












































































































































































































































































































































































































































































Автор: Форсайт Д. Понс Ж.
Теги: компьютерные технологии компьютерные науки компьютерная графика переводная литература издательский дом вильямс
ISBN: 5-8459-0542-7
Год: 2004




Текст
компьютерное
зоение
СОВРЕМЕННЫЙ ПОДХОД
Computer Vision
A MODERN APPROACH
DAVID A. FORSYTH
University of California at Berkeley
JEAN PONCE
University of Illinois at Urbana-Champaign
Prentice
Hall
UPPER SADDLE RIVER, NJ 07458
Компьютерное зрение
СОВРЕМЕННЫЙ ПОДХОД
ДЭВИД ФОРСАЙТ
Калифорнийский Университет в Беркли
ЖАН ПОНС
Иллинойский Университет в Урбана-Шампейн
W
Москва • Санкт-Петербург • Киев
2004
ББК 32.973.26-018.2.75
Ф79
УДК 681.3.07
Издательский дом “Вильямс”
Зав. редакцией С.Н. Тригуб
Перевод с английского А.В. Назаренко, И.Ю. Дорошенко
Под редакцией А.В. Назаренко
Научный консультант В.Ю. Чех
По общим вопросам обращайтесь в Издательский дом “Вильямс” по адресу:
info@williamspublishing.com, http://www.williamspublishing.com
Форсайт, Дэвид А., Понс, Жан.
Ф79 Компьютерное зрение. Современный подход.: Пер. с англ. — М.: Издательский дом
“Вильямс”, 2004. — 928 с.: ил. — Парад, тит. англ.
ISBN 5-8459-0542-7 (рус.)
Компьютерное зрение — это одна из самых востребованных областей на современном этапе
развития цифровых компьютерных технологий. Оно требуется на производстве, при управлении
роботами, при автоматизации процессов, в медицинских и военных приложениях, при наблюдении
со спутников и при работе с персональными компьютерами, в частности поиске цифровых изобра-
жений. Книга ориентирована на широкий круг читателей, интересующихся данной областью, в
первую очередь — на студентов и преподавателей технических вузов, занимающихся аналитиче-
ской геометрией, компьютерной графикой, обработкой изображений и робототехникой.
Книга построена в форме сборника лекций (по возможности независимых), посвященных раз-
нообразным вопросам, так что ее можно использовать и как учебник по компьютерному зрению.
ББК 32.973.26-018.2.75
Все названия программных продуктов являются зарегистрированными торговыми марками соагветстмук чцнх фирм.
Никакая часть настоящего издания ни в каких целях не может быть воспроизведена в какой бы то ни было
форме и какими бы то ни было средствами, будь то электронные или механические, включая фотокопирование и
запись на магнитный носитель, если на это нет письменного разрешения издательства Prentice Hall, Inc.
Authorized translation from the English language edition published by Prentice Hall, Ptr., Copyright © 2003 by Pear-
son Education, Inc.
All rights reserved. No part of this book may be reproduced or transmitted in any form or by any means, electronic or mechanical, in-
cluding photocopying, reck^ifing or by any information storage retrieval system, without permission from the Publisher.
Russian language edition published by Williams Publishing House according to the Agreement with R&I Enterprises
International, Copyright © 2004
ISBN 5-8459-0542-7 (pyc.)
ISBN 0-13-085198-1 (англ.)
