



































































































































































































































































































































Автор: Шулухин О.И. Тенякшев А.М. Осин А.В.
Теги: электротехника электрическая связь моделирование телекоммуникации учебное пособие информационные системы серия радиотехника
ISBN: 5-93108-072-4
Год: 2005




О. И. Шелухин
А. М. Тенякшев
А. В. Осин
МОДЕЛИРОВАНИЕ
ИНФОРМАЦИОННЫХ
СИСТЕМ
учебное пособие
САИНС-ПРЕСС
ИНФОРМАЦИОННЫХ СИСТЕМ
Авторы
Олег
Иванович
ШЕЛУХИН
Заслуженный деятель
науки Российской Феде-
рации. Окончил МИИТ
(1973), МГУ им. М.В.Ло-
моносова (1981); д.т.н.,
профессор; заведующий
кафедрой «Радиотехника
и радиотехнические сис-
темы МГУС.
Автор более 250 научных
работ. Область научных
интересов - радио и
телекоммуникации.
Александр
Михайлович
ТЕНЯКШЕВ
Окончил МЭИС (1969);
к.т.н., профессор кафед-
ры «Инженерная и ком-
пьютерная графика»
МТУСИ.
Генеральный директор
ЗАО «АмРуссТел».
Автор более 70 научных
работ. Область научных
интересов - спутниковые
системы связи.
Андрей
Владимирович
ОСИН
Окончил МГУС (2002);
аспирант кафедры
«Радиотехника и радио-
технические системы»
МГУС.
Автор 20 научных работ.
Область научных интере
сов - статистическая
обработка и моделиро-
вание сигналов.
САИНС-ПРЕСС
Москва, ул. Рождественка, д. 619120
Тел./факс.: (095) 921-4837, 925-9241
E-mail: lprzhr@online.ru
О. И. Шелухин, А. М. Тенякшев, А. В. Осин
МОДЕЛИРОВАНИЕ
ИНФОРМАЦИОННЫХ
СИСТЕМ
Под научной редакцией
заслуженного деятеля науки РФ
докт. техн, наук, проф. О. И. Шелухина
Рекомендовано УМО по образованию в области телекоммуникаций
в качестве учебного пособия для студентов высших учебных
заведений, обучающихся по специальностям
20090 - «Сети и системы коммутации» и
201000 - «Многоканальные телекоммуникационные системы»
САЙНС-ПРЕСС, 2005
УДК 621.395
Ш42
ББК 32.882
Рецензенты:
Военный университет связи, кафедра №17;
докт. техн, наук, проф. МГТУ им. Н.Э. Баумана В. И. Соленов
Шелухин О.И, Тенякшев А.М, Осин А.В.
Ш42 Моделирование информационных систем. / Под ред. О. И. Ше-
лухина, Учебное пособие. —М.: Радиотехника, 2005. - 368 с.: ил.
ISBN 5-93108-072-4
Рассмотрены алгоритмы моделирования дискретных и непрерывных
случайных величин и процессов; изложены принципы и алгоримы модели-
рования информационных сигналов, описываемых марковскими процессами
с дискретным и непрерывным временем, а также принципы моделирования
систем массового обслуживания; даны особенности описания и использова-
ния фрактальных (самоподобных) процессов для моделирования телеком-
муникационного трафика; проанализированы методы моделирования ин-
формационных систем с использованием специализированных пакетов при-
кладных программ.
Для студентов вузов, обучающихся по специальностям 20090 — «Сети и
системы коммутации», 20100 — «Многоканальные телекоммуникационные
системы», а также «Информационные системы и технологии». Может
быть полезна инженерам и специалистам, работающим в области радио- и
телекоммуникации.
УДК 621.395
ББК 32.882
ISBN 5-93108-072—4
© Издательство «САЙНС-ПРЕСС», 2005
© Научный редактор О. И. Шелухин
ОГЛАВЛЕНИЕ
ПРЕДИСЛОВИЕ...........................................9
ГЛАВА 1. ОБЩИЕ ПРИНЦИПЫ МОДЕЛИРОВАНИЯ
СИСТЕМ...............................................12
1.1. Общие понятия модели и моделирования.........12
1.2. Классификация моделей........................13
1.3. Структура моделей............................15
1.4. Методологические основы формализации
функционирования сложной системы..................16
1.5. Моделирование компонентов системы............18
1.6. Этапы формирования математической модели.....20
1.7. Имитационное моделирование...................22
Контрольные вопросы к главе 1.....................26
ГЛАВА 2. ОБЩИЕ ПРИНЦИПЫ ПОСТРОЕНИЯ СИСТЕМ И
СЕТЕЙ СВЯЗИ..........................................27
2.1. Концепция построения систем и сетей связи....27
2.2. Многоуровневые модели сети...................30
2.2.1. Трехуровневая модель.......................30
2.2.2. Архитектура протоколов TCP/IP..............32
2.2.3. Эталонная модель OSI.......................34
2.3. Структура сетей связи........................36
2.3.1. Глобальные сети............................36
2.3.2. Локальные вычислительные сети..............37
2.3.3. Топологии вычислительной сети..............38
2.3.4. Локальные сети Ethernet....................42
2.4. Сети Frame Relay............................ 43
2.5. Сети ATM.....................................48
2.6. IP-телефония.................................55
Контрольные вопросы к главе 2.....................60
ГЛАВА 3. МОДЕЛИРОВАНИЕ СЛУЧАЙНЫХ ЧИСЕЛ...............62
3.1. Общие сведения о случайных числах............62
3.2. Программное генерирование равномерно распределенных
случайных чисел...................................64
3.3. Методы формирования случайных величин с заданным
законом распределения.............................67
3
Оглавление
3.4. Алгоритмы моделирования часто употребляемых случайных
величин........................................71
3.5. Алгоритмы моделирования коррелированных случайных
величин...........................................73
3.6. Формирование реализаций случайных векторов
и функций.........................................74
Контрольные вопросы к главе 3.....................76
ГЛАВА 4. МОДЕЛИРОВАНИЕ ДИСКРЕТНЫХ
РАСПРЕДЕЛЕНИЙ........................................78
4.1. Распределение Бернулли.......................78
4.2. Биномиальное распределение...................79
4.3. Распределение Пуассона.......................80
4.4. Моделирование испытаний в схеме случайных событий.82
4.5. Потоки событий...............................84
4.6. Обработка результатов моделирования..........88
4.6.1. Точность и число реализаций................89
4.6.2. Первичная статистическая обработка данных..91
Контрольные вопросы к главе 4.....................95
ГЛАВА 5. АЛГОРИТМЫ МОДЕЛИРОВАНИЯ
СТАТИСТИЧЕСКИХ СИГНАЛОВ И ПОМЕХ
В СИСТЕМАХ СВЯЗИ.....................................96
5.1. Алгоритмы моделирования нестационарных случайных
процессов..........................................96
5.2. Алгоритмы моделирования стационарных случайных
процессов..........................................97
5.3. Методы моделирования сигналов и помех в виде
стохастических дифференциальных уравнений..........101
5.4. Примеры моделей случайных процессов
в системах связи.................................103
5.4.1. Модели информационных процессов...........103
5.4.2. Модели помех..............................105
5.4.3. Основные виды помех и их характеристики...106
Контрольные вопросы к главе 5....................112
ГЛАВА 6. МАРКОВСКИЕ СЛУЧАЙНЫЕ ПРОЦЕССЫ И ИХ
МОДЕЛИРОВАНИЕ.......................................113
6.1. Основные понятия марковского случайного процесса.113
4
Оглавление
6.2. Основные свойства и характеристики
дискретных цепей Маркова............................115
6.3. Непрерывные марковские цепи.........................119
6.4. Модели непрерывнозначных марковских
случайных процессов на основе стохастических
дифференциальных уравнений..........................124
6.5. Моделирование марковских случайных процессов........127
6.5.1. Моделирование дискретных процессов..........127
6.5.2. Моделирование скалярных непрерывнозначных процессов. 128
6.5.3. Моделирование непрерывнозначных векторных процессов . 130
6.5.4. Моделирование гауссовского процесса
с дробно-рациональной спектральной плотностью.......132
6.5.5. Моделирование многосвязных последовательностей....133
6.5.6. Моделирование марковских процессов с помощью
формирующих фильтров................................134
6.5.7. Алгоритм статистического моделирования
марковских цепей....................................138
Контрольные вопросы к главе 6......................139
ГЛАВА 7. ПРИМЕРЫ РАЗРАБОТКИ
МАРКОВСКИХ МОДЕЛЕЙ....................................140
7.1. Марковские модели речевого диалога абонентов........140
7.1.1. Состояния речевого сигнала..................140
7.1.2. Модели диалога..............................141
7.2. Марковские модели речевого монолога...........145
7.3. Марковские модели цифровых последовательностей на
выходе кодека G.711.................................150
7.4. Марковские модели цифровых последовательностей на
выходе кодека G.728.................................166
7.5. Марковские модели оценки QoS мультимедийных сервисов
реального времени в Интернете.......................170
7.5.1. Понятие мультимедийных сервисов реального времени.170
7.5.2. Анализ и моделирование задержек и потерь....171
7.6. Модель потока мультимедийного трафика.........175
Контрольные вопросы к главе 7......................179
ГЛАВА 8. СИСТЕМЫ МАССОВОГО ОБСЛУЖИВАНИЯ И ИХ
МОДЕЛИРОВАНИЕ.........................................180
8.1. Общая характеристика систем массового обслуживания ..180
8.2. Структура системы массового обслуживания......187
5
Оглавление________________________________________________
8.3. Системы массового обслуживания с ожиданием..........189
8.3.1. Система обслуживания М1М1\........................189
8.3.2. Система обслуживания M/G/X........................192
8.3.3. Сети с большим числом узлов,
соединенных каналами связи.........................194
8.3.4. Приоритетное обслуживание..................196
8.3.5. Система обслуживания M/MINIm...............198
8.4. Системы массового обслуживания с отказами....200
8.5. Общие принципы моделирования систем массового
обслуживания.......................................202
8.5.1. Метод статистических испытаний.............202
8.5.2. Блочные модели процессов функционирования систем..204
8.5.3. Особенности моделирования с использованием Q-схем.205
Контрольные вопросы к главе 8.....................206
ГЛАВА 9. МОДЕЛИРОВАНИЕ УЗЛА СЕТИ FRAME RELAY................208
9.1. Основные положения протокола Frame Relay.....208
9.2. Проектирование узла сети Frame Relay.........212
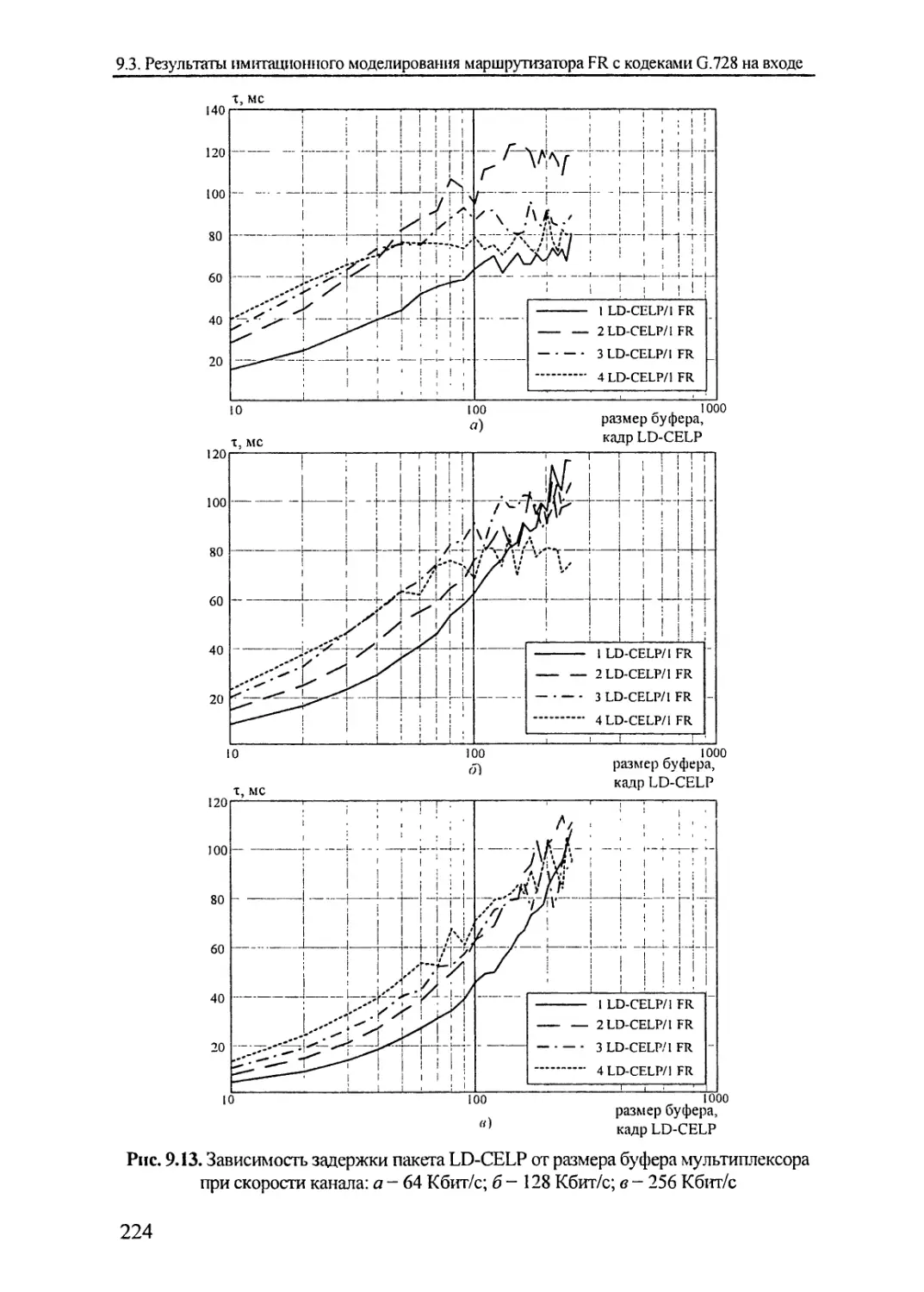
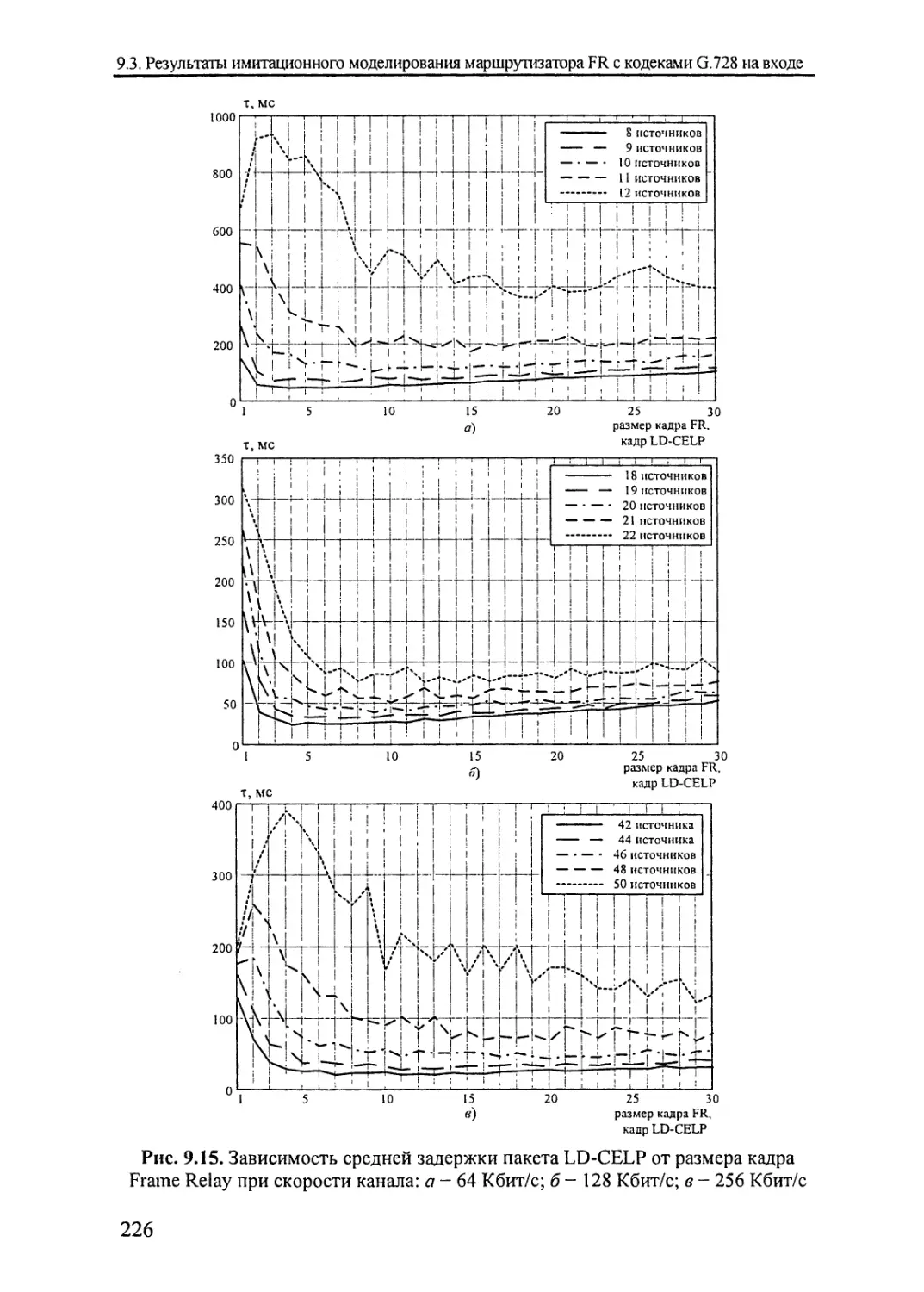
9.3. Результаты имитационного моделирования
маршрутизатора FR с кодеками G.728 на входе........218
Контрольные вопросы к главе 9.....................229
ГЛАВА 10. МОДЕЛИРОВАНИЕ СИСТЕМ ПЕРЕДАЧИ
ИНФОРМАЦИИ...........................................230
10.1. Типовая система передачи данных.............230
10.2. Помехоустойчивость передачи дискретных сигналов.
Оптимальный прием..................................233
10.3. Оценка вероятности ошибочного приема сигналов
с полностью известными параметрами..................237
10.4. Помехоустойчивость дискретных сигналов
со случайными параметрами...........................239
10.5. Помехоустойчивость дискретных сигналов
при некогерентном приеме............................240
10.6. Помехоустойчивость дискретных сигналов со случайными
существенными параметрами...........................241
10.7. Алгоритмы формирования помех
и дискретных сигналов..............................243
10.8. Структура имитационного комплекса
и его подпрограмм..................................246
Контрольные вопросы к главе 10....................250
6
Оглавление
ГЛАВА 11. МОДЕЛИРОВАНИЕ ИНФОРМАЦИОННЫХ СИСТЕМ
С ИСПОЛЬЗОВАНИЕМ ТИПОВЫХ
ТЕХНИЧЕСКИХ СРЕДСТВ....................................251
11.1. Моделирование систем и языки программирования..251
11.2. Основные сведения о языке GPSS.................254
11.2.1. Динамические объекты GPSS.
Транзактно-ориентированные блоки...........256
11.2.2. Аппаратно-ориентированные блоки..........258
11.2.3. Многоканальное обслуживание..............260
11.2.4. Статистические блоки GPSS................267
11.2.5. Операционные блоки GPSS..................272
11.2.6. Другие блоки GPSS........................276
11.3. Имитационное моделирование сети Ethernet
в среде GPSS.....................................281
Контрольные вопросы к главе 11.......................290
ГЛАВА 12. ФРАКТАЛЬНЫЕ ПРОЦЕССЫ И
ИХ ПРИМЕНЕНИЕ В ТЕЛЕКОММУНИКАЦИЯХ..................292
12.1. Основы теории фрактальных процессов.......292
12.2. Оценка показателя Херста..................297
12.3. Обзор методов моделирования самоподобных процессов
в телетрафике...................................299
12.4. Исследование самоподобной структуры
трафика Ethernet............................303
12.5. Перегрузочное управление самоподобным трафиком.306
Контрольные вопросы к главе 12...................308
ГЛАВА 13. МЕТОДЫ МОДЕЛИРОВАНИЯ ФРАКТАЛЬНЫХ
ПРОЦЕССОВ..........................................309
13.1. Фрактальное броуновское движение...........309
13.1.1. RMD-алгоритм генерации ФБД...............311
13.1.2. SRA-алгоритм генерации ФБД...............313
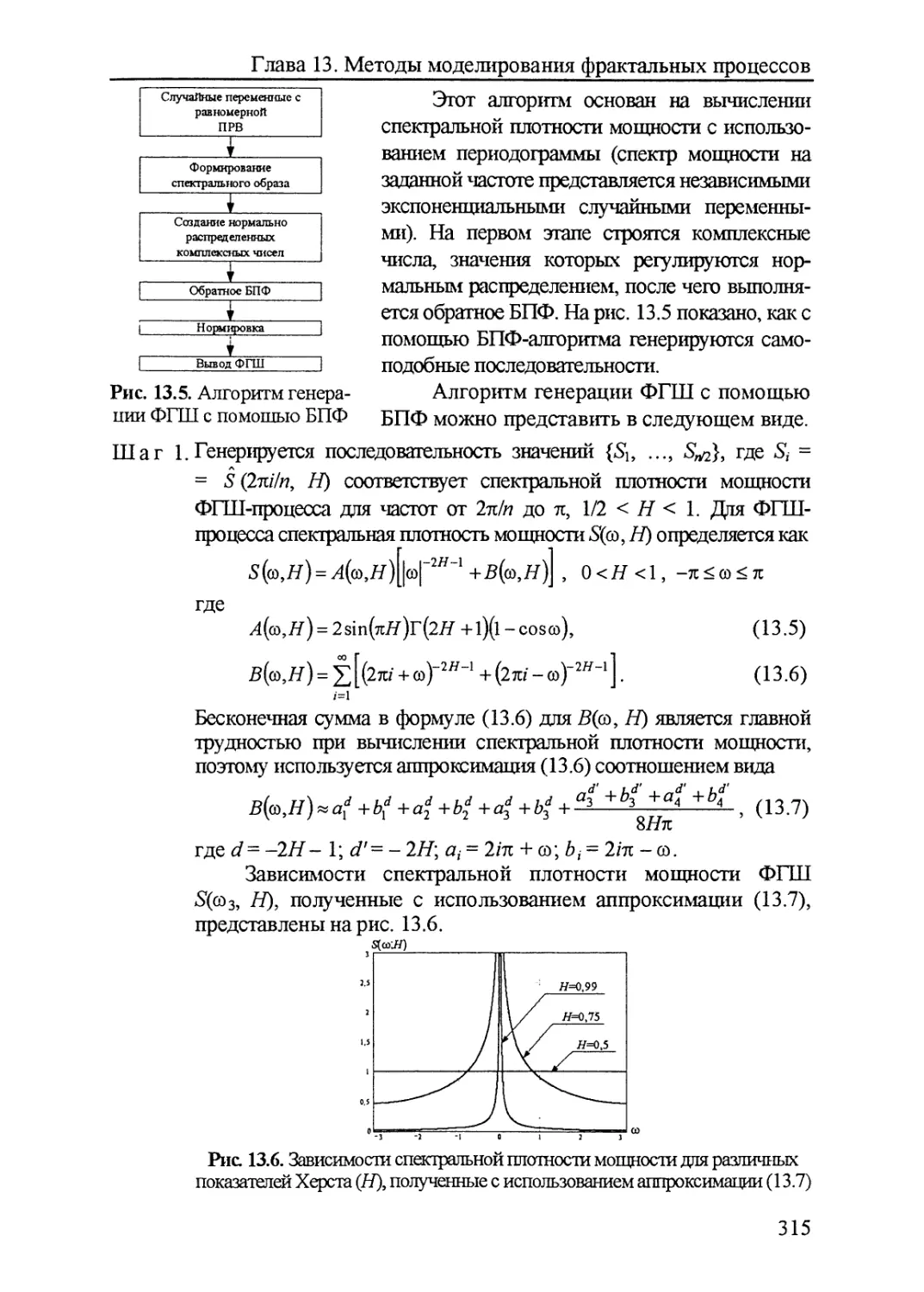
13.2. Фрактальный гауссовский шум................313
13.2.1. БПФ-алгоритм синтеза ФГШ.................314
13.3. Сравнительный анализ алгоритмов формирования
самоподобных последовательностей................325
13.4. Достоинства н недостатки ФБД/ФГШ-моделей в сетевых
приложениях.....................................333
13.5. Регрессионные модели трафика...............334
Контрольные вопросы к главе 13...................339
7
Оглавление
ГЛАВА 14. СПЕЦИАЛИЗИРОВАННЫЕ СИСТЕМЫ
ИМИТАЦИОННОГО МОДЕЛИРОВАНИЯ
ВЫЧИСЛИТЕЛЬНЫХ СЕТЕЙ..........................340
14.1. Общая характеристика специализированных пакетов
прикладных программ сетевого моделирования..340
14.2. OPNET.................................343
14.3. COMNET................................345
14.4. Общие принципы моделирования с помощью COMNET
и OPNET.....................................347
14.5. Технология моделирования информационных систем с
использованием COMNET III...................348
14.6. Сетевой имитатор ns2..................360
Контрольные вопросы к главе 14..............362
ЛИТЕРАТУРА....................................363
ПЕРЕЧЕНЬ СОКРАЩЕНИИ...........................364
Предисловие
При проектировании, реализации и обслуживании информацион-
ных телекоммуникационных систем и сетей связи часто встречаются
случаи, когда аналитическое решение задачи практически невозможно в
силу значительных математических трудностей, а проведение экспери-
ментальных исследований и натурных испытаний требует весьма боль-
ших затрат времени и средств. Одной из эффективных мер по преодоле-
нию этих трудностей является применение современных вычислитель-
ных средств и программного обеспечения для моделирования изучае-
мых явлений.
Вопросам моделирования информационных процессов, систем и
сетей посвящена эта книга.
Материалы книги может быть условно разделен на пять тематиче-
ских разделов.
В главах 1 и 2, рассматриваются принципы и методы построения
моделей информационных процессов, систем и сетей связи. Вводятся
общие понятия математических моделей, классификация и структура
математических моделей; сформулированы требования к моделям. Из-
лагаются методологические основы формализации функционирования
сложной системы, а также вопросы моделирования компонентов; этапы
формирования математической модели. Вводится понятие имитацион-
ного моделирования.
Рассматривается структура сетей и систем связи, различные виды
топологии сети типа «звезда», кольцевая, шинная; а также особенности
сетей с коммутацией каналов и коммутацией пакетов. Дается характе-
ристика типовых протоколов и показаны особенности построения сетей
Frame Relay, ATM , IP. Вводится понятие модели взаимодействия от-
крытых систем.
В главах 3-5 и 9 рассматриваются вопросы моделирования слу-
чайных величин и процессов. Рассматриваются наиболее распростра-
ненные способы формирования случайных величин с заданным законом
распределения: метод обратных функций; приближенные методы; метод
отсеивания (метод генерации Неймана). Излагаются методы формиро-
вания реализаций случайных векторов и функций, а также анализиру-
ются методы описания и особенности моделирования случайных вели-
чин с дискретными распределениями (Бернулли, биномиальным, пуас-
соновским) и случайных потоков.
Рассматриваются алгоритмы моделирования случайных процессов,
используемых в системах связи. Анализируются особенности модели-
рования сигналов и помех, алгоритмы моделирования как нестационар-
9
Предисловие
ных, так и стационарных коррелированных случайных процессов. Изла-
гаются наиболее важные аспекты моделирования систем передачи ин-
формации. На основе анализа структуры типовой системы передачи
данных моделируется помехоустойчивость передачи дискретных сигна-
лов при оптимальном приеме с полностью известными параметрами, а
также со случайными параметрами при когерентном и некогерентном
приеме. Рассматриваются алгоритмы формирования и демодуляции
дискретных сигналов и анализируется структура комплекса имитацион-
ного моделирования системы передачи сообщений и его подпрограммы.
Главы 6-9 составляют центральное место учебного пособия. В них
излагаются элементы теории марковских процессов и теории массового
обслуживания, которые играют в моделировании систем и сетей связи
чрезвычайно важную роль.
Подробно анализируется моделирование телекоммуникационных
процессов марковскими процессами. Анализируются алгоритмы моде-
лирования марковских случайных процессов в непрерывном и дискрет-
ном времени, а также методы оценки их статистических параметров.
Анализируются особенности моделирования дискретных марковских
процессов, скалярных непрерывнозначных марковских процессов, не-
прерывных векторных марковских процессов, многосвязных марков-
ских последовательностей.
Приводятся многочисленные примеры разнообразных марковских
моделей (в частности, модели речевого монолога и диалога, модели
цифрового речевого трафика на выходе гибридных кодеков речи, а так-
же модели оценки QoS мультимедийных сервисов реального времени в
Интернете).
Важное место в пособии занимают материалы, связанные с осо-
бенностями моделирования систем массового обслуживания (СМО).
Анализируются наиболее распространенные модели СМО. Рассматри-
ваются модели СМО в сетях с большим числом узлов, соединенных ли-
ниями связи, а также блочные, иерархические модели процессов функ-
ционирования систем.
В качестве примера анализируются возможности применения тео-
рии массового обслуживания при моделировании сетей связи на приме-
ре имитационного моделирования маршрутизатора узла сети Frame Re-
lay с кодеками G728 на входе.
В главах 12 и 13 излагаются современное состояние и перспективы
нового направления в моделировании информационных систем - теории
и практики фрактальных ( самоподобных) процессов.
Излагаются основы теории и методы моделирования самоподоб-
ных процессов в телетрафике. Подробно анализируются особенности
построения моделей трафиковых потоков, исследуется самоподобность
структуры телекоммуникационного трафика, а также перегрузочное
управление подобным трафиком.
10
Предисловие
Рассматриваются методы моделирования наиболее распространен-
ных фрактальных процессов, используемых при моделировании теле-
коммуникационных процессов и сетей: фрактального броуновского
движения и фрактального гауссовского шума. Приведен сравнительный
анализ известных методов формирования самоподобных последова-
тельностей.
В главах 11 и 14 анализируются типовые технические средства
моделирования и языки программирования для моделирования систем и
сетей связи. Значительное внимание уделяется вопросам имитационного
моделирования информационных систем и сетей на базе моделирующей
системы General Purpose System Simulator (GPSS), различным подходам
к моделированию информационно-вычислительных процессов. Дается
общая характеристика специализированных пакетов прикладных про-
грамм сетевого моделирования OPNET и COMNET.
Для лучшего усвоения материала, в конце каждой главы приведе-
ны контрольные вопросы и задания.
Данная книга является учебным пособием, в основу которого по-
ложен курс лекций, читаемых студентам МТУ СИ, обучающимся по
специальности 210200 - «Автоматизация технологических процессов и
производств».
Авторы благодарны коллективу кафедры «Защита информации и
почтовая связь» МТУ СИ, поддержавшему авторов при подготовке
учебного пособия. Особая благодарность заведующему кафедрой «За-
щита информации и техника почтовой связи», заслуженному деятелю
науки РФ, докт. техн, наук, проф. А.В. Петракову за полезные критиче-
ские замечания, способствующие улучшению содержания пособия.
Авторы также благодарят докт. техн, наук, проф. Ю.В Лазарева и
докт. техн, наук, проф. В.Н Гордиенко за содействие в издании пособия.
Особую признательность авторы выражают рецензентам книги:
кафедре №17 Военного университета связи, лично докт. техн, наук,
проф. А.Н. Путилину, канд. техн, наук, ст. научн. сотр. М.И. Макарову,
а также лауреату Государственной премии, докт. техн, наук, проф.
МГТУ им. Баумана В.И. Соленову за внимательное и доброжелательное
рецензирование.
Авторы
И
Глава 1
ОБЩИЕ ПРИНЦИПЫ
МОДЕЛИРОВАНИЯ СИСТЕМ
1.1. Общие понятия модели и моделирования
Модель - представление объекта, системы или понятия в некоторой форме,
отличной от реального существования. Модель - это средство, помогающее
в объяснении, понимании или совершенствовании системы.
Модель может быть точной копией объекта (хотя и в другом масштабе
и из другого материала) или отображать некоторые характерные свойства
объекта в абстрактной форме. Поэтому модель - инструмент для прогно-
зирования последствий при действии входных сигналов на объект, а
моделирование - метод, повышающий эффективность суждений и ин-
туиции специалистов.
Все модели - упрощенные представления реального мира или абст-
ракции. Абстракция сосредотачивает в себе существенные черты поведе-
ния объекта, но не обязательно в той же форме и столь детально, как в
объекте. Обычно отбрасывают большую часть реальных характеристик
изучаемого объекта и выбирают те его особенности, которые идеализируют
вариант реального события. Таким образом, большинство моделей являют-
ся абстрактными.
Степень сходства модели с объектом называют степенью изоморфизма.
Чтобы модель была изоморфной (или сходной по форме), необходимо выпол-
нение двух условий:
1) существование взаимнооднозначного соответствия между элементами мо-
дели и представляемого объекта;
2) сохранность точных соотношений или взаимодействий между этими эле-
ментами.
Большинство моделей — гомоморфные, т.е. сходные по форме при
различии основных структур, причем имеется лишь поверхностное подо-
бие между различными группами элементов модели и объекта. Гомоморф-
ные модели - результат упрощения и абстракции. Для разработки гомо-
морфной модели систему обычно разбивают на более мелкие части, чтобы
легче было произвести требуемый анализ. При этом необходимо найти час-
ти, не зависящие в первом приближении друг от друга.
С такого рода анализом связан процесс упрощения реальной системы
(пренебрежение несущественными деталями или принятие предположения
о более простых соотношениях). Например, допускаем, что между пере-
менными имеется линейная зависимость. Часто предполагают, что процес-
сы либо детерминированы, либо их поведение описывается известными ве-
роятностными функциями распределения.
12
Глава 1. Общие принципы моделирования систем
После анализа частей системы производят их синтез, что должно де-
латься корректно, с учетом всех взаимосвязей.
Основой успешной методики моделирования должна быть тщатель-
ная отработка модели. Начав с простой модели, обычно продвигаются к
более совершенной ее форме, отражающей сложную ситуацию более точ-
но. Между процессом модификации модели и процессом обработки дан-
ных имеется непрерывное взаимодействие.
Процесс моделирования заключается в следующем:
1) общая задача исследования системы разлагается на ряд более простых;
2) четко формулируются цели;
3) подыскивается аналогия;
4) рассматривается специальный численный пример, соответствующий
данной задаче;
5) выбираются определенные обозначения;
6) записываются очевидные соотношения;
7) расширяют полученную модель, если она поддается математическому
описанию, если нет - ее упрощают.
Поэтому конструирование модели не сводится к одному базовому ва-
рианту. Все время возникают новые задачи с целью возможно большего
соответствия модели и объекта.
1.2. Классификация моделей
Модели можно классифицировать по-разному. Укажем некоторые типовые
группы моделей, которые могут быть положены в основу системы класси-
фикации. В частности, в информационных системах можно выделить фи-
зическую и информационную среду. В свою очередь, каждая из этих сред
может быть описана физическими или теоретическими моделями.
Физические модели часто называют натурными, так как внешне
они напоминают изучаемую систему. Они могут быть как в уменьшен-
ном (модель солнечной системы), так и в увеличенном (модель атома)
масштабе, т.е. масштабируемые модели. В дальнейшем будут рассмотре-
ны только теоретические модели информационных систем.
Теоретические модели могут быть разделены на математические и
графические.
Математические модели (ММ) - совокупность математических объ-
ектов и отношений между ними, которая адекватно отображает некоторые
свойства объекта. К ним относятся те, в которых для представления про-
цесса используют символы (например, дифференциальные уравнения и
т.п.), а не физические свойства. Таким образом, ММ является упрощением
реальной ситуации и представляет собой абстрактный, формально описан-
ный объект, изучение которого возможно математическими методами.
Графические модели показывают соотношение между различными
количественными характеристиками и могут предсказывать, как будут из-
меняться одни величины при изменении других.
13
1.2. Классификация моделей
Рассмотрим классификацию ММ с учетом дальнейшей направлен-
ности изложения.
В зависимости от характера отображаемых свойств
объекта ММ делятся на функциональные и структурные. Функцио-
нальные модели отображают процессы функционирования объекта. Они
имеют чаще всего форму системы уравнений. Структурные модели мо-
гут иметь форму матриц, графов, списков векторов и выражать взаим-
ное расположение элементов в пространстве. Эти модели обычно ис-
пользуют в случаях, когда задачи структурного синтеза удается ставить
и решать, абстрагируясь от физических процессов, протекающих в
объекте. Они отражают структурные свойства проектируемого объекта.
Для получения статического представления моделируемой системы
могут быть использованы методы, называемые схематическими моделями,
т.е. включающие графическое представление работы системы (например,
технологические карты, диаграммы, многофункциональные диаграммы
операций и блок-схемы).
По способам получения функциональных ММ различают
теоретические и формальные модели. Теоретические ММ получают на
основе изучения физических закономерностей. Структура уравнений и
параметры моделей имеют определенное физическое толкование. Фор-
мальные ММ получают на основе проявления свойств моделируемого
объекта во внешней среде, т.е. рассмотрения объекта как кибернетиче-
ского «черного ящика».
Теоретический подход позволяет получать модели более универсаль-
ные, справедливые для более широких диапазонов изменения внешних па-
раметров, тогда как формальные ММ более точны в точке пространства па-
раметров, в которой производились измерения.
В зависимости от линейности и нелинейности урав-
нений ММ могут быть линейные и нелинейные.
В зависимости от множества значений переменных
ММ бывают непрерывные и дискретные.
По способу описания бывают стохастические и детер-
минированные ММ.
По форме связей между выходными, внутренними и внеш-
ними параметрами различают: алгоритмические ММ в виде систем
уравнений; аналитические ММк виде зависимостей выходных парамет-
ров от внутренних и внешних воздействий; численные ММ в виде чи-
словых последовательностей.
В зависимости от учета в модели инерционности
физических процессов в объекте различают динамические или стати-
ческие ММ.
В общем случае вид математической модели зависит не только от
природы реального объекта, но и от тех задач, ради решения которых
она создается, и требуемой точности их решения.
14
Глава 1. Общие принципы моделирования систем
1.3. Структура моделей
Прежде чем начать разработку модели, необходимо понять, что из себя
представляют структурные элементы модели, из которых она состоит. Хотя
математические и физические модели могут быть очень сложны, основы их
построения всегда просты.
В общем виде структуру модели можно представить в виде математи-
ческой формулы
£ = /(Л,У,),
где Е - результат действия системы; Х} - переменные и параметры, которы-
ми можно управлять; Y, - переменные и параметры, которыми нельзя
управлять; f - функциональная зависимость между Xi и Yh которая опреде-
ляет величину Е.
Для динамических систем (рис. 1.1) сложилось устоявшееся пред-
ставление их моделей. Сложная система функционирует в некоторой
внешней среде, состояние и свойства которой в каждый момент времени
характеризуются набором пара-
метров, образующих вектор z
(возмущающее воздействие).
Состояние и свойства самой
системы в каждый £-й момент
времени характеризуются набором
внутренних параметров, которые
подразделяются на вектор со-
Вход
Ик Управление
Выход
Рис. 1.1. Модель динамической системы в
терминах «вход-выход»
стояния х и вектор управления и.
Динамическая модель, как
правило, содержит:
описание множества возможных состояний системы;
описание закона, в соответствии с которым система переходит из
одного состояния в другое:
где F - вектор-функция.
Множество возможных состояний системы иначе называют про-
странством состояний системы. Оно может быть непрерывным или
дискретным. Закон, в соответствии с которым система переходит из одного
состояния в другое, называют функцией переходов или оператором переходов.
В общем случае модель представляет собой комбинацию следующих
составляющих: компоненты, переменные, параметры, функциональные за-
висимости, ограничения, целевые функции.
Компоненты - составные части, которые при соответствующем объе-
динении образуют систему. Иногда считают компонентами элементы сис-
темы или ее подсистемы. Система определяется как группа или совокуп-
ность объектов, объединенных некоторой формой регулярного воздей-
ствия или зависимости для выполнения заданной функции.
15
1.5. Моделирование компонентов системы
3) объединить выявленные факторы по общим признакам, сократив их пе-
речень;
4) установить количественные соотношения между ними.
Как правило, самая трудная стадия процесса моделирования - перевод
выявленных существенных факторов на язык математических понятий и оп-
ределение соотношений между этими величинами. Дело в том, что требова-
ния содержательности и дедуктивности модели противоречивы по своему
существу. Чтобы удовлетворить требованию содержательности, необходимо
учесть в модели как можно большее количество факторов реального процес-
са. При этом модель становится более сложной, что затрудняет ее исследова-
ние и получение содержательных результатов. Однако желание получить ре-
зультат возможно более простым путем приводит к необходимости упроще-
ния модели, снижая таким образом ее содержательность. Необходимо до-
биться разумного компромисса, обеспечив возможность получения нетриви-
альных результатов и не упуская существа реального процесса. В этом слу-
чае прилагается уточненная совокупность всех исходных данных, известных
параметров и начальных условий.
Содержательное описание может не дать необходимых сведений для
построения формализованной схемы, и тогда необходимы дополнительные
эксперименты и наблюдения за исследуемым процессом. Но в этом случае
при разработке формализованной схемы они должны быть полностью ис-
пользованы.
Дальнейшее преобразование формализованной схемы в модель вы-
полняется без поступления дополнительной информации.
В математическом моделировании для преобразования формализо-
ванной схемы в математическую модель необходимо записать в аналитиче-
ской форме все соотношения, которые еще не были записаны, выразить ус-
ловие в виде системы неравенств, а также придать аналитическую форму
другим сведениям, содержащимся в формализованной схеме (например,
числовым характеристикам, содержащимся в формализованной схеме в ви-
де таблиц и графиков).
Обычно на ЭВМ числовой материал используют в виде аппроксими-
рующих выражений, удобных для вычислений. Для значений случайных
величин выбирают плотность типичных законов распределений.
1.5. Моделирование компонентов системы
Рассмотрим простую систему (рис. 1.2). Здесь три основных объекта: вход',
собственно сама система; отклик (выход). Чтобы моделировать систему,
необходимо знать два из этих трех объектов.
Моделируя отдельные компонен-
ты (элементы, подсистемы) сложной
системы, сталкиваемся с задачами не-
Вход
Система
Рис. 1.2. Модель системы
скольких типов, которые можно разде-
лить на прямые и обратные.
18
Глава 1. Общие принципы моделирования систем
Прямая задача', зная уравнение, описывающее систему, можно
знать отклик на входной сигнал. Эту задачу просто моделировать.
Уравнение можно вывести в ходе проектирования системы либо на ос-
нове исследования подобных систем.
Обратная задача', по отклику и математическому описанию системы
найти входной сигнал. Эта задача относится к классу задач управления.
Гораздо сложнее, если известны входные и выходные сигналы системы, а
необходимо найти математическое описание самой системы. Это - задача
идентификации или структурного синтеза системы. Трудность состоит в
том, что одно и то же состояние между входами и выходами может быть опи-
сано различными математическими выражениями.
В общем случае назначение компонентов - преобразовывать входные
сигналы в выходные.
Имеется три вида компонентов (рис. 1.3):
1) преобразование - один или несколько входных сигналов преобразуются
в один или несколько выходных сигналов;
2) сортировка - один или несколько входных сигналов распределяются
(сортируются) по двум или нескольким разным выходам;
3) обратная связь - входной сигнал некоторым образом изменяется в за-
висимости от выходного сигнала.
---► К —► —► к
Преобразование Сортировка
Обратная связь
Рис. 1.3. Виды компонентов системы
Степень трудности, с которой задают структуру компонентов сис-
темы, зависит от априорного знания системы. Если природа исследуе-
мого процесса совершенно неизвестна или известна слабо, то ставится
задача идентификации «черного ящика». В этом случае систему описы-
вают линейными или нелинейными уравнениями передаточных харак-
теристик. В некоторых случаях можно знать многое о природе процесса
и не знать только значения некоторых параметров (задача идентифика-
ции «серого ящика»).
Основными методами конструирования математических моделей
являются: аксиоматический метод, метод уравнений элементов и метод
идентификации.
Аксиоматический метод состоит в том, что в самом начале фор-
мулируются (или постулируются) некоторые утверждения относительно
реальных объектов, которые представляются в виде набора математиче-
ских выражений - аксиом. Далее из них делают определенные выводы.
19
1.6. Этапы формирования математической модели
Достоинством этого метода является то, что он обеспечивает в пределах
принятых аксиом непротиворечивые выводы относительно существен-
ных свойств объекта. Основным недостатком метода является то, что
сами аксиомы не проверяются непосредственно в ходе эксперимента.
Метод уравнений элементов обычно используется тогда, когда надо
составить математическую модель объекта на основе свойств его частей
или когда из заданного набора элементов необходимо составить сложный
объект и определить его свойства. Как правило, сложная система расчленя-
ется на подсистемы и элементы таким образом, чтобы стали доступны
формализации каждого элемента и взаимодействие между ними.
В зависимости от характера элементов системы (детерминирован-
ные, стохастические, с непрерывным или дискретным временем и т.д.)
для их описания используются те или иные типичные математические
схемы: дифференциальные уравнения, конечные и вероятностные авто-
маты, переключательные сети, графовые модели, системы массового
обслуживания и т.д.
Детерминистические объекты, функционирующие в непрерывном
времени, обычно описываются дифференциальными уравнениями.
Математическими моделями стохастических объектов с непрерыв-
ным временем служат системы массового обслуживания или марков-
ские случайные процессы. В этом методе кажется, что учитывается все.
Однако в действительности объект проявляет ряд свойств, которые не сво-
дятся к совокупности свойств его элементов.
Метод идентификации состоит в том, чтобы по данным наблюдения
за входными и выходными сигналами объекта на конечном интервале вре-
мени построить такую математическую модель, которая оптимально опи-
сывала изучаемый объект относительно заданного критерия.
Если никаких априорных условий на структуру модели не накла-
дывается, то имеется в виду идентификация в широком смысле слова.
Общего метода решения такой задачи в настоящее время не существует.
При идентификации в узком смысле добавляется априорный вид струк-
туры некоторой математической модели. В этом случае определению
подлежат только параметры принятой математической модели.
1.6. Этапы формирования математической модели
Обобщенная структурная схема формирования модели представлена на
рис. 1.4.
Рис. 1.4. Структурная схема формирования математической модели
Этап 1. Определяется целевое назначение модели. Поскольку не сущест-
вует однозначного понятия «модель системы», можно моделировать ее любым
20
Глава 1. Общие принципы моделирования систем
способом в зависимости от того, что необходимо получить. Поэтому элементы
модели и их взаимосвязи должны быть выбраны в зависимости от специфика-
ции задачи, которую должна решать каждая система. (Если рассматривать дом,
то строитель видит его как объект тяжелой работы, а социолог - как окружаю-
щую среду.) Этап* 1 обеспечивает получение наиболее удачной математиче-
ской модели, например, с использованием структурных схем, применением
системы уравнений и другими математическими приемами.
Этап 2. На этом этапе осуществляется разработка структурной
схемы дискретного процесса и приведение системы уравнений к дис-
кретной форме. Этот этап завершается математическим описанием и
структурной схемой всей дискретной системы.
Этап 3. На данном этапе необходимо строго соблюсти временные
соотношения в синтезируемой математической модели.
Этап 4. Этот этап представляет собой испытание, проверку и от-
ладку синтезируемой модели.
После построения модели ее следует подвергнуть проверке. Суще-
ствует несколько аспектов проверки адекватности', сама математическая
основа модели должна быть непротиворечивой и подчиняться всем обычным
законам математической логики; справедливость модели определяется ее
способностью адекватно описывать исходную ситуацию.
В зависимости от сложности аналитического описания системы
выделяют следующие основные способы использования математиче-
ских моделей', аналитическое исследование, а также качественное иссле-
дование, исследование с помощью численных методов, имитационное
моделирование на цифровых вычислительных машинах (противопо-
ложность аналоговому моделированию).
Аналитическое исследование предполагает наличие достаточно пол-
ного и точного аналитического описания системы в целом. Как правило,
математическая модель в первоначальном виде непригодна для непосред-
ственного исследования (например, она может не содержать в явном виде
интересующие величины). В данном случае необходимо преобразовать
первоначальную модель относительно искомых величин так, чтобы было
возможно получение результата аналитическими методами. При этом по-
является возможность получить достаточно полную информацию о функ-
ционировании изучаемых объектов. Однако применить такое исследование
на практике удается сравнительно редко.
Качественное исследование проводят тогда, когда, не имея решения в
явном виде, тем не менее, можно найти некоторые свойства решения, на-
пример, оценить устойчивость решения и т.п. Сюда же можно отнести и
исследования структурной устойчивости моделей методами довольно но-
вой математической теории катастроф.
Исследование с помощью численных методов производят после преобра-
зования модели в систему уравнений относительно искомых величин, и реше-
21
1.7. Имитационное моделирование
ние находится путем реализации соответствующего численного метода. Одна-
ко решение задачи при этом обычно бывает менее полным по сравнению с
аналитическим исследованием, так как не выявляет структуры и характера
функционирования системы в целом, а лишь позволяет оценить ее состояние
при выбранных численных значениях параметров.
Использование численных методов стало особенно эффективным с
применением современных средств вычислительной техники. Однако при-
менение ЭВМ не имеет здесь принципиального значения, ибо ограничива-
ется лишь автоматизацией вычислений.
Имитационное моделирование не ограничивается только машинными
моделями. Результаты могут быть получены и при помощи листа бумаги,
ручки и настольного калькулятора.
Имитационные модели не способны формировать решение в таком виде,
как в аналитических моделях, а служат лишь средством для анализа поведения
системы в условиях, которые определяются экспериментатором. Поэтому ими-
тационное моделирование является экспериментальной и прикладной методо-
логией, имеющей целью описать поведение системы, построить теории и гипо-
тезы, которые могут объяснить наблюдаемое поведение, а также использовать
эти теории для предсказания будущего поведения системы.
При формировании модели решающую роль (при имитационном мо-
делировании) играют экспертные оценки и интуиция. Экспертные оценки
применяются при выборе наиболее плодотворного подхода при решении
вопроса о том, что включается в модель при ее проектировании и расчете.
1.7. Имитационное моделирование
Имитационное моделирование - один из нескольких имеющихся в распо-
ряжении исследователя методов решения проблем. Так как необходимо
приспосабливать метод к решению задачи, возникает вопрос: в каких усло-
виях имитационное моделирование полезно? Имитационное моделирова-
ние целесообразно применять при наличии одного из следующих условий.
1. Не существует законченной математической постановки данной задачи
(например, модели систем массового обслуживания, .связанные с рас-
смотрением очередей).
2. Аналитические методы имеются, но очень сложны и трудоемки, а ими-
тационное моделирование дает более простой способ решения.
3. Аналитические решения имеются, но их реализация невозможна из-за
недостаточной подготовки имеющегося персонала. В этом случае со-
поставляются затраты на работу с имитационным моделированием и за-
траты на приглашение специалистов со стороны.
4. Кроме оценки определенных параметров необходимо осуществлять на-
блюдение за ходом процесса в течение определенного периода.
22
Глава 1. Общие принципы моделирования систем
5. Имитационное моделирование может быть единственно возможным
вследствие трудности постановки эксперимента и наблюдения явлений в
реальных условиях (наблюдение за поведением космических кораблей).
6. Может понадобиться снятие шкалы времени (как замедление, так и
ускорение).
Преимуществами имитационного моделирования являются: возмож-
ность его применения в сфере образования и профессиональной подготовки;
возможность розыгрыша при имитационном моделировании реальных про-
цессов в ситуациях, которые могут помочь исследователю понять и прочув-
ствовать проблему, что стимулирует поиск нововведений. В силу этого ими-
тационное моделирование находит широкое применение, составляющее око-
ло 30% от используемых других методов, несмотря на то, что людям с высо-
кой математической подготовкой имитационный подход представляется гру-
бым приемом или последним средством, к которому следует прибегать.
Однако имитационное моделирование имеет ряд сложностей, кото-
рые заключаются в следующем.
Разработка хорошей имитационной модели часто обходится доро-
го и требует много времени и высококвалифицированных специалистов.
Имитационное моделирование в
принципе неточно, и трудно измерить
степень точности. Частично эго можно
преодолеть путем анализа чувствитель-
ности модели к изменению определен-
ных параметров.
Имитационное моделирование в
действительности не отражает ре-
ального положения вещей, и это не-
обходимо учитывать.
Результат имитационного моде-
лирования обычно является числен-
ным, а его точность определяется ко-
личеством знаков после запятой. По-
этому в имитационном моделирова-
нии могут приписывать числу боль-
шую значимость.
Так как имитация представляет
собой крайнее средство, применяемое
для решения задач, то, если задача мо-
жет быть сведена к простой модели и
решена аналитически, нет нужды в
имитации. Кроме того, каждый раз при
накоплении информации о решаемой
задаче вопрос о применении имитации
следует подвергать переоценке.
моделирования
23
1.7. Имитационное моделирование
Имитация требует применения мощных ЭВМ и большой выборки
данных, поэтому издержки при моделировании велики по сравнению с ана-
литическими моделями.
Процесс имитации представлен на рис. 1.5.
Поскольку имитация применяется для исследования реальных сис-
тем, можно выделить следующие этапы этого процесса:
определение системы - установление границ, ограничений и измери-
телей эффективности системы, подлежащей изучению;
формулирование модели - переход от реальной системы к логической
схеме (абстрагирование);
подготовка данных - отбор данных, необходимых для построения
модели, и представление их в соответствующей форме;
трансляция модели - описание модели на языке, приемлемом для
использования в ЭВМ;
оценка адекватности - повышение до приемлемого уровня степени уве-
ренности, с которой можно судить о корректности выводов о реальной системе;
стратегическое планирование - планирование эксперимента, кото-
рый должен дать необходимую информацию;
тактическое планирование - определение способа проведения ка-
ждой серии испытаний, предусмотренных планом эксперимента;
экспериментирование - процесс осуществления имитации с целью
получения желаемых результатов (данных);
интерпретация - построение выводов по данным, полученным пу-
тем имитации;
реализация - практическое использование модели и результатов
моделирования;
документирование - регистрация хода осуществления проекта и
его результатов, а также документирование процесса создания и ис-
пользования модели.
Для качественной оценки сложной системы удобно использовать ре-
зультаты теории случайных процессов. Опыт наблюдения за объектами по-
казывает, что они функционируют в условиях действия большого количе-
ства случайных факторов, поэтому предсказание поведения сложной сис-
темы может иметь смысл только в рамках вероятностных категорий. Дру-
гими словами, для ожидаемых событий могут быть указаны лишь вероят-
ности их наступления, а относительно некоторых значений приходится ог-
раничиться законами их распределения или другими вероятностными ха-
рактеристиками (например, средними значениями, дисперсиями и т.д.).
Для изучения процесса функционирования каждой конкретной слож-
ной системы с учетом случайных факторов необходимо иметь достаточно
четкое представление об источниках случайных воздействий и весьма на-
дежные данные об их количественных характеристиках. Поэтому любому
расчету или теоретическому анализу, связанному с исследованием сложной
системы, предшествует экспериментальное накопление статистического
24
Глава 1. Общие принципы моделирования систем
материала, характеризующего поведение отдельных элементов и системы в
целом в реальных условиях. Обработка этого материала позволяет полу-
чить исходные данные для расчета и анализа.
Основными источниками случайных воздействий являются факторы
внешней среды и отклонения от нормальных режимов функционирования
(ошибки, шумы и т.д.), возникающие внутри системы.
Из сказанного следует, что учету случайных факторов при исследова-
нии сложных систем необходимо уделить весьма серьезное внимание.
Влияние случайных факторов на течение процесса имитируется при
помощи случайных чисел с заданными вероятностными характеристиками.
При этом результаты, получаемые при однократном моделировании, сле-
дует расценивать лишь как реализации случайного процесса. Каждая из та-
ких реализаций в отдельности не может служить объективной характери-
стикой изучаемой системы. Искомые величины обычно определяются ус-
реднением и статистической обработкой данных большого числа реализа-
ций, поэтому часто такой подход называют еще методом статистическо-
го моделирования. Однако имитационные модели могут применяться и в
детерминированном случае, где нет никаких статистических задач.
Метод статистического моделирования позволяет вычислить значе-
ние любого функционала, заданного на множестве реализаций изучаемого
процесса. Например, имея возможность находить значение показателя эф-
фективности системы с помощью статистических испытаний, можно ре-
шать целый ряд задач анализа сложных систем, таких как: оценка влияния
на эффективность изменений различных параметров системы или началь-
ных условий; оценка эффективности различных принципов управления.
Результаты моделирования оказываются полезными и при синтезе
системы для оценки качества тех или иных вариантов ее структуры, пер-
спективного планирования.
Однако методу статистического моделирования присущ общий не-
достаток любых численных методов - полученные результаты этого метода
носят частный характер и оценивают эффективность системы лишь в тех
ситуациях, для которых проводилось моделирование.
Несмотря на этот весьма серьезный недостаток, имитационное модели-
рование является в настоящее время наиболее эффективным методом исследо-
вания сложных систем, а иногда и единственным практически доступным
средством получения интересующей информации о поведении системы (осо-
бенно на стадии ее проектирования или модернизации).
Аналитические модели (AM) предполагают наличие математического
описания процессов, протекающих в оригинале. Обычно строятся при же-
стких ограничениях на параметры оригинала и внешней среды. AM позво-
ляют получать зависимости вида Р, =f (ос!,..., а,).
Имитационные модели (ИМ) являются наиболее универсальными и
могут быть построены при отсутствии математической модели оригинала.
25
{Я. Имитационное моделирование
Идея имитационного моделирования очень проста и заключается в том, что
строится некий алгоритм поведения подсистем и отдельных элементов сис-
тем во времени. При анализе производительности интересно только со-
стояние подсистем (работает или не работает). Этот алгоритм может быть
реализован в виде программы для ЭВМ. Многократно «прогоняя» ИМ в
условиях случайных потоков событий на входе и в самой системе, можно
накопить статистическую информацию об изменении существенных пере-
менных состояниях ИМ. Статистическая обработка этой информации по-
зволяет получить статистические оценки показателей эффективности. В
отличие от AM, имитационная модель обладает принципиальной методи-
ческой погрешностью, существенно зависящей от объема выборки и, соот-
ветственно, от времени наблюдения за ИМ.
Контрольные вопросы к главе 1
1. В чем заключается процесс моделирования ?
2. Приведите классификацию математических моделей в зависимости от
характера отображаемых свойств объекта.
3. В чем разница между алгоритмическими и аналитическими моделями ?
4. Каковы основные компоненты динамических моделей ?
5. В чем разница между экзогенными и эндогенными переменными ?
6. Каковы особенности моделирования отдельных компонентов (элементов,
подсистем) сложных систем ?
7. Перечислите основные этапы формирования математической модели.
8. Перечислите и охарактеризуйте основные способы использования
математических моделей.
9. Каковы отличительные особенности имитационного моделирования ?
10. При выполнении каких условий целесообразно применять имитационное
моделирование ?
11. В чем заключаются сложности имитационного моделирования ?
12. Перечислите основные этапы имитационного моделирования при
исследовании реальных систем.
26
Глава 2
ОБЩИЕ ПРИНЦИПЫ ПОСТРОЕНИЯ
СИСТЕМ И СЕТЕЙ СВЯЗИ
2.1. Концепция построения систем и сетей связи
В 1970 - 80-х годах произошло слияние отраслей компьютерных наук и
передачи данных, кардинально изменившее технологии, продукты и
характер деятельности компаний объединенной индустрии компьютер-
ной передачи данных. В результате исчезли существенные различия
между обработкой данных (выполняется компьютерами) и передачей
данных (выполняется аппаратурой передачи и коммутации). Сгладились
различия между однопроцессорным и многопроцессорным компьюте-
рами, локальной сетью, региональной сетью и глобальной сетью.
Одним из результатов этих тенденций стало усиливающееся слия-
ние компьютерной индустрии и индустрии передачи данных, имеющее
место как при производстве компонентов, так и при интеграции систем.
Другим результатом этих тенденций стало развитие интегрированных
информационных систем, выполняющих передачу и обработку всех
типов данных и информации. Организации, разрабатывающие как тех-
нические, так и технологические стандарты, направляют их развитие в
сторону интегрированных общественных систем, что позволяет легко и
единообразно получать доступ практически ко всем источникам данных
и информации во всем мире.
Простейшая модель системы передачи информации (СПИ) может
быть представлена схемой на рис. 2.1, а.
Система источника
Система адресата
Рабочая станция
б)
Рис. 2.1. Схема простейшей модели системы передачи информации:
а - общая схема СПИ; б - частный случай системы передачи данных
Основной целью СПИ является обмен информацией между пере-
дающей и приемной сторонами. На рис. 2.1, б представлен частный слу-
чай СПИ - система передачи данных (СПД), когда в качестве источника
27
2.1. Концепция построения систем и сетей связи
информации выступает рабочая станция, а в качестве получателя ин-
формации - сервер, которые обмениваются данными с помощью моде-
ма через телефонную сеть общего пользования (ТФОП).
Основные элементы модели. Рассмотрим более подробно основ-
ные элементы этой модели.
Источник - устройство, генерирующее данные, требующие пере-
дачи (например телефон, персональный компьютер).
Передатчик. Как правило, данные генерируются системой источ-
ника и передаются непосредственно в той форме, в которой они были
созданы. Передатчик выполняет преобразование и кодирование инфор-
мации с целью создания сигналов, которые можно передавать через не-
которую передающую систему (например, модем принимает от персо-
нального компьютера или другого присоединенного устройства инфор-
мационный поток двоичных сигналов и преобразует его в аналоговый
сигнал, который может обрабатываться телефонной сетью).
Передающая система - простая линия связи или сложная сеть, со-
единяющая источник и адресат информации.
Приемник - устройство, получающее сигнал от передающей сис-
темы и преобразующее его в форму, пригодную для обработки адреса-
том (например, модем принимает из сети аналоговый сигнал и преобра-
зует его в цифровой).
Адресат получает от приемника поступающую информацию.
Рассмотрим основные функции, выполняемые системой передачи
информации.
Функции передающей системы. Передающая система реализует
возможности средств связи, как правило, совместно используемых не-
сколькими пользователями. Для распределения общей пропускной спо-
собности среды передачи между разными пользователями осуществля-
ются различные методы (например, уплотнение). Чтобы передающая
система не была перегружена чрезмерным спросом на услуги связи,
может потребоваться управление нагрузкой каналов связи.
Для сообщения с другими СПИ используются специальные устройст-
ва: сопряжения и генерирования несущих сигналов. Свойства сигнала, такие
как форма и интенсивность, должны, во-первых, делать возможным его
прохождение через передающую систему и, во-вторых, обеспечивать воз-
можность приемнику корректно интерпретировать принимаемый сигнал.
Для удовлетворения требований передающей системы и приемни-
ка недостаточно просто генерировать сигналы. Должна существовать
некоторая синхронизация между передатчиком и приемником.
Кроме основного вопроса выбора природы и синхронизации сиг-
налов существует множество требований по установке связи между
двумя сторонами, объединенных общим названием - управление ин-
формационным обменом. Если в течение некоторого периода времени
требуется передать данные в обоих направлениях, то участники обмена
28
Глава 2. Основные принципы построения систем и сетей связи
должны взаимодействовать друг с другом. Например, если две стороны
должны провести телефонный разговор, то один абонент должен на-
брать номер другого, генерируя сигнал вызова. Вызываемая сторона
завершает установку соединения, поднимая трубку телефона. Для уст-
ройств обработки данных простой установки соединения недостаточно.
Должны быть согласованны определенные условия: режим обмена (мо-
гут ли оба устройства передавать одновременно или они должны делать
это по очереди); объем данных, который можно передавать единовре-
менно; формат данных; перечень действий, необходимых в определен-
ных обстоятельствах, таких как возникновение ошибки.
Следующие два элемента СПИ можно было бы включить в задачу
управления обменом, однако они достаточно существенны и сами по себе.
Во всех СПИ потенциально возможны ошибки, поскольку передаваемые
сигналы, как правило, искажаются, прежде чем достигают адресата. При
условиях, не допускающих искажения сигналов, требуется выявление и
исправление ошибок. Обычно такие условия предъявляются в системах об-
работки данных. Например, при передаче файла с одного компьютера на
другой случайное изменение содержимого этого файла просто
недопустимо.
Управление потоком данных требуется для гарантии того, что ис-
точник не будет поставлять адресату данные быстрее, чем последний
сможет их принять и обработать.
Важное значение имеют родственные, но различные концепции
адресацгш и маршрутизации. Если СПИ используется более чем двумя
устройствами, то система источника должна указать конкретного пла-
нируемого адресата. Передающая система должна гарантировать, что
передаваемые данные получит система-адресат, причем только она.
Кроме того, передающая система сама может быть сетью, в которой
существуют различные пути передачи данных. Следовательно, необхо-
димо выбрать определенный маршрут через эту сеть.
Восстановление - понятие, отличное от понятия исправления
ошибок. Методы восстановления требуются в ситуациях-, когда обмен
информацией (например, при операциях с базой данных или при пере-
даче файла) прерывается из-за сбоя где-либо в системе. При этом необ-
ходимо или возобновить прерванный процесс с момента прерывания,
или хотя бы восстановить состояние задействованных систем, предше-
ствовавшее началу обмена.
Форматирование сообщений должно выполняться по соглашению,
принятому двумя сторонами относительно формы данных, участвую-
щих в обмене или передаче. Примером может служить двоичный код,
принятый для передачи символов.
В СПИ часто важно обеспечить некоторый уровень безопасности.
Отправитель может пожелать, чтобы данные получал только опреде-
ленный приемник, а принимающая сторона может пожелать гарантии
29
2.2. Многоуровневые модели сети
того, что данные не были изменены в процессе передачи и, что они дей-
ствительно исходят от предполагаемого отправителя.
Устройство передачи информации является сложной системой, ко-
торая не может активизироваться и работать сама по себе. Для настрой-
ки системы, контроля ее состояния, реагирования на сбои и перегрузки
в работе, а также для разумного планирования дальнейшего развития
этой системы требуются возможности сетевого управления.
Коммутация каналов и коммутация пакетов занимают важное
место в функционировании сетей связи.
В сети с коммутацией каналов узлы сети используются для создания
отдельного маршрута передачи данных между двумя станциями. Этот
маршрут представляет собой связную последовательность физических ка-
налов сообщения между узлами. В каждом из таких каналов для передачи
данных выделяется логический канал. Данные, генерируемые исходным
устройством, передаются по выделенному маршруту с максимально воз-
можной скоростью. В каждом узле входящие данные немедленно перена-
правляются или коммутируются в подходящий выходной канал. Общеиз-
вестным примером сети с коммутацией каналов является телефонная сеть.
В сети с коммутацией пакетов применяется несколько иной подход.
Здесь выделение специализированного канала по маршруту через сеть уже
не обязательно. Вместо этого данные передаются в виде последовательно-
сти небольших пакетов, каждый из которых проходит сеть от узла к узлу по
некоторому маршруту, ведущему от источника к адресату. Каждый узел
принимает пакет в полном объеме, временно фиксирует его в памяти и пе-
редает следующему узлу. Сети с коммутацией пакетов обычно использу-
ются при передаче данных между двумя компьютерами или между терми-
налом и компьютером.
2.2. Многоуровневые модели сети
2.2.1. Трехуровневая модель
Рассматривая в самых общих чертах трехуровневую модель сети, можно
сказать, что в передаче данных участвуют три агента: приложения, компь-
ютеры и сети. Одним из примеров приложения является операция передачи
файла. Такие приложения выполняются на компьютерах, которые часто
могут поддерживать множество одновременно работающих приложений.
Компьютеры объединяются в сети, и данные, предназначенные для обмена,
передаются по сети от одного компьютера к другому. Таким образом, пере-
дача данных от одного приложения к другому включает, во-первых, полу-
чение данных компьютером, на котором находится приложение, и, во-
вторых, передачу их нужному приложению внутри компьютера.
30
Глава 2. Основные принципы построения систем и сетей связи
С учетом этих концепций естественным выглядит разделить передачу
данных на три относительно независимых уровня (рис. 2.2): 1) уровень при-
ложений, 2) транспортный уровень, 3) уровень доступа к сети.
Протокол доступа к сети
Рис. 2.2. Простейшая трехуровневая архитектура сети
На уровне доступа к сети происходит обмен данными между ком-
пьютером и сетью, к которой он подключен. Компьютер, отправляющий
данные, должен предоставить сети адрес компьютера-адресата, чтобы
сеть могла выбрать соответствующий маршрут передачи этих данных.
Тот же компьютер может пожелать воспользоваться некоторыми услу-
гами, предоставляемыми сетью (например, установка приоритета). Кон-
кретное программное обеспечение, применяемое на этом уровне, зави-
сит от типа используемой сети; разработаны различные стандарты для
сетей с коммутацией каналов, коммутацией пакетов, локальных и дру-
гих типов сетей. Поэтому целесообразно выделить функции доступа к
сети в отдельный уровень. При этом остальное программное обеспече-
ние, относящееся к уровню доступа к сети, не должно зависеть от спе-
цифики используемой сети. Это программное обеспечение, относящееся
к более высоким уровням, должно корректно функционировать в любой
сети, к которой подключен компьютер.
Независимо от природы приложений, выполняющих обмен дан-
ными, существует обычное требование надежности обмена (т.е. уверен-
ность в том, что все данные достигли приложения-адресата и что они
пришли в том же порядке, в каком были отправлены). Как будет показа-
но далее, механизмы обеспечения надежности в значительной степени
независимы от природы приложений. Следовательно, имеет смысл объ-
единить эти механизмы в общий уровень, совместно используемый все-
ми приложениями. Он называется транспортным уровнем.
Уровень приложений содержит логику, необходимую для под-
держки различных пользовательских приложений. Для каждого типа
приложения (например, передачи файлов) требуется отдельный модуль,
предназначенный именно для этого приложения.
Модули одного и того же уровня на различных компьютерах сооб-
щаются посредством протоколов. Архитектура протоколов сети представ-
лена на рис. 2.3, где показаны три компьютера, объединенные в сеть.
31
2.2. Многоуровневые модели сети
Рис. 2.3. Архитектуры протоколов и сети
Каждый компьютер содержит программное обеспечение на уровне дос-
тупа к сети и транспортном уровне, а также программное обеспечение на
уровне приложений, предназначенное для одного или более приложений. Для
успешной передачи данных каждый объект в системе должен иметь уникаль-
ный адрес. Фактически требуется даже два уровня адресации. Каждый ком-
пьютер в сети должен иметь уникальный сетевой адрес, позволяющий сети
доставлять данные нужному компьютеру. Помимо этого, каждое приложение
в компьютере должно иметь уникальный адрес в этом компьютере, что позво-
ляет транспортному уровню поддерживать на каждом компьютере многочис-
ленные приложения. Эти последние адреса называются точками доступа к
службе (SAP- Service Access Point), подчеркивая то, что каждое приложение
индивидуально получает доступ к службам транспортного уровня.
2.2.2. Архитектура протоколов TCP/IP
В качестве основы для разработки стандартов взаимодействующих средств
связи используются две архитектуры протоколов: набор протоколов TCP/IP
(Transmission Control Protocol/Intemet Protocol) и эталонная модель OSI
(Open System Interconnection). Протокол ТСРЛР представляет собой наибо-
лее широко используемую архитектуру взаимодействия, а модель OSI стала
стандартной моделью «Классификации функций связи».
В отличие от модели OSI, официальной модели протоколов TCP/IP
не существует. Тем не менее на основе разработанных стандартов мож-
но разделить задачи протоколов TCP/IP на пять относительно независи-
мых уровней: физический, доступа к сети, межсетевой, транспортный или
межузловой, приложений.
Физический уровень включает физический интерфейс между устрой-
ством передачи данных (например, рабочей станцией или компьютером) и
передающей средой или сетью. Задача этого уровня - установление харак-
теристик среды передачи, природы сигналов, скорости передачи и прочих
подобных параметров.
32
Глава 2. Основные принципы построения систем и сетей связи
Уровень доступа к сети касается обмена данными между конеч-
ной системой и сетью, к которой она подключена. Передающий компь-
ютер должен предоставить сети адрес компьютера назначения, чтобы
сеть могла проложить маршрут передачи данных к конечному пункту.
Передающий компьютер может затребовать определенные услуги, пре-
доставляемые сетью, такие, например, как установка приоритета. Какое
именно программное обеспечение будет использоваться на этом уровне,
зависит от типа используемой сети. Для сетей с коммутацией каналов,
коммутацией пакетов (например, сетей с протоколом Х.25), локальных
сетей (например, сети Ethernet) и других типов сетей разработаны раз-
личные стандарты. Задача уровня доступа к сети - обращение с сетью и
определение маршрута данных по сети для двух конечных систем, под-
ключенных к одной сети.
Меле сетевой уровень обеспечивает механизм перехода данных из од-
ной сети в другую в случае, если устройства подключены к различным сетям.
Задачу перехода между сетями на этом уровне выполняет прото-
кол IP. Он реализуется не только в конечных системах, но и на маршру-
тизаторах. Маршрутизатор - узел обработки, соединяющий две сети;
его основная функция - передача данных из одной сети в другую по
маршруту от источника к адресату.
Транспортный (или мелсузловой) уровень включает в себя меха-
низмы, обеспечивающие надежную доставку данных в случае, если уст-
ройства продключены к различным сетям. Независимо от природы при-
ложений, выполняющих обмен данными, существует обычное требова-
ние надежности такого обмена. Иными словами, необходимо гаранти-
ровать, что все данные достигли приложения-адресата и что они при-
шли в том же порядке, в каком были отправлены. Для этой цели обычно
используется протокол управления передачей TCP.
Уровень приложений содержит логику, необходимую для под-
держки различных пользовательских приложений. Для каждого типа
приложения (например, передачи файлов) требуется отдельный модуль,
предназначенный именно для этого приложения.
На рис. 2.4 показана реа-
лизация протоколов TCP/IP в
конечных системах. Заметим,
что физический уровень и уро-
вень доступа к сети обеспечи-
вают взаимодействие между
конечной системой и сетью,
тогда как транспортный уро-
вень и уровни приложений
осуществляют взаимодействие
Рис. 2.4. Архитектура протоколов
между конечными системами.
Межсетевой уровень чем-то
2—3834
33
2.2. Многоуровневые модели сети
похож на физический и уровень доступа к сети. На этом уровне конечная
система сообщает сети информацию о маршруте. Кроме того, она также
должна обеспечивать некоторые функции на всем протяжении между двумя
конечными системами.
2.2.3. Эталонная модель OSI
Эталонная модель OSI не является реализацией сети, а только определяет
функции каждого уровня. Рис. 2.5 иллюстрирует семиуровневую модель OSI.
Уровень приложении
Предоставляет пользователям доступ к среде OSI и распределенные
информационные услуги
Уровень представления
Обеспечивает независимость прикладных процессов от различий
в представлении данных (синтаксисе)
Сеансовый уровень
Предоставляет управляющую структуру для связи между приложениями;
устанавливает, контролирует и завершает соединения (сеансы) между
взаимодействующими приложениями
Транспортный уровень
Обеспечивает надежную, прозрачную передачу данных между конечными
пунктами; обеспечивает сквозное восстановление после ошибок и
управление потоком данных
Сетевой уровень
Обеспечивает верхним уровням независимость от используемых для
соединений систем методов передачи данных и коммутации; отвечает
за установку, поддержание и завершение соединений
Канальный уровень
Обеспечивает надежную передачу информации по физическому каналу
связи; посылает блоки (кадры) с необходимой синхронизацией, контролем
ошибок и управлением потоком данных
Физический уровень
Занимается передачей неструктурированного потока битов через
физическую среду; управляет механическими, электрическими,
функциональными и процедурными характеристиками для доступа
_______________________к физической среде___________________
Рис. 2.5. Семиуровневая модель OSI
1
i
i
i
I
I
/
Уровень приложений {прикладной уровень) - самый близкий к пользо-
вателю уровень OSI. Он отличается от других уровней тем, что не обеспе-
чивает услуг ни одному из других уровней OSI, однако обеспечивает ими
прикладные процессы, лежащие за пределами масштаба модели OSI. При-
мерами таких прикладных процессов могут служить программы обработки
крупномасштабных таблиц, программы обработки слов, программы бан-
ковских терминалов и т.д. Прикладной уровень идентифицирует и устанав-
ливает наличие предполагаемых партнеров для связи, синхронизирует со-
вместно работающие прикладные программы, а также устанавливает со-
глашение по процедурам устранения ошибок и управления целостностью
информации. Прикладной уровень также определяет, имеется ли в наличии
достаточно ресурсов для предполагаемой связи.
34
Глава 2. Основные принципы построения систем и сетей связи
Уровень представления (представительный уровень) отвечает за
то, чтобы информация, посылаемая из прикладного уровня одной сис-
темы, была читаемой для прикладного уровня другой системы. При не-
обходимости представительный уровень осуществляет трансляцию ме-
жду множеством форматов представления информации путем использо-
вания общего формата представления информации.
Уровень занят не только форматом и представлением фактических
данных пользователя, но также структурами данных, которые используют
программы. Поэтому, кроме трансформации формата фактических данных
(если она необходима), уровень представления согласует синтаксис пере-
дачи данных для прикладного уровня.
Сеансовый уровень устанавливает, управляет и завершает сеансы
взаимодействия между прикладными задачами. Сеансы состоят из диалога
между двумя или более объектами представления. Сеансовый уровень
обеспечивает своими услугами уровень представления, а также синхрони-
зирует диалог между объектами уровня представления и управляет обме-
ном информации между ними. В дополнение к основной регуляции диало-
гов (сеансов) сеансовый уровень предоставляет средства для отправки ин-
формации и уведомления в исключительных ситуациях о проблемах сеан-
сового, представительного и прикладного уровней.
Транспортный уровень пытается обеспечить услуги по транспортировке
данных, избавляя высшие слои от необходимости вникать в ее детали. В част-
ности, заботой транспортного уровня является решение таких вопросов, как
выполнение надежной транспортировки данных через объединенную сеть.
Предоставляя надежные услуги, транспортный уровень обеспечивает меха-
низмы для установки, поддержания и упорядоченного завершения действия
виртуальных каналов, систем обнаружения и устранения неисправностей
транспортировки и управления информационным потоком (с целью предот-
вращения переполнения системы данными из другой системы).
Граница между сеансовым уровнем и транспортным уровнем мо-
жет быть представлена как граница между протоколами прикладного
уровня и протоколами низших уровней. В то время как прикладной,
представительный и сеансовый уровни заняты прикладными вопросами,
четыре низших уровня решают проблемы транспортировки данных.
Сетевой уровень - комплексный уровень, обеспечивающий возмож-
ность соединения и выбор маршрута между двумя конечными системами,
подключенными к разным «подсетям», которые могут находиться в разных
географических пунктах. В данном случае «подсеть» можно рассматривать
как независимый сетевой кабель (иногда называемый сегментом).
Поскольку две конечные системы, желающие организовать связь,
может разделять значительное географическое расстояние и множество
подсетей, сетевой уровень является доменом маршрутизации. Протоко-
лы маршрутизации выбирают оптимальные маршруты через последова-
тельность соединенных между собой подсетей. Традиционные протоко-
лы сетевого уровня передают информацию вдоль этих маршрутов.
35
2.3. Структура сетей связи
Канальный уровень (формально называемый информационно-
канальным уровнем) обеспечивает надежный транзит данных через физиче-
ский канал. Выполняя эту задачу, канальный уровень решает вопросы фи-
зической адресации (в противоположность сетевой или логической адреса-
ции), топологии сети, линейной дисциплины (каким образом конечной сис-
теме использовать сетевой канал), уведомления о неисправностях, упоря-
доченной доставки блоков данных и управления потоком информации.
Физический уровень определяет электротехнические, механические,
процедурные и функциональные характеристики активации, поддержания
и дезактивации физического канала между конечными системами. Специ-
фикации физического уровня определяют такие характеристики, как уров-
ни напряжений, синхронизацию изменения напряжений, скорость передачи
физической информации, максимальные расстояния передачи информации,
физические соединители и другие аналогичные характеристики.
На рис. 2.6 показано сравнение уровней архитектуры TCP/IP и OSI
с приблизительным соотношением функций, выполняемых в рамках
обеих моделей. Также на рисунке предлагаются общепринятые средства
реализации различных уровней.
OSI TCP/IP
Уровень
приложений
Уровень
представления
Уровень
приложений
Сеансовый
уровень
Транспортный
уровень
Сетевой
уровень
Канальный
уровень
Транспортный,
(межузловой)
уровень
Межсетевой
уровень
-..Уровень-—
доступа к
сети
Физический Физический
уровень
уровень
Рис. 2.6. Сравнение архитектур TCP/IP и OSI
2.3. Структура сетей связи
2.3.1. Глобальные сети
Глобальные септ (ГС), как правило, охватывают большие географические
области, требуют возможности пересечения границ общедоступных каналов
и зависят, по крайней мере частично, от этих каналов. Обычно глобальная
сеть состоит из некоторого числа взаимосвязанных коммутирующих узлов.
Схема простейших моделей сети представлена на рис. 2.7. Сообщение, пере-
даваемое любым устройством, определенным путем проходит через внут-
ренние узлы к заданному адресату. Эти узлы (в том числе и граничные) не
36
Глава 2. Основные принципы построения систем и сетей связи
затрагивают содержание передаваемых данных, их целью является только
обеспечение возможности коммутации, посредством которой данные будут
передаваться от узла к узлу, пока не прибудут к нужному адресату.
Рис. 2.7. Схема простейших моделей сетей
Исторически глобальные сети создавались на базе одной из двух тех-
нологий: коммутации каналов или коммутации пакетов. В более современ-
ных сетях основная роль отводится технологиям Frame Relay и ATM.
2.3.2. Локальные вычислительные сети
Локальные вычислительные сети (ЛВС) (см. рис. 2.7) - совместное под-
ключение нескольких отдельных компьютерных рабочих мест (рабочих
станций) к единому каналу передачи данных. Благодаря вычислительным
сетям была получена возможность одновременного использования про-
грамм и баз данных несколькими пользователями. Понятие «локальная
вычислительная сеть» (англ. LAN - Local Area Network) относится к гео-
графически ограниченным (территориально или производственно) аппа-
ратно-программным реализациям, в которых несколько компьютерных
систем связаны друг с другом с помощью соответствующих средств ком-
муникаций. Благодаря такому соединению пользователь может взаимодей-
ствовать с другими рабочими станциями, подключенными к этой ЛВС.
В производственной практике ЛВС имеют очень большое значе-
ние. Посредством них в систему объединяются персональные компью-
теры, расположенные на многих удаленных рабочих местах, которые
используют совместно оборудование, программные средства и инфор-
мацию. Рабочие места сотрудников перестают быть изолированными и
объединяются в единую систему. Рассмотрим преимущества, по-
лучаемые при сетевом объединении персональных компьютеров для
внутрипроизводственной вычислительной сети.
37
2.3, Структура сетей связи
Разделение ресурсов позволяет экономно использовать ресурсы (на-
пример, управлять периферийными устройствами, такими как лазерные
печатающие устройства) со всех присоединенных рабочих станций. Разде-
ление ресурсов процессора дает возможность использовать вычисли-
тельные мощности для обработки данных другими системами, входя-
щими в сеть. Предоставляемая возможность заключается в том, что
имеющиеся ресурсы используются не непосредственно, а только через
специальный процессор, доступный каждой рабочей станции.
Разделение данных предоставляет возможность доступа и управления
базами данных с периферийных рабочих мест, нуждающихся в информации.
Разделение программных средств предоставляет возможность од-
новременного пользования ранее установленными централизованными
программными средствами.
Многопользовательский режим системы содействует одновремен-
ному пользованию ранее установленными и управляемыми централизо-
ванными прикладными программными средствами (например, если
пользователь системы начинает работать с новым заданием, то выпол-
няемая до этого момента работа отодвигается на задний план).
Все ЛВС работают в одном стандарте, принятом для компьютер-
ных сетей - в стандарте OSI.
