


















































































































































































































































































































Текст
STATISTICS AND
EXPERIMENTAL DESIGN
in Engineering and the Physical Sciences
volume I,
second edition
NORMAN L. JOHNSON
FRED С LEONE
John Wiley & Sons, New York • London • Sydney • Toronto
1977
H. Джонсон
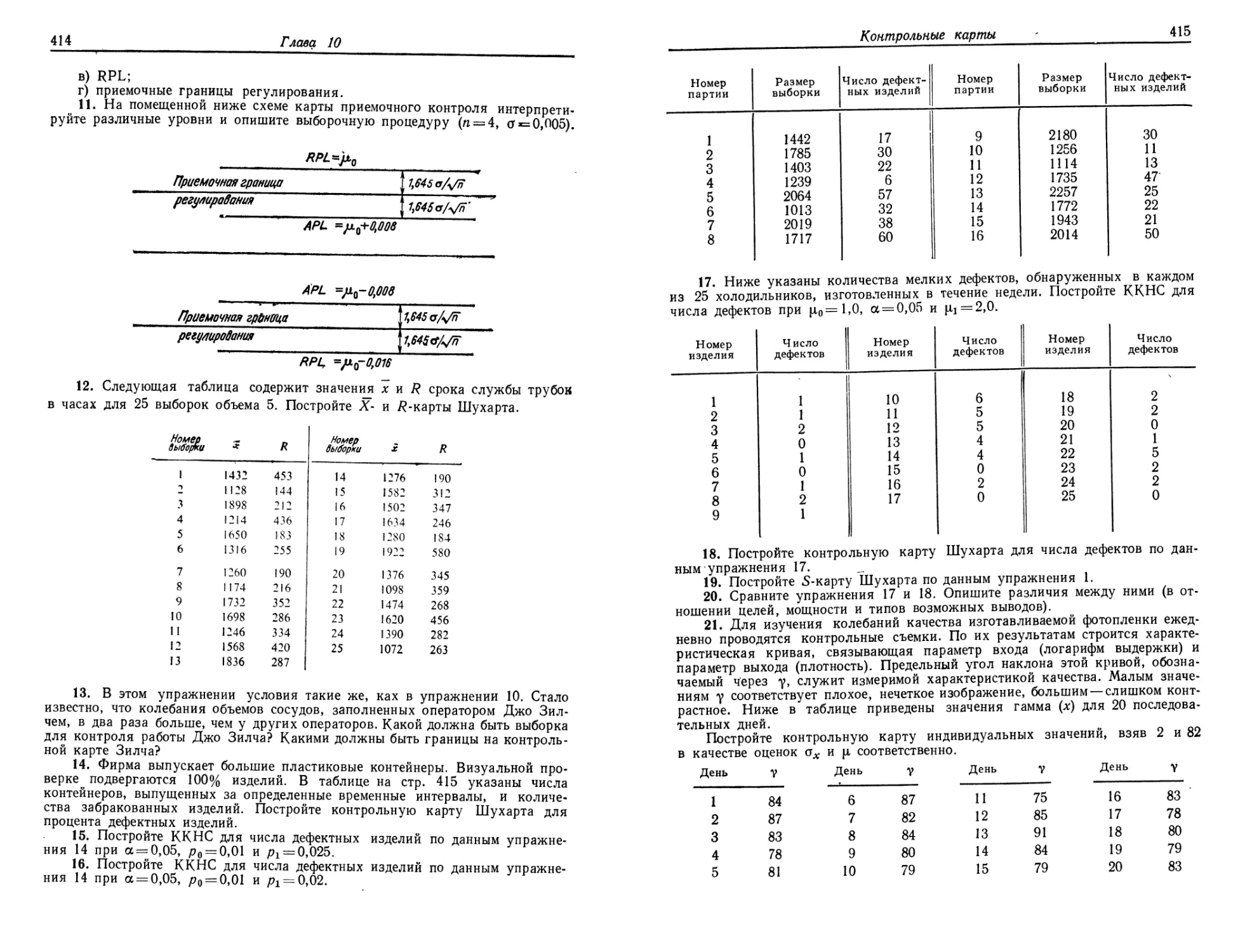
Ф.Лион
СТАТИСТИКА И ПЛАНИРОВАНИЕ
ЭКСПЕРИМЕНТА В ТЕХНИКЕ
И НАУКЕ
МЕТОДЫ ОБРАБОТКИ ДАННЫХ
Перевод с английского
под редакцией
канд. техн. наук Э. К. ЛЕЦКОГО
Издательство «Мир»
Москва 1980
УДК 001.89
В книге излагаются основы техники статистических вычисле-
вычислений Наряду со стандартными приемами оценивания и проверки
гипотез рассматриваются методы статистического контроля, эле-
элементы теории статистических решений, вопросы регрессионного
и корреляционного анализов. Приведены статистические таблицы
и графики, полезные при решении прикладных задач, а также
большое число примеров и упражнений
Предназначена для специалистов, желающих применять мето-
методы математической статистики и теории планирования экспери-
эксперимента, и представляет несомненный интерес для студентов вузов и
аспирантов естественнонаучных и технических специальностей.
Редакция литературы по новой технике
1502000000
20204-168
Copyright © 1964, 1977 by John Wiley & Sons,
Inc All rights reserved Authorized translation from
enghsh language edition published by John Wiley
& Sons, Inc.
ZUZO4-lt>8 «¦ ouiu», uu,.
Д 04Г@1)-80 168~80 © Перевод на русский язык, «Мир», 1980
ПРЕДИСЛОВИЕ РЕДАКТОРА ПЕРЕВОДА
В предлагаемом вниманию читателей первом томе известной моно-
монографии Н. Джонсона и Ф. Лиона излагаются стандартные ста-
статистические методы и приемы, широко используемые при выпол-
выполнении любой экспериментальной работы. Цель авторов—научить
экспериментаторов правильно использовать статистические методы,
очертить круг экспериментальных задач, для которых они при-
применимы.
Значительная часть первого тома посвящена изложению осно-
основных разделов теории вероятностей и математической статис-
статистики, включаемых обычно в большинство руководств по этим
дисциплинам. Несмотря на традиционное содержание этой части
книги, представленный в ней материал интересен многочисленными
примерами, как правило носящими нестандартный характер.
Приведенные здесь сведения необходимы для понимания материала
второго тома, включающего такие разделы, как дисперсионный
анализ, планирование эксперимента при исследовании поверхности
отклика, последовательный анализ. Второй том монографии
будет переведен на русский язык.
В первом томе рассматриваются также техника контрольных
карт и элементы теории статистических решений. Эти вопросы
авторы не пытаются осветить исчерпывающим образом. Контроль-
Контрольные карты рассматриваются как пример использования идей про-
проверки статистических гипотез при управлении производством, а
элементы теории статистических решений излагаются для иллю-
иллюстрации возможности совершенствования процедур оценивания и
контроля при наличии некоторой априорной информации об иссле-
исследуемом объекте.
Из материала книги вытекают следующие полезные рекомен-
рекомендации для исследователей.
1. Для совершенствования процедур оценивания и контроля
целесообразно использовать априорные сведения об исследуемых
совокупностях, даже если эти сведения неполные.
2. При выборе способа обработки данных необходимо учиты-
учитывать характеристики устойчивости методов по отношению к нару-
нарушениям исходных предпосылок (или характеристики робастности
методов).
Предисловие редактора перевода
3 Целесообразно подходить к решению задач планирования
любого экспериментального исследования на научной основе.
В широком смысле к планированию эксперимента следует
отнести методы решения всего комплекса задач организации и
проведения эксперимента, включая задачи определения объема
выборки и способов ее извлечения, выбора условий и очередности
проведения опытов, моментов измерения, моментов окончания исс-
исследования и т. д. В первом томе монографии отсутствует система-
систематическое изложение вопросов планирования эксперимента. Авторы
ограничились здесь рассмотрением примеров решения частных
задач планирования. Это задачи выбора характеристик процедур
оценивания, контроля качества, приемочного контроля. Более об-
обстоятельно проблемы планирования эксперимента представлены
во втором томе монографии.
Авторы стремятся дать читателю информацию не только о
том, как следует обрабатывать данные, но и почему следует исполь-
использовать тот или иной метод. Эти сведения необходимы экспери-
экспериментатору, ибо поверхностное знакомство с математической теорией
и формальное применение ее аппарата в наше время уже недос-
недостаточны для того, чтобы выполнять экспериментальную работу
с требуемыми эффективностью и качеством.
Экспериментатору не обязательно быть специалистом по ма-
математической статистике, но он должен хорошо понимать идей-
идейную сторону математической теории, четко представлять ее воз-
возможности, уметь применять теорию к конкретным нестандартным
задачам, возникающим на практике. Книга может оказать в этом
неоценимую помощь.
Перевод выполнен Е Г. Коваленко (гл 1—3), канд. техн.
наук Ю П Адлером (гл. 4, 5), канд техн. наук М. Г. Борча-
ниновым (гл. 6—9), В. М. Ханиным (гл. 10—12).
Э. К. Лецкий
ПРЕДИСЛОВИЕ К ПЕРВОМУ ИЗДАНИЮ
Цель этой книги — познакомить научных работников и студентов
технических специальностей с основными статистическими методами
и научить применять эти методы В книге изложены основные
разделы математической статистики и для полного понимания
материала необходимо хорошее знание прикладной математики.
Главная задача, которую ставили перед собой авторы, состояла
в том, чтобы дать четкое представление о способах применения
статистических методов и принципах, лежащих в основе их исполь-
использования. Эта книга не энциклопедия и не академический курс.
Усложнение материала и математическая строгость не были само-
самоцелью. Иногда это оказывалось необходимым, чтобы обеспечить
требуемую гибкость, предотвратить появление ошибочных выво-
выводов или разъяснить доказательство При этом всякое усложнение
материала подчинялось главной цели—научить правильно при-
применять статистические методы
Полезную информацию может почерпнуть из книги и чита-
читатель, не знакомый с основами высшей математики. Приводимые
доказательства можно опустить, рассматривая только постановку
задачи и теоретические выводы. Чтобы студенты или научные
работники могли легко усвоить рассматриваемые статистические
методы, в книгу включено большое число примеров. Эти при-
примеры приведены не для того, чтобы получился сборник готовых
рецептов. Напротив, их назначение состоит в том, чтобы выде-
выделить и разъяснить тот или иной вопрос.
Некоторые разделы помечены звездочкой. При первом чтении
они могут быть опущены. Однако было бы неправильно считать
их второстепенными Обычно здесь рассматриваются специальные
вопросы или дается другой подход.
В конце каждой главы приводится большое количество упраж-
упражнений. Они имеют различную степень трудности, что дает читате-
читателям с разной подготовкой возможность выбора и позволяет закре-
закрепить материал, изложенный в соответствующей главе Примеры
и упражнения взяты из различных областей науки и техники
Ответы приводятся в конце книги примерно для десяти упражне-
упражнений из каждой главы (за исключением гл 1) Списки литературы
не претендуют на полноту и являются недостаточными для тех
Предисловие к первому изданию
читателей, которых интересуют главным образом теоретические
вопросы математической статистики.
Материал этой книги предназначен студентам старших курсов,
специализирующимся в области прикладной статистики, для изу-
изучения в течение двух-трех семестров. Книга будет полезна также
студентам других специальностей.
Первый том может быть положен в основу курса, рассчитанного
на один семестр. Однако может оказаться желательным отложить
изучение гл, 11, а возможно и гл. 10, до следующего семестра.
В приложении к первому тому содержится ряд таблиц, исполь-
используемых в статистической работе. Некоторые из этих таблиц
потребуются только при изучении материала второго тома, однако
для удобства все таблицы собраны в одном томе.
Мы хотим выразить глубокую признательность всем, чья по-
помощь и поддержка сделали возможным появление данной книги.
Приносим искреннюю благодарность нашим семьям и друзьям,
терпение которых было важным фактором, способствовавшим
завершению этого труда. Особенно хочется поблагодарить за
помощь секретарей Маргарет Лачко и Мэри Фуллер из технологи-
технологического института Кейса в Лондоне и Джоан Сиборн из коллед-
колледжа Лондонского университета.
За разрешение использовать соответствующие материалы мы
весьма призйательны редакторам журналов Annals of Mathema-
Mathematical Statistics, Applied Statistics, Biometrics, Biometrika, Bulletin
of the International Statistical Institute, Industrial Quality Cont-
Control, Journal of the American Statistical Association, Journal of
the Royal Statistical Society, Technometrics и других изданий,
посвященных не только вопросам статистики.
Хочется поблагодарить проф. Пирсона и попечителей Общест-
Общества биометрии за разрешение воспроизвести некоторые таблицы,
опубликованные в книге Pearson E. S., Hartley H. О., Biometrika
Tables for Statisticians, Vol. 1. Мы обязаны покойному сэру
Рональду Фишеру, члену Королевского общества (Кембридж),
д-ру Фрэнку Иейтсу, члену Королевского общества (Ротамстед)
и издательству Oliver and Boyd (Эдинбург) за разрешение пе-
перепечатать таблицы III, VI и XXIII из книги Fisher A., Yates
F., Statistical Tables for Biological, Agricultural and Medical
Research. Авторы признательны также О. Дэвису и издательству
Oliver and Boyd за разрешение перепечатать таблицы Е, Е1,
G и Н из книги Davies О. L., Design and Analysis in Indust-
Industrial Experiments.
Июль, №4
H. Джонсон,
Ф. Лион
ПРЕДИСЛОВИЕ КО ВТОРОМУ ИЗДАНИЮ
Эта книга значительно отличается от первого издания A964 г.),
но основные принципы изложения материала те же, что указаны
в предисловии к первому изданию.
Изменения первого издания проводились в следующих нап-
направлениях:
1. Исключение материала, который в настоящее время пред-
представляется менее важным (например, метод Дулиттла для реше-
решения нормальных уравнений в гл. 12).
2. Включение нового материала либо потому, что он обеспе-
обеспечивает более широкое освещение темы (например, материал о
дисконтировании в гл. 11), либо потому, что он отражает новые
результаты, полученные после выхода первого издания книги
(например, некоторые результаты в области последовательного
анализа в гл. 16). Добавлено также несколько новых иллюстра-
иллюстративных примеров.
3. Перестановка материала внутри глав и его перераспреде-
перераспределение между главами. Глава 17 разделена на две главы, одна
из которых посвящена поверхностям отклика, а другая—много-
другая—многомерному анализу. В каждую из этих глав включен новый мате-
материал. Особо следует отметить, что изменен порядок следования
упражнений в каждой главе—-упражнения сгруппированы по
темам. Кроме того, добавлено значительное число новых упраж-
упражнений, а некоторые исключены.
4. Важной особенностью второго издания является значитель-
значительное увеличение количества упражнений с ответами. Приведено
больше упражнений с решениями, и, кроме того, многие реше-
решения выполнены значительно подробнее. Это будет особенно по-
полезно для студентов, использующих данную книгу как учебник.
5. В конце первого тома, как и во втором томе, помещены
таблицы. Теперь каждый том имеет таблицы, соответствующие
содержащимся в нем материалам.
Мы хотим выразить благодарность всем тем, кто упоминался
в предисловии к первому изданию, а также Джун Максвелл из
университета шт. Северная Каролина и Дороти Циммерман за
помощь в подготовке второго издания.
Чепел-Хилл, шт. Северная Каролина // Джонсон
Кб Ф- Лион
Глава I
ВВЕДЕНИЕ
Математическую статистику определяют как научную дисцип-
дисциплину, изучающую числовые данные. Это определение указывает
на широту возможных применений статистических методов. В нас-
настоящее время вряд ли существует какая-либо область, где
количественные измерения в той или иной степени не играли бы
определенной роли. В повседневной работе многих людей, и,
конечно, не только специалистов в области математической ста-
статистики, мы наблюдаем применение количественных измерений
во многих формах. При сборе точной информации для любых
целей человек автоматически применяет некоторые статистичес-
статистические методы (возможно, в очень малой степени, возможно, даже
не зная об этом), чтобы эффективно использовать получаемые
данные в качестве прочной основы для своих выводов и реше-
решений.
Слово «статистика» употребляется в самом различном смысле.
К сожалению, непрофессионал, не знакомый со статистическими
методами,—будь это человек с невысоким образовательным уров-
уровнем или выдающийся ученый в определенной области (в том
числе и в математике) — обычно считает, что статистика—это
только совокупность определенных данных, например таких, как
„Статистические данные ООН", „Материалы переписи населения
страны", „Таблицы смертности", „Статистика дохода фермеров"
и т. п. Безусловно не следует пренебрежительно относиться к
таким совокупностям данных, поскольку существует определен-
определенная необходимость в информации такого рода, наличие которой
действительно является важной предпосылкой для последующих
статистических исследований. Однако это лишь небольшая часть
статистики. В данной книге основное внимание уделяется тех-
технике статистического вывода. С помощью данных, собранных
(как мы надеемся) в контролируемых условиях (или, во всяком
случае, в условиях, о которых, как обоснованно полагается, у нас
имеется известное представление), мы получаем информацию, на
основании которой делаем определенные выводы.
Введение
И
Ы. ВЫБОРКА И СОВОКУПНОСТЬ
Накопленные данные можно рассматривать как измерения
определенных свойств объектов, выбранных из некоторой боль-
большой совокупности. Необходимо с особой тщательностью опре-
определить, что понимается под совокупностью. Мы регистрируем
информацию об определенных характеристиках элементов выбор-
выборки. Например, берется группа стержней, обработанных на станке,
и для каждого элемента этой выборки определяется предел проч-
прочности на разрыв. Здесь объектами являются стержни, а изме-
измеряемым признаком—предел прочности на разрыв. Измеряемыми
характеристиками объектов (контрольных образцов, проб мате-
материала и т. д.), составляющих выборку, могут быть содержание
углерода в контрольных образцах; число частиц, регистрируе-
регистрируемых за единицу времени при радиоактивном излучении; сниже-
снижение веса детали за счет истирания; количество осадков за ме-
месяц в определенном городе.
Обычно принимаются некоторые допущения относительно
выборки. Они могут быть различными для разных задач. Часто
принимается допущение о том, что выборка является однород-
однородной, т.е. она получена только из одной совокупности. Кроме
того, нам хотелось бы иметь выборку, не содержащую систе-
систематических ошибок.
С помощью выборочных измерений определяются (или вычи-
вычисляются) некоторые статистические показатели (статистики).
В свою очередь они используются как основа для выводов отно-
относительно некоторых количественных характеристик (или пара-
параметров) исходной совокупности, из которой была взята вы-
выборка.
Существует неограниченное множество задач, однако некото-
некоторые свойства распределения значений совокупности изучаются
особенно часто. Например, обычно нас интересует среднее зна-
значение некоторой характеристики совокупности. Кроме того,
нередко нас интересует общая форма распределения. Часто удобно
представлять его в виде математической кривой y = f{x), где
f(x) показывает (во всяком случае, приближенно) частость появ-
появления в рассматриваемой совокупности значений, равных х
(с определенной степенью точности). Если такое математическое
описание возможно, то мы получаем ответ на следующие вопросы:
1) каковы пределы распределения, 2) является ли распределение
унимодальным (т. е. имеет ли оно только один максимум) и 3)
является ли оно колоколообразным
12
Глава 1
{/-образным
или /-образным
—^—или "^—
Очень часто важно знать, является ли распределение симметрич-
симметричным или насколько оно асимметрично. [Говорят, что функция
}(х) симметрична относительно некоторого значения х, например
xQ, если f(xo + A)^f(xo—Д) для всех значений Д.]
1.2. ПОРЯДОК СЛЕДОВАНИЯ ГЛАВ
При изложении материала этой книги мы рассмотрим вна-
вначале эмпирические распределения и числовые характеристики,
используемые для их обобщенного описания (гл. 2). Сюда входят
представление выборочных значений в табличном виде и вычи-
вычисление на основании выборки некоторых статистик, а также
графическое представление этих результатов. После этого мы
рассмотрим отдельные разделы общей теории вероятностей (гл. 3)
и некоторые основные законы и свойства распределений в целом
(гл. 4 и 5). Глава 4 посвящена наиболее часто используемым
дискретным распределениям, а в гл. 5 рассматриваются непре-
непрерывные распределения. Непрерывные распределения используются,
если существуют любые возможные значения (за исключением,
может быть, некоторого числа значений) случайной величины
(в определенных пределах). Если имеется только последователь-
последовательность отдельных возможных значений, то приемлемо дискретное
распределение. Результаты счета обычно являются примерами
дискретных случайных величин. С другой стороны, вес конт-
контрольного образца, рост человека, долговечность некоторого мате-
материала и угол вхождения ракеты в атмосферу являются приме-
примерами непрерывных случайных величин.
Глава 6 посвящена порядковым статистикам, применяемым к
данным, которые естественным образом упорядочены во времени,
по величине и т. д. или размещаются в определенном порядке.
В гл. 7 и 8 рассматриваются наиболее известные критерии зна-
значимости и методы оценивания параметров совокупности с помо-
помощью выборки. Эта тема продолжается в гл. 9, где вводятся не-
непараметрические критерии. Большинство задач аналогичны рас-
рассмотренным в гл. 7 и 8, но в этой главе ослаблены некоторые
допущения о форме совокупности или ее характеристиках.
Введение
13
В гл. 10 весьма кратко описаны контрольные карты и мето-
метода выборочного контроля. Контрольные карты накопленных сумм
рассматриваются достаточно подробно, чтобы читатель смог оце-
оценить возможности этого метода. В гл. 11 кратко излагаются та-
такие вопросы, как функции -стоимости и применение функций
априорного распределения. Эта глава приведена для того, чтобы
показать читателю, что статистика и статистический вывод суще-
существуют не в вакууме, а связаны с такими требующими постоян-
постоянного внимания проблемами, как стоимость научных исследований
И экспериментов.
Глава 12 называется „Регрессия и корреляция". Цель вклю-
включения этих двух вопросов в одну главу состоит не в том, чтобы
попытаться показать, что они взаимосвязаны (очень часто они
вообще не связаны друг с другом). Причина здесь скорее в том#
что многие используемые методы вычислений одинаковы.
Главы 13—151} посвящены дисперсионному анализу (более
правильно было бы называть его анализом изменчивости) и ста-
статистическому планированию эксперимента. Здесь читатель най-
найдет множество стандартных статистических методов, используемых
многими научными работниками в области естественных наук. В
гл. 16 излагаются методы последовательного анализа данных.
Некоторые критерии, первоначально введенные в гл. 7 и 8, здесь
модифицированы таким образом, чтобы их можно было применять
при последовательном анализе и на каждом этапе получения вы-
выборочных значений можно было принимать решения относитель-
относительно рассматриваемой совокупности. Однако не ставится задача
полностью охватить все возможные ситуации (да это и невоз-
невозможно).
При обсуждении в гл. 18 методики исследования поверхности
отклика рассматриваются как регрессионный анализ, так и ме-
методы планирования эксперимента. В гл. 17 дается элементарное
изложение многомерного анализа. В гл. 19 описаны различные
способы выборочного обследования и их свойства. В частности,
нас интересует использование имеющихся сведений о структуре
совокупности, которые помогают выбрать лучшие способы полу-
получения выборок.
. Данная книга написана главным образом для специалистов
в области физических и технических наук. Однако авторы наде-
надеются, что она будет полезна исследователям, работающим в дру-
других областях. Статистические методы, важные для одной облас-
области, часто имеют большую ценность и для других областей, так
как основы статистического анализа являются общими для мно-
многих сфер деятельности. Разумеется, при переходе от одной об-
1* В первый том входят 12 глав, остальной материал помещен во втором
томе.—Прим. ред.
Глава 1
ласти к другой акценты могут смещаться. Авторы уделяют основ-
основное внимание потребностям специалистов в области физических
и технических наук, ибо в попытке охватить очень широкую
аудиторию им пришлось бы слишком разбавлять материал (в ма-
математическом смысле). Авторы опасались, что такая попытка
снизила бы ценность книги, и она ни для кого не представляла
бы интереса. Кроме того, эта конкретная аудитория ближе всего
к естественным интересам авторов и обеспечивает очень широкую
область приложений.
1.3. ИНТЕРПОЛЯЦИЯ
Материал этого раздела при необходимости можно использо-
использовать как справочный. Некоторые упоминаемые здесь функции
определяются ниже, однако знание этих функций не обязательно
для понимания рассматриваемых методов.
При статистической обработке данных используются некото-
некоторые таблицы значений математических функций. Естественно,
что такие таблицы могут содержать лишь конечное число зна-
значений. Так, например, таблица значений функции g (хУ может
содержать конкретные значения этой функции только для конеч-
конечного числа значений аргумента х. Если требуется найти значение
функции g(x) для такого х, которого нет в таблице, то либо
значение функции g(x) вычисляется специально для заданного
значения х> либо значение функции g(x) находится с помощью
табличных значений этой функции путем интерполяции. Разра-
Разработаны очень сложные методы интерполяции, однако здесь мы
ограничимся тем минимумом, который необходим для эффектив-
эффективного практического использования таблиц, приведенных в этой
книге. Если читатель желает получить более полное представ-
представление о существующих методах интерполяции (а также о методах
численного дифференцирования и интегрирования), то полезные
сведения можно почерпнуть в соответствующей литературе [2, 3, 5].
Стандартные методы интерполяции эквивалентны подбору
многочлена от х по заданному набору табличных значений функ-
функции g(x). Простейшим является случай линейной аппроксимации.
Допустимого g(x0) и g(Xi)—табличные значения функции g(x).
Интерполированное значение функции g(x) при х = х' опреде-
определяется по формуле
(l.i)
Этот прием называется линейной интерполяцией. Обычно зна-
значение хг находится между х0 и xiy а интерполированное значение
функции g(x) будет тем точнее, чем ближе g(x) к линейной
функции х в интервале (хи, хг).
Введение
15
Полезной проверкой точности представления g(x) как линей-
линейной функции переменного х является вычисление отношений
первых разностей [g(xt)—g(x0)] к длине соответствующих интер-
интервалов (хг—х0). Вычисление этих интервалов показано в табл. 1Л.
Линейная интерполяция
Таблица 1Л
X
х0
xt
х2
Отношение разности
к ширине интервала
[?(*i)— g(xo)]/(*i—*o)
[*(*2)—?(*i)J/(*a — *i)
l?(x*)-g(xnMx9-xj
Если g(x)—линейная функция переменного х, то отношения этих
первых разностей должны быть почти постоянны. Если после-
последовательные значения х отстоят друг от друга на равные интер-
интервалы, т.е. х±—х0— х2—Х| = ха — х2—...,то деление на ширину
интервала (общую) можно не производить.
Даже если g(x) не является линейной функцией от х (во
всяком случае, при точной аппроксимации), то, заменив х моно-
монотонной функцией от х9 можно применять линейную аппроксима-
аппроксимацию. В частности, если функцию g(x) можно представить как
В{х) = ао + а1х-1 + алх-?+ ..., то при больших х можно аппрокси-
аппроксимировать g(x) линейной функцией от лг1. Например, табличным
значениям ?B0), ?B4), ?C0), $D0), ?F0), ?A20) и g(oo) соот-
соответствуют значения функции G(у) = gA2О0-1) при #=6, 5, 4, 3,
2, 1,0. Если G(y)—приближенно линейная функция у, то путем
линейной интерполяции можно найти, например, значение функ-
функции g D8) = С B,5) как V,[GB) + GC)] = Vi[?F0)+?D0)]. Этот
метод называется гармонической интерполяцией; он особенно по-
полезен, так как позволяет проводить интерполяцию по бесконечным
интервалам. Следует заметить, что табл. Е, К, П и Р приложения
составлены таким образом, чтобы облегчить гармоническую интер-
интерполяцию. (Например, используемое в примере 12.9 значение
/4б; о,975 может быть получено из табл. Е путем гармонической
интерполяции.)
Пример 1.1. Допустим, что требуется вычислить верхние
5%-ные точки F-распределения при 1) 10 и 50 степенях свободы
и 2) при 18 и 50 степенях свободы.
Из табл. Ж приложения находим значения F\o-Vt; 0,95» приве-
приведенные в табл. 1.2. Здесь в первом столбце даны значения;
16
Тлта 1
Таблица L2
Интерполяция в таблице /^-распределения
5
4
3
2
1
0
24
30
40
60
120
00
2,25
2Л6
2,08
1,99
1,91
1,83
Разности
0,09
0,08
0,09
0,08
0,08
#=120/v2, а в четвертом столбце приведены разности последо-
последовательных значений F1OtVt; 0i95t Постоянство чисел в последнем
столбце указывает на то, что Flo;Vt]Ot9& очень хорошо представ-
представляется линейной функцией переменного у в интервале рассматри-
рассматриваемых значений. Например, можно записать
*ю; v2; о,95 ^l>oo + U,Uo4 — .
v2
При v2 = 50 имеем у = 120/50=^2,4, и с помощью этой формулы
получаем F10; во; о,95=* 1,83 + 0,084-2,4 = 2,02. Обычно использу-
используются только два соседних значения; при этом получаем
1,99+ 0,4-0,09 ==2,03.
Это решение для первого случая. Для второго случая нельзя
использовать этот метод, так как табл. Ж не содержит значений
для v^ie, Здесь требуется интерполировать как по vlf так и
по v2, т. е. необходима двумерная интерполяция. Выведено мно-
множество формул для двумерной интерполяции. Они дают интер-
интерполированное значение как функцию (обычно линейную, даже
если интерполяция не является линейной) табличных значений
соседних пар значений аргумента. В данном случае используется
более простой поэтапный подход. Сначала находятся значения
Fvt-, so; 0,95 путем интерполяции, как и в первом случае. Затем
с помощью последовательности значений FVi; 50; о.эб путем интер-
интерполяции находится F1$; 50;o,96. Порядок вычислений представлен
в табл. 1.3, которая не требует объяснений.
Получены следующие интерполированные значения FVl;so; 0,95*
U/Vt
5
4
3
2
Vi
12
15
20
30
Fvt; во; о,»б
2,04
1,96
1,88
J,78
Разность
0,08
0,08
ОЛО
&
X
¦2
Г
I
1
СО
11
11
о
II
ю
¦и
о*
1
§
S
а
•о
о
м
в
1
(в
а
гЛ
«к
О
>
X
Раз
ю
а»
А
ост
азн
Си
43
*
>¦
о"
1.94
00
2
о*
2
о
о
о*
i *
2,01
L
8
8
со
2
8
О*
8
о"
S
©¦
•
-
8
S
8
О
8
О*
!
\
\
о"
S
О*
1,65
ю
1,84
а
120 1
18
Глава I
60 I
Если vt = 18, то у* = jg — 3y. Путем интерполяции данных в по-
последней таблице находим F18; Бо; о,»& = 1,91 -
Если мы уверены, что линейная интерполяция дает удовлетво-
удовлетворительные результаты, то достаточно использовать только четыре
центральных табличных значения, очерченные в табл. 1.3 прямо-
прямоугольником.
Разумеется, иногда могут применяться другие функции пере-
переменного х. В частности, если g(x) = aQ-{-a1x-1/2+a2x-1 + ...,
то можно взять такие значения х, как 9, 16, 36, 144, ... (так
что 12//*= 4, 3, 2, 1).
Если точность линейной интерполяции недостаточна, то могут
использоваться многочлены более высокого порядка. В прикладной
статистике часто нет необходимости использовать многочлены
выше третьего порядка. Быстрый способ интерполяции с помощью
кубических многочленов основан на использовании формулы
Эверетта для центральных разностей до вторых разностей вклю-
включительно. Вывод формулы, объяснение ее применения, а также
таблицы» облегчающие использование данной формулы, приво-
приводятся в книге Томпсона [5J.
Иногда бывает необходимо путем интерполяции находить
значение аргумента, при котором функция принимает некоторое
конкретное значение, т. е. требуется найти такое значение х0, что
0 ( У \ ft ( \ О\
о v^O/ — SO* \**~/
где g0 — заданное значение функции. Такая задача называется
обратной интерполяцией. Используя значения g{x0), gix^,
g{x2), ..., соответствующие значениям аргумента х0, xt, х2, ...,
требуется с помощью последовательности значений х путем интер-
интерполяции найти х0, удовлетворяющее уравнению A.2). Можно
показать, что этот процесс можно рассматривать как прямую
интерполяцию, если поменять ролями аргумент и функцию.
Обычно значения этих новых аргументов отстоят друг от друга
на неравные интервалы.
Пример 1.2. Допустим, что требуется найти такое значение 0,
что значение случайной величины X, распределенной по закону
Пуассона с математическим ожиданием 0,-с вероятностью 0,975
будет не меньше 4. Из табл. Б приложения находим
в Р = Рг [X ^ 4] Разность
8,6
8,7
8,8
8,9
0,9719
0,9738
0,9756
0,9772
0,0019
0,0018
0,0016
Введение
19
Вероятности Р следует рассматривать как значения аргумента,
а математические ожидания Э—как значения функции. Если бы
вероятности Р линейно зависели от математического ожидания 9,
то математическое ожидание 9 тоже было бы линейной функ-
функцией Р и можно было бы использовать метод обратной линейной
интерполяции. В данном случае получаем промежуточное значе-
12
ние 9 ж 8,7 + 0,1 - jk = 8,77. При использовании многочленов более
высокого порядка можно подобрать кубический многочлен, беря
четыре пары заданных значений. В общем случае, когда задано k
различных значений g(xt) (i= I, 2, ..., k) функции g(x), много-
многочлен (k—1)-го порядка, воспроизводящий эти значения, имеет вид
— Хх). , ,(Х— Xj-{) (x —
— Хь) ( ч
Этб известная формула Лагранжа. В рассматриваемом случае
с помощью данной формулы получаем кубическое уравнение
8,6 (лг-0,9738) (ж—0,9756) (*-0,9772)
(»0,0019) (-0,0037) (-0,0053)
8.7 (jc—0t9719X(Jg—0,9756) (jc—0,9772)
0,0019 (—0,0018) (—0,0034)
8.8 (х—0,9719) (х — 0,9738) (х-0,9772)
0,0039-0,0018(—0,0016)
8.9 (х — 0,9719) (х—0,9738) (л:^0,9756)
0,0053-0,0034.0,0016
Подставляя сюда х = 0,9750, находим интерполированное значение
а 8,6-12 (-6) (-22) 8,7-31 -(-6)-(-22)
(-19)-(-37) (-53) + 19-(~ 18)-(-34) +
-19)-(-37)-(-53)
. 8,8*ЗЫ2-(—22)
"*" 37-18-(—16)
19- (-18). (-34)
8,9-ЗЫ2.(-6)
53.34-16
-—8,6.0,04251+8,7-0,35191+8,8-0,76802 —
—8,9*0,07741 = 8,77 (как и при линейной интерполяции).
Заметим, что это интерполированное значение является линей-
линейной функцией табличных значений 8,6; 8,7; 8,8 и 8,9 и что
(с точностью до ошибок округления) сумма этих четырех коэф-
коэффициентов равна единице.
Вычисления, аналогичные описанным в этом примере, исполь-
используются при построении приближенных доверительных интервалов
Для математического ожидания случайной величины, распреде-
распределенной по закону Пуассона (см. пример 8.13).
Глава 2
1.4. СПОСОБЫ ПЕРЕЧИСЛЕНИЯ
При вычислении вероятностей появления тех или иных собы-
событий необходимо перечислять все множество выборочных точек,
в которых происходит событие.
Особенно широко используются два способа перечисления:
перестановки и сочетания. Перестановка—это упорядоченная
последовательность элементов. Пусть, например, требуется опре-
определить, сколькими способами можно установить порядок следо-
следования друг за другом четырех различных элементов:
4-3-2.1 = 4!
Существуют четыре способа заполнить первую позицию и три
способа заполнить вторую позицию, так как один элемент уже
использован. Существуют два способа заполнить третью позицию
и один способ завершить последовательность. Число перестано-
перестановок четырех элементов записывается как 4Р4 = 4!. В общем случае
пРл = п\ A-3)
С другой стороны, если выбирать всякий раз только г из п
элементов, то получим число размещений из п элементов по г.
Оно определяется как
ePr = n(n-l)(n-2)...(n-r + l) = <^^. A.4)
Число сочетаний из п элементов по г по существу представ-
представляет собой число способов выбора г элементов из п независимо
от того, в каком порядке выбираются элементы. Заметим, что
размещение п элементов по г можно выполнить путем выбора г
элементов из п (пСг) и перестановки этих выбранных г элемен-
элементов {ГРГ). Следовательно, aPf = (nCr)(rPr) или пСг= пРг1гРт-
Подставляя сюда пРг = п\/(п—г)!, получаем
Сп\1(п — /*)! /1 е\
п т^ л . A.5)
Более широко используемой является запись пСг в виде ( r j.
Поэтому
A.6)
nl
ЛИТЕРАТУРА
1. Fox L., Tables of Everett Interpolation Coefficients, Mathematical Tables,
Vob 2, Department of Scientific and Industrial Research, London, 1956.
2. Freeman H., Finite Differences for Actuarial Students, Cambridge University
Press, 1960.
3. Milne-Thomson L. M., The Calculus of Finite Differences, Macmillan,
London, 1944, Ch. 1, 3,
Введение
4. Tanur J. M., Mosteller F., Kruskal W. H., Link R. F., Pieters R, S.,
Rising G. R., Statistics: A Guide to fhe Unknown, Holden-Day, San Fran-
Francisco, 1972.
6. Thompson A. J., Tables of Coefficients of Everett's Central Difference Inter-
Interpolation Formula, Cambridge University Press, 1943.
6. Tukey J. W., Exploratory Data Analysis, Vol. 1, Addison-Wesley, Reading,
Mass., 1971.
7. Wall is W. A., Roberts H., Statistics, A New Approach, Free Press of Glen-
coe, 111., 1956.
УПРАЖНЕНИЯ
1. С помощью табл. Д вычислите Хз4;а ПРИ а = 0»25; 0,50; 0,75; 0,90.
2. Предполагается^что подходящей функцией для интерполяции явля-
является %v, а—V — иа ]^2v, где значения иа берутся из табл. Г. Проверьте,
так ли это.
3. С помощью табл. Ж вычислите /\^. Vj. 0 999 ПРИ а) vx = 4, v2 = 50;
5) vi=50, v2 = 4.
4. С помощью табл. И вычислите Qk;\; о,»5 при a) k — 5, v = 40; б) fe = 5,
v=17,
5. С помощью табл. Б оцените значение 6, при котором
в. Используя отношение (х$; а —Ху; о ьУиа> с помощью табл. Д оцените
значения: а) х|0;080; б) x!;0fM7B; в) х!б;О,'оо26-
7. В бейсбольной команде малой лиги 13 игроков. Только трое нз них
владеют подачей и только двое (не из числа первых трех) — захватом. Сколько
различных вариантов команды из девяти игроков может составить тренер,
заполняя остальные семь вакансий.
8. Из 12 имеющихся кандидатов необходимо составить комитет из пяти чле-
$08. Сколькими способами это можно сделать?
9. На пять должностей—председатель, заместитель председателя, секре-
секретарь, казначей и администратор —имеются 12 претендентов. (Один человек не
«ожет занимать более одной должности.) Сколькими способами можно про-
произвести назначения?
10. В ситуации, описанной в упражнении 8, среди претендентов шесть
женщин н шесть мужчин. Необходимо, чтобы в комитет вошли две женщины
и трое мужчин либо три женщины н двое мужчин. Сколькими способами
можно составить этот комитет?
11. Если в упражнении 9 любые две должности должны быть заняты
женщинами, а три —мужчинами, либо наоборот, и имеется шесть мужчин и
Шесть женщин, то сколькими способами можно заполнить эти вакансии?
12. Выполните упражнение 9 при следующих дополнительных условиях:
вШШнистратором должна быть женщина, а председатель и вице-председатель
#>лжны быть разного пола.
13. Вычислителю Джо Зилчу сообщили, что можно улучшить способы
выполнения упражнений 2 и 6, используя значения
_%v: a—
0,5
Прн интерполяции по v или а. Он решает проверить это на соответствующих
упражнениях данной главы. Опишите и проделайте вычисления, которые дол-
должен выполнить Джо, и прокомментируйте полученные результаты.
Глава 2
ЭМПИРИЧЕСКИЕ РАСПРЕДЕЛЕНИЯ
И ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ
2.1. ВВЕДЕНИЕ
Обширной областью математической статистики, имеющей наи-
наибольшее практическое применение, является теория статистиче-
статистического вывода. В этой области источником информации является
выборка; с помощью полученных данных оцениваются параметры,
позволяющие описать совокупность, из которой взята выборка;
устанавливается интервал, в котором предположительно находится
истинное значение параметра, а затем проверяются гипотезы и
делаются выводы. Это неотъемлемая и важная часть работы,
выполняемой специалистом в области математической статистики.
Математическая статистика применяется как инструмент, способ-
способствующий проведению научных исследований и накоплению дан-
данных в области техники и естественных наук. Чтобы можно было
использовать аппарат математической статистики, исследователь
должен прежде всего уметь находить некоторые числовые харак-
характеристики и строить эмпирические распределения, с помощью
которых в дальнейшем можно будет сделать необходимые выводы.
Далее мы покажем, что при статистическом выводе необходимо
принимать определенные допущения. Некоторые из этих допу-
допущений касаются распределения совокупности, из которой взята
выборка. Иногда важно иметь лучшее представление о прини-
принимаемом распределении. Для этой цели используется эмпириче-
эмпирическое распределение. Может потребоваться большая выборка, по
возможности тщательно составленная. Большая выборка может
быть использована для обоснованного выбора определенного тео-
теоретического распределения. С помощью этого распределения
можно описать некоторые приближенные результаты.
Поэтому желательно заранее получать эмпирические распре-
распределения и иметь в своем распоряжении несколько простых чис-
числовых характеристик. При выборе числовых характеристик не
следует забывать, каково основное назначение этой информации.
В общем случае мы должны с помощью выборки сделать вывод о
том, какое именно распределение имеет совокупность, из кото-
которой взята выборка. Такой вывод обычно является неопределен-
неопределенным. Значительная часть математической статистики связана с
измерением и минимизацией этой неопределенности, однако
основной предпосылкой грамотных статистических исследований
является применение обоснованных выборочных методов.
Эмпирические распределения и числовые характеристики
23
2.2. ЭМПИРИЧЕСКИЕ РАСПРЕДЕЛЕНИЯ
В этом разделе рассматривается представление необработан-
необработанных данных в табличном виде. Сюда относятся принятие реше-
решений о ширине интервалов, некоторые необходимые определения,
а также ряд эмпирических логических правил.
2.2.1. Подготовка к табличному представлению данных
Допустим, что получены данные, подобные представленным
в табл. 2.1. Такие числовые характеристики, как среднее зна-
значение или среднее абсолютное отклонение от некоторого задан-
заданного значения, могут быть вычислены непосредственно. Однако
нередко необходимо иметь более полную информацию без сохра-
сохранения точных деталей первоначальных наблюдений. Удобным
способом, обеспечивающим выполнение этих требований, явля-
является группировка данных. В процессе группировки данных пер-
первоначально наблюдаемые значения теряются, но если группы
выбраны правильно, то сохраняется удовлетворительное общее
представление о полученных фактических данных.
Первым этапом при составлений таблиц сгруппированных
данных является принятие решения об объеме групп (или ширине
интервалов группировки). Можно выбрать такую малую группу,
что даже небольшие случайные колебания будут способны иска-
исказить общую картину. С другой стороны, при слишком малом
числе групп нельзя получить достаточно детальной картины.
Обычно берется 10—20 интервалов группировки. Выбор точного
адсла интервалов зависит от: 1) размаха имеющихся данных,
f. e. разности между наибольшим и наименьшим выборочными
Значениями, 2) удобного объема группы и 3) общего числа
наблюдений. Например, если измеряется внутренний диаметр
трубы и выборочные значения лежат в интервале от 0,352 до
0,431 см, то размах составляет 0,079 см. При ширине интервала
0,010 см получаем 8—9 интервалов, а при ширине интервала
0,005 см получаем 17 интервалов. Если общий объем выборки
доставляет 300—400 наблюдений, то разумно выбрать интервал
шириной 0,006—0,007 см, тогда получим 12 интервалов. Если
имеется выборка общим объемом в 100 наблюдений, то 12 интер-
Щлоъ может оказаться слишком много.
Дадим теперь несколько определений, связанных с нашей
Таблицей. Нам нужно иметь данные, распределенные по группам
(или интервалам), каждая из которых охватывает некоторый
ййтервал значений (обычно) постоянной ширины, т. е. интервал
Щ$ппировки. Интервал группировки представляет собой группу
Значений, попадающих в данный интервал. Вначале выбираем
Ширину интервала группировки и находим границы интервалов.
24
Глава 2
В каждом из этих интервалов группировки определяем частоту
попадания в интервал, или просто частоту /. Теперь каждый
интервал группировки имеет определенные границы, и целесо-
целесообразно задать в нем некоторое представительное значение.
Определим вначале пределы интервала группировки. Это наи-
наибольшее и наименьшее возможные значения, которые могут
находиться в данном интервале. С другой стороны, границы
интервала лежат где-то между наибольшим значением одного
интервала и наименьшим значением следующего интервала, со-
содержащего большие значения. Это относится ко всем границам
интервалов, кроме первой и последней, которые можно вычис-
вычислить исходя из условия постоянства расстояния между грани-
границами каждого интервала. Наконец, в качестве представительного
значения каждого интервала группировки будем использовать
срединное значение X. Оно находится посредине между преде-
пределами интервала или между границами интервала. В некоторых
случаях ширина интервала группировки может быть переменной,
например на краях диапазона, где наблюдаемые значения встре-
встречаются реже.
2.2.2. Табличное представление данных
Данные, приведенные в табл. 2.1, представляют собой объемы
плавок в тоннах, полученные в течение месяца, причем эти зна-
значения округлены до ближайшего целого числа.
Таблица 2.1
Объемы плавок, полученные в течение месяца, т
144
141
152
163
160
147
15S
145
161
14S
146
177
167
125
156
174
143
121
164
124
148
132
!57
184
155
149
153
169
158
170
154
150
139
137
145
142
136
129
156
162
142
155
154
168
153
153
147
152
161
16?
187
152
160
154
146
153
150
131
144
138
162
170
180
137
134
133
153
183
154
161
146
146
159
139
172
143
134
152
145
166
135
147
144
141
.148
132
157
144*
166
142
150
160
153
145
165
142
157
125
175
146
161
168
136
155
173
156
143
137
156
154*
170
158
154
150
172
149
147
161
139
171
149
150
14Q
137
134
127
144
154
162
148
147
159
166
173
127
154
169
164
169
156
.135
138
150
158
133
161
118
152
151
164
163
157
142
161
153
156
155
145
174
151
158
179
167
145
163
149
164
132
172
146
157
162
157
150
164
155
162
160
166
159
164
152
176
143
138
174
151
165
161
153
175
143
137
141
148
142
165
138
171
173
167
134
157
165
176
137
151
156
148
143
136
116
165
158
179
169
В табл. 2.2 данные из табл. 2.1 сгруппированы по интерва-
интервалам. В первом столбце табл. 2.2 указаны границы интервалов
группировки, а во втором столбце записаны срединные значения
Эмпирические распределения и числовые характеристики
25
Таблица 2.2
Табличное представление данных об объемах плавок
115,5-119,5
119,5-123,5
123,5427,5
127,5-131,5
131,5-135,5
135,5-139,5
139,5-143,5
143,5-147,5
147,5-151,5
151,5-155,5
155,5-159,5
159,5-163,5
163,5-167,5
167,5-171,5
171,5-175,5
175,5-179,5
179,5-183,5
183,5-187,5
(г)
веданное
значение^
117,5
121,5
125,5
129,5
133,5
137,5
141,5
145,5
149,5
153,5
157,5
161,5
165,5
169,5
173,5
177,5
181,5
185,5
Сз)
Распределение данных
и
I
Ж
II
Ш Ж!
muni mi
тшт!
гшжтжа
жжт ж /
пн тж ж ж if
Ж7ШЖ7Ш1Н
ж т ж ж i
ж ж ж т
Ш Ж 1
Ш Ж 1
т
и
и
W
Частоте
I
5
2
11
16
16
22
21
27
23
21
18
11
11
5
2
2
E)
Накопленная
частоте
2
3
8
10
21
37
53
75
96
123
146
167
185
196
207
212
214
216
F)
Накопленная
частость
0,009
0,014
0,037
0,046
0,097
0,171
0,245
0,347
0,444
0,569
0,676
0,773
0,856
0,907
0,958
0,981
0,991
1,000
216
для каждого интервала. Можно было бы указать также и пре-
пределы интервала группировки. Однако при любом табличном
представлении данных нет необходимости задавать более одной
характеристики интервала группировки, так как, зная одну из
них, легко определить две остальные. При использовании границ
интервалов, а также срединных значений обеспечивается лег-
легкость'и точность табличного представления данных. В случае
задания только срединного значения возрастает вероятность по-
появления ошибок при составлении таблиц. Срединное значение
играет исключительно важную роль при некоторых способах
графического представления данных.
Заметим, что здесь границы интервала заданы с точностью
W величины, меньшей основной единицы измерения (в данном
случае 1 т). Это не создает неопределенности при распределении
Данных по интервалам. Заметим также, что срединные значения
Шгут не совпадать с фактически полученными значениями. Сре-
Дшшые значения могли быть выражены целым числом тонн, но
этЪ не обязательно.
26
Глава 2
2.2.3. Некоторые общие правила
Существует несколько общих правил группировки необрабо-
необработанных данных по интервалам, помогающих избежать путаницы
и обеспечивающих более эффективное составление таблиц, а
впоследствии облегчающих подбор теоретической кривой, соот-
соответствующей этим данным. Приведем наиболее важные правила.
1. При выборе числа интервалов группировки лучше всего
ориентироваться на 10—20 интервалов. Несомненно, иногда де-
делаются исключения из этого правила, но при числе интервалов,
большем 20, вся картина может исказиться. При слишком боль-
большом числе интервалов ощущается влияние даже небольших слу-
случайных колебаний. С другой стороны, если число интервалов
меньше 10, то построение теоретической кривой по эмпириче-
эмпирическим данным может быть затруднено.
2. Обычно предпочтительно иметь интервалы одинаковой ши-
ширины. Если же интервалы имеют разную ширину, то площади
должны быть пропорциональны соответствующим частотам попа-
попадания в интервал (см. рис. 5.6).
3. Необходимо охватывать всю область данных. Если не-
неизвестны предельные значения, то невозможно вычислить неко-
некоторые выборочные статистики.
4. Следует избегать открытых интервалов, т. е. интервалов,
ограниченных только с одной стороны. Обычно они затрудняют
составление таблицы. Например, какую ширину следует при-
приписывать открытым интервалам?
5. Интервалы не должны перекрываться. Не должно возни-
возникать никаких сомнений относительно того, в какой интервал
попадает любое конкретное значение.
6. Нужно выбирать удобные интервалы группировки. Сле-
Следует выбирать более естественную либо обоснованную ширину
интервала. Кроме того, если отчетливо наблюдается определен-
определенная последовательность равноотстоящих значений, то их можно
использовать в качестве срединных значений интервалов.
2.3. ГРАФИЧЕСКОЕ ПРЕДСТАВЛЕНИЕ
ЭМПИРИЧЕСКИХ РАСПРЕДЕЛЕНИЙ
Наиболее распространенными способами представления эмпи-
эмпирических данных являются гистограмма, полигон частот и по-
полигон накопленных частот. Существуют и другие способы: сек-
секторная диаграмма, столбиковая диаграмма и т. п. Последние
способы здесь не рассматриваются. В большинстве книг по при-
прикладной статистике они обсуждаются довольно подробно.
Эмпирические распределения и числовые характеристики
27
2.3.1. Гистограмма
Гистограмма состоит из последовательности примыкающих
друг к другу прямоугольников, как показано на рис. 2.1.
Объем плавок, m
Рис. 2.1. Гистограмма распределения плавок по объемам (в тоннах).
Ширина этих прямоугольников равна ширине интервалов груп-
группировки и откладывается по оси абсцисс (X), а их высота
измеряется по оси ординат (Y) прямоугольной системы коорди-
координат. Число наблюдений, попадающих в определенный интервал,
выражается площадью соответствующего прямоугольника. Осно-
Основание прямоугольника равно ширине интервала группировки, а
высота его такова, что площадь прямоугольника пропорцио-
пропорциональна частоте попадания в данный интервал. Например, если
Для данных из табл. 2.2 взять интервал со срединным зна-
значением 145,5, то соответствующий прямоугольник гисто-
гистограммы будет иметь вершины (Х(; Yt) в точках с координатами
A43,5; 0), A47,5; 0), A43,5; 22) и A47,5; 22). На рис. 2.1 по-
показана гистограмма, построенная по данным из табл. 2,1. Если
ширину интервала группировки удвоить, то при одной и той же
частоте попадания в интервал высота прямоугольника умень-
уменьшится вдвое. Если же, например, объединить группы со сре-
Динными значениями 145,5 и 149,5, то прямоугольник, изобра-
26
Глава 2
жающий объединенную группу, будет иметь вершины в точках
с координатами A43,5; 0), A51,5; 0), A43,5; 21,5) и A51,5;
21,5).
Обратим внимание читателя на излом оси X в самом ее на-
начале. Это означает, что если оси координат X и Y пересекаются в
точке @; 0), то горизонтальная ось обрывается до области наших
данных.
При построении гистограмм и других подобных графиков
необходимо добиваться ясности. Слишком часто в научной ли-
литературе наблюдается одна из крайностей: на графике слишком
мало или слишком много информации. Дополнительная инфор-
информация, например название графика, формула (если она имеется)
и единицы измерения, должна даваться, но в кратком виде.
График должен быть полным, но не перегруженным деталями.
Приходится удивляться, как часто в литературе можно встретить
график, который фактически представляет собой наложение
трех-четырех, а то и большего числа графиков при попытке
представить всю информацию на одной „картинке". В этом слу-
случае смысл графика может быть затемнен и трудно уловим.
Инженер или ученый, обрабатывающий статистические данные,
должен думать о ясности представления результатов и избегать
ненужной сложности.
Если для эмпирических данных необходимо подобрать теоре-
теоретическое распределение, то, возможно, потребуется сравнение
двух графиков, которые строят в сравнимом масштабе, чтобы
получить либо равные общие площади (в непрерывном случае),
либо равные общие суммы ординат (в дискретном случае).
В последнем случае более предпочтительным может оказаться
построение графика, состоящего только из вертикальных отрез-
отрезков прямых, показывающих наблюдаемые частоты. В этом слу-
случае вертикальные отрезки будут иметь следующие координаты
{Xt\ Yt) конечных точек: (срединное значение; нуль), (средин-
(срединное значение; частота). Например, в табл. 2.2 для интервала,
срединное значение которого равно 145,5, конечные точки вер-
вертикального отрезка будут иметь следующие координаты: A45,5; 0)
и A45,5; 22).
2.3.2. Полигон частот и полигон накопленных частот
Еще одним способом графического изображения данных
является построение полигона частот, представляющего собой
многоугольник с вершинами в точках, соответствующих средин-
срединным значениям интервалов и частотам, как показано на рис. 2.2.
Вершины имеют координаты A13,5; 0), A17,5; 2), A21,5; 1),
A25,5; 5), ....
Эмпирические распределения и числовые характеристики
29
Объем плавок m
Рис. 2.2. Полигон частот объемов плавок (см. табл. 2.2).
т
0,75
0t50
0,26
u 0"V
О#ъем л/юдок, m
Рис. 2.3. Йолигон накопленных частот объемов плавок (см. табл. 2.2).
В столбце 5 табл. 2.2 записаны суммарные (или накоплен-
накопленные) частоты, начиная с самого первого интервала 115,5—119,5.
Вершины полигона накопленных частот имеют координаты, соот-
соответствующие верхней границе интервала и накопленной частоте.
Заметим, что используется верхняя граница интервала. Если
30
Глава 2
говорят, что накопленная частота для наименьшего интервала
равна 2, то это означает, что имеются два значения, меньшие
119,5, но нельзя гарантировать, что эти два значения будут
меньше любого какого-либо другого числа, меньшего 119,5. На-
Например, для интервала, срединное значение которого равно
145,5, вершина имеет координаты A47,5; 75). На рис. 2.3
показан полигон накопленных частот для данных, приведенных
в табл. 2.2. На дополнительной вертикальной шкале отложены
накопленные частости, т. е. доли общего числа значений, не пре-
превышающих границы данного интервала. Например, интервал со
срединным значением 145,5 имеет на этой шкале координаты
A47,5; 0,347).
Полигон накопленных частот используется главным образом
для представления дискретных данных, например таких, как
число дефектных изделий в партии или число спичек в коробке.
2.3.3. Двумерные данные
Определение „двумерный" употребляется в том случае, когда
для каждого объекта измеряются две характеристики и каждое
измерение выражается двумя величинами; аналогично исполь-
используются определения „трехмерный" (три характеристики) и „мно-
„многомерный" (несколько характеристик) и т. д. Более конкретно
этот вопрос рассматривается в последующих главах. Здесь же
мы приведем два примера. В табл. 2.3 представлены результаты
Таблица 2.3
Результаты проверки калибровки поплавкового
расходомера (х-— высота поплавка, мм; у — расход воды,
фунт/ч при 77° F)
X
4
5
6
7
8
9
10
У
5,765
7,746
10,44
13,64
16,63
19,28
22,20
11
12
13
14
15
16
17
У
25,38
27,83
30,66
33,20
35,73
38,49
41,40
X
18
19
20
21
22
23
24
У
44,46
47,88
51,95
56,38
60,14
64,65
68,80
проверки точности калибровки поплавкового расходомера.
Абсцисса х—высота поплавка в миллиметрах, а ордината у —
расход воды (при 75° F) в фунт/ч. Объем выборки равен 21.
Эмпирические распределения и числовые, характеристики
31
На рис. 2.4 эти данные изображены графически. Целью
исследования был вывод уравнения достаточно высокого порядка
для определения расхода как функции высоты поплавка.
65
60
55
50
45
30
25
20
15
10
6
*
t
•
•
#
•
5 10 15 20 25
Высота поп/юбка, мм
Рис. 2.4. Калибровка поплавкового расходомера.
Еще одним примером двумерного графика является диа-
диаграмма рассеяния. Рассмотрим представление данных, получен-
полученных при проведении испытаний в Бристольской лаборатории
(Brumbaugh M. A. (Ed.), Quality Control in Central New York
Industry—A Case Book, 1952), когда для определения некото-
некоторой характеристики качества пенициллинового бульона в анали-
аналитической лаборатории использовались два метода. Хотя эти
методы дают различные результаты, полученное соотношение
позволяет построить номограмму для перехода от одного метода
к другому. Диаграмма рассеяния данных приведена на рис. 2,5.
2.4. ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ
Составление таблиц необработанных данных и последующее
графическое представление их в виде гистограммы, полигона
частот или диаграммы дает большой объем информации. Однако
нередко этого бывает недостаточно, и требуется охарактеризо-
охарактеризовать имеющуюся совокупность значений некоторыми количест-
32
Глава 2
Эмпирические распределения и числовая характеристики
33
5,0
4,3
4,8
47
4,6
4.S
4,4
4,3
§40
3,9
3,8
3,7
3,6
3,5
3,4
3,3
Л
* •
•
У.
• •
•
••
i
•>/
#
••
у
• *
••
• •
•
•
•
Ш W 9 ш ' * г • w
Метод I
Рис. 2.5. Диаграмма рассеяния результатов, полученных двумя методами
анализа.
венными показателями. Показатели, характеризующие положе-
положение, рассеяние (или разброс) и асимметрию, дают количествен-
количественное представление об эмпирических данных и помогают срав-
сравнить одну совокупность данных с другой.
2.4.1. Характеристики положения
Существует несколько характеристик положения (или мер
положения центра) совокупности эмпирических данных. Наи-
Наиболее распространенными из них являются среднее (арифмети-
(арифметическое среднее), медиана и мода. Кратко говоря, среднее пред-
представляет собой первый момент распределения, т. е. значение,
относительно которого может быть „сбалансировано" все эмпи-
эмпирическое распределение (фактически это абсцисса центра масс
гистограммы). Иначе говоря, среднее х — это такое значение
величины х, для которого алгебраическая сумма расстояний
выборочных значении xlf x2f . ., хп от 7 равна нулю. С другой
стороны, медиана х представляет собой такое значение х, что
одна половина значений х меньше ее, а другая—больше (ме-
(медиана делит площадь гистограммы пополамI». Мода—это наи-
наиболее часто появляющееся значение х. Если данные сгруппиро-
сгруппированы, то в качестве моды обычно выбирается срединное значение
интервала с наибольшей частотой. Обычно мода не используется,
так как ее трудно определить или интерпретировать.
Начнем рассмотрение вычислений выборочного среднего ариф-
арифметического со случая необработанных (несгруппированных) дан-
данных xlf л:2, ..., дгд. Среднее равно
t = l, 2,
п.
B.1)
Однако если данные сгруппированы, как в табл. 2.2, х сре-
срединное значение t-ro интервала, а Д.—частота попадания'в дан-
данный интервал, то
B.2)
1=1
1=1
где п обозначает общий объем выборки, a k-число интервалов
Для данных из табл. 2.2
При вычислении выборочного среднего может оказаться це-
целесообразным представление данных а следующем виде:
ui = c-l(xi-*o)> B.3)
где х0 —некоторое произвольное начало отсчета, а с—ширина
интервала группировки. Тогда
B.4)
ПрИ четном числе наблюдений медиана не может быть определена
^^\Г^^МЛИаНаГКУПН0СТИ 3 ? 5 4 ^*
819
Глава 2
Рассмотрим данные, представленные в табл. 2.4. В первом
Таблица 2А
Табличное представление данных об объемах плавок
CD
Срединное
значение
117,5
121,5
125,5
129,5
133,5
137,5
141,5
145,5
149,5
153,5
157,5
161,5
165,5
169,5
173,5
177,5
181,5
185,5
B)
Частотаf
2
1
5
2
11
16
16
22
21
27
23
21
18
11
11
5
2
2
C)
и
-9
-8
-7
-6
-5
-4
-3
-2
-1
0
1
2
3
4
5
6
7
8
D)
fu
-18
-8
-35
-12
-55
-64
-48
-44
-21
0
23
42
54
44
55
30
14
16
fu2
162
64
245
72
275
256
144
88
21
0
23
84
162
176
275
180
98
128
Итого
216
-27
2453
См. табл. 2.1 и 2.2
столбце приводятся срединные значения интервалов группировки.
Второй столбец содержит наблюдаемые частоты. В третьем
столбце записаны преобразованные значения ui = {xi —153,5)/4
при хо = 153,5 и с = 4,0. В четвертом столбце дано произведе-
дение // и и{. Тогда
Таким образом,
/!.«1. = -^6= -0,125.
= 4,0(—0,125) + 153,5= 153,0.
1
Чтобы определить медиану х по несгруппированным данным,
находим срединное значение, если объем выборки п —нечетное
число. Если же объем выборки —четное число, например п = 2г,
1
то медиану х можно рассматривать как полусумму двух средин-
срединных значений: х = 1/2{хг + хг+1). В случае сгруппированных
данных х находится путем интерполяции. Это удобно выполнять
Эмпирические распределения и числовые характеристики 35
графически путем построения полигона накопленных частот (см.
разд. 2.3.2). В случае данных из табл. 2.2 требуется найти
значение л;, при котором накопленная частота равна 216/2=108
(Заметим, что в общем случае медиана больше 108-го и меньше
109-го из упорядоченных по возрастанию значений х в наблю-
наблюдениях.) При х= 151,5 накопленная частота равна 96; при
л;= 155,5 накопленная частота равна 123. Полагая, что увели-
увеличение происходит по линейному закону (как при линейной
интерполяции, см. разд. 1.3), получаем
(Можно вывести формулы, основанные на более сложных мето-
методах интерполяции, однако на практике дополнительное повыше-
повышение точности вряд ли необходимо.)
- На рис. 2.6 изображена гистограмма, построенная по данным
табл. 2.2, где указаны среднее, медиана и мода.
25
Рис. 2.6. Гистограмма распределения плавок (см. табл. 2.2.)', указаны среднее
значение, медиана и мода.
В качестве характеристики положения может использоваться
также среднее геометрическое. В случае выборки объема п сред-
среднее геометрическое определяется как
B.5)
36
Глава 2
Еще одной характеристикой положения является гармоническое
среднее, определяемое как
(л^ЗхГ1)-1. B.6)
2.4.2. Характеристики рассеяния
Одной из наиболее часто используемых характеристик рас-
рассеяния (или разброса) данных является среднее квадратическое
(стандартное) отклонение. Вначале определим квадрат этой ве-
величины, называемый дисперсией. Для выборки несгруппирован-
ных данных дисперсия находится как
2 <*-
п—1
Если данные сгруппированы, то
2 м*1-х)г
1=1
и—1
B.7)
B.8)
Внимательное изучение этого выражения показывает, что оно
(если исключить —1 в знаменателе) представляет собой момент
инерции, или второй момент относительно среднего.
Среднее квадратическое отклонение определяется как поло-
положительный квадратный корень из дисперсии. Для несгруппиро-
ванных данных
/2 <*-
д-1
для сгруппированных данных
/2 м*
^4
B.9)
В случае несгруппированных данных при использовании фор-
формулы B.9) для выполнения вычислений ее можно записать в
следующем виде:
rt-l
Эмпирические распределения и числовые характеристики
37
Пусть, например, требуется вычислить среднее квадратиче-
квадратическое отклонение для следующей выборки наблюдаемых значений-
10, 18 15, 20, 19, 14, 15, 12, 13, 18. Среднее арифметическое
этих 10 чисел равно 154/10 = 15,4. При использовании формулы
B.9) потребовалось бы вычислить A0—15,4J, A8—15 4Jит л
Проще вычислить 102 + 182 + ... + 182 - 2468; тогда
-1 B468 —10 -15,42) = 3,27.
В прикладной статистике можно встретить немало случаев,
когда исходная формула, подобная формуле B.9), довольно гро-
громоздкая либо легко приводит к ошибкам округления, особенно
при больших выборках. Часто целесообразно находить формулу,
удобную для выполнения вычислений. Если в данном случае
использовать 2 С*/—ХУ как часгь формулы, то потребуется
определять среднее, вычитать из него каждое значение, возво-
возводить в квадрат полученный результат, а затем находить сумму.
Формулу B.8) можно преобразовать следующим образом:
k
2 ft
Л—1
lesl
rt—1
n—\
B.10)
Полученная формула B.10) весьма удобна для вычислений.
Еще одним весьма полезным упрощением вычислений явля-
является использование преобразованных данных, рассмотренных в
разд. 2.4.1. Этот способ очень полезен, особенно при отсутствии
Вычислительных устройств (даже ручного вычислительного устрой-
устройства) или когда существует большая вероятность появления
ошибок округления. Пусть, как и ранее, и; — (х{—xQ)/c. Мы
используем для дисперсии индекс х или и, чтобы различать
соответствующие дисперсии. Тогда хг=^си{~\-х^ и применяется
формула B.4). Подставив это значение х( в формулу B.8),
38
Глава 2
будем иметь
n—\
ft _ k _
2 fi(cui-cu)* c* 2 Л" («/-«)"
f= 1 1= 1
ft—1
ft—1
Это дает следующее соотношение между средними квадратиче-
скими отклонениями:
sx = csa. B.11)
Результаты B.4) и B.11) можно сформулировать в более
общем виде. При линейном преобразовании х, например вида
z = a + bxt среднее значение и среднее квадратическое отклоне-
отклонение соответственно равны
sz = bsx. B.12)
Вычислим среднее квадратическое отклонение для данных,
приведенных в табл. 2.4. Вначале вычислим sa, а затем по фор-
формуле B.11) определим sx. Напомним, что ui = (xi—153,5)/4,0.
Столбец D) этой таблицы содержит произведения ut и ft для
каждого интервала. При л = 216, /г = 18, с = 4,0
2/Л---27, 2/^ = 2453,
1
Тогда sx = 4,0-3,38= 13,5 т.
Иногда может потребоваться получить более точную оценку
среднего квадратического отклонения с помощью поправки Шеп-
парда на группировку. Метод состоит в уменьшении дисперсии si
на величину, равную (ширина интервалаJ/12. Следовательно, в
случае данных из табл. 2.4 дисперсия sl= 11,3936 уменьшится
до s* = 10,8936. Тогда sx = 4,0-3,30= 13,2 т.
Еще одной весьма полезной характеристикой рассеяния
является размах Rt представляющий собой разность между наи-
наибольшим и наименьшим наблюдениями:
R — *макс — -^мин* B.13)
Особенно широко используется размах в контрольных кар-
картах, применяемых при управлении качеством. Вследствие про-
простоты этой характеристики по сравнению со средним квадрати-
ческим отклонением задачу нанесения точек на контрольную
Эмпирические распределения и числовые характеристики
39
карту и определения пределов регулирования с помощью раз-
размаха можно поручить персоналу, обслуживающему установку,
так как необходимые вычисления сводятся к минимуму. Если
точность информации, получаемой при использовании размахов,
достаточна, то простота вычислений делает этот способ весьма
ценным. Использование размаха в контрольных картах рассмат-
рассматривается в гл. 10, а также в других частях книги в связи с
некоторыми иными приложениями. В данный момент мы не на-
намерены подробно обсуждать, в каких именно случаях целесо-
целесообразно применять размах. Однако следует заметить, что при
использовании размахов объем выборки не должен быть слишком
большим. Размахи, вычисленные для выборок, содержащих более
10 наблюдений, следует использовать с большой осторожностью.
Еще одной характеристикой рассеяния является среднее
отклонение, равное
2 1*'-
B.14)
Полезной формулой для вычисления среднего отклонения явля-
является следующая;
(Среднее отклонение) — 2 [(Сумма значений х> пре-
превышающих л;) — (Число значений х, превышаю- B.15)
щих х)х]/п.
Среднее отклонение обладает тем преимуществом, что оно менее
чувствительно к изменению формы распределения, чем среднее
квадратическое отклонение или размах.
Среднее отклонение, вычисленное для сгруппированных дан-
данных, может быть скорректировано путем введения поправки на
группировку, которая вычисляется как
(Доля наблюдений в группе, содержащей арифметическое
среднее)
где с — ширина интервала, а л;—средняя точка группы, содер-
содержащей среднее значение.
Пример 2.1. За каждый час 8-часовой смены изготовлено сле-
следующее число изделий: 115, 120, 124, 130, 128, 119, 120, 123.
Для упрощения вычислений примем 120 за произвольное начало
отсчета, т. е.
и = х — хо = х—120.
40
Глава 2
Тогда выборочное среднее вычисляется-как
- , - , 5 + 0+4+ . ..+3 100 Q7C
х^х0 + и =xo+ g — = 122,375.
Выборочная дисперсия равна
n(n-l)
18Л7
Пример 2.2. Для определения способности стали к глубокому
отпуску проводились испытания 150 образцов. При испытаниях
по методу Эриксона в образец вдавливается конус с шаровым
наконечником. Глубина вдавливания измеряется в миллиметрах.
Полученные данные представлены в табл. 2.5. Требуется по-
Таблица 2.5
Данные о способности 150 стальных образцов
к глубокому отпуску (глубина вдавливания, мм)
10,62
10,18
10,85
11,02
9,78
10,42
10,90
10,23
9,45
10,50
Ю,48
П,П
11,58
9,53
10,05
9,72
10,59
9,68
10,92
9,87
10,27
10,22
10,97
ю(а2
10,66
10,69.
10,80
9,42
10,69
10,54
10,85
10,24
10,48
10,35
11,07
9,54
11,18
9,67
П,43-
9,80
10,86
11,15
10,23
10,08
9,75
И 05
10,07
10,03
10,57
10,27
9,97
9,92
10,62
Л 0,87
10,47
10,12
10,08
9,99
9,96
9,85
9,85
10,63
10,22
9,30
9,83
10,75
10,65
10,20
9,57
9,89
10,17
10,05
10,02
10,35
10,34
10,22
9,75
10,00
9,85
10,77
11,23
10,05
10,30
10,03
10,73
9,79
10,88
10,03
10,17
10,22
9,10
10,02
11,53
11,40
9,80
9,80
9,83
10,13
10,23
10,50
11,45
10,51
10,67
10,45
10,77
9 97
10;72
10,55
10,42
им
9,31
9,46
10,00
11,35
9,33
10,05
10,27
10,38
10,24
10,43
10,30
4,61
10,22
9,08
10,34
10,41
11,22
11,28
9,85
9,63
10,0}
10,40
10,93
10,46
10,58
10,57
9,2$
10»»
9,12
10,32
9,23
11,51
10,33
9,30
9,65
9,98
ЩТГ
№07
9,57
10,24
строить гистограмму и полигон накопленных частот. Необхо-
Необходимо также вычислить выборочное среднее и среднее квадрати-
ческое отклонение. В табл. 2.6 представлены данные, сгруппи-
сгруппированные по интервалам. Здесь столбцы A) и E) те же, что и
в табл. 2.2. В столбце F) приводятся данные, преобразованные
по формуле
*,—10,305
и'~" 0,20 '
Мы используем это преобразование для вычисления
1^ /14 \2.
н 150
t—i
150-149
Эмпирические распределения и числовые характеристики
41
Таблица 2.6
Данные о глубине вдавливания для 150 стальных образцов
A)
fffSfruUOf
фпертв
гпитмобки. мм
9,005- 9,205
9,205- 9,405
9,405- 9,605
9,605- 9,805
9,805-10,005
10,005-10,205
10,205-10,405
10,405-10,605
10,605-10,805
10,805-11,005
11,005-11,205
11,205-11,405
И ,405-11,605
11,«05-11,805
B)
я, мм
9,105.
9,305
9,505
. 9,705
9,905
10,105
10,305
10,505
10,705
10,905
11,105
11,305
11,505
11,705
C)
Распределение данных
1/1
t-HJ 1
tHJ II
mi mi it
1WN44H-UI
ПЧ4' m4HJJ W4
№1 ГИ4 tHJ W4 FH4
tHJttUtHJ III
ti+lfi+J №4
ГН4N44
ГН11
Ш4
И44
a
D)
Частота
3
6
7
12
16
20
25
18
15
10
6
•5
5
2
E)
Накопленная
частота
3
9
16
28
44
64
89
107
122
. 132
138
143
148
150
F>
и
-6
-5
-4
-3
-2
-1
0
1
2
3
4
5
6
1
G)
Ju
-18
-30
-28
-36
-32
-20
0
18
30
30
24
25
30
14
(8)
I
108
150
П2
108
64
20
0
18
60
90
96
125
180
98
Итого
150
7 1229
На рис. 2.7 изображена гистограмма, построенная по данным
табл. 2.5 и 2.6. На рис. 2.8 показан полигон накопленных
частот, построенный по этим данным.
J0
§§§§§§§§§§§§
Глубина ддадлибаиия^ мм
2.7. Гистограмма распределения 150 стальных образцов по глубине
вдавливания.
42
Глава 2
1 700
I 50
Глубина 6дйвмвания> мм
Рис. 2.8. Полигон накопленных частот глубин вдавливания для 150 стальных
образцов.
Вычислим выборочное среднее и выборочную дисперсию слу-
случайной величины и:
и = 0,0467, 4 = 8,2461.
Следовательно, выборочное среднее и выборочная дисперсия
случайной величины х равны
х= 10,305 + 0,20*7= 10,314 мм,
s|-0,04s* =0,329844,
откуда
5^ = 0,574 мм.
Меры асимметрии здесь не рассматриваются. Характеристики
асимметрии, используемые для распределений вероятностей, при-
приводятся в разд. 3.14. Можно построить аналоги этих характе-
характеристик для использования их при описании эмпирических рас-
распределений.
В последние годы появились новые способы графического
представления данных. Некоторые интересные примеры приво-
приводятся в статье Чернова [2] и книге Тьюки [10].
ЛИТЕРАТУРА
1. Bennett С. A., Franklin N. L., Statistical Analysis in Chemistry and the
Chemical Industry, Wiley, New York, 1954, Ch. 2.
2. Chernoff H., The Use oi Faces to Represent Points in ^-Dimensional Spa-
Space Graphically, Journal of the American Statistical Association, 68, 361 —
368 A973).
Эмпирические распределения и числовые характеристики
43
3. Hahn G. J., Shapiro S. SM Statistical Methods in Engineering, Wiley,
fsfew York, 1967. [Имеется перевод: Хан Г., Шапиро С. Статистические
модели в инженерных задачах.—М.: Мир, 1969.]
4. Hald A., Statistical Theory with Engineering Applications, Wiley, New York,
1952. Ch. 3. [Имеется перевод: Хальд А. Математическая статистика с тех-
техническими приложениями.— М.: ИЛ, 1956.]
5. Hays W. L., Winkler R. L., Statistics: Probability, Inference and Deci-
Decision, Vol. I, Holt, Rinehart & Winston, New York, 1970, Ch. 5.
6. Hoel P. G., Introduction to Mathematical Statistics, 4th ed., Wiley, New
York, 1971, Ch. 2.
7. Kempthorne O-, Folks L., Probability, Statistics and Data Analysis, Iowa
State University Press, Ames, Iowa, 1971.
8. Mosteller F., Kruskal W. H., Link R. F., Pieters R. S., Rising G. R.,
Eds., Statistics by Example, Exploring Data, Addison-Wesley, Reading,
Mass., 1973.
9. Yule G. U., Kendall M. G., An Intro<Juction to the Theory of Statistics,
14th ed., Hafner, New York, Griffin, London, 1950, Ch. 4—6. [Имеется
перевод: Юл Дж., Кендалл М. Теория статистики, М., Госстатиздат, I960.]
10. Tukey J. W., Exploratory Data Analysis, Vol. 1, Wiley, New York, 1971.
УПРАЖНЕНИЯ
I. Ниже в таблице приводятся данные о ширине (в дюймах с точностью
до 0,0001 дюйма) 115 образцов из цинка марки ВВ. Ширина этих образцов
измерялась до проведения коррозионных испытаний.
Измеренная ширина 115 образцов, дюйм
0,4998
0,5005
0,5009
0,4998
0,5001
0,4999
0,4998
0,5003
0,5000
0,5002
0,5008
0,4997
0,5000
0,5001
0,4993
0,4999
0,4995
0,5000
0,4994
0,5002
0,5000
0,4998
0,4994
0,5002
0,5000
0,5005
0,4997
0,5003
0,4992
0,5005
0,5008
0,5005
0,5000
0,5009
0,4997
0,5001
0,5003
0,4994
0,4998
0,4995
0,4999
074998
0,4996
0,4993
0,5004
0,5000
0,5000
0,5008
0,5001
0,4998
0,4996
0,4999
0,5005
0,5000
0,5008
0,4994
0,5010
0,4999
0,5002
0,4990
0,4999
0,5001
0,4992
0,5000
0,4990
0,5000
0,5002
0,4998
0,4996
0,4995
0,5000
0,5004-
0,4994
0;4994
0,5001
0,5002
0,4999
0,5007
0,4998
О?5ОО5
0,5001
0,4995
0,4993
0,4996
0,5006
0,4995
0,5002
0,5000
0,5007
0,5001
0,4999
0,4997
0}5001
0,5005
0,5000
0,4999
0,5001
0,5004
0,5003
0,4999
0,5008
0,4991
0,5006
0,5003
0,4996
0,5000
0,4997
0,4998
0,4992
0,4997
0,5000
0,5005
0,5003
0,5000
0,5001
44
Глава 2
а) Постройте гистограмму, полигон частот и полигон накопленных частот.
б) Определите среднее значение и среднее квадратическое отклонение:
1) г<утем непосредственного вычисления по табличным данным; 2) с помощью
линейного преобразования вида и — (k—kQ)/c.
2. М. Крауч и Дж. Хейнем (Crouch M. F., Haynam G. E., Monte Carlo
Calculation of the Slowing-Down Time for Neutrons in Hydrogen, Nuclear
Science and Engineering, Sept. 1957) изучали распределение времени замедле-
замедления нейтронов до различных энергий в водородсодержащем замедлителе. Приве-
Приведенные ниже данные представляют собой сгруппированную выборку, содержа-
содержащую 1000 значений времени t замедления нейтронов (в микросекундах) до
энергии 0,025 эВ.
а) Постройте гистограмму, полигон частот и полигон накопленных частот.
б) Определите среднее значение и среднее квадратическое отклонение:
1) путем непосредственного вычисления по табличным данным; 2) с помощью
линейного преобразования вида u = (k — ko)/c.
Время t, мкс
0
1
2
3
4
5
6
. 7
8
9
10
Частота /
40
104
124
150
121
106
104
76
49
42
29
Время t, мкс
11
12
13
14
15
16
17
18
19
20
21
Частота /
20
14
10
6
1
2
0
1
0
0
1
3. При изготовлении миниатюрных радиоламп их выводы крепятся с по-
помощью автоматического оборудования. Важно, чтобы проводники для выводов
ламп были прямыми, иначе они не попадут в нужное место, что вызовет за-
заедание подающего механизма, а это приведет к изготовлению некачественных
ламп, которые должны браковаться. Прямизна проводника измеряется с по-
помощью оптического компаратора при закрепленном одном конце проводника
во вращающейся колодке. Прогиб определяется как разность между максималь-
максимальным и минимальным положениями, принимаемыми незажатым концом провод-
проводника при вращении, минус диаметр проводника. Так, прогиб идеально прямого
проводника равен нулю. Ниже в таблице приведены данные, полученные при
проведении эксперимента.
а) Вычислите выборочное среднее и выборочную дисперсию.
б) Постройте гистограмму и полигон,накопленных частот.
4. Ниже приводятся 150 результатов анализов, проведенных в течение
месяца для определения процентного содержания трехокиси серы в порошке
смеси.
а) Постройте гистограмму.
б) Вычислите среднее значение и дисперсию.
Эмпирические распределения и числовые характеристики
45
Данные о прогибе 487 проводников х> (упр. 3)
Прогиб, 10~6 м
1
3
5
7
9
п
C
E
17
19
21
Наблюдаемая частота
12
26
36
50
45
49
51
44
44
40
32
Прогиб, 10~$ м
23
25
27
29
31
33
35
37
39
41
43
Наблюдаемая частота
18
14
12
4
7
2
5
2
2
1
1
*) Leone F.
Technometries, 3
15,8
15,7
15,9
16,0
16,1
15,6
55,6
15,9
15,7
15,S
15,7
15,4
15,4
15,7
С, Nelson
, No.
L. S.,
Nottingham
4 (November 1961).
R. B.
, The
Folded Normal Distribution.
Процентное содержание трехокисн серы
16,0
15,8
15,8
15,8
15,7
15,8
15,8
15,8
16,0
15,8
15,7
16,0
15,9
15,6
15,7
15,7
15,5
15,9
16,1
15,8
15,8
15,5
15,6
15,9
15,5
15,7
15,6
15,6
16,0
15,9..
16t0
16,2
15,9
15,6
15,9
15,9
16,0
.16,1
16,2
15,5
16,0
159
15,7
16,0
15 J
15,7
15,8
15,7
55,5
15,6
16,1
15,5
15,7
15,8
15,7
1U
15.9
157
15,7
15,5
J6,0
15,6
15,8
15,8
15,6
15,7
15,6
15,4
15,8
1.5,5
16t0
15,7
15,7
15,9
16,1
15,9
15,4
15,6
15,5
16,0
16,0
15,7
15,9
155
15,7
157
15,9
15,7
15,7
15,8
15,5
15,7
15,6
15,9
15,6
16,3
16,0
15,8
158
15,7
15,7
15,6
15,8
15,5
15,7
15,5
15,7
15,7
15,9
16,0
(упр.
15,7
15,8
15,8
15,3
15,5
15,8
15,7
15,7
16,0
15,5
15,3
15,6
15,8
4)
15,4
15,8
15,6
15,8
15,9
15,6
15,7
15,5
16,1
15,5
15,7
15,9
5. Приведенные ниже данные представляют собой количество изделий,
изготовленных за час в цехе небольшого предприятия, работающего по зака-
заказам. Представьте данные в табличной форме, определите среднее значение и сред-
среднее квадратическое отклонение
136
134
143
118
Ш
141
134
150
122
127
122
149
134
128
136
144
125
126
142
142
132
138
128
122
132
138
140
135
127
144
128
127
131
I3O
126
133
135
136
127
125
123
119
118
139
124
127
129
150
132
132
133
137
133
145
117
150
138
135
145
145
130
133
131
122
139
144
138
138
140
137
131
130
132
130
132
133
147
140
133
132
46
Глава 2
6. Ниже приводятся данные о температуре (°F) соляного раствора при
производстве хлора и каустической соды. Данные получены в два различных
месяца. Определите среднее значение и среднее квадратическое отклонение для
каждой выборки. Постройте гистограмму для каждой выборки. О чем говорят
эти данные?
Выборка А Выборка В
155
159
157
155
154
158
160
157
153
158
156
155
158
156
155
157
155
159
156
147
148
149
149
147
148
153
149
144
144
145
149
151
150
143
150
152
147
148
146
142
7. При 25 проверках октанового числа одного и того
получены следующие результаты:
же сорта бензина
38
41
41
42
39
38
41
44
45
41
44
42
41
40
40
42
45
41
44
43
43
37
40
39
41
Определите среднее значение и среднее квадратическое отклонение.
8. а) Вычислите среднее квадратическое отклонение для каждого столбца
данных, приведенных в упражнении 7.
б) Вычислите среднее арифметическое этих средних квадратических откло-
отклонений.
в) Извлеките квадратный корень из среднего арифметического значения
соответствующих дисперсий.
г) Обсудите различия между средним квадратическим отклонением, опре-
определенным в упражнении 7, и результатами, полученными в пунктах б) и в).
9. Определите медиану и моду для данных из упражнения 1.
10. Постройте полигон накопленных частот для данных из упражнения 4.
Определите медиану.
11. Постройте полигон частот и полигон накопленных частот для данных
из упражнения 5. Определите медиану, первый квартиль B5%-ную точку) и
третий квартиль G5%-ную точку).
12. Ниже приводятся данные о пределе текучести для 100 образцов из
титанового сплава при_1000 фунт/кв. дюйм. Постройте гистограмму для этих
данных. Определите х и 5.
150
152
163
161
139
166
142
156
154
160
154
150
141
159
153
135
144
148
150
148
148
166
148
149
154
158
150'
153
151
138
149
158
139
146
136
155
145
151
154
141
160
138
153
156
166
138
145
150
138
158
147
151
171
152
169
136
146
158
154
156
158
147
141
130
147
J36
157
168
158
167
164
136
J43
137
152
150
125
139
134
155
153
160
156
142
156
159
144
139
146
144
135
160
164
152
154
173
132
164
154
147
Эмпирические распределения и числоёые характеристики
47
13.- Студент Дж. Зилч вычислил среднее арифметическое и медиану для
каждого из десяти столбцов данных предыдущего упражнения. Он утверждает,
что в четырех случаях нз десяти медиана ближе к среднему по всем 100 на-
наблюдениям, чем среднее по десяти наблюдениям, а поэтому медиана почти так
же хороша, как и среднее арифметическое. Проверьте вычисления Зилча и
прокомментируйте его утверждение.
14. При бросании двух игральных костей возможны 36 комбинаций. Сколь-
Сколькими способами можно получить общее число очков, равное 2, 3, 4, . . ., 12?
Подбросьте две игральные кости 36 раз и сравните полученные результаты.
15. Подбросьте восемь монет 100 раз. Запишите число выпадений цифры
в каждом случае. Полученные результаты занесите в таблицу. Вычислите
х и s.
Число выпадений
цифры
Частота
Число выпадений
цифры
Частота
Всего
100
16. Проводились испытания на долговечность авиационных пневматических
шин определенной марки (марка ?/), применяемых в самолетах, базирующихся
иа авианосце. Для испытаний использовались десять самолетов; получены дан-
данные, показывающие число посадок до разрушения шины. Для каждого само-
самолета получены пять результатов.
а) Для каждого набора данных определите размах и нанесите полученные
данные на график, где по оси абсцисс откладывается номер самолета, а по оси
ординат — размах.
б) Заметны ли какие-либо особенности этих данных? Объясните их.
Номер самолета
Число посадок
до разрушения
шины
123456789 10
7 14 25 24 57 10 57 26 68 66
5 45 8 56 32 5 46 7 17 8
64 7 61 38 14 14 7 64 18 14
5 55 5 32 56 7 14 32 10 8
5 14 24 27 49 24 38 41 32 24
17. Для данных из предыдущего упражнения пычислите среднее геомет-
геометрическое каждой выборки. Сравните полученные значения и обсудите эти
результаты.
18. В эксперименте, аналогичном описанному в упражнении 16, были по-
получены следующие данные:
21 22 23 24 25 26 27 28 29 30
27 8 27 13
Номер самолета
Число посадок до
разрушения
шины
11
3 43 27 13
15
11 36 44 15 17 43 26 8 8 10
43 34 8 43 8 24 33 46 30 44
112 30 33 34 15 27 29 30 9 19
35 3 17 15 13 34 29 17 28 43
48
Глава 2
Вычислите среднее квадратическое отклонение для каждой выборки и нане-
нанесите его значение на график, где по оси абсцисс откладывается номер само-
самолета, а по оси ординат—среднее квадратическое отклонение. Дают ли эти
данные какую-либо информацию о долговечности шин? Эти данные получены
для марки шин, отличной от марки шин предыдущей задачи.
19. Для данных из упражнения 18 вычислите х в каждой выборке. Срав-
Сравните среднее каждой выборки со средним по всем результатам.
20. Для данных из упражнения 18 вычислите среднее значение средних
квадратических отклонений каждой выборки. Сравните полученное значение
со средним квадрэтическим отклонением для всех 50 шин, рассматриваемых
как одна большая выборка. Обсудите полученные результаты.
21. Сравните размах данных о долговечности шин самолетов с номерами
1—10 (упражнение 16) с размахом данных для самолетов с номерами 21—30
(упражнение 18). Какие выводы можно сделать?
22. Приведенные ниже данные взяты из публикации Бюро переписей
Министерства торговли США VUSA Statistics in Brief— 1973" („США. Краткие
статистические данные. — 1973 г."):
Год
Мощность всех первич-
первичных двигателей, 1012 Вт
Потребление энергии
1018 Дж
в том числе в промыш-
промышленности, %
Производство электро-
электроэнергии, Ю12 Вт-ч
Ассигнования на научные
исследования и разра-
разработки, млрд. долл.
Федеральные расходы на
программу космических
исследований, млрд.
долл.
Численность ученых, тыс.
человек
(Прочерк означает, что данные отсутствуют,)
I960
8,09
47,05
33
842
13,7
0,9
201
1965
11,01
56,22
32
1158
20,4
6,9
224
1970
15,00
70,89
30
1640
26,6
5,4
313
1971
16,01
72,48
29
1718
27,3
5,0
1972
16,84
76,38
29
1853
29,2
4,8
i ^
Постройте для этих данных соответствующие графики, отложив годы по
оси абсцисс, а по оси ординат—рассматриваемые показатели. Прокомменти-
Прокомментируйте каждый набор данных.
23. Приведенные ниже данные характеризуют коррозионную стойкость
керамических плит при испытаниях на долговечность. Данные представляют
уменьшение веса плит в миллиграммах (после преобразования).
а) Постройте гистограмму для этих данных,
б) Определите среднее значение и среднее квадратическое отклонение.
Эмпирические распределения и числовые характеристики
49
Уменьшение веса
0
1
2
3
4
5
Частота
23
47
58
44
35
18
Уменьшение веса
6
7
8
9
10
Частота
13
6
3
2
1
24. Выберите 120 случайных чисел из табл. А приложения. Представьте
результаты в табличной форме и постройте гистограмму. Оцените х с помощью
гистограммы, а затем вычислите х и s2.
25. Ниже приводятся данные об испытаниях 20 образцов из тогожемате-
рийла, что и в упражнении 1:
0,4997
0,4996
0.4999
0,4996
0,4997
0,4992
0,4993
0,4996
0,4994
0,4997
0,4998
0,4997
0,4999
0,4996
0,4993
0,4994
0,4996
0,4999
0,4997
0,4996
а) Вычислите среднее значение и среднее квадратическое отклонение.
б) Сравните эти данные с результатами, приведенными в упражнении 1.
в) Какие выводы можно сделать?
26. Дж, Зилч в духе своих комментариев, приведенных в упражнений 13,
рекомендует вычислять медиану для каждого столбца таблиц данных, рассмат-
рассматриваемых в упражнениях 16 и 18. Действуя в соответствии с его рекоменда-
рекомендациями, прокомментируйте полученные вами результаты и покажите, почему
идея Зилча в данном случае может оказаться ценной^
27. а) Для данных из упражнения 1 определите х для 23 групп по пяти
значений в каждой (рассматривая строки таблицы). _
б) Используя эти 23 значения х, определите s2 для значений х.
в) Сравните это значение со значением s2, определенным в упражнении^
28. а) Для каждого столбца таблицы данных из^упражнения 7 определите х.
б) Вычислите дисперсию этих пяти значений х.
в) Сравните ее с дисперсией, определенной в упражнении 7,
29. Приведенные ниже данные показывают процентное содержание влаги
Щ ВО кирпичах, используемых для футеровки печи, после хранения их в те-
течение месяца. Каждая группа из четырех результатов _представляет собой
?»Ыборку из суточного объема производства. Вычислите х и s2 для всех 80
кирпичей. Постройте полигон частот.
7,5
7,1
68
6,9
7,2
7,2
6,9
7,1
7,1
7,2
7,1
6,8
6,7
7,6
6,9
7,0
7,1
6,9
7,5
7,0
6,5
7,1
7,2
7,0
7,3
6,8
7,1
6,9
6,7
7,3
7,1
7,2
6,7
6,8
7,2
¦ 7,2
6,8
7,4
7,3
6;8
6,9
6,7
7,1
6,9
6,9
7,1
7,0
7,3
7,1
7,2
7,1
6,8
7,1
7,0
7,0
6,9
6,9
7,2
6,7
7,0
7,0
6,9
6,9
6,8
6,8
6,9
7,1
7,2
7,3
7,0
6,7
7Д
7,5
7,0
7Д
7,1
7,0
6,8
7,2
7,0
50
Глава 2
Эмпирические распределения и числовое характеристики
30. а) Для данных из упражнения 29 вычислите х в каждой выборке из
четырех значений.
б) Вычислите дисперсию значений х.
в) Сравните ее с дисперсией первоначальных значений х. Обсудите полу-
полученные результаты.
31. Готовится резиновая смесь, из которой затем делаются образцы для
испытаний. Ожидаемая прочность на изгиб в условных единицах равна 11.
Какие выводы можно сделать на основании приведенных ниже данных? Вы-
Вычислите х и сделайте выводы.
10,3
13,6
12,3
13,3
9,5
11,1
12,0
12,5
10,5
11,4
11,8
12,5
12,6
10,7
11,3
12,0
11,6
12,5
10,5
13,1
10,8
12'2
13,7
12,2
9,8
32. а) Вычислите s2 для данных из упражнения 31. б) Вычислите s\ с по-
помощью средних для каждого столбца, в) Найдите отношение s2 к si. Проком-
Прокомментируйте полученные результаты.
33. а) Для данных из упражнения 12 вычислите средние значения для
групп из пяти значений (полученных путем разбиения каждого столбца на
две части).
б) Вычислите s2 для этих средних.
в) Сравните полученный результат со значением s2 для 100 исходных на-
наблюдений.
34. а) Для данных из упражнения 12 вычислите средние значения по
10 столбцам.
б) Определите дисперсию s2 этих средних, в) Сравните ее с дисперсией,
полученной в упражнениях 33 и 12.
35. Приведенные ниже данные показывают число трещин на стержень,
обнаруженных при испытаниях 600 нейлоновых стержней. Определите среднее
значение и дисперсию.
Число трещин на стержень 0 1234 5
Число стержней
36. Для уменьшения
275 207
81
23
8 6
выхода нежелательного побочного продукта приме-
применялись два различных катализатора —Л и В. При использовании каждого
катализатора были получены выборки данных, приведенные ниже. Определите
х и s2 для каждой выборки. (Наблюдаемой величиной является выход неже-
нежелательного продукта в процентах.)
Катализатор Л
40
32
29
39
45
42
53
43
45
27
57
46
Катализатор В
32
12
31
58
67
48
60
25
40
36
37. Предполагается, что механический кухонный таймер работает с боль-
большой погрешностью. Было проведено 100 проверок для выдержки, равной 1 мин.
Полученные результаты (с точностью до секунды) приводятся ниже. Вычислите
51
Продолжи-
Продолжительность
работы х, с
50
51
52
53
54
55
Частота /
1
3
5
4
8
13
Продолжи-
Продолжительность
работы х, с
56
57
58
59
60
61
Частота /
16
15
11
8
6
2
Продолжи-
Продолжительность
работы л:, с
62
63
64
69
Частота f
4
1
2
1
38. Допустим, что в упражнении 37 отсчет, равный 69 с, представляет
собой выброс, вызванный неправильной установкой. Как повлияет исключение
этого значения на х, х и s? Вычислите эти характеристики для остальных 99
наблюдений,
39. Ниже приводятся данные о числе дефектных изделий, полученных за
час, и указывается общее число изготовленных изделий. Выборку составляют
данные для 20 одночасовых интервалов.
Номер
выборки
1
2
3
4
5
6
7
8
9
10
Объем
выборки
200
186
210
145
139
186
174
178
149
168
Число
дефектных
изделий
16
12
10
14
10
13
12
14
12
16
Номер
выборки
11
12
13
14
15
16
17
18
19
20
Объем
выборки
177
182
142
156
138
179
193
148
159
167
Число
дефектных
изделий
12
13
П
16
12
11
15
14
13
15
X И S.
а) Вычислите взвешенную среднюю долю дефектных изделий (р = 2^'/2п*)
и невзвешенную среднюю долю дефектных изделий — 2 (йAщ) и сравните их.
б) Формула для оценивания дисперсии случайных величин Pt — dilni
имеет вид рA—р)/п, где я=ол2л«- Вычислите дисперсию по этой формуле.
в) Сравните эту величину с невзвешенной дисперсией значений р. Обсу-
Обсудите полученный результат.
40. В отчете Роупера, изданном в 1974 г., содержатся оценки, показыва-
показывающие, какой процент граждан не возражает, чтобы 1) правительственный
52
Глава 2
орган, ведущий секретные работы, 2) частная компания, 3) местное отделение
полиции или 4) фирма, предоставляющая кредит, имели следующие данные:
A)
B)
C)
D)
Данные о занятости
Данные о психическом состоянии
Данные о состоянии здоровья
Данные о членстве в ассоциациях
Сведения о дорожно-транспортных проис-
происшествиях
Налоговые декларации
Сведения о взаимоотношениях в семье
Представите эти данные графически и прокомментируйте их.
74
66
64
53
43
39
31
64
38
50
20
19
13
12
27
34
25
22
50
15
20
44
10
13
7
а
10
5
Глава 3
ТЕОРИЯ ВЕРОЯТНОСТЕЙ,
ОБЩИЕ ПОЛОЖЕНИЯ
3.1. ВВЕДЕНИЕ. ОПРЕДЕЛЕНИЯ
Из предыдущих глав читатель уяснил, что необходим набор ме-
методов, связанных с относительной частотой появления событий
Е длинной серии наблюдений. Эти методы дает хорошо раз-
разработанная область математики, называемая теорией вероятностей.
В этой и двух последующих главах рассматриваются наиболее
важные методы.
Некоторые основные понятия теории вероятностей выводятся
с помощью двух различных подходов. Один из них—теоретико-
множественный подход—является более абстрактным и, по-ви-
по-видимому, используется чаще. Другой подход, основанный на пе-
переходе к пределу при последовательных испытаниях, применяется
не так широко, но является интуитивно более привлекательным.
Этот подход, по-видимому, более доступен для понимания, хотя
в действительности он не менее абстрактен. Для каждого под-
подхода даются только необходимые начальные понятия.
3.1.1. Теоретико-множественная концепция вероятности
Множество можно рассматривать как совокупность абстракт-
абстрактных объектов. Этими абстрактными множествами могут быть
образцы для испытаний, удовлетворяющие определенным требо-
требованиям; бейзбольные команды высшей лиги, выигравшие в сред-
среднем более половины матчей; ученицы средней школы ростом
выше 167 см или любая другая, четко определенная группа.
Объект, принадлежащий множеству, называется элементом мно-
множества. Символическое обозначение х? А означает, что х является
элементом множества А. Обычно прописные буквы обозначают
множества, а строчные—элементы множества. Например, множе-
множество образцов, измеренная толщина (л:) которых не выходит за
заданные пределы (от 1,37 до 1,65 см), можно обозначить как
Л-{1,37; 1,38; 1,39; ...; 1,64; 1,65},
или
54
Глава 3
(Это означает, что множество Л' состоит из всех значений х>
удовлетворяющих условию 1,37^x^1,65.) Эти два множества
Л и Л' не одинаковы, если х не измеряется с точностью до
0,01 см.
Два множества Л и Б равны (А = В), если все элементы мно-
множества Л являются также элементами множества В, и наоборот.
Обозначение А с: В означает, что Л является подмножеством
множества В. Это значит, что все элементы множества Л явля-
являются также элементами множества В. Если А с: В и Б с: Л, то
Пример 3.1. Пусть Л = {jc:0<jc<2}, В = {у:у = 0, 1, 2}, С =
=-{г:0<2<1} и D = {0, 1, 2}. Тогда справедливы следующие
соотношения: ВаА, СаА, Б — D и D<zA.
Вероятность определяется как некоторая мера на множествах,
соответствующих рассматриваемым сложным событиям. Предпо-
Предполагается, что эта мера аддитивна над счетным числом непересе-
непересекающихся множеств. (Два множества А и В являются непересе-
непересекающимися, если у них нет общих элементов.)
3.1.2. Концепция последовательных испытаний
Второй подход основан на понятии последовательных испы-
испытаний. Модель строится в предположении, что рассматривается
последовательность наблюдений (часто называемых испытаниями);
в каждом случае отмечается, произошло или не произошло
определенное событие, обозначаемое Е. Под событием может
подразумеваться почти любое наблюдаемое явление, hq всегда
должна существовать последовательность (абстрактных) испытаний,
которую можно рассматривать как часть очень большой после-
последовательности. Обозначим число испытаний, в которых наблю-
наблюдается событие Е после N первых испытаний, через nN- Пола-
Полагаем, что если существует вероятность появления события Е
в этой последовательности, то существует предел
lim M
равный этой вероятности и обозначаемый как Рг[?].
Обычно nN называется частотой, a nN/N — частостью появ-
появления события Е в первых N испытаниях. В данном случае
вероятность определяется как предел частости в длинном ряду
испытаний.
Следует заметить, что это определение невозможно проверить
непосредственно в том смысле, что мы не можем получить беско-
Теория вероятностей. Общие положения
55
нечную последовательность (реальных) испытаний и обнаружить,
действительно ли существует единственное предельное значение
отношения nN/N. Разумеется, это определение достаточно хорошо
согласуется с нашими интуитивными представлениями, однако
следует иметь в виду, что оно основано на идее бесконечной
последовательности испытаний, а не на реальной последователь-
последовательности, какой бы большой она ни была.
Основанием для использования любого из этих определений
(или какого-либо другого) является полезность результатов
в различных ситуациях. Если эти результаты получают по су-
существу одинаковую интерпретацию, то не имеет значения, какой
именно подход используется.
3.1.3. Основные свойства
Определение вероятности, основанное на концепции последо-
последовательности испытаний, имеет вид
Поскольку nN и N — неотрицательные числа, a nN не больше N,
Следовательно,
0<Рг[?]<1. C.1)
Если событие Е появляется при каждом испытании, то nN^N
и nN/N^\ для всех N, поэтому
Рг[?]=1.
Это соотношение можно сформулировать следующим образом:
„Вероятность достоверного события равна 1".
Поскольку возможно, что limnN/N=l при nN=?N для лю-
бых значений N, то обратное утверждение не всегда справедливо,
т. е. вероятность, равная 1, не обязательно означает достовер-
достоверность.
Если событие Е никогда не появляется, то %=0и nN/N=0
для всех N, поэтому
Рг[?] = 0.
Это соотношение можно сформулировать следующим образом:
„Вероятность невозможного события равна 0".
И в данном случае обратное утверждение не всегда справед-
справедливо, так, как возможно, что lim nN/N = 0 даже при яЛг>0.
N
56
Глаза 3
Несмотря на сделанные оговорки, полезно рассматривать ве-
вероятность, изменяющуюся от (почти) невозможности до (почти)
достоверности (от 0 до 1).
При теоретико-множественном подходе мера появления всех
возможных событий (в любой конкретной задаче) произвольно
принимается равной 1, а мера пустого множества (т. е. множества,
не содержащего никаких элементов) равна 0.
3.2. СЛОЖНЫЕ СОБЫТИЯ
Чтобы применять теорию вероятностей, необходимо уметь
связать вероятность появления сложного события с вероятностями
появления составляющих его более простых событий. Это оказа-
оказалось возможным благодаря использованию двух стандартных
способов комбинирования двух событий, называемых объедине-
объединением и пересечением.
Объединением двух событий Ех и Е2 является событие, кото-
которое происходит при появлении события Ех или Е2 либо обоих.
Символически объединение обозначается как ЕХ\}Е%.
Пример 3.2. Допустим, что проверяются две характеристики
металлической пластины—толщина и качество покраски. Пластина
бракуется, когда ее толщина превышает 6,35 мм либо качество
покраски не превышает 8 баллов по заданной произвольной
шкале. Обозначим первое событие через Ех> а второе через Е2.
Тогда объединение событий ЕХ[)Е2 представляет собой событие,
приводящее к браковке пластины, т.е. пластина бракуется, если
появляется событие Ех или событие Е2 либо оба.
Это определение можно непосредственно распространить на
случай более двух событий. Например, если Е3— третье событие,
то событие (E1[fEi)\iEB имеет место в том случае, когда проис-
происходит одно из событий: (ЕХ[)Е2) или ?3 либо оба, т.е. появ-
появляется одно из событий Е19 ?2, Е3 либо любая их комбинация.
Проще говоря, происходит хотя бы одно из событий ЕХУ Е2 или
?3. Очевидно, что (EL[J Et)\J E9 = E1\J(Et\i Es)f и запись в виде
Ex\jE2UE3 имеет однозначный смысл-.
Пересечение двух событий Ех и Е2 представляет собой собы-
событие, которое происходит при появлении обоих событий Ех и Е2.
Символически пересечение событий записывается как /^ Л fa-
Пример 3.3. В примере 3.2 событие Exf]Et происходит, ко-
когда толщина пластины превышает заданное значение и качество
покраски является слишком низким.
Теория вероятно&пей. Общие положения
Если ?3— третье событие, например чистота поверхности ме-
менее 6 единиц по некоторой произвольной шкале, то {Ег пЕ2) Г) Е3—
событие, которое происходит при появлении событий Ех (] Е% и Е3,
т. е. всех трех событий. Это событие однозначно обозначается
как E%f)E%f\Et.
Эти два определения можно распространить на любое число
событий k. Таким образом, запись в виде Ex[jE2\} ... \}Ek
означает, что происходит хотя бы одно из событий Е1У ?2,..., Ekt
а запись в виде Ег П Е2 П .. • П Ек означает, что, происходят все
события Ег, Е%> ..., Ек.
Комбинируя эти две стандартные формы, можно построить
более сложные комбинации событий. Например, запись в виде
?iU(?2n?s) означает, что происходит событие Ех> либо события
Е2 и j?at либо все три события.
Однако таким способом невозможно обозначить событие,
означающее, что событие Е не происходит. Для этой цели вво-
вводится такое понятие, как дополнительное событие. Событие, до-
дополнительное к ?, обозначается как Е. Если происходит собы-
событие Е_у то событие Е не происходит; если же происходит собы-
событие Е, то событие Е не происходит.
Событие Е можно комбинировать с другими событиями опи-
описанными выше способами.
а) Событие Exf\E2 означает, что происходит событие Ех,
% событие Е2 не происходит.
б) Событие E1uE2(jE3 имеет место,, если не происходит хотя
бы одно из событий Е% и Е3> либо происходит событие Ех. Это
означает, что либа происходит событие Е19 либо не происходят
события ?!, или /?8, либо появляется любая комбинация атцх
трех элементарных событий.
в) События (?j и ?2) и (^п^а) идентичны; каждое из них
иредставляет собой событие „ни Е1У ни ?2".
Пример 3.4. Если в N испытаниях событие Е появляется
ш раз, то событие Е обязательно появится (N—п) раз. Поскольку
Pr[?] = lim -f, ^
—n)jN = l, to
Pr[?]=l.
C.2)
При теоретико-множественном подходе для описания событий
используются множества. Например, в случае изготовления
58
Глава 3
пластин событием Ех может быть множество пластин, толщина
которых меньше заданной (т. е. множество бракованных пластин),
а событием Е2— множество пластин, цвет которых не удовлет-
удовлетворяет заданным требованиям, Тогда множество ЕХ{}Е2 можно
представить, как показано на рис. 3.1, а. Это множество всех
пластин, не удовлетворяющих одному или обоим требованиям.
Более темная область на рис. 3.1,6 изображает множество
a) EiUEi <f) ?Л?*2
Рис. 3.1. События Ех и Е2,
пластин, не удовлетворяющих обоим требованиям, а именно
событие Exf\E2. Диаграмму, изображенную на рис. 3.1, часто
называют диаграммой Венна.
* Пример 3.5. Рассмотрим графическое представление событий
Ех и Е2 (рис. 3.1). Без потери общности можно принять, напри-
например, что Ех и Е2 — события, рассмотренные в примере 3.2 (со-
(событие Ех — толщина, превышающая 6,35 мм, и событие ?2 —ка-
—качество покраски ниже 8 баллов). На рис. 3.1, а изображено
объединение (логическая сумма) событий Ег и ?2 (Ех и ?2), кото-
которому соответствует вся заштрихованная область. С точки зрения
рассматриваемого примера вся эта область представляет собой
сложное событие, состоящее в том, что изделие является дефект-
дефектным. На рис. 3.1,6 более темная область представляет собой
пересечение (логическое произведение) событий Ех и Е2(Е1(]Е2)У
т. е. сложное событие, состоящее в том, что изделие является
дефектным по двум причинам (несоответствие по толщине и ка-
качеству покраски). На рис. 3.2 показано пересечение событий Elf
Е9 и ?ч.
Дальнейшее развитие некоторых основных положений теории
вероятностей может проводиться в соответствии с концепциями
разд. 3.1.1 или разд. 3.1.2. Мы будем следовать подходу, осно-
основанному на рассмотрении последовательности испытаний, хотя
Теория вероятностей. Общие положения
59
Рис. 3.2. Ех П Е2 П Е3.
вполне можно было бы использовать теоретико-множественный
подход. С данным подходом читатель может познакомиться
в литературе [3, 8].
3.3. УСЛОВНАЯ ВЕРОЯТНОСТЬ
Допустим, что в последовательности испытаний наблюдается
появление двух событий Ех и Ег. Нас интересует исследование
возможной связи между этими двумя событиями. Естественно
разделить последовательность испытаний на две подпоследова-
подпоследовательности в соответствии с появлением или непоявлением собы-
события Ех и определить частоты появления другого события Е2
в каждой из этих подпоследовательностей. В частности, можно
определить вероятность появления события Е2 в каждой из двух
подпоследовательностей, если существуют соответствующие пре-
пределы.
Эти вероятности (если они существуют) называются условными
вероятностями. Вероятность появления события Ег в подпосле-
подпоследовательности испытаний, в которой имеет место событие Ех,
называется (условной) вероятностью появления события Е2 при
условии появления события Ех и обозначается как Prfi:^^];
вероятность появления события Е2 в другой подпоследователь-
подпоследовательности испытаний обозначается как Prf^JfJ. Очень часто опре-
определение „условная" можно опустить, так как слова „при условии
появления события Ех" уже означают, что вероятность является
условной.
Если при первых TV испытаниях событие Ех (и не Е2) появ-
появляется пх раз, событие ?а (и не Ех) появляется пг раз, а оба
60
Глава 3
события {Ei и ?3) появляются ni2 раз, то
Pr[?2] = lira
C.3)
C.4)
C.5)
Эти определения условной вероятности справедливы и в том
случае, когда Et и (или) ?2 заменяются сложными событиями.
Например, Рг [Ег U Е2\Е3 П ?4] означает вероятность появления
события Et или события ?2 (либо обоих) при условии, что про-
происходит событие ?3 и не происходит событие ?4.
В общем случае три вероятности, заданные формулами C.3)—
C.5), не равны. Однако если любые две из них равны, то и
третья вероятность равна их общему значению, за исключением
некоторых частных случаев. Чтобы показать это, заметим, что
N
N
.-(.-!
- +
Переходя к пределу, когда N стремится к бесконечности, по-
получаем
Допустим теперь, что
Тогда
{-1 - Pr [?J} Рг [?J = {1 - Рг [?J} Рг [?t|?j.
Если Рг [Е^ф!, то
Это соотношение может быть справедливо даже при Pr[?j — 1,
но это возможно не всегда.
Читателю предлагается рассмотреть другие случаи самостоя-
самостоятельно* начиная с любых двух выражений C.3) —C.5).
Если условие Рг [Е2] = Рг [?21 ?J выполняется, на частость
появления события Е2 в длинной последовательности не влияет
появление или непоявление события Et. Когда это условие вы-
выполняется, говорят, что событие Е2 не зависит от события Е±.
Согласно этому определению, событие Е± не зависит от со-
события ?г, если PrffJ^Prff^lEa]. В следующем разделе мы
Теория вероятностей. Общие положения
61
покажем, что если событие ?2 не зависит от события Е19 то
событие ?х не должно зависеть от события Е2 (и наоборот), если
только Рг[?2]=^=0. Это означает, что независимость, определяемая
выше, является взаимным свойством, и можно сказать, что со-
события Ех и Е% независимы (друг от друга).
При рассмотрении множеств из трех и более событий следует
иметь в виду, что попарная независимость еще не гарантирует,
что какое-либо одно событие будет независимым от любой ком-
комбинации других событий. Этот случай рассматривается в при-
примере 3.6.
Пример 3,6. В сумке находятся девять шаров: три желтых,
один белый, один красный, один голубой и три разноцветных.
Разноцветные шары окрашены в следующие цвета: один в белый,
синий и желтый, один в красный, белый и желтый и один в
красный, синий и желтый. Шар вынимается из сумки случайным
образом (т. е. вероятность вынуть какой-либо один конкретный
шар равна 1/9). Пусть ?х, ?2, Е3 и ?4 —события, состоящие
в том, что вынуты шары, имеющие желтый, белый, красный и
синий цвета соответственно.
Тогда
Рг [Е2] - Рг [?,] - Pr [?J = 3/9 - 1/3.
Кроме того, Рг[?21?3] —1/3, поэтому события ?2 и ?3 вза-
взаимно независимы.
Аналогично, ?2 и ?4 —независимые события, события ?3 и ?4
также независимы. Однако событие ?3П?4 может произойти
только в том случае, если вынутый шар окрашен в красный,
синий и желтый цвета, поэтому Рг[?я|?яп?4] = 0#:Рг[?а].
Следовательно, событие ?а и сложное событие ?3П?4 не яв-
являются независимыми.
Можно также показать, что события ?х и ?2 и события Ег
и ?3 взаимно независимы, но Рг [Ег \ Е2 Г) ?3] = 1, поэтому Ех и
??3—'Не являются взаимно независимыми событиями.
3.4. ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ
В этом разделе мы докажем две фундаментальные теоремы,
которые используются при вычислении вероятностей сложных
событий (при допущении, что все соответствующие вероятности
существуют).
Теорема 3.1
Рг [?, и ?2] - Рг [Ег] + Pr [?J - Рг [Е± П ?,]. C.6)
62
Глава 3
Доказательство. Используя те же обозначения, что и
в разд. 3.3, имеем
7V-* оо
N
±p; Pr[?2]= lim
N ^ oo
ПОСКОЛЬКУ Пх + rta + 2 = ("i + «ia) + К + «ia) ~ rtl2> Д6ЛЯ обе
части этого равенства на N и переходя к пределу когда N стре-
стремится к бесконечности, получаем выражение C.6).
Теорема 3.2
] [[|?1]. C.7)
Доказательство. Ограничимся вначале случаем
По определению
Рг[?!П?,]= Ит ^-
N -> оо ;v
Pr[?8|?J= lim
7V-> oo «1+«12 *
Поскольку эти вероятности лежат между 0 и 1 включительно и
«12
N
«12
N
ТО
«12
TV-* oo
что доказывает справедливость теоремы.
Допустим теперь, что Рг[?х] = О, а вероятность
может принимать любое значение от 0 до 1 включительно. Но
Рт[Е1()Е2] не может превышать Pr[?J. Следовательно, если
Рг[?\]=:О, то Pr[E1f]E2] = 0, и обе части уравнения, выра-
выражающего теорему, равны 0 (и, следовательно, равны друг другу).
Используя определение независимости событий, данное в конце
разд. 3.3, видим, что если событие Е2 не зависит от события Е19
то теорема 3.2 принимает более простой вид
Меняя местами события Ех и Е2 в теореме 3.2, получаем
Теория вероятностей. Общие положения
63
Следовательно, уравнение C.8) справедливо также, если собы-
событие Ег не зависит от события Е2. Действительно, если при
Рг[?2]=?0 событие Е2 не зависит от события Е1У то событие Et
должно быть независимо от события Е2. Итак, в этом случае
имеем
Pr[?1]Prf?J = Pr[?a]Pr [?,!?,],
откуда следует, что
если Рг[?2]^=0.
Аналогично если Рг[?х]^=О и событие Ег не зависит от E2i
то Е2 не зависит от Ех.
Если ни вероятность PrffJ, ни вероятность Рг[?2] не равны
нулю, то независимость должна быть общим свойством этих двух
событий. Это означает, что если событие Ег не зависит от собы-
события ?2, то событие Е2 должно быть независимым от ?\, и наоборот.
Частный случай теоремы 3.1, аналогичный специальной форме
C.8) теоремы 3.2, можно получить, если положить Рг \Е1 П Е2] = 0.
Это условие выполняется обязательно, если совместное появление
событий Ех и Е2 невозможно, т. е. если эти события взаимно
исключающие (несовместные). (Например, если ?1 — событие, со-
состоящее в том, что при бросании кости на верхней грани выпа-
выпадает 1, а Е2 — событие, состоящее в том, что при бросании этой
же кости на верхней грани выпадает 2, то это несовместные
события, так как на верхней грани не может появиться 1 и 2
одновременно.) В.этом случае
Теоремы 3.1 и 3.2 остаются справедливыми, если ограни-
ограничиться подмножеством испытаний, в котором появляется, напри-
например, событие G. В этом случае имеем (из теоремы 3.1)
Рг [(?х U E2)\G] = Рг [Е, | G] + Рг [Е21G] — Рг [Ег n ?, | G] C.9)
и (из теоремы 3.2)
Рг [?, П Е21G] - Рг [?, | G] Рг [Д21 Ег П С]. C.10)
Каждую из двух теорем легко обобщить на случай произ-
произвольного числа событий.
Заменяя в теореме 3.1 событие Е2 сложным событием ?2и?3>
имеем
+ Pr[?2u?3]-Pr[?1n(?aU?,)]. C.11)
Здесь E1(](E2\JE3)—сложное событие, состоящее в том, что
происходит событие Ех и одно из событий Ей или Е3 либо оба,
64
Глава $
что эквивалентно появлению одного из событий Ег Л ?2 или,
Exf\Ea либо обоих. Поэтому можно записать
Применяя теорему 3.1 к вероятностям Рг [Е2 (J Е3] и Рг [(Е1Л ?2) U
U (Ех П Е3)] в выражении C.11) и используя соотношение
(?tПЕ2)П(Ег П?3) = Е1пЕ20Е3у после преобразований получаем
-{Рг [?2 П ?8] + Рг [?i Л ?,] + Рг [Ех П ?2]} + Рг [^i Л ?г Л ?3].
C.12)
Повторяя эту процедуру для k событий ?х, ?2, ..., Ек, полу-
получаем формулу Уоринга:
и
C.13)
В этой формуле
Если все k событий являются иесовместньши, то формуя»
Уоринга приобретает леяко запоминающуюся форму
C.14)
Обратимся теперь к теореме 3.2. Если заменить Е2 на?*П?8>
то будем иметь
Рг [Ег ПЕ2{] Е3] = Рг [Ег] Рг [Е2 П ?,|?J.
Используя снова теорему 3.2 в виде формулы C.10) и заменяя
G ад Е1% получаем
Рг [?а П ад] = Рг [?a|?J Рг [Е9\Вг П ? J.
Следовательно,
Рг [Я, П ?2 П Е9] - Рг [?j Рг [?а|?х] Рг [?,[?, П ?J. C.15)
Разумеется, эти события можно брать в любом порядке.
Правую часть формулы C.15) можно записать, например, как.
Pr[?JPr[?,|?JPr [?,!
Теория вероятностей. Общие положения
65
Повторяя эту процедуру для k событий Elf ?8,
лучаем формулу
Если события взаимно независимы, то
., Eki по-
по. C.16)
C.17)
Пример ал. Допустим, что вероятности наличия у изделий
дефектов по каждому из трех свойств равны Рг[?1] = 0,03,
Рг [?2] = 0,05 и Рг [?3] = 0,02 соответственно. Если предположить,
что эти три события взаимно независимы, то вероятность появ-
появления в одном изделии всех трех дефектов равна
Рг П ?/ =П
L/=i J /=i
.0,05-0,02-0,00030.
Теорема 3,3 (теорема Байеса). Если событие Е можно раз-
разделить на к несовместных событий Е19 ?2, ..., Ек$ а событие Я
на / несовместных событий Ях, Hi9 ..., Hv то
^(Е(пНг) и(?/ ПЯ2) и ... U(?,ПHt)
Если Рг[Я]=1, а
, то
и, согласно теореме C.2),
2
/ = 1
ЛЯ/1
[Е(
C.18)
Эта формула позволяет определить условные {апостериорные)
вероятности Рг [#,]?,.] с помощью обратных условных вероят-
вероятностей Рг[?,.|//)], если известны априорные вероятности Рг[Я;].
Теорема Байеса является очень мощным средством статистичес-
819
66
Глава 3
Теория вероятностей. Общие положения
67
кого анализа, когда выполняются условия ее применимости.
Ситуации, в которых может использоваться теорема Байеса, время
от времени встречаются в последующих главах этой книги.
Пример 3.8. Три предприятия Н19 Я2 и Я3 поставляют алю-
алюминиевые оконные рамы фирме „Оптима". Предприятие Нг по-
поставляет 25% рам, предприятие Н2—50%, а Я3—25%. Пред-
Предприятие Н± изготавливает 2% дефектных рам, предприятие
#2 — 1%, а #3 —0,5%. Проверяется одна рама (изготовитель
неизвестен) и оказывается, что она дефектна (D). Какова веро-
вероятность того, что ее поставило предприятие Нг? Имеем Рг [Ях] =
- 0,25, Рг [Я2] - 0,50, Рг [Я3] = 0,25, Pr [D | Нг] - 0,02,
Pr[D|#J = 0,01 и Рг[О|Я,] = 0,005.
Получаем
2
i = 1
* = 1
0,25.0,02
0,25-0,02+0,50-0,01+ 0,25-0,005
Аналогично можно вычислить
(Вследствие ошибок округления в данном случае сумма вероят-
вероятностей оказалась равной 0,99, а не 1,00.)
3.5. СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
При измерении определенной характеристики какого-либо
объекта получаем некоторую величину X, которая обычно яв-
является действительным числом. Можно определить Е как собы-
событие, состоящее в том, что X не больше х, где х — некоторое
заданное действительное число. В последовательности испытаний,
т. е. при выполнении измерений для некоторой последователь-
последовательности объектов, иногда может появляться событие Е. Если
частость появления события ? = (X<x) стремится к некоторому
пределу при любом значении х, т. е. когда вероятность Рг[Х<х]
существует для всех действительных чисел х, то X называется
случайной величиной.
Важность этого понятия совершенно очевидна. При проведе-
проведении прикладных научных исследований выполняются измерения,
и результаты измерений представляют собой последовательности
чисел. Очень часто обнаруживаются закономерности среди этих
чисел. Если общие условия эксперимента достаточно стабильны,
то вполне приемлемо принять допущение о существовании веро-
вероятностей Рг[Х^х]. Таким образом, случайные величины яв-
являются существенным элементом любой модели, предназначенной
для описания условий и результатов очень многих научных
исследований.
Обычно рассматриваются два типа случайных величин: диск-
дискретные и непрерывные. Эти два класса не охватывают всех слу-
случайных величин, но для практических целей можно построить
удовлетворительные модели, используя только эти два типа слу-
случайных величин или их комбинацию.
Дискретная случайная величина принимает одно из множества
различных (дискретных) значений; вероятность появления какого-
либо одного данного значения больше нуля. Символически эта
вероятность выражается как
Рг[Х = ^.]-р,, i=... , -1, 0, 1, ....
(Индекс i может принимать значения от —<х> до +оо.)
Дискретные случайные величины особенно хорошо подходят
для описания измерений, принимающих целочисленные значения,
например таких, как число дефектных изделий, число телефонных
вызовов, число дефектов в изделии, т. е. фактически любых из-
измерений, основанных на счете. Однако дискретные случайные
величины могут использоваться для измерений более широкого
класса. Строго говоря, они должны использоваться при любых
измерениях, так как на практике измерения выполняются с точ-
точностью до некоторого значения; длина измеряется, например,
с точностью до 0,01 см, вес—с точностью до 0,1 унции, время —
с точностью до 0,2 с и т. д. В этих случаях фактически наблю-
наблюдаемые величины могут принимать лишь одно из множества
возможных различных значений: длина —..., 9,98; 9,99; 10,00;
10,01; ... см; вес—0,0; 0,01; 0,02; ... унции; время—...; 5,0;
5,2; 5,4; ... с и т. д.
Однако в этих случаях число возможных значений часто бы-
бывает настолько велико, что значительно удобнее представлять
измерение в виде непрерывных случайных величин, которые могут
принимать любое значение в некотором интервале. В этом случае
вероятность того, что будет получено какое-то из возможных
значений (фактически таких значений бесконечно много), должна
быть равна нулю. Это следует из того факта, что число значений
с ненулевыми вероятностями является счетным, т. е. множество
значений может быть упорядочено. [Это можно видеть из того
факта, что значения с ненулевыми вероятностями можно объеди-
объединить в группы с вероятностями появления от т~х до (т + 1)"*
для /п=1, 2, ..., каждая из которых может содержать лишь
Некоторое конечное число значений, фактически меньшее (т+1).]
Однако все значения в любом непрерывном интервале не могут
3*
68
Глава 3
быть записаны подобным образом, и поэтому существуют неко-
некоторые значения, имеющие нулевую вероятность. Формальное
определение непрерывных случайных величин дается в разд. 3.6.
3.6. ФУНКЦИИ РАСПРЕДЕЛЕНИЯ
Различие между двумя видами случайных величин наглядно
проявляется при изучении свойств вероятности Рг[Х^х]. Сле-
Следует напомнить, что существование вероятности Рг[Х^х] для
всех значений случайной величины X было основой для опреде-
определения случайной величины, данного в начале разд. 3.5.
Очевидно, что Рг[Х<х] для данной случайной величины
является некоторой функцией х (в обычном математическом
смысле). Запишем эту функцию в следующем виде:
Fx(x). C.19)
Заметим, что Fx(x) всегда обозначает функцию распределения
случайной величины X, а не конкретную математическую функ-
функцию переменного х.
Допустим, что X—дискретная случайная величина с вероят-
вероятностями
1>Г [* = *,]=,>„
где
События (Х=^х{)—несовместные, так как случайная величина X
принимает каждый раз только одно значение, поэтому
(суммирование производится по всем значениям i). Рассмотрим
теперь значение вероятности Рг[Х^л:], где х^г ^.х < Xj. Собы-
Событие (Х^х) представляет собой объединение несовместных со-
событий (Х^хе) для всех l^j—1. Используя соотношение C.14),
получаем
i= 2 л
Аналогично
Fx(x)=2pi + Pj (*/<*<¦
Поэтому функция Fx(x) остается постоянной при Ду?<
и в точке x = xj возрастает на величину p/=Pr[X = jc/]. Fx()
является ступенчатой функцией (рис. 3.3). Это типичная функ-
функция распределения любой дискретной случайной величины.
(x)
Теория вероятностей. Общие* положения
69
Рис. 3.3. Распределение дискретной случайной величины.
Пример З.9. Если Pi
E) =2 2~* = 31/32 и
x= 1
= х] = 2-* при л:=1, 2, 3, ..., то
Возвращаясь к непрерывным случайным величинам, рассмотрим
вычисление вероятности
Pr fa < X <х,] - Fx (x2)-Fx (x,)
для любой пары значений х± < х2 в некотором интервале воз-
возможных значений х. Имея в виду замечания, изложенные в конце
разд. 3.5, видим, что в данном случае ни в одной точке невоз-
невозможны скачкообразные изменения, как на рис. 3.3. Однако при
x2>xt имеем FxW<^W, если /^(х)—возрастающая функ-
функция х (в интервале рассматриваемых значений). Назовем случай-
случайную величину X непрерывной, если функция Fx(x) является не-
непрерывной. Это означает, что за исключением сравнительно не-
небольшого числа точек, должна существовать производная функ-
функции Fx(x). Кроме того, поскольку из непрерывности функции
Fx(x) следует, что lim Fx(x)^Fx(x2),
имеем
.и поскольку
lim Pr |X < X < x2] = 0,
Xi-tx,
Pr [X = x2] < Pr [xx < X < xt],
70
Глава 3
то Рг[Х = л;2] = 0 при любых х2. Следовательно, непрерывные
случайные величины обладают тем весьма неудобным свойством,
что вероятность появления какого-либо конкретного значения
равна нулю. Вспомним, однако, что, как говорилось в разд. 3.2,
нулевая вероятность не означает невозможности. Следует заметить,
что вследствие этого особого свойства непрерывных случайных
величин нет необходимости задумываться над тем, как правильно
писать: (xt ^ X < х9), (xt < X < х2) или (хг ^ X ^ х2)—все эти
события имеют одинаковую вероятность появления. В случае не-
непрерывной случайной величины важную роль играет вероятность
попадания в заданный интервал (как, например, рассматривавшаяся
выше вероятность Prfx^X < x2]), а не вероятность появления
определенного численного значения.
Мы уделили некоторое внимание различию между функциями
распределения дискретных и непрерывных случайных величин и
заключаем этот раздел перечислением свойств, общих для всех
функций распределения. К ним относятся следующие:
2) Fx(x)— неубывающая функция х.
Так как Fx(x)—вероятность, то свойство 1 следует непосред-
непосредственно. Относительно свойства 2 заметим, что если х± < х2, то
(X < х2) = (Х
т. е.
Еще одним свойством, которым обладают почти все рассмотрен-
рассмотренные функции распределения, является следующее:
3) lim Fx {x) - 1; lim Fx (x) = 0..
Х-*- со X ->— со
Это означает, что фактически с вероятностью, большей нуля,
х не становится бесконечно большой величиной.
3.7. ПЛОТНОСТЬ РАСПРЕДЕЛЕНИЯ ВЕРОЯТНОСТЕЙ
В случае непрерывных случайных величин производная F'x(x) =
= {d/dx)[Fx(x)] существует почти для всех значений х. Эта ве-
величина имеет исключительно важное значение при аналитическом
исследовании непрерывных случайных величин. Она называется
плотностью распределения вероятностей [и обозначается рх{х)\
Заметим, что рх(х), как и Fx(x), описывает свойство случайной
величины X, а не просто какую-то математическую функцию х.
Любопытно рассмотреть, почему рх (х) называется плотностью
распределения вероятностей. По определению для непрерывной
Теория вероятностей. Общие положения
71
случайной величины
Pr[x1<X<x,]=lPx(x)dx,
C.20)
где Xi < х9.
Полагая xt--=x—V2(^), x2 = x + 1/2(8x), имеем
х+фх)/2
Рг [х - V2 (вх) < X < х + V, (Ьх)] = J рх (и) du & рх (х) (8х),
х~Fх)/2
C.21)
если 6х мало. Поэтому рх(х) можно рассматривать как плотность
вероятности в окрестности х. Это доказательство не является
строгим, и оно служит лишь для установления полезной основы
для понимания природы плотности вероятности px(x)t
3.8. СОВМЕСТНЫЕ РАСПРЕДЕЛЕНИЯ
Если X и Y—две случайные величины, то вероятности Рг [Х^ х]
и Pr[Y<#] существуют. Если вероятность Рг[Х^л\ Y^y]
существует для всех х и у, то функция совместного распределе-
распределения случайных величин X и Y определяется по формуле
Если X и Y—дискретные случайные величины, то функция
Рх,у(х>У) будет скачкообразно изменяться в каждой точке, со-
соответствующей паре значений X^xi{i Y = yfJ где существует не-
ненулевая вероятность. Если X и Y—непрерывные случайные ве-
величины, то плотность их совместного распределения рх,у(х,у)
определяется с помощью уравнений
C.23)
Рг[(Х,У) в области Щ = JJ px,y{x, y)dxdy,
91
где (X, Y) обозначает точку с координатами X и F, а 91—любая
односвязная область в плоскости (%, у). Легко показать (беря
область 91, определяемую неравенствами Х<%, Г<#, и диффе-
дифференцируя), что
Не представляет труда перейти к совместным распределениям
большего числа случайных величин.
72
Глава В
Функция совместного распределения т случайных величин
XtJ Х2, ..., Хт имеет вид
[т -1
Д {Xj< x,)J = FXl Хт {xlt .... xj, C.24)
а плотность вероятности равна
Распределение каждой отдельной случайной величины назы-
называется частным (маргинальным) распределением. Функцию рас-
распределения случайной величины Xj легко найти, полагая, что
в функции Fxu ...Дя (хгу - * • у хт)все х» кроме хр стремятся к бес-
бесконечности.
Условие Х2^оо всегда выполняется* поэтому
Рг [Хх < Xl] = Pr [(X, < Xl) n (X, < оо)];
следовательно,
Аналогично
W*.jr,(*i.«>). C.26)
f xlf .... x*-t (*i. .... хт^) - /^ xra (**, - •, ^-i, оо). C.27)
Если совместное распределение случайных величин Хг, ,.,ДВ
непрерывно и имеет некоторую плотность вероятности, то с по-
помощью соотношения C.27) получаем
i- C-28)
В частности, при т =
-СО
имеем
— О»
Условная плотность распределения случайной величины Х2
при заданном значении случайной величины Xt определяется как
, , ч РХи )
Аналогично условная плотность распределения случайной ве-
величины Хт при заданных значениях случайных величин
Xif . ..,Хт-г определяется как
/ f v_ Рхх xm(Xl> ••'Хт) /з 31)
Если знаменатель в формулах C.30) и C.31) равен нулю, то
с помощью совместной плотности вероятности мы не сможем вы-
Теория вероятностей. ОбщиЬ положения
73
вести выражения для условной плотности распределения случай-
случайной величины Х2 (или Хт) при заданных значениях хг или
(хг, - - -» x*-i) соответственно.
Необходимо проводить строгое различие между условным рас-
распределением случайной величины Х2 при Хг = хг [имеющим плот-
плотность распределения C.30)] и условным распределением случай-
случайной величины Х2 при Xt^xlf имеющим функцию распределения
Условное совместное распределение случайных величин Х% н
Х2 при заданных значениях Х3, ..., Хт имеет плотность вероят-
вероятности
Рхг.хш\х.
C.32)
Другие условные совместные распределения определяются ана-
аналогичным образом.
3.9. НЕЗАВИСИМОСТЬ
Две случайные величины X и Y (взаимно) независимы, если
события (Х<х) и (F<i/) взаимно независимы для любой пары
значений х и у. Это естественное и вполне понятное определение.
Оно означает, что распределение значений случайной величины X
не зависит от значения случайной величины Y, и наоборот.
В- случае независимости имеет место простое соотношение
между совместным распределением и распределениями случайных
величин X я Y:
\
(так как X и К —независимые случайные величины). Это озна-
означает, что
?х. г(*> У) ^ Fx, y(x) Fx, Y(y). C.33)
В случае непрерывных случайных величин аналогичное соот-
соотношение существует между плотностями распределения вероят-
вероятностей:
Рх<у(х>У) = Рх(х)Ру(У)- C.34)
Это важное соотношение можно вывести из того факта, что
можно записать как
х у
Px(ti)pY{v)dudv
для всех х и всех у.
74
Глава 3
ЗЛО. БИНОМИАЛЬНОЕ РАСПРЕДЕЛЕНИЕ
Допустим, что случайные величины Xi(i=\f29 ..., п) неза-
независимы и каждая из них принимает значения 0 и 1 с вероят-
вероятностями 1 —р и р соответственно @ ^ р ^ 1). Найдем вероятность
того, что случайная величина
примет значение r(r = Of 1, 2, ..., л).
Поскольку случайные величины Xlt . ..,ХЛ взаимно незави-
независимы, вероятность появления любой конкретной последователь-
последовательности, содержащей г единиц и п — г нулей (т. е. Y = r), равна
ргA—р)п~г. Например, вероятность появления сложного собы-
события (Xi = 0, X2 = l, Х3=1, Х4 = 0) равна
Вероятность появления сложного события (Хх = 1, Х2 = О, Х3 = 1,
Х4 = 0) также равна
Действительно, существует ( "f J возможных различных последо-
последовательностей, для которых У = г, т. е. последовательностей, со-
содержащих г единиц и п~г нулей (см. разд. 1.4). Каждая из
этих последовательностей появляется с вероятностью рг {\—/?)п~г,
и все ( J последовательностей несовместны. Ни для одной дру-
другой последовательности нельзя получить Y~r. Следовательно,
используя соотношение C.14), имеем
г(\—ру-гш C.35)
Эта формула очень важна. Она определяет распределение
случайной величины К, которая принимает значения уг^г =
— О, 1, ...,п с вероятностями pr r)
Случайная величина с таким распределением называется бино-
биномиальной случайной величиной, а ее распределение называется
биномиальным. Случайные величины Хх, Х2, ...Д„иК являются
дискретными. Единственными значениями, которые принимает
каждая случайная величина X с ненулевой вероятностью, явля-
являются 0 и 1, а случайная величина Y с ненулевыми вероятностями
принимает только значения 0, 1,2, ..., п.
Это распределение называется биномиальным потому, что ве-
вероятности рг являются последовательными членами в формуле
Теория вероятностей. Общие положения
75
разложения бинома [A—р) + р]п. Отсюда непосредственно сле-
следует, что
г=0
и мы знаем, что это условие выполняется, поскольку г = 0, 1,
2, ..., п являются единственными возможными значениями слу-
случайной величины Yy а события (У=г) и (Y = r'), где гфг\ не-
несовместны. Числа пир, необходимые для определения этого
распределения, называются параметрами биномиального распре-
распределения.
Это распределение широко используется как распределение
случайной величины, представляющей собой число появлений
определенного события в однородной последовательности, содер-
содержащей п испытаний.
Пример 3.10. Вероятность появления дефектного изделия со-
составляет 0,04. Допустим, что выбраны 10 независимых изделий.
Какова вероятность: а) отсутствия дефектных изделий; б) появ-
появления не более одного дефектного изделия? Поскольку /? = 0,04,
имеем
а) Pr[X = 0]
б) Рг [X = 1] = ( q°) @,04)* 0,96* = 0,2770;
в) Рг[0<Х<1] = Рг[Х = 0] + Рг[Х = 1] = 0,9418.
3.11. ПОЛИНОМИАЛЬНОЕ РАСПРЕДЕЛЕНИЕ
Рассмотрим теперь естественное обобщение задачи, приведен-
приведенной в разд. 3.10. Допустим, что независимые случайные величины
X,. могут принимать любое из конечного числа k различных воз-
возможных значений х19 х2, ..., хн,
и, разумеется,
= х/] = р, для всех i
Пусть среди п значений случайных величин Х19 Х2, ...Дв
числу значений, равных х1ч соответствует величина Y19 числу
значений, равных л:2, соответствует Y2 и т. д. Тогда вероятность
появления совместного события (К2 = rlt Y2 = г2, ..., Yk = гА) равна
rxlr/l.-r,!^»'"-^* C-36)
76
Глава 3
(разумеется, при условии, что ^г; = я; в противном случае эта
вероятность равна нулю). Справедливость этого результата дока-
доказывается путем непосредственного обобщения метода, используе-
мого в разд. ЗЛО. Заметим, что п!/( Цгу! 1 обозначает число
перестановок п элементов, гх из которых одного рода, г2 другого
рода и т. д. Распределение C.36) ^справедливо в любом случае,
когда элементы могут попадать в любую из k категорий незави-
независимо от того,, определяются ли они численными значениями.
Совместное распределение случайных величин Y19 F2, ..., Yk
называют полиномиальным распределением, а случайные величины
Yly K2, ...,Fft образуют множество полиномиальных случайных
величин.
Первыми конкретными распределениями, с которыми мы по-
познакомились, были биномиальное и полиномиальное распределе-
распределения. Эти распределения вновь рассматриваются в гл. 4, где вво-
вводятся также некоторые другие широко используемые распреде-
распределения. Существует бесконечное множество возможных типов рас-
распределений, однако, как показывает опыт, на практике часто
используется лишь ограниченное число распределений. В боль-
большинстве случаев наше внимание будет сосредоточено на этой
небольшой группе, однако следует постоянно иметь в виду воз-
возможность введения некоторого необычного распределения, если
это оправдывается условиями задачи.
3.12. МАТЕМАТИЧЕСКИЕ ОЖИДАНИЯ
Рассмотрим дискретную случайную величину Z. Пусть
Pr [Z = Zj\ = pj\ 2 Pj — 1 ? a Zlf Z2, ..., Zn — последовательность
независимых случайных величин, каждая из которых имеет такое
же распределение, что и случайная величина Z. Эта модель опи-
описывает повторные наблюдения случайной величины Z. Обозначим
число значений величин Z,, равных г,-,.через N/t так что 2Nj = n.
Тогда .среднее арифметическое значение случайных величин Zt
определяется как
Рассмотрим теперь, что происходит при увеличении п (это соот-
соответствует получению все большего и большего числа наблюде-
наблюдений). Согласно первоначальному определению вероятности, дан-
вероятностей. Общие положения
77
ному в разд. 3.1, имеем
Таким образом, видим, что среднее арифметическое случайных
величин Zj стремится к постоянному числу 2гуР/- Можно ожи-
ожидать, что эта величина будет близка к среднему арифметическому,
полученному по большому числу случайных величин Z{. Она
называется математическим ожиданием (средним значением) слу-
случайной величины Z, а иногда математическим ожиданием распре-
распределения случайной величины Z. Чтобы показать связь этого па-
параметра со случайной величиной Z, записывают ?(Z), однако
следует иметь в виду, что это не математическая функция от Z.
Фактически это некоторое постоянное число, которое точно так
же, как функция распределения, является характеристикой слу-
случайной величины Z. Заметим, что E(Z) — постоянная, поэтому
в обозначений E(Z) символ Z нельзя заменять конкретным зна-
значением. Формула для E(Z) имеет вид
JZ (/,) = J^ Z • rl \?, — ZyJ. yo.oi)
Пример 3.11. Найдите математическое ожидание случайной
величины X, если Рг[Х = г]= (^)ргA -р)п~г> гдег-0, 1, ...
...,/г (т. е. случайная величина X имеет биномиальное распре-
распределение).
^
s = 0
Для непрерывной случайной величины Z с плотностью рас-
распределения pz(z) математическое ожидание определяется по
формуле
со
E{Z)=\ zpz{z)dz.
— QO
[Заметим, что значение E(Z) не зависит от Z.]
C.38)
78
Глава S
Это определение можно пояснить, рассматривая непрерывную
случайную величину как предельный случай последовательности
дискретных случайных величин, принимающих с вероятностями,
приближенно равными Рх(х()(Ьх)9 значения хо отделенные друг
от друга интервалом (бл;), когда длина интервала Fх) стремится
к нулю. Это эвристический, а не строгий подход, который по-
помогает уяснить данное определение.
Математическое ожидание любой однозначной функции f(X)
случайной величины X определяется аналогичным образом. (За-
(Заметим, что здесь /(X) — обычная математическая функция от X.)
Если X = Xj> то f(X) = f(Xj) и, рассуждая, как и ранее, получаем
) C.39)
C.40)
для дискретных переменных и
для непрерывных переменных.
Ниже приводятся некоторые элементарные, но полезные свой-
свойства математических ожиданий. Читателю предлагается самостоя-
самостоятельно доказать их.
1) Если а —постоянная, то Е(ах) = аЕ(Х).
2) Если а —постоянная, то Е(Х + а) = Е(Х) + а.
= Е [ft (X)] + E[f2 (X)] + .'.' .+?[/» (X)].
Последнее свойство представляет собой частный случай важ-
важного результата, который можно сформулировать следующим
образом.
Если Xit X2t Хзч ..., Хп — случайные величины (зависимые
или независимые), то
/ п \ п
¦ ]??(*/)• C.41)
t=l
Докажем справедливость этого соотношения для случая ди-
дискретных случайных величин при п = 2. Пусть
о*, rv v 1 п
^г 1_Л1 — ху\ — Pi/»
В данном случае {Х2 = х21)—объединение несовместных событий
(Xi = xlf> X2^x2l), где / изменяется во всем интервале возмож-
возможных значений. Следовательно,
Р2г = 2рл и аналогично /?i/ = 2p/*- C.42)
/ 1
Теория вероятностей. Общие положения
79
Теперь
22]
у /
= 2
j
+ 2 x%lPtl = Е (X,) + Е (ХЛ).
Это доказывает справедливость данного результата для двух ди-
дискретных случайных величин (п = 2). Обобщение на случай п > 2
получается путем многократного применения результата для я = 2.
Переход к непрерывным случайным величинам осуществляется
аналогично. В частности, используем формулы
CD
= S
CO
&i. C-43)
аналогичные соотношению C.29).
Второй важный результат, который справедлив для взаимно
независимых случайных величин, имеет вид
Е {ХгХ2... Хп) = Е (X,) Е (Х2) ... Е {Хп)% C.44)
т. е.
(=1
1=1
Докажем справедливость этого результата для непрерывных
случайных величин при п = 2:
00
iX2) = J
pXu Xa (xit jc.) dXl dx2.
Поскольку Хг и Л'з —независимые случайные величины, с по-
помощью соотношения C.34) получаем
рх2 (хш).
Следовательно,
xt, х3 (xv х%) -рХх (Xj)
со
E(Xlt Xt)= J x^ixjdxt S xj^
He представляет труда перейти к произвольному значению п\
читателю предлагается доказать справедливость этого результата
для дискретных случайных величин.
Математическое ожидание случайной величины Y, когда Y
имеет распределение, обусловленное значением другой случайной
величины X, называется условным математическим ожиданием
случайной величины Y при данном значении X и записывается
как E(Y\X). Если это математическое ожидание рассматривается
80
Глава 3
как функция X, то оно называется также регрессией Y на X (см.
гл. 12).
Иногда используется формула
= EX[XEY(Y\X)]. C.45)
(?*['] обозначает математическое ожидание относительно слу-
случайной величины X.) Не представляет труда перейти к трем
и большему числу случайных величин. В более общем случае
условное математическое ожидание [например, C.30) или C.31)],
рассматриваемое как функция других случайных величин, назы-
называется регрессионной функцией, или функцией регрессии. Например,
функция регрессии случайной величины Х3 на (Х1( Х2) имеет вид
се
^=х2)]^ J
x2)dx3.
