, в свою очередь, подконтрольна компании Security Dynamics Technologies, так
11.6. Криптография с использованием открытых ключей 597
что коммерческое использование данного алгоритма требует лицензии компании RSA Data Security.
Дополнительную информацию о роли, которую играют в распространении системы PGP и алгоритма RSA упомянутый выше
патент и правительство США, ограничивающее экспорт технологий, можно узнать из источников в Internet. Удобнее
всего выполнить поиск источников с подобной информацией по ключевым словам "PGP" или "RSA".
РИСУНОК 11.13
Кодировка двоичной комбинации по методу задачи о рюкзаке
Предположим, что кто-то перехватил это зашифрованное сообщение. Более того,
будем считать, что данный человек уже знает набор чисел, применяемых при
кодировке. Однако при расшифровке этого сообщения ему потребуется дважды решить
задачу о рюкзаке, что является весьма трудоемким процессом. Кроме того, если
список, используемый для кодировки сообщений, содержит значительно больше десяти
элементов, то задача дешифровки перехваченного сообщения становится
практически неразрешимой, что и обеспечивает секретность текста сообщения.
Недостаток данной системы шифрования состоит в том, что никто не сможет
быстро расшифровать поступившее сообщение, даже его адресат. Поэтому
требуется найти некоторую уловку, которая позволит адресату быстро решить задачу
о рюкзаке, тогда как для всех остальных поиск ее решения останется
непреодолимо трудоемким процессом.
Для нахождения подобной уловки рассмотрим, какие задачи о рюкзаке
имеют достаточно простое решение. Предположим, что величины, из которых нам
нужно выбирать значения при шифровании, будут следующими:
1 4 6 12 24 51 105 210 421 850
Каждое число данного списка больше, чем сумма всех предыдущих. Таким
образом, если от нас требуется выбрать те из них, которые в сумме дадут 995,
мы сразу же будем знать, что среди этих чисел есть 850, поскольку сумма всех
предыдущих чисел в списке будет меньше требуемого значения. После
определения первого числа исходная задача упрощается до нахождения чисел, дающих в
сумме 995-850, или 145. Но это значит, что мы должны выбрать число 105, по-
598
Глава одиннадцатая. Теория вычислений
скольку сумма всех предыдущих чисел в списке будет меньше 145. Продолжая
подобным образом, можно быстро прийти к заключению, что искомыми числами
являются 850, 105, 24, 12 и 4.
В качестве последнего штриха необходимо найти подходящий способ для
преобразования подобной упрощенной задачи о рюкзаке в трудную, и наоборот. С
этой целью рассмотрим процедуру такого преобразования с использованием трех
"магических" чисел. Позже мы уточним происхождение этих "магических"
чисел и способ создания собственной шифровальной системы. А сейчас просто
воспользуемся "магическими" числами 642, 2311 и 18.
На первом этапе выполним преобразование следующего исходного списка:
1 4 6 12 24 51 105 210 421 850
Это список, который позволяет легко решить задачу о рюкзаке, а цель наших
действий состоит в том, чтобы преобразовать его в другой, не допускающий
такой возможности. Выполним преобразование посредством умножения каждого
элемента списка на 642 (первое магическое число), деления полученной
величины на 2311 (второе магическое число) и занесения в новый список остатка,
полученного при делении. Данное действие порождает следующий набор чисел:
642 257 1541 771 2184 388 391 782 2206 304
В частности, число 4 в исходном списке заменяется на число 257 в новом
списке, поскольку 4 х 642 = 2568, а 2568 + 2311 дает в остатке 257.
Отметим, что задача о рюкзаке, сформулированная в терминах нового набора
чисел, будет уже сложной, поскольку процесс преобразования уничтожил те
соотношения между величинами, которые существовали в исходном списке. Но
для нас это не имеет никакого значения, поскольку нам известны "магические"
числа. Теперь мы должны умножить полученные зашифрованные числа на 18
(третье магическое число) и поделить произведение на 2311 (второе магическое
число) с последующим использованием остатка от деления в качестве искомой
суммы для задачи о рюкзаке, сформулированной в исходной легко решаемой
системе. Числа, решающие последнюю легкую задачу, находятся на тех же
позициях, что и числа исходного списка, решающие исходную задачу.
Для демонстрации выполненных действий предположим, что поставлена
задача выбора из приведенной ниже последовательности таких чисел, сумма
которых составит 4895:
642 257 1541 771 2184 388 391 782 2206 304
По описанному выше алгоритму вычисляем, что произведение 4895 х 18 = 88110
дает при делении на 2311 остаток 292. Далее определяем, что 6, 25, 51 и 210 являются
именно теми числами из приведенного ниже набора, сумма которых равна 292:
1 4 6 12 24 51 105 210 421 850
Поскольку они находятся на третьей, пятой, шестой и восьмой позициях
данного списка, можно предположить, что сумму 4895 дают именно третье,
пятое, шестое и восьмое числа в приведенном ниже наборе:
11.6. Криптография с использованием открытых ключей 599
642 257 1541 771 2184 388 391 782 2206 304
Действительно, 1541 + 2184 + 388 + 782 = 4895, что нам и требовалось.
Система шифрования с использованием открытого ключа действует следующим
образом. Мы открыто распространяем следующую последовательность чисел:
642 257 1541 771 2184 388 391 782 2206 304
Любой пользователь может закодировать свое сообщение в терминах задачи о
рюкзаке, основываясь на предложенной ему последовательности. Однако список
исходных чисел, как и три магических числа, мы держим в тайне. При получении
зашифрованного послания мы быстро декодируем его, предварительно преобразовав
сложную задачу о рюкзаке в легкую задачу. Так как никто, кроме нас, не способен
это сделать, посылаемые нам сообщения будут абсолютно секретны (рис. 11.14).
| РИСУНОК 11.14
Шифрование с использованием открытого ключа, построенное по принципу задачи о рюкзаке
Модульная арифметика
Описанная выше система шифрования с использованием открытого ключа
основана на математическом понятии, известном как модульная арифметика.
Модульная арифметика является системой, которую мы получаем путем замены
каждого целого числа в традиционной арифметике на остаток, полученный от
деления этого числа на определенную величину, называемую модулем. Напри-
600
Глава одиннадцатая. Теория вычислений
мер, выберем значение модуля равным числу 7. В этом случае
последовательность целых чисел
О 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ...
будет преобразована в следующий ряд:
0123456012345601...
Для представления остатка от деления величины х на модуль m принято
использовать запись x(mod m), что читается как "х по модулю т". Например, 9(mod 7) равно
2, поскольку 9 + 7 дает в остатке 2. Аналогичным образом, 24(mod7) равно 3,
поскольку 24 + 7 дает в остатке 3, a 5(mod 7) равно 5, так как 5 + 7 дает в остатке 5.
Два целых числа, которые при делении на модуль m дают одинаковые
остатки, называются равными по модулю т. Так, числа 16 и 23 равны по модулю 7,
поскольку значение 16(mod 7) такое же, как и значение 23(mod 7). Действительно,
оба числа при делении на 7 дают в остатке 2. Для обозначения равенства двух
чисел по модулю m принято использовать запись х = у (mod m), что читается как
"х равно у по модулю т".
После перевода обычных целых чисел в систему по модулю m у нас остаются
только числа 0, 1,2, 3,..., т- 1. Арифметические действия над данными числами
выполняются следующим образом. Действия производятся в традиционной
арифметической системе, а результат, скажем х, переводится в модульную
систему путем замены на х (mod m). Например, в модульной системе с модулем 7 мы
ограничены только числами 0, 1, 2, 3, 4, 5 и 6. Следовательно, сумма 2 + 6 будет
равна 1, поскольку 2+6 = 8, а восемь при делении на модуль 7 дает остаток 1.
Более того, произведение 2x6 будет равно 5, так как 2х 6= 12, а число 12 при
делении на модуль 7 дает остаток 5.
Таким образом, арифметика модульной системы является искаженным
отражением обычной. Иными словами, она подобна обычной в том, что если х = a(mod m) и
у= b(modm), то х+ у= а + b(modm). Но она также отлична от обычной арифметики в
том смысле, что суммы и произведения в двух системах не совпадают. В частности,
произведение двух различных величин в модульной системе может быть равно 1, в
то время как в традиционной системе такое невозможно. Например, в системе по
модулю 7 мы видим, что 3x5 = 1 (поскольку 3x5 = 15 и 15 + 7 дает 1 в остатке). Но
это значит, что для любого х в этой модульной системе выражение 3 х 5 х х должно
равняться х, так как выражение Зх5хх=1хх = х.
Два числа, которые при умножении дают число 1, называются обратными
друг другу. В традиционной системе целых чисел не существует целого числа,
обратного числу 3. Действительно, в традиционной арифметике обратным для
числа 3 является число 1/3, которое не относится к целым числам. Но в системе
чисел по модулю 7 мы видим, что у числа 3 есть обратное целое число, равное 5.
Математики утверждают, что если хит являются целыми положительными
числами, такими, что х<т, и имеют всего один общий делитель (в традицион-
11.6. Криптография с использованием открытых ключей 601
ной системе целых чисел), равный 1, то в системе по модулю m число х будет
иметь целое обратное число.
Возвращаясь к шифрованию
Обратите внимание, если величина х неотрицательна и меньше модуля т, то
x(mod m) равно самому х. Это значит, что до тех пор, пока мы производим
арифметические действия в пределах множества 0, ..., т-1, их результаты в системе
с модулем m ничем не будут отличаться от результатов обычных
арифметических действий. Следовательно, если выбрать исключительно большой модуль, то
можно выполнять обычные арифметические действия, даже не задумываясь о
том, выполняются ли они в обычной арифметической системе или в модульной.
В частности, поскольку сумма всех элементов приведенного ниже множества
равна 1685, сложение, выполняемое при решении соответствующей задачи о
рюкзаке, никогда не приведет к числу, большему 1685:
1 4 6 12 25 51 105 210 421 850
Следовательно, при решении подобной задачи мы можем не задумываться,
работаем ли мы в традиционной арифметической системе или в модульной, но с
модулем большим, чем 1685.
Если же предположить, что приведенная ранее легкая задача о рюкзаке
формулируется в подобной системе с большим модулем, то можно получить простой
способ преобразования ее в трудную задачу с сохранением возможности
последующего обратного перевода. Чтобы пояснить данное утверждение, рассмотрим
следующий набор величин:
ai а2 а3 ад а5 аб а7 а8 Ъд а10
Будем считать, что в этой последовательности каждое значение больше суммы
всех предыдущих значений, т.е. в терминах данной последовательности задача о
рюкзаке решается легко. Выберем модуль m больше суммы всех значений в
последовательности. Кроме того, выберем еще два значения, которые будут взаимно
обратными по модулю т, — х и у. Если теперь умножить каждое значение из
исходного списка на х, то получим следующую последовательность значений:
п\Х а2х а3х ецх а5х ОбХ а7х а8х адх aiOx
В терминах этой последовательности задача о рюкзаке также решается
просто. В частности, сумма любого набора величин этого списка равна сумме
соответствующих исходных величин, умноженной на х. Например, ajx + а3х + а5х = (ai +
а3 + as)x. Поэтому задачу о рюкзаке, сформулированную в терминах второго
набора значений, можно решить посредством деления заданной суммы на х, поиска
тех чисел в исходном списке, сумма которых дает полученное в результате
деления значение, и выбора соответствующих чисел из второго набора.
Фактически задача о рюкзаке, сформулированная в терминах значений из
второго набора, решается и без деления искомой суммы на х, поскольку, как и
исходная, она является легкой для решения в том смысле, что каждое число
602 Глава одиннадцатая. Теория вычислений
второго набора тоже больше суммы предшествующих ему чисел. Все, что было
сделано, — это всего лишь увеличение значений используемых чисел.
А теперь заменим каждый член второй последовательности на эквивалентное
ему значение по модулю т. В частности, вместо ajx запишем a|X(mod m), вместо
а2х — a2x(mod m) и т.д. В результате данной операции будет порожден новый
набор значений:
bj b2 Ьз b4 bs b6 b7 bg b9 Ью
Здесь значение в каждой позиции равно по модулю m соответствующему
значению из исходного набора:
ajX a2x а3х а4х а5х г^х а7х а8х а^х а!Ох
В то же время любая сумма значений из нового набора равна по модулю m
сумме соответствующих значений из исходного набора:
ajx а2х а3х а4х а5х s^x а7х а8х ЪдХ а,ох
Теперь предположим, что имеется некоторая сумма, например b, + b2 + b3, и
требуется определить числа из приведенной ниже последовательности, сумма
которых дает это значение:
bi b2 b3 b4 b5 b6 b7 b8 b9 Ью
Нам известно, что справедливо следующее выражение:
Ь, + Ь2 + Ь3 = а,х + а2х + а3х (mod m)
Кроме того, мы знаем, что существует значение у, обратное значению х по
модулю т, поэтому можно утверждать следующее:
(bi + b2 + Ь3)у = (ajX + а2х + а3х)у (mod m)=
=(aj + а2 + а3)ху (mod m)=
=(а, + а2 + а3) (mod m)
Это означает, что если умножить на обратное значение у сумму значений,
выбранных из набора
bj b2 b3 b4 bs Ьб b7 bg b9 Ью,
а затем разделить полученное произведение на модуль m и записать остаток от
деления, то этот остаток будет суммой соответствующих величин исходного набора:
а] а2 а3 а4 а5 а$ а7 а8 а9 г10
Но поскольку в терминах этого исходного набора значений задача о рюкзаке
решается легко, можно быстро определить, какие именно значения были
выбраны. Теперь исходную задачу о рюкзаке можно решить путем простого выбора
соответствующих значений из второго набора значений:
bj b2 b3 b4 bs b$ b7 bg b9 Ью
Повторим предыдущее более кратко. Предположим, что задан приведенный
ниже вторичный набор чисел:
bi b2 b3 b4 bs Ьб b7 bg b9 Ью
11.6. Криптография с использованием открытых ключей 603
Чтобы выбрать из него значения, дающие заданную сумму s, достаточно
вычислить величину s х y(mod m), а затем определить, какие числа из приведенного
ниже исходного набора дают в сумме полученную величину:
at a2 а3 а4 а5 а<з а7 а8 ад а]0
Для получения окончательного ответа достаточно выбрать соответствующие
числа из вторичного набора:
bj hi Ьз b4 bs Ьб Ъ-j bg bg bjo
В качестве конкретного примера рассмотрим следующий исходный набор чисел:
1 4 6 12 25 51 105 210 421 850
В терминах этого набора чисел задача о рюкзаке решается легко. Поскольку
сумма всех значений в наборе равна 1685, то число 2311 будет достаточно
большим, чтобы играть роль модуля т. Кроме того, в системе с модулем 2311 числа
642 и 18 являются обратными. Поэтому выберем величину х равной 642, а
величину у равной 18. Первый этап наших действий заключается в умножении
каждой позиции исходного набора чисел на 642 и помещении на соответствующее
место остатка от деления этого произведения на модуль 2311. Полученный новый
набор чисел выглядит следующим образом:
642 57 1541 771 2184 388 391 782 2206 304
Предположим, что поставленная задача состоит в выборе из нового набора тех
чисел, которые в сумме дают значение 4507. На втором этапе умножим число
4507 на 18 и полученное произведение 81126 разделим на модуль 2311. Запишем
остаток от деления, равный 241. На третьем этапе определяем, что сумму 241
дают числа 6, 25 и 210, выбранные из исходного набора. Следовательно, сумма
4507 будет получена в результате сложения трех чисел из вторичного набора —
третьего, пятого и восьмого:
642 57 1541 771 2184 388 391 782 2206 304
Проверим это утверждение: 1541 + 2184 + 782 = 4507. Задача решена.
Подведем итоги. Как показано на рис. 11.15, описанный выше алгоритм
позволяет создавать системы шифрования с открытым ключом. Вначале записывается
набор чисел, в которых задача о рюкзаке решается легко. Затем выбираются числа
т, х и у, такие, что значение m будет больше суммы х и у, которые являются, в
свою очередь, обратными по модулю т. Затем числа из исходного списка
умножаются на х и полученные произведения делятся на т, после чего остаток от деления
записывается в соответствующую позицию нового списка. Этот список остатков и
используется в качестве открытого ключа шифрования сообщений. Любой может
закодировать свое сообщение как последовательность отдельных задач о рюкзаке,
сформулированных на базе данного набора чисел. В то же время мы будем
единственными, кто сможет легко дешифровать закодированное сообщение. Для этого
достаточно умножить каждую входящую в сообщение сумму на значение у,
разделить произведение на модуль т, а остаток от деления использовать как исходную
604 Глава одиннадцатая. Теория вычислений
сумму для решения легкой задачи о рюкзаке, сформулированной в терминах
исходной последовательности чисел. По полученному решению легко
восстанавливается поступившее зашифрованное сообщение.
I РИСУНОК 11.15
1. Выберите числа, для которых задача о рюкзаке решается просто.
Пример: 25817
2. Выберите три числа т, х и у так, чтобы т было больше суммы чисел задачи о рюкзаке,
а х было обратной величиной к у в системе с модулем т.
Пример: т = 37, х = 25, у=3
3. В исходном наборе замените каждую величину а на величину ха (mod m).
Пример: 13 14 15 18
= 17x25 (mod 37)
= 8х 25(mod37)
= 5х 25 (mod 37)
= 2x25(mod37)
4. Распространите полученный набор чисел в качестве открытого ключа,
предназначенного для зашифровки сообщений.
Принцип построения системы шифрования с открытым ключом
Следует сделать еще одно заключительное замечание. Злоумышленники
могут попытаться раскрыть используемую систему шифрования посредством
угадывания значений m, x и у, вместо решения сложных задач о рюкзаке. Поэтому
числа, используемые в реальных системах шифрования, должны быть
значительно больше тех, которые применялись в наших простых примерах. И
действительно, с помощью достаточно больших числовых значений можно добиться
того, что время вычисления закрытого ключа может даже превысить время,
необходимое для решения трудной задачи о рюкзаке.
Вопросы для самопроверки
1. Найдите в данном наборе числа, дающие в сумме 2200:
191 691 573 337 365 730 651 493 177 354
(Не тратьте на это задание слишком много времени. Суть в том, что это очень
трудоемкая работа.)
11.6. Криптография с использованием открытых ключей 605
2. Найдите в данном наборе числа, дающие в сумме 3023.
642 57 1541 771 2184 388 391 782 2206 304
Почему, в отличие от предыдущего примера, этот процесс оказался быстрым?