2.3.3. Топологии вычислительной сети
Концепция топологии типа «звезда» (рис. 2.8) пришла из области
больших ЭВМ, где головная машина получает и обрабатывает все дан-
ные с периферийных устройств как активный узел обработки данных.
Этот принцип применяется в системах передачи данных. Вся информа-
ция между двумя периферийными рабочими местами проходит через
центральный узел (файловый сервер) вычислительной сети.
Центральный узел управления (файловый сервер) реализует опти-
мальный механизм защиты от несанкционированного доступа к инфор-
мации. Вся вычислительная сеть может управляться из ее центра.
Пропускная способность сети опре-
деляется вычислительной мощностью узла
и гарантируется для каждой рабочей стан-
ции. Коллизий (столкновений) данных не
возникает.
Топология типа «звезда» является
наиболее быстродействующей из всех
топологий вычислительных сетей, по-
скольку передача данных между рабо-
чими станциями проходит через цен-
тральный узел (при его хорошей производительности) по отдельным
линиям, используемым только этими рабочими станциями. Частота за-
Рис. 2.8. Топология сети типа
«звезда»
38
Глава 2. Основные принципы построения систем и сетей связи
просов передачи информации от одной станции к другой невысокая по
сравнению с достижимой в других топологиях.
При кольцевой топологии (рис. 2.9, а) рабочие станции связаны
одна с другой по кругу, т.е. рабочая станция / с рабочей станцией 2,
рабочая станция 3 с рабочей станцией 4 и т.д. Последняя рабочая стан-
ция связана с первой. Коммуникационная связь замыкается в кольцо.
Рис. 2.9. Топологии вычислительной сети:
а - кольцевая; б - логическая кольцевая; в - шинная
Сообщения циркулируют регулярно по кругу. Рабочая станция посыла-
ет по определенному конечному адресу информацию, предварительно полу-
чив из кольца запрос. Пересылка сообщений является очень эффективной,
так как большинство сообщений можно отправлять «в дорогу» по кабельной
системе одно за другим. Очень просто можно сделать кольцевой запрос на
все станции. Продолжительность передачи информации увеличивается про-
порционально количеству рабочих станций, входящих в вычислительную
сеть. Основная проблема при кольцевой топологии заключается в том, что
каждая рабочая станция должна активно участвовать в пересылке информа-
ции, и в случае выхода из строя хотя бы одной из них вся сеть парализуется.
Неисправности в кабельных соединениях локализуются легко.
Специальной формой кольцевой топологии является логическая
кольцевая сеть (рис. 2.9, б). Физически она монтируется как соединение
звездных топологий. Отдельные «звезды» включаются с помощью спе-
циальных концентраторов (англ, hub - концентратор).
39
2.3. Структура сетей связи
В зависимости от числа рабочих станций и длины кабеля между рабо-
чими станциями применяют активные или пассивные концентраторы. Ак-
тивные концентраторы дополнительно содержат усилитель для подключе-
ния от 4 до 16 рабочих станций. Пассивный концентратор является исклю-
чительно разветвительным устройством (максимум на 3 рабочие станции).
Управление отдельной рабочей станцией в логической кольцевой сети про-
исходит так же, как и в обычной кольцевой сети. Каждой рабочей станции
присваивается соответствующий ей адрес, по которому передается управ-
ление (от старшего к младшему и от самого младшего к самому старшему).
Разрыв соединения происходит только для нижерасположенного (ближай-
шего) узла вычислительной сети, так что лишь в редких случаях может
нарушаться работа всей сети.
При шинной топологии (рис. 2.9, в) среда передачи информации
представляется в форме коммуникационного пути, доступного для всех
рабочих станций, к которому они все должны быть подключены. Все
рабочие станции могут непосредственно вступать в контакт с любой
рабочей станцией, имеющейся в сети.
Рабочие станции в любое время без прерывания работы всей вы-
числительной сети могут быть подключены к ней или отключены.
Функционирование вычислительной сети не зависит от состояния от-
дельной рабочей станции.
Благодаря тому, что рабочие станции можно включать без прерывания
сетевых процессов и коммуникационной среды, очень легко прослушивать
информацию, т.е. ответвлять информацию из коммуникационной среды.
В ЛВС с прямой передачей может существовать только одна стан-
ция, передающая информацию. Для предотвращения коллизий в боль-
шинстве случаев применяется временной метод разделения, согласно
которому для каждой подключенной рабочей станции в определенные
моменты времени предоставляется исключительное право на использо-
вание канала передачи данных. Поэтому требования к пропускной спо-
собности вычислительной сети при повышенной нагрузке снижаются,
например, при вводе новых рабочих станций. Рабочие станции присое-
диняются к шине посредством устройств ТАР (Terminal Access Point -
точка подключения терминала). ТАР представляет собой специальный
тип подсоединения к коаксиальному кабелю.
В ЛВС с модулированной широкополосной передачей информации
различные рабочие станции получают по мере надобности частоту, на
которой эти рабочие станции могут отправлять и получать информа-
цию. Пересылаемые данные модулируются на соответствующих несу-
щих частотах, т.е. между средой передачи информации и рабочими
станциями находятся соответственно модемы для модуляции и демоду-
ляции. Техника широкополосных сообщений позволяет одновременно
транспортировать в коммуникационной среде довольно большой объем
информации.
40
Глава 2. Основные принципы построения систем и сетей связи
Характеристики топологии вычислительных сетей приведены в табл. 2.1.
Таблица 2.1. Характеристики топологий вычислительных сетей
Характеристики Топология
типа «звезда» кольцевая шинная
Стоимость расширения незначитель- ная средняя средняя
Присоединение абонентов пассивное активное пассивное
Защита от отказов незначитель- ная незначительная высокая
Размеры сети любые любые ограниченны
Защищенность от прослушивания хорошая хорошая незначитель- ная
Стоимость подключения незначитель- ная незначительная высокая
Поведение системы при высоких нагрузках хорошее удовлетворительное плохое
Возможность работы в реальном режиме времени очень хорошая хорошая плохая
Разводка кабеля хорошая удовлетворительная хорошая
Обслуживание очень хорошее среднее среднее
Наряду с известными топологиями вычислительных сетей (кольцевая,
типа «звезда» и шинная), на практике применяется и комбинированная,
например древовидная структура, которая образуется в виде комбинаций
приведенных выше топологий вычислительных сетей. Основание дерева
вычислительной сети располагается в точке (корень), в которой собираются
коммуникационные линии информации (ветви дерева).
Рис. 2.10. Древовидная структура ЛВС
Вычислительные сети с древовидной структурой (рис. 2.10) при-
меняются там, где невозможно непосредственное применение базовых
сетевых структур в чистом виде. Для подключения большого числа ра-
41
4.5. Потоки событии
12 3 п
I-------I—I--------------I----------к-
0 Pl pt+p2 Pt+P2+P3 1
Рис. 4.5. Шкала соответствия вероятностей и интервалов разбиения
Выберем случайное число гг Если попало в интервал с номером
/, то случайная величина У приняла возможное значение xt.
Обоснование этого способа состоит в том, что случайная величина
R равномерно распределена на [0; 1), а значит, вероятность того, что R
окажется в некотором интервале, равна длине этого интервала, т.е.
Р{0<Г< Р|}=Р!,
P{Pl<>'< Pt + Р2}= Р2^
р{р> + р2 + ---+ Р„-1 <'•<!}= Р„-
Согласно данной процедуре Х = х, тогда, когдар\ + р2 +•• •+ Р\-\ < г <
< Pi+ Pi + • • • + р„ а вероятность этого интервала равна р,.
Моделирование полной группы событии. Рассмотренный подход
может быть обобщен и на группу событий. Моделирование полной группы
несовместимых событий А2, .... Ап, вероятности которых р2, ..., рн
известны (z;'=1A = 1), сводится к моделированию дискретной случайной ве-
личины А" со следующим законом распределения:
X 1 2 п
р Р\ Рг Рп
Достаточно считать, что если в некотором опыте случайная вели-
чина X приняла значение xz = /, то наступило событие А,. Это справедли-
во, так как число п возможных значений X равно числу событий полной
группы и Р(Х = xz) = w(/4z) =pt.
Способ моделирования полной группы событий заключается в сле-
дующем. Для того, чтобы определить, какое из событий А, произошло, надо
взять случайное число R и определить, какое значение приняла случайная
величина^ т. е. на какой интервал / попало число R. ПриХ=х, происходит
событие А,.
4.5. Потоки событий
Потоком событий называется последовательность однородных событий,
следующих одно за другим в какие-то случайные моменты времени. На-
пример: поток вызовов на телефонной станции; поток отказов (сбоев)
ЭВМ, поток железнодорожных составов, поступающих на сортировочную
станцию; поток частиц, попадающих на счетчик Гейгера и т.п. Поток собы-
тий можно наглядно изобразить рядом точек на оси времени. Нужно только
помнить, что положение каждой из них случайно, и на рис. 4.6 изображена
только какая-то одна реализация потока.
84
Глава 4. Моделирование дискретных распределений
О
Рис. 4.6. Изображение потока событий на временной оси
События, образующие поток, сами по себе вероятностями не обла-
дают; вероятностями обладают другие, производные от них события, на-
пример: «на участок времени т попадет ровно два события», или «на уча-
сток времени т попадет хотя бы одно событие», или «промежуток време-
ни между двумя соседними событиями будет не меньше т».
Опишем поток событий с помощью случайной функции Х(1), опре-
деляющей число требований, поступивших в систему за промежуток
времени (0; г). Случайная функция JV(Z) является примером дискретного
случайного процесса, так как аргумент t непрерывен, а сама функция
принимает целые неотрицательные значения и с возрастанием / не убы-
вает. График реализации процесса Дг) изображен на рис. 4.7.
Важной характеристикой потока со-
бытий является его интенсивность X -
среднее число событий, приходящееся на
единицу времени. Интенсивность потока
может быть как постоянной (X = const), так
и переменной, зависящей от времени t.
Поток событий называется регуляр-
ным, если события следуют одно за другим
через определенные, равные промежутки
времени. Чаще встречаются потоки не регу-
лярные, со случайными интервалами.
Рис. 4.7. Реализация дискретно-
го случайного процесса
На практике встречаются потоки, некоторые свойства которых по-
зволяют упростить их описание. Так, например, многие потоки облада-
ют свойством стационарности. Вероятностные характеристики таких
потоков не зависят от времени. В частности, интенсивность X стацио-
нарного потока должна быть постоянной. Поток требований называется
стационарным, если вероятность поступления определенного количест-
ва требований в течение определенного промежутка времени не зависит
от начала отсчета времени, а зависит от длины промежутка. Для ста-
ционарного потока вероятность того, что за промежуток (0; z) поступит
ровно п требований, равна вероятности поступления п требований за
промежуток (а; а + Z), где а > 0, т. е. P[X(z) = п\ = P[JT(Z + а) - Да) = п\.
Свойством стационарности обладают многие реальные потоки
требований. Стационарным является поток вызовов на АТС в опреде-
ленные промежутки времени. Но тот же поток в течение целых суток
уже не может считаться стационарным, так как вероятность вызовов в
ночное время меньше, чем днем.
85
4.5. Потоки событий
В некоторых потоках число требований, поступивших в систему
после произвольного момента времени, не зависит от числа ранее по-
ступивших требований и моментов их поступления. Поток событий, об-
ладающий таким свойством, называется потоком без последействия.
Для такого рода потоков для любых двух непересекающихся участков
времени Т! ит2 (рис. 4.8) число событий, попадающих на один из них,
не зависит от того, сколько событий попало на другой. По сути это оз-
начает, что события, образующие поток, появляются в те или другие
моменты времени независимо друг от друга, вызванные каждое своими
собственными причинами.
--------•-------•—• •-•—•—•—•--------
о------------------------------------t
Рис. 4.8. Иллюстрация потока без последействия
Свойство отсутствия последействия присуще многим реальным пото-
кам требований. Например, поток вызовов на АТС является потоком без
последействия, поскольку, как правило, очередной вызов поступает незави-
симо от того, когда и сколько было вызовов до этого момента.
Поток событий называется ординарным, если события в нем появ-
ляются поодиночке, а не группами. Например, поток клиентов, направ-
ляющихся в парикмахерскую или к зубному врачу, обычно ординарен,
чего нельзя сказать о потоке клиентов, направляющихся в загс для реги-
страции брака. Поток поездов, подходящих к станции, ординарен, а по-
ток вагонов - неординарен. Если поток событий ординарен, то вероят-
ностью попадания на малый участок времени А/ двух или более собы-
тий можно пренебречь.
Простейшим или пуассоновским потоком требований называется
поток, обладающий одновременно свойствами стационарности, ординар-
ности и отсутствия последействия. Название «простейший» объясняется
тем, что процессы, связанные с простейшими потоками, имеют наиболее
простое математическое описание.
Поскольку простейший поток является стационарным и без последей-
ствия, то для его полного описания вполне достаточно знать вероятности
№,,(/)= е . п = 0.1, 2...
п\
где X - интенсивность (или среднее число требований, поступивших в сис-
тему за единицу времени).
Для закона распределения Пуассона математическое ожидание числа
требований на интервале времени t равно дисперсии т = X/, а2 = A.Z. Таким
образом, для полного определения простейшего потока достаточно знать
параметр X.
86
Глава 4. Моделирование дискретных распределений
Простейший поток играет среди других потоков особую роль, в чем-
то подобную роли нормального закона среди других законов распределе-
ния. А именно, при наложении (суперпозиции) достаточно большого числа
независимых, стационарных и ординарных потоков (сравнимых между со-
бой по интенсивности) получается поток, близкий к простейшему. Ука-
занная особенность простейшего потока позволяет значительно облегчить
задачу выявления свойств стационарности, отсутствия последействия и ор-
динарности для установления того, является или нет поток требований про-
стейшим, что зачастую очень сложно.
Поток требований можно считать простейшим, если он получен сум-
мированием достаточно большого числа независимых между собой пото-
ков, влияние каждого из которых на сумму равномерно малое. Например,
поток поломок некоторого прибора, состоящего из большого числа дета-
лей, считается простейшим, если поломки деталей независимы между со-
бой и каждая деталь может выйти из строя лишь с малой вероятностью. На
практике обычно достаточно сложить 4-5 потоков, удовлетворяющих ука-
занным условиям, чтобы получить простейший поток.
Простейший поток обладает следующими особенностями:
1. Сумма М независимых, ординарных, стационарных потоков заявок с
интенсивностями X/ (/ = 1,..., Л7) сходится к простейшему потоку с ин-
тенсивностью X = X/ при условии, что все оказывают более или ме-
нее одинаково малое влияние на суммарный поток.
2. Простейший поток обладает устойчивостью, т.е. при сумме независи-
мых простейших получается простейший поток.
3. Для простейшего потока характерно, что поступление заявок через ко-
роткие промежутки времени более вероятно, чем через длинные , что
создает более тяжелый режим работы системы. Если реальный поток
отличен от простейшего, то система будет функционировать не хуже,
чем это следует из полученных оценок предельных значений характе-
ристик качества обслуживания.
4. Интервал времени между произвольным моментом t и моментом по-
ступления очередной заявки имеет такое же распределение, что и
интервал между двумя последовательными заявками.
Замечание. Если из состояния 5данную систему выводят несколько
потоков, то для случайной величины Т интенсивность потока X опреде-
ляется как суммарная величина интенсивности всех потоков.
Поток событий называется рекуррентным (или потоком Пальма),
если он стационарен, ординарен, а интервалы времени между события-
ми представляют собой независимые случайные величины с одинако-
вым произвольным распределением.
Пример. Технический элемент (скажем, конденсатор) работает непрерывно до
своего отказа (выхода из строя); отказавший элемент мгновенно заменяется
новым. Если отдельные экземпляры элемента выходят из строя независимо
друг от друга, то поток отказов (он же «поток замен» или «восстановлений»)
будет рекуррентным.
87
4.6. Обработка результатов моделирования
4.6. Обработка результатов моделирования
При реализации моделирующих алгоритмов на ЭВМ вырабатывается
информация о состояниях исследуемых систем. Эта информация явля-
ется исходной для определения приближенных значений или оценок ис-
комых величин.
Для сложных систем и большого количества реализаций, воспроизво-
димых при моделировании, объем информации о состояниях системы может
быть настолько значительным, что ее запоминание, обработка и последую-
щий анализ оказываются слишком трудоемким. Поэтому необходимо так ор-
ганизовать фиксацию и обработку результатов моделирования, чтобы оценки
для искомых величин формировались постепенно по ходу моделирования,
без специального запоминания всей информации о состояниях системы.
Если при моделировании данной системы учитываются случайные
факторы, то в качестве оценок для искомых величин используются
средние значения, дисперсии и другие вероятностные характеристики
случайных величин, полученных по результатам многократного моде-
лирования. Это обстоятельство позволяет формировать оценки таким
образом, что для запоминания самой оценки используется только одна
переменная (или иногда две - три), а все остальные величины, уже ис-
пользованные в данной оценке, не запоминаются.
Пусть искомая величина - вероятность некоторого события. В ка-
честве оценки для искомой вероятности используется частота наступле-
ния соответствующего события А при некотором количестве испыта-
ний. Выделим специальную переменную (счетчик), в которую будем
записывать количество наступлений события А-. если событие А насту-
пило при воспроизведении данной реализации, то к содержимому счет-
чика прибавляется единица, если же оно не наступило, то прибавляется
нуль. Пусть в результате воспроизведения W реализаций процесса мы
получили т случаев наступления события А. Тогда оценкой для вероят-
ности w(A) наступления события А может служить величина m/N.
Рассмотрим, например, оценку вероятностей возможных значений
случайной величины (закона ее распределения). Разобьем область возмож-
ных значений случайной величины на п интервалов. В специальных пере-
менных (или массиве) будем накапливать количества тк, к = 1,2, ..., п по-
паданий случайной величины в эти интервалы. Тогда оценкой для вероят-
ности попадания случайной величины в интервал с номером к служит ве-
личина рк = mk/N.
Для оценки среднего значения случайной величины X будем нака-
пливать сумму возможных значений случайной величины, которые она
принимает при различных реализациях процесса. Тогда
(4-4)
™ к=\
88
Глава 4. Моделирование дискретных распределений
Как было показано выше, оценкой дисперсии случайной величины
может служить выражение
(4-5)
В случае оценки корреляционного момента для случайных вели-
чин X и Y используется выражение
R(X, Г)= -J-f - м(х)\ук - М(у)), (4.6)
Л “ * А'=1
или в более удобном виде, требующем запоминания небольшого коли-
чества величин:
ч 1 Л' 1 У У
“^-1) ' (4'7)
Непосредственное вычисление по приведенным формулам не-
удобно, так как среднее значение изменяется в процессе накопления
значений хк, а это, в свою очередь, приводит к усложнению расчетов ли-
бо требует запоминания всех N значений хк.
В случае анализа стационарного процесса X вычисление среднего
значения т и дисперсии D производится усреднением не по времени, а
по множеству N значений, измеренных по одной реализации процесса
достаточной продолжительности.
В целях экономии памяти ПЭВМ, на которой производится моде-
лирование, т и а2 вычисляются в ходе моделирования путем наращива-
ния итогов при появлении очередного измерения случайной характери-
стики по следующим рекуррентным формулам.
Математическое ожидание случайной величины X для ее
/7-измерения хп:
П 1 Х„ /л о\
= '”«-1--+ —. (4-8)
п п
где 77?н_ I - математическое ожидание по предыдущим (и - 1) измерениям.
Выборочная дисперсия соответственно запишется как
- , и-9 1 о
• (4-9)
77 - 1 77
Начальная дисперсия п0 = 0.
4.6.1. Точность и число реализаций
Для обеспечения статистической устойчивости результатов моделиро-
вания соответствующие оценки вычисляются как средние значения по
большому числу реализаций, выбор которого производится с помощью
доверительных интервалов.
89
4.6. Обработка результатов моделирования
Пусть некоторый параметр, имеющий математическое ожидание а и
дисперсию а2, оценивается по результатам моделирования х,. В качестве
оценки параметра выбирается среднеарифметическое М(Х) (4.4). В силу
случайных причин М(Х) будет в общем случае отличаться от а.
Величину 8, такую, что \а - М(Х)\ < 8 называют точностью оценки
а вероятность того, что это неравенство выполняется, ее досто-
верностью Р(|а - Л/(А)| < е) = а. Например, для частотной интерпрета-
ции из 100 случаев применения этого правила в 100а случаях М(Х) бу-
дет отличаться от а меньше чем на 8, и только в 100(1 - а) случаях раз-
ница между ними может превосходить 8.
Воспользуемся данным правилом для определения точности ре-
зультатов, получаемых методом статистического моделирования.
Пусть целью моделирования будет вычисление вероятности р появления
некоторого случайного события А. В каждой из N реализаций процесса число
событий А является случайной величиной X, принимающей значение Х| = 1 с
вероятностью р, и значение х2 = 0 с вероятностью (1 -р).
Математическое ожидание и дисперсия случайной величины х равны:
М(х)= х{р + х2(1- р)= P'
- M(,Y)]2p+[x2 -М(Л')]2(1-р) = р(1-р) .
В качестве оценки для искомой вероятности р принимается часто-
та m/N наступлений события А в N реализациях:
1 N
-=-уЛ;,
N
/ = !
где х, - число наступлений события А в реализации с номером i.
В силу центральной предельной теоремы теории вероятностей час-
тота m/N при достаточно больших N имеет распределение, близкое к
нормальному, с математическим ожиданием и дисперсией:
Л/(/и/М) = р,
£(ш/М)=р(1-р)/Л\
Для нормированного отклонения частоты от своего математиче-
ского ожидания можно использовать выражение
ф(/)=р( —ь .
J
Поэтому для каждого значения достоверности Ф(/) = а можно вы-
брать из таблиц интеграла вероятностей такую величину /а, что точ-
ность 8 будет равна
е = /аА/^С«/Л^) или z = tajD(x)/N .
Отсюда число реализаций N = ta2D(X)/E2.
90
Глава 4. Моделирование дискретных распределений
Пример. Для а = 0,95 ta = 1,96. Подставляя вместо дисперсии Z)(A") ее значение,
можно определить количество реализаций N, необходимых для получения оцен-
ки частоты m/N с точностью £ и достоверностью а:
‘а ?
е
На практике вероятность р обычно неизвестна. Поэтому для определения ко-
личества реализаций поступают следующим образом. Выбирают Уо = 50 -г 100, по
результатам реализаций определяют т, а затем окончательно назначают N, прини-
мая, что р « m/N0. Точность £ обычно выбирают в пределах 0,01.. .0,05.
Если оцениваем одновременно дисперсию нескольких случайных
величин, то для расчета N выбираем max Dt(X).
Если D(X) неизвестно, то используют статистическую оценку вы-
борочной дисперсии.
Аналогично можно определить количество реализаций, необходи-
мых для оценки дисперсий, корреляционных моментов и других харак-
теристик случайных величин.
4.6.2. Первичная статистическая обработка данных
При обработке ряда наблюдений х2, •••> х» исследуемой случайной вели-
чины очень важно понять механизм формирования выборочных значений
xh т.е. подобрать и обосновать некоторую модельную функцию распреде-
ления FmodW, с помощью которой можно адекватно описать исследуемую
функцию распределения F(x). На определенной стадии исследования это
приводит к необходимости проверки гипотезы типа
//:Fc(x)=Fro011(x). (4.10)
В случае, когда число возможных значений случайной величины не
велико, представление о ее распред ел ении дает набор частот появления ка-
ждого из значений (гистограмма). Чтобы представить распределение более
наглядно, принято в прямоугольной системе координат строить специаль-
ный чертеж, называемый гистограммой распределения. Для этого горизон-
тальная ось разбивается на равные участки, соответствующие разрядам, и
на каждом из отрезков, как на основании, строится прямоугольник с высо-
той, пропорциональной частоте данного разряда. Полученная таким обра-
зом прямоугольная гистограмма зависит от выбора длины разрядов. Чтобы
уменьшить эту зависимость, прямоугольные гистограммы сглаживают.
Один из приемов сглаживания заключается в том, что прямыми линиями
соединяют середины соседних площадок гистограммы.
Простейший алгоритм подготовки гистограммы заключается в
сравнении х, с сеткой границ di9 d2, dn с помощью операций услов-
ных переходов и подсчете числа попаданий х, в каждый интервал. Од-
нако программа при большом числе интервалов получается громоздкой,
91
4,6. Обработка результатов моделирования
а главное, большим получается время обработки каждого х,. В большин-
стве случаев отрезки [d\, d2), \d2, d3) и т. д. имеют одинаковую ширину
С = Дх = (max(x,) - min(x))/ TV, (4.11)
где хм - максимальное значение х,; х0 - минимальное значение х,; N -
число интервалов.
В результате алгоритм ускоренной подготовки данных для по-
строения гистограммы будет следующим.
Шаг 1 . Находим хЛ,/, х0, вводим N.
Шаг 2 . Определяем массив счетчиков A(N), вычисляем С по формуле
(4.11) и полагаем / = 1.
Шаг 3 . Организуем ввод х„ вычисление J <— I + 1 (формирование те-
кущего номера i каждого х,) и вычисление вспомогательной
переменной Y = int(C(x - х0)). Значение Y указывает на номер
того отрезка, в который попадает заданное значение х,.
Шаг 4 . Вычисляем A(Y) <- A(Y) + 1 (т.е. вносим 1 в содержимое счет-
чика A(Y) и возвращаемся к шагу 3.
Ввод данных для построения гистограммы организуем с помощью
цикла с управляющей переменной у, меняющейся от значения 1 до N с
шагом 1. Число попаданий х, в J-й отрезок получаем выводом значений
А(/). Для получения данных при построении гистограммы интегрально-
го распределения вычисляем S <— а + A(j) при начальном S = 0.
Проверка гипотез типа (4.10) осуществляется также с помощью
критериев согласия и опирается на ту или иную меру различия между
анализируемой эмпирической функцией распределения f£"\x) и гипо-
тетическим модельным законом Fm0(i(x).
Критерий %2 (Пирсона). Он позволяет осуществлять проверку ги-
потезы (4.10) в условиях, когда значения параметров модельной функ-
ции распределения не известны исследователю. Процедура статистиче-
ской проверки гипотезы (4.10) складывается в данном случае из сле-
дующих этапов.
1. Весь диапазон значений исследуемой случайной величины £, разби-
вается на ряд интервалов группирования Д1, Д2, ..., Д£, не обяза-
тельно одинаковой длины. Это разбиение на интервалы необходимо
подчинить следующим условиям:
1) общее число интервалов К должно быть не менее 8;
2) в каждый интервал группирования должно попасть не менее
7... 10 выборочных значений £, причем желательно, чтобы в раз-
ные интервалы попало примерно одинаковое число точек;
3) если диапазон исследуемой величины £, - вся числовая прямая
(полупрямая), то крайние интервалы группирования будут полу-
прямыми (соответственно, один из них).
92
Глава 4. Моделирование дискретных распределений
2. На основании выборочных данных хь Хз, • • •-. X» строятся статистические
оценки 0^ неизвестных параметров ®(1), ®(2), ®(3), от
которых зависит данный закон распределения F. Более корректным
способом действий считается тот, при котором оценки 0^,0(2\ 0^
вычисляются на основе сгруппированных данных.
3. Подсчитывая число V, точек, попавших в каждый из интервалов груп-
пирования А/, вычисляются вероятности события е А/, т. е. вероятно-
сти попадания в те же интервалы А/ (и /,° - левый и правый концы
/- го интервала группирования):
р, = лЛх,°; <э(0, .... 0(3))- ; ©w.0(5)).
4. Вычисляется величина критической статистики /2(А^- 5*- I) по формуле
“ пР'
5- число параметров гипотетического распределения.
5. Из специализированных таблиц находится 100(1 - (х)-процентная
точка %2|_а/2(А?-5'- 1) и 100а/2-процентная точка %2а/2(/С - S- 1) рас-
пределения /2 с (К - 5 - 1) степенями свободы (ос, как и прежде, -
уровень значимости, который задается заранее).
Если Г l-antK-S- \)<x2(K-S- 1)< Х2а/2(^-^- D, то принима-
ется гипотеза о том, что исследуемая случайная величина £ действи-
тельно подчиняется закону распределения Fmod.
Выполнение неравенства /"(/С - S - 1) > х2а/?(^ - 5 - 1) говорит о
слишком большом отклонении исследуемого закона распределения от
гипотетического Fmod(*)- Например, при проверке гипотезы нормально-
сти гипотетический закон Fm0(i будет иметь вид
Г I 2^ 1 Г ( (»-а)21
а в качестве оценок а и о2 двух неизвестных параметров а и а2 будут
фигурировать величины
1 к
« = —УЖ0,
w ,=i
п ~ 1 / = !
где А,0 - средняя точка интервала А/, Г, - число попаданий на интервал А/.
Значения г(х;0;сс,сг), необходимые для подсчета вероятностей рь
можно найти, например, из таблиц функции нормированного нормального
распределения с учетом соотношения F(.r; а; а2) = F((x - а)/а; 0; 1). Число
степеней свободы закона распределения %2, процентные точки которого
нам понадобятся, будет равно в данном случае (К - 3), где К - число интер-
валов группирования.
93
4.6. Обработка результатов моделирования
Критерий согласия Колмогорова - Смирнова. Этот критерий
позволяет осуществлять проверку гипотезы (4.10) в условиях, когда мо-
дельная функция известна полностью, т.е. не зависит от неизвестных
параметров. В основе лежит функция выборки
D„=5ир|Л(^)- ,
где Fn(x) - эмпирическая функция распределения; FQ(x) - гипотетиче-
ская функция распределения.
Имеет место равенство
Нтр(©„<л/7^)=е(х),
где б(Х)= £(-1) к ехр(- 2к2к2).
Контрольная величина 4nDfl в пределе имеет функцию распреде-
ления Q(X). Для уровня значимости а из специальных таблиц берут та-
кое значение Хо, при котором О(Х0) = 1 - а.
Если 4nD„ > Хо, то гипотезу HQ о том, что исследуемая случайная
величина распределена по закону A’oW, отбрасывают. Критерий Колмо-
горова - Смирнова в общем случае не применим, если в FQ(x) входят
оценки параметров, которые были произведены по той же выборке, по
которой была вычислена Fn(x).
Статистикой критерия является среднеквадратическая мера расстоя-
ния между эмпирической и гипотетической функциями распределения
(•F„2 = то2, = h|(f0(x)- Г„(л)) 'dF0(x).
Применяя критерий, используется следующий вид статистики:
тг/2 ХЧ гг/ \ 2/-1У 1
ц 2п J 12л
В случае справедливости гипотезы Яо функция распределения ста-
тистики лсо2,, сходится при п -> со к предельному распределению ocj(x).
Методика использования рассмотренных непараметрических кри-
териев для проверки гипотезы согласия в основном одна и та же. Пусть
дальше Кп и F(x) обозначают соответственно значение критерия стати-
стики и функцию ее распределения (точную или предельную). Для про-
верки гипотезы согласия следует поступать следующим образом:
1) упорядочить элементы выборки в порядке возрастания;
2) вычислить значение статистики используемого критерия (или соот-
ветствующей модифицированной статистики);
3) вычислить вероятность а = 1 - Р{Кп) или сравнить величину К» с
процентными точками соответствующего распределения.
94
Глава 4. Моделирование дискретных распределений
Если вероятность а = 1 - Р(Я„) мала (Кн велико), то это означает, что
осуществилось маловероятное событие. Тогда предположение о согласии
ряда наблюдений (%ь ..., /„) с предполагаемым законом FQ(x) отвергается, а
расхождение между F„(x) и F0(x) нельзя объяснить случайностью экспери-
мента. Иногда гипотезу Яо отвергают и при слишком малых значениях К„
и, следовательно, при значениях а = I - P(Kt^ близких к 1.
Контрольные вопросы к главе 4
1. Дайте определение распределения Бернулли и опишите способ мо-
делирования случайной величины Ba:h:p.
2. Дайте определение биномиального распределения и опишите алго-
ритм моделирования случайной величины Вп.
3. Дайте определение распределения Пуассона и опишите способ мо-
делирования значений пуассоновской случайной величины с пара-
метром а.
4. Опишите моделирование случайных событий.
5. В чем состоит процесс моделирования противоположных случайных
событий ?
6. Опишите моделирование дискретной случайной величины.
7. Опишите моделирование полной группы событий.
8. Дайте определение и приведите основные статистические характе-
ристики потока событий.
9. Как оценить точность и количество реализаций при моделировании ?
10. В чем заключается первичная статистическая обработка данных ?
11. В чем заключается критерий %2 Пирсона ?
12. В чем заключается критерий согласия Колмогорова - Смирнова ?
95
Глава 5
АЛГОРИТМЫ МОДЕЛИРОВАНИЯ
СТОХАСТИЧЕСКИХ СИГНАЛОВ И ПОМЕХ
В СИСТЕМАХ СВЯЗИ
5.1. Алгоритм моделирования нестационарных
случайных процессов
Стохастический процесс - случайная функция, будущие значения кото-
рой нельзя предсказать наверняка, только с некоторой долей вероят-
ности. Это не означает, что процесс ведет себя абсолютно непредска-
зуемо, скорее его поведение управляется случайным механизмом. На
рис. 5.1 показаны пять реализаций стохастического процесса. Из рисун-
ка можно видеть, что характер процессов немного различен, но основ-
ная манера поведения повторяется.
Рис. 5.1. Пять выборок стохастического про-
цесса (зависимости /.. .5 отображают различия
в реализациях стохастического процесса)
Пространство состояний
стохастического процесса может
быть как непрерывным, так и
дискретным. В дальнейшем бу-
дем рассматривать стохастиче-
ские процессы как с дискретным
пространством состояний, так и
непрерывные во времени сто-
хастические процессы.
Пусть задан случайный
процесс XA(t) с корреляцион-
ной функцией Rx(th tj) и мате-
матическим ожиданием /лд-(/),
а на оси времени задана последовательность точек /ь 6, tn (не обяза-
тельно равноотстоящих). Требуется получить реализацию случайного
процесса. Обозначим
н
/=1
(5.1)
гдеХ - центрированные некоррелированные случайные величины с за-
данным законом распределения; f(f)~ неслучайные функции г, называе-
мые координатными функциями.
Подготовительная работа при моделировании случайных процес-
сов методом канонических разложений сводится к определению коор-
динатных функций и нахождению дисперсий.
96
Глава 5. Алгоритмы моделирования сигналов и помех в системах связи
Каноническое разложение корреляционной функции записывается в виде
, (5.2)
к=\
а каноническое разложение дисперсии - в виде
Ох(',)= . (5.3)
i'=l
Из соотношений (5.2) и (5.3) вытекают формулы для определения
координатных функций f(t) и дисперсий Д случайных величин Хг:
4,)=-----------------------,/=1,2, ..., п. (5.4)
При этом следует иметь в виду, что при i > j
Д)=о.ДО=1,
= (5'5)
А'=1
Моделирование случайного процесса, заданного каноническими
разложениями, осуществляется довольно просто. Для этого нужно про-
извести розыгрыш случайных величин х„ имеющих дисперсии Dh мате-
матическое ожидание тх = 0 и требуемое распределение.
Если получено каноническое разложение случайного процесса, то
его реализация находится следующим образом:
Х'2)= '”xG,)+ *lZ(Z2)+ xzf2(t2),
....................................................... (5.6)
/=1
5.2. Алгоритмы моделирования стационарных
случайных процессов
Для стационарных случайных процессов справедливы соотношения
'»х(') = = Яг(о)л('г'у)= ^xfr)>
где т = tj - tj.
То есть для стационарных случайных процессов корреляционная функ-
ция не зависит от величины аргументов, а зависит только от их разности.
Пусть центрированный случайный процесс Az(Z) = ^л(0 ~ задан
корреляционной функцией 7?Л(т). Требуется получить значения реализа-
ции процесса для аргументов t2, ..., tn.
97
4—3834
5.2. Алгоритм моделирования стационарных случайных процессов
Представим искомые реализации случайного процесса в виде
-*Gl)_ *" ^2Х2 * СцХн*
Х(?2)= GA2 + ‘ + C)iXn+l’ zг
Л(С/)— С\хн+ 0>Л//+1 + ”• +
где х, - реализации некоррелированных случайных величин х, с матема-
тическим ожиданием, равным нулю, и дисперсией су2.
Коэффициенты Q можно вычислить заранее из соотношения
~1\) = (р\ск + QG+1 + --- + Q/-*+iQ/)a2 • (5-8)
В этом случае в памяти ЭВМ требуется хранить п коэффициентов С, и
(2и - 1) случайных чисел х,-. Отметим, что в ряде случаев уравнение (5.8)
имеет точное решение, а в ряде случаев используются численные методы.
Если стационарный случайный процесс является гауссовским и имеются
некоррелированные нормированные распределенные по гауссовскому закону
случайные величины, то соотношения (5.7) и (5.8) примут следующий вид:
х(/1)=С1и1 + С2ц2 + --- + С,л,,
•X(g)= GW2 + GW3 * GAh-1» (5 9)
C\Un + С2^ц+\ + * G»^2/»-l’
Кх(*к -ri)= GG + QG+i + ••• + G/-*+iG,> (5.10)
где щ - реализации нормированной случайной гауссовской величины.
Для формирования стационарных гауссовских случайных процес-
сов в последнее время предложены достаточно эффективные алгорит-
мы, в основу которых положено линейное преобразование стационар-
ной последовательности X(t) независимых случайных чисел, имеющих
гауссовское распределение, в последовательность g(£), имеющую за-
данные статистические характеристики.
В этих алгоритмах дискретных белый шум Х(к) подается на вход
дискретного линейного фильтра, формирующего на выходе дискретный
случайный процесс с заданной корреляционной функцией либо спек-
тральной плотностью.
Алгоритмы формирования дискретных реализаций случайного
процесса задаются рекуррентными соотношениями следующего вида:
= ..... (5.И)
/=0
L М
g(k)=Yaix(k~l)-XbiS(k-= 1,(5.12)
/=0 J=l
где ah bp Ct - параметры алгоритмов, определяемые по корреляционной
функции Rs формируемого случайного процесса g(k).
98
Глава 5. Алгоритмы моделирования сигналов и помех в системах связи
Начальные значения g(k) в этих алгоритмах для простоты можно
выбрать нулевыми. При этом начальный участок моделируемого про-
цесса будет несколько искажен переходным процессом, после оконча-
ния которого последовательность g(k) становиться стационарной.
Для получения коэффициентов ah bj, Q , входящих в алгоритм
скользящего суммирования (5.11) и (5.12), применяются разложение в
ряд Фурье функции спектральной плотности, решение системы нели-
нейных алгебраических уравнений, правая часть которой определяется
исходной корреляционной функцией, метод факторизации и другие.
Если случайный процесс является стационарным и эргодическим,
то оценки статистических характеристик можно получить по одной реа-
лизации достаточной продолжительности.
Оценка математического ожидания для дискретной реализации
х(О, (/ = 1,2, ..., N) вычисляется по формуле
(5ЛЗ)
N м
Оценка корреляционной функции Rx(j) для j - 0, 1, ..., М (М -
число вычисляемых дискретных значений корреляционной функции)
вычисляется по формуле
> G = ОЛ • • W), (5.14)
где xz° = Xi - mx - центрированный случайный процесс; N- общее коли-
чество точек реализации дискретного процесса xz.
По формуле (5.14) путем суммирования по N произведений x^xqj+j-
для i = 1, 2, ..., N -j при фиксированном j осуществляется вычисление
корреляционной функции. При этом требуется вся реализация xz.
Формулу (5.14) для рекуррентного вычисления корреляционной санк-
ции можно преобразовать, исходя из следующих соображений. Получив
очередное значение xz, нужно при данном j вычислить произведения xzx^-
для7 = 0, 1, ..., М и прибавить полущенные произведения к содержимому М
ячеек, хранящих накопленные на предыдущих шагах суммы вида
я[о,н-1]=jyo),
/=0
W-1
7ф,п-1]=£4)х(/-1), (5.15)
/=0
N-1
-1] = X *04 ~ (^-1)) •
i=0
Несуществующие значения чисел х(/) в приведенных формулах,
например х(0), при вычислении Я(1;1) приравниваются нулю. Оконча-
тельно корреляционная функция имеет вид
(51б)
N -т
99
5.2. Алгоритм моделирования стационарных случайных процессов
При вычислении корреляционной функции по описанному выше
алгоритму требуется запомнить только NR предыдущих значений после-
довательности х(и). Так как число NR значительно меньше N, достигает-
ся существенная экономия памяти машины.
Во многих системах связи наблюдаются сигналы, которые достаточно
хорошо описываются моделями стационарных случайных процессов с ти-
повыми корреляционными функциями.
На основании вышеописанных методов были получены алгоритмы для
моделирования гауссовских стационарных случайных процессов с некото-
рыми распространенными типами корреляционных функций. В табл. 5.1
приведены соответствующие моделирующие алгоритмы. В этих алгоритмах:
h - шаг дискретизации независимой переменной; т - выбранный интервал
корреляции процесса; р - центральная частота моделируемого случайного
процесса; ос - определяет частотный диапазон, в пределах которого необхо-
димо воспроизвести моделируемый процесс.
Используя приведенные в табл. 5.1 алгоритмы, можно расширить
класс моделируемых случайных процессов. Так, из теории случайных про-
цессов известно, что при суммировании нескольких независимых стацио-
нарных гауссовских случайных процессов образуется стационарный гаус-
совский случайный процесс, корреляционная функция которого равна сум-
ме корреляционных функций слагаемых.
Таблица 5.1. Алгоритмы моделирования гауссовских стационарных случайных процессов
с некоторыми типами корреляционных функций
Корреляционная функция Моделирующий алгоритм Параметры алгоритма
о2 ехр(- а|т|) g(«)= aoxN(n)+ b\g(n - л = 0,1,... aQ = o71-P2’ bl = P’ p = e~Y; у = ah
о2 ехр(- cc|t|)cos(Pt) g(n) = аохЛ,(и)+ a}xN(n -1)+ + i|g(n-l)+i2g('’-2), n = 0,1,... aQ = oC = =aJi(c‘±Vci2-4Co j; ax =—=2pcoso; c b2 = -p2; CQ - p(p2 - ijcosS; Q = l-p4; p = e'Y;y = ah\ 5 = ВЛ
о2 ехр(-а2т2) p ё(”)=!У'скхн(п-к) -p H О II p II о IA
а2(1-р|т|)при |г|<1 0 при|т|>1 g(n)=C0^xJV(n-*:) *=o Cq=-^=-,N= - +1; jn Lt J г=₽й; Г11 1 — - целая часть числа — Y Y
100
Глава 5. Алгоритмы моделирования сигналов и помех в системах связи
5.3. Методы моделирования сигналов и помех в виде
стохастических дифференциальных уравнений
Математическое обеспечение современных ЭВМ позволяет описывать сиг-
налы и помехи как случайные векторные процессы с различными распре-
делениями. Известные методы моделирования на ЭВМ случайных процес-
сов можно разбить на две группы: точные (метод рекуррентных алгорит-
мов, метод дискретизации) и приближенные (методы формирующего
фильтра при представлении сигналов в форме разностных стохастических
уравнений (РСУ), метод скользящего суммирования). В точных методах
отсутствует методическая ошибка по корреляционной функции, т. е. корре-
ляционная функция КД1] = М[^к+\', последовательности равна дис-
кретным значениям 7^(/Д/) корреляционной функции ЯДт) моделируемого
процесса с непрерывным временем. Для приближенных методов равенство
заданных и воспроизведенных на ЭВМ характеристик выдерживается не
точно, а с определенной погрешностью.
Одним из конструктивных приближенных методов моделирования
непрерывных и дискретно-непрерывных случайных процессов, описы-
вающих случайные параметры и характеристики сигналов и помех, яв-
ляется метод формирующих фильтров, основанный на концепции пе-
ременных состояния и заключающийся в представлении соответствую-
щих процессов РСУ.
Для перехода от стохастических дифференциальных уравнений (СДУ)
к РСУ воспользуемся методами сеточной аппроксимации обыкновенных
дифференциальных уравнений разностными. Распространение методов се-
точной аппроксимации на стохастические уравнения и оценка их точности
были проведены в [11], где получена оптимальная по минимуму среднеквад-
ратической ошибки между точным решением СДУ и приближенным реше-
нием, полученным после перехода от СДУ к РСУ, разностная схема вида
x(k + 1) = х(к)+ f[.x(A:)]az + g[jv(A')]v(&)A/ +
(5.17)
( ch(l-)
Ф(Ф l,G[x(t)]^V(4+ АДл(Л-)]^,
где kAt - момент дискретного времени; - интервал дискретизации;
4 = d/d/ + Lx, в свою очередь Lx = F[x(r)]d/d/ + 0,5G[x(r)]G7 [x(/)]d2/dx2 - про-
изводящий оператор случайного процесса х(/).
В то же время, непосредственное применение РСУ (5.17) затруд-
нительно из-за значительной вычислительной сложности. Поэтому час-
то для перехода от СДУ к РСУ используют стандартные разностные
схемы, разработанные для обыкновенных дифференциальных уравне-
101
5.3. Методы моделирования сигналов и помех в виде стохастических дифференциальных уравнений
ний, точность которых в большинстве случаев приемлема для практиче-
ских приложений. При использовании разностных схем 1-го порядка
(сеточная аппроксимация 1-го порядка) имеем
dx(r) _ х(к + 1)- х(к)
dr Дг
Тогда РСУ (5.17) можно переписать в виде следующего РСУ:
х(Л +1)= Ф[х(*)]+ г[х(Л-)] V(fc),
ф[х(^)] = х(^)+ AzFfjcfA:)],
где Г[х(А)] = ArG[x(£)], х(0) = х0.
При аппроксимации 2-го порядка запишем
dx(r) _ x(k +1)- x(k -1)
dr 2Дг
В данном случае С ДУ (5.17) приобретает вид
х(к +1)= х(Л -1)+ 2A/G[x(^)]v^). (5.19)
Для РСУ (5.19) начальные условия задаются следующим образом:
х(о)=хо,х(1)=х|.
Расширим вектор состояния в (5.19):
x^)=[x(A:)|x(l--l)].
Тогда (5.19) перепишем в виде
x^ + lMjx/*)] ч-гДхД^УДл). (5.20)
где
W]-|Ы‘ - 0+M’WD’yf*- 0|);
Сравнительный анализ показывает, что РСУ (5.20) обладает более вы-
сокой точностью представления случайных процессов по сравнению с
(5.18). Это объясняется тем, что производная в (5.20) аппроксимируется бо-
лее точным разностным соотношением. Однако (5.20) сложнее при реали-
зации на ЭВМ. В общем случае РСУ, описываемое СДУ (5.17), можно
представить в виде
Л x(fc + ’)- х(А - 1)1 + x(fc+1)- х(А:)1 = G[X(A)] V(A) (5.21)
[ 2ДГ J ( ДГ J
где 0 < ц < 1.
Любому ц в (5.21) соответствует своя разностная схема. Причем,
при ц = 0 (5.21) совпадает с (5.18), а при ц = 1 - с (5.20).
102
Глава 5. Алгоритмы моделирования сигналов и помех в системах связи
Пример. Приведем алгоритм моделирования дискретного скалярного гауссов-
ского марковского процесса, описываемого СДУ
= (5.22)
где а - известная постоянная величина (коэффициент), характеризующая ширину спек-
тра процесса Х\ ах2- стационарная дисперсия процесса; n£f) - стационарный «белый»
гауссовский шум с нулевым математическим ожиданием и единичной дисперсией.
Для последовательного вычисления значений xtk) - х(4) в моменты времени
tk = кТ, по известным значениям х(к - 1) = x(4-i) (& = 1,2, • • •) использовалось рекур-
рентное соотношение
х(к) = Фх(к-1)+СУ(к), х(о)=хс,
где Ф = ехр(-аЛ/); G = [ох2( 1 - ехр(-2осДГ))]1/2; Y(k) - случайное число, генерируемое
датчиком гауссовских случайных чисел; Ar = tk = tk_ 1 - шаг дискретизации.
В дальнейшем будут рассмотрены различные методы моделирова-
ния на ЭВМ стационарных и нестационарных случайных процессов,
предполагая, что соответствующие СДУ и РСУ уже получены, по ним
возможно определение необходимых для машинного моделирования
статистических характеристик.
5.4. Примеры моделей случайных процессов
в системах связи
5,4.1. Модели информационных процессов
Наиболее распространенными информационными процессами в системах
связи являются речевые процессы. При синтезе и исследовании систем пере-
дачи речи используются различные абстрактные модели речевого процесса,
более или менее соответствующие реальной действительности. Чаще всего
модель речи представляет собой нестационарный гауссовский случайный
процесс с медленно меняющейся дисперсией и спектральной плотностью.
При использовании такой модели можно синтезировать систему связи с наи-
лучшими характеристикалш. Однако при этом получается весьма сложная
самонастраивающаяся система, синтез которой затруднен из-за отсутствия
многих статистических характеристик указанной модели речевого процесса.
Для реальных речевых процессов на достаточно продолжительных
отрезках времени выполняются условия стационарности, что дает воз-
можность рассматривать речевой сигнал как квазистациопарный.
При оценке качества передачи речевого сигнала в цифровых системах
передачи информации широко используются различные аппроксимации ус-
редненной по времени плотности распределения вероятности речи wQC). В
табл. 5.2 приведены наиболее известные ПРВ [10] (формулы (5.26 - 5.28)),
имеющие явно выраженный негауссовский характер, хотя отдельные состав-
ляющие могут иметь гауссовский характер.
Удобной для теоретического анализа считается модель аппрокси-
мации ПРВ речи (5.23), состоящая из двух компонент - ПРВ вокализо-
ванных и невокализованных звуков, вероятности которых обычно счи-
тают одинаковыми и равными 0,5.
103
5.4. Примеры моделей случайных процессов в системах связи
Более сложными моделями, содержащими также две компоненты,
являются модели (5.24), (5.25) и (5.28). Вторая гауссовская составляю-
щая в (5.25) описывает ПРВ в паузах.
Модели ПРВ речи (5.26), (5.27) являются одно компонентными.
Таблица 5.2. Модели ПРВ речевых процессов
Номер модели Плотность распределения вероятностей
1 0,5 -r=— ехР <2ос кг 2°с 0,5 Г X2 ' + —f= ехр г л/2ао [ 2аг , — = 0,1, —= 1,4 (5.23) о»
2 лГе а1Х1 +е~Р1ХП А = Ра (5.24) L J 2(а + р)
3 0,6 ехр Г Ж 0,4 Г 1 А? 1 feu = 1,21... 123 + —= ехр —- ,где (5.25) V2ax2 2a2j = 0,1...0,118
4 ^Е)Их|Г1ехр| (- *|X|), к = Где L=0;5. ! (5.26)
5 1 Л (-7з|х| J Г"ГехР LJ- V И ( 2о>. (5-27)
6 к [ —<ехр - о о + ехр -30—— о | , где К = const (5.28)
Анализ ПРВ мгновенных значений, приведенных в табл. 5.2, пока-
зывает, что речевые случайные процессы являются негауссовскими слу-
чайными процессами.
Наряду с ПРВ, важное прикладное значение при анализе систем пере-
дачи речи имеют спектральные Sx(f) и корреляционные Rrfx) характеристики.
В литературе имеется много примеров применения такой характери-
стики, как усредненный энергетический спектр речевого сигнала (спек-
тральная плотность мощности), предполагающий использование стацио-
нарной модели. Использование подобных спектральных характеристик по-
зволяет получать результаты анализа систем передачи речевой информации,
в достаточной для инженерной практики степени совпадающими с резуль-
татами экспериментальных исследований. В свою очередь, более точное
моделирование речевого сигнала существенно усложняет и, как правило,
делает невозможным применение аппарата аналитического исследования.
Наиболее известные модели спектральных Sx(f) и корреляционных
2?х(т) характеристик приведены в табл. 5.3.
Широкое распространение получила модель речевого процесса,
прошедшего предварительное ограничение спектра фильтром нижних
частот с частотой среза Fcp. Спектральная плотность мощности речевого
процесса на выходе такого фильтра описывается соотношением (5.32).
104
Глава 5. Алгоритмы моделирования сигналов и помех в системах связи
Коэффициент М определяется условием нормировки. При анализе уст-
ройств преобразования речи, например, в вокодерах, получила распро-
странение аппроксимация вида (5.31).
Таблица 5.3 Спектральная плотность мощности £>.(/) и корреляционная функция Ях(т)
речевых процессов
Анализ приведенных моделей показывает, что область применимости
стационарных моделей речевых сообщений и усредненных статистических
характеристик (спектральной плотности мощности, корреляционной функ-
ции, ПРВ мгновенных значений) ограничивается правомерностью приме-
нения к речевым случайным процессам понятия «стационарности» или
«локальной стационарности».
Учет нестационарности речевых случайных процессов требует при-
менения более «тонкого» математического аппарата теории марковских
цепей с конечным числом состояний. Подобные модели описания речевых
процессов и методы их моделирования будут рассмотрены ниже в гл. 7.
5.4.2. Модели помех
Любые случайные помехи независимо от природы возникновения и стати-
стической структуры могут быть разделены на сосредоточенные по одной
или нескольким координатам (ширина спектра по этим координатам значи-
тельно меньше ширины спектра сигнала) и шумовые, ширина спектра кото-
рых превосходит ширину спектра сигнала. Сосредоточенность помехи по
105
5.4. Примеры моделей случайных процессов в системах связи
одной или нескольким координатам относительно сигнала (либо, наоборот,
ее рассредоточенность) является главным из основных устойчивых детерми-
нированных признаков, по которому помеха может резко отличатся от сиг-
нала и из которого следуют основные принципы подавления помехи.
В таких физических координатах, как частота и время, все помехи
подразделяют на три основные группы:
1) импульсные помехи, сосредоточенные во времени;
2) помехи, сосредоточенные по частоте;
3) шумовые (флуктуационные) помехи.
Во всех группах отличительным признаком является соотношение пара-
метров сигнала и помехи (их относительная длительность, ширина спектра).
5.4.3. Основные виды помех и их характеристики
Атмосферные помехи. Источником атмосферных помех являются мно-
гочисленные грозовые разряды, происходящие одновременно в различ-
ных районах земного шара. Если не учитывать местных гроз, уровень
атмосферных помех носит квазистационарный характер и сравнительно
медленно изменяется в течении суток и от сезона к сезон}7.
Простейшей характеристикой атмосферных помех является экви-
валентная шумовая температура 7а, К, определяющая мощность помех
на входе приемника:
Отношение Га/293 К, называемое коэффициентом атмосферных по-
мех, зависит от географических координат.
Описание атмосферных помех только коэффициентом Га является весьма
упрощенным. Оно, во-первых, не учитывает влияние местных гроз, а во-
вторых, не раскрывает спектральных и вероятностных особенностей таких по-
мех. Важной особенностью атмосферных помех является наличие одномерно-
го распределения мгновенных значений помехи отличного от гауссовского за-
кона. Результаты теоретических и экспериментальных исследований показы-
вают, что атмосферную помеху можно рассматривать как сумму двух состав-
ляющих: = £ш(/) + Уи(1), где ^Ш(Г) - слабый шумовой фон, обусловленный
дальними грозами, имеющий гауссовский закон распределения; 7n(t) - им-
пульсная последовательность редких, но мощных импульсов, заполненных га-
уссовыми функциями (эта составляющая вызвана местными грозами).
Введем обозначения: аш2 - мощность шумового фона; си2 - сред-
няя мощность импульсной компоненты; сц2 = сгш2 + сгн2 - суммарная
мощность; Р - вероятность импульсной компоненты.
Для данной модели атмосферной помехи одномерная плотность
вероятности ее мгновенных значений описывается формулой
= +—JL—е""2/2ст^. (5.39)
Т2^ш
Распределение (5.39) при больших значениях сгн и Р существенно
отличается от гауссовского.
106
Глава 5. Алгоритмы моделирования сигналов и помех в системах связи
Модулированные помехи. Они чаще всего создаются модуляцией
несущего колебания шумом по частоте или фазе, т.е. формируются в
виде колебания
Г(/)= Ло cos[m0Z + (5.40)
где Ф(0 - модулирующий шум.
На входе приемника модулированная помеха присутствует в смеси
с внутренним шумом ^(Г):
n(t) = AQ cos[o)0/ + Ф(/)+б]+, (5.41)
где 0 - начальная фаза, равновероятная на интервале (0; 2л).
Спектр модулированной помехи определяется характеристиками
модулирующего шума, подобно спектру колебания с фазовой или
частотной модуляцией.
Конечномерные распределения процесса (5.41) имеют сложный
аналитический вид. В частности, одномерное распределение определя-
ется формулой
где н*= п/А0; ос = Л02/(2а^2) - отношение мощности модулированной по-
мехи к мощности внутреннего шума приемника.
Внутренним шумом для больших значений ос можно пренебречь.
При этом распределение помехи (5.42) совпадает с распределением си-
нусоидального колебания со случайной начальной фазой:
w(n)=—. * |м|< А. (5.43)
Лд//102 - п2
Модулированная по частоте помеха является негауссовым процес-
сом, для которого некоррелированность отсчетов является достаточным
условием их статистической независимости.
При полосовом спектре (ширина спектра значительно меньше
средней частоты соо) процесс (5.41) можно представить в квазигармони-
ческой форме n(t) = ^lZ7(0cos(co0Z + <pn(f)).
В этом случае огибающая Ап распределена по обобщенному закону
Рэлея:
= 2Лаехр[-а(л2 + 1)] /0(24а^ (5.44)
где А = Л,/Ло, Л(и) - модифицированная функция Бесселя мнимого аргумента.
Хаотические импульсные помехи (ХИП). Эти помехи обычно
представляют собой последовательность импульсов, имеющих постоян-
ную амплитуду со случайной длительностью и периодом. В произволь-
но выбранный момент времени на входе приемника при отсутствии по-
лезного сигнала имеем либо аддитивную смесь радиоимпульса ХИП с
внутренним шумом приемника, либо один шум. Принимая вероятность
появления импульса ХИП в произвольно выбранный момент времени,
107
5.4. Примеры моделей случайных процессов в системах связи
равной Р, одномерную плотность вероятности мгновенных значений
помехи, представляющей аддитивную смесь n(t) ХИП с шумом прием-
ника, получаем в виде
w(n*)= Pwi(n*)+(1 - P)w2(n\ (5.45)
где п = п/Ахт (в свою очередь, Ххип - амплитуда импульсов ХИП); пл(я) -
ПРВ смеси синусоиды с шумом, определяемая по формуле (5.42); w2(ri) =
= д/а/л ехр(-аи2) - ПРВ шума; а = Х2Хип/2с>ш2 - отношение мощности ХИП
к мощности шума пш2.
Для вероятностного описания ХИП иногда применяют одномерное
распределение
где Г(л) - гамма-функция; v и а - параметры распределения, опреде-
ляющие его форму.
При v = 2 плотность (5.46) является гауссовой, а при v = 1 она пе-
реходит в ПРВ Лапласа. В области, где v < 2, распределение (5.46) име-
ет положительный эксцесс, причем с уменьшением параметра v эксцесс
увеличивается, что означает повышение вероятности больших выбросов
по сравнению с гауссовым распределением. Следовательно, уменьше-
ние параметра v характеризуется усилением «импульсивности» ХИП.
Белый гауссовский шум. Это математический случайный про-
цесс, обладающий равномерным спектром во всем диапазоне частот.
Название «белый шум» получено по аналогии с «белым светом»,
имеющим в видимой части равномерный спектр. Корреляционная
функция белого шума описывается выражением
]>\1ю = ^8(т), (5.47)
2 271 J 2
-X
где 5(т) - дельта-функция.
Значение белого шума в любые два сколь угодно близкие момента
времени некоррелированы. Дисперсия белого шума а2 = оо, так как его
спектр равномерный в бесконечной полосе частот. Реальные шумы
имеют всегда ограниченный спектр и, следовательно, конечную диспер-
сию. Белый гауссовский шум (БГШ) характеризуется одним параметром
- спектральной плотностью Nq, и имеет гауссовское распределение ве-
роятностей мгновенных значений. Дискретный БГШ - последователь-
ность некоррелированных случайных величин nh имеющих гауссовское
распределение с нулевым средним и дисперсией о„2. Дискретный БГШ
можно рассматривать как результат временной дискретизации непре-
рывного шума с равномерным спектром в полосе (0; F^.
108
Глава 5. Алгоритмы моделирования сигналов и помех в системах связи
При интервале временной дискретизации А/ = 1/(2FB) получаем из
непрерывного шума дискретный с некоррелированными отсчетами,
дисперсия которого оценивается по формуле сг„2= = No/(2AZ). Пара-
метр сг„2 полностью характеризует дискретный БГШ.
Для гауссовского процесса некоррелированность отсчетов означа-
ет и их статистическую независимость. Ввиду этого плотность вероят-
ностей п отсчетов пт дискретного БГШ выражается произведени-
ем одномерных плотностей wn\:
•••>%) = П = 7--------------
(5.48)
В задачах выделения сигнала на фоне помех белый гауссовский
шум используется для описания помех, имеющих широкий спектр отно-
сительно сигнала и распределение вероятностей мгновенных значений,
близкое к гауссовскому. К таким помехам, в частности, относится внут-
ренний шум приемника.
Бельш негауссовскпй шум. Это математический случайный про-
цесс, обладающий равномерным спектром во всем диапазоне частот и
имеющий негауссовское распределение вероятности мгновенных значений.
Корреляционная функция белого негауссовского шума (БНШ) так же, как и
для БГШ, выражается через дельта-функцию. Для полного задания БНШ
недостаточно указания величины спектральной плотности NQ. Необходимо
задание одномерной плотности вероятности wn\ мгновенных значений.
Дискретный БНШ - последовательность независимых случайных вели-
чин /?/, имеющих одинаковую плотность вероятности wn\. Декретный БНШ
можно рассматривать как результат временной дискретизации непрерывного
негауссовского шума с равномерным спектром в полосе частот (0, Fe) при час-
тоте дискретизации А/ = 1/(2F6). Такое представление дискретного БНШ спра-
ведливо для негауссовского шума, в котором некоррелированность отсчетов
является достаточным условием их статистической независимости. Плотность
вероятности т отсчетов дискретного БНШ выражается по формуле
БНШ используется для описания помех, имеющих негауссовское
распределение вероятностей мгновенных значений и спектр не полосо-
вого типа (средняя частота То « AF/2; AF - ширина спектра), по ширине
превосходящий спектр сигнала. К таким помехам относятся, например,
атмосферные и индустриальные помехи.
Помехи с полосовым спектром. Полосовые помехи имеют
спектр, средняя частота которого значительно больше ширины.
Полосовой процесс n(t) представим в квазигармонической форме:
??(/) = Л(/) cos[co0/ + ф(/)]>
где Л (0, ср(0 - медленно меняющиеся процессы, которые обозначают
амплитудные и фазовые флуктуации; соо - средняя частота спектра.
109
5.4. Примеры моделей случайных процессов в системах связи
При известной частоте со о полосовой процесс n(f) может быть за-
дан своими низкочастотными квадратурными компонентами:
u(t)= л(/)со8<р(/), к(/)= ?l(r)sin(p(/),
которые полностью определяют его. В этом случае процесс /?(/) может
быть записан в виде n(f) = [/(7)cos(co0/) + K(7)sincp(r).
Таким образом, вероятностное описание полосового процесса может
быть выполнено заданием вероятностных характеристик пары не полосо-
вых процессов [/(/), К(Г) или A(t), ср(0. В дискретном представлении полосо-
вой процесс задается последовательностями ([/;, FJ) или (4,; ср,), где i обо-
значает номер временного отсчета.
Если требуется описать полосовые гауссовские или негауссовские поме-
хи с широким относительно последовательности ([/,; F) спектром, то (Л,; ср,)
берутся с независимыми элементами, т.е. представляются двухмерным дис-
кретным БИЛ или БНШ. При этом плотности вероятностей т пар отсчетов
([/(/); И(0) выражаются произведением ПРВ И(/)) каждой пары:
т
= (5.49)
/=1
Аналогично выражается плотность вероятности т пар отсчетов (Л,; ср,).
Коррелированный гауссовский процесс. Это случайный процесс
n(t\ для которого совместная плотность вероятностей wm(n^ ...,n^ для
т отсчетов (щ = л(6), ...» пт - n(tmy), взятых в произвольный момент
времени ..., tm, выражается по формуле
шт(п} ...Пт) = -7-г----5----------X
Ы"’.........’Jrl"2
Г / V V) (5-50)
1 ЧГ'ЧГ'Нт' 1Г’| ni ~ai II nJ~aJ
xex₽ -yEEh П7П •
[ 2,=1у=1" а, Д aj JJ
Формула (5.50) записана для общего случая, когда процесс n(f) не
стационарный и его среднее а, и среднеквадратическое ст, могут прини-
мать различные значения в различные моменты времени.
||Гр|| - нормированная коррелированная матрица последовательно-
сти ..., пт. В (5.50) ЦГ^П-1 - обратная матрица для ||FZJ||, |Г| - опреде-
литель матрицы ||Г^|.
Для стационарного гауссовского процесса с а, = 0, ст, = ст:
Wm= ГтЙ^еХР|~ 2 (5-5П
|Г| I z'=U=i J
где ||Ну|| = (1/сг2) НГуП"1 - обратная матрица для корреляционной матри-
цы 11^11 = С2||Гу||-
Из формулы (5.51) следует, что плотность полностью
определяется корреляционной матрицей ||7?^|. Следовательно, исчерпы-
вающей характеристикой гауссовского процесса является корреляцион-
ная функция R(t) или энергетический спектр 5((в), которые связаны ме-
жду собой формулами Винера - Хинчина.
110
Глава 5. Алгоритмы моделирования сигналов и помех в системах связи
Для заданной корреляционной функции Я(т) корреляционная мат-
рица ||7?v|| при равномерной временной дискретизации с шагом А/ равна
Rij = R(At\t -у|). Если шаг А/ взять больше интервала корреляции, то по-
лучим R^ = <з2&и, где 5У = 0 при i и = 1 при i =j. В этом случае вы-
ражение (5.51) преобразуется в выражение (5.48), описывающее распре-
деление независимых отсчетов /?ь ..., пт. Следовательно, некоррелиро-
ванность отсчетов гауссовского процесса является необходимым и дос-
таточным условием их статистической независимости.
Коррелированные гауссовские процессы применяют для описания
узкополосных (по отношению к сигналу) помех, имеющих ПРВ мгно-
венных значений, близкое к гауссовскому. К таким, в частности, отно-
сятся пассивные радиолокационные помехи, образованные множеством
отражателей, близких по эффективной поверхности рассеяния.
Коррелированный негауссовский процесс. Для вероятностного
описания коррелированных негауссовых помех в общем случае необходи-
мо задать /«-мерную плотность вероятности w,„(«i, ..., «,„)• При этом, чем
больше берется /«, тем подробней описание. Задание /«-мерной функции w,n
не всегда возможно. Кроме того, аналитический вид этой функции может
быть чрезмерно громоздким и неудобным для дальнейших применений. В
связи с этим используются различные упрощенные описания.
Одним из таких описаний является представление процесса //(Г) марков-
ской моделью. При этом /«-мерная плотность w„}(^i, • • •> пт) выражается в виде
т
«’|(«1)П w(n' । (5-52)
/ = 2
где z«(«/|/7,_J) = w2(«/, Л7;_i)/zpi(a?,-!); w2{nh «/.J - двухмерная плотность вероят-
ности пары соседних отсчетов процесса «(/); w(nl\ni_l) - условная одномер-
ная плотность вероятности; - одномерная безусловная плотность.
Согласно (5.52) для вероятностного описания процесса «(?) мар-
ковской моделью необходимо задать лишь двухмерное его распределе-
ние, что существенно проще, чем задание «-мерной плотности.
Замена реального процесса /?(Г) марковским вносит определенную по-
грешность в представление «/-мерной плотности, т.е. функция z«/w(«i, л/н),
определенная по формуле (5.52), отличается от действительного распределе-
ния процесса n(t).
Погрешность вероятностного описания отразится и на точности
результатов, которые будут получены путем такого описания. Специ-
альные исследования показывают, что во многих случаях погрешность,
вносимая марковской аппроксимацией, приводит к небольшим потерям
в точности результатов.
Погрешность аппроксимации можно снизить, перейдя к более подроб-
ному описанию обобщенным марковским процессом порядка v, при этом
"I (5 53)
= w(«j)w(«21 «,)••• z«(«v | |w(«, |
z=v+l
111
5.4. Примеры моделей случайных процессов в системах связи
В таком случае необходимо задать (v + 1)-мерное распределение
wv+i(y?z, ..., и/Л,) процесса n(J), с которым связаны условные плотности,
входящие в (5.53):
/ । \ п,.,)
I ------г •
Повышение точности описания процесса n(t) требует большой ве-
роятностной информации о нем.
Марковская аппроксимация может применятся и для гауссовых процес-
сов. При этом погрешность описания отражается на представлении корреля-
ционной функции описываемого процесса. Известно, что в классе гауссовых
процессов свойствами марковского обладают только процессы с экспоненци-
альной корреляционной функцией 7?(т) = сгехр(-сс|т|). Следовательно, марков-
ская аппроксимация заключается в замене реальной корреляционной функции
на экспоненциальную, определенным образом согласованную с реальной.
Контрольные вопросы к главе 5
1. Опишите алгоритм моделирования нестационарных случайных процессов.
2. Чем различаются алгоритмы моделирования стационарных и нестацио-
нарных случайных процессов ?
3. Опишите алгоритмы формирования дискретных реализаций случайного
процессов.
4. Приведите алгоритм моделирования гауссовских стационарных случай-
ных процессов с экспоненциальной корреляционной функцией.
5. Чем отличаются алгоритмы моделирования гауссовских стационар-
ных случайных процессов с различными типами корреляционных
функций ?
6. Опишите алгоритм моделирования дискретного скалярного гауссовского
марковского процесса, описываемого СДУ.
7. Чем отличаются алгоритмы моделирования дискретного скалярного гаус-
совского и негауссовского случайного процесса, описываемого СДУ ?
8. В чем заключаются отличия математических моделей и статистических
характеристик основных видов помех ?
112
Глава 6
МАРКОВСКИЕ СЛУЧАЙНЫЕ ПРОЦЕССЫ
И ИХ МОДЕЛИРОВАНИЕ
6.1. Основные понятия марковского случайного процесса
Пусть имеется некоторая физическая система X, которая в процессе
функционирования может принимать различные состояния Xh i = l,n.
Если состояния системы меняются во времени случайным образом, то
процесс смены состояний можно рассматривать как случайный процесс.
Полное множество состояний Xh i = 1,/? исследуемой системы может
быть либо конечным, либо бесконечно большим.
Процесс, протекающий в некоторой системе X, называется мар-
ковским или процессом без последействия, если для каждого момента
времени поведение системы в будущем зависит только от состояния
системы в данный момент и не зависит от того, каким образом сис-
тема пришла в это состояние.
Иначе говорят, что процесс обладает марковским свойством.
В зависимости от времени пребывания системы в каждом состоя-
нии различают процессы с дискретным и непрерывным временем. Сис-
темы с непрерывным временем предполагают, что переход системы из
одного состояния в другое может осуществляться в любой момент вре-
мени, т.е. время пребывания системы в каждом состоянии представляет
собой непрерывную случайную величину.
Для систем с дискретным временем длительность пребывания в
каждом состоянии фиксированная, а моменты переходов г1з t2, ..., tk раз-
мещаются на временной оси через равные промежутки и называются
«шагами» или «этапами». Время нахождения системы в некотором со-
стоянии представляет собой дискретную случайную величину.
Большинство реальных систем имеет дискретное конечное простран-
ство состояний. Последовательность состояний такой системы Xi} i= \,п и
сам процесс переходов из состояния в состояние называется цепью. Если
переходы системы из одного состояния в другое возможны в строго опре-
деленные, заранее фиксированные моменты времени то такую систему
описывает марковский случайный процесс с дискретным временем. Мар-
ковский случайный процесс с дискретными состояниями и дискретным
временем называют дискретной марковской цепью (цепью Маркова).
Случайный процесс с дискретными состояниями и непрерывным
временем описывается непрерывной марковской цепью.
113
6.1. Основные понятия марковского случайного процесса
Случайный процесс с непрерывными состояниями и непрерывным
временем функционирования описывается непрерывнозначным марков-
ским процессом.
При исследовании непрерывных и дискретных марковских цепей обыч-
но пользуются графическим представлением функционирования системы.
Отображение марковской цепи в виде графа. Обычно марковскую
цепь изображают в виде графа, вершины которого соответствуют возмож-
ным состояниям системы Х19 а дуги - возможным переходам системы из
состояния^, в состояние^. Каждой дуге соответствует переходная вероят-
ность ру(к) = - 1)] - условная вероятность перехода системы на
А-ом шаге в состояние Xj при условии, что на предыдущем (к - 1 )-ом шаге
система находилась в состоянии X,.
Марковская цепь называется однородной, если переходные веро-
ятности не зависят от номера шага. Если переходные вероятности ме-
няются от шага к шагу, марковская цепь называется неоднородной.
Классификация состояний марковской цепи. Состояние Xj дос-
тижимо из состояния Х„ если существует такое т, что ptJ > 0. Подмно-
жество С возможных состояний системы называется замкнутым, если
за один шаг невозможны никакие переходы из состояния, входящего в
С, в состояние, не входящее в С.
Цепь Маркова называется неприводимой, если соответствующее ей
множество всех возможных состояний не содержит никаких замкнутых
подмножеств кроме самого себя.
Состояние X, называется возвратным, если вероятность того, что сис-
тема, выйдя из этого состояния, когда-либо вернется в него же, равна 1. Ес-
ли же эта вероятность меньше 1, то состояние называется невозвратным.
Разложимые марковские цепи содержат невозвратные состояния,
называемые поглощающими. Из поглощающего состояния нельзя пе-
рейти ни в какое другое. На графе поглощающему состоянию соответ-
ствует вершина, из которой не выходит ни одна дуга. В установившемся
режиме поглощающему состоянию соответствует вероятность, равная 1.
Следствием этого является то, что если цепь Маркова имеет ко-
нечное число состояний, причем, если каждое из них достижимо из лю-
бого другого состояния, то все они являются возвратными.
Состояние X, называется поглощающим, если вероятность ухода
системы из этого состояния в любое другое равна 0. Очевидно, что если
в системе имеется хотя бы одно поглощающее состояние, то ни одно из
состояний системы не является возвратным.
Возвратное состояние, для которого математическое ожидание
времени возвращения равно оо, называется нулевым. Возвратное состоя-
ние, для которого возвращение возможно лишь через число шагов,
кратное d, называется периодическим (с периодом d).
114
Глава 6. Марковские случайные процессы и их моделирование
6.2. Основные свойства и характеристики дискретных
цепей Маркова
Вероятностные характеристики марковских цепей. Обозначим через
pt(tk) вероятность того, что X(t) в момент tk принимает значение А7 Век-
тор Р(4) ~ l^o(4), Pi(4), • ••, АЛЛ)] называют вектором вероятностей со-
стояний системы в момент tk. Очевидно, что элементы вектора неотри-
цательны, а сумма элементов равна единице, т.е. Е"=о^(/^) = 1. Если по-
ложить £= О, то получим вектор начальных вероятностей р(^0).
Полным описанием однородной марковской цепи служит матрица
переходных вероятностей (матрица переходов)
Р\\ Р\2 '" Ply Pin
Г-1ЫМ 1 Р21 Р22-" P2j--‘ Р2п Pil Pi2‘“ Py- Pin n J-1
_Pn\ Pn2“* Pnj-' Pnn_
1,н.
(6.1)
Равенство Маркова. Рассмотрим следующую задачу: зная пере-
ходные вероятности р^ найти вероятности Ру{тх) = Ру{т) перехода сис-
темы из состояния в состояние Xj за т шагов. С этой целью введем
промежуточное состояние Хг.
Другими словами, будем считать, что из первоначального состояния
Xi за к шагов система перейдет в промежуточное состояние Хг с вероятно-
стью р1Г(к\ после чего за оставшиеся (т - к) шагов из промежуточного со-
стояния Хг она перейдет в конечное состояние Xj с вероятностью р0(т - к).
Тогда по формуле полной вероятности
P,j(m) = Y. Р.Г (к)Рг,(т-к\ (6.2)
Г=1
Эту формулу называют равенством Маркова.
Зная матрицу переходов за один шаг Г(1), можно найти вероятности пе-
рехода р/2) из состояния Х{ в состояние А} за 2 шага, т.е. матрицу переходов
Г(2). Возьмем, например, т = 2, к = 1. Тогда из равенства Маркова получаем
PiJ (2) = Ё Р.Г (i)prj (2 - 1) = S PirPrJ ,
r=l r=l
или в матричной форме Г(2) = ГГ = Г2. Зная матрицу переходов Г(2),
можно найти матрицу переходов Г(3):
Г(3)= ГГ(2)= Г3 и т.д. (6.3)
Для простой цепи Маркова справедлива следующая теорема.
Теорема. Вектор вероятностей состояний системы в момент tk
равен произведению вектора вероятностей состояний в момент tk.\ на
матрицу переходов, т. е.
р(**) = р(<*-1)г. (6.4)
115
6.2. Основные свойства и характеристики дискретных цепей Маркова
Следствием из этой теоремы служит то, что простая однородная
цепь Маркова определяется вектором вероятностей состояний в началь-
ный момент р(/0) и матрицей переходов
р(4) = р(г0)г\ (6.5)
где Г* - к-я степень матрицы переходов.
Таким образом, при наличии начального вектора вероятностей со-
стояний системы и матрицы переходов можно проследить всю эволю-
цию системы.
Вектор предельных вероятностей. Рассмотрим предел вероятно-
стей переходоы Ру(кт) простой однородной цепи Маркова из состояния
Xj в состояние Xj за интервал времени кт при к -» со. Можно предполо-
жить, что по мере увеличения интервала кт влияние начального состоя-
ния Xt уменьшается и при достаточно большом интервале станет ни-
чтожно малым, т.е. lim /г.(1'т) = р..
Однородная простая цепь Маркова, для любых двух состояний ко-
торой справедливо данное равенство, называется эргодической. Для
простых однородных цепей с конечным числом состояний определяется
достаточное условие эргодичности.
Достаточное условие эргодичности. Если существует такое т > О,
что при любых допустимых состояниях Х{ и Xj вероятности Ру{т) поло-
жительны, то цепь эргодична.
В этом случае к-я степень матрицы переходов при к -> со стремит-
ся к предельной матрице с одинаковыми строками:
PoofaO ••• AtaM Ро
lim Г*(т)= lim Г(&т)= lim ............. = •••
^->20 А'->0О Л->00 . . .
Рп№4 РпАЩ Ро
••• Рп
(6.6)
к—>оо
••• Рп
причем все элементы предельной матрицы положительны и S”=op. = 1 •
Величина 1/pj считается средним временем возвращения в состояние А}.
Переходя к пределам в обеих частях равенства (6.5), получаем
вектор предельных вероятностей (вектор финальных вероятностей
или стационарное распределение)'.
1ипр(гЛ) = (ро,Р1,..., р„)=П.
Л->оо
Распределение П является при этом единственным и не зависит от на-
чального распределения, а целиком определяется лишь матрицей переходов.
Рассматривая пределы обеих частей равенства (6.5), в матричном
виде имеем
П = ПГ. (6.9)
Важно заметить, что существование предельного распределения и чис-
ленные значения его компонент не зависят от начального распределения веро-
ятностей состояний системы, а определяются лишь матрицей переходов. Каж-
дая компонента рг вектора таких стационарных вероятностей характеризует
116
Глава 6. Марковские случайные процессы и их моделирование
среднюю долю времени, в течение которого система находится в рассматри-
ваемом состоянии X, за время наблюдения, измеряемое к шагами.
При известной матрице переходов Г можно вычислить компонен-
ты вектора предельных вероятностей. Для этого систему линейных
уравнений (6.4) обычно дополняют условием нормировки, так как она
иногда является линейно зависимой.
Если же состояния цепи являются периодическими, то Пт Г* не
существует, хотя стационарное распределение, удовлетворяющее усло-
вию (6.4), может существовать.
Корреляционная функция. Для эргодической цепи Маркова мо-
жет быть введено понятие корреляционной функции
где /?(.¥/, Xj, кТ) = pip4(kT) - совместная вероятность принятия состояний
процессом х в моменты времени, отстоящие на кТ; р, - вероятность при-
нятия процессом i-ro значения в начальный момент времени.
Пример. Пусть вектор начальных вероятностей в момент /0 и матрица переходов
Г системы, описываемой марковской цепью, имеют вид
р(/о)=(0,5; 0,2; 0,3),
0,9
0,4
0,7
0,08 0,02
0,3 0,3
0,1 0,2
Требуется определить вектор вероятностей системы в моменты времени /1 и t2.
В соответствии с соотношением (6.4) для цепи Маркова найдем p(fi) = р(г0)Г.
Подставляя в это соотношение значение вектора р(/0) и матрицы Г, найдем
р(/1)=(0,5; 0,2; 0,3)
0,9 0,08
0,4 0,3
0,7 0,1
0,02
0,3 = (0,74; 0,13; 0,1 з).
0,2
Тогда для момента времени t2 можно записать р(/2)= р(/|)Г. Откуда
р(/2)=(0,74; 0,13; 0,13)
0,9 0,08
0,4 0,3
0,7 0,1
0,02
0,3
0,2
= (0,81; 0,11; 0,08).
Г =
Вектор предельных (финальных) вероятностей состояний системы Уо, Azh
Х2 в соответствии с системой уравнений П = ПГ в данном случае имеет вид
Pq = Pq • 0,9 + • 0,4 + р2 • 0,7,
рх = Ро • 0,08 + р{ • 0,3 + р2 • 0,1,
р2 = Pq - 0,02 + pt • 0,3 + р2 • 0,2.
Система получается линейно зависимой. Поэтому заменяем, например
третье уравнение системы уравнением р0 + р} + р2 = I.
Решением системы является вектор П = (0,84; 0,1; 0,06).
117
6.2. Основные свойства и характеристики дискретных цепей Маркова
Пуассоновский прогресс, управляемый (модулированный) марков-
ским (англ. ММРР - Markov-Modulated Poisson Process) (далее MMPP-
процесс) - часто используемая модель процесса, управляемого марков-
ским (ММРР-модель). Эта модель совмещает простоту управляющего
процесса (марковского) с тем процессом, которым он управляет (пуас-
соновским). В данном случае в механизме управления указывается, что
для процесса X в k-м состоянии поступления происходят в соответствии
с пуассоновским процессом с интенсивностью X*. При изменении со-
стояния интенсивность также изменяется.
В качестве примера использования ММРР-модели может быть
рассмотрена ММРР-модель речи с двумя состояниями, где одно из них
ON-состояние (связано с положительной пуассоновской интенсивно-
стью), а другое - OFF-состояние (связано с нулевой интенсивностью).
Такие модели также называются прерывистыми пуассоновскими. По-
добные модели широко используются при моделировании голосовых
источников трафика. ON-состояние соответствует потоку разговора (ко-
гда говорящий произносит звук), а OFF-состояние соответствует тиши-
не (когда говорящий делает паузу). Эта базовая ММРР-модель может
быть распространена на объединение независимых трафиковых источ-
ников, каждый из которых это - ММРР, управляемый отдельным мар-
ковским процессом Xt.
Процесс, управляемый марковским, также называется бистохастиче-
ским процессом, поскольку он использует вспомогательный марковский
процесс, в котором текущее состояние управляет распределением трафика.
Пуассоновский процесс используется в ММРР в качестве управ-
ляемого механизма. Введение ММРР делает возможным моделирование
нестационарных источников, сохраняя аналитическое решение относи-
тельно показателей производительности при построении очередей.
Параметры ММРР могут быть легко оценены из опытных данных пу-
тем квантования интенсивности поступлений на конечное число интенсивно-
стей, соответствующее числу состояний. Каждая интенсивность соответству-
ет состоянию марковской цепи. Интенсивность переходов из состояния / в
состояние у, обозначаемую как ру-, оценивают с помощью квантования опыт-
ных данных и вычисления того, сколько раз состояние i переходит в состоя-
ние у. ММРР- процесс с числом состояний (п + 1) можно получить путем на-
ложения п идентичных независимых источников.
Также ММРР может моделировать смешанный трафик голоса и
данных. В этом случае поступления голосовых пакетов в k-м состоянии
предполагаются пуассоновскими с интенсивностью Хк. Пакеты данных
также пуассоновские с интенсивностью Xj. Полученная результирую-
щая интенсивность для такого состояния будет Хб/ + Хк.
118
Глава 6. Марковские случайные процессы и их моделирование
6.3. Непрерывные марковские цепи
Непрерывные марковские цепи описывают функционирование систем,
принимающих в процессе работы конечное число состояний Xh i = 1,л и
осуществляющих переходы из одного состояния в другое (X, —>ХР ij = 1,и)
случайным образом в произвольный момент времени t. Иначе говоря, вре-
мя пребывания системы в любом состоянии представляет собой непрерыв-
ную случайную величину.
