








































































































































































































































































































































































































































































































































Текст
Б. А. ГОЛОВКИН
ПАРАЛЛЕЛЬНЫЕ
ВЫЧИСЛИТЕЛЬНЫЕ
СИСТЕМЫ
МОСКВА «НАУКА»
ГЛАВНАЯ РЕДАКЦИЯ
ФИЗИКО-МАТЕМАТИЧЕСКОЙ ЛИТЕРАТУРЫ
1980
22.18
Г 61
УДК 519.6
Параллельные вычислительные системы. Г о-
л о в к и в Б. А.— М.: Наука. Главная редакция*
физико-математической литературы, 1980.
В книге рассматриваются параллельные вычис-
лительные системы (вычислительные системы па-
раллельной обработки информации): многомашин-
ные, многопроцессорные, магистральные (конвейер-
ные), матричные, ассоциативные, с комбинирован-
ной и перестраиваемой структурой и некоторые*
другие. Системы таких типов отличаются повышен-
ной гибкостью и обладают высокими характерис-
тиками пройзводительности и надежности.
Дается систематическое описание организации»
структуры и функционирования параллельных вы-
числительных систем. В описании приводятся
структурные схемы и основные характеристики не-
скольких десятков отечественных и зарубежных,
параллельных вычислительных систем.
Книга рассчитана па инженеров и научных ра-
ботников в области вычислительной техники, прог-
раммирования и обработки информации, а также-
на студентов старших курсов и аспирантов соот-
ветствующих специальностей.
34-80. 1702070000
053(02)-80
(©Издательство «Наука»
Главная редакция
физико-математической*
литературы, 1980
ОГЛАВЛЕНИЕ
Предисловие . . ♦ ....... i . . 6
1. Эволюция вычислительных систем: от последовательных систем к
параллельным..................................................... 9
1.1. Эволюция однопроцессорных систем........................... 9
1.1.1. Параллельная обработка разрядов слов. Совмещение процес-
сов ввода-вывода и вычислений (9). 1.1.2. Совмещение операций и
опережающий просмотр команд и данных (11).
4.2. Эволюция многомашинных и многопроцессорных систем (на при-
мере систем IBM)................................................14
1.2.1. Ранние многомашинные системы с косвенной связью (14).
1.2.2. Ранние многомашинные системы с прямой связью. Система
DCS (15). 1.2.3. Слабо и сильно связанные системы (16). 1.2.4. Мно-
гомашинная система с вспомогательным процессором ASP (17).
1.2.5. Структуры многомашинных и многопроцессорных систем.
Тенденции развития (19).
4.3. Краткий обзор......................................... • 21
2. , Организация структуры и функционирования параллельных вычи-
слительных систем ..........................................
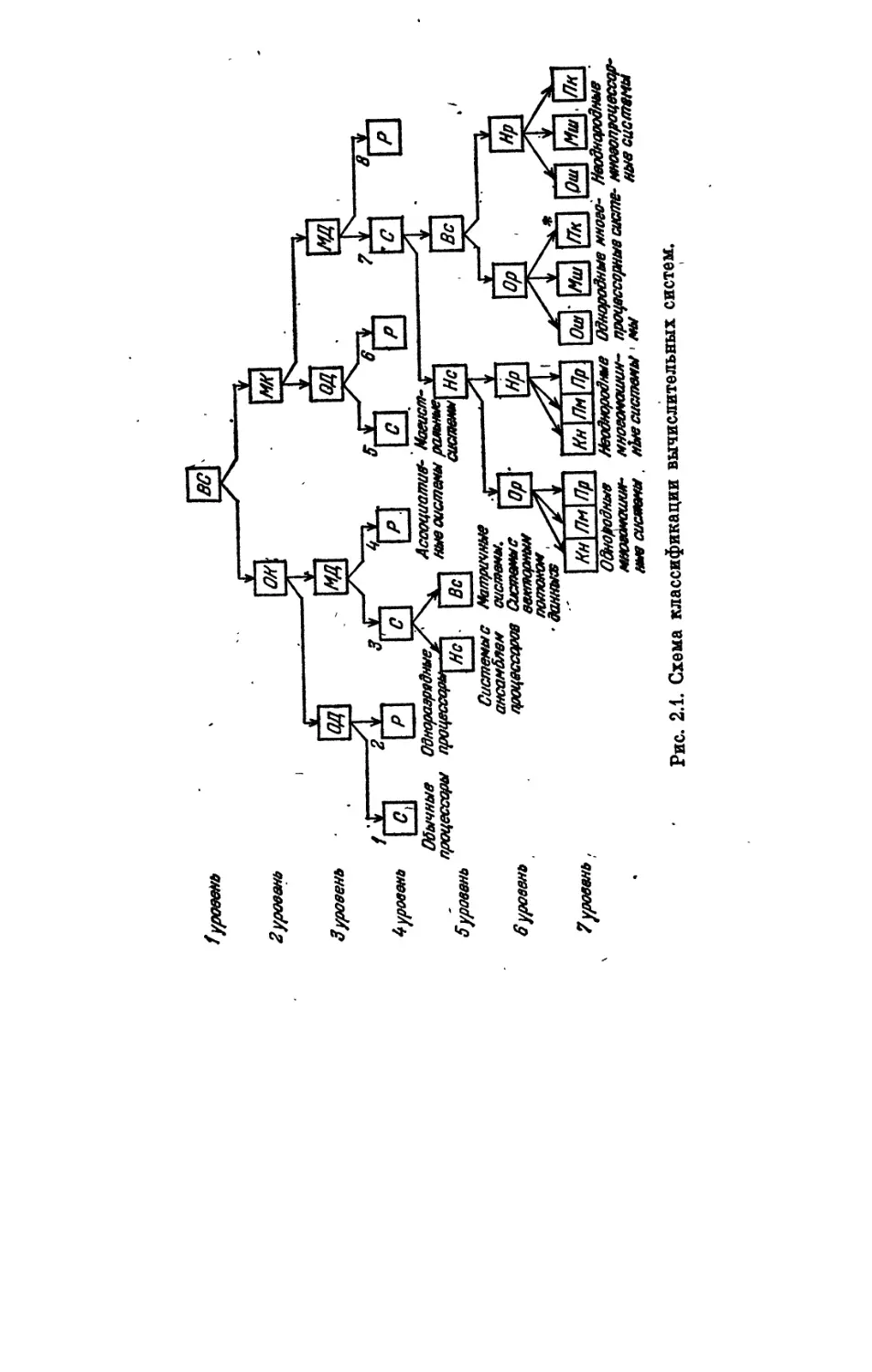
2.1. Классификация вычислительных систем......................
2.1.1. Признаки в схема классификации. Нотация классов (24).
2.1.2. Описание классов вычислительных систем (26).
2.2. Потоки команд и данных. Пословная и поразрядная обработка. '
Основные структуры и определения................................28
2.2.1. Одиночные и множественные потоки команд и данных (28).
2.2 2. Посло4ная и поразрядная обработка (31) 2.2.3. Основные
структуры и определения (32). 2.2.4. Коммутация потоков команд
и данных (38).
2.3. Некоторые основные соотношения между структурами вычисли-
тельных систем................................................ 42
2.4. Структура связей в параллельных вычислительных системах . 47
2.4.1. Межпроцессорные связи в вычислительных системах в се-
тях и их классификация (47). 2.4.2. Внутренние связи в многопро-
цессорных системах (53).
2.5. Структура связей между центральной частью вычислительных
систем и каналами ввода-вывода..................................55
2.5.1. Основные типы структуры связей (55). 2.5.2. ^Сопряжение с
периферийными устройствами (61).
*2.6. Структура многопроцессорных систем с языками высокого уровня 68
2.7. Краткий обзор............................................ 79
2.7.1. Обзор монографий, сборников и обзоров (80). 2.7.2. Обзор
схем классификации и структур параллельных вычислительных
систем (89).
*3. Многомашинные и многопроцессорные системы на базе однопро-
цессорных ЭВМ......................................................
.3.1. Концепция и ранние системы......................... * * 99
3.1.1. Концепция комплексирования однопроцессорных ЭВМ (99)*
3.1.2. Система Минск-222 (101). 3.1.3. Система КЛАСС (103)*
3.1.4. Система Днепр-2 (104).
4* 3
3.2. Системы на базе ЭВМ БЭСМ-6 . ......................... . . 106» '
3.2.1. Структура ЭВМ БЭСМ-6 (106). 3.2.2. Многомашинные систе-
мы на базе ЭВМ БЭСМ-6 (109). 3.2.3. Библиографическая справка
(117).
3.3. Системы на' базе ЭВМ семейства ЕС...........................11$
3.3.1. Структура семейства ЕС ЭВМ (118). 3.3.2. Многомашинные
и многопроцессорные системы на базе ЕС ЭВМ (123). 3.3.3. Биб-
лиографическая справка (136).
3.4. Системы на базе ЭВМ семейств АСВТ-М и СМ ЭВМ .... 137
3.4.1. Структура семейств АСВТ-М и СМ ЭВМ (137). 3.4.2. Много-
машинные и многопроцессорные системы на базе АСВТ-М и СМ
ЭВМ (146). 3.4.3. Библиографическая справка (149).
3.5. Системы на базе ЭВМ семейств IBM 360 и IBM 370. Семейство
IBM ЗОЗХ....................................................... 150
~ 3.5.1. Структура семейств IBM 360 и IBM 370 (150). 3.5.2. Многома-
шинные и многопроцессорные системы на базе ЭВМ семейств I
IBM 360 и IBM 370 (153). 3.5.3. Система IBM 360/67 (156). 3.5.4. Си-
стемы IBM 360/65 МР, 370/158 МР, 370/168 МР (158). 3.5.5. Семей-
ство IBM ЗОЗХ и новые разработки фирмы IBM (160). 3.5.6. Биб-
лиографическая справка (162).
3.6. Системы на базе ЭВМ семейства4 DEC PDP-11 . . . . . 164
3.6.1. Структура семейства PDP-11 (164). 3.6.2. Многомашинные и
многопроцессорные системы на базе ЭВМ семейства PDP-11 (167).
3.6.3. Библиографическая справка (169).
4. Многопроцессорные системы t • 171
4Л. Концепция и ранние системы .................................17®
4.1,1. ' Разработки концепций многопроцессорных систем (171).
4.1.2. Система RW 400 (176). 4.1.3. Система D825 (177). 4.1.4. Сис-
тема СЕЮ 3600 (180). 4.1.5. Система PHILCO 213 (183). 4.1.6. Систе-
ма LARC (184). 4.1.7. Система PILOT (187). 4.1.8. Система GAM-
MA 60 (189). 4.1.9. Система STRETCH (190). 4.1.10. Основные поло-
жения концепции организации многопроцессорных систем (192).
4.1.11; Библиографическая справка (200).
4.2. Системы семейства Эльбрус...........................* . 201
4.2.1. Концепция построения систем семейства Эльбрус (201).
4.2.2. Структура систем семейства Эльбрус (205). 4;2.3. Библиогра-
фическая справка (213).
4.3. Системы фирмы Burroughs.....................................214
4.3.1. Концепция построения систем фирмы Burroughs (214).
4.3.2. Структура систем фирмы Burroughs (217). 4.3.3 Библио-
графическая справка (228).
4.4 Системы семейства UNIVAC 1100 .......................... 229*
4.4.1. Структура семейства UNIVAC 1100 (229). 4.4.2. Системы
UNIVAC 1108 и 1406 (232). 4.4.3. Система UNIVAC 1110 (237). 4.4.4.
Системы UNIVAC 1100/10, 1100/20, 1100/40, 1100/80 (239). 4.4.5. Би-
блиографическая справка (244).
4.5. Системы семейства DEC System 10.............................245
4.6. Системы фирмы Honeywell....................................- 250<
4.7. Система SYMBOL .............................................255
5. Магистральные системы........................................261
5.1. Концепция и ранние системы..................................261
5.2. Системы фирмы Control Data ............................... 265
5.2.1. Системы CDC 6600 и 7600 и другие'системы семейств CDC
6000 и 7000 (265). 5.2.2. Системы семейств CYBER 70 и 170 (273).
5.2.3. Система STAR 100 (277). 5.2.4. Библиографическая справка
(280).
5.3. Системы IBM 360/91 и IBM 360/195 ........................ 282г
5.4. Система MU5 ................................................. 285»
4
5.5. Система ASC . ♦ . ..................... . < . • . 288
5.6. Система AMDAHL 470 V/6.....................................292
5.7. Система CRAY 1............................,................296
6. Матричные, ассоциативные и подобные им системы..............303
6.1. Концепция и ранние системы..................-. . . . 303
6.2. Вычислительная система М-10........................... . 307
6.3. Система РЕРЕ..............................................31£
6.4. Система ILLIAC IV '.......................................318
6.5. Системы BSP, DAP, IBM 3838 и другие матричные системы . . 327
6.6. Система STARAN и другие ассоциативные системы .... 339
7. Системы с комбинированной и перестраиваемой структурой. Отка-
зоустойчивые системы ..........................................354
7.1. Концепция и ранние системы................................354
7.1.1. Концепция систем с комбинированной структурой (354).
7.1.2. Применение микропроцессоров (357). 7.1.3? Концепция систем
с перестраиваемой структурой (358). 7.1.4. Концепция устойчи-
вости вычислительных систем к отказам (362).
7.2. Системы с комбинированной и перестраиваемой структурой . 368.
7.2.1. Системы семейства OMEN 60 (368). 7.2.2. Система МИНИ-
МАКС (371). 7.2.3. Система СУММА (374). 7.2.4. Библиографиче-
ская справка (376).
7.3. Отказоустойчивые системы..................................377
7.3.1. Системы JPLSTAR и *UDS (377). 7.3.2. Система PLURIBUS
(382). 7.3.3. Система TANDEM 16 (386). 7.3.4. Системы С. шшр/
Cm* и С. vmp. (387). 7.3.5. Система COMTRAC (396). 7.3.6. Систе-
мы FTMP и SIFT (399). 7.3.7. Вычислительная система космиче5-
ского корабля «Шаттл» (404). 7.3.8. Библиографическая справка
(406).
7.4. Новые концепции и разработки..............................411
7.4.1. Модульная асинхронная развиваемая система (411). 7.4.2. Ре-
курсивные вычислительные машины (415). 7.4.3. Управляющие
системы с перестраиваемой структурой (418). 7.4.4. Библиографи-
ческая справка (421).
8. Количественные характеристики структур систем. Производитель-
ность и стоимость систем.......................................422
8.1. Количественные характеристики структур вычислительных си-
стем ...........................................................422
8.1.1. Формализация описания^структур систем (422). 8.1.2. Опе-
рации над формальными описаниями структур систем (432).
8.2. Производительность и стоимость параллельных вычислительных
систем......................................................... 436
8.2.1. Оценка и прогноз увеличения производительности парал-
лельных вычислительных систем (436). 8.2.2. Отношение произво-
дительности к стоимости вычислительных систем (447).
8.3. Краткий обзор..........................................., 451
Литература ................................................... 460
Предметный указатель . 4 518
ПРЕДИСЛОВИЕ
В книге рассматриваются . многомашинные, многопроцессор-
ные, магистральные (конвейерные), ассоциативные и матричные
системы, системы с векторным потоком данных и ансамбли про-
цессоров, а также системы с комбинированной и перестраивае-
мой структурой. Большой интерес к этим системам и их значение
определяются тем, что они отличаются большой гибкостью и
обеспечивают высокие и рекордные показатели производитель-
ности, надежности, готовности и живучести. В последние годы
значительно повысилось отношение производительности таких
систем к их стоимости, что особенно важно для расширения
области применения систем.
В ближайшее время ожидается существенное расширение раз-
работок рассматриваемых типов вычислительных систем, увели-
чение их производства, улучшение характеристик и расширение
области применения, особенно в связи с развитием микропро-
цессорной техники и техники больших интегральных схем.
Быстрое развитие разнообразных и сложных вычислительных
систем приводит к изменению <и уточнению терминологии и к
появлению новых понятий, что особенно характерно для рассмат-
риваемой области вычислительной техники. В этих условиях
большие трудности вызывает терминология. При написании кни-
• ги была использована терминология, получившая наибольшее
распространение, хотя она во многих случаях и не является
общепринятой и устоявшейся.
Для описываемых в книге вычислительных систем было вы-
брано название «параллельные вычислительные системы» (вы-
числительные системы параллельной обработки информации).
Характерной особенностью рассматриваемых в книге систем
является то, что они имеют, по меньшей мере, более одного уст-
ройства управления или более одного центрального обрабатываю-
щего устройства, которые работают одновременно. Вследствие
этого в центральной части таких систем имеется, по мёньшей
мере, два параллельных потока команд или данных. Кроме этого,
методы программирования и методы вычислительной математики
для таких систем в большинстве случаев также называются
параллельными. Поэтому, выбрав слово «параллельный» в каче-
стве корневого, можно с достаточной степенью однозначности
6
говорить о средствах и методах параллельной обработки инфор-
мации — параллельных вычислительных системах, параллельном
программировании и параллельных вычислительных методах. При
этом, однако, не достигается полная однозначность, так как, на-
пример, элементы параллельной обработки информации имеются
Рис. 0.1. Схема логических связей между главами.
и в однопроцессорных ЭВМ: параллельность обработки разрядов
слова в арифметико-логическом устройстве, совмещение во вре-
мени работы устройств ЭВМ, опережающий просмотр команд и
данных и другие.
В первой главе настоящей книги описывается эволюция вы-
числительных машин и систем в направлении от последователь-
ной обработки информации к параллельной обработке. Во второй
главе дается систематическое изложение организации структуры
и функционирования разного типа параллельных вычислитель-
ных систем. В последней главе рассматриваются числовые ха-
рактеристики структур вычислительных систем, а также оценка
и прогноз увеличения производительности параллельных вычис-
лительных систем и отношение их производительности к стои-
мости. В остальных главах приводится сжатое описание несколь-
ких десятков характерных параллельных вычислительных систем
разнообразных типов. При этом основное внимание уделяется
действующим и новейшим ристемам, описываются также ряд ха-
7
рактерных ранних систем и ряд концепций параллельных вы-
числительных систем. Описание ориентирована на организацию
структуры и функционирования вычислительных систем и иллю-
стрировано структурными схемами систем. Схема логических
связей между главами книги приведена на рис. 0.1.
По тематике параллельных вычислительных систем опубли-
ковано несколько тысяч работ. Рассмотреть такое количество
работ или даже просто перечислить их наименования в книге
ограниченного объема не представляется возможным. В целях
облегчения знакомства читателей с литературой по параллельным
вычислительным системам и более глубокого их изучения в книгу
включены краткий обзор и библиографическая справка по
параллельным системам, разнесенные по соответствующим раз-
делам.
Книга рассчитана на читателей, знакомых с основами пост-
роения структур ЭВМ, и предназначена для инженеров и науч-
ных работников в области вычислительной техники, программи-
рования и обработки информации, а также для студентов и аспи-
рантов соответствующих специальностей.
В. А. Головкин
t ЭВОЛЮЦИЯ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ!
ОТ ПОСЛЕДОВАТЕЛЬНЫХ СИСТЕМ К ПАРАЛЛЕЛЬНЫМ
1.1. Эволюция однопроцессорных систем
1.1.1. Параллельная обработка разрядов слов. Совмещение
процессов ввода-вывода и вычислений. В основу большинства
однопроцессорных систем положена концепция вычислительной
машины Дж. фон Неймана, изложенная в отчете, подготовлен-
ном в середине Сороковых годов и в‘ последующем несколько раз
переиздававшемся [35]. В качестве основных устройств универ-
сальной автоматической ЭВМ были выделены арифметико-логи-
ческое устройство, память для хранения как данных, так и ко-
манд, устройство управления и устройства ввода и вывода
(рис. 1.1). Уже в первых машинах осуществлялась параллельная
обработка разрядов каждого слова в параллельном арифметико-
логическом устройстве. При обмене информацией в трактах
ввода-вывода и между устройствами машины разряды каждого f
слова данных и каждой команды (или _их частей) передавались
параллельно. Другие процессы в ЭВМ были последовательными,
а потоки команд и данных — одиночными.
Следует отметить, что известны ЭВМ с последовательными
арифметико-логическими устройствами, обрабатывающие инфор-
мацию бит за битом. Такие машины имеют сравнительно низкую
производительность и используются, в основном, как вспомога-
тельные вычислительные устройства..
В вычислительных машинах со структурой, изображенной "на
рис. 1.1, ввод и вывод информации осуществлялся через ариф-
метико-логическое устройство, поэтому на время ввода и вывода
вычисления прекращались. В целях повышения производитель-
ности вычислительных машин в середине пятидесятых годов
было осуществлено совмещение во времени процессов, вво^а-вы-
вода и вычислений путем организации непосредственного обмена
с памятью при вводе и выводе, минуя арифметико-логическое
устройство (рис. 1.2).'
Такая структура вычислительных машин обладала существен-
ным недостатком — снижением производительности во время
ввода ч и вывода информации из-за необходимости подробного
контроля и управления операциями ввода-вывода со -стороны
устройства управления. Поэтому на пути совмещения процессов
ввода-вывода и вычислений был сделан следующий и основной
шаг —в состав машины был включен независимый канал ввода-
вывода, представляющий собой фактически небольшую специали-
зированную ЭВМ (рис. 1.3).
Канал может выполнять функции ввода-вывода одновремен-
йо (параллельно) с работой арифметико-логического устройства
Рис. 1.1. Структурная схема машицы Дж. фон Неймана. Одинарными ли-
ниями показаны связи для сигналов управления, а двойными линиями —
связи для данных и команд.
и обеспечивает независимый доступ к памяти и автономное уп-
равление операциями ввода-вывода. Устройство управления сох-
раняет только общие функции координации ввода-вывода, связан-
' ные, например, с началом и окончанием ввода-вывода или с
реакцией на нестандартные ситуации. Программа самого канала
размещается обычно в основной памяти машины, поэтому при
Рис. 1.2. Структурная схема вычислительной машины с организацией не-
посредственного обмена с памятью при вводе и выводе. Одинарными лини-
ями показаны связи для сигналов управления, а двойными линиями — свя-
зи для данных и команд.
его работе осуществляется занятие Циклов памяти для выборки
команд канала, что приводит на время обмена к некоторому
снижению производительности машины по сравнению с потенци-
ально достижимой производительностью при полном распарал-
10
леливании процессов ввода-вывода и вычислений. Вычислитель-
ная машина может быть оборудована несколькими каналами,
способными осуществлять свои функции одновременно (парал-
лельно).
Таким образом, при работе вычислительной машины, имею-
щей каналы ввода-вывода, процесс • вычислений и один или
Рис. 1.3. Структурная схема вычислительной машины с каналом ввода-вы-
вода. Одинарными линиями показаны связи для сигналов управления,
а двойными линиями — связи для данных и команд.
несколько процессов ввода-вывода могут выполняться одновре-
менно (параллельно).
1.1.2. Совмещение операций и опережающий просмотр комаид
и данных. Другим направлением распараллеливания процессов в
ЭВМ явилось совмещение во времени этапов выполнения сосед-
них операций в центральной части машины.
Идеи об использовании принципа совмещения операций в
целях повышения скорости вычислительных машин, а также об
объединении машин и о создании многопроцессорных систем с
общей основной памятью высказал академик С. А. Лебедев
1251] на сессии АН СССР (1957 г.). Приведем некоторые выдерж-
ки из его доклада.
«Некоторые возможности повышения скорости электронных
вычислительных машин имеются... в случае использования прин-
ципа совмещения операций. Выполнение арифметических дейст-
вий в значительной мере может быть совмещено по времени с
обращением к памяти. При этом можно отказаться от стандарт-
ного цикла выполнения операций, когда вызов следующей
команды производится после отсылки результата в запоминаю-
щее устройство, и производить выборку команд перед отсылкой
результатов в запоминающее устройство... Благодаря такому из-
менению цикла работы машины на выполнение арифметического
действия.... дополнительно добавляется время, идущее на вызов
следующей команды.
А
Возможное ускорение работы машины за счет совмещения
вызова команд и чисел по двум независимым каналам также
может дать сокращение времени...
Помимо быстродействия арифметического устройства, сущест-
венным фактором, определяющим скорость работы машин, явля-
ется время обращения к ’запоминающему устройству... Одним из
решений уменьшения времени обращения к запоминающему
устройству является создание дополнительной «сверхбыстродей-
ствующей памяти» сравнительно небольшой емкости. Создание
такой «памяти» позволит сократить время для выполнения стан-
дартных вычислений...
Некоторые весьма важные задачи, в особенности многомерные
вадачи математической физики, не могут успешно решаться при
скоростях работы современных электронных вычислительных
машин, и требуется существенное повышение их быстродействия.
Одним из возможных путей для решения таких задач может
явиться параллельная работа нескольких машйй, объединенных
одним общим дополнительным устройством управления и с обес-
печением возможности передачи кодов чисел с одной машины 'на
другую. Однако может оказаться более целесообразным создание
ряда параллельно работающих отдельных устройств машины.
В такой машине должна иметься общая основная «память» для
хранения чисел и команд, необходимых для решения задачи. Из
этой «памяти» числа и команды, требующиеся для решения того
или иного этапа задачи, поступают на ряд сверхбыстродействую-
щих запоминающих устройств сравнительно небольшой емкости.
Каждое такое сверхбыстродействующее запоминающее устройст-
во связано со своим арифметическим устройством. Эти устройст-
ва имеют свое индивидуальное управление. Помимо этого,
должно быть предусмотрено общее управление всей машиной в
целом.
Для более полного использования арифметических устройств
требуется, чтобы заполнение «сверхбыстродействующей памяти»
из общей «памяти» машины осуществлялось одновременно с вы-
полнением вычислений» [251].
Несмотря на то,-что эти идеи были высказаны более 20 лет
назад — очень большой срок для вычислительной техники — и что
за это время прошли смены поколений вычислительных машин,
они актуальны и сейчас.
Продолжим рассмотрение вопросов совмещения операций.
Методы совмещения операций были усовершенствованы,
а область их действия расширена. Стал применяться опережаю-
щий просмотр нескольких команд и данных с соответствующей
Выборкой из памяти и предварительной подготовкой к выполне-
ркю операций. Была организована асинхронная работа устройств
машины,, что потребовало ввести в их состав местные устрой-
ства управления и позволило иметь в фазе выполнения сразу
несколько соседних команд. При такой организации функциони-
42
рования машины в данный момент времени первая из группы
совместно выполняемых команд проходит последний этап выпол-
нения и занимает одно из устройств машины, следующая за ней
команда проходит предпоследний этап выполнения и занимает
другое устройство и т. д. К очередному интервалу времени пер-
вая из рассматриваемых команд оказывается выполненной,
л остальные команды переходят к очередным этапам выполнения
и занимают соответствующие этим этапам устройства. В фазу
выполнения вводится новая команда, которая занимает устройст-
во для выполнения первого этапа операции, освободившееся пос-
ле выполнения первого этапа последней из команд, совместно
выполнявшихся на предыдущем интервале времени, и так далее.
Такая организация функционирования направлена на обеспе-
чение полной загрузки каждого устройства машины. Однацо,
вследствие- разного количества и неидентичности этапов выпол-
нения ‘различных операций, а также вследствие прерываний ли-
нейных участков программы ветвлениями, устройства машины
работают все же с перерывами.
Дальнейшим развитием организации функционирования вы-
числительных машин с совмещением во времени выполнения со-
седних операций явилась магистральная (конвейерная) органи-
зация функционирования, которая рассматривается в последую-
щих разделах данной книги.
В целях согласования скоростей работы арифметико-логиче-
ского устройства и памяти были совмещены во времени обраще-
ния -к памяти. Наиболее простой способ реализации такого сов-
мещения состоит в разделении памяти на несколько секций с
раздельным обращением к ним. Количество секций обычно равно
небольшой степени* числа два. Каждая секция снабжается собст-
венным адресным и числовым регистрами. Кроме этого, вво-
дится чередование адресов, суть которого состоит в следующем.
Пусть память разбита на п = 2т секций. Тогда ячейки памяти
с адресами 0, 1, ..., n — 1 реализуются как первые ячейки в каж-
дой из п последовательно расположенных секций памяти, ячейка
с адресами n, п + 1, ..., 2п — 1 — как вторые ячейки в этих сек-
циях и т. д. В адресном поле команды номер секции кодируется
в т младших разрядах адреса, а номер ячейки внутри секции —
в старших разрядах адреса.
При такой организации обращения к ячейкам памяти с после-
довательно увеличивающимися (уменьшающимися) адресами
(что является типичным) осуществляются последовательно к
жаждой секции, с циклическим возвратом к начальной секции.
В наиболее благоприятном случае цикл работы памяти сокра-
щается в п раз по сравнению с циклом работы ее отдельной
секции.
Более сложные способы реализации совмещения обращений
ж памяти состоят в построении многовходовой памяти, которая
допускает одновременное обращение к ней со стороны нескольких
13
устройств и разрешает возникающие при этом конфликты однов-
ременного обращения.
Перечисленные способы организации параллельных процессов
функционирования однопроцессорных систем являются вполне
устоявшимися и находят применение также и в параллельных
системах. В дальнейшем, за исключением характерных случаев,,
они в целях краткости изложения упоминаться не будут.
1.2. Эволюция многомашинных и многопроцессорных
систем (на примере систем IBM) [744]
*
Многомашинные и многопроцессорные системы получил»
наибольшее распространение среди параллельных систем. Рас-
смотрим их эволюцию на фоне развития однопроцессорных ЭВМ.
Это удобно сделать на примере фирмы IBM (International Busi-
ness Machines).
Фирма IBM, подобно большинству изготовителей универсаль-
ных ЭВМ, до 1960 г. прилагала незначительные усилйя для
комплексирования двух или более ЭВМ. В 1955 г. ею были соз-
даны специализированные многомашинные (дуплексные) систе-
мы, расположенные в нескольких местах по периметру Северной
Америки. Они предназначались для обработки информации в;
целях противовоздушной обороны. Эта разработка известна под
названием SAGE (Semi-Automatic Ground Equipment)— Полуав-
томатическое наземное оборудование. В системе резервирования
билетов для американских авиалиний SABRE (1958 г.) была ис-
пользована специализированная дуплексная система. Первона-
чально она представляла собой связку двух машин IBM 7090,.
каждая из которых способна обрабатывать сообщения от мно-
жества терминалов. Одна из машин осуществляла обработку со-
общений в оперативном режиме, а другая находилась в горячем
резерве.
1.2.1. Ранние многомашинные системы с косвенной связью..
До 1961—1962 гг. большинство крупных пользователей устанав-
ливали несколько машин в одном месте, причем в большинстве
таких случаев общей для этих процессоров*) была память на
магнитных лентах, на которых хранились библиотеки программ.
Память на магнитных дисках для программ и данных редко
использовалась до 1961—1962 гг., и почти всегда она была ин-
дивидуальной для каждой конкретной машины.
Ранние многомашинные системы с общей внешней памятью
на магнитных дисках включали в себя машины IBM 1410, косвен-
♦) В литературе под процессором понимается как вычислительная ма-
шина без периферийного оборудования (центральная часть), так и сово-
купность устройства управления и арифметико-логического устройства^
а также арифметико-логическое устройство. В настоящей книге использу-
ются 'все три понятия, при этом выбор того или иного из них в каждом
конкретном случае определяется контекстом.
14
2io связанные одна с другой или с большой машиной, такой как
IBM 7010 или IBM 7090, при помощи этой внешней памяти
<рис. 1.4). Память на магнитных дисках использовалась в режи-
ме разделения оборудования, при этом основной целью было
обеспечение высокой готовности системы. Если одна из машин
Тис. 1.4. Структурная схема многомашинной (слабо связанной) вычисли-
тельной системы с косвенной связью. Двухмашинная конфигурация. Одна
из машин может быть ориентирована на функции ввода-вывода.
выходила из строя или требовала профилактики, то другая мог-
ла быть использована для пакетной или оперативной обработки.
Такая связь между машинами через внешнюю Память Классифи-
цируется как слабая. Динамическое распределение программ и
данных между двумя машинами было относительно редким и
'требовало больших усилий по программированию.
1.2.2. Ранние многомашинные системы с прямой связью»
«Система DCS. В начале 1960-х годов группы крупных пользова-
телей ЭВМ в интересах научных, исследований, применяли другую
методику комплексирования машин семейства IBM 7040/7090.
.Две машины, одной из которых являлась IBM 7040 или IBM 7044
<704Х), а другой — большая машина IBM 7090 или IBM 7094
(709Х), непосредственно связывались между собой в систему,
которая получила наименование DCS (Direct Coupled System)—
система с прямой связью (рйс. 1.5). Первая из машин была
Рис. 1.5. Упрощенная структурная схема двухмашинной (слабо связанной)
вычислительной системы с прямой связью. Внешний вычислитель выполня-
ет функции ввода-вывода. t
внешним вычислителем, обслуживающим низкоскоростные пери-
-ферийные устройства и линии связи, а вторая выполняла функ-
ции центрального вычислителя. В системе использовался адаптер
жаналов для связи между машинами, а не общая память на
15
магнитных дисках. Связь между машинами через адаптер ка-
налов также классифицируется как слабая.
Входные потоки информации поступали от устройств счи-
тывания информации с перфокарт во внешний вычислитель иг
передавались от него при помощи адаптера каналов в централь-
ной вычислитель. После обработки информация поступала в об-
ратном направлении из центрального вычислителя во внешний
для последующей печати и перфорации.
Таким образом, основной функцией внешнего вычислителя в
системе DCS было управление устройствами считывания и печа-
ти информации. В то время политика цен фирмы IBM привела
к такой ситуации, что присоединять устройства ввода-вывода, к
машине IBM 704Х было значительно дешевле, чем к машине
IBM709X.
1.2.3. Слабо и сильно связанные системы. За время от начала *
1960-х годов фирма IBM активно разрабатывала многомашинные '
системы обоих типов — с косвенной связью при помощи общей
внешней памяти на магнитных дисках и с прямой связью машин
при помощи адаптера каналов. По степени связанности обе такие
системы, как отмечалось выше, относятся к слабо связанным.
При создании крупных вычислительных систем для обработ-
ки информации в научных целях и в целях экономических рас-
четов часто требуются:
— вычислительные мощности, превышающие возможности
одной машины; _
— более высокак готовность по сравнению с той, которую
может об еспечить^одн сопроцессор пая система с учетом ее отказов
и профилактики;
— уменьшение числа прерываний в системах, ориентирован-
ных на работу с линиями связи, путем выделения специального
процессора для работы-с- линиями связи и отделения прерываний
от пакетйой обработки;
— функциональное разграничение помещений для вычисли-
тельных машин, при котором все перфокарты обрабатываются
в одном месте, печать осуществляется в другом месте, работа с
машинными лентами — в третьем и т. д.; ъ
— несколько поколений прикладных программ и связанных
с ними операционных систем или оборудования. Для выполнения
этих требований однопроцессорные системы оказываются недо-
статочными/
Фирмы Burroughs, CDC (Control Data), DEC (Digital Equip-
ment), Honeywell/GE, Univac/RCA и некоторые другие много вни-
мания уделяли многопроцессорным системам. В таких системах
два или более- центральных процессоров имеют общую оператив-
ную память и общие периферийные устройства и работают в
.режиме разделения этого оборудования под управлением единой
операционной системы (рис. 1.6). Связь между процессорами
через оперативную память классифицируется как сильная»
16 *
К 1971г. фирма Burroughs разработала и выпустила многопроцес-
сорную систему В 6700, фирма CDC выпустила многопроцессор-
ную систему CDC6500, в которой два процессора CDG6400 име-
ют общую оперативную память, и многопроцессорную систему
CDG6700, в которой процессор CDC6400 имеет общую оператив-
ную память с процессором CDC 6600, фирма DEG выпустила.
многопроцессорные системы DEC
1055 и 1077, фирма Honeywell/
/GE — многопроцессорные системы
Н 6060к Н 6080 и другие системы
семейства Н 600 и, наконец, фирма
Ufiivac — многопроцессорную систему
UNIV АС 1108. Конкуренты фирмы
IBM использовали решения по аппа-
ратуре и программному обеспече-
нию, подобные решениям, принятым
в многопроцессорной системе IBM
360/65 МР и полностью дуплексной
системе IBM 360/67.
Архитектура систем CDC 6500
и CDC 6700 была типичной архи-
Рис. 1.6. Упрощенная струк-
турная схема многопроцессор-
ной (сильно связанной) вычи-
слительной системы.
тектурой сильно связанных си-
стем. Единственная копия операционной системы управляла од-
новременной работой двух процессоров в системе. "
1.2.4. Многомашинная система с вспомогательным процессором
ASP. К середине 60-х годов фирма IBM продолжила и л интенси-
фицировала создание прямо связанных систем. В этих условиях
объявление в 1964 г. семейства машин IBM 360 обескуражило-
пользователей систем DCS, поскольку первоначально в семействе*
IBM 360 не предусматривались средства поддержки комплекси-
рования машин.
В семействе IBM 360 в полной мере закреплялись архитектур-
ные решения фирмы ДВМ для больших однопроцессорных си-
стем с учетом текущей стоимости устройств. На этом фоне про-
явилась экономическая неэффективность многомашинных систем-
Мультиплексный канал семейства IBM 360 обеспечивал присое-
динение множества низкоскоростных периферийных устройств
как к большим, так и к малым машинам. В частности, аномалия*
стоимости присоединения устройств ввода-вывода, которая сти-
мулировала интерес к системам DCS, не имела места в семействе-
IBM 360, стоймость периферийных устройств которого практи-
чески не зависела от того, к какой машине семейства они присое-
диняются.
Пользователи систем DCS использовали соединение двух ма-
шин для выполнения одной задачи не только в связи с анома-
лией стоимости. В течение 1961—1966 гг. они создали библиотеки*
ярепроцессорных, постпроцессорных, служебных, и сервисных
программ для внешних вычйслителёй IBM704X систем DCS^
2 В. А. Головкин
1Z
возможности которых в системах DCS вообще использовались
мало — первоначально загрузка машин IBM 704 X составляла
20—30% их номинальной производительности вне зависимости
ют загрузки центральных вычислителей IBM 709Х. Было создано
•большое число программ для машины IBM 704Х, применение ко-
торых существенно расширило функции внешнего вычислителя,
в системе DCS. Так, например, были созданы и соединены с си*-
•стемой ввода-вывода программы для редактирования и печати
данных без участия центрального вычислителя, которые запуска-
лись по самому высокому приоритету по запросу на ввод-вывод
ют дорогого центрального вычислителя. В оставшееся время на
внешнем вычислителе выполнялись другие служебные операции.
При этом учитывалось, что машина IBM 704Х имеет команды
юбработки символьной информации, удобные для реализации
•служебных программ, тогда как машина IBM 709Х ориентирова-
ла на пословную обработку при решении научных задан и не
имеет команд обработки символьной информации.
Машина IBM 704Х осуществляла мультипрограммную обра-
ботку, а машина IBM 709Х в то же время выполняла одну рабо-
ту из пакета, при этом обеспечивался доступ почти ко всей
юперативной памяти второй машины и ко всем ее лентам и
дискам. Таким образом, было осуществлено специализированное
мультипрограммирование для машины IBM704X, но не была
решена ни одна из задач распределения памяти и устройств,
так остро вставщих в мультипрограммной операционной системе
для семейства IBM 360.
Ориентация на однопроцессорные системы и бедность функ-
ций в версиях операционной системы семейства IBM 360
(OS/360), объявленных в 1964—1966 гг., задерживали переход
пользователей систем DCS к машинам семейства IBM 360 вплоть
до 1968—1969 гг. К этому времени фирма IBM объявила о
присоединенном вспомогательном процессоре ASP (Attached
Support Processor) для OS/360.
Вспомогательный процессор присоединяется к основной обыч-
но более мощной машине при помощи адаптера канал-канал
{рис. 1.7), в результате чего образуется слабо связанная система
из двух машин семейства IBM 360 (IBM 370). Устройства ввода-
вывода основной машины заменяются связью канал-канал с вспо-
могательным процессором. Вспомогательный процессор может
присоединяться более чем к одной основной машине, образуя
•слабо связанную систему из нескольких машин. Он*может также
составлять однопроцессорную конфигурацию без основных .ма-
шин. В последнем случае вспомогательный процессор называет-
ся локальным (LASP).
С функциональной точки зрения ASP был выполнен хорошо.
Однако, операционная система OS/360 в 1968 г., когда начина-
лось внедрение ASP, была все еще весьма плохой по показателю
эффективность-стоимость. *
18
Вначале вспомогательный процессор использовался для рабо-
ты с низкоскоростными устройствами ввода-вывода и для эпизо-
дических вспомогательных работ и выполнял функции простога
мультизадачного монитора под управлением OS/360 аналогична
Рис. 1.7. Структурная схема многомашинной (слабо связанной) вычисли-
тельной системы с вспомогательным процессором. Двухпроцессорная кон-
фигурация.
внешнему вычислителю системы DCS. Кроме этого, он использо-
вался для обработки единственного пакета подобно центральному
вычислителю системы DCS.
За время с 1969 г. функции вспомогательного процессора были
существенно расширены подобно тому, как это было сделано для
внешнего вычислителя системы DCS.
Была реализована предварительная работа с лентами и дис-
ками. Управление двумя или более основными машинами осу-
ществлялось одним вспомогательным процессором. При этом
функции одной из основных машин мог выполнять набор ресур-
сов вспомогательного процессора для пакетной обработки в вида
памяти, периферийных устройств и процессорного времени. Была
реализовано приоритетное планирование работы основной маши-
ны (основных машин), учитывающее такие важные факторы, как:
— оценка времени выполнения;
— оценка процессорного времени;
— оценка требующейся памяти;
— внешние приоритеты и другие факторы.
1.2.5. Структуры многомашинных и многопроцессорных си-
стем. Тенденции развития. Методика слабого и сильного связы-
вания процессоров является основной методикой’ комплексиро-
вания вычислительных машин фирмы IBM, включая семейства
IBM 360 и 370. Сильная связанность, при которой процессоры
2* ' 19*
^разделяют общую оперативную память, поддерживается фирмой
для систем двух идентичных процессоров (рис. 1.8). Слабая свя-
занность, при которой процессоры связаны посредством адаптера
каналов и (или) они разделяют общее периферийное оборудова- •
.нйе, поддерживается фирмой, когда процессоры не являются
Рис. 1.8. Сильная связанность двух процессоров.
идентичными. При этом слабо связанная система может содер-
жать пару сильно связанных процессоров (рис. 1.9). На практике
такое построение системы является типичным, если от системы
требуется обеспечить высокую готовность при оперативной ра-
боте с сетью терминалов или с сетью удаленных абонентов.
-Отметим, наконец, что фирмой IBM выпущено несколько двух-
процессорных сильно связанных систем семейств IBM 360 и 370,
^которые рассматриваются в последующих материалах настоящей
лсниги.
На базе опыта применения систем семейства IBM 370 можно
•ориентировочно определить основные тенденции развития много-
машинных и многопроцессорных систем фирмы IBM.
'Популярность сильно связанных систем, видимо, будет воз-
растать. Большие системы семейства IBM 370 и следующего
^поколения будут, как правило, содержать по меньшей мере два
-сильно связанных центральных процессора с легко разделяемыми
.наборами модулей памяти, каналов и периферийных устройств.
Как сильно связанные, так и слабо связанные системы получат
полную поддержку операционной системы.
В будущем перспективы применения слабо связанных систем
общей памятью на дисках представляются более предпочти-
тельными по сравнению со слабо связанными системами при
ломощи адаптеров каналов. Недостатком связывания процессоров
•через адаптер канал-канал является с л ишь м широкий спектр
-состава информации, передаваемой через канал. Обычно един-
ственный канал данного процессора используется для связи с
20
другим процессором в целях передачи всех входных и выходных
потоков системы, а также для обмена всеми видами сообщений
между процессорами. Другим недостатком такой связи является
необходимость синхронизации работы процессоров. Один из
процессоров не может передавать информацию другому процес-
сору, пока этот другой процессор выдает информацию первому.
Рис. 1.9. Слабая связанность однопроцессорной системы с двухпроцессорной
(сильно связанной) системой. Типичный пример устройства с прямым до-
ступом— дисковая память.
Третий недостаток состоит в том, что для хранения данных, по-
лученных из канала, часто требуется последующая отсылка их
на диск (при наличии общих дисков хранение данных на них
попутно обеспечивает возможность возврата к данным на дисках
и широкие возможности для организации очередей). К преиму-
ществам связывания при помощи адаптера канал-канал относятся
низкая стоимость аппаратуры, высокая надежность и хорошие
возможности передачи коротких сообщений между процессорами.
Фирма IBM будет, вероятно, отстаивать, единую операционную
систему для многомашинных и многопроцессорных систем, ко-
торые могут быть поставлены в рамках одного семейства или
поколения. Внешние спецификации и общая архитектура такой
операционной системы будут сохранены и расширены в следую-
щем поколении.
1.3. Краткий обзор
Организация структур и функционирования вычислительных
машин, включая каналы и совмещение во времени работы уст-
ройств машин, подробно рассмотрены в книгах [26, 140, 141, 187t
21
188, 198, 315, 412] и во многих других работах. Совмещение опе-
раций и процессоры с просмотром вперед описаны в [581, 884].
Во второй из этих работ, например, дан обзор уже реализованных
в ЭВМ и новых методов ускорения работы процессора при помо-
щи опережающего просмотра. Рассмотрены варианты структуры
такого процессора, ограничения распараллеливания вычислений,
налагаемые отношениями конфликта и предшествования прос-
матриваемых команд. Исследованы вопросы оптимизации. В обо-
их работах совмещение операций и просмотр вперед связываются
с магистральным (конвейерным) способом обработки информации.
Эволюция вычислительных систем от однопроцессорных к
многопроцессорным системам описана в [281]. Соответствующий
материал положен в основу п. 1.1.1. Изложение материалов
п. 1.2 основано на работе [744]. Кроме этого, в части материала
п. 1.2 также использованы некоторые материалы из [281], а в
п. 1.2.4 —из [203].
Упомянутые в начале п. 1.2 вычислительные системы фирмы
IBM, созданные для систем SAGE и SABRE, описаны в [114,
339, 696, 710, 1208] и в [114, 474, 707, 837, 1062, 1069] соответ-
ственно. Система DCS представлена в [281, 842, 947], а система
с вспомогательным процессором ASP — в [203, 281, 842, 947].
Сильно связанные системы описаны также в £1177*]. Материалы
о других многомашинных и многопроцессорных системах пред-
ставлены в дальнейших разделах настоящей книги. В заверше-
ние изложения эволюции однопроцессорных, многомашинных и
многопроцессорных систем перечислим ее главные цели и этапы,
следуя, в основном, [281].
Введение в однопроцессорные системы совмещения операций
и опережающего просмотра команд и данных было направлено
на повышение производительности. На первых этапах развития
многомашинных систем главная цель состояла в разгрузке ос-
новной, обычно достаточно мощной, вычислительной машины от
функций ввода-вывода и передаче этих функций меньшей и бо-
лее подходящей для этого машине. Кроме этого, при построении
дуплексных систем преследовалась цель повышения готовности,
надежности и живучести. В дальнейшем возможности многома-
шинных систем стали использоваться также и для повышения
производительности.
Первые многопроцессорные системы создавались с целью
достижения высокой готовности, которая обеспечивалась путем
объединения в группы одинаковых устройств, способных выпол-
нять одни и те же функции и в результате реконфигурации под-
держивать систему в работоспособном, состоянии даже в тех слу-
чаях, когда сохраняется в действии лишь часть системы исход-
ного состава. После того, как эта цель была достигнута, возмож-
ности многопроцессорных систем стали использоваться также
и для повышения производительности. При этом во всех
случаях важное значение имеет большая гибкость многопро-
«2
цессорных систем и высокая степень связанности ее устройств.
Высокая готовность, надежность и живучесть многопроцес-
сорных систем обеспечивается за счет применения резервирова-
ния различных устройств и осуществления в необходимых слу-
чаях реконфигурации системы. Повышение производительности
обеспечивается за счет:
— возможности параллельного решения независимых задач
и частей задач;
— повышения эффективности работы и улучшения распреде-
ления нагрузки в системе, в том числе при помощи динамиче-
ского перераспределения загрузки и распараллеливания вычис-
лений;
— реализации наиболее экономичного обслуживания экст-
ренных заданий и заданий при пиковых нагрузках;
— достижения наиболее эффективного использования ресур-
сов без создания новых типов архитектуры систем. ,
2. ОРГАНИЗАЦИЯ СТРУКТУРЫ И ФУНКЦИОНИРОВАНИЯ
ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
2.1. Классификация вычислительных систем [109]
Описываемая ниже классификация основана на многочислен-
ных схемах классификации вычислительный систем, в первую
очередь, на схемах из работ [410, 493, 635, 796].
2.1.1. Признаки и схема классификации. Нотация классов»
В качестве основных признаков классификации, характерзую-
щих организацию структуры и функционирования вычислитель-
ных систем с точки зрения, главным образом, параллельности
работы, выберем следующие:
1) тип потока команд в центральной части вычислительной
системы;
2) тип потока данных в центральной части вычислительной
системы; 1
3) способ обработки-данных в центральных устройствах, об-
работки;
4) степень связанности компонент вычислительной системы;
5) степень однородности основных компонент вычислитель-
ной системы;
6) тип внутренних связей в вычислительной системе.
Эти шесть признаков определяют базовую схему классифи-
кации, содержащую семь уровней иерархии, в которой переход
от каждого ьго уровня к следующему более низкому i + 1-му
уровню определяется соответствующим i-м признаком (рис. 2.1).
В этой схеме и в вводимой далее нотации классов вычислитель-
пых систем используются следующие условные обозначения:
а) ВС — вычислительные системы;
б) ОК, МК — одиночный и множественный потоки команд
соответственно;
в) ОД, МД — одиночный и множественный потоки данных
соответственно;
г) С, Р — пословная и поразрядная обработка данных в цен-
тральных обрабатывающих устройствах соответственно;
д) Нс, Вс — низкая и высокая степень связанности вычисли-
тельной системы соответственно;
е) Ор, Нр — однородная и неоднородная вычислительная
система соответственно;
24
2уровень
j
3уровень
4 уровень
Обычные
процессоры
3уровень
вуровень
7 уровень,
Рис. 2.1. Схема классификации вычислительных систем.
ж) Кн, Пм, Пр — системы со связями «канал-канал», через
общую внешнюю память и непосредственно между процессора-
ми соответственно; Ош, Мш, Пк — системы со связями через
одну общую шину с разделением ее времени, со связями через
множество шин при использовании многовходовых модулей опе-
ративной памяти и с перекрестными связями при помощи мат-
ричного коммутатора соответственно.
Обозначения (нотации) классов систем будем составлять из
условных обозначений каждого узла схемы, начиная с узлов,
второго уровня, через которые нужно пройти по стрелкам от узла
ВС до узла данного класса систем включительно, отделяя, для
удобства записи, условные' обозначения узлов первых трех уров-
ней от условных обозначений узлов последних трех уровней на-
клонной чертой. Так, например, класс вычислительных систем,,
помеченный на рис. 2.1 звездочкой (*), имеет обозначение
МКМДС/ВсОрПк. Оно расшифровывается следующим образом:
вычислительная система с множественным потоком команд и
множественным потоком данных в центральной части, с послов-
ной обработкой данных в центральных обрабатывающих устрой-
ствах, с высокой . степенью связанности и однородной структу-
рой, с перекрестными связями между процессорами и модулями
памяти. Обозначения классов для более высоких уровней иерар-
хии схемы, соответственно, сокращаются.
2.1.2. Описание классов вычислительных систем. Первые три
признака классификации характеризуют организацию функцио-
нирования вычислительных систем и определяют в общих чер-
тах их структуру. Эти признаки являются двузначнымй и поэ-
тому образуют, в совокупности, 8 классов систем — см. на рис. 2.1
классы №№ 1, 2, ..., 8 четвертого уровня. Переход от пер-
вого ко второму уровню соответствует разделению систем по
типу потока команд — одиночный или множественный — между
модулями оперативной памяти и устройствами управления или
процессорами. При переходе к третьему уровню системы
разделяются по типу потока данных— одиночный или множест-
венный — между центральными обрабатывающими устройствами
и модулями памяти. Далее при переходе к четвертому уровню
иерархии системы разделяются по способу обработки данных
в центральных устройствах обработки — пословная или пораз-
рядная обработка.
Системы с одиночными потоками команд и данных и с пос-
ловной обработкой данных ОКОДС представляют собой обычные
процессоры, а с поразрядной обработкой данных ОКОДР — одно-
разрядные процессоры. Системы с одиночным потоком команд
и множественным потоком данных имеют в качестве харак-
терных представителей для случая пословной обработки дан-
ных ОКМДС матричные системы и ансамбли процессоров,
а для случая поразрядной обработки ОКМДР — ассоциативные
системы.
26
Типичными представителями класса систем с множественным
потоком команд и одиночным потоком данных при пословной
обработке информации МКОДС являются магистральные (кон-
вейерные) системы. В качестве систем с поразрядной обработ-
кой МКОДР можно представить системы с конвейером однораз-
рядных обрабатывающих устройств.
Многомашинные и многопроцессорные системы образуют
класс систем с множественными потоками команд и данных и
с пословной обработкой МКМДС. В качестве систем с поразряд-
ной обработкой МКМДР можно представить* системы однобито-
вых процессоров, связанных между собой.
Последние три признака схемы классификации (рис. 2.1) оп-
ределяют классы систем со сложной структурой. На схеме по-
казаны классы пятого, шестого и седьмого уровней для реаль-
но существующих вычислительных систем. При переходе к пя-
тому уровню схемы происходит разделение на системы с низкой
и высокой степенью связанности, к шестому уровню — на одно-
родные и неоднородные системы и, наконец, при переходе к седь-
мому уровню системы разделяются по типу связей между уст-
ройствами их центральной части.
Низкая степень связанности для систем типа ОКМДС озна-.
чает, что обрабатывающие устройства имеют индивидуальные
блоки оперативной памяти и связаны с устройством управления,
но не имеют непосредственных связей между собой. Высокая
степень связанности для систем такото класса означает, что об-
рабатывающие устройства имеют индивидуальные блоки опера-
тивной памяти и, по меньшей мере, связаны линиями с сосед-
ними обрабатывающими устройствами. Типичные представители
первых систем — ансамбли процессоров, а вторых — матричные
системы (а также системы с векторным потоком данных, имею-
щие общую оперативную память).
Наиболее сложную структуру имеют многомашинные и мно-
гопроцессорные системы. Первые из них характеризуются низ-
кой степенью связанности, а вторые — высокой степенью связан-
ности, поскольку многопроцессорные системы, в отличие от
многомашинных, имеют общую оперативную память. Многома-
шинные системы содержат обычно конструктивно законченные
вычислительные машины и могут состоять как из машин одного
типа, так и из машин различных типов. В состав многопроцес-
сорных систем могут входить как однотипные, так и разно-
типные процессоры. Поэтому предусмотрены классы одно-
родных и неоднородных многомашинных *и многопроцессорных
систем (МКМДС/НсОр и Нр, МКМДС/ВсОр и Нр) соответ-
ственно.
Характерными типами срязи в однородных и неоднородных
многомашинных системах являются связи канал-канал (Кн) при
помощи адаптера, через внешнюю память на магнитных дисках
и лентах (Пм) и непосредственно между процессорами для об-
‘ 27
мена сигналами о состоянии друг друга, прерывания работы и
для прямого управления (Пр). Многомашинные системы могут
иметь различные комбинации этйх типов связей, что условна
показано на рис. 2.1 путем плотного расположения друг к другу
узлов схемы Кн, Пм и Пр. Если одновременно реализовано не-
сколько видов связей, то в нотации класса системы указываем
обозначения каждого из них и группу обозначений заключаем
в круглые скобки. .
Характерными типами связей в однородных и неоднордных
многопроцессорных -системах между их процессорными модуля-
ми и модулями оперативной памяти являются связи при помо-
щи одной шины с разделением времени обмена информацией
при помощи этой шины (Ош), многошинные связи с примене-
нием многовходовых модулей оперативной памяти (Мш) и пере-
крестные связи при помощи сосредоточенного или распределен-
ного перекрестного (матричного) коммутатора (Пк). В связи
с тем, что связь между процессорами через оперативную память
является определяющей в многопроцессорных системах, другие-
виды связей В таких системах* (например, через общую внешнюю
память) можно в нотациях не указывать. При необходимости бо-
лее подробного описания можно воспользоваться дополнительно»
тем же способом записи связей, что описан выше для многома-
шинных систем. Отметим, что шины и матричный коммутатор
используются и для присоединения внешних устройств.
Ряд параллельных вычислительных систем обладает призна-
ками более чем одного класса. Так, например, ортогональные-
системы являются комбинацией систем типа ОКОДС и ОКМДР.
Такого рода системы с признаками отличающихся друг от дру-
га классов естественно считать системами с комбинированной
структурой. Некоторые системы в процессе работы могут так
изменять режим функционирования, что «переходят» из одного
класса в другой. Такие системы естественно считать системами
с перестраиваемой структурой.
2.2. Потоки команд и данных. Пословная и поразрядная
обработка. Основные структуры и определения
2.2.1. Одиночные и множественные потоки команд и данных»
Понятия одиночных и множественных потоков команд и данных
и четыре соответствующих класса вычислительных систем ОКОДг
ОКМД, МКОД и МКМД введены М. Дж. Флинном [410]. •
Под потоком команд понимается последовательный ряд ко-
манд, выполняемых системой, а под потоком данных — последо-
вательный ряд данных, вызываемых потоком команд, включая
промежуточные результаты. Множественность и число потоков
определяются как максимально возможное число одновременных
операций (команд) или операндов (данных), находящихся в оди-
28
наковой стадии обработки (на наиболее узком участке организа-
ционной структуры).
Упрощенные структурные схемы систем типа О КОД, ОКМД^
МКОД, МКМД изображены, на рис. 2.2—2.5, которые приведены
в [821] и воспроизведены в [188].
В системах типа ОКМД одно устройство управления осущест-
вляет управление работой множества процессорных модулей такг
Потокдан-
ных для
обработки
Поток данных
после обработ-
ки (результаты)
Рис. 2.2. Упрощенная структурная схема'систем типа ОКОД.
что каждый из них выполняет одну данную команду, затем еле*
дующую и т. д., т. е. реализуется синхронный параллельный вы*
числительный процесс. Подмножества процессорных модулей1
могут пропускать выполнение команд, что определяется при по-»
мощи операций маскирования.
В системах такого типа реальная скорость обработки инфор-
мации сильно зависит от возможностей загрузки процессорных
модулей (от возможностей распараллеливания).
В системах типа МКОД процесс обработки разбивается' на*
несколько этапов, каждому из которых соответствует один из=
процессорных модулей. Эти модули составляют в совокупности
магистраль обработки (конвейер процессоров). Реальная ско-
рость обработки зависит от возможностей заполнения магистра-
ли. Наиболее высокая скорость обработки достигается при выпол-
нении длинных линейных участков программ с однородными
операциями. При частых прерываниях линейных участков
командами ветвления скорость обработки снижается.
В системах типа МКМД несколько устройств управления осу-
ществляют управление одновременным выполнением различных
участков одной и той же программы, т. е. реализуется асинхрон-
ный параллельный вычислительный процесс. Такие системы обла-
дают большой гибкостью. Реальная скорость обработки информа-
ции зависит от возможностей загрузки процессоров, однако, если
распараллеливание вычислений при выполнении данной програм-
мы затруднено, то можно,^воспользовавшись наличием нескольких
устройств управления, одновременнно выполнять несколько
программ, повышая тем самым загрузку процессоров. Системы
29
Потоки данных
после обработки
(результаты)
Рис. 2.3. Упрощенная структурная схема систем типа ОКМД.
Поток данных
после обработ-
ки (результаты)
Рис. 2.4. Упрощенная структурная схема систем типа МКОД.
Рис. 2.5. Упрощенная структурная схема систем типа МКМД.
типа МКМД отличаются высокой надежностью вследствие хо-
роших возможностей взаимного резервирования однотипных
устройств и машин.
Схема четырех классов включена в базовую схему классифи-
кации (п. 2.1) и составляет, с учетом переходов по уровням ие-
рархии, ее первый, второй и третий уровни (рис. 2.1).
Более подробно системы различных типов рассматриваются
в последующих разделах.
2.2.2. Пословная
вычислительные системы имеют
ры и функционирования. Опи-
сание систем на базе четырех
классов ОКОД, ОКМД, МКОД,
МКМД оказывается слишком
грубым. Для более детального
описания целесообразно учиты-
вать признаки пословной и по-
разрядной обработки следую-
щим образом [ 796].
Схему четырех классов вы-
числительных систем ОКОД,
ОКМД, МКОД, МКМД можно
и поразрядная обработка. Современные
сложную организацию структур
Рис. 2.6. Схема четырех классов
вычислительных систем.
представить в виде квадрата
(рис. 2.6). Верхняя вершина
соответствует классу ОКОД.
Переход из нее к левой вершине связывается с размножением
потока данных, в результате чего получается класс ОКМД,
а переход от верхней к правой вершине связывается с размно-
жением потока команд, в результате чего получается класс
МКОД. Переход из левой и правой вершин к нижней связыва-
ется с размножением потока команд и потока данных соответст-
венно, в результате чего получается один и тот же класс МКМД.
Схема четырех классов обладает рядом недостатков. Так, нап-
ример, структурно различные ассоциативные и матричные систе-
мы попадают в один и тот же класс ОКМД. Системы с комби-
нированной и перестраиваемой структурой могут занимать два
и даже три класса из четырех.
В целях улучшения схемы ее можно модифицировать так,
чтобы обеспечивалось различие между пословной обработкой (С)
и поразрядной обработкой (Р). Такая схема изображена на
рис. 2.7*). Она содержит восемь классов. Ассоциативные и мат-
ричные системы занимают в этой схеме разные классы — ОКМДР
♦) Четвертую букву (Д) в обозначениях восьми классов можно было
бы опустить, так как при этом сохраняется однозначность обозначений.
Она оставлена в нотации для того, чтобы переход от четырех (восьми)
классов к восьми (четырем) соответствовал просто добавлению (исключе-
нию) обозначений пословной и поразрядной обработки (С и Р) в нотации
классов систем.
31
и ОКМДС соответственно. Схема обладает лучшими возможно-
стями локализации классов систем с комбинированной и пере-
страиваемой структурой. Так, например, если в исходной схеме
системы занимают два или три класса из четырех, то в моди-
фицированной схеме они могут занимать два или три класса из
Рис. 2.7. Схема классов вычисли-
тельных систем с учетом послов-
ной и поразрядной обработки.
восьми соответственно, т. е. их
описание при помощи классифи-
кации становится более опреде-
ленным, хотя, конечно, не одно-
значным.
Модифицированная схема вось-
ми классов включена в базовую
схему классификации (п. 2.1) и
составляет ее четвертый уровень
(рис. 2.1).
2.2.3. Основные структуры и
определения 1110, 111]. Упрощен-
ные структурные схемы типовых
представителей вычислительных
систем указанных выше восьми
классов изображены на рис. 2.8
(109J. Номера структурных схем
вычислительных систем на этом
рисунке соответствуют номерам классов вычислительных систем,
представленных в четвертом уровне схемы классификации
на рисунке 2.1. Отметим, что разделение памяти по типам на
рисунке 2.8 отражает, в первую очередь, ее функциональные
признаки, а не конкретную конструкцию.
Системы ОКОДС и ОКОДР представляют собой обычный и
одноразрядный процессоры соответственно и осуществляют пос-
ледовательную обработку информации. Остальные системы явля-
ются параллельными и осуществляют параллельную обработку
информации.
Параллельная обработка информации представляет собой од-
новременное выполнение двух или более частей одной и той же
программы двумя или более процессорными модулями вычисли-
тельной системы [4931. Ее следует отличать от мультипрограм-
мирования, основное содержание которого составляет разделение
времени и оборудования между двумя или более программами, *
функционирующими одновременно и размещенными полностью
или частично в оперативной памяти. Возможен мультипрограмм-
ный режим параллельной обработки.
Вычислительные системы параллельной обработки информа-
ции или, более коротко, параллельные вычислительные системы
содержат два или более процессорных модулей и подразделяют- .
ся на три основных класса: ОКМД, МКОД и МКМД. Они пред-
•ставляют собой такие системы, в центральной части которых
имеется два цли более потока команд и (или) данных.
32
Системой типа ОКМД называется некоторая параллельная
вычислительная система с единственным общим модулем управ-
ления работой множества процессорных модулей, причем все или
часть этих модулей одновременно выполняют поток команд [1221J.
Такие системы подразделяются на системы с пословной обра-
боткой ОКМДС и системы с поразрядной обработкой ОКМДР.
Условные обозначения:
□-память данных с
выборнойразрядов1
гп-память данных с выбор-
ш ной слов
г-у-память данных с выбор-
СЗ* ной разрядных срезов
-процессор (арифме-
О тино-лоеичеснов
устройства)
(^-устройствоуправления .
Рис. 2.8. Структурные схемы вычислительных систем.
Основными типами систем ОКМДС являются ансамбли про-
цессоров, системы с векторным потоком данных и матричные си-
стемы. Характерной особенностью таких систем является то, что
они обрабатывают данные параллельно и обращаются к ним при
помощи адресов, а не при помощи тэгов (признаков — флажков,
меток) или выборки по содержимому ячеек памяти [8211.
Ансамбли процессоров представляют собой такие параллель-
ные системы типа ОКМДС, в которых процессорные модули
упорядочиваются общим потоком управления и обработки, как
правило, это — сравнительно небольшие процессоры без взаимо-
связей либо с низкой степенью связанности 112211.
3 В. А. Головкин , 33
• Системы с векторным потоком данных и матричные системы
представляют собой такие параллельные системы типа ОКМДС,
в которых процессорные модули упорядочиваются общим пото-
ком управления и обработки, как правило, это — сравнительно
небольшие процессоры с высокой степенью связанности [1221].
В первых системах процессоры обычно имеют общую оператив-
ную память и являются фактически составными арифметико-
логическими устройствами обработки, которые выполняют по-
следовательно команду за командой над векторами операндов. Во
вторых системах процессоры имеют индивидуальную оператив-
ную память и составляют матричную конфигурацию со связями
между непосредственными соседями.
Тот факт, что системы типа ОКМДС могут быть как с низкой,
так и с высокой степенью связанности, отмечен условно на ри-
сунке 2.8 при помощи прерывистой линии, связывающей изобра-
жения процессоров.
Основным типом систем ОКМДР являются ассоциативные
системы. Характерной особенностью таких систем является то,
что их процессорные модули (или память с встроенной логиче-
ской обработкой) реализуют адресацию на основе свойств содер-
жимого дайных в большей степени, чем с помощью адресов
1821, 1221].
Ассоциативные системы подразделяются на системы с ассо-
циативной памятью и системы с ассоциативными процессорами
(ассоциативные матричные системы). Системы с ассоциативной
памятью представляют собой такие параллельные системы типа
ОКМДР, которые оперируют с данными при доступе к ним при
помощи тэгов или выборки по содержимому ячеек памяти в
ббльшей степени, чем при помощи адресов. Системы с ассоциа-
тивными процессорами представляют собой такие параллельные
системы типа ОКМДР, которые обычно оперируют со срезами
разрядов данных (срез разряда данных — это совокупность раз-
рядов одной и той же фиксированной позиции в множестве слов
данных) 1821J.
Перейдем к вычислительным системам типа МКОД. К па-
раллельным системам типа МКОДС относятся магистральные
(конвейерные) системы — такие системы, в которых осуществля-
ется одновременное выполнение нескольких команд при помощи
последовательного прохождения слов потока данных через ма-
гистраль (конвейер) нескольких специализированных блоков об-
работки. При этом обработка разбивается на соответствую-
щее число подзадач (этапов), каждая из которых выполняется
на одном из указанных специализированных блоков обработ-
ки [1229].
Принцип магистральной (конвейерной) обработки основан на
разделении вычислительного процесса на несколько подпроцессов,
каждый из которых выполняется на отдельном устройстве. При
этоц последовательные процессы могут выполняться одновремен-
М
но на своих устройствах подобно тому, как это имеет место в
промышленных технологических процессах. Принцип конвейер-
ной обработки может применяться на различных уровнях иерар-
хии вычислительного процесса, начиная с уровня построения
логических схем устройств [1112]. В зависимости от уровня при-
менения принципа конвейерной обработки можно выделить, рас-
сматривая уровни снизу вверх, арифметико-магистральные, ко-
мандно-магистральные и макромагистральные системы [796,800],
а в зависимости от типа применяемых команд обработки среди
магистральных систем можно выделить системы с обычными и
системы с векторными командами 11112, 1211J.
Как отмечалось выше, в качестве систем МКОДР можно рас-
сматривать системы с конвейером одноразрядных процессоров.
Системой типа МКМД называется некоторая параллельная вы-
числительная система с несколькими модулями управления рабо-
той нескольких процессорных модулей, причем эти модули выпол-
няют несколько потоков команд. Число процессоров составляет
обычно величину в пределах от 2 до 10, но может составлять и
несколько десятков и более, в особенности для микропроцессор-
ных систем. Основные типы систем МКМДС — многопроцессор*
ные и многомашинные системы.
Многопроцессорной системой называется такая параллельная
система типа МКМДС, которая содержит два или более сильно
связанных центральных процессора, общую для них оперативную
память и, целиком или частично, общие периферийные устрой-
ства, включая периферийные процессоры и канаМы ввода-вывода,
управление которыми, как единым комплексом, осуществляет
единственная операционная система [694, 744]. В вычислитель-
ной системе могут быть несколько копий одной операционной
системы. Таким образом, многопроцессорная вычислительная си-
стема содержит два или более процессорных модулей, функцио-
нирующих под единым управлением [281], и осуществляет одно-
временную обработку нескольких команд и данных при общей
иерархической памяти [1229].
Более подробно характерные черты многопроцессорных си-
стем можно представить следующим образом [281].
Многопроцессорная система включает два или несколько
центральных устройств обработки информации — центральных
процессорных модулей. Эти устройства могут иметь как одина-
ковые, так и различные характеристики. Основная память (опе-
ративная память)* должна находиться в общем пользовании и
должна быть доступной для всех процессоров системы. Процес-
соры могут иметь некоторую собственную память. В системе
должен быть общий доступ ко всем устройствам ввода-вывода,
включая каналы, устройства управления и периферийное обору-
дование. В системе должна быть единая интегрированная опе-
рационная система, осуществляющая общее управление аппа-
ратными и программными средствами. При этом должна быть
3* 35
предусмотрена возможность тесного взаимодействия аппаратных
средств и программного обеспечения:
— на уровне системного программного обеспечения при вы-
полнении системных задач;
т - на программном уровне при выполнении частей одной и
той же программы несколькими процессорами или при выпол
нении нескольких независимых программ (мультипрограммный
режим параллельной обработки);
— па уровне обмена данными;
— на уровне аппаратных прерываний. Следует отметить, что
взаимодействие аппаратных и программных средств зависит не
только от организации взаимных связей, но и от системного про-
граммного обеспечения и процедур обработки данных. Базовая
структурная. схема многопроцессорной системы изображена на *
рис. 2.9.
Многомашинной системой называется такая параллельная си-
стема типа МКМДС, которая содержит обычно две или более
бднопроцессорных или многопроцессорных слабо связанных меж-
ду собой вычислительных систем с общей внешней намятые
й/или со связями через каналы ввода-выврда, работающих сов-
местно под управлением своих операционных систем. В системе
Возможны непосредственные связи между процессорами в целях
управления. В ее состав могут входить однопроцессорные и мно-
гопроцессорные системы одного и того же или различных типов,
а также такие вычислительные системы, как магистральные,
матричные, ассоциативные и другие.
Как отмечалось выше, в качестве систем МКМДР можно рас-
сматривать системы связанных между собой одноразрядных про-
цессоров. *
В п. 2.1.2 упоминались системы с комбинированной структу-
рой и системы с перестраиваемой структурой. Системами с ком-
бинированной структурой будем называть такие параллельные
вычислительные системы, структуры которых характеризуются
комбинацией признаков существенно отличающихся друг от
друга классов.
Одним из наиболее известных типов систем с комбинирован-
ной структурой являются ортогональные системы. Они представ-
ляют собой такие параллельные системы, которые ведут обработ-
ку двумя процессорами — обычным процессором типа ОКОДС и
ассоциативным процессором типа ОКМДР — и используют об-
щую для них оперативную память в режиме разделения обору-
дования 1821]. Они являются системами с высокой степенью
связанности, поскольку пара процессоров имеет общую опера-
тивную память.
Системами с перестраиваемой структурой будем называть та-
кие параллельные вычислительные' системы, которые обладают
возможностью в процессе работы изменять тип структуры и, в
предельном случае, осуществлять «переходы» от одного класса
36
к другим существенно отличным классам. Такие системы в пос-
ледние годы получили быстрое-развитие в связи с разработкой
и созданием распределенных вычислительных систем на базе
м икропроцессоров.
Концепция распределенных вычислительных систем быстро
развивается и изменяется и еще не является сложившейся. В на-
стоящее время под такими системами понимается новый класс
Рис. 2.9. Базовая структурная схема многопроцессорной системы. Одинар-
ными линиями показаны связи для сигналов управления, а двойными ли-
ниями — связи для данных и команд.
вычислительных систем, имеющих большое число рассредоточен-
ных универсальных средств (ресурсов) аппаратного и програм-
много обеспечения с возможностью быстрой и гибкой перестрой-
ки, функционирующих автономно, -но, вместе с тем, согласован-
но под управлением операционной системы высокого уровня,
объединяющей их в единое целое и обеспечивающей их взаимо-
действие через сеть связи [684, 695, 868]. Распределенные вы-
числительные системы воплощают дальнейшее развитие много-
машинных и многопроцессорных систем с децентрализованным
управлением, в том числе существующих мини- и микропроцес-
сорных систем.
Следует выделить вычислительные сети. Они состоят из тер-
риториально разнесенных центров (узлов), образуемых самыми
разнообразными вычислительными системами, и систем связи,
линии которых соединяют центры в некоторую конфигурацию
сети. Вычислительные центры функционируют в той или иной
мере автономно друг от друга и взаимодействуют между собой
через систему связи.
Вычислительные сети, в силу своих особенностей, существен-
но отличаются от других типов параллельных вычислительных
систем и обладают ярко выраженной спецификой как' в части
организации структуры и функционирования, так и в части прог-
37
раммного обеспечения. Их целесообразно рассматривать особо.
В настоящей книге в части вычислительных сетей рассматрива-
ется только соотношение их внутренних связей с внутренними
связями других вычислительных систем.
Различие между распределенной вычислительной системой и
вычислительной сетью является, в принципе, вопросом о раз-
мерах, местоположении и функциях узлов, а также о количест-
ве взаимодействий между ними. Если все компоненты системы
относительно малы, зависимы и локализованы,. то их можно
считать частями одной распределенной вычислительной систе-
мы (мащины). Если, наоборот, они достаточно сложны и не-
зависимы, то их можно рассматривать как разные машины се-
ти. Множество разнообразных смешанных форм, вероятно, ста-
нет обычным в ближайшие годы [384].
Возможно, что концепция центрального процессора устаре-
ет. Большая вычислительная машина будет в этом случае укомп-
лектована десятками, сотнями или даже тысячами идентичных
процессоров, выполненных на одном кристалле (или даже части
кристалла), у каждого из которых будет своя функция. Неко-
торые из этих процессоров могут иметь микропрограммы * для
компиляции программ (для каждого языка — один процессор),
для выполнения программ после компиляции (также со специа-
лизацией процессоров по языкам), для осуществления связи с
пользователями в оперативном режиме, для управления боль-
шими базами данных, для аппаратной диагностики и для дру-
гих целей [384].
Одно*из направлений развития вычислительных систем име-
ет дело с высокопараллельными устройствами массовой обра-.
ботки (на уровнях вплоть до самых -элементарных операций),
называемыми вычислительными средами. Вычислительная среда
представляет собой совокупность простейших одинаковых авто-
матов, одинаковым образом соединенных между собой и про-*
граммно настраиваемых на выполнение некоторой функции из
функционально полного набора. Основные принципы построе-
ния вычислительных сред — параллельность, конструктивная
однородность и программная изменяемость структуры [90].
Основные типы параллельных вычислительных систем пред-
ставлены на рис. 2.10 [110]. На этом рисунке выделены одно-
родные и неоднородные многопроцессорный вычислительные си-
стемы, поскольку характеристики однородности и неоднородно-
сти в большой степени влияют на структуру многопроцессорных
систем в силу их сильной связанности. Вычислительные систе-
мы с повышенной надежностью, а также распределенные вы-
числительные системы и сети показаны отдельно в связи с их
спецификой.
2.2.4. Коммутация потоков команд и данных [1107, 1108L
В вычислительных системах типа ОКМД используется единст-
венная память программ и несколько модулей памяти
38
данных, устройств обработки и коммутаторов. При этом комму-
тируется только один поток команд, распределяемый между
соответствующими устройствами обработки. Структурная схема
системы типа ОКМД с учетом коммутации изображена на
Рис. 2.10. Основные типы параллельных вычислительных систем.
рис. 2.11. На схеме индексом 1 помечена память программ, ин-
дексом 2 — модули памяти данных, индексом 3 — коммутаторы
и индексом 4 —- устройства обработки. Представленная система
является ассоциативной. Каждый коммутатор при совпадении
соответствующих признаков запрещает выполнение команды в
некоторых элементах ассоциативного устройства обработки, ко-
торое обычно включает в себя ассоциативную память. Пунктир-
ной линией отмечен блок обработки в системе. Коммутация осу-
ществляется внутри каждого блока обработки.
В вычислительных системах типа МКМД нередко использу-
ется общая (например, внешняя вспомогательная) память и не-
сколько процессоров, которые могут иметь индивидуальную па-
мять команд и данных. Общая*память коммутируется е каждым
39
блок обработки
I
-Si—
~$з ~
Ъ—4 ”г
-Ро— К
Рио. 2.11. Структурная схе-
ма системы типа ОКМД.
Коммутация потока ко-
манд внутри блока обра-
ботки.
из процессоров. Для исключения конфликтов могут использо-
ваться несколько копий одной и той же программы; Структур-
ная схема системы типа МКМД с учетом коммутации изображе-
на на рис. 2.12. На схеме индексом 1 помечена общая память,
индексом 2 — модули обычной памяти для команд и данных,
м индексом 3 — коммутаторы и индексом
9 Блок пДопАптни 4 — процессоры. Здесь каждый блок
обработки содержит' процессор с инди-
видуальной памятью команд и данных
и работает в достаточной степени ав-
тономно по своей ^программе. Комму-
таторы осуществляют внешние, по от-
ношению к блокам обработки, функции
переключения связей между этими бло-
ками и общей памятью и составляют
вместе с ней необязательную часть си-
стемы, поскольку может быть органи-
зовано непосредственное взаимодей-
ствие между блоками обработки без участия общей памяти.
Применение вычислительных систем в таких областях, как
обработка радиолокационной информации^ управление воздуш-.
ным движением, прогноз погоды и им подобных связано с обра-
боткой больших массивов информации в реальном масштабе
времени. При этом обработка характеризуется интенсивными
параллельными вычислениями, а массивы информации представ-
ляют собой большое число практически независимых друг от
друга блоков данных. Для решения подобных задач эффектив-
ными оказываются специализированные вычислительные систе-
мы, ориентированные на экономное использование памяти. Так,
например, могут быть исполь-
зованы вычислительные систе-
мы, структура которых сочетает
в себе особенности структур
ОКМД и МКМД. Обозначим,
структуру систем такого типа
через К-МКМД — коммутируе-
мый множественный поток ко-
манд и множественный поток
данных. Структурная схема си-
схемы К-МКМД изображена Рис. 212. Структурная схема систе-
на рис. 2.13. На схеме индек- мы типа МКМД. Коммутация блоков
сом 1 помечены модули памяти обработки,
программ, индексом 2 — модули
памяти данных, индексом 3 ~ селекторные коммутаторы и индек-
сом 4 — микропроцессоры. Пунктирной чертой отмечен блок об-
работки. В него входит микропроцессор, селекторный коммутатор
и модуль памяти данных. В каждом модуле памяти программ
размещается одна из частей программы, причем каждая данная
40
'^Необязательная часть
Блок обработки
—мг
Mt.
часть не копируется ни в одном из других модулей памяти
программ. Селекторный коммутатор данного блока обработки
подключает друг к другу пайять данных и микропроцессор это-
го блока обработки для считывания или записи данных. Если
же требуется выборка команд, то селекторный коммутатор под-
ключает к микропроцессору тот мо-
дуль памяти программ, в котором
размещена соответствующая часть
программы. В вычислительной си-
стеме могут быть использованы се-
рийные микропроцессоры, например
Intel 8080.
В системах типа К-МКМД сег-
менты программы размещаются в
различных модулях памяти программ
так, чтобы потоки команд вызыва-
лись из различных модулей этой
памяти. В качестве сегмента про-
Рис. 2:13. Структурная схема
системы типа К^МКМД. Ком-
мутация потоков команд и
данных.
граммы выбирается такая ее часть, которая пе содержит ветвле-
ний, зависящих от результатов обработки данных. Сегмент может
содержать циклы, подпрограммы и подобные им конструкции,
но в нем не должно быть условных переходов, которые могли бы
потребовать переход к. выполнению потока команд, обслуживае-
мого другим блоком обработки.
В системах типа К-МКМД информация о логической связи
между сегментами программы используется для того, чтобы иск-
лючить конфликты ’ при обращении к памяти программ со сто-
роны различных процессоров. Каждый сегмент помещается в
один из модулей памяти программ. Каждый модулы связан при
помощи шин со всеми блоками обработки. Массив данных по
частям располагается -в обычно небольших индивидуальных мо-
дулях памяти каждого блока обработки.
При выполнении программы селекторные коммутаторы рабо-
тают следующим образом. Селекторный коммутатор данного
блока обработки подсоединяет к этому блоку (к микропроцес-
сору блока) шины модулей памяти программы или же его ин-
дивидуальный модуль памяти данных для обеспечения доступа
к содержимому памяти в соответствии со следующим правилом.
Если требуется считать или записать слово данных, то комму-
татор подключает к микропроцессору нижнюю шину (см.
рис. 2.13), обеспечивая доступ к индивидуальной памяти дан-
ных. Если же осуществляется выборка команды, то коммутатор
подключает к микропроцессору шину соответствующего * моду-
ля памяти программы. Выбор шины осуществляется при помощи
управляющего слова в регистре каждого блока обработки, ко-
торое управляет работой селекторного коммутатора. В обычном
режиме управляющее слово не изменяется, поскольку блок об-
работки выполняет команды одного и того же сегмента про*
41
граммы над данными из индивидуального модуля памяти _ дан-
ных. Оно изменяется при переходе к выполнению блоком об-
работки следующего сегмента программы..
Применение изложенного способа коммутации потоков
команд и данных обеспечивает возможность непрерывного вы-
полнения сегментов программы блоками обработки. При этом
не возникает конфликтов при обращении к памяти, хотя в си-
стеме не используются копии программ в различных модулях <
памяти.
В заключение отметим, что границы эффективного приме-
нения структур К-МКМД по сравнению с другими структурами
описаны в указанных выше работах [1107, 1108].
2.3. Некоторые основные соотношения
между структурами вычислительных систем
Некоторые основные соотношения между структурами вы-
числительных систем, не зависящие от деталей архитектуры,
выявлены и проанализированы в [1161, 1162]. Результаты этих
работ кратко воспроизведены в [109, 110, 281, 1118, 1221, 12231.
ч Примем в качестве Машины I обычную ЭВМ последователь-
ной обработки информации, изображенную па рис. 2.14. Маши-
на этого типа содержит устройство управления (УУ), процес-
сорный модуль (ПрМ), память программ (ПмП) и память дан-
ных (ПмД) (разделение памяти для программ и данных —
функциональное). Считывание данных из единственной памяти
данных осуществляется путем выборки всех разрядов некото-
рого слова для их параллельной обработки в процессорном мо-
дуле.
Повернем условно на 90° память данных и процессорный
модуль, причем структуру самих данных оставим в прежнем
положении. Получим машину, изображенную на рис. 2.15.'На-
зовем ее Машиной II. Каждое слово данных все еще распола-
гается горизонтально, поэтому их считывание из памяти дан-
ных теперь осуществляется путем выборки содержимого одного
разряда всех слов (разрядного среза) вместо всех разрядов од-
ного слова. Обычно в памяти Машины II размещаются разряд-
ные срезы длиной, как правило, 128—256 разрядов.
Можно говорить, что в Машине I осуществляется последова-
тельйая обработка слов при параллельной обработке разрядов'
слова в горизонтальном процессорном модуле (горизонтальная
обработка), а в Машине II — последовательная обработка раз-
рядных срезов при параллельной обработке входящего в них
содержимого множества слов в вертикальном процессорном мо-
дуле (вертикальная обработка). При этом адресация данных в
Машине I осуществляется по отношению к словам, а в Маши-
не II — к разрядным срезам.
42
ПнД
ПнП
ПрМ
Рис. 2.14. Машина I.
Обычная ЭВМ. Последо-
вательная обработка
горизонтально располо-
женных слов при парал-
лельной обработке их
разрядов.
Структура Машины II лежит в основе структуры систем с
ассоциативными процессорами, осуществляющих^ последователь-
ную поразрядную обработку множества слов. Фактически имеет
место не один процессорный модуль, а множество сравнительно
простых устройств поразрядной обработки. Высокая скорость
обработки информации такими системами
обеспечивается за счет сравнительно
большой длины разрядных срезов и до-
стигается преимущественно при выполне-
нии логических операций. Для выполне-
ния арифметических операций, в большей
степени свойственных Машине I, процесс
сорный модуль Машины II должен быть
модифицирован так, чтобы получать не-
обходимые результаты по завершении
последовательной обработки всех разря-
дов каждого данного слова из памятилан-
ных. Поэтому скорость выполнения ариф-
метических операций Машиной II ока-
зывается в этом случае сравнительно
низкой. Соотношение скоростей выполне-
ния операций Машиной I и Машиной II,
при прочих сопоставимых условиях, определяется длиной слова
и длиной разрядного среза.
Сравнивая Машины I и II, заметим, что в первом случае
операции выполняются обычно над словами, причем внутри ело*
пм п ва разряды связаны между собой
” смысловой зависимостью и обычно
не имеют самостоятельного значения,
тогда как во втором случае опера-
ции выполняются над соответству-
ющими разрядами внутри каждого
слова из множества слов, участвую-
щих в обработке.
Структура Машины II харак-
терна для структуры системы
STARAN (за исключением ввода-
вывода).
В целях объединения достоинств
Машины I и Машины II в одной
вычислительной системе можно по-
строить комбинацию этих двух ма-
шин, в результате чего получим Ма-
шину III (рис. 2.16). Эта Машина
имеет два процессорных модуля — горизонтальный и вертикаль-
ный — и модифицированную память данных, которая обеспечи-
вает доступ как к словам, так и к разрядным срезам. Системы
с такой структурой получили название ортогональных.
ПнП
Рис. 2.15. Машина II. Систе-
ма с ассоциативными процес-
сорами. Последовательная об-
работка вертикально располо-
женных разрядных срезов
множества слов при парал-
лельной обработке входящего
в них содержимого множест-
ва слов.
Рассмотрим скорости работы Машин I, II и III. Пусть про-
цессорные модули Машин I и II построены так, что в первом
приближении Машина I обрабатывает слово примерно за то
же время, в течение которого Машина II обрабатывает разряд-
ный срез. Тогда,
ПмД
Рис. 2.16. Машина III. Ортого-
нальная система. Комбинация
Машины I и Машины II.
ПмП
если память данных имеет структуру квадрата
(п слов по н разрядов в каждом),
обе Машины выполняют обработку
всего содержимого памяти за одно
и то же время, при этом каждая
команда обеспечивает обработку оче-
редного слова или очередного разряд-
ного среза из памяти данных соот-
ветственно. Всякий раз, как неко-
торая команда Машины I при сох-
уу ранении скорости поступления ко-
манд обеспечивает обработку сразу
^нескольких слов, скорость обработки
информации Машиной I оказывает-
ся выше по сравнению с Ма-
шиной И.
Полагая структуру памяти данных в виде квадрата, мы не
учитывали важную особенность Машины II, состоящую в том,
что длина разрядного среза данных Машины II обычно намного
больше длины слова данных Машины I. Поэтому, как правило,
•Машина II обрабатывает одно и то же множество слов быстрее
Машины I.
Пусть теперь увеличивается вертикальный размер памяти
данных и сохраняется прежним горизонтальный размер, т. е.
наращивается память путем увеличения числа ее слов при со-
хранении их длины. При этом соответственно наращивается
процессорный модуль Машины II, и сохраняется неизменным
процессорый модуль Машины I. Тогда, с увеличением верти-
кального размера памяти данных, время обработки всех дан-
ных памяти Машиной I будет увеличиваться, а для Машины II
это время сохранится неизменным. При этом сначала, когда ко-
личество слов меньше числа разрядов в них, время работы Ма-
шины. I будет меньше времени работы Машины II, а в даль-
нейшем, когда число слов станет больше числа разрядов в них,
время работы Машины I станет больше времени работы Ма-
шины II. Если ввести понятие относительной скорости обработ-
ки, всех данных в зависимости от объема памяти данных для
фиксированной длины слов, то рассмотренные выше качествен-
ный соотношения можно изобразить в виде графиков (рис. 2.17).
Линия для Машины II параллельна оси абсцисс, а линия для
Мащинц Г, с учетом дополнительных факторов обработки боль-
шого, числа слов, монотонно снижается.
На., атом же рисунке 2.17 показана относительная скорость
обработки информации фашиной III.. Для нее, подобно Маши-
пё I, относительная скорость обработки монотонно уменьшается
с увеличением объема памяти для фиксированной длины слов.
Однако, если относительная скорость для ’Машины I асимпто-
тически стремится к нулю, то для Машины II эта скорость
асимптотически стремится к некоторой фиксированной величи-
не, равной относительной скорости обработки Машиной II. При
этом во всех случаях относи-
тельная скорость обработки
Машиной III выше по срав-
нению с Машинами I и II.
Машина III сочетает в
себе достоинства Машин I и
II. Горизонтальный процес-
сорный модуль обеспечивает
эффективное выполнение ко-
манд над словами памяти
данных, в то время как вер-
тикальный процессорный мо-
дуль обеспечивает эффектив-
ное выполнение команд пад
разрядными срезами памяти
данных.
Структура Машины III
характерна для вычисли-
тельных систем OMEN 60.
Рис. 2.17. Относительная скорость об-
работки для фиксированной длины
слов.
Если «размножить» процессорные модули и память данных
Машины I, то получим Машину IV, структура которой изобра-
жена на рис. 2.18. Единственное устройство управления выдает
команду за командой всем процессорным модулям. Такую струк-
туру, получившую название ансамбля процессоров, имеет вы-
числительная система РЕРЕ (про-
цессорный модуль РЕРЕ состоит из
двух отдельных основных частей —
из устройства корреляционной обра-
ботки и арифметического устрой-
ства). Емкость модулей памяти дан-
ных обычно фиксирована, и нара-
щивание системы можно осуществ-
лять путем добавления новых моду-
Рпс. 2.18. Машина IV. Ан- лей памяти данных и соответствую-
самбль процессоров. щих процессорных модулей. Поэтому
относительная скорость обработки
информации Машиной IV, подобно Машине II, является постоян-
ной. Ее фактическое значение определяется выбранным объемом
памяти в модулях памяти данных и сложностью построения
процессорных модулей.
Отличие концепций построения Машины II и Машины IV
состоит в том, что если данное устройство обработки Машины II
45
имеет дело, например, с форматом расположенных в линию
256 разрядов данных, то устройство обработки Машины IV име-
ет дело, соответственно, с форматом данных 16 X 16 разрядов.
При этом в первом случае осуществляется последовательная
поразрядная обработка, в то время как во втором случае раз-
ряды каждый раз обрабатываются параллельно.
Гис. 2.19. Машина V. Матричная система.
Рис. 2.20. Машина VI. Содер-
жит память данных с матрич-
ной структурой и встроенной
логической обработкой.
Если ввести непосредственные линейные связи между сосед-
ними процессорными модулями Машины IV, расположенными,
например, в виде матричной конфигурации, то получим машину
с более универсальными возможностями обработки информации
(рис. 2.19). Назовем ее Машиной V. Такая структура характер-
на для квадранта системы ILLIAC IV. Относительная скорость
обработки информации Машиной V, подобно Машинам II и IV,
является постоянной. Вследствие имеющихся связей между.
процессорными модулями Машина V' представляется, отчасти,
более сложной по сравнению с Машиной IV.
При другом подходе к построению структуры вычислительной
системы, когда хранение и обработка данных совмещаются в
одном устройстве, получаем Машину VI (рис. 2.20). Она харак-
теризуется наличием устройств памяти данных матричной кон-
фигурации с встроенной логической обработкой LIMA (Logic In
Memory Arrays). Подобно Машинам II, IV и V, Машина yi
имеет постоянную относительную скорость обработки. Концеп-
ция Машины VI эквивалентна концепции Машины* IV с моду-
лями памяти данных только для одного слова в каждом из мо-
дулей.
Таким образом, можно отметить следующие основные соот-
ношения между структурами рассмотренных вычислительных
систем:
— Машина I есть обычная ЭВМ с последовательной обра-
боткой слов и параллельной обработкой разрядов;
— Машина II есть t система с параллельной обработкой слов
и последовательной обработкой разрядов (системы с ассоциа-
тивными процессорами);
46
— Машина III получается в результате комбинации Ма-
шин I и II (ортогональные системы);
— Машина IV получается в результате «размножения» про-
цессорного модуля и памяти данных Машины I и имеет память
программ, единственное устройство управления и множество
процессорных модулей с индивидуальными модулями памяти
данных (ансамбли процессоров);
— Машина V получается путем введения непосредственных
линейных связей между соседними процессорными модулями
Машины IV (матричные системы);
— Машина VI получается путем объединения логики обра-
ботки с элементами памяти данных Машины I и имеет память
программ, устройство управления и набор совмещенных ассо-
циативных запоминающих устройств и процессоров, использую-
щих матрицы памяти с встроенной логикой.
В заключение классифицируем перечисленные машины: I —
ОКОДС, II — ОКМДР, III-одновременно ОКОДС и ОКМДР,
IV-ОКМДС/Нс, V-ОКМДС/Вс, VI - одновременно ОКМДР
п одноразрядные ОКМДС/Нс (см. рис. 2.1 и 2.8).
2.4. Структура связей
в параллельных вычислительных системах
2.4.1. Межпроцессорные связи в вычислительных системах и
сетях и их классификация [460, 461]. Если рассмотреть свя^и
для обмена информацией между процессорами на уровне обо-
рудования, обеспечивающие соединение каждого процессора с
любым другим в вычислительных системах и сетях, то можно
построить схему классификации и структурную схему^ межпро-
цессорных связей, изображенную на рисунке 2.-21. Схема имеет
пять уровней, первый из которых является исходным, второй
определяет стратегию организации обмена информацией, тре-
тий — метод управления соединением трактов обмена,, четвер-
тый — структуру путей передачи информации, а пятый уровень
определяет соответствующие типы структур вычислительных
систем и сетей.
Первый уровень — исходный, он включает внутренние связи
для обмена информацией. Второй уровень включает прямые и
косвенные (непрямые) тракты обмена. В первом случае осущест-
вляется прямая передача информации, когда передатчик выби-
рает путь, а приемник распознает предназначающиеся для него
сообщения. При этом в канале связи никакой логики не пре-
дусмотрено, за исключением, возможно, буферных устройств и
устройств повторения сообщений. Во втором случае осуществля-
ется непрямая передача информации, когда между передатчиком
и приемником предусматривается логика выбора одного из не-
скольких альтернативных путей передачи на промежуточных
47
1-уроввнъ
2-уровем-
— прямые
Свяви для
обмена информацией
централизованное
косвенные
„—J L
децентрализованное
„ , ч централизованное децентрализованное
о-цровень------------(ничего)---я-----назначение трбктов—---------назначение трцктов
г——. ( .обмена обмена
индивидуальные распределяемые индивидуальные распределяемые индивидуальные распределяемые
.— тракты--------тракты-------г трант“
Г*п Ни г п
5~уроввнь—~1----2—-----3^------------Л-—-Л
4-уровень-
эракты-----утракты.
.тракты—:
тракты
процессорный
злемент
____д,
тракт
обмена
-----—/С.
память
коммутатор
Рис. 2,21, Схема классификации и
структура межпроцессорных связей.
пунктах, а также, в некоторых случаях, дополнительное преоб-
разование сообщения.
Управление соединением трактов обмена ’ может быть цент-
рализованным и децентрализованным (третий уровень). При
прямой передаче альтернатив не существует и не требуется
управления соединением трактов обмена. Непрямая передача
при помощи централизованного управления характеризуется
тем, что все сообщения передаются через единый пункт, выпол-
няющий функции промежуточного пункта назначения и, одно-
временно, источника для всех дальнейших передач. Непрямая
передача при помощи децентрализованного управления харак-
теризуется тем, что осуществляется выбор одного из нескольких
пунктов передачи информации.
Четвертый уровень соответствует двум структурам путей
передачи информации. Первая определяет индивидуальные (раз-
дельные) тракты обмена, которые назначаются (выделяются)
для осуществления обмена. Вторая структура определяет общие
(разделяемые) тракты обмена, передача по которым осущест-
вляется при помощи разделения времени этих трактов.
Прямая передача по раздельным путям характеризуется тем,
что каждый источник информации имеет один или несколько
альтернативных путей передачи, причем ни один путь не ис-
пользуется более чем одним источником информации. Такая ор-
ганизация обеспечивает параллельность передач, однако не га-
рантирует максимальной скорости передачи из-за возможной за-
держки сообщений. Прямая передача с использованием общего
пути осуществляется для всех сообщений только по этому об-
щему пути. Непрямая передача при помощи раздельных путей
и централизованного управления означает, что каждый источ-
ник имеет свой путь к промежуточному пункту и от него —
к каждому приемнику. Непрямая передача при помощи общего
пути и централизованного управления отличается от предыду-
щей тем, что используется единственный путь от промежуточ-
ного пункта к приемникам информации. Непрямая передача при
помощи раздельных путей и децентрализованного управления
предусматривает, что каждый путь имеет единственный источ-
ник, но может иметь много пунктов назначения. Непрямая пе-
редача при помощи общего йути и децентрализованного управ-
ления означает, что передача осуществляется по многим путям,
каждый из которых может быть одновременно (совместно) ис-
пользован многими приемниками информации в режиме разде-
ления времени для обмена данными.
Пятый уровень включает различные типы структур вычис-
лительных систем и сетей (№№ 1, 2, ..., 10).
Прямой передаче по раздельным путям соответствует коль-
цевая структура процессорных элементов без коммутаторов
(№ 1), каждый элемент которой имеет соседа-предшественника
и соседа-преемника. Передача инициируется данным предшест-
Б А. Головкин 49
пенником, после чего каждый последующий элемент проверяет
адрес сообщения и, в случае необходимости, передает его по
индивидуальному пути дальше своему преемнику. Передача j
прекращается в пункте назначения. Такая структура отличается 1
логической простотой и обладает явно выраженной модуль- I
ностью, но она не обладает высокой надежностью, а скорость 1
передачи в ней ограничена из-за последовательного характера
передачи информации по кольцу. В качестве примера можно
указать кольцевую версию САМАС.
Другим типом структуры при прямой передаче по раздель-
ным путям является структура с полным набором связей (№ 2).
В этом случае каждый источник имеет пути ко всем приемни-
кам. Такая структура не отличается модульностью построения
и характеризуется высокой стоимостью системы при большом
числе элементов, но она обеспечивает высокую скорость обмена
информацией при сравнительно простой логике организации
этого обмена. Структуру с полным набором связей имеет вы-
числительная сеть MERIT, в которой соединены CDC 6500 и
две машины IBM 360/67.
Прямой передаче с общим путем соответствует классическая
многопроцессорная структура с общей основной памятью (№ 3).
В таких системах все сообщения передаются через основную
память. При этом обеспечивается очень высокая пропускная
способность, поскольку обмен фактически представляет собой за-
пись в оперативную память и чтение из нее. Если такая память
используется также и для обработки данных, что является ти-
пичным случаем, то она оказывается нередко узким местом си-
стемы.
Другим типом структуры при прямой передаче с общим пу-
тем является структура с общей шиной (магистралью передачи),
используемой для связи со всеми системными элементами в
режиме разделения ее времени (№ 4). Такие структуры часто
применяются в авиационно-космических системах и системах
военного назначения, а также при построении автоматизирован-
ных систем в промышленности и научных лабораториях. Они
отличаются простотой и явно выраженной модульностью, одна-
ко при их использовании требуется тщательное планирова-
ние занятия времени шины в целях повышения производитель-
ности всей системы. В качестве примера рассматриваемой
структуры можно привести соответствующую конфигурацию
САМАС.
Непрямой передаче по раздельным путям при централизован-
ном управлении соответствует структура в виде звезды (№ 5).
При передаче сообщения проходят через центральный комму-
татор. Такая структура часто реализуется на основе матричного
коммутатора, однако в некоторых случаях применяется также
процессор как центральный элемент системы. Она отличается
простотой логики работы, но не имеет высокой надежности.
50
В качестве примера можно указать вычислительную сеть IBM
Network/440.
Другим типом структуры при непрямой передаче по раз-
дельным путям при централизованном управлении Является
кольцевая структура процессорных элементов с центральным
коммутатором (№ 6). Такая структура сочетает в себе особен-
ности кольцевой структуры (№ 1) и структуры в виде звезды
(№ 5). Пересылка сообщений осуществляется по кольцу через
центральный коммутатор или же пересылка ведется по коль-
цу под управлением центрального коммутатора, который осу-
ществляет адресацию пересылок. В качестве примера можно
отметить экспериментальную систему обмена информацией
SPIDER.
Непрямой передаче по общему пути при централизованном •
управлении соответствует структура с общей шиной и централь-
ным коммутатором (№ 7). Такая структура в функциональном
отношении эквивалентна структуре в виде звезды (№ 5). При
этом главное отличие первой состоит в том, что процессоры свя-
зываются друг с другом не через индивидуальные тракты, сое-
диняемые центральным. коммутатором, а при помощи общей ши-
ны и организации доступа к ней.
При передаче информации процессорный элемент посылает
сообщение- через общую шину к центральному коммутатору, ко-
торый переправляет его к процессорному элементу-приемнику
данного сообщения. На время передачи сообщения между ка-
ким-либо процессорным элементом и центральным коммутато-
ром шина занята этой передачей и другие процессорные элемен-
ты не имеют к ней доступа, т. е. заблокированы по входу и по
выходу. Рассматриваемая структура сочетает в себе качества
экономичности и логической простоты, но при ее применении
приходится преодолевать некоторые трудности, связанные с не-
высокой степенью модульности и сравнительно невысокой на-
дежностью.
Непрямой передаче по раздельным индивидуальным трактам
при децентрализованном управлении ‘ соответствует регулярная
структура (№ 8). Каждый процессорный элемент связан с бли-
жайшим соседом слева, справа, сверху и снизу, причем регуляр-
ный характер связи сохраняется и для крайних процессорных
элементов, которые соединяются с соответствующими-им край-
ними процессорными элементами на противоположной стороне.
Сообщения проходят через сеть от одного элемента к другому
соседнему, причем каждый из процессорных элементов выбирает
тракт для отсылки сообщения. Можно считать, что кольцевая
структура без центрального коммутатора (№ 1) есть частный
случай регулярной структуры, когда в последней каждый эле-
мент имеет два связанных с ним соседних элемента и когда
не принимается решений о выборе тракта для отсылки сооб-
щения.
4ф 51
Модульность и высокие характеристики надежности опреде-
ляются регулярным характером рассматриваемой структуры.
Вместе о тем, такая структура требует сложной логики органи-
зации работы, выдвигает проблемы полной загрузки узлов сети
и соединяющих их линий и другие. В настоящее время Такие
структуры представляют интерес, скорее, с точки зрения ис-
следований, однако перспективы их Применения на практике
представляются, очень обнадеживающими.
Другим типом структуры при непрямой передаче по раздель-
ным индивидуальным трактам и децентрализованном управле-
нии является нерегулярная структура (№ 9). Она становится
все более распространенной в таких системах, в которых про-
цессоры и связи между ними имеют высокую стоимость. Здесь
не требуется связь процессора с каждым соседним процессором,
что усложняет логику переключений при передаче сообщений,
но укрощает межпроцессорные связи. При использовании нере-
гулярной структуры достигается довольно высокая надежность
системы и, одновременно, возможность ее наращивания новыми
модулями.
Основное применение нерегулярная структура находит в вы-
числительных сетях с географически' разнесенными узлами,
пример — сеть ARPA.
Непрямой передаче по общему тракту при децентрализован-
ном управлении соответствует структура с общей шиной и ком-
бинированным подключением к ней коммутаторов и процессор-
ных элементов (№ 10). Такая структура подобна нерегулярной
структуре с точки зрения характеристик модульности и воз-
можностей наращивания. Однако, она обладает более низки-
ми характеристиками надежности и меныпими возможностя-
ми реконфигурации, поскольку процессорные элементы. и
коммутаторы используют единственный тракт передачи инфор-
мации.
Структуры с общей шицой при комбинированном подключе-
ний к ней коммутаторов и процессорных элементов становятся
все более распространенными, в особенности, в универсальных
вычислительных системах на базе мини-ЭВМ. В качество
примера- системы .с такой структурой можно отметить систему
PLURIBUS, предназначенную для выполнения функций связи
в узлах сети ARPA.
^Направления дальнейшего развития и применений рассмот-
ренных структур будут в значительной степени связаны с рас-
пределенными вычислительными системами и сетями. Среди
структур можно выделить по совокупности их основных харак-
теристик четыре «доминирующие» структуры, а именно; коль-
цевую структуру (№ 1), структуру с общей шиной (№ 4),
структуру в виде звезды с коммутатором в центре и процессор-
ными элементами в концах лучей (№ 5} и нерегулярную струк-
туру (№ 9).
52
Проведенный анализ показывает, что эта классификация или
какая-либо подобная ей представляет собой полезный инстру-
мент* для выбора структуры системных связей и колйчествен-
иой оценки выбранной системы по нескольким основные пока-
зателям. Одно из достоинств классификации состоит
пости систематического перебора и сравнения всех
Рассмотренная классифи-
кация, как обычно, обла-
дает определенной сте-
пенью условности. Некото-
рые существующие вычис-
лительные системы и сети
не могут быть однозначно
отнесены к тому или ино-
му типу
тают в
структур
типа.
2Л.2.
зи в многопроцессорных
системах. Рассмотрим не-
сколько более подробно
структуру внутрисистем-
ных связей в многопроцес-
сорных системах, т. е. структуру
ких систем (структура связей в
сана в п. 1.2).
структур и соче-
себе признаки
более чем одного
Внутренние свя-
в возмож-
вариантов.
Рис.
2.22. Схема внутрисистемных пере*
крестных связей.
связей в центральной части та-
многомашинных системах опи-
Можно выделить три основных типа структур, а именно,
структуры с перекрестными связями (рис. 2.22), с многошинны-
ми связями (рис. 2.23) и со связями через общую шину
(рис. 2.24) L635J ♦). На рисунках через МПм и ПрМ обозначены
модули памяти и процессорные модули соответственно. Пери-
ферийные устройства могут подключаться к центральной части
при помощи схем аналогичной структуры.
Схема перекрестных связей) является универсальной. Она
реализуется при, помощи матричного коммутатора, который мо-
жет быть построен как централизованным (полностью отделен
от функциональных модулей), так и распределенным между со-
ответствующими функциональными модулями системы. Комму-
тация может осуществляться в каждой точке матричной схемы,
обеспечивая физическое подсоединение любого модуля памяти
к любому процессору. При этом необходимо управлять очередям
ЯП запросов на обмен между процессорными модулями и моду-
лями памяти и разрешать конфликты, которые могут возник-
*) Такие же три типа связей выделены в [613] и рассмотрены в мно-
гочисленных последующих работах.
53
путь. Обычно конфликты разрешаются при помощи приорите-
тов, которые могут быть переменными. Имеется возможность
организовать несколько одновременно действующих путей пере-
дачи информации в матрице.
Матричный коммутатор представляет собой довольно сложное
и дорогое устройство и является узким местом системы в том
смысле, что через него
проходят все обмены ин-
формацией между процес-
сорными модулями и мо-
дулями памяти, так что
Рис. 2.23. Схема внутрисистемных много-
шинных связей.
Рис. 2.24. Схема внутрисистем-
ных связей через общую шину.
выход его из строя означает отказ системы в целом. Поэтому в
тех случаях, когда требуется повышенная надежность, матрич-
ный коммутатор может быть продублирован. Наконец, если чис-
ло процессорных модулей и модулей памяти соответствует ко-
личеству выходов коммутатора (максимальная комплектация)^
то дальнейшее наращивание системы такими модулями практи-
чески невозможно без конструктивных изменений. При этом
наращивание системы от минимальной до максимальной комп-
лектации не вызывает трудностей в силу модульности построе-
ния системы в целом.
Перечисленные недостатки Связаны с обеспечением универ-
сальности и гибкости работы коммутатора. Эти последние ха-
рактеристики матричного коммутатора в совокупности с регу-
лярностью его структуры, простотой* и однотипностью логики
являются настолько важными, что определяют его применение
во многих многопроцессорных системах.
При использовании многошинных связей каждый процессор-
ный модуль имеет доступ к любому модулю памяти при помощи
своих собственных шин (рис. 2.23). Прэтому каждый модуль
памяти должен быть многовходовым, в отличие от одновходовых
для матричного коммутатора. Кроме этого, модули памяти долж-
ны разрешать конфликты, возникающие при одновременном об-
ращении к данному модулю со стороны нескольких процессор-
ных модулей (или устройств ввода-вывода). Скорость обмена
54
в схемах с многошинными связями ниже по сравнению с мат-
ричным коммутатором, поскольку в первом случае модули па-
мяти многовходовые и сами разрешают конфликты обращений,
а во втором случае модули памяти одновходовые и не выполняв
ют функций разрешения конфликтов, которые возлагаются на
матричный коммутатор. Последний устанавливает физическую
связь между процессорным модулем и модулем памяти один
раз на весь сеанс обмена между ними.
Схемы с многошинными связями имеют меньшую стоимость
по сравнению со схемами матричного коммутатора, поскольку
первые содержат меньше точек пересечений, в которых нужно
разрешать конфликты. Размер максимальной конфигурации
схем с многошинными связями ограничивается числом входов
в модулях памяти. Такие схемы нашли широкое применение в
различных многопроцессорных системах.
Схема связей через общую шину (рис. 2.24) является Наибо-
лее простой из числа трех рассматриваемых основных схем. Ее
реализация обходится наиболее дешево, она характеризуется
высокой степенью модульности и наиболее хорошими возмож-
ностями наращивания. Управление может осуществляться, при
помощи стандартных методов разделения времени. Скорость об-
мена в такой схеме, однако, является наиболее низкой в силу
разделения времени для передачи сообщений через одну шину
1493]. Схемы связи через общую шину получили наибольшее
распространение в специализированных вычислительных систе-
мах и системах со сравнительно небольшой
иостью.
В заключение отметим, что рассмотренные типы схем внут-
ренних связей являются базовыми и что существуют их разно-
образные варианты.
2.5. Структура связей между центральной частью
вычислительных систем и каналами ввода-вывода [606]
Связи между центральной частью и каналами ввода-вывода
как однопроцессорных, так и многомашинных и многопроцес-
сорных вычислительных систем организуются в большинстве
случаев фактически по одним и тем же принципам, поэтому
рассматриваемые здесь структуры связей относятся ко всем трем
чипам указанных вычислительных систем. В целях простоты из-
ложение проводится, в основном, для однопроцессорных конфи-
гураций.
Связи между центральной частью вычислительных систем и
каналами ввода-вывода рассматриваются особо, поскольку их
структура, как правило, существенно отличается от связей внут-
ри центральной части систем.
2.5.1. Основные типы структуры связей. Несмотря на большое
разнообразие вычислительных систем, существует только три
основных типа связей между центральной частью и каналами
производитель-
55
ввода-вывода. В структурах первого тина («канал — централь-
ный процессор») каналы подключаются к центральному процес-
сору (рис. 2.25), и информация из канала поступает в процессор
(процессор фактически управляет обменом между памятью к
каналами). В структурах второго типа («канал — основная па-
мять») все данные передаются непосредственно на входы ос-
новной памяти, в которой
они могут накапливаться
для обработки процессором
или для выборки на какое-
либо устройство (рис. 2.26).
В структурах третьего типа
(«канал — системный конт-
роллер» ) предусматривается
центральный узел коммута#
ции: все передачи данных
к периферийным устройст-
вам, центральным процессо-
рам и главной памяти,
а также все передачи данных
от них осуществляются через
и под управлением систем-
ного контроллера (рис. 2.27).
В конкретных вычисли-
тельных системах устройст-
Рис. 2.25. Структура «канал — централь-
ный процессор».
ва, имеющие одинаковые функции, могут отличаться с точки
зрения деталей их функционирования, а также в названиях. На
рис. 2.25—2.27 изображены основные типы структур без каких-
либо их деталей.
В большинстве традиционных систем, в особенности одно-,
процессорных, каналы ввода-вывода подключены непосредствен-
но к центральному процессору, при этом основная память часто
конструктивно совмещается с процессором. На рисунке 2.25
представлена структура с непосредственным подключением трех
независимых каналов к центральному процессору, с которым
конструктивно совмещена основная память.
Основным достоинством такого типа структуры является тог
что требуется наименьшее количество оборудования и что стои-
мость оказывается также наименьшей. Системы со структурой
«канал — центральный процессор» наиболее целесообразно при-
менять в тех случаях, когда требования к ресурсам системы
должны или могут быть определены заранее и когда они по-
меняются в Динамике работы. Это определяется тем обстоятель-
ством, что все функции по управлению сосредоточены в про-
цессоре (данные поступают в основную память и из основной'
памяти под управлением программы, выполняемой центральным
процессором). Основной областью применения систем, в кото-
рых каналы подключены к центральному процессору, является
56
пакетная обработка, которая в настоящее время занимает глав-
ное место при использовании вычислительных машин.
Основным недостатком структуры «канал — центральный
процессор» является требование повышенной производительно-
сти центрального процессора, которое _ вытекает из необходимо-
сти быстрой обработки слу-
чайного потока прерываний.
Этот недостаток влечет не-
сколько других-не достатков.
Имеет место жесткое ограни-
чение на число подключае-
мых каналов с точки зрения
их эффективного использова-
ния, особенно при одновре-
менной работе, так как при
большом числе каналов про-
цессор большую часть вре-
мени затрачивает на обслу-
живание прерываний, свя-
занных с вводом и выводом.
Кроме этого, при обработке
со сложным взаимодействием
процессов и при работе си-
стем с виртуальной памятью
типичным является положе-
ние, когда возникает боль-
шое число непланируемых
Рис. 2.26. Структура «канал — основная
память».
запросов на ввод-вывод.
В этих условиях при использовании систем с подключением ка-
налов к центральному процессору необходима такая операци-
онная система, которая бы компенсировала недостатки структу-
ры. Наконец, ограничение на число каналов приводит, естест-
венно, к ограничению числа обслуживаемых периферийных уст-
ройств.
Проблема ограничений на число каналов и на число пери-
ферийных устройств может быть решена во многих случаях
путем введения подканалов или путем совместного использова-
ния каналов. Для повышения скорости обработки и пропускной
способности системы требуется более тщательное ^квалифици-
рованное программирование и обоснованное распределение прио-
ритетов между периферийными устройствами.
Рассмотрим структуру типа «канал — основная память»
(рис. 2.26). В этом случае имеется прямой независимый доступ
к основной памяти, которая реализуется конструктивно как от-
дельное устройство в виде двух или более компонент вычисли-
тельной системы. Запись данных в основную память и считыва-
ние их из нее осуществляются, логически и физически, без не-
посредственного вмешательства центрального процессора. Все
57
основные части системы, осуществляющие обработку и передачу
информации (центральные процессоры, процессоры ввода-выво-
да и контроллеры ввода-вывода), представляют собой устройст-
ва, подключенные к соответствующим входам модулей основ-
ной памяти. Они работают независимо друг от друга. Эти уст-
ройства, с одной стороны, имеют дело с отдельными входами
Рис. 2.27. Структура «канал — системный контроллер».
основной памяти, а с другой стороны,— с периферийными уст-
ройствами.
Главным достоинством данной структуры является одновре-
менность операций ввода-вывода и вычислений благодаря неза-
висимому доступу к основной памяти. Разделение ввода-вывода
и вычислений позволяет не только увеличить число каналов,
с которыми может работать система, но и разгружает централь-
ный процессор от большого числа прерываний. Вследствие та-
кой независимости операций ввода-вывода и вычислений рас-
сматриваемая структура наилучшим образом отвечает требова-
ниям обработки со сложным взаимодействием процессов.
Системы со структурой «канал — основная память» облада-
ют гораздо большей гибкостью по сравнению с системами со
структурой «канал — центральный процессор». Наращивание
первых для увеличения их мощности достигается простым до-
бавлением компонентов систем, при этом отпадает необходи-
мость в сложных завязках. Например, для увеличения вычисли-
тельной мощности обычно добавляется центральный процессор/
который подключается к одному из входов основной* памяти.
В таких случаях ограничения могут быть вызваны только воз-
можностями операционной системы по управлению получаемы-
ми двух- или многопроцессорными системами.
Таким образом, структура типа «Цанал — основная память»
позволяет иметь большое число дополнительных входов памя-
ти, независимых контроллеров ввода-вывода, процессоров ввода-
58
вывода и других устройств. Все эти устройства, расширяя воз-
можности системы, и, в частности, увеличивая ее гибкость, зна-
чительно увеличивают стоимость системы. Так, например, каж-
дый вход памяти должен иметь свой собственный интерфейс и
управляющую логику, а процессор или контроллер ввода-выво-
да — иметь интерфейс для обеспечения работы канала. Поэтому
дополнительные каналы повышают гибкость системы, но и при-
водят к высокой стоимости системы.
Число входов памяти может быть достаточно большим, од-
нако следует учитывать, что центральный процессор полностью
занимает вход памяти или разделяет его с ограниченным чис-
лом периферийных устройств. Например, если каждый модуль
памяти в системе имеет четыре входа, то один из входов за-
крепляется за центральным процессором.. Три оставшихся входа
обычно предоставляются для работы с дисками, лентами и низ-
коскоростными устройствами соответственно. В многопроцессор-
ной системе, в которой каждый модуль памяти имеет, например,
четыре входа, два входа выделяются центральным процессорам,
а периферийные устройства должны совместно разделять два
оставшихся входа.
Можно сохранить достоинства структуры с многовходовой
памятью и обеспечить при этом низкую стоимость системы,
если использовать мультиплексор. Мультиплексоры могут быть
пепосредствённо подключены к входу памяти, чтобы обеспечить
подключение дополнительных процессоров ввода-вывода и конт-
роллеров ввода-вывода, или же они могут быть подключены к
процессорам ввода-вывода и контроллерам ввода-вывода, чтобы
обеспечить подключение дополнительных каналов ввода-вывода.
Имеющиеся большие потенциальные возможности по организа-
ции работы множества каналов ввода-вывода не могут быть ис-
пользованы из-за необходимости предоставления входов памяти
в исключительное пользование центральным процессорам, при-
чем, очевидно, чем больше центральных процессоров в системе,
тем большее число входов основной памяти они занимают. По-
этому нередко каналам предоставляется уолько один или два
остающихся входа памяти и, следовательно, системы со струк-
турой «канал — основная память» в этом случае обеспечивают
по существу те же возможности по обслуживанию каналов, что
и системы с традиционной структурой «канал — центральный
процессор».
Существуют системы со структурой, которая может рассмат-
риваться как вариант структуры «канал — центральная память».
Такие системы имеют два центральных процессора, один из ко-
торых выполняет все функции ввода-вывода, а другой все
функции по реализации вычислений (напомним, что такого ти-
па системы рассматривались в п. 1.2). Ясно, что такой подход
представляет собой весьма дорогостоящий путь организации вы-
числительных систем.
59
Перейдем к системам со структурой «канал — системней
контроллер» (рис. 2.27).В такого типа системах центральным
входом для каналов ввода-вывода, центральных процессоров и
модулей основной памяти служит системный контролдер, кото-
рый управляет доступом к основной памяти как от каналов вво-
да-вывода, так и от центрального процессора. Этот контроллер
является логическим связывающим звеном между основной па-
мятью и центральным процессором и выполняет функции регу-
лирования потоков информации в системе.
Рассматриваемая структура имеет сходство со структурой
«канал — основная память» в том смысле, что в обоих случаях
доступ к основной памяти со стороны каналов осуществляется
без вмешательства центрального процессора. Вместе с тем си-
стемный контроллер обеспечивает доступ к основной памяти
подобно тому, как это делает центральный процессор в системах
Со структурой «канал — центральный процессор», т. е. структу-
ра «канал — системный контроллер» с этой точки зрения подоб-
на структуре «канал центральный процессор». Таким обра-
зом, структура «канал — системный контроллер» соединяет в
себе особенности структур «канал — центральный процессор» и
«канал — основная память». При этом, однако, системный конт-
роллер представляет собой самостоятельное функциональное
устройство, которое при правильном применении может обеспе-
чить в системе сочетание достоинств двух последних структур.
Основное достоинство структуры «канал — системный конт-
роллер» заключается в логической координации. всех системных
действий. Центральный процессор имеет все возможности для
выполнения вычислений, в то время как контроллер осущест-
вляет жесткое управление системой. Одна из проблем, которая
возникает для структуры «канал.—центральный процессор»,
состоит в том, что требуется постоянно взаимодействовать с ка-
налами и, как следствие, обслуживать с привлечением процес-
сора большое число прерываний. Эти прерывания возникают в
^произвольные моменты времени и их влияние на пропускную
способность системы может быть самым различным. С другой
стороны, в структуре «канал — основная память» имеются скры-
тые потери, связанные с постоянным опросом со стороны цент-
рального процессора о том, что произошло в течение последнего
цикла его работы.
Системный контроллер не "Ьмеет отмеченных выше недостат-
ков. Он освобождает центральный процессор от действий по
низкоприоритетным вводам и выводам информации и в то же
время обеспечивает постоянную готовность центрального про-
цессора к обработке прерываний. Поскольку системный контрол-
лер мощет устранить недостатки, обсуждавшиеся выше, струк-
тура с Системным контроллером может считаться эффективной
для выполнения как локальных вычислений, так и вычислений
со сложным взаимодействием.
60
Ввиду того, что стоимость оборудования, составляющего си-
стемный контроллер, близка к стоимости центрального процес-
сора, то стоимость системы минимальной конфигурации близка
к стоимости друхпроцессорной системы. Кроме этого, алгоритм,
управляющий работой системного контроллера, может либо да-
вать преимущества вычислениям перед вводом-выводом, либо
наоборот, вследствие чего возникают трудности в балансировке
работы системы. Поэтому применение рассматриваемой структу-
ры в ряде случаев । может оказаться нерациональным, а эффек-
тивность — сильно ‘зависящей от характера решаемых задач.
Существует ряд систем, н екоторых использованы варианты
структуры с системными контроллерам^. В некоторых из таких
систем эти-контроллеры выполняют функции общего интерфей-
са и управления доступом к памяти. В других системах они
выполняют только функции коммутации и не обеспечивают
приоритетного доступа к памяти, при этом все требования об-
служиваются в порядке их поступления. Эти Системы могут быть
настроены как на первоочередное выполнение вычислений, так
и на первоочередное выполнение ввода-вывода в зависимости от
требований конкретной области применения.
В настоящее время наметилась тенденция в направлении
распределенной обработки при помощи групп микропроцессоров.
Микропроцессорные компоненты системы; вероятно, не будут
крупными фиксированными функциональными устройствами,
явно отделенными друг от друга, такими кдд традиционные уст-
ройства управления, арифметико-логические устройства и блоки
ввода-вывода. Вместо этого они будут, по-видимому, динамиче-
ски перестраиваемыми элементами в целях решения некоторой
задачи обработки информации. Например, если данная програм-
ма требует большого объема вычислений, то элементы пере-
страиваются в устройства обработки. Если .же, наоборот, тре-
буется большое число операций ввода-вывода, то они перестраи-
ваются в устройства для ввода-вывода. Уже, построено несколь-
ко микропроцессорных систем с изменяемой структурой. Они
занимают промежуточное положение между системами большой
и средней производительности. Будущие системы могут быть
построены из элементов, имеющих различные возможности — от
ограниченных до самых широких. Распространению таких си-
стем будет способствовать простота наращивания элементов, ко-
личество которых будет ограничено лишь возможностями опе-
рационной системы по управлению этими элементами.
2.5.2. Сопряжение с периферийными устройствами. Схемы
трактов сопряжения центральной части вычислительных систем
с периферийными устройствами являются схемами одного ос-
новного типа. Как показано на рис. 2.28, эти схемы содержат
в качестве главного функционального устройства контроллеры
ввода-вывода, причем контроллеры могут быть совмещены с
центральным процессором, могут быть реализованы как отдель-
6t
иые устройства и, наконец, могут быть совмещены с перифе-
рийными устройствами.
Объединение контроллеров с основным оборудованием си-
стемы позволяет получить выигрыш за счет общих цепей пита-
ния (при конструктивном совмещении) и за счет совместного
использования логических возможностей (при более тесном схем-
ном объединении). При этом обеспечивается меньшая стоимость
а) Контроллер ввода-' S) Контроллер ввода-
-вывода совмещен ' -вывода выполнен
с центральным нак отдельное .
процессором устройства
в) Контроллер вводам
-вывода совмещен
с периферийными
устройствами
Рис. 2.28. Схемы трактов сопряжения центральной части вычислительных
систем с периферийными устройствами.
по сравнению с реализацией в виде отдельных устройств. Обыч-
но контроллер включается в низкоскоростные периферийные
устройства, такие, . например, как алфавитно-цифровые печа-
тающие устройства, что обусловливается простотой управления
ими. Контроллеры в виде отдельных устройств характеризуются
большой гибкостью при выборе и изменении состава перифе-
рийных устройств. В этом случае оказывается возможным так-
же комплексировать разнородное периферийное оборудование.
Вместе с тем, объединение контроллеров ввода-вывода с ос-
новным оборудованием вычислительной системы ограничивает
систему в двух направлениях. Во-первых, возникают трудности
использования периферийных устройств других разработок,
не связанных с данной вычислительной системой. Во-вторых,
контроллеры оказываются связанными с определенными кана-
лами, что ограничивает число возможных конфигураций кана-
лов в сочетании с периферийными устройствами. Объединение
контроллеров с периферийным оборудованием широко исполь-
зуется на практике и не имеет явных недостатков. В случае
62
применения контроллеров как отдельных устройств основной
недостаток заключается в относительно высокой стоимости.
Существуют три основных типа подключения и выборки ка-
налов для осуществления ввода-вывода, первый из которых ос-
нован на фиксированном индивидуальном подключении каждого
данного устройства к другому соответствующему устройству
(один к одному), второй основан на подключении ограниченной
группы каналов с возможностью выборки среди них для осу-
ществления конкретного ввода или вывода, а третий — на уни-
версальном способе подключения оборудования каналов («пла-
вающий» канал или матрица). Фиксированное подключение
индивидуального канала используется для одиночных устройств
сопряжения и одного или группы периферийных устройств. Ес-
ли имеется специализированная группа периферийных уст-
ройств, внутри которых нужно осуществлять выборку для вво-
да-вывода, то используется второй тип сопряжения. Наконец,
для обеспечения ввода-вывода при помощи любого канала и
любого периферийного устройства используется третий тип со-
пряжения. Эти способы сопряжения показаны на рис. 2.29.
Способ фиксированного подключения канала к периферийно-
му устройству (рис. 2.29 а) обеспечивает наилучшее обслужи-
вание устройства, хотя и не является выгодным с точки зрения
стоимости. При этом к одиночным каналам может быть подклю-
чена группа устройств. * Выборка каналов внутри ограниченной
группы (рис. 2.29 б) позволяет уменьшить число конфликтов
благодаря возможности доступа устройств к нескольким кана-
лам. При этом обеспечивается полное использование каналов
внутри группы. Универсальное подключение каналов (рис. 2.29 в)
обеспечивает полное использование всех каналов вычисли-
тельной системы. _
В качестве недостатков схем подключения каналов можно
отметить следующие. Обслуживание одного периферийного уст-
ройства нецелесообразно с точки зрения стоимости для систем
средней и высокой производительности. Подключение групп ка-
налов и выборка каналов внутри Таких групп обеспечивает пол-
ное использование каналов группы, но не гарантирует полного
использования каналов в системе в целом. В последнее время
наметилась тенденция к введению избыточности в оборудование
группы каналов. Она выражается в том, что в группу вводится
дополнительный канал, который включается на время пиковых
нагрузок по передаче информации. Способ универсального под-
ключения, являясь наиболее эффективным, характеризуется и
наибольшей стоимостью. Дополнительные расходы, связанные
с оборудованием для коммутации и управления, ограничивают
широкое применение способа универсального подключения ка-
налов в вычислительных системах.
Наиболее широко распространен способ обслуживания одним
каналом группы периферийных устройств. Выборка каналов
63
с
Контроллер
ввода-
-вывода
контроллер Контроллер Контроллер
ввода-
-вывода
Контроллер Контроллер Контроллер
ввода- - __в_
-вывода
ввода-
-вывода
ввода-
-вывода
а) Фиксированное-
индивидуальное
подключение
\ ^Периферийные устройства
д) Подключение ограниченной группы
ввода-
-вывода
Контроллер
ббода-
быдода
евода-
- вывода
Контроллер
б&ода-быдода.
в) Универсальное подключение
Рис. 2.29. Схема подключения и выборки каналов.
внутри группы может быть улучшена в конкретных системах
путем применения адаптеров канал-канал для наиболее критич-
ных (с точки зрения высокого быстродействия) периферийных
устройств. Такое улучшение, однако, сопряжено со значитель-
ным повышением стоимости.
Рассмотрим теперь и сравним между собой процессоры и
контроллеры ввода-вывода, а также периферийные и. внешние
(предоконечные) процессоры.
Процессоры ввода-вывода и контроллеры ввода-вывода пред-
ставляют собой такие устройства, которые непосредственно при-
соединены ко входу памяти и управляют обменом данных меж-
ду периферийным устройством и модулем памяти. Как процес-
сор, так и контроллер являются основными компонентами струк-
туры «канал — основная память». Они позволяют осуществлять
операции ввода-вывода независимо от Центрального процессора.
Несмотря на то, что эти устройства выполняют многочислен-
ные функции, с точки зрения классификации устройств они
представляют собой высокоскоростные мультиплексоры.
Большинство процессоров, и контроллеров ввода-вывода мо-
гут обеспечивать работу до 25 или более индивидуальных ка-
налов ввода-вывода. Эти устройства обеспечивают независимую
передачу информации, включая служебную информацию, ин-
формацию о состоянии устройств и основную передаваемую
информацию. Процессоры и, контроллеры ввода-вывода, допол-
нительно могут обрабатывать данные и выполнять последова-
тельность команд.
Процессоры и контроллеры ввода-вывода являются эффек-
тивными устройствами, . но, одновременно, и дорогостоящими.
При этом увеличение стоимости связано не только с их собствен-
ной стоимостью, но также и с тем, что они занимают один или
несколько дополнительных входов памяти, необходимых для их
работы. Кроме этого, управление . периферийными устройства-
ми, несмотря на их широкие возможности, остается индиви-
дуальным.
Процессоры ввода-вывода и контроллеры ввода-вывода не
являются процессорами в полном смысле этого слова. Они не
дают прямого вклада в повышение вычислительной мощности
системы, а освобождают центральный процессор ет выполнения
функций ввода и вывода, в результате чего освобождающееся
время центрального процессора используется для выполнения
вычислений.
Имеются некоторые исключения из этого правила. Су-
ществуют системы, в которых один центральный процессор
выполняет все функции ввода-вывода в интересах всей систе-
мы, а второй центральный процессор, который освобожден от
функций ввода-вывода, выполняет вычислительную работу. При
этом процессор, выделенный для ввода-вывода, производит вы-
числения в паузах между действиями по вводу и выводу ин-
5 Б. А. Головкин 65
формации (напомним, что такого рода системы упомянуты в
и. 2.5.1).
При использовании процессоров ввода-вывода и контролле-
ров ввода-вывода необходимо обеспечивать их защиту от пере-
грузок по передаваемому потоку информации. Несмотря на то,
что они обладают мультиплексным# возможностями, их скорость
работы ограничена, и необходима предварительная оценка ко-
личества возможных одновременных запросов на обслуживание4.
В отличие от процессоров и контроллеров ввода-вывода, пе-
риферийные и внешние процессоры дают непосредственный
вклад в увеличение вычислительной мощности системы. Они,
как и первые, выполняют функции ввода-вывода, но при этом
еще выполняют программы. Различие между периферийными и
внешними процессорами состоит в их взаимосвязи с вычисли-
тельной системой. Основным назначением периферийных про-
цессоров является осуществление функций ввода-вывода в целом
для системы или подсистемы периферийных устройств. Внеш-
ние процессоры обычно предназначаются для специфических
функций, таких как внешние функции связи (т. е. выступают
в качестве процессоров связи). В то время как периферийные
процессоры представляют собой часть единой вычислительной
системы, внешние процессоры являются обычно ее дополнитель-
ными (наращиваемыми) устройствами. Периферийные и внеш-
ние процессоры могут взять на себя большую часть вспомога-
тельной вычислительной работы, которая имеется в любой си-
стеме. Центральный процессор в этом случае привлекается
только к выполнению программ пользователей, т. е. своих ос-
новных программ. В таких областях, как взаимодействие через
системы связи или разделение времени, периферийные и внеш-
ние процессоры могут выполнять большинство заявок самостоя-
тельно, оставляя центральному процессору лишь незначитель-
ную часть, но наиболее трудоемких заявок.
Оба типа устройств имеют высокую стоимость. Они требуют
разработки специального программного обеспечения, в котором
необходимо учитывать и отслеживать изменения, возникающие
в вычислительной системе. Особенно высока, как правило, стои-
мость периферийных процессоров. Трудно дать количественную
оценку их вклада в эффективность вычислительных систем,
выраженную в виде отношения производительности к стоимости.
В связи с тем* что периферийные процессоры являются частью
оборудования вычислительной системы, возможности по их уста-
новке и наращиванию ограничиваются этим оборудованием. По-
пытка заменить данный процессор периферийным процессором
другого вида приводит к серьезному изменению системы. В от-
личие от периферийных, внешние процессоры допускают больше
свободы при их замене. Большинство современных вычислитель-
ных систем могут работать с внешними процессорами одного или
другого вида. Внешние процессоры могут учитывать особенности
66
тех или иных вычислительных систем или же могут быть неза-
висимыми в этом смысле от конкретных вычислительных систем.
Если их рассматривать отдельно, то они представляют собой
обычно вычислительные системы среднего класса, но с большой
избыточностью и высокой стоимостью вследствие специфики их
функций. Лучшими внешними процессорами с точки зрения от-
ношения производительности к стоимости являются системы
Рис. 2.30. Вариант системы с многошинными связями.
мини-ЭВМ. Они могут быть представлены в большом числе ва-
риантов и могут удовлетворять требованиям практически любого
уровня, предъявляемым к внешним процессорам.
Рассмотренные структуры связей в вычислительных системах
не являются практически исчерпывающими. Приведем в заклю-
чение два типа структур, первая из которых представляет собой
широко распространенный вариант многошинной структуры,
а вторая — вариант структуры с полным набором связей цент-
ральных процессоров 11153].
Вариант структуры с многошинными связями изображен на
рис. 2.30. На этом и следующем рисунках через ПрМ обозначен
центральный процессор (процессорный модуль), через МПм — мо-
дуль основной памяти и через УВВ — устройство ввода-вывода.
Многошинные связи используются в режиме разделения време-
ни, модули памяти являются многовходовыми. Такую схему с
двумя шинами (рис. 2.30) можно рассматривать как обобщение
схемы со связями через единственную шину, возможны варианты
с числом шин более двух. Устройства ввода-вывода подключены
к чтем же шинам, что и процессорные модули и модули основной
памяти. Здесь количество задействованных входов модулей памя-
ти равно числу шин. Вариант структуры с полным набором свя-
зей между центральными процессорами, е одной стороны, и мо-
дулями основной памяти и устройствами ввода-вывода, с другой
стороны, изображен на рис. 2.31. Здесь модули памяти, так же
67.
как и устройства ввода-вывода, имеют множественные входы,
причем число входов каждого из них равно числу центральных
процессоров в системе и каждый из входов непосредственно свя-
зан с одним из центральных процессоров. В системах с такой
Рис. 2.31. Вариант системы с полным набором связей центральных про-
*. цессоров.
структурой связей облегчается решение задач обмена информа-
цией за счет полного набора связей в указанном смысле. Мак-
симальная конфигурация системы ограничена числом входов
устройств.
2.6. Структура многопроцессорных систем
с языками высокого уровйя
Проблемы повышения внутреннего уровня языка вычисли-
тельных систем привлекают все больше внимания специалистов.
Повышение уровня языка однопроцессорных и многопроцессор-
ных систем оказывает существенное влияние на организацию их
структуры и функционирования. Рассмотрим вопросы развития
структур многопроцессорных систем с языками высокого уровня,
следуя работам [101, 1021.
Повышение уровня машинных языков направлено на совер-
шенствовайие характеристик систем, определяющих их способ-
ность к общению с пользователем, воспринимать и выполнять
задания и программы на языках высокого уровня, использовать
68
в диалоге средства приема и выдачи информации в удобной для
человека форме.
Одним из направлений решения рассматриваемой проблемы
является построение неоднородных многомашинных систем, име-
ющих в своем составе ЭВМ с языком высокого уровня. Приме-
рами таких систем могут служить комплекс М-220 и МИР-1 и
комплекс БЭСМ-6 и МИР-2. Машины с языком высокого уровня
могут входить в состав высокопроизводительных систем в каче-
стве коллективных интеллектуальных терминалов.
Другим направлением является построение высокопроизводи-
тельных систем, в которых адаптация к языкам пользователей
обеспечивается интерпретацией соответствующего ряда языков
высокого уровня, а достижение высокой производительности обес-
печивается за счет многопроцессорной обработки при широком
распараллеливании потока выполняемых заданий, даже если
этот поток представляет собой одну сверхбольшую задачу. Ины-
ми словами, осуществляется сочетание многопроцессорной обра-
ботки со структурной интерпретацией языков высокого уровня.
Перечислим основные факторы, способствующие реализации в
многопроцессорных системах развитых систем структурной ин-
терпретации.
Реализация в многопроцессорных системах внутренних языков
высокого уровня позволяет существенно сократить информацион-
ные обмены между их компонентами, упростить управление й
существенно сократить ряд функций операционных систем. Она
обеспечивает сокращение статической и динамической длины
программы, повышает эффективность процессов и уменьшает
связность^ в программе. Так, например, высокий уровень языка
описания данных позволяет значительную часть работы по рас-
познаванию и преобразованию информации исполнять над верх-
ними уровнями их структуры. При этом существенно уменьшает-
ся объем просматриваемой информации, так как отбрасывание
ненужных вариантов производится сразу.
Использование процессоров, микропрограммно интерпретиру-
ющих языки высокого уровня, значительно уменьшает динами-
ческую длину программы и понижает ее цикличность и ветви-
стость, а также обеспечивает компактное представление семанти-
ческих программ в управляющей памяти. Вследствие большего
быстродействия такой памяти по сравнению с оперативной па-
мятью выполнение семантических программ потребует меньше
времени, чем при чтении их в виде команд машинного языка из
общего ЗУ с последующей интерпретацией.
Использование языков высокого уровня повышает эффектив-
ность локальных буферных устройств памяти и эффективное
быстродействие динамически организованной памяти за счет
уменьшения числа обменов, что особенно важно для многопро-
цессорных систем в связи с уменьшением при этом нагрузки на
сеть связей в системе. Интерпретация языка высокого уровня
63
позволяет также повысить производительность многопроцессорной
системы вследствие уменьшения количества обращений к общей
памяти, которое является/в свою очередь, следствием уменьше-
ния частоты подкачки в локальные устройства памяти.
Использование в многопроцессорных системах только языков
высокого уровня позволяет существенно упростить также реше-
ние ряда системных проблем. Так, например, упрощается распа-
раллеливание программ, так как запись в языке высокого уровня
упрощает, восприятие структуры программы.
Следует отметить, что структурная (схемно-микропрограмм-
ная) интерпретация языков высокого уровня в многопроцессор-
ных системах должна быть более развитой по сравнению с од-
нопроцессорными машинами. Действительно, структурная ин-
терпретация данных уже является традиционным элементом
интерпретации языков высокого уровня в однопроцессорных
машинах и используется при реализации последовательных про-
цессов решения задач на них. В свою очередь для многопроцес-
сорных систем следует вводить структурную интерпретацию
сложных структур данных, которые свойственны большим зада-
чам, распараллеливаемым по процессорам системы. Кроме этого,
в многопроцессорных системах возрастает потребность в несколь-
ких языках программирования, поскольку такие системы должны
обслуживать широкий круг различных пользователей. При этом
работа может вестись на разных языках в режиме коллективного
пользования.
Реализация нескольких языков может быть выполнена раз-
личными способами. Во-первых, в каждом процессоре можно сов-
местить множество интерпретируемых языков. Это, однако, ус-
ложняет процессоры и накладывает ограничения на их количество
в системе. Во-вторых, процессоры можно жестко ориентировать
на разные языки, но при этом ограничиваются возможности си-
стемы в распараллеливании алгоритмов между процессорами.
Компромиссный способ предусматривает динамическое микро-
программное управление, т. е. индивидуальную настройку про-
цессоров на различные языки путем применения соответствую-
щих микропрограммных интерпретаторов, вводимых в процессоры
в рабочем режиме по мере необходимости. Наконец, может быть
реализован жёстким структурным способом также и язык высо-
кого уровня, но с определенной машинной ориентацией, чтобы
упростить реализацию на его основе нескольких основных вход-
ных языков при помощи «мягких» компонентов (трансляторов и
сменных интерпретаторов).
Развитие системы интерпретации приводит к расширению и
углублению адаптивных свойств вычислительных систем и., соот-
ветственнр, их виртуальности. В результате становится возможной
реализация на основе имеющегося физического и математического
оборудования не одной>виртуальной системы, а их семействе* Это
вызывает усложнение операционных систем. Поэтому для интер-
70
^третируемых программ операционной системы целесообразно ис-
пользовать также язык высокого уровня, что при программно-
структурной реализации операционной системы упрощает ее про-
ектирование и, одновременно, повышает возможности эффектив-
ного управления вычислительным процессом.
Рассмотрев вопросы развития структурной интерпретации
языков высокого уровня для построения высокоэффективных
многопроцессорных систем, перейдем к вопросам построения в
перспективе универсальных многопроцессорных систем с большим
числом процессоров. Не касаясь проблем создания элементной
базы таких систем, выделим два ключевых вопроса организации
их архитектуры: выбор типов элементарных процессоров как
структурных единиц, коммутируемых на уровне архитектуры си-
стемы, и выбор организации оперативной памяти, над которой
работают процессоры. В зависимости от решения этих вопро-
сов можно отметить две тенденции развития многопроцес-
сорных систем.
Первая тенденция, апробированная на практике и утвердив-
шаяся в ряде разработок, заключается в построении систем с
достаточно мощными процессорами, работающими над общим
полем оперативной памяти при динамической коммутации про-
цессоров и блоков общей памяти. Количество процессоров в таких
системах в значительной степени подвержено техническим
ограничениям.
Вторая тенденция, давно разрабатываемая, но только в пос-
ледние годы намечающаяся в плане возможностей практической
реализации, заключается в организации центральной (обрабаты-
вающей) части системы в виде совокупности упорядоченного
множества относительно несложных микропрограммируемых про-
цессоров и оперативной памяти, локально распределяемой между
ними. Центральная часть системы может рассматриваться как
сплошное поле оперативной памяти с встроенными процессора-
ми, работающими над информацией, находящейся в их окрест-
ностях. Такая организация отличается большой гибкостью и спо-
собностью к адаптации структуры системы к сложной задаче или
к потоку задач при помощи соответствующей интерпретации
структур данных*).
Структура связей здесь перестраиваемая и может быть иерар-
хически упорядочена так, чтобы в "процессе работы отдельные
процессоры комплектовались в структурные группы с соответ-
ствующими связями между ними. Организация динамических
связей может быть поддержана статически, например, путем
придания центральной части системы определенных конструктив-
ных характеристик. В таких системах может потребоваться боль-
шое число процессоров, но более простых по сравнению с первы-
*) Один из вариантов организации подобной структуры (EGPA) рас-
сматривается в п. 8.1.2.
71
/
ми из рассмотренных систем. Получаемые при этом- вычислитель-
ные системы совмещают в себе определенные достоинства
многомашинных и многопроцессорных систем и будут обладать
чрезвычайной гибкостью, обеспечиваемой возможностями их вы-
пуска в различных конфигурациях и перестройки этих конфи-
гураций на уровне процессоров и системы в целом в процессе
ее работы. Основные принципы построения систем такого типа
могут быть сформулированы следующим образом.
Применяются процессоры двух типов — вычислительные и спе-
циальные. Первые являются однородными процессорами с пред-
варительной или оперативной настройкой на определенный ин-
терпретируемый язык при помощи помещаемого в процессор
соответствующего микропрограммного интерпретатора. При этом
интерпретатор внутреннего языка содержится в процессоре по-
стоянно. Обрабатывающая часть процессора, в свою очередь, мо-
жет быть построена на базе микропроцессоров, в перспективе —
в виде одного микропроцессора. Вторые процессоры служат для
установления связей в системе (ее конфигурации на уровне общей
, архитектуры) и для ' непосредственного управления внешним
оборудованием.
При наиболее простом способе локального распределения опе-
ративной памяти за каждым вычислительным процессором за-
крепляется часть оперативной памяти, при этом количество раз-,
рядов «слов в операционных блоках процессора и в его памяти
устанавливается одинаковым и выбирается, исходя из условий
эффективного использования оборудования процессора при ре-
шении задач, не требующих слов с большим числом разрядов.
Ориентировочно можно выбрать слова с 16 разрядами и опера-
тивную память процессора объемом 16 тысяч слов.
Цепочки двух, трех и более соседних по горизонтали вычис-
лительных процессоров могут объединяться при помощи аппарат-
ных средств в процессоры, имеющие соответственно большее
количество разрядов операционных блоков и ячеек оперативной
памяти, что обеспечивает эффективную работу со словами боль-
шой разрядности. Такая организация удобна для решения не-
больших задач, которые могут распределяться по различным
процессорам и программироваться на различных языках высо-
кого уровня.
* Для эффективного решения больших задач устанавливаются
информационные связи между процессорами и каждая задача
распараллеливается по нескольким процессорам, при этом каж-
дый из них реализует соответствующую часть программы и ра-
ботает над своим полем оперативной памяти. Возможно совме-
щение этого режима с рассмотренным выше, т. е. использование
части процессоров для решения небольших задач на каждом из
них и, одновременно, решение одной или нескольких больших
задач, каждая из которых распараллелена по нескольким другим
процессорам.
72
Для обмена между процессорами может быть предусмотрен»
общая шина с разделением ее времени для обслуживаемых про-
цессоров, а для обмена с периферийным оборудованием, а также
для хранения глобальных переменных, часто употребляемых про-
грамм, системных таблиц и другой информации подобного тип£ —
обобщенная буферная память с прямым доступом. Эта память,
должна иметь виртуальное поле и фиксируемые отсеки. При
этом возможно и фиксированное распределение ее части по про-
цессорам, чтобы выделенные им модули памяти являлись про-
должением оперативной памяти процессоров, например, чтобь*
соответствующие диски* являлись второй ступенью оперативной
памяти процессоров.
В целях управления системой один из процессоров выделяется
для организации выполнения программ общей части операцион-
ной системы, назначая для этого свободные вычислительные
процессоры, которые работают над соответствующим полем опе-
ративной памяти и над полями буферной памяти и внешнего
оборудования. Этот же выделенный процессор может перестраи-
вать структуру системы. Локальные части операционной системы
реализуются в специальных управляющих процессорах (контрол-
лерах), а также в вычислительных процессорах в качестве узлов
связи с глобальной частью. Таким образом, управление в системе
организуется как иерархическое с сочетанием глобального и ло-
кального принципов.
В заключение отметим, что систематическое изложение ос-
новных вопросов, связанных с приближением языков машин к
алгоритмическим языкам, которыми должен оперировать поль-
зователь, и с развитием автоматических средств-посредников
(операционных систем, трансляторов, отладочных программ и
т. п.), которые обеспечивают связь между пользователями и ма-
шиной и организуют в целом процесс решения задач, дано
в книге [98] (1970 г.).
Вопросам повышения эффективности вычислительных систем
за счет аппаратной реализации ряда функций, традиционно вы-
полняемых программными средствами, включая реализацию
команд языков высокого уровня, большое внимание уделяется
в сборнике статей по многопроцессорным системам [277]. Так;
например, в первой статье этого сборника [5], посвященной воз-
можностям применения аппаратных средств для повышения эф-
фективности программирования, основное внимание уделяется
вопросам повышения производительности систем за счет реали-
зации с помощью оборудования некоторых функций, обычно реа-
лизуемых программными средствами.
Архитектура многопроцессорной вычислительной системы,
в которой учитываются результаты предыдущей статьи, а также
требования высокой живучести, возможности наращивания про-
изводительности и объемов памяти и некоторые другие, описы-
вается в [14]. Устройства разбиты по нескольким уровням иерар-_
73
хии в соответствии с тем, какую фазу обработки команды вы-
полняет то или иное устройство. На высшем уровне находятся
устройства, осуществляющие непосредственное выполнение ко-
манд, на следующем уровне — устройства подготовки команд к
выполнению и на нижнем — устройства хранения команд и
Данных (память). Память также имеет иерархическую много-
уровневую организацию в зависимости от объема и быстродей-
ствия.
Два соседних уровня системы связаны между собой при по-
мощи канала связи так, что любое устройство данного уровня
может связаться с любым устройством или несколькими устрой-
ствами соседнего уровня. В состав системы входят в качестве
основных устройств следующие: универсальные и специализи-
рованные операционные процессоры, процессоры ввода-вывода,
командные процессоры, сверхоперативные запоминающие устрой-
ства, запоминающие устройства разных типов и периферийное
оборудование.
Проект многопроцессорной вычислительной системы, ориенти-
рованной на язык алгол 60, описан в [813]. Система состоит
из семи основных и четырех вспомогательных процессоров, аппа-
ратно реализующих основные функции по трансляции конструк-
ций языка алгол во внутренний язык в виде польской инверсной
записи. К числу основных процессоров относятся: процессор вво-
да-вывода, сканер-процессор, процессор синтаксического и се-
мантического анализа, процессор доступа к стеку, процессор
обработки строк в польской записи, процессор обработки массивов
и арифметический процессор, а к числу вспомогательных — про-
цессоры проверки синтаксиса, доступа к простым переменным,
доступа к идентификаторам данных и формирования адресов
переходов.
Для обмена информацией между процессорами исполь-
зуются две основные 36-разрядные шины и несколько. вспомо-
гательных сопряжений. Синхронизация процессоров осуществля-
ется при помощи семафоров. Предполагается, что такая система
обеспечит существенное повышение быстродействия при совме-
щении во времени различных функций трансляции и выполне-
ния программ, а также улучшение диагностики при выполнении
программ за счет высокого уровня внутреннего языка. Структура
многопроцессорной системы с непосредственным использованием
языка типа алгол предложена в [711], при этом также предусмат-
риваются процессоры с функциальной специализацией. В 1812]
описана концептуальная система с непосредственной реализацией
языка deaplan без его промежуточного преобразования, содержа-
щая множество специализированных микропроцессоров, процес-
соров ввода-вывода, ленточную и дисковую память и другие уст-
ройства. Направление исследований по построению структур
систем для параллельного выполнения программ, заданных в ви-
де блок-схем, представлено,в [654, 1138] и других работах.
74
В книге 1384] дана подборка аннотаций работ в области ма-
шин с языками высокого уровня, в которой отмечается
следующее.
Конструкция машины на языке фортран предложена в [506]»
Машина имеет команды для выполнения операторов IF, GO TOr
DO, READ, PRINT и других и обеспечивает обработку перемен-
ных с индексами. Детально описывается организация памяти,
загрузка программ и интерпретатор. Введение в описание маши-
ны на языке кобол дано в 1585], при этом упоминаются, но не
описываются детально конструкция машины, дескрипторы и ко-
манды. Машина для языка APL, реализованная при помощи ин-
терпретатора языка APL, который работает на микропрограммном
уровне Модели 25 Системы 360, описана в статье Г808), при этом
рассмотрены представление программ и данных, анализатор
предложений, обращения к функциям, операторы, индексация и
ввод-вывод. Организация машины на языке euler, базирую-
щемся на языке алгол 60, а также ее интерпретатор и компи-
лятор, транслирующий исходные программы в промежуточный
язык, который и интерпетируется в конечном счете, описаны
в L1248J.
В статьях [824] рассмотрена архитектура вычислительных
систем с языками высокого уровня. Дана классификация машин-
ных языков и языков программирования, и приведен обзор си-
стем с архитектурой, ориентированной на языки высокого уров-
ня. Описаны конструкции машин с синтаксически ориентирован-
ной структурой (стековые ЭВМ), примеры машин с реализацией
языка APL и диалектов языков алгол 60 и PL/1, система
SYMBOL-2R, которая непосредственно выполняет программы на
типовом языке высокого уровня, вопросы параллельного-выпол-
нения программ и другие. Отметим также работы 1463, 504, 586,
590, 975, 1157,1242J.
В зависимости от степени близости между входным языком и
машинным языком структуры вычислительных систем можно
классифицировать следующим образом 1592J:
1) структура обычных вычислительных систем (концепция
машины Дж. фон Неймана);
2) синтаксически-ориентированная структура;
3) структура, ориентированная на косвенное выполцеиио
программ;
4) структура, ориентированная на прямую интерпретацию про-
грамм. Вычислительные системы со структурами трех последних
типов обычно относятся к системам с входным языком высокого
уровня, поскольку они способны непосредственно выполнять
программу, написанную на некотором языке высокого уровня.
Обычные вычислительные системы в большинстве случаев ос-
нащены несколькими входными языками высокого уровня»
Как правило, система программирования на языках высокого
уровня является достаточно сложным и объемным программным
75
комплексом. Тем не менее рабочие программы на языке машины,
полученные в результате трансляции, нередко оказываются не-
экономными с точки зрения требуемых машинных ресурсов вре-
мени счета и памяти, что определяется, фактически, суще-
ственным различием между входным и машинным языками.
Кроме этого, хотя и считается обычно, что пользователь должен
знать только входной язык, фактически для отладки, оптимиза-
ции и контроля рабочей программы необходимо в определенной
мере знать все промежуточные языки (загрузки, компоновки и
т. д.) и даже некоторые ^особенности алгоритмов трансляции.
Синтаксически-ориентированная структура была реализована
при разработке модульных многопроцессорных серийных систем
В 5000 и В 5500 фирмы Burroughs. Оборудование системы было
ориентировано на эффективную обработку программ на расши-
ренном алголе и включало аппаратный стек для хранения про-
межуточных операндов и управляющих слов, а также аппаратно
реализованный блок для динамического распределения памяти,
Характерного для программ на алголе. Схема процесса трансля-
ции и исполнения рабочей программы изображена на рис. 2.32.
Вычислительные системы аппаратно интерпретировали проме-
жуточный язык польской инверсной записи, отличие которого
как машинного языка от входного языка (расширенный алгол)
было сравнительно небольшим. Это позволило исключить соот-
ветствующий «слой» программного обеспечения и, как результат,
привело к существенному упрощению программного обеспечения.
Структура, ориентированная на косвенное выполнение про-
грамм, реализована в многопроцессорной экспериментальной си-
стеме SYMBOL, которая разработана фирмой Fairchild и усовер-
шенствована университетом штата Айова (США). Машинный
язык этой системы является языком высокрго уровня,, обеспечи-
вающим возможность обработки операндов переменной длины
без указания их типа и размера, тогда как в системах В 5000 и
В 5500 операнд сопровождается тэгом с указанием в нем, в част-
ности, типа операнда. Система SYMBOL не имеет системы ко-
манд в обычном смысле, поскольку непосредственно обрабаты-
вает программы на языке SYMBOL. Она является функциональ-
но-организованной многопроцессорной системой, в которой аппа-
ратно реализованы транслятор, * редактор текста, форматный
процессор, адресный процессор, супервизор и распределитель па-
мяти. Схема процесса трансляции и исполнение рабочей програм-
мы изображена на рис. 2.33.
Различие между синтаксически ориентированной структурой
и структурой, ориентированной на косвенное выполнение про-
грамм, состоит в том, что в первом случае транслятор с входного
языка в польскую запись (внутренний язык) реализован про-
граммно, 'процессоры в системе одинаковые, и каждый из них
выполняет все требуемые функции (В 5000, В 5500), тогда как
во втором случае транслятор с входного языка в польскую запись
76
Рабоошг
программ
на входном
языке
Входное
устройство
Программный
транслятор
входного тек-
ста в паль -
скую запись
Язык высокого Внутренний Нод в польской Внутренний Внешний
уровня код записи код код
Рис. 2.32. Схема трансляции и исполнения программ в вычислительных системах с синтаксически ориентированной
структурой.
Рис. 2.33. Схема трансляции и исполнения программ в вычислительных системах со структурой, ориентированной
на косвенное выполнение программ.
(внутренний язык) реализован аппаратно, процессоры-в системе
различные, и каждый из них ориентирован на выполнение соот-
ветствующих своих частных функций, обеспечивающих в сово-
купности реализацию требуемой функции обработки в целом
(SYMBOL)*), при этом в каждом из этих случаев синтаксис ин-
версной польской записи разный.
Структура, ориентированная на прямое или непосредственное
выполнение программ, разработанная в Мэрилендском универси-
тете и реализованная в определенной степени в системе В 1700
Рис. 2.34. Схема прямой интерпретации программ.
фирмы Burroughs, характерна тем, что обеспечивает интерпре-
тацию входной программы без какой-либо ее трансляции. Иными
словами, входной язык высокого уровня является собственно ма-
шинным языком системы, и нет необходимости в каком-либо
промежуточном внутреннем языке типа польской записи, нет
языка компоновки программ и языка загрузки. Схема прямой
интерпретации изображена на рис. 2.34. Вычислительная система
сканирует строку за строкой входного текста и непосредственно
интерпретирует программу. Система обладает чрезвычайно высо-
кой производительностью на этапе интерпретации. Различие
между входным языком высокого уровня и машинным языком
практически отсутствует.