3. Найдите число, обратное числу 5, в системе по модулю 23.
4. Создайте систему кодировки с открытым ключом, основанную на следующем
наборе чисел:
2 3 6 12 24
Используйте тот факт, что числа 30 и 38 являются обратными по модулю 67.
Упражнения
1. Покажите, как на простейшем языке может быть смоделирована
следующая структура:
while X равно 0 do;
end;
2. Напишите на простейшем языке программу, присваивающую
переменной Z значение 1, если переменная X меньше или равна
переменной Y, и значение 0 в любом другом случае.
3. Напишите на простейшем языке программу, которая присваивает
переменной Z значение 2х.
4. В каждом из приведенных ниже случаев напишите на простейшем языке
последовательность команд, выполняющую требуемые действия.
а) Присвоить переменной Z значение 0, если значение переменной X
четное, в противном случае — значение 1.
б) Вычислить сумму всех целых чисел от 0 до X.
5. Напишите на простейшем языке программу для вычисления частного
от деления значения X на Y.
Остатком от деления пренебрегайте, т.е. в результате деления 1 на 2
будет получено значение 0, а при делении 5 на 3 — значение 1.
6. В тексте приведен пример машины Тьюринга, которая никогда не
останавливается, поскольку работает с лентой неограниченной длины.
Спроектируйте машину Тьюринга, которая никогда не остановится, но
использует при этом единственную ячейку ленты.
7. Разработайте модель машины Тьюринга, которая будет помещать нули
во все ячейки, расположенные левее текущей, пока не встретит
ячейку, содержащую "звездочку".
606 Глава одиннадцатая. Теория вычислений
8. Предположим, что на ленте машины Тьюринга последовательности нулей
и единиц ограничиваются с обеих сторон звездочками. Спроектируйте
машину Тьюринга, которая будет циклически сдвигать эти
последовательности на одну ячейку влево, в предположении, что машина начинает
работу с крайней правой ячейки, содержащей звездочку.
9. Разработайте модель машины Тьюринга, которая инвертирует
последовательность нулей и единиц, расположенную между текущей
ячейкой ленты (содержащей звездочку) и ближайшей звездочкой слева.
10. Сформулируйте тезис Черча-Тьюринга.
11. Какой геделевский номер имеет следующая программа?
incr A;
12. Какая программа на простейшем языке представлена следующим геделев-
ским номером, построенным по принципам, описанным в этой главе?
28 258 975 461 955 643
13. Является ли самоостанавливающейся приведенная ниже программа на
простейшем языке?
While X not 0 do/
end;
14. Проанализируйте истинность последующих двух утверждений.
Следующее утверждение истинно.
Предыдущее утверждение ложно.
15. Проанализируйте истинность следующего утверждения:
Кок готовит для тех людей на судне, кто сам не готовит себе еду.
16. Охарактеризуйте значение машин Тьюринга в теории
компьютерных наук.
17. Охарактеризуйте значение проблемы остановки в теории
компьютерных наук.
18. Является ли поиск определенного значения в списке проблемой
полиномиального типа? Аргументируйте ваш ответ.
19. Создайте алгоритм для определения, является ли данное
положительное число простым. Является ли ваше решение эффективным? Имеет
ли предложенное вами решение полиномиальный тип или оно
является неполиномиальным?
20. Всегда ли полиномиальное решение задачи лучше
экспоненциального? Объясните.
21. Означает ли факт существования полиномиального решения задачи
возможность ее решения за практически приемлемый промежуток
времени? Поясните ваш ответ.
Упражнения 607
22. Перед программистом Чарли поставили задачу разделить группу
из четного количества людей на две разные подгруппы так, чтобы
между подгруппами была максимально возможная разница в
сумме возрастов людей, входящих в каждую из них. Он предложил
решение, состоящее в переборе всех возможных пар групп, с
вычислением суммарного возраста в каждой подгруппе и
последующим выбором пары с максимальной разницей вычисленных
значений. В то же время программист Мери предложила сначала
упорядочить исходную группу людей по возрасту, а потом создать одну
подгруппу из более пожилой половины упорядоченной группы, а в
другую включить молодых. Каковы сложности каждого из
предложенных решений? К какому классу относится задача сама по
себе: к полиномиальному, неполиномиальному или НП-задачам?
23. Является ли приведенный ниже алгоритм детерминированным?
Поясните ваш ответ.
procedure mystery (<число>)
if {<число> > 5)
then (ответить "да")
else (взять число меньше 5 и вывести в качестве ответа)
24. Является ли приведенный ниже алгоритм детерминированным?
Поясните ваш ответ.
Направляйтесь прямо.
На третьем перекрестке спросите у стоящего на углу человека,
куда вам повернуть — направо или налево.
Поверните так, как вам сказали.
Остановитесь, проехав два дома.
25. Укажите недетерминированные участки данного алгоритма.
Выберите три числа от 1 до 100.
if (сумма выбранных чисел больше 150)
then (ответьте "да")
else (выберите одно из используемых чисел и
выведите его в качестве ответа)
26. Какую временною сложность имеет данный алгоритм —
полиномиальную или неполиномиальную? Поясните ваш ответ.
procedure mystery (<последовательность чисел>)
выберите несколько чисел из <последовательность чисел>
if (сумма выбранных чисел превышает 125)
then (ответить "да")
else (не давать никакого ответа)
608 Глава одиннадцатая. Теория вычислений
27. Какие из приведенных ниже задач относятся к множеству Р?
а) Задача сложности п2
б) Задача сложности Зп
в) Задача сложности п2 + 2п
г) Задача сложности п!
28. Опишите различия между доказательством, что задача имеет
полиномиальный тип, и утверждением, что она является
недетерминированной полиномиальной задачей.
29. Приведите пример задачи, относящейся и к множеству Р, и к
множеству NP.
30. Предположим, что имеются два алгоритма для решения некоторой
задачи. Один имеет временною сложность п4, а другой — 4П. Для
какого объема входных данных первый алгоритм будет
предпочтительнее второго?
31. Предположим, требуется решить задачу коммивояжера для случая,
когда существует 15 городов, из которых каждые два соединены
единственной дорогой. Сколько существует различных путей,
проходящих по всем городам? Сколько времени уйдет на вычисление
длины всех путей, если предположить, что вычисление каждого из них
занимает одну микросекунду?
32. Сколько сравнений потребуется выполнить при использовании алгоритма
сортировки методом слияния (см. рис. 11.9 и 11.8.) для упорядочения
списка имен "Алиса, Боб, Кэрол, Дэвид"? Сколько сравнений
понадобится в случае упорядочения списка "Алиса, Боб, Кэрол, Дэвид, Элейн"?
33. Приведите пример задачи каждого из типов, указанных на рис. 11.12.
34. Разработайте алгоритм для нахождения целочисленного решения
уравнения х2 + у2 = п, где п — некоторое заданное положительное
число. Определите временную сложность вашего алгоритма.
35. Разработайте алгоритм определения, является ли данное
положительное число (входная величина) простым? Как время выполнения
вашего алгоритма зависит от значения входной величины?
36. Приведенный ниже алгоритм упорядочения списка называется
сортировкой по методу пузырька. Сколько сравнений между элементами
списка потребуется для упорядочения списка из п позиций?
procedure BubbleSort {<список>)
assign <счетчик> the value 1;
while (<счетчик> < количество позиций в <список>) do
[assign N количество позиций в <список>;
while (N > 1) do
(if (N-e значение в <список> меньше
Упражнения 609
предшествующего ему значения)
then (поменять местами N-e значение и
предшествующее ему значение)
Вычесть 1 из N
)
]
37. Сколько потребуется времени на перебор всех возможных комбинаций из
задачи о рюкзаке, включающей список из 40 чисел, если на проверку
каждой возможной комбинации уходит по одной микросекунде?
38. Почему проще решить задачу о рюкзаке, сформулированную для
такого набора чисел:
1 2 4 8 16 32 64 128 256 512 1024,
чем для такого:
191 691 573 337 365 730 651 493 177 354?
39. Выберите из приведенного ниже списка числа, сумма которых будет
равна 3012:
642 57 1541 771 2184 388 391 782 2206 304
(Обратите внимание, что это те же числа, которые использовались в
системе кодировки с открытым ключом, обсуждавшейся в
разделе 11.6.)
40. Найдите число, обратное числу 5, в модульной системе с модулем 8.
Найдите число, обратное 3, в модульной системе с модулем 8.
41. Разработайте схему шифрования с открытым ключом, построенную
на использовании следующей последовательности чисел:
1 3 5 10 20
Дополнительно воспользуйтесь тем, что числа 30 и 38 являются
обратными друг другу в модульной системе с модулем 67.
Общественные и социальные вопросы
Следующие вопросы приводятся для того, чтобы помочь вам разобраться в
некоторых этических, общественных и юридических аспектах использования
вычислительной техники, а также в ваших собственных воззрениях и тех
принципах, на которых они основаны. Задача не сводится к тому, чтобы просто дать
ответы на предложенные вопросы. Вы должны также понять, почему вы
ответили именно так, а не иначе, и насколько ваши суждения по различным вопросам
согласуются друг с другом.
610 Глава одиннадцатая. Теория вычислений
1. Предположим, что выполнение наилучшего алгоритма для решения
задачи потребует 100 лет. К какому разряду задач вы отнесете
данную — к разрешимым или неразрешимым?
2. Имеют ли граждане право шифровать свою переписку для
предотвращения возможного контроля со стороны государственных служб?
Предусматривает ли ваш ответ "надлежащее" обеспечение государственной
безопасности? Кто решает, что значит "надлежащее" обеспечение
государственной безопасности?
3. Если рассматривать человеческий разум как алгоритмическое
устройство, то как отразится на человечестве признание тезиса Тьюринга?
Насколько вы верите, что машины Тьюринга имеют вычислительные
возможности, сравнимые с возможностями человеческого разума?
4. Сегодня существуют Web-узлы, содержащие карты множества
различных городов. Назначение этих Web-узлов — помочь найти
конкретный адрес; причем они позволяют увеличить изображения в
целях детального просмотра планировки отдельных участков
застройки. Исходя из этих реальных возможностей, рассмотрим
следующую вымышленную ситуацию. Предположим, что данные этих
Web-узлов постоянно обновляются фотографиями, выполненными
со спутника, имеющего необходимые возможности увеличения.
Кроме того, предположим, что эти возможности увеличения
изображения возросли до такой степени, что стало возможным
получение детальных изображений зданий и их окрестностей. Более
того, эти изображения стали доступны в реальном масштабе времени,
как прямая видеотрансляция. Далее предположим, что средства
получения видеоизображений были расширены за счет технологии
обработки инфракрасного излучения. В результате была создана
система, позволяющая наблюдать за вами в вашем же собственном
доме на протяжении 24-х часов в сутки. На какой именно стадии
указанной последовательности модернизации системы было
нарушено ваше право на невмешательство в личную жизнь? На какой
стадии, по вашему мнению, мы переоценили возможности
современных спутниковых систем? Как вы думаете, насколько
изложенная ситуация является вымышленной?
5. Предположим, что некоторая компания разработала и запатентовала
систему шифрования. Должно ли правительство той страны, где
расположена данная компания, иметь право на использование данной
системы в целях национальной безопасности? Должно ли
правительство иметь право в целях национальной безопасности ограничивать
коммерческое использование компанией данной системы?
Общественные и социальные вопросы 611
Рекомендуемая литература
• Garey M. R., Johnson D. S. Computers and Intractability. — New York: W. H.
Freeman, 1979.
• Hofstadter D. R. Godel, Escher, Bash: An Eternal Golden Braid. —St. Paul, MN:
Vintage, 1980.
• Kozen D. C. Automata and Computability. — New York: Spinder-Verlag, 1997.
• Lewis H. R., Papadimitriou С. Н. Elements of the Theory of Computation.—
Englewood Cliffs, NJ: Prentice-Hall, 1981.
• Sipser M. Introduction to the Theory of Computation. —Boston: PWS, 1996.
Дополнительная литература
• Столлингс В. Криптография и защита сетей, 2-е изд. — М.: Издательский
дом "Вильяме", 2001.
• Джексон П. Введение в экспертные системы, 3-е изд. — М.: Издательский
дом "Вильяме", 2001.
612 Глава одиннадцатая. Теория вычислений
Приложения
Приложение А. Код ASCII
Приложение Б. Электронные схемы обработки чисел в двоичном дополнительном коде
Приложение В. Пример типичного машинного языка
Приложение Г. Примеры программ
Приложение Д. Эквивалентность итеративных и рекурсивных структур
Приложение Е. Ответы на вопросы для самопроверки
приложение А
Код ASCII
Ниже приведен неполный список ASCII-кодов символов. В этом списке к
исходным семиразрядным двоичным кодам слева приписаны нули — для
получения восьмибитовых кодов, общепринятых в настоящее время.
Символ
(пробел)
!
••
#
$
%
&
•
(
)
*
+
»
-
/
0
1
2
3
4
5
6
7
8
9
:
»
<
>
ASCII-код
00100000
00100001
00100010
00100011
00100100
00100101
00100110
00100111
00101000
00101001
00101010
00101011
00101100
00101101
00101110
00101111
00110000
00110001
00110010
00110011
00110100
00110101
00110110
00110111
00111000
00111001
00111010
00111011
00111100
00111101
00111110
Символ
?
@
А
в
с
D
Е
F
G
н
I
J
к
L
м
N
о
р
Q
R
S
т
и
V
W
X
Y
Z
[
\
]
ASCII-код
00111111
01000000
01000001
01000010
01000011
01000100
01000101
01000110
01000111
01001000
01001001
01001010
01001011
01001100
01001101
01001110
01001111
01010000
01010001
01010010
01010011
01010100
01010101
01010110
01010111
01011000
01011001
01011010
01011011
01011100
01011101
Символ
а
b
с
d
е
f
g
h
i
j
k
1
m
n
о
P
q
r
s
t
u
V
w
X
У
z
{
}
ASCII-код
01011110
01011111
01100001
01100010
01100011
01100100
01100101
01100110
01100111
01101000
01101001
01101010
01101011
01101100
01101101
01101110
01101111
01110000
01110001
01110010
01110011
01110100
01110101
01110110
01110111
01111000
01111001
01111010
01111011
01111101
приложение Б
Электронные схемы обработки
чисел в двоичном
дополнительном коде
В этом приложении описаны электронные схемы, предназначенные для
изменения знака числа на противоположный и для сложения чисел,
представленных в двоичном дополнительном коде. Начнем обсуждение со схемы,
представленной на рис. Б.1. Она позволяет преобразовать четырехразрядное
число в двоичном дополнительном коде в битовую комбинацию, которая
представляет то же число, но с противоположным знаком. Например,
двоичный код числа 3 будет преобразован в двоичное представление числа -3.
Данная схема выполняет данную операцию в соответствии с алгоритмом,
описанным в главе 1. Это значит, что схема копирует входную битовую
комбинацию на выход в направлении справа налево до тех пор, пока не встретит
разряд со значением 1, а затем формирует на выходе дополнения каждого
оставшегося входного бита. Поскольку на первый вход самого правого
логического элемента XOR (исключающее "ИЛИ") постоянно поступает значение
О, этот элемент просто передает на выход значение на другом его входе.
Однако этот выходной сигнал одновременно поступает и на первый вход
следующего логического элемента XOR. Если это выходное значение будет
равно 1, то этот логический элемент XOR сформирует на выходе дополнение для
его второго входного сигнала. Кроме того, этот же единичный сигнал от
первого элемента XOR через логический элемент OR (логическое "ИЛИ")
подается на правый вход третьего элемента XOR, чтобы оказать соответствующее
влияние на работу этого логического элемента. Таким образом, первая же
единица (справа), которая появится в выходной комбинации, автоматически
передается влево, на входы логических элементов старших разрядов, а это
приводит к тому, что для всех оставшихся битов числа на выходе будут
сформированы их дополнения.
Далее рассмотрим процесс сложения двух чисел, представленных в двоичном
дополнительном коде. Например, рассмотрим решение следующей задачи:
ОНО
+ 1001
Сложение выполняется суммированием отдельных разрядов "по столбцам" в
направлении справа налево с использованием одного и того же алгоритма для каждого
столбца. Таким образом, если построить электронную схему для сложения значений
в одном столбце, то схему для сложения чисел из нескольких столбцов (двоичных
разрядов) можно создать, просто копируя в необходимом количестве схему,
выполняющую суммирование для одного столбца.
I РИСУНОК Б. 1
I 1г
Электронная схема, изменяющая знак числа в двоичном дополнительном коде на противоположный
Алгоритм сложения значений в отдельном столбце для задачи сложения
чисел из нескольких столбцов состоит в следующем. Требуется сложить два
значения в текущем столбце, добавить эту сумму к биту, перенесенному из
предыдущего столбца, записать младший значащий бит этой суммы в бит
результата и перенести значение избыточного бита в следующий столбец.
Электронная схема, реализующая этот алгоритм, представлена на рис. Б.2. В этой
схеме верхний логический элемент XOR определяет сумму входных битов,
нижний элемент XOR складывает полученную сумму со значением,
перенесенным из предыдущего столбца. Два логических элемента AND (логическое
"И") вместе с логическим элементом OR передают бит переноса налево.
Поэтому если в данном столбце оба суммируемых бита равны 1 или сумма
входных битов и бит переноса одновременно равны 1, то в соседний разряд
будет перенесено значение 1.
618
Приложение Б
РИСУНОК Б.2
Электронная схема для сложения значений в отдельном столбце
На рис. Б.З показано, как несколько копий данной схемы суммирования
значений в одном столбце можно использовать для построения электронной схемы,
вычисляющей сумму двух чисел, представленных в четырехразрядном двоичном
дополнительном коде. На этой схеме каждый прямоугольник представляет собой
копию рассмотренной выше электронной схемы суммирования одного разряда.
Обратите внимание, что значение бита переноса, поступающее на вход крайнего
справа прямоугольника, всегда равно 0, поскольку для этого разряда никакого
переноса из предыдущего столбца не существует. Кроме того, бит переноса из
крайнего левого прямоугольника просто игнорируется.
Схема на рис. Б.З называется сумматором со сквозным переносом, поскольку
перенос должен проходить сквозь всю схему, от крайнего правого до крайнего
левого столбца. Несмотря на простоту реализации, такие схемы медленнее
выполняют свои функции по сравнению с более совершенными схемами, такими
как сумматор с ускоренным переносом, минимизирующий переносы от столбца к
столбцу. Поэтому схема, изображенная на рис. Б.З, хотя и подходит для наших
целей, тем не менее, в современных вычислительных машинах не используется.