© Издательский дом “Вильямс”, 2004
© by Pearson Education, Inc., 2003
Оглавление
ПРЕДИСЛОВИЕ 24
Часть I Формирование изображений и модели изображений 37
1 КАМЕРЫ 39
2 ГЕОМЕТРИЧЕСКИЕ МОДЕЛИ КАМЕР 63
3 ГЕОМЕТРИЧЕСКАЯ КАЛИБРОВКА КАМЕР 87
4 РАДИОМЕТРИЯ - ИЗМЕРЕНИЕ СВЕТА 109
5 ИСТОЧНИКИ, ТЕНИ И ЗАТЕНЕНИЕ 127
6 СВЕТ 161
Часть II Первые этапы: одно изображение 207
7 ЛИНЕЙНЫЕ ФИЛЬТРЫ 209
8 ОПРЕДЕЛЕНИЕ КРАЕВ 247
9 ТЕКСТУРА 277
6
Оглавление
Часть 111 Первые этапы: несколько изображений 307
10 ГЕОМЕТРИЯ НЕСКОЛЬКИХ ПРОЕКЦИЙ 309
11 СТЕРЕОЗРЕНИЕ 333
12 ОПРЕДЕЛЕНИЕ АФФИННОЙ СТРУКТУРЫ ПО ДВИЖЕНИЮ 355
13 ОПРЕДЕЛЕНИЕ ПРОЕКТИВНОЙ СТРУКТУРЫ ПО ДВИЖЕНИЮ 387
Часть IV Компьютерное зрение: средний уровень 421
14 СЕГМЕНТАЦИЯ ЧЕРЕЗ КЛАСТЕРИЗАЦИЮ 423
15 СЕГМЕНТАЦИЯ ЧЕРЕЗ ПОДБОР МОДЕЛИ 459
16 СЕГМЕНТАЦИЯ И ПОДБОР С ИСПОЛЬЗОВАНИЕМ
ВЕРОЯТНОСТНЫХ МЕТОДОВ 491
17 СОПРОВОЖДЕНИЕ С ИСПОЛЬЗОВАНИЕМ ЛИНЕЙНЫХ
ДИНАМИЧЕСКИХ МОДЕЛЕЙ 517
Часть V Верхний уровень компьютерного зрения:
геометрические методы 549
18 ЗРЕНИЕ НА ОСНОВЕ МОДЕЛИ 551
19 ГЛАДКИЕ ПОВЕРХНОСТИ И ИХ КОНТУРЫ 585
20 АСПЕКТНЫЕ ГРАФЫ 607
21 ДАЛЬНОСТНЫЕ ДАННЫЕ 637
Часть VI Верхний уровень: вероятностные методы
и методы логического вывода 671
22 ПОИСК ШАБЛОНОВ С ИСПОЛЬЗОВАНИЕМ
КЛАССИФИКАТОРОВ 673
23 РАСПОЗНАВАНИЕ ЧЕРЕЗ СВЯЗЬ ШАБЛОНОВ 727
24 ГЕОМЕТРИЧЕСКИЕ ШАБЛОНЫ ЧЕРЕЗ ПРОСТРАНСТВЕННЫЕ
СВЯЗИ 769
Часть VII Приложения 807
25 ПОИСК В ЦИФРОВЫХ БИБЛИОТЕКАХ 809
26 ВИЗУАЛИЗАЦИЯ НА ОСНОВЕ ИЗОБРАЖЕНИЙ 837
ЛИТЕРАТУРА 865
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ 908
Содержание
ПРЕДИСЛОВИЕ 24
Часть I Формирование изображений и модели изображений 37
1 КАМЕРЫ 39
1.1. Камеры-обскуры 40
1.1.1. Перспективная проекция 40
1.1.2. Аффинная проекция 43
1.2. Камеры с линзами 44
1.2.1. Параксиальная геометрическая оптика 46
1.2.2. Тонкие линзы 47
1.2.3. Реальные линзы 49
1.3. Человеческий глаз 52
1.4. Восприятие 54
1.4.1. ПЗС-камеры 56
1.4.2. Модели датчиков 57
1.5. Примечания 59
8
Содержание
2 ГЕОМЕТРИЧЕСКИЕ МОДЕЛИ КАМЕР 63
2.1. Элементы аналитической евклидовой геометрии 64
2.1.1. Системы координат и однородные координаты 64
2.1.2. Переход от одной системы координат к другой
и строгие преобразования 67
2.2. Характеристики камер и перспективная проекция 73
2.2.1. Внутренние параметры 74
2.2.2. Внешние параметры 76
2.2.3. Описание матриц перспективной проекции 78
2.3. Аффинные камеры и уравнения аффинной проекции 79
2.3.1. Аффинные камеры 79
2.3.2. Уравнения аффинной проекции 80
2.3.3. Описание матрицы аффинной проекции 83
2.4. Примечания 83
3 ГЕОМЕТРИЧЕСКАЯ КАЛИБРОВКА КАМЕР 87
3.1. Оценка параметров по схеме наименьших квадратов 88
3.1.1. Линейные схемы наименьших квадратов 88
3.1.2. Нелинейные схемы наименьших квадратов 93
3.2. Линейный подход к калибровке камеры 96
3.2.1. Оценка проекционной матрицы 96
3.2.2. Оценка внутренних и внешних параметров 97
3.2.3. Вырожденные точечные конфигурации 98
3.3. Учет радиального искажения 99