3.1-3. МОМЕНТЫ
В разд. 3.13 было показано, как вычислить математическое
ожидание функции f{X) случайной величины X. Математические
ожидания некоторых функций имеют важное значение. Сюда от-
относятся случаи, когда /(Х) = (Х—а)г, где а и г —постоянные,
рассматриваемые в этом разделе.
Е[(Х — а)г] называется r-м моментом случайной величины X
относительно а.
Если а = 0, то имеем г~й момент относительно нуля; часто
он называется r-м начальным моментом и обозначается как \i'r(X).
Если а = ?(Х), то имеем r-й центральный момент, который
обозначается как |лг(Х). Если путаница не возникает, то X опу-
опускается, и для обозначения r-то начального момента и r-го цен-
центрального момента употребляются символы \кг и \ir соответственно.
Как мы уже указывали,
р{ = Е(Х) C.46)
(заметим, что ^ = 0). Момент
¦щ = ?{[*-?(*)]¦} C.47)
называется дисперсией случайной величины X и часто обозначается
как Var(X), Чем больше случайная величина X отклоняется от
ее математического ожидания Е(Х), тем больше ц2. Дисперсия
измеряет изменчивость случайной величины X. Если требуется
иметь показатель изменчивости, имеющий такую же размерность,
что и случайная величина X, может использоваться величина
j/"jji7=c, называемая средним квадратическим отклонением слу-
случайной величины X,
Теория вероятностей. Общие 'положения
81
Центральные моменты {\ir\ можно выразить через начальные
моменты {)k'r\:
2 {- 1У (у) \#Е [*'-'] = 2 (_ 1)/ (J) м C.48)
В частности, \io = \, ^ = 0 и
!*¦ = l*i —
C.49)
И наоборот,
/=о
Иногда удобно вычислять факториальные моменты
Начальные моменты можно получить из факториальных моментов
с помощью простых формул.
Так,
.откуда следует, что
, — 3 [|г(
Если для дискретной случайной величины
при всех А или для непрерывной случайной величины
при всех Д, то распределение случайной величины X называется
симметричным. Эквивалентное формальное определение симмет-
симметрии, относящееся ко всем случайным величинам, имеет вид
Fx[E(X)-*l + Fx[E(X) + *\ = l C.50)
при всех Д, для которых Рг [X = Е (X) — Д] - Рг [Х=? (Х)+Д]=0.
Если распределение случайной величины симметрично, то
?{[X —?(Х)]3} = 0 (как и все центральные моменты нечет-
Глава 3
ного порядка), так как каждое положительное значение [X — Е (X)]3
сокращается с равновероятным отрицательным значением. Если
М-3 > О» Т0 это указывает на преобладание больших положитель-
положительных отклонений относительно математического ожидания; в этом
случае говорят, что распределение случайной величины X имеет
положительную симметрию. Если же \i3 < 0, то преобладают
большие отрицательные отклонения и распределение случайной
величины X имеет отрицательную симметрию. Однако третий
момент |л,8 является неудовлетворительным показателем асиммет-
асимметрии, так как зависит от единиц, в которых измеряется случай-
случайная величина X. Если вначале X измеряют в дюймах, а затем
переходят к измерениям в ярдах, то каждое значение нужно
делить на 36, a \i3 уменьшается в отношении 1:363 = 1:46 656.
Чтобы получить меру асимметрии, которая не изменялась бы
подобным образом, \i3 делится на }4/2 —а3- Отношение \kj\i\lz
обозначается через "Крх, или <х3. Если необходимо подчеркнуть,
что этот показатель относится к случайной величине X, его
записывают как KPiW или а3(Х).
Этот показатель иногда называют первым коэффициентом формы,
или коэффициентом асимметрии (либо третьим стандартным
моментом). Аналогичным образом приходим к определению ве-
величины \lJ\lI, называемой вторым коэффициентом формы, или
эксцессом (либо четвертым стандартным моментом). Этот пока-
показатель обозначается символом Р2 или а4; если необходимо под-
подчеркнуть связь со случайной величиной X, то записываем Р2(Х)
или а4 (X).
Пример 3.12. Допустим, что Xlf X2, ..., Хп — взаимно неза-
независимые случайные величины, имеющие общее математическое
ожидание |, дисперсию а2, третий центральный момент |л3=а3 ]/рх=
= а3а3 и четвертый центральный момент ti4 = 64p2 = 64a4. Каковы
соответствующие значения моментов среднего арифметического
Используя формулу C.41), получаем
EpC) = ~(nl) = l. C.51)
Таким образом, видим, что математическое ожидание выборочного
среднего равно математическому ожиданию совокупности.
Затем с помощью формулы C.47) получаем
Теория вероятностей. Общие положения
83
где 1ф\\ приведенные математические ожидания не зависят от
значений индексов. В данном случае Е\(Х( — ?J] = <т2; так как
случайные величины Х( и Xj взаимно независимы, то
а поскольку Е (Х( — I) = О, данное соотношение равно нулю. Сле-
Следовательно,
C.52)
П
Таким образом, мы видим, что дисперсия выборочного среднего
равна дисперсии совокупности, деленной на объем выборки. Ана-
Аналогично получаем
2. или ^ C.53)
или
Следовательно,
= п~3а% + 3 (л-2 — л-3) а*
?-п-3)о4 при 1ф\. C.54)
C.55)
3.14. НОРМИРОВАНИЕ
Рассмотрим Y = а + ЬХ — линейную функцию случайной ве-
величины X, где а и Ь — постоянные. Тогда математическое ожи-
ожидание случайной величины Y запишется как
84
Глава 3
а дисперсия случайной величины Y имеет вид
-E(X)?} = bW(X).
В общем случае r-е центральные моменты случайных величин
X и Y связаны уравнением
\ir(Y) = b'-iir{X). C.56)
Если принять
Е(Х) , 1
то случайная величина К = [Х —?(X)]/j/a2(X) будет иметь ма-
математическое ожидание, равное 0, и среднее квадратическое от-
отклонение, равное 1. Это так называемая нормированная случайная
величина, соответствующая X.
Поскольку
то при г = 3 и г = 4
№2
C.57)
В частности, нормированная случайная величина, соответст-
соответствующая X, имеет такие же коэффициенты формы (коэффициент
асимметрии и эксцесс) что и случайная величина X. Нормиро-
Нормирование влияет на величины среднего значения и среднего квадра-
тического отклонения, но не на отношения моментов.
3.15. КОРРЕЛЯЦИЯ
Допустим, что Xlf Х2, ..., Х„ — случайные величины и что
Рассмотрим теперь случайную величину
где а—известные постоянные, Z — линейная функция случайных
величин Х(.
Математическое ожидание случайной величины Z имеет вид
C.58)
Теория вероятностей. Общие положения
Дисперсия случайной величины Z может быть записана как
Г » I2
^С^ /у ? \ [
7л CL: V-Л / — ^у) I —
1 = 1 J
: п 1 Г п Л
а? (^,-Ч;)!+?2Zliataj(X,--g,) (Ху-%¦) =
.(=i J L l < J J
==?
n
(=1
I < /
C.59)
Рассмотрим теперь величину ?[(Х,- —2,-) (Xy—-|y)]. В примере 3.12
мы уже видели, что если X, и Ху — независимые случайные ве-
величины, то данная величина равна нулю. Если же эти случай-
случайные величины не являются независимыми, то эта величина не
обязательно будет равна нулю. Таким образом, ненулевое зна-
значение величины EKXg — l^iXy — lj)] свидетельствует об отсут-
отсутствии независимости. Данная величина называется ковариацией
между случайными величинами Х{ и Xj и обозначается следу-
следующим образом:
Cov(X,, Х/) = ?[(^-Б/)(Х/-Е/)]. C.60)
Удобно рассматривать эту величину как показатель зависимости
частного вида, так как она может принимать нулевое значение,
даже когда Х{ и X, не являются независимыми, что будет пока-
показано в приведенном ниже примере.
Пример 3.13. Случайная величина X принимает значения—1,
0, 1, а случайная величина Y принимает значения 0, 2 с веро-
вероятностями, приведенными в табл. 3.1. Вероятности, определяющие
Таблица 3J
Совместное распределение дискретных случайных
величин
X
—1 0
1/12 1/2 1/12
1/12 1/6 1/12
1/6 2/3 1/6
2/3
1/3
86
Глава 3
Теория вероятностей. Общие положения
87
распределения случайных величин X и Y, взятых в отдельности,
указаны по краям таблицы. Математические ожидания случайных
величин X и Y определяются как
1.1==0 и
соответственно.
Имеем
Е {[X—? (X)] [Y—E (Y)]}=E[XY—XE(Y)—YE(X)+E{X)E{Y)]=
= E(XY)
и
1
— ±mQ.( n_(_J_. П.0-т-~
—12 * '2 12
1.2.(-1) + 1.2-0 + 1.2-1 = 0.
12
Следовательно,
Однако
E {[X -E (X)] [Y -E {Y)]\ = 0-0-4 = 0.
Pr[X<0\K = 0] = l:4 = |
таким образом, случайные величины X и Y не являются незави-
независимыми.
Если в качестве показателя зависимости использовать кова-
риацию Е\\Х(— E(Xi)][X/—Е(Ху)]\, то серьезным недостатком
является то, что ее значение может изменяться при изменении
единиц, в которых измеряются исходные случайные величины.
Если Х( обозначает длину, а Ху—вес, то при переходе от футов
к дюймам и от футов к унциям этот показатель увеличится
в 12-16=192 раза без изменения реальной зависимости. Чтобы
исключить такой эффект, разделим данный показатель на произ-
произведение средних квадратических отклонений ог^оу. Полученное
отношение называется коэффициентом (линейной) корреляции
между Х( и Xj. Обозначив его через pijy запишем
Е {[X;-? (Х{)] [Xj-E (Xj)]\ = 9ijoflj\ C.61)
выражение C.59) принимает вид
a2 (Z) = 2 Ф* + 2 22 W^/r/cry.
/ = 1 i<j
C.62)
Пример 3.14. Четыре элемента Л, 5, С и D, размещаемые
один за другим, образуют единый узел. В налаженном производ-
производстве средняя длина и среднее квадратическое отклонение длины
элементов каждого типа имеют следующие значения:
Средняя длина, мм 57 108 108 61
Среднее квадратическое отклонение, мм 0,056 0,170 0,170 0,092
Элементы типа В и С должны быть подогнаны; в результате коэф-
коэффициент корреляции между длинами этих элементов, используе-
используемых в одном и том же узле, равен 0,70. Коэффициенты корре-
корреляции между длинами всех остальных элементов равны нулю.
Можно допустить, что между последовательными элементами нет
никаких зазоров.
Какова средняя длина узла? Каково среднее квадратическое
отклонение общей длины узла?
Чтобы получить ответ, возьмем среднюю длину элементов
каждого типа. В соответствии с формулой C.41) средняя длина
узла равна
5,7+10,8 +10,8 + 6,1 = 33,4 см.
С помощью формулы C.62) находим дисперсию общей длины:
а2-@,056J +@,170J + @,170J + @,092J + 2.0,70-0,170-0,170-
= 0,10986 мм3.
Следовательно,
0,33 мм.
среднее квадратическое отклонение а равно
Очень часто при использовании коэффициента корреляции р{/
опускается слово „линейная", однако следует иметь в виду, что
этот показатель характеризует лишь частный вид зависимости
между случайными величинами Xt и XJt
Допустим, что
Это означает, что
т. е.
E{[Xt-E\
или
-2Р? ({[X,— Е (X,.)] [Xj-E
{
C.63)
Глава 3
Полагаем Р —Pi/Voy; тогда формула C.63) принимает вид
откуда
Так как af>0 и а'?>0, 1— р!/^0, то —1<р,7<1. Здесь
р,7 принимает предельные значения ±1, когда а'* = 0, т. е. когда
Xt—E(X;) = $[Xj—E(Xj)] с вероятностью 1 и когда существует
строго линейное соотношение между Х{ и Х;-. Можно считать, что
ptj показывает, насколько близко соотношение между Хг и Xf
соответствует строго линейной завись О2ти. Другие формы зави-
зависимости (предельный случай был рассмотрен в примере 3.13) не
могут быть так хорошо измерены с помощью коэффициента кор-
корреляции рG.
Задавая величинам а, а и р, входящим в формулу C.62),
конкретные значения, можно получить ряд исключительно полез-
полезных формул. Математическое ожидание и дисперсия случайной
величины X, найденные в примере 3.12, определены при р,7 = О,
а{= 1/п, <Т; = а. Другие случаи будут встречаться в процессе изло-
изложения материала.
Еслн Z' = a[X1+a'2Xi +.. -+а'пХп—линейная функция случай-
случайных величин Х19 Хг> ..., ХпУ то
Теория вероятностей. Общие положения
89
I =9= I j
n
= 2J ata'fi\
i = l
Когда случайные величины X не являются взаимно коррелиро-
коррелированными, т.е. рG = 0, то
Cov (Z, Г) - 2 afifll
Если все случайные величины X имеют одинаковую дисперсию,
т. е.
то
Cov(Z, Z') =
Можно показать, что если случайные величины взаимно корре-
лированы и имеют одинаковую дисперсию, то необходимым и
достаточным условием того, что ковариация и коэффициент (линей-
(линейной) корреляции между Z и Z' равны нулю, является равенство
Пример 3.15. Пусть Xlf Х2> ..., Хп—взаимно некоррелиро-
некоррелированные случайные величины, имеющие одинаковую дисперсию а2.
л
Покажите, что если Х = д-1>2^1» то X и Xj — X—некоррели-
X—некоррелированные величины. Найдите также коэффициент корреляции
между Xj — X и Хр—ХиФ]').
— п — п
Имеем Х/—Х = Х/—п-1 2 Х(. Полагая Х. — Х - 2 а(Хп
получаем а? = — n~1(i=^j) и af=l—/г-1. Аналогично, полагая
_ п п
X = 2 a'iXi* имеем а^л. Следовательно, ^а^ — п X
i = \ i = 1
Х[1— л-1 — (л— 1)л-1] = 0. Кроме того,
Cov{Xj-X, Xj—X) = [{n —2){n-i
Таким образом, по формуле C.61) находим
-Х. XJf-X
3.16. НЕРАВЕНСТВО ЧЕБЫШЕВА
Пусть Y—случайная величина, которая не принимает отри-
отрицательных значений. Тогда r-й начальный момент \хг будет мате-
математическим ожиданием величины YT. Для любого фиксированного
а > 0 можно записать
Поскольку
90
Глава 3
Теория вероятностей. Общие положения
91
Ясно (в предположении, что Рг[К>а]>0), что
E{Yr\Y>a)~>ar.
Следовательно,
или
Рг
C.66)
Это так называемое неравенство Маркова.
Теперь рассмотрим случайную величину X (которая не обяза-
обязательно принимает только положительные значения). Случайная
величина Y = | X — Е (X) \ принимает только неотрицательные зна-
значения, и к ней применимо неравенство C.66).
Так как }хг = Е[\Х—Е (Х)\г]> то, следовательно, \i'r представ-
представляет собой r-й центральный абсолютный момент X, который обо-
обозначим через vr. Если г четно, то это именно r-й центральный
X П
момент X и, значит,
C.66), получаем
, р
= ^r для четного г. Применяя формулу
Рг[\Х-Е(Х)\>а]<%г.
Подставим a =
Рг [| X -Е (X) \ > tv1/']
C.67)
Это и есть известное неравенство Чебышева. Оно наиболее часто
используется в виде, который получается при г = 2. Тогда имеем
неравенство
Pr[\X-E(X)\>to]<t~\
где а —среднее квадратическое отклонение X. Ему эквивалентно
неравенство
Рг[|Х—?(X)|</a]> \—t-\ C.68)
Важно отметить, что неравенство C.68) применимо к любой
случайной величине X (в предположении, что а конечно). Таким
образом, можно сказать (взяв, например, ? = 3), что вероятность
того, что случайная величина отличается от математического ожи-
ожидания более чем на три средних квадратических отклонения,
всегда меньше, чем 1/9. Конечно, для многих случайных величин
фактическая вероятность много меньше, чем 1/9. На практике
очень полезно уметь делать утверждения, подобные C.68), ничего
не зная о виде распределения X.
Эта независимость от распределения, присущая некоторым
методам, называемым свободными от распределения, обсуждается
в разд. 9.3,
Пример 3.16. При производстве кристаллов кварца технически-
техническими условиями устанавливались границы для некоторой величины,
отстоящие по крайней мере на четыре средних квадратических
отклонения от математического ожидания. Если даже не делать
обычного предположения о форме распределения, можно сказать,
что
Рг[\Х-Е(Х)\>4о]<4-\
или что лишь доля изделий, меньшая, чем 0,0625, может ока-
оказаться за установленными границами.
3.17. ПРОИЗВОДЯЩИЕ ФУНКЦИИ МОМЕНТОВ
Величина E{etx), где t — константа, называется производящей
функцией моментов случайной величины X и обозначается как
mx(t). Может оказаться, что Е(etx) не будет функцией от t,
потому что ее математическое ожидание бесконечно. Если же эта
функция существует, то
( g) C.69)
и (поскольку правая часть сходится) имеем
mx(t) = l + tE(Х) + Ц-?(Х*)+ ... = 1 +/|il + ?|i;+ ... . C.70)
Действительно, коэффициент при \ь'г в правой части C.70) имеет
вид tr/rl. Следовательно, если продифференцировать mx(t) r раз
по ty то получим
т+х "Г f Нт+я "Г"
Подставим / = 0:
dr[mx{t)]
dtr
t=o
V-r
C.71)
Это один из возможных путей вычисления моментов случай-
случайной величины X.
Для вычисления центральных моментов можно воспользоваться
приведенной ниже формулой. Так как e~tB{X) константа, то
= Е (e-t? (X)
= Е Ц? [Х-Е (ХЩ = ? II
Г
Следовательно,
C.72)
C.73)
Величину e~iE{X)mx{t) часто называют производящей функцией
центральных моментов.
92
Глава 3
Производящая функция моментов часто оказывается полезной
при исследовании распределений сумм независимых случайных
величин. Главная причина этого заключается в том, что если Xt
и Х2 — независимые случайные величины, то
тх1+х2 @ = Е (е* (*1+*2>) = Е (е*хч*х*) - Е (etX>) E {etx>) =
^ntXl(t)mXt(t). C.74)
Следовательно, можно получить производящую функцию момен-
моментов (Х1 + Х2)9 просто перемножая производящие функции момен-
моментов Хг и Х2.
Еще один полезный результат состоит в том, что если а—кон-
а—константа, то
Теория вероятностей. Общие положения
93
@ =
= Е
^ (/)> C.75)
C.76)
Возможно, что mx(t) не существует. Например, если X — не-
непрерывная величина с
Px(x) = n(l +*2)-1 (распределение Коши),
то интеграл
00
j ef*Px(x)dx бесконечен.
В таких ^случаях применяются характеристические функции
yx() Е {ev ~их). Они существуют всегда и обладают свойствами,
похожими на свойства mx(t). Систематическое построение теории
для <px{t) в данной книге не проводится. Этот материал содер-
содержится в руководствах более высокого уровня. В двух следующих
главах приведено множество примеров применения производящей
функции моментов.
ЛИТЕРАТУРА
1. Bennett С. A., Franklin N. L., Statistical Analysis in Chemistry and the
Chemical Industry, Wiley, New York, 1954, Chapter 3.
2. Durand D., Stable Chaos, General Learning Corporation. Morristown, N. J.,
1971, Chapters 2—5, 13.
3. Hays W. L., Winkler R. L., Statistics: Probability, Inference and Decision,
Vol. 1, Holt, Rinehart & Winston, New York, 1970, Chapters 2,3.
4. Hoel P. G., Introduction to Mathematical Statistics, 4th Ed., Wiley, New York,
1971, Chapter 3.
5. Larson H. J., Introduction to Probability Theory and Statistical Inference,
Wiley, New York, 1969.
6. Mood A. M., Graybill F. A., Boes D. C, Introduction to the Theory of
Statistics, McGraw-Hill, New York, 1974, Chapters 2,5.
7. Parratt L. G., Probability and Experimental Errors in Science, Wiley,
New York, 1961.
8. Parzen E., Modern Probability Theory and its Applications, Wilev, New-
York, I960. ™ *
УПРАЖНЕНИЯ
1. Сколькими способами можно расположить буквы слова televizeTaK, чтобы
а) не было рядом двух гласных букв,
б) рядом могли находиться две буквы „е", но не три?
2. Правильная игральная кость подбрасывалась пять раз.
Если выпадет 1 или 2 очка, то это рассматривается как успех. Какова
вероятность
а) отсутствия успехов,
б) одного успеха,
в) не более двух успехов?
3. Совместная функция распределения X и У приведена ниже в таблице.
Определите
a) PrfX-2]; б)Рг[Х=1, К<1]; в) Рг[Х = 3| К= 1]; г) Pr [Х<2,У < 0];
д) Pr [Y < X].
X
1
0
1
1
1/3
1/12
0
2
0
1/4
1/6
3
1/12
0
1/12
4. В колоде 52 карты четырех мастей, по 13 карт каждой масти. Какова
вероятность:
а) вытянув две карты, получить сначала туза, а затем короля?
б) вытянув две карты, получить туза и короля?
в) вытянув пять карт, получить ровно два туза?
г) вытянув пять карт, получить не менее двух тузов?
д) вытянув одну карту, получить либо туза, либо пики?
Предполагается, что карты вытягиваются случайным образом.
5. Малая партия резины, отобранная для испытания, содержит 100 образ-
образцов. Если в этой партии есть два дефектных образца, то какова вероятность,
что они попадут в выборку объема 20? Предполагается, что отбор образцов
производится независимо.
6. Вторая партия из 100 образцов резины содержит три дефектных. Какова
вероятность того, что в выборке объема 20 из этой партии окажется больше
дефектных образцов, чем в выборке того же объема из первой партии (в кото-
которой было только два дефектных образца)?
7. Сформулируйте и докажите теорему Байеса.
Одна из двух партий, описанных в упражнениях 5 и 6, выбирается слу-
случайно. Затем из нее случайно берется выборка объема 20, причем оказывается,
что в ней два бракованных образца. Какова вероятность того, что это партия
из упражнения 5?
8. При производстве малых стальных цилиндрических стержней проверка
соответствия внешнего диаметра показала, что 5% изделий имеют больший
диаметр, чем нужно, 91% изделий укладывается в установленные границы и
4% имеют меньший диаметр. Какова "вероятность обнаружить в выборке из 10
независимо отобранных образцов
а) ровно один образец с большим диаметром и один с меньшим диаметром,
б) все годные образцы,
в) по крайней мере один образец с диаметром вне установленных границ?
9. С конвейера было отобрано 20 независимых образцов, среди которых не
оказалось бракованных.
а) Что можно сказать относительно процента брака в этом процессе?
94
Глава 3
б) Если доля брака р равна 2%, то какова вероятность наблюдаемого
сложного события?
в) Какова эта вероятность, если р = 4%?
10. Из партии, содержащей 80 образцов, из которых три дефектные, отби-
отбирается пять образцов. Считая, что X — случайная величина, обозначающая
число дефектных образцов в выборке, постройте таблицу, показывающую ра-
распределение X.
11. Два человека А и В играют в следующую вероятностную игру. Л бро-
бросает монету. Если выпадает герб, то он выигрывает, в противном случае монету
бросает В. Если у В выпадает герб, то он выигрывает, а если нет, то снова
бросает А и право хода переходит к В, если выпадает не герб. Игра продол-
продолжается, пока один из игроков не выигрывает.
а) Какова вероятность того, что победит Л?
б) Сформулируйте предположения, на которых основан ваш ответ.
12. Какова вероятность того, что в группе из 40 человек хотя бы двое
родились в один день? (При вычислениях следует предполагать, что днем рожде-
рождения каждого человека с равной вероятностью может быть любой из 365 дней.)
13. Восемь игроков принимали участие в турнире с выбыванием (по олим-
олимпийской схеме) и со случайным выбором пар в каждом туре. Джо Зилч имеет
вероятность р (> г/2) выиграть у любого из остальных семи игроков, в играх
между любыми двумя из остальных семи участников вероятности победить у
игроков равны. (Игры не могут заканчиваться вничью.) Какова вероятность
того, что Джо выиграет этот турнир?
14. В условиях упражнения 13 найдите вероятность того, что в ряду таких
турниров Джо первым победит в двух турнирах подряд?
15. В относительно новом процессе все еще получается 10% брака. В выборку
отбирается восемь образцов.
а) Какова вероятность не обнаружить брака?
б) Какова вероятность получить более чем один бракованный образец?
в) Каково ожидаемое число дефектных образцов в выборке из 30 незави-
независимых образцов?
г) Можете ли вы сказать, что 0 дефектов в выборке из 30 образцов —
неожиданное событие?
16. Известно, что 92% изделий выдерживают проверку Л, а 85%— про-
проверку В. Изделия достаточно высокого качества должны быть использованы
в некотором процессе и среди них 80% изделий выдерживают проверку Л,
90%—проверку В и 98% изделий обе проверки А и В.
а) На основе приведенных данных найдите границы, между которыми должна
лежать доля изделий, выдерживающих обе проверки.
б) Рассматривая долю изделий, которые можно использовать в процессе,
покажите, что приведенные данные противоречивы. (Возможно, что изделия,
которые не выдержали либо проверку Л, либо В могут оказаться полезными
для процесса.)
17. Даны множества
Л ={1, 2, 3, ..., 9, 10},
В ={5, 10, 15, 20},
?> = {0, 1, 2, 3, 4, 5}.
Определите результаты следующих операций:
а) А[}В,
б) лис,
в) А[)В,
г) B[)D,
Д) C[)Dt
e)
ж) B(jDt
з) B\JC,
и) A\JD,
к) Bf]Cf]Dt
л) A\JB\JC,
м) A\J(B[)C),
н) Bn(C[jD),
о) (A[]B)n(CUD),
п) (A(]B)\J(C[\D)*
Теория вероятностей. Общие положения
95
18. Проиллюстрируйте случаи а), в), е) и к) предыдущего упражнения
с помощью диаграммы Венна.
19. Пусть Pr[Ei] = l/2, Pr[?2] = l/3, Рг[?8[ = 1/6 и Elt E2, ?3 взаимно
исключают друг друга, т. е, являются несовместными событиями; найдите
а) Рг [Е^Е*],
б) Рт[ЕгПЕ21
в)
г)
20. Пусть X—дискретная случайная величина с распределением Рт[Х — х] =
= п-г при Jt=O, 1, 2, ..., (я—1).
Найдите
а) вероятность того, что X меньше k\
б) вероятность того, что X больше ?, но меньше / (k < /);
в) Е (X);
r)VarX.
21. Девять случайных величин XL, Х» ...» Х9 одинаково распределены,
как X из упражнения 20.
а) Найдите Е (X), где X = (X±+X2+ .,. +Х9)/9. _
б) Найдите наибольшее число х, для которого Рг [X <: х] < 1/2.
22. Для упражнения 21 вычислите Рг[Х<:1/3].
23. В ряду независимых опытов каждый приводит только к одному из
результатов Л, В или С; каждый результат имеет вероятность появления 1/3.
Найдите математическое ожидание числа опытов до появления трех последо-
последовательных результатов в порядке Л, 5, С.
24. Определите математическое ожидание и дисперсию случайной вели-
величины X с плотностью вероятности рх(х) = 1 /2х при 0<;ж;2.
25. Найдите медиану случайной величины X из упражнения 24.
26. Определите а3 и а4 для равномерной плотности распределения вероят-
вероятностей рх(х) = в~1 при О^х^д.
27. Вероятность наступления события Е меняется в последовательности
независимых опытов циклически, принимая значения р, р + б, р, р — б, р,
р+б, где 0 < р — б < р < р+б < 1.
а) Найдите вероятность наблюдения ровно г событий Е в 4п последова-
последовательных опытах.
б) Найдите среднее и дисперсию распределения г и сравните с соответ-
соответствующими значениями для биномиального распределения (с вероятностью р).
28. В условиях, описанных в упражнении 27, рассмотрите случай
р=D/г)~1, б = (8/г)~1, когда п велико. Обсудите ваши результаты.
29. В условиях, описанных в упражнении 27, предположите, что опыты
продолжаются непрерывно до тех пор, пока событие Е не произойдет точно
k оаз. Полагая, что на это понадобится # опытов, постройте распределение N.
ПрКб = 0 и k^2 покажите, что (/г—1)/(#— 1) имеет математическое ожи-
дани^р.
30. а) Покажите, что Е (XYZ) = E [XE (YZ\X)].
б) Подбрасывается правильная шестигранная кость и записывается число
(X), оказавшееся на ее верхней грани. Две (правильные) монеты подбрасы-
подбрасываются каждая X раз и отмечается число гербов, выпавших при этом. Число
Y обозначает X плюс число гербов для первой монеты, a Z—это X плюс
число гербов для второй монеты. Найдите коэффициент корреляции между
X и YZ.
31. Сделано п измерений физической величины 6: Хъ Х2, •••» Хл. Можно
полагать, что среднее квадратическое отклонение Xf — константа (для всех t)
и коэффициент корреляции между Х\ и Х*+1есть р (> 0) для ? = 1, 2, ..., п— 1,
однако коэффициенты корреляции между всеми остальными парами X равны 0.
Найдите такую линейную функцию X, которая имела бы наименьшую
дисперсию среди всех линейных функций с математическим ожиданием 0.
96
Глава 3
Теория вероятностей. Общиет положения
97
Получите формулу для дисперсии этой линейной функции от X. [Полагая,
что E(Xj)^d для всех t.]
Ъ2. В условиях, описанных в упражнении 31, найдите математические
ожидания величин
а) п-*
п-\
33. Взаимно независимые случайные величины U, Vi, V2t ..., Vn и
t^i, W2, ..., Wn имеют математическое ожидание 0 и дисперсию а2. Вели-
Величина X не зависит от всех этих случайных величин и имеет дискретное рас-
распределение с
N
Рт[Х — г]^=рг>0 при г = 0, 1, 2, ..., N; 2 Р/в1«
Случайные величины Y и Z задаются уравнениями
X X
а) Покажите, что X и YZ некоррелированы, но не независимы*
б) Определите коэффициент корреляции между У и Z.
34. к совокупностей смешаны в долях ръ р2, ..., р%, причем 2*V=*'
В /-й совокупности величина X распределена по пуассоновскому закону со
средним Оу; никакие два из чисел 01( 82> ..., % не равны. Получите фор-
формулу распределения значений X для объектов, выбранных из этой смеси
распределений случайным образом.
35. Пусть Flt F2, ..., /^ — полное множество несовместных событий, так
k
что 2 Рг [i7,-] = 1; покажите, что
а) Рг |
6J
36. Звезды классифицируются по светимости как карлики, гиганты и
сверхгиганты. Среди голубых звезд а—доля карликов, р—доля гигантов и
Y = l— а—р— доля сверхгигантов. Метод классификации включает научение
спектра звезд и подвержен ошибкам. Пусть
рх—вероятность принять
р2—вероятность принять
Рз—вероятность принять
pi — вероятность принять
рь—вероятность принять
рб — вероятность принять
карлика за гиганта,
карлика за сверхгиганта,
гиганта за сверхгиганта,
гиганта за карлика,
сверхгиганта за гиганта,
сверхгиганта за карлика.
Сделаны три независимых измерения спектра каждой звезды. Пусть X — число
случаев, когда по результатам измерений звезда классифицируется как гигант.
Найдите Рг[Х»*].
37. Ежедневно экспресс-методом проверяется качество материала в боль-
большой числе М малых изделий массового производства. Лишь в малой доле
случаев наблюдаются дефекты, но поскольку дефекты в материале могут быть
связаны с серьезными дефектами обработки, в каждом случае обнаружения
дефектов экспресс-методом отбирается три изделия для всесторонних прове-
проверок. Такие проверки значительно более строги- и, если р изделий (в среднем)
окажутся ©тбрако&анньши при пе|шой проверке, то вторая проверка даст
(в среднем) х/40 {\-\~Шр) долю таких изделий.
а) Выразите распределение числа изделий, ежедневно отбраковываемых
f проверкой, через р предполагаемое постоянным для данного дня).
б) Найдите среднее значение и среднее квадратическое отклонение для
распределения.
38. Логарифмическое распределение случайной величины X задается выра-
жением
= 1, 2,
О < а
Получите общую формулу для моментов этого распределения. Из нее найдите
среднее значение, среднее квадрати-ческое отклонение и моменты а3 и а4.
39. Геометрическое распределение случайной величины X задается выра-
выражением
Wj^a'O—а), г = 0, 1,2,
О < а < 1.
Получше общую формулу для моментов этого распределения. Из нее найдите
ередяее значение, ереднее квадратическое отклонение, а также третий и чет-
четвертый стандартные моменты а3 иа4.
40. Даны- случайные величины Хи Х2, ...» Xk. Покажите, что для любых
положительных чисел йъ d2, ..., d%
Vr[\Xi-E(Xi)\ <d( для всех t = l, 2,
1
k
2 *Т
2
41. Случайная величина У принимает значения, ограниченные интерва-
интервалом 0 < У < В\ плотность распределения вероятностей У является убываю-
убывающей функцией у. Покажите, что при 0 < А < В
Покажите, как из этих неравенств выводятся неравенства типа неравенства
Чебышева.
42. Изготовитель утверждает, что егтэ изделия будут выдерживать нагрузку
в 2500 ± 200 фунт/кв. дюйм. Если известно, что среднее квадратическое откло-
отклонение равно 40 фунт/кв. дюйм, то какова вероятность выполнения требуемых
условий? Предполагается, что среднее равно 2500 фунт/кв. дюйм, но нет
сведений о форме распределения.
43. Штамповочный автомат имеет 10 головок. В условиях нормальной
работы вероятность получить бракованную штамповку составляет 0,001 для
хорошо отрегулированной головки и 0,01 для разрегулированной головки.
Можно считать, что число разрегулированных головок распределено по бино-
биномиальному закону с параметрами 10 и 0,02.
Среди 100 полученных штамповок две оказались бракованными. Найдите
апостериорную функцию распределения числа разрегулированных головок.
(Требуется найти формулу для вероятности того, что разрегулировано точно /
головок, и предложить способ вычисления.)
4 № 819
98
Глава 3
44. Известно, что среди пяти шестигранных игральных - костей одна
неправильная. Для этой неправильной кости вероятности выпадения 1, 2, 3,
4, 5, 6 равны либо
1) 1/12, 1/6, 1/6, 1/6, 1/6, 1/4 соответственно, либо
2) 1/12, 1/12, 1/6, 1/6, 1/4, 1/4.
Эти альтернативы равновероятны.
Случайным образом из этих пяти костей взяли одну и бросили ее 12 раз.
Получились следующие результаты (в порядке появления): 2, 6, 6, 3, 1, 4,
5, 5; 6, 1,3, 2.
а) Найдите апостериорную вероятность того, что выбранная кость непра-
неправильная.
б) Если допустить, что выбрана именно неправильная кость, то какой
из вариантов A) или B) имеет большую апостериорную вероятность?
45. В упражнении 7 из гл. 2 найдите нормированные величины для 25
октановых чисел.
46. Определите коэффициент корреляции между X и У для совместной
функции распределения из упражнения 3.
47. Ниже представлена совместная плотность распределения вероятностей
случайных величин X и У:
Рх,у(х>У) = х2 + ^> 0<дс<1, 0<*/<2.
Вычислите а) Рг [X < 1/2]; б) Рг [X < У}; в) Рг [У < 1/2 | X < 1/2].
48. Найдите в предыдущем упражнении частные плотности распределения
вероятностей рх(х) и ру(у)- „
49. Пусть рх у(х>У) = *хУ ПРИ °^*<! и 0<#<1; найдите
а) ру(х), ' б) Рг[Х > У],
в)Рт[Х< 1/2|К< 1/2], г) Рг[Х<1/2,
д) Рг[Х<1/2].
Глава 4
ДИСКРЕТНЫЕ РАСПРЕДЕЛЕНИЯ
4.1. ВВЕДЕНИЕ
Как отмечалось в разд. 3.5, многие распределения вероятностей
можно классифицировать как дискретные и непрерывные. В этой
главе рассматриваются только дискретные распределения веро-
вероятностей и прежде всего 1) биномиальное, 2) пуассоновское,
3) гипергеометрическое и 4) равномерное распределения. Кроме
того, описываются следующие распределения: 1) полиномиаль-
полиномиальное, 2) отрицательное биномиальное, 3) Неймана типа Л, 4) лога-
логарифмическое и 5) дзета-распределецие. В каждом случае приво-
приводятся некоторые параметры распределений, такие, как моменты
и.другие числовые характеристики. Там, где возможно, даются
ссылки на существующие таблицы. Приведены также примеры
приложений.
Напомним, что общие свойства дискретной функции распре-
распределения вероятностей включают
D.1)
Нт 2 />(*) = О,
lim 2 />(*)=!.
<К
4.2. БИНОМИАЛЬНОЕ РАСПРЕДЕЛЕНИЕ
Пусть в некотором процессе получается 2% брака. Берется
выборка из 10 независимых образцов. Интересно узнать вероят-
вероятность того, что в этой выборке не окажется дефектов. Ясно,
что это может произойти только тогда, когда ни один из десяти
образцов не будет бракованным. Вероятность этого события
равна @,98I0, или 0,8171, так как 0,98— вероятность получения
одного недефектного образца. Можно представить этот результат
и иначе: @°) @,98I0 @,02)°. Здесь первый сомножитель
указывает на то, что имеется только один вариант появления
события, второй сомножитель 0,98 х 0,98х ... 0,98—вероятность
4*
100
Глава 4
появления десяти последовательных недефектных образцов, тре-
третий сомножитель @,Q2)° — вероятность непоявления бракованных
образцов.
Обобщая этот результат, запишем выражение для вероятности
Р(х) получения ровно х „успехов" (успешных исходов) в выборке
объема п, если вероятность „успеха" (появления дефектного об-
образца) равна /?, а вероятность неудачи есть 9=1 — Р:
p (x) - ( x j q"-*px при x - 0, 1, 2, .. ., n. D.2)
Иными словами, это выражение содержит 1) (XJ — число спо-
способов получения х успехов при п образцах, 2) qn'x—вероят-
qn'x—вероятность получения ровно п—х неудач, наконец, 3) р*—вероят-
р*—вероятность получения ровно х успешных исходов. Это было показано
в разд. 3.10.
Такое распределение известно как биномиальное; его назва-
название происходит от разложения бинома, которое имеет вид (см.
также разд. 3.10)
~~ =1. D.3)
Каждый член в этом разложении представляет одно из (я + 1)
дискретных значений Р(х).
В биномиальном распределении предполагается, что отбор
отдельных образцов (с целью проверки: успех или неудача) не
меняет вероятности успеха, т. е. параметр р постоянен. Все от-
отборы независимы и вероятность успеха неизменна. Это важное
предположение, поскольку в конечном множестве с фиксирован-
фиксированным числом дефектных образцов выбор одного образца факти-
фактически меняет долю дефектных среди оставшихся.
При определении моментов этого распределения можно вы-
вычислять каждый момент непосредственно (разд. 3.13) или при
помощи производящих функций (разд. 3.17). Производящая
функция моментов в данном случае имеет вид
mx(t) =
х) =
х=0
D.4)
Возьмем первые две производные:
Дискретные распределения
101
Теперь, полагая / = 0, получим
= п2р2- — Пр2 + Пр.
Среднее и дисперсия равны
\л = \л'1='Пр D 5)
а2 = \i2—\хх2 — — прг + пр — прA — р).
Следовательно,
o2 = npq. D.6)
Аналогично вычислив
Г^/п*(О1 и Г<*4/пх('I
получим fXg и (i4- Используя формулу C.49), можно найти fx3 и fx4:
Наконец, третий и четвертый стандартные моменты равны
__ я-р
а --
3
Ы3/3
D.8)
Эти результаты можно также получить и из формулы ii(s) =
=n{s)ps для s-ro факториального момента.
Из формулы D.8) видно, что при п^оо величина ая стре-
стремится к нулю, а а4 —к трем. Ниже будет показано, что эти
величины представляют собой третий и четвертый стандартные
моменты для нормального распределения. Для любого симмет-
симметричного распределения а3 = 0.
Пример 4.1. Какова вероятность ровно трех успехов в 8 опы-
опытах в случае постоянной вероятности события р = 0,5? Это экви-
эквивалентно вероятности выпадения трех гербов при восьми под-
подбрасываниях монеты. Имеем
Рг [X = 3] = (I) @,5Г3 @,5K = зШ @>5)8 = 0,2188.
Рассмотрим теперь графическое представление биномиального
распределения для случаев
а) р — 0,1, /г —8,
б) /7-0,3, /г-8,
I у — UjUj fl === О.
102
Глава 4
На рис. 4Л показаны вероятности х успешных исходов при п
независимых опытах, когда вероятность успеха в каждом отдель-
отдельном опыте равна р. Для этих случаев среднее \i и среднее
квадратическое отклонение а равны
Ч-/
Q.
0,4
0,3
0,2
0,1
0
a) \i
= 0,8,
б) м-= 2,4,
в) ц = 4,0,
-
-
0 1 <
Р
i J
а
о
о
4 5
/7 =
-0
j
= 1
¦¦8
,85,
,30,
,41.
7
8
а
0,4 Г
0,1
0
±
01Z345S78
р=0,3 П = 8 $
0,4
Н
0,1
о
JL
0 113 4 5 6 7 8
Р~ у $
>х
-*~х
Рис. 4.1. Биномиальные распределения.
В третьем случае среднее совпадает с модой. Это верно
для таких биномиальных распределений, где пр оказывается
целым числом. В табл. 4.1 приведены числовые значения вероят-
вероятностей для п = 8 и р = 0,1; 0,3; 0,5; 0,7 и 0,9. Отметим подобие
распределений при р = 0,1 и 0,9, а также при р = 0,.3 и и,/.
Действительно, распределение X при р = р0 то же самое, что и
для п—X при р = 1 — р0.
Дискретные распределения
103
а:
О
1
2
3
4
5
6
7
8
0,4305
0,3826
0,1489
OtO33i
0,0046
0,0004
0,0000
0,0000
0,0000
Биномиальное
[значения
р=9,з
0,0576
0,1977
0,2965
0,2541
0,1361
0,0467
0,0100
0,0012
0.0001
распределение: я = 8
Р(х) из
0,0039
0,0312
0,1094
0,2188
0,2734
0,2188
0,1094
0,0312
0,0039
D.2)]
/>=0,7
0,0001
0,0012
0,0100
0,0467
0,1361
0,2541
0,2965
0,1977
0,0576
Таблица 4Л
Р=0,9
0,0000
0,0000
0,0000
0,0004
0,0046
0,0331
0,1489
0,3826
0,4305
Если известна Pr[X — k], то Рг[Х = Л+1] можно вычислить,
пользуясь рекуррентной формулой. Это полезно при больших п,
особенно когда нуя^но определить сумму некоторого числа чле-
членов. (Надо лишь следить, чтобы точность сохранялась в требуе-
требуемом числе десятичных знаков.) Так как
п
k
то можно легко увидеть, что
D.9)
Поскольку pfq — константа, то можно очень быстро вычислить по-
последующий член при известном предыдущем члене распределения.
В последнем примере при р —0,3 и п = 8 можно определить
вероятность не более двух успешных исходов. Эта вероятность
равна
8-^ @,3)* = 0,5518.
Следует проявлять осторожность при установлении границ для х.
Так как X может принимать только дискретные значения, выра-
выражение Рг[0^Х < 2] должно отвечать на вопрос: „Какова вероят-
вероятность менее чем двух успешных исходов?". Действительно,
Рг[0<Х< 2]-0,2553.
104 Глава 4
4.2Л. Таблицы биномиального распределения
Существует несколько таблиц для вычисления как значений
Рг[х], так и накопленных вероятностей. Из множества таблиц
укажем следующие с их границами для аргументов:
1) Harvard University, Tables of the Cumulative Binomial
Probability Distribution, Harvard University Press» 1955
[p = 0,01@,01H,50; 1/12A/12M/12; 1/16A/16O/16;
n « 1 A) 50 B) 100 A0) 200B0) 500 E0) 1000].
2) National Bureau of Standards, Tables of the Binomial
Probability Distribution, Government Printing Office, 1949 [p=
=0,01@,01H,50; /1 = 2AL9].
3) H. G. Romig, 50—100 Binomial Tables, Wiley, 1953
[p = 0,01 @,01H,50; n = 50EI00].
4) U. S. Office of the Chief of Ordnance, Tables of the Cumu-
Cumulative Binomial Probabilities» Aberdeen Proving Grounds, Mary-
Maryland, Ballistics Research Laboratory, 1952 [p = 0,01 @,01H,50;
/1=1AI50].
5) CRC Handbook of Tables for Probability and Statistics,
2nd ed., CRC Press, Cleveland, Ohio, 1968 [/?== 0,05 @,05) 0,50;
n=l(lJ0f 4 десятичных знака].1*
(Можно вычислять биномиальные вероятности и по таблицам
отношения неполной бета-функции [6.7], используя результат
упражнения 22 из гл. 5.)
4.2.2. Распределение долей
Иногда вероятность заданной доли успешных исходов пред-
представляет больший интерес, чем число успешных исходов в п
опытах. Например, в случае р = 0,5 и п -=20 может представ-
представлять интерес вероятность того, что доля успешных исходов
в выборке будет не более 0,10. Это эквивалентно вероятности
не более двух успешных исходов в 20 опытах. Функция распре-
распределения вероятностей для доли у есть
=0,^ 1. D.10)
Дискретные распределения
105
*) В ссылках на таблицы границы аргументов обозначены крайними чис-
числам», а шаг— в скобках. Отметим также, что биномиальное распределение,
как и многие распределения, упомянутые ниже, читатель может найти, напри-
например, в следующих таблицах на русском языке: Большее Л. Н., Смирнов Н. В.
Таблицы математической статистики,—М,: Наука» 1965; Оуэн Д. Б. Сборник
статистических таблиц.— М.: ВЦ АН СССР, 1973.— Прим. перев.
Величина Y—это просто линейное преобразование величины X.
Можно показать, что среднее и дисперсия Y составляют 1/л
среднего и 1/я2 дисперсии X соответственно. Следовательно,
D.11)
Пример 4.2. Лабораторные образцы эмалированных пластин
были подготовлены для испытаний на скручивание. Все они
находились в одинаковых условиях контроля. Наш опыт под-
подсказывает, что в этом конкретном эксперименте не выдержат
испытания около 5% образцов.
а) Какова вероятность того, что в выборке объема 10 ока-
окажется: 1) нуль дефектов, 2) один дефект, 3) менее трех дефектов?
б) Как много образцов надо включить в выборку, чтобы
в ней с 95%-ной вероятностью оказалось не менее пяти безде-
бездефектных образцов?
а) Вероятность дефекта р = 0,05. Вероятность х дефектов
в десяти опытах равна
() @,95)»-*.@,05)*.
Отсюда получаем
1) Рг[Х-0] = @,95I0- 0,5987;
2) Рг[Х=1]=10.@,95)*-@,05) = 0,
2
3) Рг [0 < X < 3] - ? A0) <0,95I0~* @,05)* = 0,9884.
б) Для определения объема выборки потребуем, чтобы
Другими словами, мы хотим, чтобы число дефектов было по
крайней мере на 5 единиц меньше, чем объем выборки. Из
таблицы биномиального распределения находим
Рг[Х<1] = 0,97 при л = 6,
Рг[Х-0] = 0,85 при п = 5.
Следовательно, наш ответ: 6.
4.2.3. Отрицательное биномиальное распределение
Рассмотрим последовательность независимых опытов, в каж-
каждом из которых вероятность наступления событий Е равна р.
Пусть опыты продолжаются до тех пор пока событие Е не про-
произойдет ровно k раз. Вероятность того, что для этого потре-
потребуется точно г опытов, равна
106
Глава 4
Дискретные распределения
107
Рг[(& — 1) раз событие Е происходит в первых (г —1)
опытах и событие Е происходит в r-м опыте] =
— Рг[(?— 1) раз событие Е происходит в первых (г—1)
опытах] Рг [событие Е происходит в г-м
опыте] = (? Z1) Pk'xqr~kP = (? Z i
где ? = 1—р.
Случайная величина /? имеет распределение
Ь ¦¦¦)¦
Заметим, что по структуре эти вероятности похожи на бино-
биномиальные. Можно показать, что они образуют последовательные
члены в отрицательном биноме.
Действительно,
где
a Q-P=
Распределение, определяемое по формуле
(k + S-\\ /PV ,019
= ^_1 )Q *{-q) . s = 0, 1, 2, .
D.12)
называется отрицательным биномиальным распределением. Его
моменты можно получить по соответствующим формулам для
биномиального распределения, заменяя в них п на — &, q на Q*
и р на — Р. Это дает
'. Var (X) - kPO = kP(l+P),
D.13)
Производящая функция моментов есть (Q —
Записывая вероятность в виде
P V
можно распространить отрицательное биномиальное распределе-
распределение на случай, когда k — нецелое число1*.
» Здесь Г (А) —гамма-функция (см. разд. 5.6.1).— Прим. ред.
Пример 4.3. Несколько примеров отрицательного биномиаль-
биномиального распределения дано Эренбергом в работе The Pattern of
Consumer Purchases, AppL Stat., 8 A959). Один из них приве-
приведен в табл. 4.2. Он относится к покупкам товаров широкого
Таблица 4.2
Отрицательное биномиальное распределение числа единиц товара,
приобретенных в течение недели (по выборке в 2000 семей за 26 недель)
Число куп-
купленных единиц
товара X
0
1
2
3
4
5
6
7
8
9
10
11
12
13
Частота
наблюдаемая
1612
164
71
47
28
17
12
12
5
7
6
3
3
5
теоретическая
1612,0
156,9
74,0
44,2
29,2
20,3
14,7
10,8
8,2
6,2
4,8
3,8
2,9
2,3
Число куп-
купленных единиц
товара X
14
15
16
17
18
19
20
21
22
23
24
25
26
27
Частота
наблюдаемая
2
1
2
1
2
теоретическая
1,8
1,5
1,2
0,9
0,8
0,6
0,5
0,4
0,3
0,3
0,2
0,2
0,1
0,9
потребления недлительного пользования. Эти товары обычно про-
продаются расфасованными или в фабричной упаковке. В первом
и четвертом столбцах табл. 4.2 приведено число единиц товара (X),
купленного в течение недели. Во втором и пятом столбцах ука-
указаны числа семей (из 2000 обследованных), которые приобрели х
единиц. Выборка охватывает 26 недель. В третьем и шестом
столбцах даны теоретические частоты, полученные после оценки
параметров k и Р, подстановки этих оценок в формулу D.12)
и затем вычисления Р(х) длял: = 0, 1, .... Следует отметить,
что формулы D.13) указывают метод оценки параметров, причем
оценки Е[Х] и Var(X) берутся как х и s2 соответственно. Все
остальное имеется в распоряжении. Эти вопросы обсуждаются
в упомянутой статье Эренберга.
Если взять k — 1, то получим частный случай отрицательного
биномиального распределения, известный как геометрическое рас-
распределение. Для этого распределения
s] = W*, s=0, I, 2
108
Глава 4
[Отметим, что последовательные вероятности образуют геометри-
геометрическую прогрессию со знаменателем <?(<1), т. е. прогрессия умень-
уменьшается с ростом s.]
4.3. РАСПРЕДЕЛЕНИЕ ПУАССОНА
Распределение Пуассона является дискретным распределением,
очень полезным в промышленных применениях статистики. Оно
получается из биномиального распределения D.2) при устремле-
устремлении п к бесконечности, ар — к нулю таким образом, чтобы мате-
математическое ожидание пр оставалось постоянным и равным, ска-
скажем, в.
Подставив p = Q/n и q=l—Q/n в формулу D.2), получим
Правую часть этого уравнения можно преобразовать к виду
Когда п стремится к бесконечности, A — Q/n)n стремится к е"°,
каждый из (х—1) членов A — 1/п), A—2/п), ..., [1— (я— 1)/п]
стремится к единице так же, как и член A — 8/я)~*. (Напомним,
что мы считаем х постоянным числом.)
Следовательно» предел Р(х) при п—+оо равен
х\ '
Распределение Пуассона определяется как распределение, для
которого
при х«0, 1, 2 D.14)
Отметим, что
2/>(*)=!.
Параметр 8 должен быть положительным. С другой стороны, ис-
используя производящую функцию моментов, получим
D.15)
х=0
Дискретные распределения
109
Первые две производные равны
i^=?0 <*'-!> [(ОеО2+&?<].
Подставляя / = 0, получаем
Отсюда среднее и дисперсия равны
,1 = 9, 02 = е. D.16)
Если взять третью и четвертую производные от D.15) и поло-
положить t~0t то получим \i's и ^4- Снова применяя формулы C.49),
найдем значения \iz и |о,4:
Цз^9, ц4 = 9A+3в). D.17)
Показатель асимметрии и эксцесс (третий и четвертый стан-
стандартные моменты) равны
а, = 0-1/*, а4 = 3 + в-1. D.18)
Эти формулы можно также вывести и из соотношения ^E) = 05.
В табл. Б приложения приведена функция распределения Пуас-
Пуассона при 0, изменяющемся от 0,1 до 20.
Пример 4.4. В окрестностях города Кливленда (шт. Огайо)
среднегодовое число погибших в автомобильных катастрофах за
период 1945—1951 гг. составило 0,5. В 1952 г. в автомобильных
катастрофах погибло 3 человека. Не указывает ли это на реаль-
реальный рост транспортной опасности? (Действительно, как следствие
этого наблюдения предельная скорость на главных трассах была
снижена на 10 миль/ч на период в несколько месяцев.)
Не будем вдаваться в политические аспекты ситуации, а от-
ответим на следующие вопросы: какова вероятность а) точно трех
смертей, б) трех или более смертей? Предполагаем, что распре-
распределение числа смертей в год хорошо представляется распределе-
распределением Пуассона со средним 0,5.
а) Рг [X = 3] = Р C) = в" м <°'5)Э = 0,0126.
3!
б)
е-<ь5@,5)*
р-0.5
@,5)*
xl
= 1 - 0,6065 - 0,3033 - 0,0758 = 0,0144.
Читателю предлагается сделать собственные выводы, а также
обсудить, насколько применимо в этом случае распределение
Пуассона.
по
Глава 4
*4.3.1. Применения распределения Пуассона
Распределение Пуассона широко применяется при решении
многочисленных задач науки и техники. Оно часто используется
как первое приближение для описания данных об отказах, таких,
как число отказов в течение заданного отрезка времени. Другие
примеры—число несчастных случаев за определенный интервал
времени, число импульсов, зарегистрированных счетчиком Гей-
Гейгера в единичном интервале, число дефектов на зеркальном
стекле и число дефектов в некоторой большой совокупности.
Более общее, хотя и несколько опасное утверждение (из-за от-
отсутствия упоминания о необходимости независимости), касаю-
касающееся распределения Пуассона, состоит в том, что оно часто
используется в ситуации, где вероятность наступления отдель-
отдельного события чрезвычайно мала, хотя подходящих случаев для
его наступления очень много. Рассмотрим, например, число
несчастных случаев на дорогах пригорода Кливленда. Распреде-
Распределение числа несчастных случаев можно считать пуассоновским,
так как в любую данную минуту вероятность несчастного случая
мала, а год содержит большое число минут. Однако возможность
наступления нескольких смертей в одном происшествии показы-
показывает, что независимость может оказаться очень сомнительным
предположением.
На рис. 4.2 приведены три примера распределений Пуассона:
а) 0 — 0,5; б) 0=1,0 и в) 0^6,0. При малых 0 наблюдается
асимметрия. Заметна также тенденция к симметрии с рос-
ростом 0.
В табл. Б приложения приведена функция распределения
Пуассона. Значения 0 меняются от 0,1 до 20. Как образец при-
применения этой таблицы рассмотрим пример 4.4. Используя эту
таблицу непосредственно, можно вычислить
а) Рг[X = 3]=Рг[X>3]—Рг[X>4]-=0,0144—0,0018=0,0126;
б) Рг[Х>3] = 0,0144.
Более подробные таблицы пуассоновского распределения при-
приводятся в следующих публикациях:
1) Poisson Exponential Binomial Limit by E. С Molina (D. Van
Nostrand, 1942) со значениями Р(х) и Рг[Х^с] при 0,001 <
<<
2) Tables of the Individual and Cumulative Terms of the Poisson
Distribution by the Defence Systems Department of the General
Electric Co. (D. Van Nostrand, 1962) со значениями P(x) и
Pr[X<c] при 0,00000010<8<205.
3) Tables of Poisson Distribution by T. Kitigawa (Baifukan,
Tokyo, 1952) со значениями Р(х) при 0,001 ^9< 10.
Дискретные распределения
111
0,5
^0,3
0,1
0,1
-
-
-
-
1
°'° 0 11
3 4 5 6 7 8 9 10 11 11
$ = 0,5
0,4-
&0,l
0,1
0,0
0,3
* 0,1
0,0
0 1 13 4 5 6 7 8 9 10 11 11
6 = 7,0
I
1
0 1 13456789 10 11 12
Рис. 4.2. Распределения Пуассона.
. x
4Л. ГИПЕРГЕОМЕТРИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ
Обозначим число элементов в совокупности через N и поло-
положим, что именно D из них обладают некоторым свойством -ф
(например, являются в некотором смысле дефектными). Если слу-
случайная выборка объема п отбирается по одному элементу и каж-
каждый элемент возвращается в совокупность прежде, чем будет
осуществлен выбор следующего, то вероятность того, что выбирае-
выбираемый элемент обладает свойством *ф, одна и та же {D/N) в каждом
опыте. Общее число X элементов, обладающих свойством гр
в выборке объема п, описывается случайной величиной, распре-
распределенной по биномиальному закону с функцией распределения
вероятностей
112
Глава 4
Но если каждый элемент не возвращается после отбора, то
мы не будем иметь постоянную вероятность или независимость
при переходе от одного элемента к другому. Если, например,
первый отобранный элемент обладает свойством if, то условная
вероятность того, что и следующий элемент будет им обладать,
равна {D— \)I(N — 1); если первый элемент наоборот не обла-
обладает свойством я|>, то вероятность того, что следующий элемент
будет им обладать, равна D/(N — 1). Вероятность того, что х эле-
элементов среди п элементов выборки обладают свойством % можно
получить, рассматривая число способов получения выборки „без
(N\
возвращения". Существует ( п ) равновероятных способов отбора
группы из п элементов в совокупности объема N. Группы, со-
содержащие х элементов, которые обладают свойством "ф, можно
перечислить, используя тот факт, что они образуются при выбо-
выборе х элементов из D элементов, обладающих свойством г|>, и (п — х)
элементов из остальных (N — D) элементов. Перебирая все воз-
возможные комбинации исходов, видим, что число различных воз-
fD\/N — D\ ^
можных групп равно \х )\ п — х ) ' ° й дает гипеРгеометРи-
ческое распределение:
, где max @, n-j-D —
D<Nt n<N.
>, n),
D.19)
P(x) =
Величина х заключена в пределах O^x^D; O^n — x^N — D.
Гипергеометрическое распределение приведено для различных
значений N, п и D в Tables of the Hypergeometric Probability
Distribution by Lieberman and Owen (Stanford University Press,
1961). Параметры изменяются в пределах от iV = 2, п=1 до
N =100, л = 50.
Применение производящих функций моментов при определе-
определении моментов гипергеометрического распределения приводит
к сложным вычислениям. Однако, используя определения
удается непосредственно найти
(л = Пр, а2 = пр A — р) -
D.20)
Дискретные распределения
ИЗ
Можно показать, что s-й факториальный момент равен
Пример 4.5. Необходимо проверить партию, состоящую из 100
изделий. План контроля предусматривает проверку 20 изделий.
Если среди них оказываются плохие, мы возвращаем всю партию,
в противном случае принимаем. Чтобы оценить, насколько хорош
план, которым мы пользуемся, ответим на следующие вопросы.
а) Если в партии 5 бракованных изделий, как часто будет
приниматься решение об ее приеме? б) Если в партии 10 бра-
бракованных изделий, как часто она будет возвращаться? в) Пред-
Предположим, что в выборке допустим один случай брака; какого
рода гарантии хотели бы мы иметь как потребители? Чтобы от-
ответить на вопрос а), необходимо найти Рг[Х = 0] или просто Р@),
когда партия объема jV = 100, число дефектов в ней D = 5, а объем
выборки п = 20. Из формулы D.19) имеем
а) Р@) =
с»
-0,3193,
и значит можно ожидать принятия примерно 32% партий, имею-
имеющих по пять бракованных изделий.
В случае б) D= 10. Отсюда
/ION /904
I o A 20;
/1OO\
-0,0951.
Но если в выборке оказывается 0 дефектов, то партия прини-
принимается. Таким образом, вероятность возврата партии равна 0,9049.
В случае в) просто ответим на вопрос: „Какова вероятность
принять партию с пятью дефектными изделиями, если в выборке
допустим один случай брака?" Тогда
/1004 '
\2o;
= 0,3193 + 0,4201= 0,73941(.
100
1> Ошибка округления: должно быть 0,7395.
114
Глава 4
*4.5. СРАВНЕНИЕ БИНОМИАЛЬНОГО,
ПУАССОНОВСКОГО И ГИПЕРГЕОМЕТРИЧЕСКОГО
РАСПРЕДЕЛЕНИЙ
Существуют две проблемы, связанные с этими тремя распре-
распределениями, а именно: 1) когда и какое из этих распределений
следует выбирать; 2) когда одно из них можно использовать как
аппроксимацию другого? Первая проблема, конечно, более фунда-
фундаментальна. Мы не будем здесь детально рассматривать вопрос
о выборе подходящей модели. Сравнение моделей проведено
ниже. Следует отметить, что распределение Пуассона полезно
само по себе, а не просто как предельный случай биномиального.
В табл. 4.3 распределения сравниваются по их параметрам р,
nt D и N.
Таблица 4.3
Сравнение биномиального, пуассоновского
и гипергеометрического распределений
Распределение
Пара-
Параметры
Биномиальное
Пуассона
Гипергеометри-
Гипергеометрическое
р, п
A n, N
Постоянно
Очень мало
D—x
р — ,., при
(л+ 1)-м наблю-
наблюдении; р изме-
изменяется по мере
увеличения вы-
выборки
Задано
Неизвестно, но
очень велико
Задано
Бесконечно
(или очень
велико)
Неизвестно
Конечно
Вопрос о том, когда можно использовать одно из этих рас-
распределений вместо другого, перестал быть таким важным, каким
он был 25 лет назад или еще раньше. Возросшие вычислитель-
вычислительные возможности позволили получить таблицы многих распреде-
распределений, в том числе и биномиального распределения, так что
вряд ли надо брать пуассоновское распределение при малых р
и больших п для аппроксимации биномиального, за исключением
случаев, когда это упрощает аналитические исследования. Срав-
Сравним распределения с помощью табл. 4.4, где даны три варианта
биномиального распределения для пр= 1, а именно р = 0,2, п = 5;
Дискретные распределения
115
Таблица 4.4
Биномиальные и пуассоиовское распределения вероятностей
Биномиальные
X
0
1
2
3
4
5
6
7
&
0.3277
0,4096
0,2048
0,0512
0,0064
0,0003
р=0,1, л=Ю
0,3487
0,3874
0,1937
0,0574
0,0112
0,0015
0,0001
0,0000
р = 0,05, л=20
0,3585
0,3774
0,1887
0,0596
0,0133
0,0022
0,0003
0,0000
Пуассоновское
6=1
0,3679
0,3679
0,1839
0,0613
0,0153
0,0031
0,0005
0,0001
0,0000
р —0,1, л=10 и р = 0,05, л = 20. Заметьте, как хорошо распре-
распределение Пуассона, приведенное в последнем столбце при 0=1,
аппроксимирует их, особенно при малых х.
4.6. ПОЛИНОМИАЛЬНОЕ РАСПРЕДЕЛЕНИЕ
Полиномиальное распределение (см. разд. 3.11) можно рас-
рассматривать как обобщение биномиального. Его параметры не
просто р и л, а р19 р2, ..., pft_! и л. В этом случае совокуп-
совокупность состоит из элементов, имеющих k различных взаимно
исключающих признаков, каждому из которых соответствует
вероятность появления р0 Заметим, что параметрами являются
Pi» Л» •••» Pk-г и л» поскольку рк задается требованием
S
D.21)
Вероятность того, что в выборке объема п будет х1 элементов
с первым признаком, х2 — со вторым и т. д., равна
Величина Xt имеет биномиальное распределение с параметрами
п и р^ Поэтому среднее и дисперсия равны
116
Глава 4
Таким образом, если два или большее число признаков объеди-
объединяются, то получающаяся сумма частот будет иметь биномиаль-
биномиальное распределение. Например, X( + Xj + Xk распределена по бино-
биномиальному закону с параметрами п, P/ + P/ + /V Вообще если
множество признаков объединяются в непересекающиеся подмно-
подмножества, результирующие частоты будут иметь полиномиальное
распределение.
Пример 4.6. В некотором производстве систематически полу-
получается 1% металлического лома и 5% исправимого брака, т. е.
5% продукции применимо лишь после некоторой дополнительной
обработки, а 1% продукции вообще не может быть использован.
Остальная продукция хорошая. С поточной линии взята выборка
объема 50 образцов, а) Надо ли рассматривать 2% лома и 8% ис-
исправимого брака как нечто необычное? б) Какова вероятность
обнаружить в этой выборке два плохих (неисправимых) образца?
Пусть Хх — число плохих образцов и Х2 —число исправимых
образцов. Вопрос а) относится к случаю Хх^=1, Х2 = 4. Чтобы
на него ответить, следует сначала найти вероятность этой пло-
плохой ситуации или ситуаций, еще худших, а именно PfX^l
4]
X2>4]= V
E0-^-^1
X
X @,01)*! @,05)** @,94M0 - * -*¦ = 1 - {Рг [Хг = 0] +
+ Рг[Х2<4]-Рг[Х1 = 0, Х2< 4]} = 0,0913.
В этом случае вероятность 0,0913 следует рассматривать как не-
необычную. При ответе на вопрос б) нужно воспользоваться бино-
биномиальным распределением при р1 = 0,01 и 1— р1 = 0,99. Тогда
¦ B) = E2°) @,01J @,99L8 = 0,0756.
4.7. РАВНОМЕРНОЕ РАСПРЕДЕЛЕНИЕ
(ДИСКРЕТНОЕ)
В наиболее общем смысле понятие о равномерном распреде-
распределении относится к непрерывному равномерному распределению.
Существуют, однако, некоторые задачи, в которых величина х
принимает конечное множество значений, имеющих равные вероят-
вероятности появления. Например, при подбрасывании игральной кости
число очков х может оказаться равным 1, 2, 3, 4, 5 или 6,
каждое с вероятностью 1/6. При подбрасывании монеты можно
Дискретные распределения
117
приписать гербу значение 0, а цифре— значение 1. При каждом
исходе Р(х)=1/2 при х = 0 или лг'^1. Пусть из десяти мужчин
нужно выбрать „добровольца" для выполнения некоторого зада-
задания. Им можно приписать номера 1, 2, ..., 10 и выбрать одного
из них случайно. Тогда Р(х)^ 1/10 при х= 1, 2, ..., 10. Во всех
этих случаях мы исходим из предпосылки, что различные ситуа-
ситуации равновероятны.
Вообще функция дискретного равномерного распределения
определяется как
P(x)=~t x =
а + 2А, ..., а + (?-2)Д, Ь, D.24)
где
—1)Д = & —а.
Величина X принимает равноотстоящие (эквидистантные) дискрет-
дискретные значения от а до Ь. Постоянная вероятность 1/^ —обратная
величина от числа значений, которые может принять Л", т. е.
Среднее и дисперсия этого распределения соответственно равны
D.25)
12
Если А стремится к нулю, a k—к бесконечности, причем
так, что величина Д(&— 1) остается равной (Ь — а), то а2 стре-
стремится к величине (Ь — аJ/12, соответствующей непрерывному рав-
равномерному распределению (см. разд. 5.3).
Пример 4.7. При выборе случайных цифр с одинаковой вероят-
вероятностью может быть взята каждая цифра 0, 1,2, ..., 9. В выборке
объема 3 все три отобранные цифры превосходят 6. Можно ли
считать это неожиданным событием? Чтобы ответить на этот
вопрос, сформулируем его следующим образом: какова вероят-
вероятность в трех независимых выборах получить все цифры, боль-
большие, чем 6? Сначала возьмем равномерное (дискретное) распре-
распределение и найдем
> 6] - ?/>(*)= 710,
так как
Р(х)>
10 >
=0, 1, .... 9.
118
Глава 4
Затем обратимся к биномиальному распределению и определим
Рг[У = 3 успешным исходам)р = 3/10].
Это дает
"" 'таУС^У-0,027.
Если считать вероятность, меньшую, чем 5%, необычной, то полу-
получилось редкое событие и мы будем вынуждены приписать его
появление чему-то большему, чем просто случайность. Следует
признать, что более принято делить возможные события на классы
и рассматривать вероятность того, что произойдет событие из
данного класса.
4.8. ОТРИЦАТЕЛЬНОЕ БИНОМИАЛЬНОЕ
РАСПРЕДЕЛЕНИЕ КАК СМЕШАННОЕ
РАСПРЕДЕЛЕНИЕ ПУАССОНА
Если некоторое событие имеет малую вероятность появления
в коротком случайно выбранном интервале времени, то число X
появлений этого события в заданном интервале времени длиной 9
распределено по закону Пуассона с функцией распределения
Р(х) =
\
х = 0, 1,
В этом случае предполагается, что каждое единичное событие
независимо и появление одного из них не оказывает влияния
на другие. Однако существует класс задач, для которых это не
так. Например, при изучении промышленного травматизма решаю-
решающим фактором является предрасположенность к травматизму.
Изучение статистики несчастных случаев на производстве в круп-
крупных фирмах часто показывает, что есть группы, в которых не-
несчастные случаи повторяются значительно чаще, чем этого можно
было бы ожидать. Иными словами, риск попасть в промышлен-
промышленную аварию не одинаков для всех членов совокупности. Гринвуд
и Юл [An Inquiry into the Nature of Frequency Distributions
Representative of Multiple Happenings, Journal of the Royal Sta-
Statistical Societyy 83 A920)] подошли к этой задаче с помощью
впервые введенной ими функции травматизма (представляющей
собой распределение на множестве людей среднего числа травм
в год)
е~екУк~г °<<
где у— индекс травматизма. Предполагается, что число травм
при данном у распределено как пуассоновская случайная вели-
Дискретные распределения
11
чина со средним значением
вероятностей X есть
у. Тогда функция распределения
После интегрирования и упрощения она принимает вид
р {Х) = (~)^ г (ГЯ)( р+Д 1} (щг[)* при х = 0, 1,2,3, ....
D.26)
Но это и есть отрицательное биномиальное распределение (см.
разд. 4.2.3). Вероятность Р(х) — это член разложения
\
Среднее и дисперсия этого распределения равны
D.27)
Отрицательное биномиальное распределение можно предста-
представить как смешанное распределение Пуассона, если приписать
среднему гамма-распределение (см. разд. 5.6.1). Это частная раз-
разновидность смешанного распределения Пуассона. Любое распреде-
распределение, получаемое приписыванием распределения („смешиваемого
распределения") среднему пуассоновского закона, называют сме-
смешанным пуассоновским распределением.
Пример 4.8. События Et и Е2 происходят независимо во вре-
времени, так что для любого данного момента времени вероятность
того, что Et не произойдет в следующие Т секунд, равна
ехр (— Т/6;) при t = 1, 2. Найдем вероятность того, что в период
времени То произойдет ровно k событий (либо Elf либо Е2).
Поскольку события Ег и ?2 происходят независимо, то и
случайные величины Rx и R2, представляющие число появлений
?х и Е2 соответственно за время То, можно полагать взаимно
независимыми.
Разделим То на N временных интервалов каждый длиной
To/N. Вероятность появления Et (i = 1, 2) в любом заданном интер-
интервале равна 1— ехр(— TjNQ^ а появления событий в различных
интервалах взаимно независимы. При устремлении Й к беско-
бесконечности можно ожидать, что распределение /?,- будет прибли-
120
Глава 4
жаться к распределению Пуассона со средним значением
lim
Следовательно, Rt и R2 будут независимыми пуассоновскими
случайными величинами со средними значениями Т0/дг и Го/02
соответственно. Тогда [см. упражнение 34, п. a)] Rx + R9 тоже
будет пуассоновскои величиной со средним значением T0(9f1
так что
Рг [k событий] -
ехр ^_
Отметим, что, хотя такое распределение и можно назвать
смешанным пуассоновскнм распределением, в действительности
это обычное распределение Пуассона.
*4.9. НЕКОТОРЫЕ ДРУГИЕ РАСПРЕДЕЛЕНИЯ
Ниже будут описаны распределения, которые используются
не так широко, как предыдущие. Они предназначены для осо-
особых ситуаций и позволяют расширить область применения ста-
статистического анализа.
*4.9.1. Распределение Неймана типа A (Contagious
distributions)
Простые биномиальные и пуассоновские распределения можно
комбинировать различными способами в распределения, подхо-
подходящие для более сложных ситуаций. Пусть, например, число
несчастных случаев на производстве, происшедших на некоторой
операции за определенный период, описывается пуассоновскои
случайной величиной (/) со средним К1У а число тяжелых травм,
приходящихся на каждый несчастный случай, тоже описывается
независимой пуассоновскои случайной величиной со средним Х2.
Тогда, если произошло / несчастных случаев, общее число X
тяжелых травм будет распределено по закону Пуассона со сред-
средним jk2, т. е. условное распределение X при данном / имеет вид
Ь
Безусловное распределение X равно
D.28)
Оно известно как распределение Неймана типа А. По-видимому
это распределение можно применять, когда события сгруппиро-
Дискрепгные распределения
121
ваны вместе, а не разбросаны случайно. Это смешанное распре-
распределение Пуассона с пуассоновским смешиваемым распределением.
Во многих случаях могут оказаться эффективными модифи-
модификации этого распределения, соответствующие требованиям конк-
конкретных ситуаций. Можно, например, полагать, что исключена
возможность легких травм, т. е. все травмы тяжелые. В этом
случае условное распределение X при данном / оказывается
возможным представить распределением суммы / независимых
усеченных пауссоновских величин Yl% Y2, ..., Y^ где
Возвращаясь к распределению D.28), заметим, что его мо-
моменты можно вычислить методом, вытекающим из формулы
Например,
и, следовательно,
Аналогично
а значит,
/)=А,
Следовательно,
Var (Х>- Ь
Отметим, что для распределения Неймана типа А
+ Var (J)] -
. D.30)
тогда как для распределения Пуассона
4.9.2. Логарифмическое распределение
При 0 < Э < 1 имеем разложение
отсюда
D.31)
Если последовательные члены этого ряда отождествить с вероят-
вероятностями того, что случайная величина X примет значения
122
Глава 4
1, 2, 3, ..., то получится распределение, называемое логариф-
логарифмическим. Для этого распределения
?х[Х = х\ = Р{х) = [—Щ\-Щ-гх-х&, *=1,2,.... D.32)
Из формулы D.31) следует
Факториальный 'момент X порядка s равен
E[X{S)] = [— ln(l— в)]-» S^-lV'-
= [— 1пA—в)]-1^ A — в)-^,
Из формулы D.33) получим
D.33)
Максимум Я(*) достигается при *=1.
Это распределение оказывается полезным при описании мно-
множества категорий наблюдений, например числа различных видов
дефектов в стандартных товарах или числа разных насекомых,
попавших в световую ловушку [8].
*4.9.3. Дзета-распределение
Как показывают наблюдения, распределения, порождаемые
числом повторений каждого данного класса событий,^можно
представить простой формулой (во всяком случае, во всей суще-
существенной части области варьирования)
Pr[X = r]ocr-<e+1>, г=1, 2, ...,
где р > 0. Чтобы получить точную формулу для каждой вероят-
вероятности, воспользуемся условием
и найдем
где ?(p_|_i)=
г=1
г=1
D.34)
— дзета-функция Римана1). Ее числен-
г=1
ные значения приведены в Tables of the Rieman Zeta Function
by C. Haselglove and J. C. P. Miller (Royal Society Mathematical
!} Подробности относительно дзета-функции Римана см., например, в ра-
работе: Бейтмен Г., Эрдейи А. Высшие трансцендентные функции.—М.: Наука,
1965.— Прим. перев.
5
ее
О.
I
I
ё
I
§
3
й
о.
t-
3
X
н
о.
8
1
coCU
|
о
55-59
Н Р
«а
СП
¦ф
За
т
о
СЧ
см ^
-а
2Х
Число
поли-
полисов
СО
24,
S
о
СО
S
00
ж
см
8
108 1
СО
00
00
200
СО
229
233
СО
t^
о
со
СО
о
СО
см
283
о
3
см
LO
00
СП
101
о
ю
LO
00
ю
со
со
35'
ю
ю
t*-
со
00
о
со
00
8
о
8
Si
СО
со
см
со
СО
о
со
8
26 23
00
00
со
со
ю
см
СО
см
СО
см
см
СО
го
со
ю
о
СП
^
о
см
Ю
00
*
СО
со
см
°|
о
LO
о
СО
см
см
1
—«
со
см
со
LO
со
СО
со
см
со
см
СО
00
о
СО
о
см
о
о
о
см
а>
о
СО
—
00
см
со
см
СО
со
см
f-
о
см
о
to
со
о
со
о
00
о
1
1
ю
СО
1
СО
о
см
СО
о
см
о
со
о
о
со
о
1
00
о
1
о
~
о
—
00
о
«
СО
о
1
о
СО
о
со
о
"^
о
1
о
о
-
со
о
1
со
о
1
о
см
о
00
со
о
см
о
со
о
1
о
1
о
1
о
1
о
1
СО
о
см
о
см
о
см
о
см
о
1
со
о
о
СО
о
1
СО
о
1
см
о
о
см
о
см
о
см
о
1
см
о
СО
о
см
о
1
см
о
см
см
о
1
см
о
см
о
см
о
1
см
о
см
1 *. ^
см
о
см
о
—
со ; со
124
Глава 4
Tables, 6: Cambridge University Press, 1960). Дзета-распределе-
Дзета-распределение дает хорошее представление для распределения „дублирован-
„дублированных" вкладов страховых полисов (т. е. числа полисов, принадле-
принадлежащих одному лицу). В лингвистических исследованиях это рас-
распределение (часто называемое в этой связи законом Ципфа) хо-
хорошо представляет число повторений одного и того же слова в
длинном однородном тексте.
Момент s-ro порядка случайной величины X с распределе-
распределением D.34) равен
g(+l)
При
момент (Xg становится бесконечным.
*Пример 4.9. В табл. 4.5 (в столбцах Н) показано число дер-
держателей заданного количества полисов одной страховой компа-
компании (Seal H. L., A Probability Distribution of Deaths at Age x
When Policies Are Counted Instead of Lives, Skandinavisk Aktua-
rietidskrifty 30, 1947.) Данные классифицированы по возрасту
застрахованных лиц.
В качестве грубого приема оценивания величины р берется
отношение числа (/2) держателей двух полисов к числу (/х) дер-
держателей только одного полиса и приравнивается к отношению
теоретических частот (соответствующих дзета-распределению),
что дает
р-
Iog2
— 1.
Значения этих оценок приведены в табл. 4.6.
Оценки р
Таблица 4.6
Возрастная группа
15-19
20-24
25-29
30-34
35-39
40—44
45-49
50—54
55—59
60—64
65-69
70-74
Середина возраст-
возрастного интервала х
17,5
22,5
27,5
32,5
37,5
42,5
47,5
52,5
57,5
62,5
67,5
72,5
5
2,58
3,27
2,66
2,22
2,02
2,31
1,73
2,06
1,43
1,79
1,22
1,37
р^З,38— 0,032 х
2,82
2,66
2,50
2,34
2,18
2.02
U86
1,70
,54
,38
.22
Дискретные распределения
125
В четвертом столбце этой таблицы представлены значения
р, полученные по формуле
р^3,38 — 0,032* D.35)
(где х—возраст, соответствующий середине данной возрастной
группы).
Столбцы табл. 4.5 с расчетными значениями (столбцы Р) содер-
содержат средние частоты дзета-распределений с параметрами р, вычис-
вычисленными по формуле D.35).
ЛИТЕРАТУРА
1. Durand D., Stable Chaos, General Learning Corporation, Morristown, N. J.,
1971, Chapters 5, 9, 11.
2. Hahn G. J., Shapiro S. S., Statistical Models in Endineering, Wiley. New
York, 1967, Chapter 4. [Имеется перевод: Хан Г., Шапиро С. Статистиче-
Статистические модели в инженерных задачах.—М.: Мир, 1969.]
3. Hays W. L., Winkler R. L., Statistics: Probability, Inference and Decision,
Vol. 1, Holt, Rinehart & Winston, New York, 1970, Chapter 4.
4. Hoel P. G., Introduction to Mathematical Statistics, 4th Ed., Wiley, New
York, 1971, Chapter 3.
5. Johnson N. L., Kotz S., Distributions in Statistics —Discrete Distributions,
Wiley, New York, 1969.
6. Mood A. M., Graybill F. A., Boes D. C, Introduction to the Theory of
Statistics, McGraw-Hill, New York, 1976, Chapter 3.
7. Parzen E., Modern Probability Theory and Its Applications, Wiley, New
York, 1960, Chapters 2-8.
8. Rowe J. A., Mosquito Light Trap Catches for Ten American Cities, 1940,
Iowa State College Journal of Science, 16, 487—518 A941).
УПРАЖНЕНИЯ
1. Вероятность того, что потребуется сверхнормативная сборка, равна
0,035.
а) Если в смену производится 200 сборок, то как много случаев сверхнор-
сверхнормативной сборки можно ожидать? (Предполагается независимость сборок.)
б) Будет ли появление 11 или более таких случаев неожиданностью?
2. В упражнении 1, п. а), определите вероятность
а) самое большее пяти сверхнормативных сборок,
б) двух или менее таких сборок,
в) более шести таких сборок.
3. Из партии объема 80 ваята выборка объема 20.
а) Пусть в партии четыре дефектных образца; найдите вероятность
отсутствия брака в выборке.
б) Какое среднее число дефектных изделий можно ожидать в такой
выборке?
в) Как часто можно ожидать именно этого (среднего) результата?
4. Подбросьте пять монет 50 раз. Зафиксируйте число случаев появления
герба 0, 1, 2, ..., 5 раз. Сравните полученные данные с теоретическими часто-
частотами для биномиального распределения с параметрами 5, х/2*
5. В одном городе в среднем из-за автомобильных катастроф гибнет 8 че-
человек в месяц. В предположении, что все смерти,наступившие в течение месяца,
независимы и их число имеет распределение Пуассона, найдите вероятность
того, что в течение двух месяцев погибнет в автомобильных катастрофах 23
или более человек.
126
Глава 4
Дискретные распределения
127
6. Вероятность попадания в цель равна 0,90.
а) Найдите математическое ожидание числа попаданий в 10 независи-
независимых попытках.
б) Какова вероятность более чем пяти попаданий?
в) Какова вероятность двух или менее попаданий?
7. Как много независимых попыток нужно сделать в условиях упражне-
упражнения 6, чтобы вероятность попасть хотя бы один раз была не менее 0,99?
8. Среднее число дефектов некоторого вида для фанеры равно 2 на лист.
Оцените вероятность нуля дефектов. На какой доле листов можно ожидать
более чем по три дефекта?
9. По заявлению некоторой фирмы вероятность того, что данное покрытие
устойчиво против коррозии (что определяется путем стандартных испытаний),
равна 0,95. Было отобрано 20 независимых образцов.
а) Если эти покрытия столь хороши, как утверждается, то как много
брака можно ожидать?
б) Какова вероятность того, что будет обнаружен более чем один случай
брака?
10. Испытываемые пластины делятся на четыре категории в зависимости
от чистоты их поверхности. Математические ожидания чисел пластин различ-
различных категорий находятся в соотношении 1:1:2:4. Исследовано 100 образцов.
Какова вероятность того, что среди них не окажется пластин первых двух
категорий?
П. Для категорий из упражнения 10 найдите, какова вероятность того,
что в выборке объема 40 окажется 5 пластин первой категории, 5 — второй,
10 — третьей и 20— четвертой? Является ли это ожидаемым результатом для
выборки в* 40 единиц? Если так, то почему вероятность столь мала?
12. При испытании металлических образцов ожидается, что 20% из них
окажутся негодными, 30% будут на грани возможного использования и 50%—
хорошего качества. Испытывалось 40 образцов. Какова вероятность того, что
а) все отобранные образцы хорошие,
б) самое большее один плохой и. ровно два на грани возможного исполь-
использования,
в) ровно один плохой, два на грани возможного использования и 37 хоро-
хороших?
13. Бейсболист Джо Зилч достиг среднего результата 0,280 в 400 попыт-
попытках. Когда он подписывал контракт, ожидалось, что он покажет результат
0,300. Есть ли причина для тревоги (со статистической точки зрения)? Пояс-
Поясните, что вы понимаете под „причиной для тревоги" и сделайте вывод.
14. Другой бейсболист Стри Каут имеет в среднем 25 успешных перебежек
за последние 10 сезонов. Но к концу данного сезона, в котором он сыграл
то же число игр, что в среднем в последние 10 сезонов, он имеет лишь 17
успешных перебежек. Какие выводы вы могли бы из этого сделать? (Предпо-
(Предполагается, что было 400 попыток.)
15. Процент выхода, характеризующий эффективность химического про-
процесса, распределен симметрично около среднего 87%. В каждом из шести неза-
независимых лабораторных испытаний выход оказался менее 87%.
а) Какова вероятность такого события?
б) Какова вероятность того, что эффективность окажется выше 87% (для
этого процесса) в 8 случаях из 10?
16. Максимальное сопротивление резиновой ленты должно составлять
2,0Ом-см~. Ниже приведены числа дефектов (X), полученные в 1000 выборках
по 10 образцов.
х } х f х f
0 353 4 11 8 0
1 382 5 2 9 0
2 196 6 1 10 0
3 55 7 0
а) Сравните эти результаты с биномиальным распределением при р—0,1
и я=10.
б) Сравните результаты с распределением Пуассона при 0=1.
в) В каком случае данные аппроксимируются лучше? Почему?
17. Пусть вероятность получения качественного листа при нанесении на
него покрытия равна 0,90.
а) Сколько бракованных листов следует ожидать в выборке объема 50?
б) Какова вероятность того, что в выборке объема 50 окажется более
пяти плохих листов?
в) Какова вероятность того, что окажется менее трех плохих листов?
18. Какова вероятность двух или более дефектных образцов в выборке
объема 20, если средняя доля дефектных образцов равна 0,12?
19. Фирма провела полевые испытания шести образцов одинакового обо-
оборудования и не обнаружила среди них неисправных. Как часто можно ожи-
ожидать, что в выборке объема 6 будут отсутствовать неисправные образцы, если
а) ожидаемая доля неисправных образцов равна 5%?
б) ожидаемая доля неисправных образцов равна 10%?
20. В партии объема 100 пять плохих образцов и пять образцов на грани
возможного использования, которые можно доработать и использовать. Какова
вероятность того, что в выборке объема 30 окажется самое большее один об-
образец на грани возможного использования и не будет плохих?
21. Найдите среднее значение и дисперсию распределения Пуассона не-
непосредственно, не обращаясь к производящей функции моментов.
- 22. Найдите среднее значение биномиального распределения Р (х) =
~ \х)
хРх ПРИ * = 0» 1» 2,
п непосредственно, не обращаясь к про-
производящей функции моментов.
23. Сравните вероятности А* —0, 1, ..., 10 для выборки объема 10 в слу-
случае биномиального распределения при р=1/2 и в случае пуассоновского рас-
распределения при 0 = 5.
24. Сравните значения, полученные в упражнении 23, с соответствующими
вероятностями гипергеометрического распределения при N = 20, п =10 и тем
же самым средним значением, что и у двух распределений из упражнения 23.
25. Сравните значения, полученные в упражнениях 23 и 24, с соответст-
соответствующими вероятностями для отрицательного биномиального распределения при
?=10 и тем же самым средним значением, что и у трех распределений из
упражнений 23 и 24.
26. Джозеф Зайличстоун очень тревожился насчет 20 образцов нового
изделия. Изготовитель утверждал, что при сегодняшнем состоянии производ-
производства можно в лучшем случае получить 5% брака. Как много образцов должен
был бы поставить изготовитель, чтобы среди них с не менее чем 99%-ной ве-
вероятностью было как минимум 20 хороших изделий?
27. В табл. А приложения приведены некоторые случайные числа. Пред-
Представьте в виде таблицы число появлений 0, 1, 2, ..., 9 в 200 последовательных
цифрах. Можете ли вы рассматривать этот результат как выборку из равно-
равномерного дискретного распределения с р~0,1 и я=10?
28. Возьмите еще одну выборку, такую же, как в упражнении 27. Согла-
Согласуется ли она с теоретическими частотами? Сравните с данными упражнения 27.
29. Исследовательская лаборатория состоит из 10 технологов, 4 химиков
и 3 физиков. По жребию выбирается группа из трех человек для представи-
представительства при переговорах. Какова вероятность того, что все трое окажутся
технологами?
30. Фирма провела кампанию по уменьшению числа несчастных случаев.
Среднее число таких случаев за предыдущие годы было 20. В год проведения
указанной кампании их число оказалось равным 16. Можете ли вы сказать,
что это произошло под влиянием неслучайных причин? Оцените вероятность 16
или менее несчастных случаев, полагая, что условия не изменились.
\28
Глава 4
31. Десять фотовспышек были извлечены случайным образам из продук-
продукции, содержащей 0,5% брака.
Из множества в 10 фотовспышек были отобраны тоже случайно две, кото-
которые оказались бракованными. Какова вероятность того> что ии один из осталь-
остальных восьми образцов не бракованный?
32. В двух мешках А и В лежат по восемь белых шаров. Из третьего1
мешка с четырьмя черными шарами шары извлекаются но одному и кладутся
случайным образом в мешок А или В.
Из мешка А случайно выбираются четыре шара: один черный и три белых.
Найдите математическое ожидание числа шаров в мешке В?
33. Изобразите графически распределение Пуассона при ?у(Х}=5.
34. а) Покажите, что если Xt и Xz—независимые случайные величины
с распределениями Пуассона, то (JVj + A^) тоже имеет распределение Пуассона.
б) Найдите условное распределение Хх при заданном значении Хг-\-Х&
35. а) Покажите, что если Хх и Xа— независимые случайные величины,
имеющие отрицательные биномиальные распределения с равными значениями Р,
но различными kt а именно А, и k2t то (Хг-^-Х2} тоже имеет отрицательное
биномиальное распределение.
б) Найдите условное распределение Хх при заданном значении (Xi+^2).
Зв. Пусть вы отвергаете утверждение о том, что монета правильная,
если происходит событие, вероятность которого меньше чем 0,0-1. Сколько раз
должен выпасть Fep6 в 55 подбрасываниях, чтобы вы сказали, что монета не-
неправильная, если событие состоит в том, что герб выпал h или меньшее
число раз?
37. Сохраняются все условия упражнения 36, за исключением того что
„событие"—это' появление либо h или менее, либо E0—h) или более гербов.
38. Случайные величины Xi и Х% взаимно независимы и каждая из них
имеет дискретное равномерное распределение -
Рг[Х = х}=1/Ш [* = 5 A0)95].
Найдите распределение x/2(^i+^2)-
39. Случайные величины Х\, X%t ..., Хт независимы и распределены по
закону Пуассона со средним значением 0.
а) Найдите условное распределение Хг при заданном значении суммы
б) Покажите, что распределение Х\ (X1-j-X2+ .. . Н-^/Л не зависит
от 9 и найдите его среднее и дисперсию.
40. Величина X распределена по закону Пуассона с Е (Х} = Х1. Условное
распределение (У—1) при данном X будет пуассоновским с Е(У—l) = %zx.
Покажите, что при у = 1, 2, ...
Дискретные распределения
129
42. В партиич содержащей п изделий, D изделий дефектные. Осущест-
Осуществляется случайны^ выбор (без возвращения) до тех пор, пока не получится
ровно k дефектных изделий. Покажите, что если iV —число извлечений, то
a)
где
'•I/'-1}
6)
43. Выборка из полиномиальной совокупности с k категориями A), B),
..., (к), имеющими вероятности ръ р2) ..., рь производится до тех пор,
пока не получится т объектов из категории (/) \Pi > 0
Покажите, что число объектов в выборке из i-й категории (I ф /) имеет
отрицательное биномиальное распределение с параметрами m, p( (pi+p/)^1.
Предложите возможное применение этого результата.
44. Величина X имеет распределение Пуассона со средним значением 6.
Покажите, что математическое ожидание Ах равно
ехр[6(Л-1)],
Каково среднее значение, если X имеет биномиальное распределение с пара-
метрами лир?
л
«у-1I
41. Случайная величина X принимает значения r/s, где г и s—положи-
s—положительные целые числа, не имеющие общих множителей, с вероятностями
K(er+S — 1)-1. (Все возможные значения целых г и s содержатся в распреде-
распределении х.)
а) Найдите значение К-
б) Найдите вероятность того, что X < 1.
в) Найдите вероятность того, что X ^ L
5 № 819
Глава 5
НЕПРЕРЫВНЫЕ РАСПРЕДЕЛЕНИЯ
5.1. ВВЕДЕНИЕ
В двух предыдущих главах были приведены некоторые основ-
основные принципы и законы теории вероятностей, функции распре-
распределения вероятностей для дискретного случая и плотности рас-
распределения вероятностей для непрерывного случая. Описаны
производящие функции моментов и их применения к некоторым
более общим дискретным распределениям; дано множество при-
примеров. Теперь перейдем к рассмотрению непрерывных распреде-
распределений. Для каждого из них определим некоторые свойства и
приведем примеры. В подходящих местах будут представлены
таблицы и примеры их использования. Рассмотрим нормальное,
равномерное и экспоненциальное распределения, гамма- и бета-
распределения, ^-распределение, ^-распределение Стьюдента,
F-распределение и распределение Вейбулла. Приведем также
общие идеи и примеры применения наложенных и усеченных рас-
распределений, а также рассмотрим преобразование переменных.
Представим двумерные распределения, причем особое внимание
будет уделено двумерному нормальному распределению. Наконец,
опишем подбор теоретических распределений по эксперименталь-
экспериментальным данным.
5.2. НОРМАЛЬНОЕ (ГАУССОВО)
РАСПРЕДЕЛЕНИЕ
Нормальное распределение— самое важное в прикладной ста-
статистике по нескольким причинам. Прежде всего, многие наблю-
наблюдаемые данные можно успешно описать нормальным распреде-
распределением, или по крайней мере нормальное распределение может
стать первым приближением. Не существует таких распределений
эмпирических данных, которые были бы в точности нормальными,
поскольку (как увидим) пределами любой нормальной величины
являются —оо и +оо, и для ее представления необходимо бес-
бесконечно много десятичных знаков. Зато как приближение нор-
нормальное распределение очень часто хорошо подходит. Проводятся
ли какие-либо измерения в технологическом процессе, рассмат-
рассматриваются ли ошибки измерений, проводится ли контроль тем-
температуры, оценивается ли концентрация или же собираются
Непрерывные распределения
131
данные, подверженные влиянию множества случайных источни-
источников вариации,— как правило, оказывается, что данные распре-
распределены приблизительно по нормальному закону.
Предположение о нормальном распределении как основа для
анализа выборочных данных очень часто используется при по-
построении статистической теории. Мы покажем, что распределение
многих выборочных статистик стремится к нормальному при
возрастании объема выборки.
Пример 5.1. В табл. 5.1 представленны данные об отклоне-
Таблица 5.1
Распределение частот отклонений от установленного чистого веса X
(в 0,01 унции) для масляных орехов без скорлупы 1)
Границы
интервалов
группировки
-12-(-11)
_10_(_9)
-8-(-7)
-6-(-5)
_4_(_3)
-2-(-1)
X
-11,5
-9,5
-7,5
-5,5
-3,5
-1,5
f
3
10
6
14
29
74
Границы
I* tj f*?l Y\ ТЛ St
лив 1 jjy и**
пировки
0-1
2-3
4—5
6-7
8-9
X
0,5
2,5
4,5
6,5
8,5
/
236
346
371
240
79
Границы
интервалов
группировки
10—11
12—13
14—15
16—17
18—19
X
10,5
12,5
14,5
16,5
18,5
f
29
13
14
9
3
J) Lifson К. A., Package Weight Controls through Statistical Analysis, 9th Midwest
Quality Control Conference Papers A954).
ниях веса ореха без скорлупы от требуемого чистого веса для
каждого из отобранных 1476 масляных орехов. Эти данные со-
собирались при исследовании потерь, возникающих из-за малых
колебаний в весе, т. е. в пределах допусков, при превышении
требуемого чистого веса, хотя и не слишком большом. Было
установлено, что превышение среднего веса на 0,01 унции по
отношению к установленному чистому весу обходится фирме
в 8000 долл. в год. Эти данные представлены на рис. 5.1; они
распределены приближенно нормально. В разд. 5.15 рассмотрим
подбор по таким данным нормального распределения. После этого
можно проверить, достоверно ли наше предположение о нор-
нормальности.
132
Глава 5
Till г
X= отклонение от чистого веса S сотых долях унции
Рис. 5.1. Распределение частот отклонений от чистого веса орехов бе»
скорлупы.
5.2.1. Свойства нормального распределения
Продолжим рассмотрение нормального распределения с по-
помощью плотности нормального распределения вероятностей,
имеющей вид1)
-oo<*<oo.
E.1)
График этой функции приведен на рис. 5.2. Отметим, что рх(х)
стремится к нулю при приближении х к —оо или +°°. Кривая
симметрична относительно x = [i. Дифференцируя рх(х) дважды
*) Ниже будем считать, что а) если рх (х) и Р (х) не определены для не-
некоторого частного значения х, то их значения равны нулю, б) если формула
для рх(х) справедлива при всех конечных х, то условие —оо < х < оо опус-
опускается*
Непрерывные распределения
133
по я и приравнивая производные нулю, определим еще два свойства:
1) р(х) достигает максимума в точке x = \i и 2) при x — \i±a
имеют место две точки перегиба нормальной кривой.
JC
Рис. 5.2, Нормальное распределение.
Для определения Е (X) и Var (X) можно воспользоваться фор-
формулами C.38) и C.47):
=$ xPx{x)dx,
— 00
со
= J [x-E(X)YPx(x)dx= E(Х*)-[Е(Х)]\ E.2)
Теперь с учетом E.2) получим
Сделав подстановку (# — |л)/<г = у, найдем
Поскольку
~=-
-оо<у<сс.
то
E.3)
Определим дисперсию с помощью формулы E.2):
V ' V2no
134
Глава 5
При использовании указанной выше подстановки интеграл сво-
сводится к виду
Это в свою очередь дает
и, наконец,
Var(X)=a2
E.4)
Нормальное распределение симметрично относительно сред-
среднего, медианы и моды, которые совпадают и равны \х. Его сред-
среднее квадратическое отклонение а (или корень квадратный из
дисперсии) дает расстояние от \i до каждой из двух точек пере-
перегиба. Третий и четвертый моменты этого распределения вычи-
вычисляются (в разд. 5.2.5) с помощью производящей функции мо-
моментов, хотя могут быть легко найдены прямо по определениям
= S xrpx(x)dx
(см. разд. 3.13).
5.2.2. Нормированное нормальное распределение
Распределение E.1) описывает семейство кривых, зависящих
от двух параметров [ina. Оба этих параметра имеют одинаковые
размерности (дюймы, градусы Цельсия, фунты на квадратный
дюйм, проценты концентрации и т. п.). Для определения, на-
например, того, какая доля распределения лежит за точкой х = х0,
надо интегрировать по области х>х0. Это требует численного
интегрирования и весьма утомительно. Чтобы избежать этого,
введем нормированное нормальное распределение с jji = O и а=1.
Площадь под этой кривой представлена в табличном виде в ши-
широком диапазоне значений х. Тогда можно решать простые за-
задачи о площадях, преобразуя данные к случаю jx —О, а=1 и
находя искомые значения прямо из таблиц.
Для этого надо нормировать X по уравнению
Непрерывные распределения
135
Среднее значение и среднее квадратическое значение U равны О
и 1 соответственно, а плотность распределения вероятностей есть
Ри (a)-
E.6)
Из сравнения формул E.1) и E.2) видно, что
?[?/] = О,
Var(?/) = 1.
Кривая плотности нормированного нормального распределения
изображена на рис. 5.3, где указаны доли площадей под этой кри-
-J -2 -/
Рис. 5.3. Нормированное нормальное распределение N @, 1). (Показано при-
приблизительное распределение площадей под кривой.)
вой. Функция нормального распределения, т. е. Fx {х) — Ф (л;) =
= ? y(u)duy приведена на рис. 5.4.
— 00
Обычно используются обозначения
и
Ф(«) = (|/2я)~1 J r'
И
E.7)
J
-СО
Эти общепринятые обозначения мы и будем использовать.
Теперь введем другое обозначение. Пусть символ N (\х, о)
обозначает нормальное распределение со средним значением (или
математическим ожиданием) \i и средним квадратическим откло-
отклонением а. Тогда #@, 1) есть нормированное нормальное рас-
распределение.
136
Глава 5
Рис. 5.4. Нормированное нормальное распределение.
5.2.3. Таблицы нормированного нормального распределения
Функция нормированного нормального распределения при
ведена в табл. В приложения для значений и от « = 0,00 до
и = 3,99 с шагом 0,01. Эта таблица широко используется при
решении таких задач, как вычисление вероятности, соответст-
соответствующей появлению случайной величины в желаемых границах
области изменений, или доли, попадающей в „стандарт", и во
многих других случаях, когда предполагается нормальное рас-
распределение. Заметим, что область и начинается от м = 0. Для
других (отрицательных) значений и можно использовать свойство
симметрии. Рассмотрим несколько примеров, иллюстрирующих
применение таблицы.
5.2.4. Примеры использования таблиц нормального
распределения
Ниже приведено три примера, чтобы проиллюстрировать при-
применение таблиц нормального распределения. Первый из них
решается многократным обращением к таблице. Второй требует
преобразования к нормированной нормальной форме [#@, 1)].
В третьем примере сначала используются таблицы нормального
распределения, а затем —биномиальное распределение.
Непрерывные распределения
137
Пример 5.2. Задана нормированная нормальная величина ?/.
Найдем следующие вероятности. (Заметим, что Рг[а<Х<Ь] =
=Рт[а^Х^Ь] для всех а и Ь, что обусловлено непрерыв-
непрерывностью. В дискретном случае, вообще говоря, это неверно.)
а) Pr[t/<l,60], в) Рг[1,55<?/<1,69],
б) Рг[(/< —1,60], г) Рг[—2,00 <?/< 0,45].
а) Рг[?/^ 1,60] — 0,94520, что получается прямо из таблицы.
б) Pr [U < - 1,60] = 1 - Pr [U < 1,60] - 1 - 0,94520 = 0,05480.
в) Рг[1,55<?/< l,69J-Pr[?/<1,69]-Рг[?/< 1,55] =
-0,95449-0,93943-0,01506.
г) Рг [-2,00 < U < 0,45] - Pr [U < 0,45] -
_ рг [U <—2,00] - Pr [U < 0,45] - {1 - Рг [*/ < 2,00]} -
- 0,67364 - 0,02275 - 0,65089.
Существует очень много методов вычисления этих вероятнос-
вероятностей. Приемы зависят от формы представления таблиц и предпочи-
предпочитаемых арифметических операций. Начинающим полезно изобра-
изображать нормальную кривую, чтобы они были уверены в том, что
рассматривают правильную площадь. Некоторые таблицы непре-
непрерывных распределений, представленные в приложении, сопро-
сопровождаются рисунками и уравнениями. Это особенно полезно как,
гарантия того, что читатель и авторы имеют в виду одни и те^
же вероятности.
Пример 5.3. Предполагается, что внешний диаметр (ВД) год-
годных для сборки стальных стержней распределен приблизительно
по нормальному закону со средним 2,30 дюйма и средним квад-
ратическим отклонением 0,06 дюйма, т. е. #B,30; 0,06). Пределы
допуска 2,31±0,10 дюйма. Изделие с ВД ниже нижнего предела
допуска считается ломом, тогда как при превышении ВД верх-
верхнего предела возможна доработка. Нужно получить ответы на
следующие вопросы: а) каков получающийся" процент лома?
б) сколько процентов продукции нуждается в доработке? и в) каков
ожидаемый процент лома и изделий, требующих доработки, будет
иметь место, если изменить средний ВД до 2,31 дюйма?
а) Надо узнать вероятность PrfX < 2,21 | jjl = 2,30].
Если нормировать рассматриваемую величину, то получим
и — •
0,06
138
Глава 5
Следовательно, Рг [X < 2,21] == Рг [U < — 1,50] = 0,06681.
Вырабатывается примерно 6,7% лома.
б) Pr[X
=Pr[f/ > 1,83] = 0,03362.
Значит, приходится дорабатывать ~3,4% продукции.
в) Если бы среднее значение ВД равнялось 2,31, то
.2,41—2,31
Рг [2,21
^Х<2,41] = Рг
= Рг[—1,67<?
1,67] = 0,90508.
0,06
Процент лома и изделий, требующих доработки, уменьшил-
уменьшился с 10,1 до 9,5%.
Пример 5.4. Следующий пример требует использования и нор-
нормального и биномиального распределения. Цель группы бомбо-
бомбометания—разрушить железнодорожное полотно. На основе прош-
прошлых стрельб было установлено, что хорошим приближением для
среднего квадратического отклонения ошибки упреждения (при
этом X измеряется на перпендикуляре к рельсам, лежащем в
плоскости полотна) является 20 футов, тогда как ошибка относа
бомбы (вдоль полотна) равна нулю. Допустим, что расстояния
от точек падения бомб до центра полотна распределены нор-
нормально с #@, 20). Бомба, упавшая в полосе шириной 8 футов
от рельсового пути, считается достигшей цели. Как много бомб
надо сбросить, чтобы с вероятностью не менее 95% получить
хотя бы одно попадание? Допустим, что бомбометания незави-
независимы.
Нормирование величины X дает U = {Х — 0)/20. Сначала най-
найдем вероятность одного попадания на одно метание. Она равна
Рг[—8<Х<8] = Рг[—0,40<?/<0,40]-0,31084. Теперь уста-
установим наименьшее значение д, для которого Рг[У^1|/? =
=0,31084, я] > 0,95, где / — число попаданий.
Иными словами,
Это эквивалентно
или
S
@,68916)" < 0,05.
Взяв десятичный логарифм, получим
nig 0,68916 <lg 0,05,
так что
-1,30103
-0,16168 =
:8,05.
Непрерывные распределения
139
Следовательно, в данных условиях необходимо совершить девять
бомбометаний, чтобы с не менее чем 95%-ной уверенностью по-
получить хотя бы одно попадание.
Таблицы Ф(х) полезны и при аппроксимации биномиальных
распределений вероятностей. Если X имеет биномиальное рас-
распределение с параметрами пу р (см. разд. 4.2), то
Для больших п необходимые вычисления очень трудоемкие.
Когда п стремится к бесконечности, распределение X стре-
стремится к нормальному. Для большого п и целого R@^R^n)
E.8)
Лучшая аппроксимация получается при подстановке вместо R—пр
в аргументе Ф(-) выражения R — др+1/2. (Это так называемая
поправка на непрерывность Иейтса.)
Еще лучшие приближения получаются с помощью формулы
Рг[Х<#]^Ф({4Я + 3)A-/>)}!/*-{Dп—47?-I)/?}1/2). E.9)
Для вероятностей на хвостах распределения (< 0,05 или > 0,95)
эту формулу нужно модифицировать следующим образом:
Pr[X</?]«OB{(i?Hhl)(l-p)}1/2-2{(n~JR)/?}^). E.10)
Когда р близко к 1/2, нужно применять соотношения E.9)
и для хвостов, хотя вместо E.10) следует взять формулу
E.11)
Если X имеет распределение Пуассона со средним значе-
значением 0, то для целого положительного R
/=0
По мере того как Э стремится к бесконечности, распределение X
смещается к бесконечности и
140
Глава 5
Учитывая поправку на непрерывность, имеем
Еще лучшее приближение получается с помощью формулы
Рг[Х<Я]^Ф B1/^ + 3/4 — 2/0), E.12)
переходящей в
Рг [X < R] & Ф B /?+Т_2Уг6) E.13)
для хвостов.
Подробно эти приближения рассмотрены Моленаром [11].
5.2.5. Производящие функции моментов
Используя определение и свойства производящей функции
моментов, представленной в гл. 3, получим эту функцию для
нормированного нормального распределения и применим ее к
N{\i, а). Для распределения ЛГ(О, 1) производящая функция
моментов есть
m(t)= r—
со
E.14)
уш J
Следовательно,
Таким образом, поскольку X =
Точно так же можно получить высшие моменты нормированного
нормального распределения (иди стандартные моменты любого
нормального распределения). Они равны
ar = \inu = 0 для г нечетного;
аг = ц,г:1/ = 1'3'5... (г—1) для четного г.
Непрерывные распределения
141
Например, а2=1, а4 = 3 и а6 = 16. Кроме того,
а2* = B* —1) a2ft_2.
5.3. РАВНОМЕРНОЕ РАСПРЕДЕЛЕНИЕ
Непрерывное равномерное (или прямоугольное) распределе-
распределение встречается в прикладной статистике в основном в двух
типовых ситуациях: во-первых, когда в некотором интервале все
значения случайной величины равновозможны и, во-вторых, при
аппроксимации других непрерывных распределений в относи-
относительно малых интервалах. Если, например, величина X распре-
распределена как Af (fi, <т), а интерес представляет ее поведение в интер-
интервале ^i—0/3 < X <; \х + о/3, то равномерное распределение —
хорошая аппроксимация значений X в этом интервале для неко-
некоторых целей.
Пример 5.5. Испытывалось 500 образцов бумаги, которую в
экспериментальных целях покрывали жидким полимером и су*
шили, а затем разбили на пять классов по весу. В среднем из
этих классов измерялась толщина образцов для выяснения того,
нет ли здесь равномерного распределения. В табл. 5.2 пред-
Таблица 5.2
X
— 4
-3
— 2
-I
0
Толщина
/
13
14
8
14
7
5
образцов
X
1
2
3
4
5
6
f
8
6
10
9
10
12
ставлены значения толщины (средние по пяти точкам—центр
листа и четыре угла) 116 образцов этого класса. Данные зако-
закодированы в единицах отклонения от нормы.
На рис. 5.5 построена гистограмма по этим данным с нало-
наложенным теоретическим распределением 116р(лг) = 9,67.
142
Глава 5
Рис. 5.5. Толщина 116 образцов.
5.3.1. Свойства равномерного распределения
Равномерное распределение задается плотностью
Р*(х) = (Р—а)-1,
E.16)
Вероятность того, что величина X попадет в некоторый диапа-
диапазон значений между аир, равна вероятности того, что она
попадет в любой другой диапазон той же длины, т. е. Рг[с<
<X<d] = Pr[c'<X<<f], если d—c^d! -— с', а с, d, ё и df
лежат между аир. Хотя EЛ6) представляет собой наиболее
общую форму равномерного распределения, обычно использует-
используется формула другого вида:
и 0<9, E.17)
где Э^р—а [получается подстановкой у=^(х—а)/9]. Централь-
Центральные моменты этого распределения равны
е/2
-е/2
Следовательно,
для нечетного г,
четного г.
E.18)
Второй и четвертый центральные моменты равны
б2 в4
Щ = -12 и I1* =§0'
Третий и четвертый стандартные моменты равны
а3 = 0 и а4 = 9/5.
E.19)
E.20)
Непрерывные распределения
143
5.4. ЭКСПОНЕНЦИАЛЬНОЕ РАСПРЕДЕЛЕНИЕ
Частное распределение, известное как экспоненциальное, выде-
выделяется потому, чтс оно широко используется. Его можно было
бы рассматривать как особый случай гамма-распределения (см.
разд. 5.6) или распределения Вейбулла (см. разд. 5.5). Экспо-
Экспоненциальное распределение часто служит первым приближением
в задачах о надежности и т. п. Для иллюстрации этого распре-
распределения рассмотрим пример 5.6,
Пример 5.6. В табл. 5.3 представлены данные о долговеч-
Таблица 5.3
Число часов до отказа (X) индикаторных ламп на 600 В
Долговечность X, ч
50
150
250
350
Частота f
29
22
12
10
Долговечность X, ч
500
700
1000
Частота /
10
9
8
ности в часах для 100 индикаторных ламп на 600 В, приме-
применяемых в авиационных радиолокационных станциях (радарах)
woo
Рис. 5.6. Гистограмма срока службы в часах (X) для 600 —вольтовых индика-
индикаторных ламп. (Гистограмма построена так, что площади пропорциональны
соответствующим частотам.)
144
Глава 5
[Davis D. J., An Analysis of Some Failure Data, Journal of the
American Statistical Association, 47 A952)]. Гистограмма по этой
выборке (с наложенной теоретической кривой) построена на
рис. 5.6. Пунктиром нанесена подобранная экспоненциальная
кривая плотности распределения вероятностей.
5.4.1. Свойства экспоненциального распределения
Экспоненциальное распределение определяется формулой
рх(х) = &-**, о<л; и 0 < 9. E.21)
Используя для отыскания моментов производящую функцию,
получим
Это приводит к
= 6
= 5zrr=1 +"9 +"Р + ё*
при t < в.
E.22)
Дифференцируя г раз по t и приравнивая t к нулю, получим
Отсюда
E.23)
Третий и четвертый стандартные моменты (отношения моментов)
равны
«а = 2, а, = 9. E.24)
5.5. РАСПРЕДЕЛЕНИЕ ВЕЙБУЛЛА
Распределение Вейбулла весьма широко применяется в послед-
последние два десятилетия. Особенно оно полезно в задачах о долго-
долговечности и надежности. Его можно рассматривать как обобще-
обобщение экспоненциального распределения, поскольку в нем три
параметра и оно сводится к экспоненциальному при подходящем
выборе (с= 1) одного из них. Параметры задают область и форму
распределения (и, конечно, его моменты). Плотность распреде-
распределения вероятностей Вейбулла определяется как
Непрерывные распределения
145
при х^ау &>0, <;>0. Обычно проще работать с функцией
распределения Вейбулла, которая имеет вид
E.26)
Заметим, что (Х — а)с распределено по экспоненциальному закону
со средним значением Ьс. График рх (х) представляет собой коло-
колообразную кривую (т. е. распределение унимодально) при
с>1 и L-образную кривую (т. е. функция является убываю-
убывающей от л:) при 0<?^1. При а=0 и с=1 уравнение E.25)
превращается в E.21) после замены b на 9.
При у~(х—а)/Ь соотношения E.25) и E.26) соответственно
принимают вид
с>0,
Fy(y)=l-
-е-/.
Математические ожидания X и Y соответственно равны
E.27)
E.28)
E.30)
E.31)
и называется гамма-функцией. Интегрируя E.31) по частям,
можно получить
Г(*) = (*-1)Г(*-1).
Следовательно, если k—целое,
где Г (Л) находится как определенный интеграл
Дисперсия У есть
Высшие моменты равны
E.32)
E-33)
Пример 5.7. В качестве примера распределения Вейбулла
рассмотрим некоторые данные, представленные Берреттони [Вег-
146
Глава 5
rettoni J. N., Practical Applications of the Weibull Distribution,
Proceedings of the 16th Convention on the American Society for
Quality Control (May, 1962)]. Данные табл. 5.4 показывают
Таблица 5.4
Возвраты товаров, классифицированные по числу недель,
прошедших после отгрузки для 83 случаев
Число недель jM0-1
(середина интервала)
4
6
8
10
12
Частота /
5
17
15
16
13
Число недель jf-lO
(середина интервала)
14
16
18
20
Частота f
7
5
5
0
частоту возвратов товаров, которые классифицированы по числу
недель, прошедших после отгрузки до того, как они были воз-
возвращены. Случайная величина X — число недель (-10). (Для
изучаемого производства и данного продукта было установлено,
что степень „дефектности" зависит от числа недель, прошедших
от отгрузки до возврата товара.)
Графически данные представлены в виде гистограммы на
рис. 5.7.
4 6 S 10 11 14 16 18 20
Рис. 5.7. Гистограмма и кривая плотности распределения Вейбулла.
Непрерывные распределения
147
Уравнение распределения Вейбулла, аппроксимирующего эти
данные, имеет вид
Чтобы приравнять площади под кривой и гистограммой, рх(х)
умножается на 83/2 (или на объем выборки, деленный на длину
интервала).
5.6. ЕЩЕ НЕСКОЛЬКО ПОЛЕЗНЫХ
РАСПРЕДЕЛЕНИЙ
В этом разделе опишем несколько распределений, весьма
полезных в статистической работе. Гамма-распределение, как и
распределение Вейбулла, полезно при представлении распреде-
распределения величин (таких как вес или длина), которые не могут
быть отрицательными или значения которых ограничены снизу
известным числом. Как и семейство распределений Вейбулла,
семейство гамма-распределений включает экспоненциальное рас-
распределение как частный случай [при обращении а в нуль в выраже-
выражении E.34)].
Бета-распределение полезно при описании распределений вели-
адн, возможные значения которых ограничены с двух сторон
(к ним относятся, например, доли). Семейство бета-распределе-
бета-распределений включает равномерное как частный случай.
Как бета-, так и гамма-распределения допускают обобщение
путем „вейбуллизации". При этом принимается, что Xе (гдес=#=1)
имеет гамма-или бета-распределение. Такие распределения, однако,
используются не очень часто.
Распределение Парето оказалось полезным при представлении
(во всей ограниченной области) распределений экономических
индексов доходов и производства. Для этих целей используется
Также логарифмически нормальное распределение, которое ока-
оказалось весьма удачной аппроксимацией распределения размеров
частиц в природных образованиях. Эти распределения не обоб-
обобщаются „вейбуллизацией"; если величина X распределена по
закону Парето или по логарифмически нормальному закону, то
й Xе будет распределена по тому же закону.
Логистическое распределение применяется в экономических
и биологических исследованиях. Простой вид этого распреде-
распределения делает его особенно полезным.
5.6.1. Гамма-распределение
Гамма-распределение определяется формулой
1
Г(а+1)Р'
х>0,
E.34)
148
Глава 5
где Р>0 и а> — 1. Для получения моментов снова возьмем
производящую функцию
1
Г(«+1)Р'
а +1
о
Г(а+1)Р"
а +1
Если положить
У =
то будем иметь
тх (t) =-=
Следовательно,
1
и ^=A —
ftOC+l
Г(а+1)Ра+1 A
при
Начальный момент порядка г тогда будет равен
Это дает
E.35)
E>36)
E.37)
Так как |х3 = 2р3(ос+ 1) и (х4 = 3р4(а + 1)(а + 3), то третий и чет-
четвертый стандартные моменты равны
„ _
4 ~~
E.38)
(
а+ 1
Неполная гамма-функция Г^ (а+ 1) равняется j x?e~*dx. Bepo-
о
ятность того, что случайная величина X с функцией плотности
E.34) окажется меньше или равной К, дается отношением непол-
неполной гамма-функции Г^ (а + 1)/Г (а + 1).
E-39)
5.6.2. Бета-распределение
Бета-распределение определяется формулой
Непрерывные распределения
149
где а > — 1, р> — 1. Бета-функция в свою очередь определя-
определяется как
Момент /--го порядка проще вычислить непосредственно, чем
через производящие функции:
Интеграл в E.40) равен
f ^Г(а+р + 2)Г(а + г+1)
1K К } Г(а+1)Г(а+р+г + 2)*
E.40)
Из формулы E.40) можно получить
величины а3 и а4 можно вычислить непосредственно.
к
//епол«аябета-функция JB^ (a+1 tP+1) равняется ]xa(l—xftdx.
о
Вероятность того, что случайная величина X с плотностью веро-
вероятности E.39) окажется меньше или равной К> задается отно-
отношением неполной бета-функции
5.6.3. Логарифмически нормальное распределение
Когда распределение положительной величины (например,
веса, дохода) имеет положительную асимметрию, часто доста-
t©4HO простым преобразованием этой величины можно получить
faKoe распределение, которое для преобразованных значений
будет нормальным по крайней мере приближенно.
Если 1пХ имеет (строго) нормальное распределение N(I, а),
то говорят, что X имеет логарифмически нормальное распре-
распределение.
В таком случае
{\nx-Dfo
Fx (х) = Рг [X < х] - Рг [In X < In x] = у= j e-«V2 dtla
Следовательно, плотность вероятности X равна
150
Глава 5
Непрерывные распределения
151
Момент X порядка s равен (с учетом того, что Xs = eslnX)
Из этой формулы получаем
Показатели асимметрии и эксцесса (третий и четвертый стан:
дартные моменты) V§[ и р2 зависят только от е°г и не зависят
от ?. У логарифмически нормального распределения моменты \i's
конечны при любом s. Его медиана соответствует 1пх = ? и,
таким образом, равна ехр(?), а мода x = exp(?—а2).
Если значения эмпирической функции распределения нанести
на нормальную вероятностную бумагу в зависимости от logx, то
в том случае, когда величина X распределена по логарифмиче-
логарифмически нормальному закону, должна получиться приблизительно
прямая линия. Имеется миллиметровая бумага с нормальными
ординатами и логарифмическими абсциссами; для построения
графика на ней нужны лишь фактические значения эмпириче-
эмпирической функции распределения и соответствующие х. Эта разно-
разновидность миллиметровой бумаги называется логарифмической
нормальной вероятностной бумагой. Из графика на такой бумаге
можно оценить а как величину, обратную углу наклона прямой
к абсциссе и ? —как абсциссу точки, соответствующей значению
0,5 функции распределения.
При малых а логарифмически нормальное распределение столь
похоже по форме на нормальное, что одно из них можно исполь-
использовать вместо другого. Если величина X существенно положи-
положительна, то предположение о нормальности содержит логическую
некорректность, поскольку вероятностям такого рода, как Рг [X <
^—1], приписываются ненулевые значения. Эту трудность уда-
удается обойти, если положить, что logx имеет нормальное распре-
распределение (а значит, X распределена по логарифмически нормаль-
нормальному закону) с малым значением а [и подходящими значениями
(значением) остальных параметров], поскольку logX изменяется
от — оо до оо, когда X изменяется от 0 до оо.
В предположении, что log(X—0) имеет нормальное распре-
распределение N (I, а), можно ввести третий параметр 8. Ясно, что
дисперсия, а3(Х) и а4(Х) не зависят от 0, но значения Е (X),
медианы и моды увеличатся на 0.
* 5.6.4. Распределение Парето и логистическое
распределение
Распределение Парето является еще одним распределением,
полезным в экономических исследованиях (особенно при ана-
анализе дохода и других экономических индексов). Это распреде-
распределение случайной величины X с плотностью вероятности
рх (х) = pX?Jt-<e+1>, х > Хо > 0, р > 0. E.43)
Такое распределение применимо только к значениям х, превос-
превосходящим Хо (например, к доходам, превышающим заданный
уровень). Часто величина X ограничена еще и сверху; тогда не
стоит пользоваться подобным распределением, поскольку оно
хорошо не воспроизводит фактическое положение.
Любопытно, что распределение Парето — это непрерывный
аналог дзета-распределения (разд. 4.9.3). Как и дзета-распреде-
дзета-распределение, распределение Парето обладает тем свойством, что его
моменты могут быть бесконечными. Действительно,
-s), s<p,
и jis обращается в бесконечность, если ^p
Еще одним распределением, широко используемым в эконо-
экономических исследованиях, является логистическое распределение.
Оно имеет функцию распределения
?р] } . E.44)
ехр [ -
Это распределение симметрично относительно значения х = а,
которое является математическим ожиданием. Дисперсия равна
Va^P2 [и,_ следовательно» среднее квадратическое отклонение
есть (Jt/J/)P/I,8p, а величина а4 = 4,2]. Хотя значение а4 в этом
случае отличается от значения а4 для нормального распреде-
распределения (при котором а4 = 3), логистическое распределение очень
похоже на нормальное в большей части диапазона с тем же
самым средним значением и средним квадратическим отклоне-
отклонением на 1/15 больше (чем у нормального). Так же, как и лога-
логарифмически нормальное, логистическое распределение можно
использовать вместо нормального. Правда, это связано не с исклю-
152
Глава 5
чением отрицательных значений из области изменений (у логи-
логистического закона неограниченная область), а со стремлением
использовать простую математическую форму логистической
функции распределения.
5.7. х2-РАСПРЕДЕЛЕНИЕ
Следующие три распределения играют в статистической мето-
методологии исключительно важную роль. Они широко использу-
используются наряду с нормальным распределением, когда рассматри-
рассматриваются распределения выборочных статистик. В этом и двух
следующих разделах представлены х2"РаспРеДеление» ^-распре-
^-распределение Стьюдента и F-распределение. Описаны сами эти рас-
распределения и их свойства, показано, как пользоваться их таб-
таблицами, а также даны некоторые примеры. Никакие выводы
не приводятся.
5,7Л, Свойства х2~РаспРеДеления
Пусть f/f, ?/2, ,.., Uv — независимые случайные величины,
каждая из которых имеет нормальное распределение Af(O, 1).
Обозначим сумму их квадратов через %**•
ti=Ul + Ul+...+Ul E.45)
Эта сумма квадратов имеет плотность распределения (см. разд.
5.13)
/Uv~le~xl2 @^ E-46)
Выражение E.46) описывает гамма-распределение [см. формулу
E.34)] с a^VaV—1 и р-2. Производящую функцию моментов
можно получить непосредственно или с помощью формулы
E.35). Имеем
v/a. E.47)
т „а(*) = A —
Отсюда [или из формулы E.36)] находим моменты и показатели
асимметрии и эксцесса (третий и четвертый стандартные моменты):
E(f) = v, E.48)
a =3 + -. E.49)
Параметр v называется числом степеней свободы. Пока мы
можем считать v просто параметром семейства %2-распределений.
Непрерывные распределения
153
В приведенных выше формулах v —целое. Правда, плотность
вероятности E.46) можно использовать при любом положитель-
положительном значении v (не обязательно целом). Ниже будет показано,
что число степеней свободы можно связать с числом независимых
величин, остающихся после оценки параметров или подбора рас-
распределения. Этот термин имеет разный смысл в различных за-
задачах.
Как видно из рис. 5.8, %3-распределение имеет положитель-
положительную асимметрию. На этом рисунке представлены %2-кривые с
числами степеней свободы v, равными 2, 4, 8 и 16. При %2 = 0
тангенс угла наклона кривой обращается в бесконечность для
v = 3, он остается конечным и ненулевым при v = 4 и обраща-
обращается в нуль при v > 4. С ростом v кривая приближается к сим-
симметричной.
5.7.2. Таблицы х2-распределения
В табл. Д приложения приведены процентные точки %2-рас-
пределения. В таблице содержатся значения F (%2) для v^ меня-
меняющихся от 1 до 30 с шагом 1, затем до v=100 с шагом 10.
Каждая строка этой таблицы имеет 14 различных значений х2>
которые соответствуют указанным значениям /\(%2), т. е. для
фиксированной площади под кривой таблица содержит абсциссу %2.
Пример 5.8. Следующие значения %2 можно просто выписать
из таблицы:
%!; о.«о= 1,635, Xlo; о,95о= Ю1,9,
Xie; o..7i = 31,53, Х2зо; 0,900^40,26.
Первый индекс здесь обозначает число степеней свободы, а вто-
второй—накопленную вероятность. Другой способ получения тех
же самых результатов, например в первом случае, таков: %2< --*=
х2
= 1,635 —значение, для которого j pX2(x)dx = 0,050 при шести
степенях свободы.
В следующих главах х2-распределение будет использоваться
в критериях значимости, доверительных интервалах, таблицах
сопряженности признаков и при проверке согласия теоретичес-
теоретического распределения с эмпирическими данными.
Непрерывные распределения
155
0,6
0,5
0,4
0,2
0,1
f Г I i
1
1 ! 1 1 1
2
i
0,4 0,8 7,2 /,ff 2,0 2,* 2,<? «?,2 J,? ^ 4,4 4f8 St2 5fi
0,8 1,6 Zfl 3,2 4ft 4,8 5,6 6,4 7,2
ft* 3JS ЮЛ 77,2
X
5.7.3. Приближения
Когда число степеней свободы стремится к бесконечности,
значения а3 и а4 стремятся к нулю и трем соответственно, т. е.
к значениям этих моментов для нормального распределения.
Действительно, можно показать, что распределение нормирован-
нормированной величины
стремится к нормированному нормальному распределению' при
стремлении v к бесконечности. Еще лучшие приближения полу-
получаются, если использовать величины
1 (аппроксимация Фишера)
или
1Л v / "T" 9
(аппроксимация Уил-
сона —Хилферти),
E.50)
E.51)
которые имеют нормированное нормальное распределение.
Ifi 3,2 4,8 6,4 8ft 3,6 11,2 12,8 Щ 16,0 Ц6 19t2 21,6
x
0,05
J,2 6L 5,5 72,iS 75,^7 /5,2 22,4 25,S 28,8 32,0 35,2 38,4 Щ Щ
x
Рис. 5.8. х2-распРеДеление с v степенями свободы.
5.7.4. Свойство аддитивности
Если U19 U2, ..., f/Vl+v2 есть (v1~\-v2) взаимно независимых
случайных' величин, распределенных нормально N@, 1), то
Vj Vi+V2
^1 = 2 Щ и ^2 = 2 Щ тоже являются взаимно независимыми
/ = 1 /=Vi+l
случайными величинами, имеющими распределения х2 с vi и v2
Vi+V2
степенями свободы соответственно. Тогда Х± + Х2^= 2 U) имеет
распределение %2 с (v1 + v2) степенями свободы. Этот результат,
иногда называемый аддитивностью х2» можно выразить формаль-
формально: „сумма двух взаимно независимых величин, имеющих х2-рас-
пределение, подчинена распределению х2 с числом степеней сво-
свободы, равным сумме степеней свободы обеих исходных величин".
5.8. ^-РАСПРЕДЕЛЕНИЕ СТЬЮДЕНТА
Вторым из числа распределений, широко используемых в ста-
статистических проверках, является t-распределение Стьюдента, или
просто t-распределение. Это распределение было впервые предло-
предложено Госсетом (под псевдонимом „Стьюдент"I* и затем более
*> То есть „студент". — Прим. перев.
156
Глава 5
строго обосновано Фишером. Оно лежит в основе множества про-
процедур статистического анализа в науке и технике. На простом
/-критерии основаны очень многие более сложные статистические
критерии. Теперь рассмотрим это распределение прежде всего
как статистическую функцию. Различные статистические крите-
критерии, использующие /-распределение, приводятся в следующих
главах.
5.8.1. Определение /-распределения
Рассмотрим независимые случайные величины U и К, где U
распределена нормально N (О, 1), а V имеет распределение х2
с v степенями свободы. Можно показать, что случайная вели-
величина
имеет плотность вероятности
V 2
г —
_oo
E.52)
E.53)
которая, как и у ^-распределения, зависит только от парамет-
параметра v. Это /-распределение с v степенями свободы; Tv означает „Г
с v степенями свободы".
Кривые /-распределения для v=l и 4 представлены на
рис. 5.9, где показано также нормированное нормальное рас-
Рис. 5.9. ^-распределение Стьюдента при v = l и v = 4.
пределение. Следует отметить, что с ростом v распределение t
стремится к нормированному нормальному распределению N@,1).
Нормальная аппроксимация N @, |/v/(v —2)) очень хороша при
^30. /-распределение симметрично относительно нуля. Его
Непрерывные распределения
157
среднее и дисперсия (при v > 2) равны
E.54)
Обычное отношение, к которому применимо /-распределение,
представляет собой статистику
X — Е(Х)
E.55)
где
Это отнох^ение имеет /-распределение с (п— 1) степенями свободы,
если каждый Х( подчинен одному и тому же нормальному рас-
распределению, а значения Х{ независимы. Если же все Xt распре-
распределены нормального и Х = 2^//м тоже распределена нормаль-
нормально. Тогда [X — E(X)]/aj распределено как N @, 1). Отношение
(я—\)S2/o* имеет ^-распределение с п— 1 степенями свободы
и независимо от X. Используя формулу E.52), получим
' п—1
X — Е(Х) а
а/УК ^
поскольку Ox^o/Vn* Это выражение сводится к E.55).
Аналогично можно показать, что если Хг, Х2, ..
Y19 Y2
Yn взаимно независимы и имеют одно и то же нор-
нормальное распределение, то
будет иметь /-распределение с
— 2) степенями свободы.
5.8.2. Таблицы /-распределения
Процентные точки /-распределения приведены в табл. Е при-
приложения. Таблица содержит значения t для указанных сверху на-
накопленных вероятностей. Каждая строка соответствует определен-
определенному значению v и, следовательно, различные строки относятся
к разным членам семейства этих распределений.
158
Глава 5
Пример 5.9. Определим значения t для следующих вероятно-
вероятностей:
t
a)
при v=15; б)
при ^v = 8;
t
в) J рт (t) Л = 0,990 при v = 5.
а) ^ = 0,691 непосредственно берется из таблицы.
б) Благодаря симметрии относительно t=--0 значения / для
t t
$/?г(/)Л=0,450 и \ pT(t)dt = 0,950 будут одинаковы. Тогда
О —<Ю
f =1,860 можно просто найти в таблице при v = 8.
в) Значение t для J pT(t)dt = 0,990 такое же, что и t для
t
. Его можно прямо взять из таблицы. Получим
= 4,032 при v = 5.
5.9. F РАСПРЕДЕЛЕНИЕ
Третье распределение, часто применяемое при анализе выбо-
выборочных данных из нормальной совокупности, — это F-распределе-
ние. Прежде всего оно используется в задачах, связанных с дис-
дисперсиями.
5.9.1. Свойства F-распределения
Если величины U и V независимые и каждая распределена
как х2 с vi и V2 степенями свободы соответственно, то
/7 "/VI
V/v2
E.56)
имеет плотность вероятности
\ О / /« \V,/2
Получилось двупараметрическое семейство распределений с па-
параметрами Vj и v2, называемыми степенями свободы. Константа
Непрерывные распределения
159
обозначается как B(vj2, va/2). Это бета-функция (см. разд. 5.6.2),
определяемая формулой
В(т, n)^
= В(п, т).
E.58)
Предположим, что мы имеем случайные выборки объема щ и
п2 из нормальных совокупностей Пх и П2 с дисперсиями а? и а\
соответственно. Пусть S\ и S\ обозначают выборочные дисперсии.
Тогда SJ/SJ будет распределено как (of/oi)x(F с п1 — 1 и п2—1
степенями свободы). Действительно, \пх—l)S!/of распределено
как х2 с v1 = n1 —1 степенями свободы. Аналогично (ля — 1) Sl/af
независимо распределено как %2 с v2 = n2—1 степенями свободы.
Тогда, согласно формуле E.56), отношение
Г(/и-1)зП / Г(^-1)^1
| oUnx~\)\l [ot(n2~\)\
будет распределено как Frtl_itrt2_i.
Таким образом, SJ/SJ распределено как (ol/oi) Fnx-\,n^i с
vl = n1—1 и v2 = n2— 1 степенями свободы соответственно.
Среднее и дисперсия FVit У2-распределения равны
E.59)
vi. v2; vi(v2-2)a(v2-4) *
Величина E(FVl, Vi) стремится к единице как к пределу, когда
v2 стремится к бесконечности независимо от значения v^.
Следует отметить два крайних случая/^-распределения: 1) Когда
Vl = 1, F-распределение превращается в распределение fi с v2
степенями свободы. Это рассматривается в гл. 13. 2) Когда va
стремится к бесконечности, /^распределение стремится к виду
(Х2 с Vj степенями свободы)/^. Заметим, что Е (F) —> 1, Var (F) ~*
-~+2/v1 при va—¦- оо.
5.9.2. Таблицы F-распределения
Процентные точки /^-распределения приведены в табл. Ж при-
приложения. В этой таблице даны верхние процентные точки для
Р=1— сс = О,95; 0,975; 0,990 и 0,999. Нижние процентные
точки можно получить из тождества
/4.V., « = /4,!vi. 1-е, E.60)
где jpa—значение, удовлетворяющее уравнению
160
Глава 5
Непрерывные распределения
161
Чтобы доказать справедливость тождества E.60), сначала
нужно показать, что
Это вытекает из того факта, что неравенство (%l /v1)/(%l /v2) <
идентично неравенству
Следовательно, нижние процентные точки FVl, v2 можно полу-
получить, используя обратные значения дополнительных процентных
точек для Fvj.Vf
Пример5Л0. Согласно равенству E.60), значение F12; 5; 0(UU
равно обратному /ч,-12; 0,95- Следовательно, Fi2: 5; o,oe = ^u; ot95 =
05
*5.10. МОДИФИКАЦИИ РАСПРЕДЕЛЕНИЙ
В этом разделе опишем различные приемы, с помощью кото-
которых стандартные распределения могут быть модифицированы
в соответствии с конкретными обстоятельствами. Попытаемся дать
лишь беглый набросок, однако из этого вовсе не следует, что
не важны общие идеи. Напротив, для хорошей работы в при-
прикладной статистике построение достаточной Модели имеет фунда-
фундаментальное значение, а это часто влечет за собой модификацию
стандартных распределений статистической теории. Нужно
обладать достаточно большим опытом, чтобы уметь выбирать под-
подходящую модификацию. Данная книга является лишь введением
в эти проблемы.
*5.10.1. „Наложение" (folding)
В экспериментальной практике иногда встречаются случаи,
когда наблюдения регистрируются без знака (плюса или минуса).
Такие наблюдения должны рассматриваться как имеющие одина-
одинаковый знак (условный плюс). Эту ситуацию стоит выделить из
(гораздо более общей) ситуации, где измерения (вес, плотность
и т. п.) существенно положительны. В рассматриваемом здесь
случае на самом деле действительные измерения либо положи-
положительные, либо отрицательные, но об этом нет информации. Ко-
Конечно, благодаря этому распределение меняется; его отрицатель-
отрицательная часть „поворачивается" и добавляется к положительной.
Два типичных примера, в которых могут быть использованы
наложенные распределения: 1) измерение изогнутости выводов
миниатюрных радиоламп (см. пример 5.11) и 2) определение цент-
центральности перфораций движущейся пленки по данным о разли-
различиях в расстояниях левой кромки пленки от левой перфорации
и правой кромки пленки от правой перфорации. Поскольку не-
неиспользованная пленка не ориентирована, алгебраический знак
теряется.
Если действительные значения распределены нормально, то
величины без учета знака не имеют нормального распределения.
Их распределение называют наложенным нормальным распреде-
распределением. Форма такого распределения зависит от отношения сред-
среднего квадратического отклонения к математическому ожиданию
(коэффициента вариации) исходного нормального распределения.
В предельном случае (когда математическое ожидание исходного
распределения равно нулю)—это полунормальное распределение,
описанное Дэниелом [Daniel С, Use of Half-Normal Plots in In-
Interpreting Factorial Two Level Experiments, Technometrics, 1 A959)].
Однако часто точка наложения бывает неизвестна. Тогда необ-
необходимо оценить два параметра исходного нормального распреде-
распределения по наблюдениям, которые имеют наложенное распределение.
Плотность вероятности для такого распределения равна
рх(х)= -т=-[<?-е-д1)/»* + в-<*+и«)/»а"]> х -> о, E.61)
где \i и а2 —среднее и дисперсия исходного нормального распре-
распределения.
Методы оценивания |х и а представлены в работах [10] и [2].
Эти методы используют моменты, вычисленные по наблюдениям
в данном примере. В первой из этих работ содержатся таблицы,
помогающие оценить \х и а по выборочному среднему и среднему
квадратическому отклонению. Джонсон [8] показал, что такие
методы (в больших выборках, при любых соотношениях) дают
почти точно оценки максимума правдоподобия (см. разд. 7.3).
Можно показать, что среднее \if и среднее квадратическое
отклонение оу случайной величины с распределением E.61) свя-
связаны с (I и о формулами
ц/а
= ~r= f
У2Я/
Следует отметить, что второе из этих соотношений хправед-
ливо для любого наложенного распределения независимо от того,
является ли исходное распределение нормальным или каким-либо
другим. Математическое ожидание X2 при наложении не меняет-
меняется [поскольку (—xf = ( + xf] и, следовательно,
819
162
Глава 5
*Пример 5.11. Для иллюстрации наложенного нормального
распределения рассмотрим следующий пример. При производстве
миниатюрных радиоламп выводы устанавливаются автоматически.
Важно, чтобы они были прямыми; иначе они могут не попасть
в нужное положение и произойдет сбой направляющего меха-
механизма. В результате некоторое число ламп будет* не полностью
укомплектовано и их придется забраковать. Изогнутость измеря-
измеряется оптическим компаратором при закрепленном одном конце
провода во вращающемся зажиме. Она фиксируется как разность
между минимальным и максимальным положениями в предполо-
предположении, что нет биений, за вычетом диаметра провода. Тогда у
совершенно прямого провода изогнутость будет равна нулю. Пред-
Предполагается, что рассматриваемое распределение нормально; тре-
требуется оценить среднее значение и среднее квадратическое откло-
отклонение. В табл. 5.5 приведены данные, для которых х = 14,0140
Таблица 5.5
Изогнутость 497 выводов радиоламп
Отклонение1*
1
3
5
7
9
11
Наблюдаемая
частота
12
26
36
50
45
49
Отклонение
23
25
27
29
31
33
Наблюдаемая
частота
18
14
12
4
7
2
13
15
17
19
21
1J В десятых долях
интерпалов группировки.
51
44
44
40
32
мила A мил =
35
37
39
41
43
2,5-Ю м).
5
2
2
1
1
Указаны середины
и s = 7,7868. С помощью таблиц из работы [10] найдем, что сред-
среднее и дисперсия исходного нормального распределения оценива-
оцениваются величинами 13,642 и 70,987 соответственно. На рис. 5.10
приведена гистограмма, построенная по этим данным, а также
изображены теоретическая нормальная кривая с наложением
(сплошная линия) и обычная нормальная кривая (штрихпунктир-
Непрерывные распределения
163
ная линия, переходящая в сплошную). [Значение РхМ умно-
умножается на объем выборки, деленный на длину интервала, для
получения равных площадей под гистограммой и кривыми.]
14,0140, o
N {/л* 13,6414, 0=8,4154)
t 1 1 1 J L_ I I I I I 1
Рис. 5.10. Изгибы 497 выводов.
*5.10.2. Усеченные и цензурирование распределения
Иногда значения случайной величины можно точно зафикси-
зафиксировать только в некотором интервале или из-за ограничений
измерительного инструмента, или из-за чисто практических обсто-
обстоятельств легкости и быстроты наблюдений.
Если наблюдаются лишь те значения X, которые меньше, чем
заданное значение х0, то говорят, что распределение X усечено
по х0. Чтобы характеризовать отбрасываемые значения, усечение
иногда называют положительным, но само ограничение нередко
опускается,,если оно и так ясно. Иногда известно, сколько наблю-
наблюдений превышает х0 (так как нет никаких более точных мер для
этих величин). Такой случай иногда называют цензурированным
распределением в противоположность усеченному распределению,
когда предполагается, что о значениях, превышающих jtu, ничего
не известно. Хотя это -различие можно считать довольно педан-
педантичным, может случиться, что на практике оно окажется важным.
Дополнительная информация, появляющаяся в случае цензури-
6*
164
Глаза 5
рования, может и должна использоваться для улучшения мето-
методов статистического анализа.
Пример усеченного распределения получается, когда произ-
производятся прутки для некоторого устройства и с помощью сорти-
сортирующего инструмента те из них, которые оказываются короче
заданного размера (а также и длиннее), исключаются. Этот слу-
случай явно отличается от случая наложения. Усечение может
сочетаться, а может и не сочетаться с наложением.
В задачах, связанных с исследованием долговечности, часто
встречаются усеченные распределения. Пусть, например, испы-
тываются рассчитанные на 500 ч непрерывной работы лампы на-
накаливания, для которых среднее квадратическое отклонение срока
службы равно 150 ч. Из этих ламп можно взять выборку для
исследования долговечности. Чтобы проверка не слишком затя-
затянулась, можно закончить ее после 650 ч. работы. Тогда не будет
точной информации о сроках службы, больших, чем 650 ч. (По-
(Поскольку обычно известно, сколько ламп проработало свыше 650 ч,
то в соответствии с данным выше определением имеет место слу-
случай цензурирования.) Эта ситуация иллюстрируется на рис. 5.11.
500 650
Рис. 5.11. Усеченное нормальное распределение для исходного #E00, 150).
В данном примере усечением отбрасывается порядка 16%
исходного распределения.
Если плотность вероятности исходного распределения равна
Рх{х)> то плотность усеченного распределения есть
_ ,. Рх(х).
x<xQ.
E.62)
) dx
Как и в случае наложенного распределения часто представляют
интерес выражения для моментов усеченного распределения через
параметры исходного.
Непрерывные распределения
165
Если исходное распределение нормально /V(fi, а), то можно
показать, что среднее значение и среднее квадратическое откло-
отклонение усеченного распределения равны
*— —а —
г
И
, где
*5.10.3. Смеси
Другой тип модификации простых распределений появляется,
когда смешиваются изделия, полученные из двух или большего
числа источников. Если k станков производят простые изделия
и признак X распределен по нормальному закону для изделий,
полученных на любом станке, однако со средним значением и
(или) средним квадратическим отклонением, меняющимися от
станка к станку, то смешанная продукция всех k станков уже
не будет в общем случае иметь нормальное распределение X.
Пусть I; и <у?- обозначают среднее значение и среднее квадра-
1гйческое отклонение X для изделий ?-го станка. Тогда, если
Pi—ДОля изделий /-го стайка в смешанной продукции (при усло-
условии, конечно, 2 Pi— 1)» то Д°ля значений X, меньших, чем за-
данное хъ$ равна
Плотность распределения X есть
E.63)
Легко йййш моменты X. Если r-й момент (начальный) изделий
0? f-ro станка обозначить через \irh то очевидно, что
2
166
Глава 5
Если, как в данном случае, X имеет распределение N (?,., а?) для
1-го станка, то
Непрерывные распределения
167
1=1
и, следовательно,
k k
Vav(X) — \i2{X)—[\i1(X)f =2j Pi<t*+2i Pile
i
i=\
t=l
где
1=1
Заметим, что этот результат сохраняется при любом распре-
распределении X для изделий каждого станка, независимо от того,
будет оно нормальным или нет.
Частный случай, когда одно из р9 скажем piy велико, а все
остальные р{ малы, часто называют загрязнением первого распре-
распределения всеми остальными.
Пример 5.12. Новый автомат делает сигары со средним квад-
ратическим отклонением веса 0,020 унции. У старого автомата
соответствующее значение составляло 0,025 унции. Можно пола-
полагать, что при соответствующей регулировке оба автомата будут
давать желаемый средний вес, например б унций, и что откло-
отклонения распределены приблизительно нормально. Какова макси-
максимальная доля сигар, полученных на старом автомате, если доля
сигар общей продукции, вес которых больше, чем F + 0,05)
унций, не превышает 1%?
Доли сигар, вес которых превышает F + 0,05), для каждого
автомата в отдельности равны
Новый автомат: 1 -Ф
-1 —Ф B,5) - 0,00621;
Старый автомат: 1 —Ф (?^|) = 1 —Ф B) - 0,02275.
Следовательно, если продукция этих автоматов смешана в отно-
отношении (новая продукция)/(старая продукция) =-A — р)/р> то доля
сигар, вес которых превышает F + 0,05), равна
0,00621 A — р) + 0,02275/? = 0,00621 —0,01654р.
Чтобы эта доля не превышала 1%, должно выполняться соотно-
соотношение
0,00621 + 0,01654/? < 0,01,
т. е.
0>0037Э —
Максимальная доля (с точностью до 0,1%) равна 22,9%.