Приложения
619
РИСУНОК Б.З
Электронная схема сложения двух четырехразрядных чисел в двоичном дополнительном коде,
построенная из четырех копий схемы, представленной на рис. Б.2
620
Приложение Б
приложение В
Пример типичного машинного
языка
Архитектура машины
Рассматриваемая гипотетическая машина имеет 16 регистров общего
назначения, пронумерованных от 0 до F (в шестнадцатеричной системе счисления).
Длина каждого регистра равна одному байту (восьми битам). Для
идентификации регистров в машинных командах каждому регистру присвоен уникальный
четырехбитовый код, который представляет собой номер этого регистра. Таким
образом, регистр 0 идентифицируется как 0000 (шестнадцатеричный 0), а
регистр 4 — как 0100 (шестнадцатеричное 4).
Поскольку память рассматриваемой машины состоит из 256 ячеек, каждая
ячейка будет иметь уникальный адрес, представляющий собой целое число в
диапазоне от 0 до 255. Следовательно, адрес любой ячейки памяти может быть
представлен восьмибитовыми числами от 00000000 до 11111111 (в шестнадцате-
ричном представлении от 00 до FF).
Предполагается, что числа с плавающей запятой хранятся в следующем формате:
Машинный язык
Длина каждой машинной команды равна двум байтам. Первые четыре бита
содержат код операции, последние 12 битов образуют поле операндов. В
приведенной ниже таблице перечислены и кратко описаны команды, показанные в
шестнадцатеричном представлении. Буквы R, S и Т используются для указания в
поле операндов позиции шестнадцатеричных цифр, являющихся идентификато-
рами регистров, которые меняются в зависимости от конкретной команды.
Буквы X и Y используются для указания в поле операндов позиций тех шестнадца-
теричных цифр, которые не являются идентификаторами регистров.
Код операции Операнд Описание
1 RXY Загрузка в регистр R двоичного кода числа из
ячейки памяти с адресом XY
Пример. Команда 14A3 помещает в регистр 4
содержимое ячейки памяти с адресом A3
2 RXY Загрузка в регистр R двоичного кода числа XY
Пример. Команда 20АЗ помещает в регистр 0
значение A3
3 RXY Сохранение двоичного кода числа, хранящегося в
регистре R, в ячейке памяти с адресом XY
Пример. Команда 35В1 помещает содержимое
регистра 5 в ячейку памяти с адресом В5
4 0RS Перемещение двоичного кода числа из регистра R в
регистр S
Пример. Команда 4 0А4 копирует содержимое
регистра А в регистр 4
5 RST Суммирование двоичных кодов чисел, хранящихся в
регистрах S и Т, с сохранением суммы в регистре R
Пример. Команда 572 6 суммирует двоичные коды
чисел, хранящиеся в регистрах 2 и б, а сумму
помещает в регистр 7
6 RST Суммирование двоичных кодов чисел в формате с
плавающей запятой, хранящихся в регистрах S и Т,
с размещением результата в формате с плавающей
запятой в регистре R
Пример. Команда 634Е суммирует числа в формате
с плавающей запятой, хранящиеся в регистрах 4
и Е, и помещает результат в регистр 3
7 RST Выполнение поразрядной операции OR над
двоичными кодами чисел, хранящихся в регистрах S и Т,
и помещение результата в регистр R
Пример. Команда 7СВ4 помещает в регистр 7
результат операции OR над содержимым регистров В и 4
8 RST Выполнение поразрядной операции AND над
двоичными кодами чисел, хранящихся в регистрах S
и Т, и помещение результата в регистр R
Пример. Команда 8045 помещает в регистр 0
результат операции AND над содержимым
регистров 4 и 5
622 Приложение В
9 RST Выполняется поразрядная операция XOR над
двоичными кодами чисел, хранящихся в регистрах S
и Т, и результат помещается в регистр R
Пример. Команда 95F3 помещает в регистр 5
результат операции XOR над содержимым
регистров F и 4
A R0X Выполняется операция циклического поразрядного
сдвига вправо на X позиций над двоичным кодом
числа, хранящегося в регистре R. При каждом
одиночном сдвиге бит из младшего разряда
перемещается в старший разряд
Пример. Команда А403 выполняет циклический
поразрядный сдвиг вправо на 3 бита в содержимом
регистра 4
В RXY Выполняется переход к команде, размещенной в
ячейке памяти по адресу XY, если двоичный код
числа в регистре R совпадает с двоичным кодом
числа в регистре О
Пример. Команда В43С сначала сравнивает
содержимое регистра 4 с содержимым регистра 0. Если
они равны, последовательность выполнения команд
изменится так, что следующей будет выполнена
команда, расположенная в памяти по адресу ЗС. В
противном случае выполнение программы
продолжится в обычной последовательности
С 000 Прекращение выполнения программы
Пример. Команда СО00 останавливает выполнение
программы
Приложения 623
приложение Г
Примеры программ
В этом приложении приведены примеры программ на языках Ada, С, C++,
FORTRAN, Java и Pascal. Каждая из программ получает на вход список имен,
поступающий с клавиатуры, сортирует его с помощью алгоритма сортировки
вставками и выводит отсортированный список на экран дисплея.
Язык Ada
Язык программирования Ada, названный в честь Августы Ады Байрон
(Augusta Ada Byron) (1815-1851), помощницы Чарльза Бэббиджа (Charles
Babbege) и дочери поэта лорда Байрона, был создан по инициативе министерства
обороны США. Военные хотели получить единый язык общего назначения,
который можно было бы использовать во всех разработках программного
обеспечения, проводимых в этом министерстве. Основной упор при разработке языка Ada
был сделан на средствах программирования компьютерных систем реального
времени, которые являются частью более крупных систем, таких как системы
управления полетами ракет, системы контроля состояния окружающей среды,
системы управления в автомобилях и небольшие домашние системы управления.
В результате в язык Ada были включены возможности программирования
параллельных процессов, а также удобные средства для обработки особых случаев
(называемых исключительными ситуациями), которые могут возникать при
работе систем. Самая современная версия языка Ada, известная как Ada 95,
охватывает также объектно-ориентированную парадигму программирования.
Пример программы на языке Ada приведен на рис. ГЛ.
РИСУНОК Г. 1
--Программа обработки списка
with TEXT_IO;
иве ТЕХТ.Ю;
procedure MAIN is
subtype NAME.TYPE ie STRING (1..8);
LIST_LENGTH: constant:=10;
NAMES: array (1..LIST_LENGTH) of NAMEJTYPE;
PIVOT: NAMEJTYPE;
HOLE: INTEGER;
begin
--Прежде всего получаем список имен с клавиатуры
for К in 1 .. LIST_LENGTH loop
GET(NAMES(К));
end loop;
--Сортируем список (переменная HOLE содержит номер пропуска в
списке с момента удаления элемента из списка
и до момента его повторной вставки)
for N in 2 .. LIST_LEN*GTH loop
PIVOT := NAMES(N);
HOLE := N;
for M in reverse 1 . N-l loop
if NAMES(M) > PIVOT
then NAMES(M+l) := NAMES(M);
else exit;
end if;
HOLE := M;
end loop;
NAMES(HOLE) := PIVOT;
end loop;
--Теперь печатаем отсортированный список
for К in 1 .. LI STRENGTH loop
NEW_LINE;
PUT (NAMES (KM;
end loop;
end MAIN;
Пример программы на языке Ada
Язык С
Язык С был разработан в начале 1970-х годов Деннисом Ритчи (Dennis Ritchie),
работавшим в то время в компании Bell Laboratories. Хотя первоначально язык С
создавался для разработки операционных систем и компиляторов, он быстро
получил популярность в среде программистов и приобрел дополнительные преимущества
благодаря его стандартизации, выполненной Американским институтом
национальных стандартов (ANSI — American National Standards Institute).
Язык С сначала рассматривался просто как некоторый шаг вперед по сравнению
с машинным языком. По этой причине его синтаксис более краток и выразителен,
626 Приложение Г
чем синтаксис других языков высокого уровня, использующих полные слова
английского языка для выражения тех языковых конструкций, которые в языке С
представляются с помощью специальных символов. Эта лаконлчность является
одной из причин чрезвычайной популярности языка С, поскольку позволяет
программистам эффективно выражать сложные алгоритмы. (Часто краткое представление
алгоритма более доступно пониманию, чем его пространное описание.)
Пример программы на языке С приведен на рис. Г.2.
РИСУНОК Г2
/* Программа обработки списка */
#include <stdio.h>
#include <string.h>
main()
{
char names[10][9],pivot[9];
int i,j;
/* Ввод имен с клавиатуры */
for (i = 0; i < 10; ++i)
scanf("%s",names[l]);
/* Сортировка списка имен */
for (i = 1; i < 10; ++i)
{
strcpy(pivot,names[i]);
j = i - 1;
while((j>=0) && (strcmp(pivot,names[j]) < 0))
{strcpy(names[j + 1],names[j]); --j; };
strcpy (names [ j-i-1], pivot) ;
}
/* Печать отсортированного списка */
for ( i = 0; i < 10; ++i)
printf("%s\n",names[i]);
}
Пример программы на языке С
Язык С + +
Язык C++ был разработан Бьярни Страуструпом (Bjarne v?>trausstrup) из
компании Bell Laboratories как усовершенствованная версия языка С. Цель создания
языка C++ — достижение совместимости языка С с объектно-ориентированной
парадигмой программирования.
Приложения
627
РИСУНОК ГЗ
// Программа обработки списка
flinclude <lostrearn.h>
#include <string.h>
const int ListLength = 10;
// Все объекты класса list содержат список имен и три открытых
// метода, которые называются getnames, sortlist и printnames.
class list
{private:
char names[ListLength][9];
public:
void getnames()
{int i;
for(i = 0; i< ListLength; ++i)
cin » names[i];
}
void sortlist()
{int i,j;
char pivot[9];
for (i = 1; i < ListLength; ++i)
{strcpy(pivot, names[i]);
j = i - 1;
while((j >= 0) && (stremp(pivot, names[j]) < 0))
{strcpy(names[j+1], names[j]);
— j;
};
strcpy(names[j+1],pivot);
}
}
void printnames()
{int i;
cout « endl;
ford = 0; i < ListLength; ++i)
cout « names[i] « endl;
>;
// Создание объекта с именем namelist и обращение к нему с
// требованием ввести несколько имен, отсортировать их, а
// затем вывести отсортированный список на экран.
void main()
{ list namelist;
namelist.getnames();
namelist.sortlist();
namelist.printnames();
}
Пример программы на языке C++
628 Приложение Г
Реализация алгоритма сортировки вставками на языке C++ представлена на
рис. Г.З. Последние четыре оператора этой программы требуют, чтобы объект
name list был создан как объект, имеющий "тип" (класс) list, после чего новый
объект должен выполнить операции getnames, sortnames и printnames.
Предыдущий фрагмент программы определяет свойства, которыми должны обладать любые
объекты "типа" (класса) list. В частности, любой такой объект должен содержать
массив символов под названием names и три процедуры — getnames, sortnames и
printnames. Обратите внимание, что определения этих процедур такие же, как и в
программе на языке С, представленной на рис. Г.2. Отличие заключается в том, что
в программе на языке C++ эти операции рассматриваются как часть свойств
объекта, в то время как в программе на языке С они считаются отдельными модулями той
части программы, где эти процедуры описываются.
Язык FORTRAN
FORTRAN (сокращение от FORmula TRANslator — транслятор формул) был
одним из первых языков программирования высокого уровня (впервые
опубликован в 1957 году) и первым языком, получившим широкое признание в
компьютерном сообществе. Со временем его официальное описание претерпело
многочисленные изменения, так что теперь можно встретить ссылки на языки
FORTRAN IV и FORTRAN 77. Последним в этом ряду стоит FORTRAN 90,
который является дальнейшим развитием языка FORTRAN 77 и обладает такими
свойствами, как рекурсия и определяемые пользователем типы данных.
Несмотря на то что язык FORTRAN критикуется многими авторами, он остается
популярным в научном мире. В частности, многие пакеты программ по численному
анализу и статистике написаны и, вероятно, до сих пор пишутся на языке
FORTRAN. Пример программы на этом языке представлен на рис. Г.4.
Язык Java
Java — это объектно-ориентированный язык программирования, разработанный
компанией Sun Microsystems в начале 90-х годов. Его разработчики много
позаимствовали из языков С и C++. Будучи новым языком, Java еще не подвергался
стандартизации. Действительно, язык Java все еще находится на стадии эволюции. Однако
многие восторженно относятся к этому языку, поскольку он обещает стать
стандартом для тех программ, которые известны как "аплеты Java" и которые можно
передавать через Internet в виде выполняемых модулей и запускать на любой клиентской
машине. Благодаря такой способности статичные по своей природе гипертекстовые
документы можно заменить динамичными программами, с которыми пользователь
сможет взаимодействовать непосредственно.
Пример программы на языке Java представлен на рис. Г.5. Обратите
внимание на сходство языков Java и C++.
Приложения 629
РИСУНОК Г.4
! Программа обработки списка
INTEGER J,K
CHARACTER(LIJ^B) Pivot
CHARACTER(LFN=8) DIMENSION(IO) Names
! Сначала получаем имена
READ(UNIT=5, FMT=100) (Names(K), K=l,10)
100 FORMAT(A8)
! Теперь сортируем err эк
OuterLoop: DO J=2,10
Pivot = Names(J)
InnerLoop: DO K=J-l,l,-i
IF (Names(K) .GT. Pivot) THEN
Names(K+l) = Names(K)
ELSE InnerLoop
ENDIF
END DO InnerLoop
Names (K+l) = Pivot
END DO OuterLoop
! Теперь выводим отсортированный список на экран
WRITE(UNIT=6,FMT=400) (Names(K), K=l,10)
400 FORMAT C\A8)
END
Пример программы на языке FORTRAN
Язык Pascal
Язык Pascal назван в честь французского математика и изобретателя Блеза
Паскаля (Blaise Pascal) (1623-1662). Разработанный Никлаусом Виртом (Niklaus
Wirth) в 1971 году, этот язык подвергался многочисленным более поздним
улучшениям, в частности особое внимание было уделено типам данных,
созданным в дополнение к структурам, разработан синтаксис со свободным форматом и
добавлены многочисленные управляющие структуры. Сегодня Pascal
используется в основном при обучении компьютерным наукам, поскольку способствует
выработке у обучающихся организованного подхода к разработке программ.
Пример программы на языке Pascal представлен на рис. Г.6.
630 Приложение Г
I РИСУНОК Г.5
// Программа обработки списка
import java.io.*
// Все объекты класса list содержат список имен :i -ри открытых
// метода, которые называются getnames, sortlist v. prir.tnames.
class list {
final int ListLength = 10;
private String[] names;
public list() {
names = new String[ListLength]
}
public void getnames() {
int i;
Datalnput data = new DatalnputStream(System,it);
ford = 0; i < ListLength; i + + )
try( names [1] = data.readLineO; {
catch(IOException e){};
}
public void sortnames() {
int i,j;
String pivot;
for (i = 1; i < ListLength; i++) {
pivot = names[i]);
j = i - 1;
while((j >= 0) && (pivot.compare'^ (names[j]) < 0)) {
names[j +1]=names[j];
j—;
}
names[j+l] = pivot;
}
}
public void printnames() {
int i;
ford = 0; l < ListLength; i + + )
System.out.println(names[i]);
}
}
// Создание объекта с именем namelist и обращение \ нему с
// требованием ввести несколько имен, отсортировав.» их, а
// затем вывести отсортированный список на экран.
class sort {
public static void main (String args[]) {
list namelist = new list();
namelist.getnames();
namelist.sortnames();
namelist.printnamesO ;
}
}
Пример программы на языке Java
Приложения 631
РИСУНОК Г6
{Программа обработки списка}
program InsertSort(Input, Output);
const Blanks = ' ';
ListLength =10;
type NameType = packed array [1 .. 8] of char;
var Names: Array[l .. ListLength] of Nametype;
Pivot: Nametype;
LocationFound: Boolean;
J,M,N: Integer;
{ GetName - это процедура чтения отдельного имени}
procedure GetName(var Name: NameType);
var J: Integer;
begin J := 1;
repeat read(Name[J]); J := J+l; until (J > 8) or eoln;
readln;
end;
begin
{Сначала вводим имя с клавиатуры}
for J := 1 to ListLength do
begin Names[J] := Blanks; Getname(Names[J]) end;
{Сортируем список}
N := 2;
repeat
Pivot := Name[N];
M := N - 1;
LocationFound := false;
while (not LocationFound) do
if Names[M] > Pivot
then begin Names[M+l] := Names[M];
M := M-l;
if M = 0 then LocationFound := true;
end
else LocationFound := true;
Names[M+l] := Pivot;
N := N + 1
until N > ListLength;
{ Теперь выводим отсортированный список на экран }
for J := 1 to ListLength do writeln (Names[J])
end.
Пример программы на языке Pascal
632
Приложение Г
приложение Д
Эквивалентность итеративных
и рекурсивных структур
В этом приложении мы будем использовать наш простейший язык, описанный в
главе 11, в качестве инструмента для поиска ответа на вопрос об относительной
мощности итеративных и рекурсивных структур, поставленный в главе 4.
Напомним, что наш простейший язык содержит только три оператора присваивания
(clear, incr и deer) и одну управляющую структуру (построенную из пары
операторов while-end). Кроме того, он имеет ту же вычислительную мощность, что и
машина Тьюринга. Таким образом, если мы принимаем тезис Черча-Тьюринга, то
должны прийти к заключению, что решение любой задачи, теоретически имеющей
алгоритмическое решение, можно выразить с помощью нашего простейшего языка.
Первый шаг при сравнении мощности итеративных и рекурсивных структур
заключается в замене итеративных структур простейшего языка рекурсивными.