Случайный процесс с непрерывным временем называется непре-
рывной марковской цепью, если поведение системы после произвольного
момента времени tQ зависит только от состояния процесса в момент
времени z0 и не зависит от поведения процесса до момента времени tQ.
Определим для непрерывной марковской цепи вероятности всех
состояний системы для любого момента времени как p^t), i = 1,п. По-
скольку для любого момента времени Z все состояния системы образуют
полную группу событий, то X"=Qpl(t)= 1 .
Рассмотрим параметры, характеризующие непрерывную марков-
скую цепь.
1. Пусть система в момент времени t находится в состоянии X,.
Рассмотрим элементарный промежуток времени Az, примыкающий к
моменту времени t. За интервал А/ система может перейти из состояния
Xt в состояние Х} с переходной вероятностью pt)(t, Аг), зависящей в об-
щем случае как от Z, так и от А/.
Рассмотрим предел отношения этой переходной вероятности к
ширине интервала А/ при условии, что А/ —> 0:
(о. (6.10)
А/—>0 Д/ '
Эта характеристика называется интенсивностью переходов или
плотностью вероятностей переходов и в общем случае зависит от t.
Из формулы (6.10) следует, что при малом Az вероятность перехо-
дов ptJ(j, Az) с точностью до бесконечно малых высших порядков равна
p,7(Z, AZ) = \t.
Если плотности вероятностей переходов представляют собой
функции времени Xzy(Z), марковский процесс называется неоднородным.
Если все плотности вероятностей переходов не зависят от Z (т.е. от нача-
ла отсчета элементарного участка AZ), то марковский процесс называет-
ся однородным (X^t) = = const).
Для непрерывных марковских цепей интенсивности переходов
проставляются у соответствующих дуг графа. Такой граф называется
размеченным.
119
6.3. Непрерывные марковские цепи
2. Кроме интенсивностей переходов, для описания непрерывных
марковских цепей должен быть задан вектор начальных вероятностей
состояний системы р(0) = (/’КО), •••, А?(0)), т.е. вектор вероятно-
стей состояний системы в исходный (нулевой) момент времени.
Зная множество состояний системы, значения интенсивностей пе-
реходов а также вектор р(0), можно определить вероятности со-
стояний z?i(t), i = 1, п.
3. В непрерывной марковской цепи для любого (t + Дг)-го момента
времени справедливо соотношение, описывающее вероятности состояния
pi (t + д?) = X Pj (OPj, (ДО = p, (0р},(ДО + S Pi (Opji (ДО •
y=l 7=1
Из свойства матрицы переходных вероятностей следует, что
р„(Д0 = 1- Хру(ДО-
Тогда
р,(' + Д0 = Р,(0{1- рь(^О}+ ^Pj(OPj,(^O,
7=1 7=1
JOI JOI
ИЛИ
p,u+ao-p,(o=-p,(oX р,ддо+ Hpj(Opj,(^o .
Разделим обе части последнего равенства на Д/ и перейдем к пределу
при Дг стремящемся к нулю:
Ii,„
Л/->0 Дг
V1 I* ’А /#\ Г Р
= -Pi(0 L lim —Л--------+ X Pj(O lim --------------
Д/ J д/->о Д/
В результате для вероятностей состояний непрерывной марков-
ской цепи получим систему дифференциальных уравнений, носящую
имя ее автора - советского математика А.Колмогорова:
^^•=-Р,(')ХЧ+ ZP7(O^-7,-' = 1-«,
at j=i 7=1
JOI JOI
где /7,(0) =plQ - элемент вектора начальных условий.
Интегрирование этой системы по времени позволяет получить ве-
роятности состояний как функцию времени pt(f). Существенно, что в
системе Колмогорова можно ограничиться (и - 1) уравнением. Допол-
нительно используется условие нормировки = 1.
Анализируя дифференциальные уравнения Колмогорова, можно
сформулировать формальное правило для их написания непосредствен-
но по размеченному графу системы.
120
_________Глава 6. Марковские случайные процессы и их моделирование
Правило. В левой части уравнения стоит производная от вероятности
рассматриваемого состояния по времени, а в правой части — столько сла-
гаемых, сколько дуг графа связано с рассматриваемым состоянием. Каждое
слагаемое равно произведению плотности вероятностей переходов, соот-
ветствующей данной дуге графа, на вероятность того состояния, из кото-
рого исходит дуга графа. Если стрелка направлена из рассматриваемого со-
стояния, соответствующее произведение имеет знак минус. Если стрелка
направлена в рассматриваемое состояние, то произведение имеет знак плюс.
Это правило составления дифференциальных уравнений Колмого-
рова для вероятностей состояний является общим и справедливо для
любой непрерывной марковской цепи.
Для эргодических однородных марковских цепей существует ста-
ционарный режим при t -> оо. При стационарном режиме вероятности
состояний стремятся к некоторым установившимся значениям - пре-
дельным вероятностям limp,(t) = р,, которые постоянны и не зависят от
начального состояния системы.
Поскольку в установившемся режиме вероятности состояний ста-
новятся постоянными величинами, производные от них равны нулю.
Поэтому система дифференциальных уравнений Колмогорова с посто-
янными коэффициентами вырождается в систему линейных алгебраиче-
ских уравнений.
Как и дискретные марковские цепи, непрерывные марковские цепи
описываются предельными вероятностями, характеризующими сред-
нюю долю времени, в течение которого система находится в данном со-
стоянии при наблюдении за системой в течение достаточно продолжи-
тельного времени (на бесконечном интервале).
Пример. Рассмотрим марковскую модель системы, граф функционирования ко-
торой представлен на рис. 6.1.
Рис. 6.1. Граф модели
В соответствии с видом графа запишем систему линейных дифференци-
альных уравнений Колмогорова:
^^ = *АюЮ+Ц|Ло(0+Ц2А11(0,
121
6.3. Непрерывные марковские цепи
~7^-=Ь-Рш (0 - (н । + Мрю (0+м 2 Pi । (О ,
СП
•^7^- = -(А.+Ц, )р01 (О+М iPi । (/),
а/
= А.Рю(0 + Ха„(П - (И । + Н2) А ।(О,
СП
Аю(') + Ао(') + Ан(') + Ри(О=1.
Пусть начальные условия заданы вектором вероятностей с компонентами:
Аю (0) = 1, Рю (0) = Ан (°) = A i (°) = °-
Решение этой системы при заданных начальных условиях позволяет
определить вероятности состояний как функции времени. Последние, в свою
очередь, позволяют определить требуемые характеристики рассматриваемой
системы. Поскольку марковский процесс, описывающий работу системы,
является эргодическим, существует стационарный режим, при котором ве-
роятности состояний стремятся к постоянным величинам. При этом система
дифференциальных уравнений Колмогорова вырождается в систему сле-
дующих линейных уравнений:
“^Аю + МчАо + И зАи =
^A)o-(Mi+^)Ao+H2Ai =0>
-G<+H2)A)1+PiAi = 0>
^Ао + ^Аи " (Pi +P2)Ai = °,
Аю + P\q + Ан + А । = 1 •
Выражения для вероятностей в установившемся режиме имеют вид
_ц1ц2(2Х+ц1+ц2)
А)() - /л , ч Al’
2?v(X + р2)
_ц2(^ + ц1+ц2)
Ао - . .. , . Рп j
Щ + Рз)
_____________2Х___________
2X^-(2?v + h, +Ц2) + Х(ц, + |Л2)
Х + р2
Процессы гибели и размножения. Полезным классом непрерыв-
ных марковских процессов при анализе систем построения очередей яв-
ляются процессы гибели и размножения, граф состояния которых при-
веден на рис. 6.2. В таких процессах возможен переход либо из состоя-
ния z в (/ - 1), либо из i в (z + 1). Интенсивность перехода из состояния /
в состояние (z + 1) обозначается X/ для i > 0, а интенсивность перехода
из состояния z в состояние (z - 1) обозначается ц z для / > 1.
Пространство состояний процесса гибели и размножения может
быть как бесконечным {0, 1,2, 3, ...}, так и конечным.
122
Глава 6. Марковские случайные процессы и их моделирование
X, X,
*3'
Ц. Ц2 Цз Цч
Рис. 6.2. Граф состояний процесса гибели и размножения
В случае, рассматриваемом на рис. 6.2, матрица интенсивностей
будет иметь трехдиагональный вид, поскольку есть только два способа
выйти из состояния:
х0 о 0 0 •••'
ц, -(>-|+Ц|) >-1 0 0
0 |Л2 -(Х2 + ц2) Х2 0 •••
Некоторые типы систем построения очередей удобно моделиро-
вать при помощи процессов гибели и размножения. Так например вели-
чины {X,} и {pz} могут рассматриваться как интенсивность поступлений
в очередь и интенсивность обслуживания, соответственно.
Пример. В качестве примера процесса гибели и размножения с конечным чис-
лом состояний можно рассмотреть наложение голосовых источников, где число
состояний отражает число источников, которые находятся в ON-состоянии на
данных момент. Граф состояния суперпозиции У голосовых источников пред-
ставлен на рис. 6.3. Состояние i подразумевает, что i источников активны (рече-
вая активность). Степень рождения определяется при помощи среднего значе-
ния экспоненциально распределенных периодов молчания, которое обозначим
как 1/р. Степень гибели определяется при помощи среднего значения длитель-
ности периодов активности и обозначается 1/а. Вероятность p0N того, что ис-
точник находится в состоянии ON, определяется как p0N= а/(а+р).
Вероятности предельного состояния л„ показывающие что процесс нахо-
дится в состоянии i, определяются при помощи биномиального распределения с
параметром p0N- А вероятностная функция для л, (/ = 0, ..., N) выглядит сле-
дующим образом:
^PonO “ Pon)V '>
где У - число источников, которые складываются.
Тогда матрица интенсивностей процесса описывается выражением
'-Лф wp 0 0 0 0 0 0 "
а -[a + (W-l)p] Gv-i)p 0 0 0 0 0
0 2а -[2a + (,V-2)p] (W-2)p 0 0 0 0
Q =
0 0 0 0 (W-2)p -[2P + (7V-2)P] 2P 0
0 0 0 0 0 (V-l)a -[(.V - l)a+p] P
ч 0 0 0 0 0 0 Ata - Ma ?
123
6.4. Модели непрерывнозначных марковских случайных процессов...
л;р (ЛМ)Р ф р
..
ОС 2а (Л-1)а Лга
Рис. 6.3. Суперпозиция /V голосовых источников
В соответствии с изложенным выше можно сложить интенсивно-
сти источников, которые на данный момент испытывают периоды голо-
совой активности, и получить для суперпозиции новый процесс.
6.4. Модели непрерывнозначных марковских
случайных процессов на основе стохастических
дифференциальных уравнений
Рассмотрим некоторую динамическую систему. Если ее входной сигнал за-
фиксировать, то сигнал на выходе будет полностью определяться параметра-
ми системы. Если, в частности, на входе действует стандартный случайный
процесс с заданными вероятностными характеристиками, то процесс на вы-
ходе также будет полностью определяться параметрами системы. Эту систе-
му называют формирующим фильтром, а в качестве стандартного процесса
обычно выбирается белый шум, если моделируется непрерывный процесс, и
последовательность 5-импульсов если моделируется разрывный процесс.
Формирующий фильтр можно описывать по-разному, однако наи-
большее применение получило описание в форме дифференциальных
уравнений на основе метода переменных состояния:
(6.12)
а/ ; = i
где Х,(г) - переменные состояния; X(r) = [M(t), ..., Хп(/)] - вектор состояния;
/(/), некоторые детерминированные функции; - независимые
гауссовские случайные процессы типа белого шума с моментными функ-
( ] / —
циями £*(/)= 0Л,(О^(/ + т) = 5я.5(т). (Здесь и далее -символ
! U, I 7^ /С
Кронекера; 5(т) - дельта-функция.)
Уравнения состояния (6.12) удобно записывать в векторной форме:
^=f(l)+G(k)^), (6.13)
где f(X) = [А(Х), ...,/„,(Х)]7; W) = £,(/), .... UOf;
• ••
G(X) =
Уравнение вида (6.13) и связанные с ними интегралы получают
рациональное толкование только в рамках теории стохастических диф-
124
Глава 6. Марковские случайные процессы и их моделирование
ференциальных уравнений, получившей развитие сравнительно недав-
но. К этому типу относят дифференциальные уравнения, в которые вхо-
дят обобщенные случайные процессы типа белого шума.
Остановимся на свойствах случайных процессов, описываемых СДУ
вида (6.13). Обычно предполагается, что функции f(X), G(X) непрерывны и
удовлетворяют условиям Липшица:
||f(kj)-+< g||k-к'||,
где g, l- некоторые положительные константы; ||*|| - знак нормы векто-
ров и матриц в соответствующих пространствах.
Случайные процессы, описываемые СДУ вида (6.13) при указан-
ных условиях, образуют класс диффузионных марковских процессов.
Многомерная плотность вероятностей марковского процесса раз-
лагается в произведение
Х 1^0’0’^0 )’
т. е. полностью определяется плотностью вероятностей переходов л(*) и
начальной плотностью w(X0, Го).
Вид функции л(Х, z|X'/) может быть весьма разнообразным. У
диффузионного марковского процесса она не произвольна, а удовлетво-
ряет уравнению Фоккера - Планка - Колмогорова (УФПК)
(6.15)
коэффициенты которого и /^(А,) называют коэффициентами сноса и
диффузии или локальными характеристиками марковского процесса.
Плотность вероятностей w(k, t) удовлетворяет тому же УФПК. Заметим,
что при начальной плотности вида w(k, /0) = 5(Х - А.о) имеет место равенство
л(х, t |Х, t') = w{k, t). (6.16)
Не останавливаясь на определении смысла локальных характеристик
<7;(Х)и ЬУ(Х), подробно освещенного в литературе [11], отметим здесь глав-
ное: если марковский процесс описывается СДУ вида (6.12), то его локаль-
ные характеристики полностью определяются коэффициентами СДУ. Эта
связь задается соотношениями, зависящими от принятой формы записи
стохастических интегралов. В частном случае при использовании стохас-
тических интегралов Стратоновича
J clA,
> j J
(6.17)
125
6.4. Модели непрерывнозначных марковских случайных процессов...
Соотношения (6.15) и (6.17) устанавливают фундаментальную
связь вероятностных характеристик марковского процесса, порождае-
мого СДУ, с коэффициентами этого СДУ.
Многомерные диффузионные марковские процессы, описываемые
СДУ (6.13), образуют весьма обширный класс. Он включает в себя как
стационарные, так и нестационарные процессы с различными функция-
ми распределения. Стационарные процессы описываются СДУ, у кото-
рых коэффициенты f(X), G(X) не зависят от времени.
Линейные СДУ вида (6.13), у которых f(X, /) = F(r)X(/), G(X, /) = G(r),
порождают гауссовские процессы. В общем случае, когда модель нелиней-
на, функции распределения могут быть весьма разнообразными.
Существует, однако, важный класс случайных процессов, который не
охватывается непрерывной моделью типа (6.13). Это различного рода им-
пульсные случайные процессы, в первую очередь импульсные помехи, ко-
торые играют существенную роль во многих реальных каналах связи.
Применяя для представления таких процессов метод формирующих
фильтров, можно рассматривать импульсный случайный процесс как
реакцию некоторой динамической системы на последовательность 5-
импульсов. Такой подход приводит к модели в виде СДУ:
^ = f(l)+G(k>< (6.18)
at
где г|(Г) = ХИ*5(г - tk) - вектор пуассоновских последовательностей
5-импульсов с независимыми векторами «амплитуд» А, распределенны-
ми по закону ы(А).
Относительно векторной функции f(X) обычно предполагается, как
и в случае модели (6.13), что она удовлетворяет условиям Липшица.
Матрица G(X) чаще всего принимается единичной (G = 1).
Процесс, порождаемый СДУ (6.17), будучи я-мерным марковским в
отличие от СДУ (6.13), в общем случае уже не является непрерывнознач-
ным, и уравнение (6.15) для его плотности вероятностей не имеет силы. Ис-
следование такой модели осуществляется в рамках теории дискретно-
непрерывных (скачкообразных) марковских процессов, которые для крат-
кости названы разрывными. Плотность вероятностей ^-мерного разрывного
марковского процесса, описываемого СДУ (6.15) при G = 1, удовлетворяет
интегродифференциальному уравнению Колмогорова - Феллера (УКФ):
а/ ;=1 оЛ/ (6.19)
+ vjn(x- ,4,/|X',/')w(/l)cL4 - vn
где v - интенсивность пуассоновского потока 5-импульсов.
Аналогичному уравнению удовлетворяет и плотность вероятно-
стей w(X, t).
126
Глава 6, Марковские случайные процессы и их моделирование
6.5. Моделирование марковских случайных процессов
Будем рассматривать марковские процессы с непрерывным временем
{X,, Ге(О; Т)} и марковские процессы с дискретным временем {X™, /?/б(0; Л/)}.
Обычно последовательность {Xw} рассматривают как совокупность отсче-
тов Xw = Xw/ гипотетического или реального процесса {XJ, причем tm =
(Д - интервал дискретизации по времени), tM = МА = Т. Пространство со-
стояний A(XZ е Л) может быть как дискретным, так и непрерывным (конти-
нуальным). В первом случае процесс X, будем называть дискретным, а во
втором случае - непрерывнозначным. Процесс X, может быть как скаляр-
ным, так и векторным многомерным. В последнем случае он представляет
совокупность некоторого числа (г) случайных процессов - компонент
X/- {X,, i = l,r }.
При моделировании случайных процессов на ЭВМ следует их предва-
рительно описать при помощи стохастических уравнений с дискретным
временем, в случае необходимости осуществляя дискретизацию процессов
по времени. В качестве исходных случайных последовательностей обычно
выбирается последовательность независимых случайных величин {ocw},
равномерно распределенных на интервале [0; 1), и последовательность стан-
дартных независимых гауссовых величин {^т} с параметрами - 0,
= 1, (wf&n) ~ N(0; 1)). В библиотеке стандартных подпрограмм, как
правило, всегда имеется подпрограмма получения чисел {ocw} и подпро-
грамма получения последовательности {tm}. Если последней подпрограммы
нет, то последовательность , т = \,М } может быть получена, например,
в соответствии с алгоритмами, приведенными выше (п. 3.5).
6.5.1. Моделирование дискретных процессов
Рассмотрим дискретную последовательность {Хш} = {0ш}(ш = ),
причем Qm е {14, к - \,К }. Предполагаются заданными статические ха-
рактеристики: начальное распределение вероятностей Р(0! = К) = Рк\ и
распределение вероятностей переходов
Случайная величина 01 моделируется согласно алгоритму
0! = 14, если «1 • (6.21)
у=1 у=1
По этому же правилу моделируется последовательность независимых
дискретных величин {0ш} с заменой индекса 1 на т. В случае моделирования
марковской последовательности на шагах т - 2,М используется правило
Л-1 к
Qm=vk, если ^7ГЛ„, <а„, <^2^, (6.22)
у=1 у=1
где j - номер предыдущего состояния 0^-1= Vj9 т.е. значение J фиксировано.
127
6.5. Моделирование марковских случайных процессов
Дискретный процесс с непрерывным временем {0т, / е (0; Т)}
(0, е {Vk, к= К}) обычно описывается при помощи начальных вероятно-
стей рло и вероятностей переходов Ajk(f) из состояния Р} в состояние Vk в еди-
ницу времени (j = к). Цифровое моделирование процесса 0, является адек-
ватным, если время дискретизации удовлетворяет условиям Лд(/)А « 1. То-
гда вероятности переходов njkm, описывающие модель {0W}(0W = 0(Q), удов-
летворяют соотношениям
= Ац (отд) «1), j * к, (6.23)
Яы» 1 - 2 AkJ (я**”1 = • (б24)
J=k
Начальные вероятности рк1 для модели {0W} находим из соотношения
(6.25)
Цифровая модель дискретного процесса {0Ш} реализуется при по-
мощи ЭВМ на основе формул (6.21) и (6.22), взятых с учетом соотно-
шений (6.24), (6.25).
Однородный дискретный марковский процесс 0/ характеризуется
экспоненциальными распределениями длительностей состояний
= <^) = 1-ехр]-| (6.26а)
I V-* ) J
Здесь tk - случайное время пребывания в состоянии Vk.
С целью описания одного дискретного процесса с произвольными
распределениями длительностей состояний часто используют полумарков-
скпи процесс, характеризуемьш функциональными зависимостями вероят-
ностей переходов А^ = Ajk(x) в 1 от длительности состояния. В этом случае
^(*) = р(г* <*') = !-ехр'
(6.266)
Полумарковский дискретный процесс моделируется на ЭВМ ана-
логично дискретному марковскому.
6.5.2. Моделирование скалярных непрерывнозначпых процессов
Рассмотрим непрерывнозначный скалярный марковский процесс 4 удов-
летворяющий функциональному дифференциальному уравнению (с произ-
водной, понимаемой в обычном смысле)
i(4=Z(xz)+gz(xzXz, (6.27)
где Да,) и ~ известные функции с ограниченными производными;
- «белый» гауссовский шум с ограниченной полосой или «физиче-
ский белый шум», математической моделью которого служит стандарт-
ный гауссовский процесс с бесконечной шириной спектра («математи-
ческий белый шум») со свойствами: М(&) = 0, М(Е^/+х) = 5(т).
128
Глава 6. Марковские случайные процессы и их моделирование
В случае однородного (стационарного) процесса имеем
Ж) = /(4),Ш= «(*,), (6.28)
и стационарная плотность вероятностей равна
* (6-29)
Выбор постоянных С\ и С2 осуществляется из условия нормировки
1.
Процесс обладающий стационарным распределением (6.29),
может моделироваться на ЭВМ на основе уравнения (6.27) с учетом
формул (6.28). При этом модель физического белого шума реализуется в
виде широкополосного гауссовского процесса, время корреляции (т^)
которого удовлетворяет условиям
йД = Z(4) + 7^(^fe(\) d' + gXxJdv,,
(6.31)
\ «[df/dX,]-1, «[dg/d\f'. (6.30)
Переход к цифровому моделированию может быть осуществлен на
основе уравнения Ито
[/44
либо на основе стохастически эквивалентного уравнения Стратоновича
dA = Z(\)dz + st )d vt, (6.32)
где {v6 t e (0; T)} - стандартный винеровский процесс, у которого v0 = 0,
M(vtvt+z) = t, — t — x.
Винеровский процесс vt можно приближенно моделировать при дос-
таточно больших временах интегрирования при помощи соотношения
(6.33)
О
поскольку в этом случае под интегралом справедлива замена физического
белого шума на математический. Отметим, что в (6.31) и (6.32) исполь-
зуются стохастические дифференциалы Ито (dAz) и Стратоновича (dsM-
Если указанные дифференциалы совпадают, то индекс опускается.
Если интервал дискретизации А удовлетворяет соотношениям
2
Ш g,(4)
Ж)’ g,'(4)j ’
(6.34)
то цифровое моделирование является адекватным аналоговому, причем
уравнениям (6.31) и (6.32) соответствуют следующие разностные моде-
ли, эквивалентные друг другу:
2
(4-i )sU (4-i) д + gm-i(4-i Ь/д 4 ,(6.35)
-^и-1
5—3834
129
6.5. Моделирование марковских случайных процессов
4+1 - Vi = Л(Ч)2Д + гя(4)7д(4+1 +4), (6.36)
где т = 2^7; Ч = \ /„(4) = Л(Ч)i 4 = (« = 4^) •
Д Ч-i
Последовательность {^w} является гауссовой с независимыми значениями.
Для решения уравнения (6.35) следует задать начальное значение
например, . Для решения уравнения (6.36) помимо значения сле-
дует задать также и Х2. В случае необходимости Х2 можно нормировать в
соответствии с правилом (6.35) (при А = 1). Уравнение (6.36) справедливо
также при А < т^. Однако в этом случае последовательность {tm } не являет-
ся стандартной с независимыми значениями.
Рассмотрим частный случай, когда
M=g,, (6.37)
причем gt не зависит от Xt. Тогда вместо (6.27) имеем
4=/,(4)+g,4 (6.38)
В рассматриваемом случае уравнения Ито (6.31) и Стратоновича
(6.32) по форме совпадают, так как#'(0 = 0. Поэтому цифровое модели-
рование удобно осуществлять в виде
К - = Л-,(ХЯ-,)Д + g„,-i л/Д4, (6.39)
следующим из (6.35).
Если процесс является гауссовским марковским, имеем
/,(х,)=-а,х„ ^(х,)=г„
Tm-l^m-l)- ~g.-lC^m-l) — g.-Г (6.40)
Тогда на основе соотношения (6.39) получим
4=44-1+44, (6-41)
где т = \,М ; 4 = 0;
4=1- 1Д, 4 = g„ 1 Va • (6.42)
Формула (6.41) определяет гауссовскую марковскую последова-
тельность независимо от формул (6.42), причем на шаге (т = 1) следует
положить = 0.
6.5.3. Моделирование непрерывнозначных векторных процессов
Рассмотрим непрерывнозначный векторный процесс \ = {ХЛ i = 1,г }, удов-
летворяющий системе функциональных дифференциальных у равнений:
4 =Z,(4)+£gU4)4« ’=17’ (6-43)
у=1
где /*(•), gfyzC) - функции известного вида с ограниченными производ-
ными; {^(0} - независимые физические белые гауссовские шумы (с ог-
раниченными полосами), т.е. = 0, Л/(^^^/+х)= б/Дт).
130
Глава 6. Марковские случайные процессы и их моделирование
Цифровое моделирование компонент Xit осуществляется в соответ-
ствии с уравнениями
К
1 ^dg^.XV,)
gy5-"”‘
(6.44)
либо
1,г.
(6.45)
)у/л+1
В соотношениях (6.44), (6.45) использованы те же обозначения,
что и в формулах (6.35), (6.36). Так,
К
гут
= тиД, т
(6.46)
В случае gryt(^t)= giyt (giyt не зависит от X,) вместо (6.43) имеем
(б-47)
у=1
Тогда цифровое моделирование удобно осуществлять на основе
соотношений
К -\„-1 ' = V t =2jw). (6.48)
у=1
Особо важным случаем является гауссовский марковский процесс,
у которого
fit (X/ ) = — S ^iyt^yt» &iyt ) = Sqt >
у=1
4»-i(Vi)=(6-49)
у=1
Следовательно, векторный гауссовский марковский процесс
описывается системой уравнений
Ч =-Z%Ay/ »=U (6.50)
у=1 у=1
Цифровое моделирование гауссовского марковского процесса {А,#}
осуществляется в соответствии с уравнением
(6.51)
у=1
где т = 1,Л/ , причем при т = 1 можно полагать
^=о, (6.52)
либо задать значения на первом шаге ^Д.
131
6.5. Моделирование марковских случайных процессов
Отметим, что в (6.51) используется обозначение
(6-53)
Формула (6.51) определяет многомерную гауссовскую марковскую
последовательность, и ее можно использовать для моделирования гау-
ссовской марковской последовательности на ЭВМ.
6.5.4. Моделирование гауссовского процесса с дробпо-рашкшалыюй
спектральной плотностью
Скалярный стационарный гауссовский процесс X, с дробно-рациональной
спектральной плотностью стремится к нулю на высоких частотах и может
быть описан при помощи уравнения
---- + а.--г + ... + аХ =р,---Y- + ... + P (6.з4)
dr" dr"-1 dr”“
где аь ал и рь ..., р„ - константы; - стандартный белый гауссов-
ский шум (Л1(^) - 0, М(££/+х) = 5(т)).
Процесс можно получить из системы уравнений, эквива-
лентной уравнению (6.54):
Х^-а^+Х^+Р^,,
^2t = “а2^1/ + Х3/ + р2£, ,
.................................................... (6.55)
^nt = ~anKt +Р;Д/-
Рассматриваемый гауссовский процесс = Xu представляет собой
компоненту векторного марковского процесса X, = {kit, \,п }, описывае-
мого системой уравнений (6.55). Цифровое моделирование гауссовского
процесса с дробно-рациональный спектральной плотностью можно
осуществить на основе системы уравнений
= 0+ ^2,т-1
^2т =~а2^\,т-\ + ^2,т-\ + + p25/^w>
.................................................... (6.56)
— ~СЧ:-1 п-2,т-1 + Рп-1 ’
К,т = +х-„л,-1 +₽,>Va^„,
непосредственно следующей из системы уравнений (6.55). Здесь -
стандартная гауссовская последовательность с независимыми значе-
ниями (Жт) = О,
132
Глава 6. Марковские случайные процессы и их моделирование
6.5.5. Моделирование многосвязных последовательностей
Вместо (6.51) в качестве частного случая часто рассматривают уравне-
ние линейной регрессии
(6.57)
где m = \,М , причем для значений m < п следует положить
И = 0 (у > m -1, m = 1,и) или п m -1. (6.58)
Последовательность {Х^} (6.57) называется ^-связанной гауссовской. Она
представляет собой компоненту многомерной гауссовской марковской после-
довагельности {Х^, 1= 1,г } при условиях
Л — /7, Х;>„ — X^-_jyw_Q — Х/Л_/+|, 1 — 2,п, (6.59)
^Im ~ Xw> ^тбт-\ ~ ^т-п > ^>1т ~ ^т'
К (Glft о - 0^
II || 1 0 • • • 0 к к о 0
1Кф»11= о о 11<^Г|'”11= (6.60)
J> - 1 0 J. Ь оу
Негауссовская и-связанная последовательность может быть опре-
делена на основе рекуррентного соотношения
^т=<Рж(^т и, •“Ат 1Ат)> т тщ \ т—п' * nt—1’ (6.61)
где cpw(-) - кусочно-непрерывная нелинейная функция заданного вида,
имеющая однозначную обратную функцию
t -Л i> X J. (6.62)
nix тп—ti* у /л-1" m / \ /
Здесь m = \,М , причем для значении m = 1,л следует разложить п -> m - 1.
При тп = 1 имеем cpi(Xb 50 = <pi(£0vpi(Х0.
Последовательность {Xw}, определяемая на основе (6.61), характери-
зуется начальной плотностью вероятностей переходов tcw(xw | X£j,r) и опре-
деляется на основе соотношений
GAq
(6.63)
где п^(-) = ЛА(0; 1) “ стандартное гауссовское распределение.
Векторный многосвязный негауссовский процесс Х^ = {Х^, i = 1,г }
можно моделировать при помощи соотношений
(6.64)
где 5/и = {^im} - независимые стандартные белые гауссовские шумы со
статистическими характеристиками Л/(^) = О, фА0 -
кусочно-непрерывные функции заданного вида, имеющие однозначные
обратные функции
= ^(хГ», х ), i=й (6.65)
^1ТП Т ЦП \ 9Т1 J ’ 7 \ '
133
6.5. Моделирование марковских случайных процессов
При т = 1,72 в формулах (6.64), (6.65), а также в последующих форму-
лах, следует положить п -> т - 1 и учесть соотношение f (Xi°; х) =flx).
Статистические характеристики для последовательности {А,} (6.64)
определяются на основе соотношений
w\ (^i)= wл (^i)] |*А |» (6 66)
ки(хи । сл)=Я м т=w,
где Jm - якобиан преобразования в Хт, Jm = |I.
В тех случаях, когда обратные функции неоднозначны, в правых
частях формул следует взять суммы по каждой из подобласти.
Отметим, что в соотношениях (6.61), (6.64) вместо независимых
гауссовых величин Е>т, i = l,r } можно брать независимые, рав-
номерно распределенные на интервале [0; 1) случайные величины ат,
{^im, i= V }• При этом упрощается расчет статистических характе-
ристик. Так, вместо формул (6.66) теперь имеем
w,(X,тся(хм |Х7'„)=
Л 1/ „ п) dx
1 т
(6.67)
Одновременно упрощается решение обратной задачи: по заданным ста-
тическим характеристикам найти функциональную зависимость \|/ш(«) = ут.
Векторная гауссовская я-связная последовательность представляет
собой частной случай негауссовой последовательности {Хт} (6.64), ха-
рактеризуемый линейными функциями {ср™}, {\у™}. Поэтому указанная
последовательность моделируется в соответствии с формулами
X,. = У* VihmX.. ш v ,2=1, г,
Im / j / j yym J,m-y ijnfbjm ’ ’ ’
(6.68)
где m = , причем для значений tn = 1,и следует положить и -> от - 1 или
vinm s 0 (у > от -1, от = 1,от). (6.69)
6.5.6. Моделирование марковских процессов с помощью
формирующих фильтров
Распространенной формой описания случайных марковских процессов
служат системы стохастических дифференциальных уравнений, запи-
санные относительно переменных состояния (6.13). Под переменными
состояния понимают величины, содержащие всю информацию о пре-
дыстории системы при t <t\, требуемую для полного описания выход-
ных сигналов при t > На понятии переменных состояния базируется
понятие формирующей динамической системы или формирующего
фильтра (ФФ).
134
Глава 6. Марковские случайные процессы и их моделирование
Под ФФ понимается некоторая гипотетическая система, на вход
которой подается белый шум, а на выходе формируется непрерывный
процесс Х(Г). В общем случае ФФ описывается СДУ в некоторой обоб-
щенной форме:
= (6.70)
аГ
где пф) - вектор независимых гауссовских случайных процессов типа бе-
лого шума; Х(Г) - вектор состояния; ф, Х(Г), пх(0] ~ векторная функция.
Эти уравнения дополняются в общем случае нелинейными урав-
нениями наблюдения
у(г)=ф,х(у),пп(/)], (6.71)
где пп(г) - вектор возмущений в канале наблюдения.
Наибольшее распространение получили линейные относительно
входных возмущений в формирующей системе (6.70) и в уравнениях
наблюдения (6.71) модели:
= Ф-ф)]+ g('.Ф)К(')- (6 72)
dr (O./ZJ
y(/) = s|/,x(r)]+n„(z),
где nz(r) - гауссовский случайный процесс с характеристиками ЛУ[пф)] = 0;
A4nz(/)n\(T)] = R,3(/-T).
В зависимости от вида функций ф, X,] и s[r, X,] возможны различ-
ные варианты. Очевидно, что наиболее общим является вариант, при
котором функции ф, XJ и s[r, X/] - нелинейные, a wn(n) - негауссовская.
Предположим, что поведение формирующей системы описывается
скалярным СДУ
dr (о./j)
0; Лф’х('1 ЫД]= к2/2>(/2 - г,).
гдеф, X/] и g[r, XJ - детерминированные функции, удовлетворяющие условию
Липшица (6.14).
Из структуры ФФ (рис. 6.4), реализующего алгоритм (6.73), видно,
что в нем содержатся два блока нелинейных преобразований (БНП), вы-
числяющих функцииф, XJ и g[r, XJ, однозначно определяемые коэффици-
ентами сноса a(t, X,) и диффузии 6(r, X,) марковского процесса Х(г) [11].
Располагая дифференциальным
стохастическим уравнением 1-го по-
рядка, описывающим марковский
процесс 1-го порядка, можно вычис-
лить коэффициенты сноса и диффу-
зии, а по ним составить уравнение
Фоккера - Планка - Колмогорова,
которое в свою очередь описывает в
частных производных одномерную ПРВ случайного марковского процесса.
/(<л)|------
Рис. 6.4. Структурная схема форми-
рующего фильтра
135
6.5. Моделирование марковских случайных процессов
Может быть решена и обратная задача, т.е. по уравнению Фоккера - План-
ка - Колмогорова найдено дифференциальное уравнение для случайного
процесса. Например, для стационарного скалярного марковского процесса
с ПРВ w(X) коэффициенты сноса и диффузии связаны уравнением
= Г2Лх)/б(х)-^б(х)/2|к(х), (6.74)
а/ |_ аЛ / 'J
решение которого имеет вид
да(х)=Ж)ехр
где g(X,/)= 26(Х,/)Л\2.
Если коэффициенты сноса и диффузии заданы, из (6.75) видно, ка-
кой стационарной плотности w(X) они соответствуют.
Если относительно процесса Х(Г) известна лишь одномерная ПРВ w(X),
то функции f[t, XJ, g[Z, XJ (a(t, АД b(t, А,,)) необходимо найти. Эта задача не
имеет единственного решения, однако, если задаться из каких-либо сообра-
жений коэффициентом сноса, то коэффициенты диффузии можно найти из
уравнения (6.75), и наоборот. Так, если 5(r, Xz) = fe(X) = b = = const
(коэффициент диффузии, имеющий физический смысл локальной средней
скорости изменения дисперсии приращения марковского процесса, есть ве-
личина постоянная), задача синтеза упрощается.
В этом случае уравнение ФФ можно представить в виде
w(M+n^.(') • <6-76)
Таким образом, когда относительно процесса X(Z) известна одномер-
ная плотность распределения вероятностей щ(Х), а относительно коэффи-
циента диффузии справедливо предположение о его постоянстве, ФФ пол-
ностью определен коэффициентом сноса, вычисляемым из (6.75).
Неизвестное значение постоянного параметра b может быть также най-
дено, если имеется дополнительная информация о корреляционной функции
процесса 7?х(т). Наиболее просто задача решается, если корреляционная функ-
ция 7?х(т) имеет экспоненциальный характер: Ях(т) = сгх2ехр(-£2х|т|). Синтез не-
линейных моделей при таком предположении подробно рассмотрен в [11, 12].
Пример. Рассмотрим структуру ФФ и характеристики процесса А(г) на его выходе
для ПРВ:
»(М.)=
= V2r(l/vJaJr(3/vJ/r(l/v,.)] ,/2х (6.77)
х exp{|x|'’ /<T^[r(3/v,) r(l/v, )]’, /2},V; > 0,5
где vx - параметр распределения; и Г(*) - гамма-функция.
При vx = 2 распределение переходит в гауссовское, при = 1 - в лапласовское.
В соответствии с (6.76) характеристика нелинейного преобразования опреде-
ляется как
In w(x, V,) = -[г(3 /V;_ )/г(1 / vx(vx/сГ) sgn X .
136
Глава 6. Марковские случайные процессы и их моделирование
Окончательно запишем СДУ формирующего фильтра последовательности
{X/,} = {Х(/Л), h = 1, 2, ...} в виде разностного уравнения
ХА+1 =X;,-^|4p/2signX/, + 7a5nM’ пи, (6.78)
где А = [Г(ЗЛ>х)/ Щ/vx)]Vx/2 n\h - стандартный дискретный бе-
лый гауссовский шум (независимые гауссовские случайные величины с пара-
метрами М(/?х/) = 0 и М^п-^п-ц) = Ъч\ th+[ - tfl = 7о - шаг дискретизации при пере-
ходе от непрерывного времени к дискретному; - постоянная, характеризую-
щая широкополосность процесса Х(г).
Описывающие ФФ уравнения для некоторых широко употребляе-
мых одномерных ПРВ w(A,) сведены в табл. 6.1.
Таблица 6.1. Формирующие фильтры стохастических процессов , заданных одно-
мерными ПРВ
ПРВ ш(Х) СДУ формирующего фильтра
ПРВ Иакагами / \П1 /» у! 2 1 fn i2w-Irt а,2 • / \ ( 2т . 2/л - Й _ / \ Ц0 = , +*V’>.('), 4 X ) Х(г)= --^Х’’4"' +л/2Х,’2тлД0, _• / \ ст2 (2т - 1 „ . G-. п- (/) Х(/) = *— 2тк + 4«Ик»р1 ) ^2x^1
Обобщенное нормальное распределение v гr(3/vV'2 схJ. Г г(з/у)7'21*Н 2r(l/V)a-Lr[l/v]lJ Д |_r(l/v)j ^(0 = -Хх PC sSn 1 + у,2п,! Гг(зМТ/2 1 Х’-= 4 Lrd/vj'j <
ПРВ Рэлея -^-ехр(-Х2 /2<т2) °). •/ ч Nfal ( х i 'I n X(,) = ~ 4 U’J Л(0 3-(')=-n>A+-^-+«>.(0
Логарифмически нормальное распределение 1 [. (1пХ —1плл)2П. г- сх^ . М > 0 1] 4A. a? J i(/)= 1п(Х//и)+ПхХлх(/), X(/)=-JilMofekbllf In-UcA а>:^кор I "< J + СГ/»[ехр(а21ехр(ст2)- i]]'/2"iW У ^кор
Г амма-распределение [р'”'Г(а + 1)]‘‘Ха ехр(-Х/р), X S 0 м М2П?Г1 а') „ (Z)=" 4\p“p/ ,A()’ x(z)=^L[“- 1L_Р-+[3₽Г| ,!;(z) г„Дх pj 2tKOp (ткор J
137
6.5. Моделирование марковских случайных процессов
6.5.7. Алгоритм статистического моделирования марковских цепей
В общем случае распределение вероятностей реализации различных ис-
ходов может быть получено непосредственно статистическим модели-
рованием алгоритма функционирования системы.
Например, очень эффективным является использование метода
статистических испытаний при моделировании процесса функциониро-
вания таких сложных систем, эволюция которых может быть представ-
лена в виде некоторой последовательности элементарных тактов. Каж-
дый из них состоит в переходе системы из одного состояния в другое с
определенной вероятностью.
Пусть в процессе функционирования система в некоторый момент
времени оказалась в состоянии Xt. Известны также вероятности перехо-
дов ри из состояния Xj в другое состояние.
Моделирование элементарного такта перехода из х, осуществляет-
ся с помощью датчика случайных чисел, распределенных равномерно
на интервале [0; 1). Ситуацию моделируем как полную группу событий.
Событием А, считаем то, что система в момент времени I = 0 находилась
в /-ом состоянии. Поскольку система обязательно находилась в каком-то
состоянии, то имеем полную группу событий 1 . Возьмем слу-
чайное число гк, оно находится в некотором интервале, его номер соот-
ветствует состоянию, в котором находится система.
Вероятности перехода из f-го состояния записаны в /-й строке мат-
рицы переходов. Событием с номером j будем считать переход системы
из /-го ву-е состояние. Так как система или перейдет ву-е состояние или
останется в /-ом, то = 1.
Моделируем это как полную группу событий, с вероятностями из /-й
строки переходов. Для этого интервал [0; 1) разбиваем на совокупность по-
динтервалов [ajt-ь аД число которых равно числу возможных состояний сис-
темы. Тогда правая граница каждого подынтервала вычисляется из условия
= (6.79)
7=1
Поскольку вероятность попадания случайного числа внутрь каждого
такого интервала равна его длине (ак - ак^ = р,к), то закон распределения
вероятностей р„ переходов системы из х, в другие состояния совпадает с
законом распределения вероятностей попадания случайной величины в по-
дынтервалы отрезка [0; 1). Теперь, для того чтобы определить номер со-
стояния, в которое переходит система в данный момент, достаточно узнать,
внутри какого из подынтервалов оказалось случайное число.
Для этого берем случайное число гк+{, находим подынтервал попа-
дания в отрезок [0; 1). Его номер т\ будет номером состояния, в которое
перешла система, т.е. номером строки для дальнейшего моделирования.
Получим цепь событий А,Anh,А .....
138
Глава 6. Марковские случайные процессы и их моделирование
Подсчитаем относительную частоту « Кт !М попадания в со-
стояние /, где М - число испытаний, К - число попаданий в т-е со-
стояние (/ = 1,2, ..., У).
Необходимо заметить, что для эргодических цепей Маркова влия-
ние начальных вероятностей с ростом номера испытаний быстро
уменьшается. Поэтому в качестве величин ро(/о)> Pi(^o), •••, Pntto) могут
быть выбраны произвольные величины, например, \/(п + 1).
Структура рассмотренной процедуры сохраняется и для более
сложных случаев цепей Маркова, например для неоднородных цепей.
Контрольные вопросы к главе 6
1. Дайте определение марковского случайного процесса.
2. Дайте определения дискретной марковской цепи, непрерывной марков-
ской цепи, непрерывнозначного марковского процесса.
3. Приведите классификацию состояний марковской цепи.
4. Какую формулу называют равенством Маркова ?
5. Каковы различные способы вычисления вектора предельных вероятно-
стей марковской цепи ?
6. Дайте определение корреляционной функции эргодической цепи Маркова.
7. Дайте определение пуассоновского процесса, управляемого Марковским.
8. Приведите пример составления системы дифференциальных уравнений
Колмогорова непосредственно по размеченному графу системы.
9. Какой вид имеет матрица интенсивностей процесса гибели и размножения ?
10. Дайте определение коэффициентов сноса и диффузии марковского
процесса.
11. Запишите алгоритм формирования непрерывнозначного скалярного
марковского процесса в виде стохастического дифференциального
уравнения.
12. Как определить стационарную плотность вероятностей случайного про-
цесса, если известно СДУ его формирующего фильтра ?
13. Запишите алгоритм моделирования непрерывнозначного векторного
процесса.
14. Приведите алгоритм моделированимя гауссовского процесса с дробно-
рациональной спектральной плотностью.
15. Запишите СДУ для формирования многосвязных гауссовских последо-
вательностей.
16. Запишите СДУ для формирования многосвязных негауссовских после-
довательностей.
17. Запишите уравнение и нарисуйте структурную схему формирующего
фильтра в случае гауссовского процесса.
18. Запишите уравнение и нарисуйте структурную схему формирующего
фильтра в случае случайного процесса с ПРВ Лапласа.
19. Опишите алгоритм статистического моделирования марковской цепи с
двумя состояниями.
139
Глава 7
ПРИМЕРЫ РАЗРАБОТКИ МАРКОВСКИХ МОДЕЛЕЙ
7.1. Марковские модели речевого диалога абонентов
Статистическому анализу характеристик фрагментов речевого сигнала
уделялось большое внимание. Результатом этих исследований явилась
разработка ряда моделей, описывающих изменение состояний сигналов
во время телефонного разговора. Сложность модели возрастает при бо-
лее точном описании данных, полученных при экспериментальных из-
мерениях параметров речевого сигнала. Марковские процессы с необ-
ходимым числом состояний достаточно хорошо описывают механизм
формирования речевого сигнала, знание которого необходимо для ана-
лиза сетевых проблем при пакетной передачи речи.
Рассмотрим статистические модели, которые могут быть исполь-
зованы для описания процесса передачи речевых сообщений.
Точность модели определяется способностью предсказать продолжи-
тельность различных состояний речевого сигнала. Большинство из извест-
ных достаточно подробных моделей позволяют получить распределение
длительностей каждого из этих состояний с необходимой точностью. Ме-
нее сложные модели описывают распределения только некоторых состоя-
ний, например таких, как длительность активного состояния речевого сиг-
нала или длительность пауз. Однако именно эти состояния являются наи-
более важными при анализе моделей трафика и сетевых статистических
характеристик. Упрощенные модели позволяют получить удобные анали-
тические выражения для анализа основных характеристик сети и могут
быть использованы для анализа сетей со статистическим уплотнением.
7.1.1. Состояния речевого сигнала
Можно выделить десять характерных состояний, отражающих особенности
динамики речи и загрузки канала при телефонном разговоре двух абонентов:
1) речь (активный речевой сигнал);
2) пауза;
3) одновременный разговор (активный речевой сигнал двух абонентов
одновременно);
4) полное молчание;
5) молчание одного из абонентов;
6) пауза одного из абонентов;
7) активный речевой сигнал одного из абонентов;
8) перебивание одного абонента другим;
9) возобновление речи после перебивания;
10) возобновление речи перед перебиванием.
140
Глава 7. Примеры разработки марковских моделей
Определим основные состояния при разговоре двух абонентов А и В.
«Речь/пауза» (или «активность/пауза»). Техника выделения состоя-
ний «речь/пауза» может осуществляться, например, следующим способом.
Триггер устанавливается в 1 каждый раз, когда огибающая речевого сооб-
щения абонента А превышает пороговое значение. Каждые 5 мс состояние
триггера анализируется, и если речевое сообщение ниже порогового уров-
ня, триггер сбрасывается в 0. С целью устранения интервалов активности
менее 15 мс анализируется результирующий поток, состоящий из 1 (актив-
ность) и 0 (пауза). После чего определяются участки активности речи, меж-
ду которыми паузы имеют длительность менее 200 мс. Такие паузы счита-
ются микропаузами внутри активного состояния речевого сигнала. Резуль-
тирующий поток 1 и 0 на выходе триггера рассматривается как поток со-
стояний речевого сигнала «активность/пауза». Аналогично определяются
состояния для абонента В.
Могут быть предложены и другие методики определения состояний.
«Одновременный разговор» - характеризует интервалы времени, в
которые речевой сигнал находится в состоянии «активность» у двух
абонентов одновременно.
«Полное молчание» - интервалы времени, в течение которых речевое
сообщение находится в состоянии «пауза» одновременно у двух абонентов.
7.1.2. Модели диалога
Предположим, что имеются средства передачи речи, в которых для ка-
ждого пакета выделяется определенный интервал времени, т.е. некото-
рое устройство разделяет временную ось на кадры, в течение которых
от каждого из абонентов может быть получен пустой или заполненный
пакет в зависимости от уровня энергии его речевого сообщения. Поток
кадров не имеет синхронизации с моментами появления активного ре-
чевого сигнала. Только один из абонентов, ведущих диалог, может ме-
нять состояние речевого сигнала в течение одного кадра.
Модель с шестью состояниями (модель Броди). Эта модель вклю-
чает в себя шесть состояний поведения абонентов (рис. 7.1.): 1 - абонент А
говорит, абонент В молчит; 2 - абонент А собирается замолчать, абонент В
говорит; 3 - взаимное молчание, абонент А говорил последним; 4 - або-
нент В говорит, абонент А молчит; 5 - абонент В собирается замолчать,
абонент А говорит; 6 - взаимное молчание, абонент В говорил последним.
Рис. 7.1. Поведение абонентов, описываемое моделью Броди
141
7.1. Марковские модели речевого диалога абонентов
Ориентированный граф модели представлен на рис. 7.2.
Рис. 7.2. Ориентированный граф модели с шестью состояниями
Матрица переходных вероятностей, соответствующая этой модели,
имеет вщ 1 % Р12 0 Р14 0 0
Р21 Р22 0 0 0 Р26
Р = Р31 0 Рзз 0 0 Рзв
Р41 0 0 Р44 0 Р46
Psi 0 0 0 Pss Р56
1° 0 РбЗ 0 Рб5 Рбб
где pi! - абонент А говорит, абонент В молчит; р12 -абонент В говорит; /?14 -
абонент А собирается замолчать; р2\ - абонент В собирается замолчать; р12
-абонент А говорит, абонент В говорит, В начал говорить вторым; р2б -
абонент А собирается замолчать; р31 - абонент В собирается замолчать; р33
- абонент А говорит, абонент В говорит, А начал говорить вторым; рзв -
абонент А говорит; р^ -абонент А говорит; р^ - взаимное молчание, або-
нент А говорил последним; р46 - абонент В говорит; р51 - абонент А гово-
рит; р55 - взаимное молчание, абонент В говорил последним; р56 - абонент
В собирается замолчать; рвз - абонент А говорит; рв5 - абонент В собирает-
ся замолчать; р^ - абонент В говорит, абонент А молчит.
Модель с шестью состояниями представляет значительный интерес,
поскольку отлично описывает динамику всех возможных состояний диало-
га. Однако чаще используются более простые модели, достаточно точно
отражающие смену и длительности состояний активности и пауз.
Модель с четырьмя состояниями (рис.7.3). Объединяя состояния 2 и
5, 3 и 6 для модели с шестью состояниями в одно, можно получить модель,
описываемую цепью Маркова с четырьмя состояниями: 1 - абонент А гово-
рит, абонент В молчит; 2 - абонент А говорит, абонент В говорит; 3 - або-
нент А молчит, абонент В говорит; 4 - абонент А молчит, абонент В молчит.
142
Глава 7. Примеры разработки марковских моделей
....... абонент В
Рис. 7.3. Поведение абонентов, описываемое моделью с четырьмя состояниями
Граф такой модели показан на рис. 7.4. Матрица переходных вероят-
ностей, соответствующая этой модели, имеет вид
' Рм Р\2 Р\3 ° '
р2, р22 0 р24
Рз: 0 р33 р34
< о рп р43 р44 J
где р\j - абонент А говорит, абонент В молчит; рп - абонент В начинает
говорить; /?1з - абонент А прекращает говорить; р3\ - абонент В прекра-
щает говорить; рп - абонент А говорит, абонент В говорит; р24 - або-
нент А прекращает говорить; р31 -
абонент А начинает говорить; р33 -
абонент А молчит, абонент В мол-
чит; рз4 - абонент В начинает гово-
рить; р42 - абонент А начинает гово-
рить; /?4з - абонент В прекращает го-
ворить; р44 - абоненты А и В молчат.
Из рисунков видно, что актив-
ность речи абонента А в этой модели
сконцентрирована в состояниях 7 и 2.
Данная модель хорошо отражает рас-
Рис. 7.4. Ориентированный граф
модели с четырьмя состояниями
пределение длин пауз и активности
речи, но не соответствует действительному потоку событий при появлении
состояния активности у двух абонентов одновременно.
Модель с тремя состояниями. Если исключить возможность появ-
ления активного состояния у двух абонентов одновременно, что соответст-
вует исключению состояния 2 в предыдущей модели, то получится модель
с тремя состояниями, которая по-прежнему достаточно хорошо отражает
распределение пребывания в состояниях «активность» и «пауза».
молчание
---------- абонент А
-------- абонент В
Рис. 7.5. Поведение абонентов, описываемое моделью с тремя состояниями
143
7.1. Марковские модели речевого диалога абонентов
Такая модель включает в себя следующие состояния (рис. 7.5): 7 -
абонент А говорит, абонент В молчит; 2 - абонент А молчит, абонент В
молчит; 3 - абонент А молчит, абонент В говорит.
Граф данной модели показан на рис. 7.6.
Рис. 7.6. Ориентированный граф модели с тремя состояниями
Матрица переходных вероятностей, соответствующая этой модели,
имеет вид
Рп
Р1\
О
Р =
Р12 0
Р22 Р23 j
Р32 РзЗ ) .
где рц - вероятность того, что абонент А говорит, абонент В молчит; р12 -
вероятность того, что абонент А прекращает говорить; p2i - вероятность
того, что абонент А начинает говорить; р22 - вероятность того, что абонент
А молчит, абонент В молчит; /?2з - абонент В начинает говорить; р32 - веро-
ятность того, что абонент В прекращает говорить; р33 - вероятность того,
что абонент А молчит, абонент В говорит.
Активное состояния диалога описываются двумя состояниями це-
пи, а состояние молчания обоих абонентов - одним. Для этой модели
длительности активного состояния имеют геометрическое распределе-
ние, а длительность пауз распределена иначе, что соответствует реаль-
ным характеристикам речевого сигнала.
Модель речи с двумя состояниями. В результате дальнейшего упро-
щения получается простейшая модель с двумя состояниями (рис 7.7): 7 - або-
нент А говорит, абонент В молчит; 2 - абонент А молчит, абонент В говорит.
речь
молчание
абонент А
•• абонент В
Рис. 7.7. Поведение абонентов, описываемое моделью с двумя состояниями
Подобная модель соответствует экспериментальным данным о рас-
пределении активного состояния, но не отражает особенности распределе-
ния длительности пауз. В этом случае исключается возможность появления
полного молчания двух абонентов, т.е. исключается состояние 2 из модели
144
Рис. 7.8. Ориентированный граф
модели с двумя состояниями
____________________Глава 7. Примеры разработки марковских моделей
с тремя состояниями (ориентированный граф на рис. 7.8). Матрица пере-
ходных вероятностей, соответствующая этой модели, имеет вид
\ А1 Р12
р =
\P2l Р12
где р\ 1 - вероятность того, что абонент А говорит абонент В молчит; рп
- вероятность того, что абонент А прекращает говорить, абонент В на-
чинает говорить; р2\ - вероятность то-
го, что абонент А начинает говорить,
абонент В прекращает говорить; /?22 -
вероятность того, что абонент А мол-
чит, абонент В говорит.
Для этой модели длительности
активного состояния и пауз имеют гео-
метрическое распределение.
Другие модели. Для исследования сетевых характеристик наибо-
лее важными являются также спектры модели диалога, которые связаны
с отображением механизма возникновения потоков пакетов, т.е. распре-
делений длительностей активного состояния абонента. Сравнивая пред-
ложенные модели, следует отметить, что экспериментальные данные
согласуются с распределениями длительностей активного состояния,
близкими к геометрическому. Однако интуитивно можно предполо-
жить, что абонент чаще всего использует две модели: первая соответст-
вует случаю, когда абонент, который управляет, ведет диалог; вторая
модель соответствует характеру ведения диалога, когда абонент отвеча-
ет, реагируя на информацию, полученную от другого абонента.
Любая из предложенных моделей может быть расширена включением
двух отдельных состояний для активного абонента, когда, например А го-
ворит, В молчит. Модель с двумя состояниями, приведенная на рис. 7.8,
может быть использована как основа описания каждого из таких особых
состояний. В одном из таких состояний вероятности переходов должны от-
ражать тенденцию продолжения активного состояния в следующем кадре.
В другом - вероятности остаться в активном состоянии значительно мень-
ше. Таким образом, говорящий абонент может быть в одном из двух со-
стояний - с длинными сериями пакетов или с короткими.
7.2. Марковские модели речевого монолога
Рассмотрим процесс получения марковских моделей речевых сигналов
на примере речевого монолога.
Для моделирования монолога речи нужно определить возможные со-
стояния и вероятности переходов между ними. Сопоставим возможные со-
стояния речи с состояниями дискретной однородной цепи Маркова. Для
данной цепи составим граф и по нему определим матрицу переходных ве-
145
12. Марковские модели речевого монолога
роятностей. Проанализируем цепи Маркова, моделирующие монолог речи
с двумя, тремя, четырьмя, пятью и шестью состояниями. Для двух - пяти-
элементных цепей Маркова дается лишь качественный анализ; для случая
цепи Маркова, моделирующей монолог речи с шестью состояниями, при-
водится и количественный анализ, для чего взяты определенные вектор на-
чальных вероятностей и матрица переходных вероятностей. На основе этих
данных можно рассчитать вектор финальных вероятностей.
Модель монолога речи с двумя состояниями. Обозначим гово-
рящего человека как А.
Рю
Poi
Рис. 7.10. Ориентированный граф
модели с двумя состояниями
будет такой:
Теперь определим возможные со-
стояния цепи Маркова, моделирующей
монолог этого человека двумя состоя-
ниями: 1 - А говорит; 0 - А молчит (граф
цепи Маркова показан на рис. 7.10).
В этом случае вектор начальных
вероятностей будет иметь вид ро(л?о; Р\\
а матрица переходных вероятностей
(7.1)
Модель монолога речи с тремя состояниями. Для этого случая граф
цепи Маркова будет иметь вид (рис. 7.11). Определим три состояния моноло-
га речи: 1 - А говорит (вокал); 2 - А говорит (не вокал); 0 - А молчит.
Рис. 7.11. Ориентированный граф цепи Маркова
для модели с тремя состояниями
Вектор начальных вероятностей и матрица переходных вероятно-
стей соответственно будут р0(р0, Р\, Pi) и
Роо
|рУ| = Рю
<Рго
Poi
Ри
Р1\
Poz'
Pl 2
Р22 >
(7-2)
146
Глава 7. Примеры разработки марковских моделей
Модель монолога речи с четырьмя состояниями. На основе экспе-
риментальных данных можно определить четыре состояния монолога речи:
О - А делает короткую паузу (например, между словами); 1 - А делает
длинную паузу (молчит); 2 - А говорит - вокал; 3 - А говорит - не вокал
(граф цепи Маркова показан на рис. 7.12).
Рис. 7.12. Ориентированный граф модели с четырьмя состояниями
В этом случае вектор начальных вероятностей и матрица переход-
ных вероятностей будут иметь вид р0(р0з Pi, Pi, Рз)
^Роо
О
Р20
<Рзо
О
Ри
Р21
Р31
Р02
Р12
Р22
Р32
Роз
Р13
Р23
Рзз
(7.3)
Как видно из графа и матрицы, некоторые переходные вероятности
равны нулю. Это определяется смысловым содержанием моделируемого
объекта, в данном случае - монолога речи. В рассматриваемой модели не
имеет смысл случай, когда человек делает короткую паузу, а потом делает
длинную паузу, - вероятность такого перехода должна быть равна нулю.
Модель монолога речи с пятью состояниями. Можно опреде-
лить и пять состояний монолога речи: 0 - А молчит ; 1 - А говорит -
вокал; 2 - А говорит - не вокал; 3 - А делает паузу на участке вокала;
4 - А делает паузу на участке не вокала.
Для этого случая граф цепи Маркова показан на рис. 7.13 (в целях эко-
номии места подписи вероятностей переходов не показаны, они очевидны).
В этом случае вектор начальных вероятностей и матрица переход-
ных вероятностей будут следующими: р0(р0, Р\, Pi, Рз, Рл),
Роо
Pl О
P1Q
Рзо
<Р40
Poi
А1
Р2|
Рз\
Р4\
Ро2
Р\2
Р12
Р32
Р42
Роз
Аз
Р13
Рзз
Раз
Р14
Р24
Рзл
Р44 )
(7.4)
147
7.2. Марковские модели речевого монолога
Видно, что в данной марковской цепи присутствуют все переходные
вероятности, т.е. возможен переход из одного состояния в любое другое.
Рис. 7.13. Ориентированный граф модели с пятью состояниями
Модель монолога речи с шестью состояниями. Эта модель луч-
ше всего отражает монолог речи, поэтому именно для этой модели бу-
дет сделан математический расчет, основанный на экспериментальных
данных. Данные состояния и их расположение привязаны к эксперимен-
тально полученной таблице переходных вероятностей.
Определим для данной модели шесть состояний: 0 - А делает ко-
роткую паузу; 1 - А делает длинную паузу; 2 - А говорит - вокал; 3 - А
делает паузу на участке вокала; 4 - А говорит - не вокал; 5 - делает
паузу на участке не вокала.
Для этого случая граф цепи Маркова будет иметь вид, показанный
на рис. 7.14 (в целях экономии места подписи вероятностей переходов
не показаны, они очевидны).
Рис. 7.14. Ориентированный граф модели с шестью состояниями
148
Глава 7. Примеры разработки марковских моделей
Расчет вектора финальных вероятностей, В качестве примера
рассчитаем вектор финальных вероятностей для цепи Маркова с задан-
ной матрицей переходных вероятностей. Пусть вектор начальных веро-
ятностей: ро(0,16666; 0,16666; 0,16666; 0,16666; 0,16666; 0,1667), а мат-
рица переходных вероятностей, определенная на основании результатов
статистической обработки, как это показано в [10], имеет вид
'0,99758 0,00000 0,00006 0,00012 0,00027 0,00197"
0,00000 0,99955 0,00001 0,00002 0,00005 0,00037
0,00000 0,00000 0,95897 0,04068 0,00029 0,00006
0,00014 0,00004 0,71356 0,28423 0,00072 0,00131
0,00055 0,00014 0,00232 0,00012 0,73209 0,26478
^0,00170 0,00042 0,00024 0,00022 0,18941 0,80801,
(7.5)
Найдем вектор финальных вероятностей экспериментальным пу-
тем, последовательно находя векторы рь р2, ..., Ра до тех пор, пока не
будет выполнено условие - /ty-iyl < s,j = 1, 2, 3, 4, 5, 6, где ру -j-я
координата вектора переходных вероятностей рЛ Таким образом, нахо-
дим векторы переходных вероятностей путем умножения предыдущего
вектора на матрицу переходных вероятностей до тех пор, пока все коор-
динаты последующего вектора не будут отличаться от соответствую-
щих координат предыдущего на величину е. Расчеты проведем с точно-
стью до шестого знака после запятой (табл. 7.1).
Таблица 7.1. Зависимость требуемого числа шагов от точности вычисления
Точность е Требуемое число шагов к Условие обеспечения требуемой точности Вектор р2
10'3 6 Равенство первых двух знаков после за- пятой всех координат векторов р* и рм (0,166655,0,16681 ГД 316813; 0,01813;0,138705 0,192888)
10й 758 Равенство первых трех знаков (0,133363Д169754Д44649; 0,025451Д0936346Д131308)
10'5 3257 Равенство первых четырех знаков (0,0981199,0,146113;0,535763; 0,0305165Д0789438Д110543)
10‘6 7718 Равенство первых пяти знаков (0,096826;0,131967;0,55146; 0,0314084Д0784758Д109863)
10’7 12763 Равенство первых шести знаков (0,0968474;0,129994; 0,553281; 0,0315119Д078488Д109878)
10’8 17804 Равенство первых семи знаков (0,09685;0,129797;0,553462; 0,0315222Д0784894Д109879)
Ю'9 22845 Равенство первых восьми знаков (0,0968503,0,129777;0,55348; 0,0315232;0,0784895;0,10988)
Ю’10 27886 Равенство первых девяти знаков (0,0968503;0,129775;0,553482; 0,0315233;0,0784895;0,10988)
149
7.3. Марковские модели цифровых последовательностей на выходе кодека G.711
Рассмотрение полученных результатов показывает, что векторы pf
сходятся к некоторому предельному вектору.
Проверим экспериментально полученные данные, найдя теорети-
ческий вектор финальных вероятностей П(р0, р\, рг, Ръ, Ра, Ps)- Восполь-
зовавшись формулой полной вероятности, определим его как решение
системы уравнений, которая в данном случае принимает вид
pQ - О,99758/?о + 0 •/?j + 0- р2 + 0,00014/?3 + 0,00055/?4 + 0,00170/?5
/?!=()• р0 +0,99955/?! + 0-/?2 + 0,00004/?3 + 0,00014/?4 +0,00042р5
/?2 =0,00006/?0 +0,00001/?! +0,95 897/?2 + 0,71356/?3 +0,00232/?4 +0,00024/?5 (7.6)
/?3 = 0,00012/?0 +0,00002/?! + 0,04068/?2 +0,28423/?3 + 0,00012/?4 +0,00022/?5
/?4 = 0,00027/?0 + 0,00005/?! +0,00029/?2 +0,00072/?3 +0,73209/?4 +0,18941/?5
.Р0 + Р1 + Р2+Л + А+Р5 =1-
Уравнение для р5 было исключено из системы как избыточное, по-
скольку для решения системы требуется только 6 уравнений.
•Преобразуем систему уравнений (7.6) к виду
-0,00242/?0 + 0- pt + 0- р2 + 0,00014/?3 + 0,00055/>4 + 0,00170/?, = 0
0 • /?0 - 0,00045pt + 0 • р2 + 0,00004р2 + 0,00014 р4 + 0,00042/?, = 0
0,00006 р0 + 0,00001pi - 0,04103/?2 + 0,71356р3 + 0,00232/?4 + 0,00024р5 = 0
0,00012р0 + 0,00002Pi + 0,04068/?2 - 0,71577/?3 + 0,00012рА + 0,00022р5 = 0
0,00027р0 +0,00005/?, + 0,00029р2 + 0,00072/?3 - 0,26791/?4 + 0,18941/?, =0
чРо + Pi + Рг + Рз + Ра + Рз = 1 •
Решив эту систему уравнешш, найдем вектор финальных вероятностей:
П = (0,0968503; 0,1297753; 0,5534821; 0,0315233; 0,0784895; 0,1098795).
Сравнивая численные значения компонент вектора финальных веро-
ятностей с полученными в результате вычислений (см. табл. 7.1) видим, что
полученный теоретически вектор финальных вероятностей хорошо согла-
суется с аналогичным вектором, полученным экспериментально. Хорошее
совпадение результатов подтверждает верность проведенных расчетов.
Таким образом, наибольшая точность при создании марковских
моделей достигается оценкой численных значений матрицы переходных
вероятностей. Ниже рассмотрим методику оценки элементов матрицы
переходных вероятностей речевого диалога на основании статистиче-
ской обработки экспериментальных результатов.
7.3. Марковские модели цифровых последовательностей
на выходе кодека G.711
Рассмотрим создание марковской модели на примере реализации рече-
вого сигнала, наблюдаемого на выходе кодека G.711 в виде цифровой
последовательности со скоростью 64 Кбит/с.
Длительность записи речевого диалога составила 59 мин 11с 232 мс,
что эквивалентно 28 409 856 выборок при частоте дискретизации 8 КГц и
150
л-И
_____________________Глава 7. Примеры разработки марковских моделей
8-битном квантовании. Для того чтобы «прочитать» полученный wav-файл
на предмет извлечения отдельных выборок из него, была написана специ-
альная программа, при помощи которой был получен профиль записанного
речевого процесса, отражающий десятичный формат каждой из выборок
(рис. 7.15).
250
200
150
100
50
0
20 40 60 ВО 100 1 20 140 1 60 1 ВО
Рис. 7.15. Часть профиля записанного речевого процесса
Перед тем как перейти к непосредственному определению парамет-
ров марковской модели, рассмотрим вопрос разделения (сегментации) на-
блюдаемой реализации речевого сигнала на периоды активности и пауз.
Сегментация. Под сегментацией подразумевается объективное
разделение речевого сообщения на единицы, соотносимые с элементами
принятого алфавита. В качестве основной цели сегментации преследу-
ется адекватность расчленения амплитудно-временного представления
на отрезки. Для оценки достижимости указанной цели сформулируем
задачу сегментации в рамках идеологии принятого определения. Рас-
смотрим некоторые подходы к решению этой задачи.
Амплитудный метод. При этом методе речевой сигнал из N от-
счетов разбивается на т отрезков по п отсчетов в каждом. В качестве
примера рассмотрим случай, когда число наблюдаемых отсчетов N =
= 10000, по п= 300 отсчетов в каждом отрезке. Для каждого из т =32 от-
резков вычисляется величина
299
Л=0
Здесь / - номер отрезка (0 < i < 32); X,* - значение амплитуды рече-
вого сигнала на £-ом отсчете z-го отрезка.
Величины Xjk принимают целочисленные значения от 1 до 256, так
что под знаком суммы стоят отклонения от средней линии. Результи-
рующее значение р вычисляется как среднее величин р,\
Ро +Р1+-+Р32
р 33
Таким образом, речевой сигнал разбивается на участки, состоящие
из отрезков, для которых pt < р, и участки, состоящие из отрезков, для
которых pi > р. Границы между ними принимаются за искомые границы
сегментации.
151
7.3. Марковские модели цифровых последовательностей на выходе кодека G.711
Данный метод с высокой надежностью позволяет выделить участки
речи отвечающие звукам «с», «ш», «щ», «ц», «ч», «ф», «х», «б», «г», «д»,
«п», «к», «т», и выделять также другие согласные, особенно при отсутствии
в слове вышеперечисленных звуков. Этот простой метод может с успехом
служить целям предварительной сегментации речевого сигнала.
Метод кодовой книги. Как и в предыдущем методе, разобьем ре-
чевой сигнал на отрезки по 300 отсчетов. Для каждого из отрезков раз-
биения вычислим 29-мерный вектор признаков, использующий относи-
тельные частоты длин полных колебаний. В результате получим множе-
ство векторов а0, аь ..., а32.
Выберем некоторое число к, принадлежащее интервалу' 2 < к < 31,
и построим два вектора:
Ь,=
с а* + ... + а32
к — \ ’ к 32 —(Ar —1)
Введем в рассмотрение функцию
фМ=^а'~ь‘1+]Е1а'~с*1 ’ 2-/:-32 •
/=1 !=к
Если наименьшее значение этой функции достигается при к = к0,
то правый конец отрезка с номером к0 принимается за границу сегмента.
Отрезки по одну сторону найденной границы не учитываются, а к ос-
тавшейся части речевого сигнала применяется вышеописанная проце-
дура. Этот метод позволяет весьма надежно разделять две соседние
гласные фонемы или гласную и соседствующую с ней согласную.
Спектральный метод. Речевое сообщение, представленное в виде
отсчетов xif i=0,N, разбивается на перекрывающиеся фрагменты
(обычно объемом 256 отсчетов) с шагом 5. В результате формируется
множество векторов v = {vA.}^0, где Л/ = (N - 256)/S. Для каждого векто-
ра вычисляются спектральные коэффициенты дискретного преобразо-
вания Фурье, которые могут быть определены по формуле
__ 1 . Znlni
' кт ~ 256 2иеХр|ч 7 256 J
На следующем шаге формируется множество векторов, представ-
ляющих собой мгновенные логарифмические спектральные срезы рече-
вого сообщения: Э={ЭА}^0,где 3* = (log|ArA.0|,...,log|Xjt255|).
В полученном множестве векторов выделяются смежные группы, со-
стоящие из D векторов. Для каждой из групп определяется среднее значе-
ние логарифмического спектра мощности в соответствии с формулой
1
и 7=0
где /? = 0,Л/ - D .
152
____________________Глава 7. Примеры разработки марковских моделей
Затем вводится функция однородности речевого сообщения, опре-
деляемая соотношением
^g = exp(-||9g-Sgbl||),
где g - О, М - D -1.
Полученные значения функции сглаживаются методом скользяще-
го среднего, и выполняется поиск локальных минимумов функции од-
нородности, соответствующих границам однородных участков. Найден-
ные границы принимаются за границы между фонемами.
Алгоритм разделения реализации фразы на речь и паузы на основе
кратковременной энергии и среднего числа переходов через ноль. В качест-
ве эталонной берется реализация фразы, которая не содержит кадров с
паузами и поделена на слова. По этой причине алгоритм применяется только
к поступающей новой реализации фразы А*0,..., AXz),..., где Л - длина но-
вой реализации фразы. Требуется отделить кадры, содержащие речь, от кад-
ров, содержащих паузу. Звонкие звуки речи, особенно гласные, имеют высо-
ты уровень кратковременной энерпш. По этому параметру они легко отде-
ляются от пауз. Глухие звуки имеют низкий уровень кратковременной энер-
гии. Однако большая часть их энерпш лежит в области высоких частот, что
приводит к большому числу переходов интенсивности сигнала через нуль.
Этот факт используется для отделения глухих звуков речи от пауз. Таким об-
разом, совместное использование контуров кратковременной энерпш
1 При 5 > 0 ,
-1 при 5<0 ,
и интенсивности числа пересечений через ноль
z =TS|sign(5*)-sign(5*-i)|, где signU) =
k=2
позволяет точнее отделить речь от пауз.
Поскольку предполагается, что первые 10 кадров не содержат речевого
сигнала, то по этому участку, для определения статистических характеристик
шума, вычисляются среднее значение и дисперсия каждой из величин
По найденным статистическим характеристикам шума и макси-
мальным на реализации фразы значениям Et, Zt вычисляются пороги ТЕ
для кратковременной энергии сигнала и Tz для интенсивности числа пе-
ресечений через ноль. Для вычисления указанных порогов эксперимен-
тально выбраны следующие формулы:
тЕ = м (ел о)+3^d(e,w) +— max Е. <— maxE.,
L v v ' 400 25 is»sl
T. = jV/(Z,10) + 3Jd(Z,10) +—maxZ, < — maxZ,,
где М(Р,*) = -£р,; Г>(Р,«) = -Ц-£(Р,-Л/(Р,и))2 •
H /=1 n ~ 1 /=1
153
7.3. Марковские модели цифровых последовательностей на выходе кодека G.711
Каждому кадру ставится в соответствие двоичный признак Ьь рав-
ный 1, если кадр содержит речь, и 0 в противном случае. Сначала отмечают
единицами кадры, на которых кратковременная энергия Et> ТЕ, и нулями -
остальные кадры. Полученные отметки сглаживают медианным фильтром
с окном шириной в 2h + 1 кадров (например, h = 3). Признаки bt могут при-
нимать всего два значения. Поэтому фильтрация сводится к тому, что по-
следовательно для t=h + 1,..., L-h значение bt заменяется на единицу, если
^t-hb,- >h .В противном случае значение bt заменяется на ноль. В резуль-
тате выделяются непрерывные участки, содержащие речь. Далее каждьш
такой участок пытаются расширить. Пусть, например, участок начинается с
кадра и заканчивается на кадре Перемещаются влево от
(вправо от и сравнивают число нулей интенсивности Zt с порогом Tz.
Это перемещение не должно превышать 20 кадров слева от А<М) (справа от
Если Zt превысило порог в три и более раз, то начало речевого участ-
ка переносится туда, где Zt впервые превышает порог. В противном случае
началом участка считается кадр Аналогично поступают и с УЛ2'. Если
два участка перекрываются, то их объединяют в один. Таким образом,
окончательно выделяются непрерывные участки, содержащие речь. Такие
участки будем называть реализациями слов. Приведенный алгоритм позво-
ляет перейти от сравнения реализаций фраз к сравнению реализаций слов.
Пороговый метод. Поскольку информация, полученная в резуль-
тате изучения активности и пауз в речевом процессе, должна быть пре-
образована к двоичному виду, то можно использовать простейший по-
роговый метод сегментации. Если значение выборки превышает шумо-
вой порог, то выборка приравнивается к 1, в противном случае - к 0.
Для удобства профиль речевого процесса был преобразован к виду
Яг] = (хИ-128)2. (7.7)
Из речевого сигнала вычитается уровень 128, так как при 8-битном
ИКМ этим уровнем кодируется «идеальная» тишина. Зададимся, что для
шума выборки пауз находятся в диапазоне ±5 от этого уровня, поэтому
после преобразования (7.7) пороговое значение для определения тиши-
ны было выбрано равным 30, т.е.
г-. [0, если у[/1<30,
Г1 (7.8)
(1, если у[/]>30.
Пример использования порогового метода сегментации. В резуль-
тате преобразований (7.7) и (7.8) получаем двоичный файл, который был
подвергнут обработке. На рис. 7.16 показана структура полученного двоич-
ного файла с указанием интервалов активностей и пауз.
0000011000111111000000...ц 0_0_0. . .
Л[/] Уа[/] Л(2] /,[2] Л[3] ЛИ у„[и]
Рис. 7.16. Структура двоичного файла, полученного в результате обработки ис-
ходных данных
154
Глава 7. Примеры разработки марковских моделей
а]
В частности, сформированный файл использовался для получения
длительностей периодов активностей и пауз. Полученные в результате
обработки выборки показаны на рис.7.17 и 7.18.
3 000
2 500
2000
1 500
1 000
500
О
О 50000 100000 150000 200000 250000
Рис. 7.17. Профиль выборки для интервалов «активности»:
а - в натуральную величину; б - увеличенный вариант
ЛИ
140 000
120 000
100 000
80 000
60 000
40 000
20 000
О 50000 100000 150000 200 000 250 000
а)
Рис. 7.18. Профиль выборки для длительностей «пауз»:
а - в натуральную величину; б - увеличенный вариант
155
7,3. Марковские модели цифровых последовательностей на выходе кодека G.711
Гистограммы приведенных выше выборок представлены на рис. 7.19,
7.20. На гистограммах интервал столбца равен 1; N - число попаданий в
интервал; Ny - общее число значений процесса; к - индекс интервала.
Рис. 7.19. Гистограмма выборок для длительностей интервалов «активности»
N/Nv
0,16
0,14
0.12
0.1
0.08
0,06
0,04
0,02
5 10 15 20 25 30 35 40 45 50
Рис. 7.20. Гистограмма выборок для длительностей интервалов «пауз»
Разработка марковских моделей для описания эксперимен-
тальных данных. Приведем результаты подбора марковской модели к
описанным выше реально измеренным данным.
Используя программные средства, разделим имеющийся файл исход-
ных данных на два файла, в каждом из которых будут содержаться отдель-
но длительности ON- и OFF-периодов. Под ON-периодами будем понимать
переменные уа[л], под OFF-периодами -;и„[и]. Соответствующие дополни-
тельные функции распределений (ДФР) приведены на рис. 7.21 и 7.22.
/г*
Рис. 7.21. ДФР Г* экспериментальных данных для ON-периодов
156
Глава 7. Примеры разработки марковских моделей
Проведем аппроксимацию ДФР реальных процессов, используя
марковскую модель с матрицей 8x8. Для аппроксимации будем исполь-
зовать пакет прикладных программ MathCad.
Исследования процессов показывают, что самой важной частью
распределения является его хвостовая часть. Поэтому корректное опи-
сание хвостовой части ставится первостепенной задачей при подборе
марковской матрицы. Для аппроксимации хвостовой части распределе-
ния воспользуемся формулой
/ф)=Р(Ил]>/0=Ле-'\ (7.9)
где А, В - коэффициенты, подбираемые методом последовательного
приближения до наилучшего согласования с конечным значением ДФР.
После проведения этой процедуры для дополнительного распреде-
ления ON-периодов были выбраны следующие значения этих парамет-
ров: А = 0,0002; В = 0,001.
/7*
Рис. 7.22. ДФР Г’ экспериментальных данных для OFF-периодов
На рис. 7.23 показаны подобранная по (7.9) хвостовая часть рас-
пределения (сплошная линия) и исходное распределение для ON-
периодов (серый фон).
Рис. 7.23. Исходная ДФР Г* и подобранная к хвостовой части для ON-периодов
аппроксимация ДФР F*
157
13. Марковские модели цифровых последовательностей на выходе кодека G.711
После подбора функции, описывающей хвостовую часть ДФР, вы-
чтем ее из исходного дополнительного распределения и опишем полу-
ченную разность суммой экспонент:
F*(k) = А^ + . (7.10)
График функции (7.10) (сплошная линия), подобранной к разности
выражения (7.9) с соответствующими коэффициентами и исходной ДФР
F (серый фон), показан на рис.7.24.
Рис. 7.24. Подбор аппроксимирующей функции к разности между исходной
ДФР и (7.9)
В результате были получены следующие коэффициенты для выра-
жения (7.10):
4 = 1,0822, aj = 0,1574,
А, = 0,0138, a2 = 0,0089145,
А3 = 0,000020845, а3 = 0,00076031.
В соответствии с полученными коэффициентами выражение, ап-
проксимирующее исходное дополнительное распределение длительно-
стей ON-периодов, можно записать в виде
Fa'(/c)= 1,О822е"01574* + 0,0 1 38е“0 0089145 * +
+ 0,000020845е~°’0007603'к + 0,0002с-0’001*. (7.11)
После нормировки перепишем выражение (7.11) следующим образом:
F*{k)= 0,98721е'01574 к + 0,012589е'0’0089145 к +
+ 0,00001 Qe-0’00076031 к + 0,000182е"0 001Л. (7.12)
Аналогичную аппроксимацию проведем для ДФР длительностей
OFF-периодов с помощью выражения вида
= B,e-pl* + B2e"₽1* + В^'к . (7.13)
158
________________Глава 7. Примеры разработки марковских моделей
Коэффициенты, входящие в выражение (7.13), имеют вид
=0,7036, aj =0,1545,
В2 =0,3078, ос2 =0,0468,
В3 = 0,0263, ос3 = 0,002018.
В соответствии с полученными коэффициентами запишем выра-
жение, аппроксимирующее исходное дополнительное распределение
длительностей OFF-периодов:
F*(k) = 0,7036е’°’1545* + О,ЗО78е~0’0468* +
+ 0,0263е'0,002018 /: +О,006е“°’00009х' (7.14)
или после нормировки
Fn*(/c) = 0,67417e~°’1545/: +0,295074еЧ)’°4б8/; +
+ О,О25ОО6е-0’002018* + 0,005750е~°’ОО0()9\ (7.15)
После получения аппроксимирующих выражений дополнительных
распределений длительностей ON- и OFF-периодов составим матрицу
переходных вероятностей
0 0 0 (l-e^fe 6-Х d2 (1 — е**1) б-е*} ^4
0 еа’ 0 0 (1-e“H В2 (1- еа’] (1- е“’] 1о4
0 0 е“3 0 (1-еа’к (1-еаз 1 &2 (1 - е“3 1 (1-е“3 1о4
г = 0 0 0 с“4 (1-е^Д (l-eaJ ®2 (l-e“4J 1В3 (l-ettJ 1о4
(1 - eft Иг (1 - ер‘) Ах 6-Х к еЬ 0 0 0
П - e₽J к (1-Х ( 2 (1-Х 1 “ е₽2 к 0 е* 0 0
(1 - U (l-e* и2 (l-eM ^3 (1 - еРз к 0 0 еРз 0
Д1-с₽4^ (i-X V -е₽4) (1-ер< 0 0 0 ер4 /
Граф этой матрицы показан на рис. 7.25.
Рис. 7.25. Граф марковской модели
Подставляя значения соответствующих коэффициентов, получим
А1 А2 АЗ А4 ш П2 ПЗ П4
А1 (0,854362 0 0 0 0,098185 0,042974 0,003642 0,000837)
А2 0 0,991125 0 0 0,005983 0,002619 0,000222 0,000051
АЗ 0 0 0,99924 0 0,000513 0,000224 0,000019 0,000004
А4 0 0 0 0,999 0,000674 0,000295 0,000025 0,000006
Ш 0,141326 0,001802 0,000003 0,000026 0,856843 0 0 0
П2 0,045137 0,000576 0.000000 0,000008 0 0,954278 0 0
ПЗ 0,00199 0,000025 0.000000 0.000000 0 0 0,997984 0
П4 к0,000089 0,000001 0.000000 0.000000 0 0 0 0,99991 у
159
7.3. Марковские модели цифровых последовательностей на выходе кодека G.711
Исходя из записанной матрицы, можно вычислить матриц}’ фи-
нальных вероятностей, которая будет выглядеть следующим образом:
'0,070748'
0,014791
0,000194
0,001817
П =
0,049150
0,067357
0,129528
ч0,666415? .