5.11. СОВМЕСТНЫЕ РАСПРЕДЕЛЕНИЯ
Статистическая работа очень часто связана с совместной вариа-
вариацией двух или большего числа случайных величин. Например,
при испытаниях сталей на прочность могут представлять инте-
интерес одновременно и прочность на разрыв и относительное удли-
удлинение; эффективность некоторой операции может быть связана
с температурой и с влажностью; это могут быть пары перемен-
переменных, например внутренний и внешний диаметры цилиндра, или
же скорость процесса фрезерования и срок службы инструмента,
взаимосвязь между которыми имеет важное значение.
Статистическими моделями, подходящими для этих случаев,
являются многомерные распределения. Здесь будут рассмотрены
в основном двумерные распределения, и прежде всего двумерное
нормальное распределение.
Соответствующие определения совместной и условной совме-
совместной плотностей вероятности, а также регрессионных функций
были введены в разд. 3.§. Этот раздел стоит перечитать, прежде
чем идти дальше.
5.11.1. Двумерное нормальное распределение
О двух случайных величинах X п Y говорят, что они имеют
двумерное нормальное распределение, если их совместная плот-
плотность вероятности равна
У)=
X
2лохву V\ — p2
\ 2A—Р2)
X
для всех значений х и у.
Интегрируя по у, получаем
рх (х) = — ехр
у 2л ах
Г L(x_n «I
168
Глава 5
Следовательно, величина X распределена нормально N (\хх, ox).
Аналогично и величина Y распределена нормально N (\ir, ov).
Можно показать, что коэффициент корреляции между X и Y
равен р. Если р = 0, то
Px,y(*> У) = Рх(*)Ру(у)>
и для двумерного нормального распределение нулевая корреляция
влечет независимость, хотя, как мы видели в примере 3.13,
в общем случае это не имеет места.
Деля рх% к(х, у) на рх{х), получаем
X
Хехр
г
1
L 2<#A-р»)
Таким образом, условное распределение Y нормальное с мате-
математическим ожиданием
I Р^К / \ /С СС\
Lly —j [X Mot/ V «OD J
и дисперсией Оу(\— р2).
Следует заметить, что эта дисперсия не зависит от х и рег-
регрессия линейна с угловым коэффициентом $ = роу/ах. Эти усло-
условия появятся позднее (в гл. 12) среди обычных предположений,
вводимых при подборе линии регрессии методом наименьших
квадратов. Формулы, подобные E,65), справедливы и для рег-
регрессии X на У.
На рис. 5.12 представлена функция рХч к(л*, у) [формула E.64)].
Вершина „горы" имеет координаты *=={;, // = tj.
Рис. 5.12. Двумерное нормальное распределение.
Непрерывные распределения
169
5.11.2. Многомерные нормальные распределения
Если есть п случайных величин Х19 Х2,
ным распределением
Хп с совмест-
совмест-V3 S
5.66)
то говорят, что это многомерное нормальное распределение.
Можно показать, что Е(Х{) = ^ для всех /=1, 2, ..., п.
Матрица дисперсий и ковариаций X размером (пхп) является
матрицей, обратной к симметричной матрице (с,у). Отсюда
следует, что (коэффициент корреляции между X, и Х/,)х
X V^Var (Xt) Var (Х(,) равен элементу 1-я строки и /'-го .столбца
матрицы {cijY1.
Условное совместное распределение любого подмножества X
при заданном любом другом подмножестве X является много-
многомерным нормальным. Условные математические ожидания пер-
первого подмножества являются линейными функциями значений
элементов второго, условные дисперсии и корреляции постоянны
(не зависят от значений элементов второго подмножества).
Подробные формулы и другие свойства многомерных нормаль-
нормальных распределений приведены в работах [3] и [9].
Полагая м = 2, получим двумерное нормальное распределе-
распределение. Матрица дисперсий и ковариаций в этом случае равна
а матрица, обратная к ней, имеет вид
1 Г о'х2 — poXlOx21
5.11.3. Линейные функции нормально распределенных
величин
Ниже будет использоваться следующий важный результат.
Если две нормально распределенные величины Хх и Х2 имеют
совместное распределение E.64), то любая линейная функция
У = а1Х1+а2Х2 этих переменных распределена тоже нормально.
Докажем это в случае, когда Е(Х1) = Е(Х2) = 0, Var(Xi) =
s=Var(Xa)=lf т. е. когда
^..A^) [(р
X exp [-V, A - р2) -1 №-
170
Глава 5
Поскольку можно записать
0^ + 0,*,= (ед.) [Xl
+ а2Е (Xt),
наше доказательство охватывает также и общий случай.
Вероятность того, что Y меньше, чем у, равна
X JJ
У<у
Теперь воспользуемся преобразованием вида
г ^линейная функция от хг и л:2,
так что
tK[2 + *l
где /( — константа. Тогда Pv[Y<y] пропорциональна
у &
f
т. е.
Отсюда следует, что величина Y распределена по нормаль-
нормальному закону. Поскольку ?(У) = 0 и Var (Y) = al + 2ра±а2 + a\, то
4 1
Обобщение этого результата на произвольные значения средних
и дисперсий тривиально и предоставляется читателю.
Отметим, что в частном случае р — 0 верно следующее утверж-
утверждение.
Любая линейная функция двух независимых нормальных вели-
величин распределена нормально.
Э^ги результаты можно распространить на произвольное число
п многомерных нормальных величин или в частном случае на п
взаимно независимых нормальных случайных величин.
Следует сделать одну оговорку. Возможно, что две нормаль-
нормальные величины будут иметь совместное распределение, которое
не является двумерным нормальным (как описано в данном раз-
разделе). В этом случае уже нельзя сказать, что распределение
любой линейной функции таких величин нормальное.
Непрерывные распределения
171
*5.12. ПРЕОБРАЗОВАНИЕ ПЕРЕМЕННЫХ
Часто требуется получить совместное распределение некото-
некоторых функций („статистик") от случайных величин с известным
совместным распределением. Например, при данном совместном
распределении п случайных величин Xlt Х2У ..., Хп может
понадобиться узнать совместное распределение среднего арифме-
п
тического X и выборочной дисперсии 52 = (n— l)~1S(^i — XJ.
С= 1
Задачи такого типа могут возникнуть как для дискретных,
так и для непрерывных величин. В этом разделе речь пойдет
в основном о непрерывных величинах.
При прямом обобщений C.43) можно увидеть, как получается
совместная плотность вероятности любого подмножества из мно-
множества случайных величин Yl9 У2, ..., Yn при усреднении по
мешающим переменным совместной функции плотности вероят-
вероятности. Таким образом,
РУх YsiVu •¦•¦ Ум) =
PYl Yn
Последовательно применяя формулы типа E.67), можно исклю-
исключить из множества Y17 ..., Yп любые мешающие переменные и
получить совместное распределение любого подмножества слу-
случайных величин.
Но сначала определим совместное распределение всех Y. Для
этого надо вывести pYl>. ., Yn (ylt ..., уп) из pXl Хп (xlf . . ., хя).
Если преобразование (хи х2, ..., хп) в (уг, у2, ..., уп) взаимно
однозначно (т. е. одному набору значений х соответствует одно
множество значений у и наоборот), то событие
Erx = »(Xi> ^2» ¦••» Хп) произойдет в области Rx"
оказывается эквивалентным событию
Ецу==„(Уи Y2, ..., Yn) произойдет в области Ry",
где Ry соответствует Rx. (Если преобразование взаимно одно-
однозначно, то Ry однозначно определяется по Rx.)
Следовательно
, y д
Следовательно,
т. е.
• • • \ Р*1 хп (а:,, ..., xn)dx1 ... dxn =
= J ••• J p*x VniUv •••• yn)dyi ¦¦•dyn.
Тла&а Ъ
Но левую часть этого уравнения можно выразить (с помощью
стандартной формулы преобразования кратных интегралов) сле-
следующим образом:
J
Ry
X
д(хих2, ...,
...dya9
где рх, xnfe • • •, хп)х.=х. (У1 уп) — совместная плотность
вероятности Хг, Х%, ..., Хп9 выраженная через ylt yv ..., yat
а д(хг, х2, ..., хп)/д(у19 у2, ..., г/J — определитель матрицы, в
которой элемент на пересечении г~й строки и ого столбца равен
дхг/дус. Такой определитель называется якобианом, здесь б
его абсолютное значение
Хъ ..,, Хп)
Итак, если записать
РГг Уп(У1> •••> yn) =
X
мсщно найти правильную вероятность по формуле
JJ
то
y
Таким образом, E.68) можно использовать как формулу для
совместной плотности распределения вероятностей Ylt Y2J ..., Кя.
Отметим, что число Г-ов должно равняться числу Х-ов. Тогда
должно быть эффективно и преобразование к совместному рас-
распределению подмножества Y с помощью формулы E.67).
*Пример 5.13. Совместная плотность вероятности X и Y равна
pXtY(X, Y) = 4xy, 0<х<1, 0<у<1.
Надо найти совместную плотность распределения вероятностей
U = X2 и V = Y2. Отметим, что преобразование взаимно одно-
однозначно для всех значений х и у, для которых pKi v(x, y)>0.
(Если бы рассматривались отрицательные значения х или у, то это.
преобразование не было бы взаимно однозначным.)
Выражая х и у через и и у, получим х = +У"и; y=+Vv;
якобиан равен
~д(и, v)
о
О
Непрерывные распределения
173
Отсюда, используя формулу E.68), найдем
при
Заметим, что всегда важно точно установить границы, в кото-
которых справедлива математическая формула для плотности вероят-
вероятности. Границы для и и v получаются преобразованием границ
для х и у.
Интегрируя по у, найдем
Аналогично
Следовательно, ри, v(w. t;) = pt/ (u) pv (f). a t/ и V взаимно неза-
независимы (как и исходные X и У).
*Пример 5.14. Функция
есть совместная плотность вероятности случайных величин Хг
"и Х2, которые взаимно независимы и каждая из них имеет экспо-
экспоненциальное распределение
pXi{Xi) = e-\ 0<к„ / = 1, 2.
Нужно найти плотность вероятности их среднего арифметичес-
арифметического V^1/2(X1JrX2). Сначала введем преобразование
или, наоборот,
Якобиан равен
д (и,
= 2v—и.
1 О
— 1 2
Отсюда, используя формулу E.68), найдем
Интегрируя по и, получим
2v
174
Глава 5
Чтобы определить вероятность того, что среднее арифмети-
арифметическое Хг и Х2 меньше, чем хч вычислим
*5.13. ВЫВОД х2-РАСПРЕДЕЛЕНИЯ
Напомним, что %2-распределение с v степенями свободы опре-
определяется как распределение суммы квадратов v взаимно незави-
независимых случайных величин, имеющих нормированное нормальное
распределение N @, 1).
Если Ut — нормированная нормальная величина, то
Vv
-V
f e~u^2 du = -^=
при и = -\-Vv.
Отсюда плотность вероятности Уг = U\ равна
E.69)
Следовательно, это распределение %2 с одной степенью свободы.
Теперь получим общую формулу для распределения Vn=Ul +
_1_ щ+ .., +t/J, где п—любое число. Воспользуемся для этого
методом математической индукции, т. е. допустим, что p(vn)
описывается некоторым выражением, и покажем, что это следует
из того, что аналогичное выражение имеет место для p(vn+1)t
т. е. при переходе от п к п+\.
Допустим, что
Pvn(pa)=Kavnn/i~1e-°"/t, vn>0, E.70)
где /сд_константа ( такая, что Кп J t?/a~ V*»/a dt?B = 1 ). Пола-
\ о /
гая п=\у придем к формуле для p(fx), которая уже получена.
Теперь положим, что Ц7я+1 = ?/;+1, где Un+1—случайная вели-
величина с нормированным нормальным распределением N @, 1), не
зависимая от Vn. Тогда
n, w
n+i.
Непрерывные распределения
175
Теперь введем преобразование
Обратное преобразование таково:
и якобиан равен
Следовательно,
Интегрируя по t?+1, получаем
0 1
1 —1
„ 1
y^
Подстановка в этот интеграл v'n+1 = tvn+1 дает
где
E.71)
Выражение E.71) имеет такой же вид, что и E.70), только п
увеличилось до п + \. Так как ту же форму имеет и распреде-
распределение Vx (при п~ 1), то отсюда следуют аналогичные выражения
для распределений V2 (как уже было показано), V3, V, и вооб-
вообще Vn.
Величина Кп определяется из условия
Подставляя значение pvn{vn) из E.70), получим
откуда
176
Глава 5
Непрерывные распределения
177
Следовательно, плотность распределения %2 с v степенями сво-
свободы равна
При
будем иметь
Тогда распределение V2 (%2 с двумя степенями свободы) экспо-
экспоненциальное (см. разд. 5.4) с 6=2. Начальный момент порядка г
от Vv равен
\кг
2v/2r(V2v)
—1)].
5.14* НЕЦЕНТРАЛЬНЫЕ РАСПРЕДЕЛЕНИЯ
Эти распределения полезны в теоретической статистике, хотя
очень редко используются для описания непосредственно наблю-
наблюдаемых величин.
5.14.1. Нецентральное ^-распределение
Нецентральное %2-распределение с v степенями свободы опре-
определяется как
где alt аЛ, ..., av—константы. Распределение Xv2 [нецентраль-
[нецентральное у?-распределение) зависит от значений at только через Пара-
Параi Действительно,
метр Я™
Удобно рассматривать правую часть этого уравнения как смесь
(см. разд. 5Л0.3) центральных х2-распределений с (v + 2t) сте-
степенями свободы и с весами, равными вероятностям
"л")
пуассоновского распределения со средним К/2.
Существуют различные способы получения выражения E.73).
Один из них включает следующие шаги;
а) доказательство этого результата для v=l (и, конечно,
б) с помощью доказательства а) демонстрация того, что если
результат верен при а1 = да= ... =av-i = 0, т. е.
а Xv-i и У\> взаимно независимы, то %'г имеет плотность вероят-
вероятности E,73) с % = а%\
в) с помощью результата б) демонстрация того, что если соот-
соотношение E.73) верно,, то распределение
где Yv+l — нормированная нормальная величина, независимая от
ОС'2» av+i—константа, имеет тот же самый вид, что и E.73) с v,
увеличившимся до v + 1, и Я, увеличившейся до A, + aJ+1.
Повторяя этот процесс от а) до в), методом математической
индукции можно получить выражение E.73) в общем случае.
Из формулы E.73) и таблиц центрального распределения %2
непосредственно получается распределение х'2- Правда, если
нужен более быстрей метод вычислений, то формулу E.73) заме-
заменяют на многомерное центральное распределение %2 с теми же
средним и дисперсией, что и х'2» и получают полезные резуль-
результаты, если v больше 5.
Среднее и дисперсия (У(-\-а(У равны A+af) и
— A -f afJ^=2 + 4at? соответственно и, таким образом,
Var (X;a) =¦¦ 2 B + 4af) = 2 (v + 2Я,).
1=1
Если с%* имеет те же самые среднее и дисперсию, что и х'2» то
и, следовательно,
г,._У
' V
+
V+2A."
E.74)
5J4.2. Нецентральное /^-распределение
Центральное F-распределение — распределение отношения двух
взаимно независимых средних квадратов (Xv/vi)/(Xv2/v2)- Нецент-
Нецентральное /^распределение — распределение того же о'тношения, но
С нецентральным %2 в числителе,
178
Глава 5
Непрерывные распределения
Можно записать
'2
где х'2 — нецентраль-
нецентраль^^J р
ное ^-распределение с параметром нецентральности X, которое
не зависит от х2а- Распределение отношения двух независимых
центральных х2: bVl, v2 = l%Jl%2 есть
r (i
r (i
Поскольку нецентральное х'2-распределение можно представить как
смесь центральных х?1+2гРаспРеДелений с весами ^^[(Va^iI"/*!]»
то отсюда следует, что G;,, Va = x'2/Xv2 распределено как смесь
распределений величин GVl + 2ivt с теми же весами, т. е.
g' > 0. E.75)
Распределение F'Vi> Va = v2Gvn vJv1 можно получить непосредственно
из формулы E.75).3 Воспользовавшись аппроксимацией, описан-
описанной в конце разд. 5.13, найдем, что х'2 приблизительно распре-
распределено как [(v + 2^1)/(v + ^i)] %(vt-hXt^/(vt + 2%1)y a FVltV2 — как
т. е. как
5.14.3. Нецентральное ^-распределение
Нецентральное ^-распределение с v степенями свободы— рас-
распределение (t/ + S)/(xv/Kv), где U — нормированная независимая
от Xv нормальная случайная величина, а б (параметр нецентраль-
нецентральности)—константа. Это распределение используется при вычис-
вычислении функции мощности ^-критерия. Полезная аппроксимация
(при условии, что v> 10) получается, если учесть, что
а аппроксимирующее распределение U — (K/Vv)%v—нормальное
распределение со средним значением (—KlV v) E (xv) и средним
квадратическим отклонением [l +(/C/KvIVar(xv)]1/2.
Другое полезное приближение получается при рассмотрении
Arsh[*j/3/Bv)] как величины с iV(Arsh[6K3/Bv)], 0 (см. [9]).
5.15. ПОДБОР РАСПРЕДЕЛЕНИЯ
ПО ЭКСПЕРИМЕНТАЛЬНЫМ ДАННЫМ
Пусть для определения вида распределения, к которому при-
принадлежат некоторые данные, взята большая выборка. Фактически
мы не знаем точного распределения совокупности, из которой
извлечена выборка. Было бы разумно спросить: „Оправдано ли
наше предположение о том, что имеет место тот конкретный вид
распределения, которому удовлетворяет наша выборка?" Исследуя
собранные данные, можно, конечно, увидеть, допускают ли они
распределение некоторого вида, и потом проверить, приемлемы
ли наши идеи в дальнейших исследованиях.
Рассматриваемый метод подбора распределения заключается
в построении по данным гистограммы, умножении теоретической
функции распределения на общее число наблюдений и, наконец,
сравнении полученных таким образом чисел с соответствующими
наблюдаемыми числами из гистограммы. В сущности при этом
в случае непрерывного распределения (так же, как и дискрет-
дискретного) проводится сравнение наблюдаемых и теоретических частот.
Если расхождения слишком большие, то отклоняется предполо-
предположение о том, что данная выборка взята из совокупности с ука-
указанным распределением. В противном случае говорим, что разумно
считать, что выборка порождена именно этим распределением
или что это распределение является достаточно хорошей аппрок-
аппроксимацией. Методы, основанные на этих проверках, обсуждаются
в гл. 8. Сначала рассмотрим только методы подбора распределе-
распределений по экспериментальным данным. Это по существу методы
оценивания, теория которых приведена в гл. 7. Здесь же огра-
ограничимся лишь некоторыми практическими примерами. Другие
примеры и пояснения можно найти в специальных книгах, таких,
как книга Элдертона и Джонсона [3J.
5.15.1. Некоторые примеры подбора распределений
Выделим ряд общих этапов, осуществляемых при подборе
нормального распределения, а затем дадим два примера. Пред-
Предположим, что взята выборка объема п. Измерения представлены
в виде несгруппированных данных. Метод состоит в следующем:
1. Данные объединяются в интервалы группировки, опреде-
определяются частоты для каждого интервала.
2. Если параметры (среднее 6 и среднее квадратическое от-
отклонение о) не заданы, по данным вычисляются х и s.
3. Границы интервалов группировки xi нормируются по фор-
формулам
или Ус = -
X; — X
180
Глава 5
Непрерывные распределения
181
4. Для каждого интервала группировки по теоретической
кривой вычисляется вероятность. Она равна
5. Эта вероятность умножается на объем выборки «, что дает
подобранную (теоретическую) частоту.
Пример 5.15. Этот пример уже приводился раньше в гл. 2,
и данные содержатся в табл. 2.2. Данные относятся к перемен-
переменной X—объему плавок в тоннах. Выборка—результат одноме-
одномесячной работы. В табл. 5.6 к этим данным присоединены допол-
Таблица 5.6
A)
Срединное
117,5 :
121,5
125,5
329,5
333/3
137,5
341,5
145,5
149,5
153,5
157,5
261,5
165,5
169,5
173,5
377,5
181,5
185,5
Объемы
B)
IS
им
119,5
123,5
127,5
131,5
135,5
. 139,5
143,5
147,5
151,5
155,5
159,5
Ш,5
I«j745
171,5
175,5*
179,5
183,5
187,5
плавок
(з)
2
1
5
2
•10
а
is
i$
гг
21
27
23
21
18
а
и
X
2)
, полученные в
D)
•$
-1,59
—1.30
-1,00
-0,70
-0,40
-0,11
0,19
0,48
0,78
1,07
№
1,67
E)
0,05592
0,09680
0,1587
0,2420
0,3409
0,4562
0,5753
0,6844
0,782.3
0,8577
0,9147
0,9525
течение месяца
: №
0,05592
0,04088
0,0619
0,0833
0,0989
0,1153
0,1191
0,1091
0,0979
0,0754
0,0570
0,0378
0,0475
G) | (8)
fto&odpamo
чвстта
»•«
13,4
18,0
21,4
24,9
25,7
&fi
21,1
16,3
12Л
IV
0,364^
0,550A
0,504$
0,2225
0,016S
0,610«
0,0655
0.015J
0,000 S
0,1773
0,1374
0,9561
нительные столбцы, используемые при рассмотрении примера.
Будем применять предложенный метод по этапам, обращаясь
к табл. 5.6. Мы хотим подобрать по данным нормальную кривую.
1. Срединные значения интервалов группировки приведены
в столбце A), границы интервалов —в столбце B), а наблюдаемые
частоты—в столбце C). Срединные значения интервалов группи-
группировки можно было бы опустить, но они использованы при пост-
построении полигона частот.
2. Е(Х) и K 1
() ( оцениваютсях) как 1=153,0, а =13,5.
3. Для каждой границы интервалов группировки определим
у( = (хг —153,0)/13,5. Эти значения приведены в столбце D). За-
Заметим, что первые четыре интервала объединены, как и три по-
последних. Этим обеспечивается требование, чтобы частоты не были
много меньше десяти.
4. Определим области под кривой #@,1), приходящиеся-на
разные интервалы. Сначала вычислим Ф(у{I приведенные в столб-
столбце E). Затем, взяв разности, найдем площади, относящиеся
к разным интервалам [столбец F)].
5. Теоретические частоты получаются путем умножения столб-
столбца F) на л. Результаты приведены в столбце G) и изображены
графически на рис. 5.13.
Рис. 5.13. Подбор нормального распределения по экспериментальным данным
(объемы плавок в тоннах).
216
1,0000 216,1
3,7853
1J Эти значения не отличаются от тех, которые получены по сгруппирован-
сгруппированным данным в табл. 2.2. Для исходных данных среднее арифметическое равно
153,2, а среднее квадратическое отклонение составляет 13,5 т.
182
Глава 5
6. Теперь сравним f( с соответствующими наблюдаемыми ча-
частотами foi. [Величины (foi — fiY/fij приведенные в столбце (8),
используются в формальном критерии сравнения теоретических
(f() и наблюдаемых foi частот в разд. 8.9.1.]
Аналогичными методами подбираются и другие распределения.
Пример 5.16 демонстрирует подбор дискретного распределения.
Пример 5.16. Рассмотрим следующую гипотетическую задачу.
Пусть вероятность попадания при стрельбе по мишени некото-
некоторого вида должна быть 0,50. Проводилось обучение с общим
числом стрельб, равным 200, с шестью попытками в каждой
стрельбе, т. е. состоялось 200 стрельб с шестью независимыми
попытками в каждой. Два первых столбца табл. 5.7 содержат
Таблица 5.7
Частота числа попаданий в шести независимых попытках для 200 стрельб
A)
Число попада-
попаданий х-
0
1
2
3
4
5
6
B)
Частота f0(.
42
65
49
200
C)
p(*i)
0,015625
0,093750
0,234375
0,312500
0,234375
0,093750
0,015625
1,000000
D)
Подобранная
частота f>
46,9
62,5
46,9
18'8i21 9
3,1/ '
200,1
E)
(forf{)*
fi
0,4388
0,5119
0,1000
0,0940
0,3840
1,5287
число попаданий и частоту числа попаданий, приходящихся на
одну стрельбу. Если допустить биномиальное распределение» то
вероятность х попаданий равна
Р (*)=
* = 0,1, 2, 3, 4, 5, 6,
где р = 0,50. В столбце C) приведены теоретические значения
Р{х{). В столбце D) даны теоретические частоты fi^nP{xi) для
я = 200. В остальном эта таблица аналогична табл. 5.6.
Непрерывные распределения
183
5.15,2. Некоторые другие процедуры
Для всех других непрерывных распределений процедура под-
подбора распределения аналогична. Нормирование (этап 3) не всегда
сводится к вычислениям типа (переменная — среднее)/(среднее
квадратическое отклонение); скорее речь идет здесь о приведении
данных к некоторой стандартной форме. На этапе 4 искомая
функция зависит от заданного распределения. Если ее трудно
вычислять и нет подходящих таблиц, подбор может оказаться
практически невозможным без ЭВМ. Однако даже для очень
сложных функций подходящие таблицы могут сделать подбор
возможным и простым.
ЛИТЕРАТУРА
L Durand D., Stable Chaos, General Learning Corporation, Morristown, N J
1971, Chapters 12, 13, 18. *'
2. Elandt R., The Folded Normal Distribution, Technometrics, 3 A961).
3. Elderton W. P., Johnson N. L., Systems of Frequency Curves, Cambridge
University Press, 1969, Chapter 4. s
4. Hahn G. J., Shapiro S. S., Statistical Models in Engineering, Wiley New
York, 1967, Chapters, 8. [Хан Г., Шапиро С. Статистические модели
в инженерных задачах.—М.: Мир, 1969.]
5. Haynam G. E., Govindarajulu Z., Leone F. С, Tables of the Cumulative
Non-central Chi-Square Distribution, Selected Tables in Mathematical Sta-
I, 1У73.
Winkler R. L., Statistics: Probability, Inference and Deci-
, ., Holt, Rinehart & Winston, New York, 1970, Chapter 4.
7. Hoel P. G., Introduction to Mathematical Statistics, 4th ed., Wiley, New
York, 1971, Chapter 4.
8. Johnson N. L., The Folded Normal Distribution: Accuracy of Estimation
by Maximum_ Likelihood, Technometrics, 4 A962).
Distributions of Statistics—Continuous Univari-
Continuous Multivariate Distributions, Wiley,
tistics, Vol.
6. Hays W. L.
sion, Vol. 1
9.
10
11.
12
Nottingham R., The Folded Normal Distribution,
Johnson N. L., Kotz S.
ate Distributions 1, 2,
New York, 1970, 1972.
Leone F. C, Nelson L. S.
Technometrics, 3 A961).
Molenaar W., Approximations to the Poisson* Binomial and Hypergeometric
Distribution Functions, Mathematical Centre, Amsterdam, 1970.
Mood A. M., Graybill F. A., Introduction to the Theory of Statistics,
McGraw-Hill, New York, 1963, Chapter 4, 6, 9.
13. Plait A., The Weibull Distribution, Industrial Quality Control, 19A962).
УПРАЖНЕНИЯ
I. Наружные диаметры втулок распределены нормально. Среднее этого
распределения равно 2000 дюймов, а среднее квадратическое отклонение со-
составляет 0,003 дюйма. Определите вероятность того, что наружный диаметр
а) равен или больше, чем 2,009 дюйма;
б) меньше, чем 1,994 дюйма;
в) заключен между 1,997 н 2,003 дюйма;
г) между 1,994 и 2,006 дюйма.
184
Глава 5
Непрерывные раепределения
185
2. Пусть установлено, что выход в граммах красителя стандартного цвета
со специальным оттенком распределен нормально со средним 1550 и средним
квадратическим отклонением 50. В скольких из 100 проверок вы ожидаете, что
выход в среднем будет
а) ниже 1550,
б) выше 1650,
в) между 1525 и 1575,
г) выше 1470?
3. Для некоторого процесса получены оценка среднего значения, равная
101,7, и оценка среднего квадратического отклонения, равная 11,5. В ходе про-
процесса через равные промежутки берутся выборки объемом 4 наблюдения; най-
найденные по ним средние наносятся на график. Требуется найти нижнюю грани-
границу, ниже которой выборочное среднее может оказаться не более чем два раза
в среднем на 1000 наблюдений в предположении, что отклонения от среднего в
процессе распределены нормально.
4. В некотором химическом процессе стандартная жидкость из трех буты-
бутылей сливается в большой бак. Если среднее квадратическое отклонение объема
жидкости в каждой бутыли равно 0,07 унции, то каково среднее квадратиче-
квадратическое отклонение общего объема жидкости в большом баке?
5. Для производства металлических трубок с внутренним диаметром (ВД),
равным 0,35 дюйма, требуется некоторая операция. Допустимые отклонения
± 0,04. Предполагается, что ВД этих трубок распределен нормально с а = 0,025
дюйма. Если номинальный диаметр @,35) в среднем выдерживается, то
а) каково математическое ожидание числа дефектных образцов в выборке
объема 100?
б) какова вероятность того, что в этой выборке окажется менее четырех
дефектных образцов?
6. Для некоторого процесса получены оценка среднего, равная 10,264, и
оценка среднего квадратического отклонения, равная 2,51. В этом процессе
через равные промежутки извлекаются выборки объема 5 наблюдений; полу-
полученные по ним средние наносятся на график. Найдите верхнюю границу, за
которой среднее значение может оказаться не более чем один раз на 1000 на-
наблюдений в среднем, в предположении, что отклонения от среднего в процессе
распределены нормально.
7. Изделия типа А должны подгоняться к изделиям типа В. Предпола-
Предполагается, что критический внешний размер А распределен нормально со сред-
средним 4,30 дюйма и средним квадратическим отклонением 0,04 дюйма. Изделия В
имеют критический внутренний размер, который считается распределенным
нормально со средним 4,36 и средним квадратическим отклонением 0,04 дюйма.
а) Какова ожидаемая доля случаев, когда изделия А п В, выбранные не-
независимо и случайно, окажутся непригодными друг для друга?
б),Надо ли считать необычным два случая несовместимости из 20?
8. Рычаг собирается из пяти секций. Исследование отдельных секций по-
показало, что средняя длина крайних секций составляет 1,001 дюйма, а трех
средних 1,999 дюйма. Средние квадратические отклонения длин всех секций
равны 0,004 дюйма. Если осуществить случайную сборку и отдельные секции
предполагаются распределенными нормально, то
а) какова средняя длина сборки,
б) каково среднее квадратнческое отклонение длины сборки,
в) какова вероятность того, что длина рычага превысит 8,002 дюйма?
9. Две части А и В соединяются в одну трубу С. Средние квадратиче-
квадратичее отклонения длин А я В равны 0,22 и 0,45 мм соответственно. Длине,
добавляемая при соединении, имеет среднее квадратическое отклонение о мм.
Получите формулу для среднего квадратического отклонения длины С, пред-
предполагая, что А и В взаимно независимы.
10. При сборке два изделия С (см. упражнение 9) должны отличаться по
длине менее чем на 1,25 мм. Предполагая нормальное распределение, найдите.
выражение для вероятности того, что два случайно взятых изделия С окажутся
совместимыми. Как мала должна быть величина а, чтобы эта вероятность со-
составляла не менее 90%?
11. Если в упражнении 10 величина сг = 0,12 мм, а пары С отбираются
случайно до тех пор, пока не найдется пара, пригодная для сборки, то каково
среднее число пар, которые придется перебрать?
12. Подберите нормальное распределение для данных табл. 2.6, которые
относятся к глубинам вдавливания для 150 стальных образцов.
la. На одном крупном газовом месторождении на западе США фирма за
последние 10 лет пробурила 75 скважин. Ниже приведены данные о распре-
распределении запасов газа на скважину в единицах 108 фут3. Подберите по этим
данным экспоненциальное распределение px(x) = Qe~Qx @<x^ оо), оценивая
в как (Х)~х> и вычислите теоретические частоты.
ж f х f
0-1,999
2-3,999
4-5,999
6—7,999
8—9,999
30
15
11
9
3
10-11,999
12—13,999
14—15,999
16-17,999
26-27,999
1
2
1
2
1
14. В таблице, приведенной ниже, X—твердость D по Шору сложного
сплава. Постройте гистограмму и сравните ее с нормальным распределением
при fi = 73,5 и о = 3.
X f X f
57-58
59-60
61-62
63-64
65-66
67-68
69-70
71-72
1
3
5
8
10
13
20
25
73-74
75—76
77-78
79-80
81-82
83-84
85-86
87-88
38
22
18
15
И
6
3
2
• 15. В выборку включены 224 последовательные бобины медной проволоки.
Измеряется толщина (в миллах) пластикового покрытия проволоки. Можно ли
на основе приведенных ниже данных считать, что толщина имеет нормальное
распределение? [Данные взяты из работы: Harry Thompson, A Talk with the
Foreman about Quality Control, Industrial Quality Control, May, 1950.] Срав-
Сравните наблюдаемые и теоретические частоты.
Толщина
х
146
147
148
149
150
Частота Толщина
f
3
3
7
11
25
х
151
152
153
154
155
Частота
/
33
34
37
25
23
Толщина
х
156
157
158
159
160
Частота
/
11
9
2
0
1
186
Глава 5
16. Приведенные ниже данные получены из большой выборки, собранной
на одном промышленном предприятии. [Данные основаны на работе Vollen-
weider L. К., Preparation and Use of Area Curve in Presenting Information,
Quality Control Conference Papers, 1951.] Измерен диаметр шага резьбы ме-
металлического штифта. Приведены отклонения от заданного среднего, сгруппи-
сгруппированные в интервалы длиной 0,0003 единицы. Подберите по данным нормальное
распределение.
X / X f
от —0,0018 до —0,0015 3
от —0,0015 до —0,0012 11
от —0,0012 до —0,0000 32
от —0,0009 до —0,0006 89
от —0,0006 до —0,0003 149
от —0,0003 до —0,0000 178
от 0,0000 до 0,0003 147
от 0,0003 до —0,0006 91
от 0,0006 до 0,0009 43
от 0,0009 до 0,0012 12
17. Подберите нормальное распределение по данным примера 5.1.
18. Найдите следующие критические значения распределений F, %2 и tf
используя соответствующие таблицы. Первые индексы обозначают степени сво-
свободы, а последний — накопленную вероятность.
a) t8; 0,975; б) *а0; o.oid; в) %\ъ; 0i990"> г) %% о,о5о; д) F б в; 0,990; e) F8; 5; о,99о;
Ж) F$; Ю; 0,050; З) Fb; 8; 0,975-
19. Величина X распределена нормально со средним значением 50 н сред-
средним квадратическим отклонением 5.
Вычислите:
а) Рг [X > 47]; б) Рг [X < 45]; в) Рг [49 < X < 52].
20. Величина X распределена нормально и 1) Рг [Х>7]=0,05; 2) Рг [Х<5]=
= 0,50. Найдите Рг [4 < X < 6].
21. Величина X распределена как смесь двух нормальных распределений
с общим (неизвестным) средним значением 100 и средними квадратическимн
отклонениями 1 и 5 соответственно. Известно, что Рг [X < 95] = 0,1; вычислите
(приближенно) Рг [99 < X < 100].
22. Функция
х Г 1 -1
L
J ^-i(i_*)*-i^
называется отношением неполной бета-функции.
а) Покажите, как можно использовать таблицы этой функции для подбора
по данным бета-распределения.
б) Покажите, что если К—распределенная по биномиальному закону ве-
величина с параметрами п и р, т. е. если
то
-р)п-г9 r==Ol 1,2, ..., п,
= Ip(k, n-k+l).
23. Функция
o J Lo
называется отношением неполной гамма-функции.
Непрерывные распределения
187
а) Покажите, как можно использовать таблицы этой функции для подбора
по данным гамма-распределения.
б) Покажите, что если К —распределенная по закону Пуассона величина
со средним значением 0, то
24. а) Выразите распределение %2 через отношение неполной гамма-функции.
б) Выразите распределения t и F через отношение неполной бета-функции.
25. Распределение рх(х) = Кх при 0 < х < 0 называется треугольным рас-
распределением.
а) Определите К с учетом того, что рх(х)—плотность вероятности.
б) Определите производящую функцию моментов.
в) Найдите Е (X) и Var (X).
26. а) Покажите, что л-й момент х3"РаспРеДеления с v степенями свободы
равен
2"ar([v+r]/2)/r(v/2).
б) Получите формулы для первых четырех центральных моментов ^-распре-
^-распределения с v степенями свободы.
27. Найдите плотность вероятности суммы Z = X-\-Y, если рх у (х, #) = 1;
0<<1 0<<1
28, В длинных рядах наблюдений выполняется соотношение
Среднее—Мода _ .
Среднее — Медиана ~
Проверьте, так ли это для распределений Парето и логарифмически нормального.
29. Величины X и У имеют совместное двумерное нормальное распределе-
распределение с Е [Y\ ^ оу Покажите, что с хорошей степенью приближения
где
30. С помощью аппроксимации Уилсона —Хилферти (с. 155) и результата
упражнения 29 найдите приближение для F-распределения. Сравните точные и
приближенные значения
1) ^з; ю; 0.05J 2) F3: ю; 0,95;
3) ^з; 20; о,9б; 4) F5; jo; 0,95.
31. Точка Р случайным образом падает на прямую. Известно, что рас-
расстояние (с соответствующим знаком) точки Р от заданной точки О на этой
прямой распределено по нормальному закону со средним | и средним квадра-
квадратическим отклонением а. 5 и а известны. Требуется выбрать три точки Л, В и
С на прямой так, чтобы математическое ожидание наименьшего из трех абсо-
абсолютных расстояний | АР |, \ВР\ и | СР] было минимальным.
Предполагая, что точка В должна быть расположена в ожидаемом поло-
положении точки Р (т. е. ОВ = |), найдите оптимальные положения для Л и С.
32. Полагая, что положения точек Л и С в упражнении 31 оптимальны,
выведите формулу для распределения минимума | АР j, \BP \ и \СР |; найдите
среднее квадратическое отклонение этой величины.
Глава 6
ПОРЯДКОВЫЕ СТАТИСТИКИ
Порядковые статистики
189
6.1. ВВЕДЕНИЕ
Статистики, основанные на упорядоченных по Величине наблю-
наблюдениях, часто оказываются относительно простыми в вычисли-
вычислительном отношении. Чтобы глубже понять их свойства, необхо-
необходимо выяснить, как применять теорию распределений при работе
со статистиками указанного типа. Это основной вопрос, рассма-
рассматриваемый в данной главе. Используя описываемые здесь методы,
получим некоторое представление о возможностях применения
„порядковых статистик" при анализе различных данных1).
Термин „порядковые статистики" применяется только по отно-
отношению к данным, упорядоченным по величине. Достаточно часто
данные оказываются упорядоченными некоторым естественным
образом во времени или пространстве. Однако такое упорядо-
упорядочение не имеет отношения к теме исследования данной главы,
где слово „порядок" употребляется только в рассмотренном выше
узком смысле.
Ограничимся сначала изучением непрерывных случайных
величин, а в конце главы рассмотрим, как можно перенести эти
методы на случай дискретных величин. Такой подход обусловлен
тем, что порядковые статистики при исследовании непрерывных
случайных величин используются значительно чаще, чем при
работе с дискретными случайными величинами.
6.2. ОПРЕДЕЛЕНИЯ
Будем использовать модель, соответствующую случайной бы-
борке из очень большой (бесконечной) совокупности, 6 случае,
когда измерения непрерывной величины X проведены для каж-
каждого объекта выборки. Измерения, относящиеся к выборке
объема /г, представляются случайными величинами Хх, Х2, ..., Х„.
Все Х{ взаимно независимы и обладают одинаковыми Плотностями
х> Детальное рассмотрение порядковых статистик см. в книгах: Бояр-
Боярский Э. А. Порядковые статистики.—М.: Статистика, 1972; Гумбель Э. Ста-
Статистика экстремальных значений.—М.: Мир, 1965; Введение в теорию поряд-
порядковых статистик,— М.: Статистика, 1970,— Прим. ред.
вероятности, т. е. pxi{xi)^f{x)x=x., при i= 1, 2, ..., /г, где /(#) —
математическая функция от х. Функция распределения имеет вид
xi
Fx.{Xi)~ $ f{*)dx.
-00
Введем теперь п новых случайных величин XJ.XJ, ..., Х'ПУ
представляющих собой исходные случайные величины Х1( Ха, ...,
Х„, расположенные в порядке возрастания их значений, так что
хк х; < ... < Х'п
(вероятность того, что две величины из множества X могут
оказаться равными между собой, пренебрежимо мала, поскольку
в данном случае используются непрерывные случайные величины).
Достаточно серьезной проблемой оказывается нахождение
таких характеристик случайных величин Х'и Хг, ..., Х'п, как их
совместные распределения, а также распределения основанных на
них статистик, таких, например, как размах Х'п—Х[. Последние
называются порядковыми статистиками. Их следует отличать
от статистик, основанных на рангах (равных 1, 2, 3, ... для вели-
величин Xi, Xg, Xg, ... соответственно), которые иногда называются
ранговыми порядковыми статистиками. Эти статистики лежат
в основе многих непараметрических статистических методов. Не-
Некоторые из последних будут рассмотрены в гл. 9.
6.3. РАСПРЕДЕЛЕНИЕ НАИМЕНЬШЕГО
И НАИБОЛЬШЕГО ЗНАЧЕНИЙ
В ВЫБОРКЕ
Событие (Х'п^х) эквивалентно пересечению событий (Хг ^x)f
{Xz^x), . ..,(ХЯ^#). Если наибольшее из выборочных значе-
значений X/ меньше или равно хч то это справедливо и для всех
остальных X/, и наоборот, если все X/ меньше или равны х9 то
$то справедливо и для наибольшего из них.
Следовательно,
Рг [Хп < *] = П Pr [Xt < х] = Ц FXt (х) = [Fx (,*)]*.
i—\ 1=1
Таким образом, функция распределения величины Х'п есть
а плотность вероятности
F.1)
F.2)
190
Глава 6
Порядковые статистики
191
Пример 6.1. Если f(л:) = 1 @<х<1), т. е. X' имеет равно-
равномерное распределение, то Fx(x)--= х@^х^ 1) и
Рх{Хп) = п(Хп)п~\ 0<<<1.
Начальный момент порядка г для величины Х'п равен
1
Следовательно, среднее значение наибольшего из Л" в случайной
выборке объема п равно п/(п-\~\), а дисперсия наибольшего зна-
значения равна n(n + 2)-l—ni(n+l)-2=:n(n + 2)-1(n+l)-\ Даль-
Дальнейшие вычисления показывают, что
Если /г стремится к бесконечности,
а3—>—2, а4
Распределение XI, наименьшего среди п значений X', можно
исследовать аналогичным образом. Событие (XI > х) эквивалентно
пересечению п событий (Хх > х), (Х2 > х), ..., (Х„ > х). Следо-
Следовательно,
1J
Отсюда
*0 = n[l-Fx (xi)]"-1
F.3)
F-4)
Если распределение величины X симметрично относительно
математического ожидания, которое равно, скажем, ?, то / (?+8) =
ЧA-Ь) и Fx(g + 6)=l-Fx(g + 6).
Отсюда следует, что
($ + 6) (Ъ8)
Распределение величины XI является зеркальным отображением
распределения Х'п. В частности,
а (XI) - а
а3 (XI) = - а.
6.4. РАСПРЕДЕЛЕНИЕ ПОРЯДКОВЫХ
СТАТИСТИК, ПОСТРОЕННЫХ ПО СЛУЧАЙНЫМ
ВЫБОРКАМ
Событие (Х'г^х) является логической суммой следующих
событий:
„точно / среди случайных величин Хх, Х2, ...,ХИ
меньше или равно х", при j — rf r+1, r+ 2, . ..,/г.
Все эти события взаимно исключающие, поэтому
Рг[х;
Следовательно, плотность вероятности для Х'г равна
"-^^
1 [1 -^(*;)]»-'/(-v;). F.5)
I—1\
Ьдесь I 1 = 0.
Ниже приводится другой метод вывода рассмотренной функ-
функции, более поучительный, хотя и менее строгий. Вероятность
того, что r-е по степени малости значение случайной величины
находится между хг—72 (&х'г) и Xr + 1/2(8x/r)t приближенно
равна рХ' (х'г) {бх'г). Другое приближенное выражение для веро-
вероятности того же самого события можно получить, используя
полиномиальное распределение вероятностей. Случай, когда
r-е по малости значение X находится между xr—1/й(бх'г) и
х'г + 1/2(8х'г), можно считать эквивалентным следующему событию:
г — 1 из п значений X меньше, чем x'r—1U(bx'x),
1 из п значений X лежит между х'г—1/2{&х'г) и Хг + г/гFхг)9
а п — г из п значений X больше, чем x/rJr1/2(8x'r).
[При этом исключается возможность попадания более одного
значения X между х'г—11г(Ьх'г) и х'г + 1/2(8х'г). Вероятность та-
такого события имеет порядок (б^;J.]
192
Глава 6
Порядковые статистики
193
Для любого X имеем
рг [х < л-;- v, (в*;)]« f* (*;)-V,f (*0 («О.
Рг [*,- v, (б<) < х < xr+v, (fix;)]«/ (х;) (бх;),
рг [X > *;+v, F*;)]»1 - Fx (x'r) - v,/ (*;) (б*;).
Отсюда, используя выражение для полиномиального распреде-
распределения, можно получить
?к (*;> (бх;>«(г_1)^_г)! [Fx му-1 [i-Fx (*;)]»-' f (*;) F*;) +
+ Члены, кратные (Ьх'г)* и более высоким
степеням величины (бх,).
Разделив обе части полученного выражения на (8х'г) и устремив
(бдгр) к нулю, получим выражение, совпадающее с F.5).
Рассмотренный метод можно применить при выводе выраже-
выражений для совместных распределений величин Х'п Эти выражения,
которые проверяются путем прямых вычислений, приводятся ниже.
При г < s
P (Х X') X
X [Fx №)]'-* [Fx (x's)-Fx (x'W-1 X
x [l - fx (x;)]-' / (*;) / (x's), x's > x;. F.6)
В частном случае r=l,s = /i плотность вероятности совместного
распределения наибольшего и наименьшего значений из п вели-
величин X имеет следующий вид:
- я (л-1) [Fx (*'n)-Fx (хО]я-? / (х;) / (*0. < > <• (б-7)
При г <s<.t справедливо равенство
Рх'г ^', х\ (*'» х*> *'*) = (г— 1)! (s—г— 1)Г(^ —s—1)! (л —01
X [Fx (x's)-Fx (x'r)]'-'-1 [Fx (x't)-Fx (xdY-8-1 X
x [i -fx w)]-*f (x;) f (x,-) / (xo. xj > x; ^ x;. F.8)
Плотность вероятности совместного распределения всех п упо-
упорядоченных величин Х'х, X;, ..., Х^ имеет вид
Рх'1гх'л х'п№> х» • • •. ^) = я'/W)/W) • • • /W)^
= я! 33 / (^г). х; < х; <... <х;. F.9)
роятности
Как распределена величина
к-\
где Х[ < Xg < ... < Х^—множество fe наименьших из л значе-
значений X?
Сначала отметим два момента, которые полезно доказать:
1) все Х( распределены как BК)~1-(%2> с двумя степенями
свободы);
2) условное распределение величины (Х(—х) при Xi > x сов-
совпадает с (безусловным) распределением Х?.
С учетом формулы F.4) плотность вероятности величины Х'х
можно записать как
Следовательно, Х{ имеет распределение [см. приведенное выше
утверждение 1)]
BпК)~1х(%2 с двумя степенями свободы).
В силу утверждения 2) условное распределение величины
(X'2 — X'i) при заданном Х'г [т. е. когда (п — 1) оставшихся слу-
случайных величин из X превышают Х[] совпадает с распределе-
распределением (п—1) взаимно независимых случайных величин, имеющих
такие же распределения', как и Xf. Как мы только что видели,
условное распределение есть
[2(п—1)^]~1Х(х2 с двумя степенями свободы),
причем (Хз—Х[) и Х[ взаимно независимы.
Проводя аналогичные рассуждения, можно убедиться, что
величина (XJ — Х'2) имеет распределение
[2 (л — tyty^xix2- с двумя степенями свободы);
Пример 6.2. Пусть Х1? Х2, ..., Хд—взаимно независимые
случайные величины, имеющие экспоненциальные плотности ве-
в общем случае (X)— Х)_х) распределена как
[2(л—/+1)Л]-1х(ха с Двумя степенями свободы)
и все указанные случайные величины взаимно независимы. Сле-
Следовательно пХ[ и (л—/ + 1) (Х~Х/_Х) при у = 2, 3, ..., k пред-
представляют собой k взаимно независимых случайных величин,
которые распределены как
BА,)~1х(х2 с двумя степенями свободы).
819
194
Глава 6
Отсюда их сумма
i-1
распределена как (см. разд. 5.13)
BХ)~1х(х2 с 2k степенями свободы).
Плотность вероятности случайной величины Yk равна
(Этот результат будет использован в примерах 7.4 и 17.2.)
6.5. ТОЛЕРАНТНЫЕ РАСПРЕДЕЛЕНИЯ
Плотность вероятности вероятностного интеграла Fx{X;) ве-
величины X', выбранной случайным образом, есть
F-10)
поскольку
x(xt)= lf(x)dx.
При любом f(x), но только при условии, что X является
непрерывной случайной величиной, Fx{Xg) представляет собой
равномерно распределенную на интервале между 0 и 1 случай-
случайную величину. Поскольку при г < s Fx (X'r) ^ Fx (XJ) (причем
вероятность равенства стремится к нулю), п величин Y'r=^Fx{X?)
подчиняются такому же распределению, как и упорядоченная
выборка объема п из совокупности с плотностью вероятности
Используя формулу F.6), можно показать, что при
л!
'(г — l)!(s — r—\)l(n — s)\
Теперь применим для отыскания распределения величины Y[—Y'r
методы, рассмотренные в гл. 5. Во-первых, сделаем переход
Порядковые стапгисгйики
195
к новым переменным
Якобиан этого преобразования имеет вид
д(у'г> y's)_
1 0
1 1
= 1.
Следовательно,
Pzr,
л!
zr~1zs-r-1
Далее, проинтегрировав выражение по гп получим плотность
вероятности для Zrs в виде
•= 3 P*r.z,t(zr,
— со
л!
-' Г*"
Упростим выражение следующим образом:
— Ъ ?s-r-l /1 - \n-s + r Г/уГ-1 /1 ij
-(r_1)lE_r_l)|(n_s)J:/'s U Zrs) jW ^1 U
где
Так как
получаем
(n-s+r)\ J
n\
0<zr,<l. F.12)
Следовательно, числ? ?™{п) можно определить таким образом»
что
196
Глава 6
(Эти числа достаточно легко получаются путем решения урав-
уравнения
1
При этом можно использовать таблицы неполной бета-функции
[10] или аналогичные им.)
Полученный результат имеет полезную статистическую интсф-
претацию, которая приводится ниже. Вероятность того, что при
случайной выборке, включающей п точек, доля совокупности,
заключенная между значениями Х'г и Х'$> окажется больше z(rf(n),
составляет 1 — е. Путем соответствующего подбора значений п,
г и s всегда можно добиться требуемой точности (т. е. желаемой
степени малости величины е), так чтобы по крайней мере задан-
заданная доля совокупности, допустим р, была заключена между
двумя заранее определенными выборочными значениями. Следо-
Следовательно, нужно всего лишь выбрать такие rT s и п, при которых
(для требуемого значения г) z(rf (n) будет по крайней мере равно ?5.
Необходимо отметить, что это справедливо для любых непрерыв-
непрерывных случайных величин с любой плотностью вероятности f(x) и,
следовательно, не нужна никакая информация о виде f(x). Изло-
Изложенное выше является примером построения толерантных обла-
областей, которые будут рассмотрены в разд. 9.8.1,
Пример 6.3. Требуется установить пределы, в которых должно
находиться по крайней мере 90% значений X. Предлагается
оценить эти пределы с помощью значений Х«, Х'п+1-.а> взятых
из упорядоченной случайной выборки объема п.
Используя формулу F.12), получим для плотности вероят-
вероятности величины
Z=Pr[X'a<X<X'n+1_a]
выражение
М*у\ * -yrt — 2(Х ( 1 ___ -?\2tt — 1 П ^-*" t ^
Z) — /и_о«\1 /9«_t\i Z (L — Z) , U < Z <
— 2а)\Bа — \
Отсюда следует
Pr[Z>0,90] =
n — 2a)\Ba-
— /0,io Ba, rt
1)!
f
0,90
-2cc+l).
AХ — отношение неполной бета-функции, определенное
в разд. 5.6.2,) В табл. 6.1 приведены некоторые значения ука-
указанной вероятности для различных значений п и а.
Порядковые статистики
197
Таблица 6.1
а \^
1
2
3
4
5
0
0
10
,2639
,0128
—
—
—
Толерантные
20
0,6083
0,1330
0,0113
0,0004
—
вероятности
30
0,8163
0,3526
0,0732
0,0078
0,0005
40
0,9195
0,5769
0,2063
0,0419
0,0051
50
0,9662
0,7497
0,3839
0,1221
0,0245
Из указанной таблицы следует, что для получения предель-
предельных значений, между которыми с вероятностью, не меньшей 95%,
находятся не менее 90% объектов совокупности, необходима
выборка с минимальным объемом, равным примерно 47 объектам
(при а = 1). (При больших объемах выборок (и соответствующих
значениях а) можно получить толерантные пределы, обладающие
меньшей изменчивостью в том смысле, что заключенная между
ними часть совокупности в меньшей степени изменяется от одной
выборки к другой.)
6.6. НЕКОТОРЫЕ ПРИБЛИЖЕНИЯ
ДЛЯ БОЛЬШИХ ВЫБОРОК
В этом разделе предполагается, что выборки содержат нечетное
число точек n = 2m+lf где т—целое число. Тогда медиана
выборки определена однозначно как Х'т+1. С вероятностью еди-
единица т выборочных значений оказываются меньшими Х'т+и а
т значений превышают эту величину. Положив л==2/я + Ь
г = /п+1 в выражении F.5), получим
* f {x'm+lY F'13)
Значение |л, удовлетворяющее уравнению Fx{\i)= 1/2, является
медианой совокупности.
Можно показать, что для больших выборок (т. е. при боль-
большом т) распределение величины (Х'т+1 — \i)V^n приближенно
описывается нормальным законом с математическим ожиданием,
равным 0, и дисперсией D[/(jjl)]2)~1. Если Х'т+1 — медиана, то
Е (Х'т+1)ж\1,
F.14)
198
Глава 6
Порядковые статистики
199
В общем случае при больших п
F.16)
F.17)
где Fx(lp) = p при условии, что r/п стремится к пределу р при
О < р < 1, когда п стремится к бесконечности.
Анализ выражения F.6), проведенный аналогичными методами,
приводит к равенству
Соу(х;д;,) = -^[/(У/(^)]-1рA-р/), F.18)
где r<r', а r'/n-^р'. Опять эта формула должна рассматри-
рассматриваться как предельное соотношение,, которое получается при воз-
возрастающем п, но остающихся неизменными отношениях r/п и г'/п.
Необходимо отметить, что формулы F.16) —F.18) нельзя
использовать с какой бы то ни было степенью доверия при а)
малом объеме выборки п (например, менее 15) или б) при исследо-
исследовании экстремальных наблюдаемых значений (наибольших или
наибольших среди наибольших и т. п.).
Выражения F.16) и F.17) можно уточнить следующим образом:
F.16)'
F.17)'
Var (X'r) « [1 +n [/= (Up [p A -
В пределе совместное распределение величин Yn{X'r — lp)
и У п(Х'г,—ЕР') представляет собой двумерное нормальное рас-
распределение.
Пример 6.4. Пусть плотность вероятности наблюдаемых зна-
значений имеет вид f(x). Получим нижнее граничное значение для
дисперсии медианы случайной выборки объема 2/и+1> когда
максимальное значение f(x) находится в точке медианы 0 сово-
совокупности, а сама функция симметрична относительно д: = 0.
Дисперсия величины X'm+i равна
(/п!J
х'т+г) [1 -
f (**+i) dx'm+1,
где
F{x)= j f(x)dx и
Далее, поскольку /(х
\F (x'm+1)-l/2\^\x'm+1-Q\f (Q),
Имеем
X {F (x'm+1) [1 — F (xm+1)]\m f (x'm+1) dx'm+1.
Таким образом,
где n^+
Поучительно сравнить последнее выражение с F.15).
6.7. РАСПРЕДЕЛЕНИЕ РАЗМАХА ВЫБОРКИ
Размах, имеющий в принятой нами форме записи вид {Х'п~Х[),
равен разности между наибольшим и наименьшим выборочными
значениями. Эта величина представляет особый интерес, поскольку
часто используется как мера рассеяния вместо выборочной оценки
среднего квадратического отклонения или усредненного выбо-
выборочного отклонения. Применение размаха обусловлено тем, что
его можно вычислить с меньшими трудностями, однако для эф-
эффективного использования этой величины, а также для того,
чтобы можно было оценить возможные потери точности по срав-
сравнению с другими статистиками, необходимо иметь достоверную
информацию об ожидаемом распределении величины размаха вы-
выборки. Зная средние потери точности, можно компенсировать их
выигрышем, получаемым за счет упрощения вычислений.
Распределение размаха выборки можно найти прямым мето-
методом, рассмотренным в гл. 5, используя совместное распределение
величин Х[ и Х„ [как в F.7)]. Кроме того, можно предложить
и другие способы получения распределения величины размаха.
Если классифицировать все выборки в соответствии с величиной Х'п
(наибольшим значением), то вероятность того, что размах вы-
выборки W меньше или равен w, когда наибольшее из выборочных
200
Глава 6
значений находится между х'п — 1/2(Ьх'п) и х'п + г/2Fхп)у прибли-
приближенно равна
Pr [W < w | хД » (-jr^Tj{ [f x (*;) -f* (*; - а;)]»-* / {х'п) Ьхп. F.19)
Проводя суммирование по всем значениям х'п [всякий раз на ин-
интервале (бХп)] и устремляя величину 8х'п к 0, получаем
00
Рг[Г<ш] = п J [Fx(x)—Fx{x—w)]"-1f(x)dx. F.20)
— со
Плотность вероятности величины W имеет вид
-ш)Ле. F.21)
Если Fx(x) — какая-нибудь простая функция от х> то можно
получить явное выражение для интеграла; в остальных случаях
необходимо проводить численное интегрирование. Для норми-
нормированного нормального распределения
X
f
отсутствуют простые явные выражения для распределения вероят-
вероятностей величины W, однако составлены достаточно полные таб-
таблицы (например, табл. 20, 22 и 23 из [7]I), пользуясь которыми
можно получить вполне адекватное представление об ожидаемом
поведении размаха выборки из совокупности, подчиняющейся
нормированному нормальному распределению. Указанные таблицы
можно также использовать и в случае, когда совокупность имеет
обычное нормальное распределение с произвольными средним зна-
значением и средним квадратическим отклонением. Размах выборки
в последнем случае распределен как
(Среднее квадратическое отклонение совокупности) х
X (Размах выборки при нормированном нормальном
распределении).
Так, если требуется определить вероятность того, что размах
случайной выборки объема 7 из совокупности, имеющей нормаль-
*) См. также: Большее Л. Н.( Смирнов Н. В. Таблицы математической
статистики.—М.: Наука, 1965.— Прим. ред.
Порядковые статистики
201
ное распределение со средним квадратическим отклонением 2,5,
превышает 4, то по указанным таблицам определяют вероятность
того, что размах выборки объема 7 из совокупности, имеющей
нормированное нормальное распределение, превышает величину
4/2,5= 1,6. (В данном случае вероятность этого события равна
0,9186).
Математическое ожидание величины размаха выборки равно
Е(Х'п) — Е(Х1). Поскольку вероятность того, что размах выборки,
заданный значениями Х[ и Х'п, не накроет интервал от х—1/2(&х)
до х + 1/2(&х), равна (приближенно) [/^ (#)]"+[1—Fx{x)]n, можно
непосредственно получить формулу
F,22)
(Это сумма вероятностей событий
и Х[>х.)
Пример 6.5. Опять рассмотрим случайную выборку объема л,
а именно Х1У Х2, ..., Хп из совокупности, где наблюдаемая
величина X имеет экспоненциальную плотность вероятности
Рх (Х) -
о < е, о < х.
Требуется найти распределение величины размаха выборки W =
= Хп—Х[. Первый метод основан на использовании совместного
распределения Х[ и Х'п. Согласно формуле F.7), имеем
p*v К (*i, x'n) - п (п- 1) {e-<P-e-x*l*Y~% e-e-W+*«>/ef
Перейдем к новым переменным
или, обратно,
хк = Ч,(и>+и), xi = l/t(u—w).
Якобиан этого преобразования имеет вид
1/2 1/2
д (w, и)
— 1/2 1/2
-1/2,
откуда
1/3П (П —
0 < W < И.
202
Глава 6
Наконец,
= (n— 1) e-^-^6 A
Второй метод, в котором используются выражения F.20) и F.21),
дает
Рг [W J
lo
4-
= пО-1 И [1 — е-*
lo
Дифференцируя по ш, найдем
+ (л — 1) 9-1 A — e-w/e)*-* Q-w/e = (n — 1) Q^e-^e A — e-w^)n'2t
что совпадает с уже полученным результатом.
6.8. ДИСКРЕТНЫЕ ВЕЛИЧИНЫ
Упорядоченные величины редко используются в статистиче-
статистических исследованиях, если применяется модель с дискретными
случайными величинами. Однако теория распределений упорядо-
упорядоченных дискретных случайных величин опирается на те же по-
положения, что и теория для упорядоченных непрерывных случай-
случайных величин. Важно однако обратить внимание на случаи совпада-
совпадающих значений (т. е. одинаковых результатов наблюдений), которые
возможны при использовании дискретных величин.
Рассмотрим дискретную случайную величину X, принимаю-
принимающую значения xh которые возрастают вместе с i так, что jc*, < xh
если V < i. Пусть Рг[Х = *,-] = р(. Тогда вместо формулы F.20)
можно записать
Рг [W < w] -
, \п (р, ~\~ р• -4- A-D- * )Л1 ^6 23)
Порядковые статистики
203
где V (I) определено следующим неравенством:
Х( —Х(, (й < W < Хг — Xiv(ft_!.
Вместо формулы F.22), основываясь на тех же рассуждениях,
получаем
Е {W) =S[*i-^-J[l-(- •• ]
F.24)
Пример 6.6. Рассмотрим дискретное равномерное распределе-
распределение (см. разд. 4.7), которое можно задать с помощью следующих
уравнений:
Если /Д ^ш < (/ + 1) А (где / — целое число, не превышающее
k — 2), то
+ (/ + /) A]-Pr[a + /A< XI
А-/-1
2
F.25)
(Отметим, что при Х„^^+/А должно выполняться неравенство
W < /А, поскольку XJ ^ а.) Размах выборки от а + /А до а+ (/+/) А
заключает 1+1 возможных значений случайной величины X,
а размах от а + /А до а + (/ + /~ 1) А содержит / возможных зна-
значений. Отсюда, учитывая взаимонезависимость ХЁ- и XJt получаем
U
Из формулы F.25) следует
откуда
а также
Рг [Г = /Д] = Рг [ W < /Д]-Рг [W < (/- 1) Д] =
-(А-'-1)(г)". <6-26)
F.27)
204
Глава 6
Рассмотрим теперь предельный случай, когда k стремится
к бесконечности, а А стремится к нулю так, что ?Д = h и (?Д) [l/k) =w
остаются неизменными.
В этом случае
[('+ \)lk]n — (ljk)n dwn
\/k dm
и, следовательно,
И7Д|И~1
стремится к
ч?)+(*)"•
Это выражение представляет собой функцию распределения раз-
размаха случайной выборки объема п из совокупности с непрерыв-
непрерывным равномерным распределением
Px(x)=h-1y a^x^a + h.
Продифференцировав ее, можно получить плотность вероятности
(ft — ш), G<w<ft. F.28)
(Конечно, значительно проще было бы получить этот результат
непосредственно.)
*6.9. НЕКОТОРЫЕ ПРИБЛИЖЕННЫЕ
РЕЗУЛЬТАТЫ ДЛЯ НОРМАЛЬНЫХ РАСПРЕДЕЛЕНИЙ
Во многих работах распределения порядковых статистик вы-
вычисляются в предположении нормальности распределения случай-
случайных величин. Точные формулы для распределений и средних
значений рассмотренных статистик достаточно сложные, однако
могут быть получены полезные аппроксимации.
Известны две аппроксимации распределения размаха случайной
выборки объема п (W ~Х'п — Х{) из совокупности, имеющей нор-
нормальное распределение:
1) величина W распределена примерно как oCjXvJVvi,
2) величина W распределена примерно как oc2%ljv2t
причем с1( с2, Vj и v2 зависят от п\ некоторые значения этих
констант даны в табл. 6.2. Исследования, проведенные Пирсоном
[6], показывают, что в первом случае лучшие результаты обес-
обеспечиваются при п < 10, а во втором — при больших объемах вы-
выборок п. Поскольку размах относительно редко используется при
п> 10, то первая аппроксимация представляется более полезной
для практических целей.
Порядковые статистики
205
Таблица 6.2
Приближенное распределение размаха случайной выборки
объема п из нормально распределенной совокупности
п
3
4
5
6
7
8
9
10
11
12
13
14
15
1
2
2
2
2
2
3
3
Аппроксим*
ci
,9164
,2374
,4812
,6721
,8295
,9630
,0778
,1789
—
—
—
_
—
щия A)
Vi
1,93
2,95
3,83
4,69
5,50
6,26
6,99
7,69
—
—
—.
—
—
Аппроксимация
—
—
—
—
2,8472
2,9700
3,0775
3,1729
3,2585
3,3360
3,4068
3,4718
B)
v2
—
—
—
—
24,11
27,01
29,81
32,48
35,04
37,50
39,87
42,16
Замечания: 1) с2 равно ожидаемому значению размаха случайной вы-
выборки объема п из совокупности, имеющей нормированное нормальное рас-
распределение (а=1); 2) Vi я: 74 (v2+ 1) при п > 10.
Рассмотренные способы аппроксимации можно использовать
для приближенного построения распределений статистик, осно-
основанных как на размахе, так и на различных его комбинациях
с другими статистиками. Это приводит к важному выводу, что
многие стандартные таблицы статистических функций оказываются
применимыми при исследовании распределений таких статистик.
Вместо размаха иногда используется статистика
J,« =
' (г)
2
/ = 0
л;.
называемая усиленным размахом (thickened rangeI) [2, 3].
Таблицы могут использоваться и в случае, когда сг является
сомножителем, таким, что E(crJ{r)) = a. Среднее квадратическое
отклонение crJir) (при больших п) имеет минимальное значение
при выборе гжО,255п. Полезный и легко запоминающийся ре-
результат состоит в том, что при выборе г/п ж 1/6 (при больших п)
величина сгжCг)-1.
г) Используется также термин „сумма подразмахов". (См. Боярский Э. А.
Порядковые статистики.—М.: Статистика, 1972.)—Прим. ред.
206
Глава 6
Рассмотренные статистики особенно полезны в случаях, когда
а) объем выборки велик и б) есть сомнения в том, что реальные
отклонения от математического ожидания (на „хвостах" распределе-
распределения) адекватно описываются нормальным распределением. В обоих
случаях статистика ограждается от влияния случайных выбро-
выбросов.
Экстремальные значения вообще можно отбрасывать. Тради-
Традиционным показателем изменчивости является междуквартильное
расстояние, определяемое как разность между верхним и нижним
квартилями. Для объемов выборок n = 4m + 3, где т — целое число,
выборочное значение Х'зт+Ъ является верхним квартилем, а Х'т+1—
нижним квартилем. (При других объемах выборки квартили оп-
определяются не так просто, однако для больших п можно исполь-
использовать любую подходящую интерполяцию для значений Хз/4(Л_3)+з
И Xi/4 (л-з) + 1-)
При выборках большого объема из нормальной совокупности
Е (междуквартильного расстояния) ^ {1,349 + 1 ,252 (п + 2)} а.
Статистика A,349) {Х'ш+3-Х'т+1) ^0,74(Хзт+3-Х;+1) имеет
математическое ожидание, равное а (приблизительно.) Среднее
квадратическое отклонение этой величины равно 1,166/i~1/s о (при-
(приблизительно). Оно несколько больше, чем среднее квадратическое
отклонение выборочного среднего квадратического отклонения
(приблизительно 0,71п-ха). Вообще для статистик вида
br(X'n_r+1 — X'r)
с математическим ожиданием, равным а, наименьшая величина
среднего квадратического отклонения (для больших п) может быть
получена при выборе г да 0,069л.
Рассуждения, аналогичные приведенным выше (см. случаи а
и б) лежат в основе использования медианы вместо арифметиче-
арифметического среднего.
Среди статистик вида
х
с математическим ожиданием ? наименьшее значение среднего
квадратического отклонения (при больших п) достигается при
г да 0,270 п.
Более высокую точность можно получить при использовании
„усеченных средних" (trimmed means). В этом случае арифме-
арифметическое среднее вычисляется после того, как отброшены г наи-
наибольших и г наименьших среди наблюдаемых значений. В при-
принятых обозначениях усеченные средние могут быть представлены
в виде
(„-2Г)-1 if X}.
Порядковые статистики
207
Свойства усеченных средних рассмотрены в работе [4]. (См.
также [II].I)
В табл. 6.3 (взятой из [4]) приведены отношения средних
Таблица 6. 3
Отношение средних квадратических отклонений для усеченных
и обычных выборочных средних
„\
3
4
5
6
7
8
9
10
11
12
13
14
15
1
1,16
1,09
1,07
1,05
1,04
1,03
1,03
1,03
1,02
1,02
1,02
1,02
1,02
2
1,20
1,14
1,11
1,09
1,07
1,06
1,06
1,05
1,05
1,04
1,04
3
,21
1,16
1,13
1,11
1,10
[,09
[,08
,07
1,07
4
1,22
1,18
1,15
1,13
1,12
1,11
1,10
5
1,23
1,19
1,16
1,15
1,13
6
1,23
1,20
1,17
7
1,23
квадратических отклонений для усеченных средних к соответ-
соответствующим средним квадратическим отклонениям для обычного
арифметического среднего (равным п'1^х [дисперсия совокуп-
совокупности]1/2) в предположении, что совокупность имеет нормальное
распределение.
Если, например, среднее квадратическое отклонение совокуп-
совокупности равно (т0, а выборка объема 8 преобразована путем отбра-
отбрасывания наибольшего и наименьшего выборочных значений, то
среднее квадратическое отклонение усеченного среднего равно
(Заметим, что диагональные члены соответствуют медианам выбо-
выборок с нечетным числом элементов. Например, выбор /г = 7, г = 3
приводит к 7—2-3= 1 наблюдению, которое и является медианой.)
Если а0 неизвестна, может возникнуть необходимость в полу-
получении оценки этой величины по данным для того, чтобы опре-
х) См. также: Боярский Э. А. Порядковые статистики.—М.: Статистика,
1972,— Прим. ред.
208
Глава в
делить точность оценивания среднего значения. При использовании
только усеченных средних значений (т. е. при отброшенных
экстремальных значениях) необходимо принимать во внимание,
как была получена оценка среднего. В табл. 6. 4. (взятой из [4])
Таблица 6. 4
Поправочные коэффициенты, на которые следует делить сумму
квадратов для получения несмещенной оценки дисперсии
совокупности (по усеченным данным)
П >ч
4
5
6
7
8
9
10
11
12
13
14
15
1
0,301
0,719
1,22
1,79
2,40
3,05
3,73
4,44
5,18
5,93
6,69
7,47
2
0,144
0,375
0,679
1,04
1,46
1,92
2,42
2,96
3,52
4,Н
3
0,0845
0,231
0,436
0,692
0,996
1,34
1,72
2,14
0
0
0
0
0
0
4
,0555
,157
,256
,494
,725
,993
0
0
0
0
5
,0393
,114
,194
,372
6
0,0293
0,0862
приведены поправочные коэффициенты, на которые необходимо
разделить сумму квадратов отклонений от (усеченного) среднего
значения, чтобы получить несмещенную оценку дисперсии о\.
Следует отличать усеченные средние от средних значений,
полученных после отбрасывания выделяющихся наблюдений (выб-
росов) (см. разд. 8. 3. 4). При вычислении усеченных средних
общее число Bг) и относительные величины (г наибольших и г
наименьших) наблюдений, которые не будут приниматься во вни-
внимание, определяются до анализа выборочных данных.
Усеченные средние используются для того, чтобы относительно
малой ценой в смысле увеличения дисперсии выборочного сред-
среднего (как показано в табл. 6. 3) уменьшить влияние отклонений
от нормальности, особенно на хвостах распределений сово-
совокупностей.
Пример 6. 7. Из совокупности, имеющей нормальное распреде-
распределение, взята первая серия обычных случайных выборок объема
по шесть элементов каждая. Усредненная величина размаха этих
Порядковые статистики
209
выборок составляет 3,4 единицы. Предполагается уменьшить
объемы выборок до четырех элементов. Какие значения следует
использовать в качестве 2V2-h 0,1-процентных пределов для раз-
махов выборок при указанном уменьшении их объема?
Предположим, что в первой серии выборки имели достаточный
объем для того, чтобы величину 3,4/2,5344=1,34 можно было
считать хорошей оценкой среднего квадратического отклонения
(а) совокупности. (Знаменатель 2,5344 взят из табл. 3 приложе-
приложения.) Среднее квадратическое отклонение среднего значения раз-
махов в N выборках объема по шесть элементов каждая равно
0,8480 o/N, а среднее квадратическое отклонение оценки вели-
величины о равно @,8480/2,58441)аЛ^-1/2, что составляет 0,3346х
хаЛ/'/2. Таким образом, при N, равном 25 и более, отношение
среднего квадратического отклонения оценки а, найденной по
среднему размаху выборки, к величине а не превышает 7%.
Положив а, равным 1,34, определим по табл. 3 верхнюю
272-11роц;ентную точку для размахов при объеме выборок 4:
1,34-3,98-5,33.
Верхняя 0,1 -процентная точка равна
1,34-5,31-7,12.
Отметим, что второй и третий столбцы табл. 3 содержат
соответственно средние значения и средние квадратические откло-
отклонения для размаха п взаимно независимых нормально распреде-
распределенных случайных величин, обладающих одинаковыми средними
значениями и средними квадратическими отклонениями, равными
единице. Если каждая из величин имеет среднее квадратическое
отклонение ох, то
Е (размаха) = [Значение в столбце
0 (размаха) = [Значение в столбце
Таким образом, [размах/значение из столбца B)] оказывается
несмещенной оценкой величины 0^, которая имеет среднее квад-
квадратическое отклонение, равное [значение из столбца C)/значение
из столбца B)]-0^. Среднее значение для N независимых оценок
указанного типа равно [средний размах/значение из столбца B)]
при среднем квадратическом отклонении [значение из столбца
C)/значение из столбца B)]-ах/УЫ. Если ак оценивается путем
усреднения по нескольким оценкам, то среднее квадратическое
отклонение полученного среднего значения можно оценить сле-
следующим образом:
Значение из столбца C) Средний размах
[Значение из столбца B)]2
210
Глава 6
Порядковые статистики^
211
ЛИТЕРАТУРА
1. David H. A., Order Statistics, Wiley, New York, 1970.
2. Dixon W. J., Massey F. J., Introduction to Statistical Analysis, 3rd Ed.,
McGraw-Hill, New York, 1969, Chapter 9.
3. Jones A. E., A Usefull Method for the Routine Estimation of Dispersion
from Large Samples, Biometrika, 33 A946).
4. McLaughlin G., Tukey J. W., The Variance of Means of Symmetrically
Trimmed Samples from Normal Populations, and its Estimation from Such
Trimmed Samples, Technical Report No. 42, Statistical Techniques Re-
Research Group, Princeton University, 1961.
5. Nair K- R., Efficiencies of Certain Linear Systematic Statistics for
Estimating Dispersion from Normal Samples, Biometrika, 37 A950).
6. Pearson E. S., Comparison of Two Approximations to the Distribution of
Range in Small Samples from Normal Populations, Biometrika, 39 A952).
7. Pearson E. S., Hartley H. O., Biometrika Tables for Statisticians, Vol. 1,
Cambridge University Press, 1968.
8. Pearson K. (Ed.), Tables of Incomplete _ Beta Function, 2nd. ed., Camb-
Cambridge University Press, 1969.
9. Renyi A., On the Theory of Order Statistics, Ada Math, Acad. Sci. Hung,
Budap., 4 A953).
10. Sarhan A. E., Greenberg B. G. (Eds.), Contributions to Order Statistics,
Wiley, New York, 1962, Chapters 2, 5, 7, 8, 10.
11. Tukey J. W., The Future of Data Analysis, Annals of Mathematical
Statistics, 33 A962).
12. Wilks S, S., Order Statistics, Bulletin of the American Mathematical
Society, 54 A948).
УПРАЖНЕНИЯ
1. При исследовании некоторой продукции с использованием последователь-
последовательности выборок, содержащих пять элементов каждая, получены следующие
размахи для каждой из них (в мм):
1,0
1,5
0,2
0,7
0,5
0,8
1,4
0,2
1,1
0,8
0,8
0,6
0,9
1,3
0,9
а) Получите несмещенную оценку величины а, предполагая, что наблюде-
наблюдения имеют нормальное распределение с неизменным средним квадратическим
отклонением а.
б) Принято решение уменьшить объемы выборок до 4. Оцените пределы,
за которые величина размаха выборок уменьшенного объема будет выходить
не более, чем в 5% случаев.
2. Требуется оценить 50%-зону разброса снарядов при стрельбе в обычных
условиях. Известны результаты 4N-\-3 выстрелов, а 50%-зона определяется
как диапазон между (Af-f 1)-м среди наименьших и (W+1)-m среди наиболь-
наибольших из расстояний наблюдаемого разлета. Как велико должно быть N, чтобы
вероятность того, что действительное число попаданий в зону, определенную
таким образом, составляет от 40 до 60%, была бы не меньше 0,90?
3. Предположим, что при условиях, описанных в упражнении 2, проведено
55 измерений (N=13) и зафиксированы их результаты. Укажите, как найти
такой интервал, чтобы не менее 50% снарядов падали вне этого интервала с
вероятностью не менее 90%.
4. Используя табл. 3, вычислите среднее квадратическое отклонение не-
несмещенных оценок среднего квадратического отклонения, полученных на основе
размаха выборки из совокупности, имеющей нормальное распределение.
5. Дана случайная выборка объема 8 из совокупности, имеющей нормаль-
нормальное распределение. Нужно оценить среднее квадратическое отклонение сово-
совокупности. Предлагается сделать это одним из трех способов:
а) по размаху выборки;
б) по среднему значению размахов двух выборок, каждая объема 4, по-
полученных путем случайного разбиения восьми выборочных значений на две
выборки;
в) по среднему значению размахов четырех выборок, каждая объема 2,
полученных случайным разбиением восьми выборочных значений.
Какой из этих способов обеспечивает наиболее точную оценку среднего
квадратического отклонения для совокупности?
6. а) Получите приближенное выражение для дисперсии величины
х/г (^r+^n-r+i), гдеХ].<;Х2<:. . *<Х'п являются упорядоченными членами
случайной выборки объема п из совокупности, имеющей нормальное распре-
распределение с математическим ожиданием ? и дисперсией а2.
б) Получите для достаточно большого п приближенную формулу, опре-
определяющую число л, минимизирующее дисперсию величины г/2 (Хг+Хд-г-ц).
(Заметим, что эта формула дает несмещенную оценку ?, обладающую наимень-
наименьшей дисперсией среди всех оценок, зависящих от двух порядковых статистик.)
7. Проведите исследование, аналогичное рассмотренному в упражнении 6,
и найдите (приближенно) несмещенную оценку а, обладающую минимальной
дисперсией, в виде с (Xn-r+i — X'r).
8.^ а)^Используя соответствующие таблицы, определите оптимальный объем
случайной выборки из совокупности, имеющей нормальное распределение, при
оценивании среднего квадратического отклонения с помощью выборочного зна-
значения размаха.
б) Проведите аналогичное исследование в случае, когда совокупность имеет
распределение вида
РхМ^в-Чхр [~(х~у)/В1 0 > 0, х> у.
9. Найдите распределения а) наименьшего и б) наибольшего значений среди
п независимых непрерывных случайных величин, каждая из которых распре-
распределена в соответствии с законом
в) Найдите среднее значение размаха случайных выборок объема п из со-
совокупности с указанным законом распределения.
10. а) Найдите распределение размаха выборки при условиях, описанных
в упражнении 9.
б) Постройте таблицы процентных точек для распределения размаха вы-
выборки в виде сомножителей к величине среднего квадратического отклонения
указанного распределения.
11. Хг, Х2, ..., Хп—взаимно независимые случайные величины, имеющие
одинаковые плотности вероятности. Покажите, что если Хп.г означает г-е по
порядку сверху значение среди п случайных величин, то для любого а спра-
справедливо равенство
Объясните, как можно использовать это уравнение при построении таблиц
математического ожидания (и других моментов) порядковых статистик.
12. Найдите распределение медианы случайной величины X в выборках
объема 2^+1 из совокупности, в которой половина элементов имеет распре-
распределение с плотностью вероятности
212
Глава 6
а другая половина —с плотностью
13. Из большой партии случайным образом выбрано пять лампочек.
Их сроки службы исследовались на пяти установках (одна лампочка на каж-
каждой установке). Четыре установки измеряют срок службы лампочек точно,
а пятая (установка Зилча) завышает оценку этой характеристики на величину
0,1Х(срок службы).
Срок службы распределен по закону, весьма близкому к экспоненциаль-
экспоненциальному qo средним значением Э:
а) Какова вероятность того, что установка Зилча покажет максимальный
из пяти зафиксированных сроков службы лампочек?
б) Найдите распределение медианы для пяти наблюдений.
14. Из достаточно большой совокупности отобраны две независимые слу-
случайные выборки объема щ и я2 соответственно. Величина X измерялась для
каждого из объектов указанных выборок. Запишите выражение для вероят-
вероятности того, что значение с номером гъ считая от максимального для первой
выборки, превосходит соответствующее значение с номером г% из второй вы-
выборки.
Почему эта вероятность не зависит от того, какую форму имеет распре-
распределение совокупности X?
15. а) Покажите, что для случайных выборок объема п из совокупности,
имеющей нормальное распределение, размах и среднее между наибольшим v
наименьшим значениями взаимно независимы.
б) Покажите на примере, что это выполняется не для йсех симметричных1
распределений, хотя две эти статистики всегда некоррелированы. (Замечание:
вероятно, это проще показать, если в качестве примера использовать дискрет-
дискретное распределение.)
18. X— дискретная случайная величина, принимающая значения 0, 1,
00
2, ... с вероятностями Ро, Plf Я2, ...,; 2 />у = 1. Хи Х2> ..-, Хп — взаимно
/=0
независимые случайные величины, каждая из которых распределена как X.
а) Найдите выражение для распределения размаха выборки X.
б) Чтобы упростить это выражение, предлагается заменить X непрерыв-
непрерывной случайной величиной, добавляя к ней У, причем величина У равномерно
распределена между 0 и 1 (Х-\-У является,-таким образом, непрерывной ве-
величиной). Оцените качественно соотношение распределений размахов выборок
Хъ ..., Хп и Хг + Уг, .... Хп+Уп.
17. Su S2* ..., Sk^независимые случайные величины, каждая из кото-
которых распределена как 1/2о2'Х? с двумя степенями свободы. Найдите распре-
распределения а) максимального значения среди S2, б) отношения наибольшего зна-
значения из S2 к наименьшему, в) отношения наибольшего значения из S2
к сумме всех S2.
.18. К данным, приведенным в упражнении 17, добавляется случайная
величина S2,, распределенная (независимо от остальных величин S2) как
a2v-i^2 c v степенями свободы. Найдите распределение отношения наиболь-
наибольшей из величин Si, Sj, •.., S{ к St
19. Покажите, что величины
Порядковые статистики
213
имеют такое же совместное распределение, как и порядковые статистики для
случайной выборки объема (k—1) из совокупности с равномерным распреде-
распределением, если Т= 21 S/, а S?, .... S| распределены так же, как в упраж-
/ = 1
нении 17.
20. Описанный ниже критерий был предложен для обнаружения асим-
асимметрии. Он используется в случаях, когда можно ожидать, что (симметрич-
(симметричная) плотность вероятности совокупности имеет вид f(x).
По случайной выборке Xv Л, ..., Хп вычисляются значения К,-=
xi
= \ f (x) dx. Пусть Yx < Y2 < ... <Уп представляют собой расположенные
— со
в порядке возрастания величины Уи Уъ ..., Yn.
Вычислим отношение
Верхний квартиль величин F+Нижний квартиль величин У —2 (Медиана У)
Верхний квартиль величин К —Нижний квартиль величин У
При n = 4m + 3 (m — целое число) это выражение можно переписать как
Найдите распределение величины S, предполагая, что / (х) — плотность вероят-
вероятности для совокупности. Покажите, как вычислять критические точки для «S.
21. Хъ Х2, ..., Хп~независимые случайные величины, каждая из кс-
торых имеет двойное экспоненциальное распределение
Покажите, что дисперсия медианы X (при n = 2m-fl, где т —целое число)
равна
_^
Сравните этот результат с приближенной величиной дисперсии медианы, за-
задаваемой выражением F.15).
22. Случайная выборка объема 5 извлечена из совокупности, имеющей
нормальное распределение с математическим ожиданием 5 и средним квадра-
тическим отклонением 2. Первое из полученных значений равно 4,2. Какова
вероятность того, что оно является медианой выборки?
23. Случайная выборка объема п включает значения х[ < х'г < ... < х'п
непрерывной случайной величины X [с плотностью вероятности f (х)]. Для
оценивания среднего значения совокупности предлагается использовать ста-
статистику
Получите в общем виде приближенное выражение для дисперсии величины Тп
Предполагая, что величина X распределена по нормированному нормаль-
нормальному закону, получите какие-нибудь числовые результаты по построенной
вами приближенной формуле.
24. Кусок радиоактивного вещества излучает a-частицы случайно во вре-
времени при средней скорости излучения m частиц в секунду. Измерительный
прибор фиксирует каждую излученную частицу, кроме тех частиц, которые
214
Глава 6
излучались в течение d секунд после последней зарегистрированной частицы
(„мертвое время" прибора). Покажите, что вероятность того, что прибор за-
зафиксирует все частицы, излученные за Т секунд (в предположении, что в те-
течение d секунд, предшествующих началу периода измерения, частицы не из-
излучались), равна
jmT)N
ЛМ
где суммирование должно проводиться от ЛГ = О до N, равного целой части
величины T/d (Институт статистических исследований, 1953 г.).
Замечание: вероятность того, что N частиц излучается за Т секунд, равна
T T)N/N l С б
e~mT
ам р , у
(mT)N/N l Следовательно, необходимо показать, что
Р [ йй d
Pr [no крайней мере, d
секунд проходит
Г (N-~\)d
моментами излучения | /V]= I —-—=;
между последовательными
Глава 7
ОЦЕНИВАНИЕ И ПРОВЕРКА ГИПОТЕЗ
7.1. ВВЕДЕНИЕ
В предыдущих главах был рассмотрен ряд методов, полезных
при проведении конкретных статистических исследований, но не
делалось попыток систематизировать эти методы в рамках еди-
единого подхода к решению статистических проблем. В этой главе
делается такая попытка. Для успешного анализа, результатов
исследования необходимо обладать весьма полной информацией
об условиях (обстоятельствах), при которых оно проводилось.
Эта информация включает затраты, связанные с реализацией
каждого из допустимых способов извлечения выборки и каждой
из возможных линий поведения (последовательности этапов
исследования) при справедливости любой из рассматриваемых
гипотез. В нее также входят априорные вероятности всех ги-
гипотез. Такая обширная информация, особенно связанная с по-
последним замечанием, довольно редко оказывается в распоряжении
исследователя. Часто ему удается получить только некоторую
часть этой информации. Например, информация, касающаяся
соотношения первоначальной стоимости извлечения выборки (на
каждый добавочный опыт) к стоимости ошибки в оценке сред-
среднего, грубо может быть отражена в увеличении доли объектов,
не отвечающих заданным требованиям. Или же можно распола-
располагать информацией о том, что априорная вероятность дефекта для
некоторого механизма находится скорее всего в пределах 1—5%,
а не в диапазоне 5—10%, хотя точное распределение априорных
вероятностей дефектов и неизвестно.
Гл. 11 является введением в общую теорию решений, исполь-
использование которой возможно при наличии исчерпывающей инфор-
информации указанного выше типа. Хотя не так уж часто представ-
представляется возможность применять эту теорию в общем виде, все-таки
полезно уметь распознавать природу используемой информации.
При глубоком изучении общей теории решений появляется воз-
возможность распознать ситуацию и применить при принятии решения
информацию нестандартного типа, которая предоставляется в
распоряжение исследователя.
Как правило, статистическое исследование полезно начинать
с наиболее пессимистических предположений, сводящихся к тому,
что п ^явление специфической информации является весьма мало-
216
Глава 7
вероятным событием, и выбирать такие статистические методы,
чтобы для их применения требовалось как можно меньше доба-
добавочной информации. В связи с этим представляется удобным
разделить основные проблемы статистического исследования на
два класса: оценивание и проверка гипотез. Основной задачей
при оценивании является получение наилучших среди возмож-
возможных оценок значений одного или нескольких параметров. Про-
Проверка гипотез охватывает методы, использующие выборочные
данные для проверки предположений (гипотез) относительно со-
совокупности, , сделанных до знакомства с выборкой, по которой
будут проверяться эти предположения. Очевидно, что такое
разграничение является произвольным, поэтому возможно неко-
некоторое перекрытие между указанными классами. Эти классы
входят как часть в общую теорию статистических решений. Нако-
Наконец, достаточно часто в распоряжении исследователя оказывается
добавочная информация, которую иногда удается использовать
для модификации стандартных методов.
7.2. ТОЧЕЧНОЕ ОЦЕНИВАНИЕ
Оценивание. Термин „оценивание" относится к классу стати-
статистических методов, которые используются с целью получения
представления о значении одного или нескольких параметров
с максимально возможной точностью. При этом на основании
исходных данных либо получают определенные значения, иначе
говоря точенные оценки, которые стремятся максимально при-
приблизить к значениям соответствующих параметров, либо вы-
вычисляют граничные значения, между которыми с большой вероят-
вероятностью должны находиться значения параметров. Сначала будет
рассмотрено точечное оценивание, а затем второй метод —построе-
—построение доверительных интервалов.
С точки зрения общей теории решений точечное оценивание
является процедурой, в результате которой мы „решаем**, какую
величину 9 следует принять в качестве оценки для 0. Функция
потерь W (в, 9) является функцией от 0 и 0. Очень часто функ-
функцию W (9, 9) выбирают так, чтобы она зависела только от ошибки
оценки (9 — 0). Нередко функция W ф, в) бывает связана только
с абсолютным значением |0—9|.
Наиболее широкое применение находит критерий, в котором
функция W(d, 0) пропорциональна @—вJ. Точечная оценка,
минимизирующая математическое ожидание величины @ —0J,
называется оценкой наименьших квадратов. Поскольку распре-
распределение величины F — 9J зависит от 0, то очевидно, что полу-
Оценивание и проверка^ гигютез
217
ченная методом наименьших квадратов оценка, которая мини-
минимизирует
?[(9-0J|0],
в общем случае также зависит от 0. Так как мы не знаем зна-
значения 0 (иначе не было бы необходимости его оценивать), то
построить оценку 0 также невозможно.
При наличии априорной информации о распределении 0 появ-
появляется возможность обойти указанную трудность путем усред-
усреднения по 0 и отыскания такой оценки 0, которая минимизирует
Когда 0, 0 — непрерывные случайные величины, то рассмотренное
выше выражение может быть переписано в виде
Г о©
[ I (i-tyPe(t\t)di \dt.
Несмотря на то что критерий наименьших квадратов широко
используется, это ни в коей мере не означает, что только его
всегда следует применять. Часто более подходящими оказываются
оценки, минимизирующие абсолютные значения ошибок, т. е. вы-
выражение
|
ИЛИ
E{E[\Q-Q\\Q]\.
Однако математический анализ при таком методе оценивания
чрезвычайно громоздкий.
Требование другого рода, предъявляемое к оценкам, состоит
в том, что оценки должны быть несмещенными. Это означает,
что математическое ожидание оценки 0 должно совпадать со зна-
значением 9, т. е.
0. G.1)
Пример 7.1. а) Если Х19 Х2, ...» Хп — случайные величины
_ п
с одинаковыми средними значениями, то X = 2 Xtfn является
несмещенной оценкой величины \i независимо от того, являются
ли X независимыми величинами, и даже в том случае, когда
они имеют различные распределения (при условии, однако, что
*|А при всех /').
218
Глава 7
Известно, что для любого распределения [см. C.51)]
Е(Х) = Е(Х).
_ Для нормального распределения E(X) = \i. Следовательно,
X является несмещенной оценкой ц, поскольку
б) Наработки до отказа восьми элементов, выраженные в ча-
часах, равны: 10,8; 15,7; 12,0; 9,2; 13,2; 11,6; 10,4; 12,7. Пред-
Предполагая, что наработки до отказа всех элементов имеют одно
и то же распределение, получим несмещенную оценку средней
наработки элемента до отказа. Вычислим среднее арифметическое
78[Ю,8 + 15,7 + ... +12,7]= 11,95.
Существуют, конечно, и другие несмещенные оценки, кото-
которые в отдельных случаях окажутся более тонными, чем ариф-
арифметическое среднее. Однако ранее было показано, что арифме-
арифметическое среднее при рассмотренных условиях всегда является
несмещенной оценкой.
Требование несмещенности кажется естественным, хотя с точки
зрения общей теории оно оказывается не столь уж важным, как
может показаться. Только в очень редких случаях функция по-
потерь W @, 0) имеет вид, который приводит к несмещенности как
к обязательному свойству оценки 8. Тем не менее на самом деле
этому условию обычно придается важное значение, и оно часто
фигурирует в требованиях к оценке. Это означает, что мы в пер-
вую очередь ограничиваемся рассмотрением только несмещенных
оценок (8), а затем уже пытаемся минимизировать ?[tt^ @, 0) |0]
на указанном ограниченном классе оценок.
Выбор функции W @, 0), пропорциональной величине @ —0J,
означает, что мы пытаемся минимизировать дисперсию оценки 0.
При этом в действительности производится поиск несмещенных
оценок с наименьшей дисперсией. Если имеется (что очень жела-
желательно) единственная оценка 0 этого типа для всех значений 0,
то ее называют несмещенной оценкой с равномерно наименьшей
дисперсией. В некоторых случаях такие оценки можно найти
методом, разработанным Блэкуэллом [Blackwell D., Conditional
Expectation and Unbiased Sequential Estimation, Annals of Mathe-
Mathematical Statistics, 18 A947)].
Предположим, что совместное распределение случайных ве-
величин Х1( Х2, ..., ХЛ зависит от параметра 0 и требуется найти
несмещенную оценку параметра 0 с равномерно наименьшей
дисперсией. Для этого необходимо иметь такую статистику 7\
Оценивание и проверка гипотез
219
чтобы распределения величин Х1У Х2, ..., Хп при заданном Т
не зависели от 0. В этом случае Т называют достаточной ста-
статистикой для 0. Предположим теперь, что Y является статис-
статистикой (т. е. функцией от X), которая представляет собой несме-
несмещенную оценку 0, т. е. ?(У) = 0. Тогда Z = E(Y\T) также
оказывается несмещенной оценкой©, поскольку E(Z) = E[E(Y\T~\ =
= Е (Y) = 0. При этом
Далее,
Поскольку Z зависит только от статистики 7\ в выражении
E[(Y-Z)(Z-Q)\T]
Z является константой. При этом имеем (Z — Q){E(Y\T)~Z} = 0,
так как Z = E(Y\T). Отсюда следует, что Var (Y) = Е[(Y — ZJ] +
+ Var(Z) и Var (Y) ^ Var (Z). Иначе говоря, задавая некоторую
несмещенную оценку Y параметра 0, можно, вычисляя ?" (К} Т),
получить функцию достаточной статистики 7\ которая также
оказывается несмещенной оценкой параметра 0, а ее дисперсия
не превышает дисперсии оценки Y.
Таким образом, несмещенную оценку с равномерно наимень-
наименьшей дисперсией всегда можно найти в виде функции достаточной
статистики (если последняя существует). Теперь (путем исследо-
исследования корреляции между двумя оценками такого типа) можно
показать, что рассмотренная оценка действительно единственная.
Если отсутствует функция от Т (не равная тождественно нулю),
имеющая математическое ожидание 0, то величина Z = E(Y\T)
является искомой оценкой. Итак, выше дан метод нахождения
оценок в случае, когда существует достаточная статистика.
Пример 7.2. Х19 Х2, ..., Хп — независимые случайные вели-
величины, каждая из которых распределена по закону Пуассона
со средним значением 0. Требуется найти несмещенную оценку
с равномерно наименьшей дисперсией для величины е~е, пред-
представляющей собой вероятность того, что наблюдаемое значение
равно 0.
Совместная функция распределения вероятностей имеет вид
Рхг....
п
-¦I ч
220
Глава 7
Сумма 2 х( распределена по закону Пуассона с математиче-
математическим ожиданием п9 (см. упражнение 34 гл. 4), поэтому
S
G.2)
где 2#/~0, 1, 2, ..., а условная функция распределения ве-
вероятностей не зависит от величины 0, поскольку в силу C.7)
•> Xn
р(г. ,
11 ; (
1=1
'(?"
_ 2 х
Таким образом, 2j Xt представляет собой достаточную статис-
п
тику для 0. Величина Д] Xt имеет распределение Пуассона со
средним значением п0, и выполнение для всех 0 условия
2^
возможно только, если g(j) = O при любом /.
Совместное распределение G.2) представляет собой поли-
полиномиальное распределение с элементарными вероятностями п~х,
л*1, ..., п*. Величина Х1% следовательно, имеет (условное)
п
биномиальное распределение с параметрами 2 ^/» п~х*
t-i
Величина
/1 при Хг = 0,
\0 при Хг^\
имеет математическое ожидание е"е. Теперь, используя теорему
Блэкуэлла, вычислим
[
y
Дисперсия полученной оценки равна
Е [A -п-1J ^ *'"] ^^-2e
(см. упражнение 44 из гл. 4).
Оценивание и проверка гипотез
22!
7.3. ОЦЕНИВАНИЕ МЕТОДОМ МАКСИМАЛЬНОГО
ПРАВДОПОДОБИЯ
Метод максимального правдоподобия представляет значитель-
значительный интерес. Оценки, полученные этим методом на основании
случайных выборок из совокупностей с неизменными характе-
характеристиками, при самых общих условиях и достаточно больших
выборках обладают желаемыми свойствами. Они являются почти
несмещенными, имеют нормальное распределение и, кроме того,
среди всех оценок с аналогичными свойствами при больших вы-
выборках обеспечивают наименьшее значение величины [(объем вы-
выборки) х (дисперсия)]. Необходимо отметить, что все сказанное
имеет отношение только к асимптотическим свойствам и может
не выполняться для выборок конечного объема.
Функция плотности вероятности (для непрерывных случайных
величин) и функция распределения вероятностей (для дискрет-
дискретных случайных величин) зависят не только от значений (.v1( ...,
..., хп)у которые принимают случайные величины (Х1( ..., Х„),
но и от значений параметров в1( 02, ..., в,. Эти функции, рас-
рассматриваемые как функции от параметров при фиксированных
выборочных значениях случайных величин, называются функциями
правдоподобия, относящимися к данной выборке.
Оценки 6ьМП, ..., 0S, мп параметров 9lf 02, ..., 0^, постро-
построенные по выборочным значениям случайных величин и макси-
максимизирующие функцию правдоподобия, называются оценками макси-
максимального правдоподобия. В большинстве случаев (но не всегда)
для выбранных значений параметров 0 имеется только одно
множество оценок такого типа, и, следовательно, 01( мп, • • •. 0s, мп
определены однозначно. В этой книге везде предполагается, что
последнее утверждение справедливо.
Рассмотрим теперь более подробно свойства оценок при боль-
больших выборках, упоминавшиеся в первом разделе. Предположим,
что требуется оценивать только один параметр 0.
Если Х19 Х2, ..., Хп — независимые случайные величины,
обладающие одинаковыми функциями распределения с парамет-
параметрами 0, то оценки 0Мп максимизируют
п
1 / v v у |п\ ТТ / / V I Й\ A *V\
/(.Л*, Ля> •••> А-п\ ) == LI. \ i \ )' > '
Тогда при самых общих условиях, наиболее важным из кото-
которых является независимость от величины 0 граничных значений
области, в пределах которой / (х|0) > 0, оценки 0МП обладают
следующими свойствами:
1) lira Е @МП10) = 0, поэтому 0Мп является асимптотически
несмещенной оценкой 8; G.4)
222
Глава 7
Оценивание и проверка гипотез
223
2) ^пфмп — в) имеет асимптотически нормальное распреде-
распределение при п—>оо;
3) Ш
4) для всех оценок 0, которые являются несмещенными и
распределены по асимптотически нормальному закону [т. е. та-
таких, как 0МП, обладающих свойствами 1) и 2)],
Последнее условие означает, что при достаточно большом
объеме выборок оценки 0МП по крайней мере не хуже большин-
большинства других оценок параметров 0. Однако в общем случае нет
гарантий, что указанное преимущество оценок Фмп по сравнению
с другими оценками сохранится и для конечных выборок. Оче-
Очевидно, что в любой практической ситуации очень важно иметь
некоторое представление о том, как велико должо быть п для
того, чтобы оценки 0Мп были не хуже любых других оценок.
Получить такую информацию удается не всегда, но тем не менее
известно, что оценка максимального правдоподобия обычно яв-
является по крайней мере хорошим начальным приближением
искомой оценки.
Легко заметить, что если Т является достаточной статисти-
статистикой, то
^| 1 Хп) G.5)
и §мп зависит только от 7\ В этом случае ?мп обладает опре-
определенными оптимальными свойства-ми даже при выборках малого
объема. Во всех же остальных случаях нужно четко представ-
представлять себе, что основные достоинства оценок максимального правдо-
правдоподобия проявляются в выборках большого объема, и оценки
любого другого типа могут успешно конкурировать с указан-
указанными оценками, если они обладают теми же свойствами при
больших выборках.
Пример 7.3. Чтобы найти оценку максимального правдоподо-
правдоподобия параметра 0, имеющего нормальное распределение N @, а)
с известным значением а, используя при этом случайную выборку
X, ..., Хл, взятую из совокупности с распределением N(Q,a)t
запишем сначала следующую функцию правдоподобия:
Часто оказывается, что проще прологарифмировать 1(Х1У ...
..., Хп 10) и найти максимум полученной функции относительно 0.
Воспользовавшись натуральными логарифмами, получим
откуда
Полагая обе части уравнения равными нулю и разрешая его
относительно 0, приходим к
0мп = я S %i= X.
i
Пример 7.4. Рассмотрим ситуацию, описанную в примере 6.2.
Предположим, что требуется оценить параметр К методом макси-
максимального правдоподобия, используя при этом k наименьших
среди п выборочных значений величины X, обозначаемых как
Х Х Х
Совместная плотность вероятности для Х'и X'z, ..., Х'и имеет
вид
п\
п — k + l)x'b, как и в примере 6.2. Частная про-
ft-1
где yh= S
изводная функции р по к равна
Приравнивая ее нулю, находим %=^kyil. Можно показать,
что это значение X действительно максимизирует функцию
(x'i> х'*> *•*'
П0ЭТ0МУ оценка максимального правдо-
правдоподобия параметра К записывается в виде
224
Глава 7
Оценивание и проверка гипотез
225
В примере 6.2 было показано, что величина Yk распределена
как BХ)х(%2 с 2 k степенями свободы), а X распределена
как 2kk/%lk, так что
Последнее уравнение можно использовать для построения
100A —а)%-го доверительного интервала для параметра 1.
Метод максимального правдоподобия можно распространить
на множество случаев, когда требуется оценить kQ^2) парамет-
параметров. Найдем значения параметров, при которых функция правдо-
правдоподобия 1(Х1У Х2, ..., Хп\В1У 62, ..., Qk) достигает максимума.
В случае, когда наблюдения представляют собой независимые
одинаково распределенные случайные величины, предел, к кото-
которому стремится пX (матрица дисперсий и ковариаций), представ-
представляет собой (при некоторых вполне разумных условиях) матрицу,
обратную матрице, элемент которой, стоящий на пересечении
строки г и столбца с, имеет вид
i
У
где г, ?=1,2, ...,?, a t(X\Qlt ..., 0ft)—функция правдоподо-
правдоподобия для единичного наблюдения. Так, при k = 2 имеем
lim
lim (корреляции между
L\Y^fJ^lL\e(^L) '
G.6)
. G.7)
Пример 7.5. Рассмотрим, как можно вычислить оценки макси-
максимального правдоподобия для параметров двойного экспоненциаль-
экспоненциального распределения (называемого также распределением Лапласа),
обладающего плотностью вероятности
рх {х) = B9,)-1 ехр
0 < 92.
G.8)
Если Х19 Х2, ..., Хп — независимые случайные величины,
каждая из которых имеет плотность вероятности G.8), то функ-
функцня правдоподобия выражается в виде
1(Хг, ..., .Х„)~B0а)~иехр — Qt1
откуда
При любом значении параметра 02 оценка максимального правдо-
правдоподобия 0Х для параметра 0Х может быть получена путем мини-
п
мизации 2 l^y^Qil по $1- При нечетном п оценка 0Х совпадает
с медианой множества Хг, Xt Хп. При четном п оценка §г
может равняться любому из значений, заключенных между по-
порядковыми статистиками Х!/,я-1 и Xi/,e.
Оценка максимального правдоподобия % параметра 82, удсда-
летворяющая уравнению
ain/l
^2 k
имеет вид
т. е. она равна средней величине отклонения от 0Х.
Пример 7.6, Рассмотрим особый, но очень важный случай,
когда 0Х ярляется параметром положения, а 63 — параметром
масштаба. Функция правдоподобия в этюм случае имеет вид
" " 02
где §(•) —явная функция. [Отметим, что формула G.8) пред-
представляет собой .особый случай.]
Легко показать, что совместное распределение [(Х;- — 610)/6а0]
(У = 1, ..., л) не зависит от 61в и Qn, когда 910 и 02О —истинные
значения параметров.
Статистиками 01,мп и 02(Мп являются значения параметров
0Х и 02, максимизирующие выражение
Следовательно,
от \(Xj—бю)/©
8 № 819
п/®ж и (в1#мп — 610)Д,мп являются функциями
(/ = 1,2, ...,/г), а их совместное распределе-
226
Глава 7
ние не зависит от 610 или 920. То же самое справедливо для
распределения величин (91(МП — ®ю)/%о-
Эти результаты в силу их общности весьма важны. В част-
частности, при нормальном распределении, когда
/ (х 19lf 92) = (
оказывается, что 9uM
.S
^expi-V.t^-Qi)
t
Хг=Х (ср. с примером 7.2) и
[П _ 11/2
t = l .1
В этом случае (91)МП-010)/920 имеет распределение N @,1), а
отношение 92 Мп/920 распределено как %n-dVn.
Возможности применения этих результатов при других рас-
пределениях рассмотрены в разд. 7.7.
Пример 7,7. Метод максимального правдоподобия не всегда
удается применить даже в достаточно простых ситуациях.
Предположим, что величины Х19 Х2, ..., Хп взаимно неза-
независимы и каждая распределена как сумма двух случайных ве-
величин, имеющих нормальное распределение с плотностью веро-
вероятности
Тогда
Далее, если положить 1г = Х( для некоторого t(=l, . ..,я)> то
f (X,) > A -со) 0/2^с2Г ехр [-1/2
при
Таким образому
-(о^-^г^^-^ехр Г—1/2 S (^Г1) J
и при выборе достаточно малой величины <тх можно получить
сколь угодно большое значение /. Следовательно, такого мно-
Оценивание и проверка випотез
227
жества значений со, aiy <т2, ?х и |2, которые обеспечивали бы
максимальную величину /, не существует.
Аналогичные рассуждения остаются в силе даже в том слу-
случае, когда можно предположить, что а^^^а^
При построении оценок параметра 9 можно различными спо-
способами использовать апостериорное распределение этого пара-
параметра. Оценки такого типа иногда называются байесовскими
оценками.
В общем случае в качестве оценки параметра 9 можно брать
моду его апостериорного распределения. (В частности, при рав-
равномерном распределении параметра 9 такой способ, как было
показано выше, приводит к оценке максимального правдоподо-
правдоподобия.) Другая возможность — это вычисление математического
ожидания-или медианы апостериорного распределения.
Апостериорное распределение можно также применять и для
получения границ, в которых с известной вероятностью, скажем
1-е, должно лежать значение параметра 9. Эти границы
®l(Xi* •••» ^я)» ^(Xj, ..., Хп) подбираются таким образом,
чтобы
Когда существует апостериорная плотность вероятности пара-
параметра 9, должно быть справедливо уравнение
S
7.4. ОЦЕНИВАНИЕ С ПОМОЩЬЮ
ДОВЕРИТЕЛЬНЫХ ИНТЕРВАЛОВ
Для того чтобы можно было с уверенностью применять то-
точечные оценки даже в том случае, когда они вычислены по
наилучшим из возможных формул, требуется некоторая доба-
добавочная информация. Необходимо знать, по крайней мере при-
приближенно, величину ошибок оценивания, т. е. конкретное зна-
значение разности (9 — 9). Часто эту величину удается получить
в виде (оцененного) среднего квадратического отклонения иско-
искомой оценки или в более общем случае в виде корня квадратного
из среднего квадрата ее ошибки. Если оценка 9 не смещена и
имеет приближенно нормальное распределение, то можно ут-
утверждать, что
ff |ej»l-af G.10)
8*
228
Глава 7
где
a <T? является средним квадратическим отклонением оценки 0.
Неравенства
можно преобразовать так, чтобы они оказались записанными
относительно значения параметра 8:
|e]»l-a. G.11)
Необходимо четко отличать это выражение от G.9I}. Фор-
Формула G.11) представляет собой запись доверительного интервала
и означает, что если вычислить 0±Ux^a^a^ ранее описанным
методом, то фиксированное значение 0 попадает между этими
границами (примерно) в 100 A — а)% случаев. При этом не сле-
следует считать, что параметр 0 имеет распределение, скажем /?е@»
где 0 —непрерывная случайная величина, для которой
Правильная точка зрения на концепцию доверительных ин-
интервалов отражена в следующих словах одного статистика, рабо-
работающего в промышленности: „Доверительный интервал и связан-
связанные с ним понятия похожи на то, с чем мы сталкиваемся при
игре с набрасыванием подковы на кол. Кол здесь играет роль
проверяемого параметра (его положение никогда не изменяется
вопреки ошибочным представлениям некоторых спортсменов).
Подкова выступает в роли доверительного интервала. Если при
100 бросаниях подковы удается в среднем 90 раз набросить ее
на кол, то имеется 90%-ная гарантия (или уровень доверия)
набросить подкову на кол. Доверительный интервал, подобно
подкове, изменяет свое положение. Параметр же, подобно поло-
положению кола, остается неизменным. При любом броске (или при
построении некоторой интервальной оценки) кол (или параметр)
может как попасть внутрь подковы (интервала), так и оказаться
1} Существует три подхода к проблеме интервального оценивания: дове-
доверительно-интервальный, байесовский (эти подходы рассмотрены выше) и фиду-
циальный. Полезное описание и сопоставление этих подходов содержится
в книге: Кендалл М. Джм Стьюарт А. Статистические выводы и связи.—М.:
Наука, 1973; См. также: Климов Г. П. Фидуциальный подход в стати-
статистике.— М.; Изд-во МГУ, 1970.— Прим. ред.
Оценивание и проверка 'гипотез
229
вне ее. Таким образом, делаются вероятностные утверждения
относительно переменных величин, характеризующих положение
подковы".
Формально доверительный интервал для параметра 9 опре-
определяется следующим образом. Интервал [0L(Xlf ..., Хп)9
eH(Xlt ..., Хп)] является доверительным для 0, если
Pr[e?(xlf ..., ха)<в<е„(хи ..., -хя)|в]=1—« G.12)
при любом 0. Величина 1 —а называется доверительной вероят-
вероятностью.
Очевидно, что для практического применения это определе-
определение должно быть дополнено некоторыми соображениями. Дейст-
Действительно, при оценивании, например, среднего квадратического
отклонения в совокупности можно было бы выбрать границы
81(Х1, ..., Хя)^=0; QH{X11 ..., Хл)^оо (независимо от конк-
конкретных значений X) и получить доверительный интервал
0<а<оо,
имеющий 100%-ную доверительную вероятность. Хотя в этом
случае мы всегда были бы правы, никакой пользы извлечь отсюда
не удалось бы, так как наши знания о значении а не возросли.
Вообще говоря, нужно стремиться к тому, чтобы доверительный
интервал был как можно более узким. Мы не будем здесь зани-
заниматься интерпретацией понятия „узость", отметим только, что
доверительные интервалы, которые рассматриваются ниже и
сведены в табл. 7.1, следует считать одними из лучших при
оценивании по случайным выборкам из нормально распределен-
распределенных совокупностей.
Методика построения доверительного интервала сводится по
существу к
1) получению вероятностного утверждения, включающего оце-
оцениваемые параметры;
2) преобразованию утверждения к виду неравенства относи-
относительно искомого параметра (или параметров).
Предположим, например, что требуется оценить среднее зна-
значение параметра 0 совокупности, имеющей нормальное распре-
распределение, при неизвестном значении дисперсии. Если Х19 Х2, ..., Хп
представляют собой выборку случайных наблюдений объема п> то
[из E.55)] известно, что случайная величина
где
s
1
1
m
о
8-
ь
X
Я
ерительных
дов
границ
к
"р.
вычислен!
|
О.
о
-е-
а
X
1
с
о
а
п
о.
тельный инте
1
о
^ ас
* 1
к
BQ
0
5
етр
рам
Р
ЛЬНО(
со
S.
о
X
8"
1
И
?j
IX
V
а.
V
+
»Х
IX
1
« CJ
я
=*-
ев
1
-Сты
со
8"
1
1
IX
V
V
ел
"а
с
IX
IX
льно
орма
X
-t-
to
1
t
IX
1
\
!
N
-)
/
м
51
/
8"
IX
IX
1
•И
IX
w^ X
ц
1
-Сть:
--
о.
1?
1
<я
V 1
-I* :-
^^- IX
й, 1
°г |^
ь V
f ?
-с v
IX
1
IX
с*
IX
1
IX
X
to и
X
(Я
р
юден
|
7
+
ix3
V
V
со
<м
8"
tt
i5
IX
и I
ix ix*
II
е-2 с g
я? с; cj
11
II
н
t
X
7
1
V
Ъ
V
о
\
н
1-4
1
<я si
ел
7
on
ел
to
1
Н
14
1
С
tH
1
V
V
V
1
н
1
'col'co
'со
СО
wto
Оценивание и проверка гипотез
231
распределена как fBei. Следовательно,
РГ [-<„-!. х-а/2 <УРД(Д~6) <<«-ь 1-а/. |в] = 1-а.
Неравенства в этом выражении могут быть переписаны в виде
/с
у *«-!, 1-а/2 °
Л -^=
у а
Следовательно, равенства
/ о
v Л-1. l-Ot/2 °
-^=
у п
i
V
-t, i-a/2
V~n
J — л +
задают доверительный интервал со 100A—а)%-ной доверитель-
доверительной вероятностью, или, короче: 100A—а)%-ный доверительный
интервал для 6.
Пример 7.8. Предположим, что требуется оценить разницу
между средними значениями двух совокупностей, имеющих нор-
нормальное распределение, полагая при этом, что дисперсии обеих
совокупностей равны а2. Обозначим среднее в первой совокупно-
совокупности через |ilt а во второй — через fx2. Если Хи, Х12, ..., Х1Пх —
выборка случайных наблюдений объема п± из первой совокупно-
совокупности, a X2if X22, ...,X2rta—случайная выборка объема п2 из вто-
второй совокупности, то случайная величина
п2
распределена как /Л1_Л2_2. Здесь Х± и Х%—средние арифмети-
арифметические значения для выборок из первой и второй совокупностей
соответственно, a S2P—объединенная оценка дисперсии (а2), одина-
одинаковой для обеих совокупностей (см. разд. 8.5.2). Величина S*
вычисляется по формуле
2 .
Пг+пш-2 '
где Si и SI—оценки а2, полученные раздельно по каждой вы-
выборке.
Следовательно, можно утверждать, что
РгГ-^
*Л!+Ла-2, i-a/2
-2,1-ОЬ/2 |Ml
¦"]
232
Глава 7
Неравенства в квадратных скобках могут быть преобразованы
так, чтобы получился 100A— а)%-ный доверительный интервал
для fix —ti2:
< Х1 — Х2 + *Л| + я,-а, i-aftSp
Это неравенство приведено в четвертой строке табл. 7.1. Отметим,
что tfa/a = — fi-a/2 в СИЛУ симметрии ^-распределения относи-
относительно ? = 0.
Предположим теперь, например, что обработка данных, отно-
относящихся к случайным выборкам из совокупностей А к В, дает
результаты, приведенные в табл. 7.2. Тогда
8A0,02)+6A6,08)
л '
Таблица 7.2
Выборки из двух
Совокупность
А
В
Выборочное
среднее
12,6
8,9
совокупностей
Выборочная
дисперсия
10,Ю2
16,08
Объем
выборки
9
7
95%-ный доверительный интервал для величины \аА—\ив имеет
вид
12,6—8,9—2,1451/Т2^2{1/9+1/7I/2<
< Va-Vb < 12,6-8,9 + 2,145^1^62 A/9+ 1/7)*/«,
= 2,145. Эти неравенства приводятся к следующему
—0,1 Ол— нв<7,5.
где /
виду:
Пример 7.9. Случайная выборка, состоящая из 20 образцов
полиэтиленовых полос, подвергается испытанию на растяжение.
Наряду с другими характеристиками измеряется относительное
удлинение образцов в процентах. Среднее значение и дисперсия
измеряемой величины, вычисленные по указанной выборке, со-
составляют соответственно 625% и 0,34-104(%J. Что можно ска-
сказать относительно дисперсии совокупности, из которой взята
выборка?
Можно было бы записать выражение для вероятности и изме-
изменить его, как это было показано в предыдущем примере, чтобы
Оценивание и проверка гипотез
233
получить 100A—<х)%-ный доверительный 'интервал» используя
цри этом тот факт, что величина (п—l)S2/aa распределена как
Xn-i- Однако обратимся непосредственно к табл. 7.1 и построим
99%-ный доверительный интервал для величины а2. При этом
получим следующие граничные значения для о2:
(л-1M* „ (n
49; 0,005
в рассматриваемом случае имеем для о-2
0,17.104(%J и 0,94.104(%K,
а для 0
42% и 97%
В табл. 7.1 приведены также доверительные интервалы для ц
при известной величине <Д для \\, при неизвестной а2 и для от-
отношения двух дисперсий. Случай парных наблюдений рассмотрен
в гл. 8.
Если случайные величины, представляющие наблюдения, ди-
дискретные, то, как правило, не удается получить заданное зна-
значение доверительной вероятности точно. Это объясняется тем,
что вероятность Pt [»L (Xlt ..., Хп) < 6 < вн(Х1У ..., Ха)\ Щ мо-
может принимать только отдельные значения (а иногда лишь ко-
конечное число значений). Часто стремятся не к достижению точного
значения доверительной вероятности, а к получению значения,
которое было бы не меньше заданного. Приближенные довери-
доверительные интервалы в этом случае можно строить, используя
методы, аналогичные разработанным для непрерывных случайных
величин.
7.4.1. Определение необходимого объема выборки
для получения доверительного интервала заданного размера
Обычно исследователи задают следующий вопрос: „Какой
объем выборки нужен для того, чтобы оценка 0 находилась в пре-
пределах заданного „расстояния" от истинного значения параметра 0?".
Очень редко можно это гарантировать, но ответить на поставлен-
поставленный вопрос все-таки удается, если ввести доверительную вероят-
вероятность и выбрать п таким образом, чтобы доверительный интервал
имел заранее заданный размер. Рассмотрим этот подход более
подробно на примере. Предположим, что величина а равняется
10 единицам1*, и требуется, чтобы X находилось не далее чем
5> В большинстве прикладных задач точная величина а неизвестна, но
иногда а известна приближенно.
234
Глава 7
на расстоянии 1,2 единиц от \х. Для нормального распределе-
распределения это требование означает, что половина ширины доверитель-
доверительного интервала, т. е. половина от
должна равняться 1,2. Следовательно,
_2»1-а/2Р
Полагая, например, а=0,05 при ст=10, получаем из табл. Г
или
1,96-^=1,2,
„= A^1° V =266,8.
Таким образом, необходимый объем выборки равен 267; при
этом вероятность того, что выборочное среднее будет отличаться
от среднего совокупности не более чем на 1,2 единицы, состав-
составляет 0,95. Отметим, что если разность между X и \л должна
быть меньше 2,4 а не 1,2 единиц, то объем выборки можно
уменьшить в 22, или в 4 раза, что дает в рассматриваемом слу-
случае п = 67.
7.4.2. Доверительные интервалы для долей
Пусть х0—наблюдаемое значение случайной величины X,
имеющей биномиальное распределение с параметрами пир.
Частость хо/п = р является несмещенной оценкой параметра р.
Требуется построить 100A—а)%-ный доверительный интервал
для р. Приближенно такой интервал можно построить, найдя
значения рх и р2 {рг < р2), удовлетворяющие уравнениям
• 1Л] = ТГ G.13)
.|ftbf. GЛ4)
Эти значения являются решениями (относительно р) уравнений
Оценивание и проверка гипотез
235
Границы доверительных интервалов для различных объемов
выборок содержатся в табл. Л в виде доверительных зон. Поль-
Пользуясь этой таблицей, можно получить граничные значения 80,
95 и 99%-ных доверительных интервалов для величины р в случаях,
когда оценка р строится по выборке объема п. Рассмотрение
этого вопроса будет продолжено в разд. 8.7.
Пример 7.10. Из 50 изделий случайной выборки пять оказа-
оказались дефектными. Что можно сказать относительно параметра ру
показывающего, какова в действительности доля дефектных изде-
изделий? Оценка р параметра р равняется 5/50 = 0,10. Используя
табл. Л, можно построить 95%-ный доверительный интервал.
Проведем через точку с абсциссой 0,10 вертикальную линию.
Ординаты пересечений этой линии с кривыми при п = 50 дают
р1 и р2. Следовательно, 95%-ный доверительный интервал для
р равен
0,03 <р< 0,22.
7.4.3. Доверительные области
Иногда приходится одновременно оценивать два или большее
число параметров. Например, может возникнуть необходимость
одновременно оценить среднее значение и среднее квадратическое
отклонение совокупности или средние значения нескольких со-
совокупностей.
Задачи такого типа можно решать двумя методами. Можно
строить доверительные интервалы отдельно для каждого пара-
параметра, получая при этом множество одновременных (simulta-
(simultaneous) доверительных интервалов, или же можно строить дове-
доверительную область, содержащую точки с координатами, равными
значениям параметров, с заданной вероятностью. Результаты,
получаемые этими методами, значительно различаются. По суще-
существу первый из них является частным случаем второго. Действи-
Действительно, область, получаемая совмещением одновременных дове-
доверительных интервалов, совпадает с доверительной областью
только в том случае, если последняя имеет вид квадрата или
прямоугольного параллелепипеда со столькими измерениями,
сколько параметров подлежит оцениванию. На рис. 7.1 и 7.2
наглядно показано сходство и различие между двумя указанными
случаями.
Если определить доверительную вероятность в многопараме-
многопараметрическом случае как вероятность того, что доверительная область
включает точки истинных значений параметров, то становится
236
Глаза 7
очевидным, что для метода одновременных доверительных ин-
интервалов доверительная вероятность лишь является вероятностью
того» что каждый из доверительных интервалов, рассматриваемых
раздельно, содержит истинное значение соответствующего па-
параметра.
h
Рис. 7.1. Совмещение одновременных Рис. 7.2. Доверительная область для
доверительных интервалов для 6г и 02. §г и 90.
Доверительные области в любой конкретной задаче можно
строить более чем одним способом, так же как для отдельного
параметра всегда существует множество способов построения до-
доверительного интервала.
Пример 7.11. Предположим, что Xlt X2—независимые слу-
случайные величины, имеющие нормальное распределение с извест-
известным значением среднего квадратического отклонения оге, но не-
неизвестными ^(Х^^в! и ?(Л2)^=82. Доверительные интервалы,
построенные раздельно для 6Х и 82 с доверительными вероятно-
вероятностями A— aL) й A—ос2) соответственно, имеют граничные значения
/=1,2. t G.15)
Поскольку Хх и Х% взаимно независимы, доверительная вероят-
вероятность для пары совмещенных одновременных доверительных
интервалов равна
)
С другой стороны, можно использовать тот факт, что
Оценивание и проверка гипотез
237
имеет х2*РаспРеД?ление с двумя степенями свободы. Следова-
Следовательно,
PrKX.-e^ + fX.-G,)» < xLi-aCj]= 1-а. G.16)
В формуле G.16) выражение (Xl — Qiy + (Xi — Bty = xl^aol
определяет границы доверительной области для дг и 62 с дове-
доверительной вероятностью A—ос).
Выбором a1 = a2 = l—]/ 1 —а можно добиться равенства дове-
доверительных вероятностей соответствующих областей.
Интересно сравнить площади доверительных областей рас-
рассмотренных типов при равных доверительных вероятностях.
Доверительные интервалы, определяемые выражениями G.15),
имеют размер %и[1+гтг?]/2ао> а площадь области при этом равна
Граница доверительной области, задаваемой формулой G.16),
представляет собой окружность радиуса %2; i-a<V Площадь обла-
области равна
Поскольку [см. E.70)]
дующему уравнению:
2, l-a
приходим к сле-
слекоторое имеет решение
Xl,l-a = — 21na.
Отсюда площадь области равна (—2nlna)ao.
В табл. 7.3 проводится сравнение сомножителей ^и\1+та\1ъ
и —2jtlna при нескольких значениях а. Можно заметить, что
площадь меньше у области, имеющей форму круга.
Таблица 7,3
Множители в выражениях для площади доверительных областей
a
0,Ю
0,05
0,025
0,01
0,005
4«[1+1/Т^]/2.
15,193
20,008
24,908
31,485
36,311
-2и In a
14,468
18,823
23,178
28,935
33,290
238
Глава 7
7.5. КРИТЕРИИ ЗНАЧИМОСТИ
Стандартные критерии значимости подробно будут рассмотрены
в гл. 8. Здесь мы коснемся лишь общих принципов построения
критериев.
7.5.1. Гипотезы
Критерии значимости предназначены для оказания помощи
исследователю в тех случаях, когда требуется принять некото-
некоторое решение относительно проверяемых статистических гипотез.
Статистическая гипотеза—это утверждение относительно распре-
распределения случайных величин, соответствующее некоторому пред-
представлению о реальном мире. Предположим, например, что введен
новый способ управления процессом, при котором измеряется
характеристика X выходного продукта, причем среднее значе-
значение 0О и среднее квадратическое отклонение а0 результатов изме-
измерений до изменения способа управления—известные величины.
Требуется проверить следующие утверждения:
1) среднее значение и среднее квадратическое отклонение
характеристики X остались неизменными;
2) среднее значение осталось неизменным, а среднее квадра-
квадратическое отклонение увеличилось;
3) изменение среднего значения не превышает величины сред-
среднего квадратического отклонения.
Конечно, все возможные утверждения не ограничиваются
только перечисленными. Пусть 0 и а представляют собой среднее
значение и среднее квадратическое отклонение после изменения
способа управления; тогда приведенные выше утверждения можно
сформулировать в следующем виде:
1) е = 0о, о = о0;
2) е=е0, g<oq]
3) ео-а<е<ео+а.
Это три разные статистические гипотезы.
Гипотеза называется простой, если она точно определяет
распределение случайной величины; в противном случае она на-
называется сложной* Предположим, что после изменения способа
управления проведено п измерений величины X, а результаты
этих измерений представлены случайными величинами Xi9 Х2, ¦..
..., Х„. При отсутствии других предположений три указанных
утверждения являются сложными гипотезами, поскольку они не
определяют полностью совместного распределения величин X,
а касаются только значений первого и второго моментов распре-
распределения для каждого из X. Однако если заранее определить вид
Оценивание и проверка гипотез
239
распределения для каждого из X (принять, например, нормаль-
нормальное распределение) и потребовать, чтобы Xit Х2, . ..,Х„ были
взаимно независимы, то гипотеза 1) становится простой, так как
распределение
I (Xit ..., Хп | Эо, а0) =
ехр
- 72а0 2 (*,-60J]
оказывается полностью определенным. Гипотезы 2) и 3) по-преж-
по-прежнему остаются сложными даже при указанных условиях, по-
поскольку в рамках гипотезы 2) остается неопределенной величина 0,
а гипотеза 3) заранее не устанавливает значений ни 0, ни а.
7.5.2. Критические области
Процедура проверки гипотез—правило, которое позволяет
для любого множества значений Xit ...,ХЯ получить решение:
принять или отклонить проверяемую гипотезу #0. Полезно по-
попытаться представить множество Xf, Х2, ..., Хп в виде точки
в n-мерном пространстве. Тогда точки, для которых гипотеза Яо
отклоняется, можно отнести к области w исследуемого простран-
пространства. Эта область называется критической.
Пример 7.12. Проверяя утверждение о том, что внутренний
диаметр трубы равен в среднем 1,20 дюйма, можно формально
выдвинуть гипотезу
Яо: fi-^o (=l>20).
Можно произвольно принять решение отклонить ее, если
выборочное среднее X меньше, чем 1,10, или больше, чем
1,30 дюйма. При этом мы не обращаем внимания на ошибки,
присущие нашему решению (это будет сделано в следующем
разделе), а просто (произвольно) назначаем критическую область.
Эта критическая область задается соотношениями X < 1,10 и
X > 1,30. * Теперь перейдем к разработке систематических методов
построения критических областей.
7.5.3. Ошибки
Удобно разделить ошибки, допускаемые при проверке гипотез,
на два основных типа:
1) отклонение гипотезы Яо, когда она верна—ошибки пер-
первого рода;
2) принятие гипотезы Яо, когда верна какая-либо другая
гипотеза—ошибки второго рода.
240
Глава 7
Противопоставление гипотезы Яо всем остальным является
искусственным, но весьма удобным приемом.
Вероятность ошибки первого рода равна
Рг[(Хх, ..., Хп) принадлежит w\H0]. G.17)
Ее принято обозначать через а.
Величина а может быть явно определена только в отдельных
случаях (когдаЯо является, например, простой гипотезой). Однако
возможность находить а представляется весьма удобной, потому
что это дает очевидные преимущества. Уменьшая или увеличивая
критическую область w, можно активно воздействовать на а.
Обычно величина а принимается равной 0,05 или 0,01, хотя,
конечно, можно использовать и другие значения а. Чтобы упро-
упростить задачу построения критериев, для многих стандартных
случаев разработаны таблицы.
Величина а называется уровнем значимости критерия; иногда
ее называют размером критической области ш.
Вероятность ошибки второго рода зависит от гипотезы Н,
которая верна в действительности. Эта вероятность равна
1 -^Рг [(X,, ..., Хя) принадлежит w\H]. G.18)
Гипотезу Я обычно называют альтернативной гипотезой (по от-
отношению к Яо). Вероятность ошибки второго рода принято обо*
значать через р и называть оперативной характеристикой (ОХ)
критерия по отношению к Я. Дополнение к ОХ
и ..., Хп) принадлежит w \ Я] G.19)
называют мощностью критерия по отношению к Я. Мощность
и ОХ функционально связаны; в этой книге термин „мощность"
будет употребляться чаще, чем ОХ, но не следует думать, что
это является общепринятым.
Предположим, что рассматриваются только две простые гипо-
гипотезы Яо и Ях. В э?ом случае аир можно представить так, как
это сделано в табл, 7.4, где покаэаны две возможности принятия
Таблица 7А
Решения и ошибки
Справедлива Яо
Справедлива Нг
Решение
Принять Яо
Правильное
р
Принйть Ht
а
Правильное
Оценивание и проверка гипотез
241
решения и ошибки двух типов по отношению к гипотезе Яо.
Отметим, что если гипотеза Яо справедлива и она принимается,
то в таблице указано, что решение принято правильно. Если
справедлива гипотеза Ях, а принимается Яо, то при решении
допущена ошибка второго рода. Если справедлива гипотеза Яв,
а принимается гипотеза Ях, то при решении допущена ошибка
первого рода.
На рис. 7.3 показан другой способ интерпретации ошибок.
Ps(t/B0)
Рис. 7.3. Ошибки первого и второго рода.
Предположим, что статистика 0 имеет распределение pQ (t |0О), если
гипотеза Яо справедлива. Будем также считать, что критическая
область, задаваемая соотношением 9>Л, такая, как показано
на рисунке. Если гипотеза Я2 справедлива, то статистика 0 имеет
распределение /?e(^|6i)> а вероятность ошибки, состоящей в при-
л
нятии Яа, равняется C^ jj p%{t\§x)dt. Эта область отмечена на
-00 ;
рис. 7.3 вертикальной штриховкой. Величина а равняется
00
} pQ{t\®o)dt; соответствующая ей область отмечена на рисунке
л
наклонной штриховкой.
7.5.4. Кривые мощности
Мощность критерия зависит от гипотезы Я; эта характери-
характеристика, рассматриваемая как функция от Я, называется функцией
мощности критерия. Ее графическое представление (обычно
мощность откладывается по ординате, а параметр, определяю-
определяющий Я,— по абсциссе) называется кривой мощности критерия.
. Чтобы построить кривую мощности, необходимо в первую
очередь определить способ проверки гипотезы. Как указывалось
выше, сюда входят объем выборки, процедура проверки гипотезы
и уровень значимости,
242
Глава 7
Предположим, что проверяется гипотеза Яо: [i = \i0 ( = 20).
Допустим, что величина а2 известна и равна 16, а также заранее
решено, что объем выборки равен 9. Пусть имеет место нормаль-
нормальное распределение. Если сх=0,05 и принято решение отклонять
гипотезу #0, когда Х>А, а значение А выбирается так, что
Рг[Х>Л|ц,0 = 20, 0^ = 4/3] = 0,05
(т. е. уровень значимости равен 0,05), то величина А должна
^>ыть такой, чтобы
1р1(х\20, 4/3)dx = 0,05, .
Л
где p-x(x\\i, 0j) — плотность вероятности нормального распреде-
распределения N(\i, 0^), Величина А равна 22,2, а критическая область
определяется неравенством X > 22,2. Это показано на рис. 7.4.
Рис. 7.4. Критическая область для Но: |л = 20.
Рассмотрим теперь гипотезы: 1) Н: ft = 22; 2) Н: ц = 24;
3) Н: [г = 26. Определим мощность критерия относительно каждой
из этих гипотез согласно G.19):
1) Рг [X > 22,21 [i=22],
2) Рг[Х> 22,21 jx = 24J,
о\ Г)г Г V **ч. ОО О I ¦¦ ОС!
OJ irl ^Л. J> ZZ,Z I |X = ZDJ.
Эти вероятности можно записать в виде интегралов
со
1) 5 Рх(х |22,4/3) Л,
22,2
2) J pj[{x\24,4/3)?,
22t2
со
3) ) Px(x\26,4/3)dx.
22,2
Оценивание и проверка гипотез
243
Нормируя данные и используя табл. В, получим мощности,
соответствующие каждой из гипотез:
1) 1—р = 0,44038,
2) 1 — р = 0,91149,
3) 1_р = 0,99781.
Для гипотез |i = 21, ji = 23 и ft = 25 можно получить мощности,
равные 0,18406; 0,72575 и 0,98214 соответственно. Эти резуль-
результаты графически представлены на рис. 7.5 для всех значений ft.
ую
13 20 21 22 23 24 25 26 27 28
Среднее совокупности /4
Рис. 7.5. Кривая мощности для Яо: ji — 20 при а = 4, л = 9, а=0,05.
Пример 7.13. В рассмотренном выше случае разобран только
односторонний критерий. Гипотеза Яо отклонялась только при
слишком больших значениях X, т. е. критическая область была
определена неравенством X > 22,2. Рассмотрим теперь гипотезу
Яо: ? = ?0 (=20), но альтернативную гипотезу определим значе-
значениями |, большими или меньшими |0. Положим опять, что
о2-= 16, п = 9, а распределение является нормальным. Jlpn a=0,05
гипотезу Но отклоняют теперь, если X < А1 или X > Л2, как
показано на рис. 7.6. Отметим, что величина X распределена
а/2 =0,025,
Рис. 7.6, Критическая область для Но: и «=20 при использовании двусторон-
двустороннего критерия.
244
Глава 7
как N (I, 4/3). На этом рисунке ? = 20, что соответствует случаю
справедливости гипотезы Яо. Разделим произвольно величину а
на две равные части. Нет необходимости поступать именно так
во всех возможных случаях. (В рассмотренном ранее примере
две части составляли 0 и 0,05.) Гипотезу отклоняют, если X
оказывается меньше, чем 17,4, или больше, чем 22,6, т. е.
Искомые значения равны Ад = 17,4 и Л2 = 22,6. Чтобы по-
построить кривую мощности для двустороннего критерия при Яо:
? = 20 и а =4, лг = 9, а =0,05, вычислим такие величины, как
2) 1 -Рг [А, < X < А21? - 24] = 1 —Рг [А, < X < Л21 g = 16],
3) 1 —Рг[И1<Х<Л||? = 26]=1—Рг[Л1<Х<Л,|?=14].
Получается симметричная кривая со значениями ординат
1) 0,327; 2) 0,853; 3) 0,995 для Я: 5-22 и 18, Я: 5- 24 и 16,
Я: | — 26 и 14 соответственно. Отметим, что для гипотезы Яо:
? = 20 мощность 1 —р равна а = 0,05. Кривая мощности приве-
приведена на рис- 7.7.
0}5
0,05
°0 * 14 16 18 20 11 24 26
Рис. 7.7. Мощность двустороннего критерия. Яо: \~\
7.5.5. Определение объема выборки при заданных а и
Яо: 9 =
0
Рассмотрим задачу, в которой требуется проверить гипотезу
9 6 Если заданы ос и максимальное значение |3 для Н±:
^0!, то при построении статистики критерия необходимо вы-
выбрать такой минимальный объем выборки, чтобы удовлетворялись
указанные требования к ошибкам первого и второго рода. Напри-
Например, при случайной выборке из совокупности, имеющей нормаль-
нормальное распределение с известным средним квадратическим откло-
отклонением а, для проверки гипотезы Яо: G^G0 с заданной вероят-
вероятностью ошибки первого рода а и при альтернативной гипотезе
Оценивание и проверка гипотез
245
ffx: B^Gj, вероятность ошибки второго рода для которой не
должна превышать р, следует рассмотреть множество ситуаций,
подобных двум ситуациям, показанным на рис. 7.8. Каждая из
Рис. 7.8. Соотношения между а, ? и п при проверке статистических гипотез.
этих ситуаций зависит от а и р, которые в свою очередь опре-
определяют значение п. Необходимо, чтобы (при критической области
К > К) удовлетворялись следующие условия:
G.20)
При заданных аир эти уравнения (обычно) можно решить и
определить подходящую величину п. В данном случае требуется,
чтобы
К
ее
246
Глава 7
Исключая К, находим п^[о0 (Wi_a — ^p)/^ —90)]2. Поскольку
нижняя граница для п не обязательно оказывается целым чис-
числом, то п обычно округляют до большего целого значения.
Пример 7.14. Средняя производительность машины равна
200 единиц продукции в час. Предложено усовершенствование
машины, в результате внедрения которого ожидается увеличение
выхода продукции. Руководитель предприятия готов принять это
предложение при условии, что выход возрастет в среднем по
крайней мере на 30 единиц в час. Проведенные исследования
позволяют предполагать, что среднее квадратическое отклонение
составляет 20 единиц в час. Выберем величину а равной 0,05,
а р=0,01, т.е. только в одном случае из 20 допускается воз-
возможность обнаружить наличие изменения в производительности,
когда на самом деле его нет, а если (что может быть более
важно в этой задаче) на самом деле изменение производитель-
производительности составляет не меньше 30 единиц в час, то в среднем это
может остаться незамеченным не чаще, чем в одном случае из 100.
Здесь X является выборочной статистикой, а критическая
область имеет вид Х>/С В соответствии с формулами G.20)
мы хотим иметь
р
+ 30,
0,99.
Графически эта ситуация представлена на рис. 7.8. В рассматри-
рассматриваемом случае а = 0,05, C = 0,01. Два записанных выше уравне-
уравнения нужно разрешить относительно К и /г. Предполагая, что X
имеет нормальное распределение со средним квадратическим
отклонением 20/,|/*л, запишем
/С = 200+1.6449 B0/Кл) для первого уравнения,
— 2,3263 B0/Кл) Для второго уравнения,
так как ио%9Ь= 1,6449 и uo%Qt=— 2,3263, что следует из табл. Г
приложения. Исключая как /С, так и \iQt можно получить для п:
J> 7,01.
30< 3,9712 B0/У^), откуда п> C,9712-™
Следовательно, искомый объем выборки п = 8.
Оценивание и проверка гипотез
247
Предположим, что значение среднего квадратического откло-
отклонения совокупности неизвестно. Тогда в качестве критерия
может использоваться статистика Т = Y~n (X — 90)/5. Эта стати-
статистика при справедливости гипотезы #О(9 = 0О) имеет /-распреде-
/-распределение с (п— 1) степенями свободы, а критическая область
Т > tn_lt j_a задана уровнем значимости а. Мощность по отно-
отношению к H1(Q=Ql) равна
Рг[Г>^1-а|61,(т], G.21)
где X имеет распределение N (в1У о/Уп), a S2 распределено неза-
независимо от X как [х2 с (я—1) степенями свободы]/(л — 1).
Следовательно,
3
+
где D = (Q1—Q0)/a и U — случайная величина, имеющая норми-
нормированное нормальное распределение #@,1).
Таким образом, величина Т имеет нецентральное t-pacnpede-
ление с параметром нецентральности У nD и числом степеней
свободы (л—1). [Johnson N. L., Welch В. L., Applications of
the Noncentral /-Distribution, Biometrika, 31 A940); Resnikoff G.,
Lieberman G., Tables of the Noncentral /-Distribution, Stanford
University Press, 1957.] Мощность G.21) зависит от D, т. е. от
отношения (Q1 — Q0)/o. Если значение а неизвестно, то невоз-
невозможно оценить мощность критерия, а также построить критерий,
удовлетворяющий необходимым условиям. Однако можно срав-
сравнить свойства /-критерия со свойствами критерия, который
используется при известном значении среднего квадратического
отклонения, сопоставляя их мощности при соответствующих
значениях величины (вх — 90)/а- Таблицы Н, О, П и Р приложения
помогают сопоставить объемы выборок, необходимые для получе-
получения примерно одинаковых мощностей по отношению к заданным
альтернативным гипотезам; пояснения приводятся вместе с таб-
таблицами. (См. также разд. 5.14.3.)
Пример 7.15. Рассмотрим задачу, описанную в примере 7.14.
Из табл. Н следует, что когда /-критерий используется при
неизвестном значении а, то объем выборки, необходимый для
достижения заданного уровня значимости а =0,05 при условии,
что мощность 1 —р^0,99, а F1 — 80)/(т = 30/20= 1,5, равен 9.
При известном среднем квадратическом отклонении совокупности
в тех же условиях достаточна выборка объема 8 (почти 7).
Это дает некоторое представление о добавочной работе, необ-
необходимой для восстановления отсутствующей информации о значе-
248
Глава 7
нии среднего квадратического отклонения совокупности. К сожа-
сожалению, табл. Н нельзя использовать для принятия решения о
подходящем объеме выборки, когда значение а неизвестно,
поскольку в атом случае невозможно оценить величину D = 30/o.
Если имеется некоторая оценка величины а, ее можно исполь-
использовать для того, чтобы получить приближенное представление
о соответствующем значении D. Когда оценка достаточно точна
и, пользуясь ею, можно вполне удовлетворительно оценить вели-
величину D, последнюю допустимо брать в качестве основы для
критерия, предполагающего, что значение среднего квадратиче-
ского отклонения известно.
7.6. Критерии отношения правдоподобия
Для того чтобы уменьшить размер критической области wf
понижают вероятность ошибки первого рода или уровень значи-
значимости а. Это обычно сопровождается снижением мощности (или
возрастанием ОХ) критерия по отношению к альтернативной
гипотезе Нг т. е. увеличивается вероятность ошибки второго
рода. Требования снижения вероятностей ошибок первого и вто-
второго рода противоречивы. Для того чтобы разрешить это противо-
противоречие, задают уровень значимости и максимизируют при выбран-
выбранном уровне мощность критерия по отношению к альтернативной
гипотезе Я.
Предположим, что обе гипотезы Яо и Ht — простые, а
Xlf Х2, ...,ХД—непрерывные случайные величины. Аналитиче-
Аналитически задачу можно сформулировать следующим образом: требуется
так выбрать критическую область ш#> чтобы
(обеспечение заданного уровня значимости) и при условии
а) достигалось максимальное значение величины
б)
xt хп(хх, ...,xn\H)dxx ... dxn.
Решение этой математической задачи получается с помощью
весьма полезного результата, известного как лемма Неймана —
Пирсона. В ней утверждается, что условия а) и 6} будут удов-
удовлетворены, если wQ определяется из выражения
'), G-22)
Рхг
где /С—число, выбираемое так, чтобы выполнялось условие а).
Оценивание и проверка гипотез
249
Отношение рХх хп (Xlf ..., X J H)/pXl Хп (Хг, ...,ХЯ\Н,)
можно рассматривать как отношение функций правдоподобия для
гипотез Н и #0. Критерий с критической областью G.22) назы-
называется критерием отношения правдоподобия.
Доказывается лемма весьма просто. Если через w0 обозна-
тоть критическую область G.22), а через w любую другую кри-
критическую область, удовлетворяющую условию а), то
5$
, хп(хх, ...,ха\Н9)<гхг...Aха —
. xn(x1,...,xn\Ho)dx1...dxH = O. G.23)
Общую для w0 и w часть, обозначенную через ww07 можно
удалит* из каждой области, по которой проводится интегриро-
интегрирование, не изменяя при этом величину левой части выражения
G.23). Поскольку wo~ww0 лежит в пределах области wQJ то
w0 - wwQ
Так как значение отношения правдоподобия вне критической
области меньше или равно /С, а ш — ww0 лежит вне области w0,
то, проводя аналогичные рассуждения, приходим к неравенствам
w-ww0
1 *п (^i» •••.*«! Н0Lхх ... dxn
..: J pXl xa(x1,...,xa\H)dx1... dxn.
w-ww0
Подставляя эти неравенства в уравнение G.23), прибавляя
и вычитая величину
S5S ... dXnf
получаем
*"*[$$•;• J/»x. xnix, xn\H)dXl...dxa-
— И •;• $/>*• x*(*i xn\H)dXl...dxn]^0.
Отсюда следует неравенство
SS -¦ \pxt х„{х1У ...,xn\H)dx1...dxnp;
>JJ — lPxt xn{xl xn\H)dXi...dxn,
локазывающее, что условие 6) также выполняется.
250
Глава 7
Подобные рассуждения могут быть проведены и в случае, когда
Х1У ..., Хп являются дискретными случайными величинами. Кри-
Критическая область для критерия отношения правдоподобия в этом
случае определяется неравенством
Ру х (Хъ ...,хп\Н)
л
К
G
а величина К выбирается так, чтобы уровень значимости был
как можно ближе к а. Для дискретных величин невозможно
в общем случае достигнуть точного совпадения этого уровня
с величиной а.