Вычислительные системы с прямой интерпретацией оказыва-
ются достаточно простыми вследствие наличия только одного
языка. Они обеспечивают единство языка для разработчиков как
программ, так и аппаратурных схем. Существенно упрощается от-
ладка программ, поскольку фактически нет различий между
входным и машинным языками, при этом режимы отладки и вы-
полнения программ становятся по существу идентичными, так
как этапа компиляции как такового нет. Последнее позволяет
♦) С точки зрения функциональной ориентации процессоров система
SYMBOL реализует черты командно-магистральной обработки.
78
построить новые, основанные на принципе интерпретации (а не
компиляции, как в традиционных системах) системы отладки.
Такие системы отладки оказываются гибкими вследствие свойств
интерпретации, при этом они не будут снижать эффективную
производительность рассматриваемых вычислительных систем
в силу интерпретационного характера выполнения программ в
них, в отличие от случая реализации программ интерпретации на
обычных машинах. Таким образом, обеспечивается возможность
упрощения и удешевления разработки и отладки программ,
а также, в определенной степени, разработки самой вычислитель-
ной системы [592].
В последующих разделах . настоящей книги рассматривается
конкретная организация структур и функционирования ряда па-
раллельных вычислительных систем с языками высокого уровня,
таких как системы Эльбрус, системы фирмы Burroughs и система
SYMBOL.
2.7. Краткий обзор
Применение к многомашинным, многопроцессорным, магист-
ральным, ассоциативным, матричным и подобным им системам
объединяющего названия «параллельные» не является новым.
Так, например, в [827] под параллельными понимаются многома-
шинные, многопроцессорные, матричные, ассоциативные и другие
системы, в которых несколько операций выполняется па-
раллельно.
Первые определения в области параллельных вычислительных
систем и параллельной обработки информации, сохранившие свое
значение до настоящего времени, появились в начале 60-х годов
1456, 520, 631J. Ранние многомашинные и многопроцессорные си-
стемы были проанализированы и описаны в обобщающих работах
в конце 1950-х и начале 1960-х годов. Так, например, в книге
по ЭВМ [1176] описаны системы PILOT, LARC, STRETCH. Ран-
ние системы PILOT, LARC, GAMMA 60, RW 400, TX 2, KDF. 9,
DCS, STRETCH, DEUSE, PERSEUS, объединение машин SEAC
и DYSEAC, IBM 1401 и IBM 7090, системы на базе CPC 3600,
а также семейство В 5000 и системы D -825 и CDC 6600 пред-
ставлены в обобщающих статьях [131, 209, 456, 520, 613, 631,
635] (1958—1963 гг.). Эти статьи, в свою очередь, опираются на
предшествующие им ключевые статьи по каждой из систем и на
статьи, описывающие те или- иные особенности систем. Так, на-
пример, система RDF. 9, в которой была предпринята одна из
первых попыток решения проблем удобства программирования и
которая характерна наличием безадресной системы команд, сте-
ковой памяти, переменного формата команд и регистровой памя-
ти, описана в 1644, 679, 789] (1960—1962 гг.), в более поздней
работе [825] и в других.
79
2.7.1; Обзор монографий, сборников и обзоров [110, 111]. Рас-
смотрим очень кратко некоторые обобщающие материалы по па-
раллельным вычислительным системам, которые, как правило,
целиком посвящены таким системам и затрагивают по нескольку
типов параллельных систем.
Первые монографии, целиком посвященные параллельным вы-
числительным системам, появились, вероятно, в 1966—1967 годах.
В книге [147] (1966 г.) рассмотрена концепция однородных вы-
сокопроизводительных систем на базе вычислительных сред и
приведено несколько примеров реальных параллельных систем:
различного типа того времени (LARC, PILOT, ТХ 2, STRETCH
и другие). Указанная концепция была описана в предшествующей
статье 1146] и других. В книге [334] (1967 г.) описаны однород-
ные структуры для построения логических и вычислительных
устройств. . Ранние многомашйнные системы, предназначенные
для работы в режиме реального времени, и некоторая методоло-
гия исследования таких систем представлены в книге [1141
(1967 г.).
В книге [738J, первое издание которой вышло в 1970 г.,
а второе — в 1976 г., исследуются, наряду с другими, вопросы
повышения производительности систем за счет введения парал-
лельности обработки и рассматриваются системы CDC 6600,
STRETCH и другие. Структура, принципы работы и эффектив-
ность вычислительных систем с несколькими процессорами,
а также примеры системы D 825 и некоторых других описаны
в книге [280] (1971 г.). Систематическое изложение структур
разнообразных вычислительных систем, включая параллельные,
дано в книге 1522] (1971 г.), в которой разработаны стандартные
PMS (Processor — Memory — Switches) и ISP (Instruction Set
Processor) нотации для описания структуры, команд и функциони-
рования систем, приведена 22-мерная классификация вычисли-
тельных систем, а также переизложены ключевые статьи, со-
держащие описания около 40 систем, с использованием введен-
ной стандартной терминологии. Краткое описание семантических
и некоторых синтаксических аспектов PMS и ISP-нотаций со-
держится в 1295]. PMS-нотация использована в материалах
п. 2.2.4 настоящей книги. Вопросы структуры систем с несколь-
кими процессорами, наряду с другими вопросами, изложены в
[26] (1971 г.).
Несколько книг по параллельным вычислительным системам
вышло в 1972 году. В [1571, наряду с другими вопросами, на
базе анализа теории параллельного программирования и возмож-
ных1 структур перспективных систем в качестве первоочередного
претендента на высокопроизводительную вычислительную систему
четвертого поколения была выдвинута однородная система с об-
щей памятью с достаточно развитыми рабочими процессорами,
содержащими в качестве заложенной структуры сложившийся
алгоритмический базис (арифметические действия и отношения
80
над числами, ассоциативный и адресный поиск информации).
Математическое обеспечение для систем такого типа описано
в статье U58J. В книге отмечается также, что в 80-х годах вы*,
числительные среды смогут стать побеждающим конкурентом в
проблеме ^повышения мощности вычислительных средств , и в соз*
дании искусственного интеллекта 1157J.
Вопросы анализа, диспетчеризации и эффективности много*
машинных систем, предназначенных для реализации заранее оп-
ределенного набора алгоритмов, наложены в книге (347J.
Теоретические проблемы, возникающие при объединении ти-
повых машин в вычислительную систему или при проектировании
специализированных систем, изложены с точки зрения связи
структур систем и реализуемых на них алгоритмов в книге 1331J,
а также в предшествующих статьях [329,. 330] и других. В ука-
занную книгу включен обзор по теории алгоритмических струк-
тур и операционных систем вычислительных систем, а также
примеры систем Минск-222, IBM 360/67 и некоторых других.
В книге [368] рассмотрено несколько подходов к построению
структур параллельных систем и подробно описан магистральный
(конвейерный) метод обработки информации.
В книге [947] объемом более 500 страниц дано неформальное
изложение вопросов параллелизма между компонентами машину
между машинами и между частями программного обеспечения
по материалам, в основном, фирмы IBM *). Для однопроцессор**
ных машин рассматриваются возможности совмещения операций
выборки, декодирования и выполнения команд, операций обра-
щения к памяти при помощи чередования адресов, а также воз-
можности совмещения операций при помощи методов буфери-
зации памяти и другие. Для таких систем со сложной структурой,
как CDC 6600, рассматриваются возможности использования
функциональных обрабатывающих устройств и периферийных
процессоров. Параллельность работы на уровне между машинами
исследуется на примере конфигурации системы ASP в составе
машин IBM 360/50 и 360/65 и предшествующего ей типа систем
DCS. Для высокопараллельных систем, таких как SOLOMON/и
ILLIAC IV, рассматриваются проблемы разделения памяти, иден-
тификации процесса, использования команд FORK и JOIN и дру-
гие. В книгу включены также материалы по многопроцессорным
расписаниям, алгоритмам замены страниц памяти, использования
кэш-памяти и другие.
Несколько книг было выпущено в 1974 году. В книгах [218,
395] часть материала посвящена параллельным системам. В пер-
вой из них описаны структура и программное обеспечение боль-
шого числа однопроцессорных систем и около 20-ти разнообраз-
ных параллельных систем, таких, как например, ILLIAC IV,
♦) Рассматривается здесь несколько подробнее других книг в связи
с тем, что она целиком посвящена параллельности систем.
6 Б А Головкин 8.1
В 6500, В 6700, SYMBOL, CDC 6600, CDC 7600, STAR 100. Bo 1
второе издание книги (1978 г.) включены дополнительно мате- »
риалы по новым системам (DAP, CRAY 1 и другие). Вторая из ;
указанных книг содержит в качестве отдельных разделов мате- >
риалы по организации вычислительного процесса в многопроцес- 1
сорных системах и материалы по нескольким параллельным си- 1
стемам (IBM 360/65 МР, В 6500, В 6700, ILLIAC IV, семейство !
UNIVАС 1100). В книге [281J, перевод которой на русский язык (
опубликован в 1976 году, рассмотрена организация многопроцес- *
сорных и многих других параллельных систем в части.аппарату-
ры и, более кратко, программного обеспечения. При изложении
использованы примеры более 100 машин и систем, а в приложе-
нии дано сжатое описание более 20-ти параллельных систем,
таких как PEPE, D 825, В 6700, CDC 6500, модели 72-2Х, 73-2Х
и 74-2Х семейства CYBER-70, DEC 1055 и 1077, STARAN,
OMEN 60, IBM 360/65 MP, IBM 370/158 MP и 168 MP, ASC,
UNIVAC 1108 и 1110. Прогноз развития основных типов парал-
лельных вычислительных систем на период времени до 1990 г.
сделан в книге [1229] и связанных с нею статьях 11230—1232],
при этом в качестве основной характеристики используется про-
изводительность систем. Обзор материалов указанной книги вы-
полнен в 12571. Попытка формализованного анализа и оптими-
зации структур многомашинных и многопроцессорных систем
предпринята в книге [3561.
Крупные матричные, ассоциативные, ортогональные системы и
системы с ансамблем процессоров, такие как ILLIAC IV, STA-
RAN, PEPE, OMEN 60, проект системы SOLOMON, концептуаль-
ные машины Холланда и Унгера, а также области применения,
возможности и анализ развития высокопараллельных и ассоциа-
тивных систем представлены в книге [1222] (1976 г.) и предше-
ствующем обзоре [1221] (1975 г.). Крупные матричные, ассоциа-
тивные и магистральные системы и системы с ансамблем про-
цессоров, такие как ILLIAC IV, DAP, STARAN, STAR 100, ASC,
CRAY 1, PEPE, описаны в [283] (1977 г.); приведены данные о
применении крупных систем и об их производительности.
Однородные среды и структуры рассмотрены в ряде книг [149,
152, 307, 406].
В справочнике по вычислительным машинам [429], первое и
второе издания которого вышли в 1973 и 1978 гг. соответственно,
при изложении материала по ЭВМ семейств ЕС и АСВТ-М ука-
зываются возможности построения на их базе многомашинных и
многопроцессорных систем. Укажем также справочник [1251.
Материалы по параллельным вычислительным системам и.
смежным вопросам представлены в сборниках трудов многочис-
ленных конференций.
В наклей стране периодически проходят конференции по од-
нородным вычислительным системам и средам — см., например,
труды Третьей и Четвертой Всесоюзных конференций [95, ЗОбЪ
82
Институт математики СО АН СССР в течение более пятнадцати
лет периодически выпускает сборник «Вычислительные системы»,
многие выпуски которого целиком или в значительной степени
посвящены однородным вычислительным системам и средам
183—941, включая вопросы концепции, аппаратурной реализации,
программного обеспечения и численных методов.
Состояние отечественной вычислительной техники к середине
1970-х годов, а также проблемы и перспективы ее развития пред*
ставлены в сборнике тезисов докладов Всесоюзной научно-тех-
нической конференции по проблемам электронной вычислитель-
ной техники «ЭВМ-76» [370] и в выпусках сборника «Вопросы
кибернетики» [72, 73], при этом большое внимание уделено мно-
гомашинным и многопроцессорным системам. Описаны состояние
и перспективы развития основных направлений работ в области
вычислительной техники — по высокопроизводительным много-
процессорным вычислительным комплексам, по системам семей-
ства ЕС и по малым управляющим вычислительным системам,
изложены проблемы развития электронной вычислительной тех-
ники. Рассмотрены вычислительные сети, системы передачи данг
пых, автоматизированные системы управления и вычислительные
системы коллективного пользования, периферийное оборудование
и терминалы, элементная база. Системы с перестраиваемой струк-
турой рассмотрены в сборнике [74J.
В 1977 году состоялся научно-технический семинар «Много-
процессорные вычислительные комплексы». Часть докладов, пред-
ставленных на этот семинар, была опубликована [59, 197, 284,
338J.# Тематика семинара охватывала семейство многопроцессор-
ных вычислительных комплексов Эльбрус, многомашинные и
многопроцессорные системы семейства ЕС, многопроцессррные си-
стемы с перестраиваемой структурой и рекурсивные вычислитель-
ные машины, а также вопросы взаимного соответствия структур
вычислительных систем и задач разных классов, численные ал-
горитмы распараллеливания для задач математической физики,,
вопросы распараллеливания вручную и автоматически, методы
построения языков и трансляторов параллельного програм-
мирования.
На научно-технический семинар «Разработки и исследования
рациональных структур вычислительных систем реального вре-
мени» (1979 г.) был представлен ряд докладов по параллельным
вычислительным системам, а именно, по многопроцессорным вы-
числительным комплексам Эльбрус, по комплексироваиию СМ-1
и СМ-2, по микропроцессорным системам с перестраиваемой
структурой и другим вопросам. Часть докладов опубликована в
сборнике материалов семинара [352J.
Институт точной механики и вычислительной техники АН
СССР имени С. А. Лебедева ежегодно выпускает сборники обзо-
ров состояния вычислительной техники за рубежом — см. сбор-
ники за период с 1971 по 1978 годы [174—176, 77—-79, 127, 369,
6* 83
80, 313, 81, 314] соответственно. В этих сборниках, наряду с дру- *;
гимн данными, содержатся основные характеристики большого
числа зарубежных параллельных вычислительных систем различ- •
пого типа, а также описание характерных особенностей некото- ;
рых из них.
Среди конференций, проводимых за рубежом, следует отме-
тить, в первую очередь, ежегодную конференцию по параллельной
обработке информации [1085—10901 (обзор трудов Третьей кон- ’
ференции, состоявшейся в 1974 г., сделан в работе [621). Первая J
конференция, проведенная в 1972 г., рассмотрела доклады, свя-
занные с системой RADCAP, имеющей в своем составе ассоциа- '
тивную систему STARAN. В последующие годы тематика конфе- 7
ренции была существенно расширена, а сама конференция стала 1
«Международной конференцией по параллельной обработке ип- 1
формации». За время с 1972 по 1977 гг. на конференции состоя- ;
лось около 250 докладов, в которых рассматривались системы |
STARAN, ILLIAC IV, PEPE и многие другие, концепции и при-
менения параллельных спс!ем, методы и теоретические вопросы
параллельной обработки и широкий круг других проблем, свя- 1
ванных с методами и средствами параллельной обработки
информации.
Параллельность структур вычислительных систем занимает
одно из центральных мест в тематике ежегодных (кроме 1974 г.)
симпозиумов по архитектуре вычислительных систем, проводи-
мых с 1973 г. [1080—10841. С 1971 г. ежегодно проводятся меж-
дународные симпозиумы по надежности вычислительных систем
и 'процессов [1091 — 1098]. Как известно, структурные методы
повышения надежности базируются на резервировании, кбторое ,
можно рассматривать как один из подходов к построению и при- ;
менению параллельных структур вычислительных систем.
Отметим симпозиум по высокопроизводительным вычислитель-
ным системам и методам организации алгоритмов решения задач i
на таких системах, состоявшийся в 1977 г. [11021, на котором
центральное место отводилось параллельным системам и парал-
лельным методам обработки информации. Наконец, в 1978 г. со-
стоялась первая конференция, посвященная модульным вычис-
лительным системам [1103] (1978 г.). ।
В 1973 и 1977 гг. вышли специальные выпуски журнала
«IEEE Transactions on Computers» [851, 8521, посвященные мето-
дам и вычислительным системам параллельной обработки инфор-
мации. В них содержатся материалы по ассоциативным системам,
системам с перестраиваемой матрицей микропроцессоров и другие.
Специальный выпуск журнала «Communications of the АСМ» за
1978 г. по архитектуре вычислительных систем [603] содержит
описание системы MU 5, семейств VNIVAC 1100, DEC SYSTEM 10
и IBM 370, системы CRAY 1 и других. Специальные выпуски ;
периодического сборника обзоров по вычислительной технике ’
«Computing Surveys» [607, 6101 (1975 г., 1977 г.) посвящены ;
84
4
архитектуре вычислительных систем и вычислительным системам
и методам параллельной обработки информации соответственно.
В первом из указанных выпусков рассмотрены системы с про-
смотром вперед, структуры межпроцессорных связей в вычисли-
тельных системах и сетях, ассоциативные и высокопараллельные
системы, а во втором — структуры ассоциативных и ортогональ-
ных систем, систем с ансамблем процессоров и других.
Вопросам надежности вычислительных систем посвящен вы-
пуск журнала ТИИЭР 1398] (1978 г.), при этом основное вни-
мание уделяется структурным методам повышения надежности.
Рассматриваются параллельные системы PLURIBUS, С. mmp, ,
Cm *, С. vmp, бортовые вычислительные системы и другие.
Разнообразные вопросы параллельных вычислительных систем
изложены в сборниках 1277, 316, 856, 858, 860, 1057J. Так, на-
пример, в [860J, наряду с другими вопросами архитектуры вы-
числительных систем, рассмотрена архитектура некоторых па-
раллельных систем, включая магистральные.
Вопросы архитектуры и операционных систем изложены в
1312], включая описание системы Днепр-2. В [1039] дан обзор
основных понятий и концепций в области операционных систем
и приведены описания 14-ти реальных операционных систем,
в том числе Scope 3 для CDC 6400/6500/6600, Ехес 8 для UN IVАС
1108 и Master Control Program для В 6500. Общие вопросы по-
строения операционных систем и описание ряда конкретных
операционных систем для CDC 6600, В 5500, В 6700, KDF. 9,
UN I VAC 1107/1108, PDP-10 и для других вычислительных систем,
изложены в сборнике докладов, представленных на семинар по
методам построения операционных систем [1040]. Языки програм-
мирования, методы компиляции и компиляторы для высокопа-
раллельных, матричных и магистральных систем, таких как
RADCAP, ILLIAC IV, STAR 100, ASC и MU 5, описаны в [11671.
Перейдем к обзорам. Напомним, что здесь кратко рассмат-
риваются некоторые из комплексных обзоров, охватывающих не-
сколько разделов из области параллельных вычислительных си-
стем и, в редких случаях, из смежных с ними областей парал-
лельной обработки информации.
В короткой статье [456] (1962 г.) были намечены пути по-
вышения производительности вычислительных систем, реализо-
ванные в дальнейшем, рассмотрены методы перекрытия операций
и просмотра вперед^ режимы мультипрограммирования и парал-
лельной обработки и их совмещение, примеры систем ТХ 2, LARC,
RW 400, KF. 9, STRETCH, CDC 6600, GAMMA 60, В 5000, комп-
лекс машин IBM 1401 и 7090. В статье даны определения муль-
типрограммирования как распределения времени единственного
процессорного модуля между различными задачами и параллель-
ной обработки как распределения нагрузки одной или более вы-
числительных работ между двумя или более процессорными
^модулями.
85
Определение, классификация, обоспование целесообразности:
многомашинных систем, а также проблемы анализа и перспекти-
вы развития таких систем изложены в короткой статье [520]
(1962 г.). В качестве примеров представлены системы LARC,
GAMMA 60, G 21, В 5000, CDC 3600, STRETCH, RW 400 и комп-
агекс машин IBM 7040 и 7094..
Краткий обзор многопроцессорных систем и параллельного
программирования на период конца 1950-х и начала 1960-х годов
содержится в [631] (1963 г.). Обстоятельный обзор структур мно-
гомашинных и многопроцессорных систем и программирования
для них на время к началу 1960-х годов сделан в [635] (1963 г.).
Даны описания систем PILOT, LARC, GAMMA 60, RW 400 и
затронуты системы D 825, CDC 3600, В 5000.
Системы с параллельными процессорами переходного периода
развития от ранних к современным, некоторые ранние системы,
а также методы параллельного программирования на период се-
редины и конца 1960-х годов отражены в обзорах [253, 827]
(1966 г. и 1970 г. соответственно). Разнообразные концептуаль-
ные и реальные высокопараллельные системы на период середины
1960-х годов, а также применения систем, методы трансляции
и алгоритмы решения ряда задач на системах указанного типа
рассмотрены в обстоятельном обзоре [1016] (1966 г.). Концепции
высокопроизводительных систем и примеры реальных систем
STRETCH, CDC 6600, IBM 360/91, ILLIAC IV представлены в
кратком обзоре [1155] (1967 г.). Обзор исследований по микро-
электронным однородным структурам представлен ~ в [9901
(1967 г.).
Сравнение структур однопроцессорных, многопроцессорных,
ассоциативных и матричных систем выполнено в [834] (1967 г.),
организация разнообразных вычислительных систем, таких как
KDF. 9, STAR, В 5000, В 6500 и семейство IBM 360, вопросы
векторного программирования и некоторые другие кратко описа-
ны в [505] (1970 г.). Краткий обзор исследований в области
структур вычислительных систем и влияния на них развития
технологии сделан в 1523] (1972 г.), при этом главное внимание
уделяется параллельным системам, таким как ILLIAC IV, STAR
100, STARAN, С. mmp.
В обзоре по формализации понятия программы [156] (1967 г.)
впервые сделано обобщение работ по теории параллельного про-
граммирования. Состояние теории схем программ на период на-
чала 1970-х г.г. описано в докладе [701] (1971 г.) и связанным
с ним обзоре [159] (1973 г.). Недавно выпущены монографии по
террин программирования и лежащей в ее основе теории схем
программ [160, 229] (1977 г. и 1978 г. соответственно).
При параллельном программировании и организации несколь-
ких параллельно выполняемых последовательных вычислительных
процессов возникает проблема их взаимодействия и синхрониза-
ции. Первое решение этой проблемы дано в 1659] (1965 г.). Оно
66
оказалось громоздким, но продемонстрировало, что можно обой-
тись без каких-либо специальных операторов языка. Исследова-
ние проблемы синхронизации * вычислительных процессов и ее
решение с использованием семафоров, методы предупреждения
тупиков и некоторые другие вопросы параллельного программи-
рования изложены в 11331 (1968 г.). Подробное обсуждение кон-
цепции семафоров и мониторов в связи с проблемой синхрониза-
ции содержится в 1660] (1971 г.). К настоящему времени полу-
чено большое число различных решений рассматриваемой про-
блемы, обзор пяти из них сделан д докладе 1о92] (1973 г.).
Недавно выпущена монография [802] (1977 г.), посвященная ме-
тодам эффективного проектирования параллельных программ для
мультипрограммных и многопроцессорных вычислительных си-
стем с ориентацией на разработку программных систем реального
времени и операционных систем.
Вернемся к обзорам. В 1973—1974 гг. вышел ряд достаточно
полных обзоров методов и средств параллельной обработки ин-
формации [228, 287, 493, 880, 9831.
В обзоре прикладных аспектов теории параллельного програм-
мирования [228] (1974 г.) рассмотрены языки, методы и опера-
ционные проблемы параллельного программирования, а также
методы автоматического построения параллельных программ, а в
обзоре [287] (1974 г.) — разнообразные формальные модели па-
раллельных программ. Описание и сравнение трех формальных
моделей параллельных программ, а именно, сетей Петри, вычис-
лительных графов и схем параллельных программ, выполнено в
[983] (1973 г.).
В обзоре теоретических аспектов параллельной обработка
информации 14931 (1973 г.) рассмотрены языки параллельного
программирования, автоматическое распознавание параллельности
в программах, сети Петри, графы, схемы и другие формальные
модели параллельных программ, а также оценка производитель--
мости систем при помощи теории очередей, анализа графовых
моделей и моделирования. В заключение обзора дано краткое
описание концепций параллельных систем и структуры ряда
ш реальных однородных и неоднородных многопроцессорных, а так-
же матричных и магистральных систем. Обзор структур матрич-
ных, многопроцессорных и магистральных систем ILLIAC IV,
С. mmp, С. ai, PRIME, IBM 360/91, CDC 6600, CDC 7600, STAR
100 и других, ряда параллельных методов вычислительной мате-
матики, концепций управления параллельными процессами и
языков параллельного программирования содержится в [8801
(1973 г.).
Матричные, многопроцессорные и магистральные системы, та-
кие как ILLIAC IV, IBM 360/65 МР, IRIS 80, С. mmp, CDC 6600,
CDC 7600, IBM 360/91 и семейство GE 600, рассмотрена в обзоре
[966] (1974 г.). В этой же работе изложены вопросы синхрони-
зации и распараллеливания процессов. Системы с параллельными
> 87
процессорами, а также языки параллельного программирования,
распознавание параллельности в вычислениях и некоторые па-
раллельные численные методы описаны в кратком обзоре [1012]
(1975 г.).
Структура матричных, магистральных и многопроцессорных
систем и соответствующие примеры систем ILLIAC IV,
STAR 100, ASC, С. mmp, GAMMA 60, а также ассоциативная
система STARAN и концептуальная машина с общими ресурсами
Флинна рассмотрены в обзоре [364] (1975 г.). Обзор операцион-
ных систем для таких параллельных вычислительных систем, как
ILLIAC IV, PEPE, MU 5, SYMBOL, SERF, JPL STAR сделан в
1275] (1974 г.), при этом наряду с традиционной программной
реализацией операционных систем определенное внимание уде-
ляется вопросам аппаратурной реализации функций операцион-
ных систем. Обзор структур параллельных систем выполнен - /
в [910] (1975 г.). j
Ряд работ обзорного характера был опубликован в последние j
годы. Концептуальные основы архитектуры вычислительных ей- ]
стем, включая стеки, виртуальность и тэги, обсуждаются в [11181 ;
(1976 г.). Рассматриваются концепции построения матричных и
магистральных систем, систем с модульной структурой и других, .
приводятся примеры систем GDC 6600, ILLIAC IV, ASC, В 6700, <
семейства IBM 370. Вопросы параллельности и скорости работы
вычислительных систем обсуждаются в [1203] (1976 г.). Ассо- ;
циативные, ортогональные и матричные системы, системы с ан- j
самблем процессоров, примеры систем STARAN, RADCAP, APCS,
АААР, RAP, НАРРЕ, OMEN 60, ILLIAC IV, PEPE и других
рассматриваются в [8] (1977 г.). В этой же работе приводятся j
характеристики производительности некоторых из указанных си- ;
стем, рассматриваются области их применения и некоторые спо- ,
собы реализации вычислений на таких системах.
Описание и сравнительный анализ магистральных, матричных
систем и систем с ансамблем процессоров даны в [1193] (1977 г.)
на примерах систем STAR 100, ASC, ILLIAC IV и PEPE. Очень :
краткий обзор параллельных систем х привлечением примеров
систем ILLIAC IV, SYMBOL, С. mmp, STARAN, семейств систем.
фирм Burroughs и CDC, включая систему STAR 100, и других ;
систем приведен в [123] (1977 г.). ;
Краткий обзор параллельных систем и распараллеливания
вычислительных процессов дан в [396J. Рассмотрены магистраль- j
ные и матричные системы, а также многопроцессорные системы :
с общей шиной, с матричным коммутатором и с множественными
шинами.
Структура универсальных и специализированных систем они- ;
сана в [1223J. В качестве универсальных представлены много- *
процессорные системы с общей шиной, с множественными ши- ;
нами и с матричным коммутатором, а также магистральные си-
стемы, включая примеры систем STAR 100, ASC, CRAY L
В аннотированных библиографических указателях [780, 7811
<1976 г.) и в их переформированных и дополненных варианта^
1782, 783] (1977 г.) содержится 207, 227 и 275, 237 резюме работ
по параллельным системам, соответственно, включая вопросы их
разработки и применения, диспетчирования работы, а также по*
строения параллельных методов вычислительной математики. v
В приведенном кратком обзоре затронуты монографии, сбор-
ники и обзоры по паралельным вычислительным системам, при
этом материалы по параллельному программированию и парал-
лельным методам вычислительной математики упоминаются фак-
тически только в тех случаях, когда они сопутствуют материалам
собственно по параллельным системам. В обзоре, как правило,
не упоминались работы, рассмотренные в предыдущих материа-
лах книги. Часть обобщающих работ, в которых описываются
•отдельные типы параллельных систем, рассматриваются в соот-
ветствующих материалах настоящей книги. Краткий библиогра-
фический обзор методов и средств параллельной обработки ин-
формации, включающий как параллельные вычислительные си-
стемы, так и параллельное программирование и параллельные
вычислительные методы, приведен в [111J (1979 г.). Более полный
обзор методов и средств параллельной обработки информации
дан в [110] (1979 г.). Библиография первого из указанных обзо-
ров содержит 433, а второго — 553 наименования работ, в основ-
ном, обобщающего характера.
2.7.2. Обзор схем классификации и структур параллельных
вычислительных систем [109, 110]. Рассмотренная в предыдущих
материалах классификация по признакам одиночного или множе-
ственного потока команд и данных [410], основу которой состав-
ляют классы ОКОД, ОКМД, МКОД, МКМД, была детализирова-
на в работах [733—735], при этом в первой из них была рас-
смотрена также классификация, названная макроскопической,
согласно которой системы разделяются с учетом количества по-
токов команд и данных, характеристик матрицы взаимодействия
указанных потоков, величин коэффициентов инерции вычисли-
тельных процессов и длительностей выполнения команд.
Классификация систем на базе классов ОКОД, ОКМД, МКОД,
МКМД используется в [31, 188, 281, 368, 493, 494, 796, 800, 821,
827, 880, 1203, 1221—1223, 1229] и во многих других работах.
Детальная классификация систем типа ОКМД приведена и про-
анализирована в [821, 1221—1223]: выделены матричные систе-
мы, системы с ассоциативными процессорами и с ассоциативной
памятью, ортогональные системы, системы с ансамблем процес-
соров, при этом в [1221], например, дана обстоятельная иерархи-
ческая схема классификации структур систем типа ОКМД.
В [1229], наряду с обычной классификацией для систем типа
ОКОД, ОКМД, МКОД и МКМД, отмечается, что к системам типа
МКМД относятся территориально разнесенные, вычислитель-
ные сети.
Перечисленные схемы классификации отражают функциональ-
ные характеристики систем и учитывают конкретные способы >
параллельной обработки информации, реализуемые в вычисли-
тельных системах. Подобного рода схемы, охватывающие те или
иные классы систем, рассматриваются в ряде работ с различных
точек зрения.
В [1016] выделяется четыре класса систем высокопараллель-
ной обработки информации, первый из которых составляют систе-
мы со структурой параллельной сети, такие как проект
SOLOMON, второй — системы со структурой в виде сети с рас-
пределенным управлением, такие как концептуальная машина
Холланда, третий — специализированные системы типа ассоциа-
тивных, для распознавания образов и другие, а четвертый — си- ,
стемы с множественным потоком команд или же многофункцио-
нальные системы, такие как концептуальные машины Эстрина,
Конвея и другие. В [947] различаются высокопроизводительные
однопотоковые системы, как например, SOLOMON и ILLIAC IV,
многомашинные и многопроцессорные системы, при этом реаль-
ная параллельность функционирования таких систем сопостав-
ляется с кажущейся параллельностью функционирования, при
которой работа осуществляется последовательно, но программное
обеспечение организует работу так, что для пользователя она
представляется параллельной.
Три типа систем — матричные, многопроцессорные, а также
с опережающим просмотром, чередованием адресов и магистраль-
ной обработкой арифметических выражений — рассмотрены в
[880]. Схемы классификации, близкие к упомянутой схеме, ис-
пользованы в [966, 1211]. В первой работе выделяются матричные
системы, магистральные системы с независимыми процессорами,
а во второй работе среди высокопроизводительных систем выде-
ляются магистральные, среди которых различаются скалярные
системы, такие как CDC 7600 и IBM 360/195, и векторные систе-
мы, такие как STAR 100 и ASC.
Рассматривая возможности параллелизма работы управляю-
щих модулей, функциональных обрабатывающих модулей и па-
раллельность потоков данных, в [827] вводятся четыре класса
систем — многомашинные и многопроцессорные, ассоциативные,
матричные, функциональные,— на базе которых строится обстоя-
тельная классификация с многочисленными примерами систем.
Эта классификация кратко Воспроизведена в работах [1221, 1223].
Функциональные характеристики систем и реализуемые в них
способы параллельной обработки информации находятся в опре-
деленной взаимосвязи со структурными характеристиками си-
стем, включая степень связанности элементов систем и тип свя-
вей меж/{у Ними. Рассмотрим схемы классификации, основанные
на структурных характеристиках систем.
В одной из первых схем классификации*(520] (1962 г.) мно-
гомашинные системы характеризуются по двум основным приз*
90
лакам, а именно — по признаку распределения и иерархии функ-
ций между машинами системы и признаку типа связей между
машинами. Первый признак определяет две главные возможности:
иерархические системы, в которых один или несколько процес-
соров являются центральными, а другие — специализированными
(пример PHILCO S 2000—2400), и распределенные системы, ко-
торые содержат два или более эквивалентных по мощности про-
цессора (пример RW 400). Второй признак определяет два глав-
ных подхода: а) принцип, используемый в подстанциях связи,—
иерархия уровней, наличие коммутаторов (в том числе в виде
памяти) для установления связи с периферийными машинами;
б) принцип централизованной связи, основанной на звездообраз-
ной конфигурации с центром и виде коммутатора и с окончания-
ми лучей в виде периферийных и центральных процессоров. Вы-
деляются также системы с одной шиной для обмена информа-
цией и системы с перекрестной (матричной) коммутацией связи
(такой, как в RW 400).
Три типовые конфигурации связей — перекрестная, много-
шинная для модулей памяти с множественным доступом и одно-
шинная с распределением в ней информации во времени — вы-
делены в [6351 (1963 г.) — см. п. 2.4.2, а также см. [613]. Такие
типы конфигураций связи, как перекрестные, одношинные, ради-
альные, древовидные, линейные и матричные, а также симмет-
ричные (связь каждого элемента с каждым), рассмотрены в [261.
В качестве основных структур связей в многопроцессорных рас-
пределенных системах в [1181] называется двухэлементная
структура со связью от элемента к элементу, многоэлементная
структура с общей шиной связей, структура в виде звезды,
иерархическая структура в виде дерева, циклическая структура
и структура с полны'м набором связей между каждой парой мно-
жества элементов, а в качестве общих структур — многоэлемент-
иая структура с двойной шиной связей, структура с общей
памятью и структура с перекрестными связями матричного комму-
татора. Наиболее полная й~ логически завершенная классифика-
ция вычислительных систем и сетей на базе конфигураций
связей дана в [460, 461] — см. п. 2.4.1. Классификация распреде-
ленных вычислительных систем, очень близкая к указанной вы-
ше, представлена в [771].
В основу обширной иерархической классификации вычисли-
тельных систем [47] положены признак конструкции — разде-
лимость (как у многомашинных систем, когда каждая из ЭВМ
системы может работать самостоятельно) и неразделимость (как
у многопроцессорных систем, когда каждый из процессоров может
выполнять свои функции только в составе системы) и признак
однородности/неоднородности систем (процессоры цли ЭВМ си-
стемы идентичны цли неидентичны соответственно). Эти два дву-
значных признака определяют четыре основных класса систем:
1) однородные неразделимые системы (ILLIAC IV);
91
2) однородные разделимые системы, иначе — однородные
комплексы (Минск-222, построенная на основе машин Минск-
2/22, выполняющих функции основного и вспомогательного про-
цессоров);
3) разнородные неразделимые системы (некоторые модели,
построенные на базе АСВТ);
4) разнородные разделимые системы (КЛАСС и INTIP, кото-
рая состоит из двух четырехпроцессорных однородных нераздели-
мых систем PHILCO 2000-212, машины GE 235, периферийных
машин GE 115, IBM ИЗО и др.).
Признаки однородности/неоднородности и универсальности/
/специализированности систем используются в обстоятельной
классификации [493], которая содержит четыре основных класса
(здесь и далее перечисляются как реальные, так и концептуаль-
ные системы):
1) однородные универсальные многопроцессорные системы
(идеальная машина IT, машина Холланда, машина блочного типа,
«распределенный» процессор);
2) неоднородные универсальные многопроцессорные системы
(PILOT, машина с переменной структурой Эстрина, макромо-
д^льные машины IBM 360/91, CDC 6600, CDC 7600, машина с об-
щими ресурсами Флинна, истинный мультипроцессор IMP,
STRETCH, GAMMA 60);
3) матричные системы (SOLOMON I и SOLOMON II,
ILLIAC IV, VAMP);
4) магистральные системы (IBM 360/91 — оба модуля с ариф-
метикой с плавающей запятой, CDC 7600 — все девять процессор-
ный модулей, STAR 100, ASC, MU 5).
Первый из указанных классов разделяется на три, таких же
как в [635], подкласса: а) системы с матричным (перекрестным)
коммутатором — RW 400, D 825, В 5700, модели В 6700, машина
Шварца; б) системы с множеством соединительных шин —
CDC3600, UNI VAC 1108, PHILCO 213, IBM 360/67, IBM 9020,
HIS(GE)645 MULTICS; в) системы с разделением времени ши-
ны — LARC, CDC 6600 (в части связей между периферийными
процессорами и основной памятью). На такие же три класса раз-
деляются многопроцессорные системы в [694], при этом указан-
ные системы рассматриваются как подкласс класса МКМД.
Подход к классификации с точки зрения соединений машин
и процессоров в единую систему наиболее подробно изложен, по-
видимому, в книге [281]. Отметим только, что выделены системы
с общей или разделенной во времени шиной (машины PDP Ис
шиной связи UNIBUS, STRETCH, LARC, CDC 6600 в части свя-
зей между центральной памятью и периферийными процессора-
ми и др.), системы с перекрестной коммутацией (Н 4400,
IBM 360/75, D825, В 5500, В 6700, В 7700, RW400, PRIME,
CDG6600 в части связей между периферийными процессорами и
каналами ввода-вывода и др.), многошинные многовходовые си-
92
стемы (IBM 360/67, UNI VAC 1108, HIS 635, CDC 3600, XDS
SIGMA 7, HIS(GE) 645 MULTICS), асимметричные и неоднород-
ные системы (PILOT, CDC 6600, CDC 7600, IMP, машина Эстри-
на и др.), системы с магистральной обработкой (ASC, STAR 100,
IBM 360/9L CDC 7600), параллельные, матричные и векторные
системы (SOLOMON I и SOLOMON II, ILLIAC IV, STARAN,
PEPE, OMEN 60) и системы, ориентированные на устойчивую к
сбоям и отказам работу (JPL STAR, SIRU, EXAM, ACGN),
а также виртуальные процессоры (периферийные процессоры си-
стем CDC 6600 и ASC, центральные процессоры систем MRX 40
и 50) и множественные арифметические устройства (функцио-
нальная параллельность центрального процессора системы
CDC 6600 — 10 функциональных блоков). Отметим, что первые
три класса соответствуют схеме классификации [635], при этом
классификация в целом близка к классификации [493], но явля-
ется более детальной.
В книге [147] вычислительные системы классифицируются по
назначению — на проблемно-ориентированные и универсальные,
по конструкции — на однородные, неоднородные и смешанные, по
структуре — па системы с жесткой и переменной структурой и
ло уровню распараллеливания — на малые, средние и большие.
При этом однородные вычислительные системы подразделяются
па проблемно-ориентированные (машины Унгера и Холланда^ си-
стема SOLOMON) и универсальные. Последние, в свою очередь,
подразделяются на три подкласса: системы малой и средней про-
изводительности (комплекс машин SEAC и DYSEAC, системы
LARC, STRETCH, PILOT, комплекс Систем CDC 3600), сети тер-
риториально разнесенных систем, а также системы с переменной
структурой (ТХ 2, машина Эстрина). Системы с переменной
структурой классифицируются в книге более детально.
Классификация систем по признакам степени централизации
вычислений, закрепления функций за отдельными вычислитель-
ными средствами (с жестким и плавающим закреплением), сте-
пени однородности (однотипные, однородные, неоднородные и
унифицированные), временного, режима работы (оперативный —
в реальном масштабе времени и неоперативный) и организации
информационного обмена (параллельный, последовательный и
параллельно-последовательный коды для обмена, наличие или
отсутствие коммутационных ЭВМ в составе системы) дана в кни-
ге [114].
В работе [1015] рассматриваются системы с параллельными
процессорами трех классов: универсальные сети машин (с общим
централизованным управлением и с независимо выполняемыми
командами на идентичных процессорах), специализированные се-*
ти машин с глобальным параллелизмом (процессоры Для распоз-
навания образов, ассоциативные процессоры и др.) и негдобаль-
пые полунезависимые сети с локальным параллелизмом. Эта
классификация кратко воспроизведена в [827, 1221, 1223].
93
Шесть классов многопроцессорных систем выделены в книге
(2801: системы с соподчинением (DCS, GUS); системы с маши-
ной-диспетчером (NTDS, машина для комплексирования несколь-
ких ЦВМ [191]); однородные системы (OBC.I147J, D825, В 8500);
дуплексные и дуальные системы (дуплексная система двух ма-
шин IBM 7090 для системы BMEWS); системы с переменной
структурой (машина Эстрина); высокопараллельные системы (ма-
шина Холланда).
По территориальному признаку классифицируются системы и
работе [294], в которой выделяются распределенные по террито-
рии системы (сети) и локальные системы, причем последние под-
разделяются на системы с функциональной специализацией ма-
шин (ДНЕПР-2), с распараллеливанием, а также с резервирова-
нием и дублированием.
Деление систем на два класса — федеративные и интегриро-
ванные — дано в [629] и воспроизведено в [281]. Первые состоят
из нескольких машин, каждая из которых предназначена для вы-
полнения какой-либо частной задачи, а вторые состоят из про-
цессоров о общей основной памятью и могут работать в мульти-
программном режиме, выполняя при этом каждую задачу в мно-
гопроцессорном режиме.
“ В книге [142J приводится классификация систем:
а) пр назначению — универсальные и специализированные;
б) по типу машин и процессоров — однородные и неодно-
родные;
в) по степени территориальной разобщенности — совмещенно-
го типа и разобщенного типа (вычислительные сети);
г) по постоянству структуры — с постоянной и переменной
структурой;
д) по степени централизации управления — с централизован-
ным, децентрализованным и смешанным управлением;
е) по принципу закрепления функций за отдельными маши- '
нами (процессорами) — с жестким и плавающим закреплением
функций.
Классификация многомашинных систем в зависимости от фи-
зической структуры, принципов построения, принципов управ-
ления, режима работы и назначения дана в (193J. Пять основных
классов вычислительных систем, в которых реализована в той
или иной степени идея параллелизма, рассматриваются в [1056]:
многопроцессорные системы, системы с ассоциативными злемен- *
тамй, распределенные управляющие системы, магистральные си-
стемы и многомашинные сети. я
Функционально-распределенные системы разделяются в [8771 :
иа однородные и неоднородные системы и сети, территориально !
разнесенные сети, универсальные и специализированные системы
и другие: J
Наиболее полной является, по-видимому, классификация [331], ‘
в которой учитываются шесть, признаков структурной и двена-
дцать признаков функциональной классификации. Первые при-
знаки определяются способами:
а) организации обмена системы с внешней средой — через
специальную или любые машины (модули);
б) хранения программ и входных данных — в одном заранее
отведенном или в любом месте;
в) организации обмена между машинами внутри системы —
через специальную или любые машины;
г) централизованного или непосредственного обмена между
машинами того или иного типа информации — управляющей,
программной и числовой (два признака);
д) построения структуры памяти — общая или разделенная
среди машин оперативная и внешняя память. В классификации
указываются также промежуточные способы решения перечислен-
ных вопросов.
В соответствии со структурной классификацией системы раз-
биваются на четыре основных класса: абсолютно централизован-
ные, абсолютно децентрализованные, централизованные и децен-
трализованные.
Признаки функциональной классификации определяются:
а) режимом работы — запрос/ответ,, параллельный, пакетный
и разделение времени (4 признака);
б) уровнями внешнего, системного и машинного языка
(3 признака);
в) организацией обмена информацией с внешними источника-
ми и пользователями и формирования очередей — при обмене
процессор простаивает или продолжает решение задачи, имеется
или отсутствует возможность прерывания, глубина прерывания
больше 1 или не допускаются прерывания в прерывании, имеется
или отсутствует механизм формирования очередей на обслужива-
ние в системе (4 признака);
г) оперативностью обработки — в реальном масштабе време-
ни или без такой регламентации (1 признак).
Характерной особенностью этой классификации является то,
что значениям признаков сопоставлены условные количественные
величины и на этой основе предложены количественные оценки —
* две функции структурных и функциональных возможностей си-
стем [331].
Классификация вычислительных систем по степени связанно-
сти процессоров дана в [196, 881]. Первый класс составляют
асинхронные системы, в которых каждый процессор имеет от-
дельное устройство управления, отдельную программу и имеет
независимый от других ритм работы. Обмен между процессорами
производится либо через каналы ввода-вывода, либо через общую
память, либо по специальным каналам связи, при этом во всех
случаях требуется предварительная синхронизация процессоров.
Примеры — объединения систем CDC 3600 и систем семейства
IBM 360, система CDC6600, а также ОВС, изложенные в 1147].
95
Во втдрой класс входят синхронные системы, в которых име-
ются отдельные программы и устройства управления для каждо-
го процессора, при этом? существует общий для всех-процессоров
ритм работы, определяемый единым задающим генератором. Та-
кие системы могут работать и как асинхронные, но при необ-
ходимости в них устанавливается синхронизм и тогда обмен меж-
ду процессорами производится в каждом такте без какой-либо
дополнительной синхронизации.
Системы с общим управлением составляют третий класс.
Арифметические и запоминающие устройства процессоров таких
систем связаны с одним устройством управления и управляются
общими командами. Здесь невозможен раздельный (асинхронный)
режим работы процессоров, когда каждый из них выполняет
свой относительно независимый участок алгоритма.
Четвертый класс составляют системы с общим кодом опера-
ций, в которых несколько процессоров соединены с общим уст-
ройством управления так, что все они выполняют одну и ту же
команду — каждый над своими операндами. Примеры — системы
SOLOMON и ILLIAC IV.
Кроме этих четырех характерных классов, rf [196, 881] рас-
смотрены также варианты с комбинациями признаков указанных
классов.
Классификация систем, которая, как и предыдущая, опира-
ется на степень и уровень связанности процессоров, приведена
в [744] — см. п. 1.2.
В [494] рассматриваются многопроцессорные (не многомашин-
ные) системы на основе классификации ОКОД — ОКМД —
МКОД — МКМД [410] и предпринимается попытка включить в
нее элементы классификации на базе структурных признаков.
В классе ОКМД выделяются матричные и ассоциативные систе-
мы и обрабатывающие ансамбли, а к классу МКОД относятся ,
магистральные системы (функциональные блоки — сумматор с
плавающей запятой и умножитель в IBM 360/91, системы
STAR 100, ASC и др.). Особое внимание уделяется классу МКМД,
при анализе структуры систем которого в качестве ключевых вы- 1
деляются факторы организации связи между процессорами и мо-
дулями памяти и степень однородности процессоров (обрабаты-*
вающих модулей).
В системах МКМД с непосредственной связью число процес- j
соров фиксировано и они функционируют обычно под жестким
управлением устройства управления с аппаратной реализацией j
его функций, при этом характерна неоднородная структура с при- j
менением множества специализированных обрабатывающих мо- j
дулей — сумматоров, умножителей и т. п. (CDC 6600, CDC 7600» 1
IBM 360/91). Если же функции устройства управления выполни- |
ет операционная система, то процессоры в системе обычно вы- 1
полняют несвязанные задачи (мультисистемы IBM 360 и 370, |
системы UNIVAC 1108 и 1100k
96 3
Отмечается, что непосредственные связи.характерны только
для очень больших систем, а в современных однородных много-
процессорных системах преобладают тенденции к ослаблению
связей и построению более свободных модульных структур. При
этом указываются три типа организации связей — координатная,
т. е. с перекрестной коммутацией любого процессора и любого
модуля памяти (С. щтр), с разделенными шинами и с много-
входовыми блоками памяти, когда каждый процессор имеет дос-
туп по собственной шине ко всем блокам памяти (многопроцес-
сорная ЭВМ в узле сети ARPA). Напомним, что это соответст-
вует схеме [635].
Отмечается взаимное проникновение характерных черт систем
одних классов в системы других классов. Подчеркивается, что
магистральные системы могут быть отнесены как к классу
МКОД, так и к классу ОКМД и, по совокупности, к классу
МКМД и что неизвестны системы, которые можно было бы от-
нести только к классу МКОД и ни к какому другому. Отмечает-
ся также, что* фиксированность числа процессоров и жесткое ап-
паратное управление в системах с непосредственной связью меж-
ду процессорами и модулями памяти характерны для матричных
и магистральных систем [494].,
Вопросы универсальности связей в системах исследуются в
[1163, 1164]. Связи полагаются универсальными, если они спо-
собны мЪделировать любые межпроцессорные соединения. Анали-
зируется универсальность пяти различных структур связей, ко-
торые используются в системах ILLIAC IV, STARAN, OMEN 60,
SIMDA и RAP. Эффективность некоторых соединений между
процессорами и памятью рассматривается в [1251]. Способы сое-
динения отдельных вычислительных систем в единую систему
при помощи линии связей, путем объединения каналов, памяти
и т. д. обсуждаются в [279], при этом исследуются принципы
соединения процессоров, находящихся на близких расстояниях
друг от друга, а также принципы самого тесного соединения мно-
гих процессоров некоторого целевого назначения в полипроцес-
сорные системы многоцелевого назначения. Рассматривается по-
липроцессорцая система PPS 1.
Несколько классов структур многопроцессорных систем и че-
тыре способа управления многопроцессорными системами пред-
ставлены в [845]. Рассматриваются структуры систем с общей
многомодульной и многовходовой памятью и с чередованием ад-
ресов, характерные просмотром вперед команд. Такие структуры,
используются для универсальных систем. Рассматриваются так-
же практические примеры проектирования систем с учетом спе-
циальных требований к их аппаратуре, возможностей построения
шин, организации интерфейса и разделения памяти и перифе-
рийного оборудования, затрагиваются вопросы надежности систем
во взаимосвязи с отношением их производительности к стои-
мости.
7 Б. А. Головкин 97
Систематический. подход к построению структур связей в вы-
числительных системах предложен в [1219L Предварительно
формулируются функциональные требования и спецификации для
системы, после чего выполняются следующие пять шагов анализа
и выбора:
1) типа и количества шин;
2) методов управления связями;
3) способов организации связей;
4) принципов передачи информации;
. 5) ширины шин (количества проводов в шинах).
На первом шаге на основе функциональных требований и спе-
цификации для вычислительной системы решается принципиаль-
ный вопрос о построении раздельных (индивидуальных) и/или
совмещенных (общих) шин для информации различного вида.
При этом учитываются такие факторы, как необходимая пропуск-
ная способность, стоимость кабелей, разъемов и т. п., сложность
управления обменом, сложность организации связей, надежность,
модульность и готовность. На втором шаге, с учетом результатов
первого шага, выбирается один из методов централизованного
или децентрализованного управления связями. Выбор синхрон-
ного, асинхронного или смешанного способа организации связей
осуществляется на третьем шаге в зависимости от необходимой
пропускной способности, стоимости, надежности, скорости, кото-
рую может обеспечить элементная база, эффективноствГ исполь-
зования шин, возможных принципов передачи информации п
длин шин.
На четвертом шаге проводится выбор принципов передачи
информации с учетом как результатов предыдущих шагов, так
и возможностей аппаратурной реализации алгоритмов обмена и
требований к нему в совокупности с программными средствами
и реализуемым распределением памяти. Выбор количества про-
водов в шинах, осуществляемый на пятом шаге, определяется,
в основном, требуемой пропускной способностью с учетом стои-
мости, надежности, способа организации связей и возможностей
аппаратуры.
Прохождение шагов не является обязательно последователь-
ным: возможны, в целях уточнения или пересмотра решений,
возвраты к предыдущим шагам с последующими пропусками тех
ранее выполненных шагов, принятые решения на которых не
подвергаются пересмотру. В конечном счете после выполнения
пятого шага, если не требуется возврат к одному из предыдущих-
шагов, осуществляется переход к детальному проектированию
связей на базе результатов пяти рассмотренных шагов.
В работе 11219] рассматриваются также типы структур связей/
подробно излагаются вопросы синхронизации и приводится соот-
' ветствукццая аннотированная библиография около 100 работ.
Обзоры схем классификаций вычислительных систем выпол-
нены в 1109—111, 281, 778, 866, 1221 — 1223] и других работах.
3. МНОГОМАШИННЫЕ И МНОГОПРОЦЕССОРНЫЕ
СИСТЕМЫ
НА БАЗЕ ОДНОПРОЦЕССОРНЫХ ЭВМ
ЗЛ. Концепция и ранние системы
3.1 Л. Концепция комплексирования однопроцессорных ЭВМ.
Не повторяя сказанного ранее о концепции комплексирования
однопроцессорных ЭВМ, отметим, что в основе этой концепции
лежит сравнительная оценка возможностей однопроцессорных
ЭВМ, многомашинных и многопроцессорных систем. Один из
наиболее известных вариантов такой оценки разработан в [12651
и воспроизведен в [281].
Рассмотрим некоторую стандартную однопроцессорную ЭВМ,
которую обозначим через [р + т], где р и т — ее стандартные
процессор, и оперативная память соответственно. Пусть теперь
Р — процессор с удвоенной производительностью по сравнению
с р, а М — оперативная память с удвоенными емкостью и про-
пускной способностью каналов по сравнению с т. Рассмотрим,
кроме стандартной’ЭВМ, однопроцессорную ЭВМ со стандартным
процессором р и удвоенной памятью М и однопроцессорную ЭВМ
с процессором удвоенной производительности Р и удвоенной па-
мятью Л/, которые обозначим через [р + М] и [P + Jf] соответ-
ственно. Наконец, рассмотрим совокупность двух стандартных
ЭВМ, которую обозначим через [2(р + т)], и двухпроцессорную
систему, состоящую из двух стандартных процессоров р и общей
для них оперативной памяти удвоенной емкости Л/, которую обо-
значим через [2р + Л7]. Перечисленные конфигурации изображе-
ны на рис. 3.1.
Результаты сравнительной оцейки четырех последних систем-
ных структур приведены в таблице 3.1. В этой таблице исполь-
зованы следующие условные, обозначения для качества системных
структур по указанным в таблице критериям: 0 — обычные воз-
можности, 1 — улучшенные возможности и, наконец, 2 — самые
лучшие возможности, обеспечиваемые рассматриваемыми струк-
турами (оценки О, 1 и 2 не содержат смыслового значения кон-
кретных чисел).
Из данных таблицы видно, что двухпроцессорная конфигура-
ция [2р + М] обладает' некоторыми преимуществами и определен-
ных областях, однако надо иметь в виду, что ее производитель-*
ность не достигает удвоенной производительности конфигурации
7* 99
[p + m], т. e. производительности конфигурации [Р+Л/]. Следу-
ет отметить, что двухпроцессорная конфигурация с общей па-
мятью [2р + М} равноценна другим конфигурациям или превос-
ходит их по критериям критической готовности, выполнения осо-
бо трудоемких заданий и работы в условиях кратковременных
. а)[р*т1 б)[р*м]
г)[2(р+т)] В)[2р+М]
Рис. 3.1. Варианты системных конфигураций. '
перегрузок, т. е. при пиковых нагрузках. Недостаток этой
конфигурации по критерию частоты перезапуска системы явля-
ется следствием повышенной сложности ее операционной систе-»
мы и других управляющих механизмов, что может приводить к
Таблица 3.1
Сравнительная оценка системных структур
[2р+М] [р+М] [2 (РЧ-m)] СР+М]
Производительность 1*) 0*) 1*) 2
Защита (надежность хранения) наиболее важных данных 0 0 2 (для дуб- лирования систем) 0
Частота перезапусков системы при выполнении заданий 0 2 1 неизвестно
Критическая готовность систе- мы 2 0 1 0
Выполнение особо трудоемких заданий и работа при пиковых нагрузках 2 1 0 2
♦) Получены в результате измерений; остальные данные получены в ре-
зультате теоретических оценок.
необходимости относительно брлее частых перезапусков. Нако-
нец, меньшая надежность хранения данных в такой конфигура-
ции по сравнению с парой продублированных машин определя-
ется собственно дублированием.
Приведённые качественные сравнительные оценки относятся
к таким системам, для которых не ставится цель достижения
100
сверхвысокопропзводительной обработки информации. В послед-
нем случае, начиная с некоторого уровня производительности,
обработку могут обеспечить только те или иные параллельные
системы.
Вопросы производительности и связанные с ними вопросы
стоимости параллельных систем рассматриваются в главе 8.
Как отмечалось в главе 2, в Современных однопроцессорных
ЭВМ могут предусматриваться четыре уровня комплексирования:
па уровне процессоров для синхронизации и управления, на уров-
не каналов ввода-вывода при помощи адаптеров, на уровне опе-
ративной памяти (за счет возможностей многовходовой памяти)
п на уровне внешней памяти, при этом может допускаться лю-
бая или некоторые комбинации уровней комплексирования. Такая
концепция реализуется в тех или иных моделях семейств
ЕС ЭВМ, IBM 360 и 370. При комплексировании на уровне опе-
ративной памяти основной является двухпроцессорная конфигу-
рация, хотя возможны конфигурации с ’большим числом про-
цессоров.
Исторически первыми были созданы однопроцессорные сис-
темы, хотя идеи параллелизма обработки информации возникли
практически одновременно с идеями построения самих вычисли-
тельных машин. Так, по данным [906, 913], еще в середине про-
шлого века Ч. Бэббидж отмечал возможность совмещения длин-
ных серий идентичных вычислений.
Первая экспериментальная многомашинная система появи-
лась, по-видимому, в 1954 г. [147, 209], когда под руководством
А. Л. Лейнера были непосредственно связаны между собой две
обычно самостоятельные вычислительные машины SEAC и
DYSEAC [82, 452, 923]. Эти машины различны по своей конст-
рукции, но система кодирования чисел и команд у них одинако-
вая. Соединение машин SEAC и DYSEAC было выполнено таким
образом, что каждая из. них вела себя так, как если бы она была
устройством ввода-вывода для другой. Получилась система, с ус-
пехом справлявшаяся с задачами, с которыми каждая машина
в отдельности едва ли могла бы справиться.
Краткий библиографический обзор многомашинных систем
содержится в [110, 111J.
В главе I были рассмотрены некоторые ранние системы, по-
строенные на базе однопроцесорных ЭВМ. Рассмотрим теперь
системы Минск-222, КЛАСС и Днепр-2.
3.1.2. Система Минск-222 [150]. Система Минск-222 разработа-
на Институтом математики СО АН СССР совместно с конструк-
торским бюро завода им. Г. К. Орджоникидзе (г. Минск).
Она является многомашинной и строится па основе ЭВМ
Минск-2 или Минск-22 путем их объединения при помощи (за-
мыкаемых в кольцо) линейных связей между произвольным чис-
лом ЭВМ в пределах от 2 до 16' (предусмотрена также однома-
шинная конфигурация). Первый образец системы был создан
101
в 1966 г. Структурная схема системы Минск-222 изображена
на рис. 8.2.
Связь ме'жду машинами осуществляется через каналы и си-
стему коммутации. Система коммутации образуется из коммута-
торов (К), распределенных цо машинам системы. Коммутатор
реализует такой набор соединительных функций, который позво-
ляет организовать связь данной машины с ближайшими соседя-
ми. Вид соединительной функции определяется содержимым ре-
гистра настройки (PH). Коммутатор и ЭВМ, дополненная бло-
ком реализации системных операций (БОС), составляют элемен-
тарную машину системы.
Системные операции реализуются "командами, добавляемыми '
к системе команд ЭВМ Минск-2/22, и позволяют организовывать
и изменять взаимодействие ЭВМ в процессе функционирования
системы при помощи изменения содержимого,регистров настрой-
ки, организации обмена информацией между машинами и дру-
гих действий. Стоимость системных устройств не превышает 1%
стоимости группы объединяемых ЭВМ.
Для системы Минск-222 было разработано программное обес-
печение, опирающееся на программное обеспечение базовых ЭВМ,
входящих в ее состав. При решении прикладных задач был на-
коплен опыт работы с многомашинными системами.
Из сказанного видно, что система Минск-222 относится к
классу МКМДС/НсОрКн — система с множественными потоками
команд и данных, с пословной обработкой, с низкой степенью
связанности и однородной структурой, со связями между маши-
нами при помощи каналов (при этом связи линейные — между
каждой парой соседних ЭВМ).
Библиографическая справка*). Система Минск-222
описана в ключевой статье [148], в статье [150], в книге [331], ~
--------j----
*) В эту и в последующие библиографические справки, в целях удоб-
ства пользования ими, включены, как правило, как повторные ссылки на
те работы, материалы которых непосредственно использовались при напи-
сании соответствующего раздела книги, так и новые ссылки.
102
в которой дана количественная оценка возможностей системы,
в книге 1152] и других работах. Программное обеспечение систе-
мы описано в [124, 164, 213, 214], примеры и опыт решения за-
дач на системе Минск-222 — в [64, 221—223, 273, 326].
3.1.3. Система КЛАСС [15, 129]. Система КЛАСС (Комплекс-
ная Лабораторная Автоматическая Счетная Станция) представля-
ет собой объединение разнородных (по аппаратуре, формату
Рпс. 3.3. Структурная схема системы КЛАСС.
представления информации и внутреннему языку) машин в це-
лях решения разнообразных задач в следующих основных
режимах:
— моделирование при взаимодействии с реальной аппара-
турой;
— пакетная обработка;
— обслуживание абонентов с разделением времени;
— автономный режим, при котором некоторые или все ма-
шины работают без обмена информацией с другими машинами.
Структурная схема системы приведена на рис. 3.3.
В состав системы КЛАСС входят:
— универсальный вычислитель специальной структуры
(ЭВМ-1), предназначенный для использования в качестве управ-
ляющей машины системы (на нем реализуются основные блоки .
операционной системы);
— универсальная вычислительная машина (ЭВМ-2);
— быстродействующий вычислитель (ЭВМ-3);
— устройства ввода-вывода системы (УВВ системы);
— внешние запоминающие устройства системы (ВЗУ системы);
— стойки преобразующих устройств (СПУ), предназначенные
для связи с аналоговой аппаратурой.
103
Каждое из перечисленных устройств системы связано с уст-
ройством управления обменом (УУО), а именной
— ЭВМ-1 — при помощи .четырех каналов (К-1/1, К-1/2,
К-1/3, К-1/4);
— ЭВМ-2 — при помощи одного канала (К-2);
— ЭВМ-3 — при помощи одного канала (К-3);
— УВВ системы — при помощи одного мультиплексного ка-
нала (МК);
ВЗУ системы — при помощи четырех селекторных каналов
(CKi, СК2, СКз, СК4);
— СПУ — при помощи трех каналов, по одному для каждой
стойки (Ki, К2 и К3 СПУ).
Устройство управления обменом выполняет функции цент-
рального коммутатора системы, а устройства, связанные с ним
при помощи каналов, выполняют с точки зрения обмена функ-
ции абонентов. При этом последние делятся на активные абонен-
ты (ЭВМ-1, ЭВМ-2, ЭВМ-3), которые инициируют обмен инфор-
мацией при помощи специальных команд обмена, и пассивные
абоненты (УВВ, ВЗУ, СПУ).
Функции коммутации устройства управления обменом состоят
в обеспечении связей , между перечисленными каналами.
Учитывая, что к этому устройству подсоединены 14 каналов, об-
щее число возможных парных связей равно 91. Из этого количе-
ства связей в устройстве управления обменом реализовано 70,
которые действительно необходимы.
Обмен информацией организуется следующим образом.
Начало обмена инициируется активным абонентом, который
вступает в обмен только с каким-либо одним из других абонен-
тов, при этом замыкание каналов связи пары абонентов, всту-
пивших в обмен, устанавливается в устройстве управления обме-
йом на все время передачи информации. Направление обмена
между парой абонентов может быть как в сторону инициатора
обмена, так и в противоположную сторону, при этом информация
передается побайтно (разряды байта передаются параллельно).
Обмен информацией с машинами происходит через их оператив-
ные запоминающие устройства.
* Система КЛАСС относится к классу МКМДС/НсНрКн — сис-
тема с множественными потоками команд и данных »и с послов-
ной обработкой, с низкой степенью связанности и неоднородной
структурой, со связями между машинами при помощи каналов
(при этом для обмена информацией в процессе работы организу-
ются те или. иные парные связи).
З.1.4. Система Днепр-2. Описание системы Днепр-2, вклю-
чая описание ее структуры и функционирования, а также
программного обеспечения, представлено в [163, 192, 233, 293,
400, 401] и других работах. Рассмотрим кратко эту систему,
следуя последней по времени выхода работе из числа указан-
ных (2331.
104
Система Днепр-2 создана в ИК АН УССР. Она представляет
собой управляющую вычислительйую систему, ориентирован-
ную на применение в качестве центрального звена в инфор-
мационно-управляющих системах на промышленных предприя-
тиях. Эта система состоит из двух основных частей — вычисли-
тельного комплекса (ВК) Днепр-21 и управляющего комплекса
(УК) Днепр-22.
Вычислительный комплекс предназначен для обработки ин-
формации, поступающей от внешних устройств, а также от уп-
равляющего комплекса. Он может быть применен как самостоя-
тельная вычислительная машина для обработки* экономических
данных и решения инженерно-технических задач. Оперативная
память имеет до 32 К *) 42-х разрядных ячеек, среднее быстро-
действие — 20 тысяч операций в секунду. Слова содержат 9-раз-
рядные символы (до 8'символов для чисел и до 127 символов для
буквенно-цифровой информации). В памяти адресуется каждый
символ. Команды содержат одно или несколько машинных слов
в зависимости от типа команды и количества адресов в ней.
В машине имеются 0-адресные, 1-адресные, 2-адресные и, в не-
которых случаях, многоадресные команды. Адреса могут быть
одно-, двух- и трехсимвольными.. В состав вычислительного ком-
плекса входит один мультиплексный и два селекторных канала.
Структура системы прерывания позволяет организовать любую
логику многопрограммной обработки информации.
Управляющий комплекс предназначен для приема информа-
ции от управляемого объекта, выдачи управляющих воздействий
на объект, а также первичной обработки информации. Он реали-
зует также связь между оператором и вычислительным комплек-
сом. На управляющий комплекс могут поступать входные сигна-
лы, общим количеством свыше 1600, от датчиков тока, частоты,
потенциала, двухпозиционных датчиков и др. Выходные сигналы,
общим количеством свыше 1000, могут подаваться на реле и раз-
личные регуляторы.
В состав программного обеспечения системы Днепр-2 входят
автокод, ориентированный на систему машинных команд, и авто-
код, ориентированный на программы управления процессами и
объектами в реальном масштабе времени, трансляторы с алгола 60
и кобола, программы-диспетчеры.
Система Днепр-2 относится к классу МКМДС/НсНрКн — сис-
тема с множественными потоками команд и данных с пословной
обработкой, с низкой степенью связанности и неоднородной
структурой, со связями между двумя машинами системы при по-
мощи каналов.
♦) Здесь и далее, при обозначении количества ячеек или других еди-
ниц информации, К =1024; кроме этого, М=1024 К.
105
3.2. Системы на базе ЭВМ БЭСМ-6
Машины БЭСМ-6 до настоящего времени составляют основу
большого числа крупных отечественных вычислительных центров.
Во многих из таких вычислительных центров созданы многома-
шинные системы на базе ЭВМ БЭСМ-6.
3.2.1. Структура ЭВМ БЭСМ-6 [218, 332, 429]. ЭВМ БЭСМ-6,
разработанная в Институте точной механики и вычислительной
техники АН СССР под руководством академика С. А. Лебедева,
предназначена для использования в крупных вычислительных
центрах для решения научных и экономических задач, требую-
щих большого объема вычислений. Разработка машины была за-
кончена в конце 1966 г., а в 1967 г. она вступила в строй. ЭВМ
БЭСМ-6 выпущена в большом числе экземпляров. Машина имеет
быстродействие около 1 млн. одноадресных операций в секунду.
Характерными чертами внутренней организации центральной
части машины являются, в частности, следующие: высокая сте-
пень локального параллелизма, наличие сверхбыстродействующе-
го буферного запоминающего устройства, расширенная система
операций, возможность организации магазиннной памяти и раз-
биение оперативной памяти на независимые блоки. В машине
широко используется совмещение выполнения операций обраще-
ния к оперативной памяти с работой арифметико-логического уст-
ройства и устройства управления, имеется пять уровней предва-
рительного просмотра команд.
Структура машины рассчитана на применение ее в режиме
мультипрограммирования и разделения времени, что обеспечива-
ется аппаратной схемой прерывания, схемой защиты памяти, ин-
дексацией и развитой системой преобразования математических
адресов в физические адреса оперативной памяти в динамике
счета. В машине предусмотрены также косвенная адресация п
широкие возможности переадресации.
Центральный процессор машины содержит в своем составе 16
быстродействующих регистров с циклом обращения 0,33 мксек.
Он имеет следующие основные технические характеристики: дли-
на слова 50 разрядов, из которых 2 — контрольные; система
счисления — двоичная, числа представляются с плавающей запя-
той; среднее время выполнения операций: сложения — 1,2 мксек,
умножения — 2,1 мксек, деления — 5,4 мксек, поразрядных логи-
ческих — 0,55 мксек; система команд — одноадресная; длина
команды — 24 разряда (2 команды на слово); количество
команд — 76; емкость оперативной памяти на сердечниках —
32768 слов (8 блоков), ее можно расширить до 131072 слов; дли-
тельность цикла блока оперативной памяти —2 мксек; время вы-
борки из памяти — 0,8 мксек; тактовая частота — 10 Мгц. Элек-
тронная ^асть машины выполнена на полупроводниках. Внеш-
няя память может содержать до .16 магнитных барабанов емко-
стью по 32 768 50-разрядных слов и до 16 накопителей на маг-
106
питпых лентах, имеющих по два лентопротяжных механизма с
емкостью бобины 1 млн. 50-разрядных слов в каждом. Машина
БЭСМ-6 имеет развитую систему устройств ввода-вывода^
С 1972 г. в комплектацию серийных машин включены диски,
а с 1978 г. машина БЭСМ-6 поставляется с внешними устройст-
вами номенклатуры ЕС ЭВМ.
Во многих организациях в целях решения сложных задач,
требующих одновременно ресурсов нескольких центральных вы-
числителей БЭСМ-6, по нескольку БЭСМ-6 объединены \ общим
К магнитным барабанам
I ____-_______I____
Коммутатор Коммутатор
магнитных --------------
барабанов
О
1
2
3
4
5
6
7
буферные
регистры
и устрой-
ства связи
Устройство
управления и
магнитных
барабанов
/ К накопителям
/ на магнитных лентах
-po7i"ea<o7 Коммутатор —.
Устройство fcmSe “О
______________устройства-___УстРои Пульт
ми i" Г Г"Т
устройство
внешних
К устройствам вводам вывода
оператора
Рис. 3.4; Структурная схема ЭВМ БЭСМ-6.
полем внешних запоминающих устройств при помощи устройства
коммутации магнитных дисков.
ЭВМ БЭСМ-6 имеет развитое программное обеспечение, в сос-
тав которого входят: операционная система управления мульти-
программным решением потока задач и система программирова-
ния на символических машинно-ориентированных языках и на
языках высокого уровня — фортране, алголе и лиспе. Имеются
библиотека программ, средства отладки программ, набор тест-
программ. Объем программного обеспечения составляет более
миллиона команд.
Структурная схема ЭВМ БЭСМ-6 приведена на рис. 3.4 1429].
Буферные регистры и устройства связи организуют связь ариф-
метико-логического устройства и устройства управления с опера-
тивной памятью через быстродействующую буферную память не-
большого объема. Буферная память машины выполнена, _как
отмечалось выше, в виде 16 50-разрядных регистров с циклом
обращения 0,33 мксек. Логически она разбита на три группы:
буфер командных слов (4 регистра), буфер чисел (четыре реги-
стра) и буфер записи результатов (8 регистров). Схема управле-
ния адресной частью буферной памяти имеет возможность срав-
нивать каждый новый адрес с ранее накопленным и исключать
лишние обращения к оперативной памяти в случае совпадения.
107
Устройство управления и арифметико-логическое устройство
выполняют обычные функции, при этом обеспечивается одновре-
менная обработка до девяти команд в устройствах центральной
части, обмен информацией между оперативной памятью и внеш-
ними запоминающими устройствами, а также работа нескольких
устройств ввода-вывода. Оперативная память, для случая 32 768
слов, состоит из 8 отдельных блоков емкостью по 4096 слов. На-
личие автономного управления в каждом блоке позволяет сов-
местить, их работу во времени. Обращение отдельных устройств
машины к оперативной памяти организовано через общие кана-
лы для всех ее блоков, вследствие чего обращение к отдельным
блокам памяти является последовательным (минимальный сдвиг
по времени составляет 0,3 мксек). При возникновении одновре-
менно нескольких запросов к оперативной памяти организуется
очередь обращений в соответствии с установленным приоритетом.-
Устройство управления внешними устройствами осуществляет
управление устройствами ввода-вывода, выдачу информации в
них и прием от них информации, обмен информацией между опе-
ративной памятью и внешними запоминающими устройствами,
выдачу в центральный процессор информации о состоянии внеш-
них устройств. Коммутатор внешних устройств осуществляет ком-s
мутацию устройств ввода-вывода по 42 медленным каналам.
Коммутация внешних запоминающих устройств па магнитных
барабанах и лентах осуществляется по шести быстрым каналам.
Внешние запоминающие устройства работают независимо друг от
друга, причем их работа совмещается с работой центральной ча-
сти машины. На каждом из быстрых каналов в данный момент
времени может работать в режиме «запись-чтение» только одно
внешнее запоминающее устройство. ПоцсК требуемой зоны на
магнитных лентах (перемотка) может производиться одновремен-
но на всех устройствах [429].
Рассмотрим особенности структуры ЭВМ БЭСМ-6, направлен-
ные (не говоря о параллельной обработке разрядов слов в ариф-
метико-логическом устройстве) на обеспечение внутреннего рас-
параллеливания и высокой скорости обработки информации
в машине [218].
В оперативной памяти, разбитой па блоки, реализовано чере-
дование адресов, что обеспечивает уменьшение времени выборки
из цамяти по сравнению с длительностью цикла одного ее блока
(см. приведенные выше технические характеристики машины).
Нижняя граница времени выборки из памяти для восьми блоков
составляет величину 2 мксек/8 = 0,25 мксек.
Второй особенностью является буферизация при обращении
к оперативной памяти (накопление очередей заказов к оператив-
ной памяти). В машине БЭСМ-6 существуют регистры, на кото-
рых хранятря запросы (адреса), называемые буферами адресов
слов и команд., Устройство управления машины обеспечивает опе-
режающий просмотр команд, в результате чего заранее готовятся
108
запросы и организуется эффективная работа буферов. Буфера
адресов позволяют в итоге сглаживать неравномерность поступле-
ния запросов к памяти и тем самым повысить эффективность ее
использования.
Третьей особенностью является использование быстрых ре-
гистров чисел и команд как сверхоперативной памяти, неадресуе-
мой из программы (использование быстрых регистров осущест-
вляет аппаратура самой машины). Эта сверхоперативная память
управляется таким образом, что часто используемые операнды
и небольшие внутренние командные циклы оказываются на быст-
рых регистрах и могут быть немедленно поданы в арифметико-
логическое устройство или в устройство управления. В результате,
обеспечивается автоматическая экономия обращений к основно-
му оперативному запоминающему устройству и, следовательно,
уменьшаются затраты времени на ожидание чисел и команд из
основной памяти. В ряде случаев быстрые регистры позволяют
экономить до 60% всех обращений к основной памяти.
Эти особенности структуры БЭСМ-6 получили название «водо-
проводного» принципа построения структуры машин. В резуль-
тате его применения существенно повышается скорость обработ-
ки информации за счет глубокого внутреннего параллелизма вы-
полнения команд, просмотра вперед, наличия буфера адресов
и быстрых регистров при сравнительно большом времени выпол-
нения каждой отдельной команды от начала до конца. При этом
достигается необходимый баланс между более высокой скоростью
работы арифметико-логического устройства по сравнению со
скоростью работы отдельных блоков оперативной памяти [218].
3.2.2. Многомашинные системы на базе ЭВМ БЭСМ-6. Во мно-
гих организациях на базе ЭВМ БЭСМ-6 созданы многомашинные
системы, в состав которых обычно входят и ЭВМ других типов.
Рассмотрим кратко некоторые из таких систем.
В целях разгрузки ЭВМ БЭСМ-6 от работы с медленными
внешними устройствами в Институте кибернетики АН УССР бы-
ли объединены ЭВМ БЭСМ-6 и ЭВМ Днепр-21 в единук> двух-
машинную систему [178, 179]. ЭВМ БЭСМ-6 в этой системе
выполняет основные функции по обработке информации, а ЭВМ
Днепр-21 — функции ввода-вывода. При этом обеспечивается об-
мен информацией с многочисленными, в том числе и удален-
ными, пультами и внешними устройствами. Связь между маши-
нами реализована по седьмому направлению БЭСМ-6 и селектор-
ному каналу Днепр-21. Передача информационных массивов
(программы задачи и данные) между двумя ЭВМ в обоих направ-
лениях осуществляется массивами длиной 1024 X 6 байтов, т. е.
единицей обмена выбран лист БЭСМ-6.
В процессе ввода, с внешних устройств ЭВМ Днепр-21 накап-
ливает информацию и передает ее в ЭВМ БЭСМ-6 в таком виде,
как если бы опа вводилась в БЭСМ-6 непосредственно с устройств
ввода с перфокарт. Вся дальнейшая работа по редактированию
109
и обработке информации выполняется БЭСМ-6. Результаты счёта
накапливаются на магнитной ленте и выводятся по окончании
решения задач в оперативную память ЭВМ Днепр-21, откуда они
выдаются на внешние устройства. Обмен информацией между
машинами синхронизован, поскольку одновременно возможен как
ввод информации в БЭСМ-6, так и вывод из нее результатов
решения сразу нескольких задач путем обмена с ЭВМ Днепр-21.
Синхронизация выполняется посредством передачи управляющей
информации между операционными системами машин по так
называемому диспетчерскому каналу, в качестве которого со
стороны БЭСМ-6 использован канал ввода-вывода на перфоленту,
а со стороны Днепр-21 — мультиплексный канал.
Для отработки принципов организации технического и про-
граммного обеспечения комплекса автоматизации проектирования
в Институте кибернетики АН УССР создана Экспериментальная
многомашинная система, в состав которой вначале вошли ЭВМ
БЭСМ-6 и М-220, а затем - МИР-2 [1Q0]. ЭВМ МИР-2 и М-220
используются в системе как периферийные машины, обеспечи-
вающие взаимодействие проектировщика с системой, а БЭСМ-6 —
как центральный вычислитель для реализации основных алгорит-
мов проектирования. При этом сохраняется возможность исполь-
зования накопленного программного обеспечения. Для объедине-
ния нескольких ЭВМ в единую систему был разработан специа-
лизированный коммутатор К0У-1М, позволивший организовать
двухсторонний обмен информацией между устройствами систе-
мы. Система оснащена разнообразным периферийным оборудова-
нием: телетайпы, пишущие машинки, экраны типа Видеотон-340,
специализированный графопостроитель и другие устройства.
Структура реализованной системы показана на рис. 3.5. Имеется
возможность наращивать количество ЭВМ и устройств и заме-
нять устаревшее оборудование новым.
При объединении ЭВМ в систему различаются следующие
уровни связи между ними. Связь по данным предполагает единое
внутреннее и внешнее представление данных для всех компонен-
тов системы, а также единую организационную структуру архива
данных. Для всех ЭВМ выбраны элементарные структуры дан-
ных (биты, байты и др.), из которых составляются машинные
слова, объединяющиеся в однородные структуры (массивы). Не-
однородные структуры (списки, деревья) в качестве своих состав-
ляющих могут иметь как слова, так и более мелкие объекты
(части слов, байты). Массивы и структуры именуются и компо-»
нуются в порции. Массивы порций данных составляют архив
системы, который реализуется как рассредоточенный и размеща-
ется на лентах и барабанах М-220 л БЭСМ-6. Совместная работа
ЭВМ регламентируется управляющими словами — сообщениями.
Связь по управлению процессами на уровне операционных .
систем (операционная связь) предполагает совместное выполнение
двумя или несколькими ЭВМ одной задачи. Для ее организации
110 '
операционные системы каждой ЭВМ дополнены специальными
блоками обслуживания линии связи. Взаимодействие двух ЭВМ
при осуществлении операционной связи реализуется путем пере-
дачи информации по каналу связи. Связь по технике " передачи
данных между ЭВМ системы реализована в виде передачи дан-
ных через пакеты перфокарт непосредственно из памяти одной
ЭВМ в память другой по каналу свя-
зи К0У-1М с синхронизацией пере-
дачи, реализована также передача по
телетайпным каналам связи. Связь
по технологии изготовления про-
грамм реализована в виде технологи-
ческих линий использования рабочих
программ машины М-220 на машине
БЭСМ-6, изготовления рабочих про-
грамм для машины БЭСМ-6 на ма-
шине М-220 и построения программ
на языке директив [100].
Машинный парк Объединенного
института ядерных исследований на-
считывает более 50 машин практиче-
ски всех типов, выпускаемых серий-
Рис. 3.5. Структура многома-
шинной системы для автома-
тизированного проектирова-
ния.
но в нашей стране и других странах-участницах ОИЯИ, а также
ряд машин некоторых западных фирм [106]. Потребность в са-
мом разнообразном использовании вычислительных машин пред-
определила создание в ОИЯИ высокопроизводительной многома-
,шинной системы.
Многомашинная система ОИЯИ имеет развитую иерархичес-
кую структуру. Верхний уровень образован мощными машинами
БЭСМ-6 и CDC 6200 суммарной производительностью около 2 млн.
операций в секунду, которые составляют основу общеинститут-
ского центрального вычислительного комплекса. Они предназна-
чены дл^ выполнения сложных расчетов и решения математиче-
ских задач, связанных с научными исследованиями, проводимыми
в лабораториях института, а также для обработки большого объе-
ма экспериментальной информации, получаемой на ускорителях
и импульсном реакторе.
Средний уровень образован машинами типа ЕС-1040, БЭСМ-4,
CDC 1604, Минск-22, Минск-32 и другими. Они предназначены
для автономного решения задач, специфических для отдельных
лабораторий, и находятся.в крупных научных подразделениях,
образуя основу измерительно-вычислительных центров лаборато-
рий. Некоторые из машин этого уровня имеют кабельную связь
с БЭСМ-6.
Нижний уровень представлен малыми вычислительными ма-
шинами советского производства* (М-6000, М-400, Электрони-
ка-100 и др.), производства стран-участниц (ТРА, ЕС-1,010 и др.),
а также ЭВМ некоторых западных фирм (PDP-8, CDC 160 А
Ш
и др.). Они применяются в системах контроля и управления ра-*
ботой физических установок, сканирующих устройств, а также
в устройствах, повышающих эффективность доступа к машинам
верхнего уровня (удаленные станции ввода-вывода, дисплейные
стацции и т. п.). На базе малых машин созданы системы накоп-
ления и предварительной обработки экспериментальной ин-
формации. «
Обмен между ЭВМ разных уровней осуществляется при по-
мощи переноса магнитных лент, перфолент и перфокарт и (для
БЭСМ-6) по быстродействующим кабельным линиям связи с про-
пускной способность^) до 500 К байт в сек.
В качестве основных направлений развития центрального вы-
числительного комплекса выбраны увеличение его мощности,
совершенствование средств и методов непосредственного доступа
пользователей к центральным вычислительным средствам и соз-
дание банка данных и программ. Для увеличения мощности цен-
трального вычислительного комплекса ЭВМ CDC 6200 развива-
ется до CDC 6400 и, далее, до CDC 6500, подключается большая
вспомогательная память на магнитных сердечниках емкостью
256 К слов и расширяется память на дисках до 80 млн. слов. Для
дальнейшего развития оперативного обмена информацией между
машинами и между пользователями и машинами при помощи
линий связей к БЭСМ-6 подключаются машины, непосредственно
занятые в экспериментах, выносные станции ввода-вывода и дис-
плейные станции с графическим дисплеем.
При создании банка программ и данных к нему нужно обес-
печить доступ, с одной стороны, всем пользователям индивиду-
альных терминалов машин центрального вычислительного ком-
плекса и машинам измерительно-вычислительных центров, а с
другой стороны — машинам самого центрального вычислительного
комплекса (БЭСМ-6, CDC 6500 и вновь поступающим мощным
ЭВМ). При этом желательно, чтобы пользователь любого терми-
нала или любая конкретная машина измерительно-вычислитель-
ных центров (ИВЦ) дрогли с использованием этого общего банка
сформировать задание для любой из машин центрального вычис-
лительного комплекса.
В качестве наилучшего, с учетом денежных затрат, выбира-
ется вариант системы, структура которой показана на рис. 3.6.
В этой системе предусматривается использование буферной ма-
шины класса ЕС-1040, управляющей взаимодействием всех пери-
ферийных установок (машин и станций ввода-вывода ИВЦ, тер-
миналов и концентраторов терминалов) с машинами централь-
ного вычислительного комплекса. На эту же буферную машину
возлагается и управление общим банком программ и данных. По-
скольку через каждую из машин М-6000 и ЕС-1010 можно под-
ключить ограниченное число терминалов (из-за ограничений, свя-
занных с малой емкостью памяти), то часть терминалов подклю-
чается непосредственно через ЕС-1040, в том числе терминалы
112
- из серии ЕС ЭВМ (например, графические дисплеи). Поэтому
ЕС-1040 должна выполнять также функции концентраторов [1001.
ЭВМ БЭСМ-6 также является центральным вычислителем
в многомашинной системе Института теоретической и экспери-
ментальной физики [1211. В качестве периферийных машин ис-
пользуются ЭВМ типа М-220, БЭСМ-4, Раздан-3 и М-6000. Все
Рис. 3.6. Структура многомашинной системы для ядерных исследований.
эти машины объединены линиями связи в единую систему, что
позволяет обмениваться информацией между ЭВМ при помощи
программ обмена. Последние передают сообщения задачам поль-
зователей, заказавшим обмен. В результате появилась возмож-
ность проводить обработку результатов физических эксперимен-
тов в оперативном режиме и управлять ходом эксперимента,
так как обмен информацией может идти в диалоговом режиме.
Система двухсторонней связи между ЭВМ БЭСМ-6 и М-6000,
например, предназначена для передачи информации, получаемой
при сканировании снимков на измерительном приборе, управ-
ляемом машиной М-6000. Обмен между машинами осуществля-
ется 16-разрядными словами, он совмещен с работой процессоров.
Максимальный поток данных через систему связи составляет
75 тысяч слов в секунду для формата ЭВМ типа М-6000, длина
линии связи — около 200 м [40].
В многомашинной вычислительной системе, созданной в Ин-
ституте атомной энергии им. И. В. Курчатова, ЭВМ БЭСМ-6
является центральным процессором [210]. В состав первой оче-
реди системы, кроме БЭСМ-6, входят буферный процессор (ЭВМ
НР-2100, изготовитель США) и связной процессор (ЭВМ М-6000),
а также банк данных. В стандартной аппаратуре проведены не-
которые изменения й дополнения, в том числе изготовлен ком-
мутатор на два направления для,-работы двух различных ЭВМ
8 Б. А Головкин 111
с восемью дисковыми устройствами емкостью 7,25 М байт на
каждый привод, в ЭВМ НР-2100 образован селекторный канал
ЕС ЭВМ и подключено восемь накопителей на магнитных лентах
ЕС-5012 (банк данных емкостью 200 М байт), изготовлены уст-
ройства передачи данных (УПД) по линиям связи.
Центральный процессор объединен с буферным через общие
диски при помощи коммутатора магнитных дисков. Связь буфер-
ного процессора со связным осуществляется через канал прямого
доступа. Передача информации от периферийных процессоров
в связной производится по выделенным телефонным линиям со
скоростью 10 К бод при помощи указанной выше аппаратуры
УПД. Очередь задач накапливается на дисках, а в центральном
процессоре производится пакетная обработка информации. По-
становка задач в очередь может осуществляться с внешних уст-
ройств центрального процессора, с абонентских пунктов (Видео-
тон-340, Т-63) и удаленных ЭВМ. Диалоговый режим и редакти-
рование информации выполняются с абонентских пунктов. Выда-
ча информации из центрального процессора может адресоваться
его алфавитно-цифровым печатающим устройствам, абонентским
пунктам, периферийным ЭВМ, графопостроителю и банку дан-
ных. Возможна работа в режиме, когда периферийные ЭВМ
общаются только с банком данных.
В дальнейшем предполагается увеличить производительность
центрального процессора путем объединения двух ЭВМ БЭСМ-6,
подключить к каналу ЕС ЭВМ буферного процессора емкие на-
копители на магнитных дисках и расширить сеть абонентских
пунктов [2101.
Таким образом, ЭВМ БЭСМ-6 находят широкое применение
в качестве центрального процессора в многомашинных системах
самого различного назначения, обеспечивающих решение задач
в крупных научно-исследовательских институтах и конструктор-
ских бюро, в университетах и других организациях. Эта машина
находит также применение и в территориальных многомашинных
системах.
В Новосибирском научном центре объединенными усилиями
Сибирского отделения АН СССР и заинтересованных ведомств
и организаций создается на базе Вычислительного Центра СО
АН СССР территориальный вычислительный комплекс (центр)
коллективного пользования (ВЦКП) [262]. Работы по созданию
ВЦКП ведутся с учетом возможности последующего тиражирова-
ния общесистемного и проблемно-ориентированного программного
обеспечения, технических средств комплексации и связи с тер-
минальным оборудованием — в интересах разработки типового
проекта регионального ВЦКП и выработки рекомендаций по про-
ектированию ВЦКП как составляющих компонентов государст-
венной сет;и вычислительных центров. При проектировании ВЦКП
СО АЩСССР соблюдаются принципы стандартизации? децентра-
лизации функций, совмещенной реализации, преемственности по
114
поколениям и обобществления и автономности информации.
Стандартизация в применении к техническим средствам озна-
чает: использование отечественных стандартных вариантов, этих
средств, развитие технических средств для комплексирования,
организацию системы передачи данных в терминальной сети на
базе унифицированных модулей и удовлетворение требованиям
интерфейса ЕС ЭВМ для всех технических компонентов ВЦКП.
Этот принцип в применении к общесистемному программному
обеспечению означает ориентацию на поставляемую изготовите-
лями систему математического обеспечения ЕС ЭВМ и ев техно-
логические возможности, соблюдение требований межпрограммно-
го интерфейса при развитии системы и недопустимость при этом
ее адаптации к условиям функционирования ВЦКП. В информа-
ционном обеспечении ВЦКП должны применяться общесоюзные
системы классификации и кодирования информации, а* также
унифицированные системы документации.
Функции общесистемного и проблемно-ориентированного про-
граммного обеспечения должны быть децентрализованными, что
позволит более эффективно использовать технические средства —
в тех областях, которые соответствуют их индивидуальным воз-
можностям. При этом возможна совмещенная реализация тех
пли иных функций при создании менее мощных конфигураций
ВЦКП в других организациях региона на их технических сред-
ствах. Преемственность по поколениям означает, что комплекс
проблемного программного обеспечения должен функционировать
в течение ближайших 10—15 лет на двух-трех поколениях тех-
нических средств и четырех-шести поколениях операционных
систем ВЦКП. Предпринимается попытка решить эту проблему
путем создания операционно-ориентированного языка высокого
уровня.
Наконец, централизованный информационный фонд ВЦКП
образуется путем обобществления информации для потребителей,
а удовлетворение информационных потребностей абонентов будет
происходить централизованно по запросу или регламентирование.
При этом любой абонент может создать индивидуальный инфор-
мационный фонд, используя принятые в ВЦКП системы класси-
фикации и кодирования информации, а также общесистемные
п проблемные программные средства. Индивидуальный информа-
ционный фонд может быть размещен на технических средствах
ВЦКП, на собственном абонентском пункте или же на ведомст*
венном вычислительном центре, связанном с ВЦКП.
Схема организации ВЦКП СО АН СССР изображена на рис. 3.7
[262]. Основные вычислительные и информационные мощности
ВЦКП сосредоточиваются в трех базовых вычислительных ком-
плексах (ВК), реализуемых на основе ЭВМ БЭСМ-6, ЕС ЭВМ и
перспективных ЭВМ четвертого поколения. Эти ВК взаимодейству-
ют с другими компонентами ВЦКП через связной процессор в ци-*
де малой отдельной ЭВМ. Разворачиваются также периферийные
8* 115
Абоненты*
комплекса
коллективного
пользования
Ябпяенты*
' комплекса
коллективного
пользования
Система
передачи данных
Периферийный
центр обработ-
ка информации
Связной \
\процессор\
базовый ВК
наоснове
перспективных
ЗВМ
Периферийный
центр обработ
киинформации
Абоненты
комплекса
коллективного
пользования
Абоненты
базового
вычислительного
комплекса
Периферии-
информации
Рис. 3.7. Схема организации территориального вычислительного центра коллективного пользования.
центры обработки информации на базе малой ЭВМ типа
М-7000 и/или М-400. Базовые вычислительные комплексы и пе-
риферийные центры обработки информации связываются между
собой при помощи системы передачи данных так, чтобы, в целях
повышения надежности, между любой парой (комплексов и цен-
тров) существовало не менее двух путей связи.
Абоненты комплекса коллективного пользования концентри-
руются по территориальному признаку и подключаются к соот-
ветствующим периферийным центрам. Последние обеспечивают
как доступ к основным вычислительным и информационным
мощностям, так и связь абонентов между' собой. Абонент ком-
плекса является для ВЦКП источником и приемником информа-
ции и управляющих сигналов.
Абоненты базовых вычислительных комплексов функциональ-
но не являются абонентами ВЦКП, поскольку отдельные ЭВМ
базовых ВК могут иметь собственную разветвленную терминаль-
ную сеть. Аналогично, абоненты ВЦКП функционально не явля-
ются абонентами отдельной ЭВМ базового ВК. Вместе с тем,
работая за некоторым терминалом, можно быть абонентом либо
ВЦКП, либо отдельной ЭВМ базового В.К, поскольку обеспечи-
вается транзит сообщений абонентов базового ВК в соответству-
ющий периферийный центр обработки и транзит сообщений або-
нентов комплекса коллективного пользования непосредственно
отдельной ЭВМ базового ВК [262].
3.2.3. Библиографическая справка. Описание ЭВМ БЭСМ-6,
включая организацию структуры и функционирования, а также
программное обеспечение, дано в [217—219, 258, 264, 332, 349,
429] и других работах. Вопросам построения сетей ЭВМ и ком-
ллекспровапия ЭВМ на базе БЭСМ-6' посвящен раздел в сборни-
ке [342].
Структура, функционирование и программное обеспечение
многомашинных систем, включающих в свой состав ЭВМ
БЭСМ-6, созданных: в Институте кибернетики АН УССР, описа-
ны в [100, 178—180, 215], в Объединенном институте ядерных
исследований — в [103—106, 168, 169], в Институте/теоретической
и экспериментальной физики — в [32, 39, 40, 66, 121, 136], в Ин-
ституте атомной энергии им. И. В. Курчатова — в [210].
Методрлогия и проект создания в Новосибирском академго-
родке территориального вычислительного центра коллективного
пользования Сибирского отделения АН СССР, в котором преду-
сматривается использование БЭСМ-6, изложены в [261, 262, 270].
Некоторые аспекты построения этого вычислительного центра
представлены в [305].
Организация комплекса с терминальной сетью предлагается в
171] на основе опыта эксплуатации разработанного в Вычисли-
тельном центре СО АН СССР мультиплексного канала ввода-вы-
вода для БЭСМ-6 и анализа работы двух БЭСМ-6 с общими дис-
ками. Возможная архитектура программного обеспечения для
* 117
комплекса взаимодействующих БЭСМ-6 рассматривается в [442].
В [48] описана операционная система вычислительной системы,
состоящей из ЭВМ БЭСМ-6 и М-220 и их периферийного обору-
дования. Программно-аппаратный метод обмена между машина-
ми БЭСМ-6 и М-220А предлагается в [346] для создания вычис-
лительной системы на базе этих ЭВМ. Организация связи между
БЭСМ-6 и PDP-8/L описана в [170].
3.3. Системы на базе ЭВМ семейства ЕС
3.3.1. Структура семейства ЕС ЭВМ [218, 244, 246, 429]. Еди- .
ная система электронных вычислительных машин (ЕС ЭВМ}/
представляет собой семейство программно совместимых стацио- *
парных ЭВМ третьего поколения ♦), обладающих широким диа- л
пазоном производительности и предназначенных для решения 1
разнообразных научно-технических, экономических, управлепче-;
ских и других задач. Над созданием ЕС ЭВМ работают колле кти-J
вы научно-исследовательских учреждений и предприятий стран-;
участниц СЭВ — Болгарии, Венгрии, ГДР, Кубы, Польши, Румы-з
нии, СССР и Чехослрвакйи. Промышленный выпуск первых ма-;
шин начат в 1972 г. В настоящее время машины ЕС ЭВМ состав-*
ляют основу парка ЭВМ социалистических стран. 1
Программная совместимость ЭВМ семейства достигается за I
, счет единой формы и форматов представления данных, системой
адресации, набором команд, одинаковой структурой всех входя- J
щих в ЕС ЭВМ моделей. В ЭВМ семейства обеспечивается сов- J
местимость снизу вверх, т. е. программы, составленные для ма- J
шин с меньшей производительностью, могут выполняться на ма- Я
шинах с большей производительностью. Я
Ядром Единой системы являются процессоры, охватывающиеся
диапазон скоростей вычислений от нескольких тысяч до нееколь-Я
ких миллионов операций в секунду. В процессоре реализуются Я
операции с фиксированной и плавающей запятыми и операции3
над десятичными числами. Для данных и команд принято - не- Я
сколько форматов, в основе которых лежит байт и слово, состоя-Я
щее из 4 байт. Операции можно производить над половинными, 1
целыми и двойными словами, а также над полями переменной 1
длины (наибольшая длина 256 байт). В ЕС ЭВМ принята побай-J
товая адресация при 24-битовом адресе, что дает возможностью
формирования прямого адреса для обращения к памяти с мак-Я
симальной емкостью до 1677^216 байт. В зависимости от форма-^й
та (2, 4, 6 байт) команды могут быть безадресными, одноадр'ес-Я
ными, двухадресными и трехадресными. Полный типовой набоиЦ
команд имеет 144 команды. Объем оперативной памяти варьиру-Я
♦) ЭВМ ЕС-1010 и ЕС-1021 имеют отличия в структуре и системе коЧ
манд от других ЭВМ Единой системы. *
113 ’ j
ется в моделях в широких пределах, в некоторых моделях ис-
пользуется чередование адресов в параллельно работающих бло-
ках памяти.
В процессоре имеются 16 регистров общего назначения ем-
костью в одно слово каждый, для выполнения операций повы-
шенной точности с плавающей запятой в состав процессора вво-
дятся четыре регистра емкостью в двойное слово каждый. В про-
цессорах развита система прерываний. Дополнительно в процес-
сор вводятся таймер и средства комплексирования.
Рис. 3.8. Структурная схема вычислительной машины ЕС ЭВМ.
В ЕС ЭВМ используется также и параллельно-последователь-
ный принцип выполнения операций, например, однобайтовая об-
работка данных при двухбайтовой выборке ив оперативной памя-
ти в машине ЕС-1020.
К процессору подсоединяются селекторные и мультиплексные
каналы, количество и пропускная способность которых, а также
набор внешних устройств, подключаемых к каналам, зависят от
конкретной модели. В состав внешних устройств входят накопи-
тели на магнитных лентах, дисках и барабанах, -нерфокартиое
и перфолентное оборудование ввода-вывода, устройства построч-
ной печати, пишущие машинки, экранные пульты и графопо-
строители различного типа. Предусмотрены также средства пе-
редачи. данных с разной скоростью по телефонным и телеграф-
ным линиям связи.
119
Структура ЭВМ Единой системы показана на рис. 3.8 [245].
Основу программного обеспечения ЕС ЭВМ составляют дис-
ковая операционная система . ДОС ЕС и операционная система
ОС ЕС, которые могут использоваться на всех программно сов-
местимых моделях. Операционные системы обеспечивают мульти-
программную работу.
Модели ЕС-1010 и ЕС-1021 (ЕС-1020А) отличаются по струк-
туре и системе команд как от других моделей, так и между со-
бой, и ймеют поэтому собственное программное обеспечение. Для
модели ЕС-1010 разработана операционная система ОС-10 ЕС,
а для модели ЕС-1021 — малая операционная система МОС ЕС.
Вернемся к операционным системам ДОС ЕС и ОС ЕС. Опе-
рационные системы имеют несколько версий. ДОС ЕС ориентиров
вана на младшие модели ЕС ЭВМ с оперативной памятью огра-
ниченного объема (64—128 К байт) и при использовании на та-
ких моделях обеспечивает наибольшую эффективность. Система
ОС ЕС является наиболее универсальной и мощной по своим
функциям и существенно превосходит ДОС ЕС. Она применяет-
ся на моделях с оперативной памятью объемом более 128 К байт
и* в полной мере проявляет свои возможности на ЭВМ, имеющих
оперативную память среднего и большого объема и достаточную
внешнюю память.
Система ОС ЕС имеет четкую модульную структуру, которая
делает ее наиболее перспективной для расширения по мере усо-
вершенствования и накопления технических средств ЕС ЭВМ.
ОС ЕС предоставляет возможности по распараллеливанию
процессов вычислений и содержит обеспечение средств комплек-
сирования, предназначенных для организации многомашинных
систем. К таким средствам относятся адаптер канал-канал, кото-
рый позволяет непосредственно связать каналы двух (различных)
моделей ЕС ЭВМ, совместно используемые устройства внешней
памяти, а также средства прямого управления. На базе указан-
ных средств пользователь может строить разнообразные конфигу-
рации многомашинных систем, используя программное обеспече-
ние средств комплексирования [377].
В состав операционных систем входят управляющие и обслу-
живающие программы, трансляторы с языков программирования
(обычно они включаются в состав отдельной системы програм-
мирования), средства генерации системы для конкретного ком-
плекта технических средств и другие средства. В качестве вход-
ных языков приняты ассемблер, фортран, PL/1, кобол, алгол 60 *> !
и РПГ (генератор программ отчетов). Имеются средства отлад-
ки и редактирования программ. Программное обеспечение' вклю-
чает также большое число пакетов различных прикладных про- !
грамм. По входным языкам системы ДОС и ОС ЕС в достаточной ‘
степени совместимы, а по получаемым объектным программам —
*) Транслятор с алгола 60 входит в ОС ЕС.
120
несовместимы, т. е. программы, полученные при помощи системы
программирования одной операционной системы не могут выпол-
няться под управлением другой операционной системы.
В настоящее время вычислительные машины Единой систе-
мы составляют ЭВМ I и II очереди выпуска (ряд 1 и ряд 2).
Машины I очереди близки по своей архитектуре к машинам
семейства IBM 360, при этом в ЭВМ ЕС обеспечена программная
преемственность (сохранение системы команд, принципов орга-
низации внешнего обмена и операционного окружения IBM 360).
Машины II очереди близки по своей архитектуре к машинам
более совершенного семейства IBM 370. Машины II очереди сох-
раняют программную преемственность по отношению к машинам
I очереди и имеют по сравнению с ними расширенную систему
команд. Расширение коснулось, главным образом, команд для
операционной системы (привилегированные команды), при этом
число команд для пользователей увеличилось незначительно (ма-
шина ЕС-1035 имеет, например, 172 команды). Повышена точ-
ность вычислений, введены другие усовершенствования.
Машины II очереди имеют по сравнению с машинами I оче-
реди более совершенную логическую структуру, расширенные
средства контроля и диагностики и лучшие технические парамет-
ры, их элементная база имеет более высокие характеристики йо
сравнению с интегральными схемами ЭВМ I очереди. В машинах
II очереди предельная производительность центральных процес-
соров семейства увеличена до 4—5 млн. операций в секунду, по-
вышена емкость оперативной памяти до 16 М байт и введена
виртуальная- адресация.
Важно отметить, что если машины I очереди имели некото-
рые средства по их комплексированию в многомашинные систе-
мы, то в машины II очереди введены расширенные средства мно-
гомашинной и многопроцессорной организации вычислительных
систем.
В результате принятых мер переход от I ко II очереди должен
обеспечить улучшение отношения производительности к стои-
мости'машин в 2—3 раза и повышение их надежности и живуче-
сти примерно в 2 раза.
Основные технические характеристики ЭВМ Единой системы
I и II очереди сведены в таблицу 3.2 [246] (в этой таблице ВП
означает виртуальную память, а БМР — блок-мультиплексный
режим). Следует отметить, что в литературе разных лет
приводятся различные значения некоторых характерис-
тик ЭВМ.
При переходе ко II очереди улучшается также программное
обеспечение ЕС ЭВМ, что связано с обеспечением виртуальной
памяти, расширением состава трансляторов и библиотек, разви-
тием режимов разделения времени, форм диалогового взаимодей-
ствия, средств телеобработки и средств обеспечения режима
реального времени, организацией банков данных, развитием
121
проблемных систем программирования, обеспечением многома-
шинных и многопроцессорных систем и др. В операционной си-
стеме обеспечивается возможность объединения в единый ком-
плекс до четырех вычислительных систем, каждая из которых
может представлять собой двухпроцессорную систему [246].
Таблица 32
Основные технические характеристики ЭВМ Единой системы I и II ’очереди
п/п Страна-раз- работчик Модель № очереди Производитель- ность {тыс. оп./сек.] Максимальный объ- ем оперативной па- мяти £К байт] Мульти- плексные каналы Селектор- ные кана- лы Дополни- тельные средства
количество | Пропускная способность [К байт/сек] количество 1 Пропускная способность [К байт/сек]
1 ВНР ЕС-1010 I 3 64 1 16
2 ВНР ЕС-1012 I 6 128 1 20
3 ВНР ЕС-1015 II 12-16 160 1 20 1 ВП
4 СССР, НРБ ЕС-1020 I 10-20 256 1 16 2 300
5 ЧССР ЕС-1021 I 20 564 1 35 1 250
6 СССР ЕС-1022 I 80-90 512 1 80 2 500
ЧССР ЕС-1025 II 60 256 1 24 1 800 ВП
8 СССР, ПНР ЕС-1030 I 60 512 1 40 3 800
9 ПНР ЕС-1032 I 200 512 1 40 3 400
10 СССР ЕС-1033 I 200 512 1 70 3 800
11 СССР, НРБ ЕС-1035 И 140 512 1 30 4 800 ВП, БМР
12 ГДР ЕС-1040 I 400 1 024 1 50 6 1250
13 СССР, ПНР ЕС-1045 II 500 3 072 1 40 5 1300 ВП, БМР
14 СССР ЕС-1050 I 500 1 024 1 110 6 1300
15 ГДР ЕС-1055 II 600 2 048 2 40 4 1500 ВП, БМР
16 СССР ЕС-1060 II 1300 8 192 2 НО 6 1500 ВП, БМР
17 СССР . ЕС 1065 II 4500 16 324 2 200 И 1500 ВП, БМР
В ЕС-1065, например, как основной универсальный вариант '
обеспечивается двухпроцессорный комплекс. Предусматривается <-
также и четырехпроцессорный вариант, но для специальных при-
менений, когда имеются хорошие возможности распараллелива-
ния вычислений. *
В 1977 г. основные работы по II очереди ЕС ЭВМ находились 1
в завершающей стадии технического проектирования и подготов-
ки к представлению на испытания значительной части опытных 1
образцов технических средств [246J. На период начала 1978 г. 1
были проведены испытания новых машин Единой системы, в том |
числе ЭВМ ЕС-1060, имеющей производительность более миллио- |
на операций в секунду. У следующей более мощной ЭВМ ЕС-1065 1
Единой системы, производительность свыше четырех миллионов *3
операций в секунду [61]. Л
В целйх дальнейшего всестороннего улучшения ЕС ЭВМ пла- |
нируется создание. III очереди (ряд 3) на элементной базе
интегральных схем с высоким уровнем интеграции. )
Основные особенности технических и программных средств
ЕС ЭВМ I и II очередей, а также планируемой III очереди при-
ведены в таблице 3.3 [246].
3.3.2. Многомашинные и многопроцессорные системы на базе
ЕС ЭВМ. Из рассмотрения структуры вычислительных машин ЕС
ЭВМ следует, что при разработке технических средств и про-
граммного обеспечения ЕС ЭВМ предусмотрено комплексирова-
лие на уровнях процессора, каналов, внешней памяти (внешних
устройств) и оперативной памяти. При комплексировании на
уровнях процессора, каналов и внешней памяти, что является
характерным для малых и средних моделей ЕС ЭВМ I очереди,
создаются многомашинные системы. При комплексировании на
уровне оперативной памяти, с ‘сохранением возможностей комп-
лексирования на других уровнях (все модели ЕС ЭВМ обеспечи-
вают комплексирование на уровне каналов и/или общих внешних
устройств), что является характерным для ЕС-1050 и моделей II
очереди, создаются многопроцессорные системы. 1
Отметим, что принятая логическая структура ЭВМ Единой
системы в принципе допускает работу процессоров с общим полем
оперативной памяти, хотя программная организация такого ре-
жима принципиально сложнее, чем при взаимодействии процес-
соров на уровне внешнего оборудования. Работа собщей опера-
тивной памятью представляется более актуальной для высоко-
производительных машин и в таких машинах - как ЕС-1020,
ЕС-1030*) и ЕС-1040 не предусматривается [238].
При комплексировании наибольшее распространение получа-
ют среди многомашинных — двухмашинные, а среди многопро-
цессорных — двухпроцессорные конфигурации, поскольку они
отличаются простотой, улучшают надежность и позволяют по-
высить производительность. При необходимости существен-
itoro повышения производительности типичным является переход
к старшей модели по сравнению с применяемой, что решает зада-
чу вплоть до самой старшей модели. Вместе с тем, предусматри-
вается возможность комплексирования более двух моделей, кото-
рые могут потребоваться, например, для специальных применений.
Рассмотрим средства компЛексирования на каждом из указан-
ных уровней [142, 247].
Для обмена управляющей или синхронизирующей информа-
цией между процессорами вычислительной системы или между
процессором и внешним устройством используются средства пря-
мого управления, к которым относятся команды ПРЯМАЯ ЗА--
ПИСЬ и ПРЯМОЕ ЧТЕНИЕ. Один из процессоров может связы-
ваться с' другим процессором или устройством при помощи
указанных t выше . команд и механизма внешних прерываний.
♦) Оборудование оперативной памяти модели ЕС-1030 может распре-
деляться между процессорами мультисистемы, образуя общее поле па-
мяти [142]. '
123
Таблица 3.3
Технико-экономические показатели ЕС ЭВМ
Объекты сравнения Этапы развития ЕС ЭВМ
I очередь II очередь III очередь
Отношение производитель- ности к стоимости (услов- ные единицы) 1 2-3 10—15
Надежность и живучесть (условные единицы) 1 2 10
Программное обеспечение Развитые операционные сис- темы Развитые операционные сис- темы с виртуальной памятью Развитые- операционные сис- темы с аппаратной реализа- цией управляющих функций
Входные языки Языки высокого уровня Языки высокого . уровня, диалоговые версии Языки высокого уровня, на- циональные версии, языки описания графических обра- зов
Структура комплексов ЭВМ Многомашинные системы Многопроцессорные системы Системы функциональных , мо- дулей с параллельным выпол- нением процессов
ОЬеспечение систем коллек- тивного пользования Средства организации ВЦ коллективного пользования и распределенных вычисли- тельных'систем Типовые вычислительные комплексы и средства органи- зации распределенных вычис- лительных систем Типовые вычислительные комплексы сверхвысокой про- изводительности и типовые комплексы ; средств организа- ции сетей обработки данных
Периферийное оборудование • Единая номенклатура тра- диционных устройств 1 Расширение номенклатуры средствами внешних запоми- нающих устройств большой емкости и групповыми систе- мами подготовки и ввода дан- ных Средства упрощения общения с ЭВМ и расширения возмож- ностей периферийного обору- дования
Телеобработка Удаленный ввод-вывод данных и заданий Интеллектуальные терминалы и диалоговая . • обработка
Физическая связь между процессорами осуществляется по кабелям
интерфейса прямого управления. К линиям прямого управления,
связывающим два процессора, может быть подключен пульт
управления вычислительным комплексом^ позволяющий операто-
ру отслеживать и изменять режимы работы ЭВМ и комплекса.
При комплексировании на уровне каналов используется адап-
тер, который имеет два выхода на стандартный интерфейс ввода-
вывода и подключается к селекторным (или мультиплексным)
каналам двух моделей ЕС ЭВМ. Скорость передачи информации
через адаптер близка к скорости передачи, информации через ка-
пал. При работе вычислительного комплекса скорость обмена
определяется фактически скоростью обмена через каналы, если
они одинаковые, или скоростью более медленного канала, если
они разнотипные. Режим работы адаптера в канале — монополь-
ный. При помощи адаптера осуществляется быстрый обмен меж-
ду процессорами не только управляющей информацией, но и мас-
сивами данных.
При комплексировании на уровне внешней памяти на маг-
нитных дисках и лентах используются двухканальные переклю-
чатели ♦). Двухканальный переключатель позволяет подключать
устройства управления накопителями на магнитных лентах и
дисках к двум каналам различных ЭВМ, в результате чего обра-
зуется общее поле памяти на управляемых ими накопителях.
Для согласования работы с общим полем внешней памяти той
или иной ЭВМ используются специальные команды двухканаль-
пых переключателей, обеспечивающие резервирование (подклю-
чение) устройства на время его работы с данным каналом и ос-
вобождение его после завершения этой работы. В связи с тем,,что
здесь прием и выдача информации процессорами разнесены по
времени, непроизводительные затраты времени пары процессоров
на взаимодействие между собой уменьшаются, но при этом умень-
шается и скорость обмена по сравнению со связыванием каналов
при помощи адаптера.
При использовании двухканального переключателя комплек-
сирование осуществляется фактически на уровне устройств
управления внешних запоминающих устройств. Возможно также
комплексирование на более низком уровне собственно внешних
запоминающих устройств при помощи переключателя на два
направления. Наконец, оба способа могут применяться для ком-
плексирования устройств ввода-вывода.
Наиболее гибкой и быстрой является связь процессоров через
общее поле оперативной памяти. Общее поле оперативной памя-
ти организуется по принципу построения многошинной много-
входовой памяти.
♦) Такой способ называется та'кже комплексированием на уровне уст-
ройств управления внешними устройствами.
125
Отметим также, что возможно взаимодействие процессоров по
телефонным и телеграфным линиям связи.
Рассмотрим теперь некоторые примеры комплексирования мо-
делей ЕС ЭВМ. Начнем-с машины ЕС-1030 [437].
При помощи ЭВМ ЕС-1030 можно реализовать многомашин-
ные системы, состоящие: из двух ЭВМ, соединенных линиями
прямого управления; из нескольких ЭВМ, имеющих доступ к
общему полю внешней памяти; из нескольких ЭВМ, соединенных
адаптером канал-канал.
В системах, в которых две ЭВМ связаны линиями прямого
управления, обмен информацией выполняется, как обычно, по
командам прямого управления. По этим командам из одного про-
цессора лередается один байт информации, прерывающий работу
другого процессора. Такая огранизация комплексирования эф-
фективна только в тех случаях, когда объем и скорость передачи
информации небольшие.
При организации многомашинной системы, связанной общим
полем внешней памяти, передача информации одним процессо-
ром и прием ее другим происходят неодновременно, вследствие
чего производительность связанных между собой ЭВМ не снижа-
ется. Поэтому такая организация комплексирования является бо-
лее эффективной по сравнению со связыванием при помощи ли-
ний прямого управления.
При организации многомашинной системы с использованием
адаптера канал-канал прямая связь между каналами ЭВМ осу-
ществляется через стандартный интерфейс. Обмен, информацией
происходит байтами со скоростью, определяемой пропускной спо-
собностью каналов.
В результате комплексирования двух ЭВМ ЕС-1030 может
быть реализована двухмашинная система, известная под назва-
нием вычислительный комплекс ВК-1010 [437].
ВК-1010 состоит из двух ЭВМ ЕС-1030, соединенных между
собой по шинам прямого управления через блок состояния вы-
числительного комплекса (БСВК), через раздельные внешние
устройства и через адаптер канал-канал (АКК). Структурная
схема ВК-1010 показана на рис. 3.9.
Если обе машины исправны, то возможны три режима работы
ВК. При первом режиме обе машины принимают информацию
с внешних устройств и обрабатывают ее, но выдачу информации
осуществляет только основная ЭВМ, а другая, следовательно, ре-
зервирует первую. Если оказывается, что основная ЭВМ не может *
выполцять свои функции, то их полностью принимает на себя
резервная ЭВМ. При втором режиме работы ВК функции основ-
ной ЭВМ сохраняются, а резервная выводится на профилактику.
В этом режиме работа осуществляется без резервирования. Если
основная ЭВМ выходит из строя, то профилактика на второй ;
ЭВМ может быть прервана и ее можно ввести в рабочий режим г
(за большее время, чем для первого режима работы ВК), ;
426
к НМЛ К НМД
Рис. 3.9. Структурная схема ВК-1010.
Наконец, обе ЭВМ могут работать как независимые — это третий
режим работы ВК.
Текущее состояние каждой ЭВМ фиксируется в виде байта
состояния и хранится в оперативной памяти и на регистрах
БСВК. Задание режимов работы ЭВМ ВК-1010 и перевод их в
требуемое состояние осуществляется оператором с пульта управ-
ления ВК. Изменение байтов состояния ЭВМ комплекса возмож-
но также программным путем при помощи команд прямого
управления.
•Блок состояния вычислительного комплекса предназначен для ,
хранения и изменения состояния машин ВК-1010. Он связан с
ЭВМ по двум стандартным интерфейсам прямого управления.
Адаптеры канал-канал предназначены для передачи массивов
данных между каналами ввода-вывода машин- ВК-1010, а также
для связи с другими ЭВМ или системами (см. рис. 3.9). Адаптер
работает в монопольном режиме и передает данные со скоростью <
более медленного канала из. двух соединенных. Для каждого из
каналов, с которыми соединен адаптер, он является устройством
управления внешними устройствами, которое выбирается кана-
лом, реагирует в ответ на запросы канала, принимает и расшиф-
ровывает команды канала так же, как и любое устройство управ-
ления внешними устройствами, но отличается от последнего тем,
что использует эти команды не для работы и управления устрой-
ствами ввода-вывода а для обеспечения связи между каналами
н синхронизации их работы.
, Структурная схема адаптера изображена на рис. 3.10. В его
состав входят два блока управления, каждый из которых обслу-
живает свой канал. Эти блоки связаны между собой как непо-
средственно при помощи нескольких сигнальных линий, так и
через общий однобайтный буферный регистр.
Устройства управления (УУ) накопителями на магнитных
лентах (НМЛ) и дисках (НМД) могут быть одновременно под-
ключены к селекторным каналам (СК) двух машин ВК-lCflO. Че-
рез эти разделенные устройства управления канал одной ЭВМ
может связываться с накопителями другой ЭВМ и наоборот (ка-
нал любой ЭВМ может связываться с НМЛ и НМД) [437].
Для управления работой ВК-1010, состоящего из двух ЭВМ
ЕС-1030, используется операционная система ОС К1, которая
является расширением операционной системы ОС ЕС с мульти-
программированием в режиме фиксированного числа задач. Про- j
граммное обеспечение средств комплексирования включено в со- ‘
став операционной системы ОС К1. Оно предоставляет возмож- ]
ность управлять техническими средствами комплексирования и J
обменом информацией при их помощи на уровне системных мак- , <
рокоманд ассемблера и стандартных средств управления данны- ;
ми. Для йостроения общего поля памяти на магнитных дисках
могут использоваться все методы доступа ЕС ЭВМ, так как в j
таком поле могут содержаться наборы данных с любой их орга- j
128 I
ппзацией, допустимой в ОС ЕС. Для работы с общими полями на
магнитных лентах могут использоваться только последователь-
ные методы доступа — базисный и с очередями. Последнее отно-
сится и к средствам адаптера канал-канал, так как передаваемые
при их помощи данные имеют последовательную структуру [247]•
Вычислительный комплекс ВК-1010 можно охарактеризовать
как МКМДС/НсОр (КнПмПр) — однородная система с множест-
венными потоками команд и данных п с пословной обработкой.
Рис. 3.10. Структурная схема адаптера канал — канал.
имеющая низкую степень связанности при помощи каналов, об-
щей внешней памяти и прямой связи между процессорами.
Ряд особенностей имеет машина ЕС-1035 [256]. Эта машина
является моделью усовершенствованной II очереди ЕС ЭВМ.
Возможности ЕС-1035 развиты, прежде всего, за счет расшире-
ния системы команд (172 команды), организации виртуальной
памяти, коррекции одиночных опТибок при чтении информации
из оперативной памяти и обнаружения двойных ошибок. В ЭВМ
предусмотрена совместимость с ЭВМ Минск-32 [3401, для чего
разработан комплекс средств совместимости: конверторы языков
фортран и кобол Минск-32, эмулятор программ Минск-32 на
ЕС-1035 и средства переноса данных. Эмулятор представляет со-
бой программу, работающую под управлением ДОС ЕС, причем
работа эмулятора совмещается с выполнением других программ
ЕС ЭВМ в мультипрограммном режиме. Необходимость обеспе-
чения быстродействия процессора ЕС-1035, не менее высокого,
чем в ЭВМ Минск-32, определила, в условиях заметного различия
в принципах выполнения операций ЕС ЭВМ и Минск-32, микро-
программную базу в качестве основного средства эмуляции [256].
Наличие в ЭВМ ЕС-1035 адаптера канал-канал позволяет соз-
давать на базе этой машины многомашинные комплексы путем
сопряжения трех ЭВМ, в том числе с привлечением других моде-
лей ЕС ЭВМ. Возможно комплексирование и при помощи блока
прямого управления, позволяющего обмениваться управляющей
информацией процессорам, объединенным в систему. В ЭВМ
ЕС-1035 значительно расширены возможности организации внеш-
ней памяти за счет наличия в составе модели интегрального
файлового адаптера, позволяющего непосредственно, к процессору
Б. А. Головкин 129
подключить (без устройства управления) накопители на магнит-
ных дисках со скоростью передачи информации до 312Кбайт/сек
[218, 429].
Старшей моделью I очереди ЕС ЭВМ, имеющей среди моделей
I очереди наиболее высокую производительность, является ЭВМ
ЕС-1050. Рассмотрим многомашинные и многопроцессорные си-
стемы на базе этой ЭВМ [439].,
Характерной особенностью ЭВМ ЕС-1050 является то, что эти
машины можно объединять как в многомашинные, так и в много-
процессорные системы. Они позволяют организовывать связи на
Комплексирования
Рис. 3.11. Структурная схема двухпроцессорной системы на базе ЭВМ
ЕС-1050.
уровне процессора, каналов, внешней памяти (внешних устройств)
и оперативной памяти (ОП) при помощи средств комплексирова-
ния, а именно: средств прямого управления, адаптеров канал-
канал (АКК), двухканальных переключателей устройств управ-
ления внешними устройствами (УВУ), а также при помощи
пульта реконфигурации соответственно. При этом можно реали-
зовать любую комбинацию из перечисленных вариантов связы-
вания. Связывание на первых трех из указанных уровней воз-
можно для двух и более процессоров, а связывание на четвертом
уровне (построение общего поля оперативной памяти) возможна
для двух процессоров. Структурная схема двухпроцессорной си*-
стрмы, включающей комплексирование на всех четырех уровнях»
изображена на рис. 3.11.
Для организации общего поля оперативной памяти система
должна иметь двухвходовые устройства оперативной памяти
130
(в первых образцах ЭВМ ЕС-1050 оперативная память не была
двухвходовой}. В двухпроцессорной системе с общей оперативной
памятью задание режима работы системы, физического распре-
деления ресурсов системы между процессорами и исключения
неисправных устройств из системы производится при помощи
Рис. 3.12. Структурная схема вычислительной системы с тремя процессора-
ми на базе ЭВМ ЕС-1050.
пульта реконфигурации системы. Прямоадресуемая область па-
мяти одного из двух процессоров во избежание наложения её на
прямоадресуемую область памяти другого процессора смещена
путем префиксации адреса.
Двухпроцессорная система с общим полем оперативной памя-
ти, общим полем памяти на внешних запоминающих устройствах
и связью между процессорами через средства прямого управления
является основным вариантом вычислительной системы на базе
ЭВМ ЁС-1050. Все средства комплексирования ориентированы,
в основном, на этот вариант. На базе ЭВМ ЕС-1050, однако, мо-
гут быть построены вычислительные системы и с большим чис-
лом процессоров.
Структура вычислительной системы с тремя процессорами,
в которую входит одна двухпроцессорная система с общей опе-
ративной памятью на базе ЭВМ ЕС-1050 и процессор, связанные
между собой при помощи адаптеров канал-канал и имеющие об-
щее поле внешних устройств, изображена на рис. 3.12. На этом
рисунке обозначено: ОП — оперативная память, ЦП — централь-
ный процессор, МК и СК — мультиплексный и селекторный ка-
налы соответственно, АКК — адаптер канал-канал, , УВВ —
устройство ввода-вывода, УВУ — устройство управления «внешни*
я*
131
мй устройствами, МПД — аппаратура передачи данных, ВЗУ —
внешние запоминающие устройства. В зависимости- от характера
решаемых задач процессор, изображенный на рисунке слева, мо-
жет быть процессором не обязательно ЭВМ ЕС-1050, но шдругого
типа. Он может быть менее мощным по сравнению с ЕС-1050,,
например, процессором ЕС-2030 ЭВМ ЕС-1030 и выполнять функ-
ции по загрузке системы и распределению общего потока задач
между другими процессорами.
Работа системы, получаемой в результате комплекспрованпяг
осуществляется под управлением операционной системы, основой
которой является модификация управляющей программы, обеспе-
чивающей мультипрограммирование с переменным числом задач.
Основные функциональные возможности многопроцессорного ва-
рианта управляющей программы (ОС-МПР) заключается в ис-
пользовании процессоров как единого ресурса при обработка
очереди заданий, осуществлении ввода7вывода для задачи, вы-
полняемой одним процессором, при помощи другого процессора,,
обработке аппаратных неисправностей двумя процессорами. Реа-
лизация этих функциональных возможностей основана на исполь-
зовании средств прямого управления: команд ПРЯМАЯ ЗАПИСЬ
и ПРЯМОЕ ЧТЕНИЕ, сигнала «Сообщение об ошибке» и коман-
ды ПРОВЕРИТЬ И УСТАНОВИТЬ [439J.
Основные данные о комплексировании сведены в таблицу 3.4.
Не только однотипные или разнотипные машины одного се-
мейства ЕС ЭВМ могут комплексироваться между собой, но воз-
можно также комплексирование машин ЕС ЭВМ с машинами дру-
гих типов и классов. Рассмотрим в качестве примера комплекси-
рование между ЭВМ Единой системы и мини-ЭВМ М-6000
АСВТ-М [54]. В получаемых при этом системах мини-ЭВМ вы-
полняет функции процессоров ввода-вывода, дисплейных, комму-
тационных процессоров и другие функции.
Комплексирование можно выполнить путем связывания кана-
лов или построения общего поля внешней памяти. Эти варианты
требуют относительно небольших доработок в конструкции ЭВМ
и программном обеспечении. Если требуется быстрая связь меж-
ду ЭВМ системы, то выбирается вариант связи через каналы.
Анализ логики построения каналов семейства ЕС и ЭВМ
М-6000 показывает, что интерфейс ввода-вывода М-6000 являет-
ся более простым и в большей степени программным. Поэтому
при построении блока связи (согласователя) целесообразно воз-
ложить на него некоторые функции по схемной реализации стан-
дартного интерфейса ЕС ЭВМ, а большую часть их реализовать
программно на М-6000. Структурная схема соединения ЕС ЭВМ
с М-6000 изображена на рис. 3.13 (структура АСВТ-М описана
в п. 3.4).
В ЭВМ М-6000 согласователь может подключаться как к про-
граммному каналу (рис. 3.13 а), так и к каналу прямого досту-
па в память (рис. 3.13 б). Для подключения используются две-
182
Т а б л и ц а 3.4
Комплекспровапие вычислительных машин LC ЭВМ
Устройства ЭВМ — уровни комплекси- рования Технические и программные средства комплексирования Что реализуется в результате комплексирования Что обеспечивается в результате комплек- сирования
Процессор Средства прямого управления (включая шины прямого уп- равления, ' линии синхрони- зации и специальные команды) и механизм внешних прерыва- ний Прямая связь между двумя процессорами . Обмен управляющей информацией меж- ду процессорами и необходимая при )том синхронизация их работы
Оперативная па- мять Пульт реконфигурации, средства операционной сис- темы и средства прямого управления Общее поле оперативной па- мяти и прямая связь между двумя процессорами Быстрый параллельный доступ про- цессоров к программной и числовой информациц в общем поле оперативной памяти, реализуемый с участием рас- ширенных средств прямого .управления
Каналы Адаптер канал-канал и сред- ства операционной системы Соединение канала одной ЭВМ с каналом другой ЭВМ Быстрая синхронизированная переда- ча программной и числовой информации из оперативной памяти одной ЭВМ в оперативную память другой ЭВМ
Внешняя память « Двухканальный переключа- тель (входной коммутатор)* устройств управления внеш- ними устройствами и средст- ва операционной системы Общее поле внешней памяти , Одновременный и разнесенный во вре- мени доступ процессоров к большим объемам программной и числовой ин- формации в общем поле внешней памяти
интерфейсные карты — управляющая (УИК) и информационная
(ИИК), при этом первая — для передачи всей управляющей ин-
формации и байтов состояния, а вторая — для передачи данных.
Такое разделение позволяет использовать одни и те же интер-
фейсные карты для подключения согласователя к программному
Рис. 3.13. Структурная схема соединения ЭВМ Единой системы и ЭВМ*
М-6000.
каналу и к каналу прямого доступа в память. К ЭВМ Единой
системы согласователь может быть подключен через селекторный
канал как быстрое внешнее устройство.
Описанный вариант комплексирования реализован на маши-
нах ЕС-1030 и М-6000 [51].
Примером более сложной неоднородной многомашинной си-
стемы является экспериментальная вычислительная система Ака-
демии наук Латвийской ССР [446, 447]. Рассмотрим ее струк-
туру (рис. 3.14).
По состоянию на конец 1977 г. вычислительная система вклю-
чала девять машин, четыре из которых образуют центральный
вычислительный комплекс, а пять машин составляют основу вы-
числительных комплексов институтов. Кроме этого, в состав
системы входит аппаратура передачи данных — адаптеры (А),
устройства коммутации каналов машин — переключатели каналов
(ПК) и каналы — линии связи между адаптерами. Создание
экспериментальной вычислительной системы преследует цели
проведения научных исследований по архитектуре вычислитель-
ных систем и построения машинной базы общеакадемической
системы автоматизации научных исследований.
Три рабочие машины (две ЕС-1030 и одна М-4030) централь-
ного вычислительного комплекса принимают задания, выполняют
их и выдают пользователям полученные результаты. С одной из
рабочих ЭВМ ЕС-1030 взаимодействуют абонентские пункты с
134
дисплеями (Д), работающие в диалоговом режиме., Диспетчерская
машина (М-4030) центрального вычислительного комплекса
управляет каналами, управляет потоками информации от
устройств местного ввода-вывода, принимает задания от пользо-
вателей терминальных ЭВМ и передает им результаты, контро-
лирует правильность принимаемой информации и выполняет пов-
торный прием при появлении ошибок, преобразовывает форматы
г М-4030 -1
ЕС-1030
Устройства
местного
ввода-вывода
1---Г— 1 i|
пп Рабочие'^
EC'IOdO машинь\
А
ПК
А
А
M-WO
ЕС-1010
HP-2116 WAKGZZW WANG’ZZOO
||
I $
Диспетчерская
машина ‘ §
Терминальные
машины вычи-
слительных
комплексов
институтов
1
Рис. 3.14. Структурная схема неоднородной многомашинной вычислитель-
ной системы..
и коды, осуществляет буферизацию сообщений в оперативной
памяти, ведет сбор статистики о работе вычислительной системы.
В случае аварии функции диспетчерской машины принимает на
себя рабочая машина М-4030.
Пять терминальных мини-ЭВМ, установленные в трех инсти-
тутах АН Латвийской ССР, осуществляют сбор информации с
экспериментальных установок и управление ими, диалог исследо-
вателя с мини-ЭВМ, подготовку заданий на входных языках ра-
бочих машин, удаленный ввод заданий и вывод результатов на
внешние устройства, терминальных и рабочих машин. Взаимодей-
ствие машин построено на основе иерархии протоколов [446, 447L
135
3.3.3. Библиографическая справка. Описание ЕС ЭВМ, отдель-
ных ЭВМ семейства и их устройств содержится в многочислен-
ных работах. Укажем некоторые из них, в основном, обобщаю-
щего характера.
Технические и программные средства ЕС ЭВМ описаны в клю-
чевых книгах [155, 377]. Семейству ЕС посвящены книги [142,
430]. В этих книгах рассматриваются архитектура и модели се-
мейства, устройства машин, программное обеспечение, комплек-
сирование машин и другие вопросы. Так, например, материал
книги [142] базируется, главным образом, па схемах и структу-
рах машин ЕС-1020, ЕС-1030, ЕС-1050, в книге рассматривается
комплексирование машин ЕС-1030 и ЕС-1050. Такой же широкой
тематике посвящен ряд разделов в книгах [218, 429], при этом
в первой из них акцент сделан на структуру и программное
обеспечение, а во второй — на описание характеристик ЭВМ и их
устройств. В обоих книгах охвачены машины вплоть до II оче-
реди, рассматриваются, в особенности в первой книге, вопросы
комплексирования. Некоторые данные об ЕС ЭВМ содержатся
в [188].
Принципы построения, технико-экономические и эксплуата-
ционные характеристики, программное обеспечение, перспективы
и концепции развития ЕС ЭВМ рассмотрены в цикле статей
[236-246].
Отдельные ЭВМ, включая, как правило, вопросы их комплек-
сирования, рассмотрены: ЕС-1020 —в [195, 345, 434]: ЕС-1022 —
в [435, 436]; ЕС-1030-в [4371; ЕС-1035 - в [255,256,438];
ЕС-1050-в [439]; ЕС-1055-в [46J; ЕС-1060-в [12, 440].
В [61] говорится о создании и испытаниях старших моделей II
очереди ЕС ЭВМ. Уровни комплексирования и типовая структура
двухмашинного комплекса ЕС ЭВМ описаны в [153].
Программное обеспечение, в первую очередь операционные
системы ОС и ДОС описаны в книгах [249, 276, 309, 310, 319,
383, 427], языки для ЕС ЭВМ и (в меньшей степени) их реализа-
ция, а также методология программирования для ЕС ЭВМ из-
ложены в книгах [254, 343г 349, 413, 443].
Состав» и функциональные характеристики программного
обеспечения ЕС ЭВМ и вопросы его развития изложены в стать-
ях [235, 318, 353, 354].а
Рассмотрим теперь статьи, основное содержание которых сос-
тавляют вопросы комплексирования ЭВМ Единой системы между
собой и с другими типами ЭВМ. Технические и программные
средства комплексирования ЕС ЭВМ и некоторые комплексы
описаны в [10, 172, 190, 247, 365], а программное обеспечение
комплексирования и некоторые вопросы организации параллель-
ных вычислений в ЕС ЭВМ рассмотрены в [139, 171, 208, 259,
260]. Комйлексированпе ЭВМ Единой системы с мини-ЭВМ (ЭВМ
М-6000) описано в [1, 51, 52, 54, 97, 119], программное обеспече-
ние связи между указанными ЭВМ — в [53, 120], а некоторые
136
вопросы программирования периферийной мини-ЭВМ в ДОС ЕС
ЭВМ-[3271.
Экспериментальная многомашинная вычислительная. система
АН Латвийской ССР, в которую вошли ЭВМ Единой системы и
АСВТ-М и некоторые другие, описана в [357, 444—447J.
Базовый вычислительный комплекс на основе ЭВМ Единой
системы, который должен войти как составная часть в разраба-
тываемый вычислительный центр коллективного пользования СО
АН СССР (см. п. 3.2.2), описан в [271J. Основа комплекса —
две — четыре ЭВМ ЕС средней и большой мощности (ЕС-1033,
ЕС-1050, ЕС-1060), одна мини-ЭВМ (М-7000) семейства АСВТ-М,
дополнительные накопители на магнитных лентах и дисках,
объединенные под управлением спецпроцессора. Технические
средства комплексирования — кольцевая мультиплексная магист-
раль с пропускной способностью порядка 1 М байт в секунду.
Функции по обработке предполагается резделить в соответствии с
возможностями технического оборудования.
Разработка однородной вычислительной системы на базе
средств старшей модели ЕС ЭВМ описана в [150, 152J, а разра-
ботка операционной системы для такой вычислительной систе-
мы — в [250].
Данные о вычислительном комплексе ЭВМ ЕС-1020 п
Минск-22 и используемом в нем мультиплексном канале ЕС ЭВМ
приведены в [380]. Расширение возможностей операционной си-
стемы ОС ЕС для обеспечения функционирования матричного
процессора в составе ЕС ЭВМ описано в [286].
Краткий библиографический обзор вопросов комплексирова-
пия машин Единой системы содержится в [110J.
Не делая повторных ссылок, отметим, что некоторые много-
машинные системы, в состав которых входят ЭВМ семейства
ЕС, рассмотрены в п. 3.2.
3.4. Системы на базе ЭВМ семейств АСВТ-М
и СМ ЭВМ [154, 289-291, 429]
3.4.1. Структура семейств АСВТ-М и СМ ЭВМ. Структуру се-
мейств АСВТ-М и СМ ЭВМ рассмотрим несколько более подроб-
но, поскольку структура моделей этих семейств менее однотип-
на при переходе от модели к модели по сравнению с ЕС ЭВМ.
Агрегатная система средств вычислительной техники (АСВТ)
представляет собой набор агрегатных устройств с унифициро-
ванными внешними связями для обеспечения сбора, хранения,
переработки и выдачи информации. Технические и программные
средства АСВТ нашли широкое применение в АСУ предприяти-
ями с дискретным, непрерывным и непрерывно-дискретным про-
изводством, в АСУ технологическими процессами и в системах
автоматизации научных экспериментов.
1'37
В АСВТ реализован агрегатно-блочный принцип построения
средств вычислительной техники, обеспечивающий компоновку
разнообразных вычислительных систем с заданными техничес-
кими параметрами, при этом предусмотрены различные возмож-
ности комплексирования и построения многопроцессорных систем.
Семейство АСВТ обеспечивает, с некоторым перекрытием,
спектр более низкой производительности по сравнению с семей-
ством ЕС и характеризуется ориентацией на работу в реальном
масштабе времени.
Разработка АСВТ была начата с 1965 г. Первая очередь
АСВТ создана с использованием дискретной элементной базы.
Вторая очередь АСВТ, которая получила название АСВТ-М,
создана на микроэлектронной элементной базе (на интегральных
схемах) по усовершенствованным структурным и архитектур-
ным принципам по сравнению с первой очередью. В частности,
вместо многофункциональных устройств,^обладавших аппаратур-
ной избыточностью и, как следствие, повышенной стоимостью,
в основу АСВТ-М полоясен агрегатный модуль — устройство, ко-
торое имеет унифицированные внешние связи и выполняет какие-
либо функции по обработке или хранению информации, коммута-
ции передач, преобразованию физических сигналов и т. п. Модули
объединяются по функциональному назначению в группы уст-
ройств и комплексы. Устройства и комплексы АСВТ-М совмес-
тимы по данным (форматы и коды) для обеспечения взаимного
обмена информацией в системах. Производство комплексов
М-6000, М-7000, М-400, М-40. АСВТ-М было освоено в 1971—
1975 гг. Как АСВТ первой очереди, так и АСВТ-М созданы в на-
шей стране.
Средства АСВТ-М включают в себя набор процессоров, пери-
ферийных устройств, устройств ввода и вывода аналоговых и
дискретных сигналов, средств отображения цифровой и графиче-
ской информации, систем программного обеспечения, позволяю-
щих компоновать различные проблемно7ориентированные комп-
лексы, как одномашинные, так и многомашинные. В состав
АСВТ-М входит ряд управляющих вычислительных комплексов
различной сложности и производительности — от микропрограм-
много автомата М-40 (нижний уровень) до управляющих вычис-
лительных машин (комплексов) М-400, М-6000, М-7000, М-4030
{верхний уровень). Рассмотрим кратко указанные управляющие
вычислительные машины [289, 429], начав с наиболее мощной
из них. w .
Машина М-4030 имеет наиболее высокую производительность
среди АСВТ-М. Она может быть использована как в различных
автоматизированных системах управления, так и в вычислитель-
ных центрах, может служить центральным звеном многомашин-
ных иерархических систем с использованием младших моделей
АСВТ-М. М-4030 разработана -ПТО ВУМ совместно с ИНЭУМ.
Она была запущена в серийное производство в 1973 г.
138
Машина М-4030 имеет среднюю производительность 100 тыс.
операций в секунду (максимальная производительность — 300
тыс. операций в секунду). Емкость устройства оперативной памя-
ти составляет 128 К байт, она может быть расширена до 512 К
байт. Имеется сверхоперативная память емкостью 384 36-разряд-
ных слов. Предусмотрено подключение трех селекторных кана-
лов, каждый из которых позволяет адресоваться, к 256 внешним
устройствам и имеет пропускную способность 1 М байт в секун-
ду* *), и одного мультиплексного канала, к которому можно под-
ключить да 184 периферийных устройств. Важно отметить, что
система команд М-4030 представляет собой совокупность систем
команд АСВТ-М и ЕС ЭВМ, внутренний код М-4030 соответству-
ет стандарту ЕС ЭВМ, а сопряжение между каналами и перифе-
рийным оборудованием в М-4030 производится через стандартный
интерфейс ввода-вывода, соответствующий ЕС ЭВМ. Последнее
позволяет использовать в-составе модели' М-4030 периферийные
устройства не только АСВТ-М, но и ЕС ЭВМ, а также обеспечи-
вает проведение работ по созданию многомашинных систем на
базе моделей ЕС ЭВМ и АСВТ-М.
Развитое программное обеспечение М-4030, основой которого
является операционная система ОС АСВТ и дисковая операцион-
ная система ДОС АСВТ, обеспечивает работу в мультипрограм-
мном режиме, выполнение программ в реальном масштабе време-
ни, а также работу многомашинных комплексов как на базе соб-
ственно М-4030, так и на базе М-4030, М-400, М-6000. Оно
обеспечивает программную совместимость с моделями АСВТ
М-2000, М-3000 и М-4000, а также с моделями ЕС ЭВМ на уров-
не общих языков, используемых в АСВТ-М и ЕС ЭВМ. В прог-
раммном обеспечении имеются трансляторы с языков ассемблер,
ал мо, ал гаме, кобол, РПГ, фортран IV, алгол 6(£ библиотеки
стандартных и проблемно-ориентированных программ, тестовые,
сервисные и другие программы.
Машина М-400, разработанная ИНЭУМ совместно с ПТО
ВУМ, предназначена, в первую очередь, для автоматизации
научных экспериментов. Она может быть использована как ЭВМ-
сателлит машины М-4030 в иерархических вычислительных си-
стемах.
Машина М-400 относится к классу мини-ЭВМ и имеет типич-
ные черты структуры таких ЭВМ: длина слова —16 разрядов,
емкость оперативной памяти — от 16 К до 32 К слов, прямая ра-
бота процессора с внешними устройствами. Вместе с тем в маши-
не имеется многоуровневая приоритетная система прерываний,
различные виды адресации, позволяющие расширить стандартный
набор команд от 65 команд до 400 команд, гибкая система модифи-
кации адресов. Процессор, память и периферийные устройства
___________ .<
*) Общая пропускная способность трех селекторных каналов ограни-
чена возможностями оперативной памяти и составляет 2 М байт и се-
кунду [18].
13*
скомпонованы вокруг общей шины, включающей 56 линий, по ко-
торой происходит весь информационный обмен в машине. Вид
связи для всех устройств, подключаемых к шине, одинаковый.
Периферийные устройства подсоединяются к общей шине при
помощи блоков интерфейса, выполняющих задачи сопряжения и
некоторые стандартные управляющие функции.
Программное обеспечение включает в себя перфоленточную
систему ПМО-400, систему реального времени РВС-400 и диско-
вую операционную систему ДОС-400. Первая предназначена для
использования машины с базовой конфигурацией технических
средств при наличии оперативной памяти емкостью 16 К байт,
вторая — для использования машины, когда в ее состав вводятся
устройства связи с объектом, а оперативная память расширяет-
ся до 24 К байт, и третья — для использования машины с опера-
тивной памятью не менее 24 К байт и с подключенными двумя
или более накопителями на магнитных дисках. При этом РВС-400
обеспечивает мультипрограммный режим работы в реальном вре-
nAbhh (до 128 одновременно работающих управляющих программ
пользователя). ДОС-400 обеспечивает обработку потока заданий
и отладку программ в диалоговом режиме, она включает в себя
трансляторы с языков ассемблер, фортран и бэйсик.
Широкую популярность завоевала машина М-6000, разрабо-
танная НПО «Импульс». Она с 1972 г. применяется в АСУ тех-
нологическими процессами и агрегатами. Машина М-6000 в
иерархии средств АСВТ-М стоит ниже, чем М-400, относится к
классу мини-ЭВМ и ориентирована на решение задач контроля
и управления. Она имеет 16-разрядные слова, основную память
емкостью 32 К слов и одноадресную систему команд, удобную
систему приоритетного прерывания и выполняет 200 тысяч опе-
раций в секунду. Скорость обработки безадресных микрокоманд —
1800 тысяч операций в секунду. Основная память включает до
четырех оперативных и постоянных запоминающих устройств в
любом необходимом сочетании емкостью 8 К слов каждое.
В М-6000 возможно подключение'ДО двух каналов — прямого
доступа в память и инкрементного — в любом сочетании. Канал
прямого доступа в память, выполняющий операции ввода-вывода
без прерываний процессора, обеспечивает передачу данных со
скоростью 650 К байт в секунду. Инкрементный канал, предназ-
наченный для выполнения групповых операций (увеличение на
единицу содержимого ячеек оперативной памяти с адресами, оп-
ределяемыми поступающими в канал кодами от внешних уст-
ройств), имеет скорость работы до 250 К байт в секунду. Для
подключения внешних устройств используются интерфейсные
карты (интерфейсные блоки), которые, в свою очередь, подклю-
чаются к процессору и каналам.
Перфоленточная система программного обеспечения СПО-
-6000А М-6000 обеспечивает выполнение одной задачи, диалог
оператора с машиной и некоторые другие виды работ и имеет
140
б своем составе систему трансляторов с языков мнемокод, фортран
и алгол, систему ввода-вывода, основную управляющую систему,
библиотеку стандартных программ, систему интерпретации , с
языка бэйсик и тестовую систему.
Машина М-7000, выполненная на базе усовершенствованных
модулей АСВТ-М, имеет по сравнению с М-6000 более высокую
производительность, большую емкость оперативной памяти, по-
вышенную надежность, более развитую систему команд и, в об-
щем, более развитые системные возможности {184, 429]. Она пол-
ностью совместима с М-6000 по сопряжению ввода-вывода и по
программному обеспечению. Кроме этого, в М-7000 предусмотре-
ны полная совместимость по форматам данных и односторонняя
(снизу вверх) совместимость с М-6000 на уровне перемещаемых
программ. Иными словами, все перемещаемые программы, разра-
ботанные для М-6000, будут выполняться на М-7000, но без
использования некоторых дополнительных возможностей М-7000,
а программы, подготовленные на М-7000, не могут выполняться
на М-6000.
М-7000 имеет одноадресную систему команд с 17-разрядным
полем для адресации, выполняет операции над 16-разрядными
операндами и имеет оперативную память емкостью до 128 К'18-
разрядных слов (16 информационных и 2 контрольных разряда).
В М-7000 возможна прямая адресация любой ячейки как в нуле-
вой, так и в текущей странице, косвенная адресация как через
нулевую, так и через текущую страницу, а также адресация при
помощи индексации и автоиндексации. Первые четыре способа
адресации применяются также и в М-6000, а последние два явля-
ются в М-7000 новыми по сравнению с М-6000. При индексации
адрес формируется путем сложения содержимого индексного реги-
стра с адресной частью команды, а при автоиндексации в каче-
стве адреса используется содеряушое индексного регистра с по-
следующим изменением его на величину адресной части команды.
В машине предусмотрена защита памяти. Кроме основного,
реализуется дополнительный набор команд при помощи расшири-
теля арифметического устройства.
В целях обеспечения больших производительности и живуче-
сти в М-7000 имеются как шины памяти — для обмена данными
и управляющей информацией между процессорами, каналами
прямого доступа в память и устройствами оперативной памяти,
так и отдельные шины ввода-вывода — для обмена информацией
между процессорами, каналами прямого доступа в память и раз-
личными периферийными устройствами, подключаемыми через
модули группового управления (расширители ввода-вывода). Ка-
нал прямого доступа обеспечивает скорость передачи 680 К байт
в секунду. Управление этим каналом возможно не только от
процессора М-7000, но и от процессоров М-6000 и М-6010.
В состав комплекса М-7000 входят следующие модули: про-
цессор, оперативное запоминающее устройство (ОЗУ), канал пря-
141
мого доступа в память (КПДП), расширитель ввода-вывода (РВВ>
и расширитель арифметического устройства (РАУ). Базовая кон-
фигурация М-7000 включает в себя процессор и одно ОЗУ емко-
стью 16 К слов. На базе процессора М-7000 можно компоновать
системы различной конфигурации: однопроцессорные с емкостью
оперативной памяти от 16 К до 128 К слов с использованием или
без использования РАУ; КПДП и одного, двух или трех РВВ;
многомашинные системы различной сложности; двухпроцессорные
системы с общим полем оперативной памяти и общими или раз-
дельными периферийными устройствами.
Обслуживание терминалов высокого и среднего быстродей- .
ствия может осуществляться мультиплексным каналом. В М-7000
предусмотрено подключение’ двух мультиплексных каналов, каж-
дый из которых имеет четыре независимых подканала.
Операционные системы М-7000 компонуются из набора прог-
раммных модулей при помощи генераторов с учетом данной конфи-
гурации технических средств М-700, режима работы и характера
решаемых задач. Предусмотрено обеспечение работы двухпроцес-
сорной системы, при этом в случае выхода из строя одного из про-
цессоров его задачи передаются второму процессору. Работа в ре-
жиме реального времени совмещается с решением фоновых задач.
Перейдем к Международной системе малых электронных вы-
числительных машин — СМ ЭВМ [290, 291].
В целях разработки комплекса средств вычислительной техни-
ки в классе малых ЭВМ и организации их крупносерийного про-
изводства на основе специализации и кооперирования социали-
стических стран НРБ, ВНР, ГДР, Республика Куба, ПНР, СРРГ
СССР и ЧССР приняли в середине 1974 г. решение об организа-
ции совместных работ по созданию системы малых ЭВМ в рамках
межправительственной комиссии по сотрудничеству социалисти-
ческих стран в области вычислительной техники 1290, 291J.
Система малых ЭВМ (СМ ЭВМ) создается как агрегатная си-
стема технических и программных средств вычислительной тех-
ники на современном перспективном техническом уровне. В кон-
цепции создания СМ ЭВМ системные применения определены как
первоочередные и предусмотрена ориентация на значительное
развитие технического уровня АСУ в следующих направлениях:
1) рациональное сочетание децентрализации и централизации
функций контроля технологических процессов и научных экспе-
риментов при построении систем; 2) создание систем адаптив-
ного управления; 3) развитие функций диспетчеризации и опе-
ративной корректировки заданий; 4) ориентация системных при-
менений СМ ЭВМ на технические испытательные станции и
диагностику сложных объектов; 5) повышение уровня резервиро-
вания и функциональной живучести средств и комплексов СМ
ЭВМ; 6) развитие методов и средств взаимодействия оператора с
машиной; 7) обеспечение возможности управлять сложными из-
мерительными комплексами или технологическим оборудованием
142
€ применением «встроенных», средств СМ ЭВМ; 8) создание си*
• стем модульного программирования типовых задач контроля и
управления, специализированных командных языков*
Технические средства СМ ЭВМ создаются в рамках первой и
' второй очереди. В состав первой очереди вводит базовый ряд про-
цессоров СМ-1, СМ-2, СМ-3, СМ-4 различной производительности
<до 1 млн. операций в секунду), широкий набор устройств ввода*
вывода, внешней памяти, отображения, связи с объектом, дистан-
ционной связи, внутримашинной и межмашинной связи. Произ-
водство базовых процессоров начато в 1977—78 ггг
Производительность СМ-1 и СМ-3 составляет 200, а СМ-2 и
СМ-4—400—500 тысяч коротких операций в секунду соответственг/
но, а объем оперативной памяти — 4 К — 32 К слов у СМ-1 и СМ-3
п 16 К —128 К слов у СМ-2 и СМ-4. В составе первой очереди
предусматривается наиболее мощный процессор СМ-5 с произво-
дительностью в 1 млн. коротких операций и 250 тысяч операций
с плавающей запятой в секунду и с оперативной памятью емко-
стью в 16 К — 256 К слов.
Номенклатура технических средств второй очереди СМ ЭВМ
базируется па применении больших интегральных схем и микро*
процессоров для построения программируемых контроллеров пе-
риферийных устройств и микропроцессорной реализации младших
моделей СМ ЭВМ. В конфигурациях вычислительных комплексов
предусматривается расширение возможностей по сравнению с мо-
делями первой очереди, в основном, за счет построения их в виде
систем с процессорами-расширителями с сохранением совмести-
мости. В. составе. второй очереди СМ ЭВМ предусматривается
создание старших моделей с производительностью в несколько
миллионов операций в секунду при емкости оперативной памяти
до 1—2 М байт с сохранением сходных экономических показате-
лей моделей первой очереди.
В программном обеспечении СМ ЭВМ реализуется принцип
построения программных компонентов (агрегатов) различного тиг
па, из которых по заказам пользователя создаются системы кон*
кретного назначения. Это позволяет, с одной стороны, экономить
ресурсы вычислительной системы в интересах рабочих программ
и, с другой стороны, иметь общую базу программного обеспече-
ния. В качестве основных типов программных компонентов можно
выделить следующие: программы логико-математической обработ-
ки данных вне зависимости от области применения; программы
обеспечения эффективного функционирования различных техни-
ческих средств; программы реализации функций взаимодействия
пользователей с системой с учетом особенностей области приме-
нения; программы реализации методов организации вычислитель-
ного процесса. Значительное внимание уделяется программным
средствам обеспечения повышенной надежности и живучести си-
стем на базе СМ ЭВМ с резервированием наиболее ответственных
устройств и функций.
143
Рассмотрим кратко управляющие вычислительные комплексы
(машины) СМ-1, СМ-2, СМ-3, СМ-4.
Комплексы СМ-1 и СМ-2 [359, 360] компонуются по специфи-
кации заказчика на базе процессоров СМ-1П и СМ-2П из агрегат-
ных модулей СМ ЭВМ/ с использованием, при необходимости, пе-
риферийных устройств из номенклатуры М-6000/М-7000 АСВТ-М*
Они обладают подной программной совместимостью с М-7000 и
односторонней совместимостью на уровне перемещаемых программ
с М-6000 (совместимость от М-6000 к СМ-1 и СМ-2), а также
полной совместимостью с М-6000 и М-7000 по интерфейсу ввода-
вывода. По техническим параметрам и структурным возможно-
»стям СМ-1 и СМ-2 полностью заменяют М-6000 и М-7000 соот-
ветственно.
На базе процессоров СМ-2П можно компоновать многопроцес-
сорные системы с общим полем оперативной памяти и общими
или раздельными периферийными устройствами. На базе комп-
лексов СМ-1 и СМ-2 можно компоновать многомашинные системы,,
как локальные, так и территориально рассредоточенные.
Помимо процессора СМ-1П комплекса СМ-1 пользователям
может быть поставлен вариант процессора с системой команд
М-6000, обеспечивающий полную программную совместимость
с процессором М-6000 не только по перемещаемым, но и по абсо-
лютным программам.
В состав программного обеспечения СМ-1 и СМ-2 входят опе-
рационные системы, библиотеки, проблемно-ориентированные па-
кеты программных модулей, система подготовки программы, сер-
висные и контрольно-диагностические программы. Оно поставля-
ется по спецификации пользователя в виде специфицированных ;
программных систем или набора программных модулей, из кото-
рых-пользователь компонует нужную программную систему.
Операционная система может быть однозадачной, многозадач- j
ной однопроцессорной и, только для СМ-2, многозадачной много-
процессорной. В бездисковых вариантах операционных систем
все программы операционной системы и все рабочие программы -
постоянно находятся в оперативной памяти комплекса. В диско- i
вых операционных системах и системные и рабочие программы
делятся на два типа: ОЗУ-резидентные, которые во время ра- <
боты постоянно находятся в оперативной памяти, и диск-рези- }
дентные, хранящиеся на диске и вызываемые, в оперативную
память только при необходимости их выполнения. Пользовате- J
лям могут поставляться также операционные системы М-6000, *
адаптированные к однопроцессорным конфигурациям комплек-
сов СМ-1 и СМ-2 с объемом оперативной памяти не более ]
32 К слов. ’
Для подготовки программ предоставляются мнемокод М-6000, i
мнемокод М-7000, макроязык, фортран II, фортран IV -и диалект
алгола 60, а в режиме интерпретации может использоваться так- 4
же язык бэйсик. Программы можно готовить не только на СМ-1 J
14* j
и СМ-2, но и на М-6000 и М-7000, предусматривается также воз-
можность подготовки программ для СМ-1 и СМ-2 на ЕС ЭВМ.
Комплексы СМ-3 и СМ-4 [292, 407]. Комплексы СМ-3 и СМ-4
обеспечив'ают преемственность по архитектуре с машинами М-400
подобно тому,’ как комплексы СМ-1 и СМ-2 обеспечивают преем-
ственность с машинами М-6000 и М-7000.
Комплексы СМ-3 и СМ-4, ориентированные на архитектуру
М-400, их технические и программные средства, строятся на базе
процессоров СМ-ЗП и СМ-4П и компонентов, входящих в номен-
клатуру технических средств СМ ЭВМ. Основным конструктив-
ным элементом является автономный комплексный блок с источ-
ником питания и вентиляцией. Автономный комплектный блок
процессора СМ-3 включает в себя собственно процессор, оператив-
ную память емкостью 8 К слов, интерфейс-для подключения не
более восьми устройств ввода-вывода, таймер, источник питания
и блок вентиляции. Оперативная память допускает наращивание
до 32 К слов.
Основной особенностью архитектуры комплекса СМ-3 является
однотипная организация связей процессора с оперативной па-
мятью и внешними устройствами. Все эти устройства, как и сам
процессор, подключены к общему последовательно-параллельному
каналу обмена (общей шине). Каждое устройство периодически
выставляет запрос на использование этого общего канала. Обра-
ботку запросов и распределение канала между устройствами осу-
ществляет специальный блок диспетчера, управляемый от про-
цессора. Операции ввода-вывода выполняются при этом в процес-
соре как обычные адресные команды, что значительно упрощает
программирование внешних устройств. Универсальность подклю-
чения устройств к каналу обмена позволяет достаточно просто
организовывать внепроцессорные обмены информацией устройств
как между собой, так и с оперативной памятью.