После получения матрицы переходных вероятностей смоделируем с
ее помощью реализацию искусственного речевого потока. Алгоритм моде-
лирования искусственного процесса с использованием марковской матри-
цы показан на рис. 7.26.
Рис. 7.26. Схема алгоритма моделирования марковского процесса на основе
матрицы вероятностей переходов
160
Глава 7. Примеры разработки марковских моделей
Рассмотрим основные этапы алгоритма моделирования марковского
процесса, заданного матрицей переходных вероятностей и вектором на-
чальных вероятностей.
Шаг 1. Начало выполнения программы (описание используемых пере-
менных, функций, процедур и модулей).
Шаг 2. Ввод в программу двухмерного массива матрицы переходных ве-
роятностей. В разработанной программе такая матрица задавалась
в виде массива констант в разделе описаний. Данный массив был
назван markov.
Шаг 3. Задается состояние, с которого начинается моделирование. Так как
была выбрана модель с 8 состояниями (рис. 7.25), то переменная
state может принимать целые значения на интервале [1; 8]. Также
на этом этапе алгоритма обнуляем аккумулирующие переменные
summa_on и summa_off, которые отражают длительности ON- и
OFF-периодов соответственно.
Шаг 4. Начинаем цикл с параметром /. Число повторений цикла равняется
числу переходов в моделируемой системе.
Шаг 5. Воспользовавшись встроенным генератором псевдослучайной
равномерно распределенной последовательности, генерируем слу-
чайное значение на интервале [0; 1). Присваиваем это значение пе-
ременной md. Фактически в момент генерирования переменной
md система переходит в следующее состояние. В какое именно
состояние она попала, будет определено дальнейшими действиями
алгоритма. Обнуляем переменную summa.
Шаг 6. Начинаем цикл с параметром к. Число повторений цикла равно чис-
лу состояний моделируемой системы. В нашем случае число повто-
рений равно 8. Этот цикл используется для того, чтобы выяснить, в
какое из состояний система перешла в данный момент времени.
Шаг 7. Проводится проверка, попало ли значение md в k-Q состояние мар-
ковской цепи. При этом задействованы переменные: summa - ак-
кумулирует в себе вероятность всех состояний до £-го;
markov[state, £] - двухмерный массив, в котором записана матрица
переходных вероятностей. Если md попадает в интервал вероятно-
стей, соответствующий £-му состоянию, тогда переходим к блоку
8, в противном случае - к блоку 9.
Шаг 8. Выполняется проверка - в каком из состояний находится процесс.
Если в активном, тогда переходим к блоку 10, в пассивном - к
блоку 11.
Шаг 9. Переменная summa увеличивается на значение вероятности пре-
бывания в состоянии к. Далее переходят к следующей итерации
цикла в блоке 6.
Шаг 10. Осуществляется проверка, было ли предыдущее состояние матри-
цы пассивным. Если было, то переходим к блоку 12. В противном
случае переходим к блоку 16.
6—3834
161
7.3. Марковские модели цифровых последовательностей на выходе кодека G.711
Шаг 11. Осуществляется проверка, было ли предыдущее состояние матри-
цы активным. Если было, то переходим к блоку 13. В противном
случае переходим к блоку / 7.
Шаг 12.Переход в блок 12 означает окончание OFF-периода. Поэтому в
файл или на печать выводится значение переменной summa_off.
Шаг 13.Переход в блок 13 означает окончание ON-периода. Поэтому в
файл или на печать выводится значение переменной summa_on.
Шаг 14. Так как OFF-период закончился, обнуляем переменную
summa_off, чтобы начать записывать туда информацию нового
OFF-периода, когда процесс окажется в пассивном состоянии.
Шаг 15.Так как ON-период закончился, обнуляем переменную summa on,
чтобы начать записывать туда информацию нового ON-периода,
когда процесс окажется в активном состоянии.
Шаг 16.Переход в блок 16 означает продолжение или начало нового ON-
периода, поэтому инкрементируем переменную summa_on и при-
сваиваем переменной state значение параметра цикла к.
Шаг 17.Переход в блок 17 означает продолжение или начало нового OFF-
периода, поэтому инкрементируем переменную summa_off и при-
сваиваем переменной state значение параметра цикла к.
Шаг 18.При попадании в блок 18 был осуществлен переход системы в
очередное состояние, поэтому обращаются к следующей итерации
цикла с параметром I.
Шаг 19. Завершение программы.
Профили выборок длительностей ON- и OFF-периодов, сгенериро-
ванных в соответствии с приведенной выше матрицей переходных веро-
ятностей, показаны на рис. 7.27, 7.28.
3 500
3 000
2 500
2 000
1 500
1 000
500
0
0 50 000 100 000 1 50 000 200 000 250 000 300 000
Рис. 7.27. Длительность ON-периодов
140 000
120 000
100 000
80 000
60 000
40 000
20 000
О
0 50 000 1 00 000 1 50 000 200 000 250D00 300 000
Рис. 7.28. Длительность OFF-периодов
162
Глава 7. Примеры разработки марковских моделей
Оценка корреляционных свойств. Проведем оценку корреляционных
свойств реальных данных и данных, полученных с использованием матрицы
переходных вероятностей. Алгоритм этой оценки приведен на рис. 7.29.
Рис. 7.29. Схема алгоритма оценки корреляционных свойств данных
163
7.3. Марковские модели цифровых последовательностей на выходе кодека G.711
Шаг 1. Начало выполнения программы (описание используемых пере-
менных, функций, процедур и модулей).
Шаг 2. Осуществляется ввод последовательности, для которой будет
оцениваться корреляционная функция.
Шаг 3. Начинается цикл с параметром /. Число итераций этого цикла
определяется максимальной задержкой, для которой требуется
оценить корреляционную функцию. После выполнения задан-
ного числа итерации переходим к блоку 22.
Ш а г 4. Присваиваем логической переменной con (определяет, ON-
или OFF-период присутствует в процессе при данной задерж-
ке) значение False, подразумевая, что последовательность на-
чинается с ON-периода. Обнуляем num (переменная, в кото-
рой будет суммироваться корреляция).
Шаг 5. Открываем цикл по 7 до п (общее число ON- и OFF-периодов в
исследуемых данных). По окончании заданного числа итера-
ций переходим к блоку 21.
Шаг 6. Переписываем значение параметра цикла по / в служебную
переменную /7.
Шаг 7. Выполняем проверку - какой период процесса наблюдается
для данной задержки. Если ON-период, тогда переходим в
блок 9, если OFF-периода - в блок 8.
Шаг 8. В переменную end_ (определяет конечное значение для теку-
щего периода) записывается z-e значение из массива z off (од-
номерный массив длительностей OFF-периодов), а перемен-
ные sample (значение выборки после сдвига) и sample_ (зна-
чение выборки, от которой происходит сдвиг) обнуляются.
Шаг 9. В переменную end_ записывается z-e значение из массива z_on
(одномерный массив длительностей ON-периодов), а пере-
менные sample и sample_ приравниваются 1.
Шаг 10.Определяется логическая переменная coni (показывает, в ка-
ком периоде находится процесс при сдвиге).
Шаг 11. Открывается цикл по J до значения end_. По завершении числа
заданных итераций переходим к блоку 19.
Шаг 12.Открывается цикл с предусловием, что end_ - j < t. Пока это
условие имеет значение True, выполняем последовательно
блоки 13, 14, 15 или 16. Если это условие примет значение
False, переходим к блоку 17.
Шаг 13. Инкрементируется служебная переменная И.
Шаг 14.Проверяется, какой период определен в переменной coni. Ес-
ли в coni записан OFF-период, то переходим к блоку 16, если
ON-период - к блоку 15.
Шаг 15.Переменная end_ увеличивается на длину следующего OFF-
периода. Кроме того, инвертируется переменная con 1, а пере-
менной sample присваивается значение 1.
164
Глава 7. Примеры разработки марковских моделей
Шаг 16.Переменная end_ увеличивается на длину следующего ON-
периода. Кроме того, инвертируется переменная coni, а пере-
менной sample присваивается значение 1.
Шаг 17.Проверяется условие/ + t <= end_. Если это условие выполняет-
ся, тогда переходим к условию блока 18. В противном случае пе-
реходим к следующей итерации цикла, заданного в блоке II.
Шаг 18.Проверяется условие совпадения той выборки, с которой на-
чинали откладывать задержку, и той, в которую пришли. Сю-
да же добавляется условие sample = 1 или 0, в зависимости от
того, ищем мы корреляционные свойства активных выборок
или пассивных. Если эти оба условия выполняются, перехо-
дим к блоку 19. В противном случае переходим к следующей
итерации цикла, заданного в блоке 11.
Шаг 19.Инкрементируется значение переменной num.
Шаг 20.Инвертируется переменная con и осуществляется переход к
следующей итерации цикла по /, заданного в блоке 5.
Шаг 21. Вывод значения num в виде точки на графике для соответст-
венной задержки либо в текстовый файл. Переход к следую-
щей итерации цикла по Z, заданного в блоке 3.
Шаг 22.Завершение работы программы.
На рис. 7.30 приведены корреляционные функции активных выбо-
рок, полученные для реальных и искусственных данных.
Рис. 7.30. Корреляционные функции активных выборок исследуемых процессов
Полученные результаты позволяют оценить адекватность предложен-
ной марковской модели реальному речевому процессу. Для этого обработаем
исследуемые данные специальной программой, которая разбивает исходные
выборки на интервалы, и в качестве выходной последовательности выдает
число активных выборок на соответствующем интервале. На рис. 7.31 по-
строены ДФР реального процесса и процесса, полученного в результате мо-
делирования ( искусственные данные) для различных длительностей интер-
165
1А. Марковские модели цифровых последовательностей на выходе кодека G.728
валов разбиения. Сравнение характеристик показывает, что реальные данные
обладают ДФР с более «тяжелыми» хвостами, чем искусственные, что, оче-
видно, объясняется недостаточной размерностью марковской модели.
Рис. 7.31. ДФР искусственного и реального процессов для различных длитель-
ностей интервалов разбиения т
7.4. Марковские модели цифровых последовательностей
на выходе кодека G.728
Разработаем марковскую модель речевого потока на выходе кодека G.728,
реализующего алгоритм сжатия речи LD-CELP, в виде матрицы переход-
ных вероятностей. Аналогично вышеизложенному, используя программ-
ные средства, разделим имеющийся файл исходных данных на два файла, в
каждом из которых отдельно будут содержаться длительности ON- и OFF-
периодов в LD-CELP-потоке. Соответствующие дополнительные функции
распределений приведены на рис. 7.31 и 7.32.
Рис. 7.31. ДФР ON-периодов (внутри графика показан хвост ДФР
на большем масштабе)
166
Глава 7. Примеры разработки марковских моделей
Рис. 7.32. ДФР OFF-периодов (внутри графика показан хвост ДФР
на большем масштабе)
Проведем аппроксимацию дополнительных функций распределения
реальных процессов, используя марковскую модель с матрицей 8x8. Для ап-
проксимации будем использовать пакет прикладных программ в среде Math-
Cad. Подобранные дополнительные функции распределения показаны ниже.
Для аппроксимации ДФР длительностей ON/FF-периодов в LD-CELP-
выборках используем такой же механизм, как и для ИКМ-выборок.
На основе полученных коэффициентов запишем выражение, аппрокси-
мирующее исходную ДФР длительностей ON-периодов LD-CELP-выборок:
Га*(£) = 0,95599Ое~0,3708* + 0,041849е~0’0386* + 0,001681е-°’0083869 * +
+ О,ООО48Ое~0’007*.
Выполним такую же аппроксимацию для длительностей OFF-периодов:
Гп*(&)= 0,618832е~°’6293* + 0,3 1 6 О99е~0’2013* + O,O5O324e"°’ol,4Ar +
+ О,О14743е'0’0007*.
После аппроксимации дополнительных распределений длительно-
стей ON- и OFF-периодов составим матрицу переходных вероятностей
(граф которой показан на рис. 7.25) аналогично ИКМ-сигналу. После
подстановки значений соответствующих коэффициентов матрица пере-
ходных вероятностей будет записана так:
А1 А2 АЗ А4 П1 П2 ПЗ П4
А1 '0,690183 0 0 0 0,191725 0,097933 0,015591 0,004568 >
А2 0 0,962136 0 0 0,023432 0,011969 0,001905 0,000558
АЗ 0 0 0,991649 0 0,005168 0,002640 0,000420 0,000123
А4 0 0 0 0,993024 0,004317 0,002205 0,000351 0,000103
П1 0,446481 0,019545 0,000785 0,000224 0,532965 0 0 0
П2 0,174308 0,007630 0.000307 0,000088 0 0,817666 0 0
ПЗ 0,010836 0,000474 0.000019 0.000005 0 0 0,988666 0
П4 0,000669 0,000029 0 000001 0.000001 0 0 0 0,9993 >
167
7 А. Марковские модели цифровых последовательностей на выходе кодека G.728
Исходя из записанной матрицы, можно вычислить матрицу фи-
нальных вероятностей, которая будет выглядеть следующим образом:
'0,093438
0,033462
0,006084
0,002138
0,040124
0,052497
0,134449
ч0,637808,
(7.17)
После того как получена марковская матрица, смоделируем с ее
помощью реализацию искусственного речевого процесса. Алгоритм мо-
делирования искусственного процесса с использованием марковской
матрицы тот же, что и в случае ИКМ.
Профили выборок, сгенерированных в соответствии с приведенной
выше матрицей переходных вероятностей, показаны на рис. 7.33. Как и в
случае ИКМ-выборок, длительности ON-периодов больше походят на реаль-
но измеренные, а длительности OFF-периодов уже не так разительно отли-
чаются от реальных, возможно, в силу эффекта «сглаживания» сильных вы-
бросов при переходе от случая ИКМ к случаю LD-CELP.
0 20 000 40 000 60000 80 00С 100 000 120 000 140 300 1 60 000 180 000
а)
9000
8000
7 000
6 000
S000
4000
3 000
2000
1 000
0
0 20 000 40 000 60 000 80 000 100 000 120 000 140 000 160000 180 000
Л7
б)
Рис. 7.33. Смоделированные длительности:
а - ON-периодов; б - OFF-периодов
168
Глава 7. Примеры разработки марковских моделей
Оценка корреляционных свойств для кодеров LD-CELP. Оце-
ним корреляционные свойства реальных данных, преобразованных к
виду LD-CELP, и данных, полученных с использованием матрицы пере-
ходных вероятностей. Корреляционные функции для активных выборок
приведены на рис. 7.34.
Аналогично ИКМ, для кор-
реляционной функции LD-CELP
выборок наблюдается расхожде-
ние в средней части между реаль-
ными и полученными искусст-
венным путем данными. Корре-
ляционная функция марковского
процесса лишь на начальном и
конечном участках хорошо согла-
суется с корреляционной функци-
ей реально измеренных данных.
Оценка адекватности мар-
ковской модели реальному рече-
Рис. 7.34. Корреляционные функции ак-
тивных выборок исследуемых процессов
вому процессу может быть проведена аналогично вышеизложенному. С этой
целью обработаем исследуемые данные специальной программой, которая
разбивает исходные выборки на интервалы и в качестве выходной последо-
вательности выдает число активных выборок на соответствующем интерва-
ле. На рис. 7.35 построены ДФР искусственного и реального процессов для
различных длительностей интервалов разбиения.
Как и в случае с ИКМ-выборками, видно, что реальные данные имеют
распределение с более тяжелыми хвостами (в пределах выбранного интер-
вала разбиения). Предложенная марковская модель не полностью согласу-
ется с реальными данными в силу значительных ошибок аппроксимации
средней части моделируемого распределения, что подтверждает рис. 7.35.
В средней части распределения также наблюдается существенное расхож-
дение между ДФР реальных и полученных искусственным путем дан-
ных.Это означает, что размерность марковской цепи следует увеличить.
Рис. 7.35. ДФР искусственного и реального процессов для различных длитель-
ностей интервалов разбиения
169
7.5. Марковские модели оценки QoS мультимедийных сервисов реального времени...
7.5. Марковские модели оценки QoS мультимедийных
сервисов реального времени в Интернете
7.5.1. Понятие мультимедийных сервисов реального времени
К мультимедийным приложениям реального времени относятся IP-
телефония, видеоконференции и т.д. Информационное содержание этих
сервисов поступает в сеть в виде пакетов, следующих с определенным
интервалом, и должно быть переправлено к получателю без существен-
ных потерь и с наименьшей задержкой. Более того, эти пакеты должны
иметь наименьшее изменение задержки (джиттер) для предотвращения
потерь из-за того, что пакет поступил слишком поздно.
В таких приложениях аудио/видео сигналы перед передачей оциф-
ровываются. Если на сторону получателя придут все пакеты, то качест-
во сервиса будет идеальным. Но если в пути пакеты будут теряться, то
качество будет снижаться, за исключением тех случаев, когда помогает
система коррекции ошибок. Это система основана на прямом исправлен
нии ошибок (FEC - forward error correction) или повторной передаче.
Потери из-за опоздания в результате джиттера задержки оказывают та-
кое же влияние, как и обычная потеря пакета. Высокая общая задержка
может сильно препятствовать такой связи, как, например, при телефон-
ном звонке. Следовательно, QoS (quality of service) мультимедийных
сессий в основном определяется на базе потерь пакетов и их задержки.
На рис. 7.36 показано, как устройства информационного и канального
кодирования/декодирования, регулировки задержки воспроизведения
совместно воздействуют на типичное мультимедийное приложение ре-
ального времени.
Рис 7.36. Схема взаимодействия мультимедийных сервисов реального времени
В сетях с коммутацией пакетов, таких как Интернет, задержки не
являются постоянными, поскольку возникающие в результате нахожде-
ния пакета в очереди задержки могут со временем изменяться.
170
____________________Глава 7. Примеры разработки марковских моделей
Для управления задержкой воспроизведения разработано большое ко-
личество методик. Суть этих методик сводится к использованию фиксиро-
ванной или случайной задержки воспроизведения, или задержки, определяе-
мой в начале сеанса. Более сложные методики пользуются существованием
речевых периодов (речи) и пауз (тишины) в человеческой речи. Распределе-
ние длин речевых периодов и пауз зависит от установок детектора речевой
активности говорящего, но средняя длина периодов речи и пауз колеблется
обычно около 1 с. Так как восприятие речи человека менее чувствительно к
длине паузы, приложение может выбрать новую задержку воспроизведения в
начале каждого речевого периода, тем самым эффективно уменьшая или уд-
линяя интервалы тишины. Когда джиттер не очень велик, таким способом
можно сохранить низкую задержку воспроизведения.
Поскольку задержка и потери - определяющие факторы качества
мультимедийных сервисов реального времени, исследуем проблемы из-
мерения задержек и потерь, а также различные их решения.
7.5.2. Анализ и моделирование задержек и потерь
Разработка различных моделей задержки и потерь может обеспечить
разработчикам и проектировщикам лучшее понимание сетевой динами-
ки, а также помочь предсказать поведение сети в ближайшем будущем
и, следовательно, повысить качество обслуживания сети.
Сначала рассмотрим причины сетевой задержки и потерь. Сетевая
задержка состоит из задержки распространения, задержки обработки,
задержки передачи и задержки в результате нахождения в очереди, ко-
торая вызвана перегрузкой в сети.
Задержка распространения постоянна (для оптоволокна и медных
проводов равна 5 мкс/км). Задержка передачи линейным образом зави-
сит от размера пакета. Совместно они формируют сетевую задержку,
которая является частью сквозной задержки.
К причинам, вызывающим потери, можно отнести перегрузку (пере-
полнение буферов маршрутизатора), неустойчивость маршрутизации (на-
пример, изменение пути следования пакетов), повреждение канала связи и
линии с потерями (например, модемные линии и беспроводные каналы).
Перегрузка - самая частая причина потерь пакетов. Неустойчивость мар-
шрутизации и линии с потерями реже становятся причиной потерь. Повре-
ждение канала также редко возникает в магистральных сетях.
Пакетные потери плохо аппроксимируются моделью Бернулли (мо-
делью для случайного процесса, который использует испытания по схеме
Бернулли). То есть исход каждого эксперимента (например, потеря пакета
или доставка) должен быть не зависим от предыдущих экспериментов. По-
тери пакетов чаще всего являются показателем ситуации нарастания пере-
грузки. Поэтому в Интернете следующий пакет с высокой долей вероятно-
сти может быть потерян, что приводит к необходимости учета временной
зависимости для потерь.
171
7.5. Марковские модели оценки QoS мультимедийных сервисов реального времени...
Модель Гильберта. Для моделирования временной зависимости в
потерях рекомендуется использование марковской модели. Проанали-
зируем марковскую модель из двух состояний, также известную как мо-
дель Гильберта (рис. 7.37).
В данном случае р - вероятность того, что следующий пакет был поте-
рян при условии, что предыдущий пакет был успешно доставлен; q - вероят-
Рис. 7.37. Модель Гильберта
Воспользовавшись сведениями из
ность, что следующий пакет
доставлен при условии, что
предыдущий пакет был поте-
рян. Как правило, р + q < 1.
Если р + q = 1, то модель
Гильберта сводится к модели
Бернулли.
теории марковских процессов,
можно вычислить вероятности pQ и р\ (вероятность состояния 0 и 1 со-
ответственно). Для модели Гильберта они отражают среднюю вероят-
ность отсутствия и наличия потерь (усреднение по времени).
Процедура вычисления pQ и р\ выглядит следующим образом. В
устойчивом состоянии получаем
Р р ,q ¥Ро ¥ fРо ^=> Ро=о - +<ip\’ Р\=1 - Ро> с7-18)
I Р 1~?ДР| ) (Pi )
тогда р0 = q(p + q), pt = р(р + q).
Можно также вычислить рк (вероятность групповой потери,
имеющей длину к) при условии, что произошла как минимум одна по-
теря. Частота потерь длины к и среди потерянных пакетов, и среди не
потерянных пакетов определяется как
/к = р<?0 - ?)*''•
Суммируя все/i, получаем
^Л = Р</^0
1 1
= p4^YpqTp
Так как вероятности должны сходится к 1, то рк не должна охваты-
вать не потерянные пакеты, т.е.
Л=А = р(1-?Г.
р
(7.19)
Следовательно, длины интервалов потерь в модели Гильберта
имеют геометрическую функцию распределения вероятностей.
Чтобы вычислить р и q из пакетной трассы, мы можем или прове-
рить всю трассу, или, что гораздо проще, использовать статистику рас-
пределения длины потерь. Пусть о, , где z = 1,2, ..., п - 1 обозначает
число интервалов потерь, имеющих длину /, где п - 1 - длина самого
172
Глава 7. Примеры разработки марковских моделей
большого интервала потерь. Пусть oQ обозначает число доставленных
пакетов. Тогда pnq могут быть вычислены по формулам
Обобщенная марковская модель. Наиболее общей для описания
зависимостей между событиями является модель марковской цепи с п
состояниями (/7 - число последних событий, которые необходимо дер-
жать в памяти). Предполагается, что следующее событие зависимо от
последних п событий, поэтому’ для описания последних п бинарных со-
бытий существует 2п возможных состояний. Пусть X обозначает бинар-
ное событие для /-го пакета: 1 для потери и 0 для отсутствия потери. К
параметрам, которые необходимо определить в марковской модели /?-го
порядка, относятся условные вероятности Р(Х|Х-ь Х-2, • .Х-и) для всех
комбинаций из X, Х-i, Х-2, • • • > Х-я-
Например, Р(Х = 0|Х-ь Х-2,Х-з = 001) подразумевает вероятность то-
го. что пакет i не потерян при условии, что пакеты (i - 1)-й, (/ - 2)-й не по-
теряны, а пакет (/ - 3)-й потерян. Для описания прошлых событий необхо-
димо 2" состояний, и существует два выбора при переходе: 0 (следующий
пакет будет доставлен) или 1 (следующий пакет потерян). Следовательно,
нам потребуется измерить 2n+1 параметров, что является очень большим
числом даже для такого небольшого /?, как 20. Как правило, требуется и < 6,
но для некоторых экспериментальных трасс требуется п = 20...40, что прак-
тически не реализуемо. Для небольших и (п < 8) полная марковская модель
/7-го порядка все еще остается приемлемой.
Расширенная модель Гильберта. Проблема обобщенной марков-
ской модели /7-го порядка заключается в том, что она описывается пока-
зательным числом состояний.
Основное различие между обобщенной марковской моделью и рас-
ширенной моделью Гильберта заключается в следующем: первая модель
предполагает, что все прошлые п потерь могут оказать влияние на будуще-
ис; вторая предполагает, что только прошлые (вплоть до) п потерь, сле-
дующие друг за другом, будут воздействовать на будущее. Последнее
предположение может и не всегда оказаться справедливым. Если мы заре-
гистрируем доставленный пакет между двумя интервалами потерь (что яв-
ляется вероятным показателем ослабления ситуации перегруженности), то
корреляция между двумя такими интервалами будет небольшой.
Последовательность прошлых событий (потерь) приводит к
уменьшению числа состояний в расширенной модели Гильберта по экс-
поненциальному закону. Это означает, что система сохраняет показание
счетчика /, которое равно числу следующих друг за другом потерянных
пакетов, но счетчик сбрасывается всякий раз, когда следующий пакет
будет доставлен. В этой модели учитываются только прошлые смежные
173
7.5. Марковские модели оценки QoS мультимедийных сервисов реального времени...
потери, что не всегда может быть корректным, но может служить хоро-
шим приближением. В расширенной модели Гильберта следует опреде-
лить параметр P(A,]A/_i до Хч - все потерянные), где AS определяется так
же, как и в марковской модели. На рис. 7.38 показана работа расширен-
ной модели Гильберта.
Рис. 7.38. Расширенная модель Гильберта
Следовательно, матрица переходов для приведенной выше модели
выгля дит как Poo Р10 Р20 Poi 0 0 . 0 P12 0 . Р(п-2)0 0 0 Р(л-1)0 0 0 (7.21)
] 0 Все 0 0 . устойчивые •• /7(п-2Хн-1) (предельные) верояп ЮСТИ (Ро, Pl, •> д^1)) могут
быть вычислены в соответствии с методикой, изложенной в п. 6.2, и опре-
делены из уравнения
Роо Р\о Р20 • Р(л-2)0 Р(«-1)0 ( \ Ро ( \ Ро
Ро\ 0 0 . 0 0 Р\ Р\
0 Р12 0 . 0 0 Р2 = Р2 (7.22)
0 0 0 . •• А"-2Х«-1) Р(л-1Хп-1), 5
п-1
i=0
Теперь очевидно, что модель Гильберта является частным случаем
расширенной модели Гильберта при п = 2. Формулы для вычисления пара-
метров расширенной модели Гильберта выглядят следующим образом:
Ро\ =
°0у Р(к-\\к}~
°i >
(7.23)
где к = 2, 3, ..., и - 1; ог> - определяется аналогично изложенной выше
модели Гильберта.
174
________________Глава 7. Примеры разработки марковских моделей
7.6. Модель потока мультимедийного трафика
Главной особенностью мультимедийных сервисов является присутствие
внутримедийных связей, т.е. связей между различными медийными средст-
вами, составляющими мультимедийный поток. Они влияют на характери-
стики трафика, подаваемого в сеть, и, следовательно, их необходимо при-
нимать во внимание при исследовании стратегий распределения сетевых
ресурсов и управления. С этой целью можно смоделировать мультимедий-
ный источник путем наложения разнородных коррелированных ON- и
OFF-процессов, каждый из которых моделирует мономедийный источник.
Мультимедийный сервис обеспечивает интегрированную обработ-
ку различных медийных средств, по меньшей мере одно из которых яв-
ляется средством, зависящим от времени. Это означает, что основные
характеристики потоков мультимедийного трафика связаны с син-
хронизацией, которая гарантирует встроенную зависимость между
медийными средствами. Проще говоря, внутри- и межмедийные вре-
менные связи характеризуют трафик, подаваемый в сеть и, следователь-
но, они должны учитываться при исследовании стратегий распределе-
ния ресурсов п управления, чтобы избежать излишне оптимистичного
предсказания производительности.
Для того, чтобы охватить структуру мультимедийного потока w(f),
можно описать процесс поступления мультимедийного источника как ре-
зультат наложения двух коррелированных процессов поступления х(7) и y(t\
каждый из которых моделирует один из образующих мономедийных источ-
ников (трафиковых потоков) (рис. 7.39). На рисунке используются обозначе-
ния: Вх ~ битовая интенсивность x(f) в ON-состоянии; BY - битовая интен-
сивность у(0 в ON-состоянии. Каждый мономедийный источник можно мо-
делировать как ON/OFF-процесс, где интенсивности переходов являются
функциями от состояний остающихся источников.
х(/)д
Рис. 7.39. Принцип формирования мультимедийного потока
175
1.6. Модель потока мультимедийного трафика
Мультимедийный источник в среднем состоит из М мономедийных
источников, коррелированных друг с другом. Каждый мономедийный ис-
точник может генерировать информационный поток, такой как видео (слай-
ды, движущиеся изображения), аудио и данные. Корреляция между моно-
медийными источниками возникает из-за того, что поведение каждого ис-
точника зависит от поведения других источников. Например, в слайд-шоу с
аудиокомментариями смена слайдов обладает временной зависимостью от
комментариев, обеспечивающих аудиооформление каждого слайда.
Следовательно, модель мультимедийного источника должна учитывать
не только статистические характеристики каждого из составляющих моно-
медийных источников, но также и корреляцию между ними. Будем генери-
ровать мономедийный источник при помощи прерывистого пуассоновского
хо) процесса, граф ON/OFF-модели которого пока-
ту зан на Рис- 7-40- Считается, что если лежащая в
/ \ \ основе марковская цепь находится в состоянии
OFF ON
\ J V j OFF, то передачи нет; когда лежащая в основе
2^7 марковская цепь находится в ON-состоянии, то
ц(/) источник передает с постоянной битовой интен-
Рис. 7.40. ON-OFF модель сивностью. При этом у-й мономедийный источ-
дляу-го мономедийного ник (j = 1, ..., М) характеризуется пиковой бито-
источника вой интенсивностью в течение ON-периодов и
экспоненциально распределенными периодами активности и бездействия со
средними и соответственно.
Пусть 5</)(/)0{0N, OFF} - состояние у-го мономедийного источника,
и - интенсивности переходау-го мономедийного источника из OFF в
ON и наоборот. Для того чтобы смоделировать влияние каждого источника
на поведение других, определим эти интенсивности в соответствии с со-
стоянием остающихся источников, образующих мультимедийный источ-
ник, т.е.:
.... S(A/)(/))=
_ 1_____________________________
....... 5(w)(0) ’ (7 24)
цЬ> = ц(/)($()(,).5G-0(z); 5O»(z); .. „ £(•'')(,))=
_ 1
Мультимедийный источник будет наложением описанных выше мо-
номедийных источников, и, следовательно, его можно смоделировать как
ММРР. Рассмотрим мультимедийный источник, состоящий из двух моно-
медийных источников, для чего введем обозначения: х(/) - процесс по-
ступления для первого мономедийного источника; X(t) - состояние ле-
176
Глава 7. Примеры разработки марковских моделей
жащей в основе цепи первого мономедийного источника в момент /;
Bw - пиковая битовая интенсивность первого мономедийного источни-
ка в ON-состоянии; y(t) - процесс поступления для второго мономедий-
ного источника; К(0 “ состояние лежащей в основе цепи второго моно-
медийного источника в момент Z; - пиковая битовая интенсивность
первого мономедийного источника в ON-состоянии; w(t) - процесс по-
ступления для всего мультимедийного источника; IV(t) - состояние
мультимедийного источника в момент Л
По определению
'о, в(-х\ если если X(/) = OFF, X (/) = ON,
'о, если К (/) = OFF,
Я0=ч если F(Z) = ON.
(7.25)
Так как X(t) и Y(f) могут принимать только два значения (OFF и
ON), процесс ГГ(/) может принимать четыре значения, т.е. все возмож-
ное комбинации состояний X(t) и
Y(t). Битовая скорость мультиме-
дийного источника В^ЦГ) в со-
стоянии / (/ = 0, 1, 2, 3) является
суммой битовых скоростей двух
образующих источников в состоя-
ниях, характеризуемых состояни-
ем /, как показано в табл. 7.2. Сле-
довательно, процесс, генерируе-
мый мультимедийным источни-
ком iv(г), представляет собой
cvMxMy двух мономедийных про-
цессов х(0 и y(t), т.е. ур(О =
=х(0 +Х0 (см. рис. 7.39).
Ориентированный граф
мультимедийного источника
приведен на рис. 7.41. Вероят-
ность того, что оба мономедий-
ных источника выполнят переход
одновременно, считается незна-
чительной, поэтому переходы
между состоянием 0 и 3 и меж-
ду состоянием 1 и 2 не учи-
тываются.
Таблица 7.2. Состояния и битовые ин-
тенсивности мультимедийного источника
W) A'W П0
0 OFF OFF 0
i OFF ON
2 ON OFF
3 ON ON bw+b™
Рис. 7.41. Ориентированньш граф
мультимедийного источника
177
7.6. Модель потока мультимедийного трафика
Для вычисления интенсивности переходов для мультимедийно-
го источника на рис. 7.41, запишем интенсивности переходов для
каждого из марковских процессов, моделирующих мономедийныс
источники в виде
А.(-ПМП)=/^0’ если S(r)W = OFF,
[Хп, если S(r)(z) = ON,
^)(s(n)=Ko- если SiY>(t) = OFF,
' ' |цу., если S(1%) = ON,
f , (7.26)
rtw)=rro’если s v)=off,
|Xn, если S^(r) = ON,
ц(г)($(х))= P™’ “и*1 S(X)(') = OFF,
[цп, если S^x\t) = ON.
Следовательно, переходная матрица для мультимедийного источ-
ника, чей общий элемент - интенсивность перехода из состояния /
в состояние у, определяется как
~ ^А0 Луо ^A0 0
q(’f) = Pro Рао - p.ro 0 0 “ PaO “ ^A1
I 0 Pai Pri “Pai “Priy
7.27)
Вероятности установившегося состояния 7г(ГГ)= (л0(я°, л/”0, тг2(^, Лз(И°)
для мультимедийного источника могут быть вычислены из системы
я^И = 0,
<г28)
Корреляционная функция мультимедийного источника зависит от
авто- и кросскорреляционных функций образующих его мономедийных
источников. По этой причине она может считаться показателем и для
внутримедийных временных взаимосвязей каждого образующего моно-
медийного источника, и для межмедийных временных взаимосвязей
среди активностей различных образующих мономедийных источников.
Хотя корреляционная функция мультимедийного источника может
быть вычислена при помощи матрицы Q(ir), заданной в (7.27), вычислим ее
как сумму авто- и кросскорреляционных функций образующих источников:
Rww (т) - Rxx (т) + Ryy (т) + ^xy (т)+ Ryx (т) • (7.29)
В соответствии с определением автокорреляционной функции, имеем
ЛДхЮ=Л/{у(г)х(г + т)}= = 1, +т) = 1}, (7.30)
178
Глава 7. Примеры разработки марковских моделей
и по теореме полной вероятности получаем
ЛАТ(т)= И’)2[Р{^)= 1, Г0= А'(/ + т)= 1, Y(t + т)= 0}+
+ ₽{%(/)= 1, у(г)= о. Az(/ + t) = 1, }'(/ + т)= 1}+
+ Р{М/)= 1, Г(Л=1, %(/ + т)=1, У(г + т)= о}+
(7-31)
= (в(х))2[р{и/(г)= 2,w(t + т)= 2} + P{ir(f) = 2,W(t + т)= з}+
+ Р{ГК(0=ЗЛГ(г + т)=2}+Р{ГК(/)=2, If'(t + т)= 3}] .
Rxx(s) может быть выражена на основе вероятностей совместных
состояний в мультимедийном источнике.
Контрольные вопросы к главе 7
1. Каковы основные состояния речевого сигнала в случае диалога двух
абонентов ?
2. Сравните марковские модели речевого диалога в случаях шести и
четырех состояний.
3. Сравните марковские модели речевых монологов в случае двух, трех
и четырех состояний.
4. В чем заключается вычислительный алгоритм вектора финальных
вероятностей марковской модели речевого сообщения ?
5. В чем заключается алгоритм получения марковской ON/OFF-модели
цифрового речевого сигнала по экспериментальным данным ?
6. На какие параметры марковской модели речевого сигнала влияет
точность аппроксимации дополнительной функции распределения
ON- и OFF-состояний ?
7. В чем заключается алгоритм моделирования речевого процесса на
основе марковской цепи ?
8. Чем отличаются марковские модели цифровых речевых сигналов на
выходе кодеков G.711 и G.728 ?
9. Опишите модель Гильберта для мультимедийных сервисов.
10. Опишите расширенную модель Гильберта для мультимедийных сервисов.
11. В чем заключаются особенности моделей потоков мультимедийного
трафика ?
179
Глава 8
СИСТЕМЫ МАССОВОГО ОБСЛУЖИВАНИЯ
И ИХ МОДЕЛИРОВАНИЕ
8.1. Общая характеристика систем массового
обслуживания
Одним из математических методов исследования сложных стохастиче-
ских систем является теория массового обслуживания (ТМО), зани-
мающаяся анализом эффективности функционирования так называемых
систем массового обслуживания (СМО).
Под СМО понимают динамическую систему, предназначенную для эф-
фективного обслуживания случайного потока заявок при ограниченных ресур-
сах системы. Системы массового обслуживания называют также Q-схемами
(англ, queuing system). Обобщенная схема СМО приведена на рис. 8.1.
Рис. 8.1. Обобщенная схема СМО:
обязательные связи;------возможные связи
Работа любой такой системы заключается в обслуживании поступаю-
щего на нее потока требований или заявок (вызовы абонентов, приход поку-
пателей в магазин, требования на выполнение работы в мастерской и т.д.).
Заявки поступают в систему одна за другой в некоторые случайные моменты
времени. Обслуживание поступившей заявки продолжается какое-то время,
после чего система освобождается для обслуживания очередной заявки.
Каждая такая система может содержать конечное число элементов
обслуживания, называемых каналами обслуживания (линия связи, при-
боры). Примерами таких систем могут быть телефонные станции, би-
летные кассы, аэродромы, радиолокационные станции, ЭВМ, вычисли-
тельные центры, информационные системы различных видов.
180
Глава 8. Системы массового обслуживания и их моделирование
Отметим случайный характер поступления заявок и случайный ха-
рактер промежутков времени, необходимого для выполнения заявок. В це-
лом, имеем случайный процесс, в котором возможны как перегрузки, так и
простои. Если в момент появления заявки на входе СМО есть свободный
канал, ее обслуживание начинается немедленно. Если СМО загружена (т.е.
все каналы заняты), заявка занимает место в очереди. На число мест в оче-
реди может быть наложено ограничение. При этом возможны конфликтные
ситуации, решением которых может быть либо отказ системы принять
заявку, либо принятие заявки в систему за счет выталкивания из оче-
реди другой, менее ценной в данный момент времени заявки.
Процесс продвижения заявок в СМО осуществляется по некоторому
закону управления, который задается дисциплинами ожидания DI и об-
служивания D2. Дисциплина ожидания определяет порядок приема заявок
в систему и размещения их в очереди, а дисциплина обслуживания - поря-
док выбора заявок из очереди для назначения на обслуживание.
Поступающие на вход СМО (рис. 8.1) однородные заявки в зави-
симости от порождающей причины делятся на типы. Совокупность зая-
вок всех типов образует входящий поток СМО. Интенсивность потока
заявок типа i (/ = 1, ..., Л7) обозначим Л,.
Обслуживание заявок выполняется т каналами (/0. Различают
универсальные и специализированные каналы обслуживания. Для уни-
версального канала типа j считаются известными функции распределе-
ния длительности обслуживания заявок произвольного типа. Для
специализированных каналов функции распределения длительности об-
служивания заявок некоторых типов являются неопределенными.
В качестве примера процесса обслуживания можно рассматривать
различные по своей физической природе процессы функционирования
экономических, производственных, технических и других систем, на-
пример, потоки поставок продукции некоторому предприятию, потоки
деталей и комплектующих изделий на сборочном конвейере цеха, заяв-
ки на обработку информации ЭВМ от удаленных терминалов и т.д. При
этом характерными для работы таких объектов являются случайное по-
ведение заявок (требований) на обслуживание и завершение обслужи-
вания в случайные моменты времени.
Основными элементами сети связи, представляемой как СМО, вы-
ступают узлы и линии (каналы) связи. Эти элементы предназначены для
обслуживания вызовов и, следовательно, являются системами массово-
го обслуживания.
Обслуживание вызова в узле характеризуется заданным алгорит-
мом и может быть описано как последовательность логических опера-
ций. Свойства узла СМО (производительность коммутатора, потери вы-
зовов на групповых устройствах и т.д.) могут быть описаны моделями
элементарных СМО, которые и будут рассмотрены в дальнейшем.
181
8.1. Общая характеристика систем массового обслуживания
Пропускная способность СМО зависит от числа каналов, их про-
изводительности и характера потока заявок.
Теория массового обслуживания устанавливает зависимость меж-
ду характеристиками потока заявок, числом каналов, их производитель-
ностью, правилами работы СМО, ее эффективностью и часто включает
экономический аспект. Например, стремятся найти наименьшую пол-
ную стоимость единицы времени ожидания обслуживания требования-
ми в накопителе и простоя приборов. Кроме того, к задачам ТМО близ-
ки задачи повышения надежности технических устройств.
Для характеристики СМО обычно применяют следующие показа-
тели: среднее число заявок, которые система может обслужить за еди-
ницу времени; средний процент необслуженных заявок; вероятность то-
го, что поступившая заявка будет принята к выполнению; среднее время
ожидание в очереди; закон распределения времени ожидания; среднее
число заявок в очереди; закон распределения числа заявок в очереди;
средний доход системы в единицу времени.
Наиболее удобны для анализа те системы, в которых случайный
процесс является близким к марковскому, т.е. состояние системы в бу-
дущем зависит от состояния системы в настоящее время, но не зависит
от того, каким образом эта система пришла к этому состоянию (не учи-
тывает прошлое). В таком случае задачу ТМО можно описать обыкно-
венными дифференциальными уравнениями и выразить в явном виде
основные характеристики обслуживания через параметры системы. В
остальных случаях характеристики оцениваются приближенно.
В любом элементарном акте
обслуживания можно выделить две
основные составляющие: ожидание
обслуживания заявки и собственно
обслуживание заявки. Это можно
отобразить в виде некоторого /-го
прибора обслуживания Я„ состояще-
го из накопителя заявок и канала
обслуживания заявок К, (рис. 8.2). В
накопителе может находиться одновременно I, = 0, ..., L,H заявок, где
Цн - емкость /-го накопителя. На каждый элемент прибора обслужива-
ния 77, поступают потоки событий: в накопитель Н, поток заявок на
канал К, - поток обслуживания z<.
Потоком событий (ПС) называется последовательность событий,
происходящих одно за другим в какие-то случайные моменты времени. Раз-
личают однородные и неоднородные потоки событий. Однородный ПС (ОПС)
характеризуется только моментами поступления этих событий (вызывающи-
ми моментами) и задается последовательностью {/„} = {0 < tx< t2 < .. < !„}, где
tn - момент поступления я-го события - неотрицательное вещественное число.
Однородный ПС может быть также задан в виде последовательности проме-
жутков времени между п- и (п- 1)-ым событиями {т,,}.
182
Рис. 8.2. Схема прибора СМО
Глава 8. Системы массового обслуживания и их моделирование
Неоднородным ПС называется последовательность {tn; f„}, где tn -
моменты поступления заявки; fn - набор признаков события. Например,
может быть задана принадлежность к тому или иному источнику заявок,
наличие приоритета, возможность обслуживания тем или иным типом ка-
нала и т.п.
Рассмотрим ОПС, для которого т, е {т„}, где т - случайные вели-
чины, независимые между собой. Тогда ПС называется потоком с огра-
ниченным последействием.
Поток событий называется ординарным, если пренебрежимо мала
вероятность того, что на малый интервал времени А/, примыкающий к
моменту времени Z, попадает больше одного события P^(t; At).
Стационарным ПС называется поток, для которого вероятность
появления того или иного числа событий на интервале времени At зави-
сит от длины этого интервала и не зависит от того, где на оси времени t
взят этот интервал. Для ординарных ПС справедливо
О Ро(г; At) + 1-Р^Г; At) = Pt(r; At).
Среднее число событий, наступающих на интервале At в единицу
времени, составляет Р1(/;Д/)/Д/. Рассмотрим предел этого выражения
при At -» 0:
lim Pjr, At)/At = Х(г)(1/ед.вр).
A/—>0
Если этот предел существует, то он называется интенсивностью
(плотностью) ОПС. Для стационарного ПС Х(/) = X = const.
Применительно к элементарному каналу обслуживания К, можно
считать, что поток заявок w, е W, т.е. интервалы времени между момен-
тами появления заявок на входе К, образуют подмножество неуправляе-
мых переменных, а поток обслуживания и, е U, т.е. интервалы времени
между началом и окончанием обслуживания заявки образуют подмно-
жество управляемых переменных. Заявки, обслуженные каналом Kh и
заявки, по различным причинам не обслуженные и покинувшие прибор
Я„ образуют выходной потоку, е Y.
Процесс функционирования прибора обслуживания Я, можно
представить как процесс изменения состояний его элементов во време-
ни Z,(Z). Переход в новое состояние Я, означает изменение количества
заявок, которые в нем находятся (в канале К, и накопителе Я,). Таким
образом, вектор состояний для Я, имеет вид Z, = (z/z; ztK), где z^ - со-
стояния накопителя (z,H = 0 - накопитель пуст, z, = 1 - в накопителе
одна заявка, z,H = LtH - накопитель занят полностью); z,A - состояние ка-
нала k, (ztK = 0 - канал свободен, zf = 1 - канал занят).
Для реальных объектов Q-схемы образуются композицией многих
элементарных приборов обслуживания Я,. Если каналы различных при-
боров обслуживания соединены параллельно, то имеет место многока-
нальное обслуживание (многоканальная Q-схема), а если приборы Я, и
их параллельные композиции соединены последовательно, то имеет ме-
сто многофазное обслуживание (многофазная Q-схема).
183
8.1. Общая характеристика систем массового обслуживания
Таким образом, для задания Q-схемы необходим оператор сопряже-
ния R, отражающий взаимосвязь элементов структуры. Связи в Q-схеме
изображают в виде стрелок (линий потока, отражающих направление дви-
жения заявок). Различают разомкнутые и замкнутые Q-схемы. В разомкну-
той схеме выходной поток не может снова поступить на какой-либо эле-
мент, т.е. обратная связь отсутствует.
Собственными (внутренними) параметрами Q-схемы являются:
количество фаз Лф; число каналов в каждой фазе Л/; число накопите-
лей каждой фазы Л/7; емкость /-го накопителя у-ой фазы где где
j = 1, ..., Лф. Следует отметить, что в ТМО, в зависимости от емкости
накопителя, существуют:
системы с потерями (Дя = 0, накопитель отсутствует);
системы с ожиданием (LtH -» оо, емкость накопителя бесконечно
большая);
системы с ограниченной емкостью накопителя Я, (смешанные).
Обозначим всю совокупность собственных параметров Q-схемы как
подмножество Я. Для задания Q-схемы также необходимо описать алгорит-
мы ее функционирования, которые определяют правила поведения заявок в
различных ситуациях.
В зависимости от места возникновения таких си-
туаций различают алгоритмы (дисциплины) ожидания заявок в накопителе
Я. и алгоритмы обслуживания заявок каналом Kh Неоднородность потока
заявок учитывается с помощью введения класса приоритетов.
В зависимости от динамики различают статические и
динамические приоритеты Q-схем. Статические приоритеты назначают-
ся заранее и не зависят от состояний Q-схемы, т.е. они являются фикси-
рованными в пределах решения конкретной задачи моделирования. Ди-
намические приоритеты возникают при моделировании.
В зависимости от правила выбора заявок из
накопителя Я, на обслуживание каналом Kh можно выделить отно-
сительные и абсолютные приоритеты.
Относительный приоритет означает, что заявка с более высоким при-
оритетом, поступившая в накопитель Я„ ожидает окончания обслуживания
предыдущей заявки каналом К, и только после этого занимает канал.
Абсолютный приоритет означает, что заявка с более высоким при-
оритетом, поступившая в накопитель, прерывает обслуживание каналом
К, заявки с более низким приоритетом и сама занимает канал (при этом
вытесненная кГя заявка может либо покинуть систему, либо перейти в
другую ячейку Я,).
Необходимо также знать набор правил, по которым заявки покидают
Я/ и К,: для Н, это либо правила переполнения, либо правила ухода, связан-
ные с истечением времени ожидания заявки в Я,; для К, - правила выбора
маршрутов или направлений ухода. Кроме того, для заявок необходимо за-
дать правила, по которым они остаются в канале Kh т.е. правила блокиро-
184
________Глава 8. Системы массового обслуживания и их моделирование
вок канала. При этом различают блокировки К, по выходу и по входу. Такие
блокировки отражают наличие управляющих связей в Q-схеме, регули-
рующих поток заявок в зависимости от состояний Q-схемы. Набор воз-
можных алгоритмов поведения заявок в Q-схеме можно представить в виде
некоторого оператора А алгоритмов поведения заявок.
Таким образом, Q-схема, описывающая процесс функционирова-
ния СМО любой сложности, однозначно задается в виде набора мно-
жеств: Q = <IT, U, И, Z, R, А>.
В ТМО существуют следующие дисциплины обслуживания: бес-
приоритетная, приоритетная, со смешанным приоритетом.
Бесприоритетное обслуживание осуществляется по правилу FIFO
и LIFO или по случайному правилу. Дисциплины FIFO и LIFO по сред-
нему значению или математическому ожиданию ничем не отличаются,
однако, приоритетной считается дисциплина FIFO, которая минимизи-
рует дисперсию времени ожидания (т.е. уменьшается разброс времени
относительно среднего значения).
Приоритетное обслуживание заявок, находящихся в очереди, мо-
жет выполняться по правилу относительного и абсолютного обслужи-
вания. Для приоритетного обслуживания заявкам необходимо указать
уровень приоритета СМО (0 > 1 > 2 > ...):
относительная дисциплина обслуживания заключается в следую-
щем: заявка, пришедшая на обслуживание с более высоким приорите-
том, не прерывает заявку, находящуюся на обслуживании, и только по-
сле окончания обслуживания в канале приоритетная очередная заявка
поступает на обслуживание;
абсолютная дисциплина обслуживания заключается в том, что
пришедшая на канал заявка с более высоким приоритетом вытесняет с
обслуживания заявку с меньшим приоритетом.
При смешанном обслуживании наряду с различными дисциплинами
приоритетного обслуживания используется бесприоритетное обслуживание.
Классификация СМО. В теории массового обслуживания приня-
ты сокращенные обозначения, в основе которых лежит трехбуквенное
обозначение вида А/В/т, где А и В описывают соответственно законы
распределения промежутков времени между последовательно посту-
пающими заявками и распределение времени их обслуживания, а вели-
чина т - число обслуживающих приборов; А и В принимают значения
из следующего набора символов: М- показательное распределение; Ег-
распределение Эрланга порядка г; D - детерминированное распределе-
ние; G - распределение произвольного вида.
Так, система обслуживания MIGIX представляет собой систему с
пуассоновским входным потоком, произвольным распределением вре-
мени обслуживания и одним обслуживающим прибором. Символ D оз-
начает, что время обслуживания - постоянная величина, поэтому систе-
ма с пуассоновским входным потоком в этом случае обозначается как
MIDIX. Иногда приходится указывать также емкость накопителя систе-
185
8.1. Общая характеристика систем массового обслуживания
мы (которую обозначим через К) или число источников нагрузки (кото-
рое обозначим через Л/); в этом случае будет использоваться пятибук-
венное обозначение: А/В/т/К/М. В случае отсутствия одного из послед-
них индексов предполагается, что его значения сколь угодно велико.
Запись вида DIMI2I2Q означает систему с двумя обслуживающими при-
борами, постоянным (детерминированным) временем между двумя по-
следовательно поступающими заявками, показательным распределени-
ем длительности обслуживания и накопителем емкостью 20 заявок.
Различают два вида СМО: одноканальные и многоканальные. Так-
же различают системы с отказами, в которых заявка получает отказ,
если все каналы заняты, и системы без отказов (с ожиданием или оче-
редью), которые делятся на упорядоченные и неупорядоченные.
Упорядоченные системы отличаются тем, что освободившиеся ка-
налы принимают заявки в порядке очереди. Неупорядоченные системы
характеризуются тем, что при освобождении канала заявка выбирается
случайным образом. Например, поступившее требование может занять
место в самой короткой очереди; в этой очереди оно может располо-
житься последним (такая очередь будет упорядоченной), а может пойти
на обслуживание вне очереди.
Кроме того, системы с ожиданием разделяются на системы с огра-
ниченным и неограниченным временем ожидания.
Смешанной системой обслуживания называется система, в кото-
рой требование, заставшее все приборы занятыми, становится в очередь
лишь в том случае, когда число требований, находящихся в системе, не
превосходит определенного уровня (в противном случае происходит
потеря требования).
Показатели эффективности и основные характеристики СМО.
Показатели эффективности СМО зависят от вида систем.
Для систем с отказами это абсолютная и относительная пропуск-
ная способность систем.
Абсолютная пропускная способность - среднее число выполненных
заявок в единицу времени. Относительная пропускная способность - сред-
няя доля поступивших заявок, определяемая отношением среднего числа вы-
полненных заявок к общему числу поступивших заявок в единицу времени.
Кроме того, можно определить среднее число занятых каналов или сред-
нее относительное время простоя одного канала или всей системы в целом.
Для систем без отказов (с ожиданием) выбираются другие показатели
эффективности. Если система с неограниченным ожиданием, то за показате-
ли эффективности принимают: среднее число заявок в очереди, среднее число
заявок в системе, время ожидания в очереди, время выполнения заявок.
Для систем с ограниченным временем ожидания применимы обе груп-
пы показателей: абсолютная и относительная пропускная способность и ха-
рактеристики ожидания. При этом нужно знать следующие параметры: п -
число каналов; X - интенсивность потока заявок; ц = 1//обсл - производитель-
ность (интенсивность обслуживания) каждого канала (среднее число заявок).
________Глава 8. Системы массового обслуживания и их моделирование
Основные характеристики простейшихСМОследующие:
Коэффициент загрузки устройства или канала - р, ~ АУц < 1. При
этом коэффициент загрузки является вероятностью обслуживания заяв-
ки в канале. Пусть СМО работает достаточно длительное время Т, тогда
число заявок в системе будет определяться как XT и среднее время об-
служивания заявок будет определяться как Х7тобсл. В этом случае
1!т^Ь^=Х7’обсл=р.
г->х 7
Коэффициент загрузки р имеет смысл только лишь для устано-
вившихся режимов.
Коэффициент простоя канала ц = 1 - р.
Время пребывания заявки в системе Тс = Тож + М^Т^п), где Тож - время
ожидания заявки на обслуживание; МД^^) - среднее время обслуживания.
Время оэ!сидания в СМО, которое в общем случае может состоять тоже
из двух компонент: Гож = Т44 + 7°, где Т44 - время ожидания обслуживания или
время начала обслуживания; 741 - время ожидания в прерванном состоянии.
Длина очереди, которая определяется как / = Х.744.
Среднее число заявок в системе и = Х( 7й + Л/(Гобсл)) (формула Литтла).
8.2. Структура системы массового обслуживания
Структуру простейшей СМО наглядно можно представить в следующем
виде (рис. 8.3):
Рис. 8.3. Структура простейшей СМО: И-источник заявок (при моделировании -
генератор случайных событий - ГСС); Н~ накопитель; Kj-j-м канал обслуживания
Для более сложных, многофазных систем выделяются фазы об-
служивания, когда заявка, получив обслуживание в первой СМО, сразу
попадает во вторую СМО и т.д. (рис.8.4)
Рис. 8.4. Структура многофазной СМО: Н, - накопитель перед z-й фазой;
К,, -j-й канал обслуживания /-й фазы
187
8.2. Структура системы массового обслуживания
Система массового обслуживания считается заданной, если опре-
делены следующие характеристики:
Входящий поток требований или, иначе говоря, моменты поступ-
ления требований в систему. (В дальнейшем будем считать, что источ-
ник располагает неограниченным числом требований и что требования
однородны, т.е. различаются только моментами появления в системе.)
Структура системы обслуживания, состоящая из накопителя и
узла обслуживания, представляющего собой одно или несколько обслу-
живающих устройств, которые в дальнейшем будем называть каналами.
Может оказаться, что требованиям придется ожидать, пока каналы ос-
вободятся. В этом случае требования находятся в накопителе, образуя
одну или несколько очередей.
Время обслуживания каждым каналом.
Дисциплина ожидания, т.е. совокупность правил, регламентирую-
щих хранение требований, находящихся в один и тот же момент време-
ни в системе.
Дисциплина очереди, т.е. совокупность правил, в соответствии с
которыми требование отдает предпочтение той или иной очереди (если
их несколько) и располагается в выбранной очереди.
Дисциплина обслуживания, т.е. совокупность правил, в соответствии с
которыми требование выбирает прибор, которым оно будет обслужено.
На практике обычно моменты поступления требований в систему
случайны. Часто бывает, что поток требований тоже случайный, тогда
случайна и длительность обслуживания.
По аналогии с вышеизложенным модели элементарных СМО, как
правило, включают: модель обслуживания вызовов (заявок) группой уст-
ройств (пучком линий) при дисциплине обслуживания с потерями; модель
обслуживания вызовов (заявок) устройством при дисциплине обслужива-
ния с ожиданием.
Модель процесса поступления вызовов (заявок) показана на рис. 8.5.
I I IM I f I
‘,.2
Z ~ С+1 ~ с
Рис. 8.5. Модель процесса поступления вызовов (заявок)
Вероятность того, что промежуток времени Z между вызовами
меньше некоторой величины z, называется функцией распределения ве-
роятностей промежутков времени между вызовами P(Z < z) = F(z). Каж-
дый вызов характеризуется временем его обслуживания (временем за-
нятия). Предположим, что продолжительность обслуживания вызовов
потока является случайной величиной с экспоненциальным законом
распределения, тогда
f(/)= I — е-м/; zp(/) = J.Iе-ц/: М(т)=-, (8.1)
Ц
где ц - интенсивность обслуживания; Л/(7) - средняя продолжитель-
ность обслуживания.
188
Глава 8. Системы массового обслуживания и их моделирование
Задача моделирования потока заявок и времени обслуживания за-
ключается в получении последовательности случайных чисел с задан-
ными законами распределения вероятностей. Модель процесса обслу-
живания вызовов показана на рис. 8.6.
t t t t t t t t
______________EZZZZ3_______________
____________________m
Рис. 8.6. Модель процесса обслуживания вызовов
8.3. Системы массового обслуживания с ожиданием
8.3.1. Система обслуживания Ml МП
В качестве модели процесса поступления сообщений в такой СМО бу-
дем предполагать пуассоновский поток поступлений. В таком случае
интервалы времени т между последовательными поступлениями сооб-
щений являются непрерывными случайными величинами, распределен-
ными по экспоненциальному закону:
№(т)=Хе"х\ (8.2)
Как было показано выше, среднее время между поступлениями со-
общений в этом случае определяется из выражения
Л/(т) = J Tw(t)c1t = I / к .
Параметр X, введенный как коэффициент пропорциональности при
определении пуассоновского процесса, определяет интенсивность вход-
ного потока. Будем также полагать, что длина сообщения г распределе-
на по экспоненциальному закону со средним значением 1/ц (в теории
очередей говорят об экспоненциальном распределении времени обслу-
живания), так что плотность распределения длины сообщения г опреде-
ляется из выражений (8.1).
Подобное предположение о распределении данных, как правило,
не соответствует действительности. На практике длина сообщения яв-
ляется дискретной величиной (длина кратна используемой единице
данных), в то время как величина г непрерывна. Вместе с тем, предпо-
ложение об экспоненциальном распределении длины сообщения позво-
ляет быстро получить искомый результат и облегчает изучение более
сложных моделей обслуживания, поэтому в литературе его часто ис-
189
8.3. Системы массового обслуживания с ожиданием
пользуют. Статистический анализ существующих сетей передачи дан-
ных показывает, что предположение об экспоненциальном распределе-
нии длины сообщения приводит к относительно хорошим результатам.
Если пропускная способность выходного канала С единиц данных/с, то
очевидно, что на передачу или обслуживание сообщения длиной г единиц
потребуется г/С с. Плотность распределения времени обслуживания можно
записать в виде (8.1), т.е. w(Z) = (С/£)ечс/Л)z. В этом случае М(Т) = L/C -
среднее время передачи сообщения.
Заметим, что величина C/L используется для обозначения интен-
сивности обслуживания сообщений, а распределение времени обслужи-
вания, как и распределение времени между последовательными поступ-
лениями сообщений, является экспоненциальным.
Пуассоновский
Один
обслуживающий
входной поток-
PUC. 8.7. Модель системы обслуживания
Рассмотрим модель системы обслуживания Л/7Л//1, представлен-
ную на рис. 8.7. Процесс поступления сообщений - пуассоновский, объ-
ем буферной памяти не ограничен, распределение времени обслужива-
ния - экспоненциальное. Сообщения обслуживаются по принципу FIFO
(«первым пришел - первым обслужен»). Такая модель обслуживания
является одной из простейших в теории очередей.
Предположение о бесконечности числа мест для ожидания означает
на практике выделение для хранения запросов, входной и выходной ин-
формации таких объемов памяти буферов и базы данных, которые при пра-
вильной эксплуатации гарантируют отсутствие информационных потерь в
системе вследствие их возможного переполнения. В последние годы про-
слеживается устойчивая тенденция к существенному увеличению объемов
оперативной и внешней памяти и их удешевлению в современных средст-
вах электронно-вычислительной техники. Поэтому проблемы с недостат-
ком памяти возникают все реже и в ближайшем будущем, по-видимому,
перестанут вызывать практические затруднения. С учетом изложенного
введенное предположение о бесконечности числа мест для ожидания в сис-
теме представляется вполне обоснованным.
Для модели обслуживания Л//Л//1 определим pn(t) - вероятность
того, что в буферной памяти в момент времени t находится п сообще-
ний. Эта вероятность позволяет определить различные статистические
характеристики рассматриваемой СМО (среднее число сообщений в
буферной памяти, вероятность превышения заданного уровня заполне-
ния буферной памяти и т. д.).
Общее выражение для р» имеет вид рп = р„р0.
Очевидно, что должно выполняться соотношение р = "KL/C = Х/ц < 1,
чтобы вероятности состояний уменьшались с ростом п. Справедливость
190
Глава 8. Системы массового обслуживания и их моделирование
этого соотношения согласуется с нашим интуитивным представлением о
том, что среднее число сообщений, поступающих за единицу времени (X),
должно быть меньше пропускной способности системы. Напомним, что
объем буферной памяти предполагается неограниченным. В модели, учи-
тывающей ограниченность объема буферной памяти при ее переполнении,
дальнейшее поступление сообщений блокируется. Следовательно,
X ОС
Е Р„ = 1 = РоЕр" = Р°/(1 -р) ’
//=0 //=0
а также
Ро = 1“Р •
Отметим физическую интерпретацию
р из уравнения (8.4): р = (1 - ро) - вероят-
ность того, что буферная память не пуста.
Выражение для вероятностей раз-
личных состояний системы обслуживания
М/М/\ можно использовать для определе-
ния всех интересующих статистических
характеристик системы. Например, сред-
няя длина очереди
^('0= =р/(1-р) • (8-5)
w=0
Средняя длина очереди превышает
любые ограничения при р —> 1. График
ее зависимости от р в М!М!\ изображен
на рис. 8.8. При р < 0,5 среднее число со-
общений в очереди меньше 1. При р > 0,5
это число резко возрастет. Так, при М(п) = 3 коэффициент загрузки
р = 0,75; при М(и) = 4 значение р = 0,8; при М(п) = 9 значение р = 0,9 и т. д.
Пусть в момент поступления очередного сообщения в буферной памяти
уже находятся и сообщений. Тогда среднее время пребывания сообщения в
концентраторе можно описать соотношением М(Т) = + Тож = ЫС + nL/C.
Записанное выражение отражает зависимость между временем за-
держки и длиной очереди. Используя выражение (8.5), определяющее
среднюю длину очереди, найдем среднее время задержки:
(8.3)
Рис. 8.8. Средняя длина очереди
в системе М1М1\
W)=£+^=^=-L-
С С С(1-р) ц-Х
(8-6)
Основное предположение, которое было сделано ранее, заключа-
лось в том, что каждый узел сети может моделироваться как система
обслуживания М1М1\, причем каждая система обслуживания статисти-
чески не зависит от других. Последнее предположение означает, что
длины сообщений выбираются независимо из экспоненциального рас-
191
8.3. Системы массового обслуживания с ожиданием
пределения в каждой узловой точке или точке концентрации. Очевидно,
на практике это не так. Изучение реальных сетей показывает, что ре-
зультаты, полученные при этом предположении, хорошо согласуются с
практическими результатами.
Другой, более общей формулой по сравнению с (8.6) является
формула Литтла, соответствующая следующей теореме.
Теорема, Средняя длина очереди в системе равна среднему време-
ни задержки, умноженному на интенсивность входного потока'.
М(г) К = М(п). (8.7)
Эта формула справедлива как для сети очередей, так и для отдельных
систем обслуживания. Подставляя (8.5) в (8.7), получим формулу (8.6).
8.3.2. Система обслуживания MIGIX
Для исследования системы массового обслуживания M!G!\ (однолинейная
система с пуассоновским входным потоком и произвольным распределени-
ем времени обслуживания) используется подход, отличный от описанного
выше. Этот подход состоит в изучении случайного процесса изменения со-
стояний системы в моменты окончания обслуживания сообщений (переда-
ча сообщения заканчивается, и оно покидает концентратор).
В буфер поступает последовательность сообщений, каждое из которых
обладает случайной переменной длиной (или временем обслуживания). Об-
служивающее устройство обрабатывает сообщения поочередно (т. е. по ка-
налу сообщения передаются одно за другим). Закончив обработку одного со-
общения, оно приступает к обработке следующего сообщения по принципу
«первым пришел-первым обслужен».
Временная диаграмма обслуживания у-го сообщения изображена
на рис. 8.9.
Завершено Завершено
обслуживание обслуживание
(/ -1 )-го |ообщения У-го сообщения
_____|УУ_____________l_2___
v Время
7-1 7
Рис. 8.9. Временная диаграмме! обслуживанияу-го сообщения
Пусть tij - длина очереди после окончания обслуживания у-го со-
общения (J - переменный индекс). Можно записать простое соотноше-
ние, связывающее ц и п^- длину очереди после завершения обслужи-
вания (/-1)-го сообщения. Получим
nj = (nJ_l-\) + vJf
nj=vr
192
_________Глава 8. Системы массового обслуживания и их моделирование
Здесь Vj - число сообщений, поступивших в течение времени обслужи-
вания j-го сообщения (или j-го требования). (Это, естественно, также
случайная величина.)
После преобразований получаем выражение для средней длины
очереди:
Л/(н) = |-!-|Гр-1р2(1-ц2СТ2)Р (8.9)
U-pJL 2 'j.
Здесь а2 - дисперсия длины сообщения.
Таким образом, средняя длина очереди сообщений в буфере зави-
сит непосредственно от р, средней длительности сообщения 1/ц и дис-
персии длины сообщения а2.
Пример. Пусть длительность сообщения распределена по экспоненциальному
закону. Тогда
о2 = 1/ц2 и М(п) = р/(1 -р).
Этот результат был получен ранее для системы Ml MIX.
Пример. Пусть сообщения имеют фиксированную длительность т0 = 1/ц. Тогда
су2 = 0 и М(п) = (I - р/2)(р/[ 1 - р]). (8.10)
Таким образом, при сообщениях фиксированной длительности средняя
занятость буферной памяти, меньше, чем для модели MIMIX. Теперь, используя
формулу Литтла, можно найти среднее время задержки для сообщений, посту-
пающих в буферную память. Учитывая, что р = Х/ц, для модели MIGIX получим
М(П = (1/Х)ЛДл) = (1/[2ц{1 -р}])(2-р[1 -Ц2с2]). (8.11)
Для экспоненциального распределения длины сообщения, когда а2ц2 = 1,
находим
М(Т)= 1/(|л[1-р]). (8.12)
При фиксированной длине сообщения
М(7) = (1-р/2)/(ц[1-р]). (8.13)
Другие случаи можно исследовать аналогично.
Выражение для среднего времени задержки в системе MIGIX анало-
гично выражению, полученному7 для системы MIMIX, и отличается лишь
наличием в формуле (8.11) второго члена в скобках, зависящего от величи-
ны разности (1 - ц2п2). Для законов распределений длин сообщений, у ко-
торых а2 < 1/ц2, среднее время задержки меньше, чем в случае экспоненци-
ального распределения длины сообщения. Для законов распределений длин
сообщений, у которых о2 > 1/ц2, среднее время задержки выше. Интуитив-
но ясно, что с увеличением дисперсии вероятность появления более длин-
ных сообщений увеличивается и, следовательно, время задержки растет.
Формула (8.11), называемая также формулой Поллачека - Хинчина,
определяет среднее время задержки для модели MIGIX. Эквивалентная
формула в более компактной форме может быть записана для среднего
времени, затрачиваемого на ожидание в очереди на обслуживание. Это
время равно разности времен задержки и обслуживания (передачи) сооб-
щения. Формула для времени ожидания будет использоваться позже при
7—3834 •
193
8.3. Системы массового обслуживания с ожиданием
Сообщение Обслуживание
поступает в начинается
систему
____I_____________I_____►
Т,,*Время
Время ожидания
Рис. 8.10. Время ожидания в
системе обслуживания
М(ТОЖ) = -^^.
X ОЖ / П 1 ~
2 1 - р
описании систем массового обслуживания с
приоритетами. Среднее время М(Т) равно
сумме среднего времени ожидания М(Т0^ и
среднего времени обслуживания (передачи)
сообщения 1/ц (рис. 8.10).
М(П = Л/(Г0Ж)+1/р. (8.14)
Подставляя выражение (8.14) в (8.11),
решая его относительно М(Т0Ж) и упрощая,
получим
(8.15)
Таким образом, среднее время ожидания зависит от второго
момента Л/(т2) распределения длины сообщения.
8.3.3. Сети с большим числом узлов, соединенных каналами связи
Рассмотрим сеть, содержащую большое число узлов, соединенных канала-
ми связи. Пусть для буферной памяти, связанной с /-й линией, интенсив-
ность входного потока среднее число ожидающих и обслуживающихся
сообщений М(п1) и среднее время задержки М(Т^). Тогда, согласно теореме
Литтла, ЪМЩ = i = 1... w, где ni~ число узлов в сети.
Рассмотрим теперь модель полной сети, заключенную в традици-
онный «черный ящик». Пусть у - среднее число сообщений, поступаю-
щих в «черный ящик» за единицу времени; М(Т) - среднее значение
времени задержки сообщений в сети и M(ri) - среднее число сообщений,
находящихся в сети. «Черный ящик» сам ведет себя как система обслу-
живания, для которой по теореме Литтла можно записать:
Л/(7’)у=А/(и) .
Тогда, суммируя по всем системам обслуживания в сети и приме-
няя теорему Литтла к каждой из них, получим
m in
/=1 /=|
Очевидно, что это приводит к выражению
I in
т. е. к формуле (8.7), которая ранее использовалась при определении
пропускной способности каналов сети.
Часто представляет интерес нахождение вероятности того, что размер
очереди превышает определенную величину. Выражение для этой вероят-
ности обычно используют при решении задачи выбора объема буферной
памяти при наличии ограничения на вероятность переполнения этой памя-
194
Глава 8. Системы массового обслуживания и их моделирование
ти. Может быть найдена вероятность того, что число сообщений, ожидаю-
щих в очереди в системе М/М/\, превысит заданное число N:
P(n<N)= f р„ = (1-р) £р"=р"+1 . (8.16)
п= Л'+1 л=М+1
Ниже указаны значения Р(л > N) при р = 0,6 и различных значениях N.
N... 1; 3; 9; 19;
P(m>7V)... 0,36; 0,13; 6,1-10'3; 3,7-10'5.
Как видно, вероятность уменьшается с ростом N, что следует из
выражения (8.16).
Рассмотрим модель обслуживания, в которой предполагаются огра-
ниченный объем буферной памяти, пуассоновский входной поток и экспо-
ненциальное распределение длин сообщений. При выводе формулы (8.3)
для стационарных вероятностей длины очереди не использовалось предло-
жение о неограниченном объеме буферной памяти. Следовательно, выра-
жение для р„ является справедливым и в случае ограниченного объема бу-
ферной памяти, с той лишь разницей, что сумма вероятностей конечного
числа состояний должна быть равна единице. Используя выражения для
N N
]Гр„ = 1 = Ро^р" = Ро
//=0 //=0
суммы членов геометрической прогрессии, имеем
1-р"+|1
'-р 1г
Следовательно,
р0 = (1-р)/(1-р"+1) И р„ = (1-р)р"/(1-рЛ'+|).
(8-17)
(8.18)
Вероятность того, что буферная память заполнена и очередное по-
ступающее сообщение получит отказ (блокируется), равна вероятности
того, что N сообщений находятся в буферной памяти:
pN =(l-p)pA'/(l-pv+l). (8.19)
*0-/0
Очередь
ограниченного
размера (N сообщений)
(Ро)иг
Рис. 8.11. Система обслуживания М1М1\
с ограниченным объемом буферной памяти
Рассмотрим систему обслуживания М/М/Х с ограниченным объемом
буферной памяти (рис. 8.11). Предположим, что интенсивность входного
потока - X (сообщений/с) и объем буферной памяти рассчитан на прием и
хранение только 7V сообщений. Если вероятность блокировки обозначить
через РБ, то интенсивность потока сообщений, поступающего на вход сис-
темы, должна составлять Х(1 - РБ) сообщений/с. В стационарном режиме
эта интенсивность должна совпадать с интенсивностью выходящего пото-
ка. Вероятность того, что сообщение покинет систему за интервал А/, равна
195
8.3. Системы массового обслуживания с ожиданием
цД/, если хотя бы одно сообщение находится в системе. Вероятность того,
что очередь не пуста, определяется как (1 - ро). Следовательно, интенсив-
ность выходного потока равна (1 -/?0)ц и тогда
Х(1-РБ) = (1-р0)Ц • (8.20)
Для систекгы М/М/\ с ограниченным объемом буферной памяти вероят-
ность ро определяется формулой (8.18). Подставляя ее в (8. 20), и учитывая, что
р = Л/р, получим выражение для вероятности блокировки РБ, которое совпада-
ет с (8.19). Полагая с целью проверки РБ = 0, из (8.20) имеем р = (1 - р0), что
согласуется с уравнением (8.20).
8.3.4. Приоритетное обслуживание
В сетях связи для ЭВМ характерной является передача сообщений с
различными приоритетами. Коротким сообщением, содержащим под-
тверждения, часто назначают более высокий приоритет, чем информа-
ционным сообщениям. По сети могут передаваться сообщения двух и
более категорий срочности. Например, некоторые пользователи, пере-
дающие в среднем сообщения более короткие, чем у других абонентов,
получают приоритет для ускорения общей доставки сообщений. В связи
с этим представляет интерес исследование системы M!G/[ с нескольки-
ми классами сообщений, обладающих разными приоритетами. Для уп-
рощения этой задачи основное внимание будет уделено определению
среднего времени ожидания, а не времени задержки. Как видно из вы-
ражения (8.14), среднее время задержки всегда можно получить, доба-
вив среднее время передачи сообщения к среднему времени ожидания.
Будем предполагать, что сообщения разных классов обладают относи-
тельными приоритетами. При этом сообщение с более высоким приори-
тетом располагается в очереди перед сообщениями с более низким при-
оритетом, но уже начавшееся обслуживание сообщений с более низким
приоритетом не прерывается.
В рассматриваемой системе обслуживания предполагается, что
классы сообщений, обозначаемые индексомр = 1,2, 3, ..., г, пронумеро-
ваны в порядке уменьшения приоритета. Рассмотрим сообщение с при-
оритетом р, которое прибывает в систему в момент времени /0 и через
интервал времени TQyKp поступает на обслуживание, т.е. начинается его
передача. Получим выражение для M(TQ^P среднего времени ожидания
сообщений с приоритетом р. Для этого разберем, из каких компонентов
складывается Гож. Очевидно, что сюда входят: время TQi необходимое
для завершения текущего обслуживания; времена Тк необходимые для
обслуживания сообщений с приоритетами к = 1, 2, ..., р, уже ожи-
дающих обслуживания в очереди к моменту поступления рассматри-
ваемого сообщения, и времена Т'к{к = 1,2, ..., р - 1) необходимые для
обслуживания сообщений с более высоким приоритетом, которые могут
196
Глава 8. Системы массового обслуживания и их моделирование
поступить за интервал ожидания и будут обслужены раньше данного
сообщения. Суммируя средние значения всех этих случайных величин,
получим
Л/(ТОЖ)„ = Л/(Г0) + £ WJ + SwD. (8.21)
А'=1 к=1
Для оценки Л7(77) допустим, что среднее число ожидающих сооб-
щений с приоритетом к составляет Если каждое из них требует
для обслуживания в среднем 1/ц* единиц времени, то
М(Тк) = АЦтк)/^к. (8.22)
Но М(т^ представляет собой разность двух величин - среднего
числа сообщений, ожидающих и обслуживаемых в системе М(пк\ и
среднего числа обслуживаемых сообщений. Число последних составля-
ет р* = где Хк - интенсивность потока сообщений £-й категории.
Из теоремы Литтла следует, что
А/(«*)=^^(г)=Цл/(Гож)4 +1/ц*]=Л/(ш*)+р4. (8.23)
Тогда
M(mk) = XkM(T0.Jk, (8.24)
М(Тк} = ркМ(Т^к. (8.25)
Рассмотрим теперь член М(Т'к) в формуле (8.21), представляющий
собой среднее время, необходимое для обслуживания сообщений с при-
оритетом к> р, которые поступят в течение среднего времени ожидания
МТ’ож)/?- Путем рассуждений, аналогичных тем, которые использовались
при нахождении Л/(77), получим
М(т;)=рЛЛ/(7'ож)/,. (8.26)
Можно показать, что время ожидания для сообщений с приорите-
том р можно найти по формуле
(8.27)
где •
Определим теперь величину времени Л/(Т0), необходимого для завер-
шения текущего обслуживания. Рассмотрим сначала систему обслужива-
ния M/G/X с одним классом требований. Сравнивая выраж ения (8.27) и
(8.15), получим в этом случае Л/(7о) = ХЛ/(т2)/2. С целью проверки предпо-
ложим, что распределение длин сообщений экспоненциальное. Тогда легко
показать, что Л/(Т0) = р/ц. Указанная величина может рассматриваться как
произведение вероятности занятости системы обслуживания р на среднюю
длину сообщения 1/ц. В более общем случае, для системы обслуживания с
несколькими классами требований, получим
Л/(7’0) = Мт2)=|х^Л/(т,)=1ххА.Л/(тх2), (828)
2 2 к=} Л Лк=1
197
8.3. Системы массового обслуживания с ожиданием
Пример. Рассмотрим случай, когда существуют два приоритетных класса: р = 1
и р = 2. Предположим также, что распределения длин сообщений подчинено
экспоненциальному закону со средними значениями 1/ц 1 и 1/ц2 соответственно.
Тогда из выражений (8.27) и (8.28) при а2к = 1 /ц\., Л/(т2^) = 2/ц2А. легко найти, что
М(Г ) । = , (8.29)
1-Pi
. (8.ЗО)
Среднее время ожидания для сообщений с более низким приоритетом (р = 2)
больше, чем у сообщений с более высоким приоритетом (р = 1), так как сообщение с
более высоким приоритетом помещается в очередь перед низкоприоритетными со-
общениями. Для определения среднего времени задержки необходимо соответст-
вующее среднее время обслуживания прибавить к среднему времени ожидания. При
отсутствии приоритетов сообщения обслуживаются по правилу «первым пришел -
первым обслужен», т. е. справедлива общая формула для системы MIGIX и среднее
время ожидания любого сообщения можно определить из выражения (8.15). Сред-
нее время задержки сообщения каждого класса можно опять получить, прибавив
среднее время обслуживания (передачи).
Пример. Рассчитаем среднее время задержки в случае трафика трех видов: голос, ви-
део и данные.
Пусть трафик голоса имеет приоритет р = 1, трафик видео имеет приоритет
р = 2, трафик данных имеет приоритет р = 3.
Среднее время задержки будем рассчитывать по формулам:
^(Г),.„,„ = Л/(7-0Ж. То,„)+Л/С,
A/(rU = Hr0X<to,J+Z3/C.
, х У’.рДД/С)
Здесь Л/(ти.т,„)=±^-------;
1-Р1
Е’,р.(А/о
М Рож (lalaj- Л Yi ¥1 V
_ Х1£1 _ X2L2 . „ _
Pl"“ р2"~’Рз""с“’
где: £2, L3 - средняя длина пакетов с речью, данными и видео, соответственно;
Х2, - средняя интенсивность пакетов с речью, данными и видео, соответственно.
8.3.5. Система обслуживания MIMINIm
Пусть на СМО MIMINIm с числом обслуживающих приборов N и чис-
лом мест для ожидания т поступает поток заявок с интенсивностью X,
которые обслуживаются каждым прибором с интенсивностью ц. Пусть
также время ожидания в очереди распределено по экспоненциальному
закону с параметром (интенсивностью) у.
198
________Глава 8, Системы массового обслуживания и их моделирование
Определим вероятность обслуживания требований, вероятность
ожидания требованием начала обслуживания и среднее время ожидания.
В рассматриваемой СМО существуют следующие рабочие состояния:
система обслуживает5требований с интенсивностью sp, если 0<s<N\
система ставит требование в очередь, если число требований
больше числа обслуживающих приборов, но меньше числа мест ожида-
ния N < 5 < т, при этом интенсивность поступления требований из оче-
реди равна (5 - N)v9
система отказывает требованиям в обслуживании, если 5 > (N+ т).
Под состоянием сети будем понимать значение числа требований,
находящихся на обслуживании (в системе распределения ресурса и в
очереди) в момент времени t. Обозначим через 5 = 0, S номер со-
стояния СМО (число требований в ней), где S= N+ т.
Для аппроксимации вероятностно-временного механизма перехода
СМО из одного состояния в другое используем аппарат марковских цепей.
Граф состояния системы представлен на рис. 8.12.
уУц (N^i+yiv)
Рис. 8.12. Граф состояния СМО с ожиданием
Пусть задан вектор вероятностей начальных состояний СМО
Р(0,х) "Р" ' "°-
[0 При 5 > 0,
а также матрица интенсивностей переходов Q = {qsi}, элементы которой
определены следующими выражениями:
{X при / = 1,1
л /sol ДЛЯ 5 “ 0’
0 при / > 2,J
X при 7 = 5 + 1,
5Ц при 7 = 5-1,
0 при 17 — 51 > 2
X при 7 = 5 + 1,
N[i + (5 - W)v при 7 = 5 -1, > для N < 5 < (N + т],
0 при |5-71 > 2,
[ТУр, + niv при 7 = N + т -1,1 / \
4N+m,l= п / А7 I 1 ДЛЯ5 = (У+ж),
[0 при 7 < N + т -1 J
где 7 - номер состояния СМО.
199
8.4. Системы массового обслуживания с отказами
Можно показать, что для установившегося режима работы СМО
имеет место вектор финальных вероятностей состояний СМО р = {ps}.
Зная вектор финальных вероятностей, нетрудно определить среднее
время пребывания заявок в очереди и другие характеристики СМО с
очередями.
Решение данной задачи для случая Z < N и для т = 0, т = 0 было
найдено Эрлангом (2-я формула Эрланга):
Р(7ож > о) = ---• (8.31)
Zj f! N\ N-Z
i=Q
Для т > 0 решение последнего уравнения определяется формулой
Бухмана:
Р^ож > т) = Р(тож > 0)Р„(Тож > г) = Р(гож > 0) . (8.32)
Среднее время ожидания начала обслуживания определяется вы-
ражением
Р(7? > 0)-
цУ -X
Средняя длина очереди находится по формуле Литтла (8.7).
Математический аппарат ТМО охватывает широкий класс СМО с
простейшими, примитивными и рекуррентными потоками и может быть
использован для анализа и синтеза СМО с отказами, с ожиданием и не-
надежными единицами ресурса. Трудность аналитического разрешения
уравнений состояния для СМО большой размерности делает целесооб-
разным применение для их исследования методов имитационного моде-
лирования и численных методов расчета на ЭВМ. Особо следует отме-
тить важность постановки и решения оптимизационных задач для СМО.
В качестве целевых функций критериев при этом целесообразно ис-
пользовать полученные вероятностно-временные характеристики
(ВВХ), а оптимизируемыми переменными могут стать интенсивности
входящего потока требований, число мест для ожидания, число обслу-
живающих приборов, дисциплина обслуживания, алгоритм предостав-
ления ресурса.