Пример 7.16. Требуется построить критерий для проверки
гипотезы Яо о равенстве среднего значения 9 совокупности,
имеющей нормальное распределение с известным средним квадра-
тическим отклонением а0, величине 90 против альтернативной
гипотезы Я^ 9 = 9i(>0o)- Имеется случайная выборка, включаю-
включающая п независимых наблюдений Хх, Х2, ..., Х„.
Отношение правдоподобия Нх к Яо равно
(У2л ао)-*ехр
ао)-"ехр
2J (Xi-
2 (^/"
Неравенство Я>/( эквивалентно неравенству 1пА,>1п/С, т. е
п
или
(вх —в0) [2 _S X,-n F1 + e0)"
Поскольку 9j больше, чем 0О, последнее неравенство можно
упростить следующим образом:
где X = n~
Полученное неравенство можно переписать в виде
На самом деле К' равно [оЦп (Qx — Эо)] In /C + 1/2 (90+9х), но этого
можно и не знать. Необходимо только выбрать такое значение/С',
Оценивание и проверка гипотез
251
чтобы уровень значимости соответствовал а. Это означает, что
или поскольку X имеет распределение N (Qo, oJVn) при справед-
справедливости гипотезы Яо, то
CD
1 (*
У2п J
Уп (K'-Q0)fo0.
Решая последнее уравнение относительно /(', получаем
или
7.7. РАВНОМЕРНО НАИБОЛЕЕ МОЩНЫЕ КРИТЕРИИ
Критерий отношения правдоподобия является наиболее мощным
критерием для гипотезы Яо (с заданным уровнем значимости)
по отношению к заданной простой альтернативе Нг. Иногда
оказывается, что получается один и тот же критерий при произ-
произвольном выборе альтернативной гипотезы Ях из заданного мно-
множества Q. Следовательно, используя этот критерий, можно быть
уверенным в том, что он окажется наиболее мощным, какая бы
из гипотез, составляющих множество Q, ни была в действитель-
действительности справедливой. В большинстве случаев такого удачного
стечения обстоятельств нет, но если это имеет место, то крите-
критерий называется равномерно наиболее мощным по отношению
к множеству Q. Такой критерий, если его применение не вызы-
вызывает чрезмерных трудностей, следует предпочесть любому дру-
другому, разумеется, в тех случаях, когда имеется уверенность
в достаточной близости постулируемых предпосылок применения
к реально существующим условиям.
В примере 7.14 при построении критерия для гипотезы
#О@ = 9О) использовалась критическая область Х>/(', не зави-
зависящая непосредственно от Qif поэтому этот критерий является
равномерно наиболее мощным по отношению ко всем 0/, превы-
превышающим 90. Однако он не останется равномерно наиболее мощ-
мощным по отношению ко всем значениям альтернативной гипотезы
Qlf как большим, так и меньшим 90.
252
Глава 7
«7.8. КРИТЕРИИ ОТНОШЕНИЯ ПРАВДОПОДОБИЯ
ДЛЯ СЛОЖНЫХ ГИПОТЕЗ
В случае, когда проверяется гипотеза Яо, а альтернативная
гипотеза оказьшзется сложной, метод отношения правдоподобия
в том виде, как он был рассмотрен в разд. 7.6, оказывается
неприменимым. Тем не менее дальнейшее развитие метода путем
эвристических предположений позволяет распространить его и
на случай сложных гипотез. Для такого метода уже нельзя
гарантировать, что он обладает свойствами наиболее мощного
критерия, но в действительности он оказывается весьма полез-
полезным среди известных хороших критериев.
Каждую сложную гипотезу можно рассматривать как множе-
множество простых гипотез. Если предположить, что среднее значение
совокупности, имеющей нормальное распределение, равно 80,
а значение среднего квадратического отклонения остается неоп-
неопределенным, то такая сложная гипотеза будет эквивалентна мно-
множеству простых гипотез о том, что совокупность имеет нормаль-
нормальное распределение #@,G), где а может принимать любое неот-
неотрицательное значение.
Обозначим символом со множество простых гипотез, определяе-
определяемое Яо. Множество всех возможных простых гипотез (включающее
#о и все альтернативы) будем обозначать символом й. Тогда
вместо отношения правдоподобия G.22) можно использовать
отношение максимальных функций правдоподобия для соответст-
соответствующих множеств простых гипотез. Таким образом, имеет место
критическая область
± Хп
„ | Ь2макс)
Здесь К опять является числом, выбираемым так, чтобы уровень
значимости совпадал с некоторой желаемой величиной. При этом
необходимо отметить, что последнее неравенство противоположно
по знаку неравенству G.22). Это объясняется тем, что
Рхг хп(Х1У ..., Xtt|coMaKC) —плотность вероятности выборки для
наиболее правдоподобной среди всех (простых) гипотез из мно-
множества а> и соответствует рХх, .... х2{Х1У ..., Xn\HQ), тогда как
Рхх хп(Хи.. .,XJQMaKC)соответствует/?Xl xn(Xv...,Хп\Нх)9
и, следовательно, отношение правдоподобия G.25) является
обратным к тому, что записано в выражении G.22.) Иногда
такая перестановка может приводить к путанице, но это только
лишний раз подчеркивает необходимость делать различие между
двумя типами записи отношения правдоподобия. Хотя выражение
G.22) и можно рассматривать как частный случай G.25), когда
со заменяется на простую гипотезу Яо, a Q—на простые гивд-
Оценивание и проверка гипотез
253
тезы #0 и Я1Э при этом следует помнить, что критерий гаранти-
гарантирует оптимальные свойства только в первом случае G.22).
Были предложены и другие методы построения критериев
для сложных гипотез. В частности, Рой [11] предложил исполь-
човать критические области, представляющие собой сумму (объ-
(объединение) критических областей, на которых мощность (тип I)
или значение отношения правдоподобия (тип II) имеют постоян-
постоянную величину для всего множества альтернативных гипотез.
ЛИТЕРАТУРА
1. Bennett С. A., Franklin N. L., Statistical Analysis in Chemistry and the
Chemical Industry, Wiley, New York, 1954, Chapter 5.
2. Blackwell D., Conditional Expectation and Unbiased Sequential Estimation,
Annals of Mathematical Statistics, 18, 105—110 A947).
3. Cox D. R., Hinkley D. V., Theoretical Statistics, Chapman and Hall,
London, Halstead Press, New York, 1974, Chapters 3—5, 7, 8. [Имеется
перевод: Кокс Д., Хинкли Д., Теоретическая статистика,—М.: Мир, 1978.]
4. Davies О. L. (Ed.), Statistical Methods in Research and Production, 3rd
ed., Oliver and Boyd, London, 1958.
5. Dixon W. J., Massey F. J., Introduction to Statistical Analysis, McGraw-
Hill, New York, 1969, Chapter 6.
6. Hays W. L., Winkler R. L., Statistics: Probability, Inference and Deci-
Decision, Vol. 1, Holt, Rinehart and Winston, New York 1970, Chapter 6.
7. Kempthorne O., Folks L., Probability, Statistics and Data Analysis, Iowa
State University Press, Ames, Iowa, 1971.
8. Mood A. M., Graybill F. A., Boes D., Introduction to the Theory of Sta-
Statistics, McGraw-Hill, New York, 1963, Chapter 8.
9. Natrella, M. G., Experimental Statistics, N. B.S. Handbook No. 91,
U. S. Dept. of Commerce, Washington, D. C, 1963, Chapters 1,2.
10. Pearson E. S., Hartley H. O., Biometrika Tables for Statisticians, Vol. 1,
Cambridge University Press, 1968.
11. Roy S. N., Some Aspects of Multivariate Analysis, Wiley, New York,
1957, Chapters 1,2.
УПРАЖНЕНИЯ
При выполнении некоторых упражнений этой и последующих глав для
построения моделей нужно сделать некоторые предположений.
1. Следующие цифры представляют собой значения тзердости 15 образцов
сплава в условных единицах: 12,1; 13,7; 11,0; 11,6; 11,9; 12,9; 13,4; 12,2; 12,5;
11,9; 11,9, 11,5; 12,9; 13,0; 10,5. Проверьте гипотезу о том, что среднее значение
твердости равно 12,0. (Используйте двусторонний критерий с уровнем значимо-
значимости примерно равным 5%.)
2. Проверьте, используя данные упражнения 1, гипотезу о том, что сред-
среднее квадрэтическое отклонение составляет 1,4 условных единиц.
3. Какой потребуется объем выборки для того, чтобы с доверительной
вероятностью, равной 99%, среднее выборочное значение твердости (X) отли-
отличалось от его математического ожидания не более чем на 0,3 условных единиц,
если стандартное отклонение известно и равно 2,0 условным единицам?
4. При шести измерениях концентрации в процентах получены следующие
результаты: 1,20; 1,27; 1,33; 1,19; 1,09 и 1,24. Требуется оценить ожидаемое
значение концентрации в процентах, предполагая, что результаты измерения
254
Глава 7
являются случайными независимыми величинами и имеют нормальное распре-
распределение с дисперсией, равной 3-10-3. Постройте 95%-ный доверительный интер-
интервал для величины Е (X).
5. В упражнении 4 постройте 99%-ный доверительный интервал для Е (X),
считая дисперсию неизвестной величиной.
6. Для данных, приведенных в упражнении 4, постройте совместную 95%-ную
доверительную область для Е (X) и а2.
7. Получите выражение для оценки максимального правдоподобия диспер-
дисперсии нормального распределения N (В, а). Оцените дисперсию последующим
данным: 12,80; 13,27; 13,06; 12,95; 13,10; 13,30; 12,88; 13,06; 12,98; 12,86;
13,09; 13,20; 12,92; 12,90; 12,83; 12,80.
8. Покажите, что оценка максимального правдоподобия для дисперсии
нормального распределения может быть смещена.
9. Найдите 90%-ный доверительный интервал для отношения дисперсий
предела прочности на разрыв по двум приведенным ниже выборкам (предпо-
(предположительно однородным), полученным при испытаниях на прочность на двух
разных испытательных стендах.
Стенд А Стенд В
1,324
1,322
1,327
1,342
1,301
1,309 1
1,374 1
1,319 1
1,392 ]
1,396 ]
,358
1,318
,318
,321
[,414
1,398
1,375
1,341
1,366
1,408
10. При обучении методам расчета надежности в качестве примера выбрали
исследование деревянных брусков при осевой нагрузке. Пяти бригадам было
дано задание исследовать 100 брусков из древесины твердой^ породы. Весь
материал был доставлен из одного места. В процессе исследования деревянные
бруски по одному помещались в гидравлический пресс, давление увеличива-
увеличивалось до тех пор, пока брусок не ломался, а его величина в этот момент изме-
измерялась и регистрировалась. Использовались бруски размером 3/8Х5/В4Х41/4
дюйма. На стр. 255 приведены результаты измерений в форме таблицы. Опре-
Определите 95%-ный доверительный интервал для среднего значения в каждом из
пяти экспериментов. Какие можно сделать выводы?
П. Эффективность некоторого процесса доведена до 89%. Внесение неко-
некоторых изменений позволит повысить эффективность процесса. Руководитель
предприятия считает, что не следует вносить изменения в процесс, если ожи-
ожидаемое увеличение эффективности меньше, чем 4% (имеется в виду не 4% от
89%). В целях проверки проведено 16 экспериментов. Что можно сказать от-
относительно мощности критерия, если "среднее квадратическое отклонение вели-
величины эффективности для отдельного эксперимента известно и равно 2%? Четко
сформулируйте все предположения, которые вы используете.
12. Для задачи, рассмотренной в упражнении 11, постройте кривую мощ-
мощности при а = 0,05 и а) /г = 4, б) п = 9, в) п = 16, г) п —25. Сравните построен-
построенные кривые.
13. Предположим, что при условиях, рассмотренных в упражнении 11,
каждый четвертый эксперимент будет проводиться под руководством Джо
Зилча. Можно ожидать, что эффективность процесса, управляемого Джо,
в среднем такая -же, как у другого мастера, однако у Джо среднее квадрати-
квадратическое отклонение составляет не 2, а 21/2%. Проведите соответствующие вычис-
вычисления и покажите, какое влияние могла бы оказать такая информация на
ответы, полученные в упражнениях 11 и 12.
14. Пользуясь результатами, полученными при выполнении упражнения 12,
найдите для упражнения II план эксперимента, имеющего целью выяснить,
действительно ли приводит предполагаемое изменение к повышению эффектив*
Оценивание и проверка гипотез
255
Частота
Интервал
0,00— 2,0
2,01— 4,0
4,01— 6,0
6,01— 8,0
8,01—10,0
10,01-12,0
12,01—14,0
14,01—16,0
16,01—18,0
18,01—20,0
20,01—22,0
22,01-24,0
24,01—26,0
26,01—28,0
28,01—30,0
30,01—32,0
32,01—34,0
2
3
10
16
32
24
9
2
2
2
1
0
3
6
7
17
18
11
14
9
6
1
2
0
1
2
Эксперимент
3
3
9
12
19
19
28
9
1
4
1
3
5
11
11
20
29
9
10
1
5
1
0
9
10
28
31
20
1
98
100
100
100
100
ности процесса. Установите объем выборки, вероятности ошибок и решающие
правила. г -
15. Сколько потребуется провести пар наблюдений на двух различных типах
эмалевых покрытий для того, чтобы каждое иа выборочных средних отличалось
от соответствующего математического ожидания на величину, не превосходящую
0,50 условной единицы, с совместной вероятностью не менее 90%? Предпо-
Предполагается, что наблюдения взаимно независимы и каждое из них имеет среднее
квадратическое отклонение 3,5 условных единиц.
16. Как велика должна быть выборка для того, чтобы обнаружить отно-
отношение действительного значения дисперсии совокупности к заданной величине
равное 2,4t если
а) а=0,01 и E = 0,01?
б) а=0,05 и 0 = 0,01?
(Предполагается, что используется односторонний критерий и необходимо выяв-
выявлять случаи, когда значение дисперсии совокупности превышает заданную
величину.) у
17. Одно время в паспорте на катапульту для пилота реактивного само-
самолета указывалось: „вероятность того, что частота отказа не превышает 1 иа
10 000 случаев, составляет 95%„. Какого объема должна быть выборка, чтобы
гарантировать справедливость такого утверждения?
18. Как велика должна быть выборка, чтобы гарантировать с а = 0,05, что
разность между выборочным средним и средним значением совокупности, рав-
равная 0,6 среднего квадрэтического отклонения, будет выявлена с Р<0,01.
256
Глава 7
19. Две независимые выборки извлечены из нормально распределенных
совокупностей. Разность между математическими ожиданиями совокупностей
не превосходит величины 0,3-(среднее квадратическое отклонение). Как велика
должна быть каждая из выборок, чтобы можно было обнаружить это различие
с вероятностью не менее 0,99 при использовании критерия с уровнем значи-
значимости 0,01?
20. В отчетах отдела сбыта одной фирмы отмечалось, что некоторый эле-
элемент прибора в полевых условиях оказывается неисправным в 1% случаев.
Это значит, что за шесть месяцев с момента поставки выходит из строя 1%
приборов этого типа. Фирмой были проведены шестимесячные испытания шести
таких приборов и п#и этом не наблюдалось каких-либо отказов. Оценка доли
неисправных приборов (по результатам упомянутого эксперимента) оказалась
равной 0%. Что можно сказать об этой оценке ожидаемой доли неисправных
приборов? Объясните, в чем состоит недостаток использованной процедуры
и способа вычисления рисков, а таже наметьте план другого эксперимента.
21. Два типа красок для внешних покрытий требуется исследовать на од-
одном станке. Хотелось бы выявить среднюю разницу в потерях веса, равную
0,02 г. Известно, что дисперсия результатов измерения составляет @,100 гK.
При заданных значениях а=0,05 и C—0,01 определите объем выборки и
приведите швные формулы для использованного критерия.
22. Одна фирма производит два типа покрытий для подземных трубопро-
трубопроводов. Намечен эксперимент, при проведении которого покрытие можно, нанести
на 40 труб. Эти трубы затем будут размещены в образцах весьма однородного
(по плотности, влажности, типу и т. д.) грунта. Составьте план эксперимента
для исследования этих двух типов покрытий, предполагающий исключение
мешающих воздействий, связанных с тем, что образцы представляют различные
типы грунта. Сформулируйте гипотезу и необходимые предположения, а также
разработайте процедуру проведения эксперимента.
23. Вычислите (для нормально распределенной совокупности) мощность стан-
стандартного критерия проверки гипотезы Яо: [дисперсия совокупности (а2) = Оо]
против альтернативных гипотез: o*~iol, где 1=1/6, 1/4, 1/2, 3/2, 2, 3. Сле-
Следует предположить, что случайная выборка может включать десять измерений,
а уровень значимости критерия составляет 5%. Постройте кривую мощности
критерия.
24. Случайные выборки объема по 10 элементов взяты из двух нормально
распределенных совокупностей. Обозначив неизвестные дисперсии этих сово-
кулностей через о\ и в?, постройте оперативную характеристику стандартного
одностороннего критерия проверки гипотезы cff/oi = be 5%-ным уровнем значи-
значимости против альтернативы с|/о^ > 1. (Можно предложить для проведения вы-
вычислений следующие значения отношения aJ/оЦ: 1,5; 2,0; 2,5, ..., 5Д)
25. Найдите оценку максимального правдоподобия для среднего значения
треугольного распределения рх (х) ~ kx@< х < Y 2//г), если наблюдения Х%,
-^2» • • •» Хп представляют собой случайную выборку объема п.
26. Случайные выборки объема пх и п% извлечены из совокупностей, имею-
имеющих нормальные распределения N @i, <*) и N (82, а) соответственно. Предпо-
Предполагается, что среднее квадратическое отклонение а известно, a 100A —а)%-ные
доверительные интервалы, построенные для 0i и 62, соответственно равны
Оценивание и проверка гипотез
267
x±-
vt;'
VT,'
Предлагается отклонять гипотезу 61=82, если два указанные интервала не
пересекаются.
Запишите этот критерий в аналитическом виде и покажите, что в действи-
действительности уровень значимости критерия меньше а.
27. Рассмотрите задачу, аналогичную той, которая была поставлена в упраж-
упражнении 26, для случая, когда а — неизвестная величина.
28. Предполагается, что случайная величина X имеет усеченное распреде-
распределение Пуассона
Используя п независимых величин Хъ Х2, .... ХПУ каждая из которых рас-
распределена как X, выведите формулы оценки максимального правдоподобия
для параметра 6 и приближенной дисперсии этой оценки.
29. Для задачи, сформулированной в упражнении 28, постройте другие
оценки параметра 6, основанные на выборочных моментах случайных величин
Хи ..., Хп при г = \ и г = 2.
30. Оценка Тх параметра 6 называется более точной, чем оценка Г2, е^ли
Рг[|7\-е| < |Г2-6|] > i/a.
Покажите на примере, что могут существовать три статистики Ti} Г2, Г3,
такие, что
Тх оценивает параметр 6 точнее, чем Т2,
Т2 оценивает параметр 0 точнее, чем Г3,
но Г3 оценивает параметр 9 точнее, чем Тг.
3J. Хъ Х2, ..., Хп являются взаимно независимыми случдйными зели-
чинами, каждая из которых имеет дзета-распределение
' = 1, 2, .,, .
Составьте уравнение, которое можно использовать для построения оценки
максимального правдоподобия параметра р.
Выведите также приближенную формулу для среднего квадратического
отклонения указанной оценки.
32. Случайная величина X имеет плотность вероятности рх(х \ 6), завися»
щую только от значений параметра 0; Рх(х\§) положительна для всех (коне-
(конечных) значений х.
Хъ Х2, ..., Хп — взаимно независимые случайные величины, каждая из
которых распределена как X, а Т (Хи Х2, ... , Хп)~ статистика, вычисленная
по значениям этих случайных величин. Исследуя корреляцию между величи-
величинами Т и px(Xlt .... Хп | 62) / рх(Хъ ..., Хп\ б/), покажите, что
0i)^ г —
Рассмотрите поведение этого неравенства в предельном случае, когда 62
стремится к 6Х, a Gj остается неизменной.
33. Функция распределения непрерывной случайной величины Т является
-непрерывной монотонно убывающей функцией единственного параметра 6.
Покажите, что решения 0^ (Т) и Оя(^) уравнений
\-4&x, FT(T\QH(T))=42a2
соответственно образуют 100 A — 1/z!0(,1 — 1/2а2)%-ный доверительный интервал
для 8.
Объясните, почему полученный результат нельзя применять в случае,
когда Г —дискретная случайная величина. Используйте распределение Пуас-
Пуассона в качестве иллюстрации.
34. Используя метод Блэкуэлла (разд. 7.2), покажите, что если Xlt X2, ...
..., Хп являются независимыми случайными величинами, имеющими нормальное
9 № 819
258
Глава 7
распределение с известным средним квадратическим отклонением <т0, но неиз-
неизвестным средним значением, то для любых х1у х2 (при х1 < х2) величина
Ф (С?2) — Ф (^i) является несмещенной оценкой величины Ф (х2) — Ф (jci), когда
Gj = {(xj — Х)/ао}A— п~х)~Х1г при / = 1, 2 (X = n-12tXi). [Указание. Сна-
Сначала покажите, что условное распределение величины Хх при заданном X имеет
вид N{X, сг0 ]Л—/i-1). См. Barton D. E., Unbiased Estimation of a Set of
Probabilities, Biometrika, 48 A961).]
35. Xly X%, ..., Xn — независимые случайные величины с распределением
__ п Г л ~|i/2
?, а), X^ft-^X,; 5= (л-1)-1 2№-^J • Покажите, как опре-
L !
делить L, чтобы
n у
Г л ~|i/2
L «-=i _!
Рг[Рг[Х < lX + LS\X распределен как Л'(?, в)]
] = 1—8.
(На основе этого соотношения можно построить толерантные пределы для
распределения случайных величин X/. См. разд. 9.8, где описаны толерантные
области и методы их построения, свободные от распределений.)
Глава 8
НЕКОТОРЫЕ СТАНДАРТНЫЕ КРИТЕРИИ
ЗНАЧИМОСТИ" И ДОВЕРИТЕЛЬНЫЕ
ИНТЕРВАЛЫ
8.1. ВВЕДЕНИЕ
В предыдущей главе в общем виде были рассмотрены методы
оценивания и критерии значимости. Обсуждались такие вопросы,
как назначение критерия, необходимые предпосылки, вероятно-
вероятности ошибок и мощность. Кроме того, были отмечены различия
между доверительными интервалами и критериями значимости,
но при этом указывалось, что соответствующие доверительные
интервалы часто легко можно использовать при построении кри-
критериев проверки гипотез и наоборот. Вообще критерии значимо-
значимости предназначены для того, чтобы помочь исследователю прийти
к решению: принять или отклонить определенную гипотезу.
Методы же построения доверительных интервалов позволяют про-
продвинуться несколько дальше и получить дополнительные сведе-
сведения относительно совокупности, из которой была взята выборка.
Поскольку процедура проверки значимости в общем виде была
рассмотрена выше, перейдем непосредственно к изучению частных
критериев. Приведем для каждого из них проверяемые гипотезы,
необходимые предпосылки, вероятности ошибок, положенные в
основу статистики, критические области и возможные выводы.
В качестве иллюстраций представим несколько примеров.
Сначала остановимся на нескольких критериях значимости,
основанных на предположении нормальности. В частности, рас-
рассмотрим критерии значимости для дисперсий и средних значений,
когда исходные данные имеют нормальный закон распределения.
Затем обсудим еще несколько полезных критериев.
8.2. ПРИМЕРЫ КРИТЕРИЕВ ЗНАЧИМОСТИ
Рассмотрим два примера применения критериев значимости.
В первом из них предполагается, что выборка взята из совокуп-
совокупности с нормальным распределением, а во втором исходная со-
совокупность имеет распределение Пуассона.
Пример 8.1. На трубопрокатном заводе выпускаются стан-
стандартные трубы с внутренним диаметром (ВД), равным 2,40 дюй-
дюйма, причем дисперсия этой величины (а2) составляет 0,0004 дюйм2.
260
Глава 8
Для выборки, включающей 25 труб, проведены соответствующие
измерения. Среднее значение ВД, вычисленное по этой выборке
(измерения проводились в определенном месте трубы), составляет
2,41 дюйма. Можно ли утверждать, что выборка взята из ука-
указанной совокупности? Другими словами, есть ли основания счи-
считать, что среднее значение отклонилось от исходной величины
(р,0), равной 2,40 дюйма? Различие между выборочным средним
и предполагаемым средним значением совокупности (|и0) можно
исследовать, используя отношение
(8.1)
ах
где aj =
Эта величина U сравнивается с соответствующим теоретическим
распределением. Если она больше по абсолютной величине, чем
значение, которое можно было бы получить в силу случайного
характера измерений, то делается вывод, что ход процесса нару-
нарушился в смысле изменения среднего значения. В противном слу-
случае можно сказать, что нет оснований считать, что изменилось
среднее значение ВД. Используем критерий и сделаем выводы.
Вычисленное значение U равно
т, 2.41-2,40 -п
Если предположить, что исходная совокупность имеет нор-
нормальное распределение, а выборка извлекалась случайным обра-
образом, то величина U должна быть распределена по нормальному
закону N@, 1), если среднее значение равно 2,40 дюйма.
При использовании 5%-ного уровня значимости гипотеза о ра-
равенстве среднего значения 2,40 дюйма отклоняется, если \U\>
> 1,96. Поскольку вычисленное абсолютное значение \U\ пре-
превышает 1,96, то, применяя критерий, приходим к выводу, что
среднее значение совокупности не равно 2,40 дюйма. Однако не
следует утверждать (и даже подозревать), что вся производимая
продукция дефектная или процесс в целом претерпел изменения.
Скорее именно эта выборка (и любая из входящих в нее изме-
измеренных величин) взята из совокупности, про которую можно
сказать, что ее среднее значение не совпадает с величиной 2,40.
Пример 8.2. При работе специального счетчика в некоторых
заданных условиях среднее число отсчетов в течение одной минуты
0О = 4,О. За 10-минутный интервал было зарегистрировано Хо =
= 31 отсчетов. Можно ли считать этот результат совместимым
t ожидаемым? Предположим, что нас устраивает ситуация, когда
мы с 5%-ной вероятностью совершаем ошибку, делая вывод
Критерии значимости и доверительные интервалы
261
о несовместимости выборки и совокупности, когда на самом деле
они совместимы.
Среднее число отсчетов за 10-минутный интервал составляет 40.
Положим, что есть основания принять для числа отсчетов закон
распределения Пуассона.
Можно ли утверждать, что наблюдаемая величина 31 оказа-
оказалась так далека от среднего значения 40 отсчетов за 10 мин
только в силу случайности? Гипотеза о том, что среднее значе-
значение числа отсчетов за 10 мин равно 40, может быть отклонена
с уровнем значимости, примерно равным 5%, если наблюдаемое
число отсчетов не попадает в диапазон между значениями хх и х2,
где
0,05
х=х2
Значения хх и х2 равны соответственно 27 и 55. Следовательно,
нет оснований полагать, что выборка взята из совокупности,
отличающейся от предполагаемой.
Приближенно границы 95%-ного доверительного интервала
для 10 6, среднего числа отсчетов за 10 мин, получаются при
решении относительно 10 G следующих уравнений:
0,05
7\
(Отметим, что выбрать уровень значимости точно равным 0,05,
или доверительную вероятность точно равной 95%, невозможно
из-за дискретного характера распределения Пуассона.)
Другой подход состоит в том, что рассматривается довери-
доверительный интервал для ожидаемого числа отсчетов за 10 мин при
условии, что в эксперименте был зафиксирован 31 отсчет. Тогда
95% ный доверительный интервал (построенный с использова-
использованием табл. М) равен
21,0 < Юе<44,0.
Отсюда 95%-ный доверительный интервал для 9 равен
2,1<9<4,4.
262
Глава 8
Можно утверждать с вероятностью ошибки, составляющей 5%,
что выборка совместима с совокупностью, поскольку значение
0О = 4,О лежит внутри построенного доверительного интервала.
8.3. ПРИМЕНЕНИЕ КРИТЕРИЕВ ЗНАЧИМОСТИ
8.3.1. Процедура проверки значимости
В каждом из двух рассмотренных примеров были определены
вероятности ошибок, статистики, лежащие в основе критериев,
сделаны некоторые предположения и окончательные выводы. Про-
Проанализируем все это еще раз, но не с позиции общего подхода
к проверке гипотез, а скорее с точки зрения статистика, кото-
которому нужно принять определенное решение. Используем в ка-
качестве иллюстрации пример 8.1. Рассматривался действующий
процесс. Предполагалось, что имеет место определенное распре-
распределение совокупности значений (Х = ВД в дюймах).
В данном случае было принято предположение о нормаль-
нормальном распределении, причем значение одного из параметров рас-
распределения считалось известным (а2 ^0,0004 дюйм2). Если бы не
было оснований для принятия какого-либо определенного закона
распределения совокупности, то пришлось бы воспользоваться
критерием, свободным от распределения. Решение о том, что
объем выборки п должен равняться 25, принято, быть может, в
результате проведенного исследования мощности критерия. Про-
Проверялась гипотеза H0:\i^[iQi где \i — среднее,значение совокуп-
совокупности, из которой в действительности взяты выборочные значе-
значения, a \io{ = 2,40) — предполагаемое в соответствии с гипотезой
среднее значение совокупности. Были сделаны следующие пред-
предположения относительно выборки. Полагалось, что случайные
величины, которым соответствуют выборочные значения Х19
Х2, ..., Х2Ь, взаимно независимы, а вероятность ошибки пер-
первого рода составляет 0,05. Ошибка второго рода связана с
альтернативной гипотезой. Как показано в (8.1), статистика
„.*=*.
лежащая в основе критерия, при рассмотренных предположениях
имеет нормальное распределение Af(O, 1), критические значения
для U равны ±1,96, что показано на рис. 8.1. Гипотеза была
отклонена, поскольку вычисленная величина превышала 1,96.
При проведении рассмотренной выше процедуры проверки гипо-
гипотезы нужно выполнить следующие этапы.
Критерии значимости и доверительные интервалы
263
1. Сделать предположения, указать гипотезу, вероятности
ошибок (уровень значимости), статистику и критерий для при-
принятия решения, как показано ниже.
Отклонить Нь\
Принять Н{
-ffl 0 1,98
Рис. 8.1. Критические значения для нормального распределения N @, 1) при
Предположения: Х( являются независимыми величинами, взятыми
случайным образом из совокупности, имеющей нор-
нормальное распределение; а2 =0,0004.
Гипотеза: H0:\i = \i0.
Альтернативная гипотеза: \1ф\10.
Уровень значимости: а = 0,05._
Статистика критерия: ?/—^иЛ°#
Решения: если | U | < 1,96, то Яо принимается,
если \U |^1,96, то Яо отклоняется.
Оперативная характеристика: р (fx) = Pr [| U | < 1,961 Е [X] = ц].
2. Извлечь выборку в соответствии с требованиями п. 1.
3. Сделать выводы.
Заметим, что объем выборки можно найти из условия
tHfO^Pi (гДе H-i и Pi являются заданными величинами).
8.3.2. Односторонние и двусторонние критерии
В предыдущей главе уже были рассмотрены различия между
односторонними и двусторонними критериями, поэтому здесь следу-
следует лишь напомнить основные выводы. В первую очередь для любого
конкретного критерия значимости ни в коем случае нельзя произ-
производить выбор между односторонней и двусторонней формами кри-
критерия после завершения эксперимента. Пусть, например, нужно
сравнить средние значения для выборок Л и В. Если нет осно-
оснований для априорных предположений, что одно из средних зна-
значений больше другого, то следует проверять гипотезу о равен-
равенстве средних. Альтернативной гипотезой будет предположение
о том, что средние значения не равны между собой; при этом
264
Глава 8
их разность может иметь как положительный, так и отрицатель-
отрицательный знак. Конечно, любая из двух выборочных статистик может
оказаться как большей, так и меньшей. Уже одно это никак не
может оправдать использования одностороннего критерия.
Иногда двусторонний критерий считают более подходящим,
чем односторонний, даже в том случае, когда ожидается, что
одна выборочная статистика будет больше другой. Например,
известно, что некоторая термическая обработка стальных образ-
цов^ приводит к определенному улучшению их прочностных
свойств. Первая группа образцов подвергается термической
обработке, а вторая нет. Одна из возможных гипотез записы-
записывается следующим образом:
Если ожидается улучшение свойств обработанных образцов
по отношению к свойствам необработанных точно на К единиц,
то можно сформулировать более подходящую гипотезу:
Две рассмотренные гипотезы связаны с двумя разными вопро-
вопросами. В рамках первой из них ставится вопрос, есть ли какой-
нибудь эффект от термической обработки в смысле улучшения
прочностных свойств образцов, а в рамках второй гипотезы
выясняется, окажется ли усредненный результат для обработан-
обработанных образцов на К единиц выше, чем для необработанных.
При правильной формулировке множества альтернативных
гипотез подход, связанный с построением отношения правдопо-
правдоподобия, всегда позволит выяснить, какой из критериев—одно-
критериев—односторонний или 'двусторонний —лучше в каждом конкретном
случае. *
В практических приложениях очень важно, чтобы выдвиже-
выдвижение гипотез, выбор предположений, уровня значимости и крити-
критической области производились до того, как станет известно пер-
первое из выборочных значений. Никогда нельзя, глядя на уже
полученную выборку, ставить вопрос: какие следует сделать
предположения (или какие принять вероятности ошибок и т д )
чтобы доказать определенные утверждения?
Конечно, всегда полезно анализировать данные, чтобы выяс-
выяснить, не подскажут ли они еще каких-нибудь гипотез. Это один
из основных методов научного исследования. Статистические
критерии могут быть применены неформально только при усло-
условии, что гипотезы формулировались независимо от данных Новые
гипотезы лучше проверять по результатам дополнительных опы-
опытов, а обоснованными могут считаться только те выводы, которые
сделаны на основе дополнительных данных.
Критерии значимости и доверительные интервалы
265
8.3.3. Связь с доверительными интервалами
При принятии или отклонении гипотез удобно пользоваться
таблицами критических значений статистики, положенной в основу
критерия. Ряд таких таблиц приводится в приложении.
Часто при проверке гипотез можно использовать таблицы,
предназначенные для построения доверительных интервалов для
рассматриваемого параметра (или параметров). Если предпола-
предполагаемое значение параметра попадает в пределы 100A—а)%-ного
доверительного интервала, то при критерии, основанном на со-
соответствующей статистике, и уровне значимости а принимают
решение о справедливости гипотезы и наоборот. Не всегда
удается поступать подобным образом, но для критериев общего
типа, которые рассматриваются в этой главе, это вполне воз-
возможно.
Связь между проверкой гипотез и построением доверительных
интервалов можно пояснить, используя следующую таблицу:
Проверка гипотезы
1. Построение теоретической модели
2. Выдвижение гипотезы Я0:Э = Э0
3. Выбор статистики критерия
4. Определение критических значений
5. Извлечение выборки
6. Формулировка выводов
Доверительный интервал
1. Построение теоретичесхг;& модели
2. Формулировка правила построения
доверительного интервала
3. Извлечение выборки
4. Определение доверительного интер-
интервала для Э
5. Сравнение 0О с доверительным
интервалом для 9
6. Формулировка выводов
Преимуществом подхода, основанного на построении довери-
доверительных интервалов, является то, что получается дополнитель-
дополнительная информация об истинном значении параметра.
В этой главе дан обзор критериев значимости и показано,
как использовать доверительные интервалы при проверке гипо-
гипотез. Каждый, кто хочет пользоваться статистическими методами,
должен владеть обоими рассмотренными подходами. При прос-
простых критериях подход, основанный на доверительных интер-
интервалах, реализуется довольно легко, но его использование в
более сложных случаях, как, например, при анализе дисперсий
(см. гл. 13 и 15), оказывается трудной задачей.
8.3.4. Исключение выбросов
Время от времени мы подчеркиваем, что выбор проверяемой
гипотезы должен производиться до того, как начат анализ дан-
данных. Новая гипотеза, конечно, может быть сформулирована в
результате анализа данных, но тогда для ее проверки необходимо
провести дополнительные эксперименты. Выбор процедур анализа
266
Глава 8
данных не должен быть связан с идеями, возникающими при
изучении тех же данных.
Однако данные не только можно, но и необходимо проверять,
если возникли явные отклонения от условий, при которых пред-
предполагалось использовать статистическую процедуру. При выборе
метода экспериментирования, отборе экспериментального мате-
материала или просто при регистрации результатов наблюдений
всегда могут быть допущены такие ошибки, которые приводят
к совершенно неверным выводам, даже в том случае, если
применялась формально корректная процедура.
Возможны различные воздействия ошибок на результат, но е
данном разделе будут рассмотрены только такие ошибки, кото-
которые приводят к существенному отклонению отдельных значений
от основной массы результатов, полученных при наблюдении
одной переменной. С такими ошибками приходится сталкиваться
наиболее часто, но и выявляются они, к счастью, весьма просто.
Ошибочным наблюдениям иногда дают естественные названия
„грубые", „невероятные" или просто „выбросы*. На рис. 8.2
Критерии значимости и доверительные интервалы
267
Р
Рис. 8.2. Выброс.
приведена точечная диаграмма, иллюстрирующая ситуацию, когда
можно подозревать наличие выбросов. Здесь представлены ре-
результаты десяти опытов. Наблюдение, обозначенное буквой Р,
представляется подозрительным.
Разработан ряд критериев, с помощью которых принимаются
решения, следует ли такое наблюдение, как Р, считать слишком
подозрительным, чтобы включать его в выборку.
Эти критерии носят скорее эвристический характер, чем опи-
опираются на общие принципы, такие, как требование наибольшей
мощности. Кроме того, почти все они относятся к совокупно-
совокупностям, имеющим нормальное распределение, но если это потре-
потребуется, то можно построить подобные критерии для других типов
распределений.
В табл. К приложения приведены доверительные границы
для некоторых критериев исключения выбросов, применимых
в предположении, что совокупность имеет нормальное распре-
распределение2). Во всех случаях исключение выбросов (т. е. удаление
*> Ошибочные наблюдения также называют аномальными, выпадающими,
резко выделяющимися.—Прим. ред.
2> См. также: Большев Л. Н., Смирнов Н. В. Таблицы математической
статистики. —М.: Наука, 1965,— Прим. ред.
их из выборки) производится, когда расчетное значение крите-
критерия превосходит табличное. Доверительные границы вычислены
таким образом, что вероятность превышения этих границ в слу-
случае, когда случайная выборка целиком взята из одной нормально
распределенной совокупности, совпадаете определенным уровнем
значимости. Поскольку статистики, используемые в критериях,
основаны на экстремальных выборочных значениях (наибольших,
наименьших, наибольших среди максимальных и т. д.), то их
распределения, по-видимому, окажутся весьма чувствительны к
отклонениям от нормальности. Это общий недостаток всех кри-
критериев, используемых для исключения выбросов.
Наиболее простым является случай, когда имеется только
один выброс. Выбросов, конечно, может быть и больше. Обычно
используется процедура последовательного типа, когда выбросы
удаляются по одному до тех пор, пока результаты не окажутся
незначимыми. Однако наличие нескольких выбросов может
уменьшить кажущуюся значимость большего из них. Критерии
R2i и R22 предназначены для случая, когда предполагается на-
наличие двух выбросов. Однако все возможные ситуации учесть
слишком трудно.
Если число ошибочных наблюдений превышает 3 или 4, то
возникает серьезный вопрос об однородности выборки наблю-
наблюдений. В-этом случае приходится решать, была выборка взята
из одной совокупности (имеющей, скажем, нормальное распреде-
распределение) или из смеси двух и более (нормальных) совокупностей.
Последняя задача здесь не рассматривается.
Пример 8.3. При следующих температурах (по шкале Фарен-
Фаренгейта) происходит сгорание десяти образцов керамических по-
покрытий: 1430, 1520, 1460, 1470, 1480, 1340, 1460, 1520, 1450 и
1500. Если упорядочить результаты наблюдений по [величине,
т. е. Х[ < Х'ъ <... < Xni то получится следующая последова-
последовательность наблюдений: 1340, 1430, 1450, 1460, 1460, 1470, 1480,
1500, 1520, 1520. Запишем отношение
Xi—Xl 1430-1340 90
X*n-i-xi 1520-1340 180
Обращаясь к табл. К приложения, находим, что критическое
значение при а = 0,05 и п =10 равно 0,477. Следовательно,
имеются достаточные основания для того, чтобы исключить (этим
объективным методом) выброс 1340 из рассмотренных экспери-
экспериментальных данных. Далее можно продолжить проверку наличия
выбросов среди оставшихся девяти наблюдений, но теперь уже
ясно, что они отсутствуют.
268
Глава 8
8.4. КРИТЕРИИ ЗНАЧИМОСТИ
ДЛЯ ДИСПЕРСИЙ НОРМАЛЬНЫХ РАСПРЕДЕЛЕНИЙ
В этом и последующих разделах предполагается, что мощ-
мощность используемого критерия -известна, и эта информация при-
принимается во внимание при определении необходимого объема
выборки. Сначала рассмотрим критерии, основанные на предпо-
предположении о нормальности распределения исходной совокупности.
Рассмотрим три случая, относящихся к проверке гипотез о
дисперсиях нормально распределенных совокупностей: 1) про-
проверка совместимости выборочного значения дисперсии с предпо-
предполагаемым или известным значением дисперсии совокупности,
2) сравнение двух выборочных дисперсий и 3) проверка одно-
однородности нескольких выборочных дисперсий.
8.4.1. Совместимость выборочной дисперсии с известной
величиной
Предположим, что значение дисперсии совокупности установ-
установлено на основе прошлого опыта. Обозначим это значение через о2.
Взята выборка объемам. Можно ли принять гипотезу #о:а2 = ао,
где а2— дисперсия нормально распределенной совокупности, из
которой взята выборка?
В гл. 5 было показано, что статистика (п—1M2/ао распреде-
распределена как х2 с п — \ степенями свободы. Используем процедуру,
рассмотренную в разд. 8.3.
Предположения: Х{ являются независимыми случайными вели-
величинами, имеющими нормальное распределение N (\i, a).
Гипотеза: Н0:о2 = о1.
Альтернативная гипотеза: о%фо\*
Уровень значимости: а.
Статистика критерия: S2.
Решение: если x?-i, «/г < (п— 1M2а0 < xS-i.i-a/a» то принимается
Яо; в противном случае Яо отклоняется.
Оперативная характеристика:
1-1. an
J-i. i-a/J-
Пример 8.4. В результате проведения стандартной процедуры
проверки коэффициента упругости образцов резины установлено,
что среднее квадратическое отклонение при измерении этого
коэффициента составляет 18,0 единиц. Взята выборка объема 20
и получено S = 23,2 единицы. Обосновано ли предположение о
нестабильности стандартной процедуры проверки коэффициента
Критерии значимости и доверительные интервалы
269
упругости? Гипотеза записывается следующим образом: a2^
==(j2( = 324). Пусть вероятность ошибки первого рода а состав-
составляет 0,05. Вычисленное значение статистики критерия равно
(nl)S319B32)8_Q1 ,fi
— О1,0О.
(J2 A8,0J
Критические значения для двустороннего критерия оказались
равными Xi»; о,о25 -=8,907 и Xi9;of»7s = 32,85. Критическое значение
для одностороннего критерия (также при а =0,05) равно либо
Х19; o,o5 — Ю,12, либо х?9; о,95 = 30,14. Первое из них применимо
при' проверке альтернативной гипотезы а2 < а2, а второе при
а2 > а?. В последнем случае, проверяемую гипотезу следует от-
отклонить; нельзя утверждать при использовании двустороннего
критерия, что рассеяние изменилось —для этого недостаточно
„объективных" данных. Несомненно, что решение о том, какая
из альтернатив применима в каждом конкретном случае, должно
быть принято до начала анализа результатов эксперимента.
В рассмотренной задаче подход, основанный на использова-
использовании доверительных интервалов, требует построения 100A—а)%-
ного доверительного интервала для а2, а именно
(n-l)S> ЯЛ (n-\)S* (g2)
ОТ
ДО
-\, i-a/2
¦1-1, а/2
Для примера 8.4 95%-ными границами интервала для а2 должны
быть
A9)-B3,2J A9)-B3,2J
32,85
8,907
или 311,3 и 1148,1. Соответствующие границы для а должны
быть равны 17,6 и 33,9. Отметим, что предварительно заданное
значение ао = 18,О находится между этими границами.
8.4.2. Сравнение дисперсий нормально распределенных
совокупностей
Предположим, что взяты две выборки А и В объема пл
и пв. Требуется решить, есть ли основания считать, что они
взяты из совокупностей, имеющих нормальные распределения
с одной и той же дисперсией. Кратко можно записать:
Предположения: XAlt XA2i ..., ХАпА представляют собой неза-
независимые случайные величины, взятые из совокупности
ХВ1, ХВ2, ..., Хл„в—независимые случайные вели-
величины, взятые из совокупности N (\lb$ oB).
270
Глава 8
Гипотеза: HQ:aA^o%.
Альтернативная гипотеза: о*лФо%.
Уровень значимости: а.
Статистика критерия: S2A/S%.
S2
Решение: если Fv v», а/2 < ~г < Fv
в противном случае Яо отклоняется
v .-^ . п
Как показано в гл. 5, в данном случае
, vj,, i-a/21 то принимается Яо,
А пА 1»
с-2 / 2
имеет ^-распределение Фишера с числом степеней свободы
vA, vB. Если гипотеза Яо справедлива, то это отношение можно
записать просто как SA/S%.
Следовательно, оперативная характеристика имеет вид
, a/2
52
| ^ vA, vB, l-a/2 | <*a> °
- Pr [{oBfoA)%FVAt 4b a/2 < FVa. vB < (oBlaA)% FVj[t v^ 1-a/J.
В таблицах обычно приводятся значения FvA,vB, i-a/2 только для
малых а, но всегда можно применить соотношение
*vA,VQ,a/2=VvA,vB,i-a/v
Чтобы проверить гипотезу Яо', используя двусторонний кри-
критерий, вычисляют
/?* = s;/sj>i (8.3)
(т. е, большую из двух выборочных дисперсий обозначают через
Si). Вычисленную величину сравнивают с критическим значе-
значением FVl,v,,i-a/2i где v,.—число степеней свободы, соответствую-
соответствующее оценке SJ (t = l, 2).
Пример 8.5. Чтобы выяснить, варьирует ли от одного дня
к другому величина изменчивости температуры высокоскорост-
высокоскоростного аппарата, в первый день было проведено 12 измерений,
а во второй 10. Среднее квадратическое отклонение в первый
день (Л) составило 23° F, а во второй (В) 30° F.
При рассмотренных предположениях и a =0,05 критическое
значение F-критерия с 9 и 11 степенями свободы /v, 11; 0)97б =3,59.
Можно сказать, что различий в дисперсиях, измеренных в раз-
разные дни, не обнаружено, так как F* = 302/23a = 1,70, что меньше
Критерии значимости и доверительные интервалы
271
критического значения. Такой же вывод можно сделать, прове-
проверив, включает ли доверительный интервал для оА/о% значение 1
при заданных S% -= 23 и S% = 30.
8.4.3. Равенство дисперсий нескольких нормально
распределенных совокупностей
Теперь рассмотрим случай, когда имеется k выборок с дис-
дисперсиями 51 (г=1, 2, ..., k). Гипотеза состоит в том, что Яо:
ог^дг^ ... ==а| = а2. Предположения и критические значения
такие же, как и в предыдущем случае, за исключением того,
что сравниваются не две, a k выборок. Статистика критерия,
построенная методом максимального правдоподобия, имеет вид
1 ["vlnSJ-2v,lnS!lf (8.4)
v,)-i/v L i J v ;
где S* H v, — соответственно дисперсия и число степеней свобо-
свободы (tii—1), относящиеся к t-й выборке, а
S* = v-*2v,Sf . (8.5)
v = 2)v,. (8.6)
Если гипотеза Яо справедлива, то величина %2* распределена
примерно как %2* с (k—1) степенями свободы. Очень часто при
вычислении %2* корректирующий множитель х/3 (k— l)-1x
x[Svtrl — v~1] м°жно опустить. Рассмотренный критерий — это
предложенная Бартлеттом модификация критерия, разработан-
разработанного Нейманом и Пирсоном.
Гипотезу Яо отклоняют, если наблюдаемое значение %2* доста-
достаточно велико. Отметим, что этот критерий является существенно
односторонним.
Пример 8.6. Требуется решить вопрос об однородности дис-
дисперсий, полученных при определении предела прочности на раз-
разрыв нескольких- различных по структуре полимеров. Испытания
проводились на восьми образцах каждого из шести исследуемых
полимеров. Следующие числа представляют собой оценки дис-
дисперсий в кодированном виде: 3,24; 4,18; 4,06; 3,98; 4,19; 4,02
(единицJ. Нужно проверить гипотезу Яо: а\ = о*= ... =о26. До-
Допустим, что необходимые предположения выполняются, а уро-
уровень значимости а = 0,01. Тогда, используя формулы (8.4) и
272
Глава 8
(8.6), получаем
откуда
2(i/v,)-i/v
42 In 7 C,24+4,18+.. . + 4,02)
42
— 7(ln3,24 + ln4,18+...+ln4,02)l ,
так как k = 6, vi = ni—1=7, v = 42. Следовательно,
X2*-18/!, [42 In 3,945 — 7 (In 3,24 +In 4,18 + ...+In 4,02)] =r.
-18/i9 [0,15666]-0,1484.
Поскольку эта величина значительно меньше %l- Ot99, то нет осно-
оснований считать дисперсии неоднородными. Гипотеза принимается.
Следует помнить, что критерии, описанные в этом разделе и
разд. 8.4.1, 8.4.2, можно использовать только при исследовании
выборок из нормально распределенных совокупностей. Они не
могут быть рекомендованы в случае, когда можно ожидать откло-
отклонений от нормальности. Такой случай будет рассмотрен в разд. 9.1.
Существуют критерии для сравнения дисперсий нескольких
совокупностей, когда альтернативной гипотезой является не
просто неоднородность дисперсий, а наличие среди них диспер-
дисперсии (неизвестной), превосходящей по величине остальные. К таким
критериям относится критерий Кохрэна, рассматриваемый
в разд. 13.14.3.
8.5. КРИТЕРИИ ЗНАЧИМОСТИ ДЛЯ СРЕДНИХ
ЗНАЧЕНИЙ НОРМАЛЬНЫХ РАСПРЕДЕЛЕНИЙ
В этом разделе рассматриваются следующие задачи: ^сравне-
^сравнение выборочного среднего со средним значением совокупности,
2) сравнение двух выборочных средних значений при некорре*
лированных выборках, 3) сравнение двух выборочных средних
при коррелированных выборках и 4) сравнение более чем двух
средних значений. В большинстве таких задач следует учиты-
учитывать, известны ли дисперсии совокупностей и предполагаются
ли они равными,
Критерии значимости и доверительные интервалы
273
8.5.1. Проверка гипотезы о равенстве среднего значения
совокупности заданной величине
Эта статистическая процедура при условии, что величина о2
известна, характеризуется следующим.
Предположения: величины X/f распределенные по нормальному
закону N (\i, а), являются случайными и независимыми.
Гипотеза: Но: \i = ^0.
Альтернативная гипотеза: |а^|10.
Уровень значимости: а.
Статистика критерия: U = —.
Решение: если \U\ < Ui_a/2, то гипотеза Яо принимается, в про-
противном случае Яо отклоняется.
Такая процедура использована в примере 8.1. Предположим
теперь, что величина а2 неизвестна. Нужно получить выбороч-
выборочную оценку а2. В качестве такой оценки можно использовать
выборочную дисперсию S2. В гл. 5 отмечалось, что статистика
(8.7)
имеет ^-распределение Стьюдента с п—1 степенями свободы.
Эта статистика вычисляется так же, как и в рассмотренном выше
случае, но критические значения tn-i, a/2 и *я_1р 1-а/2 выбираются
по таблицам ^-распределения Стьюдента. Этот критерий также
получен методом максимального правдоподобия. Возвращаясь
к примеру 8.1 в разд. 8.2, найдем критические значения
± ^24; 0,975 = ± 2,064. Необходимо заметить, что критические
значения, вычисленные при неизвестной дисперсии, больше, чем
при известной (или предполагаемой) величине дисперсии. Это
понятно, поскольку при неизвестной дисперсии уровень неопре-
неопределенности выше, и, чтобы сделать вывод о различии между
средними значениями совокупностей с той же достоверностью,
требуется большее расхождение между выборочными средними.
8.5.2. Сравнение средних значений совокупностей
В данном случае предполагается, что выборки некоррелиро-
ваны. Рассмотрим четыре варианта возможных предположений,
а именно: а) обе дисперсии известны и равны между собой,
б) обе дисперсии известны, но не равны между сббой, в) обе
дисперсии неизвестны, но предполагается, что равны между
собой, г) обе дисперсий неизвестны, а предположения об их
равенстве не сделано. Гипотезы, предположения и вероятности
ошибок для всех четырех случаев могут быть одинаковыми, за
исключением единственного предположения о равенстве диспер-
274
Глава 8
а альтернативная гипо-
гипосий. Проверяется гипотеза: ffo:\i1 =
теза имеет вид ii^IV
Для случая, когда обе дисперсии известны и равны между
собой, статистика, лежащая в основе критерия, имеет вид
** (8.8)
о I/ h —
где Х1 =
«1
«г12
и ^1—выборочное среднее значение и объем
п2
первой выборки, а Х^п^Д] Х2/ип2 — выборочное среднее зна*
чение и объем второй выборки. Статистика критерия имеет нор-
нормальное распределение при обычных предположениях о нормаль-
нормальности, случайности и независимости значений в каждой из выбо-
выборок. Критические значения представляют собой 100а/2 и
100A—а/2)%-ные точки распределения N@, 1).
В случае, когда значения обеих дисперсий известны, но не
равны между собой, статистика критерия имеет вид
(/=•
(8.9)
п2
Она распределена как N @, 1) при тех же дополнительных пред-
предположениях и критических значениях, как в случае а).
В том случае, когда значения дисперсий неизвестны, но пред-
предполагаются равными между собой, критерий может опираться на
выборочные дисперсии совокупностей. Обе выборочные диспер-
дисперсии SI и SI являются оценками одной и той же дисперсии сово-
совокупности а2. В связи с этим представляется разумным ввести
объединенную оценку с числом степеней свободы, равным сумме
степеней свободы исходных оценок. Объединенная оценка
имеет вид
S2
i=\
, где vi = ni—l. (8.10)
2
(Последнее выражение предпочтительнее, поскольку позволяет
уменьшить вычислительные погрешности, связанные с ошибками
округления.) Статистика критерия
Т=-
Yk-k
имеет ^-распределение Стьюдента с
боды при ^1 —И'г-
kk
(8.11)
— 2 степенями сво-
Критерии значимости и доверительные интервалы
275
Пример 8.7. Чтобы определить силу сцепления клеевых сое-
соединений двух стекол, были проведены испытания на растяжение.
Исследовались образцы, у которых обработка склеиваемых по-
поверхностей производилась двумя различными методами, называе-
называемыми 1) перекрестной шлифовкой (cross lap) и 2) торцевой обточ-
обточкой (square center).
Требуется решить при уровне значимости а = 0,05, могут ли
эти данные быть взяты из нормально распределенных совокуп-
совокупностей с одинаковыми средними значениями. Необходимо прове-
проверить гипотезу H0i\i1 = \i2 в предположении случайности и неза-
независимости выбора образцов при испытании соединений каждого
типа, а также равенства дисперсий. Поскольку величина диспер-
дисперсии неизвестна, оценим ее по обеим выборкам, используя фор-
формулу (8.10), следующим образом:
—2
Таблица 8.1
Сила сцепления образцов склеенных поверхностей
Перекрестная
шлифовка
Торцевая обточка
Перекрестная
шлифовка
Торцевая обточка
16
14
19
20
15
18
13
19
14
14
15
10
18
19
17
18
17
21
13
15
Вычислим оценки Xi = 1
ния в (8.11), получим
17,4-15,1
и Х2 = 15,1. Подставив эти значе-
значе7=-
= =1,97.
^6^5 V ±+^
Следует принять нулевую гипотезу И-х^И^, поскольку кри-
критические значения двустороннего 5%-ного критерия равны
± ^1в; о,97б = ±2,101. Нет оснований утверждать, что один из
типов соединений прочнее другого. Двусторонний критерий был
использован потому» что отсутствовала априорная информация,
позволяющая предположить, что одно из соединений прочнее
другого.
276
Глава 8
Как выбрать один из двух типов соединений? Конечно, сле-
следует выбрать тип соединения, в среднем наиболее прочный.
Однако статистически доказать его преимущество не удается
(при а = 0,05, произвольно выбранном до начала исследования).
Наконец, в случае когда обе дисперсии неизвестны и не пред-
полаштся, что они равны, статистика критерия [10] есть
Т =
(8.12)
П2
Ее распределение близко к ^-распределению Стьюдента с числом
степеней свободы
(§.13)
Отметим, что величина v всегда лежит между наименьшим из
(пх—1) и (я2—1) и их суммой (п1+п2—2).
Пример 8.8. При производстве синтетического волокна для
уменьшения последующей усадки продукция, движущаяся непре-
непрерывным потоком, подвергается термической обработке. В табл. 8.2
Упадка синтетического волокна в процентах
120°С 140е С
Таблица 8.2
3,45 3,62 3,60 3,49
3.64 3,56 3,52 3,53
3,57 3,44 3,56 3,43
3,72 4,01 3,54
4,03 3,40 3,96
3,60 3,76 3,91
3,67
приведена величина усадки в процентах для волокон после обра-
обработки при двух температурах 120 и 140° С. До начала экспери*
мент предполагалось, что дисперсии усадки а? и а| при рас-
рассмотренных температурах не равны между собой. Требуется
проверить при а = 0,01, будет ли усадка при 140° С больше, чем
при 100° С. Сначала преобразуем данные следующим образом:
У/у = 100(Х,у-3,40),
Критерии значимости и доверительные интервалы
277
где Хи представляет собой величину усадки в процентах для
/-го волокна при температуре i [1) i=120°C, 2) t'=l40°C].
В результате преобразования получаем
120°С 140°С
5
24
17
22
16
4
20
12
16
9
13
3
32
63
20
61
0
36
14
56
51
27
ВыОорочные статистики, вычисленные по значениям У, равны
F1==13,4, У, «36,0,
Sf-49,54, Si-456,89,
Л1 = 12, п%**10.
Подставив эти значения в формулу (8.12), получим
13,4 — 36,0 —22,6
Т =
/49,54 456,39 /49,8173
12~+ Ю
= —3,20.
Число степеней свободы v, вычисленное по формуле (8.13), равно
10,6. Поскольку есть априорная информация о том, что большая
усадка имеет место при более высокой температуре, сравним
вычисленное значение t с t1Qt6- Qi01^—2,735 (или 1ю,о;о,99^
я^ +2,735, если в качестве числителя в выражении для t взять
величину У2—Ух). Далее, если требуется построить 98%-ный
доверительный интервал для величины усадки при 120° С в про-
процентах, то в первую очередь нужно закодировать заново данные
'О
i "Г"
/12
Это соответствует следующему выражению ъ исходных единицах:
@,0^ +.3,40)—o,oi tll[yi^Sl < |i».. <
< @,017х + 3,40) + 0,01 ~" n9flSl
3 534-0 01.2,718-2,03 < 1Нж < 3,534 + 0,01 -2,718-2,03.
Границы'доверительной области для цш равны приблизительно
3,479 и 3,589.
278
Глава 8
8.5.3. Равенство средних значений совокупностей
при парных или коррелированных выборках
Существует много задач, в которых две выборки взаимосвя-
взаимосвязаны в силу особенностей планирования эксперимента или потому,
что избежать этой связи невозможно. Иначе говоря, существует
посторонний фактор (или факторы), не относящийся к различию
между выборками А и В. Например, это имеет место тогда, когда
признаки А и В измеряются на одном и том же объекте. Чтобы
учесть взаимосвязь выборок, берут соответствующие выборочные
значения парами (Х± из А и Уг из 5, Х2 из А и К2 из В и т. д.)
и исследуют их разности Di = Xi — Yi. Гипотеза и предположе-
предположения в этом случае отличаются от предыдущих случаев, но они
совпадают с описанными в последней части разд. 8.5.1. Их можно
записать следующим образом.
Предположения: случайные величины D19 D2, ..., Dn выбраны
случайным образом из совокупности с распределением
N (\iD, aD).
Гипотеза: \iD = 0.
Альтернативная гипотеза:
Уровень значимости: а. _
Статистика критерия: Т = —^- .
D
Решение: если |Г| < tn-i% i-a/2, то гипотеза Но принимается;
в противном случае Но отклоняется.
Заметим, что число степеней свободы на единицу меньше, чем
число пар (т. е, равно я— 1). Оно всегда оказывается меньше
числа п1-{-п2 — 2( = 2п — 2), за счет чего мы по существу сни-
снижаем дисперсию, связанную с посторонним фактором, если
такой имеет место. Часто эта посторонняя дисперсия скрывает
истинное различие выборок, которое и является целью исследо-
исследования.
Рассматриваемая процедура применима, когда модель запи-
записана в виде
Х( =
Критерии значимости и доверительные интервалы
279
Здесь величины х{ могут быть как константами (параметрами),
так и случайными величинами; 6 — константа; ZJ, Zg, ..>Z'n—
взаимно независимые случайные величины, так же как и Zi\ Z2', ...
..., Z"n. Величина Z\ может быть связана с Z't:, но она должна
быть независима от Z) при \фг. Тогда
и при условии, что Var(Z;) не зависит от i [а это так, если
каждая из величин Var(ZJ), Var(Z^) и Cov(Zt', Z1) является кон-
константой], можно использовать описанный метод для проверки
гипотезы 6 = 0.
Пример 8.9. В качестве примера проверки гипотезы о средних
значениях рассмотрим данные, полученные при испытаниях шин.
Несмотря на то что использовался критерий, специально пред-
предназначенный для выявления различий между парными наблюде-
наблюдениями, на первом этапе эти различия выявлены небыли (иссле-
(исследование было проведено некорректно). Значимого различия не
было обнаружено. В дальнейшем при исследовании использова-
использовалась методика, более подходящая для анализа парных наблюде-
наблюдений, что позволило получить полезные выводы. В табл. 8.3 при-
Таблица 8.3
Условные значения температур левой и правой передних шин
Левая
передняя
(ЛП)
36
42
55
59
79
108
79
41
36
47
Правая
передняя
(ПП)
27
45
84
84
70
99
84
77
56
86
?> = ПП-ЛП
9
3
29
25
-9
-9
5
36
20
39
Левая
передняя
(ЛП)
41
40
100
58
38
73
89
58
60
Правая
передняя
(ПП)
60
34
117
78
56
85
65
72
85
?>=ПП-ЛП
19
—6
^ 17
20
18
12
—24
14
25
ведены результаты такого исследования. Эти данные представляют
собой температуру, до которой нагревается шина при движении
рейсового автобуса. Приведенные цифры являются результатами
испытания левых и правых передних шин 19 автобусов. Рассмот-
Рассмотрены три варианта нагрузки на каждую шину —один при дви-
движении по поверхности с частыми и острыми ребрами и два при
движении по более мелким неровностям. При этом замечено, что
при движении по поверхности с частыми ребрами шины нагре-
нагреваются до более высокой температуры. Не будем рассматривать
все три случая, а изучим сначала только наблюдения, полученные
при движении автобусов по поверхности с частыми ребрами. Эти
данные приведены в табл. 8.3.
Глава 8
Критерии значимости и до$ерительные интервалы
281
Для указанных результатов D= 11,84, а
вив эти величины в выражение
получим
D — О
; = 3,92. Подста-
(8.14)
При а = 0,05 критическое значение /i8;o,975 =2,101, и гипотезу
о равенстве температур правой и левой передних шин следует
отклонить. Теперь уже есть основания для продолжения иссле-
исследований по выявлению различий в температуре. Нужно опреде-
определить, какие особенности дорожного покрытия или другие факторы
следует включить в рассмотрение. Если все полученные резуль-
результаты удастся обосновать, то появится возможность разработать
некоторые модификации шин с учетом того, что повышенная тем-
температура свидетельствует о большем износе шин.
8.5.4. Сравнение более двух средних
Иногда возникают вопросы, связанные со сравнением более
двух средних значений. Большинство таких ситуаций будет рас-
рассмотрено в первой из глав (гл. 13), посвященных дисперсионному
анализу. Здесь мы остановимся лишь на одном особом случае.
Предположим, что требуется проверить гипотезу о равенстве
k средних значений, т. е. //0:fA1 = |i2= ... = \ьк, когда извлечено k
выборок. Нужно выяснить, могут ли все выборки относиться
к одной нормально распределенной совокупности N (\i, а). Отме-
Отметим, что дисперсии всех совокупностей предполагаются равными
(но неизвестными). Предполагается также, что выборки являются
случайными. При этих ограничениях можно получить несмещен-
несмещенную оценку а2, а именно
2 2 <*'/-**
(8.15)
где i = 1, ..., k\ j = 1, ..., n{\ п{ — объем i-и выборки, a S? —
оценка дисперсии по /-й выборке.^Величина Sp/ft,- является оцен-
оценкой дисперсии среднего значения Хг Один из методов проверки
указанной выше гипотезы состоит в исследовании размаха средних
значений с использованием распределения спгьюдентеризованного
размаха. Предположим, что все п,- равны_ (скажем п), а размах
для значений X,- записывается как /?х = -^макс — -^мин- Распреде-
Распределение стьюдентеризованного размаха Q,
(8.16)
q~spiV-n '
табулировано и приведено в табл. И.
Пример 8.10. На сталелитейном заводе возникли подозрения
относительно постоянства содержания марганца в одной из марок
выпускаемой стали. В течение восьми недель производилось по
10 отливок в неделю (при разной температуре ковшей). В табл. 8.4
Таблица 8.4
Процентное содержание марганца, установленное при анализе отливок
Номер
выборки
Средние
значения
Диспер-
Дисперсия-104
1,
1
1
1
1
12
20
17
15
21
14
17
18
21
25
14
,182
,6222
о
1,39
1
1
¦
,31
,29
1,28
1,30
1,28
1,34
1,32
1,30
1,35
1,316
12,2667
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1
25
з
18 1
17 1
08 1
15 ]
18
09
06
08
15
06
120
4
,22
,15
,17
,22
1,26
1,27
1,19
1,22
1,20
1,15
1,205
3333 17,1666
1,
1,
1,
1,
1,
1,
1
1,
1
1
1
10
5
21
24
19
17
15
18
17
17
25
18
,191
,5444
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1
16
6
30
35
25
26
23
24
26
33
28
24
274
,4889
7
1
1
,33
,35
1,27
1,30
1,24
1,30
1,27
1,29
1,34
1,28
1,297
12,0111
1
1
1
8
,13
,П
,20
,12
,13
,08
,15
,17
1,16
1,136
12,0444
приведены результаты исследований этих отливок. Приведенные
цифры показывают процентное содержание марганца в каждой
отливке. Необходимо решить, можно ли при уровне значимости
а = 0,01 считать, что отливки относятся к совокупностям с одним
и тем же средним значением, т. е. #0:щ=|ла= ... =[ie. Пред-
Предполагая, что выборки взяты из совокупностей с нормальным
распределением и одинаковыми (но неизвестными) значениями
282
Глава 8
дисперсии, определим эту дисперсию как
Тогда наблюдаемое значение стьюдентеризованного размаха равно
^ 1,316— 1,120 0,196 lfi 07
0,0385/
0,0122
Критическое значение, взятое из табл. И, равно qn==8t v=72;o,99 «
^ 5,2. Поэтому можно сказать, что отсутствие однородности
средних значений совокупностей, из которых взяты выборки,
достаточно очевидно.
8.6. НЕКОТОРЫЕ СТАНДАРТНЫЕ КРИТЕРИИ
ЗНАЧИМОСТИ
Стандартные критерии проверки гипотез относительно диспер-
дисперсий и средних значений, рассмотренные в разд. 8.4 и 8.5, све-
сведены в табл. 8.5. Знакомство с этой таблицей ни в коей мере
не может заменить тщательного изучения проблем, связанных
с проверкой различных предположений. Она служит скорее для
облегчения ссылок и сравнения рассматриваемых критериев."
В первом столбце таблицы представлены проверяемые пара-
параметры, а во втором—условия, при которых производится про-
проверка. Далее приведены статистики критериев, их распределения
и критические значения двустороннего критерия. Во всех слу-
случаях предполагается, что выборочные значения являются случай-
случайными независимыми величинами и имеют нормальное распреде-
распределение.
8.7. КРИТЕРИИ ЗНАЧИМОСТИ
ДЛЯ БИНОМИАЛЬНОГО РАСПРЕДЕЛЕНИЯ
В этом разделе рассматриваются две задачи; а) сравнение
выборочной оценки параметра р с предполагаемым значением р0
этого параметра для совокупности и б) сравнение двух и более
оценок параметра р совокупности, имеющей биномиальное рас-
распределение.
8.7.1. Сравнение значения р0 параметра совокупности
и его выборочной оценки
Пластмассовые контейнеры должны обладать определенной
прочностью. При исследовании 100 образцов контейнеров было
обнаружено, что два из них не удовлетворяют критерию проч-
прочности. Что можно сказать относительно вероятности A— /?} того,
284
Глава 8
что выбранный случайным образом контейнер будет удовлетйо-
рять требованиям прочности? Известно, что величина Х/п, где
X — число дефектных контейнеров, является оценкой максималь-
максимального правдоподобия для Параметра р< Предположим, что требуется
проверить гипотезу о равенстве доли дефектных изделий величине
/70 = 0,01. Эта гипотеза записывается следующим образом: Н0:р =
= Ро (^^ 0,01), где р — истинная доля дефектных изделий в сово-
совокупности, из которой взята выборка, а р0 — ее предполагаемое
значение.
В этом случае представляется естественным рассматривать
альтернативные гипотезы р > р0. Таким образом, имеется следу-
следующая информация.
Предположения: величины X имеют биномиальное распределение
с параметрами п, р.
Гипотеза: Н0:р = р0.
Альтернативные гипотезы: р > р0.
Уровень значимости: ^а (см. последующие замечания).
Статистика критерия: Х/п.
Нужно еще определить правило принятия решения. Представ-
Представляется естественным делать это следующим образом: принимать
Яо, если Х/п^К, отклонять Но в противном случае.
Не всегда удается найти такое значение К, чтобы Рг[Х/п<
^/С|#о] точно совпадала с а. Поэтому величина К выбирается
так, чтобы уровень значимости имел наибольшее возможное зна-
значение, не превосходящее а»
Когда альтернативами рассмотренной гипотезы являются все
значения рФр0 (т. е. р < р0 и р > р0), то необходимо исполь-
использовать правило принятия решения следующего вида: принимать
Яо, если K1^X/n^.K2i й отклонять Яо в противном случае.
Константы Л^, К2 следует выбирать так, чтобы уровень значимости
не превышал величины а, но максимально приближался бы к ней.
(Можно использовать и другие правила, например часто требуют,
чтобы Рг[Х/п</С1|Я0]<1/2а и Рг [Х/п > К21 Но] < V2 а или
просто Рг [Кг < Х/п < К2] « 1 — а.)
Один из подходов основан на использовании доверительных
интервалов. Можно приближенно построить 100A—а)%-ный до-
доверительный интервал для параметра р. Если величина р0 по-
попадает в пределы этого интервала, то гипотезу Но принимают
с уровнем значимости а,1 в противном случае гипотезу отклоняют.
Доверительный интервал для р имеет вид Рг<р < Р2, где гра-
границей Рг является наибольшее из значений р, удовлетворяющих
уравнению
-/>)-*< у,
(8.17)
Критерии значимости и бШришл^ыеинтервалы $&&
^ — наименьшее из значений р, удовлетворяющих урайнению
(8.18)
Указанные значения Р1 и Р2 могут быть взяты из таблиц,
упоминавшихся в гл. 5. Эти значения можно также найти с по-
помощью кривых, приведенных в табл. Л, где даны 80, 95 и 99%-ные
доверительные интервалы для величины р при заданных х0 и п.
Чтобы воспользоваться этими кривыми, нужно сначала выбрать
значение абсциссы xjn. Из точки хо/п восстанавливается верти-
вертикальная прямая. Эта линия пересекает две кривые, задающие
область возможных значений л, в точках, ординаты которых со-
соответствуют нижней и верхней доверительным границам для р.
Их значения можно прочесть на вертикальной оси.
а х0 — наблюдаемое значение X.
Пример 8.11. В задаче, поставленной вначале раздела, было
задано jr0 = 2,a/i= 100. Эти данные определяют значение оценки
максимального правдоподобия для параметра р, р --=хо/п = 0,02.
Чтобы проверить гипотезу Яо:' р = 0,01 при а = 0,05 с использо-
использованием двустороннего критерия, обратимся к табл. Лртриложения
(доверительная вероятность 0,95), взяв значение абсциссы, рав-
равное 0,02. Вертикальная линия пересекает пару кривых, соответ-
соответствующих я =100, примернЬ в точках P1 = 0i00 и Р2 = 0,07. Нет
оснований отклонять гипотезу Яо, поскольку величина р0 = 0,01
попадает в пределы доверительного интервала. В случае когда
значения Рг и Р2 определяются непосредственно по уравнениям
(8.17) и (8.18), доверительные границы оказываются равными
0,002 <р< 0,071.
Заданная величинаро=О,О1 попадает в пределы этого интервала.
При достаточно большом объеме выборки можно использовать
аппроксимацию биномиального распределения нормальным зако-
законом, которая приводит к выражениям
(8.19)
Отсюда следует, что нижняя доверительная граница для р в рас-
рассматриваемом примере равна
Л = 0,02- 1,96 /@,02)@,98) @,01) = - 0,0074,
и, следовательно, вместо нее используется 0, а верхняя граница
Р2 = 0,02 + 1,96 ]/@,02)@,98)@,01) = 0,047.
286
Глаза 8
Следует заметить, что в данном случае аппроксимация недоста-
недостаточно хороша из-за относительно малого объема выборки и того
факта, что величина р далека от 0,5. Несколько лучшая аппрок-
аппроксимация дает границы
что в рассматриваемом случае приводит к
Л = 0,0100, Р2 = 0,0655.
8.7.2. Сравнение двух долей
Требуется проверить гипотезу о томь что две выборки взяты
из совокупностей, имеющих биномиальное распределение с одина-
одинаковыми параметрами/?. Эту гипотезу можно записать как Н0:рг=р2,
или #o:Pi — Рг^О- При достаточно большом объеме выборки
можно использовать аппроксимацию нормальным распределением.
Если нулевая гипотеза справедлива, то оценки, относящиеся
к каждой из выборок, являются несмещенными оценками одного
и того же параметра. Следовательно, эти оценки можно объеди-
объединить следующим образом:
Р =
(8.20)
где Хх — число событий, содержащихся в первой выборке объема
п19 а Х2 — число событий во второй выборке объема п2. Приве-
Приведенная величина фактически является оценкой максимального
правдоподобия для параметра р. Чтобы выяснить, может ли раз-
разность рх—р2 равняться нулю, следует оценить среднее квадра-
тическое отклонение разности выборочных оценок
о
P
l_il
nx+n2
Наконец, статистика критерия имеет вид
ГУ — Рх—Р% —
Pi-Pi p
П2
(8.22)
При рх = р2 ее распределение почти совпадает с нормированным
нормальным распределением N@,1).
Приведем формальную запись отмеченных выше положений.
Предположения: величины Хг и Х2 независимы; Xj имеет бино-
биномиальное распределение с параметрами п/у р. (/=1, 2).
Гипотеза: рх = р2.
Критерии значимости и доверительные интервалы
287
Альтернативные гипотезы:
Уровень значимости: примерно а.
Статистика критерия: U согласно (8.22).
Решение: если |?/| < и^а/а. то #о принимается, в противном
случае Но отклоняется.
Когда рлфр2, распределение статистики U приближенно сов-
совпадает с распределением величины, подчиняющейся нормальному
закону с математическим ожиданием (рх —р2) [{п~} + п~\) Р X
ХA—Р)]/2 и средним квадратическим отклонением
{[n-\Pl (I -Pl) + n-lp2 A -рЛ)] Цп-{ + гг\) Р(\ -Р)]-1}172 [где Р =
)()]
Учитывая это, можно приблилюнно рассчитать мощность критерия.
Пример 8.12. На каждом из двух имеющихся на заводе стан-
станков производят новые изделия одного типа. При пробном пусие
из 350 изделий, изготовленных на станке Л, при проверке по
принципу годен—не годен, 15 оказались дефектными. Среди 320
изделий, изготовленных для сравнения на станке 5, оказалось
всего 8 дефектных. Можно ли, приняв уровень значимости рав-
равным а = 0,05, ожидать, что в продукции, производимой на срав-
сравниваемых станках, окажется одинаковая доля дефектных изделий?
Объединенной оценкой доли дефектных изделий будет (при
справедливости гипотезы о равенстве параметров) величина
Чтобы проверить, есть ли различие между сравниваемыми долями
рх и р2, оценим дисперсию разности рг — р2, используя для
этого формулу (8.21):
S2 {f\ HQ/!Q\ /П QfiPV7\( __ J _\ П ПППЮЯ
^ в= IU,UO*±O) (и,УиО/ )\ о^л ~Г оол ) —W,UUUlc7O|
Pi~~P2 \ oDU (jZ\j)
ИЛИ
Подставляя эту величину в (8.22), получаем
fr 0,0429-0,0250 t OQ
Полученное значение находится между доверительными гра-
границами ±1,96. Следовательно, нет никаких оснований для того,
чтобы утверждать, что средние доли дефектных изделий для
рассматриваемых станков различны.
Глава 8
Критерии значимости и доверительные интервалы
289
8.7.3. Сравнение нескольких долей
Рассмотрим следующую ситуацию.
Предположения: Xlt. . .,ХС— независимые величины; Xj имеетбино-
миальное распределение с параметрами яу-, ру-
(/=1,..., с).
Гипотеза: рг = р2 = ... =рс.
Альтернативные гипотезы: не все значения р равны между собой.
Эту ситуацию можно рассматривать как особый случай про-
проверки гипотезы независимости по двумерной таблице сопряжен-
сопряженности признаков, состоящей из двух строк и с столбцов.
Задачи такого типа рассмотрены в разд. 8.9.2.
8.8. ДОВЕРИТЕЛЬНЫЕ ИНТЕРВАЛЫ
И КРИТЕРИИ ЗНАЧИМОСТИ ДЛЯ ПАРАМЕТРА 9
РАСПРЕДЕЛЕНИЯ ПУАССОНА
Если известно, что совокупность имеет распределение Пуас-
Пуассона, то может потребоваться оценить параметр 0 функции рас-
распределения
1 г, , ч е-Ч*
х = 0, 1, 2, ... .
(8.23)
Несмещенная оценка параметра 0, основанная на единственном
значении X, определяется самой величиной X. Границы
100A—сс)%-ного доверительного интервала для параметра 0
приведены в табл. М для значений а = 0,05 и 0,01.
Если было проведено более чем одно наблюдение и эти наб-
наблюдения представляют собой независимые случайные величины
Хх, Х2, ..., Хк (при k > 2), каждая из которых имеет распре-
распределение Пуассона (8.23), то 2Ху имеет распределение Пуассона
с параметром Ш. Для вычисления доверительных интервалов для
параметра ?0, основанных на 2Ху, можно использовать табл. М.
Доверительный интервал для параметра 0 находится простым
делением граничных значений А и В неравенства
А <№<В
на значение k:
fe-M <Q<k~1B.
Табл. М можно воспользоваться также при построении крите-
критериев значимости для параметра 0. В случае двустороннего кри-
критерия проверка гипотезы ЯО:0 = 0О с уровнем значимости, рав-
равным приблизительно а,, включает построение 100A—а)%-ного
доверительного интервала и выяснение, попадет ли в этот интер-
интервал значение 80. Если оно попадает, то гипотеза Яо принимается;
в противном случае Яо отклоняется. Предположим, что мы
столкнулись со следующей ситуацией.
Предположения: Хх, Х2, ..., Хк—независимые величины, каждая
из которых распределена по закону Пуассона с
параметром 0.
Гипотеза: 0 = 0О.
Альтернативные гипотезы: 0 > 0О.
Уровень значимости: ^а.
к
Статистика критерия: Т = 2 ^/*
/=i
Один из методов решения связан с использованием нижней
границы 100A—2а) %-ного доверительного интервала, взятой
из табл. М. Гипотеза Яо принимается, если табличное значение
превышает величину &0О, в противном случае Но отклоняется.
Другой способ — это отыскание с использованием табл. Б наи-
наименьшего значения величины Го, при котором справедливо нера-
неравенство
2 (о)/<
х-Т0
При Т <Т0 принимается гипотеза Яо, в противном случае
она отклоняется.
Пример. 8.13, По записям строительной фирмы число несчаст-
несчастных случаев за период в несколько лет составляло в среднем
1,5 в месяц. В течение последнего года было зарегистрировано
25 несчастных случаев. Хотелось бы выяснить, превосходит ли
зарегистрированное число несчастных случаев то их количество,
которое можно было бы ожидать. Пусть а = 0,05. В данном слу-
случае рассматриваются альтернативы типа 0 > 0О (увеличение интен-
интенсивности появления несчастных случаев) и табл. М использовать
нельзя, поскольку она не содержит 90%-ных доверительных гра-
границ. Имеем k = 12, а 0О = 1,5, поэтому &0в=18. Обращаясь к
табл. Б, находим, что 2 (е~*в*/х !)=== 0,0683 > 0,05 при 6=П8.
ЛГ=2б
Таким образом, нет достаточно веских оснований для того, что-
чтобы отклонить гипотезу Яо и, следовательно, сделать вывод об
увеличении интенсивности появления несчастных случаев.
Если нет таблиц распределения Пуассона, то можно исполь-
использовать следующую аппроксимацию:
10
819
290
Глава 8
Критерии значимости и доверительные интервалы
291
8.9. КРИТЕРИИ СОГЛАСИЯ
8.9.1. %2-критерий
Рассмотрим теперь важную группу критериев, связанных с
проверкой гипотез относительно вероятностей, задающих полино-
полиномиальное распределение.
Сначала напомним некоторые свойства полиномиального рас-
распределения (разд. 3.11). Если событие может происходить одним
из k возможных способов Glf G2,..., Gk, причем
для любого испытания (конечно, при выполнении равенства
2/^-=1)>то в последовательности п независимых испытаний
вероятность того, что G19 G2,..., Gk появятся соответственно
N19 N2,..., Nk раз [согласно C.36)], равна
P(Nlt N2,...1Nk)=---T^±-flpi»i.
Величина N{ распределена по биномиальному закону с парамет-
параметрами л, р?9 так что
Предположим теперь, что требуется проверить гипотезу Но о
том, что Рх = р10> р. = ряо..--. Pk = Pko> где р10, р20,..., р*о явля-
являются заданными значениями вероятностей PrfGj], Pr[G2J, ...
. .., Pr[G^], удовлетворяющими условию
2
i-l
Функция правдоподобия в случае наблюдаемых величин N19 N2,
..., Nk при справедливости гипотезы Но имеет вид
Предположим, что множество альтернативных гипотез включает
все возможные сочетания значений параметров р19 р2,..., рА,
k
удовлетворяющих условиям р/^0, 2 Р/ = 1.
Постараемся найти Ямакс, соответствующую множеству значе-
значений р19 р2, ..., pk, максимизирующих функцию правдоподобия
•д,,"..
(8.24)
Логарифмируя это выражение, получаем
п\
II "/'
Запишем pk= 1 —pl — ... —pk-x, поскольку независимо могут
быть определены только (k— 1) значений из р19 р2,..., рл, и про-
продифференцируем полученное выражение по р{\
dpi Pi Pk
Приравнивая правую часть этого выражения нулю, находим, что
Pi пропорционально N(\ и снова, используя условие
к
приходим к равенству р( = Ы?/п. Можно утверждать, что полу-
полученные значения р{ соответствуют максимальному значению L
(а также и /), определенному путем дифференцирования dL/dpit
или что pi = Niln является единственным множеством таких зна-
значений р, для которых dL/dpi = O9 a L стремится к минус беско-
бесконечности, когда какая-либо вероятность р, (для которой N{ > 0)
стремится к нулю (или некоторая вероятность р{ стремится к 1).
Подстановка полученных значений в уравнение (8.24) дает
„•![»>¦¦'"
Таким образом, появляется возможность использовать для про-
проверки гипотезы Но критерий
/ (Nl9 N2, . . ., Nk 1 Яо) __ Л fnpio\Ni (R 9С.ч
(Nlt TV 2, . . ., Nk\ /7MaKC) " V N[ J x
Введем для удобства следующие обозначения:
прi0 — математическое ожидание числа событий Gj = Eit
Nr-наблюдаемое число событий G; = Oi.
Ю*
292
Глава 8
Теперь правую часть равенства (8.25) можно переписать в виде
пAГ-
Натуральный логарифм от этой величины равен
Вспоминая, что математическое ожидание Ot есть npi0 = Eh а его
среднее квадрэтическое отклонение равно У npi0(l — pi0), т. е.
величине порядка V^Eh можно показать, что (О,—?,) обычно
оказывается порядка ]/"?,. (или Vn).
Теперь, развернув выражение для логарифма и оставив в нем
члены до порядка малости м~1/2, получим [используя тождество
2@,- ?,) = о]
(О,
(порядка 1)
(О, —Я,-)
... (порядка я-1'2). (8.26)
Наибольший вес имеет член — 1/2Z(Oi — EiJEi1.
Для большинства задач точность этого выражения вполне
достаточна, и его можно использовать вместо отношения правдо-
правдоподобия (8.25).
Отметим, что большие значения величины
(8-27)
i=\
соответствуют малым значениям отношения правдоподобия (8.25),
поэтому гипотезу (или определенные значения pt) при большом
X2 следует отклонять.
Распределение величины X2 было детально исследовано Пир-
Пирсоном [9], а позднее еще рядом авторов. Эти математические ис-
исследования чрезвычайно остроумны, но очень утомительны. По-
Поэтому сошлемся просто на наиболее важные результаты, которые
можно резюмировать следующим утверждением:
„Распределение X2 близко к ^-распределению. Число степе-
степеней свободы равно числу групп (k) за вычетом числа различных
линейных соотношений, связывающих разности (О/ — ?/)".
Критерии значимости и доверительные интервалы
293
Во-первых отметим, что результат должен носить приближен-
приближенный характер, поскольку X2 — дискретная величина, а распреде-
распределение х2 применимо только к непрерывным величинам. Во-вторых,
требование линейности соотношения может быть заменено на
условие приближенной линейности. Наконец, применимость вы-
выражения для X2 зависит от степени малости членов высокого
порядка в формуле (8.26). Это в свою очередь зависит от мате-
математических ожиданий частот ?,., которые не должны быть „слиш-
„слишком малы". На практике рекомендуется стремиться к тому,
чтобы Е{ были бы не меньше, чем 5 (иногда 10), однако последние
исследования показывают, что можно пользоваться даже такими
малыми значениями Е{ как 2 при незначительной вероятности
получить сильно искаженные результаты.
Чтобы приближенно оценить значимость X2, можно исполь-
использовать табл. Д приложения.
Применим теперь %2~критерий для анализа данных, приведен-
приведенных в примерах 5.15 и 5.16. В этих примерах наблюдаемые ча-
частоты foi — это числа О/, теоретические частоты ft—числа Et.
Пример 8.14. Используемый в примере 5.15 метод подбора
таков, что для теоретических и наблюдаемых частот выполняются
соотношения
Таким образом, имеется три различных линейных соотношения
между разностями (Oi — Ei). Отметим, что в табл. 5.6 группы,
расположенные на хвостах распределения, объединены для того,
чтобы увеличить средние значения частот в крайних группах.
Число групп равно 13; следовательно, число степеней свободы
для
S-//I/*-1 (8.28)
1=1
составляет
13-3-10.
Величина Х% [сумма столбца (8)] равна 3,7853. Очевидно, что
в данном случае наблюдаемая величина незначима, поскольку
среднее значение %% при 10 степенях свободы равно 10. E%-ное
критическое значение одностороннего критерия %?6; 0,95 в данном
случае равно 18,31.)
294
Глава 8
Пример 8.15. В примере 5.16 имеется пять групп (получен-
(полученных после объединения). При этом имеет место только одно со-
соотношение между наблюдаемыми (/0/) и теоретическими (ft) ча-
частотами
2 (f•?-//) = <>.
Значение Х2 = 1,5287 [из столбца E)] следует оценить, пользуясь
^-распределением при 5—1=4 степенях свободы. Здесь опять
следует сделать вывод, что наблюдаемая величина незначима.
E%-ное критическое значение %\; 0,95^9,488.)
Заметим, что приближенное распределение статистики X2 не
зависит от истинных значений частот ft. В этом смысле оно
является до некоторой степени свободным от распределения.
В гл. 9 рассматриваются критерии, действительно свободные от
распределения.
8.9.2. Проверка независимости по таблице сопряженности
признаков
Критерий %2, как известно, используется для проверки со-
согласия при подборе вида распределения; кроме того, он лежит
в основе одного из методов проверки независимости двух при-
признаков, не измеряемых в непрерывной шкале значений. Признаки
такого рода встречаются достаточно часто; приведем три примера:
географическое положение, профессия, склонность. Результаты
измерения двух признаков указанного типа для каждого из N
исследуемых объектов можно представить в виде таблицы сопря-
сопряженности двух признаков1). Строка i соответствует i-му уровню
одного из признаков (или факторов), а /-й столбец — /-му уровню
другого признака. Величина Ni/y расположенная на пересечении
i-й строки и /-го столбца, есть число объектов (из N), для ко-
которых первый признак находится на i-м уровне, а второй на
/-м. Предположим, что матрица содержит г строк и с столбцов,
причем i=l, 2, ..., г; / = 1, 2, ..., с.
Для оценивания доли объектов из некоторой совокупности,
у которых первый признак находится на i-м уровне, будем ис-
использовать отношение Ni./N9 где Nt.= 2 Ntj. Аналогично, доля
объектов, у которых второй признак находится на уровне /,
оценивается отношением N.j/N, где N.J- =
Предположим
(на некоторое время), что два признака взаимно независимы
(для объектов совокупности); тогда естественной оценкой доли
объектов, принадлежащих i-му уровню по первому признаку и
х) См. также: Закс Л. Статистическое оценивание.—М.: Статистика,
1976. — Прим. ред.
Критерии значимости и доверительные интервалы
295
/-му по второму, будет величина (N{jN)(NmJ/N). Таким образом,
оценка среднего значения частоты в выборке объема N равна
N(NiJN)/(N.j/N). Следовательно, имеется гс наблюдаемых частот
ij'v ГС теоретических частот Nt.N.jlN. Теперь можно вычислить
X2 = 2j (Наблюдаемая частота — Теоретическая частотаJ х
X (Теоретическая частота) =
N
Разности Nij—
соотношениям
и с линейным соотношениям
удовлетворяют одновременно г линейным
o, ,_, ,.
причем в каждой из рассмотренных систем линейных соотноше-
соотношений предполагается, что
и, следовательно, общее число различных линейных соотношений
равно г-\-с— 1.
Если признаки независимы, то X2 должно приближенно со-
соответствовать %2-Распределению с rc — (r + c—l) = (r—l)(c—l)
степенями свободы. Получение значимо большого значения X2
рассматривается как очевидное свидетельство отсутствия незави-
независимости.
Ниже приведена общая формула, полезная для вычисления
значений X2 по таблице размером 2x2.
a
с
r
b
d
s
m
n
N
c+d= nt
=--N.
Имеем
— bcLmnrs.
(8.29)
296
Глава 8
Вместо X2 часто используют статистику
X>2^N (\ad—bc\ —
mnrs
(8.30)
распределение которой ближе к ^-распределению с одной сте-
степенью свободы.
Пример 8.16. Табачная фирма хотела бы знать, можно ли
отправлять заказчикам сигареты и трубочный табак в одной
упаковке. Если при этом качество сигарет или трубочного табака
не ухудшится, то можно существенно сократить затраты по пе-
перевозке. Признаком ухудшения качества сигарет является изме-
изменение их аромата (возможно, из-за сильного запаха трубочного
табака). Для проведения исследований изготовили 400 картонных
коробок и в 250 из них положили табачные изделия обоих ти-
типов. В оставшиеся 150 коробок были положены только сигареты.
Через месяц коробки открыли, и все 400 упаковок сигарет рас-
расположили в случайном порядке. Несколько экспертов анализи-
анализировали аромат сигарет и пытались обнаружить его отличие от
(предполагаемого) исходного. Результаты экспертизы приведены
в табл. 8.6. Можно ли сказать, что связь между ароматом сига-
сигарет и видом упаковки отсутствует?
Таблица 8.6
Таблица
Мнение об
Не изменился
Изменился
сопряженности
аромате
признаков: аромат
табака
Вид упаковки
совместная
72
178
250
раздельная
119
31
150
191
209
400
Вычисленные значения частот равны
119,375 71,625
130,625 78,375
250
150
191
209
400
Критерии значимости и доверительные интервалы
297
(Значение 119,375 определено следующим образом: Nx.N.jN —
Наконец,
у2__G2— 119,375)* A19 — 71,625J . A78
119,375
71,625
¦130,625J C1-78,375J__
130,625 + 78,375
= 95,96,
а соответствующее число степеней свободы равно B — 1) • B — 1)=1.
Значение 95,96 значительно превышает табличное значение
Хи о,999= 10,83. Следовательно, имеются очень убедительные ос-
основания для того, чтобы отклонить гипотезу о независимости
аромата сигарет от способа упаковки.
При проведении повторного исследования с выборками, вклю-
включающими Л^.! = 250, АЛа=150 упаковок, значения Nlt и N2. мо-
могут измениться. Использовалось приближенное условное распре-
распределение величины X2 при заданных #ь = 191 и N2. = 209.
Уравнение (8.29) при а = 72, & = 119. с =178, d = 31 дает
Х2 = 400G231 — 119-178K/A91-209-250-150) =
= 400(— 18950)а/1 496 962 500 = 95,96, как и раньше.
Обращаясь к формуле C.30), получаем
у/2 _ 400A8 950-200J Qo Q4
~~ 1496 962 500 Ус*,У4.
Выводы не изменились.
8.9.3. Критерии Колмогорова — Смирнова и оценивание
Другая группа критериев согласия основана на сравнении
эмпирической функции распределения, определяемой (для выборки
объема п) как
значений X, меньших или равных х,
с теоретической функцией распределения F(x).
Значения отклонений функции F*n(x) от F (х) можно исполь-
использовать для построения критериев проверки гипотезы о том, что
F(x) является истинной функцией распределения величины X
(в предположении, что наблюдаемые значения получены из слу-
случайной выборки). Критерии такого типа известны как критерии
Колмогорова—-Смирнова—двух русских статистиков, которые
впервые использовали их.
Если F(x)—истинное распределение,которое является непрерыв-
непрерывным, то распределения таких статистик, как D = тах)Лг | F*n (x) —
X
— F(x)\, D+ = max]/"n[F* {x) — F(х)] и т. д., не зависят от F{х)\
X
критерии, построенные на основе этих статистик, называются
298
Глава 8
свободными от распределения (см. гл. 9). [Независимость распре-
распределений статистик D и D+ от функции распределения F (х) вы-
вытекает из следующего: 1) любое непрерывное распределение можно
преобразовать в любое другое, используя подходящее монотон-
монотонно возрастающее преобразование переменной, и 2) такое пре-
преобразование оставляет величины D и D+ неизменными.]
Для проверки гипотезы о том, что F(x) является истинным
распределением, используют критерий с критической областью
D>dnt x_a, где константу dnt i_a выбирают так, чтобы уровень
значимости оказался равным а. Это приводит к построению
двустороннего критерия. Для построения одностороннего крите-
критерия используют статистики D+ или D_[ = min ]/rn(Fn(x) — F(x))].
х
Предположим, что F (х) — истинное распределение. Тогда Fn(x)
при любом х имеет биномиальное распределение с параметрами
я, F {х). Однако для того, чтобы оценить распределение величины!),
необходимо найти такие значения dn> i_a, для которых
Pr [max | F*n(x)-F(x)\> 4, i-« ] = «,
что представляет значительную трудность. К счастью, есть по-
полезные асимптотические результаты.
Известно, что
lim Pr[D > z] = 1 - 2? (— \yexp(—2j*z*)=g(z).
П-+ CD /=1
Следовательно, если g(d'1_a) = a, то для больших п
n, l-a '
VI'
В табл. 8.7. приведены некоторые значения d[_a.
Незначительная модификация этого выражения
(8.31)
позволяет получить точные результаты для значений п, не пре-
превышающих 10.
Таблица 8.7
Значения d[-a
а
0,005
0,01
0,025
0,05
di-a
1,73
1,63
1,48
1,36
а
0,10
0,15
0,20
0,25
1,22
1,14
1,07
1,02
Критерии значимости и доверительные интервалы
299
Для вычисления D+ также используют выражение (8.31),
куда вместо d[_a подставляют величину d'+t 1_a:
d'+; о,9о =1,073; d'+; o,95 = l,224; d'+; 0,99 -1,518.
Приведенные результаты можно использовать, когда функция
F (х) известна. Хотелось бы сделать их применимыми и в том
случае, когда эта функция содержит параметры, требующие
оценивания. Рассмотренные асимптотические формулы нельзя
использовать непосредственно, даже если п велико. Например,
если F(x) — функция, имеющая нормальное распределение, а оценки
среднего значения и дисперсии получены по выборке, то хорошую
точность для процентных точек D (даже если п составляет
всего 10) можно получить, используя
-« (Кл —0,01 +0,85//л)-1,
где
.„ -0,819;
-0,895; d;,M - 1,035.
Более подробно этот подход изложен в работе [11].
Процентили распределения величины D можно использовать
для построения доверительных коридоров функции F (х) отно-
относительно наблюдаемой функции F*n{x). Эти области с заранее
определенной вероятностью включают все возможные линии гра-
фика^/^х). Приближенно построим доверительный коридор для
функции распределения F (х) с доверительной вероятностью 1 —а,
располагая его границы на расстоянии ±dn§1_a от линии, со-
соответствующей Fn(x). Способ построения такого коридора по-
поясняется на рис. 8.3. Ступенчатая (сплошная) линия, располо-
Рис.8.3. Доверительный интервал для/7 (х).
женная в центре, представляет F*n(x). На рисунке показано во-
восемь ступенек, каждая из которых соответствует одному наблю-
наблюдению: объем выборки равен 8.
Штриховыми линиями обозначены границы доверительного
коридора для F (х). Они расположены на расстоянии dn> i_a выше
и ниже F*n (jc), кроме тех случаев, когда они должны были бы пройти
выше единицы или ниже нуля. Следует заметить, что довери-
доверительная вероятность представляет собой вероятность того, что
300
Глава 8
функция распределения целиком, т. е. при любых значениях х,
окажется внутри доверительного коридора. Это согласуется
с концепцией совмещенных доверительных интервалов, рассмот-
рассмотренной в разд. 7.4.3.
Описанная методика в случае, если допустимо использовать
асимптотическое распределение, является непараметрической
и свободной от распределения. Если X — непрерывная случайная
величина, то методика действительно оказывается свободной от
распределения, поскольку любое монотонное преобразование X
оставляет неизменным значение разности F*n-^F при новой пе-
переменной.
Пример 8.17. Измерялось сопротивление 10 образцов прово-
проволоки типа В-302. Результаты измерений (в омах): 0,129; 0,132;
0,128; 0,120; 0,126; 0,137; 0,124; 0,135; 0,119и0,123. Воспользуемся
этими данными для построения 95%-ного доверительного кори-
коридора для функции распределения значений сопротивления. По-
Получим dio; o,95 «0,41. Таким образом, доверительный коридор
ограничен следующими значениями:
(Наблюдаемая частость) ±0,41,
которые заменяются на 0 или 1, если они соответственно меньше 0
или больше 1.
Доверительный коридор, построенный по приведенным данным,
показан на рис. 8.4.
рдр д фуц ррд
ротивления проволоки типа В-302.
0,120 0,124 0,Ш ^ 0,132 0,136 0,140
Рис. 8.4. Доверительный коридор для функции распределения значений соп-
Критерйй
1 -1 ,
У=1
(8-32)
Критерии значимости и доверительные интервалы
301
где X) является /-м по порядку от наименьшего из Х19 Х2, ...
..., Хп, также может быть использован для проверки гипотезы
о том, что F(x) является функцией распределения величины X.
Большие значения статистики nW2 свидетельствуют о значимости
отличий. Асимптотические границы приведены в табл. 8.8 (осно-
(основанной на данных, взятых из [8]I).
Для повышения точности используют формулу
[(Асимптотическое значение) — 0,4п-14-0,6я~2]A +n~l).
Доверительные границы для nW2
Таблица 8.8
Уровень значимости
0,20
0,10
0,05
0,01
0,001
Граница для nW*
0,241
0,347
0,461
0,743
1,168
Если F(x) — функция нормального распределения, а в качестве
среднего значения и дисперсии используются их оценки, постро-
построенные по выборочным моментам, то верхняя 100а%-ная точка
распределения величины nW? приближенно равна
где
nWln = 0,140; nW\.b = 0,126; nW\tW - 0,148.
Пусть рассматриваются две случайные выборки значений X
объема пх и п2 из двух совокупностей, имеющих одно и то же
распределение. Тогда
Pr
= 2 (—
/= - 00
при условии, что
lim
% п2 ->
?Тдля
~2 2 (- l
/ = 1
njn2 — конечное положительное число.
1) См. также: Большее Л. Н., Смирнов Н. В., Таблицы математической
статистики.—М.: Наука, 1965; Оуэн Д. Б. Сборник статистических таблиц.—
М.: Изд-во ВЦ АН СССР, 1966.-Прим. ред.
302
Глава 8
Полученный результат может быть использован при проверке
гипотезы об идентичности распределений двух совокупностей X.
Используя табл. 8.7, можно приближенно выбрать уровни зна-
значимости для
Если отношение njn2 достаточно мало, то выражение (8.31)
при п = пг дает хорошие результаты. На самом деле статистика Т
имеет дискретное распределение с числом отдельных значений
с ненулевыми вероятностями, превышающим (пг + 1) (п2+ 1). По-
Подробные таблицы значений процентилей этого распределения при-
приведены в [9]1}.
8.10. НЕСКОЛЬКО ДОПОЛНИТЕЛЬНЫХ
КРИТЕРИЕВ И ОЦЕНОК
Взяв за основу распределение непрерывной случайной вели-
величины Y, можно сформировать семейство распределений, вклю-
включающее распределения случайных величинX = Q1-\-Q2Y(при 02 > 0)
для различных значений 0Х и 02. Например, если Y имеет норми-
нормированное нормальное распределение, то указанным путем можно
получить семейство распределений, включающее все нормальные
распределения. Результаты, полученные в примере 7.5, показы-
показывают, что если 01, мп и 02,мп являются соответственно оценками
параметров 0Х и 02, полученными методом максимального правдо-
правдоподобия по случайной выборке объема п из совокупности, имею-
имеющей распределение, относящееся к рассмотренному классу, то
W(n) — Qi,Mn—8x ш) _ 91,мп— 8t т( __ 0а, мп
W 1 — д » w 2 — ~ п * 2 "
ё2
имеют распределения, которые не зависят от 0Х и 02 (однако они
зависят от объема выборки и распределения Y).
Это свойство можно использовать в процедурах оценивания
и проверки гипотез.
Обозначим процентные точки распределений величин Wly W2
и Т2 через W{% WB?e и 72%, так что, например,
Рг[ТРГ<1Р1%| объем выборки /i] = e.
8.10.1. Оценивание
Из выражения
Рг [п%2 < ^2- < T«\_a/i 192] = 1 - а
г) См. также: Оуэн Д. Б. Сборник статистических таблиц.—М.: ВЦ
АН СССР, 1973.- Прим. ред.
Критерии значимости и доверительные интервалы
303
следует
Рг [92,
-в/, < 02 < 92, мп/7Та/21 вJ = 1 - е,
где @2, Mn/^i-a/2, 0а, мп/^а/2)—Доверительный интервал для 02
с доверительной вероятностью 100A—а)%. 100A—а) %-ные до-
доверительные интервалы для 0Х можно записать следующим обра-
образом:
а) при известном значении 02
б) при неизвестном значении 02
(Эх, МП — IFgW^.MII,
1, МП —
[Отметим, что 01>Мп в случаях а) и б) может выражаться одной
и той же статистикой, но не всегда.]
8.10.2. Критерии
Гипотезу 91 = 01О можно проверить, используя статистики
1>M^~ei
W[nH= 1>M^
или
WBnH=
е
при известном значении 92
ПрИ неизвестном значении 62.
2, МП
Гипотезу
терия:
можно проверять с помощью следующего кри-
криг •.»=.
7 2, МП
020
Критические области могут быть построены естественным обра-
образом; например, для проверки гипотезы 02 = 02О против альтерна-
альтернатив 02 > 02О следует использовать критическую область
Т(П) ^ Т|(/г)
1 2 s> 1 2,1-а*
Некоторые процентные точки для статистик W[n\ W2n) и ТBп)
при логистическом распределении, а также при распределениях
Вейбулла и Коши приведены в табл. ЭЗ. Следующий пример иллю-
иллюстрирует возможность применения этих таблиц. Необходимо под-
подчеркнуть, что указанные таблицы можно использовать только
в том случае, когда параметры 0Х и 02 оценены методом макси-
максимального правдоподобия. При рассматриваемом подходе часто
требуются слишком трудоемкие вычисления, которые нельзя вы-
выполнить без применения вычислительной техники. Тем не менее
304
Глава 8
предлагаемые таблицы дают хорошее представление о предельно
дсстижимой точности, например, в отношении ширины довери-
доверительных интервалов.
Пример 8.18. Предположим, что требуется проверить гипотезу
о том, что срок службы некоторого изделия имеет экспоненциаль-
экспоненциальное распределение против альтернативных гипотез о совпадении
этого распределения с распределением Вейбулла. Рассмотрим
сроки службы 20 изделий Хи Х2, ..., Х20, выбранных случай-
случайным образом, и предположим, что каждый из них имеет следую-
следующую функцию распределения:
Требуется проверить гипотезу с=\ против альтернатив сф\.
Вычислим по указанным данным Х19 Х2, ..., Х20 методом
максимального правдоподобия оценку с. По табл. ЭЗ находим,
что Рг [0,743 < с < 1,5791 с = 1 ] « 0,96 при п = 20; следовательно,
правило „отклонять гипотезу (экспоненциальности) при с <, 0,743
и с> 1,579" — определяет критерий, уровень значимости которого
примерно равен 4%.
Мощность критерия по отношению к гипотезе о том, что функ-
функция распределения имеет вид
1-ехр[-(|)°'5] (т. е. с=0,5),
равна
1 _ рг [0,743 < с < 1,5791 с - 0,5] -
= 1—Рг [0,743 < (Э/0,5) < 1,579|с=1] =
= 1— Рг[0,3715<с< 0,7895|с=1]«0,95. (из табл. ЭЗ)
ЛИТЕРАТУРА
1. Anscombe F. J., Table of the Hyperbolic Transformation ^
Journal of the Royal Statistical Society, Series A, 113 A950),
2. Bennett C. A.,' Franklin N. L., Statistical Analysis in Chemistry and the
Chemical Industry, Wiley, New York, Chapter 5.
3. Cox D. R., Hinkley D. V., Theoretical Statistics, Chapman and Hall, Lon-
London, Halstead Press, New York, 1974, Chapters 3—5. [Имеется перевод:
Кокс Д. Р., Хинкли В. В., Теоретическая статистика.—М,: Мир, 1978.]
4. Dixon W. J., Massey F. J., Introduction to Statistical Analysis, 3rd ed.,
McGraw-Hill, New York, 1969, Chapters 7,8.
5. Durand D., Stable Chaos, General Learning Corporation, Morristown, N. J.,
1971, Chapters 19—21.
Критерии значимости и доверительные интервалы
305
6. Fischer R. A., Yates F., Statistical Tables for Biological Agricultural and
Medical Research, 6th ed., Hafner, New York, Oliver and Boyd, London, 1964.
7. Hald A., Statistical Theory with Engineering Applications, Wiley, New
York, 1952, Chapters 14,15. [Имеется перевод: Хальд А. Математическая
статистика с техническими приложениями.— М.: ИЛ, 1956.]
8. Hays W. L., Winkler R. L., Statistics Probability, Inference and Decision,
Vol. 1, Holt, Rinehart and Winston, New York, 1970, Chapter 7.
9. Pearson E. S., Hartley H. O., Biometrika Tables for Statisticians, Vol. 1,
Cambridge University Press, 1968.
10. Poch F. A., Sobre la Distribucion t No Central. I, II, Trabajos de Esta-
bistica, 4 A953).
11. Stephens M. A., EDF Statistics for Goodness of Fit and Some Comparisons,
Journal of the American Statistical Association, 69 A974).
12. Welch B. L., The Significance of the Difference between two Means When
the Population Variances are Unequal, Biometrika, 29 A938).
УПРАЖНЕНИЯ
При выполнении некоторых из предлагаемых упражнений потребуется сде-
сделать предположения относительно используемых моделей.
1. Требуется оценить долю писем, в которых отсутствует краткий код
адреса. Предполагая, что 1) эта доля составляет менее 10% и 2) выборочные
значения могут отбираться случайным образом, определите, как велика должна
быть случайная выборка, чтобы 95%-ный доверительный интервал для доли
писем без кода адреса был меньше 0,04%.
2. При проверке 100 единиц продукции производственной линии было
обнаружено два дефектных. Что можно сказать относительно процента брака
в исследуемом процессе?
3. Среднее время выхода кислородного конвертера на температурный ре-
режим для двух последовательных дней составило соответственно 22,0 и 20,2 мин.
а) Определите 99%-ный доверительный интервал для математического ожи-
ожидания изменения этого времени от одного дня к другому, если известно, что
дисперсия каждого из этих выборочных средних значений составляет 2,00 мин2.
б) Подтверждает ли этот доверительный интервал предположение о равен-
равенстве средних значений в разные дни.
4. Минимальный допустимый вес консервной банки равен 16 унциям.
Отклонение веса более чем на 0,5 унции ниже этого значения является осно-
основанием для отбраковки изделия. Какие ограничения надо наложить на выбо-
выборочное среднее значение, чтобы вероятность браковки не превосходила 0,001 при
а) л = К),
б) /1 = 20,
в) /i = 50?
Можно сделать предположение, что среднее квадратическое отклонение веса
консервной банки составляет 0,1 унции. (Используйте уровень значимости 0,01.)
5. Шариковые подшипники проходят проверку на овальность в специаль-
специальном измерительном устройстве, которое автоматически фиксирует отклонение
от заданных условии. Это устройство осуществляет только часть общей про-
процедуры заводского контроля. Возникло подозрение, что время, необходимое
для проведения проверки, у разных контролеров различно. Были отобраны
четыре контролера, и время, необходимое каждому из них на проведение про-
проверки, регистрировалось. Измерения повторялись каждым контролером шесть
раз. Приведенные ниже данные представляют собой время измерения в секундах.
а) Наблюдаются ли различия в скорости работы контролеров?
б) Какие предположения необходимо сделать при выбранном критерии
значимости?
306
Глава 8
Контролер
А
В
С
D
13
14
11
12
12
14
14
15
Время
11
16
11
14
измерения
14
15
13
16
12
14
14
13
13
16
11
16
6. Найдите 99%-ный доверительный интервал для разности средних зна-
значений времени измерения для контролеров А и D из упражнения 5.
7. Измерялось сопротивление проволок пяти типов. Утверждается, что
между сопротивлениями проволок разных типов в среднем нет различий.
Результаты проверки сопротивлений проволок каждого типа в шести выборках
приведены ниже.
а) Можно ли принять гипотезу Но об одинаковом значении среднего со-
сопротивления для проволок пяти типов?
б) Если принимают гипотезу #0> то что это значит?
Проволока А
0,126
0,131
0,126
0,127
0,124
0,130
0,128
0,124
Проволока В
0,121
0,121
0,124
0,122
0,120
0,124
0,125
0,120
Проволока С
0,121
0,119
0,126
0,128
0,126
0,124
0,122
0,127
Проволока D
0,129
0,132
0,136
0,139
0,130
0,132
0,137
0,136
Проволока Е
0,128
0,135
0,134
0,129
0,135
0,132
0,134
0,126
8. Проверьте по данным, приведенным в упражнении 7, гипотезу об одно-
однородности дисперсий. Определите 95%-ный доверительный интервал для общего
значения сопротивления, если принята нулевая гипотез-а.
9. Проверка скорости полимеризации проводится на нескольких образцах
полимеров. Предполагаемая средняя скорость полимеризации составляет 24%
в час. В восьми опытах получены следующие результаты: 23,6; 22,8; 25,7;
24,8; 26,4; 24,3; 23,9 и 25,0% в час.
а) Есть ли достаточные основания для того, чтобы утверждать, что полу-
полученные результаты не совместимы с предполагаемым значением средней ско-
скорости?
б) Какие предположения следовало бы сделать при проверке этой гипотезы?
10. Полный вес упаковки с натуральным красителем должен составлять
50 фунтов ± 2 унции. Известно, что дисперсия равна 0,91 унция2. Приведенные
ниже результаты получены при исследовании выборки 20 упаковок (вес ука-
указан в фунтах).
а) Соответствует ли средний вес упаковки, вычисленный по приведенным
ниже данным, предъявляемым требованиям?
б) Какие нужно сделать предположения?
50,10
50,07
49,93
49,81
49,70
49,76
50,08
50,18
49,79
51,02
49,97
49,88
50,23
50,30
50,24
49,90
50,10
50,13
49,89
50,01
Критерии значимости и доверительные интервалы
307
11. На двух станках производят одинаковую продукцию. Критическим
размером изделий является внешний диаметр. Установлено, что за один и тот
же период времени дисперсия этой величины для первого станка А составила
1,07 мм2, а для станка 5 — 0,84 мм2. Со станка А была взята выборка, вклю-
включающая 15 изделий, а со станка В — выборка из 10 изделий. Можно ли утвер-
утверждать, что математические ожидания исследуемых величин равны между собой,
если A^ = 45,3 мм, ^д = 46,1 мм?
12. Для определения прочности на разрыв целлофановых мешков разрабо-
разработан специальный критерий. Исследовались 15 мешков типа Л и 20 мешков
типа В. Каждый из мешков наполняли и бросали до тех пор, пока он не раз-
разрывался. Обозначим число падений мешка до момента разрыва через X. Полу-
Получены следующие результаты:
Тип
А
в
X
75,
89,
5
3
s
83
128
2
Д7
,20
п
15
20
а) Можно ли говорить, что мешки одного типа прочнее, чем другого?
б) Сделайте необходимые предположения и задайте значение вероятности
ошибки.
13. Анализ ранних произведений Жозефа Зайлича показал, что предложе-
предложения, включающие разное число слов, распределены в них следующим образом:
Число слов
2-3
4—5
6—8
9—12
13—16
17—20
21—24
25—28
Свыше
28
Доля пред-
предложений
0,010
0,034
0,067
0,091
0,210
0,174
0,181
0,143
0,09
Джо Зилч, наследник автора, заявил о находке рукописи ранее неопубли-
неопубликованного произведения своего предка. В выборке, состоящей из 2000 предло-
предложений, было обнаружено следующее распределение фраз по длине
Число слов
Число пред-
предложений
2-3
15
4—5
51
6—8
118
9—12
227
13—16
476
17—20
401
21—24
352
25—28
239
Свыше
28
121
Проверьте, могут ли эти данные подтвердить заявление Джо Зилча.
14. Определите 95%-ный доверительный интервал для разности двух сред-
средних, значений |ы^ — |ыд, если Хд=\3,8, А"я=16,2, /1,4=15, пв = 20, а также
известно, что дисперсии сравниваемых совокупностей равны а2 = 4,41. Вычи-
Вычислите 95%-ные доверительные интервалы раздельно для jn^ и \iB. Сравните
первый из доверительных интервалов с двумя последними.
15. Выборка А обладает дисперсией 55,4 фунт2, а выборка В— диспер-
дисперсией 87,3 фунт2.
а) Можно ли сказать, что выборки взяты из совокупностей с одним и тем
же значением дисперсии, если их объемы равны соответственно 15 и 12?
б) Какие при этом необходимо сделать предположения?
16. Дисперсия предела прочности на разрыв некоторого волокна состав-
составляет 35,63 фунт2. Ожидается, что внесенные в технологический процесс изме-
308
Глава 8
нения снизят указанную дисперсию. В выборке объема 15 были зарегистриро-
зарегистрированы следующие значения предела прочности на разрыв в фунтах:
Критерии значимости и доверительные интервалы
309
151
148
161
156
160
154
147
149
162
153
160
163
155
156
149
а) Привело ли изменение процесса к снижению дисперсии?
б) Установите критическую область, где должно производиться отклонение
нулевой гипотезы.
17. Исследован предел прочности на разрыв у шести плавок титанового
сплава. Из слитков каждой плавки было изготовлено пять образцов, и на них
проверена однородность дисперсий предела прочности. Шесть значений диспер-
дисперсий, измеренных в 10 000 фунт/дюйм2, оказались равными: 16,1; 30,3; 36,4;
7,3; 40,6 и 39,5.
а) Можно ли сказать, что все шесть дисперсий одинаковы?
б) Какие следует сделать предположения?
в) Считая дисперсии однородными, найдите 99%-ный доверительный интер-
интервал для предполагаемой величины общего значения дисперсии.
18. Исследовались потери веса одиннадцати резиновых стержней при испы-
испытаниях на износ. От каждого стержня было отрезано по два образца Для про-
проведения исследований. Один из них прошел вулканизацию при 80°, а дру-
другой—при 150°.
а) Можно ли утверждать, исходя из приведенных ниже данных, что на-
наблюдается значимое различие между средними потерями веса образцов, про-
прошедших различную вулканизацию, при а = 0,05.
б) Какая гипотеза проверяется?
Стержни
80°
150°
3
2
1
,02
,91
2
2
2
,22
,30
4
4
3
,60
,15
4
2
4
,53
,63
2
2
5
,31
,40
3
3
6
,11
,20
2
2
7
,70
,50
2
2
8
,58
,29
3
3
9
,27
,11
4
3
10
,192
,80 2
п
,90
,72
Температура
вулканизации
19. Проведено исследование предела прочности на разрыв шести различ-
различных по химической структуре твердых смол. Было взято по два образца каж-
каждой из них. При этом требовалось выяснить, вносят ли действия операторов
какое-нибудь смещение в результаты наблюдений. Двум операторам А и В
предложили испытать по одному образцу смол каждого типа.
а) Можно ли говорить, что наблюдаются различия между результатами
измерений у разных операторов?
б) Если да, то определите 95%-ный доверительный интервал для матема-
математического ожидания разности. Приведенные данные измерены в фунтах на
квадратный дюйм.
Смола I 127 135 138 139 146 152
Оператор Л
Оператор В
5240
5230
4975
4980
5050
5020
5075
5080
4795
4750
5190
5120
20. Температура в автоклаве регистрируется через равные промежутки
времени. Для проведения некоторого эксперимента потребовалось поддерживать
заданную температуру. Температура регистрировалась в течение двух последо-
последовательных дней в случайные моменты времени. В первый день было зафиксиро-
зафиксировано 16 значений температуры со средним квадратическим отклонением 15,6,
во второй день —21 значение со средним квадратическим отклонением 9,8.
Можно ли утверждать, что наблюдения относятся к одной совокупности?
21. В одной из общин 92% жителей получили соматическую вакцину Са-
Сабина, а в другой общине только 87%. Численность общин составляет соответ-
соответственно 1200 и 1520 жителей. Можно ли говорить о том, что в одной из общин
вакцинация проходит более активно, чем в другой?
22. Найдите 95%-ный доверительный интервал для дисперсии коэффициента
преломления различных образцов стекла, если по выборке, включающей 10 об-
образцов, получены следующие результаты:
1,589 1,587 1,559 1,596 1,583
1,569 1,574 1,592 1,590 1,561
23. Ожидается, что число дефектных шин среди изготовляемых заводом Л
должно составлять три шины в неделю. В течение последних 20 недель было
обнаружено 47 дефектных шин. Можно ли сказать, что наблюдается значимое
снижение уровня брака?
24. Пяти лабораториям было поручено участвовать в проведении хими-
химического анализа образцов каменного угля с целью определения содержания
в них золы. Один образец был расколот на 40 частей, и в каждую из лабора-
лабораторий отправили по восемь кусков. Дисперсии результатов измерений в разных
лабораториях получились следующими: 3,86; 4,27; 1}35; 3,90 и 1,64. Можно
ли отклонить гипотезу об однородности дисперсий?
25. Ожидается, что после определенной термической обработки образцов
стали их предел прочности на разрыв возрастет приблизительно на
1200 фунт/дюйм2. Укажите этапы процедуры статистической проверки того, что
указанный показатель удалось повысить, по крайней мере, на 1200 фунт/дюйм2.
Какие при этом нужно сделать предположения? Как выбрать гипотезу, уровень
значимости и мощность критерия?
26. Одним из методов количественного анализа величины износа шины
является измерение глубины проникновения щупа в канавку на рисунке про-
протектора в определенном месте шины. Есть подозрение, что значительная часть
дисперсии измерений связана с действиями контролеров. Чтобы выделить из
общей дисперсии измерений указанную часть» трех контролеров попросили про-
провести по 12 независимых измерений в одной и той же точке. Результаты изме-
измерений приведены ниже.
а) Однородны ли дисперсии измерений, проведенных разными контроле-
контролерами?
б) Отличается ли дисперсия измерений, проведенных контролером Зилчем,
от дисперсий, которые имеют место при измерениях, проводимых контроле-
контролерами X и К, если предположить, что измерения, проводимые двумя послед-
последними, характеризуются одинаковой дисперсией?
Объясните различие между а) и б).
Контролер X Контролер Y Контролер Зилч
121
130
127
119
121
127
124
126
126
131
125
123
120
136
138
136
129
117
124
135
128
112
119
134
141
ПО
134
113
111
135
113
139
118
134
123
129
исследовании восьми
0,136
; о,
139; 0,132;
27. Измеряется сопротивление проволоки D. При
образцов получены следующие результаты: 0,129; 0,132:
0,137; 0,125 и 0,136.
а) Есть ли достаточные основания для того, чтобы исключить из выборки
одно или несколько значений?
310
Глава 8
б) Какие предположения были сделаны при использовании статистиче-
статистического критерия?
28. Для 10 выборок, каждая из которых включала по 6 образцов вини-
виниловых стержней, было проведено измерение удлинений этих стержней. Ниже
приведены средние значения удлинений в процентах для каждой из выборок:
781, 726, 719, 735, 742, 722, 730, 728, 742 и 736. Можно ли классифицировать
некоторые из приведенных средних значений как выбросы, если используется
а = 0,05?
29. Проверьте, есть ли выбросы в результатах измерений контролера
Зилча, приведенных в упражнении 26. (Используйте а = 0,01.)
30. Выясните, есть ли выбросы в данных упражнения 10.
31. Проверьте, есть ли выбросы среди данных упражнения 5 из гл. 12.
32. Используя критерий согласия, исследуйте данные упражнения 13
из гл. 5.
33. Используя критерий согласия, исследуйте данные упражнения 14
из гл. 5.
34. Используя критерий согласия, исследуйте данные упражнения 16 из гл. 5.
35. Используя критерий согласия, исследуйте данные упражнения 15
из гл. 5.
36. Астрономы М. Л. Хумасон и Н. В. Майал определяли поправку
Критерии значимости и доверительные интервалы
15
на
красное смещение (в км/сек) для галактик типа SO. Ниже приведены резуль-
результаты, полученные в серии из 10 наблюдений.
Номер по
каталогу NGC 1332 3607 3998 4111 5308 5866 6661 6703 7625 7679
М. Л. Хумасон 1507 858 1205 832 2206 924 4607 2592 1930 5378
Н. В. Майал 1471 778 1155 915 2194 1033 4430 2670 2050 5278
[Данные взяты из Humason, Mayall, Sandage, Astronomical Journal, 61 (April,
1956).]
а) Можно ли обнаружить расхождения в результатах, полученных двумя
астрономами?
б) Какие сделаны предположения при использовании критерия?
37. Исследовалась сила сцепления при комнатной температуре двух типов
клейких веществ: изобутила 2-цианакрилата и MBR-4197. Приведенные ниже дан-
данные представляют собой значения силы сцепления, измеренные в фунтах на
квадратный дюйм для каждого из образцов.
Изоб. MBR
Изоб. MBR
Изоб. MBR
Изоб. MBR
365
169
210
297
228
518
403
473
329
457
146
163
213
300
218
419
437
396
424
363
222
121
205
283
134
461
441
402
346
571
227
250
218
202
234
477
498
330
352
495
а) Проверьте гипотезу о том, что выборки имеют одинаковые дисперсии.
61 Взяты ли эти выборки из совокупностей с одинаковыми средними зна-
значениями?
в) Какие предположения были сделаны в пп. а) и б)? Подтверждаются
ли они?
38. В рамках исследований, описанных в упражнении 37, для дополни-
дополнительной проверки было испытано еще 20 образцов клейких веществ каждого
типа. Клейкое вещество на каждый образец было нанесено за 24 часа до испы-
испытаний. Результаты приводятся ниже.
311
Изоб. MBR
Изоб. MBR
Изоб.
MBR
311
330
249
351
335
517
403
472
329
457
Изоб.
298
297
353
319
293
419
437
396
424
363
MBR
328
362
260
543
308
465
442
402
346
571
358 477
329 498
332 330
324 352
328 495
а) Можно ли утверждать, что выдержка существенно влияет на силу
сцепления?
б) Определите, что понимать под словами „существенно влияет".
в) Определите по двум выборкам, есть ли различия в средней силе сцеп-
сцепления у сравниваемых клейких веществ после выдержки.
39. Изучая усовершенствованную программу школьного гигиенического и
физического воспитания г-н Джозеф Зилч разослал анкеты в 463 школы, из
них 120 в сельские общеобразовательные школы, 200-—в городские общеобра-
общеобразовательные школы и 143 —в частные школы. Процент удовлетворительных
ответов составил для
сельских общеобразовательных школ
городских общеобразовательных школ
частных школ
89,2%,
85,0%,
73,4%.
Джозеф сделал вывод, что имеет место значимое различие между долями
удовлетворительных ответов. Согласны ли вы? Почему?
40. Определите 95%-ный доверительный интервал для величины разности
между долями удовлетворительных ответов для общеобразовательных и част-
частных школ.
41. В течение 20 последовательных недель число невыполненных заказов
одной небольшой почтовой фирмой составляло: 12, 15, 18, 16, 8, 4, 21, 15,
14, 7, 25, 10, 16, 13, 12, 17, 11, 15, 10, 15.
а) Согласуются ли эти данные с предположением о том, что среднее число
невыполненных в неделю заказов составляет 12?
б) Какие были сделаны предположения?
42. Два оператора провели 14 независимых опытов по исследованию тем-
температуры воспламенения эмали одного состава. Каждый оператор проверил
семь образцов. Ниже приведены результаты опытов.
а) Наблюдается ли значимое различие между средними значениями резуль-
результатов, полученных разными операторами?
б) Какая проверялась гипотеза, какие были сделаны предположения и
принят уровень значимости?
Оператор Л I 1450 1425 1420 1410 1370 1360 1270
Оператор В \ 1430 1420 1380 1320 1320 1290 1280
43. В отчете, опубликованном Национальной академией наук (Doctoral
Scientists and Engineers in the United States, 1973 Profile, March, 1974), при-
приведены данные, свидетельствующие о том, что в 1973 г. безработными были
3,9% женщин-инженеров и докторов наук. При опросе 300 женщин-инженеров
и докторов каук в восточных штатах оказалось, что среди них 5% безработ-
безработных. Совместима ли последняя оценка с отчетным уровнем безработицы?
Сформулируйте ваши предположения.
44. Для того чтобы определить, сокращается ли время сварки на отлив-
отливках, если при литье вместо сырой формовочной смеси использовать сухую
смесь или формовочную смесь с СО2, было проведено специальное исследова-
исследование. Совершенно ясно, что стоимость литья в случае сухой формовочной смеси
312
Глава 8
или смеси с С02 выше, но есть мнение, что это может быть оправдано, если
стоимость сварки значимо уменьшится. Ниже приведены значения времени
сварки в минутах при использовании формовочных смесей разных типов.
а) Можно ли сказать, что имеет место значимое уменьшение времени сварки,
если предположить, что все факторы, кроме рассматриваемого, поддержива-
поддерживались на одном уровне?
б) Какие нужно сделать добавочные предположения?
Сырая смесь
Сухая смесь
Смесь с СО 2
45. Для того чтобы выяснить, какому виду транспорта оказывают пред-
предпочтение студенты, добираясь до университетского городка и обратно, в двух
университетах опросили группы по 1000 студентов. Ниже приведены их ответы.
19
21
14
28
15
20
14
11
15
29
12
19
15
21
17
Пешком
На велосипеде
На частном автомобиле
Автобусом
Университет Л
407
313
171
109
Университет В
302
266
244
188
А отличается от
а) Можно ли говорить о том, что дорога в университет
дороги в университет В?
б) Что можно сказать относительно „моды на транспорт"?
в) Какие были сделаны предположения?
46. На заводе микроэлектронного оборудования алюминиевую проволоку
очень малого диаметра (примерно 0,003 дюйма) сваривают ультразвуковым
методом. Для определения прочности полученного соединения ряд образцов
испытали на разрыв; силы, при которых происходит разрыв, измерялись в грам-
граммах. Приведенные ниже данные сгруппированы в пределах пятиграммовых
интервалов. Они представляют собой силы связи, измеренные на 1000 образ-
образцах соединения, выполненных на одном устройстве.
Сила связи
16-20
21-25
26-30
31-35
36-40
41—45
46—50
51-55
Частота
2
4
3
10
19
21
43
89
Сила связи
56-60
61-65
66-70
71—75
76—80
81—85
86—90
Частота
112
206
206
222
169
55
13
Критерии значимости и доверительные интервалы
313
б)
Обсудите
Время, v
0- 1,
1,0- 5,
5,5—10,
проблему подбора закона
[ Число отказов
0 51
5 20
5 7
распределения
Время, ч
10,5—15,5
15,5—20,5
20,5—25,5
по этим данным.
Число отказов
8
2
2
48. Случайные величины Хъ Х2, ..., Хщ независимы и распределены как
JV @, о^); случайные величины Уъ Y2, ..., УПг независимы и распределены
как N @, а2).
а) Постройте критерий отношения правдоподобия для проверки гипотезы
о1 = о2 против альтернативной гипотезы ог Ф а2.
б) Покажите, что критерий является двусторонним и использует хвосто-
хвостовые области F-распределения, точность аппроксимации которых в случае, если
нарушено равенство nl = n2, низка.
49. Общее число наблюдений, представленных случайными величинами
Уъ ^2» •••> Yw равно п. Известно, что эти наблюдения взяты из случайной
выборки, в которой каждая величина имеет плотность вероятности
но неизвестно, составляют ли рассматриваемые п значений полную выборку
или же усеченную выборку, полученную путем отбрасывания г наибольших
и г наименьших значений из выборки объема (п-\-2г).
Покажите, что критерий проверки гипотезы Но (г = 0) о том, что п наблю-
наблюдений представляют собой полную исходную выборку, против альтернативных
гипотез (г > 0) о том, что исходная выборка была усечена рассмотренным выше
способом, является равномерно наиболее мощным.
50. Определите мощность рассмотренного выше критерия по отношению
к а) альтернативе г = \ и к б) альтернативе г = 2, если п = Б при уровне зна-
значимости 0,05.
51. Случайные величины Х{, Х2, ..., Хп взаимно независимы и
2,
п.
а) Покажите, что величина М = тах(Хъ Х2,
максимального правдоподобия для 9.
б) Найдите такое с, чтобы E[cM] = Q.
в) Найдите такое с, чтобы E[(cM — QJ] было минимально.
г) Найдите такое с, чтобы Е [ | сМ — б | ] было минимально.
Хп) является оценкой
а) Постройте по приведенным данным гистограмму.
б) Подберите соответствующее распределение и проверьте качество под-
подгонки по критерию согласия.
47. В лаборатории контроля качества авиационного оборудования для
выявления неисправного блока проводят так называемые „термические упраж-
упражнения", состоящие в одновременном воздействии вибрации и циклического
изменения температуры. Приведенные ниже данные представляют собой время,
прошедшее до отказа 90 блоков оборудования, подвергавшихся испытанию
методом „термических упражнений".
а) Постройте по этим данным гистограмму и подберите подходящее рас*
пределение.
Глава 9
МЕТОДЫ, СВОБОДНЫЕ
ОТ РАСПРЕДЕЛЕНИЯ
Методы, свободные от распределения
315
9.1. РОБАСТНОСТЬ
В предыдущих главах был описан ряд статистических методов.
Полезность каждого из них подтверждается большим числом прак-
практических применений, и любой из них можно использовать, если
только статистик подтвердит правильность вывода о возможно-
возможности применения метода.
Однако следует отметить, что большинство из этих методов
было введено в предположении, что удовлетворяются некоторые,
точно определенные предпосылки. Например, /-критерий осно-
основан на предположениях, что 1) наблюдения представляются неза-
независимыми случайными величинами, 2) эти случайные величины
имеют одно и то же математическое ожидание и одинаковые
дисперсии, 3) все они нормально распределены. Теперь если
объективно и внимательно рассмотреть указанные предположе-
предположения, то нельзя не сделать вывода, что точное выполнение не
только всех, но и некоторых из них было бы большой удачей.
Тем не менее широко распространенный подход, теоретическое
обоснование которого и соответствующие статистические таблицы
можно встретить в работах многих авторов, требует точного
выполнения всех оговоренных условий. При этом предполагается,
что реальные условия не так уж сильно отличаются от тех иде-
идеальных условий, которые постулировались при формальном обо-
обосновании методов.
Очевидно, что нарушение предпосылок окажет на результаты
одних статистических процедур более сильное воздействие, чем
на результаты других. Действительно, чем меньше это влияние,
тем шире область, где результаты, основанные на „стандартных
предпосылках", будут практически приемлемыми, и с тем боль-
большей уверенностью можно использовать стандартные процедуры
так, как будто бы выполняются эти предпосылки.
Наиболее ценными, конечно, являются методы, которые можно
применять в широком диапазоне изменения условий; разработке
таких методов всегда уделялось значительное внимание. Слабая
чувствительность к отклонениям от стандартных условий называ-
называется робастностью. Методы, практически применимые в широком
диапазоне реальных условий, называют робастными.
Очевидно, что робастность является относительным понятием,
которое не может быть определено точно. Оно связано с опре-
определенным типом отклонений от стандартных условий.
Так, можно говорить о робастности по отношению к неодно-
неоднородности дисперсий, к отсутствию независимости, к нарушению
нормальности и т. д. Очень часто подразумевают робастность
только по отношению к нарушениям нормальности, хотя, конечно,
это не единственный вид робастности, который представляет
интерес.
Примером критерия, не очень устойчивого к нарушениям
нормальности, является критерий равенства дисперсий двух или
нескольких совокупностей. Влияние отклонений от нормальности
на этот критерий так велико, что он может использоваться как
хороший критерий нормальности (конечно, если в действитель-
действительности дисперсии однородны).
Существуют и другие методы проверки неоднородности диспер-
дисперсий. Один из наиболее перспективных предложен Левене [14].
Идея этого метода состоит в том, что в выборке размера nt из
совокупности П; непосредственно наблюдаемые случайные пере-
переменные ХA, Х/2, ..., Xini заменяются некоторыми случайными
_ _ ni
величинами Yif = \Xif — X(\, где X^nj1 2 Х(/. Равенство сред-
/=i
них значений Y эквивалентно равенству дисперсий совокупно-
совокупностей П1, II2, ..., TLk. Переменные Yily ..., Yini для каждой
совокупности не являются независимыми величинами, тем не
менее, по-видимому, можно построить полезные на практике
критерии равенства средних значений, которые были бы более
робастными (по отношению к нарушениям нормальности), чем
стандартные критерии равенства дисперсий.
9.2. МЕТОДЫ, СВОБОДНЫЕ
ОТ РАСПРЕДЕЛЕНИЯ
Робастность является сравнительной характеристикой. Для
каждого конкретного случая достаточно просто сделать вывод
о том, что одна из процедур „более робастна", чем другая (хотя
выбор точной числовой характеристики для сравнения может
оказаться трудной задачей). Идеальная в смысле робастности
процедура должна обладать одинаковыми характеристиками при
любом распределении исследуемых случайных величин.
Существуют ситуации, где этого можно добиться по отноше-
отношению к определенным свойствам статистических критериев при
некоторых практически несущественных ограничениях. Например,
316
Глава 9
требования независимости или идентичности распределений слу-
случайных величин обычно выполняются.
Чаще всего независимости от распределения удается добиться
при вычислении статистики критерия и ее распределения в слу-
случае справедливости нулевой гипотезы.
Например, в разд. 9.6.1 рассматриваются критерии для про-
проверки гипотезы о том, что функции распределения Fx(x) и FY{y)
случайных величин X и Г идентичны, т. е. Fx(x) = FY(y)u=x.
На множествах независимых случайных величин, распределенных
как X и 7, строится статистика Т, для вычисления которой
не требуется знания функций Fx(x) и FY(y) и распределение
которой полностью известно, когда Fx (х) = FY(y)y=x (если только
эти распределения непрерывны). Критерии, описанные в разд, 8.9.3,
обладают этим свойством. Далеко не всегда удается распростра-
распространить свойство „независимости от распределения" на ситуации,
когда имеют место отклонения от нулевой гипотезы, поскольку
такое обобщение требует очень детального описания истинного
распределения. Таким образом, критерии, функция мощности
которых оказывается полностью „свободной от распределения",
встречаются редко. Тем не менее свойство „независимости от
распределения" может иногда сохраняться в пределах более или
менее строго ограниченной области возможных распределений
[определенной, например, как Fx(x) = FY{y)y=x+6 для некото-
некоторого действительного числа б].
Можно непосредственно показать, что свободный от распре-
распределения критерий, основанный на независимых случайных вели-
величинах, должен зависеть только от их взаимного расположе-
расположения после упорядочения по величине. Следовательно, если име-
имеется N независимых случайных переменных Z19 Z2, ..., ZN
и Zai <Za2 < ... < ZaN> то используемый статистический критерий
является функцией от N величин, полученных путем замены значе-
значений Za. на (заранее установленное) число а;-. Обычно полагают
aj = Gty или ay = # + 1—об/» причем это справедливЬ для любого
заданного множества переменных (см. разд. 9.6.2 и 9.6.4.).
Такие критерии известны как ранговые порядковые статистики.
Их следует отличать от порядковых статистик, рассмотренных
в гл. 6. Последние используют действительные значения случай-
случайных величин.
Важно отметить, что ранговые порядковые статистики зависят
только от порядка расположения значений случайных величин.
По этой причине для того, чтобы имела место независимость от
распределения, статистика критерия должна оставаться неизмен-
неизменной при любом монотонном преобразовании1).
х) О ранговых критериях см.: Гаек Я., Шидак 3. Теория ранговых кри-
критериев.— М,: Наука, 1971.— Прим. ред.
Методы, свободные от распределения
317
Свободные от распределения методы можно с уверенностью
использовать на практике в силу их применимости в широком
диапазоне изменения условий, но, кроме того, в некоторых ситуаци-
ситуациях только они и могут быть применены. Действительно, иногда мы
можем располагать лишь ранговыми порядками случайных вели-
величин. При этом следует пользоваться свободными от распределе-
распределения процедурами. Такой подход выбран в эксперименте по дегус-
дегустации, описанном в примере 9.1.
Наконец, рассмотренные методы хороши еще и тем, что рабо-
работать с ними часто оказывается проще, чем со стандартными
методами, связанными со специальными распределениями. Глав-
Главное же, чего невозможно избежать, —это потеря информации,
заключенной в числовых значениях случайных величин, которые
умышленно игнорируют.
Пример 9.1. Хорошо известно, что сахар слаще глюкозы, но
глюкоза как составная часть джема обладает некоторыми поло-
положительными свойствами. Как будут реагировать отдельные
потребители на использование в джеме глюкозы, если не рас-
рассматривать стоимость джема? Для проведения эксперимента
к четырем предпринимателям обратились с просьбой изготовить
земляничный и малиновый джем. Джемы каждого вида были
изготовлены а) обычным способом и б) с заменой 1/4 части сахара
на глюкозу. 48 дегустаторов сравнивали джемы а) и j6), чтобы
установить, 1) какой из них лучше и 2) какой слаще. Несмотря
на то что каждый раз дегустаторов просили высказать свое
мнение (хотя бы и не совсем твердое), в некоторых случаях это
не было сделано. Результаты эксперимента приведены в табл. 9.1.
(Предприниматель II не смог изготовить малиновый джем.)
Приведенные данные представляют собой результаты сравнения,
а не измерения свойств джема по непрерывной шкале. Например,
при дегустации земляничного джема, изготовленного предпринима-
предпринимателем I, 21 из 48 дегустаторов оказали предпочтение обычному
джему и нашли его более сладким, чем джем, в котором часть
сахара была заменена глюкозой. Другие 10 дегустаторов также
оказали предпочтение обычному джему, но при этом нашли его
менее сладким, чем джем измененного состава.
Приведенные результаты можно использовать для ответа на
следующие вопросы.
1. Оказывает ли влияние замена некоторой части сахара глюко-
глюкозой в джемах различного вида, изготовленных разными пред-
предпринимателями, на а) их вкус и б) заключение дегустаторов?
2. Есть ли взаимосвязь между вкусом джема и заключением
дегустаторов?
318
Методы, свободные от распределения
319
48 дегустаторами х
сделанные
И
О
0)
S
Заключения о сладости
Малиновый
Земляничный |
Слаще
Слаще |
безраз-
безразлично
с глюкозой
обычный
состав
Предпочитаемый
состав джема
безраз-
безразлично
с глюкозой
обычный
состав
Предпочитаемый
состав джема
Предприниматель
оо —
00 <?>^
СО<У> О
Обычный
С глюкозой
Безразлично
оо сч
о to о
— ^- <м
Обычный
С глюкозой
Безразлично
О О^
t^ t^ О
°°, 2 ~
Обычный
С глюкозой
Безразлично
1—1
OO<N
°^п ^
—.00 -н
Обычный
С глюкозой
Безразлично
о —
Обычный
С глюкозой
Безразлично
III
о© -«
юо <м
Обычный
С глюкозой
Безразлично
оо ^
о> <м о
ЮО -ч
Обычный
С глюкозой
Безразлично
>
ш
2
3. Одинаков ли эффект введения глюкозы в земляничный и
малиновый джемы?
4. Согласуются ли эффекты на продукции разных предпри-
предпринимателей?
5. Становится ли слаще джем при замене сахара глюко-
глюкозой?
Заметим, что заключение дегустаторов „безразлично" не содер-
содержит информации для ответа на одни вопросы, такие, как 5, а
для ответа на другие, такие, как 3 и 4, оказывается информа-
информативным.
9.3. НЕПАРАМЕТРИЧЕСКИЕ МЕТОДЫ
В разд. 9.2 рассматривалась гипотеза типа Fx(x) = FY(y)y=x.
Вид распределений здесь не указан, в частности, не указаны
значения параметров. Гипотезы такого типа называются непара-
непараметрическими. Это прилагательное можно использовать и с дру-
другими существительными, а именно непараметрический критерий
(в котором не используются значения параметров) и непарамет-
непараметрическое оценивание („естественных" количественных характерис-
характеристик, таких, как границы, между которыми с определенной веро-
вероятностью попадают значения случайной величины). Некоторые
из этих методов рассматриваются в разд. 9.9.
Во многих ситуациях применимость термина „непараметри-
„непараметрический" оказывается сомнительной. Рассмотрим, например, гипо-
гипотезу о том, что независимые случайные величины Zx, Z2, ..., ZN
распределены по одному и тому же нормальному закону. Эта
гипотеза непараметрическая в том смысле, что ни среднее зна-
значение, ни среднее квадратическое отклонение заранее не опреде-
определены. Однако третий и четвертый стандартные моменты в рамках
данной гипотезы определены (как 0 и 3 соответственно), а это
равноценно заданию параметров распределения. Вообще область
применения прилагательного „непараметрический" можно распро-
распространить на те случаи, когда наиболее явные параметры (число
которых конечно) не влияют на характеристики процедуры.
Иногда возникает путаница в понятиях „свободный от рас-
распределения" и „непараметрический". Это происходит потому, что
оба термина указывают на то, что некоторые количественные
изменения не оказывают влияния на результаты, и это сходство
действительно должно вызывать небольшие трудности в различе-
различении двух указанных понятий. Конечно, оба эти прилагательные
могут употребляться и одновременно, но не всегда. Вообще говоря,
понятие „свободный от распределения" подразумевает более силь-
сильное требование, чем „непараметрический".
320
Глава 9
Методы, свободные от распределения
321
9.4. ПЛАН ОСТАВШЕЙСЯ ЧАСТИ ГЛАВЫ
Существует довольно много свободных от распределения и
(или) непараметрических критериев. В этой главе рассматрива-
рассматриваются те из критериев указанного типа, которые, как мы
полагаем, являются наиболее общеупотребительными или полез-
полезными для расширения кругозора. Сначала сделаем краткий
обзор проблем, которым посвящены последующие разделы,
поскольку эти проблемы несколько различаются по своей сути и
области приложения. В разд. 9.5 рассматриваются критерии, осно-
основанные на знаках и игнорирующие фактические значения случай-
случайных величин; в разд. 9.6 описана группа критериев проверки иден-
идентичности распределений. Наиболее известный из них —критерий
Вилкоксона —специально предназначен для выявления различий
в расположении, которые могут быть представлены разностями
между математическими ожиданиями случайных величин. Однако
он непосредственно не связан со сравнением математических ожи-
ожиданий*. Метод построения критерия можно изменить так, чтобы
он был более чувствительным к различиям в рассеянии или,
если это требуется, к другим видам различия между совокупно-
совокупностями (далее будут описаны эти модификации, а также неко-
некоторые способы распространения критерия на случай двух вы-
выборок).
В разд. 9.3 упоминалось, что ранговая порядковая статистика
не обязательно должна принимать целочисленные значения
1, 2, 3, .... В отдельных случаях можно улучшить некоторые
свойства (например, чувствительность) свободных от распределе-
распределения критериев (которые могут быть и обычно бывают связаны
с распределениями специального вида) путем подходящего выбора
системы меток. Способы, использующиё^метки, которые особенно
полезны, если в действительности имеет место (приближенно) нор-
нормальное распределение, рассматриваются в разд. 9.6.4. Критерии
остаются при этом свободными от распределения (и непараметриче-
непараметрическими), и существует некоторая гарантия избежать ошибок,
которые могли бы иметь место, если бы использовались стан-
стандартные методы, основанные на нормальном распределении.
В разд. 9.7 внимание сконцентрировано на проблемах двух
выборок. Рассматриваются методы ранговой корреляции и кон-
кордации.
До сих пор речь шла только о процедурах проверки гипотез.
Свободные от распределения методы могут успешно применяться
и при решении некоторых задач оценивания. Они рассмотрены
в разд. 9.8 (толерантные области). В этом же разделе описан
метод вероятностного интегрального преобразования. В разд. 9.9
рассмотрен подход, основанный непосредственно на этом преоб-
преобразовании.
9.5. КРИТЕРИИ, ОСНОВАННЫЕ НА ЗНАКАХ
Один из простейших способов записи данных — это регистра-
регистрация того, превышает ли значение наблюдаемой величины заданный
уровень или оказывается меньше его. Хотя этот способ записи
результатов и приводит к потере значительного количества ин-
информации, можно построить полезные критерии для работы с
данными такого типа. Эти критерии в значительной степени об-
обладают таким свойством, как независимость от распределения,
но они не обязательно являются непараметрическими.
Пусть \i — медиана совокупности значений X. Требуется про-
проверить гипотезу \i = \iQ. Предположим, что взята случайная вы-
выборка, содержащая п элементов, и каждый элемент несет инфор-
информацию только о том, больше или меньше наблюдаемое значение X
величины (л0. (Будем предполагать, что совокупность достаточно
велика и наблюдения, представляющие случайные величины,
можно рассматривать как взаимно независима.)