Основными отличиями процессора СМ-4П от СМ-ЗП являются
следующие: возможность наращивания оперативной памяти до
128 К слов; расширенный состав команд, включающий расширен-
ные арифметические операции с фиксированной запятой и опера-
ции с плавающей запятой; наличие постраничной защиты памя-
ти; более высокая производительность (500—700 тыс. коротких
операций в секунду).
Комплексы СМ-3 и СМ-4 обеспечивают программную совмес-
тимость с М-400.
Для создания иерархических многомашинных вычислительных
систем на базе СМ ЭВМ и ЕС ЭВМ, М-4030 АСВТ-М, БЭСМ-6
предусматриваются соответствующие адаптеры сопряжения.
Программное обеспечение СМ-3 и СМ-4 включает операцион-
ные системы реального времени, разделения времени, телекомму-
никационные и др., средства программирования и отладки, сред-
ства проверки и тестирования оборудования, проблемно-ориенти-
рованные пакеты программ.
Ю в. А. Головкин , 145
В первую очередь операционных систем (ОС) входят: 1) лен-
точная ОС с языками программирования ассемблер, бэйсик и
фокал; 2) дисковая ОС с языками программирования макроас-
семблер и фортран IV; 3) ОС реального времени Фобос с фоновым
режимом и с языками ассемблер, макроассемблер, бэйсик и фор-
тран; 4) малая мультипрограммная перфоленточная ОС реально-
го времени; 5) дисковая мультипрограммная ОС реального време-
ни с языками ассемблер, макроассемблер, фортран IV и фортран
реального времени; 6) большая мультипрограммная ОС реально-
ного времени, позволяющая выполнять до 250 задач реального
времени и производить в фоновом режиме подготовку и отладку
программ на языках ассемблер, макроассемблер, фортран IV,
фортран реального времени, кобол; 7) универсальная модульная
система программного обеспечения телеобработки данных; 8) диа-
логовая многотерминальная ОС; 9) дисковая ОС разделения вре-
менных ресурсов. Кррме этого, предусматривается операционная
система для целей обучения с диалоговым языком типа бэйсик,
система подготовки и отладки программ для СМ ЭВМ на ЕС ЭВМ
и М-4030 АСВТ-М и др.
При развитии СМ-3 и СМ-4 предполагается создание модифи-
каций этих моделей и расширение их спектра как вниз (малые,
встраиваемые в оборудование и микро-ЭВМ), так и вверх (увели-
чение производительности и объема оперативной памяти). Ориен-
тировочные параметры малых встраиваемых ЭВМ и больших
ЭВМ следующие: объем оперативной памяти до 28 К и 124К —
512 К слов, производительность — в среднем 100 тысяч и до 900
тысяч'операций в секунду соответственно.
3.4.2. Многомашинные и многопроцессорные системы на базе
АСВТ-М и СМ ЭВМ. Рассмотрим сначала комплексы на базе
ЭВМ М-4030 1171. Построение двухмашинной системы осущест-
вляется так же, как и для ЕС ЭВМ — при помощи адаптера ка-
нал-канал, устройств управления внешними запоминающими уст- ?
ройствами, средств прямого управления и соответствующих л
средств программного обеспечения. При комплексировании М-4030
с другими машинами АСВТ-М первая выполняет основные функ- J
ции центрального вычислителя (рис. 3.15). При этом ДОС АСВТ ,1
на М-4030 должна содержать специальные программные средства !
доступа к процессорам более низкого уровня иерархии в системе, :
а операционные системы последних должны иметь программы "обг
служивания адаптера связи и программы доступа к центральной *
машине. -L
Адаптеры связи соединяют непосредственно интерфейсы ма<
шин. Обмен между машинами ведется побайтно. Для организации >
межмашинной дистанционной связи (на расстояние до 3 км) ис-
пользуется устройство сопряжения (УС), осуществляющее побай*
тный обмен в полудуплексном режиме по инициативе любой из )
взаимодействующих машин. Для связи с управляемыми объекта* |
ми используются, как обычно, устройства связи с объектом (УСО)> 1
146 1
Разнообразные многомашинные комплексы могут быть пост-
роены на базе машин M-6000/M-60t0 [68] Г дуплексные системы,
иерархические системы со структурой в виде дерева и Одноуров-
невые системы, например, с кольцевой структурой, системы с кон-
центраторами (М-40) на нижнем уровне, а также иерархические
М-4030
МК CKWftt Cfti
Интерфейс ввода-вывода
Адаптер
уё~\
\l-6000
Г\
Адаптер
Адаптер
\озу I
Адаптер
Внешние
. устройства
у со
Внешние
устройства
Общая шипи
УСО
4
' УС
Сменной адаптер .
для М-4030, М-6000и М-400
И одвехту
управления
Рис. 3.15. Структурная схема иерархической многомашинной системы на
базе процессоров М-4030, М-6000, М-7000.
системы, на верхнем уровне которых используются модели ЕС
ЭВМ, и другие виды систем.
При комплексирования машин М-7000 важную роль играют
шины памяти и шины ввода-вывода. Пример структуры двухпро-
цессорной системы на базе машин М-7000 изображен на рис. 3.16
[115, 184, 429] (функции и обозначения устройств приведены в
предыдущем п.х 3.4.1). К шинам памяти, с одной стороны, под-
ключаются до двух процессоров и до двух КПДП и, с другой Сто-
роны,— до восьми ОЗУ общей емкостью 128 К слов. К шинам вво-
да-вывода в системе с общими периферийными устройствами под-
ключаются, с одной стороны, до двух процессоров и до двух ка-
налов и, с другой стороны, до трех РВВ, к каждому из которых
подводится до шестнадцати периферийных устройств. Таким об-
разом, при помощи шин основные устройства становятся общими
в системе.
Пример структуры многомашинной системы, состоящей из
двухпроцессорной системы на базе М-7000 и машины М-6000
(М-6010), изображен на рис. 3.17 [115, 429]. Управление каналом
КПДП осуществляется через сопряжение, по отношению к кото-
рому он является обычным периферийным устройством. Наличие
40* Ш
1
у канала двух управляющих входов позволяет осуществлять уп-
равление им от двух* комплексов, благодаря чему он выполняет
функцию канала межпроцессорной связи для обращения в опера-
тивную память М-7000.
ОЗУ
Шины памяти
процессор
м-7000
тдв КПДП
Кпериферийным
устройствам
/(периферийным
устройствам
Шины ввода-вывода
РВВ РВВ РВВ
118 116 1 16^
К периферийным устройствам
Рис. 3.16. Структурная схема многопроцессорной системы на базе двух про-
цессоров М-7000.
Рис. 3.17. Структурная схема системы на базе процессоров М-7000 и М-6000
(М-6010).
В Многопроцессорной системе на базе СМ-2 [359] обеспечива- 1
ется ttpif помощи операционной системы одновременное выполне- "
- 148 |
F
ние на двух процессорах двух старших по приоритету задач. За-
дачи, как и операционная система, хранятся в общей оперативной
памяти в единственном экземпляре и заранее к процессорам не
привязываются. Если задача, решаемая одним из процессоров,
переходит в состояние ожидания какого-либо внешнего по отно-
шению к ней события, то процессор переключается на решение
яенее важной задачи, которая не выполняется другим процессо-
ром. Если не оказывается готовой к выполнению задачи, то про-
цессор переводится в состояние динамического останова. Если за-
дача переходит в состояние готовности к выполнению, то она за-
нимает процессор, находящийся в состоянии динамического оста-
нова, или процессор, решающий менее приоритетную задачу.
Переключение на новую задачу не происходит, если процессоры
решают задачи с более высокими приоритетами. Возможен другой
режим работы, при которохМ учитывается также размещение задач
в оперативной памяти.
3.4.3. Библиографическая справка. АСВТ первой очереди,
включая принципы ее построения, описана в [4, 225, 226]. Прин-
ципы построения АСВТ-М (вторая очередь) изложены в [288].
Краткое описание первой и второй очередей АСВТ приведено в
[154]. Общее описание АСВТ-М содержится в 12891. Набор агре-
гатных модулей АСВТ-М описан в [227, 358]. Описание моделей
АСВТ-М и их устройств приведено в [429]. Машины М-6000 и
М-7000 кратко рассмотрены в [218].
Принципы построения и общее описание СМ ЭВМ приведены
в [252, 290, 291]. Тематическая подборка статей о СМ ЭВМ при-
ведена в трех последних выпусках журнала «Приборы и системы
управления» за 1977 г. L268J.
Отдельные модели АСВТ-М рассмотрены: М-4030 — в [17, 18];
М-6000 —в [298]; М-7000 —в [184]. Перспективы развития комп-
лексов М-6000/М-7000 рассмотрены на Всесоюзной научно-техни-
ческой конференции [325]. Отдельные комплексы СМ ЭВМ
описаны: СМ-1 и СМ-2 — в [360], СМ-3 и СМ-4 — в [292,
402, 407]. Системные интерфейсы комплексов СМ ЭВМ изложены
в [285].
При описании вычислительных средств во многих из указан-
ных выше работ рассматриваются вопросы комплексирования.
Специально вопросам комплексирования машин АСВТгМ посвя-
щены статьи [17, 68, 115, 308, 328].
Аналогично, во многих из указанных выше работ рассматри-
ваются вопросы программного обеспечения. Специально этим воп-
росам посвящен ряд статей. Дисковая операционная система ДОС
АСВТ-2 описана в 142, 424J. Она представляет собой расширение
ДОС АСВТ за счет включения трансляторов с языков PL/1 и
РПГ-2, обеспечения обслуживания многомашинных комплексов
АСВТ-М, повышения степени автоматизации выполнения зада-
ний и других7 улучшений. ДОС модели М-4030 описана в [212],
программное обеспечение М-6000 —в [69, 366, 367]. В последней
149
работе рассмотрена распределенная база данных в многомашинч
ном комплексе с перекрестными связями, содержащем до восьми*
машин М-6000. Материалы по операционной системе М-6000
включены также в книгу [38U. Организация программного обес-
печения двухмашинного комплекса на базе М-6000 описана в
13871. Система модульного программного обеспечения BSX для
ЭВМ М-400 рассмотрена в [211].
Агрегатная система программного обеспечения (АСПО)
М-7000 изложена в [61, а построение ядра операционных систем
АСПО описано в [7]. При помощи модулей АСПО могут быть
построены операционные системы, обеспечивающие создание од-
нозадачных и многозадачных бездисковых и дисковых однопро-
цессорных систем, . а также многозадачных двухпроцессорных:
бездисковых и дисковых систем. ОС ДИРАК для М-7000, имею-
щая, в частности, средства синхронизации процессов, и машинно-
ориентированный язык уровня макроассемблера маем для
М-7000, снабженной ОС ДИРАК, описаны в [248] и в [30] соот-
ветственно.
Программное обеспечение комплексов СМ-1, СМ-2, СМ-3 н
СМ-4 изложено в [359, 363, 403, 408].
Вопросы построения систем сбора и передачи информации и
измерительно-информационных систем на базе СМ ЭВМ описаны
в [122, 143].
Машины рассматриваемых здесь семейств могут быть связаны
не только между собой, но и с машинами других типов и классов.
Некоторые примеры такого рода приведены в [96, 126, 173, 220].
Краткий библиографический обзор вопросов комплексирова-
ния машин АСВТ-М и СМ ЭВМ сделан в [НО]. •
Не делая повторных ссылок, отметим, что некоторые многома- *
шинные системы, в состав которых входят машины АСВТ-МJ
рассмотрены в пп. 3.2 и 3.3. j
Отметим также, что список рассмотренных в пп. 3.1—3.4 мнц- J
гомашинных и многопроцессорных систем может быть продолжен
в части комплексирования как рассмотренных, так и других
типов ЭВМ, таких как, например, Минск, Наири, М-220 [И, 21,!
189, 269]. '
3.5. Системы на базе ЭВМ семейств IBM 360
и IBM 370. Семейство IBM ЗОЗХ \
3.5.1. Структура семейств IBM 360 и IBM 370 [65, 76, 218^
606]. Семейство машин третьего поколения IBM 360 было объяв-
лено в апреле 1964 г. Первые образцы машин семейства поступи-]
ли заказчикам в 1965 г. Многие модели семейства выпущены]
очень крупными сериями, хотя некоторые модели не доведены до]
серийного производства. Семейство перекрывает производитель-!
ность от нескольких десятков тысяч операций в секунду до не-^
сколько миллионов и более операций В секунду. При разработке!
150
в структуру и программное обеспечение был заложен ряд общих
принципов, основными из которых являются следующие:
— программная совместимость моделей семейства, обеспечи-
вающая преемственность программ при переходе с одной модели
на другую;
— стандартность сопряжения устройств ввода-вывода с кана-
лами и возможность подключения большого числа устройств
ввода-вывода;
Устройства
ввода- вывода,
Устройства
управления
внешними
устройствами
Устройства
управления
внешними
-° устройствами
ввода-вывода
а) Структура машины
б) Структура центрального вычислителя
Рис. 3.18. Основная логическая структура ЭВМ семейства IBM 360.
— универсальность и возможность использования машин се-
мейства практически во всех областях применения ЭВМ;
— универсальность программного обеспечения, единого для
разных машин семейства;
151
— возможность комплексирования нескольких машин в мно-
гомашинную систему.
Архитектура семейства IBM 360 оказала большое влияние на
развитие вычислительной техники. Это семейство с темп или
иными изменениями в структуре и технологической базе воспро-
изведено в ряде других семейств.
Основной вариант структуры модели семейства состоит из ос-
новной памяти, центрального вычислителя, селекторных и муль-
типлексного каналов и устройств ввода-вывода, которые подсое-
• динены к каналам через устройства управления внешними уст-
ройствами (рис. 3.18). Стандартная система команд насчитывает
86 команд. Добавление к ним 8 команд десятичной арифметики
дает систему команд для экономических расчетов. При добавле-
нии 44 команд, реализующих операции с плавающей запятой, по-
лучается система команд для научных расчетов. При дальнейшем
добавлении средств защиты памяти получается универсальная
система команд, насчитывающая более 140 команд.
Адресация памяти осуществляется с точностью до одного
байта, максимально возможное число адресуемых единиц инфор-
мации составляет -16777216 при использовании 24-разрядного
двоичного адреса. Используются следующие основные форматы
данных: байт, полуслово — два байта, слово — четыре байта, двой-
ное слово — восемь байт, а также поля переменной длины — до
256 байт.
Центральный вычислитель имеет 16 32-разрядных регистров
общего назначения й 4 64-разрядных регистра для операций
с плавающей запятой. Команды имеют переменную длину — 2, 4 и
6 байт, большинство команд — двухадресные, есть также одно-
и трехадресные команды. Предусмотрено пять классов прерыва- j
ний — от схемы контроля, от ввода-вывода, при обращении к |
супервизору, внешние и программные, приоритеты обслужива-;
ния которых совпадают с приведенным порядком при их пере- j
числении. ;
Основу программного обеспечения составляют несколько раз-
работанных операционных систем, из которых наиболее извест- *
ными являются развитые системы DOS и OS. Первая из них бо-
лее эффективна на малых и средних моделях. В состав OS входят
управляющие и обрабатывающие программы. Первые из них осу-
ществляют управление данными, заданиями и работами (задача- ;
ми). Обрабатывающие программы содержат трансляторы с таких
наиболее распространенных языков, как фортран, кобол, РП1\
алгол 60 и PL/1. Языком низшего уровня является ассемблер. J
Общий объем программного обеспечения насчитывает многие з
миллионы команд. 1
В начале 1970-х годов фирма IBM начала выпускать новое J
семейство IBM 370 совместимых моделей, которое сохраняет про- -
граммную преемственность с семейством IBM 360 (семейство
IBM 370 совместимо с семейством 360 «снизу вверх»), но имеет
152
усовершенствованную структуру и улучшенные возможности
комплексирования. Модели IBM 370 выполнены на новой интег-
ральной технологии, имеют новые привилегированные команды,
буферную кэш-память, блок-мультиплексные каналы, виртуаль-
ную память (усовершенствования структуры коснулись разных
моделей в разной стейени). Этими моделями заменялись модели
семейства IBM 360.
Основные технические характеристики моделей семейств IBM
360, 370 и ЗОЗХ, рассматриваемого далее, приведены в таблице
3.5, в которой использованы, в основном, данные из [386, 576,
606], а также из некоторых других источников. Отметим, что
модель IBM 360/44 может быть оборудована двумя быстрыми
мультиплексными каналами с пропускной способностью в 200 К
байт в секунду в мультиплексном режиме и 500 К байт в секун;
ду — в монопольном режиме. В моделях IBM 370/165 и 168 общее
число каналов не может быть больше двенадцати, а в IBM
370/195 — не может быть больше четырнадцати.
Следует отметить, что оценки производительности моделей,
приводимые в разных работах, нередко значительно отличаются
друг от друга. Так, например, в [127] указаны для IBM
370/168 и IBM 370/195 значения производительности 3,8 и 10
млн. операций в секунду соответственно, а в ряде других работ
производительность IBM 370/195 оценивается в пределах до 15
млн. операций в секунду (сравните эти цифры с данными, при-
веденными в таблице 3.5). Поэтому к данным о производитель-
ности в таблице 3.5 следует относиться с определенной степенью
условности. •
В семействе ’IBM 360 выпущена дуплексная модель IBM 360/67
специально для систем разделения времени. Она резко отличает-
ся по структуре от типичных моделей семейств IBM 360 и 370, для
нее разработана специальная операционная система. Следует упо-
мянуть модель IBM 360/85, характерную наличием кэш-памяти
(быстрой буферной памяти). Такая память стала широко приме-
няться в семействе IBM 370. Особой, с точки зрения структуры,
является модель IBM 360/91, в которой реализована арифметико-
магистральная обработка информации с высокой скоростью.
В высокопроизводительной модели IBM 360/195 также реали-
зован магистральный принцип обработки, как и в модели IBM
370/195, близкой, к первой по своей структуре. На базе моделей
IBM360/65, IBM 370/158 и IBM370/168 были разработаны двух-
процессорные системы с общей оперативной памятью. •
3.5.2. Многомашинные и многопроцессорные системы на базе
ЭВМ семейств IBM 360 и IBM 370. Несколько моделей семейства
IBM 360 могут быть объединены в единую многомашинную вычис-
лительную систему, при этом связь между отдельными централь-
ными процессорами можно реализовать на трех уровнях. Связь
со сравнительно большим быстродействием достигается при
использовании общего устройства ввода-вывода, например,
153
Таблица 3.5
Основные технические характеристики ЭВМ семейств IBM 360, IBM 370 и IBM ЗОЗХ
1 П/П »№ЛГ 1 Модель Год первой постав- ки Производи- тельность [тыс. оп./сек] Процессор * Оперативная память Кэш-память Мул ьтип лексные каналы Селектор- ные каналы Блок- му л ьти- плексные каналы
Цикл [нсек] Ширина [байт] 1 Объем [К байт] Цикл [нсек] Объем [К байт] Цикл [нсек] Количество 1 Пропускная способность |К байт/сек] количество иponyсиная способность [К байт/сек] Количество I Пропускная способность (К байт/сек]
1 360/22 1971 750 1 24-32 1500 нет 1 30/170 ** 1 170
2 360/25 1968 30 900 1 16—48 1800 нет — 1 10,4/18,5** 1 60
3 360/30 1965 45 750 1 16-64 1500 нет — 1 30/180 ** 2 275
4 360/40 1965 90 625 2 32-256 2500 нет — 1 30/200 ♦* 2 600
5 360/44 1966 210 250 4 32—256» 1000 нет — 1 50/200 *♦
6 360/50 1955 225 500 4 128-256 2000 нет — 1 40/200 *• 3 1000
7 360/65 1965 . 550 200 8 256—1024 750 нет — 1 ' /1300** 6 670
8 360/67 1966 200 8 256-1024 750 нет — 2 110-30/0—640 6 1300
9 360/75 1966 600 195 8 256-1024 750 нет — 1 /1300 ** 6 670
10 360/85 1969 1000-2000 80 8 512-4096 960 16—32 80-160
11 360/91 1967 2000—4000 60 8 2048-6144 780 нет — 1
12 360/195 1971 7000—10000 54 8 1024-4096 756 32 54—162 2 670 6 1300 6 3000
13 37,0/115 1974 480 1 - 64—192 480 нет —
14 370/115-2 1976 480 2 64—384 480 нет —
15 370/125 1973 110 480 2 96—256 480 нет — 1 29 •> 806
16 370/125-2 1976 320 2 96-512 480 нет —
17 370/135 1972 200 275-1485 2 96—512 935 нет — 1 41/149 ♦♦ 2 1300
18 370/135-3 1973 275—1485 2 256-512 880/935 ♦ чнет —
п/п Модель Год первой поставки Производи- тельность |тыс. оп./сек] Процессор Оперативная память / Кэш-память Мультиплексные каналы Селектор- ные каналы Блок- мульти- плексные каналы
Цикл [нсек] Ширина (байт] 1 Объем [К байт] Цикл [нсек] Объем [К байт] Цикл [нсек] Количество 1 Пропускная способность [К байт/сек] Количество Пропускная способность (К байт/сек] Количество пропускная способность [К байт/сек]
19 370/138 1976 260 275-1430 2 512-1024 880/935 ♦ ПОТ —
20 370/145 1971 400 203-315 4 160-2048 540/608 * **) нет — 1 —/200 ♦♦ 3 1850 f
21 370/145-3 1973 180-270 4 192-1984 405/540 ♦ нет —
22 370/148 1977 500 180-270 4 1024—2048 405/540 * нет —
23 370/155 1971 800 115 4 256-2048 2070 8 115^-230 2 — — 5
24 370/158 1973 1000 115 4 512-6144 920/1035 ♦ 8 115-230 1 — — 5 1500
25 370/158-3 1976 1100 115 4 4 512-6144 920 16 115-230
26 370/165 1971 2000 80 8 512—3072 200’0 8—16 80-160 2 670 6 1300 И 3000
27 370/168 1973 2700 80 8 1024-8<92 320 8-16 ' 80-160 2 670 6 1300 И 3000
28 370/168-3 1976 2900 80 8 1024-8192 320 32 80-160
29 370/195 1973 7000-10000 54 8 1024-4096 756 32 54-162 2 670 6 1300 13 3000
30 3031 1300 115 4 2048-6144 920 32 115—230 2 75 10 1500
31 3032 1978 2900 80 8 2048-6144 320 32 80-160 2 75 10 1500
32 3033 1978 5000 58 8 4096-8192 290 । 64 58-116 2 ' 75 10 1500
*) Числитель соответствует считыванию из памяти, а знаменатель — записи в память.
**) Числитель соответствует мультиплексному режиму работы канала, а знаменатель — монопольному режиму.
» К *
накопителя на магнитных дисках. Более быстрая передача
информации может быть реализована при непосредственной свя-
зи между каналами двух отдельных машин. Крбме этого, в не-
которых моделях два центральных процессора могут иметь
общую оперативную память, что позволяет производить обмен
информацией со скоростью работы памяти. Наконец, наряду с
перечисленными способами связывания, существует возможность
одному центральному процессору прерывать работу другого и
получать информацию о его состоянии [76].
В семействе IBM 370 связывание моделей можно реализовать
теми же способами, при этом возможности комплексирования
улучшены.
При связывании процессоров с помощью общего поля ос-
новной памяти, в целях повышения готовности системы и ор-
ганизации общих данных и ресурсов, предполагаются следующие
возможности: разделение общей основной памяти, префиксация,
межпроцессорная сигнализация, синхронизация часов. При этом
на пульт управления системой возлагаются некоторые дополни-
тельные функции (управление конфигурацией, функции запуска,
загрузки и сброса и другие) [341].
Напомним, что структура многомашинных и многопроцессор-
ных систем на базе ЭВМ семейств IBM 360 и IBM 370 рассмот-
рена в п. 1.2 при описании эволюции многомашинных и много-
процессорных систем фирмы IBM.
3.5.3. Система IBM 360/67 [757]. Типовая конфигурация систе-
мы IBM 360/67 содержит два центральных процессора, работаю-
щих над общей оперативной памятью (рис. 3.19). Каждый про-
цессор может работать либо отдельно, со своей подсистемой
внешних устройств, либо совместно с другим процессором (дру-
гими процессорами) в симметричной многопроцессорной конфи-
гурации. Система IBM 360/67 создана в 1966 г. Она разрабаты-
валась как многопроцессорная и рассматривается в настоящем
разделе вследствие принадлежности к семейству IBM 360 и
вследствие наличия в ней обычных процессоров.
В целях реализации разделения времени и параллельной об-
работки система имеет отличия по сравнению с типовыми моде-
лями семейства IBM 360.
Модули общей оперативной памяти двухпроцессорной систе-
мы имеют четыре общие шины. Первая и вторая шины подсое-
диняются к процессорам, а третья и четвертая — к контроллерам
(устройствам управления) каналов. Каждый модуль памяти ем-
костью 256 К байт работает с временем обращения в 750 нсек
независимо от других модулей и к нему возможно обращение од-
новременно по трем шинам. Конфликты между различными ши-
нами разрешаются в самом модуле, за счет чего время обращения
при конфликте увеличивается на 150 нсек. Запросы на обмен с
оперативной памятью, поступающие от контроллеров каналов,
имеют более высокий приоритет по сравнению с запросами от
156
процессоров. В модулях памяти возможно двухкратное чередова-
ние адресов.
Центральные процессоры не связаны жестко с определенным
модулем памяти. Два канала могут одновременно обмениваться
информацией с двумя модулями оперативной памяти с макси-
мальной скоростью без какого-либо вмешательства со стороны
Рис. 3.19. Структурная схема типовой конфигурации системы IBM 360/67.
центральных процессоров, если они в это время работают с
третьим модулем оперативной памяти.
Контроллер каналов позволяет связывать каналы непосредст-
венно с модулями памяти без взаимодействия с блоками управ-
ления шин, подключенных к центральным процессорам. Оба про-
цессора могут адресовываться к каждому из каналов, а каналы
могут вызывать в процессорах прерывания. Это обеспечивает
общую и гибкую организацию системы. Таким образом, внешние
устройства не привязаны конкретно к тому’или другому процес-
сору,-но могут вызывать прерывание в том из них, который при
помощи маскирования может на них реагировать.
К контроллеру каналов могут быть подключены до шести
селекторных * каналов и один мультиплексный канал, работаю-
щие с внешними устройствами. В целях • повышения надежности
и гибкости в системе предусмотрены двойные информационные
пути между памятью и любым внешним устройством (не менее,
чем по двум линиям). еЭто обеспечивается наличием двух про-
граммно управляемых входов в устройствах управления внеш-
157
*
' *?
ними устройствами, благодаря чему они могут подсоединяться
более чем к одному каналу.
В системе реализована виртуальная память и аппаратно осу-
ществляется динамическое распределение памяти.
Возможно расчленение системы на те или иные конфигура-
ции как программным, так и физическим путем, т. е. посредст-
вом переключателей.
Типовая конфигурация не является единственно возможной.
Минимальная конфигурация содержит один процессор, один мо- ;
дуль памяти и три канала. Количество модулей оперативной па- v
мяти может быть увеличено до восьми, т. е., наибольший объем
памяти равен 2097152 байт. Каждый модуль может цметь до j
восьми шин для обмена по восьми независимым направлениям. ;
Количество центральных процессоров может изменяться от одно- ;
го до четырех. В систему можно'включить четыре контроллера j
каналов. Наибольшее количество внешних устройств, которые
можно подсоединить к системе, равно 7168.
Система IBM 360/67 без динамического распределения памя-
ти (при блокировке механизма преобразования адреса виртуаль- .
ной памяти) совместима с другими машинами семейства IBM
360, а при однопроцессорной конфигурации в режиме без ди- I
намического распределения памяти работает так же, как модель |
IBM 360/65.
Система IBM 360/67 классифицируется как однородная мно- ,
гопроцессорная система МКМДС/ВсОрМш —с множественными
потоками команд и данных и пословной обработкой, g высокой
степенью связанности, однородной структурой и многошинной |
организацией, с общими многовходовыми модулями оперативной |
памяти. J
Эффективность операционной системы IBM 360/67, выражен- |
ная в виде процента времени, которое процессор проводит в ре- •]
жиме задач, в зависимости от количества активных процессоров, I
составляет в среднем 25%, а системные издержки до 35%. При |
этом, как только число активных процессов превышает некото- • J
рую величину, эффективность резко падает вследствие лавино- ।
образного развития процесса затирания старых страниц для не- ?
реписи новых и система фактически работает впустую [1131].
3,5.4. Системы IBM 360/65 МР, 370/158 МР, 370/168 МР. На :
базе однопроцессорных моделей IBM 360/65, 370/158, 370/168
были созданы двухпроцессорные системы с общей оперативной
памятью, получившие название IBM 360/65 МР, 370/158 МР, • ;
370/168 МР (MultiProcessor) соответственно. Эти системы имеют
обычную структуру с сильной связанностью двух процессоров,
подобную, например, той, что изображена на рис. 1.8.
В системе IBM 360/65 МР, созданной в 1969 г., общая one-
ративная» память может содержать от двух до восьми блоков ем-
костью в 256 К байт каждый, т. е. максимальный объем состав- J
ляет 2 М байт й равен удвоенному максимальному объему одно- •
158
процессорной модели IBM 360/65 (см. таблицу 3.5). Центральные
процессоры имеют по одному входу, а запоминающие устройст-
ва — несколько входов для связи с центральными процессорами
и каналами. К центральным процессорам, имеющим прямое со-
единение между собой, подключаются каналы, к которым,
в свою очередь, подключаются контроллеры ввода-вывода и, далее,
устройства ввода-вывода. Здесь контроллеры каналов, в отличие
от IBM 360/67, не применяются и система ввода-вывода обла-
дает меньшей гибкостью по сравнению с IBM 360/67. В модели
IBM 360/65 МР каждый контроллер ввода-вывода может под-
соединяться к любому отдельному собственному каналу процес-
соров, что с учетом прямой связи между процессорами позволяет
использовать резервный путь к внешним устройствам, если ка-
кой-либо из каналов занят или вышел из строя [281].
Двухканальные переключатели обеспечивают доступ любому
центральному процессору к большинству периферийных уст-
ройств. При этом модель может работать под управлением одной
операционной системы как единая двухпроцессорная система.
Возможен и другой режим, когда модель работает как две от-
дельные однопроцессорные системы под управлением двух опе-
рационных систем, причем каждая из систем имеет собственные
оперативную память и периферийные устройства.
К каждому процессору можно подсоединить не более семи
Каналов, в том числе не более двух мультиплексных, при этом,
в зависимости от числа мультиплексных каналов, используются
комбинации двух типов селекторных каналов.. Селекторный ка-
нал может адресоваться к 256 устройствам ввода-вывода. Наи-
большее число общих устройств ввода-вывода для IBM 360/65
МР, однако, не может превышать наибольшего числа таких уст-
ройств для IBM 360/65. В двухпроцессорной системе можно
использовать адаптер канал-канал, причем соединяемые каналы
могут относиться либо к одной и той же системе, либо к раз-
личным системам [281].’
Для IBM 360/65 МР разработана операционная система М65
МР, представляющая собой версию OS/MVT. Эта специализиро-
ванная версия имела серьезные недостатки. Было установлено,
что добавление втброго центрального процессора модели IBM
360/65 к однопроцессорной конфигурации увеличивает произво-
дительность примерно на 30% даже при загрузке работами с ог-
раниченными потребностями в вычислительных ресурсах. Это
обстоятельство, наряду со значительными ценами, препятствова-
ло переходу от производства моделей IBM 360/65 к моделям
IBM 360/65 МР. Из общего числа центральных процессоров IBM
360/65, вероятно, 3% относились к двухпроцессорным системам.
В дальнейшем отношение производительности к стоимости и
готовность IBM 360/65 МР были улучшены [744].
Двухпроцессорные системы IBM 370/158 МР и 370/168 МР
с общей физической и виртуальной памятью, созданные в 1974 г.,
159
построены на базе сильного связывания двух IBM 370/158 и
двух 370/168 сооветственно при помощи специального блокаг уп-
равления и работают под управлением единственной копии опе-
рационной системы 0S/VS2 Release 2.
Каждая, задача и пользователь могут иметь в своем распоря-
жении виртуальную память объемом в 16 М байт. Возможен
режим раздельной работы процессоров.
В состав IBM 370/158 МР (370/168 МР) может входить опе-
ративная память емкостью от 1 до 8 (от 2 до 16) М байт; число
каналов — до 12 (24) при комбинациях до 10 блок-мультиплекс-
ных и до 4 байт-мультиплексных (до 22 блок-мультиплексных)
каналов. Кроме этого, имеется быстрая буферная память ем-
костью 8 К байт (8 К байт или 16 К байт).
Двухпроцессорные системы имеют мультисистемное устрой-
ство или устройство межсистемной связи с панелью управления
конфигурацией, размещаемые физически между процессорами.
При помощи панели осуществляется переключение на двухпро-
цессорную конфигурацию или же на конфигурацию двух одно-
процессорных систем. Устройства ввода-вывода с удаленными от
них двухканальными переключателями могут подсоединяться
к каждому или к обоим процессорам системы [1007].
Рассмотренные здесь двухпроцессорные системы классифици-
руются так же, как и система IBM 360/67.
В результате дальнейшего усовершенствования моделей IBM
370/158 и 370/168 были выпущены модели IBM 370/158-3 и
370/168-3. Наконец, в 1976 г. были созданы новые варианты мо-
делей IBM 370/158 и 370/168 - IBM 370/158 APS и 370/168
APS соответственно (Attached Processor System), характерные
введением вспомогательного процессора (модуль 158 APS содер-
жит большинство компонентов основного процессора, но в нем
полностью отсутствует память) [112].
3.5.5. Семейство IBM ЗОЗХ и новые разработки фирмы IBM
[113, 388, 1264]. В семейство IBM ЗОЗХ, называемое также IBM
3030, входят модели IBM 3031, IBM 3032 и IBM 3033, объявлен-
ные в 1977 г. (см. таблицу 3.5). Машины этого семейства пол-
ностью совместимы с семейством IBM 370. Производительность
самой большой машины IBM 3033 этого семейства, которая на-
чала выпускаться в 1978 г., составляет 4—6 млн. операций в
секунду, максимальная емкость оперативной памяти — 8 М байт,
емкость быстрой буферной памяти — 64 К байт. Аналогичные
данные о машине IBM 3032, которая также начала выпускаться
в 1978 г., составляют: 2,2—3,3 млн. операций в секунду; 6М байт
и 32 К байт соответственно. Максимальная емкость оперативной
памяти и емкость быстрой буферной памяти машины IBM 3031
такие ясе, как и у IBM 3032, а производительность равна 1,0—
1,5 млн., операций в секунду.
Оборудование каналов содержит две независимые группы по
шесть каналов, каждая из которых содержит один байт-мульти-
160
плексный канал с пропускной способностью 75 тыс. байт в се-
кунду и пять блок-мультиплексных каналов с пропускной спо-
собностью 1,5 млн. байт в секунду. В подсистему управления
входят два различных пульта операторов с экранами и два сне-
диализированных процессора.
Предполагается, что модель IBM 3033 заменит собой модель
IBM 370/178, которая, вероятно, так и не будет выпущена, мо-
дель IBM 3032 заменит мо-
дель IBM 370/168, а модель
IBM 3031 заменит модель
370/158.
При разработке семейст-
ва IBM ЗОЗХ предусматри-
вались следующие основные
возможности комплексиро-
вания.
Машины семейства объ-
единяются вокруг модуля уп-
равления памятью, что поз-
воляет множеству машин,
процессорам ввода-вывода и
другим устройствам иметь
одновременный доступ к об-
щей оперативной памяти.
Таким образом, все процес-
соры могут работать с об-
щим потоком заданий. По-
добные системы при своем
полном развитии должны быть модульными даже в большей
степени, чем многопроцессорная конфигурация IBM 3033.
Машины семейства IBM ЗОЗХ являются, по-видимому, пере-
ходными моделями соотносительно коротким сроком жизни вслед-
ствие ограниченности диапазона адресов (16 млн. байт), недоста-
точной интеграции схем и информационной емкости устройств
памяти по сравнению с требованиями 1980-х годов и других
причин. - ’ .
Вариант будущих систем семейства может быть следующим
(рис. 3.20). Пульт управления с одним или несколькими обслу-
Пульт управления.
и обслуживающий '
процессор
Микрокод
Языковый
процессор
Микрокод
Языковый
процессор
Микрокод
Процессор
ввода-вывода
Микрокод
Файловый
процессор
Микрокод^
Процессор _____Управление
ввода-вывода v памятью
| Буфер \
Микрокод
Основная
памяти
Рис. 3.20. Вариант структуры будущих
систем фирмы IBM.
живающими процессорами связан через модуль управления ос-
новной памятью с языковыми процессорами, процессорами вво-
да-вывода, файловыми процессорами и основной памятью. Все
процессоры реализуются как микропрограммные.
Для выполнения программ пользователей в процессорах ап-
паратно реализуются языки высокого уровня (языковые процес-
соры). Фирма IBM уже делает это в некоторых малых машинах
(5110 и 3790), а фирма Burroughs предлагает большой процессор
с микропрограммной реализацией фортрана (процессор предназ-
начается для присоединения к большим системам). Применение
И Б. А. Головкин
161
языковых процессоров обеспечивает бблыпую производительности
при том же оборудовании — примерно на 30—50% увеличивает-
ся пропускная способность с учетом того, что отпадает необходи-
мость в трансляции. В системе могут быть также высокоскорост-
ные магистральные или матричные процессоры.
На левой стороне рис., 3.20 показано множество процессоров; '
ввода-вывода, а на правой стороне — файловый процессор, свя- ;
ванный с большим буфером и, далее, с параллельно подключен-
ными к буферу дисками и, в наилучшем случае, устройством
оперативной памяти большой емкости.
Применение микропрограммной реализации процессоров де- '
лает систему более гибкой. С введением в них системных функ- ;
ций роль операционной системы будет уменьшена до распреде-
ления ресурсов и диспетчирования. В качестве супервизора всей -
системы будут использоваться, вероятно, мониторы виртуальной :
машины.
Таким образом, система является виртуальной и неоднород- ;
пой, имеет общую оперативную память, отличается- модуль-^
ностью построения, непосредственной реализацией языков высо-
кого уровня в процессорах, применением микропрограммного*
принципа во всех процессорах и обеспечивает легкую доступность- •
и простоту в обращении с ней. Следует отметить, что пользова-
тель ведет диалог на языках высокого уровня для работы с язы- '
новыми процессорами или на специальных языках управления* j
для работы с файловыми процессорами с виртуальной системой >
в целом, а не с отдельными процессорами системы и, в принци- j
пе, не знает, какой именно процессор выполняет его задания-
Примерно такие же принципы закладываются в разработку .
Тлашин следующего поколения System/80 (семейство 80-х годов)..
.Аппаратура обработки разрабатывается в виде ряда специализи- ;
рованных блоков для выполнения функций управления потока-г
ми данных, связи, управления базами данных, вычислений, вво-
да-вывода, матричной и векторной обработки и других. Система:
строится как модульная с набором тех модулей, которые нужны
пользователю, с централизованной базой данных. Простота поль- j
зования обеспечивается виртуализацией памяти, процессоров^ .
ввода-вывода и терминалов. ;
Предполагается дальнейшее улучшение отношения произво- '
дительности к стоимости, причем если в 1960-х и в начала •
1970-х годов двухкратное повышение значения этого показателя
достигалось за 5—7 лет, то в конце 1970-х годов — за 2—3 года,. '
а в начале 1980-х годов, по прогнозу, будет достигнуто за 2 года
' (таблица 3.6).
3.5.6. Библиографическая справка. Семейства IBM 360 и 370*
описаны в обширной литературе.
Архитектура семейства IBM 360 изложена в ключевой статье*
Г9]. Ей посвящены также книга [76] и статьи [65, 539]. Значи-
тельное место семейству IBM 360 отведено в книгах [412, 522^ :
162
- *947], обзоре [505] и статье [441], формальное-описание семейст-
ва выполнено в [714]. Программирование и программное обес-
лечение рассмотрены в книгах ИЗО, 311, 382, 416, 564, 727, 728,
1213J.
Семейству IBM 370 посвящены книги [202, 341], программное
«обеспечение описано в [41, 500], а вопросы структуры и орга-
низации — в [756, 1118] и других.
Во многих книгах, наряду с другими вопросами, рассматри-
ваются семейства IBM 360 и, IBM 370. Структура и программное
Таблица 3.6
Улучшение отношения производительности к стоимости для машин фирмы IBM
<(в качестве единицы принято значение отношения для первых моделей семейст-
ва IBM 360)
ЭВМ Год первых поставок Отношение производи* тельности к стоимости Количество лет после предыду* щей разработки
Первые модели семейства IBM 360 Первые модели семейства IBM 370 Усовершенствованные модели се- мейства IBM 370 ‘Семейство IBM ЗОЗХ ‘Семейство System/80 1965 1971—1972 1976—1977^ 1978—1979 1980-1981 (прогноз) 1 2 3,5-4 8 16 6-7 4-5 2-3 2
обеспечение семейств, а также их модели описаны в [218], а ор-
ганизация семейств с точки зрения иерархического построения
их моделей — в [384]. В [282] собраны данные о проектировании,
использовании и анализе функционирования операционных си-
стем машин фирмы IBM. Вопросы системного программирования
с использованием языка PL/1 и с ориентацией на структуру IBM
360 и 370 изложены в [138].
Описания операционных систем семейств IBM 360 и 370
включены в сборник обзоров операционных систем [1039].
Отметим статью [576], в которой описана архитектура семей-
ства IBM 370. Рассматривается мотивировка создания, а также
цели усовершенствования архитектуры семейства по сравнению
с IBM 360, обсуждаются такие новые черты архитектуры машин
IBM 370, как виртуальная память, развитие программного уп-
равления, новые команды, комплексирование, аппаратные сред-
ства отладки программ, усовершенствования в системе ввода-
вывода. Приводятся таблицы технических характеристик цент-
ральной части почти всех моделей семейств IBM 360 и 370. Но-
вое семейство IBM ЗОЗХ, направления развития и новые разра-
ботки рассмотрены в [113, 388, 1264].
Во многих из указанных выше работ рассматриваются воп-
росы комплексирования машин фирмы IBM. Комплексирование
*1* 163
моделей IBM 360 описано в ключевых статьях [538, 540]. Опи-
сание многомашинных и многопроцессорных систем фирмы IBM,
включая их программное обеспечение и примеры применения,
содержится в [744]. Различные аспекты большого числа много-
машинных и многопроцессорных систем фирмы IBM рассмотрены
в [281], при этом в тексте книги приведено очень краткое опи-
сание системы IBM 360/67, а в приложении — более подробные-
описания систем IBM 360/65 МР, 370/158 МР и 370/168 МР.
Вопросы параллельности в системах IBM рассмотрены в [947].
Напомним, что системы DCS и ASP и некоторые другие рас-
смотрены в п. 1.2. Система IBM 360/67 описана в ключевой
статье [757], а также в [49, 331, 468, 694]. Опыт разработки и
использования, а также результаты исследования эффективности
операционной системы модели IBM 360/67 рассмотрены в [1131г
1150]. Версия операционной системы семейства IBM 360 для
двухпроцессорной системы IBM 360/65 МР описана в [1265], а
сама вычислительная система кратко рассмотрена в [966]. Систе-
ма IBM 902Q, представляющая собой многопроцессорную модифи-
кацию модели IBM 360/50 с полностью автоматической реконфи-
гурацией и предназначенная для управления воздушным движе-
нием, описана в трех статьях [883, 542, 658], которые составляют
первую, вторую и третью части одной работы соответственно.
Двухпроцессорные системы IBM 370/158 МР и 370/168 МР
описаны в [1007]. Программно-аппаратные усовершенствования^
введенные в IBM 370 и позволившие реализовать децентрализо-
ванную многопроцессорную обработку, рассмотрены в [957].
Программное обеспечение комплексирования моделей IBM 370
описано в [469, 835].
3.6. Системы на базе ЭВМ семейства DEC PDP-11
3.6.1. Структура семейства PDP-11 [296, 384]. Вычислительные
машины PDP-11 (Programmed Data Processor) фирмы DEC (Di-
gital Equipment Corp.) представляют собой семейство малых и
средних ЭВМ, называемых обычно мини-ЭВМ в связи с корот-
ким 16-разрядным машинным словом. Машины PDP-11 нашли
широкое применение при сборе данных, в управлении научным
экспериментом и в управлении технологическими процессами,,
в системах связи. Они удобны в организации режима диалога
человека с машиной. В машинах PDP-11 обеспечивается прог-
раммная и аппаратная совместимость ранних моделей малой
производительности, таких как PDP-11/15 и PDP-11/20, с мо-
делями более высокой производительности PDP-11/45 и PDP-
11/70.
Характерной особенностью машин семейства PDP-11 является
Применение в них унифицированной общей шины ввода-вывода
UNIBUS, к которой подключаются параллельно отдельные уст-
ройства ЭВМ. В этих машинах имеется большое число регист-
164
ров общего -назначения, применяется чередование адресов, реа-
лизована многоуровневая система прерывания, используются
стековая память, специализированные процессоры для операций с
плавающей запятой. и др., что, за некоторым исключением, до
появления ЭВМ PDP-11 в мини-ЭВМ не применялось.
ЭВМ PDP-11 состоит из центрального процессора, основной
памяти и различных устройств ввода-вывода (рис. 3.21), кото-
рые соединены между собой единственной шиной асинхронного
Рис. 3.21. Структурная схема ЭВМ PDP-11.
типа UN I BUS, используемой для передачи информации по мето-
ду «ведущий-ведомый» от одного устройства ЭВМ к другому.
В каждый момент времени возможна передача информации
только между какой-либо одной парой устройств ЭВМ, причем
переключение шины с одной пары устройств на другую зани-
мает время порядка микросекунды. Для разрешения конфлик-
тов занятия шины каждому устройству присваивается приори-
тет (приоритет центрального устройства может быть установлен
программно). Наличие общей шины обеспечивает модульность
структуры ЭВМ, возможность их наращивания и комплексиро-
вания, но приводит к простоям устройств с низшим приорите-
том, если им необходим обмен информацией в то время, когда
шина UNIBUS занята для выполнения обмена устройствами бо-
лее высокого приоритета.
Шина UNIBUS рассчитана на передачу 2,5 млн. 16-разрядных
слов в секунду и содержит 56 линий (таблица 3.7), т. е. данные
передаются только по 16 линиям, а 40 линий используются
для сигналов управления, адресов и служебных сиг-
налов.
Слово в PDP-11 занимает два байта, наименьшая адресуемая
часть памяти — байт. Операции могут производиться над слова-
ми или байтами. Применяется очень гибкая адресация, включая
косвенную, стековую и автоиндексируемую. Максимальная емкость
оперативной памяти изменяется от 28 К слов для PDP-11/05,
11/10, 11/15 и 11/20 до 124 К слов для PDP-11/35, 11/40,
11/45 и 1919 К слов для PDP-11/70. В семействе отсутствует
постраничная организация памяти. Количество регистров общего
назначения равно 8 для первых шести и f6 для двух последних
моделей. Регистры содержат по 16 разрядов. Для случая вось-
165
ми регистров первые шесть из них используются для разнооб-
разных целей, а последние два выполняют специальные функ-
ции. Один из них является указателем стека, а второй — счет-
чиком команд, который всегда содержит адрес следующей вы-
бираемой команды. Длина команд равна двум, четырем или
Таблица 3.7
Линии шины UNIBUS
Количество линий Функций линий (наименование передаваемой информации)
16 18 2 Передача данных Адресные линии Комбинации сигналов, определяющие ведомому устройству, со стороны ведущего, способ передачи (запись, чтение, обмен байтами, пауза)
2 2 8 2 Синхроимпульсы р готовности к обмену (запрос и ответ) Сигналы об ошибках, формируемые при проверке на четность передаваемой информации Запрос на прерывание и ответ на запрос Непроцессорный запрос на прерывание и ответ на непроцессор- ный запрос
1 1 1 1 1 1 Прерывание Шина занята Ответ на запрос принят Начальная установка Сигнал о неисправности системы питания Сигнал о выходе какого-либо номинала напряжения за уста- новленные границы
Всего 56 линий
восьми байтам. Системы команд различных моделей отличают-
ся незначительно друг от друга. Операции с плавающей запя-
той реализуются для младших моделей программным способом,
а для старших моделей — могут быть реализованы аппаратным
способом. \
Старшие модели семейства представляют собой достаточно раз-
витые машины средней производительности. Такг например,
комплекс из двух ЭВМ PDP-11/45, объединенных при помощи
коммутатора каналов, превосходит по производительности такие
ЭВМ, как IBM 360/30, 360/40, 370/135, 360/44 и 360/50. Другой
пример: в модели PDР-11/70 имеются 16-разрядное поле вирту-
альных адресов/ 18-разрядное поле адресов UNIBUS и 22-раз-
рядное поле адресов физической памяти.
С целью получения более высокой производительности в мо-
делях семейства PDP-11, начиная с PDP-11/45, введены до-
полнительные шины для передачи данных и полупроводнико-
вые запоминающие устройства. В ЭВМ PDР-11/70 (рис. 3.22),
выпущенной в 1975 г., используется дополнительная шина с 32
166
линиями, которая обеспечивает обмен информацией со скоро*
стью около 6 М байт в секунду, что почти в шесть раз превыша-
ет скорость передачи по шипе UNIBUS. Общая оперативная
память в этой ЭВМ подключается к шине UNIBUS не непос-
редственно, а через сверхоперативную память. Структура ЭВМ
К дополнительным накопи-
телям на мзенитных дисках
и лентах
Рис. 3.22. Структурная схема ЭВМ PDP-11/70.
»
позволяет наращивать оперативную память до 2 М байт с циклом
обращения 400 нсек. Операционная система модели позволяет
одновременно выполнять задачи в реальном масштабе времени
и в режиме пакетной обработки.
3.6.2. Многомашинные и многопроцессорные системы на базе
ЭВМ семейства PDP-11 [296]. В ЭВМ PDP-11/45 для операций с
плавающей запятой используется специальное устройство, под-
ключаемое к центральной части ЭВМ при помощи дополнитель-
ной шины UNIBUS 2, которая является более короткой и име-
ет более высокую пропускную способность по сравнению с ос-
новной шиной UNIBUS 1. Используя эти две шины, можно
построить двухпроцессорную систему (рис. 3.23) с общей полу-
проводниковой памятью.
Если к шине UNIBUS нужно подключить более 20 устройств,
то последовательно к этой шине можно подключить вторую
шину через устройство, называемое расширителем магистрали,
причем на число этих устройств ограничений не накладывается.
Если же использовать еще одно устройство — коммутатор шины
(КМ),—то можно создавать разнообразные системы с широки-
ми функциональными возможностями, в том числе многопроцес-
сорные системы. Коммутаторы могут быть однополюсными
(КМ 1) и двухполюсными (КМ 2).
Вариант двухмашинной структуры показан на рис. 3.24, где
через ВУ обозначены внешние устройства, а через ЦП — цент-
ральные процессоры.
167
Подключаемую шину можно рассматривать ка^ выход комму-
татора, а шину, к которой подключен процессор,— как вход
коммутатора. Одна шина может подключаться к нескольким
входам различных коммутаторов, вследствие чего подключе-
ния со стороны входов оказываются параллельными. Выход од-
ного коммутатора может подключаться ко входу другого, но
Рис. 3.23. Структурная схема двухпроцессорной системы на базе ЭВМ
PDP-11 с шинами UNIBUS 1 и UNIBUS 2.
выходы коммутаторов не могут соединяться вместе (рис. 3.25).
На базе устройств КМ1 и КМ2 можно создавать системы раз-
личной конфигурации. Так, например, можно построить двух-
машинную систему с функциями взаимного дублирования ЭВМ
в целях повышения надежности работы системы в целом
Рис. 3.24. Структурная схема двух- Рис. 3.25. Структурная схема двух-
машинной системы с коммутатора- машинной системы с коммутатора-
ми КМ 1 и КМ 2. - ми КМ 2.
(рис. 3.26; через ОП обозначена оперативная память). Систему
с такой конфигурацией можно использовать также как обычную
двухмашинную систему с общими внешними устройствами.
Наконец, в простейшем случае, к одной шине может быть
подключено более одного центрального процессора (рис. 3.27)
[281].
168
Системы на базе ЭВМ семейства PDP-11 являются типич^
ными системами с общей шиной и разделением ее времени; при
более сложных конфигурациях они могут иметь более одной
шины. Некоторые из систем на базе PDP-11 рассматриваются
в соответствующих разделах последующих материалов данной
книги.
3.6.3. Библиографическая справка. Архитектура мини-ЭВМ
DEC PDP-11 описана в [521]; семейству этих машин, в том
Рис. 3.26. Структурная схема двухмашинной системы со взаимным резер-
вированием и с частью общих внешних устройств.
числе комплексированию ЭВМ, посвящен обзор [296]. Струк-
тура машин семейства ш PDP-11 рассмотрена, наряду с другими
вопросами, в [384, 756], а их комплексирование при пдмощи об-
щей шины и применение в некоторых системах (например,
в OMEN 60) — в [281]. Машинам PDP-11 посвящена также
статья [526] и ряд других. Структура минимашинных систем
и соответс!вующие методы программирования на примере PDP-
11 описаны в книге [683].
Типичная систем^ с распределенными функциями и меж-
машинными связями через UNIBUS рассмотрена в [661]. Объ-
единения двух разных ЭВМ типа PDP-11 и PDP-15 описаны в
[599]. Система в составе трех ЭВМ типа PDP-11, общей шины дан-
ных и трех процессоров сопряжения для подсоединения PDP-11 к
общей шине рассмотрена в [965]. Комплекс'на базе мини-ЭВМ
PDP-11 и микро-ЭВМ Intel MCS-8 описан в [879]. Структура
169
трехуровнего программного обеспечения межмашинной связи 1
изложена в [632], при этом описан состав такого программного «
обеспечения фирмы DEC для ее ЭВМ PDP-11, когда ЭВМ ис- J
пользуется в качестве связного процессора. Многопроцессорная '
операционная система MUN1X, представляющая собой модифи- 4
кацию однопроцессорной операционной системы UNIX для ма- I
шин PDP-11, рассмотрена в [811], а реализация адаптивного л
алгоритма многопроцессорного расписания для MUNIX — j
в [878]. 1
В 1977 г. фирма DEC разработала' новую ЭВМ PDP-11/60 в Я
семействе PDP-11, предназначенную для обработки результатов 1
лабораторных исследований, управления производственными 3
процессами и для обучения. Центральный процессор включает |
буферную кэш-память емкостью 2 К байт с временем цикла i
170 нсек и устройство обработки данных с плавающей запятой. ;
Емкость оперативной памяти — 256 К байт, эффективное время *
цикла — 532 нсек. Используются языки программирования 1
бэйсик и фортран IV [ИЗ]. 1
Отметим, что кроме семейства PDP-11, фирмой DEC выпус- /
кается семейство больших ЭВМ DEC System-10, часть из крто- *
рых имеет многопроцессорные варианты (рассматриваются в '
х следующей главе). С целью ликвидировать разрыв между боль- '
шими ЭВМ и мини-ЭВМ, выпускаемыми фирмой, фирма DEC ,
начала разрабатывать и выпускать новое семейство DEC Sys-
tem-20 средних ЭВМ (ЭВМ DEC-2030, DEC-2040, DEC-2050 и •
DEC-2060), обладающих возможностями больших ЭВМ при стой- \
мости малых ЭВМ. '
Структура ЭВМ'семейства DEC System-20 рассчитана на под- "
ключение до 64 пользователей для их обслуживания в режиме, ?
разделения времени. Используются языки высокого уровня,
виртуальная память и динамическое распределение памяти. Ем-
кость оперативной памяти — до 1,2 М байт, время цикла одного
модуля —1,28 мксек, эффективное время цикла памяти может
быть уменьшено за счет перекрытия при обращении по двум или J
четырем каналам. Физически память разбита па сегменты емко- 5
стью по 512 36-разрядных слов. В качестве периферийного про- i
цессора используется одна из ЭВМ PDP-11 [142,113,773]. Фирма $
DEC известна также по выпускаемым ЭВМ семейства PDP-8 и >
другим ЭВМ, она начала создавать 32-разрядные ЭВМ нового \
семейства VAX (Virtual Address Extension), совместимые co ;
всеми 16-разрядными машинами фирмы DEC, включая PDP-11.;
4. МНОГОПРОЦЕССОРНЫЕ СИСТЕМЫ
Системы, рассматриваемые в настоящей главе, характерны
тем, что при их разработке, как правило, сразу предусматрива-
ется общая. оперативная память. При развертывании такой си-
стемы осуществляется, скорее, комплектование, ее модулями, чем
комплексирование машин при помощи общей оперативной памя-
ти. Тем не менее, граница .между многопроцессорными система-
ми, рассмотренными в предыдущей главе и рассматриваемыми
в настоящей главе, в достаточной степени условна, поскольку
многие многопроцессорные системы представляют собой модифи-
кации однопроцессорных моделей тех или иных семейств ЭВМ.
4.1. Концепция и ранние системы
Не повторяя сказанного в главе 2 относительно концепции
многопроцессорных систем, рассмотрим кратко некоторые гипо-
тетические и ранние реальные многопроцессорные системы, а в
заключение раздела приведем основные положения концепции
современных многопроцессорных систем.
4.1.1. Разработки концепции многопроцессорных систем. Рас-
смотрим гипотетические многопроцессорные системы, начав с
однородных.
Однородная система, названная идеальной машиной IT
(Ideal Multifunction Machine) 110161, должна состоять из N
идентичных процессоров, каждый из которых имеет обычный
набор команд и может работать асинхронно с другими процес-
сорами. Полагается, что число процессоров N может быть таким
большим, как это потребуется для решения задач. Далее, каж-
дый процессор может передавать свои результаты любому дру-
гому процессору без потерь времени. Считается также, что
отсутствуют проблемы, связанные с памятью, и что индексирова-
ние, выборка, запись и другие действия подобного рода не зани-
мают времени. Следовательно, машина IT является только
инструментом, для идеализированного представления программы
в параллельной форме [4931.
Несколько более реалистичной концептуальной системой яв-
ляется итеративная машина Холланда, предложенная в [83U;
она описана, исследована и усовершенствована в ряде работ
171
[147, 419, 441, 493, 600, 601, 772, 787, 827, 832, 1016, 1221,
1222].
Итеративная машина состоит из обрабатывающих устройств
(модулей) и имеет структуру матрйцы. Каждое устройство (мо-
дуль) содержит регистр памяти, набор команд и обладает ком-
мутационными (адресными) способностями. В стандартном ва-
рианте матрица модулей является двумерной, а каждый модуль
непосредственно связан с четырьмя соседними. Каждый модуль
может быть в активном или пассивном состоянии, причем мо-
дули работают независимо друг от друга. В процессе их функ-
ционирования происходит передача выполняемых программ от
модуля к модулю, т. е. реализуется концепция «рабочих прог-
рамм, плавающих в море оборудования».
Программы в машине могут выполняться одновременно. Для
этого можно применять методы, используемые при построении
асинхронных схем. Так, например, подпрограммы могут быть
записаны так, что, когда их вычислительная часть готова, соот-
ветствующие выходные регистры переводятся в состояние го-
товности. Подпрограмма начинает выполняться тогда, когда все
необходимые операнды находятся в состоянии готовности
[419, 441].
На базе машины Холланда в комбинации с концепцией мат-
ричной обработки разработана концепция так называемой «рас-
пределенной» машины (562, 897, 898], по узлам которой рас-
пределяется возможно большее число работ и операций, выпол-
няемых одновременно и независимо друг от друга. Машина
состоит из идентичных блоков, включающих в себя универсаль-
ный процессор и память небольшого объема. Блоки разбиты на
группы. Внутри каждой группы блоки связаны между собой.
Группы блоков также связацы между собой (при помощи спе-
циальных межгрупповых шин). Параллелизм обработки может
быть реализован как между группами, так и внутри группы. Во
второе случае блоки могут работать независимо или под управ-
лением специального управляющего блока, осуществляющего
синхронизацию выполняемых операций. Управляющий блок мо-
жет также, управлять связями между группами блоков. Такая
структура обеспечивает возможность как локального, так и гло-
бального управления каждым блоком, позволяет блокам рабо-
тать как в качестве самостоятельных процессоров, так и в ка-
честве элементов коалиции процессоров, и повышает надежность
системы [493].
Концептуальная машина блочного типа [194,566,567] состоит
из большого числа простых идентичных блоков обработки, со-
ставляющих матричную конфигурацию машины. Блоки могут
быть связаны между собой, причем связи могут коммутироваться
программными средствами, чтобы образовывать различные схемы.
В машине возможны два вида связи между блоками', обеспечи-
ваемые шинами различного назначения. Первый из них исполь-
172
зуется для последовательной обработки и для доступа к данные
в памяти блоков, а второй — для связи между блоками. Систе-
ма характеризуется высокой степенью параллелизма обработки
и высокой надежностью. При отказе одного из блоков диспет-
черская программа исключает его из работы, а система продолжа-
ет вычисления с незначительной потерей производительно-
сти [493].
В реальных однородных многопроцессорных системах большое
распространение нашли структуры трех типов: с перекрестными
связями, с множеством шин и с общей шиной.
В системах первого типа N процессоров связаны при помощи
матрицы перекрестных связей с М модулями памяти. Модифика-
ция такой схемы в виде концептуальной машины предложена в
11148] (см. также [1016]). Для выборки команды или слова дан-
ных процессор помещает запрос на них в специальную секцию.
Пользуясь этими запросами каждый модуль памяти выполняет
необходимое действие, после чего информация распределяется по
процессорам. В результате реализуется многопроцессорный кон-
вейер операций [493] (машина Шварца).
Перейдем к неоднородным системам. Концепция машины
Эстрина «с переменной структурой» предложена и описана в
1441, 702—705], а также описана в [493, 1016] и других работах.
Машина состоит из трех частей: фиксированной части на базе
обычного процессора, изменяющей части, которая состоит из не-
скольких специализированных устройств, и супервизорной систе-
мы, которая состоит из блоков управления с супервизорами, свя-
зывает первые две части машины и управляет их совместной
работой (рис. 4.1). Изменения структуры и связей устанав-
ливаются каждый раз либо при помощи электронных схем под
управлением супервизорной системы, либо электромеханически
посредством переключателей, либо механически при помощи
сменных модулей в изменяющейся части. Полагается, что маши-
на анализирует допустимые в ней структуры и выбирает, а затем
настраивается на ту из них, которая обеспечивает наибольшее
отношение производительности к стоимости с учетом характера
задачи [441, 493].
Подобная концепция заложена в проект макромодульных ма-
шин [594]. Эта машина компонуется из таких модулей, как ре-
гистры, сумматоры, блоки памяти, блоки управления и тому по-
добные. Модули объединяются в устройства с встроенными
блоками для связи между этими устройствами. Машина состоит
из обрабатывающей сети, которая осуществляет обработку и рас-
пространение данных, и упорядочивающей сети, которая посред-
ством управляющих узлов сети управляет упорядочиванием опе-
раций. Управление является асинхронным, параллельные ветви
сходятся и разделяются при помощи аппаратно реализованного
механизма FORK — JOIN, предусматривается разрешение конф-
ликтов между последовательностями операций [493]. Пример не-
173
большой универсальной4 машины, основанной на макромодульногг
концепции, описан в [1044].
Вариант неоднородных систем, названный истинной много-
процессорной системой IMP для параллельной обработки (for
Intrinsic MultiProcessing) предложен в [4711. Этот вариант был
L
блоки
управлениях
Вспомогатель-
ная память
Иерархия эле-
ментов у прае-
хления_____
Структуры
специального
назначения быстрая
система
Изменяющаяся часть
блоки
управления
память
управления
Внешняя память и
устройства
ввода-вывода
®==» -Информационные связи -
—— -Связи по управлению
Рис. 4.1. Машина с переменной структурой. j
'1
уточнен (известен как машина Флинна) и описан в [730—7361 > 1
а также описан в [364] и других работах. 1
В этой концептуальной неоднородной машине четыре как »
бы «вращающихся» кольца, каждое из которых образовано иэ
восьми расположённых одно за другим последовательных уст- <
ройств управления, имеют в качестве общих устройств обработки •
множество из семи функциональных устройств — двух суммато- \
ров с плавающей запятой, устройства умножения с плавающей i
запятой, устройства деления с плавающей/фиксированной вапя- 1
той и других. Число колец может быть более четырех. Указанные?
устройства управления, называемые также «скелетными» процес-
сорами, можно рассматривать как обычные универсальные про-
цессоры без возможностей арифметико-логической обработки.
В каждом рабочем цикле устройство управления каждого*
кольца может послать запрос для выполнения обработки к функ-
циональным устройствам, которые составляют магистраль обра-
171
ботки так, что они могут принимать запросы на вход в каждом
цикле работы. Кольцам присвоены приоритеты, согласно которым
разрешаются конфликты запросов к функциональным устрой-
ствам. Приоритеты могут перемещаться по кругу от кольца к
кольцу. Структурная схема машины изображена на рис. 4.2.
Рис. 4.2. Машина с общими ресурсами.
Таким образом, в машине реализуется совместная работа 32-х.
процессоров при помощи разделения вычислительных ресурсов
как в прцстранстве, так и во времени [493, 735].
Исследование задачи приближения языка машины к языку
описания обработки информации в целях повышения эффектив-
ности работы вычислительной системы показывает, что необходи-
мы функциональное расширение состава обычной вычислительной
•системы и специализация ее компонентов. Сбалансированный
подъем уровня языка системы может быть достигнут путем вы-
деления нескольких областей специализации, каждая из которых
отражает определенную функцию, выполняемую машиной при
ее работе. Эти функции можно закрепить в машине аппаратно,
в результате чего «квалификация» машины повышается; Соответ-
ствующая Базовая Система Повышенной Квалификации (БСПК)
предложена в [166, 167]; при этом предполагается обеспечить
возможность распараллеливания на всех уровнях — от счета не-
зависимых задач до счета внутри одной формулы.
В состав системы БСПК предлагается включить пять специа-
лизированных процессоров: арифметический, символьных преоб-
разований, работы со справочными системами (архив), связи с
175
внешними органами, управления данными и программами* Каж-
дый из процессоров может иметь свою собственную память и свое
управление. Общее управление осуществляет. процессор управле-
ния данными и программами. Предполагается, что часть его- па-
мяти предоставляется для временного использования другим
процессорам. Процессоры основаны нач именах, а не на адресном
принципе. Поэтому, если адресная система и реализована в аппа-
ратуре, то она недоступна программисту. Особое значение в такой
системе имеет выбор языка каждого процессора, например, в ка-
честве входного языка можно выбрать такой язык, в который
легко отображаются арифметические операторы языков APLr
алгола 60 и фортрана, дополнив его некоторыми средствами
универсальных языков PL/1, алгол 68 и симула 67, а для/процес-
сора символьных преобразований — язык рефал, дополнив его
некоторыми машинными операциями [166, 167J.
Отметим, что рассмотренные в настоящем разделе концепту-
альные машины в ряде случаев имеют черты систем, выходящих
за рамки класса многопроцессорных систем. Перейдем к ранним
многопроцессорным системам.
4.1.2. Система RW 400 [635]. Однородная многопроцессорная
система с перекрестными связями RW 400 фирмы Ramo-Wo old-
ridge была построена в 1960 г., причем работы, до конца не были
доведены и структура системы в полном объеме не была развер-
нута, хотя блоки системы были изготовлены. Система получила
название «полиморфной». Ниже рассматривается проект систе-
мы, многие идеи которого нашли свое отражение в последующих
разработках различных многопроцессорных систем. I
Структурная схема системы RW 400 изображена на рис. 4.3.
Все указанный на рисунке части системы оформлены в виде мо-
дулей.
Центральное положение в структуре системы занимает мат-
ричный коммутатор перекрестных связей между модулями систе-
мы, в котором в качестве переключающих элементов использу-
ются трансфлюксоры. Матричный коммутатор связывает между
собой, с одной стороны, 16 вычислительных машин (вычислитель-
ных модулей) и буферных модулей и, с другой стороны, до 64 мо-
дулей периферийного оборудования.
В качестве вычислительных модулей использовались универ-
сальные двухадресные ЭВМ с собственной оперативной памятью
емкостью в 1024 слов в каждой, способные автономно выполнять
обработку информации. Длина слова— 26 информационных раз-
рядов и 2 разряда для контроля по четности. Передача информа-
ции между вычислительными модулями предусматривалась в
параллель половинами слов. В систему команд наряду с другими
командами, входили 20 команд — для операций арифметического
типа, 10 -y для операций управления и 5 — для операций ввода-
вывода. Буферные модули представляли собой, фактически, не-
большие специализированные ЭВМ, предназначенные для управ-
176
ления периферийным оборудованием в соответствии с заданием
от вычислительных модулей. Они также осуществляли основные
функции по управлению обменом информацией в системе.
Структура системы является очень громоздкой. Слишком боль*
пюй набор функций, в том числе достаточно мелких, вынесен на
общесистемный уровень. Так, например, при .помощи буферных
Рис. 4.3. Структурная схема системы RW-400.
модулей п матричного коммутатора организуется доступ извне к
внутренней оперативной памяти вычислительных модулей в усло-
виях, когда процессорные модули и модули оперативной памяти
не являются самостоятельными устройствами, а объединены в-
вычислительные модули.
4.1.3. Система D 825 [465]. В качестве второго примера одно-
родных многопроцессорных систем с перекрестными связями
рассмотрим систему D 825 фирмы Burroughs. Она является пер-
вой модульной системой с идентичными процессорами и общими
модулями оперативной памяти. Эта система была укомплектована
операционной системой AOSP (Automatic Operating and Scheduling
12 Б А. Головкин
177
Program). Назначение системы D 825 — для управления и коман-
дования в военных целях. Система была выпущена в большом
числе экземпляров и в различных модификациях (ее первый об-
разец был выпущен в 1962 г.). Можно считать, что с созданием
<истемы D 825 начался этап построения современных многопро-
цессорных систем.
Структурная схема системы D 825 изображена на рис. 4.4.
В состав системы входят: от одного до четырех процессорных (вы-
числительных) модулей; от одного до шестнадцати модулей опера-
тивной памяти; один или два комплекта устройств ввода-вывода,
в каждый из которых входят от одного до десяти модулей управ-
ления вводом-выводом (ВВ) и от одного до шестидесяти четырех
периферийных устройств (диски, магнитные ленты, устройства
•считывания с перфокарт и другие). При максимальной комплек-
тации в состав системы входит либо четвертый вычислительный
«модуль, либо второй комплект устройств ввода-вывода.
Модульное построение системы, как с точки зрения функцио-
нальной структуры, так и конструктивного исполнения, обеспечи-
вает высокую надежность при непрерывном функционировании
в реальном масштабе времени и возможность изменения состава
оборудования без изменений программ. Модули являются функ-
ционально независимыми и работают независимо друг от друга.
Их можно подключать для совместной работы с другими модуля-
ми так, что выход из строя одного из них не приведет к отказу
системы. Управление системой обеспечивает возможность пере-
коммутации функциональных модулей системы.
Матричный коммутатор перекрестных связей (переключатель
первой ступени) конструктивно распределен между соответствую-
щими функциональными модулями системы в виде отдельных
«элементов, связанных между собой соединительными кабелями.
В его состав входят схемы для приоритетного разрешения конф-
ликтов одновременного обращения к модулям оперативной памя-
ти со стороны вычислительных модулей или устройств ввода-вы-
вода. Комплекты устройств ввода-вывода имеют собственные
коммутаторы периферийных устройств и подключаются каждый
к одной индивидуальной шине коммутатора перекрестных связей.
Модули оперативной памяти системы выполнены на магнит-
ных сердечниках и имеют емкость в 4096 49-разрядных слов
Ходин разряд в слове — для контроля по четности, а остальные
.являются информационными); цикл обращения составляет
4,33 мксек, а время передачи слова в вычислительный модуль —
порядка 1—2 мксек.
Вычислительные модули имеют схемы для выполнения ариф-
метико-логических операций, причем каждый из них содержит
внутреннюю оперативную память емкостью в 128 слов с циклом
работы В|300 нсек, выполненную на тонких магнитных пленках,
*15 индексных регистров и ряд специальных адресных регистров.
Рабочая тактовая частота модуля равна 3 Мгц. Все команды и
/ 478
Ряс. 4.4. Структурная с^ема системы D825,
данные программы имеют косвенные адреса, их можно независи-
мо и произвольно перераспределять, а для их привязки служат
два соответствующих регистра базовых адресов. В системе ис-
пользуются безадресные, одноадресные, двухадресные и трехад-
ресные команды. Средние значения времени сложения с фиксиро-
ванной и плавающей запятой составляют 1,7 и 7,0 мксек соответ-
ственно.
Модули управления вводом-выводом (контроллеры) представ-
ляют собой фактически небольшие специализированные ЭВМ,
управляемые операционной системой AOSP. Каждая из них мо-
жет обслуживать до 64 периферийных устройств (32 входных и
32 выходных каналов). Модули управления вводом-выводом со-
единены с периферийными устройствами при помощи своего мат-
ричного переключателя (переключатель второй ступени), кото-
рый обеспечивает подключение любогю внешнего устройства к
любому из каналов указанных модулей и обеспечивает скорость
передачи информации в 2 млн. бит в секунду.
В состав системы могут входить также до пяти модулей за-
просных данных, предназначенных для передачи данных между
системой и каналами связи, причем каждый из них может обслу-
живать до 512 линий связи для передачи дискретной информации
по телеграфным каналам со скоростью 100—200 слов в минуту и
по телефонным каналам — со скоростью 1200—2400 бит в секун-
ду. Любая линия связи может быть подключена к любому каналу
модуля запросных данных при помощи матричного переключате-
ля третьей ступени. К переключателю первой ступени одновре-
менно может быть подключена только одна линия связи. Модуль
запросных данных работает в сочетании с буферным модулем,
который предназначен для согласования уровней и синхрониза-
ции по каждой линии связи.
Операционная система AOSP храни!ся в основной памяти
системы D 825 и выполняет функции координации работы D 825,
осуществляет планирование параллельным выполнением различ-
ных ветвей одной программы и параллельным выполнением одной
и той же программы с различными исходными, данными, управ-
ляет реконфигурацией системы, ведет оперативное наблюдение
за ходом вычислительного процесса. AOSP обрабатывает преры-
вания (как внутренние, так и внешние) во всех случаях в реаль-
ном масштабе времени. При программировании для системы
D 825 используются языки алгол 60, jovial и другие. Имеется
библиотека подпрограмм.
Однородная многопроцессорная система D 825 является типич-
ным представителем класса систем с множественными потоками
команд и данных и пословной обработкой; имеющих однородную
структуру с высокой степенью связанности при помощи матрич-
ного коммутатора перекрестных связей (МКМДС/ВсОрПк)
4.1.4. ’Система CDC 3600 [1209]. В качестве примера однород-
ных многопроцессорных систем с многомашинными связями рас-
180
смотрим систему CDC 3600, в основу которой положен модуль-*
ный принцип построения. Основными функциональными модуля-
ми являются: 3604 — вычислительный модуль (процессор); 3603 —
модуль памяти; 3602 — модуль связи. В базовую однопроцессор-
ную конфигурацию системы CDC 3600 входят по одному из пере-
численных модулей, устройство 3601, включающее электрическую
Рис. 4.5. Базовая однопроцессорная конфигурация системы GDG 3600.
пишущую машинку и дисплей, а также, панель управления
(рис. 4.5). Каналы ввода-вывода 3606 подсоединяются к цент-
ральной части системы через модуль связи 3602, а считывающее
перфокартное устройство подсоединяется к вычислительному
модулю. v
Система CDC 3600 имеет следующие основные характеристи-
ки. Слово содержит 48 информационных разрядов плюс 3 разряда
для проверки на четность. Модуль памяти на магнитных сердеч-
никах имеет 32 768 слов, память может быть расширена до
262 144 слова. Время цикла памяти равно 1,5 мксек, эффективное
время цикла — 0,7 мксек. Модуль связи обеспечивает работу
четырех двухсторонних каналов ввода-вывода, при этом наи-
большее число подключаемых к нему таких каналов составляет
восемь. К каждому каналу можно подключить до восьми уст-
ройств (управляющие и/или периферийные устройства). В систе-
му дополнительно могут быть включены еще три модуля связи с
1—8 каналами для каждого модуля. Полное время выполнения
операций составляет: сложение с фиксированной и плавающей
запятой —1,5—2,2 и 4 мксек соответственно; умножение с пла-
вающей запятой — 1—6 мксек; деление с плавающей запятой
1—14 мксек. Имеются операции с двойной точностью: сложение,
умножение и деление с плавающей запятой выполняются в этом
случае за 5, 2—26 и 2—26 мксек соответственно.
Полная однопроцессорная конфигурация* имеет восемь моду-
лей памяти 3603 с пятью входами-выходами в' каждом, при этом
се суммарная емкость равна 262 144 51-разрядных слова. Память
181
работает под управлением пяти асинхронных схем управления в
каждом из модулей. Четыре входа-выхода подключаются к четы-
рем модулям связи 3602 соответственно, а пятый — к вычисли-
тельному модулю 3604. К модулям связи подключается максимум:
32 канала, по 8 каналов к каждому модулю.
В многопроцессорной конфигурации системы могут быть свя-
заны между собой до пяти однопроцессорных моделей (рис. 4.6k
J
Рис. 4.6. Многопроцессорная конфигурация системы CDC 3600.
1
При этом используется одна из двух следующих возможностей,
или их комбинация.
Во-первых, вычислительный модуль каждой модели 3600 мо-
жет адресовываться к восьми модулям памяти. Поэтому наиболь-
шее число модулей общей оперативной памяти не может превы-
шать восьми. Если в общую память выделить меньшее число
модулей (например, шесть — см. рис. 4.6), то в составе каждой
модели 3600 может быть оставлена индивидуальная оперативная
память с числом модулей, равным или меньшим разности между
числом восемь и числом модулей в общей памяти (в варианте на
рис. 4.6 индивидуальная память каждой модели состоит из двух
модулей памяти). При этом каждая из пяти моделей 3600 адре-
суется к модулям общей памяти независимо и асинхронно.
Во-вторых, каждый модуль связи может обслуживать до вось*
ми 48-разрядных межмашинных двухсторонних каналов передачи
данных» Каждый из этих каналов может быть использован для
связи непосредственно с идентичными каналами других моделей
3600 в многопроцессорной системе.
В состав программного обеспечения CDC 3600 входит ядро
операционной системы MCS (Master Control System), компилято-
182
ры с языков фортран и кобол и другие элементы операционной
системы и системы программирования. Наконец, система CDC
3600 комплектуется магнитными лентами и дисками, считываю-
щими и печатающими устройствами и другим периферийным
оборудованием.
4.1.5. Система PHILCO 213 [560]. В качестве второго примера
однородных систем с многошинными связями рассмотрим много-
процессорную систему PHILCO 213 (рис. 4.7).
Система PHILCO 213 может иметь от одного до четырех цент-
ральных процессоров, каждый из которых обрабатывает около
К периферийному К устройствам массовой К общей ап- К удаленным
оборудованию промежуточной памяти паратуре устройствам
телефонных/
телеграфных
линий
Рис. 4.7. Структурная схема системы PHILCO 213.
одного миллиона одноадресных команд в секунду. В ней исполь-
зуется дискретная элементная база, оперативная память построе-
на на ферритовых*сердечниках. Параллельно с созданием систе-
мы PHILCO 213 разрабатывался ее перспективный вариант
(была предпринята попытка построения семейства систем),
который полностью подобен первой по концепции и организации
и отличается от нее только в следующем: ’ производительность
каждого процессора — четыре миллиона одноадресных операций
в секунду; элементная база — интегральные схемы; дополнитель-
ные возможности машинного языка и некоторые усовершенство-
вания во внутренней организации устройств системы.
183
1
Система PHILCO 213 предназначена для мультипрограммной з
и параллельной обработки информации и рассчитана на решение ;
задач научного и экономического характера, включая задачи с
числовыми и нечисловыми данными. Она оборудована множест-
вом терминалов для работы с разделением времени и может ра-
ботать с телефонными и телеграфными линиями связи. Память
имеет страничную организацию и механизмы защиты.
Минимальная конфигурация системы содержит один цент- "
ральный процессор, оперативную память емкостью 32 К слов,
один коммутатор ввода-вывода, одно устройство управления мас-
совой промежуточной памятью, одно устройство памяти на маг-
нитном барабане (емкость 1,85 М слов), а также одно устройство *
управления вводом-выводом с одним считывающим перфокарт- ;
ным устройством, одним устройством, перфорации, одним устрой-
ством печати и одним устройством памяти на магнитной ленте.
На рисунке 4.7 изображена схема двухпроцессорной конфи-
гурации, тогда как система может иметь четыре центральных
процессора. Система PHILCO 213 имеет ряд структурных эле-
ментов, присущих современным многопроцессорным системам,
например, иерархическую структуру, массовую промежуточную
память большой емкости, процессоры связи. Кроме устройств
быстрой оперативной памяти емкостью по 32 К слов, в системе
имеются устройства медленной оперативной памяти емкостью по
256 К слов. Каждый из центральных процессоров соединен фи-
зически с устройствами оперативной памяти при помощи комму-
татора памяти, а с устройствами управления (контроллерами) вво-
дом-выводом, массовой промежуточной памятью и с процессорами
связи — при помощи коммутатора ввода-вывода.
В состав периферийного оборудования входит память на маг- \
нитных лентах, считывающие и печатающие устройства, графо- 1
построители и другие устройства. Каждый контроллер массовой ’
промежуточной памяти может обслуживать до восьми устройств
памяти, которая в стандартном случае содержит два устройства
дисковой памяти емкостью 10 М слов каждое и два устройства i
памяти на барабанах емкостью 1,85 М слов каждое. Все внутрен-
ние связи являются симметричными и, с учетом иерархической
структуры, обеспечивают при необходимости взаимное дублиро-
вание однотипных функциональных устройств.
4.1.6. Система LARC [6351. Рассмотрим систему LARC (Liver-'
more Atomic Research Computer), которая является однородной
многопроцессорной системой с общей шиной. Один экземпляр си-
стемы, содержащей один центральный процессор и один процес- J
сор ввода-вывода, был установлен в 1960 г. в Ливерморской ла- J
боратории. 1
Структурная схема полной конфигурации системы LARC
фирмы UNIVAC изображена на рис. 4.8. Основными модулями •
системы являются следующие: два центральных процессора, до
39 независимо адресуемых блока оперативной ферритовой памяти
184
Устройства оперативной памяти •
10 устройств •—
памяти на I
магнитных▼
лентах дляУ^п^,
каждого \1Л ' L
контроллера I
МЛ-1
—t. —____ "
Контроллер счи
тывания-записи
магнитныхлет —
1 Ж Г
I
Процессор
ввода-вывода
Контроллер за- Магнитные барабаны
• писи магнит-
ных барабанов
-5Z
MS-J
Контроллер |
Графопостроитель граркюостроите^
Контроллер Г
считывания ф
магнитных
Электричес-
кие пишущие
машинки
—JL
ПМ~1
ПМ-2
барабанов (3)
Контроллер
считывающего
перфонартного
устройства
Рис. 4.8. Структурная схема системы LARC.
Считывающее
персронартное
устройство
и процессор ввода-вывода. Последний управляет основным пери*
ферийным оборудованием.
Центральный процессор системы представляет собой одноад-
ресную машину с десятичной системой счисления. Трехадресцые
операции могут реализовываться в режиме имитации при помо-
щи двух из числа 99-ти быстрых регистров процессора. Быстрые
регистры используются как индексные регистры и как регистры
д^я взаимодействия процессора и блоков оперативной памяти. Си-
стема команд насчитывает 75 команд. Каждый модуль (блок)
оперативной памяти имеет емкость 2500 слов, при этом слово
содержит 12 десятичных цифр. Таким образом, 39 модулей опера-
тивной памяти имеют суммарную емкость 07 500 слов. Централь-
ный процессор может адресовываться к модулям общей.оператив-
ной памяти и к 99-ти своим быстрым регистрам.
Важное значение имеет организация работы шины системы
LARC, которая основана на разделении времени цикла памяти,
равного 4 мксек, на 8 одинаковых по длительности интервалов
в 0,5 мксек каждый. Эти интервалы времени распределяется
следующим образом.
В течение первого интервала времени процессор ввода-выво-
да имеет доступ к шине и операнды или команды передаются
для программ ввода-вывода. В течение второго интервала време-
ни первый центральный процессор может получать команды, при
этом второй центральный процессор использует третий интервал
для получения операндов. Секция диспетчера процессора ввода-
вывода использует четвертый интервал времени, а пятый интервал
не используется. Шестой и седьмой интервалы являются резервом
для действий, предусмотренных во втором .и третьем интервалах,
а восьмой интервал обеспечивает процессору ввода-вывода воз-
можность дополнительного доступа к информации в шине.
Таким образом, в системе предусматривается перекрытие во
времени обращений к общей оперативной памяти. Наличие про-
цессора ввода-вывода позволяет разгружать центральные процес-
соры от операций ввода-вывода и осуществлять их непосредст-
венно между процессором ввода-вывода, с одной стороны, и пе-
риферийным оборудованием или оперативной памятью, с другой
стороны.
Процессор ввода-вывода имеет три главных части (секции):
центральная часть, синхронизаторы (контроллеры) и диспетчер.
Центральная часть представляет собой универсальную двухадрес-
ную машину с собственной независимой программой, хранимой
в памяти этой машины.
Синхронизатор (контроллер), работающий под управлением
центральной части процессора ввода-вывода, управляет потоком
информации между периферийным устройством и одним из че-
тырех своих буферов, имеющих формат слова, а также осущест-
вляет контроль ошибок и необходимые преобразования форматов.
Для каждого типа периферийных устройств требуется соответст-
186
вующий тип синхронизатора, при этом данный синхронизатор
обслуживает несколько однотипных периферийных устройств.
Синхронизатор занимает часть времени центральной части про-
цессора ввода-вывода и, пока он выполняет задание, центральная
часть может, связаться с другим синхронизатором и так далее.
Таким образом, обеспечивается одновременная'работа нескольких
синхронизаторов и нескольких периферийных устройств.
Функции диспетчера сводятся к управлению передачей инфор-
мации из буферов синхронизатора в устройства основной памяти
через память центральной части процессора ввода-вывода по
сигналам от синхронизатора, когда он заканчивает формирование
слова в буфере.
В полный комплект периферийного оборудования системы
входят 24 устройства памяти на магнитных барабанах,
40 устройств памяти на магнитных лентах, два постраничных
электронных регистратора информации (электрические пищущие
машинки), два устройства печати, перфокартное устройство счи;
тывания, пульт оператора для каждого центрального процессора
и инженерный пульт управления системой (на рисунке 4.8 в
скобках после названия контроллеров указано их количество).
Каждый магнитный барабан имеет емкость 250000 слов длиной
12 десятичных разрядов.
В заключение приведем время выполнения основных арифме-
тических операций [11761: сложение —4 мксек, т. е. совпадает с
длительностью- цикла памяти; умножение — от 8 до 12 мксек;
деление — от 28 до 32 мксек. Операции выполняются над десят
тичными числами как с фиксированной, так и с плавающей запя-
той, каждое число представляется в виде одиннадцати десятичных
разрядов плюс разряд для знака. Наконец, время доступа цент-
рального процессора к быстрым регистрам составляет 1 мксек.
Перейдем к Примерам ранних неоднородных многопроцессор-
ных систем.
4.1.7. Система PILOT 1635, 926]. После ‘ экспериментального
соединения между собой в 1954 г. машин SEAC и DYSEAC при
помощи линии обмена информацией последовало развитие систем
из двух и более фактически независимых процессоров, тесно свя-
занных для быстрого взаимодействия. К таким системам относит-
ся система PILOT, созданная в 1958 г., которую можно считать,
по-видимому, одной из первых параллельных систем, фактически
выполнявших практическую работу. На этой трехпроцессорной
системе была достигнута производительность, превышающая про-
изводительность машины SEAC болре чем в 100 раз. Характерной
особенностью системы PILOT является то, что одна из машин,
специально разработанная для осуществления управления, коор-
динирует работу других машин.
Структурная схема системы PILOT изображена на рис. 4.9.
В состав системы входят три различных и независимых процес-
сора, каждый из которых ориентирован на выполнение функций,
187
отличных от функций двух других процессоров. Эти три процес-
сора могут совместно работать и решать одну задачу.
Процессор № 1 является трехадресной универсальной маши-
ной и предназначен для выполнения основной программы систе-
мы. Он имеет 16 команд, в том числе 7 — арифметических, 5 —
z Процессор Л/Н
Процессор №2
Периферийное
ооорудввание
Пульт
управления
| Дисплеи
j Устройства
^Считывания
{Устройства
Г печати
Устройства
памяти на
магнитных
лентах
и другие
Устройство
управления
внешними
устройствами
Процессор
N»3
и память
№3
Арифме-
тико-ло-
гическое
устрой-
ство
Устройство;
управления [.
вводом- ,
-выводом г
Память N9!
Управля-
ющее
устрой-
ства
Управля-
ющее
устрой-
ство
Арифме-
тико-ло-
гическое
устрой-,
ство
Адреса
Данные прог-
рампы
' Память№2
Данные
I
1
ч
1
v
Рис. 4.9. Структурная схема системы PILOT.
ветвления, 2 — логических и 2 — управляющих. Память № 1 этого
процессора разбита на модули емкостью 256 68-разрядных слов
в каждом. Общее4 число модулей равно 128, общая емкость памя-
ти составляет 32 768 слов. Время выполнения сложения с фикси-
рованной и плавающей запятой равно 6—9 и 19—21 мксек соот-
ветственно, время выполнения умножения с фиксированной и
плавающей запятой равно 22—40 и 28—46 мксек соответственно,
а время выполнения деления с фиксированной запятой равно
72—74 мксек. Процессор № 1 взаимодействует с двумя другими
процессорами.
Процессор № 2 является двухадресной машиной и взаимодей-
ствует только с процессором № 1 (см. рис. 4.9). Он предназначен
для выполнения таких специальных функций, как индексирова-
ние, модификация адресов и других в интересах выполнения ос-
новной программы процессором № 1. Процессор № 2 имеет 16
команд, его память имеет емкость в 60 16-разрядных слов. Ука-
занная срециализация процессора № 2 потребовала высоких ха-
рактеристик скорости работы: сложение выполняется за
1—2 мксек, а время доступа к памяти составляет 1 мксек.
188
Процессор № 3 является независимо программируемой ма-
шиной с восемью командами и предназначен для управления по-
током входной и выходной информации системы, включая конт-
роль и преобразования форматов.
Таким образом, процессор № 1 ведет основную обработку ин-
формации, а процессор № 2 выполняет при этом вспомогательные
Ши на-коллектор данных
Шина-распределитель данных
Рис. 4.10. Укрупненная структурная схема системы GAMMA 60. Сплошной
линией показаны связи для передачи данных, штриховой линией показаны
связи для передачи сигналов, управления.
функции. Процессор № 3 осуществляет управление» потоком
входной и выходной информации системы. Система в целом яв-
ляется многопроцессорной, 'поскольку часть оперативной памяти
является общей для процессоров.
4.1.8. Система GAMMA 60 [231, 635]. Неоднородная много-
процессорная система GAMMA 60 французской фирмы Machines
Bull также является одной из первых параллельных систем. Она
содержит независимые и различные по функциям процессоры,
связанные по информации через высокоскоростную память при
помощи двух общих односторонних шин и управляемые централь-
ным устройством управления. Количество и типы процессоров за-
висят от конкретных приложений (в системе предусмотрено до
128 процессоров). Память содержит команды и операнды про-
грамм и через нее обязательно проходит вся информация при
передаче ее от одного процессора к "другому, т. е. память выпол-
няет функции буфера между процессорами. Структурная схема
системы.GAMMA 60 изображена на рис. 4.10.-
Система содержит специализированные функционально раз-
личные процессоры. Центральное устройство управления состоит
из двух главных устройств, первое из которых называется распре-
делителем передач, а второе — распределителем программ. Рас-
пределитель передач управляет передачей данных из быстрой па-
мяти к процессорам, через шину-распределитель данных и от
процессоров к быстрой памяти через шину-коллектор данных в
соответствии с приоритетной схемой по запросам от процессоров,
которые работают автономно и являются инициаторами передач.
* 189
Распределитель программ получает от процессоров запросы на
команды аналогично тому, как распределитель передач получает
ют процессоров запросы на передачи, осуществляет считывание
команд из быстрой памяти и направляет их по шине-распредели-
телю к соответствующему процессору. Для того, чтобы считать
команду из быстрой памяти, распределитель программ делает
«запрос распределителю передач так же, как это делают про-
цессоры.
В системе GAMMA 60 предусмотрено пять типов устройств:
1) арифметическое устройство, выполняющее обычные арифмети-
ческие операции над 24-разрядными словами в десятичной систе-
ме счисления (каждая десятичная цифра представляется четырь-
мя двоичными разрядами) и над словами некоторых других фор-
матов, а также операции над буквенно-цифровыми данными;
2) логическое устройство, выполняющее булевские операции над
парами двоичных операндов; 3) главное устройство сравнения
буквенно-цифровых операндов различной длины; 4) устройство-
транслятор, осуществляющее переформирование кодов и форма-
тов при передаче информации от периферийных устройств соб-
ственно в систему GAMMA 60 и при передаче информации в про-
тивоположном направлении; 5) память на магнитных барабанах,
которая является просто дополнительной памятью для программ
и операндов (емкость — 25 600 слов, время доступа — 10 мсек).
В системе имеются также периферийные устройства.
Быстрая память построена на магнитных сердечниках, имеет
емкость в 32 768 24-разрядных слов и время доступа —10 мксек.
В качестве периферийного оборудования используются устройст-
ва считывания с перфокарт и с * лент, печатающее устройство,
устройства памяти на магнитных лентах.
Следует отметить, что в системе GAMMA 60 были предус-
мотрены команды для разветвления последовательности вычисле-
ний на параллельные ветви и для объединения таких ветвей в
последовательность вычислений, т. е. прообразы команд FORK
и JOIN.
4.1.9. Система STRETCH [344]. Неоднородная многопроцессор-
ная система STRETCH (IBM 7030) фирмы IBM, характерная на-
личием общей шины с разделением ее времени, была создана в
1961 г. В структуру системы был заложен ряд перспективных
идей. Так, например, предполагалось использование отдельных
процессоров для посимвольной обработки информации и двоич-
ной арифметики, что, однако, не было реализовано. Поэтому си-
стема STRETCH фактически не стала многопроцессорной, но
оказала определенное влияние на развитие многопроцессорных
юистем. Всего было поставлено только семь экземпляров системы
(281]. Первый образец системы был перевезен в Лос-Аламосскую'
научно-исследовательскую лабораторию в 1961 г.
Программа работ по созданию системы STRETCH была нача-
та в 1954 г. В качестве основной была поставлена задача получить
190
ври решении математических задач, требующих очень большого
объема вычислений, самое высокое быстродействие, какое можно
реализовать нри определенных ограничениях в сроках разра-
ботки и используемых ресурсах. Предполагалось получить систе-
му в 100 раз более быструю по сравнению с самой быстродей-
ствующей из применявшихся тогда машин. Предусматривалось
Модули оперит ио иди ломя т и
Устройство коммута-
ции шин памяти
\ кыходнаяшина
Входная шина
Данные
Устройство_
обмена
Ж
Каналы для
устройств
Ъвоаагвывода
Команды и данные
^Улрабпякнцре
Устройство
управления
дисками
ад
ад
Память на
мавнитных
диенах
Устройство
управления
Индексное
АУ
Устройство
опережения
Арифметичес-
кие ресистры
Параллельное
АУ
Последователе *
ноеАУ
Центральноеуст-
ройство обработки
ИндвкснА
Рис. 4.11. Структурная схема системы STRETCH.
использование в системе полупроводниковых элементов, введение
средств автоматического контроля и обеспечение возможно более
широкой универсальной системы. В систему вводился новый
по тому времени мультипрограммный режим работы, реализовы-
вались совмещение операций и опережающий просмотр.
Структурная схема системы STRETCH изображена на
рис. 4.11. Эта система состоит из центрального устройства обра-
ботки, одного или нескольких модулей оперативной памяти,
устройства обмена и устройств ввода-вывода. К устройствам
внешней памяти относятся память на магнитных дисках в
устройство управления дисками.
Устройство обмена осуществляет управление передачами меж-
ду устройствами ввода-вывода и оперативной памятью» Централь-
191
ное устройство обработки состоит из нескольких устройств, ко-
торые могут работать одновременно: устройства управления вы-
боркой и индексированием команд (выполняет также команды
индексной Арифметики); устройства опережающего просмотра,
осуществляющего управление записью и выборкой данных с опе-
режением в несколько команд относительно выполняемой ко-
манды; параллельного арифметического устройства, оперирующе-
го с числами в двоичной системе счисления с плавающей запя-
той; относительно медленного последовательного арифметического
устройства, выполняющего операции десятичной арифметики,
буквенно-цифровые операции и операции логического сравнения
над полями переменной длины.
Управление центральным устройством обработки как логиче-
ски единым устройством осуществляется от одного счетчика ко-
манд. Устройство коммутации шин памяти управляет обменом
между оперативной памятью и тремя устройствами — устройст-
вом обмена, устройством управления дисками и центральным
устройством обработки.
Каждый модуль памяти имеет емкость в 16 384 72-разрядных
слова (64 разряда — информационные, 8 разрядов — контрольные,
для исправления одиночных и обнаружения двойных ошибок).
Цикл работы памяти равен 2,1 мйсек. В системе может быть 1,
2, 4, 8 или 16 модулей памяти, работающих независимо друг от
друга и допускающих одновременное обращение к разным моду-
лям (для случаев числа модулей, превышающего 1). Применяет-
ся чередование адресов памяти для групп в составе 4 (и 2)
модулей.
Индексное запоминающее устройство содержит 16 индексных
регистров, построено на магнитных сердечниках и имеет цикл
считывания длительностью 0,6 мксек и цикл стирания/записи
длительностью 1,2 мксек. Имеется также 16 специальных адре-
суемых регистров. Команды могут иметь длину в 32 или
64 разряда.
В заключение приведем средние знамения времени выполне-
ния основных арифметических операций: сложение, умножение
и деление с плавающей запятой занимают 1,5 мксек, 2,7 мксек и
9,9 мксек соответственно.
Рассмотрим теперь кратко основные положения концепции
организации современных многопроцессорных систем с учетом
сказанного об этом в предыдущих разделах.
4.1.10. Основные положения концепции организации многопро-
цессорных систем [694]. Основные характеристики вычислитель-
ной системы (в первую очередь — производительность) зависят,
главным образом, от характеристик быстродействия элементной
базы, от реализуемых алгоритмов работы функциональных
устройства — центральных процессоров, устройств управления,
памяти и процессоров ввода-вывода, от организации системы,
определяемой характером внутрисистемных связей функциональ-
192
ных устройств, и от программного обеспечений — операционной
системы, трансляторов и других программных средств.
Многопроцессорные системы, как и многомашинные, осуще-
ствляют одновременное выполнение операций в параллель друг
другу, однако, первые представляют собой единую систему с мно-
жеством устройств обработки информации, тогда как вторые со-
стоят из связанных между собой отдельных самостоятельных
машин.
Типичная многопроцессорная система обладает следующими
основными характеристиками:
1) содержит два или более центральных процессора с пример-
но одинаковыми вычислительными возможностями;
2) все процессоры системы разделяют доступ к общей опера-
тивной памяти;
3) все процессоры разделяют доступ к каналам ввода-вывода,
устройствам управления вводом-выводом и к периферийному
оборудованию;
4) система управляется единственной операционной системой,
обеспечивающей взаимодействие между процессорами и их про-
граммами. Совокупность этих характеристик составляет основу
определения многопроцессорной системы.
Существуют три основных способа организации многопроцес-
сорных систем (см. п. 2.4.2), а именно, при помощи общей шины
с распределением ее времени (рис. 4.12), при помощи матричного
коммутатора перекрестных связей (рис. 4.13) и при помощи мно-
жества шин с использованием многовходовой памяти (рис. 4.14)
[281, 694]. Следует подчеркнуть, что для типичных* систем при
каждом из трех способов организации соответствующие схемы
связей используются для всех основных типов функциональных
модулей — для центральных процессоров, модулей оперативной
памяти и устройств ввода-вывода.
Перечислим основные сравнительные характеристики трех
указанных типов структур многопроцессорных систем, выбрав в
качестве главных для сравнения стоимость, готовность, гибкость,
возможность наращивания и степень универсальности систем,
а также их пропускную способность. f
Системы с общей шиной Апри разделении ее времени имеют
следующие £арактерные особенности.
1) Такая организация обеспечивает наименьшую, общую сто-
имость оборудования системы.
2) Такая организация обеспечивает наименьшую сложность
(шина связи может быть полностью пассивным элементом).
3) Изменение конфигурации оборудования системы не вызы-
вает каких-либо трудностей и осуществляется посредством добав-
ления или исключения функциональных устройств.
4) Общие возможности системы ограничены скоростью пере-
дачи информации через шину (эта скорость передачи может ог-
раничивать общую производительность системы).
13 В. А. Головкин „ 493
5) Отказ шины приводит к катастрофическому отказу всей
системы.
6) Расширение системы путем добавления функциональных
устройств может привести, начиная с некоторой конфигурации,
к уменьшению производительности системы (пропускной спо-
собности системы).
а) Единственная двусторонняя шина
б) Две односторонних шины
е)Две двустороних шины
Рис. 4.12. Структура многопроцессорных систем с общей шиной при разде-
лении ее времени.
7) Достижимая эффективность системы при одновременном
использовании всех готовых к работе устройств является наибо-
лее низкой по сравнению с двумя другими типами структур мно-
гопроцессорных систем.
8) Структура с общей шиной может быть рекомендована
обычно только для сравнительно малых систем.
Системы с перекрестным коммутатором имеют следующие ха-
рактерные особенности.
194
1) Такая организация* характеризуется наибольшей слож-
ностью внутренних связей.
2) Функциональные устройства являются наиболее простыми
и дешевыми, поскольку логика управления и коммутации реали-
зуется в коммутаторе (интерфейсы функциональных устройств,
Рис. 4.13. Структура многопроцессорных систем с матричным коммутато-
ром перекрестных связей.
связанных с коммутатором, являются простыми и обычно не тре-
буют шинных сопрягающих устройств).
3) Такая организация обычно используется только в много-
процессорных системах, поскольку основная коммутационная мат-
рица требуется для объединения некоторых функциональных
устройств в рабочую конфигурацию.
13* W5
4) Такая организация обеспечивает потенциально наиболее
высокую общую скорость передачи информации.
5) Расширение системы (добавление функциональных уст-
ройств) обычно приводит к увеличению ее общей производи-
тельности.
6) Такая организация обеспечивает потенциально наиболее
высокую эффективность системы.
7) Такая организация позволяет наращивать систему без пе-
репрограммирования операционной системы.
б) Структура с приоритетами входов модулей памяти
Рис. 4.14. Структура многопроцессорных систем с множестввм шин и с мно-
говходовыми модулями памяти.
196
8) Расширение системы ограничено, в принципе, тольш>Е|)аз-
мером матричного коммутатора. ia отон
9) Надежность коммутатора и, следовательно, системьгувпце*-
лом, может быть повышена посредством сегментации и/иЛипяэег’
дения избыточности в рамках коммутатора. quvein
10) Такая организация позволяет обычно без каких-либо
трудностей удалить из системы плохие функциональные устройг
ства и разделить систему на несколько отдельных систем. жаня;
Системы с множеством шин и многовходовыми модулями нпф
мяти имеют следующие характерные особенности. из г» г
1) Такая организация требует наиболее дорогих устройся
оперативной памяти, поскольку основные цепи управления и вди?
мутации входят в устройства памяти. ;
2) Функциональные устройства обеспечивают построением от-
носительно дешевых однопроцессорных конфигураций. м л •
3) Такая организация обеспечивает потенциально очень выссн-
кую скорость передачи информации в’ системе полной конфи*
гурации. ] о
4) Размер и конфигурация возможных дополнений к системе
определяются и ограничиваются числом и типо^л имеющихся
типов памяти, хотя и могут применяться расширители входов
(соответствующий выбор осуществляется на ранней стадии разра-
ботки системы и в дальнейшем изменить его очень трудней
5) Такая организация требует большого числа кабелей и со*
прягающих устройств.
В целях уменьшения недостатков базовых типов структур
(рис. 4.12а, 4.13а, 4.14а) применяются те или иные их модифи-
кации. Так, например, в целях уменьшения ограничения, накла-
дываемого единственной двусторонней шиной (рис. 4.12а) на об*
щую производительность системы вводятся две односторонних
шины, в результате чего за счет усложнения структуры повыша-
ется пропускная способность шин (рис. 4.126). В этом случае мо-
дификатор шин организует путь передачи информации. Следую-
щим шагом является применение двух или более двусторонних
шин с разделением их времени (рис. 4.12в). Здесь сложность
структуры существенно увеличивается, но за счет этого обеспе-
чивается возможность осуществления нескольких передач одно-
временно. Такую структуру можно рассматривать как переход-
ную к структуре с матричным коммутатором перекрестных
связей.
Важнейшей характеристикой матричного коммутатора пере-
крестных связей является то, что он обеспечивает одновременные
передачи для f всех модулей оперативной памяти (рис. 4.13а).
В целях улучшения гибкости доступа к периферийному обору-
дованию, к основному коммутатору подключается при помо-
щи контроллеров или процессоров ввода-вывода аналогичный
перекрестный матричный коммутатор периферийных устройств
(рис. 4.136).
197
Если функции управления, коммутации и логики приоритет-
ного выбора, которые распределены по элементам матричного
коммутатора, сконцентрировать в интерфейсах устройств опера-
тивной памяти, то получим структуру, в которой каждый про- -
цессор имеет собственную шину, а устройство памяти — несколь-
ко входов (рис. 4.14а). Приоритеты входов модулей памяти мож-
но распределить в соответствии с принятой очередностью обслу-
живания одновременных обращений к памяти от тех или иных
функциональных устройств (рис. 4.146, приоритеты каждого из
четырех входов модулей памяти обозначены через 1, 2, 3 и 4).
Возможно уменьшение числа связей в системе за счет выделения
индивидуальных модулей памяти или их комбинаций для процес-
соров и устройств ввода-вывода (рис. 4.14в). Такая организация
системы может применяться в тех случаях, когда не требуются
связи каждого модуля памяти с каждым процессором и устройст-
вом ввода-вывода. При этом, однако, существенно понижается
степень универсальности, что приводит к уменьшению гибкости
операционной системы, трудностям обеспечения работоспособно-
сти системы в условиях ремонта какого-либо функционального
устройства и к другим нежелательным последствиям.
Несмотря на различия между параллельной обработкой и
мультипрограммным режимом совместного выполнения несколь-
ких программ (см. п. 2.2.3), концептуальные требования к систем-
ному программному обеспечению многопроцессорной системы п
большой однопроцессорной системы для ее работы в мультипро-
граммном режиме невелики, хотя внутренняя организация про-
граммного обеспечения для первого и второго случаев сущест-
венно отличаются друг, от друга. Основные функциональные воз-
можности, которыми должна обладать операционная система
многопроцессорной системы, состоят в следующем:
1) распределение ресурсов и управление ими;
2) защита множества системных таблиц и данных;
3) предотвращение тупиковых ситуаций;
4) обработка ненормальных окончаний вычислений^
5) балансировка нагрузки ввода-вывода;
6) балансировка нагрузки процессоров;
7) реконфигурация.
Фактически только две последних функции операционных си-
стем являются специфическими для многопроцессорных вычисли-
тельных систем.
Существуют три основных типа организации операционных
систем многопроцессорных вычислительных систем, определяю-
щих системную организацию их функционирования: 1) с рас-
пределением функций управления и исполнения между процес-
сорами системы; 2) с распределением выполнения заданий между
процессорами системы; 3) с симметричной обезличенной обработ-
кой'во всех процессорах [281, 694]. Рассмотрим кратко их основ-
ные особенности.
128
Операционные системы с распределением функций управления
п исполнения между процессорами являются наиболее простыми,
не требуют сложного оборудования и характерны тем, что для
супервизорных функций выделяется один из процессоров системы
такой же, как и другие процессоры, или специально разработан-
ный для выполнения супервизорных программ. Этот процессор
обычно называется ведущим, а другие процессоры системы, вы-
полняющие рабочие программы, называются обычно ведомыми.
Основные недостатки такой организации заключаются в ее малой
гибкости и в том, что при сбоях и отказах ведущего процессора
нарушается работоспособность всей системы. Наибольшая эффек-
тивность при .такой организации достигается для неоднородных
систем с процессорами различной мощности и для специальных
применений.
Операционные системы с распределением функций управле-
ния и исполнения между ведущим и ведомыми процессорами бы-
ли применены в многопроцессорных системах RW 400, PILOT,
IBM 360/67 (операционная система IBM OS/360 TSS), В 5500 (опе-
рационная система МСР — Master Control Program) и других.
Операционные системы с распределением заданий между про;
рессорами системы характерны тем, что функции управления и
исполнения реализуются каждым процессором при выполнении
им фактически автономно своего задания, вследствие чего каж-
дый процессор выполняет супервизорные функции в соответ-
ствии с его собственными потребностями, сам организует ввод-вы-
вод как бы через свои устройства ввода-вывода, имеет индиви-
дуальный набор системных таблиц и т. п. Такая организация,
в отличие от предыдущей, требует обеспечения повторной входи-
мости в супервизорные программы или их копирования для за-
грузки в каждый процессор (возможна комбинация этих спосо-
бов), так как эти программы выполняются несколькими процессо-
рами. Отказ какого-либо процессора не приводит к отказу системы
в целом, однако запуск процессора после отказа обычно оказыва-
ется сложной задачей. В такого рода системах нередки ситуации,
когда один или несколько процессоров загружены длительное
время, а другие простаивают без работы.
Операционные системы с симметричной обработкой во всех
процессорах ориентированы на однородные многопроцессорные
системы и хгфактерны тем, что функции управления и исполне-
ния динамически перераспределяются между процессорами в це-
лях обеспечения наиболее эффективной работы системы в целом.
Такая организация обеспечивает наиболее полное использование
ресурсов системы, высокую надежность работы и готовность си-
стемы, продолжение вычислений с меньшей производительностью
при отказах функциональных модулей и автоматическую рекон-
фигурацию в этих и других случаях. При этом, однако, требуется
разрешать конфликты одновременного обращения к системным
таблицам и наборам данных, обеспечить повторную входимость
199
в программные модули, эффективно решать задачи диспетчери-
зации и балансировки нагрузки процессоров и некоторые другие»
которые в этом случае являются сложными и трудными.
4.1 Л1. Библиографическая справка. Многопроцессорные кон-
цептуальные и реальные системы на начало 1970-х годов кратко
описаны в обзоре [493]. Работы обзорного характера 1494, 693,
694, 1196] посвящены, в основном, многопроцессорным системам;
взаимосвязи между процессорами и модулями памяти исследова-
ны в [916] и в других работах. Напомним, что в обзоре моногра-
фий, сборников и обзоров (п. 2.7.1) рассматривались, наряду с
другими, работы по многопроцессорным системам.
Система RW 400 описана в ключевой статье [1073] и в работе
[635], а также кратко рассмотрена в [281, 694, 842] и в других
работа'х. Система D 825 описана в ключевой статье [464], а также
в [280, 281, 465, 842, 1216] и других работах. Описание системы
CDC 3600 содержится в ключевой статье [1209] и в [147, 575],
а системы PHILCO 213 — в [560]. Система LARC представлена в
ряде рдбот: ее предварительное описание приведено в [681], а до-
статочно полное описание в ключевой статье [682, 952], состоя-
щей из двух частей. Эта система рассмотрена в книге [1176], в об-
зоре [635] и в статье [931]; краткое описание системы включено
в книгу [147].
Все перечисленные выше системы являются характерными
представителями ранних однородных многопроцессорных систем,
при этом первые две из них имеют структуру с матричным ком-
мутатором перекрестных связей, третья и четвертая — структуру
с множеством шин и с многовходовыми модулями памяти, а пя-
тая имеет структуру с одной общей шиной (с разделением вре-
мени шины).
Неоднородная многопроцессорная система PILOT,' являющая-
ся одной из первых многопроцессорных систем, описана в ключе-
вой статье [924], в статьях [452, 925, 926, 1258], в обзоре [635],
в книге [1176], а также, очень кратко, в книге [147].
Неоднородная многопроцессорная система GAMMA 60 описана
в ключевой статье [674], ц стАтьях [554, 672, 673] и в обзоре
[635]. Вопросам программирования для GAMMA 60 посвящена
книга [231]. Обобщение организации структуры и функциониро-
вания систем, подобных GAMMA 60, выполнено в [414], соответ-
ствующие материалы воспроизведены в обзоре [364Т. Неоднород-
ная система STRETCH подробно описана в посвященной ей кни-
ге [3441 и в статьях о STRFTCH [543, 598, 680]. Сведения об
этой системе можно найти также в обзоре [1155] и в книгах [147,
738, 11761.
Наконец, неоднородная двухпроцессорная система GUS
(George Unified System) описана в [984] и в некоторых других
работах.
В обзоре [475], содержащем характеристики архитектур более
150 средних и больших зарубежных вычислительных систем, рас-
200
смотрено 45 систем, идентифицированных как многопроцессорные.
Обзор организации многопроцессорных систем, включая таблицы
основных характеристик большого числа многопроцессорных си-
стем выпуска по 1977 год, дан в работе [694], которую можно»
рассматривать как дополнение к книге 1281].
Краткие сведения о некоторых концепциях и ранних много-
процессорных системах содержатся в обзорах [НО, 111].
В заключение отметим, что многие неоднородные многопроцес-
сорные системы имеют черты, характерные для параллельных
систем других типов. Так, например, способ обработки информа*
ции в системе GAMMA 60 можно рассматривать как переходный
к магистральному способу обработки.
4.2. Системы семейства Эльбрус
4.2.1. Концепция построения систем семейства Эльбрус [56—
60, 563]. При разработке систем высокой производительности се*
мейства Эльбрус особое внимание уделено решению следующих
проблем:
1) обеспечение высокой надежности решения задач;
2) преодоление трудностей создания и эксплуатации рабочих
программ;
3) обеспечение совместимости систем;
4) увеличение объемов оперативной памяти и скорости рабо-
ты внешней памяти;
5) обеспечение комплексирования территориально разнесен-*
ных вычислительных средств при помощи линий связи (построе-
ние вычислительных сетей), поскольку неудовлетворительное ре-
шение этих проблем сдерживало развитие и внедрение больших
вычислительных систем. В качестве путей решения перечислен-
ных проблем было принято следующее.
Надежность. Требования высокой надежности решения задач
состоят в обеспечении гарантированного получения достоверных
результатов в течение того или иного заданного интервала време-
ни и в обеспечении гарантированного хранения больших объемов
информации в течение длительного времени.
Решить проблему надежности только за счет увеличения на-
дежности элементов машин не представляется возможным, пос-
кольку предъявляются все более и более высокие требования к
расширению возможностей обработки в процессорах, увеличению
емкости оперативной памяти, улучшению оснащения машин пе-
риферийным оборудованием. При реализации таких требований
обычно запас надежности новых элементов как бы расходуется
и надежность новых машин остается нередко у$ким местом. Кар-
динальное решение проблемы надежности может быть получено
только структурным способом. Одним из таких способов являет-
ся использование модульного принципа построения вычислитель-
201
ной системы }с реализацией полного аппаратного контроля в каж-
дом модуле.
Вычислительная система, состоящая из одинаковых модулей
каждого тйпа (процессоров, оперативной и внешней памяти,
устройств ввода-вывода), может обеспечить в принципе любую
требуемую вероятность получения достоверных результатов ре-
шения задачи в течение заданного интервала времени. Значение
указанной вероятности определяется, при прочих равных услови-
ях, глубиной резервирования. Надежность хранения информации
обеспечивается при этом за счет ее дублирования на разных
уровнях иерархии памяти с учетом оперативности использования
и объема хранимой информации.
Многопроцессорный модульный принцип построения вычисли-
тельных средств имеет и другие достоинства. Такт например, он
позволяет строить вычислительные системы с перекрытием ши-
рокого диапазона производительности и с требуемым соотноше-
нием производительности и емкости оперативной и внешней
памяти.
Создание и эксплуатация рабочих программ. Если при разра-
ботке структур вычислительных систем не принимать соответст-
вующих мер, то большое количество актуальных задач, вероятно,
будет невозможно запрограммировать из-за их сложности. Учиты-
вая, что в деле облегчения программирования сложйых задач
важное значение имеют языки высокого уровня, внутреннюю
структуру управления и систем команд вычислительной системы
целесообразно строить таким образом, чтобы обеспечить наиболь-
шую эффективность выполнения программ, написанных па язы-
ке высокого уровня. К такому машинному языку можно предъ-
явить два основных требования: язык не должен включать в себя
какую-либо информацию, кроме собственно описания алгоритма,
и должен обеспечивать наиболее компактное представление алго-
ритма в виде программы па этом языке. Иными словами, програм-
ма на машинном языке должна быть конкретной реализацией
алгоритма в наиболее компактном виде без информации
об управлении физическими ресурсами вычислительной си-
стемы.
Для выполнения первого требования в машинном языке не
должно быть информации о типе памяти и о физических адресах
операндов, а такя£е не должно быть информации, прямо или кос-
венно указывающей устройства, на которых нужно выполнять
обработку. Задача исключения физических адресов внешней па-
мяти из машинных языков фактически решена. Учитывая срав-
нительно медленную работу внешней памяти, соответствующие
функции выполняются операционными системами программными
средствами. Что же касается исключения адресов оперативной и
регистровой памяти, то в этом направлении возможными реше-
ниями могут быть организация математической и соответствую-
щей физической оперативной памяти в виде сегментов любой
202
необходимой длины как системных единиц информации и аппара-
турное динамическое распределение регистровой памяти соответ-
ственно. Применение, базирования и математической памяти
приблизило решение проблемы, но не решило ее. Действительно,,
при базировании имеет место прямое соответствие между исполь-
зуемой ограниченной линейной областью адресов и эквивалент-
ной областью физической памяти. При адресации *с использовани-
ем математической памяти последняя сама -служит ресурсам п/
кроме этого, не выполняется требование компактности вследст-
вие избыточности информации математических адресов модулей
программ.
Для исключения из программы на машинном языке информа-
ции о том, какого типа устройства обработки нужно использовать,
вместе с кодом величины должен храниться и признак ее типа
подобно описаниям типов в алгоритмических языках. Пользуясь
типами величин, машина динамически осуществляет выбор соот-
ветствующего устройства обработки.
Для выполнения второго требования (о компактном представ-
лении алгоритмов на машинном языке) нужно оптимизиро-
вать кодирование информации об адресах и операторах. В этих
целях целесообразно реализовать непосредственно в аппаратуре
устоявшиеся методы описания алгоритмов и организации вычис-
лительных процессов, используемые в языках высокого уровня и
операционных системах, в первую очередь,— реализовать выра-
жения и процедуры. В этом случае программа на машинном
языке становится иерархически структуризованной, машинный
язык (как основной вариант) — языком с безадресным указанием
операндов при помощи имен, а соответствующие узлы машины —
аппаратно реализованными процедурами тех или иных операций
(считывание, запись, арифметические* операции и другие). Рас-
ширение возможностей аппаратуры не снижает быстродействия,
поскольку сокращается время на выполнение часто повторяемых
вспомогательных операций. При этом, конечно, оборудование вы-
числительной системы в целом реализует более сложные логиче-
ские функции.
Совместимость. Аппаратурная реализация языков высокого
уровня существенно продвигает вперед решение проблемы совме-
стимости машин разные поколений, поскольку программы на язы-
ках высокого уровня можно перетранслировать на языки вновь
создаваемых машин. Кроме этого, даже зафиксировав машинный
язык высокого уровня, можно создавать новые машины с большей
степенью свободы в изменении структурных решений, чем в слу-
чае сохранения или расширения традиционного машинного язы-
ка. Однако для обеспечения программной совместимости нужно
сохранить функции старых операционных систем по взаимодейст-
вию с рабочими программами и структуру старых архивов. Ре-
шение этой проблемы требует внедрения и стандартизации базо-
вых способов организации структуры и функционирования
203
-
оЙ&^ВДйбнных систем и архивов, что, в свою очередь, позволит
к их реализации в структуре машин.
]'^Нр&блемы памяти. Структура и основные характеристики
КруйФйй? высокопроизводительных вычислительных систем во
Мй<ЯЧй1Р 'определяются характеристиками памяти. Основными
й^^ШйЯйВми здесь являются увеличение емкости и быстродействия
опёрй<?й'й*ой памяти и увеличение средней скорости обмена меж-
ду ^^й^йльной частью вычислительных сиртем и внешней па-
м'яййб^ойьшого суммарного объема. Решение первой проблемы
Фр&ф&Р качественного и количественного улучшения элементной
базы. Одним из основных путей решения второй проблемы, наря-
дУлИ'’^#^1Й1ением характеристик внешней памяти, является вве-
дё^^^тфеййежуточной памяти, например, как это делается в ряде
ёй^Чай^, ведение (в качестве промежуточной) памяти на дисках
d WSfoffiftJi на тракт или на ферритах, что улучшает согласование
СЙЙфЪСтЙ&^йаботы оперативной и внешней памяти.
Кроме улучшения характеристик, следует также стремиться
ГС1 нагрузки на память, в первую очередь, на оператив-
за счет структурных решений. Реализация машинно-
^Йзьнса'ййЬокого уровня сокращает длину программы и сущест-
йВйнЬ^ЧЗйбкает частоту обращений к памяти, т. е. позволяет
&йбйбйиЧ,ВпЙ1еративную память для хранения программ и, одно-
йр&ййййб, бо’лее экономно использовать ее ресурсы быстродейст-
: Мольных участках алгоритмов длина программ сокра-
3 раза, а количество обращений к оперативной памя-
Н^йНйрй(й(аеАя в несколько десятков раз. Аппаратная реализация
ййВййййк<йЙйболее устоявшихся функций операционных систем
ТЯЙ^Й^ЙЫЙКЙЙ? нагрузку на оперативную память.
км^^ййёвйеййе сверхоперативной памяти, наряду с сокращением
вЙё^еЦй^дбй&щения процессоров к данным, резко снижает сред-
Обращений к оперативной памяти, и, следовательно,
л*Асование скоростей работы процессоров и оператив-
ней тЙЙЙй. -Это особенно важно в многопроцессорных системах,
п^ОдЙйкУ^Й^ ’йих несколько процессоров работают над общей
оперативной памятью. Следует отметить, что построение единой
бЙё^гй^а-йЙЙЙЬй памяти для всех процессоров неприемлемо,
т?^?сй динамический ресурс такой сверхоперативной
гб^ййР'узким местом всей системы и, кроме этого,
Зб^йхДеййя к этой памяти окажется недопустимо большим
иУ1Ш?^й6сй’Йй4>но длинных линий связи между процессорами
й' ЙрВЯЬперативной памятью. Вместе с тем, принимав*
Индивидуальных устройств сверхоперативной па-
п₽™ затРУДняет их Р^У с общими
'г^ЕЖй^^ятЙйя^е отметить, что оперативную память большого
ббъ^Й^Н^ЪьК^им быстродействием нельзя реализовать в виде
дй®Й)%нВЯ^ЙНтй&^а технических ограничений. Поэтому оператив-
Шг/^Й’бМУйвается разделеннной на многие блоки, что, хотя
систем
данных, возло-
них основные
взаимодействия
рода объектами
специализированные процессоры приема-
§
I
в
10 Р ы
Ш&-
П IP 101Д Е <
i
ВНЕШНЯЯ ПАМЯТЬ
Н устройства ввода-вы вода |
Рис. 4.15. Упрощенная структурная схема
систем Эльбрус.
и неизбежно, с рассматриваемой точки зрения, соответствует
общему модульному принципу.
Создание вычислительных сетей. В целях объединения терри-
ториально разнесенных вычислительных средств при помощи
линий передачи данных целесообразно включать в состав вычис-
лительных
передачи,
жив на
функции
с разного
через линии связи. Про-
цессор приема-передачи
данных должен работать
со своей памятью и быть
способным эффективно
обеспечивать работу вы-
числительной сети. Тогда
основные вычислительные
системы узлов сети полу-
чают возможность адапта-
ции к различным услови-
ям построения и развития
вычислительной сети без необходимости изменения своих основ-
ных программ и оборудования.
Таким образом, основу концепции построения вычислитель-
ных систем семейства Эльбрус составляют: модульный принцип
построения систем с многими одинаковыми основными процессо-
рами и общей оперативной памятью; система команд процессоров
в виде языка высокого уровня; аппаратурная реализация устояв-
шихся методов работы операционных систем и принципов пост*
роения архивов; многоуровневая память с расширенной оператив-
ной памятью и с массовой относительно быстрой промежуточной
памятью большой емкости; специализированные процессоры при-
ема-передачи данных, вводимые для работы с различными объек-
тами через телефонные и телеграфные линии связи. Соответ-
ствующая упрощенная структурная схема изображена на
рис. 4.15 [56].
4.2.2. Структура систем семейства Эльбрус. Рассмотрим струк-
туру вычислительных систем — многопроцессорных вычислитель-
ных комплексов (МВК) Эльбрус, обращая внимание на эффек-
тивность использования оборудования, обеспечение возможно
более высокой производительности, надежность резервируемых
структур, возможность наращивания конфигурации и возмож-
ность адаптации к решаемым задачам.
Общая структурная схема МВК Эльбрус-А
рис. 4.16 [59]. На. этой
пмякчдои «1«эа оз игимен
Рассмотрим структуру МВК Эльбрус [59, 348]. Построенный
по модульному принципу МВК Эльбрус содержит модули цент-
ральных процессоров, оперативной памяти, процессоров ввода-
вывода, процессоров приема-передачи данных, внешней памяти
па магнитных барабанах, дисках и лентах, а также устройства
ввода-вывода.
10
UJL
нм
Модули
центральный?
процессоров
1
Шк
\км
НМ
ОП
1
Н-
о
й
Удаленные
терминалы
^Управление
АдарадаыГ
УВД миидису.
нами\
НМ
ОП
2
НМ
ПВВ
/I
НМ
ОЛ
31
НМ
ОП
32
Модули *
оперативной
памяти
нм
ПВВ
2Г
1 Парабаны
Модули
процессоров
ввода-вывода
Модули
внешней
помета
Магнитофоны
Устройства
ввода-вывода
АлЛавитно- Перфо- Перфо- Алфавит- Графичес- Графопо-
ленты но-ирфро- ниЗдисп- строители
4Мающие уст- выедим- леи
ройстеа леи
АЦПУ
ПН пл.
ЩД \ГД
ГП
Рис. 4.16. Структурная схема МВК Эльбрус.
Модули центральной части МВ*К, а именно, модули централь-
ных процессоров, оперативной памяти и процессоров ввода-выво-
да, связаны между собой при помощи центрального коммутатора
(КМ), модули которого разнесены по соответствующим функцио-
нальным модулям. Реализованный модуль центрального коммута-
тора имеет размерность 4X14 и соединяет 4 модуля оперативной
памяти со всеми модулями центральных процессоров и процессо-
206
ров ввода-вывода. Процессоры приема-передачи данных, проме-
жуточная и внешняя память и устройства ввода-вывода подклю-
чаются к центральной ч^сти системы через процессоры ввода-
вывода.
Внешняя память подключается к каналам процессоров ввода-
вывода через устройства управления магнитными барабанами,
дисками и лептами соответственно. Телефонные и телеграфные
линии связи подключаются к процессорам приема-передачи дан-
ных, которые имеют свою систему команд и внутреннюю память,
через адаптеры и групповые устройства сопряжения. Таким обра-
зом, информация qt удаленного терминала, например, поступает
в центральную часть системы последовательно через линию связи,
адаптер, групповое устройство сопряжения и процессор приема-
передачи данных.
Модули системы работают параллельно и независимо друг от
друга, ресурсы системы динамически распределяются операцион-
ной системой. Однотипные модули являются идентичными и не-
зависимыми (с точки зрения как коммутации, так и электропита-
ния). Все модули, включая отнесенные к ним узлы центрального
коммутатора, ' охвачены 100%-м аппаратным контролем, цепи
которого вырабатывают сигнал неисправности соответствующего
модуля при появлении хотя бы одиночной ошибки в процессе
вычислений. Операционная система, получив указанный сигнал,
исключает неисправный модуль из работы и переводит его при
помощи аппаратной системы реконфигурации в ремонтную кон-
фигурацию. После восстановления этот модуль снова может быть
включен операционной системой в рабочую конфигурацию.
Таким образом, резервирование осуществляется на уровне
однотипных функциональных модулей и устройств. При выходе
из строя какого-либо модуля его работа может быть передана
другим модулям такого же типа, что приводит к снижению рабо-
чих характеристик, но не к отказу МВК в целом. Выбирая ту
пли иную конфигурацию, можно настраивать МВК на решение
того или иного класса задач. Иными словами, многопроцессорная
модульная структура обеспечивает гибкость и задаваемые надеж-
ность и живучесть МВК. « '
В основу организации вычислений положен стек (область
памяти со считыванием последнего записанного слова), приме-
няемый как для вычисления выражений, так и для динамическо-
го распределения памяти под имена процедур. Каждая процедура
в процессе выполнения имеет свою область прямоадресуемых дан-
ных, адрес начала которой является базой процедуры, и адресный
контекст в виде области известности имен, которую составляют
ее собственные имена и имена охватывающих процедур в соот-
ветствии с блочной структурой программы.
Каждое слово сопровождается тэгом, указывающим тип дан-
ных (целое, вещественное, набор, дескриптор, адрес, метка про-
цедуры и т. д.) и формат данных (32, 64 или 128 разрядов).
207
В основу системы команд положен безадресный принцип, что поз*
воляет исключить из кода команд адреса быстрых регистров.
Адресация осуществляется при помощи адресной пары в виде
кода лексикографического уровня данной процедуры (уровень
вложенности), определяющего базу этой процедуры, и порядково-
го номера слова в стеке данных этой же процедуры, определяю-
щего смещение относительно базы (индексирование). Наиболее
часто используемые команды имеют длину в один, два и три
байта, имеются и многобайтовые команды.
’Обрабатываемые данные представляются массивами, описан-
ными дескрипторами. Коды команд загружаются в физическую
память, а собственно данные «помещаются» в математическую
память.
Вычислительный процесс может быть активным или пассив-
ным. В первом случае, когда работает процессор, вычислительный
процесс аппаратно отображается стеком, обычна находящимся в
оперативной памяти, указателем стека, базовыми регистрами,
сверхоперативной памятью и другим оборудованием центрального
процессора. Во втором случае, когда процесс ожидает какого-либо
события, он аппаратно отображается только данными в памяти.
В целях распараллеливания вычислений под каждую процедуру
может быть отведен отдельный стек. Несколько процессов одно-
временно могут быть активными, при этом любой процессор
может работать на любом стеке. В целях синхронизации процес-
сов используются семафоры, система команд содержит операции
«открыть семафор» и «закрыть семафор».
Пусть все процессоры заняты работой и имеются также гото-
вые к выполнению щЯщессы в очереди процессов, ожидающих
освобождения процессора. Тогда, как только некоторый активный
процесс переходит по той или иной причине в пассивный или
заканчивается, соответствующий процессор освобождается от ра-
боты,'обращается к очереди готовых процессов и начинает выпол-
нять первый из них. Процессы могут перераспределяться в очере-
ди в зависимости от приоритетов. Диспетчеризация' работы МВК
осуществляется при помощи операционной системы.
4 Сверхоперативная память распределена по центральным про-
цессорам и разбита по функциональным признакам в каждом
процессоре на виртуальные быстрые регистры для буферизации
вычисления выражений (верхушка стека), прямоадресуемую
память для буферизации локальных данных процесса (непрерыв-
ный линейный участок памяти стека), ассоциативную память
для буферизации глобальных данных процесса, ассоциативную
память для буферизации команд и ассоциативную память для
буферизации массивов. Буфер команд убыстряет их выборку,
в особенности если команды часто повторяются (циклы), а буфер
массивов обеспечивает опережающую подкачку данных.
Наличйе многих процессоров и возможность наращивания их
количества (наряду с другими достоинствами модульной струк-
208
туры) обеспечивает высокую производительность системы. Узким:
местом здесь является общая оперативная память, эффективность
использования которой во многом определяется аппаратно и про-
граммно реализуемыми способами ее распределения.
В МВК Эльбрус принята' аппаратная реализация рекурсии,
что позволяет иметь в оперативной памяти один экземпляр про-
грамм и, следовательно, обеспечивает экономию памяти.
При трансляции программ однородная информация каждого
типа объединяется, а получаемые сегменты описываются каждый:
своим дескриптором с дискретностью до слова. Объем выделяемой
физической памяти определяется только требованиями дескрип-
торов. Математическая память разбивается на страницы длиной
в 512 слов, и, при «заполнении», содержит обычно неполностью
занятые страницы (сегмент, длина которого не является кратной
числу 512, одну из страниц занимает неполностью). Математиче-
ская память используется только один раз, что позволяет беа
конфликтов отсылать данные на внешнюю память, восстанавли-
вать их и осуществлять перераспределение. Сегментное распреде-
ление физической памяти без жестких границ ориентировано на
обмен с устройствами системы более высокого уровня иерархии,
а страничное распределение математической памяти — на обмен
с устройствами более низкого уровня иерархии.
Организация вычислений на базе стека позволяет вызывать
данные практически в самый последний момент и освобождать
память в любой момент после завершения соответствующих вы-
числений/
Перечисленные меры повышают эффективность использования
оперативной памяти, но усложняют операционную систему и до-
ступ процессора к дапным, что, в свою очередь, существенно ком-
пенсируется введением сверхоперативной памяти.
Основные функции обмена в МВК Эльбрус, включая органи-
зацию обмена как между оперативной памятью и периферийными
устройствами, тдк и между парами периферийных устройств,
выполняет процессор ввода-вывода. Он имеет буферную память,
необходимые арифметические и логические схемы и работает на
фоне работы центрального процессора, по заданию последнего
в виде заявки на обращение к внешнему устройству, «составляе-
мой» операционной системой. Список таких заявок хранится в
оперативной памяти. Выполняя очередную заявку, процессор
осуществляет запуск соответствующего внешнего устройства на
выполнение обмена, реализует передачу данных, завершает обмен
и корректирует список заявок на обмен. Если существует несколь-
ко путей обмена информацией (внешнее устройство может рабо-
тать через любой из четырех процессоров и через любьде соответ-
ствующие устройства управления внешними устройствами), то
осуществляется выбор пути обмена по мере освобождения соот-
ветствующего оборудования. Все функции управления внеш-
ним оборудованием, включая диспетчеризацию, резервирование и
14 Б. А. Головкин 209
выбор исправного канала, реализуются аппаратно. Это позво-
ляет экономить оперативную память и существенно разгружать^
центральные процессоры от прерываний внешними устрой-
ствами.
В процессорах приема-передачи данных, в отличие от про-?
цеёсоров ввода-вывода, принят программный способ взаимодейст—
вия с объектами, поскольку число таких объектов велико, а ти-л
лы — разнообразные. При этом йрограммное обеспечение первых^
процессоров организуется по модульному принципу так, что-'
бы для подключения нового объекта требовалось бы толь-,
ко добавить по существу новый программный модуль с описанием ;
этого объекта. , ;
В основу программного обеспечения МВК заложен принцип^
достижения высокой эффективности счета при помощи гибкости;
и адаптируемости вычислительной системы. Реализация этого]
принципа предусматривает интегральную разработку технических^
и программных средств системы [24]. При этом тщательно выби-^
рается сравнительно малый набор основных возможностей про-?
граммного обеспечения и разрабатываются максимально эффек-^
тивные средства комплексирования, чтобы программист мог *
эффективно конструировать те или иные программы. В этом слу-;
чае вычислительная система с ее программным обеспечением как
бы адаптируется к решаемым задачам, что характерно для МВК *
Эльбрус, а не наоборот, когда в целях реализации алгоритма в.З
жестких рамках негибкой вычислительной системы приходится <
модифицировать алгоритм.
МВК Эльбрус хорошо приспособлен для применения указан- ;
ного принципа, поскольку имеет машинный язык высокого уров-J
ня, является гибким, реализует многочисленные динамические ;
механизмы и обладает высокой степенью виртуальности. Так, ,
например, механизмы динамического распределения ресурсов 1
реализованы в аппаратуре и в операционной системе, т. е. на j
внутренних уровнях системы, а распределение процессоров осу- ?
ществляется в динамике автоматически.
Следствием такого положения является упрощение програм-
мирования, экономия ресурсов системы и повышение эффектив-^
ноет и решения задач, исключение специфики управления зада-^
ниями, упрощение запусков и перезапусков системы и упрощенне е
работы оператора системы.
Программное обеспечение МВК Эльбрус, как и его оборудова- '
ние, строится по модульному принципу, при этом обеспечивается
структуризация как собственно программ, так и данных. Кроме 1
этого, при создании программного обеспечения были приняты 1
меры, чтобы сблизить системное программирование и программи- *
рование со стороны пользователей. В обоих случаях программи-1
рование ведется на языке высокого уровня, почти все механизмы ’
для пользователей реализованы в программном обеспечении. Это '
позволяет как можно раньше обеспечить пользователей хорошо *
41
210 <
г
отработанными неэффективными механизмами программирования,
улучшить технологию как системного, так и пользовательского
программирования и, например, позволяет сократить объем про-
граммного обеспечения [24].
Первой моделью семейства Эльбрус является МВК Эльбрус-L
Этот МВК характеризуется следующими основными дайны-
~ МИ [278].
Эльбрус-1 имеет производительность от 1,5 до 12 млн. опера-,
ций в секунду и емкость оперативной памяти от 576 до
4608 К байт в зависимости от комплектации. В его состав может
входить от 1 до 10 модулей центральных процессоров, от 4 до 32
модулей оперативной памяти, от 1 до 4 модулей процессоров вво-
да-вывода, от 1 до 16 модулей процессоров приема-передачи дан-
ных (по 4 на каждый процессор ввода-вывода), модули внешней
памяти на магнитных барабанах, дисках и лентах, разнообразные
устройства ввода-вывода>
Центральный процессор оперирует с числами, имеющими фор-
мат в 32, 64 и 128 разрядов, и с алфавитно-цифровой информа-
цией. Он обеспечивает практически неограниченную виртуаль-
ную память (232 слов). Сложение с фиксированной и с плавающей
запятой выполняется за 520 и 780 нсек соответственно, умноже-
ние 32-разрядных и 64-разрядных чисел — за 780 и 1300 нсек
соответственно, а логические операции и операции с полями —
за 520 нсек. Максимальная производительность центрального
процессора равна 1,5 млн. операций в секунду. Логическая часть
процессора выполнена на интегральных схемах.
МВК Эльбрус-1' может выполнять программы пользователей
БЭСМ-6 применительно к системе Диспак. Для этого взамен
одного из центральных процессоров нужно подключить специаль-
но разработанный процессор, реализующий систему команд
БЭСМ-6. Этот спецпроцессор имеет производительность 3 млн.
операций в секунду и выполняет сложение за 240 нсек, умноже-
ние — за 400 нсек и логические операции — за 80 нсек.
Оперативная память выполнена на сердечниках и подключа-
ется к центральным процессорам и процессорам ввода-вывода
через коммутатор оперативной памяти. Каждый коммутатор свя-
зывает 4 модуля оперативной памяти, работающие с перекрытием
Пиклов обращения, с не более чем 14 центральными процессора-
ми и процессорами ввода-вывода (10 первых и 4 вторых процес-
соров). Четыре модуля памяти имеют общую емкость 64 К** 72-
разрядных слов. Модули состоят из блоков памяти, каждый из
которых имеет емкость 4 К 36-разрядпых слов, время цикла —
1,2 мксек и время доступа — 0,5 мксек.
В процессорах ввода-вывода аппаратно реализованы основные
алгоритмы диспетчеризации ввода-вывода операционной системы
и управления работой периферийного оборудования. Каждый
такой процессор получает внешние прерывания, получает пре-
рывания от 10 центральных процессоров и сам может прерывать.
14* 211.
работу этих процессоров. Он связан с оперативной памятью поя
8 направлениям, с внешней памятью, с устройствами ввода-выво-я
да и с процессорами приема-передачи данных. 1
В состав процессора ввода-вывода входят: 1) блок быстрых]
каналов, обеспечивающий подключение к нему через 4 канала]
блока до 64 накопителей на магнитных барабанах и сменных ]
магнитных дисках и одновременную работу четырех из них; ]
2) блок стандартных каналов, обеспечивающий подключение к]
нему 16 каналов блока до 256 устройств памяти на магнитной]
ленте и устройств ввода-вывода и одновременную работу шест-1
надцати из них; 3) блок сопряжения и оптимизатор, обеспечи-1
вающий подключение к нему через один канал блока до 4 одно-1
временно работающих процессоров приема-передачи данных и]
через оптимизатор блока до 16 устройств памяти на магнитных ]
барабанах с сокращением среднего времени доступа к ним в 4—6 .1
раз. Количество блоков быстрых каналов и стандартных каналов. 1
в процессоре ввода-вывода определяется комплектацией, при этом |
каждый процессор имеет по одному блоку сопряжения и оптими- 1
затору. z |
Максимальная скорость обмена одного процессора ввода-выво- 1
да с оперативной памятью составляет до 36 млн. байт в секунду,. J
а скорости обмена через быстрый канал, стандартный канал и I
канал для процессора приема-передачи данных составляют до 1
4; 1,3 и 1 млн. байт в секунду соответственно. |
В качестве внешней памяти и устройств ввода-вывода исполь- 1
зуются, в основном, соответствующие стандартные'устройства ЕС. |
Процессор приема-передачи данных с собственной оператив- 1
ной памятью, развитой системой команд, ориентированных на 1
работу с удаленными абонентами и гибкой операционной систе- I
мой характеризуется производительностью в 700 тысяч операций ]
в секунду и может обслуживать при помощи групповых ]
устройств сопряжения до 160 телефонных или телеграфных линий ]
связи. Групповое устройство сопряжения может обслуживать до 1
16 телефонных или телеграфных линий связи и обеспечивает про- |
граммную адаптацию к разного типа системам передачи данных |
и динамический контроль линий. Подсистема телеобработки в це- 1
лом рассчитана на 2560 каналов.
Рекомедуются четыре типовых комплектации МВК Эльбрус-1,
которые содержат 1, 2, 4 и 10 центральных процессоров, опера- |
тивную память емкостью 576, 1152, 2304 и 4608 К байт и дру- 1
гое оборудование соответственно и характеризуются производи- 1
тельностью 1,5; 3,0; 5,5 и 12,0 млн. операций в секунду. I
В состав программного обеспечения МВК Эльбрус-1 входят |
система программирования, единая операционная
ма стандартных и сервисных программ, система телеобработки,
тестовые и диагностические программы.
Система программирования предоставляет
система, систе-
_______ х х я пользователям 1
языки высокого уровня алгол 60, фортран, кобол,- РЬ/4,<>аи1ЮЛя68| |
212 5
спмула 67, паскаль, автокод Эльбрус и обеспечивает отлад-
ку программ на уровне исходного языка, диагностику програм-
пых ошибок при компиляции и исполнении, комплексирова-
ние и сегментацию программ, повторную входимость в про-
граммы, разнообразные возможности защиты, редактирования
и другие.
Операционная система обеспечивает мультипрогралшные ре-
жимы ближней и дальней пакетной обработки, режинг разделе-
ния времени и терминальную обработку. Она управляет работой
процессоров и осуществляет их синхронизацию, а также реали-
зует динамическое распределение всех ресурсов системы, вирту-'
альную память и распределение физической памяти на сегмен-
ты без жестких границ с точностью до слова. Операционная
система обеспечивает также автоматическую реконфигурацию
МВК, восстановление файлов и перезапуск задач и системы в
целях ее функциональной надежности и ряд других возможно-
стей. Следует отметить малый объем резидентной части опера-
ционной системы на языке машины [278]. Несмотря на широ-
кий набор функций операционной системы, ее объем относи-
тельно невелик: общий объем операционной системы и трансля-
тора с автокода составляет 250 тысяч строк [25].
К началу 1978 года была изготовлена опытная партия МВК
Эльбрус-1. Дальнейшее развитие принципов построения Эль-
брус-! позволило разработать и перейти к внедрению в произ-
водство следующей модели — МВК Эльбрус-2 производительно-
стью более 100 млн. операций в секунду, начато проектирование
вычислительных сицтем еще более высокой производительности.
В МВК Эльбрус-2 применяются большие интегральные схемы,
его модули функционально идентичны модулям Эльбрус-1. Про-
граммное обеспечение МВК Эльбрус-1 пригодно для использо-
вания на МВК Эльбрус-2 без изменений [61].
Системы семейства Эльбрус классифицируются как
МКМДС/ВсОрПк — системы с множественными потоками команд
и данных и с пословной обработкой, имеющие однородную
структуру с высокой степенью связанности и (с некоторыми
особенностями) перекрестными связями в центральной части.
В заключение отметим, что развиваемые направления созда-
ния систем семейств СМ, ЕС и Эльбрус охватывают, со взаим-
ным перекрытием границ, практически весь спектр диапазонов
малых — средних, средних — высоких и высоких — сверхвысоких
значений производительности соответственно.
4.2.3. Библиографическая справка. Концепция построения,
структура, основные характеристики систем Эльбрус, а также
перспективы развития подобного рода систем описаны в [22, 56—
61, 278, 304, 347, 348, 563]. Краткое описание систем Эльбрус со-
держится в [218], а очень краткое описание — также в 1447].
Принципы построения, реализация, и основные характеристики
программного обеспечения рассматриваемых систем изложены в
213
[23—25, 29, 144, 145, 181, 199, 200, 320-324, 375, 376, 3941
421—423]. Некоторые основные данные об МВК Эльбрус и соот|
ветствующие литературные источники перечислены в [НО]. j
4.3. Системы фирмы Burroughs j
4.3.1. . Концепция построения систем фирмы Burroughs!
В 1961 г. фирма Burroughs начала свою линию создания болЦ
ших вычислительных систем, структура которых радикальна
отличается от структуры обычных ЭВМ. Первой была выпущена
~в 1963 г. система, названная В 5000. Последующая модифика!
дня этой системы, созданная в 1964 г. и выпускавшаяся в тече|
ние длительного периода времени, получила название В 5500|
Вариант этой системы для военных применений, известный пой
названием D 825, рассмотрен в п. 4.1.3. Логическим преемников
системы В 5500 стала система В 5700. В 1969 г была создан!
система В 6500, вобравшая в себя новые идеи и наиболее эф-!
фективные решения и механизмы предыдущих систем. В далН
нейшем, в результате некоторого усовершенствования В 650СЙ
была выпущена в 1971 г. система В 6700 и, наконец, ее боле*!
быстрый вариант — система В 7700 (1973 г.) [597, 1043]. 1
В указанных системах был реализован ряд новых структур*
ных решений, многие из которых стали применяться в дал1Я
нейшем (см. также п. 2.6, рис. 2.32). Уже в системе В 5000 бй5
ла введена виртуальная память, а часть функций, выполняв^
шихся ранее программно, была реализована аппаратно. Систем!
команд машины основана на польской записи и является бёз|
адресной. В зависимости от комплектации, система могла содер*
жать один или два центральных процессора и до восьми моду-^
лей оперативной памяти. Для реализации супервизорных функ^
ций была разработана операционная система — Главная Управ^
ляющая Программа MCR, (Master Control Program). Пользовате^
ли программировали только на эффективно реализованных язья
ках высокого уровня (алгол 60, кобол) Л281]. 1
Рассмотрим некоторые принципы проектирования вычисли
тельных систем В 5500/6500/6700/7700*), следуя работе [59711
Основной принцип проектирования состоит в том, что сист^
му как единое целое должен проектировать в конечном сче1!
один человек. При этом должен использоваться подход сверху
вниз, а обсуждение и реализация деталей должны быть обесп^
чены в группе разработчиков вплоть до последнего возможного
момента времени. |
Следующий принцип состоит в том, что разработчики про!
граммного обеспечения и разработчики аппаратуры должны рам
♦) Кроме серии указанных систем, фирмой выпущены и другие cj
стемы.
214
f ботать в тесном взаимодействии, т. е. как оборудование, так и
F программное обеспечение должна проектировать одна и та же
I труппа специалистов. Этот принцип интегрального проектирова-
ния является логическим следствием предыдущего основного
принципа. Так, например, процессор В 6700 был первоначально
представлен в виде множества блок-схем, описывающих необхо-
димые действия. Затем эти блок-схемы были переведены на
язык алгол 60 и записаны в виде программы на этом языке.
Далее, блок-схемы были согласованы в группе между разработ-
чиками оборудования и программистами и использовались пер-
выми при проектировании оборудования. Поэтому с точки зре-
ния программистов, оборудование процессора является аппарат-
ной моделью упомянутой выше программы на алголе 60.
Ясно, что такой подход, когда параллельно разрабатывается
оборудование и программное обеспечение и когда на ранних ста-
диях обеспечивается проверка и контроль логики построения
оборудования, был бы невозможным, если бы разработчики обо-
рудования не знали создаваемого программного обеспечения и,
наоборот, программисты не знали создаваемого оборудования.
Согласно третьему принципу разработка всех без исключения
программ — операционной системы, компиляторов, программного
обеспечения тех или иных задач, а также пользовательских
программ — осуществляется на языке высокого уровня с после-
дующей компиляцией. Такой подход является вполне естествен-
ным, поскольку структура оборудования при использовании рас-
сматриваемых принципов отражает необходимые черты языка
высокого уровня. Так, например, системы В 5700 и В, 6700 ори-
ентированы на алгол 60, а В 2500, В 3500 и В 4500 — на кобол.
Далее, важное значение имеет концепция виртуальной ма-
шины. В .качестве виртуальных могут рассматриваться, напри-
мер, системы В 5500, В 6700, В 2500, В 3500, В 4500. Концеп-
ция виртуальности изменяется с развитием систем и, с совре-
менной точки зрения, виртуальными можно назвать системы
В 700 и В 1700. Так, например, систему В 1700 [1260] можно
представить как набор отдельных различных виртуальных ма-
шин, таких как Фортран- и Алгол-машины. Отметим, что В 700
и В 1700, используемые как приставки к более мощным маши-
х нам, имеют сменяемые микропрограммируемые команды, что
позволяет изменять, оптимизировать и настраивать их ко-
дировку.
Для данных и программ в системах фирмы .Burroughs преду-
сматриваются естественные границы при размещении, определя-
емые потребностями самих данных и программ, а не структур-
ной вычислительной системы. Так, например, данные и програм-
мы распределяются в большей степени по сегментам, чем по
страницам. Сегменты имеют изменяемую длину, причем размер
каждого сегмента зависит от содержащейся в нем информации
(данные или программная процедура). Кроме этого, кодировка
215
должна быть возможно более компактной. Команда системе
В 5500 и В 6500 содержит один или несколько необходимым
слогов (или байт) в отличие от обычного командного слова.
Важным является принцип, согласно которому система подЯ
разделяется на несколько подсистем, каждая из которых выполЛ
няет свои функции и, по возможности, требует как можно меньЖ
1пе ресурсов. Полезным является принцип виртуальности памятиЯ
Так же важным является принцип, согласно которому инфорЯ
мационные элементы должны содержать признаки типа своей инЯ
формации (могут быть программами и данными). В системе
В 6700 каждое слово содержит тэг, указывающий тип информаЯ
ции в слове. Например, слово, содержащее команды программьЯ
(числовую информацию), помечается при помощи тэга как «преЯ
грамма» («число»). Этот принцип имеет множество важных приЯ
менений. у Я
Наконец, должен соблюдаться принцип экономии памяти п
времени вычислений. Хотя доказательства здесь затруднепыЯ
ясно, что польская инверсная запись и, как следствие, механизм!
аппаратного стека, используемые в В 5500, не только ускоряют!
работу трансляторов, но и существенно уменьшают длину полу-1
чаемой программы. Команды в этом случае становятся без-i
адресными, что позволяет сократить их длину, а число операций]
выборки из памяти уменьшается, что позволяет сократить вре-^
мя выполнения программ. 1
'Перейдем к особенностям структуры систем В 5500/6500/ 2
/6700/7700.
В системе В 5500, являющейся преемником В 5000, реализа-^
ция вычислений основана на концепции стека. Применение S
польской инверсной записи аппаратно поддерживается стековой!
архитектурой. Команды (операторы) состоят из 12-разрядных1
слогов. I
Виртуальная память организуется при помощи дескрипторов.!
Дескриптор описывает данные или программу. Он содержит в 1
себе адрес и длину соответствующего сегмента в памяти. Сег-1
мент может находиться либо в основной (оперативной) ^феррито-1
вой памяти, либо во вторичной дисковой памяти с фиксирован-j
ными головками. Один из разрядов дескриптора показывает J
тип памяти (основная или вторичная), в которой размещен сег-^
мент. В принципе, доступ к любой информации (данные и про-
грамма) осуществляется через дескрипторы. Таким образом,^
команды доступа к памяти обращаются только к дескрипторам, J
а не к абсолютным адресам. j
Информация в системе В 5500 снабжается тэгами в соотвцт-1
ствии с типом информации. Однако, тэги не полностью изолиро-^
ваны от информационного содержания, что вызывает некоторые ‘
трудности,
Система В 5500 была разработана небольшой единой группой •’
специалистов по аппаратуре и по программному обеспечению.
216
Операционная система была написана на языке espol, представ-
ляющем собой расширение алгола 60. Все трансляторы, включая
и транслятор с алгола, были написаны на расширенном для
В 5500 алголе 60, который, являясь входным языком этой маши-
ны, включает в себя с некоторыми оговорками алгол 60 в качестве
подмножества.
Система В 6500 является логическим преемником В 5500 и сов-
местима с ней. Она может иметь 1 или 2 центральных про-
цессора. Команды в В 6500 имеют переменный формат размером
от 8 до 96 разрядов с шагом в 8 разрядов, причем наиболее
часто используемые команды имеют формат размером в • 8 раз-
рядов. Дескрипторный механизм^является существенно более об-
щим: дескриптор может рассматриваться как «программа» для
оперирования с сегментами. Слово в системе В 6500 содержит
51 разряд, из числа которых первые три разряда отведены для
тэга (полностью отделенного от информации, которую он харак-
теризует). По сравнению с системой В 5500, в системе В 6500
расширен состав оборудования для распределенной обработки,
а именно: 1) система имеет один иди несколько мультиплексо-
ров, обеспечивающих в большей степени независимую работу
устройств ввода-вывода; 2) имеется возможность подключения
одного или нескольких процессоров передачи данных.
В В 6500 была реализована более общая концепция стека
по сравнению с В 5500, а именА, была реализована концепция
дерева стеков и дерева процессов. Стек как бы представля-
ет процесс, а дерево стеков показывает зависимости между стека-
ми и, следовательно, между процессами. Это обеспечило реализа-
цию рекурсивных процедур и параллельных процессов.
Языки и операционная система в В 6500 расширены в части
механизмов управления процессами и операций синхронизации
процессов.
Отметим, что производительность процессора системы В 6500
в 5 раз выше, чем у системы В 5500, время обращения к опера-
тивной памяти в 7 раз короче (600 нсек), емкость оперативной
памяти на тонких пленках в три раза больше (от 16384 до
106496 48-разрядных слов); кроме того, система имеет и удвоен-
ные возможности ввода-вывода (8 быстрых каналов ввода-вывода,
управляемые мультиплексором). Время сложения равно 400 нсек,
а время умножения и деления с плавающей запятой равно 6,4 и
11,2 мксек соответственно.
Систему В 6500 заменила система В 6700, в которую был
введен ряд усовершенствований и улучшений. Система В 7700
представляет собой версию В 6700 с более высокой производи-
тельностью.
4.3.2. Структура систем фирмы Burroughs. Многопроцессорные
системы фирмы Burroughs построены по модульному принципу
и классифицируются как 'МКМДС/ВсОрПк — вычислительные
системы с множественными потоками команд и данных, с по-
21Т
словной обработкой в центральных процессорах, с высокой сте-
пенью связанности и с однородной структурой, с перекрестным®
связями между модулями процессоров и модулями памяти. Ком-
мутатор в системах — централизованный, в отличие от системь
D 825, имеющей распределенный коммутатор.
Рассмотрим структуру системы В 6700. как типичного пред-
ставителя систем фирмы Burroughs [281, 606] (рис. 4.17). В со
став системы могут входить от 1 до 3 центральных процессоре!
Рис. 417. Структурная схема системы В 6700.
с производительностью до 1 млн. операций в секунду каждый,
от 1 до 64 модулей оперативной памяти и от 1 до 3 процессоров
ввода-вывода. Эти устройства связаны между собой при помощи
перекрестного коммутатора. Оперативная память — шестивходо-
вая, цикл обращения к модулю памяти равен 1,5 мксек;
1,2 мксек или 500 нсек. Возможны любые комбинации модулей
оперативной памяти емкостью 16 К или 64 К слов, при этом
суммарная емкость не должна быть более 1048 576 слов (от
98304 До 6 291456 байт).
Максимальная скорость обмена с оперативной памятью через
один вход составляет 6750 К байт в секунду. Эта же величина
218
является максимальной скоростью обмена с процессором ввода-
вывода. Каждый из процессоров ввода-вывода подключается к
периферийному, оборудованию через несколько (4—12) своих
«плавающих» каналов коммутации данных. Три процессора вво-
да-вывода могут одновременно выполнять максимум 36 операций
ввода-вывода. К каждому каналу подключается до 20 контролле-
ров ввода-вывода, а к каждому контроллеру — до 10 периферий-
ных устройств. Максимальное количество адресуемых перифе-
рийных устройств равно 128. В состав периферийных устройств
входят память на магнитных лентах и дисках, графопостроитель,
алфавитно-цифровое печатающее устройство, перфокартные и
другие устройства.
Каждый процессор ввода-вывода связан с 1—4 процессорами
передачи данных, каждый из которых связан с 1 — 16 группами
адаптеров, а каждая группа адаптеров, в свою очередь, с 1—16
линиями связи.
Массовая промежуточная память реализована в виде дисков
с головкой на каждую дорожку и в виде пакетов дисков.
Основные отличия структуры системы В 7700 от В 6700 со-
стоят в том [606], что'число центральных процессоров может
быть от 1 до 7, при этом производительность каждого из них
равна 4—5 млн. операций в секунду, число процессоров ввода-
вывода может быть от 1 до 7, при этом общее количество
центральных процессоров и процессоров ввода-вывода не должно
быть более 8, оперативная память имеет не более 8 модулей,
при этом память — восьмивходовая, число каналов ввода-вывода
на один процессор ввода-вывода составляет 32, при этом 20 из
лих используются для стандартного сопряжения с периферий-
ным оборудованием, а остальные 12 каналов подключаются ины-
ми способами, максимальное количество адресуемых внешних
устройств составляет 255.
Рассмотрим структуру системы В 7700 [10681 (рис. 4.18).
На рисунке вынесены по одному модулю оперативной памяти,
центрального процессора и процессора ввода-вывода. Вследствие
того, что входы в коммутатор для модулей центральных процес-
соров и процессоров ввода-вывода обезличены, подключение вы-
несенных модулей центрального цроцессора и процессора ввода-
вывода показано через ИЛИ.
Каждый модуль оперативной памяти имеет четыре блока
емкостью по 384 К байт и блок управления. Суммарная емкость
памяти модуля составляет 1536 К байт. Максимальная емкость
оперативной памяти в составе 8 блоков составляет 12 288 К
байт, при этом каждый из процессоров имеет непосредственную
адресацию только к памяти емкостью 6144 К байт. Адресация
осуществляется к словам. Слово имеет 52 разряда, из числа ко-
торых 48 — информационные, 3 — управляющие, 1 — для контро-
ля по четности. Все эти разряды слова доступны центральным
процессорам, процессорам ввода-вывода и процессорам связи
219
Рис. 4.18. Структурная схема системы В 7700.