8.4. Системы массового обслуживания с отказами
Рассмотрим задачу построения модели и анализа вероятностно-
временных характеристик СМО с отказами на примере многоканальных
систем. Пусть на вход СМО, содержащей N обслуживающих приборов,
действует простейший поток требований (поток, обладающий свойст-
вами стационарности, ординарности и отсутствием последействия) с
интенсивностью X, а обслуживание требований каждым прибором СМО
осуществляется с интенсивностью ц. При занятости всех N приборов
вновь пришедшая заявка получает отказ и покидает СМО. Данная зада-
ча была рассмотрена Эрлангом, и им впервые определены выражения
для вероятности отказов (обслуживания) в СМО данного класса.
200
Глава 8. Системы массового обслуживания и их моделирование
На рис. 8.13 представлен граф состояний СМО M/M/N с отказами.
Ц /?|1 Mi
Рис. 8.13. Граф состояния СМО M/M/N с отказами
Как видно из рисунка, СМО может находиться в одном из сле-
дующих состояний:
все приборы свободны, заявок на входе СМО нет;
один прибор занят, обслуживается одна заявка;
и приборов занято, обслуживается п требований;
все N каналов заняты, обслуживается W требований, а вновь при-
шедшая заявка теряется.
Динамика вероятностей состояний СМО может быть описана сис-
темой дифференциальных уравнений, составленных по следующему
мнемоническому правилу:
производная dpn(Z)/dZ вероятности пребывания системы в состоянии и
равна алгебраической сумме членов, число которых равно числу стрелок на
графе состояния, соединяющих состояние п с другими состояниями;
если стрелка направлена в состояние п, то член берется со знаком
«минус»;
если стрелка направлена из состояния п, то член берется со знаком
«плюс»;
каждый член суммы равен произведению вероятности того со-
стояния, из которого направлена стрелка, и интенсивности потока собы-
тий, переводящего систему по данной стрелке. Данная система уравне-
ний описывает вероятностный механизм смены состояний марковского
процесса гибели и размножения:
-^^=-Хро(0+ИА(0>
а/
-(х. + лц)р„(0+ ^P,>-i(0+ (« + *)мр»+|(0.
(8.33)
at
гдеp„(t) - вероятность принятия СМО состояния п ~ 1, ..., N.
Для установившегося режима работы СМО справедливы условия
dpll(t)/dt= 0, Х/ц < 1, п = 1, ..., N. В этом случае финальные вероятности,
найденные из решения системы уравнений (8.33), имеют вид
х р" . V
Ц //=0
201
8.5. Общие принципы моделирования систем массового обслуживания
Здесь введено понятие загрузки прибора (единицы ресурса) р = Х/(яц).
Из условия нормировки =X1^=Qp(p/п\= 1 нетрудно получить
выражение для вероятности сохранения незанятого состояния СМО:
На основе выражения (8.34) может быть определена вероятность
отказа, т. е. вероятность того, что все N приборов заняты:
а также вероятность обслуживания поступающих требований (1-я фор-
мула Эрланга)
Робел ~ 1 — Ротк •
Вероятность отказа в СМО с примитивным потоком заявок Z = zuS
(от конечного числа 5 источников) определяется формулой Энгсета:
Уравнения для математического ожидания и дисперсии числа заявок,
находящихся в СМО в момент времени t, определяются выражениями:
“ ”м)р„ = * - Ц«<х(').
и/ 11=0
dD*^ = £(* + «Ц + 2л(Х - лц)- 2»ir(zXx - «ц))р„ =
(8.37)
4/ ц=о
= Х + ц/ях -2pZ)x(/); =ц0 = 0.
8.5. Общие принципы моделирования систем массового
обслуживания
8.5.1. Метод статистических испытаний
Задачи, встречающиеся на практике, зачастую оказываются настолько
сложными, что получить их характеристики с помощью аналитического
метода невозможно (например, поток поступающих требований не являет-
ся простейшим, время обслуживания не распределено по показательному
закону, дисциплина обслуживания может быть достаточно сложной, в сис-
теме могут существовать обратные связи и т.д.). В таких случаях целесооб-
разно использовать метод статистических испытаний СМО. Если процесс
функционирования СМО случайный, то моделирование подобной системы
состоит в построении реализаций случайного процесса на ее выходе.
202
________Глава 8. Системы массового обслуживания и их моделирование
Метод статистических испытаний позволяет исследовать зависимость
эффективности системы обслуживания от параметров потока заявок и са-
мой системы. Кроме того, этот метод позволяет оценить не только про-
стейшие характеристики эффективности системы, но значения многих дру-
гих важных показателей системы (дисперсию доли отказов, вероятность
того, что значение доли отказов будет не ниже заданного и т.п.).
Сущность метода статистических испытаний применительно к анализу
СМО состоит в следующем. С помощью специальных алгоритмов формиру-
ются реализации потока заявок с заданным законом распределения интервалов
между ними. Далее моделируется процесс функционирования обслуживающей
системы. Все интересующие показатели работы системы фиксируются. Общий
алгоритм модели многократно воспроизводит случайные реализации процесса
функционирования системы при некоторых заранее заданных условиях. Нако-
пленная в результате информация статистически обрабатывается.
Входящий поток требований однозначно задается последователь-
ностью моментов времени поступления заявок в систему Ть Т2, .... Од-
нако для моделирования удобнее рассматривать случайные величины т*,
определяющие длину интервалов между моментами поступления зая-
вок. Тогда для задания входящего потока достаточно получить последо-
вательность случайных величин тк с заданным законом распределения.
Пусть на вход системы поступает простейший поток. Плотность
распределения длин интервалов между заявками для такого потока со-
ответствует показательному закону w(t) = Хе~\ t > 0 Тогда, как отмеча-
лось, для получения последовательности чисел {тк, к = 1,2,...} использу-
ется соотношение тк = -(1/Х)1пх^, где хк - случайное число из последова-
тельности с равномерным распределением на интервала [0; 1).
Аналогично может быть получена последовательность и для других за-
конов распределения длин интервалов между заявками. Те же приемы ис-
пользуются и для формирования случайных значений времени обслуживания.
Рассмотрим простую СМО, которая состоит из 3 одинаковых каналов;
входящий поток - простейший с параметром X; время обслуживания в кана-
ле одного требования постоянно и равно /обсл- Данная СМО является систе-
мой без ожидания, т.е. требование, заставшее все каналы занятыми, покидает
систему. Дисциплина обслуживания такова: если в момент поступления А-го
требования первый канал свободен, то он приступает к обслуживанию тре-
бования; если этот канал занят, то требование обслуживает второй канал и
т.д. Надо определить, сколько требований в среднем обслужит система за
время Т и сколько в среднем она даст отказов ?
За начальный момент расчета выбирают момент поступления пер-
вого требования Т\ = 0. Введем следующие обозначения: Тк- момент
поступления А:-го требования; тк - промежуток времени между поступ-
лением в систему £-го и (к + 1)-го требования; tt — момент окончания об-
служивания требования z-м каналом.
Предположим, что в момент 7\ все каналы свободны. Первое требо-
вание поступает на 1-й канал. Таким образом, в течение Гобсл этот канал за-
нят. Поэтому полагают = Т\ + добавляют единицу к счетчику обслу-
женных требований и переходят к рассмотрению второго требования.
203
8.5. Общие принципы моделирования систем массового обслуживания
Предположим, что £ требований уже рассмотрено. Определим момент
поступления (£ + 1)-го требования. Для этого найдем очередное значение хк
равномерно распределенной случайной величины и вычислим очередное
значение т* = -(1/Х)1пх^, а затем момент поступления (к + 1)-го требования
Д+1= Тк + тк.
Чтобы узнать, свободен ли в этот момент первый канал, необходимо
проверить условие > 77+1. Если это условие выполнено, то к моменту 77+1
первый канал освободился и может обслуживать требование. В этом случае
Г1 заменяется на + /обс, добавляется единица к счетчику обслуженных
требований и происходит переход к следующему требованию.
Если t\ > 77+1, то первый канал в момент 77+1 занят. В этом случае
проверяем, свободен ли второй канал. Если условие t2 < Тк+[ выполнено,
заменяем t2 на 77+1 + /Обсл3 добавляем единицу к счетчику обслуженных
требований и переходим к следующему требованию.
Если 6 > 77ы, то проверяем условие t3 < 71+ь Если все каналы оказались
заняты, то в этом случае прибавляем единицу в счетчик отказов и переходим
к рассмотрению следующего требования. Результаты моделирования можно
оформить в виде таблицы, имеющей следующий заголовок (рис. 8.14):
№ заявки Случайное число хк Время между двумя последовательными заявками Момент поступления заявки Тк Момент окончания обслуживания заявки 0 каналом /, Счетчик обслуженных заявок Счетчик отказов
1 2 3
Рис. 8.14. Заголовок таблицы для регистрации результатов моделирования
Каждый раз, вычислив 77+1, надо проверить еще условие оконча-
ния реализации 77+1 > Т. Если это условие выполнено, то одна реализа-
ция случайного процесса функционирования системы воспроизведена и
опыт заканчивается. В счетчике обслуженных требований и в счетчике
отказов находятся числа яОбСЛ и т?0ТК.
Получив п реализаций случайного процесса, т.е., повторив такой опыт
п раз, определяем оценки математических ожиданий числа обслуженных
требований Л/(77обСл) и числа требований, получивших отказ А/(иотк).
8.5.2. Блочные модели процессов функционирования систем
Рассмотрим машинную модель Мт системы 5 как совокупность блоков
{/??/}, i = 1,2, ..., л. Каждый блок модели можно охарактеризовать ко-
нечным набором возможных состояний {ZQ}, в которых он может нахо-
диться. Пусть в течение рассматриваемого интервала времени (0; 7)
блок i изменяет состояние в моменты времени tjJ < Т, где J - номер мо-
мента времени. Моменты времени можно разделить на три группы: слу-
чайные, связанные с внутренними свойствами блока; случайные, свя-
занные с изменением состояния других блоков, имитирующих воздей-
ствие среды Е; детерминированные моменты, связанные с заданным
расписанием функционирования блока.
204
________Глава 8. Системы массового обслуживания и их моделирование
Смена состояний модели для случая трех блоков (z = 1, 2, 3) пока-
зана на рис. 8.15.
Рис. 8.15. Смена состояний модели для случая трех блоков
Моментами смены состояний модели в моменты времени < Т
будем считать все моменты изменения состояния блоков {/и,}. При этом
моменты и ? являются моментами системного времени, т.е. времени, в
котором функционирует система 5. При машинной реализации модели Мп1
ее блоки представляются соответствующими программными модулями.
8.5.3. Особенности моделирования с использованием Q-схем
Рассмотрим фрагмент Q-схемы (рис. 8.16.).
При моделировании Q-схем следует адекватно учитывать как свя-
зи, отражающие движения заявок (сплошные линии), так и управляю-
щие связи (пунктирные линии). Примерами управляющих связей явля-
ются различные блокировки обслуживающих каналов (по входу и по
выходу), где «клапаны» изображены в виде треугольников. Блокировка
канала по входу означает, что этот канал отключается от входящего по-
тока заявок. Блокировка канала по выходу указывает, что заявка, об-
служенная блокированным каналом, остается в этом канале до момента
снятия блокировки. В результате, если перед накопителем нет «клапа-
на», то при его переполнении будут иметь место потери заявок.
205
8.5. Общие принципы моделирования систем массового обслуживания
Моделирующий алгоритм должен отвечать следующим требова-
ниям: обладать универсальностью относительно структуры, алгоритмов
функционирования и параметров системы 5; обеспечивать одновремен-
ную и независимую работу системы S; укладываться в приемлемые за-
траты ресурсов ЭВМ (памяти, времени расчета для реализации машин-
ного эксперимента); проводить разбиение на достаточно автономные
логические части (блоки); гарантировать выполнение рекуррентного
правила расчетов.
При этом необходимо иметь в виду, что появление одной заявки
входящего потока в некоторый момент времени г, может вызвать изме-
нение состояния не более чем одного из элементов Q-схемы. Окончание
обслуживания заявки в момент г, в некотором канале К может привести
в этот момент времени к последовательному изменению состояний не-
скольких элементов (Я; К), т.е. будет иметь место процесс распростра-
нения смены состояний в направлении, противоположном движению
заявки в системе S. Поэтому просмотр элементов Q-схемы должен быть
противоположным движению заявок.
На рис. 8.17 показано, как можно классифицировать все виды мо-
делирующих алгоритмов Q-схемы.
|Моделирующие алгоритмы]
__________I I I_____________________________
| Детерминированные | ] Стохастические |
Г '
__________i________ i______
| Асинхронные [ |Синхронные
* \ *
Циклические____| | Спорадические
Рис. 8.17. Виды моделирующих
алгоритмов Q-схем
Алгоритмы, моделирующие Q-схему по принципу «А/», являются де-
терминированными (по шагу), а по принципу особых состояний - стохас-
тическими. Последние могут быть реализованы синхронным и асинхрон-
ным способами.
Контрольные вопросы к главе 8
1. Дайте определение СМО.
2. Приведите обобщенную структурную схему СМО и дайте характе-
ристику ее компонент.
3. Дайте определение потоков событий, стационарных потоков.
206
Глава 8. Системы массового обслуживания и их моделирование
4. Дайте определение Q- схемы и охарактеризуйте ее параметры.
5. Дайте определение и сравнительный анализ видов приоритета.
6. Приведите классификацию СМО и их основных характеристик.
7. Дайте определение и характеристику дисциплин обслуживания СМО.
8. Дайте определение и характеристику СМО М/М/\.
9. В чем заключается моделирование сетей с большим числом узлов,
объединенных каналами связи ?
10. Охарактеризуйте модель обслуживания с ограниченным объемом
буферной памяти.
11. Дайте определение и характеристику СМО M/G!1.
12. Дайте определение и характеристику СМО с приоритетным обслу-
живанием.
13. Приведите примеры моделей приоритетного обслуживания трафика.
14. Охарактеризуйте модели многоканальных СМО с отказами.
15. Охарактеризуйте модели многоканальных СМО с ожиданием.
16. В чем заключаются особенности моделирования СМО ?
17. В чем заключаются особенности моделирования процессов с исполь-
зованием Q-схем ?
Глава 9
МОДЕЛИРОВАНИЕ УЗЛА СЕТИ FRAME RELAY
9.1. Основные положения протокола Frame Relay
Основные положения технологии передачи речи по сетям Frame Relay
(FR) нашли отражение в документе FRF. 11 форума по развитию техно-
логии Frame Relay, который получил название «Соглашение по внедре-
нию» (Implementation Agreement) и является фактическим стандартом
для производителей оборудования и операторов сетей. Данный стандарт
предусматривает поддержку множества алгоритмов кодирования речи,
эффективное использование низкоскоростных соединений Frame Relay,
мультиплексирование до 255 подканалов в одном логическом соедине-
нии, поддержку различных речевых информационных элементов раз-
личных подканалов в пределах одного кадра, мультиплексирование
подканалов данных и речевых подканалов.
Информация пользователя упаковывается в пакеты, которые явля-
ются субкадрами, и размещается в информационном поле кадра Frame
Relay. Модель мультиплексирования речевых подканалов в устройствах
VFRAD (Voice Frame Relay Access Device) показана на рис. 9.1.
Данные
пользователя
Данные
пользователя
Службы пользователя
DLCI 16
FRF.3.1
многопротокольная
инкапсуляция
FRF.3.1
многопротокольная
инкапсуляция
DLCI 17
DLCIN
Физический интерфейс Frame Relay
Рис. 9.1. Модель мультиплексирования речевых каналов через Frame Relay
208
Глава 9. Моделирование узла сети Frame Relay
Структура пакетов Frame Relay с различными вариантами инкапсуля-
ции приведена на рис. 9.2, где иллюстрируется случай, когда один DLCI
(Data Link Connection Identifier) используется для поддержки трех речевых
каналов и одного канала передачи данных, причем речевые пакеты перено-
сятся в одном кадре Frame Relay. Форматы пакетов и их синтаксис при пе-
редаче различных видов информации (цифры набора номера, сигнальная
информация, данные, факс, речевая информация) при различных методах
сжатия описаны в приложениях к документу FRF. 11.
Рис. 9.2. Метод инкапсуляции пакетов пользователя в кадры Frame Relay
В табл. 9.1 указаны объекты спецификации различных приложе-
ний FKF.l 1.
Таблица 9.1. Содержание приложений FRF.11
Предмет спецификации Приложение
Передача цифр набора номера А
Передача бит сигнализации В
Передача данных С
Передача факсимильных сообщений D
Передача речи с использованием базовых CS-ACELP (G.729) Е
Передача речи с использованием базовых ИКМ/АДИКМ (G.711, G.726) F
Передача речи с возможностью сброса пакетов при использовании EADPCM (G.727) G
Передача речи с использованием LD-CELP (G.728) Н
Передача речи с использованием кодера MP-MLQ (G.723.1) I
В технологии Frame Relay кадры формируются на основе протоко-
ла LAP-F, формат которого приведен на рис. 9.3.
Рис. 9.3. Формат кадра LAP-F
209
9.1. Основные положения протокола Frame Relay
Поле номера виртуального соединения DLCI (Data Link Connection
Identifier) состоит из 10 битов. Возможно, что поле DLCI будет занимать
больше разрядов, это зависит от значения признака Extended Address
(расширенный адрес). Если бит в нем окажется установленным в 0, то
признак называется ЕАО и это означает, что в следующем байте имеется
продолжение поля адреса, а если бит признака равен 1, то поле называ-
ется ЕА 1 и это указывает на окончание поля адреса.
Поле данных может иметь до 4096 байт. Поле C/R - это признак
«команда-ответ».
Поля DE, FECN и BECN используются протоколом для управле-
ния трафиком и поддержания заданного качества обслуживания вирту-
ального канала. Формат пакета приведен на рис. 9.4.
Октеты 1а и 1b заголовка являются не обязательными, и их наличие оп-
ределяется значениями бит Е1 и L1 обязательного октета 1. Младшие 6 разря-
дов октета 1 определяют номер подканала - CID (Subchannal identification) в
случае, если по одному виртуальному каналу Frame Relay с фиксированной
DLCI передаются пакеты между различными парами «источник-получатель».
8 7 6 5 4 3 2 1 Октеты
Е1 L1 Идентификатор подканала (CID) (младшие 6 бит) 1
CID (старшие 2 бита) 0 резерв 0 резерв Тип информационного поля 1а
Длина информационного поля 1b
Р
Полезная информация Р+1 Р+80
80*М
Рис. 9.4. Формат одного речевого пакета
Очевидно, что в этом случае значения CID могут изменяться от 0 до 63.
При необходимости расширения диапазона значений CID можно воспользо-
ваться октетом I а, тогда бит индикации расширения заголовка - El (Extension
Indication) в октете 1 должен быть установлен (Е1=1). В этом случае два
старших разряда октета 1а увеличивают поле CID и интерпретируются как
два его старших разряда. Отметим, что коды CID от 00000000 до 00000011
зарезервированы и не используются как при обычном, так и при расширен-
ном формате заголовка. Младшие 4 разряда октета 1а определяют тип ин-
формационного поля данного пакета в соответствии с табл. 9.2.
210
Глава 9. Моделирование узла сети Frame Relay
Таблица. 9.2. Содержание разрядов информационного поля пакетов
Разряды 4 3 2 1 Вид передаваемой информации
0 0 0 0 Полезная кодовая информация, структура которой определяется ме-
тодом кодирования речи
0 0 0 1 Передача набора номера
0 0 10 Передача бит синхронизации
0 0 11 Передача факсимильных сообщений
0 10 0 Передача описания паузы
Если значение бита EI равно 0 и октет 1а в заголовке отсутствует, значе-
ние кода типа информационного поля подразумевается равным 0000. Уста-
новка значения бита LI (Length Indication) указывает на наличие в заголовке
октета расширения 1Ь. Если в одном кадре Frame Relay переносится несколь-
ко пакетов, то в заголовках всех пакетов кроме последнего бит LI должен быть
установлен в I. В поле октета 1b указывается количество октетов, составляю-
щих поле полезной информации следующего за заголовком пакета. В послед-
нем (или единственном) пакете в кадре Frame Relay бит LI всегда равен 0.
Структура поля полезной информации определяется его типом и
при передаче речи - методом сжатия.
В рассматриваемом случае для передачи информации о паузе мо-
жет быть использован второй предусмотренный стандартом тип пакета
SID (Silence insertion descriptor). Формат информационного поля пакета
SID показан на рис. 9.5.
8 7 6 5 4 3 2 1 Октет
N Резерв Р
Уровень шума, дБм
Рис. 9.5. Формат информационного поля пакета SID
Данный пакет несет информацию об уровне шумов в канале при
паузах и может посылаться периодически или, например, при измене-
нии уровня шума. Учитывая малую длину пакета SID, в дальнейших
расчетах не будут учитываться затраты времени на его передачу.
В соответствии с алгоритмом сжатия речевого сигнала кодер G.728
(LD-CELP) формирует кодовое слово длиной 10 бит при поступлении на его
вход пяти отсчетов ИКМ последовательности. Для передачи в кодер Frame
Relay эти кодовые слова должны быть трансформированы в блочную струк-
туру, определенную в стандарте FRF.11, приложение Н. Основной информа-
ционный блок пакета несет информацию о речевом сигнале длительностью
5 мс и имеет распределение бит в кодовых словах, показанное на рис. 9.6.
Каждая группа из 5 октетов содержит биты четырех 10-битных кодо-
вых слов кодера и соответствует интервалу речевого сигнала в 2,5 мс. Две
таких группы объединяются в блок данных длительностью 5 мс. В резуль-
тате старший разряд каждого кодового слова совпадает с первым разрядом
группы. Каждый блок содержит 8 кодовых слов, размещенных в 10 окте-
тах. Размер информационного поля пакета зависит от индекса пакетизации
М, значение которого может лежать в диапазоне от 1 до 12.
211
9.2. Проектирование узла сети Frame Relay
В итоге появилась возможность выбирать длину пакета из значений,
равных 80 *М бит.
(MSB) 7 бит вектора формы (0) (LSB) |(MSB) 1 бит усиления (0) Окгет Р+1
2 бита усиления (0) (LSB) |(MSB) 6 бит вектора формы (1) Октет Р+2
1 бит вектора формы (1) (LSB) | (MSB) 3 бита усиления (1) (LSB) | (MSB) 4 бита вектора формы (2) Октет Р+3
3 бита вектора формы (2) (LSB) | (MSB) 3 бита усиления (2) (LSB) | (MSB) 2 бита вектора формы (3) Октет Р+4
бит вектора формы (3) (LSB) | (MSB) 3 бита усиления (3) (LSB) Октет Р+5
(MSB) 7 бит вектора формы (4) (LSB) | (MSB) I бит усиления (4) Октет Р+6
2 бита усиления (4) (LSB) |(MSB) 6 бит вектора формы (5) Октет Р+7
I бит вектора формы (5) (LSB) (MSB) 3 бита усиления (5) (LSB) I (MSB) 4 бита вектора формы (6) Октет Р+8
3 бита вектора формы (6) (LSB) | (MSB) 3 бита усиления (6) (LSB) | (MSB) 2 бита вектора формы (7) Октет Р+9
5 бит вектора формы (7) (LSB) | (MSB) 3 бита усиления (7) (LSB) Октет Р+10
Рис. 9.6. Структура основного информационного пакета
при использовании кодека G.728
9.2. Проектирование узла сети Frame Relay
Проектирование узла сети Frame Relay, предназначенного для передачи
речевых сообщений, требует решения двух основных задач:
1. Обеспечение требуемого качества обслуживания абонентов;
2. Выбор параметров системы передачи пакетов, которые обеспечат вы-
полнение первой задачи с наименьшими экономическими потерями.
Чаще всего - с наименьшей договорной пропускной способностью, за-
прашиваемой от сети Frame Relay.
Пакетная передача речи является стратегией передачи трафика в
реальном времени. Поэтому существуют строгие ограничения по дос-
тавке пакетов с учетом возможных задержек, потерь и ошибок при пе-
редаче по сети.
При малых вероятностях ошибок в процессе передачи по магист-
ралям сети качество обслуживания абонентов, т.е. качество восприятия
переданного речевого сигнала, прежде всего зависит:
от искажений речевого сигнала, связанных с алгоритмом его коди-
рования и восстановления;
от мешающих эффектов, связанных с общей задержкой при пере-
даче по сети, которая должна быть достаточно малой;
от мешающих эффектов, связанных с прерывистой передачей, вы-
званной случайным характером времени доставки кадра из конца в ко-
нец, возможными потерями кадров из-за переполнения буферов, сброса
опоздавших пакетов и т.п.
В общем случае разработчики сети должны контролировать не
только математическое ожидание времени задержки, но и дисперсию.
212
Глава 9. Моделирование узла сети Frame Relay
Задержка пакетов при передаче по сети Frame Relay. Общая
сквозная задержка пакетов может быть рассчитана по формуле
D(t)=V + h+d(t)+B, (9.1)
где V - задержка в устройствах аналогово-цифрового преобразования,
существенная часть которой определяется алгоритмической задержкой,
различной для возможных методов кодирования (для анализируемого
метода кодирования LD-CELP она составляет всего 5 мс); h - время па-
кетизации, которое определяется длиной пакета и скоростью его фор-
мирования; d(t) - задержка внутри сети во время Z, определяемая време-
нем поступления пакета до начала его передачи (время ожидания в оче-
реди) и самим временем передачи пакета; В - время обработки пакета на
приемном конце, которое часто определяется емкостью буфера, вклю-
чаемого перед декодером, служащим, в свою очередь, для сглаживания
флуктуаций времени задержки и уменьшающим его дисперсию.
С точки зрения восприятия речевого сигнала, задержка D(t) не должна
превышать 200...250 мс. Использование алгоритма LD-CELP позволяет зна-
чительную часть задержки отнести за счет увеличения объема буфера.
Моделирование маршрутизатора Frame Relay. Основной частью
оборудования, обеспечивающего доступ абонентов к услугам технологии
VoFR (Voice over Frame Relay), являются мосты-маршрутизаторы, в состав
которых входит необходимое количество плат подключения абонентских
или соединительных линий.
Методы кодирования речевых сигналов и соответствующие им форма-
ты пакетов определены документом FRF. 11. Важно подчеркнуть, что данный
стандарт предусматривает возможность изменения оператором сети длины
информационной части речевого пакета, что является инструментом повы-
шения эффективности использования пропускной способности магистраль-
ной линии сети Frame Relay. При выборе оптимальных параметров узлов па-
кетной передачи речи часто используют модель узла как узла СМО.
Рассмотрим работу маршрутизатора, в котором есть т портов для
подключения источников речевого сигнала и один выходной порт для
подключения к сети Frame Relay.
Предполагается, что выходной порт используется только для пере-
дачи речевых пакетов, а при необходимости передачи данных исполь-
зуются другие порты подключения к Frame Relay. Маршрутизатор по-
следовательно опрашивает выходные регистры устройств кодирования
всех л? портов. Период опроса определяется временем пакетирования h.
Следовательно, моменты времени, в которые пакет может поступить
для передачи, являются дискретными.
Вероятность появления активного пакета на выходе каждого коде-
ка определяется текущим состоянием речевого сигнала данного абонен-
та. Эта вероятность описывается моделью речевого сигнала, разрабо-
танной для LD-CELP-источника ранее.
213
9.2. Проектирование узла сети Frame Relay
Для оценки качества работы проектируемого узла сети и выбора оп-
тимальных параметров настройки используется метод статистического мо-
делирования. Сущность метода состоит в разработке имитационной модели
и получении с ее помощью оценок вероятностных характеристик узла.
Программа должна обеспечить сбор статистической информации о числе
поступивших, обслуженных (переданных), задержанных и потерянных па-
кетов, а также о задержке каждого пакета.
На основе собранной информации определяются следующие величины:
вероятность появления на выходе пакета с задержкой d(t\ равной
числу пакетов, задержанных на время г, отнесенному к числу принятых
на вход активных пакетов;
вероятность появления на выходе пакета с задержкой, не превы-
шающей d(t) - как сумму вероятностей появления пакетов с задержкой,
не превышающей данную;
математическое ожидание задержки в выборке из N пакетов при
определенных параметрах настройки маршрутизатора (определенном
числе абонентов на входе и числе пакетов в выходном кадре FR) как
сумму произведений всех задержек на вероятности их появления;
коэффициент использования канала как отношение числа передан-
ных пакетов к числу пакетов, которые потенциально возможно было бы
передать за время, определяемое длиной выборки.
В дальнейшем предполагается, что быстродействие маршрутизатора
велико настолько, что опрос всех входных портов происходит одновременно.
Очевидно, что при числе входных портов, превышающем число
пакетов в кадре Frame Relay, в маршрутизаторе должен быть буфер, в
котором сохраняются поступившие пакеты, образующие очередь. Нали-
чие такого буфера является отличительным признаком системы стати-
стического мультиплексирования.
Архитектура буфера выглядит следующим образом: буфер хра-
нения очереди - одномерный массив; количество ячеек буфера, в
которые могут быть записаны пользовательские пакеты, строго за-
дано перед началом работы программы. В процессе работы посту-
пающие пакеты записываются в свободные ячейки буфера, после че-
го из пакетов, которые берутся из начала очереди буфера, формиру-
ется кадр FR. Следующий этап - перезапись содержимого буфера
(продвижение пакетов из очереди на место переданных пакетов),
после чего цикл повторяется. Алгоритм обслуживания очереди -
первым вошел, первым вышел (FIFO).
Время формирования выходного кадра FR является постоянным. В
анализируемом маршрутизаторе это время определялось временем фор-
мирования речевого пакета, равным 5 мс.
214
Глава 9. Моделирование узла сети Frame Relay
Обобщенный алгоритм программы, имитирующей работу мар-
шрутизатора FR (рис. 9.7), описывается следующей последователь-
ностью команд.
Рис. 9.7. Схема программы, моделирующей маршрутизатор FR
215
9.2. Проектирование узла сети Frame Relay
Шаг 1. Начало программы (описание используемых переменных, функ-
ций, процедур и модулей).
Ш а г 2. Ввод параметров, необходимых моделирующей программе.
Шаг 3. На этом этапе осуществляется предварительная подготовка к
моделированию (обнуление массивов, которые используются
при моделировании), а также задается начальное состояние
источника речи. Поскольку начальное состояние является
случайным, то и состояние, с которого начинается моделиро-
вание выбирается случайным образом, с использованием мат-
рицы финальных вероятностей (см. 7.17).
Шаг 4. Открывается цикл, в котором число итераций равно числу
кадров LD-CELP, необходимых для моделирования одним ис-
точником речи. После того как заданное число итераций будет
выполнено, программа переходит к блоку 12.
Шаг 5. Открывается цикл, в котором число итераций равно числу не-
обходимых для моделирования источников речевых сообще-
ний. По окончании цикла (когда все источники сгенерировали
по 1 пакету LD-CELP) программа переходит к блоку II.
Шаг 6. В этом блоке программа генерирует пакет LD-CELP (актив-
ный или пассивный). Генерирование осуществляется на осно-
вании заданной марковской матрицы переходных вероятно-
стей Г(см. 7.4).
Шаг 7. Проверяется, какой тип кадра был сгенерирован. Если был сге-
нерирован активный кадр, то программа переходит к блоку 8, ес-
ли пассивный, то переходят к следующей итерации цикла - бло-
ку 5, генерирующему пакет от следующего источника.
Шаг 8. Проверяется, в каком состоянии находится на данный момент
очередь мультиплексора. Если очередь не переполнена, то про-
грамма переходит к блоку 9, в противном случае - к блоку 10.
Шаг 9. Пакет ставится в очередь мультиплексора, что фиксируется в
массиве, который в программе представляет собой очередь.
Шаг 10.Пакет отбрасывается, что фиксируется переменной, учиты-
вающей число отброшенных пакетов.
Шаг 1 l.Ha данном этапе выполняется обработка очереди мультиплек-
сора (осуществляется формирование пакетов FR из имеющих-
ся в очереди пакетов LD-CELP, а также их отправка в выход-
ной канал). Все перечисленные действия фиксируются в соот-
ветствующих массивах.
Шаг 12.В этом блоке осуществляется статистическая обработка масси-
вов, которые были заполнены в процессе моделирования. На ос-
нове информации, полученной в результате обработка, вычисля-
ются основные показатели производительности мультиплексора.
Шаг 13.Информация, полученная в блоке 72, выводится на экран или
на принтер.
Шаг 14.Завершение работы программы.
216
Глава 9. Моделирование узла сети Frame Relay
На рис. 9.8 изображена модель маршрутизатора с подключен-
ными абонентами к пяти входным портам. В каждый момент време-
ни от всех абонентов могут поступить активные пакеты. Если к это-
му моменту в буфере уже хранились задержанные пакеты, то запись
поступивших активных пакетов происходит в конец очереди. Затем
маршрутизатор формирует кадр Frame Relay, в информационную
часть которого входят пакеты, хранящиеся в начальных ячейках бу-
фера и посылает его в выходной порт.
Рис. 9.8. Модель маршрутизатора FR: 1,2, 3 - пакеты, формирующие кадр FR
(пунктирными стрелками показаны возможные поступления кадров LD-CELP с
выходов кодеков)
В рассматриваемом случае число пакетов в кадре равнялось
трем. Буфер задержанных пакетов обновляется, а все пакеты, храня-
щиеся в буфере, перемещаются на 3 ячейки вперед. После чего по-
вторяется опрос входных портов и только что пришедший на вход
пакет от любого из абонентов записывается в конец очереди буфера.
В результате в информационную часть следующего кадра Frame Re-
lay войдут речевые пакеты, хранящиеся в первых трех ячейках буфе-
ра. Затем цикл повторяется.
Используя разработанные модели источника речевых пакетов и узла
статистического мультиплексирования, можно получить зависимости, позво-
ляющие осуществить выбор параметров реального узла сети.
217
9.3. Результаты имитационного моделирования маршрутизатора FR с кодеками G.728 на входе
9.3. Результаты имитационного моделирования
маршрутизатора FR с кодеками G.728 на входе
Рассмотрим графики, представленные на рис. 9.9 - 9.15 (здесь под запи-
сью LD-CELP/FR понимается число кадров LD-CELP, приходящихся на
один кадр FR). Графики представлены для различного числа кадров LD-
CELP, интегрированных в кадр Frame Relay, и различных скоростей вы-
ходного канала.
Зависимости коэффициента использования р выходного канала FR от
числа LD-CELP источников на входе т, полученные с помощью разработан-
ного программного обеспечения, представлены на рис. 9.9.
На рис. 9.10 показаны зависимости изменения средней задержки т кад-
ра LD-CELP от числа источников на входе т. Графики представлены в полу-
логарифмической шкале для различного числа кадров LD-CELP, интегри-
руемых в кадр Frame Relay, а также для различных скоростей выходного ка-
нала. Видно, что с увеличением числа абонентов на входе средняя задержка
на кадр LD-CELP возрастает, поскольку скорость передачи данных выходно-
го канала остается неизменной. Однако на начальном участке кривой можно
наблюдать, что чем меньше кадр FR, тем меньше и задержка. На графиках
можно наблюдать «переходный участок», где задержка становится мини-
мальной для больших кадров FR.
На рис. 9.11 показаны графики изменения зависимости вероятности
блокировки пакета LD-CELP от числа источников т на входе мульти-
плексора. Графики представлены для различного числа кадров LD-CELP,
интегрируемых в кадр Frame Relay, при различных скоростях выходного
канала. Видно, что с увеличением числа входных источников вероятность
потери кадра LD-CELP возрастает, что объясняется неизменной скоро-
стью передачи данных выходного канала FR. С увеличением скорости
передачи данных входного канала вероятность потерь кадров LD-CELP
снижается. Следует отметить, что с увеличением числа встраиваемых
кадров LD-CELP характер кривой вероятности потерь остается неизмен-
ным, наблюдается лишь смещение по оси абсцисс, т.е. с увеличением
длины кадра FR вероятность потери кадров LD-CELP уменьшается.
Для иллюстрации того, как размер буфера влияет на описанные характе-
ристики (рис. 9.9 - 9.11), использовалась фиксированная задержка т = 100 мс
(см. рис. 9.10). В результате моделирования было найдено, какое число пользо-
вателей удовлетворяет такой средней задержке на один кадр, которое и исполь-
зовалось при дальнейшем моделировании.
На рис. 9.12 показаны графики зависимости коэффициента использова-
ния канала от размера буфера для различного числа кадров LD-CELP, кото-
218
Глава 9. Моделирование узла сети Frame Relay
рые интегрируются в кадр Frame Relay, при различных скоростях выходного
канала. Видно, что коэффициент использования канала достаточно равноме-
рен на всей исследуемой области, исключая начальный участок. Необходимо
отметить, что уменьшение размера буфера ведет к снижению коэффициента
использования, что благоприятно сказывается на средней величине задержки
на пакет. При уменьшении размера кадра FR коэффициент использования
возрастает, но общий характер зависимости сохраняется.
На рис. 9.13 показаны графики зависимости задержки кадра LD-CELP
от размера буфера для различного числа кадров LD-CELP, интегрируемых в
кадр Frame Relay, а также для различных скоростей выходного канала. Вид-
но, что задержка при небольших размера?; буфера быстро возрастает, но по-
сле некоторого порогового значения (—150 кадров) задержка стабилизируется
и больше не испытывает столь резкого подъема, как на начальном этапе. Для
различных скоростей выходного порта эта тенденция сохраняется.
Уменьшая размер буфера при постоянном числе абонентов и скорости
выходного порта, можно достичь снижения средней задержки на кадр LD-
CELP. Однако одновременно со снижением размера буфера увеличивается
вероятность отбраковки кадра LD-CELP. Поэтому должно быть выбрано
компромиссное значение размера буфера, обеспечивающее требуемый уро-
вень качества обслуживания абонента.
На рис. 9.14 показаны графики зависимости вероятности блоки-
ровки кадра LD-CELP от размера буфера для различного числа кадров
LD-CELP, интегрируемых в кадр Frame Relay, при различных скоростях
выходного канала. Видно, что с уменьшением размера буфера увеличи-
вается вероятность отбраковки кадра LD-CELP, что неблагоприятно от-
ражается на качестве обслуживания абонента. Однако в некоторых слу-
чаях выбранный уровень качества обслуживания допускает определен-
ную долю потерянных пакетов, что позволяет снизить среднюю задерж-
ку для этого абонента. С ростом размера кадра FR вероятность потери
кадра LD-CELP незначительно снижается, что, можно объяснить эф-
фективностью статистического мультиплексирования. Эта тенденция
сохраняется для всех значений скоростей выходных портов.
На рис. 9.15 показаны графики зависимости средней задержки
кадра LD-CELP от размера кадра FR для различного числа пользовате-
лей. Анализируя приведенные зависимости, можно заметить, что для
небольших размеров кадра FR задержка резко спадает, достигая некото-
рого минимального значения, а затем начинает незначительно возрас-
тать. Такое явление объясняется тем, что задержка является величиной,
включающей в себя несколько составляющих: с одной стороны - сни-
жении задержки в очередях с увеличением размера кадра FR, а с другой
- рост задержки передачи кадра. Вместе эти две тенденции и приводят к
виду графиков, показанных на рис. 9.15.
219
9.3. Результаты имитационного моделирования маршрутизатора FR с кодеками G.728 на входе
Рис. 9.9. Зависимость коэффициента использования р канала от числа источни-
ков т при скорости канала: а - 64 Кбит/с; 6-128 Кбит/с; в - 256 Кбит/с
220
Глава 9. Моделирование узла сети Frame Relay
Z, мс
Рис. 9.10. Зависимость задержки пакета LD-CELP от числа источников т на входе муль-
типлексора при скорости канала: а - 64 Кбит/с; 6-128 Кбит/с; в - 256 Кбит/с
221
9.3. Результаты имитационного моделирования маршрутизатора FR с кодеками G.728 на входе
0,uuui
в) пг
Рис. 9.11. Зависимость вероятности блокировки пакета LD-CELP от числа ис-
точников пг на входе мультиплексора при скорости канала: а - 64 Кбит/с;
6-128 Кбит/с; в - 256 Кбит/с
222
Глава 9. Моделирование узла сети Frame Relay
р
а) размер буфера, кадр
Рис. 9.12. Зависимость коэффициента использования канала от размера буфера муль-
типлексора при скорости канала: а - 64 Кбит/с; 6-128 Кбит/с; 6 - 256 Кбит/с
223
9.3. Результаты имитационного моделирования маршрутизатора FR с кодеками G.728 на входе
Рис. 9.13. Зависимость задержки пакета LD-CELP от размера буфера мультиплексора
при скорости канала: а - 64 Кбит/с; 6-128 Кбит/с; в - 256 Кбит/с
224
Глава 9. Моделирование узла сети Frame Relay
10 30 50 70 90 НО 130 150 170 190 210 230 250
а) размер буфера,
размер буфера,
0)
кадр LD-CELP
Рис. 9.14. Зависимость вероятности блокировки пакета LD-CELP от размера буфера
мультиплексора при скорости канала: а - 64 Кбит/с; 6-128 Кбит/с; в - 256 Кбит/с
8—3834
225
9.3. Результаты имитационного моделирования маршрутизатора FR с кодеками G.728 на входе
т, мс
размер кадра FR.
т, мс кадр LD-CELP
в) размер кадра FR,
кадр LD-CELP
Рис. 9.15. Зависимость средней задержки пакета LD-CELP от размера кадра
Frame Relay при скорости канала: а - 64 Кбит/с; 6-128 Кбит/с; в - 256 Кбит/с
226
_______________________Глава 9. Моделирование узла сети Frame Relay
Из рисунков видно, что с увеличением числа источников коэффициент
использования канала возрастает и существует некоторое «критическое»
число абонентов, превышение которого ведет к тому, что использование ка-
нала становится близким к 1 и влечет за собой большие потери и задержки.
С увеличением числа кадров LD-CELP, приходящихся на кадр FR,
коэффициент использования канала ниже для того же числа источников на
входе. Но такая ситуация наблюдается лишь до некоторой области, кото-
рую условно будем называть «переходный участок», где коэффициент ис-
пользования для меньших кадров FR немного ниже.
Рассмотрим гистограммы задержек кадров LD-CELP и сравним их с
экспоненциальными распределениями, имеющими совпадающие с экспе-
риментальными данными средние значения.
На рис. 9.16 представлены гистограммы задержек и подобранные к
ним экспоненциальные функции. В верхнем правом углу каждого графика
показано число абонентов (user) и размер кадра FR, для которых проводи-
лось моделирование, а также указано среднее значения задержек, которое
испытывали кадры LD-CELP, и их дисперсия. Ниже показан выбранный на
основе среднего значения параметр интенсивныости эквивалентного экс-
поненциального распределения.
т = 462 мс 12 аб.
ст = 459.3 мс 15 яч
). = 10,967
Рис. 9.16. Гистограммы задержек для различных условий эксплуатации системы
и подобранные к ним экспоненциальные функции при скоростях передачи дан-
ных: а - 64 Кбит/с; 6-128 Кбит/с; в - 256 Кбит/с
227
9.3. Результаты имитационного моделирования маршрутизатора FR с кодеками G.728 на входе
На рис. 9.17 представлены ДФР задержек для различного числа або-
нентов и различной скорости выходного порта. Из графиков видно, что из-
менение числа абонентов при постоянной скорости передачи данных по
каналу связи влияет на скорость спада кривой вероятности задержки. На
всех графиках можно наблюдать некую «точку отсечки», за пределами ко-
торой график резко спадает, но в силу ограниченного размера буфера кри-
вая обрывается. Если использование системы не слишком высоко (р < 0,8),
то можно наблюдать участок резкого спада кривой до того, как будет дос-
тигнут максимальный размер буфера.
Р(г>/)
Рис. 9.17. ДФР задержек для различных
условий эксплуатации системы (меняет-
ся число абонентов (источников)) при
скорости: а — 64 Кбит/с, 8 пакетов LD-
CELP HaFR; 6-128 Кбит/с, 8 пакетов
LD-CELP на FR; в - 256 Кбит/с, 10 паке-
тов LD-CELP на FR
Рис. 9.18. ДФР задержек для различ-
ных условий эксплуатации системы
(меняется количество LD-CELP паке-
тов на FR) при скорости: а - 64 Кбит/с,
10 абонентов; б - 128 Кбит/с, 22 або-
нента; в - 256 Кбит/с, 48 абонентов
На рис. 9.18 приведены зависимости ДФР задержек от размера кадра
FR. Учитывая, что для этих графиков единицей масштаба является коли-
чество кадров FR, для получения реальных задержек следует умножить
значение по оси абсцисс на время, требуемое для передачи одного кадра
FR. Приведенные зависимости показывают, что путем изменения макси-
228
Глава 9. Моделирование узла сети Frame Relay
мально допустимого размера кадра FR можно оказывать воздействие на
распределение задержек в системе. Уменьшая размер буфера, можно до-
биться изменения характера ДФР. В частности, переполнение объема бу-
фера ведет к возникновению потерь в системе. Воспользовавшись харак-
теристиками, приведенными на рис. 9.18, можно судить о потерях в сис-
теме при соответствующих условиях эксплуатации.
Контрольные вопросы к главе 9
1. Опишите структуру протокола Frame Relay.
2. В чем суть метода инкапсуляции речевых потоков в кадры Frame Relay ?
3. В чем заключается проектирование узла сети Frame Relay ?
4. Из чего складывается общая задержка пакетов при передаче по сети
Frame Relay ?
5. Охарактеризуйте обобщенный алгоритм моделирования маршрути-
затора Frame Relay.
6. Изобразите модель маршрутизатора Frame Relay при использовании
речевых кодеков G.728.
7. Каковы результаты имитационного моделирования маршрутизатора
Frame Relay ?
Глава 10
МОДЕЛИРОВАНИЕ СИСТЕМ ПЕРЕДАЧИ
ИНФОРМАЦИИ
10.1. Типовая система передачи данных
Любая система передачи данных (СПД) может быть описана тремя ос-
новными компонентами: передатчик (или «источник передачи инфор-
мации»), канал передачи данных и приемник (также называемый «полу-
чателем» информации). При двухсторонней (дуплексной) передаче ис-
точник и получатель могут быть объединены так, что их оборудование
может передавать и принимать данные одновременно. В простейшем
случае СПД между точками А и В (рис. 10.1) состоит из следующих ос-
новных частей:
оконечного оборудования данных ООД в точках J и В;
аппаратуры передачи данных АПД к точках А и В;
канала связи между точками А и В;
интерфейса (или стыка) С1 аппаратуры передачи данных;
интерфейса (или стыка) С2 между ООД и АПД.
Интерфейс АПД с
каналом (стык С1)
Рис. 10.1. Типовая система передачи данных:
а - схема системы передачи данных;
6 - реальная система передачи данных
Оконечное оборудование данных (ООД) — обобщенное понятие,
используемое для описания оконечного прибора пользователя или его
части. ООД может являться источником информации, ее получателем
или тем и другим одновременно. ООД передает и (или) принимает дан-
ные посредством использования аппаратуры передачи данных и канала
230
Глава 10. Моделирование систем передачи информации
передачи. В литературе часто употребляется соответствующий между-
народный термин - DTE (Data Terminal Equipment). Часто в качестве
ООД может выступать персональный компьютер, большая ЭВМ (main-
frame computer), терминал, устройство сбора данных, кассовый аппарат,
приемник сигналов глобальной навигационной системы или любое дру-
гое оборудование, способное передавать или принимать данные.
Аппаратуру канала данных также называют аппаратурой передачи
данных (АПД). Широко используется международный термин DCE
(Data Communications Equipment). Функция АПД состоит в обеспечении
возможности передачи информации между двумя или большим числом
АПД по каналу определенного типа, например по телефонному. Для
этого АПД должен обеспечить соединение с ООД с одной стороны, и с
каналом передачи - с другой. На рис. 10.1, а АПД может являться ана-
логовым модемом, если используется аналоговый канал, или, например,
устройством обслуживания канала/данных, если используется цифровой
канал типа Е1/Т1 или ISDN.
Слово модем является сокращенным названием устройства, осу-
ществляющего процесс МОдуляции/ДЕМодуляции. Модуляцией назы-
вается процесс изменения одного либо нескольких параметров выход-
ного сигнала по закону входного сигнала. При этом входной сигнал яв-
ляется, как правило, цифровым и называется модулирующим. Выход-
ной сигнал - обычно аналоговый и часто носит название модулирован-
ного сигнала. В настоящее время модемы наиболее широко использу-
ются для передачи данных между компьютерами через коммутируемую
телефонную сеть общего пользования (КТФОП) (рис. 10.1, б).
Важную роль во взаимодействии АПД и ООД играет их интер-
фейс, который состоит из входящих/исходящих цепей в АПД и ООД,
разъемов и соединительных кабелей. В отечественной литературе и
стандартах также часто употребляется термин стык.
Под каналом связи понимают совокупность среды распростране-
ния и технических средств передачи между двумя канальными интер-
фейсами или стыками типа С1 (см. рис. 10.1). По этой причине стык С1
часто называется канальным стыком. В зависимости от типа передавае-
мых сигналов различают два больших класса каналов связи - цифровые
и аналоговые. Цифровой канал является битовым трактом с цифровым
(импульсным) сигналом на входе и выходе канала. На вход аналогового
канала поступает непрерывный сигнал, и с его выхода также снимается
непрерывный сигнал. Как известно, сигналы характеризуются формой
своего представления.
Параметры сигналов могут быть непрерывными или принимать толь-
ко дискретные значения. Сигналы могут содержать информацию либо в
каждый момент времени (непрерывные во времени, аналоговые сигналы),
либо только в определенные, дискретные моменты времени (цифровые,
дискретные, импульсные сигналы).
231
10.1. Типовая система передачи данных
Цифровыми являются каналы систем ИКМ, ISDN, каналы типа Т1/Е1
и многие другие. Вновь создаваемые СПД стараются строить на основе
цифровых каналов, обладающих рядом преимуществ перед аналоговыми.
Аналоговые каналы являются наиболее распространенными по
причине длительной истории их развития и простоты реализации. Ти-
пичным примером аналогового канала является канал тональной часто-
ты (КТЧ), а также групповые тракты на 12, 60 и более каналов тональ-
ной частоты. Телефонный канал КТФОП, как правило, включает много-
численные коммутаторы, устройства разделения, групповые модулято-
ры и демодуляторы. Для КТФОП этот канал (его физический маршрут и
ряд параметров) будет меняться при каждом очередном вызове.
При передаче данных на входе аналогового канала должно находиться
устройство, которое преобразовывало бы цифровые данные, приходящие от
ООД, в аналоговые сигналы, посылаемые в канал. Приемник должен содер-
жать устройство, которое преобразовывало бы обратно принятые непрерыв-
ные сигналы в цифровые данные. Этими устройствами являются модемы.
Аналогично, при передаче по цифровым каналам данные от ООД приходит-
ся приводить к виду, принятому для данного конкретного канала. Этим пре-
образованием занимаются цифровые модемы, очень часто называемые
адаптерами ISDN, адаптерами каналов Е1/Т1, линейными драйверами и так
далее (в зависимости от конкретного типа канала или среды передачи).
Система передачи дискретных сообщений является одной из важнейших
составных частей автоматизированных систем сбора и обработки информации,
автоматизированных систем управления и систем массового обслуживания.
Круг задач для математического моделирования СПД на ЭВМ рас-
смотрим на примере цифровой системы передачи (рис. 10.2), предназна-
ченной для передачи информационного процесса И. С помощью передаю-
щего устройства (ПДУ) формируется информативный сигнал uc[t, Х(И)], в
котором полезная информация содержится в информационном (модули-
рующем) параметре Х(И). Сигнал ec[Z; Х(И)], распространяясь по каналу
связи, далее обрабатывается приемным устройством (ПМУ) и в виде неко-
торого решения поступает к потребителю информации.
Рис. 10.2. Схема цифровой передачи информационного процесса
В канале связи на сигнал ес|/; Х(И)] могут воздействовать случай-
ные помехи П и преднамеренные внешние воздействия В.
232
______________Глава 10. Моделирование систем передачи информации
Характерными особенностями системы связи является разнообразие
типов решения D(H), которые ПМУ формирует на выходе при обнаруже-
нии, различении сигналов, измерении их параметров, фильтрации (демоду-
ляции) параметра сигнала и так далее.
В соответствии с этим работа системы связи должна быть описана ста-
тистически, а воздействие на входе приемного устройства eD[Z; Х(И); В; П]
является в общем случае векторным и зависит от указанных факторов.
10.2. Помехоустойчивость передачи дискретных
сигналов. Оптимальный прием
Основным (базовым) показателем качества цифровой системы передачи
(канала связи) как при передаче дискретных, так и аналоговых сообще-
ний, является вероятность ошибочного приема элементарных символов
Рош. Вероятность Рои1 зависит от вида и модели цифровых сигналов, ме-
тода приема и энергетического отношения сигнала к шуму.
Рассмотрим методику расчета Рош при оптимальном приеме эле-
ментарных дискретных сигналов различных моделей.
Пусть элементарное дискретное сообщение X,- может принимать
одно и только одно из а возможных дискретных значений (например 0,
1, 2, ..., -I), соответствующих значениям цифр используемой системы
счисления. Априорные вероятности этих сообщений соответственно
обозначим w(X0), w(X0, ..., w(Xa_ J
Поскольку события Хо, Хь ..., Ха_ t образуют полную группу несовмес-
тимых событий, то сумма их вероятностей равна единице, т.е. E"T0,w(X/)= 1.
Каждому значению сообщения X/ соответствует свой элементарный сигнал
(символ) С, с (X/) = С, с,. Поэтому априорные вероятности сигналов С, ci и соот-
ветствующих сообщений X, равны, т.е. Ci) = w(K). В большинстве прак-
тических случаев можно считать, что все дискретные сообщения равноверо-
ятны, т.е. w(£C/) = = 1/ос= const.
Предположим, что на вход приемника поступает аддитивная смесь
дискретного сигнала с (Х^; t; РО и белого гауссова шума n(t) так, что
наблюдаемая аддитивная реализация имеет вид
гдеСс(^;/;р4) = ^сА(/;Р^) = ^ саг - А>й элементарный сигнал, являющийся
функцией передаваемого сообщения X*, времени t и случайных неин-
формативных параметров сигнала Р^ (частоты, фазы, времени).
При полностью известных сигналах неинформативные параметры
Р* = 0. Можно показать, что в этом случае максимально полезная ин-
формация о передаваемом дискретном сообщении или сигнале заклю-
чена в апостериорном распределении вероятностей Wy(Q СД вычисляе-
мой для всего ансамбля дискретных сигналов.
233
10.2. Помехоустойчивость передачи дискретных сигналов. Оптимальный прием
Прежде всего, оптимальный приемник дискретных сообщений
должен вычислить апостериорное распределение вероятностей для всех
возможных дискретных сообщений Х7 (сигналов С;) и на основании его
анализа принять решение о передаваемом сообщении (сигналов Q сД
В соответствии со сказанным, оптимальный приемник дискретных сиг-
налов (как аналоговых, так и импульсных ) должен состоять из опти-
мального приемно-фильтрующего устройства ПФУ и решающего уст-
ройства РУ (рис. 10.3).
Рис. 10.3. Схема оптимального приемника дискретных сигналов
Операция вычисления апостериорных вероятностей обеспечивает
наилучшую (оптимальную) фильтрацию полезного сигнала от помех.
В решающем устройстве могут использоваться различные правила
принятия решений: по максимальной апостериорной вероятности, макси-
муму функции правдоподобия, в соответствии с критерием Неймана -
Пирсона и др.
При передаче различных сообщений в системах связи обычно оди-
наково опасны ошибки различного вида. В этом случае оптимальным
решающим правилом является решение по максимуму апостериорной
вероятности или максимуму функции правдоподобия. Апостериорная
плотность вероятностей (АПРВ) wy(kj) однозначно связана с функцией
взаимной корреляции g(X7). Например, для полностью известных сигна-
лов АПРВ имеет вид
• (10.1)
Здесь w^Cj(y) ~ функция правдоподобия, т.е. условная вероятность того, что
передавался сигнал при условии приема реализации у(0-
В случае, когда w(£c/) = const, решение по максимуму апостериор-
ной вероятности равноценно решению по максимуму функции взаимной
корреляции g((^c/)- Поэтому в реальных оптимальных приемниках вычис-
ляется обычно лишь функция взаимной корреляции. Так как g(^cy) пред-
ставляет собой логарифм от функции правдоподобия w^Cj(y), то такой ал-
горитм работы приемника часто называется алгоритмом максимального
правдоподобия.
Этот алгоритм работы оптимального приемника дискретных сигналов
находит наиболее широкое применение в технике связи, что связано со мно-
гими причинами. Прежде всего, для системы связи наиболее характерно как
одинаковая априорная вероятность элементарных символов, так и одинако-
234
_______________Глава 10. Моделирование систем передачи информации
вая опасность ошибок разного вида. Заметим, что одинаковая априорная ве-
роятность ошибок характерна для симметричных каналов при флуктуацион-
ной помехе в канале. Такой алгоритм существенно упрощает схему опти-
мального приемника. Функция взаимной корреляции при передаче дискрет-
ных сообщений (сигналов) определяется для всех сигналов ^q(Z) выражением
4с,)=Af = 4c^q,)+ hfcci) > (10.2)
где - передаваемый fc-й элементарный сигнал; - ансамбль
опорных сигналов; й(£Су) - случайные гауссовские величины с нулевым
средним и дисперсией D(h) = 2oci2, корреляционной матрицей, элементы
которой определяются какЛс(^ок; £су)-
Как видно из выражения (10.2), g(Ccy) состоит из сигнальной и по-
меховой составляющих. Сигнальную составляющую при полностью из-
вестных сигналах можно представить в виде
gj =g* = 4с*£с,)= А/Х«(<Хс,(0^ = 2а?7?с(^,^), (10.3)
где оц2 - отношение энергии элементарного символа (сигнала) Е2 к
спектральной плотности белого шума NQ\ Rc(£/ck', Qy) - нормированный
коэффициент взаимной корреляции между Cpj&t) и сигналами,
Пу
Соответственно, при QCi = и полностью известных сигналах,
gm» = 2(Xi2, так как 7?с = (Cai Сс,)-
При Ф Qcj и полностью известных сигналах сигнальная функция
принимает вид g# = 2oti2/?cfe; Ссу) 2oti2.
При наличии случайных параметров у сигналов сигнальная функ-
ция принимает вид g^ = 2oti27?c(^cfc; ^су; ДРу), где ДРу - сдвиг по соответ-
ствующему параметру между принимаемым и опорным сигналами.
Приемник, действующий по принципу максимальной апостериорной
вероятности, каждый раз выдает на выходе сигнал, вероятность которого при
данной Х0 наибольшая. Эго означает, что правильный прием сигнала будет
иметь место, если наибольшей будет вероятность = w/^), т.е. если из
всех величин gy наибольшей окажется g(Ccb ^ct) = Sk- Вполне очевидно, что
при равных априорных вероятностях дискретных сообщений оптимальный
приемник воспроизводит сигнал ^с(Х; 0, если будет соблюдаться условие
для всех
или соответственно
=н >0 •
235
10.2. Помехоустойчивость передачи дискретных сигналов. Оптимальный прием
Отметим, что Ag будет иметь нормальную плотность вероятности
с параметрами
=< Д§>=2а^[1-Т?с(ххЛ7)],
В этом случае плотность распределения вероятностей сигнальной
функции g(^c7) для канала, где имеется лишь помеха, и канала, где имеется
одновременно и сигнал и помеха, будет определяться в виде
Из этих формул видно, что в общем случае помехоустойчивость
таких сигналов будет определяться отношением сигнал/шум о^2 и ко-
эффициентом взаимной корреляции Rc(Qck\ Сс/) между сигналами.
Таким образом, оптимальный приемник прежде всего должен вы-
числять функции взаимной корреляции g(Xj) для всех возможных дис-
кретных значений т.е. для всех возможных дискретных сигналов
соответствующих Xj. В соответствии с (10.2) структурная схема
оптимального приемника полностью известных сигналов может быть
изображена в виде многоканального коррелятора и решающего устрой-
ства, представляющего собой детектор максимального сигнала, который
выбирает сигнал с максимальной амплитудой (рис. 10.4).
Вычисление g(^) для всех возможных значений Xj может также
производится с помощью набора (гребенки) оптимальных согласован-
ных фильтров или устройств комбинированного типа.
Рис. 10.4. Схема оптимального приемника полностью известных сигналов
236
Глава 10. Моделирование систем передачи информации
10.3. Оценка вероятности ошибочного приема
дискретных сигналов с полностью известными
параметрами
Следует отметить, что общая теория обработки сигналов в системах
связи с произвольным ансамблем дискретных сигналов практически не
разработана. Однако для отдельных случаев с помощью более или ме-
нее искусственных приемов удается получить точные решения или при-
ближенные оценки для Рош, которые и будут рассмотрены ниже.
Обобщенное выражение для ошибки различения элементарных
равноудаленных сигналов с одинаковой энергией (£)2 = Е2 = const;
7?c(Cci, Ccj) = const) при оптимальном приеме в условиях флуктуаци-
онного шума будет определяться выражением
Рош =1-Г„[l-pjg, ^^(W), (10.6)
где Pi(gi>H} = $2wn (h)dh - вероятность того, что в канале, где нет сиг-
нала, напряжение превысит некоторую величину Н = 2а2 + h в канале,
где имеется сигнал и шум; в свою очередь wn(h) = wn(g/) - плотность
распределения вероятностей gj на выходе канала, где нет сигнала ^СЛ(0;
шсп(Я) “ плотность распределения вероятностей Н в канале, где имеется
сигнал и шум; а - число (ансамбль) дискретных сигналов.
Заметим также, что равноудаленные сигналы часто называются эк-
видистантными.
В общем случае, интеграл (10.6) не выражается в элементарных функ-
циях и расчет по приведенной формуле может быть произведен лишь числен-
ными методами. Значение зависит от модели ансамбля сигналов (полно-
стью известные сигналы, сигналы с неизвестной начальной фазой, сигнал со
случайной амплитудой и начальной фазой), определяющих выражение для
wn(gj) и wcn(gy), а также от вида корреляционной матрицы 2?c(Cat; СсД
При оптимальном приеме полностью известных равноудаленных
сигналов, имеющих одинаковую энергию, приближенное выражение
для Рош можно получить на основании формулы (10.6):
Рош = (а - (Ю.7)
где И(а.|) = (1/72л)| e'z2/2dZ - интеграл вероятностей (табулированная
функция).
Как показано В. Котельниковым, ансамбль оптимальных дискрет-
ных равноудаленных сигналов, при использовании которых обеспечи-
вается минимальная Рош, должен иметь коэффициент взаимной корре-
ляции, определяемый выражением RcCQct, Qcj) = -1/(а - 1). Например,
при а = 2, RctQci', Qcj) == -Т Таким Rc(£>ci> Qcj) обладают противополож-
ные сигналы типа КИМ2 - ФМ со сдвигом фаз на 180°.
237
10.3. Оценка вероятности ошибочного приема дискретных сигналов ...
Если используется ансамбль ортогональных сигналов с одинако-
вой энергией, для которых
^с(^лс,)=?0 при/:Л
J [0 при г Ф j,
тогда приближенно можно записать
Заметим, что точное решение для этого случая имеет вид
РОш = 1—7==jZo[1”r(^ai +Йа
\2тс L J J
Из приведенного выражения видно, что Рош зависит от отношения
энергии сигнала Е2 к спектральной плотности мощности шума NQ2 и
функции взаимной корреляции между сигналами RC(Q с/, Q сД причем
наибольшей помехоустойчивостью обладают сигналы с минимальной
взаимной корреляцией.
Если сигналы обладают одинаковой энергией, то RC(Q a', Q с/) мо-
жет меняться от -1 (при Q Ci(0 = - С сгО) до +1 (при £ ci(0 = - Ссгй)-
КогдаRdiQci, Qcj) = 1, сигналы невозможно различтпъ и w(Qc^ = 1/ос.
Пример. Пусть используются сигналы типа КИМ2 - ЧМ прямоугольной формы:
?ci0=P«cos(®if + <Pi)
^С20=(/жСО8(®2^+Ф2) j
Тогда, согласно (10.3),
7(шп)тс,
Jo (coj-coJtc
где£12= U^Tcn.
Из приведенной зависимости видно, что при данном способе манипуляции мак-
симальная помехоустойчивость получается при (со2 - ® >У2 = 0,7/тС- В этом случае
Рош =^(“iW •
При меньших значениях разностей ®2 - ®i помехоустойчивость будет
уменьшаться.
При (®2 - coj)/27e = 1/тс сигналы считаются ортогональными и Рош= Hai)>
что совпадает с (10.8).
Пример. Пусть используются сигналы типа КИМ2 - ФМ:
^ci(')=[/»cosm' 1
0ТГ / \ г г Г => 0 < t < Тс .
= U„COS((»t + n)=~UmCOSG)t j
Для таких сигналов RcCQcb Сс/) ~ 1 и вероятность ошибки будет опреде-
лятся выражением
Рош= V(T2 а0.
238
________________Глава 10. Моделирование систем передачи информации
Можно показать, что при оптимальном приеме полностью известных сиг-
налов типа КИМ2 - AM вероятность ошибки на бит можно вычислить,
воспользовавшись соотношением
?ош = r(a,/V2).
Результаты расчета Рош по полученным формулам при а = 2 в виде
сплошных кривых представлены на рис. 10.5.
Рис. 10.5. Результаты расчета Рош по полученным формулам при а = 2
Из приведенных формул и графиков видно, что наивысшей поме-
хоустойчивостью из двоичных сигналов обладают противоположные
сигналы типа КИМ2 - ФМ. Далее следуют ортогональные сигналы вида
КИМ2 - ЧМ и КИМ2 - AM.
При использовании многоосновных дискретных сигналов, когда а > 2,
близкими к оптимальным являются ортогональные сигналы.
Приведенные соотношения получены в предположении, что все па-
раметры сигналов на приемной стороне известны, т.е. известны Um, ю, ф, т.
10.4. Помехоустойчивость дискретных сигналов
со случайными параметрами
Реальные каналы связи являются каналами со случайными параметра-
ми. Это означает, что в подавляющем большинстве случаев принимае-
мые сигналы являются сигналами со случайными параметрами (случай-
ной амплитудой, частотой, фазой).
Случайные параметры сигналов-переносчиков, подразделяются на суще-
ственные (частота, временная задержка, амплитуда) и несущественные, напри-
мер, фаза. Иногда существенные параметры называются фиксируемыми, а не-
существенные - нефиксируемыми. При необходимости обеспечения опти-
мального когерентного приема фаза сигнала считается существенным пара-
метром, а когда необходимо обеспечить оптимальный некогерентный прием,
то фаза считается несущественным параметром. Оптимальный прием сигналов
239
10.5. Помехоустойчивость дискретных сигналов при некогерентном приеме
со случайными параметрами требует усреднения апостериорной вероятности
по несущественным параметрам и изменения существенных параметров.
Выясним сначала, какие особенности в вычислении wy(Q Ct) появ-
ляются при наличии у сигнала Л Р/) несущественных («паразит-
ных») случайных параметров рь р2, Р„. Для этого случая имеем
y(t) = Сс(а7, t, Р/) + n(t).
По аналогии с (10.1) можно также записать
ТУ V(X;,P;)= ) W)yJJ7(A.) ,
где - вероятность того, что при приеме данной реализации у(0
случайные параметры сигнала РЭ равны и Р, соответственно,
причем неинформативные параметры не содержат полезной информа-
ции, т.е. статистически независимы от X.
Нас же интересует wy(kj), т.е. плотность вероятности того, что при
данной реализации Х0 сообщение равно X,. При этом значение паразит-
ных параметров Р, может быть любым. Очевидно, что для определения
wY(Xj) следует проинтегрировать функцию ыу(Х/, Р,) по всем возможным
значениям случайных параметров р,:
гуг(ч)= J- P»^(Pt)-- Tt<P„)dPi • -dp,,.
где Р/ - области всех возможных параметров р, соответственно.
10.5. Помехоустойчивость дискретных сигналов
при некогерентном приеме
Как уже отмечалось выше, при некогерентном приеме фаза сигнала от-
носится к несущественным параметрам. При этом в большинстве случа-
ев принимается, что фаза сигнала равномерно распределена на интерва-
ле (-л; л) т.е. со(ф) = 1/2л.
Поскольку имеется один несущественный параметр - фаза сигнала, то
расчет соответствующих вероятностей ошибок должен вестись путем усред-
нения WylQcjQ', ф)] по ф, т.е. оптимальный приемник должен вычислять усред-
ненную по фазе апостериорную вероятность в соответствии с выражением
wycp(Cc7)= I" w^c//,<p)]w(<p)d<p = to(<;cy)/0[|^c./)|],
J-л
где 7o[g] - модифицированная функция Бесселя нулевого порядка; |g(^с;)| ~ Igl -
модуль функции взаимной корреляции, определяемый по формулам
(Ю.9)
где gl 2j = (г/л'о2) О - квадратурные (сдви-
нутые по фазе на 90°) составляющие опорного (опорных) сигналов.
240
______________Глава 10. Моделирование систем передачи информации
При работе приемника по максимуму апостериорной вероятности
(по максимуму функции правдоподобия, когда = const) в нем дол-
жен вычисляться модуль функции взаимной корреляции в соответствии с
(10.9) для всех сигналов и выбираться канал с максимальной амплитудой.
Структурная схема устройства, вычисляющего |gj, представлена на
рис. 10.6.
Рис. 10.6. Схема вычисления модуля функции взаимной корреляции
Плотность распределения вероятностей для каналов, где присутст-
вуют только помеха iun(g) или полезный сигнал и помеха wCH(g), будут
определяться следующими выражениями:
№n(gJ=w(g)=-^-exp(-g/[4af]), (10.10)
2ос ।
w’cn(g7)=(g/2a^)exp(-[g2 + 4a|]/[4a^])/0(ig|). (10.11)
Для расчета вероятности появления ошибки при некогерентном
оптимальном приеме а ортогональных сигналов, имеющих одинаковую
энергию, может использоваться формула (10.6), в которую необходимо
подставить выражения (10.10) и (10.11) для wn(g) и wcn(g).
В результате подстановки и приближенного интегрирования мож-
но получить
Рош = 1-f0“[1-e’>’1/2]a 1yexp[-(//2 + a2)]/0(V2a1?)d^« (JQ
& ехр(а?/2)(д- 1)/2.
Результаты расчета Рош по формуле (10.12) для различных значений
сс 1 (при ос = 2) представлены на рис. 10.5 (пунктирная линия). Из сопостав-
ления расчетных формул и графиков для Рош при когерентном и некоге-
рентном приеме ортогональных сигналов видно, что некогерентный прием
незначительно уступает по помехоустойчивости когерентному приему.
10.6. Помехоустойчивость дискретных сигналов
со случайными существенными параметрами
При приеме цифровых сигналов со случайными существенными пара-
метрами нужно проводить измерения этих параметров и формировать
опорные сигналы, необходимые для оптимальной корреляционной об-
работки с учетом этих измерений.
241
10.6. Помехоустойчивость дискретных сигналов со случайными существенными параметрами
Структурная схема оптимального корреляционного приемника
дискретных сигналов со случайными существенными параметрами
представлена на рис. 10.7. Измерение существенных случайных пара-
метров сигналов-переносчиков возлагается на специальное устройство,
обычно называемое системой синхронизации, которая может работать,
используя или только информационные сигналы, или специальные син-
хронизирующие сигналы.
Поскольку измерения случайных существенных параметров (3, мо-
гут производиться лишь с определенной погрешностью, то вероятность
ошибки в опознании элементарных сигналов (символов) будет являться
функцией ошибок 8, в измерениях этих параметров (частоты, временной
задержки, фазы сигнала при когерентном приеме).
Проведенные исследования показывают, что степень влияния неиде-
альности системы синхронизации (неточности измерения существенных
параметров) на помехоустойчивость цифровых сигналов зависит от сле-
дующих факторов: отношения энергии цифровых сигналов к спектральной
плотности мощности белого шума в информационном канале; от качества
работы системы синхронизации (вида распределения w(s,) и его характери-
стик); от вида функции корреляции сигнала RC(P,) = Rcfe) по соответст-
вующему параметру (3„ например, временной задержке.
Рис. 10.7. Схема оптимального корреляционного приемника
дискретных сигналов со случайными существенными параметрами
Если с течением времени величина сдвига е, по соответствующему па-
раметру изменяется случайным образом с плотностью вероятности w((3z), то
средняя вероятность ошибочного приема элементарного символа может быть
найдена путем усреднения по всем возможным значениям соответствующих
сдвигов параметров:
/>ошср = 1 ..J ^ош(е>МЕ| •••£„)&! •••Ен '
В, В,
Ухудшение помехоустойчивости в приеме сигналов со случайными
существенными параметрами происходит, прежде всего, за счет уменьше-
242
________________Глава 10. Моделирование систем передачи информации
ния отношения сигнал/шум на выходе приемно-фильтрующего устройства
(ПФУ) и увеличения остаточных напряжений переходных процессов от
предыдущих сигналов. Если, как и раньше, предполагать, что в качестве
выходного эффекта ПФУ используется функция взаимной корреляции
sb'-j’ ₽J= 2ai лс(а;>₽;)+
то максимальное отношение мощности сигнала к мощности шума будет
определяться выражением
И =2а^(0,р,.).
\ чт )
х 11 'вых макс
Можно показать, что помехоустойчивость при когерентном прие-
ме двоичных сигналов КИМ2-ФМ, ФИМ2-ЧМорт, КИМ2-АМ при нали-
чии только сдвига по фазе на угол ф между принимаемым и опорным
сигналом будет определяться выражением
/>оШ = г(г“1с05ф),
где у - коэффициент, зависящий от вида вторичной манипуляции (уФМ =
= 7? ,учм = 1, удм = 1/72).
При записи учитывалось , что Ас(0; ср) = cos ср.
Если предположить, что при когерентном приеме КИМ2-ФМ сиг-
налов фаза опорного сигнала, измеряемая относительно принимаемого
сигнала, случайно и медленно изменяется с известной плотностью веро-
ятности ги(ср) на интервале (-л; л), то
/’ош ср = COStp d(P •
Аналогичным образом могут быть получены расчетные формулы для
^ош сР при случайном характере временной задержки дискретных сигналов.
Анализ проведенных исследований показывает, что для того чтобы система
синхронизации несущественно снижала помехоустойчивость системы пе-
редачи информации (при флуктуациях оценки временного положения сиг-
нала), она должна обеспечивать малые ошибки в оценке временного поло-
жения границ символов, т.е. пт2« Тс-
10.7. Алгоритмы формирования помех и
демодуляции дискретных сигналов
Для передачи дискретных сообщений X, по различным каналам связи
наиболее широко используется гармонические сигналы-переносчики с
АМ-, ЧМ-, ФМ-, и ОФМ- манипуляцией. Формирование перечисленных
сигналов-переносчиков на ЭВМ осуществляется по соответствующим
формулам для дискретных моментов времени:
th =(/»-!) Г0,й = 1, 2,..., И,
где TQ - период опроса (дискретизации); тс - длительность элементарно-
го символа; Н = тс /Го - количество отсчетов на длительности элемен-
тарного символа (бита).
243
10.7. Алгоритмы формирования помех и демодуляции дискретных сигналов
Для ускорения работы алгоритма вычисление синусов и косинусов
производится по рекуррентным формулам:
= CS^ + SCfl_}; = 0,
где Ch = CCh_} - SSh_{; Со = 1: С = cosco Го; 5 = sin со 7"0 .
Алгоритм формирования помехи. Для формирования помехи
при дискретном наблюдении сигнала производится обраще-
ние к стандартной программе датчика для равномерной случайной ве-
личины на интервале [0; 1). В результате образуется совокупность не-
равномерно распределенных чисел {/,}. Затем при помощи специально-
го вида нелинейных преобразований образуется совокупность случай-
ных чисел {и,} с требуемым одномерным законом распределения w0(n).
Функциональное преобразование при этом имеет вид
п. = Г-\1.\г = 1,
1 Г 1
где г (/,) - функция, обратная интегральной кривой wQ(n)dn .
Данный способ генерации, получивший название метода нелиней-
ного преобразования, дает независимую совокупность выборок {п,} ти-
па белого шума.
Широко используются гауссовская wni(«) и лапласовская ?ип2(я)
одномерные ПРВ значений помехи:
wni(«)= Д- ехр[- п2 /2а,2,],
2ла„
-7==exp[-i/j|V2/Gn
V2CTn
где оп2 - дисперсия (мощность) помехи.
Соответствующие формулы функционального преобразования
имеют вид:
для гауссовского закона распределения = an[-2!n/2/_i]1/2 sin2^/2/;
для лапласовского закона распределения /?, = -(оп/ Ji )ln/2/-isign(/2/ - 5),
где sign - знаковая функция (sign(x) = 1 при х > 0 и sign(x) = -1 при х < 0).
Алгоритм формирования аддитивной смеси сигнала и
помехи представляет собой операцию суммирования дискретных
значений сигнала-переносчика и помехи:
Я'л) = Уь = Si, + П„, при 0 < t < естс .
Алгоритм демодуляции дискретных сигналов. Моделирование
оптимального когерентного приема для полностью известных сигналов
как правило, производится по критерию максимального правдоподобия:
rnax{g(X!)}= max{ 5(Х,)}.
При использовании алгоритма максимального правдоподобия ос-
новной необходимой и достаточной операцией оптимального и асим-
птотически оптимального приемника полностью известных сигналов
является формирование функции взаимной корреляции g(S,) для всех
244
________________Глава 10. Моделирование систем передачи информации
дискретных сигналов S, = к,, которая при дискретном наблюдении и по-
мехе с независимыми значениями определяется выражением
н
gfc,)= g(5,)= ^2(Л,)5уО(о,), (10.13)
//=1
где ^ofe) - ансамбль опорных дискретных сигналов; Н- число выборок на
длительности элементарного символа тс; Z(y/z) - в общем случае преобразо-
ванный входной сигнал y(t^ с оператором безынерционного преобразова-
ния (БНП),
Z(n)=-Alnwn(y). (10.14)
dy
Здесь wn(y) - одномерная плотность распределения вероятностей помехи;
При воздействии белого гауссовского шума на безынерционный
преобразователь оператор (10.14) приобретает вид Z(yh) = yh/G„2, то есть
представляет собой линейный усилитель, а приемник в целом является
оптимальным линейным.
При помехе с лапласовским законом распределения характеристика
БНП имеет вид
^(л)=[2/Оп],/28'ёп[л].
т.е. БНП представляет собой жесткий ограничитель. Заметим, что при
воздействии негауссовской помехи алгоритм (10.13) является лишь
асимптотически оптимальным при условии малого входного отношения
сигнал/помеха и большого числа выборок Н —> оо.
Варианты структурных схем приемника дискретных двоичных
полностью известных сигналов с различными видами модуляции будут
приведены далее (см. рис. 10.7 - 10.10).
Из выражения (10.13) видно, что в общем случае приемник являет-
ся корреляционным нелинейным. Амплитудная характеристика БНП
однозначно связана с одномерной плотностью распределения помехи.
При гауссовской помехе БНП отсутствует.
Вероятность ошибки различения элементарного символа Рош при
оптимальном и асимптотически оптимальном приеме двоичных дис-
кретных равновероятных сигналов при дискретном наблюдении опре-
деляется выражением
/>ои. = и{[рсНц?(1-Пс)4пп)]1/2}, (10.15)
где и(х)= (1/д/2л) j ехр(-z2 Zr])dz - интеграл вероятностей, табулирован-
ные значения для которого приведены в табл. 10.2; Рс - мощность сиг-
нала, определяемая выражением
//=1 то
245
10.8. Структура имитационного комплекса и его подпрограмм
г|с - нормированный коэффициент взаимной корреляции между сигна-
лами, вычисляемый по формуле
1 н
Л с ~ ’
((1-Лс)=1/2 при AM; (l-ric^hO при ортогональной ЧМ, (1-г|с)=2,0 при ФМ);
и* =ст„ J [r'(/?)]2zpn(n)d/? - коэффициент, показывающий, во сколько раз
увеличивается отношение сигнал/помеха на выходе БНП с характеристикой
преобразования мгновенных значений Z(n), определяемой по (10.14), по
сравнению с отношением сигнал/помеха на входе БНП, если помеха характе-
ризуется одномерной симметричной относительно нуля плотностью распре-
деления вероятностей wn(w). Коэффициент ц02 всегда больше или равен еди-
нице, причем равенство имеет место лишь при гауссовской помехе.
Таблица. 10.2. Значение интеграла вероятностей
X 0 0,1 0,2 0,3 0,4
V(X) 0,5 0,46 0,42 0,382 0,345
X 0,5 1,5 1,75 2,25 2,5
V(X) 3,08-10"' 6.68-101 4-10'1 1,22-1 O'2 6,21-IO’13
X 2,75 3,25 3,5 4,0 4,25
V(X) 2,98- IO’3 5,77-Ю*4 2,32-10*4 3.16-10’5 1,07-10’5
Из (10.15) видно, что при прочих равных условиях помехоустой-
чивость при негауссовских помехах может быть выше, чем при гауссов-
ских. Это объясняется тем, что при равной дисперсии гауссовская поме-
ха обладает большей неопределенностью (энтропией).
10.8. Структура имитационного комплекса
и его подпрограмм
При имитационном моделировании СПД объектами исследования могут быть
источники дискретных сообщений, модуляторы, линии связи, демодуляторы.
На рис. 10.7 приведена схема канала связи при передаче дискрет-
ных двоичных сигналов с помощью амплитудной манипуляции (схема
AM-канала связи).
лс
Рис 10.7. Схема AM-канала связи
246
Глава 10. Моделирование систем передачи информации
Рис. 10.8. Схема ЧМ-канала связи
На рис. 10.8 изображена схема канала связи с частотной модуляцией
На рис. 10.10 приведена схема ОФМ-канала связи
Рис. 10.10. Схема ОФМ-канала связи
На рисунках 10.7 - 10.10 обозначено: ИС - источник сигнала;
Мод - модулятор; Г- гетеродин; ЛС - линия связи; ИП - источник помех;
БНП - блок нелинейного преобразования; Сум - сумматор; РУ- решающее
устройство; - опорный сигнал; СТС - система тактовой синхронизации.
Для каждого из блоков должна быть разработана соответствующая
подпрограмма, моделирующая их работу. Также в пакет программ
должны входить сервисные подпрограммы, служащие для организации
диалога при вводе исходной информации, для статистической обработ-
ки результатов исследования объектов и их вывода в виде чисел, графи-
ков-осциллограмм. Приведем описание некоторых подпрограмм, моде-
лирующих СПД, и сервисных подпрограмм.
247
10.8. Структура имитационного комплекса и его подпрограмм
Подпрограмма «Источник дискретных сообщений». Она выраба-
тывает двоичную последовательность элементарных символов, которая
может быть трех типов: непрерывная серия из одних нулей (0000...) или
единиц (1111...); серия из чередующихся нулей и единиц (101010...);
псевдослучайная серия нулей и единиц.
Тип и длина последовательности задаются в исходных данных, ко-
торые запрашиваются в диалоговом режиме на экране дисплея в виде
соответствующих вопросов. Псевдослучайная серия нулей и единиц
может генерироваться, например, по рекуррентному алгоритму на осно-
ве циклического кода с образующим полиномом Р(х) = х5 + х2 + 1. Ре-
куррентная формула имеет вид
= ^А--5 ® ^-3>
где Хк - элементы двоичной псевдослучайной последовательности; © -
операция сложения двоичных чисел по модулю два, которая находится
по правилу: 1 + 1=0+0=0; 1+0=0+1=1.
Подпрограмма «Модулятор» имитирует работу аналоговых модуля-
торов АМ-, ЧМ- и ФМ-сигналов. В результате работы подпрограммы на
экран дисплея выдаются графики-осциллограммы дискретных сообщений
и соответствующего им сигнала-переносчика с AM, ЧМ или ФМ.
Подпрограмма «Канал связи» моделирует линию связи с аддитив-
ными помехами. В качестве помехи может быть выбрана помеха с гаус-
совским или негауссовским законами распределения с независимыми
значениями. Подпрограмма линии связи по окончании работы выдает на
экран дисплея либо график чистого сигнала-переносчика, либо график
реализации аддитивной смеси сигнала и помехи, а также результаты
статистической обработки помехи. Подпрограмма позволяет исследо-
вать степень влияния помехи на передаваемый по линии связи сигнал
5(Г), а также оценить плотность распределения помехи wn(ri).
Подпрограмма статистической обработки случайных реализаций
дискретного процесса производит расчет значений выборочного сред-
него тп и дисперсии нп2 массива дискретной реализации по формулам:
•".—tv
п р L-i р
/>=1
где ^-элементы массива; А: - объем массива.
Подпрограмма также строит гистограмму данного массива. Для
того, чтобы гистограмма позволяла выявить закономерность оценивае-
мого ею закона распределения wn(n) случайной величины наилучшим
образом, ширина интервала выбирается из соотношения
AP = ("raax-«minV>Og2
где яП1ах и 77min - максимальное и минимальное значения элемента масси-
ва выборок.