Мы удалим из нашего языка операторы while и end, а вместо этого наделим
язык поддержкой разделения программы на модули и средствами вызова одного
модуля из другого, входящего в состав программы. Точнее говоря, мы
предположим, что каждая программа на модифицированном языке будет состоять из
нескольких синтаксически раздельных программных модулей. Кроме того,
предположим, что каждой программе разрешается содержать только один
модуль MAIN, имеющий следующую синтаксическую структуру:
MAIN: begin
end;
(Здесь точки обозначают наличие других операторов нашего простейшего
языка.) Дополнительно предполагается, что все другие модули (семантически
подчиненные модулю MAIN) должны иметь следующую структуру:
<unit>: begin
return;
(Здесь параметр <unit> представляет имя модуля, которое синтаксически не
отличается от имен переменных.) Семантика этой модульной системы заключается в
том, что программа всегда начинает свое выполнение с модуля MAIN и прекращает
работу, когда в этом модуле будет достигнут оператор end. Другие программные
модули могут вызывав я как процедуры с помощью следующего условного оператора:
if <name> not 0 perform <unit>;
(Здесь параметр <л<зл?е> может быть именем любой переменной, а параметр
<unit> — именем гтобого модуля в программе, кроме MAIN.) Более того, мы
позволим любому модулю, кроме MAIN, рекурсивно вызывать самого себя.
Благодаря наличию в модифицированном языке указанных дополнительных
возможностей можно смоделировать исключенную while-end структуру.
Например, рассмотрим программу на простейшем языке следующего вида:
while X not 0 do;
S;
end;
(Здесь S обозначает любую последовательность операторов простейшего
языка.) Эта программа может быть заменена следующей модульной структурой:
MAIN: begin;
if X not 0 perform unitA;
end;
unitA: begin;
S;
if X not 0 perform unitA;
return;
Следовательно, можно сделать вывод, что модифицированная версия языка
имеет все те же возможности, что и исходная версия простейшего языка.
Можно также показать, что любая задача, которая может быть решена с
помощью модифицированного языка, может быть решена и с помощью исходного
простейшего языка. Для того чтобы показать это, докажем, что любой алгоритм,
выраженный на модифицированном языке, может быть записан и на
простейшем языке. Однако для этого необходимо явно определить способ, которым
рекурсивная структура новой версии языка может быть смоделирована с помощью
структуры while-end простейшего языка.
Для наших целей проще сослаться на тезис Черча-Тьюринга, описанный в
главе 11. В частности, из тезиса Черча-Тьюринга и того факта, что простейший
язык имеет ту же мощность, что и машина Тьюринга, следует, что ни один язык
не может иметь мощность, превышающую мощность исходного простейшего
языка. Таким образом, мы можем сделать заключение, что любая проблема,
допускающая решение средствами модифицированного языка, может быть также
решена средствами исходного простейшего языка.
Теперь мы можем обоснованно утверждать, что мощности модифицированного и
исходного простейшего ч:ыка равны между собой. Единственное отличие состоит в
том, что один реализуем итеративные управляющие структуры, а другой —
рекурсивные. Таким обргзом, мы приходим к выводу, что в смысле вычислительной
мощности эти две управляющие структуры фактически эквивалентны.
634 Приложение Д
приложение с
Ответы на вопросы
для самопроверки
Часть I
Глава 1
Раздел 1.1
1. Значение 1 должно быть на одном и только на одном из двух верхних
входов, а значение на нижнем входе татсже должно быть равно 1.
2. Единица на нижнем входе вызывает появление значения 0 на выходе
логического элемента NOT. Это приводит к тому, что на выходе логического элемента AND
появляется 0. В результате на оба входа логического элемента OR подается
значение 0 (не забывайте, что на верхнем входе триггера сохраняется входное
значение 0), так что на выходе логического элемента OR устанавливается 0. А это
означает, что на выходе логического элемента AND значение 0 сохранится и
после того, как на нижний вход триггера вновь будет подано значение 0.
3. На выходе верхнего логического элемента OR появится значение 1. Это
приведет к тому, что на выходе верхнего логического элемента NOT появится 0.
В результате на выходе нижнего логического элемента OR появится
значение 0, которое будет преобразовано в 1 на выходе логического элемента NOT.
Это единичное значение будет представлять собой выходное значение
триггера и одновременно сигнал обратной связи, подаваемый на верхний
логический элемент OR. В результате на его выходе значение 1 будет сохраняться и
после того, как на оба входа триггера вновь будет подано значение 0.
4. Триггер будет закрыт, когда значение сигнала синхронизации будет равно 0,
и открыт, когда значение сигнала синхронизации будет равно 1.
5. a) 6AF2 б) Е85517 в) 4 8
6. а) 010111111110110010111
б) 0110000100001010
в) 1010101111001101
г) 0000000100000000
Раздел 1.2
1. В первом случае после завершения операции ячейка памяти с адресом 6 будет
содержать значение 5. Во втором случае эта ячейка будет иметь значение 8.
2. В результате выполнения первой же операции предыдущее значение в
ячейке с адресом 3 будет удалено, поскольку новое значение
записывается поверх него. Следовательно, после выполнения второй операции
предыдущее значение из ячейки с адресом 3 не будет перенесено в ячейку с
адресом 2. В результате обе ячейки будут содержать значение, которое
исходно хранилось в ячейке с адресом 2. Правильная процедура должна
быть следующей.
Шаг 1. Переместить содержимое ячейки с адресом 2 в ячейку с адресом 1.
Шаг 2. Переместить содержимое ячейки с адресом 3 в ячейку с адресом 2.
Шаг 3. Переместить содержимое ячейки с адресом 2 в ячейку с адресом 3.
3. 32 768 бит.
Раздел 1.3
1. Более высокая скорость считывания и передачи данных.
2. Здесь следует вспомнить, что механическое движение намного медленнее
электронных процессов, протекающих в компьютере. Это вынуждает нас
минимизировать количество перемещений магнитных головок. Если
необходимо полностью заполнять поверхность данными перед тем, как
перейти к следующей поверхности, придется перемещать магнитную
головку каждый раз, когда очередная дорожка будет закончена. В
результате количество перемещений головок будет приблизительно равно
общему количеству дорожек на обеих поверхностях. Однако если
переходить с одной поверхности на другую путем электронного переключения
между магнитными головками, то перемещать магнитные головки
потребуется только после того, как будет заполнен очередной цилиндр.
3. В этом приложении объем данных постоянно то увеличивается, то
уменьшается. Если бы информация хранилась на ленте, это привело бы к
бесконечному перезаписыванию данных. При этом остаток записей постоянно
записывался бы туда и обратно вследствие сдвига записей при обновлении
данных или их удалении. Однако при хранении данных на диске каждое
изменение происходит только в том блоке данных, который располагается в
соответствующем секторе. Следовательно, при обновлении данных
понадобится намного меньше перезаписей.
4. Распределение логических записей по разным секторам означает, что для
получения полной логической записи понадобится прочитать с диска
несколько секторов. Затраты времени на чтение этих дополнительных
секторов легко может перевесить преимущества экономии дискового
пространства.
636 Приложение Б
Раздел 1.4
1. Computer science (Компьютерные науки).
2. Две эти битовые комбинации практически одинаковы, за исключением того,
что шестой бит, считая от младших разрядов к старшим, всегда равен 0 для
прописных букв и 1 — для строчных.
3. а) 01010111 01100101 01100101 01110101
01101000 00100000 00100000 00111111
01100101 01100001 01111001
01110010 01111001 01101111
б) 00100010 01001000 01101111 01110111
00111111 00100010 00100000 01000011
01101000 01100101 01110010 01111001
01101100 00100000 01100001 01110011
01101011 01100101 01100100 00101110
в) 00110010 00101011 00110011 00111101
00110101 00101110
4.
5. а) 5 б) 9 в) 11 г) 6 д) 16 е) 18
6. а) 110 б) 1101 в) 1011 г) 10010
д) 11011 е) 100
7. В 24 битах можно хранить три символа в кодировке ACSII, т.е. числа от 0
до 999. Однако если использовать эти биты как разряды двоичного числа, то
в них можно будет хранить целые числа, вплоть до 16 777 215.
8. а) 15.15 б) 51.0.128 в) 10.160
Раздел 1.5
1. а) 42 б) 33 в) 23 г) 6 д) 31
2. а) 100000 б) 1000000 в) 1100000 г) 1111 д) 11011
3. а) 374 б) 57/8 в) 2V2 г) 63Д Д) 5Л
4. а) 100.1 б) 10.11 в) 1.001 г) 0.0101 д) 101.101
5. а) 100111 б) 1011.110 в) 100000 г) 1000.00
Раздел 1.6
1. а) 3 б) 15 в) -4 г) -6 д) 0 е) -16
2. а) 00000110 б) 11111010 в) 11101111
г) 00001101 д) 11111111 е) 00000000
Приложения
637
3. а) 11111111 б) 10101011 в) 00000100
г) 00000010 д) 00000000 е) 10000001
4. а) При 4 битах наибольшее число равно 7, а наименьшее 8.
б) При 6 битах наибольшее число равно 31, а наименьшее 32.
в) При 8 битах наибольшее число равно 127, а наименьшее 128.
5. а) 0111 (5+2=^) б) 0100 (3+1=4) в) 1111 (5+(-6)=-1)
г) 0001 (-2+3 ) д) 1000 (-6+(-2)=-8)
6. а) 0111 б) ООН (переполнение) в) 0100 (переполнение)
г) 0001 д) 1000 (переполнение)
7. а) ОНО б) ООН в) 0100 г) 0010 д) 0001
+0001 4-11Ю +1010 +0100 +1011
0111 1001 1110 ОНО 1100
8. Нет. Переполнение возникнет при попытке записать в память число, которое
слишком велико для используемой системы. При добавлении положительного
числа к отрицательному результат будет равен числу, не превышающему по
модулю каждое из этих слагаемых. Таким образом, если исходные числа
достаточно малы, чтобы храниться в памяти, то и результат также поместится в памяти.
9. а) б поскольку 1110 —» 14-8
б) -1 поскольку 0111 -> 7-8
в) 0 поскольку 1000 -> 8-8
г) -6 поскольку 0010 -» 2-8
д) -8 поскольку 0000 —> 0-8
е) 1 поскольку 1001 -» 9-8
10. а) 1101 поскольку 5+8 = 13 -» 1101
б) ООН поскольку -5+8=3 —> ООН
в) 1011 поскольку 3+8=11 —> 1011
г) 1000 поскольку 0+8 =8-> 1000
д) НИ поскольку 7 + 8 = 15 -> 1111
е) 0000 поскольку -8 + 8 -> 0000
11. Нет. Наибольшее число, которое можно представить в двоичной нотации с
избытком 8, равно 7, т.е. 1111. Чтобы представить большее число (которое
использует 5 бит), нужно выбрать основание, равное, как минимум, 16.
Аналогично число б не может быть выражено в двоичной нотации с избытком 4.
(Наибольшее число, которое может быть представлено в этом коде, равно 3.)
Раздел 1.7
1. а) 5Д б) п/А в) 732 г) -11/2 д) -п/б4
2. а) 01101011 б) 01111010 (ошибка округления) в) 01001100
г) ИЮНЮ д) 11111000 (ошибка округления)
638 Приложение Б
3. 01001001 (9/,6) больше 00111101 (1Я/Зг). Ниже приведен простой способ
определения, какой из двоичных кодов представляет собой большее число.
Случай 1. Если знаковые биты чисел разные, тогда из двух чисел больше то, у которого
знаковый бит равен 0.
Случай 2. Если оба знаковых бита чисел равны о, нужно просмотреть оставшуюся часть кода
слева направо, пока не встретится битовая позиция, в которой числа отличаются друг от друга.
Двоичный код, у которого в этой позиции сто: -1, представляет собой большее число.
Случай 3. Если знаковые биты обоих чисел равны 1, необходимо просмотреть оставшуюся часть
кода слева направо, пока не встретится битовая позиция, в которой числа отличаются друг от
друга. Двоичный код, у которого в этой позиции стоит о, представляет собой большее число.
Простота этого способа сравнения двух чисел является одной из причин, по
которой экспоненты чисел с плавающей точкой представляются в двоичной
нотации с избытком, а не в дополни ^>льном коде.
4. Большим значением было бы 7г/2, которое в двоичной системе счисления
имеет вид 01111111. Что касается наименьшего положительного значения, то
можно было бы сказать, что существуют "два" правильных ответа. Если
придерживаться описанного в тексте процесса кодирования, требующего, чтобы
самый старший значащий бит мантиссы был равен 1 (нормализованная
форма), то в этом случае ответом является число */з2» которое в двоичной системе
счисления имеет вид 00001000. Однако большинство машин не накладывает
ограничений на значения, близкие к нулю. Для таких машин правильным
ответом будет число 1/25ы которое в двоичной системе счисления будет равно
00000001.
Раздел 1.8
1. В шестнадцатеричном представлении сообщение будет иметь вид
B5E95EFA56.
2. Ответы могут быть различными. Один из возможных вариантов —
рраррраара (5,5, р) (10,7,а).
3. Цветные мультфильмы состоят из блоков сплошного цвета с резкими
контурами. Кроме того, количество используемых цветов ограничено.
4. Может существовать до 1049576 пикселей, для кодирования цвета
каждого из которых потребуется 1 байт. Таким образом, максимальный
размер изображения в формате GIF — 1 Мбайт. Этот размер можно
значительно уменьшить за счет применения при кодировании изображений в
формате GIF дополнительных алгоритмов сжатия информации, хотя их
эффективность зависит от сложности изображения. При кодировании в
формате GIF простого изображения размер файла обычно не превосходит
нескольких килобайт. Если же используется стандарт JPEG, каждый
блок пикселей размером 2x2 элемента требует определения только 6
компонентов. Если предположить, что одному компоненту соответствует
один байт, то для кодирования изображения размером 1024x1024 пиксе-
Приложения 639
лей потребуется максимум 1,5 Мбайт дискового пространства, однако с
помощью дополнительных методов сжатия размер файла изображения
можно будет сократить до 100 Кбайт и меньше.
5. Стандарт JPEG использует преимущество того, что человеческий глаз не
так чувствителен к изменению цвета изображения, как к изменению его
яркости. По этой причине в формате JPEG сокращено количество битов
для представления информации о цвете без ощутимой потери качества
изображения.
Раздел 1.9
1. Пункты б, в и д.
2. Да. Если в одном байте окажется четное количество ошибок, то проверка
четности не позволит их обнаружить.
3. В этом случае ошибки возникают в байтах а и г из вопроса 1. Ответ на
вопрос 2 тот же.
4. а) 001010111 001101000 101100101
101110010 101100101 100100000
001100001 101110010 101100101
000100000 001111001 101101111
001110101 100111111
б) 100100010 101001000 101101111
101110111 100111111 100100010
000100000 001000011 001101000
101100101 101110010 001111001
101101100 001000000 001000001
001110011 001101011 101100101
001100100 100101110
в) 000110010 100101011 100110011
000111101 100110101 100101110
5. a) BED б) CAB в) HEAD
6. Одно из решений таково:
А 0 0 0 0 0
В 1110 0
С 0 1111
D 10 0 11
640
Приложение Е
Глава 2
Раздел 2.1
1. На малых машинах это действие часто представляет собой процесс, состоящий
из следующих двух этапов: сначала содержимое первой ячейки копируется в
регистр, а затем записывается в предназначенную для него ячейку памяти. На
большинстве больших машин этот процесс выполняется за один этап.
2. Значение, которое должно быть записано; адрес ячейки, в которую должно
быть записано значение и команда записи.
3. Термин переместить (move) часто означает удаление значения из одного места
и запись его в другое, при этом предыдущее место его хранения остается
пустым. Однако в большинстве случаев обработки данных в компьютерах объект,
подлежащий перемещению, просто копируется (или клонируется) в новое место.
4. Общий прием, называемый относительной адресацией, заключается в
указании, насколько далеко, а не куда именно переходить. Например, перейти на
три команды вперед или на две команды назад. Следует заметить, что такие
команды потребуется изменять, если между исходной командой перехода и
командой, на которую следует перейти, позднее будут вставлены
дополнительные команды.
5. Ответ на этот вопрос можно обосновать по-разному. Команда записана в
форме условного перехода. Однако, поскольку поставленное условие, что
О должен быть равен 0, выполняется всегда, переход всегда будет
выполняться так, как если бы никакого условия вовсе не было. Машины с
такими командами встречаются часто, поскольку эти команды очень
эффективны. Например, если машина разработана для выполнения команд,
имеющих структуру вида "Если..., то перейти на ...", то такую команду
можно использовать как для условного, так и безусловного перехода.
Раздел 2.2
1. 156С = 0001010101101100
166D = 0001011001101101
5056 = 0101000001010110
306Е = 0011000001101110
2. а) Сохранить (STORE) содержимое регистра б в ячейке памяти с адресом 8А.
б) Перейти (JUMP) на команду в ячейке с адресом DE, если содержимое
регистра А равно содержимому регистра 0.
в) Выполнить поразрядную операцию И (AND) над содержимым регистров 3
и С, поместив результат в регистр 0.
г) Переместить (MOVE) содержимое регистра F в регистр 4.
3. Команда 15АВ требует, чтобы центральный процессор запросил у схемы
управления основной памятью содержимое ячейки с адресом АВ.
Извлеченное из памяти значение помещается в регистр 5. Команда 25АВ не преду-
Приложения 641
сматривает такого запроса к памяти. Точнее говоря, в регистр 5 просто
помещается значение АВ.
4. а) 2356 б) А503 в) B7F3 г) 80А5
Раздел 2.3
1. Шестнадцатеричное 34.
2. a) OF б) СЗ
3. а) 00 б) 01 в) Четыре раза
4. Машина прекращает работу. Это пример того, что принято называть
самоизменяющимся кодом, т.е. программа сама изменяет себя. Обратите
внимание, что первые две команды помещают шестнадцатеричное число СО в
ячейку памяти с адресом F8, а следующие две команды — значение 00 в
ячейку с адресом F9. Таким образом, в то время, когда машина выберет
команду из ячейки с адресом F8, там уже будет храниться команда
прекращения работы СО00.
Раздел 2.4
1. а) 00001011 б) 10000000 в) 00101101
г) 11101011 д) 11101111 е) 11111111
ж)11100000 з) 01101111 и) 11010010
2. 0011100 с операцией AND
3. 0011100 с операцией XOR
4. а) Окончательный результат равен 0, если строка содержит четное
количество вхождений цифры 1. В противном случае значение будет равно 1.
б) Результат равен значению бита четности при проверке четности.
5. Логическая операция XOR фактически совпадает с операцией сложения, за
исключением случая, когда оба операнда равны 1. В этом случае результат
операции XOR равен 0, в то время как сумма будет равна 10. Таким образом,
операция XOR может рассматриваться как операция сложения без переноса
разряда переполнения.