DCP (Data Communication Processors). Блок управления модулем
оперативной памяти образует дополнительно 7 проверочных раз-
рядов и 1 разряд для контроля по четности, т. е. слово в этом
случае имеет 60 разрядов. Дополнительные 8 разрядов исполь-
зуются для исправления ошибки в любом одном разряде и для
обнаружения ошибок в двух любых разрядах (для обнаружения
некоторых множественных ошибок в разрядах), вызванных не-
верной работой модуля оперативной памяти.
Номера процессоров, с которыми связываются модули опе-
ративной памяти, устанавливаются Главной Управляющей Про-
граммой в одном из регистров блока управления модулем па-
мяти. Это позволяет однозначно распределять между процессо-
рами всю или часть оперативной памяти и, при необходимости,
логически исключать некоторые модули памяти из рабочей кон-
фигурации. Кроме этого, имеется возможность использования
части исправных ячеек неисправного модуля памяти при помощи
регистров верхней и нижней границ* доступных адресов. Нако-
нец, еще один регистр в блоке управления модулем памяти ис-
пользуется для хранения информации о рабочей конфигурации
оперативной памяти. В целях ускорения выборки информации
используется чередование адресов по блокам модуля памяти,
осуществляемое блоком управления модуля.
Центральный процессор содержит 3 независимых блока, асин-
хронно выполняющих: а) интерпретацию цепочки команд про-
грамммы (выполняет блок управления программой); б) всю
арифметическую и логическую обработку данных (выполняет
арифметический блок); в) функции обращения к общей опера-
тивной памяти и к местной памяти (выполняет блок доступа к
памяти). Иными словами, в центральном процессоре реализуется
магистральный принцип обработки. Каждая из трех указанных
функций выполняется независимо от других, а необходимые свя-
зи реализуются при помощи аппарата очередей.
Местная память центрального процессора построена на инте-
гральных схемах и содержит три устройства: буфер программы,
буфер данных и бу$ер стеков. Буфер программы позволяет ис-
пользовать чередование адресов при считывании команд из опе-
ративной памяти, хранить циклические участки программы,
исключить (существенно уменьшить) время ожидания на обмел
командами с оперативной памятью. Емкость буфера составляет
192 байта, информация в буфере обновляется группами по 48
байт. Как только в буфере остаются необработанными 16 бай-
тов кодов команд, в блок управления соответствующего модуля
оперативной памяти посылается запрос на выборку очередной
группы кодов команд.
Каждый процесс имеет область в виде стека процесса, кото-
рый расположен в оперативной памяти и содержит историю ре-
шения задачи, переменные, дескрипторы программ и данных.
Та часть информации стека, которая используется наиболее
221
часто, хранится в буфере стеков центрального процессора. Эт<
буфер имеет емкость в 192 байта. Для хранения обращений
дескрипторам и переменным, которые не попали в буфер стеков*
используется буфер данных, который выполнен в виде ассоциа-
тивной памяти емкостью 6 К байт. В этом буфере каждые 4 со-
седних слова объединены в группу.
Для обнаружения ошибок в центральном процессоре исполь-
зуются: при хранении данных в памяти и при их передаче
проверка на четность, при выполнении всех арифметических
операций над числами и адресами — контроль по модулю, ai
также контроль на непрерывность, использующий синхро
сигналы. -
Три управляющих разряда каждого слова составляют тэг.
позволяющий-различать операнды, управляющие слова, дескрип-
торы данных и коды и признак, разрешающий только считыва
ние. Исключением здесь являются коды команд операционной
системы.
Процессор ввода-вывода состоит из нескольких параллельна
работающих устройств и выполняет все операции обмена между
периферийным оборудованием и центральной частью системы и
может обслуживать до 255 периферийных устройств и 4-х про-
цессоров связи DCP. Он связан с центральным процессором че-
рез область оперативной памяти, в которой указывается кон-
фигурация подсистемы ввода-вывода, операции ввода-вывода и
пути передачи команд от центрального процессора к периферий-*
ному. Запросы на ввод-вывод образуют очередь и хранятся ik
памяти в виде блоков информации. 2
В целях профилактики всех модулей системы и лока-
лизации неисправностей используется блок диагностического*
обслуживания.
Для взаимодействия с удаленными объектами используется
подсистема связи с процессорами связи DCP (процессорами ne-i
редачи данных). Каждый такой процессор может обслуживать^
до 256 линий связи, оборудованный разнообразными устройств
вами. Он имеет локальную память емкостью до 96 К байт и сог/
прягается с остальной частью системы через оперативную *;
память. '
Программное обеспечение системы В 7700 является разви-
тием программного обеспечения В 6700. Все системные программ
мы, кроме Главной. Управляющей Программы, и все прикладные,-
программы могут работать как на В 6700, так и на В 7700 без}
каких-либо изменений.
Программное обеспечение, в дополнение к аппаратуре, выпол-’
няет функции обеспеченйя надежности системы
В 7700 в части •
обнаружения, локализации и устранения ошибки, а также вы-
дачи Сообщений об ошибках. При наличии отказов осуществля- ’
ется динамически изменение рабочей конфигурации. Операцион- ;
мая система, по командам оператора или после обнаружения и ’
222
локализации отказа, исключает из рабочей конфигурации неис-
правные модули или программы с ошибками, не влияя на рабо-
тающие программы.
В последние годы фирма Burroughs продолжала совершенст-
вовать систему В 7700 [112]: в 1976 г. было объявлено о четы-
рех более мощных моделях: В 7755, В 7765, В 7775 и В 7785
системы В 7700. В этих моделях центральный процессор иден-
тичен прежнему (содержит буферную память емкостью 6144
байт), а оперативная память — новая: максимальная емкость,
как и ранее, равна 6 М байт, но выполнена память на новой
элементной базе и имеет новую конфигурацию в связи с введе-
нием модулей емкостью 786432 байта вместо 1,5 М байт; эффек-
тивное время выборки сокращено с 88 до 78 нсек. В новых мо-
делях используются также новые процессоры ввода-вывода, име-
ющие по 28 каналов с буфером емкостью 24 байта в каждом,
и новые процессоры связи. Подсистема связи обслуживает до
2048 линий при помощи 8 процессоров связи с памятью ем-
костью в 393 216 байт в каждом.
Модель В 7785 является самой большой из числа указанных
моделей; она содержит 4 центральных процессора и 2 процес-
сора ввода-вывода, оперативную память емкостью в 6 М байт,
6 перфокарточных и 7 печатающих устройств, 24 устройства
памяти на магнитных лентах и систему дисковой памяти ем-
костью в 5,6 млрд, байт [112].
Системы В 6700 и В 7700 могут быть отнесены к большим
п очень большим системам. Так, например, система В 7700 по
своим техническим характеристикам превосходит систему IBM
370/195. Еще более мощной является сверхбыстродействующая
система В 8500, созданная фирмой Burroughs в 1968 г. Эта си-
стема, однако, не вошла в ряд серийно выпускаемых, фирма
Burroughs прекратила работы по этой системе и переключилась
па разработку и выпуск других систем*). Тем не менее, струк-
тура системы В 8500 представляет значительный интерес.
Система В 8500 содержит по одному или более модулей цен-
тральных процессоров и процессоров ввода-вывода, общее коли-
чество которых не превышает 16 (при этом может быть не бо-
лее 14 процессоров как первого,'так и второго типа), от 1 до
16 модулей оперативной памяти и большое число разнообразных
периферийных устройств. Единая модульная структура обору-
дования и программного обеспечения системы В 8500 обеспе-
чивает ее гибкость, практически исключает время простоя и
позволяет вести мультипрограммную и параллельную обработку
в различных режимах, включая диалоговый и разделение време-
*) По данным [283] был установлен один экземпляр системы В 8500.
По данным журнала Datamation 1967, v 13, № 2 на начало 1967 г. были,
выпущены две системы В 8500.
223.
яй. Структурная схема системы приведена на рис. 4.1
1492, 953J.
Модуль центрального процессора^ производительностью в
3 млн. операций в секунду выполняет с высокой скоростью
«арифметико-логические операции, а также соответствующие
функции управления, передачи данных и прерывания. В целях
Модуль опера-
тивной памяти
Модуль опера-
тивной памяти
76
Модуль опера-
тивной помят
Модуль централь-
IН08“ ПР°Цесс°Ра
г
16
К периферийнымустройствам
и к каналам связи
т
Модуль централы
ного процессора
2
4
16
Модульпроцес- 99
' сори ввода-вывода
Модуль процес-
сора ввода-вывода
255
Общая скорость обмена 320 млн.
бит в секунду
Рис. 4.19. Структурная схема системы
В 8500.
повышения скорости обработки используется
данных и команд. В состав процессора входят стек, четыре внут-
ренних сверхоперативных запоминающих устройства, в том чис-
ле устройства емкостью в 32 52-разрядных слова и в 24 70-раз-
рядных слова с бременем цикла в 50 нсек и ассоциативная па-
просмотр вперед
Спорость обмена до 36
млн бит в секунду дли
каждого процессора ,
ввода-вывода
мять емкостью в 28 18-разрядных слов.
Модули оперативной памяти на тонких пленках с произволь-
ной выборкой содержат по 16 384 52-разрядных слова каждый
(информационные разряды данных занимают по 48 разрядов).
Слова хранятся и выбираются группами по 4 слова. Время
полного цикла памяти равно 500 нсек.
МЪдуль процессора ввода-вывода, обеспечивающий обмен со
скоростью до 30 млн. бит в секунду, полностью независим от
модулей центральных процессоров и имеет собственную внутрен- ;
нюю память, логику и арифметику, а также средства связи. On i
работает под управлением своЪй программы, которая кодируется
на специализированном компилируемом языке для ввода-вывода,
вводится с необходимыми данными с перфокарт для трансляции
(транслятор написан на алголе), выводится после трансляции на;
ленту и затем загружается в систему. Внутренняя память выпол*
£24
пеппая па тонких пленках, имёет емкость в 1024 10-разрядных
слова и время цикла в 500 нсек (цикл обслуживания —
1,7 мксек).
Каждый процессор ввода-вывода может обслуживать до 512
симплексных каналов к периферийным устройствам, выполняя
функции буферизации данных и управления такими устройств-
мп, как перфокартное оборудование, память на магнитных лентах
Таблица 4.1
Огновяые характеристики структуры систем В 2700, В 3700, В 4700, В 5700
fl/ll Оснрвные характеристики структур Модели
В 2700 1 R 3700 | В 4700 | " В 5700
1. Количество централь- ных процессоров 1 или 2 1 или 2 от 1 до 4 1 или 2
2. Количество каналов ввода-вывода- от 6 до 40 от 18 до 40 от 8 до 80 - 4
3. Максимальная' ско- рость обмена канала ввода-вывода 2 М байт в сек 3 М байт в сек 4 М байт в сек 330 К байт в сек
4. Количество контролле- ров ввода-вывода на один канал ввода-вы- вода 1 1 1 универсаль- ная схема подключе- ния
5. Количество периферий- ных устройств на один контроллер ввода-выво- да до 10 до 10 до 10 до 10
и дисках, телетайпное оборудование, дисплеи и др. В целях муль-
типлексирования каналов ввода-вывода к «модулям процес-
сора ввода-вывода могут подключаться, дополнительно, контрол-
леры ввода-вывода или модули передачи данных для линий свя-
зи (эти устройства не показаны на рис. 4.19).
. Программное обеспечение включает в свой состав исполни-
тельную и планирующую программу ESP (Executive and Schedu-
ling Program), которая рассчитана на полную конфигурацию
системы и, наряду с другими функциями, осуществляет динами-
ческое распределение модулей оборудования, таких как процес-
соры, память, каналы ввода-вывода, а также обслуживающие
программы, включая программы ввода-вывода, и компиляторы с
расширений языков алгол 60, фортран IV и кобол 61 [492, 9531.
Завершая рассмотрение структуры систем фирмы ’ Burroughs
с индексами 500 и 700, приведем таблицу основных характери-
стик структуры систем В 2700, В 3700, В 4700 и В 5700 (табли-
ца 4.1) [606]. Отметим, что в последней из указанных систем ис-
пользуется общий набор обезличенных устройств управления
(процессоров ввода-вывода) периферийным оборудованием, кото
рое подключается непосредственно через универсальную схему
15 в А. Головкин 226*
(см. рис. 2.29в). К этой же схеме можно подсоединить, дополни*
тельно, вспомогательную оперативную память.
В последние годы фирма Burroughs разработала и выпускает}
новые средние и большие системы с индексом 800, такие как :
В3800 (1976 г.), В4800 (1976 г.), В6800 (1977 г.), В7800
(1978 г.) [112, 113, 314]. Первыр две системы могут иметь 1 или j
2 Центральных процессора, а третья и четвертая системы — от J
1 до 4 центральных процессоров. Рассмотрим кратко системы
В 6800 и В 7800 1112, 113, 303, 432].
Системы В 6800 по производительности вдвое превосходят
находящиеся в эксплуатации системы такого же класса В 6700.
Производительность одного процессора В 6800 составляет 1 —
2 млн. операций в секунду. Системы В 6800 совместимы на
уровне машинных кодов с системами В, 6700 и В 7700, но не- <
совместимы с менее мощными системами В 2800, В 3800 и
В 4800 серии с индексом 800, вследствие чего программы по- |
следних нужно перекомпилировать для перехода к работе на 1
системе В 6800. |
Максимальная конфигурация системы В 6800 включает 1
4 центральных процессора, 4 процессора ввода-вывода и 16 про- 1
цессоров связи, обеспечивающих подключение 4096 линий связи. |
Используются в отличие от В 6700 два уровня непосредственно 1
адресуемой памяти — оперативная память каждого процессора 5
емкостью в 3 М байт и общая оперативная память емкостью ]
также в 3 М байт, т. е. наибольшая суммарная емкость опера-
тивной памяти равна 15 М байт. Цикл работы центрального ’
процессора —150 нсек, время выборки из оперативной памяти
с двухкратным чередованием адресов — 325 нсек при ширине
выборки в 8 байт. В центральном процессоре реализован опере- |
жающий просмотр, существенно совмещены операции вызова и 1
выполнения команд.
Процессоры ввода-вывода работают независимо от централь-
ного процессора и обеспечивают передачу данных с суммарной
скоростью в 2,2 М байт в секунду. К каждому процессору под-
ключается 20 каналов ввода-вывода, из которых 12 имеют бу-
ферную память емкостью в 512 байт, а 8 каналов — буферную
память емкостью в 256 байт. ।
Управление всеми техническими и аппаратными средствами 1
осуществляет операционная система, которая, используя налично 1
локальной оперативной памяти у каждого центрального процес- 1
сора и общей оперативной памяти, обеспечивает режим разделе-
пия ресурсов, когда каждый процессор обрабатывает собствен- ’
ный потоц задач, и, при необходимости, связывается с другими •
процессорами, а также многопроцессорный режим параллельной ’
обработки с динамическим распределением ресурсов центральных ;
процессоров. В программное обеспечение входит также система
управления данными DMS II, система управления сообщениями I
MCS (Message Control System) и язык описания сети NDL (Net- ,
22$
work Definition Language). Программирование ведется на языках
кобол, алгол, фортран, PL/1, basic, а также APL, благодаря кото-
рому достигается эффективный диалог с системой.
Важно отметить, что система В 6800 приспособлена для ра-
боты в составе вычислительных сетей. Это достигается благодаря
подсистеме передачи данных, которая имеет память емкостью
384 К байт, осуществляет контроль целостности сети и обеспе-
чивает ее сохранность при неготовности центрального процессо-
ра. Связной процессор DCP обслуживает при помощи устройства
управления и сопряжения с широкополосными каналами связи
многочисленные линии связи, рассчитанные на передачу дан-
ных со скоростями от 19,2 до 1300 К бит в секунду.
В системах В 6800 большое внимание уделено повышению
их надежности, готовности и ремонтопригодности: предусмот-
рен широкий набор средств автоматического контроля и диагно-
стики, включая обслуживающий процессор и дисплей, обеспечи-
вается повторное выполнение команд и повторные обращения к
памяти при появлении ошибок, осуществляется контроль состо-
яния центрального процессора при помощи встроенных в него
схем самоконтроля. Диагностические программы выполняются
в процессе работы системы под управлением операционной си-
стемы МСР.
Таким образом, создание систем В 6800 является новым ша-
гом в эволюции больших многопроцессорных систем фирмы
Burroughs.
В рамках системы В 6800 имеются модели В 6807, В 6811
л В 6821, соответствующие по производительности моделям IBM
370/138, 148 и-158.1 Первые две модели В 6807 и В 6811 имеют
но одному центральному процессору и процессору ввода-вывода
каждая, а третья модель В 6821 имеет два центральных процес-
сора и два процессора ввода-вывода. В дальнейшем производи-
тельность модели В 6807 была повышена на 60% за счет
уменьшения вдвое времени выборки из оперативной памяти
(5 машинных циклов вместо 10), были добавлены новые модели
В 6803 и В 6805 с первоначальной производительностью модели
В 6807 и объявлена новая модель В 6817 с оперативной па-
мятью емкостью в i М байт. Последние разработки рассматрива-
ются как ответ на выпуск фирмой IBM семейства ЗОЗХ.
Система В 7800 является наиболее мощной в серии 800. По
сравнению с В 7700 ее производительность в 2,5 раза выше, пре-
вышает производительность системы IBM 370/168 APS и сравни-
ма с производительностью систем 470 фирмы Amdahl. Система
В 7800 предназначена для работы в составе больших вычисли-
тельных сетей и управления большими базами данных. Она сов-
местима с системами В 6700, В 7700 и В 6800. Имеется возмож-
ность применения функциональных устройств системы В 7700
совместно с основными устройствами системы В 7800 для постро-
ения единой многопроцессорной конфигурации.
15*
227
Система В 7800 представлена моделью В 7811 с одним цент-»
ралыаым процессором и одним процессором ввода-вывода и мо-
делью В 7821 с двумя центральными процессорами и двумя про-
цессорами ввода-вывода. Модели могут иметь до 4 центральных
и до 4 периферийных процессоров, оперативную память емко-
стью до 6 М байт, разбитую на модули'емкостью по 768 К байт,
широкий набор периферийного оборудования.
Центральный процессор производительностью 8 млн. опера-
ций в секунду (цикл процессора — 125 нсек) представляет собой
модернизацию процессора В 7700 с улучшенными логическими
схемами и с усовершенствованиями в виде (расширенной в 64
раза) буферной памяти программ емкостью 12 К байт, что прак-
тически исключает задержки в работе процессора из-за ожида-
ния передачи команд из оперативной памяти. Реалнзованно вось-
микратное перекрытие обращений к памяти. Это уменьшает
(на 35%) время выборки одного байта до 50 нсек и обеспечивает
выполнение большого числа .команд за один цикл. Центральный
процессор содержит адресное устройство, устройство управления
командами, устройство обращения к памяти и исполнительное
устройство, которые, работая асинхронно и выполняя различные
функции одновременно, реализуют тем самым магистральный спо-
соб обработки в процессоре и обеспечивают получение одного ре-
зультата любой операции за каждый цикл процессора. Данные,
после выборки из оперативной памяти, загружаются в буфер дан-
ных емкостью 6 К байт. В целях временного хранения данных/ до
их передачи в оперативную память, используется специальная
буферная память в виде локальной памяти процессора емкостью
192 байта.
Процессор ввода-вывода обслуживает до 28 информационных
каналов. Подсистема передачи данных, как и в В 6800, рассчи-
тана на работу с широкополосными линиями связи со скоростя-
ми передачи данных от 19,2 до 1300 К бит в секупду. Процес-
сор связи DCP принимает запросы и сообщения, поступающие
пр каналам связи, накапливает их и передает в быстродействую-
щую память на магнитных дисках, из которых информация
поступает затем в основные функциональные устройства В 7800.
Устройство управления подсистемой связи обеспечивает высо-
кую скорость обмена блоками информации между устройствами
памяти связного и центрального процессоров независимо от ра-
боты первого. К системе В 7800 можно Подключить до 8 связ-
ных процессоров, обслуживающих до 2048 линий связи.
Программирование для системы В 7800 ведется на языках
алгол, фортран, кобол, PL/1 и basic.
4.3.3. Библиографическая справка. Принципы проектирования
сиётем фирмы Burroughs описаны- в [505, 597, 626, 628]. Кроме
этого, <во второй работе рассмотрены особенности структуры
систем фирмы Burroughs и приведены соответствующие приме-
ры реализации структурных решений в системах В 5500, В 6500,
228
в 6700, В 7700, В 2500, В 3500, В 4500 и других, а также рас-
смотрены вероятные направления развития структур подобных
систем. В третьей и четвертой работах акцент сделан на струк-
туру системы В 6500.
Принципы построения рассматриваемых систем, организация
их программ, построения программного обеспечения, а также
краткие технические характеристики таких систем, как
В 6500, В 7500, В 1700, В 2700, В 3700, В 4700, В 6700, В 7700,
В 8500 и других, приведены в книге [218]. Подробное описание
структуры систем В 5700 и В 6700. с обоснованием и пояснения-
ми структурных решений содержится в книге [1043]. Ряд систем
фирмы Burroughs рассмотрен в обзоре [880]. Упрощенные струк-
турные схемы систем В 2700, В 3700, В 4700, В 5700, В 6700 и
В 7700, а также основные характеристики структур этих систем
приведены в [606].
Описание системы В 5000 содержится в [9461. Система
В 6500 рассмотрена в 1395, 596, 1063]. Система В 6700 доста-
точно подробно описана в [281], сведения о ней содержатся
также в [395, 1118]. Стековый механизм В 6500/В 7500 представ-
лен в [8091. Описание системы В 8500 содержится в [492, 953,
970J, а системы В 770 —• в [ 1068]. Основные характеристики
новых систем фирмы Burroughs, в том числе систем В 6800 и
В 7800, приведены в 1112, 113, 303, 432].
Операционная система для В 5500 описана в [974], а эффек-
тивность размеров сегментов в В 5500 исследована в [518].
Операционная система МСР (Master Control Program) систе-
мы В 6500 описана в [1039], а также в [627]. Особенности
операционной системы для В 5500 и В 6700 изложены в [1040].
Ряд вопросов программирования для В 6700/В 7700, построения
программного обеспечения для этих систем, а также эффектив-
ности систем рассмотрен в [573, 623, 677, 722, 1042, 11491 .
Краткая библиографическая справка по системам фирмы Bur-
roughs приведена в [110].
4.4. Системы семейства UNIVAC 1100
4.4.1. Структура семейства UNIVAC 1100 [378, 553]. Семей-
ство UNIVAC 1100 или, сокращенно, семейство 1100 объединяет
совместимые большие вычислительные системы фирмы Uni vac.
Это семейство содержит, по данным на конец 1978 г., восемь ба-
зовых систем. Первой была выпущена система 1107 (1962 г.) с опе-
рационной системой EXEC I. Всего на 1977 г. выпущено, более
1200 процессоров разных систем семейства.
Структура семейства 1100 основана на применении 36-раз-
рядных слов и на выполнении операций с выборкой одного опе-
ранда из памяти, а второго — из’ быстрого регистра или же с вы-
боркой обоих операндов из быстрых регистров. В основу коСЩеп-
Ции семейства положен принцип создания широкого спектра
— 229
универсальных вычислительных систем, в которых оборудование
и программное обеспечение составляют* дополняющие друг друга
части единой интегральной системы.
В 1965 г. была выпущена большая система 1108, более позд-
ние модификации которой были многопроцессорными системами.
Одновременно с этими работами проводилась модернизация ра-
нее созданного и разработка нового программного обеспечения.
Соответствующая операционная спстехма сначала называлась
, ЕХЕСП, а затем —ЕХЕС8. В это время.была сформулирована
концепция, действующая и поныне, единой операционной систе-
мы, обслуживающей все наличные вычислительные системы се-
мейства вне зависимости.от комплектации систем и типов процес-
соров, запоминающих устройств и периферийного оборудования.
В конце шестидесятых годов в семейство была включена си-
стема меньшей мощности 1106, поставляемая в виде одно- или
двухпроцессорной конфигурации. В начале семидесятых годов в
семейство была включена система цовыщеппой мощности 1110,
поставляемая в виде ряда многопроцессорных конфигураций.
В 1972 г. операционная система получила наименование 1100
EXECUTIVE (ОС 1100).
В 1975—1977 гг. были начаты поставки систем 1100/20,
1100/10, 1100/40 и 1100/80, выпускаемых в различных одно- и
многопроцессорных конфигурациях. Эти системы охватывают
широкий диапазон производительности: производительность кон-
фигурации 1100/44 в 40 раз превышает производительность кон-
фигурации 1100/11. Все системы обслуживаются единой опера-»
ционной системой ОС 1100.
Одним из главных достоинств семейства 1100 является ори-
ентация на многопроцессорную обработку. Первыми многопро-
цессорными системами в семействе были двухпроцессорная и
трехпроцессорная конфигурации системы 1108, выпущенные в
1968 г. Они представляли собой универсальные симметричные
системы, идентичные процессоры которых равноправно без под-
чиненности разделяют одну и ту же общую память и каналы
ввода-вывода и пользуются одной копией операционной системы.
.Операционная система разрабатывалась таким образом, чтобы
обеспечить работу симметричной многопроцессорной системы в
режимах мультипрограммной обработки, параллельной обработ-
ки, разделения времени и работы в различных условиях внешнего
окружения, в том числе в реальном масштабе времени. Эти прин-
ципы были сохранены и развиты в последующих системах семей-
ства . 1100, обеспечив высокую эффективность, стабильность
оборудования и программного обеспечения и готовность вы-
числительных систем.
Наличие модульных многопроцессорных конфигураций и еди-
ной операционной системы позволяет расширять конфигурацию
в пределах семейства либо путем сохранения существующей ап-
паратуры и увеличения числа ее компонентов, либо путем заме-
230
пы некоторых из них компонентами с более высокими техниче-
скими характеристиками, при этом нет необходимости в измене-
нии программ. Аналогично решается проблема при переходе от
1962 63 6k 65 66 67 68 69 70 71 72 73 7k 75 76 77 76
Рис. 4.20. Эволюция семейства UNIVAC 1100.
Рис. 4.21. Генеалогия структур систем семейства UNIVAC 1100.
системы к системе семейства, поскольку они используют одина-
ковую операционную систему и полностью совместимы по про-
граммному обеспечению.
231
Системы семейства — однородные, с многошинной организа- I
дней связей и классифицируются как МКМДС/ВсОрМш. 3
Эволюция и генеалогия семейства показаны на рис. 4.20 и ’«
4.21 соответственно. Структуры систем семейства разделяются на
четыре класса (классы на рисунках разделены пунктирными ли-
ниями). Наличие многопроцессорных конфигураций увеличило
общее число систем семейства до двадцати трех (см. рис. 4.20)
при восьми базовых системах, перечисленных выше (см. рис. 4.21).
Количество центральных процессоров в конфигурациях на
базе систем 1108, 1106 и 1110 указано в виде цифры перед бук-
вой Р в окончании наименования конфигурации, а для конфигу-
раций на базе систем 1100/20, 1100/10, 1100/40 и 1100/80 — в
виде последней цифры в окончании наименования конфигурации
(см. рис. 4.20).
Основные характеристики структуры систем семейства, а так-
же характеристики скорости работы процессоров, в качестве ко-
торых выбраны время сложения целых чисел (базовая операция)
и время деления с плавающей запятой, приведены в таблице 4.2.
Системы строятся так, чтобы v длительность базовой операции
совпадала с временем цикла памяти.
4.4.2. Системы UNIVAC 1108 и 1106. Непосредственной пред-
шественницей и, одновременно, первой системой семейства 1100
была система 1107, структура которой явилась базовой для дру-
гих систем семейства.
В качестве характеристик структуры системы 1107 отметим
следующие 15531: 1) 36-разрядные слова; 2) 16 индексных и 16
арифметических регистров; 3) использование в типичных случа-
ях выполнения операций одного операнда из памяти и одного j
операнда из регистра или, как дополнительный варпант, исполь- i
зование двух операндов из регистров; 4) неограниченная цепочка ;
косвенной адресации с возможностью индексирования на каж- '
дом уровне; 5) 16-разрядное адресное поле; 6) наибольшая ем-
кость оперативной памяти — 64 К слов; 7) ввод-вывод через 16 |
двухсторонних каналов и другие. j
Важнейшим компонентом структуры системы 1107 является
набор регистров общего назначения GRS (General Register Set), i
Большинство команд выполняет ту или иную операцию над ве- i
личинами, расположенными в одном или более (до четырех) этих <
быстрых регистров. Набор регистров GRS состоит из трех под-
множеств, первое из которых составляют регистры дня выполне- *
~ния индексирования, второе — универсальные арифметические i
регистры и третье подмножество — регистры для выполнения !
специальных функций (маскирование, часы реального времени j
и др.). ‘
Память организована в виде двух независимых модулей. Если <
текущий аргумент и следующая команда — в разных модулях, то j
их выборка выполняется одновременно, что удваивает скорость Ч
работы памяти. 1
232 _ . ;
Табл и ц a 4L2
Характеристики систем семейства UNIVAC 1100
। п/п 1 Характеристики* Модель
1107 1108 1106 1110 о OJ о о W4 г iiooho 1100/10 о о о
1. 2. Год первой поставки Максимальное число 1962 1965 1969 1972 1975 1975 1976 1977
центральных процес- соров 1 3 2 4 2 6 2 4
3. Время, сложения целых чисел (нсек] (базовая операция) 4 000 750 1 000 300 875 300 1125 200
4. Время деления с пла- вающей запятой [нсек] 26 700 8250 И 000 5200 8325 5200 8625 4800
5. Количество базовых регистров 0 2 2 4 2 4 2 4
6. Число каналов ввода- вывода на один цент- ральный процессор 16 16 16 0 16 0 16 0
7. Число каналов ввода- вывода на один процес- сор ввода-вывода ♦) 16 24 24 26
8. Максимальное число процессоров ввода-вы-* вода* ) 0 2 0 4 0 4 ' 0 4
9. Структура основной (оперативной) памяти У У У г/Д У г/д У К/0
10. Пространство логичес- ких адресов [слова] 64К 256К 256К 23 * 512К 2зо 512К 2зо
11. Емкость физической основной памяти 64К 256К 256К 256К/ 512К 512К/ 512К 16К/
12. {слова] Ко ичество команд 117 151 151 /1М 206 151 /1М 206 151 /4М 201
*) В ряде моделей устройства с функциями процессора ввода-вывода имеют
различные наименования.
Примечание: У — один уровень, Г/Д — главная/дополнительная. К/ —
кэш/основная.
Процессор системы 1107 выполнен на полупроводниковых
дискретных элементах, за исключением регистров GRS, в кото-
рых используются тонкопленочные элементы памяти. Оператив-
ная память выполнена на сердечниках.
Систем 1108, первая поставка которой относится к 1965 г.,
имела ряд усовершенствований по сравнению с системой 1107
[553]. Основные усовершенствования заключались в том, что бы-
ла увеличена производительность системы и улучшена защита
при мультипрограммной обработке. При этом была реализована
структура с относительной адресацией, обеспечившая возможно-
сти динамического перераспределения. В дополнение к конфигу-
233
Р4Цип системы 1108, в 1968 г. были введены многопроцессорные
конфигурации, которые обеспечили повышенную производитель-
ность и высокую готовность систем. 1
В качестве наиболее важных новых особенностей системы j
1108 можно указать следующие [5531: 1) изменения в целях *
обеспечения * многопроцессорной обработки (команда «проверки
и установки» для обеспечения связей между процессами, реали-
зация внутрипроцессорного прерывания); 2) относительная адре-
сация при помощи двух базовых регистров; 3) улучшенная за-
щита памяти как часть структуры с относительной адресацией;
4) расширенный диапазон логических адресов — до 64 К слов для
программ и до 256 К слов для данных;*5) команды выполнения
с удвоенной точностью операций с фиксированной запятой;
6) возможность выполнения с удвоенной точностью операций
с плавающей запятой; 7) использование части кода команд в це-
лях расширения числа функциональных кодов; 8) ускоренное
выполнение команд; 9) устройство управления готовностью; 10)
коммутаторы памяти для обеспечения доступа нескольких про-
цессоров к каждому модулю памяти; 11) общий интерфейс пери-
ферийного оборудования для коммутации связей между несколь-
' кими процессорами и периферийными устройствами; 12) совме- *’
стимость с системой 1107, возможность «сохранения» адресации
системы 1107; 13) увеличенная физическая оперативная память
емкостью до 256 К слов.
Поздние версии системы 1108 могут образовывать (сильно
связанные) симметричные многопроцессорные конфигурации.
В этих целях каждое устройство оперативной памяти было реа-
лизовано как многовходовое. Была добавлена команда «прове-
рить и установить», которая облегчила синхронизацию процес-
сов при помощи механизма семафоров. Кроме этого, был введен
системный компонент нового типа — устройство управления го-
товностью. Это устройство позволяет разделить систему на три
независимых системы для наладки оборудования или отладки
программного обеспечения, которые выполняются на одной из
них в то время, как оставшаяся часть системы продолжает обыч-
ную работу с пониженной производительностью [553].
Структурная схема максимальной конфигурации многопро-
цессорной системы 1108 изображена на рис. 4.22 [694] (мини-
мальная конфигурация содержит один процессор и оперативную
память емкостью 64 К слов). Рассмотрим основные компоненты
многопроцессорной конфигурации [1236].
Максимальная конфигурация оперативной памяти имеет ем-
кость в 256 К 36-разрядпых слов. Эта память выполнена в виде
четырех банков емкостью в 64 К слов каждый, при этом каждый
банк, оформленный конструктивно в виде одной стойки, содер-
жит по два модуля памяти емкостью в 32 К слов. К каждой по-
ловине 36-разрядного слова добавляемся разряд четности и при
любых обращениях к• памяти осуществляется контроль по чет-
234
лости. Время обращения — 750 нсек. Обращение к оперативной
памяти осуществляется одновременно со стороны трех процес-
соров и двух контроллеров ввода-вывода. Память имеет систему
аппаратурной защиты, причем защищаемая область может со-
стоять из блоков по 512 слов.
И (от) интерфейсам перифериных
устройств
Рис. 4.22. Структурная схема максимальной конфигурации системы
UNIVAC 1108.
При обращении к памяти используется косвенная адресация
в базирование. В процессоре формируется 18-разрядный адрес.
Три старших разряда адреса используются для выбора одного
из восьми модулей памяти и в память не передаются. Пятнад-
цать младших разрядов адреса передаются в адресный регистр
выбранного модуля и определяют соответствующую ячейку в мо-
дуле. Модуль содержит устройство мультидоступа, в котором
235
имеются 5 каналов связи с тремя процессорами и двумя контрол*
лерами ввода-вывода, а также приоритетная система разрешения
конфликтов между запросами, поступающими по указанным вы-
ше каналам.
Как и в системе 1107, предусматривается одновременная вы-
борка текущего аргумента и следующей команды. Если они на-
ходятся в разных модулях, что является желательным, то запрос
на их выборку выполняется одновременно и быстродействие уд-
ваивается. Кроме этого, используется чередование адресов: в си-
стеме с 8 модулями четные адреса располагаются в 0-м, 2-м, 4-м
и 6-м модулях, а нечетные — в 1-м, 3-м, 5-м и 7-м модулях. В ре-
зультате время обращения к памяти сокращается до 375 мксек.
Процессор системы 1108 состоит из шести устройств: управ-
ляющего и арифметического устройств, устройства ввода-вывода,
индексного устройства, устройства классификации и набора
быстрых регистров. Не останавливаясь на первых двух, устрой-
ствах, отметим, что устройство ввода и вывода управляет пото-
ком данных между оперативной памятью и 16 каналами. Ин-
дексное устройство используется для формирования адресов, ди-
намической переадресации и управления обменом с внешними
накопителями. Устройство классификации устанавливает адрес-
ную и информационную связь с одним из модулей оперативной
памяти на основе машинного адреса и с учетом текущей рабочей
конфигурации памяти. Набор индексных регистров GRS содер-
жит 128 программно адресуемых регистров с циклом работы
в 125 нсек, используемых для индексации, арифметических опера-
ций, управления вводом и выводом и для других функций [1236].
Контроллер ввода-вывода, являясь по существу независимым
специализированным процессором ввода-вывода, содержит управ-
ляющую память емкостью в 256 слов (расширяется до 512 слов)
с временем цикла 250 нсек. К контроллеру можно подключить
до 16 каналов. Связь между периферийными устройствами и под-
системой дистанционной связи, с одной. стороны, и контроллера-
ми ввода-вывода и центральными процессорами, с другой сторо-
ны, осуществляется через адаптеры процессоров. Адаптер может
служить также для связи двух независимых систем 1108 с об-
щим полем периферийного оборудования (т. е. для построения
многомашинной системы на базе систем 1108). В качестве пери-
ферийных устройств используются магнитные барабаны, накопи-
тели на магнитных лентах, перфокартные устройства, устройства
печати и другие [1185, 1236].
Процессор 1108 выполнен на дискретных элементах, за ис-
ключением набора регистров GRS, который построен на инте-
гральных схемах. Оперативная память выполнена на сердечни-
ках [553J.
Таким образом, многопроцессорная конфигурация системы
может содержать 2 или 3 центральных процессора, 1 или 2 конт-
роллера ввода-вывода, от 8 до 16 каналов ввода-вывода на один
238
центральный процессор, от 4 до 16 каналов ввода-вывода на один
контроллер ввода-вывода, по одному контроллеру периферийных
устройств на один канал ввода-вывода и от 8 до 16 периферий-
ных устройств на один контроллер периферийных устройств. При
этом максимальная скорость передачи информации как централь-
ным процессором, так и контроллером ввода-вывода составляет
5 200 К байт в секунду, а каналами центрального процессора и
каналами контроллера ввода-вывода — 1700 К и 1000 К байт в
секунду соответственно [606].
Система 1106 была введена в 1969 году как альтернатива бо-
лее дорогой большой системе 1108. С точки зрения структуры
система 1106 подобна системе 1108, основные отличия касаются
памяти и временных характеристик. Два устройства оперативной
памяти, оба на сердечниках,' были созданы для системы 1106.
Первое из них может иметь емкость в 128 К слов и состоять из
одного модуля с циклом длительностью 3 мсек или же иметь уд-
военную емкость в 256 К слов, когда появляется возможность
совмещения во времени выборки операнда и следующей коман-
ды, вследствие чего цикл сокращается до 1,5 мксек. Второе
устройство оперативной памяти является более быстрым, оно
компонуется из модулей емкостью 32 К слов. Системы, в кото-
рых используется эта память, называются 1106II (см. рис. 4.20)
п выполняют сложение целых чисел за 1 мксек [5531.
Многопроцессорная конфигурация системы 1106 имеет 2 цен-
тральных процессора, каждый из которых обеспечивает передачу
информации с максимальной скоростью 2660 К байт в секунду.
Она может содержать от 4 до 16 каналов ввода-вывода на один
центральный процессор, при этом каналы ввода-вывода осуще-
ствляют передачу информации с максимальной скоростью 1140 К
байт в секунду. К каждому каналу подключается по одному кон-
троллеру периферийных устройств, к которому, в свою очередь,
подключаются от 8 до 16 периферийных устройств [606].
4.4.3. Система UNIVAC 1110. Система UNIVAC 1110, первые
поставки которой выполнены в начале семидесятых годов, явля-
ется следующим за системой 1108 улучшенным членом семейства
1100 4см. рис. 4.21). Она обладает улучшенными возможностями
мультипрограммирования, обеспечивает создание более мощных
многопроцессорных конфигураций и имеет ряд других преиму*
ществ.
Основные отличия системы 1110 от системы 1108 состоят в
следующем [553]: 1) 212 сегментов и 230 слов в логическом адрес-
ном пространстве, улучшенная защита памяти, расширяемое до
16 М слов физическое адресное пространство; 2) двухуровневая
основная (оперативная) память с максимальной емкостью в 256 К
слов главной памяти (первый уровень) и 1024 К слов дополни-
тельной памяти (второй уровень); 3) новые устройства для ввода-
вывода; 4) дополнительные команды ввода-вывода; 5) команды
для облегчения отладки; 6) команды для оперирования, с байта-
237
ми; 7) увеличенное до 4 число устройств для ввода-вывода; 8}
увеличенное с 16 до 24 число каналов на одно устройство для
ввода-вывода; '9) ускоренное выполнение команд; 10) увеличен*
ное до 4 число центральных процессоров в многопроцессорной
конфигурации; 11) перекрытие во времени выполнения четырех
команд; 12) идентичность интерфейса каналов ввода-вывода.
Главная память
Г (от) системе ввода-вьтода
Рис. 4.23. Упрощенная структурная схема двухпроцессорной конфигурации
системы UNIVAC 1110. ИМД — интерфейс мультидоступа.
Упрощенная структурная схема двухпроцессорной конфигу-
рации системы 1110 изображена на рис. 4.23 1281J. Эта конфи-
гурация является базовой. Она может быть расширена, макси-
мально, до четырех командно-арифметических устройств и до
четырех устройств доступа к системе ввода-вывода.
Командно-арифметпческое устройство* осуществляет обработ-
ку 1,8 млп. команд в секунду и выполняет одну базовую опера-
цию (сложение целых чисел) за 300 нсек. Оно может одновре-
менно обрабатывать до четырех команд, находящихся в разных
стадиях выполнения. Каждое командно-арифметическое устрой-
ство может связываться с четырьмя блоками главной памяти по
трактам доступа к командам и к операндам, а также может свя-
238
зываться по двойным, трактам с дополнительной памятью через
интерфейсы мультидоступа (ИМД). Доступ к памяти в обоих
случаях осуществляется с перекрытием и с чередованием адресов.
Управление обменом между периферийным оборудованием,
с одной стороны, и главной и дополнительной памятью, с другой
стороны, осуществляет устройство доступа к системе ввода-выво-
да. Оно имеет секцию управления и от 8 до 24 каналов ввода-вы-
вода и обеспечивает передачу до 4 млн. 36-разрядных рлов в се-
кунду [281]. Организация двухуровневой основной памяти с'пря-
мой адресацией ясна из сказанного выще и из рис. 4.23. Отме-
тим только, что базовый блок главной памяти емкостью в 32 К
слов состоит из четырех модулей по 8 К слов, а минимальная,
необходимая для работы, емкость главной памяти равна 96 К слов.
Система 1110 — первая в семействе 1100, полностью построен-
ная на интегральных схемах. Главная память выполнена на про-
водниках с магнитным покрытием, имеет цикл считывания
280 нсек (без разрушения информации) и цикл записи, 480 нсек.
Дополнительная память выполнена на сердечниках и имеет цикл
считывания/записи 1,5 мксек [553].
4.4.4. Системы UNIVAC 1100/10, 1100/20, 1100/40, 1100/80
1378, 553]. Универсальные полностью совместимые системы
1100/10, 20, 40 и 80 являются современными представителями се-
мейства 1100.
Системы 1100/20 и 1100/10 — преемники систем 1108 и
1106 — начали поставляться заказчикам в 1975 и 1976 гг. соот-
ветственно. Эти системы имеют такой же набор команд, что и
1108 и 1106. Можно считать, что системы 1108, 1106, 1100/10 и
1100/20 образуют в рамках семейства 1100 свой класс структур
(см. рис. 4.20 и 4.21).
Самой младшей моделью среди новых систем НОО/Ю,
1100/20, 1100/40 и 1100/80 семейства 1100 является система
1100/10. Ее основу составляют центральный процессор и основ-
ная память, в состав системы входит также пульт.
Центральный процессор системы 1100/10 имеет набор из 128
36-разрядных регистров с доступом от программ, используемый
для арифметических операций, индексирования и управления
вводом-выводом при выборке. Регистры включают в себя по два
контрольных разряда четности, построены на интегральныхсхе-
мах и имеют основной цикл длительностью в 125 нсек. Полупро-
водниковый модуль памяти на интегральных схемах имеет ем-
кость в 128 К и составляет минимальную конфигурацию основной
памяти системы 1100/10. К нему может быть добавлен дополни-,
тельный модуль, который вместе с первым образует блок памяти
емкостью в 256 К слов. Максимальный объем памяти — 512 К
слов. Каждое слово Имеет 36 информационных разрядов, а так-
два контрольных разряда (по одному — на каждую половину
слова) и 7 контрольно-корректирующих разрядов, что обеспечи-
вает исправление ошибки в одном разряде и обнаружение ошиб-
239
' эд
ки в двух разрядах любой ячейки'памяти. Время цикла нами гит |
й время выполнения базовой операции равны 1125 нсек. Процес- j
сор обеспечивает работу 4 интегральных каналов, при сохрани- ?
нии четности это число может быть увеличено до 16.
Система 1100/10 может иметь конфигурацию с одним процес- 5
сором (1100/11) и с двумя процессорами (1100/12). В двух про- i
цессорной конфигурации (рис. 4.24) идентичные процессоры ра- ’
ботают с общими устройст- [
вами памяти и внешними
устройствами под управле-
нием единой операционной
системы. Производитель-
ность однопроцессорного ва-
рианта — 680 тыс. операций , <
Рис. 424. Упрощенная структурная схе- в секунду.
ма многопроцессорной конфигурации Следует отметить, что* )'
1100/12 системы UNIVAC 1100/10. блок памяти может состоять ’
либо из двух модулей, либо из одного модуля, при этом во вто- 1
ром случае обеспечивается сдвоение каналов информации" и со-
ответствующее снижение вероятности конфликтов в основной па-
мяти. ;
Система 1100/20 по структуре подобна системе 1100/10, но ,
имеет более высокую производительность (производительность '
при одном процессоре — 860 тыс. операций в сёкупду). Основные
отличия первой по сравнению со второй состоят в следующем. ?
Модуль памяти имеет емкость в 64 К слов и может быть расши- . J
рен до 128 К слов. Память может расширяться приращениями i
64 К и 128 К слов (максимум до 512 К слов). Время цикла памя- j
ти и время выполнения базовой операции — 875 нсек.
Система 1100/20 может иметь однопроцессорную конфигура-
цию, известную как 1100/21, и двухпроцессорную конфигурацию, j
ч известную как 1100/22. 1
Система 1100/40 имеет структуру, подобную системе 1110 |
(см. рис. 4.21). Первая поставка системы выполнена в 1975 г. J
Время выполнения команд в системе 1100/40 такое же, что и |
для 1110, когда в последней процессор работает с первым уров- 3
нем основной памяти. Однако, два изменения в 1100/40 по срав- I
нению с 1110 обеспечивают более высокую общую производи-
тельность первой системы. Во-первых, дополнительная памяти I
(вторрй уровень) имеет цикл чтения/записи в 800 нсек (вместо J
1,5 мксек в 1110), что обеспечивает более высокую скорость ра- |
боты с командами и данными, расположенными в этой памяти 1
(при этом осуществляется исправление ошибки в одном разряде 1
и обнаружение ошибки в двух разрядах каждой ячейки). Во-вто- |
рых, главная память (первый уровень) выполнена на более ком-
пактных (Элементах, что позволило уменьшить длину ^соедини- 1
тельных кабелей по сравнению с 1110, и имеет максимальную ;
емкость_в 512 К слов (вместо 256 К" слов в 1110).
- з
Основу системы 1100/.40 составляют командно-арифметиче-
ское устройство, вводное-выводное устройство выборки, двухуров-
невая основная память, а также пульт оператора.
Командно-арифметическое устройство (КАУ) выполняет ко-
манды из стека емкостью в четыре команды. Оно имеет 112 ре-
гистров общего назначения с основным временем цикла в
90 нсек, используемых для арифметических операций и индекси-
рования. КАУ не .выполняет операций ввода-вывода. Конфигу-
рация системы 1100/40 может включать до четырех КАУ. Ввод-
ное-вывоМпое устройство выборки (ВВУВ) запускает передачи
ввода-вывода между главной или дополнительной памятью и
внешними устройствами и управляет этими передачами, не за-
нимая циКйы у КАУ вследствие независимости информационных
каналов к обоим типам основной памяти. ВВУВ имеет от 8 до
24 каналов, что обеспечивает возможность использования много-
численных разнообразных внешних устройств и устройств свя-
зи. Конфигурация системы 1100/40 может включать до четырех
ВВУВ (суммарная скорость передачи ВВУВ — от 1М до 3 М
байт в секунду).
К обоим уровням основной памяти возможен непосредствен-
ный доступ. Гибкость и высокая скорость работы главной памя-
ти дополняются большими емкостями более дешевой дополни-
тельной памяти, что оптимизирует соотношения между стои-
мостью и техническими характеристиками. Выборга как из глав-
ной памяти (ГП), так и из дополнительной памяти (ДП) произ-
водится по независимым каналам через КАУ и через ВВУВ.
ГП состоит из высокоскоростных биполярных полупроводни-
ковых модулей памяти с временем считывания в 280 нсек и вре-
менем записи в 380 нсек. Минимальная конфигурация ГП имеет
емкость в 32 К слов и состоит из четырех логических модулей,
что обеспечивает возможность небольших приращений памяти
и возможность одновременных независимых операций выборки.
Первое приращение при расширении минимальной конфигура-
ции ГП составляет 64 К слов. ’Приращения могут продолжаться
модулями по 64 К слов до достижения максимальной емкости
512 К слов. ДП состоит из полупроводниковых модулей емкостью
в 128 К слов на интегральных схемам имеет время считывания
и записи в 800 нсек и компонуется из этих модулей вплоть до
достижения максимальной емкости в 1024 К слов. Как пользова-
тель, так и операционная система имеют возможность распреде-
лять и перераспределять ГП и ДП между программами и дан-
ными.
Конфигурации; обеспечиваемые системой 1100/40, приведены
в таблице 4.3. Конфигурация 1100/44, известная также как кон-
фигурация 4X4, изображена на рис. 4.25. Здесь, как и в других
многопроцессорных системах семейства 1100, все центральные
процессоры (КАУ) занимают равноправное положение (нет под-
чиненности) и каждый из них может выполнять любую програм-
ме в. А. Головкин 241
му, включая программы операционной- системы. В системе обес- !
печивается высокая степень резервирования, она готова к рабо- ;
те, даже если только по одному из ее основных функциональных
компонентов находятся в рабочем состоянии.
Четыре процессора в системе 1100/40 — не предел: в 1976 г.
начаты поставки шестипроцессорной конфигурации 1100/46.
Таблица 4.3 *
Конфигурации системы 1100/40 ;
ям п/п Конфигура- ция Количество КАУ Количество ВВУВ Емкость ГП [слова] Емкость ДП [слова] *
1 1100/41 1 1 32 К—512 К 128 К-1024 К 1
2 1100/42 2 1-2 64 К-512 К 256 К-1024 К
3 1100/43 3 2-3 128 К-512 К 256 К-1024 К
4 1100/44 4 2-4 128 К—512 К 256 К—1024 К
Пульт каждой из систем 1100/10, 20 и 40 полностью совме- :
стим с каждой из двух других систем. В его состав входит тер-
минал с визуальным устройством воспроизведения и клавишное ;
устройство. Все сообщения, .передаваемые между оператором и ’
системой, выводятся на дисплей. Эти сообщения, а также другая
информация могут регистрироваться - на однократно используе- •
мом носителе печатающих устройств, которые можно подбоеди- J
нять к пульту. Системы оборудуются массовыми запоминающи- '
ми устройствами на дисках и накопителями на магнитной ленте
разных видов, перфокартными и другими устройствами.
В целях осуществления дистанционной связи в вычислитель- j
ны^ системах используются либо универсальная подсистема свя- J
зи, либр специализированный процессор связи. Универсальная ;
подсистема связи основана на мультиплексировании до 32 полу-
дуплексных и/или дуплексных линий связи и может осущест- '
влять связь с разнообразными комбинациями телеграфных линий j
и различных телефонных линий связи со скоростью до 56 000 бит «
в секунду. Специализированный процессор связи представляет i
собой процессор-контроллер с программным управлением, спо-
собный оперировать как с линиями связи, так и с перфокарт- з
ными устройствами. Он передает информацию центральному ;
процессору системы крупными блоками, освобождая его от вспо- $
могательных операций по обработке информации при вводе-
выводе.
Система 1100/80, имеющая время выполнения базовой опера- ;
ции 200 нсек, является наиболее мощной в семействе 1100 (вре-
мя цикла процессора 50 нсек). Поставки однопроцессорных и ,
двухпроцессорных конфигураций 1100/81 и 1100/82 производи- <
тельностью в 1,75 и 3 млн. операций в секунду соответственно ,
начаты в 1977 г., а трехпроцессорных и четырехпроцессорных J
242 ?
конфигураций 1100/83 и 1100/84 — в 1978 г. Система может ис-
пользоваться в составе вычислительной сети. Она конкурентно-
способна с системами IBM 3032 и IBM 3033 как по производи-
тельности, так и по стоимости.
Система 1100/80 имеет ряд усовершенствований в структуре
по сравнению со своей предшественницей — системой 1110, наи-
более важными из которых являются следующие: 1) адресуемая
Главная память
Дополнитель-
ная память
Рис. 4.25. Упрощенная структурная схема максимальной конфигурации
1100/44 системы UNIVAC 1100/40.
основная память возвращена к одноуровневой структуре; 2)
структура адресации памяти упрощена; 3) эффективная скорость
работы основной памяти увеличена за счет введения кэш-памя-
ти; 4) ошибки в одном разряде любой ячейки основной памяти
исправляются, а в двух разрядах — обнаруживаются; 5) в ариф-
метико-логическом устройстве применено микропрограммирова-
ние; 6) введен эмулятор для выполнения некоторой системы ко-
манд; 7) повышенная пропускная способность достигнута за счет
использования более быстрых логических компонент и более вы-
сокой плотности монтажа; 8) улучшены возможности автоматиче-
ского восстановления процесса вычислений при сбоях и отказах за
счет введения двух новых команд и использования системного
устройства перехода (подобного устройству управления готов-
ностью в системе 1108), осуществляющего «очистку», перезагруз-
ку и перезапуск системы.
Производительность конфигураций 1100/81 и 1100/82 равна
1,75 и 3 млн. операций в секунду соответственно.
В системе используется быстрая кэш-память между про-
цессором и основной памятью, выполненная на логических эле-
ментах с эмиттерными связями. Опа имеет емкость в 16 К слов
в обеспечивает доступ за время 120 нсек. Основная полупровод-
16* .243
виковая память на интегральных схемах имеет .емкость до. 4М?
слов и обеспечивает считывание за 1250 нсек.
В системе 1100/80 имеются каналы ввода-вывода двух типов:
каналы передачи слов, совместимые с системой 1110 и, дополни-
тельно, байтовые каналы для прямой связи через отдельные
адаптеры с «интеллектуальными» терминалами, ориентирован-
ными на байтовый обмен информацией. Скорости передачи по
каналу первого и второго типов составляют 1500 и 200 тыс. байт
в секунду соответственно.
В заключение перечислим основные компоненты и некоторые
возможности программного обеспечения систем семейства 1100.
Основу программного обеспечения составляет единая опера-
ционная система ОС 1100 с языком управления решением задач.
Она обеспечивает мультипрограммную и параллельную обработ-
ку в самых разнообразных окружениях и случаях применения
вычислительных систем, включая работу в реальном масштабе
времени и в диалоговом режиме, и. сочетает работу при кратко-
временных пиковых перегрузках с обработкой в пакетном ре-
жиме потока данных низкого приоритета. ОС 1100 оперирует
всеми средствами в пределах системы и осуществляет гибкое
динамическое распределение и перераспределение памяти и про-
цессоров как ресурсов системы без каких-либо искусственных
границ и ограничений.
В качестве языков используются кобол, фортран. IV и V,
PL/1, алгол, basic, для которых разработаны трансляторы и раз-
нообразные вспомогательные программы, APL, для которого раз-
работан интерпретатор, и другие языки.
Важными компонентами программного обеспечения являются
система управления базой данных DMS (Data Management Sy-
tern) и система управления связью CMS (Communication Mana-
gement System). Имеются также ориентированные на базу дан-
ных процессор языка запросов QLP (Query Language Processor)
и система дистанционной обработки BPS (Remote Processing*
System), а также другие компоненты.
При дальнейшем развитии семейства 1100, вероятно, процес-
соры. будут строиться на базе наборов микропроцессорных бло-
ков, будут применяться магистральные и матричные способы
обработки, а в качестве элементной базы будут использоваться
субнаносекундные логические схемы. В программном обеспечет
нии будут улучшены интерфейсы между его компонентами, по-
вышена надежность хранения информации на уровне операцион-
ной системы, повышена эффективность языковой части про-
граммного обеспечения, развита система дистанционной обра-
ботки RPS.
4.4.5. Библиографическая справка. Архитектура и програм -
мное обеспечение систем 1107, 1108, 1106, 1100/10, 1100/20,
1100/40 и 1100/80 семейства 1100, включая эволюцию и перспек-
тивы развития этого семейства, изложены в [553J. Упрощенные
244
**
структурные схемы и основные характеристики систем 1106,
1108 и 1110, а также систем UNIVAC 90/60 и 90/70 приведены
в [606).
Эволюция семейства 1100 и системы 1100/10, 1100/20,
1100/40, включая их программное обеспечение, описаны в [378].
Объявления о системах 1108II, 1100/10, 1100/80 и 90/80
сделаны в [299—301, 1182].
Описание многопроцессорной системы 1108 содержится в клю-
чевой статье 11185], а также в [1236]. Материалы с описанием
многопроцессорных систем 1108 и 1110 содержатся в [281].
Структурная схема система 1108 приведена в [694], ряд мате-
риалов о системах 1108 и 1110 содержится в [395, 544, 568].
Вопросы проектирования операционной системы для вычис-
лительных систем 1107 и 1108 изложены в [954], а особенности
операционной системы для систем 1107 и 1108 — в [1040]. Опе-
рационная система ЕХЕС8 для системы 1108 описана в [1039],
а для системы 1110 — в 1381]. Транслятор с языка pascal и на-
дежность операционной системы Chi/OS для системы 1108 рас-
смотрены в [1234] и [955, 956] соответственно, а программа
управления прохождением задач операционной системы E5fEC8
для семейства 1100 — в 11235].
Некоторые вопросы исследования систем 1108 и 1110, вклю-
чая их операционную систему, изложены в [548, 656, 716, 1140,.
1197, 1226].
Новые системы UNIVAC 1100/80 и 90/80 кратко описаны в
[112, ИЗ], причем во второй из указанных работ содержится
краткое изложение материала о системе 1100/80 из работы [553].
* 4.5. Системы семейства DEC System 10
Системы семейства DEC system 10 фирмы Digital Equipment,
известные также под названием PDP-10, ведут свою линию раз-
вития от 18-разрядной машины PDP-6 (1963 г.). Машина PDP-6,
однако, не оказалась в числе членов семейства совместимых ма-
шин. К началу 1978 г. была создана серия из пяти базовых про-
цессоров (PDPr6, КА 10, KI 10, KL 10 и KL 20), составивших
основу более 700 вычислительных систем, установленных у за-
казчиков. Рассмотрим структуру систем на базе процессоров
КА 10, KI 10 и KL [527]*).
Пользователям предоставляются значительные возможности
выбора конфигураций систем, включая возможности увеличения
или уменьшения объема памяти и производительности системы,
а также выбора внешних интерфейсов к человеку, к другим ма-
♦) Процессор KL 20 имеет радикальные отличия от перечисленных про-
цессоров (повышенная интеграция, пониженная стоимость процессоры вво-
да-вывода и др.).
245
/ * 3
шинам и к оборудованию, предназначенному для работы в ре*|
альном масштабе времени. I
Команда имеет 36 разрядов, из числа которых 9 отведены для]
кода операции, 4 —для адресации регистров общего назначения^
1 — для указания типа адреса, 4 — для адресации индексных^
регистров и 18 — для адресации основной памяти (адрес памяти’
представляет собой адрес или буквенную информацию). Булевым
данные могут быть представлены каш одноразрядные или вектор—
ные (36 разрядов). Слово и половину слова занимают данные ти-;
па «целый» (соответственно 36 и 18 разрядов). Вещественные!
числа имеют 9-разрядный порядок и 27-разрядную мантиссу.
Слово в стеке занимает 36 разрядов. Векторные данные имеют1
формат R слов X 36 разрядов. Кроме этого, в процессоре KL 101
предусмотрены данные типа «строка» разных видов и данные;
типа «целый» с удвоенным форматом (72 разряда), а в процес-
сорах KI10 и KL 10 — данные типа «вещественный» с удвоен-
ным форматом (по 9 разрядов для порядка, а также 54 и 63 раз-
ряда для мантиссы соответственно) [527].
На базе процессоров КА 10 и KI 10 могут быть построены од-
нопроцессорные или двухпроцессорные системы. Структурная
схема двухпроцессорных систем на базе процессоров КА 10 и
KI 10, известных как системы DEC 1055 и 1077 соответственно,
изображены на рисунке 4.26 [281, 527, 606]. Эти системы могут
иметь различные комплектации, они имеют определенные отли-
чия друг от друга, но структура у них практически одинаковая.
Процессор KI 10 является более совершенным по сравнению с
КА 10: он имеет, в частности, в два раза более высокую произво-
дительность, в нем применяется опережающий просмотр команд.
Каждый центральный процессор обоих систем включает в себя
по одному мультиплексному каналу для обслуживания низко-
скоростных периферийных устройств.
В системах используются до 16 четырехвходовых модулей
оперативной памяти размером в ^6 К, 32 К или 64 К 36-разряд-
ных слов. Максимальная суммарная емкость оперативной памяти
равна 256 К слов для DEC 1055 (16 модулей по 16 К 36-разряд-
ных слов), а для DEC 1077 может быть расширена до 4 М слов;
(64 модуля по 64 К 36-разрядных слов). При обращении к памя-.
ти используется перекрытие и двух- или четырехкратное чередо-
вание адресов. Время цикла обращения — 1 мксек для 36-раз-
рядного слова. В системе 1055 отсутствует механизм виртуаль-
ной памяти, хотя имеются регистры перемещения программ и
защиты, а в системе 1077 реализована страничная система.
Характерной особенностью систем является наличие расши-
рителя входа памяти, реализуемого при помощи коммутатора и
буферов данных в трактах селекторных каналов. Расширитель
применяется в связи с ограниченным числом входов памяти,
к каждому из которых может быть подключен либо один цент-
ральный процессор, либо один селекторный канал, либо один
*246
16
Рис. 4.26. Структурная схема многопроцессорных систем на базе процессоров КА 10, и KI10 семейства DEC Sys-
tem 10 (системы DEC 1055 и 1077).
'Шина UN!BUS Шина MAS$B
расширитель входов, к которому, в свою очередь, может быт
подключено уже до восьми контроллеров.
Максимальная скорость передачи информации по шине вв
да-вывода от/к КА 10 и KI 10 равна 220 К и 370 К слов в секун*
ду соответственно. Максимальная скорость передачи информаций
через один вход памяти равна 1000:К байт в секунду для обей
Шина памяти
1\ Модуль
памяти W-
2 Модуль^
3\ Модуль Н
памяти -
Модуль Ъ
памяти к
| Модуль
памяти
1
\8
1
8\
Шина
ввода-вывода
ватвль 1
8
1
7 ЗУ на магнитныхХ $\ЗУна маенитныаА
1 ледтдх II ленра&—J
\ЗУ на магнитный ...[ЗУ на магнитных}
дисках дисках I
8
74 Модуль Нг
памяти LL.
7<?| Модуль^?
памяти к-
г
1
Модуль И
памяти U-
1
Рис. 4.27. Структурная схема многопроцессорной системы на базе процео
сора KL 10 семейства DEC System 10.
систем. К каждому контроллеру периферийных устройств может
быть’ подключено до 8 таких устройств, максимальное количество
периферийных устройств, к которым может адресовываться си-
стема, равно 128 [281, 527, 606].
Структурная схема многопроцессорной системы на базе про-
цессора KL 10 изображена на рис. 4.27 [527]. Структура этой
системы радикально отличается от структуры систем на базе;
процессоров КА 10 и KI10, при этом первая имеет более высо-
кую производительность.
В системе на базе процессора KL 10 может быть до 16 моду- :
лей основной памяти, каждый из которых может иметь емкость
в 64 К, 128 К или 256 К слов. Максимальная суммарная емкость
памяти —4 М слов. Модули компонуются на Группы по 4 моду- ;
ля в каждой. В каждой группе модулей применяется чередование
адресов и обеспечивается одновременный доступ к четырем сло-
. вам (по»одному слову из каждого модуля группы) за каждый
цикд* Связь между модулями памяти и центральными процес- i
сорами осуществляется через распределенный перекрестный ком- j
248
мутатор 16X8, причем каждый модуль памяти обеспечивает пе-
редачу информации через одну шину памяти с максимальной
скоростью 1 млн. слов в секунду.
Система может содержать от 1 до 8 центральных процес-
соров, причем вместо одного или нескольких из них могут ис-
пользоваться контроллеры. Центральный процессор имеет про-
изводительность 1,8 млн. операций в секунду и содержит кэш-
память емкостью в 2 К слов, на которую приходится около 90%
обращений процессора к памяти, и 8 X 16 регистров общего на-
значения. Он обеспечивает передачу информации через шину
ввода-вывода со скоростью до 370 К слов в секунду. Кроме это-
го, он обменивается информацией с от 1 до 4 минимашип
PDP-11, выполняющих функции периферийных процессоров.
PDP-11, в свою очередь, связана с периферийными устройствами
ввода-вывода через шину UNIBUS. Центральный процессор со-
держит до 8 каналов, при помощи которых он связывается через
шины MASSBUS шириной в 18 разрядов каждая с устройствами
массовой памяти, такой как диски и магнитные ленты. К этим
устройствам организован двухвходовый доступ.
Следует отметить хорошую согласованность скоростей пере-
дачи информации в системе. Каждая шина MASSBUS может
передавать до 1,6 М слов в секунду, вследствие чего все восемь
каналов обеспечивают скорость передачи до 12,8 М слов в секун-
ду, тогда как, например, для 8-ми устройств памяти на дисках
требуется скорость передачи 8 X 250 К = 2000 К словив секунду.
Скорость обмена между центральным процессором и четырьмя
модулями основной памяти составляет 4 М слов в секунду, при-
чем, как отмечалось выше, около 90% обращений центрального
процессора к памяти приходится на кэш-память [527].
Двухпроцессорная система на базе процессора KL10, извест-
ная как система DEC 1088, совместима с машинами семейства и
предназначена, главным образом, для* решения задач научного
характера. С точки зрения фирмы Digital Equipment эта систе-
ма может конкурировать с системами IBM 370/158 и 168 и
UNIVAC 1100/10. Основная конфигурация системы содержит два
центральных процессора, оперативную память на сердечниках
емкостью 256 К 36-разрядных слов, дисковую память емкостью
88 млн. байт, память на магнитных лентах, устройство связи с
32 каналами и другие устройства. Кроме этого, разработана двух-
процессорная система DEC 1099 на базе модернизированного про-
цессора KL 10В с кэш-памятью емкостью в 2 К слов, имеющая
оперативную память емкостью от 256 К до 4М 36-разрядных
слов. Дата первой поставки системы 1088 — 1976 г., а системы
1099 — 1977 г. [112, 314].
Библиографическая справка. Системы семейства
DEC System 10, включая базовые процессоры, многопроцессор-
ные конфигурации и программное обеспечение систем, рассмот-
рены в [527]. Описание систем DEC 1055 и 1077 Содержится в
249
[281]. Обобщенная структурная схема и основные характеристи-
ки систем DEC 1055 и 1077, а также некоторых однопроцессор-
ных систем- рассматриваемого семейства приведены в [606].
Краткое описание систем DEC 1088 и 1099 дано в [112]. Про-
граммное обеспечение машин семейства DEC System 10 рассмот-
рено в [545, 862, 943, 1040].
Фирма Digital Equipment выпускает также и другие типы
многопроцессорных систем, например, двухпроцессорную систе-
му XVM-20 и двухпроцессорную систему Super 8 (двухпро-
цессорный вариант машины PDP-8/A) [3141.
4.6. Системы фирмы Honeywell
В начале семидесятых годов фирма Honeywell Information
System (HIS) выпустила в составе семейства HIS 6000 системы
HIS 6050*) и 6070, а также их варианты HIS 6060 и 6080 соот-
ветственно, которые могли содержать от 1 до 4 центральных
процессоров. Эти системы, а также близкая к ним система HIS
Рис. 4.28. Структура многопроцессорных систем семейства HIS6000 и си-
стемы HIS6180.
6180 (MULTICS) базируются на структуре систем GE 635 и •
GE645 (MULTICS). В последующие годы фирма продолжила ли- j
нию создания семейств с многопроцессорными системами. .
Рассмотрим многопроцессорные системы HIS 6050/6060, 6070/
/6080 ц 6180 (рис. 4.28) [281, 606, 694]. Системы построены по
♦) Вместо HIS в обозначениях моделей используется также просто Н.
250
7 '1
модульному принципу и имеют асинхронное распределенное уп-
равление, чему в значительной степени способствует системный
контроллер (см. п. 2.5), в совокупности с которым память, кроме
обычных функций, обеспечивает управление системными связя-
ми. Непосредственные связи между центральным процессором и
Таблица 4.4
Характеристики систем HIS 6050, 6060, 6070, 6080, 6180
п/п Наименование характеристики HIS 6050 HIS 6060 . Модель
HIS 6070 HIS 6080 HIS 6180
1. Количество центральных^процес- от 1 до 4 от 1 до 4 от 1 до 4
2. Максимальная производитель- 500 ♦) 1000 ♦) 1000 ♦)
ность [тыс. коман д/сек] 900 ♦♦) 1800 ♦♦) 1800 ♦♦)
3. Максимальная емкость основной памяти (36-разрядные слова) 512 К 1024 К 2048 К
4. Длительность цикла памяти для 8 байтов [мксек] 1,2 0,5 0,5
5. Количество системных контролле- 1 для каж- 1 для каж- 1 для каж-
ров дой пары модулей памяти дой пары модулей памяти дой пары модулей памяти
6. Количество мультиплексоров ввода-вывода от 1 до 4 от 1 до 4 от 1 до 4
7. Максимальная скорость передачи информации мультиплексором ввода-вывода [байт/сек] 3700 К 6000 К 6000 К
8. Количество каналов ввода-выво- да на один мультиплексор ввода- вывода от 8 до 24 от 8 до 24 от 8 до 24
9. Максимальная скорость передачи информации каналом ввода-вы- вода [байт/сек] 1300 К 1300 К
10. Количество контроллеров пери- ферийных устройств на один ка- нал ввода-вывода 1 1
11. Количество периферийных уст- ройств на один контроллер пери- ферийных устройств До 16 до 16
12. Максимальное количество пери- ферийных процессоров связи с сетью 3 3 3
♦) для однопроцессорной конфигурации;
♦♦) для двухпроцессорной конфигурации.
контроллерами ввода-вывода отсутствуют. Основные характери-
стики систем приведены в таблице 4.4. Для систем HIS 6070/
/6080 и HIC 6180 указаны одинаковые значения максимальной
производительности, однако, вторая система является в целом
251
'ZSZ
Табл и\ а 4.5 1
Характеристики систем Н-66/40, 66/60, 66/80, 66/85, 68/60, 68/80
М п/ц. Характеристики Модель
Н-66/40 Н-66/60 Н -66/80 Н-66/85 , Н-68/60 MULTICS Н-68/80 MULTICS
1. Год выпуска 1975 1975 1975 1979 ♦) 1975 1975
2. Центральные процессоры: а) количество б) производительность одного про- цессора [млн. оп./сек] 1-2 0,375 1—2 0,715 1-4 0,75—1,0 1-4 2,0—2,5 1-2 1,0-2,0 1—4 1 2,0-3,0
3, Буферная память (кэш, биполярные интегральные схемы): а) емкость б) время цикла [мксек] 8 К байт 0,2 8 К байт 0,2 8 К байт 0,2
4. Оперативная память (МОП-схемы): а) емкость б) время цикла [мксек] в) длина слова [двоичные разряды] 128 К— —1024 К слов 1,4 36 0,7 М-4М байт 0,75 36 1М-4М байт 0,75 ! 36 ' 512 К— -2048 К слов 0,5 36 0,7 М-4М байт 0,75 36 IM—8М байт 0,75 36
5. Промежуточная память (сердечн.): а) емкость одного модуля [М байт] б) время цикла [мксек] в) скорость обмена [М байт/сек] • 1 1,5 10 1 1,5 , ю 1 1,5 10
6. Селекторные каналы: а) количество б) скорость обмена [тыс. зн./сек] 24 1300 24-96 । 1300 24-96 1300 32 24-96 870 24-96 870
7. Мультиплексные каналы: а) количество каналов/подканалов б) скорость обмена [тыс. зн./сек] 1/8 4000 1-4 - 6000 1-4 6000 6 1-4 6000 6000
. *) Относительно выпуска системы Н-66/85 см. соответствующие материалы в данном разделе.
т
253
более мощной. Все рассматриваемые системы имеют операции
с плавающей запятой, в них реализовано аппаратное преобра-
зование системы счисления.
В целях ускорения вычислений применяются перекрытие опе-
раций и чередование адресов при обращении к памяти. Слова в
основной памятью — 36 разрядные. Эта память в системах HIS
6050/6060 может содержать до 16 модулей емкостью в 32 К слов,
в HIS 6070/6080 — до 16 модулей емкостью в 64 К слов, а в HIS
6180 — до 32 модулей емкостью в 64 К слов. В ^системах реали-
зована защита памяти. Логика прерываний — приоритетная, при-
чем имеется возможность ее практически неограниченного рас-
ширения путем соответствующего использования разрядов ячеек
памяти.
Функциональные модули системы HIS 6180 незначительно
отличаются в лучшую сторону от соответствующих модулей рас-
сматриваемых систем семейства HIS 6000, за исключением цен-
трального процеесора HIS. 6180, который представляет собой
существенно улучшенную модификацию процессора системы
GE 645 (совместимость с программным обеспечением семейства
HIS 6000 сохранена).
Центральный процессор систем семейства HIS 6000 содер-
жит блоки управления и операций, а также десятичный блок.
Эти блоки входят и в процессор HIS 6180, образуя в нем отдель-
ный процессор, который взаимодействует с новым дополнитель-
ным блоком. При помощи ручного переключателя дополнитель-
ный блок может быть либо исключен из работы, и тогда процес-
сор системы HIS6180 работает как процессор систем семейства
HIS 6000 (режим операционной системы GCOS), либо он включа-
ется в работу, и тогда процессор системы HIS 6180 реализует
^расширенные функции (режим операционной системы MULTICS).
Расширение состоит, в основном, в аппаратной реализации рабо-
ты с сегментами и страницами памяти, реализации 24-разряд-
ной адресации памяти и расширении возможностей модификации
адресов. Это обеспечивается наличием в дополнительном блоке
до 16-ти дескрипторов сегментов и 16-страничной таблицы, де-
скрипторного регистра базы сегмента, 8-ми регистров указателей
сегмента и других компонентов.
Мультиплексор, основная и массовая память, централь-
ный процессор и системный контроллер HIS 6180 имеют по
8 входов.
Для связи с терминалами используются периферийные про-
цессоры (связи с сетью) Datanet 355, которые могут работать с
большим числом самых разнообразных устройств.
Программное обеспечение системы НIS 6180 базируется на
широко известной системе MULTICS.
К середине семидесятых годов и в последующие годы фирма
HIS развернула выпуск систем семейств Н-61, 62, 64, 66, 68. Ха-
рактеристики старших моделей семейств Н-66 и Н-68 приведены
254
в таблице 4.5. (113, 127, 313, 314, 385] (в таблице под скоростью
обмена канала понимается максимальная скорость передачи ин-
формации при полной загрузке канала, а под количеством муль-
типлексных подканалов — максимальное количество управляемых
устройств, адресуемых в пределах одного мультиплексного кана-
ла). Отметим, что время, необходимое для извлечения из памяти
и выполнения одной операции сложения системами Н-66/40 и
66/60 равно 2,2 и 0,9 мксек.
Новая система Н-66/85, старшая в семействе Н-66 и един-
ственная несовместимая система с системами других рассматри-
ваемых семейств (кроме Н-66), имеет для максимальной четы-
рехпроцессорной конфигурации более высокую производитель-
ность по сравнению с системой IBM 370/168 APS. Часть опера-
тивной памяти может использоваться как буферная кэш-память
для дискового запоминающего устройства. Размер такой кэш-па-
мяти устанавливается программно и в типичном случае равен
256 К слов. Периферийные процессоры, построенные с примене-
нием микропрограммных микропроцессоров, допускают подклю-
чение до 4 быстрых и 2 медленных мультиплексных каналов
[112].
Фирма .HIS встретилась с трудностями микромонтажа про-
цессорных схем системы Н-66/85, в результате чего сначала было
объявлено о задержках в выпуске системы, а затем появились
сообщения о возможном прекращении ее разработки. Фирма со-
общила также о возможном выпуске в 1979 г. новых систем
H-66/DPS и H-68/DPS с более компактной оперативной памятью
и с буферной кэш-памятью емкостью до 6 тыс. слов, а также с
процессорами связи повышенной производительности.
Первая из указанных систем предназначена заменить собой
системы Н-66/60 и 66/80, а вторая система предназначена для за-
мены системы Н-68/60 и 68/80. Наибольшая многопроцессрр-
ная конфигурация в семействе Н-68 будет иметь 6 процессо-
ров [изГ.
Библиографическая справка. Описание систем HIS
6050, 6060, 6070, 6080 и 6180 содержится в [281], структурная
схема таких многопроцессорных систем фирмы HIS дана в [694].
Обобщенная структурная схема систем HIS 6030, 6040, 6050,
6060, 6070 и 6080 (первые две системы не имеют многопроцес-
сорных конфигураций) и их основные характеристики приведены
в [606], а структурная схема модели 6080 — в [447]. Новые мно-
гопроцессорные системы фирмы HIS представлены в 1112, 1131
и в других материалах [79—81, 127, 313, 314]. Описание систе-
мы MULTICS (MULTiplexed Information and Computing Service)
с учетрм опыта работы на двухпроцессорной конфигурации
GE 645 содержится в [616, 617] и во многих других работах,
а описание операционной системы GECOSIII для вычисли-
тельных систем GE 615, 625, 635 семейства Honeywell 600—
в [1039].
255
ЬЛ. Система SYMBOL [379]
SYMBOL представляет собой большую экспериментальную |
неоднородную вычислительную систему, предназначенную для |
работы с терминалами в режиме разделения времени. Эта много- |
процессорная система была разработана и изготовлена фирмой |
Fairchild Camera and Instruments в 1962—1970 гг. в качестве де- 3
монстрационной модели и испытательного стенда, установлена I
в начале 1971 г. в университете штата Айова в городе Эймсе 1
к в течение года с небольшим введена в эксплуатационный ре- |
жим. Она содержит 8 функционально-ориентированных процес- |
соров, систему виртуальной памяти с быстродействующим запо- |
минающим устройством в качестве буфера дисковой памяти и 3
обеспечивает взаимодействие одновременно с 31 независимыми 1
терминалами [1277] (см. также п. 2.6, рис. 2.33). Созданию си-
стемы предшествовала разработка языка высокого уровня 1
SYMBOL. , *
Главная цель исследований, которые легли в основу проекта 1
системы SYMBOL, состоит в увеличении функциональных воз- ।
можностей аппаратуры. При этом было'пересмотрено традициоп-
ное разделение функций между аппаратурой и программным J
обеспечением, пересмотрена роль программных команд и памяти 1
данных в интересах уменьшения общей сложности и стоимости J
вычислений J1125]. Многие вопросы разработки аппаратуры с 3
повышенными возможностями были изучены до создания систе- 1
мы SYMBOL. Кроме этого, в системе приняты многочисленные |
упрощения в тех местах, которые не служат основным целям |
проекта (например, некоторые ограничения модульности), и она <
не является оптимальной универсальной многопроцессорной си- ।
стемой с разделением времени. Однако, система SYMBOL обеспе- >
чи&а существенное продвижение в направлении создания много- ’
процессорных систем с повышенными функциональными возмож- \
ностями аппаратуры, причем проверка эффективности принятых
технических решений была выполнена на реально созданной и '
введенной в эксплуатацию экспериментальной установке
• SYMBOL.
Система SYMBOL включает в себя 8 специализированных
процессоров: Супервизор, Центральный процессор, Транслятор, •
Управление каналом. Управление памятью, Управление дисками, >
Восстановитель памяти, Интерфейсный процессор (рис. 4.29).
Каждый процессор работает автономно. Процессоры связаны J
между собой при помощи главных шин. Основная память и па- i
мять на дисках подключены к системе через шины памяти. j
Одной из специфических важнейших особенностей системы
является непосредственное динамическое распределение памяти ?
аппаратурой, реализуемое процессором, называемым Управление 1
памятью. Этот процессор распределяет память по требованию,
выполняет адресную арифметику и управляет ассоциативной па-
256
мятью, при помощи которой осуществляется страничная органи-
зация. Он полностью изолирует основную память от главных шин
и других процессоров и имеет вместо обычных операций считы-
вания и записи набор из пятнадцати операций, доступных дру-
гим процессорам системы. Процессор Восстановитель памяти до-
полняет процессор Управление памятью. Он работает в режиме
Главные
Рис. 4.29. Структурная схема системы SYMBOL.
задачи с низким приоритетом доступа в память и реорганизует
возвращаемые области памяти для их последующего использо-
вания.
Транслятор воспринимает в качестве входного язык высокого
уровня SYMBOL и создает объектную строку в польской ин-
версной записи и таблицу имен для их дальнейшей обработки
центральным процессором, он выполняет также прямую аппа-
ратную компиляцию при помощи таблицы размером около .100
слов, находящейся в основной памяти. Центральный процессор
осуществляет все операции с полями как действия над полями
с динамической переменной длиной, при этом обработка буквен-
но-цифровых строк выполняется Форматным процессором, а об-
работка чисел— Арифметическим процессором. В динамике об-
работки допускается любое изменение структуры данных (размер,
формат, глубина). Управление размещением и выборкой, хране-
нием и ссылкой на~ массивы и структуры данных выполняет Ссы-
лочный процессор, являющийся частью Центрального процессора.
При работе Центрального процессора интенсивно используются
ресурсы и операции процессора Управление памятью.
17 в. А. Головкин 257
Управление работой с разделением времени осуществляет Су-
первизор системы, который управляет всеми переходами от од-
ного режима обработки информации к другому и очередями ко
всем процессорам и выполняет аппаратно реализованные алго-
ритмы составления расписания задач и управления страничной
организацией памяти. Функции ввода и вывода в системе осуще-
ствляет Интерфейсный процессор, который может производить
общее редактирование текста в .диалоговом режиме. При вводе,
выводе и редактировании ресурсы Центрального процессора на
используются.
В системе используется виртуальная память с простой стра-
ничной организацией, не требующей адресации уровня выше,
чем страничный уровень. Управление страницами осуществляет-
ся аппаратно. Если Управление памятью обнаруживает, что нуж-
ной страницы нет в основной памяти, то оповещает об этом тот
процессор, который затребовал эту страницу, и Супервизор систе-
мы. Последний в этом случае выдает команды передачи с диска
Управлению дисками. Отсылка страниц из основной памяти про-
изводится под управлением Супервизора при помощи ^аппаратно
реализованного гибкого алгоритма.
Основная память емкостью в 8 К слов разделена на 32 стра-
ницы по 256 64-разрядных слов в каждой и организована как
простая двухуровневая память. В виртуальном адресе указывает-
ся 16 разрядов номера страницы и 8 разрядов относительного
адреса. Последний1 вместе с 8-разрядным адресом страницы, по-
лучаемым в результате преобразования номера страницы при
помощи механизма ассоциативной памяти, составляет адрес ос-
новной памяти. Одна страница основной памяти занимается табли-
цами Супервизора системы, три страницы — таблицами управле-
ния терминалами*, одна — две страницы — буферами ввода и вы-
вода, а остальные отводятся под страницы виртуальной памяти.
Основная память выполнена на ферритах и имеет цикл 2,5 мксек.
Промежуточная память страниц находится на малом диске с
фиксированными головками и содержит 500 страниц такого же*
размера, что и основная память, а массовая, память страниц на- j
ходится на большом диске и содержит 50000 страниц.
Управление каналом рассчитано на обслуживание 31 канала.
В системе был использован один высокоскоростной канал с про-
пускной способностью 100 тыс. бит в секунду и три канала теле-
фонных линий с пропускной способностью по 2400 бит в секунду ,
каждого.
Главные шины имеют 111 параллельных линий, из числа i
которых 64 линии отведены для данных, 24 — для адреса,.
6 —для кода операции, 5 —для идентификации терминала,
1Q —для приоритетов и по одной шине для часов и системного i
сброса. ‘
Относительные размеры аппаратуры процессоров системы
SYMBOL показаны на рис. 4.30.
258
В результате разработки, ввода и опыта эксплуатации сис-
темы SYMBOL были получены положительные ответы на вопро-
сы о том, можно ли сделать аппаратный компилятор и аппарат-
ный супервизор, может ли аппаратура управлять и распреде-
лять память данных, можно ли аппаратно реализовать основные
Супервизор
системы
Управление
памятью
Ссылочный
процессор
Процессор
команд
Восстанови-
тель памяти
> Управление
диенами
Управление
навалом
Арифмети-
ческий процес-
сор
Форматный
Рис. 4.30. Схема распределения аппаратуры между процессорами системы
х SYMBOL.
функции программного обеспечения и, наконец, можно ли отла-
дить реальную вычислительную систему с такими расширен-
ными и сложными функциями аппаратуры.
Библиографическая справка. Система SYMBOL бы-
ла представлена в серии работ на весенней конференции AFIPS
1971 года [379, 584, 624, 1125], причем первую и последнюю из
указанных работ следует рассматривать как ключевые по систе-
ме SYMBOL. На весенней конференции в следующем 1972 году
система SYMBOL рассматривалась в работах [565, 723]. Эта си-
стема была широко представлена на конференции COMPCON
1972 года [591, 1126, 1127, 1178, 1276]. Проблемно ориентиро-
ванный процессор системы был предварительно описан в [1005].
Основная память в системе организована так, как это предложе-
но в работе [886]. Описание системы SYMBOL содержится
также в [218, 1277], причем в первой работе рассмотрены как
структура и технические параметры системы, так и язык
SYMBOL. Сведения об операционной системе для SYMBOL со-
держатся в [275].
В завершение главы отметим, что список примеров многопро-
цессорных систем, конечно, не исчерпывается рассмотренными
здесь системами и может быть продолжен. Так, например, в [281]
приведено описание систем Н4400 фирмы HUGHES AIRCRAFT,
UNIVAC AN/UYK-7, SIGMA-9 фирмы XEROX DATA SYSTEMS
и системы 215 фирмы RCA. Структура предпоследней системы
я ее характеристики даны в [606], а структура последней систе-
мы — в [694].
17*
259
Неоднородная система с общей памятью и одной копией опе-
рационной системы, построенная из процессов HITAC '8700 и
HITAC 8800, описана в [1025, 1037]. Сведения о четырехпроцес-
сорной системе IRIS 80 можно найти в [966]. В этой системе,
созданной в 1970 г., процессоры обезличены и применяется вир-
туальная память. Физическая оперативная память содержит до
32 модулей емкостькГ 128 К байт каждого с циклом обращения
650 нсек для 32-разрядного слова. Имеется память- на магнитных
дисках и лентах. Связь с внешними устройствами осуществля-
ется через шйну ввода-вывода. В [113] можно найти также све-
дения о двух- и трехпроцессорных конфигурациях систем разра-
батываемого семейства P7G, четырехпроцессорных конфигурациях
системы М-200 и других.
5. МАГИСТРАЛЬНЫЕ СИСТЕМЫ
5.1. Концепция и ранние системы
Магистральные системы относятся к классу МКОД — системы
с множественным потоком команд и одиночным потоком данных.
Принцип магистральной (конвейерной) обработки нашел ши-
рокое применение в большинстве наиболее мощных универсаль-
ных систем, разработанных в последние годы. Так, например*
системы STAR 100, ASC, CRAY1 и AMDAHL 470V/6, а также
более ранние системы CDC 6600, CDC 7600, 1БМ 360/91, IBM
360/195 и некоторые другие имеют блоки магистральной обработ-
ки. Принцип магистральной обработки основан на разделении вы-
числительного процесса на несколько подпроцессов, каждый из
которых выполняется на отдельном устройстве, причем последо-
вательные подпроцессы могут выполняться на своих устройствах
подобно тому, как это имеет место на промышленных конвейер-
ных линиях. Этот принцип может применяться на различных
иерархических уровнях вычислительного процесса, начиная
с уровня логического вентиля 11112].
В качестве основных уровней реализации магистрального
принципа можно выделить уровень устройств выполнения элемен-
тарных операций над битами данных, уровень арифметико-логи-
ческих . устройств и уровень управляющих устройств, которым
сопоставляются арифметико-магистральная, командно-магистраль-
ная и макромагистральная обработка соответственно [800]. Схе-
мы процессов трех указанных видов магистральной обработки
приведены на рис. 5.1.
На рис. 5.1 а показана схема четырехэтапной арифмети-
ко-магистральной обработки, когда каждая команда выпол-
няется последовательно на четырех устройствах, а последователь-
ность четырех соседних команд заполняет арифметическую маги-
страль системы так, что одновременно на последнем четвертом
устройстве выполняется завершающий четвертый этап первой
команды, на третьем устройстве — третий этап второй команды,
на втором устройстве — второй этап третьей команды и на первом
устройстве — начальный, первый этап четвертой команды. После
завершения выполнения устройствами своих этапов обработки
первая команда оказывается выполненной и выводится из маги-
страли, вторая, третья и четвертая команды поступают на оче-
редные четвертый, третий и второй этапы соответственно* а в
первое устройство поступает очередная пятая команда для нача-
261
ла выполнения на первом этапе и так далее. Арифметико-маги-
стральная обработка реализована в системах STAR 100 и ASC,
в первой из которых используется четырехэтапная магистраль
для сложения и шестиэтапная магистраль для умножения, а во
второй — магистраль из восьми этапов общего назначения.
Smanf
&пап2
ЗтапЗ
Swank.
а)Арифметино~
^магистральная
обработка
в) Макро магистральная
обработка
Рис. 5.1. Схемы процессов магистральной обработки.
Более высокий уровень магистральной обработки представля-
ет собой командно-магистральная обработка (рис. 5.16). В этом
случае каждая команда потока команд выполняется на соответ-
ствующем ей функциональном обрабатывающем устройстве, кото-
рые могут работать одновременно. Ясно, что для эффективной
работы обрабатываемые команды должны быть независимыми,
а их состав в динамике счета — по возможности идентичным со-
ставу функциональных устройств, чтобы одновременно загружать
как можно большее число функциональных устройств. Такой спо-
соб магистральной обработки является развитием способа опере-
жающего просмотра команд в обычных ЭВМ и называется также
способом «параллелизма функциональных устройств». Наиболее
известным примером реализации командно-магистральной об-
работки является система CDC 6600, в которой имеется 10 спе-
циализированных устройств обработки (устройства умножения о
плавающей запятой, сложения целых чисел, приращения и дру-
гие). На практике оказалось, что в среднем загружена примерно
четвертая ч^сть ее функциональных устройств одновременно.
Концепция макромагистральной обработки (рис. 5.1 а) осно-
вана на следующих соображениях. Пусть множество данных мо-
жет быть обработано посредством решения последовательно двух
262
(или более) различных задач. Тогда эту обработку можно осуще*
ствить при помощи двух различных процессоров, каждый из ко*
торых выполняет решение одной из задач. Данные из буфера
поступают на исполнение в первый процессор, который выполня-
ет решение первой задачи, после чего результаты поступают в
следующий буфер, откуда они передаются во второй процессор
для решения второй задачи. В это же время следующий массив
данных -поступает из первого буфера в первый процессор для ре-
шения первой задачи и так далее, в результате чего оба процес-
сора работают одновременно (в наиболее благоприятном случае —
без перерывов). Ясно, что макромагистральная обработка может
быть реализована при помощи обычных процессоров [800].
Таким образом, все три вида обработки характерны тем, что
имеется магистраль (конвейер) обработки с независимыми ком-
понентами, которые при заполнении магистрали работают, по
возможности, одновременно и без перерывов.
Магистральные системы можно различать не только по спосо-
бу магистральной обработки, но и по типу конфигурации магист-'
рали — статические и динамические с аппаратной или с програм-
мной перестройкой, а также по типу команд — с обычными или
векторными командами [109].
Функциональные возможности, магистральной обработки на-
иболее полно проявляются при векторной обработке данных,
когда при помощи так называемых векторных команд выполня-
ются однотипные операции над упорядоченной группой данных.
Векторная структура магистральных систем характерна наличием
одной или более многофункциональных магистралей в исполни-
тельном устройстве и соответствующих средств управления в
процессоре. В случае магистрали статической конфигурации уст-
ройство управления оказывается достаточно простым. При дина-
мической конфигурации- управление сложнее, но и существенно
выше производительность вследствие одновременного существо-
вания нескольких конфигураций [1112].
Векторная обработка сопряжена с некоторыми недостатками,
главными из которых являются усложнение векторных операций
по сравнению со скалярными и существенный разрыв между
алгоритмами скалярной и векторной обработки. Для подготовки
векторной операции требуется определенное время, необходимы
вспомогательные средства управления конфигурацией магистрали
и подготовкой операндов, а для оптимизации машинного кода
требуются более развитая система команд и более эффективные
компиляторы [1112].
Вероятно, «чисто магистральные» системы не существуют.
Магистральными обычно считаются такие системы, в которых
центральные блоки обработки основаны на использовании маги-
стрального принципа. При этом, как правило, система в целом
имеет явно выраженные черты структур систем других типов.
Так, например, в системах CDG 6600 и CDG 7600 реализована
' 263
командно-магистральная обработка, однако их можно отпестй п
к неоднородным многопроцессорным системам, поскольку они со-
держат и достаточно мощные независимые периферийные процес-
соры. В системах STAR 100 и ASC реализована векторная
арифметико-магистральная обработка, но первая из нихх содержит
две неидентичных статических магистрали, а вторая может со-
держать две или четыре идентичных динамических магистрали,
поэтому STAR 100 и ASC можно считать неоднородной и~однород-
ной многопроцессорными системами соответственно. Макрома-
гистральная обработка может быть реализована фактически на
любой многопроцессорной или многомашинной системе. Более
того, работа таких неоднородных систем, как GAMMA 60,
STRETCH и SYMBOL, а также системы с ансамблем процессоров
РЕРЕ и некоторых других имеет явные черты магистральной
обработки, не говоря о таких широко используемых способах ус-
корения счета, как опережающий просмотр команд и данных
с перекрытием операций и мультипрограммен работа.
Перекрытие операций, собственно, явилось первым шагом на
пути создания магистральных систем. Начало использования
перекрытия относится к пятидесятым годам. Так, уже в машине
UNIVAC 1 применялось перекрытие в процессоре, памяти и
устройстве ввода-вывода, а в машине IBM 7094 перекрытие опе-
раций обеспечило существенное повышение производительности.
В машине Н-800, в которой впервые была осуществлена муль-
типрограммная обработка, было реализовано существенное пере-
крытие операций обработки команд, обращения к памяти и вво-
да-вывода. В начале шестидесятых годов способ перекрытия
получил дальнейшее развитие. Так, например, в системе LARC
сложение с плавающей запятой осуществлялось за один такт в
4 мксек за счет перекрытия операций обращения к памяти и четы-
рехкратного перекрытия при обработке команд (извлечение и ин-
дексирование команды, извлечение данных и выполнение коман-
ды) [1112]. Как отмечалось в предыдущих материалах, перекры-
тие операций и опережающий просмотр широко использовались
в БЭСМ-6, использовались они также и в некоторых более
ранних отечественных машинах. Можно сказать, что магистраль-
ные системы появились в результате естественного процесса эво-
люции структур вычислительных машин. И если в системах IBM
360/91, IBM 360/195 имелись блоки магистральной обработки, то
в современных и новейших системах STAR 100, ASC, CRAY
1, AMDAHL 470 V/6 магистральный принцип в выбранных вари-
антах реализован в полной мере.
Считается, что применение магистральной обработки повыша-
ет эффективность операций сложения на 47%, а операций умно-
жения — на 230% [791].
Библи*ографическая справка. Концепции арифмети-
ко-магистральной, командно-магистральной и макромагистраль-
ной обработки выделены в [796, 800]; при этом последняя кон-
264
цепция рассмотрена в [793, 794]. Концептуальные основы маги-
стральной обработки изложены кратко в [1118] и, очень кратко,
в [493, 1193];, при этом в последней из работ акцент сделан на
векторную обработку. Концепции скалярной и векторной магист--
ральной обработки рассмотрены в [1211].
Обстоятельный .обзор арифметико-магистральных систем вы-
полнен в [1109, 1112], а обзор способов перекрытия и магист-
ральной обработки —в [581]. В 1972 г. была выпущена книга
[368], в значительной степени посвященная магистральной обра-
ботке. Архитектура магистральных систем, наряду с другими
вопросами, рассмотрена в [162, 283]. Магистральное выполнение
арифметических операций описано в [790, 791].
Некоторые проблемы магистральной обработки обсуждены в
[615, 1110, 1207]. Краткий библиографический обзор работ но
магистральным системам содержится в [110].
Кроме упомянутых выше ранних систем с чертами магист-
ральной обработки, отметим системы "DEUCE [131, 678, 788], и
PERSEUS [131], в которых умножение и деление выполнялось
спецйальными схемами, действующими независимо от устройства
управления.
5.2. Системы фирмы Control Data
В настоящем разделе рассматриваются, в основном, магист-
ральные системы фирмы Control Data, а также, для лолноты из-
ложения, некоторые другие системы этой фирмы.
5.2.1* Системы CDC 6600 и 7600 и другие системы семейств
CDC 6000 и 7000. Рассмотрим систему CDC 6600 [1118, 1217],
центральный процессор которой является типичным представи-
телем командно-магистральных процессоров. Структурная схема
системы .приведена на рис. 5.2.
Разработка системы была начата в 1960 г., а в 1964 г. систе-
ма CDC6600 была создана. Эта система, со средней производи-
тельностью 3—4 млн. операций в секунду,, предназначена для
решения больших задач научно-технического характера и для
решения в режиме разделения времени небольших задач. Для
решения больших задач в системе реализован высокоскоростной
центральный процессор с операциями с плавающей запятой,
имеющий доступ к центральной памяти большой емкости. Кроме'
этого, было принято не столь очевидное (особенно, с учётом
даты создания системы), но важное решение .об изоляции цент-
рального процессора от всех видов периферийных действий.
В результате окончательно оформилась концепция множества не-
зависимых периферийных процессоров, которая в дальнейшем
получила широкое распространение. Если канал имеет, обычно,
память всего в несколько слов и ограниченный набор специали-
зированных команд, то периферийный процессор — по существу,
вполне законченная, фактически универсальная ЭВМ со своей
памятью и достаточно развитой системой команд. Более того, если
265
работа канала обычно может быть инициирована или прекраще-
на центральным процессором, то на работу периферийного про-
цессора центральный процессор не может оказывать никакого
воздействия и даже не может осуществлять функции контроля.
Все десять периферийных процессоров системы CDC 6600
имеют, с одной стороны, доступ к центральной памяти и, с другой
Периферийные
ввода-вывода
Рис. 5.2. Структурная схема системы CDC6600.
Центральный процессор
Сложеннее
--------> плавающей
запятой
•^Приращение |
^Приращение |
Переход
(ветвление)
стороны, доступ к 12 каналам. Управление работой системы всег-
да осуществляется одним из периферийных процессоров, в то
время как другие периферийные процессоры выполняют функции
обмена. Процессоры могут осуществлять независимые передачи
в центральную память и из Этой памяти.
.Каждый из десяти периферийных процессоров имеет собст-
венную память для программ и буферных зон, что обеспечивает
изоляцию и защиту большинства критических управляющих си-
стемных операций, выполняемых отдельными процессорами.
Центральный процессор оперирует с данными из центральной па-
мяти через перераспределяемые рабочие регистры, при этом осу-
ществляется защита каждой программы в центральной памяти.
Память1 каждого периферийного процессора выполнена на
сердечниках и имеет емкость в 4096 12-разрядных слов. Команды
процессора могут быть 12-разрядными и 24-разрядными, причем
266
обеспечивается прямая, косвенная и «относительная адресация.
Они реализуют логические операции, сложение, вычитание, сдвиг
и условное ветвление. Команды периферийного процессора обес-
печивают передачу одного слова или массива слов к любому из
двенадцати каналов вв^да-вывода и от любого из каналов, а
также к центральной памяти и от центральной памяти. Слово
центральной памяти длиной в 60 разрядов компонуется из пяти
последовательных слов периферийного процессора. Каждый пери-
ферийный процессор имеет команды для прерывания централь-
ного процессора.
Каналы ввода-вывода обеспечивают передачу информации в
прямом и обратном направлении по 12-разрядной линии. Одно
12-разрядное слово может быть передано в том или ином направ-
лении в течение одного главного цикла длительностью 1 мксек.
Поэтому максимальная скорость передачи информации при помощи
всех десяти периферийных направлений равна 120 млн. бит в
секунду. Фактически же скорость передачи информации — около
50 млн. бит в секунду. Каждый канал может обслуживать не-
сколько периферийных устройств и может быть связан с други-
ми системами, такими как ЭВМ-сателлиты.
Центральный процессор системы CDC 6600 представляет со-
бой высокоскоростное арифметико-логическое устройство
(рис. 5.3). Его программа, операнды и результаты помещаются
в центральной памяти. Он не имеет связей с периферийными
процессорами, кроме как через центральную память. Связь осу-
ществляется для обмена при запуске системы и при прерыва-
нии центрального процессора периферийным процессором.
Центральный процессор содержит десять независимых функ-
циональных устройств обработки, двадцать четыре рабочих реги-
стра для данных и адресов и координирующее устройство. Функ-
циональные устройства могут выполнять операции одновременно
в параллель друг другу. Они являются специализированными и
рассчитаны на выполнение сложения с плавающей и с фиксиро-
ванной запятой (по одному устройству), умножения (два устрой-
ства), приращения (два устройства), деления, логических опера-
ций, сдвигов и ветвления для переходов (по одному устройству).
Рабочие регистры разделяются на три группы по восемь регист-
ров в каждой: * 60-разрядные регистры данных (операндов) Х{,
18-разрядные адресные регистры и 18-разрядные индексные
регистры В{ (f = 0, 1, ..., 7). Таким образом, здесь являются спе-
циализированными не только функциональные устройства, но и
регистры, в отличие, например, от регистров общего назначения
в IBM 360/370.
Регистры данных Xj* .. .,• Х$ служат для считывания операн-
дов из центральной памяти, а регистры Хв, Х7 — для записи ре-
зультатов в память. При этом адрес памяти для слова i-ro реги-
стра данных Xi хранится в f-ом адресном регистре (1=1. ...
4.., 7). Индексные регистры используются для модификации
267
Р-рееистр
18-разрядные >
адресные
регистры
18-разрядные
индексные
60-разрядный
стен команд
10-функциональнькв
устройств
сложение
умножение
умножение
деление
сложение с
фиксирован-.
ной запятой
приращение
приращение
логические
£Ц£раци&_
сдвиг
17
___16
15
К
___13
12
11
10
ветвление
1 Буферный
J регистр
MLL
ML.
ио
ч Координирую-
J щееустройство
Регистры
команд
Рис. 5.3. Структурная схема центрального процессора системы CDC6600.
адресов (операции приращения), а также для кратковременного
хранения целых чисел и для преобразований чисел с плавающей
запятой. Регистры и Хо используются для обращения к до-
полнительной части ферритовой памяти. Все операции в функ-
циональных устройствах выполняются над данными из двадцати
четырех рабочих регистров, результаты отсылаются в эти же ре-
гистры соответственно.
Команды загружаются в устройство обработки под управле-
нием P-регистра. Стек команд содержит восемь 60-разрядных
регистров, в которых может разместиться до 32 команд. Команды
могут занимать 15 или 30 разрядов. Команды в 15 разрядов
имеют следующий формат: шесть разрядов отводятся для кода
операции и по три разряда — для адресов результата и двух опе-
рандов. Формат 30-разрядной команды отличается от формата
15-разрядной только тем, что трехразрядное поле одного из опе-
рандов заменяется кодом 18-разрядного операнда. Таким образом,
команды имеют очень простую структуру и, хотя в системе
CDC6600 применяются трехадресные команды, под каждый пря-
мой адрес отводится только по 3 разряда вследствие оперирова-
ния с группами из 8 рабочих регистров, а не с ячейками цент-
ральной памяти.
Команды из стека поступают к трем регистрам команд tZj,
€72, U3, содержимое которых интерпретируется и декодируется
координирующим устройством. Это устройство определяет, ка-
кое функциональное устройство и какие регистры необходимы
для выполнения команды, и, если они готовы для выполнения
команды, направляет данную команду на исполнение. В против-
ном случае команда ожидает готовности к ее выполнению функ-
ционального устройства и соответствующих регистров. Коорди-
нирующее устройство обеспечивает быстрое прохождение команд
и одновременную работу функциональных устройств и рабочих
регистров.
Центральная память организована в виде 32 секций по 4096
слов в каждой, при этом применяется чередование адресов так,
что адреса двух соседних ячеек одной секции отличаются друг
ют друга на величину 32. Адресация возможна каждые 100 нсек
(этот интервал называется малым циклом). Скорость передачи
информации составляет для. центральной памяти, в типичном
случае, около 250 млн. бит в секунду. В принципе, возможно
выполнение команд с завершением каждой из них на очередном
малом цикле за счет параллельности обработки, если нет ника-
ких задержек. При этом команды по отдельности занимают бо-
лее длительные интервалы времени (сложение с фиксированной
занятой — 3, умножение с плавающей запятой —10 и деление
с плавающей запятой — 29 малых циклов).
Схемы системы CDC6600 выполнены на транзисторах.
Таким образом, с точки зрения организации обработки ин-
формации в центральной части система CDC6600 относится к
269
командно-магистральным системам. В части периферийных про-
цессоров, если, рассматривать их связи с каналами ввода-вывода,,
система CDC6600 относится к системам с перекрестным комму-
татором, а если рассматривать их связи с. центральной па-
мятью,— она относится к системам с общей шиной (с разделе-
нием времени шины). В целом CDC 6600 следует отнести к
неоднородным системам с командно-магистральной обработкой»
Преемником системы CDG 6600 явилась система CDC 7600*
созданная в 1968 г. Обе системы имеют близкие структуры*
но вторая содержит двухуровневую. центральную память и об-
ладает в четыре раза более высокой производительностью —
10—15 млн. операций в секунду. ’ Система CDG 7600 длительное*
время была наиболее мощной универсальной вычислительной
системой. Рассмотрим основные характеристики этой системы .
[547, 9761.
Центральный процессор содержит вычислительную секцию*
малую память на сердечниках, большую память на сердечниках
и секцию ввода-вывода. Вычислительная секция оперирует с 60*
разрядными словами в форматах с фиксированной и с плаваю-
щей запятой, причем каждое слово имеет, кроме указанных раз-
рядов, еще 5 разрядов четности. Обработку выполняют 9 неза-
висимых функциональных устройств в параллель друг другу»
Имеется стек команд емкостью в 12 слов, в котором может
находиться от 24 до 48 команд. При выполнении операций ис-
пользуются 24 рабочих регистра (8 адресных, 8 индексных и 8
для операндов). Длительность такта вычислительной секции со-
ставляет 27,5 нсек, в течение каждого такта возможно обраще-
ние к малой памяти.
Малая память на сердечниках имеет емкость в 65 536 слов*
каждое из которых содержит 60 информационных разрядов и 5
разрядов четности. Она разбита на 32 независимых секции па
2048 слов в каждой, причем используется чередование адресов»
Время цикла записи/считывания равно 275 нсек, при макси-
мальной скорости передачи на одно слово затрачивается 27,5*
нсек. Большая память на сердечниках имеет емкость в 512 К
слов, каждое из которых содержит 60 информационных разря-
дов и 4 разряда четности. Она разбита на 8 независимых секций
по 64 К слов в каждой. Время цикла записи/считывания равно
1760 нсек. Одновременно могут считываться 8 слов. При мак-
симальной скорости передачи на одно слово затрачивается
27,5 нсек.
Обычно вычислительная секция работает с малой (сверхопе-
ративной) памятью, куда, при необходимости, «подкачивается»
информация из большой (оперативной) памяти.
Секция ввода-вывода имеет 15 независимых асинхронных
универсальных дуплексных 60-разрядных каналов, каждый из
которых имеет буфер в 64 или 128 слов и обеспечивает переда-
чу-60-разрядного слова за 55 нсек.
270
Вычислительная секция имеет связь с памятью обоих уров-
ней, при этом малая и большая память связаны также и между
собой. Наконец, малая память связана с секцией ввода-вывода,
каналы которой, в свою очередь, связаны с периферийными про-
цессорами. .
Периферийный процессор оперирует с 12-разрядными сло-
нами (имеется также по 1 разряду четности) с использованием
•арифметики с фиксированной запятой. Он построен по синхрон-
ному принципу и работает с тактом в 27,5 нсек. Память пери-
ферийного процессора на сердечниках имеет емкость в 4096 слов.
Она разбита на 2 независимых секции по 2048 слов, время цик-
ла считывания/записи — 275 нсек. В процессоре есть секция
ввода-вывода, содержащая 8 независимых (асинхронных) пол-
ностью дуплексных каналов ввода-вывода шириной в 12 разрядов
в каждом из двух направлений. К каналам ввода-вывода под-
соединяются контроллеры периферийных устройств, к которым,
в свою очередь, подсоединяются периферийные устройства или
же их контроллеры. По 6 периферийных процессоров, наряду с
другим оборудованием, объединяются в центр по обслуживанию
операторских станций. Имеются станции двух типов —для мест-
ного и дистанционного использования системы. Важной особен-
ностью CDC 7600 является впервые введенный срециализиро-
ванный процессор профилактического обслуживания.
В системе CDC7600 используется дискретная элементная ба-
за с плотной упаковкой.
Система CDC7600 имеет сравнительно бедное программное
обеспечение. Оно включало, первоначально, три операционных
•системы, одна из которых — усовершенствованный вариант опе-
рационной системы SCOPE для CDC6600 с переписанными мо-
дулями ввода-вывода, вторая ориентирована на пакетную обра-
ботку больших задач, а третья — на разделение времени. Кроме
этого, были разработаны ассемблер COMPASS и компилятор с
фортрана. Система команд CDC6600 целиком входит в систему
команд CDC 7600, при этом программы на второй системе вы-
полняются в 4—8 раз быстрее. Следует отметить, что в целях
разгрузки ‘центрального процессора подготовку программ можно
осуществлять на периферийных процессорах CDC 7600. Так, на-
пример, компиляция с фортрана на периферийном процессоре CDC
7600 осуществляется с такой же скоростью, что и на CDC 6600.
В дальнейшем на CDC7600 были реализованы алгол, кобол и
введены другие усовершенствования программного обеспечения.
В заключение Описания систем CDC6600 и 7600 отметим, что
на их базе создавались многомашинные системы. Структурная
схема одной из таких систем изображена на рисунке 5.4 [447,
588, 589].
Системы CDC6600 и 7600 являются основными представите-
лями семейств CDC6000 и 7000 соответственно и характеризует-
ся высокой степенью распараллеливания операций зй счет коман-
271
дно-магистральнои организации их центральных процессоров*’
В остальном структуры этих систем и других систем семейств
CDC6000 и 7000 достаточно близки друг к другу.
В состав семейства CDC 60001 входят системы CDC 6200, 6400,
6500, 6600 и.6700.
Наличие периферийных процессоров — характерная черта
структуры систем фирмы Control Data. Так, например, в системе
CDC*6400 с одним функциональным устройством было 10 перифе-
рийных процессоров.
Л термина- К терминальным
лам минимашинам
Рис. 5.4. Упрощенная структурная схема вычислительной системы Лос-Ала-
мосской лаборатории на базе CDC 6600/7600.
Система С DC 6500, созданная в 1966 г., имеет в своем соста-
ве два процессора типа CDC 6400 с общей, основной памятью,
причем оба процессора одновременно управляются единственной
копией операционной системы. Оперативная память может иметь
емкость в 64 К или 128 К 60-разрядных слов. Каждый из двух
центральных процессоров имеет 24 рабочих регистра. В состав
системы входят 10 периферийных управляющих процессоров,
каждый из которых имеет свою память емкостью в 4 К 12-раз-
рядных слов, 12 дуплексных каналов со скоростью передачи дан-
ных в 2 млн. шестибитовых символов в секунду, центральная
память, разбитая на секции по 4 К 60-разрядных слов. Длитель-
ность большого цикла обращения к памяти равна 1 мксек, а ма-
лого цикла — 0,1 мксек, причем слова могут записываться в па-
мять или считываться из нее каждый малый цикл. Программное
обеспечение включает операционную систему для CDC 6400/6500/
/6600, в которой специально учтены условия работы со сдвоен-
ными процессорами [612].
Сдваивание процессоров применено также в созданной в
1967 г. системе CDC 6700, которая состоит из двух моделей — CDC
6400 (6600) и CDC6600 [281, 283, 744]. Эта система, как и CDC
272
6500, имеет общую оперативную память и управляется единст-
венной копией операционной системы. Наконец, фирма Control
Data вела разработку системы С DC 6800, близкой по структуре
к CDC 6600, но с более высокой производительностью." Эта систе-
ма, однако, не была доведена до серийного выпуска и вместо нее
стала выпускаться система CDC7600 [218].
В семействе CDC7000, кроме рассмотренной системы CDC
7600, отметим созданную в 1974 г. систему CDC7700, которая
состоит из двух центральных процессоров CDC7600 с общей опе-
ративной памятью и может работать с производительностью до»
20—30 млн. операций в секунду [283, 314].
5.2.2. Системы семейств CYBER 70 и 170. На смену системам:
семейств CDC6000 и 7000 фирма Control Data начала в 1972 г.
выпуск совместимых с ними систем семейства CYBER 70, одно-
процессорные системы которого CYBER 72, CYBER 73, CYBER 74
и CYBFR 76 с точки зрения программирования и организации
структуры почти эквивалентны системам CDC6200, 6400, 6600,.
7600 соответственно. Первые три из указанных систем семейства
CYBER 70 могут иметь по два процессора. В этом случае системы
CYBER 73 и CYBER 74 почти эквивалентны системам CDC6500k
и CDC6700 соответственно [281, 384]. Если процессоры систем
CYBER 74 и CYBER 76 выполняют команды параллельно, подоб-
но CDC6600 и CDC7600, то процессоры систем CYBER 72 и
CYBER 73 выполняют команды последовательно с небольшим
перекрытием за счет считывания последующей команды во время
выполнения предыдущей.
Структурная схема систем CYBER 72, CYBER 73 и CYBER 74
изображена на рисунке 5.5 [6061. Эти системы имеют двухвходо-
вую память и могут иметь один или два центральных процес-
сора, количество периферийных процессоров в каждой из си-
стем —10, 14, 17 или 20. Максимальная скорость передачи ин-
формации через один вход памяти равна 2000 К байт в секунду.
Эта же величина составляет максимальную скорость црредачи
информации для периферийного процессора. На каждый пери-
ферийный процессор приходится по одному каналу ввода-выводаг
а на каждый канал, в свою очередь,—по одному контроллеру
ввода-вывода. Связь между периферийными устройствами и ос-
новным оборудованием осуществляется при помощи перекрестно-
го коммутатора. Каждый контроллер может обслуживать до 8-
периферийных устройств.
Основная память может содержать 16, 24 или 32 независи-
мых секции 60-разрядных слов в каждой с чередованием адресов,
от секции к секции, т. е. имеет обычную для систем CDC струк-
туру. Ее емкость равна 64 К, 96 К или 128 К слов соответствен-
но. В центральном процессоре имеются, как обычно, три группы
регистров для адресов, индексов и операндов по 8 регистров в.
каждой. Длина команд систем равна 15, 30 или 60 разрядов.
Скорость выполнения команд системами CYBER 72, CYBER 75-
18 Б, А, Головнин
273
я CYBER 74, для одного процессора (двух процессоров) равна 0,9
(1,5); 1,2 (2,0) и 3,0 (3,7) млн. операций в секунду соответствен-
но. Два периферийных процессора используются для реализации
«функций операционной системы SCOPE, при этом один из них
работает как монитор вычислительной системы и как ее управля-
ющий процессор, а второй — как процессор связи между дисплей-
ным пультом оператора и системой [281, 384].
Рис. 5.5. Структурная схема систе^ CYBER 72, CYBER 73, CYBER 74. 1
•
Система CYBER 76, как и CDC 7600, имеет двухуровневую
оперативную память (рис. 5.6) [606]. Емкость «малой» памяти на -
биполярных ИС — от 64 К до 128 К, а емкость «большой» массо-
. вой памяти на сердечниках — от 256 К до 512 К 60-разрядных
о лов. Количество входов памяти, как и количество периферийных
процессоров, равно 6—15. Мультиплексор способен обеспечивать
работу периферийных процессоров, даже если все они работают
одновременно. Скорость передачи может быть от 36000 К до
90000 К байт в секунду в зависимости от числа одновременно
работающих периферийных процессоров, при этом максимальная '
скорость передачи для одного периферийного процессора равна |
6000 К байт в секунду. Каждый периферийный процессор обслу-
живает (Удин канал ввода-вывода, который, в свою очередь, обслу- *3
^ивает один контроллер ввода-вывода. К каждому контроллеру 1
ввйда-вывода подсоединяется до 8 периферийных устройств. Про- J
274
изводительность системы составляет до 15 млн. операций в
секунду.
В 1976 г. в рамках семейства CYBER 70 была создана систе-
ма CYBER 71 (самая младшая модель семейства), которая яв-
ляется упрощенным и более дешевым вариантом системы CYBER
72. Система CYBER 71 может содержать один или два централь-
ных процессора с 24 регистрами в каждом и имеет производи-
тельность 1,2 или 2 млн. операций в секунду соответственно^
Основное оборудование
Рис. 5.6. Структурная схема системы CYBER 76.
Емкость оперативной памяти составляет от 64 К до 256 К 60-
разрядных слов. Память разбита на 16 независимых модулей с
чередованием адресов, время цикла модуля — 1 мксек. В памяти
обнаруживаются двойные и исправляются одиночные ошибки.
В систему входят 10—20 периферийных процессоров, каждыиг
из которых имеет свою оперативную память емкостью 4 К 12-
разрядных слов с временем цикла 1 мксек и от 12 до 24 каналов
ввода-вывода. В режиме разделения времени система обслужива-
ет до 500 терминалов 1112, ИЗ]»
18* 27&
В 1975 г. фирма Control Data начала выпуск семейства f
CYBER 170 на смену семейству CYBER 70 и на 1977 г. в соста- 1
не семейства были системы CYBER 171, CYBER. 172, CYBER ?
173, CYBER 174 и CYBER 176. Эти системы совместимы с си-
стемами семейства CYBER 70 и, с точки зрения структуры и
программирования, почти эквивалентны им, но имеют усовер-
шенствованную оперативную память.
Система CYBER 171 производительностью 0,8 млн. операций
в секунду имеет оперативную память емкостью в 64 К — 256 К
4
60-разрядных слов, один или два центральных процессора и 10—
20 периферийных процессоров. Система CYBER 172 имеет па- ?
мять первого уровня емкостью в 32—128 К и второго уровня
(массовая память) — емкостью в 2048 К 60-разрядных слов. Си- |
стема CYBER 174 имеет оперативную память первого уровня |
емкостью в 64 К — 256 К и второго уровня — емкостью в 2048 К J
00-разрядных слов, в ее состав входят один или два центральных 1
процессора, время цикла синхронизации — 50 нсек, входные язы-
ки — алгол, фортран, кобол, basic, PL/1, APL, RPG, jovial. Такие ।
же параметры памяти и входные языки у систем CYBER 173 и 1
CYBER 175 (в последней время цикла синхронизации равно *
25 нсек). Память первого уровня реализована на МОП-схемах,
а массовая память второго уровня — на сердечниках [314]. з
Наиболее мощной из указанных систем является CYBER 176, 1
предназначенная для замены систем CDC 7600 и CYBER 76.
Она с точки зрения структуры почти эквивалентна заменяемым |
системам, полностью программно совместима с ними, имеет, как |
и они, один командно-магистральный центральный процессор с
9 независимыми функциональными устройствами и стеком ко-
манд на 12 60-разрядных слов (с предварительным просмотром
двух команд) и обеспечивает такую же производительность до .
15 млн. операций в секунду, но память системы усовершенствова- ;
на и имеет существенно увеличенную емкость: 128—256 К 60-раз- Э
рядных слов первого уровня на биполярных элементах и 512— <
2048 К 60-разрядных слов второго уровня (массовая память) на сер-
дечниках. Как и в других системах семейства, в оперативной па-
мяти автоматически обнаруживаются двойные и исправляются ]
одиночные ошибки. При работе системы CYBER 176 по классу ]
систем CDC 7600 и CYBER 76 она содержит до 14 периферийных ,
процессоров, а при работе ' по классу своего семейства
CYBER 170 —до 20 периферийных процессоров. Один или два <
процессора системы CYBER 176 могут служить ядром системы, Л
к которому может быть подключена периферийная система из Я
10—20 других процессоров семейства CYBER 170 [113J. Я
В заключение отметим, что появились сообщения о предпола- Я
гаемом объявлении двух следующих больших универсальных Я
систем QYBER 177 и CYBER 178 [113]. Кроме этого, появились Ц
сообщения [577] о новой серии 700 систем 720, 730, 750 и 760 Я
семейства CYBER 170, которая^ должна выпускаться с 1979 г. Я
.276
Системы этой новой серии имеют два типа центральных процес-
соров — стандартный и рабочий, построенные на базе схем с
эмиттерными связями. Минимальная емкость оперативной памя-
ти систем —96 К 60-разрядных слов. В системах предусматри-
вается подсистема дистанционного управления»
5.2.3. Система STAR 100. Разработка системы STAR 100 фир-
мой Control Data осуществлялась с 1965 по 1973 гг. После соз-
дания системы фирма с 1973 г. в течение нескольких лет прово-
дила ее модернизацию. STAR 100 (STring ARray computer) яв-
ляется сверхвысокопроизводительной вычислительной системой
с арифметико-магистральной обработкой информации, обеспечи-
вающей обработку со скоростью до 100 млн. операций в секун-
ду. Если в таких системах, как IBM 370/195 и 470V/6 приме-
няется арифметико-магистральная скалярная обработка, а в си-
стемах CDC 6600, CDC 7600, CYBER 76 и SYBER 170 — команд-
но-магистральная скалярная обработка, то в STAR 100, также
как и в ASC и CRAY 1,— арифметико-магистральная векторная
обработка, что обеспечивает в рамках магистрального способа
дополнительное существенное увеличение производительности за
счет обработки упорядоченного множества величин как единого
операнда.
Рассмотрим структуру и функционирование системы STAR
100 1826, 1193] (рис. 5.7).
Система содержит две основных независимых магистрали, ко-
торые подобны друг другу, но не являются идентичными. Третья
магистраль является специальной. Первая магистраль содержит
магистральное устройство сложения с плавающей запятой и м«н
гистральное устройство умножения с плавающей запятой. Вто-
рая магистраль содержит магистральное устройство сложения о
плавающей -запятой, немагистральное устройство деления с пла-
вающей запятой и магистральное многоцелевое устройство, которое
может выполнять умножение с фиксированной запятой, деление
и извлечение квадратного корня. Эти магистрали построены так*
что через каждые 40 нсек на выходе каждой из них появляются
в результате векторной обработки одно слово удвоенной длины
(64 разряда) или же двД слова обычной для системы длины
(32 разряда). Поэтому две магистрали обеспечивают получение
четырех результатов в виде 32-разрядных слов на каждом цикле
в 40 нсек, т. е. максимальная производительность системы
равна 100 млн. операций в секунду для 32-разрядных фор-
матов. Время выполнения отдельной операции сложения с пла-
вающей запятой и умножения с плавающей запятой равно 160 нсек
и 320 нсек соответственно. Структурная схема магистрального
устройства сложения с плавающей запятой приведена на рис. 5.8.
Это устройство выполняет операции в четыре этапа. Специальная
магистраль имеет ширину в 16 разрядов и выполняет арифметиче-
ские операции с фиксированной запятой, операции объединения
и специального редактирования, операции перемещений и другие.
277
Оперативная память системы выполнена на магнитных сер-1
дечниках и имеет, как основной вариант, емкость в 512 К
64-разрядных слов (плюс 2 контрольных разряда). За счет допол- <
нительной памяти ее емкость может быть удвоена. Память имеет j
32 модуля (банка) с чередованием адресов, каждый из которых? 1
содержит 2048 512-разрядных суперслов. Цикл памяти равен 1
1,28 мксек. Этот цикл состоит из 32 малых циклов (по числу мо- *
дулей), каждый из которых имеет длительность 40 нсек. Таким ;
УлрсЯленсе '
нонснЯсме
г
Яереая мпоосп?-
роль олерпоео
с плсЯанпее#
залял/оо
Ялюроя мш/ст-
роль елерщие
С ллоУанмцее
ЗЯЛЯЛ700
Укрепление
0ХО&Н6/М
полюном
fyfiepOMt
СчолшЯа-
/fire
Gvanwftr-
с ное
СчолшУе-
ное
Золось r
Залом
Учены-
Яснее
Слецеелънея
него&лроль
УлраДееное
—* м/коаным
--> ПОНТОНОМ
ФойлоЗые
реыстры
УлроЯле-
ймирмн
ломято
Золем
ж» JIII
W ЛкЕВ,
/7ОМЯЛ7Ь не
СфЯООНенаХ
(вжцй
емносл?ью
Я/К*М
яяа
f-i--— —I I
.4 ДОЛОЛНО- ft ]
J мольная i 1
J ЛСМИЛ/Ь e J ,
j
Рис. 5.7. Структурная схема системы STAR 100.
образом, система памяти из 32 модулей обеспечивает передачу 1
512 бит информации за 40 нсек с учетом перекрытия, В системе 1
используется виртуальная адресация. 1
Каждые 4 модуля объединены в секцию, общее число кото- ]
рых равно 8 (см. рис. 5.7). Каждая секция использует 132-раз- j
рядную (2X64 + 2X2) шину для обмена данными с устройст- J
вом управления доступом к памяти. Восемь таких шин (8 для :
считывания и 8 д^я записи) комплексируются устройством уп- ]
равления доступом к памяти так, что обесдечивается тройной 1
доступ для считывания и двойной доступ для записи. Возмож- 1
ности двух доступов для считывания и одного доступа для запи- J
си достаточны, чтобы обеспечить работу двух магистралей с |
плавающей запятой с производительностью, равной 3/4 макси* 1
мальной производительности. Важно отметить, что в системе ис* |
пользуется регистровая память (файлов) емкостью в 256 64-раз* |
рядных с^гов. |
278
Структурная схе*
сложения с плаваю-
запятой системы
STAR 100.
Рис. 5.8.
ма магистрального устрой-
ства
щей
В функции управления потоком входит управление потоком
операндов и команд между устройством управления доступом к
памяти, магистралями и устройством управления командами.
Последнее имеет буфер опережающего просмотра команд
емкостью в 4 суперслова со стековым механизмом рабо-
ты [826, 1193].
Система STAR 100 имеет набор из 230 команд, причем около
65 команд предназначены для работы с векторами и 130 ко-
манд—для работы со скалярами. В качестве основного языка
программирования используется расширенная версия фортрана
для векторной обработки. Используется также язык APL-STAR
и другие. Эти языки, соответствующие компиляторы, ассемблер,
операционная система и комплект обслуживающих программ вхо-
дят в состав программного обеспечения STAR 100 (112, 283].
К 1977 г. фирма Control Data .выя-
вила более 12 возможных пользовате- Выход
лей системы STAR 100 и установила
4 системы: 2 — в Ливерморской радиа-
ционной лаборатории им. Лоуренса
(Калифорния), 1 — в исследователь-
ском центре NASA в Лэнгли и 1 — в
одном из центров вычислительной се- t
ти CYBERNET фирмы Control Data
около-г. Арден Хилз (штат Миннесота).
При этом в последнем случае STAR
100 функционирует в комплексе с ма-
шиной CDC 6400, используемой как
входной процессор, и имеет оператив-
ную память емкостью 4 М байт, кото-
рая должна быть удвоена, и внешнюю
память на дисках емкостью более
2,5 млрд, байт [63, 112, 2831.
К концу семидесятых годов в ре-
зультате модернизации STAR 100 дол-
жен быть создан вариант STAR 100А
с использованием больших интеграль-
ных схем с эмиттерной связью и полу-
проводниковой памяти, в котором про-
изводительность скалярной обработки
в 6 раз выше по сравнению с STAR
100, а также вариант STAR 100С с
увеличенной в 4 раза производитель-
ностью векторной обработки по сравнению с STAR 100. В обоих
вариантах модернизации емкость оперативной памяти должна быть
доведена до 16 М байт (2 М 64-разрядных слов) [63, 112, 283].
В 1979 г. в печати появились сообщения [371, 611] о произ-
водстве фирмой Control Data новой сверхмощной системы
CYBER 203 производительностью, как и STAR 100, в 100 млн.
279
операций в секунду, которая" первоначально называлась STAR
100А. Эта система, как и STAR 100, использует векторную обра-
ботку, имеет ту же систему команд и полностью совместимое с
STAR 100 программное обеспечение, но, в отличие от STAR 100,
CYBER 203 содержит новый обычный (скалярный) процессор,
обеспечивающий в 6 раз более быструю скалярную обработку, ;
оперативную память емкостью до 2М 64-разрядных слов и име- -
ет скорость выборки из памяти до 100 млрд, бит в секунду. В си-
стеме применены современные большие интегральные схемы, что |
должно повысить ее надежность. Система CYBER 203 должна 1
быть подключена к сети CYBERNET. Анонсированием этой си- |
стемы фирма представляет семейство своих наиболее мощных J
суперсистем. i
В начале 70-х годов сообщалось о разработке системы CDC
8600 (называемой также SUPERSTAR) производительностью в
4 раза более высокой, чем STAR 100 1218]. В системе предусмат- I
ривалось до 16 центральных процессоров, четыре из которых
могли бы обеспечить производительность в 150 млн. операций в
секунду, что в 10 раз превышает производительность CDC 7600. ’
Наконец, фирмой Control Data рассматривался по заказу
Эймского научно-исследовательского центра NASA проект соз- :
дания системы. производительностью в 1 миллиард операций в 1
секунду (в 100 раз более мощной по сравнению с CDC 7600> -
со сроком окончания разработки в начале восьмидесятых годов. >
Такую сверхвысокую производительность предполагается достиг- J
путь при помощи восьми параллельных магистральных процес- <
соров со сложной структурой [ИЗ].' J
5.2.4. Библиографическая справка. Фирма Control Data извест- Я
на как разработчик высокопроизводительных и сверхвысокопро- Я
изводительных систем. С 1960 г. она выпустила системы семейств Я
CDC 3000, CDC 6000, CDC 7000, CYBER 70, CYBER 170 и си- Я
стему STAR 100. Характерной особенностью этих наиболее из- Я
вестных систем фирмы является ориентация на наиболее быстрое Я
решение задач научно-технического характера. Фирма создала Я
и наращивает свою вычислительную сеть CYBERNET, основу Я
центров обработки которой составляют системы семейств CYBER. /Я
Из систем семейства CDC 6000 наиболее широко в литерату- Я
ре представлена система CDC 6600. Она описана в дважды из- Я
данной ключевой статье [1217] и в посвященной ей книге [1218L |я
Описание центрального процессора системы CDC 6600 дано
[1118]. Система CDC 7600 рассмотрена в ключевых статьях [547,JH
976], в [297, 333, 688]; в последней значительное внимание уде-]я
лево операционной системе SCOPE 76. Описание системы GDC^M
6700 и ее программного обеспечения содержится в [1238]ЛЯ
а краткое изложение характеристик системы CDC 6500 в [612]ё|я
В ряде книг, наряду с другими вопросами, рассмотрены си^М
стемы фирмы Control Data: в [1621—CDG 6600, CDC 7600Йи
STAR 100; в [218] - CDC 6600, CDC 7600, CDC 6800, CDC 8600»
280 »
STAR 100, системы -семейств CYBER 70 и 170 и. другие; в
[2811 -CDC 6600, CDC 6500 и CYBER 72, 73, 74; в [3841-си-
стемы семейства CYBER 70; в [738, 947] — CDC 6600. В рабо-
тах обзорного характера описаны: в [311 —CDC 7600; в [3511 —
CDC 7600 и STAR 100; в [441, 842, 1155] — CDC 6600; в [447,
588, 5891 — комплекс систем CDC 6600 и 7600; в [6061 — системы
CYBER 72, 73, 74, 76; в [7431 — комплекс систем CDC 6400 и
6600 с разнотипными операционными системами; в [8801 — CDC
6600 и 7600, а также STAR 100; в [966] - CDC 6600 и 7600;
в 11223]—STAR 100.
Программное обеспечение системы CDC 6600, включая опера-
ционные системы и систему программирования, рассмотрено в
149, 381, 453, 508, 595, 618, 768, 804, 861, 863, 869, *941, 974,
1039, 1040, 1144, 1224]. Описаны различные версии операцион-
ной системы SCOPE, которая широко применяется в различных
системах фирмы Control Data, операционная система SIPROS,
система разделения времени SHARER, входной язык pascal и
его реализация на CDC 6600, язык высокого уровня для системы
разделения времени CDC 6600 и другие компоненты програм-
много обеспечения.
Планировщик заданий для CYBER 76, работающий на CDC
3600, описан в [4761. Древовидные структуры планирования вы-
полнения заданий на магистральных и некоторых других парал-
лельных системах (CDC 6600, CDC 7600, IBM 360/91,' IBM 360/195,
STAR 100, ASC, PEPE) исследованы в [933]. Вопросы вектори-
зации, включая приложения для программ- на фортране, иссле-
дованы в [930, 11211; при этом в качестве систем для векториза-
ции рассматриваются CDC 7600, STAR 100, ASC, CRAY 1.
Исследование и сравнение некоторых программных моделей,
реализованных на CDC 6500, CDC 7600, STAR 100 и РЕРЕ, вы-
полнено в [451, 900, 995].
Исследованию функционирования и оценке характеристик
CDC 6600 посвящены работы [769, 944, 1151, 1189, 1275]. Мо-
дели системы CDC 6400, построенные при помощи сетей Петри
и Е-сетей, описаны в цикле статей [1022—1024].
Система STAR 100, как и CDC 6600, описана в обширной ли-
тературе. Не повторяя сделанных выше ссылок на некоторые' ра-
боты, в которых рассматривается STAR 100, отметим следующее.
Описание STAR 100 содержится в ключевой статье [8261. Исто-
рия STAR 100 и переход от кода CDC 7600 к коду STAR 100
рассмотрены в [818]. Системе STAR 100 и ее отдельным уст-
ройствам посвящены статьи [587, 630, 636, 830, 833, 875, 8901,
а также часть материала книг и обзорных статей [31, 63, 152,
283, 864, 523, 874, 927, 935, 1112, 1193, 1211, 1223],
Результаты измерения производительности STAR 100 описа-
ны в [11051: при работе системы с 32- и 64-разрядными числами
с плавающей запятой производительность оказалась свыше
50 млн. операций в секунду, при этом решаемая задача соответ-
281
ствовала структуре STAR 100. Существует точка зрения, что про*
ектная производительность системы в 100 млн. операций в секун-
ду фактически не была достигнута [1131: в 1977 г. STAR10O
обеспечивала выполнение 26 и 60 млн. операций в секунду с 64-
разрядными и 32-разрядными словами, причем в обоих случаях для
полностью векторизованных программ.
Проблема построения и примеры реализации программного*
обеспечения для STAR 100 рассмотрены в [5071 (язык SL/1,
напоминающий PL/1), [807, 902, 915, 1280] (расширенный форт-
ран, диалект фортрана Irltran, трансляция), [1278] (расширенно
алгола 60 — язык ALA), [665, 1124, 12271. Некоторые вопросы
программирования и примеры реализации программ решения
разнообразных задач на STAR 100 рассмотрены в [675, 761, 764,.
914, 958, 1026—1028, 1049, 1180]. Вопросы обучения пользова-
телей работе на STAR 100 обсуждаются в {90U. Новые системы
фирмы Control Data описаны в [112, 113, 371, 577, 61U.
5.3. Системы IBM 360/91 и IBM 360/195
Система IBM 360/91 (см. таблицу 3.5) была создана в 1967 г.
В целом она является неоднородной многопроцессорной системой.
Система характерна тем, что имеет независимые арифметико-ма-
гистральные устройства для выполнения сложения/вычитания и
умножения/деления с плавающей запятой, входящие в устройст-
во выполнения операций с плавающей запятой [415, 493]. В ней
реализован принцип перекрытия, т. е. одновременного выполнения
нескольких соседних команд, находящихся на разных последова-
тельных стадиях выполнения, таких как выборка команды, де-
кодирование команды, генерация адреса операнда, выборка опе-
ранда'и собственно исполнение команды [459]; такая организа-
ция потребовала введения буферов устройств системы для сгла-
живания потоков информации между ними. В системе реализова-
но чередование адр'есов при обращении к основной памяти.
Структурная схема центральной части системы IBM 360/91
изображена на рис. 5.9 [459]. На этой схеме под данными пони-
маются команды и операнды, а после названий буферов в скоб-
ках указаны их размеры. Буфер выборки команд имеет емкость
в 8 64-разрядных (двойных) слов. Буфер операндов с фиксиро-
ванной запятой имеет емкость в 6 32-разрядных слов, а буфер
операндов с плавающей запятой —Л 64-разрядных слов. Буфер
данных памяти, рассчитанный на 64-разрядные операнды, соот-
ветствует буферу адресов памяти и оба они имеют емкость в 3
слова. Эти два буфера вместе с буфером конфликтных обращений
к памяти (4 слова) обеспечивают управление работой памяти.
Наконец, имеются буферы «операций» с фиксированной и плаваю-
щей запятой емкостью в 6 и 8 слов соответственно.
Система IBM 360/195 (см. таблицу 3.5), являющаяся стар-
шей и наиболее мощной моделью семейства IBM 360, была соз-
282
дана в 1971 г. Она совместима с другими машинами сёмейства,
имеющими универсальный набор команд семейства IBM 360.
В ней используются магистральная обработка в параллельно рабо-
тающих устройствах и улучшенный по сравнению с IBM 360/91
вариант одновременного выполнения команд с перекрытием,
а также улучшенная буферная память IBM 360/85. В системе со-
хранены лучшие магистральные алгоритмы IBM 360/91 для опе-
раций с плавающей запятой и введены новые аппаратно реали-
зованные алгоритмы сложения для параллельных десятичных
Мо&уЛЯ ееЯО&ШШ ЛЯМЯЯШ
Даяяые
Данные
(8)
/лелея
ffe/rrf-
леяяя
(V
ж,
ЛЯЯЛ/Off
лаяялш
(4)
ЮДеСЛ#
яямялф
(8)
яыг/мг-
МЯЛ7Я
(3)
ал ер ял ~
Мсляя^
оянмцеЯ
зялялю#
УмпдойслМл улряЯле/шя
УСЛ/ДЯЛЛЛМЛ
Ядлюллеляя
лледацяя
я р/л«м/де-
мшй,
зяллл/оя
Яел/дляел/^л
Яа/лаляеяяя
елед/шяя
е лляяям-
щей ' *
залял/ля
Рис. 5.9. Структурная схема центральной части системы IBM 360/91.
операций. Пять основных устройств системы реализуют свои от-
дельные функции и работают одновременно * и независимо друг
от друга, сохраняя при этом целостность программы. Структур-
ная схема центральной части системы изображена на рис. 5.10
I1014J (буферная память входит в блок управления памятью).
Основная память на магнитных сердечниках состоит из 8, 16
или 32 модулей с быстрым доступом, каждый из которых имеет
емкость 128 К байт с циклом 756 нсек. Вариант памяти с сум-
марной емкостью в 1 М байт имеет 8-кратное чередование адре-
сов, а варианты с емкостью в 2 М и 4 М байт — 16-кратное
чередование адресов. Буферная память (кэш-память), обеспечива-
ющая более быстрый обмен информацией с устройствами обработ-
ки, выполнена на монолитных полупроводниковых элементах. Она
имеет емкость в 32 К байт и цикл, равный одному (трем) циклу
работы центрального процессора, т. е. 54 нсек (162 нсек). Буфер-
ная память программно не адресуется, т. е. программист адресует
основную память так, как будто буферной памяти не существует.
Фактически наличие буферной памяти резко уменьшает частоту
283
обращения к основной памяти, поскольку основная обработка ве-
дется с информацией из буферной памяти. Если же запрашивае-
мой информации нет в буферной памяти, то организуется обра-
щение к основной памяти при помощи аппаратно реализованного
алгоритма.
Блок управления памятью работает по принципу конвейера
и обеспечивает 8-кратное или 16-кратное перекрытие обращений
к основной памяти и возможность обработки с перекрытием в.
центральном процессоре, а также управляет обменом с буфер-
ной памятью и с каналами ввода-вывода. .
Центральный процессор включает в свой состав устройство*
выполнения операций с плавающей запятой, устройство выполне- ]
ния операций с фиксированной запятой и операций десятичной |
арифметики, а также процессор команд. Во втором из указанных
устройств предусмотрены операции над полями переменной дли-
ны. Центральный процессор ^имеет цикл работы длительностью в
54 нсек, обрабатывает 64-разрядные слова, при этом „форматы ;
чисел в зависимости от типа арифметической операции могут .
быть 32-, 64- или 128-разрядными. Стек для опережающего про- *
смотра команд имеет емкость в 64 байт. Имеются 16 регистров
общего назначения и четыре регистра для операций с плаваю- *
щей запятой [977, 10141.
Рис. 5.10. Структурная схема центральной части системы IBM 360/195.
В системе IBM 360/195 в каждом цикле памяти осуществляв^
ется: выборка до восьми команд, декодирование 16 команд, 'Я
могут быть начаты до трех индексных операций, центральный!
процессор может начать выполнение до трех операций, однако,9
в каждом цикле может выполняться только одна операция ветв-Я
ления. Одновременно в центральном процессоре может находить-^
ся на различных этапах выполнения до 50 команд [11461. Я
Библиографическая справка. Описание системы IBM Ц
360/91 дано в [459]; эта система и ее устройства описаны такжеИ
в [466, 546, 729]. Сведения о системе IBM 360/91 содержатся в-1
обзорах [880, 966, 1112, 11551; структура и характеристики си-
стемы приведены в [606J.
Описание системы IBM 360/195 дано в [977, 1014, 11461. Эф-
фективный алгоритм умножения, реализованный в системах,
представлен в [12251. Сведения о системе IBM 360/92, структура
которой имеет сходные черты со структурой системы IBM
360/91, содержатся в [4111.
5Л Система MU 5 [8491
MU 5 является пятой вычислительной системой, созданной и
Манчестерском университете (MU — Manchester University, 5 —
пятая система). Из предыдущих систем наибольшую известность
получила система Atlas, в которой впервые был решен ряд узло-
вых вопросов построения структуры и программного обеспечения
вычислительных систем.
MU 5 представляет собой экспериментальную систему с ма-
гистральной Обработкой в главном процессоре системы и с ап-
паратно реализованными в нем командами высокого уровня.
Работа над проектом была начата в 1966 г. В 1972 г. оборудова-
ние системы было установлено в Манчестерском университете.
Система начала работать с середины 1974 г., когда стало возмож-
ным выполнять программы, написанные на алголе^и фортране,
под управлением операционной системы [8491.
В процессе проектирования и реализации системы в ее кон-
цепцию были внесены некоторые изменения, однако, базовые
принципы первоначального проекта были сохранены. Наиболее
важный из них состоит в том, что внутренняя структура систе-
мы, определяемая машинным кодом, должна отражать структуру
языков программирования. .В качестве таких языков были выбра-
ны алгол и фортран. При этом была поставлена задача построить
такую систему, производительность которой в 20 раз выше, чем
у системы Atlas за счет: а) улучшенной технологической базы;
б) перекрытия во времени операций, реализующих выполнение
команды (магистральная обработка); в) более экономного и эф-
фективного машинного кода; г) улучшений, по сравнению с си-
стемой Atlas, в операционной системе для повышения ее произ-
водительности, в частности, улучшения организации ядра про-
граммного обеспечения и более экономного управления мульти-
программной работой и вводом-выводом [849].
В системе используются два основных формата команд, один
из которых предназначен для функций вычислений, а другой,—
для функций организации вычислений [849]. При выполнении
команды различаются два класса операндов: именованные опе-
ранды, которые могут быть вещественными и целыми числами
или дескрипторами массивов, и элементы массивов. Учитывая,
что в программах на алголе и фортране около 80% всех обраще-
ний к операндам составляют обращения, к именованным операн-
285
Лам, в состав процессора системы введена ассоциативная память ]
-емкостью в 52 слова для хранения именованных операндов, ис- ’
пользуемых в данный момент времени [848, 1201].
Аппаратно реализованные команды высокого уровня, обеспе-
чивающие, в частности, обращение к переменным и массивам по
имени и возможность построения машинных программ в виде
совокупности независимых процедур, способны к самостоятель-
ному выполнению некоторых участков программ на алголе и
фортране, хотя в целом компиляция остается необходимой [570Г.
Структурная схема системы MU 5 изображена на рис. 5.11
1849]. Основу системы составляют процессор MU 5 и местная па-
мять, которые соединены между собой непосредственно и через
^коммутатор. В процессоре MU 5 реализована магистральная об-
работка с одновременным выполнением до 7 команд. Местная
Рис. 5.11. Структурная схема системы MU 5.
память состоит из .четырех стеков с циклом в 260 нсек, каждый
-стек имеет емкость в 2 К 128-разрядных слов (плюс дополни-
тельные разряды четности). При нормальной работе в стеках .
используется чередование адресов, однако, в случае отказа од- d
ного или более стеков осуществляется их реконфигурация щ J
с точки зрения отказоустойчивости, каждый стек целесообразно
использовать как самостоятельное устройство. , i
Массовая память выполняет функции следующего уровня па-1
мяти nociie местной памяти и функции буфера для информации, 1
которой обмениваются процессоры системы. Она состоит из двух
стеков на магнитных сердечниках емкостью в 128 К 32-разряд-
.286
ных слов и имеет цикл в 2,5 мксек. Передача блоков информа-
ции между местной и массовой памятью осуществляется под уп-
равлением устройства управления обменом блоками информации.
Следующим уровнем памяти являются диски с фиксированной
головкой. Эта подсистема памяти имеет свой блок передачи ин-
формации с высокой скоростью и рассчитана на 4 диска, при:
этом 3 установленных диска имеют суммарную емкость в 8 И
байт. Машины 1905Е и PDP-11/10 выполняют функции перифе-
рийных процессоров системы MU 5.
Монитор системы представляет собой специализированное
устройство для сбора, обработки и регистрации в удобном для
использования виде информации о функционировании системы
в целях ее анализа и определения условий наиболее эффектив-
ной работы системы. Он имеет 16 32-разрядных счетчиков и па-
мять емкостью в 512 16-разрядных слов, разработана библиотека
процедур монитора. Монитор может подключаться как одно из;
устройств к коммутатору, он может получать необходимую ин-
формацию о работе системы в режиме регистрирующего устрой-
ства, а также в режиме промежуточного устройства в тракте пе-
редачи информации между компонентами системы.
Основное устройство обработки процессора MU 5 обеспечива-
ет производительность до 20 миллионов операций в секунду. Ре-
зультаты измерений, выполненные при прогоне программ для
оценки производительности, показывают, что система MU 5 ра-
ботает в 10 раз' быстрее, чем система Atlas. Если рассматривать/
уровень алгол-программ и учитывать, что фактор замедления
выполнения программ системой Atlas относительно этого уровня
равен примерно 2, то (как считают разработчики) можно сде-
лать вывод, что для алгол-программ производительность системы
MU 5 в) 20 раз превышает производительность системы Atlas>
1849]. •
Операционная система MU 5 организовывает виртуальные ма-
шины, каждая из которых может создавать другие виртуальные
машины. Все функции управления заданиями могут выражаться
на языках высокого уровня, поэтому специальный язык управле-
ния заданиями не нужен [741]. Комплекс программ диагностики
и .реконфигурации обеспечивает диагностику ошибок, а также
реконфигурацию системы в процесое обслуживания пользовате-
лей й по запросу оператора. В случае прерывания выполнения
программ (требующих длительного прогона) из-за реконфигура-
ции обеспечивается возобновление их выполнения с контроль-
ных точек [919].
Операционная система разрабатывалась для «идеальной ма-
шины» на специальном языке высокого уровня для системного-
программирования. Реализация такой базовой операционной си-
стемы возможна на различных машинах при помощи настройки
переменных интерфейсов. Следует отметить, что реализация ба-
зовой операционной системы на MU 5 оказалась достаточно эф-
287
фективной. Более того, концепция «идеальной машины» лозво- J
.лила реализовать базовую операционную систему также и на си- 1
«темах ICL 2900 и В 7700 [1001]. * 1
Библиографическая справка. Проект системы MU5 |
€ыл впервые изложен в 1968 г. на конгрессе IFIP [887]. Описа- j
ние системы дано в ключевой статье [1202], а описание маги-
страли команд —в [846]. Система MU 5 рассмотрена также в ра-
<5отах [921, 1000, 1201, 12041, а ее устройства и подсистемы —в а
[472, 686, 847, 848, 889, 919, 998, 1184, 1266]. Программное обес- •
печение системы и некоторые вопросы программирования для
лее изложены в [275, 569—571, 741, 844, 997, 999]. .
На конгрессе IFIP в 1977 г. была сделана серия итоговых ч
докладов по системе MU 5 [920, 1001, 1214, 1272] Аннотации
^тих докладов содержатся в обзоре [1611. Развитие концепции
системы MU 5 и итоговая конфигурация системы описаны в [849].
5.5. Система ASC .
Система ASC (Advanced Scientific Computer) фирмы Texas
Instruments является большой многопроцессорной арифметико-
магистральной системой и предназначена для решения научно-
технических задач, требующих очень большого объема вычисле-
ний. Характерней особенностью системы является объединение
принципов построения многопроцессорных систем и магистраль-
ных систем: в конфигурацию ASC может входить до 4 мощных
идентичных арифметических магистралей, работающих над об-
щей оперативной памятью.
Работы над проектом ASC были начаты в 1966 г. Поставка j
первой системы была осуществлена в 1972 г., а в 1973 г. эта I
первая система была введена в рабочий режим [1247]. По дан- 1
ным на 1975 г. было произведено семи систем ASC, из числа ко- I
торых пять являются одномагистральными, одна — двухмаги- 1
«тральной и еще одна — четырехмагистральной [1188]. - •
Структурная схема системы изображена на рис. 5.12 [1247]. «
Основными устройствами системы являются центральная память, .
центральный процессор, периферийный процессор, массовая па- '
мять, периферийное оборудование с устройствами сопряжения
и подсистема цифровой связи.
. Центральная память содержит устройство управления па- ’
мятью и модули высокоскоростной или среднескоростной цент- *
ральной памяти. Устройство управления центральной памятью «
организовано в виде двусторонней сети каналов обмена парал- :
лельно 256 разрядами (8 32-разрядных слов) между 8 независи- '
мыми процессорными входами и 9 шинами памяти, причем каж-
дый процессорный вход имеет доступ ко всем модулям памяти. •
Девять йшн памяти обесценивают 8-кратное чередование адресов '
для первых 8 шин и, дополнительно, с 9-й шиной, используемой
для дополнительной центральной памяти (эта память и ее шина
288
Уешп/ммьжм /ягнят
»►
о
й
о
Е
s
S
Рис. 5.12. Структурная схема системы ASC с четырехмагистральным центральным процессором < данные приведены для
32-разрядных слов). ; ..
на рис. не показаны). Устройство управления центральной па*
мятью обеспечивает управляемый доступ со стороны 8 процессор-
ных входов к центральной памяти, имеющей 24-разрядное адрес*
ное поле для 16 М слов. В целях увеличения числа процессорных
входов используются расширители входа памяти..
Модули полупроводниковой высокоскоростной центральной
памяти имеют цикл длительностью 160 нсек и время чтения
140 нсек. Все передачи осуществляются блоками в составе 8 32-
разрядных слов (256 разрядов) с защитой при помощи кода Хем-
минга, обеспечивающего исправление ошибок в любом одном
разряде и обнаружение ошибок в любых двух разрядах каждого
32-разрядного слова.
В типичном случае центральная память состоит из 8 модулей
одинаковой емкости в 128 К 32-разрядных слов (суммарная ем-
кость 1 М слов) с 8-кратным чередованием адресов. Эта память,
может быть расширена при помощи подключения к устройству
управления центральной памяти дополнительной центральной
памяти емкостью в 1М слов через устройство управления по-
следней. К этому устройству подсоединяются 8 среднескоростных
модулей памяти с чередованием адресов между ними.
Центральный процессор обеспечивает выполнение как ска-
лярных, так и векторных команд. Основные команды содержат
по 32 разряда и оперируют с 16-, 32- или 64-разрядными операн-
дами. При этом, за некоторым исключением, возможны операции
как с фиксированной, так и с плавающей запятой^ Поток команд,
содержащий смесь из скалярных и векторных команд, проходит
предварительную неарифметическую обработку в устройстве об-
работки команд, которое распределяет их между магистралями.
В состав центрального процессора могут входить 1, 2, 3 или
4 идентичных магистрали, каждая из которых содержит буфер-
ную память и арифметическое устройство (АУ). Эти магистрали
работают в режимах скалярной и векторной обработки с опере*
жающим просмотром операндов. Непрерывность работы маги-
стралей поддерживается при помощи двойной буферизации. Одна
магистраль может одновременно обрабатывать 12 скалярных
команд.
В режиме векторной обработки она выполняет одну вектор-
ную команду каждые 60 нсек, т. е. для четырехмагистральной
конфигурации обеспечивается в благоприятном случае получение
результата каждые 15 нсек.
В результате измерений, выполненных при прогоне программ
для оценки производительности, установлено, что ASC работает
в 8,2 раза быстрее, чем IBM 360/91. Принимая в качестве услов-
ной единицы производительность системы IBM 360/65, в [12471
установлены следующие соотношения производительности меж-
ду вычислительными системами: S(ASC) = 41; SUBM 360/195) =
= S(CDG ‘ 7600) =8; S(IBM 360/95) = 7; S(HITAC 8800)==
«== S(IBM 360/91) = 5; S(IBM 370/165) = 3,5; S(CDC 6600) = 2,5;
290
S(CDC 6500) = S(IBM 360/75) = 1,5; S(IBM 360/65) = 1, где че-
рез S обозначена относительная производительность в условных
единицах той системы, наименование которой указано в скобках.
Арифметическое устройство магистрали (рис. 5.13) содержит
восемь секций обработки, каждая из которых выполняет свой
этап обработки за 60 нсек. Оно имеет основной цикл работы
также длительностью в 60 нсек. На рис. 5.13 показано, как ис-
пользуются различные секции устройства для выполнения сло-
жения с плавающей запятой и умножения с фиксированной за-
пятой. Арифметическое устройство представляет собой 64-pa3pa/r-
ное параллельное устройство обработки для большинства ска-
лярных и векторных команд. Исключениями являются умножение
64-разрядных чисел и все виды деления. В этих случаях исполь-
зуются специальные комбинации секций, а для выполнения
соответствующих операций
требуется более одного цик-
ла работы устройства [1247].
Таким образом, если ма-
гистрали системы STAR 100
являются неидентичными,
хотя две основные магистра-
ли STAR 100 и близки доуг
к другу, то магистрали си-
стемы ASC — идентичные,
что обеспечило модульность
структуры центрального про-
цессора ASC (1, 2, 3 или 4
магистрали). Принцип мо-
дульности лежит в основе
также структуры централь-
ной и других видов памяти
ASC, периферийных и дру-
гих устройств, подсистемы
которых традиционно явля-
ются модульными в различ-
ных системах.
Рланежге * Рюныге/ше
с я/пМающеи i । с фшсщюбм-
80ЛЯ/Ю# || /W зсглялге#
I Рхядмш реЫМф |
‘ I 1
^юмгю&щряйиМ\ I
I I
I | *
----. J
| Ушмеме |
Z3__________L_
I Рлмгеяяе |
| 1
\ Рярюллзсщля | ।
| Ршяллыяе | |
----“3___________£Z----J
РыхяРI
f ~~ r-J
Резуль/псг/п Результат
Периферийный процессор
является мощной многопро-
цессорной системой и вы-
полняет функции управле-
ния заданиями и данными,
называемых виртуальными,
качестве общих для них устройств арифметическое устройство,
устройство обработки команд, буфер центральной памяти и па-
мять периферийного процессора, работающую только в режиме
считывания. Последняя имеет ёмкость в 4 К 32-разрядных слов
и используется как память программ. В ней хранятся короткие
часто используемые процедуры, которые должны быстро выпол-
Рпс. 5.13. Структурная схема арифме-
тического устройства магистрали сис-
’ темы ASC.
Он содержит восемь процессоров,
Эти процессоры используют в
49*
291
пяться периферийным, процессором. Массовой памятью системы
ASC. являются, диски с головкой на тракт.
Подсистема связи управляется концентратором данных, ко-
торый подсоединяется к устройству управления памятью через
устройство управления' каналом. Периферийные устройства яв-
ляются стандартными. Состав периферийных устройств и
устройств, подсоединяемых к ASC через подсистему связи, может
изменяться в широких пределах.
В состав программного обеспечения системы входит язык
фортран с векторными операциями и оптимизирующий компиля-
тор ASG НХ с этого языка, рассчитанный па 1, 2, 3 и 4 маги-
страли, библиотека математических подпрограмм, метаассемблер,
редактор связей, язык описания заданий и универсальная опе-
рационная система ASC с модульной структурой [12471.
Сравнивая системы ASC и STAR 100, можно отметить, что
обе они имеют страничную память и контроль по четности, при-
чем в ASC, в отличие от STAR 100, применяются корректирую-
щие коды Хемминга и лучше организовано перекрытие скаляр-
ных команд, тогда как в STAR 100, в отличие от ASC, имеется
виртуальная адресация и более широкий набор форматов слов
[11931.
Библиографическая справка. Описание системы
ASC дано в ключевой статье [1246]. Это описание переизложено
с некоторыми изменениями и с добавлением разделов о про-
граммном обеспечении, о вводе и применении первых четырех
установок ASC, а также а производительности ASC в [1247].
Примерно это же описание, кроме двух последних дополцитель-
ных разделов, содержится в [281]. Краткое описание ASC при-
ведено в [31, 43, 44, 152, 283, 364, 454, 1112, 1118, 1193, 1211,
1223, 1245].
Некоторые вопросы построения, анализа и оптимизации обо-
рудования и программного обеспечения ASC рассмотрены в [755,
760, 829, 1050, 1188, 1249].
£.6 Система AMDAHL 470 V/6 [409, 457^
Фирма Amdahl, создавшая систему 470 V/6, основана в
1970 г. бывшим руководителем отделения перспективных систем
фирмы IBM, главным конструктором машин IBM 704, 709 и 7030
и архитектуры семейства IBM 360 Дж. М. Амдалом (G. М, Ат-
dahl). В 1975 г. фирма начала поставки заказчикам образцов
своей первой системы — большой универсальной магистральной* j
системы четвертого поколения 470 V/6, которая имеет в 2 раза j
более высокую производительность, в 2 раза ббльшую емкость i
памяти и занимает в 3 раза меньшую площадь по сравнению с J
.такой мощной системой, как IBM 370/168 (по состоянию на J
292
1975 г.), причем по стоимости первая система незначительно
уступает второй. Время цикла центрального процессора системы
470V/6 равно 32,5 нсек. Длина слова —32 разряда.
Особенности системы 470 V/6 обусловлены широким примене-
нием в процессоре и вхканалах БИС, а также использованием
сравнительно простого магистрального способа обработки. Си-
стема содержит основную память, центральный процессор, кана-
лы ввода-вывода, пульт управления и устройство распределения
электроэнергии. Система охлаждения — воздушная. Конструктив-
но 470 V/6 состоит из трех устройств: стойки основного оборудо-
вания (включающей процессор, основную память и каналы вво-
да-вывода), пульта управления и устройства распределения
электроэнергии (полное название системы — AMDAHL 470V/6).