Если pt = ^0» то ПРИ условии, что т из п значений X равны ^0,
число элементов, для крторых наблюдаемое значение меньше (л0,
распределено по биномиальному закону с параметрами (п — т), 1/2.
Таким образом,
Рг[г значений меньше jA0|m значений равно jao] =
"(n"")> /- = 0,1,2, ...,(я-Л1). (9.1)
При /п = 0, что можно принять, когда X—непрерывные случай-
случайные величины, справедливо равенство
Рг[г значений меньше щ] = (^J 2'\ г = 0, 1, 2, ..., п. (9.2)
В любом случае распределение (условное) числа значений,
меньших \i0, можно использовать для получения границ значи-
значимости, определяемых неравенствами типа
2GJ
Критические области при проверке гипотезы |л = |а0 в случае
одностороннего критерия имеют вид
(Число значений, меньших \io)^Ra
или
(Число значений, меньших |ло)^я — т—Ra,
и уровень значимости каждой из них не превосходит а. Первое
из выражений следует использовать, если альтернативные гипо-
гипотезы определены как \i > ji0, а второе в случае ц < |л0.
11
819
322
Глава 9
Если альтернативные гипотезы включают как случай \i > fx0,
так и \i < [х0, следует использовать двусторонний критерий с
критической областью
Методы, свободные от распределения
323
[(Число значений, меньших [хо)
+ [(Число значений, меньших \io)^n— т — Ra/z].
В табл. С приложения приведены значения 7?о,оь Ro,os и
#о,1о для л = 1, 2, ..., 50. Для больших значений п можно исполь-
использовать аппроксимацию симметричного биномиального распреде-
распределения нормальным распределением, как.это сделано в следую-
следующем примере.
Пример 9.2. Нужно сравнить новый метод очень быстрого
(однако грубого) измерения влажности ткани с существующим
(также быстрым) способом, про который известно, что он дает
несмещенные оценки. Результатом измерения для обоих методов
служит показание стрелочного прибора. Предварительно для
того, чтобы убедиться по крайней мере в несмещенности нового
метода, влажность нескольких кусков ткани была измерена двумя
методами. В серии, состоящей из 150 измерений, 14 раз пока-
показания приборов оказались неразличимыми, а 53 раза новым мето-
методом была зафиксирована более высокая влажность.
В этом примере мы имеем п= 150, т = 14. Проверим гипотезу
о том, что медиана разностей между двумя показаниями (для
одного и того же куска ткани) равна нулю. Проверка этой гипо-
гипотезы не совпадает с проверкой несмещенности нового метода;
при проверке несмещенности следует рассматривать гипотезу о
равенстве математического ожидания разностей нулю. Тем не
менее проведение описанного исследования было бы полезным.
В силу симметрии вместо числа разностей, меньших 0, можно
использовать (как это делалось выше) число разностей, больших 0.
Требуется вычислить
г=0\
Решение этой задачи достаточно утомительно, поэтому удобно
использовать аппроксимацию E.9) —E.11), описанную в
разд. 5.2.4.
При использовании этой аппроксимации в данном случае
получаем
го
где X = 1Л07,25 —}Л65,25 = — 2,495. Используя табл. В прило-
приложения, находим
53
Таким должен быть уровень значимости для одностороннего
критерия; для двустороннего он равен примерно 0,0126.
При использовании как одностороннего, так и двустороннего
критерия проверяемая гипотеза о несмещенности нового метода
должна быть подвергнута серьезному сомнению.
Отметим, что в данном случае" была рассмотрена параметри-
параметрическая гипотеза (^ = 0), но применен свободный от распределения
метод. (Использование функции нормального распределения ка-
касается только численного способа вычисления вероятностей.)
Пример 9.3. Чтобы определить, оказывает ли жарение арахиса
воздействие на протеин, была проанализирована прибавка веса
десяти пар крыс в граммах за две недели, причем одна из крыс
в каждой паре получала протеин, потребляя сырой арахис, а
другая жареный. Данные анализировались с использованием
критерия знаков.
Данные
Сырой арахис 61 60 56 63 59 63 59 56 44 61
Жареный 55 54 56 59 60 61 57 54 62 58
Знак ++ 0 + - + + + - +
Яо: прибавка в весе одинакова при потреблении как сырого
так и жареного арахиса.
Нг\ прибавка в весе при откорме сырым арахисом выше.
а: 0,05.
Статистика. Рассмотрим разности (сырой арахис) — (жареный
арахис) и подсчитаем число положительных знаков разностей.
При этом найдем Т = 7.
Критическая область. Поскольку используется односторонний
критерий, область отклонения гипотезы задается неравенством
Т>9 — t, где t=\ при а-0,0195, t = 2 при а = 0,0898, причем
Т — число положительных знаков. Таким образом, Яо отклоняется
в случае Т>8 при а = 0,0195 или 7>7 при а = 0,0898.
Решение. Гипотеза Яо отклоняется при а = 0,0898.
9.5.1. Серии знаков
Последовательность знаков можно использовать как основу
для различных критериев. Можно рассмотреть серии знаков, т. е.
последовательности значений, превышающих (или не достигаю-
11*
324
Глава 9
щих) величины \i0. Вероятность того, что длина серии окажется
равной т, составляет 2"т.
Вероятности, связанные с сериями, сведены в таблицы Сви-
дом и Эйзенхартом [Swed, Eisenhart, Tables for Testing Ran-
Randomness of Groupings in a Sequence of Alternatives, Annals of
Mathematical Statistics, 14 A943).]
Данные, взятые из этих таблиц, частично приведены в табл. Т
приложения.
Пример 9.4. Проведены измерения радиальной скорости звезд,
яркость которых превышает видимую звездную величину 7,0;
звезды расположены в двух областях в окрестности точки с ко-
координатами 18*30"* и 6 = 30°. Каждая область представлена ре-
результатами измерения скоростей (в км/час) восьми звезд, приве-
приведенными ниже.
Область 1 —21 2 —38 —26 —29 8 —27 16
Область 2 —22 —25 —36 —6 —23 6 5 —23
Упорядочивая эти значения по абсолютной величине и под-
подчеркивая данные, относящиеся к области 1, получаем
—23 —22
-38
—21
-36
-6
-29
2
—27
5
-26 -
6
—25
8
—23
16
Последовательность содержит девять серий. Обращаясь к табл. Т
приложения (при N1 = N2 = 8), находим, что критические зна-
значения для двустороннего критерия при уровне значимости 5%
равны 4 и 13. Следовательно, вероятность того, что число серий
не превышает 4 или не меньше 13, составляет менее 5%. Можно
утверждать, что при данной выборке критерий серий не позво-
позволяет обоснованно отклонять гипотезу о равенстве радиальных
скоростей звезд в двух рассмотренных областях.
Несколько более сложная форма использования знаков в кри-
критериях основана на рассмотрении возрастающих и убывающих
серий. К таким критериям часто обращаются при проверке гипо-
гипотезы об отсутствии однородности в последовательности наблюде-
наблюдений, в частности в последовательности наблюдений, представлен-
представленных в контрольных картах, которые рассматриваются в следующей
главе. Регистрируются знаки разности между каждым из наблю-
наблюдений и предшествующим ему наблюдением в последовательности.
Следовательно, при исходной последовательности наблюдаемых
значений
Методы, свободные от распределения
325
указанные величины имеют вид
sign (Х2 — Х^у sign (Х3 — Х2)
Здесь
. / +1» если Xi+1 — Х?>0,
sign(X/+1-Xf) = j_^ если Xi+1-Xi<0.
Случай, когда XiJri — Xt равно 0, игнорируется, а объем выборки
при этом уменьшается на единицу. Если наблюдается длинная
последовательность значений +1, то это означает, что величины X
в данной части изучаемой выборки составляют возрастающую
последовательность. Такая последовательность (из +1 или —1)
называется серией знаков. Число последовательных значений
+ 1 или —1 в серии знаков называется длиной серии. Показан-
Показанная на рис. 9.1 последовательность состоит из серии возрастаю-
i i i i i t
Серии
Рис. 9.1. Серии.
щих значений длиной 1, серии убывающих значений длиной 3,
серии возрастающих значений длиной 1, серии убывающих зна-
значений длиной 1, серии возрастающих значений длиной 1. Можно
упорядочить все наблюдения (в количестве N) и переписать ис-
исходную последовательность в виде ряда рангов упорядоченных
величин Х[, Xg, Х'3, ..., где Х[ — ранг величины Хг после упо-
упорядочения, Ла~ранг величины Х2 и т. д. Например, если Хг —
второе по величине значение среди N наблюдаемых значений X,
то Х[ = 2. Таким образом, установлен порядок чисел 1,2, ..., jV,
который зависит от относительных величин в последовательности
Xlf Х2У ..., Xn- При отсутствии тренда можно ожидать появле-
появления любой из N\ различных возможных последовательностей,
вероятности которых одинаковы и, следовательно, равны 1/ЛЧ .
Для любой статистики, основанной на наблюдаемых сериях зна-
знаков и определенным образом связанной с полученной в результате
упорядочения последовательностью, распределение при нулевой
гипотезе может быть получено с использованием того факта, что
различные последовательности равновероятны. Любой критерий,
основанный на таком распределении, оказывается свободным от
326
Глава 9
распределения независимо от того, является ли гипотеза пара-
параметрической или непараметрической.
При других типах серий можно использовать точно такой же
метод анализа.
Методы, свободные от распределения
327
появления точно совпадающих значений в сравниваемых выбор-
выборках будем полагать, что X представлен непрерывной случайной
величиной (также обозначенной через X). Проверяемая гипотеза
(Яо) состоит в утверждении, что
Пример 9.5. Приведенные ниже данные представляют собой
средние веса изделий, изготовленных в течение 20 последователь-
последовательных дней, в выборках по 10 штук. Используя критерий серий,
покажите, что средние веса носят случайный характер.
Данные
Вес
День
Вес
День
13.0 12,8 12,9 13,0 13,1 12,9 12,6 12,6 12,7 12,9
123456789 10
13.1 13,1 13,2 13,3 13,2 13,1 12,9 13,2 13,3 13,2
И 12 13 14 15 16 17 18 19 20
Яо:' средние веса имеют случайный характер.
Нг: имеется неслучайная закономерность изменения средних
весов.
а: 0,05.
Статистика. Медиана совокупности равна 13,05. Веса, боль-
большие и меньшие 13,05, обозначаются соответственно через + и —;
тогда последовательность принимает вид
Следовательно, N± = N2 = 10, а г = числу серий знаков =^6.
Критическая область. В соответствии с табл. Т при Nt =
=Af2 = 10 гипотеза Яо отклоняется, если число серий знаков
меньше или равно 6, и в случае, если оно больше или равно 15.
Решение. Отклонить Яо.
9.6. КРИТЕРИЙ ВИЛКОКСОНА И СВЯЗАННЫЕ
С НИМ КРИТЕРИИ
Один из наиболее широко используемых ранговых критериев
связывают с именем Вилкоксона, хотя многие авторы разраба-
разрабатывали критерии (как подробно показано в историческом обзоре
Крускала [12]) такого же или аналогичного типа. Рассмотрим
двухвыборочный критерий Вилкоксона.
Предположим, что имеются случайные выборки объема пх
и п2 из двух совокупностей П^ и П2 соответственно. Требуется
проверить гипотезу о том, что закон распределения измеряемого
признака X одинаков для обеих совокупностей. Во избежание
где Fj (x) — функция распределения X в совокупности Пу. Отме-
Отметим, что вид функций распределения при этом не задается, а
гипотеза Яо — всего лишь предположение, что они одинаковы.
Таким образом, требуется найти критерий, который был бы не
только свободным от распределения, но и непараметрическим в
том смысле, что при определении функций Ft(x) и F2(x) не ис-
используются какие-либо параметры. В этом примере второе свой-
свойство вытекает из первого.
Обозначим через Хи (? = 1, 2; ?—1,2, ..., щ) i-e значение
в выборке из совокупности П^. Расположим теперь все i^ + n^
элементов в порядке убывания и припишем значение / элементу,
для которого наблюдаемая величина хи расположена на /-м по
порядку месте. Таким образом, исходное множество величин
{Xti\ заменяется на новое множество {Х'и), которое содержит
целые числа 1, 2, ..., i^ + n^.
Вычислим теперь сумму всех новых значений для выборки из
совокупности П].:
Пример 9.6. Два предприятия А и В изготовляют кирпичную
футеровку для кислородных конвертеров. Потребителю хотелось
бы знать, совпадают ли распределения числа плавок, которые
можно произвести в конвертере до того, как создается необхо-
необходимость в замене футеровки, изготовленной на каждом из пред-
предприятий. Предполагается, что различия проявляются в несовпа-
несовпадении математических ожиданий, а не других характеристик, но
для того, чтобы судить о конкретной форме распределения, нет
достаточных оснований. Получены следующие значения числа
плавок до замены футеровок.
Предприятие А
237, 224, 218, 227, 234,
215, 219, 225, 230 (9 значений)
Предприятие В
216, 202, 205, 200,
198, 222, 214, 226,
A0 значений)
207,
204
Будем использовать в качестве приближения теорию, разра-
разработанную для непрерывных величин.
328
Глава 9
Расположим значения в порядке убывания и подчеркнем те
из них, которые относятся к предприятию Л.
9, 218, 216
237,
215,
234,
214,
230,
207,
227,
205,
226,
204,
225,
202,
224,
200,
222,
- 198
Наблюдаемое значение величины St равно
1+2 + 3 + 4 + 6 + 7 + 9+10 + 12 = 54.
(Решение задачи будет продолжено в примере 9.7.)
При Fx (х) = F2 (х) можно получить распределение 51Э исгголъ*
зуя тот факт, что все возможные перестановки чисел 1,2, ...,
(n1Jrn2) для множества значений \xti\ равновероятны. Другими
словами, значения хх из совокупности Пх в равной степени мотут
Л
у
Mi + ^Л
возможных
представлять собой любое из
включающих пх чисел из последовательности 1,2, i^ )
В табл. У приложения приведены границы значимости для Slf
Они вычислены так, что сумма вероятностей для S± и больших
(меньших) значений для верхней (нижней) процентных точек не
превышает указанной номинальной^ вероятности. В основу этих
данных положены таблицы,, разработанные Сиджелом и Тьюки
[Siegel, Tukey, A Nonparametric Sum of Ranks Procedure for
Relative Spread in Unpaired Samples, Journal of American Sta-
Statistical Association, 55 (I960)]. В этой же статье приведена дне»
куссия о приближениях, полезных в случае, когда объем одной
из выборок велик, а другой мал.
*9.6Л. Моменты St
Для каждого X'lt
Следовательно,
nt+n2
/
Кроме того, при 1Ф1\ \ф\'
Методы, свободные от распределения
329
Отсюда
' /П1+П2 \2 щ + Пш "|
2/1-2 р\
I)
а также
(9.4)
1). (9.5)
Таким образом,
»(ft
(9.6)
(9.7)
Величина
может изменяться от /2ni(^i + l) до
Поскольку любая перестановка имеет одина-
одинаковую вероятность с перестановкой, имеющей обратную последо-
последовательность значений, то вероятности S1 = 1/2n1(ni + \) + r и
Si = V2#i(fli +1)+пЛ-->* одинаковы, а величина Sf обладает
сим!юетричньш распределением.
Далее можно показать, что распределение нормированной
величины
1
(9.8)
1 2
приближается к нормированному нормальному распределению при
у г 2, j/g р ,
заключенному между 0 и 1. Для достаточно больших щ и п2
наблюдаемое значение статистики (9.8) можно сравнивать с нор-
330
Глава 9
мированным нормальным распределением. К числителю могут
быть добавлены в качестве поправки на непрерывность при вы-
вычислении верхнего или нижнего хвостов распределения значения
—1/2 или +1/2 соотЁетственно.
Пример 9.7. Из табл. У приложения при щ — 9 и п2 = 10
находим, что критическая область для двустороннего критерия
с 1%-ным уровнем значимости задается неравенствами ^^бв,
Sx^122. При этом наблюдаемое значение S1 = 54, полученное
при рассмотрении примера 9.6, следовало бы считать достаточно
серьезным свидетельством различий между Fl(x) и F2(x).
Отметим, что использование критерия серий привело бы к
получению восьми серий. Обращаясь к табл. Т приложения,
находим, что этот результат не является значимым. Это пример
того, как два критерия приводят к существенно различным вы-
выводам. Полученный результат не является следствием непосле-
непоследовательности статистической теории, а только служит примером
ситуации, когда один из критериев оперирует с более подходя-
подходящей информацией, чем другой, и поэтому оказывается более
чувствительным. Подобрать после знакомства с данными крите-
критерий, который привел бы к выводу о значимости результатов, часто
бывает несложной задачей. Поэтому критерий, по которому впо-
впоследствии будет приниматься решение, необходимо выбрать до
того, как будет начат анализ данных.
Некоторые математики считают, что удобно использовать
другие формы статистики Sx. Критерий для каждой из этих форм
подобен критерию для исходной статистики, и хорошо было бы
проследить связь между различными формами.
Манн и Уитни [Mann, Whitney, On a Test of Whether One of
Two Random Variables Is Stochastically Larger than the Other,
Annals of Mathematical Statistics, 18 A947)] ввели статистику U',
основанную на подсчете числа пар, для которых результаты
измерений, относящиеся к совокупности П19 превышают резуль-
результаты наблюдений, относящиеся к совокупности П2. Очевидно, что
- (П1 - 2)] +
[(п, +п2 -
Следовательно, выражения для U и St при таком построении
критерия эквивалентны.
Методы, свободные от распределения
331
Иногда используется показатель, изменяющийся в диапазоне
от —1 до +1. Он имеет вид
Тьюки [Tukey, A Quick, Compact Two-Sample Test to Duck-
Duckworth's Specifications, Technometrics, 1 A959)] предложил простой
критерий, обладающий очень полезным свойством: его границы
значимости при изменении объема выборки варьируют в чрезвы-
чрезвычайно узких пределах, что позволяет легко запомнить их. Конечно,
все критерии, основанные на распределениях, близких к норми-
нормированному нормальному, в некоторой степени обладают этим
свойством, но критерий Тьюки особенно выделяется простотой
вычислений; а также тем, что его можно использовать даже при
довольно малых объемах выборки. Однако возможности приме-
применения этого критерия ограничены тем, что объемы выборок из
двух совокупностей не должны различаться слишком сильно.
Критерий предполагает следующие вычисления: если выборка
из совокупности Иг содержит наибольшее из пх-\-п2 выборочных
значений, а в выборке из П2 находится наименьшее из этих
выборочных значений, то число выборочных значений, из сово-
совокупности П1У превосходящих все значения выборки из П2, сум-
суммируют с числом выборочных значений из П2, меньших, чем
любое значение из выборки, относящейся к совокупности П*.
В этом случае границы значимости (двусторонние) для исполь-
используемого критерия задаются числами
7 при 5%-ном уровне,
10 при 1%-ном уровне,
13 при 0,1%-ном уровне.
Когда отношение объемов выборок (п1/п2) превышает 4/3 или не
достигает 3/4, критерий следует модифицировать путем вычита-
вычитания целой части выражения
или выражения
— 1 при
п2.
Пример 9.8. Для данных, приведенных в примере 9.6, значе-
значение критерия равно 4 + 7-^11. Оно оказывается значимым для
1%-ного уровня (при использовании приведенных выше прибли-
приближенных значений), что согласуется с результатами исследования,
проведенного при решении примера 9.7.
332
Глава
9.6.2. Доверительные интервалы, основанные на критерии
Вилкоксона
Доверительные интервалы можно строить, опираясь на про-
процедуру проверки значимости, подобно тому как при определен-
определенных условиях, пользуясь доверительными интервалами, можно
вывести критерии значимости, что показано в гл. 8. В част-
частности, если известно, что два распределения /ч(*) и F2(x) раз-
различаются только параметром положения 8 (значение которого
неизвестно), так что
Л(*НМ*-в),
то критерием Вилкоксона можно воспользоваться для построения
доверительного интервала для параметра 6. Это осуществляется
путем добавления постоянного числа / ко всем наблюдаемым
значениям, относящимся к выборке из второй совокупности, и
использования затем критерия Вилкоксона. Все значения /, для
которых при двустороннем критерии и 100 а% -ном уровне
значимости принимается решение о незначимости различий рас-
распределений, составляют 100A —а)%-ный доверительный интервал
для 0. (Очевидно, что множество значений /, выбранных описан-
описанным способом, действительно образуют доверительный интервал,
поскольку Sx является неубывающей функцией от t.)
Пример 9.9. Рассмотрим данные из примера 9.6 и табл. У при-
приложения. Для * = 1, 2, 3 и 4 различие (при а = 0,01) остается
значимым, несмотря на то что к каждому из наблюдений второй
выборки добавлена указанная величина t. (При этом совпадающие
значения сравниваемых выборок удалены, а их объем уменьшен.)
При значениях t от 5 до 28 различия в соответствии с критерием
Вилкоксона можно считать незначимыми и, следовательно,
99%-ный доверительный интервал для в [при Рг{х)^Рш{х~~Щ
равен
9.6.3. Нормальные метки
Полезным свойством критериев, рассматриваемых в этой главе,
является то, что они свободны от распределения. Они также
обладают достаточно хорошей чувствительностью, т. е. их отно-
относительная мощность оказывается выше, чем можно было бы
ожидать, учитывая то, что при их использовании прцходится
пренебрегать частью информации (или она недоступна).
Методы, свободные от распределения
333
Вполне возможно, что в случае, когда в действительности
имеет место нормальное распределение исследуемой совокупности
(или близкое к нему), свойства рассмотренных критериев не-
несколько улучшатся без потери свободы от распределения. Ранее
было установлено, что вместо рангов 1, 2, ..., (п1+п2) можно
использовать серии фиксированных чисел. Легко показать, что
если i заменяется математическим ожиданием i-й наибольшей
величины в случайной выборке объема (п1 + п2) из совокупности,
имеющей нормированное нормальное распределение, то двухвы-
борочный критерий Вилкоксона обладает такой же асимптоти-
асимптотической мощностью, как и двухвыборочный ^-критерий для нор-
нормальных совокупностей с равными дисперсиями.
Имеются таблицы значений Е (Х$ (см. [6]); они приведены
в сокращенном виде в приложений (табл. X). Эти значения на-
называются нормальными метками. Каждому члену выборки при-
присваивается метка в соответствии с местом, которое занимает
измеренная величина X в последовательности всех наблюдаемых
значений, расположенных в порядке убывания. В указанных
п
таблицах приводятся также значения 2
1
Пример 9.10. Будем использовать нормальные метки при
решении задачи, рассмотренной в примере 9.6. Пользуясь табл. X
приложения при п = п1+п2 = 9+10= 19, заменим ранги сред-
средними значениями соответствующих порядковых статистик норми-
нормированного нормального распределения. Ниже приведены резуль-
результаты:
Предприятие А Предприятие В
1,844 0,402 0,000 0,886 —0,131 —1,099 —0,707 —1,380
1,380 —0,264 0,131 0,548 —0,548 —1,844 0,264 —0,402
1,099 0,707 —0,886
Формально в двухвыборочном критерии для проверки разли-
различия средних значений нужно использовать (в предположении
известной дисперсии) статистику
тт (Средняя метка для А) — (Средняя метка для В)
которая распределена (приближенно) как нормированная нор-
нормальная величина, если дисперсии распределений обеих совокуп-
совокупностей (А и В) в действительности равны. Поскольку сумма всех
19 меток равна нулю, то
(Средняя метка для В) = — №\ (Средняя метка для А).
334
Глава 9
Таким образом, числитель величины U можно представить как
l-j-5!) (Средняя метка для А)= —— (Сумма меток для Л).
Подставляя соответствующие числовые значения [ и учитывая, что
19
2 [E(Xi)]*= 16,6923 ), находим
j. п Сумма меток для А 19 F,026) 9 954
Эта величина свидетельствует о значимости различия (при ис-
использовании 0,5%-ного двустороннего критерия) и подтверждает
вывод, сделанный при рассмотрении примера 9.7.
9.6.4. Распространение на случай k выборок
Если выборочные значения взяты из k совокупностей, то
множество N наблюдений тоже можно упорядочить и присвоить
его элементам ранги 1, 2, ..., N. Математическое ожидание
среднего ранга каждой выборки должно быть равно 1/2(Л/г + 1)>
если справедлива гипотеза о том, что распределения k совокуп-
совокупностей не различаются. Эту гипотезу можно проверить, используя
критерий, основанный на статистике
к
где nt — число наблюдений в выборке из совокупности t, a XI—
среднее значение рангов для этой совокупности. Представляется
естественным использовать статистику
(9.9)
знаменатель которой является средним квадратом отклонения
всех N рангов от их среднего значения. Крускал и Уоллис
[Kruskal, Wallis, Use of Ranks in One-Criterion Variance Ana-
Analysis, Journal of the American Statistical Association, 47 A952);
48 A953)] показали, что статистика (9.9) распределена примерно
как N/(N—l)(%2 с (&—1) степенями свободы).
Методы, свободные от распределения
335
Пример 9.11. Для трех типов люминесцентной краски при
испытаниях на истирание измерялась потеря веса через опреде-
определенный промежуток времени. Краска каждого из трех типов
(А-102, А-106 и А-108) наносилась на 8 панелей (всего получи-
получилось 24 панели). В табл. 9.2 приведены результаты исследования
в закодированном виде.
Таблица 9.2
Потеря веса окрашенных панелей
Краска
А-102
А-106
А-108
17
13
19
10
6
17
19
15
16
Потеря
17
9
2
веса
33
12
35
20
7
25
22
5
23
8
17
21
Расположим все 24 результата в порядке убывания их вели-
величины. Значения для краски А-102 выделены курсивом, а для
краски А-106 заключены в скобки
35 33 25 23 22 21 20 19 19 17 17 A7)
17 16 A5) A3) A2) 10 (9) 8 G) F) E) 2.
По этому массиву значений можно определить ранг для краски
каждого типа. (При совпадениях вычисляются средние значения
рангов всех совпавших величин. Этот вопрос кратко обсуждается
в разд. 9.7.4.)
Краска
А-102
А-106
А-108
11,
16
8,5
5 18 1
22 15
11,5
Ранги потерь
19
14
11,5 2
17 21
24 1 3
веса
7
23
4
5
11
6
20
,5
Средний ранг
Xl= 10,4375
Х2 == 18,0625
Ja = 9;0000
Находим
з _
8 2 [Xi—12,5]2 = 8[A0,4375K + A8.0625J + (9.0000J—3A2,5J]=
= 379,5625.
Из выражения (9.9) получаем
C79,5625)-12 _7ПО
575 -'.!"•
336
Глава 9
(Знаменатель необходимо слегка модифицировать из-за наличия
совпадающих рангов. См. разд. 9.7.4.)
Верхнее 5%-ное значение %2-критерия с двумя степенями
свободы равно 5,991, а 2*/23%%; М6 = 6,25. (Кроме того,
24/2з%1;а,»7& = 7,70.) В результате анализа обнаружено некоторое
различие между использованными красками (при 2V2%-hom уровне
значимости). Действительно, потеря веса для краски А-106 су-
существенно меньше, чем для двух остальных красок.
9.6.5. Критерии для дисперсии
Сначала опишем модифицированный критерий Вилкоксона,
который используется как критерий равенства дисперсий при
условии равенства характеристик положения для двух совокуп-
совокупностей. Этот критерий можно также применять, если разница
в характеристиках положения для двух совокупностей известна;
ее можно вычесть из наблюдаемых значений одной из совокуп-
совокупностей, чтобы сделать эти характеристики равными.
В маловероятной ситуации, когда известны обе медианы
совокупностей | и т|, можно применить ранговые порядковые
методы к статистикам
X'i = Xt — I и Y) = Yj — r\% t'=l, ..., т\ / = 1, ..., п.
Теперь имеются выборочные значения Х[, Х'2, ..., Х'т и Y[9
Y'%y ..., Y'n из совокупностей с равными медианами. (В действи-
действительности значения обеих медиан равны нулю.)
Предположим, что X и Y имеют функции распределения ве-
вероятностей вида /[(* —S)/ffi] и f[(y—r\)/o9] соответственно и тре-
требуется проверить гипотезу о±=о2.
Модифицируем предложенную Вилкоксоном процедуру, изме-
изменив способ приписывания рангов. Вместо приписывания наиболь-
наибольшему из (fti + ft2) значений номера 1, следующему за ним зна-
значению номера 2 и т. д. будем присваивать наибольшему из
значений номер I, наименьшему номер 2, следующему по малости
номер 3, второму по величине номер 4, третьему по величине
номер 5 и т. д., как показано ниже:
14589 7632
Вычислим опять по рангам элементов первой выборки Sf
(или U, или некоторую связанную с ними статистику) так же,
как в разд. 9.6.1. Распределение при нулевой гипотезе совпадает
с ранее рассмотренным, поскольку если в действительности
отсутствуют различия между распределениями двух совокупно-
совокупностей, то все возможные перестановки рангов равновероятны.
Однако при новой ранжировке будет наблюдаться преобладание
Методы, свободные от распределения
337
меньших рангов среди элементов выборки из первой совокуп-
совокупности, если первая совокупность обладает большей дисперсией,
чем вторая (но одинаковым с ней значением параметра положе-
положения). При этом S± будет иметь меньшую величину, чем можно
было бы ожидать.
Для двустороннего критерия как малые, так и большие зна-
значения величины St должны рассматриваться как значимые.
Пример 9.12. При двух температурах проверялась относитель-
относительная усадка синтетического волокна. Ожидалось, что средние
усадки при каждой из температур должны быть одинаковы, но
при более высокой температуре величина усадки имеет большее
рассеяние.
При более высокой температуре проверка проводилась 10 раз,
а при более низкой 12. В табл. 9.3 приведены полученные данные.
Таблица 9.3
Усадка в процентах
Более низкая температура Более высокая температура
3,65 3,82 3,80 3,69 3,60 4,03 3,67 3,64
3,84 3,76 3,73 3,73 3,91 3,96 3,72
3,77 3,54 3,76 3,63 3,75 3,40 4,01
Ниже приведены эти значения в порядке убывания, причем
подчеркнуты те из них, которые относятся к опытам при более
высокой температуре.
4,03 4,01 3,96 3,91 3,84 3,82 3,80 3,77 3,76 3,76
Я,75 3,73 3,73 3J2 3,69 ^67 3,65 3^64 3,63
3,60 3,54 3,40.
Теперь, нумеруя ранги в соответствии с рассмотренной выше
схемой (для значений, полученных при более высокой темпера-
температуре), найдем
S^ 1+4+ 5 + 8+ 21+ 18+14+10 + 6+ 2 = 89.
Полученное значение точно совпадает с 5%-ной границей зна-
значимости (одностороннего критерия) при п1 = \0, п2 = \2.
В результате принято решение исследовать возможность суще-
существования большего рассеяния с помощью других критериев.
В критерии Ансари —Брэдли используется несколько другой,
но похожий способ ранжировки. Расположим n~(nt + nt) значе-
338
Глава 9
ний в порядке возрастания (или убывания) и расставим метки
следующим образом:
-пг), ^К + п,)-!,...^, 1, 1,2, ...,4k
если (»*?! + n2) четное;
5-3), ...,2,1,0, 1,2, ..., 1(П1+п2— 1);
если (nx+/22) нечетное.
(Наименьшее и наибольшее из наблюдаемых значений обозна-
обозначаются наибольшей меткой.)
При этом используется следующая статистика:
W = Средняя метка для элементов первой выборки (объема /ц).
Если пх и п2 велики, а а1 = о2> т. е. в случае одинаковых рас-
распределений совокупностей Х\ и Y), распределение величин
H7' = [V — ~(п + :
W ~Г 4 п J
п2(п-2)(п+2) ПРИ ЧеТН0М П>
^(п+Уп+З) ПРИ нечетном ^
примерно совпадает с нормированным нормальным распределе-
распределением. Таблицы границ значимости для п1 + м2^20 приведены
в книге [5].
Пример 9.13. Используем критерий Ансари — Брэдли для ана-
анализа данных примера 9.12.
Поскольку п = пх + п2 =Ю + 12 = 22 и является четным чис-
числом, то ранги, приписанные значениям, полученным при более
высокой температуре, равны 11, 9, 7, 5, 3, 1, 8, 9, 10, 11.
Величина W равна
' A1+9+. ..+10+11)^7,4,
10
откуда
Г'=/т1таG>4-6)=]^-Ь4-1,852.
Вводя поправку на непрерывность, получаем W = V7/4-1,35 =
= 1,786. Поскольку Ф A,852) = 0,968, а Ф A,786) = 0,963, то
можно утверждать, что наблюдается значимое различие диспер-
дисперсий при 5%-ном уровне значимости.
Если медианы совокупностей не известны (что имеет место
в большинстве случаев), то представляется естественным исполь-
Мепгоды, свободные от распределения
339
зовать выборочные значения | и ц вместо медиан | и ц соответ-
соответственно. Вычислим величины {Х] = Х( — f}, {Y* = Yy — r]}, при-
припишем им ранги и расставим метки так, как было описано выше.
Вычисленные значения уже не будут независимыми, а теория
окажется намного более сложной.
При больших выборках (и ог = о2) распределение полученной
статистики W*' совпадает с распределением W> за исключением
того, что дисперсия возрастает от 1 до 1 +12 [/С/f (О)]2, где f(x) —
общая плотность распределения вероятностей величин (X — |)/сг
и G — r])/(i, a
- S [f(x)fdx.
Отметим, что если распределение симметрично (например,
нормальное), то для распределений величин W и W*' исполь-
используется одна и та же аппроксимация.
Пример 9.14. Обратимся опять к данным примера 9.12, но
опустим при этом предположение о примерном совпадении сред-
средних значений совокупностей. Будем использовать выборочные
оценки медиан
1 = 1C,72 + 3,75) = 3,735
1C,73+ 3,76) = 3,745.
Эти значения весьма близки друг к другу, поэтому их исполь-
использование влияет на критерий очень незначительно. Действительно,
достаточно добавить 0,01 к каждому значению, полученному при
более высокой температуре, чтобы скорректировать разность
медиан выборок.
В отличие от примера 9.13 результаты, полученные при более
высокой температуре, имеют теперь ранги 11, 9, 7, 5, 2 , 2| ,
8, 9, 10, 11. Эта последовательность отличается от ранее рас-
рассмотренной только значениями, которые заключены в квадрат.
В данном случае значение W осталось неизменным. (Здесь был
использован практически полезный способ приписывания среднего
ранга при совпадающих величинах.)
340
Глава 9
9.7. ДВУМЕРНЫЕ МЕТОДЫ
Обсудим теперь, как можно анализировать двумерные данные
непараметрическими и свободными от распределения методами.
9.7.1. Ранговая корреляция
При вычислении любой выборочной статистики вместо изме-
измеренных значений можно использовать ранги. Если исследователь
располагает только значениями рангов, то статистики, основан-
основанные на этих рангах, можно подставлять при вычислениях на
место точных статистик. Рассчитанные на основе рангов коэффи-
коэффициенты выборочной корреляции, краткое описание способов вы-
вычисления и использования которых приводится ниже, играют
особенно важную роль.
Пусть (Хц Y{) представляют собой измеренные значения двух
признаков X и Y, относящихся к i-му члену выборки объема /г.
Тогда коэффициент выборочной корреляции равен
у 2 <*'-
V t = 1
(9.10)
i=i
Заменим теперь Х{ на его ранг Х\ для всех п наблюдаемых
значений признака X, а К,-—-на ранг Y\ также для всех наблю-
наблюдаемых значений. Тогда коэффициент выборочной корреляции/?',
вычисленный на основе данных (XJ, Y\) (i=l, 2, ..., я), яв-
является коэффициентом ранговой корреляции X и Y для данной
выборки. Очевидно, что он тесно связан с R и иногда исполь-
используется вместо R даже и тогда, когда могут быть измерены дейст-
действительные значения (Xiy Yt). Часто это происходит из-за того,
что величина R' вычисляется легче, чем R, но иногда причиной
является то, что #' —свободная от распределения статистика.
Следующее замечание упрощает вычисление R':
/ = i L
Аналогично 2 (У* — ^'J = 1/i2Al (я2 — 1)» и» следовательно, зна-
знаменатель R' всегда равен х/12п(п2— 1).
Методы, свободные от распределения
341
Числитель также можно упростить:
*;— X')(?',-?') =
t =i
4=1
t =1
Таким образом, коэффициент ранговой корреляции можно вычис-
вычислить по формуле
2 (*;-^-)
(9.11)
в которой по исходным данным вычисляется только величина
1«1
Вывод распределения величины R' можно свести к выводу
п
распределения суммы 2 (** — ^/J» гДе ^4/ —ранг величины У, со-
i = i
ответствующей t-му по величине значению среди всех X. Если
(в исходной совокупности) отсутствует корреляция, то ряд
(А19 А2, ..., Ап) с равной вероятностью может совпасть с любым
из п\ возможных порядков следования целых чисел 1, 2, ...,п.
Отсюда [см. (9.4)]
? (Л?) =4 (я+1) B,1
и, следовательно,
t- — 2^ (Л,) ]Ct + Аг?" (Л?) j =
! 6 Гд(л+1)<2я+1) *(*+1)а1 _о
— 1 п(п2-\) [ 3 2 J *
Аналогично можно показать, что Var(/?7) = (/z — I)". Пределы
значимости коэффициента ранговой корреляции (при независимых
переменных) приведены в табл. Ш C) приложения.
342
Глава 9
Пример 9.15. Для выяснения соотношения между весами от-
отливок до (X) и после (Y) обработки исследовалась предваритель-
предварительная выборка, включающая 12 отливок. Коэффициент ранговой
корреляции, вычисленный по данным, приведенным в табл. 9.4,
можно рассматривать как первую оценку тесноты свя^и. Проран-
жировав в отдельности множества из 12 значений, относящихся
к каждой величине, получим следующие пары данных.
Таблица 9.4
Веса отливок до и после обработки (в фунтах)
Вес до обработки 3,715 3,685 3,680 3,665 3,660 3,655
Вес после обработки 3,055 3,020 3,050 3,015 3,010 3,015
Вес
Вес
до обработки
после обработки
X' 1
V 1
3
3
2
3
—1
,645
,005
3
2
4
4
1 —0
3
3
,5
,5
,630
,010
5
7
—2
3,625
2,990
6
4,5
7
9
1,5 —2
3
3
,5
,5
,620
,010
8
7
1 -
9
11
-2
3,
3,
10
7
3
610
005
11
9,5
1,5
12
12
0
3,
2,
595
985
Разности приведены в третьей строке таблицы рангов. Под-
Подставляя их в формулу (9.11), получаем
12-A22-1)
= 0,89.
[Можно отметить, что линейный коэффициент корреляции, вы-
вычисленный по формуле (9.10) с использованием этих данных,
равен 0,84.]
При независимых X и Y среднее квадратическое отклонение Rr
равно Ц-1/2 = 0,3. Даже не обращаясь к таблице критических
значений для R' [табл. ШC)], ясно, что вычисленная величи-
величина 0,89 свидетельствует о значимой корреляции. [При объеме
выборки п = 12 верхняя 0,5%-ная точка для R' (при независи-
независимых X и Y) равна 0,78.]
9.7.2. Коэффициент конкордации
При наличии k ранжировок для N членов выборки естественно
проверить, хорошо ли согласуются эти k ранжировок друг с дру-
другом. Конечно, можно вычислить B) коэффициентов ранговой
корреляции, рассматривая все возможные пары ранжировок. Это
поможет отобрать ранжировки, особенно хорошо или, наоборот,
особенна плохо согласующиеся между собой. В большинстве слу-
случаев нежелательно тратить время для такого детального расчета,
Методы, свободные от распределения
343
а можно было бы удовлетвориться одной общей мерой согласия
ранжировок.
Мерой согласия ранжировок является коэффициент конкорда-
ции, обозначаемый символом W. Чтобы определить величину W,
просуммируем все k рангов для соответствующих членов выборки,
а затем вычтем из каждой суммы среднее значение кг/2(Ы + 1).
Просуммируем далее квадраты отклонений и разделим получен-
полученную сумму на максимальное из всех возможных значений этой
суммы квадратов. Указанный максимум имеет место в случае,
когда все k ранжировок идентичны. Суммы рангов тогда образуют
последовательность
k, 2k, 3k, ..., Nk,
а отклонения соответственно равны
-±(N-\)kt _l(tf-3)ft, ..., i(JV-3)ft,l(JV
Наконец максимальное значение суммы квадратов есть
Тогда
12 (сумма квадратов отклонений)
(9.12)
При полном совпадении ранжировок W=l, а чем хуже со-
согласуются ранжировки, тем меньше W.
В случае, когда ранжировки взаимно независимы, величина
(k — 1)W7A—W) распределена примерно как F с N — 1, (N — 1)х
x(k—1)—2 степенями свободы. (Несколько лучшее приближение
получено путем увеличения первого и уменьшения второго из
чисел степеней свободы на 2Ik.)
Интересно заметить, что величина W функционально связана
с арифметическим средним ( 2 ) коэффициентов ранговой корреля-
корреляции между различными парами ранжировок. Можно показать, что
k (средний коэффициент ранговой корреляции) — 1
W ¦
k—\
Пример 9.16. Двенадцать типов цветных кинопленок, покры-
покрытых несколько различающимися эмульсиями, были представлены
группе экспертов для выявления лучшей среди них. Каждого из
шести членов этой группы попросили упорядочить пленки по
степени предпочтения (присвоение одинаковых рангов не допуска-
допускалось). Результаты приведены в табл. 9.5. В двух последних столб-
столбцах приведены суммы рангов и их отклонения от средней суммы
344
Глета
рангов F-6,5= 39). Коэффициент конкордации [вычисленный с ис-
использованием формулы (9.12) при N=\2 и k = 6] равен
W — *2 (сумма квадратов отклонений) __ ^ «go
~~ 36-12-Г43 "" *'
Таблица Р.5
Номер
образца
1
2
3
4
5
6
7
8
9
10
И
12
i
11
4
3
6
1
5
7
8
10
2
12
9
Заключения
2
8
7
4
5
3
2
6
9
12
1
11
10
экспертов
Эксперты
3 4
9
8
5
6
1
7
2
11
12
3
10
4
И
3
2
8
1
4
5
10
9
6
12
7
&
8
7
1
4
6
2
И
12
3
10
5
6
9
6
4
П
3
7
1
5
10
2
12
8
Сумма
56
35
19
t 4S
13
: 31
23
54
65
17
67
43
Отклонение
17
~^4
—20
6
—26
; —16
: 15
26
—22
28
4
Вычислим (k— l)W(l — 1Г)-1 = E-0>762)/0,238=16>0. При сраа-
нении со значением F при II и 53 степенях свободы обнаружи-
обнаруживается высокая значимость коэффициента конкордации. Это пока-
показывает, что согласие экспертов в оценке 12 образцов пленки
реально существует.
9.7.3. Т-раепределение Кендалла
Другая мера корреляции* основанная на ранговых порядковых
статистиках, связана с подсчетом числа таких пар объектов, по-
порядок следования которых в ранжировках по признакам X и Y
одинаков. Возьмем каждую из B) возможных пар и подсчитаем,
сколько раз знак разности между значениями признака X совпа-
совпадает со знаком разности между значениями Y. Обозначим полу-
полученный результат через /?.
Так, если имеется выборка, содержащая пять наблюдений
B,1; 3,7) D,0; 5,1) C,7; 4,2) C,5; 5,3) и B,5; 3,8), то их ранги
Методы у свободные от распределения
345
равны соответственно
E; 5) A; 2) B; 3) C; 1) и D; 4).
Расположив значения X в порядке A, 2, ..., 5), получим сле-
следующую последовательность рангов для значений Y:
2 3 14 5.
Величины 2 я 3 расположены в правильном порядке, так же
как 2 и 4, 2 й 5, 3 и 4, 3 и 5, 1 и 4, 1 и 5, 4 и 5. Поэтому R
равно 8.
Максимально возможное значение R равно \2) • 0й0 лолу-
чается, если обе ранжировки одинаковы. Минимальное значение
равно 0 и получается когда ранжировки прямо противоположны
E4321 для рассмотренного выше примера). Вычисляя стати-
статистику
найдем величину, изменяющуюся от —1 (для противоположных
ранжировок) до +1 (для одинаковых ранжировок). Эта ста-
статистика подробно исследована Кендаллом [10] и обычно назы-
называется Г-распределением Кендалла (иногда т-распределением Кен-
Кендалла ш соответствии с первоначальным обозначением). Можно
показать, что при полной взаимной независимости переменных
X и Y математическое ожидание Е (Т) = 0, а Уж{Т) — 2/9<2#4-5)х
Х[п{п-Т)]-К
Пример 9.17. Здесь мы завершим технический анализ данных,
введенных в этом разделе. Имеем /? = 8, а я = 5, поэтому
Т = 4^ 1 =0 6
(Заметим, что коэффициент ранговой корреляции для этих дан-
данных #' = 0,7.)
JIpn/i = 5 величина Уат(Т) = 2/9A5)(Щ^ = 0,1667 при пол-
полной независимости переменных. Рассмотренная выборка столь
мала, что предположение, будто бы значение 0,6/j/Var (Т) = 1,470
может относиться к величине, имеющей даже приближенно нор-
нормированное нормальное распределение N@, 1), совсем не оправ-
оправдано. (При п, превышающем величину порядка 10, маловероятно,
что рассмотренная процедура приведет к серьезным ошибкам.)
Существуют таблицы, содержащие границы значимости для Т
(используемого как критерий независимости) (см. [10]). По этим
таблицам иайдем,, что при я = 5 вероятность долучения 71, pas-
346
Глава 9
ного или превосходящего 0,6, составляет 0,042. Следовательно,
наблюдаемая величина является значимой при 5%-ном уровне
значимости в случае одностороннего критерия.
9.7.4. Совпадающие ранги
В некоторых случаях несколько элементов выборки нельзя
различить по рангу. Тогда представляется естественным припи-
приписать каждому из таких „связанных" элементов среднее значение
рангов, относящихся к ним всем. Например, если невозможно
различить второй, третий, четвертый и пятый по порядку эле-
элементы, то каждому из них можно приписать ранг
~u 2 *
Такая модификация оказывает непосредственное влияние на ве-
величину знаменателя в выражении для коэффициента ранговой
корреляции. Для статистики Т Кендалла величина [п(п — 1)],
стоящая в знаменателе, уменьшается на суммарное число срав-
сравнений между элементами внутри связанных групп, т. е. на
^t(t— 1), где суммирование проводится по всем группам свя-
связанных элементов, a t — число элементов в каждой группе. Срав-
Сравнение элементов этих групп ничего не добавляет к сумме R.
Совпадающие ранги в критерии Вилкоксона и родственных
критериях используются так же, как и обычные ранги. Если они
не слишком многочисленны, то теория остается применимой.
9.8. ТОЛЕРАНТНЫЕ ОБЛАСТИ
И ПРЕОБРАЗОВАНИЕ ВЕРОЯТНОСТНОГО
ИНТЕГРАЛА
Если Х1У Х2У ..., Хп являются взаимно независимыми слу-
случайными величинами, каждая из которых имеет плотность вероят-
вероятности Рх{х)> то совместная плотность вероятности случайных
величин Yt= J px(x)dx есть pYi Yn(y19 ..., уп) = 1 @ < yt< 1).
— со
Рассмотрим теперь некоторые полезные методы, основанные на
приведенном результате.
9.8.1. Толерантные области
В разд. 6.5 уже было рассмотрено, как по наблюдаемым зна-
значениям случайной выборки построить границы, в пределах кото-
которых с определенной вероятностью окажется, по крайней мере,
Методы, свободные от распределения
347
заданная доля совокупности. Эти границы называются толерант-
толерантными пределами. Формально их можно определить как статистики
XL(X±, Х2> ..., Хп) и Хи(Х19 Х2, ..., Хп),
вычисленные по выборочным значениям Х1У Х2У ..., Хп, так что
Pt[Fx(Xv)-Fx(Xl)> p] = l-a. (9.14)
Когда XL и Хц являются порядковыми статистиками, можно
быть уверенным, что левая часть (9.14) не зависит от функцио-
функционального вида распределения совокупности.
Будем использовать обозначение, введенное в гл. 6, где при-
принято, что ХУг—г-я по степени малости величина в случайной
выборке объема п.
Плотность вероятности величины
Zra = Fx(Xu)-Fx(XL), s>r,
равна
Д9.15)
[см. F.12)].
Формула (9.14) при XL = X'r и Хи=Х'8 принимает вид
Pr[Zrt>p]=l-a.
Подставляя выражение для pzrs(zrs) из (9.15), получаем соотно-
соотношение
v
связывающее р и а.
Это не единственный способ использования статистики Zrs.
Было показано, что наименьший объем выборки я, при котором
справедливо выражение (9.15), можно получить, если выбрать
г=1, s = /z, т. е. когда толерантные пределы включают размах
выборки. Однако такое использование собранных данных не всегда
оказывается наиболее правильным. Вместо этого можно стремиться
к тому, чтобы для пары порядковых статистик выполнялось соот-
соотношение
Рг[Л <FX{XU)-FX(XL) < /72]> 1-а,
где /?!, р2 и а—заранее определенные величины. При выборе
достаточно близких значений рх и р2 можно гарантировать, что
толерантные пределы включат долю совокупности, величина ко-
которой будет определена с приемлемой точностью. Опять потребуем
348
Глава 9
минимального объема выборки. Необходимо добиться, чтобы вы-
выполнялось неравенство
*} (V-r-iA_ zy-s+'&z^\— a.
(s —г—1)!(я —s+г)! J v ' "^
Pi
Поскольку E(Zrs) = (s — г)/(л + 1), то требуется так выбрать зна-
значения s, r и я, чтобы неравенства
выполнялись при малом а (как это обычно и бывает).
Пример 9.18. Xi% X2, ..., Л„—взаимно независимые случай-
случайные величины, каждая из которых имеет плотность вероятности
f(x). Требуется найти толерантные границы, между которыми
с вероятностью, не меньшей 0,99, содержится от 85 до 92% вы-
выборочных значений, т. е. нужно так выбрать функции g±(X19 ...»
Хп) и gt(Xi9 ..., Хп), чтобы
[«.(*! ХП) "I
0,85 < J f(x)dx< 0,92 >0,99.
&t(Xt Хп) J
Если вместо функций gt и g2 используются соответственно г-е
и s-e по степени малости значения (г < s^n) X^ и X's, то можно
потребовать [см. F.12)], чтобы
0,92
и У С*
0,85
или в виде отношения неполной бета-функции
Очевидно, что разность в левой части неравенства опреде-
определяется только величинами (s—г) и п. Поддерживая постоянной
величину (s—г) и увеличивая л, можно найти значение п, удо-
удовлетворяющее приведенному неравенству. Для рассматриваемых
в этом примере данных значение /г, при котором можно было бы
использовать таблицы отношения неполной бета-функции [6.8J,
должно быть достаточно велико.
Это приводит к необходимости применения приближенных фор-
формул. Поскольку (см. упражнение 22 гл. 5)
Методы, свободные от распределения
349
где X—случайная величина, имеющая биномиальное распреде-
распределение
на хвостах биномиального распределения можно применить
аппроксимацию выражениями E.9) — E.11), используемыми для
нормального закона, что приводит к неравенству
ФЮ-Ф(и1)>0,99,
где
щ - 2К0,92(л —s + r + 1) —2 1Л),08 (s— г)
и
-s + r + l)-2 J/O,15(s —r).
Требуется определить наименьший объем выборки я, для ко-
которого
Ь=у — 0,5657|/у})-
—Ф (Уп + Т {1,8439 УУ—У-0,7746|/у}) > 0,99 (9.16)
при y=(s — r)/(n + \).
Решение можно найти методом проб и ошибок. При отсутст-
отсутствии соответствующей программы для вычислительной машины
воспользуемся тем, что значение у, максимизирующее левую часть
(9.16) при любом /г, близко к решению следующего уравнения:
1,9183 J/U^—0,5657 Уу = — A,8439 ]/Т=^--0,7746
Отсюда следует, что
у = 0,8874.
Соответствующее значение левой части (9.16) равно
Ф @,1 №8Уп+Л)— Ф(—0,1 Ю88Уп+Л)=2Ф @,11088 Уп+1)—\.
Оно превышает 0,99, если
0,11088 Уп+А> 2,5758.
Таким образом,
и, следовательно,
2'5758 V
0,11088;
л > 538.
- 23
350
Глава 9
Первое приближение для минимального значения п при s — r==
= 540-0,8874 = 479 составляет 539. Некоторые результаты пря-
прямых вычислений, приведенные ниже, подтверждают, что макси-
максимальная величина левой части неравенства (9.16) фактически
имеет место примерно при у = 0,8874, причем это приближение
обладает разумной точностью.
У
0,885
0,886
0,887
0,888
0,889
Значение левой части неравенства (9.16) при
/г + 1=450
0,9798
0,9808
0,9813
0,9812
0,9803
/г+1=500
0,9855
0,9864
0,9868
0,9867
0,9862
/2+1=540
0,9889
0,9896
0,9900
0,9899
0,9895
(Эти цифры показывают, что если можно было бы допустить сни-
снижение уровня доверия с 99 до 98%, то удалось бы уменьшить
необходимый объем выборки на 100 элементов.)
Очень полезно иметь толерантные области при отсутствии ин-
информации о виде распределения совокупности (за исключением
информации о его непрерывности). Если же в действительности
вид распределения все-таки известен (например, нормальное рас-
распределение), то можно получить наилучшую (т. е. наиболее точно
определенную) толерантную область (см. упражнение 36 гл. 7).
9.8.2. Вероятностное интегральное преобразование
Во всех приводимых ниже методах используется удобный мате-
математический прием, известный как вероятностное интегральное
преобразование. Если плотность вероятности случайной величины
X имеет вид /?#(#), то случайная величина
х
Y= S px(x)dx
обладает плотностью вероятности
dy/dx
Методы, свободные от распределения
351
Следовательно, величина У равномерно распределена на интер-
интервале @,1).
Таким образом, если взять п независимых случайных вели-
величин Х19 Х2У ..., Хп и вычислить для каждой из них вероятно-
вероятностное интегральное преобразование
(9.17)
то совместное распределение величин У1Э У2, ..., Yn окажется
равным
pYl уп(у19 ..., #„)=1, 0<^.<1, /=1, 2, ..., /г. (9.18)
Совместное распределение (9.18) сохраняет свой вид при лю-
любом исходном распределении (распределениях) величин Х( при
условии, что они взаимно независимы. Критерии, построенные на
основе У, будут обладать таким свойством, как независимость от
действительного распределения величин X. Они оказываются сво-
свободными от распределения, хотя вычисление У само по себе и тре-
требует знания распределения (распределений) величин X. Поскольку
то, следовательно,
Отсюда
или
Рг[-21пУ?>-21пу] = у
Pr[—2\nYi>v] = e-v/*.
Таким образом, случайная величина Vt = —2 In У; имеет плот-
плотность вероятности
(9.19)
Большие значения V{ соответствуют малым значениям Yt и на-
наоборот.
Уравнение (9.19) означает, что величина Vt имеет %2-распре-
/2
деление с 2 степенями свободы. Следовательно, 2 Уч распреде-
i=i
лена как %2 с 2п степенями свободы.
Этот результат дает возможность проверить гипотезу о том,
что величины Хи Х2У ..., Хп имеют соответственно функции
распределения р1(х1)у р2(х2)у ..., рп{хп). Вычислим
21
Л (
Л
352
Глава 9
и сравним полученную величину со значением х2-распределения
с 2/г степенями свободы. Как большие, так и малые наблюдаемые
величины этой статистики можно рассматривать как значимые,
если не иметь в виду определенную альтернативную гипотезу.
В следующем примере рассматривается случай, когда следует
применять односторонний критерий.
Методы, свободные от распределения
353
Пример 9.19. Для проверки гипотезы Яо было проведено семь
независимых исследований. Уровень значимости а] для наблюдае-
наблюдаемого значения статистики Т% положенной в основу критерия,
при i-м исследовании вычисляется так:
Рг[Г;>7?|#0] = с4 *=1, 2, ...,7.
Результаты вычислений приведены в табл, 9.6. Необходимо све-
свести все эти результаты в один критерий.
Используем тот факт, что величина
распределена равномерно, т. е.
когда справедлива гипотеза Яо.
Таблица 9.6
Уровни значимости семи критериев
= 1 а? = 0,261 * = 5 а! = 0,517
t=3 al = 0,412
i = 4 a? = 0,075
a?
0,202
7
Теперь можно сравнить—22 In a? с %и-распределением. В дан-
t= 1
ном случае представляет интерес только ответ на вопрос, будут
ли наблюдаемые значения а достаточно малы, и поэтому следует
использовать односторонний критерий, при котором только боль-
большие значения, полученные при вычислении —2 2 1^а?> рассмж-
t= 1
триваются как значимые.
Вычислим по данным, приведенным в табл. 9.6,
-2 [In 0,261 +lnO,151 + ...+in0,202] = 2
Сравнивая это значение с х?*; о,9о= 21,06 и xf4; 0,95 = 23,68, можно
заметить, что результат значим при 5%-нам уровне.
(Если значение, соответствующее / = 5, оказалось бы равным
а? = 0,052 вместо 0,517, то вычисленное значение критерия должно
было бы стать больше, чем 26,8, и его следовало бы признать
значимым при 272%-ном уровне значимости.)
Этот метод комбинирования уровней значимости особенно по-
полезен, когда проводится ряд проверок, каждая из которых опи-
опирается на малую выборку. Критерий для каждой проверки при
этом обладает довольно низкой мощностью, а мощность комби-
комбинации критериев значительно выше, причем могут быть получены
значимые результаты, которых могло бы не быть, если бы каждый
из критериев рассматривался изолированно от остальных.
В рассмотренном примере был использован тот факт, что
l-Y, = l pXt(xt)dx,
имеет такое же распределение, как и
В некоторых случаях можно использовать и тот факт, что то же
самое распределение имеет 2\Yt —1/21. Допустимо применять
также статистику
которая тоже имеет рассмотренное равномерное распределение.
Существует много других вариантов, которые читатель может
найти самостоятельно. Выбор подходящей функции зависит, ко-
конечно, от тех альтернативных гипотез, которые ожидаются в каж-
каждом конкретном случае.
9.9. ДОВЕРИТЕЛЬНЫЕ ИНТЕРВАЛЫ
ДЛЯ ПРОЦЕНТИЛЕЙ
Пусть Y'ly Y'2y ..., Y'n — вероятностные интегральные преобра-
преобразования [см. (9.17)] упорядоченных значений Х[<Х'2<.,.<Х'п
в случайной выборке объема п, когда F(x)—функция распреде-
12 М 819
354
Глава 9
ления совокупности. Тогда вероятность того, что в интервал
(Х'п XI) попадает значение хр, удовлетворяющее уравнению
равна вероятности того, что Y'r меньше Р, a Y's больше Р. Фор-
Формально это записывается следующим образом:
Рг [Х'г <хР< Х8] = Рг [Г; < Р < Y'8].
Правую часть этого равенства можно преобразовать к виду
р 1
.J J
0 P
nL
(r_l)](s_rLl)]{n_s)]
X
р 1
X
(9.20)
О Р
Так как Y'r<i P <У^ означает, что число значений У, меньших
чем Я, заключено между г и (s—1) включительно, то это выра-
s~l / \
жение можно иначе записать как V у\ \ PJ (\ — P)n~J' или с уче-
учетом результатов упражнения 22F) гл. 5, как 1р(г, п — r+l) —
—Ip{sf n — s+ 1). Рассмотренные выражения зависят только от
г, s, п и Р. Соответствующим выбором значений г, s и п доби-
добиваются, чтобы
Рг[Х'г<хР< Х;]>1—а.
Тогда интервал (Х'п XI) можно использовать как доверительный
для хр [т. е. для 100A —Р)%-ной точки распределения сово-
совокупности X] с доверительной вероятностью, равной по крайней
мере 100A—а)%.
В частности, выбирая Р = 0,5 и s = n — r-\-l, получаем сим-
симметричные границы доверительного интервала (Х'п Х'п_г+1) для
медианы совокупности xOib. Доверительная вероятность при этом
равна
1/2 1
0 1/2
ИЛИ
(9.21)
Упрощенный подход к построению доверительных интервалов
для л:р сводится к следующему: гипотеза о том, что 100 A — Р)%-ная
Методы, свободные от распределения
355
точка равна хр при уровне значимости а/2, отклоняется, если
точно гг значений X меньше хр (т. е. Х'Гх < хр < ХГ1 + 1) и
(9.22)
/=о
Таким образом^ в качестве границ доверительного интервала
для хр выбираются такие значения Х'Гх, Х'г^, для которых гг
удовлетворяет (9.22), а г2 удовлетворяет'такому же неравенству,
но ^а/2 заменено на ^1—а/2.
Рассмотрим еще один критерий для проверки гипотезы о том,
что медиана (xOi5) симметричного распределения равна заданной
величине [i0. Найдем ранги абсолютных отклонений наблюдаемой
величины от |i0, а затем вычислим S — сумму рангов положитель-
положительных отклонений. Распределение S не совпадает с распределением
для двухвыборочного критерия Вилкоксона, поскольку в послед-
последнем число положительных отклонений не фиксируется. Для задан-
заданного объема выборки п число положительных отклонений может
оказаться равным от 0 до п включительно. Однако при заданном
числе положительных отклонений пх распределение S (в предпо-
предположении, что истинное значение медианы равно (i0) соответствует
распределению St для двухвыборочного критерия с п2 = п — п^
Таким образом, имеются сведения двух типов. Во-первых, из-
известно значение п1У которое используется в критерии знаков,
как описано в разд. 9.5, и, во-вторых, для /гх положительных
отклонений известна величина S. Результаты, полученные при
использовании двух критериев, можно объединить с помощью
методов, рассмотренных в разд. 9.8.2.
Пример 9.20. Предположим, что среди п =100 наблюдений
п2 = 60 меньше |i0, а п1 = 40 больше, причем величина S при
40 наблюдениях, превышающих |i0, равна 1871. Вычислим
од
/ = 0
а°2- Рг [s < 1871] + у Рг [S - 1871]
и сравним —2 In [ajajj] со значением ^-распределения с четырьмя
степенями свободы.
Рассмотренные методы могут использоваться и тогда, когда
исследуются „связанные" выборки, как, например, в случае двух
наблюдений на каждом объекте Из некоторого множества. При
12*
356
Глава §
этом берутся разности между проведенными на одном объекте
наблюдениями и проверяется гипотеза \к = 0 (полагая, что \i0
равно нулю), с использованием при вычислениях рангов абсо-
абсолютных значений разностей.
9.10. ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
Большинство описанных в этой главе методов обладают двумя
преимуществами:
1) они просты с вычислительной точки зрения;
2) приводят к процедурам проверки гипотез с уровнями зна-
значимости, которые (во всяком случае приближенно) могут быть
определены при любом распределении совокупности (из доста-
достаточно широкого класса).
Кроме того, рассмотренные процедуры проверки гипотез во
многих случаях сравнимы в смысле мощности с другими проце-
процедурами, для использования которых требуются более сложные
вычисления и (или) предположения о виде распределения сово-
совокупности.
Тем не менее следует отметить, что эти методы в основном
относятся к процедурам проверки гипотез. Используя свободные
от распределения методы, можно строить (как показано в разд. 9.7)
оценки (параметров совокупностей), но сами методы оказываются
при этом значительно менее мощными. (Конечно, вряд ли можно
ожидать, что цецараметрические методы окажутся очень полез-
полезными при оценке параметров.) Необходимость использования
некоторых специальных таблиц для границ значимости также
может снижать практическую ценность этих методов.
Свободные от распределения методы, которые были описаны
выше, особенно полезны на начальных стадиях изучения объекта,
когда форма распределения совокупности не определена ц осо-
особенно желательно уменьшить вычислительные трудности.
Мощность описанных в данной главе процедур проверки ги-
гипотез еще не обсуждалась. При рассмотрении мощности ранговых
порядковых критериев необходимо сформулировать специальные
альтернативные распределения, чтобы сделать возможной коли-
количественную оценку мощности. В том, что при обсуждении свойств
свободных от распределения критериев вводятся какие-то распре-
распределения, нет противоречий. Естественно, представляет интерес,
как поведут себя некоторые критерии (срободные от распределе-
распределения или нет) в ситуациях, которые могут иметь место. Опреде-
Определение „свободный от распределения" обычно относится только
к распределению нулевой гипотезы, проверяемой с помощью
критерия. Возможно, такой подход достаточно удобен, но не
всегда предполагает, что мощность будет также свободна от рас-
распределения.
Методы, свободные от распределения
367
С математической точки зрения влияние различия в распре-
распределениях совокупностей на двухвыборочный критерий Вилкоксона,
например, проявляется в распределении п\ возможных переста-
перестановок чисел 1, 2, ...,п. Теперь они не равновероятны. Вероят-
Вероятность присвоения элементу выборки объема пг (взятому случай-
случайным образом) ранга г среди всех пх и п2 наблюдений в этом
случае уже не равна {п1-\-п2)~1. Тем не менее математическое
ожидание S± можно оценить следующим образом. Каждый элемент
выборки объема пг вносит в 5Х вклад [(число элементов, значения
которых превышают Х) + 1]- Для каждого элемента выборки
с вероятностью 1/2 любой из оставшихся (nx — 1) элементов той
же самой совокупности может иметь значение, превосходящее X.
Пусть для любого из п2 элементов выборки, взятой из второй
совокупности, эта вероятность равна, скажем, р. Тогда матема-
математическое ожидание EiSj) равно
в отличие от величины п1[1/2(п1-{-1 -}-п2)] (имеющей место при
нулевой гипотезе). Если р=1/2, то математическое ожидание
не изменится. Можно ожидать, что критерий Вилкоксона в этом
случае окажется весьма чувствительным. С другой стороны, можно
показать, что при проверке изменения среднего значения этот
критерий остается достаточно хорошим по сравнению со стандарт-
стандартными критериями даже при наилучших для них условиях.
ЛИТЕРАТУРА
1. Ansari A. R., Bradley R. A., Rank Sum Tests of Dispersion, Annals of
Mathematical Statistics* 31 (I960).
2. Bradley J. V., Distribution-Free Statistical Tests, Prentice-Hall, Englewood
Cliffs, N. J., 1968.
3. Conover W. J., Practical Nonparametric Statistics, Wiley, New York, 1971.
4. Cox D. R., Hinkley D. V.? Theoretical Statistics, Ch. 6, Chapman, and
Hall, London; Halstead Press, New York, 1974. [Имеется перевод: Кокс Д. Р.,
Хинкли Д. В. Теоретическая статистика.—М.: Мир, 1978.]
5. David H. A., Order Statistics, Wiley, New York, 1970.
6. Fisher R. A., Yates F., Statistical Tables for Biological, Agricultural and
Medical Research, 5th ed Hafner, New York; Oliver & Boyd, London, 1975
(Tables XX, XXI).
7. Fraser D. A. S., Nonparametric Methods in Statistics, Wiley, New York, 1957»
8. Gibbons J. D., Nonparametric Statistics, McGraw-Hill, New York, 1970.
9. Hollander M., Wolfe D. H., Nonparametric Statistical Methods, Wiley,
New York, 1973.
10. Kendall M. G., Rank Correlation Methods, 2nd ed., Griffin, London, 1955.
[Имеется перевод: Кендэл М. Ранговые корреляции.—М.: Статистика,
1975.]
П. Kendall M. GM Stuart A., The Advanced Theory of Statistics, Vol. 2,
Ch. 31, Griffin, London, 1961.
12. Knaskal W. H., Historical Notes on the Wilcoxon Unpaired Two-Sample
Test, Journal of the American Statistical Association, 52 A957).
358
Глава 9
13. Kruskal W. H., Ordinal Measures of Association, Journal of the American
Statistical Association, 53 A958).
14. Levene H., Robust Test for Equality of Variances, Contribution to Proba-
Probability and Statistics: Essays in Honor of H. Hotelling, Ed. I. Olkin, Stan-
Stanford University Press, 1960.
15. Quenouille M. N., Rapid Statistical Calculations, Hafner, New York, 2nd.
ed., Griffin, London, 1959.
16. Walsh J. Е.ч, Handbook of Nonparametric Statistics, 3 vols., Van Nostrand,
Princeton, N. J., 1962-1968.
17. Wilcoxon F., Some Rapid Approximation Procedures, American Cyanamid
Company, Stamford, Conn., 1949.
УПРАЖНЕНИЯ
1. В дискуссии, касающейся выбора одного из двух типов упаковки для
новой продукции, свое мнение высказали 100 участников. Пятьдесят из них
отдали предпочтение упаковке типа А, 40 предпочли упаковку типа В, а
остальные не приняли решения. С помощью критерия знаков определите, будет
ли такое предпочтение значимым. (Используйте 5%-ный уровень значимости.)
2. В течение длительного времени среднее число дефектных изделий в вы-
выборках объема по 150 изделий было равно 2. Возникли подозрения, что их
число увеличилось. Для проверки было взято 14 новых выборок, в которых
оказалось следующее количество дефектных изделий: 1, 3, 2, 3, 2, 3, 2, 4, 2, 3,
3, 4, 3, 2. При помощи критерия знаков определите (а = 0,05), обосновано ли
высказанное подозрение.
3. С использованием критерия, основанного на сумме рангов, проанализи-
проанализируйте данные упражнения 18 из гл. 8.
4. Контролеры, проверяющие качество продукции, производят отбраковку
изделий у движущегося конвейера. Двенадцать контролеров, размещенных слу-
случайным образом на двух конвейерах, пользуются различными осветительными
системами. Процент отбракованных каждым из контролеров изделий зареги-
зарегистрирован. Используя критерий быстрого обнаружения Тьюки (при а = 0,01),
определите, какая из систем лучше.
Система 1 46
Система 2 44
48
40
32
59
42
44
39
55
48
50
49
47
30
71
48
43
34
55
38
59
43
62
5. При измерении кровяного давления у 95 человек до и после принятия
некоторого лекарства оказалось, что у 54 человек оно повышается, у 27 — по-
понижается, а у 14 —остается неизменным. Определите с использованием крите-
критерия знаков, оказывает ли прием этого лекарства значимое воздействие на кро-
кровяное давление. Используйте при этом а = 0,05.
6. Проанализируйте данные, приведенные в упражнении 26 гл. 8, с помощью
критерия, основанного на сумме рангов.
7. Проанализируйте данные, относящиеся к контролерам ХиУиз упраж-
упражнения 26 гл. 8, используя критерий, основанный на сумме рангов. Восполь-
Воспользуйтесь аппроксимацией нормальным законом, а также точными критическими
значениями для уровня значимости а = 0,05.
8. При 20 бросаниях монеты зафиксирована следующая последовательность
выпадений герба (Г) и цифры (Ц): ГГГЦГЦЦЦЦГГГЦЦГГЦЦГГ. Используя
критерий серий, решите, есть ли основания считать, что эта последователь-
последовательность получена не случайным образом.
9. Двух экспертов попросили оценить качество поверхности десяти экспе-
экспериментальных кафельных плиток. К ним обратились с просьбой расположить
плитки в порядке предпочтения с присвоением лучшей из них номера 10, сле-
следующей по качеству —номера 9 и т. д. до 1. Ниже приведены результаты.
Методы, свободные от распределений
359
Наблюдается ли существенное различие между заключениями экспертов?
(Используйте а = 0,05.)
Эксперт Л 10 9 87654321
Эксперт В 98 10 5742631
10. Проволоки А и В обладают одинаковым средним удельным сопротив-
сопротивлением. Однако есть подозрение, что дисперсия сопротивлений этих проволок
не одинакова. Ниже приведены результаты измерений удельного сопротивления
(в Омах на единицу длины) для 20 образцов проволоки каждого типа. Используя
свободный от распределения критерий, проверьте, различаются ли дисперсии.
Проволока А
Проволока В
0,124
0,120
0,125
0,121
0,122
0,125
0,120
0,119
0,125
0,123
0,122
0,126
0,124
0,121
0,126
0,123
0,124
0,126
0,124
0,121
0,120
0,123
0,119
0,124
0,126
0,129
0,118
0,129
0,117
0,126
0,120
0,118
0,123
0,127
0,120
0,124
0,126
0,125
0,119
0,127
П. Трем группам мышей были сделаны инъекции экспериментального ле-
лекарства. Время реакции (в минутах) приведено ниже. Используя критерий
Крускала — Уоллиса (при а=0,05), проверьте нулевую гипотезу о том, что
среднее время реакции для всех трех групп одинаково.
Группа А
Группа В
Группа С
8,6
9,3
8,5
10,5
9,6
9,1
11,4
8,4
7,4
9,4
10,1
6,9
9,0
10,2
9,0
10,8
7,6
8,8
,8 7,6
9,2
12. В лаборатории, изучающей воздействие окружающей среды на человека,
были исследованы 10 мужчин и 10 женщин для того, чтобы установить ком-
комнатную температуру, при которой они чувствуют себя наиболее комфортабельно.
Ниже приведены результаты исследования (в °F): мужчины — 74, 71, 77, 76,
76, 72, 75, 73, 74, 75; женщины —75, 77, 78, 79, 77, 73, 78, 72, 78, 80. Пред-
Предполагая, что значения температуры соответствуют случайной выборке из соот-
соответствующей совокупности, воспользуйтесь критерием Манна — Уитни для того,
чтобы установить, имеются ли достаточные основания для отклонения гипотезы
о том, что в среднем температура наибольшего комфорта для мужчин и жен-
женщин одинакова.
13. Два контролера определенным способом измеряют (для оценки износа)
глубину канавок на шинах после каждого опыта в рамках дорожно-эксплуата-
ционных исследований. Основной трудностью при проведении измерений
является то, что каждому контролеру присуще определенное смещение резуль-
результатов измерения, связанное с силой давления, от которой зависит глубина
проникновения щупа. Предполагается, что один контролер, Джо Зилч, получает
более высокие результаты, чем другой—Пит Экс. Ниже приведены результаты
10 измерений, проведенных каждым из контролеров в 10 фиксированных точках
на шине.
Точка
Зилч
Экс
1
126
125
2
128
120
3
157
163
4
131
118
5
142
129
6
159
152
7
152
150
8
133
136
9
138
140
10
142
136
Проверьте, будут ли результаты, полученные Джо, значимо более высокими.
360
Глава 9
14. Ожидается, что медиана (Lt0 прочностных характеристик опор типа Д
изготовленных из нескольких сплавов, равна 74. Ниже приведена выборка,
включающая 16 результатов измерения.
64 72 81 74
78 70 76 65
68 79 85 80
76 71 74 72
Используя свободный от распределения критерий, проверьте, согласуются ли
эти данные с гипотезой |яо = 74.
15. Определите коэффициент ранговой корреляции для данных, приведен-
приведенных в табл. 12.8 (разд. 12.3.2.).
16. Ниже приведены температура обжига и класс чистоты поверхности
(по шкале значений от 0 до 10) 15 образцов металлизированных керамических
плиток. Значим ли коэффициент ранговой корреляции при 10%-иом уровне?
Температура 1430 1370 1390 1500 1420 1600 1520 1390
Класс чистоты 4 1 4 6 6 8 10 2
Температура 1470 1450 1400 1380 1460 1460 1470
Класс чистоты 9 4 6 5 8 7 10
17. Завершите решение примера 9.26.
18. Постройте 95%-ный доверительный коридор, основываясь на данных,
приведенных в упражнении 2 гл. 2.
19. Можно ли следующие 10 чисел рассматривать как случайную выборку
из равномерно распределенной на интервале от 0 до 1 совокупности (при
а = 0,05): 0,48; 0,57; 0,16; 0,42; 0,90; 0,85; 0,14; 0,67; 0,89; 0,93?
20. Как велика ожидаемая доля значений совокупности в пределах раз-
размаха выборки, если ее объем равен 10?
21. Используя критерий Колмогорова — Смирнова, проверьте нулевую
гипотезу о том, что 10 (упорядоченных) результатов наблюдений, приведенных
ниже, взяты из совокупности, имеющей нормальное распределение со средним
значением 32 и средним квадрэтическим отклонением 1$.
31,0; 31,4; 33,3; 33,4; 33,5 33,7; 34,4; 34,9; 36,2; 37,0.
22. Используя результаты измерения температуры левой и правой перед-
передних шин, приведенные в примере 8.9, проверьте гипотезу о том, что медиана
распределения разностей пар температур равна 0. Сравните этот результат
с полученным в примере.
23. При сравнении токсичности двух лекарств А н В исследование про-
проводилось на двух группах по 50 мышей. Каждой мыши из первой группы
было введено лекарство Л, а каждой мыши из второй группы — такая же доаз
лекарства В. Числа мышей, оставшихся в живых по прошествии различных
периодов времени, приводятся ниже.
Период,
Живые
Живые
ч
мыши
мыши
А
В
1
29
35
3
21
23
а
16
16
is
12
13
24
10
10
48
9
S
72
7
7
Проверьте гипотезу об отсутствии различий между средними значениями
откликов для исследуемых лекарств. Поясните, как можно определить границы,
соответствующие уровню значимости.
Методы, свободные от распределения
361
' 24, Произведено по 160 бросаний четырех исследуемых монет. Результаты
приведены ниже.
Число выпадений герба 0 12 3 4
Наблюдаемая частота 10 33 61 43 13
Используя критерий Колмогорова—Смирнова (при а=0,05), проверьте нуле-
нулевую гипотезу о том, что среди этих монет нет поддельных.
25, Используя критерий Колмогорова—Смирнова, проверьте, могут ли две
приведенные ниже выборки принадлежать одной совокупности.
Выборка 1: —1,61; —1,48; —1,27; —0,89; —0,83;
—0,22; 0,24; 0,30; 0,59; 1,06; 1,65; 2,36.
Выборка 2: —3,76; —3,18; —2,29; —2,24; —2,09;
-0,85; 0,62; 1,38; 1,55; 1,70; 2,59; 3,14.
—0,40; —0,39;
-1,49; —1,18; —0,95;
26. Два астронома А и В измеряли в угловых минутах больший диаметр
наиболее ярких галактик. Каждый измерил диаметры восемнадцати галактик.
Результаты измерений (взятые из работы A Study of Double and Multiple Ga-
Galaxies, Annals of the Observatory of Lund, No. 6, Lund, Sweden, 1937) Приве-
Приведены ниже.
80S
0,8
272
1,5
1,5
313
1,3
354
4,5
4,1,
377
3,5
4,5
391
1,5
407
1,0
1,2
427
3,0
2,ft
436
1,2
M
441
1,1
1,1
557 | 563
5,5 j 2,0
5,6 1 2,1
573 J 604
1,7 j 1,9
1,7 1 2,2
638
1,4
1.3
796
2,3
2,8
805
2,3
2,6
а) Используя 1) ^-критерий и 2) ^параметрический метод, определите, есть
ли значимое различие между результатами наблюдений астрономов.
б) Какова средняя квадратическая ошибка для среднего диаметра, рассчи-
рассчитанного по наблюдениям двух астрономов?
в) Обсудите сделанные заключения в свете принятых предположений.
27. Ответьте на вопрос, поставленный в упражнении 36 гл. 8, не делая
предположения о нормальности.
28. Проверьте, разумно ли предполагать, что приведенные ниже данные
получены при условии, что наработка данного электронного блока до отказа
имеет экспоненциальное распределение со средним, равным 170 ч [Fx(x) =
= 1 — e~~x/l7Q]. Данные взяты из книги Foster J. A., Kolmogorov—Smirnov
Test for Goodness of Fit, Industrial Quality Control, 18 (January, 1962).
67 343 225 23 114 209 376 174 204 102 43 62
116 139 176 212 50 29 410 247 210 34 193 67
48 84 21 63 219
175 163 230 135 18
409 310 250 171 9
133 327 213 118 171 356 117
116 174 384 100
111 314 339 220
60 327 48
1 248 175
Изобразите графически предполагаемое распределение [Fx(x)h и распре-
распределение, полученное по результатам наблюдений.
29. ^Проверьте, могут ли данные упражнения 28 относиться к совокупности,
имеющей нормальное распределение с математическим ожиданием, равным
170 ч, и средним квадратическим отклонением, равным ПО ч. Проведите кри-
кривую предполагаемого распределения и постройте график распределения по
результатам наблюдений. Используйте а = 0,05,
362
Глава 9
30. Случайная выборка объема 10 взята из совокупности с неизвестным
распределением. Упорядоченные выборочные значения равны 0,53; 1,12; 1,20;
1,29; 1,92; 1,96; 2,31; 2,63; 2,67; 3,20. Постройте 9Оо/о-ный доверительный
коридор для функции распределения совокупности.
31. Случайная выборка объема 20 взята из нормально распределенной
совокупности с нулевым средним значением и единичной дисперсией. Она
представлена следующими числами: —0,99; —0,08; —0,03; 0,38; 0,48; —0,55;
0,01; 0,12; 0,99; —0,65; 0,90; 0,30; 0,46; 2,13; —0,30; —0,85; 0,32; 0,84;
—0,39; —0,48. Постройте по этой выборке 95%-ный доверительный коридор
для функции распределения, не используя при этом информацию о виде рас-
распределения. Постройте также график истинной функции распределения и
сравните построенные функции.
32. Как велик должен быть объем выборки, чтобы в рамках выборочного
подхода вероятность попадания по крайней мере 95% значений неизвестной
совокупности между экстремальными выборочными значениями составила 90%?
33. Каким должен быть объем выборки, чтобы с вероятностью 0,9 по
крайней мере 85% значений совокупности находились ниже наибольшего вы-
выборочного значения?
34. При изучении процессов возникновения и развития солнечной си-
системы необходимо иметь представление о последовательности происходивших
событий. Такая информация в настоящее время, конечно, недоступна. Однако
наблюдаемые особенности строения солнечной системы, такие, например, как
распределение кратеров на лунной поверхности, в какой-то мере отражают
последовательность происходивших событий. На дне крупного кратера Птоле-
Птолемея обнаружено большое число мелких кратеров. Кратеры одного класса,
вероятно более раннего происхождения, названы призрачными, а кратеры
другого, вероятно более позднего происхождения, — кратерами послептоле-
меевского типа. Призрачные кратеры представляют собой старые, почти пол-
полностью засыпанные пылью и лавой образования. Их еле различимые края
резко контрастируют с хорошо заметными послептолемеевскими кратерами.
а) Учитывая приведенные ниже данные о кратерах, которые взяты из
работы Палма, Строма и Строма (Palm, Strom, Strom, The Craters in the Walled
Plain Ptolemaeus, Planetary and Space Science, 1963), и не делая предположе-
предположений относительно распределения диаметров кратеров, находящихся внутри
кратера Птолемея, проверьте гипотезу о том, что распределения кратеров
обоих типов идентичны (критерий медиан).
б) Разумно предположить (до изучения данных), что мелких кратеров
больше, чем крупных. Проверьте указанную выше гипотезу, рассматривая
какой-либо процентиль, а не медиану, как было принято ранее.
в) Что по сути означает рассмотренная выше нулевая гипотеза? Что
представляют собой альтернативные гипотезы? Предположим, следуя одной из
теорий, что мелкие кратеры преобладают среди кратеров более раннего про-
происхождения. Например, если кратеры возникают благодаря взрывным ударам
при падении метеоритов, а размеры метеоритов увеличиваются из-за разрас-
разрастания, т. е. присоединения пылевидных частиц в облаках космической пыли,
то мелких метеоритов и соответственно сделанных ими кратеров в ранние
эпохи должно было бы быть относительно больше, чем в поздние эпохи.
Проверьте эту гипотезу при сделанных в пп. а) и б) предположениях.
г) Призрачные кратеры наблюдать, конечно, труднее, чем послептолеме-
евские. Окажет ли это серьезное влияние на результаты? Могло ли, напри-
например, случиться так, что тот, кто измерял и подсчитывал число кратеров,
очень мелкие кратеры обычно рассматривал как послептолемеевские?
Диаметр кратера, мм
Призрачные кратеры
Послептолемеевские
кратеры
1
0
14
1,5
2
6
2
3
2
2,5
1
1
3
2
1
3,5
1
0
4+
7
1
Методы, свободные от распределения
363
35. Средний объем стока воды в реке фиксируется (в кубических футах
за секунду) каждый месяц в течение двух лет. Можно сравнивать объемы
стока в различные годы для соответствующих месяцев, поскольку сток под-
подчиняется годовым циклам. Используя критерий Вилкоксона, проверьте нуле-
нулевую гипотезу об отсутствии систематического изменения объема стока из года
в год (а = 0,05).
Март; Апр. Май Июнь Июль Авг. Сент. Окт. Нояб. Дек.
104,0 220,0 110,0 86,0 92,8 74,4 75,4 51,7 29,3 16,0
123,0 190,0 138,0 98,1 88,1 80,0 75,6 48,8 27,1 15,7
Янв. Февр.
Год I 14,1 12,2
Год II 14,2 10,5
36. Следующие данные представляют собой выработку четырех различных
станков в течение пяти дней. Дни рассматриваются как блоки, а станки как
варианты опытов. Используя коэффициент конкордации, проверьте нулевую
гипотезу о равенстве эффектов.
День
1
2
3
4
5
А
293
298
280
288
260
Число деталей, изготовленных
В
308
353
323
358
343
на станке
С
323
343
350
365
340
D
333
363
368
345
330
37. Хъ Х2, ..., Хп — независимые случайные величины. Чтобы проверить,
обладает ли каждая из этих величин заданной плотностью вероятности рх(х)>
вычисляется вероятностное интегральное преобразование
= J Px(*)dx, * = 1, 2,
Все (п-\-1) интервалов, на которые полученные п значений Y делят отрезок
от 0 до 1, пронумерованы в порядке возрастания их длины. Кроме того, они
пронумерованы числами 1, 2, ..., (я+1) слева направо, начиная с интервала
@, наименьший из Y) и кончая интервалом (наибольший из F, 1). Обсудите
свойства критерия, основанного на ранговой корреляции между двумя указан-
указанными последовательностями чисел.
38. Покажите, как путем изменения системы нумерации, описанной
в упражнении 37, построить критерии, которые должны быть особенно чувст-
чувствительны к различным типам отклонения от проверяемых гипотез [о том, что
Рх(х) действительно является плотностью вероятности для каждого X].
39. Рассчитайте мощность двухвыборочного критерия Вилкоксона для
выборок объема
п1 — п2= 10
из совокупностей, имеющих нормальные распределения (с одинаковыми диспер-
дисперсиями), когда разность между средними значениями совокупностей равна
удвоенному среднему квадратическому отклонению каждой из совокупностей.
40. Как изменится ответ в упражнении 39, если средние квадратические
отклонения не равны, но
364
Глава 9
(Разность между средними значениями
совокупностей)
/(Сумма дисперсий обеих^
совокупностей)
(Можно получить качественный ответ, но полезнее было бы провести вы-
вычисления.)
41. а) Постройте критерий для проверки гипотезы о том, что нижний
квартиль распределения равен 10. Подробно опишите выборочные данные, на
которых основан критерий.
б) Каким образом информация о форме распределения позволила бы
улучшить ответ на вопрос, поставленный в п. а)?
42. Предположим, что в ситуации, когда используется двухвыборочный
критерий Вилкоксона, исходная выборка (объема щ) цензурирована двумя
величинами Xf и Х2, так что п[ элементов оказались меньше Xlt а п[ —
больше Х2, причем известны значения только nx — ri\ — п[ оставшихся эле-
элементов выборки. Другая выборка (объема п2) не цензурирована. Покажите,
как модифицировать критерий Вилкоксона, чтобы его можно было исполь-
использовать с такими данными.
43. Предложен следующий метод оценивания величины отношения 0О ме-
медиан распределений двух положительных случайных величин Y и X.
Проведены наблюдения над п независимыми случайными величинами
Xjt X2, ..., ХПУ каждая из которых распределена как X, и (я+1) независи-
независимыми случайными величинами Уъ У2, .,., Yn + i* каждая из которых распреде-
распределена как Y. Каждое из п значений X умножено на постоянное число 0. Медиана
B/1+1) значений 6ХЬ 6Х2, ..., 6Х„, Ylf К2, ..., Уп обозначена через тд.
Если п—четное число, то все значения 0, для которых т @) — медиана
совокупности Y, рассматриваются как оценки отношения 90. При нечетном п
все значения 6, для которых тF) равно 0-(медиана X), можно рассматривать
в качестве оценок 0О.
а) Покажите, что этот метод (в предположении, что X ylY—непрерывные
случайные величины) приводит к построению единственного интервала, вклю-
включающего все оценки 0.
б) В каком смысле метод является 1) свободным от распределения и
2) непараметрическим?
в) Почему было бы неправильно называть рассмотренный интервал дове-
доверительным?
44. Пусть при условиях, рассмотренных в упражнении 43, 0ОХ имеет
такое же распределение, как и Y. Найдите вероятность попадания истинного
значения 0О в пределы интервала, образованного оценками 0О, получен-
полученными как описано в указанном упражнении.
Как ответить на вопросы пп. б) и в) упражнения 43, учитывая предпо-
предположение об одинаковом распределении 0^Х и F?
45. Какой должна быть диаграммная бумага для того, чтобы;
а) получать первые приближения для аир при заданных парах значе-
ний (х§, Ш) и ?(К]*) = Ф(а+р*);
б) получать то же, что и в п. а), но при Е (У[х) = Ф (а+р \пх)'г
в) получать то же, что и в п. а), но при Е (Y{x) = aP .
46* На каждом из большого числа малых станков с постоянной скоростьк?
Я (в единицу времени) производятся некоторые изделия. Моменты времени (Г),
соответствующие началу работы каждого из станков, распределены (взаимно)
независимо с плотностями вероятности pr(t)- Покажите, что общее количество
т
изделий, произведенных на момент времени т, равно к V (% — t)pf(t)dt.
о
Опишите метод графического оценивания среднего значения распределения
исследуемой величины, если плотность вероятности имеет вид (О
Глава 10
КОНТРОЛЬНЫЕ КАРТЫ
10.1. ВВЕДЕНИЕ
Контрольные карты—самая распространенная форма применения
статистики в производстве. Статистические карты контроля качества
стали настолько общепринятыми, что любая достаточно большая
фирма, не пользующаяся ими в том или ином виде, оказывается
в невыгодном положении по сравнению с конкурентами. Многие
предприятия имеют отделы контроля качества, аналогичные
службы в других отделах, инженеров по контролю качества
(иногда по надежности). Контроль качества осуществляется не
только на производстве, но и в исследовательских лабораториях.
Одним из основных средств, используемых при этом, являются
контрольные карты, предложенные в 1931 г. Шухартом [20].
Идея контрольной карты очень проста. Делаются предполо-
предположения о распределении совокупности или выборочных статистик
из совокупности* Берутся повторные (независимые) случайные
выборки. Полученные статистики наносятся на карту вместе
с соответствующими 100A — а)%-ными точками. Если результаты
оказываются в данных пределах, считается, что процесс стати-
статистически управляем, если нет —управление нарушено. Техника
контрольных карт отличается от простого выборочного метода,
когда берется изолированная выборка, вычисляются статистики
и делаются выводы относительно параметров совокупности.
Метод контрольных карт динамичен, т. е. дает информацию
о процессе в ходе его развития. Он позволяет увидеть, когда
и где наблюдаемые величины выходят за рамки случайных коле-
колебаний, указывая на возможные изменения в процессе. Становится
легче понять причину последних. Карта заполняется прямо на
производстве или в исследовательской лаборатории, а не в спе-
специальном отделе предприятия. Выводы, сделанные с ее помощью,
могут в случае необходимости вызвать немедленные действия.
Она используется в отчетах и описаниях, а также облегчает
связь между отделами.
В этой главе излагается методика построения контрольных
карт, приводятся примеры их применения и математические обо-
обоснования *). Авторы не стремились дать исчерпывающее описание,
1) При переводе этой главы использована терминология, соответствующая
в основном ГОСТ 15895*77 (СТ СЭВ 547-77). Статистические методы управле-
управления качеством продукции. Термины и определения.-— Прим. ред.
366
Глава 10
поскольку контрольным картам посвящено много хороших книг1*.
Здесь нет возможности описать многочисленные варианты и мо-
модификации карт, но о некоторых из них будет сказано. Стати-
Статистикам-прикладникам, решающим физические или технические
задачи, не следует пренебрегать этим мощным и одновременно
простым методом.
Ниже рассматривается несколько типов контрольных карт, вклю-
включая основные контрольные карты Шухарта, контрольные карты на-
накопленных сумм (ККНС), карты приемочного контроля. Каждый
вариант иллюстрируется примерами. Карты Шухарта и ККНС
делятся на две категории: для количественных и качественных
признаков. К первой категории относятся X, /?-(размах) и S
(или 52)-карты, ко второй — /?-(или пр-) и с-карты. В первых
трех случаях предполагается нормальное распределение, в двух
последних — биномиальное и пуассоновское. Кроме того, будут
определены основные понятия выборочного контроля.
10.2. КОНТРОЛЬНЫЕ КАРТЫ ШУХАРТА
Контрольные карты на производстве дают динамическое изо-
изображение процесса, помогающее правильно действовать. Как
и в случае любой выборочной статистики, делаются предположе-
предположения о способе извлечения выборки и о совокупности. Разумеется,
неправильные предпосылки приводят к неверным значениям веро-
вероятностей и обесценивают результаты. Изучение карт Шухарта
начнем с Х- и #-карт. Обычно ими пользуются одновременно.
Можно рассматривать использование контрольной карты как
многократное применение критерия значимости, хотя это и не
принято среди контролеров и инженеров. Выборочная статистика
служит оценкой 6 параметра совокупности Э. На карту значе-
значений Э наносятся критические значения (верхняя и нижняя гра-
границы регулированияJ). Они зависят от а и объема выборки /г,
но а не всегда указывается точно. Гипотеза отвергается в том
случае, когда выборочная точка (индивидуальное значение или
статистика, рассчитанная по п наблюдениям) выходит за эти
границы. Тогда говорят, что процесс статистически неуправляем3).
х) Техника контрольных карт детально описана в книге Э. Шиндовский,
О. Шюрц. Статистические методы управления качеством.—М.: Мир, 1976; см.
также: ГОСТ 15893-77; ГОСТ 15894-70.— Пр им. ред.
2) Термин „границы регулирования" (control limits) имеет следующий
смысл: при выходе выборочной статистики за указанные границы требуются
управляющие (регулирующие) воздействия на процесс с целью восстановления
его стабильности.— Пр им. ред.
3) В этом случае представляются вполне обоснованными попытки найти
причины нестабильности. Обсуждение возможных причин см. в работах
[5,8-10]
Контрольные карты
367
Следует помнить, что границы регулирования далеко не всегда
совпадают с точными доверительными границами, соответствую-
соответствующими заданным вероятностям. Границы регулирования исполь-
используются лишь для принятия решений о том или ином действии.
Поэтому границы часто устанавливаются приблизительно; при
этом свои функции они выполняют достаточно хорошо.
10.2.1. Х- и Я-карты1*
Предположим, что последовательно берутся выборки объема п,
и для каждого входящего в них элемента измеряется характе-
характеристика х. Для всех выборок вычисляются среднее арифмети-
арифметическое х и размах варьирования R наблюдаемых значений. Обо-
Обозначим эти величины для t-й выборки через х{ и Rt. Значения
х( откладываются на одной карте, R{ — на другой. Арифметиче-
Арифметическое среднее всех R> R, умноженное на константу, зависящую
от объема выборки, используется затем как оценка иг _а/2 о-. Эта
величина в свою очередь добавляется к общему среднему х и
вычитается из него. В результате получаются границы регули-
регулирования для Х-карты: х± (оценка иг -а/2О-).
Предположим для определенности, что данные представлены
в форме табл. 10.1. По k выборкам объема п вычислим оценку
Номер выборки
1
2
3
k
Данные для Х- и #-карт
Измерения
*11*12*13- • *Х\П
#21*22*23' • -Х2п
*31*32*33- • 'ХЗп
xkixkixk3- • -xkn
Среднее
Ъ
х2
хъ
Ч
Таблица 10.1
Размах
#1
r\
математического ожидания совокупности Е (X):
2J
i, j
A0.1)
г) Символом X обычно обозначают карты выборочных средних. Сохраним
это обозначение независимо от употребления символа ранее.
368
Глава 10
Этой оценке соответствует так называемая центральная линия
(Qlt-карты. Границами регулирования Х-карты часто служат
оценки За-, отложенные вверх и вниз от х, но иногда приме-
применяются 100A ¦—<%)%-ные границы, где а обычно равно 0,01 или
0,05. Для получения За—границ была рассчитана таблица вели-
величин Л2, зависящих от объема выборки и таких, что A2R — оценка
3aj. Верхняя и нижняя границы регулирования для Х-карт
равны
х±А2%, A0.2)
где /\ = /v jfja/»
i __
При построении Х-карты предполагают, чтб 1) Xil9 Xtt, ...
..., Xi — случайные независимые нормально распределенные как
N (в{, а() величины и 2) все а] равны. Если распределение xif
не является нормальным, результатами все-таки можно пользо-
пользоваться, поскольку и в этом случае распределение х( близко
к нормальному. Гораздо важнее нарушение предположений
о случайности и независимости. Можно рассматривать Я- карту
с точки зрения процедур проверки гипотез; тогда нулевая гипо-
гипотеза состоит в том, что
Я0:01 = Э2— ... =вЛ = заданному значению, A0.3)
причем для стандартных границ, приведенных в табл. 10.2,
ошибка первого рода а равна 0,003. С помощью этой таблицы
можно получать не только Зсг-границы, но и любые другие. На-
Например, при а = 0,05 верхняя и нижняя границы регулирования
(ВГР и НГР) вычисляются по формуле
A0.4)
где ± 1,96 — верхнее и нижнее 2,5%-ные критические значения
нормированного нормального распределения N @, 1).
Оценка математического ожидания Rf т.е. величина Е(R),
для карты размаха равна
р7п\ Ъ /in ъ\
и За-границы составляют
D3R и D4#,
где D3 и D4, как и выше, зависят от принятых предположений и
объема выборки. Для получения других границ регулирования
можно воспользоваться таблицей распределения размахов, напри-
например табл. 3 приложения.
3
I
К
о
Си
I
05
s
s
5
2
2
I
о
?•«• оо >с о* cNvi-v
чО чО nO OG Г» ОО — NO •
N <ЛкМ О^ О^ОО ОО^ 1*^1
iWW Г Г ~ Г
»— On Г» «ЛП-«
vO W-> »r> irttn«n
^vo — r
OOf^r-SOs
ОО *П ~ SO О
©ч©"ч©>©">©"
©"©"©"©"о"
»n sS oo о -« гч cr> rt ir> so
©*©"©"©*©" ^©"©"©"©"
oovo-чо <-«©»r»ONfn vot^-©mif4 M*^v6^ot*»
^»onoC ^^^P^^ ^^opo?» ??«--'
o SO О Г
n On On On On
©"©"©"©*'©'*
On^O^OW
o*©4 ©*©"©"*
OO 0O On On ©
.- .- .- T_ _ OO OO OO OO On
On On On On^ OK On On On On On
©©"©"©© ©" ©" ©" ©"©""
S-S-»5- I2-5S2-
I — <n| vo —< e
«л vo ^- oo —
Г- VO «r> rf "ЧГ
«r> ir» >r> ir» ir»
VOSO4*"^ VO^OOONOO Tf-ONtS^'* «Л^ММО\
t^mOOfS «/-vOOOfSTf sOr-ON©»-< C4fn^t»n«O
©©©© ©©©©o" ©©© ©**© © © © © © ©*© © ©"*©
» © t~- 1Л
Г4 r^ -rf Г- © f^l^fSr^f^
*-1 © On 00 00 f"ssoso«r»«0
CM f4 ~ — •-. »л^«^„
*^ OO I4" GO v4 1/^ ^5 \& ^ч| ^^
t*4^ f*** f*14» ^O ^O \^^ vp ^O ^O ^O
о ©* ©* ©л d4 ©** ©" о ©" о*
S
as
370
Глава 10
Контрольные карты
371
10.2.2. Примеры Х- и /?-карт
Таблица 10.3
Сопротивление сжатию (отклонения от 5200 фунт/дюйм2)
Пример 10.1. В табл. 10.3 приведены закодированные изме-
измерения сопротивления сжатию цементных образцов. Даны откло-
отклонения от 5200 фунт/дюйм2; единичное отклонение соответствует
25 фунт/дюйм2. Выборки делались пять раз в день через случай-
случайные интервалы в течение 25 последовательных дней.
Столбцы х и R табл. 10.3 содержат выборочные средние и
размахи. Соответствующие карты изображены на рис. 10.1 и 10.2.
2
1
х О
„2 TJ—Jbz!
О 5 10 15 20 25 30
Номер выборки
Рис. 10.1. Контрольная Х-карта для сопротивления сжатию»
°о°
о
— ттяшт ^__
1
о оо оо о о
о ° °
о °
1 1
ВГР=2,085
о
00 о
° oQ=
о °
НГР =-2,069
i i
0,008
Номер
Выборка
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25-
Итого
{Вый
*\
1
-2
0
1
2
2
-2
1
0
-1
1
2
0
0
-3
0
3
-1
0
0
2
0
3
1
-1
рочны
? измерения)*
'*' фунпг^Экшм*
хг
-1
0
0
2
1
-1
-1
1
-2
-1
-1
2
-2
-1
0
-1
1
—2
0
—5
-1
0
1
-3
0
Ч
-2
-2
1
-I
-1
2
0
0
1
0
2
-1
2
I
0
0
-3
-1
0
2
1
-3
4
0
1
Ч
2
2
-1
2
1
— 1
-2
1
-1
-2
-4
-1
-2
•-1
0
1
-2
-1
1
о
0
2
-2
1
0
*в
0
0
3
-2
0
0
0
-1
4
1
0
0
0
2
-1
2
0
0
1
0
0
-3
-1
-1
1
X
0
-0,4
0,6
0,4
0,6
0,4
-1,0
0,4
0,4
-0,6
0,2
0,4
-0,4
0,2
-0,8
0,4
-0,2
-1,0
0,4
-0,2
0,4
-0,8
1,0
-0,4
0,2
+0,2
Статистики
R
4
4
4
4
3
3
2
2
6
3
3
3
4
3
3
3
6
2
1
7
3
5
6
4
2
90
2,50
2,80
2,30
3,30
1,30
2,30
1,00
0,80
5,30
1,30
1,70
2,30
2,80
1,70
1J0
1,30
5,70
0,50
0,30
8,20
1,30
4,70
6,50
2,80
0,40
s
1,58
1,67
1.52
1,82
1,14
U2.
1,00
0,89
2,30
1.14
1,30
1,52
1,67
1,30
1,30
1,14
2,39
0,71
0,55
2,86
1,14
2,17
2,55
1,67
0,63
10
о о
о
о о о о
о С=3,ео
ОО ООО Оо О О
0 0 О О
о
I | | г |
Для Х-карты эти величины равны
С = х = ^2^ = ^/1)-!
^ = 0,008,
2^ ^/1) 2
НГР = 0,008- 0,577 (§) = 0,008-2,077 = —2,069,
ВГР = 2,085,
О 5 10 15 20 25 30
Номер выборки
Рис. 10.2. Контрольная R-карта для сопротивления сжатию.
Центральные линии и границы регулирования для этих карт
вычисляются по формулам A0.1), A0.2), A0.5) с помощью табл.
10.2.
с=/г* 2 #/=з,бо,
для /?-карты
ВГР = D,R = 2,115-3,60 = 7,61,
где х{ и R; — среднее арифметическое и размах варьирования
i-й выборки.
372
Глава 10
Из рис. 10.1 и 10.2 видно, что процесс статистически управ-
управляем. При оценивании а можно воспользоваться величиной A2R,
равной За-. Для выборки объема 5 получим
или a - 2,077/C// 5) = 1,548.
Поскольку процесс протекает стабильно, можно предположить,
что дисперсия средних значений выборок (дисперсия между вы-
выборками) равна нулю. Тогда получаем другую оценку а:
s =
124
-1,5476.
(Столь тесная близость значений а и s, разумеется, случайна.)
Последняя формула применима только тогда, когда можно пред-
предположить отсутствие разброса средних значений выборок.
10.2.3. Контрольная карта Шухарта для среднего
квадратического отклонения
S-Карта для выборочного среднего квадратического откло-
отклонения более чувствительна к изменению рассеяния, чем /?-карта.
На практике она применяется реже последней, поскольку тре-
требует более сложных вычислений, в ходе которых могут появ-
появляться ошибки. При построении этой карты получается объеди-
объединенная оценка дисперсии совокупности по k выборкам:
где t^/1,-1; t'=l, 2, ..., k A0.6)
(см. гл. 8). Если объемы выборок одинаковы, формула для оценки
дисперсии имеет более простой вид:
Центральная линия и За-границы получаются с помощью табл. 10.2:
? = <&,,
*В'#„ A0.7)
В табл. 10.2 приведены также значения с2, В2 и В4. К ним
обращаются, когда применяют смещенную оценку дисперсии
Контрольные карты
373
к п
k~l 2 2 [(*// —*/)а/я]» ЧТо часто делается в работах по контролю
качества1).
Пример 10.2. Вычислим по данным табл. 10,3 а*~оценку о2.
В предпоследнем столбце таблицы приведены значения sj. Сле-
Следовательно,
Е|- 2,5920,
s^-1,610.
Центральная линия контрольной S-карты (рис. 10.3) описыва-
W 15 20
Номер Шорки
25
Рис. 10.3. Контрольная 5-карта для сопротивления сжатию (для кодированных
данных).
ется выражением
= ^s. = 0,9405, = 1,51,
а нижняя и верхняя границы регулирования вычисляются по
формуле A0.7):
НГР = 0,
ВГР = 1,889-1,61 =3,04.
Заметим, что выборка с номером 20 близка к ВГР. То же самое
наблюдалось и на карте размаха. Рис. 10.2 и 10.3, как и сле-
1) Когда контрольными картами только начинали пользоваться, символ ff*,
к сожалению, применялся для обозначения этой смещенной оценки дисперсии
совокупности. Такое обозначение используется в большинстве современных работ.
374
Глава 10
довало ожидать, похожи. Впрочем, S-карта более чувствительна
к изменениям рассеяния, зато построение 7?-карты связано с более
простыми вычислениями.
* 10.2.4. Контрольные карты Шухарта для х и s в случае
неравных объемов выборок
Иногда возникает ситуация, когда равные объемы выборок
невозможны или нежелательны. Тогда центральная линия Х-карты
задается взвешенным средним всех выборок. Для S-карты берут
s , где Sp —взвешенное среднее выборочных дисперсий. Соответ-
Соответствующие формулы имеют вид
.__ j !_
2'
A0.8)
[cm. A0.6)],
где п{ —объем i-и выборки, a s? — ее дисперсия. Если объемы не
равны хотя бы приближенно, границы регулирования X и S-карт
меняются от выборки к выборке. Они равны
Г> у m
ВГР =
A{sp,
НГР = x—A{sp
С =c'2iS; или
вгр = 5;^,
A0.9)
A0.10)
где Л,., Сам BJi и В^ зависят от объема i'-й выборки.
Пример 10.3. Чтобы выяснить влияние обжига на устойчи-
устойчивость эмали, в течение месяца было подготовлено большое число
идентичных выборок. Для каждой из них записывалась темпе-
температура обжига в градусах Фаренгейта. К сожалению, технолог,
производящий обжиг, не получал каждый раз одинаковое число
образцов. Поэтому объемы выборок в табл. 10.4 не равны.
Контрольные карты
375
Таблица 10 А
Номер
вы-
выборки
1
2
3
4
5
6
7
8
9
10
Объем
8
10
12
7
10
6
8
6
5
12
Температура обжига (в
X
1356
1380
1448
1358
1372
1430
1356
1426
1444
1404
S2
1281,06
2570,36
1901,10
1384,21
4035,24
1672,04
1354,60
643,08
3418,54
1608,98
s
35,8
50,7
43,6
37,2
63,5
40,9
36,8
25,4
58,5
40,1
градусах Фаренгейта)
Границы
НГР
1348,7
1358,8
1357,5
1345,4
1358,8
1341,3
1348,7
1341,3
1336,1
1357,5
ДЛЯ X
ВГР
1444,3
1439,2
1435,5
1447,6
1439,2
1451,7
1444,-3
1451,7
1456,9
1435,5
Границы для s
НГР
9,7
13,6
16,4
7,1
13,6
3,8
9,7
3,8
0
16,4
ВГР
77,2
74,0
71,6
79,3
74,0
81,8
77,2
81,8
85,1
71,6
Столбцы 3 и 4 этой таблицы вычислены по результатам 10 выборок.
Предполагалось, что последние различаются только интервалом
времени, когда проводился обжиг.
Константы контрольных карт X и S равны
С= х = 1396,5° для Х-каргы (я —взвешенное среднее)*
9178,
= ^=0,967.45,03 = 43,54° для S-карты.
Границы Х-карты вычисляются отдельно для каждого объема
выборки по формуле x±A(si9 где А( зависит от объема. Они
приведены в табл. 10.4 и нанесены на рис. 10.4. На рис. 10.5
показана «S-карта для случая разных объемов выборок. Поскольку
ошибки небольшие, центральная линия может быть одна, но c^Si
вычисляются отдельно для каждой выборки. Значение с'2 (= 0,967)
соответствует среднему объему выборки, равному 8,4. Заметим,
что х3 выходит за границы, но все значения s,- лежат между
границами. Это свидетельствует о больших колебаниях в резуль-
результатах изо дня в день при незначительных вариациях среднего
квадратического отклонения.
37G
Глава 10
1480
1460
1440
НЮ
V1400
1Ш\
1360
1340^
о
С= 1Z96,5
; -•-r-jriij-L_r4__r
ИГР
\ \ 1 Г
I I I
0 1 2 3 4 5 6 7 8 3 10 11 12
Номер Выборки
Рис. 10.4. Контрольная Х-карта для температуры обжига (°F).
30 г
sol
10
12
4 6 8
Номер выборки
Рис. 10.5. Контрольная S-карта для температуры обжига <°F).
10.2.5. Контрольная карта для доли дефектных изделий р
Перейдем к рассмотрению контрольных карт для качествен-
качественных признаков. Здесь приходится обращаться к биномиальному
и пуассоновскому распределениям. Параметром первого является
доля дефектных изделий р или их число пр. Будем рассматри-
рассматривать общий случай неравных объемов выборок.
Контрольные карты
377
Если выборка достаточно велика, можно воспользоваться
нормальным распределением (как это делалось в гл. 8). Оценка
математического ожидания р имеет вид
A0.11)
где х,«—число дефектных единиц в г-й выборке объема nh i =
= 1, 2f ..., k. (Для обозначения оценки математического ожи-
ожидания р в статистическом анализе обычно пользуются симво-
символом р, а в контрольных картах — символом р.) Верхняя и ниж-
нижняя границы регулирования для i-n выборки равны
A0.12)
ВГР, = р + 3
Если объемы выборок примерно одинаковы, вычисляется только
одна пара границ регулирования, а именно
где
A0.13)
Пример 10.4. Построим контрольную карту, фиксирующую
текущий уровень доли дефектных единиц в производстве сили-
силиконовых вафель. Через определенные промежутки времени про-
проверяются большие партии разного объема. В табл. 10.5 приве-
приведены их номера и размеры, а также число и доля дефектны^
изделий. Центральная линия и границы регулирования вычисля-
вычисляются по формулам A0.11) и A0.12). Эти величины представлены
графически на рис. 10.6, где для сравнения изображены верхняя
и нижняя границы регулирования, вычисленные по формулам
A0.13) для среднего объема выборки п (= 1241).
Из рис. 10.6 следует, что колебания доли дефектных единиц
выходят за тот уровень, когда их можно объяснить случайными
причинами. Результаты свидетельствуют о необходимости иссле-
исследования не только самого процесса, но и методов контроля.
378
Глава 10
Таблица 10.5
Доля дефектных изделий в производстве вафель
Номер
партии
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Итого
Объем
быборки
981
1422
1174
1524
1353
847
1535
1248
1296
985
1371
863
1197
1459
1356
18611
Число
дефектных
изделий
27
87
87
76
80
25
37
19
49
42
44
21
83
121
103
901
ДОЛЯ
дефектных
изделий
0;028
0,061
0,074
0,050
0,059
0,030
0,024
0,015
0,038
0,043
0,032
0,024
0,069
0,083
0,076
0,0484
Границы
регулирования
НГР
0,0278
0,0313
0,0296
0,0319
0,0309
0,0263
0,0320
0,0302
0,0305
0,0279
0,0310
0,0265
0,0298
0,0315
0,0309
0,0301
ВГР
0,0690
0,0655
0,0672
0,0649
0,0659
0,0705
0,0648
0,0666
0,0663
0,0689
0,0658
0,0703
0,0670
0,0653
0,0659
0,0667
О 2 4 6 8 10 12 14 16 18 20 22 24
Номер партии
Рис. 10.6. Контрольная карта для доли дефектных изделий.
Контрольные карты
379
10.2.6. Контрольная карта для числа дефектов с
При работе с качественными признаками часто применяется
с-карта, где с имеет распределение Пуассона
при
= 0, 1, 2, ....
A0.14)
(Некоторые предпочитают символ X, но чаще используется сим-
символ с.) Обычная центральная линия и границы вычисляются по
формулам
НГР -7-
ВГР =
A0.15)
Опять имеются в виду За-границы. Предполагается, что нор-
нормальное распределение хорошо аппроксимирует пуассоновское.
При малых значениях п это не так, тем не менее аппроксима-
аппроксимация нормальным распределением широко используется при конт-
контроле качества. Выйти из затруднительного положения можно
тремя способами. Первый состоит в том, чтобы признать неточ-
неточность аппроксимации и принимать решения с некоторой осто-
осторожностью. Второй, более разумный, подход заключается в таком
выборе базовой единицы, чтобы математическое ожидание числа
появлений события (с) было не меньше 30. В приведенном ниже
примере среднее значение числа дефектов на одно изделие равно
5,42. В случае необходимости основную единицу можно увели-
увеличить в 5 или 6 раз. Этим достигается большая точность аппрок-
аппроксимации нормальным распределением.
Третий (и лучший) выход состоит в применении точного рас-
распределения Пуассона, например с помощью табл. Б приложения.
Пример 10.5. При окончательной проверке небольших сде-
сделанных по заказу самолетов обнаруживаются мелкие дефекты.
Последние не влияют на принятие или браковку изделия. Они
лишь требуют добавочных затрат труда для удовлетворения
заказчика. Проведено небольшое исследование, чтобы выяснить,
можно ли считать число мелких дефектов примерно постоянным
и статистически управляемым или есть признаки изменений числа
дефектов, превосходящих ожидаемые. Результаты проверки пер-
первых 12 изделий приведены в табл. 10.6. Графически данные
3S0
Глава 10
Номер
изделия i
1
2
3
4
5
6
Число
Число
дефектов с-
4
3
7
4
5
5
дефектов
Номер
изделия i
7
8
9
10
11
12
Число
дефектов с^
4
5
7
8
6
7
Таблица 10.6
Сумма
65
с соответствующими границами и центральной линией представ-
представлены на рис. 10.7. С помощью формул A0.15) получаем
14
п
10
о8
В
4
2
0
и
—
-
-
- о
о
*
2
о
о
?
4
8ГР
о
о с
0
° ° о о
...... 1 ! Т
6 & 1/1 19
Номер Шорки
Рис. 10.7. Контрольная карта для числа дефектов.
НГР = J_3y^=_ 1,57,
= 12,41.
НГР —отрицательна и не может быть использована. Если
обратиться к точному распределению Пуассона (табл. Б прило-
приложения), то оказывается, что НГР отсутствует, а ВГР находится
Контрольные карты
381
между 14 и 15 (это соответствует вероятностям попадания в
„хвосты* распределения, меньшим 0,001). Эти границы показаны
на рис. 10.7.
Самые крайние точки, соответствующие изделиям с номерами
2 и 10, не выходят за границы регулирования. Беспокойство
может вызвать тот факт, что последние четыре точки 9—12 ока-
оказались высоко, тогда как пять предыдущих были ниже выбороч-
выборочной медианы. Этот результат не значим при 2,5%-ном уровне
одностороннего критерия. [Это видно из табл. Т приложения
E значений выше и 7 ниже медианы).] Здесь нет причин для
беспокойства, но эти серии, особенно последнюю, следует помнить
при анализе следующих выборок.
10.2.7. Серии в контрольных картах
Обычно рассматривают контрольную карту, на которой изоб-
изображены последовательные значения, например х{ для каждого
номера выборки it центральная линия и две границы регулиро-
регулирования, однако кроме границ регулирования существуют и другие
признаки, указывающие на необходимость действий. Многие инже-
инженеры по контролю качества отмечают на картах „предупреждаю-
„предупреждающие" границы 2 или 2,5ст по отношению к центральной линии.
Они соответствуют уровням а, равным примерно 5 и 1 %. В дру-
других случаях выход из статистически управляемого состояния
обнаруживают путем вычисления вероятностей серий определен-
определенных длин (последовательностей точек, лежащих выше или ниже
центральной линии) или числа серий в k идущих друг за другом
значениях х{.
В расчетах, связанных с длинами серий, применяется бино-
биномиальное распределение при вероятности нахождения выше или
ниже центральной линии (точнее медианы), разной 1/2. В этом
случае серия длины 7 свидетельствует о том, что процесс статис-
статистически неуправляем (при а=0,01). С другой стороны, слишком
редкие или частые серии могут объясняться неучтенными факто-
факторами или скачкообразным смещением процесса. Серии кратко
обсуждались в гл. 9. Здесь нужно применить принципы, изложенные
в разд. 9.5, к последовательным выборочным величинам. Крити-
Критические значения для проверки гипотезы о стабильности процесса
по числу наблюдаемых серий приведены в табл. Т.
Пример 10.6. В примере 10.4 всего наблюдалось четыре серии.
Для выборки, восемь значений которой находятся ниже и семь
значений выш§ центральной линии, вероятность такого или мень-
меньшего числа серий не превышает 5%. Из табл. Т приложения
382
Глава 10
Контрольные карты
383
видно, что 5%-ные границы равны 4 и 12. Эти границы не столь
строги, как За-границы нормального распределения (соответствую-
(соответствующие вероятности 0,0015), но выход за них вполне может слу-
служить признаком потери управления (или предупреждением).
10.2.8. Контрольная карта индивидуальных значений
Контрольными картами индивидуальных значений пользу-
пользуются также, как картами средних, но в этом случае гораздо
важнее сделать правильные предположения о распределении. Если
оправдано допущение нормальности и известна дисперсия ох (или
ее оценка), границы регулирования равны
х± ЗоХУ
при известном ох или
x±3sy
если оценка о2х, s2, основана на выборке, содержащей по край-
крайней мере 30—40 наблюдений. Любую пару границ регулирова-
регулирования для заданного уровня а можно найти в табл. Г.
Обычно стараются, чтобы За-границы соответствовали грани-
границам допуска процесса. При этом естественная изменчивость про-
процесса согласуется с нормативами, установленными заказчиком.
Иногда статистик наносит индивидуальные значения i-и вы-
выборки (xix, xia, ..., xi ) на ту же карту, где изображены выбо-
выборочные средние х{. Разумеется, при этом карта дает более под-
подробную информацию. Впрочем, если не принять мер крайней
осторожности, такое представление скорее затемнит, чем про-
прояснит картину. Например, может возникнуть вопрос, чему соот-
соответствует данная пара линий —границам регулирования для х,
пределам вариации процесса или границам допуска.
10.2.9. Карта скользящего размаха
Рассмотрим контрольные карты индивидуальных значений и
карты скользящего размаха. Пусть общее число измерений х
равно N. Если вычислять абсолютные величины разностей после-
последовательных пар значений х, например x{_t и xiy получается
N—\ величин R(. Их можно нанести на карту скользящего раз-
размаха. Центральная линия и границы регулирования для этой
карты описываются выражениями
x=N-1%xi и R = (N-l)-1%Ri. A0.16)
Абсолютные величины разностей \(xi• — х(^±) | можно рассматри-
рассматривать как размахи последовательных выборок объема 2. Послед-
Последние нельзя считать независимыми, поскольку как \xi+1 — х(\,
так и \xi — xi-1\ зависят от xt.
Нижняя и верхняя границы регулирования равны
для
и D3Ry D^R для R. (ЮЛ7)
Значение d2 берется из табл. 10.2 для объема выборки /г— 2,
a 3R/rf2 —оценка Зах. Заметим, что, поскольку эти выборки
объема 2 нельзя считать независимыми, имеет смысл брать какие-
нибудь более узкие пределы, например 2R/d2 или другие, при
заданной вероятности. Отметим также, что А2 = 3/d2Vny где п —
объем выборки (см. табл. 10.2).
Карты индивидуальных значений и скользящего размаха осо-
особенно удобны в тех случаях, когда наблюдения берутся через
большие промежутки времени. Например, когда ежедневно выпус-
выпускается несколько единиц продукции и невозможно сформировать
выборку объема /г, эти карты, учитывающие каждое наблюдение
с момента его появления, обеспечат непрерывный контроль за
процессом.
Пример 10.7. В табл. 10.7 приведены промежутки времени,
необходимые для завершения выплавки стали в кислородной
печи. Фиксировалась длительность 30 плавок. Для каждой после-
Таблица 10.7
Время (в минутах) выплавки стали
Номер
выборки
1
2
3
4
5
6
7
8
9
10
X
19,1
19,3
20,4
21,5
18,2
22,3
19,4
20,2
21,4
21,0
R
0,2
1,1
1,1
3,3
4,1
2,9
0,8
1,2
0,4
Номер
выборки
11
12
13
14
15
16
17
18
19
20
X
18,6
21,1
20,2
20,1
19,1
19,3
19,6
18,9
19,4
20,9
R
2,4
2,5
0,9
0,1
1,0
0,2
0,3
0,7
0,5
1,5
Номер
выборки
21
22
23
24
25
26
27
28
29
30
X
19,2
20,6
20,9
20,4
21,8
22,0
21,6
17,5
19,8
19,1
Г)
н
i;7
1,4
0,3
0,5
1,4
0,2
0,4
4,1
2,3
0,7
Сумма 609,2 38,2
384
Глава tO
Контрольные карты
довательной пары (всего их было 29) вычислялся размах. Конт-
Контрольные карты для х и R показаны на рис. 10.8 и 10.9. Гра-
24,0-
23,0
22,0-
21,0
X 20,0 ¦¦
19,0
385
по
160
о
I
о
о
о
о
I
—
о
о
у
о
I
о
О
I
0°
—
о
° о
о
* "
ВГР =23,58
о°о
о°о С = 20,10
о
0 О
о
ИГР = 76 61
i i 1 i i
3 S 3 11 15 18 21 24 27 30 33 36
Номер дыборки
Рис. 10.8. Контрольная карта индивидуальных значений для времени
выплавки.
ГвГР=4,303
\ О? 1,317
1 1 1
3 6 3 12 15 18 Ш 24 27 30 J3 3S
Шмеррошшхш {номер 5ы6щ>ки-1)
Рис. 10.9. Контрольная карта скользящего размаха для времени выплавки.
ницы регулирования и центральные линии для Х-карты вычис-
вычисляются по формулам
602,9
Г—
_ 30
: = 20,10,
НГР = х-4^20,10—i
16,62,
а для R соответственно получаем
С= 1,317,
ВГР
3,267A,317) = 4,303.
Из рис. 10.8 и 10.9 видно, что ни одна точка на карте не
выходит за границы регулирования, но две точки на карте раз-
размаха оказались вблизи границ регулирования.
Обе контрольные карты были построены с помощью последо-
последовательных пар. Тем же способом можно легко построить карты
в случае, когда группы содержат три, четыре и т. д. наблюдений.
На каждом шаге добавляется новое значение х и отбрасывается
крайнее с другого конца. Разумеется, нужно изменить величины
коэффициентов d2, D3 и D4.
10.3. КАРТЫ ПРИЕМОЧНОГО КОНТРОЛЯ
Карты приемочного контроля тесно связаны с приемочной
выборочной процедурой (см. разд. 10.6). В общем случае рас-
рассматриваются непрерывные переменные (см. пример 10.8), но тем
же способом легко строятся карты для дискретного случая. Эти
карты основаны на принципах проверки гипотез, но, чтобы знать,
не сместился ли процесс с желаемого уровня на недопустимый,
наносятся границы регулирования.
Выбираются приемочный уровень процесса АРЕ (acceptable
process level) и браковочный уровень процесса RPL (rejectable pro-
process level). С APL связана ошибка первого рода а, а с RPL —
ошибка второго рода C. Задача состоит в том, чтобы принимать
продукцию с качеством APL и выше с вероятностью не меньше
A—а) и отклонять изделия с качеством RPL и ниже с вероят-
вероятностью не меньше A — C). Для этого определяются границы, зави-
зависящие от APL, RPL, а, |3 и п (объема выборки). Если величина х
оказывается в пределах приемочных границ регулирования, про-
процесс считается удовлетворительным. Если она выходит за гра-
границы, необходимо принять меры.
Подробно контрольные карты этого типа описаны в работе
Р. А. Фрейда [Freund R. A., Acceptance Control Carts, Indust-
Industrial Quality Control (октябрь 1957 г.)]. В статье нет математи-
математического обоснования, но дано несколько примеров (включая при-
приведенный ниже) и таблиц для расчета границ.
Пример 10.8. Рассмотрим пример карты приемочного конт-
контроля, взятый из упомянутой выше работы Р. А. Фрейда.
Партию установочных штифтов длиной 1,1250 ± 0,0625 дюйма
принимают в том случае, когда за указанные пределы допуска
выходит не более 0,5% изделий. Из опыта прошлой работы из-
известна оценка среднего квадратического отклонения процесса:
0,0039 дюйма. Для партии с APL величина а должна быть
равна 0,05. С другой стороны, если партия настолько плохая,
13
819
386
Глава 10
что достигает RPL, следует требовать вероятности отклонения,
равной 0,99. Берутся выборки объема 4.
Вычислим такие границы для среднего совокупности, что если
принять их за RPL, не более 1% продукции окажется вне пре-
пределов допуска (возможностью выйти за пределы допуска в менее
правдоподобном направлении пренебрегаем):
A,1250+ 0,0625)-2,576 @,0039) = 1,1775,
A,1250-0,0625) + 2,576 @,0039) -1,0725
B,576 — критическое значение, соответствующее 0,5%-ному уровню
нормированного нормального распределения).
С помощью RPL находим приемочные границы регулирования
для выборочного среднего 7, соответствующие р = 1 % (маловеро-
(маловероятной возможностью опять пренебрегаем):
Контрольные карты
387
х = 1,1775-2,326
х = 1,0725 + 2,326
= 1Л730,
= 1,0770
B,326—1%-ный уровень для нормированного нормального рас-
распределения).
Приемочный уровень качества процесса получается с помощью
приемочных границ регулирования следующим образом:
1,1730- 1,645
1,0770+ 1,645
где 1,645 —значение, соответствующее одному 5% -ному хвосту
нормального распределения. Получаем величины APL, равные
1,1698 и 1,0802. Они показаны на рис. 10.10. Заметим, что на
рис 10.10 плотности вероятности при средних, равных RPL, пред-
представляют распределения х, тогда как остальные^ функции отно-
относятся к распределениям выборочных средних х, рассчитанных
по выборкам объема 4. Константы для границ в этом примере
равны
RPL: 1,0725, 1,1775,
APL: 1,0802, 1,1698.
Приемочные границы регулирования: 1,0770, 1,1730.
1,1730 —?
\0,005
\
У
*
X
p
=0,01
X
Граница
a.-0,05
допуска
RPL
— APL
¦1,1875
Номинальное значение
-1,1250
-1- 1,0770
0,005
x
/2 = 0,01
Ф
Л^> APL
0.-0,05
Граница допуска
X
1,0602
1,0725
1,0625
Рис. 10.10. Карта приемочного контроля.
10.4. КОНТРОЛЬНЫЕ КАРТЫ НАКОПЛЕННЫХ
СУММ (ККНС)
Другая форма контрольных карт, получившая широкое при-
применение в последние 20 лет —контрольная карта накопленных
сумм (ККНС). Она имеет несколько иное назначение, чем карта
Шухарта, и более чувствительна, чем последняя, к скачкообраз-
скачкообразным изменениям параметров процесса (в отличие от постепенного
тренда). Относительная стоимость ККНС (измеряемая числом
необходимых наблюдений) ниже, чем у карты Шухарта, но не
при всех значениях а и не для всякого изменения среднего зна-
значения процесса. Это становится понятным при рассмотрении сред-
средней длины серии (СДС) — среднего числа наблюдений, необходи-
необходимых для обнаружения заданного изменения характеристик про-
процесса (см. разд. 10.6).
Разработка ККНС связана с работами Е. С. Пейджа [19],
Дж. А. Бернарда [3], П. Голдсмита и X. Уайтфилда [13].
Довольно подробное описание ККНС с несколькими не очень
строгими доказательствами дано в трех работах Н. Джонсона и
13*
388
Глава 10
Ф. Лиона, опубликованных в журнале Industrial Quality Control
[16]. Полезное и более детальное изложение дано де Брюном [21]*).
Можно лучше понять ККНС, если рассматривать ее как
последовательную выборочную процедуру {ст. гл. 16), применяемую
в обратном порядке. Вывод формул для критических значений
и границ регулирования ККНС основан на последовательном
критерии отношения вероятностей. Он будет описан в гл. 16 и
поэтому здесь не рассматривается. В этом разделе описаны ККНС
для средних, дисперсий, размахов, пр и с. Для каждой из них
будут приведены правила построения шаблонов и границ регули-
регулирования.
Отличительная особенность ККНС состоит в том, что нане-
нанесенные на карту точки не соответствуют отдельным наблюдениям
или статистикам, вычисленным по одной выборке. Все они, начи-
начиная с исходной, дают информацию о наблюдениях от первого до
текущего включительно. В каждом рассматриваемом здесь вари-
варианте ККНС ордината наносимой в данный момент точки равна
ординате текущего наблюдения плюс значение статистики, вычис-
вычисленной по предшествующей выборке.
10.4.1. ККНС для среднего
Опять обозначим среднее значение i-й выборки объема п через
X;. На контрольную карту наносятся точки с координатами (m, Ym),
где т — номер выборки и
Контрольные карты
389
|л0 равно предполагаемому „нормативному среднему". Для интер-
интерпретации карты на нее накладывается шаблон (заштрихованная
часть рис. 10.11), причем точка О должна совпадать с послед-
последней точкой, нанесенной на карту, а линия ОР должна-быть гори-
горизонтальной. Считается, что процесс статистически неуправляем,
если какие-либо точки ККНС оказываются накрытыми шаблоном.
Если они лежат ниже прямой AxBly говорят об увеличении
среднего процесса, если выше Л_1В_1 —об уменьшении. (Для
каждой карты выбирается свой масштабный коэффициент. О нем
будет сказано несколько ниже.)
При определении размеров шаблона нужно вычислить вели-
величину 29 угла В^ЛРВ1 и расстояние d от О до вершины Р этого
угла на рис. 10.11. Сначала следует выбрать вероятности ошибок
первого и второго рода. (Если величина C очень мала, например
меньше 0,01, ее можно исключить из формулы.) Приближенные
/ 2
Рис. 10.11. Шаблон контрольной карты накопленных сумм для средних
значений.
формулы для Э и d имеют вид
e=arctg(|)f
d = —26-Чпа,
A0.19)
х) См. также: Химмельблау Д. Анализ процессов статистическими мето-
методами. Пер. с англ.—М.: Мир, 1973.—Прим. ред.
где 6 = Д/сг-, a D — минимальный сдвиг (в любом направлении),
который желательно выявить почти наверное (с вероятностью
или мощностью 1— р). Вероятнасть ошибки первого рода для
двустороннего критерия обозначена здесь через 2а, а для одно-
одностороннего критерия — через а.
Процедура применения ККНС для средних состоит из сле-
следующих этапов.
1. Задать величины а (или 2а) и D.
2. Вычислить Э и а по формулам A0.19).
3. Нанести последовательные точки Ym, всякий раз передви-
передвигая шаблон.
4. Принять одно из трех решений: а) продолжать проверку;
б) признать наличие смещения |lio + D или в) признать на-
наличие смещения \х0—D.
(Если имеющихся знаний недостаточно для теоретического
выбора значений параметров формул типа A0.19), можно полу-
получить границы методом проб и ошибок, как было предложено
Дж. Бернардом [3].)
Если величина а (и, следовательно, о-х) не известна к началу
испытаний, ее можно оценить по формуле
Контрольные карты
391
5Г
3
Is
ВС
&
X
2
vo
2
4
ВС
S
I
с
S
ев
95
О
X
•О
I
X
§
к
S
X
I
S
X
се
U
!
oo
II II
0,002
0,001
II II
t^ en
0,002
0,001
II II
si
о о
II II
« •«
CN
= 0,02
= 0,01
CN
,05
,025
О О
II II
a a
cn
2 S
о о
II II
CN
«С
C^ О N ОС Г^ \0ж 1—^ О\ >?>л 00ж —^ NO^ ГЧи О\ NOe
о \п гч" **Г vT о* г^" vT ^t со сЧ" гГ сГ —* ~
О© ON ^ <N - -
П- «_ ^ уо оо «^ Ол т^ Г4л тГж оол ^ Ол ^ ч\
ир^^оо*ч--'"г*^сСг^<гГт1^ггГг>4чгТгч '™| 1—'
^" оо m cn —«
СО
Г-м|- м^_ Ъ ^Ч /\^1 /Я^ ДГ1 ^ЧЪ 1^4 ^ЧЧ t" In,
ОО TJ" У© ОО О ^О ON •*» ON Г^
rJ-VO|^sOfN""f^'~-Ofor^fNONNO^t
О* fS VO О П ОС ^О "О t fi N (N « - -^
П 00 f) N «
C^)
SO — ^t^«O0N^r^«O00
ONtNTfsosocnrj"'— (NSO — OO^fi-
¦^sOONVOOf^^^frrOCNCS'-*'-"'-*-*
fN
ro m <N —
CN
OONVOOOOO^tMOO^^N
Tj-,— ти^сп-ч t^ooc4oo«ofNOONOO
^t* so O* —Г I4» «O CO (N CN — —' — — OO
00 rj- cN »-<
SOONSOVOrflOO^t^ON^Ot-
oo^vOc^on — Omoo«r>fNOoof^so
Tj1 n *4
mONCNOOTfOOv OONv TttNsOOQON
OOOOOCOOOOOCOOo
Y^ — SO — soO«O00 — «nt^OCNrj-sO
•—< •"« CN CN СП ГП СП ^ ^q* 'q* *ri V^ yf\ *O
N'tvOOCON^vOOOOfS^vOoOO
l
где s?—дисперсия /-й выборки, a /n — количество выборок. Если
число степеней свободы v = m(n — 1) больше, чем 30 или 40, эту
оценку sp можно считать надежной.
Вместо того, чтобы вычислять значения 9 и d, можно вос-
воспользоваться табл. 10.8. Из нее сразу берутся значения 9 и d
для определенных б и а.
Вычисление размеров шаблона теряет смысл, если не учиты-
учитывать масштабный коэффициент. Здесь есть отличие от карты
Шухарта, для которой важен только масштаб по вертикальной
оси. Пусть k единиц ординаты равны одной единице абсциссы.
Тогда уравнения для 9* и d* имеют вид
rf A0.20)
Значения 9* и d* можно получить из табл. 10.8. При этом
к табл. 10.8 следует обращаться дважды:
1) Взять Э* из строки, которой в столбце б соответствует зна-
значение D/k.
2. Взять значение d* из строки б и столбца, соответствую-
соответствующего заданному значению а или 2а.
Пример 10.9. Данные, приведенные в табл. 10.9, взяты из работы
Таблица 10.9
Суммарные высоты оснований осколочных бомб1) (Выборки объема 5)
Номер дь/dbp
1
2
3
4
5
6
7
8
9
10
11
12
13
и
15
16
wt х
0,8324
0,8306
0,8262
0,8326
0,8290
0,8316'
0;8336
0,8310
0,8336
0,8306
0,8302
0,8258
0,8280
0,8264
0,8292
0,8228
5-0,831
0,0014
0,0004
-0,0048
0,0016
-0,0020
0,0006
0,0026
0,0000
0,0026
-0,0004
-0,0008
-0,0052
-0,0030
-0,0046
-0,0018
-0,0082
^-ZGr,--0,831)
0,0014
0,0010
-0,0038
-0,0022
-0,0042
-0,0036
-0,0010
-0,0010
0,0016
0,0012
0,0004
-0,0048
-0,0078
-0,0124
-0,0142
-0,0224
R
0,014
0,008
0,020
0,004
0,013
0,013
0,012
0,020
0,010
0,011
0,018
0,006
0,016
0,023
0,003
0,025
*) Данные заимствованы из Quality Control and Industrial Statistics, A. J. Duncan,
Irwin Publishing Co., 1952.
392
Глава 10
[8]. Они представляют собой последовательность измерений высот
оснований осколочных бомб с точностью до тысячной доли дюйма.
В исходные данные были внесены следующие изменения: первые
десять выборок объема 5 остались прежними; средние значения
каждой из следующих шести выборок были уменьшены на 0,003.
Это было сделано для демонстрации работы шаблона. В таблице
приведены порядковые номера выборок, средние выборок объема 5,
отклонения от предполагаемого среднего значения 0,831, накоп-
накопленные суммы отклонений и размахи R.
Для расчета размеров шаблона сначала выбираем D и а.
Пусть D равняется одному среднему квадратическому отклоне-
отклонению среднего, а а = 0,00135 (как в обычной карте Шухарта для
средних с Зсг-границами). Пусть ох = 0,0054. (Эту величину можно
вычислить по выборкам или считать известной.) Имеем
Контрольные карты
393
= g-x = -^=-0,0024,
а-0,00135,
& = 0,002 (масштабный коэффициент), 5=1.
Применение формул A0.20) дает
d* = d= —2(lnO,OO135)= 13,215,
Заметим, что в табл. 10.8 d* = 13,2 (строка 5=1) и 9*=30°58'
(строка 8 = D/k=l,2).
В результате получаем шаблон, показанный на рис. 10.12.
Если выбрать другое а, угол 0* останется прежним, а расстоя-
расстояние d* изменится.
На рис. 10.12 изображены границы регулирования, соответ-
соответствующие За, 2,36а (а = 0,01) и 2а (а = 0,025).
В этом примере последнее наблюдение вышло бы за границы
и на обычной контрольной карте. Однако с помощью ККНС
можно понять, в какой точке сместилось среднее значение про*
цесса.
10.4.2. ККНС для выборочных размахов
Для распределения выборочных размахов, применяемого при
построении соответствующей ККНС, можно взять две аппрокси-
аппроксимации (в случае выборки объема п из совокупности с нормирован-
нормированным нормальным распределением): а) с- (% с vx степенями свободы) и
б) с'-(х2 с v[ степенями свободы). Некоторые значения с, vlf с1
и v[ приведены в табл. 10.10. В разд. 6.9 отмечалось, что ап-
аппроксимация а) лучше, если п меньше 10; в противном случае
предпочтительнее аппроксимация б). Предполагается, что объем
выборки п постоянен, ас, с'9 v* и v'x зависят от него.
-0,052
9 0 2 4 6 8 10 12 14 16 18 20 22 24 26 2830
НОМер выборки /77
Рис. 10.12. ККНС для выборочного среднего1).
г) Хотя на рис. 10.11 величина Ут определялась как о^1 2( )
лучше использовать эту формулу. Значения 6* и d* учитывают среднее квад-
ратическое отклонение и масштабный коэффициент.
Параметры ККНС для выборочных размахов
Таблица 10.10
Объем выборки
п
1
4
5
6
7
8
9
10
Аппроксимация (а)
с
1,378
1,302
1,268
1,237
1,207
1,184
1,164
1,146
1,93
2,95
3,83
4,69
5,50
6,26
6,99
7,69
Аппроксимация (б)
с'
0,233
0,188
0,160
0,142
0,128
0,118
0,110
0,103
v;
7,27
10,95
14,49
17,86
21,08
24,11
27,01
29,82
1) с и v взяты из работы П. Б. Патнайка [Patnaik P. В,, The Use of the Mean Ran-
Range in Statistical Test, Biometrika, 37 A950)]. с' и v'— из работы Д. Р. Кокса [Сох.
D. R., The Use of Range in Sequential Analysis, Journal of the Royal Statistical Society,
Series B, 11 A949)]. ' -?
394
Глава 10
При построении ККНС размахов также необходимо сначала
ввести масштабный коэффициент. Затем на график наносятся точки
т, 2Д, A0.21)
с масштабным коэффициентом k (т. е. k единиц ординаты имеют
ту же длину, что и одна единица абсциссы). В случае исполь-
использования аппроксимации б) критические значения, показанные на
рис 10.13, равны
0* -
ln
d* = —21n -7
Ь l-(ao/°i)Jf
a d
A0.22)
v; In
v[ '
1 2
Номер дыборки /77
Рис. Ю. 13. Масштабирование в ККНС для выборочных размахов.
Пример 10.10. В табл. 10.11 приведены размахи и накоплен-
Таблица 10.11
Размахи выборок объема
Номер выборки
m
1
2
3
4
5
6
7
8
5 для внешних
диаметров
(единица размаха равна 0,001 дюйма)
1,4
0,8
2,0
0,4
1,3
1,3
1,2
2,0
т
2*/
1,4
2,2
4,2
4,6
5,9
7,2
8,4
10,4
Номер выборки
т
9
10
11
12
13
14
15
16
1,0
1,1
2,0
0,7
1,8
2,5
0,3
2,8
т
i = i
ПА
12,5
14,5
15,2
17,0
19,5
19,8
22,6
Контрольные карты
395
ные размахи выборок объема 5 для внешних диаметров стальных
труб. Всего было взято 16 выборок. Принято, что 2а = 0,0027
(что эквивалентно За-границам), сго = О,5О и а1 = 0,72. Значения
6* и d* равны
п "
-2 ln 0,00135
14,49 In 1,44
Данные изображены на рис. 10.14.
123456789 10111113141516171819
Номер Выборки т
Рис. 10.14. ККНС размахов для внешних диаметров.
10.4.3. ККНС для выборочных дисперсий
Рассмотрим двустороннюю контрольную карту. Пусть нуле-
нулевая гипотеза Яо состоит в том, что G2 = ol, Нг — в том, что
о2=^о1 (> сг2,) и #_!—в том, что a2 = ai2 (< Go). Опять обозначим
ошибку первого рода через а. Если масштаб осей контрольной
карты таков, что k единиц ординаты равны одной единице абс-
абсциссы, значения 9* и d* вычисляются по следующим формулам:
| In (CJi/G0) I
In a
d* = —
A0.23)
ln (о±/о0) '
Эти величины можно найти в табл. 10.12 как для двустороннего,
так и для одностороннего критерия. На ККНС для выборочных
дисперсий наносятся точки с координатами
21 v*> 2
A0.24)
Контрольные карты
397
s
о
&
X
X
?
со
X
2
с
S
О*
X
X
л
I
X
о
о
о,
S
«=3
S
X
с*
I
ll
О Q*4
» II
гч ь
§1
О о*
II II
г- *°
гч П!
§§
о сГ
II II
si
о о
II II
. '« а
гч
гч —<
о о
о о4
II II
°~ ч
о о
II II
« 8
ГЧ
С •/->
*""* Я»
о о
II II
гч 8
00
УГ)
00
ON
77
00
ri
«
vO
ГЧ
10" 28
ri
Q
ON
O\
ON
s
rl
•o
24'48
о
ЧО
ГЧ
о
гч
о
rf
00
О
-О
оо
О
чО
ГО
Г-
О
ON
гч
чО
ON
ГЧ
г»
Г!
О
Г1
о
•о
п
ЧО
М
О
п
ON
"
о
00
•О
rl
ЧО
г*-
—
80
On
00
р.
ч©
57 2'
чО
mm
ON
rj
ОО
=
о
ON
00
00
Cl
ч?>
2
•л
59'32
ОС
»—
О
г-
ON
On
53
On
64
г-
чО
чО
Г J
«Л
61 '35
о
гч
о
00
м
00
г-
«о
о
о
г-
Г1
65 ' 23
п
г)
ON
чО
29
чО
О
чО
оо
^t
ON
О
ri
?
о
m
.07
чО
27
•о
ОО
о
Ov
ГЧ
ON
ГЧ
691' 52
00
оо
On
77
Г1
00
ЧО
Г1
ON
О
ff
if
СО '
" с я д -
Ь ч ° ^5
где V/ и s2i — число степеней свободы и дисперсия t-й выборки
соответственно. Пример ККНС для дисперсий с односторонней
границей дан на рис. 10.15. Контрольная карта в случае дву-
Q
Рис. 10.15. ККНС для выборочных дисперсий (односторонняя граница для
обнаружения увеличения дисперсии).
стороннего критерия с параметрами границы для принятия
гипотезы #_х, равными A*'и 9*', показана на рис. 10.16. Заме-
СО rq^,
§
Рис. 10.16. ККНС для выборочных дисперсий (двусторонние границы).
тим, что если a1/a0>l,d откладывается в отрицательном на-
направлении, т. е. справа налево. Табл. 10.12 можно использовать
для оценки d, если положить
1— Pi
398
Глава 10
10.4.4. ККНС для числа пр или доли р дефектных изделий
Диаграмма границ регулирования та же, что и в случае раз-
размаха и дисперсии. Линия PQ на рисунке, который выглядит
аналогично рис. 10.17, наклонена под углом 9* к оси порядко-
Номер выборки {объема п)
Рис. 10.17. ККНС для числа дефектных изделий.
вых номеров выборок, а Р находится на расстоянии d* вправо
от последней точки на графике. При этом
9* = arctg Г ln[(l-Po)/(l-Pi)l 1
ъ [_Л1п [pi (I— Po)/Po(l— Pi)]] '
d* = — .
lna
A0.25)
Опять масштаб по осям таков, что длина k единиц ординаты
равна длине одной единице абсциссы. На ККНС наносятся точки
с координатами
т
23 я/,
A0.26)
где ti;—объем f-й выборки и х,--^ число дефектных изделий в
ней. На рис. 10.17 показан пример ККНС для доли дефектных
изделий р с координатами точек
(/и, 2*,) 0°-27)
и одинаковыми объемами выборок п. При указанном выше масш-
масштабе значения 0** и d** равны
A0.28)
Контрольные карты
399
Пример 10.11. Построим др-карту для данных табл. 10.13.
По оси абсцисс откладывается сумма объемов выборок, а по оси
ординат—суммарное число дефектных изделий. Не предполагает-
предполагается, что объемы выборок п{ равны.
Таблица 10.131)
Число дефектных изделий
Номер
выборки
1
2
з ¦
4
5
6
7
8
9
10
11
12
13
Объем
выборки
ni
900
650
750
450
275
700
450
800
1200
1200
600
1300
600
Число
дефектных
изделий
xi
29
20
15
6
5
5
9
8
3
6
2
4
2
Процент
дефектных
изделий
3,22
3,07
2,00
1,33
1,81
0,71
2,00
1,00
0,25
0,50
0,33
0,30
0,33
Накопленный
объем
выборок
900
1550
2300
2750
3025
3725
4175
4975
6175
7375
7975
9275
9875
Накопленное
число
дефектных
изделий
29
49
64
70
75
80
89
97
100
106
108
112
114
») Chateauneuf R., Modern Quality Control Pays in Woodwork, Industrial Quality
Control, 17, 3 (Sept. 1960).
Желательно проверить гипотезу о наличии 1 % брака с уров-
уровнем значимости (ошибкой первого рода).а = 0,005, допуская воз-
возможность обеих альтернатив.
Данные представлены на рис. 10.18. Заметим, что сразу же
обнаруживается „вышедшая из-под контроля" точка — вторая вы-
выборка. Если поместить вершину угла шаблона на расстоянии d*
по горизонтали вправо от нее, первая точка окажется за гра-
границами регулирования. [Напомним, что границы регулирования
зависят от а, /?0, рх (или р[) и проводятся от последней нанесен-
нанесенной точки.] Выборка 10 [с координатами G375, 106)] также вы-
выходит за границы. Однако здесь наблюдается уменьшение брака
по сравнению с 1%-ным уровнем. Выборки 11 — 13 не включены
в анализ. Напомним, что если точка вышла за границы, естест-
естественно начать карту заново.