6. Для преобразования строчных букв в прописные можно использовать
операцию AND с маской 01011111. Для преобразования прописных букв в
строчные — операцию OR с маской 00100000.
7. а) 01001101 б) 11100001 в) 11101111
8. а) 57 б) В8 в) 6F д) 6А
9. 5
10. В двоичном дополнительном коде — 00110110; в виде числа с плавающей
точкой — 01011110. Дело в том, что процедуры сложения двух чисел
отличаются в зависимости от интерпретации заданных двоичных кодов.
11. Одно из решений будет следующим:
642 Приложение Б
12А7 (загрузка в регистр 2 содержимого ячейки с адресом А7)
2380 (загрузка в регистр 3 значения 80)
7023 (операция OR над содержимым регистров 2 и 3 с помещением
результата в регистр 0)
30А7 (запись содержимого регистра 0 в ячейку памяти с адресом А7)
СО00 (прекращение выполнения программы)
12. Одно из решений будет таковым:
15Е0 (загрузка в регистр 5 содержимого ячейки памяти с адресом Е0)
А502 (циклический сдвиг содержимого регистра 5 на два бита вправо)
2 60F (загрузка в регистр б значения OF)
8056 (поразрядная операция AND над содержимым регистров 5 и б
с помещением результата в регистр 0)
30Е1 (запись содержимого регистра 0 в ячейку памяти с адресом Е1)
СО00 (прекращение выполнения программы)
Раздел 2.5
1. а) 37В5
б) Миллион раз.
в) Нет. Обычная страница текста содержит меньше 4000 символов. Таким
образом, возможность напечатать 5 страниц в минуту означает, что
скорость печати приблизительно равна 20 000 символов в минуту, что
значительно меньше, чем один миллион символов в минуту. (Дело в том, что
компьютер может посылать символы на принтер намного быстрее, чем
принтер сможет их напечатать; таким образом, принтер должен иметь
возможность попросить компьютер подождать.)
2. Диск будет выполнять 50 оборотов в секунду. Это означает, что за одну секунду
под головкой чтения/записи будет проходить 800 секторов. Поскольку каждый
сектор вмещает 1024 байта, биты будут проходить под головкой чтения/записи
со скоростью приблизительно 6,5 Мбайт/с. Таким образом, обмен данными
между контроллером и дисководом должен происходить с этой же скоростью,
чтобы контроллер мог успевать получать данные, проходящие под головкой диска.
3. Роман в триста страниц, записанный в кодах ASCII, содержит около
1 Мбайт, или 8 000 000 бит информации. Таким образом, для передачи
всего романа со скоростью 57 600 бит/с потребуется приблизительно 139 секунд
(или 2*/з минуты).
Раздел 2.6
1. Один набор регистров используется для извлечения, декодирования и
выполнения микрокоманд, тогда как другой применяется для извлечения,
декодирования и выполнения команд машинного языка в соответствии с
микропрограммой.
2. Конвейер может содержать команды В1В0 (выполняемая в данный момент),
5002 и, возможно, даже ВОАА. Если значение в регистре 0 равно значению в
Приложения 643
регистре 1, выполняется переход к ячейке с адресом ВО и работа,
затраченная на подготовку команд на конвейере, оказывается бесполезной. Однако
при этом не происходит потери времени, поскольку работа, затраченная на
эти команды, не требовала дополнительного времени.
3. Если не предпринять меры предосторожности, информация из ячеек с адресами
F8 и F9 будет извлечена в качестве команды еще до того, как предыдущая часть
программы получит возможность изменить содержимое этих ячеек.
4. а) Первым прочитать хранящееся в этой ячейке значение может
центральный процессор, который пытается добавить 1 к ее содержимому. Затем
это же значение читает другой центральный процессор. (Обратите
внимание, что в этом случае оба процессора считали одно и то же значение.)
Если первый центральный процессор завершит операцию сложения и
запишет результат назад в ячейку до того, как второй процессор завершит
операцию вычитания и запишет свой результат, то окончательное
значение, хранящееся в ячейке, будет отражать результаты работы только
второго процессора.
б) Центральные процессоры считывают данные из ячейки так же, как это
было описано выше, но на этот раз второй центральный процессор может
записать результаты своей работы раньше первого центрального
процессора. В результате окончательное значение, записанное в ячейке, будет
отражать результаты работы только первого центрального процессора.
Часть II
Глава 3
Раздел 3.1
1. Традиционным примером является очередь людей, желающих купить билет
на представление. В этом случае может найтись некто, желающий обойти
очередь, что может привести к разрушению структуры FIFO.
2. Пункты бив.
3. Обработка в реальном времени означает согласование выполнения
программы с процессами, происходящими в машине. Интерактивная обработка
означает взаимодействие человека с программой во время ее выполнения. Для
успешной интерактивной обработки требуются хорошие показатели
обработки в реальном времени.
4. Разделение времени — это метод, с помощью которого многозадачность
реализуется на машине с одним процессором.
Раздел 3.2
1. Оболочка. Осуществляет взаимодействие с внешней средой, окружающей
компьютер.
644 Приложение Е
Менеджер файлов. Координирует использование внешних запоминающих
устройств.
Драйверы устройств. Обеспечивают взаимодействие системы с
периферийными устройствами.
Менеджер памяти. Координирует использование основной памяти компьютера.
Планировщик. Координирует выполнение в системе различных процессов.
Диспетчер. Контролирует распределение времени центрального процессора
между различными процессами.
2. Граница между этими понятиями неясна и различие часто проводится лишь
умозрительно. Грубо говоря, утилиты выполняют основные, универсальные
задачи, тогда как прикладное программное обеспечение выполняет задачи,
специфические для данного пользователя.
3. Виртуальная память — это воображаемое пространство памяти, которое
обеспечивается процессом перемещения (подкачки) данных и программ из
памяти на жесткий диск и обратно.
4. При включении машины центральный процессор начинает выполнять
программу начальной загрузки, текст которой хранится в ROM. В процессе
загрузки центральный процессор копирует программы операционной системы
из внешнего запоминающего устройства в некоторую область основной
памяти. После завершения копирования он передает управление
соответствующей программе операционной системы.
Раздел 3.3
1. Программа — это множество команд. Процесс — это действия,
выполняемые в соответствии с этими командами.
2. Центральный процессор завершает текущий машинный цикл, сохраняет
состояние текущего процесса и устанавливает в счетчике адреса заранее
определенное значение (которое является адресом обработчика прерываний).
Таким образом, следующая выполняемая команда — это первая команда в
обработчике прерываний.
3. Они могли бы получить более высокий приоритет и, значит, пользоваться
определенным предпочтением у диспетчера. Другой вариант — выделить
больший промежуток времени для выполнения процессов, имеющих более
высокий приоритет.
4. Каждую секунду машина сможет выделять по одному полному кванту
времени 18 процессам.
5. В целом 10/,, машинного времени может быть затрачено на собственно
выполнение вычислительных процессов. Когда процесс запрашивает
выполнение операции ввода/вывода данных, выделенный этому процессу квант
времени процессора завершается и процессор приступает к обработке запроса.
Таким образом, если каждый процесс будет выдавать запрос на ввод/вывод
Приложения 645
через 5 миллисекунд после получения кванта времени, эффективность
работы машины может снизиться до 1/2. Иными словами, машина будет
затрачивать на выполнение необходимых переключений столько же времени,
сколько и на выполнение самих процессов.
6. В качестве примеров можно предложить работу компании "Товары-почтой"
и обслуживаемых ею клиентов, биржевого брокера и его клиентов или
фармацевта и его клиентов.
Раздел 3.4
1. Эта система гарантирует, что в каждый момент времени ресурс будет
использоваться не более чем одним процессом. Однако это требует выполнять
распределение ресурсов совершенно иным образом. Если процесс
использовал и освободил ресурс, он должен ожидать, пока другие процессы
воспользуются им, прежде чем он снова сможет получить к нему доступ. Этот
порядок будет сохраняться даже в том случае, когда процесс очень скоро вновь
будет нуждаться в данном ресурсе, а другой процесс какое-то время сможет
обходиться без него.
2. Если два автомобиля одновременно въезжают в туннель с противоположных
концов, каждый из них не будет знать о присутствии другого. Процесс въезда и
включения света — это другой пример критической области или, в данном
случае, критического процесса. Пользуясь этой терминологией, можно обобщить
недостатки, сказав, что автомобили на противоположных концах туннеля могут
начать выполнение критического процесса одновременно.
3. а) Это гарантирует, что потребности в разделении ресурса не возникнет и он
не будет распределяться между многими процессами, т.е. автомобиль
получает в свое распоряжение или весь мост или не получает ничего.
б) Это означает, что неделимый ресурс может быть получен принудительно.
в) Это превращает неделимый ресурс в разделяемый, что устраняет всякую
конкуренцию.
4. Последовательность стрелок, образующих замкнутый цикл в направленном
графе. На этой основе был разработан метод, позволяющий операционной
системе распознать ситуацию взаимной блокировки и предпринять
соответствующие действия по ее устранению.
Раздел 3.5
1. Открытая сеть — это сеть с открытыми спецификациями и протоколами,
позволяющими различным поставщикам производить совместимые продукты.
2. Маршрутизатор — это компьютер, соединяющий между собой две сети.
Точнее, маршрутизатор — это компьютер, соединяющий между собой две сети,
использующие один и тот же протокол Internet. Шлюз — это компьютер,
соединяющий между собой две сети, которые для работы в Internet
используют разные протоколы.
3. Полный адрес узла в Internet состоит из идентификатора сети и адреса узла.
646 Приложение Е
4. Адрес URL — это, в сущности, адрес документа в подсистеме World Wide
Web. Броузер — это программа, которая помогает пользователю получить
доступ к гипертекстовому документу.
5. Любой разрыв в кольце может нарушить связь. Если же сообщение можно
передавать в обоих направлениях, то один разрыв в кольце может и не
повредить связь.
Раздел 3.6
1. Канальный уровень получает сообщение и передает его на сетевой уровень.
На сетевом уровне обнаруживается, что сообщение предназначено для
другого компьютера, после чего к сообщению присоединяется адрес
промежуточного компьютера и оно возвращается назад на канальный уровень.
2. В отличие от протокола TCP, UDP — это протокол без обратной связи,
который не подтверждает получения сообщения адресатом.
3. Каждому сообщению присваивается счетчик переходов по сети, который
определяет максимальное число выполнения передачи сообщения между
компьютерами.
4. Фактически ничего. На любом компьютере в Internet программист может так
модифицировать программное обеспечение, чтобы этот компьютер мог сохранять
такие записи. Вот почему конфиденциальные данные следует шифровать.
Раздел 3.7
1. Использование паролей защищает данные (а значит, и информацию).
Использование шифрования защищает только информацию.
2. В контексте нашего изложения ЕСРА определяет права собственности,
имеющие отношение к электронным средствам связи.
3. Если соответствие закону технически невозможно, то этот закон не будет (не
может) выполняться. Требования CALEA как технически, так и финансово
трудновыполнимы. Это означает, что соответствие закону является
проблематичным.
Глава 4
Раздел 4.1
1. Процесс — это выполнение алгоритма. Программа — это запись алгоритма.
2. Во вступительной глав? этой книги приводились примеры алгоритмов для
исполнения музыкальных произведений, управления стиральными машинами,
конструирования моделей, исполнения фокусов, а также алгоритм Евклида.
Многие из "алгоритмов", с которыми мы сталкиваемся в обыденной жизни, не
соответствуют его формальному определению. В тексте был приведен пример
алгоритма деления столбиком. Другой пример — алгоритм, который день за днем
выполняют часы, перемещая свои стрелки и отсчитывая время.
Приложения 647
3. Неформальное определение не отвечает требованию, по которому шаги
алгоритма должны быть последовательными и однозначными. Оно сводится к
общим требованиям, чтобы шаги были выполнимыми и в итоге приводили к
определенному результату.
4. Здесь есть два важных момента. Первый заключается в том, что эти
команды определяют бесконечный процесс. Однако в действительности процесс
рано или поздно достигнет ситуации, когда в кармане больше не останется
ни одной монеты. Второй момент состоит в том, что фактически в этой
ситуации алгоритм может даже начаться. С данной точки зрения задача
является неоднозначной. Представленный алгоритм не "говорит" нам, как
поступить в этой ситуации.
Раздел 4.2
1. Один из примеров можно получить методом композиции. На химическом
уровне примитивами считаются молекулы, хотя в действительности эти
частицы состоят из атомов, которые, в свою очередь, образуются из электронов,
протонов и нейтронов. Сегодня мы знаем, что даже эти "примитивы" имеют
составные части.
2. Если процедура составлена правильно, ее можно использовать в качестве
строительного блока для более крупных программных структур без
пересмотра ее внутреннего устройства.
3. assign X the value большее из двух заданных чисел;
assign Y the value меньшее из двух заданных чисел;
while (Y не нуль) do
(assign Remainder the value остаток от деления X на Y;
assign X the value Y;
assign Y the value Remainder)
assign GCD the value X
4. Все цвета можно получить в результате сочетания красного, синего и
зеленого цветов, поэтому телевизионные электронно-лучевые трубки
разрабатываются так, чтобы генерировать именно эти три основных цвета.
Раздел 4.3
1. a) if (п = 1 или п = 2)
then (Ответ - это список, содержащий одно число п)
else (Разделить п на 3, получив частное q и остаток г.
if (г = 0)
then (Ответ - это список, содержащий q троек)
if (г = 1)
then (Ответ - это список, содержащий q-1 троек и 2 двойки;)
if (r = 2)
then (Ответ - это список, содержащий q троек и одну двойку)
)
648 Приложение Б
б) Результатом был бы список, содержащий 667 троек.
в) Возможно, вы экспериментировали с малыми входными величинами
перед тем, как нашли подходящий вариант решения.
2. а) Да. Подсказка. Поместите первую фишку в центр доски так, чтобы она не
попала в квадрант, содержащий вырезанный квадрат, а накрыла по одному
квадрату во всех остальных квадрантах. В результате каждый квадрант
будет представлять собой уменьшенный вариант исходной задачи.
б) Доска с одним вырезанным квадратом содержит 2 — 1 квадратов, и
каждая фишка покрывает точно три квадрата.
в) Части а и б этого вопроса представляют собой замечательный пример
того, как знание решения одной проблемы позволяет решить другую. См.
четвертую фазу Полна.
3. Он говорит: "Это правильный ответ".
Раздел 4.4
1. Изменить условие в операторе while так, чтобы он читался следующим
образом: "Искомое значение не равно текущему входному значению, и есть
еще входные значения, подлежащие проверке".
2. assign Z the value 0;
assign X the value 1;
repeat (assign Z the value Z + X;
assign X the value X + 1)
until (X = 6)
3. Cheryl Alice Alice
George Cheryl Bob
Alice George Cheryl
Bob Bob George
4. Настаивать на том, чтобы предшествующий элемент помещался на то же
место в списке, бессмысленно. Например, сделайте предложенные изменения,
а затем примените новую программу к списку, все элементы которого
одинаковы.
5. procedure sort(<список>)
assign N the value 1;
while (N меньше длины <список>) do
(assign J the value N + 1;
while (J не больше длины <список>) do
(if (элемент в позиции J меньше, чем элемент в позиции N)
then (поменять местами эти два элемента)
assign J the value J + 1)
assign N the value N+ 1)
Приложения 649
6. Приведенное ниже решение является неэффективным. Можете ли вы
сделать его более эффективным?
procedure s о г t(< список>)
assign N the value длина <список>;
while (N больше чем 1) do
(assign J the value длина <список>;
while (J больше 1) do
(if (элемент в позиции J меньше элемента в позиции J - 1)
then (поменять местами эти два элемента)
assign J the value J - 1)
assign N the value N - 1)
Раздел 4.5
1. Первый подсписок состоит из имен, следующих за именем Henry, т.е. Irene,
Joe, Karl, Larry, Mary, Nancy и Oliver. Далее идут имена из этого списка,
предшествующие имени Larry, т.е. Irene, Joe и Karl. Теперь в очередном
цикле поиска искомое имя Joe будет найдено в середине рассматриваемого
подсписка.
2. 8, 17
3. Alice Alice
Carol Bob
Bob Carol
Larry Larry
John John
В итоге будет выполнено четыре вызова процедуры.
4. В результате выполнения процесса список будет отсортирован. Однако его
выполнение будет сопровождаться излишней потерей времени, поскольку
при первом вызове процедуры первый элемент списка сначала удаляется, а
потом возвращается на прежнее место.
5. Будет выполнено несколько вызовов процедуры. При каждом из них элемент
будет просто удаляться из списка, а затем возвращаться на прежнее место.
Раздел 4.6
1. Если машина может отсортировать список из 100 имен за секунду, то она
способна выполнять V-rdO 000 - 100) сравнений в секунду. Это означает,
что каждое сравнение выполняется приблизительно за 0,0004 секунды.
Следовательно, сортировка списка из 1000 имен (которая в среднем потребует
выполнения VvtЮ 000 000 - 1000) сравнений) займет около 100 секунд,
или 12/3 минуты.
650 Приложение Б
2. Алгоритм бинарного поиска принадлежит к классу 0(lgn), алгоритм
последовательного поиска — к классу 0(п), а алгоритм сортировки вставками — к
классу 0(п2).
3. Класс 0(lg n) содержит наиболее эффективные алгоритмы, за которыми
следуют алгоритмы классов 0(п), 0(п2) и 0(п3).
4. Нет. Ответ неправильный, хотя может показаться верным. На самом деле у
двух из трех карт обе стороны одинаковы. Следовательно, вероятность
выбора такой карты равна 2/3.
5. Нет. Если делимое меньше делителя, как, например, в дроби 3/7, ответ будет
равен 1, хотя он должен быть равен 0.
6. Нет. Если значение переменной X равно 0, а значение переменной Y не
равно 0, то полученный ответ будет неверным.
7. Каждый раз, когда выполняется проверка условия прекращения
суммирования, утверждение "Sum = 1 + 2 + ... + I и I меньше или равно N" является
истинным. Объединяя его с условием прекращения суммирования "I больше
или равно N", мы получим желаемый вывод "Sum = 1 + 2 + ... + N". Поскольку
переменная I инициализирована нулем и увеличивается на каждом шаге
цикла, в итоге ее значение обязательно должно достичь значения N.
8. К сожалению, нет. Проблемы, выходящие за рамки управления разработкой
аппаратного и программного обеспечения, такие как механические сбои и
электрические помехи, могут оказать влияние на ход вычислений.