Восемь вариантов комплектации основной памяти обеспечи-
вают емкость непосредственно адресуемой памяти в пределах от
1 М байт до 8 М байт. Применение чередования адресов в основ-
ной памяти большой емкости в сочетании с быстродействующей
буферной памятью делает доступ к памяти гибким и эффектив-
ным. В состав системы могут входить до четырех устройств основ-
ной памяти емкостью 1 М байт или 2 М байт каждое, ми-
нимальное приращение памяти составляет'модуль емкостью 1 М
байт. Для конфигурации памяти с четным числом модулей ис-
пользуется 4;кратное чередование адресов, а для конфигурации
с нечетным числом модулей в последнем из них чередование
2-кратное, а для всех предыдущих — 4-кратное.
В основной памяти исправляются одиночные ошибки (в од-
ном разряде) и обнаруживаются двойные ошибки (в двух разря-
дах). Кроме этого, контролю на четность подвергаются все дан-
ные, посылаемые в буферную память и, наконец, контроль по
четности применяется для всех адресов основной памяти. Если
устройство памяти емкостью 2М байт выдает ошибочную инфор-
мацию, не поддающуюся исправлению, то тот модуль емкостью
1 М байт данного устройства, который выдает эту информацию,
выводится из рабочей конфигурации, а второй модуль такой же
емкости остается в рабочей конфигурации.
Быстродействующая буферная память (кэш-память) имеет
емкость в 16 К байт. Передача информации между этой памятью
и основной памятью осуществляется при помощи аппаратно реа-
лизованных алгоритмов строками длиной по 32 байта за 4 цик-
ла, а между буферной памятью и центральным процессором —
словами длиной по 4 байта за один цикл. Каждый запрос к <па-
мяти обрабатывается буферной памятью. Имеется возможность
модификации данных в самом буфере, а также возможность
предварительного вызова информации в буфер. В системе пре-
дусмотрено расчленение буфера для исключения из работы от-
казавшего участка буфера.
Виртуальная память разбита на сегменты емкостью 64 К
байт или 1024 К байт, которые, в свою очередь, разбиты на стра-
293
ницы емкостью 2 К байт или 4 К байт. Преобразование программ-
ных адресов в адреса ячеек памяти осуществляют средства ди-
намической трансляции. Для преобразования адресов использу-
ются таблицы сегментов и страниц, размещаемые в основной
памяти. В целях ускорения преобразования, чтобы не задержи-
вать центральный процессор, применяются транслирующий по-
исковый буфер емкостью в 256 слов и стек формирования таб-
лиц сегментов емкостью в 32 слова, т. е. до 31 виртуальных
устройств памяти могут иметь текущую определяющую их ин-
формацию в стеке.
Основная память выполнена на МОП БИС, а буферная па-
мять — на сверхбыстродействующих биполярных компонентах.
Время цикла буферной памяти равно времени цикла централь-
ного процессора, а время цикла основной памяти — в 10 раз
больше.
Центральный процессор выполняет арифметические и логи-'
ческие операции и управляет работой памяти и каналов. Он по-
строен по арифметико-магистральному принципу и осуществля-
ет обработку в 6 этапов, т. е. одновременно на различных после-
довательных фазах выполнения может находиться до 6 команд.
Функции процессора распределены между командным и испол-
нительным блоками.
Командный блок осуществляет выборку и буферизацию ко-
манд, а также обработку команд (декодирование команды, уп-
равление магистралью, генерирование исполнительных адресов,
направление команд в исполнительный блок и в каналы ввода-
вывода, обработка результатов выполнения команд, обработка
прерываний). В командном блоке все команды проверяются на
четность.
Команда обычно определяет 12 отдельных операций и занима-
ет в благоприятных случаях один машинный цикл вслед-.
ствие магистральной организации работы, хотя от начала и до
конца выполнения одной команды требуется не менее 12 циклов:
3 цикла для выборки, не менее 2 циклов на каждую из трех пер-
вых фаз и не менее 1 цикла на каждую из трех последних фаз *
обработки.
Набор команд системы 470V/6 включает в свой состав уни-
версальный набор команд систем семейства IBM 370 с команда-
ми для операций с виртуальной памятью и три новых дополни-
тельных команды.
Исполнительный блок выполняет команды, поступившие от
командного блока, он содержит четыре части: умножитель, сум-
матор, сдвигатель и передатчик байтов. Операнды, используемые
при выполнении команды, поступают от командного блока или
от основной памяти в зависимости от места их формирования
(общие регистры, командный блок или основная память). Ин-
формация, получаемая в результате работы исполнительного бло-
ка, направляется в командный блок.
£94
Центральный процессор выполнен на биполярных логических
схемах с эмиттерной связью.
В состав стандартной конфигурации 470 V/6 входят 16 кана-
лов ввода-вывода, каждый из которых может быть организован
как байт-мультиплексный, блок-мультиплексный или селектор-
ный. К 470 V/6 может быть подключено любое устройство, сов-
местимое со стандартным интерфейсом ввода-вывода систем се-
мейств IBM 360 и 370. Каналы 470 V76 являются внутренними
по отношению к центральному процессору системы, однако, их
логика не зависит от логики процессора.
Система 470 V/6 может использовать все программное обес-
печение систем семейства IBM 370 и выполнять прикладные
программы для систем этого семейства (за исключением кодов,
изменяемых во времени, и кодов, являющихся специфическими
для конкретной модели IBM 370).
Совместимость системы. 470V/6 с системами семейства
IBM 370 по системе команд, программному обеспечению и пери-
ферийному оборудованию, а также ее преимущества по произво-
дительности, памяти и занимаемой площади перед старшими
моделями семейства IBM 370, обеспечили заказы на установку
системы 470 V/6 взамен систем семейства IBM 370, причем для
пользователей эта замена оказывалась безболезненной, так как
не требовала перепрограммирования ранее разработанных про-
грамм.
Для большинства больших вычислительных систем процесс
их ввода занимает от нескольких недель до нескольких месяцев.
Время ввода системы 470 V/6, от момента поставки системы за-
казчику до момента начала прогона программ пользователей в
обычном эксплуатационном режиме, сокращено до 1—5 суток
(обычно составляет 24—48 час.). Для первой системы это время
составило 5 суток, а одна из систем была введена за 17 часов.
Такое сокращение времени ввода достигнуто за счет высокого
качества элементной базы и конструкции системы, а также бла-
годаря специально разработанной диагностической системе
AMDAC в сочетании со встроенными в 470 V/6 дополнительны-
ми схемами контроля.
Система AMDAC установлена в здании фирмы Amdahl в
г. Саннивейле (Калифорния) и обслуживает системы 470 V/6,
размещенные на территории Северной Америки. AMDAC по-
строена на базе системы 470 V/6 и стандартной телефонной ап-
паратуры, при помощи Которой эта система диагностики может
быть подключена к удаленной системе 470 V/6, может получать
от нее информацию о текущем состоянии технических средств и
быстро и точно установит/, причину отказа. После рбнаружения
неисправности отказавший модуль в системе 470 V/6 заменяется
исправным.
После выпуска. первых систем 470 V/6 фирма Amdahl нара-
щивала темп их производства, вносила некоторые усовершенство-
295
вания в эту систему и осуществляла разработку новых моделей
1113, 302, 314].
На конец 1977 г. было установлено более 80 систем 470 V/6.
Было произведено сравнение производительности процессоров
470 V/6 и IBM 370/195 на контрольном пакете из 200 задач в ус-
ловиях примерно одинаковых конфигураций систем, чтобы в
наибольшей степени исключить влияние периферийного обору-
дования на сравнительную оценку производительности собствен-
но процессоров. Оказалось, что на основном классе работ про-
изводительность процессора 470 V/6 выше на 15—20%. По дан-
ным из различных источников производительность системы
470 V/6 составляет от 4,5—5 до 7—9 млн. операций в секунду.
Начиная с 1977 г. фирма Amdahl объявила о выпуске моде-
лей 470 V/5, 470 V/5-2, 470 V/6-2, 470 V/7 и 470 V/8 (начало
поставок — в 1977, 1979, 1977, 1978 и 1979 гг. соответственно),
совместимых с 470 V/6 и с IBM 370. Модели 470 V/5, 470 V/6
и 470 V/7 имеют емкость буферной памяти (кэш-памяти) 16 К,
16 К и 32 К байт соответственно, тогда как соответствующие им
модели 470V/5-2, 470V/6-2 и 470 V/8 имеют удвоенную буфер-
ную память, т. е. по 32 К, 32 К и 64 К байт соответственно. За
счет этого каждая модель нового выпуска имеет на 10% более
высокую производительность по сравнению с соответствующей
ей моделью предыдущего выпуска. Производительность младшей
модели 470V/5 примерно на 25% ниже, а производительность
модели 470 V/7 —примерно на 75% выше по сравнению с 470 V/6.
При этом 470 V/7 имеет увеличенную оперативную память —от
4М до 16 М байт. В старшей модели 470 V/8 длительность внут-
реннего цикла сокращена до 26 нсек, что дополнительно повы-
шает ее производительность на 10%, а за счет использования
предварительной выборки данных производительность повышена
еще на 3—5%. Таким образом, высокопроизводительные модели
семейства фирмы Amdahl перекрывают достаточно широкий диа-
пазон производительности [113, 302, 314].
Библиографическая справка. В [409, 457] приве-
дены примерно одинаковые описания системы 470 V/6, краткие
описания даны в [458, 1112]; этой системе посвящена также
статья [689]. Новые системы фирмы Amdahl кратко представле-
ны в [113, 302].
5.7. Система CRAY 1
Фирма Cray Research основана в 1972 г. бывшим главным
конструктором систем CDC6600 и 7600 С. Креем (S. Cray), ко-
торый вел также работы по созданию CDC8600 и возглавлял
разработку, системы CYBER 76. В 1976 г. фирма установила в
Лос-Аламосской научной лаборатории первый образец своей
первой системы CRAY 1 с памятью 512 К слов. По данным на
конец 1977 года, установлено два образца системы и на три образ-
296
ца имеются заказы [283, 314]. В системе нашли отражение и раз-
витие многие принципы, использованные ранее в CDC66OO и
7600.
CRAY 1 является сверхвысокопроизводительной системой, ос-
нованной на магистральном принципе векторной и скалярной
обработки информации. Она предназначена для решения слож-
ных научных и технических задач. По производительности эта
система эквивалентна пяти IBM 370/195. Результаты измерений,
полученные при прогоне программ для оценки производительно-
сти, показывают, что при полном использовании вычислительных
возможностей системы она обеспечивает производительность
138 млн. операций с плавающей запятой в секунду, а на некото-
рых коротких по времени пиках производительности обеспечива-
ет производительность 250 млн. операций с плавающей запятой
в секунду [1139]. Производительность системы в среднем оцени-
вается величиной в. 80 млн. операций в секунду [314].
Такая высокая производительность достигнута благодаря ор-
ганизации структуры системы, обеспечивающей как одновремен-
ное выполнение вычислений в нескольких магистралях, так и,
что не менее важно, возможность объединения магистралей в
разнообразные цепочки с передачей данных от одной магистрали
к другой через их регистры без отсылки в* память. Магистрали
в системе — короткие, что‘ существенно облегчает проблему , их
заполнения. Система выполняет как скалярные, так и векторные
операции, причем одновременно могут выполняться по нескольку
как скалярных, так и векторных операций [1139].
Другими особенностями системы, повышающими ее вычисли-
тельное возможности, являются следующие: малые размеры си-
стемы, в результате чего электрические сигналы внутри системы
распространяются на короткие расстояния, что, в свою очередь,
позволило 4 достигнуть длительности цикла работы системы в
12,5 нсек; полупроводниковая память емкостью до 1М 64-р>аз-
рядных слов с обнаружением и коррекцией > ошибок (вначале
был предусмотрен только контроль по четности); оптимизирую-
щий транслятор с фортрана. Возможность построения цепочек
магистралей и развязка устройств обработки от памяти обеспе-
чивается наличием большого числа регистров. .
Малые размеры системы естественно отражают принцип, что
с уменьшением размера повышается скорость работы. Конструк-
тивно система выполнена в виде 12 клинообразных стоек высо-
той 196 см, расположенных по дуге в 270° внутри окружности
диаметром 263 см, причем на высоте 48 см диаметр окружности
уменьшается До 144 см. Охлаждение в системе — фреоновое,
В системе используется достаточно отработанная и ранее прове-
ренная элементная база, причем применяется всего четыре типа
кристаллов [1139].
Структурная схема системы CRAY 1 изображена на рисунке
5.14 [12231. Система подразделяется на четыре функциональные
297
секции: управления программой, функциональных устройств,
регистров, памяти и ввода-вывода;
Лидаг ЛЛООЛОАЛТО^
I Jfegrwy MUfUWO "1
. У
fr
/7л&ы&мие
"филнциемглмые
?ееие
&#& ц
fo
tytfe/w ломтмО
Тёлцил
лезислулсО
"Ж.
07
£L
£L
У Осилил
j /нглллши
S ООиОи-ОыОе&Г
целых
wee# (2)
Унныге/ше целых
чисел (О)
Олелиции
о aOpecuw
Al _______
>£_
A3
AU
$r—
~aT .
♦ ЛЙЯЯИ0/#
ЗШ-
077
1L
ZL
Ммилы
(72 ОхиОмых;
720ыхе0еых)
ОыОсО
Оли^елие целых
wve/> №________
ЛУеечеслие
елеиеции(7)
СООиа(2 или 3)
Очетчил (3)
so
Sf
777
777
Ьгслядлые слелиции
ОцЫГеЛСе ($)
ЗЁ2*
Гу
/I
f I леаиыплы
МцигОле-
лее
ООсОмч-
O&Oetfwr
1Г
Tfape/fiWUI?
о
6
^лилгелие (7)
Оычислелие ифмглг-
лои Оеличилы(74)
Олелиции и ллеои/ё^
/цел зиллтлеО
Олмхелие целых
чисел (3)
Лееичеслие
елелйциии)
ОЙ7ее(4)
^ех/лцлеые
ллериццО^
TL
XL
У7О
7777
Оеллусллые Лееиыули/
Рис. 5.14. Структурная схема системы CRAY 1 (количества регистров даны
в восьмеричной системе счисления).
Память’системы, емкостью до 1М слов организована в виде
16 независимых банков емкостью в 64 К слов каждого. Каждый
банк, в свою очередь, содержит 72 модуля памяти, причем каж*
298
дый модуль хранит один разряд всех слов данного банка. Таким
образом, слово содержит 72 разряда, из числа которых .64 — ин-
формационные и 8 — контрольные для исправления одиночных
и обнаружения двойных ошибок в слове (при первоначальной
реализации системы были только разряды четности).
Наличие 16 независимых банков позволило организовать
16-кратное чередование адресов, время цикла одного банка рав-
но четырём циклам системы, т. е. составляет 50 нсек [1139].
Система осуществляет векторную и скалярную обработку
64-разрядных слов и выполняет операции с плавающей и фикси-
рованной запятой при помощи 12 функциональных устройств,
организованных в виде четырех групп устройств: для адресных
операций, скалярных операций, операций с плавающей запятой
и векторных операций (см. рис. 5.14). Каждое функциональное
устройство представляет собой магистраль, сегменты которой
выполняют свою функцию за один цикл (т. е. за 12,5 нсек). Ко-
личество циклов, затрачиваемых сегментами устройств, указано
в скобках после наименования устройств на рисунке 5.14. Каж-
дое функциональное устройство может выдавать результаты на
каждом цикле работы. Все функциональные устройства могут
работать одновременно, т. е. в дополнение к магистральной об-
работке в каждом устройстве осуществляется также обработка
информации этими устройствами в параллель друг другу. В си-
стеме нет устройства деления. Деление с плавающей запятой
выполняется в CRAY 1 при помощи устройства вычисления об-
ратной величины и основано на алгоритме приближения, ранее
использовавшемся в IBM360/91 [1139].
Основной набор регистров с программным доступом состоит
из: 1) 8 24-разрядных адресных А-регистров; 2) 64 24-разрядных
промежуточных адресных В-регистров; 3) 8 64-разрядных ска-
лярных S-регистров; 4) 64 64-разрядных промежуточных скаляр-
ных Т-регистров; 5) 8 64-элементных векторных V-регистров,
причем каждый элемент вектора есть 64-разрядное слово (см,
рис. 5.14). Эта регистровая высокоскоростная память (6 нсек)
имеет суммарную емкость в 4888 байт.
Функциональные устройства для получения операндов и от-
сылки результатов используют только А-, S- и V-регистры. На-
личие емкой и быстрой регистровой памяти является принципи-
альным фактором структуры системы. Нельзя организовать це-
почки функциональных устройств, если векторные регистры пе
готовы к временному хранению промежуточных или итоговых
результатов. В- и Т-регистры существенно повышают скорость
скалярной обработки. Скорость передачи для В-, Т- и V-регист-
ров равна одному слову за цикл, а для А- и S-регистцов — одно-»
му слову за два цикла. Если не использовать В-, Т- и V-ре-
гистры как память для кратковременного хранения данных, то
пропускная способность системы в 80 млн. слов в секунду будет
существенно ограничивать производительность.
29Q
Команды системы могут иметь одну или две 16-разрядных
части. Секция функциональных устройств обрабатывает коман-
ды с максимальной скоростью в одну часть за цикл. Арифмети-
ческие, логические и некоторые другие команды имеют формат
в виде одной части, при этом код команды занимает 7 разрядов,
адрес регистра для результата — 3 разряда и адреса регистров
для двух операндов — по 3 разряда, причем последние могут
объединяться в 6-разрядную комбинацию для адресации В- или
Т-регистров. Эти же шесть разрядов в совокупности с 16 разря-
дами второй части используются для адресации основной памяти,
как непосредственный операнд и в командах ветвления, когда
требуется формат команды в виде двух частей. Система команд
содержит 128 основных команд. В целях ускорения'выполнения
команд йредусмотрена их буферизация при помощи четырех бу-
феров команд емкостью в 64 16-разрядных частей команды в
каждом. Скорость передачи для буферов команд равна четырем
словам за цикл, т. е. до 16 команд за цикл.
Кроме рассмотренных пяти групп основных регистров, в си-
стеме имеется программно управляемый регистр, устанавливаю-
щий необходимую для обработки длину вектора, 64-разрядный
регистр маскирования векторов, разряды которого соответствуют
элементам векторных регистров, 64-разрядный регистр часов ре-'
ального времени и другие регистры. В системе осуществляется
управление приоритетными прерываниями.
Арифметические операции с фиксированной запятой выпол-
няются над 24- или 64-разрядными форматами. Для выполнения
арифметических операций с плавающей запятой под мантиссу
отводится 49 разрядов, а* под порядок —15 разрядов, что обеспе-
чивает очень большой диапазон представления чисел от Ю”2500
до 10+2500. ' . .
Ввод-вывод осуществляется через 24 канала, организованных
в виде 4 групп по 6 каналов в каждой, причем в группу входят
либо каналы ввода, либо каналы вывода. Каждая группа каналов
обслуживается памятью с периодом в 4 цикла, приоритетность
каналов устанавливается внутри группы. Обмен осуществляется
16-разрядными форматами данных, причем предусматриваются
контрольные, разряды. Максимальная скорость передачи для ка-
нала равна одному 64-разрядному слову в каждые 100 нсек.
Максимальный поток информации имеет скорость передачи
500 тыс. 64-разрядных слов в секунду. Для эффективной связи
CRAY 1 с внешним миром (для дистанционной пакетной обра-
ботки) применяется периферийная машина.
Операционная система COS (Cray Operating System) рас-
считана на пакетную обработку до 63 задач в мультипрограм-
мном режиме. Оптимизирующий транслятор CFT (Cray Fortran
Compiler) с языка ANSI 66 FORTRAN IV учитывает некоторые
Особенности параллельной векторной обработки в системе CRAY 1,
в дальнейшем возможности распараллеливания программ транс-
300
лятором будут расширены. В программное обеспечение входят
также макроассемблер CAL (Cray Assembler Language), библио-
тека стандартных программ, загрузчик и другие средства [11391.
Таким образом, структура системы CRAY 1 сочетает в себе
как черты командно-магистральной структуры, поскольку имеет
(как и CDC6600 и CDC7600) набор функциональных устройств,
так и черты арифметико-магистральной структуры, поскольку
имеет в качестве функциональных устройств устройства арифме-
тико-магистральной обработки, в том числе векторной обработки,
как это имеет место в устройствах обработки STAR 100 и ASC.
Таблица 5.1
Основное характеристики систем STAR 100, ASC, CRAY 1
Система STAR 100 ASG CRAY 1
Длина командного слова, раз- рядов . 32 и 64 32 16 и 32
Длина слова данных, разрядов 1,8, 32, 64 и 16, 32, 64 64
128
Основная память
максимальная емкость [М байт] 4(8) 4(8) 8
время цикла [нсек] 1280- 160 50
пропускная способность [Мбайт7сек] Центральный процессор 1600 1600 640
состав устройств обработки 2 неидентич- 1—4 иден- 12 специали-
- ных магистра- тичных ма- зированных
* ii гистрали магистраль- ных уст- ройств
время цикла, нсек 40 60 12,5
число векторных регистров — 8—32 . 8
число слов в векторном ре- гистре — 1 64
суммарная емкость регистров 262 8—32 524
[слов] (многоцелевые (специализи-
регистры) рованные ре- гистры)
Максимальная скорость вы- полнения операции для 64-раз- рядных форматов [млн. оп./сек]: 37 80
сложение 50
умножение 25 21 80
Однако, в отличие от последних систем, в CRAY 1 могут образо-
вываться разнообразные цепочки магистралей.
Фирма Cray Research разрабатывает новую более мощную
систему CRAY 2 с предполагаемой производительностью в
200 млн. операций в секунду; перрая поставка системы, планиру-
ется на 1980 г. 1112, 314].
301
Представляет интерес сравнение характеристик трех наиболее
мощных магистральных систем STAR 100, ASC и CRAY 1. Соот-
ветствующие данные приведены в таблице 5.1 [112, 1223]. Ия
таблицы видно, что память STAR 100 медленнее, чем у двух дру*
гих систем. Этот недостаток в определенной степени компенси-
руется тем, что обмен осуществляется широкоформатными су-
персловами. Это, в свою очередь, требует особого внимания к
упорядочению данных в памяти. Вместе с тем в STAR 100 суще*
ственно более развита регистровая память по сравнению с ASC.
Система CRAY 1 практически по всем показателям существенно
превосходит системы STAR 100 и ASC.
Библиографическая справка. Подробное описание
системы CRAY 1 содержится в [1139]. Эта система описана так-
же в [112, ИЗ, 162, 218, 283, 433, 872, 1018, 1112, 1156, 1168,
1223].
Некоторые вопросы оценки системы и программирования для
нее рассмотрены в [509, 737, 767, 876].
Кроме тех магистральных систем, которые рассмотрены в на-
стоящей главе, в литературе содержатся сведения о ряде других
такого рода системах — см., например, [963, 1113, 11321.
6. МАТРИЧНЫЕ, АССОЦИАТИВНЫЕ И ПОДОБНЫЕ
ИМ СИСТЕМЫ
6.1. Концепция и ранние системы
•
Матричные и ассоциативные системы и системы с ансамблем
процессоров являются типичными представителями систем клас-
са ОКМД — с одиночным потоком команд и множественным по-
током данных. Эти системы имеют одно устройство управления,
которое интерпретирует команды и управляет синхронным вы-
полнением этих команд параллельно работающими обрабатываю-
щими устройствами. Таким образом, каждое устройство оперй-
рует со своими данными, а система в целом — с большими
массивами упорядоченных данных. Для матричных систем эти
массивы представляют собой матрицы слов, для систем с ансамб-
лем процессоров, фактически,— векторы слов, а для ассоциатив-
ных систем, обычно — наборы двоичных разрядов. Отклонения
от синхронного выполнения, как правило, небольшие. Так, на-
пример, в матричных системах применяется маскирование, по-
зволяющее учитывать размеры конкретных массивов данных.
Обработка упорядоченных массивов данных присуща не толь-
ко системам класса ОКМД, но и магистральным системам век-
торной обработки. Разница в том, что в первом случае элементы
вектора подаются на обработку как бы параллельно друг другу,
а во втором случае — один за другим с перекрытием в магистрали.
В наиболее высокопроизводительных из существующих си-
стем —• STAR 100, ASC, CRAY 1 (магистральных), PEPE (с ан-
самблем процессоров), ILLIAC IV (матричной) — использовав
принцип векторной обработки. В последнее время введено поня-
тие поколений векторных систем, при этом STAR 100, ASC, PEPE
(первоначальная модель) и ILLIAC IV обычно относят к первому
поколению [1193], a CRAY 1 — ко второму поколений) векторных
систем.
Одна из первых систем класса ОКМД, известная как Машина
Унгера I, была предложена в 1958 г. для задач распознавания
образцов (рис. 6.1) [1233] (называется также просто Машиной
Унгера). Эта машина представляет собой прямоугольную сеть
идентичных модулей, каждым из которых управляет общее цен-
тральное устройство управления. Модуль состоит из одноразряд-
ного накапливающего сумматора и небольшой памяти с произ-
вольной выборкой (6 разрядов) и обладает элементарными логи-
303
ческими возможностями. Эта концепция явилась основой для
разработок SOLOMON II и ILLIAC III 11016].
Система ILLIAC III, разработанная и сконструированная в
Иллинойском университете, представляет собой систему для рас-
познавания образов 1968]. Ее основное устройство обработки
является специализированным двумерным устройством в виде
итеративной матрицы размером 32 X 32, управляемой программ-
но, причем память обладает ассоциативными возможностями.
Упомянем также Машину Унгера II- для специальных задач рас-
познавания образов. В этой машине не требуется центральное
устройство управления,^ модули матрицы не имеют элементов
памяти [1016].
Рис. 6.1. Схема машины Унгера I. •
Большое влияние на развитие матричных систем оказали \
разработки систем SOLOMON (Simultaneous Operation Linked
Ordinal MOdular Network).
Первым проектом большой матричной системы был проект *
системы SOLOMON I (называется также просто SOLOMON)
[1171Г. Система содержит номинально 1024 процессорных эле- ]
мента (ПЭ), образующих матрицу размером 32X32 (рис. 6.2k
Каждый ПЭ представляет собой небольшое арифметико-логиче-
ское устройство с последовательной поразрядной обработкой. Он v
имеет намять емкостью в 16 К разрядов, разбитую на модули по 4
4 К разрядов в каждом. Длина слов — переменная, от 1 до 128 j
разрядов, причем необходимая длина слова устанавливается
программно. Все ПЭ в данный момент времени могут выполнять Ч
только одну операцию над числами, хранящимися в их ячейках
памяти с одними и теми же адресами. При этом каждый ПЭ 1
может находиться либо в активном состоянии и выполнять, ко* Ч
манды, Поступающие - из центрального устройства управления^
либо в пассивном состоянии и не реагировать на эти команды.
Интересно отметить, что были построены работавшие матрицы^ J
304, 3
ПЭ размером 3 X 3 в 1963 г. и размером 10 X 10, причем во вто-
ром случае в качестве управляющей, использовалась машина
GDC 160А и на этой системе были выполнены реальные про-
граммные эксперименты [1016]. *
Следующей была разработка более совершенной системы
SOLOMON II (рис 6.3), работы по созданию которой дальше про-
екта (1966 г.) не продвинулись, хотя и были проведены экспе-
рименты с программированием и оборудованием. В проекте
предполагалось, что SOLOMON II будет матричной системой
с идентичными ПЭ' на интегральных схемах. Каждый ПЭ дол-
жен был иметь память на
сердечниках со словами дли-
ной в 24 разряда или иную,
кратную 8, длину слова, два
24-разрядных регистра и не-
обходимые схемы для выпол-
нения 53 команд передачи
данных, а также арифмети-
ческих, логических и других
операций. Умножение,' на-
пример, предполагалось вы-
полнять в ПЭ за 19,1 мксек,
а деление —за 84,6 мксек
[1016].
Основными недостатка ми
систем SOLOMON I и II яв-
ляются их громоздкость и
малая гибкость. В [1154]
предложена система VAMP
(Vector Arithmetic Mjilti-Pro-
cessor Computer), которая no
своим функциональным воз-
можностям близка к системе
SOLOMON, но имеет органи-
зацию, менее отличающуюся
от организаций обычных
ЭВМ. VAMP содержит арифметическое устройство в виде одно-
мерной системы одинаковых устройств (вектор устройств обра-
ботки), которые работают параллельно, одновременно обрабаты-
вают информацию и 'управляются общим устройством управ-
ления.
Система ТХ-2, созданная в конце 50-х годов, могла одновре-
менно обрабатывать 36 разрядов [147]: она могла выполнясь
операцию либо над четырьмя 9-разрядными словами, либо пад
27- и 9-разрядными словами, либо над двумя 18-разрядными сло-
вами, либо, наконец, над одним 36-разрядным словом,, при этом
управление числом одновременно выполняемых операций и дли-
ной слов осуществлялось программно.
20 Б. А. Головкин
305е
Ассоциативные системы, также относящиеся к классу ОКМД,
имеют много специфических особенностей и должны рассматри-
ваться особо. Поэтому концепции ассоциативных систем рас-
Рис. 6.3. Структурная схема системы
SOLOMON II.
смотрим в соответствую-
щем п. 6.6, где и приве-
дем их библиографические
данные.
Библиографичес-
кая справка. Концеп-
ция построения и обзор
многочисленных систем
класса ОКМД — матрич-
ных, ассоциативных и дру-
гих — представлены в ра-
ботах обзорного характера
18, 493, 821—823, 827, 989,
1016, 1221, 1223, 1273,
1274], причем ранние па-
раллельные системы клас-
са ОКМД и некоторые
другие наиболее полно
представлены, вероятно, в
[827, 1016], а ассоциатив-
ные системы, включая их
генеалогию, обширную
многоуровневую внутрен-
нюю классификацию и
примеры систем от ран-
них до современных,— в
[989, 1221, 1274].
Краткий библиографи-
ческий обзор систем класса
ОКМД приведен в (НО,
111]. Ассоциативной памя-
ти и ассоциативным систе-
мам посвящены книги [230, 473, 740], обзоры и библиографии
1801, 988, 1060].
Системам класса ОКМД в целом, как матричным, так и ас-
социативным, а также системам с ансамблем процессоров и не-
которым другим посвящена книга [1222], написанная в развитие
упомянутого выше обзора [1221]. В этой книге рассматриваются
концепция и примеры большого числа систем класса ОКМД,
а также будущее таких систем и вопросы их оценки.
Машины Унгера и системы ILLIAC III, SOLOMON и VAMP
рассмотрены в обширной литературе: Машины Унгера — в [147,
368, 827, 1016, 1221, 1222, 1233], система ILLIAC III —в [968,
969, 1016], системы SOLOMON-в [147, 368, 441, 498, 572, 605,
779, 947, 988, 1016, 1171, 1172, 1221, 1222], система VAMP—
306
в [1154] и система ТХ-2 — в [147, 593, 742]. При этом, в каче-
стве ключевых, можно назвать статьи: по Машине Унгера I
[1233], а по системе SOLOMON I — дважды издававшуюся статью
[1171].
Отметим, наконец, что в [746, 747] предложена и рассмотре-
на система АРР (Associative Parallel Processor), близкая по струк-
туре к системе SOLOMON.
6.2. Вычислительная система М-10 [196, 197, 881]*)
Разработка системы М-10 ориентирована на использование па-
раллелизма- множества объектов, который характерен для задач
обработки массивов данных, описывающих большое число иден-
тичных или почти идентичных объектов, и параллелизма смеж-
ных операций в алгоритмах, который состоит в том, что смежные
операции можно выполнять одновременно, если результаты неко-
торой операции не используются как входные данные в одной
или в нескольких следующих операциях.
Общая концепция системы М-10 состоит в следующем.
Процессоры (Пр) группируются в линии по I процессоров
таким образом, чтобы каждая линия была связана с одной соот-
ветствующей группой управляющих сигналов устройства управ-
ления и управлялась общим кодом операции. При этом не обяза-
тельно, чтобы процессоры линии были одинаковыми и чтобы
они получали одинаковые управляющие сигналы. Для эффектив-
ного использования линии в системе команд должны быть груп-
повые операции над массивами, над векторами чисел и над век-
торами функций. Оперативную память процессоров целесообраз-
но организовать в виде общей основной памяти линии с управ-
ляемым широким форматом при обращении (от 1 до i слов).
Несколько линий можно объединить в связку, например, из
7 линий так, чтобы все линии были соединены с общим устрой-
ством управления связки (У), каждая команда которого содер-
жит / кодов операций — по одному на каждую линию связки.
Режим работы — синхронный вследствие управления линиями
общим устройством управления связки, хотя и имеются раздель-
ные коды операций. При этом не обязательно, чтобы все / линий
связки были одинаковыми и имели одинаковое количество про-
цессоров. Далее, k связок можно объединить в синхронную си-
стему комбинированного типа (рис. 6.4), имеющую общий ритм
работы, который задается при помощи общего управления систе-
мой. На отдельных участках параллельной программы такая си-
стема может работать как асинхронная, но при необходимости
*) При написании п. 6.2 привлечены также материалы статьи: Кар-
цев М. А. Вычислительная машина М-10. Доклады АН СССР, 1979, т. 245,
№ 2, с. 309—312 (эта статья стала известна автору настоящей книги при
завершении оформления рукописи книги). Краткую информацию о системе
М-10 можно найти в заметке: Пять миллионов в секунду. Газета «Социа-
листическая индустрия», 13 сентября 1979, Xs 211 (3103).
20* 307
программно устанавливается синхронный режим работы системы
с указанием операций для процессоров на каждом цикле выпол-
нения команд.
Рассмотрим теперь собственно систему М-10.
М-10 является многопроцессорной синхронной системой со
средней производительностью более 5 млн. операций в секунду
п внутренней-.памятью емкостью 5 М байт (1310 720 32-разряд- }
ных слов). Она имеет такт длительностью в 1,8 мксек. Система J
оперирует с числами трех форматов. Числа первого формата за-
нимают 16 разрядов (полуслово) и являются числами только с
фиксированной запятой (целыми или дробными). Числа второго i
Рис. 6.4. Структурная схема системы комбинированного тппа. |
и третьего* форматов занимают 32 разряда (слово) и 64 разряда '<
(двойное слово) соответственно'и могут быть числами как с фик- ’
сированной запятой (целыми или дробными), так и с плавающей
-запятой. При этом в последнем случае под порядок отводятся 8 ;
разрядоввдля чисел обоих форматов с плавающей запятой. Mo- *
гут использоваться также и 128-разрядные числа, для оперирова-
ния с которыми используется неполный список операций систе- ;
мы М-10. ’
' Основные функции обработки информации в системе выпол- '
яяют две программно перестраиваемые линейки процессоров, j
каждая из которых в зависимости от кода операции представляет Я
собой либо восьмерку 16-разрядных процессоров, либо четверку Ц
32-разрядных процессоров, либо пару 64-разрядных процессоров, Я
выполняющих одну и ту же операцию над (разными) данными. Я
. Процессоры линейки объединяются в единый векторный процес- Я
сор при прмощи определенных кодов операций. Так, например, Я
при вычислении скалярного произведения векторов процессоры дя
линейки выполняют . в течение одного такта системы попарное
308
перемножение восьми пар 16-разрядных чисел или четырех пар
32-разрядных чисел, суммирование полученных произведений
между собой и с суммой, накопленной в предыдущем такте. Две
линейки могут выполнять одновременно одинаковую операцию
или различные операции.
Вычисление результатов операций над числами сопровожда-
ется выработкой в линейках до 5 строк значений булевских пере-
менных, каждое из которых характеризует один из операндов
пли результат операции. Так, например, при выполнении сложе-
ния восьми пар 16-разрядных чисел или четырех пар 32-разряд-
ных чисел или же двух пар 64-разрядных чисел вырабатываются
строки из восьми, четырех или двух значений булевских пере-
менных соответственно, содержащие признаки: 1) переполнения;
2) равенства слагаемых; 3) превышения первого слагаемого над
вторым; 4) равенства нулю результата; 5) получения отрица-
тельного результата. Эти признаки могут’ передаваться непосред-
ственно или через память в специальный процессор обработки
«строк булевских переменных, который обладает полным на-
бором логических операций над булевскими переменными,
и функционирует одновременно с линейками основных про-
цессоров.
Строки значений булевских переменных, получаемые Непо-
средственно при выполнении операций над числами в линейках
основных процессоров или при выполнений операций в специаль-
ном процессоре или же получаемые в результате выборки из па-
мяти, могут использоваться для условных передач управления
или для наложения масок на основные процессоры.
Внутренняя память системы содержит главную оперативную
память емкостью в 512 К байт (131072 слова), главную посто-
янную память такой же емкости и большую оперативную память
в 4 М байт (1048576 слов). С процессорами системы непосредст-
венно сообщаются главная оперативная память и главная посто-
янная память, при этом между главной оперативной и боль-
шой оперативной памятью организован двусторонний обмен со
скорсткю около 20 М байт в секунду в каждую сторону, выпол-
няемый одновременно с вычислениями в процессорах линеек.
Внешний обмен осуществляется как через главную, так и через
большую оперативную память. Все три устройства внутренней
памяти являются с точки зрения пользователя единым полем па-
мяти. Вся внутренняя память имеет единую виртуальную адреса-
цию. Адресация производится с точностью до полуслова, испол-
нительный адрес содержит 22 разряда.
Для адреса в команде отведены 30 разрядов, из которых 4
разряда содержат номер регистра для базирования, 4 разряда
содержат номер регистра для индексации, а 22 разряда исполь-
зуются для смещения. Имеется 16 специальных регистров, вы-
полняющих функции базовых и индексных регистров. Они свя-
заны с памятью и со специальным процессором для выполнения
309
индексных операций. Формирование исполнительного адреса об- }
ращения к памяти организовано по аналогии с системой IBM '
360/85 и семейством IBM 370 [202]. Формирование математиче- ;
ского адреса регламентируется пользователем, а исполнительного
адреса — операционной системой при помощи дескрипторов.
В системе реализован широкий переменный формат обраще- •
ния к главной памяти — за одно обращение можно извлечь от 2
до 64 байт информации. ,
Формат команд, интерпретируемых центральным устройством
управления,— переменный: от 4 до 24 байт. При исполнении ко-
манды полного формата за один такт системы выполняются: одна
операция устройства управления, две арифметико-логические
операции в двух линейках основных процессоров, два обращения
к главной памяти за операндами по разным адресам и еще одно
обращение за следующей командой (и непосредственным one- j
рандом). При этом может также осуществляться обмен массива- j
ми информации с другими системами М-10. <
Внешний обмен осуществляется через мультиплексный канал,, J
который обеспечивает суммарную пропускную способность около ;
7 М байт в секунду и имеет 24 дуплексных подканала. К каждо- J
му подканалу можно подключить до 6 однотипных устройств, 1
таких как терминалы с пишущей машинкой и перфолентным
оборудованием, алфавитно-цифровые печатающие устройства, j
перфокартное оборудование, пишущая машинка инженерного
пульта для ведения аппаратного журнала. К каналу можно под-
ключить через дополнительные устройства сопряжения так-
же периферийные устройства ЕС ЭВМ, такие как терминалы
со штриховым дисплеем с клавиатурами и световым пером и маг- <
нитные диски и ленты.
В системе М-10 можно выделить 3 основных параллельных
процесса: 1) вычисления в центральной части, являющиеся, в '*
свою очередь, параллельными- синхронными процессами; 2) об- :
мен информацией между главной и большой оперативной па- *
мятью; 3) внешний обмен через мультиплексный канал. К этим i
процессам можно также добавить процессы контроля (специаль- J
ными цепями) исправности аппаратуры и контроля программ
пользователя (например, отсутствия в них привилегированных >
операций). Взаимодействие этих независимых и одновременно |
идущих процессов осуществляется через многоуровневую систе-
му прерывания программ, на свободные входы которой могут
также приниматься до 32 внешних сигналов.
Операционная система вычислительной системы М-10 обеспе- |
чивает: диалоговую работу пользователей в режиме разделения >
времени, доступ к трансляторам и средствам отладки программ на
алгоритмических языках, обращения на логическом уровне к пе- .
риферий^ому оборудованию, обращения к стандартным проце-
дурам, а также использование типовых программ библиотеки как
готовых модулей загрузки. В состав библиотеки входят типовые
31Q
’программы линейной алгебры, аппроксимации функций, квадра-
тур, интегрирования обыкновенных дифференциальных уравне-
ний и уравнений в частных производных и другие.
Резидейтные части операционной системы хранятся в глав-
ной постоянной памяти, В процессе работы операционная систе-
ма вместе с автоматом обмена обеспечивает подкачку необходи-
мых сегментов из большой памяти в главную оперативную па-
мять. Каждому пользователю при работе в режиме разделения
времени отводится квант времени в 20—80 мсек, что обеспечива-
ет согласованность характеристик основных процессоров, глав-
ной и большой памяти [198].
Расчетная производительность системы обеспечивается при
решении задач с естественным параллелизмом, требующих, в ос-
новном, выполнения операций над многомерными векторами или
над функциями, заданными значениями на множествах дискрет-
ных значений аргументов. При решении такого рода задач, ког-
да требуются большие объемы памяти, реальная производитель-
ность может существенно превышать расчетную.
Основные логические цепи системы М-10 выполнены на мик-
росхемах. Оба устройства оперативной памяти построены на
ферритовых сердечниках. Носителем информации в постоянной
памяти являются сменные металлические перфокарты, тип этой
памяти— конденсаторный. Первые промышленные образцы М-10
показали высокие эксплуатационные характеристики.
В системе М-10 предусмотрены цепи, позволяющие объеди-
нять до 7 систем в синхронный комплекс с общим тактовым ге-
нератором и виртуальной адресацией систем в комплексе. В каж-
дом такте работы система может выдать на свои выходные шины
массив в 64 байта и принять массив такого же размера от лю-
бой другой системы комплекса. Такие комплексы пока не реали-
зованы, а регистры связи вычислительных систем используются
как дополнительная сверхоперативная память:
Систему М-10 можно классифицировать как ОКМДС/Вс с
векторным потоком данных (см. 2.1), если не учитывать воз-
можность использования двух независимых кодов операций в
двух линейках.
Библиографическая справка. Общая концепция си- ’
стемы М-10 описана в [196, 197, 881], а собственно* система
М-10 — в работе, указанной в сноске в начале настоящего параг-
рафа. Некоторые вопросы программного обеспечения и програм-
мирования для такого рода систем (трансляция, стандартные
программы, распараллеливание) рассмотрены [33, 425, 4261#
4 %
6.3. Система РЕРЕ
Система РЕРЕ (Parallel Element Processing Ensemble), раз-
работанная для обработки радиолокационной информации, пред-
ставляет собой сверхвысокопроизводительную вычислительную
ЗИ
систему с ансамблем процессорных элементов. Она может быть ;
отнесена к классу ОКМДС/Нс, в который входят системы с оди-
ночным потоком команд и множественным потоком данных, с по-
словной обработкой в процессорах и с низкой степенью связан-
ности между-ними (см. 2.1).
Работу над системой РЕРЕ вели несколько фирм: Bell Te-
lephone Laboratories, System* Development, Honeywell, Burroughs
(2811.
Начало разработки (в Bell Telephone Laboratories) относится
еще к 1960 г. Первые работы были сконцентрированы на созда-
нии ассоциативной памяти с распределённой логикой DLM
^Distributed Logic Memory). В дальнейшем память DLM была
существенно усовершенствована для параллельного выполнения
многих арифметических операций над данными из нескольких
больших массивов, причем свойства ассоциативной выборки со-
хранились; были введены также и другие модификации [6251.
Экспериментальный образец системы, получивший название*
PEPE IC Model, был создан в 1971 г. В его состав входит маши-
на IBM 360/65 в качестве ведущего процессора (связана с ос-
новным оборудованием РЕРЕ через 2 селекторных канала), 16-
процессорных элементов, каждый из которых состоит из ариф-
метического устройства, корреляционного устройства и оператйв-
ной памяти емкостью .в 512 32-разрядных слов, и центральное
устройство управления, содержащее такие основные компоненты,
как устройство управления арифметическим устройством и уст-
ройство управления корреляционным устройством. Последние
два устройства осуществляют связь всех процессорных элементов
с ведущим процессором. Эта первоначальная модель описана в
[619, 625, 1193, 1261J и в других работах.
Промышленный образец системы, структурная схема которо-
го изображена на рис. 6.5 [709, 1250], был создан в 1977 г. Эта
вторая модель системы имеет усовершенствованную структуру
и, кроме этого, в ней использована улучшенная элементная ба-
за. Описание модели можно найти в указанных выше работах,
в [662, 708, 1240, 12741 и других работах. Система эксплуатиру-
ется в Исследовательском центре армии США (Хантсвилл, шт.
Алабама). По данным на 1977 г. она имела 11 процессорных
.элементов [1131.
Рассмотрим современную модель системы РЕРЕ [7081. Си-
стема содержит три основных компонента: а) ведущий процес-
сор, в качестве которого используется вычислительная система
CDQ 7600; б) 288 независимых идентичных процессорных элемен-
тов (ПЭ), каждый из которых состоит из арифметическою уст-
ройства (АУ), корреляционного устройства (КУ), ассоциативно-
го выходного устройства (АВУ) и оперативной памяти (ОП);
в) три независимых устройства управления (УУ) — УУ АУ„
УУ КУ и УУ АВУ, каждое из которых является общим для всех
соответствующих ему устройств каждого ПЭ (см. рис. 6.5)*
312-
Структура системы нетрадиционна и представляет‘значитель-
ный интерес. При обработке системой радиолокационной инфор-
мации в реальном времени каждый ПЭ собирает и подготавливает
данные, связанные с одним из отслеживаемых объектов. Разра-
ботка велась из расчета 288 отслеживаемых объектов, поэтому
РЕРЕ по проекту имеет 288 ПЭ. В ОП некоторого ПЭ хранятся
данные, связанные с тем объектом, который отнесен к этому ПЭ,
л КУ, АУ и АВУ этого же ПЭ обеспечивают ввод, обработку и
вывод данных, описывающих соответствующий объект. *
Рис. 6.5. Структурная схема системы РЕРЕ. ПЭ — процессорный элемент,
У У — устройство управления, КУ — корреляционное устройство, А У — ариф-
метическое устройство, АВУ — ассоциативное выходное устройство, ОП —
устройство оперативной памяти, УВВ — устройство ввода-вывода, МК —
мультиплексный канал.
Все ПЭ независимы и не имеют непосредственных связей
между собой, причем каждый из них может одновременно вы-
полнять операции, задаваемые каждым из трех УУ. Поэтому
313
РЕРЕ может параллельно выполнять до 864, операций, при этом
общая ОП любого ПЭ используется АУ, УУ и АВУ данного ПЭ
в режиме разделения оборудования.
Конкретные ПЭ переводятся в активное состояние или воз-
вращаются в пассивное состояние в зависимости от текущей за-
грузки РЕРЕ и потребностей в параллельных вычислениях.
К системе можно добавить дополнительные ПЭ и при этом
не потребуется изменять программное обеспечение, так как
структура РЕРЕ не накладывает ограничений на количество ПЭ,
а ассоциативная адресация обеспечивает нечувствительность
протраммного обеспечения к количеству ПЭ.
При отказе одного или нескольких ПЭ другие ПЭ продолжают
работать вследствие независимости всех ПЭ между собой. Это
обеспечивает высокую надежность РЕРЕ.
Хотя РЕРЕ содержит свои собственные команды, программы,
механизмы прерывания, часы и т. д, целесообразно все же иметь
внутреннюю связь с некоторой универсальной вычислительной
системой (ведущим процессором), которая выполняла бы быст-
рую обработку частей задач, не связанных с параллельными вы-
числениями, а также осуществляла бы функции управляющего
периферийного устройства. Эту систему можно использовать и
для таких функций, как трансляция программ для РЕРЕ. Для
этих целей в системе РЕРЕ применяется такая мощная вычисли-
тельная система, как CDC 7600, которая связана с устройствами
управления через три мультиплексных канала.
Программа РЕРЕ содержит смесь последовательных и парал-
лельных команд. К командам первого типа относятся команды
управления последовательностью выполнения программы (услов-
ный переход, ввод-вывод) и осуществления некоторых пре-
образований (сдвиг, маскирование, целочисленные операции).
Параллельные команды, в свою очередь, относятся к двум типам,
первые из которых оперируют с состоянием активности элемен-
тов, а вторые выполняют функции арифметики с плавающей и '
фиксированной запятой, сдвига и маскирования. В число команд,
оперирующих с плавающей запятой, входят команда преобразо-
вания чисел с плавающей запятой в целые числа и команда на-
хождения квадратного корня. В команде системы 32-разрядного
формата 8 разрядов отводится для кода операции, 1 разряд — для
выбора устройства памяти (данные/программа), 3 разряда — для
указания источника операнда и типа команды (последователь-
ная или параллельная), 4 разряда —- для адресации индексных
- регистров (в каждом устройстве управления имеется 15 индекс- -
ных регистров) и 16 разрядов — для адреса операнда. ’
Конструктивно РЕРЕ выполнена в виде стойки управления, •
от которой расходятся радиально кабели по восьми направлены- ,
ям, соединяющие с этой стойкой восемь отсеков. Каждый из от- ’
секов содержит 36 процессорных элементов при их полном ком-
плекте. К стойке управления подведены также кабели связи с
314
CDC 7600 и с оборудованием текущего контроля за состоянием
РЕРЕ и ее технического обслуживания, для чего используется
ЭВМ В 1700. В памяти и в логической части системы применены
интегральные схемы с эмиттерными связями.
Рассмотрим основные устройства системы. ПЭ не имеют ло-
гики управления выполнением команд и должны получать все
синхронизирующие и управляющие сигналы от стойки управле-
ния, в которой размещены УУ АУ, УУ КУ и УУ АВУ. Послед-
ние осуществляют управление устройствами АУ, КУ и АВУ со-
ответственно для всех ПЭ. Управление устройствами ОП всех
ПЭ осуществляется со стороны логики управления памятью, так-
же реализованной в стойке управления.
Каждое устройство АУ, КУ и АВУ всех ПЭ имеет однораз-
рядный регистр (индикатор) активности. Когда устройство уп-
равления обрабатывает параллельную команду, все соответствую-
щие ему активные устройства (т. е. устройства, имеющие ,«1» в
их регистре активности) процессорных элементов исполняют эту
команду, причем максимум 288 ПЭ могут одновременно выпол-
нять данную команду. Поскольку каждый ПЭ содержит три вы-
числительных устройства, соответствующих трем независимым
УУ, ансамбль из 288 ПЭ может одновременно оперировать с
тремя независимыми параллельными командами*) и эффектив-
но выполнять при этом 864 операции однсеременно, как это от-
мечалось выше. Следует отметить, что при таком режиме работы
обращения трех вычислительных устройств ПЭ. к 'его ОП могут
вызвать конфликты обращения, которые рассматриваются далее.
С регистром активности связан 21-уровневый стек активности
для АУ и АВУ. Все устройства ПЭ содержат 8-разрядный пораз-
рядно адресуемый регистр тэгов, который используется для вы-
полнения ассоциативных операций совпадения над данными, по-
ступающими из устройства управления.
Каждое АУ содержит обычные накапливающий А-регистр,
В-регистр. операнда и Q-регистр для результата, которые обеспе-
чивают выполнение параллельных целочисленных и логических
операций, а также операций с плавающей запятой. Накапливаю-
щий A-регистр АУ используется дополнительно при выполнении
ассоциативного вывода к УУ А У через шину данных в режиме
ее разделения совместно с АВУ. Каждое АВУ содержит обыч-
ные А- и В-регистры, которые обеспечивают выполнение парал-
лельных целочисленных и логических команд. A-регистр исполь-
зуется дополнительно при выполнении ассоциативного вывода к
УУ АВУ через шину данных в режиме ее разделения совмест-
но с АУ. Каждое КУ, основанное на концепции памяти DLM, со-
держит В-регистр и 16 корреляционных регистров. Эти регистры
обеспечивают выполнение параллельных целочисленных и логй-
♦) При классификации РЕРЕ обычно учитывается основной поток ко-
манд для арифметических устройств. г
315
ческих команд. Допускаются корреляционные операции типа
регистр-регистр. Передача выходных данных КУ к УУ КУ на
предусмотрена.
Каждое устройство ОП имеет емкость в 1 К (или 2 К [1250])
32-разрядных слов. Оно получает адреса и сигналы о режиме
работы от схем управления памятью, находящихся в стойке уп-
равления. Все устройства ОП получают идентичную информацию-
от указанных схем в течение выполнения параллельной коман-
ды. Устройство ОП связано с АУ, АВУ и КУ посредством общей
шины данных, причем схемы управления памятью предоставля-
ют эту шину устройствам ПЭ в соответствии с постоянными
приоритетами: первый приоритет — для КУ, второй — для АВУ
и третий — для АУ. Такие приоритеты были введены потому, что*
команды КУ обычно являются самыми короткими по времени:
выполнения (200—300 нсек), а команды АУ наиболее длинными
(умножение с плавающей запятой занимает 1,9 мксек). Из-за
конфликтов обращения к ОП время выполнения программ уве-
личивается, вероятно, не более чем на 5%. Результаты модели-
рования показывают, что при изменении указанного порядка
приоритетов время выполнения программ значительно возра-
стает.
Устройства У У АУ, УУ АВУ и УУ КУ, размещенные в стой-
ке управления, являются общими для соответствующих им уст-
ройств всех ПЭ и осуществляют системные функции управления
операциями над базой данных, находящейся в ансамбле устройств
ОП (операциями вывода результатов обработки базы данных и
операциями ввода новых данных соответственно). Кроме указан-
ных УУ, стойка управления содержит также функциональные-
устройства, которые обеспечивают внутрисистемное управление-
прерываниями, восстановление после ошибки, вывод из ПЭ, раз-
решение конфликтов обращения к ОП, выполнение задач техни-
ческого обслуживания и
при вводе-выводе.
Каждое из трех УУ имеет собственную память программ и:
память данных. Эти устройства могут связываться между собой
через логическое устройство внутренних связей. Выполняемые-
программы находятся в памяти программ и состоят из некоторой
последовательности последовательных и параллельных команд.
Память программ УУ АУ имеет наибольшую емкость (32 К'слов)
среди трех УУ, вследствие чего ее цикл является относительно» |
длинным: он равен 200—300 нсек, тогда как время цикла дру- Ц
гих устройств памяти программ /данных равно 100 нсек. Это,. Я
однако, согласуется с тем положением, что УУ АУ отвечает за Я
выполнение относительно длинных по времени параллельных ко- Я
манд обработки с плавающей, запятой. Я
Каждоё УУ имеет два устройства ввода-вывода (УВВ), кото- Я
рые обеспечивают полностью дуплексный обмен с CDC 7600 а Я
оборудованием контроля и технического обслуживания. Я
316 Я
диагностики и преобразование данных
При обнаружении ошибки в работе РЕРЕ осуществляется
специальное прерывание УУ АУ, причем УУ АУ должно иден-
тифицировать ошибку. Программное обеспечение восстановления
после ошибки использует супервизорные команды, которые име-
ют доступ по записи и считыванию ко всем регистрам УУ/
В системе имеются. 8 24-разрядных регистра для анализа про-
изводительности программного обеспечения и оборудования [7081.
Итак, организацию структуры и функционирования РЕРЕ в
целом можно представить следующим образом [1250].
Независимые идентичные ПЭ, количество которых определяет
производительность РЕРЕ и несущественно с точки зрения ор-
ганизации структуры и функционирования системы, работают
параллельно под общим управлением. Каждый из ПЭ содержит
три устройства обработки с ассоциативными возможностями КУ,
А У и АВУ, каждое из которых управляется своим общим для
всех устройств данного типа устройством управления, независи-
мым от двух других устройств управления. Устройства обработ-
ки КУ, АУ и АВУ каждого ПЭ работают в режиме разделения
общей для ких оперативной памяти данного ПЭ. Эти устройства
построены так, чтобы оптимизировать корреляционный поиск в
базе данных и ввод данных, выполнение арифметических опера-
ций с плавающей запятой, а также ассоциативный поиск в ба-
зе данных и вывод данных соответственно, что отражает особен-
ности обработки радиолокационной информации.
Каждое устройство управления УУ КУ, УУ АУ, УУ АВУ
имеет память данных и память программ, которые независимы *
от двух других устройств управления. Эти общие устройства уп-
равления имеют ограниченные возможности обработки. Набор их
команд сводится к командам логического контроля и проверки,,
условных переходов, операций с индексными регистрами и уп-
равления вводом-выводом. Имеются также такие команды цело-
численной арифметики, которые достаточны для вычислений ин-
дексов и адресов. Этот набор команд обеспечивает, в основном,
управление последовательностью параллельных команд РЕРЕ и,
в меньшей степени, управление исполнением команд, непосред-
ственно относящихся к решению задач. Параллельные команды
и команды общих устройств управления размещаются в памяти
программ, относящейся к данному общему устройству управления.
.Параллельные команды декодируются в общих устройствах
управления, в результате чего образуется последовательность,
микрокомандных сигналов управления. Эти сигналы поступают
из широкоформатной памяти, работающей только в режиме счи-
тывания, в шину параллельных команд для передачи к процес-
сорным элементам и выполнения. Сигналы управления порожда-
ют одновременные и идентичные операции в каждом активном
ПЭ. Таким образом, три устройства обработки каждого ПЭ уп-
равляются независимо друг от друга через три шины своими уст-
ройствами управления [1250].
31Т
Производительность РЕРЕ оценивается величиной до 300—500
в более млн. операций в секунду [491,961]; в [4911 указывается,
что (при 288 ПЭ) РВРЕ может выполнять почти 300 млн. опе-
раций с плавающей запятой в секунду плюс почти 3 миллиарда
целочисленных операций в секунду.
Программное обеспечение системы содержит транслятор с
параллельного фортрана (pfor)r, учитывающего параллелизм и
ассоциативные возможности РЕРЕ, и машинный эмулятор системы
РЕРЕ, которые реализованы на CDC7600, а также операцион-
ную систему и другие средства [503, 662, 961, 1228]. 1
Кроме обработки радиолокационной информации в реальном
масштабе времени, для чего по одному УВВ УУ КУ и УУ АВУ
должны подключаться к локатору [541], система может приме-
няться для управления воздушным движением, слежения за
спутниками, управления движением автомобилей, прогноза пого-
ды и для решения других задач [708].
Библиографическая справка. Система РЕРЕ обсуж-
далась на конференциях COMPCON в 1972 г. Д534, 619, 625,
1261], в 1975 г. [637, 1241] и в 1977 г. [1193], на конференциях
WESCON в 1972 г. [620, 871] и WORKSHOP в 1973 г. [1240], на
Сагаморской/Международной конференции по параллельной об-
работке информации в 1973 г. [451, 503, 662, 708, 1228], в 1975 г.
[663, 1273], в 1976 г. [888] и в 1977 г. [541, 709, 1250], на сим-
позиуме по высокопроизводительным системам в 1977 г. [961],
Одно из первых описаний РЕРЕ было представлено на кон-
ференцию NAECON в 1970 г. [762] и приведено в сборнике
работ по параллельным системам [763] (1970 г.) Методы компи-
ляции с учетом параллелизма РЕРЕ впервые рассмотрены, ве-
роятно, в [687]. Ключевыми работами, в которых описаны пер-
воначальная и современная модели РЕРЕ, следует считать
указанные выше [6251.и [7081^ соответственно. Подробное описание
РЕРЕ приведено в [2811. Эта система рассмотрена также в [8,
34, 152, 275, 283, 531, 533, 1221, 1222, 1223, 1274]. Краткую
информацию о РЕРЕ можно найти в [112, ИЗ, 491].
Сравнение производительности РЕРЕ IC Model, STARAN и
CDC 7600 для условий решения ими задач системы противоракет-
ной обороны Сэйфгард в реальном времени выполнено в [945] *
а сравнение производительности новой модели РЕРЕ и систем
CDC 7600, CDC 7700, ASC, CRAY 1 для условий решения подоб-
ных задач выполнено в упомянутой выше работе [541].
6.4. Система ILLIAC IV
Система ILLIAC IV, разработанная Иллинойским универси-
тетом и изготовленная в одном экземпляре фирмой Burroughs,
является матричной сверхвысокопроизводительной системой. Она
классифицируется как ОКМДС/Вс, т. е. так же как и РЕРЕ,
за исключением того, что степень связанности ее процессорных
318
элементов является высокой (Вс) вследствие наличия непосред-
ственных связей между соседними элементами матрицы
ILLIAC IV.
Работы над системой были начаты в 1967 г. В конце 1971 г.
система с одной матрицей (одним квадрантом) процессорных эле-
ментов была изготовлена и в начале 1972 г. установлена в Эй-
мском научно-исследовательском центре NASA (шт. Калифор-
ния). Наладка системы продолжалась в течение примерно года»
после чего проводилась, опытная эксплуатация системы. В нача-
ле 1974 г. ILLIAC IV была введена в режим эксплуатации, од-
нако, работы по ее доводке продолжались еще в 1974—75 гг.
ILLIAC IV — наиболее мощная система в ряду реализован-
ных разработок вычислительных систем Иллинойского универ-
ситета. Первая система ILLIAC I на электронных лампах, соз-
данная в ,1952 г., выполняла 11 тыс. арифметических операций
в секунду. Система ILLIAC II на транзисторах и диодах, соз-
данная в 1963 г. [558], могла выполнять до* 500 тыс. операций
в секунду и имела фактически обычную структуру. Система
ILLIAC III (см. п. 6.1), начавшая работать в 1966 г., является
специализированной. Она осуществляет неарифметическую об-
работку изображений и поэтому ее быстродействие нельзя не-
посредственно сравнивать «с быстродействием • указанных выше
систем. Система ILLIAC IV основана на концепции системы
SOLOMON (см. 6.1), прототип которой был изготовлен фирмой
Westinghouse Electric в начале 1960-х годов. В ILLIAC IV одна
последовательность команд программы управляет работой мно-
жества из 64 процессорных элементов (ПЭ), одновременно вы-
полняющих одну и ту же операцию над данньйш, которые мо-
гут быть и обычно являются различными и хранятся в оператив-
ной памяти каждого ПЭ. ILLIAC IV способна выполнять от
100 до 200 млн. операций в секунду и отличается от своих
предшественниц и других систем построением структуры [1174].
Целью проекта ILLIAC IV было создание матричной систе-
мы производительностью порядка одного миллиарда операций в
секунду. Для достижения такой производительности система по
проекту должна былах содержать 256 ПЭ, работающих под об-
щим управлением и сгруппированных в четыре квадранта (мат-
рицы) по 64 ПЭ в каждом. В каждом квадранте предусматрива-
лось собственное устройство управления, причем предусматри-
валась возможность оперативного объединения квадрантов в два
квадранта по 128 ПЭ в каждом или в один квадрант из 256 ПЭ.
В ходе выполнения работ из-за, в основном, сложности изготов-
ления, в проект были внесены существенные изменения, что
повлекло за собой увеличение стоимости и сроков изготовления
системы и, в конечном счете, к ограничению системы до одного
квадранта с общим быстродействием до 200 млн. операций в се*
кунду [36, 45]. Далее рассматривается система с одним квадран-
том [45, 1174]. *
319
Система ILLIAC IV содержат центральную часть и подси-
стему ввода-вывода (рис. 6.6). Центральная часть системы содер-
жит устройство управления (УУ) и матрицу из 64 ПЭ. УУ
представляет собой фактически простую вычислительную ма-
лпину небольшой производительности и может выполнять опе-
рации над скалярами одновременно с выполнением матрицей
ПЭ операций над векторами, однако, все команды исходят от
УУ. УУ посылает команды в независимые ПЭ и передает адреса
Сын АРРА
Рис. 6.6. Структурная схема системы ILLIAC IV.
ъ их индивидуальные устройства оперативной памяти (ОП), при
этом все арифметико-логические устройства (АУ) каждого ПЭ
одновременно и синхронно выполняют одну операцию за другой
над операндами в виде векторов. Подсистема ввода-вывода вклю-
чает в свой состав управляющую машину В 6500, устройство
управления вводом-выводом, файловые диски, буферную память
и коммутатор ввода-вывода. Операционная, система, ассемблеры
л трансляторы размещаются в памяти В 6500.
УУ системы содержит буфер данных в составе 64 64-разряд-
ных регистров на интегральных схемах, 4 64-разрядных накап-
ливающих регистра и простое арифметико-логическое устройст-
во. Буфер данных можно использовать как сверхоперативную
память, а‘накапливающие регистры — как накапливающие сум-
маторы для выполнения целочисленного сложения, сдвига, ло-
гических операций, а также для хранения информации управле-
ния циклами (нижняя граница, приращение и верхняя граница
«320
цикла). Кроме этого, накапливающие регистры можно исполь-
зовать в качестве регистров переадресации для модификации
обращений в рамках ОП ПЭ. Таким образом, УУ системы вы-
полняет собственно функции управления и функции скалярной
обработки, причем управление системой осуществляется с опе-
режающим просмотром команд.
Каждый ПЭ имеет достаточно сложное арифметико-логиче-
ское устройство с полным набором арифметических и логических
схем и собственную ОП емкостью 2048 64-разрядных слов с
временем обращения не более 350 нсек. В системе используют-
ся 64-разрядные слова, причем числовые данные могут иметь
следующие форматы: 64 разряда для чисел с плавающей запя-
той; 64 разряда для логических данных; 48 разрядов для чисел
с фиксированной запятой; 32 разряда для чисел с плавающей за-
пятой; 24 разряда для чисел с плавающей запятой и 8 разрядов
для данных с фиксированной запятой (символьная информация).
Таким образом,\ в каждом ПЭ предусматривается как бы рас-
членение АУ и обеспечивается внутренний векторный поток
данных уменьшенного формата, при этом 64 ПЭ, оперирующие
с 64-, 32- и 8-разрядными форматами, могут обрабатывать век-
торные операнды из 64, 128 и 512 компонент соответственно
(сравните с ТХ-2 и с Системой комбинированного типа). Систе-
ма ILLIAC IV обеспечивает целочисленное суммирование 512
8-разрядных операндов примерно за 66 нсек, поэтому она может
выполнять почти до 10 млрд, коротких арифметических опера-
ций в секунду над данными малого формата. Если же рассматри-
вать сложение 64-разрядных чисел с плавающей запятой с уче-
том округления и нормализации, то количество таких операций,
выполняемых ILLIAC IV за секунду, равно примерно 150 млн.
АУ каждого ПЭ имеет 6 программно адресуемых регистров:
накапливающий сумматор; регистр для второго операнда в двух-
местных операциях; регистр пересылок для передачи информации
от одного ПЭ к другому; регистр для кратковременного хранения
информации; регистр переадресации (для модификации адрес-
ного поля команды) и регистр управления состоянием ПЭ. Пос-
ледний регистр имеет 8 разрядов, предпоследний — 16 разрядов,
а остальные регистры имеют по 64 разряда.
Содержимое регистра управления состоянием ПЭ определяет,
будет ли данный ПЭ в активном или же в пассивном состоянии
т. е. будет ПЭ выполнять команду или нет. Предусмотрено гибкое
программное управление этим регистром. Так, например,-имеются
команды, переводящие в пассивное состояние все те ПЭ, у кото-
рых содержимое регистра пересылок по величине больше содер-
жимого накапливающего сумматора.
Процессорные элементы, как и их АУ и ОП, имеют номера
от 0 до 63, причем г-е АУ имеет доступ только к i-му устройству
ОП данного 1-го ПЭ и не может изменить содержимое ОП дру-
гого ПЭ. Однако, информация от одного ПЭ к другому может
21 В Головкин 321
быть передана через сеть пересылок данных (рис. 6.7) при по-
мощи специальных команд обмена. Регистры пересылок каж-
дого г-го ПЭ связаны высокоскоростными линиями обмена с
регистрами пересылок ближайшего левого (i — 1-го) и ближайше-
го правого (i + 1-го) ПЭ, а также с регистрами пересылок ПЭ,
отстоящего влево на i позиций от данного (г — 8-й) и отстоящего
вправо на i позиций от данного (i + 8-й), при этом нумерация
Рис. 6.7. Структурная схема сети пересылок матрицы процессорных элемеп- j
тов системы ILLIAC IV. - j
ПЭ рассматривается как циклическая с переходом от 63 к 0 <
слева направо и от 0 к 63 справо налево. Расстояния между ПЭ J
в сети пересылок и соответствующие пути передачи информации |
задаются при помощи комбинаций из (— 1, +1,-8, +8). I
Команды или данные группами по 8 слов пересылаются по |
вызову из ОП ПЭ в УУ по односторонней шине УУ на 8 слов. |
Команды распределяются по различным ОП ПЭ и по мере необ- ;
ходимости вызываются программой в УУ, хотя вообще вызов и i
исполнение команд обеспечиваются операционной системой. Кро-
ме этого, предусмотрена возможность пересылки операндов из «
*УУ в ПЭ по односторонней шине данных шириной в 64 разряда. '
При этом информация может передаваться из УУ одновременно J
ко всем ПЭ, вследствие чего общие величины можно хранить в <
одном экземпляре в УУ, а не в ОП "Каждого активного ПЭ. Ад-
322
ЙЬЙЪ
респая часть команды посылается в любые ПЭ также через ши-
ну данных.
Шина разряда состояния содержит 64 провода, каждый из
которых соединяет УУ с одним из ПЭ. По этой шине в накап-
ливающий регистр УУ может передаваться содержимое одного из
восьми разрядов регистра управления состоянием ПЭ. Если
этот разряд указывает состояние ПЭ, то в накапливающем регист-
ре УУ оказывается информация о состоянии активности или
пассивности всех ПЭ, на основании которой обеспечиваются ус-
ловные переходы и другие операции.
Каждый ПЭ систематически подвергается контролю в авто-
матическом режиме. Если какой-либо ПЭ не выдерживает хотя
бы одного из разнообразных контрольных испытаний, он может
быть изъят и заменен исправным. После изъятия ПЭ точная
причина его отказа определяется при помощи специальной ди-
агностической ЭВМ. Отремонтированный ПЭ передается в хра-
нилище запасных узлов.
Таким образом, кроме синхронного выполнения всеми ПЭ
потока команд, предусмотрено маскирование любых ПЭ (состо-
яние активности или пассивности), а также обмен информацией
между любым ПЭ и четырьмя ближайшими соседями в матрице
непосредственно через связывающие их линии, , а с другими ПЭ —
через цепочку промежуточных. ПЭ. Каждый ПЭ обрабатывает
один поток данных 64-разрядного формата или одновременно
более одного потока данных меньших форматов в синхронном ре-
жиме. Кроме этого, каждый ПЭ может индексировать свою ОП
независимо от других ПЭ, что особенно важно для операций
матричной алгебры, когда к двухмерному массиву данных тре-
буется доступ как по строкам,’так и по столбцам.
Следует также отметить, что доступ к устройствам ОП име-
ют АУ каждого данного ПЭ, УУ системы и подсистема ввода-
вывода. Управление доступом и разрешение конфликтов при
доступе к ОП осуществляет УУ системы.
Перейдем^к подсистеме ввода-вывода ILLIAC IV, которая
представляет собой достаточно сложный комплекс.
Устройство управления вводом-выводом (УУ ВВ), получив зап-
рос на ввод-вывод от УУ системы, осуществляет прерывание уп-
равляющей машины В 6500, которая обслуживает-запрос и по-
мещает ответный код в УУ системы через УУ ВВ (соответству-
ющие связи для передачи управляющих сигналов изображены
на рис. 6.6 пунктирными линиями). Этот код определяет статус
данного запроса в центральной части системы. Кроме этого, ма-
шина В 6500 по сигналам от УУ ВВ начинает загрузку матри-
цы ОП ПЭ программами и данными с файловых дисков, после
завершения которой УУ ВВ может передать управление УУ си-
стемы, которое начнет выполнение программы.
_ Скорсть передачи 'информации из В 6500 через ее централь-
ный процессор составляет 80 млн. бит в секунду, тогда как ско-
21* 323
рость приема информации файловыми дисками составляет 500
млн. бит в секунду. Кроме этого, В 6500 имеет 48-разрядные
слова, a ILLIAC IV — 64-разрядные слова. Для согласования
скоростей обмена В 6500 и файловых дисков и для преобразо-
вания форматов слов В 6500 и ILLIAC IV предусмотрена буфер*
пая память ввода-вывода, которая содержит четыре устройства
ОП ПЭ общей емкостью в 8192 64-разрядных слов. Буферная
память выдает 64-разрядные слова ILLIAC IV к файловым дис-
кам парами через 128-разрядную шину.
Коммутацию информации между направлениями на файло-
вые диски и на устройства, работающие в реальном масштабе
времени, осуществляет коммутатор ввода-вывода (КВВ). Через
КВВ осуществляется передача основного' объема информации
в обе стороны между подсистемой ввода-вывода и центральной
частью системы, а именно, устройствами ОП ПЭ, причем в каж-
дый момент времени передача может осуществляться по одному
из двух указанных выше направлений. КВВ выполняет также
функции буфера между матрицей ОП ПЭ и файловыми дисками,
поскольку со стороны файловых дисков обмен осуществляется
через две 256-разрядных шины, а со стороны матрицы ОП ПЭ —
через 1024-разрядную шину.
Система файловых дисков представляет собой второй после
ОП ПЭ уровень памятц системы и содержит два диска емкостью
по 1 млрд, бит, каждый диск имеет 128 головок — по одной на
дорожку. Обмен информацией с КВВ осуществляется по двум
256-разрядным шинам через два канала системы дисков, по
каждому из которых данные можно передавать и принимать со
скоростью 500 млн. бит в секунду. При этом начальное время
обращения, т. е. среднее время поворота диска в такое положе-
ние, когда требуемый для записи или считывания участок до-
рожки оказывается под фиксированной головкой и можно начать
обмен, равно половине времени одного оборота диска и составляет
20 мсек, что в 50—70 тыс. раз больше времени обращения к ОП
ПЭ. Вместе с тем, емкость памяти системы файловых дисков
примерно в 250 раз больше по сравнению с матрицей ОП ПЭ.
Лазерная память, представляющая собой третий уровень па-
мяти системы и выполняющая функции архива, имеет еше боль-
шее время обращения, более низкую скорость обмена и большую
емкость. Эта постоянная память с однократной записью, обла-
дающая огромной емкостью в 1012 бит, разработана фирмой
Precision Instrument. Запись информации ведется в двоичной
системе счисления при помощи луча аргонового лазера, выжига-
ющего микроскопические отверстия в тонкой металлической
пленке, нанесенной на полоски листа из полиэфирного материала
и укрепленной на вращающемся барабане. Каждая полоска
вмещает «примерно 2,9 млрд. бит. Комплекс из 400 таких полосок
имеет емкость более триллиона бит. Время поиска данных ка-
кой-либо одной из 400 полосок составляет примерно 5 сек, а в
324
пределах одной полоски на поиск затрачивается 200 мсек. Ско-
рость записи и считывания данных по каждому из двух кана-
лов — 4 млн. бит в секунду. Предусмотрена возможность полу-
чения копий файлов, хранящихся в лазерной архивной памяти.
Управление лазерной памятью, а также обычными перифе-
рийными устройствами (перфокарточные устройства, блоки
магнитных дисков и лент, печатающие устройства, клавиатура)
осуществляет ‘В 6500. Часть функций этой машины были упо-
мянуты выше. Ее можно рассматривать как мощную периферий-
ную машину системы ILLIAC IV. В 6500 управляет запросами
рабочих программ на ресурсы ILLIAC IV, осуществляет выпол-
нение программы операционной системы, служебных программ,
программ трансляции и компоновки рабочих программ. Если
В 6500 не’ занята трансляцией, предварительной обработкой
данных, обработкой выходных результатов или -управлением
заданиями ILLIAC IV, на ней могут решаться задачи, не свя-
занные с обслуживанием ILLIAC IV.
Система ILLIAC IV подключена к ✓ вычислительной сети
ARPA, через которую осуществляется доступ к системе.
Операционная система ILLIAC IV состоит из набора асинх-
ронных программ, выполняемых под общим управлением опера-
ционной системы МСР (Master Control Program) машины В 6500.
Управление операционной системой при выполнении конкретного
задания осуществляет программа на управляющем языке ICL
(ILLIAC Control Language), определяющая это задание.
Разработка языков для ILLIAC IV была начата с алголопо-
добного языка tranquil, полностью независимого от структуры
ILLIAC IV. Однако, системные затраты на маскировку струк-
туры ILLIAC IV привели к существенному снижению скорости
выполнения рабочих программ. Поэтому, хотя транслятор с это-
го языка был почти завершен, работы были приостановлены и
началась разработка расширенного фортрана. Тем не менее,
идея полной маскировки структуры ILLIAC IV представляет
значительный интерес. Язык* glypnir также является алголо-
подобным с блочной структурой, но в нем «обнажена» структу-
ра ILLIAC IV, что затрудняет программирование, но позволяет
опытным программистам полнее использовать возможности
ILLIAC IV и получать высокоэффективные параллельные рабо-
чие программы. Для рядовых пользователей разработан фортран
ILLIAC IV, в котором с меньшей детализацией отражена струк-
тура ILLIAC IV по сравнению с glypnir и который позволяет
до перевода про^аммы в параллельную форму проверить ее пра-
вильность в режиме последовательного выполнения на одном
ПЭ. Следует отметить, что все трансляторы были разработаны
для трансляции программ с входных языков на ассемблер
ILLIAC IV, ILLIAC IV управляется одним потоком команд и
позволяет одновременно выполнять одинаковые операции над 64
множествами данных, находящихся в различных ОП ПЭ. Поэто-
325
му, например, эта система удобна для вычисления одной и той
же функции на множествах аргументов при условии, что мас-
сивы данных, содержащие эти множества аргументов, упорядо-
чены определенным образом.
Имеются задачи, алгоритмы решения которых хорошо распа-
раллеливаются на синхронные ветви и обеспечивают высокую
степень использования процессорных элементов системы. Другие
задачи обеспечивают неполное использование * процессорных
элементов. Наконец, имеются задачи, при решении* которых до-
стигается только низкая степень использования процессорных
элементов. Среди научных задач большой размерности к задачам
указанных трех типов можно отнести следующие: 1) исчисление :
конечных разностей, матричная арифметика, быстрое преобразо- J
вание Фурье, обработка сигналов, линейное программирование;
2) задачи движения частиц, включая нелинейный метод стати-
стических испытаний, решение систем линейных уравнений *и ,
обращение матриц, решение нелинейных уравнений, отыскание
корней полиномов; ЗЬ обращение трехдиагональных матриц, про-
смотр больших неупорядоченных таблиц данных. Такое разбие-
ние задач не может рассматриваться как окончательное, так как ;
проблемы распараллеливания еще далеко не разрешены.
В заключение отметим, что в последние годы продолжались
работы по совершенствованию системы ILLIAC IV. После ввода
системы в эксплуатацию и подключения ее к сети ARPA систе- •
ма работала только в режиме пакетной обработки. Усовершенст- 5
вования направлены на увеличение мощности системы при ис- 1
пользовании ее в сети ARPA и заключаются в обеспечении воз- . ;
можности приема информации от спутников связи, обработки
информации в реальном масштабе времени и выполнения one- з
раций в диалоговом режиме. Было упорядочено расписание ра-
бот. В 1977 г. появилось сообщение об увеличении производи- ;
тельности ILLIAC IV до 310 млн. операций в секунду вместо I
прежних 200 млн. операций в секунду за счет повой -системы 1
программного обеспечения [112, ИЗ].
Наконец, фирма Burroughs, как и Control Data, рассматри-
вала по заказу Эймского научно-исследовательского центра *
NASA возможность создания вычислительной системы произво- ;
дительностью в 1 миллиард операций в секунду. При этом, -
в отличие от Control Data (см. п. 5.2.3), предполагалось создание •
варианта ILLIAC IV с 512 процессорными элементами [ИЗ].
Библиографическая справка. Системе ILLIAC IV "
посвящена обширная литература. Проект системы с 256 ЛЭ опи- =
сан в ключевых статьях [36, 904], а вариант системы с 64 ПЭ,
который был реализован,—в ключевой статье [45]. Эта система 1
рассмотрена в книгах [152, 162, 218, 283, 368, 395, 947, 1222] и 3
в работах обзорного характера [8, 31, 275, 351, 364, 523, 827, 1
880, 927, 966, 988, 989, 1118, 1155, 1193, 1221, 1223, 1243]. Описа- 1
нию системы и ее отдельных частей посвящены статьи [355, *3
326 1
362, 495, 645,4 972, 1013, 1173—1175, 1192]. В некоторых ИЗ ука-
занных выше работ, наряду с другими вопросами, рассматрива-
ются также вопросы программирования для ILLIAC IV. Опера-
ционная система OS4 ILLIAC IV описана в [455], параллельный
ассемблер —в [1114], параллельный фортран для ILLIAC IV и
соответствующий транслятор — в [986, 987, 1010], фортраноподоб-
ь'ыи язык CED для ILLIAC IV4*-в [1190]. Язык ivtran, являю-
щийся расширением фортрана для параллельных операций на
ILLIAC IV, анализатор параллелизма и синтезатор параллельных
программ на ivtran’e, а также транслятор с этого языка^ описаны
в [604, 700, 1078]. Экспериментальный язык vectran для вектор-
ных и матричных операций на ILLIAC IV кратко рассмотрен в
[1065]. Алголоподобные языки tranquil и glypnir представлены
в [448, 922].
Операционная система, пять языков для ILLIAC IV Cglypnir,
cockroach, tranquil и ассемблеры ASK, pandora) и соответствую-
щие трансляторы кратко описаны в [973]. Трансляторы с язы-
ков фортран и ivtran, а также три системные программы (parse,
paralyzer, transcriber) подробно рассмотрены в [985].
Методы оптимизации программ и их применение к програм-
мам на фортране для ILLIAC IV изложены в [951]. Некоторая
модель параллельных вычислений и ее применение к ILLIACIV
описаны в [1279]. Основные концепции программного обеспече-
ния и программирования применительно к ILLIAC IV представ-
лены в 1706]. Вопросы программирования разнообразных задач
на ILLIAC IV и применения этой системы описаны в [450, 496,
501, 502, 640, 669, 671, 885, 892, 905, 1020, 1041, 1195, 1263].
Некоторые новые усовершенствования программного обеспече-
ния ILLIAC IV кратко рассмотрены в [112, ИЗ].
'W
6.5. Системы BSP, DAP, IBM 3838
и другие матричные системы
В последние годы был разработан ряд матричных систем.
Рассмотрим сначала систему BSP (Burroughs Scientific Proces-
sor) [864, 1239], объявленную в 1977 г. фирмой Burroughs. Эта
большая матричная система предназначена для решения очень
крупных задач для научно-исследовательских, промышленных и
правительственных организаций.
Система способна производить обработку числовых данных с
плавающей запятой со скоростью до 50 млн. операций в секун-
ду. В ней используется файловая (массовая) память, которая
может вмещать до 64 М 56-разрядных слов. Система содержит
16 процессорных элементов, работающих параллельно. Эти эле-
менты образуют матричную структуру, что позволяет решать с
высокой скоростью трудоемкие задачи, ориентированные на век-
торную обработку.
327
Система BSP работает совместно с другой вычислительной
системой, выполняющей функции управляющей. В качестве уп-
равляющей применяется система В 7800 (или В 7700). Кроме
основной конфигурации BSP, предусмотрены две другие конфи-
гурации BSP/7811 и BSP/7821, которые используют в качестве
управляющих системы В 7811 и В 7821 соответственно. Важно
отметить, что при сопряжении в 7800 (В 7811, В 7821) с мат-
ричной системой возможности обработки информации первой
Рис. 6.8. Структурная схема системы BSP.
системой сохраняются и при этом добавляются новые возможно-
сти обработки за счет BSP. Кроме этого, допускается модульное
наращивание BSP.
Система BSP имеет весьма простую структуру (рис. 6.8), 1
Она содержит управляющий процессор (процессор команд), фай-
ловую память и параллельный процессор, причем параллельные
процессорные элементы, входящие в состав параллельного про-
цессора, управляются одним потоком команд. " i
К началу разработки BSP сформировался ряд положений, i
связанных с обработкой линейных векторов, основными из ко-
торых являются следующие: 1) прежде всего следует увеличи-
вать эффективную скорость вычислений, а не максимальную,
т. е. увеличение производительности не следует достигать за
счет специализации систем и утраты ими универсальности (си- *
стемы должны оставаться в наибольшей степени универсальны-
ми); 2) обычная одномерная память не обеспечивает необходи-
328 ’
мой общности адресации для матричных систем; 3) язык ассем-
блера непригоден, а средства фортрана недостаточны для прог-
раммирования обработки линейных векторов; можно построить
программу-анализатор, эффективно распознающую внутрен-
ний параллелизм программ на фортране, но программа-синте-
затор не сможет построить соответствующую эффективную прог-
рамму, если матричная система не обладает достаточно простой
структурой; 5) теория параллельной обработки только формиру-
ется и многие проблемы не решены (неясно, например, как ре-
ально обеспечивать параллельность при рекуррентных соотно-
шениях); 6) при создании новых систем должна обеспечиваться
программная преемственность и при появлении новой системы
векторной обработки пользователь не должен перепрограммиро-
вать задачи.
Основной проблемой здесь является проблема рационального
совмещения скалярной и векторной обработки, т. к. если иметь
только векторный процессор, то даже при сравнительно неболь-
шом числе невекторизуемых конструкций программы эффектив-
ность использования векторного процессора и скорость обработ-
ки очень резко снижаются (см. главу 8). С другой стороны, удов-
летворить одновременно требования 1, 4 и 6 можно путем вве-
дения в систему мощного скалярного процессора. В этом случае,
однако, возрастает стоимость системы, транслятор должен авто-
матически делать выбор между векторным и скаляршм процес-
сорами и обеспечивать при этом эффективную машинную прог-
рамму фактически для двух разных машин при одном и том W
входном языке. Наконец, использование мощного скалярного про-
цессора почти гарантирует необходимость существенной пе-
реработки программ при переходе к ‘следующей новой модели
системы.
В силу перечисленных соображений в состав BSP, в отличие,
например, от STAR 100 (CYBER 203), не включен мощный ска-
лярный процессор. Вместе с тем, управляющий процессор* имеет
в своем составе скалярный процессор, который может использо-
ваться транслятором для скалярной обработки. В этом случае,
однако, транслятор обычно либо рассматривает скаляры с пла-
вающей запятой как векторы единичной длины, либо рассмат-
ривает последовательность таких скаляров как нелинейный век-
тор. Такой подход, во-первых, обеспечивает единообразие при
оперировании с данными и достаточную эффективность трансля-
ции, во-вторых, позволяет при переходе к следующей новой мо-
дели ограничиться, в худшем случае, перетрансляцией программ
и, в-третьих, позволяет достаточно просто выполнять первона-
чальное преобразование программ для BSP.
Управляющая система В 7800 со своей операционной систе-
мой МСР разгружает BSP от ведения общесистемных операций.
Пользователь связывается с BSP через В 7800, которая, кроме
этого, выполняет функции управления периферийными устройст-
329
вами, внешними подсистемами памяти, процессорами связи,
внешним вводом-выводом и расписанием потока работ. В 7800
может, в дополнение к указанным функциям автоматического
планирования решения задач и динамического распределения
ресурсов BSP, осуществлять одновременно также оперативное
управление сетями терминалов с большими интегрированными '
базами данных и выполнять программы пользователей,
написанные на коболе, PL/1, алголе, фортране и языках
basic и APL. -
Как указывалось выше, собственно BSP содержит три асинх-
ронных секции: управляющий процессор, многоэлементный па-
раллельный процессор и файловую память..
Управляющий процессор содержит устройство управления и
обслуживания, устройство управления параллельным процессо-
ром, скалярный процессор производительностью 1,5 млн. опера-
ций в секунду, а также свою собственную биполярную память
емкостью в 256 К слов. Он работает в режиме обмена управля-
ющей информацией с управляющей системой В 7800, выполняет'
определенные скалярные (^одномерные») операторы и управля-
ет параллельным процессором и файловой памятью. Асинхрон-
ная работа секций является развитием работы с перекрытием
в ILLIAC IV, в которой В 6500 заранее готовит команды для ис-
полнения процессорными элементами, что примерно удваивает
производительность ILLIAC IV. В BSP для реализации перек-
рытия, аналогично ILLIAC FV, предусмотрена очередь меж-
ду управляющим процессором и процессорными элемента-
ми параллельного процессора, но; в дополнение к ILLIAC IV,
обеспечивается контроль границ массивов, оптимизация выбора
между внутренними и внешними циклами оператора DO фортра-
на и другие возможности.
Параллельный процессор содержит параллельную память па
биполярных элементах емкостью от 0,5 М до 8 М слов, сеть свя-
зи этой памяти с процессорными элементами и 16 процессорных
элементов с суммарной производительностью до 50 млй. опера-
ций с плавающей запятой в секунду. Он выполняет векторные
или матричные операторы программы.
Управляющий и параллельный процессоры имеют цикл дли-
тельностью 80 и 160 нсек соответственно, время цикла парал- J
лёльной памяти равно 160 нсек.
В интересах пользователя файловая память построена как
расширение параллельной, чтобы файловой памятью могла в |
максимальной степени распоряжаться рабочая программа, а не 1
операционная система. Для работы в таком оперативном режиме 4
скорость электромеханических устройств памяти оказывается |
недостаточной, поэтому файловая память BSP выполнена на 1
приборах с зарядовой связью (ПЗС). Емкость этой памяти сос- ;
тавляет от 4 М до 64 М слов, время доступа — 500 мксек, ско-
рость передачи информации — 75 млн. байт в секунду. В ячей-
330
\ , .
ках памяти йх в каналах передачи информации обеспечивается
исправление одиночной ошибки и обнаружение двойной ошиб-
ки при помощи кода Хэмминга. Файловая память хранит прог-
раммы и данные для использования их управляющим процессо-
ром и параллельным процессором.
Выше отмечалось, что В 7800 и BSP работают параллельно.
Кроме этого, структура соответственно BSP обеспечивает четыре
уровня параллелизма: 1) арифметические операции в 16 процес-
сорных элементах; 2) запись/считывание данных и обмен дан-
ными между памятью и процессорными элементами; 3) индек-
сация, определение длины векторов и управление циклами уст-
ройством управления параллельным процессором; 4) подготовка
векторных операции скалярным процессором. Работа параллель-
ной памяти, сети связи памяти с процессорными элементами и
16 процессорных элементов организована по принципу конвей-
ера, загрузку которого обеспечивает устройство управления парал-
лельным процессором при помощи специальных микрокоманд.
Эти микрокоманды кодируются заранее и определяют различные
совокупности арифметических операций в 16 процессорных эле-
ментах, операций обращения к параллельной памяти и операций
пересылок так, что в процессе выполнения программы осуществ-
ляется только выбор наилучших последовательностей микроко-
манд в соответствии с подготовленными командами для выпол-
нения. Такое использование микрокоманд позволяет также осу-
ществлять повтор операции, если при ее выполнении не удалось
устранить ошибку.
Как отмечалось выше, программирование для BSP ведется
на фортране, причем транслятор преобразует операторы языка
в векторные операции.
В 1977 г. фирма Burroughs анонсировала еще одну матрич-
ную систему, получившую название AFP (Attached Fortran Pro-
cessor) [113]. Эта система предназначена для решения задач
научного характера, запрограммированных на фортране, расши-
ряет и эффективно использует возможности фортрана и может
выполнять 1,5 млн. операций с плавающей запятой в секунду.
AFP работает в совокупности с одной из универсальных систем
В 68Д0, В 7800, В 6700 или В 7700, которая выполняет функции
управляющей системы.
Основные характеристики AFP: оперативная память имеет
общую емкость от 128 К до 1 М слов и время цикла 160 нсек;
в течение цикла могут быть записаны в оперативную память и
считаны из нее 4 командных слова; время цикла процессора
равно 80 нсек. Связь с управляющей системой осуществляется
через устройство управления сопряжением AFP. Для ускорения
выполнения арифметических операций используются регистры.
Имеется стек памяти и специальные регистры для эффективного
выполнения часто повторяемых подпрограмм. Файловая память
построена на дисках с головкой на тракт с временем выборки
331
5 мсек и скоростью передачи информации 650 т^гс. байт в се-
кунду, ее емкость — от 2 до 16 млн. слов [J13J* /
Разработка большой матричной системы DAP/ (Distributed Ar-
ray Processor) была начата английской фирмой ICL в 1972 г.
Предполагалось, что на разработку и изготовление системы пот-
ребуется примерно 5 лет. Был построен опытный образец систе-
мы, причем в нем применены дискретные элементы. Серийные
1
dj /Яюцемщлых м&г&м?
Рис. 6.9. Структурная схема системы DAP.
образцы должны быть построены на больших интегральных схе-
мах. Из-за недостатка средств работы над развитием системы
в последнее время были заторможены [112, 113, 283]. Рассмот-
рим систему DAP, следуя [1203].
Структурная схема системы DAP изображена на рис. 6.9.
DAP связана через высокоскоростной канал обмена с универсаль-
ной вычислительной системой, которая выполняет все обеспечи-
вающие системные функции и сосредотачивает данные и коман-
ды в форме, пригодной для DAP. Эта вычислительная система
является ведущим процессором для DAP. Устройство управле-
ния DAP направляет команды, адреса и другую управляющую
информацию ко всем процессорным элементам и следит за вы-
полнением матричных операций.
Каждый процессорный элемент (ПЭ) представляет собой од-
норазрядный микропроцессор и имеет связанную с ним память
емкостью в 4096 бит. Матрицу ПЭ и их память удобно рассмат-
ривать как прямоугольный параллелепипед, содержащий 4097
332
горизонтальных слоев. ПЭ располагаются в верхнем слое в виде
матричной конфигурации, строка которой имеет длину АХш
бит, где w — длина слова ведущего процессора, N — некоторое
целое число машинных слов ведущего процессора, а столбец
имеет длину 2W, где т — некоторое выбранное целое положи-
тельное число. Таким образом, матрица ПЭ имеет размеры 2тХ
X (N X w). Под каждым ПЭ в параллелепипеде располагаются
в виде вертикальной колонки 4096 разрядов его памяти, причем
каждый слой разрядов этой памяти пронумерован от 0 до 4095
и представляет собой AX2W ш-разрядных слов памяти ведущего
процессора. Перепривязка и переформирование информации из
слов ведущего процессора в форму 4096-разрядной памяти ПЭ и
наоборот осуществляется устройством управления.
Каждый ПЭ связан с памятью четырех его ближайших сосе-
дей, расположенных сверху, снизу, слева и справа от него, что
обеспечивает возможность распространения данных по матрице.
Арифметико-логическое устройство (АУ) ПЭ представляет со-
бой простой процессор с последовательной поразрядной обработ-
кой информации, способный выполнять обычные арифметические
операции. Операнд, получаемый в результате выполнения опера-
ции, отсылается из соответствующего регистра внутри АУ в па-
мять данного ПЭ или в регистр одного из четырех соседних ПЭ
при помощи нижнего мультиплексора данного ПЭ (см. рис. 6.9,
б). Каждый ПЭ содержит разряд активности, который, если он
установлен в «пассивное» состояние, запрещает ПЭ выполнять
поступающую команду. Этот разряд активности используется для
маскирования частей матриц ПЭ или отдельных ПЭ в зависимо-
сти от условий выполнения вычислений.
Команды DAP, направляемые устройством управления систе-
мы всем ПЭ внутри-матрицы, содержат всю информацию, требуе-
мую для выполнения арифметических операций (адреса исход-
ных операндов и операнда — результата операции и др.). Для вы-
полнения некоторой операции каждый бит в операнде должен
быть обработан отдельно. Поэтому, например, для выполнения
сложения 20-разрядных чисел с фиксированной запятой требует-
ся 20 раз (по числу разрядов в операнде) повторить цикл из трех
команд DAP. Время цикла работы DAP равно 200 нсек, поэтому
ПЭ на выполнение указанной операции затрачивает 12 мксек.
Однако, матрица из 4096 ПЭ выполняет такие операции сложе-
ния с максимальной скоростью около 340 млн. операций в се-
кунду.
Одной из наиболее интересных особенностей DAP является
то, что вместо обычного высокопроизводительного параллельного
АУ используется очень простое и очень дешевое одноразрядное
АУ, в котором все операции выполняются при помощи програм-
мы. Такое АУ в отдельности имеет низкую скорость работы, од-
нако матрица из большого числа параллельных АУ с оперативно
изменяемыми связями между ними обеспечивает высокую произ-
333
водительность. Такой подход является очень гибким с точки
зрения выполнения арифметических операций, т. W. пользователь
может по своему усмотрению выбирать точность Арифметических
операций. Это, во-первых, дает значительную экономию памяти»
т. к. операнды занимают только столько разрядов, сколько требу-
ется при данной точности представления чисел/и, во-вторых, дает
значительную экономию числа двоичных операций, т. е. эконо-
мию непосредственно времени выполнения, так как последова-
тельные двоичные операции производятся только собственно над
разрядами операнда, количество которых соответствует требуемой
точности представления чисел.
Второй важной особенностью DAP является то, что ее память
может использоваться как обычная память для ведущего процес-
сора в то время, когда DAP не выполняет работу.
Построенный опытный образец DAP имеет матрицу в составе
32 X 32 ПЭ, каждый из которых имеет 1 К разрядов памяти.
Предполагается расширение этого образца до 64 X 64 X 4 К раз-
рядов. Результаты моделирования позволяют сделать вывод, что
скорость работы такой конфигурации будет, в 5—10 выше по
сравнению с IBM 360/195 при решении задач, удобных для реа-
лизации на системе DAP, причем стоимость системы будет отно-
сительно невысокой [1203].
Опытный образец DAP использует в качестве ведущего про-
цессора систему CDC 7600. В дальнейшем предполагается в каче-
стве ведущего процессора использовать большие системы семейст-
ва ICL 2900, в которых применяется магистральная обработка
данных и может быть организована многопроцессорная работа
(до 2 процессоров), выполнение команд отделено от управления
выборкой из памяти, предусмотрена виртуальная организация
использования всех основных машинных ресурсов (процессоров,
оперативной памяти, контроллеров, периферийных устройств, про-
межуточной памяти и др.), введены стеки, дескрипторы и много-
уровневая защита данных (до 16 уровней) [112]. Учитывая по-
разрядную обработку информации в ПЭ DAP, эту систему следует
классифицировать как ОКМДР/Вс.
Кроме DAP известна другая английская разработка матрич-
ной системы, называемой Clip 4, которая также задерживалась
из-за ограниченности средств. В ней предусмотрена матрица раз-
мером 96 X 96 ПЭ на больших интегральных схемах. Clip 4 ори-
ентирована на высокоскоростную обработку изображений в реаль-
ном масштабе времени и имеет мощный набор команд. Проект
Clip 4 выполнен в Лондонском университете, в котором в течение
длительного времени разрабатываются матричные’ процессоры:
в 1967 г. была продемонстрирована матрица 20 X 20 ПЭ для об-
работки фотографий, получаемых в пузырьковой камере; в 1969 г.
создана матрица из 25 ПЭ, в 1971 г. — матрица 10 X 10 ПЭ Clip 1,
выполняющая 3 функции, в 1972 г. — матрица 16 X 12 ПЭ Clip 2,
выполняющая 256 функций, а в 1973 г. начала работать матрица
334
\
Clip 3, котора^, как и Clip 4, ориентирована на обработку изобра-
жений 11131.
Clip 3 имее\ матрицу из 192 идентичных ПЭ (16X12),
каждый из которых связан только с соседними. ПЭ содержит
входной и выходной регистры, устройство выполнения булевских
операций и память. Команды подразделяются на три основных
типа: загрузка, обработка, ветвление. Команды обработки ориен-
тированы на двумерные матричные операции, что позволяет одно-
временно обрабатывать все части* изображения. Система обеспе-
чивает очень высокую скорость анализа структуры дискретных
изображений, обработки данных в реальном времени и распоз-
навания образов. Она является частью аппаратурного комплекса
обработки изображений [676].
Более широкими функциональными возможностями обладает
первый матричный процессор АР/130 фирмы Data General, выпу-
щенный в продажу в 1978 г. [265]. Он предназначен для обработ-
ки сложных сигналов в акустических и радиолокационных систе-
мах, для анализа речи и анализа сейсмической информации, для
применения в системах связи. В процессоре используется машина
Eclipse S/130, имеется возможность работы с плавающей запятой.
Матрица состоит из 1024 ПЭ, производит обработку комплексных
чисел и выполняет быстрое преобразование .Фурье. Операции вы-
полняются над 32- или 64-разрядными словами с использованием
языка фортран IV.
Подключение матричных процессоров к универсальным маши-
нам в целях повышения производительности последних находит
все более широкое применение. Предусматривается подключение
матричного процессора к ЭВМ Единой системы, причем для
обеспечения работы такого комплекса расширяются возможности
операционной системы ОС [2861. Фирма IBM разработала в 1977 г.
матричный процессор IBM 3838 для выполнения с высокой ско-
ростью векторных операций. IBM 3838 работает совместно с од-
ной из систем IBM 370/145, 148, 158 или 168, к которой она под-
ключается через блок-мультиплексный канал, при этом соответ-
ствующая универсальная вычислительная система работает под
управлением операционной системы MVS и выполняет функции
ведущего процессора. В частности, она обеспечивает доступ поль-
зователя к IBM 3838 при помощи рабочих программ на языках
фортран, PL/1 и ассемблер. IBM 3838 рперирует с 36-разрядными
словами, может иметь основную память емкостью.в 256 К, 512 К
или 1 М байт и, кроме этого, имеет управляющую память ем-
костью в 16 К байт [112, 113, 314].
Западногерманская фирма PCS GmbH в 1976 г. выпустила
матричный процессор APS (Array Processor System), который
предназначен для подключения к различным ЭВМ с целью повы-
шения их производительности" при решении сложных задач вы-
числительного характера. Он имеет модульную структуру и со-
держит модули двух типов: процессорные элементы и процессоры
335
I
ввода-вывода. Конфигурация APS формируется в зависимости от
конкретного круга решаемых задач. При наличии 16 ПЭ APS
обеспечивает выполнение 50 млн. операций с плавающей запятой
.в секунду. Процессор APS поставляется вместе^ с операционной
системой. Первый из проданных образцов предназначался для ра-
боты в комплексе с PDP-11 [266].
Матричный процессор AP-190L, анонсированный в 1977 г.
фирмой Floating Point Systems наряду с другими матричными
процессорами, предназначен, как и APS, для использования
с. большими универсальными ЭВМ с целью увеличения скорости
векторной и матричной обработки. Матричные процессоры указан’
ной фирмы содержат быстрые регистры, память программ, па-
мять данных, конвейерные устройства сложения с плавающей
запятой и конвейерные устройства умножения с плавающей за-
пятой [113].
Сравнивая матричные процессоры APS фирмы GmbH и
АР 120В фирмы Floating Point Systems, имеющие примерно оди-
наковые возможности, можно отметить, что скорость выполнения
умножения с плавающей запятой равна максимум 17,5 и 6 млп.
операций в сёкунду Для первого и второго процессоров соответст-
венно. При наличии 16 ПЭ APS обеспечивает выполнение алго-
ритма быстрого преобразования Фурье для 1024 точек за 1,4 мсек
и вычисление корреляционных функций для 32 зависимостей по
1024 точкам при работе с плавающей запятой за 4 мсек, тогда
как АР 120В затрачивает на эти операции 2,5 и 5,8 мсек соот-
ветственно [266].
Таким образом, в последнее время наблюдается активизация
разработок матричных систем различной мощности, причем соз-
даются как экспериментальные, так и серийные системы. Прак-
тически во всех случаях, за исключением узкоспециализирован-
ных применений, предусматривается работа матричной системы
в комплексе с универсальной, системой. Достоинства матричных
систем определяются особенностями класса ОКМД: а) высокая
производительность при решении хорошо распараллеливаемых за-
Лач; б) высокая экономичность вследствие модульности матрицы
процессорных элементов и наличия только одного центрального
устройства управления. Матричные системы, однако, обладают
и недостатками: а) жесткость и неполнота непосредственных свя-
зей между процессорными элементами; б) жесткий характер син-
хронного управления со стороны единственного устройства управ-
лейия; в) недостаточная эффективность операций собственно в
процессорных элементах.
* В целях исключения или уменьшения влияния указанных не-
достатков была разработана система, получившая, возможно, не-
окончательное название Новая процессорная матрица, в которой:
1) слова имеют переменную длину; 2) для передачи информации
между ПЭ используется логарифмическая структура связей;
3) поток микрокоманд является частично управляемым. Эта си-
336
стема имеет, по существу, переменную, а не жесткую матричную
структуру. Рассмотрим Новую процессорную матрицу, следуя
11038].
Система содержит, как обычно, ведущий процессор, который
связан с общим центральным устройством управления, которое,
в свою очередь, связано с множеством ПЭ, каждый из которых
оперирует с 8-разрядными словами.
Удобно считать, что ПЭ расположены в линию. Каждая пара
соседних ПЭ может быть связана между собой при помощи четы-
рех каналов, которые называются линией переноса, линией сдвига,
линией сдвига-вращения с переменной структурой и каналом уп-
равления. В этом случае два связанных ПЭ образуют составной
ПЭ с 16-разрядным словом. Такой способ связи позволяет образо-
вывать из цепочек соседних ПЭ составные ПЭ с длиной слова,
равной произведению числа 8 на количество исходных ПЭ в це-
почке связанных ПЭ, т. е. обеспечивает переменную длину слов.
Рис. 6.10. Переменная структура связей между процессорными элементами.
Включение и отключение связи между каждой парой ПЭ осуще-
ствляется динамически под у]Травлением микрокоманд и задается
содержимым соответствующего разряда регистра признаков пар-
ных связей в центральном устройстве управления, определяющих
переменную структуру связей в зависимости от текущих резуль-
татов процесса вычислений. Ha* рис. 6.10 изображены в качестве
примера пять ПЭ, составившие 16-разрядный и 24-разрядный
процессоры в соответствии с содержимым разрядов регистра
связей L..t 1, 0, 1, 0, 0, 1, ...]. #
Для передачи информации между ПЭ используется так назы-
ваемая логарифмическая структура связи, суть кЪторой состоит
в том, что связываться могут только «логарифмически близкие»
ПЭ, т. е. такие, для которых номера удовлетворяют соотношению
j = i + 2\ где fcs0, 1, ... при условии 0<i^N и 0</<7V.
Пример трех возможных вариантов логарифмической структуры
связей для восьми ПЭ показан на рис. 6.11, причем слева для
каждого варианта ПЭ изображены в виде линейной конфи-
гурации, а справа — в виде матричной конфигурации (для случая
в) матрица вырождается в столбец). Логарифмическая структу-
22 б. А. Головкин 337
ра связей является переменной, причем предусматривается на 1
более loga/V различных конфигураций связи на базе «логарифмы- 1
ческой близости» и является экономной с точки зрения числа |
требуемых линий и числа шагов передачи данных между раз- 1
личными ПЭ. 1
Выше отмечалось, что поток микрокоманд является частично ।
управляемым. Это означает, во-первых, что каждый ПЭ может не 1
выполнять микрокоманду, т. е. используете^ обычное для матрич- |
ных систем маскирование ПЭ, и, во-вторых, каждый ПЭ может^.
выполнять часть микрокоманды. Отключение ПЭ‘ осуществляется
Рис. 6.11. Логарифмическая структура связей между процессорнымц эле- J,
ментами. 1
1
яри помощи соответствующего разряда в регистре маски цент-
рального устройства управления, а выбор частей в микрокоманде j
•задается микропрограммой и может быть как условным, так и
безусловным.
Центральное устройство управления связано с ведущим про- ,
щессором' и управляет работой всех ПЭ, имеющих собственную J
память, при помощи потока 44-разрядных микрокоманд, задаю- j
Щих арифметические и логические операции ПЭ, операции счи-
тывания из регистров ПЭ и записи в них, операции считывания
из памяти ПЭ и записи в память, операции с регистрами цент- 5
рального ’ устройства управления, операции перехода, повторения 1
и другие. Основной цикл работы равен 300 нсек, однако в целях 5
согласования с максимальным временем переноса разрядов оп мо-
338
*Г
жет быть лрограммно увеличен. Ведущий процессор инициирует
и прекращает работу матрицы ПЭ, считывает и записывает ин-
формацию в управляющую память и в память ПЭ, осуществляет
общее управление выполнением микрокоманд.
Для проверки концепции рассматриваемой системы был изго-
товлен ее опытный образец с управляющей памятью емкостью
в 4 К слов и с 16 ПЭ, каждый из которых имеет собственную
быстродействующую память емкостью в 4 К байт. Ведущий про-
цессор с гибким диском, устройство управления, все ПЭ, блок
сопряжения и блок питания размещены в системной стойке, в ко-
торой предусмотрен также экранный пульт для контроля и диаг-
ностики матрицы ПЭ.' Предусмотрено программное обеспечение»
включающее кросс-микроассемблер, загрузчик и системные под-
программы. Запланирована разработка матричной системы с не-
сколькими сотнями ПЭ, предназначенной для решения задач
распознавания и обработки изображений.
Библиографическая справка. Система BSP описана
в [864, 1194, 1223, 1239] и, более кратко в [112, ИЗ, 350]. Неко-
торые сведения о системе AFP содержатся в [113]. Система DAP
описана в [726, 1116, 1203], причем в третьей работе представлен
проект системы с Детальным описанием ее арифметических и
логических возможностей,4 рассмотрено программное обеспечение
и проанализирована производительность системы. Краткие сведе-
ния о системе DAP содержатся в [112, ИЗ, 152, 218, 283], а о
матричных процессорах Clip 1, 2, 3 и 4 — в [ИЗ]. Описание Clip 3,
включая вопросы программирования, дано в [676]. Краткая ин-
формация о АР/130 приведена в [2651.
Разработка программного обеспечения матричного процессо-
ра, ориентированного для работы в комплексе с ЭВМ Единой си-
стемы, представлена в [2861. Матричный процессор IBM 3838,
предназначенный для работы в комплексе с одной из систем IBM
370/145, 148, 158 или 168, кратко рассмотрен в [112, 113, 12231.
Матричный процессор APS .кратко описан в [266]. Краткая ин-
формация о новых матричных процессорах фирмы Floating Paint
Systems приведена в (113, 2661. Новая процессорная матрица
представлена в [1038].
6.6. Система STARAN и другие ассоциативные системы
Система STARAN фирмы Goodyear Aerospace получила наи-
большую известность среди ассоциативных систем. Она харак-
теризуется последовательной поразрядной обработкой множества
слов (см. главу 2). Однако ассоциативные системы могут ис-
пользовать и другие способы' обработки, рассматриваемые далее
[1274].
Ассоциативную систему (ассоциативный процессор) можно
представить в общем случае как систему, обладающую следующи-
22* 339
ми двумя свойствами: 1) данные, находящиеся в памяти, могут
выбираться на основании их содержания или части их содержа-
ния (не по их адресам); 2) операции преобразования данных, как
арифметические, так и логические, могут осуществляться над не-
сколькими множествами аргументов при помощи одной команды.
Такая система содержит ассоциативную память, арифметико-ло-
гическое устройство, подсистему управления, память команд (уп-
равляющая память) и интерфейс ввода-вывода (рис. 6.12).
Рис. 6.12. Структурная схема ассоциативной системы.
Главное отличие ассоциативной системы от обычной системы <
последовательной обработки информации состоит в использовании
ассоциативной памяти или подобного устройства, а не памяти
с адресуемыми ячейками. Это главное' отличие влечет за собой
отличия и в других устройствах. Таким образом, ассоциативная
память является основой ассоциативной системы и структура ас-
социативной системы мо>йет быть классифицирована на базе ор-
ганизации ассоциативной памяти.
Ассоциативную память можно определить как память систе-
мы, из которой находящиеся в ней данные могут быть выбраны
па основании их содержания или части их содержания, а не по
адресам данных (соответствует первому свойству ассоциативных
систем). В ассоциативной памяти выборка слов происходит по со-
ответствию их содержимого (или части содержимого), заданным
ключевым словам для поиска информации, а не по адресам,
как в памяти с адресуемыми ячейками. Основной запоминаю-
щий элемент ассоциативной памяти называется ячейкой разряда
(разряд-ячейка). Такая ячейка может один бит информации за-
писать в себя, считать его вовне и сравнить с запрашиваемой .
информацией.
Операции поиска, которые состоят из маскирования и срав-
нения, выполняются по-разному в зависимости от организации
ассоциативной памяти. Типичными операциями сравнения, выпол-
няемыми ассоциативной памятью, являются следующие: «рав-
но — не равно», «меньше, чем — больше, чем», «не больше, чем —
не меньше, чем», «максимальная величина — минимальная вели-
чина», «между границами — вне границ», «следующая величина
больше — следующая величина меньше». При помощи маскиро-
вания можно выделить только те поля в ключевом слове, кото-
рые нужно использовать для сравнения при поиске.
340
С точки зрения обработки информации ассоциативная система
может выполнять сложные операции преобразования данных в
дополнение к операциям сравнения, которые может выполнять
ее ассоциативная память. С точки зрения структуры ассоциатив-
ные системы входят в класс ОКМД (см. главу 2), и, в свою оче-
редь, могут быть разбиты на четыре категории в соответствии
с организацией процесса сравнения в их ассоциативной памяти:
1) полностью параллельные; 2) поразрядно последовательные;
3) пословно последовательные; 4) блочно ориентированные ассо-
циативные системы. В полностью параллельных системах логика
сравнения может быть предусмотрена в каждой ячейке разряда
каждого слова или же в каждой группе ячеек (например, в бай-
те), представляющих код символа при фиксированном числе раз-
рядов в коде (или в группе кодов, н&пример, в слове). В пораз-
рядно-последовательных системах операции выполняются в каж-
дый момент времени только над одним разрядным срезом всех
слов, из-за чего такие системы называются также поразрядно-
последовательными, пословно-параллельными системами. Эти две
категории ассоциативных систем являются наиболее Важными
и им уделялось наибольшее внимание в практических разработ-
ках. С точки зрения ассоциативного характера обработки к пол-
ностью параллельным ассоциативным системам с логикой сравне-
ния в группе разрядов можно отнести РЕРЕ, а к поразрядно-пос-
ледовательным — STARAN. Наибольшую производительность
могли бы иметь полностью параллельные системы с логикой срав-
нения в каждом разряде, но оборудование в таких системах слож-
ное и дорогостоящее, и поэтому они не нашли сколько-нибудь
широкого применения.
Первая ассоциативная матрица была разработана в 1956 г.
с использованием криотронов L1170J, а первая ассоциативная си-
стема — вероятно, в 1963 г. с использованием также криотронов.
В последующие годы был реализован ряд ассоциативных матриц
с применением различной элементной базы, включая интеграль-
ные схемы, и построен ряд лабораторных моделей ассоциативных
систем с применением ассоциативной памяти различных типов.
Однако начало практического применения ассоциативных систем
было положено только с созданием систем РЕРЕ и STARAN.
Пословно-последовательная ассоциативная система фактиче-
ски представляет собой аппаратную реализацию простого про-
граммного цикла для поиска. Главный фактор, способствующий
относительно более высокой эффективности этого подхода по
сравнению с запрограммированным поиском в обычной ЭВМ, за-
ключается в том, что уменьшается время декодирования команды,
поскольку в пословно-последовательном процессоре требуется
только одна команда для выполнения операции поиска. Такие
процессоры могут быть реализованы на основе вращающегося уст-
ройства ассоциативной памяти, цифровых ультразвуковых линий
задержки, барабанов или дисков с логикой сравнения на каждый
341
тракт. Вследствие низкой скорости пословно-последовательной ас-
социативной памяти были построены только экспериментальные
модели пословно-последовательных ассоциативных систем.
Блочно-ориентированную ассоциативную систему можно рас-
сматривать как компромисс между дорогостоящей поразрядно-
последовательной ассоциативной системой и низкоскоростной по-
словно-последовательной ассоциативной системой. Система исполь-
зует вращающееся устройство памяти большой емкости, такое
как диск с ограниченными ассоциативными возможностями, име-
ющий головку на тракт и некоторую логику для каждого, трак-
та. Было предложено и построено несколько блочно-ориентирован-
ных ассоциативных систем.
МяЛиль’
асыциелп/Ллой
мглгдяцы Л
Ободу Зя-1
оаяяе I Л •
лользоОо-ъ Лядил-
лгелей Хлелышй
| JffoO-
.Дь/июли^*'^
тельные'
дойные —-—
у отдои-J
СЛМо
if
Лядяллельный
Дя З/Лялаяни-
/пельнягя
лоЛдля
МяФ/Л£>
ЯЯЯЯЦЯЯЛШЛ/ДШ
М0Л7ДЦЦ6/ л
Ляняль/
блешялх
Ляглчесюе
услгдяЛстЛя w
.Дюллей |
. Оеюяд- [
ные^ус/л-
'ЗОЯЯННЫи
I ООоО-
\~ОыбоО
! Лдяной
ХОюлгилн
L — — -I лиНЯЛЮ
ДМ№
Ляфеля-
зяЯгллый
-3^/ЛяЛ
Лдяняй
Ляя/лдл^
*—»я лмгялш
Ляеячесяяе
услгдяюлМя
леслеЛяЛл-
/ПЯ/76НЯ8Я
улдяДееяля
Ломчеелое
ус/пдяяялМя
ялгдялщ
Логическое
усл?длЛсл?Ло
ОССОЦШГЛШО-
лягя
улдлЛлем/я
Лязячеяяяе у&лгдлЛялМя ЛгяЛл Л ллмялтя
УлдяЛляющяя ллмуля tMWMb/
Лядслялуемг улд&Ллеяяя
2
Рис. 6.13. Структурная схема системы STARAN.
Одна из наиболее известных таких систем, называемая RAPID
(Rotating Associative Processor for Information Dissemination )r
представлена в [1059]. Блочно-ориентированная ассоциативная
память содержит три связанных между собой устройства: устрой- J
ство управления, диск с головкой на тракт и память с логикой '!
- сравнения символов, причем обмен между диском и указанной па-
мятью осуществляется строками, состоящими из кодов символов.
[1274]. к ;
Рассмотрим теперь высокопроизводительную систему STARAN.
Структурная схема STARAN изображен^ на рис. 6.13 [1274]. i
Система содержит подсистему управления и до 32 модулей ассо-
циативных матриц, обеспечивающих ассоциативную выборку и оп- ;
ределяющих возможности параллельной обработки информации. |
.342 1
Каждый модуль содержит: 1) 65536 разрядов памяти, которая ор-
ганизована в виде матрицы с многомерным параллельным досту-
пом и имеет размер 256 слов X 256 разрядов; 2) 256 простых про-
цессорных элементов; 3) коммутационную сеть перестановок;
4) селектор. Структурная схема модуля ассоциативной матрицы
изображена на рисунке 6.14 (регистры не показаны) [1274]. Каж-
дый процессорный элемент связан с одним из соответствующих
ему слов памяти и выполняет операции последовательно, обраба-
тывая информацию слова бит за битом. Доступ к данным в па-
мяти может быть осуществлен через канал параллельного ввода-
вывода одновременно к 256 (или менее) битам информации как
Рис. 6.14. Структурная схема модуля ассоциативной матрицы системы
STARAN.
в направлении разрядного среза, так и в направлении расположе-
ния разрядов слова; возможен также доступ, представляющий со-
бой комбинацию этих двух способов. При этом используется ком
мутационная сеть перестановок. Она используется также длГя
сдвига и переформирования данных в модуле ассоциативной мат-
рицы, что обеспечивает выполнение параллельного поиска, ариф-
метических и логических операций между словами памяти 11274L
Операционная концепция модуля ассоциативной матрицы пред-
ставлена на рисунке 6.15 [1136, 1274]. '
Подсистема управления состоит из адресуемой обычным спо-
собом управляющей памяти для хранения программ и буфериза-
ции данных, связи с которой осуществляются через логическое
устройство входа в эту память, и логического устройства управ-
ления, включающего в свой состав четыре устройства (четыре
логических схемы), показанные на рисунке 6.13. Управляющие
сигналы вырабатываются подсистемой управления и поступают
Параллельно ко всем процессорным элементам, при этом все про-
цессорные элементы выполняют одну команду за другой одновре-
менно [1136].*
Такая организация системы позволяет достаточно полно ис-
пользовать возможности обработки информации разнообразных
форматов Модулями ассоциативных матриц: в одной части про-
343
граммы может быть задана обработка содержимого большого чис-
ла разрядов одного или нескольких слов, а в другой части про-
граммы — обработка содержимого одного или нескольких разря-
дов* большого числа слов [513].
* Как отмечалось выше, память с многомерным доступом орга-
низована в виде матрицы размером.256 слов X 256 разрядов. Ти-
пичными операциями для такой матрицы являются операция счп-
2#
" до?
Ж-
Рис. 6.15. Операционная концепция мо-
дуля ассоциативной матрицы системы
STARAN.
тывания содержимого i-го
разряда каждого слова дан-
ных памяти в соответствую-
щие им процессорные эле-
менты и операция записи в
нее содержимого г-го разряда
из соответствующих процес-
сорных элементов. Режим до-
ступа к разрядному срезу
используется в ассоциатив-
ных операциях для парал-
лельного обращения к одно-
му разряду всех слов, тогда
как режим доступа к сдГову
используется в операциях
ввода-вывода для параллель-
ного обращения к некоторым
или всем разрядам одного
слова. Структура памяти не ограничивается только форматом
матрицы 256 X 256. Так, например, данные могут быть сформирова-
ны в виде 256-байтовых записей. 32 таких записи могут быть поме-
щены в память, образуя структуру 32 записей X 256 байт, причем
доступ к данным возможен различными путями (рис/6.16). Для
ввода и вывода записей доступ может быть осуществлен каждый
раз параллельно к 32 последовательно расположенным байтам
некоторой записи (рис. 6.16 а). В целях поиска ключевых полей
в данных доступ может быть осуществлен каждый раз параллель-
но к соответствующим байтам всех записей, т. е. к байтам всех
записей, имеющих один и тот же порядковый номер в каждой
записи (рис. 6.16, б). В целях поиска такой записи, в которой
содержится особый байт, доступ может быть осуществлен каж-
дый раз параллельно к некоторому одному биту из каждого бай-
та одной записи (рис. 6.16е). При этом во всех случаях одно-
кратный доступ, как и ранее, обеспечивает одновременную вы-
борку содержимого 256 разрядов [513].
Быстрая биполярная память модулей ассоциативных матриц
имеет время цикла считывания меньше, чем 150 нсек, и время
цикла записи меньше, чем 250 нсек [513].
Модуль ассоциативной матрицы содержит, кроме перечислен-
ных выше устройств, три 256-разрядных регистра, связанных
с памятью модуля через коммутационную сеть перестановок:
344
М-регистр маски и X- и Y-регистры, соответствуюгЦие двум ко-
ординатам матричной конфигурации памяти. Можно считать, что
каждый процессорный элемент имеет по одному соответствующе-
му разряду каждого из этих трех регистров.
Логические схемы, связанные с Х-регистром, и логические
схемы, связанные с Y-регистром, обеспечивают. выполнение лю-
бой из 16 булевских^функций двух переменных при отдельном
и совместном оперировании с этими регистрами [5131.
1111 1.Л I I Г
32
2М
а) Доступ к 32 последова- б)Доступ к соответст- в) Доступ к одному раз-
только расположенным сующим байтам одной ряду каждою байта
байтам одной записи записи в одной записи
Рис. 6.16. Режимы доступа к 32 256-байтовым записям в памяти модуля ас-
социативной матрицы системы STARAN.
Управляющая память, которая адресуется и индексируется
обычным способом, разделена на несколько блоков и использует-
ся для хранения прикладных программ. Она используется также
для хранения данных и в качестве буфера между подсистемой
управления и другими компонентами системы. Циклы управляю-
щей памяти и модулей ассоциативных матриц перекрываются.
Логическое устройство последовательного управления содержит
обычную ЭВМ (PDP-11), устройства печати, перфорации, счи-
тывания и другие. Оно используется для системы программного
обеспечения, в состав которого входят такие программы, как ас-
семблер, операционная система, диагностические программы, от-
ладочные и сервисные программы [1136]. Следует отметить, что
в целях эффективного использования ассоциативных возможнос-
тей и возможностей параллельной обработки STARAN разработан
и реализован специальный язык APPLE (Associative Processor
Programming LanguagE) [643, 1136]. Устройство интерфейса
обеспечивает сопряжение между собой устройств, показанных на
рисунке 6.13, причем его состав определяется конкретным кру-
гом решаемых задач. Каждый модуль ассоциативной матрицы мо-
жет иметь до 256 входов и 256 выходов в устройстве интерфейса.
Эти входы могут использоваться для повышения скорости обмена
данными между матрицами, они позволяют связывать STARAN
с высокоскоростными широкоформатными устройствами ввода-вы-
вода и позволяют подключать некоторое устройство непосредствен-
но к модулям ассоциативных матриц [1274].
При решении многих прикладных задач, таких как матрич-
ные вычисления, управление воздушным движением, обработка
сенсорных сигналов и ведение баз данных, гибридная система,
составленная из ассоциативной системы и обычной универсаль-
345
ной вычислительной системы, обеспечивает повышенную про-
пускную способность, требует менее сложное программное обес-
печение и характеризуется при этом относительно невысокой сто-
имостью. Как отмечалось выше, система STARAN может осуще-
ствлять быстрый ввод-вывод и легко подключается к обычным вы-
числительным системам.
В гибридной системе каждый модуль ассоциативной матрицы
решает те задачи, которые лучше соответствуют его возможнос-
тям. При этом STARAN выполняет параллельную обработку,
а универсальная вычислительная система решает те задачи (вы-
полняет те задания), которые должны быть обработаны в режиме
единственного последовательного потока данных [1274]:
Первая рабочая модель — прообраз, системы STARAN [752]
была продемонстрирована фирмой Goodyear Aerospace в 1969 г.
После некоторой модификации эта модель, в комплексе с UN I VAC
1230, применялась в 1971 — 1972 гг. в экспериментах по реше-
нию задач управления воздушным движением. Накопленный опыт
был использован в новом проекте серийной системы, названной
STARAN S *), которая была запущена в производство в 1971 г.
В модели предусматривалось несколько вариантов комплектации.
Первая модель STARAN S, выпущенная на рынок, была публич-
но продемонстрирована в 1972 г. [1136]. Базовая модель систе-
мы получила наименование STARAN В. Все логические схемы и
запоминающие устройства STARAN выполнены на интегральных
схемах.
По данным на 1977 г. (555, 1274], помимо системы, установ-
ленной в Goodyear Aerospace Corporation, регулярно использова-
лись три образца системы STARAN, рассматриваемые далее
11274].
В 1973 г. в Римском центре развития авиации RADC (Rome
Air Development Center) был установлен комплекс, получивший
название RADCAP (RADC Associative Processor). Он состоит из
системы STARAN и разнообразных периферийных устройств, соп-
ряженных с универсальной вычислительной системой HIS 645,
работающей под управлением своей операционной * системы . раз-
деления времени MULTICS. Комплекс RADCAP предназначен
для исследования систем реального времени. При расширении
комплекса [891] в целях исследования структур вычислительных
систем, основанных на применении наборов микропроцессоров,
в RADCAP была введена весьма гибкая ЭВМ QM-1 с двумя уров-
нями микропрограммирования, а также матрица микропроцессо-
ров, имеющая "возможность реконфигурации.
В 1974 г. другой образец системы STARAN был установлен
в топографических лабораториях армии США (U. S. Army Engi-
neer Topographic Laboratories) в Форт Бельвор (Fort Belvoir), Вир-
гиния. Этд система сопряжена с ведущим процессором CDC 6400
♦) Для серийной модели известно также обозначение STARAN IV [1229].
346
при помощи устройства интерфейса, одна из частей которого обес-
печивает обычную передачу данных и команд, а другая — широ-
коформатная — обеспечивает передачу данных собственно меж-
ду модулями ассоциативных матриц STARAN и расширенной
ферритовой памятью CDC 6400. В этом комплексе система
STARAN использовалась в работах по автоматизации картогра-
фии, цифровой обработке изображений, хранению больших мас-
сивов и поиску данных. Наконец, в 1975 г. еще один экземпляр
системы STARAN с двумя модулями ассоциативной матрицы был
установлен в Джонсоновском центре космических исследований
(NASA Johnson Space Center) в Хьюстоне, Техас. Эта система бы-
ла связана с универсальной системой IBM 360/75 и использова-
лась в крупномасштабном эксперименте NASA по оценке урожая
(Large LACIE Area Inventory Experiment) при помощи космиче-
ских средств и в других работах [1274].
Таким образом, STARAN представляет собой большую мо-
дульную ассоциативную систему класса ОКМД, в которой множе-
ство идентичных операций может быть выполнено одновременно.
Модуль ассоциативной матрицы, являющийся основным компо-
нентом STARAN, содержит матрицу памяти размером 256 слов X
X 256 разрядов, 256 простых процессорных элементов,-каждый из
которых ориентирован на последовательную поразрядную • обра-
ботку информации, селектор, а также коммутационную сеть пере-
становокг обеспечивающую гибкий многомерный параллельный
доступ к матрице памяти. Единственное устройство управления
системы передает команды модулям, которые имеют возможность
маскирования данных. Модульная конструкция системы обеспе-
чивает пошаговое наращивание памяти для рабочих программ и
модулей ассоциативных матриц. Так, например, если в системе
STARAN с одним Таким модулем операция сложения может быть
выполнена одновременно для 256 пар чисел (для 256 потоков дан-
ных) при помощи 256* процессорных элементов модуля соответ-
ственно, то в системе с двумя модулями ассоциативной матрицы
га такое же время может быть выполнена операция сложения для
512 пар чисел. При этом высокая производительность и высокая
пропускная способность системы есть прямое следствие ее па-
раллельной структуры и соответствующего параллелизма обработ-
ки информации [555].
С момента начала серийного выпуска (в 1972 г.) система
STARAN В применялась для решения различных задач. Однако,
независимо от области применения, все‘выполненные на ней за-
дачи можно разделить на два основных типа, а именно, на зада-
чи оперирования с битами и на задачи оперирования с группами
битов. Задачи первого типа характерны для установок STARAN
в Римском центре развития авиации и в топографических лабо-
раториях, а задачи второго тйПа характерны для установки
STARAN в Джонсоновском центре космических исследований
[555].
347
На основании опыта решения многочисленных задач на ука-
занных установках STARAN и с учетом новых достижений полу-
проводниковой промышленности была выполнена модернизация
рассматриваемой системы, при этом организация системы факти-
чески сохранена прежней. Новая улучшенная модель получила
наименование STARAN Е. В этой модели по сравнению с первой
моделью системы значительно увеличена емкость памяти моду-
лей ассоциативных матриц и увеличена скорость работы этой па-
мяти [517], увеличена емкость и скорость работы управляющей
памяти, повышена скорость обработки данных, а также разрабо-
тано новое устройство ввода-вывода для матриц памяти. При
этом сохранены возможности прежнего программного обеспечения
[516, 517].
Наиболее важным является усовершенствование матриц памя-
ти. STARAN Е может иметь от 1 до 8 модулей ассоциативных
матриц, каждая из которых, как и прежде, содержит 256 процес-
сорных элементов и память емкостью в 256 слов, однако, длина
слова увеличена с 256 «бит максимум до 65536 бит (в модулях
первого варианта STARAN Е длина слова равна 9216 бит). Та-
ким образом, максимальная суммарная емкость памяти всех моду-
лей равна 428 М бит и (16 М байт). В каждом модуле часть памя-
ти — биполярная с временем считывания и записи в 120 и 160
нсек соответственно, а другая часть является МОП-памятью
с одинаковым временем считывания и записи, равным 420 нсек.
Эта память разделена в каждом модуле на квадратные сегменты
формата 256 X 256 бит.
Важно отметить, что, как и в первой модели STARAN, в
STARAN Е можно параллельно считывать строки, столбцы и ком-
бинированные наборы данных, их можно перегруппировать в
коммутационной сети перестановок, а также выполнять другие
операции. При этом процессорные элементы некоторого модуля
имеют доступ к данным любого другого модуля [516, 555].
Кроме STARAN можно указать также следующие поразряд-
но-последовательные ассоциативные системы: Гибридная ассоциа-
тивная система (Hybrid associative processor), RAP (Raythe-
on Associative/Array Processor), ALAP (Associative Linear Array *
Processor) и ECAM (Extended Content Addressed Memory). Рас-
смотрим очень кратко эти системы, следуя, в основном, [1274].
Гибридная ассоциативная система фирмы Hughes Aircraft со-
держит 10-разрядные устройства ассоциативной памяти последо-
вательного типа и МОП-память регистров сдвига, разбитую на
секции емкостью 16 К бит каждой. Назначение этой системы со-
стоит в обеспечении эффективных операций в ассоциативной па-
мяти в условиях, когда база данных размещена в недорогой мас-
совой памяти большой емкости.
Систему RAP предназначена для работы с базой данных и
представляет собой автономную систему, которая связывается с
универсальной вычислительной системой только для получения
348
от нее содержимого базы данных и оттранслированных программ,
а также для отсылки в нее результатов выполнения запросов
пользователей. Система RAP может вместить «сжатую» информа-
цию базы данных объемом 108 бит и обеспечить время задержки
ответа после поступления запроса порядка 50 мсек. Для больших
баз данных предусматривается модификация системы, при этом
работа основывается на принципе работы системы виртуальной
памяти с обычной массовой памятью [1052].
Система RAP содержит матрицу процессорных элементов и
канал прямого доступа к матрице, который облегчает переда-
чу данных к указанной матрице и от нее. Процессорный элемент
выполняет поиск данных, а также операции арифметической и
логической обработки над данными, находящимися в его собст-
венной памяти. Каждый процессорный элемент может рассмат-
риваться как поразрядно-последовательный микропроцессор с ас-
социативными возможностями.
Новую систему ALAP фирмы Hughes Aircraft можно рассмат-
ривать как поразрядно-последовательную ассоциативную систе-
му с распределенной логикой. Ячейка ориентирована на хранение
слова, а не разряда, и является элементом (микропроцессором),
имеющим память и способным вести обработку. Такие ячейки
слов, количество которых может быть очень большим, распо-
ложены в линию и имеют связи с соседними ячейками слева и
справа, причем эти связи — односторонние (в направлении слев^
направо). В целях демонстрации ALAP с 13 словами (ячейками)
была реализована в виде БИС на одной пластине. Груцпа пораз-
рядно-последовательных шин, общих для всех ячеек, использует-
ся для передачи данных и сигналов управления. Общий блок дан-
ных и управления интерпретирует программу для ее выполнения
линией ячеек. Программа хранится в памяти программ с произ-
вольным доступом.
Для системы ALAP разработаны программное обеспечение и
программа на ассемблере для обработки радиолокационных дан-
ных в реальном масштабе времени [949].
Новая система ЕСАМ фирмы Honeywell представляет собой
систему ассоциативной памяти для использования при обработке
информации базы данных с высокой скоростью в условиях при-
менения в ВВС США. Эта система может оперировать с базами
данных размером в 109 бит. Она основана на, так называемой,
технологии суперкрдсталлов с надежным соединением большого
числа отдельных устройств памяти в рамках одного суперкристал-
ла. Однако БИС других типов также могут быть использованы
для построения ЕСАМ.
ЕСАМ имеет устройство управления и матрицы ассоциативной
памяти емкостью до миллиарда бит. Основным устройством в ус-
тройстве управления является управляющий процессор, который
представляет собой стандартную мини-ЭВМ. Собственно мини-
ЭВМ и ее память, устройство сопряжения с ведущим процессо-
349
ром, а также вспомогательное устройство управления матрицами
ассоциативной памяти подключены к шине памяти мини-ЭВМ
(рис. 6.17). Устройство сопряжения построено таким образом, ^что
ведущий процессор подключается к шине подобно стандартному
высокоскоростному периферийному устройству, такому как диск.
Это устройство управляется мини-ЭВМ аналогично программиру-
емому вводу-выводу и передает блоки информации между веду-
щим процессором и управляющей памятью (памятью управля-
ющего процессора). С системой ЕСАМ могут быть связаны не-
сколько ведущих процессоров.
Рис. 6.17. Структурная схема системы ЕСАМ.
В дополнение к управляющему процессору имеется вспомога- . «
тельное устройство управления, основными компонентам^ кото-
рого являются интерпретатор языка запросов и устройство управ-
ления итерациями. Интерпретатор представляет собой высокоско-
ростное микропрограммируемое устройство. Его управляющая па- :
мять обладает свойством перезаписи, что обеспечивает адаптацию
к языку запросов. Поток сигналов -с выхода интерпретатора по- 3
ступает через буферы к устройству управления итерациями, ко- ?
торое, в свою очередь, генерирует соответствующую последова-
тельность сигналов управления, определяющую операции в ассо- /
циативной памяти.
Матрица ассоциативной памяти имеет до 250 тыс. 4096-раз-*
рядных слов, причем каждое слово содержится в 46 256-разряд-
350
ных сдвиговых регистрах и имеет сложную структуру. Для каж-
дого слова предусмотрен логико-арифметический блок и 16-раз-
рядная память для выполнения ассоциативных сравнений Г12741.
Следует отметить, что в последнее время все чаще появляют-
ся сообщения об ассоциативных системах для оперирования с ба-
зами данных — см., например, AFP (Associative File Processor)
[573], концепцию системы для базы данных [499] и другие/
Одной из относительно развитых является концепция побайт-
но-последовательных пословно-параллелвных ассоциативных
систем. В качестве примера можно указать концепцию системы
APCS (Associative Processor Computer System), в которой преду-
смотрены два устройства ассоциативной обработки и канал вво-
да-вывода и которая ориентирована на логику сравнения бай-
тов [1274].
Ассоциативные системы НАРРЕ (Honeywell Associative Paral-
lel Processing Ensemble) и AAAP (Airborne Associative Array Pro-
cessor) по своей структуре близки к РЕРЕ. Первая система со-
держит две управляющие секции и множество процессорных эле-
ментов, подобных мини-ЭВМ, со своей памятью, арифметическим
блоком и двумя регистрами, которые выполняют арифметические
операции, сдвиги и ассоциативные операции сравнения. Демон-
страционная модель системы способна обрабатывать данные от
радиолокационной станции с фазированной антенной решеткой.
Данные о целях поступают в соответствующие процессорные эле-
менты, каждый из которых, если он в активном состоянии, мо-
жет уточнять траекторию цели при работе в арифметическом ре-
жиме и обновлять входные данные о «своей» цели при работе
в корреляционном режиме. Вторая из указанных систем АААР
является бортовой и содержит 25(Г процессорных элементов, уп-
равляемых одним микропрограммным устройством управления.
Каждый процессорный элемент имеет 8-разрядный арифмети-
ческий блок, ассоциативный блок и два устройства опера-
тивной памяти [8].
Библиографическая справка. Ассоциативным си-
стемам посвящены книги [740, 1222]. В первой из них рассмат-
ривается концепция ассоциативных систем, представлены логи-
ческие и арифметические алгоритмы, обсуждаются применения
таких систем, описывается система STARAN. Во второй книге и
в предшествовавшем ей обзоре [1221], кроме ассоциативных, рас-
сматриваются также некоторые другие параллельные системы.
При этом изложена концепция, указаны применения и приведена
генеалогия'систем класса ОКМД с соответствующими примера-
ми. Значительное внимание уделено ассоциативным системам и их
наиболее известному представителю системе STARAN.
Кроме указанного выше обзора, ассоциативным системам по-
священы обзоры [8, 801, 988, 989, 1060, 1273, 1274]. В них рас-
сматривается концепция ассоциативных систем и ассоциативной
памяти и приводятся соответствующие примеры. При этом в об-
351
зорах, вышедших в прследние годы, представлены следующие ас-
социативные системы: в 1989] (1975 г.) — STARAN; в (1273, 1274]
(1975 г., 1977 г.) — STARAN, ALAP, ЕСАМ, Гибридная ассоциа-
тивная система, RAP, APCS, RAPID; в [8] (1977 г.) — STARAN
и RADCAP, Универсальный и Специализированный ассоциатив-
ные процессоры, НАРРЕ, АААР, RAP. Первая ассоциативная мат-
рица описана в [1170]. Отметим также книги [230, 473].
Система STARAN рассмотрена в обширной литературе. Пер-
вая рабочая модель —прообраз STARAN — представлена в [752].
Первая версия серийной системы STARAN описана в ключевых
статьях {513,1136]. Установка RADCAP, содержащая сопряжен-
ные между собой STARAN и HIS 645, ее расширение, примене-
ния и программное обеспечение рассмотрены в [512, 642, 717, 718,
882, 891, 1079, 1186]. Установка STARAN в комплексе с CDC
6400 описана в [753]. Анализ опыта решения задач на различных
установках STARAN, обоснование необходимых усовершенство-
ваний и их описание приведены в [555]. Новая модель STARAN Е,
полученная в результате введения в STARAN В указанных выше
усовершенствований, описана в ключевой статье [516].
Описание системы STARAN с той или иной степенью подроб-
ности можно найти в [31, 152/281, 283, 364, 511, 523, 557, 1142],
описание памяти модуля ассоциативной матрицы — в цикле ра-
бот [514, 515, 517], а описание организации выполнения арифме-
тических операций в системе — в [1183].
Вопросы построения ассоциативных систем, устойчивых к от-
казам, рассмотрены в [1061].
Программное обеспечение системы STARAN рассмотрено в не-
которых из указанных выше работ, а также в ключевой работе
1643], в работах [806, 917, 964] и в других. Языкам ассоциатив-
ной обработки посвящена статья [1064].
Сравнительный анализ производительности систем STARAN,
РЕРЕ и CDC 7600 при решении ими задач обработки радиолока-
ционной информации в реальном масштабе времени выполнен в
1945]. Сравнение ассоциативных систем, матричных систем и ан-
самблей для условий работы, подобных указанным выше, произ-
ведено в [625]. Анализ сетей внутренних связей в системах клас-
са ОКМД с привлечением примеров систем STARAN, RAP,
ILLIAC IV, SIMDA, а также системы с комбинированной струк-
турой OMEN выполнен в [1163, 1164].
Принципы рабдты ассоциативных систем (STARAN, RAP),
варианты их применения, а также концепция системы ААР (As-
sociative Array Processor) обсуждаются в [822, 823]. Методы ре-
шения ряда задач на системе STARAN, некоторые применения
этой системы, а также вопросы методологии ассоциативной обра-
ботки информации рассматриваются в [449, 497, 519, 582, 583,
670, 712, 758, 759, 903, 1003, 1004, 1071, 1077, 1134, 1200].'Про-
блемы построения баз данных в ассоциативных системах иссле-
дованы в цикле работ [535, 647— 650].
352
Крдме системы STARAN* можно указать другие поразрядно*
последовательные ассоциативные системы: RAP [8, 622,
1053, 1147, 1274]. Гибридная ассоциативная система [948, 1274J*
ALAP (725, 949, 950, 1274], ЕСАМ [462, 1274]. В качестве при-
мера блочно-ориентированной системы можно указать RAPID
11059, 1274], а побайтно-последовательной — A PCS [936, 1274].
Известны также ассоциативнные системы НАРРЕ [8, 962], АААР
[8, 1237], AFP [537] и другие. В [670, 770, 777, 817, 1163, 1221,
1254] представлена микропрограммируемая система SIMDA с ас-
социативными возможностями, содержащая матрицу из 1024 че-
тырехбитовых процессорных элементов. Команды и общие опе-
ранды размещаются в основной памяти системы.
Концепция и способ реализации памяти AREC, в которой ас-
социативные связи определяются при помощи некоторой меры
близости, представлены в [850]. Эта память ориентирована на
задачи распознавания образов и может использоваться также в
вычислительных системах с внутренними языками высокого
уровня.
В заключение главы напомним, что системы с ансамблем про-
цессоров, матричные системы и поразрядно-последовательные ас-
социативные системы, являющиеся основными представителями
класса систем ОКМД, классифицируются как ОКМДС/Нс,
ОКМДС/Bq, и ОКМДР соответственно, а их структура* может
быть представлена при помощи Машин IV, V и II Шора соот-
ветственно (см. главу 2).
23 в. А. Головкин
Ч. СИСТЕМЫ, С КОМБИНИРОВАННОЙ
И ПЕРЕСТРАИВАЕМОЙ СТРУКТУРОЙ.
ОТКАЗОУСТОЙЧИВЫЕ СИСТЕМЫ
7.1. Концепция и ранние системы
Общее описание структур и основные определения систем
с комбинированной структурой и с перестраиваемой структурой
приведены в главе 2.
7.1.1. Концепция систем е комбинированной структурой. Одна
из первых концепций систем с комбинированной структурой бы-
ла предложена в 1960 г. и известна как концепция ортогональ-
ной машины Шумана 11159]. Эта машина состоит из горизон-
тального и вертикального арифметических устройств, совместно,
использующих ортогональную память.
Ортогональная память представляет собой запоминающее*
устройство, которое обеспечивает доступ горизонтальному ариф-
метическому устройству к словам, расположенным в памяти в
виде горизонтальных слоев (срезов), а вертикальному арифме-
тическому устройству обеспечивает доступ к вертикально рас-
положенным разрядным срезам. Ортогональная память могла бы
быть реализовапа как ассоциативная память, однако, первона-
чально она рассматривалась как устройство для оперирования
с разрядными срезами, которое должно обеспечпть обработку
сигналов с высокой скоростью (12211. Сведения об ортогональ-
ной машине, кроме указанных выше работ, содержатся в (8, 147г
821, 1160, 1222, 1273, 1274]. На базе концепции ортогональной
машины создана реальная система OMEN 60, которая рассматрп- -
вается в п. 7.2.1 настоящей главы.
Напомним, что ортогональная машина и система OMEN 60
являются представителями одновременно классу ОКОДС и клас-
са ОКМДР и соответствуют Машине III Шора (см. главу 2).
Значительный интерес представляет концепция большой си-
стемы MAP (Multi Associative Processor), которая сочетает в се-
бе черты ансамблей, матричных систем и ассоциативных систем,,
т. е. черты основных представителей класса ОКМД, а также чер-
ты многопроцессорных систем (класс МКМД). Рассмотрим эту
систему 11029—10331.
Структурная схема системы приведена на рис. 7.1, на кото- '
ром обозначено: ПЭ— процессорный элемент, ОП —модуль опе-
ративной памяти системы, УУ — устройство управления, S —
354
коммутатор сектора ПЭ. Система содержит 1024 ПЭ и, в отли-
чие от традиционных систем класса ОКМД, имеет восемь УУ
вместо, как обычно, одного, при этом системное программное обес-
печение реализуется не на отдельном ведущем процессоре, а
| Подсистема ввода-вывода |
0П1
0П2 | • ••
0П8 |
УУв
УУ 2
УУ1 -
1
4 I.
ПЭ 128
м
М
У
------4
"-----I
------т
О I
ПЭ 256
\ПЭ837
^1ЭЮ2Ь\^
Рис. 7.1. Структурная схема системы МАР.
непосредственно в самой системе МАР. Кроме этого, предусматри-
вается программное управление связями между ПЭ вместо обыч-
ных фиксированных связей.
23* 355
В системе с .такой организацией ПЭ являются распределяе-
мыми ресурсами, что, в сочетании с несколькими УУ, позволяет
одновременна выполнять несколько программ, причем часть из
них может выполняться в режиме параллельной обработки,
а другие программы, требующие последовательных операций, мо-
гут выполняться в режиме последовательной обработки. Таким
образом, в системе МАР гибко сочетаются режимы параллель-
ной и последовательной обработки одновременно, что позволяет,
в отличие от матричных и ассоциативных систем, отказаться от
применения универсальной вычислительной системы в качестве
сопрягаемого ведущего процессора.
Вместе с тем, организация системы МАР имеет ряд недостат-
ков. Быстрый ввод информации в собственную память ПЭ и бы-
стрый вывод из этой памяти, в отличие, например, от ILLIAC IV,
невозможен. Загрузка памяти ПЭ осуществляется через модуль
ОП при помощи того УУ, за которым в данный момент закреп-
лен расматриваемый ПЭ. Скорость обмена между соседними ПЭ
ограничена, т. к. связи между ПЭ "не являются фиксированными,
хотя любой отдельный ПЭ может передать данные любому на-
бору других ПЭ в течение одного системного цикла работы..
Для реализации УУ и ПЭ предполагается использовать
микропроцессоры, такие как двухразрядные Intel 3000 или четы-
рехразрядные AMD 2900.
В оперативной памяти хранится информация трех типов: все
команды, общие данные и данные, которые передаются в уст*
ройства памяти процессорных элементов и вызываются из них.
Все входные и выходные потоки информации проходят через
оперативную память, которая связана с подсистемой ввода-выво-
да. Последняя содержит периферийные устройства, контроллеры
и информационные каналы.
Каждое УУ должно управлять процессом выполнения парал-
лельной программы, для чего в нем реализуются функции фор-
мирования адресов и выборки команд из оперативной памяти,
функции связи внутри системы, дешифрации команд и передачи
к ПЭ сигналов управления и общих данных и другие. Каждый
ПЭ примерно соответствует арифметико-логическому устройству
обычной ЭВМ и имеет свою память емкостью в 4096 32-разряд-
ных слов. В ПЭ осуществляется прием сигналов управления (ко-
манд для ПЭ) и реализуется выполнение арифметических и ло;
гических команд, обмен данными с УУ и другими ПЭ. В системе
МАР применяется усложненное маскирование ПЭ при помощи
так называемых ассоциативных команд (поэтому в названии си-
стемы присутствует слово Associative). Эти команды проверяют
выполнение определенных условий, информация о которых хра-
нится на специальных регистрах, и включают ПЭ для выполне-
ния команд программы или выключают его.
Центральный коммутатор осуществляет передачу команд и
данных от любого УУ одновременно к любому набору ПЭ,
856
а также обеспечивает передачу данных от любого, ПЭ к любому
набору других ПЭ, закрепленных за некоторым УУ. На рис. 7.1
в части центрального коммутатора штриховыми линиями пока-
заны шины для передачи команд, а сплошными линиями — ши-
ны для передачи данных. Полное число коммутаций командных
шин составляет 8 X 1024. Шестиразрядные команды для ПЭ пе-
редаются от каждого УУ к процессорным элементам через ко-
мандные шины с циклом 100 нсек.
Частота передари данных к ПЭ намного меньше частоты пе-
редачи команд. Это позволяет разбить все ПЭ на несколько
секторов, шины данных ПЭ каждого сектора подключить к ком-
мутатору S этого сектора, а коммутаторы всех секторов подклю-
чить через шины данных центрального коммутатора к устройст-
вам управления. В результате моделирования было установлено,
что можно иметь не более 8—12 секторов ПЭ. На рис. 7.1 изоб-
ражен вариант с 8 секторами ПЭ. В этом случае число коммута-
ций шин данных составляет всего 8X8.
В результате анализа МАР была получена оценка, согласно
которой стоимость выполнения одной команды этой системы
примерно в 2 раза меньше, чем в обычной ЭВМ с аналогичными
характеристиками [1033].
7.1.2. Применение микропроцессоров. В последнее время, бла-
годаря интенсивному развитию технологии больших интеграль-
ных схем, все более четко проявляется тенденция построения
вычислительных систем на базе микропроцессоров. Пока микро-
процесоры с упехом применяются там, где требуется небольшой
объем вычислений (калькуляторы, контрольно-измерительные
приборы, контроллеры, «интеллектуальные» терминалы, бытовые
устройства, игровые автоматы), а вопрос создания серийных си-
стем, состоящих из большого числа микропроцессоров, остается
открытым*). Тем не менее,, уже предложен ряд структур систем
с большим числом микропроцессоров, включая системы с ком-
бинированной и с перестраиваемой структурой и отказоустойчи-
вые системы, а также построено нёсколько вариантов подобных
систем [415].
Возрастающий интерес к системам на базе большого числа
микропроцессоров определяется следующими факторами. В на-
стоящее время микропроцессоры позволяют получать дешевые
вычислительные мощности, а в ближайшее время ожидается
дальнейшее улучшение отношения производительности к стои-
мости. Кроме этого, вычислительные системы из большого числа
идентичных процессоров способны обеспечить высокую надеж-
ность, т. к. основу построения надежных систем на базе отра-
ботанных элементов составляет та или иная форма резервирова-
*) По данным на 1978 г. не имелось сведений о серийных многомикро-
процессорных системах [415]. Однако известны серийно выпускаемые мно-
гопроцессорные системы, построенные на базе мини-ЭВМ,— PLURIBUS,
TANDEM 16 (рассматриваются в п. п. 7.3.2. и 7.3.3).
357
ния (до появления микропроцессоров построение систем с боль-
шим числом процессоров было нереально из-за высокой стоимости
самих процессоров). Наконец, системы с большим числом микро-
процессоров обладают высокой степенью модульности, что обес-
печивает блочное наращивание систем, упрощает их техническое
обслуживание и облегчает расширение производства.
Несмотря на перечисленные достоинства, однозначный ответ
на вопрос, можно ли использовать набор определенным образом
связанных микропроцессоров для решения бсьлыпих задач столь
же или более эффективно, как это обычно делается при помощи
одной ЭВМ с производительностью в несколько миллионов опе-
раций в секунду, остается все еще открытым. Это объясняется
наличием ряда нерешенных проблем, основные из которых пе-
речисляются ниже [415].
Распараллеливание: каким образом распараллеливать задачи?
Следует ли автоматически распараллеливать задачи при помощи
трансляторов или же эту работу следует оставить программисту?
Как минимизировать взаимные помехи множества параллельных
процессов? Структура внутренних связей: какова наиболее эф-
фективная структура связей процессор — память и процессор —
процессор и соответствующие протоколы обмена информацией?
Формирование адресов: какой механизм формирования адреса
является наиболее эффективным с учетом необходимости совме-
стного использования процессорами команд и данных? Структу-
ра программного обеспечения: как решать вопросы управления ре-
сурсами, организации распределенных вычислений, защиты, на-
дежности и другие для больших систем с сотнями процессоров?
Как предотвращать тупиковые ситуации в таких условиях? От-
казоустойчивость: какой должна быть структура аппаратного и
программного обеспечения, чтобы система с большим числом
процессоров продолжала функционировать с возможно более
высокой эффективностью при отказе отдельных ее компонентов?
Ввод-вывод: какова должна быть структура связей для ввода-
вывода и как использовать вспомогательную память для ввода-
вывода?
В целях поиска ответов на подобного рода вопросы развер-
нут ряд теоретических и экспериментальных исследований. Не-
давно в университете Карнеги — Меллона, например, завершена
разработка и реализация экспериментальной микропроцессорной
системы Стф, которая, наряду с другими экспериментальными
системами этого университета, рассматривается в п. 7.3.4.
7.1.3. Концепция систем с перестраиваемой структурой. Проб-
лема повышения эффективности вычислений путем адаптации
вычислительной системы к задачам при помощи динамической
программной перестройки структуры системы давно привлекает
внимание исследователей. Однако возможности построения та-
ских действующих систем появились фактически только в послед-
нее время. Особенпо перспективным для систем с перестраиваемой
358
структурой представляется применение микропроцессоров. Так,
например, появляется возможность динамически соединять п-
разрядно наращиваемые микропроцессоры и соответствующие
блоки памяти с тем, чтобы получать формат слова и структуру
системы, соответствующие решаемой задаче 1939].
Концепция переменной структуры была впервые предложена,
вероятно, в 1960 г. [702] и известна как концепция машины
Эстрина. Эта машина имеет неоднородную структуру. Она рас-
смотрена в п. 4.1.1. В предыдущих разделах настоящей* книги
рассмотрены также некоторые возможности перестройки структу-
ры ряда других концептуальных и реальных систем.
Концепция переменной однородной параллельной структуры
исследована в цикле работ, поэтапные результаты которых обоб-
щены в [147, 150—152, 224] *). На основе результатов этих ис-
следований выполнены соответствующие разработки и построено
несколько систем, из которых система Минск-222 рассмотрена
в п. 3.1.2,ч а МИНИМАКС и СУММА рассматриваются в п.п.
7.2.2 и 7.2.3 соответственно.
Многопроцессорные вычислительные системы с перестраивае-
мой структурой исследованы в [267] и других работах*). Соот-
ветствующие системы с решающим полем рассматриваются в
п. 7.4.3.
В последнее время выдвинуты новые концепции систем и
начат ряд • новых разработок. К таким системам относится Мо-
дульная асинхронная развиваемая система [263], которая рас-
сматривается в п. 7.4.1, и рекурсивные вычислительные машины
199, 284, 765], которые рассматриваются в п. 7.4.2.
В [272] отмечено, что в основе концепции организации ма-
шин с изменяемой структурой лежит принцип, согласно которо-
му структура машины Должна соответствовать естественной струк-
туре реализуемого алгоритма, а не наоборот, как в обычных
ЭВМ с хранимой в их памяти программой, когда алгоритму при
его программной реализации придается форма, соответствующая
жесткой структуре ЭВМ. В этой же работе представлены кон-
цепции двух машин с изменяемой структурой.
Первая из указанных машин, названная поисковой, является
универсальной и состоит из памяти, множества активных опера-
ционных устройств и искателя. Каждое операционное устройство,
закончив очередную задачу, запрашивает через искатель новую
задачу. Искатель осуществляет поиск в памяти задачи, подхо-
дящей для запросившего устройства с учетом его специализа-
ции. Операционные устройства представляют собой сумматоры,
блоки умножения, блоки проверки условий, модули макроопера-
ций, устройства ввода-вывода и другие. Программа в поисковой
машине не используется, как обычно, для установления после-
♦) См. также п. 2.7.1.
35Я
доватеЛьности выполняемых операций, а на порядок выполнения
операций не накладываются обычные ограничения последова-
тельного характера программы и специфики управления обыч-
ной машины. Производительность такой поисковой машины за-
висит от общего числа и разнообразия типов операционных
устройств, эффективной скорости памяти и характеристик
искателя.
Важным достоинством рассматриваемой концепции является
то, что традиционные понятия программы, языков высокого
уровня, методов трансляции и подобные им легко переносятся
на класс поисковых машин. При этом учитываются те обстоя-
тельства, что порядок выполнения алгоритма в таких машинах
зависит прежде всего от готовности операндов и от ограничений,
определяемых информационными зависимостями между данны-
ми в алгоритме, а алгоритм может выполняться параллельно
с указанными естественными ограничениями.
Перевод программы в форму для поисковой машины доста-
точно прост и основан на так называемой методологии потока
данных. В последние годы эта методология была развита как в
части языка параллельного программирования с процедурами,
ориентированными на поток данных, так и в части концепции
параллельной асинхронной вычислительной системы для обра-
ботки потоков данных [651—655, 993, 994, 1137, 1138].
Вторая машина' с изменяемой конфигурацией, названная
коммутаторной [272], является специализированной. Она, как и
поисковая машина, использует концепцию изменения конфи-
гурации в соответствии с реализуемым алгоритмом, но произ-
водит это изменение путем установления непосредственных свя-
зей между выходами одних операционных устройств и входами
других в соответствии со структурой всего алгоритма или его
части (структурой модели информационных потоков). Указан-
ную функцию коммутации выполняет коммутатор, который явля-
ется основным устройством машины.
В последние годы предложен ряд систем с переменной струк-
турой на основе динамической коммутации поразрядно наращи-
ваемых микропроцессоров [470, 937, 1038]. В первой из таких
систем [937] применялась древовидная структура для коммута-
ции микропроцессоров, которая оказалась сложной в реализации.
В матричной системе с переменной структурой 11038J, рассмот-
ренной в п. 6.5, предусматривались линии передачи данных от
каждого 1-го процессорного элемента к. процессорным элементам
с номерами t±l, i±2, ..., i±2n. Такая структура, как и пере-
менная структура [938], может быть использована фактически
при сравнительно небольшом числе процессоров [939].
В системах с большим числом процессоров и с возможностью
перестройки эффективность и экономичность структуры в значи-
тельной степени определяются характеристиками коммутатора,
определяющего возможность эффективного взаимодействия меж-
860
коммутации: теряется
Рис. 7.2. Структура коммутационной се-
ти матричной системы с реконфигура-
цией и переменной структурой.