Для определения границ регулирования воспользуемся фор-
формулами A0.25). Необходимо, однако, учесть еще и масштабный
400
Глава 10
140
«Г
I wo-
| 80
| 60
X 4°
I 20
j ~
0 Ш 2000 3000 4000 5000 6000 7000 6000 3000 10000
m
Сумма объемов выборок *?пс
Рис. 10.18. ККНС для числа дефектных изделий.
коэффициент k. Он равен 1/50. Для обнаружения увеличения
процента дефектных единиц положим а= 0,005, /?0 = 0,01 и
рх = 0,02. Это дает
-
-
—
х>
- /
S\ ft*
-, s$
X
P
У
' X
X
У
У
/
У
fill
1
^*-
У
У
У
У
\ \ \ \
-ху^
i i i i i
Для обнаружения уменьшения доли брака примем а —0,005,
р0 = 0,01, pi = 0,005. Получим
d\ = —1051 (отрицательное направление),
в;=19°5Г.
10.4.5. ККНС для числа дефектов г, основанная
на распределении Пуассона
Границы регулирования ККНС для числа дефектов зависят
от констант
d =
— \п ос
Н-1 — И-о
Координаты точек контрольной карты равны
A0.29)
A0.30)
Контрольные карты
401
где Х( — число дефектов в выборке i. На рис. 10.19 показан при-
пример ККНС для числа дефектов в случае двустороннего критерия.
Чтобы вычислить 0' и d' нужно подставить в формулы A0.29)
Hi (<Ио) вместо \ilu
-In a
113
Номер быборки т
Рис. 10.19. ККНС для числа дефектов (с).
Пример 10.12. Пример с-карты для числа дефектов взят из
той же статьи, что и пример 10.11. Данные приведены в табл. 10.14.
Таблица 10.14
Номер
выборки
т
1
2
3
4
5
6
7
8
9
10
Число дефектов
Число
дефектов
с
1
2
2
1
0
0
0
2
0
2
Накопленная
сумма
дефектов
1
3
5
6
6
6
6
8
8
10
после полировки
Номер
выборки
т
И
12
13
14
15
16
17
18
19
20
Число
дефектов
(исправленное)
с
4
2
2
3
2
2
1
1
2
2
Накопленная
сумма
дефектов
14
16
18
21
23
25
26
27
29
31
Для демонстрации применения ККНС числа дефектов в каждой
исходной выборке, начиная с 11 и по 20, был добавлен один
дефект,
402
Глава 10
Контрольные карты
403
В целях наглядности среднее с и границы регулирования вы-
вычислялись по первым десяти выборкам. Для стандартной карты
они равны:
<Г=1,00, ВГР-4,00, НГР-0.
При построении ККНС нужно выбрать |л0, |л1 и а. Положим
|л0 = 1,0, |Л1 = 2,О; 2а ==0,0027 (двусторонние За-пределы).
Находим значения констант
9 = 55°16' и d = 6,61.
На рис. 10.20 показана ККНС для с.
Таблица 10.15
34
J2
30
28
26
24
12
20
18
*? 16
W 14
12
10
8
6
4
2
0
X /
У /
xx /
X /
X /
X /
X /
x /
/
X /
XX /
XXX X /
x /
-x q/л
X I I i/i \I I I ! I I ! I I I ! 1
0 14 6 8 10 1114 16 U 2022 24 2628 303234
Рис. 10.20. Контрольная карта для числа дефектов.
10.4.6. Сводки формул для границ ККНС
В табл. 10.15 приведены формулы расчета 0* и d* для раз-
разных ККНС с масштабным коэффициентом, равным k.
10.5. СРЕДНЯЯ ДЛИНА СЕРИИ
Выше было показано, что статистическую процедуру (про-
(проверку гипотез или оценивания) удобно характеризовать одним
показателем—мощностью или доверительной вероятностью. Уже
Формулы для границ ККНС (односторонних: а)
(С учетом масштабного коэффициента k)
*) Аппроксимация б (см.. разд. 10.4.2).
Выборочная
статистика
Среднее х
Дисперсия s2
Размах R1)
Число
дефектов с
Число
дефектных
изделий пр
пр
(неравные объ-
объемы выборок)
Координаты
т, 2(*} — fx0)
Zv/, Zv/s»
m, 2Ri
m, Z*/
(*/ = 0 или 1)
m, 1>Х{ (x{=0
или 1)
m — номер выбор-
выборки
n — фиксирован-
фиксированный объем вы-
выборки
Z/i/, 2л:/
(AT/ — 0 ИЛИ 1)
d*
(—2 In a)/6
—In а
\n(o1/o0)
— 2 In а
v[ In (gJgq)
— In а
И —»*o
— lna
U— Pi)
— lna
inf! РЛ
\\-pi)
tg 0*
D/2k
[D = fi! —fl2]
2 {p\lk) In (ojoo)
l-K/axJ
«V'vJ In Woo)
k l-tae/aO
fXi — \l0
?ln Оах/щ)
«lnfJ-Л)
\1—Pi/
Мп/ЛA-А))
?lnU(i-pi)J
ln(f-M
U—Pi/
Vpo(i—Pi)y
отмечалось, что технику контрольных карт Шухарта можно рас-
рассматривать как многократное применение критериев проверки
значимости, так что формально к ней та*кже применимо понятие
мощности. Однако на практике принято сравнивать карты с
помощью средней длины серии (СДС): среднего числа точек, нано-
наносимых на карту после изменения характеристик процесса до того
момента, когда поступит сигнал о выходе процесса из ста-
статистически управляемого состояния. Это самый распространенный
показатель, применяемый для сравнения контрольных карт
разного типа.
404
Глава 10
Контрольные карты
405
СДС можно вычислить для любой карты. Особенно важную
роль этот показатель играет в связи с ККНС, что будет ясно
после изучения материала гл. 16.
СДС контрольной карты Шухарта, имеющей вероятность р
выхода из управляемого состояния в каждой нанесенной точке,
равна р. Некоторые данные о СДС различных карт приведены
в табл. 10.16. Сюда входят тип и характеристики карт, мера
Таблица 10.16
СДС для некоторых контрольных карт
Тип карты
Шухарта
ккнс
Шухарта
ккнс
Шухарта
ккнс
Шухарта
ккнс
Шухарта
ккнс
Характерис-
Характеристика
Среднее
«
«
Размах
(/2 = 4)
Среднее
квадратическое
отклонение
(л = 4)
Обнаруживаемое
расхождение
Разность
G-
X
«
«
Отношение
средних
квадратических
отклонений
Отношение
средних
квадратических
отклонений
СДС
Величина
разности
0,5 1,0 1,5
13,9 5,9 3,1
29,5 7,4 3,3
52,7 17,4 7,1
42,4 10,6 4,7
161,0 44,0 15,0
52,9 13,2 5,7
Величина
отношения
1,2 1,5 2,0
35 8,0 2,0
48 8,2 2,2
Величина
отношения
1,2 1,5 2,0
33 7,9 2,8
47 8,0 2,2
Уровень
значимости
а
0,05
0,01
0,00270
(За-границы)
0,01
0,01
10.6. ВЫБОРОЧНЫЙ КОНТРОЛЬ
В этом разделе не преследуется цель дать подробное описа-
описание выборочных планов, а приводятся лишь некоторые фундамен-
фундаментальные понятия. Более систематический анализ читатель, смо-
сможет найти в литературе, перечисленной в конце главы.х)
Не следует путать понятия выборочный контроль и „извлече-
„извлечение выборки", или „выборочное обследование". Последние рас-
рассматриваются в гл. 19. Под выборочным контролем понимается
статистическая проверка партии или процесса, когда случайная
выборка определяет решение о принятии или отклонении рас-
рассматриваемого материала. Обычно речь идет о качественных приз-
признаках2), но это не всегда так. Иногда, например, желательно
убедиться в том, что процент брака в партии не выше заданного
уровня или что сохраняются данные номинальные характерис-
характеристики. Вообще говоря, выборочный контроль возможен как по
качественным, так и по количественным признакам. Кроме того,
не обязательно фиксировать объем выборки. В гл. 16 будут рас-
рассмотрены последовательный анализ и последовательные выбороч-
выборочные процедуры. При применении этих методов решение может
быть принято до получения выборки заранее установленного
объема.
Выборочный контроль можно рассматривать как применение кри-
критерия значимости. Поэтому процедура контроля связана с такими
понятиями, как нулевая гипотеза, случайная выборка, статистика
критерия, критическая область, альтернативные гипотезы и
ошибки первого и второго рода. Следовательно, каждый план
имеет свою оперативную характеристику. Пусть есть нулевая
гипотеза Но и альтернативная гипотеза Нх. Рассмотрим приемоч-
приемочный уровень дефектности AQL (acceptable quality level), представ-
представленный Яо, и браковочный уровень дефектности RQL (rejectable
quality level), представленный Н1У и соответствующие им риски
(рис. 10.21). Здесь а называется риском поставщика. Это значит,
что если поставщик выпускает продукцию с приемочным уровнем
дефектности, он тем не менее ожидает, что в 100а% случаях
продукция будет забракована из-за выборочных ошибок. С дру-
другой стороны, если производится продукция с браковочным
уровнем дефектности, в 100|3% случаях она будет принята по
той же самой причине. Вероятность последнего события |3 на-
называется риском потребителя. По оси ординат на рис. 10.21
изменения параметра и СДС для а = 0,05, 0,01 и 0,00270 (За-
(Заграницы) в случае двустороннего критерия.
2> См. также: Хэнсен Б. Контроль качества. Теория и применение.—М.:
Прогресс, 1968; Э. Шиндовский, О. Шюрц. Статистические методы управления
качеством. Пер. с нем.—М.: Мир, 1975.— Прим. ред.
2) В работах по контролю качества признаки, измеряемые дискретными
величинами, принято называть качественными в отличие от количественных,
представленных непрерывными величинами.
406
Глава 10
AQL RQL f Качество процесса
Рис. 10.21. Оперативная характеристика плана выборочного контроля.
отложена Овероятность принятия партии или процесса, а по оси
абсцисс представлено качество процесса (доля брака или какая-
либо другая характеристика).
Число выборочных планов практически не ограничено.
При выборе плана задаются примерно те же вопросы, что и
в связи с критерием значимости. Кроме того, иногда нужно
минимизировать количество проверок для данной контрольной
процедуры. В план включаются также такие характеристики,
как предел среднего выходного уровня дефектности AOQL (ave-
(average outgoing quality limit) и толерантный уровень дефектности
в партии LTPD (lot tolerance percent defective). AOQL опреде-
определяет предельное качество принятого материала, измеряемое пара-
параметрами распределений наиболее для него важных характерис-
характеристик (например, максимумом математического ожидания доли
брака). Ясно, что он зависит от первоначального распределения
и от применяемого выборочного плана. LTPD задает уровень
плохого качества. Продукция с таким или худшим качеством
должна приниматься не чаще, чем в 100|3% случаях. Способ
расчета и смысл AOQL и LTPD иллюстрируются в примере 10.13.
Пример 10.13. Для иллюстрации определений AOQL и LTPD
рассмотрим следующий выборочный план. Предположим, что
партии состоят из 1000 изделий, объемы выборок равны 100 и
приемочное число с равно 2. Это означает, что берется выборка
объема 100; если число дефектных изделий в ней не больше 2,
партия принимается. В противном случае она отклоняется. Для
определения AOQL следует уточнить способ работы с выборками.
Предположим для простоты, что принятые партии более не ис-
исследуются, а отклоненные проверяются полностью для выявления
дефектных изделий и замены их исправными. Предположим так-
также, что дефектные изделия, обнаруженные в принятых партиях,
также заменяются.
Контрольные карты
407
Сначала определим средний выходной уровень дефектности
AOQ для каждой доли дефектных изделий в партии @,00; 0,01;
0,02; ...). AOQL равен максимальному значению AOQ для дан-
данного выборочного плана. Предположим, что в партии содержится
D дефектных изделий. Тогда
AOQ равен щ^ (математическое ожидание числа необнаруженных
- „ч D.Pr[X<2|D] —ЬРг[Х=1 |D] —2.Pr[X = 2|D]
дефектных изделии)= L ' J L10QQ ' - — ,
где D—число дефектных изделий в партии (объема 1000), а X —
число дефектных изделий в выборке (объема 100).
Результаты для р = D/100 = 0,00; 0,01; 0,02; ... приведены
в табл. 10.17 и представлены графически на рис. 10.22. Можно
Таблица 10.17
AOQ для #=1000, Л = 100, с =
Качество поступаю-
поступающей партии р
0,00
0,01
0,02
0,03
0,04
Средний выходной
уровень дефект-
дефектности AOQ
0,0000
0,0085
0,0127
0,0121
0,0092
Качество поступаю-
поступающей партии р
0,05
0,06
0,07
0,08
0,09
Средний выходной
уровень дефектно-
дефектности AOQ
0,0060
0,0036
0,0020
0,0011
0,0005
О 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,03 0,10 0,11
р входное качество)
Рис. 10.22. Средний уровень дефектности для плана, описанного в табл. 10.17.
аналитически доказать, что максимум AOQ достигается при
/7 = 0,023. Соответствующий AOQL равен 0,0129. LTPD характе-
характеризует качество партий, которые должны быть приняты не чаще,
чем указанную долю случаев (обычно 10%). Он интерпретируется
как предельный уровень плохого качества. В данном примере
408
Глава 10
LTPD определяется максимальным значением D, для которого
(D\ /1000—
>01Q
*=° i looj
Если воспользоваться пуассоновской аппроксимацией и табл. Б
приложения, получим значение 8(=?>/10), такое, что
--0,90.
х=3
Из табл. Б имеем 0=5,33. Следовательно, LTPD соответствует
?) = 53, или доля дефектных изделий /7=0,0533. Это значит, что
примерно в 10% случаев будут приняты партии объема 1000,
содержащие 0,0533-1000= 53 дефектных изделия.
Следует отметить, что если D не меняется от партии к пар-
партии, в каждой принятой партии будет по меньшей мере D — 2
дефектных изделия, а в каждой отклоненной после 100%-ной
(сплошной) проверки не останется ни одного. Если D меняется
от партии к партии, большая доля отклоненных партий соответ-
соответствует более высокому уровню D.
Самая простая форма контроля—одноступенчатый план. При
этом, например в случае контроля по качественному признаку,
берется одна выборка объема п. Если число дефектных изделий
не превышает заданного (с), партия принимается, в противном
случае—отклоняется*).
При двухступенчатом плане задаются объемы двух выборок,
пг и п2. После проверки выборки объема пг контролер может
принять одно из трех решений: признать партию приемлемой,
отклонить ее или взять вторую выборку объема п2. В последнем
случае окончательное решение о принятии или отклонении зави-
зависит от результатов двух выборок. Этот подход естественно обоб-
обобщается на случай нескольких последовательных выборок путем
увеличения числа допустимых выборок и (или) уменьшения объема
каждой из них. Большой вклад в построение двухступенчатых
процедур внесли Додж и Ромиг. Их таблицами [7] удобно поль-
пользоваться на практике.
Выбор того или иного плана существенно зависит от риска,
допускаемого как потребителем, так и поставщиком. Существует
ряд правительственных публикаций на эту тему (например, [18];
они периодически пересматриваются, особенно в случае контроля
г) Такой способ контроля называют контролем по альтернативному при-
признаку.— Прим. ред.
Контрольные карты
409
новых и стратегических материаловI). Выбор плана зависит
также от механизма извлечения выборок и связанных с ним
ошибок. В некоторых случаях потребитель проверяет очень не-
незначительное число изделий, поскольку знает, что может поло-
положиться на качество продукции поставщика. При этом по суще-
существу используются идея априорных вероятностей и теорема Байеса
(см. гл. 3), даже если тот или иной потребитель не знаком
с ними.
Примеры 10.14 и 10.15 иллюстрируют одноступенчатые и двух-
двухступенчатые планы.
Пример 10.14. Пусть нужно построить оперативную характе-
характеристику (ОХ) для одноступенчатого плана со следующими пара-
параметрами: N = 200, л = 50, с=1. Допустим, что при р0 = 0,01
качество считается хорошим (D = 2), а при р1 = 0,05 — плохим
или предельным. Определим риск поставщика (а) и риск потре-
потребителя (C).
Если воспользоваться гипергеометрическим распределением,
получим вероятность принятия партии
Рг[*<1|ЛГ = 200, п = 50, ?>] =
1 = 0
При D = 1 получаем
р
99Л
SO)
(Ж™
/2004
v so;
199\
/2004
v so;
i ) \ n-i J
о
!5=l,00.
Такой ответ следовало ожидать, поскольку в партии имеется
только одно дефектное изделие. При D = 2 (/?0 = 0,01)
/2\ /198\ /2\ /198\
р _\о) {so; и; У 49/_о ^ао4-о 477-0Q37
^~ /200\ + /200 \ O,t>bU + U,d//-U,y^/.
v so; V 5о;
Продолжая эти вычисления, получим следующие результаты:
D 0 1 2 3 4 5 ... 10 ... 15
Уровень брака, % 0 0,005 0,010 0,015 0,020 0,025 ... 0,050 ... 0,075
Р (принятия) 1,00 1,00 0,94 0,85 0,74 0,62 ... 0,24 ... 0,07
Кривая ОХ для выборочного плана показана на рис. 10.23.
Заметим, что а =0,06 и р = 0,24.
х) Следующие стандарты СССР устанавливают планы выборочного приемоч-
приемочного контроля: ГОСТ 16490-70, ГОСТ 16493-70, ГОСТ 18242-72, ГОСТ
20736-75.— Прим. ред.
410
Глава 10
1,00
0,80
0,60
Г
55 о,го
I I I I \ I I I I I I I I I I [
и0 0,01 0,01 0,03 0,04 0,05 0,06 0,07 0,08
Доля дефектных изделии
Рис. 10.23. Оперативная характеристика при Л^ = 200, я = 50, с=1.
Пример 10.15. Для партий из 400(УУ) изделий предложен сле-
следующий двухступенчатый план контроля по качественному при-
признаку. Нужно взять выборку объема 30 (ях); если нет ни одного
дефектного изделия, принять партию; при наличии двух и более
дефектных изделий отклонить партию; если есть одно дефектное
изделие, взять вторую выборку объема 60 (я2); если во второй
выборке отсутствуют дефекты, принять партию, в противном слу-
случае—отклонить. Вычислить вероятности ошибок первого и вто-
второго рода, если при 5 (Do) и меньшем числе дефектных изделий в
партии качество считается приемлемым, а при 10 (Dx) и большем
числе—предельным или плохим.
В основе лежат гипергеометрические распределения с пара-
параметрами 1) Do = 5, пг = 30 и Af = 400 для приемлемого качества
и 2) ?>! = 10, ^ = 30 и Л^ = 400 для неприемлемого. Если необ-
необходима вторая выборка, параметры равны 1) D'0 = 4, д2 = 60,
N' = 370 и 2) D[ = 9, п2 = 60, N' = 370. Вероятность принятия
партии при Do = 5 составит
Pr[X = 0|D0^5, Л1 = 30, # = 400] +
+ Рг [X = 11 5, 30, 400]-Рг[Х = 0|4, 60, 370]= 1—а.
Подставив значения констант, получим
395
366
/400\
/400 Л
I 30 j
/370\ ~
V во;
= 0,6758 + 0,1361=0,8119; a = 0,1881.
Контрольные карты
411
Если в партии 10 дефектных изделий, вероятность принятия
равна
Рг[Х = 0| 10, 30, 400] + Рг[Х = 1|10, 30, 400] X
X Рг[Х = 0|9, 60, 370] = р.
После подстановки соответствующих значений имеем
Ч0\ ^390\ (Щ(Ш\ (9\ /361 \
7з70л° = °'4544 + °'0753 = °'5297-
o)(b3oj , l'ijl»j loM go;
/400\
I 30 J
/400\
I зо;
Полученные значения а = 0,1881, р = 0,5297 показывают, что
план не очень эффективно различает хорошее и плохое качество.
ЛИТЕРАТУРА
1. ASQC Standard Al-1971-Definitions, Symbols, Formulas and Tables for
Control Charts, American Society for Quality Control, 1971.
2. ASQC Standard A3-1971-Glossary of General Terms Used in Quality Cont-
Control, American Society for Quality Control, 1971.
3. Barnard G. A., Cumulative Charts and Stochastic Processes. Journal of the
Royal Statistical Society, Series B, 21 A959).
4. Bissel A. F., Cusum Techniques for Quality Control (with discussion),
Applied Statistics, 18, 1—30 A969).
5. Burr I. W.; Statistical Quality Control Methods, Dekker, New York, 1976.
6: Cowden D. J., Statistical Methods in Quality Control, Prentice-Hall, Eng-
lewood Cliffs, N. J., 1957.
[Имеется перевод: Коуден Д. Статистические методы контроля качества.—
М.: Физматгиз, 1961.]
7. Dodge H. F., Romig H. G., Sampling Inspection Tablis, Wiley, New York,
1959.
8. Duncan A. J., Quality Control and Industrial Statistics, 4th ed., Irwin,
Homewood, 111., 1974.
9. Enrick N. L., Quality Control and Reliability, 6th ed., Industrial Press,
New York, 1972.
10. Ewen W. D., Kemp K. W.f When and How to Use Cusum Charts, Techno-
metrics, 5 A963).
11. Freund R. A., Graphical Process Control, Industrial Quality Control, 18,
A962).
12. Goel A. L., Wu S. M., Determination of ARL and a Contour Nomogram
for Cusum Charts to Control Normal Means, Technometrics, 13, 221—230
A971).
13. Goldsmith P. L., Whitfield H., Average Run Lengths in Cumulative Sum
Chart When a V-Mask Is Used, Technometrics, 3A961).
14. Grant E. L., Leavenworth R. S., Statistical Quality Control, McGraw-Hill,
New York, 1972.
15. ICI Monograph No. 3, Cumulative Sum Techniques, Van Nostrand, Prince-
Princeton, N. J., 1964.
16. Johnson N. L., Leone F. C, Cumulative Sum Control Charts, Industrial
Quality Control, 18, 19 (three papers) A962).
17. Lucas J. M., A Modified V-Mask Control Scheme, Technometrics, 15, 833—
847 A973).
412
Глава 10
18. MIL-STD-105D Sampling Procedures and Tables for Inspection by Attribu-
Attributes, Dept. of Defense, U. S. Government Printing Office, 1963.
19. Page E. S., Cumulative Sum Charts, Technometrics, 3 A961).
20. Shewhart W. A., Economic Control of Quality of Manufactured Product,
Van Nostrand, New York, 1931.
21. Van Dobben de Bruyn C. S., Cumulative Sum Tests (Griffin's Statistical
Monographs No. 24), Hafner, New York, 1968.
22. Woodward R. H., Goldsmith P. L., Cumulative Sum Techniques, Oliver
" & Boyd, Edinburgh, 1964.
УПРАЖНЕНИЯ
1. Приведенные ниже данные являются закодированными результатами
измерений удлинений контрольных образцов полиэтилена. Всего было взято
20 выборок объема 4.
а) Постройте Х- и #-карты Шухарта и проанализируйте результаты.
б) Оцените а2.
Контрольные карты
413
номер
выборки
1
2
3
4
5
6
7
8
9
in
Ш
12
U
2
13
9
11
12
10
13
5
Измерения
3
10
6
8
14
2
5
1
10
1
10
1
3
2
5
12
16
12
9
11
7
5
1
12
16
1
14
16
14
6
Номер
выборки
11
12
13
14
15
16
17
18
19
20
Измерения
8
6
15
13
б
3
2
14
16
6
5
10
5
16
13
4
3
5
5
15
7
12
б
12
5
11
5
7
И
16
1
15
7
14
9
13
16
6
10
2. При производстве Пушкового чугуна большое значение имеет содержа-
содержание кремния. Для серии последовательных партий плавок (объем 4) были полу-
получены приведенные ниже результаты. Постройте X и R—карты Шухарта.
литер
Сыборм
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Процент
1,13
ОЛ7
0,80
0,34
0,85
0,84
0,60
0,70
0,97
0,71
0,92
0,74
0,94
0,97
0,72
1,00
0,65
0,94
0,60
0,62
1,00
0,32
0,91
1,00
0,72
1,00
1,32
0,89
0,94
0,65
кремния
0,96
0,83
0,96
0,79
0,60
0,99
0,87
1,20
1,08
0,74
0,67
0,85
0,98
0,60
0,88
0,67
0,92
0,76
0,73
0,66
0,96
0,89
1,00
0,85
0,96
0,77
0,94
0,87
0,72
1,00
3. Постройте ККНС для средних по данным упражнения 1. Положите
а = 0,05 и 6=1,2.
4. Постройте ККНС для средних квадратических отклонений по данным
упражнения 1. Положите а = 0,01 и о1/о0= 1,6.
5. Постройте ККНС для размахов по данным упражнения 1. Положите
а = 0,05 и о1/о0~\) 4.
6. Ниже приведены результаты измерений (в дюймах, с точностью до
0,0001) толщины образцов цинка сорта С, сделанные перед испытанием на
коррозию. Постройте Х- и R-карты Шухарта с За-границами.
Измерения
1
2
3
4
5
Ъ
7
8
9
10
11
12
13
14
15
16
17
18
19
.70
21
22
23
24
25
0,5005 0,5000 0,5008 0,5000 0,5005
0,4998 0,5002 0,4995 0,4998 0,4995
0,4998 0,4997 0,4998 0,4994 0,4999
0,5005 0,4997 0,4995 0,5001 0,5000
0,4995 0,4995 0,4996 0,4994 0,4995
0,4990 0,4997 0,4994 0,5010 0,4993
0,4998 0,5005 0,5002 0,5005 0,5003
0,4995 0,4995 0,4990 0,5005 0,4998
0,5000 0,5005 0,5008 0,5007 0,5008
0,5001 0,5003 0,5007 0,5005 0,5001
0,5010 0,5009 0,5008 0,5006 0,5005
0,5010 0,5005 0,5005 0,4998 0,5001
0,5001 0,5000 0,5002 0,4995 0,4996
0,5000 0,4996 0,4994 0,5001 0,4995
0,4993 0,4994 0,4999 0,4996 0,4997
0,4995 0,4995 0,4996 0,4998 0,5000
0,4995 0,4992. 0,4991 0,4995 0,4995
0,4998 0,5005 0,5006 0,4995 0,4999
0,4998 0,4994 0,5000 0,4990 0,5000
0,4994 0,5008 0,5000 0,4998 0,5005
0,4998 0,5005 0,5001 0,5003 0,5002
0,5000 0,4995 0,4997 0,4998 0,5001
0,5005 0,4997 0,5001 0,4998 0,4996
0,4995 0,4991 0,4992 0,4993 0,4995
0,4993 0,4999 0,4996 0,4993 0,4994
7. Постройте ККНС для средних по данным упражнения 2. Положите
а = 0,01 и 6 = 0,3.
8. Постройте ККНС для размахоЪ по данным упражнения 2. Положите
а = 0,05 и ^/00=1,2.
9. Постройте ККНС для средних квадратических отклонений по данным
упражнения 2. Положите а = 0,05 и ах/а0= 1,2.
10. Номинальный объем наполняемых сосудов равен 20,0 см3. Границы
допуска: 20,0 ±0,1 см3. Колебания объема существенно зависят от работы
оператора машины. Нужно построить карту приемочного контроля и прини-
принимать работу оператора, если не более 0,1% наполняемых им сосудов выходит
за указанные пределы. Если более 2,5% сосудов оказываются за границами
допуска, следует признать работу оператора неудовлетворительной. Уровни
риска аир положить равными 5%. Определите
а) объем выборки /г, считая, что а = 0,20;
б) APL;
414
Глава 10
в) RPL;
г) приемочные границы регулирования.
И. На помещенной ниже схеме карты приемочного контроля интерпрети-
интерпретируйте различные уровни и опишите выборочную процедуру (п = 4, а = 0,005).
Приемочная граница
регулирования
APL
1>645а/у/п
APL
Приемочная грШца
регулиродания
RPL, =/х0
12. Следующая таблица содержит значения х и R срока службы трубок
в часах для 25 выборок объема 5. Постройте Х- и #-карты Шухарта.
Номер
выборки
\
т
3
4
5
6
7
8
9
10
11
12
13
г *
1432
1128
1898
1214
1650
1316
1260
1174
1732
1698
1246
1568
1836
R
453
144
212
436
183
255
190
216
352
286
334
420
287
Номер
выборки
14
15
16
17
18
19
20
21
22
23
24
25
X
1276
1582
1502
1634
1280
1922
1376
1098
1474
1620
1390
1072
R
190
312
347
246
184
580
345
359
268
456
282
263
13. В этом упражнении условия такие же, ках в упражнении 10. Стало
известно, что колебания объемов сосудов, заполненных оператором Джо Зил-
чем, в два раза больше, чем у других операторов. Какой должна быть выборка
для контроля работы Джо Зилча? Какими должны быть границы на контроль-
контрольной карте Зилча?
14. Фирма выпускает большие пластиковые контейнеры. Визуальной про-
проверке подвергаются 100% изделий. В таблице на стр. 415 указаны числа
контейнеров, выпущенных за определенные временные интервалы, и количе-
количества забракованных изделий. Постройте контрольную карту Шухарта для
процента дефектных изделий.
15. Постройте ККНС для числа дефектных изделий по данным упражне-
упражнения 14 при а = 0,05, /70 = 0,01 и р1 = 0,025.
16. Постройте ККНС для числа дефектных изделий по данным упражне-
упражнения 14 при а = 0,05, /?0 = 0,01 и /?1 = 0,02.
Контрольные карты
415
Номер
партии
1
2
3
4
5
5
7
8
Размер
выборки
1442
1785
1403
1239
2064
1013
2019
1717
Число дефект-
дефектных изделий
17
30
22
6
57
32
38
60
Номер
партии
9
10
И
12
13
14
15
16
Размер
выборки
2180
1256
1114
1735
2257
1772
1943
2014
Число дефект-
дефектных изделий
30
11
13
47'
25
22
21
50
17. Ниже указаны количества мелких дефектов, обнаруженных в каждом
из 25 холодильников, изготовленных в течение недели. Постройте ККНС для
числа дефектов при [хо=1,О, а = 0,05 и fXj—2,0.
Номер
изделия
1
2
з
4
5
6
7
8
9
Число
дефектов
1
1
2
0
1
0
1
2
1
Номер
изделия
10
11
12
13
14
15
16
17
Число
дефектов
6
5
5
4
4
0
2
0
Номер
изделия
18
19
20
21
22
23
24
25
Число
дефектов
2
2
0
1
5
2
2
0
18. Постройте контрольную карту Шухарта для числа дефектов по дан-
данным упражнения 17.
19. Постройте 5-карту Шухарта по данным упражнения 1.
20. Сравните упражнения 17 и 18. Опишите различия между ними (в от-
отношении целей, мощности и типов возможных выводов).
21. Для изучения колебаний качества изготавливаемой фотопленки ежед-
ежедневно проводятся контрольные съемки. По их результатам строится характе-
характеристическая кривая, связывающая параметр входа (логарифм выдержки) и
параметр выхода (плотность). Предельный угол наклона этой кривой, обозна-
обозначаемый через у, служит измеримой характеристикой качества. Малым значе-
значениям у соответствует плохое, нечеткое изображение, большим —слишком конт-
контрастное. Ниже в таблице приведены значения гамма (х) для 20 последова-
последовательных дней.
Постройте контрольную карту индивидуальных значений, взяв 2 и 82
в качестве оценок ох и (л соответственно.
День V День у День V День Y
1
2
3
4
5
84
87
83
78
81
6
7
8
9
10
87
82
84
80
79
11
12
13
14
15
75
85
91
84
79
16
17
18
19
20
83
78
80
79
83
416
Глава 10
22. По данным упражнения 21 постройте карту скользящего размаха для
выборок объема 2.
23. Постройте ККНС для средних по данным упражнения 21 при а ^=2,
а-0,05 и 6 = 2.
24. В таблице приведены измерения вязкости разбавленной желатины.
В течение 15 недель брали по пять выборок. Постройте Х-и /?-карты Шухарта.
Данные для простоты закодируйте.
Контрольные карты
417
Номер
недели
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
124
126
130
132
122
125
129
127
126
119
130
129
124
121
127
127
124
124
122
127
123
122
128
134
125
129
126
129
125
125
130
130
127
128
123
122
123
122
122
124
127
121
129
131
125
129
127
131
127
128
126
127
128
128
124
125
128
129
129
126
126
126
125
129
128
130
125
124
129
130
127
132
129
129
123
25. Ниже приведены данные о процентном содержании воды в метаноле
для 22 последовательных партий. Постройте карту скользящего размаха для
групп из трех наблюдений.
Номер
партии
1
2
3
4
5
6
7
Процент
воды
7,6
8,9
7,7
8,1
7,9
8,0
7,8
Номер
партии
8
9
10
11
12
13
14
Процент
воды
8,0
7,7
7,9
8,2
7,5
7,5
7,9
Номер
партии
15
16
17
18
19
20
21
22
Процент
воды
8,2
8,2
7,5
7,8
7,5
8,5
7,7
8,0
26. Исследователь Джо Зилч построил с-карту „Число аварий за месяц"
для разных отраслей промышленности одного географического района. Она
показана на первом графике. По просьбе руководства он построил вторую
карту „Среднее число ежедневных аварий в каждом месяце" за тот же период.
Сравните эти два графика и прокомментируйте их смысл и возможное при-
применение.
Октябрь
66
300
Декабрь
1967 67
l i I i i ь i i I i i
W68
I 1 | | | | |
J"*"» Май
1963 1970 1971
I I I I I I I I I I I I I I I I I I I I l I I
Л8
2 4 6 8 10 12 14 16 18 10 22 243032 54 36 3d 40 42 44 46 485051 54
^Месяцы
Числе аварий 0 месяц
2 4 6 8 10 12 14 16 16 202224 30525Ф 36 S&4042 44 46 48 505254
Месяцы
1967 1968 ЖЭ 1970 1971
Среднее число ежеднедмых аварии в каждом месяце
27. Постройте ККНС для средних по данным упражнения 24. Положите
а=0,05 и 6 = 2.
28. Постройте ККНС для размахав по данным упражнения 24. Положите
а = 0,05 и 0^/G0=1,4.
14 № 819
418
Глава 10
29. Ниже в таблице приведены результаты 20 выборок объема 3, получен-
полученных при дублировании фильма. Постройте Х- и /?-карты Шухарта.
Номер
выборки
1
2
3
4
5
6
7
8
9
10
0,93
0,98
0,96
1,02
1,03
0,98
1,05
0,96
0,95
1,06
X
(Y)
0,94
0,96
1,05
1,00
0,92
0,92
0,98
0,99
1,04
0,97
1,04
1,04
0,98
1,04
0,99
1,04
0,99
1,04
0,96
1,01
Номер
выборки
11
12
13
14
15
16
17
18
19
20
0,96
1,03
0,94
0,99
1,03
- 0,98
1,04
0,99
0,98
1,01
X
(У)
0,94
0,99
1,05
1,02
1,01
1,03
1,01
1,03
0,99
0,97
1,02
1,01
0,97
0,97
0,99
0,99
1,02
0,99
0,97
1,00
30. В таблице приведена контрольная выборка результатов анализов на
содержание меди, сделанных разными сотрудниками. Постройте ККНС для
размахов при а = 0,01, а!/ао= 1,5 (Хг и Х2 — независимые результаты, полу-
полученные одним сотрудником).
Сотрудник
1
2
3
4
5
6
7
8
9
10
Х±
37,94
37,91
37,95
37,55
37,74
37,79
37,88
37,78
37,86
37,82
х2
38,11
37,85
37,87
37,70
37,92
37,82
37,81
38,03
37,76
37,85
Сотрудник
11
12
13
14
15
16
17
18
19
20
37,52
37,95
38,30
38,02
37,72
37,59
38,13
38,33
37,92
37,75
Л2
38,02
38,04
38,35
37,35
37,84
37,55
38,01
38,69
37,54
37,86
31. Постройте ККНС для средних по данным упражнения 30. Положите
<х = 0,91, 6 = 0,2.
32. Предложен следующий выборочный план для партий из 300 изделий:
взять выборку объема 150 и принять партию, если число дефектных изделий
не больше 2; в противном случае партию отклонить. Чему равны риск постав-
поставщика при ро = О,О1 и риск потребителя при /?1 = 0,03?
33. Каким должен быть объем выборки при одноступенчатом контроле для
партии из 300 изделий, если ро = О,О\, pj—0,05 и желательно, чтобы риск
поставщика не превышал 3%, а риск потребителя 10%?
34. Для партий упражнения 32 предложен следующий двухступенчатый
план: взять первую выборку объема 50, принять партию, если дефектные изде-
изделия отсутствуют; если дефектных изделий два или больше, выборку отклонить;
если в первой выборке окажется одно дефектное изделие, взять вторую объема
100; принять партию, если в объединенной выборке (объема 150) не больше
дзух дефектных изделий, в противном случае — отклонить. Чему равны риск
поставщика при ро = О,О1 и риск потребителя при рх = 0,03?
Контрольные карты
419
35. Для партии из 300 изделий постройте двухступенчатый план со сле-
следующими параметрами: р0 = 0,01, ^ = 0,03, а ^0,05, Р^0,10.
36. В бронзовых отливках после 10 плавок измерялся процент меди.
Объемы выборок менялись. Постройте Х- и S-карты по данным, приведенным
ниже.
Номер
выборки
1
2
3
4
5
6
7
8
9
10
77,3
80,1
76,5
79,1
76,6
77,3
74,7
78,1
78,5
78,6
79,2
76,0
78,4
78,7
76,4
75,9
72,6
75,6
75,1
79,2
77,4
76,1
76,2
72,6
77,2
75,8
76,6
77,4
79,1
76,4
Измерения
76,3
76,5
75,5
77,9
76,1
78,9
72,0
77,7
76,9
81,6
75,6
72,3
75,9
78,7
74,2
78,7
77,1
77,4
78,5 73,2
77,1 77,7 74,2 76,6
75,8
37. На одном предприятии было обнаружено, что процент дефектных изде-
изделий распределен следующим образом:
Процент
дефектных
изделий
0—1/4
1/4—1/2
1/2—1
1 —IV»
W2-2
2-2V2
2V2-3
Доля
партий
0,14
0,07
0;08
0,06
0,06
0,07
0,09
Процент
дефектных
изделий
3—4
4-5
5—6
6—7
7—8
8-9
9—10
Доля
партий
0,16
0,10
0,06
0,04
0,03
0,02
0,02
Каждая партия готовой продукции (содержащая большое число наимено-
наименований) подвергается а) проверке с отбраковкой, в результате которой удаляется
некоторая доля дефектных изделий, и б) двухступенчатому выборочному кон-
контролю. Можно по выбору применять одну из трех процедур проверки. Их
эффективность определяют формулы, связывающие г, долю удаленных дефект-
дефектных изделий (от общего числа бракованных изделий в партии), и р> процент
брака в партии (при 0 < р < 6):
процедура А
процедура В
процедура С
г = 0,6,
г= 1—0,06р,
- = 0,0125 (р — бJ + 0,4.
14*
420
Глава 10
По техническим причинам схема двухступенчатого выборочного контроля должна
иметь вид:
Первая выборка объема п: если 0 дефектных —принять;
если 1 дефектное —взять вторую выборку объема п\
если 0 дефектных во второй выборке —принять.
В противном случае партию следует полностью проверить и заменить все де-
дефектные изделия исправными. Раньше считалось, что партии, содержащие пять
и больше процентов брака, безнадежны и нет смысла добиваться более низкого
среднего процента брака, чем 1/2%. Требуется описать и прокомментировать
возможные последствия в связи с а) изменением числа необходимых выборок,
б) изменением среднего выходного уровня качества AOQL и в) (качественно)
улучшением какого-либо метода проверки с отбраковкой.
Глава II
ТЕОРИЯ И АНАЛИЗ СТАТИСТИЧЕСКИХ
РЕШЕНИЙ
11.1. ВВЕДЕНИЕ
Эта книга посвящена главным образом вопросам применения ста-
статистических методов. При этом требуется понимание основных
идей теории вероятностей и умение пользоваться статистическими
таблицами. Эти вопросы легко поддаются формальному изложе-
изложению. Впрочем, нужно еще научиться судить о возможности при-
применения тех или иных статистических методов в практических
задачах. В любой конкретной ситуации длительное и кропотливое
исследование позволит разработать наиболее адекватный стати-
статистический аппарат, но на практике обычно приходится выбирать
один из уже известных методов. Ясно, что чем обширнее знания,
тем больше шансов выбрать подходящий аппарат, но с другой
стороны, сам выбор становится трудным, если не уметь система-
систематически использовать имеющуюся информацию о данной задаче.
Существуют две противоположные точки зрения относительно
применения статистических методов. Согласно одной из них сле-
следует как можно меньше пользоваться априорной информацией:
в идеале данные должны „говорить сами за себя". Другая точка
зрения состоит в том, что для применения любого статистического
метода необходимо полное знание обстоятельств, связанных с ре-
решаемой задачей. Действительно, только в этих условиях можно
правильно выбрать оптимальный метод решения. Верно также и
то, что каждый применяемый метод оптимален лишь в какой-то
определенной ситуации. Но идти дальше и утверждать, что в не-
некотором конкретном случае выполнены условия, обеспечивающие
оптимальность метода, можно далеко не всегда. Обычно есть
основания для надежды, но не для уверенности.
В этой главе описываются формы представления априорной
информации и методы ее использования. Эти методы иногда объ-
объединяют термином „анализ решений"; соответствующая теория
называется теорией статистических решений.
11.2. ВСПОМОГАТЕЛЬНЫЕ ДАННЫЕ
Авторы рекомендуют использовать априорную информацию,
отдавая себе отчет в том, в каких отношениях она несовершенна.
Есть много стабильных (или „робастных") методов, применимых
422
Глава 11
Теория и анализ статистических решении
423
в широком диапазоне ситуаций, но важно помнить, что имею-
имеющиеся сведения позволяют подобрать гораздо более мощный аппа-
аппарат для каждой конкретной задачи.
В этой главе описаны наиболее распространенные формы пред-
представления предварительной информации. Кроме того, рассматри-
рассматривается вопрос о способах получения дополнительных данных.
Идеи излагаются в общей форме, но их применение в конкретных
ситуациях не должно встретить трудностей.
Термин „теория решений" используется для объединения при-
приводимых ниже понятий и служит только для удобства. Формаль-
Формального изложения соответствующей теории здесь не дается.
Пусть для ряда объектов измеряется набор величин X (вектор
или скаляр). На основе этих данных нужно принять некоторое
решение.
Предположим, что совместное распределение компонент X
можно описать одной из (возможно, бесконечного) множества
функций \Fi(x)\. Допустим также, что принимаемое решение
является элементом (возможно, бесконечного) множества {dj} и
принятие решения d/y когда истинная функция распределения X
равна Fi(x), приводит к средним (ожидаемым) потерям Wi;-.
(Последние могут выражаться деньгами, временем, мерами на-
надежности или другими единицами.) Предположим далее, что
вероятность того, что F{(x)— истинное распределение, равна wt.
Кроме того, будем считать, что при любых методах извлечения
выборок (S), измерения X и принятия решений известны 1) сред-
средняя стоимость C{(S) (в тех же единицах, что и Wif), когда
Ft(x) — истинное распределение X, и 2) вероятность Pij{S) при-
принять решение dj, когда /^(х)— истинное распределение X для
любой комбинации i и /.
Тогда можно выражение для математического ожидания стои-
стоимости всей процедуры (называемого иногда риском) записать в виде
(В случае необходимости суммы заменяются интегралами.)
Затем выбирается метод исследования S, минимизирующий
это математическое ожидание.
Следует отметить, что описанная выше ситуация полного зна-
знания параметров задачи маловероятна. В ряде случаев, например
при наличии большого опыта решения аналогичных проблем,
можно смело полагаться на свои знания. Однако гораздо чаще
исследователь располагает лишь частичной информацией. Иногда
он знает функцию потерь Wijy но не имеет сведений об априор-
априорных вероятностях, иногда наоборот. В такой ситуации,не следует
пренебрегать имеющимися данными из-за их неполноты. Нужно
максимально использовать все, что есть. Конечно, если имею-
имеющихся сведений мало, то усилия, связанные с их использова-
использованием, могут не оправдаться. Однако нельзя забывать, что во
многих случаях даже сравнительно простое исследование су-
существенно расширяет запас имеющихся сведений.
Рассмотрим теперь более подробно способы учета априорной
информации.
11.3. ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ Fi(x)
При работе с одной непрерывной переменной чаще всего пред-
предполагают, что она распределена по нормальному закону с мате-
математическим ожиданием 6 и средним квадратическим отклонением а.
Если числовое значение а считается известным, множество {F{(x)\
состоит из нормальных распределений с заданным средним квад-
квадратическим отклонением а и всеми возможными значениями мате-
математического ожидания Э. Это множество можно сузить еще больше,
считая Э либо положительным, либо лежащим между двумя
известными пределами и т. п. Другое общее предположение состоит
в том, что все наблюдаемые X можно представить независимыми
случайными величинами.
Важно помнить, что обращение к теории нормального рас-
распределения предполагает априорные знания. Тоже можно сказать
о независимости, часто ассоциируемой с понятием „случайной
выборки". В действительности же нормальную теорию (и незави-
независимость) часто применяют при весьма незначительной исходной
информации, следуя обычным научным стандартам. Очень трудно
установить, что данная непрерывная форма распределения на
самом деле подходит для описания некоторой величины (или
группы величин). Например, выбор нормального распределения
основывается (или должен основываться) на
1) уверенности, что нет существенных отклонений формы рас-
распределения от нормальной;
2) результатах обширных теоретических исследований влия-
влияний отклонений от нормальности на стандартные статистические
методы, основанные на „нормальной теории".
Разумеется, аналогичные соображения должны оправдывать
применение любой другой формы F?(x).
Множество {F{(x)\ образует так называемую математическую
модель явления. Даже при желании минимально использовать
предварительную информацию какие-то предположения о модели
необходимо сделать. Разумные соображения о форме Ft(x)% как
правило, подсказывает большой экспериментальный материал,
однако приближенно модель можно выбрать на основе достаточно
общих представлений о характере наблюдаемого явления. На-
Например, если в качестве наблюдений рассматривается число по-
424
Глава 11
явлений некоторого случайного события, полезно обратиться
к распределению Пуассона или какой-либо его модификации.
Можно исследовать результаты применения данного метода
при разных предположениях о функциях распределения. Обычно
такие исследования утомительны и отнимают много времени.
Полезнее запомнить общую картину влияния изменений в функ-
функциях распределения на ожидаемые результаты применения дан-
данного метода. Особенно важны следующие закономерности:
а) В дисперсионном анализе (см. гл. 13 и далее) отклонения
от нормальности обычно существенно не влияют на критерии
значимости. Однако неравенство дисперсий уменьшает мощность
критериев. (Это относится и к /-критерию, использованному и
описанному в гл. 7 и 8.)
б) При сравнении дисперсий распределение отношения двух
независимых величин весьма чувствительно к колебаниям значе-
значений а4 (или Р2). Если а4 больше 3, рассеяние отношения больше
ожидаемого, так что, фактические уровни значимости оказываются
больше номинальных. Обратная ситуация имеет место, если а4
меньше 3.
в) Решающие правила, основанные на величине наблюдаемого
арифметического среднего, часто нечувствительны к изменению
формы распределения отклонений от среднего значения совокуп-
совокупности (но, разумеется, сильно зависят от величины последнего).
г) Вместо нормального распределения можно пользоваться
распределением %2 с большим числом степеней свободы (см.
разд. 5.7). Для положительных случайных величин такое пред-
представление более реалистично. Можно применять также логариф-
логарифмически нормальное распределение (см. разд. 5.6.3).
11.4. АПРИОРНЫЕ ВЕРОЯТНОСТИ
При выборе оптимальной процедуры используются вероятно-
вероятности w{ того, что истинной функцией распределения является
F;{x). В большинстве случаев точные значения w( не известны.
Напомним, что вероятность рассматривалась как предел частости
в длинной серии опытов. Поэтому для точного вычисления wt необ-
необходимо связать данное конкретное исследование с длинной серией
аналогичных исследований, после чего появляется возможность оце-
оценить предел частости с достаточной точностью. Иногда это удается,
но обычно нет. С другой стороны, очень часто о wt имеются
некоторые сведения. Например, если взвешиваются контейнеры
с номинальным весом 100 фунтов, средний вес окажется с боль-
большей вероятностью между 100 и 102 фунтами, чем между 90 и
92 фунтами. Опыт работы в аналогичных ситуациях позволяет
исследователю постулировать нормальное распределение среднего
веса с математическим ожиданием, большим 100 и меньшим 103
Теория и анализ статистических решений
425
фунтов, и средним квадратическим отклонением, например между
1 и 2 фунтами. Модель не точна (так как вес не бывает отрица-
отрицательным, а также по другим причинам). Но лучше неточная
модель, чем полное игнорирование имеющегося опыта.
Пример 11.1. Будем считать известным, что распределение
(априорное распределение) Э нормально с математическим ожи-
ожиданием Эо и средним квадратическим отклонением а0. (Числовые
значения Эо и а0 заданы.) Предположим далее, что при данном Э
величина X имеет нормальное распределение с математическим
ожиданием Э и известным средним квадратическим отклонением а.
Располагая результатами п независимых наблюдений X, нужно
оценить 0.
Это можно сделать, найдя апостериорное распределение Э
с помощью теоремы Байеса (см. разд. 3.4). Следует отметить, что
здесь речь идет о непрерывном распределении априорных вероят-
вероятностей, а не о дискретном множестве значений wi9 как это было
ранее. Впрочем, непрерывное распределение можно рассматривать
как предел дискретных наборов величин wh где
и последовательные значения в лежат в уменьшающихся интер-
интервалах F0(^).
Плотность априорной вероятности Э равна
Следовательно, по теореме Байеса апостериорное распределение
при данном среднем X, полученном по реализациям п независи-
независимых случайных величин, каждая из которых распределена по
нормальному закону с математическим ожиданием Э и средним
квадратическим отклонением а, имеет вид
Ре @ Р-у
A1.1)
где
Отсюда
2al
426
Глава 11
Это выражение преобразуется к виду
где К не зависит от t.
Поскольку из формулы (ИЛ) следует, что
получаем
Pe(t\X) =
где
. ("-2)
а0
Следовательно, апостериорное распределение Э нормальное с ма-
математическим ожиданием % (X) и средним квадратическим откло-
отклонением (а^2 + па)~1/2.
Теперь можно построить такой интервал, что (апостериорная)
вероятность попадания в него 0 равна любому заданному числу
1—г. Он имеет границы
где
Его нельзя назвать доверительным интервалом в смысле гл. 7,
но интересно сравнить с последним:
A1.4)
Во-первых, замечаем, что середина Эо(Х) интервала A1.3) нахо-
находится между априорным математическим ожиданием Эо и наблю-
наблюдаемым средним X, причем тем ближе к последнему, чем больше п.
Во-вторых, отношение длин интервалов A1.3) и A1.4) равно
(l-ftt^a2^)/2 < 1. Этот факт можно интерпретировать как
увеличение точности за счет использования априорной информа-
информации. Заметим, что при увеличении п это отношение стремится
к единице. Иначе говоря, по мере поступления новых данных
априорная информация теряет свое значение.
Теория и анализ статистических решений
427
Следует подчеркнуть, что приведенные выше результаты имеют
смысл только в том случае, когда действительно известно, что
априорное распределение имеет данную форму (на практике при-
приблизительно). Если не помнить об этом, применение теоремы
Байеса превратится в ряд занимательных математических упраж-
упражнений, не имеющих отношения к прикладной статистике.
Пример 11.2. В ситуации примера 11.1 предположим, что
исследователь не знает точного значения среднего квадратического
отклонения а априорного распределения. Известно только, что
оно лежит между двумя заданными величинами а' и а" (а' < а").
В этом случае нельзя вычислить точные доверительные гра-
границы, но можно показать, что границам X ±их- г/ъо'1Уп соот-
соответствует доверительная вероятность не выше 100 A—е)%, а
границы X±a1-g/2a"/)/'n имеют доверительную вероятность по
меньшей мере 100 A -—е)%. Кроме того, минимальная доверитель-
доверительная вероятность для X ± и1-е/2о'1угп равна [2Ф(о'и1-е/2/о")—1],
а максимальная для X ±их-г/2огг\Уп есть [2O(a//w1_8/2/a')— 1].
Возможны и другие варианты. Например, может быть известно
совместное априорное распределение Э и а. В этом случае сов-
совместное апостериорное распределение находится по формуле
pQt o (t, s)p(E\ и s)
Pe,o(t,s\E) = -
-сю б
\pQ,o(t,s)p(E\t,s)dsdt
Тогда плотность /?е (t \ E) оказывается равной
{Е означает выборочные данные).
В любом случае, чем точнее знания о параметрах, тем более
надежные выводы получаются путем комбинирования выборочных
данных и априорной информации.
Впрочем, необходимо действительно знать функции, входящие
в формулы, а не просто подставлять кажущиеся правдоподобными
значения. Такую подстановку можно делать, выясняя значение
априорных знаний того или иного вида, но результаты нельзя
рассматривать как серьезные оценки или как основу для прак-
практических выводов.
42a
Глава 11
Подведем итог сказанному. Следует пользоваться любыми
сведениями об априорных вероятностях при условии, что это
действительно сведения, а не игра воображения.
Источником сведений обычно служит опыт проведения анало-
аналогичных экспериментов либо описанные в литературе исследова-
исследования. На „общее впечатление" можно полагаться только в отно-
отношении самых общих свойств распределений, встречающихся
в работе.
11.5. РЕШЕНИЯ И ФУНКЦИИ ПОТЕРЬ
При планировании исследований редко удается точно охарак-
охарактеризовать все возможные решения. Однако в формальном ана-
анализе точность необходима, поскольку для каждого решения рас-
рассматривается величина потерь при любом возможном F{(х). Резуль-
Результаты применения формальной теории при сокращении массива
допустимых решений и приблизительных оценках их последствий
приходится рассматривать как рекомендации, а не как прямые
указания. Иначе говоря, изучение правдоподобных ситуаций может
оказать помощь при планировании исследования, но поскольку
обычно не удается предсказать ситуацию со всеми подробностями,
не следует автоматически использовать теорию для выбора про-
процедур и способов действий.
Тем не менее оценки вероятных последствий будущих действий
часто оказываются полезными. В этом разделе описываются наи-
наиболее типичные решения, но, разумеется, на практике каждую
проблему следует рассматривать во всех ее аспектах и по мере
возникновения.
Самый элементарный случай — выбор одной из двух простых
гипотез. Если можно измерять потери ошибками без учета их
утилитарного или денежного эквивалента, задача сводится к про-
проверке гипотезы, обсуждавшейся в разд. 7.5.
Допустим, что нужно выбрать одну из двух функций распре-
распределения Fx (x) и F2\x), имеющих априорные вероятности wt и w2
соответственно (w1-\-w2=\). Заметим, что х может соответство-
соответствовать множеству наблюдаемых величин.
Возможны лишь два решения:
dx = F1 (%)—действительная функция распределения,
d2 = F2(x)—действительная функция распределения.
Функция потерь W [dh Fj(x)] определена равенствами
W[dh Ff(x)]=l, если [ф\.
Из этих уравнений следует, что ошибка (любого рода) приводит
к единичной потере.
Теория и анализ статистических решений
429
Средний риск равен
(Математическое ожидание стоимости выборки)+
+ w1Pr[d2\F1(x)] + w2Pr[d1\ F2(x)].
При данной стоимости выборки естественно искать процедуру
принятия решений (или правило), минимизирующую
Естественное обобщение этой задачи заключается в выборе
одной из трех простых гипотез, обозначаемых как Fx (x), F2 (x)9
F3(x) соответственно. Теперь есть три возможных решения (d19
d2, d3) — выбор первой, второй или третьей гипотезы. Если задача
состоит только в правильном выборе, функция потерь задается
уравнениями
W[
^[di\Fj(x)]=l при 1ф\ (/, /=1, 2, 3).
Однако может оказаться, что при верной первой гипотезе
выбор третьей будет более грубой ошибкой, чем выбор второй.
Предположим, например, что три гипотезы соответствуют трем
значениям параметра — среднего квадратического отклонения со-
совокупности, равным 4, 6 и 8 соответственно. Если на самом деле
среднее квадратическое отклонение равно 4, естественно считать
выбор 8 менее удачным, чем выбор 6. Чтобы учесть это обстоятель-
обстоятельство, нужно отразить его в функции потерь. Функция W [d;- \ Ft (x)]
должна быть определена так, чтобы 0 < W [d2 [Fx (x)] < W [d3| F± (*)].
Другая проблема связана с выбором фактических значений
W [d2 j F± (х)] и W [d3 | Ft (х)] или хотя бы их отношения.
Даже если можно считать, что W [dj \ Ft (с)] зависит только
от I*— /I (т- е- является функцией [/ — /1), задача остается не-
нерешенной. В некоторых случаях количественные значения этой
функции можно получить, исходя из физических или экономи-
экономических соображений.
Пример 11.3. Смесь считается смесью первого сорта, если ее
активная компонента составляет более 1%, и второго сорта, если
активная компонента составляет 1/2—1%.
Доля активной компоненты оценивается методом, имеющим
стандартную ошибку вида
0,1-(истинная доля)-(вес [в унциях] оцениваемой смеси)~1/2%.
Если оцененная доля больше Хх(> 1) процентов, смесь продается
первым сортом; если она больше Х2(> 1/2) процентов, но меньше
Х19—вторым; если доля меньше Х2 процентов, смесь возвращает-
возвращается на фабрику.
430
Глава 11
В этом случае, несмотря на то что истинная доля может
иметь бесконечное число значений, принимается одно из трех
решений.
Достаточно точное знание функции потерь позволило бы наи-
наилучшим образом выбрать а) значения Хг и Х2 и б) вес смеси
для оценки доли активной компоненты.
Функция потерь зависит от вероятности того, что будет про-
продана смесь с меньшим содержанием активной компоненты, чем
следует, и от связанных с этим убытков. Последние не всегда
легко оценить, поскольку речь может идти не о штрафе, а об
отмене возможных будущих заказов. Стоимость выборки обычно
растет с весом используемой смеси.
Более точный анализ возможен в том случае, когда имеется
достаточная информация об априорном распределении доли ак-
активной компоненты.
Предположим, что оценка доли активной компоненты распре-
распределена по нормальному закону со средним, равным истинной
доле (точно не известной). Для данной истинной доли 0 вероят-
вероятности отнесения смеси к первому и второму сортам будут равны
1— Ф[1_о(Х1е-1—i)Vw] и Ф[ю(Х1е-1—\)Vw\—Ф^ода-1 —
— l)l/V| соответственно, где w вес смеси, взятой для оценивания.
Функцию потерь для данного Э можно записать формально в
виде
—Ф[Ю(Х1е-1 —
где ?/(Э)—средние потери от продажи /-м сортом при истинной
доле 6 (/=1,2), Е3(в)—средние потери вследствие браковки при
истинной доле 0, С (до) — средняя стоимость выборки весом до ун-
унций. [С (до) может зависеть и от 0, например, при использовании
последовательной выборочной процедуры.]
Для получения окончательного вида функции потерь нужно
взять математическое ожидание по 0. Результат зависит от имею-
имеющихся сведений об априорном распределении доли активной ком-
компоненты.
Даже если последнее известно, расчеты оптимальных значе-
значений Х19 Х2 и до могут оказаться сложными. Они относятся ско-
скорее к области вычислительной математики, чем статистики.
Аналогичный подход возможен и в случае большего числа
допустимых решений. Если эти решения заключаются в том, что
параметр 0 находится в определенном интервале, возникает ситуа-
ситуация, близкая к той, которая имеет место при оценивании пара-
параметра. Пусть, например, dj заключается в том, что р (параметр
Теория и анализ статистических решений
431
биномиального распределения) заключен между (/ — \)/k и j/k
(/=1,2, ...,&)• Если k велико, выбор решения почти эквива-
эквивалентен оцениванию р. Гипотезам в этом случае можно сопоста-
сопоставить определенные дискретные значения р. Однако часто удобнее
воспользоваться континуумом возможных гипотез, соответствую-
соответствующих любому значению р от 0 до 1 включительно. (Читателю
может оказаться полезным рассмотреть априорные вероятности
для этого случая, представленные в виде априорной плотности
вероятности р.) Если главная задача — получить точные оценки,
функция потерь зависит от представления исследователя о точ-
точности. Так, она может быть пропорциональной абсолютной вели-
величине ошибки оценки, ее квадрату или отношению ее абсолютной
величины к р A—р). Конечно, существует много других мер,
определяемых конкретными условиями исследования.
Пример 11.4. Сопротивления выпускаются партиями по 210 штук.
Из каждой извлекается случайная выборка объема 10. Если г
единиц оказывается годными, считается, что годны 20г из остав-
оставшихся 200 сопротивлений. К партии добавляется такое число
заведомо годных изделий, которое в сумме с 20г дает 180. (При
г = 9 или 10 изделия не добавляются.) Если в партии оказы-
оказывается меньше 180 годных сопротивлений, за каждое недостаю-
недостающее до 180 приходится платить штраф в 5 единиц; стоимость
поставки каждого дополнительного сопротивления равна трем
единицам. В случае, когда г меньше 10 и N меньше 20г, функ-
функция потерь имеет вид
W(r, Л^) = 3A80— 20r) + 5A80—[N+180—20г]) =
= 3 A80— 20r)+ 5B0r — N).
(Здесь N -{-г—истинное число годных изделий среди исходных 210.)
Другие значения W (г, N) равны
W(IO,N) = 5A8O — N) при N < 180,
W(l0,N) = 0 ПРИ #>180,
W(r, N) = 3A80 —20г) при N^20r и г < 10.
Заметим, что величина г соответствует одному из 11 возмож-
возможных решений, а N—одной из 201 возможной ситуации.
В приведенном выше примере можно было считать N пара-
параметром, а 20г—оценкой этого параметра. Однако каждое реше-
решение означало некоторую последовательность действий (хотя и
было связано с наблюдаемым значением г).
В общем случае решения не всегда связаны с гипотезами или
конкретными значениями параметров. Например, часто нужно
432
Глава 11
понять, продолжать исследование или нет, и какой оно должно
иметь вид в случае продолжения. Вероятные потери, связанные
с той или иной последовательностью действий, нужно оценивать
при каждой возможной гипотезе, однако прямого соответствия
между множеством решений и множеством гипотез может не быть.
11.6. СТОИМОСТИ ВЫБОРОК
Осталось рассмотреть стоимость получения выборочных дан-
данных. Желательно, чтобы стоимостная функция выборок учиты-
учитывала не только непосредственные расходы на получение выборки
(т. е. измерение и запись определенных характеристик всех вы-
выбранных объектов), но также стоимость статистического анализа
и дополнительные расходы на планирование и выборочный конт-
контроль в случае последовательных процедур (см. гл. 16).
Если выборка содержит п объектов и извлечение каждого
объекта связано с одним измерением, стоимостную функцию
выборки можно записать в виде с^-^-с^п. Значение с0 соответст-
соответствует накладным расходам или фиксированным начальным затра-
затратам на эксперимент, не зависящим от объема выборки. Величина
с1 интерпретируется как дополнительный расход на каждый
элемент выборки.
Иногда простая линейная функция от п оказывается недо-
недостаточно точной. При увеличении объема выборки дополнитель-
дополнительные расходы на каждый отобранный объект могут сокращаться.
Это объясняется „эффектом обучения"—измерения упрощаются
в результате повторения. В таких случаях можно воспользо-
воспользоваться функцией вида ?0-}-?1/га, где 0<а<1. Функция более
сложной формы с^-\-с1па-\-с2рР употребляется редко. Если по
окончании определенного периода времени (смены или рабочего
дня) приходится начинать выборочную процедуру с некоторой
промежуточной стадии, применяют квазипериодические функции.
Интересен частный случай, когда задача состоит в посещении
М пунктов, расположенных более или менее случайно на опре-
определенной площади. Пройденное расстояние (обычно тесно связан-
связанное с компонентой стоимости) считают приблизительно пропор-
циональнЫхМ ]/~М.
Другая особенность — неравенство расходов, приходящихся
на один объект. Такая ситуация возникает при расслоенных
(стратифицированных) выборках (см. гл. 19). Очень часто сум-
суммарные расходы на один объект меняются от слоя к слою.
До сих пор предполагалось, что объем и форма выборки
фиксируются перед началом исследования. Это не всегда так:
последовательные выборочные процедуры (см. гл. 16) приводят
к выборкам разного объема, То же самое можно сказать о ста-
Теория и анализ статистических решений
433
дийных исследованиях, даже если в отличие от формальных после-
последовательных выборочных процедур отсутствуют четкие формулиров-
формулировки очередных шагов. Если объем выборки переменный, то наряду
со стоимостью выборки в расчетах следует использовать средние
стоимости. Так, вместо со-\-сх п нужно взять Cq-^-c^^IF^x)].
Заметим, что это выражение зависит от истинного распределения
измеряемой характеристики в совокупности. Иногда применяются
более сложные выражения средней стоимости выборки. При опре-
определении констант (с0, сх и т. д.) необходимо учесть влияние на
стоимости самих выборочных процедур. Например, суммарные
расходы на один объект при последовательной выборочной про-
процедуре могут оказаться больше, чем в случае фиксированного
объема выборки, поскольку тратится дополнительное время на
решение вопроса, продолжать наблюдения или нет.
11.7. ПРИМЕРЫ
Приведем три примера, иллюстрирующие соображения, изло-
изложенные в предыдущих разделах.
В первом определяются принципы минимаксного риска и мини-
минимаксного сожаления. При работе с ними требуется большая осто-
осторожность, но они оказывают помощь в выборе подходящих про-
процедур. Интересный пример применения принципа минимакса мож-
можно найти в работе Р. А. Фишера [Fisher R. A., Randomisation,
and an Old Enigma of Card Play, Mathematical Gazette, 18
A934)].
Пример 11.5. Среди совокупностей нужно выбрать одну с
наибольшим средним значением некоторой характеристики X.
Для этого естественно взять из каждой совокупности случайную
выборку объема п, измерить для каждого выбранного объекта
признак Ху вычислить выборочные средние Xlf X2, ..., Xk и
выбрать совокупность с наибольшим выборочным средним. Обо-
Обозначим совокупности через П^ П2, ..., Y\k.
Можно считать, что X взаимно независимы. Предположим
далее, что все X имеют распределения одинаковой формы и
где а(>0) известно, Q{ — неизвестный параметр и G(-) — извест-
известная функция. (Очень часто можно считать, что все X распреде-
распределены нормально. В этом случае G(-) = O(-)-) Тогда величины
434
Глава 11
Теория и анализ статистических решений
435
^1 = Уп(Х{—0^/а имеют известное распределение. Вероятность
выбора Пу (решение dj) равна
Pr[n {Xj-Xt > 0)] = Рг [ П {Zj-Zt> - ^^
где 6 обозначает вектор с компонентами 6^ = 0,.—9,.
Если взять линейную стоимостную функцию выборки (=^0+^/1),
риск при заданных Q19 . ..,0Л (или, что эквивалентно, 6) равен
7=1
Если, кроме того, функция потерь W (d-18) пропорциональна
max/F//) = (max/0I.) —е^ЛуСб), то
Поскольку Q. не известны, нельзя выбрать п, минимизирую-
минимизирующее /?, так как оно зависит от 0. Воспользуемся принципом ми-
нимакса. Он заключается в том, что максимальная величина R
(по отношению к вариациям 0) минимизируется по п. Тогда мак-
максимальный риск (по отношению к вариациям величин 0) равен
max R = с0 + cxti
е
где
= max
/=i
8*)/,F*).
[Заметим, что g не зависит от п, поскольку можно заменить
УПЬ/а на 8* и max f (у) = max f (У пу/о).] Величина м, мини-
у у
мизирующая максимальный риск, получается путем дифференци-
дифференцирования max R по п и приравнивания результата к 0. Получаем
v. = 0 или п=
Соответствующее значение max R равно
0
2 A ъКЪ*
i = с0
Заметим, что если не считать фиксированных расходов с09 стои-
стоимость выборки равна половине средних потерь при минимаксном
значении п.
Эти результаты применимы ко многим задачам планирования
исследований. Величина К зависит от важности принимаемых
решений. Например, если 9 означает средний выход процесса,
К может равняться стоимости единицы выхода. Очень часто
К связано с шкалой полезности результатов исследования.
В ряде случаев численное определение g вызывает значитель-
значительные (но преодолимые) технические трудности.
Если исследователь располагает достаточной информацией
для получения априорных распределений каждого из 9Л нет
необходимости применять принцип минимакса: средний риск
известен точно, и его зависимость от п можно изучать непосред-
непосредственно.
Альтернативой принципу минимакса является принцип мини-
минимаксного сожаления.
Для любого набора величин 0,- существует значение п, минимизи-
минимизирующее R. Это минимальное значение Rmin @)—наименьшее из всех
возможных. (Конечно, нельзя быть уверенным, что этого минимума
удастся достичь.) Превышение фактического значения /? над/?min@)
называется сожалением. Принцип минимаксного сожаления состоит
в применении принципа минимакса не к /?, а к сожалению. Иначе
говоря, ищется значение п, минимизирующее max[R—#min(9)].
0
Пример 11.6. Большая совокупность состоит из k слоев Slf
S2, . . ., Sk. (Расслоенные совокупности рассматриваются в гл. 19.)
(k \
2 Р/ = 1 )• Нужно изв-
/ = 1 /
лечь случайную выборку, содержащую по меньшей мере т1
объектов из Sx, пг2 объектов из 52 и т. д. Если объект извле-
извлекается случайно из всей совокупности, стоимость на один объект
равна с. Взятие объекта случайным образом из определенного
слоя Sj связано с затратами с;-, и поскольку это более сложное
задание, Cj обычно больше с. Предлагается взять начальную
выборку из Af объектов, извлеченных случайно из всей совокуп-
совокупности. Если какой-либо слой представлен недостаточно, дополни-
дополнительно берется более дорогая выборка из этого слоя. Кд^эе
значение N минимизирует суммарную среднюю стоимость полу-
получения выборки?
Стоимость первой выборки равна cN. Допустим, что из этих
/V объектов п1У п2, ..., nk были извлечены из слоев Sti S2, ...,
..., Sk соответственно. Тогда, если п;- меньше ту-, из слоя S;- нужно
еще извлечь (mf—nj) объектов; дополнительные затраты при этом
составят Cj(ntj—nj). Следовательно, средняя суммарная стоимость
436
Глава 11
равна
/=1
Нужно найти величину N, минимизирующую эту функцию.
В данном случае нецелесообразно непосредственно минимизиро-
минимизировать стоимость. Рассмотрим изменение средней стоимости при
переходе от N к N-\-\ путем случайного выбора еще одного
объекта. Этот дополнительный объект с вероятностью pj будет
извлечен из Sj. Если му. уже не меньше т^ это не отразится на
стоимости дальнейших выборок. Но если tij меньше trij, новый
объект уменьшает объем дополнительной выборки из Sf на 1,
а стоимость—на Cj. Стоимость дополнительного объекта в началь-
начальной выборке равна с. Следовательно, изменение средней стои-
стоимости равно
/=1
В этом выражении от N зависят только вероятности
Prf/iy<my]f / = 1, 2, ..., А.
Каждая из них уменьшается с увеличением N. Для малых N
изменение средней стоимости отрицательно, но начиная с опре-
определенного значения, скажем No, оно становится положительным.
Следовательно, No есть значение N, минимизирующее среднюю
стоимость.
Значение No приходится подбирать методом проб и ошибок,
но вычисления даже в самом общем случае не очень трудные,
если No невелико. (При большом No можно воспользоваться
аппроксимациями.) В полностью симметричном случае, когда
—ск = с\ изменение стоимости становится равным
m~1 -N,
Таким образом, No—наименьшее целое число, для которого
Числовое значение NQ можно получить с помощью таблиц бино-
биномиального распределения. Несколько типичных величин приве-
приведены в табл. 11.1.
Теория и анализ статистических решений
437
Таблица 11.1
k
5
5
с/с'
0,5
0,8
Оптимальные объемы первой
т
5
10
5
10
24
49
16
38
k
10
10
выборки
с/с'
0,5
0,8
т
5
10
5
10
47
97
32
74
Если число наблюдений не фиксировано и считается случай-
случайной ве-личиной, могут возникнуть неясности в отношении точ-
точности оценок. Для примера рассмотрим три подгруппы (или
слоя) Пц П2, П3 в очень большой совокупности в соотношении
1:1:1. К какой подгруппе относится объект, можно узнать
только после того, как он попал в выборку. Пусть нужно полу-
получить оценку среднего значения признака X в Пг с заданной
точностью. Выборочная процедура продолжается, пока не на-
наберется 10 объектов из П^ после чего она прекращается. Чис-
Численности попавших в выборку объектов из П2 и П3 изменяются
и могут рассматриваться как случайные величины.
Допустим, нужно узнать точность среднего арифметического
признака X оказавшихся в выборке объектов из П2, получен-
полученного в виде оценки математического ожидания (?2) признака X
в П2. В описанной выборочной схеме число N2 элементов из П2
имеет отрицательное биномиальное распределение с параметрами
10, 1/2 (см. гл. 4). Его математическое ожидание равно 5, а дис-
дисперсия A0.1/2-3/2-7,5).
Условная дисперсия среднего арифметического выборки из П2
при заданном Af2(>0) равна ol/N2f где о|— дисперсия в под-
подгруппе П2. (При Af2 = 0 оценка отсутствует.) Математическое
ожидание равно ?2 для всех N2 > 0.
В случае N2> Q дисперсия среднего арифметического равна
' ° \ " — 2 гг2
-S- — тг" ~ "т-СГг-
Эта величина может быть использована при планировании ис-
исследования. Однако, если важно знать точность оценки ?2, луч-
лучше не применять эту дисперсию к оценке, основанной на N2
наблюдаемых значениях X.
438
Глава 11
Для N2 наблюдаемых значений подходящая формула имеет
вид ol/N2. Неважно, что в другой выборке будет другое N2 или
вообще не удастся получить оценку.
Пример 11.7. Для практических целей приближенно можно
считать, что вес малой детали распределен по нормальному закону
с известным средним (вычисленным по данным о весах 100 000 де-
деталей, выпущенных за смену), но неизвестным средним квадра-
тическим отклонением (а).
Продукция проверяется прибором, „взвешивающим" каждую
деталь и относящим ее к одной из трех широких весовых групп
(<L, между L и [/, > U). (Веса отдельных деталей не важны.)
L и U фиксируются на уровнях
(среднее) —а и (среднее) -\-а (а > 0)
соответственно. Партия принимается, если среди М проверенных
деталей доля изделий, веса которых оказались между L и (/,
превышает заданную величину со.
Потери на одну деталь в результате браковки равны С. Если
партия принимается, из нее случайным образом извлекаются пары.
Последние годятся к употреблению, есла только веса входящих
в них единиц различаются менее чем на б. В противном случае
обе детали бракуются с потерями К-
Требуется построить функцию потерь.
Доля деталей в совокупности, попадающих между пределами
(среднее) ±а, равна [2Ф(а/а)—1]. Доля деталей случайной вы-
выборки объема М, оказавшихся в этих пределах, имеет приблизи-
приблизительно нормальное распределение со средним {2Ф(а/о)—1} и
дисперсией 2М~1[2Ф(а/о)—1][1—Ф(а/с)]. Вероятность отклоне-
отклонения партии равна примерно
о)-[2Ф(а/а)-1]
1—Ф
Средние потери на одну партию получаются умножением этой
величины на Сп (п — число деталей в партии).
Разница весов двух деталей из одной партии, согласно нашим
предположениям, распределена приблизительно по нормальному
закону с математическим ожиданием 0 и,средним квадратическим
отклонением oV%- Две детали окажутся несовместимыми с ве-
вероятностью
Теория и анализ статистических решений
439
и средние потери на одну партию по этой причине составят
Суммарная функция средних потерь на партию приблизительно
равна
о)-[2Ф(а/д)-1]
{2М-1[2Ф(а/а)— 1][1— Ф(а/а)]}1/2
Это функция пу сг, С, /С, б, М, со и а. Три последних параметра
определяют применяемую схему приемки; остальные не так просто
поддаются изменению.
11.8 ДИСКОНТИРОВАНИЕ
Во всех описанных выше примерах не учитывался тот факт,
что потери могут относиться к разным моментам времени. Послед-
Последнее обстоятельство приводит к необходимости рассмотрения дис-
дисконтирования— увеличения величин будущих платежей по отно-
отношению к настоящему моменту времени за счет процентов, накап-
накапливаемых при отсрочке платежа.
Если считать, что процентная ставка на единицу времени
равна i (= 100 /%), то через т единиц времени величина S вырастет
до S(l-j-?)OT- Соответственно текущее значение суммы Л, которую,
нужно будет уплатить спустя т единиц времени от настоящего
момента, равно A(l+i)"m = Avm, где t>= (I-fO- Ниже приве-
приведены примеры вычисления стоимости, приведенной к текущему
моменту времени.
Пример 11.8. Стоимость, производимая в единицу времени
работы единицы оборудования, равна со, а плотность вероятности
срока службы оборудования есть pT{t). Каково математическое
ожидание производимой стоимости, приведенной к моменту начала
эксплуатации оборудования?
Предполагается, что время службы совпадает с календарным
временем.
Если оборудование выходит из строя через время 7, то стои-
стоимость, приведенная к моменту начала эксплуатации, равна
т
со
440
Глава 11
где § = — \nv. (Заметим, что поскольку v<.\, б > 0.)
Усредняя по распределению Т, получаем
Пример 11.9. Предположим, что срок службы (Г) единицы
оборудования имеет экспоненциальное распределение
Рг[7<?] = 1—ехр(^-
6>0,
Стоимость, производимая единицей оборудования в единицу вре-
времени, составляет ф, а стоимость оборудования с учетом расходов
на установку равна /С. Каким должно быть К, чтобы эксплуатация
оказалась рентабельной, если допустить, что процентная ставка
на единицу времени равна ft
Воспользовавшись вычислениями примера 11.8, получим сред-
среднюю стоимость, связанную с эксплуатацией оборудования:
1 — е-1
Прибыль на единицу оборудования равна сов A -f 06)-1—/С; нужно,
чтобы К было меньше, чем ©0A-f вв)-1.
Предельная стоимость оборудования уменьшается с ростом /.
Например, 5-0,0488 при /-0,05 E%) и 6-0,0770 при/-=0,08
(8%). Чтобы скомпенсировать увеличение процентной ставки с 5
до 8 нужно повысить 9 (средний срок службы оборудования) до
уровня
6'=6A— 0,0282 в)-*
(считая, что со и К постоянны).
Разумеется, на практике очень трудно предсказать процентную
ставку за весь период работы системы. Чем длиннее период, тем
труднее сделать точный прогноз. Тем не менее вычисления с Дис-
Дисконтированием часто оказываются полезными, так как могут дать
результаты при разных процентных ставках. Иногда последние
можно считать зависящими от времени. При этом вычисления
усложняются; а трудности, связанные с точностью предсказаний
процентных ставок, остаются.
Пример 11.10. В условиях примера
процентная ставка равна ix при 0^/^
11.9 предположим, что
, а затем i2.
Теория и анализ статистических решений
441
Тогда приведенная стоимость для единицы оборудования со-
составит
Заметим, что процентная ставка иногда определяется для дробных
единиц времени, т. е. как т-гЬ{т) на т~г единиц. В этом случае
ставка на единицу времени (i) связана с б(/й) формулой
[В последнее время вместо 8{т) иногда применяется символ i{m).
Здесь мы избегаем использовать такое обозначение.]
При увеличении т получаем предельный случай
где S называется силой ставки. Если б —непрерывно выплачивае-
выплачиваемая номинальная процентная ставка, то i = e6—1 соответствует
действительной процентной ставке.
ЛИТЕРАТУРА
1. Сох D. R., Hinkley D. V., Theoretical Statistics, Chapman and Hall, London,
Halstead Press, New York, 1974, Chapter 11. [Имеется перевод: Кокс Д. Р.,
Хинкли Д. В. Теоретическая статистика.—М.: Мир, 1978.]
2. Davies О. L., Some Statistical Aspects of the Economics of Analytical Testing,
Technometrics, 1 A959).
3. De Groot M. H., Optimal Statistical Decisions, McGraw-Hill, New York, 1970.
[Имеется перевод: Де Гроот М. Оптимальные статистические решения.— М.:
Мир, 1974.]
4. Hays W. L., Winkler R. L., Statistics, Vol. 1, Holt, Rinehart, Winston,
New York, 1970.
5. Moore P. G., A Statistical Approach to the Allocation of Technical Effort
in Some Industrial Situations, Journal of the Royal Statistical Society, Series
A, 126 A963).
6. Raiffa H., Schaifer R. L., Applied Statistical Decision Theory (Part 1)
Graduate School of Business Administration, Harvard University, Cambridge,
Mass., 1961. [Имеется перевод: Райфа Г. Шейфер Р. Прикладная теория
статистических решений.—М.: Статистика, 1977.]
442
Глава 11
7. Wald A., Decision Theory, Wiley, New York, 1950. [Имеется перевод:
Вальд А. Статистические решающие функции, в сб.: Позиционные пары.—
М.: Наука. 1967.]
8. Weiss I., Statistical Decission Theory, McGraw-Hill, New York, 1961.
УПРАЖНЕНИЯ
В упражнениях 1—4 рассматривается следующая ситуация: для каждого
элемента выборки фиксируется значение качественного признака. Если послед-
последним обладают более г объектов в выборке объема п, принимается решение d±
(например, отклонить); в противном случае — решение d2- Совокупность можно
считать неограниченной, а долю объектов с данным признаком — равной р.
Стоимость /Ci, связанная с решением dlf не зависит от р\ стоимость, связанная
с решением d2, равна К2Р-
1. Известно, что стоимость выборочной процедуры —линейная функция
соЛ~с1п от объема п выборки. В результате изменения условий оплаты вели-
величина сг увеличилась до (ci-f6). Решено сохранить расходы на выборочную
процедуру на прежнем уровне, уменьшив объем примерно до ^^/(сх + б).
Объясните, почему это не лучшая стратегия.
2. Пусть априорное распределение р имеет вид
Рг [/7 = 0,01] =0,6, Рг [/? = 0,04] =0,3,
Рг [/? = 0,08] =0,07, Рг [р = 0,15] = 0,03.
Запишите уравнения для оптимального объема п.
3. Как зависит оптимальное значение п в упражнении 2 от а) сх и б) /Сг?
4. а) Не меняя вероятности отклонения, можно укоротить выборочную
процедуру. Для этого нужно прекращать ее всякий раз, когда число выбран-
выбранных объектов, обладающих определенным признаком, окажется равным т.
Выведите формулу для ожидаемой экономии за счет применения этого метода.
б) Пусть имеется выборочная оценка /7, а потери за счет ошибки равны
/С3Х[ошибка р]2. Как это повлияет на решение об укорочении выборочной
процедуры?
В упражнениях 5—8 используются данные, представленные ниже в виде
таблиц. Эти данные отражают результаты проверки некоторого изделия массо-
массового производства. Полагается, что каждая партия содержит 10 000 изделий.
Были взяты выборки объема 50, 100, 150 и 200. Результаты для каждого
объема приведены в виде отдельной таблицы.
Объем выборки 50
Объем выборки 100
Число
дефектных
изделий
0
1
2
3
4-5
6-7
8—9
10—12
Число
партий
17
27
24
31
30
30
13
3
175
Число
дефектных
изделий
0—1
2-3
4—5
6—7
8—9
10—12
13-15
16—18
19—21
Число
партий
27
40
44
37
15
5
3
1
172
Теория и анализ статистических решений
443
Объем
Число
дефектных
изделий
0—1
2-3
4—5
6-7
8-9
10-12
13—15
16—18
19—21
22—24
выборки 150
Число
партий
9
10
13
10
11
8
4
1
1
1
~68
Объем
Число
дефектных
изделий
0—2
3—5
7—9
10—12
13—15
16—18
19—21
22—24
25—27
28—30
34—36
выборки 200
Число
партий
5
10
11
10
7
3
—
2
1
1
2
52
Суммарные стоимости выборок (включая накладные расходы) были равны
Объем Расходы, долл.
50 12 740
100 21 020
150 11510
200 11 400
Решено воспользоваться выборочной схемой приемки, основанной на количестве
дефектных изделий в выборке объема N. Потери на одно изделие в отклонен-
отклоненной партии составляют 2,00 долл., обнаружение дефектного изделия в принятой
партии приводит к потерям в 2k долл.
5. С помощью табличных данных оцените выборочную стоимостную функ-
функцию и априорное распределение числа дефектных изделий в партии. (В предпо-
предположении, что имеет место бета-распределение.)
6. Воспользуйтесь этими оценками для построения суммарной стоимостной
функции.
7. Найдите выборочную процедуру описанного типа, минимизирующую
средние потери на одну партию. (Положите & = 20.)
8. Обсудите в общих чертах возможности улучшения ситуации за счет
расширения диапазона выборочных процедур (например, применения двухсту-
двухступенчатых выборок или последовательных выборочных схем, описанных в гл. 16).
Упражнения 9—12 были предложены на специальных экзаменах на звание
бакалавра естественных наук в Лондонском университете в 1952 г. Рассматри-
Рассматривалась следующая ситуация. Продукция выпускается большими партиями.
Выгоднее ввести выборочный контроль и дорабатывать отклоненные партии,
чем устранять все дефекты в процессе производства. Поставщик старается
выпускать не более 0,45% дефектных изделий. Он проверяет выборку из 200 изде-
изделий и, если обнаруживает в ней 5 или больше дефектных, считает партию
неудовлетворительной. Потребитель совершенно независимо проверяет посту-
поступающие к нему партии. Он отклоняет их, если выборка объема 150 содержит
4 или больше дефектных изделия.
Проданными считаются только партии, прошедшие обе проверки. Пусть
С* A00 долл.) — первоначальная стоимость изготовления партии; С—стоимость
444
Глава 11
доработки партии, отклоненной поставщиком; С" —стоимость доработки партии,
отклоненной потребителем. Каждая доработанная партия считается проверенной
и проданной.
9. Оцените стоимость партии, принятой потребителем, при разных долях
дефектных изделий в исходной продукции (от 0,5 до 3%).
10. Дано: С =0,4 С, С" = 0,6 С и
С =185 —?
где р — процент дефектных изделий в исходной продукции @,2% < р < 4%).
Проанализируйте стоимость одной партии и постройте график зависимости
стоимости от величины ру принимающей значения от 0,5 до 3%. При каком
значении р стоимость минимальна?
11. Вместо того чтобы отклонять партии при 5 и более дефектных изделиях
в выборке объема 200, поставщик может воспользоваться следующими крите-
критериями браковки:
а) шесть и более дефектных изделий в выборке объема 200;
б) четыре и более дефектных изделий в выборке объема 180;
в) два и более дефектных изделий в выборке объема 90;
г) наличие дефектных изделий в выборке объема 20.
Предполагая, что проверка потребителя осталась прежней, исследуйте
стоимостную функцию и найдите процент дефектных изделий в принятых
партиях для каждого варианта. Представьте результаты в виде диаграмм.
(Предполагается, что в доработанных партиях дефектных изделий нет.)
12. Введите в описанный выше анализ стоимость выборочной процедуры.
Обратите особое внимание на то, как она меняет стоимостную функцию в упраж-
упражнении 11.
13. Известно, что обычный прибор для измерения твердости дает несме-
несмещенные результаты со средней квадратической ошибкой 0,1 единицы. Фирма
Зилча выпустила новый прибор — более дешевый и прочный. Он также дает
несмещенные измерения со средней квадратической ошибкой 0,07 единицы.
Единственный его недостаток состоит в том, что из-за дефекта передающей
системы для доли р замеров регистрируемый показатель оказывается на Л
больше истинного значения.
Материал, проверяемый прибором, принимается, если регистрируемая ве-
величина превосходит 16 единиц. Принятие некондиционного материала обходится
в 1000 долл., а неправильное отклонение —всего в 50 долл. Можно считать,
что все ошибки распределены по нормальному закону и
Рг [истинная твердость > Н] = (-^ Я -f
Получите уравнение, устанавливающее связь между р, А и отношением стои-
стоимостей обоих приборов, которое можно было бы использовать для их сравнения.
14. В условиях упражнения 13 фирма Зилча, учитывая дефект своего
прибора, предложила делать по два замера и брать меньшую из двух величин.
а) При каких условиях такой подход предпочтительнее, чем единственный
замер?
б) При каких условиях выгоднее пользоваться средним двух замеров?
(Предположения, принятые для получения ответа, должны быть точно
сформулированы.)
15. После долгих усилий фирме Зилча удалось устранить дефект своего
прибора. Известно, что измерения остались несмещенными, но средняя квадра-
тическая ошибка возросла. Оба прибора — Зилча и обычный — имеются в нали-
наличии. Предложено п раз измерить один и тот же материал новым прибором, а
затем решить, какой из двух приобрести. Стоимость измерения С долл.; выбран-
выбранный прибор будет использован для 500 измерений.
Примените принцип минимакса для выбора величины п. Получите значе-
значение п, предположив, что стоимость нового прибора Зилча составляет 3/4 стой-
Теория и анализ статистических решений
445
мости обычного прибора, а затраты, связанные с измерениями, одинаковы.
Возьмите разные значения С и стоимости приборов.
16. Известно, что в каждой из k совокупностей признак X распределен по
нормальному закону с известным средним квадратическим отклонением о*0.
Нужно выбрать совокупность с наибольшим математическим ожиданием X. Для
этого из каждой совокупности следует извлечь выборку объема п и взять сово-
совокупность, у которой выборочное среднее окажется наибольшим. Пусть 1) стои-
стоимость выборки равна с^-\-сЛкп и 2) потери в результате неправильного выбора
составляют К -(наибольшее математическое ожидание — математическое ожидание
выбранной совокупности), где с0, сх и К — известные константы. Примените
принцип минимакса и покажите, что полученная величина п пропорциональна
(/CcToAiJ/3 с множителем пропорциональности, зависящим от числа совокупно-
совокупностей k.
17. Покажите, что результаты, подобные полученным в упражнении 16,
верны не только для нормального распределения.
Подробно рассмотрите случай, когда X распределен экспоненциально в каж-
каждой из совокупностей.
18. В ситуации, описанной в упражнении 16, предложен альтернативный
подход, k совокупностей делятся на два множества, содержащих kx и k2 сово-
совокупностей (ki~\-k2~k)* Из каждой берется случайная выборка объема п' и
в каждом множестве выбирается совокупность с наибольшим выборочным сред-
средним. Затем в двух выбранных совокупностях извлекаются случайные выборки
объема п" и выбирается та совокупность, для которой среднее по выборке
объема п" окажется больше.
Пусть математическое ожидание одной совокупности больше математического
ожидания всех остальных на определенную величину. Примените принцип
минимакса для выбора къ k2, п' и п". [Так поступают, если желательно срав-
сравнивать относительно малое число совокупностей одновременно. Сравнивая не-
небольшое число совокупностей, можно, например, добиться уменьшения рассеяния
результатов (а0). Иногда на последнем этапе можно воспользоваться средним
суммарной выборки объема (п'-\-п")у но если абсолютные величины средних
не постоянны, так поступать нельзя.]
19. Пусть в условиях упражнений 16 и 18 k = 8. Решено поделить сово-
совокупности на четыре пары и из каждой извлечь выборку объема п0; з^тгм
отобрать четыре совокупности с большими выборочными средними и разбить
их на две пары; еще раз взять из каждой по выборке объема п0; в обеих парах
выбрать совокупность с большим средним; извлечь случайную выборку объема
п0 из каждой отобранной совокупности и взять ту совокупность, у которой
выборочное среднее больше. Примените принцип минимакса для нахождения
объема всех выборок п0. (Можно считать, что математическое ожидание одина-
одинаково во всех совокупностях, кроме одной, где оно максимально.)
20. С помощью численных расчетов сравните методы упражнений 16 и 19.
[Замечание. При этом может оказаться полезной статья Gupta S. S., Probability
Integrals of Multivariate Normal and Multivariate t, Annals of Mathematical
Statistics, 34 A963).]
21. Прежде чем сдать оборудование в эксплуатацию, его подвергают уско-
ускоренным испытаниям на долговечность. При этом нагрузка в течение / единиц
времени эквивалентна нормальной за время g(l). Если оборудование выдержи-
выдерживает в течение т единиц, его сдают в эксплуатацию.
Постройте стоимостную функцию для испытываемого комплекта оборудова-
оборудования при следующих предположениях:
1) Каждый комплект оборудования имеет собственный срок службы Т\
оборудование не проходит проверку, если T^g(i). В случае успешных испы-
испытаний срок службы в нормальных условиях будет равен Т—g(T). T имеет
плотность f (t) @ < t).
2) Стоимость ускоренных испытаний одного комплекта оборудования равна
(с0, сх > 0).
446
Глава И
3) Комплекты оборудования, не прошедшие ускоренное испытание, заме-
заменяются без убытков для поставщика, но средние накладные расходы и потери
в связи с отсрочкой на замену равны do-\-dLx на каждый комплект оборудования.
4) Стоимость запуска одного комплекта оборудования в эксплуатацию
равна С.
5) Стоимостной эффект работающего оборудования в единицу времени
равен D.
Предложите альтернативный вид стоимостной функции, полезный при дру-
других обстоятельствах.
22. В упражнении 21 считайте, что
^р) , 9>0, *>0,
Ф' (Ф >0).
Рассмотрите вопрос о выборе подходящего т, учитывая относительные значения
констант 9, с0, Ci, dOi dlt С и D.
23. Как отразится на результатах упражнений 21 и 22 принятие постоян-
постоянной процентной ставки 100 i% в год?
24. Рассмотрите ситуацию поимера 11.9 с ^ = 0,08; i2 = 0,05. Каким должно
быть 9, чтобы даже при о>//С = 1/2 осталась возможность нерентабельной
эксплуатации?
25. В ситуации примера 11.9 было предложено заменять оборудование
через т единиц времени даже при нормальной работе. К' ='кК- Каким должно
быть максимальное значение К', чтобы такое изменение не привело к потерям
(по сравнению с прежними условиями)?
Исследуйте зависимость этой величины от процентной ставки. [Замечание.
Сначала следует вычислить среднюю стоимость с учетом замены, равную
) /<'Р(Г)]
Глава 12
РЕГРЕССИЯ И КОРРЕЛЯЦИЯ
12.1. ВВЕДЕНИЕ
В предыдущих главах рассматривались главным образом одно-
одномерные данные. Перейдем теперь к более сложным ситуациям.
В регрессионном анализе предполагается, что можно прямо или
косвенно контролировать одну или несколько независимых пере-
переменных Х19 Х2> . . ., Xk, и их значения вместе с множеством пара-
параметров 0Х, 02, .. ., Qm определяют математическое ожидание зави-
зависимой переменной Y. Задача состоит в вычислении оценок пара-
параметров с помощью выборочных данных.
В спличие от регрессии при анализе корреляции представляет
интерес совместное распределение всех измеряемых переменных,
причем особое внимание уделяется точности оценивания одних
величин с помощью других.
В качестве примера рассмотрим двумерное нормальное рас-
распределение, описанное в разд. 5.11. Регрессия любой из пере-
переменных на другую линейна, поскольку математическое ожидание X
при Y = y линейно зависит от у, а математическое ожидание Y
при Х = х линейно зависит от х. Корреляция между X и Y в этом
случае определяется параметром р (коэффициентом корреляции),
но для корреляционного анализа требуется знание вида функции
распределения.
12.1.1. Функция регрессии
„Регрессия" и „корреляция", упомянутые выше, охватывают
очень широкий круг вопросов. Сначала ограничимся часто встре-
встречающимися задачами специального вида. Начнем с линейной рег-
регрессии— случая, когда функция регрессии E(Y\x1> х2 . . ., xk)
П
линейно зависит от х1
рр (\1 2
Предполагается, что
E(Y\Xl,
A2.1)
Возникает естественный вопрос, почему представляет интерес рег-
регрессия? Очень часто применение регрессии связано с необхо-
необходимостью оценить (или предсказать) среднее значение Y при
конкретных значениях независимых (контролируемых) переменных.
448
Глава 12
Иногда требуется установить определенную функциональную
связь между х и математическим ожиданием F, когда Х = х. Это
может понадобиться, например, для калибровки или интерполя-
интерполяции. В общем случае какая-нибудь форма функциональной связи
является полезным источником информации о зависимости пере-
переменной Y от х. Очевидный вопрос состоит в том, как узнать, что
конкретное уравнение действительно полезно. Ответ на этот во-
вопрос дают специальные критерии значимости и, в частности, ме-
методы дисперсионного анализа, которые будут описаны в гл. 13—15
и 18.
При попытках аппроксимировать данные кривой (в случае
одной контролируемой переменной) или поверхностью (для двух
и более контролируемых переменных) сначала предполагается
существование функциональной зависимости определенного вида
[например, типа A2.1)]. С помощью данных и соответствующих
математических вычислений находят оценки параметров, дающие
наилучшее приближение согласно какому-либо критерию. Нельзя
сказать, что таким образом получается самое хорошее описание
функциональной связи. При данном выборе функции и критерия
получаются наилучшие оценки параметров. Можно выяснить, на-
насколько хороша данная зависимость, но не исключено, что удастся
получить лучшую, выбрав другую функцию и другой критерий.
Здесь стоит подчеркнуть одно существенное обстоятельство.
Имея в своем распоряжении мощный компьютер, сравнительно
легко перебрать большое количество разных функций, аппрокси-
аппроксимирующих данные. Это сильное искушение, так как можно без
конца перебирать комбинации и преобразования данных, надеясь
получить „то, что искали с самого начала". Совершенно непра-
неправильно считать, что найденное уравнение (т. е. некоторая функ-
функциональная форма) будет наилучшим только потому, что оно дает
хорошее приближение, если оно нисколько не соответствует реаль-
реальным физическим или техническим связям. В любой регрессион-
регрессионной задаче в первую очередь следует рассматривать физически
обоснованную конкретную функциональную форму независимо от
того, была ли она получена с помощью аналитических выводов
или благодаря какому-нибудь иному предварительному знанию
свойств переменных. Вполне возможно, что для аппроксимации
этой функции понадобятся другие функциональные связи.
Предположим, что форма зависимости не известна или она
настолько сложна, что необходимо воспользоваться аппроксима-
аппроксимацией. Тогда очень полезно начать с построения графика данных.
Он помогает угадать форму функциональной зависимости. В ка-
качестве первого приближения обычно берется какое-нибудь простое
уравнение, например линейное, полиномиальное или экспоненци-
экспоненциальное. Удачная форма может быть подсказана диаграммой рас-
рассеяния или графиком данных.
Регрессия и корреляция
449
12.1.2. Примеры регрессионных задач
Рассмотрим несколько примеров, иллюстрирующих применение
регрессионного анализа.
1) В первом примере изучается зависимость октанового числа
бензина от чистоты катализатора. В табл. 12.1 [Volk W., Indust-
Industrial Statistics, Chemical Engineering (March, 1956), pp. 165—190]
Таблица 12.1
Чистота Х и октановое число К в 11 опытах
Чистота X, %
99,8
99,7
99,6
99,5
99,4
99,3
Октановое число
У
88,6
86,4
87,2
88,4
87,2
86,8
Чистота X, %
99,2
99,1
99,0
98,9
98,8
Октановое число
Y
86,1
87,3
86,4
86,6
87,1
приведены октановые числа бензина для нескольких партий, по-
полученных в примерно одинаковых условиях, но с разной чисто-
чистотой катализатора. Задача состояла в установлении зависимости
между октановым числом и чистотой катализатора и оценке окта-
октанового числа для 98%-ной чистоты катализатора. На рис. 12.1
! I I I I I I I I ! I I
8,838,999,093,199,299,399,4 99,599,6 99,7 93,833,9100,0
Чистота X, %
Рис. 12.1 Чистота X и октановое число У.
изображены точки, соответствующие исходным данным, и линия
вычисленной регрессии.
2) Вторая иллюстрация представляет часть эксперимента, по-
поставленного для проверки некоторой'гипотезы, относящейся к теп-
тепловой обработке вставных токарных резцов. Испытывались резцы
сечения в 1/2 кв. дюйма. Они применялись для обработки загото-
15
819
450
Глава 12
вок диаметром 8 дюймов и длиной 33 дюйма из твердой никеле-
никелевой стали. Полный эксперимент включал два разных тепловых
режима обработки резцов при четырех скоростях. Здесь рас-
рассматривается только один тепловой режим с четырьмя заготов-
заготовками для каждой скорости. Зависимая переменная —время до
разрушения (срок службы) резца, измеренное в минутах. Неза-
Независимая (или контролируемая) переменная —скорость резания,
измеренная в квадратных футах в минуту. Предполагалось, что
были приняты меры, обеспечивающие однородность условий экспе-
эксперимента во всех 16 опытах. Данные представлены в табл. 12.2.
График изображен на рис. 12.2.
Таблица 12.2
Скорость резания X и
Скорость резания X,
кв. фут/мин
90
90
90
90
100
100
100
100
Срок службы
резца У, мин
41
43
35
32
22
35
29
18
срок службы резца
Скорость резания X,
кв. фут/мин
105
105
105
105
ПО
ПО
ПО
ПО
У
Срок службы
резца У, мин
21
13
18
20
15
11
6
10
~80 85 S0 95 100 105 110 115 120
Скорость резания X, футг/жн
Рис. 12.2. Скорость резания X и срок службы резца У.
3) Третья иллюстрация связана с оцениванием и предсказанием
световой эффективности ламп в люменах. После того, как нача-
началось широкое промышленное производство флюоресцентных ламп,
Регрессия и корреляция
451
предсказание их эксплуатационных характеристик приобрело боль-
большое значение. Возникают вопросы: через какое время требуется
замена лампы из-за того, что световой поток в люменах стано-
становится меньше заданного уровня или каков ожидаемый уровень
потока через х' часов? Цель исследования состояла в предсказа-
предсказании потока через 1250 часов и оценке величины остаточной ошибки
для этого момента времени.
Механизм разрушения лучше всего описывается суммой убы-
убывающих экспонент, но его сложность делала предсказание сомни-
сомнительным. Пришлось обратиться к аппроксимирующему нелиней-
нелинейному уравнению.
В табл. 12.3 приведены данные для двух из 20 испытанных
ламп. Зависимая переменная —поток в люменах, независимая —
время в часах.
Таблица 12.3
Время X и световой поток У для двух ламп
Время X, ч
250
500
750
1000
1250
Световой поток У, лм
лампа Л
5290
4б09
4276
4040
3720
лампа В
5465
4803
4578
4321
3999
На рис. 12.3 изображены графики зависимости потока от вре-
времени для двух ламп. В каждом случае представлена кривая рег-
регрессии.
3700,
7500.
Рис. 12.3. Время X в часах и световой поток У в люменах для двух ламп.
15*
452
Глава 12
12.2. ОДНОФАКТОРНАЯ ЛИНЕЙНАЯ
РЕГРЕССИЯ
Рассмотрим сначала линейную регрессию зависимой перемен-
переменной Y на единственную независимую (или контролируемую) пере-
переменную X. Для получения этой регрессии нужно вычислить оценки
двух параметров аи р в формуле Е (У\х) = а + $х. Рассмотрим
интерпретацию этого уравнения и оценок параметров.
12.2.1. Предположения
Регрессия и корреляция
453
Уравнение у = a + ftx определяет прямую линию, пересекающую
ось у (при х = 0) в точке а с тангенсом угла наклона к оси дс,
равным р. В следующем разделе будет описан метод получения
оценок параметров аир. Этот метод, называемый методом
наименьших квадратов, очень широко применяется и особенно
успешно, если выполняются некоторые предположения о способе
получения данных, описанные в этом разделе. Часто нет возможно-
возможности проверить точность их выполнения, и во многих случаях ме-
методом наименьших квадратов пользуются при очень слабых ука-
указаниях на его обоснованность. Чтобы избежать грубых ошибок,
важно знать природу этих предположений.
Для формального вычисления оценок наименьших квадратов
параметров аир нужны лишь наблюдения, по меньшей мере над
двумя объектами с разными значениями контролируемой пере-
переменной х. От выполнения перечисленных ниже предположений
зависит качество получаемых оценок и возможность применения
к ним процедур статистического анализа.
Основное предположение состоит в том, что условное матема-
математическое ожидание Y при данном х линейно зависит от х. Кроме
того, считаются известными и некоторые свойства этого условного
распределения. В частности, предполагается, что условная дис-
дисперсия Уаг(У|д:) не зависит от величины х, так что Var (Y \ х)=о2у
где а2 —константа. Это свойство называется гомоскедастшностью,
а сами дисперсии — гомоскедастичными. (Обычно в статистическом
анализе не требуется точное знание а2. Впрочем, если известна
приближенная оценка а2, результаты анализа можно улучшить.)
Кроме того, предполагается, что результаты наблюдений над
разными объектами можно считать независимыми случайными
величинами. Это вполне естественное предположение. Оно пред-
представляется разумным, если нет очевидной связи между выбором
объектов и свойствами измерительного процесса.
Можно показать, что при сделанных предположениях метод
наименьших квадратов, описанный в разд. 12.2.2, дает несмещен-
несмещенные оценки аир, имеющие минимальные дисперсии в классе
всех несмещенных, линейно зависящих от наблюдений оценок.
Применение многих стандартных статистических методов требует
принятия еще одного предположения: условное распределение Y
при данном х должно быть нормальным.
Были введены следующие предположения:
1. Значения х задаются и (или) измеряются без ошибок.
2. Регрессия Y на X линейна, т. е. E(Y\x) = a + fix.
3. Отклонения Y/ — E(Y\x/) взаимно независимы.
4. Эти отклонения имеют одну и ту же дисперсию а2 (точное
значение которой обычно неизвестно) при всех х (рис. 12.4).
Рис 12.4. Графическое представление математической модели Е (У \ х)
5. Отклонения распределены по нормальному закону.
Далее работа будет практически полезной при выполнении сле-
следующих предположений.
6. Данные действительно были взяты из совокупности, отно-
относительно которой должны быть сделаны выводы.
7. Не было посторонних переменных, существенно уменьшаю-
уменьшающих значение связи между X и Y.
Полезно отметить последствия невыполнения некоторых пред-
предположений. Многие считают наиболее важным из этих предполо-
предположений третье. Зависимость между переменными, представляющими
измерения над разными объектами, может существенно повлиять на
характеристики применяемых статистических методов. К счастью,
третье предположение не выполняется гораздо реже, чем, напри-
например, четвертое или (особенно) пятое.
Отклонения от нормальности (предположение 5) встречаются
довольно часто, но они имеют значение, только если весьма зна-
значительны. Незамеченное отсутствие гомоскедастичности (предпо-
(предположение 4) не приведет к несмещенности оценок а и р, но в этом
случае метод наименьших квадратов, описанный в разд. 12.2.2,
не гарантирует упомянутой выше минимальности дисперсий оце-
454
Глава 12
нок. Кроме того, не удастся интерпретировать результаты вычисле-
вычислений с помощью стандартных статистических методов. Если из-
известно, что значения o2(Y\x) пропорциональны некоторой функ-
функции g{x)y можно воспользоваться методом взвешенных наимень-
наименьших квадратов. При этом считается, что каждое наблюдение как
бы повторено [g(^)]" Раз (даже если это дробная величина).
Нельзя надеяться, что во всех физических задачах выпол-
выполняется требование постоянства условной дисперсии (независимость
от значений х). Ниже будут рассмотрены задачи, в которых до-
допускается нарушение этого требования.
Достаточно простой и обоснованный теоретически анализ воз-
возможен лишь при выполнении первых пяти предположений, однако
два последних F и 7) также имеют принципиальное значение.
Если они не выполнены, полезность исследования незначительна.
Кроме того, большую роль играет правильный выбор модели (в пре-
пределах заданной точности).
12.2.2. Оценки наименьших квадратов для аир
Данные можно представить в виде п пар величин (х^у Yj),
/ = 1, •••> п. Предположим, что линейная функция регрессии
E{Y \x) = а-\-$х правильно представляет физическую ситуацию
(рис. 12.5) Требуется найти оценки аир, соответственно А и В,
Рис. 12.5. Метод наименьших квадратов.
определяющие наиболее близкую к экспериментальным точкам
регрессионную прямую. Если „близость" измеряется суммой квад-
квадратов разностей между наблюдаемыми значениями У и теми, кото-
которые дает построенная регрессионная прямая, приходим к методу
наименьших квадратов.
Этим методом находят величины А и В, минимизирующие
сумму квадратов расстояний по вертикали до прямой линии
у=А + Вх. Определим эту сумму как
D=
A2.2)
Регрессия и корреляция
455
где Yj — наблюдаемое значение Y, а А -\-Bxj — величина, вычислен-
вычисленная с помощью построенной регрессионной прямой.
Для минимизации D приравняем к нулю частные производные
по Л и В:
Это дает
dD л dD
дА = ° и 5В=
A2.3)
/=1
A2.4)
нения
После упрощений получаем так называемые нормальные урав-
2
2
П2.Б)
2
.2 41/
*iYi- 2 *i 2
> 1 i l
A2.6)
»2 *Ы 2 */
/г
= Л2Л7- Найденное уравнение можно
П
где Y = n~1 2 У
/ = i / = _ _
также записать в виде E(Y\x) = Y-\-B(x — x).
12.2.3. Оценки максимального правдоподобия
Если при каждом х значения Y распределены по нормальному
закону со средним на прямой регрессии Е (Y\х) = а + |3л;, описан-
описанные выше оценки наименьших квадратов аир являются одно-
одновременно оценками максимального правдоподобия. В этом случае
условная плотность вероятности Y имеет вид
Рг\х(у\х\ а, р, а)=у^
Она показана на рис. 12.4. Для каждого данного х распределе-
распределение Y нормальное со средним E(Y\x)> равным ос р
456
Глава 12
Если (Лу, Yj), j = 1, 2, ..., я,— /г выборочных точек, функция
правдоподобия
а натуральный логарифм этой функции равен
Для получения оценок максимального правдоподобия параметров
а, р и а нужно взять частные производные In L по а, C и а и
приравнять их к нулю. В результате получим
2 too-«-fc/) (*/)]=о,
пст2= 2 (Yj-a—pXjf.
A2.9)
При замене а на А и C на 5 первые два из этих уравнений
совпадают с уравнениями A2.5), дающими оценки наименьших
квадратов для аир. Третье уравнение дает оценку дисперсии
отклонений от прямой регрессии:
Можно показать, что математическое ожидание а2 равно (п — 2)о2/п,
так что эта оценка имеет смещение. Обычно пользуются несме-
несмещенной оценкой а —квадратным корнем из по2/(п — 2).
Пример 12.1. В 1955 г. Федеральное агентство проводило об-
обширное исследование под названием „Экономия стратегических
материалов". Изучались условия, при которых металлы можно
заменять пластиками и другими синтетическими материалами —
полиэтиленом, полиэфиром, стекловолокном и т. п. Несколько
полиэфирных смол подвергались испытаниям прочности на разрыв
и удлинение (модуль разрыва). В табл. 12.4 представлены дан-
данные для 19 образцов полиэфирной смолы толщиной 0,01 дюйма.
Они разрывались при разных скоростях ползуна, измеряемых
в дюймах в минуту. Предел прочности на разрыв дается в фун-
фунтах на квадратный дюйм, а модуль разрыва —в процентах. Ряд
Регрессия и корреляция
457
Таблица 12.4
Предел прочности на разрыв и модули разрыва для 19 испытанных
образцов толщиной 0,01 дюйма
Скорость ползуна X,
дюйм/мин
0,25
0,25
0,25
0,25
0,25
1,00
1,00
1,00
1,00
10,00
10,00
10,00
10,00
10,00
10,00
20,00
20,00
20,00
20,00
x = \og X
—0,60206
—0,60206
—0,60206
—0,60206
—0,60206
0,00000
0,00000
0,00000
0,00000
1,00000
1,00000
1,00000
1,00000
1,00000
1,00000
,30103
[,30103
1,30103
1,30103
Предел прочности
на разрыв У,
фунт/кв. дюйм
5520
5390
5730
4940
5810
6840
5720
6120
6400
7100
7150
7260
7650
8210
7960
7950
6470
8720
8460
Модуль разрыва
Z, %
1S6
196
213
191'
209
213
194
203
213
225
225
234
238
244
238
234
200
250
244
предварительных исследований и аналитические соотношения по-
позволили считать предел прочности на разрыв приблизительно
линейной функцией логарифма скорости. При этом задача све-
свелась к оценке параметров в уравнении
где
х = log (скорости), Y — предел прочности на разрыв.
Чтобы воспользоваться формулами A2.6), нужно вычислить
2^ = 8,19382, 2*/*/ = 69952,12460,
2^/= 129400, 2UH14'58310-
В данном случае п=19. Окончательно получаем
д 268810,05940
В==
В== 209,94021
А = 6810,53 -1280,41 -0,431254 = 6258,35.
458
Глава 12
Уравнение регрессии имеет вид
г/ = 6258,35 + 1280,41л:.
Наблюдения и прямая регрессии показаны на рис. 12.6.
9000\
-0,60206-0,30103 0 0,30103 0,60206 1,00000 1,301031,60206
Логарифм скорости ползуна х
Рис. 12.6. Линейная аппроксимация предела прочности на разрыв как функции
логарифма скорости ползуна.
12.2.4. Качество аппроксимации
Полезная мера качества аппроксимации —среднее квадратиче-
ское отклонение от построенной прямой. Его оценкой (см.
разд. 12.2.3) для уравнения регрессии вида у=А + Вх служит
величина
(Yj-A-BxfYl{n-2) . A2.10)
Статистика S2 оценивает дисперсию отклонений от линии рег-
регрессии. Формулой A2.10) целесообразно пользоваться при нали-
наличии ЭВМ. При расчетах вручную более удобно выражение
S Y)-A %
/ = 1 J
A2.11)
Следует отметить, что поскольку А и В тоже случайные вели-
величины, дисперсия разности между А + Вх и наблюдаемыми Y
больше а2. [Она равна a2 + Var (А + Вх).] Эту дисперсию можно
вычислить, используя результаты следующего раздела. ^Заметим,
что в этом случае нельзя использовать критерий согласия %2,
описанный в разд. 8.9, поскольку Yj и (A + Bxj) не являются
наблюдаемыми и теоретическими частотами. По этой причине
в связи с регрессией термин „адекватность" используют чаще,
чем „согласие".
Регрессия и корреляция
459
12.2.5. Доверительные интервалы
Чтобы на основании оценок А и В сделать выводы о пара-
параметрах совокупности аир, воспользуемся предположением, что
распределение Y — нормальное при фиксированном xf. Оценка В
оказывается линейной комбинацией нормально распределенных
величин
р_
*!
п \2
У, X,
/ = 1
п
-х
(X; -X)Y,=*
где
Это линейная комбинация взаимно независимых величин, распре-
распределенных по нормальному закону. Следовательно, она тоже имеет
нормальное распределение. Математическое ожидание В равно
ЬР- A2Л2>
Дисперсия В задается выражением
A2.13)
Поскольку Л = У — Вх, то эта статистика также представляется
линейной комбинацией независимых нормально распределенных
величин. Ее математическое ожидание равно
= Е(?)-Е(ВТ).
460
Глава 12
Поскольку х фиксированы, то
-/ = 1
=1 J
п 1
/ = 1 J
Ковариация Y и В равна нулю, поскольку ^
разд. 3.15). Следовательно, дисперсия А имеет вид
l-i
а2-
A2.14)
!= О (см.
["v _- Т
lk{Xj х)'\
" 1
п
+
п
S
2
X
а".
A2.15)
В большинстве задач истинная дисперсия отклонений от ли-
линии регрессии (а2) не известна и заменяется оценкой S2, вычис-
вычисляемой по формуле A2.10) или A2.11). Отношение (п — 2)S2/a2
распределено как %2 с п — 2 степенями свободы. Используя это,
можно построить доверительные интервалы для параметров. По-
Поскольку В распределено по нормальному закону, то 100A —
— у)%-ный1) доверительный интервал для |3 имеет вид
A2.16)
где ^_2; 1-7/2 —верхняя 50у%-ная точка /-распределения Стью-
дента с (п — 2) степенями свободы, которая соответствует накоп-
накопленной вероятности 1 —у/2. Аналогично 100 A — у)%-ный дове-
доверительный интервал для а равен
г, ж ,
5<а<
** *п-2
2 (*/-*)
/ - j
^ ^ -j- tn-z; l -7/2
г±
_2
X
L
S. A2.17)
J
х) В ,9moi/ глаб^ вероятность ошибки обозначается через у, так как сим-
символ а, применявшийся в предыдущих главах [A—ос)—доверитель на я вероят-
вероятность], используется здесь как параметр уравнения регрессии.
Регрессия и корреляция
461
100 A—у)%-ный доверительный интервал для а2 имеет вид
An-2; i-y/2
Пример 12.2. Вернемся к данным примера 12.1. Оценим сна-
сначала среднее квадратическое отклонение наблюдений от построен-
построенной линии регрессии (часто называемое средней квадратической
остаточной ошибкой1*). Вычислим
/904 635 200 — F258,35) A29 400) —A280,41) F9952,12460)" _
17 ~~
= /308 077,0671 = 555,05.
Теперь перейдем к построению доверительных интервалов для а,
Р и а2. Следует не забывать, что формулы A2.16) и A2.17) не
позволяют получить совместную 100A —у)%-ную доверительную
область для р и а. Однако обычно коэффициенты р и а рассмат-
рассматриваются раздельно.
Границы 95%-ного доверительного интервала для Р равны
B, ПО) E55,05)
^
H
B,110) E55,05)
3^241
поскольку tl7- о < 75 - 2,110. В результате получаем границы 928,09
и 1632,73.
Границы 95%-ного доверительного интервала для а равны
1 , 0,185980 U/2
-[^+ 11,04948 j E55>05)
3,35 — 2,1
6258,35 + 2,110 (-^
11>04948
E55,05).
В результате получаем границы 5949,68 и 6567,02.
Границы 95%-ного доверительного интервала для а2 равны
17E55,05J 17E55,05J
30,19 И 7,564
поскольку х27; 0>975 -30,19 и х27; ОрОЯБ = 7,564. В результате до-
доверительный интервал для а2 имеет границы 173 480,2 и 692 407,3,
а для а —416,5 и 832,1.
1} Величину S2, где S определяется из A2.10) или A2.11), называют оста-
остаточной дисперсией.— Прим. ред.
462
Глава 12
12.2.6. Доверительные интервалы для линии регрессии
Допустим, что нужно построить 100 A —у)%-ный довери-
доверительный интервал для математического ожидания Y при x = xQ.
Последнее равно a + |3j\;0, а его оценка
Ё(У\хо) = .
Поскольку A = Y — Вх, это выражение можно переписать в виде
E(Y\xo) = Y + B(xo-x). A2.19)
Получилась линейная комбинация нормально распределенных
величин Y и В. Поскольку последние не коррелированы, дис-
дисперсия А + Вх0 равна
п
а математическое ожидание есть
В самом распространенном случае, когда а2 не известна,
опять обращаются к ^-распределению Стьюдента с (п — 2) степе-
степенями свободы. 100A — у)%-ный доверительный интервал для
функции регрессии при каждом значении х0 имеет вид
y(je,_J,.
/
1/2
s<
Г" 1
р-Ц"
A2.20)
Пример 12.3. 95%-ный доверительный интервал для линии
регрессии в примере 12.1 имеет вид
6258,35+
X E55,05)
6258,35+ 1280,41х0-
, (х0 — 0,43125J
Э" 11,04948
E55,05).
Вычисленные значения А+Вх0 для 8 уровней х0 вместе с ниж-
нижними и верхними границами 95%-ного доверительного интервала
приведены в табл. 12.5. График изображен на рис. 12.7.
Отметим, что не менее 10 из 19 точек, представляющих наблю-
наблюдения, оказываются за 95%-ными доверительными границами.
Это не противоречит теории, поскольку границы вычислены для
математического ожидания Y, а не для индивидуальных значе-
значений Y.
Регрессия и корреляция
463
Таблица 12.5
Оцененные значения Yo и 95%-ные доверительные интервалы
х0
—0,60206
—0,30103
0,00000
0,30103
0,60206
1,00000
1,30103
1,60206
Нижняя граница
доверительного
интервала
5034,99
5500,41
5949,68
6371,22
6753,89
7203,59
7516,65
7817,34
Оценка
F (V 1 х \
5487,47
5872,91
6258,35
6643,79
7029,23
7538,76
7924,20
8309,64
Верхняя граница
доверительного
интервала
5939,95
6245,41
6567,02
6916,36
7304,57
7873,93
8331,75
8801,94
3000
4000
-0,60206-0,30103 0 0t30103 0,60206 1Щ00 %3QW3 Щ206
Логарифм скорости ползуна X
Рис. 12.7. 95%-ные доверительные границы для математического ожидания У.
Если появляется новое наблюдение У, соответствующее Х = х0,
ошибка предсказания
имеет математическое ожидание 0 и дисперсию
Var (У) + Var (F) + {х0 - xf Var (В) -
A2.21)
464
Глава 12
В случае данных примера 12.1 можно ожидать, что примерно
в 95% случаев \Y — yo\ будет меньше, чем
9 1 1П (\ _L Х г (*о--О,43125J У/2 --- П-.
z'uui1 "^Тэ" 11,04948 ) ч&м.ио;.
Верхние и нижние границы для Y у вычисленные по этой фор-
формуле, нельзя применять к выборочным значениям примера 12.1,
поскольку последние использовались при вычислении Y и В.
(См. упражнение 30.)
Другая задача — расчет доверительной области для всей ли-
линии регрессии. Эту область можно рассматривать как результат
совмещения множества доверительных интервалов для условных
математических ожиданий Y при Х = х0. Если в область вклю-
включены точки (х0У a-f Р^о) ПРИ всех хо> в нее входит и линия рег-
регрессии, и наоборот. Соответствующая вероятность A —а) является
доверительной вероятностью совмещенного множества доверитель-
доверительных интервалов.
Нужно найти множитель су такой, что
0 лежит в интервале Y + B(x0 — я) ±
±cS
п "• у (Х ;
L /
Это эквивалентно равенству
Рг
max
--? (В)](хо-х)У
для всех хЛ = 1 — ее.
A2.22)
Можно показать, что максимум (92 + в2тJ @Х + 02t2)~х (где ф1у
02 > 0) достигается при т = 0162/@261) и максимальное значение
равно б^г' + б^. Положив Q1 = Y — E(X)9 % = В—Е(В)У фг =
= п, 02= (*о ~"xJ/ 2 (^у"^J и т^л:о—^» находим, что выра-
выражение A2.22) эквивалентно
Рг
n[Y-E{Y)f+[B-E{BW
-1—а.
Величина в левой части неравенства распределена как 2F2tn-2y
так что получаем
или , Г7^-—lU!L_
Регрессия и корреляция
465
При каждом данном х0 интервал для Е (Y/xo) = a + $xo гораздо
шире интервала, который получился бы, если оценивать только
это частное значение услодного математического ожидания. В при-
примере 12.3 множитель t 17;0(|Ч|6 = 2,110 пришлось бы заменить на
17 ; о, 9 5 —
=2,69.
Эту цену приходится платить за возможность определения
доверительных границ условного математического ожидания Y
при любом х0.
12.2.7. Критерии значимости
Перейдем к рассмотрению критериев значимости для проверки
гипотез относительно значений р, а и а2. Напомним, как про-
проверку гипотез можно иногда связать с построением доверитель-
доверительных интервалов. Пусть, например, проверяется нулевая гипотеза
ЯО:6 = 0О с заданной ошибкой первого рода (уровнем значимости),
скажем, 0,01. Для двустороннего критерия можно просто по-
построить 99%-ный доверительный интервал для 0. Если он вклю-
включает 0О, Яо принимается, в противном случае —отклоняется.
Здесь будут сформулированы обычно применяемые критерии
значимости. Следует помнить, что их можно рассматривать с точки
зрения доверительных интервалов. В разд. 12.2.6 было пока-
показано, что В имеет нормальное распределение, а (п — 2)S2/o2 рас-
распределено независимо от В как %2 с (п — 2) степенями свободы.
Это значит, что гипотезу #о:|3 = ро (против альтернативы Р =#= Ро)
можно проверить с ошибкой первого рода у путем сравнения
отношения
1Л=-
Pol
с tn-
2; i-v/2-
A2.23)
(Если |5 = Р0, величина | Т\ должна быть распределена как |^_2|.)
Для гипотезы Н0:а = а0 (против альтернативы а > а0) статис-
статистика критерия имеет вид
A2.24)
1
п
+
А
— а0
—2
X
1/2
S
(Если а = а0, Т должна быть распределена как tn_2.) Заметим,
что знаменателями в правых частях формул A2.23) и A2.24)
являются оценки средних квадратических отклонений В и А
соответственно.
466
Глава 12
Для гипотезы
о1 статистика критерия равна
%*= (n"~2JS2 с п — 2 степенями свободы. A2.25)
Если о2 = а>1, эта статистика должна иметь распределение х2
с п —2 степенями свободы.
Пример 12.4. С помощью данных примера 12.1 из разд. 12.2.3
проверим гипотезу Я0-.р=1350 с ошибкой первого рода (уров-
(уровнем значимости), равной 1%.
Даже 95%-ный доверительный интервал для |3, вычисленный
в примере 12.2, включает значение 1350; следовательно, Но при-
принимается.
С другой стороны, применяя критерий значимости, вычислим
гр_ 1280,41 — 1350 __п ,17
1 ~ 166,98 "~ и'41/'
Поскольку критические значения Т равны ± t17- 0>99Ъ =
= ±2,898, гипотеза C=1350 принимается.
12.2.8. Уравнение регрессии E(Y\x) = Px
Допустим, что еще в начале исследования известно, что имеет
место равенство Е (Y | х) = 0 при х = 0.
Вывод формулы для ?', оценки р, описанный в разд. 12.2.2,
приводит к выражению
A2.26)
Уравнения для 100A—у)%-ного доверительного интервала и для
применяемых критериев значимости получаются тем же способом,
как и в предыдущих разделах. 100A — у)%-ный доверительный
интервал для р имеет границы
/I
' /=1
pf
A2.27)
где S'2= 5] (У/ — B'xjJl(n—1). Статистика критерия при про-
проверке гипотезы р = Р0 (против альтернативы р^=C0) имеет вид
Т=
A2.28)
Регрессия и корреляция
467
Если р = Р0, Т имеет ^-распределение Стьюдента с (п— 1) степе-
степенями свободы.
12.2.9. Два линейных уравнения регрессии
Допустим, что нужно сравнить линейные уравнения регрессии
в двух совокупностях. Случайная выборка (объема п^ из первой
совокупности содержит величины х119 Y^', x12, Y12; ...; xlni, Ylnr
Случайная выборка из второй совокупности (объема п2) вклю-
включает x2it Y2i, ..., х2П2у Y2Tl2. Обозначим их через х1/у Ylf
(/=1, 2, ..., пг) и яа/', Y2J*>, /' = 1, 2, ..., п2. По формулам
типа A2.6) для каждой выборки вычисляются оценки тангенсов
углов наклона прямых регрессии: В± для параметра $± и В2 для
параметра Р2. Прежде всего интересно узнать, можно ли считать
наклоны равными (т. е. линии параллельными). Нулевая гипо-
гипотеза имеет вид Яо: Рх = Р2> а Два уравнения записываются как
E(Y 1x^=0^
Можно опять построить критерий значимости с помощью дове-
доверительного интервала для Р2 — Р2. Если последний содержит 0,
нулевая гипотеза принимается. В противном случае отклоняется.
Предположим, что дисперсии в обеих совокупностях равны а2,
и воспользуемся объединенной оценкой S2P, основанной на двух
выборках. Поскольку Вг и 5а взаимно независимы, дисперсия
(Вг — В2) равна
+¦
2
/'=1
100A — 7)%-ный доверительный интервал для р\—|32 имеет вид
R-R-f Я X" 1 1
вг а2 "*! ' я|/ 5^ж —* • У * -х 2
V i=i /'=i 2/
X
Y&
¦+
«1
-, A2.29)
где
sP=
a Sf —оценка дисперсии в /-й выборке.
46Я
Глава 12
Соответствующий критерий значимости будет основан на ста-
статистике
I/ 2j(^i/ —;
A2.30)
2
/'=1
которая при Pi = Р2 должна иметь /-распределение Стьюдента
с (п1 + п2 — А) степенями свободы.
Пример 12.5. Известно, что небольшие примеси углерода
делают металлы хрупкими. Недавно была изучена способность
углерода вызывать замедленное разрушение стали.
Замедленное разрушение, или статическая усталость, озна-
означает, что материал портится при длительной нагрузке, несмотря
на то что может выдержать гораздо большую нагрузку в течение
короткого периода времени. Стали, главным образом сверхтвер-
сверхтвердые, особенно подвержены статической усталости. С этим связана
серьезная проблема создания авиационных конструкций, некото-
некоторая составная часть которых, какое-то время работающая нор-
нормально, может затем подвергаться хрупкому разрушению. Сталь-
Стальные части, подверженные статической усталости, обычно попадали
в процессе обработки в углеродную среду, так что очевидной
причиной замедленного разрушения является углерод.
Испытания на статическую усталость проводятся с помощью
схемы сопротивлений, в которой испытываемый образец вклю-
включается в одно из плеч мостика Уитстона. Возникновение трещины
сопровождается увеличением сопротивления образца, так что гра-
график зависимости сопротивления данного образца, находящегося
под фиксированной нагрузкой, от времени отражает кинетику
трещины. Сначала требуется некоторая выдержка (инкубацион-
(инкубационной период), чтобы собралось достаточно углерода и образова-
образовалась трещина, после чего последняя начинает разрастаться и
происходит разрушение. Целью одного исследования являлось
изучение связи между прилагаемой нагрузкой и временем вы-
выдержки (длительностью инкубационного периода).
Несколько выборок были сделаны при разных температурах,
сроках прокаливания и гальванизирующих растворах Все выбо-
выборочные образцы кадмировались. Две из этих выборок различа-
различались главным образом температурой во время испытания. Вы-
Выборка 1 испытывалась при 80° F, выборка 2 —при 25° F. Образцы
в обеих выборках прокаливали по 3 часа. Экспериментатор дол-
должен был построить для каждой выборки уравнение регрессии,
в котором прилагаемая нагрузка была контролируемой перемен-
переменной, а время выдержки (в минутах) —зависимой.
Регрессия и корреляция
469
Результаты выборок 1 и 2 приведены в табл. 12.6. Графики
показаны на рис. 12.8. Нужно проверить, свидетельствуют ли
коэффициенты регрессии Вг и В2 о различии4 в наклонах линий
Таблица 12.6
Приложенная нагрузка и логарифм времени выдержки
Выборка 1
Приложенная
нагрузка
X • 1 03 фунт/кв. дюйм
200
185
185
175
175
160
150
135
135
125
Логарифм времени
выдержки У в ми-
минутах
0,1139
0
0
0,3010
0,3010
0,2553
0,2788
0,3010
0,4150
0,3979
Выборка 2
Приложенная
нагрузка
Х-103 фунТ/КВ.
190
180
160
160
150
140
125
цюйм
Логарифм времени
выдержки У в ми-
минутах
1,7782
1,6021
1,7782
1,7324
1,8921
1,8195
2,0086
100 120 140 160 160 200 220
Приложенная нагрузка X* 10] фунт/дкшм2
Рис. 12.8. Приложенная нагрузка X и логарифм времени выдержки Y.
470
Глава 12
регрессий, т. е., иначе говоря, проверить гипотезу Яо: Pi = P2.
Положим 7^0,05 и начнем с определения 9596-ного доверитель-
доверительного интервала для |31 — р2. Для этого понадобятся следующие
величины.
Выборка 1:
2*1/= 1625; 2*1/^17 = 357,1995; 2 У2ц = 0,758233;
/ / /
2хЬ -269875; 2 Yu = 2,3639; nt=l0.
i i
Выборка 2:
2*2/' - П05; 2*а/<Уа/" = 1977,5520; 2^2/' = 22,817021;
2*2/'=177 425; 2 У»/'= 12,6111; п2 = 7;
дх = —0,00463; ?2 = —0,00441;
5? - 0,00932287; S\ - 0,00776425;
SJ = 0,00872340.
95%-ные границы для Рх —Р2 равны
—0,00022 - 2,160 @,093399) @,022498)
и
—0,00022 + 2,160 @,093399) @,022498).
Это дает
—0,00476 и 0,00432.
Следовательно, при 7 = 0,05 можно утверждать, что две выборки
были взяты из совокупностей с одинаковым наклоном. Оценка
этого общего наклона равна —0,00454. Если воспользоваться
критерием значимости для проверки гипотезы Pi = P2> вычислен-
вычисленное значение Т окажется равным 0,105. Гипотеза о равенстве
наклонов принимается.
Если при проверке значимости разности Bt — B2 нельзя пред-
предположить, что две дисперсии а? и а2 равны, вместо
•л/jT--
Г /=1
п2
V (х . — Л
/'=1
следует использовать величину
2
/'=1
Регрессия и корреляция
471
при условии, что п± и п2 достаточно велики, например не мень-
меньше 20. Вместо ^-распределения Стьюдента можно применить при
этом нормальную аппроксимацию. Это довольно грубое прибли-
приближение, но для достаточно больших выборок оно оказывается
вполне приемлемым.
Если пг и(или) п2 малы, распределение можно аппроксими-
аппроксимировать /-распределением с v степенями свободы, где
и с-
И С-
S\
~xxf
Заметим, что v зависит от S1/S2 и всегда заключено между мень-
меньшим из чисел (^ — 2), (п2 — 2) и величиной (ni + n2--i) (см.
разд. 8.5.2).
Можно также проверить значимость различия дисперсий.
Поскольку (ni — 2)S2ilo\ имеет распределение %2, отношение оце-
оценок Si и S\ распределено как {oJo^^F с (п1 — 2), (д2—2) сте-
степенями свободы]. Критерии такого рода были описаны в гл. 8,
поэтому нет необходимости приводить их здесь.
12.2.10. Сравнение нескольких линейных регрессий
Методы, изложенные в разд. 12.2.9, можно применить к k (>2)
различным совокупностям. Здесь намечены основные этапы ана-
анализа; более подробное изложение содержится в гл. 13.
Модель имеет вид
и предполагается, что условное распределение Y при фиксиро-
фиксированном х нормальное с дисперсией а2. Пусть объем выборки из
/-й совокупности равен пу (/=1, 2, k). Обозначим оценку
наименьших квадратов для ру (полученную, разумеется, только
по данным выборки из /-й совокупности) через В,.
Тогда
1) Bj распределена по нормальному закону с математическим
ожиданием (Зу. и дисперсией
Wj — [сумма квадратов отклонений х от их среднего в /-й
совокупности] а2.
472 Глава 12
2) объединенная оценка а2 (обозначения очевидны)
k
распределена как %1о2 с v= 2(я/ — 2).
3) В19 В2, ..., Bk и S2 взаимно независимы.
Из 1) и 2) следует, что
k
где
имеет умноженное на а2 нецентральное %2-распределение с (k— 1)
степенями свободы и параметром нецентральности а~2 2^/ (Р/ — РJ,
f *
где р-< 2
2^. Из 3) следует, что S*p и 2^/E/ —5)*
взаимно независимы.
Статистика
применяется для проверки гипотезы о равенстве всех наклонов
(т. е. Pi = Р2 = • • • =$k и все прямые регрессии параллельны).
Если гипотеза верна, статистика имеет ^-распределение с (&—1),
k
2 (я, —2) степенями свободы. Большие значения статистики сви-
детельствуют об отклонении от гипотезы, поэтому применяют
верхние критические границы ^-распределения.
12.3. КОРРЕЛЯЦИЯ
Как уже отмечалось в начале этой главы, корреляция слу-
служит мерой линейной связи между двумя переменными X и Y,
Регрессия и корреляция
473
В двумерном нормальном распределении
1
Рх. у (х, У) =
\ — р2
:Х
мерой этой связи является параметр р(—l^p^l). При р, рав-
равном ±1, имеет место полная корреляция, т. е. X и Y связаны
детерминистически (с вероятностью единица) линейным уравне-
уравнением.
12.3.1. Оценка коэффициента корреляции
Во многих практических задачах величина р не известна, и
ее нужно оценить по выборке. Оценка максимального правдопо-
правдоподобия коэффициента корреляции, основанная на случайной вы-
выборке из п пар величин (Ху, Yj) (/ = 1, 2, ..., я), имеет вид
A2.32)
Уравнение A2.32) можно интерпретировать следующим образсм:
выборочный линейный коэффициент корреляции (или просто
коэффициент корреляции) равен отношению выборочной ковариа-
ции X и Y к квадратному корню из произведения выборочной
дисперсии X на выборочную дисперсию Y.
Из соотношения A2.32) выводится простая расчетная формула
*/*7-(S*/
2 *Ы2*у)я] [" 2 yi-
A2.33)
Ее преимущество состоит в том, что не нужно округлять про-
промежуточные результаты вплоть до извлечения корня и оконча-
окончательного деления.
Интересно отметить, что при линейных преобразованиях дан-
данных абсолютная величина коэффициента корреляции не меняется.
Например, если положить
с,
A2.34)
то, согласно формуле A2.32),
' П2-111/2 #
474
Глава 12
Подставив выражения A2.34) для U и ]/, получим
^-ч — - -
Ruv = '
Следовательно,
Ruv = ±Rxv A2-35)
Знаки будут одинаковыми, если cd > 0, и разными при cd < 0.
Заметим, что сильная корреляция двух переменных не обяза-
обязательно означает причинную взаимосвязь между ними. Возможно,
что имеется некоторая иная независимая переменная, которая
обусловливает значения первых двух, так что между ними наблю-
наблюдается зависимость, близкая к линейной.
12.3.2. Несколько примеров корреляционных
и регрессионных задач
В этом разделе приводятся четыре практических примера при-
применения корреляции и регрессии и один теоретический для слу-
случая р = 0. Они даются не только для иллюстрации, но и с целью
сравнения разных величин коэффициентов корреляции. Первый
пример был взят из эксперимента по выяснению связи между
характеристиками конструкций шины и протектора, с одной сто-
стороны, и силой „ударов" по колесу—с другой. Имитировались
помехи, возникающие при движении по шоссе из состыкованных
бетонных блоков со скоростью примерно 35 миль в час. В рам-
рамках более широкого эксперимента было решено исследовать связь
между балансом и центровым размером и силой удара. Баланс —
это мера сбалансированности шины, измеряемая в дюймах на
унции. Отклонения центрового размера означают колебания тол-
толщины шины по окружности, измеренные с точностью до тысячной
доли дюйма. Данные, приведенные в табл. 12.7, были получены
на 36 шинах. Линейный коэффициент корреляции R между
балансом и силой удара оказался равным 0,087. (Ниже будет
показано, что эта величина незначимо отличается от нуля.) Дан-
Данные для баланса и силы удара приведены на рис. 12.9.
В качестве второй иллюстрации рассмотрим исследование
характеристик аккумуляторной батареи. Изучались несколько
факторов, в том числе максимальная температура в градусах
Фаренгейта в верхней части батареи (X) и доля активного веще-
вещества (У). Кроме того, учитывались процент влажности после
нагрузки, процент металла и процент окиси свинца. Данные пред-
Регрессия и корреляция
475
Таблица 12.7
Сила удара X и характеристики шины: баланс Y в дюймах на унции
и отклонение центрового размера Z в дюймах
Сила удара
X
4,7
6,0
4,7
4,0
5,0
5,3
5,0
5,3
5,0
4,7
5,7
5,3
4,0
к о
6 0
и, v
6 0
w, \J
о, о
5,0
Баланс Y
5
10
8
5
5
7
16
0,5
15
10
3
10
18
15
8
4
7
14
Отклонение
центрового
размера Z
0,034
0,050
0,034
0,039
0,041
0,049
0,048
0,042
0,033
0,029
0,051
0,041
0,026
0,044
0,034
0,021
0,044
0,031
Сила удара
X
5,3
4,0
5,0
5,3
5,0
6,0
5,0
6,0
4,3
6,0
4,3
5,0
5,0
4,3
5,7
5,0
5,3
6,0
Баланс
У
9
5
20
5
8
8
18
14
5
18
5
8
6
10
10
11
12
11
Отклонение
центрового
размера Z
0,045
0,026
0,055
0,056
0,053
0,032
0,033
0,058
0,029
0,028
0,034
0,021
0,055
0,021
0,036
0,034
0,053
0,029
4,0 4,3 4fi 4,3 59Z 5,5 5,8 6,1
Симf ударе X
Рис. 12.9. Корреляция между силой удара X и балансом Y (#=0,087).
476
Глава 12
ставлены графически на рис. 12.10. Коэффициент корреляции для
выборки объема 109 оказался равным 0,20.
^ 0,230
| Ot220
I
| ощ
^ 0,190
0,180\-
f/ л >.:: • ::
• •• < % •.*
.« ^ :.• -::
100 110 ПО 130 140 ISO 150 170
Температура Ху Т
Рис. 12.10. Корреляция между максимальной температурой X и долей актив-
активного вещества Y(R =0,20).
Третьей иллюстрацией служит пример небольшой выборки
с отрицательной корреляцией. При изучении отказов прядиль-
прядильных машин [Armstrong J., Jr., Some Uses of Statistics in Plant
Maintenance, Industrial Quality Control (January, 1956)] была
обнаружена очевидная связь интенсивности отказов с наружной
температурой. Сначала причина была совершенно не ясна, по-
поскольку машины работают в помещении с кондиционированным
воздухом и постоянной температурой. Однако был замечен сла-
слабый отклик на внешние температурные колебания. Вполне воз-
возможно, что повышение наружной температуры вызывало умень-
уменьшение тяги в дымовой трубе предприятия, а это приводило к
сокращению подачи охлажденного воздуха к двигателям. Было
сделано 12 измерений потока воздуха в вытяжной системе с одно-
одновременной фиксацией наружной температуры. Данные приведены
в табл. 12.8, а график —на рис. 12.11 (/?=- —0,80).
Четвертая иллюстрация заимствована из работы Джекобса
(Jacobs R. M., Quality Control in Central New York Industry,
Ed. M. A. Brumbaugh, 1952). Одна фирма, выпускающая кон-
кондиционеры, не могла удовлетворить требованиям, предъявляемым
к окончательному весу соединительной тяги в компрессорах.
Компрессор —главное устройство в этих установках. Его балан-
балансировка существенно зависит от веса тяги. В связи с невозмож-
Регрессия и корреляция
477
Таблица 12.8
Наружная температура X в градусах Фаренгейта
и поток воздуха в вытяжной системе Y
Наружная
температура X
34
46
66
42
49
66
Поток воздуха
У
233
233
232
231
231
230
Наружная
70
60
73
64
81
79
Поток воздуха
230
229
227
226
225
224
23S
20
30 40 50 S0 70
Наружная температура Ху °F
80
Рис. 12.11. Наружная температура X и поток воздуха б вытяжной системе Y
(#=—0,80).
ностью удовлетворить требованиям спецификации накапливалось
слишком много брака. Дополнительные расходы на измерение
окончательного веса компрессора повышали стоимость продукции.
Нужно было узнать, достаточную ли информацию об оконча-
окончательном весе компрессора дает взвешивание необработанной
отливки. Выборка состояла из 25 отливок, взвешенных до и после
механической обработки. Данные приведены в табл. 12.9. График
показан на рис. 12.12. Оценка коэффициента корреляции R
оказалась равной 0,92.
В последнем примере коэффициент корреляции вычислен по
случайной выборке из двумерной нормально распределенной сово-
478
Глава 12
Регрессия и корреляция
479
Вес отливок до и после обработки (в фунтах)
Таблица 12.9
Номер тяги
1
2
3
4
5
6
7
8
9
10
11
12
13
Начальный вес
X
2,745
2,700
2,690
2,680
2,675
2,670
2,665
2,660
2,655
2,655
2,650
2г650
2,645
Окончатель-
Окончательный вес Y
2,030
2,045
2,050
2,005
2,035
2,035
2,020
2,005
2,010
2,000
2,000
2,005
2,015
Номер тяги
14
15
16
17
18
19
20
21
22
23
24
25
Начальный вес
X
2,635
2,630
2,625
2,625
2,620
2,615
2,615
2,615
2,590
2,590
2,590
2,565
Окончатель-
Окончательный вес У
1,990
1,990
1,995
1,985
1,970
1,985
1,990
1,995
1,975
1,975
1,995
1,955
' 2,55 2,60 2,65 2,70 2,76
Вес до обработки X, фунт
Рис. 12.12. Веса отливок до обработки X и после обработки У в фунтах
(#=0,92).
купности с р = 0. Выборка объема 100 была извлечена из сово-
совокупности с распределением
т. е. |xx^[xF=0, gx = gy= 1 и р = 0. В этом случае X и У —
независимые переменные, имеющие нормированное нормальное
распределение.
Диаграмма рассеяния представлена на рис. 12013.
3,00
2,00
1,00
Y
0
4,00
-1,00
•
•
•
•
•: ••• • •
• ' V: •
% • • • •
• ••
• • • • - • •
•• •
• •
•
L ! 1 1 1 1
•
> •
•
•
!
^-2,00 -1,00 0 1,00 2,00
X
Рис. 12.13. Случайная выборка из двумерного нормального распределения с
M-X = ^F = °> gx = oy=1 и р=0.
* Пример 12.6. В качестве иллюстрации вычислим коэффи-
коэффициент корреляции между весом необработанной отливки и окон-
окончательным весом по данным табл. 12.9. Данные можно сущест-
существенно упростить с помощью линейного преобразования:
t/=1000X —2500,
У=1000К-1900.
Затем получаем
Подстановка в формулу
я = 25;
= 3575;
- 2620;
=547 925;
=292 650;
= 398 225.
Rtjv —"
t 1/2
480
Глава 12
Регрессия и корреляция
481
дает
Ruv =
B5) • C98225) — C575). B620)
{[B5) • E47925) — C575J] [B5)• B92650) — B620J]} 1/2
Следовательно [см. формулу A2.35)],
Rxy= 0,915.
¦=0,915.
12.3.3. Доверительные интервалы и критерии значимости
для коэффициента корреляции
Чтобы построить доверительные интервалы для р, нужно
знать выборочное распределение R. Можно показать, что мате-
математическое ожидание и дисперсия величины R, рассчитанной по
формуле A2.32) или A2.33), равны (если только п не слишком
мало):
Распределение R довольно сложное и здесь рассматриваться не
будет. Доверительные границы, или зоны, для доверительных
вероятностей 95 и 99% были вычислены Ф. П. Дэвидом [1] и
приведены на стр. 559 приложения. Заметим, что абсциссой
служит оценка коэффициента корреляции по выборочным данным.
Для каждого данного объема выборки и значения R можно
найти доверительный интервал для величины р, изменяющейся
как и /?, в пределах от —1,0 до +1,0.
Например, для 7? = 0,40 и п = 25 95%-ный доверительный
интервал равен 0 < р < 0,68 (см. Ш A) приложения). Его грани-
границы определяются ординатами пересечения прямой /? = 0,40 с
двумя кривыми, соответствующими д = 25.
При построении критериев значимости для р можно восполь-
воспользоваться доверительными зонами. Допустим, что нужно прове-
проверить гипотезу Я0:р = р0. Если считать, что выполнены перечи-
перечисленные выше предположения, для данного объема выборки полу-
получим 100 A — y)% -ный доверительный интервал, зависящий от
значений R и п. Если р0 попадает в него, гипотеза Но прини-
принимается с уровнем значимости у. В противном случае отклоняется.
Очень часто нужно проверить, отличается ли р от нуля, т. е.