Глава 5
Раздел 5.1
1. Программа на языке третьего поколения является машинно-независимой в
том смысле, что ее команды не содержат машинные атрибуты, такие как
номера регистров и машинные адреса ячеек памяти. Кроме того, она
является машинно-зависимой, поскольку в ней по-прежнему возможны ситуации
арифметического переполнения и появления ошибки округления.
2. Основное отличие заключается в том, что ассемблер переводит каждую
команду исходной программы в единственную машинную команду, тогда как
компилятор часто порождает сразу несколько команд на машинном языке,
чтобы получить эквивалент единственной команды исходной программы.
3. Декларативная парадигма программирования основывается на разработке
описания задачи, которую требуется решить. Функциональная парадигма
требует от программиста описывать решение задачи в виде решений более
мелких задач. Объектно-ориентированное программирование делает упор на
описании компонентов предметной области задачи.
Приложения 651
4. Вот несколько примеров подстрок:
forward backward cha cha cha
backward forward cha cha cha
swing right cha cha cha
swing left cha cha cha
Раздел 5.5
1. Класс — это описание объекта.
2. Класс Employee может содержать информацию об имени сотрудника, его
адресе, стаже и т.п.; класс FullTimeEmployee — сведения о пенсионных
выплатах; класс PartTimeEmployee — информацию о количестве рабочих
часов, отработанных за неделю, о почасовой ставке и т.п.
3. Инкапсуляция — это ограничение доступа. Инкапсулировать свойства
объекта — значит ограничить доступ к ним только самим этим объектом.
Раздел 5.6
1. Список может включать способы инициирования выполнения параллельных
процессов и методы реализации обмена данными между ними.
2. Первые делают упор на процессах, а вторые — на данных. Вторые имеют
преимущество, заключающееся в концентрации задачи в единственной точке
программы.
Раздел 5.7
1. Высказывания R, Т и V. Например, мы можем показать, что высказывание R
является следствием, посредством добавления его отрицания к совокупности
высказываний и применения резолюции, которая может привести к пустому
высказыванию, как показано ниже.
Приложения
653
2. Нет. Совокупность высказываний является противоречивой, поскольку
резолюция может привести к пустому высказыванию, как показано ниже.
3. a) thriftier(sue,carol)
thriftier(sue, John)
б) thriftier(sue,carol)
thriftier(bill, carol)
в) thriftier(carol, John)
thriftier(bill, sue)
thriftier(sue, carol)
thriftier(bill, sue)
thriftier(sue, John)
Глава 6
Раздел 6.1
1. В контексте разработки программы длинная последовательность операторов
присваивания не сложнее нескольких вложенных операторов if.
2. Один подход заключается в преднамеренном внесении некоторых ошибок в
программное обеспечение при его разработке. Затем, после того как
программное обеспечение предположительно отлажено, проверяют, много ли
внесенных ошибок осталось неисправленными. Если из 7 внесенных
ошибок 5 было исправлено, можно сделать вывод, что только 5/7 от общего
количества ошибок было исправлено.
3. Как возможный вариант, в качестве метрики можно предложить количество
ошибок, найденных после некоторого периода эксплуатации программного
обеспечения. В данном случае одна из возможных проблем заключается в
том, что эту величину невозможно измерить заранее.
654 Приложение Е
Раздел 6.2
1. Системные требования формулируются в терминах предметной области
приложения, тогда как спецификации формулируются в технических терминах
и определяют, как именно будут удовлетворяться системные требования.
2. При анализе определяются задачи, которые должна решать предполагаемая
система. На стадии разработки уточняется, как именно система будет
выполнять свои задачи. При реализации осуществляется реальное создание
системы. Стадия тестирования предназначена для того, чтобы
удостовериться, что система действительно делает то, для чего она была предназначена.
3. Традиционный нисходящий подход требует, чтобы анализ, разработка,
реализация и тестирование выполнялись строго последовательно. Модель с построением
прототипов предусматривает применение более гибкого метода проб и ошибок.
Раздел 6.3
1. Главы романа следуют одна из другой в единой сюжетной линии, в то время
как статьи энциклопедии в значительной степени независимы друг от друга.
Следовательно, между главами в романе существует больше связей, чем
между статьями в энциклопедии. Однако статьи в энциклопедии, вероятно,
имеют более высокий уровень связности, чем главы в романе.
2. Явное связывание включает определение козырной масти, кто пасует, кто
имеет право хода и т.д. Сведения, полученные при объявлении ставок,
например о том, у кого какие карты, можно рассматривать как неявную связь.
3. Это сложная задача. С одной стороны, можно было бы начать, поместив все
в один модуль. В результате была бы достигнута низкая степень связности
при полном отсутствии связей между модулями. Если затем начать деление
этого отдельного модуля на более мелкие модули, то в результате уровень
связанности модулей будет повышаться. Отсюда мы можем заключить, что
увеличение связности приводит к повышению связанности модулей задачи.
4. С другой стороны, предположим, что рассматриваемая задача естественным
образом разделяется на три связных модуля, которые мы назовем А, В и С. Если
исходный проект не будет отражать это естественное разделение (например,
половина задачи А оказалась объединена в одном модуле с половиной задачи В и
т.д.), то можно ожидать, что связность будет низкой, а связанность модулей —
высокой. В этом случае пересмотр структуры системы с целью выделения задач
А, В и С в отдельные модули, скорее всего, приведет к ослаблению связей между
модулями, причем внутренняя связность модулей будет возрастать.
5. Для того чтобы придать связи персональный характер, объект класса Room мог
бы использовать имя игрока при обмене сообщениями с ним. Чтобы получить
это имя, объекту класса Room потребуется послать соответствующий запрос
объекту класса PlayerRecord. Кроме того, объекту класса PlayerRecord может
потребоваться передать объекту класса Room сведения об уровне игрока.
Приложения 655
Раздел 6.4
1.
2.
3. В некотором смысле структуру цикла, представленную в нашем псевдокоде
оператором while, можно рассматривать как шаблон проектирования.
Другим хорошим примером является модель "клиент/сервер".
4. Исследователи надеются, что структуры будут служить готовыми
строительными блоками, из которых можно будет собирать большие системы
программного обеспечения подобно тому, как из готовых компонентов
собираются различные сложные приборы.
Раздел 6.5
1. Задача тестирования программного обеспечения состоит в обнаружении
ошибок. Поэтому разработчики программного обеспечения рассматривают
как неудачный такой тест, который не позволил обнаружить новую ошибку.
2. Можно оценить степень разветвленности в модуле. Например, процедурный
модуль, содержащий многочисленные циклы и операторы if-then-else,
вероятно, будет более подвержен ошибкам, чем модуль с простой логической
структурой.
3. Анализ крайних значений предполагает, что тестирование программного
обеспечения будет выполнено как с входным списком из 100 элементов, так и с
пустым входным списком. Кроме того, полезно будет проверить, как поведет себя
программа, если входной список уже будет иметь требуемую упорядоченность.
656
Приложение Е
Раздел 6.6
1. В виде сопроводительной документации; внутри программы в форме
комментариев и ясно написанного кода; в виде интерактивных сообщений,
которые программа может выводить на экран дисплея; в виде словарей данных
и в виде проектной документации, такой как структурные схемы,
диаграммы классов, схемы потоков данных и диаграммы "сущность-связь".
2. И на стадии разработки, и на стадии модификации. Дело в том, что вносимые
изменения должны быть документированы так же тщательно, как и исходная
версия программы. (Программное обеспечение документируется и на стадии
использования. Например, пользователь системы может обнаружить проблемы,
которые затем будут описаны в руководстве пользователя. Более того, широко
распространены книги, написанные об использовании и разработке популярных
систем программного обеспечения. Иногда их пишут люди, которые не
принимали участия в их разработке, после того, как программное обеспечение уже
некоторое время использовалось и приобрело определенную популярность.)
3. Разные люди будут иметь различные мнения об этом. Некоторые будут
утверждать, что цель всего проекта — это программа, поэтому именно она
является более важной. Другие будут утверждать, что программа ничего не
стоит, если она не документирована. Поскольку если невозможно понять,
что она делает, то и использовать (или модифицировать) ее будет также
невозможно. Более того, при наличии хорошей документации задача создания
программы может быть "легко" решена заново.
Раздел 6.7
1. Это проблема, которая относится к компетенции судебных органов. Ее
решение определенно затронуло бы много дополнительных аспектов, помимо
учета формата программы и выбора имен переменных.
2. Авторские права и патентное законодательство приносят обществу выгоду,
поскольку они стимулируют создателей новой продукции делать ее
общедоступной. Законы о коммерческой тайне также приносят обществу пользу,
поскольку они позволяют компании защищать от конкурентов свою
продукцию, пока она находится на стадии разработки.
3. Отказ от ответственности не защищает компанию от юридического
преследования за небрежность.
Часть III
Глава 7
Раздел 7.1
1. 537428196
2. Если R — количество строк в матрице, то формула такова: R(J - 1) + (I - 1).
Приложения 657
3. Начиная с адреса 25, мы должны пропустить 11(3- 1) + (6- 1) =27
элементов матрицы, каждый из которых занимает две ячейки памяти.
Таким образом, мы должны пропустить 54 ячейки памяти. Окончательный
адрес может быть найден посредством прибавления числа 54 к адресу первого
элемента, что в результате дает адрес 7 9.
4. (C-I) + J.
Раздел 7.2
1. Например, чтобы найти пятый элемент плотно заполненного списка,
следует умножить количество ячеек, в которых хранится отдельный
элемент, на 4 и добавить результат к адресу первого элемента. В случае
связанного списка ситуация совершенно иная, поскольку адрес пятого
элемента никак не связан с адресом первого элемента. Таким образом,
чтобы найти пятый элемент, нужно просто перебрать все предыдущие
элементы.
2. Указатель на начало списка содержит значение NIL.
3. assign Last the value имя, которое должно быть напечатано
последним
assign Finished the value ложь
assign CurrentPointer the value указатель на начало списка
while (CurrentPointer не NIL and Finished = ложь) do
(напечатать элемент списка, на который указывает
CurrentPointer,
if(только что напечатанное имя = Last)
then (assign Finished the value истина)
assign CurrentPointer the value указатель, хранящийся в элементе,
на который указывает CurrentPointer)
4. procedure delete(<элемент>)
assign Current the value указатель на начало списка
assign Previous the value NIL
assign Found the value ложь
while (Current не NIL and Found = ложь) do
(if(элемент, на который указывает Current - это <элемент>)
then (assign Found the value истина)
else (assign Previous the value Current;
assign Current the value указатель, хранящийся в элементе,
на который указывает Current))
if (Found = истина)
then (if(Previous = NIL)
then (assign указатель на начало списка the value
значение указателя, хранящееся в элементе,
на который указывает Current)
else (assign указатель, хранящийся в элементе,
658 Приложение Б
на который указывает Previous,
the value указатель, хранящийся в элементе,
на который указывает Current))
Раздел 7.3
1. Традиционным примером является подставка со стопкой подносов в
кафетерии. Многие типы таких подставок снабжаются дополнительными
пружинами, позволяющими поддерживать верхний поднос на требуемом уровне. В
этом случае термин "вставка" действительно описывает процесс добавления
нового элемента в стек.
2. _ „ Состояние стека сразу
Действие
после выполнения действия
Главная программа вызывает подпро- Положение в главной программе
грамму А
Подпрограмма А вызывает подпро- Положение в подпрограмме А
грамму В Положение в главной программе
Подпрограмма В завершила работу Положение в главной программе
Подпрограмма А вызывает подпро- Положение в подпрограмме А
грамму С Положение в главной программе
Подпрограмма С завершила работу Положение в главной программе
Подпрограмма А завершила работу Стек пуст
3. Указатель стека указывает на ячейку, которая находится непосредственно
ниже основания стека.
4. procedure pop()
if(указатель стека указывает ниже основания стека)
then (прекратить выполнение программы и выдать сообщение об ошибке)
Извлечь элемент стека, который адресуется указателем стека;
Переместить указатель стека вниз на следующий элемент
5. Представьте стек в виде одномерного массива, а указатель стека — как
переменную целого типа. Затем этот указатель стека используйте в качестве
индикатора положения вершины стека в массиве вместо указания точного
адреса памяти.
Приложения 659
Раздел 7.4
1.
2. И при пустой, и при полностью заполненной очереди значения в указателях
на ее вершину и хвост совпадают. Поэтому, чтобы различить эти два
состояния очереди, потребуется дополнительная информация.
3. procedure insert{<новый элемент>)
if (Full = истина) then (завершить работу с сообщением об ошибке)
Поместить <новый элемент> в позицию, определяемую указателем/
Увеличить значение указателя на конец очереди на длину элемента;
if(значение указателя на конец очереди превышает адрес конца
660
Приложение Б
зарезервированного блока ячеек памяти)
then (значение указателя на конец очереди установить равным
адресу начала зарезервированного блока ячеек памяти)
if(указатель на начало очереди = указатель на конец очереди)
then (assign Full the value истина)
Раздел 7.5
1. Корень равен 11, а листья — 1, 2, 6, 3 и 4. Существует четыре (непустых)
поддерева ниже узла 9 с корнями 5, 1, 2 и 6. Узлы 9 и 10 являются
дочерними для одного и того же родительского узла, как и пары узлов 5 и 6, 1 и
2, 7 и 8.
2. Указатель на корень равен NIL.
4.
5. При поиске J:
Приложения
661
При поиске Р:
6.
Раздел 7.6
1. Начисление на счет и снятие денег со счета могут быть выполнены только
посредством определенных процедур, установленных законом.
2. Абстрактный тип данных — это понятие, а экземпляр некоторого типа
данных — это реальный объект такого типа. Например, собака — тип
животного, а Лесси и Рекс — это экземпляры данного типа.
3. И абстрактные типы данных, и классы являются шаблонами и выражают
собой понятие связывания данных с процедурами, которые манипулируют
ими. Однако классы — это более общее понятие, поскольку они могут не
включать никаких структур данных.
4. Очередь, состоящую из целых чисел, можно реализовать с помощью либо
непрерывного, либо связного списка. Ее можно реализовать также как
циклическую очередь, ограниченную фиксированным или перемещающимся блоком
ячеек памяти, хотя последний вариант реализации может представлять собой
опасность для других структур данных, также размещенных в памяти.
Раздел 7.7
1. а) А5 б) А5 в) А5
2. D50F, 2EFE, 5FFE
3. 2ЕА0, 2FB0, 2101, 20В4, D50E, E50F, 5ЕЕ1, 5FF1, DF14, В008, С000
662
Приложение Б
Глава 8
Раздел 8.1
1. Физические записи считываются из запоминающего устройства в буфер, где
прикладная программа получает доступ к данным в виде логических записей.
2. Дескриптор файла — это таблица, содержащая информацию, необходимую
операционной системе для манипулирования файлом.
3. Дескриптор файла создается менеджером файлов.
Раздел 8.2
1. Необходимо пройти через следующие стадии.
А В С D -•
2. Задача заключается в следующем. Сначала нужно разделить файл так,
чтобы хранить его содержимое во многих отдельных файлах, содержащих
по одной записи. Затем необходимо сгруппировать содержащие по одной
записи файлы попарно и применить к каждой паре алгоритм сортировки
слиянием. В результате будет получено в два раза меньше файлов,
содержащих по две записи каждый. Более того, каждый из этих (содержащих
по две записи) файлов уже отсортирован. Теперь можно снова сгруппиро-
Приложения
663
вать их попарно и вновь применить к этим парам алгоритм сортировки
слиянием. В итоге получим вдвое меньше файлов вдвое большего размера,
каждый из которых уже упорядочен. Продолжая действовать подобным
образом, в итоге получим один файл, который будет содержать все
исходные записи, отсортированные в требуемом порядке. (Если на какой-либо
стадии этого процесса встречается нечетное количество файлов, следует
просто отложить один из файлов в сторону и объединить его с файлом
большего размера на следующей стадии.)
Раздел 8.3
1. По существу, текстовый файл является последовательным файлом, в
котором логическая запись представляет собой отдельный символ.
2. Документы, созданные с помощью текстовых процессоров (письма,
рукописи, распоряжения, брошюры), обычно сохраняются в виде текстовых
файлов. Сообщения, передаваемые через электронную почту, также обычно
представляют собой текстовые файлы.
3. Обычно значительная часть документа хранится в основной памяти, что
обеспечивает произвольный доступ к любому фрагменту этой части документа. Однако
при обработке следующих частей документа предыдущие части могут быть
перемещены на устройство массовой памяти. Если позднее возникает
необходимость вернуться к предыдущей части документа и эта часть уже была сохранена
в виде текстового файла, то текстовый процессор должен будет прочитать
начало документа, чтобы найти ту часть, которую требуется обновить.
4. Клавиатура должна сгенерировать двоичные коды 00110010 и 00110100,
представляющие собой коды символов 2 и 4. Переменной Age будет
присвоена битовая комбинация 0000000000011000, представляющая собой
двоичное представление числа 24.
Раздел 8.4
1. Операционная система сначала ищет индекс, чтобы определить
запрашиваемый сегмент. Установив номер требуемого сегмента, операционная система
может проверить, не находится ли уже этот сегмент в основной памяти. (Это
может быть сегмент, доступ к которому уже требовалось получить ранее.)
Если он уже находится в основной памяти, операционная система
просматривает его и передает нужную запись программе. В противном случае
операционная система сначала извлекает сегмент из запоминающего устройства, а
затем просматривает его.
2. Операционная система с поддержкой разделения времени предпринимает
попытки использовать время процессора наиболее эффективно. Если
требуемый сегмент запоминающего устройства еще не находится в основной
памяти, операционная система требует от контроллера дисковода считать
нужный сегмент. Но чтобы не ждать бесполезно момента поступления
требуемых данных, операционная система прерывает выполнение исходного
процесса и начинает выполнение другого. После того как контроллер загру-
664 Приложение Е
зит запрошенный сегмент в основную память, операционная система вновь
обращается к исходному процессу и передает ему нужную запись, после чего
предоставляет возможность продолжить выполнение в обычном порядке.
Раздел 8.5
1. Это хороший пример тех аспектов проблемы, которые нужно рассмотреть при
выборе алгоритма хеширования. В данном случае использовать три первые
цифры номера социального страхования неудобно, поскольку они представляют код
того региона, в котором этот номер был присвоен человеку. Следовательно, у
всех граждан, проживающих в этом регионе, три первые цифры кода
социального страхования будут одинаковы, а это приведет к более высокой степени
кластеризации, чем обычно бывает в хешированных файлах.