248
Глава 10. Моделирование систем передачи информации
Построение гистограммы проводится в соотв етствии со следую-
щим алгоритмом.
1. Определяется максимальный и минимальный элементы массива ме-
тодом перебора.
2. Вычисляется оптимальный шаг интервала Ар.
3. Определяется количество интервалов, укладываемых в диапазон
(^max
4. Подсчитывается методом перебора количество попаданий Кр эле-
ментов массива в каждый из интервалов.
5. Строится график из прямоугольников, основаниями которых явля-
ются интервалы, а высоты пропорциональны или равны числу попа-
даний Кр в данный интервал Ар. Обычно высоту прямоугольников
нормируют по формуле Lp = К?/(КАр) с тем, чтобы сумма всех пло-
щадей прямоугольников гистограммы равнялась 1.
Подпрограмма «Демодулятор» реализует алгоритм (10.13). Для обес-
печения своей работы подпрограмма вызывает подпрограмму моделирова-
ния линий связи, в результате чего формируется массив реализации у1ь со-
стоящей из N элементарных сигналов (символов). Данный массив обраба-
тывается в соответствии с (10.13). При этом подсчитывается число ошибок
путем сравнения значений, переданных от источника двоичных символов
со значениями принятых символов Хк, которые появляются на выходе
решающего устройства. В процессе работы подпрограммы на экран выда-
ются сообщения о текущем числе ошибок N0Ul и числе переданных симво-
лов. По окончании своей работы подпрограмма запрашивает номер иссле-
дуемого символа. При задании данного номера производится вывод графи-
ков чистого сигнала и смеси, соответствующих данному символу. Также на
экран выводятся диаграммы, показывающие процесс накопления выходных
эффектов алгоритма для данного символа в соответствии с формулой
(10.13). Задавая различные законы распределения помех и их параметров
(мощность), а также меняя вид исследуемого алгоритма (линейный корре-
ляционный алгоритм, нелинейный корреляционный алгоритм), тем самым
можно экспериментально исследовать помехоустойчивость алгоритмов
(вероятность ошибок) и сравнить ее с теоретической по формулам при раз-
личных видах и параметрах модуляции, соотношении сигнал/помеха, виде
помехи, количестве обрабатываемых выборок на элементарный сигнал и
так далее. Экспериментальная оценка помехоустойчивости при этом про-
изводится по формуле
р =n /м
ОШ ОШ ' ’
где N - общее число переданных элементарных символов; NQU1 - число
ошибочно принятых символов.
249
10.8. Структура имитационного комплекса и его подпрограмм
Контрольные вопросы к главе 10
1. Какой круг задач для математического моделирования СПД решает-
ся на ЭВМ ?
2. Запишите сигнальную и помеховую составляющие при оптимальном
приеме полностью известных сигналов.
3. Запишите алгоритм различения двух полностью известных сигналов.
4. Опишите алгоритм и схему оптимального приемника полностью из-
вестных сигналов.
5. В чем заключаются различия алгоритмов оценки вероятности оши-
бочного приема дискретных сигналов с полностью известными па-
раметрами и сигналов со случайными параметрами ?
6. Сравните алгоритмы различения сигналов с КИМэ-АМ, КИМ2-ЧМ и
КИМ2-ФМ.
7. Опишите алгоритм оценки помехоустойчивости дискретных сигна-
лов со случайными существенными параметрами.
8. Опишите алгоритмы формирования дискретных сигналов и адди-
тивных помех с заданным законом распределения.
9. Опишите алгоритм демодуляции дискретных сигналов в гауссовских
помехах.
10. Опишите алгоритм демодуляции дискретных сигналов в негауссов-
ских помехах.
11. Чем отличаются друг от друга структурные схемы имитационного мо-
делирования демодуляторов с КИМ2-АМ, КИМ2-ЧМ и КИМ2-ФМ ?
250
Глава 11
МОДЕЛИРОВАНИЕ ИНФОРМАЦИОННЫХ СИСТЕМ
С ИСПОЛЬЗОВАНИЕМ типовых
ТЕХНИЧЕСКИХ СРЕДСТВ
11.1. Моделирование систем и языки программирования
Большое значение при реализации модели на ЭВМ имеет вопрос правильно-
го выбора языка программирования, который при описании широкого круга
понятий должен отражать внутреннюю структуру этих понятий. Высокий
уровень языка моделирования (ЯМ) значительно упрощает программирова-
ние моделей. Основными критериями при выборе ЯМ являются: проблемная
ориентация; возможности сбора, обработки, вывода результатов; быстродей-
ствие; простота отладки; доступность восприятия. Этими свойствами, как
правило, обладают языки программирования высокого уровня.
Для моделирования могут быть использованы языки имитацион-
ного моделирования (ЯИМ) и языки общего назначения (ЯОМ). Пред-
почтение отдается ЯИМ, поскольку они удобны при программировании
информационных систем и проблемно ориентированы. К недостаткам
ЯИМ относятся неэффективность рабочих программ, сложность отлад-
ки, а также недостаток документации.
Основными функциями языков программирования являются
управление процессами (согласование системного и машинного време-
ни) и управление ресурсами (выбор и распределение ограниченных
средств описываемой системы).
Как и специализированные языки, ЯИМ обладают некоторыми
программными свойствами и понятиями, которые не встречаются в
ЯОН. К ним относятся совмещение, размер, изменения, взаимосвязь,
стохастичность, анализ.
Совмещение. Параллельно протекающие в реальных системах 5 про-
цессы представляются с помощью последовательно работающей ЭВМ. Эту
трудность ЯИМ обходят путем введения понятия системного времени.
Размер. ЯИМ используют динамическое распределение памяти (ком-
поненты модели системы М появляются в ОЗУ и исчезают в зависимости
от текущего состояния). Эффективность моделирования достигается путем
использования блочных конструкций: блоков, подблоков и т.д.
Изменения. ЯИМ предусматривают обработку списков, отражаю-
щих изменения состояний процесса функционирования моделируемой
системы на системном уровне.
Взаимосвязь. Для отражения большого количества взаимосвязей меж-
ду компонентами модели в статике и динамике ЯИМ включает системно-
организованные логические возможности и реализации теории множеств.
251
11.1. Моделирование систем и языки программирования
Стохасптчность. ЯИМ используют специальные программные
генераторы последовательностей случайных чисел, программы преобра-
зования в соответствующие законы распределения.
Анализ. ЯИМ предусматривают системные способы статистиче-
ской обработки и анализа результатов моделирования.
Для языков, используемых в задачах моделирования, можно соста-
вить классификацию следующего вида (рис. 11.1).
Рис. 11.1. Классификация языков моделирования
Наиболее известными из ЯМ являются DYNAMO, GAPS, SIM-
SCRIPT, FORSIM, SIMULA, GPSS и некоторые другие.
Язык DYNAMO используется для решения разностных уравнений.
При использовании языка GAPS на пользователя возлагается рабо-
та по составлению на языке FORTRAN подпрограмм, в которых описы-
ваются условия наступления событий и правила их перехода из одного
состояния в другое, законы изменения непрерывных величин.
SIMSCRIPT - язык событий, созданный на базе языка Фортран. В
нем каждая модель Mj состоит из элементов, с которыми происходят со-
бытия, представляющие собой последовательность формул, изменяю-
щих состояние моделируемой системы с течением времени.
FORSIM - пакет подпрограмм на языке Фортран, который позво-
ляет оперировать только фиксированными массивами данных, описы-
252
Глава 11. Моделирование информационных систем ...
вающих объекты моделируемой системы. Удобен для описания систем с
большим числом разнообразных ресурсов. Полное описание динамики
модели можно получить с помощью подпрограмм.
SIMULA - универсальный язык программирования, в котором получи-
ли развитие основные возможности алгоритмического языка Алгол-60. Важ-
ным достоинством языка является возможность построения на его основе
специализированных языков и пакетов прикладных программ, ориентирован-
ных на использование в различных предметных областях. Язык SIMULA ши-
роко используется для ИМ сложных систем. Средства моделирования, ориен-
тированные на представление исследуемой системы в виде совокупности
взаимодействующих процессов, определены в системном классе simulation. В
основе этих средств лежат несколько механизмов: возможность квазипарал-
лельного функционирования объектов и организации их взаимодействия,
средства иерархического описания классов и средства организации и обработ-
ки упорядоченных множеств объектов (списков).
GPSS - интегрирующая языковая система, применяемая для опи-
сания пространственного движения объектов. Подобные динамические
объекты в GPSS называются транз актами и представляют собой эле-
менты потока. Транзакт может восприниматься как динамическая единица
материального или информационного потока, способная перемещаться от
объекта к объекту и имитировать последовательность обслуживания, кото-
рую получает транзакт за время пребывания его в системе.
Транзакты «создаются» и «уничтожаются». Функцию каждого из
транзактов можно представить в виде движения его через модель М с по-
очередным воздействием по мере продвижения на ее блоки. Функциональ-
ный аппарат языка образуют блоки, описывающие логику модели, сообщая
транзактам, куда двигаться и что делать дальше. Данные для ЭВМ подго-
тавливаются в виде пакета управляющих и определяющих карт, которые
составляются по схеме модели, набранной из стандартных символов. Соз-
данная программа GPSS, работая в режиме интерпретации, генерирует и
передает транзакты из блока в блок. Каждый переход транзакта приписы-
вается к определенному моменту системного времени.
При моделировании предпочтение отдают языку, который более
знаком, универсален. Вместе с увеличением числа команд возрастают
трудности использования ЯИМ. Экспертные оценки ЯИМ по степени их
эффективности приведены в табл. 11.1.
Таблица. 11.1. Оценки эффективности ЯИМ
Баллы Возможности Простота применения Предпочтение пользователя
5 SIMULA GPSS SIMSCRIPT
4 SIMSCRIPT SIMSCRIPT GPSS
3 GPSS SIMULA SIMULA
Суммарный бал: SIMULA - 11; SIMSCRIPT- 13; GPSS - 12.
253
11.2. Основные сведения о языке GPSS
Если предпочтение отдается блочной конструкции модели при на-
личии минимального опыта в моделировании, то следует выбрать язык
GPSS, но при этом следует помнить, что он негибок, требует большого
объема памяти и затрат машинного времени для счета.
11.2. Основные сведение о языке GPSS
Язык имитационного моделирования GPSS (General Purpose System Simulator)
разработан в 1961 г. фирмой IBM вслед за разработкой компилятора языка
Фортран. Представляет собой фортран-ориентированную версию языка ИМ.
Первые реализации GPSS строились в виде препроцессора, т.е. исходным тек-
стом программ, анализирующих предложения GPSS, были тексты на Фортра-
не. Существует много версий GPSS, являющегося наиболее распространенным
ЯИМ данного класса. В настоящее время разработаны полные версии GPSS
для ПЭВМ. С 1968 г. этот язык входит в математическое обеспечение машин
фирмы IBM и является одним из наиболее популярных языков ИМ.
GPSS составлен из объектов и операций (логических правил). Объ-
екты делятся на семь классов.
Динамические объекты (ДО) - элементы потока обслуживания за-
явки или «транзакты». Они создаются и уничтожаются. С каждым тран-
зактом может быть связано некоторое число «параметров»
Аппаратно-ориентированные объекты (АО) соответствуют эле-
ментам оборудования, которые управляют ДО. К ним относятся накопи-
тели, устройства, логические переключатели.
Статистические объекты (СО) включают очереди и таблицы.
Запоминающие объекты (30) состоят из ячеек и матриц ячеек.
Группирующие объекты (ГО) - группы и списки.
Вычислительные объекты (ВО) состоят из арифметических и бу-
левых переменных, а также функций.
Операционные объекты (00) - блоки, формирующие логику систе-
мы, давая транзактам указания, куда идти дальше.
Чтобы смоделировать систему, необходимо составить ее описание
в терминах GPSS. Затем симулятор генерирует транзакты, продвигает
их через заданные блоки и выполняет действия, соответствующие бло-
кам. Продвижение создает блок GENERATE. Каждое продвижение
транзакта является событием, которое должно произойти в определен-
ный момент времени. Симулятор регистрирует время наступления каж-
дого события, после чего производит обработку событий в правильной
хронологической последовательности.
Если транзакты заблокированы, то симулятор сможет продвинуть их
только тогда, когда изменятся блокирующие правила. Симулятор моделирует
часы, показания которых в любой момент времени называют абсолютным
временем. Относительное время показывает текущее время в модели. При
помощи специальной операции относительное время может устанавливаться
254
________________Глава 11. Моделирование информационных систем ...
в нуль, и последующий счет времени будет производиться от этой точки.
Специальной операцией оба значения времени могут устанавливаться в нуль.
Относительное и абсолютное время в модели отображаются целыми числа-
ми. Сггмулятор рассчитывает схему по принципу ближайшего события. Цен-
тральной задачей симулятора является просмотр и проверка всех возможных
событий. Транзакты входят в цепи. Существует пять видов цепей.
1. Цепь текущих событий включает в себя те транзакты, планируемое
время наступления которых равно или меньше текущего часового.
Цепь текущих событий организуется в порядке убывания приорите-
тов транзактов и в порядке очередности поступления;
2. Цепь будущих событий включает в себя транзакты, время которых
не дошло для обслуживания;
3. Цепь прерванных событий;
4. Цепь парных транзактов - в текущий момент времени транзакты
имеют статус парности (ожидают прибытия синхронизирующих
транзактов);
5. Цепь пользователя включает транзакты, которые пользователь уда-
лил из цепи текущих транзактов.
В зависимости от различных условий и требований пользователя
система помещает транзакты в те или иные цепи.
Программа на GPSS создается в текстовом редакторе в определен-
ном формате. Формат ввода содержит 3 различные поля: метка, опера-
ция и переменные. Поле переменных содержит подполя, которые обо-
значены А, В, С, D, ..., Н. Последующие поля отделяются от предыду-
щих запятыми. Пропущенное значение в поле переменных выделяется
запятыми (кроме конца поля). Каждый из объектов требует определен-
ного числа ячеек ОЗУ, в которых во время моделирования хранятся ат-
рибуты объекта (АТО). Те из АТО, к которым может обращаться про-
граммист, называются стандартными числовыми атрибутами (СЧА),
имеющими одно- или двухбуквенные мнемонические обозначения.
Мнемонические обозначения указывают на тип СЧА, а целочисленное
значение - на конкретное значение СЧА.
Номера блоков можно определять символическими обозначения-
ми. При этом обозначение должно включать от трех до пяти знаков, от-
личных от пробела, первые три из которых должны быть буквами. Эти
ограничения необходимы, чтобы не смешивались атрибуты системы и
символы. Дополнительным ограничением является недопустимость та-
ких специальных знаков, как «-», «+», « " » и т.д.
Если в полях блока А, В, С представлены стандартные числовые
атрибуты Nj или Wp то необходимо, чтобы номер блока был представлен
в качестве аргумента. Если этот номер блока определяется символиче-
ски, то такое представление должно быть отличным от мнемонических
обозначений указанных СЧА (У или PF). В префиксе символического
имени используется знак доллара - $.
255
11.2. Основные сведения о языке GPSS
Пользователь может использовать относительную адресацию. В сим-
волической записи «CROSS ± /?» символ CROSS указывает на нужный
блок, а число п - на номер блока, отсчитываемого от номера блока CROSS.
При косвенной адресации предполагается, что нужный аргумент представ-
лен некоторым параметром, обозначаемым звездочкой (*), за которой сле-
дует целое число. Например, 5* 10 соответствует текущему значению нако-
пителя, номер которого задан параметром 10 (буква S означает накопи-
тель). Косвенная адресация не применяется для СЧА Cl, М\, RNn. Общий
формат предложений GPSS показан в табл. 11.2.
Таблица 11.2. Общий формат предложений GPSS
{Метка} Оператор Операнды {Комментарии}
до 20 символов: цифры А, В, С, D, Е. —
Каждому исполняемому оператору может быть сопоставлен блок
со стандартизованным графическим изображением, что позволяет при
построении моделей до написания текстов программ построить блок
диаграмм, отображающих последовательность продвижения динамиче-
ских объектов.
11.2.1. Динамические объекты GPSS.
Транзактно-ориентированные блоки
В системах массового обслуживания транзакт - это динамический объект,
соответствующий заявке на обслуживание в СМО. Язык GPSS располагает
средствами для порождения (генерации) транзактов, последовательного про-
движения их от объекта к объекту, их задержки на время, соответствующее
длительности активности, уничтожения (удаление из системы) транзактов.
Оператор GENERATE. Первоначальный ввод транзактов в модель
всегда осуществляется специальным блоком GENERATE. Моменты поро-
ждения транзактов и ввода их в модель могут образовывать как детермини-
рованный, так и случайный поток событий. Если тип потока событий будет
детерминированным, то интервалы между моментами ввода транзактов в
модель будут отстоять друг от друга на равные временные промежутки. В
табл. 11.3 приводятся обозначения блока GENERATE в Q-схемах, на блоч-
ных диаграммах, а также запись этого блока на языке GPSS.
Таблица 11.3. Описание блока GENERATE
Q-схема Блок-диаграмма Оператор Примечание
С 1 А, В, С, D, Е 1 GENERATE А, В, С. А Е
Значения интервалов в единицах модельного времени задает целая
константа в поле А. Следует иметь в виду, что модельное время в GPSS
- целое без знака (0. 1, 2, ....). Следовательно, все параметры закона рас-
256
Глава 11. Моделирование информационных систем ...
пределения случайных интервалов между соседними событиями в пото-
ке, имеющие смысл времени, должны быть приведены к целому форма-
ту с помощью масштаба времени.
Если А = const, В = const, то
оператор GENERATE описывает
равномерный закон распределения
длины интервала между соседними
событиями в потоке (рис. 11.2, где
S = I /X - математическое ожидание
(МО); А > В; S = 2Bh\ h = l/(2B)).
Опишем назначение остальных
параметров, используемых в блоке
GENERATE:
S' - площадь
А-В j А+В
Рис. 11.2. ПРВ для транзактов, созда-
ваемых блоком GENERATE
при А= const, В = const
™(')1
В - может быть отличен от const и рассматривается как модифика-
тор, в этом случае длина интервала определяется как А В;
С - задержка начала генерации;
D - число генерируемых транзактов (емкость источника);
Е - приоритет транзактов. Целое без знака: 0, 1,2, ...
Операнды могут быть опущены, тогда по умолчанию А = В=С = Е=0,
D = 0-0.
Оператор ADVANCE. В процессе движения транзактов по модели
в определенных точках может возникать необходимость задержки тран-
зактов на детерминированное или на случайное время. Чаще всего за-
держка транзакта связана с имитацией обслуживания (обработки). В
табл. 11.4 приведены обозначения блока ADVANCE в Q-схемах, на
блочных диаграммах, а также запись этого блока на языке GPSS.
Таблица 11.4. Описание блока ADVANCE
Q-схема Блок- диаграмма Оператор Примечания
Активность, имеющая слу- чайную длительность 1 А,В 1 ADVANCE А,В Задержка на случайное время со сред- ним значением А = 1/1 и равномерным распределением
Задержка транзактов осуществляется блоком ADVANCE, имеющем
два поля - А и В. Если поле В пусто, а в поле А указана целая константа, то
транзакт, войдя в блок ADVANCE, остается в нем в течение интервала
модельного времени, длительность которого определяется полем А.
Если в поле В указывается целая константа, не превышающая
константы в поле А, то осуществляется случайная задержка транзакта с
равномерным распределением на интервале (А + В, А - В).
Оператор TERMINATE. Начав свой путь на выходе блока GEN-
ERATE и пройдя то число операционных блоков GPSS-модели, которое
при создавшейся случайной ситуации предусмотрено логикой модели,
9—3834
257
11.2. Основные сведения о языке GPSS
транзакт выводится из модели. Вывод транзакта из модели сопровожда-
ется уничтожением в памяти ЭВМ всех записей, характеризовавших со-
стояния транзакта во время его продвижения по модели. Уничтожение
транзакта производит блок TERMINATE. В табл. 11.5 приводятся обо-
значения блока TERMINATE в Q-схемах, на блочных диаграммах, а
также запись этого блока на языке GPSS.
Таблица 11.5. Описание блока TERMINATE
Q-схема Блок-диаграмма Оператор Примечания
Выходной поток Уничтожение тран-
Удаление транзакта из TERMINATE [А] закта, входящего в блок TERMINATE
системы
Блок TERMINATE имеет одно поле А, в котором записывается це-
лая константа (или же дается ссылка на СЧА). В момент входа транзакта
в блок TERMINATE следует вывод его из модели, при этом из специ-
ального счетчика вычитается указанная в поле А константа. В момент
модельного времени, когда значение счетчика станет равным 0 (или
меньше 0), моделирование прекращается, и на печать выдаются резуль-
таты в виде таблиц с соответствующими комментариями, статистики,
накопленные в процессе моделирования.
При пустом поле А блока TERMINATE его значение считается
равным 0, из счетчика ничего не вычитается.
11.2.2. Аппаратно-ориентированные блоки
Аппаратно-ориентированные блоки (операторы) описывают действия
по занятию и освобождению ресурсов (каналов обслуживания) с обра-
зованием очередей к занятым ресурсам.
Операторы SEIZE и RELEASE. В начале моделирования все одно-
канальные приборы обслуживания считаются свободными (их статус счи-
тается равным NU- от английского NOT USE). Занятие устройства проис-
ходит в момент прохода транзактом блока SEIZE, в поле А которого указы-
вается символическое имя (или порядковый номер прибора). Особенно-
стью блока SEIZE является его способность задерживать транзакты, если в
момент подхода транзакта к блоку SEIZE прибор с указанным именем за-
нят другим транзактом (находится в состоянии U- от английского USE). В
табл. 11.6 приводятся обозначения блока SEIZE в Q-схемах, на блочных
диаграммах, а также запись этого блока на языке GPSS.
Таблица 11.6. Описание блока SEIZE
Q-схема Блок- диаграмма Оператор Примечания
SEIZE J Занять канал с номером А, при занятом канале занять место в очереди
258
Глава 11. Моделирование информационных систем ...
Если в течение некоторого интервала модельного времени несколь-
ко транзактов пытаются войти в блок SEIZE, то организуется очередь
транзактов, ждущих разрешения на вход в блок SEIZE. Это эквивалентно
образованию на входе устройства очереди с неограниченным числом
мест. В реальной системе моделирования длина очереди ограничена ре-
сурсами, выделяемыми системой моделирования для организации очере-
дей. Чтобы не было бесконечного возрастания длины очереди, необходи-
мо обеспечить выполнение условия, при котором существует установив-
шийся режим в системе с чистым ожиданием: р < 1, р = Х/ц.
По умолчанию принимается дисциплина обслуживания очереди FIFO.
Освобождение прибора (перевод прибора из состояния U в состоя-
ние NU) происходит в момент прохода транзактом блока с именем RE-
LEASE. В поле А этого блока должно указываться то же имя, что и в
блоке SEIZE. Попытка входа транзаката в блок RELEASE, ранее не
прошедшего блок SEIZE с тем же именем в поле А, что и в блоке RE-
LEASE, приводит к прекращению моделирования из-за нарушения ло-
гики моделирования. В табл. 11.7 приводятся обозначения блока RE-
LEAZE в Q-схемах, на блочных диаграммах, а также запись этого блока
на языке GPSS.
Таблица 11.7. Описание блока RELEAZE
Q-схема Блок- диаграмма Оператор Примечания
RELEASE/* Освободить канал с номером/!, назна- чить на обслуживание транзакт из голо- вы очереди
Транзакты всегда пропускаются блоком RELEASE, причем в этот
момент сразу же начинается просмотр очереди на вход в блок SEIZE
(если, конечно, она была организована).
Пример» Требуется построить имитационную модель одноканальной СМО с
чистым ожиданием (рис. 11.3). Реальным объектом моделирования является,
например, однопроцессорная ЭВМ, обрабатывающая в оперативном режиме
запросы пользователя для случая, когда область памяти, выделенная для буфе-
ризации запросов, настолько велика, что влиянием ее размера на характеристи-
ки системы можно пренебречь.
Рис. 11.3. Имитационная модель одноканальной СМО с чистым ожиданием
Интенсивность поступления транзактов (запросов) в очередь X - 20 с'1, интен-
сивность обслуживания ц = 40 с-1, коэффициент использования р = Х/ц = 0,5 < 1.
Общее число транзактов, которое необходимо смоделировать, равно 1 000.
Будем считать, что входной поток и поток обслуживания имеют равномерно
распределенные длины интервалов с 20%-м отклонением от средних длин (не про-
стейшие потоки).
259
11.2. Основные сведения о языке GPSS
Распределение интервалов входящего потока и потока обслуживания по-
казано на рис 11.4.
Входящий поток Поток обслуживания
40 мс 50 мс 60 мс 20 мс 25 мс 30 мс
Рис. 11.4. ПРВ входящего потока и потока обслуживания
Масштаб (единица модельного времени) моделирования Д/ = 1 мс.
На рис. 11.5 приведена блок-диаграмма ИМ.
Основная секция Таймерная секция
Рис. 11.5. Блок-диаграмма ИМ
Общее время моделирования (в единицах модельного времени) запишется
как TLIM = N/(XA.t) = 1000/(20-10~3) = 50-103, где /V - общее число транзактов.
На основании блок-диаграммы ИМ запишем программу на языке GPSS (лис-
тинг 11.1).
Листинг 11.1.
GENERATE 50,10
SEIZE 1
ADVANCE 25,5
RELEASE 1
TERMINATE
;Time Section
GENERATE 50000
TERMINATE 1
11.2.3. Многоканальное обслуживание
Для моделирования многоканального обслуживания в GPSS использу-
ются специальные объекты, называемые накопителями.
Моделирование параллельно работающих каналов обслуживания в
GPSS осуществляется с помощью накопителей (STORAGE). Накопите-
ли (многоканальные устройства), в отличие от устройства (канала об-
служивания), позволяют моделировать сложный ресурс, который может
выделяться частями, причем отдельными частями накопителя (канала-
260
________________Глава 11. Моделирование информационных систем ...
ми) может одновременно обслуживаться несколько транзактов. Накопи-
тели характеризуются емкостью (CAPASITY), задаваемой целым поло-
жительным числом. Емкость накопителей описывается оператором
STORAGE, в поле А которого указывается имя (порядковый номер) на-
копителя, а в поле В - целая константа, определяющая емкость. Напри-
мер, запись TERM STORAGE 24 означает, что накопитель с именем
TERM имеет емкость, равную 24.
Емкость накопителя можно интерпретировать как число мест для
размещения транзактов, хотя на самом деле транзакты не размещаются
в накопителе.
Для фиксации входа транзакта в память применяется блок ENTER
(табл. 11.8), в поле А которого указывается имя или номер памяти, а в
поле В - число единиц памяти, занимаемых в ней транзактом. Поле В
может быть опущено, в этом случае считается, что занимается одна
единица памяти. В табл. 11.8 приводятся обозначения блоков ENTER и
LEAVE в Q-схемах, на блочных диаграммах, а также запись этих
блоков на языке GPSS.
Таблица 11.8. Описание операторов ENTER, LEAVE
Q-схема Блок- диаграмма Оператор Примечания
Q hiiH ' 1 1 ENTER A,В Войти в накопитель с именем А, заняв В единиц ресурса, иначе занять место в Q
Q 1111H -1- F 1 LEAVE A,В Выйти из накопителя с именем А, освобо- дить В единиц ресурса, назначить тран- закт из головы очереди
Если в момент подхода транзакта к блоку ENTER все места в
накопителе заняты (статус накопителя в этот момент равен SF - от
английского STORAGE FULL), или же число свободных мест меньше
константы в поле В блока ENTER, то транзакт не пропускается блоком
ENTER. При этом организуется очередь транзактов на вход блока
аналогично тому, как организуется очередь к блоку SEIZE.
Если в памяти нет достаточного числа свободных единиц,
запрашиваемых блоком ENTER, то транзакт задерживается на входе этого
блока до тех пор, пока в памяти не будет освобождено необходимое число
единиц памяти. Причем в то время, пока этот транзакт ждет входа в блок
ENTER, другой транзакт, пришедший позже, может войти в блок ENTER,
если для него достаточно свободных единиц памяти.
Отметим, что в начальный момент времени все накопители свободны
и их статус считается равным SE - от английского STORAGE EMPTY.
261
11.2. Основные сведения о языке GPSS
Освобождение мест в накопителе происходит в момент прохода
транзактом блока LEAVE; поля этого блока имеют тот же смысл, что и
поля блока ENTER. Транзакт, входящий в блок LEAVE, обязательно
должен перед этим пройти блок ENTER, в противном случае будет
зафиксирована ошибка в процессе моделирования. Значения же полей
В блоков ENTER и LEAVE не должны обязательно совпадать.
Логика работы блоков ENTER и LEAVE позволяет моделировать
обслуживание в многоканальных СМО. В этом случае занятие одного
места в накопителе можно интерпретировать как занятие одного
канала обслуживания. Задержка канала в течение некоторого времени
соответствует обслуживанию в многоканальной СМО и моделируется
блоком ADVANCE аналогично случаю одноканального обслуживания.
Блок ADVANCE помещается между блоками ENTER и LEAVE.
Приведем пример моделирования многоканальной СМО в GPSS.
Пример. Необходимо разработать имитационную модель многопроцессорной
ВС с чистым ожиданием (рис. 11.6) , которая предполагает, что для хранения
запросов, которые не могут быть назначены на обслуживание из-за отсутствия
свободного процессора, выделена память настолько большого объема, что уве-
личение ее размера не будет сказываться на характеристиках производительно-
сти системы.
Рис. 11.6. Схема многоканальной СМО с чистым ожиданием
Каналу обслуживания Kh i = 1,2, .... т соответствует свой процессор, так
что каждый запрос обслуживается отдельным процессором.
Листинг 11.2
SIMULATE
S_K STORAGE т
GENERATE Ли, Ви
ENTER S_K, 1
ADVANCE Ак, Вк
LEAVE S_K, 1
TERMINATE 1
START N
END
262
Глава 11. Моделирование информационных систем ...
Рассмотренные операторы автоматически собирают статистику о прохожде-
нии транзактов через устройства или накопители. В частности, подсчитывается чис-
ло транзактов и измеряется время их пребывания в аппаратно-ориентированных
блоках. Это позволяет по завершении моделирования обработать накопленный ста-
тистический материал и создать протокол испытаний, содержащий количественные
характеристики законов распределения показателей эффективности.
Многофазное обслуживание. Если приборы и их параллельные
композиции соединены последовательно, то имеет место многофазное
обслуживание (многофазная Q-схема).
Собственными параметрами Q-схемы будут являться количество фаз ф,
емкостьу-го накопителя каждой фазы Sj, где у = 1,ф , количество накопителей
каждой фазы, количество каналов в каждой фазе. Напомним, что в ТМО, в
зависимости от емкости накопителя, применяют следующую терминологию:
СМО с потерями (5^ = 0), т.е. накопитель в приборе П7 отсутствует, а имеется
только канал обслуживания Kjm; системы с ожиданием (SJ -> оо), т.е. накопи-
тель Sj имеет бесконечную емкость и очередь заявок ничем не ограничена;
системы смешанного типа (с ограниченной емкостью накопителя Sj.
На рис. 11.7 приведен пример двухфазной Q-схемы смешанного типа.
Qi
Q2
Ап Лк1 Лк2
7Й1 7?к1 Вк2
)-я фаза 2-я фаза
Рис. 11.7. Пример двухфазной Q-схемы
Пример. Необходимо разработать имитационную мо-
дель Q-схемы, приведенной на рис. 11.7. Параметры
моделируемой Q-схемы следующие: интенсивность
поступления транзактов X = 20 с-1, интенсивность об-
служивания первым устройством Ц! = 40 с"1, интенсив-
ность обслуживания вторым устройством ц2 = 50 с-1,
общее время моделирования выбрать равным 1000
модельных единиц.
Будем считать, что входной поток и поток об-
служивания имеют равномерно распределенные длины
интервалов с 20%-м отклонением от средних длин. То-
гда параметры блока GENERATE будут такими: Ли =
50 мс; Ви = 10 мс. Параметры Лк1 =25 мс; Вк1 = 5 мс
будут параметрами первого блока ADVANCE. Пара-
метры Як2 = 20 мс; Вк2 = 4 мс будут параметрами
второго блока ADVANCE. Соответственно единица
модельного времени Ar= 1 мс.
На рис. 11.8. показана блок-диаграмма имита-
ционной модели, соответствующей схеме на рис.
11.7. В листинге 11.3 приведена программа на языке
GPSS, составленная в соответствии с блок-
диаграммой ИМ.
ИМ
263
11.2. Основные сведения о языке GPSS
Листинг 11.3.
GENERATE 50,10
; 1-я фаза
SEIZE 1
ADVANCE 25,5
RELEASE 1
; 2-я фаза
SEIZE 2
ADVANCE 20,4
RELEASE 2
TERMINATE 1
START 1000
Моделирование систем с несколькими типами транзактов. Ха-
рактерной особенностью этого случая является то, что, ожидая освобо-
ждения ресурса, заявки нескольких типов, претендующие на общий ре-
сурс, используют общую очередь (рис. 11.9). Условие существования
PR1
PR2
PR3
Рис. 11.9. Пример СМО с несколькими типами
транзактов
установившегося режи-
ма выглядит следующим
образом: р = Z^,p, < 1.
После того как был
дан общий обзор элемен-
тов СМО и их представ-
ление в GPSS, рассмотрим
дисциплины обслужива-
ния очередей, которые
можно использовать при
моделировании в GPSS.
Дисциплина FIFO является используемой по умолчанию процедурой
обслуживания любой очереди. Для организации очереди, работающей в
соответствии с дисциплиной FIFO, программа строится в виде последова-
Ли!. Ли! Ли2,Яи2 ЯиЗ,ЯиЗ 1
ц SEAZE 1 SEAZE Z\ Ц SEAZE /|\
1 ADVANCE Як!. Як! 1 ADVANCE Як2. Нк2 1 ADVANCE ЯкЗ. НкЗ
Рис. 11.10. Блок-диаграммы СМО с различ-
ными типами транзактов, обслуживаемых в
одной очереди
TER
TER
тельности фрагментов, начи-
нающихся оператором GEN-
ERATE и завершающихся
оператором TERMINATE.
Блок-диаграммы СМО с
различными типами обслужи-
ваемых в одной очереди тран-
зактов показаны на рис. 11.10.
GPSS позволяет созда-
вать независимые процессы
для каждого типа транзак-
тов, автоматически выявляя
конфликты на общих ресур-
сах и образуя очереди к ним.
264
Глава 11. Моделирование информационных систем ...
Ли1, Ви1,,, PR1
1, PR
Ак 1, Вк1
1
Яи2, Ви2,,, PR2
1
Лк2, Вк2
1
ЛиЗ, ВиЗ,,, PR3
1
ЛкЗ, ВкЗ
1
УЗ ; УЗ - объем выборки для транзактов 3-го типа
Дисциплина с относительными приоритетами (0П) реализуется с
использованием тех же операторов с добавлением в список операндов
GENERATE операнда Е, задающего приоритет. По умолчанию дисциплина
ожидания организует очередь с учетом PRy. Внутри каждого приоритета
транзакты располагаются в соответствии с дисциплиной FIFO. Блок-
диаграмма строится аналогично предыдущему случаю, изменяются лишь
операторы GENERATE в каждой из ветвей за счет добавления операнда Е,
задающего приоритет соответствующих транзактов (PR 1/2/3). В листинге
11.4 приведена программа на языке GPSS, составленная в соответствии с
блок-диаграммой ИМ, показанной на рис. 11.10.
Листинг 11.4
; секция транзактов 1-го типа
GENERATE
SEIZE
ADVANCE
RELEASE
TERMINATE
; секция транзактов 2-го типа
GENERATE
SEIZE
ADVANCE
RELEASE
TERMINATE
; секция транзактов 3-го типа
GENERATE
SEIZE
ADVANCE
RELEASE
TERMINATE
START
END
Для реализации дисциплины с абсолютными приоритетами (АП)
необходимы специальные операторы PREEMPT и RETURN.
Операторы PREEMPT, RETURN. С помощью этих операторов
удобно описывается обслуживание с прерыванием, т.е. такие ситуации,
когда обслуживающий прибор временно прекращает обслуживание по-
ступившей на него заявки и переходит на обслуживание «срочной» за-
явки, и, обслужив ее, возвращается к обслуживанию первой менее при-
оритетной заявки.
Блок PREEMPT работает совместно с блоком SEIZE, который за-
дает обслуживание менее приоритетного транзакта; блок PREEMPT
прерывает обслуживание менее приоритетной заявки и передает обслу-
живание более приоритетной.
При поступлении транзактов на блок PREEMPT при использовании
происходит следующее. Устройство, указанное в поле А этого блока, преры-
вает обслуживание транзакта, который его занимал (этот транзакт будем на-
265
11.2. Основные сведения о языке GPSS
зывать прерванным), и начинает обслуживание прерывающего транзакта.
Прерванный транзакт ждет окончания обслуживания прерывающего тран-
закта. При этом время его ожидания автоматически не фиксируется. Обслу-
живание устройством прерывающего транзакта прекращается тогда, когда
этот транзакт пройдет блок RETURN, в котором указано это устройство.
Если в момент поступления транзакта на блок PREEMPT указанное в
нем устройство уже занято обслуживанием прерывания, то такой транзакт
задерживается на входе блока PREEMPT. Когда указанное устройство за-
кончит обслуживание первого прерывания, транзакт, задержанный на вхо-
де PREEMPT, войдет в него, и устройство займется обслуживанием второ-
го прерывающего транзакта, а не прерванного транзакта. Один транзакт
может прерывать одновременно несколько устройств.
Q-схема, схема моделирования и описание операторов PREEMPT
и RETURN приведены в табл. 11.9.
Таблица 11.9. Описание операторов PREEMPT и RETURN
Q-схема Блок-диаграмма Оператор Примечания
Прерывание 1 1 1 д PREEMPT Я,[PR] Захватить (занять с прерыванием) канал с номером А, иначе занять место в Q
Прерывание 1 SHIM П 1 RETURN А Снять прерывание с каналаЯ, назначить на обслуживание транзакт из головы очереди
1
Если в операторе PREEMPT не указывается второй операнд (символь-
ная константа PR), то реализуется одноуровневое прерывание, т.е. можно за-
хватить устройство, которое не было захвачено другим транзактом. Если ука-
зан операнд PR, то разрешается прерывание при условии захвата устройства
транзактом с более низким приоритетом. Для транзактов с наименьшим при-
оритетом должны быть использованы операторы SEIZE и RELEASE.
Рис. 11.11. Блок-диаграмма моделирования СМО с абсолютными приоритетами
266
Глава 11. Моделирование информационных систем ...
Приведем пример использования операторов PREEMPT и RETURN.
Пример. Пусть требуется построить модель СМО, заданную на рис. 11.9. Параметры
этой СМО выберем следующим образом: X] = Х2 = Х3 = 40 с'1, ц 1 = 100 с'1, ц2 = 50 с"1, ц3
= 25 с'1. Тогда параметры блоков модели запишутся как Ли 1 = Ли2 = ЛиЗ = 25 мс,
Лк1 = 10 мс, Лк2 = 20 мс, ЛкЗ = 40 мс. Общее время моделирования выбрать равным
1000 модельных единиц. Последовательность приоритетов выберем произвольно.
Будем считать, что входной поток и поток обслуживания имеют равномерно
распределенные длины интервалов с 20%-м отклонением от средних длин. Блок-
диаграмма требуемой модели СМО приведена на рис. 11.11. Программа на языке
GPSS представлена в листинге 11.5.
Листинг 11.5
; 1 -й тип транзактов
GENERATE 10,2,.J
SEIZE 1
ADVANCE 10
RELEASE 1
TERMINATE
;2-й тип транзактов
GENERATE 9,2,„2
PREEMPT 1,PR
ADVANCE 9
RETURN 1
TERMINATE
;3-й тип транзактов
GENERATE 9,2,„3
PREEMPT 1,PR
ADVANCE 9
RETURN 1
TERMINATE
GENERATE 1000
TERMINATE 1
11.2.4. Статистические блоки GPSS
Статистические блоки GPSS используются для сбора дополнительной не-
стандартной статистики, которая не собирается блоками операционной ка-
тегории по умолчанию. Для этой цели в GPSS имеются специальные сред-
ства, называемые регистраторами очереди (РО) и таблицами (Т).
Регистраторы очереди предназначены для сбора статистики о
транзактах, ожидающих в очереди входа в блок, моделирующий разде-
ляемый ресурс в объекте-оригинале. Очередь на входе формируется по
умолчанию исполняющей подсистемой GPSS, но для сбора статистики о
процессе ожидания надо специально включать в текст программы опе-
раторы для РО.
Операторы QUEUE и DEPART. Эти операторы используются для
решения следующих задач. Оператор QUEUE фиксирует вход транзакта в
очередь, а оператор DEPART - выход из очереди. В табл. 11.10 приводятся
обозначения блоков QUEUE и DEPART в Q-схемах, на блочных диаграм-
мах, а также запись этих блоков на языке GPSS.
267
11.2. Основные сведения о языке GPSS
Таблица 11.10. Описание операторов QUEUE, DEPART
Q-схема Блок-диаграмма Оператор Примечания
Q В в QUEUE В Зарегистрировать вход транзакта в очередь А, занять В мест очереди
^llll
Q в в DEPART А, В Зарегистрировать выход транзакта из оче- реди А, освободить В мест очереди
llll^
При входе транзакта в блок QUEUE интерпретатор увеличивает
длину очереди, указанной в поле А этого блока, на число, заданное в по-
ле В. Если это число опущено, то длина очереди увеличивается на 1.
Интерпретатор вычисляет временной интервал длины очереди,
фиксируя время, в течение которого длина очереди была неизменной.
По окончании моделирования эти данные используются для определе-
ния средней длины очереди.
Проход транзакта через блок DEPART имитирует выход его из очере-
ди. При этом интерпретатор вычитает из длины очереди, указанной в поле А,
число, указанное в поле В, фиксируя время пребывания транзакта в очереди,
причем, если оно оказалось равным 0, то число из поля В прибавляется к
счетчику числа транзактов, прошедших через данную очередь без задержки.
Один и тот же транзакт может регистрироваться в нескольких очере-
дях, что позволяет собирать как частные статистики, так и общую статисти-
ку. Например, если моделируется система с несколькими типами транзактов,
то можно собрать статистику о процессах ожидания как для каждого типа
транзактов в отдельности, так в различных объединениях транзактов различ-
ных типов, вплоть до статистики о суммарных потоках транзактов.
Если транзакты регистрируются в нескольких очередях, то пары
операторов QUEUE и DEPART должны быть вложенными.
Рис. 11.12. Имитационная модель
СМО с чистым ожиданием
Пример. Рассмотрим имитационную модель
СМО с чистым ожиданием (рис. 11.12). Зада-
дим параметры этой СМО: X = 100 с’1; ц = 50 с'1;
входной и выходной потоки равномерно рас-
пределены с 20%-м отклонением от средних
длин. Общее время моделирования составит
1000 модельных единиц. Текст программы такой системы на языке GPSS приведен в
листинге 11.6. Вследствие того, что транзакт входит в блок QUEUE независимо от со-
стояния устройства, возможно нулевое время пребывания в очереди транзакта.
Листинг 11.6
GENERATE 10,2
QUEUE I
SEIZE I
DEPART I
ADVANCE 20,4
RELEASE 1
TERMINATE
GENERATE 1000
TERMINATE 1
268
_________________Глава 11. Моделирование информационных систем ...
Пример. Рассмотрим /л-канальную СМО с двумя типами транзактов (рис. 11.13).
Рис. 11.13. Имитационная модель м-канальной СМО
с двумя типами транзактов
Программа на языке GPSS для такой СМО приведена в листинге 11.7. В про-
грамме регистрируется как статистика очереди, в которую попадают оба типа транзак-
тов, так и статистика очередей для каждого из типов транзактов в отдельност и. В про-
грамме Ли1 - среднее время между генерированием транзактов 1-го типа, Ви1 - поло-
винный размах ПРВ равномерно распределенных интервалов времени между генери-
рованием транзактов 1-го типа. Для транзактов 2-го типа эти величины заданы пара-
метрами Ли2 и Ви2 соответственно. Размер накопителя S_K задается параметром т.
Параметрами обслуживания 1-го типа транзактов являются Ян1, Вн1 (среднее время
обслуживания и половинный размах ПРВ равномерно распределенных времен обслу-
живания соответственно). Параметры обслуживания 2-го типа заявок Ли2 и Ви2 име-
ют ту же физическую интерпретацию что и для 1-го типа заявок. Чтобы программа на
языке GPSS стала рабочей, эти буквенные обозначения надо заменить на конкретные
цифровые.
Листинг 11.7
S_K STORAGE т
\ транзакты 1 -го типа
GENERATE Л и 1, Ви I
QUEUE 1 QUEUE 3 ; частная статистика ; общая статистика
ENTER S_K DEPART 3 DEPART 1 ; общая статистика : частная статистика
ADVANCE Ан1,Вн1
LEAVE S_K
TERMINATE
; транзакты 2-го типа
GENERATE Ли2, Ви2
QUEUE 2 QUEUE 3 ; частная статистика ; общая статистика
ENTER S_K DEPART 3 DEPART 2 ; общая статистика ; частная статистика
ADVANCE Лн2, Вн2
LEAVE S_K
TERMINATE 1 START V2 ; N2 - объем выборки транзактов 2-го типа
Таблицы. Они являются удобным средством исследования слу-
чайной величины в GPSS.
269
i 1.2. Основные сведения о языке GPSS
Таблица состоит из набора
частотных интервалов, в каждом
из которых организован счетчик
числа попаданий значений аргу-
мента в этот интервал. Структура
таких частотных интервалов по-
казана на рис. 11.14.
На рис. 11.14 используются
следующие обозначения:
т - общее число интервалов;
л(0 - число попаданий на У-й
интервал, i = l,m;
Рис. 11.14. Структура оценочной функ- АХ - ширина частотного
ции распределения F'(X) интервала;
У-объем выборки, N = ;
F'(X) - оценочная интегральная функция распределения, описы-
ваемая выражением F(x) = w(t)c!t .
J-00
Оператор TABLE. Таблица задается с помощью блока TABLE, кото-
рый записывается в следующем виде:
NAME TABLE А,В,С,D,
где NAME - имя таблицы (в поле метки); А - аргумент таблицы; В - верх-
няя граница нижнего интервала Хи\ С - ширина интервала АХ; D - число
интервалов т.
В качестве аргумента А разрешается использовать стандартные чи-
словые атрибуты транзактов (СЧА): Ml и Рг Транзактное время Ml (время,
прошедшее от момента TIN появления транзакта в системе до текущего
момента TIME) можно описать выражением Ml = TIME - TIN. Pj - пара-
метр транзакта с номером j,j = 1, 256 . Параметры позволяют хранить атри-
буты транзакта, отличающие его от других транзактов в потоке.
Блок TABLE является описательным - через него транзакты не
проходят. Для заполнения таблицы необходимо, чтобы транзакты про-
шли через блок TABULATE.
Оператор TABULATE. Оператор обращения к таблице TABULATE
выглядит следующим образом:
TABULATE А,В,
где А - имя таблицы; В - вес измерения, указывает сколько единиц
должно быть добавлено к счетчику числа попаданий на интервал при
одном обращении к таблице. По умолчанию В= I.
При прохождении транзакта через блок TABULATE интерпрета-
тор обновляет содержимое таблицы, указанной в его поле А, увеличивая
270
________________Глава 11. Моделирование информационных систем ...
на число, записанное в поле В, счетчик числа попаданий того интервала,
внутрь которого попало значение аргумента. (Если В пусто, то это экви-
валентно записи 1 в данном поле.)
В конце моделирования интерпретатор распечатывает содержимое
всех таблиц в виде нескольких колонок чисел.
Пример, Построить модель многопроцессорной системы, показанной на рис. 11.15 с
двумя типами транзактов. Моделью системы является многоканальная СМО с чис-
тым ожиданием. Необходимо оценить среднее время пребывания в системе как для
каждого типа транзактов в отдельности, так и для входного потока в целом.
р!,|л2
Рис. 11.15. Модель многоканальной СМО с чистым ожиданием
для двух типов транзактов
Программа на языке GPSS для такой СМО приведена в листинге 11.8.
Листинг 11.8
S_K STORAGE тп ; многоканальное устройство
7/1В1 TABLE /V/1, В, С, D ; для транзактов 1-го типа
ТАВ2 TABLE Ml, В\ С, D' ; для транзактов 2-го типа
ТАВЗ TABLE Ml, В", С", D" ; для транзактов обоих типов
GENERATE/1 и 1, Ви 1 ; LAX
ENTER S_K
ADVANCE Лкl, Вк1 ; MUX
LEAVE S_K
TABULATE 7ЛВ1 ; для транзактов 1-го типа
ABUL АТЕ ТАВЗ ; для транзактов обоих типов
TERMINATE 1
GENERATE Аи2, Ви2 ; LA2
ENTER S_K
ADVANCE Лк2, Вк2 ; MU2
LEAVE S_K
TABULATE ТАВ2 ; для транзактов 2-го типа
TABULATE ТАВЗ ; для транзактов обоих типов
TERMINATE 1
START N2 ; N2 - объем выборки
Операторы, используемые для описания очередей и таблиц, позволя-
ют собирать нестандартную статистику, которую не собирают по умолча-
нию аппаратно-ориентированные блоки.
271
11.2. Основные сведения о языке GPSS
11.2.5. Операционные блоки GPSS
Операционные блоки GPSS позволяют управлять потоками транзактов и
изменять маршруты их движения.
Оператор GATE. Этот оператор условного перехода позволяет
изменять маршрут движения транзакта в зависимости от состояния ре-
сурса (устройства или накопителя). В табл. 11.11 приводятся обозначе-
ния оператора GATE в Q-схемах, на блочных диаграммах, а также за-
пись этих блоков на языке GPSS.
Транзакт проходит через
блок по основному пути (7), т.е. к
следующему по порядку записи
блоку, если R = TRUE, и по аль-
тернативному пути (2), если R =
FALSE, для устройства с номером
А (накопителя с именем А).
Оператор условного пе-
рехода записывается в сле-
дующем виде:
GATE 7? Л, В,
где 7? - проверяемое логиче-
ское условие (для устройства R
может принимать значения: U - занято; NU - свободно; 7- прервано; NI
- не прервано; если R - для памяти, то: SF - память полна; SNF- память
не заполнена; SF - память пуста; SNE - память не пуста); А - номер уст-
ройства или имя накопителя; В - метка, указывающая блок, лежащий на
альтернативном пути.
Пример. Построим ИМ многопроцессорной ВС с буфером запросов конечной емко-
сти (рис. 11.16). Блок-диаграмма СМО представлена на рис. 11.17, а соответствую-
щая ей программа на языке GPSS для такой СМО приведена в листинге 11.8.
Таблица 11.11. Описание оператора GATE
Q-схема
Блок-диаграмма
GATE Я Я,Я
GATE Я Я,Я
tn Н (-’)
имя______
накопителя
Оператор
Рис. 11.16. ИМ многопроцессорной ВС с буфером запросов конечной емкости
272
Глава 11. Моделирование информационных систем ...
Листинг 11.8
S_Q STORAGE п ; емкость накопителя
S_K STORAGE п ;емкость многоканального устройства
GENERATE Ли,Ви
QUEUE 1
GATE SNF S Q. BREAK QUEUE 2 ENTER 5 О ; войти в очередь
ENTER S_K ; занять канал
LEAVE S_Q DEPART 2 DEPART 1 ; выйти из очереди
ADVANCE Ak,Bk LEAVE S_K TERMINATE 1 ; освободить канал
BREAK DEPART 1:
TERMINATE 1
STARTW
Оператор TRANSFER. При описании ИМ
сложных систем часто появляется необходимость пе-
редать транзакты в блоки, которые непосредственно
не следуют за данным блоком. Для выполнения таких передач в GPSS ис-
пользуется блок TRANS-
FER. В табл. 11.12 приве-
дено обозначение блока
TRANSFER в Q-схемах, на
блок-диаграммах, а также
описание блока на языке
GPSS.
Блок TRANSFER
Таблица 11.12. Описание оператора TRANSFER
Q-схема Блок-диаграмма Оператор
с х Р- А / Ч— r'= ’ Р TRANSFER А,В,С
может работать в нескольких режимах передачи транзактов. Режим пе-
редачи определяется операндом, указанным в поле А этого блока. Метки
блоков-приемников записываются в полях В, С.
Блок TRANSFER может работать в нескольких режимах передачи
транзактов. Режим передачи определяется операндом, указанным в поле
А этого блока. Метки блоков-приемников записываются в полях В и С.
Рассмотрим наиболее часто используемые режимы работы блока
TRANSFER.
1. Режим безусловного перехода (детерминированная передача). В
этом режиме блок TRANSFER передает все поступившие на него
транзакты на метку, указанную в поле В. Поле А должно быть при
этом пустым. При использовании такого режима запись блока
TRANSFER может выглядеть как TRANSFER, BLOCK NAME. В
данном случае все транзакты, поступившие в этот блок, будут пере-
даны в блок, имеющий метку BLOCK NAME.
2. Статистический режим. В поле А записываются десятичная точка и
за ней цифры. Содержимое интерпретируется как вероятность, с ко-
273
11.2. Основные сведения о языке GPSS
торой транзакт направляется по метке С. По метке В транзакт будет
передан с вероятностью (1 -А). При использовании статистического
режима запись блока TRANSFER может выглядеть как
TRANSFER AOO,BLOCK_NAME\,BLOCK_NAME2.
В этом случае блок будет случайным образом передавать 40% по-
ступающих на него транзактов по метке BL0CK_HAME2, а 60% - по
метке BLOCKJJAMEL
3. Режим условной передачи. Для использования этого режима в поле А
оператора TRANSFER указывается слово BOTH, а в полях В и С - мет-
ки некоторых блоков. При работе в режиме безусловной передачи тран-
закт переходит по метке в поле В, если передача возможна. В против-
ном случае осуществляется проверка возможности перехода по метке,
указанной в поле С. Если транзакт не сможет войти ни в один из этих
блоков, то происходит его задержка до тех пор, пока не освободится
один из блоков, указанный в полях В и С. Если в режиме BOTH одно из
полей опущено, то считается, что в нем указан блок, следующий за бло-
ком TRANSFER. Проверка возможности вхождения в каждый из бло-
ков выполняется каждую единицу системного времени.
Приведем пример использования различных режимов блока
TRANSFER при моделировании СМО на языке GPSS.
Пример. Построим модель ВС, концептуально представляющую из себя стохас-
тическую сеть, состоящую из трех СМО с чистым ожиданием (рис. 11.18).
Рис. 11.18. Модель ВС, состоящей из трех СМО с чистым ожиданием
Разветвления, используемые в СМО на рис. 11.18, более наглядно изображены
на рис. 11.19.
Ml JUМ2
РЮ / \I-P10
МЗуХ^М4
Р12 / \ Р13
Рис. 11.19. Реализация трех разветвлений
274
Глава 11. Моделирование информационных систем ...
Программа СМО, модель которой показана на рис. 11.18, приведена в лис-
тинге 11.9. В программе предусмотрена возможность измерения /ож каждой из
СМО и время пребывания транзакта в системе, т. е. в стохастической сети.
Листинг 11.9.
TAB TABLE АЛ. В, С, D
S_K3 STORAGE in
GENERATE Ли, Ви
SMOl QUEUE 1
SEIZE 1
DEPART 1
ADVANCE Л к 1, Як 1
RELEASE I
TRANSFER PIO, Л/2, Ml
АУ2 TRANSFER Pl2, SMO3, SMOl
Ml TABULATE TAB
TERMINATE I
SMOl QUEUE 2
SEIZE 2
DEPART 2
ADVANCE Лк2, Вк2
RELEASE 2
TRANSFER ,SMOl
SMO3 QUEUE 3
ENTER S_K3
DEPART 3
ADVANCE ЛкЗ, ВкЗ
LEAVE S_K3
TRANSFER ,SMOl
START N
Оператор TEST. Он позволяет изменять маршрут транзакта в за-
висимости от выполнения некоторого условия (Я). Это условие форми-
руется относительно двух стандартных числовых атрибутов, один из ко-
торых может быть const. TEST пропускает транзакт к следующему бло-
ку, если R истинно, иначе - отправляет транзакт к блоку с меткой С.
Структура оператора имеет следующий вид:
TEST R А,В,С
В этой записи Л, В - стандартные числовые атрибуты, а условия,
которые могут быть, записываются
Время пребывания в СМО
транзактов
как Е (=), NE (о), GT (>), GE (>=),
LT (<), LE (<=)(в скобках дана ма-
тематическая запись условия).
Приведем пример использования
блока TEST.
Пример. Построим модель СМО с
двумя типами транзактов (рис. 11.20).
Необходимо измерять время пребыва-
Рис. 11.20. Модель СМО с двумя типами ния транзакта в системе раздельно по
каждому типу транзактов.
275
11.2. Основные сведения о языке GPSS
Особенностью модели является использование общей цепочки блоков,
описывающей общие процессы ожидания и обслуживания транзактов.
Программа на языке GPSS, реализующая модель СМО на рис. 11.20. при-
ведена в листинге 11.10.
Листинг 11.10
ТАВ\ TABLE Ж Я', С, D'
ТАВ2 TABLEAU, В", С\ D"
GENERATE Аи 1. Ви 1
ASSIGN Pl, I ; 1-йтип
TRANSFER ,ММ
GENERATE А и2, Ви2
ASSIGN Pl, 2 ; 2-й тип
ММ QUEUE I
SEIZE 1
DEPART 1
ADVANCE Лк, Вк
RELEASE 1
TESTE Pl, 1, Ж Pl = I
TABULATE TAB\
TRANSFER .BREAK
М2 TABULATE TAB2
BREAK TERMINATE I
START N
11.2.6. Другие блоки GPSS
Функции в GPSS. Для реализации различных функциональных зави-
симостей наряду с формулами, которые записываются в выражении для
переменных, используются функции. Функции часто используются для
генерации случайных величин со сложным законом распределения.
Оператор FUNCTION. Оператор описания функции имеет вид
name FUNCTION А, В
В GPSS имеются два типа функций - непрерывные и дискретные.
В поле А записывается правило для образования значения аргумента
функции. Аргументом функции могут быть любые стандартные число-
вые атрибуты, а также другие функции. В поле В - тип функции и коли-
чество пар координат «аргумент - значение функции». Непрерывная
функция кодируется буквой С, дискретная - буквой D.
При задании дискретной функции аппроксимация между двумя
точками (значениями) выполняется горизонтальной линией («ступень-
кой»). При попадании значения аргумента в интервал значение функции
остается постоянным.
При задании непрерывной функции применяется кусочно-
линейная аппроксимация. В этом случае при попадании значения аргу-
мента в интервал значение функции вычисляется по наклонному отрез-
ку, аппроксимирующему функцию на данном интервале.
276
Глава 11. Моделирование информационных систем ...
Приведем пример использования функций при моделировании на
языке GPSS.
Пример. Для моделирования простейших потоков событий (ПС) необходимо ра-
зыгрывать значения Т случайной величины, распределенной по экспоненциальному
закону, которая определяет длины интервалов между соседними событиями в пото-
ке, как это показано на рис. 11.21.
Т1 Т2 ТЗ T4
Рис. 11.21. Интервалы между соседними событиями в потоке
В соответствии с методом обратной функции можно получить экспонен-
циальное распределение путем логарифмического преобразования равномерно-
го распределения. В качестве базисного используется равномерное распределе-
ние на интервале [0; 1), которое соответствует стандартным датчикам псевдо-
случайных величин, используемым в ЭВМ. Отсчет экспоненциально распреде-
ленной случайной величины Т_ЕХР с математическим ожиданием 1/Х вычисля-
ется с помощью «обратного» преобразования
Г = -11п(Л) = -3-1п(1-Л),
К к
где R - отсчет равномерно распределенной на интервале [0,1) случайной вели-
чины, формируемой с помощью датчика псевдослучайной величины.
Описание кусочно-ступенчатой функции, аппроксимирующей функцию
ln( 1 - R), имеет вид
LN_R FUNCTION RN], С24
0.0/0.1, 0.104/0.2, 0.222/0.3, 0.355/0.4, 0.509/0.5, 0.69/0.6,
0.915/0.7, 1.2/0.75, 1.38/0.8, 1.6/0.84, 1.83/0.88, 2.12/0.9,
2.3/0.92, 2.52/0.94, 2.81/0.95, 2.99/0.96, 3.2/0.97, 3.5/0.98,
3.9/0.99, 4.6/0.995, 5.3/0.998, 6.2/0.999, 7/0.9997, 8
Значение В = С24 означает, что используется кусочно-линейная аппрок-
симация (КЛА) и число точек в ней равно 24.
Данная функция может быть использована для модификации среднего
значения длины интервала. Математическое ожидание функции LN_R при рав-
номерно распределенном аргументе равно 1.
Пример. Построим модель СМО с простейшими ПС. Интенсивности А. и ц из-
вестны. СМО - многоканальная с чистым ожиданием (рис. 11.22).
И
Рис. 11.22. Многоканальная СМО с чистым ожиданием
Параметры СМО, изображенной на рис. 11.22, вычисляются из соотношений
Ап = 1/Х и Ак = 1/ц. Программа на языке GPSS, реализующая модель этой СМО,
приведена в листинге 11.11.
277
11.2. Основные сведения о языке GPSS
Листинг 11.11
LN_R FUNCTION /?V1, С24
0.0/.. . /0.9997, 8
S_K STORAGE т
GENERATE Ли, FN$LN_R
QUEUE 1
ENTER S_K
DEPART 1
ADVANCE Лк, FN$LN_R
LEAVE V
TERMINATE 1
START n
Ячейки в GPSS. Язык GPSS позволяет запоминать в так называе-
мых ячейках и обрабатывать в процессе моделирования некоторую ин-
формацию о свойствах транзактов и системы в целом. Ячейки обозна-
чают стандартным числовым атрибутом Xj, где j - номер ячейки.
Оператор INITIAL. Для начальной установки состояния ячейки пе-
ред началом моделирования можно использовать оператор INITIAL Xj,В.
Здесь В - значение, соответствующее некоторому СЧА либо const.
Оператор SAVEVALUE. В процессе функционирования содер-
жимое ячейки можно изменить с помощью этого оператора:
SAVEVALUEу[+ -], В
j ,В -+Xj := В
J+, В -^Xj := Xj + В
j—+Xj'=Xj-B
Пример. Построим модель СМО, в которой входной поток и поток обслужива-
ния являются потоками Эрланга (ПЭ). ПЭ - просеянные потоки. Они могут
быть получены выборкой событий из простейшего потока.
Для моделирования входящего потока Эрланга необходимо имитировать
«просеивание» простейшего потока с экспоненциальным распределением интерва-
лов и интенсивностью ХА, порождаемого оператором GENERATE. Для этого надо
пропускать в основную часть программы транзакт с номером, кратным порядку Кп
входящего потока Эрланга. Для моделирования потока обслуживания необходимо
суммировать Кк экспоненциально распределенных интервалов из простейшего по-
тока обслуживаний. При этом производящие простейшие потоки должны иметь ин-
тенсивности в Кп и Кк раз выше по сравнению с интенсивностями ПЭ. Суммируя
длительности интервалов, получаем Ли = 1 DJKw. Ак = 1/ц/Кк.
В листинге 11.12 приведена программа на языке GPSS для предлагаемой в
этом примере СМО.
Листинг 11.12
LN_R FUNCTION /?1, С24
0.0/.../0.9997, 8
ТА В TABLE Ml. Хи, Dx. М
S K STORAGE т ; многоканальное устройство
INITIAL XI, 1 ; начальная установка СЧТ1 для входного потока
GENERATE Ли, FN$LN_R
278
Глава 11. Моделирование информационных систем ...
TESTED, Ли, OUT
SAVEVALUE 1,1 ; восстановление СЧТ1 для входящего потока
QUEUE I
ENTER S_K
DEPART 1
SAVEVALUE 2,1 ; начальная установка СЧТ2 для потока обследования
М_К ADVANCE Лк, FN$LN_R
SAVEVALUE 2+, 1 ; инкрементные СЧТ2для потока обслуживания
TEST G А2, Аобс, М_К
LEAVE S_K ; освобождение в многоканальном устройстве 1-го канала
TABULATE TAB
TERMINATE I
OUT SAVEVALUE 1+, 1 ; инкрементные СЧТ1 для входного потока
TERMINATE уничтожение «лишних» транзактов
STARTN
Оператор MARK (отметить время). Каждый транзакт, двигающий-
ся в модели, имеет специальный параметр, называемый отметкой времени,
с помощью которого можно определить время пребывания транзакта в мо-
дели. Начальное значение отметки времени транзакта равно времени входа
этого транзакта в модель. Таким образом, время пребывания любого тран-
закта в модели всегда может быть вычислено как разность текущего сис-
темного времени и его отметки времени. Эта разность может быть получе-
на обращением к стандартному числовому атрибуту М\. Текущее время
системы также является стандартным числовым атрибутом и обозначается
как С1. Блок MARK позволяет записывать текущее время системы в отмет-
ку времени проходящего через него транзакта или в один из его парамет-
ров. Запись оператора MARK в общем случае имеет вид
MARK Pj,
где Pj - параметр транзакта, в который будет записано значение абсолютного
модельного времени (АМВ) TIME, т.е. времени от начала прогона модели.
Иначе говоря, оператор MARK позволяет записать в параметр Pj
показание системных часов:
Pj = TIME.
Если операнд Pj не указывается, то значение АМВ замещает старое
значение времени входа транзакта в систему: TIN = TIME. Это означает,
что относительное транзактное время Mi, т.е. время существования
конкретного транзакта в системе, равное разности АМВ и времени вхо-
да (Mi = TIME - TIN), будет сброшено в нуль (Mi := 0).
Оператор MARK позволяет моделировать замкнутые стохастические
сети, отличием которых от разомкнутых является циркуляция в сети неко-
торого фиксированного числа транзактов. Интенсивность входящего пото-
ка теперь не является параметром, она совпадает с интенсивностью выход-
ного потока и является искомой характеристикой. Это происходит потому,
что каждый новый транзакт на входе появляется мгновенно после ухода из
замкнутой сети обслуженного транзакта.
279
11.2. Основные сведения о языке GPSS
Пример. Смоделируем СМО, структурная схема которой показана на рис. 11.23. В
этой СМО: 51 - процессор и память; S2 - обращение к быстрой периферии; 53 - обра-
щение к медленной периферии; М-число циркулирующих в сети заявок (транзактов).
Рис. 11.23. Модель СМО
Листинг 11.13. реализует модель системы в виде замкнутой сети с про-
стейшими потоками событий на входе.
Листинг 11.13
TAB TABLE Л/1, Xh, Dx, n \n - число участков LN _R FUNCTION PL C24 0.0/. . . /0.9997, 8 S_K3 STORAGE m GENERATE ;D = M- емкость источника SMO\ QUEUE 1 SEIZE 1 DEPART I ADVANCE Лк 1, FN $ LN R RELEASE 1 TRANSFER PIO, PROD, OUT PROD TRANSFER P12*, SMO_3, SMO_2 ; разветвление
OUT TABULATE TAB MARK ; сброс ОТВ
TRANSFER. SMOi SMO 2 QUEUE 2 SEIZE 2 DEPART 2 ; «замыкание» сети
ADVANCE Лк2, FN $ LN_R
RELEASE 2
TRANSFER, SMO\
SMO_3 QUEUE 3
ENTER S_K3
280
Глава 11. Моделирование информационных систем ...
DEPART 3
ADVANCE ЛкЗ, FN $ LN_R
LEAVE S_K3
TRANSFER ,SMO\
; таймер
GENERATE TL1M ; TLIM- время наблюдения за проведением ИМ
TERMINATE 1
START 1
11.3. Имитационное моделирование сети ETHERNET в
среде GPSS
Рассмотрим ИМ сети связи на примере сети
Ethernet, собранной по топологии с общей
шиной (рис. 11.26).
Зная принципы работы Ethemet-
протокола, можно изобразить обобщенную
схему алгоритма обработки коллизии, которая
представлена на рис. 11.27. На основании этого
алгоритма и будет составлена программа на
GPSS. На схеме: Nе 16}- номер после-
довательной коллизии; Ke {1, ..., 10} - пара-
метр, используемый при вычислении времени
ожидания повторной передачи.
Рис. 11.26. Сеть Ethernet,
собранная по топологии с
общей шиной
Рис. 11.27. Обобщенная схема обработки коллизии в Ethernet
281
11.3. Имитационное моделирование сети Ethernet в среде GPSS
Разработка программы. Ниже перечислим основные моменты,
которые учитывались при разработке программы.
Предполагается, что сообщения от отдельных компьютеров поступа-
ют в случайные моменты времени, имеющие экспоненциальное распреде-
ление, и бывают двух типов - длинные и короткие. Выбранный узел удер-
живается в течение передачи сообщения, а также в случае коллизии.
Каждый узел Ethernet может быть занят одним сообщением до тех
пор, пока оно не будет отправлено или пока не произойдет некоторое
число коллизий (во время попыток передачи другими узлами), после че-
го объявляется ошибка и узел освобождается.
Подразумевается, что отдельные узлы отстоят друг от друга на не-
большое расстояние (при моделировании - 2,5 м). При расчете окна
коллизии для определения разделяющего расстояния используется
идентификационный номер узла. Межкадровый интервал моделируется
путем приостановки функционирования сети на некоторое дополни-
тельное время после передачи узлом сообщения.
Коллизия возникает из-за одновременных попыток передачи двумя
или более узлами. Задержка распространения сигнала препятствует од-
новременному распознаванию узлами друг друга, тем самым приводя к
возможности коллизии. Интервал времени, в течение которого сигнал из
другого узла не может быть обнаружен, называется «окном коллизии».
При моделировании коллизия инициирует лишение передаваемого тран-
закта права занимать Ethernet путем отправки его в подпрограмму задержки на
некоторый интервал времени (время передачи). При возникновении коллизии
генерируется jarn-последовательность, которая на небольшой промежуток
времени блокирует Ethernet, после чего каждый кадр, попавший в коллизию,
ждет еще некоторый временной интервал до попытки повторной передачи.
При отправке сообщения транзакт занимает устройство Ethernet с приоритетом
О и может быть вытеснен только транзактом с приоритетом 1. Транзакт с при-
оритетом, равным 1, никогда не отдаст занятую им среду (устройство).
Если бы все узлы попытались повторно передать кадр сразу после кол-
лизии, то это закончилось бы другой коллизией. Поэтому протокол обязан
гарантировать низкую вероятность одновременной повторной передачи.
Принятая схема Ethernet использует случайный период, где каждый узел вы-
бирает случайное число, умножает его на время минимального периода кадра
(при моделировании этот период предполагался равным 51,2 мкс) и ждет в
течение этого случайного периода перед попыткой повторной передачи.
Также добавляется технологическая пауза (IFG), равная 9,6 мкс.
В загруженной сети повторная передача одного узла может возникать
одновременно с повторной передачей другого узла. Протокол подсчитыва-
ет число попыток повторной передачи (переменную N в вышеупомянутой
схеме) и пытается повторно передавать тот же самый кадр до 15 раз.
Для уменьшения вероятности возникновения повторных коллизий
используется процедура регулирования задержки повторной передачи:
^defer ~ ^CD^,
где Tdefer - величина интервала времени отсрочки повторной передачи;
282
Глава 11. Моделирование информационных систем ...
Tcd - размер коллизионного домена или окна коллизий для данного ва-
рианта реализации Ethernet; R - целое число, которое выбирается слу-
чайным образом из диапазона {2^-1}.
283
11.3. Имитационное моделирование сети Ethernet в среде GPSS
Текст программы на языке GPSS
;3адание постоянных параметров
Node_Count EQU 100 ; количество узлов в сети
Intermessage_Time VARIABLE 100/Node_Count; время, через которое создаются сообщения
Min_Msg EQU 512 ; размер короткого сообщения в битах
Max_Msg EQU 12144 ; размер длинного сообщения в битах
Fraction_Short_Msgs EQU 600 : часть коротких сообщений из 1000
Slot_Time EQU 0.0512 ; интервал отсрочки в мс
Jam_Time EQU 0.0032 ; длительность jam-последовательности в мс
Backoff_Limit EQU 10 : число попыток повторной передачи
Interframe_Tiine EQU 0.0096 ; межкадровый интервал
;3адание переменных параметров:
Backoff_Delay VARIABLE Slot_Time#V$Backrandom ; вычисление случайной паузы
Backrandom VARIABLE l+(RN4@((2AV$Backmin)-l))
Backmin VARIABLE (10#(1O'L'PSRetriesjj+IPSRetries#! 1O'GE'PSRetries))
Node_Select VARIABLE l+(RN3@Node_Count) ; выбор узла
Collide VARIABLE ABS((X$Xmit_Node-P$NodeJD)/100000)'GE'(ACl-X$Xmit_Begin)
вычисление коллизии
Msgtime VARIABLE (0.000 l)#V$Msgrand ; вычисление длины сообщения
Msgrand VARIABLE Min_Msg+(RN 1 'G‘Fraction_Short_Msgs)//(Max_Msg-Min_Msg)
Построение гистограммы
Msg_Delays QTABLE Global-Delays J ,1,20
;Тело программы
;Генератор сообщении
GENERATE (Exponential! 1,0,Intermessage_Time)); генератор одного сообщения
ASSIGNNode_ID,V$Node_Select; присвоение узлу номера Node ID
ASSIGN Message_Time,V$Msgtime ; присвоение длины сообщения
ASSIGN Retries,0 ; в начале нет коллизий
QUEUE Global_Delays ; запуск счетчика гистограммы
SEIZE P$Node_ID ; занятие yзлaNode_ID
Try_To_Send PRIORITY I
SEIZE Jam
RELEASE Jam
TEST E F$Ethernet,l,Start_Xmit; если Ethernet свободна, то переход на метку Start_Xmit
TEST Е V$Collide,l,Start_Xmit; проверка на наличие коллизии
;Коллизия
Collision PREEMPT Ethernet,PR,Backoff„RE
SEIZE Jam ; отправка jam-последовательности
ADVANCE Jam_Time ; задержка на время jam-последовательности
RELEASE Jam ; конец jam-последовательности
RELEASE Ethernet; освобождение Ethernet.
PRIORITY 0 ; возвращение нормального приоритета
Backoff ASSIGN Retries+,1 ; увеличение количества попыток повторной передачи на 1
TEST LE PSRetries,Backoff_Limit,Xmit_Error ; ограничение количества попыток повтор-
ной передачи
ADVANCE V$Backoff Delay ; задержка на случайный интервал времени
TRANSFER ,Try_To_Send ; переход к метке Try_To_Send
284
___________________Глава 11. Моделирование информационных систем ...
;3ахват сети Ethernet и начало передачи сообщения
Start_Xmit SEIZE Ethernet ; занятие сети
SAVEVALUE Xmit_Node,P$Node_ID идентификация передатчика
SAVEVALUE Xmit_Begin,ACl
PRIORITY О
ADVANCE P$Message_Time ; задержка на время сообщения
ADVANCE Interframe_Time ; задержка на межкадровый интервал
RELEASE Ethernet ; освобождение Ethernet
Free_Node RELEASE P$Node_ID ; освобождение узла
DEPART Global-Delays ; остановка счетчика для гистограммы
TERMINATE ; удаление сообщения
Xmit_Error SAVEVALUE Error_Count+,l ; подсчет ошибок
TRANSFER ,Free_Node ; переход на метку Free_Node
GENERATE 1000 ; задание времени моделирования в мс
SAVEVALUE USE_ETHERNET,(FR$Ethernet/1000) ; коэффициент использования сети
TERMINATE I
Описание работы программы. При описании программы под
кадрами/сообщениями следует понимать транзакты, поскольку именно
ими оперирует GPSS.
Создание кадра и выбор узла. С помощью блока GENERATE ге-
нерируются сообщения (транзакты), интервалы между которыми рас-
пределены по экспоненциальному закону. В блоке ASSING переменной
NodeJD присваивается номер узла Node_Select, тем самым выбирается
компьютер, отправляющий кадр. В блоке ASSING переменной Mes-
sage-Time присваивается значение Msgtime, тем самым выбирается дли-
на передаваемого кадра.
Занятие узла и Ethernet. При помощи блока SEIZE занимается
выбранный узел, после чего идет проверка занятости среды. Это делает-
ся в блоке TEST, где проверяется, свободна среда Ethernet или нет. Если
да, то с помощью блока SEIZE она занимается. Если среда занята, то с
помощью блока TEST ее проверяют на наличие коллизии. При наличии
коллизии сообщение поступает в часть программы, занимающуюся об-
работкой коллизий. Если коллизии нет, то сообщение продвигается по
программе дальше и устройство Ethernet занимается.
Прохождение сообщения. После занятия Ethernet сообщением с по-
мощью блока SAVEVALUE происходит выделение отправителя и сохране-
ние начального времени передачи сообщения. В блоке ADVANCE выполня-
ется задержка, продолжительность которой определяется длиной сообщения.
По окончании задержки на длину сообщения происходит задержка длиной в
межкадровый интервал, которая выполняется в блоке ADVANCE.
Освобождение Ethernet и узла. После окончания прохождения со-
общения через Ethernet с помощью блока RELEASE происходит осво-
бождение сети. При этом происходит освобождение узла с номером
Node_ID, что свидетельствует о том, что сообщение полностью переда-
но. Затем оно уничтожается в блоке TERMINATE.
285
11.3. Имитационное моделирование сети Ethernet в среде GPSS
Обработка коллизий. Если в сети возникла коллизия, то сообщение
после второго блока TEST, который отвечает за распознавание коллизий,
поступает в блок PREEMPT. Если приоритет сообщения «захватчика» вы-
ше, чем приоритет обслуживаемого сообщения, то с помощью этого блока
происходит захват Ethernet. Прерванное сообщение будет направлено на
метку Backoff, и оно теряет право на восстановление. Затем с помощью
блока SEIZE занимается устройство Jam, и транзакт в этом устройстве
удерживается блоком ADVANCE на время передачи jam-
последовательности. После прохождения времени задержки устройство
Jam освобождается при помощи блока RELEASE, а после этого блоком
RELEASE освобождается устройство Ethernet. При каждом попадании со-
общения на метку Backoff в блоке ASSING происходит суммирование по-
пыток повторной передачи сообщения. Дальше происходит сравнение бло-
ком TEST количества попыток повторной передачи сообщения с предель-
ным количеством попыток. Если число попыток не достигло предельного
значения, то происходит задержка на время случайной паузы блоком AD-
VANCE. По истечении случайной паузы сообщение направляется на по-
вторную передачу. Если же число попыток достигло предельного значения,
то инициируется ошибка в сети и пакет отбрасывается, при этом узел и
Ethernet освобождаются, а сообщение удаляется в блоке TERMINATE.
Результаты моделирования. После моделирования сети Ethernet
в программе имитационного моделирования GPSS World выводится от-
чет, в котором содержится следующая информация:
общие сведения о модели и ее прогоне, включающие модельное
время начала (START_TIME) и конца (END TIME) прогона, число бло-
ков в модели (BLOCKS), число устройств (FACILITIES), число много-
канальных устройств (STORAGES);
сведения об именах объектов модели, включающие для каждого
имени идентификатор (NAME) и присвоенное ему числовое значение
(VALUE);
сведения о блоках модели, номер или имя блока (LOC), название
блока (BLOCK_TYPE), количество транзактов, прошедших через блок
(ENTRY_COUNT), текущее количество транзактов в блоке в момент за-
вершения моделирования (CURRENT_COUNT);
сведения об устройствах модели, включающие для каждого уст-
ройства его имя или номер (FACILITY), количество занятий устройства
(ENTRIES), коэффициент использования (UTIL), среднее время на одно
занятие (AVE TIME);
сведения об очередях модели, включающие для каждой очереди ее
имя или номер (QUEUE), максимальную длину очереди в процессе мо-
делирования (МАХ), текущую длину очереди в момент завершения мо-
делирования (CONT), общее количество транзактов, вошедших в оче-
286
Глава 11. Моделирование информационных систем ...
редь в процессе моделирования (ENTRIES) и количество «нулевых»
входов в очередь (ENTRIES(O)), среднюю длину очереди (AVECONT.),
среднее время ожидания в очереди с учетом всех транзактов
(AVETIME) и без учета «нулевых» входов (AVE(-O));
сведения о статистических таблицах модели, включающие для каждой
таблицы ее имя или номер (TABLE), среднее значение (MEAN) и средне-
квадратическое отклонение (STD.DEV.) табулируемой величины, границы
частотных интервалов (RANGE), частоты (FREQUENCY) и накопленные
частоты в процентах попадания наблюдений (CUM.%) в эти интервалы;
сведения о сохраняемых величинах модели, включающие для каж-
дой сохраняемой величины ее имя или номер (SAVEVALUE) и значе-
ние в момент завершения моделирования (VALUE).
Число произошедших коллизий в сети во время моделирования
определяется количеством попадания транзакта в блок PREEMPT под
меткой COLLISION.
В программе моделирования сети Ethernet строится гистограмма
времени нахождения сообщения в сети с помощью блока QTABLE. По
оси X откладываются интервалы времени нахождения сообщения в сети
(0, а по оси У - количество сообщений (У), которые, находясь в сети,
укладываются в соответствующий временной интервал.
Гистограммы, построенные при моделировании 10-мегабитной
сети Ethernet для 50, 100, 150, 175, 200, 225 узлов и времени
моделирования 10 тыс. ед., изображены на рис. 11.29. На графиках
также приведены оценки среднего значения т и среднеквадратического
значения ст для каждого из случаев моделирования.
Рис. 11.29. Полученные в результате моделирования гистограммы времени нахож-
дения транзактов в очередях сети Ethernet для различного числа узлов:
а - 50 узлов; 5-100 узлов; в - 150 узлов; г - 175 узлов; д - 200 узлов; е -225 узлов
Анализ результатов моделирования сети Ethernet. Проведем
ряд экспериментов по моделированию 10-мегабитной сети Ethernet, ме-
няя исходные данные, число узлов и общее время моделирования. В ре-
зультате получаем следующие показатели, приведенные в табл. 11.13.
287
11.3. Имитационное моделирование сети Ethernet в среде GPSS
Таблица 11.13. Численные результаты проведенного эксперимента с 10-мегабитной
Ethemet-сетыо
№ эксперимента Число узлов (л) Время моделирования (7) Число коллизий (к) Коэффициент использования Ethernet (р)
1 50 1000 1 0,216
2 50 2000 1 0,241
3 50 5000 4 0,247
4 50 10000 16 0,256
5 100 1000 3 0,477
6 100 2000 7 0,497
7 100 5000 45 0,497
8 100 10000 86 0,504
9 125 1000 9 0,620
10 125 2000 20 0,622
11 125 5000 56 0,644
12 125 10000 140 0,647
13 150 1000 12 0,720
14 150 2000 45 0,746
15 150 . 5000 159 0,776
16 150 10000 324 0,775
17 175 1000 51 0,842
18 175 2000 235 0,912
19 175 5000 583 0,921
20 175 10000 1262 0,931
21 200 1000 119 0,944
22 200 2000 673 0,966
23 200 5000 3266 0,986
24 200 10000 10241 0,993
25 225 1000 775 0,987
26 225 2000 2177 0,993
27 225 5000 7305 0,997
28 225 10000 16159 0,999
По полученным в результате экспериментов данным строятся зави-
симости (рис. 11.30). Из графика зависимости числа коллизий от числа уз-
лов (рис. 11.30, а) видно, что оптимальное число узлов с учетом выбранных
параметров экспоненциального распределения, определяющего интервалы
между кадрами, и распределения, определяющего длительность занятия
сети, в 10-мегабитном Ethernet равно 175. Дальнейшее увеличение числа
узлов ведет к резкому увеличению числа коллизий.
Из графика зависимости коэффициента использования сети от числа 53-
лов ( рис. 11.30, б) видно, что почти полное насыщение сети достигается при
200 узлах и, следовательно, использование большего числа узлов не желатель-
но, поскольку кадр слишком долго будет находится в сети, ожидая передачи.
Изменив исходные данные так, чтобы сеть стала 100-мегабитной, мож-
но провести ряд экспериментов, изменяя число узлов. Полученные в резуль-
тате моделирования результаты приведены в табл. 11.14.
Графики и гистограммы, построенные в результате исследования
100-мегабитной сети Ethernet, показаны на рис. 11.31, 11.32.
288
Глава 11. Моделирование информационных систем ...
Рис. 11.30. Графические зависимости, полученные в результате экспериментов: а -числа
коллизии от числа узлов; б - коэффициента использования сети от числа узлов;
в -коэффициента использования сети от времени моделирования для 175 узлов;
г-коэффициента использования сети от времени моделирования для 100 узлов
Из графика зависимости коэффициента использования сети от числа уз-
лов (рис. 11.31, а) видно, что почти полное насыщение сети достигается при
1850 узлах и, следовательно, использование большего числа узлов не жела-
тельно, так как кадр слишком долго будет находиться в сети, ожидая передачи.