ду процессорами и обеспечивающего церестройку системы в за-
висимости от изменения ее загрузки. В [939] предлагается си-
стема с коммутационной сетью [766], в которой показатель эко-
номичности коммутации пропорционален величине т • log тп, а не
величине т2, что является типичным, для матричного коммутато-
ра с полным набором перекрестных связей для т процессорных
и других модулей. Такое преимущество, однако, достигается за
счет некоторого ухудшения i
примерно 10% связей меж-
ду модулями и, следователь-
но, соответствующая часть
модулей системы остаются
некоммутирумыми.
Предлагаемая в [939] вы-
числительная система назва-
на матричной системой с ре-
конфигурацией и переменной
структурой. Вариант комму-
тационной сети этой системы
для случая связывания -16
модулей изображен на ри-
сунке 7.2. Такая сеть по гиб-
кости аналогична матрично-
му коммутатору, но проще
его и легче реализуется в
виде аппаратуры, хотя, как
указано выше, небольшая
часть коммутационных воз-
можностей в ней теряется.
К вершинам сети подключа-
ются микропроцессоры Пр
(типа Intel 3000 и AM 2901),
а к корням (базовым узлам) сети — модули памяти Пм и устрой-
ства ввода-вывода ВВ (см. рис; 7.2).
Каждая шина сети может содержать, например, 8 линий
данных, 16 адресных линий, 4 линии управления и 3 линии
контроля и диагностики. Линии данных и адресные линии ис-
пользуются для формирования связей между процессорами и
модулями памяти. Процессоры связываются между собой че-
рез вершины сети. Они представляют собой побайтно наращи-
ваемые микропроцессоры. В 4их ’ постоянной памяти хранятся
микрокоманды, формат адреса — 16-разрядный. Обмен с памятью
и с устройствами ввода-вывода осуществляется байтами. Систем-
ная память в виде модулей Пм имеет страничную логику управ-
ления, которая распределена по отдельным страницам, что об-
легчает изменение структуры и конфигурации системы. Помимо
системной (основной) памяти, предусматривается вторичная па-
мять и логика подкачки данных из нее.
361
При выполнении задачи динамически устанавливаются соеди-
нения между процессорами, модулями памяти и устройствами
ввода-вывода при помощи указанных выше линий управления.
В связи с тем, что процессоры в системе обезличены, сначала
выбираются модули памяти и устройства ввода-вывода, а затем
они коммутируются с любыми свободными процессорами (про-
цессором). В целях вычислений с повышенной точностью не-
сколько процессоров могут быть логически объединены для об-
работки слов формата, составленного из нескольких форматов
исходных слов микропроцессоров. В системе могут быть исполь-
зованы различные режимы параллельной обработки, в ней не-
трудно реализовать также макромагистральный способ обработки.
По предварительной оценке, рассматриваемая система будет
удобна для решения задач научного характера с высокой ско-
ростью, а отношение ее. производительности к стоимости окажет-
ся ^значительно более высоким по сравнению с обычными ЭВМ
с аналогичными характеристиками. Структура описанной систе-
мы является, вероятно, наилучшей из числа известных структур
систем с большим числом микропроцессоров [939].
7.1.4. Концепция устойчивости вычислительных систем к
отказам. Важнейшей характеристикой вычислительных систем
является надежность. В настоящее время в большинстве вычис-
лительных систем надежность обеспечивается комбинацией
принципа предотвращения неисправностей и принципа обслужи-
вания системы техническим персоналом, включая восстановле-
ние им системы после отказа. Предотвращение неисправностей
требует таких физических компонентов и методов их сборки,
которые были бы как можно ближе к безотказным [3].
Характерным примером достижений в области предотвра-
щения неисправностей является сверхвысокопроизводительная
система CRAY f. В результате оценки надежности этой системы,
выполненной в Лос-Аламосской научной лаборатории при помо-
щи длительных прогонов специальной программы, имеющей при-
мерно 500 тыс. слов кода и данных, было установлено, что в
условиях "постоянного присутствия специалистов по ремонту и
наличия необходимых запчастей средняя наработка па отказ
равна 4 часам, а средняя продолжительность ремонта —- 25 мин,
т. е. готовность системы равна примерно 90% ♦). Это соответст-
вует очень высокому уровню надежности: в среднем между от-
казами система успешно выполняла последовательность из 1012
операций, если принять производительность CRAY 1 в 80 млн.
операций с плавающей запятой в секунду. Такая надежность
уже в первом серийном экземпляре системы представляет собой
существенный шаг вперед по сравнению с ILLIAC IV и другими
действующими высокопроизводительными системами.
—_.л..........
♦) По техническим условиям средняя наработка на отказ должна быть
яе менее 4 часов, а средняя продолжительность ремонта — не более 1 часа.
362
На основании этих результатов оценки надежности CRAY 1
можно сделать также следующие выводы. Каждый раз из-за не-
верной работы одной из 34 миллионов триггерных и других схем
CRAY 1 простаивает в среднем в течение времени, за которое
она могла бы выполнить 120 миллиардов операций, т. е. средняя
продолжительность одной операции восстановления более чем в
10н раз превосходит среднюю продолжительность одной нормаль-
ной операции. Кроме этого, 90%-ная готовность означает, что
из-за 10 %-го простоя невыполненная работа системой CRAY 1
соответствует непрерывной работе некоторой большой вычисли-
тельной системы производительностью в 8 млн. операций с пла-
вающей запятой в секунду*).
Таким образом, имеется огромный разрыв между скоростью
работы аппаратуры и скоростью ручного техобслуживания. Су-
ществует, вероятно, какое-то несоответствие в принципах проек-
тирования вычислительных систем, если системам приходится
останавливаться и терять миллионы и миллиарды операций из-
за какого-то отказавшего транзистора, ослабшего контакта или
медленного триггера, находящихся среди нескольких миллионов
вполне работоспособных элементов. Из сказанного ясно, что не-
обходимо разрабатывать и внедр’ять достаточно экономные авто-
матические методы устранения таких ситуаций путем, обеспече-
ния устойчивости к отказам. Внедрение полной отказоустойчи-
вости для CRAY 1г, например, означает добавление 10% вычис-
лительной мощности и возможность использования периодиче-
ского технического обслуживания системы вместо постоянного
присутствия ремонтного персонала L3J.
Отказоустойчивость — это такое свойство вычислительной си-
стемы, которое обеспечивает ей, как логической машине, воз-
можность продолжения действий, заданных программой, после
возникновения неисправностей. Введение отказоустойчивости
требует избыточного аппаратного и программного обеспечения,
которые были бы излишними в безотказной системе [3].
Направления, связанные с предотвращением неисправностей
и с отказоустойчивостью,— основные в проблеме надежности.
Возможности предотвращения неисправностей, как отмечалось
выше, зависят от характеристик физических' компонентов и ме-
тодов их сборки, тогда как устойчивость к отказам зависит от
организации структуры и функционирования системы, включая
ее программное обеспечение.
Концепции параллельности и отказоустойчивости вычисли-
тельных систем естественным образом связаны между собой,
поскольку в обоих случаях требуются дополнительные функци-
ональные компоненты. Поэтому, собственно, на параллельных
♦) К имевшемуся в первых образцах системы CRAY 1 средству конт-
роля в виде разряда четности в словах в дальнейшем были добавлены раз-
ряды, позволяющие обнаруживать двойные и исправлять одиночные ошиб-
ки (см. 5.7).
363
вычислительных системах достигается как наиболее высокая
производительность, так и, во многих случаях, очень высокая
надежность. Имеющиеся ресурсы избыточности в параллельных
системах • могут гибко использоваться как для повышения про-
изводительности, так и для повышения надежности. Структура
многопроцессорных и многомашинных систем приспособлена
для ’ автоматической реконфигурации и обеспечивает возмож-
ность продолжения действий, заданных программой, после воз-
никновения неисправностей. В параллельных системах другого
типа, например, в матричных и в ансамблях, возможность про-
должения действий после возникновения неисправностей в процес-
сорных элементах обеспечивается путем отключения таких эле-
ментов, как* это делается при обычных операциях маскирования.
Наиболее полно концепция отказоустойчивости представлена,
вероятно, в цикле работ (3, 479, 482, 483, 485—490]. Рассмот-
рим кратко эту концепцию, следуя статье [3].
Методика реализации устойчивости к физическим отказам
предусматривает определение целей надежности, выбор алгорит-
мов обнаружения неисправностей и восстановления работы си-
стемы, оценку отказоустойчивости и итеративную доводку раз-
работки вычислительной системы.
При реализации автоматической устойчивости к отказам ал-
горитм восстановления (как и алгоритм обнаружения неисправ-
ностей) должен выполняться без участия человека, т. е. он дол-
жен осуществлять возобновление нормальной работы только ав-
томатически. При этом ремонт после восстановления может как
предусматриваться, так и не предусматриваться. Если ремонт
не проводится (например, для спутника на орбите), то по ис-
черпании ресурсов избыточности вычислительная система неиз-
бежно отказывает. В ремонтопригодных вычислительных систе-
мах можно предусматривать ручной ремонт после автоматиче-
ского возобновления нормальной работы, причем проводить та-
кой ремонт можно как непосредственно после завершения
работы алгоритма восстановления, так и по заранее составленно-
му графику периодического технического обслуживания с учетом
ресурсов избыточности. Типичными примерами ремонтопригод-
ных систем являются отказоустойчивые телефонные системы
электронной коммутации ESS (Electronic Switching System).
Алгоритмы восстановления могут быть реализованы аппарат-
но с программной поддержкой или же могут быть реализованы
чисто программными средствами. В первом случае восстановле-
ние называется аппаратно-управляемым. Оно реализовано, на-
пример, в системе JPL STAR, рассматриваемой в п. п. 7.3.1, и
в недавно созданном опытном образце отказоустойчивой борто-
вой системы FTSC. Во втором случае восстановление называется
программно-управляемым. В зависимости от характера отказа и
алгоритма восстановления системы осуществляется либо полное
восстановление системы с возвратом к исходным условиям рабо-
364
ты и с заменой неисправного модуля на запасной, либо восста-
новление системы в исправное состояние при снижении вычис-
лительных возможностей, либо, как предельный случай, осуще-
ствляется безопасный останов, если оставшаяся производитель-
ность ниже приемлемого порога (информация в памяти при этом
остается без искажений).
Частным случаем аппаратно-управляемого восстановления яв-
ляется маскирование неисправностей, когда в статически избы-
точной аппаратуре при помощи, например, тройного модульного
резервиров*ания и голосования эффект неисправности остается
в рамках соответствующего модуля и оказыается «невидимым»
для программного обеспечения. При маскировании могут дубли-
роваться модули самого различного уровня — от аппаратных
элементов до функциональных устройств системы. В предельном
случае дублируемый модуль — это сама вычислительная машина.
Достоинства маскирования — простота и мгновенность действия,
а главный недостаток — необходимость в 3, 4 и более раз увели-
чивать объем оборудования для многократного дублирования.
Следует отметить, что если при использовании других мето-
дов алгоритм восстановления работает на основе данных о неис-
правности, поступающих в результат^ выполнения алгоритма
обнаружения неисправностей, то при использовании маскирова-
ния этот последний алгоритм вообще не нужен и неисправность
не обнаруживается, а данные с выхода от резервируемых моду-
лей вовне передаются на основе их сравнения между собой в
соответствии с принципом голосования.
Защита при помощи тройного модульного резервирования п
голосования предусмотрена в центральном процессоре вычисли-
тельной системы наведения ракеты SaturA V. Первым примером
применения такого тройного модульного резервирования в цен-
тральном процессоре и голосования была релейная машина с
памятью, на магнитных барабанах SAPO, разработанная в Чехо-
словакии в 1950—1954 гг. и запущенная в эксплуатацию в
1956 г. Для считывания из памяти использовался контроль чет-
ности, а для записи в память — непосредственное считывание
после записи со сравнением. Если исправление по принципу
голосования не давало нужного результата, то осуществлялось
повторное выполнение одной команды, и при повторений отка-
за — автоматический останов с сохранением состояния машины,
т. е. осуществлялся безопасный останов. Данные по всем выяв-
ленным ошибкам автоматически распечатывались на пульте опе-
ратора. За SAPO последовала машина EPOS с десятичной си-
стемой счисления, выполненная на электронных лампах и имев-
шая ферритовую память, в которой также широко использовались
методы отказоустойчивости.
Имеется ряд важных существующих и предполагаемых об-
ластей применения вычислительных систем, для которых устой-
чивость к отказам имеет особое значение: 1) управление поезда-
365
ми, самолетами, пилотируемыми космическими кораблями и дру-
гими транспортными средствами; управление атомными электро-
станциями и системами обороны; контроль и жизнеобеспечение
в автоматизированных больницах и т. д.-т- отказ вычислительной
системы в этих случаях будет угрожать жизни человека;
2) управление непрерывными технологическими процессами;
управление распределением электроэнергии и управление комму*
тацией в системах связи; обслуживание крупной вычислитель-
ной системой множества территориально совмещенных и разне-
сенных терминалов в оперативном режиме — отказ вычислитель-
ной системы в этих случаях даже на короткое время может по-
влечь тяжелые экономические последствия; 3) обеспечение ’
функционирования объектов в условиях без ручного техническо-
го обслуживания (спутники и межпланетные корабли, необслу-
живаемые подводный и наземные станции различного пазначе-1
ния и др.) — отказ вычислительной системы в этом случае мо-
жет повлечь к полному нарушению функционирования объекта.
Следует отметить, что кроме физических причин возникнове-
ния отказов (старение элементов, невыявленные частичные де- -
фекты и др.), существуют также проектные причины, вызывае-
мые ошибками в созданий аппаратного и программного обеспече-
ния, а также интерактивные причины, вызываемые неверными
действиями операторов при их взаимодействии с машиной через
пульты управления или обслуживания (повреждения, вызывав- i
мые действиями людей — закорачивания выводов, нарушения
соединений и подобные им —являются физическими неисправ- t
ностями и относятся к той же категории, что и другие физичес- •
кие неисправности). - j
- Доля такого рода нефизических отказов достаточно велика. 3
Так, например, упомянутые выше отказоустойчивые электронные- |
системы коммутации ESS с программным управлением и про- |
дублированными блоками, которые обслуживают большое чисЛа |
автоматических телефонных станций в США, характеризуются. 1
следующим распределением времени простоев системы: 35% — i
из-за несовершенства восстановления; 30% — из-за ошибок персо- *1
нала; 20% — из-за ненадежности аппаратуры; 15% — из-за несо- |
вершенства программного обеспечения 1389J. Интересно отметить,
что до накопления обширных данных по эксплуатации систем ESS '
все простои приписывались обычно ненадежности аппаратуры., ?
Проблемы нефизических отказов не удавалось решить сразу
при помощи какого-нибудь технического достижения, как эта 3
было, например, с физическими неисправностями при внедрении
полупроводников и ферритовых сердечников. Прогресс в области
выявления причин и выработки методики устранения нефизиче-
ских неисправностей протекает с трудом и не поспевает за ро- >
стом сложности систем и увеличением потребностей в их безот- j
казной работе. Принимаемые меры по предупреждению проект- ।
ных неисправностей, в особенности в части программного обес- 1
366
печения, все еще недостаточны и почти во всех системах в ходе
эксплуатации выявляются проектные ошибки. Интерактивные
неисправности также продолжают оставаться одним из главных
источников неприятностей при эксплуатации систем.
Такое положение выдвигает задачу расширения области дей-
ствия методов отказоустойчивости, чтобы они охватывали не
только физические, но и проектные и интерактивные неисправ-
ности. В настоящее время интенсивно ведутся работы в области
отказоустойчивости программного обеспечения, причем разраба-
тываемые подходы нередко напоминают подходы обеспечения
устойчивости к физическим неисправностям.
Элементная база, машин первого поколения — реле, электрон-
ные лампы, электронно-лучевые трубки и линии задержки —
отличалась низкой надежностью, поэтому уже на первом этапе
развития вычислительной техники появились схемы обнаруже-
ния неисправностей и некоторые методы автоматического вос-
становления. В программировании широко применялся метод
двойного — тройного просчета, когда повторялись достаточно ко-
роткие участки программ и, только при совпадении результатов
двукратного просчета, осуществлялся переход к очередному
участку.
Естественный ход развития методов устойчивости к отказам
был фацуически прерван с появлением полупроводниковых схем
и ферритовых сердечников, Иримепениё которых позволило удов-
летворять требованиям надежности и без встроенных схем обес-
печения устойчивости к отказам. Остался, да и то не во всех
системах, только разряд четности для контроля в памяти и, ре-
же, в центральном процессоре. Ставшие более редкими, но все-
таки неизбежные отказы . устранялись вручную. В условия^
почти полного отсутствия встроенной вспомогательной аппарату-
ры начался период разработки диагностических программ, кото-
рым на смену в настоящее время приходит микродиагностика,
использующая преимущества микропрограммирования. Функции
по обнаружению отказов и по восстановлению оказались сосре-
доточенными в большей части в программном обеспечении.
В этот период 1960-х годов методы отказоустойчивости нахо-
дили применение, главным образом, в специальных вычислитель-
ных системах, в которых неисправность могла либо угрожать
жизни человека, либо вызвать нарушение работы дорогостоящих
систем, в которых используются вычислительные системы. Кро-
ме этого, отказоустойчивые вычислительные системы нашли при-
менение в новых областях техники, в которых требуется обес-
печить высокую надежность в течение длительного времени без
обслуживания систем. Здесь особое место занимают вычисли-
тельные системы для искусственных спутников ш3емли и меж-
планетных кораблей.
В настоящее цремя наблюдается некоторое расширение при-
менения принципа отказоустойчивости. Удобства в эксплуатации
367
fl снижение эксплуатационных затрат, которые может принести \
отказоустойчивость, дают основания предположить, что к 1990-м ’•
годам устойчивость к физическим, проектным и интерактивным <
отказам станет в вычислительных системах одним из основных и
обязательных свойств [3].
7.2. Системы с комбинированной
и перестраиваемой структурой
7.2.1. Системы семейства OMEN 60. OMEN 60 (Orthogonal
Mini EmbedmeNt) представляет собой семейство совместимых
снизу-вверх вычислительных систем, основанных на концепции
ортогональной машины Шумана. Семейство создано фирмой
Sanders Associates (1966 г.) и включает четыре модели:
OMEN 61, 62, 63 и 64. В системах семейства используется мо-
дифицированная память с ассоциативным доступом к разрядным
Рис. 7.3. Структурная схема системы семейства OMEN 60.
срезам, основные ячейки которой построены на базе кристаллов
Intel 1103. Структурная схема системы семейства OMEN 60 изоб-
ражена на рис. 7.3 [1221]. Основными особенностями OMEN 60
являются: 1) использование коммутационной платы в целях
управления системой (устройство управления как таковое отсут-
ствует); 2) реализация ортогональной памяти; 3) использование
мини-ЭВМ PDP-11 (см. п. 3.6) в качестве горизонтального ариф-
метического устройства, что позволяет не разрабатывать систем-
ное программное обеспечение и применять развитое программное
обеспечение PDP-11. В OMEN 60 имеются 64 идентичных про-
цессорных элемента, составляющих вертикальное арифметиче-
ское устройство. Четыре указанных выше модели OMEN 60 раз-
личаются сложностью этих процессорных элементов.
Ортогональная память построена таким образом, что для
горизонтального арифметического устройства она представляется
обычной памятью с 16-разрядными словами, как это показано
368
отметить,
Горизонтальное*
слово О
Горизонтальное
слоео1
Вайт О Вайт 1
Вайт 2 Вайт 3
’----------1---------J слово 65535
• 64 разряда на один разряд
дный срез
Разрядный срез О
Разрядный срез 1
Разрядный срез 2
Разрядный срез 3
Разрядный срез А
Разрядный срез 3
Разрядный срез 6
Разрядный срез У
Разрядный срез 8
Разрядный срез 3.
Разрядный срез 10
Разрядный срез 11
Разрядный срез 12
Разрядный срез 13
Разрядный срез /4
Разрядный срез 15
Вертикальный
* разрядный срез
О
Вертикальный
разрядный срез
на рис. 7.4а, а для вертикального арифметического устройства
она представляется памятью с данными в виде разрядных сре-
зов длиной по 64 разряда, как это показано на рис. 7.46, при-
чем обеспечивается произвольный доступ к разрядным срезам
как в ассоциативных системах. Интересно отметить, что
стоимость ортогональной па-
мяти, построенной на кри-
сталлах Intel 1103, только на
19% выше по сравнению со
стоимостью сравнимой с ней
памятью С произвольным ДО- а)Горизонтальные словаортогональнойпамяти
ступом, обеспечивающей ре-
жимы считывания и запи-
си и построенной также
на кристаллах 'Intel 1103
11221J.
Вертикальное арифмети-
ческое устройство содержит
8 запоминающих регистров.
Эти регистры вместе с соот-
ветствующими логическими
схемами перестановок верти-
кального арифметического
устройства обеспечивают:
1) передачу данных ко всем
процессорным элементам;
2) предварительные операции
при умножении
3) завершающие операции
при умножении
4) полное перемешивание
данных, аналогичное разделе-
нию колоды карт на две рав-
ные части с последующим
тасованием их так, что в ко»-
лоде вслед за первой картой
первой
карта
вторая
вторая
и так
сдвиг и другие операции пе-
рестановок. Такого рода воз-
можности обеспечивают эффективную обработку матриц, векторов
и выполнение алгоритмов обработки сигналов, например, алгорит-
ма быстрого преобразования Фурье.
Программное обеспечение систем семейства OMEN 60 содер-
жит расширенные фортран и бэйсик, реализованные в PDP-11,
матриц;
матриц;
Разрядный срез 16376
Разрядный срез 16377
Разрядный срез 16378
Разрядный срез 16378
Разрядный срез 16380
Разрядный срез 16381
Разрядный срез 16382
Разрядный срез 16383
Вертикальный
> разрядный срез
2047
части следует
второй
карта
карта
далее;
части,
первой
второй
5) круговой'
первая
*затем Вертикальные разрядные срезы
части, ортогональной памяти
части
Рис. 7.4. Структурная схема ортогональ-
ной памяти.
24 в. А. Головкин
369
• св
ВТ
Я
\D
св
Варианты процессорных элементов моделей семейства OMEN 60
Модель семейства OMEN
64 Емкость 133 бита на каждый процессорный элемент (в том числе 8 16-разрядных регист- ров общего назначения) Полностью параллель- ная аппаратно реали- зованная арифметика с плавающей запяток
в? Практически такие же, как и в OMEN 64 Полностью параллель- ная аппаратно реали- зованная арифметика с плавающей запятой
62 Емкость 37 бит на каж- дый процессорный эле- мент (в том числе 4 16-разрядных регистра общего назначения) Последовательная по- разрядная арифметика
19 Емкость 8 бит на каж- дый процессорный эле- мент Последовательная по- разрядная арифметика
Устройства Регистры I Арифметико-логиче- ское устройство
а также операционную сцсте- <
му PDP-11. Кроме этого, пре- 1
дусмотрена реализация рас-
ширенной версии языка APL. J
Варианты процессорных |
элементов OMEN 60 пред- j
ставлены в таблице 7.1 [1221J. \
Процессорные элементы вы-
полняют одновременно коман- j
ду за командой, допускается 1
маскирование. Ввод-вывод |
осуществляется через шину 1
UNIBUS или непосредствен- •«
но через ортогональную па- !
мять при помощи параллель-
ного канала ввода-вывода.
Младшие Модели OMEN 61
и 62, имеющие последова-
тельные поразрядные процес- ':-
сорные элементы вертикаль-
ного., арифметического уст-
ройства, приспособлены в
большей степени для ассо-
циативных операций и могут
эффективно использоваться
для сортировки, распознава-
ния образов, поиска и других J
аналогичных операций. Стар- 1
шие модели OMEN 63 п 64, J
в процессорных элементах 1
которых обрабатываются ело- |
ва, а не разряды, и выполни- I
ются арифметические опера- |
ции с плавающей запятой, 1
могут эффективно использо- |
ваться для решения задач 1
линейной алгебры и других J
задач; требующих выполне- 1
пия разнообразных арифме- |
тических операций. Эти осо- 1
бенности позволяют эффек- |
тивно комплексировать млад- -з
шую и старшую модели се- j
мейства. < 3
На рис. 7.5 изображена i
типичная конфигурация сис- J
темы, состоящей из двух свя- 1
занных между собой вычис-
370
лительных систем OMEN 61 и 64 [820]. Малая вычислительная
система, которой в данном случае является OMEN 61, работает в
качестве буферной памяти и преобразователя формата данных
между каналом, передающим данные с очень высокой скоростью
в реальном масштабе времени, и основной вычислительной систе-
мой OMEN 64, осуществляющей собственно обработку сигналов.
OMEN 61 . может также использоваться для управления той
частью системы, которая остается свободной .от основной‘работы.
Обмен через параллельную шину память-память осуществляется
Гис. 7.5. -Структурная схема вычислительной системы, состоящей из сис-
тем OMEN 61 и 64.
более чем в 10 раз быстрее по сравнению с обменом через после-
довательную шину процессор-процессор, поскольку ширина пер-
вой равна 64 разрядам и, кроме этого, ее частота синхронизации
в четыре раза выше по сравнению с шиной UNIBUS.
7.2.2. Система МИНИМАКС. Система МИНИМАКС (МИНИ-
МАшинная программно Коммутируемая Система) является мо-
дульной однородной системой и имеет программно коммутируе-
мые (перестраиваемые) связи между элементарными машинами,
входящими в ее состав. Эта система создана Институтом мате-
матики СО АН СССР и Научно-производственным объединением
«Импульс» (г. Северодонецк). Работы над- системой были начаты
в 1971 г., технический проект разработан в 1976 г., опытно-про-
мышленный образец изготовлен и отработан в 1977 г., серийное
производство предусматривалось с 1978 г. [67, 150, 152]. Одной
из главных целей создания МИНИМАКС было получение реаль-
ного опыта в создании модульной системы с большим числом
24*
371
процессоров, обладающей возможностью реконфигурации при 1
неисправностях, адаптации структуры к решаемым задачам и 1
постепенного наращивания числа модулей системы, причем в ка- 1
честве процессоров предусматривалось использовать серийные I
мини-ЭВМ [207]. i
Структурная схема системы МИНИМАКС изображена на ри-
сунке 7.6 [67]. Система содержит элементарные машины (ЭМ)
с программно коммутируемыми связями между ними. Количе-
ство ЭМ в системе может быть от 2 до 64. Каждая ЭМ содержит •
ЭВМ, выполняющую функции обработки информации, и систем-
ное устройство, выполняющее функции связи-внутри ЭМ и меж-
ду ЭМ. В качестве ЭВМ используется вычислительный комплекс
б) Структура связей в система
Рис. 7.G. Структурная схема системы МИНИМАКС.
па базе АСВТ-М, в состав которого входит процессор М-6000
(см. п. 3.4.1). Системное устройство выполнено в виде автоном-
ного модуля АСВТ-М. Оно обеспечивает взаимодействие между
ЭМ по двумерным связям (тип 1: связь с четырьмя непосредст-
венными соседями слева, справа, сверху и снизу) и по» одномер-
ным связям (тип 2: связь с двумя непосредственными соседями
слева и справа), причем соответствующие крайние ЭМ считаются
непосредственными соседями (см. рис. 7.66). Кроме этого, сис-
темное устройство взаимодействует с ЭВМ данной ЭМ (тип 3:
связь системного устройства с ЭВМ данной ЭМ, осуществляемая
со стороны ЭВМ так, как это предусмотрено для ее работы с
внешними устройствами). Передача информации синхронизиру-
ется по сигналам запрос/ответ, что обеспечивает передачу при
рассогласовании скоростей работы ЭМ. При передаче информа*
372
цпи по связям типа 1 и 2 осуществляется контроль по четности
[67, 207J.
В системе МИНИМАКС взаимодействия между ЭМ могут
быть типа управления и типа обмена. Взаимодействия реализу-
ются в три этапа, на первом из которых формируется область
связности между ЭМ, участвующими во взаимодействии, на вто-
ром этапе осуществляется собственно взаимодействие и на треть-
ем этапе — выполняются действия, связанные с возможностью
использования ЭМ в других взаимодействиях [2071.
Типичными взаимодействиями являются: 1) пересылка инфор-
мации из оперативной памяти одной ЭМ в оперативную память
других ЭМ (обмен); 2) синхронизация работы ЭМ; 3) выполне-
ние обобщенного безусловного перехода; 4) выполнение обобщен-
ного условного перехода по значению обобщенного признаку та-
кого перехода; 5) программное изменение топологии структуры
системы и степени участия ЭМ в перечисленных выше взаимо-
действиях (настройка). Взаимодействия 1—4 ^реализуются через
связи типа 1, а взаимодействие 5 — через «вязи типа. 2. Дву-
мерность связей типа 1 обеспечивает компромисс между гибко-
стью п живучестью системы, с одной стороны, и сложностью
системного устройства, с другой стороны. Сравнительно» малая
частота выполнения настроек позволяет использовать для их реа-
лизации одномерные связи (тип 2). При этом живучесть системы
обеспечивается замыканием связей типа 2 в кольцо (см. рис. 7.6)
и возможностью обхода неисправностей в связях типа 2 по свя-
зям типа 1 [67].
Взаимодействия' между ЭМ задаются специальными систем-
ными командами, которые реализуются аппаратно системными
устройствами и соответствующими программами операционной
системы.
Настройка может осуществляться в обе стороны (влево и
вправо) от настраивающей ЭМ вдоль одномерных связей типа 2
при помощи регистров настройки, имеющихся в каждом систем-
ном устройстве. Регистр настройки — трехразрядный, содержи-
мое регистра может быть изменено ЭВМ данной ЭМ или ЭВМ
любой другой ЭМ. Содержимое двух разрядов регистра настройки
задает одно из четырех направлений приема данных по связям
типа 1, а содержимое w третьего разряда указывает, «согласна»
ли данная ЭМ взаимодействовать по связям типа 1 (де = 1 — да,
де = 0 — нет). Передача информации осуществляется по всем че-
тырем направлениям [207].
В системе'может быть организовано несколько подсистем, ра-
ботающих независимо, причем в подсистеме только одна ЭМ —
передающая, а все остальные ЭМ являются принимающими или
транзитными. В транзитных ЭМ де = 0 и передача данных осу-
ществляется при помощи системного устройства без участия ЭВМ,
которые не отвлекаются от выполнения текущей работы. Каж-
дая ЭМ входит в одну из подсистем, образованных по связям ти-
373
па 1 и при этом может входить или же не входить в одну из под* 1
систем, образованных по связям типа 2. ЭМ, которая входит как 4
в подсистему первого из указанных видов, так и в подсистему ]
второго вида, не может одновременно участвовать в нескольких 1
взаимодействиях. Подсистемы первого вида могут существовать |
в течение нескольких последовательных взаимодействий, а под-"!
системы второго вида создаются только для одного взаимодей- J
ствия и после его выполнения разрушаются [67, 152, 207]. ।
Операционная система МИНИМАКС обеспечивает параллель- J
ную обработку, автономную работу машин, а также режим сме- |
шанного функционирования, когда одна подсистема выполняет j
параллельную обработку, а машины другой подсистемы работают з
автономно. В состав операционной* системы включены основная
управляющая система и супервизор реального времени АСВТ-М. ;
Система параллельного программирования содержит языки для J
записи параллельных алгоритмов, являющиеся расширением
Мнемокода, фортрана и алгола, средства отладки программ, экс- !
периментальный расцараллеливатель алгоритмов, а также языко- -i
вые средства для организации устойчивых вычислительных про- <
цессов. Последние основаны на задании контрольных точек в '
программе, на которые делается возврат при сбоях или неисправ- j
ностях, осуществляемый операционной системой * или опера- 1
тором [207J. 1
Области применения системы МИНИМАКС определяются на- <
значением применяемых в системе средств АСВТ-М. Системы !
МИНИМАКС могут работать автономно, в комплексе с более
мощными вычислительными системами как вспомогательные под- ;
системы, а также в составе распределенных вычислительных
систем или сетей [152].
7.2.3. Система СУММА. Система СУММА (Система Управляю- j
щая Мини-МАшинная) является модульной однородной системой -
с программируемой структурой. Она создана Институтом мате-
матики СО АН СССР совместно с промышленностью. Работы над !
системой были начаты в 1972 г., технический проект разработай .
в 1976 г., опытно-промышленный образец изготовлен и отработан ‘
в 1977 г., серийное производство предусматривалось с 1979 г. ;
[19, 150, 1521. Рассмотрим систему СУММА, следуя [75J. ;
Система СУММА содержит связанные между, собой элемеп- :
тарные машины (ЭМ). Каждая ЭМ содержит мини-ЭВМ Элек- J
троника-ЮОИ и системное устройство (СУ), при этом конфигура- -Я
ция мини-ЭВМ может быть произвольной вплоть до ЭВМ с пол- i
ным набором внешних устройств. Реализованный вариант 1
операционной системы рассчитан на число ЭМ от 1 до 11. Мини- 1
ЭВМ выполняет функции обработки информации. Она имеет одно- I
адресные команды, 12-разрядные слова, оперативную память с I
циклом 1,5 мксек и емкостью 4 К слов (может быть расширена Я
до 32 К слов); производительность ЭВМ — до 300 тыс. операций 1
с фиксированной запятой в секунду. |
374 |
. Системное устройство выполняет функции взаимодействия
машин. Оно представляет собой отдельный модуль и подключа-
ется к ЭВМ как одно из внешних устройств. Каждое СУ может
быть свободным или же занятым. В первом случае оно — пассив-
ное устройство/ Перевод СУ в состояние занятости может осу-
ществить ведущее по отношению к этому СУ устройство, в каче-
стве которого может выступать собственная ЭВМ, входящая в
данную ЭМ, или же одно из СУ, являющееся непосредственным
соседом данного СУ. Во всех случаях СУ может принимать ин-
формацию только от ведущего устройства. Скорость обмена через
СУ — 2,6 млн. бит в секунду.
СУ имеет информационные и управляющие входы и выходы,
которые соединяются соответственно с выходами и входами со-
седних СУ, причем образуемая при этом наращиваемая сеть свя-
зи системы СУММА может иметь различные виды конфигурации
(примеры — см. рис. 7.7). Настройка сети состоит в формирова-
нии соединительных функций и активизации взаимодействующих
Рис. 7.7. В&^ианты конфигураций
сети связи системы СУММА.
ЭВМ и осуществляется под действием распространяющейся по
сети информации. Формат сообщений стандартизован в виде па-
кета, имеющего служебную и информационные части.
Адресное поле и управляющее поле, входящие в служебную
часть пакета, используются для настройки сети связи. Каждая
ЭМ может иметь несколько адресов, которые определяют степень
ее участия в системных взаимодействиях. Адреса назначаются
программой. Если адрес в служебной части пакета соответствует
одному из адресов, присвоенных СУ, то соответствуЪощая ЭВМ,
входящая в состав данной ЭМ, активизируется для приема ин-
формации, поступающей в СУ. В противном случае СУ ретранс-
лирует поступающую информацию как транзитный узел сети
связи системы СУММА, а соответствующая ЭМ в данном взаимо-
действии не участвует.
В состав программного обеспечения системы СУММА входит,
ядро операционной системы, которое управляет асинхронным
взаимодействием процессов, и система программирования, кото-
рая позволяет создавать параллельные программы. В состав пос-
ледней входят входной язык тасго-8С и транслятор с этого язы-
375
ка, символический
редактор, отладчики, загрузчики и сервисные >
программы.
Система СУММА предназначена для применения
системах
в
управления технологическими процессами, научными эксперимен-
тами и т. п« Ядро операционной системы позволяет настраивать
структуру системы СУММА на определенные режимы работы,
такие как режим матричной обработки, когда она работает как
система типа ОКМД, режим магистральной обработки, когда она
работает как система типа МКОД, режим обработки, когда она
работает как система типа МКМД.
7.2.4. Библиографическая справка. Не повторяя сделанных ра-
нее ссылок на работы, посвященные построению систем с пере-
страиваемой структурой, отметим, что эти вопросы и некоторые
другие вопросы, связанные с первыми, рассмотрены в [74, 1021,
1055, 1117, 1119]. Краткий библиографический обзор систем с
комбинированной структурой и с перестраиваемой структурой со-
держится в [110, 111].
В системах с перестраиваемой структурой и во многих других
все более широкое применение находят минимашины и, в осо-
бенности, микропроцессоры. Мини- и микро-ЭВМ, а также мик- '
ропроцессоры рассмотрены в [116, 188, 397, 417, 418, 971, 12101
и во многих других работах, при этом большое внимание уделя-
ется системам из многих мини-ЭВМ и микропроцессоров. Кон-
цепция построения и примеры таких систем, в большинстве
случаев с’перестраиваемой структурой, представлены в [152, 399,
470, 552, 803, 810, 843, 865, 934, 940, 967, 1002, 1054, 1058, 1143;
1153, 1262]. В [1054], например, отмечается, что стало возможным
создавать вычислительные системы с таким числом процессоров,
которое исчисляется двухзначным и даже трехзначным числом.
В [152] указывается разработка фирмой LMS Associates системы
ГИПЕРКУБ, состоящей из 512 микропроцессоров и имеющей
структуру в виде четырехмерной решетки (матрицы) с двумя
микропроцессорами в каждом из 256 узлов, причем один из этих
микропроцессоров осуществляет функции управления и связи,
а второй — функции обработки информации. В [1058] рассматри-
ваются высокопараллельные и магистральные структуры на базе
микропроцессоров.
Перейдем к .конкретным вычислительным системам с комби- ,
нированной и перестраиваемой структурой.
Системы семейства OMEN 60 представлены в ключевой статье
[820]. Примерно такое же описание этих систем приведено в кни-
ге [281]. Системы семейства OMEN 60 рассмотрены в книге
[1222] и в предшествующем ей обзоре [1221], а также в обзорах
.[8, 1273, 1274]. Принципы работы и применения ортогональных
систем (в совокупности с ассоциативными системами) обсужда-
ются в [822, 823]; применение указанных систем для обнаруже-
ния конфликтов при управлении воздушным движением обсуж-
дается в [670].
376
Система МИНИМАКС представлена в ключевой статье 1671,
в книге [152], а также в [135, 150]. Программное обеспечение
этой системы описано в [204—207, 274]. Описание системы
СУММА, включая ее программное обеспечение, содержится в
ключевой статье [19], в книге 1152], а также в работах [20, 75,
150, 374]. ЭВМ Электроника-100И, входящая в состав системы
СУММА, описана в [429]. Высокопроизводительная однородная
система на базе микропроцессорных больших интегральных схем,
концепция построения которой является развитием концепции по-
строения систем МЙНИМАКС и СУММА, представлена в [28,
152, 216]. Программное обеспечение однородных вычислительных
систем рассмотрено в обзоре [224].
Микропроцессорная система MINERVA, имеющая централь-
ную шину и процессоры двух типов, представлена в [1256, 1257].
Система MULTI-INTERPRETER фирмы Burroughs, в которой
микропроцессоры могут настраиваться на выполнение функций
либо основного процессора, либо процессора ввода-вывода, либо
процессора для специфических задач, описана в [281, 646, 694,
1120]. Микропроцессорная система POPSY (POlyProcessor
SYstem) со структурой в виде двумерной решетки представлена
в [152, 417, 805]. Микропроцессорная система MICS с общей раз-
деляемой основной памятью рассмотрена в [399, 1035, 1036].
В первой из указанных работ рассмотрена также система DIMS
(Distributed Intelligence Microcomputer System).
Укажем также большую систему GALAXY/5, состоящую из
множества микро-ЭВМ [918], а также микропроцессорные систе-
мы: АСЕ (Adaptive Computer Experiment) [1006]; MUMP-2 [1009];
система для обработки отраженных радиолокационных сигналов,
имеющая 64 микропроцессора [1067]; SMS 201, имеющая 128
микропроцессоров [895, 896]; GORAIL [1074] и другие системы
[639, 867, 868, 1011, 1187, 1199].
В следующем разделе рассматриваются отказоустойчивые си-
стемы. Следует отметить, что во многих случаях граница между
системами с комбинированной и перестраиваемой структурой и
отказоустойчивыми системами в достаточной степени условна и
соответствующие системы могут обладать фактически как приз-
наками систем первого из указанных видов, так и второго вида.
Отличительным признаком, однако, не вполне однозначным, явля-
ется требование особо высокой устойчивости к отказам систем
второго из указанных видов.
7.3. Отказоустойчивые системы
7.3.1. Системы JPL STAR и UDS. Системы JPL STAR (Self-
Testing And Repairing) и UDS (Unified Data System) разрабо-
таны в Лаборатории реактивного движения JPL (Jet 'Propulsion
Laboratory) Калифорнийского технологического института, в ко-
377
торой созданы космические аппараты, исследовавшие Луну, Марс,
Венеру и Меркурий, и направленные к Юпитеру и Сатурну^
Наиболее важное требование, предъявляемое к бортовой вы-
числительной системе космических аппаратов,— большая долго-
вечность без обслуживания, причем на потребляемую мощность,
на массу и габариты системы накладываются жесткие ограниче-
ния (как правило, 30—40 Вт, 45 кг и объем несколько тысяч
кубических сантиметров). В JPL около двадцати лет проводится
программа по созданию отказоустойчивых вычислительных сис-
тем в целях обеспечения требований к надежности космических
апаратов.
В период 1961—1972 гг. была выполнена первая часть про-
граммы, в результате которой, вероятно, впервые была практи-
чески построена самовосстанавливающаяся (лабораторная демон-
страционная) система, получившая название JPL STAR (1969 г.).
Эта система ориентирована на технологию производства устройств
для бортовых систем начала 1970-х годов (биполярные элементы
с малым и средним уровнем интеграции и память на цилиндри-
ческих магнитных пленках). Всесторонняя проверка в условиях
введения неисправностей в макет JPL STAR показала, что при-
мерно при 99% всех вносимых неисправностей следовало успеш-
ное самовосстановление макета. После этой проверки система JPL
STAR прослужила несколько лет в качестве лабораторной маши-
ны. Был разработан также* бортовой вариант модели JPL STAR,
рассчитанный на 10—15 лет работы в космическом полете, по
его реализация была приостановлена, так как NASA прекратило
работы по подготовке полета, для которого презназначалась этй
модель.
После завершения испытаний JPL STAR с 1973 г. начались
работы по второй части указанной программы, которая продол-
жается по настоящее время. Успехи в технологии создания ма-
ломощных микропроцессоров с высокой степенью интеграции
позволили заменить относительно дорогие общие сконцентрирован-
ные вычислительные ресурсы на распределенные ресурсы, реали-
зуемые в виде малых ЭВМ. Эти ЭВМ распределенной системы
располагаются там, где они непосредственно нужны. Возникаю-
щие здесь вопросы' связаны со сложностью системы, надежно-
стью программного обеспечения, отказоустойчивостью аппара-
туры. Был построен макет подобной системы, названной UDS,
который используется для эмуляции ряда функций вычислитель-
ной системы космического аппарата [3, 361J.
Структурная схема окончательного варианта системы JPL
STAR'изображена на рис. 7.8 [361]. Жесткие ограничения на по-
требляемую мощность не позволили применить структуры с боль-
шой избыточностью, например, одновременно работающие сдво-
енные йли строенные системы со сравнением их сигналов или с
мажоритарным голосованием на выходе соответственно. Был* при-
нят вариант, при котором должна функционировать одна ЭВМ^
378
имеющая развитые схемы контроля для обнаружения внутренних
неисправностей. При этом затраты на обнаружение неисправно-
стей должны быть-минимальными вследствие жестких совокуп-
ных ограничений на потребляемую мощность, массу и габариты.
В .целях восстановления после отказа для обеспечения большой
долговечности был принят вариант, когда один рабочий блок
имеет несколько резервных, причем на резервные блоки питание
Рис. 7.8. Структурная схема системы JPL STAR.
не подается (ненагруженный резерв). Модули замены не долж-
ны содержать слишком большое число компонентов, чтобы ин-
тенсивность их отказов была допустимой. Поэтому, например,
центральный процессор, имевший более 1000 кристаллов, был
разбит на четыре модуля (см. рис. 7.8), каждый из которых обес-
печивался необходимым числом резервных модулей.
Поскольку в рабочем состоянии находится одна вычислитель-
ная машина, требуется специальное центральное устройство для
непрерывной диагностики неисправностей в машине, перезапус-
ков программ, выработки управляющих сигналов для запуска
379
программных процедур восстановления и автоматической замены
неисправных модулей на резервные путем переключения питания
сразу же после обнаружения отказа какого-либо рабочего модуля.
Таким устройством является процессор контроля и восста-
новления [361].
Система JPL STAR имеет семь типов модулейг являющихся
функциональными блоками (см. рис. 7.8). Управляющий процес-
сор модифицирует адреса команд перед их выполнением; он со-
держит счетчик команд и индексные регистры. Логический и ос-
новной арифметический процессоры выполняют логические и
арифметические операции над словами данных соответственно.
Процессор ввода-вывода управляет запросами на прерывания и
содержит буферные регистры для ввода-вывода и процессор пре-
рываний. Процессор контроля и восстановления управляет рабо-
той вычислительной машины и осуществляет диагностику и вос-
становление; для взаимодействия с аппаратурой восстановления
была разработана операционная система STAREX.
Постоянная* память имеет емкость в 16 К слов. Оперативная
память содержит до 12 блоков емкостью в 4 К слов каждый.
В каждый момент времени питание подается только на одну
копию каждого функционального блока, за исключением следую-
щих случаев. В логическом процессоре питание подается сразу
на две копии блока. В оперативной памяти питание подается
минимум на две копии блока, а в процессоре контроля и восста-
новления — на три копии. Для памяти предусмотрены одинако-
вые имена нескольким модулям, что Позволяет осуществить вы-
борочное копирование особо важных программ и данных.
Функциональные блоки соединены между собой при помощи
двух чбтырехпроводных шин (записи и считывания) через свои
стандартные устройства сопряжения. По шинам передаются 32-
разрядные слова в виде восьми 4-разрядных единиц информации.
Модули обработки рассчитаны на последовательную обработку
указанных единиц информации, что экономит аппаратуру и, сле-
довательно, уменьшает потребляемую мощность и вероятность
отказов модулей [361].
Для обеспечения устойчивости к отказам при наличии боль-
ших интегральных схем с малой потребляемой мощностью можно
использовать большую часть аппаратуры, чем это было при уров-
не технологии начала 1970-х годов. При этом если в JPL STAR
разбиение на модули вынужденно осуществлялось на уровне под-
процессоров, то при современной технологии систему можно раз-
бивать на модули на уровне микро-ЗВМ, т. е. отдельные вычис-
лительные машины становятся модулями замены. Наконец, сеть
вычислительных машин удобна для обслуживания достаточно ав-
тономных подсистем космического аппарата и позволяет реали-
зовать (алгоритмы восстановления в отдельных машинах, а не в
центральном модуле типа процессора контроля и восстановления
системы JPL STAR. В основу таких систем второго поколения
380
для крсмических аппаратов закладывается концепция самопро-
веряемого вычислительного модуля, представляющего собой ма-
лую вычислительную машину, способную обнаруживать своп
неисправности. Такой модуль содержит серийно выпускаемые
микропроцессоры, а также стандартные блоки четырех типовг
Типовой самопроверяемый блок состоит из двух синхронно рабо-
тающих микропроцессоров, 23 блоков памяти с произвольной вы-
боркой, одного* стандартного блока сопряжения с памятью,
трех стандартных блоков сопряжения с шиной, двух стандарт-
ных блоков ввода-вывода и одного центрального стандартного
блока.
Стандартные блоки контролируют правильность работы и об-
наруживают неисправности в контролируемых ими процессоре,
шине связи, памяти и схемах ввода-вывода. Информация о неис-
правностях сосредотачивается в центральном стандартном бло-
ке,' который при появлении неисправностей в модуле может либа
остановить обработку до вмешательства извне модуля, либо
перезапустить программу или осуществить повторный запуск
процессора, либо провести перезагрузки памяти ’ и повторный
запуск программы. При повторении ошибки центральный стан-
дартней блок отключает свой неисправный модуль и вырабаты-
вает соответствующий сигнал неисправности.
Каждый модуль при помощи своих схем ввода-вывода и уст-
ройства сопряжения соединяется через шину с другими модуля-
ми, образуя отказоустойчивую систему, в которой на уровне мо-
дулей применяется способ ненагруженного резерва. Если какой-
либо модуль вырабатывает сигнал неисправности, то восстанов-
ление может быть выполнено при помощи внешнего модуля,
предназначенного для распознавания нерабочего состояния
неисправных модулей. Укрупненная структурная, схема соответ-
ствующей системы UDS приведена на рис. 7.9а. Функции дис-
петчера выполняет командный процессор, который управляет
терминальными модулями. Командный процессор получает комап-
дь? с Земли и хранит их, а также контролирует состояние других
модулей. Форматный процессор по* командам командного процес-
сора формирует картину перемещения данных между различны-
ми машинами, а также .осуществляет'обобщающую обработку ин-
формации в системе UDS [36U.
Укрупненная структурная схема макета системы UDS изобра-
жена на рисунке 7.96 [929]. Макет содержит шесть мини-ЭВМ
и трехмагистральную схему связи между ними. Оборудование
реальной бортовой системы будет существенно отличаться от ап-
паратуры макета, однако, в нем представлены все элементы UDS,
и поэтому программное обеспечение макета обладает основными
свойствами, необходимыми для реальной бортовой системы UDS.
В состав макета дополнительно включена мини-ЭВМ, выполняю-
щая функции наземного процессора, что позволяет. отрабатывать
не только собственно макет бортовой системы, но и ее взаимо-
381
действие с наземным вычислительным комплексом. Каждая мини-
ЭВМ макета системы имеет память емкостью 8 К 16-разрядных
слов и выполняет одну команду в среднем за 2,5 мксек.
Модули высокого уровня
б) Структура макета системы
МШ-контраллершины, АШ- адаптер шины
Рис. 7.9. Структурная схема системы UDS.
7.3.2. Система PLURIBUS [201]. Серийно выпускаемая систе-
ма PLURIBUS предназначена для выполнения функций процес-
сора связи — интерфейсного процессора сообщений IMP (Inter-
face Message Processor) в вычислительной сети ARPA. Опа пред-
ставляет собой модульную симметричную многопроцессорную си-
стему, ориентированную на отказоустойчивую работу, обеспечи-
ваемую, в основном, программными средствами. Особенности при-
менения PLURIBUS: 1) круглосуточная работа, в том числе в
необслуживаемых пунктах; 2) допустимость пропуска отдельных
сообщений, а также допустимость кратковременных перерывов
-382
в работе. В случаях пропуска сообщений или кратковременных
перерывов работы данной системы PLURIBUS в узле сети ARPA
последняя обеспечивает повторную передачу сообщений.
а) Структура связей между функциональными
модулями системы
Шина памяти
Соединитель
"1 шин _
б) Структурные схемы функциональных *
' модулей системы
Рис. 7.10. Структурная схема системы PLURIBUS.
PLURIBU& содержит функциональные модули трех типов с
общим адресным пространством и раздельными трактами связи
между ними (рис. 7.10а); эти модули получили название процес-
сорных шип, шин памяти и шин ввода-вывода (рис. 7.106). Связи
3*3
между модулями реализуют фактически матричный перекрестный
коммутатор, элементы которого называются соединителями шин.
Элементы коммутатора распределены между модулями системы,
чтобы не было точек, отказ в которых приводит к отказу всей
системы. Таким образом, PLURIBUS можно отнести к классу
МКМДС/ВсОрПк систем с распределенным коммутатором
(см. рис. 2.1).
Соединители шин определяют диапазон адресов в процессор-
ной шине или шине ввода-вывода и вырабатывают запрос на дос-
туп к соответствующей шине, они программно отображают 16-
разрядные адреса процессора в 20-разрядцые системные адреса.
Программа может перезапускаться и всегда доступна для любого
процессора. Малоиспользуемые программы хранятся в шинах
памяти и являются общим ресурсом процессоров, тогда как ин-
тенсивно используемые программы хранятся в виде копии в мест-
ной памяти каждой процессорной шины. Это уменьшает число
конфликтов доступа к общей памяти и не приводит к большим
затратам, поскольку активно используется только небольшая
часть программ. Все связи между процессорами осуществляются
через области общей памяти, при этом доступ некоторого процес-
сора к местной памяти и управляющим регистрам процессора,
подключенного к другой шине, обеспечивается соединителями шин
путем организации тракта через любую общую шину ввода-
вывода.
В качестве базовой ЭВМ в системе PLURIBUS используется
46-разрядная мини-ЭВМ SUE фирмы Lockheed, похожая на
PDP-11. В PLURIBUS применяется шина, процессоры, устройства
памяти и некоторые блоки ввода-вывода из ЭВМ SUE.
Шины построены по модульному принципу. Процессорная ши-
на (см. рис. 7.10) содержит один или два процессора со своей
местной памятью, емкостью от 8 К до 12 Ы слов на каждый про-
цессор (этот параметр может варьироваться), арбитражную логи-
ку и соединители шин для каждого из логических устройств ши-
ны. Шина общей памяти содержит арбитражную логику, соеди-
нители шин для всех подсоединяемых трактов и модули памяти,
количество которых определяется в зависимости от каждого кон-
кретного применения системы. В типичных конфигурациях сис-
темы каждая шина имеет от 32 К до 80 К слов. Система может
иметь до 512 К слов общей памяти. В шине ввода-вывода содер-
жатся, как обычно, арбитражная логика и соединители шин,
а также интерфейсы связи для каждого типа ввода-вывода (ин-
терфейсы модемов, терминалов, периферийных устройств, веду-
щих машин и других) и, кроме этого, специальные блоки, такие
как датчик реального времени для синхронизации процессов и ли-
ний сврзи по времени и устройство псевдопрерываний для орга-
низации очереди приоритетных запросов на прерывание. Шины
связаны между собой таким образом, что все процессоры имеют
доступ ко всей общей памяти и могут управлять работой и сле-
384 '
дить за состоянием любого блока ввода-вывода (см. рис. 7.10л).
Это обеспечивает возможность любому процессору выполнять лю-
бую задачу системы.
В целях резервирования вводится, по меньшей . мере, одна
дополнительная шина каждого типа, что обеспечивает выживание
системы при различных комбинациях многократных отказов
вследствие принятой структуры PLURIBUS. Так, .например, если
для работы с минимально Допустимой производительностью тре-
буется четыре процессора, то для обеспечения отказоустойчиво-
сти в части процессоров в составе системы будут шесть процес-
соров, т. к. отказ любой процессорной шины выводит из работы
два процессора. Следует нодчеркнуть, что резервные ресурсы
обезличены и не простаивают, а используются для решения задач
в работающей системе, обеспечивая характеристики, превышаю-
щие минимально допустимые.
Аппаратура PLURIBUS построена так, что повышение на-
дежности системы достигается программными методами. Поэтому
именно системное программное обеспечение отвечает, в ос-
новном, за надежность PLURIBUS. В PLURIBUS осущест-
вляются обычные проверки ошибок в самой аппаратуре и перио-
дически запускаются тесты. При обнаружении отказа аппарату*
ры программное обеспечение системы образует за счет избыточ-
ных аппаратных средств новую логическую конфигурацию систе-
мы, в которой отказавший блок исключен и заменен резервным.
При этом до отказа ни один блок не находится в состоянии ре-
зерва, т. к. всегда занимаются все ресурсы, и отказ какого-либо
одного или нескольких блоков ухудшает характеристики систе-
мы, но не нарушает ее работу.
В PLURIBUS проверяется также правильность работы прог-
раммного обеспечения путем введения в различные точки масси-
вов данных специальной избыточной информации с последующей
проверкой получаемых результатов. Периодически используются
повторные вычисления значений некоторых переменных, ранее
вычисленных в нормальном режиме работы, и соответствующие
сравнения результатов. Учитываются также ситуации, когда
отказ проявляется не сразу, а через некоторое время в виде не-
увязок хода обработки. В этом случае не удается выполнить
мгновенное восстановление и система ищет пути скорейшего во-
зобновления нормальной работы. Управление конфигурацией
системы и функции восстановления осуществляет небольшая опе-
рационная система STAGE.
По данным о работе 8 систем в. 1977 г. в обычных рабочих
условиях и в условиях испытаний на месте эксплуатации готов-
ность PLURIBUS оценивается величиной 99,7% (отношение фак-
тического рабочего времени к полному времени использования
без времени простоя из-за отказов источников питания и конди-
ционеров). Почти все простои явились следствием программных
ошибок, которые по мере обнаружения были устранены. Позднее
25 в. А. Головкин 385
готовность превысила 99,9%. По мере завершения периода при*
работки ожидается дальнейшее' повышение готовности.
Кроме основного применения-PLURIBUS в качестве процес-
сора связи р территориально разнесенной вычислительной сети
ARPA, эта система может применяться в различных системах об-
мена сообщениями, для обработки информации в реальном мас-
штабе времени, в универсальных системах разделения времени,
в системах резервирования мест в самолетах, гостиницах и т. п.
7.3.3. Система TANDEM 16 [713, 7451. Серийно выпускаемая
система TANDEM 16 фирмы Tandem Computers представляет со-
бой вычислительную систему, обеспечивающую непрерывное
функционирование, в том числе при отказе одного пли нескольких
элементов аппаратуры. Она предназначена для использования
в режиме реального времени, когда требуется быстрый отклик и
высокая надежность.
Рис. 7.11. Структурная схема системы TANDEM 16.
Структурная схема системы изображена на рисунке 7.11.
В состав системы может входить от 1 до 16 процессорных моду-
лей, каждый из которых содержит блок управления общей ин-
формационной шиной, 16-раз рядный процессор, блок памяти и
канал ввода-вывода. Каждый модуль имеет отдельный источник
питания. Все модули связываются между собой при помощи двух
полностью дублирующих друг друга шин, называемых DYNABUS.
Каждая из шиц способна осуществлять межпроцессорную связь,
386
обеспечивая взаимодействие программы одного из модулей сх
программами других модулей. При этом каждая шина полностью
автономна и управляется независимо и одинаково. В состав сис-
темы входят также блоки управления внешними устройствами.
Система находится в работоспособном состоянии, пока рабо-
тает хотя бы один процессорный модуль, и один блок управления
внешними устройствами (основной режим работы предусматри-
вает однопроцессорную обработку с резервированием). Если, на-
пример, один из процессорных модулей выходит из строя, то его
функции автоматически принимает на себя избыточный модуль,
и система продолжает нормально работать. О своей работоспособ-
ности процессоры сообщают друг другу сигналами через общую
информационную шину. Обмен данными между процессорными
модулями осуществляется пакетами по 15 слов с контрольной
суммой в каждом пакете. Кроме этого, в памяти реализованы ч
коды для исправления одиночных и обнаружения двойных оши-
бок и предусмотрены меры повышения отказоустойчивости систе-
мы. Восстановление работоспособности после отказа любого эле-
мента производится без перерыва работы системы.
Перечислим основные характеристики устройств системы.
В процессорном модуле емкость памяти равна 32 К слов. Каждый
модуль рассчитан на работу с приводом дисков, емкость которых
10 мегабайт, блоком памяти на магнитной ленте, пультом опера-
тора и 16 линиями ввода-вывода данных. При полной 16-модуль-
ной комплектации система может использовать 1000 терминалов.
Устройства ввода-вывода работают в темпе запоминающих уст-
ройств. Последние могут быть либо полупроводниковыми, либо
ца магнитных сердечниках. Время выборки 16-разрядного слова
из полупроводниковой памяти с учетом указанной выше коррек-
ции кодов составляет 500 нсек. Аналогичное время для памяти
на магнитных сердечниках равно 800 нсек. Блок памяти разбит
на четыре отдельных устройства для системных данных, систем-
ных программ, данных пользователя и программ пользователя
соответственно. Команды имеют 16-разрядный формат.
Программное обеспечение содержит виртуальную операцион-
ную систему и позволяет осуществлять многопроцессорную и
мультипрограммную обработку. Разделение времени между про-
граммами определяется их приоритетами.
7.3.4. Системы С. mmp, Cm* и С. vmp. С 1970 г. в университе-
те Карнеги — Меллона проводятся экспериментальные исследо-
вания в области многопроцессорных систем с широкой общей
полосой пропускания между процессорами и памятью. За это
время разработаны, реализованы и введены в эксплуатацию три
экспериментальные многопроцессорные системы: С. mmp вы-
сокопроизводительная минппроцессорная система; Ст* — расши-
ряемая модульная микропроцессорная-система высокой готовности
и С. vmp — отказоустойчивая микропроцессорная система с огра-
ниченной расширяемостью. Цели и технические условия создания
25# 387
этих систем различны, однако, во всех случаях в основу разра-
ботки был заложен принцип максимального использования серий-
ной аппаратуры [372, 373]. При этом в проводимых работах одно
из центральных мест отведено отказоустойчивости и измерению
надежности [3].
Рассмотрим сначала первую из указанных выше систем, сле-
дуя [372, 3731.
Целью разработки системы С. mmp (Carnegie — Mellon Multi-
Mini-Processor) было создание высокопроизводительной дешевой
многопроцессорной системы для распознавания речи и образов.
Принципы построения С. mmp разрабатывались в 1970 г., когда
стоимость мини-ЭВМ была сравнительно высокой. Поэтому вы-
брана возможно более простая структура системы, а обеспечение
надежности н управление ресурсами возложено на программное
обеспечение. _
Система С. mmp содержит 16 процессоров, каждый из которых
представляет собой незначительно модифицированную мини-ЭВМ
PDP-11 (см. 3.6) с небольшой локальной памятью емкостью в
8 К байт. Эти процессоры связаны через центральный матричный
коммутатор 16X16 с 16 модулями общей оперативной памяти,
что обеспечивает адресное пространство в 32 М байт. Каждый
модуль общей памяти имеет емкость в 64 К 16-разрядных слов,
т. е. суммарная емкость общей оперативной "памяти равна 2 М
байт. В полной 16-процессорной конфигурации системы 5 про-
цессоров представляют собой PDР-11/20 и 41 процессоров —
PDP-11/40. Структурная схема системы изображена на рис. 7.12.
Каждый из процессоров имеет доступ к Любому модулю общей
памяти. Все процессоры соединены общей межпроцессорной шн;
пой, которая обеспечивает межпроцессорные прерывания с тремя
уровнями приоритета, непрерывную передачу 60-разрядного бес-
повторного тактирующего слова с частотой 250 кГц, а также
функции управления (каждый процессор может останавливать,
возобновлять и продолжать работу любого другого процессора).
При обращении к общей памяти процессор генерирует 18-раз-
рядный адрес, который преобразуется в блоке отображения адре-
са в 25-разрядный физический адрес. Конфликты запросов к дан-
ному модулю памяти разрешаются при помощи формирования
приоритетной очереди запросов в регистрах модуля.
Локальная память каждого процессора подключена к нему
через шину UNIBUS. Через эту же шину подключены перифе-
рийные устройства: накопители на магнитных дисках (в том чи-
сле на магнитных дисках с фиксированными головками), состав-
ляющие память второго уровня, и устройства ввода-вывода. Если
локальная память есть у каждого процессора, то память второго
уровня имеется только у части процессоров, причем ее комплек-
тация неодинакова.
Для системы разработано программное обеспечение с ядром
операционной системы Hydra.
ЗЙ8
Выбор варианта построения С. mmp на базе существующих
мини-ЭВМ ограничил возможности введения механизмов отказо-
устойчивости. Применяемые в системе модели PDP-11 и шина
UNIBUS не имеют средств обнаружения ошибок. Поэтому в об-,
щей памяти и в трактах обращения к ней реализован лишь про-
стой контроль на четность, так как применение более эффективных
методов только в одной части системы неоправдано. Межпроцес-
сорная шина не имеет аппаратного контроля. Фактически все
Рис. 7.12. Структурная схема системы С. mmp.
функции контроля и восстановления осуществляются программно,
причем в С. mmp такой подход дает хорощие результаты. Тща-
тельный контроль осуществляется в целях сохранности целост-
ности программного обеспечения.
В целом система после приработки оказалась достаточно на-
дежной: на основе помесячной статистики время работы Между
отказами экспериментальной системы с учетом всех* видов оши-
бок, приводящих к выходу из строя системы, составляет, в сред-
нем 6—15 часов. При этом время простоя после отказа лишь
немного превышает 5 минут, причем вмешательство оператора
практически не требуется вследствие автоматической повторном
загрузки системы (С. mmp не имеет оператора). Матричный ком-
389
мутатор — самое сложное устройство системы — оказался, неожи-
данно, одним из наиболее надежных устройств.
Таким образом, в С. mmp достигнутая надежность обеспечена,
в основном, за счет применения отработанных серийных компо-
нент аппаратуры, за счет простоты структуры, тщательного вы-
полнения системы и применения программных механизмов отка-
зоустойчивости (в ядре операционной системы);
Систему С. mmp можно отнести к классу МКМДС/ВсОрПк
(см. рис. 2.1), если не учитывать различие между моделями
PDP-11/20 и PDP-11/40 и отсутствие общего доступа к перифе-
рийным устройствам.
Рассмотрим теперь систему Ст*, следуя [132, 372, 373, 415].
Основной целью разработки Ст* было создание эксперимен-
тальной структуры со многими процессорами, которую можно
было бы использовать для исследования вариантов организации
многопроцессорных систем. Необходимая для экспериментов гиб-
кость Ст* обеспечивается за счет микропрограммных контролле-
ров межпроцессорной связи.
Работы над созданием системы Ст* на базе БИС были нача-
ты в 1972 г., причем предполагалось создать 100-процессорную
систему. Разработка окончательного варианта системы была от-
ложена до появления в 1975 г. сравнительно дешевой микро-ЭВМ
LSI-11 фирмы Digital Equipment. Учитывая опыт эксплуатации
С. mmp, при разработке Ст* большое внимание уделено вопро-
сам надежности и .поддержки операционной системы, а также
средствам для облегчения процесса программирования. Кроме
этого, предусматривалось обеспечение незаметности для пользо-
вателей процесса восстановления после ошибок и оперативности
обслуживания без потери производительности.
В 1977 г. в университете Д{арнеги-Меллона введена в эксплуа-
тацию 10-процессорная система Ст* (рис. 7.13), причем к концу
1978 г. предусматривалось ее расширение до 50-процессорной
системы. В. дальнейшем в перспективных системах Ст* предпо-
лагается использование более совершенной элементной базы. Сле-
. дует отметить, что размеры системы, в принципе, не имеют огра-
ничений, а конфигурацию и связи системы можно формировать
в соответствии с конкретными применениями. Структура связей
допускает совместное* использование ресурсов и взаимодействие
большого числа недорогих вычислительных модулей, которые
предполагается выпускать серийно. В системе нет критического
ресурса, потеря которого приводила бы к отказу системы, при-
чел* неисправные компоненты можно отключать из рабочей кон-
фигурации при помощи механизма отображения адресов.
Многопроцессорная система Ст* состоит из вычислительных
модулей> Cm (Computer Module), каждый из которых содержит
серийный микропроцессор LSI-И производительностью в 170 ты-
сяч операций в секунду, программно совместимый с PDP-11,
стандартную шину LSI-11, серийную местную память емкостью
390
28 К слов, серийные устройства ввода-вывода, а также местный
коммутатор, разработанный и построенный в университете Кар-
неги-Меллона (на рис. 7.13 один из вычислительных модулей
изображен более подробно»). В целях подключения местного ком-
мутатора между процессором и шиной процессор LSI-11 несколь-
ко модифицирован. '
Рис. 7.13. Структурная схема системы Cm*. ВМ — вычислительный модуль.
Основная память системы представляет собой совокупность
устройств местной памяти вычислительных модулей, при ^этом
вся основная память потенциально доступна для непосредствен-
ной адресации каждому про»цессору. Обращениями процессора к
памяти, внешней по отношению к данному модулю, а также об*
ращениями к своей памяти из удаленных источников управляет
местный коммутатор. Он использует, информацию из своих таб-
лиц размещения сегментов для передачи запросов, поступивших
от своего процессора на доступ к памяти, либо на местную шину,
либо вовне модуля на контроллер преобразования адреса, а так-
же производит обращения к местной памяти по заявке контрол-
лера преобразования адреса независимо от процессора данного
вычислительного модуля. Механизм адресации на уровне процес-
сора не зависит от физического расположения элемента памяти,
к которому производится обращение.
К шине отображения адреса можно подключить до 14 вычис-
лительных модулей. Такие модули, их шина отображения и со-
ответствующий контроллер преобразования адреса образуют блок
системы Ст*. Вычислительный модуль соответствует первому
уровню иерархии структуры системы Ст*, а блок —второму
391.
уровню. Третий уровень иерархии структуры образуется соеди-
нением блоков при помощи межблочных шин, подключаемых к
контроллерам преобразования адреса, причем каждый контроллер
может сопрягаться с двумя такими шинами. Система Ст* может
содержать произвольное число блоков, причем конфигурация свя-
зи между ними может быть различной и выбирается исходя из
требований приложений. Для блока, входящего в систему, нали-
чие прямой связи при помощи межблочной шины с каждым дру-
гим блоком системы не является обязательным.
Таким образом, контроллеры преобразования адреса не только
объединяют вычислительные модули в блоки, но и обеспечивают
объединение блоков в систему. Эти контроллеры, разработанные
в , университете Карнеги — Меллона, представляют собой микро-
программные процессоры с временем цикла в 150 нсек и с пе-
резаписываемой управляющей памятью емкостью 2 К X 80 раз-
рядов. Совокупность контроллеров образует гибкую распределен-
ную структуру коммутации процессоры — память системы Ст*.
Каждый контроллер управляет одним блоком модулей и осу-
ществляет полный контроль над процессорами и памятью данного
блока. Он осуществляет также обработку обращений к внешней
памяти от модулей своего блока и организацию связи с местными
коммутаторами данного блока и контроллерами других блоков,
включая разрешение конфликтов. В организации контроллеров
используется магистральный принцип обработки.
Совместное использование группой модулей одного контролле-
ра дает выигрыш в числе кристаллов, обеспечивает значительную
гибкость и производительность системы при относительно неболь-
шой стоимости контроллеров по сравнению с суммарной стоимо-
стью большого числа вычислительных модулей.
Адреса, поступающие в контроллер от внешнего процессора,
отображаются этим контроллером в, адреса физической памяти.
Сегментированное виртуальное адресное пространство системы
Ъмеет емкость 228 байт с не более чем 2,в сегментами разного раз-
мера, не превышающего 4 К-байт. Собственно процессоры гене-
рируют 16-разрядные адреса. Система адресации обеспечивает
значительную поддержку операционной системе при коммутации
сигналов управления и передаче сообщений' между процессорами.
Структура межпроцессорных связей в Ст* значительно более
экономна, чем, например, в С. mmp и обеспечивает объединение
большого числа микропроцессоров в систему, причем устройства
памяти модулей как бы составляют одну общую большую память
для микропроцессоров всех модулей и представляются для про-
граммиста единой целой памятью. Однако, с точки зрения про-
изводительности системы память организована иерархически:
времена1 выполнения местных, внутриблочных и межблочных об-
ращений, составляют примерно 3, 9 и 26 мксек. Поэтому наибо-
лее высокая производительность системы достигается при обра-
щениях процессоров'к местной памяти своих модулей, более низ-
892
кая производительность — при обращениях к памяти других мо-
дулей данного блока и еще более низкая — при обращениях к*
памяти других блоков. Следует отметить, . что за исключением
шины местной памяти, вся связь в системе осуществляется при
помощи пакетной коммутации, т. е. шины предоставляются толь-
ко на время, необходимое для передачи данных.
Таким образом, в целях наиболее эффективного использования
системы Ст* возможно большая ?асть программы и данных,,
с которыми работает каждый процессор, должна храниться в
местной памяти данного модуля, т. е. в структуру системы Ст*
заложено предположение о локальности программ. Предваритель-
но проведенные измерения для различных типов применения си-
стемы показали, что отношение чиСла обращений к местной па-
мяти к числу обращений ко всей общей памяти реально достигает
величины 0,9.
В реализованном экспериментальном варианте Ст* (рис. 7.13)
10 микропроцессоров LSI-11 объединены в три блока из 4, 2 и 4
модулей. Для выполнения специальных операций управления
контроллерами преобразования адреса используются два дополни-
тельных микропроцессора LSI-И, не входящие в состав Ст*. Они
обеспечивают выполнение таких вспомогательных функций, как
загрузка и отладка микропрограмм, а также обеспечивают функ-
ции диагностики аппаратуры. Каждый процессор вычислитель-
ных модулей связан при помощи последовательного канала через
общий мультиплексор с машиной-диспетчером PDP-11/10, на ко-
торой реализована простейшая операционная система. К этой
машине подключены терминалы непосредственной связи с дис-
петчером, накопители на магнитной ленте.и, через последователь-
ный канал,—буферный процессор PDP-H/4Q, К буферному про-
цессору, в свою очередь, подключены буферные терминалы и дру-
гие ЭВМ университета Карнеги — Меллона.
Пользователи удаленных терминалов имеют возможность за-
гружать свои программы из накопителей на магнитных лентах
в процессоры модулей, запускать и останавливать процессоры и
осуществлять с ними непосредственную связь.
В исходное программное обеспечение, кроме упомянутой опе-
рационной системы (фактически, ядра операционной системы),
входят автономно работающие типовые программы оценки произ-
водительности, система, обеспечивающая выполнение программ
па подмножестве языка алгол 68, а также прикладные программы
для распознавания речи.
Перейдем к системе С. vmp (Computer, voted multi-processor)
[372, 3731.
Исследования с целью изучения отказоустойчивых структур,
предназначенных для условий промышленного применения, были
начаты в 1975 г. При этом были поставлены задачи сохранения
работоспособности системы при устойчивых и перемежающихся
отказах, реализации принципа независимости программного обес-
395
печения с точки зрения пользователя от механизмов отказоустой-
чивости, обеспечения возможности работать в реальном масшта-
бе времени, обеспечения модульности построения для сокращения
времени простоя, применения серийных компонент и, наконец,
осуществления динамического изменения соотношения между
производительностью и надежностью.
В соответствии с принципами независимости программного
обеспечения и модульности построения системы было выбрано
голосование на уровне шин в качестве основного механизма от-
казоустойчивости. В системе имеются три процессора LSI-11 и
три устройства памяти, соединенных при помощи -шин через
схему голосования (рис. 7.14). Голосование осуществляется па-
раллельно по разным разрядам и происходит при каждом обраще-
нии процессоров к шине для передачи или приема информации,
т. е. только в том случае, когда через схему голосования прохо-
дит информация. Схема голосования осуществляет сравнение
информации в трех соответствующих шинах, для чего память не
требуется. Любые рассогласования сигналов между процессорами
не попадают в память и наоборот, т. е. рассогласование обнару-
живается и корректируется прежде, чем оно успевает распростра-
ниться в системе.
В системе предусматривается также режим независимой рабо-
ты процессоров, при переходе к которому обеспечивается повы-
шение производительности за счет снижения отказоустойчивости
(работа без голосования). В таком режиме производительность
процессоров совпадает с производительностью стандартных
LSI-И, а при переходе к режиму с голосованием произво-
дительность спижается за счет процесса голосования примерно
на 14%.
В качестве црограммного обеспечения С. vmp используется
стандартная операционная система RT-11 на гибких магнитных
дисках, предназначенная для работы в реальном масштабе вре-
мени. При этом пользователям система С. vmp представляется
обычной однопроцессорной ЭВМ LSI-11 со стандартным програм-
мным обеспечением.
По оценкам срёдняя наработка до выхода из строя системы
С. vmp должна быть не менее 1000 часов. Фактически, по мере
приработки системы, надежность С. vmp приближается к этому
уровню. Так, например, по ежемесячным данным с 1 августа
1977 г. по 30 апреля 1978 г. средняя наработка до выхода из
строя изменялась от 35,5 часов для худшего случая до 704,7 часа
для лучшего случая (без учета выхода из строя по вине пользо-
вателей, вследствие программных ошибок и повторных отказов
из-за одной и той же причины).
При большинстве отказов потребовалось мало усилий для вос-
становления работоспособности. В системе предусмотрены пять
уровней восстановления: 1) продолжить выполнение программы;
2) повторить программу; 3) повторить загрузку программы в
394
память; 4) установить процессоры в исходное состояние и повто-
рить загрузку программы; 5) устранить неполадки в аппаратуре.
Только в немногих случаях потребовалась фактическая установка
процессора в исходное состояние и лишь в нескольких случаях —
повторный пуск резидентного монитора.
7.3.5. Система COMTRAC [185]. Система COMTRAC (СОМри-
ter-aided TRAffic Control system) предназначена для управления
скоростными поездами для Японских национальных железных
дорог. Она применяется на важнейшей транспортной линии Япо-
нии — на новой железнодорожной линии Токайдо между ТокЯо
и Хакатой, о. Кюсю. Эта линия имеет следующие основные ха-
рактеристики: 1) протяженность — 1600 км; 2) число станций —
31; 3) общее число поездов — 1200, максимальное число поездов
на линии —200; 4) среднее число остановок поезда — И; 5) ко-
личество вариантов составов — 220; 6) число маршрутов, уста-
• навливаемых централизованно,— 700.
Наблюдение за работой и управление движением всех поез-
дов сосредоточено в главном центре управления на станции То-
кио. Функционирование линии обеспечивается штатом операто-
ров, использующих интерактивный режим работы с вычислитель-
ной системой. Это повышает оперативность вмешательства
оператора и упрощает переключение с машинного управления на
ручное при крайней необходимости и при возникновении не-
поладок.
Управление поездами и маршрутами осуществляется с 6 ча-
сов утра до 1 4аса ночи. Данные, получаемые с каждой станции,
характеризуются следующими параметрами: 1) число контроли-
руемых точек — 880; 2) число контролируемых поездов — НО;
3) количество данных для системы сигнализации — 730; 4) коли-
чество данных от путевых цепей — 1650; 5) количество данных
об отказах сигналов управления движением — 1380. Ввод этих
данных для наблюдения и управления поездами и оборудованием
станции осуществляется через каждые 3 секунды.
В системе COMTRAC объединены три управляющие машины
Н-700 фирмы «Хитати» (рис. 7.15). При нормальном функциони-
ровании две машины работают в режиме дублирования и пол-
ностью синхронизированы, а третья машина держится в резерве.
Сбор информации и планирование осуществляют две машины
Н-8450 фирмы «Хитати». При нормальном функционировании они
работают совместно в режиме разделения нагрузки. В случае
отказа одной из них другая обеспечивает возобновление работы
при любых видах сбора информации и планирования. Этц две
системы (управления и планирования) тесно связаны. Так, на-
пример, при отказе машины, осуществляющей сбор информации,
запись движения переписывается на магнитную ленту системы
управлений. Комплекс двух систем представляет собой отказоус-
тойчивую структуру. Повышение отказоустойчивости достигается
также избыточностью в устройствах ввода-вывода.
396
Рис. 7.15. Упрощенная структурная схема системы COMTRAC. ЦП — центральный процессор,
МБ — магнитный барабан, Пи — переключатель интерфейса, ЦУД — центральное управление
движением, лДС — контроллер дублированной системы, ОД — блок обмена данными.
Я периферийным
' устройствам
Таким образом, высокая надежность системы управления до-
стигается благодаря использованию трех машин Н-700. Собствен-
но дублирование двух из них со сравнением результатов дает
высокую надежность, а использование третьей машины в каче-
стве резервной улучшает готовность и ремонтопригодность систе-
мы, а именно, обеспечивает: 1) поддержание в действующем
состоянии дублированной системы путем замены отказавшей ма-
шины на резервную; 2) проведение наладки вне контура управ-
ления работающей системы как в одномашинном, так и в дубли-
рованном режиме; 3) добавление, удаление или изменение частей
программы с помощью резервной машины при работе системы
без ее остановки. Для достижения этих целей к управлению кон-
фигурацией системы предъявляются требования высокой аппа-
ратной и программной надежности, независимости подсистем
управления конфигурацией и быстрой реакции во время переклю-
чений и восстановления.
Три машины системы управления объединены в полностью
симметричную систему с идентичными функциями и идентичным
программным обеспечением машин. Каждая из машин может
находиться в одном из трех состояний: 1) управление в опера-
тивном режиме; 2) резерв; 3) работа вне контура управле-
ния. Всего трехмашинная система имеет 39 функциональных
состояний.
В системе COMTRAC приняты меры по исключению таких
состояний, когда она полностью теряет способность к управлению.
Эти меры основаны на процедурах частичного отхода при отказах
.аппаратуры и программного обеспечения. При отказах аппара-
туры полагается, что неисправность в одной из трех* машин си-
стемы управления есть отказ всей машины. Периферийные уст-
ройства разрабатываются так, чтобы их отказы не влияли на
машины, а работа устройств ввода-вывода, используемых в опе-
ративном режиме, организуется таким образом, чтобы их отказы
не влияли на систему. Процедура частичного отхода при отказах
программного обеспечения строится по принципу исключения
' поврежденных областей при обнаружении отказан продолжения
работы с использованием оставшихся функций системы без ее
отключения в целом. Программная реализация частичного отхода
выполнена так, что огход можно осуществить для каждой функ-
ции Программного обеспечения.
Применяемая в системе управления машина Н-700 имеет
27 команд, а длина машинного слова — 16 разрядов, объем памя-
ти на сердечниках —128 К слов, объем внешней памяти —
2 X 768 К слов. Программа управления в реальном масштабе вре-
мени занимает 420 К слов памяти (без учета служебных
программ). -
РаботА системы вначале была нестабильной из-за неопытности
операторов и,дефектов аппаратуры и программ. При завершении
отладки системы в 1975 г. ее работа постепенно переходила от
398
стадии тяжелых отказов к стадии стабильного функционирования.
В 1975 г. коэффициент готовности составил в среднем 99,97%,
а при переходе в стабильный режим, начиная с 1976 г., он стал
равным в среднем 99,99%. Коэффициент готовности дублирован-
ной системы превысил к 1976 г. величину 99,9%.
Весьма показательными являются отказы системы (за три го-
да система отказала 7 раз). В 1975 г. было пять отказов системы,
а в 1976 г. и в 1977 г.— по одному отказу, причем пять из этих
семи отказов вызваны ошибками программного обеспечения,
один — дефектом аппаратуры, и еще один, предположительно,
также дефектом аппаратуры. Последние по времени три отказа
произошли из-за программных ошибок, причем два из них —
из-за простой ошибки кодирования, которую трудно найти при
отладке программ. Эта ошибка была выявлена только после того,
как был выполнен рейс поезда вне расписания. С сентября
1977 г. по июль 1978 г. система работала вообще без перебоев
практически 100% времени.
Если рассматривать отказы каждой из трех составляющих
подсистем системы управления, то можно отметить общую тен-
денцию уменьшения числа отказов по отношению к 1975 г., при-
чем в каждом году большинство отказов приходится на аппарату-
ру и малое число отказов — на ошибки оператора.. Последнее
обусловлено наличием хороши* инструкций по эксплуатации и
высоким уровнем автоматизации системы.
Таким образом, отказы ЭВМ *в значительной степени компен-
сируются механизмом отказоустойчивости системы, а отказы
программного обеспечения компенсируются в меньшей степени.
Вероятность отказа системы в целом из-за программных ошибок
выше по сравнению с вероятностью отказа из-за дефектов аппа-
ратуры. Поэтому программному обеспечению необходимо и в
дальнейшем уделять большое внимание;
7.3.6. Системы FTMP и SIFT. Разработки систем FTMP и
SIFT, начатые в 60-х годах и основанные на двух различных
подходах к обеспечению отказоустойчивости многопроцессорных
систем, проводятся в расчете на их использования на пассажир-
ских самолетах в качестве управляющих вычислительных систем.
Обе системы находятся в стадии реализации. Они должны обес-
печить сверхпадежную работу: вероятность отказа системы не
должна превышать 10“9 при десятичасовом полете [3].
Рассмотрим сначала систему FTMP (Fault Tolerant Multipro-
cessor) [420], разрабатываемую Лабораторией им. Дрейпера. Со-
здание опытного образца системы предусмотрено в 1979 г. Кроме
применения на пассажирских самолетах, система FTMP предназ-
начается для решения задач управления другими транспортными
средствами, а также для управления технологическими процес-
сами, системами жизнеобеспечения и в других приложениях, где
нарушение управления приводит с высокой вероятностью к чело-
веческим жертвам или к материальным потерям и где техниче-
399
ское обслуживание проводится периодически или с за-
держками.
Системы для указанных приложений должны обладать высо-
кой живучестью в условиях возникновения многократных неис-
правностей, не обязательно происходящих одновременно. Исправ-
ление ошибок должно выполняться без повтора прогона програм-
мы, например, путем маскирования ошибок. Все ресурсы системы,
должны индивидуально проверяться в процессе работы вычисли-
тельной системы. Наиболее действенным способом выполнений
таких требований является построение многопроцессорных или
многомашинных систем, по крайней мере, с трехкратным резер-
вированием.
В FTMP принята одна из разновидностей схемы тройного
модульного резервирования, при которой создается такой фонд
резервных элементов, что любой элемент из параллельных троек
элементов может быть заменен любым элементом из резервного
фонда. При этом применяется троекратное резервирование всех
ресурсов, необходимых для работы системы, а также предусмат-
ривается произвольное число дополнительных устройств в сово-
купности с таким аппаратным и программным обеспечением,
которое необходимо для управления резервированием, т. е. для
обнаружения и локализации неисправностей, проведения рекон-
фигурации и восстановления. В системе обесценивается плавное
изменение характеристик при возникновении неисправностей.
Так, например, в разрабатываемых самолетах предусматривается
осуществление наиболее важных функций управления при мини-
мальных ресурсах. Это позволяет ресурсам для этих функций
обеспечить наивысший приоритет при сокращении фонда ресур-
сов вследствие отказов.
В FTMP аппаратно реализована полная синхронизация и ап-
паратно осуществляется поразрядное голосование для сравнения
всех сообщений, что позволяет применить мажоритарный прин-
цип и изменять назначение модулей, используя их либо в составе
различных троек модулей, либо в качестве резерва. Кроме этого,
конфигурацию модулей можно изменять в целях диагностики
места неисправностей, для проверки механизма реконфигурации,
для включения запасного оборудования в рабочую конфигурацию
системы в целях проверки и восстановления и в связи с отключе-
нием неисправных модулей.
Структурная схема системы FTMP изображена на рис. 7’16.
В отличие от обычных многопроцессорных систем все шины связи
памяти с интерфейсом доступа зарезервированы, а число факти-
чески используемых модулей в три раза больше необходимого,
причем добавлено еще некоторое число запасных модулей. В нор-
мальном режиме работают тройки модулей и тройки шин. Каждая
тройка мцдулей образуется объединением трех одинаковых моду-
лей. Одна тройка линий шины подключена к одному модулю па-
мяти или интерфейсу. Каждый модуль каждого типа может полу-
400
чать данные от всех подключенных к нему линий шины. Он
содержит решающее устройство для выработки версии о правиль-
ности поступающих данных. Три линии, по которым в данный
момент модуль получает независимые наборы данйых, соединены
со схемой голосования данного модуля, образуя элемент тройного
модульного резервирования.
В состав каждого процессора, модуля памяти и блока доступа
к вводу-выводу включены блоки защиты шины для управления
состоянием связанных с ними модулей (выбор режима питания,
Шины
доступа
к памяти
п
Модуль памяти
„ а 2
Модуль памяти
оЗш
63Ш
63UM3H
блок процессора
инзшламяти
блок процессора
и наш-памяти
интерфейсу
блон процессора
и нэш-памяти
\бД№ I
К системе/От системы
#системе/От системы
Рис^7.16. Упрощенная структурная схема системы FTMP. ВИШ — вентили
изоляции шины, БЗШ — Ълыи защиты шины, БЦВВ —-блок доступа к вво-
ду-выводу.
троек шин модулей памяти и тракта передачи, а также выбор не-
которых схем самопроверки). При образовании любой конфигу-
рации системы все модули подключаются через блоки защиты,
что обеспечивает высокую гибкость системы реконфигурации и
защиту против поломки рабочих модулей, передающих инфор-
мацию.
Таким образом, все модули и шины организованы в тройки,
причем в каждый момент времени существует большое число
троек процессоров и модулей памяти, а также одна тройка шин
памяти и одна тройка шин интерфейса. Каждая тройка процессо-
ров рассматривается с функциональной точки зрения как один
процессор, при этом несколько таких процессоров могут? работать
параллельно. Каждая тройка модулей памяти рассматривается
как страница памяти, при этом несколько таких страниц могут
существовать одновременно, но только * одна из них в каждый
момент может быть связана с некоторой тройкой процессоров.
Главное достоинство резервирования в FTMP состоит в том,
что неисправные тройки перестраиваются в новые тройки, в ко-
26 Б. А. Головкин 401
торых они снова могут маскировать неисправности, т. е. осуще- >
ствлять восстановление способности к отказоустойчивости.
Опытный образец системы FTMP, по проекту, состоим из со-
единенных между собой наборами шин 10 идентичных линейных
заменяемых блоков, каждый из которых содержит по одному
процессору, модулю кэш-памяти, модулю основной памяти,
устройству входа в память для ввода-вывода и генератору тактог
вых импульсов, а также содержит соответствующие периферий- (
ные схемы управления и обеспечения. В работе может участво-
вать одновременно до трех процессорных троек, использующих 9
из 10 модулей в составе процессор — кэш-память. Из 9 модулей
памяти можно сформировать до трех троек модулей, оставляя
десятый модуль памяти в качестве запасного. Адресное прост-
ранство каждой тройки и трех троек модулей памяти рассчита-
но на 16 К и 48 К слов соответственно. Программное обеспе-
чение в варианте для демонстрации содержит исполнительную •
программу для осуществления простейшей диспетчеризации и
прикладные программы.
Перейдем к системе SIFT (Software Implemented Fault To-
lerance) [405], разрабатываемой Стэнфордским международным
исследовательским институтом. На первом .этапе разработки сис-
темы были определены основные требования к системе и сфор-
мулирована концепция ее построения. На втором этапе было раз-
работано аппаратное и программное обеспечение системы и
составлено точное техническое задание на синтез системы. На
третьем еще не завершенном этапе создается экспериментальный
образец системы, причем построение и проверка этого образца
предусмотрены на 1979 г. Продолжается начатая ранее работа
над доказательством корректности системы. ;
Основной принцип построения системы SIFT, нашедший свое j
отражение в ее названии, состоит в обеспечении отказоустойчи- 4
вости программными способами, а не аппаратными (как, напри- s
мер, в FTMP). При этом предусматривается обнаружение и кор-
рекция ошибок, диагностика неисправностей, перестройка систе-
мы и предотвращение нежелательного влияния неисправного ;
блока на систему в целом. Отказоустойчивость достигается при
помощи параллельного выполнения каждого задания нескольки-
ми модулями. 1
Структурная схема аппаратного обеспечения системы SIFT
изображена на рис. 7.17. Вычисления выполняются основными j
модулями обработки- данных, каждый из которых содержит про- л
цессор и память, соединенные обычным широкополосным каналом 1
связи. Каждый такой модуль подключен К/ многошинной системе j
связи. Защита нормально работающего модуля от воздействия
неисправных модулей или шины осуществляется при помощи
методов локализации неисправностей. Структура процессоров и
устройств памяти ввода-вывода близка к структуре процессоров
и устройств памяти основных модулей обработки, но вычисли-
402
тельная мощность и емкость памяти первых значительно меньше.
В системе не используются какие-либо предположения о видах
отказов, причем различаются лишь исправные и неисправные
блоки. Основной метод обнаружения, ошибок сводится к выявле-
нию искаженных данных, поэтому конкретная причина, вызвав-
шая искажения, не имеет значения. Локализация неисправностей
обеспечивается при помощи специально разработанной избыточ-
ной системы шинных соединений блоков обработки. Процедуры
обнаружения и анализа оши-
бок, а также реконфигурации
системы возложены на про-
граммное обеспечение. Бло-
ками, на уровне которых ве-
дется обнаружение неисправ-
ностей и реконфигурация, яв-
ляются модули (процессоры,
устройства памяти) и шины.
В системе не используются
локальные методы отказоус-
тойчивости, такие как коди-
рование с обнаружением в
исправлением ошибок в па-
мяти, дак как их примене-
ние, хотя и возможно, но
приведет в данном случае
лишь к незначительному уве-
личению надежности.
Работа системы SIFT op?
ганизуется по принципу вы-
полнения заданий, каждое из
которых разбивается па по-
следовательность итераций.
Выходные данные некоторой
итерации являются входны-
ми данными для следующей
итерации. Каждая итерация
органов управления
Рис. 7.17. Упрощенная структурная схе-
ма системы SIFT.
выполняется независимо несколькими модулями, причем результа-
ты выполнения отсылаются в память данного модуля. Перед вы-
полнением следующей итерации процессор определяет правильные
значения результатов предыдущей итерации, сравнивая резуль-
таты, полученные каждым процессором (обычно, голосованием по
методу двух совпадений из трех сравниваемых результатов). Ите-
ративный характер v выполнения заданий позволяет уменьшить
число голосований, сокращает поток данных в шинах и позволяет
нежестко синхронизировать работу процессоров (примерно с точ-
ностью до 50 мксек).
Система SIFT рассчитана максимум на 8 основных процессо-
ров и 8 устройств памя1и, 8 процессоров и 8 устройств памяти
26ф
403
ввода-вывода, а также на 8 шин и 8 внешних интерфейсов. В ка- 1
честве основного процессора используется 16-разрядная совре- ;
менная малая ЭВМ на БИС В D micro X, разработанная фирмой ]
Bendix для применений на борту, имеющая производительность в
500 тыс. операций в секунду и оперативную память емкостью в ,
32 К слов. Устройство основной памяти также 16-разрядное, его
емкость — 32 К слов. В качестве процессоров ввода-вывода ис-
пользуются хорошо известные микропроцессоры Intel 8080.
Программное обеспечение содержит исполнительные и при- ;
кладные программы. При создании программного обеспечения j
. широко применялись методы структурного программирования. |
Требования к исполнительным программам* строго сформулирова- J
вы на языке special. Они используются при доказательстве кор- 1
ректности системы SIFT с помощью иерархической системы мо- |
делен, последний уровень которой представляет собственно систе- 1
му SIFT. ' 1
7.3.7. Вычислительная система космического корабля «Шаттл»
11076]. Вычислительная система для космического транспортного ’
корабля многоразового использования «Шаттл» (Shuttle — чел-
нок) разрабатывается фирмой IBM с 1972 . г. Основным требова-
нием к системе является требование автоматического восстанов- i
ления и гарантированного получения правильных результатов до j
и после первых двух отказов, в том числе подобных друг другу, i
Система строится как многомашинная па базе серийных модифи- i
цированных ЭВМ АР-101 фирмы IBM, имеющих встроенный
контроль и программы самопроверки. ;
Если требуется только обнаруживать отказ, то достаточно ,
иметь две ЭВМ в системе. Однако, если требование заключается
в получении гарантированно правильных результатов после отка- .
за, то в многомашинной системе должны быть три ЭВМ, чтобы ;
идентифицировать отказавшую ЭВМ и игнорировать результаты '
ее работы. Минимум четыре машины необходимы, если система
должна продолжать вырабатывать правильные результаты после <
двух отказов. Именно такое число ЭВМ выбрано для работы в :
наиболее ответственных фазах полета корабля «Шаттл», я всего
в состав вычислительной системы этого корабля входят пять ЭВМ •'
(рис. 7.18). . I
Центральный процессор и процессор ввода-вывода каждой Я
ЭВМ используют общую оперативную память емкостью в 64 К Л
32-разрядных слов. Л
Упомянутые выше четыре ЭВМ составляют так называемый Л
избыточный набор ЭВМ. Они идентично запрограммированы для Л
работы на критических фазах полета, тогда как пятая ЭВМ про- Я
граммируется независимо. Ее можно рассматривать невидимом} Я
в качестве дубля первых четырех ЭВМ в случае, когда их про* Я
граммы1 генерируют ошибку (единственная ошибка в идеи- Я
тичном программном обеспечении четырех ЭВМ избыточного на- Л
бора делает систему всех этих ЭВМ некорректной). Определение Я
•404 /Я
б)Избыточная структура Зля особо ответственных
этапов палета
Рис. 7J8. Структурная схема вычислительной системы космического кораб-
ля «Шаттл»,
1
правильных результатов вычислений и выявление-ошибок в ре-
зультатах вычислений основано на принципе голосования, для
выполнения которого привлекаются сами ЭВМ и используется
межмашинный обмен. *
Связи между элементами системы осуществляются через
28 последовательных шин, разбитых на 7 функциональных групп
(см. рис. 7.18а). При этом каждая ЭВМ связана с 23 общими раз- 1
деляемыми шинами и 1 индивидуальной шиной: 1) 5 шин —для 1
межмашинного обмена; 2) 2 шины—для обмена с массовой па- J
мятью; 3) 4 шины — для обмена с дисплеями; 4) 2 шины —для J
работы с полезной нагрузкой; 5) 2 шины — для обмена при пред- I
стартовых операциях; 6) 1 шина — инструментальная для работы J
по приборам (индивидуальная шина); 7) 8 шин —для работы на 1
критических фазах полета. Каждая ЭВМ, работая под управле- 1
нием программного обеспечения, может управлять некоторыми 1
или всеми этими шинами. Фактически, однако, каждая ЭВМ уп- 1
равняет предварительно намеченным подмножеством шин. 1
Для особо ответственных этапов полета ко входам каждой из 1
четырех ЭВМ избыточного набора подключены четыре шины 1
(рис. 7.186), причем каждая ЭВМ управляет одной из шин и 1
обеспечивает прием из нее информации и только принимает ин- ]
формацию (без функций управления) из трех других шин так, J
что каждая из четырех шин управляется одной из ЭВМ. Таким ]
образом, все ЭВМ избыточного набора получают данные от дат- |
чиков и размещают их в своей памяти. После обработки резуль- 1
таты проходят процедуру голосования.
Единая точка зрения на структуру рассматриваемой вычисли-
тельной системы еще не выдаботалась. Так, например, построение \
этой системы на базе машин с минимумом соединений для обме-
на данными с целью сравнения при параллельной работе четырех
машин в режиме избыточности рассматривается в [3] как шаг
назад по сравнению с отказоустойчивой ЭВМ ракеты Saturn*). *
Отмечается, что ограниченная возможность сравнения и отсут-
ствие аппаратурного обнаружения неисправностей предъявляют
большие требования к программному обеспечению системы и ста-
вят под вопрос возможность реального обеспечения отказоустой-
чивости в разрабатываемой системе.
7.3.8. Библиографическая справка. Концепция, эволюция и. ;
основные направления дальнейшего развития отказоустойчивых Л
вычислительных систем, а также соответствующие примеры таких я
систем представлены в 13] и в предшествующем цикле работ [479, Я
482, 483, 485-490]. Я
Ряд ранних американских вычислительных систем повышен- Я
ной надежности, основанных па многомашинном принципе и Я
*) ЭРМ наведения ракеты Saturn V имела тройную избыточность для Я
защиты каждого из последовательных центральных процессоров, состоя- 9
щих из семи модулей, задублированную ферритовую память с параллель- Я
ным доступом и другие средства отказоустойчивости [3]. Я
406 Я
предназначенных для систем ПВО североамериканского конти-
нента SAGE, системы раннего обнаружения баллистических ра-
кет BMEWS, системы контроля космического пространства
S PAD ATS, системы управления стратегического авиационного
командования США, системы управления воздушным движением,
систем управления полетом пилотируемых космических кораблей
по программам Mercury, Gemini и Apollo и некоторых других,
представлены в книге [1141.
Проблеме надежности многопроцессорных систем, в особенно-
сти, вопросам резервирования, включая конкретные структуры
дуальных и дуплексных систем (например, для BMEWS), боль-
шое внимание уделяется в книге 1280]. *
Ранние аэрокосмические вычислительные системы описаны в
[137]. В [117], наряду с другими, рассмотрены вопросы построе-
ния структур бортовых вычислительных машин, причем выделе-
ны структуры многопроцессорных систем. Обзор разработок бор-
товых вычислительных систем и примеры систем AADC, DAIS и
системы космического корабля «Шаттл», приведены в [428]. Обзор
методов построения космических бортовых вычислительных •сис-
тем и примеры систем орбитальной астрономической лаборатории
(ОАО), космического аппарата «Скайлэб», космического корабля
«Шаттл», JPL STAR и некоторых других представлены в [431].
В книге [165], посвященной надежности и контролю вычисли-
тельных систем, в отдельной главе рассматриваются многопро-
цессорные системы. В книге [281] и последовавшем за ней обзоре
[694] изложена концепция организации многопроцессорных, отка-
зоустойчивых вычислительных систем и приведены примеры от-
казоустойчивых систем SIRU и ACGN Массачусетского техноло-
гического института, EXAM фирмы Hamilton Standard, JPL
STAR, PLURIBUS и ее прототипа, Plessy System 250, С. тшр>
В книге [1229] и последовавшей за ней статье [1231] дан
анализ характеристик аэрокосмических вычислительных систем»
рассмотрены системы JPL STAR и AADC в качестве примеров
созданных и будущих универсальных бортовых систем и сделан
прогноз развития бортовых систем на период времени до 1990 г.
Данные прогноза потенциально возможной производительности
многопроцессорных высоконадежных самолетных систем для од-
нопроцессорной/четырехпроцессорной конфигурации следую-
щие*): 1980 г,— 10,6/37; 1985 г.-20/70; 1990 г.- 38,5/135 млн.
операций в секунду при оперировании с 32-разрядными словами.
Отмечается, что в реальных системах производительность может
быть в 2—3 раза меньше. Для космических бортовых вычисли-
тельных систем, с учетом более трудный условий их работы,
предсказывается более низкая потенциально возможная про-
изводительность: 1980 г.— 2,5/8,8; 1985 г.— 6,3/22; 1990 г.—
*) Основные положения расчета производительности для такого рода
прогнозов рассмотрены в п. 8.2.1.
407
14,4/51 млн. операций в секунду также для однопроцессорной/че-1
тырехпроцессорной конфигурации и 32-разрядных слов. |
Вопросам развития отказоустойчивых вычислитвшрых систем 1
для космических аппаратов посвящена статья 16141. 1
Многопроцессорные и многомашинные системы рассмотрены-!
в [1128, 1145] с точки зрения их применения в больших техниче- Я
ских системах и в системах управления технологическими про- J
цессами в реальном масштабе времени. Краткий обзор нескольких 1
отказоустойчивых систем сделан в [574, 715]. Многопроцессорные '
и многомашинные вычислительные системы на базе микропро-
цессоров с разделенными функциями, предназначенные для ра-
ботыв реальном масштабе времени (в основном, для управления*^
технологическими процессами), рассмотрены ji обзоре [1181]: ’
описаны методы построения таких систем, приведен ряд приме- j
ров, изложены вопросы защиты от ошибок и диагностики систем <
и другие вопросы. Высоконадежным системам посвящена статья,
обзорного характера [840], в которой обсужден принцип безава- *
рийности (см. также предыдущую работу) и выделены задачи4'
управления резервированием многомашинных систем, и задачи
надежности программного обеспечения процессов в реальном
масштабе времени.
Анализ аппаратного и программного способов внесения избы-
точности в целях устойчивости к отказам вычислительных систем -я
выполнен в [528]. Выделяются три метода внесения избыточно- 3
сти: аппаратный, программный и временной. При этом первый 3
подразделяется на метод статического внесения избыточности Я
(например, тройное резервирование с голосованием) и метод ди- Я
намического внесения избыточности (резервирование с «холод- Я
ным» и «горячим» резервом и с идентификацией отказа). Про- Я
граммная избыточность предполагает наличие дополнительного Я
программного кода, а временная избыточность предполагает по- Я
вторение операций, в которых были обнаружены ошибки, путем Я
перезапуска программ от контрольных точек. Анализ отказоус- Я
тойчивости выполнен в обзоре [1198]. Прикладные аспекты тео- Я
рии отказоустойчивых вычислительных систем (анализ, проекти- Я
рование и моделирование) изложены в [1111]. Краткий библио- Я
графический обзор аппаратного и программного обеспечения "Я
высокой надежности применительно к структурам параллельных д
вычислительных систем содержится в [110, 111]. 3
Богатый материал по устойчивости вычислительных систем
к отказам содержится в трудах ежегодного международного сим-Я
позиума по этой проблеме, проводимого с 1971 г. [1091—-10981. Я
Надежности вычислительных систем посвящен выпуск сборника.Я
[857]. Упомянутая в начале настоящей библиографической справ-1Я
ки статья [3] явдяется вводной в тематическом выпуске журнала Я
[398], цосвященном отказоустойчивым системам. В вводной статье Я
дается общее представление о проблеме, а в других статьях вы- Я
пуска описываются отказоустойчивые системы PLURIBUS, Я
408 1
COMTRAC, C. mmp, Cm*, C. vmp, FTMP, SIFT, JPL STAR a
UDS, рассмотренные в настоящем п. 7.3, а также описывается
система ESS.
После проведения в 1953—1959 гг. экспериментальных разра-
боток, в 1959—1965 гг. была создана электронная система ком-
мутации ESS № 1 (Electronic Switching System) фирмы Bell
Telephone [6681 на базе быстродействующих локальных процессо-
ров, явившаяся важным шагом на пути от электромеханических
телефонных систем коммутации к электронным системам и цент-
рализованному программированному управлению. Суммарное вре-
мя простоя этой системы должно быть не более 2 часов за* 40 лет
эксплуатации в условиях, допускающих замену неисправных ком-
понентов вручную. Все ответственные части этой системы про-
дублированы, а для обнаружения, локализации и идентификации
неисправных компонентов очень широко применяется программ-
ное обеспечение, а также некоторая специализированная аппара-
тура. Развитие отказоустойчивых электронных систем коммутации
продолжается и в настоящее время 1389]. Они являются, вероят-
но, самыми многочисленными и наиболее широко используемыми
отказоустойчивыми цифровыми системами [31. Описание систем
ESS, а также JPLSTAR и PLURIBUS содержится в обзоре [11151.
Упомянутые выше отказоустойчивые системы, которые рас-
смотрены в настоящем 7.3, представлены в следующих работах:
JPL STAR-в [275, 361, 477, 478, 489, 481, 786, 1133], UDS-
в [361, 664, 928, 929, 1122, 11231, PLURIBUS £ ее прототип —
в [201, 559, 785, 814-816, 899, 1019, 1045-1048, 1129, ИЗО],
С. mmp - в 1364, 372, 373, 523, 721, 749, 751, 880, 966, 1008, 1019,
1267—12711, Ст*-в [132, 372, 373, 415, 525, 748, 750, 819, 873,
1166, 1205, 1206], С., vmp —в 4372, 373, 1165], COMTRAC -
в 1185, 854,855, 10511, FTMP-в [420, 838, 8391, SIFT-в 4405,
1252, 1253]. В 7.3 рассмотрены также вычислительная система
TANDEM 16 и вычислительная система космического корабля
«Шаттл». Эти системы представлены в [713, 745] и в [614, 685,
960,982,1034,1075, 1076, 1135, 1158, 1169] соответственно. В при-
веденных перечнях ссылок не повторяются ссылки на те работы,
в которых содержатся данные о перечисленных здесь системах и
которые упомянуты выше в настоящей библиографической справке.
Список отказоустойчивых вычислительных систем может быть
продолжен/' Перечислим некоторые ранние системы такого рода:
центральная система' обработки данных для системы резервирова-
ния билетов «Сирена» [501, дуплексная вычислительная система
для системы резервирования билетов SABRE (литература указана
в 1.3), дуплексная вычислительная система для упомянутой выше
системы BMEWS [667, 980], вычислительная система для упомя-
нутой выше системы SAGE (литература указана в п. 1.3), само-
летные, космические и другие высоконадежные системы [638, 666,
754, 836, 841, 932, 1141, 1152]. Известны также процессор обра-
ботки данных и система хранения данных для орбитальной астро-
409
комической обсерватории ОАО (Orbiting Astronomical Observatory)
(см., например, [932]), созданные в период 1961—1965 гг., ЭВМ
наведения для ракет-носителей Saturn IB и Saturn V в соответ-
ствии с программами полетов Apollo и Skylab [3] и другие.
Перечислим теперь некоторые отказоустойчивые системы
1970-х годов. Отказоустойчивый цифровой управляющий комплекс
со 100 %-м дублированием каждого функционального модуля опи-
сан в [234]. Он предназначен для использования в автоматических
телефонных станциях, центрах коммутации и в других системах
реального времени. Особенности структуры управляющего комп-
лекса Для системы коммутации рассмотрены в предшествующей
работе [232]. Организация дуплексной системы для автоматиче-
ской телефонной станции рассмотрена в [2]. Операционная систе-
ма для управления дуплексной вычислительной системой в реаль-
ном масштабе времени описана в [55]. Мажоритарное резервиро-
вание рассмотрено в [13].
Двухмашинная отказоустойчивая система GCSC представлена
в [713]. С такой системой на борту два космических аппарата со-
вершили мягкую посадку на Марсе. Разработка системы AADC
(Advanced Avionic Computer System) описана в [529, 530, 532,
697—699, 870, 1179], а системы DAIS (bistributed Avionics Info-
rmation System) —в [536, 942]. Система FTSC (Fault Tolerant
Spacebom Computer) представлена в [561].
Модульная система PRIME с перекрестной коммутацией для
внешнего доступа, предназначенная для работы с множеством тер-
миналов и разрабатывавшаяся как отказоустойчивая, описана в
1510, 549—551, 880, 1106]. Система С. ai для исследования проб-
лем искусственного интеллекта представлена в [524, 880]. Струк-
тура отказоустойчивой системы SYSTEM 250 для длительной ра-
боты в реальном масштабе времени изложена в [621, 690, 691,
828, 12(59]. Укажем также следующие отказоустойчивые системы:
SERF [275, 1191], MECRA [959], COPRA [978, 979], система из
двух ЭВМ для управления ракетной установкой па подводной лод-
ке [1072]t дуплексная система для работы в реальном времени
[1215] и другие системы [484, 641, 657, 1244]. Система с голосо-
ванием при тройном модульном резервировании на базе микро-
процессора Intel 8080 описана в [404].
Общие характеристики надежности вычислительных систем во
многом зависят от надежности программного обеспечения, т. е.
от уровня правильности и отказоустойчивости программ. Пробле-
ма надежности программного обеспечения рассмотрена в моногра-
фиях [70, 128, 134, 186, 1017], в обзорах [107, 608, 609, 996] и в
сборнике [859]. Она обсуждалась на нескольких посвященных ей
конференциях и симпозиумах, труды которых опубликованы в
сборниках и журналах [602, 853, 1099—1101, 1104]. Классифика-
ция методов обеспечения надежности программ представлена в
11081. Библиография работ по проблеме надежнести программно-
го обеспечения содержится в [37, 467].
410
ТА. Новые концепции и разработки
ТА. 1. Модульная асинхронная развиваемая система E263L
Основу концепции модульной асинхронной развиваемой системы
(МАРС) составляет комплексный подход к устранению таких рас-
пространенных недостатков вычислительных систем, как: 1) жест-
кость архитектуры; .2) недостаточное увеличение итоговой произ-
водительности при улучшении характеристик устройств и увели-
чении мощности ресурсов, в том числе при увеличении количества
центральных процессоров и объемов памяти; 3) неудовлетвори-
тельная совместимость и переносимость программного обеспече-
ния; 4) слишком большие затраты времени и ресурсов на систем-
ные процессы в ущерб процессам пользователей; 5) недостаточ-
ность внедрения удобных, надежных и эффективных методов па-
раллельного программирования, а также ориентация архитектуры
многопроцессорных систем на методы последовательного програм-
мирования с использованием групповых операций и на параллель-
но-последовательные методы (не на развитую высокопараллель-
ную обработку информации). *
В целях устранения указанных недостатков вычислительных
систем в архитектуре системы МАРС предусматривается реали-
зовать следующие основные принципы:
1) осуществление развитой аппаратной поддержки и иерархи-
ческого распараллеливания как проблемных, так и системных
процессов;
2) построение иерархической структуры вычислительных мо-
дулей в виде типовых крупноблочных элементов;
3) организация асинхронного взаимодействия модулей с исполь-
зованием как централизованных, так и распределенных средств
организации взаимодействия и с обеспечением перестраиваемого
(программируемого) управления;
4) обеспечение удобной и эффективной адаптации системы и,
в определенных пределах, динамической реконфигурации;
5) использование возможностей, предоставляемых перспектив-
ной элементной базой, включая микропроцессоры, с учетом воз-
можностёй микропрограммирования.
Возможны различные пути воплощения этих принципов в кон-
кретные структуры. В концепции системы МАРС структурная
организация основывается, в первую очередь, на комплексном рас-
параллеливании всех процессов в системе и на их эффективном
отображении на базовый уровень системы. При этом предусмат-
ривается унификация правил и средств компоновки системы из
модулей различных уровней, развитие функциональных возмож-
ностей системы и ее возможностей к адаптации за счет аппарат-
ных средств, виртуализации и специализации модулей, а также
организация базовой системы, вычислительных процессов и про-
грамм на основе единого асинхронного принципа.
411
f
Аппаратная поддержка и иерархическое распараллеливание
всего комплекса процессов обработки информации обеспечивают
повышение итоговой производительности системы.
Для реализации проблемных процессоров предусматривается
небольшое число типов процессоров, таких как скалярный, мат-
ричный или. векторный процессор и, возможно, процессор для
сложных структур данных.
Наличие в системе небольшого набора таких специализирован-
ных процессоров не приведет к усложнению коммутации и рас-
пределения данных, если связи между ними асинхронные, об-
- мены осуществляются через общий «рынок данных», а сами дан-
ные тэгированы..
Организация управления и обменов может меняться в зави-
симости от уровня иерархии процессора, но для каждого данного
уровня целесообразно выбрать один и тот жё-метод организации.
На самом нижнем уровне, при выполнении микроопераций и
операций, следует применять синхронное управление (синхронные
процессоры) и распределенную память. На уровне, соответствую-
щем вычислению выражений и выполнению групповых операций,
также следует применять синхронные процессоры и распределен-
ную память, однако, с повышением уровня более эффективной ста-
новится асинхронная организация. Так, если для уровня вычис-
ления выражений и выполнения групповых операций может при-
меняться, наряду с синхронным, также и асинхронное распреде-
ленное управление, -то для вычисления операторов и работы со
средними модулями программ целесообразно асинхронное центра-
лизованное управление и общая память. При дальнейшем повыше-
нии уровня, для работы с большими программными модулями
(подпрограммами) следует использовать асинхронное распределен-
ное управление и распределенную память.
Системные процессы максимально совмещаются во времени с
проблемными процессами пользователя и реализуются при помо-
щи оборудования, ориентированного на их выполнение, т. к. они
обладают соответствующей спецификой и являются для системы
стандартными.
Для системных процессов выделяются процессоры в -базовой
системе или более сложные модули, причем оборудование для
процессов обработки и процессов управления разделяется на
соответствующие подсистемы (возможно и дальнейшее разбиение
подсистемы управления на подсистемы управления процессами,
заданиями, данными и т. п.).
Как отмечалось выше, модульность — один из главных прин-
ципов построения системы МАРС. Как аппаратное, так и про-
граммное обеспечение системы — модульное, 4то, в сочетании с
модульностью языков параллельного программирования, должно
обеспечить - возможность статической и динамической, реконфигу-
рации. системы и взаимную адаптацию программ пользователя,
системных программ и собственно базовой системы МАРС.
412
Система МАРС формируется как некоторая иерархическая
структура по унифицированным правилам из типовых модулей
разных уровней и различного назначения. Модуль в системе
МАРС —это функционально замкнутый блок повышенной квали-
фикации в смысле, как это представлено [166] (см. п. 4.1.1), спе-
циализируемый или программируемый на определенные функции
в системе. Он может хранить и обрабатывать информацию и имеет
автономное устройство управления для организации и контроля
работы подмодулей и для связи с другими модулями. Модуль мо-
жет быть аппаратным, виртуальным (программным) или смешан-
ным программно-аппаратным.
*В иерархической структуре модулей выделяются элементарные
и составные модули. Последние содержат подмодули, относящиеся
к зонам интерфейса, управления, обработки и памяти. Подмодули
зоны интерфейса обеспечивают все управляющие и информацион-
ные связи данного модуля с другими модулями так, что извне
модуль представляется «черным ящиком» с доступной для обозре-
ния только зоной интерфейса. Внутреннее управление модуля яв-
ляется автономным и программируемым и осуществляется подмо-
дулями зоны управления, которые организуют управление и, час-
тично, информационные связи между подмодулями модуля. В зоне
управления функционирует как бы операционная система модуля.
Обработка заданий, поступающих в модуль, ведется подмодуля-
ми зоны обработки. Данные, которыми обеспечиваются подмодули,
хранятся в зоне памяти. Подмодуль, в свою очередь, может быть
составным модулем. Общая схема модуля системы МАРС изобра-
жена на рис. 7.19Г х
Параметры, конкретная структура и тип управления модуля
определяются его назначением в системе. Модули разных уров-
ней описываются при помощи языков спецификации соответствую-
щих уровней, обеспечивающих соответствие между структурой
описания модуля системы и структурой самого модуля. В описа-
нии модуля содержится в явном виде информация для настройки
модуля на соответствующие конфигурацию и режим работы. Внут-
реннее автономное управление организует работу модуля, при
этом модуль проходит через состояния: пассивный, проверка спус-
ковой функции, анализ результата проверки (возврат к пассив-
ному состоянию, если значение — «ложь»), инициация модуля,
активный и завершение.
В системе МАРС предполагается применение' микропроцессо-
ров для управления работой отдельных специфических устройств,
таких как, например, печатающие устройства, и длд выполнения
особых функций в системе, а также применение микропроцессо-
ров в качестве достаточно универсальных компонентов базовой
системы, т. е. в качестве элементарных модулей. Для применений
микропроцессоров в качестве элементарных модулей требуется их
усовершенствование (улучшение основных параметров, развитие
модульности и адаптируемости структуры).
При достаточно полном решении проблем модульности и пере-
страиваемости спектр конфигурацией системы МАРС может быть
довольно широким как по проблемной ориентации, так и по мощ-
ности получаемых систем — от минимашин до мощных универсаль-
ных или специализированных систем, распределенных вычисли-
тельных комплексов и т. п. При этом объединяются две линии
Рис. 7.19. Общая схема модуля.
развития вычислительной техники, одна из которых состоит в со-
здании семейств совместимых систем различной мощности, а дру-
гая—-в создании стандартных микропроцессорных вычислитель-
ных модулей, конкретное назначение которых определяется поль-
зователем при компоновке вычислительной системы из этих мо-
дулей. Вычислительные модули системы МАРС применяются
также, как и стандартные микропроцессорные модули, по явля-
ются значительно более крупными блоками и перекрывают боль-
ший диапазон мощности. При фиксации конфигурации система
МАРС становится замкнутой и представляет собой модуль, содер-
жащий иерархический комплекс модулей. Однако к системе мож-
но добавлять новое оборудование и расширять ее возможности,
а также изменять ее свойства. С этой точки зрения система
МАРС — открытая система. При этом в целях обеспечения эффек-
тивности вычислений возможна статическая реконфигурация си-
стемы (добавление или изъятие аппаратных или программных
модулей, < замена модулей, добавление или замена системных
программ и т. п.), когда при решении задач после реконфигура-
ции система фиксируется, и динамическая реконфигурация (про-
414
граммируемые изменения режимов и процессов управления в мо-
дулях, в том числе в элементарных модулях-микропроцессорах),
когда изменения осуществляются при переходе от одних задач
к другим и даже в процессе решения одной задачи.
В качестве основных типов модулей можно указать следующие:
— модули для хранения и предварительной обработки прог-
рамм (периферийные процессоры, модули вспомогательной памяти,
модули-трансляторы, ориентированные на один язык программи-
рования или на одно семейство языков, модули управления за-
даниями);
— модули оперативной памяти, модули управления оператив-
ной памятью, вспомогательной памятью и файлами;
— проблемно-ориентированные процессоры (универсальные
арифметические, векторные, матричные и ассоциативные, символь-
ные, специальные);
— модули быстрых и специальных устройств памяти, модули
для реализации процессов управления, в том числе процессов
виртуализации памяти и процессоров, обработки прерываний и
управления параллельными процессами;
— модули для организации обменов и коммутации.
Концепция системы МАРС позволяет организовать необходи-
мые исследования и проектирование системы, при этом требуется
создание экспериментальных систем и макетов. Сначала можно
создать системы-прототипы систем МАРС с ограниченными про-
изводительностью и возможностями, но обладающие всеми основ-
ными свойствами систем, осуществляя в дальнейшем непрерыв-
ный отбор апробированных архитектурных решений, наращива-
ние возможностей и унификацию модулей [263].
7А.2. Рекурсивные вычислительные машины [284]. Структур-
ная и программная организация рекурсивных вычислительных
машин (РВМ) определяется следующими основными принципами
[765]:
1) внутренний язык РВМ включает рекурсивно определяемые
программные элементы как обобщение машинных команд и эле-
менты данных как обобщение машинных слов — операндов, кото-
рые могут иметь произвольную сложность;
2) в РВМ осуществляется рекурсивно-параллельное управле-
ние выполнением программы, причем порядок выполнения про-
граммных элементов может задаваться неявно при помощи функ-
циональных (в общем случае — рекурсивных) отношений и опре-
деляться |В процессе выполнения программы;
3) внутренняя память РВМ состоит из блоков, которые могут
.состоять из ячеек, или же из блоков с программно перестраивае-
мыми связями между ними;
4) внешняя физическая структура однозначно определяется
при помощи конечного числа рекурсивных отношений;
5) внутренняя структура, определяющая связи между вычис-
лительными процессами в РВМ, является гибкой, программно
4L5
1
перестраиваемой и динамически отражает структуру решаемых
задач.
Эти принципы являются весьма общими и позволяют постро-
ить самые разнообразные РВМ. Ниже рассматривается один из
подклассов таких систем, в которых учитывается современный
уровень микроэлектронной элементной базы.
Структуру РВМ можно представить в виде вычислительной
сети, в узлах которой размещены процессоры различных типов,
терминалы, внешние устройства и рекурсивные машины более
низких уровней иерархии. В отличие от обычных вычислительных
сетей и многопроцессорных систем, внутренний язык РВМ ори-
ентирован на параллельную реализацию вычислений с децентра-
лизованным управлением. Поэтому распараллеливание в РВМ
осуществляется не внешними средствами при помощи сложных
операционных систем, а интерпретацией внутреннего языка.
Основной способ/ управления, принятый во внутреннем языке
РВМ, основан на принципах асинхронного управления вычисли-
тельными процессами [228] и управления на базе схемы потока ’
данных, ориентированной на применение в РВМ [390—3921. ।
Согласно этому способу порядок выполнения операторов опреде- 1
ляется динамически в зависимости от готовности операторов к
выполнениюг которая определяется, обычно, по наличию всех
операндов рассматриваемых операторов. При этом, однако, тре-
буется проверять на готовность большое число операторов и эле-
ментов данных. Эту проблему можно решить, распараллелив
управление и сведя к минимуму число проверяемых операторов
и элементов данных, что можно обеспечить путем глубокого
структурирования программ и данных. Такой подход позволяет
сохранить в программах естественный параллелизм задач и ис-
пользовать его для распараллеливания, при этом не требуется
участия операционной системы. Однако этот подход имеет ряд
недостатков, таких как несоответствие традиционных алгоритмов
и языков программирования методу управления в РВМ, необхо-
димость использовать рекурсивные процессы вместо обычных
итерационных, необходимость регенерации данных, если они пов-
торно используются, и другие.
В целях исключения или уменьшения влияния указанных
недостатков во внутренний язык РВМ вводится ряд механизмов
для блокировки программных элементов и элементов данных, для
снятия блокировки, для стирания переменных и другие, Кроме
этого, допускается применение способов управления вычислитель-
ным процессом, соответствующих обычному последовательному
-j
1
управлению, последовательному управлению в режиме интерпре-
тации с возможностью параллелизма на нижних уровнях иерар-
хии, управлению на базе статического * распараллеливания и
управлению на базе динамического распараллеливания с выделе-
нием отдельных процессоров тем программным элементам, для
которых подготовлены входные данные.
416
В состав РВМ входят две основные части — коммутационное
поле и операционное поле. Первое поле состоит из одинаковых
или различных коммутационных процессоров, соединенных между
собой в некоторую рекурсивную структуру. Рекомендуется много-
уровневая структура в виде пирамиды с древовидными связями
между уровнями и матричными связями между элементами каж-
дого уровня. Операционное поле состоит из управляющих и
исполнительных процессоров и внешних устройств. Его элементы
обычно не имеют непосредственных связей между собой и под-
ключаются к элементам коммутационного поля нижнего уровня,,
причем допускается их подключение и к элементам коммутацион-
ного поля более высоких уровней. Соединения между элементами
операционного поля реализуются динамически через элементы
коммутационного поля при помощи настройки и перестройки
связей между ними. Управление коммутационным полем распре-
делено между его коммутационными процессорами, которые при
работе используют информацию только о своем состоянии и а
состоянии своих непосредственных соседей.
Внутренняя память РВМ распределена между процессорами,
по любой операционный процессор может использовать память,
других операционных процессоров, подключив их к себе. Про-
граммы оперируют с виртуальной памятью, причем адресация
данных и программных элементов осуществляется только при.
помощи индексов и имен, а переход к физическим адресам орга-
низуется только в пределах памяти’своего процессора в процесса
интерпретации программы.
Операционная система РВМ имеет такую же структуру на
внутреннем языке машины, как и другие программы, причем про-
граммы пользователя рассматриваются как внутренние блоки
операционной системы. Она размещается в коммутационных про-
цессорах, а при необходимости может занимать и операционные
процессоры. Многие обычные функции операционной системы
в РВМ отнесены к функциям интерпретаторов элементов внут-
реннего языка машины благодаря его высокому уровню и рекур-
сивно-параллельному способу управления.
Возможности перестройки структуры РВМ и контроля комму-
тационными процессорами смежных с ними операционных и ком-
мутационных процессоров определяют высокую надежность и
живучесть РВМ, а глубокая структурированность программ на
внутреннем языке РВМ обеспечивает локализацию программ-
ных ошибок.
При построении рекурсивных машин можно образовать прак-
тически непрерывное по параметрам и стоимости семейство сов-
местимых ЭВМ. При этом в малых РВМ целесообразно применять
однотипные операционные процессоры, в средних РВМ они могут-
быть различными. В больших РВМ в число исполнительных про--
цессоров могут входить, например, матричные или магистральные
процессоры. Важно отметить, что при наращивании РВМ допол-
27 Б. А. Головкин
417”
нительными процессорами или при объединении двух РВМ не
требуется изменять структуру исходных РВМ, а программа при
использовании стандартной версии внутреннего языка не зависит
от структуры и состава конкретной РВМ.
Реализацию РВМ целесообразно начинать с построения мини-
РВМ на базе микропроцессоров, ограничившись для них только
коммутационными и исполнительными процессорами и возложив
на эти процессоры также функции управления. Такие мини-РВМ
по своим техническим параметрам будут соответствовать средним
(или даже большим) ЭВМ. Так, например, РВМ в составе четырех
коммутационных и четырех исполнительных 16-разрядных про-
цессоров, способных оперировать с числами произвольного фор-
мата, при суммарной емкости памяти в 256 К байт оценивается
по производительности как машина, бодее чем в 2 раза превос-
ходящая ЭВМ типа, ЕС-1050 при решении различных задач.
7.4.3, Управляющие системы с перестраиваемой структурой
[338], Управляющие системы с перестраиваемой структурой пред-
назначаются, в первую очередь, для применения в системах
управления в реальном масштабе времени и в системах автомати-
зации исследований, в которых требуется производительность до
100 млн. операций в секунду. Системотехнические и конструктив-
ные принципы построения рассматриваемых вычислительных
систем разработаны Институтом проблем управления совместно с
НПО «Импульс». Системы выполняются на конструктивной базе
СМ ЭВМ.
Повышение производительности, пропускной способности, на-
дежности и живучести управляющих систем достигается путем
применения в них многих процессоров и перестраиваемой струк-
туры. В целях улучшения отношения производительности к сто-
имости предусматривается^ проблемная ориентация вычислитель-
ных систем, причем предусмотрено реализовать пять моделей
систем. Адаптация к классу задач проблемно-ориентированной
системы — статическая. Она определяется типами, числом и взаи-
мосвязью моделей в системе. Второй уровень адаптации — дина-
мический. Он определяется возможностями перестройки структу-
ры в процессе решения задач. ,
Основу конфигурации системы с перестраиваемой структурой
составляет, как правило, центральный вычислительный комплекс^ :
с достаточно широкими возможностями как собственно обработки
данных, так и диспетчеризации потоков информации между моде-
лями. Другие модели являются более специализированными и
предназначены для использования в качестве периферийных про-
цессоров для центрального вычислительного комплекса, а также '
для автономной работы в качестве специализированных вычисли-
тельных систем для соответствующих классов задач.
Ниже «рассматриваются первые две модели комплексов — цен- 1
тральный вычислительный комплекс и вычислительный комплекс |
групповой обработки данных. j
418
Центральный вычислительный комплекс [3351 ориентирован
на решение достаточно хорошо распараллеливаемых задач в
многозадачном ^режиме, т. е. классифицируется как система с
множественными потоками команд и данных (МКМД). Он содер-
жит однородное управляющее поле, однородное решающее 'поле,
оперативную память и мониторную подсистему.
Управляющее поле состоит из однотипных блоков обработки
команд (БОК), .работающих асинхронно и независимо друг от
друга. Каждый БОК оперирует с одной из ветвей программы так,
что в системе одновременно может выполняться несколько ветвей,
соответственно числу БОК, одной или нескольких программ.
В функции БОК входит буферизация команд и операндов, посту-
пающих из оперативной памяти, а также результатов вычислений,
получаемых в решающем поле. После подготовки в БОК команд
к выполнению, они образуют очередь заявок к решающему полю.
Кроме указанных, БОК выполняет также часть функций управ-
ления ветвями, а также оперирует с 8-разрядными символьными
операндами и выполняет короткие операций над 16- и 32-разряд-
ными операндами* с фиксированной запятой.
Решающее поле состоит из однотипных арифметико-логиче-
ских модулей (АЛМ), представляющих собой процессорные эле-
менты (или микропроцессоры) с микропрограммным управлением.
АЛМ осуществляет операции над 32- и 64-разрядными операнда-
ми с плавающей запятой и длинные операции над 16- и 32-раз-
рядными операндами с фиксированной запятой. АЛМ работают
асинхронно и независимо друг от друга, что позволяет выполнять
в решающем поле одновременно однотипные и разнотипные опе-
рации над скалярами и векторами с одинаковой и различной раз-
рядностью при различной длительности операций.
Связь между управляющим и решающим полями осуществля-
ется через управляющие и информационные шины, по которым
в АЛМ поступают готовые к выполнению команды и их операн-
ды, а в БОК поступают результаты выполнения команд.
Оперативная память образует общее поле, одинаково доступ-
ное всем БОК и процессору операционной системы. Память пост-
роена по модульному принципу и позволяет одновременно считы-
вать/записывать несколько слов. Связь с оперативной памятью
осуществляется через модульный распределитель-коммутатор.
Как оперативная память, так и память внешних устройств явля-
ются виртуальными.
Мониторная подсистема выполняет функции операционной
системы и в^ода-вывода. Она размещается в двухпроцессорном
комплексе СМ-2 (см. п. 3.4). Функции каналов обмена между глав-
ной оперативной памятью и памятью операционной системы
выполняют специально разрабатываемые модули обмена. Приме-
нение СМ-2 упрощает разработку операционной системы и позво-
ляет использовать периферийное оборудование СМ ЭВМ и систем
М6000/М 7000 АСВТ-М.
27*
419
В системе, кроме обычных уровн/й управления задачами и
командами, предусматривается управление ветвями задачи и
управление операторами.
Для центрального вычислительного комплекса предусматрива-
ются автокод и языки программирования высокого уровня. Авто-
код позволяет использовать все возможности комплекса. В транс-
ляторы с языков высокого уровня вводится блок статического рас-
параллеливания, который выделяет в исходной программе такие
конструкции, как линейные участки, простые циклы и другие.
Далее в процессе трансляции осуществляется объединение от-
дельных команд на промежуточном языке внутри указанных вы-
ше программных конструкций в параллельные операторы, после
чего формируются параллельные ветвп программы.
Таким образом, после трансляции имеются выделенные парал-
лельные ветви, которые с учетом соответствующих логических
условий могут выполняться параллельно. Управление ветвями —
динамическое, функции управления распределены между БОК
и процессорами операционной системы (СМ-2). Распределение
БОК между задачами осуществляет процессор -опёрационной си-
стемы, причем после закрепления данного БОК за некоторой
ветвью он полностью управляет ее выполнением независимо от
работы других БОК. Управление операторами и командами осу-
ществляется в БОК по магистральному принципу.
Итак, в процессе решения задач ресурсы управляющего и
решающего полей динамически перераспределяются в зависимо-
сти от текущих потребностей вычислительных процессов, при
этом параллельными являются не только сами процессы вы-
числений на разных уровнях, но и процессы управления вы-
числениями.
Перейдем к вычислительному комплексу групповой обработки
данных. Этот вычислительный комплекс ориентирован на реше-
ние достаточно хорошо распараллеливаемых задач в однозадач-
ном режиме (обработка больших массивов информации по регу-
лярным алгоритмам), и характеризуется как система с одиночным
потоком команд и множественным потоком данных (ОКМД).
Однородное решающее поле комплекса состоит из однотипных
процессорных элементов, количество которых выбирается в зави-
симости от конкретных приложений. - Процессорный элемент со-
держит арифметико-логическое устройство для операций с фикси-
рованной и плавающей запятой, оперативную и сверхоперативную
память и устройства сопряжения с другими процессорными эле-
ментами и с устройством управления. Таким образом, процессор-
ные элементы имеют собственную оперативную память и не име-
ют устройства управления. Они работают по микрокомандам,
поступающим из общего устройства управления, который содер-
жит управляющую оперативную память, оперативную память
микрокоманд и блок микропрограммного управления. Каждый
процессорный элемент связан с соседними элементами. Устройст-
420
во управления связано со всеми процессорными ЬлементЬми через
параллельный канал связи.
Вычислительные комплексы групповой обработки данных це-
лесообразно использовать совместно с центральным вычислитель-
ным комплексом или с машинами типа СМ-1, СМ-2, М-7000 (см.
3.4). Последние в этом случае выполняют диспетчирование, связь
с периферийным оборудованием, а также выполняют такие вы-
числения, которые неэффективно реализуются на комплексе
групповой обработки.
В программном обеспечении комплексов групповой обработки
предусматриваются операционные системы, библиотеки стандарт-
ных процедур и пакетов прикладных программ, системы подго-
товки программ, системы связи с операторами, контрольно-диаг-
ностические системы. Операционные системы разрабатываются на
базе операционных систем СМ-1 и СМ-2.
7.4.4. Библиографическая справка. Концепция системы МАРС
изложена в (2631. В этой работе проанализированы тенденции и
актуальные проблемы развития вычислительной техники и про-
граммирования и рассмотрены структуры вычислительных систем,
таких как многопроцессорные, магистральные и матричные си-
стемы, однородные вычислительные системы, а также рассмотре-
ны параллельные программы и процессы и развитие архитектур-
ных принципов. На базе выполненного анализа предложены ос-
новные принципы и описаны особенности построения системы
МАРС.
Принципы структурной и программной организации рекурсив-
ных вычислительных машин предложены в [99, 765]. Основной
способ управления, принятый во внутреннем языке, а также
принципы организации и структура внутреннего математического
обеспечения таких машин описаны в [390—393]. Описание орга-
низации рекурсивных вычислительных машин, включая принцип
управления и внутренний язык, коммутационное поле и опера-
ционное поле, а также вопросы применения микропроцессоров в
таких машинах, представлены в [284].
Первые две модели управляющих комплексов с перестраивае-
мой структурой из числа пяти, предусмотренных к реализации,
описаны в [338]. Краткое описание структур перестраиваемых
комплексов дано в [218]. Вопросы построения таких структур и
соответствующего программного обеспечения, организация решаю-
щего поля и другие вопросы рассмотрены в 138, 118, 182, 183,
267, 335, 336] (напомним, что литература по концепциям систем
с перестраивающейся структурой рассмотрена в предыдущих раз-
делах настоящей книги). Перспективы применения однородных
программируемых микропроцессорных систем в системах управ-
ления изложены в [3371.
8. КОЛИЧЕСТВЕННЫЕ ХАРАКТЕРИСТИКИ
СТРУКТУР СИСТЕМ. ПРОИЗВОДИТЕЛЬНОСТЬ
И СТОИМОСТЬ СИСТЕМ
8.1. Количественные характеристики структур
вычислительных систем
8.1.1' Формализация описания структур систем. Существует
несколько подходов к построению количественных характеристик
структур вычислительных систем. Один из наиболее простых и
наглядных из них характеризует степень параллельности струк-
тур вычислительных систем следующим образом [719, 720] (ма-
териалы этих работ кратко воспроизведены в 1110, 281, 800J).
' Выбираются два параметра — длина основного машинного
слова ip, которая используется в обрабатывающих устройствах,
н число параллельно обрабатываемых двоичных позиций данного
разряда множества слов р, т. е. ширина обрабатываемого разряд-
ного среза. В качестве характеристики максимально возможной
степени параллелизма системы принимается совокупность этих
параметров (ш, р). Тогда получаем:
а) (1, 1) — полностью последовательная обработка одного би-
та информации за другим (одноразрядный процессор);
б) (ш, 1) — последовательная обработка w-разрядных слов при
параллельной обработке разрядов каждого слова в обычном про-
цессоре (ш>1);
в) (1, р) — последовательная обработка разрядных срезов р
слов при параллельной обработке содержимых данного разряда
множества слов (р>1) как, например, в системах с ассоциатив-
ными процессорами;
г) (ip, р) — полностью параллельная обработка всех w разря-
дов каждого из р слов одновременно (р > 1, w > 1).
При помощи этой двумерной характеристики максимально
возможная степень параллельности обработки информации обыч-
ной однопроцессорной системой IBM 360/50 (для основного фор-
мата) может быть представлена в виде (32,1), одним модулем
системы с ансамблем процессоров РЕРЕ —в виде (32,16), одним
квадрантом матричной системы ILLIAC IV — в виде (64,64) и
одним модулем ассоциативной системы STARAN — в виде (1,256).
Графическое изображение этих примеров приведено на рис. 8.1.
Характеристики параллельности структур в совокупности с
частотой синхронизации работы устройств вычислительных си-
стем определяют их максимальную производительность или, в бо-
422
лее общем случае, максимальную полосу пропускания, которая
может быть определена как наибольшее число двоичных разря-
дов, которые вычислитель-
ная система может обрабо-
тать за единицу времени.
Приведенные характе-
ристики параллельности
непосредственно связаны
с классификацией вычис-
лительных систем (см.
п. 2.2.2). Действительно,
системы с' характеристи-
кой (1,1) составляют класс
ОКОДР, с характеристи-
ками (u?, 1), где ш>1,—
класс ОКОДС, с характе-
ристиками (1, р), где v>
> 1, относятся к классу
ОКМДР, а с характеристи-
ками (ш, р), где w > 1 и
v > 1, классифицируются
неоднозначно. Кроме это-
го, вторые и третьи из ука-
занных систем представля-
ют собой Машины I и II
соответственно (см. п. 2.3).
Проанализируем рас-
смотренные характеристи-
ки параллелизма структур
вычислительных систем
1800]. Отметим, что шири-
на обрабатываемого раз-
рядного среза и для боль-
шого числа типов систем,
таких как: обычные одно-
процессорные, с ассоциа-
тивными процессорами,
матричные, с ансамблем
процессоров, многомашин-
ные и многопроцессор-
ные — совпадает с макси-
мальным числом одновре-
менно (параллельно) обра-
батываемых слов и, следовательно, с числом обрабатывающих
процессоров.
Характеристики структур систем в виде двоек чисел (ш, р)
не отражают различий между уровнями обработки и управления
в тех или иных параллельных системах. Так, например, ширина
423
256
i и и(ширинаразрядного
' среза)
! STARAN один модуль
1
&
I
1
к
16
1
Полностью
параллельная
обработка
Юдин квадрант
(W
PEPE-
Один модуль
Послвдовательнав
$2 fflf wr [длина слова)
Рис. 8.1. Максимальная параллельность об->
работки.
обрабатываемого разрядного среза v может быть представлена
как количество процессоров в многопроцессорной системе и как
количество обрабатывающих процессоров в матричной системе,
хотя в первом случае может одновременно выполняться несколько
программ, а во втором случае выполняется одна программа. Ины-
ми словами, не учитывается соотношение даже между числом
модулей управления и обрабатывающих модулей, и, следователь-
но, не учитываются различия между многопроцессорными систе-
мами и матричными системами и т. п. Подобные трудности встре-
чаются при попытках составления характеристик для структур
магистральных систем.
Таким образом, характеристики структур систем в* виде двоек
чисел (ш, v) приспособлены фактически только для систем с един-
ственным потоком команд, т. е. систем классов ОКОД и ОКМД.
Другим естественным и простым подходом к построению ко-
личественных характеристик структур систем является использо-
вание двоек чисел (А, и), где Лип — количества потоков команд
и данных соответственно. Такие характеристики непосредственно
связаны с классификацией систем в зависимости от единственно-
сти и множественности потоков команд и данных. Они применя-
ются в ряде работ, например, в [12291.
Четыре основных класса вычислительных систем — с одиноч-
ными потоками команд и данных ОКОД (обычные процессоры),
с одиночным потоком команд и множественным потоком данных
ОКМД (ассоциативные и матричные системы, системы с ансамб-
лем процессоров и с векторным потоком данных), с множествен-
ным потоком команд и одиночным потоком данных МКОД (ма-
гистральные системы) и с множественными потоками команд и
данных МКМД (многомашинные п многопроцессорные системы) —
характеризуются двойками целых чисел (1,1), (1, п), (Л, 1), (Л,
п) соответственно, где Л>1 и n> 1. Здесь, в отличие от преды-
дущего подхода, фактически указывается количество устройств
управления, т. е. количество возможных независимо выполняе-
мых программ, и, как и в предыдущем случае, количество обра-
батывающих процессоров (п == у), но при этом количество разря-
дов слов, обрабатываемых в параллель, не находит отражения.
Сохранить, в определенной степени, достоинства обоих подхо-
дов и устранить их недостатки можно путем комбинации обоих
подходов, хотя в этом случае несколько усложняется описание.
Такая комбинация, ее анализ и развитие описаны в (796, 799,
800] (основные результаты кратко воспроизведены в (12231).
Рассмотрим такой комбинированный подход.
В качестве основных требований к описанию структур вычис-
лительных систем при помощи числовых характеристик примем
следующие.
Описание должно охватывать широкий круг вычислительных
систем всех четырех классов ОКОД, ОКМД, МКОД и МКМД,
включая обычные процессоры, ассоциативные и матричные си-
424
стемы, магистральные системы, многомашинные и многопроцес-
сорные системы. Оно должно явно выражать основные особен-
ности структур и их главные различия между собой й должно
быть однозначным. Описание должно содержать параметры, соот-
ношения между которыми должны соответствовать соотношениям
между структурами. При этом для каждой конкретной конфигу-
рации системы значения параметров должны быть представлены
числами. Кроме этого, описание должно характеризовать не толь-
ко собственно структуру и ее возможности распараллеливания,
но и гибкость структуры. Оно должно давать возможность анали-
за соответствия структур систем и структур алгоритмов и
программ.
В качестве основной цели описания примем количественные
характеристики параллельности обработки, при этом связи между
процессорами и блоками памяти как таковые не будем включать
в описание. Описание построим на базе различий между тремя
основными уровнями обработки, которые рассмотрены ниже.
Обработка первого уровня осуществляется в устройстве уп-
равления. Это устройство интерпретирует команды программы
одну за другой, используя счетчик команд и некоторые другие
регистры. Арифметико-логическое устройство получает внешние
управляющие сигналы от устройства управления, вырабатывает
соответствующую исполнительную последовательность микроко-
манд (второй уровень обработки), которая реализуется в виде
элементарных логических операций над содержимым разрядов
данных (третий уровень обработки).
Конфигурация вычислительной системы может содержать од-
но или несколько устройств управления. Каждое устройство уп-
равления может осуществлять управление одним или несколь-
кими арифметико-логическими устройствами. Наконец, каждое
арифметико-логическое устройство обычно обрабатывает сразу
группу разрядов (слово), хотя в ряде простейших случаев оно
оперирует в каждый момент времени с отдельным разрядом. Та-
ким образом, на каждом из уровней возможна как последова-
тельная, так и параллельная обработка. В соответствии с этим
описание структур систем можно представить в виде упорядочен-
ной тройки:
t(a) = (к, d, w),
где:
а — наименование или тип вычислительной системы;
к — количество устройств управления, т. е. наибольшее коли-
чество независимо и одновременно выполняемых программ в си-
стеме (соответствует PMS/ISP-нотации [522]);
d — количество арифметико-логических устройств, приходя-
щихся на одно устройство управления;
w — количество разрядов, содержимое которых обрабатывается
одновременно (параллельно) одним арифметико-логическим
устройством, т. е. длина слова процессора.
425
Здесь величины к и w имеют тот же смысл, что и в описаниях
для двух первых подходов, а величины у, к и d связаны соотно-
шением v — к • d для случая, когда арифметико-логические уст-
ройства поделены поровну между устройствами управления. Пос-
леднее условие и возможность его выполнения неявно предпола-
гаются при построении троек (A, d, w).
Рассмотрим примеры описания некоторых вычислительных
систем.
1. ^MINIMA) = (1, 1, 1).
Последовательный одноразрядный процессор, на всех трех уров-
нях осуществляется последовательная обработка.
2. ШВМ 701) =.(1, 1,36).
-Пример обычного процессора раннего выпуска, параллельная об-
работка осуществляется только на третьем уровне.
3. ^SOLOMON) « (1,1024, 1).
Концепция матричной системы, параллельность обработки име-
ется только на втором уровне.
4. ^(ILLIAC IV) « (1, 64, 64).
Один квадрант матричной системы ILLIAC IV, параллельная об-
работка осуществляется на втором и третьем уровнях.
5. f(PEPE) == (1, 16, 32).
Один модуль системы с ансамблем 16 процессоров, здесь парал-
лельная обработка осуществляется также на втором и третьем
уровнях.
6. KSTARAN) = (1, 8192, 1).
Многомодульная конфигурация системы с ассоциативными про-
цессорами (32 блока, каждый из которых содержит 256 бит).
В описании не учитывается обычный последовательный управ-
ляющий процессор.
7. £(C. mmp) = (16, 1, 16).
Комбинация из 16 минимашин PDP-11 в виде многопроцессорной
системы, параллельная обработка осуществляется на каждом
уровне, причем с каждым устройством управления связано одно
из арифметико-логических устройств.
8. f(PRIME) « (5, 1, 16).
В основу разработки многопроцессорной системы PRIME поло-
жена концепция параллельной обработки в режиме разделения
времени 1510, 8801.
Список примеров легко может быть продолжен, однако и при-
веденных примеров достаточно, чтобы убедиться в выполнении
предъявленных требований к описаниям систем типов ОКОД,
426
ОКМД и МКМД. Следует отметить, что матричные системы и
системы с ансамблем процессоров не различаются друг от друга
по виду описания (см. примеры №№ 4, 5), поскольку оба вида
этих систем относятся к классу ОКМД и отличаются друг от
друга связанностью обрабатывающих процессоров. Матричные си-
стемы с одноразрядными обрабатывающими процессорами и си-
стемы с ассоциативными процессорами также не различаются друг
от друга по виду описания (см. примеры 3, 6).
Дополним рассмотренные тройки описанием магистральной
(конвейерной) обработки. Поскольку во многих системах магист-
ральный принцип сочетается с другими принципами обработки,
описание первого целесообразно включить непосредственно в трой-
ки (Л, d, w).
Магистральная обработка может быть реализована на тех же
трех уровнях, что были рассмотрены выше, а именно, на уровнях
управляющих устройств, арифметико-логических устройств п
устройств выполнения элементарных операций. Для первого
уровня имеем макромагистральную обработку, для второго — ко-
мандно-магистральную обработку и для третьего — арифметико-
магистральную обработку.
Примером систем с магистральной обработкой на третьем
уровне являются хорошо известные арифметико-магистральные
системы STAR 100 и ASC. Обработка информации в магистрали
первой из систем осуществляется на четырех этапах, а в магист-
рали второй системы — на восьми этапах. Поэтому в магистрали
системы STAR 100 обрабатываются одновременно четыре слова
(длиной w = 64), а в магистрали системы ASC — восемь слов
(длиной w « 64), если магистрали заполнены. Одновременность
обработки слбв в магистралях можно записать в виде 64 X 4 и
64 X 8 для STAR 100 и ASC соответственно. Тогда, с учетом чис-
ла магистралей в рассматриваемых системах, их описание можно
представить в виде:
t(STAR 100) = (1, 2, 64X4);
f(ASC) == (1,4, 64X8).
Здесь значения выражений 64 X 4 и 64 X 8 показывают число
одновременно обрабатываемых битов информации в каждой ма-
гистрали соответственно. В дальнейшем для количества этапов
обработки данных в арифметической магистрали будем использо-
вать обозначение и/.
Применяя для описания произведение w X мы неявно
предполагаем, что количество этапов в каждой арифметической
магистрали является одним и тем же, что не всегда выполняется
на практике. Так например, в системе STAR 100 магистраль для
сложения имеет четыре этапа, а магистраль для умножения —
шесть этапов. Поэтому описание системы в виде (1, 2, 64X4)
является отчасти приближенным. Эту неточность можно было бы
427
исключить, если представить описание в виде (1, 64 X 4 + 64 X 6).
Однако при этом нарушается единая структура описаний и ухуд-
шается их наглядность. Наконец, функциональное различие ма-
гистралей системы STAR 100, что и является причиной разного
числа этапов в ее магистралях, придает ей признаки командно-
магистральной обработки. Напомним, что в системе ASC магист-
рали идентичны как в функциональном плане, так и в отно-
шении количества этапов обработки в них.
Введем теперь описания магистральной обработки для второго
и первого уровней, используя ту же методологию, что и. для
третьего уровня. При этом будем использовать обозначение d'
для количества арифметико-логических устройств при реализации
командно-магистральной обработки и обозначение А' для коли-
чества устройств управления при реализации макромагистраль-
ной обработки.
Системы с командно-магистральной обработкой содержат мно-
жество функциональных устройств, которые могут одновременно
выполнять обработку под управлением одной программы, мно-
жество очередных команд которой передается без конфликтов в
динамике счета соответствующим функциональным устройствам
обработки. Такой метод в литературе называется также опере-
жающим просмотром команд и параллельностью функциональных
устройств.
Типичным примером командно-магистральной системы явля-
ется CDC 6600. Если не учитывать ее периферийные процессоры,
то внутренняя структура системы может быть описана в виде:
^(Центральная часть CDC 6600) = (1, 1 X 10, 60). В этой системе
10 специализированных арифметико-логических устройств (т. е.
d' == 10), таких как устройства умножения с плавающей запятой,
сложения целых чисел, приращения, логических операций и т. п.,
могут в наиболее благоприятном случае одновременно выполнять
обработку. Реальная средняя загрузка устройств на практике
оказывается, конечно, более низкой. В качестве второго типич-
ного примера командно-магистральных систем можно указать
CDC 7600, описание центральной части которой можно предста-
вить в виде: ^Центральная часть CDC 7600) «= (1, 1 X 9, 60).
Перейдем к макромагистральной обработке. Напомним, что
если, например, в простейшем случае нужно решить последова-
тельно две различные задачи и при этом нужно использовать
одно и то же множество данных, то такую обработку можно вы-
полнить при помощи двух различных процессоров, каждый из
которых будет занят решением одной задачи. Данные вводятся
в первый процессор, предназначенный для решения первой за-
дачи, и размещаются в одном или нескольких блоках его памяти,
к которым второй процессор также имеет доступ, что позволяет
ему получать данные для решения второй задачи. В течение того
времени, когда второй процессор не ожидает результатов работы
первого и оба процессора ведут обработку одновременно (над
428
различными данными), эффективная скорость обработки достига-
ет суммы скоростей обработки данных каждым из процессоров»
В более сложных случаях такой метод макромагистральной обра-
ботки может быть распространен на несколько процессоров.
Если рассмотреть структуру системы РЕРЕ более подробно,
чем это было сделано выше в примере № 5, и учесть возможности
организации макромагистральной обработки при помощи корре-
ляционного устройства, арифметического устройства и ассоциа-
тивного выходного устройства в каждом из 288 элементарных
процессоров, то без учета общего управления системой ее струк-
туру можно описать в виде
J(PEPE) = (1 X Зс288, 32),
т. е. реализуется трехэтапная макромагистральная обработка ;
(£' = 3).
Таким образом, описание структур систем состоит в общем
случае из упорядоченной тройки, каждый элемент которой пред-
ставляет собой произведение двух соответствующих величин:
t(a) == (кХ к', dX d', w X w').
Здесь, как и ранее, через а обозначен тип или наименование си-
стемы. Количество одновременно работающих устройств управле-
ния по независимым программам или по независимым ветвям
большой программы, как в обычных многомашинных и многопро-
цессорных системах, обозначено через Л, а количество одновре-
менно работающих устройств управления при макромагистраль-
ном режиме обработки системы — через к'. Количество одновре-
менно работающих в параллель арифметико-логических устройств
(как в матричных системах), приходящихся на одно устройство
управления, обозначено через d, а количество одновременно рабо-
тающих в одной магистрали специализированных по командам
(операциям) арифметико-логических устройств с реализацией про-
смотра команд вперед, как в командно-магистральных системах,
обозначено через d'. Наконец, количество одновременно и парал-
лельно обрабатываемых двоичных разрядов информации обраба-
тывающим устройством (длина слова) обозначено через а ко-
личество4 этапов обработки в арифметической магистрали ариф-
метико-магистральных систем — через w'.
Такая детальная расшифровка описания структур систем при-
ведена, чтобы подчеркнуть единство трех уровней описания во
всех случаях, с одной стороны, и совмещение двух способов рас-
параллеливания на каждом уровне, с другой стороны.
В конкретных системах могут не использоваться те или иные
возможности распараллеливания, например, возможно к ** 1 илу
к' == 1 или же d = 1 и так далее. В этих случаях целесообразно
использовать сокращенные формы описания:
(1 X к\ d X d't w X w') « (X k\ dXd\ wX w'\ если к' + 1; ,
429
(к X 1, d X d', w X w') = (Zc, d X d', w X w')\
(к Xk't IX d', w X w') = (A X k\ Xd\ wX w'), если d' 1;
(к X fc', d X 1, w X w') = (к X k\ d, wX w’)\
(k Xk\ d X d', 1 X w') =» (к X k', dXd', X u>'), если w' 1;
(к X k', dXd', w X 1) = (к X k\ dXd', w).
Если более чем одна из рассматриваемых величин равна 1, то
описание соответственно сокращается. Знак умножения для слу-
чаев к = 1 или d = 1 или же w = 1, если Л' =#= 1, d' 1 и w' 1,
соответственно, оставлен для того, чтобы отличать в этих случаях
позиции для описания магистральности. Вместе с тем, если в
системах не предусматривается тот или иной вид магистральной
Обработки, то описание приближается к исходной тройке и, в
пределе при к' = d' = w' = 1, описание принимает исходный вид
тройки t(a) (к, d, w).
Рассмотрим теперь кратко вопросы соответствия описания
структур вычислительных систем возможностям распараллелива-
ния вычислительных процессов. В 1197] выделены следующие
основные типы параллелизма в вычислительных процессах.
Параллелизм независимых ветвей задачи (первый тип) со-
стоит в том, что отдельные большие разделы задачи могут ре-
шаться независимо друг от друга, лишь время от времени обме-
ниваясь между собой результатами. Параллелизм смежных опе-
раций (второй тип) состоит в том, что результат выполнения
некоторой операции не обязательно используется в качестве
входного операнда в последующей за ней операции, а может быть
и в нескольких последующих операциях, вследствие чего эти
смежные операции могут выполняться одновременно. Паралле-
лизм обработки данных о множестве объектов (третий тип) со-
стоит в том, что для задач, имеющих дело с массивами инфор-
мации, нередко можно одновременно проводить почти идентичную
обработку данных о большом числе одинаковых или почти оди-
наковых объектов. В более общем случае в задаче используется
естественный параллелизм и она сразу формулируется по возмож-
ности в наиболее параллельном виде.
Параллелизм независимых ветвей задачи находит свое есте-
ственное воплощение при построении систем, у которых к > 1.
Типичными представителями таких систем являются многома-
шинные и многопроцессорные системы. Параллелизму смежных
операций соответствует d' > 1, т. е. командно-магистральная об-
работка. Наконец, параллелизму обработки данных о множестве
объектов соответствует d > 1, т. е. матричная, ассоциативная и
подобная им обработка. Следует отметить, что здесь речь идет
о наибольшем соответствии отдельных типов параллелизма вы-
числений отдельным типам структуры вычислительных систем,
тогда как на практике задачи содержат в себе обычно, в той или
иной мере, параллелизм различных типов, а вычислительные си-
430
стемы, в свою очередь, нередко совмещают в себе структуры
более одного тина. Вместе с тем, если на вычислительной систе-
ме, имеющей явно выраженный тип структуры, реализовать вы-
числения с явно выраженным типом параллелизма, не соответ-
ствующим типу структуры вычислительной системы, то произ-
водительность и загрузка оборудования последней снижаются,
причем для некоторых сочетаний типов параллелизма и типов
вычислительных систем это снижение может быть значительным.
Можно отметить и другие случаи соответствия типов парал-
лелизма вычислений и типов структур вычислительных систем.
Так, например^ необходимость оперирования с многоразрядными
словами данных привела с самого начала к построению ариф-
метико-логических устройств с параллельной обработкой разря-
дов слов (w > 1). Возможность расчленения арифметических и
некоторых других операций на этапы привела, к построению си-
стем с арифметико-магистральной обработкой (w' > 1). Наконец,
кажущийся на первый взгляд несколько искусственным макро-
магистральный способ обработки (А/ > 1) также отражает до-
статочно распространенные виды параллельности вычислений.
В работе [197] рассмотрен пример организации вычислений, опи-
сываемый ниже, который можно отнести к организации макро-
магистральной обработки.
Пусть требуется решить на многопроцессорной системе круп-
ную задачу, приче*м ее решение содержит много циклов с боль-
шим объемом вычислений. Тогда работу процессоров можно орга-
низовать так.
В течение любого, например, /-го цикла накапливаются ис-
ходные данные для следующего цикла вычислений. В это же
время первый процессор осуществляет свою часть обработки дан-
ных, накопленных в (/—1)-м цикле, и готовит массив данных для
топ части программы, которая должна исполняться вторым про-
цессором. Одновременно с этим второй процессор выполняет свою
часть программы и использует при этом тот массив, который был
подготовлен первым процессором в (i—1)-м цикле по данным,
принятым в (i — 2)-м цикле, и готовит массив данных для той
части программы, которая должна исполняться третьим процессо-
ром, и так далее. Ясно, что программа может быть распределена
между большим количеством процессоров, при этом, как обычно
для магистральной обработки, получение конечного результата
отстоит от момента получения исходных данных на все время
прохождения обработки через все процессоры магистрали, хотя
средняя скорость обработки может быть близкой к суммарной
скорости работы процессоров организованной магистрали.
Отметим, что выше рассматривались возможности распарал-
леливания вычислений при выполнении одной программы. При
этом во всех случаях не исключалась возможность организации
мультипрограммной работы. Отметим также, что с увеличением
степени параллельности любого типа на любом уровне обработки
431
средняя производительность системы возрастает, хотя средняя
загрузка ее оборудования може1 и уменьшиться. Последнее мо-
жет привести к уменьшению отношения производительности к
стоимости, что является одним из главных препятствий на пути
массового распространения высокопараллельных вычислительных
систем.
Возможность реализации магистральной обработки на различ-
ных уровнях вычислительной системы говорит, с одной стороны,
об универсальности принципа магистральной обработки и, с дру-
гой стороны, о том, что вряд ли будут развиваться «чисто ма-
гистральные системы». Действительно, рассмотренные примеры
реальных магистральных систем говорят скорее о том, что в этих
системах сделан акцент на магистральную обработку, но в целом
они являются все же системами с комбинированной структурой.