2. Неудачно выбранный алгоритм хеширования приводит к более высокой
кластеризации данных, чем обычно, а значит, и к частому возникновению
переполнения. Поскольку записи переполнения каждого раздела запоминающего
устройства организуются в виде связанного списка, поиск записей в области
переполнения, по сути, является поиском в последовательном файле.
3. Номера назначенных сегментов будут следующими:
а) 0 б) 0 в) 3 г) 0 д) 3
е) 3 ж) 3 з) 3 и) 3 к) О
Следовательно, все записи будут помещены в сегменты с номерами 0 и 3, а
сегменты 1, 2, 4 и 5 останутся пустыми. Проблема состоит в том, что число
участков памяти, которые нужно использовать (6), и значения в ключевом
поле имеют общий делитель 3. (Можно проверить работу этого же алгоритма
хеширования для этих же значений ключевых полей, но с использованием
семи участков памяти и лично убедиться, насколько ситуация улучшится.)
4. По сути, задача сводится к тому, чтобы использовать алгоритм хеширования
при распределении людей из некоторой группы в одну из 365 категорий.
Очевидно, что алгоритм хеширования сводится к вычислению дня
рождения. Забавно, что достаточно только 23-х человек, чтобы вероятность
совпадения дней рождения хотя бы у двух из этой группы превысила 0,5. В
терминах хешированных файлов это означает, что при хешировании записей по
365 доступным участкам памяти запоминающего устройства кластеризация
может возникнуть уже после ввода первых 23 записей.
Глава 9
Раздел 9.1
1. Отдел снабжения может быть заинтересован в записях о запасах на складе,
чтобы размещать заказы на сырье, в то время как бухгалтерия нуждается в
информации для составления балансового отчета.
2. Работники, студенты, выпускники, финансы, регистрация, оборудование,
поставщики и т.д.
Приложения 665
3. Подсхема для отдела снабжения могла бы, вероятно, включать адреса
различных производителей, поставляющих детали на склад, и, возможно,
имена торговых агентов, представляющих каждую из этих компаний. Подсхема
для бухгалтерии, вероятно, не будет включать эту информацию.
Раздел 9.2
1. Нет. Использование файловой системы однозначно требует, чтобы
прикладная программа учитывала реальную организацию записей в файле. По этой
причине в случае изменений в структуре записей понадобилось бы вносить
изменения во все программы, имеющие доступ к этому файлу.
2.
3. Прикладное программное обеспечение переводит запросы пользователей с языка
приложения на язык системы управления базой данных. Система управления
базой данных, в свою очередь, преобразует эти запросы в форму, понятную
программам, которые осуществляют реальные операции с данными на
запоминающем устройстве. Именно эти программы реально извлекают данные из базы.
Раздел 9.3
1. a) G. Jerry Smith
б) Cheryl H. Clark
в) S26Z
2. Одно из решений будет следующим:
TEMP <r- SELECT from JOB
where Dept=MPERSONNEL"
LIST <- PROJECT JobTitle from TEMP
В некоторых системах это приводит к появлению списков, в которых одно и
то же название работы повторяется несколько раз. Это значит, что в нашем
списке может несколько раз встречаться должность "секретарь". Однако
обычно операцию PROJECT разрабатывают так, чтобы удалить
повторяющиеся кортежи из результирующего отношения.
3. Одно из решений таково:
TEMPI <- JOIN JOB and ASSIGNMENT
where JOB.Jobld = ASSIGNMENT.Jobld
TEMP2 <- SELECT from TEMPI
666
Приложение Б
where TermDate = "*"
TEMP3 <- JOIN EMPLOYEE and TEMP2
where EMPLOYEE.EmplId = TEMP2.Emplild
RESULT <- PROJECT Name, Dept from TEMP3
4. select JobTitle
from JOB
where Dept = 'PERSONNEL'
select EMPLOYEE.Name, JOB.Dept
from JOB, ASSIGNMENT, and EMPLOYEE
where ((Job.Job = ASSIGNMENT.Jobld) and
(ASSIGNMENT.Emplld = EMPLOYEE.EmplId) and
(ASSIGNMENT.TermDate = '*')
5. Сама по себе модель не обеспечивает независимость данных. Это прерогатива
системы управления базой данных. Независимость данных достигается путем
наделения системы управления базой данных способностью предоставлять
прикладному программному обеспечению неизменную структуру организации
отношений, даже если реальная организация отношений будет изменяться.
6. Посредством наличия общих атрибутов. Например, отношение EMPLOYEE в
этом разделе связано с отношением ASSIGNMENT через атрибут Emplld, а
отношение ASSIGNMENT — с отношением JOB с помощью атрибута Jobld.
Атрибуты, используемые для соединения отношений между собой, иногда
называют атрибутами соединения.
Раздел 9.4
1. Это могут быть методы присваивания и извлечения как атрибута Start Date,
так и атрибута TermDate. Еще один метод может применяться для
подготовки отчета о полном стаже работника.
2. Один из способов — создать объект для каждого типа продукции на складе.
Каждый из этих объектов мог бы хранить сведения об остатке
соответствующей продукции на складе, ее стоимости и содержать ссылки на
неоплаченные заказы на нее.
3. Как было показано в начале раздела, объектно-ориентированные базы
данных были созданы для упрощения работы с неоднородными типами
данных — по сравнению с реляционными базами данных. Кроме того, то, что
объекты могут содержать методы, которые будут играть важную роль при
подготовке ответов на запросы, дает объектно-ориентированным базам
данных дополнительное преимущество над реляционными базами данных, в
которых базовые отношения содержат только данные.
Раздел 9.5
1. После того как транзакция достигнет точки фиксации результатов, система
управления базой данных принимает на себя обязанность следить за тем,
Приложения 667
чтобы транзакция была завершена полностью. Транзакция, которая не
достигла своей точки фиксации, лишена такой гарантии. Если возникают
проблемы, ее может потребоваться выполнить еще раз.
2. Один из способов — на мгновение приостановить выполнение
пересекающихся транзакций, что позволит всем конкурирующим транзакциям
полностью завершить свою работу. Таким образом, будет зафиксирована точка, на
которой потенциальный каскадный откат будет остановлен.
3. Если бы транзакции выполнялись по одной, конечный остаток на счету был
бы равен $100. Если же первая транзакция будет выполнена после того, как
вторая считает исходное значение остатка, но до того, как она сохранит свои
результаты, окончательный остаток на счету будет равен $200. Если же
вторая транзакция будет выполнена после того, как первая считает исходное
значение остатка, но до того, как она сохранит результаты своего
выполнения, окончательный остаток на счету составит $300.
4. а) Если никакая другая транзакция не имеет монопольного доступа,
совместный доступ к данным разрешается.
б) Если другая транзакция уже имеет некоторую форму доступа, система
управления базой данных обычно заставляет новую транзакцию
подождать или выполняет откат других транзакций и предоставляет доступ
новой транзакции.
5. Ситуация взаимной блокировки может возникнуть в том случае, если
каждая из двух транзакций получает монопольный доступ к различным
элементам данных, а затем требует получения доступа к тем элементам, которые
уже захвачены другой транзакцией из этой пары.
6. Указанную выше ситуацию взаимной блокировки можно устранить
посредством отката одной из транзакций (с использованием файла журнала) и
предоставления другой транзакции доступа к тому элементу данных, который
ранее удерживался первой транзакцией.
Раздел 9.6
1. Сравните ваш ответ на этот вопрос с ответом на следующий вопрос. Оба они
поднимают одну и ту же проблему, но в разном контексте.
2. См. предыдущий вопрос.
3. Вы могли бы получить сообщения или приглашения, которые иначе не
смогли бы получить, но вы могли бы также стать объектом приставаний или
жертвой преступления.
4. Дело здесь в том, что свободная пресса может предупреждать публику об
имевших место потенциальных злоупотреблениях и таким образом
будоражить общественное мнение. В большинстве случаев, описанных в тексте,
именно свободная пресса вынудила предпринять действия по исправлению
ошибок, предупредив общественность о существующей проблеме.
668 Приложение Е
Часть IV
Глава 10
Раздел 10.1
1. Мы не преследуем здесь цель получить однозначный ответ на данный
вопрос. Мы используем его только для того, чтобы показать, насколько
тонкими являются аргументы, касающиеся вопроса интеллекта.
2. Хотя большинство, без сомнения, ответят "нет", мы, вероятно, дали бы
положительный ответ на этот вопрос, если бы он касался тех же действий и в
той же обстановке, но совершаемых человеком. Обратите внимание, что эта
реакция могла бы иметь место даже в том случае, если бы мы не смогли
объяснить, в чем же в каждом случае заключаются отличия.
3. Не существует правильного или неправильного ответа на этот вопрос.
Правильнее всего будет утверждать, что машина демонстрирует поведение,
напоминающее разумное.
Раздел 10.2
1. В случае дистанционного управления система нуждается только в получении
изображения, тогда как робот, чтобы воспользоваться изображением для
маневрирования, должен "понимать" его смысл.
2. Возможная интерпретация одной части рисунка никак не согласуется с
интерпретацией другой его части. Для того чтобы отразить эту точку зрения в
программе, можно было бы выделить интерпретации, допустимые для
различных пересечений линий, а затем написать программу, которая пытается
найти множество совместимых интерпретаций (по одной на каждое
пересечение). В действительности, если глубже обдумать предложенное решение,
то, вероятно, оно так или иначе совпадет с теми действиями, которые вы
сами предпринимаете при попытке распознать изображение. Замечаете ли
вы, что переводите глаза с одного конца рисунка на другой, одновременно
пытаясь совместить различные возможные интерпретации? (Если эта тема
вас заинтересует, обратитесь к работам Д.Э. Хоффмана (D.A. Huffman), М.Б.
Кловса (М.В. Clowes) и Д. Уолтца (D. Waltz).)
3. В стеке есть четыре блока, но только три являются видимыми. Дело в том,
что для понимания этого требуются значительные умственные усилия.
Раздел 10.3
1. Порождающие системы обеспечивают унифицированный подход к
различным задачам. Это означает, что хотя исходно задачи могут иметь самую
разную формулировку, все они могут быть переформулированы в терминах
порождающих систем с приведением их к задаче нахождения пути в графе
состояний.
Приложения 669
2.
3. Глубина дерева равна четырем. Верхняя часть дерева выглядит следующим
образом:
4. Для решения этой задачи потребуется слишком много бумаги и времени.
5. Наша эвристическая система для решения головоломки из восьми элементов
построена на анализе текущей ситуации по методу, который использует
альпинист, взбирающийся на гору. Такая близорукость позволяет нашему
алгоритму сначала пойти по неверному пути, как в примере из данного раздела,
подобно тому, как альпинист может подвергнуть себя опасности,
прокладывая путь по ориентирам только в непосредственной близости от себя.
(Благодаря такой аналогии эвристические системы, основанные на
локальной или текущей информации, часто называются системами восхождения.)
6. Система перемещает фишки с цифрами 5, 6 и 8 либо по часовой стрелке,
либо против часовой стрелки, пока требуемое состояние не будет достигнуто.
7. Проблема здесь заключается в том, что наша эвристическая система
игнорирует важность анализа свойств свободного места, расположенного по
соседству с фишкой, которая находится не на своем месте. Если свободное место
окружено фишками, занимающими правильные позиции, то некоторые из
них потребуется предварительно переместить, чтобы иметь возможность
переместить те фишки, которые находятся не на своих местах. Таким образом,
было бы неправильно рассматривать все окружающие свободное место
фишки как занимающие требуемые места. Чтобы устранить этот недостаток, мы
должны сначала заметить, что фишку, которая находится на правильном
670 Приложение Е
месте, но отделяет свободную позицию от неправильно расположенных
фишек, следует переместить с правильной позиции в другое место, а затем
возвратить обратно. Таким образом, каждая правильно расположенная фишка
на пути между свободным местом и ближайшей неправильно расположенной
фишкой находится, как минимум, в двух шагах от своего окончательного
положения. Следовательно, используемый алгоритм вычисления
предположительной стоимости можно модифицировать следующим образом.
Сначала надо вычислить предположительную стоимость так, как это делалось
раньше. Однако если свободное место совершенно изолировано от
неправильно расположенных фишек, найти ближайший путь между свободной
позицией и любой неправильно расположенной фишкой, умножить число
фишек на этом пути на 2 и добавить результат к предыдущей оценке стоимости.
В этой системе листья дерева, показанного на рис. 10.10, будут иметь
предположительную стоимость 6, 6 и 4 (слева направо), поэтому правильная
ветка будет выбрана с самого начала работы алгоритма.
Тем не менее новая система тоже недостаточно надежна. Например,
рассмотрим приведенную ниже конфигурацию. Решение заключается в том,
чтобы сдвинуть фишку 5 вниз, повернуть два верхних ряда по часовой
стрелке, пока фишки в них не займут правильное положение, вернуть
фишку 5 назад и, наконец, переместить фишку 8 в верхнюю позицию. Но
согласно нашей новой эвристической системе, следует начать с фишки 8,
поскольку состояние, полученное в результате этого начального хода, имеет
стоимость 6, тогда как все остальные состояния — стоимость 8.
Раздел 10.4
1. Все варианты приводят к появлению на выходе значения 0, за исключением
варианта 1,0, для которого выходное значение будет равно 1.
2. Присвоить каждому входному значению весовой коэффициент, равный 1, и
установить пороговое значение, равное 1,5.
3. Разработать двухуровневую сеть, как описано в тексте. В блоках обработки
нижнего уровня каждому входному значению следует присвоить весовой
коэффициент, равный 1, и установить для этих блоков пороговый уровень,
равный 71/2- Таким образом, один из этих блоков обработки выдаст
выходной сигнал, равный 1, если фигура в поле зрения является кругом. В
противном случае все блоки обработки нижнего уровня выдадут на выходе зна-
Приложения 671
чение 0. В свою очередь, если в блоках обработки верхнего уровня каждому
из их входных значений присвоить весовой коэффициент, равный 1, и
установить пороговое значение, равное г/2, то вся сеть выдаст на выходе
значение 1, если фигура в поле зрения является кругом, и значение 0, если
фигура в поле зрения — буква X.
4. Разработать двухуровневую сеть, как описано в тексте. В каждом блоке
обработки нижнего уровня установить пороговое значение, равное 2х/2>
присвоить весовой коэффициент, равный 0, входным сигналам, поступающим от
угловых квадратов в их поле зрения, и весовой коэффициент, равный 1, для
всех остальных входных значений, поступающих от оставшихся квадратов.
Единственный вариант, при котором один из этих блоков обработки может
выдать на выходе значение 1, — это обнаружение в поле зрения
изображения буквы С. В действительности, если появляется буква С, то выходной
сигнал 1 выдадут сразу два блока обработки нижнего уровня. Следовательно,
если в блоке обработки верхнего уровня присвоить каждому из его входных
значений весовой коэффициент, равный 1, и установить пороговый уровень,
равный 1, то он выдаст на выходе значение 1, если в поле зрения находится
буква С, и значение 0, если в поле зрения находится буква V.
Раздел 10.5
1. 0010100110000010000100000
2. Примером может служить задача разработки инвестиционной стратегии на
фондовом рынке.
3. Структура программы, построенной с использованием функциональной
парадигмы, сводится к вызову функций внутри функций. Это означает, что
такая структура является однородной на всех уровнях. Однако программы,
основанные на объектно-ориентированной парадигме, состоят из объектов,
которые могут содержать как методы, так и другие объекты. Таким
образом, эта структура не является однородной, в отличие от функциональной
парадигмы. Поэтому смешивать компоненты объектно-ориентированных
программ, чтобы получить новую программу, намного труднее.
Раздел 10.6
1. Как вы считаете, предложение описывает, какими являются лошадьми, или
сообщает о действиях некоторых людей?
2. Процесс грамматического анализа порождает идентичные структуры, но
семантический анализ распознает, что предложная фраза в первом
предложении сообщает, где был построен забор, в то время как фраза во втором
предложении сообщает, когда был построен забор.
3. Они брат и сестра.
4. Используется предположение о замкнутости мира.
672 Приложение Е
5. Во многих отношениях обе базы данных идентичны. Однако традиционные
базы данных в основном содержат только факты, такие как имя сотрудника,
его адрес и т.п., в то время как базы знаний включают правила, такие как,
например, "если идет дождь, проверьте дождемер", которые можно
использовать для управления процессом рассуждения.
Раздел 10.7
1. Не существует правильного или неправильного ответа.
2. Не существует правильного или неправильного ответа.
3. Не существует правильного или неправильного ответа.
Глава 11
Раздел 11.1
1. clear AUX;
incr AUX;
while X not 0 do;
clear X;
clear AUX;
end;
while AUX not 0 do;
incr X;
clear AUX;
end;
2. while X not 0 do;
deer X;
end;
3. move X to AUX;
while AUX not 0 do;
SI;
clear AUX;
end;
move X to AUX;
invert AUX;
while AUX not 0 do;
S2;
clear AUX;
end;
while X not 0 do;
clear AUX;
clear X;
end;
Приложения 673
4. Если предположить, что X обозначает ячейку памяти с адресом 4 0 и каждый
сегмент программы начинается с нулевого адреса, мы получим следующую
таблицу преобразований:
Адрес Содержимое
clear X; 00 20
01 00
02 30
03 40
Адрес Содержимое
incr X; 00 11
01 40
02 20
03 01
04 50
05 01
06 30
07 40
Адрес Содержимое
deer X; 00 20
01 00
02 23
03 00
04 11
05 40
06 22
07 01
08 В1
09 10
0А 40
0В 03
ОС 50
0D 02
0Е В1
0F Об
10 33
11 40
Адрес Содержимое
while X not 0 do; 00 20
01 00
02 1С
03 40
674
Приложение Е
Адрес Содержимое
04 В1
end; 05 WZ
WX ВО
WY 00
5. Как и в реальных машинах, с отрицательными числами можно работать с
использованием соответствующей системы кодирования. Например, самый
правый бит в каждой строке можно использовать в качестве знака, а
остальные — для представления абсолютной величины числа.
Раздел 11.2
1. В результате получится следующая диаграмма:
Состояние машины = HALT Текущая позиция
2.
3.