Из графика зависимости числа коллизий от числа узлов (рис. 11.31,6)
видно, что оптимальное число узлов с учетом выбранных параметров экс-
поненциального распределения, определяющего интервалы между кадра-
ми, и распределения, определяющего длительность занятия сети кадрами, в
100-мегабитном Ethernet равно 1750. Дальнейшее увеличение числа узлов
ведет к резкому увеличению числа коллизий.
«) б)
Рис. 11.31. Графические результаты экспериментов: а -зависимость коэффициента
использования сети от числа узлов; б - зависимость числа коллизий от числа узлов
16000
т « 23.Ы6
<т = 0,237
23456789
а)
Рис. 11.32. Гистограммы времени нахождения транзактов в очередях сети Ethernet,
полученные в результате моделирования для различного числа узлов:
а - 1500 узлов; б - 1750 узлов; в - 2000 узлов
10—3834
289
11.3. Имитационное моделирование сети Ethernet в среде GPSS
Таблица 11.14. Численные результаты проведенного эксперимента с 100-мегабитной
Ethemet-сетью
№ эксперимента Количество узлов (л) Число коллизий (£) Коэффициент использования Ethernet (р)
1 50 0 0,025
2 100 0 0,051
3 125 5 0,064
4 150 15 0,077
5 175 25 0,090
6 200 23 0,102
7 225 40 0,115
8 500 464 0,263
9 750 1792 0,393
10 1000 4280 0,524
11 1250 7679 0,660
12 1500 12986 0,795
13 1600 16084 0,846
14 1650 18543 0,874
15 1700 21342 0,901
16 1750 26977 0,932
17 1800 40511 0,962
18 1850 132599 0,994
19 1900 214921 0,998
20 2000 263694 0,999
По итогам проведенного моделирования можно сформулировать ре-
комендации по проектированию сетей Ethernet, а также получить различ-
ные характеристики производительности для достаточно широкого диапа-
зона начальных условий. Ограничивающим фактором моделирования
можно считать выбор экспоненциального распределения для интервалов
между поступлениями кадров в сеть.
Контрольные вопросы к главе 11
1. Какие языки программирования чаще всего употребляются для ими-
тационного моделирования ?
2. Каковы основные отличительные свойства языков имитационного
моделирования ?
290
Глава 11. Моделирование информационных систем ...
3. Дайте общее описание языка GPSS и его объектов.
4. Дайте характеристику динамическим объектам GPSS и приведите
основные операторы, используемые для их обработки.
5. Напишите участок кода программы на языке GPSS, описывающий про-
хождение транзактов через обслуживающее устройство (интервалы вре-
мени между поступлениями транзактов распределены равномерно с
математическим ожиданием Л/, границы распределения находятся на
расстоянии В\ длительность обслуживания также задается равномерным
распределением с математическим ожиданием Ml, границы распреде-
ления находятся на расстоянии В).
6. Какие операторы языка GPSS используются для организации много-
канального обслуживания ? Нарисуйте пример Q-схемы многока-
нального обслуживания.
7. Какая область применения в языке GPSS операторов PREEMPT и
RETURN ? Приведите участок кода на языке GPSS с использованием
этих операторов.
8. Для чего в GPSS используются статистические блоки ? Перечислите опера-
торы, применяемые для описания этих блоков.
9. Определите назначение операционных блоков в языке GPSS. Перечислите
и дайте краткое описание операторов, используемых для описания опера-
ционных блоков.
10. Опишите алгоритм обработки коллизий в Ethernet.
Глава 12
ФРАКТАЛЬНЫЕ ПРОЦЕССЫ И ИХ ПРИМЕНЕНИЕ
В ТЕЛЕКОММУНИКАЦИЯХ
12.1. Основы теории фрактальных процессов
Самоподобность и фракталы - понятия, впервые введенные Б. Мандельбро-
том. Фракталы описывают явление, при котором некоторое свойство объекта
(например, реального изображения, временного ряда) сохраняется при мас-
штабировании пространства и/или времени. Объект является самоподобным
или фрактальным, если его части при увеличении подобны (в некотором смыс-
ле) образу целого. В отличие от детерминированных фракталов, стохастиче-
ские фрактальные процессы не обладают четким сходством составных частей в
мельчайших деталях. Несмотря на это, стохастическая самоподобность являет-
ся свойством, которое может быть проиллюстрировано наглядно и оценено
математически.
Для количественной оценки и описания пульсирующей структуры те-
лекоммуникационного трафика в большинстве случаев достаточно исполь-
зовать статистические характеристики 2-го порядка. Корреляционная
функция самоподобного процесса играет весьма важную роль, являясь ос-
новным критерием, относительно которого успешно определяется мас-
штабная инвариантность подобных процессов. Существование корреляции
«на расстоянии» называется долговременной зависимостью (ДВЗ). Отличи-
тельной особенностью корреляционной функции самоподобных процессов
от функции, которая обычно имеет место, является то, что корреляция как
функция временной задержки предполагает полиномиальное, а не экспо-
ненциальное убывание.
В телекоммуникационных приложениях свойствам стохастической
самоподобности (фрактальности) удовлетворяют измеренные трафиковые
трассы. Здесь предполагается, что мерой схожести является вид трафика с
соответствующей амплитудной нормировкой. Для измеренных трафиковых
трасс сложно наблюдать четкую структуру, однако самоподобность позво-
ляет учитывать стохастическую природу многих сетевых устройств и со-
бытий, которые совместно влияют на сетевой трафик. Будем считать, что
трафик телекоммуникационной сети является выборкой реализации сто-
хастического процесса. Тогда, ослабив степень схожести обоих процессов и
выбрав некоторую статистическую характеристику перемасштабированно-
го временного ряда, можно получить точную подобность математических
объектов и асимптотическую подобность их конкретных выборок относи-
тельно этих ослабленных критериев схожести.
292
Глава 12. Фрактальные процессы и их применение в телекоммуникациях
Последние исследования локального и глобального трафика показали,
что сетевой трафик проявляет изменчивость в широком диапазоне масшта-
бов времени. Поразительна повсеместность этого явления, наблюдаемого в
различных сетевых технологиях, от Ethernet до ATM, LAN и WAN, сжатом
видео и WWW трафике, основанном на HTTP. Такая масштабно-
инвариантная изменчивость не совместима с традиционными моделями сете-
вого трафика, которые проявляют пульсирующий характер на коротких
масштабах времени, но сильно сглажены на больших масштабах времени,
поэтому в них отсутствует ДВЗ. Поскольку инвариантная к масштабу пуль-
сирующая структура трафика может оказывать сильное влияние на произво-
дительность сети, то анализ причин и последствий самоподобности в трафи-
ке является очень важной задачей. Многочисленные измерения сделали оче-
видным, что инвариантная к масштабу пульсирующая структура является не
отдельным, побочным явлением, а скорее характерной особенностью, сло-
жившейся в пределах сетевых окружений.
Известны работы по физическому моделированию фрактальных про-
цессов, в которых делаются попытки объяснить физические причины са-
моподобности в сетевом трафике. Эти исследования основываются на сете-
вых механизмах и опытно установленных свойствах распределенных сис-
тем, которые совместно генерируют самоподобную пульсирующую струк-
туру, мультиплексируя процессы на сетевом уровне.
Ведутся работы по разработке математических моделей долговремен-
но зависимого трафика с позиции облегчения анализа эффективности при
построения очередей. Эти работы чрезвычайно важны, поскольку позволя-
ют очертить границы сетевой производительности, исследуя характер по-
строения очередей с долговременно зависимым входом. В частности, пока-
зывается, что распределение длины очереди в бесконечном буфере системы
при долговременно зависимом процессе на входе затухает медленнее,
чем экспоненциально (или субэкспоненциально). Напротив, для
кратковременно зависимых процессов на входе затухание имеет экспонен-
циальный характер.
Когда трафик на входе является самоподобным, буферизация оказывает-
ся неэффективной, поскольку возникают несоразмерные задержки в очереди.
Самоподобность подразумевает существование корреляционной
структуры на промежутке, который может использоваться с целью управ-
ления трафиком. Для этих целей, на больших временных масштабах извле-
кается информация о корреляционных свойствах анализируемых процес-
сов, корректируя выходной характер структуры управления перегрузками.
Стохастический процесс называется фрактальным, когда некото-
рые из его важных статистических характеристик проявляют свойства
масштабирования с соответствующими масштабными показателями.
Поскольку масштабирование математически приводит к степен-
ным соотношениям в масштабируемых величинах (т.е. степенной
зависимости статистических характеристик), можно сделать вывод, что, на-
пример, телекоммуникационный трафик проявляет фрактальные свойства,
когда некоторые из его оцененных статистических характеристик проявляют
степенную зависимость в широком временном или частотном диапазонах.
293
12.1. Основы теории фрактальных процессов
Самоподобность и фракталы тесно связаны между собой. К числу ос-
новных понятий, определяющих свойства фрактальных процессов, относятся
самоподобность, долговременная зависимость, медленно затухающая диспер-
сия, бесконечные моменты, фрактальные размерности, распределения с «тя-
желыми хвостами», зависимость спектральной плотности S(co) по закону \/f
Рассмотрим дискретный во времени случайный процесс или времен-
ной ряд X(t\ t e Z, где X(t) интерпретируется как объем трафика (измеряе-
мый в пакетах, байтах или битах) в момент времени t.
Будем считать процесс X(t) стационарным в широком смысле, наклады-
вая ограничения, что его корреляционная функция /?(гь t2) = ^[(ХЦд - m)(X(t2) -
- ли)] инвариантна относительно сдвига, т.е. Я(/ь /2)= R(t\ +k, t2 + к) для любых
t\, t2e Z. Предполагается, что первые два момента существуют и конечны, и
равны для любых t 6 Z. Здесь Л/(-) - операция усреднения; т - первый цен-
тральный момент; а2- дисперсия процесса X(t). Примем для удобства т = 0.
Поскольку при условии стационарности R(t\, /2)= R(t\ -12, 0), обозначим корре-
ляцию как R(k), а коэффициент корреляции r(k) = R(k)/R(ti) = RQtya2.
Чтобы сформулировать масштабную инвариантность, сначала опре-
делим объединенный (агрегированный) процесс }6п,] для Xпри уровне объе-
динения т. Этот процесс можно описать следующей формулой:
%«(/)= 1
т t=ni(l-1)+1
Отсюда видно, что X(t) разбивается на неперекрывающиеся блоки раз-
мером т. Их значения усредняются, и i используется в качестве индекса этих
блоков. Обозначим корреляционную функцию Х^ как R^)n\k). В предполо-
жении стационарности в широком смысле рассматриваемых случайных про-
цессов справедливы следующие определениям самоподобности 2-го порядка
(самоподобность в широком смысле).
Определение. Случайный прогресс X(t) является точно самоподобным в
широком смысле с показателем Херста Я (1/2 < Н < 1), если R(k) =
= (сг/2)((£ + l)2^ - 2А277 + (к - 1)2//) для любых к > 1. Случайный процесс X(t)
является приближенно самоподобным в широком смысле, если lim R^n,\k) =
m—w
= (<j2/2)((A + I - 2A2" + (к - 1A
Самоподобность 2-го порядка (в точном или приблизительном смыс-
ле) - основная структура, характерная для моделирования сетевого трафика.
Определение. Непрерывный во времени стохастический процесс Х^ 6 7?+)
со стационарными приращениями У, = X, - Х^ (/ g N) с показателем Хер-
ста Н (0,5 < Н< 1,0) для любого действительного, положительного коэф-
фициента расширения а считается:
статистически самоподобным, если процессы Xt и перемасштабиро-
ванный процесс (с масштабам времени at) а ИХс11 имеют одинаковые конечно-
мерные плотности распределения вероятностей w{Xh Х2, ..., Хп} ~ w{aHXa,
анХ2а,..., а~нХпа} для всех положительных целых п\
294
Глава 12. Фрактальные процессы и их применение в телекоммуникациях
самоподобным в широком смысле, если процессы Ха1 и aHXt имеют
одинаковые статистические характеристики до 2-го порядка (среднее
значение М[Х} = М\Ха}/сР, дисперсию а2[Х] = а2\Хси\/а2И и корреляционную
функцию R(t, т) = R(at, сп)1а2Иу
асимптотически самоподобным в широком смысле, если статистиче-
ские характеристики до 2-го порядка дляХа1 и с?Х( одинаковы при а-^^о.
Таким образом, показатель Херста Я самоподобного ряда лежит на
интервале (0,5; I). При приближении Як 1 ряд становится все более са-
моподобным.
Самоподобные процессы в дополнение к статистической подобности
при масштабировании обладают некоторыми количественными свойства-
ми. В результате самоподобные процессы можно обнаружить по несколь-
ким равноценным признакам.
Во-первых, они обладают гиперболически затухающей корреляцион-
ной функцией вида R(k) - ^2H~2}L(t) при к -> со, где L(t) - медленно меняю-
щаяся функция на бесконечности, т.е. г(/л)/ £(/)= 1 для всех х > 0. Сле-
довательно, корреляционная функция является не суммируемой и ряд, образо-
ванный последовательными значениями корреляционной функции, расходит-
ся, т.е. Е*/?(£) = оо.
Эта бесконечная сумма является еще одним определением ДВЗ, поэто-
му почти все самоподобные процессы являются долговременно зависимыми.
Последствия этого очень существенны, так как кумулятивный эффект в ши-
роком диапазоне задержек может значительно отличаться от того, который
наблюдается в кратковременно зависимом процессе (КВЗ-процессе). В каче-
стве примеров КВЗ-процессов могут выступать пуассоновский, марковский
или авторегрессионный процесс. Хотя анализ телетрафика в прошлом, в ос-
новном, базировался на КВЗ-моделях, последствия ДВЗ в телетрафике могут
быть весьма серьезными. Поскольку ДВЗ является причиной длительных
пульсаций, которые превышают средние уровни трафика, это может привес-
ти к переполнению буферов и вызвать потери и/или задержки.
Во-вторых, дисперсия выборочного среднего затухает медленнее, чем
величина, обратная размеру выборки. Если ввести в рассмотрение новую
временную последовательность i = 1,2, ...}, полученную путем ус-
реднения первоначальной последовательности {X; 1= 1,2, ...} по непере-
секающимся последовательным блокам размера т, тогда для самоподоб-
ных процессов характерно более медленное уменьшение дисперсии по за-
кону а2(Ах,п)) ос т{2Н "2) при т -> оо, в то время как для традиционных ста-
ционарных случайных процессов дисперсия ст2({Х(ш); /= 1, 2, ...}) = <з2иГ1,
т.е. уменьшается обратно пропорционально объему выборки. Это говорит о
том, что статистические характеристики выборки, такие как среднее значе-
ние и дисперсия, будут сходиться очень медленно, особенно при Н —> 1,
что отражается на всех мерах самоподобных процессов.
295
12.1. Основы теории фрактальных процессов
В-третьих, если рассматривать самоподобные процессы в частотной
области, то явление ДВЗ приводит к степенному характеру спектральной
плотности вблизи нуля. Фактически (при слабых условиях регулярности на-
кладываемых на медленно меняющуюся функцию Ц), X является долговре-
менно зависимым, если 5(со) ~ со~Я2(со) при со -> оо, где 0 < у < 1; Ь2 - функция
медленно изменяющаяся в нуле; 5(со) = lLkR(K)^ - спектральная плотность.
Следовательно, с позиции спектрального анализа, ДВЗ подразумевает, что
S(0) = S* = оо, т.е. спектральная плотность стремится к + оо, когда частота
со приближается к 0 (подобное явление в дальнейшем названо 1//чиум). И
наоборот, - процессы с КВЗ характеризуются спектральной плотностью,
имеющей положительное и конечное значение при со = 0.
До сих пор обсуждалась роль самоподобности при условии стацио-
нарности в широком смысле и немного говорилось о роли показателя Хер-
ста Н и его предельных значений. Вернемся к определению взаимосвязи
самоподобности в широком смысле и коэффициента корреляции г(£). Для
значений 0 < Н < 1 и Н ф 1/2 коэффициент корреляции полагают г(к) ~
Н{2Н- О^прик-Х».
В частности, если 1/2 < Я < 1, то г(к) приблизительно ведет себя как
ск "Р при 0 < Р < 1, где с > 0 - константа; Р = 2 - 2Я, и тогда = оо .
Таким образом, коэффициент корреляции медленно (гиперболически) за-
тухает, что является основной причиной несуммируемости. Когда ?^к) затухает
гиперболически, соответствующий стационарный процесс Xt является долго-
временно зависимым. И наоборот, процесс Х{ является кратковременно зави-
симым, если нормированная корреляционная функция суммируема, т.е.
Е^=_даг(ЛО = const< оо . В принципе, можно дать эквивалентное определение и в
частотной области, где необходимо, чтобы спектральная плотность процесса,
описываемая выражением S(co) = (2л)"1 г(т)е/Асо, удовлетворяла условию
S(co) ~ cjcop, со —> 0 (здесь с > 0 - константа; 0 < а = 2Я- 1 < 1). Поэтому спек-
тральная плотность 5(со)при приближении со к нулю предполагает все большие
вклады низкочастотных компонент.
Рассмотрим несколько частных случаев влияния различных значений
Н на г(к)\
если Я= 1/2, тогда г(к) = 0 и Xt- заведомо кратковременно зависимый
процесс в силу его полной некоррелированности;
если 0 < Я < 1/2, тогда г(т) = 0, что является искусственной си-
туацией, редко встречающейся в реальных приложениях;
случай Я = 1 не интересен, так как он ведет к вырожденной ситуации
r(k) = 1 для любых к > 1.
Таким образом, самоподобные процессы не обязательно подразумева-
ют ДВЗ и наоборот. Например, броуновское движение, получившее в лите-
ратуре специальное обозначение 1/2-sssi (Self-Similar process with self-
similarity parameter 1/2 with Stationary Increments) является самоподобным
процессом с белым гауссовским шумом в качестве процесса приращения.
296
Глава 12. Фрактальные процессы и их применение в телекоммуникациях
Однако белый гауссовский шум не является долговременно зависимым. На-
против, некоторые фрактальные авторегрессионные процессы FARTMA
(Fractional AutoRegressive Integrated Moving Average) порождают ДВЗ, но они
не самоподобны в распределительном смысле. В случае асимптотической
самоподобности 2-го порядка, при условии 1/2 < Н< 1, самоподобность под-
разумевает долговременную зависимость и наоборот по определению. По
этой причине и из-за того, что асимптотически самоподобные процессы 2-го
порядка используются как «канонические» модели трафика, иногда исполь-
зуется взаимозаменяемость понятий «самоподобности» и «долговременной
зависимости» в тех случаях, когда это не приводит к путанице.
Для самоподобного процесса дисперсия выборочного среднего умень-
шается медленнее, чем величина, обратная размеру выборки ст2[А/л,)] ~
для достаточно большого т. Напротив, для кратковременно зависимых про-
цессов (в дальнейшем КВЗ-процессов) параметр р = 1 и cr2[JVz('n)] ~ гп\
Свойство медленно затухающей дисперсии может быть легко выявлено
путем нанесения на log-log график функции cr2[JV/'"J] от т (график изменения
дисперсии). Прямая линия с отрицательным наклоном (меньшим, чем 1 (в ши-
роком диапазоне т)) указывает на медленно затухающую дисперсию.
Важное следствие свойства медленно затухающей дисперсии заклю-
чается в том, что в случае классических статистических тестов (например,
вычисление доверительных интервалов) общепринятая мера среднеквадра-
тического отклонения ст (когда размер выборки увеличивается) является
ошибочной с коэффициентом, стремящимся к бесконечности.
Это свойство является проявлением ДВЗ в частотной области. В частно-
сти, спектральная плотность мощности S(co) для долговременно зависимых
процессов (далее ДВЗ-процессов) в низкочастотной области имеет (как указы-
валось выше) специфический характер. Это отличает ДВЗ- от КВЗ- процессов,
для которых спектральная плотность на низких частотах остается равномер-
ной. Другими словами, 5(со) для ДВЗ-процессов проявляет степенное поведе-
ние вблизи нулевой частоты, т.е. 5(со) ~ 1/|со |а, где |со|->ОиО<ос< 1. Пара-
метр ос связан с параметром Р как а = 1 - Р = 2Н- 1.
Для КВЗ-процессов спектральная плотность мощности остается ко-
нечной, когда |со| —> 0, т. е. когда ос = 0. Это говорит о том, что значения
корреляционной функции R(k) для больших к затухают достаточно быстро.
12.2. Оценка показателя Херста
Проверка на самоподобность и оценка показателя Херста Н являются
сложной задачей. В реальных условиях всегда оперируют с конечными
наборами данных, поэтому невозможно проверить, является или нет
трасса трафика самоподобной по определению. Следовательно, необхо-
димо исследовать различные свойства самоподобности в реальном из-
меренном трафике. При этом возникают следующие проблемы.
297
12.2. Оценка показателя Херста
1. Даже если подтверждаются некоторые перечисленные выше свой-
ства самоподобности, нельзя сразу сделать вывод, что проанализированные
данные имеют самоподобную структуру, так как существуют другие эф-
фекты, которые могут приводить к таким же свойствам (например, неста-
ционарность). И поскольку анализ основывался только на тех тестах, кото-
рые могут ввести в заблуждение, разумно говорить о самоподобной струк-
туре в заданном масштабном диапазоне для заданного набора данных.
2. Оценка показателя Херста зависит от многих факторов (напри-
мер, методика оценки, размер выборки, масштаб времени, корреляци-
онная структура и т.д.), что затрудняет нахождение самой уместной для
поставленной задачи «оценки Я».
3. При использовании показателя Херста в практических целях
(например, определение размеров буферов) интерпретация этого пока-
зателя, очевидная для теоретических самоподобных процессов, не оче-
видна для реального трафика, который может никогда не рассматри-
ваться как теоретически самоподобный процесс.
На сегодняшний день известно несколько методов оценки самопо-
добности во временных рядах, самыми популярными из которых явля-
ются анализ R/S-статистики и анализ графика изменения дисперсии.
Анализ нормированного размаха (Л7Х-метод). Нормированная безраз-
мерная мера, способная описать изменчивость трафика названа нормирован-
ным размахом (R/S). Для заданного набора наблюдений Х= {ХП9 пе X} с вы-
борочным средним М(Х) = \1пЪ"1=ЛХ вводится понятие размаха (т.е. разности
между максимальным и минимальным отклонением) R(ri) = тахД. - min А ,
\<J<n J \^1<п 7
где Д* = (X,- Ш(Х)\ \/k = 1, п. Эта характеристика отличается от размаха
временной последовательности случайной величины Хр который равен
max X. - min %,. Вместо него выбрана величина, учитывающая накопление
1<7^У 7 7
Ду и характеризующая изменчивость величины Х} относительно среднего зна-
чения. Для описания изменчивости более удобна нормированная безразмерная
характеристика:
^(л)_ _ max(0.A1,A2,...,A„)-min(Q,A1,A2,...,A/>)
Это отношение названо нормированным размахом. Показано, что
для многих природных явлений справедливо эмпирическое соотноше-
ние M[R(n)/S(ny] - спн при п -> оо, где с - положительная конечная кон-
станта, не зависящая от п.
Прологарифмировав обе части последнего выражения, получим
log{M[R(n)/S(n)}} ~ 771og(n) + log(c) при п —> оо.
Таким образом, параметр Херста можно получить, изобразив график
зависимости 1о§{Лф?(и)/|$(и)]} от log(n) и, используя полученные точки,
подобрать по методу наименьших квадратов прямую линию с наклоном Н.
298
Глава 12. Фрактальные процессы и их применение в телекоммуникациях
График изменения дисперсии. Как было показано выше для са-
моподобного процесса, связь между дисперсией объединенного процес-
са и размером блока т выражается соотношением о2(Л7"°) ~ ат~^
при т —> оо, где а - некоторая конечная положительная константа. Про-
логарифмировав обе части последнего соотношения, получим зависи-
мость log(0-2(A/(w))) ~ -Plog(/7z) + log(6?) при т —> оо.
Следовательно, можно получить оценку Р, вычислив log(a2(X(zn)))
для различных значений т и графически отображая результаты в зави-
симости от log(m) , проводя прямую линию методом наименьших квад-
ратов через полученные точки. Оценку для р определим как отрица-
тельный наклон прямой линии, подобранной по методу наименьших
квадратов. Поскольку известно, что Я связан с р выражением Я= 1—{3/2,
это дает И = 1 — р/2.
12.3. Обзор методов моделирования самоподобных
процессов в телетрафике
Основное отличительное свойство самоподобных или фрактальных явле-
ний заключается в том, что они охватывают широкий диапазон масштабов
времени. В литературе по телетрафику понятие пульсирующая структура
(burstiness) часто используется именно в этом контексте. Математические
модели, которые экономичным образом стремятся охватить и описать са-
моподобные, фрактальные или пульсирующие явления, используют сто-
хастические самоподобные процессы и должным образом выбранные ди-
намические системы. Общей характеристикой этих моделей является то,
что их пространственно-временная динамика определенным об-
разом управляется при помощи функций степенного (power-law) рас-
пределения («Эффект Ноя») и гиперболически затухающей корреляционной
функции («Эффект Джозефа»). Традиционные подходы к моделированию
фрактальных явлений опираются на сильно параметризированную много-
уровневую иерархию традиционных моделей, которые, в свою очередь, ха-
рактеризуются распределениями и корреляционными функциями, зату-
хающими экспоненциально.
Пульсирующие или фрактальные явления наблюдались во многих от-
раслях науки и техники: гидрологии, экономике финансов, биофизике и дру-
гих. Модели, учитывающие данные явления, относительно новы для теории
телетрафика и отражают современный вклад в уже существующий большой
класс альтернативных моделей описания трафика в сетях с коммутацией па-
кетов. Хотя использование фрактальных моделей и обосновано многочис-
ленными измерениями, их практическое внедрение и анализ игнорировались,
в основном из-за того, что они рассматривались как модели, с трудом под-
дающиеся аналитическому описанию. Успешное применение фрактальных
моделей в теории телетрафика будет зависеть не только от того, как хорошо
они описывают реальный сетевой трафик, но еще от того, насколько велики
возможности использования их для сетевого анализа и управления.
299
12.3. Обзор методов моделирования самоподобных процессов...
Моделирование трафика исторически исходило из традиционной те-
лефонии и было почти исключительно основано на пуассоновских (или,
более обобщенно, марковских) предположениях относительно структуры
трафиковых поступлений и экспоненциальных предположениях
относительно требований удержания ресурса. Однако с появлением совре-
менных высокоскоростных сетей с коммутацией пакетов (ячеек) возникла
проблема объединения новых и существующих технологий передачи и
коммутации с чрезвычайно разнородными смесями сервисов и приложений.
В результате пакетный трафик стал более сложным или пульсирующим, чем
голосовой трафик, просто из-за того, что он охватывает сильно отличаю-
щиеся масштабы времени (от микросекунд до секунд и даже минут).
Ранее доступность реальных измерений трафика в реальных сетях с
коммутацией пакетов (ячеек) действительно составляла проблему. В [13]
отмечается, что между 1966 и 1987 гг. было опубликовано несколько тысяч
работ о проблемах построения очередей, но только около 50 из них описы-
вали результаты измерения трафика. В настоящее время для исследовате-
лей собраны и доступны огромные архивы трафиковых данных из реально
функционирующих сетей: CCSN/SS7, ISDN (Integrated Services Digital Net-
work), Ethernet LAN, WAN и NSFNet (National Science Foundation Network),
VBR (Variable Bit Ка1е)-трафик.
Некоторые из этих данных содержат измерения трафика с высоким
разрешением на временных интервалах, измеряемых в часах и днях, другие
дают информацию на грубых масштабах времени в пределах от недель до
месяцев и даже лет. Первые обычно используются с целью описания харак-
тера трафика, а последние дают понимание долговременно возрастающих
тенденций и сетевого использования. Подробный статистический анализ из-
мерений трафика, проведенных с высоким разрешением, дает убедительное
доказательство того, что данные трафика из реально функционирующих се-
тей с коммутацией пакетов или ячеек согласуются с предположением стати-
стической самоподобности или фрактальных характеристик. Кроме того, эти
опытно полученные свойства часто существенно отличаются от свойств, на-
блюдаемых у трафика, сгенерированного традиционными моделями. Основ-
ной причиной такого очевидного различия является структура лежащей в ос-
нове зависимости. В то время как традиционные модели пакетного трафика
являются кратковременно зависимыми (т.е. имеют экспоненциально зату-
хающие корреляции), данные измеренного пакетного трафика проявляют
долговременную зависимость (т.е. гиперболически затухающие корреляции).
С практической точки зрения, при прогнозе сетевого трафика и ана-
лизе производительности сетей широко используются стохастические мо-
дели трафиковых потоков, поскольку они с приемлемой степенью точности
способны предсказать пропускную способность сетей связи. Кроме того,
доверие к модели трафика сильно возрастает, если модель, помимо аппрок-
симации его статистических характеристик, охватывает визуальные свой-
ства опытно наблюдаемого трафика.
300
Глава 12. Фрактальные процессы и их применение в телекоммуникациях
В традиционной телефонии классические модели трафика превосход-
но работают при проектировании и анализе производительности системы в
целом. Но с приходом современных высокоскоростных коммуникацион-
ных сетей (например, В-ISDN в ATM) появляется поразительно разнород-
ная трафиковая смесь. Пульсирующая структура, присущая некоторым
широко используемым B-ISDN-сервисам (в основном, сжатое видео и пе-
редача файлов), и определяет несостоятельность традиционных моделей
относительно кратковременной и долговременной зависимостей.
Однако инженеры и администраторы сетей только начинают осозна-
вать практическую значимость фрактальных моделей трафика, фрактальные
свойства которых оказывают существенное влияние на производительность
сети в целом. Это направление еше мало исследовано, а то немногое, что из-
вестно, носит предварительный характер и иллюстрирует трудности, связан-
ные с такими моделями. Поэтому фрактальный трафик (в том числе стохас-
тическое моделирование, статистический вывод, искусственное генерирова-
ние трафика и анализ построения очередей) открывает новую и перспектив-
ную область математических исследований.
Результаты, приведенные в [13], показывают, что измерения характе-
ристик систем построения очередей с фрактальным трафиком могут суще-
ственно отличаться от тех, что предсказываются соответствующими систе-
мами с традиционными моделями трафика. Особый интерес вызывает по-
ведение хвостов распределения длины очереди Q в устойчивом состоянии
Р{2 > В} для одного сервера с бесконечной вместимостью очереди. Для
марковского трафика, обрабатываемого в такой очереди, распределения
хвостов являются приблизительно экспоненциальным, т.е.
Р(2> В)- е~’1Н при В->со, (12.1)
где г| > 0 - асимптотическая степень затухания.
Зависимость (12.1) положена в основу концепции эффективной про-
пускной способности, где управление доступом или распределяемая ем-
кость канала обслуживания основана на распределении вероятностей хво-
стов выбора случайных переменных. В отличие от (12.1), трафиковые по-
токи с ДВЗ (в частности, модели, основанные на фрактальном броуновском
движении) приводят к асимптотике распределения вероятностей хвостов
вейбулловского типа, т.е.
P(g> В)~е~уВ" при (12.2)
где у-константа; р =2-2Яе (0; 1].
Формулы (12.1) и (12.2) существенно отличаются. Первая дает относи-
тельно оптимистические предсказания. Вопрос о том, приводят ли другие
модели трафика к корректным (по сравнению с их опытными двойниками)
прогнозам производительности сети, до сих пор остается открытым. Если
фрактальные свойства или статистические характеристики 2-го порядка
приводят к принципиально иному поведению системы, тогда интерес при-
301
12.3. Обзор методов моделирования самоподобных процессов...
обретают способности традиционных (поддающихся аналитической трак-
товке) моделей трафика охватить такие свойства и их влияние (скажем на
статистические характеристики при построении очередей). Например, хотя
не фрактальные модели (такие как модели, основанные на марковских про-
цессах) наследуют КВЗ, тем не менее известно, что добавление параметров
может привести к моделям с «приблизительно» фрактальными свойствами.
Можно легко выявить различия между структурой трафика, предска-
зываемой моделями и реальными, измеренными в современных сетях трас-
сами трафика, что ставит под вопрос корректность использования традици-
онных подходов при моделировании трафика. Продемонстрируем, на-
сколько самоподобная структура сетевого трафика на макроскопическом
уровне (т.е. объединенный трафик, генерируемый всеми активными хоста-
ми в сети) обеспечивает новое понимание трафиковой динамики на этом
уровне (т.е. структура трафика, генерируемого отдельными хостами).
С этой целью рассмотрим два из наиболее часто встречаемых сетевых
окружений: локальные сети (LAN) и глобальные сети (WAN). Взамен тра-
диционного подхода по принципу «черного ящика», который часто исполь-
зуется при анализе временных рядов, остановимся на структурных моде-
лях. Они принимают во внимание специфические свойства сетевой струк-
туры, а следовательно, дают физическое объяснение наблюдаемых явле-
ний, таких как самоподобность.
Локальные сети были введены в середине 1970-х гг. для взаимосвязи
оборудования, обрабатывающего данные (центральные ЭВМ, файловые
серверы, принтеры и т.д.) в офисах, научной исследовательской сфере или в
пределах университетских факультетов. Одна из самых популярных техно-
логий LAN - Ethernet. Чтобы продемонстрировать самоподобную структуру
LAN-трафика, были использованы измеренные Ethemet-трассы. Покажем
ниже, как самоподобность LAN-трафика приводит к структурным моделям,
которые могут быть сведены к ON/OFF-источникам (известным также как
пакетные серии) с характерным свойством (их ON- и/или OFF-периоды
подчиняются распределениям с тяжелыми хвостами (РТХ) с бесконечной
дисперсией). Конвергенция (или наложение) таких ON/OFF-процессов оп-
ределяет непосредственную связь между характеристиками самоподобности
на макроскопическом уровне и явлениями, наблюдаемыми на микроскопи-
ческом уровне, т.е. между объединенным потоком трафика и структурой
трафика, которая присуща отдельным парам источник-получатель.
В отличие от локальных сетей, WAN обеспечивают взаимосвязь меж-
ду пользователями (например, центральные ЭВМ для различных LAN), ко-
торые расположены, как правило, в различных географических регионах.
Самая известная WAN - это Интернет (глобальная сеть, объединяющая бо-
лее десяти миллионов хостов и пользователей). Доказательство самоподоб-
ности WAN-трафика представлено в многочисленных исследованиях [13],
где на основе анализа нескольких различных трасс WAN-трафика показана
неадекватность традиционных моделей экспоненциального (пуассоновско-
го) трафика при описании ключевых моментов поведения WAN-трафика.
Таким образом, для LAN так же, как и для WAN, самоподобность
объединенного сетевого трафика является прямым результатом структур-
302
Глава 12. Фрактальные процессы и их применение в телекоммуникациях
ных моделей, которые повторяют сетевую динамику на нижних сетевых
уровнях и определяют характеристики трафика на этих уровнях, что под-
тверждено реальными измерениями трафика с высоким разрешением. Та-
кие модели являются простыми и экономичными, давая возможность полу-
чить требуемые свойства, которые были бы устойчивы к постоянно изме-
няющимся условиям сети.
12.4. Исследование самоподобной структуры
трафика Ethernet
Проиллюстрируем исследование реального сетевого трафика, собранного в
небольшой коммерческой сети, основную часть которого составлял про-
смотр web-страниц в сети Интернет и небольшой домашней локальной се-
ти, чей трафик создавался типичными приложениями, используемыми в
подобного рода сетях (пересылка файлов, чат, netmeeting, игры и другие).
Как видно из схемы, приведенной на рис. 12.1, топология сети типа
«звезда». В качестве соединительных кабелей используется витая пара
UTP-5 (10-BaseT), кроме небольшого сегмента из трех машин, на котором в
качестве соединительных кабелей использовался тонкий коаксиальный ка-
бель RG-58 (10-Base2). Интернет-кафе на схеме обозначено как отдельный
пользователь, который содержит свою локальную сеть, являющуюся под-
сетью основной сети.
Dbwork-server
Рис. 12.1. Схема сети типа «звезда»
Измерения в указанной выше сети проводились с использованием
анализатора трафика, который устанавливался на прокси-сервере (PROXY),
улавливая таким образом всю информацию, курсирующую по выделенно-
му Интернет-каналу (скорость 2 Мб/с).
Для исследования структуры трафика и иллюстрации его фрактального
(самоподобного) характера использовалось специально разработанное про-
граммное обеспечение, в котором были реализованы соответствующие тесты.
303
12.4. Исследование самоподобной структуры трафика Ethernet
Примеры соответствующих профилей байтовой интенсивности (И7), а также
интенсивностей пакетов (N) в единицу времени, равную 0,5 с, приведены на
рис. 12.2 (на рисунке к- индекс соответствующего временного интервала).
б)
Рис. 12.2. Измеренные реализации:
а - байтовая интенсивность; б - интенсивность пакетов
На рис. 12.3 приведены «хвосты» функций распределения для выбо-
рок, приведенных выше. Для удобства сравнения на тот же график нанесе-
на кривая функции гауссовского распределения с нулевым математическим
ожиданием и единичной дисперсией.
б)
Рис. 12.3. «Хвосты» функций распределения для гауссовского случая и для данных
измерения (л - байтовая нагрузка; б - интенсивность пакетов): кривая 1 - ФР для нор-
мированных экспериментальных данных; кривая 2 - ФР для гауссовских СВ
304
Глава 12. Фрактальные процессы и их применение в телекоммуникациях
Оценка результатов тестов. Приведем результаты тестов на выявле-
ние самоподобности для рядов, отражающих загрузку сети в байтах в еди-
ницу времени. Очевидно, что для практических целей более полезной явля-
ется информация о степени загруженности сети. Информация о количестве
пакетов в единицу времени может визуально вводить в заблуждение, по-
скольку в сети могут присутствовать много небольших управляющих паке-
тов, не несущих полезной информации, и пакетов минимальной длины, ко-
торые создают пики, не совпадающие с пиками байтовой скорости.
График изменения дисперсии. На рис. 12.4 приводятся результаты
тестирования характера изменения дисперсии при увеличении размера
блока объединения. Для всех измерений минимальный и максимальный
размеры блока выбирались равными соответственно 10 и 400 дискрет-
ным точкам. Все измерения исследуемого ряда были взяты с временным
разрешением 0,5 с.
Рис. 12.4. График изменения дисперсии
Исходя из приведенных выше результатов, очевидно, что рассмат-
риваемый трафик обладает самоподобными свойствами, поскольку на-
блюдается явное отклонение от значения показателя Херста Н - 0,5
(диагональная пунктирная прямая).
R/S статистика. На рис. 12.5 приведены результаты теста, иссле-
дующего R/S статистику при увеличении размера исследуемого блока. Для
всех измерений минимальный размер блока выбирался равным 50, а макси-
мальный -400 дискретным точкам. Временное разрешение равно 0,5с.
Результаты, полученные для R/S статистики, еще раз подтверждают эв-
ристический характер рассматриваемых тестов, так как численные результаты
для R/S статистики значительно отличаются от тех, что получены для метода
изменения дисперсии. Но оба теста дают понять, что истинный Н рассматри-
ваемых наборов данных находится в диапазоне 0,7 ... 0,8.
1 1—3834
305
12.5. Перегрузочное управление самоподобным трафиком
Оценка корреляционной функции. Известно, что самоподобные про-
цессы сН от 0,5 до 1 обладают свойством ДВЗ, т. е. их автокорреляционная
функция на бесконечности не сходится к нулю. Оценив степень затухания
корреляционной функции, можно оценить Н. Поскольку невозможно ана-
лизировать бесконечный набор данных, рассмотрим при построении кор-
реляционной функции первые 100 задержек. График корреляционной
функции приведен на рис. 12.6.
а)
Рис. 12.6. Исследование корреляционной функции:
а - зависимость коэффициента корреляции г от задержки к\
б - зависимость lg-lg г от задержки к
Даже для 100 задержек эта функция не сходится к нулю, а проявляет
степенное затухание, что подтверждает график корреляционной функции в
двойном логарифмическом масштабе. Оценка графика корреляционной
функции также является эвристическим методом, а, следовательно, резуль-
таты, полученные с его помощью, качественно подтверждают присутствие
самоподобной структуры в исследуемых данных.
12.5. Перегрузочное управление самоподобным
трафиком
Под управлением самоподобным трафиком будем понимать регулирование
трафика таким образом, чтобы эффективность сети (в том числе пропуск-
ная способность) была оптимальной. Масштабно инвариантная структура
трафика вносит новые сложности в общую картину, что делает задачу пре-
доставления качества обслуживания (QoS) (совместно с достижением вы-
сокого коэффициента использования) гораздо более сложной. Главным яв-
306
Глава 12. Фрактальные процессы и их применение в телекоммуникациях
ляется то, что инвариантная к масштабу пульсирующая структура подразу-
мевает существование периодов скученности высокой активности на круп-
ных масштабах времени, что неблагоприятно воздействует на управление
перегрузкой. Пульсирующая структура на конечных масштабах времени
похожа на пульсирующую структуру, наблюдаемую для традиционных
кратковременно зависимых моделей трафика. Подобное свойство наблюда-
ется на более грубых масштабах, где появляются дополнительные интерва-
лы перегрузки или недоиспользования и снижения общей эффективности.
Однако ДВЗ (по определению) подразумевает существование необычной
корреляционной структуры, что может быть использовано для целей пере-
грузочного управления, и не используется в существующих алгоритмах.
Рассмотрим стратегию перегрузочного управления, называемую се-
лективным управлением агрессивностью (СУА) (рис. 12.7). Проиллюстри-
руем эффективность стратегии перегрузочного управления для улучшения
эффективности работы сети при использовании структуры предсказуемо-
сти, присутствующей в долговременно зависимом трафике. Схема управ-
ления является видом предсказательного перегрузочного управления, осно-
ванного на многомасштабной структуре перегрузочного управления. Для
используемой схемы перегрузочного управления модуль СУА активен на
масштабе времени, превышающем масштаб времени петли обратной связи.
Точное предсказание I долгосрочного состояния сети выполняется в
масштабе времени СУА (1...5 с). Конкретное действие по управлению е(/)
выполняется СУА, основываясь на информации о будущем, и внедряется в
используемую схему перегрузочного управления, воздействуя на решения,
принимаемые относительно управления трафиком.
Задача СУА - повышать эффективность существующих перегрузоч-
ных схем управления. Чтобы продемонстрировать это, выберем в качестве
основного управления управляющего модуля простое, часто используемое,
базирующееся на скорости перегрузочное управление. СУА всегда под-
держивает решение, принятое используемой схемой перегрузочного управ-
ления относительно непосредственного изменения скорости трафика (уве-
личения или уменьшения). Вместе с тем, СУА может регулировать величи-
ну изменения. То есть, если в какой-либо момент времени используемая
схема перегрузочного управления примет решение об увеличении скорости
трафика, СУА никогда не предпримет противоположного действия по
уменьшению скорости пересылки. Вместо этого, основываясь на предска-
занном будущем состоянии сети, СУА усилит или ослабит величину
непосредственного изменения.
Основная идея метода заключается в следующем. СУА будет пытать-
ся агрессивно занимать полосу пропускания, если предсказано, что буду-
щее состояние сети будет не загруженным. Для этого СУА подбирает уро-
вень агрессивности как функцию от предсказанной незагруженное™. В ре-
зультате выигрыш в производительности будет тем выше, чем более долго-
временно зависимым является трафик.
307
12.5. Перегрузочное управление самоподобным трафиком
Предполагая, что будущее состояние сети предсказуемо с достаточной
степенью точности, остается вопрос о том, как воспользоваться информацией
о долговременной зависимости трафика для улучшения сетевой эффективно-
сти. Выбор действий ограничен сетевым контекстом и тем, какая степень
свободы допустима. В традиционных настройках сквозной схемы перегру-
зочного управления сеть, которая разделяет ресурсы, рассматривается как
черный ящик, и для управления потоком доступна только одна переменная -
интенсивность трафика л.
Рис. 12.7. Обобщенная схема предсказательного перегрузочного управления
Предлагаемый протокол СУА разбивается на две части: предсказание
и применение агрессии. С целью повышения эффективности работы сети
СУА использует информацию о корреляционной структуре долговременно
зависимого трафика.
Селективная агрессивность в связке с предсказуемостью может при-
водить к улучшению производительности по сравнению с той, которая мо-
жет быть достигнута при использовании обычных схем перегрузочного
управления, основанных на обратной связи. Этот выигрыш возрастает с
возрастанием ДВЗ трафика.
Таким образом, чем больше ДВЗ трафика, тем более эффективно мо-
жет быть использована его структура для перегрузочного управления.
Контрольные вопросы к главе 12
1. Дайте определение стационарного в широком смысле процесса.
2. Чем отличаются точно самоподобный и асимптотически самоподобный
в широком смысле процессы ?
3. Какими свойствами обладают процессы с долговременной зависимостью ?
4. Каковы трудности, возникающие при оценке показателя Херста ?
5. В чем суть R/S-метода оценки показателя Херста ?
6. В чем суть метода изменения дисперсии ?
7. Каковы особенности ON/OFF-модели, используемой при структурном
моделировании трафика локальных сетей Ethernet ?
8. Опишите схему перегрузочного управления самоподобным трафиком.
308
Глава 13
МЕТОДЫ МОДЕЛИРОВАНИЯ ФРАКТАЛЬНЫХ
ПРОЦЕССОВ
13.1. Фрактальное броуновское движение
Классический винеровский процесс броуновского движения B(t) является
примером случайного процесса, обладающего фрактальными свойствами.
Под броуновским движением понимается случайный процесс, начинаю-
щийся в нуле координат, приращения которого на непересекающихся ин-
тервалах времени ti независимы и имеют гауссовское распределение.
Траектория винеровского процесса обладает свойством масштаб-
ной инвариантности. Траектория и график винеровского процесса нигде
не дифференцируемы и в то же время непрерывны с вероятностью, рав-
ной единице. Плотность распределения вероятностей координаты час-
THHbiJf(Z = /7T)= имеет вид
/,и 1 f w 1
где ДХ=X(t) - -АТ/о); &t=t- Го; kD - коэффициент диффузии.
Введенная ПРВ удовлетворяет соотношению подобия:
X (&0)] }= 5°>5w[x(t)-х(/0)],
где b > 0 - произвольный коэффициент.
Приращение координаты броуновской частицы характеризуется
выражением
ДХ~£|Д/|°’5, W>/0. (13.1)
Здесь £ - суммарное число из гауссовского распределения.
Таким образом, броуновское движение - это стохастический вине-
ровский процесс, обозначаемый {Bt} для t > 0 и характеризуемый сле-
дующими свойствами: приращения B(t + Zo) - #(/о) или Bt+tQ - Bto нор-
мально распределены с нулевым средним и дисперсией а2(/2 - 6) = а2;
приращения Bt* - В1з и В(2 - В^ на соответствующих им неперекрываю-
щихся временных интервалах [^; /2] и [Z3; /4] являются независимыми
случайными переменными; Bq = 0, a Bt является непрерывной при t = 0;
математическое ожидание приращения броуновского движения равно
Л/[|В(Г2) - В(Л)|] ~ 1^2 - Л|0,5; функция распределения описывается выра-
жением вида
1
г X 7. ,
| е ст ‘du .
J -СО
К(х) = Р[дУ <х]
309
13.1. Фрактальное броуновское движение
Понятие обобщенного фрактального броуновского движения (ФБД)
Bj^t) = fBt было введено путем замены показателя степени в правой части
(13.1) на любое действительное число из интервала Я g [0; 1], где Я- показа-
тель Херста. Случай, когда Я = 0,5, соответствует независимым прираще-
ниями и описывает классическое броуновское движение. Таким образом,
ФБД отличается от броуновского движения (БД) наличием приращений с
дисперсией <ЗнЧ2Н. Определим дисперсию процесса приращения как
стя2= M{(JBt -увм)2} = M{(JBX - JBo)}2 = M{fB2} (при уво = 0). Тогда
-Al)} ~ |А'Г, А/ = t2 - tx.
В свою очередь, можно записать
= <32Ht 22Н +v2Ht 2W -2R(jB,},fBl2),
R(jBti,JBn)=0^2H(t2H-(t2+t2H).
Следовательно, корреляция приращений для двух неперекрываю-
щихся интервалов времени определяется как
= R(jBl„JBl2)-R{jBa,JB,i)-R{jBt3,JB,2'}+R(jBt3,jBlX')= (13.2)
В дискретном случае нормированная корреляционная функция по-
следовательности приращений получается заменой и tA в выра-
жении (13.2) на w, w + 1, ...,п + кип+к+1 соответственно и делением
его на с2:
гЛ=1[(^+1Г-2^+(^-1Г]. (13.3)
Эта последовательность приращений называется фрактальным га-
уссовским шумом (ФГШ). Корреляция в (13.3) проявляет ДВЗ, посколь-
ку ~ k^~2 при £ -> оо (согласно разложению Тейлора).
Фрактальное броуновское движение {JBt} может быть выведено из
броуновского движения {Bt} взятием интеграла:
Здесь Г(-) - гамма функция.
Согласно этому выражению, значение случайной функции в момент
времени t зависит от всех предшествующих (и < f) приращений бВ(и) слу-
чайного процесса. Поэтому можно сказать, что взаимная зависимость меж-
ду приращениями фрактального броуновского движения бесконечна.
Все конечномерные маргинальные распределения ФБД являются га-
уссовскими. Значение процесса в момент времени t может быть вычислено
при помощи соотношения Biif) = Xi1, где X - нормально распределенная
случайная переменная с нулевым средним и единичной дисперсией.
310
_____________Глава 13. Методы моделирования фрактальных процессов
Также из самоподобности следует, что B^at) = ДдяН= 0,5
получается обычный процесс броуновского движения. Основные стати-
стические свойства ФБД-процесса следующие:
среднее значение M[BH(t\] = 0;
дисперсия <32[BH(f)] = сг2[УЛ| = Z277;
коэффициент корреляции гВн (Z,t) = Ш^+т277-!/-?!277);
стационарные приращения а2[Вн(/) - Вн(т)] = |/ - т|2.
Модель ФБД широко используется в аналитических и экспери-
ментальных исследованиях с привлечением моделирования при оцен-
ке производительности систем, управляемых самоподобным трафи-
ком, особенно при моделировании трафиковых данных на системном
уровне. ФБД может использоваться для генерирования суммарного
или объединенного самоподобного трафика (как тот, что наблюдается
в сетевых буферах или соответствует размерам файлов из аудио или
видеопотоков и т.д.). Его приращения являются фрактальным гауссов-
ским шумом.
13.1.1 . RMD-алгоритм генерации ФБД
Основной принцип алгоритма случайного перемещения средней точки
(RMD-алгоритм) - рекурсивно расширять сгенерированную выборку, до-
бавляя новые значения в средних точках относительно значений в оконеч-
ных точках.
На рис. 13.1 показано, как работает RMD-алгоритм, а на рис. 13.2 - пер-
вые три шага алгоритма, которые приводят к генерации последовательности
(J3jl; di,2, ^зл)- Цель деления интервала между 0 и 1 - построение гауссов-
ских приращений для X. Добавляя смещение к средним точкам, создают нор-
мальное маргинальное распределение полученной последовательности.
Вывод ФБД
Рис. 13.1. Генерация ФБД с
помощью RMD-алгоритма
Рис. 13.2. Первые три шага RMD-алгоритма
311
13.1. Фрактальное броуновское движение
Шаг 1. Процесс вычисления X(f) для 0 < t < 1 начинают с установки ДО) = О,
а выбор Az(l) осуществляется как псевдослучайное число из гауссов-
ского распределения с нулевым средним и дисперсией cr2[Az(l)] = а02
Тогда oW)-ДО)] = сто2
Ш а г 2. Значение Д1/2) определяется как среднее между ДО) и Д1), т.е.
Д1/2) = 1/2(Д0) + Д1)) + dx. Смещение dx - гауссовская случай-
ная переменная (GRN - Gaussian Random Number) с нулевым
средним значением и дисперсией С]2 для dXi которая должна быть
умножена на масштабный коэффициент 1/2. Визуализация этого и
дальнейших шагов приведена на рис. 13.2. Для выполнения равен-
ства <32[X(ti) -Дб)] = |^2 - Al^o2 при 0 < Л < t2 <1 требуется, чтобы
с2[Х(1/2) - Х(0)] = 1/4с2[Х(1) - Х(0)] + С]2 = (Ш)211^2 Поэтому
с12 = (1/21)2Н(1-22Н-2)со2
Шаг 3. Уменьшая масштабный коэффициент в 72 раза, т.е. полагая его
равным 1/78 , снова делим пополам каждый из двух интервалов
от 0 до 1/2 и от 1/2 до 1. Значение Х(1/4) определяется как среднее
1/2(Х(0) + Х(1/2)) плюс смещение dZ}9 которое является GRN, по-
множенной на текущий масштабный коэффициент 1/78 . Соот-
ветствующая формула справедлива для ДЗ/4), т.е. ДЗ/4) =
=1/2(Д 1/2) + Д1)) + dZ2, где d22 - случайное смещение, вычислен-
ное, как и раньше. Таким образом, дисперсия сг22 для dz* должна
быть выбрана так, что сг2|Д 1/4) -ДО)] = 1/4а2[Д 1/2) -ДО)] + <з2 =
= (Ш2)2^2 Поэтому сг22 = (1/22)2Н(1 - 22Н"2)с02.
Шаг 4.Масштабный коэффициент уменьшается в 72 , т.е. становится
равным 1/716 . Тогда
Д1/8) = 1/2(Д0) + Д1/4)) + J3.i,
ДЗ/8) = 1/2(Д 1/4) + Az(l/2)) + d3Z,
Az(5/8) = 1/2(Д 1/2) +ДЗ/4)) + d3j>
Д7/8) = 1/2(ДЗ/4) + Д1)) + Д4-
В каждой формуле d3 * вычисляются как различные GRN, умножен-
ные на текущий масштабный коэффициент 1/716 . На следующих
шагах, используя масштабный коэффициент, снова уменьшенный в
72 , вычисляют ДО при t = 1/16, 3/16, ..., 15/16, и все повторяется
аналогично вышеизложенному. Поэтому дисперсия а32 для d3* долж-
на выбираться такой, чтобы а2(Х(1/8) - Х(0)) = 1/4а2 (Х( 1/4) - Х(0)) +
+ S32 = (Ш3)21^2, т.е. а32 = (Ш3)2^! - 22Н~2)с02. Следовательно, дис-
персия а„2 для d„* выражается как (Ш")2^! - 22Н"2)суо2-
312
____________Глава 13. Методы моделирования фрактальных процессов
13.1.2 . SRA-алгоритм генерации ФБД
Другим, альтернативным алгоритмом прямого получения ФБД-процесса яв-
ляется алгоритм последовательного случайного сло-
жения (SRA - Successive Random Additional). SRA-
алгоритм (как и RMD-алгоритм) использует средние
точки, но для увеличения устойчивости генерируемой
последовательности добавляет возможность переме-
щения всех точек с соответствующей дисперсией.
На рис. 13.3 показано, как SRA-алгоритм ге-
нерирует приблизительную самоподобную после-
довательность. Цель интерполяции средних точек
заключается в построении гауссовских прираще-
ний для Н, которые являются коррелированными.
Добавляя смещение ко всем точкам, получаем са-
моподобную последовательность, имеющую нор-
Рис. 13.3. Генерация мальное распределение.
ФБД с помощью SRA- SRA-алгоритм состоит в выполнении сле-
алгоритма дующих шагов:
Ш а г I. Если процесс {Х(} вычисляется для моментов времени 0 < t < 1, на-
чинают с установки XQ = 0, и выбор Х[ осуществляется в виде псев-
дослучайной переменной из гауссовского распределения с нулевым
средним и дисперсией <j2[Xi] = су02. Тогда а2^ -Хо] = су02.
Ш а г 2. Значение -АГ1/2 определяется путем интерполяции средней точки:
Х1/2=1/2(Х0+Х1).
Ш а г 3. Прибавляя перемещение с соответствующей дисперсией ко всем
точкам, получаем выражение Хо = Хо + d^X^ = Xlf2 + d^2, Хх =Х\ +
+ d\y Смещение d\* управляется гауссовским шумом. Чтобы вы-
полнялось равенство п2[ Xt - X, ] = |/2 - ^il^o2 ДЛЯ любых t2,
О < t[<t2< I, требуется, чтобы <з2\Х{Г2 - JV0] = l/4o2|l¥i - + 2g?' =
= (1/2)2^о’02> т.е. о/ = l/2(l/2l)2H(l - 22Н-2)ао2, где су02 - начальная
дисперсия; 0 < Н< I.
Ш а г 4. Далее шаги 2 и 3 повторяются. Следовательно, су,2 = 1/2(1/2'7)2/У(1 -
-2W-2>02.
Используя приведенные выше шаги, с помощью SRA-алгоритма
генерируют приблизительно самоподобный ФБД-процесс.
13.2. Фрактальный гауссовский шум
Фрактальный гауссовский шум (ФГШ) - это процесс приращений ФБД, т.е.
Хя(/)= 1/§(£я (/ + §)- Яя(/)), где 5 - приращение.
Процесс Хн(£) является нормально распределенным - 7V(0, су|5|/7), с
корреляционной функцией вида
Я(т) = (|т + 1|2" - 2|т|2Н + |т -1|2") / 2. (13.4)
313
13.2. Фрактальный гауссовский шум
Вид корреляционной функции (13.4) представлен на рис. 13.4.
</) б)
Рис. 13.4. Корреляционные функции ФГШ, экспоненциальных и гауссовских
процессов: а - в линейном масштабе; б - в полулогарифмическом масштабе
Корреляционные кривые непрерывны, без разрывов производной,
кроме крайнего случая, когда Н= 0,5. При Н= 0,5 корреляция в диапазоне
0 < т < 1 отображается прямой линией Я(т) = 1 - т, а при т > 1 выполняется
равенство R = 0. Вид функции 7?(т) интересен тем, что предполагает спад в
корреляции гораздо более медленный, чем для экспоненциальных (е“М2) или
гауссовских (е-^2) кривых, представленных для сравнения на рис. 13.4.
Может быть легко показано, что Я(т)~Я(2Я- 1)|т|2Я~2 при т —> оо,
а также что все объединенные процессы имеют одинаковое рас-
пределение для всех 0 < Н < 1. Поэтому ФГШ является точно самопо-
добным процессом с показателем Херста Я, изменяющимся на интерва-
ле 1/2 <Я< 1.
Популярность ФГШ объясняется возможностью формировать с его
помощью стационарный в широком смысле самоподобный гауссовский
процесс, который поддается аналитической трактовке. Кроме того, ФГШ
полностью описывается только двумя параметрами - дисперсией и показа-
телем Я. Когда ФГШ-поток подается на вход очереди бесконечной длины с
постоянной интенсивностью обслуживания, распределение хвоста очереди
затухает асимптотически по закону Вейбулла Р[£) > х] - ехр(- 8х2 ~ 2/7),
где 8 - положительная константа, которая зависит от интенсивности обслу-
живания в очереди.
Исследования показали, что затухание распределения хвоста оче-
реди для ФГШ с Я > 1/2 происходит гораздо медленнее, чем экспонен-
циальное, предсказываемое кратковременно зависимыми классически-
ми моделями, которые соответствуют случаю Я= 1/2.
13.2.1. БПФ-алгоритм синтеза ФГШ
Алгоритм быстрого преобразования Фурье (БПФ-алгоритм) позволяет гене-
рировать приблизительные самоподобные последовательности, используя
быстрое преобразование Фурье, и процесс, известный как фрактальный
гауссовский шум.
314
Глава 13. Методы моделирования фрактальных процессов
Рис. 13.5. Алгоритм генера-
ции ФГШ с помощью БПФ
Этот алгоритм основан на вычислении
спектральной плотности мощности с использо-
ванием периодограммы (спектр мощности на
заданной частоте представляется независимыми
экспоненциальными случайными переменны-
ми). На первом этапе строятся комплексные
числа, значения которых регулируются нор-
мальным распределением, после чего выполня-
ется обратное БПФ. На рис. 13.5 показано, как с
помощью БПФ-алгоригма генерируются само-
подобные последовательности.
Алгоритм генерации ФГШ с помощью
БПФ можно представить в следующем виде.
Шаг 1.Генерируется последовательность значений {£ь ..., S^}, где S', =
= 5 (2тй1п, Н) соответствует спектральной плотности мощности
ФПЛ-процесса для частот от 2л//? до л, 1/2 < Н < 1. Для ФПЛ-
процесса спектральная плотность мощности £(со, Н) определяется как
5(®,Я) = Л(®,Я)[|®|+В(®,Н)] , 0<Я<1, -тс<®<тс
где
Л(<в,Я) = 2яп(яЯ)г(2Я+1Х1-со8®), (13.5)
В(®,я) = 2;[(2га+®)_2Я"1 +(2тп-®)“2/м]. (13.6)
/=1
Бесконечная сумма в формуле (13.6) для В(со, 77) является главной
трудностью при вычислении спектральной плотности мощности,
поэтому используется аппроксимация (13.6) соотношением вида
В(у,Н)*а? +bf +а*г +bf + а% +b^ + ?* + Ь* +а< + Ь* , (13.7)
где d=-2H- 1; d1-- 2Н\ а, = 2/л + со; bj = 2/л - со.
Зависимости спектральной плотности мощности ФГШ
£(со3, 77), полученные с использованием аппроксимации (13.7),
представлены на рис. 13.6.
$(сйЛ)
Рис. 13.6. Зависимости спектральной плотности мощности для различных
показателей Херста (77), полученные с использованием аппроксимации (13.7)
315
13.2. Фрактальный гауссовский шум
Ш а г 2. Корректир^лот последовательность значении {Si, ..., S^} для оцен-
ки спектральной плотности мощности, используя периодограмму.
Ш а г 3. Генерируется последовательность комплексных чисел {Zb ..., Z^},
для которой |Z,.| = и фаза Z, является равномерно распределен-
ной между 0 и 2л.
Шаг 4. На основе вектора {Zb Zw/2} строится вектор {Zo', Zn'_ J,
элементы которого вычисляются в соответствии с выражением
О, если i = О,
Z,, если 0<i<n/2,
Zn_i9 если п! 2 < i < п,
где Zn_i обозначает операцию комплексного сопряжения для Zn_i.
Шаг 5. Для получения приблизительной ФГШ последовательности {X}
для {Z/} вычисляется обратное БПФ.
Интерфейс программы, реализующий описанный выше алгоритм
генерирования ФГШ, показан на рис. 13.7.
Файл fl программ»
j Генератор ; Оценка График кор <р. |
Рис. 13.7. Интерфейс программы моделирования ФГШ
Выборки, полученные при помощи этой программы, и соответст-
вующие им коэффициенты корреляции (для первых 500 задержек) при-
ведены на рис. 13.8- 13.10.
Применимость ФГШ к трафиковому моделированию отчасти ограни-
чена его четкой корреляционной структурой. Это ограничение делает его ме-
нее пригодным для моделирования трафиковых потоков, которые имеют
316
______________Глава 13. Методы моделирования фрактальных процессов
очень сильную КВЗ (например, VBR-видео), однако для некоторых явлений
ФГШ может быть приемлемой аппроксимацией. Отметим также, что хотя
ФГШ - гауссовский процесс, выборка ФГШ может быть преобразована в
выборку с произвольным маргинальным распределением с сохранением Н.
б)
Рис. 13.8. Результаты моделирования: а- реализация ФГШ (Я = 0,99; ЛГ = 4096);
б - коэффициент корреляции
%(/)
3
2
1
0
-1
-2
-3
Рис. 13.9. Результаты моделирования: а- реализация ФГШ (Н= 0,75; N = 4096);
б- коэффициент корреляции
317
13.2. Фрактальный гауссовский шум
Рис. 13.10. Результаты моделирования: а - реализация ФГШ (Н= 0,5; N = 4096);
б - коэффициент корреляции
Оценка результатов моделирования. Для проверки правильно-
сти моделирования и соответствия сформированного процесса заданно-
му показателю Херста будем использовать специальную программу,
реализующую тесты на определение показателя Херста: график измене-
ния дисперсии (variance-time plot) и R/S-статистика.
£«Ал Q программе
Рис. 13.11. Интерфейс программы для тестирования самоподобных процессов
318
_____________Глава 13. Методы моделирования фрактальных процессов
Интерфейс программы для тестирования конечной дискретной вы-
борки отображен на рис. 13.11. Входными параметрами для каждого из
тестов являются тестируемый набор данных, а также параметры m_min
и m_max, которые используются тестами для определения минимально-
го и максимального размера блока разбиения. Тестируемый набор дан-
ных может быть подключен к программе при помощи выбора тексто-
вого файла с данными в диалоговом окне открытия файла.
Учитывая направленность дальнейшего изложения, приведем краткие
теоретические сведения и алгоритмы работы каждого из используемых тес-
тов на определение Н.
График изменения дисперсии. Анализ изменения дисперсии основы-
вается на свойстве медленно затухающей дисперсии самоподобных процес-
сов при объединении. В соответствии с этим дисперсия объединенного (точ-
но или приблизительно) самоподобного процесса удовлетворяет зависимости
g2[xW] ~»Гр, (13.7)
где Р - параметр, связанный с Н соотношением р = 2 - 2Я.
При агрегировании процесса с различными уровнями т дисперсия
обычно затухает очень быстро (при Н = 0,5). Исключение составляют само-
подобные процессы, для которых дисперсия затухает медленно, согласно
степенному закону (при больших значениях Н).
Прологарифмировав обе части соотношения (13.7) для объединенной
дисперсии, получим выражение
log(c2(х))~ -р log(zw) + log(tf) при т —> оо .
Как видно, оценку р можно получить вычислением log(o2(A(zw))) для
различных значений т, отображая результаты от log(m) и проводя прямую
линию по методу наименьших квадратов через полученные точки. Оценка
р для р определяется как отрицательный наклон линии. Значения наклона
в интервале (- 1; 0) подразумевают самоподобность.
Если метод применяется к некоррелированному потоку данных, то по-
лучается значение Р = - 1, так как q2(A(w)) = (1 /т2)т<з2(Х) = т~'(52(Х).
Метод изменения дисперсии является всего лишь эвристическим
методом и используется только для грубого тестирования. С помощью
этого метода можно оценить, является ли временной ряд самоподоб-
ным, и если является, то можно получить достаточно грубую оценку Н.
Рассмотрим результаты моделирования конкретных реализаций сто-
хастических случайных процессов. Использовались следующие параметры:
Н = 0,6; 0,75; 0,9; п = 32768 (л - число точек в генерируемом процессе; по-
скольку для синтеза ФГШ использовался алгоритм с применением БПФ, то
п задавалось равным 2*, где к = 1,2,...).
Для проведения теста служебные параметры m_min и m_max выбира-
лись равными 1 и 40 соответственно. Варьируя эти параметры, можно по-
добрать такие их значения, при которых оцененное значение Н будет мак-
319
13.2. Фрактальный гауссовский шум
симально приближаться к заданному. При увеличении показателя Херста
для получения более точной оценки максимальную величину блока следует
снижать. В случае, если показатель Херста не известен заранее, выбор этих
параметров затруднен и осуществляется опытным путем.
Примеры графиков изменения дисперсии приведены на рис. 13.12.
Цифрой 1 обозначены точки, полученные для ФГШ с показателем Херста
Н = 0,6. При аппроксимации полученных точек по методу наименьших
квадратов (сплошная линия, проходящая по точкам) была получена оценка
показателя Херста (наклон подобранной прямой линии) Н = 0,6076 .
Рис. 13.12. Графики изменения дисперсии для трех реализаций ФГШ с разными
показателями Херста
Цифрой 2 обозначены точки, полученные для ФГШ с показателем
Херста Н = 0,75. При аппроксимации полученных точек по методу наи-
меньших квадратов была получена оценка показателя Херста Н = 0,7446 .
Цифрой 3 обозначены точки, полученные для ФГШ с показателем
Херста Н = 0,9. При аппроксимации полученных точек по методу наи-
меньших квадратов была получена оценка показателя Херста И = 0,8747 .
Видно, что при увеличении показателя Херста точность метода изме-
нения дисперсии снижается и все большее значение приобретает выбор
значений управляющих параметров теста (m_min и m_max). Кроме того,
моделирование показало, что с увеличением размера выборки синтезируе-
мого ФГШ точность оценки показателя Херста увеличивается.
R/S- стати стика. Основываясь на исследовании различных явле-
ний, для описания изменчивости самоподобных процессов при задан-
ном наборе наблюдений X = {Xfb п g Z*} с выборочным средним А^л),
выборочной дисперсией ^(и) и размахом R(n) разработана нормализо-
ванная безразмерная мера, названная нормированным размахом R/S.
На практике удобно пользоваться выражением log{AT[/?(/7)/S(/7)]} ~
~ //log(w) + log(c) при п —> оо. Воспользовавшись этим выражением, можно
оценить 77, изобразив график зависимости log{A7[7?(«)/S(rc)]} от log(zz). Под-
бирая прямую по методу наименьших квадратов к точкам R/S-графика (R/S-
выборки для самых маленьких и самых больших значений п отбрасываются),
по наклону линии регрессии находят оценку для Н.
320
Глава 13. Методы моделирования фрактальных процессов
Вместе с тем, R/S-статистика, так ясе как и график изменения дис-
персии, не слишком точен и дает только оценку уровня самоподобности
во временном ряде. Следовательно, этот метод может использоваться
только для того, чтобы протестировать, является ли временной ряд са-
моподобным и, если является, получить грубую оценку Н.
При моделировании ФГШ для оценки его параметров использовались
такие же установки, как и в предыдущем примере {Н = 0,6; 0,75; 0,9,
п = 32768). При вычислении R/S-статистики использовалось разбиение на
блоки с последующим изменением размеров блоков. По умолчанию для рох-
графиков управляющие параметры mrnin и minax устанавливались равны-
ми 10 и 150 соответственно. Варьируя m_min и m_max, можно убедиться, что
оценки показателя Херста будут существенно изменяться. На рис. 13.13 при-
ведены графики R/S-статистики (в литературе также встречается название
рох-графики), полученные с помощью вышеописанного теста. Цифрой 1
обозначены точки, полученные для ФГШ с показателем Херста Я= 0,6. При
аппроксимацгп! полученных точек методом наименьших квадратов (сплош-
ная линия, проходящая через точки) была получена оценка показателя Хер-
ста (наклон подобранной прямой линии) Н = 0,6372 .
Рис. 13.13. Графики R/S-статистики для ФГШ
Цифрой 2 обозначены точки, полученные для ФГШ с показателем
Херста. Н = 0,75. В результате обработки была получена оценка показателя
Херста Н = 0,748.
Цифрой 3 обозначены точки, полученные для ФГШ с показателем Хер-
ста Н = 0,9. При аппроксимации полученных точек методом наименьших
квадратов была получена оценка показателя Херста Н = 0,8555 .
Приведенные данные, а также многочисленные эксперименты показали,
что R/S-статистика при Я < 0,75 переоценивает показатель Херста, а при Я >
0,75 - недооценивает его. Как и в случае графика изменения дисперсии, на-
блюдается ухудшение оценки показателя Херста с увеличением его значения.
Улучшения качества оценки можно добиться, используя оптимальный выбор
установочных параметров m min и m inax и увеличивая объем выборки.
Зависимости коэффициента корреляции от задержки. Коэффици-
ент корреляции самоподобного процесса проявляет долговременную зави-
симость, т.е. R(r) -> Поэтому один из методов для оценки параметра
ос заключается в том, чтобы начертить кривую R(x) для измеренных данных
321
13.2. Фрактальный гауссовский шум
на log-log шкале и, если будет наблюдаться линейное поведение, оценить
параметр р, исходя из наклона (бс = 1 - р ). Для оценки зависимости коэф-
фициента корреляции от задержки для конечной выборки данных восполь-
зуемся формулой
'• (0=уЯ Е - "OU+x -»»)[Е U - "О21 >
где Т - длина набора данных; т - задержка; ni - выборочное среднее.
Интерфейс программы, реализующей вычисление этой зависимо-
сти для конечного набора данных, приведен на рис. 13.14.
Д программе
Генерирование и иссяддование самоподобны» процессовV-'
Генератор Оценка j График корФ
Рис. 13.14. Интерфейс программы оценки зависимости
коэффициента корреляции от задержки
и оценки показателя Херста Н от размера блока разбиения m
Ниже изображены графики оценки показателя самоподобности
сгенерированного ФГШ. Отметим, что при оценке наклона графика за-
висимости коэффициента корреляции от задержки в log-log масштабе
очень важно правильно выбрать предельную задержку, поскольку из-за
ограниченности набора данных при больших задержках график в log-log
масштабе ведет себя крайне нестабильно и поэтому оценка показателя
самоподобности будет неточна. При моделировании ФГШ выбирались
/7 = 32768; Я =0,99; 0,8; 0,6.
При анализе зависимостей, представленных на рис. 13.15, становится
очевидным, что для большого значения Я, задаваемого при моделировании
ФГШ, график зависимости г(т)в log-log масштабе ведет себя линейным обра-
зом (визуально почти полностью совпадает с подобранной прямой по методу
наименьших квадратов). Оценка показателя Херста составила Я = 0,887, что
322
Глава 13. Методы моделирования фрактальных процессов
хуже, чем в случае использования в качестве теста графика изменения диспер-
сии (И = 0,9215 ) с параметрами mjnin = 1 и mjnax = 40, и лучше, чем в слу-
чае R/S-статистики (Н = 0,8766) с параметрами mjnin = 10 и mjnax = 500.
С 17 3 4 5 6 7
1п(г)
б)
Рис. 13.15. Графики оценки показателя самоподобности сгенерированного ФГШ:
а - зависимости коэффициента корреляции от задержки (исходный Н= 0,99);
б - log-log график (maxjag = 300)
Для больших значений показателя Херста можно выбирать срав-
нительно большие задержки. При этом поведение графика зависимости
коэффициента корреляции от задержки все еще будет иметь линейный
характер. Это объясняется тем, что для конечной выборки долговремен-
ного процесса, чем больше показатель Херста, тем медленнее спадает
его корреляционная функция. При больших задержках сохраняется мед-
ленное затухание корреляционной функции.
На рис. 13.16 иллюстрируется определение оценки показателя Херста,
которая при истинном значении Я=0,8 составила Н = 0,7819 . Полученный
результат несколько хуже, чем при использовании в качестве теста графика
изменения дисперсии (Н = 0,7855 ) с параметрами m_min = 1 и mjnax = 40,
и лучше, чем в случае R/S статистики (Н = 0,7685) с параметрами mjnin =
10 и mjnax = 500.
Эксперименты с выбором граничной задержки (max_lag) для оценки
показателя Херста показали, что порог, при котором график зависимости
коэффициента корреляции от задержки сохраняет приблизительно линей-
ный характер, смещается в область больших аргументов. Уже при значении
max_lag = 150 наблюдается некоторая флуктуация графика в log-log мас-
штабе, что объясняется ограниченностью объема исследуемых данных.
323
13.2. Фрактальный гауссовский шум
Рис. 13.16. Графики оценки показателя самоподобности сгенерированного ФГШ:
а - коэффициент корреляции (исходный Н= 0,8); б - log-log график (max_lag = 150)
Оценка показателя Херста для данных, представленных на рис. 13.17,
составила Н = 0,584 , что хуже, чем в случае использования в качестве теста
графика изменения дисперсии (И = 0,6003) с параметрами m_min = 1 и
m_max = 40, и лучше, чем в случае R/S-статистики (Н = 0,6201) с парамет-
рами mjnin = 10 и mjnax = 500.
При уменьшении величины показателя Херста до 0,6 становится
очевидным уменьшение предельной задержки (max_lag), при которой
графики 7?(т) сохраняют приблизительно линейный характер. Из графика
(рис. 13.17, б) видно, что в log-log масштабе при задержках, больших ~20,
график ведет себя очень нестабильно. При бесконечной выборке корре-
ляционная функция становится несуммируемой, что иллюстрируется зна-
чительными разбросами оценок на log-log графиках (рис. 13.17, б).
Нг)
1 : : : : ; ~ ~
0 5 10 15 20 25 30 35 40 45 50 55 00 6 5 70 7 5 80 85 И 95 1N
а)
!п(г(т))
б)
Рис. 13.17. Графики оценки показателя самоподобности сгенерированного ФГШ:
а - зависимости коэффициента корреляции от задержки (исходный Н= 0,6);
б - log-log график (max_lag = 100)
324
_____________Глава 13. Методы моделирования фрактальных процессов
Таким образом, чем меньше предполагаемая величина показателя
Херста в исследуемой выборке, тем больший объем выборки требуется
для его корректной оценки. В тех случаях, когда предполагаемое значе-
ние показателя Херста неизвестно заранее, нахождение оценки значи-
тельно затрудняется. В этих случаях для корректной оценки следует
ориентироваться на линейное поведение графика зависимости коэффи-
циента корреляции от задержки в log-log масштабе.
13.3. Сравнительный анализ алгоритмов формирования
самоподобных последовательностей
Проведем сравнительный анализ эффективности трех рассмотренных выше
алгоритмов формирования самоподобных последовательностей (RMD-,
SRA- и БПФ-алгоритмов) на предмет их точности. Каждый из них исполь-
зовался для генерации 100 выборочных последовательностей из 32768 (215)
точек с различными случайными начальными числами. Профили выборок,
полученные с помощью перечисленных алгоритмов для различных значе-
ний показателя Херста Н, представлены на рис. 13.18-13.20.
Самоподобность и распределения сгенерированных последова-
тельностей оценивались с помощью наиболее распространенных в на-
стоящее время методик.
Для доказательства того, что распределение выборочных последо-
вательностей, полученных с использованием всех трех методов, являет-
ся нормальным или почти нормальным, использовался критерий согла-
сия, поскольку все три метода основаны на гауссовском процессе.
Для визуальной иллюстрации того, что сгенерированная последо-
вательность имеет ДВЗ-свойства с предполагаемым значением Н, ис-
пользовался профиль выборки.
«) г)
Рис. 13.18. Профиль выборки для RMD-алгоритма:
а-Н= 0,55; б-Н= в-Н= 0,9; г - Н= 0,95
325
13.3. Сравнительный анализ алгоритмов формирования самоподобных последовательностей
4|------------------,-----------------/
0 500 1000 1500 2000 2500 3000
4 -------------------------------.------ 1
0 500 1000 1500 2000 2500 3000
Рис. 13.19. Профиль выборки для SRA-алгоритма:
а-Н= 0,55; б-Н= 0,7; в - Н= 0,9; г-Н= 0,95
Рис. 13.20. Профиль выборки для алгоритма БПФ:
а-Н= 0,55; б-Н= 0,7; в - Н = 0,9; г - Н= 0,95
Для оценки, является ли сгенерированная последовательность долго-
временнозависимой, использовался график периодограммы (рис. 13.21). Этот
график получается нанесением графика зависимости 1g (периодограмма) от
^(частота). При этом оценка показателя Херста определяется как
Н = (1-Р3)/2,где рз - наклон.
326
Глава 13. Методы моделирования фрактальных процессов
^(периодограмма)
Рис. 13.21. Графики периодограмм для RMD-алгоритма:
а-Н= 0,55; б-Н= 0,7; в - Н = 0,9; г-Н= 0,95
Для оценки показателя Херста Н опытных данных использовался
график R/S-статистики. Напомним, что при этом методе оценка нахо-
дится как асимптотический наклон прямой линии по методу наимень-
ших квадратов к полученным точкам на графике р2 графика R/S-
статистики, т.е. Н = р2 •
Также для оценки этого показателя использовался график изменения
дисперсии, получаемый путем нанесения зависимости Igfa2^"0)) от lg(/7?) и
подбором прямой линии по методу наименьших квадратов к полученным
точкам на графике. Оценка показателя Херста находится при помощи соот-
ношения Я = 1-р]/2,где Pj - наклон прямой.
Оценки показателя Херста, полученные из периодограммы, R/S-
статистики, графики изменения дисперсии, были использованы для
сравнения точности трех рассматриваемых алгоритмов. Для оценки от-
носительной неточности вычислений использовалось соотношение
ДЯ = [[я - я)/ н\ 100%, где Н - исходное значение; Н - опытное усред-
ненное значение. Все приведенные численные результаты усреднялись
на 100 последовательностях.
Из графиков, показанных на рис. 13.21 для RMD-алгоритма, видно,
что с увеличением Н периодограммы имеют уменьшающиеся наклоны.
Отрицательные наклоны всех графиков для Я= 0,55; 0,7; 0,9; 0,95 слу-
жат доказательством самоподобности. Аналогичные графики для БПФ-
и SRA- алгоритмов дают близкие результаты.
327
13.3. Сравнительный анализ алгоритмов формирования самоподобных последовательностей
Графики R/S-статистики (рис. 13.22-13.24) убедительно иллюст-
рируют самоподобную структуру сгенерированных последовательно-
стей. Результаты говорят о том, что БПФ-алгоритм немного лучше, чем
другие два (за исключением 0,9; 0,95).
Ig(w) Ig(m)
в) г)
Рис. 13.22. Графики R/S-статистики для алгоритма БПФ:
а — Н = 0,55; б-Н= 0,7; в-Н= 0,9; г - Н= 0,95
Ig(R/S) lg(R/S)
IgW lg(w)
Рис. 13.23. Графики R/S-статистики для RMD-алгоритма:
а-//=0,55; б-//=0,7; в-//=0,9; г-//=0,95
328
Глава 13. Методы моделирования фрактальных процессов
ч lg(w) .
*) г)
Рис. 13.24. Графики R/S-статистики для SRA-алгоритма:
а-Н= 0,55; б-Н= 0,7; в - Н = 0,9; г - Н = 0,95
Графики изменения дисперсии, приведенные на рис. 13.25-13.27,
подтверждают предположение о том, что сгенерированные последова-
тельности являются самоподобными.
Рис. 13.25. Графики изменения дисперсии для БПФ-алгоритма:
а -/7= 0,55; б-//= 0,7; в-77= 0,9; ?-Я = 0,95
329
13.3. Сравнительный анализ алгоритмов формирования самоподобных последовательностей
Рис. 13.26. Графики изменения дисперсии для RMD-алгоритма:
а-Н = 0,55; б-Н= 0,7; в - Н= 0,9; г-Н= 0,95
Рис. 13.27. Графики изменения дисперсии для SRA-алгоритма:
а - Н = 0,55; б - Н = 0,7; в-Н= 0,9; г-Н= 0,95
Все три алгоритма моделирования сравнимы по качеству выходных по-
следовательностей, оцениваемых величиной параметра Н. Относительная
неточность увеличивается с ростом параметра Я, но остается в пределах 8%.
Результаты экспериментального анализа средних времен, мин:с, не-
обходимых генераторам для получения псевдослучайных самоподобных
последовательностей заданной длины, а также данные, позволяющие оце-
нить временную сложность каждого из алгоритмов приведены в табл. 13.1.
330
Глава 13. Методы моделирования фрактальных процессов
Таблица. 13.1. Средние времена прогона генераторов* для последовательности точек, мин:с
Алгоритм Сложность Последовательности точек
32768 131072 262144 524288 1048576
БПФ <S>(rtlOgZ7) 0:5 0:20 0:35 1:12 3:47
RMD О(») 0:3 0:11 0:29 0:40 1:33
SRA О(п) 0:3 0:10 0:20 0:40 1:31
БПФ-алгоритм является самым медленным из трех анализируе-
мых. Это обусловлено его относительно высокой сложностью. Для того,
чтобы сгенерировать последовательность из 32768 (215) точек с помо-
щью БПФ-алгоритма, потребовалось 5 с, а генерация последовательно-
сти из 1048576 (220) точек потребовала 3 мин 47 с. БПФ-алгоритм требу-
ет <S>(/?log/?) вычислений для генерирования п точек.
RMD-алгоритм быстрее и проще, чем БПФ. Генерация последова-
тельности из 32768 (215) точек заняла 3 с. Для генерации последователь-
ности из 1048576 (220) точек потребовалась 1 мин 33 с. Теоретическая
алгоритмическая сложность метода - О(п).
SRA-алгорим выглядит предпочтительнее, чем RMD-алгоритм.
Теоретическая алгоритмическая сложность - <9(л).
Таким образом, в случае, когда требуются длинные самоподобные
последовательности, генераторы, основанные на RMD- и SRA- алго-
ритмах, в практических приложениях предпочтительнее, чем генератор,
основанный на БПФ-алгоритме.
Графики, представленные на рис. 13.28 - 13.30 позволяют сравнить
различные методы, используемые для оценки показателя Херста. Оценка
этого показателя при помощи графика периодограммы дает как положитель-
ный так и отрицательный разброс. С ростом величины Н погрешность воз-
растает. Видно, что оценка показателя Херста при помощи графика R/S-
статистики дает завышенные значения при Н < 0,7 и заниженные оценки при
Н > 0,7. Оценка показателя Херста при помощи графика изменения диспер-
сии дает в целом заниженные оценки. Величина погрешности возрастает с
ростом Н при помощи графика изменения дисперсии.