#о:р = ро( = О). Если доверительный интервал включает 0, гипо-
гипотеза Яо принимается. В противном случае говорят, что „R зна-
значим". При этом есть достаточные основания утверждать наличие
некоторой линейной зависимости, хотя этот факт может не иметь
практического значения. Кроме того, найденная зависимость не
обязательно будет единственной имеющейся формой связи.
Эту же гипотезу (р = 0) можно проверить с помощью таблицы
критических значений R (табл. ШB) приложения или табл. VI
из [1]).
Если подобной таблицы нет под рукой, следует воспользо-
воспользоваться тем, что tn_2{n — 2-\-tl_2\-1/2 при р = 0 имеет такое же
распределение, как и R, и обратиться к таблице критических
значений для ^п_2. Например, в выборке объема 10 1%-ная
доверительная граница для | R | равна
h; 0,995 {""Ms; 0,995}" •
Табл. Е дает ts; 0>995 = 3,355, так что окончательно имеем
3,355 {8 + C,355J}-1/2 = 0,765.
Еще один вариант критерия значимости использует аппрок-
аппроксимацию, предложенную Фишером [5]. Статистика
R) A2.37)
распределена приблизительно по нормальному закону с матема-
математическим ожиданием
и дисперсией
A2.38)
С помощью этого преобразования гипотеза Н0:р = р0 проверя-
проверяется следующим образом.
Находим величину R, являющуюся оценкой для р, после
чего вычисляем Z. Если р^Ро, статистика
-> (ей)] ^«^
имеет распределение, близкое к нормальному с математическим
ожиданием 0 и дисперсией 1.
Критерий значимости применяется как обычно: U сравнива-
сравнивается с критическим уровнем ?/i_v/2 нормированного нормального
распределения для заданного у.
Для больших объемов выборки с помощью этой же статис-
статистики можно проверить гипотезу Н0:р1 = р2. Если она верна,
1— 3 п2 — 3
A2.40)
распределена приблизительно по нормальному закону с матема-
математическим ожиданием 0 и дисперсией 1. Заметим, что объемы
выборок nt и п2 могут быть разными.
16 № 819
482
Глава 12
Пример 12.7. Коэффициент корреляции, вычисленный по дан-
данным табл. 12.9, равен 0,915. Номограмма ШA) приложения дает
95%-ный доверительный интервал с границами, примерно равны-
равными 0,81 и 0,96.
С помощью формул A2.37) и A2.38) получаем
rj 1 /1,915\
Z=-2n[0Wb) =
95%-ные доверительные границы для Е(Z) равны
1,557-1,96-0,213 и 1,557+1,96-0,213,
а после вычислений
1,140 и 1,975.
Если преобразовать неравенство 1,140 < 1/2 [(In 1 + р)/( 1 —
—р)] < 1,975, то получим
0,814 <р< 0,962.
Итак, 95%-ные доверительные границы для р равны 0,814 и 0,962.
12.4. МНОЖЕСТВЕННАЯ ЛИНЕЙНАЯ
РЕГРЕССИЯ
Во многих практических задачах однофакторная линейная
регрессия дает недостаточную информацию о зависимой пере-
переменной. Большинство промышленных процессов зависит от нес-
нескольких факторов (часто 50, 60 или более). В таких случаях
бессмысленно и непрактично поддерживать все переменные, кроме
одной, на фиксированных уровнях. Рандомизация по всем осталь-
остальным переменным тоже мало что дает. Однако, если хотя бы неко-
некоторые из них управляемы, рандомизация избавляет от дополни-
дополнительного смещения.
Отметим, что даже в случае одного фактора линейное урав-
уравнение может оказаться неадекватным. Во всех этих ситуациях
обращаются к множественной линейной регрессионной модели:
E{Y\x19 x2, ..., x*) = ao + pi*i + P2*2+•••+?***• A2.41)
(При этом необязательно, чтобы все xt были исходными наблю-
наблюдаемыми величинами; например, хг и х2 могут наблюдаться, х3
может быть равным х{, x4=logx2, хь = х1х2 и т. д.)
Предположения относительно множественной регрессии ана-
аналогичны перечисленным в разд. 12.2.1 в связи с однофакторной
регрессией. Напомним, в частности, что все х{ считаются фикси-
фиксированными и что для любого набора xt значения Yj распреде-
Регрессия и корреляция
483
лены по нормальному закону с постоянным средним квадрати-
ческим отклонением.
Величины |3; называются частными коэффициентами регрессии.
12.4.1. Оценки наименьших квадратов для р/
Для получения оценок {В(, А) параметров фо а) методом
наименьших квадратов нужно минимизировать по Л, В19 ..., Вк
выражение
D^Vj-A-B^—B^j- ... -Bkxkjf. A2.42)
Приравнивание к нулю частных производных по Л, В1} ..., Вк дает
dD
A2.43)
После упрощений получаем нормальные уравнения
пА
/« A2-44)
Первое уравнение A2.43) дает
(=1
A2.45)
Подставив это значение А в остальные уравнения A2.43), полу-
получим преобразованные нормальные уравнения
a*Vt A2.46)
B2ai2
... +Bka2k = u2Y,
• • • +Bkakk=akY>
где
aw = 2 (хц — хд (xi'i — Xf) — ai'
A2.47)
A2.48)
16*
484
Глава 12
В обычных матричных обозначениях уравнения A2.46) можно
записать как
где В, kY— векторы размера &xl, а А —симметричная матрица
размером kxk.
Решение этих уравнений имеет вид
Для нахождения решения системы нормальных уравнений
необходимо вычислить матрицу, обратную к А:
Здесь cw — элементы обратной матрицы
следующими свойствами:
= Ci>i). Они обладают
Clii'Ci'i = 1 При ВСеХ I
2aii'?i'*"=0 ПРИ 1>Ф?*
V
Другими словами, все недиагональные элементы матрицы АС
равны 0, а на диагонали стоят единицы.
С помощью данных по формулам A2.47) и A2.48) вычисля-
вычисляются элементы aw к а{у а затем —элементы обратной матрицы cw*
После этого можно получить оценки коэффициентов регрессии Bi9
среднего квадратического отклонения от регрессии (средней квад-
ратической остаточной ошибки) S(Y\x19 х2, ..., xk) и средних
квадратических ошибок оценок коэффициентов Bt. Эти статистики
вычисляются по формулам
... +cikakY, A2.49)
.... xk).
A2.50)
A2.51)
Существует много программ для решения на ЭВМ нормаль-
нормальных уравнений (и обращения матрицI). Если нет возможности
воспользоваться ими и число переменных не слишком велико,
можно обратиться к какому-либо методу расчетов на микро-
микрокалькуляторе. Один из таких методов описан в следующем разделе.
х) Вычислительные аспекты решения систем нормальных уравнений подробно
рассматриваются в книге: Дж. Форсайт, К- Молер. Численное решение систем
линейных алгебраических уравнений.—М.: Мир, 1969.—Прим. ред.
Регрессия и корреляция
485
12.4.2. Метод Холеского
Метод Холеского — один из методов решения нормальных
уравнений (см. [7,13]). По существу это алгоритм обращения
матриц. Поскольку нужно решить уравнения типа
Ь = аА,
а=ЬА-1,
достаточно обратить матрицу А. Метод Холеского (для симмет-
симметричных матриц) основан на том, что
A-LL',
где каждый элемент матрицы L выше главной диагонали равен
нулю, а V —транспонированная L (так что все элементы V ниже
главной диагонали равны нулю). Поскольку A = LL', то А =
= (L')L. Умножая обе части равенства слева на L', получаем
Сначала с помощью 1/2^(^+1) уравнений вида
(г-й столбец L')-(s-fi столбец L') = (r, s)-fi элемент А*
вычисляем элементы матрицы L. Затем, воспользовавшись тем,
что (А~1)/ = А~1 и уравнениями
(/¦¦я строка L'Ms-я строка A"I) = i°f *?" r <J\ A2.52)
\L,rr При Г — Ь,
где Lrr есть r-й элемент главной диагонали L (или L'), получаем
матрицу А начиная с последней строки.
Пример 12.8. Этот пример взят из работы [Day, Del Priore,
Sax, The Technique of Regression Analysis, Quality Control Con-
Conference Papers, American Society for Quality Control, 1953.]
Задача исследования состояла в выяснении влияния разных
факторов на работу подшипников. Главными среди них считались
скорость, нагрузка и вязкость смазочного материала. Измеря-
Измерялась сила трения. Подшипник с 60°-ными сегментами испыты-
вался на стандартной машине Амслера для измерения абразивного
износа, приспособленной для измерения трения при разных
скоростях и нагрузках. Считалось, что математическая модель
имеет вид
xi *;, xi) = а(х[)ь(*;)*-(*;)*¦,
где Yx—сила трения, х[ — скорость, х2' — нагрузка, х'ъ — вязкость.
Переходя к логарифмам каждой из четырех переменных, полу-
получим (приблизительно)
E(Y\X19 X2, Х8) = « + 01*1+02*2
где К = log У, x/ = logxj и а = log Л.
486
Глава 12
Следует помнить, что применение преобразования может отра-
отразиться на совместном распределении переменных. В частности,
если при фиксированных х[, х2 и х3 дисперсия У постоянная,
Y не будет, как'правило, иметь постоянную дисперсию при любых
фиксированных xi9 x2 и х3.
В табл. 12.10 приведены суммы квадратов и парных произ-
произведений для выборки объема 49. Коэффициенты aw и aiY опре-
определяются по формулам A2.47) и A2.48).
Таблица 12.10
Матрица сумм квадратов и парных произведений
переменных *) (сила трения как функция скорости, нагрузки и вязкости)
3,297826
2,439298
8,463681
-2,086540
-3,033485
-1,960421
—0,062692
-3,350182
—0,911236
1) Дополнительная информация, необходимая для завершения вычислений оценок
коэффициентов и их средних квадратических ошибок, включает
2 x±j= 110,523, I>x3j= 95,125,
2*2/=111,091, 2*7=112,643,
Матрица С = А~Х имеет вид
4,096762 0,229647 1,522667\
0,313352 0,729291 ).
3,259197/
(Матрица С симметрична, так что достаточно привести только
верхний треугольник.)
Оценки, полученные методом наименьших квадратов, для а,
Pi> Р2 и Рз равны
А =1,128604; 5^0,549393;
В2 = — 0,399629; В3 = 0,431182.
В результате получаем аппроксимирующее уравнение
у -1,12860 + 0,54939*! -0,39963х2 + 0,43118х8.
Вычислим теперь среднюю квадратическую остаточную ошибку
и средние квадратические ошибки коэффициентов уравнения,
Регрессия и корреляция
487
подвергнутого логарифмическому преобразованию:
49
S2(Y\x1, х2, х3) = 4д_з 1 2и \Yj ^)
/ 1
it-aiyavy = ^ [2,381955 -A,096762) (—0,062692J —
t=ii'=i
— 2 @,229647) (—0,062692) (—3,350182) —
—2A,522668) (—0,062692) @,911236)-@,313352) (—3,350182J —
—2 @,729291) (—3,350182) @,911236) —C,259197) @,911236J]=
=0,С152147.
Следовательно,
S{Y\x19 х2Ух3) -0,1234,
SBl = 0,12341/1,096762 = 0,1292,
Sb2 = 0,1234 1/0,313352 = 0,06908,
SBs = 0,12341/3,259197 = 0,2228.
Можно вычислить не только оценки, но и доверительные
интервалы для каждого коэффициента. Проверка значимости каж-
каждого из этих коэффициентов показывает, что Вг и В2 отличны
от 0 (с уровнем значимости 0,05). Воспользовавшись величиной
^45; о,975 = 2,014, получаем 95%-ные доверительные интервалы
для частных коэффициентов регрессии pf:
0,2892, 0,8096 для (V,
—0,5388, —0,2605 для |32;
—0,0175, 0,8799 для рз-
Строить совместную доверительную область способом, описанным
в разд. 7.4.3, в данном случае нельзя, если оценки р не явля-
являются независимыми нормальными переменными. Доверительную
область для р можно вычислить исходя из того, что
49
4" У, K?l-
3 /tt
xlt x2,x3)
имеет F-распределение с 3,45 (=49 — 4) степенями свободы.
12.5. КРИВОЛИНЕЙНАЯ РЕГРЕССИЯ
В этом разделе рассматриваются две ситуации: 1) аппрокси-
аппроксимация полиномами высокой степени и 2) преобразование нели-
нелинейных уравнений в линейные. Сначала рассмотрим уравнения
регрессии вида
488
Глава 12,
1) ?(Г|^) = а + C^ + |32х2+...+р^ (разд. 12.5.1 и 12.5.3),
а затем
2) E(Y\x) = a$x и некоторые другие трансцендентные урав-
уравнения (разд. 12.5.2).
12.5.1. Полиномиальная регрессия
Это частный случай множественной линейной регрессии
с контролируемыми переменными х, х2, г5 и т. д.
Нормальные уравнения для построения аппроксимирующего
полинома методом наименьших квадратов получаются как в пре-
предыдущих разделах. В качестве иллюстрации возьмем уравнение
третьей степени (q=3). Сумму квадратов разностей наблюдаемых
и оцененных значений Yf с помощью уравнения регрессии
А + BxXj + В2х) + Въх) обозначим, как и раньше, через D. Нужно
минимизировать D.
D = %{Yj-A-BlXj-B2xl-Btrf)*. A2.53)
Если взять частные производные по Л, В19 В2, В3 и приравнять
их к нулю, то получим
др
0D
дВ2
A2.54)
)
= 2 И НУ/ ~А~ Bix/ - в*$ ~ ЗД) (- ^/)J =
После перестановки членов и упрощения приходим к четырем
уравнениям для оценок параметров a, pif f52 и §3:
Методы решения этих уравнений описаны в разд. 12.4. Заме-
Заметим, что если данные кодируются таким образом, что некоторые
суммы равны нулю, объем вычислений резко сокращается.
Дисперсия отклонений от кривой регрессии (остаточная дис-
дисперсия) равна, как и раньше,
A-B1x/-B2x]-B3x*.)y(n-m)9 A2.56)
где т — число оцениваемых параметров. В данном случае /я = 4.
Регрессия и корреляция
489
В качестве упражнения предлагаем читателю вывести фор-
формулы оценок, получаемых методом наименьших квадратов, при
аппроксимации параболой (^ = 2), а также построить соответст-
соответствующие критерии значимости и доверительные интервалы. Систе-
Систематические методы анализа описаны в разд. 12.5.2.
Имеется много прикладных задач, в которых однофакторная
линейная регрессия не может служить даже первым приближе-
приближением. Очень часто исследователи прибегают к однофакторным
линейным формулам из-за простоты последних, несмотря на то,
что это едва ли имеет смысл. Цель этой главы — научить чита-
читателя пользоваться нелинейной регрессией.
12.5.2. Ортогональные полиномы
Обращение к ортогональным полиномам значительно упро-
упрощает выкладки в случае полиномиальной регрессии высокой
степени. Другое, еще более важное преимущество состоит в том,
что в этом случае вклад каждого члена в уравнение регрессии
легко оценить. Уравнение
заменяется на
где
A2.57)
li = li(x)9 i = l, 2, ..., <7,—
полиномы t-й степени по х (см. табл. 12.11), удовлетворяющие
условиям ортогональности
у2 ?// = 0, /=1,2, ...,?,
п
2 lifh'j=O при 1фГ.
v i
A2.58)
Здесь li(x/) обозначено через ?,7. Минимизируя
S=± (Г,- A'-B&j- ... -B'qlqjf
A2.59)
490
Глава 12
Ортогональные полиномы г)
Таблица 12.L
C)
_1
0
+1
D 2
Я 1
+ 1
-2
+ 1
6
3
-3
-I
+ 1
+3
20
2
D)
+ 1
-1
-1
+ \
4
1
-1
+ 3
-3
+ 1
20
-2
-I
0
+1
+2
10
1
+2
-1
-2
-1
+2
14
1
E)
-1
+2
0
-2
+ 1
10
1
+ 1
-4
+6
-4
+ 1
70
и
-5
-3
-1
+ 1
+3
+5
70
2
+5
-1
М
-4
-1
+5
84
1
F)
-5
+7
+4
-4
-7
+5
180
!
+1
-3
+2
+2
-3
+ »
28
А
-1
+5
-10
+ 10
-5
+ 1
252
и
-3
-2
— 1
0
+ 1
+2
+3
28
I
+5
0
-3
-4
-3
0
+5
84
1
G)
?з
-1
+i
+1
0
-1
-1
+1
6
*
*4
+3
-7
+ 1
+6
+ 1
-7
+3
1S4
А
h
-i
+4
-5
0
+5
-4
+ 1
84
А
-7
-5
-3
-1
+ 1
+3
+5
+7
D 168
Я 2
*2
+7
+ 1
-3
-5
-5
-3
+ 1
+7
168
1
(\
-7
+5
+7
+3
-3
-7
-5
+7
264
f
+7
-13
-3
+9
+9
-3
-13
+7
616
A
h
-7
+23
-17
-15
+ 15
+ 17
-23
+7
2184
A
0
+ 1
+2
+3
+4
60
1
-20
-17
-g
+7
+28
2772
3
0
-9
-13
-7
+ 14
990
*
+ 18
+9
-11
-21
+ 14
2002
A
0
+9
+4
-11
+4
468
A
+ 1
+3
+5
+7
+9
330
2
-4
-3
-1
+2
+6
132
l
A0)
-12
-31
-35
-14
+42
8580
1
+ 18
+3
-17
-22
+ 18
2860
A
+6
+u
+i
-14
+6
780
A
h
0
+ i
+2
+3
+4
+5
D 110
Я 1
(И)
h
-10
-9
-6
-1
+6
+ Г5
858
1
h
0
-14
-23
-22
-6
+30
4290
*
+6
+4
-1
-6
-6
+6
286
A
0
+4
+4
-1
-6
+3
156
A
+i
+3
+5
+7
+9
+ 11
572
2
-35
-29
-17
+ 1
+25
+55
12012
3
A2)
-7
-19
-25
-21
-3
+33
5148
I
+28
+ 12
-13
-33
-27
+33
8008
h
+20
+44
+29
-21
-57
+33
15912
A
0
+i
+2
+3
+4
+5
+6
182
1
-14
-13
-10
-5
+2
+ 11
+22
2002
1
A3)
0
-4
-7
-8
-6
0
+ 11
572
*
+84
+ 64
+ 11
-54
-96
-66
+99
68068
0
+20
+26
+ 11
-18
-33
+22
6188
D
Я
*i
+ 1
+3
+5
+7
+9
+ 11
+ 13
910
2
h
-8
-7
-5
-2
+2
+7
+ 13
728
i.
A4)
h
-24
-67
-95
-98
-66
+ 11
+ 143
9,72,40
3"
sfc,
+ 108
+ 63
-13
-92
-132
-77
+ 143
136136
A
+60
+ 145
+ 139
+ 28
-132
-187
+ 143
235144
31,
*i
0
+ 1
+2
+ 3
+4
+5
+6
+7
280
1
-56
-53
-44
-29
-8
+ 19
+52
+91
37128
3
A5)
0
-27
-49
-61
-58
-35
+ 13
+91
39780
1
f«
+756
+621
+251
-249
-704
-869
-429
+ 1001
6466460
I*
О
+675
+ 1000
+751
-44
-979
-1144
+ 1001
10581480
U
») Часть таблицы XXIII из книги Fisher R. A., Yates F.f Statistical Tables for
Biological, Agricultural and Medical Research, Oliver & Boyd, Ltd., Edinburgh. Перепеча-
Перепечатано с разрешения авторов и издателей.
Регрессия и корреляция
491
по А\ В[, ..., B'q, получаем (q+l) уравнений типа
dA'
as _ ,fy7t —A'Y i -B'
7 = 1
-в\i б&—-—*;s 6,,6,/)=o A2.60)
при t= 1, 2, ...,?. Подстановка выражений A2.58) дает
n
и
2
/ = 1
Следовательно,
2
/ = 1
t=l,2 q.
A2.61)
Заметим, что получены явные формулы для BU так что не
нужно решать систему уравнений. Кроме того, эти формулы не
зависят от степени аппроксимирующих полиномов q. Изменение q
не отражается на В\, так что формула A2.61) позволяет вычис-
вычислить В\ независимо от того, какова степень полинома, исполь-
используемого для аппроксимации.
Минимизируемая сумма квадратов имеет вид
S, = 2 (Yf -Y-B'&j- ... -Bfatf -
.2
J
2
/ = l
')» 5 й/ —
/ = 1
n
/ = 1
A2.62)
492
Глава 12
(поскольку 2 Siv&7 = 0 при 1ф1'). Подстановка выражения
A2.61) в A2.62) дает
S,= .2UYj-YY-WY 2 Ei/-...-(^)e 2 Б5/-
у = i / i / l
у = i
2
/ = i
2
/ = l
Г *
Yy-^ *
. A2.63)
?2 .
Члены
2
= 1, 2, ...,?, A2.64)
определяют вклады полиномов соответствующей степени в сумму
п
квадратов 2 (Y/ — YJ. Эти вклады взаимно независимы (см.
разд. 5.7) и каждый распределен как %2а2 с одной степенью
свободы. По существу Т? — уменьшение остаточной суммы квад-
квадратов в результате повышения порядка полинома регрессии
с i— 1 на i.
Несмещенная оценка остаточной дисперсии имеет вид
&(Y\Xl, ...,*,)=;
Статистикой критерия значимости для В\ может быть
A2.65)
При C^ = 0 эта статистика распределена как F с одной и n—q — 1
степенями свободы.
Получим теперь явные выражения для ортогональных поли-
полиномов. Полином первой степени — линейная функция х:
Из условия A2.58) вытекает, что
91/ -
Следовательно,
Регрессия и корреляция
493
Е1 = х-х. A2.67)
Любой полином степени i, li9 можно записать как функцию от gx:
?+ . . . +иИЦ 1=1,2,..., q. A2.68)
Условия ортогональности позволяют вычислить отношения коэф-
коэффициентов uki.
Ситуация значительно упрощается, если значения х равно-
равноудалены друг от друга. Положив
S
где w = xJ+1—
A2.69)
будем иметь гу. = j (/ = 1, 2, ..., п).
В этом случае могут быть получены явные формулы для
ортогональных полиномов. Полином первой степени имеет вид
l1 = z-~z = z-n-±±. A2.70)
Полиномы более высоких степеней получаются с помощью рекур-
рекуррентной формулы
4 Dг2 1
(здесь ^ — произвольная константа).
Имеем, например,
12
3n2 — 7<
20 '
A2.72)
и т. д.
Таблицы ортогональных полиномов для значений ,г из единич-
единичного интервала и равноудаленных друг от друга имеются в книгах
Фишера и Йейтса [6] и Пирсона и Хартли [Ю]1). Чтобы избе-
избежать дробных величин и больших значений в таблицах, принято
считать, что самая высокая степень х в полиноме ?,- имеет
коэффициент А,,., приведенный в табл. 12.11, содержащей значе-
п
ния ?//• Под каждым столбцом приведены величины Dt = 2 ?!/ и ^/-
_ -I ~
При п>8 табулируются только ^-(z) при z^z. Остальные
^- (г) вычисляются следующим образом.
г) См. также: Большев Л. Н., Смирнов Н. В. Таблицы математической
статистики.—М.. Наука, 1965; Митропольский А. К. Техника статистических
вычислений.—М.: Наука, 1971.— Прим. ред.
494
Глава 12
Полиномы |2v-i являются нечетными функциями (г —г), и при
z < z их можно вычислять по формуле
[^1] A2.73)
где [(m+1)/2J — наибольшее целое число, не_превышающее (я+1)/2.
Полиномы Iw —четные функции (г — г).
Формула для вычисления ?2V при z < г имеет вид
/=1,2, ..., л/2. A2.74)
Пример 12.9. Эксперимент из области химической технологии
проводился с целью изучения степени отверждения стеклопла-
стеклопластика на основе полиэфирстирола в зависимости от температуры.
Материал аналогичного состава предполагалось использовать для
изготовления медицинской посуды. Для определения степени
отверждения полиэфирстирола в стеклопластиках проводились
динамические испытания на приборе типа крутильного маятника.
В ходе этих испытаний выяснялась зависимость модуля сдвига и
логарифмического декремента демпфирования от температуры.
Серия измерений в тщательно проверенной выборке показала,
что этот метод позволяет очень точно оценить влияние условий
отверждения на физические свойства.
Была приготовлена смесь смол, которая представляла собой
раствор атлака 382Е F0%) в мономерном стироле D0%). В ней
была растворена смесь 50% перекиси бензола в фосфате три-
крезила, взятая в количестве 2% общей массы. Слоистые мате-
материалы отверждали под давлением 3000 фунт/кв. дюйм. Модули
сдвига и логарифмические декременты фиксировались при изме-
изменении температуры от —50 до 100 °С. Часть данных приведена
в табл. 12.12: 10 значений температуры и соответствующие лога-
Таблица 12.12
Поведение слоев стекловолокон, подвергавшихся термообработке при 225° F.
Логарифмический декремент демпфирования Y как функция температуры х
Температура
X, d
~ ILL
Логарифмический
декремент
демпфирования У
0,053
0,057
0,061
0,068
0,072
Температура
х, °С
20
30
40
50
60
Логарифмический
декремент
демпфирования У
0,081
0,093
0,105
0,115
0,130
Регрессия и корреляция
495
рифмические декременты демпфирования. Эти данные графически
представлены на рис. 12.14. Нужно построить полиномиальную
-40 '30 -20 0 20 40
Температура х, °С
Рис. 12.14. Логарифмический декремент демпфирования как функция тем-
температуры.
аппроксимацию этих данных с помощью ортогональных полино-
полиномов. Данные и ортогональные полиномы для п= 10 приведены
в табл. 12.13.
Ниже проводятся вычисления, необходимые для получения
суммы квадратов и остатков для каждой степени.
При расчетах коэффициентов ортогональных полиномов и
применении критериев значимости для каждого члена нужно
знать
—Yf = [75947
= [75947,0-69722,5] • 10"» = 6224,5-10-»;
496
Глава 12
Таблица 12.13
Данные о слоях стекловолокна и ортогональные полиномы
х, °С
—30
—20
—10
0
10
20
30
40
50
60
h
г
1
2
3
4
5
6
7
8
9
10
Si!/
/
i
—9
—7
—5
—3
— 1
1
3
5
7
9
330
2
6
2
—1
—3
—4
—4
—3
—1
2
6
132
1/2
1з
—42
14
35
31
12
— 12
—31
—35
—14
42
8580
5/3
18
—22
— 17
3
18
18
3
—17
—22
18
2860
5/12
—6
14
—1
—11
—6
6
И
1
—14
6
780
1/10
Y
0,053
0,057
0,061
0,068
0,072
0,081
0,093
0,105
0,115
0,130
0,835=2^/
Y-t — 181 • Ю-3-
r = —1-10-»;
1403¦ Ю-3. , д. 1П_3.
330 -4,^-lU ,
4° _ A81 10-3J
f-2
62/
132
132
'M.^t±.l^31-l 16.10-»-
?2 8580 ">1D Ш '
ES ^/64/? _ (—75 - Ю-з
—;- —
64/
2860
^ = =^^ = -0.03.10--
2860
-23-10-3-
B3-Ю-»)»
780
Q_7.
Построенный полином пятой степени (регрессия Y на z) имеет вид
у =$,0835 + 10-3 [4,251,, (г) +1,37|2 (г) -
Регрессия и корреляция
497
Коэффициенты при двух последних членах малы, так что возни-
возникает сомнение в их необходимости. Чтобы решить, нужно ли
добавлять дополнительные члены, можно воспользоваться крите-
критериями значимости для проверки гипотезы |3i- = 0. Они будут
описаны в разд. 13.16, посвященном дисперсионному анализу.
12.5.2. Трансцендентные уравнения
Иногда опыт исследователя, аналитические выкладки или
просто диаграмма рассеяния ясно указывают на нелинейность
зависимости между переменными. Тем не менее часто удается
найти преобразование данных, приводящее к линейному урав-
уравнению. Такой подход имеет смысл, если он существенно упро-
упрощает выкладки или если не удается получить решение другим
способом. Однако следует помнить, что при этом минимизиру-
минимизируется сумма квадратов отклонений преобразованных, а не исход-
исходных переменных. Если преобразования нелинейны, найденное
решение в общем случае не дает минимума.остаточной суммы
квадратов исходных переменных, но этот факт не должен вызы-
вызывать беспокойства.
Почему, например, не заменить время логарифмом времени,
если это имеет смысл в данной математической модели? В при-
примере 12.1 независимой переменной считался логарифм скорости
ползуна, а не сама скорость. Инженеры давно знакомы с этим
приемом. Очень часто они используют в качестве абсциссы или
ординаты графика трансцендентные преобразования наблюдаемых
переменных.
В этом разделе рассматриваются несколько частных случаев.
Пусть изучаемая модель имеет вид
) = ар*. A2.75а)
Простое логарифмическое преобразование дает
E(Z\x) = a'+b'x, A2.756)
где Z —lnF, a' = lna и р' = ln^. Задача свелась к оценке коэф-
коэффициентов линейного уравнения, если, конечно, можно считать,
что для преобразованных данных выполняются условия, сформу-
сформулированные в разд. 12.2.1. После того, как будут получены
оценки параметров, можно вернуться к исходным переменным.
С этим связаны два неудобства. Во-первых, как уже отмеча-
отмечалось, оценки минимизируют остаточную сумму квадратов пре-
преобразованных переменных. Об этом нельзя забывать. Во-вторых,
в общем случае удобнее продолжать пользоваться преобразо-
преобразованными переменными, чем переходить от одних переменных к
другим. Если последнее соображение вызывает у читателя сом-
498
Глава 12
нение, советуем проверить его на практике. Однако не следует
рассматривать эту рекомендацию как универсальный рецепт.
Отметим, что уравнение
, A2.76а)
легко преобразуется к виду
E(Z\w) = a + рад, A2.766)
где ct'^lna, z-=\ny и ад = In я, а уравнение
?(K|x)=agP* A2.77а)
к виду
A2.776)
где Z=\nY и a'
Если уравнение A2.76а) выражает истинную зависимость, об
уравнении A2.766) этого уже нельзя сказать, поскольку в общем
случае Е (\пУ\х)Ф\пЕ(У\х). То же самое верно в отношении
уравнений A2.77а) и A2.776).
Можно составить перечень преобразований. Полезно в начале
исследования указать, какие из возможных преобразований имеет
смысл использовать, особенно если нельзя ограничиться линей-
линейными связями между изучаемыми переменными. Источником для
выбора преобразований являются в первую очередь аналитиче-
аналитические исследования, а также опыт инженеров и ученых.
12.6. СЕРИАЛЬНАЯ КОРРЕЛЯЦИЯ
Если наблюдаемые величины естественно упорядочены во
времени (например, состоят из данных, отбираемых каждые
20 минут в определенной точке производственного процесса), то
иногда представляет интерес корреляция между значениями,
полученными в моменты времени, отличающиеся на 20,
40, ... минут.
Обозначим наблюдаемые величины (которые в действительно-
действительности могут быть статистиками, такими, как среднее или медиана,
полученными из множества измерений) через Х19 Х2, Х3... и рас-
рассмотрим корреляцию между Xt и Xi+h при h > 0. Если есть
основания предполагать, что последняя не зависит от t, можно
написать Согг(Х^ Xt+h) = ph. Последовательность рх, р2, ... дает
полезные сведения о природе временного ряда. Величина ph на-
называется коэффициентом сериальной корреляции с запаздыва-
запаздыванием h. Во многих случаях рн уменьшается с увеличением А, но
если имеется периодичность, последовательность ph будет осцил-
осциллировать.
Регрессия и корреляция
499
12.7. ДОПОЛНИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
ПО ПОВОДУ РЕГРЕССИИ И КОРРЕЛЯЦИИ
Один из источников ошибок при использовании регрессии и
корреляции связан с тем, что несколько подгрупп или совокуп-
совокупностей объединяются в одну. Иногда деление на группы оче-
очевидно, и прежде чем объединять их, исследователь применяет
к ним критерии значимости или сравнивает доверительные интер-
интервалы. Однако часто оказывается, что инженер или физик не
заметили какой-либо фактор, расщепляющий исходную совокуп-
совокупность на две части. Речь может идти о двух экспериментаторах,
разных измерительных приборах, разных днях и т. п. Все такие
факторы необходимо учитывать, и если не удается ими управ-
управлять, то хотя бы проводить рандомизацию по ним. Этот вопрос
будет рассматриваться в трех следующих главах.
Пример 12.10. Посмотрим, что может получиться, если сме-
смешать несколько разнородных массивов информации. Американ-
Американский институт крепежных деталей проводил исследование резь-
резьбовых гаек. В него входило изучение корреляции между расши-
расширением (X) гайки при срыве резьбы и усилием (К), которое не-
необходимо приложить, чтобы сорвать резьбу. Использовались
стандартные болты и случайные выборки обычных шестиуголь-
шестиугольных гаек. Болт ввинчивался в гайку, а его головка закрепля-
закреплялась в машине, фиксирующей сопротивление. Прикладывалось
усилие, вырывающее болт из гайки. При угом расстояние между
противоположными сторонами гайки увеличивалось, пока не
происходил срыв резьбы. Расширение X определялось как рас-
расстояние между противоположными гранями после срыва минус
то же расстояние до срыва. Применялись гайки следующих трех
типов: 3/8, 1/2 и 3/4 дюйма. Обозначим их через Л, В и С, где
С —гайка наибольшего размера. Диаграмма рассеяния данных
показана на рис. 12.15. Коэффициенты корреляции равны:
j^r=0,35, /?д = 0,38, Rc = 0,29. Если объединить три совокуп-
совокупности, коэффициент корреляции „подскакивает" приблизительно
до 0,90. В данной задаче эта величина не имеет никакого смысла.
Исследователей не интересовала связь для гаек размером от 3/8
до 3/4 дюйма. Нужно было узнать, существует ли связь при
фиксированном размере.
Другая опасность при использовании регрессионного и кор-
корреляционного анализа связана с чрезмерным увлечением ЭВМ.
Разумеется, нет необходимости отказываться от ЭВМ при рас-
расчетах задач регрессии или корреляции, но не следует увлекаться
программами, дающими мириады ответов независимо от смысла
задачи. Тем, кто понимает суть регрессии и корреляции, советы
500
Глава 12
не нужны. Тем, кто не понимает, никакие советы не помогут.
Предостережение можно сформулировать следующим образом:
„если заранее написанная программа для ЭВМ снабжает иссле-
исследователя всевозможными регрессионными и корреляционными
t
Расширение X
Рис. 12.15. Расширение X и вырывающее усилие Y для трех размеров гаек
с резьбой.
коэффициентами, доверительными интервалами, ошибками и дру-
другими статистиками, из этого вовсе не следует, что все они имеют
отношение к задаче и были получены на основании заложенных
данных". Например, в регрессии величина а% не имеет смысла,
если х—управляемая переменная. Разумеется, при некоторых
точно оговоренных теоретических предпосылках можно сформули-
сформулировать правила, позволяющие извлечь из данных всю полезную
информацию, но в практической задаче всегда есть надежда по-
получить полезные выводы, применив новый подход. Эти и другие
проблемы анализа данных рассматриваются в книгах [2, 3].
ЛИТЕРАТУРА
1. David F. N., Tables of the Ordinates and Probability Integral of the
Distribution of the Correlation Coefficient in Small Samples, Cambridge
University Press, 1938.
2. Daniel C, Wood F., Fitting Equations to Data, Wiley, New York, 1971.
3. Draper N. R., Smith H., Jr., Applied Regression Analysis, Wiley, New
York, 1966. [Имеется перевод; Дрейпер Н,, Смит Г. Прикладной регрес-
регрессионный анализ.—М.: Статистика, 1973.]
4. Ezekiei M. A., Fox К. A., Methods of Correlation and Regression Analy-
Analysis, 3rh ed., Wiley, New York, 1959. [Имеется перевод: Езекиэл М„
Регрессия и корреляция
501
Фокс К. А., Методы анализа корреляций и регрессий линейных и криво-
криволинейных.— М-: Статистика, 1966.]
5. Fisher R. A.. On the Probable Error of a Coefficient of Correlation Dedu-
Deduced from a Small Sample, Metron, 1 A921).
6. Fisher R. A., Yates F.: Statistical Tables for Biological Agricultural and
Medical Research, Hafner, New York, Oliver & Boyd, London, 1957.
7. Fox L., Hayes J. G., More Practical Methods for the Inversion of Matri-
Matrices, Journal of the Royal Statistical Society, Series B, 13 A951).
8. Olds E. G., Distribution of the Sums of Squares of Rank Differences for
Small Numbers of Individuals, Annals of Mathematical Statistics, 9 A938).
9. Olds E. G., The 5 Per Cent Significance Levels for Sums of Squares of
Rank Differences and a Correction, Annals of Mathematical Statistics,
20 A949).
10. Pearson E. S., Hartley H. O., Biometrika Tables for Statisticians, Vol. 1,
Cambridge University Press, 1958.
11. Plackett R. L., Principles of Regression Analysis, Clarendon Press,
Oxford, 1960.
12. Rand Corporation, A Million Random Digits with 100 000 Normal Deviates,
Free Press, Glencoe, 111., 1955.
13. Rushton S., On Least Squares Fitting by Orthonormal Polynomials using
the Choleski Method, Journal of the Royal Statistical Society, Series B,
13 A951).
14. Williams E. J., Regression Analysis, Wiley, New York, 1959.
УПРАЖНЕНИЯ
1. Руководство швейной фабрики хотело бы иметь информацию о том,
сколько платьев каждого фасона, цвета и размера будет продано. С одной
стороны, нельзя допускать перепроизводства, так как в этом случае придется
продавать товар по заниженным ценам, с другой стороны, нехватка приводит
к необходимости выпускать больше изделий, чем было намечено к данному
сроку. Если иметь прогноз через 5 недель после поступления нового наиме-
наименования в продажу, можно обеспечить изготовление необходимого количества
продукции к намеченному сроку. Ниже приведены данные о суммарном объеме
проданных изделий каждого фасона, цвета и размера и соответствующие цифры
за пять недель. Они были получены в начале исследования.
а) Представьте графически данные и получите оценки наименьших квад-
квадратов а и р в модели Е [Y | Х~х]=а-\-$х.
б) Вычислите Sfi и S.
Продано всего (У)
392
190
74
307
200
185
291
191
Продано в первые
пять недель (X)
235
122
34
196
121
127
177
125
Продано всего (У)
314
140
235
188
142
253
96
96
Продано в первые
пять недель (X)
159
75
140
127
89
139
70
62
2. В металлургической исследовательской лаборатории проводился экспе-
эксперимент над сверхтвердыми сталями. Десять образцов стали были кадмированы
и прокалены в течение трех часов при 80° F, затем измерялась ,длительность
выдержки под нагрузкой до появления водородной трещины. Ниже приведены
502
Глава 12
величины давления в 1000 фунт/кв. дюйм и логарифмы длительности выдержки
в минутах. Оцените коэффициенты регрессии Е (Y | х) = а-}-$х и вычислите
95%-ный доверительный интервал для р.
Приложенное
давлениех
хюоо-1
фунт/кв. дюйм
200
185
18&
175
Логарифм
выдержки У
0,1139
0,1139
0,0000
0,3010
Приложенное
давление X
175
160
150,
Логарифм
выдержки Y
0,3010
0,2553
0,2788
Приложенное
давление X
135
135
125
Логарифм
выдержки У
0,3010
0,4150
0,3979
3. Ниже приведены данные о времени пригорания (в минутах) натураль-
натурального каучука при 25Q° F в зависимости от чистоты катализатора (в процентах).
а) Вычислите коэффициент корреляции (R).
б) Проверьте значимость (при уровне 0,05).
в) Определите объем выборки, при котором полученная величина R будет
значимой (взять уровень 0,01).
г) Определите предельную величину R, значимого для этой выборки при
уровне 0,01.
Чистота
катализатора
89,3
90,9
91,7
93,4
93,5
Время
пригорания
43,7
49,2
48, Г
45,5
54,0
Чистота
катализатора
94,2
94,5
97,5
98,7
99,5
Время
пригорания
47,5
49,0
50,5
50,5
53,7
4. Вязкость в расплавленном состоянии —одна из главных характеристик
полиэфиров. Она показывает степень полимеризации. С ее помощью можно
установить, как далеко зашла реакция. При химическом исследовании рас-
расплавленного полиэфира при 200° F было выделено пять средневесовых степе-
степеней полимеризации (X). Вязкость У измерялась для трех выборок, получен-
полученных под высоким давлением, и для трех —под низким. Был построен спе-
специальный вискозиметр. Результаты приведены ниже.
X
4,05
4,05
4,05
5,08
5,08
Высокое
давление
28,7
29,7
31,9
60,1
62,0
Низкое
давление
27,1
27,4
31,8
65,3
61,1
X
5,08
6,34
6,34
6,34
7,37
Высокое
давление
63
123
120
116
182
8
2
6
8
9
Низкое
давление
65,8
121,6
122,4
116,9
168,5
X
7,37
7,37
7,84
7,84
7,84
Высокое
давление
179,9
178,6
228,0
232,6
230,6
Низкое
давление
188,0
180,8
256,5
256,8
266,5
а) Постройте график зависимости Ух от X.
б) Найдите методом наименьших квадратов линейную зависимость лога-
логарифма вязкости под высоким давлением (log Уг) от средневесовой степени по-
полимеризации.
в) Найдите линейную зависимость \ogY2 от X.
г) Определите доверительные интервалы параметров зависимостей б) и в).
д) Значимо ли отличаются коэффициенты регрессии б) и в)?
Регрессия и корреляция
503
Ниже описаны условия упражнений 5—-11.
В 1958 г. проводилось исследование методов борьбы с коррозией стальных
пластин. Проект субсидировался предприятием, выпускающим оборудование
водяного отопления. Изучалась скорость ржавления стальных пластин, по-
покрытых разными эмалями. Пластины были получены от четырех поставщиков.
В ходе эксперимента пластины подвергались воздействию 10%-ной соляной
кислоты при 140, 160, 180 и 200° F в течение 4, 8, 10 и 12 ч. Измерялись
потери веса с точностью до 0,0001 г. Из прошлых опытов было известно, что
соляная кислота действует на эмаль так же, как вода, но гораздо быстрее.
(Здесь не рассматривается разница между ускоренными и обычнымм испыта-
испытаниями на долговечность. С этим связан другой вопрос прикладной статистики,
иногда играющий важную роль.)
Приведенные ниже данные являются результатами эксперимента. Они
даны полностью, так как понадобятся в нескольких упражнениях. В приве-
приведенных ниже таблицах Хг — время, ч; Х2 — температура, °F, F —потери веса, г.
N?
А-22
А-23
А-24
А-19
А-20
А-21
А-31
А-32
А-33
А-1
А-2
А-3
А-4
А-5
А-6
А-34
А-35
А-36
А-25
А-26
А-21
№
В-19
В-20
В-21
В-22
В-23
В-24
В-26
В-27
В-28
Хг
4
4
4
4
4
4
4
4
4
б
6
6
б
6
6
б
б
6
8
8
8
Хг
4
4
4
4
4
4
4
4-
4
ГО хг
160
160
160
180
180
180
200
200
200
160
160
160
180
180
180
200
200
200
160
160
160
ГО X,
160
160
160
180
180
180
200
200
200
Поставщик А
у
0,0068
0,0076
0,0081
0,0096
0,0092
0,0091
0,0115
0,0133
0,0124
0,0090
0,0209
0,0387
0,0100
0,0106
0,0764
0,0148
0,0394
0,0130
0,0076
0,0077
0,0083
N?
А-28
А-29
А-30
А-37
А-38
А-39
А-16
А-17
A-J8
А-13
А-14
А-15
А-40
А-41
А-42
А-7
А-8
А-9
А-10
А-11
А-12.
Поставщик В
у
0,0143
0,0184
0,0203
0,019!
0,0216
0,0169
0,0212
0,0228
0,0245
№
В-16
В-17
В-18
В-13
В-14
В-15
В-28
В-29
В-30
Хг
8
8
8
8
8
8
10
10
10
10
10
10
10
10
10
12
12
12
12
12
12
Xi
8
8
8
8
8
8
8
8
8
ГО х2
180
180
180
200
200
200
160
160
160
180
180
180
200
200
200
160
160
160
180
180
180
ГF) Х2
160
160
160
180.
180
180
200
200
200
У
0,0088
0,0096
0,0157
0,0265
0,0123
0,0175
0,0100
0,0095
0,0084
0,0125
0,0122
0,0144
0,0222
0,0195
0,0159
0,0413
0,0086
0,0100
0,0134
0,0174
0,0146
У
0,0147
0,0207
0,0171
0,0253
0,0250
0,0217
0,0272
0,0265
0,0290
504
B-10
в-п
В-12
В-1
В-2
В-3
В-4
В-5
В-6
В-7
В-&
б
б
6
6
6
б
б
6
6
б
Су
6
140
140
140
160
160
160
180
180
180
200
200
200
Глава
\ 12
ПатпВщик В
0,0122
0,0153
0,0148
0,0146
0,0f4O
0,0197
0,0229
0,0209
0,0219
0,0243
0,0230
0.02 \ 9
В-41
В-42
В-43
В-38
В-39
В-40
В-32
В-33
В-34
В-35
В-36
В-37
10
10
10
та
и*
га
10
10
10
12
12
12
160
160
160
180
180
180
200
200
200
200
200
200
0,0194
0,0199
0,0181
0,0240
0,0253
0,0237
0,0217
0,0197
0,0196
0,0292
0,0197
0,0311
N?
C-49
C-50
C-51
C-25
О26
C-27
C-28
C-29
C-30
C-37
C-38
C-39
c-to
C-ll
C-12
C-t
C-2
C-3
C-4
C-5
C-6
Cl
C-S
C-9
C-22
C-23
C-24
C-13
C-I4
C-15
Xi
4
4
4
4
4
4
4
4
4
4
4
4
6
6
6
6
6
6
6
6
6
6
6
6
8
8
g
8
8
140
140
140
160
160
160
180
180
200
200
200
140
140
140
160
160
160
180
180
180
200
200
200
140
140
140
160
160
160
Поставщик
у
0,0347
0,0392
0,0331
0,0249
0,0380
0,0308
0,0271
0,0337
0,0370
0,0364
0,046 Г
0,0426
0,0324
0,0438
0,0289
0,0397
0,04 И
0,0689
0,0380
0,0511
0,0464
0,0Ш
0,0428
0,0525
0,0411
0,0339
0,0330
0,0405
0,0600
0.03 И
С
NS
С-16
С-17
С-1&
О19
С-20
С-21
С-52
С-53
С-54
С-34
С-35
с-зв
C-3t
С-Э2
с-зз
С-40
С-41
С-42
С-55
С-56
С-57
С-46
С-47
С-4&
С-43
С-44
С-45
C-5S
С-59
С-60
Хг
8
8
8
3
8
8
10
10
10
10
10
10
10
10
10
10
то
10
12
12
12
12
12
12
12
12
12
12
12
12
(°F) X2
180
180
180
200.
200
20О
140
140
140
160
160
,160
180
180
180
200
200
200
140
140
140
160
160
160
180
180
180
200
200
200
У
0,0386
0,0438
0,0448
0,0730
0,0589
0,0483
0,02 Я
0,0252
0,0252
0,0328
0,0377
0,0322
0,0549
0,0500
0,0382
0,1396
0,1085
0,1585
0,0271
0,0258
0,0250
0,0380
0,0444
0,0361
0,0558
0,0537
0.047
0,2431
0,0550
0,3020
Регрессия и корреляция
505
D-11
D-12
D-10
П-48
D-49
D-50
D-16
D-17
D-18
ОИ9
d-:o
D-21
D-57
D-58
D-4
D-5
D-6
D-1
D-2
D-3
D-7
D-8
D-9
D-75
D-76
D-77
D-21
D-22
D-23
D-20
D-24
D-39
xt
4
4
4
4
4
4
4
4
4
4
4
4
6
6
6
6
6
6
6
6
6
S
8
8
8
8
8
S
(eF) A'.
140
140
140
160
160
160
180
J80
180
200
200
200
140
140
HO
160
160
160
180
180
180
200
200
200
140
140
140
160
160
160
380
180
180
Поставщик О
У
0,0065
0,0046
0,0132
0,0083
0,0080
0,0059
0,0073
0,0094
0;006S
0,0171
0,0142
0,01 U
0,0057
0,0045
€,0054
0,0065
0,0078
0,0097
0,0084
0,0092
0,0086
0,0142
0,0146
0,0111
0,0058
0,0055
0,0064
0,0093
0,0084
€,0105
0,0140
0,0115
0,0130
D-40
D-41
D-63
D-36
D-37
D-3 8
D-54
D-55
D-56
D-51
D-52
D-53
0-27
D-28
D-29
D-24
D-25
D-26
D-45
D-46
D-47
D-42
D-43
D-44
D-30
D-31
D-32
D-33
0-34
Xx
8
8
8
8
8
3
10
10
10
10
10
10
10
10
10
10
10
12
J2
12
12
12
12
12
12
12
12
12
12
(°F) X,
180
180
180
200
200
200
140
140
140
160
160
160
180
180
200
200
200
140
140
140
160
160
160
180
180
180
200
200
200
У
0,0300
0,0487
0,0265
0,0185
0,0160
0,0176
0,0070
0,0 IM>
0,0111
0,0094
0,0126
0,0130
0,0169
0,0207
0,0112
0,0325
0,0090
0,0149
0,0119
0,0148
0,0100
0,0117
0,0107
0,0105
0,0182
0,0299
0,0356
0,0485
0,0349
0,0380
5. Рассмотрите все данные. С чего вы предлагаете начать анализ? Не
кажутся ли вам подозрительными некоторые измерения потери веса? Предпо-
Предположите, что нет никаких сведений о неудачных экспериментах, и разделите
все наблюдения на допустимые и аномальные с помощью объективного кри-
критерия.
6. По данным поставщика С, соответствующим 8 ч, постройте методом
наименьших квадратов уравнение регрессии y — f(X^. При этом
а) нанесите на график 12 точек;
б) сделайте предположение о форме уравнения по диаграмме рассеяния;
в) оцените параметры;
г) вычислите средние квадратические ошибки оценок;
д) постройте 95%-ные доверительные интервалы для этих параметров.
7. Сделайте все то же, что и в упражнении 6, с данными поставщика D.
Сравните уравнения регрессии, полученные для случаев С и D.
8. По данным первых строк всех 20 комбинаций продолжительностеи и
температур в таблице поставщика D методом наименьших квадратов получите
506
Глава 12
оценки коэффициентов множественного линейного уравнения регрессии
У \1Х1\В2Х2.
Определите средние квадратические ошибки оценок коэффициентов рег-
регрессии и среднюю квадратическую остаточную ошибку.
9. Постройте уравнение регрессии методом наименьших квадратов по дан-
данным поставщика А для температур 160, 180 и 200°F и продолжительностей
4, 6, 8 и 10 ч. Возьмите все три измерения в каждом случае. Определите
среднюю квадратическую остаточную ошибку. (Сначала удалите аномальные
наблюдения.) ~^
10. Сделайте то же, что и в упражнении 9, с данными поставщика В.
П. Сравните продукцию поставщиков А и В, проанализировав соответст-
соответствующие уравнения регрессии.
12. В работе Роджерса и Санхеза [Rogers W. Т., Sanchez L. Т.. Journal
of Metals (September, 1952) (перепечатано AIME)] изучалось влияние дли-
длительности дутья на содержание кремния в чугуне, выплавляемом в шахтной
печи. Авторы пришли к выводу, что кремний должен быть удален из чугуна
в первую очередь, его содержание колеблется наиболее сильно (от 0,93
до 1,85%). Ниже в таблице приведены данные для обычного и кислородного
дутья, взятые из оригинальной статьи. Допустим, что главный интерес пред-
представляют коэффициенты регрессии Ь± и Ь2> и нужно проверить гипотезу
#o'Pi — Р2 = 0.
а) Представьте графически данные каждой выборки.
б) В каждом случае постройте уравнение регрессии.
в) Вычислите 95%-ный доверительный интервал для (рх — Р2).
Влияние длительности дутья на содержание кремния в чугуне
Кислородное дутье Обычное дутье
Содержание
кремния х, %
1,05
1,15
1,25
1,35
,45
1,55
1,65
,70
1,80
Длительность
дутья Y, мин
14,5
14,5
14,5
15,5
15,0
17,0
16,5
14,5
18,5
Содержание
кремния X, %
0,90
0,95
1,00
1,10
1,20
1,30
1,40
1,50
1,60
1,70
1,80
Длительность
дутья Y, мин
11,0
11,0
12,0
11,5
11,5
12,5
13,0
13,5
13,5
14,0
13,5
13. Статистик Джо Зилч предложил проверить гипотезу о равенстве рх и
р2 по данным упражнения 12 с помощью какого-либо метода ранговых кор-
корреляций. Перечислите трудности, связанные с реализацией его предложения.
Прокомментируйте следующий подход:
„Для каждого массива данных вычислите отношение
(Длительность дутья) —(Длительность дутья для мин. % кремния)
(% кремния)— (мин. % кремния) '
Регрессия и корреляция
507
Это дает 8 значений для кислородного дутья и 10 для обычного. Затем к этим
величинам примените критерий Вилкоксона (описанный в разд. 9.6) с ^ = 8 и
ла=10".
В упражнениях 14—19 предполагается, что отклонения от линии регрессии
имеют нормальное распределение и обладают свойством гомоскедастичности.
14. По данным табл. 12.1
а) вычислите оценки параметров а и Р;
б) проверьте гипотезу #0:р0 = 0 при уровне значимости 0,05.
15. По данным табл. 12.2
а) оцените аи Р;
б) проверьте гипотезу Я0:Р = —1,5 при уровне значимости 0,01;
в) постройте 95%-ный доверительный интервал для o2(Y\x).
16. По данным табл. 12.3
а) оцените аир в уравнении регрессии Е (In Y\ *) = a+p* для каждой
лампы;
б) проверьте гипотезу Н0:о2 (In Y | х)А = о2 (In Y \ х)в\
в) проверьте гипотезу #о:Рл = Рв« При проверке каждой гипотезы исполь-
используйте уровень значимости 0,01.
17. Используя данные табл. 12.4
а) постройте график зависимости модуля разрыва Z от * = log (скорости
ползуна);
б) методом наименьших квадратов вычислите оценки для аи Р в уравне-
уравнении регрессии Е (Z \ х) = а+ Р**>
в) постройте 95%-ный доверительный интервал для Р;
г) постройте 99%-ные доверительные интервалы для
?(Z|*=l,0) и E(Z\x= 1,30103);
д) постройте 95%-ный доверительный интервал для o2(Z\x).
18. По данным табл. 12.4
а) вычислите выборочный коэффициент корреляции;
б) можно ли считать его отличным от нуля при уровне значимости 0,05?
в) какое значение R окажется значимым на уровне 0,01 при данном
объеме выборки?
19. Проделайте то же самое, что и в упражнении 18, для переменных
Y и Z.
20. Ниже приведены данные о количестве смертельных исходов в резуль-
результате аварий мотоциклистов в шт. Айова с 1960 по 1971 г.
Предполагая, что уравнение регрессии линейно, а дисперсия отклонений
от прямой постоянна, оцените математическое ожидание числа несчастных слу-
случаев для 1972 г. Чему равна средняя квадратическая остаточная ошибка?
Какие факторы следует дополнительно учесть, чтобы ценность выводов увели-
увеличилась?
Год I960 1961 1962 1963 1964 1965
Число смертельных исходов 7 7 7 11 12 19
1966 1967 1968 1969 1970 1971
33 26 33 26 40 41
21. Все то же, что в упражнении 20, но используйте следующие данные о
числе мотоциклетных аварий в шт. Айова.
Год
Всего аварий
1960
269
1966
1227
1961
257
1967
1181
1962
302
1968
1198
1963
418
1969
1176
1964
579
1970
1512
1965
1041
1971
1834
Обсудите возможные нарушения предположений в этом и предыдущем упраж-
упражнениях.
508
Глава 12
22. Ниже приведены значения частоты (Y) и нагрузки (X) генератора
Викерса 10/(ЛЛ Нужно было проверить, отвечает ли новая конструкция нор-
нормативным требованиям. В задачу входило определить, существует ли тренд
выходной частоты с изменением нагрузки. Объем выборки очень мал из-за
высокой стоимости и других ограничений. Результаты получились следующие:
Нагрузка X 0
Выходная частота У 399,83
1/4 1/2 3/4 1 1V4
399,58 399,36 399,20 398,84 397,98
(Взято из работы Day, Del Priore, Sax, The Technique of Regression Analysis,
Quality Control Conference Papers, American Society for Quality Control, 1953.)
С помощью ортогональных полиномов постройте уравнение полиномиальной
регрессии четвертого порядка.
23. При полиэфиризации жирных кислот гликолем представляет интерес
влияние концентрации катализатора Хг и температуры Х2 на процент конвер-
конверсии У. Были выбраны три уровня концентрации 4-10~4, 8-10~4, 16-10~4
грамм-молекул хлористого цинка на 100 г жирных кислот и три температуры
(в стоградусной шкале). Результаты эксперимента приведены ниже.
а) Методом наименьших квадратов найдите оценки для параметров урав-
уравнения Е(У\хъ x2, *з) = а+01*1+02*2+0з*з, где хъ=-х\.
б) Оцените средние квадратические ошибки Въ В2 и В3.
в) Вычислите среднюю квадратическую ошибку оценивания Y при задан-
заданных хх и х2
Температура,
175
200
225
Процент
конверсии
Концентрация в грамм-молекулах/100 г
4-10-*
67,4
66,2
68,9
82,8
85,3
80,9
90,5
93,1
93,7
8-10-*
73,4
75,5
72,8
86,2
89,0
85,7
92,8
96,9
93,8
16-10-*
79,7
81,1
76,2
93,3
95,6
90,1
98,7
99,8
99,9
24. По данным упражнения 23 определите уравнение регрессии Е (Y \ х2) =
= «+02*2+022*2 Для каждого из трех уровней хх.
25. Флаттер играет важную роль в авиастроении и при проектировании
крупных сооружений, например мостов. Проведен лабораторный эксперимент
с двумя типами топкой пленки: латунной (толщиной 0,0001 дюйма и шириной
0,5 дюйма) и полиэтиленовой (толщиной 0,004 дюйма и шириной 0,5 дюйма).
Были выбраны три уровня длины и четыре скорости ветра. Ниже приве-
приведены результаты эксперимента.
Регрессил и кбрреляция
Материал
Длина X, дюйм
Скорость Z, фут/с
62,5
54,6
44,3
31,3
Флаттер
1 ,75
3740
3760
3810
3340
3250
3230
2560
2730
2640
Y (число
Латунь
2,00
3470
3410
3520
3100
3020
3150
2520
2430
2640
колебаний /мин)
2,25
3210
3180
3250
2850
2800
2820
2340
2270
2290
1750
1 ,50
5000
5050
5150
4600
4510
4510
3650
3700
3620
2300
2450
2410
Полиэтилен
1,75
4700
4800
4810
4150
4200
4300
3310
3410
3500
2200
2420
2380
2,00
4550
4510
4550
3940
3860
3960
3080
3100
3180
2030
2160
2320
а) Вычислите оценки коэффициентов уравнения регрессии для полиэтиле-
полиэтиленовой пленки
E(Y\x, z)-a+01%+022.
б) Постройте 95%-ный доверительный интервал отдельно для 0Х и 02.
в) Вычислите Rb^b^ Значимо ли он отличается от нуля при уровне 0,05?
г) Как бы вы планировали дальнейший эксперимент, имея данные пунктов
а), б) и в)?
26. Сделайте то же, что й в упражнении 25, для латунной пленки.
27. Проводился эксперимент по определению долговечности поршневого
кольца. Приведенные ниже данные были получены с помощью автомобильного
двигателя, работавшего на постоянной скорости с разными вращающими мо-
моментами. Поршневое кольцо, сделанное из радиоактивного металла, обычным
образом крепилось к поршню. Вне двигателя был установлен счетчик Гейгера.
По мере того как поршневое кольцо изнашивалось (возможно, в связи с поте-
потерей смазочной способности масла), радиоактивные частицы проносились маслом
мимо счетчика Гейгера.
а) С помощью ортогональных полиномов вычислите полиномиальную рег-
регрессию У (число импульсов в минуту) на X (время в часах). Получите урав-
уравнение минимальной возможной степени (используйте уровень значимости 0,05).
б) Представьте исходные данные графически и проведите полученную
кривую.
X • 0,5 1,5 2,5 3,5 4,5 5,5 6,5 7,5 8,5
Y 395 410 405 450 475 450 470 500 530
28. Добавьте к данным предыдущего упражнения данные,
ниже, и выполните задания пунктов а) и б) с этими данными.
X 1,0 2,0 3,0 4,0 5,0 6,0 7,0 8,0
У 410 400 400 475 475 460 495 500
приведенные
510
Глава 12
29. В производстве синтетической нити для текстильной промышленности
часто применяется операция „сгущение". При этом нить, еще имеющая вид
непрерывной кудели, подвергается действию высокой температуры в автоклаве.
После разрезания такой „сгущенной" кудели из нее можно получить пряжу
с прекрасной массой и усадкой.
Ниже приведены результаты 30 испытаний пряжи. Контролируемая пере-
переменная (х) здесь —температура в градусах Цельсия, а зависимых переменных
две: усадка в процентах (Y{) и масса в произвольных единицах (Y2)-
а) Оцените параметры о^ и pt в регрессионой зависимости Y1 от х:
У\) +^
1\) 1+^1
б) Определите S, SBv SAl.
в) Повторите пункты а) и б) для Y 2.
г) Постройте прямую у2 = Л2-\-В2х с 95%-ной доверительной зоной для
Е (У21 х). Объясните, в каком смысле ее можно называть 95%-ной доверитель-
доверительной зоной.
Температура
х, °С
150
145
142
138
139
132
130
122
124
118
116
120
132
138
134
Усадка Yt,
%
7,23
6,44
5,82
5,72
5,64
4,68
4,44
3,58
3,71
3,67
3,43
3,41
5,24
5,62
5,10
Масса Y 2»
произв. ед.
2,62
1,83
1,95
1,81
1,77
1,48
,48
1,16
1,34
,24
1,03
1,21
1,33
1,42
1,64
Температура
х, °С
136
132
124
125
127
122
120
121
148
146
138
132
130
127
123
Усадка У4,
%
5,10
4,38
3,92
4,03
3,97
3,85
3,64
3,72
6,45
6,57
5,61
5,31
4,70
4,52
3,75
Масса У2,
произв. ед.
1,26
1,21
1,09
1,45
1,26
1,13
1,16
1,20
2,16
2,06
1,60
1,58
1,55
1,22
1,13
30. Воспользовавшись обозначениями разделов 12.2.4 —12.2.6, покажите,
что для i= 1, 2, ..., п
Var [Г;-Г-? (*,-*)] =Q* И-1-<*/~*Г П
Сравните с формулой A2.21) и объясните разницу.
31. Используя результат упражнения 30, покажите, что при п > 3
L (n—2)S2
имеет бета-распределение (см. разд. 5.6.2) с параметрами х/2, 1/2(/г —3).
Регрессия и корреляция
511
Получите формулу для границ по отношению к построенной прямой рег-
регрессии [y = Y-\-B (x — х)], таких, что средняя доля не выходящих за них вы-
выборочных точек (х;, Yi) равна 100A— а)%.
32. Для B&-J-1) равноудаленных значений [—k, —(k—1), ..., —1, 0,
1, ..., (k — 1), k] переменной X были получены независимые наблюдения Y.
Нужно взять еще одно наблюдение, причем X может принимать любое значение
от — k до k включительно.
Пусть регрессия К на Л" линейна с постоянной дисперсией. Каким должно
быть значение дополнительного наблюдения X, если задача состоит в том, чтобы
а) оценить форму регрессии Y на Х\
б) оценить математическое ожидание Y при X, равном заданной величине
( &6)?
ПРИЛОЖЕНИЕ
12651
81769
36737
82861
21325
74146
90759
55683
79686
70333
14042
59911
62368
57529
15469
18625
74626
11119
41101
32123
26091
67680
15184
58010
56425
82630
14927
23740
32990
05310
61646
744 Я6
98863
54371
15732
47887
64410
98078
17969
00201
53536
08256
62623
97751
90574
23674
68394
16519
17336
91576
68409
79790
19260
45039
53996
84066
40909
22505
97446
24058
11769
02630
77240
76610
24127
2463
54179
02238
76061
86201
07779
06596
62742
54976
78033
53850
88562
27384
48951
84221
69704
48462
14073
57181
86245
13592
23900
07489
03711
91946
75109
72310
76251
94934
37431
23045
66075
91540
83748
69716
04157
48416
14891
489<7
66885
32827
70745
90199
53674
78902
82267
59278
07026
10238
32623
60642
48761
85986
63824
78437
Случайные числа
86996
45049
00654
72748
09723
41490
61051
21219
55920
78185
41172
69770
39247
74599
13936
81647
23701
79210
17880
82010
14751
44185
25264
36874
78858
17904
44860
74420
07953
34365
97669
18029
64688
44124
63529
07954
75385
17720
83612
62154
36473
68797
52242
08759
42117
80820
45630
76965
45260
30847
13151
29616
08388
28546
08143
99718
92467
21744
85965
82469
25757
07469
09343
05610
73977
22597
51378
87817
41540
77930
42123
56080
98832
78494
71831
00420
65891
99546
08575
62329
93115
76531
27182
37444
60377
63432
31742
97711
87089
12430
32535
42341
70278
53750
95218
60012
08360
41705
86492
67663
43929
14223
69533
52785
22961
63555
58220
30323
49321
63898
01437
19589
22557
80824
42925
88642
87142
36648
11687
84754
Таблица А1)
07122
98173
67331
95938
96074
98866
95946
95785
06447
29529
50533
59199
91174
68526
94225
74489
35442
31664
36191
23268
56945
83139
61501
63981
42815
37858
03607
35620
92414
19354
76763
79260
98729
01485
42138
90959
95547
12563
60568
75116
33437
30162
57979
64618
31816
80141
60414
22845
17095
74283
89661
28454
67481
39942
11159
25431
32059
97949
67257
72745
*) Перепечатано с разрешения из Rand Corporation, One Million Random Digits.
Таблицы
513
Продолжение таблицы А
21839 39937
08833 42549
58336 11139
62032 91144
45171 30557
91611 62656
55472 63819
18573 09729
60866 02955
45043 55608
17831 09737
40137 03981
77776 31343
69605 441.04
19916 52934
02606 58552
65183 73160
10740 98914
98642 89822
60139 25601
42902 5П04
82989 95401
13523 66327
74785 72548
77739 44753
58236 98093
94641 38922
15317 99242
00624 09824
23295 02389
70292 13217
08550 22580
94981 10727
70318 46657
27510 92421
41289 29535
37586 71952
65737 05451
87473 53058
89920 40997
27534 88913
93981 94051
47479 00931
75478 47431
53116 04118
60128 35609
86314 49174
74091 53994
90288 82136
82767 60890
79473 75945
07585 18128
14576 97706
40103 95635
26499 09821
07678 56619
87131 35530
44916 11322
71691 51573
93663 25547
38993 54071
97093 57790
39522 83279
36886 97749
03957 53267
81969 21510
76016 66041
46970 58119
83319 26428
05795 70981
90859 05792
43519 51755
29544 37001
73496 92074
43020 79733
33408 05708
19967 77327
24726 95840
80611 24464
03736 00992
49055 19218
28382 83725
91560 95372
52726 30289
58301 24375
63698 78356
93582 73604
10970 86557
83644 94455
74646 79485
28394 79334
11178 32601
16039 47517
05635 81673
87331 80993
65325 30705
47946 09854
89717 88189
83666 61642
02654 94829
75033 43897
09271 05895
50432 88392
52364 78430
13225 89471
20727 91655
92109 76430
15178 10125
69711 71980
05664 32846
09833 49409
50308 68330
02751 82481
63918 13428
81369 11801
76999 37772
45052 16811
89663 37418
50379 93555
80443 12071
47712 67677 51889 70926
72643 64233 97252 17133
97642 33856 54825 5568a
42411 91886 51818 78292
65609 85810 18620 49198
50682 22505
78614 78849
65661 41854
06560 78029
13619 98868
70577 38048
27994 05641
43300 59080
68657 09559
61299 36979
99582 53390
18080 02321
30143 52687
46683 33761
48672 28736
24684 62233
27692 65558
37826 81599
15990 86418
59481 53923
23601 77178
07105 45987
89295 83401
77666 57012
99935 81786
45496 62194
70244 27806
33622 8972$
13249 68163
43094 91733
97740 44905
52264 09700
31034 44631
80327 29829
57996 42605
01692 1*5291
23096 72825
26037 53296
98768 71296
40857 19415
03607 06932
22600 86064
80392 63189
23510 95875
73599 35055
463.57 13244
05809 04898-
19420 60061
47542 23551
84994 13O7L
05749 7665S
28890 75645
97612 34122.
53689 73170
52588 54986
43468 77172
62177 37542:
28737 53214
83722 06961
90285 03818:
98232 59969-
33662 90457
10488 54507
31082 72138
79865 67010-
16840 25538
08766 0845a*
02044 89446
75884 69962
92034 89189
17
819
614
Приложение
Таблицы 515-
Продолжение таблицы А
Продолжение таблицы Л
10203 39157
63864 57186
45006 51623
01839 83286
07708 41627
17655 18629
96137 55079
66495 22010
54585 37425
28180 01067
44655 45433
31321 57930
36218 26166
06853 28955
45231 95235
60484 63181
83577 81518
09724 39466
58504 66886
37033 02248
28026 12852
12831 55496
14507 71736
82424 22539
59133 35497
72031 14923
65161 59905
50062 64153
18116 19026
29105 00954
43398 79666
78711 15270
54489 52503
17324 40078
67297 25163
56959 16184
78207 34228
99508 47528
66199 99811
91987 73491
90207 07120
93586 52497
30675 56395
87159 72173
62416 05579
94121 20967
15672 21474
73641 70391
12794 71143
68577 99878
72815 11383
02748 46178
64389 39466
15516 22467
00120 85500
83125 42402
87638 08719
80440 69636
64596 23484
28174 29215
'46235 15058
60299 47364
33817 42164
73202 32091
25135 24968
44610 70690
40133 95680
20669 81461
22965 39908
71562 10193
37687 36431
42232 87128
11005 00067
14214 19160
16386 62687
32709 57507
39440 67765
01328 67220
13887 31301
22639 94096
19280 37862
32459 85507
67037 33850
69624 75457
87013 84309
82561 65520
22403 74557
31391 43927
65025 74706
01960 86209
27507 80064
27490 65081
53435 89404
54482 70997
41753 36053
86905 40988
84819 15068
37481 20907
25596 43400
51118 04863
00222 26478
52600 02906
89793 67645
97375 11126
93294 12442
35644 97897
78737 93726
80140 88536
30649 91235
41802 53790
34822, 00779
31711 77482
23146 44973
25276 05125
07398 18963
92221 82925
80627 08869
50824 47847
41034 63717
01702 48093
96041 66E52
19646 80758
94000 57166
95469 48064
56068 84979
87874 72484
10290 39575
45219 38479
30555 42290
95045 62490
26860 44549
97037 67297
45328 34152
37271 13166
04285 77365
25091 68407
60067 48628
90064 06280
04787 54631
23752 10000
73671 81592
93295 27011
06609 22483
75877 89720
89020 11700
16835 41673
.95312 18215
24552 78781
27259 08470
85828 60565
38828 71137
85873 17317
39257 65815
52020 97099
60035 35598
46064 94665
05514 24215
69726 75453'
10310 33607
35976 93334
05173 59475
31519 71022
88739 92350
31695 17608
78592 36446
86640 33610
62266 10125
80100 82717
45357 08567
34554 65505
42538 48425
54273 67483
24787 98162
32827 29958
33273 97811
18356 62600
46522 78010
57942 71723
05421 50230
33331 62358
18436 67676
42904 33856
49017 99946
88213 65129
42936 43010
63777 90758
20184 84289
39807 00018
77321 12795
09835 42761
85054 64660
94357 78210
13929 77081
77116 45921
14404 14872
73523, 23638
65237 82139
08780 53120
01858 28266
17638 65818
80125 84984
69743 16618
41686 85487
80967 75537
24148 95247
22989 64262
54147 01638
07529 10668
36379 13588
38653 73761
72327 65811
41133* 06312
15039 81095
40499 67587
46910 72907
15009 81751
10538 10295
70204 91225
30403 98849
75147 49930
20770 '53498
51096 90416
05027 43924
22013 11299
50232 30821
20724 99075
65692 61084
81215 08824
86127 96878
26483 16992
84697 87543
89691 53802
20295 92548
98925 64297
53560 52945
45034 92695
35222 86197
08071 77462
54802 07781
84209 92329
47804 90908
59364 73113
91526 28591
81999 02257
12340 39407
12716 32910
95954 66666
23743 02743
44587 31015
61363 95667
53782 01608
13340 18870
50787 28452
16761 25929
18515 12710
07942 14046
62995 16527
78307 55577
55318 99947
47054 08485
05412 19184
18721 42390
37581 31418
76690 92730
45382 85723
91270 13936
48856 34766
06387 10900
53819 10715
89421 15216
67935 72389
42595 31089
68410 15006
94922 26349
68649 31696
98157 83536
20082 60378
20243 55151
29975 44720
32234 11385
11106 43995
89143 89412
54635 77149
62232 00956
71596 53961
32303 18783
30544 67089
10252 47893
349*71 25146
03372 35800
38741 58353
27204 83187
61100 39538
43836 43466
11580 52823
54993 68001
55334 05736
78715 54507
23625 74643
91397 25614
25997 06100
31517 28366
57010 05808
10867 12748
15635 85910
74962 15346
09098 87381
83463 19773
67213 53160
71632 83429
18299 93559
20914 80542
02091 78176
58805 55911
69387 62573
55140 91189
05392 41064
02607 78441
62534 16601
09067 99793
83182 39647
39331 84989
59117 30291
24954 88932
61089 68699
65166 56622
04524 19251
83969 54252
33188 05218
58711 15872
51594 48982
91970 91498
25225 92624
80409 95407
95769 71506
13782 91933
92168 35393
21486 26920
85157 45893
83669 08353
27128 43137
30073 89021
75544 68156
58655 44844
19874 61262
05181 52254
29763 65051
83029 81689
17249 44596
96263 16342
90668 86972
96241 14487
67889 32552
80640 74650
15635 23958
98557 21505
08418 28472
12897 76800
78043 70078
84549 50498
41504 23286
92091 01383
68266 6576а
90733 35767
38891 87L53
93342 14032
57440 69100
47327 31685
17157 65663
33342 02963
85028 75444
17234 52283
18517 77361
46777 22668
39644 66877
61130 61752
01026 26984
52995 98095
49287 03567
61573 49629
77812 13101
40881 36162
75440 64496
11933 16752
74598 41321
42138 18237
91174 80750
66067 38729
76354 33601
15595 48978
42632 40502
84488 74117
62792 30147
71207 14412
75948 59883
89477 32010
39593 19710
62801 62770
13691 09599
13340 41986
17*
516
Приложение
Таблицы
517
Таблица Б1)
Распределение Пуассона
GO
Значения У^ —:—
О
X
0
1
2
3
4
5
6
7
0,1
1,0000
0,0952
0,0047
0,0002
0,0000
0,0000
0,0000
0,0000
0,2
1,0000
0,1813
0,0175
0,0011
0,0001
0,0000
0,0000
0,0000
0,3
1,0000
0,2592
0,0369
0,0036
0,0003
0,0000
0,0000
0,0000
0,4
1,0000
0,3297
0,0616
0,0079
0,0008
0,0001
0,0000
0,0000
0,5
1,0000
0,3935
0,0902
0,0144
0,0018
0,0002
0,0000
0,0000
0,6
1,0000
0,4512
0,1219
0,0231
0,0034
0,0004
0,0000
0,0000
0,7
1,0000
0,5034
0,1558
0,0341
0,0058
0,0008
0,0001
0,0000
0,8
1,0000
0,5507
0,1912
0,0474
0,0091
0,0014
0,0002
0,0000
0,9
1,0000
0,5934
0,2275
0,0629
0,0135
0,0023
0,0003
0,0000
1,0
1,0000
0,6321
0,2642
0,0803
0,0190
0,0037
0,0006
0,0001
X
0
1
2
3
4
5
6
7
8
9
1,1
1,0000
0,6671
0,3010
0,0996
0,0257
0,0054
0,0010
0,0001
0,0000
0,0000
1>2
1,0000
0,$988
0,3*374
0,1205
0,0338
0,0077
0,0015
0,0003
0,0000
O,OQOQ
1,3
1,0000
0,7275
0,3732
0,1429
0,0431
0,0107
0,0022
0,0004
0,0001
0,0000
1,4
1,0000
0,7534
0,4082
0,1665
0,0537
0,0143
0,0032
0,0006
0,0001
0,0000
1,5
1,0000
0,7769
'0,4422
0,1912
0,0656
0,0186
0,0045
0,0009
0,0002
0,0000
1,6
1,0000
0,7981
0,4751
0,2166
0,0788
0,0237
0,0060
0,0013
0,0003
0,0000
1,7
1,0000
0,8173
0,5068
0,2428
0,0932
0,0296
0,0080
0,0019
0,0004
0,0001
1,8
1,0000
0,8347
0,5372
0,2694
0,1087
0,0364
0,0104
0,0026
0,0006
0,0001
1,9
1,0000
0,8504
0,5663
0,2963
0,1253
0,0441
0,0132
0,0034
0,0008
0,0002
2,0
1,0000
0,8647
0,5940
0,3233
0,1429
0,0527
0,0166
0,0045
0,0011
0,0002
X
0
1
2
3
4
5
6
7
8
9
10
11
12
2,1
1,0000
0,8775
0,6204
0,3504
0,1614
0,0621
0,0204
0,0059
0,0015
0,0003
0,0001
0,0000
0,0000
2,2
1,0000
0,8892
0,6454
0,3773
0,1806
0,0725
0,0249
0,0075
0,0020
0,0005
0,0001
0,0000
0,0000
2,3
1,0000
0,8997
0,6691
0,4040
0,2007
0,0838
0,0300
0,0094
0,0026
0,0006
0,0001
0,0000
0,0000
2,4
1,0000
0,9093
0,6916
0,4303
0,2213
0,0959
0,0357
0,0116
0,0033
0,0009
0,0002
0,0000
0,0000
2,5
1,0000
0,9179
0,7127
0,4562
0,2424
0,1088
0,0420
0,0142
0,0042
0,0011
0,0003
0,0001
0,0000
2,6
1,0000
0,9257
0,7326
0,4816
0,2640
0,1226
0,0490
0,0172
0,0053
0,0015
0,0004
0,0001
0,0000
2,7
1,0000
0,9328
0,7513
0,5064
0,2859
0,1371
0,0567
0,0206
0,0066
0,0019
0,0005
0,0001
0,0000
2,8
1,0000
0,9392
0,7689
0,5305
0,3081
0,1523
0,0651
0,0244
0,0081
0,0024
0,0007
0,0002
0,0000
2,9
1,0000
0,9450
0,7854
0,5540
0,3304
0,1682
0,0742
0,0287
0,0099
0,0031
0,0009
0,0002
0,0001
3,0
1,0000
0,9502
0,8009
0,5768
0,3528
0,1847
0,0839
O,O3J5
0,0П9
0,0038
040011
0,0003
0,0001
*) Перепечатано с разрешения из Molina Е. С, Poisson's Exponential Binom.al
Limit, D. Van Nostrand, New York.
X
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
X
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
X
0
1
2
3
4
5
6
7
8
9
3,1
1,0000
0,9550
^ 0,8153
' 0,5988
0,3752
0,2018
0,0943
0,0388
0,0142
¦ 0,0047
0,0014
0,0004
0,0001
0,0000
0,0000
4,1
1,0000
0,9834
0,9155
. 0,7762
0,5858
0,3907
0,2307
0,1214
0,0573
0,0245
0,0095
0,0034,
0,0011
0,0003
0,0001
0,0000
0,0000
5,1
1,0000
0,9939
0,9628
0,8835
0,7487
0,5769
0,4016
0,2526
0,1440
0,0748
3,2
1,0000
0,9592
0,8288
0,6201
0,3975
0,2194
0,1054
0,0446
0,0168
0,0057
0,0018
0,0005
0,0001
0,0000
0,0000
4,2
1,0000
0,9850
0,9220
0,7898
0,6046
0,4102
0,2469
0,1325
0,063?
0,0279
0,0111
0,0041
0,0014
0,0004
0,0001
0,0000
0,0000
5,2
1,0000
0,9945
0,9658
0,8912
0,7619
0,5939
0,4191
0,2676
0,1551
0,0819
3,3
1,0000
0,9631
0,8414
0,6406
0,4197
0,2374
0,1171
0,0510
0,0198
0,0069
0,0022
0,0006
0,0002
0,0000
0,0000
4,3
1,0000
0,9864
0,9281
0,8026
0,6228
0,4296
0,2633
0,1442
0,0710
0,0317
0,0129
0,0048
0,0017
0,Q005
0,0002
0,0000
0,0000
5,3
1,0000
0,9950
0,9686
0,8984
0,7746
0,6105
0,4365
0,2829
0,1665
0,0894
3,4
1,0000
0,9666
0,8532
0,6603
0,4416
0,2558
0,1295
0,0579
0,0231
O;OO83
0,0027
0,0008
0,0002
0,0001
0,0000
4,4
1,0000
0,9877
0,9337
0,8149
0,6406
0,4488
0,2801
0,1564
0,0786
0,0358
0,0149
0,0057
0,0020
0,0007
0,0002
0,0001
0,0000
5,4
1,0000
0,9955
0,9711
0,9052
0,7867
0,6267
0,4539
0,2983
0,1783
0,0974
e
3,5
1,0000
0,9698
0,8641
0,6792
0,4634
0,2746
0,1424
0,0653
0,0267
0,0099
0,0033
0,0010
0,0003
0,0001
0,0000
4,5
1,0000
0,9889
0,9389
0,8264
0,6577
0,4679
0,2971
0,1689
0,0866
0,0403
0,0171
0,0067
0,0024
0,00Q8
0,0003
0,0001
0,0000
5,5
1,0000
0,9959
0,9734
0,9116
0,7983
0,6425
0,4711
0,3140
0,1905
0,1056
3,6
1,0000
0,9727
0,8743
0,6973
0,48^8
0,2936
0,1559
0,0733
0,0308
0,0117
0,0040
0,0013
0,0004
0,0001
0,0000
в
4,6
1,0000
0,9899
0,9437
0,8374
0,6743
0,4S68
0,3142
0,1820
0,0951
0,0451
0,0195
O,QQ78
0,0029
0,0010
0,0003
0,0001
0,0000
в
5,6
1,0000
0,9963
0,9756
0,9176
0,8094
0,6579
0,4881
0,3297
0,2030
0,1143
Продолжение таблицы Б
3,7
1,0000
0,9753
0,8838
0,7146
0,5058
0,3128
0,1699
0,0818
0,0352
0,0137
0,0048
0,0016
0,0005
0,0001
0,0000
4,7
1,0000
0,9909
0,9482
0,8477
0,6903
0,5054
0,3316
0,1954
0,1040
0,0503
0,0222
0,0090
0,0034
0,(Ю12
0,0004
0,0001
0,0000
5,7
1,0000
0,9967
0,9776
0,9232
0,8200
0,6728
0,5050
0,3456
0,2159
0,1234
3,8
1,0000
0,9776
0,8926
0,7311
0,5265
0,3322
0,1844
0,0909
0,0401
0,0160
0,0058
0,0019
0,0006
0,0002
0,0000
4,8
1,0000
0,9918
0,9523
0,3575
0,7058
0,5237
0,3490
0,2092
0,1133
0,0558
0,0251
0,0104
0,0440
0,0014
0,0005
0,0001
0,0000
5,8
1,0000
0,9970
0,9794
0,9285
0,8300
0,6873
0,5217
0,3616
0,2290
0,1328
3,9
1,0000
0,9798
0,9008
0,7469
0,5468
0,3516
0,1994
0,1005
0,0454
0,0185
0,0069
0,0023
0,0007
0,Q002
*0,000l
4,9
1,0000
0,9926
0,9561
0,8667
0,7207
0,5418
0,3665
0,2233
0,1231
0,0618'
0,0283
0,0120
0,0047
0,0017
0,0006
0,0002
0,0001
5,9
1,0000
0,9973
0,9811
0,9334
0,8396
0,7013
0,5381
0,3776
0,2424
0,1426
4,0
1,0000
0,9817
0,9084
0,7619
0,5665
0,3712
0,2149
0,1107
0,0511
0,0214
0,0081
0,0028
0,0009
0,0003
0,0001
5,0
1,0000
0,9933
0,9596
0,8753
0,7350
0,5595
0,3840
0,2378
0,1334
0,0681
0,0318
0,0137
0,0055
0,0020
0,0007
0,0002
0,0001
6.0
J,0000
0,9975
0,9826
0,9380
0,8488
0,7149
0,5543
0,3937
0,2560
0,1528
17*
819
Продолжение таблицы Б
X
10
и
12
13
14
15
16
17
18
X
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
X
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
0,0356
0,0156
0,0063
0,0024
0,0008
0,0003
0,0001
0,0000
0,0000
6,1
1,0000
0,9978
0,9841
0,9423
0,8575
0,7281
0,5702
0,4098
0,2699
ОД633
0,0910
0,0469
0,0224
0,0100
0,0042
0,0016
0,0006
0,0002
0,0001
0,0000
7,1
1,0000
0,9992
0,9933
0,9725
0,9233
0,8359
0,7119
0,5651
0,4162
0,2840
0,1798
0,1058
0,0580
0,0297
0,0143
0,0065
0,0028
0,0011
0,0004
0,0002
0,0001
0,0000'
5,2
0,0397
0,0177
0,0073
0,0028
0,0010
0,0003
0,0001
0,0000
0,0000
6,2
1,0000
0,9980
0,9854
0,9464
0,8658
0,7408
0,5859
0,4258
0,2840
0,1741
0,0984
0,0514
0,0250
0,0113
0,0048
0,0019
0,0007
0,0003
0,0001
0,0000
7,2
1,0000
0,9993
0,9939
0,9745
0,9281
0,8445
0,7241
0,5796
0,4311
0,2973
0,1904
0,1133
0,0629
0,0327
0,0159
0,0073
0,0031
0,0013
0,0005
0,0002
0,0001
0,0000
5,3
.0,0441
0,0200
0,0084
0,0033
0,0012
0,0004
0,0001
0,0000
0,0000
6,3
1,0000
0,9982
0,9866
0,9502
0,8736
0,7531
0,6012
0,4418
0,2983
0,1852
0,1061
0,0563
0,0277
0,0127
0,0055
0,0022
-0,0008
0,0003
0,0001
0,0000
7,3
1,0000
0,9993
0,9944
0,9764
0,9326
0,8527
0,7360
0,5940
0,4459
0,3108
0,2012
0,1212
0,0681
0,0358
0,0176
0,0082
0,0036
0,0015
0,0006
0,0002
0,0001
0,0000
5,4
0,0488
0;0225
0,0096
0,0038
0;0014
0,0005
0,0002
0,0001
0,0000
6,4
1,0000
0,9983
0,9877
0,9537
0,8811
0,7649
0,6163
0,4577
0,3127
0,1967
0,1142
0,0614
0,0307
0,0143
0,0063
0,0026
0,0010
0,0004
0,0001
0,0000
7,4
1,0000
0,9994
0,9949
0,9781
0,9368
0,8605
0,7474
0,6080
0,4607
0,3243
0,2123
0,1293
0,0735
0,0391
0,0195
0,0092
0,0041
0,0017
0,0007
0,0003
0,0001
0,0000.
в
5,5
0,0538
0,0253
0,0110
0,0045
0,00 i 7
0,0006
0,0002
0,0001
0,0000
6,5
1,0000
0,9985
0,9887
0,9570
0,8882
0,7763
0,6310
0,4735
0,3272
0,2084
0,1226
0,0688
0,0339
0,0160
0,0071
0,0030
0,0012
0,0004
0,0002
0,0001
7,5
1,0000
0,9994
0,9953
0,9797
0,9409
.0,8679
0,7586
0,6218
0,4754
0,3380
0,2236
0,1378
0,0792
0,0427
0,0216
0,0103
0,0046
0,0020
0,0008
0,0003
0,0001
0,0000
5,6
0,0591
0,0282
0,0125
0,0051
0,0030
0,0007
0,0002
0,0001
0,0000
0
6,6
1,0000
0,9986
0,9897
0,9600
0,8948
0,7873
0,6453
0,4892
0,3419
0,2204
0,1314
0,0726
0,0373
• 0,0179
0;0080
. 0,0034
0,0014
0,0005
0,0002
0,0001
в
7,6
1,0000
0,9995
0,9957
0,9812
0,9446
0,8751
0,7693
0,6354
0,4900
0,3518
0,2351
0,1465
0,0852
0,0464
0,0238
0,0114
0,0052
0,0022
0,0009
0,0004
0,0001
0,0000
,7
0,0648
0,0314
0,0141
0,0059
0,0023
0,0009
0,0003
0,0001
0,0000
6,7
1,0000
0,9988
0,9905
0,9629
0,9012
0,7978
0,6594
0,5047
0,3567
0,2327
0,1404
0,0786
0,0409
0,0199
0,0091
0,0039
0,0016
0,0006
0,0002
0,0001
7,7
1,0000
0,9995
0,9961
0,9826
0,9482
0,8819
0,7797
(Г,6486
0,5044
0,3657
0,2469
0,1555
0,0915
0,0504
0,0261
0,0127
0,0059
0,0026
0,0011
0,0004
0,0002
0,0001
5,8
0,0708
0,0349
0,0160
0,0068
0,0027
0,0010
0,0004
0,0001
0,0000
6,8
1,0000
0,9989
0,9913
0,9656
0,9072
0,8080
0,6730
0,5201
0,3715
0,2452.
0,1498
0,0849
0,0448
0,0221
0,0102
0,0044
0,0018
0,0007
0,0003-
0,0001
7,8
1,0000
0,9996
0,9964
0,9839
0,9515
0,8883
0,7897
0,6616
0,5188
0,3796
0,2589
0,1648
0,0980
0,0546
0,0286
0,0141
0,0066
0,0029
0,0012
0,0005
0,0002
0,0001
5,9
0,0772
0,0386
0,0179
0,0078
0,0031
0,0012
0,0004
0,0001
0,0000
6,9
1,0000
0,9990
0,9920
0,9680
0,9129
0,8177
0,6863
0,5353
0,3864
0,2580
0,1505
0,0916
0,0490
0,0245
0,0115
0,0050
0,0021
0,0008
0,0003
0,0001
7,9
1,0000
0,9996
0,9967
0,9851
0,9547
0,8945
0,7994
0,6743
0,5330
0,3935
0,2710
0,1743
0,1048
0,0591
0,0313
0,0156
0,0074
0,0033
0,0014
0,0006
0,0002
0,0001
6,0
0,0839
0,0426
0,0201
0,0088
0,0036
0,0014
0,0005
0,0002
0,0001
7,0
1,0000
0,9991
0,9927
0,9704
0,9182
0,8270
0,6993
0,5503
0,4013
0,2709
0,1695
0,0985
0,0534
0,0270
0,0128
0,0057
0,0024
0,0010
0,0004
0,0001
8,0
1,0000
0,9997
0,9970
0,9862
0,9576
0,9004
0,8088
0,6866
0,5470
0,4075
0,2834
0,1841
0,1119
0,0638
0,0342
0,0173
0,0082
0,0037
0,0016
0,0006
0,0003
0,0001
10
и
12
13
14
15
16
17
18
19
20
21
22
23
Продолжение таблицы Б
8,1 8,2 8,3 8,4 8,5
1,0000 1,0000 1,0000 1,0000 1,0001» ~
0,9997 0,9997 0,9998 0,9998 0,9948
0,9972 0,9У75 0,9977 0,9979 0,99*1
0,9873 0,9882 0,9891 0,9900 0,9907
0,9604 0,9630 0,9654 0,9677 0,9699
0,9060 0,9113 0,9163 0,9211 0,9256
0,81*78 0,8264 0,8347 0,8427 0,8504
0,6987 0,7104 0,7219 0,7330 0,7438
0,5609 0,5746 0,5881 0,6013 0,6144
0,4214 0,4353 0,4493 0,4631 0,4769
8,6
8,8
8,9
9,0
1,0000
0,9998
0,9982
0,9914
1,0000
0,9998
0,9984
0,992 1
0,9719 0,9738
1,0000
0,9998
0,99X5
0,9927
0,9756
1,0000
0,9999
0,9987
0,9932
0,9772
1,0000
0,9999
0,9488
0,9938
0,9788
0,9299
0,8578
0,7543
0,6272
0,4906
0,9340 0,9379
0,8648 0,8716
0,7645
0,63^8
0,5042
0,7744
0,6522
0,5177
0,9416 0,9450
0,8781 0,8843
0,7840
0,664 3
0,5311
0,7932
0,6761
0,5443
0,2959 0,3085 0,3212 0,3341 0,3470 0,3600 0,3731 0,3863 0.39У4 0,412ft
0,1942 0,2045 0,2150 0,2257 0,2366 0,2478 0,2591 0,270ft 0,2X22 0,'294()
0,1193 0,1269 0,1348 0,1429 0,1513 0,1600 0,1689 0,1780 0,1874 0,11ГО
0,0687 0,0739 0,0793 0,0850 0,0909 0,0971 0,1035 0,1102 0,1171 0,1242
0,0372 0,0405 0,0439 0,0476 0,0514 0,0555 0,0597 0,0642 0,0689 0,0734
0,0190 0,0209 0,0229 0,0251 0,0274 0,0299 0,0325 0,0353 0,0383 0,041*
0,0092 0,0102 0,0113 0,0125 0,0138 0,0152 0,0168 0,0184 0,0202 U,'iJM
0,0042 0,0047 0,0051 0,0059 0,0066 0,0074 0,0082 0,0091 0,0101 0()|||
0,0018 0,0021 0,0023 0,0027 0,0030 0,0034 0,0038 0,0043 0,004Х 0,005*
0,0008 0,0009 0,0010 0,0011 0,0013 0,0015 0,0017 0,0019 0,0022' 0,0024
0,0003 0,0003 0,0004 0,0005
0,0001 0,0001 0,0002 0,0002
0,0000 0,0000 0,0001 0,0001
0,0000 0,0000 o.oooo 0,0000
0,0005 0,0006 0,0007 0,0008 0,0009 0,0011
0,0002 0,0002 0,0003 0,0003 0,0004 0,0004
0,0001 0,0001 0,0001 0,0001 0,0002 0/Ю< 12
0,0000 0,0000 0,0000 0,0000 0,0001 o|ooo I
и
X
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
9,1
1,0000
0,9999
0,9989
0,9942
0,9802
0,9483
0,8902
0,8022
0,6877
0,5574
0,4258
0,3059
0,2068
0,13 16
0,0790
0,0448
0,0240
0,0122
0,0059
0,0027
0,0012
0,0005
0,0002
0,0001
0,0000
9,2
1,0000
0,9999
0,9990
0,9947
0,9816
0,9514
0,8959
0,8108
0,6990
0,5704
0,4389
0,3180
0,2168
0,1393
0,0844
0,0483
0,0262
0,0135
0,0066
0,003 I
0,0014
0,0006
0,0002
0,0001
0,0000
9,3
1,0000
0,9999
0,9991
0,9951
0,9828
0,9544
0,9014
0,8192
0,7101
0,5832
0,4521
0,3301
0,2270
0,1471
0,0900
0,0529
0,0285
0,0148
0,0073
0,0034
0,0015
0,0007
0,0003
0,0001
0,0000
9,4
1,0000
0,9999
0,9991
0,4955
0,9840
0,9571
0,9065
0,8273
0,7208
0,5958
0,4651
0,3424
0,2374
0,1552
0,0958
0,0559
0,0309
0,0162
0,008 1
0,0038
0,0017
0,0008
0,0003
0,0001
0,0000
1,0000
0,9999
0,9992
О,99ЬХ
0,9851
0,9597
0,9115
0,8351
0,73 I 3
0,6082*
0,4782
0,3547
0,2480
0,1636
0,1019
0.0600
0,0335
0,0177
0,00X9
0,0043
0,0020
0,0009
0,0004
0,0001
0,0001
9,6
1,0000
0,9999
0,9993
0,9962
0,9862
0,9622
О,9|62
0,8426
0,7416
0,6204
0,4911
0,3671
0,25X8
0,1721
0,108 |
0,0643
0,0362
0,0194
0,0098
0,0048
0,0022
0,0010
0,0004
0,1H02
0,0001
9,7
1,000V)
0,9999
0,9993
0,9965
0,9871
0,9645
0,9207
0,8498
0,7515
0,6324
0,5040
0,3795
0,2697
0,1 809
0,1147
0,0688
0,0391
0,021 1
0,0 IDS
0,0053
0,0025
и,001 1
0,0005
0,0002
0,0001
9,S
i ,0000
0,9999
0/)994
0,9967
0,98X0
0,9667
0,9250
О,85(»7
0,7612
0,6442
0,5168
0,3920
0,2807
0,1899
0,1214
0,0735
0,0421
0,0230
0,01 19
0,0059
;>,ОО28
0,001 1
0,0005
0,0002
0,0001
9,9
1,0000
1,0000
0,9995
0,9970
0,9889
0,96X8
0,9290
0,8634
0,7706
0,6558
0,5295
0,4045
0,2919
0,1991
0,1284
0,0784
0,0454
0,0249
0,0130
0,0065
0,003 1
0,0014
0,0006
0,0003
0,0001
10
1,0000
1,0000
0,9995
0,99
0,9X97
0,9707
0,9329
0,8699
0,7798
0,6672
0,5421
0,41 70
0,3032
0,20X4
0,1355
0,0X35
0,04X7
0,0270
0,0143
0,00 '2
0,0015
0,0016
0,0007
0,0003
0,0001
17**
К>ЮЮЮЮ MKJbJbJKJ t—u_iw-t-.i-i t-a^-iwwk-i
^OOvja\Ul 41ЫЮ-О Ю 00 sj ON чУ» 4^.и»Ю^-О
ррррр
оЪЪЪЪ
о с
о с
р р о рр р р ро о
*" > о о о о
> о о о о
) >— ГО 4^ ЧО
о о
§2
к».
рррро рр о о о
г о с
> О С
1§\
ооооо
ооооо
88888
88822
ооооо ооооо
1Ш\
> о о
3 О О
> о о
> о о
рррр о
О 0*0*0 О
ооооо
ооооо
ооооо
5 О О О С
> о о о с
> о о о с
> О —• t-J -
р орр о
оооог
о о о о с
ррррр
о о оЪЪ
ооооо
ооооо
ррррр
о*Ъ 0*0*0
ооооо
О О О '— fj
>— го ил О О
р ор о о
'—> l-«* s_J «^i. С
ооооо
О О — Ю L/i
ы 51 W Э\ О
ррр о о
сЪЪ о "о
о о о о —
р р р р о
о *о о *о *о
О О О '— to
ррр
о о "о "о "о
О О О — К)
>— U» ON — — '
чл О >— Оч и>
ррррр
о "о "о ЪЪ
о о —* ю -и
-й- sj 4». чл К»
О ON — О -4
ООООО
Ъ Ъ Ъ Ъ
oppp о
Ъ Ъ Ъ "
о о о — —
Ui 1л 00 W ОО
On 00 чО >— sj
ррррр ррррр рррро оооос
ооооо
"Г§881
>*0*О*0 *О*с
> о о — — i
ррррр
— *t- ~к> "k) "w
О 4^ О On JS.
-^ O\D vo
•— ЧО ЧО s»J >—'
ррррр*
рр о о о
оЪоо"-
рр о с о
о о**—**—"ю
bj On О <-л ю
sj Lk) — чЛ ОО
ррррр
On О On Ui (ч)
ррррр
sj Ki 4^ О -О
4* ОО — Cft OK
ррррр
ррррр
-4 -а о W чл
ррррр
чУ» ON hJ ОС ЧО
OOWIAU
ррр о о
vj "- Ul Ы —
ос 4*« О U»- ч©
O 4 CO rJ J
ел О 4i. oo ON
ppppp
р р О р
ао чо "чо "чс ~
4
С О
О 4»- - I ос чО
О On 4^. чС On
М С - ^ Ы
рррр о
3 C3S VC ^ ^
» — О -й-
N Lft О <*»
C Ъ с С чС
•^- О ос чС чо
j сх - 4 о
WOJ — CO W G ОС vC vC VC
О^ Ю >_Л — О tO fO NJ sj \Q
004^Ючл»-* 0\04^ГО>—
ООООО ООООО
ррррр
ЧО ON — чУ» sj
рр о о о
ЧчЪ>*чс''чОч*чо'ч0
ОО чо чС чо чо
j 4 о
ррр^
<чО**чО*чО*С
^О ^ \D С
Сл ОС ЧО С
»— оо оо с
PPJ-J-J-
"чо"чс*"о О*О
NO ЧС О С -
„О „© — j- —
\о **чС "о О *О
чо чо - - -
ЧО "-О
UA ЧО
121
о --. ¦
?3S
ОООО— —«_»-.»_
_> о •
.J^sJ-
kjmoooo
рррр о
" Ъ
р
"о
о
К)
NO — ОО W ON
ррррр
'о "о о"— ^-»
ррpppL рр op O-
_5 sj 4». чО
в»ы оо uj ui
ON О ЧО V7I и—
^^ ^>-> On ОО чО ^>^ vO ЧО *О С
—> \О и, > ОчоочОчОС
Cr4S- UJ sji*— и» ^чЛ-чУ) 06Г С
?ррр О. О-О5 О О1**'
5" ^О^ ^О ^С7 ^5 vd- *^С? |^0 1^С- ^w^X
5 О <,
> о с
?8
I
I
I
Таблица В 1)
Нормальное распределение
Ф(Х) =
1
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
,0
> —
,з
,4
,5
,6
,7
1,8
0,00
0,50000
0,53983
0,57926
0,61791
0,65542
0,69146
0,72575
0,75804
0,78814
0,81594
0,84134
0,86433
0,88493
0,90320
0,91924
0,93319
0,94520
0,95543
0,96407
0,97128
0701
0,50399
0,54380
0,58317
0,62 Г 72
0,65910
0,69497
0;729О7
0,76115
0,79 ШЗ
0,81859
0,84375
0,86650
0,886%
0,90490
0,92073
0,93448
0,94630
0,95637
0,96485
0,97193
0,02
0,50798
0,54776
0,58706
0,62552
0,66276
0,69847
0,73237
0,76424
0,79389
0,82121
0,84614
0,86864
0,88877
0,90658
0,92220
0,93574
0,94738
0,95728
0,96562
0,97257
0,03
0,51197
0,55172
0,59095
0,62930
0,66640
0,70194
0,73565
0,76730
0,7%73
0,82381
0,84850
0,87076
0,89065
0,90824
0,92364
0,93699
0,94845
0,95818
0,96638
0;97320
0,04
0,51595
0,55567
0,50483
0,63307
0,67003
0,70540
0,73891
0,77035
0,79955
0,82639
0,85083
О,&7286
0,89251
0,90988
0,92507
0,93822
0,94950
0,95907
0,96712
0;97381
0,05
0,51994
0,55962
0,59871
0,63683
0;67364
0,70884
0,74215
0,77337
0,80234
0,82894
0,85314
0,87493
0,89435
0,91149
0,92647
0,93943
0,95053
0,95994
0,96784
0,97441
0,06
0,52392
0,56356
0,60257
0,64058
0,67724
0,71226
0,74537
0,77637
0;805И
0,83147
0,85543
0,87698
0,89617
0ДГ309
0,^2786
0,94062
0,95154
0,96080
0,96856
0,97500
0,07
0,52790
0,56749
0,66642
0,64431
0,68082
0,71566
0,74857
0,77935
0,80785
0,83398
0,85769
0,87900
0,89796
0,91466
0;92922
0,94179
0,95254
0,96164
0,96926
0,97558
0,08
0,53188
0,57142
0,61026
0,64803
0,68439
0,71904
0,75175
0,78230
0,81057
0,83646
0,85993
0,88100
0,89973
0,91621
0,93056
0,94295
0,95352
0,96246
0,96995
0,97615
0,09
0,535&б
0,57535
0,6 К09
0,65171
0,68793
0,72240
0,75490
0,78524
0,81327
0,83891
0,86214
0,88298
0,90147
0,91774
0,93189
0,94408
0,95449
0,96327
0,97062
0,97670
Перепечатано с разрешения из Pearson, Hartley, Biometrika Tables for Statisticians, Vol. 1, 1958, pp. 104—108.
Продолжение таблицы в
X
2,0
2,1
2 2
2,3
>
2,4
2,5
2,6
2,7
2,8
2,9
3,0
3,1
3,2
3,3
3,4
3,5
3,6
3,7
3,8
3,9
0,00
0,97725
0?98214
0,98610
0,98928
0,99180
0,99379
0,99534
0,99653
0,99744
0,99813
0,99865
0,99903
0,99931
0,99952
0,99966
0,99977
0,99984
0,99989
0,99993
0,99995
0,01
0,97778
0,98257
0,98645
0;98956
0,99202
0,99396
0,99547
0,99664
0,99752
0,99819
0,99869
0,99906
0,99934
0,99953
0,99968
0,99978
0,99985
0,99990
0,99993
0,99995
0,02
0,97831
0,98300
0,98679
0,98983
0,99224
0,99413
0,99560
0,99674
0,99760
0,99825
0,99874
0,99910
0,99936
0,99957
0,99969
0,99978
0,99985
0,99990
0,99993
0,99996
0,03
0,97882
0,98341
0,98713
0,99010
0,99245
0,99430
0,99573
0,99683
0,99767
0,99831
0,99878
0,99913
0,99938
0,99957
0,99970
0,99979
0,99986
0,99990
0;99994
0,99996
0,04
0,97932
0,98382
0,98745
0,99036
0,99266
0,99446
0,99585
0,99693
0,99774
0,99836
0,99882
0,99916
0,99940
0,99958
0,99971
0,99980
0,99986
0,99991
0,99994
0,99996
0,05
0,97982
0,98422
0,98778
0,99061
0,99286
0,99461
0,99598
0,99702
0,99781
0,99841
0,99886
О;99918
0,99942
0,99960
0,99972
0,99981
0,99987
0,99991
0,99994
0,99996
0,06
0,98030
0,98461
0,98809
0,99086
0,99305
0,99477
0,99609
0,99711
0,99788
0,99846
0,99889
0,99921
0;99944
0,99961
0,99973
0,99981
0,99987
0,99992
0,99994
0;99996
0,07
0,98077
0,98500
0,98840
0,99111
0,99324
0,99492
0,99621
0,99720
0,99795
0,99851
0,99893
0,99924
0,99946
0,99962
0,99974
0,99982
0,99988
0,99992
0,99995
0,99996
0,08
0,98124
0,98537
0,98870
0,99134
0,99343
0,99506
0,99632
0,99728
0,99801
0,99856
0,99897
0,99926
0,99948
0,99964
0,99975
0,99983
0,99988
0,99992
0,99995
0,99997
0,09
0,98169
0,98574
0,98899
0,99158
0,99361
0,99520
0,99643
0,99736
0,99807
0,99861
0,99900
0,99929
0,99950
0,99965
0,99976
0,99983
0,99989
0,99992
0,99995
0,99997
Процентные точки (Up) нормального распределения Таблица Г
ир
1 f*
Величины Up таковы, что Q)(UP)= 1 е~и*/2 du~P
У 2л J
0,000
0,001
0,002
0,003
0,004 0,005
0,006
0,007
0,008
0,009
0,50
0,51
0,52
0,53
0;54
0,55
0,56
0,57
0,58
0,59
0,60
0,61
0,62
0,63
0,64
0,65
0,66
0,67
0,68
0,69
0,70
0,71
0,72
0,73
0,74
0,0000
0,0251
0,0502
0,0753
0,1004
0,1257
0,1510
0,1764
0,2019
0,2275
0,2533
0,2793
0,3055
0,3319
0,3585
0,3853
0,4125
0,4399
0,4677
0,4959
0,5244
0,5534
0,5828
0,6128
0,6433
0,0025
0,0276
0,0527
0,0778
0,1030
0,1282
0,1535
0,1789
0,2045
0,2301
0,2559
0,2819
0,3081
0,3345
0,3611
0,3880
0,4152
0,4427
0,4705
0,4987
0,5273
0,5563
0,5858
0,6158
0,6464
*) Перепечатано с разрешения
0,0050
0,0301
0,0552
0,0803
0,1055
0,1307
0,1560
0,1815
0,2070
0,2327
0,2585
0,2845
0,3107
0,3372
0,3638
0,3907
0,4179
0,4454
0,4733
0,5015
0,5302
0,5592
0,5888
0,6189
0,6495
из Pearson,
0,0075
0,0326
0,0577
0,0828
0,1080
0,1332
0,1586
0,1840
0,2096
0,2353
0,2611
0,2871
0,3134
0,3398
0,3665
О;3934
0,4207
0,4482
0,4761
0,5044
0,5330
0,5622
0,5918
0,6219
0,6526
0,0100
0,0351
0,0602
0,0853
0,1105
0,1358
0,1611
0,1866
0,2121
0,2378
0,2637
0,2898
0,3160
0,3425
0,3692
0,3961
0,4234
0,4510
0,4789
0,5072
0,5359
0,5651
0,5948
0,6250
0,6557
Hartley, Biometrika Tables
0,0125
0,0376
0,0627
0,0878
0,1130
0,1383
0,1637
0,1891
0,2147
0,2404
0,2663
0,2924
0,3186
0,3451
0,3719
0,3989
0,4261
0,4538
0,4817
0,5101
0,5388
0,5681
0,5978
0,6280
0,6588
0,0150
0,0401
0,0652
0,0904
0,1156
0,1408
0,1662
0,1917
0,2173
0,2430
0,2689
0,2950
0,3213
0,3478
0,3745
0,4016
0,4289
0,4565
0,4845
0,5129
0,5417
0,5710
0,6008
0,6311
0,6620
for Statisticians, Vol.
0,0175
0,0426
0;0677
0,0929
0,1181
0,1434
0,1687
0,1942
0,2198
0,2456
O;2715
0,2976
0,3239
0,3505
0,3772
0,4043
0,4316
0,4593
0,4874
0,5158
0,5446
0,5740
0,6038
0,6341
0,6651
1, 1958, p.
0,0201
0,0451
0,0702
0,0954
0,1206
0,1459
0,1713
0,1968
0,2224
0,2482
0,2741
0,3002
0,3266
0,3531
0,3799
0,4070
0,4344
0,4621
0,4902
0,5187
0,5476
0,5769
0,6068
0,6372
0,6682
112.
0,0226
0,0476
0,0728
0,0979
0,1231
0,1484
0,1738
0,1993
0,2250
0,2508
0,2767
0,3029
0,3292
0,3558
0,3826
0,4097
0,4372
0,4649
0,4930
0,5215
0,5505
0,5799
0,6098
0,6403
0,6713'
о >л oo n oo Tf — О © rN »/-> -—
r^r^r^oooo ooononon© © »—
o4 cT ©~ ©* ©" ©~ ©~ ©~ o *-T г-Г*-Г
oo
> *— 1Л> Tf OO OO VO Ю ON VO CO С
¦¦¦* С*Ч C4^ ^^ CO ^^" l/S ^O Г*** OO СЭ C4^ СЭ
on го vo on m г- О ^ oo гч г^^чО»-<
o ^ r-r- oo оодм^Ф Q о -- N
©~ ©~ ©~ о4 ©" ©Л©л©л©"Г ГГ ^Г
© © © CN <O h- w M фо ON СЧ —< —«
^ «ovo© oo - - oo m mn t h
J ON VO CO (?n| fN *O •—• i/")
< *—i О ON О т}" <Sl I
I VO -^ VO rj- гЧ ГЧ
1 ON CO VD О ^" OO
ON CO — Г^ VO
©"б"©*4©-:
00 *—¦* TJ" ON tJ" ^" fs|
n О vo vo oo »o vo
"~* '—•'—' ГО ON fN»
oo
©
Q©
^1 iot^ (Ч1Л-Н «Ot^VO©(N © © T
ON N h io ШО\ VO00VO<Nl>- VOior
^Г V0©«00«0 —« Г- rt <N © 0<Nt
О. ©.'-''—счгч ^ гл rt- >л vp г-oo
oo со о © со
О ^ ^ (NM
Tfr ON © Г-!
vo oo Ov ^i tn
p'dd'd'd' ©"*Q ©**©*" —^
•'—•© Г^-^'ОГ4)^^ r^OOV^fOrO ^ >H ih rf м
i Г— "—' •/^ON-^j-ONtJ" OVOcOOOO OOON^tI-
_л л"~1^-,г— ГЧ COCOTtUO^O VOr-ON^-,
©OOri"O\ Tf"OON^-ON rt ON (^ — VO OO IT) >Л "Л 1Л h- \O OO
t VO OO N VO (NONVOVOVO О f^ О О (N OOONlOOOO ^¦VOVO
OO - rt OO ^ "Л OO M VO О TtONrfONTt ОМЛ (N OMXJ Г^ООГЧ
VO t^ ^ Г^ OO OOOOONONO ©O — r—.fNJ ГЧГ^^1"Т^1Г) VO f^ ON
OO
VO
©©©©©"
oooor^Orf m©r
О (N IO ONf) 00 1Л П (N (N
00 «• Tf h -и ^t OO M VO О
VO r-^ Г- Г- OO OO^ OO ON^ ON О
© © © © © ©
i ON © Г4) © f^J f^* ON 00 ^O ^" © ON ON
1 CO OO CO ON •/") •—• ON f*^ VO IT^ r—* ON О
'^-^-CN D W ^t ^t in VOtJ~-ON©-
(N
I VO (N — VO Г-OO^hOON COONOOcOfNl, VO tJ- Г4- O\ VO
i •—" ON OO OO CD ^" •—• О >-~* t—• VO •"* ГО ГО ^" ГЧ ^O ^" i/^
OO »-^ lO ON T^ OO ГО OO CO OO т^ ^-* OO ^O *O VO ON t^~ VO
©" ©"©"о"
n00(Nrf O
vO 00 N VO —
O n h о Tf
TtCOTfO>0 VO 00 — OO 00 ONl^-OO^rO
VO О VD |Л VO ^ О iO iO ^t Tf©©rOVO
o тг r ло\ ^2oo(Ni(N ooTt
00 ooooononon ©^ о r- — rj r)n
<S ©**©"oK©"*©л -^т-^^Г^Г^Г ^г^г
tj- io oo л
vo h 00 о
^Ггf
(Nnt OOrOOON © — M n Tf «riVOr^OO
л OC^ OO^ 00^ ОС 00 00^ 00 OO ON^ ON ON ON ON ON On On ON
©©©©© ©©©©© ©©©©© ©©©©O ©Q ©"©"©"
Таблица Д г)
Процентные точки ^2-распределения
Величины %v р таковы, что Р =
%%, р
2W.i
\ P
V N,
1
2
3
4
5
6
7
8
9
10
II
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
11
28
19
30
40
50
60
70
80
90
100
1
' (v/2)
0,005
0,00004
0,0100
0,0717
0,2070
0,4117
0,6757
0,9893
1,344
1,735
2,156
2,603
3,074
3,565
4,075
4,601
5,142
5,697
6,265
6,844
7,434
8,034
8,643
9,260
9,886
10,52
11,16
11,81
12,46
13,12
13,79
20,71
27,99
35,53
43,28
51,17
59,20
67,33
Г V/2 - 1
\
0,010
0,00016
0,0201
0,1148
0,2971
0,5543
0,8721
1,239
1,646
2,088
2,558
3,053
3,571
4,107
4,660
5,229
5,812
6,408
7,015
7,633
8,260
8,$97
9,542
10,20
10,86
11,52
12,20
12,68
13,56
14,26
14,95
22,16
29,71
37,48
45,44
53,54
61,75
70,06
0,025
0,00098
0,0506
0,2158
0,4844
0,8312
1,2373
1,690
2,180
2,700
3,247
3,816
4,404
5,009
5,629
6,262
6,908
7,564
8,231
8,907
9,591
10,28
10,98
11,69
12,40
13,12
13,84
14,57
15,31
16,05
16,79
24,43
32,36
40,48
48,76
57,15
65,65
74,22
0
0,050
0,00393
0,1026
0,3518
0,7107
1,145
1,635
2,167
2,733
3,325
3,940
4,575
5,226
5,892
6,571
7,261
7,962
8,672
9,390
10,12
10,85
11,59
12,34
13,09
13;85
14,61
15,38
16,15
16,93
17,71
18,49
26,51
34,76
43,19
51,74
60,39
69,13
77,93
0,100
0,01579
0,2107
0,5844
1,064
1,610
2,204
2,833
3,490
4,168
4,865
5,578
6,304
7,041
7,790
8,547
9, за
10,09
10,86
11,65
12,44
13,24
14,04
14,85
15,66
16,47
17,59
18,11
18,94-
19,77
20,60
29,05
37,69
46,46
55,33
64,28
73,29
82,36
Я
0,250
0,1015
0,5754
1,213
1,923
2,675
3,455
4,255
5,071
5,899
6,737
7,584
8,438
9,299
10,17
11,04
11,91
12,79
13,68
14,56
15,45
16,34
17,24
18,14
19,04
19,94
20,84
21,75
22,66
23,57
24,48
33,66
42,94
52,29
61,70
71,14
80,62
90,13
•у р
0,500
0,4549
1,386
2,366
3,357
4,351
5,348
6,346
7,344
8,343
9,342
10,34
11,34
12,34
13,34
14,34
15,34
16,34
17,34
18,34
19,34
20,34
21,34
22,34
23,34
24,34
25,34
26,34
2t,34
28,34
29,34
39,34
49,33
59,33
69,33
79,33
89,33
99,33
х) Перепечатано с разрешения из Pearson, Hartley, Biometrika Tables for
Statisticians, Vol. 1, 1958, pp. 130, 131.
\ P
V \
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
40
50
60
70
80
90
100
0,750
1,323
2,773
4,108
5,385
6,626
7,841
9,037
10,22
11,39
12,55
13,70
14,85
15,98
17,12
38,25
19,37
20,49
21,60
22;72
23,83
24,93
26,04
27,14
28,24
29,34
30,43
31,53
32,62
33,71
34,80
45,62
56,33
66,98
77,58
88,13
98,65
109,1
0,900
2,706
4,605
6,251
7,779
9,236
10,64
12,02
13,36
14,68
15,99
17,28
18,55
19,81
21,06
22,31
23,54
24,77
25,99
27,20
28,41
29,62
30,81
32,01
33,20
34,38
35,56
36,74
37,92
39,09
40,26
51,80
63,17
74,40
'85,53
96,58
107,6
118,5
Приложение
0,950
3,841
5,991
7,815
9,488
11,07
12,59
14,07
15,51
16,92
18,31
19,68
21,03
22,36
23,68
25,00
26,30
27,59
28,87
30,14
31,41
32,67
33,92
35,17
36,42
37,65
38,89
40,11
41,34
42,56
43,77
55,76
67,50
79,08
90,53
101,9
113,1
124,3
0,975
5,024
7,378
9,348
11,14
12,83
14,45
16,01
17,53
19,02
20,48
21,92
23,34
24,74
26,12
27,49
28,85
30,19
31,53
32,85
34,17
35,48
36,78
38,08
39,36
40,65
41,92
43,19
44,46
45,72
46,98
59,34
71,42
83,30
95,02
106,6
118,1
129,6
Продолжение
0,990
6,635
9,210
11,34
13,28
15,09
16,81
18,48
20,09
21,67
23,21
24,72
26,22
27,69
29714
30,58
32,00
33,41
34,81
36,19
37,57
38,93
40,29
41,64
42,98
44,31
45,64
46,96
48,28
49,59
50,89
63,69
76,15
88,38
100,4
112,3
124,1
135,8
0,995
7,879
10,60
12,84
14,86
16,75
18,55
20,28
21,96
23,59
25,19
26,76
28,30
29,82
31,32
32,80
34,27
35,72
37,16
38,58
40,00
41,40
42,80
44,18
45,56
46,93
48,29
49,64
50,99
52,34
53,67
66,77
79,49
91,95
104,2
116,3
128,3
140,2
таблицы Д
0,999
10,83
13,82
16.27
J8,47
20,52
22,46
24,32
26,12
27,88
29,59
31,26
32,91
34,58
36,12
37,70
39,25
40,79
42,31
43,82
45,32
46,80
48,27
49,73
51,18
52,62
54,05
55,48
56,89
58,30
59,70
73,40
86,66
99,61
112,3
124,8
137,2
149,4
Таблица Е1)
Процентные точки ^-распределения Стьюдента
Величины t0 таковы, что Р —
f
t2 \
—] dt
0,750 0,900 0,950 0,975 0,990 0,995 0,999 0,9995
1
о
о
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2Г>
27
28
29
30
40
60
120
1,000
0,816
0,765
0,741
0,727
0,718
0,711
0,706
0,703
0,700
0,697
0,695
0,694
0,692
0,691
0,690
0,689
0,688
0,688
0,687
0,686
0,686
0,685
0,685
0,684
0,684
0,684
0,683
0,683
O/hSJ
0,681
0,67У
<)/>77
0.674
3,078
1,886
1,638
1,533
1,476
1,440
1,415
1,397
1,383
1,372
1,363
1,356
1,350
1,345
1,341
1,337
1,333
1,330
1,328
1,325
1,323
1,321
1,319
1,318
1,316
1,315
1,314
1,313
1,311
1,310
1,303
1,296
1,289
1.282
6,314
2,920
2,353
2,132
2,015
1,943
1,895
1,860
1,833
1,812
1,796
1,782
1,771
1,761
1,753
1,746
1,740
1,734
1,729
1,725
1,721
1,717
1,714
1,711
1,708
1,706
1,703
1,701
1,699
1,697
1,684
1,671
1,658
1.645
12,706
4,303
3,182
2,776
2,571
2,447
2,365
2,306
2,262
2,228
2,201
2,179
2,160
2,145
2,131
2,120
2,110
2,101
2,093
2,086
2,080
2,074
2,069
2,064
2,060
2,056
2,052
2,048
2,045
2,042
2,021
2,000
1,980
1,960
31,821
6,965
4,541
3,747
3,365
3,143
2,998
2,896
2,821
2,764
2,718
2,681
2,650
2,624
2,602
2,583
2,567
2,552
2,539
2,528
2,518
2,508
2,500
2,492
2,485
2,479
2,473
2,467
2,462
2,457
2,423
2,390
2,358
2,326
63,657
9,925
5,841
4,604
4,032
3,707
3,499
3,355
3,250
3,169
3,106
3,055
3,012
2,977
2,947
2,921
2,898
2,878
2,861
2,845
2,831
2,819
2,807
2,797
2,787
2,779
2,771
2,763
2,756
2,750
2,704
2,660
2,617
2,576
318,31
22,326
10,213
7,173
5,893
5,208
4,785
4,501
4,297
4,144
4,025
3,930
3,852
3,787
3,733
3,686
3,646
3,610
3,579
3,552
3,527
3,505
3,485
3,467
3,450
3,435
3,421
3,403
3,396
3,385
3,307
3,232
3,160
3,090
636,62
31,598
12,924
8,610
6,869
5,959
5,408
5,041
4,781
4,587
4,437
4,318
4,221
4,140
4,073
4,015
3,965
3,922
3,883
3,850
3,819
3,792
3,167
3,745
3,725
3,707
3,690
3,674
3,659
3,646
3,551
3,460
3,373
3,291
J) Перепечатано из Pearson, Hartley, Biometrika Tables for Statisticians,
Vol. 1, 1958, p. 138, и из таблицы III, Fisher, Yates, Statistical Tables for
Biological, Agricultural and Medical Research, Oliver and Boyd, Edinburgh, 1953»
с разрешения авторов и издателей.
VO ?
I
ем
X ^
CD ?
<u
o.
e
a
Д
4 g
s. я
B §
Ж «О __
8
120
о
NO
О
rt
О
о
гч
о
О\
ОС
so
«л
п
-
254,3
19,50
8,53
5,63
3,3
9,49
8,55
5,66
гч ""
^ 00 Г» ON
251,1
19,47
8,59
5,72
чо гч vo
,rt чО Г-
°. ON** 00*10
249,1 21
19,45 1
8,64
5,77
248,0
19,45
8,66
5,80
245,9
19,43
8,70
5,86
гч ~*
°. О*эс"чо"
п ""*
238,9
19,37
8,85
6,04
гч ""
гч ""*
230,2
19,30
9,01
6,26
гч ""*
215,7
19,16
9,28
6,59
161,4
18,51
J0J3
7,71
vo г- гп m —
О О г- Г- «о
rt Г» ГЧ On г-
гп rt О — On
rt г^гп О^
ЧО г~ rt rf гп
О — 00 00 чр
цо ос^гп <3> эо
г*" гн\~Н*г«-Г ГЧ*
4,53
3,84
3,41
3,12
2,90 :
4,56
3,87
3,44
3,15
2,94
4,68
4,00
3,57
3,28
3,07
4,74
4,06
3,64
3,35
3,14
Г-©0С<? ЭО
4,82
4,15
3,73
3,44
3,23
00 — О Q О»
оо гч^г-к*^г^
4.95
4,28
3,87
3,58
3,37
О* "¦*¦' ГЧ rt гп
— О on гч гч
00 VO Tt VO 00
ГЧ OS 00 © ГЧ
NO^P? гп^ГЧ^
ЧО ГП гП Tt Г^-
О г- г> оо —•
2,74 :
2,61 :
2,51 :
2,42 :
2,35 ;
2,77
2,65
2,54
2,46
2,39
Щ ГЧ rj гп ^О
г?Д2Я
o^^vor- ®
3,02
2,90
2,80
2,71
2,65
г- vo vn ^ ©-
O,.°\opj>_r\
3,14
3,01
2,91
2,83
2,76
3,22
3,09
3,00
2,92
2,»5
гП © —, гп чО
ОС чО чр 00 «-
3,71
3,59
3,49
3,41
3,34
чс trnr-- О
2,07
2,01
1,96
1,92
1,88
м ЧО •-« Г- ГП
с\Ггч"гч*гч*»-*'
2,20
2,15
2,10
2,06
2,03
vr, on vo ~ r-
гХгч"гчГгч*гч
On Tt On in —
гч гч — — —¦
гч"гч"гГгч"гГ
гп ОС гп On чО
гп ГЧ ГЧ — —
© in »-« г- гп
ос гч ас rt —
rt On m — Э0
2,59
2,54
2,49
2,46
2,42
Tt On «О — 0O
чс m m in^rt
гч"гГгч ГЧ ГЧ
2,71
2,66
2,61
2,58
2,54
ON rt О чО гп
rfWWVfcf
От — Г- rt
о< ос эс г- г-
mm
3,29
3,24
3,20
3,16
3 13
3,68
3,63
3,59
3,55
3,52
rt On VO — ов
VO t Tt *t rr,
00 00 Г- Г- P
©Г- rt — On
On 00 00 00 Г~
On On 00 00 00
On no rt — On
On^On On On 0C
rt-«ort
ос т гп — oo
O^ О O^OjO^
гч гч"гч"гчГ—^
= SS.S|
О 00 m ги —
2.28
2,25
2,23
2,20
2,18
ю rj О г- т
^t>rtfNg
2,45
2,42
2,40
2,37
2,36
гч"гчГгГгч H"
© r~> vo гп *-*
чо in in vr, vr^
— 00 чС rt ГЧ
Г- r* ri © JO
00 00 ос оо r-^
Ш
Ю ГЧ О 00 VO
r>Tt*rjS-
— On Г- VO rt
Г- VOfH — ©
r- r-> r- r- r-
ГЧ О On Г- VO
oc 30 r^r^f^
r- m rt гч —
гч о ас г- yi
~^L -4 - ^
— о* Г^ чО rt
О On On О О
2,09
2,07
2,06
2,04
2,03
чо vo гп гч О
2,24
2,22
2,20
2,19
2,18
0C f~ цч Tt TJ
П (N П Г^Г»
-t гч »- O» 00
"". гп гп TJ ГЧ
2,40
2,39
2.37
2,3-6
2,35
© On Г- чо т
ЧО U~\ IT, Vr, in
гГг-Ггч* г-Ггч""
VO «tro— ©
On ОС ЧО VO гп
*№№
rt rn-« © 00
ГЧ — On vo С
00 00 r^ VO ГЧ
чо m rt гп гч
rt rt ГП ГП ГЧ
Г^ чО in rt гп
Tt Tt Ю VO 40
J-4 -ч ^ i. .
On On О — rj
X h Гч vC it,
гл n m чс r-
Cn JC t-~ чС in
О О ^ f IT,
Гч|" Г Г — —"—"
2,16
2,08
1,99
1,91
1,83
r-J — О 74 oo_
г- ос Огч rt
Г* ri Гч'гГ—'
2,33
2,25
2,17
2,09
2,01
2.42
2,34
2,25
2,17
2,10
2,53
2,45
2,37
2,29
2,21
2,69
2'б1
2,53
2,45
2,37
гч rt чо оо О
3,32
3,23
3,15
3,07
3.00
г- со © гч rt
— О O^On 00
0 00 е ^
чЗ
8
120
о
чО
О
rt
О
СП
rt
ГЧ
vo
гч
о
ON
00
г-
40
VO
Tt
ГП
гч
-
т-ЯЯ
00 ON ГП ОО"
-сп-
ОН
39,49
13,95
8,31
1010 1
39,48
13,99
8,36
006
39 47
14.04
8.41
1001 1
39,46
14,08
8,46
997,2
39,46
14,12
8,51
993,1
39,45
14,17
8,56
984,9
39,43
14,25
8,66
976,7
39,41
14,34
8,75
968,6
39,40
14,42
8,84
963,3
39,39
14,47
8,90
956,7
39,37
14,54
8,98
948,2
39,36
14,62
9,07
937,1
39,33
14,73
9,20
О оо чО
00^00^
ON *"
899,6
39,25
15,10
9,60
864,2
39,17
15,44
9.98
О Tt Ю
ON гп — —
Г-
-ГЧГЛТ*
гч vo •* г- гп
©00 — чОсп
6,07
4,90
4,20
3,73
3,39
ГЧ ч© in 00 VO
— On ГЧ r^Tt^
6.18
5.01
431
3.84
3.51
6,23
5,07
4,36
3,89
3,56
00 п гч m —
ГЧ_— ^О^чО^
6,33
5,17
4.47
4.00
3,67
6,43
5,27
4,57
4,10
3,77
ГЧ Г^ Г"- © Г~-
т_гн чО^гч оо^
6,62
5,46
4,76
4,30
3,96
6,68
5,52
4,82
4,36
4,03
6,76
5 60
4',90
4,43
4,10
6,85
5,70
4,99
4,53
4,20
6.9S
5,82
5,12
4,65
4,32
VO Оч On Г» 00
— ON ГЧ 00 Tt
7,39
6,23
5,52
5,05
4,72
7,76
6,60
5,89
5,42
5,08
Tt i-A in © Г*
О* JQZK\r^K>
88?§3
3,14
2,94
2,79
2,66
2,55
3,20
3,00
2,85
2,72
2,61
3.26
3.06
2.91
2.78
2 67
3,31
3,12
2,96
2,84
2,73
3,37
3,17
3,02
2,89
2,79
3,42
3,23
3,07
2,95
2,84
3,52
3,33
3,18
3,05
2;95
3,62
3,43
3,28
3,15
3,05
3,72
3,53
3,37
3,25
3,15
O5 On rf — —
гп"гп"гн гП^гП4
3,85
3,66
3,51
3,39
3,29
3,95
3,76
3,61
3,48
3,38
г- ОС гп О О
О^ос г^о^чг^
ГЧ О ОС Г^ чО
4,47
4,28
4,12
4,00
3,89
4,83
4,63
4,47
4,35
4,24
чО ЧО О г-- чО
©ГЧ VOOn rn
TtrH ГЧ — —
чо оо гч no ©
Tt гп ГП ГЧ ГЧ
гч"гГгч*"гч"гч"
2,52
2,45
2,38
2,32
2,27
О — Tt 00 гп
т т rt гп гп
гч гч гч' г4 гч"
сГгч"гч~гч"гч"
Огп чО От
гч"гч*'гч*гч'*гГ
чО 00 гЧ чО —
чО On ГЧ Г-- ГЧ
00 r^r-^NO^^
гч" гч" гчлгч" гчГ
2,96
2,89
2,82
2,77
2,72
3,06
2,99
2,92
2,87
2,82
гч vo оо гп оо
— © ON^OO
сп"гп"гч"гч'*гч'4
О ГЧ ЧО -г ЧО
On ГЧ ЧО О Ю
гч^гч^-^—лол
— Tt ОО ГЧ Г-
rt ГЛ^ГЧ^ГЧ —
сп" гп" гп" гп" гп**
ОС О rt 00 ГП
т т rt гп гн
О гп чО — чО
гн'-н'гн СП* С Г
т ос — <г о
'-„ 0^0,0^0-^
2SC:222;
2,22
2,18
2,14
2,11
2,08
On m — 00 m
гч' гч гч гч' гч'
2,35
2,31
2,27
2,24
2,21
2,41
2,37
2,33
2,30
2,27
2,46
2.42
2,39
2,36
2.33
2,57
2,53
2,50
2,47
2,44
2,68
2,64
2,60
2,57
2,54
2,77
2,73
2,70
2,67
2,64
2,84
2,80
2,76
2,73
2,70
2,91
2,87
2,84
2,81
2,78
3,01
2,97
2,93
2,90
2,87
3,13
3,09
305
3,02
2,99
о т гч оо »о
3,51
3,48
3,44
3,41
3,38
чО гч ос т п
оо^эс r-h г-я
СПЛ.-'"-'Ггп"гп'
гч гч гч гч гч
— X VOCH «—
ON 00 d0 00 00
00 lO гп •- On
On^OnJ^On^OO^
2,05
2,03
2,00
1,98
1,96
гч On г- т гп
— о о о о
гч гч' м" гч' гч"
гч"гч*гч""гч*гч"'
rt ГЧ On Г» VO
2.30
2,28
2,25
2,23
2,21
2,41
2,39
2,36
2,34
2,32
— On Г- Ю гп
m^Tt Tt^rt^
^"rTr^VTri4
— ON t- Ю ГП
no in m ю ю
ос т гп — <7s
ЧО чО чО^»©^»^
2,75
2,73
2,71
2,69
2,67
2,85
2,82
2,80
2,78
2,76
2,97
2,94
2,92
2,90
2,88
22Д8Д
3,35
3,33
3,31
3,29
3,27
3,69
3,67
3,65
3,63
3,61
О г- Tt ГЧ О
Ю чО Г- ОС On
ГЧ ГЧ Г1 П ГЧ
Г" ГЧ 00 ГП f*
1,94
1,80
1,67
1,53
1,39
2.01
1.88
1.74
1.61
1.48
2,07
1,94
1,82
1,69
1,57
2,14
2,01
1,88
1,76
1,64
© Г" rt ГЧ -ч
2,31
2,18
2,06
1,94
1,83
— ONt-lOrt
Tt ГЧ —^О ON^
гГгч"гч"гч"»-<х
•ш On Г~ ЧО VO
^SjN^©^
гч"гч**гч ГчГгч*"
2,57
2,45
2,33
2,22
2,11
2,65
2,53
2,41
2,30
2,19
Ш Г) — О» On
г^чо u4r">4«vib
гч'г^г^Ггч"^
2,87
2,74
2,63
2,52
2,41
гп О ON Г- Г-
©^О^Г^чО^!^
3,25
3,13
3,01
2,89
2,79
3,59
3,46
3,34
3,23
3,12
ос vr гп О On
in-mu-r.o.o"
ОО ОО п
ГП rt чСГЧ 8
"8
О*
8
120
©
чО
О
СП
Tf
Гч!
8
о
О\
ЧО
ш,
Tf
m
п
-
-"/
/*,
6366
99,50
26,13
13,46
K39
99,49
26,22
13,56
»313 6
99,48
26,32
13,65
J87 t
'99,47
26,41
13,75
!61 б
99,47
26,50
13,84
чО
J35
99,46
26,60
13,93
6209 (
99,45
26,69
14,02
>157 i
99,43
26,87
14,20
06 (
99,42
27.05
14,37
чО
6056
99,40
27,23
14,55
On щ чО
CM oCr-^Tf"
gOsrs^
Г- on ©
8 598
9,36 9
7,67 21
4 98 1
5859 592
99,33 9
27,91 2
15,21 !¦
5764 1
99,30
28,24
15,52
>625
99,25
28,71
15,98
Г- чО ON
Tf
On©
«Л O^O
О» ©""©""х""
4052 4
98,50
34,12
21,20
9,02
6.88
5,65
4,86
4,31
9,11
6,97
5,74
4,95
4,40
9,20
7.06
9,29
7.14
ЙЯ
9,47
7,31
5,82
5,03
4,48
5,91
5,12
4,57
ад*.
6,07
5,28
4,73
9,55
7,40
6,16
5,36
4,81
9,72
7,56
9,89
7.72
10,05
7.87
NJOX
ON ©
©"x"
Tf Г4
10,67 11
8,47 !
ON l/-
12,06
9,78
6,31
5,52
4,96
6,47
5,67
5,11
6,62
5,81
5,26
Г1-1Л
S3!*
»,99 (
b,18 (
5,61 :
.?©
/,46
6,63
6,06
/~t — ГА
n On ON
rf in Cn
/fr-""^
10,92
9,55
8,65
8,02
16,26
13,75
12,25
1 1,26
10,56
3,91
3,60
3,36
3,17
3,00
4,00
3,69
3,45
3,25
3,09
4,08
3,78
3,54
3,34
3,18
г чО CS rn r^
m Tt о — wo
ri^O^r^ wo^m^
4,33
4,02
3,78
3,59
3,43
4,41
4,10
3,86
3,66
3,51
4,56
4,25
4,01
3,82
3,66
— © ^ *& ©
r^ Tt — On X
in rf о © Tf
x m m — On
TfmONONm
ЧС -f О © Tf
© ON rf Tf X
см x \C Tf ri
On Г» Г1 CM чО
m © x чС Tf
5,64
5,32
5,06
4,86
4,69
5,99
5,67
5,41
5,2!
5,04
6,55
6,22
5,95
5,74
5,56
О — rn О .-
Г *Г-"'чС~чО'1о"*
ОчО"ООС
©"on* сл" on" х*
2,87
2,75
2.65
2,57
2,49
\CTfv
ON^r-
3,05
2,93
2 83
3,13
3,02
2.92
3,21
3,10
3.00
3,29
3,18
3.08
Г- чО чС
3,52
3,41
3.31
Г- ш, чС
ЧС Ш *t
© On On
onxx
m-r>m'
© ON ON
о х r-
-ЛЛ
*4 © ©
чС rf -f
4,89
4,77
4,67
5,42
5,29
5,18
6,36
6,23
6,1 I
1 8 6S
I 8,5j
t 8,4C
2,66
2,58
2,775
2,67
2,84
2,76
2,92
2,84
3,00
2,92
3,08
3,00
r-~ ©
•nTt
О см
i^S
x r-~
[,0\ 2
5,94 :
4,58
4,50
5,09
5,01
6,01
5,93
Cl чС —
«SCN*fN
2,52
2,46
2.40
2,61
2,55
2.50
2,69
2,64
2.58
2,78
2,72
2.67
2,86
2,80
2,75
2,94
2,88
2,83
чО —
v*vr
2,35
2,31
2,45
2,40
2,54
2,49
ЧО WO
г-Ггм*"
2,70
2,66
2,78
2,74
3,09
3,03
2,98
2,93
2,89
5,23
(,12
r» — о
чо © ir.
rr?rr?<~n'
no — m
s*A
X 'jr. t^
SS
© ^C
5,36
f ©
4,10
4,04
3,99
3,94
3,90
4,43
4,37
4,31
4,94
4,87
4,82
5,85
5,78
5,72
x*x"t~-"
5?
r^ r-
m
f~~ ГП О
сГгГп
2,27
2,23
2.20
2,06
2,03
чо m on чО rn
2,45
2,42
2.38
2,54
2,50
2.47
2 62
2,58
2,55
2,70
2,66
2,63
2 85
2,81
2.78
On чО rn
rn on <:
-oo
СМХ-П
r^rn-
rf rf Tf"
m, m
2,44
2,41
2,52
2,49
2,60
2,57
2,75
2,73
Г-, ©
© о
CM ON
~, о
orn
in «n
3,75
3,73
4,07
4,04
4,68
4,64
4,60
4,57
4,54
5,57
5,53
5,49
I^ Г- чС
5,45
5,42
r-V
2,01
1,80
1,60
1,38
1,00
2,21
2,02
1,84
1,66
1,47
2,30
I',94
1,76
1,59
«N CM CM
2.47
2',29
2,12
1,95
1,79
2,55
2,37
2,20
2,03
1;88
2,70
2,52
2,35
2,19
2,04
x © m r- ri
O^X чО Tt -n
Г- Gs Г) ^C —
cnrfcfrici
® - 3? ? 3
Г- ON rj чС С
t rl — O> X
4,02
3,83
3,65
3,48
3/,32
4,51
4,31
4,13
3,95
3,78
ON X Г, ON —
чс — x ir, rn
© © © ©
.3
I
чО On m ч
чо t^<S Т
§ГМ t"» О «ЧОШГ^-^ 00ЧО»Л>ЛГ^ CTNfNjW^ONTf ©>cnf>Tf©
TfON4D ГПОООчО»П ГП CM — О ON ООООГ^чОЧО «ПСЧХШО
¦^. «^l^^^A м^^ шшЛ, •" — -^ -^ a*. - .^^^^N^tf^l .#^1 #V| ЛЫ tf^l *4l" ^4.1 ^Vl Г* Т
ttV-0
nO^ ^4f*J4^4r'l4
<NfMfMfM(N
tc^rlfNjTf' VOONrJvO"^ чО*-«00чО>/">
n Tf m ГЧ г* ©OnOnOOOO r^Tf©r~-^f
^rnVT en*" ro*
OooooooOn ^moocNI^ f4jf~mm4O
rn rn m m со m ^^ en со CN. O4^ ^M cn| *
Г- Г-- f-i ~> «Л
oo no ^ -_шк
Tf NO rTO 00
© On CN m X ©
f — rn r-ON Tf On
«><>??:-2V"> v?pocOTt Ooooo^oooj
0— ©mmknON
гч f~m4o о
CM OOV^rM^ON^
сосч'с'ГгГ'-Г
* Tfmrf
r- o^x-r-*4
© On CM Tf
n — On b-
n Г- ~ ^
-- m —. O\
vn On Г! T
чО C*""'
r4 —i 00 Tf On
ON^Tf^O ^\°°^
NO*" X*4 Tf" —Г On?
00t>4O4Oin 1Л 1Л WTt Tf
INO^OO 0C —i 00 On CM
SCMOOOOOO V000»n4OO\
vo in m m io
VOTfmmTf vdonNnOO гп О oo oo *-i
mTtrncM— ©Ononxoo r^-Tf©r~-in
oo г- «л t? «Si м csj- - o^ © чо rn © ri
00 in rn rn Tf VOM-iVlO Tfh-TfTf4
©jOn^OO r^NO^ ^"^Ч.*"!^ Г1СС^1/^Г1<:
>П~тГ Tf~Tf*Tf TfTfTfTf" Tf" Tfrf?tn~rn~f
rn О чО m '-'
_olS
О TfrnmTfr^ ©»л—i--©
5© ЧО О ЧО © rn CM m Г~-CM X
-«mvcoNTf oc — i*- v
^xr~•чoчo шемхк
¦ 4-^
o\ on4—"oT
«N On rn Tf
ON O\ —
VO чО Гч! О О
".4.° ¦* ^
oo"oN*'in~rro's
>Л —i —I On <-<
r-X^r^Tf Г^
ГЦ ГЧ .-I « i-i
r44O©ON00 •ЧЧОСМГЧ^
m no © Tf о t^ Tf cm^©^oo
О»»-«чО<П00 Сч)хчО<П»П ЧО 00 —< КП 00 CNrnr^-TfTf
ЧОчОчОчО1П in V)VN,^V
— On X чО *П^ TfTfrnrl— ™r~-rnON4O
IIS
Э — гл rf©mON0
о cn r^ m © r~ Tf^c
O\O\00000
5 On ЧО Vn r>- — l~
Таблица 3 х)
Моменты и процентные точки распределения размаха
1) Моменты и отношения моментов распределения размаха (w) в случайной выборке объ-
объема п из нормированного нормального распределения.
W
п,Р
2) Величины WJlt р таковы, что Р= \ р (w)
dm.
п
2
3
4
6
7
8
9
10
И
12
Математическое
ожа^ние
1,1284
1,6926
2,0588
1 з°59
2,5344
2,7044
2,8472
2,9700
3,0775
3,1729
3,2585
Среднее
бадратическое
стклонение
0,853
0,888
0 880
0 864
0,848
0,833
0,820
0,808
0,797
0,787
0,779
*32(ft)
0,991
0,417
0,274
0 ~Ч7
0,189
0,174
0,166
0,161
0,158
0,156
0,156
3,87
3,29
3,19
3 17
3,17
3,17
3,18
3,19
3,20
3,21
3,21
Нижние
0,1 0,5
0,00 0,01
0,06 0,13
0,20 0,34
0 37 0 55
0,54 0,75
0,69 0,92
0,83
0,96
1,08
1,20
1,30
,08
1,21
1,33
,45
,55
процентные точки
1,0 2,5 5,0
0,02
0,19
0,43
0 66
0,87
1,05
1,20
1,34
1,47
1,58
1,68
0,04 0,09
0,30 0,43
0,59 0.76
0 85 1
1,06 1
1,25
1,41
1,55
1,67
1,78 1
,25
,44
,60
1,74
1,86
,97
1,88 2,07
10,0
0,18
0,62
0,98
1,26
1,49
1,68
1,83
1,97
2,09
2,20
2,30
Верхние процентные точки
10,0 5,0 2,5 1,0 0,5
2,33
2,90
3,24
3,48
3,66
3,81.
3,93
4,04
4,13
4,21
4,29
2,77
3,31
3,63
3,86
4,03
4,17
4,29
4,39
4,47
4,55
4,62
3,17
3,68
3,98
4,20
4,36
4,49
4,61
4,70
4,79
4,86
4,92
3,64
4,12
4,40
4,60
4,76
4,88
4,99
5,08
5,16
5,23
5,29
3,97
4,42
4,69
4,89
5,03
5,15
5,26
5,34
5,42
5,49
5,54
0,1
4,65
5,06
5,3!
5,48
5,62
5,73
5,82
5,90
5,97
6,04
6,09
Перепечатано с разрешения из Pearson, Hartley, Biometrika Tables for Statisticians, Vol. 1, 1958, pp. 164, 165.
Таблица И
Величины
Процентные точки стьюдентизированного размаха
4k, v, I -a
v 1-а таковы что 1—а=
таковы' что 1—а= \ Р (q) dq (q определено как w/s).
о
Размах выборки- объема k из нормальной совокупности, деленный на независимую
оценку среднего квадратического отклонения совокупности, основанную на v степенях
свободы, превышает приведенные в таблице значения с вероятностью а.