В этой связи следует напомнить об определенной условности
класса МКОД как самостоятельного класса вычислительных си-
стем, к которому и только к которому могут быть отнесены те
или иные вычислительные системы (см. п. 2.7.2). Эти вопросы
рассмотрены в работах [494, 693, 8001. 1
В заключение отметим, что детальное описание иерархических
уровней вычислительных систем содержится в [3841.
8.1.2. Операции над формальными описаниями структур систем
[796, 800]. Если ввести операции над упорядоченными тройками,
то появляется возможность более полного формального описания
вычислительных систем со сложными структурами и, кроме этого,
такие описания могут быть полезными для выбора структур ал-
горитмов задач, предназначенных для решения на вычислитель-
ных системах. Так например, для систем, структура которых
представляет собой комбинацию нескольких различных структур,
описание можно составить из описаний каждой частной структу-
ры и соединить эти описания знаком умножения.
В п. 8.1.1 приведено описание структуры центральной части
системы CDC 6600. Построим теперь описание структуры системы
CDC 6600 в целом:
t(CDC 6600) « (10, 1, 12) X (1, ХЮ, 60).
Первая тройка, стоящая справа от знака «-=», описывает сово-
купность периферийных процессоров, составляющих простую
структуру из десяти двенадцатиразрядных процессоров. Вторая
тройка, как и ранее, описывает центральную часть системы. Знак
умножения здесь показывает, что все программы должны сначала
пройти через периферийные процессоры и после этого попадают
на центральный командно-магистральный процессор (1, ХЮ, 60).
Построим теперь описание структуры системы CDC 7600 в це-
лом (сравните с описанием центральной части, приведенным в
п. 8X1):
KCDC 7600) - (15, 1, 12) X (1, Х9, 60).
Эта система может использоваться как управляющая в соста-
ве системы РЕРЕ. С учетом этого описание системы РЕРЕ можно
представить в виде:
КРЕРЕ) « (15, 1, 12) X (1, X 9, 60) X (ХЗ, 288, 32)
(сравните с описанием структуры элементарных процессоров си-
стемы РЕРЕ и с более ранним описанием структуры модуля си-
стемы РЕРЕ, приведенными в п. 8.1.1).
С другой стороны, может быть выполнена декомпозиция опи-
саний. Так, например, структуру системы CDG 7600 можно пред-
ставить в виде:
(15,1,12) х (1, X 9,60)=[(1,1,12)+(1,1Л2)+...+(1Л,12)]х (1, X 9,60),
16 раз
полагая '
(г, d, w) = (1, d, w) + (1, d, w) + ... + (1, d, w).
г раз
Последний пример показывает, что 15 идентичных, процессо-
ров работают параллельно.
' Для описания систем с перестраиваемой структурой исполь-
зуем операцию «исключающее или», которую обозначим симво-
лом®. Для построения описания в целом следует составить опи-
сания каждой из возможных структур и, поскольку они являются
взаимоисключающими и в каждый момент времени работы си-
стема настроена на одну из них, соединим полученные описания
при помощи операции®- Так например, выражение для описа-
ния структуры системы С. mmp с учетом трех ее операционных
режимов можно представить в виде':
КС. mmp) = (16, 1, 16)® (X 16, 1, 16)®(1, 16, 16)
(сравните с описанием в п. 8.1.1, пример 7). Отметим, что если
перемножить значения составляющих каждой из троек, то во
всех случаях получим 256, что показывает постоянство степени
параллелизма для всех трех операционных режимов системы.
Иными словами, в данный момент времени при полной загрузке
в системе осуществляется обработка 256 бит информации с при-
менением того типа распараллеливания, который соответствует
текущему операционному режиму системы С. mmp. Число 256 оп-
ределяется, естественно, тем, что в систему входят 16 16-разряд-
ных машин PDP-11.
В качестве второго примера рассмотрим проект системы EGPA
(Erlangen General Purpose Array) [795—7981. Ограничимся слу-
чаем матрицы 4X4 идентичных процессоров, каждый из которых
оперирует с 32-разрядными словами*) (рис. 8.2).
*) В первых работах по системе EGPA говорится о 64-раэрядных про-
цессорах.
28 в. Л. Головкин 433
Каждый процессор системы может работать параллельно с
другими, как обычный процессор, над 32-разрядами слова или
же, в другом режиме, как 32 параллельных друг другу однораз-
рядных процессора. Далее, каждый процессор связан при помощи
шины со своим блоком памяти и, кроме этого, связан при помощи
шин с блоками памяти четырех соседних процессоров. Все про-
цессоры образуют матричную конфигурацию. Имеются дополни-
тельные процессоры, которые показаны на рисунке 8.2 в левой
колонке. Они' функционируют как отдельные устройства ввода-
вывода и как процессоры операционной системы, планируя ра-
боты системы и обеспечивая синхронизацию работы ее основных
процессоров.
Система EQPA может функционировать в одном из четырех
операционных режимов. В первом режиме она работает как
шины
Рис. 8.2. Структурная схема системы EGPA.
16 независимых 32-разрядных обычных процессоров, функциони-
рующих параллельно. Во втором режиме она работает как цепь
из 16 32-разряднбх обычных процессоров, образующих макрома-
гистральную систему. В третьем режиме система EGPA работает
как матричная система с одним устройством управления и 16
434
32-разрядными обычными арифметико-логическими устройствами.
Наконец, в четвертом режиме система обрабатывает в
16 X 32 = 512 бит информации и работает как ассоциативная Си-
стема. С учетом сказанного, описание системы EGPA можно пред-
ставить в виде:
J(EGPA) = (16, 1, 32) Ф (X 16, 1, 32) Ф (1, 16, 32) Ф (1, 512, 1).
Ясно, что подобные системы являются очень гибкими. Опи-
сание наглядно демонстрирует это свойство и показывает тип и
числовые характеристики параллельности.
Система EGPA может быть разбита на несколько частей, каж*>
дая из которых может работать в одном из четырех перечислен-
ных выше режимов. Так, например, возможно
i'(EGPA) = (1, 1, 32) + (7, 1, 32) + (1, 256, 1)
или
Г'(EGPA) « (3, 1, 32) + (Х2,1, 32) + (1, 7, 32) + (1, 128, 1).
Из рассмотренного ясно, что справедливы соотношения
(кх к', dxd', wxw') = fe(xfc', dxd't =
=(X к',dX df,wX ш')+(X k'.dX d'X w') +... +(X k',dX d',wX w')
h раз
И
(k, X k\ d X d', wX4') + (k2 Xk’, dX d', wX »') =
— ((ki + ftj) X Л', dX d't w X u>'),
первое из которых может рассматриваться как правило умноже-
ния и его выражение при помощи операции сложения, а второе
соотношение — как правило сложения. В первом случае слагае-
мые идентичные, а во втором — различные в части величины к.
* При рассмотрении описаний структуры систем и операций над
ними предполагалось, что d X d' и wX iff' являются постоянны-
ми. Это справедливо для систем со структурой, подобной структу-
ре С. mmp. Для структуры типа системы EGPA, однако, имеет
место соотношение:
(к X к', di X d', iffi X w') — (kX к', (dI • с) X d', (w\/c) X ш'),
причем значения выражений d = d] • с и w = W\fc должны быть
целыми (как и делитель с для Для структуры системы EGPA,
конкретно, можно записать:
t(EGPA) °= (к, dj, wi) — (к, di • с, w\/c).
Например, для этой структуры можно обеспечить w — 1, или ш>=8,
или же ш = 32. Это дает возможность осуществлять побитовую,
28» «5
побайтную или пословную обработку соответственно. Тогда ис-
ходное описание (16, 1, 32) для де = 32 можно представить, на-
пример, в виде:
KEGPA) -= (1, 512, 1) « (1, 64, 8) « (1, 16, 32)
для де = 1, 8 и 32 соответственно (первое и третье описания рас-
сматривались выше).
Описания структур систем дают естественную основу для вве-
дения одной из возможных мер гибкости систем. Если меру гиб-
кости определить как количество различных операционных ре-
жимов системы, получаемых при перестройке ее структуры,
и обозначить эту меру через F(t(a)\ то можно записать:
F(f (а)) =|(Л1ХА{, diXdJ, н^Хa/i)©(ftaXfta, d8xd8, де8Хде^)©.. .|,
где операция 11 дает количество троек, соединенных символом
Для примеров систем, рассмотренных выше, получаем:
F(t(C. mmp)) = 3 и FU(EGPA)) « 4.
8.2. Производительность и стоимость 1
параллельных вычислительных систем
8.2.1. Оценка и прогноз увеличения производительности парал-
лельных вычислительных систем. Оценка производительности
вычислительных систем всегда была и остается одной из слож-
ных проблем. Вычислительные системы имеют различную орга-
низацию структуры и функционирования, разнообразные наборы
команд и применяются для решения разцых задач. Одна и та
же задача может решаться на данной системе по разному и при
этом будет затрачено разное время. Одна из двух систем может
обеспечить более быстрое решение данной задачи по сравнению
со второй системой, а при решении другой задачи вторая система
может оказаться более быстрой. При этом с переходом от одпо-
программного режима обработки к мультипрограммному и от
последовательной обработки к параллельной оценка производи-
тельности становится еще более сложной задачей. Поэтому имею-
щиеся оценки производительности нрредко существенно отлича-
ются друг от друга, в том числе и некоторые из приведенных в
настоящей книге.
Системы первого и, частично, второго поколения оценивались
по числу команд, в основном арифметических, выполняемых в
течение секунды. Для систем второго поколения с развитыми ло-
гическими возможностями и, в особенности, для систем третьего
поколения потребовались более общие понятия производитель-
ности, учитывающие скорость работы и возможные простои цент-
рального процессора, емкость основной памяти и возможности
обмена, с периферийным оборудованием, возможности быстрых
регистров, длину и переменные форматы слов и другие факторы.
Если вначале достаточной для оценки производительности
считалась скорость выполнения операций сложения, то в даль-
436
нейшем производительность стала оцениваться путем приведения
исходной системы команд к одноадресной системе и полагалась
равной средней скорости выполнения одноадресных команд всех
типов с учетом частоты их появления в динамике счета. Были
составлены таблицы частоты появления операций разных типов
для задач различных классов, на основании которых, зная дли-
тельность выполнения операций данной машины, нетрудно вы-
числить ее производительность.
Эта методика, в силу ее простоты, нашла широкое распро-
странение, хотя и имеет очевидные недостатки (одна и та же опе-
рация в разных последовательностях команд занимает обычна
различное Время, процедура приведения системы команд к одно-
адресной неформализована и получаемые в результате данные
могут быть в достаточной степени различными). Кроме этого,
существуют специально разработанные наборы процедур (учиты-
вающие, в частности, частоты появления операций) по времени
выполнения которых оцениваются и сравниваются между собой
производительности вычислительных систем. Среди подобного ро-
да методик широкое распространение получила известная мето-
дика Гибсона.
Для оценки производительности привлекаются аналитические
методы, методы измерений в процессе работы систем при помощи
программных и аппаратных средств, методы моделирования и
другие. Рассмотрение таких методов представляет самостоятель-
ный интерес. Здесь рассматривается одна, из методик оценки
производительности и прогноз увеличения производительности
параллельных вычислительных систем, основанный на ее приме-
нении 11229, 1232] (основные результаты [1229] воспроизведены
в обзоре [257]). Прогноз делается для параллельных систем, по-
скольку именно они обладают наиболее высокой производитель-
ностью. При этом рассматриваются, скорее, те характеристики,
которые могут быть достигнуты.
Рассмотрим простые модели для оценки производительности
вычислительных систем. Начнем с однопроцессорных систем.
Время выполнения tei команды i-ro типа складывается для
систем с одноадресной системой команд из времени двух циклов
работы верхнего уровня иерархической памяти tm для выборки
команды и операнда и времени собственно выполнения коман-
ды i-ro типа:
tci e
где km — коэффициент степени «доступности» памяти, характери-
зующий эффективность совмещения во времени процессов вычис-
лений и обращения к памяти, например, за счет просмотра
вперед. При полном совмещении, когда процесс вычислений не
приостанавливается из-за ожидания при обращениях к памяти
для выборки команд и операндов, достигается наивысшая эффек-
тивность совмещения и в этом случае /стет0. Если же, наоборот,
437
При каждой выбррке команды и операнда вычисления приоста-
навливаются в ожидании их поступления, то совмещение отсут-
ствует и в этом случае &т я 1. В промежуточных случаях имеем
частичное совмещение. Таким образом, величина кт может иметь
значения 0 < кт 1.
Теперь нужно учесть частоты появления операций разного
типа в динамике счета. Если, упрощая эту задачу, принять, что
сложения с фиксированной запятой представляют все короткие
операции, а умножения с фиксированной или плавающей запя-
той — все длинные операции и обозначить долю первых через к+,
а долю вторых — через кх, так что к+ + кх = 1, то среднее время
выполнения операции можно выразить в виде:
1в == + kytx -J- 2kmtmi
где t* и tx — время выполнения указанных операций сложения
и умножения соответственно, когда они выполняются как опера-
ции типа «регистр-регистр». Тогда производительность системы
8 можно вычислить по формуле
5 = 4-. (1)
е
Многочисленные статистические данные показывают, что при
решении научных задач (задач вычислительного характера) име-
ет место, обычно, к* == 0,7 и кх » 0,3, поэтому
= 0,7i+ + 0,3$х 4- (2)
Полученные соотношения характеризуют также и производи-
тельность командно-магистральных систем. Действительно, основ-
ные факторы, определяющие их призводитегльность, являются
теми же, что и у однопроцессорных систем: обычная организация
центральной части системы, если совокупность функциональных
блоков обработки рассматривать как единый центральный про-
цессор, просмотр вперед команд и данных и другие. При этом,
конечно, значения параметров будут, как правило, лучшими,
а именно, величина кт — меньше из-за лучших возможностей ор-
ганизации опережающего просмотра, а величины t± и tx — мень-
ше из-за специализации обрабатывающих блоков.
Перейдем к арифметико^магистральным системам. Здесь необ-
ходимо учитывать последовательное прохождение потока данных
через магистраль М специализированных блоков обработки и од-
новременное выполнение при этом нескольких команд.
Итак, пусть в последовательности вычислений обрабатывает-
ся большое число N слов данных, при этом обработка разбита на
М подзадач, каждая из которых выполняется на одном из М
соответствующих устройств, последовательность которых образу-
ет магистраль обработки. В идеальном случае каждое устройство
занимает примерно одно и то же время t9 в последовательности
обработки1 в магистрали. Тогда первый результат будет получен
через Mt, единиц времени, второй — через Mt9 + t9, третий — че-
438
рез Mt. + 2t. и так далее. Если учесть время То предварительной
настройки структуры магистрали на обработку, то общее время
обработки N слов в магистрали будет То + ЛЛ, +0V—1)£„ а сред-
нее время обработки одного слова данных (среднее время выпол-
нения одной операции) будет:
в~~ N
При увеличении N величина Т« асимтотически приближается к ta.
Арифметико-магистральные системы обладают особенно боль-
шими возможностями по совмещению процессов вычислений и
выборки команд и данных, их структура непосредственно реали-
зует опережающий просмотр. Поэтому для них в идеальном слу-
чае можно принять кт == 0. Если (также в идеальном случае) при
этом поток данных непрерывно проходит через все М модулей, то
максимальная производительность магистральной системы оказы-
вается в М раз выше производительности одного процессора с
такими же характеристиками, как у одного модуля магистрали.
Если считать, что М = 4. то
_ +0,3*х
= 4
(3)
Рассмотрим теперь матричные системы. В таких системах ко-
манда выполняется с различными данными в N совместно рабо-
тающих операционных процессорах.
В идеальном случае при одновременной работе N операцион-
ных процессоров производительность S матричной системы
оказывается (в пределе) в N раз выше производительности S?
одного операционного процессора, поэтому
S = NSP.
В более реальных случаях нужно учитывать понижение произ-
водительности по сравнению с предельной:
S = kNSp,
где к — коэффициент снижения производительности (1/А^ к < 1).
Учитывая относительную простоту операционных процессоров
и их большое число, следует считать, что т. е. учитывать
наихудший случай. Тогда для одного операционного процессора
име&и:
te ®= 4- 0,3^х +
а для всей матричной системы получаем:
; 0,7^ + 0^x+2fm
---------kN * ™
Перейдем к ассоциативным системам. Здесь нужно учитывать,
что системы с ассоциативными процессорами можно рассматри-
вав
вать как специальный случай матричных систем, в которых N <
процессоров представляют собой простые устройства, как правило,
последовательной поразрядной обработки и имеют только по одно-
му слову большой длины в блоке ассоциативной памяти, т. е.
каждое слово блока ассоциативной памяти имеет свое собственное ।
устройство обработки. Выполнение операций осуществляется од-
иовременно всеми процессорами. ;
Ассоциативная память имеет возможность одновременно
сравнивать информацию каждого слова ассоциативной памяти с
некоторым рассматриваемым (входным) словом. Таким образом, *
различные операции поиска могут выполняться с высокой сте-
пенью совмещенности. Элементарные последовательные процес- \
соры, в свою очередь, также могут совместно выполнять специ- ‘J
фические операции над всеми или над выбранным подмножест- <
вом*слов ассоциативной памяти.
Напомним, в качестве примера, что один из прототипов ассо-
циативной системы STARAN IV содержит ассоциативную па- j
мять на 256 слов по 256 бит в каждом и 256 последовательных j
процессоров. '
Отношение времени обработки N n-разрядных слов однопро- <
цессорной системой к времени обработки этого же количества 1
л-разрядных слов ассоциативной системой определяется следую- \
щим выражением:
ка*ап + W J
Ассоциативная система (МИ слов по т разрядов в каждом) |
характеризуется здесь при помощи времени цикла ассоциатив- j
ной памяти ta и коэффициента сложности выполнения элемен- 1
тарной операции ка (количество последовательных шагов, каж- * j
дый из которых связан с доступом к памяти). Однопроцессорная
система обрабатывает п разрядов в параллель и имеет длитель-
ность цикла памяти tu. Коэффициент сложности выполнения опе-
рации ки выражается через количество циклов памяти, суммар-
ная длительность которых равна времени выполнения операции.
Так, например, для операции сложения ки « 2, если в однопро-
цессорной системе не предусмотрено перекрытия во времени
между доступом к памяти и собственно выполнением сложения;
для операции умножения можно считать, что 5 < ки С 10. Если
N > РГ,‘ то требуется загрузка ассоциативной памяти из памяти
более низкого уровня иерархии. Во всех разработках ассоциатив-
ных систем предусматривается параллельная загрузка ассоциа-
тивной памяти (быстрая подкачка) словами из очень быстрой па-
мяти большой емкости.
Из выражения (5) видно, что ассоциативная система может
иметь преимущество по сравнению с однопроцессорной, если:
440
— количество обрабатываемых слов N намного больше числа
л разрядов в слове;
— в ассоциативной обработке используются преимущественно
простые операции (количество операций сложения ж вычитания
больше, чем количество операций умножения);
— время цикла ассоциативной памяти невелико по сравнению
с временем цикла памяти однопроцессорной системы.
Рассмотрим теперь многопроцессорные системы. Если система
содержит N одинаковых процессоров, то ее производительность
можно оценить при помощи выражения:
0,7«+ + 0,ЗГх+2Мт’ W
где kN определяет затраты на организацию работы N процессоров
в составе системы и управление ими. В качестве возможных зна-
чений величины kjf можно использовать къ ж 0,3 и Дц = 0,5.
Производительность многомашинной системы S(N), содержа-
щей N машин с производительностью каждой, можно оценить
как
N
S(N)^kiSl, (7)
1=1
где ^ — коэффициент, учитывающий затраты на комплексирова-
ние i-й машины (0<Л«<1). Многомашинные системы и вычис-
лительные сети не имеют принципиальных структурных ограни-
чений для наращивания.
Зная необходимые количественные характеристики сущест-
вующих систем, нетрудно вычислить их производительность при
помощи соответствующих соотношений (1)—(7). Для прогноза
увеличения производительности необходимо предварительно вы-
полнить прогноз изменен^ этих количественных характеристик.
Отправной точкой здесь являются существующие и прогнози-
руемые характеристики элементной базы. Далее выбираются при-
емлемые алгоритмы быстродействующей арифметики, рассматри-
ваются возможные их улучшения и оцениваются характеристики.
Например, большая глубина предварительного просмотра может
быть достигнута в сумматорах и достаточно точно может быть
определена аппаратура для умножения. Наконец, архитектура
памяти предполагается такой, чтобы оцениваемый цикл обраще-
ния к устройству памяти верхнего уровня иерархии (кэш или ре-
гистровый стек) соответствовал скорости процессора настолько
близко, насколько это возможно.
Далее возникает проблема выбора структуры устройства уп-
равления и методов распараллеливания. Например, в устройстве
управления могут быть использованы особенности опережающего
просмотра команд и данных для улучшения степени «доступно-
сти» памяти. Большая глубина опережающего просмотра, веро-
ятно, должна использоваться в однопроцессорных ж командно-
441
магистральных системах. Она не является такой важной в боль-
ших матричных системах, в которых высокая скорость обработки
достигается благодаря распараллеливанию вычислений на множе-
стве обрабатывающих устройств, при этом сами обрабатывающие
устройства могут быть относительно простыми.
На последнем этапе разработки прогноза применяются рас-
смотренные выше соотношения.
Данные прогноза технически достижимых характеристик па-
раллельных вычислительных систем на период до 1990 г. приве-
дены в таблице 8.1. В этой же таблице приведены характеристи-
Прогноз увеличения производительности
Тип ВС Год Время сложе- ния t [нсек] • Время умно- жения <х(исек] Время цикла памяти *т1нсек]
Командно-магистральные ВС (однопроцессорные) 1968 1985 1990 55 . 1,2-2,4 0,7-1,2 135 16-32 6-10 5,6 3
Арифметико-магистраль- ные ВС (одна магистраль) 1973 1985 1990 1,2-2,4 0,7-1,2 16-32 6-10
Матричные ВС 1974 1985 1990 625 1,8-3,5 0,9-2,5 25-50 12-30 438 5,6 . 3
Многопроцессорные ВС 1972 1985 1990 300 1,8—3,5 0,9-2,5 25-50 12-30 75 5,6 3
442
ки одной из существующих систем каждого типа, выбранной в
качестве базовой (для характеристик, которые могут изменяться,
указаны наилучшие значения)» В качестве минимальных времен
задержек вентилей приняты значения порядка 0,2 и 0,06 нано-
секунды для 1985 и 1990 гг. соответственно. Напомним, что учи-
тывались операции типа «регистр-регистр» [1229, 12321.
Отметим, что данные прогноза содержат наиболее высокие,
я не средние технически достижимые характеристики. Это относит-
ся не только к предполагаемым характеристикам элементной ба-
зы, но и к характеристикам схемных решений, структур уст-
Таблица 8.1
параллельных вычислительных систем
Степень «до- ступности»» памяти Среднее вре- мя выполне- ния опера- ции £нсек| Производи- тельность S (млн. оп. /сек| Примечания
0,125 0,1 80 7—12,6 2,8—3,9 12,5 142-79 346-225 • 1. Представителем су- ществующих ВС выбрана CDC 7600 (1968 г.) 2. Данные для 64-раз- рядных слов
0 0 0 40 1,4-2,8 0,58—0,96 25 715-354 1740-1040 1. Представителем ~ су- ществующих ВС выбрана одна ма- гистраль STAR 100 (1973 г.) , 2. Данные для 64-раз- рядных слов
1 1 1 500 19,9—28,6 10,2—16,7 4 N=1 2 50-35 98-60 N=64 128 3200-2240 6270-3840 1. Представителем су- ществующих ВС выбрана ILLIAC IV (1974 г.) 2. Данные для 64-раз- рядных слов 3. N — число элемен- тарных процессоров
о,7б 0,2 11,6-20,3 5,5-12 N=1 13 86-50 182-83 N=4 6,3 300-175 637—290 1, Представителем су- ществующих ВС выбрана, UN1VAC 1110 (1972 г») 2, Данные для 64-раз- рядных слов 3. N — число процес- соров в BG
443
Тип ВС Год Время сложе- ния t (нсек] 'ремя умно- жения *х(нсек] Время цикла памяти t [нсек] WI
Ассоциативные ВС 1973 1985 1990 16 000 1400 800 • 556 000 31 000 16 700 100 5,6 3
ройств и структур систем. Во всех случаях предполагаются, па-
пример, идеальные условия распараллеливания всех видов.
Можно считать, что производительность однопроцессорных ко-
мандно-магистральных систем и многопроцессорных систем в наи-
меньшей степени зависит от характера решаемых задач по срав-
нению с системами других типов, приведенных в таблице 8.1.
Сравнительно небольшими изменениями производительности
характеризуются и арифметико-магистральные системы. В боль-
шей степени может изменяться производительность матричных
систем в зависимости от характера решаемых задач. При полу-
чении данных о производительности таких систем было принято,
что совмещение во времени процессов вычислений и обращений
к памяти в элементарных процессорах отсутствует, но рассматри-
вался случай полного распараллеливания по всем такпм процес-
сорам, т. е. при вычислении te полагалось кт = 1 и к 1 (см. вы-
ражение (4)).
Среди систем рассматриваемых типов наибольшие изменения
производительности в зависимости от характера задач, в том
числе состава операций, имеют место для ассоциативных систем
(Соответствующие условия перечислены выше). Сложилась точка
зрения, что такие системы следует применять либо для решения
Продол, табл. 8.1.
Операции поиска (логичес- кие) Арифметические операции S [млн. оп./сек] Примечания
^[нсек] Я[млн. оп./сек]й=256 И—1 *«256
6400 360 190 40 710 1350 0,006 0,097 0,18 1,5 25 46 1, Представителем су- ществующих ВС выбрана STARAN IV (1973 г, 256 слов) 2. /+=5л?ш , где п — длина слова 3. <x=(5n4-12n)tw 4. S=fc/(Q>7*++0,3*x) для арифметических операций и S~klt9 для логических опе- раций, где к — чис- ло элементарных последовательных процессоров (слов в ассоциативной па- мяти) 5. Данные для 32-раз- рядных слов
специализированных задач, соответствующих возможностям этих
систем, или же комплексировать их с теми или иными универ-
сальными системами.
В связи с тем, что эффективность матричных систем сущест-
венно зависит от возможностей распараллеливания алгоритмов
по множеству элементарных процессоров, типичными областями
их применения можно считать решение задач линейного про-
граммирования, выполнение векторных й матричных операций,
обработку таблиц, обработку сигналов от множества датчиков,
распознавание и другие. В качестве характерных задач для ассо-
циативных систем можно назвать обработку радиолокационной
информации, поиск и идентификацию информации, решение за-
дач управления воздушным движением, распознавание и другие.
В настоящее время отсутствует единая общепринятая методи-
ка оценки ‘производительности параллельных вычислительных си-
систем. Поэтому к оценкам и, в большей степени, прогнозам увели-
чения производительности следует относиться как к потенциаль-
но возможным. Так, например, производительность многопроцес-
сорных систем, указанная в таблице 8.1, вычислялась по формуле
(6). Если учесть предлагаемые значения величин ^«0,3 и
= 0,5, то производительность двухпроцессорной системы S2 и
четырехпроцессорной системы выражается через* производи-
445
тельность соответствующей однопроцессорной конфигурации как
5a-l,75i; 3,5Si. (8)
Согласно другим данным [281], при введении в большую си-
стему второго процессора увеличение эффективности (производи-
тельности) составляет 60—80%. При этом отмечается, что во
время одного из специальных 10-часовых прогонов эталонного-
потока заданий через систему В 6700 наблюдалось возрастание
эффективности на 90%. При добавлении третьего процессора уве-
личение эффективности составляет только 30—50%. Отмечается,
что был зафиксирован случай, когда при введении второго про-
цессора эффективность повысилась на 80%. Однако, когда к этой
же системе был добавлен третий процессор, общая эффектив-
ность (производительность) составила всего лишь 210% от произ-
водительности однопроцессорной конфигурации, состоящей из тех
же аппаратных элементов. Такие результаты, вероятно, объясня-
ются влиянием программного обеспечения систем, поскольку опе-
рационная система не мойсет эффективно использовать имеющие-
ся функциональные блоки и один или даже два процессора не-
редко простаивают в бездействии, ожидая задания.
Используя эти данные, получаем, что в типичных случаях
52« (1,6 - 1,8)5>; 53 == (1,9 - 2,3)51. (9>
Наконец, согласна данным [1185] (воспроизведенным в [281]),
которые использовались для оценки производительности системы
UNIVAC 1108, производительность многопроцессорных систем 5V
можно оценивать согласно формулы:
_________ТУ
С Q -|- D -j- Е ’
где N — числох процессоров; С — длительность цикла памяти;
Q — задержка из-за очередей к памяти; D — аппаратная задержка
(в многомодульных адаптерах и т. д.); 2? —время, добавляемое
для учета длинных операций.
Если величины С, Q, D и Е выразить в микросекундах, то
производительность SN будет выражена в миллионах операций в
секунду. Величины С и D являются собственно параметрами си-
стемы, значение величины Е лучше всего получить из смеси Гиб-
сона или подобной ей смеси, а значение величины Q — на основе
анализа наиболее трудных случаев обращений к памяти.
Найдем верхнюю границу производительности однопроцессор-
ной конфигурации системы UNIVAC 1108. Полагая, что отсут-
ствуют очереди к памяти и нет аппаратурных задержек, что не
используются длинные операции, а также учитывая, что длитель-
ность цикла памяти составляет 750 нсек, получаем
51 = о"75 = 1»33млн. оп./сек.
446
Максимальная производительность с учетом длинных операций
будет
$1 = = 0,95 млн. он./сек.
* U,7o -f- U,о
Вычислим теперь производительность двухпроцессорной кон-
фигурации. Используем значения параметров системы С— 0,75
мксек и /> = 0,125 мксек, оценки £“0,3 мксек и данных моде-
лирования ^-0,5 мксек для двухпроцессорного случая. По-
лучим:
S* в 0,75+ 0,5 + 0,125 + 0,3 = 1,63 млн*оп^сек*
Таким образом,
Si-S1 __ 1,63 - 0,95 _ п 7,
Sj 0,95 ’
т. е.
S2- 1,715ь (10)
Сравнивая приведенные данные (8)—(10) и сопутствующие
им выкладки, можно сделать следующие выводы. Двухпроцессор-
ная конфигурация однородной многопроцессорной системы имеет,
в среднем, в 1,7 более высокую производительность по сравнению
с однопроцессорной конфигурацией этой же системы, причем, как
правило, указанное превышение может изменяться в пределах от
1,6 до 1,8. При вводе в состав системы третьего процессора про-
изводительность получаемой конфигурации, по-видимому, оказы-
вается в среднем в 2—2,2 раза более высокой по сравнению с
однопроцессорной конфигурацией. Верхняя граница отношения
производительности трехпроцессорной и четырехпроцессорной
конфигураций системы к производительности ее однопроцессорной
конфигурации представляет собой для благоприятных случаев
величины порядка 2,6 и 3,5 соответственно. Приведенные цифры
являются ориентировочными и требуют уточнения. Кроме
этого, они будут изменяться с изменением программного обес-
печения.
8.2.2. Отношение производительности к стоимости вычисли-
тельных систем. Известно, что с развитием вычислительной тех-
ники стоимость операций обработки информации уменьшается,
т. е. происходит увеличение отношения производительности к
стоимости вычислительных систем. Так, например, значение по-
казателя, представляющего собой число бит информации, обраба-
тываемых в секунду, отнесенное к единице стоимости, увеличи-
лось за время с середины 1950-х годов более чем в 1000 раз
[1229]. За период с 1967 г. по 1977 г. стоимость выполнения
одной команды снизилась в 100 раз, хранения одного байта ин-
формации в оперативной памяти — в 4 раза или более, а во
внешней памяти — в 3 раза, выполнения тысячи строк механи-
ческой печати —в 4 раза 1177]. Этому способствует улучшение
447
характеристик элементной базы, автоматизация проектирования
и изготовления, улучшение структур вычислительных систем и
их устройств, а также развитие программного обеспечения,
позволяющего лучше использовать ресурсы систем. Анализ соз-
данных в различные годы больших параллельных систем, таких
как STRETCH, CDC 6600, CDC 7600, IBM 360/195, ILLIACIV,
STAR 100, и данные прогноза показывают, что тенденция быстро-
го повышения отношения производительности к стоимости имеет
место и для больших параллельных систем [12291.
Следует отметить, что хотя стоимость выполнения одной ко-
манды в ближайшие 10 лет снизится, вероятно, еще на два по-
рядка, проблемы программного обеспечения, по-видимому, оста-
нутся еще нерешенными, так как производительность программи-
стов повышается только на 3% в год [1771.
Типичным является такое положение, что производительность,
(количество операций, выполняемых за единицу времени), отне-
сенная к стоимости, для высокоскоростных вычислительных
систем имеет большую величину по сравнению с низкоскорост-
ными системами. Согласно эмпирическому закону Гроша [784]
зависимость между производительностью и стоимостью вычисли-
тельных систем состоит в том, что повышение производитель-
ности систем в п раз сопровождается, в среднем, повышением их
стоимости в \п раз.
Наиболее высокие показатели производительности являются
привилегией параллельных систем. Поэтому, если решаемые за-
дачи требуют очень высокой производительности, то, несмотря ни
на какие другие факторы, будут применяться большие параллель-
ные системы. Всегда имеются подобные важные задачи и поэтому
всегда существует актуальная область применения больших па-
раллельных систем.
Ясно, что в деле увеличения выпуска и расширения области
применения высокопроизводительных и сверхвысокопроизводи-
тельных вычислительных систем, одним из главных факторов яв-
ляется повышение отношения их производительности к стоимо-
сти. Для таких систем это особенно важно: хотя в количествен-
ном отношении они составляют несколько процентов от общего
числа вычислительных систем, но по стоимости их удельный вес
на порядок больше.
Новые серийные большие параллельные системы находятся
по показателю отношения производительности к стоимости в ря-
ду лучших образцов вычислительной техники. Это относится, на-
пример, к магистральной системе 470 V/6 и последовавшими за
ней системами 470 V/5, 470 V/6—2 и 470 V/7 фирмы Amdahl. Со-
ответствующие данные для этих систем и для различных систем
фирмы IBM приведены в таблице 8.2 [386]. Напомним, что ука-
занные системы фирмы Amdahl и системы семейств IBM 360
и IBM 370 совместимы, поэтому их сравнение представляет осо-
бый интерес.
448
Из таблицы видно, что в число систем, для которых величина
отношения производительности к стоимости превышает единицу,
попали высокопроизводительные большие системы — все пере-
численные выше системы фирмы Amdahl, старшие модели
семейства 370 фирмы IBM и системы нового семейства
ЗОЗХ фирмы IBM.
Здесь уместно отметить следующее (см. обзор 1386J). На раннем
этапе развития вычислительной техники сверхвысокопроизводи-
тельные системы выполняли в большей степени исследователь-
ские функции, чем практические. При их создании находились
и апробировались новые структурные решения, использова-
лась прогрессивная технология, что bi дальнейшем находило при-
менение при создании других образцов вычислительной техники.
Таблица 8.2
Изменение отношения производительности к стоимости вычислительных систем ,
(за образец сравнения взята ЭВМ IBM 370/148, производительность которой
пооядка 500 тыс. опер/сек условно принята за 20 единиц)
Модель S f n rt о Емкость опе- ративной па- мяти (млн. байт] Стоимость [тыс. долл.] Относи- тельная произво- дитель- ность Отношение производи- тельности к стоимости Гоп./сек! 1 долл. J
IBM 360/30 1965 0,065 178 1,75 0,25
IBM 360/40 1965 0,131 307 3,5 0,28
IBM 360/50 1965 0,262 663 9 0,35
IBM 360/65 1965 0,512 1360 22 0,4
IBM 370/145 1971 0,512 940 16. 0,43
IBM 370/155 1971 1 .1515 31 0,5
IBM 370/165 1971 2 2808 82 0,73
IBM 370/135 1972 0,245 413 8 0,47
IBM 370/125 1973 0,131 241 4,4 0,55
IBM 370/158 1973 2 1546 39 0,63
IBM 370/168 1973 4 2642 109 1,02
IBM 370/168-3 1975 4 2883 118 1,03
AMDAHL' 470 V/6 1975 1-8 3000-4000 177 1,1-1,48
IBM 370/138 1976 0,5 350 10,4 0,75
IBM 370/158—3 1976 2 1613 45 0,7
IBM 370/148 1977 1 689 20 0,73
AMDAHL 470 V/5 1977 130 1,55
AMDAHL 470 V/6-2 1977 1.-8 3800—4600 200 1,1-1,32
IBM 3031 1978 2 1000 52 1,3
IBM 3032 1978 4 2142 118 1,38
IBM 3033 1978 4-8 3600-4700 200 1,08—1,4
AMDAHL 470 V/7 1978 4-16 3480 320 1,55
Процесс разработки и освоения сверхвысокопроизводительных си-
стем был длительным и фактически не прекращался значитель-
ное время после ввода систем в эксплуатацию. Так, например,
системы STAR 100 и ILLIAC IV 60-х годов разрабатывались
29 в. А. Головкин 449
примерно 10 лет*), причем те или иные работы по проектировав
нию, изготовлению и наладке не прекращались и после ввода в
эксплуатацию. Сама эксплуатация имела во многом характер изу-
чения и накопления опыта, при этом происходило непрерывное
совершенствование систем, выявлялись их новые возможности
и устранялись недостатки.
Поэтому в 60-х годах, несмотря на большой интерес к сверх-
высокопроизводительным системам, стала распространяться точ-
ка зрения о том, что такие системы не прогрессивны, что по?
требность в них всегда будет ограниченной и их серийный вы-
пуск не потребуется. Действительно, практическое применение
сверхвысокопроизводительных систем было ограниченным и они
изготовлялись в единичных экземплярах.
К настоящему времени, однако, положение изменилось.
Сверхвысокопроизводительные системы выпуска середины 70-х
годов разрабатывались около пяти лет, этапы проектирования,
производства и эксплуатации для них четко разделены. Систе-
мы выпускались хорошо отлаженными, а период пуско-наладоч-
ных работ был сведен до минимума. Образцами в этом отноше-
нии могут служить системы AMDAHL 470. V/6 и CRAY 1 (пер-
вый образец CRAY 1 появился через три года после образования
фирмы Cray Research [ИЗ]).
Современный анализ и оценка фирмами-изготовителями
потребностей в сверхвысокопроизводительных системах показы-
вают, что количество потребителей таких систем быстро растет,
а актуальные области их применения расширяются и, кроме
этого, возникают новые. Фирма Burroughs, например, оценивала
потребности для своей матричной системы BSP в 175—200 штук,
а фирма Cray Research предполагала поставить 100 систем
CRAY 1 в различные организации, фирмы и учреждения [113,
386] (возможно, эти оценки завышены).
В заключение отметим, что в последнее время перспективы
существенного увеличения отношения производительности к
стоимости связываются с построением систем на базе большого
числа микропроцессоров, поскольку .последние характерны по-
тенциально низкой стоимостью [415]. Основными проблемами
здесь являются организация рациональных связей между мик-
ропроцессорами и предотвращение больших затрат времени на
синхронизацию их совместной работы.
Если стоимость вычислительных систем рассматривать с более
общих позиций, то следует учитывать также возможности систем
по хранению информации и учитывать затраты на программное
♦) Разработка системы STAR 100, начатая в 1965 г., была закончена в
конце 1973 г., а работы по ее модификации (STAR 100А и STAR 100С) заня-
ли немногим меньше времени. Разработка системы ASC проводилась с 1966
по 1973 г. С 1967 г. начались работы над системой ILLIAC IV и продолжа-
лись до 1975 г. [ИЗ].
450
обеспечение. Наконец, согласно новейшим данным*), стоимость
современных систем фактически определяется объемами опера*
тивной памяти и внешней памяти прямого доступа и годом выпу-
ска систем.
8.3. Краткий обзор
Согласно эмпирическому закону, первоначально сформулиро-
ванному Г. Р. Грошем в конце.40-х годов, известному как «за-
кон Гроша», стоимость вычислительных систем некоторого пе-
риода их развития изменяется от системы к системе, в среднем,
как квадратный корень их производительности [784] (для того
чтобы выполнить некоторую работу в два раза дешевле, ее нуж-
но выполнить в четыре раза быстрее [1212]). Этот закон был;
подтвержден по данным более чем о 300 системах трех поколе-
ний, начиная от машины MARK 1 (1944 г.) до систем выпуска
1967 г. [893, 894].
Некоторые данные о производительности и стоимости около
100 однопроцессорных систем стоимостью менее 1 млн. долларов,
выпущенных в период 1975—1977 гг., приведены в [415].
В результате проверки закона Гроша [893, 894] можно сде-
лать следующие основные выводы. Для любого года за период
1944—1967 гг. производительность приближенно равна квадра-
ту стоимости вычислительной системы, умноженной на постоян-
ный коэффициент (фактически учитывались также операции об-
мена, емкость памяти и другие характеристики). С течением
времени увеличивается количество операций на доллар затрат.
Быстрый рост производительности систем при заданной стоимо-
сти проявился уже в первый период развития ЭВМ, продолжал-
ся в 1950-е годы и стал более интенсивным в период 1962—
1967 гг., характерный появлением машин третьего поколения.
Для последнего периода имеют место отклонения от квадратич-
ного закона Гроша в лучшую сторону: показатель степени вме-
сто 2 оказался равным 2,5 для машин с ориентацией на научные
расчеты и 3,1 для машин с ориентацией на экономические рас-
четы. Таким образом, более крупные системы выполняют одни
и те же вычисления при существенно меньшей стоимости.
Следует также отметить, что анализу подвергались парамет-
ры реально построенных машин. Поэтому, во-первых, получен-
ные закономерности применимы к ограниченному диапазону ис-
следованных машин и, во-вторых: объективная значимость за-
кона Гроша остается неясной и он может быть просто следст-
вием политики цен фирм-изготовителей вычислительных систем.
В любой период существуют определенные пределы допусти-
мых габаритов и достижимых скоростей работы систем (невоз-
♦) Cale Е. G. et al. Price/performance patera of U. S. computer sy-
stems.— Common. ACM, 1979, v. 22, № 4, p. 225—233.
29» 451
можно бесконечно увеличивать размеры и усложнять систему,
оставаясь в разумных рамках по стоимости). Приращение про-
изводительности вблизи этих границ может быть получено толь-
ко за очень высокую цену. В этих случаях имеют место откло-
нения от квадратичного закона Гроша в худшую сторону. Так,
например, для вычислительных комплексов в системе SAGE и
вычислительных систем LARC и STRETCH, обладавших в свое
время рекордно высокими скоростями работы, закон Гроша не
выполняется: производительность возрастает не как квадрат
стоимости, а почти пропорционально ей. Поэтому самые мощные
вычислительные системы, которые можно построить в тот или
иной период времени, вероятно, не окажутся самыми экономич-
ными.
Учитывая закон Гроша и сказанное выше, можно сделать
вывод, что для данного времени существует некоторое достаточ-
но высокое значение производительности, соответствующее мак-
симальной эффективности по показателю производительность
(вычислительная мощность) — стоимость, причем с уменьшени-
ем или $ увеличением производительности относительно указан-
ного значения эффективность систем данного периода выпуска
снижается, а с течением времени от года к году это указанное
значение производительности возрастает.
Закон Гроша выражает общую закономерность для универ-
сальных систем и типовых задач. При этом соответствующие
усредненные оценки заметно различаются для групп систем раз-
ных лет е выпуска и, Кроме этого, разброс параметров систем
одной и той же группы оказывается значительным. В [1220] от-
мечается, что эмпирический закон Гроша требует более тщатель-
ного анализа, так как производительность и цену системы мож-
но определять по разному, и указываются реальные условия,
при которых связь между производительностью и стоимостью
не соответствует закону Гроша.
Большие трудности вызывает построение теории оценки про-
изводительности параллельных систем. Так, например, соглас-
но гипотезе Минского производительность таких систем лога-
рифмически зависит от числа процессоров [991, 992] или, более
строго, производительность пропорциональна величине log2 й,
где d — количество потоков данных, приходящихся на один по-
ток команд. Эта точка зрения поддержана в [733], где исследо-
вана эффективность вычислительных систем различных струк-
тур, в основном, их производительность с точки зрения полноты
использования внутренних ресурсов систем. В этой работе по-
лучены оценочные формулы и приведены графики зависимости
эффективности систем с единственными и множественными по-
токами команд и данных от степени параллелизма вычислений.
Результаты многолетних экспериментальных исследований,
приведенные в цикле работ [906—909, 911, 913], не подтверж-
дают гцпотезу Минского и показывают, что соответствующая
452
ей оценка производительности занижена. Так, например, на на-
боре около 140 обычных фортрановских программ, содержащих
несколько тысяч операторов, было выявлено при помощи про-
граммы-анализатора, разработанной авторами указанных работ,
нто для 10-кратного ускорения счета требуется 35 параллельных
процессоров и при этом «их загрузка достигает более 30%. Во
многих случаях ускорение > оказывалось примерно пропорцио*
нальпым числу процессоров. В работах отмечается, что про-
грамма-анализатор выявляет и учитывает не все случаи парал-
лельности, которые можно было бы распознать, и что она может
быть усовершенствована. Кроме этого, программа-анализатор
оперировала с обычными фортрановскими программами, не рас-
считанными специально на параллельную обработку.
В указанных работах делаются выводы о возможности эф-
фективной обработки информации на высокопараллельных си-
стемах, о значительной глубине параллелизма даже в обычных
программах, составленных для последовательного выполнений
без учета распараллеливания, а также о возможности достаточ-
но эффективных вычислений на существующих параллельных
системах, выполняющих одновременно порядка 8—64 операций.
В заметке [1220] и последующих обзоре [1221] и книге
[1222] отстаивается точка зрения о более высокой эффективно-
сти систем с одиночным потоком команд и множественным по-
током данных, чем это утверждается в гипотезе Минского.
Соотношения для оценки производительности систем со струк-
турами ОКОД, ОКМД и МКМД, а также анализ влияния струк-
туры систем на их производительность представлены в [1066].
Эффективность распараллеливания обработки и магистральной
обработки исследуется в [578—580].
В последнее время все большее распространение находит
понятие полосы пропускания вычислительной системы, которая
представляет собой длину слова памяти, умноженную на такое
количество слов, к которым может произойти обращение за се-
кунду. Эта характеристика все чаще признается наиболее по-
лезным количественным показателем производительности и все
чаще считается более важной, чем длительность цикла тактиро-
вания центрального процессора или скорость работы памяти
1385]. Так, например, в [415] в качестве меры производительно-
сти однопроцессорных систем используется скорость обмена
между памятью и центральным процессором, выраженная в би-
тах за секунду. Понятие полосы пропускания как в целом для
систем, так и для их отдельных компонентов, в том числе в
совокупности с понятием емкости, представляющей собой ха-
рактеристику использования полосы пропускания в системе, ис-
следовано в работе [912], где рассмотрены соответствующие со-
отношения, оценки и задачи оптимизации.
Не затрагивая собственно методов оценки производительно-
сти вычислительных систей, которые представляют самостоя-
453
тельный интерес, рассмотрим кратко некоторые работы, в J
которых сравнивается производительность тех или иных парал-
лельных вычислительных систем из числа < рассмотренных в на- J
стоящей книге. i
В 127] дано сравнение производительностей БЭСМ-6, В 6700 !
и UNIVAC 1108. Сравнение проводилось на простых арифмети-
ческих задачах, запрограммированных в системах программиро-
вания этих машин на алголе 60 и фортране. Анализ таблицы
измерений времени счета по десяти программам показывает, J
что: 1) на фортране UNIVAC 1108 в 1,2—1,7 раза быстрее J
БЭСМ-6, но на алголе БЭСМ-6 в 3,6—13,5 раза быстрее 1
UNIVAC 1108; 2) на алголе БЭСМ-6 в 1,9—3,2 раза быстрее 1
В 6700, но на фортране В 6700 в 1,0—2,2 раза быстрее БЭСМ-6 I
(за исключением одной из задач, на которой БЭСМ-6 в 1,2 раза |
быстрее). На данных задачах оказалось, что UNIVAC 1108 на |
фортране в 6,1—20,2 раза быстрее, чем на алголе, хотя на дру- j
гих задачах эта величина изменяется в пределах 2—5, Кроме 3
этого, оказалось, что В 6700 на алголе несколько быстрее,’ чем j
на фортране, хотя на других задачах эта система работает бы- j
стрее на фортране. ъ 1
В заключение статьи подчеркивается, что хотя сравнение 1
приводилось для программ на широко используемых языках I
алгол и фортран, оно все же не дает полного представления о ч
БЭСМ-6, В 6700 и UNIVAC 1108. i
Сравнительный анализ производительности матричных и |
арифметико-магистральных систем с ориентацией на системы
ILLIAC IV и STAR 100 и с привлечением данных по системам
IBM 360/75, IBM 360/195 и CDC 7600 выполнен в [774-776]. j
В них проанализированы условия эффективности работы мат- I
ричных и арифметико-магистральных систем и соотношения для
оценки их производительности, а также приведены скорости вы- <
полнения арифметических операций указанными системами
(таблица 8.3). Эти скорости указаны как для единичного вы-
полнения операции (N«=1), когда в матрице процессоров
ILLIAC IV используется только один процессор, а магистраль- <
ный процессор STAR 100 не заполнен (наихудший случай), так
и для выполнения большого числа независимых операций (N ==* .
«« °°), когда все процессоры ILLIAC IV задействованы, а магист-
ральный процессор STAR 100 заполнен (наилучший случай).
Из таблицы видно, что хотя системы CDC 7600 и IBM 360/195
выполняют вычисления гораздо быстрее, чем IBM 360/75, но
у первых двух систем в силу реализации в них (ранних) ме- ;
тодов магистральной обработки, в отличие от третьей, скорости
вычислений не являются постоянными. Системы ILLIAC IV и
STAR 100 при выполнении большого числа идентичных опера-
ций намного быстрее, чем IBM 360/195 и CDC7600, но при вы-
полпенни единичных операций скорость первых резко умень- j
шлется и они становятся сравнимыми по этому показателю с
454
системами IBM 360/195 и CDG 7600 в указанных условиях. Для
программ, половина операций которых полностью загружает
процессоры ILLIAC IV и магистральный процессор STAR 100
(случай # = «>), а другая половина соответствует случаю оди-
ночной операции в каждом этапе счета (случай N« 1), эффек-
тивность использования потенциальных возможностей по скоро-
сти вычислений для ILLIAC IV будет 3%, а для STAR 100
будет находиться в пределах от 2% до 9% (отметим, что усло-
вия расчета выбраны искусственно).
Таким образом, характерными особенностями систем типа
ILLIAC IV и STAR 100 являются непостоянство скорости вы-
числений, очень высокая максимальная и весьма низкая мини-
мальная скорости вычислений. В этих условиях первостепенное
значение имеет эффективная организация вычислений. Некото-
рые возможности их организации показаны в [775, 776] на при-
Таблица 8.3
Скорости выполнения операций типа «память-память»*) над 64-разрядными
операндами в миллионах операции в секунду (данные для ILLIAC IV и
STAH 100 являются предварительными) *
Операция Количество шагов на этапе счета IBM 360/75 IBM - 360/191 CDC 7600 CDC STAR 100 ILLIAC IV (один квад- рант)
Сложение N=oo 0,24 4,6 5,2 50 50
- N=1 0,24 0,55 1,6 0,57 0,78
Умножение N=oo 0,14 4,6 5,2 25 44
N=1 0,14 0,53 1,5 0,57 0,69
Деление N=oo 0,096 1,7 2,0 12,5 17
N=1 . 0,096 0,43 0,93 J 0,56 0,27
*1 Напомним, что в данных таблицы 8.1 учитывались операции типа «ре-
гистр-регистр»
мерах двух запрограммированных на ILLIAC IV (64 процессора)
п STAR 100 (цикл 50 нсек) реальных задач. Для пяти частей
первой задачи эффективность ILLIAC IV оказалась равной 90%,
22%, 51%, 2% и 29% .при среднем значении 32%, причем рас-
пределение времени по этим частям было 0,11; 8,80; 6,40; 0,22
и 0,35 сек. соответственно при общих затратах времени 15,88 сек.
Аналогичные данные для STAR 100 выглядят следующим обра-
зом: по эффективности — 93%, 99,8%, 98%, 67% и 74% при
среднем значении 98%, а по времени—.0,301; 1,539; 8,067;
0,009; 0,672 сек. при общих затратах времени ~ 10,59 сек.
Для второй задачи эффективность ILLIAC IV составила 85%,
занимаемое время — 6,55 сек, а эффективность STAR 100 соста-
вила 90%, занимаемое время — 15,2 сек.
Из приведенных данных видно, что разброс скорости вычис-
лений ILLIAC IV больше, чем у STAR 100, а эффективность за-
455
грузки — ниже. Основные результаты работ [774—776] легли и
основу ряда исследований по сравнительному анализу матрич-.
ных и магистральных систем.
Некоторые концепции параллельной обработки с ориентаци-
ей на ILLI AC IV описываются в [724] < Кроме этого, кратко опи-
сывается концепция магистральной обработки с ориентацией на
STAR 100 и ASC, сравниваются возможности обработки ’на мат-
ричных системах типа ILLIACIV и магистральных системах
типа STAR 100, очень кратко описываются характерные особен-
ности обработки информации на IBM 360/195, CDC 7600, ASC,
STAR 100 и ILLIAC IV. В [1203] описывается параллелизм
внутри однопроцессорных систем, имеющий место при передаче
информации внутри системы, при выполнении арифметических
операций и при вводе-выводе, параллелизм за счет перекрытия
операций, арифметико-магистральной и командно-магистральной
обработки, а также параллелизм в системах с одиночным пото-
ком команд и множественным потоком данных и в системах с
множественными потоками команд и данных. В заключение да-
ется описание матричной системы DAP фирмы ICL. Отметим,
что в обеих упомянутых здесь работах воспроизведена таблица
из [774—776] (таблица 8.3) и ее данные используются в прово-
димом анализе.
Анализ и оптимизация многофункциональных блочных* про-
цессоров, применяемых в магистральных системах, таких как
CDC 6600 и IBM 360/91, рассматриваются в [556]. Определяют-
ся условия оптимизации выбора конфигурации блочного процес-
сора при минимальной его стоимости и производительности, не
ниже допустимой, а также при максимизации отношения произ-
водительности к стоимости. Задачи оптимизации сводятся к за-
дачам нелинейного целочисленного программирования, рассмат-
риваются методы решения сформулированных задач.
Методика оценки производительности систем при помощи
аналитической модели времени выполнения команд и ее приме-
нение для оценки производительности таких систем, как
AMDAHL 470V/6 и IBM 376/168, а также сравнение получен-
ных результатов с фактической производительностью систем
приведены в [1070]. Сравнение производительности систем
STARAN, РЕРЕ и CDC 7600 при решении задач обработки ра-
диолокационной информации выполнено в [945]. В этой работе
также обсуждаются пути измерения эффективности подобных
вычислительных систем.
В [981] сделан вывод, что при добавлении второго идентич-
ного процессора производительность системы возрастает в
1,8 раза, а при добавлении такого же третьего процессора — толь-
ко в 2,1 раза по сравнению с исходной однопроцессорной систе-
мой [694].
Подход для измерения производительности на основе при-
менения синтетических задач изложен в [1255, 633], представ-
456
ляющих собой первую и вторую части одной работы соответст-
венно, и в более поздней работе этих же авторов [634]. В результате
прогона разработанных синтетических программ на нескольких
системах, включая CDC 6600, CDC 7600, KDF. 9, В 6700
и UNIVAC 1108, были определены их характеристики, которые
соответствуют характеристикам, получаемым при помощи сме-
си Гибсона.
В [81 ,ч основное содержание которой составляет изложение
организации структуры и функционирования. разнообразных си-
стем с одиночным потоком команд и множественным потоком,
данных, рассматриваются также вопросы производительности
таких систем и приведена таблица производительности систем
ILLIAC IV, РЕРЕ, STARAN и АААР.
- Вопросам развития систем рекордной производительности
посвящен обзор [31]. Рассматривается эволюция оценок произ-
водительности систем и динамика роста производительности на-
иболее мощных систем по jnepe развития вычислительной тех-
ники, дается таблица характеристик ряда подобных систем, при-
водятся упрощенные схемы систем STAR 100, ILLIAC IV,
STARAN, ASC и краткие описания (в виде аннотаций) этих и
некоторых других систем.
Существует несколько прогнозов развития архитектуры вы-
числительных’ систем. Попытка экстраполяции современных тен-
денций развития на период до 2000 г. предпринята в [414, 739].
Она основывается па анализе технологии, мини- и микромашин,
а также различных типов организации структур больших систем,
включая магистральные (IBM 370/195, STAR 100), матричные
(ILLIAC IV), ассоциативные (STARAN), многомашинные. Кро-
ме этого, рассматриваются два принципа организации структур,
названные карусельным и разделяющим ’вычислительную рабо-
ту. Первый из них реализован в структуре периферийных про-
цессоров систем CDC 6600 и Honeywell-800 и положен в основу
организации концептуальной машины с общими ресурсами
(рис. 4.2). Второй принцип был первоначально реализован в
структуре системы GAMMA 60.
Согласно прогнозу, сделанному в указанных выше статьях,
будут созданы недорогие очень малые ЭВМ на одном кристалле
с богатыми логическими возможностями. Они будут широко ис-
пользоваться для решения невычислительных задач и в каче-
стве элементов для построения высокопроизводительных и
сверхвысокопроизводительных систем. Средние машины будут
иметь многоразрядную десятичную арифметику без явно вы-
раженных регистров и будут непосредственно интерпретировать
один или несколько языков высокого уровня в однопрограммном
режиме под управлением операционной системы, загруженной
извне через линии связи. Отмечается общая закономерность:
каждый пользователь (или выделенный файл), а также каждый
ресурс, который должен быть выделен (часть памяти, доступ
к накопителю на магнитных дисках, компилятор, распределитель
общих шин и т. д.), будут иметь одну или несколько собствен-
ных микромашин, предназначенных для обслуживания множест-
ва заявок. Иными словами, вместо гигантов с жесткой струк-
турой будут использоваться объединения сотен «муравьев»,,
каждый из которых занят выполнением своей работы. Это на-
правление, с оговорками о трудностях прогнозирования, выдви-
гается в качестве основного направления дальнейшего развития
вычислительных систем.
Прогноз увеличения производительности вычислительных
систем [1229] (изложенный вп. 8.2.1) и сопутствующие ему
основные данные подтверждены с привлечением дополнитель-
ных материалов в [1230—1232]. В последней из указанных ра-
бот отмечается следующее (изложение некоторых аспектов ра*
боты [1232] содержится в [386]).
Прогноз, сделанный в [1229] на период до 1990 г. (см. таб-
лицу 8.1), может казаться слишком оптимистичным, так как ни.
одна из современных действующих сверхвысокопроизводитель-
ных вычислительных систем (на начало 1978 г.), включая
ILLIAC IV, STAR 100 и CRAY 1, не обладает быстродействи-
ем, превышающим в среднем 100 миллионов операций в секунду.
Однако, в 1960-е годы, когда системы CDC 7600 и IBM 360/195
с их быстродействием в 12—15 миллионов операций в
секунду были самыми быстрыми из известных систем, указан-
ные современные системы также казались чем-то далеким.
В других прогнозах предсказывается еще более быстрый рост
максимальной производительности вычислительных систем. Так,,
например, в [792] предсказывается, что в 1985 г. появятся од-
нопроцессорные системы (с учетом опережающего просмотра и.
др.) с производительностью 10 миллиардов операций в секунду
и матричные системы с производительностью 100 миллиардов^
операций в секунду, а в 1990 г. — в 30 раз более быстрые си-
стемы.
Будущее развитие архитектуры вычислительных систем оп-
ределяется не только собственно достоинствами микроэлектро-
ники и улучшением характеристик больших интегральных схем,,
но и тем, что микро-ЭВМ и микропроцессоры будут использо-
ваться в качестве строительных блоков будущих систем с мат-
ричной, магистральной, распределенной и другими видами слож-
ных структур. Экономически выгодным станет производство
специализированных систем, ориентированных на эффективное
применение в тех или иных областях. За счет высокой автома-
тизации сроки их проектирования и конструирования станут
короткими. Широкое распространение получат полностью твер-
дотельные машины. Системное и прикладное программное обес-
печение (будут "Все в большей мере становиться программно-ап-
паратным оборудованием в виде сменных устройств памяти с
постоянно записанной информацией, допускающих только е&
458
считывание. Этот процесс уже начался, но по настоящему он
достигнет своего расцвета, по-видимому, после 1980-х годов.
К настоящему времени исследованы конструкции, состоя-
щие из большого числа упорядоченных микропроцессоров, ко-
торые могут обеспечивать очень высокие показатели производи-
тельности, несмотря на применение в них дешевых обрабаты-
вающих элементов. Такого рода вычислительные среды с мил-
лионом микропроцессоров не выходят за рамки серьезного рас-
смотрения.
В 1990-е годы современная технология твердотельных ком-
понент,- вероятно, достигнет своих ^физических пределов и ос-
новное внимание будет направлено не на дальнейшую миниа-
тюризацию, а на новые' способы представления информации в
компонентах, например, на базе многозначной логики. Одновре-
менно с этим будут достигнуты новые успехи в генерации про-
граммного обеспечения и усовершенствовании общения челове-
ка с машиной. Достижения первых тридцати лет развития вы-
числительной техники будут, по меньшей мере, удвоены [1232L
ЛИТЕРАТУРА
1. Абаджиди В. Е., Иванов В. А., Илларионов В. Н., Смич-
JC у с Е. А., Тимашов А. А. Комплексирование мини-ЭВМ с ЭВМ
единой системы с помощью малого интерфейса.— Управляющие систе-
мы и машины, 1978, № 5, с. 87—90.
2. Абакумова Н. М., Белкина Л. М., Голомшток Л. В. Органи-
зация взаимодействия специализированных машин при дублирова-
нии.— В кн.: Операционные системы комплексов ЭЦВМ,— Киев, ИК АН
УССР, 1972, с. 77—82.
3. Авиженис А. Отказоустойчивость — свойство, обеспечивающее по-
стоянную работоспособность цифровых систем. Пер. с англ,— Труды,
ИИЭР, 1978, т. 66, № 10, с. 5-25.
4. Агрегатная система средств вычислительной техники.— Киев, 1969.
5. Адельсон-Вельский Г. М., Арлазаров В. Л., Волков А. Ф.г
Л ы с и к о в В. Т., Фараджев И. А. Возможности применения аппа-
ратных средств для повышения эффективности программирования.—
В кн.: Многопроцессорные вычислительные системы.— М.: Наука, 1975»
с. 3-11.
6. Айзенберг А. Б., Винокуров В. Г., КостелянскийВ. М.г
Резанов В. В., Смолкин В. М., Щербаков Е.< В. Агрегатная
система программного обеспечения М 7000 АСВТ-М.— Управляющие?
системы и машины, 1976, № 6, с. 93—98.
7. Айзенберг А. Б., Смолкин В. М., Филиппов Н. В., Щерба-
ков Е. В. Построение ядра операционных систем агрегатной системы
программного обеспечения.—Управляющие системы и машины, 1978».
®№ 2, с. 47-50.
Аксенов В. П. Ассоциативные процессоры и области их примене-
ния: Обзор.— Зарубежная радиоэлектроника, 1977, № 1, с. 52—80.
9. Амдаль Дж., Блоу Дж., Брукс Ф. Архитектура системы 1В М-360.
Пер. с англ.— В кн.: Кибернетический сборник. Новая серия. Вып. 1.—
М.: Мир, 1965, с. 101-136.
10. А н д р е е в Ю. Ф., Ч е р н ы ш е в Г. М. Многомашинный комплекс на
базе ЕС ЭВМ.— В кн.: Организация решения задач в вычислительных
системах в реальном масштабе времени.— М.: МДНТП, 1977, с. 88—94^
11. А н т и п о в Ю. Е., Г л у ш к о в В. М., 3 е м с к о в А. Ф., К у д р и к М. Ф.^
М о р о з о в А. А., О в с е п я н Г. Е., С к у р и х и н В. И., Шкур-
кин Ю. П. Основные направления развития АСУ и принципы их ре-
ализации на базе проблемно-ориентированных технических комплек-
< сов.— Управляющие системы и машины, 1976, № 1, с. 5—11.
12. А н т о н о в В. С., Автономов Б. Б., Е г о р ы ч е в а Н. А., Ло-
мов Ю. С., ШульгинА. Л. Особенности ЭВМ ЕС-1060 и перспективы
ее развития — Сборник тезисов докладов Всесоюзной научно-технйче*
ской конференции по проблемам электронной вычислительной техни-
ки «ЭВМ-76». Часть I.- М.: НИЦЭВТ, 1976, с. 17—18.
13. Антонов Г. В., Гуревич А. М. Управляющие вычислительные ком-
лёксы высокой надежности на базе мажоритарного резервирования.—
В кн.:‘ Разработки и исследования рациональных структур вычислитель-
ных систем реального времени.— М.: МДНТП, 1979, с. 9—14.
460
14. А р л а з а р о в В. Л., Волков А. Ф., Л ы с и к о в В. Т., Фарад-
ж е в И. А. Архитектуры многопроцессорной вычислительной систе-
мы.— В кн.: Многопроцессорные вычислительные системы.— М.: Нау-
ка, 1975, с. 12-19.
15. Артамонов Г. Т., Минаев В. С., Дерешкевич В. Ю.,
Ш к л я р О. Н. Архитектура многомашинного неоднородного комплек-
са «КЛАСС».— В кн.: Первая Всесоюзная конференция по программи-
рованию. вып. Б. Киев: ИК АН УССР, 1968, с. 27—39.
16. Афанасьев В. А., Забара С. С., Заславский Р. И., Козмиди-
а д и В. А., Ландау И. Я., Мельниченко В. Г., Окунев С. И.,
Сакаев Э. И., С т о е н к о Д. Я., Харитонов В. .Н. Модель М4030 и
ее применение.— Управляющие системы и машины, 1974, № 2, с. 124—
129.
17. Афанасьев В. А., Забара С. С., Окунев С. И. Архитектура уп-
равляющих многомашинных комплексов на базе АСВТ-М.— Управля-
ющие системы и машины, 1974, № 3, с. 133—137.
18. Афанасьев В. А., Заславский Р. И., Мельниченко В. Г.,
Стоенко Д. Я., Харитонов В. Н. Процессор ЭВМ М4030.— Управ-
ляющие системы и машины, 1974, № 3, с. 137—139.
19. Афанасьев В. П., Голодок В. Л., Горячкин В. И., Ере-
мин А. П., Желтов М. П., Ильин М. Н., Седу хин С. Г., Томи-
ло в Ю. Ф., Хорошевский В. Г., Шум Л. С. Вычислительная си-
стема «СУММА».— В кн.: Вычислительные системы. Вып. 60.— Новоси-
бирск, ИМ СО АН СССР, 1974, с. 153-169.
20. Афанасьев В. П., Хорошевский В. Г., Шум Л. С. Вычис-
лительная система «СУММА».— В кн.: Всесоюзная научная конферен-
ция «Информационные системы в АСУ «Город» (тезисы докладов). М.,
1974, с. 151.
21. Б а б а к Г. В., В е р е н к о Я. Г., М и х а й л и ш и и а Н. М., С н е ж-
к о Ю. А., Шерман М. Л. Объединение ЭВМ серии «Минск» в двух-
машинный комплекс для интегральной обработки данных.— Механиз. и
автоматиз. упр. Науч.-произв. сб., 1975, (79), № 1, с. 51—53.
22. Б а б а я н Б. А. Структура современных ЭВМ.— М.: ИТМ и ВТ АН
СССР, 1975, 14 с.
23. Бабаян Б. А. Математическое обеспечение многопроцессорных си-
стем.— В кн.: Сборник тезисов докладов Всесоюзной научно-техниче-
ской конференции по проблемам электродной вычислительной техники
«ЭВМ-76». Часть I. М.: НИЦЭВТ, 1976, с. 72.
24. Б а б а я н Б. А. Основные принципы программного обеспечения МВК
«Эльбрус». М.: ИТМ и ВТ АН СССР, 1977, Препринт № 5, И с.
25. Б а б а я н Б. А. Технология программирования математического обес-
печения МВК «Эльбрус-1».— В кн.: Технология программирования. Те-
зисы докладов I Всесоюзной конференции. Пленарные доклады и об-
щие материалы. Киев: ИК АН УССР, 1979, с. 36—37.
26. Б а й ц е р Б. Архитектура вычислительных комплексов. Пер. с англ.—
М.: Мир, 1974, том 1, 498 с. Том 2, 566 с.
27. Бакстрем Л. Я. В. Сравнение производительности ЭВМ БЭСМ-6,
Бэрроуз В 6700 и Юнивак 1108 на некоторых простых задачах.— В кн.:
Вопросы системного программирования. Вып. 2. М.: МГУ, 1976, с. 91—
93.
28. Бандман О. Л., Евреинов Э. В., Корнеев В. В., Хорошев-
ский В. Г. Однородные вычислительные системы на базе микропро-
цессорных больших интегральных схем.— В кн.: Вычислительные си-
стемы. Вып. 70. Новосибирск: ИМ СО АН СССР, 1977, с. 3—28.
29. Бежанова М. М. Компилятор с языка ИЛ/1 для МВК «Эльбрус-1»,
ИТМ и ВТ АН СССР, Новосибирский филиал, 1978, Препринт № 24,
16 с. -
30. Б е з р я к о в В. Н., Эфрос Л. Б. МАСМ — язык системного програм-
мирования для ЭВМ АСВТ М-7000, снабженной ОС ДИРАК.— В кн.:
Обеспечение вычислительных центров коллективного пользования.
461
Сборник научных трудов. Новосибирск: ВЦ СО АН СССР, 1977, с. 59—
70.
81. Белов Э.Н. Тенденции развития ЦВМ рекордной производительно-
сти: Обзор.— Зарубежная радиоэлектроника, 1975, № 8, с. 15—ЗЬ
82. Белоусова О. А., Добролюбов Л. ₽., Кобзарев К. К., Ко-
пытов М. А., Миронов С. В., Насонова Л. П., Овчарен-
ко Г. А., Поликарпов В. М., Потапова В. А., Приходь-
ко В. А., Цветков И. А., Топильский В. Ф., Шапошнико-
ва Т. М. Математическое обеспечение линий связи ЭВМ БЭСМ-6 с пе-
риферийными ЭВМ вычислительного комплекса ИТЭФ.— М.: ИТЭФ, 1974,
Препринт № 47, 48 с.
33. Беляков М. И., Натансон Л. Г. Метаязык, схема трансляции и
синтаксический анализ в системе построения высокоэффективных тран-
сляторов.—Программирование, 1975, № 1*с. 40—47.
34. Бергланд, Ханникут. Применение процессора с параллельной
структурой к обработке радиолокационной информации. Пер. с англ.—
Зарубежная радиоэлектроника, 1973, № 4, с. 62.
35. Беркс А., Голдстейн Г., Нейман Дж. Предварительное рассмот-
рение логической конструкции электронного вычислительного устрой-
ства. Пер» с англ.—1 В кн.: Кибернетический сборник. Вып. 9. М.: Мир,
1964, с. 7-67.
36. Бернс, Браун, Като, Кук, Слотник, Стокс. Многопроцес-
сорная вычислительная система ИЛЛИАК-4. Пер. с англ.— Зарубежная
радиоэлектроника, 1972, № 5, с. 53—67.
37. Библиография работ по технологии программирования.— В кн.: Тех-
нология программирования. Тезисы докладов I Всесоюзной конферен-
j ции. Пленарные доклады*и общие материалы. Киев: ИК АН УССР, 1979,
с. 52—70.
88. Бирюков А. Я., Медведев И. Л., Фищенко Е. А. Принципы
построения решающего поля многопроцессорной вычислительной си-
стемы с общим управлением.— В кн.: Вопросы кибернетики. Вып. 43.
М.; Научный совет по комплексной проблеме «Кибернетика» АН СССР,
1978, с. 25-37.
89. Бооров В. Г., Богомолов М. Н. и др. Система связи вычислитель-
ных машин в ИТЭФ.— М.: ИТЭФ, 1973, Препринт Хе 15.
40. Б о б р о в В. Г., Богомолов М. Ц., 3 а в р а ж н о в Г. Н., Лисов-
ский А. 3., Мачулина В. И., Поликарпов В. М., Пионтков-
ский Г. С., Федотов О. П., Цветков Н. А., Чусов В. Е. Систе-
ма связи вычислительных машин БЭСМ-6 и М-6000.— М.: ИТЭФ, 1974, 41
Препринт № 63, 12 с. * 1
41. Б о б р'о в н и к о в И. Д., Сорокина А. А; Функциональная струйту- j
ра операционных систем IBM/370 с виртуальной памятью: Обзор.— За-‘ ‘
рубежная радиоэлектроника, 1974, № 9, с. 3—21. 1
•42. Богуславский И. В., Г-лухова Л. Ф., Захаров В. Н., Коз- л
лова Л. М., Козмидиади В. А., Козмидиади Н. П., Лан- 3
дау И. Я., Олефир Л. В. ДОС АСВТ-2.—Управляющие системы и |
машины, 1978, № 1, с. 140—141. 1
43. Большая машина с магистральной организацией. Пер. с англ.— Элект- ;
роника, 1972, т. 45, № 8, с. 18—19. «
44. Большая ЭВМ для ракетного управления. Пер. с англ.—Электроника,
1973, т. 46, № 3, с. 98.
45. Боунайт, Диненберг, Макинтай-р, Рэнделл, Самех,
Слотник. Система Illiac IV. Пер. с англ.—Труды ИИЭР, 1972, т. 60,
№ 4, с. 36-62. J
46. Брайтф ельд Р., Бишоф Р. Электронная вычислительная машина i
ЕС-1055.— В кн.: Вычислительная техника социалистических стран, л
Вып. 3. М.: Статистика, 1978, с. 99—114. 9
47. Б р а н о в и ц к и й В. И., Р а б и н о в и ч 3. Л. Вопросы классификации я
вычислительных систем.— В кн.: Вычислительные системы, вып. 48. 9
Новосибирск: ИМ СО АН СССР, 1971, с. 3—15. |
462
48. Брона И. И., Вин герский М. П., Процив В. Н. Организация
связи двухмашинного комплекса.— В кн.: Вопросы разработки и внед-
рения АСУП в промышленности. Тематический сборник. Киев: Ин-т
экономики АН УССР, 1976, с. 96—101.
49. Б р о и е р Ю. Д. Математическое обеспечение систем с разделением
времени.— М.: Статистика, 1976, 61 с.
50. Б у б е н н о в Ю. Ф., М а к а р а н е ц И. В., Хает В. С. Архитектура
системы резервирования «Сирена».— В кн.: Первая Всесоюзная конфе-
ренция по программированию, вып. Б. Киев: ИК АН УССР, 1968, с. 66.
51. Бугаев Н. Н., Гер нет Е. Д., Городилов В. В., Догадь-
ко Г. Г., Забиякин Г. И., К о с т е л я п с к и й В. М., Ларио-
нов К. А., Пожильцов О. Ф., Розенберг А. Е., Рык о ва-
нов С. Н. Комплексирование миниОВМ М-6000 с ЕС ЭВМ.—Автома-
тика и вычислительная техника, 1976, № 2, с. 64—66.
52. Бугаев Н. Н., Г е р н е т Е. Д., Городилов В. В., Д о г а д ь к о Г. Г.,
Забиякин Г. И., Костелянский В. М., Ларионов К. А., По-
жильцов О. Ф., Розенберг А. Е., Рыкованов С. Н. Организа-
ция связи вычислительных машин ЕС ЭВМ и М-6000.— М.: Ин-т косми-
ческих исследований АН СССР, 1976, Препринт № 259, 32 с.
53. Бугаев Н. Н., Г е р н е т Е. Д., Городилов В. В., 3 а б и я к и н Г. И.,
Ларионов К. А., Розенберг А. Е., Р ы к 6 в а но в С. Н. Програм-
мное обеспечение связи мини-ЭВМ М-6000 с ЭВМ 1JC.— Автоматика и
вычислительная техника, 1976, № 4, с. 64—68.
54. Бугаев Н. Н., Г е р н е т Е. Д., Городилов В. В., Д о г а д ь к о Г. Г.,
Забиякин Г. И., Костелянский В. М., Ларионов К. А., По-
жильцов О. Ф., Розепберг А. Е., Рыкованов С. Н. Ком-
плексирование мини-ЭВМ М-6000 с ЕС ЭВМ.— В кн.: Вычислительные
комплексы в системах автоматизации научных исследований. Рига:
Зинатне, 1977, с. 120—126. .
55. Б у д а г я н Э. А., П а л я н А. X. Операционная система вычислитель-
ного комплекса, работающего в реальном масштабе времени.— В кн.:
Системное программирование. Часть 2. Новосибирск: ВЦ СО АН СССР,
1973, с. 25-33.
56. Б у р ц е в В. С. Перспективы развития вычислительной техники: Док-
лад на Юбилейной научно-технической* конференции, посвященной 25-
* летию Института точной механики и вычислительной техники АН
СССР.- М.: ИТМ и ВТ АН СССР, 1975, 29 с.
57. Б у р ц е в В. С. Перспективы создания ЭВМ высокой производитель-
ности.— Вестник АН СССР, 1975, № 3, с. 25—31.
58. Б у р ц е в В. С. Перспективы создания ЭВМ высокой производитель-
ности.В кн.; Вопросы кибернетики^. Вып. 20. Вычислительные сис-
темы. Часть I. М.: Научный совет по комплексной проблеме «Киберне-
тика» АН СССР, 1976, с. 3-16.
59. Бурцев В. С. Принципы построения многопроцессорных вычисли-
тельных комплексов «Эльбрус».— М.: ИТМ и ВТ АН СССР, 1977, Пре-
принт № 1, 53 с.
60. Б у р ц е в В. С. Тенденции развития высокопроизводительных систем и
многопроцессорные вычислительные комплексы.— М.: ИТМ и ВТ АН
СССР, 1977, 28 с.
61. Б у р ц е в В. С. ЭВМ: эстафета поколений.— Газета «Правда», 4 апре-
ля 1978 г., № 94 (21794). .
62. Вальковский В. А., Константинов В. И., Миренков Н. Н.
Теория и практика параллельной обработки: Обзор.—Зарубежная ра-
диоэлектроника, 1976, № 5, с. 72—89
63. Ввод ЭВМ STAR в состав сети CYBERNET.—Радиоэлектроника за ру-
бежом, 1977, вып. 5 (821), с. 9—10.
64. В е л е с ь к о А. А., Косарев Ю. Г., Юревич Р. В. Многогруппо-
вой расчет двумерного реактора в диффузионном приближении на си-
стеме «Минск — 222»,—.В кл.: Вычислительные системы; Вып. 30. Ново-
сибирск: И.М СО АН СССР, 1968, с. 15-21.
463
65. Вельбицкий И. В., Поход зил о П. В. IBM-360.—В кн.:’Энцикло-
педия кибернетики. Том первый. Киев: Главная редакция Украинской
Советской Энциклопедии, 1974, с. 330—333.
66. В е р е т е н о в В. Ю., Добролюбов В. Ф., И л ю ш и н В. Ф. и др.
Система математического обеспечения обменов между ЭВМ БЭСМ-6 и
П-ЭВМ. Буферные обмены по линии связи ПСП-2’—ЭВМ М-6000—ЭВМ
БЭСМ-6.- М.: ИТЭФ, 1975, Препринт № 8, 36 с.
67. Винокуров В. Г., Димитриев Ю. К., Евреинов Э. В., ‘‘К о с-
телянский В. М., Лехнова Г. М, Миренков Н. Н., Реза-
нов В. В., Хорошевский В. Г. Однородная вычислительная систе-
ма из мини-машин.— В кн.: Вычислительные системы. Вып. 51. Ново-
сибирск: ИМ СО АН СССР, 1972, с. 127—145.
.68 . Винокуров В. Г., Костелянский В. М., Новохатний А. А.,
Резанов В. В. Комплексы мини-ЭВМ и их применение (М-6000/6010).
— Управляющие системы и машины, 1972, № 1, с. 128—132.
69. Винокуров В. Г., Коган Э. Ш., Костелянский В. М., Реза-
- нов В. В., Щербаков Е. В. Программное обеспечение комплекса
М 6000 АСВТ-М.— В кн.: АСУ — технология-74. М.: ЦНИИТЭИ прибо-
ростроения, 1974, серия ТС-3.
70. Вирт Н. Систематическое программирование. Пер. с англ,— М.: Мир» 2
1977, 183 с. 1 *1
71. Вишневский Ю. Л., Кульков Н. В. Организация информацион-
но-вычислительного комплекса с разветвленной терминальной сетью.— 4
В кн.: Проблемы повышения эффективности БЭСМ-6. Материалы по ма- i
тематическому обеспечению ЭВМ. Иркутск: 1976, с. 86—91.
.72 ., Вопросы кибернетики. Вып. 20. Вычислительные системы. Часть I.— ;
4 М.: Научный совет по комплексной проблеме «Кибернетика» АН CGCP, ;
1976, 88 с.
73. Вопросы кибернетики. Вып. 21. Вычислительные системы. Часть II.—
М.: Научный совет по комплексной проблеме «Кибернетика» АН СССР, i
1977, 188 с.
74. Вопросы кибернетики. Вып. 43. Вычислительные машины и системы с
перестраиваемой структурой/Под ред. И. В. Прапгишвили,— М.: Науч- 1
ный совет по комплексной проблеме «Кибернетика» АН СССР, 1978,
180 с.
75. Вычислительная система «СУММА»: Проспект.—Новосибирск, ИМ СО J
АН СССР, 1978, 12 с. ’
76. Вычислительная система IBM/360. Принципы работы. Пер. с англ.—
М.: Советское радио, 1969, 440 с. •
77. Вычислительная техника за рубежом: Сборник материалов/Под ред. *
В. К. Зейденберга.- М.: ИТМ и ВТ АН СССР, 1974, 357 с. I
78. Вычислительная техника за рубежом в 1974 году: Сборник материа-
лов/Под ред. В. К. Зейденберга.—М.: ИТМ и ВТ АН СССР, 1975, 306 с. j
* 79. Вычислительная техника за рубежом в 1975 году: Сборник материа- ;
лов/Под ред. В. К. Зейденберга.— М.: ИТМ и ВТ АН СССР, 1976,
275 с. ’
80. Вычислительная техника за рубежом в 1976 году/Под ред. В. К. Зей-
денберга.- М.: ИТМ и ВТ АН СССР, 1977, 270 с.
81. Вычислительная техника за рубежом в 1977 году/Под ред. В. К. Зей-
денберга.-J М.: ИТМ и ВТ АН СССР, 1978, 259 с.
82^ Вычислительные машины (СЕАК и ДИСЕАК). Пер. с англ.—М.: *'
МАШГИЗ, 1958. ,
83. Вычислительные системы. Вып. 7.— Новосибирск, ИМ СО АН СССР, j
1963, 46 с.
84. Вычислительные системы. Вып. 16.— Новосибирск, ИМ СО АН "СССР,
1965, 104 с.
85. Вычислительные системы. Вып. 17.—Новосибирск: ИМ СО АН СССР,
1965/164 с.
86. Вычислительные системы. Вып. 26.— Новосибирск: ИМ СО АН СССР,
1967, 154 с.
464
87. Вычислительные системы. Вып. 30.— Новосибирск: ИМ СО АН СССР,
1968.
88. Вычислительные системы. Вып. 48.— Новосибирск: • ИМ СО АН СССР
1971, 201 с.
89. Вычислительные системы. Вып. 51.— Новосибирск: ИМ СО АН СССР,
1972, 161 с.
90. Вычислительные системы. Вып. 53. Состояние исследований в области
вычислительных сред.— Новосибирск: ИМ СО АН СССР, 1972, 213 с.
91. Вычислительные системы. Вып. 58. Вычислительные системы и про-
блемы обработки информации.— Новосибирск: ИМ СО АН СССР, 1974,
112 с.
92. Вычислительные системы. Вьш. 60. Вопросы теории и построения вы-
числительных систем.— Новосибирск: ИМ СО АН СССР, 1974, 173 с.
93. Вычислительные системы. Вып. 63. Теория однородных вычислитель-
ных систем.— Новосибирск: ИМ СО АН СССР, 1975, 162 с.
94. Вычислительные системы. Вып. 70. Вопросы теории и построения
вычислительных систем,— Новосибирск: ИМ СО АН СССР, 1977,
160 с.
95. Вычислительные системы и среды: Материалы Третьей .Всесоюзной
конференции.— Таганрог: Таганрогский радиотехнический ин-т, 1972.
96. Г е р г е и Э., Губарев- Е. Ю., Елизаров О. И., Жуков Г.П., М е-
зей И., Намеряй Ю., Останевич Ю. М., Островной А. И.,
Саламатин И. М., Хрыкин А. С. Программное обеспечение двух-
машинного комплекса PDP-11/20—М-400.— Программирование, 1979,
№ 1, с. 55-62.
97. Г ер нет Е. Д., Догадько Г. Г. Техническое обеспечение связи ми-
ни-ЭВМ М-6000 с ЭВМ ЕС.— Автоматика и вычислительная техника,
1976, Яг 6, с. 81-84.
98. Г л у ш к о в В. М., Барабанов А. А., Калиниченко Л. А.,
Михновский С. Д., Рабинович 3. Л. Вычислительные машины
с развитыми системами интерпретации.— Киев: Наукова думка,
1970, 259 с.
99. Глушков В. М., Игнатьев М. Б., Мясников В. А., Торга-
ше в В. А. Рекурсивные машины и вычислительная техника.—Киев:*
И1САН УССР, 1974, Препринт 74-57.
100. Глушков В. М., Капитонова Ю. В., Брона И. И., Никитен-
ко И. Н. Структура общесистемного математического обеспечения ком-
плекса ЭВМ, ориентированного на автоматизацию проектирования.—
Механиз. и автоматиз. упр., 1975, № 4, с. 7—11.
101. Глушков В. М., Погребинский С. Б., Рабинович 3. Л. О раз-
витии структур ЭВМ с интерпретацией языков высокого уровня.—
В кн.: Сборник тезисов докладов Всесоюзной научно-технической кон-
ференции по проблемам электронной вычислительной техники «ЭВМ-
" 76». Часть I — М.: НИЦЭВТ, 1976, с. 47-49.
102. Глушков В. М., Погребинский С. Б., Рабинович 3. Л. О раз-
витии структур мультипроцессорных ЭВМ с интерпретацией языков
высокого уровня.—Управляющие системы и машины, 1978, Яг 6,
с. 61-66. z
103. Говорун Н. Н., Ростовцев В. А., Шириков В. П. О математи-
ческом обеспечении измерительно-вычислительного комплекса ОИЯИ
«Дубна».— Дубна: ОИЯИ, 1969, Препринт 11—4655.
104. Говорун Н. Н., Ростовцев В. А., Семашко В. И., Шири-
ков В. П. О математическом обеспечении системы машин измеритель-
но-вычислительного комплекса ОИЯИ — Дубна.— В кн.: Труды 2-й Все-
союзной конференции по программированию. Заседание Б.—Новоси-
бирск: ВЦ СО АН СССР, 1970, с. 43-59.
105. Г о в о р у н Н. Н., К а р л о в А. А., Me щ е р я к о в М. Г., Поля-
ков В. Н., Ч у л к о в Н. И., Шириков В. П., Щ е л е в С. А. Вычисли-
тельный комплекс ОИЯИ и перспективы его развития.— В кн.: Труды
III Международного симпозиума по физике высоких энергий и эле-
30 б. А. Головкин
465
a
ментарных частиц. Синая. 1973.— Дубна: ОИЯИ, 1974, Препринт i
Д1—2—7781.
106. Говорун Н. Н., Карлов А. А., Мещеряков М. Г., Шири-*
ков В. П., Щ е л е в С. А. Основные направления развития централь- ,
ного вычислительного комплекса ОИЯИ.—В кн.: Проблемы повышения
эффективности БЭСМ-6. Материалы по математическому обеспечению 1
< ЭВМ. Иркутск, 1976, с. 114-123.
107. Головкин Б. А. Надежное программное обеспечение: Обзор.— За- 1
рубежная радиоэлектроника, 1978, № 12, с. 3—61. 1
108. Головкин Б. А. Классификация методов обеспечения надежности я
программ.— Управляющие системы и машины, 1979, № 5, с. 3—12. 1
109. Головкин Б. А. Комбинированная классификация вычислительных •
систем на основе признаков параллелизма обработки информации.— j
Управляющие системы и машины, 1979, Я» 3, с. 19—28. $
НО. Головкин Б. А. Методы и средства параллельной обработки инфор- 1
мации.-у В кн.: Итоги науки и техники. «Теория вероятностей. Матема- i
тическая статистика. Теоретическая кибернетика». Том 17.— М.:
ВИНИТИ, 1979, с. 85-193. i
111. Головкин Б. А. Параллельная обработка информации. Программа-.
рование, вычислительные методы, вычислительные системы.— Изв. АН ;
СССР. Техническая кибернетика, 1979, № 2, с. 116—151.
112. Головня В. Н., Дадаева О. М. Описание цифровых вычислитель- ।
ных машин.— В кн.: Вычислительная техника за рубежом в 1976 го-
ду. М.: ИТМ и ВТ АН СССР, 1977, с. 65—135.
113. Головня В. Н., Дадаева О. М. Цифровые вычислительные маши- .
ны.— В кн.: Вычислительная техника за рубежом в 1977 году. М.: ИТМ
и ВТ АН СССР, 1978, с. 72-151.
114. Голубев-Новожилов Ю. С. Многомашинные комплексы вычис-
лительных средств.— М.: Советское радио, 1967, 424 с. ]
115. Гомон Л. В., Набатов А. С., Итенберг И. И. УВК повышенной
живучести М-7000.— Приборы и системы управления, 1977, № 4, J
с. 8-10.
116. Гоноровский М. И. Микропроцессоры и микроЭВМ: состояние j
производства, опыт ‘ применения: Обзор.—’Зарубежная радиэлектрони- J
ка, 1979, № 2, с. 75-97. . 1
117. Горелик А. Л., Бутко Г. И., Белоусов Ю. А. Бортовые цифре-
вне вычислительные машины.— М.: Машиностроение, 1975, 204 с.
118. Горинович Л. Н., Трахтенгерц Э. А. Особенности математиче- \
ского обеспечения многопроцессорной вычислительной систёмы с пе-
рестраиваемой структурой.— В кн.: Системное и теоретическое прог- ,
раммирование. Том II. Кишинев: 1974, с. 153—162.
119. Городилов В. В., Ларионов К. А. Комплексирование мини-ЭВМ ;
и ЕС ЭВМ.— В кн.: Сборник тезисов докладов Всесоюзной научно-тех- i
нической конференции по проблемам электронной вычислительной тех- <
ники «ЭВМ-76». Часть I. М.: НИЦЭВТ, 1976, с. 68. ’
102. Городилов В. В., Забиякин Г. И., Ларионов К. А. Операци- -
онная система ЕС ЭВМ. Программное обеспечение связи вычислитель- 1
ных машин ЕС ЭВМ и М-6000.— М.: Ин-т космических исследований
АН СССР, 1977, Препринт № 318, 76 с.
121. Гребенников Е. А., Добролюбов Л. В., Иванов В. А., Кио-, л
с а М. Н., Кобзарев К. К, Миронов С. В., Приходько В. А.
Описание некоторых вариантов мультимашинных вычислительных •
комплексов.— М.: ИТЭФ, 1975, Препринт № 82, 8 с.
122. Г р в в ц е в В. В., 3 и м и н В. А., К е ш е к Э. В., П а р ц е в с к и й С. С.
Системы сбора и передачи информации на базе СМ ЭВМ.— Приборы и 1
системы управления, 1977, № 12, с. 2—5.
123. Грицык В. В., Златогурский Э. Р. Млогопроцессорные вычис- i
лительные систёмы для обработки массивов информации в реальном
масштабе времени.— В кн.: Отбор и йередача информации, 1977,
вып. 50, с. 106—110.
466
F
t
124. Гришаева H. К., Кербель В. Г., Колосов а Ю. И., Констан-
тинов В. И., Корнеев В. Д., Л евагина Т. А., М и ред ко в Н. Н.,
Фишерман С. Б. Транслятор с языка параллельных алгоритмов.—
В кн.: Вычислительные системы. Вып. 57. Новосибирск: ИМ СО АН
СССР, 1973, с. 55-73.
125. Грубов В. И., К и р д а н В. С. Справочник по ЭВМ и аналоговым ус-
тройствам.—Киев: Наукова думка, 1977.
126. Гусев В. А., Денисов Н. Ф., Попов В. М., Романов А. В., Си-
доров В. А., С ы с о л е т и н Б. Л. Связь- ЭВМ Ц-6000 и «Минск-32» в
' системе «Радиус».— В кн.: I Всесоюзное совещание по автоматизации
научных исследований в ядерной физике, 1976. Тезисы докладов. Ки-
ев, 1976, с. 57.
127. Д а д а е в а О. М. Основные характеристики зарубежных цифровых
вычислительных машин.— М.: ИТМ и ВТ АН СССР, 1976, 60 с.
128. Дал У., Дейкстра Э., Хоор К. Структурное программирование.
Пер. с англ.— М.: Мир, 1975, 247 с.
129. Дерешкевич В. Ю., Минаев В. С., Ш к л я р О. Н. Организация
обмена информации в многомашинном неоднородном комплексе
«КЛАСС».— В кн.: Первая Всесоюзная конференция по программиро-
ванию. Вып. Б. Киев: ИК АН УССР, 1968, с. 40-50.
130. Джермейн К. Программирование на IBM/360. Пер. с англ.— М.:
Мир, .1971, 870 с.
131. Джил. Параллельное программирование. Пер. с англ.— В кн.: Вопро-
сы теории математических машин. М.: Машиностроение, 1964, с. 233—
246.
132. Джонс А. К., Чэнс л ер Р., Дерем А., Ф ай л ер П. X., Сел-
за Д. А., Ш в а и с К., В е г д а л С. Р. Проблемы программирования
мультипроцессорных систем. Пер. с англ.—Труды ИИЭР, 1978, т. 66,
№ 2, с. 151-163.
133. Дийкстра Э. Взаимодействие последовательных процессов.
Пер. с англ.—В кн.: Языки программирования. М.: Мир, 1972,
с. 9—86.
134. Дейкстра Э. Дисциплина программирования. Пер. с англ.—М.:
Мир, 1978, 275 с.
135. Димитриев Ю. К., Евреинов Э. В., Хорошевский В. Г. Вы-
числительная система «МИНИМАКС».— В кн.: Проектирование элемен-
тов и устройств вычислительной техники (материалы к семинару). Л^
1973; с. 4-6.
136. Добролюбов Л. В., Кобзарев К. К., Миронов С. В., Н а с о н о*
ваЛ. П., Овчаренко Г. А., Потапова В. А., Приходько В. А.,
Шапошникова Т. М. Математическое обеспечение линии связи
ЭВМ БЭСМ-6 с периферийными ЭВМ вычислительного комплекса
ИТЭФ.— В кн.: Проблемы повышения эффективности БЭСМ-6. Мате-
риалы по математическому обеспечению ЭВМ.— Иркутск, 1976, с. 108—
ИЗ.
137. Дол карт В. М., Новик Г. X., Колтыпин И. Ск Микроминиатюр-s
ные аэрокосмические цифровые вычислительные машины.— М.: Совет-
ское радио, 1967, 348 с.
138. Донован Дж. Системное программирование. Пер. с англ.—М.: Мир,
1975, 540 с.
139. Дорохов В. Е., Казак А. С., Максимов Н. С., Руднев Ю. П.,
Ятлеико Б. Н. Некоторые вопросы программного обеспечения меж-
машинного обмена в вычислительном комплексе на базе ЕС ЭВМ.—
В кн.: Вопросы теории и построения АСУ. Вып. 1.—М.: Атомиздат,
1977, с. 17—19. . •
140. Дроздов Е. А., Пятибратов А. П. Основы построения и функ-
ционирования вычислительных систем.—М.: Энергия, 1973, 368 с.
141. Дроздов Е. А., Комарницкий В. А., Пятибратов А. П. Мно-
гопрограммные цифровые вычислительные машины.—М.: Воениздат,
1974, 406 с. г
30*
467
142. Дроздов Е. А., Комарницкий В. А., Пятибратов А. П.
Электронные вычислительные машины Единой Системы.— М.: Маши-
ностроение, 1976, 672 с.
143. Дубовик Е. А., Егоров Г. А., Зимин В. А. Вопросы построения
измерительно-информационных систем на базе СМ ЭВМ.— Приборы и
системы управления, 1977, № 12, с. 5—6.
144. Дятлова Л. Г., Кожухина С. К., Лесовая И. Ф., Пенько-
ва Л. Н., Петрашкова Н. Ю., Сидорова Н. А., Хмельниц-
кая С., Шишкова Ы. А. Компиляторы с языков АЛГОЛ-60 и
ФОРТРАН для высокопроизводительных ЭВМ.— В кн.: Сборник тези-
сов докладов Всесоюзной научно-технической конференции по пробле-
мам электронной вычислительной техники «ЭВМ—76». Часть I. М.:
НИЦЭВТ, 1976, с. 129-131.
145. Дятлова Л. Г., Кожухина С. К., Лесовая И. Ф., Пенько-
ва Л. Н., Петрашкова Н. Ю., Романишина Н. М., Сидоро-
ва Н. А., Шишова Н. А. Реализация АЛГОЛа-60 и ФОРТРАНа на
МВК «Эльбрус-1».—М.: ИТМ и ВТ АН СССР, Новосибирский фили-
ал, 1978, Препринт № 21, 16 с.
146. Е в р е и н о в Э. В., Косарев Ю. Г. О вычислительных системах высо-
кой производительности.— Изв. АН' СССР. Техническая кибернетика,
1963, № 4, с. 3-25.
147. Евреинов Э. В., Косарев Ю. Г. Однородные универсальные вы-
числительные системы высокой производительности.— Новосибирск:
Наука, Сибирское отделение, 1966, 308 с.
148. Евреинов Э. В., Л о п а то Г. П. Универсальная вычислительная си-
стема «Минск-222».— В кн.: Вычислительные системы. Вып. 23. Но-
восибирск: ИМ СО АН СССР, 1966, с. 13-20.
149. Евреинов Э. В., Прангишвили И. В. Цифровые автоматы с
перестраиваемой структурой (однородные среды).—М.: Энергия, 1974,
240 с.
150. Евреинов Э. В., Хорошевский В. Г. Однородные вычислитель-
ные системы.— В кн.: Вычислительные системы. Вып. 58. Новосибирск:
ИМ СО АН СССР, 1974, с. 32-60.
151. Евреинов Э. В. Однородные вычислительные системы и среды.—
В кн.: Вычислительные средства в технике и системах связи. Вып. 3.
М.: Связь, 1978, с. 3—16. ’
152. Евреинов Э. В., Хоро ш.е в с к и й В. Г. Однородные вычислитель-
ные системы.— Новосибирск: Наука. Сибирское отделение, 1978, 320 с.
153. Евсюков К. Н., Колин К. К. Основы проектирования информаци-
онно-вычислительных систем.— М.: Статистика, 1977, 215 с.
154. Е г и п к о В. М. АСВТ.— В кн.: Энциклопедия кибернетики. Том пер-
вый. Киев: Главная редакция Украинской Советской Энциклопедии,
1974, с. 143-145.
155. Единая система ЭВМ/Под общей ред. А. М. Ларионова.— М.: Статисти-
ка, 1974, 136 с.
156. Ершов А. П., Ляпунов А. А. О формализации понятия програм-
мы.— Кибернетика, 1967, № 5, с. 40—57.
157. Ершов А. П. Теория программирования и вычислительные систе-
мы.— М.: Знание, 1972, с. 61.
158. Ершов А. П. Математическое обеспечение четвертого поколения. Ки-
бернетика, 1973, № 1, с. 9—20. (
159. Еф шов А. П. Современное состояние теории схем программ.— В кн.:
Проблемы кибернетики, вып. 27. М., Наука. Главная редакция физико-
математической литературы, 1973, с. 87—110. <
160. Ершов А. П. Введение в теоретическое программирование. Беседы
о методе.—М.: Наука. Главная редакция физико-математической ли-
тературы, 1977, 288 с.
161. ЕршЬв А. П. Пргораммирование на Конгрессе ИФИП-77.— Програм-
мирование. 1978, № 3, с. 74—94.
468
462. Жиров*В. Ф. Математическое обеспечение и проектирование струк-
тур ЭВМ — М.: Паука. Главная редакция физико-математической лите-
ратуры, 1979, 159 с.
463. Ж и т н и ц к а я Л. И., Ш у р у б у р а С. И., С е р е д а Л. И., Ш у р у б у-
р а В. П. Входной язык системы программирования АКДРВ для управ-
ляющих комплексов на базе УВС «Днепр-2».— В кн.: Операционные
системы комплексов ЭЦВМ. Киев: ИК АН УССР, 1972, с. 30—38.
164. Жуков Е. Н., Буслаева Г. Н., Л е в Те н к о Г. И. Особенности ра-
боты на системе «Минск-222».— В кн.: Вычислительные системы,
вып. 24. Новосибирск: ИМ СО АН СССР, 1967, с. 77—83.
465. Журавлев Ю. П., Кот ел ю к Л. А., Циклипский Н. И. Надеж-
ность и контроль ЭВМ.— М.: Советское радио, 1978, 416 с.
466. Задыхайло И. Б., Камынпн С. С., Л ю б и м с к и й Э. 3. Вопросы
конструирования вычислительных машин из блоков повышенной ква-
лификации.— В кн.: Системное и теоретическое программирование. Но-
восибирск: ВЦ СО АН СССР, 1972, с. 126-135.
467. Задыхайло И Б., Котов Е. И., М я м л и н А. Н., Поздня-
ков Л. А., Смирнов В. К. Вычислительная система с внутренним
языком повышенного уровня.— М.: ИПМ АН СССР, 1975, Препринт
№ 41, 44 с.
468. 3 а и к и н Н. С., Ломидзе О. Н., Поляков В. Н., Шириков В. П.
Алгоритмы математического обеспечения линий связи в многомашин-
ной системе ввода-вывода БЭСМ-6.— Ду^па: ОИЯИ, BI—II—5964, 1971.
469. 3 а и к и н Н. С., Фоминых М. И., Хамраев Ф. Ш. Программы под-
готовки, приема и накопления информации в системе связи ЭВМ
Минск-2 — БЭСМ-6.— Дубна: ОИЯИ, 10-8369, 1974, 16 с.
470 3 а л я л о в Р. 3., Каминский Л. Г., Комаров В. В., Ледов-
ских Г. В., Матюшин А. А., Федотов Ю. С. Организация связи
мини-ЭВМ PDP-8/L и БЭСМ-6,— Серпухов, 1976, 12 с.
471. Заморин А. П., Локшин Я. П., Соловьев С. П. Анализ спосо-
бов реализации параллельных вычислений в ЕС ЭВМ.— В кн.: Одно-
родные вычислительные системы и среды. Часть I. Материалы IV Все-
союзной конференции. Киев: Наукова думка, 1975, с. 13—14.
472. Запольский А. П., Иванов Г. А., Пых тин В. Я. Технические
средства сопряжений ЭВМ ЕС-1035 в многомашинные комплексы.—
В кп.: Вычислительные комплексы в системах Автоматизации научных
исследований. Рига: Зинатпе, 1977, с. 113—119.
473. 3 а х в а т к и н М. Н., II е х а н е в и ч Э. Л., П о п о в В. М., Рома-
нов А. В., С ы с о л е т и н Б. Л., Ш у в а л о в Б. Н. Связь между ЭВМ
М-6000 в системе Радиус.— В кн.: I Всесоюзное совещание по автома-
тизации научных исследований в ядерной физике. Тезисы докладов.
Киев, 1976, с. 55-56.
474. Зейденберг В. К., М а т в е ехн к о Н. А., Т а р о в а т о в а Е. В. Об-
зор зарубежной вычислительной техники по состоянию на 1971 год.—
М.: ИТМ и ВТ АН СССР, 1971, 316 с.
475. Зейденберг В. К., Матвеенко Н. А., Тароватова Е. В. Об-
зор зарубежной вычислительной техники по состоянию на 1972 год.—
М.: ИТМ и ВТ АН СССР. 1972, 356 с.
176. Зейденберг В. К., Матвеенко Н. А., Тароватова Е. В. Об-
зор зарубежной вычислительной техники по состоянию на 1973 год.—
' М.: ИТМ и ВТ АН СССР, 1973, 323 с.
477. Зейденберг В. К. Рынок цифровой вычислительной техники.—
В кн.: Вычислительная техника за рубежом в 1977 году. М.: ИТМ и ВТ
АН СССР, 1978, с. 27—71.
478. И в а н н и к о в В. П., Карабутова Н. Е., Красил овец Л. В.,
Максаков В. И., Томилин А. Н., К а н а т н и к о в а 3. А., Кирее-
ва Т. В., Л о б о д е н к о 3. М., Суслова Т. М., Э л л а п с к а я Л. В.
Мониторная система комплекса ЭВМ БЭСМ-6 и Днепр-21.— В кп.; Тру-
ды семинара отдела структурных и логических схем, № 9. М.: ИТМ и
ВТ АН СССР, 1972, с. 3-22.
469
179. Иванников В. II., Киреева Т. В., Королев Л. Н., Макса-
ков В. И., Э л л а н с к а я Л. В. Мониторная система для связи
БЭСМ-6 с машиной ввода-вывода на базе диспетчера НД-70.— В кн.г
Операционные системы комплексов ЭЦВМ. Киев: ИК АН УССР, 1972,
с. 13-21.
180. Иванников В. П., Киреева Т. В., Максаков В. И., Старчен-
ко Ю. В., Суслова Т. М., Ш и ш к а л о в В. П., Э л л а и с к а я Л. В»
Организация вывода результатов решения задач в мониторе МОНБ
комплекса ЭВМ. БЭСМ-6 и Днепр-21.— В кн.: Разработка математиче-
ских и технических средств автоматизированных систем управления.—
Киев: 1973, с. 57-69.
181, Иванов А. П., Семенихин С. В. Операционная система МВК
. Эльбрус-1.— М.: ИТМ и ВТ АН СССР, 1977, Препринт № 2, 31 с.
182. Игнатущенко В. В., Костелянский В. М., Лехнова Г. М.г
Прангишвили И. В., Резанов В. В.*Трахтенгерц Э. А»
Архитектура и особенности однородной ЭВМ с перестраиваемой струк-
турой.— В кн.: Перспективы развития вычислительных комплексов
М-6000/М-7000 и применепие их в автоматизированных системах управ-
ления. Всесоюзная научно-техническая конференция: Тезисы докладов»
М.: Центральное и Ворошиловградское* областное правления НТО
ПРИБОРПРОМ им. академика С. И. Вавилова, 1976, с. 10—12.
183. Игнатущенко В. В., Точева К. Т. Организация однородных ре-
шающих полей и оценка -их эффективности,— В кн.: Вопросы •кибер-
нетики, вып. 43. М.: Научный совет по комплексной проблеме «Кибер-
нетика» АН СССР, 1978, с. 83—90.
184. И т е н б е р г И. И., Г о м о и Л. В., Л е х н о в а Г. М., Н а б а т о в А. С»
Управляющий вычислительный комплекс М 7000 АСВТ-М.— Приборы
и системы управления, 1976, № 2, с. 54—58.
185. Ихара X., Фукуока К., Кубо Ю., Ё к о т а Ц. Отказоустойчивая
вычислительная система с тремя симметричными вычислительными
машинами. Пер. с англ.—Труды ИИЭР, 1978, т. 66, № 10, с 68—89.
186. Йодан Э. Структурное проектирование и конструирование программ»
, Пер. с англ.— М.: Мир, 1979, 416 с.
187/ Каган Б. М., Каневский М. М. Цифровые вычислительные маши-
ны и системы.— М.: Энергия, 1970, 624 с.
188. Каган Б. М. Электронные вычислительные машины и системы.— М.:
Энергия, 1979, 528 с.
189. Каганов С. М., Левченко В. Д., Печерский Б. Ф. ЭВМ М-220
как элемент вычислительной системы.— В кн.: Труды 2-й Всесоюзной
конференции по программированию. Заседание 3. Новосибирск: ВЦ СО'
АН СССР, 1970, с. 67-76.
190. Казак А. С., Клюев В. Е., Максимов Н. С. О возможности по-
строения высокопроизводительных вычислительных систем на базе ЕС
ЭВМ с использованием адаптера канал-канал и устройств прямого до-
ступа с двухканальным переключателем.— В кн.: Однородные вычис-
лительные системы и среды. Часть I Материалы IV Всесоюзной кон-
ференции. Киев: Наукова думка, 1975, с. 52—53.
191. Казанцев А. М., Макаров Г. П., Максимей И. В., Метля-
ев Ю. В., Пяткин В. П., Чинив Г. Д. Специализированная управ-
ляющая машина для комплексирования нескольких ЦВМ. В кн.: Во-
просы мультиобработки информации на вычислительных системах. Но-
восибирск: Наука. Сибирское отделение, 1966, с. 39—79.
192. Калайца Е. И. Организация программного обслуживания процессо-
ра нижнего уровня в двухпроцессорном вычислительном комплексе.—
В кн.: Операционные системы комплексов ЭЦВМ. Киев: ИК АН УССР*
1972, с.’ 22—29.
193. Калинова М. Д. Классификация многомашинных систем.— Труды '
МЭИ, 1974, вып. 183, с. 15-20.
194. Кампо. Вычислительная машина блочного типа. Пер. с англ.— За*
рубежная радиоэлектроника, 1970, К® 7, с. 31—50,
470
195. Каналы ввода-вывода ЭВМ ЕС-1029/Под общей ред/ А. М. Ларионова.—
М.: Статистика, 1975, 272 с.
196. Карцев М. А. Вопросы построения многопроцессорных вычисли*
тельных систем.—Вопросы радиоэлектроники, серия «Электронная вы*
числительная техника», 1970, вып. 5—6, с. 3—19.
497. Карцев М. А. Структуры вычислительных систем и их эффектив*
ность при решении разных классов задач.— М.: ИТМ и ВТ АН СССР,
1977, Препринт № 11, 14 с.
498. Карцев М. А. Архитектура цифровых вычислительных машин.—М.:
Наука, Главная редакция физико-математической литературы, 1978.
•199. Катков В. Л. Программное обеспечение МВК Эльбрус-1 и Эльбрус-2
в НФ ИТМ и ВТ.— М.: ИТМ и ВТ АН СССР, Новосибирский филиал,
1978, Препринт № 25, 15 с.
200. Катков В. Л. Разработка программного обеспечения машинной гра-
фики для МВК «Эльбрус».— Автометрия, 1978, № 5, с. 12—18.
201. К а т с у к и Д., Э л с а м Э. С., Манн У. Ф., Робертс Э. С., Ро-
бинсон Дж. Г., С к о в р о н с к и й Ф. С., Вольф Э. В. Pluribus — от-
казоустойчивый операционный мультипроцессор. Пер. с англ.—Труды
ИИЭР, 1978, т. 66, № 10, с. 49—67.
202. Катцан Г. Вычислительные машины системы 370. Пер. с англ.—М.:
Мир, 1974, 508 с.
203. Катцан Г. Операционные системы. Прагматический подход. Пер. с
англ.— М.: Мир, 1976, 471 с.
204. Кербель В. Г., Колосова Ю. И., Корнеев В. Д., Констан-
тинов В. И., Миренков Н. Н. Программное обеспечение системы
МИНИМАКС.— В кн.: Комплекс технических средств и программного
обеспечения М-6000 АСВТ для АСУ цехами и технологическими про-
цессами. М.: 1973, с. 35—37.
205. Кербель В. Г., Колосова Ю. И., Корнеев В. Д., Мирен-
ков . Н. Н., Щербаков Е. В. Средства программирования системы
МИНИМАКС.— В кн.: Вычислительные системы, вып. 60. Новосибирск: '
ИМ СО АН СССР, 1974, с. 143—152.
206. Кербель В. Г., Корнеев В. Д., Миренков Н. Н., Щерба-
ков Е. В. Управляющая программа системы МИНИМАКС.— В кн.: Вы-
числительные системы, вып. 60.— Новосибирск: ИМ СО АН СССР, 1974,
с. 129-142.
207. К е р б е л ь В. Г., К о л о с о в а ДО. И., К р ы л о в Э. Г., К о р н е е в В. Д.,
Миренков Н. Ц. Программное обеспечение системы МИНИМАКС.—
Новосибирск: ИМ СО АН СССР, 1979, Препринт ОВС-09, 43 с.
208. Коваленко Ю. Г., Ларионов К. А. Программное обеспечение
ЕС ЭВМ для работы в многомашинном вычислительном комплексе.—
В кн.: Вычислительные комплексы в системах автоматизации научных
исследований.— Рига: Зинатне, 1977, с. 166—170.
209. К о д д Э. Ф. Мультипрограммирование. Пер. с англ.— В кн.: Современ-
ное программирование. Мультипрограммирование и разделение време-
ни. М.: Мир, 1970, с. 26-112.
. 210. Козик В. С., Мосолов В. П., Петровичева М. Е., Хлебни-
ков Б. Л., Яснопольский Л. Н., Максимычев Ю. К., Воло-
де н к о в А. Я. Многомашинный центральный вычислительный, комп-
лекс информационно-вычислительной системы ИАЭ им. И. В. Курчато-
ва.— В йн.: Материалы VI конференции по эксплуатации вычислитель-
ной машины БЭСМ-6.—Тбилиси, 1976. Аппаратное обеспечение.— Тби-
лиси: Тбилисский ун-т, 1977, с. 51—53.
211. Козлов С. С., Куценко А. В., Ступин Ю. В. Система модульно-
го нрограммного обеспечения BSX для мини-ЭВМ М-400.— В кн.: Вы-
числительные комплексы в системах автоматизации научных'исследо-
ваний. Рига: Зинатне, 1977, с. 202—214.
212. Козмидиади В. А., Ландау И. Я., Филинов Е. * Н. Дисковая
операционная система модели М4030 АСВТ-М.— Приборы и системы уп-
равления, 1974, К® 11, с. 18—19.
471
213. Колосова Ю. И. Об отладочных программах для вычислительной
системы «Минск-222».—В кн.: Вычислительные систейы, вып. 51. Но-
восибирск: ИМ СО АН СССР, 1972, с. 76-81.
214. Колосова Ю. И. Комплекс средств производства параллельных про-
грамм.— В кн.: Вычислительные системы, вып. 57. Новосибирск: ИМ .
СО АН СССР, 1973, с. 98-114.
215. КонозенкоВ. И., КухарчукА. Г., Никитина. И., Т ю- j
р и н В. В., Э л л а н с к а я JL В. Алгоритм обмена информацией между
ЭВМ БЭСМ-6 и Днепр-21.— В кн.: Конструирование и внедрение но-
вых средств вычислительной техники. Киев, 1971. ;
216. Корнеев В. В. Архитектура микропроцессорной однородной вычи- -
слительной системы.— В кн.: Микропроцессоры. Тезисы докладов Все- i
союзного совещания,— Рига: Зинатне, 1975, с. 98—99. Jf
217. Королев Л. Н., И в а н н и к о в В. П., Томилин А. Н. Функции
диспетчера операционной системы БЭСМ-6,—Журнал вычислительной
математики и математической физики, 1968, т. 8, Xs 6, с. 1403—1418. •
218. Королев Л. И. Структуры ЭВМ и их математическое обеспечение.— *
М.: Наука, Главная редакция физико-математической литературы, 1974, д
256 с. Издание второе, 1978, 351 с.
219. Королев Л. Н., Мельников В. А. Об ЭВМ БЭСМ-6.— Управляю- !
щие системы и машины, 1976, № 6, с. 7—11. ;
220. Коростиль Ю. М., Старик Ю. А., Добровольский В. С., Цы-
ганков Ю. К. Программно-аппаратная система обеспечения совмест-
ной работы ЭВМ М6000 и Мир-2.— Управляющие системы и машины, -
1977, Xs 6, с. 86-87. j
221. Косарев Ю. Г., Нагаев С. В. О потерях времени на синхрони-
зацию в однородных вычислительных системах.— В кн.: Вычис-
лительные системы, вып. 24. Новосибирск; ИМ СО АН СССР, 1967,
с. 21-40.
222. Косарев Ю. Г. Опыт решения задач на системе «Минск-222».— В кп.г ’
Труды I Всесоюзной конференции по вычислительным системам. Но- ’
восибирск: Наука, Сибирское отделение, 1968, с. 70—74.
223. Косарев Ю. Г., Н а у м о в В. А., Р о з и н С. Г., Я р о ш е в и ч А. А. а
Решение задачи о рассеянии энергии ионизирующего излучения мето- j
дом Монте-Карло на системе «Минск-222».— В кн.: Вычислительные
системы, вып. 30. Новосибирск: ИМ СО АН СССР, 1968, с. 41—45.
224. Косарев Ю. Г., Миреико.в Н. Н. Математическое обеспечение од- Я
нородных вычислительных систем.— В кн.: Вычислительные системы, Я
вып. 58. Новосибирск: ИМ СО АН СССР, 1974, с. 61—79. Я
225. К о с т е л я н с к и й В. М. Общие принципы построения АСВТ.—В кн.г «а
Первая Всесоюзная конференция по программированию, вып. Б. Киев: 1
ИК АН УССР, 1968, с. 3-14. , 1
226. Костелянский В. М. Система команд АСВТ.—В кн.: Цервая Все- Я
союзная конференция по программированию, вып. Б. Киев: ИК АН Я
УССР, 1968, с. 15-26. ]
227. Костелянский В. М., Итенберг И. И., Лехнова Г. М. Новый Я
набор агрегатных модулей — дальнейшее развитие АСВТ.— В кн.: Me- я
ханизация и автоматизация управления, Xs 4. Киев, 1971. Я
228. Котов В. Е. Теория параллельного программирования. Прикладные Я
аспекты.— Кибернетика, 1974, Xs 1, с. 1—16 и Xs 2, с. 1—18. а
229. Котов В. Е. Введение в теорию схем программ.— Новосибирск: На- Я
ука, Сибирское отделение, 1978, 257 с. Я
230. Крайзмер Л. П., Бородаев Д. А., Гутенмахер Л. И., Кузь- Я
мин Б. П., Смел янс кий И. Л Ассоциативные запоминающие ус- Я
тройства.— Л.: Энергия, Ленинградское отделение, 1967, 183 с. Я
231. Курс программирования для ГАММА-60. Пер. с франц.— М.: ИЛ, 1962, Я
309 с. * 1
232. Кух^рчук А. Г., СтрутинскийЛ. А. Особенности структуры уп- «j
равляющего комплекса для системы коммутации.— В кн.: Операцион- |
ные системы комплексов ЭЦВМ. Киев: ИК АН УССР, 1972, с. 55—66» ]
472
233. Кухарчук А. Г., Никитин А. И., С т о г н и й А. А. «Днепр-2».—*
В кн.: Энциклопедия кибернетики. Том первый.—• Киев: Главная ре-
дакция Украинской Советской Энциклопедии, 1974, с. 295—296.
234. Кухарчук А. Г., Никитин А. И., Струтинский Л. А. Некото-
рые пути развития структуры процессоров управляющих ЦВМ.— Уп-
равляющие системы и машины, 1976, № 6, с. 22—26.
235. Лапин В. С., Семенихин В. С. Концепции и перспективы разви-
тия телеобработки данных в ЕС ЭВМ.— В кн.: Вычислительная тех-
ника социалистических стран, вып. 1.— М.: Статистика, 1977».
с. 60-72.
236. Ларионов А. М., Левин В. К., Фатеев А. Е. Единая система
ЭВМ. Обмен опытом в радиопромышленности, 1972, № 12, с. 18—25.
237. Ларионов А. М. Единое семейство ЭВМ.— Наука и жизнь, 1973, Xs 8»
с. 4—11.
238. Ларионов А. М., Левин В. К., Пржиялковский В. В., Фате-
ев А. Е. Основные принципы построения и технико-экономические ха-
рактеристики Единой системы ЭВМ (ЕС ЭВМ) — Управляющие сио
темы и машины, 1973, № 2, с. 1—12.
239. Ларионов А. М., Левин В. К., Пржиялковский В. В., Фате-
ев А. Е. Технияеские и эксплуатационные характеристики моделей
Единой системы.—Управляющие системы и машины, 1973, Xs 3»
с. 77—91.
240. Ларионов А. М., Левин В. К., Пржиялковский В. В., Ша-
ру н е н к о Н. М., Фатеев А. Е. Основные принципы построения и
технико-экономические характеристики оперативных и долговременных
запоминающих устройств ЕС ЭВМ.—Управляющие системы и машины»
1973, Xs 3, с. 92-105.
241. Ларионов А. М., Левин В. К., Райков Л. Д., Фатеев А. Е.
Основные принципы построения системы математического обеспечения
ЕС ЭВМ (СМО ЕС).—Управляющие системы и машины, 1973, № Зг
с. 129-138.
242. Ларионов А. М., Левин В. К., Соловьев С. П., Брусилов-
ский Е. Л. Принципы системной организации ЭВМ Единой системы.—
Вопросы радиоэлектроники, серия «Электронная вычислительная тех-
ника», 1973, вып. I, с. 55—65.
243. Ларионов А. М., Пржиялковский В. В., Макурочкин В. Г.»
Фатеев А. Е. Технические и, эксплуатационные характеристики внеш-
них устройств моделей ЕС ЭВМ.— Управляющие системы и маши-
ны, 1973, Xs 3, с. 106-128.
244. Ларионов А. М., Левин В. К., Селиванов Ю. П. Единая систе-
ма электронных вычислительных машин (ЕС ЭВМ).—В кн.: Энцикло-
педия кибернетики. Том первый. Киев:. Главная редакция Украинской
Советской Энциклопедии, 1974, с. 309—310.
245. Ларионов А. М. Единая система ЭВМ и перспективы ее развития.—
В кн.: Вопросы кибернетики, вып. 20. Вычислительные системы».
Часть I. М.: Научный совет по комплексной проблеме «Кибернетика»*
АН СССР, 1976, с. 60-74.
246. Ларионов А. М. Основные концепции развития ЕС ЭВМ.— В кн.:
Вычислительная техника социалистических стран, вып. I. М.: Статис-
тика, 1977, с. 41—51.
247. Ларионов К. А., ЛесюкВ. Г., Макарова Т. В., Шегиде-
вич Я. С. Технические и программные средства комплексирования ЕС
ЭВМ.— В кн.: Обработка данных на ЭВМ третьего поколения. М.:
МДНТП, 1976, с. 34-36.
248. Ласкин Л. Ф., Тр е с к о в а С. П. Функциональные возможности ОС
ДИРАК.— В кн.: Обеспечение вычислительных центров коллективного
пользования. Сборник научных трудов. Новосибирск: ВЦ СО АН СССР».
1977, с. 49-58.
249. Лебедев В. Н., Соколов А. П. Введение в систему программиро-
вания ОС ЕС.— М.: Статистика, 1978, 144 с.
473»
*250. Лебедев Л. Б., Миренков Н. Н., Райков Л. Д. Разработка one*
рационной системы для однородной вычислительной системы на ос*
нове старшей -модели ЕС ЭВМ.— В кн.: Однородные вычислительные
системы и среды. Часть I. Материалы IV Всесоюзной конференции.
Киев: Наукова думка, 1975, с. 35—36.
251. Лебедев С. А. Электронные вычислительные машины.— В кн.:
Сессия АН СССР по научным проблемам автоматизации производства.
Пленарные заседания. Том. I. М.: АН СССР, 1957, с. 162—180.
252. Левин А. А., Наумов Б. Н.^ Резанов В. В. Производство и раз-
витие управляющих вычислительных комплексов.— Приборы и систе- “
мы управления, 1976, № 2.
253. Леман. Параллельная обработка и параллельные устройства обра- ‘
ботки. Обзор проблем и предварительные результаты. Пер. с англ.— '
Труды ИИЭР, 1966, т. 54, Xs 12, с. 297-311.
254. Лепин-Дмитрюков Г. А. Программирование на языке ПЛ/I (для '
ДОС ЕС ЭВМ).— М.: Советское радио, 1978.
255. Лопато Г. П., Смирнов Г. Д., Пыхтин В. Я., Заполь-
ский А. П. Особенности ЭВМ ЕС-1035. В кн.: Сборник тезисов докла-
дов Всесоюзной научно-технической конференции по проблемам элект-‘
ровной вычислительной техники «ЭВМ-76». Часть I. М., НИЦЭВТ, 1976»'
с. 39-43.
256. Лопато Г. П., Смирнов Г. Д., Пыхтин В. Я., Заполь-
ский А. П. Конструктивные особенности ЭВМ ЕС-1035.—В кн.: Алго-
ритмы и организация решения экономических задач, вып. 12. М.: Ста-
тистика, 1978, с. 78—82.
257. Лощилов И. Н. Перспективы роста производительности ЭВМ: Об-
зор.— Зарубежная радиоэлектроника, 1976, № 5, с. 3—25.
258. Мазный Г. Л. Программирование на БЭСМ-6 в системе «Дубна».—
М.: Наука, Главная редакция физико-математической литературы, 1978,
272 с. .
259. Максимов Н. С. Монитор параллельной обработки для многома-
шинной вычислительной системы на базе ЕС ЭВМ.— В кн.: Вопросы
разработки, внедрения и эксплуатации прикладных программ 'ЕС ЭВМ.'.
Материалы семинара. М.: МДНТП, 1977, с. 38—42.
260. Максимов Н. С. Некоторые вопросы организации параллельной об-
работки на многомашинных вычислительных системах, состоящих из
ЭВМ Единой системы.— В кн.: Вопросы разработки и эксплуа-
тации системы обработки данных на базе ЕС ЭВМ. М.: МДНТП,
1978. .
261. Марчук Г. И., Москалев О. В. О проекте создания территориаль-
ного ВЦКП в Новосибирском Академгородке (Концепция).— Новоси-
бирск: ВЦ СО АН СССР, 1976, Препринт, 13 с.
262. Марчук Г. И., Москалев О. В. Методология создания территори- •
альиого вычислительного центра коллективного пользования Сибир-
ского отделения АН СССР.— Кибернетика, 1977, X® 6, с. 73—77.— (Но-
восибирск, ВЦ СО АН СССР, 1977, Препринт № 76, 12 с.).
263. Марчук Г. И., Котов В. Е. Модульная асинхронная развиваемая
система (Концепция). Часть 1. Предпосылки и направления развития
архитектуры вычислительных систем. Часть II. Основные принципы
и особенности.— Новосибирск: ВЦ СО АН СССР, 1978, Препринты № 86,
49 с. и № 87, 52 с.
264. Математическое обеспечение БЭСМ-6.— М.: ИПМ АН СССР, 1970.
265. Матричный процессор повышенного быстродействия фирмы Data Ge-
. neral.—Электроника, 1978, Xs 7.
266. Матричный процессор APS.—Радиоэлектроника эа рубежом, 1977,
вып. 7, с. 20—21.
267. Медведев И. Л., Прангишвили И. В., Чудин А. А. Многопро-
цессорные вычислительные системы с перестраиваемой структурой.—
М.: Ин-т проблем управления (автоматики и телемеханики), 1975, Пре*
принт, 74 с.
474
268. Международная система малых электронных вычислительных машин —
СМ ЭВМ (Тематическая подборка).—Приборы и системы управления^
1977, № 10, с. 3—17; № 11, с. 7—11; № 12, с. 1-6.
269. М е т л я е в Ю. В., Вишневский Ю. Л., Макаров Г. П. Струк-
тура вычислительной системы АИСТ-0.— В кн.: Вычислительная тех*
ника. Новосибирск: ВЦ СО АН СССР, 1973, с. 65—88.
270. М е т л я е в Ю. В., Москалев О. В., Эфрос Л. Б. Архитектура вы-
числительного комплекса (центра) коллективного пользования СО AIL
* СССР.— В кн.: Вычислительная техника. Новосибирск: ВЦ СО АН СССР*.
1976.
271. Метляев Ю. В. Базовый вычислительный комплекс на основе ЭВИ
ЕС.— В кн.: Обеспечение вычислительных центров коллективного поль-
зования. Сборник научных трудов. Новосибирск: ВЦ СО АН СССР, 1977».
с. 88-125.
272. Миллер Р. Е., Кок Дж. ЭВМ с изменяемой конфигурацией: новый:
класс универсальных машин. Пер. с англ.— В кн.: Теория программи-
рования. Часть II. Труды симпозиума. Новосибирск: ВЦ СО АН СССР,.
1972, с. 121-131.
273. Миренков Н. Н. Реализация продольно-поперечных прогонок на ВС
«Минск-222».— В кн.: Вычислительные системы, вып. 30. Новосибирск;
ИМ СО АН СССР, 1968, С. 26-33.
274. Миренков Н. Н. МИНИМАКС — вычислительная система коллек-
тивного пользования.— В кн.: Вычислительные системы, вып. 60. Но-
восибирск: ИМ СО АН СССР, 1974, с. 115-128.
275. Миренков Н. Н. Операционные системы для многопроцессорных
комплексов: Обзор.—Зарубежная радиоэлектроника, 1974, №11, с. 3—19^
276. Митрофанов В. В., Одинцов Б. В. Программы обслуживания:
ОС ЕС ЭВМ.— М.: Статистика, 1977, 136 с.
277. Многопроцессорные вычислительные системы.— М.: Наука, 1975, 143 с.
278. Многопроцессорный вычислительный комплекс «Эльбрус-1»: Прос-
пект.- М.: ИТМ и ВТ АН СССР, 1977, 19 с.
279. Мотоока И. Соединение вычислительных систем.— В кн.: Высокоэф-
фективная обработка больших потоков информации широкого профиля-
Сборник сообщений (Коики тайрё дзёхо —но кодзи сёри. Сого хоко-
ку). Токио, 1976, с. 271—330 (япон.).
280. Мультипроцессорные вычислительные системы/Под ред. Я. А. Хетагу*
рова.— М.: Энергия, 1971, 320 с.
281. Мультипроцессорные системы и параллельные вычисления/Под ред-
Ф. Г. Энслоу. Пер. с апгл.— М.: Мир, 1976, 384 с.
282. Мэдник С., Донован Дж. Операционные системы. Пер. с англ.—
М.: Мир, 1978.
283. М я м л п н А. Н., С о с н и н А. А. Супер-ЭВМ: архитектура и области:
применения.— М.: ИПМ АН СССР, 1977, Препринт № 15, 49 с.
284. Мясников В. А., Игнатьев М. Б., Торгашев В. А. Рекурсив-
ные вычислительные машины.—М.: ИТМ и ВТ АН СССР, 1977, Пре-
принт № 12, 36 с.
285. М я ч е в А. А. Системные интерфейсы управляющих вычислительных
комплексов.— В кн.: Измерения, контроль, автоматизация, вып. 2 (14)^
М., 1978, с 46-50.
286. Налбандян Ж. С. Расширение возможпостй операционной систе-
мы ЕС ОС для обеспечения функционирования матричного процессо-
ра в составе ЕС ЭВМ.— В кн.: Сборник тезисов докладов Всесоюзной
научно-технической конференции по проблемам электронной вычис-
лительной техники «ЭВМ-76». Часть I. М.: НИЦЭВТ, 1976, с. 123.'
287. Нариньяни А. С. Теория параллельного программирования. Фор-
мальные модели,— Кибернетика, 1974, № 3, с. 1—15 и № 5, с. 1—14..
288. Наумов Б. Н., Захаров В. Г., Филинов Е. Н. Основные принци-
пы создания агрегатных комплексов средств вычислительной техники
для систем управления.— Управляющие системы и машины, 1972, № 1^
с. 104-109.
475,
289. Наумов Б. Н. Состояние и перспективы развития управляющих вы-
числительных .машин.— В кн.: Вопросы кибернетики, вып 20. Вычис-
лительные системы. Часть I. М.: Научный совет по комплексной про-
блеме «Кибернетика» АН СССР, 1976, с. 75—88.
290. Наумов Б. Н. Международная система малых ЭВМ.—Приборы и си-
стемы управления, 1977, № 10, с. 3—5.
291. Наумов Б. Н. Создание СМ ЭВМ — новый этап развития средств вы-
числительной техники.— В кн.: Вычислительная техника социалисти-
ческих стран, вып. 1. М.: Статистика, 1977, с. 84—96. •
292. Наумов Б. Н., Боярченков М. А., Кабалевский А. Н. Управ-
ляющий вычислительный комплекс СМ-3.— Приборы и системы управ- .
ления, 1977, № 10, с. 12-15.
293. Никитин А. И. Применение У ВС «Днепр-2» в качестве базовой ма-
шины в системах комплексной, автоматизации на предприятиях.—
В кн.: VI 1-я Всесоюзная сессия семинара «Управляющие машины и •
системы». Киев, 1970.
294. Никитин А. И. Вопросы архитектуры и операционных систем мно- j
гомашинных комплексов.— В кн.: Операционные системы комплексов
ЭЦВМ. Киев: ИК АН УССР, 1972, с. 3-12.
295. Никитин А. И., Окунев С. И. О формализации описания струк- 1
туры и функционирования комплексов вычислительных средств.—Уп- 4
равляющие системы и машины, 1977, № 2, с. 49—55. v '
296. Никитюк Н. М. Малые ЭВМ семейства PDP-11: Обзор.—Зарубежная
радиоэлектроника, 1976, № 3, с. 58—96.
297. Новая ЭЦВМ фирмы Control Data. Пер. с англ.— Электроника, 1968.
т. 41, № 25.
298. Новохатний А. А. Опыт и перспективы развития агрегатного ком- !
плекса средств вычислительной техники на базе М-6000.— В кн.: Авто- <
матизация химических производств, вып. 2. М.: 1975, с. 29—36. д
.299 . Новые изделия и системы фирмы Sperry Univac. Пер. с англ.— Электр
роника, 1976, № 24, с. 13. ,
300. Новые ЭВМ. БИНТИ, 1976, № 6 (1730), ТАСС 10.2.76, с. 33-42. 1
301. Новые ЭВМ. БИНТИ, 1978, № 1 (1829), ТАСС 4.1.78, с. 27-28. i
202. Новые ЭВМ серии 470 фирмы AMDAHL.— Радиоэлектроника за рубе-
жом, 1979, вып. 13, с. 24—25.
203. Новые ЭВМ серии 800 фирмы Burroughs.— Радиоэлектроника за рубе- j
жом, 1977, вып. 7, с. 14—17. ,
304. Новый советский вычислительный комплекс.— Газета «Московская j
Правда», ,8 апреля 1978 г., № 82 (17704). ।
205. Обеспечение вычислительных центров коллективного пользования, j
Сборник научных трудов/Под ред. О. В. Москалева, Л. Б. Эфроса.—
’ Новосибирск, ВЦ СО АН СССР, 1977, 170 с. i
206. Однородные вычислительные системы и среды. Материалы IV Всесо- 1
юзной конференции,— Киев: Наукова думка, 1975. Часть I, 295 с. *
Часть 2, 184 с., Часть 3, 251 с. ;
207. Однородные микроэлектронные ассоциативные процессоры/Под ред. •
И. В. Прангишвили.— М.: Советское радио, 1973, 280 с. «
208. Окунев С. И. Вопросы реализации двухуровневого иерархического *
комплекса на базе АСВТ-М.— Управляющие системы и машины, 1976, й
№ 1, с. 118-123. Я
209. Операционная система ДОС ЕС. Общие положения.— М.: Статистика, Я
1975, 119 с. ' Я
310. Операционная система ДОС ЕС: Справочник.— М.: Статистика, 1977.JM
211. Операционная система IBM/360. Супервизор и управление данными. Я
Пер. с англ.—М.: Советское радио, 1973, 312 с. Я
312. Операционные системы комплексов ЭЦВМ.— Киев: ИК АН УССР, 1972. Я
213. Основные характеристики зарубежных цифровых вычислительных ма- Я
шин/Составитель О. М. Дадаева.— М.: ИТМ и ВТ АН СССР, 1977, 63 с. я|
214. Основные характеристики зарубежных цифровых вычислительных ма- Я
шин/Составитель О. М. Дадаева.— М.: ИТМ и ВТ АН СССР, 1978, 56 с. Я
476
315. Папернов А. А. Логические основы цифровой вычислительной тех-
ники. Издание третье.— М.: Советское радио, 1972, 592 с.
316. Параллельные машины и параллельная математика: Сборник статей.—
Киев: общество «Знание» УССР, 1977, 47 с.
317. Пашкеев С. Д. Основы мультипрограммирования для специализиро-
ванных вычислительных систем.—М.: Советское радио, 1972, 183 с.
318. П е л е д о в Г. В., Райков Л. Д. Состав и функциональные характ п-
ристики системы программного обеспечения ЕС ЭВМ.—Программиро-
вание, 1975, № 5, с. 46—55.
319. П е л е д о в Г. В., Райков Л. Д. Введение в ОС ЕС ЭВМ.—М.: Статис-
тика, 1977, 119 с.
320. Пентковский В. М. Базовый язык программирования многопро-
цессорных систем.— В кн.: Сборник тезисов докладов Всесоюзной на-
учно-технической конференции по* проблемам электронной вычисли-
тельной техники «ЭВМ-76».Часть I.— М.: НИЦЭВТ, 1976, с. 73.
321. Пентковский В. М. Основные характеристики автокода МВК «Эль-
брус».- М.: ИТМ и ВТ АН СССР, 1977, Препринт № 6, 29 с.
322. Первин Ю. А., Хоперсков А. Е. Компилятор с языка КОБОЛ.—
В кн.: Сборник тезисов докладов Всесоюзной научно-технической кон-
ференции по проблемам электронной вычислительной техники
«ЭВМ-76». Часть I.- М.: НИЦЭВТ, 1976, с. 132.
323. Первин Ю. А., Хоперсков А. Е. Компилятор с языка КОБОЛ
для МВК «Эльбрус-1».— М.: ИТМ и ВТ АН СССР, Новосибирский фи-
лиал, 1978, Препринт № 23, 20 с.
324. Перекатов В. И., Ларин Е. М., Осипов А. В. Система телеоб-
работки МВК «Эльбрус-1».— М.: ИТМ и ВТ АН СССР, 1977, Препринт
№ 4, 26 с.
325. Перспективы развития вычислительных комплексов М-6000/М-7000 и
применение их в автоматизированных системах управления. Всесоюз-
ная научно-техническая конференция: Тезисы докладов.— М.: Цент-
ральное и Ворошиловградское областное правления НТО ПРИБОРПРОМ
им. академика С. И. Вавилова, 1976, 282 с.
326. Петрович А. И., Косарев Ю. Г. Исследование колебательных про-
цессов автопоездов на системе «Минск-222».— В кн.: Вычислительные
системы, вып. 30. Новосибирск: ИМ СО АН СССР, 1968, с. 12—14.
327. Погорелый С. Д., С м и ч к у с Е. А., Иванов В. В., Тима-
шов А. А., Иванов В. А. Некоторые аспекты программирования пе-
риферийной мини-ЭВМ в ДОС ЕС ЭВМ.— В кн.: Технические средства
управляющих машин и систем. Киев: ИК АН УССР, 1976, с. 16—27.
328. Попов П. И., Шилкин И. П., Д и в а к о в В. И. Организация меж-
машинного обмена информацией в многопроцессорных системах на ба-
зе ЭВМ АСВТ М-6000.- М.: МИФИ, 1975, 8 с - (Деп. в ЦНИИЭИприбо-
ростроения № 425, от 3 октября 1975 г.).
329. Поспелов Д. А. О некоторых математических проблемах, возника-
ющих при совместной работе нескольких вычислительных машин.—
Труды МЭИ, 1964, вып. 53, с. 97—110.
330. Поспелов Д. А. Теоретические проблемы, связанные с объединени-
ем типовых вычислительных машин в единую систему.— В кн.: Вычи-
слительные системы. Труды симпозиума. Новосибирск: Наука, Сибир-
ское отделение, 1967, с. 56—62.
331. Поспелов Д. А. Введение в теорию вычислительных систем.— М.:
Советское радио, 1972, 280.
332. Походзило П. В. БЭСМ.— В кн.: Энциклопедия кибернетики. Том
первый.—Киев: Главная редакция Украинской Советской Энциклопе-
дии, 1974, с. 175-177.
333. П охо д зил о П. В. CDC7600.—В кн.; Энциклопедия кибернетики
Том второй. Киев: Главная редакция Украинской Советской Энцикло-
педии, 1974, с. 309.
334. П р а н г и ш в и л и И. В., Абрамова Н. А., Бабичева Б. В., Иг-
натущенко В. В. Микроэлектроника и однородные структуры для
477
построения логических и вычислительных устройств.— М.: Наука, 1967г 1
228 с. :
335. Прангишвили И. В., Виленкин С. Я., Горинович Л. Н., Иг*
натущенко В. В., Караванова Л. В., Трахтенгерц Э. А.
Перестраиваемая управляющая вычислительная система на основе од*
породных структур. Рефераты докладов VI Всесоюзного совещания по*
проблемам управления.— М.: Наука, 1974.
336. Прангишвили И. В., Игнатущенко В. В., Трахтен**
герц Э. А. Структура и особенности математического обеспечения уп* J
равляющей ЭВМ на однородных перестраиваемых структурах.— В кн.? 1
Первый Международный симпозиум ИФАК/ИФИП по программному д
обеспечению управления процессами. SOCOCO-76.— Таллин, IFAC, 1976,. Я
Тезисы, с. 51—52, Preprints, р. 207—209. Д
337. Прангишвили И. В. Перспективы применения однородных прог* Я
раммируемых микропроцессорных комплексов в системах управления: Я
Доклад на Всемирном электротехническом конгрессе.— М., 1977, 10 с. Я
338. Прангишвили И. В., Резанов В. В. Многопроцессорные управ*Я
ляющие' вычислительные комплексы с перестраиваемой структурой.— Я
М.: ИТМ и ВТ АН СССР, 1977, Препринт № 10, 25 с. Я
339. П р е с н у х и н. Л. Н., Соломонов Л. А., Четвериков В. Н.г Я
Шаньгин В. Ф. Основы теории и проектирования вычислительных. Я
приборов и машин управления.— М.: Высшая школа, 1970, 631 с. Я
340. Пржиялковский В. В., Смирнов Г. Д., Пыхтин В. Я. Элек- Я
тронная вычислительная машина «Минск-32».—М.: Статистика, 1972/Я
160 с- Я
341. Принципы работы системы IBM/370. Пер. с англ.— М.: Мир, 1975 в Я
1978, 576 с. Я
342. Проблемы повышения эффективности БЭСМ-6. Материалы по математик Я
ческому обеспечению ЭВМ.— Иркутск: ВЦ АН СССР и Сибирский Энео*Я
гетический ин-т СО АН СССР, 1976. Я
343. Программирование на языке Ассемблера ЕС ЭВМ.—М.: Статистика» Я
1975, 296 с. - Я
344. Проектирование сверхбыстродействующих систем. Комплекс СТРЕТЧЛЯ
Под ред. В. Бухгольца. Пер. с англ.— М.: Мир, 1965, 348 с. ,Я
345. Процессор ЭВМ ЕС-1020/Под общей ред. А. М. Ларионова.—М.: Статис* Я
тика, 1975, 160 с. ' Я
346. ‘Пулатов И., Иноятов А. И., Хатамкулов Г., Ахтамк у* Л
лов А., Акбаров А. Один из способов создания' вычислительного Я
комплекса на базе ЭВМ БЭСМ-6 и М-220А.— В кн.: Вопросы киберно Л
тики, вып. 20. Ташкент: АН УзССР, 1975, с. 145—152. Я
347. Пшеничников Л. Е., Соловской А. А., Захватов М. В^Я
Кольцова С. Л. Организация ввода-вывода многопроцессорных си*И
стем.— В кн.: Сборник тезисов докладов Всесоюзной научно-техничойдЯ
ской конференции по проблемам электронной вычислительной техни^Я
ки «ЭВМ-76». Часть I. М.: НИЦЭВТ, 1976, с. 31. ;Д
348. Пшеничников Л. Е., Сахин Ю. X. Архитектура многопроцессор^Л
ного вычислительного комплекса «Эльбрус».— М.: ИТМ и ВТ АН СССг/Я
1977, Препринт № 7, 40 с. Я
349. ПярнНуу А. А. Программирование на АЛГОЛе и ФОРТРАНе.— М.1Д
Наука, Главная редакция физико-математической литературы, 1978^Я
335 с.
350. Разработка сверхвысокопроизводительной ЭВМ фирмой BURROUGHS.—*»
Радиоэлектроника за рубежом, 1977, вып. 2, с. 13—14. * Д
351. Разработка ЭВМ IV поколения.—Радиоэлектроника за рубежом, 196&Д
вып. 41, с. 3—15. >;Д
352. Разработки и исследования рациональных структур вычислительны! Я
систем реального времени. Материалы семинара,— М.: МДНТП, 1979» Д
189 с. " • Я
353; Райков Л. Д. Вопросы развития операционной системы ЕС ЭВМ.— »
В кп.: Сбррник тезисов докладов Всесоюзной научно-технической коп^Д
478
ференции по проблемам электронной вычислительной техники
«ЭВМ-76». Часть 1. М.: НИЦЭВТ, 1976, с. 58—59.
354. Райков Л. Д. Развитие системного программного обеспечения ЕС
ЭВМ.— Вычислительная техника в социалистических странах, вып. 1.
М.: Статистика, 1977, с. 97—101.
355. Райли. Работы по созданию вычислительной системы ILLIAC-IV. Пер.
с англ.— Электроника, 1970, № 12, с. 35—39. ,
356. Раков Г. К. Методы оптимизации структур вычислительных си-
стем.— М.: Энергия, 1974, 145 с.
357. Р е д ь к о В. А. Многомашинный вычислительный комплекс с буфер-
ным процессором в системе обработки научной информации.— В кн.:
Вычислительные комплексы в системах автоматизации научных иссле-
дований. Рига: Зинатне, 1977, с. 73—79.
358. Резанов В. В., Винокуров В: Г., Итенберг И. И., Костелян-
с к и й В. М., Л е х н о в а Г. М. Новый набор агрегатных модулей —
дальнейшее развитие АСВТ.— В кн.: Труды НИИ управляющих вычис-
лительных машин, вып. 2. Северодонецк, 1970.
359. Резанов В. В., Костелянский В. М. Программное обеспечение
УВК СМ-1 и СМ-2.—Приборы и системы управления, 1977, № 10,
с. 9-12.
360. Резанов В. В., Костелянский В. М. Управляющие-вычисли-
тельные комплексы СМ-1 и СМ-2.— Приборы и системы управления,
1977, 10, с. 6-9.
361. РеннелсД. А. Архитектура космических бортовых вычислитель- *
ных систем, устойчивых к отказам. Пер. с англ.—Труды ИИЭР, 1978,
т. 66, № 10, с. 186—205.
362. Р и л л е й В. Б. Проект «ИЛЛИАК-4». Пер. с англ.— Электроника, 1967,
т. 40, № 10.
363. Ростокин Б. И. Операционные системы реального времени УВК
СМ-3 и СМ-4.—Приборы и системы управления, 1977, № 12, с. 1—2.
364. Рубанов В. О., Мельникова Е. Н. Структура ЭВМ общего на-
значения. Современное состояние и тенденции развития.— Управляю-
щие системы и машины, 1975, № 5, с. 58—70.
365. Рубин А. Г., Смирнов В. К. Использование средств ОС ЕС ЭВМ
для создания специализированных программных модулей связи с
другими процессорами.—М.: ИПМ АН СССР, 1975, Препринт № 24,
27 с. -
366. Рукшин А. Г. Диспетчер реального времени для многопоточной об-
работки информации на АСВТ М6000.— Управляющие системы и ма-
шины, 1977, № 5, с 58—59.
367. Рукшин А. Г. Распределенная база данных и организация информа-
ционных связей по данным в многомашинных комплексах на основе
АСВТ М6000.— Управляющие системы и машины, 1978, № 3, с. 137—138.
368. Самофалов К. Г., Кухарчук А. Г., Луцкий Г. М. Структуры
ЭЦВМ четвертого поколения.— Киев: Техтка, 1972, 254 с.
369. Самохвалова Е. В. Зарубежные информационно-вычислительные
сети коллективного пользования в 1975 году.— М.: ИТМ и ВТ АН
СССР, 1976, 26 с.
370. Сборник тезисов докладов .Всесоюзной научно-технической конферен-
ции по проблемам вычислительной техники «ЭВМ-76»,—М.: НИЦЭВТ,
1976. Часть I. Архитектура ЭВМ, 246 с. Часть 2. Техническая диагно-
стика и надежность, 260 с.
371. Сверхмощная ЭВМ CYBER 203.—Радиоэлектроника за рубежом, 1979,
вып. 13, с. 22—24.
372. Сев.ёрек Д. П., Кини В., Мэшберн X., Макконнел Q,
Ц а о М. Исследование систем С. mmp, Cm* и С. vmp. I. Опыт обеспе-
чения отказоустойчивости в мультипроцессорных системах. Пер.
с англ.—Труды ИИЭР, 1978, т. 66, № 10, с. 89-117.
373. Севёрек Д. П., Кини В., Джуббани Р., Беллис X. Исследова-
ние систем С. mmp. Сш* и С. vmp. П. Оценка параметров и прогнози-
479
рование надежности мультипроцессорных систем. Пер. с англ.— ТруЯ
ды ИИЭР, 1978, т. 66, № 10, с. 118—141. Я
374. С е д у х и н С. Г., Ж е л т о в М. П., К а ш у н И. Н. Ядро операционном
системы СУММА.— В кн* Вычислительные системы, вып. 70. НовосиЯ
бирск: ИМ СО АН СССР, 1977, с. 113-129. Я
375. Семенихин С. В., Зотов С. А. Управление вычислительными проЯ
цессами в многопроцессорных системах.— В кн.: Сборник тезисов докЯ
ладов Всесоюзной научно-технической конференции по проблемами
электронной вычислительной техники «ЭВМ-76». Часть I. М.: НИЦЭВТЯ
1976, с. 31. . Я
376. Семенихин С. В., Молчадский В. Д. Управление заданиями
многопроцессорных системах.—В кн.: Сборник тезисов докладов Все^Н
союзной научно-технической конференции по проблемам электронно]^!
вычислительной техники «ЭВМ-76», Часть I. М.: НИЦЭВТ, 19^6, с. 7^И
377. Система математического обеспечения ЕС ЭВМ/Под общей редакцие2^В
А. М. Ларионова.— М.: Статистика, 1974, 216 с.
378. Система «Сперри Юнивак 1100»: Проспект.—Сперри Юнивак, 1976^1
41 с.
379. Смит У. Р., Райс Р., Ч е с л е й Г. Д., Л е й л и о т и с Т. А., Ланд с-Я
тром С. Ф., Кэлхаун М. А., Джераулд Л. Д., Кук Т. Г Л
СИМВОЛ: большая экспериментальная система для изучения возмож-ДЯ
ности погружения программного обеспечения в аппаратуру. Пер. оЯ
англ.— В кн.: Кибернетический сборник. Новая серия, вып. 12. М.: МиргЯ
1975, с. 115-149. Я
380. Соловьев В. В. Экспериментальное исследование пропускной спо-Я
собности мультиплексного канала ЕС ЭВМ на опыте эксплуатации вы» Я
числительного комплекса ЕС-1020 и «Минск-22».— В кн.: Системы ав*Я
томатизации научных исследований, вып. 2. Рига: Зинатне, 1976 'Я
с. 27-44. Я
381. Соловьев Г. Н., Никитин В. Д. Операционные системы цифровых Я
вычислительных машин.—М.: Машиностроение, 1977, 112 с. :Я
382. Стэбли Д. Логическое программирование в системе/360. Пер. ся
англ.— М.: Мир, 1974, 752 с. Я
3831 Супервизор ОС ЕС ЭВМ/Под ред. Л. Д. Райкова,— М.: Статистика» Я
1975, 88 с. ]
384. Таненбаум Э. Многоуровневая организация ЭВМ. Пер. с англ.— М.: Я
Мир, 1979, 547 с. 1
385. Тароватова Е. В., Головня В. Н. Структура цифровых вычисли- 1
тельных машин и логических устройств.— В кн.: Вычислительная тех» 1
ника за рубежом в 1975 году. М.: ИТМ и ВТ АН СССР, 1976, с. 34—125. 1
386. ТарОватюва Е. В. Современное состояние и тенденции развития 1
вычислительной техники.—В кн.: Вычислительная техника эа рубе-», j
жом в 1977 году. М.: ИТМ и ВТ АН СССР, 1978, с. 3-26. 1
387. Терентьев В. Г., Шилкин И. П., Волков А. С. Организация 4
программного обеспечения двухмашинного вычислительного комплек- 3
са на базе ЭВМ М6000 в АСУ ТП.- М.: МИФИ, 1975, 7 с.— (Деп. в |
ЦНИЙТЭИприборостроения № 426 от 3 октября 1975 г.). 1
388. Техническая политика фирмы IBM.—Радиоэлектроника эа 'рубежом, i
1979, вып. 13, с. 35—43. 1
389. Той В. Н. Проектирование отказоустойчивых местных процессоров 1
для систем электронной коммутации. Пер. с англ.—Труды ИИЭР, 1978, 1
т. 66, № 10, с. 26—48. ' ;
390. Торгашев В. А., Андрианов В. И., Бердников Л. И., Канун- '
ников В. А. Управляющие операторы в РЦВМ.—В кн.: Вычисли-
тельные системы и среды. Материалы III Всесоюзной конференции
«Однородные вычислительные системы и среды». Таганрог, 1972,
с. 455-456.
391. Торгашев В. А., Андрианов В. И., Бердников Л. И., Смир-
нов В. Б. Вопросы программного обеспечения ЦВМ с рекурсивной
структурой.— В кн.:'Вычислительные системы и среды. Материалы III
480
Всесоюзной конференции «Однородные вычислительные системы ж
среды». Таганрог, 1972, с. 453—455.
392. Торгашев В. А., Шейнин Ю. Е. Принципы организации внутрен-
него мдтематического обеспечения рекурсивной ЭВМ.— В кн.: Одно-
родные вычислительные системы и среды. Материалы IV Всесоюзной
конференции. Часть I.— Киев: 1975. Киев, Паукова думка, 1975,
с. 282—285.
393. Торгашев В. А., Шейнин Ю. Е. Структура системы внутреннего
математического обеспечения РВМ — В кп.: Межвузовский сборник. Л.:
Ленинградский электротехнический ин-т, 1977, № 112, с. 20—24.
394. Торчигин В. П. Система файлов МВК «Эльбрус-1». М.: ИТМ и ВТ .
АН СССР, 1977, Препринт № 3, 39 с.
395. Трахтенгерц Э. А. Программное обеспечение автоматизированных
систем управления.— М.: Статистика, 1974, 288 с.
396. Трахтенгерц Э. А. Структура многопроцессорных систем РВМ и
распараллеливание вычислительных процессов.— В кн.: Разработки и
исследования рациональных структур вычислительных систем реаль-
ного времени. Материалы семинара.— М.: МДНТП, 1979, с. 14—18.
397. Труды ИИЭР, 1978, т. 66, № 2. Тематический выпуск. Применение мик-
ропроцессоров. Пер. с англ.— М.: Мир, 1978, 198 с.
398. Труды ИИЭР, 1978, т. 66, № 10. Тематический выпуск. Отказоустойчи-
вые цифровые системы. Пер. с англ.— М.: Мир, 1979, 239 с.
399. Т у р у т а Е. Н. Мультимикропроцессорные системы: Обзор.— Зарубеж-
ная радиоэлектроника, 1979, № 3, с. 3—27.
400. Управляющая вычислительная система «Днепр-2»/Под ред. А. Г. Ку-
харчука и В. М. Египко.— Киев, Паукова думка, 1972.
401. Управляющая система «Днепр-2».— Киев, 1968.
402. Управляющий вычислительный комплекс СМ-3. УВК СМ-3: Проспект.—
М.: Ин-т Электронных управляющих машин, 1977, Ис.
403. Управляющий вычислительный комплекс СМ-3. Программное обеспече-
ние.— М.: Ин-т электронных управляющих машин, 1977, 14 с.
404. Уэйкерли Дж. Ф. Повышение надежности микро-ЭВМ путем трой-
ного модульного резервирования. Пер. с англ.—Труды ИИЭР, 1976,
т. 64, № 6, с. 68—75.
405. У э н с л и Дж. X., Лэмпорт Л., Голдберг Дж., Грин М. У., Ле-
витт К. Н., М е л л ь я р -С м и т П. М., Шостак Р. Э., Уайнс-
ток Ч. Б. SIFT: проектирование и анализ отказоустойчивой вычис-
лительной системы для управления полетом Летательного аппарата.
Пер. с англ.— Труды ИИЭР, 1978, т. 66, № 10, с. 166—186.
406. Фет Я. И. Массовая обработка информации в специализированных
однородных процессорах.— Новосибирск: Наука. Сибирское отделение,
1976, 200 с.
407. Филинов Е. Н., Дедов Ю. А., Мячев А. А. Технические и про-
граммные средства комплексов СМ3 и СМ4.— В кн.: Структура, техни-
ческие средства и организация систем автоматизации научных иссле-
дований. Материалы X Всесоюзной школы по автоматизации научных
исследований. Л.: Ленинградский ин-т ядерной физики им. Б. П. Кон-
стантинова АН СССР, 1977, с. 64—71.
408. Филинов Е. Н.у С ё м и к В. П. Программное обеспечение УВК
СМ-3.— Приборы и системы управления, 1977, № 10, с. 15—17.
409. Фирма AMDAHL и ее ЭВМ 470 V/6.— Радиоэлектроника за рубежом,
1976, 11, с. 3-25.
410. Флинн. Сверхбыстродействующие вычислительные системы. Пер. с
англ.—Труды ИИЭР, 1966, т. 54, № 12, с. 311—320Г
411. Флинн М., Амдал Г. Технические аспекты разработки большой
сверхбыстродействующей вычислительной машины. Пер. с англ.—
В кн.: Микроэлектроника и большие системы. М.: Мир, 1967, с. 58—
78.
412. Флорес А. Организация вычислительных машин. Пер. с англ.— М.:
Мир, 1972, 428 с.
31 Б. А. Головкин
481
413. ФОРТРАН ЕС ЭВМ»— М.: Статистика; 1978, 264 с. 3
414. Фостер. Направления развития архитектуры ЭВМ. Сокращ. пер.
англ.—Зарубежная радиоэлектроника, 1973, № 8, с. 42—52.
415. Фуллер С. X., Устерхут Дж. К., Раскин Л., Рубен-J
ф е л ь д П. А., Синдху П. Дж., Суон Р. Дж. Мульти микропроцессор*!
ные системы: Обзор и пример практической реализации. Пер. с англ.—И
Труды ИИЭР, 1978, т. 66, № 2, с. 135-150.
416. Функциональная структура OS/360. Пер. с англ.—М.: Советское ра-г;
дио, 1971, 89 с. J
417. Хвостанцев М. А. Микропроцессоры и системы обработки данных: i
Обзор.— Зарубежная радиоэлектроника, 1975, № 9, с. 31—60. - 4
418. X и л б у р н Дж., Д ж у л и ч П. Микро-ЭВМ и микропроцессоры*: тех*]
пические средства, программное обеспечение, применения. Пер.
англ.— М.: Мир, 1979, 463 с. "
419. Холланд Дж. Вычислительные машины, построенные по итератив*^
пой схеме. Пер. с англ.— В кн.: Микроэлектроника и большие систе*
мы М.: Мир, 1967, с. 145—153.
420. Хопкинс А. Л., Смит Т. Б., Лала Дж. X. FTMP — высоконадеж-.
ный отказоустойчивый мультипроцессор для управления самолетом»
Пер. с англ.— Труды ИИЭР, 1978, т. 66, № 10, с. 142—165;
421. Цанг Ф. Р. ОС спецпроцессора ВС, совместная с ОС ДИСПАК.—
В кн.: Сборник тезисов докладов Всесоюзной научно-технической кон*
ференции по проблемам электронной вычислительной техники
«ЭВМ-76». Часть I.- М.: НИЦЭВТ, 1976, с. 126.