Рис. 13.28. Оценка показателя Херста при помощи графика периодограммы
Каждое значение усредняется для 30 прогонов
331
13.3. Сравнительный анализ алгор!ггмов формирования самоподобных последовательностей
Рис. 13.29. Оценка показателя Херста при помощи графика R/S-статистики
Рис. 13.30. Оценка показателя Херста при помощи графика изменения дисперсии
Таким образом, все три генератора, основанные на БПФ-, RMD- и
SRA- алгоритмах, генерируют приблизительно самоподобные последова-
тельности с относительной неточностью менее 9%, если 0,5 < Н< 0,95. Од-
нако анализ средних времен, требуемых для генерации последовательно-
стей заданной длины, показывает, что для практического моделирования
трафика телекоммуникационных сетей должны быть рекомендованы два
генератора (основанные на RMD- и SRA- алгоритмах), так как они работа-
ют гораздо быстрее, чем генератор, основанный на БПФ-алгоритме.
Рассмотрим достоинства и недостатки применения моделей самопо-
добных процессов в сетевых приложениях. Наибольшее применение фрак-
тальных (самоподобных) процессов в сетевых приложениях получили мо-
дели ФБД и ФГШ. Существенным аргументом в пользу использования
этих моделей в сетях связи является то, что во многих случаях трафик мо-
жет рассматриваться как наложение большого числа независимых отдель-
ных ON/OFF-источников, имеющих распределения с тяжелыми хвостами
для длительностей ON-периодов. В этом случае после вычитания средней
скорости поступления и должной нормировки, в соответствии с централь-
ной предельной теоремой, объединенные ON/OFF-процессы сходятся к га-
уссовскому ФБД. Поэтому самоподобный трафик (для процесса прираще-
ний) моделируется просто как модель «ФГШ + среднее значение» с задан-
332
Глава 13. Методы моделирования фрактальных процессов
ной дисперсией и показателем Херста. Модели ФБД и ФГШ нашли широ-
кое применение в сетевом проектировании, поскольку их гауссовость и
строгое масштабирование позволяют проводить аналитические исследова-
ния характера построения очередей.
К сожалению, эти модели имеют жесткие ограничения при применении
их к сетевому трафику. Во-первых, реальные трафиковые трассы не прояв-
ляют строгой самоподобности и являются в лучшем случае только асимпто-
тически самоподобными. Другими словами, одного лишь параметра Н не
достаточно, чтобы охватить сложную корреляционную структуру реальных
сетевых процессов. Действительно, известны убедительные доказательства
важности кратковременных корреляций для буферизации и обнаружены так
называемые значимые масштабы времени. Во-вторых, гауссовость моделей
ФБД и ФГШ может не соответствовать реальности для некоторых типов
трафика, например, когда среднеквадратичное отклонение превышает сред-
нее значение. В этом случае выходные сигналы ФБД и ФГШ содержат
большое число отрицательных значений. В-третьих, во многих сетевых при-
ложениях реальные процессы даже близко не приближаются к гауссовскому
случаю, особенно на небольших масштабах времени. В этом случае на пути к
улучшению подбора кратковременной и долговременной корреляционной
структуры, присутствующей в реальных трассах, применяются более универ-
сальные регрессионные модели.
13.4. Достоинства и недостатки ФБД/ФГШ-моделей
в сетевых приложениях
Существенным аргументом в пользу ФБД/ФГШ-моделей в сетях является
то, что во многих случаях трафик может рассматриваться как наложение
большого числа независимых отдельных ON/OFF-источников, имеющих
распределения с тяжелыми хвостами для длительностей ON-периодов. В
этом случае после вычитания средней скорости поступления и должной
нормировки, в соответствии с центральной предельной теоремой, объеди-
ненные ON/OFF-источники (кумулятивные поступления) сходятся к гаус-
совскому ФБД. Поэтому самоподобный трафик (для процесса приращений)
моделируется как модель «ФГШ + среднее значение» с заданной дисперси-
ей и Н. ФБД/ФГШ-модели нашли широкое применение в сетевом проекти-
ровании, так как их гауссовость и строгое масштабирование позволяют про-
водить аналитические исследования характеристик построения очередей.
К сожалению, ФБД/ФГШ-модели имеют жесткие ограничения при
применении их к сетевому трафику. Во-первых, реальные трафиковые
трассы не проявляют строгой самоподобности и являются в лучшем
случае только асимптотически самоподобными. Другими словами, од-
ного лишь параметра Н оказывается недостаточно для охвата сложной
корреляционной структуры реальных сетевых процессов. Более того,
существуют исследования, доказывающие важность кратковременных
корреляций для буферизации и выявляющие значимые масштабы вре-
333
13.5. Регрессионные модели трафика
мени. Во-вторых, гауссовость ФБД/ФГШ-моделей для некоторых типов
трафика может не соответствовать реальности, например, когда средне-
квадратичное отклонение превышает среднее значение. В этом случае
выходные сигналы ФБД/ФГШ содержат большое число отрицательных
значений. В-третьих, во многих сетевых приложениях реальные процес-
сы даже близко не приближаются к гауссовскому случаю, особенно на
небольших масштабах времени. В этом случае на пути к улучшению
подбора кратковременной и долговременной корреляционных структур,
присутствующих в реальных трассах, применяются более универсаль-
ные регрессионные модели.
13.5. Регрессионные модели трафика
Модели трафика используются при проектировании для предсказания про-
изводительности сети и оценки схемы управления перегрузками, а также с
целью моделирования различных корреляционных структур и маргиналь-
ных распределений. Модели, которые не охватывают статистических ха-
рактеристик реального трафика, приводят к некорректной оценке пропуск-
ной способности сетей из-за того, что они либо переоценивают, либо недо-
оценивают ее. Модели трафика должны иметь легко управляемое количе-
ство параметров. Оценка этих параметров должна быть простой. Модели
трафика, которые не поддаются аналитической трактовке, могут использо-
ваться только для генерирования трасс трафика.
Модели трафика могут быть как стационарными, так и нестационар-
ными. Стационарные модели трафика можно разделить на две категории:
кратковременно зависимые и долговременно зависимые. Кратковременно
зависимые модели включают традиционные модели трафика, такие как мар-
ковские процессы и регрессионные модели. К таким моделям трафика
относятся AR (AutoRegressive), ARMA (AutoRegressive Moving Average),
ARIMA (AutoRegressive Integrated Moving Average) и DAR (Discrete AutoRe-
gressive) регрессионные модели.
Поскольку регрессионные модели просты в реализации, они широко
используются при моделировании. Вместе с тем, системы построения оче-
редей для регрессионных моделей, как правило, с трудом поддаются анали-
тической трактовке. В результате для получения приближенного аналити-
ческого решения регрессионные модели часто аппроксимируются марков-
скими моделями. Регрессионные модели определяют последующую слу-
чайную переменную в виде рекурсивной функции от предыдущих случай-
ных переменных. Поэтому они используются для моделирования последо-
вательностей, которые не сильно изменяются между следующими друг за
другом наблюдениями: например, количество бит на кадр для VBR-
видеотелеконференции. AR, ARMA, DAR и TES регрессионные процессы
способны моделировать только стационарные последовательности, а
ARIMA регрессионный процесс может использоваться для моделирования
и стационарных, и нестационарных последовательностей.
334
Глава 13. Методы моделирования фрактальных процессов
В общем случае AR-, ARMA- и ARIMA-процессы имеют гауссовское
распределение. Следовательно, чтобы моделировать последовательность,
имеющую произвольное распределение, необходимо двухступенчатое пре-
образование, дающее в результате процесс с требуемым распределением, по-
лученным из гауссовского. Однако это преобразование не гарантирует, что
преобразованный процесс будет иметь такую же корреляционную структуру,
как у исходного.
DAR(p)- и TES-модели позволяют формировать процессы с произ-
вольным распределением. 2Х4Т?(/7)-модели имеют корреляционные структу-
ры, подобные ЛЯ(р)-процессам. Они также поддаются аналитической трак-
товке с использованием эквивалентных моделей марковских цепей.
Развитием перечисленных моделей являются модели на основе
фрактальных авторегрессионных процессов интегрального скользящего
среднего FARIMA (Fractional AutoRegressive Integrated Moving Average),
которые имеют некоторые преимущества по сравнению с моделями, ос-
нованными на других фрактальных процессах.
FARIMA(p,d,q) модели имеют три параметра р, dn q, которые управ-
ляют корреляционной структурой и могут охватывать как кратковремен-
ную, так и долговременную зависимость моделируемых процессов.
Линейные авторегрессионные (AR) процессы. Класс AR(p) со-
стоит из линейных авторегрессивных моделей порядка р\
Х„=^0+У’.^ГХп-г+^,г
где (Х_р+1,... ,%о) - заданный случайный вектор (обычно многомерный
нормальный вектор); фг, 0 < г < р - действительные константы; 8Л - не-
коррелированные случайные переменные (белый шум) с нулевым сред-
ним, называемые остатками, которые не зависят от Хп (в «хорошей»
модели остатки должны быть меньшей величины, чем Х„).
Процессы скользящего среднего (МА). Класс MA(q) состоит из
процессов скользящего среднего порядка q:
Х„ = УЧ пЬггп>0,
п = Q Г И~1 * >
где Ь,., 0 < г < q - действительные константы; - некоррелированные
случайные переменные с нулевым средним.
С помощью MA-моделей формируются коррелированные времен-
ные последовательности, так как следующие друг за другом случайные
переменные определяются на основе общего подмножества 8„.
Авторегрессионные модели скользящего среднего ARMA(p,q).
Авторегрессионная модель скользящего среднего порядка (p,q\ обозна-
чаемая как ARMA(p,q\ имеет вид
Az =ф1АГ,_1 +ф2^/-2 “* p%t-p — — ®2е/-2 —
и может быть эквивалентно записана так:
ф(в>,=0(в)£„
где В- оператор задержки, определяемый как BjX(t) =X(t-jy, ф(В) - многочлен
от оператора В, определяемый следующим образом: ф(£) = 1- ф^ - ... - фр#7;
0(В) = (1-0|5-...-0 (]Вд) - многочлен ^-степени.
335
13.5. Регрессионные модели трафика
ARIMA-процессы. ARIMA-процесс используется для описания
класса нестационарных рядов {Y(f): t g Z}, которые проявляют однород-
ность в отличие от их локального уровня и/или тренда, т.е. одна часть ряда
ведет себя так же, как и любая другая часть. Другими словами, если убрать
изменения локального уровня и/или тренда, то ряд становится стационар-
ным. Такие ряды описываются обобщенным авторегрессионным операто-
ром ф(В), который записывается следующим образом:
ф(в)=а(в)(1-В)",
где а(В) = 1 - я(1)В' - 0(2)^ - ... -а(р)Вр- многочлен ^-степени; d- крат-
ность корня при В = 1.
FARIMA-процессы. ARlMA-процесс может быть рассмотрен как
первый шаг на пути к обобщению ARMA-процесса. В ARIMA-процессе
параметр d рассматривается только как целочисленный. FARIMA-
процесс получается снятием этого ограничения, т.е. разрешается брать
для d дробные значения.
Будем считать, что X(f) -стационарный процесс, такой, что
а(в)(1-В)^(/) = р(В>(/) (13.8)
для некоторого de (- 0,5; 0,5). ТогдаX(t) - это (^-процесс.
В случае, когда 0 < d < 0,5, FARIMA(p;d;q)-npouecc проявляет долго-
временную зависимость. Параметры р и q соответствуют порядку а (В) и
р(В) и дают возможность гибкого моделирования кратковременных ха-
рактеристик процесса. На рис. 13.31 показаны выборки из различных
FARIMA-процессов.
4
2
0
6)
50 100 150 200 250 300 350 400 450 500
в)
Рис. 13.31. Выборки из ВЛЯ/Л/Л-процессов: а - FARIMA(0;0,3;4); б -
FARIMA(2;0,3;4); в - FARIMA(0;0,45:4)
336
Глава 13. Методы моделирования фрактальных процессов
Для иллюстрации влияния присутствия или отсутствия кратковремен-
ной зависимости на корреляционную функцию на рис. 13.32 начертим тео-
ретическую кривую Я(т) для F ARIMA-процессов, показанных на рис. 13.32.
Для получения этих реализаций использовался AR-компонент а(В) = 1 -
- 1,72В - 0,81В2 и MA-компонент ₽(В) = 1 + 0,7В - 0,8В2 + 0,3В2 + 0,5В4.
Сравнивая рис. 13.32, а и 13.32, б и рис. 13.32, б и 13.32, в, видим, что
ARMA-параметры определяют корреляционную структуру при небольших
задержках, это означает, что близкие полюса а(В) вписываются в окруж-
ность небольшого радиуса. Однако, параметр долговременности d влияет на
степень затухания 7?(т) при т —> оо. Значение d, близкое к 0,5, дает более су-
щественную долговременную зависимость.
Спектр FARJMA(p,d,q) получается непосредственно из (13.8):
/ \ 2
. |-2<7
2 '
ot|e^J
Так как |1 - е~/ы| = 2|sin(co/2)|, a limo_>0 2sin(co/2)/co = 1, поведение
спектра при со —> 0 определяется как
ос 1)
(13.9)
Выражение (13.9) показывает, что при 0 < d < 0,5 спектр 5Хю)не
ограничен при со = 0, т.е. 5Ясо)|ш = о = °о, а, следовательно, Я(т) = оо, что
указывает на субэкспоненциальное затухание корреляционной функции.
-200 -150 -100 -50 0 . 50 100 1 50 200
б)
Рис. 13.32. Кратковременная и долговременная зависимости в FARIMA-процессах:
fl-FARIMA(0;0,3;4); 6-FARIMA(2;0,3;4); e-FARIMA(2;0,45;4)
12—3834
337
13.5. Регрессионные модели трафика
Синтез ^ЛЯ/Л/Л(рД7)“процесса. Синтез FARIMA-ггроцесса ва-
жен для оценки эффективности различных методик параметрической
оценки. Цель любого алгоритма синтеза FARIMA - сгенерировать по-
следовательности, которые приблизительно обладают персистентно-
стью, и быть вычислительно привлекательным для генерирования
большого количества данных.
Процедура синтеза может быть разбита на два этапа:
1) генерируется FARIMA(0;d;0) последовательность, проявляющая долго-
временную зависимость,
2) к сформированной последовательности добавляется кратковремен-
ная зависимость.
Второй этап сравнительно прост и может быть реализован в виде опера-
ции фильтрации. Например, если а = [1, «(1).. .а(р)] и b = [1, Z?(l).. .b(p)] пред-
ставляют AR- и MA-коэффициенты, тогда команда filter(b,arx) в MATLAB до-
бавит к вектору данных х характеристики кратковременной зависимости.
Обычно используемый метод для генерирования FARJMA(Q\ J;0) осно-
вывается на хорошо известном результате: для любой невырожденной кор-
реляционной матрицы Rn = [/?(/- У)]Г7=1 существует процесс, чья
корреляция при задержках 0, ..., N- 1 - это Я(0),..., R(N- 1).
В случае процессов FARIMA(fi;d'fi), используя аналитический вид вы-
ражения для 7?(т), можно сформировать RN. Лучший подход для определе-
ния AR-коэффициентов - использование алгоритма Дурбина - Левинсона,
который определяет AR-коэффициенты, а также дисперсию для независи-
мого и одинаково распределенного инновационного процесса, требуемые
для генерации последовательности. Вычислительные затраты могут быть
дополнительно уменьшены с применением решетчатых структур.
В табл. 3.2 сведены характеристики различных процессов, приведенных в
настоящем материале. На рис. 13.33 отражена связь между этими процессами.
Рис. 13.33. Связь между регрессионными процессами
338
Глава 13. Методы моделирования фрактальных процессов
Таблица 3.2. Сравнительный анализ регрессионных и фрактальных процессов
Вид процесса Обозна- чение процесса Присутствие стационарности в процессе Модель процесса Свойства процесса
4RMA(p,d,q) Xtf) Да а(ВД/) = |3(ад Проявляет кратковремен- ную зависи- мость
ARIMA(p,d,q) *(/) Нет а(В)(1-В)'Ш = Р(5)-'(/) d= целое Проявляет кратковремен- ную зависи- мость
FARIMA(p,d,q) AV) Да а(В)(1-В)'Ш = Р(В)-'« Я(т) ~ qr|M-1 de (-0,5; 0,5) Проявляет кратковремен- ную и долго- временную за- висимости
Самоподобный 5(/) Нет SiatY = He (0; 1) a = const —
ФБД В(0 Нет B(a/) = o"B(f) He (0; 1) a = const Самоподобный процесс Приращения стационарные Распределения гауссовские
ФГШ %(0 Да Я(т)-МШ(ЯХ2Я-1)|тГ2 He (0; l),H=d+ 0,5 Распределения гауссовские
Контрольные вопросы к главе 13
1. Дайте определение броуновского движения.
2. Каковы основные свойства фрактального броуновского движения ?
3. Каковы основные этапы RMD-алгоритма генерации ФБД ?
4. В чем особенность SRA-алгоритма генерации ФБД ?
5. Каковы основные свойства фрактального гауссовского шума ?
6. Опишите алгоритм быстрого преобразования Фурье (БПФ).
7. Сформулируйте основные этапы БПФ-алгоритма синтеза ФГШ.
8. В чем достоинства и недостатки применения моделей ФБД и ФГШ в
сетевых приложениях ?
9. Приведите примеры возможного применения моделей ФБД и ФГШ при
сетевом проектировании.
10. Опишите случаи, когда использование моделей ФБД или ФГШ не оп-
равдано и приведет к некорректной оценке производительности систе-
мы. Перечислите свойства этих моделей, которые препятствуют их
применению в таких случаях.
11. Какими параметрами описываются FARIMA-модели ?
12. Какая связь существует между обычными регрессионными процессами
и FARIMA ?
339
Глава 14
СПЕЦИАЛИЗИРОВАННЫЕ СИСТЕМЫ
ИМИТАЦИОННОГО МОДЕЛИРОВАНИЯ
ВЫЧИСЛИТЕЛЬНЫХ СЕТЕЙ
14.1. Общая характеристика специализированных
пакетов прикладных программ сетевого моделирования
Существуют специальные, ориентированные на моделирование вычисли-
тельных сетей, программные системы, в которых процесс создания модели
упрощен. Такие системы сами генерируют модель сети на основе исходных
данных о ее топологии и используемых протоколах, об интенсивностях по-
токов запросов, о протяженности линий связи, о типах используемого обо-
рудования и приложений. Программные системы моделирования могут
быть как узкоспециализированными, так и достаточно универсальными,
позволяющими имитировать сети самых различных типов. Качество ре-
зультатов моделирования в значительной степени зависит от точности ис-
ходных данных, переданных в систему имитационного моделирования.
Основной задачей подобного моделирования является выработка
рекомендаций для рационального использования ресурсов вычисли-
тельной сети. Необходимость в этом возникает при управлении или раз-
витии существующих, а также при проектировании новых сетей. Ре-
шить эти задачи в настоящее время помогают программные продукты
для анализа производительности сетей. Их основное назначение:
определить производительность сети при заданных топологии и
рабочей нагрузке;
проанализировать зависимость пропускной способности сети при
изменении ее топологии и при изменении рабочей нагрузки на сеть;
подобрать параметры протоколов сети для обеспечения максимальной
пропускной способности сети при заданных топологии и рабочей нагрузке;
определить оптимальные топологию и соотношение пропускной
способности и стоимости проектируемой сети.
Основными элементами, из которых состоят системы моделирова-
ния сетей, являются библиотека моделей, среда прогона, подсистема за-
дания рабочей нагрузки, подсистема задания топологии сети, подсисте-
ма анализа результатов моделирования.
Библиотеки моделей представляют собой хранилища структурных
элементов модели и могут оцениваться по следующим критериям: воз-
можность моделировать стандартные сетевые устройства; возможность
создания моделей устройств, удовлетворяющих требованиям пользова-
теля; уровень параметризации элементов библиотеки; число классов
моделируемых объектов; масштабируемость модельного времени; точ-
ность и соответствие моделей реальным объектам.
Среда прогона используется для сбора данных о функционирова-
нии модели. Как правило, ее организация не раскрывается разработчи-
340
Глава 14. Специализированные системы...
ком. Поэтому организацию функционирования среды прогона нельзя
использовать как критерий сравнения.
Графический интерфейс пользователя представляет собой модуль для
взаимодействия с подсистемами задания рабочей нагрузки и топологии се-
ти. Он должен обеспечивать максимальное удобство для пользователя и
реализовывать функции управления прогоном модели, в числе услуг кото-
рого могут находиться: механизм drag-and-drop; анимация процесса модели-
рования работы сети; возможность приостанавливать или прерывать работу
модели, «прокручивать» ее назад и запускать повторно; обеспечение на-
глядности иконок, обозначающих элементы сети; задание рабочей нагрузки
в удобной форме; возможность сворачивать отдельные фрагменты сети.
Подсистема анализа результатов моделирования обрабатывает дан-
ные, собранные при прогоне модели, вычисляет характеристики произво-
дительности и представляет результаты в удобной для пользователя форме.
В значительной степени возможность этой подсистемы зависит от тех дан-
ных, которые собирает среда прогона. Определяющими для этой части сис-
темы являются следующие моменты: количество и тип характеристик, со-
бираемых в результате работы модели, а также различные виды представ-
ления результирующей информации.
Еще одним критерием для сравнения различных систем моделиро-
вания может выступать наличие подсистемы для самостоятельной вы-
работки рекомендаций по рациональному использованию ресурсов сети.
Программные системы моделирования сетей - инструмент, кото-
рый может пригодиться любому администратору корпоративной сети,
особенно при проектировании новой сети или внесении кардинальных
изменений в уже существующую сеть. Продукты данной категории по-
зволяют проверить последствия внедрения тех или иных решений еще
до оплаты приобретаемого оборудования. Конечно, большинство из
этих программных пакетов стоят достаточно дорого, но и возможная
экономия может быть тоже весьма ощутимой.
Программы ИМ сети используют в своей работе информацию о про-
странственном расположении сети, числе узлов, конфигурации связей, ско-
ростях передачи данных, используемых протоколах и типе оборудования, а
также о выполняемых в сети приложениях.
Обычно существуют готовые ИМ основных элементов сетей (наибо-
лее распространенных типов маршрутизаторов, каналов связи, методов
доступа, протоколов и т.п.). Эти модели создаются на основании различных
данных: результатов тестовых испытаний реальных устройств, анализа
принципов их работы, аналитических соотношений. В результате создается
библиотека типовых элементов сети, которые можно настраивать с помо-
щью заранее предусмотренных в моделях параметров.
Системы ИМ обычно включают также набор средств для подготовки
исходных данных об исследуемой сети (предварительной обработки дан-
ных о топологии сети и измеренном трафике). Эти средства могут быть по-
лезны, если моделируемая сеть представляет собой вариант существующей
сети и имеется возможность провести в ней измерения трафика и других
параметров. Кроме того, система снабжается средствами для статистиче-
ской обработки полученных результатов. В табл. 14.1 приведены характе-
ристики некоторых популярных систем ИМ.
341
14.1. Общая характеристика специализированных пакетов прикладных программ...
Таблица 14.1. Характеристики систем имитационного моделирования
Компания Продукт Тип сети Требуемые ресурсы Примечания
American HYTech Prophesy ЛС 8МБ ОП, 6 МБ диск, DOS, Win- dows, OS/2 Оценка производительности при работе с текстовыми и графическими данными по отдельным сегментам и сети в целом
CACIProduct COMNET III ЛС, ГС 32 МБ ОП, 100 МБ диск, Windows, WindowsNT, OS/2, Unix Моделирование сети Х.25, ATM, Frame Relay, связи LAN-WAN, SNA, DECnet, протоколы OSPF, RIP. Доступ CSMA/CD, FDDI и др. Встроенная библиотека маршрутизаторов ЗСОМ, Cisco, DEC, ИР, Wellfleat
Make System NetMaker XA ЛС, ГС 128 МБ ОП, 2000 МБ диск, AIX, SunOS, Sun Solaris Проверка данных о топологии сети; им- порт информации о трафике, получаемой в реальном времени
NetMagic Sys- tem StressMagik ЛС 2 МБ ОП, 8 МБ диск, Windows Поддержка стандартных тестов измерения производительности; имитация пиковой нагрузки на файл-сервер
Network Analysis Cen- ter MIND ГС 8 МБ ОП, 65 МБ диск, DOS, Win- dows Средство проектирования и оптимизации сети, содержит данные о стоимости ти- пичных конфигураций с возможностью точного оценивания производительности
Network De- sign and Analysis Group AutoNet/ Designer ГС 8 МБ ОП, 40 МБ диск, Windows, OS/2 Определение оптимального расположения концентратора в ГС; возможность оценки экономии средств за счет снижения та- рифной платы, смены поставщика услуг и обновления оборудования; сравнение ва- риантов связи через ближайшую и опти- мальную точку доступа, а также через мост и местную телефонную сеть
Network De- sign and Analysis Group AutoNet/ MeshNET ГС 8 МБ ОП, 40 МБ диск, Windows, OS/2 Моделирование полосы пропускания и оптимизация расходов на организацию ГС путем имтггашш поврежденных линий; поддержка тарифной сетки компаний АТ & Т, Sprint, WiTel, Bell
Network De- sign and Analysis Group AutoNet/ Perfonn- ance-1 ГС 8МБОП, 1 МБ диск, Windows, OS/2 Моделирование производительности ие- рархических сетей путем анализа чувстви- тельности к длительности задержки, вре- мени ответа, а также узких мест в струк- туре сети
Network De- sign and Analysis Group AutoNet/ Perform- ance-3 ГС 8МБОП, 3 МБ диск, Windows, OS/2 Моделирование производительности мно- гопротокольных объединений локальных и глобальных сетей; оценка задержек в очередях; прогнозирование времени отве- та, а также узких мест в структуре сети; учет 1>еальных данных о трафике, посту- пающих от сетевых анализаторов
342
Глава 14. Специализированные системы...
Продолжение табл. 14.1
Компания Продукт Тип сети Требуемые ре- сурсы Примечания
System& Networks BONES ЛС, ГС 32МБОП, 80 МБ диск, Sun OS, Sun Solaris, HP-UX Анализ воздействия прило- жений «клиент-сервер» и новых технологий на рабо- ту сети
MIL3 Opnet — 16 МБ ОП, 100 МБ диск, DEC АХР, Sun OS, Sun So- laris, HP-UX Имеет библиотеку различных сетевых устройств, поддержи- вает анимацию, генерирует карту сети, моделирует полосу пропускания
VINT project Network simulator version 2 (ns2) — от8МБ ОЗУ до 250 МБ диск. Win 95/98/NTZ2000, Solaris, SunOS, Linux,FreeBSD, HP-UX Fixed/wireless LANs, Х.25, ATM, Frame Relay, Web cach- ing, http, все разновидности tcp и т.п., реализация собственного кода на C++ и tcl/otcl. Анимация. Исходный код полностью открыт
Примерами программ анализа и моделирования вычислительных
сетей могут служить OPNET и COMNET. Ниже приведены краткие ха-
рактеристики этих программ.
14.2. OPNET
Программа OPNET выполняет анализ работы различных локальных и терри-
ториальных гетерогенных вычислительных сетей, в том числе высокоскоро-
стных сетей FDDI и ATM, радиоканалов с временным мультиплексировани-
ем и других. На входном графическом языке задается структура сетей с ука-
занием процессоров, источников потоков данных, очередей, трансмиттеров и
т.п. Система позволяет сравнивать различные архитектуры построения сетей,
определять размещение серверов, рассчитывать трафик. В библиотеке систе-
мы имеются модели различных протоколов (Ethernet, FDDI, TCP/IP, ATM,
PSTN, Frame Relay и другие).
OPNET MODELER - программный пакет, предлагающий пользова-
телям графическую среду для создания, выполнения и анализа событийно-
го моделирования сетей связи. Это удобное программное обеспечение мо-
жет быть использовано для большого ряда задач: создание и проверка про-
токола связи, анализ взаимодействия протоколов, оптимизация и планиро-
вание сети. Также с помощью пакета возможно осуществить проверку пра-
вильности аналитических моделей и описание протоколов. В рамках «ре-
дактора проекта» могут быть созданы разнообразные сетевые объекты, ко-
торым пользователь может присвоить различные формы соединения узлов
вплоть до имеющих вид «головоломки». Автоматически создаются такие
сетевые топологии, как кольца, звезды, случайные сети. Случайный трафик
может быть автоматически сгенерирован из алгоритмов, указанных пользо-
вателем, а также импортирован из входящих в стандартную комплектацию
343
14.2. OPNET
пакета форматов реальных трафиков линий. Результаты моделирования
могут быть проанализированы, а графы и анимация трафика будут сгене-
рированы автоматически. Новой особенностью данного пакета является
автоматическое преобразование в формат html 4.Ох.
Одним из плюсов создания модели сети с помощью программного
обеспечения является то, что уровень гибкости, обеспечиваемый ядром
моделирования, тот же, что и для моделей, написанных «с нуля», но
объектное построение среды дает возможность пользователю намного
быстрее осуществлять разработку, усовершенствования и создавать мо-
дели для многократного использования.
Есть несколько сред редактора - по одной для каждого тала объекта.
Организация объектов - иерархическая. Сетевые объекты (модели) связаны
при помощи набора узлов и объектов связи, в то время как объекты узла свя-
заны набором объектов, такими как модули очередности, модули процессора,
передатчиков и приемников. Версия программного обеспечения для модели-
рования радиоканала содержит модели антенны радиопередатчика, антенны
приемника, перемещающихся объектов узла (включая спутники).
Логику поведения процессора и модулей очередности определяет мо-
дель процесса, которую пользователь может создавать и изменять в пределах
редактора процесса. В редакторе процесса пользователь может определить
модель процесса через комбинацию алгоритма работы конечного автомата
(FSM - finite-state machine) и операторов языка программирования С/С-Н-.
Вызов события модели процесса в течение моделирования управ-
ляется прерыванием, а каждое прерывание соответствует событию, ко-
торое должно быть обработано моделью процесса.
Основа связи между процессами - структура данных, называемая паке-
том. Могут быть заданы форматы пакета, т. е. они определяют, какие поля
могут содержать такие стандартные типы данных, как целые числа, числа с
плавающей запятой и указатели на пакеты (такая особенность позволяет ин-
капсулировать моделирование пакета). Структура данных, вызывающая ин-
формацию по контролю за интерфейсом (ICI - interface control information),
может быть разделена между двумя событиями моделей процесса - это еще
один механизм для межпроцессорной связи, что очень удобно для команд
моделирования и соответствует архитектуре многоуровневого протокола.
Процесс также может динамически порождать дочерние процессы, которые
упростят функциональное описание таких систем, как серверы.
В базовую комплектацию пакета входят несколько из наиболее упот-
ребимых моделей процесса, например BGP (border gateway protocol),
TCP/IP, Frame Relay, Ethernet, ATM (asynchronous transfer mode) и WFQ
(weighted fair queuing). Базовые модели полезны для быстрого развития
сложных ИМ сетевых структур широкого назначения, а также для точного
функционального описания протоколов при обучении студентов. Сущест-
вует возможность сопровождения моделей сети, узла или процесса ком-
ментариями и графикой (с поддержкой гипертекста). Главное окно
системы OPNET приведено на рис. 14.1.
344
14.3. COMNET
Рис. 14.1. Главное окно системы OPNET
14.3. COMNET
Система имитационного моделирования COMNET (http://www.caciasl.com)
позволяет анализировать работу сложных сетей, работающих на основе
практически всех современных сетевых технологий, включающих как ло-
кальные, так и глобальные связи. Исходные данные задаются на проблем-
но-ориентированных языках моделирования M0DSIM или SIMSCRIPT с
графическими расширениями. На экране ЭВМ изображается топология се-
ти с указанием узлов, линий связи, источников данных (трафика). В резуль-
тате моделирования определяются «узкие» места, задержки в передаче
данных, загрузка линий, буферов, процессоров, длины очередей, пиковые
нагрузки. Имеется библиотека моделей протоколов и аппаратных средств:
маршрутизаторов (ЗСОМ, Cisco, DEC, HP и других), алгоритмов протоко-
лов (TCP/IP, SNA, RIP, OSPF, IGRP и других) и ряда методов доступа
(CSMA/CD, FDDI, ALOHA). .
Семейство COMNET включает следующие системы.
COMNET III - система стохастического дискретного событийного
моделирования СМО, позволяющая детально моделировать сети СМО,
построенные с использованием всех известных технологий и протоко-
лов (ATM, Frame Relay, FDDI, TCP/IP, клиент-сервер и т.д.). Результа-
тами моделирования являются оценки производительности различных
вариантов построения исследуемой локальной или глобальной сети с
учетом стоимостных характеристик.
345
14.2. OPNET
ADVANCED FEATURES PACK - пакет, предоставляющий дополни-
тельные возможности пакету COMNET III для точного моделирования рас-
пределенного программного обеспечения клиент-серверных архитектур.
COMNET Predictor - система быстрого временного анализа, кото-
рая предоставляет возможность быстро оценить производительность
локальных и глобальных сетей. На основе импортированных данных по
топологии, протоколам и трафику пользователю предоставляется воз-
можность изменить такие параметры, как топология, трафик, состав
оборудования, полоса пропускания, протоколы, и быстро получить ре-
зультат в виде отчетных графических форм.
COMNET Baseliner - система импорта данных, предназначенная
для импорта данных о топологии и протоколах из установленных у
пользователя систем управления и мониторинга сетей; используется для
создания базовых моделей в пакетах COMNET III и COMNET Predictor.
COMNET Enterprise Profiler - система мониторинга сети, позво-
ляющая производить мониторинг и сбор статистики в сети без возмож-
ности администрирования; может интегрироваться с другими система-
ми мониторинга и управления.
NETWORK II.5 - автономный пакет для анализа производительно-
сти используемых компьютерных систем, позволяющий проводить мо-
делирование компьютерной архитектуры любого типа.
Общий вид главного окна системы COMNET приведен на рис. 14.2.
< loctf с* «ххН {«хгскй
Рис. 14.2. Главное окно системы COMNET
346
Глава 14. Специализированные системы...
14.4. Общие принципы моделирования с помощью
COMNET и OPNET
Модель состоит из двух частей: первая - описание топологии информа-
ционной системы; вторая - описание данных о трафике. Эта информа-
ция может быть либо получена из внешних источников - систем мони-
торинга и управления сетями, либо введена непосредственно пользова-
телем с помощью графического интерфейса.
Под топологией далее будем понимать связный граф, в вершинах кото-
рого расположены узлы (node) - объекты с описанием аппаратного обеспече-
ния (компьютеров и сетевого оборудования со своими характеристиками).
В системе COMNET, кроме того, в вершинах графа размещаются
соединения (link), описывающие технологии передачи данных и осуще-
ствляющие обмен информацией между узлами. Дуги (arcs), образующие
граф, связывают узлы, определяя, какие из них используют то или иное
соединение. Фактически дуги представляют собой порты оборудования,
расположенного в вершинах графа.
В системе OPNET технологии передачи данных описываются непо-
средственно дугами, соединяющими вершины (узлы). В системе COMNET
кроме узлов и соединений для описания иерархических топологий и для мо-
делирования независимых маршрутизируемых доменов имеются два допол-
нительных объекта, которые также могут располагаться в вершинах графа -
подсеть (subnet) для описания сложных иерархических структур и транзит-
ная сеть (transit net) - сеть, параметры которой неизвестны или их описание
не требуется. Для построения моделей глобальных сетей предназначен объ-
ект облако (WAN cloud). Эти три дополнительных объекта содержат свою
собственную внутреннюю топологическую структуру. В системе OPNET для
описания маршрутизации и иерархических структур используются также
объекты подсеть и другие способы (например, объект OSPF area).
Трафик будем рассматривать как количественную характеристику, опи-
сывающую информационные потоки между вершинами графа и распределен-
ную во времени в соответствии со статистическими законами. Описание трафи-
ка в COMNET выполняется с помощью таких объектов, как сообщение
(message), сессия (session), отклик (response), вызов (call). Для них могут быть
заданы законы, описывающие распределение моделируемого информационно-
го потока во времени и количественные характеристики передаваемой инфор-
мации. Еще одним источником трафика, который намеренно выделяют в от-
дельную группу, являются распределенные программные системы. Для их мо-
делирования в COMNET введен отдельный объект приложение (application).
Использование этого объекта позволяет моделировать сложные программные
комплексы, их взаимодействие с такими узлами обработки, как жесткие диски и
файловые системы, а также взаимодействие между различными приложениями.
В системе OPNET трафик задается другим способом: с помощью дат-
чиков (probe) данных, которые подключаются к определенным вершинам
графа топологии и позволяют генерировать и собирать данные, а также опи-
сывать различные типы источников трафика (запросы, отклики, приложения).
При этом имеется возможность задавать законы распределения параметров.
347
14.5. Технология моделирования информационных систем с использованием COMNET III
14.5. Технология моделирования информационных
систем с использованием COMNET III
Очевидный путь моделирования сложных систем состоит в их декомпо-
зиции. Полученные в результате декомпозиции подсистемы могут быть,
в свою очередь, разделены на подсистемы следующего уровня иерар-
хии: конечная стадия процесса декомпозиции (определяется низшим
уровнем абстракции, применяемым в каждой конкретной модели). Об-
наружение и выделение общих абстракций является следующим шагом,
облегчающим моделирование сложных систем.
Декомпозиция системы в сочетании с корректно выбранным уров-
нем абстракции позволяет радикально упростить построение модели
информационной системы (ИС). Обычно рассматриваются два основ-
ных вида декомпозиции: алгоритмическая, разделяющая исследуемую
систему по ее активным началам, т.е. по протекающим в ней процессам
в определенном порядке, и объектно-ориентированная, позволяющая
разделить исследуемую систему на классы однотипных абстракций.
Оба типа декомпозиции нашли свое применение в COMNET III.
Подход к построению моделей в COMNET III может быть представлен в
следующем виде:
1) описание топологии ИС и определение параметров оборудования;
2) описание источников трафика и их поведения, описание загрузки сети,
определение сценария моделирования.
С системой COMNET поставляется большая библиотека объектов
- моделей реального сетевого оборудования и методов доступа к среде.
Рассмотрим подробнее объектную модель COMNET (рис. 14.3). Объек-
ты, используемые в этой системе, могут быть разделены на два класса:
для описания топологии и для описания трафика.
—Access Link
Рис. 14.3. Базовая библиотека классов COMNET III
348
Глава 14. Специализированные системы...
Описание топологии в COMNET Ш. Кроме узлов, соединений и
дуг для описания иерархических топологий и моделирования независи-
мых маршрутизируемых доменов в систему COMNET включен еще
один дополнительный класс подсеть (Subnet), объекты которого также
могут располагаться в вершинах графа. Использование механизма на-
следования, в том числе множественного, расширяет круг используемых
классов. Класс узлов наследуют четыре новых класса.
Класс «Компьютер и узел связи» (Computer and Communications
Node - C&C Node). Эти объекты могут служить источниками или при-
емниками трафика, а также применяться для моделирования сложных
программных систем, учитывающих загрузку процессора и дисковых
подсистем. Узлы, описанные с помощью C&C Node, могут быть исполь-
зованы и для моделирования программных маршрутизаторов.
Класс «Группа компьютеров» (Computer Group Node). Объект
можно использовать только для моделирования компьютерных систем,
так как их функциональность включает в себя лишь источник и прием-
ник трафика. Как правило, с его помощью описываются группы компь-
ютеров, имеющих идентичное поведение.
Класс «Маршрутизатор» (Router Node). Объекты этого типа приме-
няются для моделирования аппаратных маршрутизаторов и могут высту-
пать как источником, так и приемником трафика, выполнять приложения,
использующие аппаратные ресурсы узла (процессоры, дисковые подсисте-
мы). Для более детального описания аппаратной реализации моделируемых
объектов введен ряд дополнительных свойств (например, наличие и пара-
метры внутренней шины), что позволяет моделировать внутреннее прохо-
ждение трафика между входными и выходными портами объекта.
Класс «Коммутатор» (Switch Node). Объекты этого класса служат
для моделирования коммутаторов, затрачивающих на передачу трафика
между внутренними портами ничтожно малое время. Однако, в отличие
от трех предыдущих, эти объекты не могут быть использованы ни как ис-
точник, ни как приемник трафика. Объекты классов C&C Node, Computer
Group Node и Router node для моделирования сложных программных сис-
тем включают репозиторий команд, использующих такие свойства объек-
тов, как характеристики дисковой подсистемы. В постоянно обновляю-
щуюся библиотеку объектов различных классов, входящих в состав
COMNET, включен широкий спектр моделей реально существующих ап-
паратных устройств. Объект Link наследует два новых объекта.
Класс «Соединение точка-точка» (Point-to-Point Link). Этот класс ис-
пользуется для описания каналов между двумя узлами. Примером таких
соединений могут быть выделенные линии, связывающие маршрутизаторы
в глобальных сетях, или соединения в сетях с коммутацией каналов.
Класс «Множественный доступ» (Multiaccess Link). Применение
данного класса возможно, когда несколько узлов имеют доступ к одной
среде передачи данных. В свою очередь, этот объект наследуется рядом но-
вых объектов, описывающих конкретные реализации метода доступа к сре-
де, такие, как Carrier detection, Token passing, SONET и т. п. (рис. 14.3).
349
14.5. Технология моделирования информационных систем с использованием COMNET Ш
Класс «Подсеть» (subnet). Используется для создания иерархических
топологий и позволяет корректно описывать подсети с различными алго-
ритмами маршрутизации, причем независимыми от алгоритма, применяе-
мого на магистрали. Кроме того, подсети используются, чтобы скрыть
излишнюю детализацию при моделировании сложных ИС. В COMNET с
их помощью описываются системы с произвольной глубиной вложения.
Соединения между внутренней топологией подсети и топологией
магистрали осуществляются с помощью точек доступа (access points),
число которых может быть произвольным.
Класс «Транзитная сеть» (Transit Net). Потомком подсетей и со-
единений является объект, сочетающий свойства родительских объек-
тов. Транзитная сеть может рассматриваться и как соединение и как
подсеть одновременно. В качестве соединения она пересылает пакеты
из выходного буфера одного узла во входной буфер другого. В роли
подсети транзитная сеть создает в своих границах область с собствен-
ным алгоритмом маршрутизации.
Класс «Облако» (WAN Cloud). Объекты этого класса, позволяю-
щие создавать абстрактные представления для глобальных сетей, также
наследуют свойства объектов-родителей - Subnet и Link. С точки зрения
топологии объект WAN Cloud функционирует подобно объекту Link,
его пиктограмма подключается непосредственно к узлам. С точки зре-
ния внутренней структуры облако состоит из набора виртуальных со-
единений (virtual circuit) и каналов доступа (access links), разновидности
соединения точка-точка для моделирования глобальных сетей.
Описание трафика и загрузки сети в COMNET III. Обратимся к
объектам, описывающим трафик (рис. 14.4).
Schadubng Meccages Destinations Text I Packets Advanced
Desbnabcn type [weightedVu
Edit Destination List .
Probacy [d.iooocoo
Рис. 14.4. Параметризация источника трафика при переносе фрагмента модели в
другую модель (Session Source)
350
Глава 14. Специализированные системы...
Класс «Сообщение» (Message). Объекты, принадлежащие к этому
классу, позволяют послать одиночное сообщение либо одному объекту-
адресату, либо множеству объектов. Пересылка таких сообщений рас-
сматривается как последовательность дейтаграмм, где каждый пакет
маршрутизируется независимо от других.
Класс «Отклик» (Response). Объекты этого класса могут быть ис-
пользованы только для посылки ответных сообщений. Они управляются
приходами сообщений, созданных объектами классов Message или Re-
sponse. Получателем сообщений класса Response всегда будет объект
класса Node, к которому подключен источник управляющих сообщений
(класса Message или Response).
Класс «Вызов» (Call). Объекты класса Call применяются для создания
моделей сетей с коммутацией каналов. Источник вызова описывается на-
бором таких параметров, как закон распределения, длительность и, с уче-
том класса маршрутизации, требований к пропускной способности.
Класс «Сессия» (Session) Эти объекты используются для модели-
рования сеансов, включающих наборы сообщений или сообщений,
маршрутизируемых по виртуальным соединениям. Сеанс инициируется
отправкой пакета установки сеанса и получением пакета-
подтверждения. В дальнейшем в рамках сеанса может быть послано
произвольное количество сообщений, также описанных в объекте клас-
са Session. Такие сообщения маршрутизируются либо как дейтаграммы,
либо как виртуальные соединения - в зависимости от алгоритма мар-
шрутизации на магистрали или в подсети, содержащей данный объект.
Отметим также, что в COMNET III применяются так называемые
внешние файлы описания трафика (external traffic files), получить которые
можно с помощью различных анализаторов трафика. Особый интерес пред-
ставляют объекты класса «Приложение» (Application), являющегося резуль-
татом множественного наследования классов Message, Response, Call и Ses-
sion (см. рис. 14.3). Эти объекты позволяют наиболее гибко описывать в рам-
ках модели рабочую загрузку сети и поведение источников трафика. Более
того, при их использовании могут быть легко смоделированы практически
любые виды программных систем, в том числе распределенных, таких, как
СУБД почтовые системы и др. Реальное приложение, описываемое объекта-
ми этого класса, включает в себя три составные части. Во-первых, это пара-
метры узла, с которым соединен объект класса Application. С помощью дан-
ных параметров задаются характеристики и число необходимых процессоров
и дисковых подсистем. Во-вторых, это так называемые репозитории команд,
использующих вышеупомянутые характеристики узла. И в-третьих, это соб-
ственно объект Application, управляющий последовательностью выполнения
этих команд. В репозитории команд узла, а следовательно, и в объекте класса
Application, могут содержаться следующие команды:
Transport Message (передать сообщение). Эта команда представля-
ет собой результат наследования объектом класса Application родитель-
ского объекта класса Message.
351
14.5. Технология моделирования информационных систем с использованием COMNET III
Setup (установить) - результат наследования класса Session.
Answer Message (ответить на сообщение) является наследником
класса Response.
Filter Message (фильтровать сообщения). Эта команда позволяет
приостановить все операции, описанные в объекте класса Application, до
тех пор, пока не будет получено сообщение, удовлетворяющее услови-
ям фильтрации.
Process (обработка). С помощью этой команды осуществляется
моделирование обработки, вызывающей загрузку процессора.
Read и Write (чтение и запись). Две эти команды также позволяют
моделировать занятость процессора узла, но уже в контексте взаимо-
действия с дисковой подсистемой чтения и записи файлов.
Таким образом, с помощью классов Application, Message, Response,
Session и Call возможно как гибкое моделирование текущей загрузки
сети, так и детальное описание поведения программных систем, входя-
щих в состав ИС. Исключительно важно, что эти классы позволяют мо-
делировать сложные распределенные программные системы и их влия-
ние на существующую сетевую инфраструктуру сети.
Говоря о базовом наборе классов COMNET III, крайне важно упомя-
нуть о применимости к ним так называемого параметрического абстрагиро-
вания. Этот подход позволяет создавать новые объекты - экземпляры класса
с различными свойствами. Такие важные технологические решения, как Gi-
gabit Ethernet, могут быть очень просто смоделированы путем изменения па-
раметров рассматриваемой абстракции (свойств выбранного класса).
Например, разработчику потребуется несколько изменить пара-
метры канального уровня оборудования проектируемой системы. Для
этого, как показано на рис. 14.5 (интерфейсное окно COMNET III ка-
нального уровня), он может редактировать параметры этого стандарта
(число ретрансмиссий в случае обнаружения коллизий, длину заголовка
кадра и т.д.). Иными словами, разработчик сам осуществляет парамет-
ризацию объекта.
Parameter tef name |Э02.3 CSMAZCO lOBASET'
Ptyrieal] Fraftwvj i CSMA/CDIEEE Utewak
Coiucn window (гм.) |660206
Jam interval (mt) (o QQ320
Iritername gap Im:} |O.OC*9SO
Retry interval (m:]
C ProbebOly tfctribubon
<♦ IEEE bir^expcnertaJ backoff
| OK | Cancel |
Рис. 14.5. Канальный уровень параметры каналов (технологий)
352
Глава 14. Специализированные системы...
При моделировании в COMNET затрагиваются следующие уровни
эталонной модели взаимодействия открытых систем (OSI ISO + IEEE 802):
приложений, транспортный, сетевой, канальный. На уровне приложений
описываются источники трафика - сообщения, сеансы, отклики, вызовы,
поведение программного обеспечения.
Пример диалоговых окон, в которых задаются параметры уровня
приложения, приведен на рис. 14.6. На транспортном уровне - транспорт-
ные протоколы и их параметры. Пример диалогового окна, в котором за-
даются параметры транспортного уровня приведен на рис. 14.7. На сетевом
уровне - алгоритмы маршрутизации, потоки пакетов, таблицы маршрути-
зации штрафные функции. Пример диалоговых окон, в которых задаются
параметры сетевого уровня приведен на рис. 14.8 - 14.11. Канальный уро-
вень - непосредственно передача пакетов, ретрансляция, описание каналов.
Пример диалогового окна, в котором задаются параметры канального
уровня, приведен на рис. 14.5.
BODE!
3
Нии |м»д31
: Sch«ijir>g j vj» De Ьлыккн I Text Pm km Advanced
; Soqixnce | Ad/ano&j |
'2 cnMie by | НЛжline
l«r> ftenmto •*!
C<^ |
SUintict- |
Рис. 14.6. Уровень приложений - описание источников трафика
| Protocol Parameter« >
Name |TCP/ip'-M»cro$oftV1^
I Packets у Efi« control | Flow control j Rate control j Open/Closo
Data bytes |l 46O
Г Pad to 12 packet
OH bytec f40
Acknowledgements
‘ Ack priority
: Ack. sue iSytes)
Protocol ID pP*
3
For packet delays at nodes
Cancel |
Рис. 14.7. Транспортный уровень - транспортные протоколы и их параметры
353
14.5. Технология моделирования информационных систем с использованием COMNET III
Backbone Propertie*
' T talfic scale (TOOOOO
Packet touting protocol ll^-StateStwtest-PathPitjJ
Calroutogp.ctocol ||Л"'ГМ"1 ГР1Т111ИШЭ
Packet node txU update interval (sec) |o 50
Packet link uti update interval (tec) |0 50
Г* Include app queueing delay in msg deteyt
OK | Comments „ | Cancel |
Рис. 14.8. Сетевой уровень - алгоритмы маршрутизации
Sat | by jc»tx> ' д] « ^caMnoaOa _£] <Ж [
Л& ] >..< | Ben»,»., | Then by lOeth'iyw»'"'"''' ""' ''t1 n [«cwsinjjCKiiw Caned j
_^_l—:____________I
Опре | ВжПмГюл | ЛроГуре | Px>xd | Inwwwat 1
1 &>Ъ*1 Сог»м< 13Л12О 135320 ЕчХ&ЖЗЭД £>«—
2 fcrfyrt ииег 135V2t 1351:21 Ex40«52!2} £ф
3 BriJo*! Sarvx 14.0051 14X51 E«4Q41 «ЗЭЙ £м>
4 ОДе1 114551 134351 b».(12SW7?55| ,£»p
5 МН $K<<i 13:56.21 13S&21 £>«<0556729 E>4>
ъ Ссжлег WqA - 13£H0 135320 £10(04329) £-ур
7 CowW $aww 135021 USO 21 b«# 306229 Ex>
♦ СоклЫ 135051 135051 СФЮ4ЭД6Л bv
S Сот* Sawu 135451 1154 51 £xX2t 81$3<1 Ex>
10 Ccwnel $K®4 135051 135051 £хЯ4СЗГ«СЭЗ) £»«v
>r
Рис. 14.9. Сетевой уровень - описание потока пакетов
Um-Defined Table Routing for Packet* -
□
Piimaty loafe xeiectiort rule
Secondary route seiection ttit
Г Conncclioo-orienied touting for teniont
Cancel |
Рис. 14.10. Сетевой уровень - таблицы маршрутизации
j PacketRoutingPenalty Table ‘ |Д|
tiaine jlwo [ Ok |
Cancel |
I ruert Before
Insert After
Oelde Row |
State Row |
Рис. 14.11. Сетевой уровень — штрафные функции
354
Глава 14. Специализированные системы...
Система COMNET Predictor. Эта система предназначена для тех
случаев, когда необходимо оценить последствия изменений в сети, но
без детального ее моделирования. COMNET Predictor работает следую-
щим образом. Из системы управления или мониторинга сети загружа-
ются данные о работе существующего варианта сети и делается предпо-
ложение об изменении параметров сети (числа пользователей или при-
ложений, пропускной способности каналов, алгоритмов маршрутиза-
ции, производительности узлов и т.п.). Затем COMNET Predictor произ-
водит оценку последствий предлагаемых изменений и выдает результа-
ты в виде графиков и диаграмм, на которых отображаются задержки,
коэффициенты использования и предполагаемые узкие места сети.
COMNET Predictor дополняет систему COMNET III, которая мо-
жет использоваться затем для более тщательного анализа наиболее важ-
ных вариантов сети.
COMNET Predictor работает в среде Windows 95, Windows NT и Unix.
Система COMNET III. Система имитационного моделирования се-
тей COMNET III позволяет точно предсказывать производительность ло-
кальных, глобальных и корпоративных сетей. Она работает в среде Win-
dows 95, Windows NT и Unix. В пакете COMNET III использован способ
конструирования модели сети, основанный на применении готовых базо-
вых блоков, соответствующих хорошо знакомым сетевым устройствам, та-
ким как компьютеры, маршрутизаторы, коммутаторы, мультиплексоры и
каналы связи.
Пользователь применяет технику drag-and-drop для графического
изображения моделируемой сети из библиотечных элементов. Затем
система COMNET III выполняет детальное моделирование полученной
сети, отображая результаты динамически в виде наглядной мультипли-
кации результирующего трафика.
Другим вариантом задания топологии моделируемой сети является
импорт топологической информации из систем управления и монито-
ринга сетей.
После окончания моделирования пользователь получает в свое
распоряжение следующие характеристики производительности сети:
прогнозируемые задержки между конечными и промежуточными
узлами сети, пропускные способности каналов, коэффициенты исполь-
зования сегментов, буферов и процессоров;
пики и спады трафика как функции времени, а не как усредненные
значения;
источники задержек и узких мест сети.
Главной проблемой при любом моделировании сети является сбор
данных о существующей сети. Именно эту проблему помогает решить
пакет COMNET Baseliner. Этот пакет может работать со многими про-
мышленными системами управления и мониторинга сетей, получая от
355
14.5. Технология моделирования информационных систем с использованием COMNET III
них собранные данные и обрабатывая их для использования при моде-
лировании сети с помощью систем COMNET III или COMNET Predictor.
COMNET Baseline позволяет создавать разнообразные фильтры, с
помощью которых можно извлечь нужную для моделирования информа-
цию из импортируемых данных. С помощью COMNET Baseline можно:
импортировать информацию о топологии сети ( возможно, в иерархиче-
ском виде); комбинировать информацию из нескольких файлов регистра-
ции трафика, которые могут импортироваться из разных средств монито-
ринга в единую модель трафика; предоставлять полученную модель трафи-
ка для предварительного беглого обзора; просматривать графическое пред-
ставление межузлового взаимодействия, в котором трафик каждой пары
узлов отображается линией определенного цвета.
Типы узлов. Система COMNET III оперирует с узлами трех типов -
процессорными узлами, узлами-маршрутизаторами и коммутаторами. Уз-
лы могут присоединяться с помощью портов к коммуникационным кана-
лам любого типа, от каналов локальных сетей до спутниковых линий связи.
Надежность узлов и каналов сети может характеризоваться средним време-
нем наработки на отказ и средним временем восстановления.
В COMNET III моделируется не только взаимодействие компьютеров
в сети, но и процесс разделения процессора каждого компьютера между его
приложениями (процессорные узлы). Работа приложения моделируется с
помощью команд нескольких типов, в том числе команд обработки данных,
отправки и чтения сообщений, чтения и записи данных в файл, установле-
ния сессий и приостановки программы до получения сообщений. Для каж-
дого приложения задается так называемый репертуар команд.
Узлы-маршрутизаторы могут моделировать работу маршрутиза-
торов, коммутаторов, мостов, концентраторов и любых устройств, кото-
рые имеют разделяемую внутреннюю шину, с помощью которой пакеты
передаются между портами. Шина характеризуется пропускной способ-
ностью и количеством независимых каналов. Узел-маршутизатор обла-
дает также всеми характеристиками процессорного узла, так что он мо-
жет выполнять приложения, которые, например, обновляют таблицы
маршрутизации или рассылают маршрутную информацию по сети. Не-
блокирующие коммутационные узлы могут моделироваться путем зада-
ния количества независимых каналов, равного числу модулей коммута-
тора. Библиотека COMNET III включает большое количество описаний
конкретных моделей маршрутизаторов с параметрами, основанными на
результатах тестирования в Harvard Network Device TestLab.
Узел-коммутатор моделирует работу коммутаторов, а также тех
маршрутизаторов, концентраторов и других устройств, которые передают
пакеты с входного порта на выходной с незначительной задержкой.
Каналы связи и глобальные сети. Каналы связи моделируются
путем задания их типа, а также двух параметров: пропускной способно-
сти и вносимой задержки распространения. Единицей передаваемых по
356
Глава 14. Специализированные системы...
каналу данных является кадр. Пакеты при передаче по каналам сегмен-
тируются на кадры. Каждый канал характеризуется минимальным и
максимальным размером кадра, накладными расходами на кадр и ин-
тенсивностью ошибок в кадрах. Можно моделировать все распростра-
ненные методы доступа к передающей среде, в том числе ALOHA,
CSMA/CD, TokenRing, FDDI и т.п. Каналы «точка-точка» могут также
использоваться для моделирования каналов ISDN и SONET/SDH.
COMNET III включает в себя средства для моделирования глобаль-
ных сетей на самом верхнем уровне абстракции. Такой подход целесообра-
зен, когда задание точных сведений о топологии физических связей и о
полном трафике ГС невозможно или нецелесообразно. Например, нет
смысла точно моделировать работу Internet при исследовании передачи
трафика между двумя локальными сетями, подключенными к Internet.
COMNET III позволяет укрупненно моделировать сети Frame Re-
lay, сети с коммутацией ячеек (например, ATM), сети с коммутацией
пакетов (например, Х.25).
Связь с ГС имитируется с помощью канала доступа, который име-
ет определенные задержку распространения и пропускную способность.
Сама ГС характеризуется задержкой доставки информации от одного
канала доступа до другого, вероятностью потери кадра или его прину-
дительного удаления из сети (при нарушении соглашения о параметрах
трафика типа CIR). Эти параметры зависят от степени загруженности
ГС, которая может быть задана как «нормальная», «умеренная» и «вы-
сокая». Имеется возможность моделировать виртуальные каналы в сети.
Рабочая нагрузка. В системе COMNET III рабочая нагрузка созда-
ется источниками трафика. Каждый узел может быть соединен с не-
сколькими источникам ’ трафика разного типа.
Источники приложения генерируют приложения, которые выполня-
ются узлами типа процессоров или маршрутизаторов. Узел выполняет ко-
манду за командой, имитируя работу приложений в сети. Источники могут
имитировать сложные нестандартные приложения, а также простые, зани-
мающиеся, в основном, отправкой и получением сообщений по сети.
Источники вызовов генерируют запросы на установление соеди-
нений в сетях с коммутацией каналов (сети с коммутируемыми вирту-
альными соединениями, ISDN, POTS).
Источники планируемой нагрузки генерируют данные периодически,
используя зависящее от времени расписание. При этом используется опреде-
ленное распределение интервала времени между порциями данных. Можно
моделировать зависимость интенсивности генерации от времени дня.
Источники «клиент-сервер» позволяют задавать не трафик между
клиентами и сервером, а приложения, которые порождают этот трафик.
Источник данного типа позволяет моделировать вычислительную за-
грузку компьютера, работающего в роли сервера, т.е. учитывать время
выполнения вычислительных операций, а также операций, связанных с
обращением к диску, подсистеме ввода-вывода и т.п.
357
14.5. Технология моделирования информационных систем с использованием COMNET Ш
Протоколы. Коммуникационные протоколы физического и каналь-
ного уровней учитываются в системе COMNET III в таких элементах сети
как каналы (links). Протоколы сетевого уровня отражены в работе узлов
модели, которые принимают решения о выборе маршрута пакетов в сети.
Магистраль сети и каждая из подсетей могут работать на основе
различных и независимых алгоритмов маршрутизации. Алгоритмы
маршрутизации, используемые COMNET III, принимают решение с
учетом вычисления кратчайшего пути. Используются различные вариа-
ции этого принципа, отличающиеся метрикой и способом обновления
таблиц маршрутизации. Применяются статические алгоритмы, у кото-
рых таблица обновляется только один раз в начале моделирования, и
динамические алгоритмы, обновляющие таблицы периодически. Воз-
можно моделирование многопутевой маршрутизации, при которой дос-
тигается баланс трафика по нескольким альтернативным маршрутам.
Протоколы, выполняющие транспортные функции и функции дос-
тавки сообщений между конечными узлами, представлены в системе
COMNET III обширным набором протоколов: ATP, NCP, NCPBurst-
Mode, TCP, UDP, NetBIOS, SNA. При использовании этих протоколов
пользователь выбирает их из библиотеки системы и задает конкретные
параметры, например, размер сообщения, размер окна и т.п.
Моделирование случайных параметров. При моделировании необ-
ходимо правильно выбрать законы распределения определенных парамет-
ров модели. COMNET поддерживает 18 основных видов дискретных и не-
прерывных распределений. Кроме того, пользователь может задать таблич-
ные распределения.
Наиболее распространенными в природе являются следующие за-
коны распределения: распределение Пуассона, экспоненциальное, а
также нормальное распределения. Чтобы выбрать требуемое распреде-
ление, необходимо рассмотреть следующие условия.
Условия выбора распределения Пуассона заключаются в стацио-
нарности потока событий (интенсивность или плотность потока посто-
янна), в отсутствии последействия (независимость появления событий в
непересекающиеся промежутки времени), в ординарности (вероятность
одновременного появление двух и более событий равна 0).
Если имеем простейший поток, то распределение времени между двумя
смежными событиями подчиняется экспоненциальному распределению.
Нормальное распределение применяем всегда, когда возможно, ес-
ли закон распределения неизвестен, или если закон известен, но вычис-
ления затруднены (при большом числе испытаний аппроксимируются
все дискретные и большинство непрерывных распределений), а также
если события - это суммы большого числа независимых или слабозави-
симых величин.
Таким образом, рекомендуем для параметров трафика экспоненци-
альное распределение, для остальных параметров - нормальное.
358
Глава 14. Специализированные системы...
Представление результатов моделирования. Оно в системе
COMNET III может быть представлено графикамии и отчетами. COMNET
III позволяет задавать форму отчета о результатах моделирования для каж-
дого отдельного элемента модели. Для этого необходимо в пункте меню
Report выбрать требуемый элемент (пункт подменю network element) и за-
дать для него опреленный тип отчета (пункт type of report).
Отчет генерируется каждый раз при запуске определенной модели. От-
чет представлен в стандартной текстовой форме, имеющей ширину в 80 сим-
волов, и его легко можно распечатать на любом принтере. Можно задать ге-
нерацию нескольких отчетов разного типа для каждого элемента сети.
Существуют другие способы получения статистических результа-
тов прогона модели, кроме отчетов. В COMNET III имеются кнопки Sta-
tistics, с помощью которых можно включить сбор статистики для каж-
дого типа элемента модели узлов, каналов, источников трафика, мар-
шрутизаторов, коммутаторов и т.п. Монитор статистики каждого эле-
мента можно установить для сбора только базовых статистических па-
раметров (минимум, масимум, среднее значение и дисперсия) или же
сбора данных во временном масштабе для построения графиков.
Если результаты наблюдений сохранены в файле для последующе-
го построения графиков и анализа, то возможно также построение гис-
тограмм и процентных показателей. Возможно построение графиков и
во время моделирования.
Мультипликация и отслеживание событий. Перед моделировани-
ем или во время него можно установить режимы мультипликации и
трассировки событий с помощью пунктов меню Animation и Trace.
Режим мультипликации (Animation) позволяет изменять скорость
тактов моделирования и скорость передвижения токенов графических
символов, соответствующих кадрам и пакетам. В этом режиме система
COMNET III показывает поступление токенов в каналы связи и выход
их из каналов, текущее количество пакетов в узлах, количество сессий,
установленье с данным узлом, процент использования и многое другое.
В режиме трассировки (Trace) можно отображать процесс наступле-
ния событий в модели либо в файл, либо на экран. При отображении на эк-
ран можно перейти в режим пошагового моделирования, когда очередное
событие в модели наступает и отображается только при очередном нажатии
на соответствующую кнопку графического интерфейса. Можно задать уро-
вень отслеживаемых событий от высокоуровневых, связанных с работой
приложений, до событий самого низкого уровня, связанных с обработкой
кадров на канальном уровне.
Статистический анализ. COMNET III включает интегрированный
набор средств для статистического анализа исходных данных и резуль-
татов моделирования. С их помощью можно подобрать подходящее
распределение вероятностей для экспериментально полученных дан-
ных. Средства анализа результатов позволяют вычислить доверитель-
ные интервалы, выполнить регрессионный анализ и оценить вариации
оценок, полученных по нескольким прогонам модели.
359
14.6. Сетевой имитатор ns2
14.6. Сетевой имитатор ns2
Работы над проектом VINT (Virtual InterNetwork Testbed), организованным
DARPA (Defense Research Projects Agency) и реализуемым под руково-
дством целого ряда научных организаций и центров (USC/ISI (University of
Southern Califomia/Information Sciences Institute), Xerox PARC, LBNL (Law-
rence Berkley National Laboratory) и UCB (UC Berkley)), были начаты в 1996 г.
В настоящее время основными спонсорами проекта являются DARPA, NSF
и ACIRI (AT&T Center for Internet Research at ICSI). Главной целью про-
екта VINT являлось построение программного продукта, позволяющего
осуществлять ИМ сетей связи и обладающего целым рядом характеристик,
среди которых высокая производительность, хорошая масштабируемость,
визуализация результатов и гибкость. В качестве основы был выбран разра-
батываемый в University of California с 1989 г. пакет network simulator (до
1995 г. известный как REAL).
Network simulator 2 (далее ns2), как и его предшественники, разра-
батывался как программное обеспечение с открытым исходным кодом
(OSS - open source code software). Такое ПО распространяется бесплат-
но, без каких либо ограничений на право использования, модификации
и распространения третьими лицами. Таким образом, с точки зрения
стоимости, ns2 безусловно является лидером по сравнению с коммерче-
ским ПО, упомянутым выше, поскольку он бесплатен. По этой же при-
чине бесплатны и всегда доступны в режиме on-line все обновления и
дополнения (новые библиотеки, протоколы и т.п.). Не менее замеча-
тельными свойствами программного обеспечения OSS является воз-
можность модификации ядра программы и гибкая настройка в соответ-
ствии с требованиями конкретного пользователя, а также мультиопера-
ционность. Полные версии, включающие все функции, на данный мо-
мент работоспособны под управлением следующих операционных сис-
тем: SunOS, Solaris, Linux, FreeBSD, Windows 95/98/ME/NT/2000.
Для инсталляции полной версии ns2 необходимо иметь 250 МБ
свободного места на диске компьютера и компилятор C++. Существует
также упрощенная версия (компилированная) для некоторых операци-
онных систем (ОС) (в частности, всех версий Windows), являющаяся не
столь гибкой как полная версия, в которой невозможно добавлять ком-
поненты, модифицировать ядро и т.п. Однако эта версия очень проста в
использовании и не требует глубоких знаний ОС и языка C++. Для
функционирования упрощенной версии ns2 достаточно иметь 3 МБ сво-
бодного места на жестком диске компьютера.
Требования к производительности компьютера у ns2 не очень жестки.
В принципе, компьютер с процессором 486 может обеспечить приемлемое
функционирование даже полной версии ns2. При необходимости использо-
вания ns2 группой пользователей достаточно иметь инсталлированную
полную версию на машине под управлением Unix. Пользователи могут
360
Глава 14. Специализированные системы...
иметь доступ в режиме терминала к ns2 и производить необходимые моди-
фикации, в том числе и ядра программы, компилируя свою версию в до-
машнюю директорию. Так же при помощи Х-сервера возможна анимация
полученных результатов.
Рассмотрим архитектуру ns2. Пакет ns2 является объектно-
ориентированным ПО, ядро которого реализовано на языке C++. Язык
скриптов (сценариев) OTcl (Object oriented Tool command language) исполь-
зуется в качестве интерпретатора. Также ns2 полностью поддерживает ие-
рархию классов C++, называемую в терминах ns2 компилируемой, и по-
добную иерархию классов интерпретатора OTcl, называемую интерпрети-
руемой. Обе иерархии обладают идентичной структурой, т.е. существует
однозначное соответствие между классом одной иерархии и таким же клас-
сом другой. Использование двух языков программирования в ns2 объясня-
ется следующими причинами. С одной стороны, для детального моделиро-
вания протоколов необходимо использовать системный язык программи-
рования, обеспечивающий высокую скорость выполнения и способный ма-
нипулировать достаточно большими объемами данных. С другой стороны,
для удобства пользователя и быстроты реализации и модификации различ-
ных сценариев моделирования привлекательнее использовать язык про-
граммирования более высокого уровня абстракции. Такой подход является
компромиссом между удобством использования и скоростью.
В ns2 в качестве системного языка используется C++, позволяю-
щий обеспечить высокую производительность, работу с пакетами пото-
ка на низком уровне абстракции модели, модификацию ядра ns2 с це-
лью поддержки новых функций и протоколов.
В качестве языка программирования высокого уровня абстракции
используется язык скриптов OTcl, который является объектно-
ориентированным расширением языка Тс1. Поэтому OTcl позволяет
обеспечить ряд положительных свойств, присущих языку Tcl/Tk: про-
стоту синтаксиса и простоту построения сценария моделирования, а
также возможность соединения воедино блоков, выполненных на сис-
темных языках программирования, и удобство манипуляции ими.
Объединение для совместного функционирования C++ и OTcl
производится при помощи TclCl (Classes Tel), который является интер-
фейсом между объектами C++ и OTcl.
В рассматриваемой архитектуре возможно обращение объектов OTcl
к библиотеке переменных C++ при помощи функции bind, в связи с чем пе-
ременные C++ могут быть модифицированы через OTcl напрямую. Ос-
тальные команды OTcl выполняются путем передачи данных в объект C++
при помощи функции TclObject::commandant argc, const char*const* argv).
Для запроса процедуры OTcl из C++ используется класс Tel. Это может
быть полезно, например, при передаче результатов в OTcl из C++. Сцена-
рий моделирования сети связи может быть полностью записан на OTcl,
включая параметры линий и узлов (задержки, очереди и т.п.). В случае, ес-
361
14.6. Сетевой имитатор ns2
ли необходимо реализовать какую-либо специфическую функцию (напри-
мер, дисциплину обслуживания, не реализованную в ns2 на уровне ядра) то
используется код на C++. Однако при подобном подходе могут возникнуть
неоднозначности. В частности, известно, что в ns2 маршрутизация, в ос-
новном, реализована на OTcl (причем базовый алгоритм Дийкстра выпол-
нен на C++). Если задача состоит в моделировании потоков HTTP, то для
работы с каждым потоком достаточно воспользоваться OTcl, при этом об-
работка на уровне пакетов будет происходить на C++. Реализация одно-
значно проста. Однако, если число HTTP-потоков в секунду превысит не-
сколько сотен, процедуру работы с потоком лучше перенести в код C++ по
причине быстродействия.
Исходная полная версия ns2 содержит несколько весьма полезных
утилит и средств: отладчик Тс1, генератор сценариев моделирования и
генератор топологии сети. Существует целое множество генераторов
топологий, например, NTG, RTG, TIRES. В состав же ns2 входит гене-
ратор топологии GT-ITM, при помощи которого можно автоматически
создать топологию очень крупной сети без необходимости вручную оп-
ределять все компоненты сети. Генератор сценариев моделирования,
как правило, используется для создания трафика между узлами сети.
При моделировании беспроводных сетей этот тип генератора также мо-
жет быть использован для определения передвижения узлов.
Контрольные вопросы к главе 14
1. В чем состоят задачи программных продуктов анализа производи-
тельности сетей ?
2. Каковы известные системы имитационного моделирования ? Укажи-
те их основные особенности.
3. Дайте краткое описание программы OPNET.
4. Опишите систему имитационного моделирования COMNET.
5. Какие классы определены в системе COMNET ?
6. Дайте краткое описание системы имитационного моделирования ns2.
Литература
1. Армстронг Дж. Р. Моделирование цифровых систем. - М.: Мир, 1992.
2. Батищев Д.И. Методы оптимального проектирования. - М.: Радио и
связь, 1984.
3. Бусленко Н.П., Калашников В.В., Коваленко И.Н. Лекции по теории
сложных систем. -М.: Сов. Радио, 1973.
4. Бусленко Н.П. Моделирование сложных систем. - М.: Наука, 1975.
5. Бурцев В.С. Тенденции развития суперЭВМ/Вычислительные маши-
ны с нетрадиционной архитектурой. СуперЭВМ. - М., 1990.
6. Месарович М., Такахара Я. Общая теория систем: Математические
основы. - М.: Мир, 1978.
7. Советов Б.Я., Яковлев С.А. Моделирование систем- М.: Высшая
школа, 1985.
8. Советов Б.Я., Яковлев С.А. Моделирование систем. Практикум. - М.:
Высшая школа, 1999.
9. Шрайбер ТДж. Моделирование на GPSS-М.: Машиностроение, 1980.
10. Шелухин О.И., Лукъянцев Н.Ф. Цифровая обработка и передача речи.
- М.: Радио и связь, 2000.
1 {.Шелухин О.И. Негауссовские процессы в радиотехнике. - М.: Радио
и связь, 1999.
12. Шелухин О.И.' Беляков И.В. Негауссовские процессы . - C-Пб.: По-
литехника, 1998.
13. Шелухин О.И., Тенякшев А.М., Осин А.В. Фрактальные процессы в
телекоммуникациях-М.: Радиотехника, 2003.
14. Артюшенко В.М., Шелухин О.И., Афонин М.Ю. Цифровое сжатие
видеоинформации и звука - М.: Изд-во «Дашков и К», 2003.
15. Шварц М. Сети ЭВМ. Анализ и проектирование - М.: Радио и связь, 1981.
{б.Клейнрок Л. Вычислительные системы с очередями. Пер с англ. /
Под ред. Б.С.Цыбакова. - М.: Мир, 1979.
Л. Бычков СП., Храмов А.А. Разработка моделей в системе моделиро-
вания GPSS. Учебное пособие-М.: МИФИ, 1997.
\Ъ. Марков А.А. Моделирование информационно-вычислительных про-
цессов. - М.: Изд-во МГТУ им. Н.Э. Баумана, 1999.
19. Математическое моделирование: Методы, описания и исследования
сложных систем / Под ред. А.А. Самарского. - М.: Наука, 1989.
2^. Блох Э.Л., Попов О.В., Турин В.Я. Модели источника ошибок в кана-
лах передачи цифровой информации. -М.: Связь, 1971.
И.Столингс. И. Компьютерные системы передачи данных. 6-е изд.:
Пер. с англ - М.: Издательский дом «Вильямс», 2002.
363
Перечень сокращений
AM - амплитудная модуляция
АП - абсолютный приоритет
АПД - аппаратура передачи данных
АПРВ - апостериорная плотность вероятностей
БГШ - белый гауссовский шум
БНП - безынерционное преобразование
БНШ - белый негауссовский шум
БПФ - быстрое преобразование Фурье
ВВХ - вероятностно-временные характеристики
ГСС - генератор случайных событий
ДВЗ - долговременная зависимость
ДПФ - дискретное преобразование Фурье
ДФР - дополнительная функция распределения
ИКМ - импульсно-кодовая модуляция
ИМ - имитационная модель
КВЗ - кратковременная зависимость
КТФОП - коммутируемая телефонная сеть общего пользования
ктч - канал тональной частоты
КФ - корреляционная функция
ЛВС - локальная вычислительная сеть
ЛНСВ - случайная величина, распределенная по логарифмически-
нормальному закону
ММ - математическая модель
НСВ - нормальная (гауссовская) случайная величина
НСП - нормальный стационарный процесс
ОЗУ - оперативное запоминающее устройство
ООД - оконечное оборудование данных
ОП - относительный приоритет
ОПС - однородный поток событий
ОФМ - относительная фазовая модуляция
ПДУ - передающее устройство
ПМУ - приемное устройство
ПРВ - плотность распределения вероятностей
ПС - поток событий
ПФУ - приемно-фильтрующее устройство
РРСЧ - равномерно распределенные случайные числа
РСУ - разностное стохастическое уравнение
РТХ - распределение с тяжелым хвостом
РУ - решающее устройство
СВ - случайная величина
364
Словарь терминов
СДУ - стохастическое дифференциальное уравнение
СМО - система массового обслуживания
спд - система передачи данных
СПИ - система передачи информации
СУА - селективное управление агрессивностью
СУБД - система управления базой данных
СЧА - стандартные числовые атрибуты
ТМО - теория массового обслуживания
ТФОП - телефонная сеть общего пользования
УФПК - уравнение Фоккера - Планка - Колмогорова
ФМ - фазовая модуляция
ФБД - фрактальное броуновское движение
ФГШ - фрактальный гауссовский шум
ФР - функция распределения
ХИП - хаотическая импульсная помеха
ЧМ - частотная модуляция
ЭВМ - электронно-вычислительная машина
ЯИМ - язык имитационного моделирования
ЯМ - язык моделирования
яон - язык общего назначения
AAL (ATM Adaptation Level) - уровень адаптации в ATM
ANSI (American National Standards Institute) - Американский нацио-
нальный институт стандартов
AR (AutoRegressive) model - авторегрессионная модель
ARIMA (AutoRegressive Integrated Moving Average) - авторегрессионные
модели интегрального скользящего среднего
ARMA (AutoRegressive Moving Average) model - авторегрессионная
модель скользящего среднего
ATM (Asynchronous Transfer Mode) - асинхронный режим передачи
В-ISDN (Broadband ISDN) - широкополосная ISDN
BECN (Backward Explicit Congestion Notification) - обратное явное уве-
домление о перегрузке
BGP (Border Gateway Protocol) - пограничный межсетевой протокол
САС (Call Admission Control) - управление доступом соединения
CIR (Committed Information Rate) - согласованная скорость передачи ин-
формации
CoS (Class of Service) - класс обслуживания
CPU (Central Processing Unit) - центральный процессор
CSMA/CD (Carrier Sense Multiple Access with Collision Detection) -
множественный доступ с контролем несущей и обнаружением
столкновений (конфликтов, коллизий)
CSU (Channel Service Unit) - модуль обслуживания канала
DAR (Discrete Autoregressive) process - дискретный авторегрессионный процесс
365
Словарь терминов
DCE (Date Circuit Equipment) - оборудование канала передачи данных
DDS (Digital Data Service) - служба цифровой передачи информации
DLCI (Data Link Connection Identifier) - идентификатор канала связи
DSP - Digital Signal Processor - цифровой процессор
DSU (Digital Service Unit) - пользовательское устройство, взаимодействующее
с цифровым устройством
DTE (Date Terminal Equipment) - оборудование терминала передачи данных
Ethernet - стандарт организации локальных сетей
FARIMA (Fractional AutoRegressive Integrated Moving Average) фрактальнаые
авторегрессионные модели интегрального скользящего среднего
FBM (Fractional Brownian Motion) - фрактальное броуновское движение
FDDI (Fiber Distributed Data Interface) - распределенный интерфейс пе-
редачи данных по волоконно-оптическим каналам
FEC (Forward Error Correction) - прямое исправление ошибок
FECN (Forward Explicit Congestion Notification) - прямое извещение о
перегрузке
FFT (Fast Fourier Transform) - быстрое преобразование Фурье
FGN (Fractional Gaussian Noise) - фрактальный Гауссовский шум
FIFO (First In, First Out) - дисциплина обслуживания по принципу «пер-
вым пришел - первым обслужен»
FR (Frame Relay) - протокол трансляции кадров
GPSS (General Purpose System Simulator) - системный имитатор общего
назначения
GRN (Gaussian Random Number) - гауссовские случайные переменные
FRF (Frame Relay Forum) - сообщество по развитию технологии FR
HDLC (High-level Data Link Control) - высокоуровневый протокол
управления каналом
НЕС (Header Error Check) - поле контрольной суммы заголовка
HTTP (Hypertext Transfer Protocol) - протокол передачи гипертекстовых файлов
ITU-T (International Telecommunications Union) - Международный теле-
коммуникационный союз (бывший МККТТ)
IP (Internet Protocol) - Интернет протокол
IPX (Internetwork Packet eXchange) -базовый протокол сетевого уровня
Novell NetWare, используемый для пересылки и маршрутизации пакетов
между сервером и рабочими станциями
ISDN (Integrated Service Digital Network) - цифровая сеть с интеграцией услуг
LAN (Local Area Network) - локальная сеть
LD-CELP (Low Delay Code Excitation Linear Prediction) - кодер линей-
ного предсказания с кодовым возбужением и низкой задержкой
LIFO (Last In, First Out) - дисциплина обслуживания по принципу «по-
следним пришел - первым обслужен»
МА (moving average) model - модель скользящего среднего
MMPP (Markov Modulated Poisson Process) - пуассоновский процесс,
управляемый марковским
366
Словарь терминов
NNI (Network-to-Network Interface) - межсетевой интерфейс (интер-
фейс, определяющий взаимодействие коммутаторов ATM)
NSFNet (National Science Foundation Network) - сеть национального на-
учного фонда
OSI (Open Systems Interconnection) - взаимодействие открытых систем
PDH (Plesiochronous Digital Hierarchy) - плезиохронная цифровая ие-
рархия (европейский стандарт для волоконно-оптических сетей)
PMD (Physical Medium Dependent) - подуровень физического уровня,
зависящий от среды передачи данных (составная часть стандарта FDDI,
определяющая характеристики ВОЛС)
POTS (Plain Old Telephone Service) - обычная телефонная сеть
PVC (Permanent Virtual Circuit) - постоянный виртуальный канал (постоян-
но существующее соединение между двумя конечными точками сети)
QoS (Quality of Service) - качество обслуживания
RMD (Random Midpoit Displacement) - метод случайного перемещения
средней точки
SAP (Service Access Point) - точка доступа к службе
SDH (Synchronous Digital Hierarchy) - синхронная цифровая иерархия
SONET (Synchronous Optical Network) - синхронная оптическая сеть
SPVC (Smart Permanent Virtual Circuit) - интеллектуальные постоянные
виртуальные каналы
SVC (Switched Virtual Circuits) - переключаемые виртуальные каналы
SPX (Sequenced Packet Exchange) - последовательный обмен пакетами
SRA (Successive Random Additional) - метод случайного последователь-
ного сложения
Т1 - линия Т1 (термин, используемый компанией AT&T для обозначе-
ния каналов передачи цифровых данных с полосой 1.544 Mbps)
ТАР (Terminal Access Point) - точка подключения терминала
ТВЕВО (Truncated Binary Exponential Back off Algorithm) - процедура
регулирования задержки повторной передачи
TCP (Transmission Control Protocol) - протокол управления передачей
TDM (Time Division Multiplexing) - временное мультиплексирование
VBA (Visual Basic for Applications) - Visual Basic для прикладных программ
VBR (Variable Bit Rate) -поток данных с переменной скоростью
VCI (Virtual Channel Identifier) - поле идентификатора виртуального канала
VoIP (Voice over IP) - Передача речи по IP-сети
VPI (Virtual Path Identifier) - поле идентификатора виртуального пути
UDP (User Datagram Protocol) - протокол дейтаграмм пользователя
UNI (User-to-Network Interface) - интерфейс пользователь-сеть, специфика-
ция UNI
WAN (Wide Area Network) - глобальная сеть
WWW (World Wide Web) - собрание гипертекстовых и иных докумен-
тов, доступных по всему миру через сеть Интернет
XON/XOFF (Transmitter On / Transmitter Off) - простейший протокол
передачи данных между устройствами по асинхронному соединению
367
Учебное издание
МОДЕЛИРОВАНИЕ
ИНФОРМАЦИОННЫХ
СИСТЕМ
Авторы:
Олег Иванович Шелухин
Александр Михайлович Тенякшев
Андрей Владимирович Осин
Под редакцией
докт. техн, наук, проф. О. И. Шелухина
E-mail: sheluhin@aha.ru
Редактор Л. А. Стасышина
Редактор-оператор Д. Е. Демин
Изд. № 15. Сдано в набор 30.09.2004.
Подписано в печать 01.11.2004. Формат 60x90 1/1
Бумага газетная. Гарнитура Таймс.
Печать офсетная.
Печ. л. 23. Тираж 1000 экз. Зак. № 3834
Издательство «САЙНС-ПРЕСС».
107031, Москва, К-31, Кузнецкий мост, д. 20/6.
Тел./факс: 921-48-37; 925- 78-72, 925-92-41.
E-mail: info@radiotec.ru
www.radiotec.ru
Отпечатано в ООО ПФ “Полиграфист”.
160001, г. Вологда, ул. Челюскинцев, д. 3.