• v
1
2
3
4
5
6
8
10
12
14
1-6-
18
20
30
60
17,97
6,08
4,50
3,93
3,64
3,46
, 3,26
3,15
3,0&
3,03
У,№
2,97
2,95
2,89
2,83
3
26,98
8,33
5,91
5,04
4,60
4,34
4,04
3,88
3,77
3,70
3,65
3,61
3,5*
3,49
3,40
4
32,82
9,80
6,82
5,76
5,22
4,90
4,53
4,33
4,20
4,11
4,05
4,00
3,96
3,85
3,74
5
37,08
10,88
7,50
6,29
5,67
5,30
4,89
4,65
4,51
4,41
4,33
4,28
4,23
4.10
3,98
6
40,41
И,74
8,04
6,71
6,03
5,63
5,17
4,91
4,75
4,64
4,56
4,49
4,45
4,30
4,16
0,05
7
43,12
12,44
8,48
7,05
6,33
5,90
5,40
5,12
4,95
4,83
4,74
4,67
4,62
4,46
4,31
8
45,40
13,03
8,85
7,35
6,58
6,12
5,60
5,30
5,12
4,99
4,90
4,82
4,77
4,60
4,44
9
47,36
13,54
9,18
7,60
6,80
6,32
5,77
5,46
5,27
5,13
5,03
4,96
4,90
4,72
4,55
10
49,07
13,99
9,46
7,83
6,99
6,49
5,92
5,60
5,39
5,25
5,15
5,07
5,01
4,82
4,65
11
50,59
14,39
9,72
8,03
7,17
6,65
6,05
5,72
5,5 \
5,36
5,26
5,17
5,11
4,92
4,73
12
5*,96
14,75
9,95
8,21
7,32
6,79
6,18
5,83
5,61
5,46
5,35
5,27
5,20
5,00
4,81
*) Перепечатано с разрешения проф. Е. С. Пирсона из таблиц Extended and Corrected Tables of the Upper Percentage Points of the
Studentized Range, составленных Дж. М. Мэем (May J. M., Biometrika, 39 A952)), и из Pachares J., Table of the Upper 10% Points of the
Studentized Range, Biometrika, 46 A959).
"8
О
о
II
rl
f-
"A
260
rl
253
245
237
rl
227
ОС
in
ri
rl
ri
Г 1
чО
185
ro
164
о
134
ro
О
О
ON
40
ro
ro
in
rl
ro
О
ro
OO
о
ГО
ro
in
ri
О
r\
ОС
ro
чО
П
r-
rt
П
r\
rl
rl
02
04
rt
N
ro
in
Г--
ro
—
-
s
in
О
О
m
rt
П
Tt
ro
ro
ro
ri
rl
чО
о
40
ri
ОС
ro
rt
00
ri
57
r)
ri
ri
ГО
-
in
in
-
о
—
ОС
in
о
96
ON
ON
rl
00
in
rt
о
о
00
о
rl
о
Г-
ON
rl
ro
Оч
ON
00
ri
rt
ОС
о
ОС
f-
00
40
о
in
«n
ОС
rt
о
ro
On
о
ON
Г--
00
00
61
00
ro
00
f-
чО
*n
ro
о
*""
ro
rt
n
40
ОС
00
ГО
О
00
ОС
f-
00
rt
rl
о
ri
чО
О
П
40
rt
чО
m
in
rt
00
ON
rt
f-
ro
r--
Г 1
in
О
ОС
чО
r-
ro
rt
чО
rt
чО
Г--
in
rl
m
00
rt
rt
О
s
94
00
чО
in
чО
rl
ro
чО
О
rt
00
in
о
in
m
05
in
rl
ro
rt
ri
ЧО
чО
rt
чО
41
чО
П
чО
08
чО
00
00
in
64
in
ri
ro
m
00
rt
П
rt
rt
чО
in
чО
чО
rt
чО
in
ГО
чО
Г 1
П
00
о
40
ri
in
rl
m
rt
in
in
79
rt
ГО
rt
rt
чО
ro
чО
О
Г 1
чО
08
rt
in
ON
m
о
m
00
ro
in
s
m
о
rt
r-
О
rt
00
ОС
ri
чО
О
чО
Г-
in
rt
OO
in
s
m
in
in
,29
in
,02
m
rt
rt
,02
О
93
m
m
00
in
чО
in
,65
in
rt
in
•n
о
rt
m
rt
r i
in
•n
О
in
о
00
rt
in
rt
rt
,89
ro
О
ГО
s
in
53
m
m
rt
in
ro
m
in
ri
m
ro
m
ON
Tt
rl
oo
rt
in
rt
OO
rl
rt
vo
ro
О
чО
Таблицы
535
Таблица К1)
Критические значения для проверки выбросов
(хг—экстремальное значение)
Статистика
^ 10 —
л я - а 1
2 "^ '* 1
Я3 1
Число
средних п
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
Критические
значения г>
а ~ 0,05
0,941
0,765
0,642
0,560
0,507
0,554
0,512
0^477
0,576
0,546
0,521
0,546
0,525
0,507
0,490
0,475
0,462
0,450
0,440
0,430
0,421
0,413
0,406
0,399
0,393
0,387
0,381
0,376
а=0,01
0,988
0,889
0,780
0,698
0,637
0,683
0,635
0^597
0,679
0,642
0,615
0,641
0,616
0,595
0,577
0,561
0,547
0,535
0,524
0,514
0,505
0,497
0,489
0,486
0,475
0,469
0,463
0,457
*) Перепечатано с разрешения из Dixon, Massey, Introduction to
Statistical Analysis, McGraw-Hill Book Co., 1951; Dixon W. J.,
Ratios inrolving extreme values, Annals of Mathematical Statistics,
1951, pp. 68-78.
2) Это величины для одностороннего критерия. Для двусто-
двустороннего а=0,Ю и 0,02.
5Л6
Приложение
Номограмма Л
Доверительные зоны для долей
(Доверительная вероятность 0,80)
п 0J 0,2 #J 0,4 US 0,6 0,7 0,8 0,3 1,0
х) Перепечатано с разрешения проф. Е. С. Пирсона из ClopperC J., Pearson E. S.,
The Use of Confidence or Fiducial Limits Illustrated in the Case of the Binomial,
Biometrika, 26 A934), p. 404.
Таблицы
537
Номограмма Л (продолжение)
(Доверительная вероятность 0,95)
0,1 0,2 0,1 0,4 0,5 0,6 0,7 0,8 0,3 1,0
Х/п
538
Приложение
Номограмма Л (продолжение)
(Доверительная вероятность 0,99)
0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,3 1,0
Таблицы
539
Таблица М1)
Доверительные зоны для среднего значения распределения Пуассона
0бщее
число
наблюдаемых
событий
0
I
2
3
4
5
6
7
8
9
п
11
12
13
14
15
16
17
18
19
20
21
22
23 '
24
25
Ур
а =
Нижняя
граница
0,0
0,0
0,1
0,3
0,6
1,0
1.5
2,0
2,5
3,1
3,7
4,3
4,9
5,5
6,2
6,8
7,5
8,2
8,9
9,6
10,3
11,0
11,8
12,5
13,2
14,0
одень значимости
0,01
Верхняя
граница
5,3
7,4
9,3
11,0
12,6
14,1
15,6
17,1
18,5
20,0
21,*
22,6
24,0
25,4
26,7
28,1
29,4
30,7
32,0
33,3
34,6
35,9
37,2
38,4
39,7
41,0
а =
Нижняя
граница
0,0
0,1
0,2
0,6
1/0
1,ь
2,2
2,8
3,4
4,0
4,7
5,4
6,2
6,9
7,7
8,4
9,4
9,9
10,7
11,5
12,2
13,0
13,8
14,6
15,4
16,2
0,05
Верхняя
граница
3J
5,6
7,2
8,8
10,2
11,7
13,1
14,4
15,8
17,1
18,4
19,7
21,0
22,3
23,5
24,8
26,0
27,2
28,4
29,6
30,8
32,0
33,2
34,4
35,6
36,8
Общее
число
наблюдаемых
событии
•»'„ = ^ *,
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
Уровень значимости
а =
Нижняя
граница
14,7
15,4
16,2
17,0
17,7
18,5
19,3
20,0
20,8
21,6
22,4
23,2
24,0
24,8
25,6
26,4
27,2
28,0
28,8
29,6
30,4
31,2
32,0
32,8
33,6
0,01
Верхняя
граница
42,2
43,5
44,8
46,0
47,2
48,4
49,6
50,8
52,1
53,3
54,5
55,7
56,9
58,1
59,3
60,5
61,7
62,9
64,Л
65,3
66,5
67,7
68,9
70,1
71,3
а =¦:
Нижняя
граница
17,0
17,8
18,6
19,4
20,2
21,0
21,8
22,7
23,5
24,3
25,1
26,0
26,8
27,7
28,6
29,4
30,3
31,1
32,0
32,8
33,6
34,5
35,3
36,1
37,0
0,05
Верхняя
граница
38,0
39,2
40,4
41,6
42,8
44,0
45,1
46,3
47,5
48,7
49,8
51,0
52,2
53,3
54,5
55,6
56,8
57,9"
59,0
60,2
61,3
62,5
63,6
64,8
65,9
Замечание. Если 2х/—суммарное число появления события при л не-
независимых наблюдениях пуассоновской величины со средним значением G,
то значение nQ с вероятностью, не меньшей 1—а, окажется между верхней
и нижней границами.
*) Перепечатано с разрешения из Ricker W. E., The Concept of Confidence or
Fiducial Limits Applied to the Poisson Frequency Distribution, Journal of the American
Statistical Association, 32 U937), pp. 349—38 6.
Таблица Н1)
Число наблюдений для ^-критерия значимости среднего
В таблице приведены количества наблюдений, необходимых nf и использовании f-критерия для проверки значимости
среднего при вероятностях ошибок первого и второго рода, равных аир соответственно
Ура&на -t-критерия
Односторонний критерий а
Двусторонний критерий
1,1
\\г
1,4
Ь5
1,6
1?
величина 1,9
Л 2,0
и = —
17 2,1
2,3
2,4
2,5
3,0
3,5
4.0
0,01
24
21
18
16
15
13
12
12
11
10
10
9
8
¦ 8
7
6
6
а
0,05
19
16
15
13
12
11
10
10
9
8
8
8
7
7
7
6i
5
= 0,01:
ОД
16
Г4
13
\2
1!
\4
9
9
1
7
7
7
€
$
>
0?
И
12
И
to
9
8
8
8
7
7
7
6
6
6
6
5
0-5
7
7
6
6
б
6
5
0-01
21
18
f&
14
; 13
12
11
: Ю
10
9
8
• 8
; 8
7
: 7
' &
5
а
0 05
16
14
\У
11
10
10
9
8
8
7
7
7
6
С
= 0,01
= 0,02
ОД
14
12
1 t
10
9
9
8
7
7
7
6
6
6
6
&
5
0 7
12
10
9
9
8
7
7
7
6
6
6
5
0 5
8
7
6
6
.6
5
0,0Г
18-
15'
14
12
11
10
9
8
8
* 7
7
> 7
• 6
6
; 6
5
а =
а =
0,05
13
12
m
9
8
8
7
7
6
6
6
6
5
0,025
0,05
ОД
И
10
9
8
Г
7
6
6
6
5
0,2 0,5
9 6
8 5
7
7
6
6
5
0v0i
15
13
И
10
9
8
8'
' 7
7
¦¦ 6
6
6
5
а
а
0,05
11
10
8
a
7
6
6
6
5
= 0,05
= 0,1
ОД
9
8
7
7
6
6
5
0,2
7
6
6
5
0,5
U
1,2
1,3
1,4
1,5
1,6
1,7
1,8
2,0
2Д
¦"> ->
2^3
2,4
2,5
3,0
3,5
4/0
d R П|реЛечатано с Разрешения из Davies О. L., Design'and Analysis of Industrial Experiments, Hafner Publishing Co., New York, 1956
продолжение щфлиирь Я1)
t-критерия
Односторонний критерий а
Двусторонний критерии
Р =
и ?
1,2 1
1,3 j
1,4 j
1,5
1^6
1,7
1,8
Величина 1,9
д 2,0
/л
X/ = —
G 0 J
3 2
2^3
2,4
.3,5
3,0
3,5
4,0
0,01
24
21
18
16
15
13
12
12
11
10
10
9
9
К
8
7
6
6
а
ода
J9
16
15
13
12
11
10
10
9
8
8
8
7
7
7
6
5
= Q/H5
= 0,01
<и
16
и
13
12
11
10
9
9
8
8
7
7
7
7
j6
<6
5
0,2
J4
12
11
10
9
8
8
8
7
7
7
6
6
6
6
5
0,5
9
8
8
V
7
6
6
6
6
5
0,01
21
18
16
14
13
12
И
10
10
9
8
8
8
7
7
6
5
а
а
0,05
16
14
13
11
10
10
9
8
8
7
7
7
6
6
6
5
= 0,01
= 0,02
<и
14
12
11
J$
9
9
8
7
7
7
6
6
6
6
6
5
0,2
10
9
9
18
7
7
7
6
6
6
5
W
7
6
0#1
1,8
15
14
12
И
10
9
8
8
7
7
7
6
¦р
о
5
а
ее
QJ05
13
12
10
9
8
8
7
7
6
6
6
6
5
= 9,025
= Q,05
ОД
И
10
9
7
7
6
6
6
5
0.2
9
8
7
7
6
6
5
0,5
6
5
Qfil
15
13
11
10
9
8
8
7
7
6
6
6
5
а
а
<tyM
И
10
8
8
7
6
6
6
5
^0,05
= -0,1
ОД
9
8
7
7
6
6
5
0,2
7
6
6
5
0,5
1,1
1,2
1;3
1,4
1,5
1,6
1,7
1,8
2,0
2,1
2,2
2,3
2,4
2,5
3,0
3,5
4,0
Число наблюдений для ^-критерия значимости разности двух средних Таблица О1)
В таблице приведены количества наблюдений, необходимых для проверки значимости разности двух средних с по-
помощью ^-критерия при вероятностях ошибок первого и второго рода, равных аир соответственно.
Уровни t-критерия
Односторонний критерий
Двусторонний критерий
Р =
0,05
0,10
0,15
0,20
0,25
0,30
0,35
0,40
0,45
Ветчина о,5О
&=- 0,55
0,60
0,65
0,70
0,75
0,80
0,85
0,90
0,95
1,00
0,01
100
88
77
69
62
55
50
а
<х
0,05
101
87
75
66
58
51
46
42
38
= 0,005
= 0,01
0,1
101
85
73
63
55
49
43
39
35
32
0,2
118
96
79
67
57
50
44
39
35
31
28
26
0,5
ПО
85
68
55
46
39
34
29
26
23
21
19
17
15
0,01
104
90
79
70
62
55
50
45
ос
а
0 05
106
90
77
66
58
51
46
41
37
33
= 0,01
= 0,02
0,1
106
88
74
64
55
48
43
38
34
31
28
0?
101
82
68
58
49
43
38
33
30
27
24
22
0,5
123
90
70
55
45
38
32
27
24
21
19
17
15
14
13
001
104
88
76
67
59
52
47
42
38
а
а
0 05
106
87
74
63
55
48
42
37
34
30
27
= 0,025
= 0,05
0,1
105
86
71
60
51
44
39
34
31
27
25
23
0^
100
79
64
53
45
39
34
29
26
23
21
19
17
05
124
87
64
50
39
32
27
23
20
17
15
14
12
И
10
9
0,01
112
89
76
66
57
50
45
40
36
33
а
а
0,05
108
88
73
61
52
45
40
35
31
28
25
23
= 0,05
= 0,1
0,1
108
86
70
58
49
42
36
32
28
25
22
20
18
0,2
102
78
62
51
42
36
30
26
23
21
18
16
15
14
0,5
137
88
61
45
35
28
23
19
16
14
12
И
10
9
8
7
7
0,05
0,10
0,15
0,20
0,25
0,30
0,35
0,40
0,45
0,50
0,55
0,60
0,65
0,70
0,75
0,80
0,85
0,90
0,95
1,00
!) Перепечатано с разрешения из Davies О. L., Design and Analysis of Industrial Experiments, Hafner Publishing Co., New York*
1956; Research, Vol., 1, 1948, pp. 520—525.
Продолжение таблицы О
Односторонний критерии
двусторонний критерий
Р =
1,1
1,2
1,3
1,4
1,5
1,6
1,7
1,8
величина I»9
D = i 2>°
а 2,1
2,2
2,3
2,4
2,5
3,0
3,5
4,0
0,01
42
36
31
27
24
21
19
17
16
14
13
12
11
11
10
8
6
6
а
а
0,05
32
27
23
20
18
16
15
13
12
И
10
10
9
9
8
6
5
5
= 0,005
= 0,01
0,1
27
23
20
17
15
14
13
И
11
10
9
8
8
8
7
6
5
4
0,2
22
18
16
14
13
И
10
10
9
8
8
7
7
6
6
5
4
4
0,5
13
11
10
9
8
7
7
6
6
6
5
5
5
5
4
4
3
0,01
38
32
28
24
21
19
17
15
14
13
12
11
10
10
9
7
6
5
а
а
0,05
28
24
21
18
16
14
13
12
11
10
9
9
8
8
7
6
5
4
= 0,01
= 0,02
од
23
20
17
15
14
12
11
10
9
9
8
7
7
7
6
5
4
4
Уровни t-критерия
0,2
19
16
14
12
И
10
9
8
8
7
7
6
6
6
5
4
4
3
0,5
11
9
8
8
7
6
6
5
5
5
5
4
4
4
4
3
0,01
32
27
23
20
18
16
14
13
12
И
10
9
9
8
8
6
5
4
а
а
0,05
23
20
17
15
13
12
11
10
9
8
8
7
7
6
6
5
4
4
= 0,025
= 0,05
0,1
19
16
14
12
11
Ю
9
8
7
7
6
6
6
5
5
4
4
3
0,2
14
12
И
10
9
8
7
6
6
6
5
5
5
4
4
4
3
0,5
8
7
6
6
5
5
4
4
4
4
3
0,01
27
23
20
17
15
14
12
И
10
9
8
8
7
7
6
5
4
4
а
а
0,05
19
16
14
12
11
10
9
8
7
7
6
6
5
5
5
4
3
= 0,05
= 0,1
0,1
15
13
11
10
9
8
7
7
6
6
5
5
5
4
4
3
0,2
12
10
9
8
7
6
6
5
5
4
4
4
4
4
3
0,5
6
5
5
4
4
4
3
U
1,2
1,3
1,4
1,5
1,6
1J
1,8
1,9
2,0
2Д
2,2
2,3
2,4
2,5
3,0
3,5
4,0
544
Приложение
Таблица П1)
Число наблюдений, необходимых для сравнения дисперсии совокупности
и заданного значения дисперсии с помощью критерия %2
В таблице приведены значения R, отношения дисперсии совокупности
of к заданной дисперсии о^, которое с вероятностью р не будет обнаружено
с помощью критерия х2 ПРИ уровне значимости а, когда оценка й* величины а2
основана на Ф степенях свободы.
a = 0,01
= 0,01 ? = 0,05 ? =
' = 0,5 p = 0,01
a = 0,05
= 0,05 ? = 0,1
0,5
1
2
3
4
5
6
7
8
9
10
12
15
20
24
30
40
60
120
oo
42 240
458,2
98,79
44,69
21,22
19,28
14,91
12,20
10,38
9,072
7,343
5,847
4,548
3,95$
3,403
2,874
2,358
1,829
1,000
1 687
89,78
32,24
18,68
13,17
10,28
8,524
7,352
6,516
5,890
5,017
4,211
3,462
3,104
2,752
2,403
2,046
1,661
1,000
420,2
43,71
19,41
12,48
9,369
7,628
6,521
5,757
5,198
4,770
4,159
3,578
3,019
2,745
2,471
2,192
1,902
1,580
1,000
14,58
6,644
4,795
3,955
3,467
3,144
2,911
2,736
2,597
2,484
2Г312
2,132
1,943
1,842
1,735
1,619
1,490
1,332
1,000
24 450
298,1
68,05
31,93
19,97
14,44
11,35
3,418
8,103
7,156
5,889
4,780
3,802
3,354
2,927
2,516
2,110
1,686
1,000
977,0
58,40
22,21
13,35
9,665
7,699
6,491
5,675
5,0S8
4,646
4,023
3,442
2,895
2,630
2,367
2,103
1,831
1,532
1,000
243,3 8,444
28,43 4,322
13,37 С
',30*
8,920 2,826
6,875 :
5,713 :
4,965 :
4,444 ;
>;544
>,354
2,217
шг
4,059 2,028
3,763 1
3,335 1
2,925
2,524
2,326
2,125
1,919
1,702
1,457
1,000
,960
1,854
1,743
1,624
1,560
1,49*
1,41»
1,333
1,228
1,000
Примеры
Проверка увеличения дисперсии. Пусть а = 0,05, C = 0,01, R = 4. Обра-
Обращаясь к таблице, устанавливаем, что значение 4 расположено между строчками,
соответствующими Ф = \Ь и Ф = 20. Грубая интерполяция показывает, что
оценка дисперсии должна быть основана на 19 степенях свободы.
Проверка уменьшения дисперсии. Пусть а = 0,05, C = 0,01 и /?=0,33.
К таблице Следует обратиться при a' = [J = 0,01, p' ^& = 0>05 и R' = l/R = 3.
Выясняем, что значение 3 оказывается между строчками, соответствующими
Ф = 24 и Ф=*30. Грубая интерполяция показывает, что Оценка дисперсии
должна быть основана на 26 степенях свободы.
х) г1ерепечатано с разрешения из Davies О. L , Design and Analysis of Industrial
Experiments, Hafner Publishing Co., New York, 1956; Eisenhart, Hastay, Wallis, Selected
Techniques of Statistical Analysis, McGraw-Hill Book Co., 1947.
*r~ ооЗ*-сГэ«Г r-"V ^"V^ Ж^'л - -
u я
546
Приложение
Таблица С1)
Границы значимости Ra для критерия знаков
(Двусторонние процентные точки для биномиального распределения с р = 0,5)
\ a
1
2
3
4
5
6
7
8
9
Ю
Л
12
13
14
15
16
17
18
19
20
21
22
23
24
25
1 °/
1 /о
0
0
0
0
I
1
1
2
2
2
3
3
3
4
4
4
5
5
5°/
0
0
0
1
1
1
2
2
2
3
3
4
4
4
5
5
5
6
6
7
10%
0
0
0
1
1
1
2
2
3
3
3
4
4
5
5
5
6
6
7
7
7
\. a
77 N.
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
1%
6
6
6
7
7
7
8
8
9
9
9
10
10
11
11
11
12
12
13
13
13
14
14
15
15
5%
7
7
8
8
9
9
9
10
10
11
11
12
12
12
13
13
14
14
15
15
15
16
16
17
17
10%
8
8
9
9
10
10
10
11
1!
12
12
13
13
13
14
14
15
15
16
10
16
17
17
18
18
) Перепечатано с разрешения из Dixon, Massey, Introduction to Statistical Ana-
Analysis, McGraw-Hill Book Co., 1951.
Таблицы
547
Таблица Т1)
Границы значимости для критериев, основанных на сериях
^0,025
N2 \
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
2
2
2
2
2
2
2
2
2
3
2
2
2
2
2
2
2
2
2
3
3
3
3
3
3
4
2
2
2
3
3
3
3
3
3
3
3
4
4
4
4
4
5
2
3
3
3
3
3
4
4
4
4
4
4
4
5
5
5
6
3
3
3
4
4
4
4
5
5
5
5
5
5
6
6
7
3
4
4
5
5
5
5
5
6
6
6
6.
6
6
8
4
5
5
5
6
6
6
6
6
7
7
7
7
9
5
5
6
6
6
7
7
7
7
8
8
8
10
6
6
7
7
7
7
8
8
8
8
9
11
7
7
7
8
8
8
9
9
9
9
12
7
8
8
8
9
9
9
10
10
13
8
9
9
9
10
10
10
10
14
9
9
10
10
10
11
11
15
10
10
11
11
11
12
16
11
11
11
12
12
17
11
12
12
13
18 19 20
12
13 13
13 13 14
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
4
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
3
6
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
7
4
8
8
8
9
9
9
9
9
9
9
9
9
9
9
9
9
9
5
9
9
10
10
11
11
11
11
11
11
11
11
11
11
11
11
6
10
11
11
12
12
12
12
13
13
13
13
13
13
13
13
7
12
12
13
13
13
13
14
14
14
15
15
15
15
15
8
13
13
14
14
15
15
15
15
16
16
16
16
16
9
14
15
15
15
16
16
17
17
17
17
17
17
//0.9
10
15
16
16
17
17
17
18
18
18
19
19
75
11
16
17
18
18
18
19
19
19
20
20
12
18
18
19
19
20
20
20
21
21
13
19
19
20
20
21
21
22
22
14
20
21
21
22
22
22
23
15
21
22
22
23
23
24
16
23
23
24
24
24
17
24
24
25
25
18 19 20
25
25 26
26 26 27
*) Перепечатано с разрешения из Swed, Eisenhart, Tables for Testing Randomness
of Grouping in a Sequence of Alternatives, Annals of Mathematical Statistics, 14 A943),
P. 66.
548
Приложение
Продолжение таблицы Т
^0,025
«0,375
^0,025 ^0,975
20
21
22
23
24
25
26
27
28
29
30
32
34
36
38
14
15
16
16
17
18
19
20
21
22
22
24
26
28
30
27
28
29
31
32
33
34
35
36
37
39
41
43
45
47
40
42
44
46
48
50
55
60
65
70
75
80
8$
96
95
100
31
33
35
37
38
40
45
49
54
58
63
68
72
77
82
86
50
52
54
56
59
61
66
72
77
83
88
93
99
104
1-09
115
Здесь значение, л^ньщее или равное и0Л2Ъ, встречаемся не чаще, чем в 2,5%
случаев, а значение, большее или равное ио^7ЪУ встречается m чаще, чем
в 2,5% случаед.
Для значений Nb и N2, больших 2Q, можно воспользоваться нормальным
приближением. Среднее равно ^+ ^+1, а дисперсия ^ ^ )\
^+ ^^ _^_ N2J(n\ + 7V2— 1)
Например, если JSt1 = N2 = 20, среднее равно 21, а дисперсия составляет 9,74.
Процентили 97,5 и 2,5 равны соответственно 21 + 1,96 ]/~9,74 = 27,1 и 21 —
— 1,96 ]/~9,74= 14,9. Вероятность того, что наблюдаемое число элементов ряда
oкaжeтqя ниже нижней границы (Л) или выше верхней границы (?), не пре-
превосходит а, т. е.
[А < г < В]^ 1—а.
Таблицы
549
Таблица У1)
Критические значения для 5,
пЛ-5
п2
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
0,5%
15
16
16
17
18
19
20
21
22
22
23
24
25
26
27
28
Нижнее
1%
16
17
18
18
20
21
22
23
24
25
26
27
28
29
30
31
2,5%
17
18
20
21
22
23
24
26
27
28
29
30
32
33
34
36f
5%
19
20
21
23
24
26
27
28
30
31
33
34
35
37
38
40
5%
36
40
44
47
51
54
58
62
65
69
72
76
80
83
87
90
Верхнее
2,5%
38
42
45
49
53
57
61
64
68
72
76
80
83
87
91
95
1%
39
43
47
51
55
59
63
67
71
75
79
83
87
91
95
99
0,5%
40
44
49
53
57
61
65
69
73
78
82
86
90
94
98
102
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
0,5%
23
24
25
26
27
28
30
31
32
33
34
36
37
38
39
Нижнее
1%
24
25
27
28
29
30
32
33
34
36
37
39
40
41
43
2,5%
26
27
29
31
32
34
•35
37
38
40
42
43
45
46
48
5%
28
29
31
33
35
37
38
40
42
44
46
47
49
51
53
S
5%
50
55
59
63
67
71
76
80
84
88
92
97
101
105
109
верхнее
2,5%
52
57
61
65
70
74
79
83
88
92
96
101
105
ПО
114
1%
54
59
63
68
73
78
82
87
92
96
101
105
110
115
119
0,5%
55
60
65
70
75
80
84
89
94
99
104
108
113
118
123
М Перепечатано с разрешения из Siegel, Tukey, A Nonparametric Sum of Ranks
Procedure for Relative Spread in Unpaired Samples, Journal of the American Statisti-
Statistical Association, 55 (I960), pp. 429—445; Corrigenda, Journal of the American Statis-
Statistical Association, December 1961.
Продолжение таблицы У
Ill
1
8
9
10
11
12
13
14
15
16
17
18
19
20
0,5%
32
34
35
37
38
40
41
43
44
46
47
49
50
52
Нижнее
1% 2,
34
35
37
39
40
42
44
45
47
49
51
52
54
56
5%
36
38
40
42
44
46
48
50
52
54
56
58
60
62
5%
39
41
43
45
47
49
52
54
56
58
61
63
65
67
5%
66
71
N6
91
95
100
105
1 10
114
119
124
129
Верхнее
2,5%
69
74
79
«ч.4
,S9
94
99
104
109
114
119
124
129
1.4
1%
71
77
S2
87
93
9S
103
109
114
119
124
130
135
^ 140
0,5%
73
78
84
89
95
100
106
111
117
122
128
133
139
144
8
9
10
11
12
13
14
15
16
17
18
19
20
0,5%
43
45
47
49
51
53
54
56
58
60
62
64
66
Нижнее
1%
45
47
49
51
53
56
58
60
62
64
66
68
70
2,5%
49
51
53
55
58
60
62
65
67
70
72
74
77
"i =
5%
51
54
56
59
62
64
67
69
72
75
77
80
83
8
5%
85
90
96
101
106
112
117
123
128
133
139
144
149
Верхнее
2,5%,
S7
93
99
105
ПО
116
122
127
133
138
144
150
155
1%
91
97
103
109
115
120
126
132
138
144
150
156
162
0,5%
93
99
105
111
117
123
130
136
142
148
154
160
166
п2
9
10
11
12
13
14
15
16
17
18
19
20
0,5%
56
58
61
63
65
67
69
72
74
76
78
81
Нижнее
1%
59
61
63
66
68
71
73
76
78
81
83
85
2,5%
62
65
68
71
73
76
79
82
84
87
90
93
5%
66
69
72
75
78
81
84
87
90
<Я
96
V9
9
5%
105
111
117
123
129
135
141
147
153
159
165
171
Верхнее
2,5%
109
115
121
127
134
140
146
152
159
165
171
177
1%
112
119
126
132
139
145
152
158
165
171
178
185
0,5%
115
122
128
135
142
149
156
162
169
176
183.
189
Таблицы
551
Продолжение таблицы У
10
11
12
13
14
15
16
17
18
19
20
0,5%
71
73
76
79
81
84
86
89
92
94
97
Нижнее
1%
74
77
79
82
85
88
91
93
96
99
102
2,5%
78
81
84
88
91
94
97
100
103
107
ПО
5%
82
86
89
92
96
99
103
106
ПО
113
117
10
5%
128
134
141
148
154
161
167
174
178
187
193
Верхнее
2,5%
132
139
146
152
159
166
173
180
187
193
200
1%
136
143
151
158
165
172
179
187
194
201
208
0,5%
139
147
154
161
169
176
184
191
198
206
213
11
12
13
14
15
16
17
18
19
20
0,5%
87
90
93-
96
99
102
105
108
111
114
Нижнее
1%
91
94
97
100
103
107
ПО
ИЗ
116
119
2,5%
96
99
103
106
ПО
113
117
121
124
128
пх -
5%
100
104
108
112
116
120
123
127
131
135
11
5%
153
160
167"
174
181
188
196
203
210
217
Верхнее
2,5%
157
165
172
180
187
195
202
209
217
224
1%
162
170
178
186
194
201
209
217
225
233
0,5%
166
174
182
190
198
206
214
222
230
238
«2
12
13
14
15
16
17
18
19
20
0,5%
105
109
112
115
119
122
125
129
132
Нижнее
1%
109
113
116
120
124
127
131
134
138
2,5%
115
119
123
127
131
135
139
143
147
СО/
120
125
129
133
138
142
146
150
155
12
5%
180
187
195
203
210
218
226
234
241
Верхнее
2,5%
185
193
201
209
217
225
233
241
249
1%
191
199
208
216
224
233
241
250
258
0,5%
195
203
212
221
229
238
247
255
264
] Таблицы
553
552
Приложение
Продолжение таблицы У
/72
13
14
15
16
17
18
19
20
0,5%
125
129
133
136
140
144
1481
151
Нижнее
1%
130
134
138
142
146
150
154
158
2,5%
136
141
145
150
154
158
163
167
n
5%
142
147
152
156
161
166
171
175
1=
13
5%
209
217
225
234
242
250
258
267
Верхнее
2,5%
215
223
232
240
249
258
266
275
1%
221
230
239
248
257
266
275
284
0,5%
226
235
244
254
263
272
282
291
14
15
16
17
18
19
20
0,5%.
147
151
155
159
163
168
172
Нижнее
1%
152
156
161
165
170
174
178
2,5%
160
164
169
174f
179
183
188
5%
166
171
176
182
187
192
197
14
5%
240
249
258
266
275
284
293
Верхнее
2,5%
246
256
265
276
283
293
302
1%
254
264
273
283
292
302
312
0,5%
259
269
279
289
299
308
318
По
15
16
17
18
19
20
0,5%
171
175
180
184
189
193
Нижнее
1%
176
181
186
190
195
200
2,5%
Г84
190
195
200
205
210
5%
192
197
203
208 f
214
220
15
5%
273
283
292
302
311
320
Верхнее
2,5%
281
290
300
310
320
330
1%
289
299
309
320
330
340
0,5%
294
305
315
326
336
347
Продолжение таблицы У
1 = 17
n2
17
18
19
20
0,5%
223
228
234
239
Нижнее
j 0/
230
235
241
246
2,5%
240
246
252
258
5%
249
255
262
268
5%
346
357
367
378
Верхнее
2,5%
355
366
377
388
1%
365
377
388
400
0,5%
372
384
395
407
«2
18
19
20
0,5%
252
258
263
Нижнее
1% 2,5%
259
265
271
270
277
283
п1 =
5%
280
287
294
18
5%
386
397
408
Верхнее
2,5% 1%
396 407
407 419
419 431
0,5%
414
426
439
л2
19
20
0,5%
283
289
Нижнее
1% 2,5%
291
297
303
309
«1 =
•> /0
313
320
19
5%
428
440
Верхнее
2,5% 1%
438 450
451 463
0,5%
458
471
«2
20
0,5%
315
Нижнее
1% 2,5%
324 337
«1 =
•> /0
348
20
5%
472
Верхнее
2,5% 1%
483 496
0,5%
505
«2
16
17
18
19
20
0,5%
196
201
206
210
215
Нижнее
1%
202
207
212
218
223
2,5%
211
217
222
228
234
5%
219
225
231
237
243
16
5%
309
319
329
339
349
Нижнее
2,5%
317
327
338
348
358
1%
326
337
348
358
369
0,5%
332
343
354
366
377
18 № 819
554
Приложение
Таблица Ф1)
Приближенные границы значимости d\-a (n) для
максимума абсолютной разности между
функциями распределения выборки
и совокупности
РгГтах \F*n(X)—F (х)х=х\ < di-a (лI = 1 — а
L х
Таблицы
555
Объем
Выборки
00
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
0,10
0,950
0,776
0,642
0,564
0,510
0,470
0,438
0,411
0,388
0,368
0,352
0,338
Q,325
0,314
0,304
0,295
0,286
0,278
0,272
0,264
Уровень значимости
0,05
0,975
0,842
0,708
0,624
0,565
0,521
0,486
0,457
0,432
0,410
0,391
0,375
0,361
0,349
0,338
0,328
0,318
0,309
0,301
0,294
(а)
0,01
0,995
0,929
0,828
0,733
0,669
0,618
0,577
0,543
0,514
0,490
0,468
0,450
0,433
0,418
0,404
0,392
0,381
0,371
0,363
0,356
1) Перепечатано с разрешения из Massey F. J., The
Kolmogorov-Smirnov Test for Goodness of Fit, Journal of
the American Statistical Association, 46 A951).
Таблица X1)
Нормальные метки
Средние значения порядковых статистик из нормальной
совокупности N @, 1)
\ п
1
2
3
4
5
6
2
0,564
3
0,846
р,000
4
1,029
0,297
5
1,163
0,495
0,000
6
1,267
0,642
0,202
7
1,352
0,757
0,353
0,000
8
1,424
0,852
0,473
0,153
9
1,485
0,932
0,572
0,275
0,000
10
1,539
1,001
0,656
0,376
0,123
11
1,586
1,062
0,729
0,462
0,225
0,000
12
1,629
1,116
0,793
0,537
0,312
0,103
\ п
i \
1
2
3
4
5
6
7
8
9
10
11
12
13
13
1,668
1,164
0,850
0,603
0,388
0,190
0,000
14
1,703
1,208
0,901
0,662
0,456
0,267
0,088
15
1,736
1,248
0,948
0,715
0,516
0,335
0,165
0,000
16*
1,766
1,285
0,990
0,763
0,570
0,396
0,234
0,077
17
1,794
1,319
1,029
0,807
0,619
0,451
0,295
0,146
0,000
18
1,820
1,350
1,066
0,848
0,665
0,502
0,351
0,208
0,069
19
1,844
1,380
1,099
0,886
0,707
0,548
0,402
0 264
0,131
0,000
20
1,867
1,408
1,131
0,921
0,745
0,590
0,448
0,315
0,187
0,062
21
1,89
1,43
1,16
0,95
0,78
0,63
0,49
0 36
0,24
0,12
0,00
22
1,91
1,46
1,19
0,98
0,82
0,67
0,53
0 4!
0,29
0,17
0,0$
23
1,93
1,48
1,21
1,01
0,85
0,70
0,57
0 45
0,33
0,22
0,11
0,00
24
1,95
1,50
1,24
1,04
0,88
0,73
0,60
0 48
0,37
0,26
0,16
0,05
25
1,97
1,52
1,26
1,07
0,91
0,76
0,64
0 52
0,41
0,30
0,20
0,10
0,00
Заметим, что среднее значение i-й порядковой статистики равно среднему
значению (я-? + 1)-й порядковой статистики с обратным знаком.
!) Перепечатано с разрешения из Pearson, Hartley, Biometrika Tables for Statis-
Statisticians, Vol. 1 A958), p. 1975; Fisher. Yates, Statistical Tables for Biological, Agri-
Agricultural and Medical Research, Oliver and Boyd, 1953.
18*
Толерантные множители для нормального распределения Таблица Ц1)
Величины К таковы, что доля Р значений совокупности находится между границами (выборочное среднее) ±
± К (выборочное среднее квадратическое отклонение) с доверительной вероятностью у (объем выборки равен /г).
5
10
15
20
25
30
35
40
45
50
55
60
65
70
75
80
85
90
95
100
110
120
130
140
150
У
> 0,75 0,90
2,454 3,494
1,775 2,535
1,594 2,278
1,506 2,152
1,453 2,077
1,417 2,025
1,390 ]
1,370 ]
1,354 ]
1,340 J
1,329 1
1,320 ]
1,312 j
1,304 ]
1,298
1,292
1,287
1,283
1,278
1,275
1,268
1,262
1,257
1,252
1,248
1,988
1,959
,935
,916
1,901
1,887
1,875
,865
1,856
1,848
1,841
1,834
1,828
1,822
1,813
1,804
1,797
1,791
1,785
-0,90
0,95
4,152
3,018
2,713
2,564
2,474
2,413
2,368
2,334
2,306
2,284
2,265
2,248
2,235
2,222
2,211
2,202
2,193
2,185
2,178
2,172
2,160
2,150
2,141
2,134
2,127
0,99
5,423
3,959
3,562
3,368
3,251
ЗД7О
3,112
3,066
3,030
3,001
2,976
2,955
2,937
2,920
2,906
2,894
2,882
2,872
2,863
2,854
2,839
2,826
2,814
2,804
2,795
У
0,999 0,75 0,90
6,879 3,002 4,275
5,046 1,987 2
4,545 1
4,300 1
4,151 1
4,049 1
3,974 1
3,917 ]
3,871 1
3,833 1
3,801 ]
3,774 1
3,751 )
3,730 1
3,712 ]
3,696 ]
3,682 J
3,669
3,657
3,646
3,626
3,610
3,595
3,582
3,571
>,839
1,735 2,480
,616 2
1,310
,545 2,208
,497 2,140
,462 2,090
,435 2,052
,414 2,021
,396 1
,382 1
,369 1
1,359 ]
,349 ]
1,341 1
1,334 1
1,327 1
1,321 ]
1,315 1
1,311 ]
1,302
1,294 ]
1,288 ]
1,282 ]
1,277
,996
,976
,958
,943
,929
,917
,907
,897
,889
,881
,874
1,861
,850
,841
,833
1,825
= 0,95
0,95
5,079
3,379
2,954
2,752
2,631
2,549
2,490
2,445
2,408
2,379
2,354
2,333
2,315
2,299
2,285
2,272
2,261
2,251
2,241
2,233
2,218
2,205
2,194
2,184
2,175
0,99
.6,634
4,433
3,878
3,615
3,457
3,350
3,272
3,213
'3,165
3,126
3,094
3,066
3,042
3,021
3,002
2,986
2,971
2,958
2,945
2,934
2,915
2,898
2,883
2,870
2,859
0,999
8,415
5,649
4,949
4,614
4,413
4,278
4,179
4,104
4,042
3,993
3,951
3,916
3,886
3,859
3,835
3,814
3,79 5V
3,778
3,763
3,748
3,723
3,702
3,683
3,666
3,652
0,75
•4,643
2,508
2,060
1,860
1,745
1,668
1,613
1,571
1,539
1,512
1,490
1,471
1,455
1,440
1,428
1,417
1,407
1,398
1,390
1,383
1,369
1,358
1,349
1,340
1,332
0,90
6,612
3,582
2,945
2,659
2,494
2,385
2,306
2,247
2,200
2,162
2,130
2,103
2,080
2,060
2,042
2,026
2,012
1,999
1,987
1,977
1,958
1,942
1,928
1,916
1,905
у = 0,99
0,95
7,855
4,265
3,507
3,168
2,972
2,841
2,748
2,677
2,621
2,576
2,538
2,506
2,478
2,454
2,433
2,414
2,397
2,382
2,368
2,355
2,333
2,314
2,298
2,283
2,270
0,99
10^260
5,594
4,605
4,161
3,904
3,733
3,611
3,518
3,444
3,385
3,335
3,293
3,257
3,225
3,197
3,173
3,150
3,130
3,112
3,096
3,066
3,041
3,019
3,000
2,983
0,999
13,015
7,129
5,876
5,312
4,985
4,768
4,611
4,493
4,399
4,323
4,260
4,206
4,160
4,120
4,084
4,053
4,024
3,999
3,976
3,954
3,917
3,885
3,857
3,833
3,811
Перепечатано с разрешения из Eisenhart, Hastay, Wallis, Techniques of Statistical Analysis, McGraw-Hill Book Co., 1947.
Продолжение таблицы ЦЛ
у - 0,90
= 0,95
у = 0,99
л\.Р 0,75 0,90 0,95 0,99 0,999 0,75 0,90 0,95 0,99 0,999 0,75 0,90 0,95 0,99 0,999
160
170
180
190
200
1,245
1,242
1,239
1,236
1,234
1,780
1,775
1,771
1,767
1,764
2,121
2,116
2,111
2,106
2,102
2,787
2,780
2,774
2,768
2,762
3,561
3,552
3,543
3,536
3,529
1,272
1,268
1,264
1,261
1,258
1,819
1,813
1,808
1,803
1,798
2,167
2,160
2,154
2,148
2,143
2,848
2,839
2,831
2,823
2,816
3,638
3,627
3,616
3,606
3,597
1,326
1,320
1,314
1,309
1,304
1,896
1,887
1,879
1,872
1,865
2,259
2,248
2,239
2,230
2,222.
2,968
2,955
2,942
2,931
2,921
3,792
3,774
3,759
3,744
3,731
220
240
260
280
300
320
340
Д60
380
400
450
500
550
600
650
700
750
800
850
900
950
1000
1,229
1,226
1,222
1,219
1,217
1,215
1,212
1,210
.1,209
1,207
1,204
1,201
1,198
1,196
1,194
1,192
1,191
1,189
1,188
1,187
1,186
.,1.185.
1,758
1,752
1,748
1,744
1,740
1,737
1,734
1,731
1,728
1,726
1,721
1,717
1,713
1,710
1,707
1,705
1,703
1,701
1,699
1,697
1,696
1,695
2,095
2,088
2,083
2,078
2,073
2,069
2,066
2,062
2,059
2,057
2,051
2,046
2,041
2,038
2,034
2,032
2,029
2,027
2,025
2,023
2,021
2,019
2,753
2,744
2,737
2,730
2,725
2,719
2,715
2,710
2,707
2,703
2,695
2,689
2,683
2,678
2,674
2,670
2,667
2,663
2,661
2,658
2,656
2,654
3,516
3,506
3,496
3,488
3,481
3,474
3,468
3,463
3,458
3,453
3,443
3,434
3,427
3,421
3,416
3,411
3,406
3,402
3,399
3,396
3,393
3,390
1,252
1,247
1,243
1,239
1,236 .
1,233 ,
1,230 ]
1,228
1,225
1,223 ]
1,219
1,215 '
1,212
1,209
1,207 1
1,204 ]
1,202 ]
1,201 1
1,199 1
•1,198 1
1,790
1,783
1,777
1,772
1,767
1,763
1,759
1,755
1-752
1,749
1,743
,737
1,733
1,729
,725
,722
,719
[,717
,714
,712
3,196 1,710
1,195 J
,709
2,133
2,125
'2,118
2,111
•2,106
2,100
2,096
2,092
2,088
2,084
2,077
2,070
2,065
2,060
2,056
2,052
2,049
2,046
2,043
2,040
2,038
2,036
2,803
2,792
2,783
2,775'
2,767
2,760
2,754
2,749
2,744
2,739
2,729
2,721
2,713
2,707
2,702
2,697
2,692
2,688
2,685
2,682
2,679
2,676
3,581
3,567
3,555
3,544
3,535
3,526
3,519
3,512
3,505
3,499
3,486
3,475
3,466
3,458
3,451
3,445
3,439 1
3,434
3,430
3,426
3,422
3,418
1,296
1,289
1,283
1,278
1,273
1,268
1,265 ,
1,261
1,258
1,255
1,248 1
1,243
1,238
1,234
1,230
1,227 1
,225 1
1,222 1
1,220
1,218 1
1,216
1,214 1
1,854
1,843
1,835
,827
1,820
1,814
,808
,803
1,798
1,794
1,785
1,777
,770
1,764
1,759
1,755
,751
1,747
,744
,741
,738
,736
2,209
2,197
2,186
2,177
2,169
2,161
2,154
2,148
2,143
2,138
2,127
2,117
2,109
2,102
2,096
2,091.
2-,086
2,082
2,078
2,075
2,071
2,068
2,903
2,887
2,873
2,861
2,850
2,840
2,831
2,823
2,816
2,809
2,795
2,783
2,772
2,763
2,755
2,748
2,742
2,736
2,731
2,726
2,722
2.718
3,708
3,688
3,670
3,655
3,641
3,628
3,617
3,607
3,598
3,589
3,570
3,555
3,541
3,530
3,520
3,511
3,503
3,495
3,489
3,483
3,477
3.472
558
Приложение
Таблица Ч1)
Доверительные интервалы для медианы
n
6
7
8
У
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
*5
Шбольше
к
1
1
1
2
2
2
3
3
3
4
4
5
5
5
6
6
6
7
7
8
8
8
9
9
10
10
10
11
11
12
е Фактическое
а < о/M
0,031
0,016
0,008
0,039
0,021
0,012
0,039
0,022
0,013
0,035
0,021
0,049
0,031
0,019
0,041
0,027
0,017
0,035
0,023
0,043
0,029
OJ019
0,036
0,024
0,043
0,029
0 020
0,035
0,024
.0,041
Наибаше
R
1
1
1
1
2
2
3
3
3
4
4
4
5
5
5
6
6
7
7
7
8
8
8
9
9
10
10
е Фактическое
а < 0,01
0,008
0,004
0,002
0,001
0,006
0,003
0,002
0,007
0,004
0,002
0,008
0,004,
0,003
0,007
0,004
0,003
0,007
0,004
0,009
0,006
0,004
0,008
0,005
0,003
0,007
0,005
0,009
0,006
N
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
Наибольшее
к\
12
13
13
13
14
14
15
15
16
16
16
17
17
18
18
19
19
19
20
20
21
21
22
22
22
23
23
24
24
25
< Фактическое
и < 0,05
1,029
0,047
0,034
0,024
0,038
,0,028
0H44
о,оз;
0,049
0,036
0,026
Д040
0,029
0,044
0,033
0;049
0,036
€,027
0,040
0,030
0,044
0,033
0,048
0,036
0,027
0,040
0,030
0,043
0,033
0,046
Наибольше
к
10
11
11
12
12
12
13
13
14
14
14
15
15
16
16
16
17
17
18
18
18
19
19
20
20
21
21
21
22
22
q Фактическое
а < 0,01
0,004
0,008
0,005
0,009
0,006
0,004
0,008
0,005
0,010
0,007
0,005
0,008
0,006
0,009
0,007
0,005
0,008
0,005
0,009
0,006
0,005
0,008
0,005
0,009
0,006
0,010
0,007
0,005
0,008
0,006
Если наблюдения упорядочены по возрастанию, т.е. х^ < х'2 < . . . < x"w то можно
утверждать, что с вероятностью 1—а медиана совокупности лежит между х'^ и х'п_^+1
где k и а приведены выше.
*) Перепечатано с разрешения Banerjee S. К. из Nair К. R., Table of Confidence
Interval for the Median in Samples from any Continuous Population, Sankhya, 4 A940),
pp. 551—558.
Таблицы
559
Номограмма Ш (II)
Доверительные зоны для коэффициента корреляции
(Доверительная вероятность 0,95. Числа на кривых указывают
объем выборки)
-
-0,6 -0,4 -42 0,0 +0,1 +0,4 +0,6
Выборочный коэффициент корреляции г
David F ТГ тТыез Во°С?Ь°еИОМ-Иг,ТС+Я ° РГЪеш?"?я проф- Е- С' Пирсона из книги
560
Приложение
Таблицы
561
Таблица Ш B)
Критические значения коэффициента корреляции
Объем
Выборки
п
3
4
5
6
7
8
9
Ш
11
12
1Л
14
15
16
17
18
Критические значения
у = 0,05
0,99692
0,95000
0,8783
0,811.4
0,7545
0,7067
0,6664
0,6319
0,6021
0,5760
0,5529
0,5324
0,5139
0,4973
0,4821
у = 0,01
0,99988
0,99000
0,95873
0,91720
0,8745
0,8343
0,7977
0,7646
0,7348
0,7079
0,6835
0,6614
0,6411
0,6226
0,6055
-/ = 0,001
0,99900
0,99116
0,97406
0,95074
0,92493
0,8982
0,8721
0,8471
0,8233
0,8010
0,7800
0,7603
0,7420
0,7246
0,7084
Объем
выборки
п.
19
20
21
22
27
32
37
42
47
52
62
72
82
92
102
Критические значения
у = 0,05
0,4555
0,4438
0,4329
0,4227
0,3809
0,3494
0,3246
0,3044
0,2875
0,2732
О;25ОО
0,2319
0,2172
0,2050
0,1946
7=0,01
0,5751
0,5614
0,5487
0,5368
0,4869
0,4487
0,4182
0,3932
0,3721
0,3541
0,3248
0,3017
0,2830
0,2673
0,2540
у = 0,001
0,6932
0,6787
0,6652
0,6524
0,5974
0,5541
0,5189
0,4896
0,4648
0,4433
0,4078
0,3799
0,3568
0,3375
0,3211
х) Таблица Ш B) — сокращенная таблица VI из книги Fisher, Yates, Statistical
Tables for Biological, Agricultural and Medical Research, Oliver and Boyd, Ltd.
Используется с разрешения авторов и издателей.
Таблица Ш C)
Критические значения коэффициента ранговой
корреляции
п
5
6
7
8
9
10
11
12
13
14
15
\ь
17
18
1У
20
21
23
24
25
26
27
28
29
30
у =0,10
0,900
0,829
0,71Л
0,643
0,600
0,564
0 523
0,447
0,475
0,457
0,441
0,425
0,412
0,399
O.3N8
0,377
0,368
0,359
0,351
0,343
0,336
0,329
0,323
0,317
0,311
0,305
-/ = 0,05
0,886
0,7X6
О,73Х
0,683
0,648
0,623
0,591
(),56Г>
0,545
0,525
0,507
0,490
0,476
0,462
0,450
0,438
0,428
0,418
0,409
0,400
0,392
0,385
0,377
0,370
0,364
)' = 0,02
0,943
О,Х93
О,КЗЗ
0,7.x 3
0,745
0,736
0,703
0,673
0,646
0,623
0,601
0,582
0,564
0,549
0,534
.0,521
0,508
0,496
0,485
0,475
0,465
0,456
0,448
0,440
0,432
у=0,01
0,S81
0,833
0,794
0,818
0,780
0,745
0,716
0,689
0,666
0,645
0,625
0,608
0,5У!
0,576
0,562
0,549
0,537
0,526
0,515
0,505
0,496
0,487
0,478
См. Olds E. G. [12.8; 12.9].
562
Приложение
Таблицы
563
Таблица Э
Продолжение таблицы Э
Процентили для некоторых распределений
1: Логистическоеfy$r\ *
U-*i)
Верхние процгнтили
95%
п
^2
97,5%
5
10
20
40
oo
2,87
2,86
2,85
2,84
2,85
Верхние процентили
п 95%
5
10
20
40
оо
4,0
3,29
3,06
2,93
2,85
@г известно)
99%
3,48
3,47
3,45
3,40
3,40
91,5%
4,23
4,13
4,05
4,03
4,03
@2 не известно)
99%
5,0
4,07
3,67
3,54
3,40
6,7
5,06
4,45
4,19
4,03
2:
Верхние
п
5
10
15
20
25
50
ОС
Коши 1
V
процентили —
90%
2,12
1,94
1,91
,88
1,86
,84
,81
Верхние процентил(
п
5
10
15
20
25
50
00
90%
3,15
2,27
2,10
2,00
1,97
1,88
1
,81
95%
3,07
2,67
2,52
2,45
2,4 Г
2,37
2,33
V'w
95%
4,77
3,11
2,79
2,63
2,58
2,45
2,33
-orctgl
9,-9,) .
9г ч
97,5%
4,24
3,36
3,18
3,03
2,95
2,87
2,77
' 2
97,5%
6,78
3,95
3,46
3,27
3,13
2,96
2,77
X — c/j \
°г )
9г известно)
99%
6,16
4,33
3,97
3,78
3,66
3,50
3,29
не известно)
99%
11,0
5,19
4,40
4,04
3,85
3,59
3,29
g
Нижние и верхние процентим ~ (^ не известно)
п
5
10
20
40
1%
0,24
0,436
0,588
0,707
2,5%
0,304
0,492
0,640
0,749
5%
0,367
0,551
0,689
0,781
95%
1,53
1,45
1,29
1,21
97,5%
1,66
1,52
1,36
1,26
99%
1,65
1,45
1,32
Таблица взята с разрешения Antle, Klimko, and Harkness, diometrika, 57,
397-401 A970)
5
10
15
20
25
50
100
o2
Нижние и верхние процентили ^- @j известно)
95%
1%
0,203
0,333
0,408
0,462
0,508
0,625
0,713
2,5%
5%
97,5%
0,268
0,406
0,473
0,532
0,567
0,674
0,761
0,337
0,471
0,541
0,597
0,623
0,721
0,790
2,932
2,129
1,834
1,689
1,607
1,389
1,267
3,777
2,455
2,062
1,867
1,760
1,484
1,328
99%
5,035
2,945
2,410
2,117
1,958
1,604
1,383
564
n
5
10
15
20
25
50
100
J
Приложение
к
Нижние и верхние процентики j- @
1%
0.084
0.256
0.357
0.424
0.473
0.610
0.712
2.5%
0.130
0.320
0.418
0.488
0.533
0.656
0.746
5%
0.201
0.387
0.479
0.546
0.583
0.702
0.77-9
95%
2.560
2.005
1.746
1.628
1.536
1.366
1.251
Продолжение таблицы Э
{Неизвестно)
97.5%
3.277
2.353
1.970
1.811
1.708
1.463
1.305
99%
4.525
2.838
2.279
2.067
1.911
1.566
1.372
Таблица взята с разрешения G. Haas, L. J. Bain, and
С. Е. Antle, Biometrika, 57, 403-408 A970).
3:Вей<*упла/^(х) = 1 - expf - (^ Л
Нижние и верхние процент или — (Ь не известна')
2%
10%
90%
95%
98%
5
10
15
20
25
50
100
п
5
10
15
20
25
50
100
0.604
0.676
0.716
0.743
0.763
0.817
0.861
0.683
0.738
0.770
0.791
0.808
0.852
0.888
0.766
0.802
0.823
0.838
0.850
0.886
0.916
Нижние и Верхние процешили с In
2%
-1.631
-0.876
-0.651
-0.540
-0.481
-0.318
-0.221
5%
-1.247
-0.665
-0.509
-0.428
-0.375
-0.254
-0.174
10%
-0.888
-0.507
-0.393
-0.332
-0.292
-0.198
-0.136
2.277
1.602
.427
.343
.292
.182
.116
(-) =
\Ъ )\
90%
0.772
0.475
0.374
0.318
0.282
0.195
0.136
2.779 :
J.518
1.807 2.070
1.564
1.449
.380 1
1.235 1
1.150
Нт)}
95%
1.107
.732
.579
.489
.301
.192
98%
.582
0.644 0.851
0.499 0.653
0.421 (
).549
0.370 0.482
0.253 (
0.175 (
).328
).226
Таблица взята с разрешения из D. R. Thoman, L. J. Bain, and С. Е. Antle,
Technometrics, 11, 445-460 A969).
Ответы
567
РЕШЕНИЯ НЕКОТОРЫХ УПРАЖНЕНИЙ
Глава 1
1. 28,Н; 33,34; 39,15; 44,90E)_(вторые разности).
2. Значения Xv, a~v — Ua V^v.
7.
V \
20
30
40
50
0,25
-0,28
—0,30
—0,31
-0,32
0,50
—0,66
—0,66
-0,66
—0,67
0,75
—0,44
—0,42
—0,41
—0,41
0,90
0,30
0,33
0,34
0,35
Благодаря малой изменчивости легко проводить интерполяцию. Например,
0,90
: 34+1,2816 /8 + 0,335 « 44,90.
3. а) 5,46 (квадратичная гармоническая интерполяция); б) 44,91 (линейная
гармоническая интерполяция).
4. а) 4,00 (линейная гармоническая интерполяция); б) 4,30 (вторые разности).
5. 2,674 [линейная интерполяция (вторые разности малы)].
6. Рассмотрите (Xv; a~~%v; о,5о)/^а как ФУНК1*ИЮ ^«- а) ^о,8о = °»8416.
Линейная интерполяция дает %l0. 080 ~ 25,04 (правильное значение с двумя
десятичными знаками 25^03). б) Интерполяция с помощью табл. Г дает
1 18'39' В) И'95 ()
0,9975
Если игроки, владеющие подачей и захватом, также могут включаться
в состав команды на 7 вакантных мест, то
8.
9. 121/7! =95 040.
10. 2 («) E) =600.
11.
12. 6.[[F.5).E.4).2.(^)] + [F.5.4).5.2]} = 28 800.
13. Значения (Xv; a""Xv; о.в)/^:
V ^^\^
20
30
40
50
0
0
0
0
0
,25
,69
,70
,70
,70
0,50
*
*
*
*
0
0
0
0
0
,75
,72
,72
,71
,71
0,90
0,73
0,72
0,72
0,72
[* Формально здесь есть неопределенность, но в качестве предельного
значения при a—^0,50 можно взять 0,71 (^ ]К"~2).]
Стабильность этих величин по отношению к колебаниям как v, так
и а вполне удовлетворительна.
Глава 2
1. б) 0,49988 дюйма, 0,000443 кв. дюйм.
2. б) 4,72 мкс, 3,16 мкс.
3. а) 14,01-Ю-5 м, 60,6343-Ю-10 м2.
4. б) 15,75%, 0,0373 (%J.
5. 133,42 изделий/ч; 7,84 изделий/ч.
7. 41,28; 2,17.
8. а) 1,64; 2,78; 1,67; 1,58; 2,24. б) 1,98. в), г) В общем случае результаты
различаются^ так как представляют собой разные величины и вычисляются
по разным формулам.
9. 0,5000 дюйма; 0,5000 дюйма.
10. 15,74%.
11. 132,9 изделий/ч; 127,8 изделий/ч; 138,9 изделий/ч.
12. 150,34-103 фунт/кв. дюйм, 9,9Ы03 фунт/кв. дюйм.
13.
Медиана
155
149
150,5
147,5
151,5
Среднее
154,3
153
148,2
152
151,5
141
147,4
149,5
150,2
154
Итог
150,34
154,0
150,9
143,5
149,9
153,5 151,00
14. 1, 2, 3, 4, 5, 6, 5, 4, 3, 2, 1.
23. б) 2,79; 1,96.
25. а) 0,49961; 0,000202. б) Все выборочные значения меньше среднего значе-
значения, полученного в упражнении 1. в) Дисперсия оказывается много меньше.
29. 7,021%; 0,041188 (%J.
31. 11,75. Полученное среднее значение больше ожидаемого. Методы, описан-
описанные в следующих главах, помогут решить, действительно ли имеет место
увеличение средней прочности на изгиб.
568
Ответы
Ответы
569
32. а) 1,3259; б) 0,2372; в) 5,6.
35. 0,83; 1,0006.
36. А: 41,5%; 80,40 (%J. В: 4О,9о/о; 297,66 (%J.
Глава 3
1. а) 5-4-4! = 480 (возможные последовательности положений гласных: 1357,
1358, 1368, 1468, 2468); б) 30-51 = 3600 (возможное число положений трех
букв е: 5 + D-5) + 5 = 30).
2 \5 32 ^ е / 1 \ / 2 \4 80
/32 80 /1\* / 2 \з_192
B) l,243+243+1U Ш IT,/ "~243"
3. а) ^:б)^;вI;гI;дI.
4. а) 0,00603; б) 0,01207; в) 0,03993; г) 0,04169; д) 0,30769.
5 19
5* 495*
7 ^
169 #
9. а) Ничего с достаточной определенностью; б) @,98J0 = 0,668.
в) @,96J0 =0,442.
б) Монета правильная и результаты бросаний независимы.
39
12. 1_ЦП
(получено с помощью логарифмов). Приближенная формула имеет вид
39 39
^(8_рз)G/?б_рз+1)-1.
Указание: вероятность =р*р-\- A —ръ) Р', где Р —/?3 + A — р3) Р' и Р' =
13.
14.
15. а) @,9)8 = 0,430. б) 1 —@,9)8 —8 @,1)-@,9O = 0,187. в) 3. г) Вероятность
отсутствия дефектных образцов равна @,9K0 = 0,0424. Это не неожиданное
событие, хотя отсутствие дефектных образцов ожидается всего один раз
в 24 выборках объема 30.
16. а) от 77 до 859J.
б) 0,8-92 = 73,6% всех изделий проходят проверку А и отбираются для
использования, но по меньшей мере 0,98-77 = 75,4% всех изделий выдер-
выдерживают проверки А и В и также отбираются для использования. Послед-
Последняя доля должна быть меньше первой.
19. а) 5/6; б) 0; в) 0; г) 1/6;
k б / k \)i )
19. а) 5/6; б) 0; в) ; ) /;
20. a) kjn\ б) (/ — k— \)in\ в) \'2(п— 1);г) 11г2(п2— 1)(при0<? < /
21. а) 1/2(п—\). б) 11%{п—\) — 1!<д для нечетных п, 1/2(^ — 2) —
п— 1).
/9 для
22. Рг [Х< 1/3]=
[№+•••
23.
24.
25. /".
26. а3 = 0, «4 = 1,8.
27. а) Вероятность наблюдения г событий Е (R = r) равна коэффициенту при
хг в разложении [рх+ A— /?)р* [(/?+6) x-j-(l—р+6)]« [(/?—Ь) *+A— р+б)]Л.
б) ?[/?]=4n/?; Var(^) = 4/z/?(l— /?) — 2/гб2.
Математическое ожидание то же, что и для биномиального распределения;
дисперсия меньше на 2/гб2.
29. Pjv= [Вероятность (?—1) событий Е в первых (N—\) испытаниях]-[Ве-
испытаниях]-[Вероятность события Е в N-м испытании] = P/fe_1. дГ_1 Р(дг).
Всегда N ^ k.
Если т равно, нулю или представляет собой положительное целое число, то
Р(Ш +1) —
3)
/ 1
X
X
где
= 2m,
= m,
Y = m,
Y = m,
Y = m+\,
K = m+1,
При 6 = 0 имеем отрицательное биномиальное распределение
= m,
= m.
30. б) Коэффициент корреляции между X к YZ равен 0,929.
m
31. Пусть Y= 2 af^t и Var(^/) = cr2. Благодаря симметрии ai равно а„
и равно, скажем а; а2 = а3= •. • — an-i — b. Для несмещенности требуется,
чтобы 2а+(п — 2) 6=1.
Var
J
четных /г.
Дисперсия достигает минимума при
а = [п — 2 + (/г — 4)р] [п(п — 2) — 4р]~1,
Ь = [п — 2 — 2р] [п(л — 2) — 4р]-х.
а2 Г, (/г —2~2рJ "I
Минимальное значение дисперсии равно -^ 1—~ ——~- ,
^ L ^ 1^ — / — ^Р J
32, а) [(/г—1) A —2р/г-!)//2] а2; б) 2A-р)а2,
570
Ответы
33. a) E[YZ\X]=d* = E[YZ]\ Е [XYZ]=o*E (X); Cov (X, YZ) = 0.
Поскольку Var (Y \ X) = (X-{-1) а2 зависит от X, Y нельзя считать неза-
независящим от X.
б) Коэффициент корреляции между Y и Z равен [1 + ? (Х)]~х.
36. Рг [.*:=?] =
37. а) Рг [N изделий отбраковано второй проверкой] =
2
/ > я/з
б)
Отсюда Е [#] = (ЗЛ*р/40) A + 39/?),
:A + 39р)A-р) + т™;
Среднее квадрэтическое отклонение N = -^
(\-\-39p) G-{-\3р).
38. Производящая функция моментов равна
?(Х)=0аA—a); Var (Х) = 0а A-6а) A -а),
/
(
3 = е-1/2а-1/2[а+A-еа)A-26а)][1-а]-з/2,
-1[1 + 4а+а2 —40а—40а2 + 692а2—
где 0-1 = —In A—а).
39. s-й факториальный момент X равен
Следовательно,
40.
Рг [| X,—
Var (X(
Кроме того,
рг г| Xt — E (Xi)\^di no крайней мере для одного
2
Ответы
571
Следовательно, Рг [| X/ —? (Х/)| < d/ для всех t = l, 2, ...,/«•] =
= 1 — Рг[|Х/ — ? (Xj) | ^ d/ по крайней мере для одного i]
Множество доверительных интервалов {Х( — d/
/г
2, ..., &, имеет доверительную вероятность не меньше 1 — 2 df2 Var (X/).
41. Неравенство справа
\i'r(Y) достигает максимума для данного значения Рг[К<:Л] (и при вы-
выполнении перечисленных условий), если ру {у) имеет вид, как показано
на рисунке
Рг[У>А]
При таком распределении \i'r (Y) равно величине в правой части неравенства.
Неравенство слева
в
Определим m = [l/pY (A)] ^ ру (у) dy.
А
Пусть* ру (А) = рд.
Поскольку ру (у) < Ра пРи У > А (А <: т < В), то
В А + т А+т В
А А
Из определения т
В
А + т
А+т
А+т
А+т
Следовательно,
А + т
А + т А
[у в интервале (А-\-т, В)^у в интервале (А, А-\-т)].
Отсюда
А+т
В
А + т
572
Ответы
С помощью (I) получаем
В А+т
\ yrdy.
А
Кроме того,
А А
J УРу (У) dy^PA] Уг dy (поскольку рл < р (у), если у < А).
о о
Складывая, получаем
А + т
т. е.
или
т
43.
максимально при т — А/г.]
Ю \ -1
2-
i=l
i = G) @,02)'@,98)"-',
где
(в предположении, что каждой головкой произведено 10 штамповок). Если
воспользоваться пуассоновской аппроксимацией, получим
и
10
?) @,02)/@,98I0-/@)l+0,0902^-@'1+0'09i')/2!
,98)8 [0,01 @,02^-°
0,98J
+ 0,00522^-0.09 @502
44. а) Апостериорные вероятности равны
= 0,006776.
то
где
. 1 / 1 W 1 \7 / 1 \з i / i \4 / j \s
is
Вычисления в случае 1) дают 675/4771, а в случае 2) 9/i6-675/477i-
Ответы
573
Глава 4 "
1. а) 7. б) С помощью пуассоновской аппроксимации получаем, что вероят-
вероятность 11 и больше сверхнормативных сборок равна 0,0985. Это не так уж
необычно.
2. а) 0,301; б) 0,030; в) 0,550.
4. В предположении, что монеты правильные и результаты независимые,
теоретические частоты появления герба 0, 1, 2, ..., 5 раз равны соответ-
соответственно 1,6; 7,8; 15,6; 15,6; 7,8; 1,6.
6. а) 9; б) 0,99985; в) 3,736-10-7.
7. Число попыток (п) должно быть таким, чтобы @,1)" < 0,01; /г = 2.
8. 0,71090.
9. а) 1; б) 0,2642.
10. C/4I00.
12. а) 0,909-Ю-12; б) 1,968.10-% в) 1,942-10.
13. Нет, поскольку Рг[*<112 попаданий | р = 0,300, п = 400] = 0,20729. Это
„нередкое" событие. Причиной для тревоги здесь является постоянное
уменьшение среднего количества попаданий.
14. Он не в форме. Рг [*< 171 р = 1/16, п = 400] = 0,05477.
15. а) 0,015625. Рг [^ = 8] = 0,04395, Рг [х^ь 8] = 0,05469,
16. а) и б).
X
0
1
2
3
4
/
353
382
196
55
11
/ (бин.)
348,7
387,4
193,7
57,4
11,2
f (Пуассона)
367,9
367,9
183,7
61,3
15,3
X
5
6
7
8
9
10
/
2
1
0
0
0
0
/(бин.)
1,5
0,1
0,0
0,0
0,0
0,0
/ (Пуассона)
3,1
0,5
0,1
0,0
0,0
0,0
в) В случае биномиального распределения.
17. а) 5; б) 0,38388; в) 0,11173.
19. а) 0,7351; б) 0,5314.
[()
29. 0,1765.
30. Нет, поскольку границы 95%-ного доверительного интервала для 6 равны
(9,4; 26,0). Рг [*< 16 | 6 = 20] =0,2211.
36. При одностороннем критерии утверждение отклоняется при выпадении
герба 16 или 34 раз. Рг [х^ 16] = 0,008. .При двустороннем критерии
утверждение отклоняется при выпадении герба 15 или 35 раз. Рг[л:^15] =
= 0,003.
а) (е — IJ; б) е/(е+\); в) 1/(??+1).
41.
Глава 5
а) 0,00135; б) 0,02275; в) 0,6826; г) 0,9545.
а) 50; б) 0,02275; в) 38,30; г) 94,52.
85,15.
0,121 унции.
13,744.
7. а) 14,5% случаев.
б) Нет, поскольку 1
«0,81.
@,855J0-^20@,145)-@,855I9 = 1—0,0436 —0,1478
574
Ответы
8. а) 7,999 дюйма; б) 0,0089 дюйма; в) 0,00038 дюйма.
10. Ф [l,25-@,2509-j-G2)-i/2]. Это выражение будет больше 0,90, если
1,25 @,2509 +о2)-1/2 > 1,2816, т. е. а < 0,84 мм.
И. J_,006.
13. Х = 4,4395; 0 = 0,22.
X
f
1
30
3
15
5
11
7
9
9
3
11
1
13
2
15
1
17
2
... 27
... 1
f 26,7 17,2 11,1 7,1 4,6 3,0 1,9 1,3 0,8 1,4
15. X = 152,4; 52 = 6,16.
X
146
147
148
149
150
f
3
3
7
11
25
? E
1,8
3,2
7,2
13,5
21,9
0,80
0,01
0,01
0,46
0,44
X
151
152
153
154
155
f
33
34
37
25
23
? i
30,0
35,2
35,0
29,7
21,5
:-'(O-?J
0,30
0,04
0,11
0,74
0,10
X
156
157
158
159
160
f
11
9
2
0
1
?
13,
6,
3,
1,
o,
2
9
1
2
5
Е-1 (О-ЕJ
0,37
0,64
0,39
0,29
^2 — 4^70. Число степеней свободы 14—3 = 11. Полученное значение у?
необычно мало (%ii; 0,05 "^^б).
18. а) 2,306; б) —2,528; в) 30,58; г) 1,635; д) 6,63; е) 10,29; ж) 0,299;
з) 4,82.
20. 0,5892.
21.
¦ 0,07926+ 1
0,34134 = 0,17616.
0,15866 v'"'— i ^ 0,15866
25. а) 20-2; б) 20-2/ (l — eet + QteQt)\ в) 20/3, 02/18.
26. б) tx'r = E[ti] = E[Ur]E[vr/2x;rl ц! = 0
|i4 = 3v2 (v — 2)-1 (v—4)-1. (Если v<2,
бесконечно.)
27. z при 0<z<l; B — г) при Kz<2; 0 в остальных случаях.
30. Величина
, M'2 M'2 v(v2), |Х3
\x2 бесконечно; если v<4,
_!i-i/2
имеет приблизительно нормированное нормальное распределение.
31. Рассмотрите задачу для переменной, имеющей нормированное нормальное
распределение со значением В в начале координат. Пусть АВ = ВС = Х0,
ВР = Х. Тогда минимальное расстояние равно X, если 0^ X < Х0/2;
Х0—Ху если Х0/2<,Х < Хо; Х—Хо, если Х0<,Х (и то же самое при
X < 0).
А В
X
С Р
Ответы
575
Е (минимальное расстояние) =
где
уп7о!ееРнийИРУЯ П° Х° И ПРиРавнивая Результат к нулю, получим после
)—Ф(Х0/2) = [— ф|
или
00
Численное решение дает Хо=1,03, так что ОА. ОВ и ОС будут равны
6—'.Uda, t, и g-|-1,03a соответственно.
32. Минимальным расстоянием является функция g(X), график которой
вид
имеет
При G<1.
G] = Pr [(~X0-G < X <-X0+G) или
(-G < X < G) или (X0~G <X< Xo+G)] =
\
1
При G > i- Xo
Плотность вероятности для g(X) равна
2[Z(X0 + g
2Z(XQ+g)
при ^ < X0/2,
при g>xQ/2.
57S
Ответы
Ответы
577
Глава 6
1. а) @,84667/2,326) = 0,36 мм; б) 0,36-3,63 = 1,31 мм.
2. Величина N должна быть такой, чтобы
0,60
ИЛИ
0,40
/o.eo[2(tf+l), 2(/V+l)]~/o,4o[2(iV+l), 2(tf+l)]^0,90.
Это дает JV = 16.
3. Имеется значительный выбор возможных ответов. Ограничимся „симмет-
„симметричными" процедурами, взяв интервал от г-го наименьшего наблюдаемого
значения до г-ro наибольшего из 55 наблюдаемых значений. Тогда г сле-
следует выбирать так, чтобы
1
55!
E5-2,)!B,-1I
1
0,50
ИЛИ
/о,5оBг, 56—2г)<0,10.
Это дает г = 17.
4. Обозначим математическое ожидание и среднее квадратическое отклонение
размаха в случайной выборке объема п символами апо и Ьпо соответст-
соответственно. (ап и Ьп приведены во втором и третьем столбцах табл. 3.) Тогда
an1-(размах) является несмещенной оценкой а, и среднее квадратическое
отклонение равно (Ьп/ап)о. С помощью табл. 3 находим
п
2
3
4
5
6
7
Ьп/ап
0,756
0,525
0,427
0,371
0,335
0,308
п
8
9
10
11
12
0,288
0,272
0,259
0,248
0,239
Среднее квадратическое отклонение уменьшается с увеличением объема
выборки. Тем не менее, поскольку размах весьма чувствителен к выбро-
выбросам, им обычно не пользуются, если объем выборок больше 10.
5. Среднее КЕадратическое отклонение среднего к независимых оценок, каж-
каждая из которых имеет вид а^1- (размах случайной выборки объема п),
равно [ьЛапУ^к)]^. Для трех случаев, перечисленных в упражнении,
имеем следующее: а) п = 8» k—\\ bjas^ 0,288. б)п = 4, ? = 2; bj(a^Y) =
= 0,302. в) п = 2, k = A\ b2l{a2Y 4) = 0,378. Если интерпретировать „наи-
„наибольшую точность" как „наименьшее среднее квадратическое отклонение",
легко видеть, что лучше всего пользоваться исходной, нерасчлененной
выборкой. (Это не всегда так; например, если я=12 и к=\, то 612/а12 =
= 0,239, тогда как прия = 6 и k = 2 имеем bG/{a6 ]/™2) = 0,236.)
8. Оптимальный объем выборки (п) минимизирует (среднее квадратическое
отклонение размаха)/(математическое ожидание размаха). (Это решение
подразумевает, что большие выборки следует разделить на подвыборки
объема п.) Для нормального распределения оптимальный объем выборки
равен 8.
9. а) Рг [наименьшее значение <: х] = 0,
= l-
= 1,
б) Рг [наибольшее значение ^х] = 0,
= (x/
= 1,
х < 0
0<*
х > 1.
х < 0
х>1.
в) Е (величины размаха) = Е (наибольшего х)—Е (наименьшего х):
10. а) Рг [размах < w] =
(W
\C2xf *\2<я-1>
"Г / w \n f w \п
)
б) Заметим, что среднее квадратическое отклонение распределения X равно
0/3 У~2.
11. В очевидных обозначениях
п р (уа \ /г — -г-f-1
— 7~\Ь \Xn-i:n-r) 7=T~
откуда следует результат.
Это соотношение можно использовать при вычислении математических
ожиданий (и других моментов) г-х порядковых статистик, если даны
соответствующие величины для (г— 1)-х порядковых статистик. Кроме
того, можно получить E(Xm.r) для всех пг < пу если дан полный набор
величин Е [Xn:rj. Недостатком такого метода является возможное накоп-
накопление ошибок в результате повторного применения формулы.
12. Плотность вероятности измеряемого X для каждого элемента равна
а функция распределения есть
578
Ответы
Ответы
579
Следовательно, плотность вероятности для медианы X'n+i имеет вид
13. а) Плотность вероятности измеряемого времени (Т') для установки Зилча
равна
10
б) Плотность вероятности для медианы (М) равна (при m > 0):
Искомая вероятность есть
оо rf n4
в-ют/11вв-т/в A _e-m/6Jj=^ ^-т/9 (, _е-
X
_е-т/в) ГA _в-
16 A -е
11
~-е~т/6}]'
г2-1
14.
Е 7
/=0 V '
Результат не зависит от формы распределения, поскольку не изме-
изменяется при использовании монотонно возрастающего преобразования.
16. а) Вероятность того, что размах (W) меньше или равен ky есть
_fe_ \п / к-\ \пг\ / к
j-k + \ . \/п=0 /
б) Размах (Х-\-У) — (Размах Х)-\-Уа — Уь, где Уа и Уъ — взаимно неза-
независимые величины, распределенные так же, как У. Следовательно,
Е [размаха (Х+У)]=Е [размаха X],
Var [размаха (Х-{-У)] > Var [размаха X],
17. Пусть max SJ = G; min S) — L.
К / < k l < / < к
a)
п-2
20. Совместная плотность вероятности У'т+ъ У^т+ъ и Кзт+з равна
Ру' \Ут+1> У2т+2> Узт + s) —
D/7Z-J-3)!
=
Уш+2
Используем следующее преобразование: г%=#2т+2—
и о>з = #т+1-
О < wl9 w2, w3 < 1;
Следовательно,
I —z&i — w2—w§)m dw^ =
Dm+3)!
(w-lW^™ A —Wi — w2Jm + 1,
0 < wlt w2 < 1; wlf w<t
Введем другое преобразование переменных: u1 = w1 — w2, u2 = w1-\-w2
2
Наконец, воспользуемся преобразованием s==— и t — u2.
u2
Следовательно,
Dm + 3)! A-
1
f
Ji
f A — t)]*m+i-dt=
Уровни значимости для 5 можно получить с помощью таблиц отношения
неполной бета-функции или рассматривая уровни значимости для коэффи-
коэффициента корреляции в выборках объема Bт + 4). Заметим, что 5 имеет то
же распределение, что и выборочный коэффициент корреляции двух не-
независимых нормально распределенных величин в выборке объема п, когда
г1г(п—4) = т, т. е. /г = 2/п+4.
580
Ответы
Ответы
581
24. Совместная плотность вероятности упорядоченных моментов излучения
@^T1<T2<Ts< ... < Tjy < t) при условии, что от 0 до / секунд
произошло излучение ровно N частиц, равна '
Совместное распределение Т± и интервалов
имеет плотность
PTXU (^1» W2» • • •> Utf) = t
]
О < tlt u2, ..., «tv; ^1+ ]
Следовательно,
/=2
N
Поэтому [при условии (N
Pr[Uj^d при всех /] = J ... J J p*/(«2. •••> uN) du2, ...,
где все нижние пределы интегрирования равны cf, а верхние (слева направо)
равны
N
Интегрирование по и2 дает
Интегрирование по и3 дает
N .
Продолжая эту процедуру, окончательно получим (после интегрирования
по uN)
Глава 7
= 12,20; S = jl
2 = @г7757I/2 =0,8808.
VTb\ 12,20—12,00 |/0,8808 — 0,879. (Сравните с распределением \tu\.)
2. Отклонение от гипотезы не значимо.
3. 148 (в предположений, что X распределено по нормальному закону).
4. Границы (симметричные) равны 1,176%; 1,264%.
5. Границы (симметричные) равны 1,086%; 1,354%.
6. Область определяется неравенствами
1,2376а2 < 8,9636 —14,34/: (X) + 6 [?(Х)]2< 14,45а2.
7. Если воспользоваться независимыми величинами Хъ Х2, ..., Хп, распре-
распределенными как N (|, а2), оценка максимального правдоподобия а2 имеет
п
вид п
Если,
с другой стороны, использовать только
2
i =1
{ — ХJ (считая, что она распределена как %п-1<з2), то оценка макси-
2
i = 1
мального правдоподобия а2 равна (п — I)
— I)
данном слу-
чае п =16, 2 (^/~^J = 0,3904 и а2 =0,0244.
i =1
9. Границы (симметричные) равны 0,273, 2,756.
11. При а (уровне значимости) « 0,05 гипотеза об отсутствии изменений будет
отклонена, если средняя эффективность 16 опытов превышает 89+1,645-2/}^/Г.
При этом предполагается, что средняя эффективность имеет приблизительно
нормальное распределение. При аналогичных предположениях мощность
при истинной средней эффективности, равной 6, есть
1 —Ф [(89 + 3,29/г-1/2 — 8)/Bп~1/2)].
13. Среднее квадратическое отклонение средней эффективности, основанное
на 16 опытах, 4 из которых проводились Зилчем, равно
16
Вычисления аналогичны тем, которые были проделаны в упражнениях
11 и 12.
15. Число пар (п) должно удовлетворять неравенству
V~nh
I
-VH/7
откуда
Наименьшее значение п равно 187.
16. а) 59; б) 46.
17. п « 30 000 (выборка такого объема не приемлема).
18. Если предположить, что распределение нормальное и известно среднее
квадратическое отклонение, объем п выборки при отклонениях оценки в обе
стороны от среднего совокупности удовлетворяет условию
<0,6-^..
У п
Наименьшее значение п равно 52. (Таблица Н при неизвестном о дает
п = 53.)
582
Ответы
Ответы
20. 95%-ный верхний доверительный уровень для доли больше 33%. Экспери-
Эксперимент имеет малую ценность, если при этом не получают какой-либо иной
информации.
23. Мощность равна 1 —Рг [i- 1х2; о,02б < Ъ < 1~гЪ; 0,975].
24. Мощность 0,10 0,25 0,50 0,75 0,90
(Si/<?2J 1,15 1,49 2,03 2,87 4,06
(Из табл. Д.)
25. Функция правдоподобия достигает максимума при наибольшем возможном k,
т. е. при & = 2(тахХ/)~2. Оценка максимального правдоподобия для Е (X)
i
равна
Цр Г2 /max ХЛ' 2Г 1/2 =|-тах Xi •
о L V i /Л о i
26. Доверительные интервалы не будут пересекаться, если
Поскольку
уровень значимости предложенного критерия меньше а.
28. 0 есть решение уравнения
Х=1
где
/(в)
/ = о
Дисперсия 6 приблизительно равна
ЭГ-2 0Г-1
,
29. Положим M^/i"
[~
^2
— 2)! (г —1)!
/(в) Л
- ПРИ г==1
ъМ[~ —l) можно использовать как оценку 0. При г = 2
Оценку 0 можно получить, решив уравнение
/7Z2 0
Эти оценки имеют смещение.
Мур [Moore P. G., A Note on Truncated Poisson Distributions, Biometrics^
10 A954)] предлагает использовать статистику
/г"*1 (сумма всех наблюдений, кроме тех, которые равны г)
как оценку 0. Математическое ожидание статистики равно
583
так что она является несмещенной оценкой 6.)
30. Если игнорировать возможность того, что какие-либо две оценки Т отли-
отличаются от 6 на одинаковую величину, имеется 6 возможных перестановок
(ijk), где (ijk) означает
31
Ту
в |
Л—в |
и (ijk) — числа 1, 2, 3 в каком-нибудь порядке. Тг — более точная оценка,
чем Т 2, если
Рг [ 123] + Рг [312] + Рг [132] > -i .
Т2 — более точная оценка, чем Т3, если
Pr[123] + Pr[213] + Pr[231] > у.
Т3 — более точная оценка, чем Тъ если
Рг [3211 +Рг [312]+ Рг [231] > -i .
Любое множество значений этих шести вероятностей (дающих в сумме 1),
удовлетворяющее трем приведенным неравенствам, может быть ответом
упражнения. Например, пусть
и
тогда
и
Рг [3211 = 1-2 (л + р^-Рг [123]
Рг [321] + Рг [312] + Рг [231] = 1 — 2/?2 — Рг [123].
Поэтому условия выполнены, если
2/72+Pr[123]<i-<p1+/?2+Pr[123] < l-Pl-p2.
Легко найти множества значений plt p2 и Рг [123], удовлетворяющих этим
условиям, например р! = 0,20, /?2 = 0,05, Рг [123] = 0,30.
Интересно отметить, что такие круговые соотношения близости могут
иметь место между тремя оценками Тъ Т2, Тв с многомерным нормальным
распределением. Это не так, если каждая оценка является несмещенной, т. е.
Е (Тг | 9) = Е (Г, | 9) = Е (Т31 6) = 9.
L (*!,..., ^„|p) = [S(p+l)]-1( Д '
dlnL/dp = 0 эквивалентно равенству
ых
584
Ответы
Ответы
585
Значение р может быть получено с помощью таблиц.
Var p «
О}2—
p"(p+D
Таблицы ?(р+1), ?' (р+ 1) и I" (9+1) или ссылки на них имеются в ра-
работе Moore "P. G., The Geometric, Logarithmic and Discrete Pareto Forms
of Series, Journal of the Institute of Actuaries, 82 A956).
32, Пусть
, рХ(Хъ ..-, Xn\Q2)
Тогда
Отсюда
Требуемый результат следует из неравенства
При 62—^0! получаем неравенство Крамера —Рао, приведенное в тексте.
Неравенство данного упражнения обладает тем преимуществом, что им
можно пользоваться,_когда Е (Т | 0) — недифференцируемая функция 0. __
34. Поскольку Xi — XnX взаимно независимые, условное распределение^ — X
при данном X" такое же, как и (безусловное) распределение Хх — Х, т. е.
N [О, а0 V A— л")]. Поэтому величина Хг при данном X распределена
как N [X, а0 Yil — n-1)]. Величина
]
— J *
~| 0
в противном случае
имеет математическое ожидание Ф (*2) — Ф (*i)- Тогда условное математи-
математическое ожидание Y при данном X равно PrJ*i < Х2 < х2| X]. С помощью
условного распределения Хг при данном X получается нужный резуль-
результат.
35. Утверждение __
Рг [X < X+LS | X имеет распределение N (?, а)] > Р
эквивалентно утверждению
fX + LS>l+ V, г*е ф (М = Я
Нужно, чтобы
т. е.
= 1 — E
или (б) Рг
lUi-8.
Это значит, что
Рг [Г > —
] - 1 — \Пь 1 = 1—8,
где 71 имеет нецентральное /-распределение с (п — 1) степенями свободы
и параметром нецентральности — ]/" пк„. Искомая величина L в этом
случае равна взятой с минусом нижней 100е%-ной точке этого распределе-
распределения, деленной на У~п.
"Воспользовавшись аппроксимацией, данной в разд. 7.8 и основанной
на равенстве (а), получим
Ь? » V~n {Xp-LE [Xn-iW^^} {1+nL* (л- I)-1 Var (%„-{)}- 1/a.
Это дает квадратное (приближенно) уравнение для L.
Глава 8
2. 95%-ный доверительный интервал для р имеет границы 0,002 и 0,07.
4. При а = 0,01 в предположении, что веса распределены нормально,
а) 15,890 унции; б) 15,867 унции; в) 15,845 унции.
5. а) Да, при 5%-ном уровне Q =4,6 > q4. 20. 095 (= 3,96).
б) Для каждой выборки величины X/ случайны, независимы, подчинены
нормальному закону распределения.
6. Если воспользоваться объединенной оценкой дисперсии, границы для \лд — |Л?>
равны —0,3 и 3,9.
7. а) Разности существенно значимы; Q ===== 11,1.
б) Нет достаточных оснований, чтобы утверждать, что проволоки различны.
8. Дисперсии равны E,71; 3,84; 10,12; 12,98; 12,27)-10~6. Можно допустить
однородность дисперсий, поскольку при 5p = 8.99-10~6 и четырех степе-
степенях свободы х2(=3,34) < х24. о,95 (=9,4877).
Границы 95%-ного доверительного интервала для а2 равны 0,00000591
и 0,00001529.
12. а) Да, f = 3,87(> tv. 0,995) ПРИ 5%-ном уровне.
б) Выборки извлечены из нормальных совокупностей, X/ — независимые
случайные величины с одинаковыми дисперсиями.
13. Нет, %2 = 61,4. Это свидетельствует о значимом отклонении от %8-распреде-
ления.
16. а) Нет свидетельств уменьшения.
б) Х2<Х?4: 0,05 = 6,571.
18. а) Нет при 5%-ном уровне; /=1,86.
б) \id = 0, парные наблюдения.
19. а) Нет, * = 2,01 (< *б; 0>975).
б) Определять не нужно.
21. Да, поскольку w = 4,17 (распределение близко к нормированному нормаль-
нормальному).
22. Если предположить, что коэффициент преломления распределен по нор-
нормальному закону, то границы равны 0,000084 и 0,000592.
23. Нужно определить вероятность того, что случайная величина, распреде-
распределенная по закону Пуассона с математическим ожиданием 60, будет не
больше 47. Таблицей М воспользоваться нельзя, поэтому нужно обратиться
к аппроксимирующему распределению N F0, ]ЛэО). Вводя поправку на
непрерывность, получаем D7,5 —60)/^60 = —1,61. Соответствующая ве-
вероятность для нормального распределения равна 0,054. Видимо, этого не-
недостаточно, чтобы утверждать, что имеет место уменьшение, но стоит про-
провести дальнейшие исследования,
.19 № 819
586
Ответы
25. Н0:\х = \х0-\-1200, альтернативы jx > |ЛО+12ОО (односторонние); предполо-
предположения: Х( — случайные, распределенные по нормальному закону и неза-,
висимые величины с постоянными средним значением и средним квадра-
тическим отклонением; а дано; критическое значение Х = |ЛО +1200 +
+ *я-1, X-a^lV п> если а не известно.
27. а) Нет, /?и = 0,33(< 0,554) (критическое значение при 5%-ном уровне),
б) Х( — случайные, независимые величины извлечены из совокупности,
распределенной по нормальному закону.
28. Да, 781, поскольку Ru=0,66 больше критического значения при 1%-ном
уровне.
34. %2 = 4,40, что значительно меньше, чем %§. 095.
36. а) С помощью проверки убеждаемся, что каждый наблюдатель фиксировал
большее значение, чем другой, в половине случаев, б) Случайность и не-
независимость выбора галактик, но не требуется никаких предположений
относительно распределения разностей.
Глава 9
40
'• S
r=0
90 \
) 2~90 > 0,05; предпочтение не значимо.
2. Да; Рг[Х<1|р=1/2, л —т = 9] = 0,02.
3. Ранги данных для вулканизации при 80° равны 1, 2, 3, 6, 8 или 9, 10,
12, 14, 16, 19, 22.
Si=113 или 114.
Из табл. Т при п1 = П2=И получаем, что наблюдаемое значение Sx ле-
лежит между верхней и нижней 10%-ными границами значимости Slt так
что этот критерий не свидетельствует о разнице в характеристиках поло-
положения.
4. Яо: Система 1 и система 2 одинаково эффективны.
Нг: Система 1 и система 2 не одинаково эффективны.
а:0,01.
Статистика: наибольшее значение объединенной группы равно 71 (для
системы 2), наименьшее значение равно 30 (для системы 1).
Наименьшее значение в группе 2 равно 40, а наибольшее
значение в группе 1 равно 49. Затем вычисляем: Т — (Число
значений в группе 2^> 49) +(Число значений в группе
1<40) = 7+5=12.
Критическая область: не принимать Яо, если Т^7 при
7^10 при
7^13 при
Решение: не принимать Яо при а = 0,01.
5. Яо: лекарство не влияет на кровяное давление.
Нг: лекарство повышает кровяное давление.
а: 0,05.
Статистика: /г = 95 —14 — 81; Г=Число случаев повышения давления=54.
Поскольку объем выборки весьма большой, можно восполь-
воспользоваться нормальной аппроксимацией с поправкой на не-
непрерывность. Пусть и = (л/2) = 81/2; а =/"/Г/2 = 9/2. Тогда
Z [(T V) 81/2]/V 2889
а = 0,05,
а = 0,01,
а = 0,005.
Критическая область: используется односторонний критерий. Не прини-
принимать Яо, если Z^rZ0 95 =1,65.
Решение: отклонить Яо.
Ответы
6. Для проверки равенства средних воспользуйтесь статистикой
587
N
36"
107,9
Величина 2W/(\ — IF) = 4,25 значима, так как имеет ^-распределение с 35
и 68 степенями свободы. Для проверки дисперсий к разностям средних
соответствующих контролеровследуетприменить критерий Сиджела—Тьюки.
7. Если воспользоваться модификацией критерия Вилкоксона для дисперсий,
наблюдаемое Sx=200 оказывается больше 1 %-ного критического значения «S,
равного 191. Следовательно, гипотезу равенства дисперсий следует откло-
отклонить. Нормальная аппроксимация при проверке средних дает
24
и=-
Следовательно, нельзя отклонить гипотезу о равенстве средних.
8. Т = число серий = 9.
Этого недостаточно, чтобы отвергнуть гипотезу о случайности.
9. Коэффициент ранговой корреляции равен 0,842. Этот результат значим
при 1%-ном уровне [см. табл. Ш C) приложения] и указывает на то, что
между экспертами есть некоторое согласие.
Ю. <S1 = 510,5 больше критического значения для а = 0,01 ( = 505) при п± =
= я2 = 20.
(См. табл. У приложения.)
12. Выборки объединены и ранжированы.
Наблюдение 71 72 72 73 73 74 74 75 75 75
Пол МЖММЖММММЖ
Ранг 1 2,5 2,5 4,5 4,5 6,5 6,5 9 9 9
Наблюдение 76 76 77 77 77 78 78 78 79 80
Пол М ММЖЖЖЖЖЖЖ
Ранг 11,5 11,5 14 14 14 17 17 17 19 20
п1 = п2= 10,
#1== 1 +2,5 + 3,5+ ... + 14 = 76,
#2 = 2,5+... +20=134,
f/ = minG9; 21) = 21.
Критическая область: U < wOO25=23 или U > w0975 = lOO—wOO25 = 76.
Решение: отклонить Яо.
13. Если воспользоваться критерием знаков, то у Зилча значение ниже в трех
случаях из десяти. Этот результат не значим. Коэффициент ранговой кор-
корреляции /?'=0,858>0,745 A%-ное критическое значение, односторонний
критерий). [См. табл. Ш C)]. Поскольку это R' значимо, следует откло-
отклонить гипотезу об отсутствии различий между контролерами. Критерий
„тау" Кендалла и вычисление коэффициента конкордации (W) должны дать
аналогичные результаты.
fl = 7, /n = 2, n2 = 7. Можно воспользоваться критерием знаков, но про-
прой тверждают ги
14.
19*
i , 2, n2 7. Можно воспользоваться критерием знаков, н
стой просмотр данных показырает, что они подтверждают гипотезу.
588
Ответы
15.
16.
17.
18.
19.
20.
21.
23.
24.
26.
27.
#'=0,82.
Да, R' = 0,804 > 0,441 (= 10%-ному критическому значению; см. табл. Ш C).
ос? «^{Ф B,1) — Ф(— 1,9)}=0,0233,
а2~ Ф(— 1,048) = 0,1473—
— 21n(aioS)=16,28.
Эта величина лежит между верхними 0,5 и 0,1%-ными критическими зна.
чениями %4- Хотя величина aj указывает на возможность значимости, го-
гораздо более определенный результат дает комбинирование критериев.
(Заметим, что в каждом случае применяется односторонний критерий,
соответствующий подозреваемому уменьшению медианы.)
Постройте распределение F (х) для N D,72; 3,16) и доверительный коридор
F (х) ± 0,043; затем с помощью данных постройте полигон накопленных
частостей.
Да, поскольку \F* (x)~F (х) \ < 0,41 для всех значений х в выборке.
9/11.
D^=max\F0(x) — Sn(x) | = 0,465, где /2=10.
Критическая область: при двустороннем критерии отклонять Но с a = 0,05,
если D > 0,409.
Решение: отклонить Яо (состоящую в том, что данные взяты из совокуп-
совокупности, распределенной по нормальному закону со средним 32 и сред-
средним квадратическим отклонением 1,8).
22. Нет достаточно сильных оснований, чтобы отвергнуть Но, если восполь-
воспользоваться критерием для медиан. Если предположить, что распределение
нормальное, Яо:^ = 0 отвергается при 1%-ном уровне.
Принять Я; критическая разница в долях выживших равна 1,36 у НК+с7л=
= 0,272.
25. D =
Критическая область: D > 1,36/Уп = 1,36//60 = 0,1075 при сс = 0,05.
Решение: принять Яо.
|Si(*)— 52 (л-) 1 = 5/15 при п = т=15.
Критическая область: не принимать Яо, если D > 7/15 (ао = О,О5).
Решение: не принимать Яо (состоящую в том, что /^ (x) = F2 (x) при
всех л-).
Замечание. Выборка 1 была извлечена из совокупности с нормиро-
нормированным нормальным распределением, а выборка 2 — из совокупности, рас-
распределенной по нормальному закону с математическим ожиданием 0 и
средним квадратическим отклонением 2.
а) Разности равны: —0,1; 0; 0,2; 0,4; —1,0; 0,2; —0,2; 1,0; 0,1; 0;
— 0,01; —0,1; 0; —0,3; 0,1; —0,5; —0,3; —0,2.
1) ^-критерий, Г = 0,47 < /18. 0f975(= 2,101).
2) критерий серий, A/i = 6, N2 = 9; критические значения 4 и 12. Всего
имеется 9 серий.
б) Не вычисляется, поскольку данные парные.
в) Если выполнено предположение о том, что распределение нормальное
(относительно разностей), нулевая гипотеза (^rf = 0) принимается. При
более слабых предположениях следовало бы, конечно, также принять
гипотезу.
Разности равны: 36; 80; 50; —83; 12; —109; 177; — 78; —120; 100.
Имеется четыре отрицательных значения. Нет значимых различий, по-
поскольку 5%-ные критические значения равны 1 и 10 (см. табл. С). Кри-
Критерий серий при A/i = 4, N2 = 6 дает 5%-ные критические значения 2
и 8 (табл. Т). Поскольку всего имеется семь серий, результат не значим.
Ответы
589
28. Таблицей Ф приложения воспользоваться нельзя, поскольку п > 20.
Вместо этого возьмем dO95FO)« 1,36/]/~6СГ= 0,1756. График для 1) эм-
эмпирической функции распределения 60 значений и 2) 95%-ного доверитель-
доверительного интервала F (х) ± 0,1756 показывает, что две точки, соответствующие
100 и 111 ч, близки к нижним границам. Значения функции распределения
для 18-й и 20-й по порядку величин равны 0,445 и 0,478 соответственно.
Поскольку 0,445 — 17/60 < 0,1756 и 0,478—19/60 < 0,1756, гипотеза при-
принимается.
29. При а = 0,05 имеет место неравенство | Fa (x) — Fn (x) | < do,95 (^0). Данные
могли быть взяты из совокупности N A70, ПО).
30. Из [9.3] ш090 =0,369.
L (x) = S (x)-wt
0,90
5 (*)
U (x)=S (x)+w
0,90
0,53
1,12
1,20
1,29
1,92
1,96
2,31
2,63
2,67
3,20
0
0
0
0,031
0,131
0,231
0,331
0,431
0,531
0,631
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
0,469
0,569
0,669
0,769
0,869
0,969
1
1
1
1
О,95. Из табл. 6 работы [9.3] видно,
32. Имеем r = \, т=1, 1—а = 0,90,
что нужна выборка объема 77.
33. л=15.
Для сравнения приведем приближенную формулу при г = 0, /п = 1,
)A,85/0,15)+у @+1 — 1) = -! D,605) A2,333) = 14,198.
35.
Следовательно, в этом случае также /г =15.
Месяц
Год 1
Год 2
Знак Ранг Ранг со
I "азность | разности | разности | знаком
Январь
Февраль
Март
Апрель
Май
Июнь
Июль
Август
Сентябрь
Октябрь
Ноябрь
Декабрь
14,6
12,2
104,0
220,0
110,0
86,0
92,8
74,4
75,4
51,7
29,3
16,0
14,2
10,5
123,0
190,0
138,0
98,1
88,1
80,0
75,6
48,8
27,1
15,7
0,4
1,7
19,0
30,0
28,0
12,1
4,7
5,6
0,2
2,9
2,2
0,3
3
4
10
12
11
9
7
8
1
6
5
2
+ 3
+ 4
— 10
+ 12
— 11
— 9
+ 7
— 8
— 1
+ 6
+ 5
+ 2
590
Ответы
Статистика: сумма положительных рангов — 3+4... + 2 = 39,
сумма отрицательных рангов = 10+ 11 + 9 + 8+ 1 =39,
следовательно, 7 = 39 при А/ = 12.
Критическая область: не принимать Яо, если Т < 17.
Решение: достигнутый уровень равен примерно 0,5; нет оснований отвер-
отвергать #0 (отсутствие различий между годами).
37. Пусть Y[ < Y2 < ... < Yn —значения, расположенные в порядке возрас-
возрастания. Тогда
0 < у[ < у'<& < ... < у'п < 1.
Совместная плотность вероятности для длин интервалов
имеет вид
0<
Любой порядок /i, /2> • ••> 1п и ln + i(= l~—y'n) равновероятен. Распреде-
Распределение коэффициента ранговой корреляции между (/) и {i/} при нулевой ги-
гипотезе такое же, как в случае двух независимых переменных. Тест, осно-
основанный на этом критерии, будет чувствителен к группировке значений у
вблизи 0 или вблизи 1, т. е. к изменению симметрии, по сравнению
с распределением, использованным для вычисления у. Дальнейшее обсуж-
обсуждение см. в работе Durbin J., Some Methods of Constructing Exact Tests,
Biometrika, 48 A961).
38. Здесь можно использовать приемы, аналогичные тем, которые применялись
в случае модификации Сиджела — Тьюки критерия Вилкоксона (см. разд.
9.6.2).
39. См. работу Sundrum R. M., The Power of Wilcoxon's 2-sample Test, Jour-
Journal of the Royal Statistical Society, Series ?, 15 A953).
40. Если средние квадратические отклонения существенно различны, ранги
совокупности с меньшим средним квадратическим отклонением имеют тен-
тенденцию к скоплению. За счет этого уменьшается изменчивость Slf но ма-
математическое ожидание остается прежним. Это в свою очередь приводит
к более чувствительной процедуре проверки, чем может дать теория, осно-
основанная на равных дисперсиях совокупностей.
41. а) Возьмите выборку объема п. Подсчитайте число измеренных величин,
меньших 10. Сравните это число с биномиальным распределением
C/4+1/4).". Выбор значений, которые следует считать значимыми, зависит
от альтернативных гипотез, б) В этом случае гипотезу можно выразить в
форме ?Fг, ..., 05)=1О. Затем можно построить критерий специально для
проверки этой гипотезы (при указанных альтернативах).
42. Воспользуемся следующей информацией: 1) для наблюдении яз интервала
(Хъ Х2) можно ввести ранги (n1 — ni — ni)-\-(n2 — n'i — n2) наблюдений
(обозначения очевидны). С их помощью обычным образом вычисляется
статистика Si Вилкоксона. 2) Можно воспользоваться также тем фактом,
что (п[, ni — n'i — n'u Щ) и (п'2, п2 — П2—П2, п2) должны быть выборками
из одной и той же триномиальной совокупности. Поэтому статистика
ПгП2
Ответы
591
должна быть распределена приблизительно как %2 с двумя степенями
свободы. Для получения приближенного объединенного критерия нужно
скомбинировать критерии 1) и 2) методом, описанным в разд. 9.8.2. Ана-
Аналогичные задачи обсуждаются в работе Halperin M., Extension of the
Wilcoxon—Mann — Whitney Test to Samples Censored at the Same Fixed
Point, Journal of the American Statistical Association, 55 A960).
43. а) Очевидно, что т F) — неубывающая функция 0. (На самом деле это
ступенчатая функция, имеющая скачки, когда QX{ — Yj при некоторых i и /.)
Отсюда следует, что все оценки 0 попадают в интервал.
б) 1) Метод свободен от распределения в том смысле, что вероятность
попадания 0 в интервал не зависит от формы распределения, хотя важно,
чтобы QX имело такое же распределение, как Y. 2) На самом деле метод
нельзя назвать непараметрическим, поскольку он используется для вычи-
вычисления параметра.
в) Чтобы можно было назвать интервал / доверительным, необходимо,
чтобы
Рг[0 в / | в] = 1 — а,
где 1—а есть доверительная вероятность при всех 0. Это не так, если не
предположить, например, что ОХ имеет то же распределение, что и Y.
Искомая вероятность вычисляется следующим образом: 1) если п четное,
она равна вероятности того, что ниже и выше медианы Y лежит одинако-
одинаковое число 00Х. Эта вероятность равна
„ 2
44
п+\) •
2) При нечетном п вероятность равна
2п+1
л+1
К последней части этого упражнения применимы комментарии к ответам
на упражнения 43, а) и в).
Глава 10
1. а) 7=8,56; границы: 1,93; 15,20. 7? =9,10, границы: 0; 20,077.
б) 24,45 (в предположении, что процесс не выходил из статистически
управляемого состояния).
2. х~= 0,838; границы: 0,591; 1,084. 7? =0,339; границы: 0; 0,773.
3. Для двустороннего критерия 0 = ЗО°58', d — 5,12 (для одностороннего
d = 4,16).
4. Для двустороннего критерия 0 = 52°37', cf=ll,0 (для одностороннего
^ = 8,90). Масштабный коэффициент не учитывался.
10. APL: 19,923; 20,777. Приемочные границы регулирования: 19,918; 20,082.
RPL: 19,910; 20,090.
12. 7=1455,1; границы: 1279,7; 1630,5. ? = 304, границы: 0; 643.
13. Объем выборки должен быть вдвое больше исходного. Вычисления те же,
что и в упражнении 10, только а заменяется на 2а.
14. /7 = 0,01785 = 1,785%. Аппроксимация пуассоновского распределения нор-
нормальным дает За-границы для доли дефектных единиц, равные 1,785 ±
± 40 У~П{. Результаты для партий 5, 6 и 8 выше верхней границы; пар-
партия 4 ниже нижней границы; партия 12 предельно ясно указывает на то,
что процесс вышел из статистически управляемого состояния.
592
Ответы
15. (Ь^0°56'; d = 201,3 (масштабный коэффициент не учтен).
18. с~=1,96; границы: 0; 6,16.
19. Границы: 0; 8,6.
24. ?=126,5; границы: 122,1; 130,9. Я = 7,6; границы: 0; 16,1.
25. 7=7,91; границы; 3,57; 12,26. ? = 2,45; границы: 0; 6,31.
28. d = 8,90, 6 = 49°40'.
30. е* = 55°35'; d* = 11,358.
31. 8 = 5°43', d = 345,4 (односторонний критерий); d = 380,0 (двусторонний
критерий).
32. Риск поставщика равен
1 —
297\,f3\f297
H9J "г ^2 Д148
Риск потребителя равен
/9\ /291\ , /9
291
291
зоо
300 \
150У =
33. Выберите множество пар /г, а (где п — объем выборки, а а —приемочное
число; при этом партия принимается, если в выборке не больше а дефект-
дефектных изделий), таких, чтобы Рг [принятия | /? = 0,01 ] ^> 0,95. Из этого
множества выберите пару, для которой Рг [принятия | /? = 0,03] <:0,10
максимальна.
34. Риск поставщика 12,9%; риск потребителя 21,6%. Интересно сравнить эти
результаты с решением упражнения 32. (Почему обе величины в упраж-
упражнении 32 меньше?)
35. Аналогично упражнению 33 за исключением того, что выборки должны
давать более близкие к желаемым значения аир. (См. [10.7]).
36. х = 76,747; s^=l,83. Ha Х-карте выборка 7 выходит за За-границы.
Глава 11
1. Средние потери равны
-p)n-J
Если Сх увеличивается до (ci+б) и п уменьшается до /гсх/^ + б), так что
член схп остается постоянным, средние потери увеличатся при К2р > Кг
и уменьшатся при КчР < К. В обоих случаях оптимальное новое значе-
значение п (минимизирующее средние потери), как правило, не будет ближай-
ближайшим целым числом к псц"
2. Средняя стоимость равна
C(nt ^^
[0,6 @,01)^@,99)"-/+0,3 @,04)/@,96)"-/+
г-\
- 0,07 @,08)/@,92)"-/+0,03 @,15)/@,85)"-/] +
П ) [0,6 @,01)/+! @,99)"-/+0,3 @,04)/+! @,96)"-/+
/ = о J
+ 0,07 @,08)/+1@,92)"-/+0,03 @,15)/+! @,85)"-/].
Однако для нахождения оптимальных значений /гиг проще рассмотреть
изменения в С (я, г), вызванные увеличением п и (или) г на 1. Так, если
Ответы
593
объем выборки увеличивается на 1,
С(/г+1, г) — С(п, r)=Cl+(n\ [0,6 @,01V @,99)"-'" 0,01 №—0,01/С2) +
+ 0,3 @,04V @,96)»-'" 0,04 (^ — 0,04^2) +
+ 0,07 @,08)^ @,92)"-/• 0,08 (/Ci— 0,08/C2) +
+ 0,03 @,15)/'@,85)«-/*0,15 (/Ci — 0,15/C2)].
Если п фиксировано, а г уменьшается до г — 1, средняя стоимость увели-
увеличивается на
С(п, г —1) —С(/г, Г) = (ПГ) [0,6 @,01V @,99)" "'•(/Ci-0,01УС2) +
+ 0,3 @,04V @,96)«-''(/Ci — 0,04/C2) +
+ 0,07 @,08)'' @,92)"-^ (/С1-0,08/С2) +
+ 0,03 @,15V @,85)"-/i(/Ci — 0,15/C2)].
3. а) С увеличением сх следует ожидать уменьшения оптимального значения п.
б) Если/C2>/Ci/@,01), всегда лучше принять решение dx\ если/C2</Ci/@,15),
всегда лучше принять решение d2. Следовательно, для К2 вне интервала
/Ci/@,15) < К2 < /Ci/@,01) оптимальное значение п равно 0. Внутри этого
интервала с увеличением /С2 значение п увеличивается, достигает макси-
максимума, а затем уменьшается.
4. Средняя экономия равна
Ciin —
7-1
[0,6 @,01)г @,99)/-|" + 0,3 @,04V @,96)/-'' +
+ 0,07@,08)^ @,92)/-^ + 0,03 @,15)/*@,85)/-;
Замечание. / ( ' J можно заменить на г
^ J .
Если нужно дать оценку р, следует рассмотреть увеличение средних по-
потерь за счет неточности оценивания, вызванной сокращением выборки, и
сравнить его со средним уменьшением стоимости выборочной процедуры.
Объем выборки
50
100
150
200
Стоимость одной
партии, долл.
72,8
122,2
169,3
219,2
Доля дефектных изделий
среднее
0,073
0,046
0,044
0,054
дисперсия
0,00282
0,00099
0,00097
0,00126
Подходящая стоимостная функция выборок имеет вид
[23 +0,98-(Объем выборки)] долл.
Если предположить, что число дефектных изделий при данной их доле
в партии р подчинено распределению Пуассона со средним, равным (Объем
выборки)-р, то математическое ожидание и дисперсия наблюдаемой доли
дефектных изделий будут равны Е (р) и {Var (/?)+[Объем выборки] ?^}
594
Ответы
6.
соответственно. Наблюдаемая дисперсия не очень хорошо согласуется
с такой моделью, но если взять
?(р) = 0,05, Var(p) = 0,001,
то получим более или менее хорошую согласованность с наблюдениями.
В качестве распределения р можно воспользоваться бета-распределением
со средним 0,05, дисперсией 0,001 и размахом 0,1.
Стоимостная функция = (Стоимость выборочной процедуры, например,
С^ + 200 000 Е [р Рг (принятия | р)] +
+ 20 000?? [Рг (отклонения |р)].
Математические ожидания берутся по отношению к р, доле дефектных
изделий. Если априорная плотность вероятности р имеет вид
то стоимостная функция (если пренебречь влиянием конечности объема
партии) равна
20 000Г(а+Р)(^«
Г(а)Гф)
\ 20000Г(а+Р) _
j Г(а)Г(Р)
20000
^
-/]
7. Необходимо выбрать N, а также г, минимизирующие среднюю стоимость
(стоимостную функцию). Это можно сделать с помощью формулы, выведенной
в упражнении 6, если подставить подходящие значения CN, а и р и вос-
воспользоваться методом проб и ошибок. С другой стороны, можно получить
приближенные значения с помощью аппроксимаций стоимостной функции,
а затем использовать их в итеративной процедуре. В любом случае не
требуется большой точности вычислений, поскольку стоимостная функция
оценивается, а не точно фиксируется.
8. В упражнении 7 рассматривались только процедуры с фиксированным
объемом выборки N [и фиксированным браковочным числом (г+ 1)]. Двух-
Двухступенчатые, многоступенчатые или последовательные выборочные схемы
могут дать более низкие значения средних стоимостей, но при этом сле-
следует учесть возможное увеличение стоимости выборки за счет применения
более сложных схем.
9. Средняя стоимость на одну партию (в долл.) равна
200
(р'—доля дефектных изделий = 0,01р).
Ответы
595
Аппроксимируя биномиальное распределение пуассоновским, получаем
среднюю стоимость одной партии, равную
где
150р'J ПбОр'K],
2 + 6 J#
Ыр')=е-16ОР 1
р
0,5
1.0
1,5
2,0
2,5
3,0
1+150р
0,9963
0,9473
0,8153
0,6288
0,4403
0,2851
0,9928
0,9344
0,8095
0,6472
0,4838
0,3423
10. Средняя стоимость (в долл.) равна
С[185 — 51рA + р)-х] [l,4 + 0,2/i(p') — 0,6/i (p')/2 (P')J>
где р=100р/.
Средняя стоимость минимальна при доле дефектных изделий между
1/2 и 1%.
11. Пусть р/=0,01р. Тогда если правило состоит в том, что партия бракуется
при R и более дефектных изделиях в выборке объема N, получаем соот-
соотношение (для больших партий)
Вероятность принятия «
Окончательная доля дефектных изделий в принятых партиях при этом
равна р'Р (р')у поскольку все доработанные партии не содержат дефектных
изделий и принимаются.
Случай
а)
б)
в)
г)
N
200
180
90
20
R
6
4
2
1
Процент дефектных изделий при р, равном (в %)
0,2
0,20
0,20
0,20
0,19
1
0,92
0,83
0,72
0,76
2
1,02
0,67
0,60
0,87
4
0,12
0,04
0,08
0,27
Можно построить график зависимости доли дефектных изделий от р и
найти максимум. Вычисления стоимостей проводятся аналогично.
596
Ответы
12. Если ввести стоимостную функцию выборочной процедуры, растущую
с увеличением объема выборки, то оптимальный объем выборки умень-
уменьшится. Естественно, что дополнительные расходы сильнее скажутся в слу-
случае больших объемов выборок.
13. Твердость можно представить случайной величиной Я, имеющей плотность
вероятности
^Л^-Л/в, 0<Л.
16.
Вероятность принятия равна
для стандартного прибора
1—Ф[10A6 —
для прибора Зилча
Если предположить, что правильное принятие (отклонение) соответствует
h > (<) 16, средняя стоимость неверного решения для N испытаний равна
для стандартного прибора
Г 16 « « 1
ЛП 1000 ^ /(A)S(A)dA+50^ / (А) [1 -S (A)] dh\ долл.;
L о i6 J
для прибора Зилча такая же, как и для стандартного, но S (А) заменяется
на Z (А). Интегралы могут быть вычислены методом интегрирования
по частям. Искомое уравнение имеет вид
(Стоимость прибора Зилча) — (Стоимость стандартного прибора) =
/-16 ОО Л
= Л^<| 1000 С /(A) [S(A) — Z(A)]dA —50 С / (A) [S (h)-Z(h)] dh \ долл.
I I
14. a) Z(h) заменяется на [Z(A)]2.
б) Z (А) заменяется на
0,07
+ A-р)Ч 1-Ф
A6 —А —А) 1^2
0,07
Необходимо учесть, что прибор Зилча можно использовать только для
N/2 образцов, если пользоваться этими методами, так как каждое измере-
измерение должно быть повторено.
Пусть Xlt ..., X/j обозначают выборочные средние, а 6Ь ..., б^ — соот-
соответствующие средние совокупностей. Средняя стоимость равна
где
и
Ру- =
при всех
j].
Ответы
597
Совместное распределение (k—l) величин (Xj — Xt) многомерное нормаль-
нормальное с математическими ожиданиями, равными @у — 0^), и матрицей дис-
персий-ковариаций
~ ' 1/2 1
Г 1 1/2
1/2 1
1/2
17.
18.
L 1/2 1/2 ... 1 _
При фиксированном п средняя стоимость достигает максимума, когда
одно среднее, скажем 6lf равно 6тах и Ql = Q1=,6 при / = 2, ..., k, где 6
максимизирует выражение
С(п, 6) = co + c1kn + K(k-lNP.
Здесь Р — общее значение всех /=-1,2 ?, зависит только от
E/а0) У(п/2). Можно написать
С (я, 6) = co+C!b + iC№—1) *И?7лУао[F/ао) ^(л/г)] Р.
Отсюда следует1_что Q^^+^^ + ZC^-1) y~B/n~HoGk, где G^ =
= max[F/0o) У(п/2)]Р принимает определенные числовые значения, зави-
зависящие от к.
Минимизируя Сп по отношению к п, находим
У1/2п
Если выписать
переменных (/ ?/) р еод анализа,
что и в упражнении 16; только функция д 9 Рг [неправильного решения |6]
будет иметь другую математическую форму
явном виде совместное распределение нормированных
(X ?)/ можно применить тот же метод анализа,
ур ; фуц д
будет иметь другую математическую форму.
Пусть среднее значение первой совокупности 0(>О) больше, чем любое
из (k—\) средних значений других совокупностей. Вероятность правиль-
правильного выбора (в очевидных обозначениях) равна
LPf[x'x'>0 1 = 2, ..., k1]Pr[xl-T>0] +
-*''> 0] ==
Замечая, что @/а) /"^72 = [F/а) j/V/2] Vn"/n't видим, что вероятность
правильного (и неправильного) выбора является функцией F/а) ]/г72
(а также п"/пг). Можно провести анализ, подобно тому, как это делалось
в упражнении 16.
19. Вероятность выбора правильной совокупности имеет вид
Средние потери
598
Ответы
Эта функция достигает максимума при У(=
выражение
максимизирующем
При этом
maxL =
dmaxL
maxg(K),
Минимаксное значение п0 равно
L 28Ci J
Соответствующее значение L равно
i/з
20. Сравнение можно провести только для случая k — 8, потому что метод,
использованный в упражнении 19, применим только при этом значении k.
Если пользоваться методом упражнения 16, вероятность правильного выбора
равна вероятности того, что каждая из семи величин, имеющих совместное
многомерное нормальное распределение с матрицей дисперсий-коварнаций
1 1/2 ... 1/2\
1/2 1 ... 1/2
ч1/2 1/2
1
и математическими ожиданиями [(б/а) У л/2, ... , (б/а) Vn/2\, положи-
положительна. Если воспользоваться методом упражнения 19, вероятность пра-
правильного выбора равна
[ ( K^T)]3
Число наблюдений будет одинаковым в обоих методах, если 8л=14л0, т. е.
п = 7яо/4. Предположим, что а одно и то же в каждом случае, хоть это и
не обязательно. Некоторые цифры для сравнения даются в следующей таб-
таблице [первый столбец получен с помощью табл. II из статьи Гупта]:
б/а У п/ 2
0,2
0,4
0,6
0,8
1,0
1,5
2,0
2,5
3,0
Вероятность
упражнение
0,165
0,223
0,314
0,405
0,500
0,727
0,884
0,963
0,991
правильного выбора
16
упражнение 19
0,176
0,237
0,308
0,385
0,466
0,662
0,817
0,914
0,965
(б/а) Упо/2 = (б/а) У л/2 У 4/7
0,151
0,302
0,454
0,605
0,756
1,134
1,512
1,890
2,268
Ответы
599
g(X)
J
() 00 00
J f(t)dt+C J f(t)dt-D J [t-g(T)]f(t)dt.
0 g (т) ()
21. o+W+io+drf J J
0 g (т) g (т)
23. Приведем все величины из решения упражнения 21 к началу испытаний.
Необходимо сделать некоторые предположения. Если каждое изделие посту-
поступает в эксплуатацию или бракуется сразу же по окончании проверки
(т.е. в момент т или в момент"отказа), то
1) 0о+din) \ f (t) dt заменяется на
о
00 00
2) С С / (/) dt заменяется на Cvx С / (/) dt;
g (т) ()
g (т)
g (т)
3) D
где h(t, т) =
заменяется на Dv* С h (/, т) / (/) dt,
g(T)
= (l/b) A — v*-&<*)).
учитывается
Предполагается, что стоимость выборочной процедуры
в начале испытаний.
Если длительность испытаний т относительно мала по сравнению со
средним сроком службы, дисконтирование в случаях 1) и 2) может не играть
большой роли.
Ясно, что возможны и другие предположения.
24. Имеем v\= A,08)~2== 0,8573; б3 = — In 1^ = 0,0770; 62 = — In v2 = 0,0488.
Требуется, чтобы
е{A— е~2/е)
[0,1427 A + 0,07706)-1+
+0,8573 A + 0,0488Э)~1]}= —=2.
Решая неравенство методом проб и ошибок, находим Э > 2,3066. Чтобы
получить начальное приближение, предположим -сначала, что про-
процентная ставка постоянна. Из примера 11.9 получаем соответствующее
значение 9:
При i=0,05 это значение равно 2 @,8460)~* = 2,36; при / = 0,08 оно равно
2 @,9024)-1 = 2,2^.
Глава 12
1. а> 0=4,091+ 1,604*; б) 5^ = 0,096, 5 = 20,24.
2. 0 = 0,92924—0,00419*; 95%-ные доверительные границы для 8 равны
—0,00670 и —0,00168.
3. a) R = 0,6325. б) При у =0,05 критическое значение R равно 0,6319. Поскольку
R =0,6325 > 0,6319, формально гипотеза Яо: р = 0 отклоняется, в) Чтобы
# = 0,6325 было значимо, при у = 0,01 объем выборки п должен быть
равен 16. г) Для я =10 критическое значение R при у = 0,01 равно 0,7646.
600
Ответы
б) #х = 0,600+ 0,227*. в) #2 = 0,538 + 0,239*. г) рх: 0,212; 0,242; аг: 0,506;
0,692; р2: 0,220; 0,258; а2: 0,562; 0,550. д) Нет, / = 1,03.
Для поставщика А значения #, соответствующие А-6 @,0764) и А-7 @,0413),
значимы при выделении аномальных значений. Для поставщика С отбра-
отбрасывается С-3 @,0689).
а) Из диаграммы рассеяния видно, что существует линейная зависимость
между Y и Х2;
б) Г = а+рХ2; в) В = 0,00035; А = —0,0139; г) S = 0,0099;
д) границы доверительного интервала для а равны
-0,0139 ±*1о:о,976 (^+Ц^I/20,0099.
Границы доверительного интервала для Р равны
0,00035 ± 2,228
5=0,00019, Л = —0,0209, S = 0,00075. Доверительный интервал для а равен
-0,0209-2,228 (]1+^I/20,00075 < а <
<_0,0209+2,228 [*-+Ц™у* 0,00075.
8.
12.
Доверительный интервал для р равен
0,00019-2,228
S < р < 0,00019+ 2,228-^S .
/6000 /6000
5Х = 0,000165, В2 = 0,000296, Л =0,007548.
Я1==3,86, ?2 = 3,33, i41 = 10,06, Л2 = 8,080, 5?= 1,14, Sf = 0,16, 5^ = 0,75.
Доверительный интервал для рх — р2 равен
<3,86 —3,33) —2,120@,75)
1
г+
1
,5339 '0,9705
< Pi —
14.
17.
18.
22.
23.
25.
26.
C,86-3,33) + 2,120@,88)
а) а = -24,84, р = 1,127; б) Г= 1,60 < ^9; 0>975.
б) z = 210,7+ 19,21*; в) 11,26; 27,16;
г) 201,1; 220,2; 219,5; 240,3; 237,3; 262,6.
а) 0,78. б) Отклонить Яо. в) R^ 0,5751.
# = 399,531 +1,783*+2,737х2 — 2,033х3.
а) # = —211,67+7750*! +2,481*2 —0,0051*з.
б) 5^ = 775,0; 5Ва=0,5132; 5^ = 0,001168.
в) S(Y\xu *2, *22) = 2,01.
В1 = — 945, 52 = 5,5, Л = 54001,4.
),9705 '
27.
Оценка
Средняя квадратическая
ошибка
# = 383,4+15,67*.
a
146,681
80,338
1,434
—948,355
82,080
0,995
0,002
Ответы
601
28. # = —245,22+155,15*.
29. а) Аг = — 9,887, Б1 = 0,112.
б) S(Y1\x) = 0,2344; SBl=0,0046; 5Л1=0,6074.
в) Л2 = —3,099; ?2 = 0,0349; 5 (Y2 \ *) = 0,4509; 5Ва=0,1740; 5Ла = 0,0
32. Пусть дополнительный X равен Хо. Для полного множества B& + 2)
значений X
Х = : Хо
г JJ_2k(k+l)Bk+l) 2
а) Нужно максимизировать j/h, n XJ|, поэтому положим X0 = ft «лм
;+-
L
Нужно минимизировать
= g(X0) (по отношению к Хо).
Если
, берем X0 = k,
— к
-, берем Яо = —fc,
k
2F+1)
< * <
, берем X0 = 2(k+l)x.
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Альтернативная гипотеза 240, 264
Анализ регрессионный. 447, 449
предположения 452
Ансари — Брэдли критерий 337
Апостериорное распределение 227, 425
совместное 427
Априорная информация 421
Априорное распределение 425
Асимметрии коэффициент (первый
коэффициент формы, третий стандарт-
стандартный момент) 82
Байеса теорема 65
Байесовская оценка 227
Бартлетта критерий 271
Бета-распределение 147, 148
— моменты 149
Бета-функция 149, 159
— неполная 149
Биномиальное распределение 74, 99
моменты 101 ,
отрицательное 105
моменты 106
Браковочный уровень дефектности 405
процесса 385
Вейбулла распределение 144
Вероятностная бумага логарифмичес-
логарифмически нормальная 150
нормальная 150
Вероятностное интегральное преобра-
преобразование 350
Вероятность 54
— апостериорная 426
— априорная 425
— доверительная 229
— сложного события 62
— условная 59
Взвешенных наименьших квадратов
метод 454
Вилкоксона критерий двухвыборочный
326
модифицированный (для диспер-
дисперсий) 336
Выборка 11, 22
— парная 278
Выборки объем 233, 244
— стоимость 432
Выборочный контроль 405
Выбросы 266
Гамма-распределение 147
— моменты 148
Гамма-функция 145
— неполная 148
Гауссово (нормальное) распределение
130
Гармоническое среднее 36
Геометрическое распределение 97, 107
— среднее 35
Ги пер геометрическое распределение
112, 409, 410
моменты 112
Гипотеза статистическая 238
альтернативная 240, 264
простая 238
процедура проверки 216, 239
сложная 238
Гистограмма 27
Гомоскедастичность дисперсий 452
Границы регулирования 366
контрольных карт накопленных
сумм для выборочных дисперсий 396
средних 390
сводка формул 403
Шухарта (коэффициенты
для вычисления) 369
предупреждающие 381
приемочные 385
Двойное экспоненциальное распреде-
распределение (распределение Лапласа) 213,
224
Двумерная интерполяция 16
Двумерное нормальное распределение
167
Предметный указатель
603
Двусторонний критерий значимости
244, 263
Двухступенчатый план 408, 410
Дзета-распределение 122, 151, 257
Диаграмма рассеяния 448
Дисконтирование 439
Дискретные распределения 12, 99
Дисперсий и ковариаций матрица 169
Дисперсия 36, 80
— объединенная оценка 231, 274, 372,
467, 472
— остаточная 461, 492
— ошибки предсказания 463
Доверительная вероятность 229
— область 235
для параметров множественной
линейной регрессии 487
Доверительные интервалы совмещен-
совмещенные (множество одновременных до-
доверительных интервалов) 235, 300,
464
Доверительный интервал 216, 228
для долей 234
коэффициента корреляции
480
линии регрессии 460
медианы 354
параметра распределения
Пуассона 288
параметров линейной регрес-
регрессии 460
процентилей 355
Долей распределение 104
Достаточная статистика 219
Зависимая переменная 450
Закон Ципфа 124
Знаков критерий 321
Значимости критерии 238
— уровень 240
Интервал группировки 23
границы 24
пределы 24
срединное значение 24
Интерполяция 14
— гармоническая 15
— двумерная 16
— линейная 14, 15
обратная 19
— обратная 18
— с помощью кубических многочленов
18
Информация априорная 421
Карты приемочного контроля 385
Кендалла t-распределение 345
Ковар нация 85
Контрольные карты 365
накопленных сумм (ККНС)
387
границы регулирования
(сводка формул) 403
для дисперсий 395
доли дефектных изде-
изделий 398
размахов 392
среднего 388
числа дефектов 398,
400
Шухарта 366
границы регулирования 369
для доли дефектных изделий
(р-карта) 377
размаха (#-карта) 368
среднего (Х-карта) 367,
374
квадрэтического от-
отклонения (S-карта) 372, 374
числа дефектов (с-карта)
379
индивидуальных значений
382
скользящего размаха 382
центральная линия 368
Корреляция 84, 472
— ранговая 340
Кохрэна критерий 272
Коэффициент асимметрии (первый
коэффициент формы; третий стандарт-
стандартный момент) 82
— конкордации 343
— корреляции 86, 447
доверительные интервалы 480
критерий значимости 481
оценка 473
— ранговой корреляции 341
— сериальной корреляции 498
Критерии значимости 238
двусторонние 244, 263
для биномиального распределе-
распределения 282
коэффициента корреляции
481
параметра распределения
Пуассона 288
параметров нормального
распределения 283
сравнения более двух сред-
средних 280
двух долей 286
средних 273
604
Предметный указатель
Критерии значимости для сравнения
дисперсий двух совокупностей 269
нескольких долей 288
средних значений 272
односторонние 243, 263
отношения правдоподобия 248
для сложных гипотез 252
исключения выбросов 266
равномерно наиболее мощные
— свободные от распределения 298
— согласия 290
Колмогорова — Смирнова 297
Критерий Ансари — Брэдли 337
— Вилкоксона 326, 336
— знаков 321
— Крускала — Уоллиса 334
— Манна — Уитни 330
— Тьюки 331
Лагранжа формула 19
Лемма Неймана — Пирсона 248
Линейная регрессия 447
множественная 482
однофакторная 452
дисперсия ошибки предска-
предсказания 463
доверительные интервалы
для параметров 460
доверительный интервал для
линии регрессии 462
оценки наименьших квадра-
квадратов 454
проверка гипотез 465
Логарифмически нормальное распреде-
распределение 147, 149
— моменты 150
Логарифмическое распределение 97,
122
Логистическое распределение 147, 151
Манна и Уитни критерий 330
Маркова неравенство 90
Математическое ожидание 77
условное 79
Матрица дисперсий и ковариаций 169,
Медиана 33, 197
Междуквартильное расстояние 206
Метки нормальные 320, 333
Метод взвешенных наименьших квад-
• ратов 454
— максимального правдоподобия 221
— наименьших квадратов 452
— Холеского (решения систем нор-
нормальных уравнений) 485
Методы непараметрические 319
Минимаксного риска принцип 433
— сожзления принцип 435
Многомерное нормальное распределе-
распределение 169
Мода 33
Модификации распределений 160
наложение 160
— — смеси 165
усечение 163
цензурирование 163
Множественная линейная регресеия
482
Множество одновременных доверитель-
доверительных интервалов (совмещенные до-
доверительные интервалы) 235, 300,
464
Моменты распределения случайной
величины 80
начальные 80
третий стандартный мо-
момент (коэффициент асимметрии) 82
центральные 80
абсолютные1 80
факториальные 81
четвертый стандартный
момент (эксцесс) 82
Мощность критерия 240
Наименьших квадратов метод 452
Независимые переменные 447, 450
Неймана — Пирсона лемма 248
— типа А распределение 120
Непараметрические методы 319
Неполной бета-функции отношение
149, 186, 196, 348
— гамма-функции отношение 148, 196
Непрерывные распределения 12, Ш
Неравенство Маркова 90
— Чебышева 89
Нецентральное F-распределение 177
— /-распределение 178
— ^-распределение 152
Нормальное (гауссово) "распределение
130
двумерное 167
многомерное 169
наложенное 161
нормированное 161
усеченное 165
Нормальные метки 320, 333
— уравнения 455, 483
преобразованные 483
Нормированная случайная величина 84
Предметный указатель
605
Область доверительная 235
— критическая 239
Объединенная оценка дисперсии 231,
274, 372, 467, 472
Объем выборки 233, 244
Одноступенчатый план выборочного
контроля 408, 409
Оперативная характеристика 240
плана выборочного контроля
406, 409
Ортогональные полиномы 492
таблицы 490, 493
Остаточная дисперсия 461, 492
Отношение функций правдоподобия
249
Оценка байесовская 227
— максимального правдоподобия 221
— наименьших квадратов 216, 452
несмещенная 217, 218
— с равномерно наименьшей дис-
дисперсией 218
Парето распределение 147, 151
Переменная зависимая 450
— независимая 447, 450
Перестановки 20
План выборочного контроля двух-
двухступенчатый 408, 410
— одноступенчатый 408, 409
Плотность вероятности (распределения
вероятностей) 70
вероятностного интеграла 194
совместного распределения 71
наибольшего и наимень-
наименьшего значений 192
условная 72
Полигон накопленных частот 26, 29
— частот 26, 29
Полиномиальная регрессия 488
Полиномиальное распределение 75, 115
Полиномы ортогональные 492
Поправка на непрерывность Иейтса
139
— Шеппарда на группировку SS
Порядковая статистика 12, 188, 189
ранговая 189
Правдолодобия функция 221
Предел среднего выходного уровня
дефектности 406
Преобразование вероятностное инте-
интегральное 350
— переменных 498
Приемочного контроля карты 385
Приемочный уровень дефектности 405
процесса 385
Проверка гипотез 216
— независимости (по таблицам сопря-
сопряженности) 294
Производящие функции моментов 91,
140, 144, 148, 152
Процедура проверки значимости 262
Процентная ставка 439
Пуассона распределение 108
смешанное 119, 121
усеченное 257
Размах 38, 199
— математическое ожидание 201
— приближенное распределение для
выборки из нормальной совокупно-
совокупности 204
— распределение 199
— стьюдентизированный 280
— усиленный 205
Размещения 20
Ранги совпадающие 346
Ранговая корреляция 340
коэффициент 341
Ранговые порядковые статистики 316
Распределение бета 147, 148
— биномиальное 74, 99
— Вейбулла 144
— гамма 147
— геометрическое 97, 107
— гипергеометрическое 112, 409, 410
— двойное экспоненциальное 213, 224
— дзета 122, 151, 257
— логарифмически нормальное 147,
149
— логарифмическое 97, 122
— логистическое 147, 151
— Неймана типа А 120
— нормальное (гауссово) 130
— отрицательное биномиальное 105
— Парето 147, 151
— полиномиальное 75, 115
— Пуассона 108
— равномерное дискретное 116
непрерывное (прямоугольное)
141
— треугольное 187
— экспоненциальное 143
Распределения апостериорные 425
— априорные 425
— дискретные 12
— наложенные 130, 161
— непрерывные 12
— симметричные 12, 81
— совместные 71, 167
— унимодальные И
— усеченные 130, 163
— цензурированные 163
— эмпирические 22, 23, 26
606
Предметный указатель
Регрессионный анализ 447, 449
Регрессия 80, 168, 447
— линейная множественная 482
однофакторная 452
— полиномиальная 488
Римана дзета-функция 122
Риск поставщика 405, 409
— потребителя 405, 409
— средний 429
Робастность 315
Свободные от распределения критерии
298
методы 315, 319
Серии (в контрольных картах) 381
Серий длина 325
— критерий 323
Случайная величина 66
нормированная 84
Смешанное распределение Пуассона
119, 121
Совмещенные доверительные интерва-
интервалы (множество одновременных до-
доверительных интервалов) 235, 300
464
Совокупность И
Совпадающие ранги 346
Сочетания 20
Сравнение двух линейных уравнений
регрессии 467
— нескольких линейных регрессий
471
Среднее гармоническое 36
— геометрическое 35
— значение 33, 37
— квадратическое отклонение 36, 80
— отклонение 39
— усеченное 206
Средний выходной уровень дефектно-
дефектности 407
Средняя длина серий 403, 404
Статистика 10, 11
— достаточная 219
— порядковая 12, 188, 189
ранговая 189, 316
Стоимость выборки 432
Стьюдента /-распределение 156, 247,
273
нецентральное 178
Толерантные пределы (границы) 258,
347
Толерантный уровень дефектности в
партии 406
Толерантных областей построение 196
Треугольное распределение 187
Тьюки критерий 331
Уилсона — Хилферти аппроксимация
^-распределения 155
Уоринга формула (для вероятности
сложного события) 64
Уровень значимости критерия 240
Усеченное распределение 130, 163
Факториальные моменты 81
Фишера аппроксимация ^-распреде-
^-распределения 155
Функции производящие моментов 91,
140, 144, 148, 152
Функций правдоподобия отношение
249
Функция мощности критерия 241
— правдоподобия 221
— распределения 68
Характеристики положения 32, 225
— рассеяния 36
— числовые случайных величин 22
Холеского метод 485
Цензурированное распределение 163
Центральная линия контрольной карты
Шухарта 368
Центральные абсолютные моменты 90
— моменты 80
Ципфа закон 124
Частость 54
Частота 54
Число степеней свободы, 152, 158
Шеппарда поправка на группировку 38
Шухарта контрольные карты 366
Таблица сопряженности признаков
288, 294
проверка независимости 294
Теория статистических решений 421
Эверетта формула 18
Экспоненциальное распределение 143
двойное (распределение Лапла-
Лапласа) 213, 224
Эксцесс 82
ОГЛАВЛЕНИЕ
Предисловие редактора перевода 5
Предисловие к первому изданию 7
Предисловие ко второму изданию 9
Глава 1. Введение 10
1.1. Выборка и совокупность И
1.2. Порядок следования глав 12
1.3. Интерполяция 14
1.4. Способы перечисления 20
Литература 20
Упражнения 21
Глава 2. Эмпирические распределения и числовые характеристики ... 22
2.1. Введение 22
2.2. Эмпирические распределения 23
2.3. Графическое представление эмпирических распределений . . 26
2.4. Числовые характеристики 31
Литература 42
Упражнения 43
Глава 3. Теория вероятностей. Общие положения 53
3.1. Введение. Определения 53
3.2. Сложные события 56
3.3. Условная вероятность 59
3.4. Теоремы теории вероятностей 61
3.5. Случайные величины 66
3.6. Функции распределения 68
3.7. Плотность распределения вероятностей 70
3.8. Совместные распределения 71
3.9. Независимость 73
ЗЛО. Биномиальное распределение 74
3.11. Полиномиальное распределение 75
3.12. Математические ожидания 76
3.13. Моменты 80
3.14. Нормирование 83
3.15. Корреляция 84
3.16. Неравенство Чебышева ' 89
3.17. Производящие функции моментов 91
Литература 92
Упражнения 93
Глава 4. Дискретные распределения 99
4.1. Введение 99
4.2. Биномиальное распределение _ 99
4.3. Распределение Пуассона 108
608
Оглавление
4.4. Гипергеометрическое распределение 111
4.5. Сравнение биномиального, пуассоновского и гипергеометриче-
гипергеометрического распределений 114
4.6. Полиномиальное распределение 115
4.7. Равномерное распределение (дискретное) 116
4.8. Отрицательное биномиальное распределение как смешанное
распределение Пуассона . . 118
4.9. Некоторые другие распределения 120
Литература • . . 125
Упражнения '. 125
Глава 5. Непрерывные распределения 130
5.1. Введение 130
5.2. Нормальное (гауссово) распределение 130
5.3. Равномерное распределение 141
5.4. Экспоненциальное распределение 143
5.5. Распределение Вейбулла 144
5.6. Еще несколько полезных распределений 147
5.7. ^-распределение 152
5.8. /-распределение Стьюдента 155
5.9. ^-распределение 158
5.10. Модификации распределений 167
5.11. Совместные распределения \ 160
5.12. Преобразование переменных 171
5.13. Вывод ^-распределения 174
5.14. Нецентральные распределения . 176
5.15. Подбор распределения по экспериментальным данным ... 179
Литература 183
Упражнения 183
Глава 6. Порядковые статистики 188
6.1. Введение 188
6.2. Определения 188
6.3. Распределение наименьшего и наибольшего значений в вы-
выборке 189
6.4. Распределение порядковых статистик, построенных по слу-
случайным выборкам , 191
6.5. Толерантные распределения 194
6.6. Некоторые приближения для больших выборок ...... 197
6.7. Распределение размаха выборки 199
6.8. Дискретные величины * . . 202
6.9. Некоторые приближенные результаты для нормальных рас-
распределений 204
Литература 210
Упражнения 210
Глава 7. Оценивание и проверка гипотез "....* 215
7.1. Введение 215
7.2. Точечное оценивание 216
7.3. Оценивание методом максимального правдоподобия 221
7.4. Оценивание с помощью доверительных интервалов 227
7.5. Критерии значимости 238
7.6. Критерии отношения правдоподобия 248
7.7. Равномерно наиболее мощные критерии 251
7.8. Критерии отношения правдоподобия для сложных гипотез 252
Литература 253
Упражнения 253
Огдрвление
609
Глава 8. Некоторые стандартные критерии значимости и доверитель-
доверительные интервалы 259
8.1. Введение 259
8.2. Примеры критериев значимости 259
8.3. Применение критериев значимости 262
8.4. Критерии значимости для дисперсий нормальных распреде-
распределений 268
8.5. Критерии значимости для средних значений нормальных рас-
распределений * 272
8.6. Некоторые стандартные критерии значимости 282
8.7. Критерии значимости для биномиального распределения . .
8.8. Доверительные интервалы и критерии значимости для пара-
параметра 9 распределения Пуассона 288
8.9. Критерии согласия 290
8.10. Несколько дополнительных критериев и оценок 302
Литература 304
Упражнения , 305
Глава 9. Методы, свободные от распределения 314
9.1. Робастность 314
9.2. Методы, свободные от распределения 315
9.3. Непараметрические методы 319
9.4. План оставшейся части главы 320
9.5. Критерии, основанные на знаках 321
9.6. Критерий Вилкоксона и связанные с ним критерии .... 326
9.7. Двумерные методы 340
9.8. Толерантные области и преобразование вероятностного ин-
интеграла 346
9.9. Доверительные интервалы для процентилей 353
9.10. Заключительные замечания - 356
Литература 357
Упражнения * 358
Глава 10. Контрольные карты * * 365
10.1. Введение 365
10.2. Контрольные карты Шухарта » 366
10.3. Карты приемочного контроля 385
10.4. Контрольные карты накопленных сумм (ККНС) ...... 387
10.5. Средняя длина серии 402
10.6. Выборочный контроль 405
Литература • 411
Упражнения * 412
Глава 11. Теория и анализ статистических решений ...*.*,.* 421
11.1. Введение . * 421
11.2. Вспомогательные данные . . . j • 421
11.3. Функция распределения/7/^) . . . « 423
11.4. Априорные вероятности . 424
11.5. Решения и функции потерь 428
11.6. Стоимости выборок « 432
11.7. Примеры 433
11.8. Дисконтирование • 439
Литература # 441
Упражнения 442
610
Оглавление
Глава 12. Регрессия и корреляция 447
12.1. Введение 447
12.2. Однофакторная линейная регрессия 452
12.3. Корреляция 472
12.4. Множественная линейная регрессия 482
12.5. Криволинейная регрессия 487
12.6. Сериальная корреляция 498
12.7. Дополнительные замечания по поводу регрессии и корре-
корреляции 499
Литература 500
Упражнения 501
Приложение
Таблица А. Случайные числа 512
Таблица Б. Распределение Пуассона 516
Таблица В. Нормальное распределение . - 521
Таблица Г. Процентные точки (Up) нормального распределения 523
Таблица Д. Процентные точки ^-распределения 525
Таблица Е. Процентные точки /-распределения Стьюдента . . . 527
Таблица Ж. Процентные точки F-распределения 528
Таблица 3. Моменты и процентные точки распределения размаха 532
Таблица И. Процентные точки стьюдентизированного размаха . . 533
Таблица К. Критические значения для проверки выбросов . . . 535
Номограмма Л. Доверительные зоны для долей 536
Таблица М. Доверительные зоны для среднего значения распре-
распределения Пуассона 539
Таблица Н. Число наблюдений для /-критерия значимости сред-
среднего 540
Таблица О. Число наблюдений для ^-критерия значимости
разности двух средних 542
Таблица П. Число наблюдений, необходимых для сравнения дис-
дисперсии совокупности и заданного значения дисперсии
с помощью критерия %2 544
Таблица Р. Число наблюдений, требуемых при сравнении двух
дисперсий совокупностей с помощью F-критерия . . 545
Таблица С. Границы значимости /?а для критерия знаков . . . 546
Таблица Т. Границы значимости для критериев, основанных на
сериях 547
Таблица У. Критические значения для Sx 549
Таблица Ф. Приближенные границы значимости d[n2a для макси-
максимума абсолютной разности между функциями распре-
распределения выборки и совокупности . . 554
Таблица X. Нормальные метки 555
Таблица Ц. Толерантные множители для нормального распреде-
распределения 556
Таблица Ч. Доверительные интервалы для медианы 558
Номограмма Ш A). Доверительные зоны для коэффициента кор-
корреляции 559
Таблица Ш B). Критические значения коэффициента корреляции 560
Таблица Ш C). Критические значения коэффициента ранговой
корреляции 561
Таблица Э. Процентили для некоторых распределений 562
Номограмма Ю. Номограмма для определения функции мощности
^-критерия 565
Решения некоторых упражнений 566
Предметный указатель 602
УВАЖАЕМЫЙ ЧИТАТЕЛЬ!
Ваши замечания о содержании книги, ее оформлении,
качестве перевода и другие просим присылать по адресу:
129820, Москва, И-110,ГСП, 1-й Рижский пер., д. 2, изд-во
„Мир".