Текущее
состояние
СТАРТ
СОСТОЯНИЕ 1
СОСТОЯНИЕ 1
СОСТОЯНИЕ 1
СОСТОЯНИЕ 2
СОСТОЯНИЕ 2
СОСТОЯНИЕ 2
СОСТОЯНИЕ 3
СОСТОЯНИЕ 3
Текущее
состояние
СТАРТ
ВЫЧЕСТЬ
ВЫЧЕСТЬ
ЗАНЯТЬ
ЗАНЯТЬ
ЗАНЯТЬ
НЕ ЗАНИМАТЬ
НЕ ЗАНИМАТЬ
НЕ ЗАНИМАТЬ
НУЛЬ
Содержимое
Ячейки
*
0
1
•
0
1
•
0
1
Текущее
содержимое
ячейки
•
0
1
0
1
•
0
1
*
0
Значение,
подлежащее
записи
•
0
0
0
•
•
0
0
Значение,
подлежащее
записи
•
1
0
1
0
•
0
1
•
0
Направление
движения
налево
налево
налево
налево
направо
направо
направо
направо
направо
Направление
движения
налево
налево
налево
налево
налево
направо
налево
налево
направо
направо
Новое
состояние
при вводе
СОСТОЯНИЕ 1
СОСТОЯНИЕ 2
СОСТОЯНИЕ 2
СОСТОЯНИЕ 2
СОСТОЯНИЕ 3
СОСТОЯНИЕ 3
СОСТОЯНИЕ 3
ОСТАНОВ
ОСТАНОВ
Новое
состояние
при вводе
ВЫЧЕСТЬ
ЗАНЯТЬ
НЕ ЗАНИМАТЬ
ЗАНЯТЬ
НЕ ЗАНИМАТЬ
НУЛЬ
НЕ ЗАНИМАТЬ
НЕ ЗАНИМАТЬ
ВОЗВРАТ
НУЛЬ
Приложения
675
Текущее
состояние
НУЛЬ
ВОЗВРАТ
ВОЗВРАТ
ВОЗВРАТ
Текущее
содержимое
ячейки
•
0
1
Значение,
подлежащее
записи
*
0
1
Направление
движения
на месте
направо
направо
на месте
Новое
состояние
при вводе
ОСТАНОВ
ВОЗВРАТ
ВОЗВРАТ
ОСТАНОВ
4. Дело в том, что концепция машины Тьюринга была предложена для
выражения понятия "вычислить". Это означает, что любую ситуацию, в которой
имеет место вычисление, можно описать с помощью компонентов и
операций машины Тьюринга. Например, человек, подсчитывающий подоходный
налог, выполняет некоторое вычисление. Тогда машина Тьюринга заменяет
собой человека, а ее лента — бумагу, на которой записываются цифры.
Раздел 11.3
1. Вычисление взноса по займу, площади круга или длины пробега автомобиля.
2. Математики называют такие функции трансцендентными. Примером таких
функций являются логарифмы и тригонометрические функции. Они
представляют собой функции, которые нельзя вычислить с помощью
исключительно алгебраических операций. Например, тригонометрические функции в
действительности можно вычислить путем рисования соответствующего
треугольника, измерения длин его сторон и только потом — посредством
применения алгебраической операции деления.
3. Функция умножения на 2.
4. Машина, описанная нижеследующей таблицей, останавливается, если
начинает работу с четного числа, и никогда не останавливается, если начинает
работу с нечетного числа.
Текущее со- Содержимое Значение, Направление Новое состоя-
стояние ячейки подлежащее движения ние при вводе
записи
СТАРТ * * налево СОСТОЯНИЕ 1
СОСТОЯНИЕ 10 0 направо ОСТАНОВ
СОСТОЯНИЕ 11 1 на месте СОСТОЯНИЕ 1
СОСТОЯНИЕ 1 * * на месте СОСТОЯНИЕ 1
Раздел 11.4
1. Deer X; (Программа)
I
01100100011001010110001101110010001000000101100000111011 (Коды ASCII)
I
28 258 975 461 955 643 (Геделевский номер в десятичной системе)
676
Приложение Е
2. Да. В действительности эта программа останавливается при любом входном
значении, поэтому она должна остановиться и в том случае, когда ее входное
значение равно ее собственному геделевскому номеру.
3. Логика рассуждений здесь такая же, как и при утверждении, что проблема
остановки не имеет алгоритмического решения. Если маляр красит свой
дом, то он не делает этого, и наоборот.
Раздел 11.5
1. Мы можем лишь заключить, что проблема имеет сложность 0(2"). Если бы
мы смогли доказать, что "наилучший алгоритм решения задачи
принадлежит классу 0(2П)", то можно было бы утверждать, что задача принадлежит
классу 0(2П).
2. Нет. Как правило, алгоритмы из класса 0(п2) ограничивают алгоритмы из
класса 0(2П), но для малых входных значений экспоненциальные алгоритмы
часто ограничивают полиномиальные. В действительности
экспоненциальный алгоритм иногда бывает предпочтительнее — когда все возможные
входные данные являются малыми числами.
3. Дело в том, что число подкомитетов растет экспоненциально, и с этой точки
зрения задача перечисления всех вариантов становится все более трудоемкой.
4. В класс полиномиальных задач входит задача сортировки списка, которая
может быть решена с помощью полиномиального алгоритма, например
алгоритма сортировки по методу вставки.
К классу неполиномиальных задач относится задача перечисления всех
подкомитетов, которые могут быть сформированы из данного комитета.
Любая полиномиальная задача является NP-задачей. Примером NP-задачи
является задача о странствующем коммивояжере, однако пока не доказано,
что она является полиномиальной.
Раздел 11.6
1. 691+365 + 651+493=2200
2. 57 + 2184 + 782 = 3023. Это — система шифрования, разработанная в данном разделе.
Решите эту задачу, преобразовав ее в задачу, построенную на использовании
следующего списка:
1 4 6 12 25 51 105 210 421 850
3. Умножьте каждый элемент списка на 30, разделите каждое полученное произведение на
67 и запишите остатки. В результате будет получен список 60, 23, 46, 55, 50, который
будет служить открытым ключом шифрования.
4. Необходимо найти число, кратное 5, которое больше числа, кратного 23. Обратите
внимание, что 5 х 14 = 70 и 3 х 23 = 69. Следовательно, в модульной системе с модулем 23
обратное число для числа 5 будет равно 14.
Приложения 677
Предметный указатель
А
АСМ, 342
Ada, 625
ANSI, 281
Apple, 30
ASCII, 64; 442
С
CALEA, 203
CASE-технология, 350; 370
CERT, 201
CISC-архитектура, 137
CORBA, 175; 287
D
DMA, 132
E
ECPA, 202
EOF, 437
F
FAT, 436
FIFO, 255; 398
FORTRAN, 629
FTP,205
G
GIF, 88
GUI, 265
H
HTML, 190
I
IEEE,343
Internet, 161; 182; 184; 193
URL-адрес, 189
Web-броузер, 188
WWW, 187
адресация, 184
домен, 184
имя домена, 185
протокол FTP, 194
протокол telnet, 194
сервер имен, 186
электронная почта, 186
InterNIC, 184
ISO, 61; 281
J
Java, 290; 309; 363; 419; 62i
аплет, 629
байт-код, 309
JPEG,89
L
LAN, 182
LIFO, 393
M
MPEG, 91
N
NIL, 389
Предметный указатель
679
р
Pascal, 290
R
RAM, 49
RISC-архитектура, 137
s
SQL, 482
T
telnet, 194; 195
U
UDP, 199
UML, 353
Unicode, 60
URL-адрес, 189
w
WAN, 182
Web-броузер, 188
World Wide Web, 187
WWW, 187
A
абстракция, 32
адресный полином, 384
алгоритм, 22; 214; 564
инвариант цикла, 263
итерационные структуры, 232
недетерминированный, 594
неоднозначность, 215
НП-типа, 594
параллельный, 214
примитивы, 217
рекурсивные структуры, 243
сложность, 586
создание, 225
циклы, 234
эффективность, 215; 254; 256
аплет, 629
аппаратное обеспечение, 22
ассемблер, 279
атрибут, 471
Б
база данных, 464
АБД, 465
механизм блокировок, 490
объектно-ориентированная, 485
распределенная, 468
реляционная модель, 470
схема, 466
транзакция, 489
целостность данных, 488
байт, 49
байт-код, 309
безопасность, 200
компьютерные вирусы, 203
программа-червь, 203
бинарные деревья, 404; 406
бит, 40
бит четности, 92
битовое отображение, 128
блокировка, 491
булевы операции, 40
буфер устройства, 132
в
взаимная блокировка, 178
виртуальная память, 168
Г
ГВС, 182
геделевский номер, 580
генетические алгоритмы, 537
гипермедиа, 189
гипертекст, 187
глобальные данные, 355
граничные условия, 367
граф состояний, 516
680
Предметный указатель
д
двоичная нотация с избытком, 76
двоичная нотация с плавающей
точкой, 79
двоичный дополнительный код, 72
двоичный поиск, 243
дерево поиска, 519
дескриптор файла, 167
диаграмма
"сущность-связь", 359
взаимодействий, 355
классов, 352
потоков данных, 359
дискета, 53
документация
пользователя, 368
системная, 369
документирование, 368
драйвер устройства, 167
древовидные структуры, 402
ж
жесткие диски, 53
з
заглушка, 348
загрузочный модуль, 316
задание, 158
очередь, 158
пакетная обработка, 158
защита, 200
шифрование, 201
и
идентификатор, 275
инвариант цикла, 263
индекс, 447
инкапсуляция, 321; 416; 417
интерактивная обработка, 160
интерпретатор, 281
искусственный интеллект, 508; 542;
552
нейронные сети, 528
обработка языка, 542
порождающая система, 516
рассуждения, 515
робототехника, 545
тест Тьюринга, 509
экспертные системы, 548
итерация, 232
К
карта CRC, 362
каталог, 167
квант времени, 160; 172
кеш, 111
класс, 319; 418
конструктор, 419
наследование, 418
кластер, 436
клиент, 174
код Хэмминга, 94
коллизия, 454
комментарии, 289; 299
компакт-диски, 54
компилятор, 281
константа, 290
контроллер, 132
кортеж, 471
криптография, 596
критическая область, 178; 324
Л
ЛВС, 182
лексема, 308
литерал, 289
логические значения, 40
логический вывод, 325
логический сдвиг, 129
локальные данные, 355
м
магнитные диски, 52
мантисса, 80
маршрутизатор, 184
Предметный указатель
681
маскирование, 127
массив, 382
индексы, 382
машина Тьюринга, 570; 577; 633
машинный цикл, 120
машинный язык, 115; 116
код операции, 116
поле операндов, 118
метод Lempel-Ziv, 86
механизм блокировок, 490
микрокоманды, 138
мнемоническое обозначение, 278
модель "клиент/сервер", 174
модель OSI, 198
модем, 136
модули, 347; 351
реализация, 351
модульная арифметика, 600
модульность, 351
н
настольный компьютер, 30
нейронные сети, 528
о
оболочка, 165
обработка
в реальном времени, 160
интерактивная, 160
обработка изображений, 66
пиксель, 66
обработка языка, 542
объектный код, 307
оконный интерфейс, 165
ООП, 286
базы данных, 485
инкапсуляция, 321
класс, 319
методы, 319
наследование, 320
полиморфизм, 321
операторы, 289
ввода/вывода, 306
присваивания, 294
управляющие, 295
операции
логические, 127
сдвига, 129
операционная система, 163; 434
Linux, 166
виртуальная память, 168
диспетчер, 168
диспетчер файлов, 167
загрузчик, 316
запуск, 168
оболочка, 165
переключение процессов, 172
планировщик, 168
прерывание, 172
разделение времени, 173
спулинг, 180
таблица процессов, 172
управление памятью, 167
управление ресурсами, 176
ядро, 167
отношение, 471
очередь, 398
п
пакетная обработка, 158
папка, 167
парадигмы программирования, 24;
282
декларативная, 283; 325
императивная, 283; 440
объектно-ориентированная, 286; 441
функциональная, 284
параллельная обработка, 139
параметры, 303
передача данных, 135
передача информации, 91
бит четности, 92
код Хэмминга, 94
переменная, 289
переполнение, 65; 76
пиксель, 66
пиктограмма, 165
ПК, 30
плоский файл, 464
682
Предметный указатель
поле ключа, 438
полиморфизм, 321
порождающая система, 516
граф состояний, 516
дерево поиска, 519
Поста, 571
эвристические методы, 522
порождение, 516
порт, 134
порядок числа, 80
постоянная память, 169
потеря значимости, 65
пошаговая модель, 349
правовые последствия, 33
прерывание, 172
приведение типов, 314
примитивы, 217
семантика, 218
синтаксис, 218
проблема остановки, 582
программа, 22; 115; 124; 214; 225
бета-версия, 368
верификация, 261
выполнение, 119
документация, 368
жизненный цикл, 345
загрузочный модуль, 316
качество, 344
обслуживающая, 164
объектный код, 307
право собственности, 370
проектирование, 358
самоостанавливающаяся, 581
связывание, 315
тестирование, 366
технология разработки, 342
трансляция, 307
утилита, 164
хранимая,115
этапы разработки, 346
программное обеспечение, 22; 163
проектирование
методы, 358
шаблоны, 362
протокол, 190
Ethernet, 191
FTP,194
TCP/IP, 199
UDP, 199
пакеты данных, 196
с передачей маркера, 190
сетевой, 190
прототипы, 350
процедура, 222; 300
параметры, 303
процесс, 171; 214
взаимодействие, 171
переключение, 172
таблица процессов, 172
псевдокод, 220
процедура, 222
путь доступа, 167
р
разделение времени, 160
распознавание изображений, 512
анализ изображения, 514
нахождение областей, 514
обработка изображения, 514
сглаживание, 514
усиление контуров, 514
регистр команд, 120
регистры, 110
редактор связей, 316
резольвента, 326
рекурсия, 243; 633
активация, 252
реляционная модель, 470
атрибут, 471
кортеж, 471
отношение, 471
реляционные операции, 475
робототехника, 545
с
связанность, 353
неявная, 355
связность, 356
логическая, 356
функциональная, 356
Предметный указатель
683
сегмент, 450
семантика, 218
семафоры, 176
критическая область, 178
сервер, 174
имен, 186
сети, 161; 182
глобальные, 182
классификация, 182
локальные, 182
модель OSI, 198
операционная система, 161
протоколы, 190
узел, 184
сжатие данных, 85
синтаксис, 218
системный администратор, 159
системы счисления
восьмеричная, 63
двоичная, 62; 68
двоично-пятеричная, 63
десятичная, 61
словарь данных, 361
слово состояния, 134
сложность задач, 586
полиномиальная, 591
экспоненциальная, 592
сложность программ
временная, 587
пространственная, 587
сортировка
выборочная сортировка, 243
метод вставки, 238
метод пузырька, 243
социальные последствия, 33
список, 385; 393; 398
связанный, 388
спулинг, 180
стек, 393
структурная схема, 351
структурное программирование, 298
структуры данных
абстрактные типы, 415
деревья, 402
инкапсуляция, 416
класс, 418
массив, 382
очередь, 398
список, 385
стек, 393
указатель, 385
СУБД, 467
сумматор, 619
счетчик адреса, 120
т
таймер, 172
тезис Черча-Тьюринга, 577
теорема
Геделя, 26
теория решения задач, 225
тест Тьюринга, 509
тестирование, 348; 366
технология разработки программ, 342
типы данных, 291
абстрактные, 415
массив, 292
определенные пользователем, 414
транзакция, 490
транслятор, 281
трансляция, 307
генерация кодов, 314
лексический анализ, 308
оптимизация кода, 314
синтаксический анализ, 309
таблица символов, 313
триггер, 43; 215
У
указатель, 385; 389
утилита, 164
Ф
файл, 57; 434
EOF, 437
графический, 88
двоичный, 442
дескриптор, 434
звуковой, 90
684
Предметный указатель
инвертированный, 447
индексированный, 447
логическая запись, 57
поле ключа, 438
последовательный, 436
сжатие данных, 85
слияние, 439
текстовый, 442; 443
физическая запись, 57
хешированный, 450
функция, 300; 305; 575
вычислимая, 575; 577
полиномиальная, 591
х
хеширование
коллизия, 454
хранение данных, 45
Ц
центральный процессор, 110
циклические структуры, 234
ч
чип,46
ш
шаблоны программирования, 419
шаблоны проектирования, 362
структуры, 364
шестнадцатеричная нотация, 46
шина, 132
шифрование, 201; 596; 602
шлюз, 184; 646
шрифты, 67
э
ЭВМ, 571
бит, 40
динамическая память, 46
контроллер, 132
массовая память, 51
машинное слово, 48
машинные команды, 112
машинный цикл, 120
машинный язык, 115; 116
обработка изображений, 66
однопроцессорные, 158
основная память, 48
память, 111
параллельная обработка, 139; 322
передача информации, 91
порт, 134
представление чисел, 61
пропускная способность, 139
регистр команд, 120
регистры, 110
счетчик адреса, 120
шина, 111
эволюционное программирование, 541
экспертные системы, 548
электронная почта, 186
я
язык управления заданиями, 159
языки программирования, 24; 217;
278; 288
Ada, 625
С, 626
C++,627
FORTRAN, 629
Java, 629
Prolog, 328
ассемблер, 279
ввод/вывод, 306
комментарии, 299
константа, 290
литерал, 289
мнемокоды, 278
операторы, 289; 294; 295
переменная, 289
процедуры и функции, 300
псевдокод, 220
реализация, 307
строгая типизация, 314
универсальный, 564
функции, 305
Предметный указатель
685
Научно-популярное издание
Дж. Гленн Брукшир
Компьютерные науки. Общий обзор, 6-е издание
Литературные редакторы ЕД. Давидян, ИЛ. Попова
Верстка О.В. Линник
Художественный редактор В.Г. Павлютин
Технический редактор Г.Н. Горобец
Корректоры Л А. Гордиенко, Л.В. Коровника,
О.В. Мишутина
Издательский дом "Вильяме".
101509, Москва, ул. Лесная, д. 43, стр. 1.
Изд. лиц. ЛР № 090230 от 23.06.99
Госкомитета РФ по печати.
Подписано в печать 05.07.2001. Формат 70x100/16.
Гарнитура Times. Печать офсетная.
Усл. печ. л. 55,5. Уч.-изд. л. 43,8.
Тираж 5000 экз. Заказ № 1118.
Отпечатано с диапозитивов в ФГУП «Печатный двор»
Министерства РФ по делам печати,
телерадиовещания и средств массовых коммуникаций.
197110, Санкт-Петербург, Чкаловский пр., 15.