422. Цанг Ф. Р. Операционная система спецпроцессора МВК «Эльбрус-1 »г
совместимая с ОС ДИСПАК.— М.: ИТМ и ВТ АН СССР, Новосибирский
аилиал, 1978, Препринт № 20, 13 с.
а н г Ф. Р., Ч и н и н Г. Д. Принципы построения и реализации опе-
рационной системы спецпроцессора МВК «Эльбрус-1».— М.: ИТМ и
ВТ АН СССР, Новосибирский филиал, 1978, Препринт № 22, 12 с.
424. Чумаков Л. Я., Козмидиади В. А., Товстик В. П. Основные
характеристики ДОС АСВТ-2.— В кн.: Проблемы и опыт создания ав-
томатизированных систем обработки данных. Материалы 'семипара.—
Киев: общество «Знание» УССР, 1975, с. 21—22.
425. Шавловская С. А. Библиотека стандартных программ для много-
процессорной машины. Вопросы радиоэлектроники, серия «Электрон-
ная вычислительная техника», 1970, вып. 9.
426. Шавловская С. А. О распараллеливании при вычислении опреде-
ленных интегралов. Вопросы радиоэлектроники, серия «Электронная,
вычислительная техника», 1973, вып. 7, с. 3—10.
427. ШатровскийЛ. И. Макропрограммирование в вычислительной сре-
де ДОС/ЕС.— М.: Советское радио, 1979, 240 с.
428. Шевченко А. М., Мамедли Э. М., Струков Ю. П. Бортовые вы-
числительные системы. Итоги науки и техники. «Авиастроение»»
Том 6 — М.: ВИНИТИ, 1978, 239 с.
429. Шелихов А. А., Селиванов Ю. П. Вычислительные машины:
Справочник.— М.: Энергия, 1973, 216 с. ИзД. второе, 1978, 224 с.
430. Шелихов А. А. Единая система ЭВМ.— М.; Энергия, 1975, 157 с»
431. Ш к о л и и В. П., Ф о г и л е в А. Н. Методы построения космических
БЦВМ: Обзор,—Зарубежная радиоэлектроника, 1978, № 3, с. 26—
37.
432. ЭВМ В 7800 фирмы BURROUGHS.—Радиоэлектроника за рубежом,.
1977, вып. 24, с.-26—28.
433. ЭВМ CRAY-1 фирмы CRAY RESEARCH.— Радиоэлектроника за рубе-
жом, 1977, вып. 6, с. 3—6.
434. Электронная вычислительная машина ЕС-1020/Под общей ред. А. М. Ла-
рионова.— М., Статистика, 1975, 128 с.
435. Электронная вычислительная машина ЕС-1022.— В кн.: Вычислитель-
ная техника в социалистических странах, вып. 1. М.: Статистика, 1977г
с. 130-131.
482
436. Электронная вычислительная машина ЕС-1022.— Мл Статистика, 19791
208 с. л
437. Электронная вычислительная машина ЕС-1030/Под общей ред. А. М. Ла-
рионова.— М.: Статистика, 1977, 256 с.
438. Электронная вычислительная машина ЕС-1035.— В кн.: Вычислитель-
ная техника в социалистических странах, вып. 1. Мл Статистика, 1977,
с. 131-133.
439. Электронная вычислительная машина- ЕС-1050/Под общей ред.
А. М. Ларионова.— М.: Статистика, 1976, 302 с.
440. Электронная вычислительная машина ЕС-1060/Составитель А. А. Ше-
лихов.— В кн.: Вычислительная техника социалистических стран,
вып. 2.— М.: Статистика, 1977, с. 162—165.
441. Э стр ин Г. Микроэлементы в системах обработки информации. Пер.
с днгл.— В кн.: Микроэлектроника и большие системы. М.: Мир, 1967,
с. 30—41.
442. Э фр ос Л. Б. Особенности системы математического обеспечения ком-
плекса взаимодействующих (сети) ЭВМ ЁЭСМ-6.— В кн.: Проблемы по-
вышения эффективности БЭСМ-6. Материалы по математическому обес-
печению ЭВМ. Иркутск, 1976, с. 79—86.
443. Языки программирования ДОС ЕС ЭВМ: Краткий справочник.— М.:
Сатистика, 1977.
444. Якубайтис Э. А. Многопроцессорные системь! автоматизации науч-
ных исследований.—Автоматика и вычислительная техника, 1976, № 3,
с. 1-9.
445. Якубайтис Э. А. Вычислительные системы и сети.—Рига: Зинат-*
не, 1977, 47 с. . •
446. Якубайтис Э. А. Архитектура вычислительных сетей и систем.—*
В кн.: Вычислительная техника социалистических стран, вып. 4.—
М.: Статистика, 1978, с. 10—19.
447. Якубайтис Э. А. Архитектура вычислительных систем и сетей.—
Рига: Ин-т электроники и вычислительной техники АН Латв. ССР, 1978»
ИЭВТ POI, 37 с.
448. Abel N. Е., В u d n i с k Р. Р., К и с к D. J., М и г а о к a Y., North-
cote R. S., Wilhelm son R. В. TRANQUIL; a language for
array processing computer.—AFIPS Conf. Proc., 1969, SJCC, v. 34,
p. 57—73.
449. Ackerman D. L. Algorithm design for digital image correlation on a
parallel processor.— Proc. 1977 Symp. high speed computer and algorithm
organization, Univ, of Illinois. Academic Press, 1977.
450. А с к i n s G. M., К и c h J. Seismic signal processing via the ILLIAC IV
computer.— IEEE Geoscience Electronics, 1969, № 1, p. 34.
451. Alexander P. T., Parker R. O. A comparison of a parallel and
serial implementation of a large real time problem.— Proc. 1973 Sagamore
Comput. Conf. Parallel Processing. New York; IEEE, 1973, p. 180—186.
452. Alexander S. N. The National Bureau of Standards Eastern Automa-
tic Computer.— NJCC Conf. Proc., 1951; Joint AIEE — IRE Comput. Conf.
1952, p. 84—98.
453 Allard R. W., Wolf K. A., Z e m 1 i n R. A. Some effects of the 6600
computer on language structure.—Commun. ACM, 1964, v. 7, №2,
p. 112-119.
454. Allen J. Computer architecture for signal processing.—Proc. IEEE,
1975, v. 63, № 4, p. 624-633.
455. Al sb erg P. A., Mills C. R. The structure of the ILLIAC IV opera-
ting system.—Proc. 2nd Symp. "Operating Systems Principles, 1969,
p. 92—96.
456. Amdahl G. M. New concepts in computing system design.— Proc.
IRE, 1962, v. 50, № 5, p. 1073-1077.
457. Amdahl 470 V/6. Features, 1975, 17 p.
458. Amdahl Corp, delivers first 470 V/6 computers.—Computer, 1975, v. 8.
№12, p. 82.
31*
' 483
459. Anderson D. W., Sparacio F. J., Tomasulo R. M. The IBflM
System/360 model 91: machine philosophy and instruction handing.
IBM J. Res. Develop., 1967, v. 11, ДО 1, p. 8—24.
460. Anderson G. A., Jensen E. D. Computer interconnection structufl
res: taxonomy, characteristics, and examples.—Computing Surveys, 197зИ
v. 7, № 4, p. 197—213.
461. Anderson G. A., Jensen E. D. Computer interconnection taxono®
my —an approach.—Proc. 8th Hawaii Int. Conf. Syst. Sci., West. Period®
Co., 1975, p. 21-23.
462. A n d e i s о n G A., Kain R. Y. A content addressed memory desigi®
for data base application.—Proc. 1976 Int. Conf. Parallel Processing. New®
York; IEEE, 1976, p. 191—195. ®
463. Anderson J. P. A computer for direct execution of algorithmic lan®
guages —AFIPS Conf. Proc., 1961, EJCC, v.,20, p. 184—193.
464. Anderson J. P., Hoffman S. A., Shifman J., Williams R. J®
D 825 —a multiple computer system for command and control.— AFIPS®
Conf. Proc., 1962, FJCC, v. 22, p. 86—96. Я
465. Anderson J. P. The Burroughs D825.—Datamation, 1964, v. 10,®
№ 4, p. 30-34. Я
466. Anderson S. F., Earle J., Goldschmidt R. E., Rowers D. M.1
The IBM System/360 model 91; floating-point execution unit.— IBM J. Res.fl
Develop., 1967, v. 11, № 1, p. 34-53. fl
467. A nd erson T., Shrivastava S. K. Reliable software: a selected an* fl
notated bibliography.—Software Practice and Experience, 1978, v. 8, № l,fl
p. 59-76. 1
468. Arden В. H. Multiprocessing and parallelism.-r-Proc. 1972 Int. Comput» fl
Symp., Venice, 1972, p. 271—282. 1
469. Arnold J. S., Casey D. P., McKinstry R. H. Design of tightly —|
coupled multiprocessing programming.— IBM Syst. J., 1974, v. 13, № 1/1
p. 60-87. 'I
470. Arnold R. G., Page E. W. A hierarchical, restructurable multi —fl
microprocessor architecture.— Proc. 3rd Symp. Comput. Architecture, 1976,1
p. 40-45. |
471. Aschenbrenner R. A., Flynn M. J., Robinson G. A. In-1
trinsic multiprocessing.— AFIPS Conf. Proc., 1967, SJCC, v. 30, 1
p. SI—86. t 1
472. Aspinall D., Kinniment D. J., Edwards D. BG. An integrated 1
associative memory matrix.—Proc. IFIP Congress 1968. Edinburgh, 1968. ’
Amsterdam: • North-Holland Pub. Co., 1969, Section D. p. 86—90.
473. Associative Information Techniques/E. J. Jacks (Ed.).—New York: Else»*
vier, 1971. j
474. A survey of airline reservation systems.— Datamation, 1962, v. 8, № 6, 4
p. 53-55. j
475. Auerbach guide to international computer systems architecture.—Phila- 4
delphia: Auerbach, 1976.
476. Austin B.*J. Job scheduling by a front end computer.—Austral. Com- 1
put. J., 1977..v. 9, *N2 3, p. 107—111.
477. Avizienis A. Design of fault-tolerant computers.— AFIPS Conf. Proc., d
1967, FJCC, v. 31, p. 733—744. .
478. Avizienis A., Mathur F. P., zRennels D. A. Automatic main- j
tenance of aerospace computers and spacecraft information and control
- systems.— AIAA Paper № 69-966, AIAA Aerospace Computer Systems
Conf., Los Angeles, 1969.
479. Avizienis A. Fault-tolerant computing: an overview.— Computer,
1971, v. 4, № 1, p. 5-8.
480. Avizienis A. A., G i 1 be у G. С., M a t h u r F. P., R e n n e 1 s D. A.,
Rohr J. A., Rubin D. K. The STAR (Self-Testing And Repairing)
computer: an investigation of the theory and practice of fault-tolerant
computer design.—IEEE Trans. Comput., 1971, v. C —20, № 11, p. 1312—
1321.
484
I 481. Avizienis A. A., Renn els D. A. Fault-tolerance experiment»
| with the JPL STAR computer.— Proc. 1ЕЁЕ COMPCON 72, 1072..
I p. 321-324.
I 482. Avizienis A. Computer systems reliability: an overview.—In: Info*
E tech State of the Art Report 20. Computer Systems Reliability, Infotech,
f Inf., 1974, p. 215—233.
f 483. Avizienis A. Fault-tolerant computing: techniques and development—
f In: Infotech State of the Art Report 20. Computer Systems Reliability»
i Infotech Inf, 1974, p. 307—333.
I 484. Avizienis A, Parhami B. A fault-tolerant parallel computer sys*
tem for signal processing.—Proc. 1974 Int. Symp. Fault-Tolerant Сотри*
ting. FTC - 4. IEEE, 1974, p. 2.8-2.13.
485. Avizienis A. Architecture of fault-tolerant computing systems.— Proc.
1975 Int. Symp. Fault-Tolerant Computing. FTC-5, Paris. IEEE, 1975»
p. 3-16.
486. Avizienis A. Fault-tolerance and fault-intolerance: complementary
approaches to reliable computing.— Proc. 1975 Int. Conf. Reliable Software»
Los Angeles. New York: ACM, 1975, p. 458—464.
487. Avizienis A. Fault-tolerant systems.—IEEE Trans. Comput., 1976»
v. C — 25, № 12, p. 1304-1312.
488. Avizienis A. Fault-tolerance and longevity in high speed сотри*
ters.— Pfroc. 1977 Symp. High Speed Computer and Algorithm Organize*
tion, Univ, of Illinois. Academic Press. 1977.
489. Avizienis 'A. Fault-tolerant computing — progress, problems, and
prospects.— Proc. IFIP Congress 77, Toronto, 1977. Amsterdam: North-
Holland Pub. Co., 1977, p. 405-420.
490. Avizienis A., Ercegovac M., Lang T., Sylvain P., Thoma*
si an A. An investigation 6f fault-tolerant architectures for large-seal»
numerical computing.— Proc. 1977 Symp. High Speed Computer and Algo*
rithm Organization, Univ, of Illinois. Academic. Press, 1977.
491. Award for supercomputer.— Computer News, 1977, v. 21, № 3, p. 5.
492. В 8500 System Reference Manual.— Burroughs Corporation, 1966.
493. Baer J. L. A survey of some theoretical aspects of multiprocessing.—^
Computing Surveys, 1973, v. 5, № 1, p. 31—80
494. Baer J. L. Multiprocessing systems.— IEEE Trans. Comput.,» 1976»
v. C — 25, № 12. p. 1271—1277.
495. Bagai I. A.{ Lang T. Reliability aspects of the ILLIAC IV сотри*
ter.—Proc. 1976 Int. Conf. Parallel Processing. New York: IEEE, 1976»
p. 123-131.
496. Bailey F. R. Computational aerodynamics — ILLIAC IV and beyond.—
Proc. IEEE COMPCON 77 Spring, 1977, p. 8-11.
497. Baldauf D. L. Experiences with a operational associative processor.—*
Proc. 1974 Sagamore Computer Conf. Parallel Processing. Leet. Notes Com*
put. Sci., 1975, v. 24, p. 270-271.
498. Ball J. R., Bollinger R. C., Jeeves T. A., McReynolds R. С.»
Shafter D. H. On the use of the SOLOMON parallel processing сотри*'
ter — AFIPS Conf. Proc., 1962, FJCC, v. 22, p. 137—146.
499. Banerjee J., Hsiao D. K., Baum R. I. Concepts and capabilities
of a database computer.—ACM Trans. Database Syst., 1978, v. DS —3»
№ 4, p. 347—384.
500. Bard Y. A characterization of VM/370 workloads. Proc. 2nd Conf. Mo*
deling and Performance Evaluation of Computer Systems, Stresa, 1976.—
Amsterdam: North-Holland Pub. Co., 1977, p. 427—434.
501. Barnes G. H. ILLIAC IV and its use.— Proc. 1972 WESCON Technical
Papers, v. 16. Parallel Processing Systems. Session 1, p. 1/2: 1—2.
502. Barnes G. H. The use of ILLIAC IV.— Proc. IEEE COMPCON 72»
1972, p. 295-296.
503. Barrett A. L. Process-construction for a parallel — sequential compu^
ter architecture.— Proc. 1973 Sagamore Computer Conf. Parallel Processing»
New York: IEEE, 1973, p. 179.
485
504. Barton R.S. A new approach to the functional design of a digital сопн
puter.— NJCC Conf. Proc., 1961, WJCC, v. 19, p. 393-396. 1
505. Barton R. S. Ideas for computer systems organization: a personal sur*
vey.— In: Software Engineering, vol. 1. New York: Academic Press, 1970,
p. 7-16.
1Ю6. Bashkow T. R., Sasson A., Kronfeld A. System design of a
FORTRAN-machine.— IEEE Trans. Electron. Comput., 1967, v. EC-16, № 8^’
p. 485-494.
307. В a s i 1 i V. R., Knight J. C. A language design for vector machi-
nes— SIGPLAN Notices, 1975, v. 10, № 3, p. 39—43.
«508. Baskett F., Browne J. C., Raike M. The management of a mul-
ti-level non-paged memory system.— AFIPS Conf. Proc., 1970, SJCC, v. 36-
p. 459-465. * ’
509. Baskett F. An evaluation of the GRAY-1 computer.— Proc. 1977 Symp.;
High Speed Computer and Algorithm Organization, Univ, of Illinois. Аса-,
demic Press 1977 *
510. Baskin H. В., В or ger son B. R., Roberts R. PRIME- a modular^
architecture for terminal-oriented systems.—AFIPS Conf. Proc., 1972,
SJCC, v. 40, p. 431-437. - «
511. Batcher KE. Flexible parallel processing and STARAN.—Proc. 1972Я
WESCON Technical Papers, v. 16, Parallel Processing Systems. Session 1,Я
p. 1/5: 1-3. Л
512. Batcher KE. STARAN/RADCAP hardware architecture.—Proc. 1973 Я
Sagamore Computer Conf. Parallel Accessing. New York: IEEE, 1973. Я
p. 147—152. Я
513. Batcher KE. STARAN parallel processor system hardware.—AFIPS Я
Conf. Proc., 1974, NCCE, v. 43, p. 405-410. Я
514. Batcher KE. The multi-dimensional access memory in STARAN.—Я
Proc. 1975 Sagamore Computer Conf. Parallel Processing. New York: IEEE,Я
1975, p. 175. Я
515. Batcher KE. The flip network in STARAN.—Proc. 1976 Int. Contfl
Parallel Processing. New York: IEEE, 1976, p. 65—71. Я
516. Batcher KE. STARAN series E.— Proc. 1977 Int. Conf. Parallel РпнЯ
cessing. New York: IEEE, 1977, p.'14O—143. НЯ
517. В a ten er KE. The. multidimensional access memory in STARAN.-тЯ
IEEE Trans. Comput., 1977, v. C — 26, № 2, p. 474—177. Я
518. Batson A., Ju S., Wood D. C. Measurements of segment size.—?Я
Commun. ACM, 1970, v. 13, № 3, p. 155-159. Я
519. Bauer L. H. Implementation of data manipulating functions on the Я
STARAN associative processor.— Proc. 1974 Sagamore Computer Conf. Pp- Я
rallel Processing. Leet. Notes Comput. Sci., 1975, v. 24, p. 209—227. Я
520. Bauer W. F. Why multi-computers? — Datamation, 1962, v. 8, № 9, Я
p. 51-55. ' _ Я
524. В ell C. G., Cady R., McFarland H., Delagi B., Q’Latigh-«
1 i n J., Noonan R., Wulf W. A new architecture for minicompu-Я
ters —the DEC PDP-11.—AFIPS Conf. Proc., 1970, SJCC, v. 36, p. 657-675.Я
522. Bell G. G., Newell A. Computer structures: readings and examples.—Я
New York: McGraw-Hill, 1971, 668 p. Я
523. Bell C. G., Chen R., Rege S. Effect of technology on near termw
computer structure.— Computer, 1972, v. 5, № 2, p. 29—38. Я
524. Bell C. G., Freeman P. С. C. ai —a computer architecture for Я
Al research.—AFIPS Conf. Proc., 1972, RJCC, v. 41, part 2, Я
p. 779—790. - Я
525. Bell C. G., Chen R. C., Fuller S. H., Grasоn J., Rege S., Я
Siewiorek D. P. The architecture and application of computer modu-Я
les: a set of components for digital system design.—Proc.-IEEE Я
COMPCON 73, 1973, p. 177-180. Я
526. Bqll C. G., Strecker W. D. Computer structures: what have, we 1е*Я
arned from the PDP-11? — Proc. 3rd Symp. Computer Architecture, 1976*3
New York: IEEE, 1976, p. 1—14. Я
486
527. Bell C. G., K-otok A., Hastings T. N., Hill R. The evolutions
of the DEC system 10.— Commun. ACM, 1978, v. 21, № 1, p. 44—63.
528. Bennetts R.G. Designing reliable computer systems. The fault-tole*
rant approach-1.—Electron, and Power, 1978, p. 846—-851.
529. Berg R. 0., J о h n s о n M. D. An associative memory for executive
control functions in an Advanced Avionics Computer System.— Proc. 1970
IEEE Int. Comput. Group Conf., 1970, p. 336—342.
530. Berg R. 0., Thurber K. J. A hardware executive control for tfee
Advanced Avionic Digital Computes System.—Proc. 1971 National Aero*,
space and Electronics Conf. NAECON’71, p. 206—213.
531. Berg R. 0., Schmitz H. G., N u s p 1 S. J. PEPE — an overview of
architecture, operation and implementation.—Proc. 1972 National Electro^
nics Conf., 1972, v. 27, p. 312—317.
532. Berg R. 0., ThurberKJ. Real time task scheduling for a multi*
computer system.—Proc. 1972 National Electronics Conf., 1972, v. 27>.
p. 275-280.
533. Bergland G. D. A parallel implementation of the fast Fourier trans-
form algorithm.— IEEE" Trans. Comput., 1972, v. C-21, № 4, p. 366—370-
534. Bergland G. D., Hunnicutt C. F. Application of PEPE to radar
data processing.—Proc. IEEE COMPCON 72, 1972, p. 65—68.
535. Berra P. B. Some problems in associative processor applications,
to data base management.— AFIPS Conf. Proc., 1974, NCCE. v. 43, p. 1-5»
536. Beum C. 0., Levin D. E. Distributed avionics information sys-
tems.—Proc. 1974 National Aerospace and Electronics Conf. NAECON’74r
p. 78—85.
537. Bird R. M., Tu J. C., Worthy R. M. Associative/parallel processor
for searching very large textual data bases.— ACM Computer Architecture
News, 1977, v. 6, № 2, p. 8-16.
538. В1 a a u w G. A. The structure of System/360. Part V. Multisystem orga*
nization.— IBM Syst. J., 1964, v. 3, № 2, p. 181—195.
539. В1 a a u w G. A., Brooks F. P. The structure of System/360.— IBM*
Syst. J., 1964, v. 3, № 2, p. 119-135.
540. В1 a a u w G. A. IBM System/360 multisystem organisation.— IEEE InU
Conv. Rec., 1965, part 3, p. 226—235.
541. Blakely C. PEPE application to BMD systems.— Proc. 1977 Int. Conf.
Parallel Processing. New York: IEEE, 1977, p.~193—198.
542. Blakeney G. R., C u d n e у L. F., E i с к h о r n C. R. An applica-
tion-oriented multiprocessing system. Part II. Design characteristics of
the 9020 system.— IBM Syst J., 1967, v. 6, № 2, p. 80—94.
543. Block E. The engineering design of the Stretch computer. Nat. Joint
Comput. Committee Conf. Proc., 1959, Eastern Joint Comput. Conf., v. 16r
p. 48-58.
544. Bo am W. D., Soss D. A. A front-end minicomputer system for the-
UNIVAC 1108.—Proc. Six IEEE Reg. West. Conf., Salt Lake City, 1975.
New York: 1975, p. 93—95. '
545. Bobrow D. G., Burchfild J. D., Murphy D. L., Tomlin-
son R. S. TENEX, a paged time sharing system for the PDP-10.— Com-
mun. ACM, 1972, v. 15, № 3, p. 135—143.
546. Boland L. J., G r a n i t о G. D., Marcotte A. U., Messina B. U.,.
Smith J. W. IBM System/360 model 91: storage system.— IBM J. Res.
Develop., 1967, V 11, № 1.
547. Bonseigneur P. Description of the 7600 computer system.— IEEE£
Computer Group News, 1969, v. 2, № 9, p. 11—15.
548. Bo rd sen D. T. UNIVAC 1108 hardware instrumentation system. ACM*
(SIGOPS) WORKSHOP on system performance evaluation.— Harvard
Univ., 1971, p. 1—29.
548. Borgerson B. R. A fail-softly system for time-sharing use.—Proc.
1972 Int. Symp. Fault-Tolerant Computing. IEEE, 1972, p. 89—93.
550. Borgerson B. R. Spantaneous reconfiguration in a fail-softly computer
utility.—Datafair 73, 1973, Conf. Papers, v. Ill, p. 326—333.
487
551. Borgerson В. R., Freitas R. F. An analysis of «PRIME» using M
new reliability model.-—Proc. 1974 Int. Symp. Fault-Tolerant Сотри tinge
FTC-4; IEEE, 1974, p. 2-26—2-31. Ж
552. Borgerson B. R. The viability of multimicroprocessor systems.—«
Computer, 1976, v. 9, № 1, p. 26—30. Л
553. Borgerson B. R., Hanson M. L., 'H a r 11 e у P. A. The evolutioqB
of the Sperry Uni vac 1100 series: a history, analysis, and projection.—»
Commun. ACM, 1978, v. 21, № 1, p. 25-43. Л
554. В о 8 s e t J. Sur certains aspects de la conception logique du GAMMA»
60.—Proc. Int. Conf. Information Processing (IFIP), Paris, 1959. ParisM
UNESCO, 1960, p. 348-353. «
555. Boulis R. L., Faiss R. O. STARAN E performance and LACIE algo*»
rithms.—Proc. 1977 Int. Conf. Parallel Processing. New York: lEEEjM
- 1977, p. 144-152.
556. В о w r a J. W., T о r n g H. C. The modeling and design of - multiple»
function-unit processors.—IEEE Trans. Comput, 1976, v. C —25, № 3M
p. 210-221. _
557. Boyd H. N. An associative processor architecture for air traffic cont-»
rol.— Proc. 1974 Sagamore Computer Conf. Parallel Processing. Leet. No-»
tes Comput. Sci., 1975, v. 24, p. 400—416. »
558. Brearley H. C. ILLIAC II — a short description and annotated bilw»
liography.— IEEE Trans. Electron. Comput., 1965, v. EC-14, № 6,»
p. 399-403. »
559. Bressler R. D., Kraley M. F., Michel A. Pluribus: a тиШрго-й»
cessor for communications networks.— In: 14th Annu. ACM/NBS Technical»
Symp. Computing in the mid-70’s: an assessment, 1975, p. 13—19. 1»
560. Bright H. S. A Philco multiprocessing system.—AFIPS Conf. Proc.,»
1964, FJCC, v. 26, part. II, p. 97-141. »
561. Burchby D. D. Specification of the fault-tolerant spaceborn сотри**»
ter (FTSC).—Proc. 1976 Int. Symp. Fault-Tolerant Computing. FTCS-6-мМ
Pittsburg, IEEE, 1976, p. 129—133. S
562. Burnett G. J., Koczela L. J., Hokum R. A. A distributed pro-^»
cessing systenf for general purpose computing.— AFIPS Conf. Proc., 1967J»
FJCC, v. 31, p. 757—768. »
563. Burtsev V. S. High-performance computers and multiprocessor сот**»
puter systems development trends.—Proc. I FAC Congr. Helsinki, 1978. ч»
564. C a d о w H. OS/360 job control language.— Englewood Cliffs: Prentice^*!»
Hall, 1970. »
565. Calhoun M. A. SYMBOL hardware debugging facilities.—AFIPS Conf.;»
Proc., 1972, SJCC, v. 40, p. 359-368. »
566. Campeau J. O. The block oriented computer.— IEEE Computer Groupjj»
Conf. Digest, 1968, p. 57—60.
567. Campeau J. O. Communication and sequential problems in the paral^SS
lei processor.— In: Parallel processor systems, technologies and applica-|g&
tions. New York: Spartan Books, 1970, p. 215—234.
568. Canaday R. H., Harrison R. D., Ivie E. L., Ryder J. L^$||£
Wehr L. A. A back-end computer for date base management.— Сот-./Ж:
тип. ACM, 1974, v. 17, № 10, p. 575-582. Ж
569. Capon P. C., Morris D., Rohl J. S., Wilson I. R. The MU-Mg?,
compiler targe language and autocode.—Computer J.1972, v. 15, № 2,1|ш
p. 109-112.
570. Capon P. C., Ibbett R. N. The implementation of record processings^
in MU 5 — IEE Conf. Proc., 1974, v. 121, p. 226—235.
571. Capon P. C., Ibbett R. N. Array operations in MU 5.— SIGPLAflpk&‘
Notices, 1975, v. 10, № 3, p. 133—137. $
572. С а г г о 11 A. B., Gregory J. G., Leonard W. H., S 1 о t n i с к D. L. A -,
The SOLOMON . II computer system.—Proc. IFIP Congress 65. New York, .
1965. Washington: Spartan Books, 1966, p. 319—320. ч ;
573. Carter H. B. Code optimization of arithmetic expressions in stacks “
environments.— Washington, 1974, 47 p.
488
374. Carter W. C., Bo*ur I ci us W. G. A survey of fault-tolerant compu-
ter architecture and its evaluation.— Computer, 1971, v. 4, J№ 1, p. 9—16.
375. Casale С. T. Planning the 3600.*— AFIPS Conf. ProcM 1962, FJCC, v. 22,
p. 73-85.
576. Case R.P., Padegs A. Architecture of the IBM System/370.—Com-
mun ACM, 1978, v. 21, № 1, p. 73—96.
577. CDC announces CYBER 170 series 700.— EDP Weekly, 1979, v. 19, № 51,
p. 1—2.
578. Chen T. C. Parallelism, pipelining and computer efficiency.—Comput.
Design, 1971, £ 10, № 1, p. 69—74.
579. Chen T. C. Unconventional superspeed computer systems.— AFIPS Conf.
Proc., 1971, SJCC, v. 38, p. 365-371.
580. Chen T. C. Parallelism, pipelining and performance enhancement mul-
tiprocessing.— Rechnerstrukturen, Munchen — Wien, 1974, n. 104—150.
581. Ch e n T. C. Overlap and pipeline processing.— In: Introduction to com-
puter architecture. Chicago; Science Research Associates, 1975, p. 375—431.
582. Cheng W.-T., Feng T.-Y. Solving some mathematical problems by
associative processing.—Proc. 1972 Sagamore Computer Conf. RADCAP
and its Applications. RADC and Syracuse Univ., 1972, p. 169—206.
383. Cheng W.-T., Feng T.-Y. Analysis and design of a cost-effective
associative processor for weather computations.— Proc. 1974 Sagamore
Computer Conf. Parallel Processing. Leet. Notes Comput Set, 1975, v. 24,
384. Shesley G. D., Smith W. R. The hardware-implemented highle-
vel machine language for SYMBOL.—AFIPS Conf. Proc., 1971, SJCC, v. 38,
p. 563—573.
585. Chevance R. J. A COBOL machine.— SIGPLAN Notices, August 1974,
p. 139-144.
586. Chevance R. J. Design of high level oriented processors.— SIGPLAN
Notices, 1977, v. 12, № 1, p. 40-51.
587. Christensen G. S., Jones P. D. The Control Data STAR-100 file
storage station.— AFIPS Conf. Proc., 1972, FJCC, v. 41, part I, p. 561—569.
588. Christman R. D. Development of the last computer network.—Proc.
IEEE COMPCON 73, 1973, p. 239-242.
589. Christman R.D. Development of a large common filing system as
part of a network. Infotech State of the Art Report 24.— Maidenhead,
1975, p. 479—489.
590. C h u Y. An Algol-like computer design language.— Commun. ACM, 1965,
v. 8, № 10, p. 607—615.
591. C h u Y. Significance of the SYMBOL computer system.— Proc. IEEE
COMPCON 72, 1972, p. 33—35.
592. Chu Y. Concepts of high-level-language computer architecture.—Proc.
ACM 75 Conf., 1975, p. 6-13.
593. Clark W. A. The Lincoln TX-2 computer development.— Proc. Nat.
Joint Comput. Committee Conf., 1957, Western Joint Comput Conf., v. 11,
p. 143-145.
594. Clark W. A. Marcomodular computer systems.—AFIPS Conf. Proc.,
1967, SJCC, v. 30, p. 333-336.
595. Clayton В. B., D о г f E. К., F a g e n R. E. An operating system and
programming systems for the 6600.— AFIPS Conf. Proc., 1964, FJCC, v. 26,
part H, p. 41—57.
596. Cleary J. G. Process handling on Burroughs B6500.— Proc. 4th Austra-
lian Computer Conf., Adelaide, 1969.
597. Cleary J. G. Development of a family of computers.— Proc. Ear. Com-
put. Congr., Brunel Univ., 1974, p. 883—899.
598. Codd E. F., Lowry E. S., McDonough E., Scalzi C. A. Mul-
tiprogramming STRETCH: feasibility consideration.—Commun. ACM, No-
vember 1959, v. 9, p. 13—17.
599. Cole G., Gray B. The hybrid digital computer: a new architectural
approach.— EDN/EEE, 1973, v. 18, № 12, p. 56-60.
489
600. Comfort W. T. Highly parallel machines. Proc. 1962 WORK SHOP
on Computer Organization.-—Washington; Spartan Books, 1963, p. 126—
155.
601. Comfort W. T. A modified Holland machine.—AFIPS Conf. Proc.,.
1963, FJCC, v. 24, p. 481—488.
602. Commun. ACM, 1977, v. 20, № 8, p. 539—604.— Selected papers from the
ACM Conference on Language Design for Reliable Software, Raleigh, 1977».
603. Commun. ACM, 1978, v. 21, № 1.— Special Issue on Computer Architectu-
re, 96 p.
604. Compiler Design for the ILLIAC IV.— Springfield, 1974; 91 p.
605. Computer organization/A. A. Barnum, M. A. Knapp (Eds.).— Washington?
Spartan Books, 1963.
606. Computer System Architecture. Special report.— Auerbach Pub. Inc., 1974*.
53 p.
607. Computing Surveys, 1975, v. 7, № 4, p. 173—255.— Special Issue: Compu-
ter Systems Architecture.
608. Computing Surveys, 1976, v. 8, № 3.— Special Issue: Reliable Software I?
Software Validation, p. 301—353.
609. Computing Surveys, 1976, v. 8, № 4.— Special Issue; Reliable Software lit
Fault-Tolerant Software, p. 355—445.
610. Computing Surveys, 1977, v. 9, Xs 1.—Special Issue; Parallel Processor»
and Processing, 129 p.
611. Control Data offers supercomputer series.—EDP Weekly, 1979, v. 19*.
Xs 40, p. 1-2.
612. Control Data unveils 6500.—Commun. ACM, 1967, v. 10, № 5, p. 330.
613. Conway M. E. A multiprocessor system design.—AFIPS Conf. Proc.,.
1963, FJCC, v. 24, p. 139-146.
614. Cooper A. E., Chow W. T. Development of on —board space com-
puter systems.— IBM J. Res. Develop., 1976, v. 20, X® 1, p. 5—19.
615. Cooper R.G. The distributed pipeline.— IEEE Trans. Comput. 1977*
v. C —26, № 11, p. 1123—1132.
616. Corbato F. J., Vyssotsky V. A. Introduction and overview of Mui-
tics.- AFIPS Conf. Proc., 1965, FJCC, v. 27, p. 185-196.
617. Corbato F., Saltzer J., Clingen C. MULTICS — the first seven
years.—AFIPS Conf. Proc., 1972, SJCC, v. 40, p. 571—583.
618. Corda E., Lanzarini M., Neri G. Programme A. D. A.— Elab.
Automatica, 1975, v. 2, Xs 1, p. 1—171.
619. Cornell J. A. Parallel processing of ballistic missile defense radar data
with PEPE —Proc. IEEE COMPCON 72, 1972, p. 69—72.
620. Cornell J. A. PEPE application and support soft-ware.—Proc*.
WESCON 72. Parallel Processing Systems. Session 1. Technical Papers*
1972, p. 1/3: 1-3. z
621. Cosserat D. C. A capability oriented multi-processor system for real-
time applications.—Proc. 1st Int. Conf. Comput. Cdinmun.: Impacts andl
Implementations, Washington 1972. New York, 1972, p. 282—289.
622. Couranz G. R., Gerhardt M., Young C. Programmable radar
signal processing using the RAP.— Proc. 1974 Sagamore Computer Conf,.
Parallel Processing. Leet. Notes Comput Sci., 1975, v. 24, p. 37—52.
623. Cowan R. M. Burroughs В 6700/7700 work flow language.—In: Com-
mand Languages. Proc. IFIP Work. Conf., 1975, p. 153—166.
624. Cowart В. E., Rice R., L u n d s t г о m S. F. The physical attribu-
tes and testing aspects of the SYMBOL system.— AFIPg Conf. Proc., 1971*
SJCC, v. 38, p. 589—600.
625. Crane B. A., Gilmartin M. J., H u 11 e n h о f f J. H., R u x P. T.,
Shively R. R. PEPE computer architecture.—Proc. IEEE COMPCON
72, 1972, p. 57-60.
626. Creech B. A. Architecture of the В 6500. In: Software Engineering*
v. l.f— New York: Academic Press, 1970, p. 29—43. ‘
627. Creech B. A. Implementation of operating systems.—IEEE 1970 InL
Convention Digest, IEEE Publ. 70 — C —15, p. 118—119,
490
€28. Creech В. A. Architecture of the В 6500. Infotech State of the Art Re-
port 2.—Giant Computers. Infotech Int., 1971, p. 383—402.
<629. Crenshaw J. H. Federated versus integrated computer systems.— Ins
Computers in the Guidance and Control Aerospace Vehicles. NATO,
AGARDograph 158, 1972, p. 9—22.
€30. Cristensen G. S., Jones P. D. The Control Data STAR-100 file
storage station.— AFIPS Conf. Proc., 1972, FJCC, v. 41, p. 561—570.
€31. Critchlow A. J. Generalized multiprocessing and multiprogramming
systems.— AFIPS Conf. Proc., 1963, FJCC, v. 24, p. 107—126.
€32. С г о a 11 I. F. Communication software.— In: Minicomput Data Com-
mun. Proc. Coursce, London, 1972. London, 1974, p. 95—104.
€33. Curnow H. J. The design of synthetic programs — IL—tn: Benchmar-
king: Computer Evaluation and Measurement, 1975, p. 99—114.
€34. Curnow H. J., Wichmann B. A. A synthetic BENCHMARK.—
Computer J., 1976, v. 19, № 1, p. 43—49.
€35. Curtin W. A. Multiple computer systems.—Advances in Computers,
1963, v. 4, p. 245—303.
€36. Curtis R. C. Management of high speed memory in the STAR —100
computer — Proc. IEEE COMPCON 71, 1971, p. 131—132.
€37. Dace R. E., Vick C. R., McKay J. M. PEPE — a fresh approach to
the BMD problem.- Proc. IEEE COMPCON 75, Spring, 1975, p. 211.
€38. Daggett D. H., Lee R. Q. The F-111D computer complex.— AIAA Pa-
per, 1968, № 837, 9 p.
€39. Dagless E. L. A multimicroprocessor — CYBA-M. Proc. IFIP Congress
77. Toronto, 1977.—Amsterdam: North-Holland Pub. Co., 1977, p. 843—
848.
€40. Daley J., Underwood B. D. Short term weather prediction of the
ILLIAC IV.—Proc. 1975 Sagamore Computer Conf. Parallel Processing.
New York: IEEE, 1975.
€41. Davidson B., Krieger M. Variable structured fault tolerant pro-
cessor.—Proc. 18th Midwest Symp. Circuits and Syst., Montreal, 1975,
p. 205—209.
€42. Davis E. W. STARAN/RADCAP system software. Proc. 1973 Sagamore
Computer Conf. Parallel Processing.— New York: IEEE, 1973, p. 153—159.
€43. Davis E. W. STARAN parallel processor system software.—AFIPS
Conf. Proc., 1974, NCCE, v. 43, p. 17—22.
€44. Davis G. M. The English Electric KDF 9 computer system.— The Com-
puter Bulletin, 1960, v. 4, № 3, p. 119—120.
€45. Davis R. L. The ILLIAC IV processing element.— IEEE Trans. Corn-
put., 1969, v. C — 18, № 9, p. 800—816.
€46. Davis R. L., Zucker S., Campbell С. M. A building block ap-
proach to multiprocessing.— AFIPS Conf. Proc., 1972, SJCC, v. 40,
p. 685-703.
€47. De Fiore C. R., Stillman N. J., Berra P. B. Associative techni-
ques in the solution of data management problems.—Proc. ACM Nat.
Conf., 1971, p. 28-36.
€48. De Fiore C. R., Vito A. A., Bauer L. H. Toward the development
of a higher order language for RADCAP.— Proc. 1972 Sagamore Computer
Conf. RADCAP and its Applications. RADC and Syracuse Univ., 1972,
p. 99-112.
€49. De Fiore C. R., Berra P. B. A data management system utilizing
an associative memory.—AFIPS Conf., Proc., 1973, NCCE, v. 42, part 1,
p. 181-186.
€50. De Fiore C. R., Вerra P. B. A quantitative analysis of the utiliza-
tion of associative memories in data management.— IEEE Trans. Comput.,
1974, v. C-23, № 2, p. 121-133.
€51. Dennis J. B. First version of a data-flow procedure language.— MIT
Project MAC, Comput. Structures Group Memo» 93—1, 1974.
€52. Dennis J. B. First version of a data flow procedure language.—Leet.
Notes Comput Sci., 1974, v. 19, p. 362—376,
491
653. Dennis J. В. First version of a data flow procedure language.—MIT j
Project MAG Techn. Memo., 1975» № 61, 21 p. I
654. Dennis J. B., Misunas D. P. A preliminary architecture for a basic;
data-flow processor.—Proc. 2nd Symp. Computer Architecture, 1975. New i
York: IEEE, 1975, p. 126-132.
655. Dennis J. B., W e n g К. K. S. Application of data flow computation; :
to the weather problem.—Proc. 1977 Symp. High Speed Computer and!
Algorithm Organization, Univ, of Illinois. Academic Press, 1977. ?
656. De Santis F., Giorgio G. V., Schaerf M. Design of a schedu- j
. ling algorithm for a multiprogramming system to meet the needs of the* 1
users of a university computer center.— Proc. Int Comput. Symp., Venice,.
1972, p. 129—138. *J
657. Deswarte Y. A high safety multi-microprocessor architecture.—Proc^ 1
1976 Int. Symp. Fault-Tolerant Computing. FTCS-6, Pittsburg. IEEE; 1976„ i
p. 171—175. j
658. Deveraux J. A. An application-oriented multiprocessing system, 3r ]
. Control program features.— IBM Syst. J., 1961, v. 6, № 2, p. 95—102. 1
659. Dijkstra E. W. Solution of a problem in concurrent programming: 1
control.— Commun. ACM, 1965, v. 8, № 9, p. 569. 1
660. Dijkstra E. W. Hierarchical ordering of sequential processes.—Acta» I
Informatica, 1971, v. 1, № 2, p. 115—138. ]
661. Dimmler D. G. Functional distribution — an architecture for multi-
user computer networks in instrumentation.— IEEE Trade. Nuct Sci., 1974,. j
v. NS-21, № 1, p. 838-850. !
662. D in geld in e J. R., Martin H. G., Patterson W. M. Operating* j
system and support software for PEPE.—Proc. 1973 Sagamore Computer
Conf. Parallel Processing. New York: IEEE, 1973, p. 170—178.
663. Di Vecchio M. C. Design and implementation of highHow magnitude**
search instruction on PEPE.— Proc. 1975 Sagamore Computer Conf. Paral-
lel Processing. New York: 1ЕЕЁ, 1975.
664. Dobrotin В. B., Rennels D. A. An application of microprocessors,
to a Mars roving vehicle.-*- Proc. 1977 Joint Automatic Control Conf., 1977,.
p. 185-196.
665. Donegan M. K., Katzke S. W. Lexical analysis and parsing techni-
ques for a vector machine.—SIGPLAN Notices, 1975, v. 10, № 3, p. 138—
145.
666. D о n n e g a n J. J. Description of the Mercury real-time computing sys- '
tern.— Computer Applications, 1961, p. 101—114.
667. Dow I." Programming a duplex computer system.— Commun. ACM, 1961». <
v. 4, № 11, p. 507-513.
668. Downing R. W., Nowak J. S., T u о m e n о к s a L. S. No. 1 ES& . j
maintenance plan.— Bell Syst. Techn. J., 1964, v. 43, № 5, part 1, p. 1961—
2019.
669. Downs H. R. Real-time algorithms and data management on ILLIAC:
IV — Proc. IEEE COMPCON 72, 1972, p. 297-300. ’
670. Downs H. R. Aircraft conflict detection in an associative processor.— *
AFIPS Conf. Proc., 1973, NCCE, v. 42, p. 177-180. <
671. Downs H. R. Real-time algoritms and data management on ILLIAC
IV.— IEEE Trans. Comput, 1973, v. C-22, № 8, p. 773—777.
672. Dreyfuss P. France’s GAMMA 60.—Datamation, 1958, v. 4, № 3r
p. 34-35. ’
673. Dreyfuss P. Programming design features for the GAMMA 60 com-
puter.— Nat. Joint Comput. Committee Conf. Proc. 1958, Eastern Joint.
Comput. Conf., v. 14, p. 174—180.
674. D-r e у f u s s P. System design of the GAMMA 60.— Nat. Joint Comput.
Committee Conf. Proc., 1958, Western Joint Comput Conf., v. 15, p. 130— I
133.,
675. Dubois P. F., Rodrigue G. An analysis of the recursive doubling 1
algorithm.— Proc. 1977 Symp. High Speed Computer and Algorithm Orga- j
nization, Univ, of Illinois. Academic Press, 1977. I
492 1
676. Duff M. J. N., Watson D. M., Deutsch E. S. A parallel computer
for array processing.— Proc. IFIP Congress 74. Stockholm, 1974. Amster-
dam: North-Holland Pub. Co., 1974, p. 94—97.
677. Duke C. S., McIntyre M. J. A new approach to data communicati-
ons in the B6700.— Proc. IFIP Congress 71. Ljubljana, 1971. Amsterdam:
North-Holland Pub. Co., 1972, p. 642-647.
678. D u n c a n F. G., Huxtable H. R. The DEUCE alphacode translator.—
Computer J., 1960, v. 3, p. 98.
679. Duncan F. C. Implementation of ALGOL 60 for KDF. 9.— Computer J.,
1962, v. 5, p. 130.
680. D unwell S. W. Design (objectives for the IBM STRETCH computer.—
Nat. Joint Comput Committee Conf. Proc., 1956, Eastern Joint Comput
Conf., v. 10, p. 20—22.
681. Eckert J. P. UNIVAC LARC, the next step in computer design.—Nat
Joint Comput. Committee Conf. Proc., 1956, Eastern Joint Comput. Cont,
v. 10, p. 16—20.
682. Eckert J. P., C h u J. С., T о n i к A. В., Schmitt W. F. Design
of UNIVAC LARC system: 1. Nat. Joint Comput Committee Conf. Proc.,
1959, Eastern Joint Comput. Conf., v. 16, p. 59—65.
683. Eckhouse R. H. Minicomputer systems organization and programming
(PDP-11).—Englewood Cliffs: Prentice-Hall, 1975, 343 p.
684. Eckhouse R. H., Stankovic J. A., Van Dam A. Issues in dist-
ributed processing — an overview of two Workshops.—Computer, 1978,
v. 11, № 1, p. 22-26.
685. Edgar R. On-board computers for the Shuttle.—Spaceflight, 1975,
1 v. 17; № 10, p. 363-364.
686. E d w a г d s D. B. G., W h i t e h о u s e D. A. E., Warburton L. E. M.,
Watson I. The MU5 disc system. IEEE Conf, on Systems and Techno-
logy, 1974.— Conf. Publication № 121, p. 185—193. >
687. Ellis C. A. Parallel compiling techniques.—Proc. 1971 ACM 26th Nat
Conf. New York, ACM, 1971, p. 508-519.
688. E1 г о d T. H. The CDC 7600 *nd SCOPE 76.— Datamation, 1970, № 4,
p. 80-85.
689. Emery A.R., Alexander M. T. Battle of the giants.—Data Syst,
1976, March, p. 13-15, 17—20.
690. England D. M. Architectural features of System 250 operating sys-
tems.— Infotech, 1972, p. 395—428.
691. England D. M. Capability concept mechanism and structure in Sys-
tem 250.— Rev. Franc. Automat., Inform., Rech. Oper. 1975, v. 9, № В — 3,
p. 47-62.
692. Englert T. Metody opisu synchronizacji procesow.— In: Materialy
sympoz. «Metody programow. i opisu systemow op er ac jin., Warszawa,
1973». Warszawa, 1974, 21-51.
693. E n s 1 о w P. H. Multiprocessors and other parallel systems: an introduo
tion and overview.— Infotech State of the Art Report Multiprocessor Sys-
tems, Infotech Int, 1976.
694. Enslow P. H. Multiprocessor organization — a survey.—Computing
Surveys, 1977, v. 9, № 1, p. 103—129.
695. Enslow P. H. What is a «distributed» data processing system? —Com-
puter, 1978, v. 11, № 1, p. 13—21.
696. E n t i с к n a p R. G., Schuster E. F. SAGE data system considera-
tion.—Communication and Electronics, 1960, № 40, p. 824—832.
697. E n t n e r R. S. The advanced avionic digital computer.— In: Parallel
processor systems, technologies, and application. New York: Spartan Books,
1970, p. 203—214.
698. E n t n e r R. S. The advanced avionic digital computer system.— Compu-
ter Design, 1970, v. 9, № 9, p. 73—76.
699. E n t n e r R. S., В e r s о f f E. H. Operating system reliability for the
Navy Advanced Avionic Digital Computer.— IEEE Trans. Aerospace and
Electronic Systems, 1971, v. AES — 7, № 1, p. 67—72.
493
700. Erickson D. В. Array processing on an array processor.—SIGPLAN
Notices, 1975, v. 10, № 3, p. 17—24.
701. Er show A. P. Theory of program schemata.—Proc. IFIP Congress 71.
Ljubljana, 1971. Amsterdam: North-Holland Pub. Co., 1972, p. 28—45.
702. E str in G. Organization of computer systems: the fuxed plus variable
structure computer.—Nat. Joint Comput. Committee Conf. Proc., 1960,
Western Joint Comput Conf. v. 17, p. 33—40.
703. Estrin G., Viswanathan C. R. Organization of a fixdfl-plus — va-
riable structure computer for computation of eigen-values and eigenvec-
tors of real symmetric matrices.— J. ACM, 1962, v. 9, № 1, p. 41—60.
704. E8trin G., Bussell B., Turn R., Bibb J. Parallel processing in
a restructurable computer system.— 1ЕЕЁ Trans. Electron. Comput:, 1963,
v. EC-12, №6, p. 747-755.
705. E s t r i n G., Turn R. Automatic assignment of computations in a va-
riable structure computer system.— IEEE Trans. Electron. Comput., 1963,
v. EC — 12, № 6, p. 755-773.
706. Evans D. J. Problem formulation using array processing techniques.—
SIGPLAN Notices, 1975, v. 10, №«8, p. 153-163.
707. Evans G. J. Experience gained from the american airlines SABRE
system control program.— Proc. ACM 22nd Nat. Conf. 1967, p. 77—83.
708. E v e n s e n A. J., Troy J. L. Introduction to the architecture of a 28&
element PEPE.—Proc. 1973 Sagamore Comput. Conf. Parallel Processing.
New York, 1973, p. 162-169.
709. Evensen A. PEPE hardware and system overview. Proc., 197*7 Int,
Conf. Parallel Processing.— New York: IEEE, 1977, p. 185.
710. Everett R. R., Zraket C. A., Bennington H. D. SAGE — a data "
processing system for air defence.— Nat. Joint Comput. Committee Conf. -
Proc., 1957, Eastern Joint Comput. Conf., v. 12, p. 148—155.
711. Fa don E. L. et al. A multilingual high level processor.—Proc. IFIP
Congress 77. Toronto, 1977. Amsterdam: North-Holland Pub. Co., 1977,
p. 613-618.
1712. F a i s s R., Lyon J., Quinn M., *R u b e n S. Application of a paral-
lel processing computer* in LACIE.— Proc. 1976 Int. Conf. Parallel Proces- ,
sing. New York: IEEE, 1976, p. 24—32.
713. Falk H. Computers: all pervasive.— IEEE Spectrum, 1977, v. 14, № 1, «
p. 38—43. i
TlAFalkoff A. D., Iverson К. E., Sussenguth E. H. A formal
description of System/360.— IBM Syst. J., 1966, v. 3, № 3, p. 213—218. 1
715. Farber D. J. An overview of distributed processing aims.— Proc. IEEE
COMPCON FALL 74, 1974, p. 191—193.
716. Feeley J. M. A computer performance monitor and Markov analysis •
for multiprocessor system evaluation.— In: Statistical computer performan- •
ce evaluation. New York: Academic Press, 1972, p. 165—225. ’
717. Feldman J. D., Reimann O. A. RADCAP: an operational parallel j
processing facility.—Proc. 1973 Sagamore Computer Conf. Parallel Pro- I
cessing. New York: IEEE, 1973, p. 140—146. J|
718. Feldman J. D., Fulmer L. C. RADCAP —an operational parallel ]
processing facility.— AFIPS Conf. Proc., 1974, NCCE, v. 43, p. 7—15. j
719. Feng T. Y. An overview of parallel processing systems.— Proc. 1972
WESCON Technical papers, v. 16. Parallel processing systems. Session 1. j
720. Feng T. Y. Some characteristics of associative/parallel processing.— I
Proc. 1972 Sagamore Computer Conf. RADCAP and its Applications. RADC 3
and Syracuse Univ., 1972, p. 5—16. 1
721. F e n n ef 1 R. D., Lesser V. R. Parallelism in artifical intelligence pro-
blem solving: a case study of Hearsay II,— IEEE Trans. Comput., 1977, !
v. C-26, № 2, p. 98-111. j
722. Fehton D. P. В 6700 «Working Set» memory allocation.— In: Opera-» |
ting systems techniques. London: Academic Press, 1972, p. 321—334. I
723. F e u s t e 1 E. A. The Rice research computer — a tagget architecture.— j
AFIPS Conf. Proc., 1972, SJCC, v. 40, p. 369-377. j
494
724. Field E. I., Johnson S. E., Stralberg H. Software development
utilizing parallel processing.— In: Struct. Meeh. Comput Programs. Surv.,
Assessments, and Availability. Charlottesville, 1974, p. 1019—1042.
725. Finnila C. A., Love H. H. The associative linear array processor.—
IEEE Trans. Comput., 1977, v. C-26, № 2, p. 112—125.
726. Flanders P. M., Hunt D. J., Red da way S. F., Parkin-
son D. Efficient high speed computing with the distributed array pro-
cessor.— Proc. 1977 Symp. High Speed Computer and Algorithm Organiza-
tion. Univ. of. Illinois. Academic Press, 1977.
727. Flores I. Computer programming system/360.—2nd ed.—Englewood
Cliffs: Prentice Hall, 1972.
728. Flores I. Operating system or multiprogramming with a variable
number of tasks.— Boston: Allyn and Bacon, 1973, 431 p.
729. Flynn M. J., Low P. R. IBM System/360 model 91: some remarks
on systems development.— IBM J. Res. Develop. 1967, v. 11, № 1,
p. 2-7.
730. Flynn M. J., Podvin A., Shimizu K. A multiple instruction
stream processor with shared resources.— In: Parallel processor systems,
technologies, and applcations. New York: Spartan Books, 1970,
p. 251—286.
731. Flynn M. J. Shared internal resources in a multiprocessor.—Proc.
IFIP Congress 71. Ljubljana, 1971. Amsterdam: North-Holland Pub. Co.,
1972, p. 565-569.
732. Flynn M. J. Multi-processors with shared resources.—Proc. IEEE
INTERCON, New York, 1972, p. 356-357.
733. Flynn M. J. Some computer organizations and their effectiveness.—
IEEE Trans. Comput. 1972, v. C-21, № 9, p. 948—960.
734. Flynn M. J. Towards more efficient computer organization.—AFIPS
Conf. Proc., 1972, SJCC, v. 40, p. 1211-1217.
735. Flynn M. J., Podvin A. Shared resourse multiprocessing.—Compu-
ter, 1972, v. 5, № 2, p. 20-28.
736. Flynn M. J. Trends and problems in computer organization.—Proc.
IFIP Congress 74, v. 1, Stockholm, 1974. Amsterdam: North-Holland Pub.
Co., 1974, p. 3-10.
737. .Fong K., Jordan T. L. Some linear algebraic algorithms and their
performance on CRAY-1.— Proc. 1977 Symp. High Speed Computer and
Algorithm Organization. Univ, of Illinois. Academic'Press, 1977.
738. Foster С. C. Computer architecture.—New York: Van Nostrand, Rein-
hold, 1976, .294 p. , '
739. Foster С. C. The next three generation.—Computer, 1972, v. 5, №’2,
p. 39-42.
740. Foster С. C. Content addressable parallel processors.—New York: Van
Nostrand Reinhold, 1976, 233 p.
741. Frank G. R. Job control in the MU5 operating system.—Computer J.,
1976, v. 19, № 2, p. 139-143.
742. Frankovich J. M., Peterson H. P. A functional description of
the Lincoln TX-2.— Proc. Nat. Joint Comput. Committee Conf., 1957, Wes-
tern Joint Comput. Conf., v. 11, p. 146—155.
743. Franta W. R., Houle P. A. On a loose communication between dis-
sijnilar CDC 6000 operating systems.— Software — Practice and Experiencer
1974, v. 4, № 3, p. 231—236.
744. Freeman D. N. IBM and multiprocessing.—Datamation, 1976, v. 22,
№ 3, p. 92—94, 99, 107, 109.
745. Full redundancy assures non-stop operation of transaction-type system.**
Computer Design, 1976, № 2.
746. Fuller R. H., Bird R. M. Ah associative parallel processor with
application to picture processing.—AFIPS Conf. Rroc.’, 1965, FJCC, v. 27f
p. 105-116.
747. Fuller R. H. Associative parallel processing.— AFIPS Coni. Proc., 1967,
p. 471-475.
ДО
748. Fuller 8. H., Siewiorek D. P., Swan R. J. Computer modules: Я
an architecture for large digital modules.—Proc. 1st Symp. Comput ч
Archit., New York, 1973, p. 231—237. J
749. Fuller S. H., Swan R. J., Wulf W. A. The instrumentation of 1
C. mmp: a multi-mini-processor.— Proc. IEEE COMPCON 73, 1973, p. 173—
176. <
750. Fuller S., Siewiorek D., Swan R. Computer modules. An archi- 1
tecture for a modular multi-microprocessor.—Proc. ACM Conf. 1975, t
p. 129-133. }
751. Fuller S. H. Price/performance comparison of C. mmp and the \
PDP-10.— Proc. 3rd Symp. Computer Architecture, 1976. New York: IEEE, :
1976, p. 198—202. . л
752. Fulmer L. C., MeilanderW. C. A modular plated-wire associative
processor-— Proc. 1970 IEEE Int. Computer Group Conf., 1970,
p. 325—335.
753. Gambino L. А., В о u I i s R. L. STARAN Complex.— Defense Map-
ping Agency, U. S. Army Engineer Topographic laboratories.— ProC. 1975 a
Sagamore Computer Conf. Parallel Processing. New York: IEEE, 1975, 1
p. 132—141. .
754. Gass S. I. et al. Project MERCURY real-time computational and data
flow system.— AFIPS Conf. Proc., 1961, EJCC, v. 20, p. 33. •<
755. Gaulding S. N. et at Optimization of SCALAR instructions for the
Advanced Scientific Computer.—Proc. IEEE COMPCON 75 Spring, 1975,
p. 189.
756. Gear C. W. Computer organization and programming.—New York:
McGraw-Hill, 1974, 456 p.
757. Gibson С. T. Time-sharing in the IBM System/360 model 67.—AFIPS
Conf. Proc., 1966, SJCC, v. 28, p. 61—78.
758. Gilmore P. A. Numerical solution to practical differential equations *
by associative processing.—AFIPS Coni. Proc., 1971, FJCC, v. 39,
p. 411-418.
759. Gilmore P. A. Matrix computations on an associative processor.—
Proc. 1974 Sagamore Computer Conf. Parallel Processing. Leet. Notes Com-
put Sci., 1975, v. 24, p. 272—290.
760. Ginsberg M. Some numerical effects of a FORTRAN vectorizing com-
piler on a Texas Instruments* Advanced Scientific Computer.— Proc. 1977
Symp. High Speed Computer and Algorithm Organization, Univ, of Illinois. J
. Academic Press, 1977.
761. Giroux E. D. A large mathematical model implementation on the
STAR-100 computers.— Proc. 1977 Symp. High Speed Computer an Algo- »
rithm Organization, Univ, of Illinois. Academic Press, 1977. .
762. Githens J. A. A fully parallel computer for radar data processing.—
Proc. 1970 National Aerospace and Electronics Conf. NAECON 1970,
p. 302—306.
763. Githens J. A. An associative, highly-parallel computer for radar data
processing.— In: Parallel processor systems, technologies, and applications, j
New York: Spartan Books, 1970, p. 71—86.
764. Glass W. F. Fast Fourier transform algorithms for the control data ,
STAR computer.—Proc. IEEE COMPCON 71, 1971, p. 5—6. }
765. Glushkov V. M., Ignatyev M. B., Myasnikov V. A.,^ Tоr-
gashev V. A. Recursive machines and computing technology.—Proc.
IFIP Congress 74. Stockholm, 1974. Amsterdam: North — Holland Pub. Co.,
4974, v. 1, p. 65-70.
766, Goke L. R., Lipovski G. J. Banyan networks for partitioning multi-
processor systems.—Proc. 1st. Symp. Computer Architecture, 1973, IEEE,
1973, p. 21-28.
767. G o’l u b G. H.,‘ В u z b e e B. L., Howell J. A. Vectorization for the
CRAY-1 of several methods for solving elliptic difference equations.—
Proc. 1977 Symp. High Speed Computer and Algorithm Organization, Univ,
of Illinois. Academic Press, 1977.
496
768. Go mm a H. An exercise in resource allocation.— Software — Practice
and Experience, 1974, v. 4, № 3, p. 199—213. '
769. G о m m a H. A modeling approach to the evaluation of computer system
performance.— In: Modeung and Performance Evaluation of Computer
Systems. Proc. 2nd Conf., Stresa, 1976. Amsterdam: NOrth-Holland Pub.
Co., 1977, p. 171—200.
770. Gonzalez M. J. SIMDA overview.— Proc. 1972 Sagamore Computer
Conf. RADCAP and its Applications. RADC and Syracuse Univ., 197?.
771. Gonzalez M. J. Problem areas in distributed processor system design.—
Proc. lEEE^Jilwaukee Symp. Automatic Comput. and Control, MSAC 76.
Milwaukee, 1976, p. 161—166. *
772. Gonzalez R. A multilayer iterative circuit computer (ICC).—IEEE
Trans. Electron. Comput., 1963, v. EC —12, № 6, p. 781—790.
773. G — P system performs batch and time-sharing operations concurrently.
Computer Design, 1976, v. 15, № 2, p. 32—37.
774. Graham W. R. The parallel and the pipeline computers.— Datamation,
1970, v. 16, № 4, p. 68-71.
775. Graham W. R. The impact of future developments in computer tech-
nology.—Computers and Structures, 1971, v. 1, № 1/2, p. 311—321.
776. Graham W. R. A review of capabilities and limitation of parallel and
pipeline computers.— In; Numerical- and computer methods in structural >
mechanics. New York: Academic Press, 1973, p. 479—495.
777. Green D. Terminal operating system for a SIMDA.— Proc. 1972 Saga-’
more Computer Conf. RADCAP and its Applications. RADC and Syracuse
Univ., 1972.
778. Greene W., Pooch V. W. A review of classification schemes for
computer communication network.— Computer, 1977, v. 10, № 11,
p. 12-21.
779. Gregory Jr, McReynolds R. The SOLOMON * computer.— IEEE
Trans. Electron. Comput., 1963, v. EC-12, № 6, p. 774—781.
780. Grooms D. W. Parallel processor (A bibliography with abstracts).—
Nat. Techn Inform. Service. NTIS/PS-76/0022/4, 1976, 212 p.
781. Grooms D. W. Parallel processors (Citations from Engineering In-
dex).—Nat. Techn. Inform. Service. NTIS/PS-76/0023/2, 1976, 232 p.
782. Grooms D. W. Parallel processors (Citations from the Engineering In-
dex Data Base).—Nat. Techn. Inform. Service, NTIS/PS-77/0025/5WC, 1977,
282 p:
783. Grooms D. W. Parallel processors (Citations from the NTIS Data Ba-
se).—Nat. Techn. Inform. Service, NTIS/PS-77/0024/8WC, 1977, 242 p.
784. Grosch H. R. High speed arithmetic»' the digital computer as a re-
search tool.— J. Optical Society of America, 1953, v. 43, № 4, p. 306—310.
785. Gudz R. T. Applications of the Pluribus multiprocessor in a distributed
data collection and processing network.—Proc. OCEANS 77, Conf. Rec.,
1977.
786. Gunderson D. C. Some effects of advances in memory system tech-
nology on computer organization.—Computer, 1970, № 6, p. 7—11.
787. Haendler W. Machine architecture.—Proc. Int Comput. Syst., Bonn,
1970. Frankfurt, 1973, p. 69—82.
788. Haley A. C. D. DEUCE: a high speed general-purpose computer.— Proc.
YEE, 1956, v. 103, part B, p. 165.
789. Haley A. C. D. The KDF. 9 computer system.— AFIPS Conf. Proc..
1962, FJCC, v. 22, p. 108-120.
790. H a 11 i n T. G., Flynn M. J. Pipelining of arithmetic functions.— Proc.
IEEE COMPCON 72, 1972, p. 91—94.
791. H a 11 i n T. G., Flynn M. J. Pipelining of arithmetic functions.— IEEE
Trans. Comput., 1972, v. C — 21, № 8, p. 880—886.
792. Hammer C. A forecast of the future computation.— Information and
Management, 1977, № 11, p. 3—7.
793. Handler W. The concept of macro-pipelining.—Arbeitsber. Inst. Math.
Masch. und Datenverarb., 1973, 6, Xs 4, p. 63—81.
32 в. А. Головкин 497
794. Handler W, The concept of macro — pipelining with high availabili-
ty.—Elektronische Rechenanlagqp, 1973, 15, № 6, p. 269—274.
795. H a n d 1 e-r W. A unified associative and von — Neumann processor
EGPP and EGPP-array.— Proc. 1974 Sagamore Computer Conf. Parallel
Processing. Leet. Notes Comput. Sci., 1975, v. 24, p. 97—99.
796. Handler W. On classification schemes for computer systems in the
post-von-Neuman-Era.— Leet. Notes Comput. Sci., 1975, v. 26, p. 439—452.
797. Handler W., Klar R. Fitting processors to the needs of a general
purpose array (EGPA).—Proc. 8th Workshop Microprogramm. Micro 8.
Chicago, 1975. New York, 1975, p. 87—97.
798. Handler W., Hofjnann F., Schneider H. J. A general purpose
array with a broad spectrum of applications.— In: Computer Architecture,
Workshop of the GI, Erlangen, 1975. Springer Verlag, 1976.
799. Handler W. Zur Genealogie, Struktur und Klassifizierung von
Rechnern.— In: Parallelismus in der Informatik, Arbeitsberichte des IMMD,
Universitat Erlangen-Nurnberg, (1976J/8, № 9, S. 1—30.
800. Handler W. The impact of classification schemes on computer archi-
tecture.— Proc. 1977 Int. Conf. Parallel Processing. New York: IEEE, 1977,
p. 7-15.
801. Hanlon A. G. Content-addressable and associative memory systems:
a survey.— IEEE Trans. Electron. Comput., 1966, v. EC-15, № 8,
6 509—521.
a n s e n P. B. The architecture of concurrent programs.— Englewood
Cliffs: Prentice-Hall, 1977.
803. Harris J. A., Smith D. R. Hierarchical multiprocessor organizati-
ons.— Proc. 4th Symp. Computer Architecture, 1977. New Yorkl IEEE, 1977,
p. 41-48.
804. Harrison M. C., Schwartz J. T. SHARER, a time-sharing system
for the CDC 6600.— Commun. ACM, 1967, v. 10, № 10, p. 659—664.
805. Harrison M. C. Preliminary design for POPSY- a polyprocessor sys-
tem.— Proc. ACM 1973, Conf., p. 39—41.
806. Harrison M. J., Harrison W. H. The implementation of APL on
an associative processor.—Proc. 1974 Sagamore Computer Conf. Parallel
Processing. Leet. Notes Comput. Sci., 1975, v. 24, p. 75—96.
807. Hartnett E. T. STAR FORTRAN. Ад overview of essential characterise
tics — SIGPLAN Notices, 1977, v. 12, Кг 4, p. 57—66.
808. Hassitt A., Lageschulte J. W., Lyon L. E. Implementation
of a high level language machine.—Commun. ACM, 1973, v. 16, № 4,
p. 199-212.
809. H a u с к E. A., Dent B. A. Burroughs’ B6500/7500 stack mechanism.—
AFIPS Conf. Proc., 1968, SJCC, v. 32, p. 245—251.
810. Hawkins C. J. B. Multi-minicomputer systems.—Proc. 1975 Minicom-.
outer Forum Conf., 1976, p. 43—54.
811. Hawley J. A., De Brito W. MUNIX, a multiprocessing version of
UNIX.—Naval Postgraduate School, AD-A012455/2, 1975, 58 p.
812. Hayashi T. A new approach to construction of computer systems.—
Proc. ACM 75 Conf., 1976, p. 19—23.
813. Haynes L. S. The architecture of an ALGOL60 computer implemented
with distributed processors.-Proc. 4th Symp. Computer Architecture,
1977. New York: IEEE, 1977, p. 95-104.
814. Heart F. E., Kahn R. E., Ornstein S. M., Crowther W. R.,
Walden D. C. The interface message processor for the ARPA computer
network.— AFIPS Conf. Proc., 1970, SJCC, v. 36, p. 551-567.
815. Heart F. E., О r n s t e i n S. M., Crowther W. R., Barker W. B.
A new minicomputer/muniprocessor for the ARPA network.— AFIPS Conf.
Proc., 1973, NCCE, v. 42, p. 529—537.
816. H e г r t F. E., О r n s t e i n S. M., С г о wt h e r W. R., Barker W. B.,
Kraley M. F., Bressler R. D., Michel A. The Pluribus multipro-
cessor system.— In: Infotech State of the Art Report. Multiprocessor Sys-
tems. Maidenhead, Infotech Int, 1976, p. 307—330.
498
817. Helms S. W. SIMDA hardware.— Proc. 1972 Sagamore Computer Cnnf,
RADCAP and its Applications. RADC and Syracuse Univ., 1972.
818. Hendrickson С. P. When you wish upon a STAR...—Proc. IEEE
COMPCON 77 Spring, 1977, p. 4—7.
819. Hibbard P., Hisgen A., Rodeheffer T. A language implemen-
tation design for a multiprocessor computer system.—Proc. 5th Symp.
Computer Architecture, 1978. New York: IEEE, 1978, p. 66—72.
820. Higbie L. C. The OMEN computers: associative array processors.—
Proc. IEEE COMPCON 72, 1972, p. 287-290.
821. Higbie L. G Supercomputer architecture.— Computer, 1973, v. 6, № 12.
822. Higbie L. C. Associative processors: panacea ar special purpose?— Corn-
put. and Elec. Eng., 1975, v. 2, № 4, p. 397—406.
823. Higbie L. C. Associative processors: a panaces or a specific?— Compu-
ter Design, 1976, v. 15, № 7, p. 75—82.
824. High-level language computer architecture.—New York: Academic Press,
1975, 273 p. (SIGPLAN Notices, 19?3, v. 8, № 11).
825. Hillman A. L., W i c h m a n n B. A. Experience with the Eldon ope-
rating system for KDF. 9.— In: Operating systems techniques. London:
Academic Press, 1972, p. 337—340.
826. Hintz R. G., Tate D. P. Control Data STAR 100 processor design.—
Proc. IEEE COMPCON 72, 1972, p. 1-4.
827„ Hobbs L. C., Theis D. J. Survey of parallel processor approaches
and techniques.— In: Parallel processor systems, technologies, and appli-
cations. New York: Spartan Books, 1970, p. 3—20.
828. Hodges K. J. H. A fault-tolerant multiprocessor design for real-time
control.—Computer Design, 1973, v. 12, № 12, p. 75—81.
829. Hogan D. W., Jensen J. C., Cornish M. The costs of proces-
sing power: the process, the programmer, and the processor.—Proc. 1977
Symp. High Speed Computer and Algorithm Organization, Univ, of Illi-
nois. Academic Press, 1977.
830. Hohn W. C., Jones P. D. The Control Data STAR-100 paging stati-
on.—AFIPS Conf. Proc., 1973, NCCE, v. 42, p. 421—426.
831. Holland J. H. A universal computer capable of executing on arbitrary
, number of sub —programs simultaneously.—Proc. Nat. Joint Comput.
Committee Conf., 1959, Eastern Joint Comput. Conf., v. 16, p. 108—113.
832. Holland J. H. Iterative circuit computers.— Proc. Nat. Joint Comput.
Committee Conf., 1960, Western Joint Comput. Conf., v. 17, p. 259—266.
833. Holland S. A., Purcell C. J. The CDC STAR-100: a large scale
network oriented computer system.—Proc. IEEE Int. Comput. Soc. Conf.,
1971, p. 55-56.
834. Hollander G. L. Architecture for large computer systems.—AFIPS
Conf. Proc., 1967, SJCC, v. 30, p. 463—466.
835. Holley L. H., Parmelee R. P., Salisbury C. A., Saul D. N.
VM/370 asymmetric multiprocessing.— IBM Syst. J., 1979, v. 18} № 1.
836. Hoover W. R., Arcaird A., Miller T. B. A real time multicom-
puter system for lunar and planetary space flight data processing.—
AFIPS Conf. Proc., 1963, SJCC, v. 23, p. 127—140.
837. Hope^JC S. SABRE; a real-time problem in teleprocessing.— Computer
J., 1961, v. 4, № 2, p. 109—111.
838. Hopkins A. L., Smith T. B. The architectural elements of a sym-
metric fault-tolerant multiprocessor.— Proc. 1974 Int. Symp. Fault-Tole-
rant Computing. FTC-4. IEEE, 1974, p. 42—4.6.
839. Hopkins A. L., Smith T. B. The architectural elements of a sym-
metric fault-tolerant multiprocessor.— IEEE Trans. Comput., 1975, v. C-24,
№ 5, p. 498-505.
840. Border A., S t r e 1 о w H., W о bi g К. H. Sichere Mehrrechnersysteme
hoher erfugbarkeit.— Elek. Rechenanlag., 1975, 17, № 3, S. 118—124
841. Hosaka M., Tani T. A real time multicomputer system for train
seat reservation.— Proc. IFIP Congress 65. New York, 1965. Washingtoni
Spartan Books, 1966, p. 320.
32*
499
842. Hubner-Biegalska E. Maszyny wieloprocesorowe.— Elektron. techn.
obliczen. Nowosci, 1974, 13, № 3, 3—19.
843. Hughes P., Doone T. Multi-processor systems^— Microelectronics
and Reliability, 1977, v. 16, № 4, p. 281—293.
844. Husband M. A., Ibbett R. N., Phillips R. The MU 5 computer
monitoring system.-^- Proc. Eurocomp., London, 1976, p. 17—28.
845. Hwang K, Ro m ago sa A. A. Multiprocessor system design: archi-
tecture, control, and hardware organizations availability.— IEEE Compu-
ter-Group Depository, 1974, № R74—84, 40 p.
846. Ibbett R. N.^The MU5 instruction pipeline.—Computer J., 1972, v. 15,
№ 1, p. 42-50.
847. Ibbett R. N., Phillips E. C., Edwards D. B. G. Control of the
MU 5 instruction pipeline.— Proc. Joint IERE — IEE — BCS Conf, on Com-
puters — Systems and Technology, 1972.
848. Ibbett R. N., Husband M. A. The MU5 name store.—Computer
J., 1977, v. 20, № 3, p. 227-231.
849. Ibbett R. N., Capon P. C. The development of the MU5 computer
system.— Commun. ACM, 1978, v. 21, № 1, p. 13—24.(
850. Ichikawa T., Sakamura K., Aiso H. ARES — a memory, ca-
pable of associating stored information through relevancy estimation.—
AFIPS Conf. Proc., 1977, NCC, v. 46, p. 947—954.
851. IEEE Trans. Comput., 1973, v. C-22, № 8, p. 709—804.— Special section on
K’lel computation. *
Trans. Comput., 1977, v. C-26, № 2.— Special Issue on Parallel Pro-
cessors and Processing.
8531 IEEE Trans. Software Eng., 1975, v. SE-1, № 2.
854. Ihara H. et al. Computer aided traffic control system ‘COMTRAC’ for
Hakata Shinkansen.—Hitachi Review, 1975, v. 24, №4, p. 181—188.
855. Inada S. et al. Shinhasen traffic control and management system,
COMTRAC, Ph. 2 - Rail Int., April 1975, p. 295—305.
856. Infotech State of the Art Report 2.— Giant computers, 1971.
857. Infotech State of the Art Report 20.—Computer systems reliability. Info-
tech Inf., 1974.
858. Infotech State of the Art Report. Multiprocessor Systems. Infotech Int^
1976.
859. Infotech State of the Art Report on Software Reliability. I. Analysis and
- Bibliography, 1977, 288 p. II. Invited Papers, 1977, 410 p.
860. Introduction to computer architecture. H, S. Stone (Ed.) — Chicago: Sci-
ence Research Associates, 1975, 565 p.
861. Irons E. T. Experience with an extensible language.—Commun. ACM,
1970, v. 13, № 1, p._ 31—40.
862. J a 1 i c s P. J., Lynch W. C. Selected measurements of the PDP-10
TOPS-10 timesharing operating system.—Proc. IFIP Congress 74. Stock-
holm, 1974. Amsterdam: North-Holland Pub. Co., 1974, p. 242—246.
863. J a s i к S. Monitoring program execution on the CDC 6000 series machi-
nes.— In: Design and optimization of compilers. Englewood Cliffs, Prenti-
ce-Hall, 1972, p. 129-136.
864. Jensen C. Taking another approach to supercomputing.— Datamation,
1978, v. 24, № 2, p. 159, 160, 162, 163, 166, 168, 170, 172. ~
865. Jensen E. D. The influence of microprocessors on computer architectu-
re: distributed processing.—Proc. ACM^75 Conf., 1975, p. 125—128.
866. Jensen E. D., Thurber K, Schneider G. M. A review of sys-.
tematic methods in distributed processor interconnection.— Proc. 1976 Int.
Conf. Commun., Philadelphia, v. 1—3, New York: IEEE, 1976,
p. 7/17-22.
867. Jensen E. D., Kain R. Y. The Homeywell modular microprogram
machine: M8.— Proc. 4th Symp. Computer Architecture, 1977. Nbw York:
IEEE, 4977, p. 17—28.
868. Jensen E. D. The Honeywell experimental distributed processor — an '
overview.— Computer, 1978, v. 11, № 1, p. 28.—38.
500
$69. Jensen К., Wirth N. PASCAL user manual and report—2nd ad.—~
New York: Springer-Verlag, 1975, 167 p. t .
$70. J о e с к e 1 С. T., M a 11 e s C. F. The all application digital computer.—
AIAA Paper, 1975, № 585, p. 1-8.
<871 . Johnson M. D. The architecture and implementation of* a parallel
element processing ensemble.—Proc. 1972 WESCON Technical Papers,
v. 16. Parallel Processing Systems. Session 1, p. 1/4:1—8.
$72. Johnson P. M. An introduction, to vector processing.— Computer De-
sign, 1978, v. 17, № 2, p. 89—97.
$73. Jones А. К., C h a n s 1 e r R. J., Durham I., F e i 1 e r P.,
Schwans K. Software management of Cm* — a distributed multipro-
cessor.— AFIPS Conf. Proc., 1977, NCC, v. 46, p. 657—663.
$74. Jones P. D., Lincoln N. R., Thornton J. E. Whither computer
architecture.—Proc. IFIP Congress 71. Ljubljana, 1971. Amsterdam:
North-Holland Pub. Co., 1972, p. 729—736.
$75. Jones P. D. Implicit storage management in the Control Data
STAR - 100.- Proc. IEEE COMPCON 72, 1972, p. 5-8. -
876. Jordan T. Vector reduction process on CRAY-1 and their performan-
ce.—Proc. 1977 Int Conf. Parallel Processing.—New York: IEEE, 1977,
ф. 215.
877. Joseph E. C. Distributed functions systems: innovative trends.— Proc.
IEEE COMPCON 74, 1974, p. 71—73.
$78. Joy R. E. Implementation of an adaptive scheduling algorightm for the
MUNIX operating system.—Naval Postgraduate School, AD-A020062/6,
1975, 65 p.
$79. К a nab у К. D., Atkins D. E. A shared — memory micro — minicom-
puter system for process control.-Proc. IEEE COMPCON 74, 1974,
p. 5—10.
880. Kaneda Y. A survey of parallel processing and parallel processor sys-
tems.—Дэнси гидзюцу сого кэнкюсё гёса хококу, Circ. Electr. Lab.,
1973, № 174, р. i-ii, 1-97.
881. Kartsev M.A. On the structure of'multiprocessor systems.—Proc.
IFIP Congress 71. Ljubljana, 1971. Amsterdam: North-Holland Pub. Co.,
1972, p., 559-564.
882. Katz R. Analysis of the Awacs passive tracking algorithms on the
RADCAP STARAN.— Proc. 1976 Int. Conf. Parallel Processing. New York:
IEEE, 1976, p. 177-186.
883. Keeley J. F. An application-oriented multiprocessing system, I: Intro-
duction.— IBM Syst. J., 1967, v. 6, № 2, p. 78—79. —4
$84. Keller R. M. Look-ahead processors.—Computing Surveys, 1975, v. 7,
№ 4, p. 177-195.
885. Kerr A., Wagenbreth G. Computer listing for ILLIAC IV versions
of FKCOMB, Alexandria, 1974, pag. var.— (Seismic Data Analysis Center,
№ SDAC-TR-74-18).
$86. Kilburn T. One-level storage system.— IRE Trans. Electron. Comput,
1962, v. EC-11, № 2.
$87. Kilburn T., Morris D., Rohl J. S., Sumner F. H. A system
design proposal.—Proc. IFIP Congress 1968. Edinburg, 1968. Amsterdam,
North-Holland Pub. Co., 1969, p. 806-811.
$88. К i m s e у D. В., H ал d L. E., N a g 1 e H. T. Application of PEPE to
real-time digital filtering.—Proc. 1976 Int. Coni. Parallel Processing.
New York: IEEE, 1976, p. 169.
889. К i n n i m e n t D. J., Edwards D. B. G. Circuit technology in a large
computer system.— The Radio and Electronic Eng., 1973, v. 43, № 7,
p. 434—441.
$90. Kishi T., Rudy T. STAR TREK-Proc. IEEE COMPCON 75 Spring,
pm 1, 1975, p. 185—188.
891. KI a уton A. R. Concept for a computer architecture facility.—proc.
1976. Int. Conf. Parallel. Processing. New* York: IEEE, 1976,
p. 189-190. / . .
501
ч
892. Knapp М. А., А с к i n s G. М., Т h о m a s. J. Application of ILLIAC
IV to urban deieuse radar problem.— In: Parallel processor systems,
technologies, and applications. New York: Spartan Books, 1970,.
p. 23-70.
893. Knight K.E. Changes in computer performance.*—Datamation, 1966,
v. 12, № 9, p. 40—42, 45-51, 54 ♦).
894. Knight К. E. Evolving computer performance, 1963—1967.— Datamati-
on, 1968, v. 14, № 1, p. 31— 35*).
895. Kober R. The multiprocessor system SMS 201 — combining 128 micro-
processors to a powerfull computer.— Proc. IEEE COMPCON 77 Fall, 1977»
. p. 225-230.
896. Kober R., Kuznia C. SMS 201 —a powerfull parallel processor with
128 microprocessors.—Euromicro J., 1979, v. 5, № 1, p. 48—52.
897. Koczela L.J. The distributed processor organization.— Advances in
Computers,. 1968, v. 9, p. 285—353.
898. Koczela L. J., Wang G. Y. The design of a highly parallel сотри*
ter organization.— IEEE Trans. Comput., 1969, v. C-18, № 6, p. 520—529.
899. Kraley M. F. The Pluribus multiprocessor.—Proc. 1975 Int. Symp.
Fault-Tolerant Computing. FTC-5. Paris: IEEE, 1975, p. 251.
900. Kr a n s к у V. J., Giroux E. D., Long G. A. Parallel implementa-
tion on a two-dimensional model.—Proc. 1973 Sagamore Computer Conf.
Parallel Processing. New York: IEEE, 1973, p. 69—77.
901. К r i d e r L. D. STAR — a de-education problem.— Proc. IEEE
COMPCON 72, 1972, p. 9—12.
' 902. Krohn H. E. A parallel approach to code generation for FORTRAN like
compilers.-SIGPLAN Notices, 1975, v. 10, № 3, p. 146-152.
903. Krygiel A. J. On implementation of the Hadamard transform on the
, STARAN associative array processor.— Proc. 1976 Int. Conf. Parallel Pro-
cessing. New York, 1976, p. 34.
904. К иск D. J. ILLIAC IV software and application programming.—IEEE
Trans. Comput., 1968, v. C-17, № 8, p. 758—770.
905. К и с к D. J., Sam eh A. H. Parallel computation of eigenvalues of real
matrices.— Йос. IFIP Congress 71. Ljubljana, 1971. Amsterdam: North-
Holland Pub. Co., 1972, v. II, p. 1266-1272.
. 906. Kuck D. J.. Muraoka Y., Chen S.—C. On the number of\opera-'
. tions simultaneously executable in FORTRAN-like programs and their
resulting speed-up.—IEEE Trans. Comput, 1972, v. C —21. № 12.
p. 1293-1310. - .
907. Kuik D. J. Multioperation machine computational complexity (someti-
mes referred to as parallelism in ordinary programs).— In: Complexity of v
sequential and parallel numerical algorithms. New York: Academic Press.
1973, p. 17—47.
908. Kuck D. J., Budnik P. P., Chen 8.— C., Davis E. W.,
Han J. С.-*- С., К r a s к a P. W., Lawrie D. H., Muraoka Y.,
Strebendt R. E., Towle R. A. Measurements of parallelism in
ordinary FORTRAN programs.— Proc. 1973 Sagamore Computer Conf. Pa-
rallel Processing. New York: IEEE, 1973, p. 23—36.
909. Kuck D. J., В и d n i к P. P., C h e n S.-C., Lawrie D. H., T о w-
l*e R. A., Strebendt R. E., Davis E. W., H a n J., К r a s-
ka P. W., Muraoka Y. Measurements of parallelism in ordinary
FORTRAN programs.— Computer, 1974, v. 7, № 1, p. 37—45.
910. Kuck D. J. Parallel processor architecture — a survey. — Proc. 1975 Saga- 1
more Computer Conf. Parallel Processing. New York: IEEE, 1975, p. 15—39. J
911. Kuck D. J. Parallel processing of ordinary programs.—Advances in .
Computers, 1976, v. 15, p. 119—179. ]
_______। .
♦) Имеется сокращенный перевод этих двух статей: Найт. Оценка
развития рабочих характеристик ЦВМ.— Зарубежная радиоэлектроника* 1
1968, Кз И, с. 63-83.
502 z <
912. К иск D. J., Kumar В. A system model for computer performance
evaluation.—Proc. Int. Symp. Comput Perform. Modeling, Measurement
and Evaluation. Cambridge, 1976, p. 187—199.
913. К иск D. J. A survey of parallel machine organization and program-
ming.—Computing Surveys, 1977, v. 9, № 1, p. 29—59.
*914. Lambiotte J. J., Voigt R. G. The solution of tridiagonal linear
systems on the CDC STAR-100 computer.—ACM Trans. Math. Software,
1975, v. 1, № 4, p. 308-329.
915. Lamport L. The coordinate method for the parallel execution of DO
loops.—Proc. 1973 Sagamore Computer Copf. Parallel Processing. New
York: IEEE, 1973, p. 1-12.
916. Lafrg T. Interconnections between processors and memory modules
using the shuffle-exchange network.— IEEE Trans. Comput, 1976, v. C-25,
№ 5, p. 496-503.
917. Lange R. G. High level language for associative and parallel computa-
tion with STARAN.— Proc. 1976 Int Conf. Parallel Processing. New York:
IEEE, 1976, p. 170—176.
918. Laughlin R. S. The GALAXY/5: A large computer composed of mul-
tiple microcomputers.—Proc. IEEE COMPCON 76 Fall, 1976, p. 90—94.
919. Lavington S. H., Viswanathan T. A diagnostic ami reconfigu-
ration system for the MU 5 multicomputer complex. Proc. 1976 Int. Symp.
Fault-Tolerant Computing. FTCS-6.—Pittsburg. IEEE, 1976, p. 176—181.
920. Lavington S. H., Knowles A. E. Assessing the power of an order
code.— Proc. IFIP Congress 77. Toronto, 1977. Amsterdam: North-Holland
Pub. Co., 1977, p. 477—480.
921. Lavington S. H., Thomas G., Edwards D. B. G. The MU5
multicomputer communication system.— IEEE Trans. Comput., 1977, v. C-26,
№ 1, p. 19-28.
922. Lawrie D. H., Layman T., Baer D., Randal J. M. GLYPNIR —
a programming language for ILLIAC IV.—Commun. ACM, 1975, v. 18,
№ 3, p. 157—166.
923. Leiner A. L., Alexander S. N. System organization of the
DYSEAC.— IRE Trans. Electron. Comput., 1954, v. EG-3, p. 1—10.
924. Leiner A. L., Notz W. A., S m i t n J. L., Weinberger A. Orga«
nizing a network of computer to meet deadlines.— Nat. Joint Comput. Corn*
mittee Conf. Proc., 1957, Eastern Joint Comput. Conf., v. 12, p. 115—128.
925. Leiner A. L., Notz W. A., Smith J. L., Weinberger A. PILOT,
the NBS multicomputer system.—Nat. Joint Comput. Committee Conf. Proc.,
1958, Eastern Joint Comput. Conf., v. 14, p. 71—75.
926. Leiner A.L., Notz W. A., Smith J. L., Weinberger A.
PILOT —a new multiple computer system.—J. ACM, 1959, v. 6, № 3,
p. 313—335.
927. Leith С. E. Some aspects of computing with array processors.— Atmos-
pheric Technology (NCAR), 1973, v. 3, p. 21—25.
928. L e s h F., L e с о q P. Software techniques for a „ distributed real-time
processing system.—Proc. 1974 National Aerospace and Electronics Conf.
NAECON76, p. 290-295.
929. Lesh F. Software development aids in distributed microprocessor sys«
terns.— Proc. 1977 Int. Sump. MINI and MICRO Cbmput. MIMI 77.
Monthreal, 1977. New York, 1978, p. 88—94
930. Levesque J. M. Application of the vectorizer for effective use of
high-speed computers.—Proc. 1977 Symp. High Speed Computer and
Algorithm Organization. Univ, of Illinois. Academic Press, 1977.
931. Lewis D. R., Mellen G. E. Stretching LARC’s capability by 100—
a new mutliprocessor system.—Proc. 1964 Symp. Microelectronics and
Large Systems. Washington, 1964— (Aviation Week Bpace Technol., 1964,
v. 81, № 22, p. 49).
932. Lewis T. B. Primary processor and data storage equipment for the
orbiting astronomical observatory.— IEEE Trans. Electron. Comput., 1963,
v. EC - 12, Кг 10, p. 667.
503
933. Li H.F. Scheduling trees in parallel/pipelined processing environments.—
IEEE Trans. Comput., 1977, v. C — 26, № 11, p. 1101—1112.
934. Liebowitz В. H. Multiple processor minicomputer systems.—Part Ir
Design concepts.— Computer Design, 1978, v. 17, № 10, p. 87—95; Part 2.—
Computer Design, 1978, v. 17, № 11.
935. Lincoln N. R. Supercomputer development: the pleasure and the-
pain.— Datamation, 1977, v. 23, № 5, p. 221—226.
936. Linde R. R., Gates R., Peng T.-F. Associative processor applica-
tions to real — time data management.— AFIPS Conf. Proc., 1973, NCCEr
v. 42, part 1, p. 187-195.
937. Lip о vski G. J. A varistructured failsoft cellular computer.—Proc. 1st
Symp. Computer Architecture, 1973. New York: IEEE, 1973, p. 161—165.
938. Lipovski G. J. On a varistructured array of microprocessors.—IEEE
Trans. Comput., 1977, v. C — 26, № 2, p. 125-138.
939. Lipovski G. J., Tripathi A. A reconfigurable varistructure array
processor.—Proc. 1977 Int. Conf. Parallel Processing. New Yojck: IEEE»
1977, p. 165-174.
940. Lipovski G. J., Doty K. L. Developments and directions in compu-
ter architecture.— Computer, 1978, v. 11, № 8, p. 54—67.
941. Lipps H. Batch processing with 6000-series scope.— In: Operating sys-
tems techniques. London, Academic Press, 1972, p. 291—303.
942. List В. H. DAIS — a major crossroad in the development of avionic:
systems. Astronaut, and Aeronaut., 1973, v. 11, № 1, p. 55—61.
943. Lister A. M., Maynard K. J. An implementation of monitors.—
Software — Practice and Experience, 1976, v. 6, >6 3, p. 377—385.
944. L i t z 1 e r W. S., Womack B. F. Transient probability models of
computing system dynamic behavior.—Texas Univ., AD-A013806/5, 1975,.
124 p.
945. Lloyd G. R., Merwin R. E. Evaluation of performance of parallel
processors in a real-time environments.—AFIPS Conf., Proc., 1973,.
NCCE, v. 42, p. 101-108.
946. Lonergan W., King P. Design of the B5000 system.— Datamation^
1961, v. 7, № 5, p. 28-32.
947. Lorin H. Parallelism in hardware and software — real and apparent
concurrency.—Englewood Cliffs: Prentice — Hall, 1972, 508 p.
948. Love H. H. An efficient associative processor using bulk storage.— Proc.
1973 Sagamore Computer Conf. Parallel Processing.—New York: IEEE.
1973, p. 103-112.
949. Love H. H. Radar data processing on the ALAP.— Proc. 1976 Int Conf.
Parallel Processing. New York: IEEE, 1976, p. 161—167.
950. Love H. A modified ALAP cell for parallel text searching.— Proc. 1977
Int. Conf. Parallel Processing. New York: IEEE, 1977, p. 153—154.
951. Loveman D. B., Faneuf R. A. Program optimization-theory and
practice.— SIGPLAN Notices, 1975, v. 10, № 3, p. 97—102.
952. Lukoff H., Spandorfer L.M., Lu F. F. Design of Univac — LARG
system: II.—Nat. Joint Comput. Committee Conf. Proc, 1959, Eastern*
Joint Comput. Conf., v. 16, p. 66—74.
953. Lynch J. T. The Burroughs B8500.—Datamation, 1965, v. 11, № 8.
p. 49-50.
954. Lynch W. C. An operating system designed for the computer utility-
environment.- In: Operating systems techniques. London, Academic Press,.
1972, p. 341-350.
955. Lynch W. C., L a n g n e r J. W., S q h w a r t z M. S. Reliability expe-
rience with Chi/OS.— IEEE Trans. Software Eng., 1975, v. SE — 1, № Z
p. 253-257.
956. Lynch W. C., Langner J. W., Schwartz M. S. Reliability expe-
rience with Chi/OS.— Proc. 1975 Int. Conf. Reliable Software, Los Angeles..
New Ybrk: ACM, 1975, p. 252-259.
957. MacKinnon R.A. Advanced function extended with tightly-coupled
multiprocessing.— IBM Syst, J., 1974, v. 13, № 1, p. 32—59.
504
958. Madsen N. К., Rodrigue G. H., Karush JI.
tion by diagonals on a vector/parallel processor.— Inform. Prooef^MlU
1976, v. 5, № 2, p. 41-45. :
959. Maison F. P. The MECRA: a self — repairable computer for highly гё*
liable process.— IEEE Trans. Comput., 1971, v. C-20, № 11, p. 1383—1393»
960. Martin F. H. HAL/S — the programming language for Shuttle. Int.
Astronautical Federation (IAF). XXVth Congress.—Amsterdam, 1974. Pa-
per № 74-092, p.' 1—52.
961. Martin H. G. A discourse on a new super computer, PEPE.— Proc.
1977 Symp. High Speed Computer and Algorithm Organization.—Univ of
Illinois. Academic Press, 1977.
962. Marvel О. E. HAPPE: Honeywell associative parallel processing en-
semble.— Proc. 1st Symp. Computer Architecture, 1973. New York: IEEE,,
1973, p. 261-267.
963. Marvel О. E. PIRATE pipeline infra-red array track electronics.— Proc.
SOUTHEASTCON 74 Reg. 3 Conf.: Invent. Model Future, Orlando,. 1974.
New York, 1974, p. 333-336.
964. Marzolf J. G. AAPL: an array processing language.—Proc. 1974 Sa-
gamore Computer Conf. Parallel Processing. Leet. Notes Comput. Sci., 1975,
v. 24, p. 230-237. '
965. Matsuura T., Sakemoto T., Yano 8., Tokura N., Fujli M.,
Okamoto T. A minicomputer complex and Its operating system.— Даё-
xo сёри, 1977, 18, № 9, 913—920.
966. Mazare G. Multiprocessor systems. CERN Sci. Report, 1974, № 23,
p. 188-222.
967. Mazare G. A few examples of how to use a symmetrical multi-micro*
processor.— Comput. Archit. News, 1977, v. 5, № 7, p. 57—62.
968. McCormick В. H. The Illinois pattern recognition computer — ILLIAC
III.— IEEE Trans. Electron. Comput., 1963, v. EC —12, № 6,
p. 791-813.
969. McCormick В. H., Roy 8. R., Smith К. C., Yamada 8. ILLIAC
III: a processor of visual information.— Proc. IFIP Congress 65. New York,.
1965. Washington: Spartan Books, 1966, v. 2, p. 359—360.
970. McCullough J. D., Speierman K.H., Zurcher F. W. A de-
sign for a multiple user multiprocessing system.— AFIPS Conf. Proc., 1965»
FJCC, v. 27, p. 611-617.
971. McGlynn D. R. Microprocessors: technology, architecture and applica-
tions.— New York: Wiley Int., 1976, 207 p.
972. McIntyre D. E. An introduction to the ILLIAC IV computer.—Data-
mation, 1970, v. 16, № 4, p. 60—67.
973. McIntyre D. E. ILLIAC IV software development.— Proc. 1972
WESCON. Parallel Processing Systems. Session 1. Techn. Papers, 1972,.
p. 1/1:1-3.
974. McKeag R.M., Wilson R. Studies in operating systems.— Londonr
Academic Press, 1976, 263 p.
975. McKeeman W. M. Language-directed computer design.— AFIPS Conf»
Proc., 1967, FJCC, v. 31, p. 413-417.
976. McLaughlin R. A. The CDC 7600.— Datamation, 1969, v. 15, № 1„
p. 61, 62, 64.
977. McLaughlin R. A. The IBM 360/195.— Datamation, 1969, v. 15, № 10»
p. 119; 122. •
978. Mera ud C., Bjowaeys F. Automatic rollback techniques of the*
COPRA computer.— Proc. 1976 Int. Symp. Fault — Tolerant Computing»
FTCS-6. Pittsburg. IEEE, 1976.
979. M e r a u d C./ L1 о r e t P. COPRA: a modular family of reconfigurable*
computers.— Proc. 1978 National Aerospace and Electronics Conf. NAECON
78, p. 822—827.
980. Miller A. E. Goldman M. Organization and program of the BMEW&
checkout data processor.— Nat. Joint Comput. Committee Conf, Proc., I960,
Eastern Joint Comput. Conf., v. 18, p. 83—96,
505»
"981. Miller J. S., Lickly D. J., Kosmal a A. L., Sap on ar о J. A.
, Multiprocessor computer system study. Final Report, Intermetrics, Inc.— Я
Cambridge, 1970, 161 p. л
-982. Miller J. S. Two-dimensional characteristics of HAL, a language fore
' spaceflight applications.— SIGPLAN Notices, 1972, v. 7, № 10, p. 137—141. Я
983. Miller R.E. A comparison of some theoretical models of parallel com- fl
putation.— 1ЕЁЕ Trans. Comput., 1973, v. C-22, № 8, p. 710—717. Я
*984. Miller W. F., Aschenbrenner R. A. The GUS multicomputer fl
system.— IEEE Trans. Electron. Comput., 1963, v. EC-12, № 6, p. 671—676. fl
985. Millstein R. E. Compiler design for the ILLIAC IV.—Massachusetts Я
Computer Associates Inc., AD-765351/2, 1973, 178 p. 3
986. Millstein R. E. Control structures in ILLIAC IV FORTRAN.—Com- fl
mun. ACM, 1973, v. 16, № 10, p. 621-627. . J
*987. Millstein R. E., Muntz C. A. The ILLIAC IV FORTRAN compi-Я
ler.— SIGPLAN Notices, 1975, v. 10, № 3, p. 1-8. 1
988. Minker J. An overview of associative or content-addressable memory fl
systems and a KWIC index to the literature: 1956—1970. Bibliogr, 25.— fl
Computing Reviews, 1971, v. 12, № 10, p. 453—504. fl
989. Minker J. Association memories and processors: a description and 3
appraisal.— In: Encyclopedia of computer science and technology, v. 2. fl
New York: Marcel Dekker, 1975, p. 283—324. Л
990. Minnick R. C. Survey of microcellular recearch.— J. ACM, 1967, v. 14, fl
№ 2, p. 203-241. Я
*991. Minsky M. Form and content in computer science. 1970 ACM Turing fl
Lecture.- J. ACM, 1970, v.,17, № 2, p. 197-215. fl
’992. Minsky M., Papert S. On some associative, parallel, and analog 9
computations.—In: Associative information technique. New York: Else-Я
vier, 1971, p. 27—47. ' ]
*993. Misunas D. P. Performance analysis of a data-flow processor.— Project 1
MAC. MIT, AD-A014567/2, 1975, 8 p. 1
994. Misunas D. P. Structure processing in data-flow computer.— Project 3
MAC, MIT, AD-A014566/4, 1975, 8 p. |
*995. Morenoff E., Ke sei P. G., Clarke L. C. Horisontal domain par- 1
titioning of the Navy atmospheric primitive equation prediction model.— fl
AFIPS Conf. Proc., 1972, FJCC, v. 41, part 1, p. 393—405. |
996. Morgan D. E., Taylor D. J. A survey of methods of achieving reli- 3
able software.— Computer, 1977, v. 10, № 2, p. 44—53. 4 fl
997. Morris D., D e 11 e f s e n G. D., Frank G. R., Sweeney T. J. |
The structure of the MU 5 operating system.—Computer J., 1972, v. 15, |
№ 2, p. 113-116. - A
998. Morris D., Frank G. R., Sweeney T. J. Communication in a 1
multi-computer system.—Proc. IERE Conf. Computers, Systems, and 1
Technology, 1972, p. 405—413. |
999. MorrLs D. Job control in Atlas and MU5.— Proc. BCS Symp. Job ContH 1
rol Languages, 1974. |
1000. Morris D. The architecture of MU5.—Proc. European Computing |
Congress, 1974, p. 587. 1
1001. Morris D. et aL Machine — independent operating systems.—Proc. 1
IFIP Congress 77. Toronto, 1977. Amsterdam: North — Holland Pub. Co., J
1977, p. 819—826. 1
1002. Moss D. Multiprocessing adds muscle to pPs.—Electron. >Des., 1978, I
v. 26, № 11, p. 238—224. J
4003. Moulder R. A data management system utilizing the STARAN asso- |
ciative processor.— Proc. 1973 Sagamore Computer Conf. Parallel Proces- i
sing. New York: IEEE, 1973, p. 161. 1
1004. Moulder R. An implementation of a data management system on an j
associative processor.— AFIPS Conf. Proc., 1973, NCCE, v. 42, p. 171—176. i
1005. M u 11 e г у A. P., Schauer R. F., Rice R. ADAM — a problem- й
oriented SYMBOL processor.—AFIPS Conf. Proc., 1963, SJCC, v. 23, 1
p. 367-380.
X06
1006. Multiple computer system.— Technocrat, 1975, v. 8, № 0, p. 62—63.
1007. Multiprocessing versions improve productivity of virtual storage sys-
tems.— Computer Design, 1973, v. 12, № 4, p. 24, 26.
1008. Multiprocessor combines 16 minicomputers.—Computer Design, 1973,.
v. 12, № 4, p. 36-37.
1009. MUMP-2.— Datamation, 1976, v. 22, № 4, p. 53. \
1010. Muntz C., Myszevski M., Schaffner S. Compiler design for
the ILLIAC IV.—Massachusetts Computer Associates Inc., AD-776323/8,
1974, 94 p.— (Nat. Techn. Inform. Service, Springfield, 1974, 94 p.)..
1011. Murakami K., Nishikawa S., Sato M. Poly-processor system
analysis and design. Proc. 4th Symp. Computer Architecture, 1977. New
York: IEEE, 1977, p. 49—56. (Comput. Archit News, 1977, v. 5, № 7,
p. 49-56).
1012. Muraoka Y. Parallel processing and processors. 1.— Дзёхо сёри, 1975,.
v. 16, № 1, p. 65-72. 2.— Дзёхо сёри, 1975, v. 16, № 2, p. 137—144.
1013. Muraoka Y. The configuration of main memory for ILLIAC IV.—
Дзёхо сёри, 1975, v. 16, № 4, p. 373—376.
1014. Murphey J. O., Wade R. M. The IBM 360/195.— Datamation, 1970,.
v. 16, № 4, p. 72—79.
1015. Murtha J. С., В e a d 1 e s R. L. Survey of the highly parallel infor-
mation processing systems.—Office of Naval Research Report № 4755,.
1964.
1016. Murtha J. C. Highly parallel information processing systenis.— Advan*
ces in Computers, 1966, v. 7, p. 1—116.
1017. Myers G. J. Software reliability: principles and practices.— New York:
Wiley, 1976, 360 p.
1018. Myers W. Why botrer with large computers? — Computer, 1978, v. 11^
№ 4, p. 78-79, 82—85.
1019. Newell A., Robertson G. Some issues in programmingtnulti — mi-
ni-processors.— Behav. Res. Math, and Instrum., 1975, v. 7, № 2, p. 75—86.
1020. Nielsen N. R. Controlling a real-time parallel processing.—Simula-
tion, 1971, v. 17, № 3/p. 97-103. *
1021. Nilsen R. N. Distributed computer architecture: a survey.— Prec. 8th*
Hawaii int. Conf, on Syst. Sci. West. Periodic Co., 1975, p. 19—20.
1022. Noe J. D. A Petri net model of the CDC 6400.— Proc. ACM/SIGOPS-
Workshop on Systems. Performance Evaluation.—Harvard Univ.. 1971,.
p. 362-378.
1023. Noe J. D., N u 11 G. J. Validation of a trace-driven CDC 6400 simula-
tion.—AFIPS Conf. Proc., 1972 SJCC, v. 40, p. 749-757.
1024. Noe J.> D.. Nutt G. J. Macro E-nets for representation of parallel sys-
tems.—IEEE Trans. Comput., 1973, v. C —22, № 8, p. 718—727.'
1025. Noguchi К., О h n i s h i I., Morita H. Design considerations for
a heterogeneous tightly — coupled multiprocessor system.—AFIPS Conf.^’
Proc., 1975, NCC. v. 44, p. 561—565.
1026. Noor A. K., Fulton R. E. Impact of CDC STAR-100 computer
in finite element systems.—J. Struct. Div., 1975, ASCE 101, p. 731—750.
1027. Noor A. K., Voigt S. J. Hypermatrix scheme for finite element sys-
tems on CDC STAR-100 computer.— Computers and Structures, 1975, v. 5,
p. 287—296.
1028. Noor A. K., Hartley S. J. Evaluation of element stiffness matrices-
on CDC STAR-100 computer.— Computers and Structures, 1978, v. 9, № 2,.
p. 151-161.
1029. Nutt G. J. An overview of a multi associative processor study.— Proc.
1974 Nat. ACM Conf., 1974, p. 101—104.
1030. Nutt G. J. A parallel processor for evaluation studies.— AFIPS Conf..
Proc., 1976, NCC, v. 45, p. 769-775.
. 1031. Nutt G. J. Some resource allocation policies in a multi associative pro-
cessor.— Acta Informatica, 1976, v. 6, № 3, p. 211—225.
1032. Nutt G. J. A parallel'processor operating system comparison.— IEE&
Trans. Software Eng.', 1977, v, SE-3, № 6, p. 467—475,
507?
4033. Nutt G. J. Microprocessor implementation of a parallel processor.-* :
Proc. 4th Symp. Computer Architecture, 1977. New York: IEEE, 1977,
p. 147—152.
4034. О ’ H e r n E. A. Space shuttle avionics redundancy management.— AIAA
Pap., 1975, № 571, p. 1—9.
1035. О h m о r i K, Koike N., N e z u K., Suzuki S. MICS — a multi-
processor system.— Proc. IFIP Congress 74. Stockholm, 1974. Amsterdam: ;
North-Holland Pub. Co., 1974, v. 1, p. 98-102. j
4036. Ohmori K., Koike N., Nezu K, Suzuki S. MICS —a multi-
microprocessor system. NEC Res. and Develop., 1975, № 36, p. 32—36.
4037. Ohnishi I., Akita H., Domen S^Kaneko K. HIT AC 8700/8800
operating system (OS7).— Дзёхо сёри, 1973, v. 14, № 10, p. 769—777.
4038. Okada Y., Tajima H., Mori R. A novel multiprocessor array.—
Proc. 2nd EUROMICRO Symp. Microprocessing and Microprogramming,
Venice, 1976. Amsterdam, 1977, p. 83—90.
4039. Operating systems survey. A. P. Sayers (Ed.).— Princeton, Auerbach, 1971, i
336 p. 2nd print.: 1972, 336 p. >
4040. Operating systems techniques. C. A. R. Hoare, R. H. Perrott (Eds.).— '
London: Academic Press., 1972, 390 p.
1041. Orcutt S. E. Implementation of permutation functions in ILLIAC IV —
type computers.— IEEE Trans. Comput, 1976, v. C-25, № 9, p. 929—936.
1042. Organick E. I., Cleary J. G. A data structure model of the B6700 ~
. computer system.—SIGPLAN Notices, 1971, v. 6, № 2, p. 83—145.
1043. Organick E. I. Computer system brganization — the B5700/B6700 se-
ries.— New York: Academic Press, 1973, 132 p.
1044. О r n s t e i n S. M., S t u с к i M. J., Clark W. A. A functional des-
cription of macromodules.—AFIPS Conf. Proc., 1967, SJCC, y. 30, p. 333, *
Ю45. О r n s t e i n S. M., Heart F. E., Crowther W. B., Rising H. K., •
Russel S. B., Michel A. The terminal for the ARPA computer net- *
work — AFIPS Conf. Proc., 1972, SJCC, v. 40, p. 243-254. >
4046. Ornstein S. M., Barker W. B., Bressler R. D„ Crowt-
h^r W. R., Heart F. E., Krale*y M. F., Michel A., Thro- <
p e M. J. The BBN multiprocessor.— Proc; 7th Hawaii Int. Conf, on Sys- ‘
tern Sci., 1974, p. 92—95. j
4047. Ornstein S. M., Crowther W. R., Kraley M. F., В res- J
sler R. D., Michel A., Hearth F. E. Pluribus —a reliable multi-
processor.—AFIPS Conf. Proc., 1975, NCC, v. 44, p. 551—559. |
4048. Ornstein .S. M., Walden D. C. The evolution of a high perfor- ;
mance modular packet-switch.—Proc. 1975 Int. Conf. Communications, <
1975, v. 1, p. 6/17-21.
4049. Owens J. L. The influence of machine organization on algorithms.— J
In: Complexity of sequential and parallel numerical algorithms. New J
• York: Academic Press, 1973, p. 111—130. $
4050. Oxley D. W. Memory management on the ASC — a performance eva- ।
1 nation.— Proc. IEEE 3rd Texas Conf. Comput. Syst., 1974,'p. 3-5/1—3-5/5.
4051. Ozeki M., Naganuma S., Inada N. Railway traffic control sys-
tem.—Proc. IFIP Congress 74. Stockholm, 1974. Amsterdam: North-Hol-
land Pub. Co., 1974, p. 802-806.
4052. Ozkarahan E. A., Schuster S. A., Smith К. C. RAP- an $
associative processor for data base management.—AFIPS Conf. Proc.,
1975, NCC, v. 44, p. 379—387.
4053. Ozkarahan E. A., Schuster S. A., Sevcik К. C. Performance
evaluation of a relational associative processor.— Database Syst., 1977, j
v. 2, № 6, p. 175-195.
4054. Ракет ¥., Bozyigit M. Variable topology- multicomputer.—Proc.
1976 2nd Euromicro Symp. on Microprocessing and Microprogramming. <
Amsterdam: North-Holland Pub. Co., 1977, p. 141—151.
4055. Paker Y., Bozyigit M. Array type variable topology multicompu-
ter systems.— Proc. 1977 Int. Conf. Parallel Processing. New York: IEEE,
1977, p. 53. j
-508
4056. Parallelism. Computer design.— Infotech State of the Art ВеропГ11ЕЯ||Д
1057. Parallel processor systems, technologies, and applications. L. C. Hobbs,
D. J. Theis, J. Trimble, H. Titus, 1. Highberg (Eds.).—New York: Spar-
tan Books, 1970, 438 p.
1058. Parasuraman B. High-performance microprocessor architectures.—
Proc. IEEE, 1976, v. 64, № 6, p. 851-859.
1059. Parhami B. A highly parallel computing system for information ret-
rieval.- AFIPS Conf. Proc., 1972, FJCC, v. 41, part 2, p. 681-690.
-1060. Parhami B. Associative memories and processors: an overview and
selected bibliography.— Proc. IEEE, 1973, v. 61, № 6, p. 722—730.
-1061. Parhami B., Avizienis A. Design of fault-tolerant associative
processors.— Proc. 1st Symp. Computer Architecture, 1973. New York:
IEEE, 1973, p. 141-145.
1062. Parker R. W. The SABRE system.—Datamation, 1965, v. 11, № 9,
p. 49-52.
1063. Patel R. M., Basic I/O handling on Burroughs B6500.— Proc. 2nd ACM
Symp. Operating System Principles. Princeton Univ., 1969, p. 120—129.
- 1064. Patterson W. W. Sojne thoughts on associative processing langua-
ges.- AFIPS Conf. Proc., 1974, NCCE, v. 43, p. 23-26.
- 1065. Paul G., Wilson M. W. The VECTRAN language- an experimental
language for vector/matrix (abstract).—SIGPLAN Notices, 1976, v.’ 11,
№ 2, p. 16.
- 1066. Pearce R. C., Majithia J. C. Performance evaluation of some com-
puter organizations.— Proc. Inst. Elec. Eng., 1976, v. 123, № 10, p. 967—
- 972.
4067. Pease M. C. Signal processing with a Network, of microprocessors.—
Proc. 1974 Nat. Aerospace and Electronics Conf., NAECON’74, p. 292—298.
4068. Perpiglia F. J., Schaible T. W., Ryan M. E. Burroughs B7700
system architecture and reliability.— Proc. IEEE 3rd Texas Conf. Comput
Syst., 1974, p. 9-2/1—9-2/10.
4069. Perry M. N., Plugge W. R. The American airways SABRE electro-
nic reservation system.— Nat. Joint Comput. Committee Conf. Proc., 1961,
Western Joint Comput. Conf., v. 19.
1070. P e u t о В. L., S h u s t e к L. J. An introduction timing model of CPU
performance.—Comput. Archit. News, 1977, v. 5, № 7, p. 165—178.
4071. Plante J. M., Gon de к D. J. Application of STARAN to support
region analysis for a mechanical robot.—Proc. 1973 Sagamore Computer
Cojf. Parallel Processing. New York: IEEE,* 1973, p. 160.
4072. Pollock R. M., McCoy W. L. Software engineering in the deve-
lopment of the Trident Fire Control System.— Proc. 2nd Int. Conf. Soft-
ware. Eng., San Francisco, 1976. New York, 1976, p. 363—369.
4073. Porter R. E. The RW-400: a new polymorphic data system.—Datama-
tion, 1960, v. 6, № 1‘ p. 8—14. •
1074. Poujoulat G. H. Architecture of the CORAIL building block sys-
tem.—Proc. 4th Symp. Computer Architecture, 1977. New York: IEEE,
1977, p. 201—204 (Comput. Archit. News, 1977, v. 5, № 7, p. 201—204).
4075. P о u p a r d R. E., Lee W. H., Steele T. D., Hudson F. J. De-
sign consideration for Shuttle information management.— Astronaut, and
Aeronaut., 1973, v. 11, № 5, p. 48—53.
4076. Poupard R.E. Space Shuttle redundant computer operation.— Signal,
1979, v. 33, № 5, p. 41-44.
1077. Prentice B. W. Implementation of the AW ACS passive tracking algo-
rithms on a Goodyear STARAN.— Proc. 1974 Sagamore Computer Conf.
Parallel Processing. Leet. Notes Comput. Sci., 1975, v. 24, p. 250—269.
1078. Presberg D. L., Johnson N. W. The Paralyzer: IVTRAN’s paral-
lelism analyzer and synthesizer.— SIGPLAN Notices, 1975, v. 10, № 3,
p. 9-16.
1079. P r e v i t e J. L., Reimann O. A. RADCAP: a parallel processing sys-
tem.—Proc. National Electronics Conf., 1972, v. 27, p. 450.
509
1080. Proc. 1st Annual Symp. Computer Architecture, 1973.— New York, IEEE»
1973.
1081. Proc. 2nd Annual Symp. Computer Architecture, 1975.—N ew York: IEEE,.
1975.
1082. Proc. 3rd Annual Symp. Computer Architecture, 1976.— New York: IEEE,.
1976, 202 p. j
1083. Proc. 4th Annual Symp. Computer Architecture, 1977.— New York: IEEE» •
1977, 210 p.
1084. Proc. 5th Annual Symp. Computer Architecture, 1978.— New York: IEEE,.
1978.
1085. Proc. 1972 Sagamore Computer Conf. RADCAP and its Applications» ’
T.-Y. Feng (Ed.). RADC ana Syracuse Univ., 1972. i
1036. Proc. 1973 Sagamore Computer Conf. Parallel Processing. T.-Y. Feng- ।
(Ed.).— New York: IEEE 1973, 190 p. j
1087. Proc. 1974 Sagamore Computer Conf. Parallel Processing. T.-Y. Feng- *
(Ed.).— Leet. Notes Comput. Sci., 1975, v. 24, 433 p.
1088. Proc. 1975 Sagamore Computer Conf. Parallel Processing. T.-Y. Feng- t
(Ed.).—New York: IEEE, 1975.
1089. Proc. 1976 Int. Conf. Parallel Processing. P. H. Enslow (Ed.).— New- !
York: IEEE, 197§, 328 p. ;
1090. Proc. 1977 Int. Conf. Parallel Processing. J. L. Baer (Ed.).—New York: <
IEEE, 1977, 246 p. $
1091/Proc. 1971 Int. Symp. Fault-Tolerant Computing, Pasadena.— IEEE, 1971»,
1092. Proc. 1972 Int. Symp. Fault-Tolerant Computing, Newton.— IEEE, 1972. <
1093. Proc. 1973 Int. Sump. Fault-Tolerant Computing. FTC/3, Palo-Alto.— IEEE, л
1973
1094. Proc. 1974 Hit. S^mp. Fault-Tolerant Computing. FTC-4.—IEEE, 1974. 1
1095. Proc. 1975 Int. Symp. Fault-Tolerant Computing. FTC-5, Paris.— IEEE,.
1975. :i
1096. Proc. 1976 Int. Symp. Fault-Tolerant Computing. FTCS-6, Pittsburg.— J
IEEE, 1976.
1097. Proc. 1977 Int. Symp. Fault — Tolerant Computing. FTCS-7, Los Ange-;^
les.— IEEE, 1977, 217 p. 1
1098. Proc. 1978 Int. Symp. Fault-Tolerant Computing. FTCS-8. Toulouse, 1978» i
1099. Proc. 1972 ACM Conf. Proving Assertions about Programs, Las Cruces.— $
New York: ACM, 1972, 211 p.
1100. Proc. 1973 IEEE Symp. Computer Software Reliability, New York. Re- i
cord.— New York, 1973, 167 p. ]
1101. Proc. 1975 Int. Conf. Reliable Software, Los Angeles.—New York: ACM»
1975, 567 p.- (SIGPLAN Notices, 1975, v. 10, N 6). t’
1102. Proc. 1977 Symp. High Speed Computer and Algorithm 'Organization, :
Univ, of Illinois.— Academic Press, 1977. . .
1103. Proc. 1st Conf. Modular Computers. Brookhaven National Lab., Upton/ :
1978. 4 J
1104. Program test method. W. C. Hetzel (Ed.).—Englewood Cliffs, Prentice-
Hall, 1973, 352 p.
1105. Purcell С. J. The Control Data STAR-100 — performance measure-^
ments.— AFIPS Conf. Proc., 1974, NCCE, v. 43, p. 385—387.
1106. Quatse J. T., Gaulene P., Dodge D. The external access net- 3
work of a modular computer system.—AFIPS Conf. Proc., 1972, SJCC,J
v. 40, p. 783—790. '
1107. Radoy С. H., Lipovsky G. J. A multiprocessor architecture for )
effective use of program memory.— Proc. IEEE COMPCON 74 Fall, 1974» ]
p. 11—14. i
1108. Radoy С. H., Lipovsky G. J. Switched multiple instruction, mul- •
tiple data stream processing.— Proc. 2nd Symp. Computer Architecture»
1975. New York: IEEE, 1975, p. 183—187.
1109. Ramamoorthy С. V., Li H. F. Pipelined processors — a survey.— j
Proc. 1975 Sagamore Computer Conf. Parallel Processing. New York: IEEE»
1975, p. 40-62. j
“» I
•.л
1110. R a m a m о о r t h у С. V., Li H. F. Some problems in parallel апЛ
line processing.— Proc. IEEE COMPCON 75 Spring, 1975, p. 177—180.
1111. R a m a m о or th у С. V., Cheung R.C. Design of faultrtolnnml com-
puting systems.— In: Applied computation theory: analysis, design and
modeling. Englewood Ciins: Prentice-Hall, 1976.
4112. Ramamorthy С. V., Li H. F. Pipeline architecture.—- Computing
Surveys, 1977, v. 9, № 1, p. 61—102.
4113. Ramseyer R. R., van Dam A. A multi-microprocessor implemen-
tation of a general purpose pipelined CPU.—Proc. 4th Computer Arch*
Symp., 1977. New York: IEEE 1977, p. 29—34 — (Comput. Archit. News,
1977, v. 5, № 7, p. 29-34).
4114. Randal J. M. A parallel assembler for ILLIAC IV.— Proc. 1973 Saga-
’ more Computer Coni. Parallel Processing. New York: IEEE, 1973, p. 78.
1115. Rand ell B., Lee P. A., Treleaven P. C. Reliability issues in
computer system design.— Computing Surveys, 1978t v. 10, № 2, p. 123—
165.
1116. Redd a way S. F. DAP —a distributed array processor.—Proc. 1st
Symp. Computer Architecture, 1973. New York: IEEE, 1973, p. 61.
1117. Red di S. S., Feus tel E. A. An approach to restructurable compu-
ter systems.— Proc. 1974 Sagamore Computer Conf. Parallel Processing.
xLect. Notes. Comput. Sci., 1975, v. 24, p. 319—337.
1118. Red di S. S., Feus tel E. A. A conceptual framework for computer
architecture.—Computing Surveys, 1976, v. 8, № 2, p. 277—300.
1119. Red di S. S., Feus tel E. A. A restructurable computer system.—
IEEE Trans. Comput., 1978, v. C-27, № 1, p. 1—20.
1120. R e i g e 1 E. W., Faber U., Fisher D. A. The interpreter — a mic-
roprogrammable building block system.—AFIPS Conf. Proc., 1972, SJCC,
v. 40, p. 705-723.
1121. Remund R. N., Taggart K. A. To vectorize or to Чгес1онге’: that
is the question.— Proc. 1977 Symp. High Speed Computer and Algorithm
Organization, Univ, of Illinois. Academic Press, 1977.
1122. Rennels D. A., Riis V., Tyree V. C. The Unified Data System:
a distributed processing network for control and data handling on a
spacecraft.— Proc. 1976 National Aerospace and Electronics Conf.
NAECON’76, 1976, p. 283-289.
1123. Rennels D. A., Avizienis A., Er cogo vac M. A study of
standard building blocks for the design of fault — tolerant distributed
computer systems.—Proc. 1978 Int. Symp. Fault-Tolerant Computing.
FTCS-8, Toulouse. 1978, p. 144—149.
1124. R e q u a J. E. STAR: a system programmer’s view.— Proc. IEEE
COMPCON’72, 1972, p. 13-15.
1125. Rice R., Smith W. R. SYMBOL —a major departure from classic
software dominated von Neumann computing systems.—AFIPS - Conf.
Proc., 1971, SJCC, v. 38, p. 575-587.
1126. Rice R. A project overview.—Proc. IEEE COMPCON’72, 1972,
p. 17-20.
1127. Rice R. The hardware implementation of SYMBOL.—Proc. IEEE
COMCON’72, 1972, p. 27—32.
1128. Richter H. Niektore zastosowania wielomaszynowych sistemow licza*
. cych.— Elektron. techn. obliczen. Nowosci, 1973, № 4, 35—75.
1129. Roberts L. G., Wessler B. D. Computer network development to
achieve resource sharing.— AFIPS Conf. Proc., 1970, SJCC, v. 36, p. 543—
549.
1130. Robinson J. G., Roberts E. S. Software fault-tolerance in the
Pluribus.— AFIPS Conf. Proc., 1978, v. 47.
1131. Rodrigues-Rosell J., Dupuy J.-P. The evaluation of a time-
sharing page demand system.—AFIPS Conf. Proc., 1972, SJCC, v. 40,
p. 759—765.
1132. Roesser R. P. Two-dimensional microprocessor pipelines for image.—
IEEE Trans. Comput., 1978, v. C — 27, № 2, p. 144—156.
511
1133. Rohr J. A. STAREX self-repair routines: software recovery in the JPI> 1
STAR computer.— Proc. 1973 Int Symp. Fault-Tolerant Computing- j
FTC/3, Palo-Alto. IEEE, 1973, p 11—16.
1134. Rohrbacher D., Potter J L. Image processing with the STARAN
parallel computer.— Computer, 1977, v. 10, № 8, p. 54—59.
1135. R ubenstein S. Z., Shroyer L. 0. Digital processing subsystem
for the space Shuttle.— Proc. 1974 National Aerospace and Electronics
Conf. NAECON’74, p. 100-105. ’
1136. Rudolphi. A. A production implementation of an associative array
processor — STARAN.—AFIPS Conf. Proc., 1972, FJCC, v. 41, part 1F
p. 229—241.
1137. Rumbaugh J. E. A parallel asynchronous computer architecture for
data flow programs.—Project MAC Techn. Report, MIT, 1975, № 150,
319 p. “ ,4
1138. Rumbaugh J. A data flow multiprocessor.—IEEE Trans. Compute J
1977, v. C-26, № 2, p. 138-146. ' . j
1139. Russell R.-M. The CRAY-1 computer system.—Commun. ACM, 1978,.
v. 21, №1, p. 63-72.
1140. Sanderova J. Simulationsmodell fur die SPERRY UNIVAC Serio
1100 — Datascope, 1975, 6, № 16, S. 36—41.
1141. Sarahan B. L. Computer system for Gemini and Apollo .ground cont-
rol.— In: World Aerospace Syst., 1965, p. 133—134. ;
1142. Sayre G. E. STARAN: an associative approach to multiprocessor archi- <
tecture.—Revue franc., automat., inform, rech. oper., 1976, v. 10, № 5, ’1
p. 59-76. ;
1143. Sch err A. L. Distributed data processing.—IBM Syst. J., 1978, v. 17, 1
№ 4, p. 324-343. :
1144. Schnupp P. Systemprogrammierung.— Berlin — New York, 1975, 245S.
1145. S c h 0 n e A. Uber Multiprozessor — und Multirechner Systeme fur die
Prozessdatenvesarbeitung.—Regelungstechn. Prax., 1976, 18, № 6,
S. 146-155. M
1146. Schorr H. Design principles for a high-performance system.—In: $
Computers and automata. New York: Wiley, 1972, p. 165—192.
1147. SchusterS. A., Nguyen H. В., О z к a r a h a n E. A., S m i t h К. С. Я
RAP. 2 — an associative processor for data base.— Proc. 5th Symp. Com-
puter Architecture, 1978, New York: IEEE, 1978, p. 52—59. 5
1148. Schwartz J. I. Large parallel computers.—J. ACM, 1966, v. 13, № 1, 1
p. 25-32. 4
1149. Schwartz J. M:, W у n e r D. S. Use of the SPASM software monitor
to evaluate the performance of the Burroughs B6700.— AFIPS Conf. Proc., * <
1973, NCCE, v. 42, p. 93—100. <
1150. Schwemm R. E. Experience gained in the. development and use of
TSS/360.— AFIPS Conf. Proc., 1972, SJCC, v. 40, p. 559—570. ;
1151. Schwetman H. D., Brown J. C., An experimental study of сотри- i
ter system performance.—Proc. 1972 ACM Conf., New York: ACM, :
p. 693-703. ?
1152. Scott M. B., Hoffnun R. The Mercury programming system.—Nat. fl
Joint Comput. Committee Conf. Proc., 1961, Eastern Joint Comput. Conf., Я
v. 20, p. 47-53. fl
1153. Searle В. C., Freberg D. E. Tutoral: microprocessor application Я
in multiple processor systems.— Computer, 1975, v. 8, № 10, p. 22—30. Я
1154. Senzig D. N., Smith R. V. Computer organization for array pro- Я
cessing.—AFIPS Conf. Proc., 1965, FJCC, v. 27, part 1, p. 117—128. Я
1155. Sen zig D. N. Observation on high-performance machines.—AFIPS fl
Conf. Proc., 1967; FJCC, v. 31, p. 791-799. fl
1156. Seymor Cray's Cray-1 super computer: almost five times faster than a fl
76O9.— Datamation, 1975, v. 21, № 7, p. 71—76. fl
1157. Shapiro M. D. A SNOBOL machine: a higher-level language proces- fl
sor in a conventional hardware framework.— Proc. IEEE COMPCON 72, fl
1972, p. 41-44. fl
512
1158. Sheridan С. Т. Space Shuttle software.—
№ 7, p. 128-131,134, 136, 140.
1159. Shooman W. Parallel computing with vertical data.—Nat,
put. Committee Conf. Proc., 1960, Eastern Joint Comput, СопЬ-Йг^Ш4
p. 111—115. . .
1160. Shooman W. Orthogonal processing.—In: Parallel processor systems,
technologies, and applications.— New York; Spartan Books, 1970, p. 297.
1161. Shore J. E. Second thoughts on parallel processing.—Proc. IEEE
INTERCON, New York, 1972 p. 358—359.
1162. Shore J. E. Second thougnts on parallel processing.—Computer and"
• Electrical Eng., 1973, v. 1, № 1, p. 95—109.
1163. Siegel H. J. Analysis techniques for SIMD machine interconnection
networks and the effects of processor address masks.— IEEE Trans. Com-
put., 1977, v. C-26, № 2, p. 153—161.
1164. Siegel H. J. The universality of arious types of SIMD machine inter-
connection networks.—Comput. Archit. News, 1977, v. 5, № 7, p. 70—79.
1165. Siewiorek D.,' Сапера M., Clark S. C. vmp: the architecture
and implementation of a fault tolerant multiprocessor.—Proc. 1977" Int.
Symp. Fault-Tolerant Computing. FTCS-7.—Los Angeles: IEEE, 1977,
p. 37-43.
1166. Siewiorek D. P., Thomas D. E., ScharfetterD. L. The use
of LSI modules in computer structures: trends and limitations.—Compu-
ter, 1978, v. 11, № 7, p. 16-25..
1167. SIGPLAN Notices, 1975, v. 10, № 3. Programming languages and compilers
for parallel and vector machines.
1168. Sites R. L. An analysis of the CRAY-1 computer.—Proc. 5th Symp,
Computer Architecture, 1978. New York; IEEE, 1978, p. 101—106.
1169. Sklaroff J. R. Redundancy management technique for space shuttle
computers.— IBM J. Res. Develop., 1976, v. 20, № 1, p. 20—28. „
1170. Slade A. E., McMahon H. O. A cryotron catalog memory sys-
tem.—Nat. Joint Comput. Committee Conf. Proc., 1956, Eastern Joint
Comput. Conf., v. 10. New York: AIEE, 1957, p. 115—120.
1171. Slot nick D. L., В orc к W. C., McReynolds R. C. The
SOLOMON computer.— AFIPS Conf. Proc., 1962, FJCC, v. 22, p. 97—107.
Reprinted in: Computer Design Development. Rochelle Park, 1976, p. 285.
1172. Slotnick D. L., Borck W. C., McReynolds R. C. The
SOLOMON computer —a preliminary report.—Proc. 1962 Workshop on
Computer Organization. Washington: Spartan Books, 1963, p. 66—92.
1173. Slotnick D. L. Unconventional systems.—AFIPS Conf. Proc., 1967,
SJCC, v. 30, p. 477—481.
1174. Slotnick. D. L. The fastest computer.— Scientific American, 1970,
v. 224, № 2, p. 76—87.
1175. Slotnick D. L. Computer structures (pipeline structure, array machi-
ne, ...).—In: Structure et conception des ordinateurs/ Architecture and
design of digital computers. Paris: Dunod, 1971, p. 19—41.
1176. Smith С. V. L. Electronic digital computers.—New York: McGraw-Hill,
1959.
1177. Smith E. C. A directly coupled multiprocessing system.—IBM Syst.
J., 1963, v. 2, № 3, p. 218—229.
1178. Smith W. System supervision algorithms for the SYMBOL compu-
ter.— Proc. IEEE COMPCON 72, 1972, p. 21—25.
1179. Smith W. R. AADC computer family architecture questions and
answers.—Comput. Archit. News, 1975, v. 4, № 3, p. 15—21.
1180. Soil D. B., R u s s e 11 G. L., H a b r a N. R. Experience with a vecto-
rized general corculation weather model on STAR-100.^- Proc. 1977 Symp.
High Speed Computer and Algorithm Organization. Univ, of Illinois.
Academic Press, 1977.
1181. Spang H. A. Distributed computer systems for control.—Proc. 1st
IFAC/IFIP Symp. Software for Computer Control.—SOCOCO-76. Tallinn,
1976. Preprints, p. 47—65. Тезисы, c. 18.
33 в. А. Головнин ' ИЗ
1182. Sperry Rand Announces new UNIVAC 1108 II multi-processor.—Commun»1
ACM, 1966, v. 9, № 1, p. 55.
1183. Stabler E. P. Mixed mode arithmetic for STARAN.—Proc. 1974 Sa-
gamore Computer Conf. Parallel Processing. Leet. Notes Comput. Sci.,. ;
1975, v. 24, p. 228—229. i
1184. Standeven J., Lanyado S., Edwards D. B. G. The MU5 <
secondary operand unit.—Proc. Joint IERE-IEE-BCS Conf. Computers — V
Systems and Technology, 1972, v. 25, p. 429—440.
1185. Stanga D. C. UNIVAC 1108 multi-processor system.—AFIPS Conf. “
Proc., 1967, SJCC, v. 30, p. 67—74.
1186. Stanke E. C. Automatic track initiation using the RADCAP
STARAN.— Proc. 1976 Int. Conf. Parallel Processing. New York: IEEE. ;
1976, p. 187-188.
1187. Steinhoff J., McGill R. An approach to solving scientific pro-
blems using multiple microprocessors.— Proc. 2nd Euromicro Symp. on !
’ Microprocessing and Microprogramming, Venice, 1976. Amsterdam:
North-Holland Pub. Co., 1977, p. 285—293.
1188. Stephenson C. Case study of the pipelined arithmetic unit for the f
TI Advanced Scientific Computer.—Proc. 2nd Symp. Computer Archi* ;
tecture, 1975. New York: IEEE, 1975, p. 168—173. ;
1189. Stevens D. F. System evaluation on the Control Data 6600.—Proc.
IFIP Congress 1968. Edinburgh, 1968. Amsterdam: North-Holland Pub. ’
Co., 1969, p. 542-547.
1190. Stevens K. G. CFD —a FORTRAN —like language for the • '
ILLIAC IV.—SIGPLAN Notices, 1975, v. 10, № 3, p. 72-76. J
1191. Stiffler J. J., Parke N. G., Barr P. C. The SERF faul-tolerant 1
computer. Parts I and IL—Proc. 1973 Int. Symp. Fault-Tolerant Com* j
puting. FTC/3. Palo-Alto: IEEE, 1973. J
1192. Stokes R. A. ILLIAC IV: route to parallel computers.—Electronic* Л
Design, 1967, v. 15, № 26, p. 64—69. -J
1193. Stokes R. A. An assessment of first generation vector computers.—
Proc. IEEE COMPCON 77 Spring, 1977, p. 12-17. J
1194. Stokes R. A. BSP: the Burroughs Scientific Processor.—Proc. 1977
Symp. High Speed Computer and Algorithm Organization. Univ, of
Illinois. Academic Press, 1977. j
1195. Stone H. S. An efficient parallel algorithm for the solution of a 1
tridiagonal linear system of equations.—J. ACM, 1973, v. 20, № 1, I
p. 27-38. 1
1196. Stone H. S. Parallel computers.—In: Introduction to computer archi* 1
tecture. Chicago: Science Research Associates, 1975, p. 318—374. ’ * !
1197. Strauss J. C. A simple thruput and response model of EXEC 8 un-
4 der swapping saturation.— AFIPS Conf. Proc., 1971, FJCC, v. • 39;
p. 39-49. 3
1198. Su S. Y. H., Spillman R. J. An overview of fault-tolerant digital
system architecture.— AFIPS Conf. Proc., 1977, NCC, v. 46, p. 19—26» $
1199. Sullivan H., Bashkov T. R. A large scale homogenous, fully dis- 4
tributed parallel machine. I and IL—Comput. Archit. News, 1977, Л
v. 5, № 7, p. 105—117 and p. 118—124. J
1200. Summers M. W., Trad D. F. The evolution of a parallel active *
tracking proggram.— Proc. 1974 Sagamore Computer Conf. Parallel
Processing. Leet. Notes Comput. Sci., 1975, v. 24, p. 238—249.
1201. Sumner F. H. MU5 — an assessment of the design.— Proc. IFIP
Congress 74. Stockholm, 1974 Amsterdam: North-Holland Pub. Co.,
1974 p. 133—136.
1202. Sumner F. H. The MU5 computer system.— CERN Sci. Rep., 1974
Яг 23, p. 65-104 '
1203. Sumner F. H. Parallelism in computer systems.—CERN Sci. Rep., ’
1976, № 24 p. 131-137.
1204 Sumner F. H., Wo о d s J. V. The MU5 computer system.— Rev»
franc, automat., inform., rech. open, 1976, v. 10, Яг 1, p. 109—130.
514
1205. Swan R. J., Bechtolsheim A., Lai K.-W., Ouster
The implementation of the Cm ♦ multi-microprocessor.—
Proc., 1977, NCC, v. 46, p. 645—655. • p.
1206. Swan R. J., Fuller S. H., S i e w i о г e к D. P. Cm ♦ — a modular,
multi-microprocessor.— AFIPS Conf. Proc., 1977, NCC, v. 46, p. 637—644.
4207. Tate D. Pipelining: design problems and implications.—Computer
Design. Infotech State of the Art Report 17, 1974, p. 251—280.
4208. T e 11 e у W. H. The role of computers in air defence. Nat. Joint Comput.
Committee Conf. Proc., 1958, Eastern Joint Comput Conf., v. 14,
p. 15-18.
1209. The CDC 3600.— Datamation, 1962, v. 8, № 5, p. 37—40:
1210. Theis D. J. Microprocessor and microcomputer survey.—Datamation,
1974, v. 20, № 12, p. 90-100.
1211. Theis D. J. Vector supercomputers.— Computer, 1974, v. 7, №/4,
p. 52—61.
1212. The sirens song of the big machine.—Computing Europe, 1977, v. 5,
№ 26, p. 16.
4213. Thomas A. System/360 programming.— San Francisco: Rinehart
Press, 1971.
1214 Thomas G., N e c u 1 a* A. G. Multidimensional array accessing in the
MU5 computer.—Proc. IFIP Congress 77. Toronto 1977.—Amsterdam:
North-Holland Pub. Co., 1977, p. 655—660.
1215. Thomas J. Duplexanlage bej der Stadt Koln. Zwei Zentraleinheiten
des Siemens-System 4004 benutzen eine gemeinsame Peripherie.—Data
Rept., 1973| 8, № 5, S. 34—37.
1216. Thompson R. N., Wilkinson J. A. The D825 automatic opera-
ting and scheduling program.— AFIPS Conf. Proc., 1963, SJCC, v. 23,
p. 41-49.
4217. Thornton J. E. Parallel operation in the Control Data 6600.—
AFIPS Conf. Proc., 1964, FJCC, v. 26, part II, p. 33—40. Reprinted ini
Comput. Des. Develop., Rochelle Park, 1976, p. 277—284
4218. Thornton J. E. Design of a computer: the Control Data 6600.—
Glenview: Scott, Foresman and Co., 1970, 250 p.
1219. Thurber K. J., Jensen E. D., Jack L. A., Kinney L. L., Pat-
ton P. C., Anderson L. C. A systematic approach to the design of
digital bussing structures.— AFIPS Conf. Proc., 1972, FJCC< v. 41,
part 2, p. 719—740.
1220. Thurber K. J., Patton P. C. The future of parallel processing.—
IEEE Trans. Comput., 1973, v. C-22, № 12, p. 1140-1143.
1221. Thurber K. J., Wald L. D. Associative and parallel processors.—
Computing Surveys, 1975, v. 7, № 4 P* 215—255.
1222. Thurber K. J. Large-scale computer architecture: parallel and assor
ciative processors.— Rochelle Park: Hayden Book Co., 1976, 325 p.
4223. Thurber K. J. Parallel processor architectures. Part I: General pur-
pose systems. Part 2: Special purpose systems.—Computer Design, 1979,
v. 18, № 1, p. 89-97, and № 2, p. 103-114.
4224 Tinker R. W., Avrunin I. b. The COMRADE executive system.—
AFIPS Proc. Conf., 1973, NCCE, v. 42, p. 331—337.
4225. T о m a s u 1 о R. M. An efficient algorithm for exploiting multiple arith-
metic units.— IBM J. Res. Develop., 1967. v. 11, № 1, p. 25—33.
1226. Torkildsen A: Simulation model for performance evaluation of
UNIVAC 1108/ЕХЕС-8.— In: Operational research in the design of ele-
ctronic data processing systems. New York: Crane, Russak and Co.,
1973, p. 115-118.
1227. Trivedi K. S. Prepaging and applications to the STAR-100 compu-
ting.—Proc. 1977 Symp. High Speed Computer and Algorithm Organiza-
tion. Univ, of Illinois: Academic Press, 1977.
4228. Troy J. L. Computer simulation of PEPE and its Host at the in-
struction level.—Proc. 1973 Sagamore Computer Conf. Parallel Proces-
sing.—New York:.IEEE, 1973, j). 187.
«33*
515
1229. Turn R. Computers in 1980s.— New York: Columbia Univ. PressJH
1974, 257 p. Я
1230. Turn R. Computers in the 1980s — trends in hardware technology.—Я
Proc. IFIP Congress 74. Stockholm, 1974; Amsterdam: North-HoilancKw
Pub. Co., 1974, p. 137—140. 1
1231. Turn R. Aerospace computers in the 1980’s.—Proc. 1975 National^
Aerospace and Electronics Conf. NAECON’75, p. 744—749. S
1232. T u r n R. Computers in the 1980s — and beyond.— Proc. IEEE я
COMPCON 78 Spring, 1978, p. 297—300. 1
1233. Unger S. H. A computer oriented toward spatial problem.— Proc.. Я
IRE, 1958, v. 46, 10, p. 1744-1750.' 4
1234. UNIT PASCAL system for the UN I VAC 1108 computer. Preliminary ver- ’
sion. Division of Computer Science the University of Trondheim.— ‘
Teknisk notat 1/74, 1974, 52 p.
1235. UNI VAC 1100 series- EXEC-8 job control.—Дзёхо сёри, 1974, v. 15,.
№ 10, p. 823-830. -
1236. UNI VAC Data Processing Division 1108. Multi-processor system. System I
description.— RAND Corp. Santa Monica, 94 p.
1237. Urban R. A. AAAP: an airborne associative array processor.— Proc..
Nat. Electron. Conf. Chicago, 1972. Vol. 27. Oak Brook, 1972r ,
p. 318-321.
1238. User’s guide for the CDC 6700 computing system.—Naval Surface 3
Weapons Center. Dahlgren Lab. Teehn. Rep. № NSWC/DL TR-3228, 1974, |
pag. var. I
1239. Vaughan F. Burroughs unveils «supercomputer» *with array de- 1
sign.—Computerworld, 1977, April 11, p. 39. d
1240. Vick C. R., Merwin R. E. An architecture description of a paral- |
lei processing element.—Proc. 1973 Int. WORKSHOP on Computer чл
Architecture 1973 ьд
1241. Vick C. R., Dace R. E., McKay J. M. PEPE — a fresh approach -I
to the BMD problem.— Proc. IEEE COMPCON 75 Spring, 1975. ' *
1242. Vineberg M. B., Avizienis A. Implementation of a higher-level >
language on an array machine.—Proc. IEEE COMPCON 72, 1972. ~
1243. W a 1 к d e n F., McIntyre H. A. J., L a w s G. T. A users view of J
parallel processors.—CERN Sci. Rep., 1976, № 24, p. 213—226.
1244. Waters S. J. Majority verdicts in multi-processingany two from
three.— Computer J., 1977, v. 20, № 3, p. ^207—212.
1245. Watson W. J. The Texas Instrument advanced scientific computer.—
Proc. IEEE COMPCON 72, 1972, p. 291—293.
1246. Watson W. J. The TI ASC — a highly modular and flexible super
computer architecture.— AFIPS Conf Proc., 1972, FJCC, v. 41, Part I,
p. 221—228.
1247. Watson W. J., Carr H. M. Operational 'experiences with the TI
advanced scientific computer.—AFIPS Conf. Proc., 1974, NCCE, v. 43,
n. 389—397.
1248. 'Weber H. A microprogrammed implementation of EULER on the
IBM 360/30.— Commun. ACM, 1967, v. 10, № 9, p. 549—558.
1249. Wedel D. FORTRAN for the Texas Instruments ASC system.—
SIGPLAN Notices, 1975, v. 10, № 3, p. 119—132.
1250. Welch H. Numerical weather prediction in the PEPE parallel
processor.— Proc. 1977 Int. Conf. Parallel Processing. New York: IEEEr
1977, p. 186-192.
1251. Wen K. Y., Lawrie D. H. Effectiveness of some processor/memory
interconnections.— Proc. 1976 Int. Conf. Parallel Processing. New York:
IEEE, 1976, p. 283-292. .
1252. W e n s 1 e у J. H. SIFT software implemented fault tolerance.— ARIPS
Conf. Proc., 1972, FJCC, v. 41, p. 243—253.
, 1253. Wen si e у J. H., Green M. W., Levitt KN., Shostak R. E.
The design, analysis, and verification of the SIFT fault tolerant sy-
stem.— Proc. 2nd Int. Conf. Software Eng., 1976, p. 458—469.
516
ггг^ 1 ~
1254 Wester А; Н. Special features i п
Computer Conf. RADCAP and its Applications. RADC аод^
Univ 1972, p. 29-40. * -
1255. Wichmann B. A. The design of synthetic programs — I.— In: Bench-
marking: computer evaluation and measurement, 1975, p. 89—98^
1256. Widdoes L. C. The Minerva multi-processor.— Stanford Univ., AD*
AO18960/5, 1975, 26 p.
1257. Widdoes L. C. The Minervq multi-microprocessor.— Proc. 3rd Syrup-
Computer Architecture, 1976. New York: IEEE, 1976, p. 34—39.
1258. Wilkinson Y. H. The PILOT ACE.— Proc. Symp. Automatic Digital
Comput. Nat. Physic. Lab., 1953, p. 5.
1259. Williams R. K. System 250-basic concepts.— Proc. IERE Conf, on*
Computers — Systems and Technology. London, 1972.
1260. W i 1 n e r W. T. Design of the Burroughs B1700.— AFIPS Conf. Proc.*
1972, FJCC, v. 41, p.'489—497.
1261. Wilson D. E. The PEPE support software system.— Proc» IEEE
COMPCON 72, 1972, p. 61—64. -
1262. Wirsching J. E. Computer of the 1980’3.-7-Is it a network of micro-
computers? — Proc. IEEE COMPCON 75 Fall, 1975, p. 23—26. ~
1263. Wishner R. P., Downs H. R., Shechter J. Real-time computing-
techniques for parallel processors.— Proc. IFIP Congress 71. Ljubljana*
1971. Amsterdam: North-Holland Pub. Co., 1972, p. 704—710.
1264. Withington F. G. IBM’s future large computers.— Datamation*
1978, v. 24, № 7, p. 115—117, 120.
1265. Witt В. M65MP: an experiment in OS/360 multiprocessing.— Proc. 23rd.
Nat. ACM Conf., 1968, p. 691—703.
1266. Woods J. V., Sumner F. H. Operand accessing in a pipelined com*
puter system.—IEE Conf. Proc., 1974, v. 121, p. 326—343.
1267. W u 1 f W. A., В e 11 C. G. C. mmp — a multi-mini-processor.— AFIPS
Conf. Proc., 1972, FJCC, v. 41, part 2, p. 765-777.
1268. Wulf W. A. C. mmp: a multi-mini-processor.— Computer Design. Info-
tech State of the Art Report 17. Part III. 1974, p. 585—600.
1269. Wulf W. A., Cohen E., Corwin W., Jones A., Levin R.*
Pierson C., Pollack F. HYDRA: the kernel of a multiprocessor
operating system.—Commun. ACM, 1974, v. 17, № 6, p. 337—345.
1270. Wulf W., Levin R. A local network.— Datamation, 1975, v. 21, № X
1271. Wulf W. A., Levin R., Pierson C. Overview of the HYDRA
operating system.—Proc. 5th Symp. Operating System Principles, 1975.
1272. Yannacopoulos N. A., Ibbett R. N., Holdate R. W. Per-
formance measurement of the MU 5 primary instruction pipeline.— Proc..
IFIP Congress 77. Toronto, 1977.—Amsterdam: North-Holland Pub. Co.*
1977, p. 471—476.
1273. Yau S. S., F u n g H. S. Associative processor architecture — a sur-
vey.— Proc. 1975 Sagamore Computer Conf. Parallel Processing. New
York: IEEE, 1975, p. 1-14.
1274. Yau S. S., Fung H. S. Associative processor architecture — a sur*
vey.— Computing Surveys, 1977, v. 9, № 1, p. 3—27.
1275. Y u v a 1 G. Gathering run-time statistics without black magic.— Soft*
- ware-Practice and Experience, 1975, v. 5, № 1, p. 105—108.
1276. Zingg R. J., Richards H. Operational experience with SYMBOL.—
Proc. IEEE COMPCON 72, 1972, p. 31—32.
1277. Zingg R. J., Richards H. SYMBOL: a system tailored to the-
structure of data.—Proc. Nat Electron. Conf. Chicago, 1972. Vol. 27 Oak
Brook, 1972, p. 306—311.
1278. Zosel M. E. A modest proposal for vector extensions to ALGOL.—
SIGPLAN Notices, 1975, v. 10, Ka 3, p. 62-71.
1279. Zuczek R. A new approach to parallel computing.— Acta Informatica*
1976, v. 7, № 1, p. 1-1£
1280. Zwakenberg R. G. Vector extensions to LRLTRAN.— SIGPLAN No-
tices, 1975, v. 10, № 3, p. 77—86.
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Адаптер канал-канал 15, 63, 120, 159
Клок системных операций 102
Вычислительная сеть 37, 49. 83. 205, 227,
243
— система ассоциативная 6, 26. 34, 43,
339
— — гибридная 346
— — дуальная 94
-----дуплексная 14, 17, 94, 153
*----магистральная (конвейерная) 6,
27, 34, 261, 427
— — матричная 6, 26, 34, 46. 303
-----микропроцессорная 357
-----многомашинная 6, 14. 27. 36. 120,
193
-----с вспомогательным процессором
17
-------с косвенной связью 14. 16
-------с прямой связью 15, 16
-----многопроцессорная 6. И, 14. 16,
27, 35. 50, 193
— — неоднородная 24, 27, 256
-----однородная 24, 27
— — ортогональная 28, 36, 43
—- — отказоустойчивая 7. 362
-----параллельная 6, 7, 32
-----распределенная 37
-----с ансамблем процессоров 6. 26. 33,
45
-----с векторным потоком данных 6.
27, 34
-----сильно связанная 16, 20. 27, 158
-----с комбинированной структурой 6.
28, 36, 354
— — слабо связанная 15, 16, 18. 20. 27
-----с« перестраиваемой структурой 6,
28, 36, 83. 358
— — с языком высокого уровня 69. 75,
. 257, 285, 457
-----типа МКМД 29. 35. 419
-----МКОД 29, 34, 261, 432
-----ОКМД 29, 33. 303, 420
-----ОКОД 29
— среда 38. 80, 81, 83
Интерфейсная карта 132, 140
Канал ввода-вывода 9, 35, 55, 119, 151,
193 217
Коммутатор матричный 26, 28. 53, 388
— селекторный 40
Контроллер ввода-вывода 56. 61, 65, 159,
219, 236
канала 157
— преобразования адреса 392
— системный 56, 60, 251
518
Конфликты обращения к памяти 42. 54 ’
Концепция базовой системы повышен-
ной квалификации 175 1
— идеальной машины 171 J
•“l истинно многопроцессорной системы 2
— итеративной машины 171 1
— коммутаторной машины 360 1
— макромодульной машины 173 ?
— машины блочного типа 172
-----Дж. фон Неймана 9, 75 /
— — с перекрестными связями 173
— — с переменной структурой 173, 359
--------------------------------------Унгера 303
•— неоднородной машины с общими ре-
сурсами 174
— ортогональной машины 354
— поисковой машины 359 i
— распределенной машины 172 ,
•— систем SOLOMON 304 1
— системы VAMP 305 *
Маскирование неисправностей 365
Машина I 42, 423
— II 42. 353. 423
— III 43, 354
— IV 45. 353
— V 46. 353
— VI 46
Машинный язык высокого уровня
203, 215, 417
Мера гибкости вычислительных систем
436
Мультиплексор 59. 65, 217, 251. 393
69,
Обработка информации векторная (век-
торные? команды) 263. 279, 290, 299,
— — в режиме разделения времени 106,
213. 223, 230, 256, 274-. 310
•— — магистральная (конвейерная) 261,
277
— — мультипрограммная (мультипро-
граммирование) 32, 85. 106. 223. 230,
244
— — пакетная 57, 114, 213, 244. 271. ЗООг
326
----параллельная 7, 32. 84. 85. 223. 230,
244
—------в мультипрограммном режиме
32, 36, 85
— последовательная 7, 32
----пословная и поразрядная 24. 31
----распределенная микропроцессор-
ная 61
— разрядов параллельная 7. 42. 46. 422
----последовательная (последователь-
ная обработка разрядных срезов) 42,
46, 304, 333, 343. 422
Обработка слов параллельная (парал-
лельная обработка содержимого раз-
рядного среза) 42. 46, 422
----последовательная 42. 46. 422
Операционная система 16. 18. 21. 120.
144, 198, 213. 230. 244. 287. 800. ЗЮ.
325. 374
Опережающий просмотр (команд, дан-
ных) 7, 12, 108, 191, 246, 279. 321. 441
Описания структур систем и операции
над описаниями 422. 432
Отказоустойчивость 363
Оценка возможностей многопроцессор-
ных систем 99
Память ассоциативная 208, 222. 224, 286.
340
—виртуальная 57
— оперативная (основная) 9, 193
----многовходовая 13. 26, 28. 54. 67,
125, 218, 234
— ортогональная 368
— промежуточна я/массовая 184. 204. 219.
286, 288, 327
— сверхоперативная (сверхбыстродейст-
вующая), кэш-память 12. 81. 109. 153.
204, 224. 243. 249, 283, 293, 441
— стековая 74, 76, 79, 88, 165. 207, 216,
221, 224, 241. 269, 270. 279. 284. 286, 294.
315. 441
— управляющая 69. 345. 420
Параллельное программирование 7
Параллельные вычислительные методы 7
Параллельный вычислительный про-
цесс 29
Перекрытие операций 264
Подключение и выборка каналов 63
Полоса пропускания вычислительной си-
стемы 423, 453
Польская инверсная запись 74. 76. 214.
257
Потоки команд/данных 6, 9, 24. 28, 38.
360, 424, 452
Производительность и стоймость вычис-
лительных систем 436, 447
Процессор 14
— ввода-вывода 58, 65. 161, 183. 185, 209.
222, 224
— ведущий 314. 332. 335
— вертикальный 42
— внешний 65, 66
— вспомогательный 18
— горизонтальный 42
— контроля и восстановления 380
— обычный 26, 32
— одноразрядный 26, 32
— периферийный 35, 66. 81. 118. 265, 273
— профилактического обслуживания 271
— связи /передачи данных/ приема —
передачи данных 115, 184, 210, 222. 227*
242. 255. 382
— файловый 161
Процессор форматный 381
— центральный 35, 38. 66. 156. 185. 183k
184, 193, 211. 218, 221, 257
— языковый 161
Разрядный срез (срез разряда данных>
34, 42, 369, 422
Распараллеливание вычислений 29. 120».
208
Самопроверяемый вычислительный мо-
дуль 381
Связи логарифмической структуры 337
— многошинные 26, 28. 54. 67. 125. 156*.
173, 180, 183, 197, 231
— одношинные (через общую шину) 26»
28. 50, 51, 52, 55, 73. 164, 173. 184. 190»
193 270
— перекрестные 26. 28. 53. 173. 176, 177*.
194, 213, 218. 270, 273
Семафор 74, 87. 208, 234
Совмещение вычислений и ввода-вывода?
— вычислительных операций и обраще-
ний к оперативной памяти 11. 106. 43Т
— обращений к оперативной памяти 13.
81
— операций/работы устройств 7. 11. 191
Структура вычислительных систем 7, 1>
— в виде звезды 50
— кольцевая 49. 51
— регулярная/нерегулярная 51. 52
— связей с каналами 56. 57, 60
•— с полным набором связей 50. 67
Тэг 33, 76, 88, 207, 216. 222, 315. 412
Уровни комплексирования ЭВМ 102. 104»
105, 110, 123, 133, 146, 153
Устройство арифметическое (арифмети-
ко-логическое) 7, 9. 14
— ввода-вывода 9
— управления 9, 14. 42. 425
----готовностью/системное устройства-
перехода 234, 243
— — обменом 104. 287
Характеристики структур вычислитель-
ных систем 7, 193
Центральная часть ЭВМ (вычислитель-
ной системы) 14, 24, 55. 106. 206
Чередование адресов 13. 81. 108. 119, 157»
165, 192, 221, 236, 246, 254. 269. 270, 278»
282, 286, 293. 299
Борис Аркадьевич Головкин
ПАРАЛЛЕЛЬНЫЕ ВЫЧИСЛИТЕЛЬНЫЕ
СИСТЕМЫ
М., 19Й0 г., 520 стр. с илл.
Редактор Р. Л. Смелянский
Техн. редактор И. Ш. Аксельрод
Корректор В. П, Сорокина
HBJi 11498
Сдано в набор 03.03.80. Подписано к печати
16.09.80. Т-14695. Бумага 60x90'/ie. Тип. № 3.
Обыкновенная гарнитура. Высокая печать.
Условн. печ. л. 32.5. Уч.-изд. л. 37.92. Тираж
10 000 вкв. Заказ Ji 84. Цена книги 2 р. 50 к.
Издательство «Наука»
Главная редакция
физико-математической литературы
117071» Москва, В-71, Ленинский
проспект. 15
4-я типография издательства «Наука»
630077, Новосибирск, 77, Станиславского. 25