3.3.1. Оценка проекционной матрицы 100
3.3.2. Оценка внутренних и внешних параметров 101
3.3.3. Вырожденные точечные конфигурации 102
3.4. Аналитическая фотограмметрия 103
3.5. Приложение: определение местонахождения мобильного
робота 105
3.6. Примечания 107
4 РАДИОМЕТРИЯ - ИЗМЕРЕНИЕ СВЕТА 109
4.1. Свет в пространстве 109
4.1.1. Ракурс 109
Содержание
9
4.1.2. Телесный угол ПО
4.1.3. Излучение 112
4.2. Свет на поверхностях 115
4.2.1. Упрощения 115
4.2.2. Функция распределения двунаправленного отражения 115
4.2.3. Пример: радиометрия тонких линз 118
4.3. Важные частные случаи 119
4.3.1. Диффузное отражение 120
4.3.2. Отражательная способность 120
4.3.3. Ламбертовские поверхности и альбедо 121
4.3.4. Зеркальные поверхности 122
4.3.5. Ламбертовская + зеркальная модель 123
4.4. Примечания 124
5 ИСТОЧНИКИ, ТЕНИ И ЗАТЕНЕНИЕ 127
5.1. Качественная радиометрия 127
5.2. Источники света и их действие 129
5.2.1. Радиометрические свойства источников света 129
5.2.2. Точечные источники 130
5.2.3. Линейные источники 133
5.2.4. Плоские источники 134
5.3. Локальные модели затенения 136
5.3.1. Локальные модели затенения для точечных
источников 136
5.3.2. Плоские источники и их тени 139
5.3.3. Естественное освещение 139
5.4. Приложение: фотометрическое стерео 140
5.4.1. Нормаль и альбедо по многим изображениям 142
5.4.2. Определение формы по нормалям 144
5.5. Взаимное отражение: глобальные модели затенения 147
5.5.1. Модель взаимного отражения 149
5.5.2. Решения для диффузного отражения 151
5.5.3. Качественное описание эффектов взаимного
отражения 152
5.6. Примечания 154
10
Содержание
6 ЦВЕТ 161
6.1. Физика цвета 161
6.1.1. Радиометрия цветного света: спектральные величины 161
6.1.2. Цвет источников 162
6.1.3. Цвет поверхности 165
6.2. Человеческое восприятие цвета 166
6.2.1. Подбор цветов 167
6.2.2. Цветовые рецепторы 170
6.3. Представление цвета 172
6.3.1. Линейные цветовые пространства 172
6.3.2. Нелинейные цветовые пространства 178
6.3.3. Пространственные и временные эффекты 182
6.4. Модель цвета изображения 183
6.4.1. Камеры 183
6.4.2. Модель цвета изображения 184
6.4.3. Приложение: нахождение бликов 186
6.5. Определения цвета поверхности по цвету изображения 190
6.5.1. Человеческое восприятие цветной поверхности 191
6.5.2. Определение освещенности 192
6.5.3. Цвет поверхности согласно линейной модели
конечной размерности 198
6.6. Примечания 200
Часть II Первые этапы: одно изображение 207
7 ЛИНЕЙНЫЕ ФИЛЬТРЫ 209
7.1. Линейные фильтры и свертка 209
7.1.1. Свертка 210
7.2. Линейные системы, инвариантные относительно сдвига 216
7.2.1. Дискретная свертка 216
7.2.2. Непрерывная свертка 218
7.2.3. Краевые эффекты при дискретной свертке 222
7.3. Пространственная частота и преобразование Фурье 222
7.3.1. Преобразование Фурье 223
7.4. Дискретизация и наложение 225
7.4.1. Дискретизация 225
Содержание
11
7.4.2. Наложение 230
7.4.3. Сглаживание и повторная дискретизация 231
7.5. Фильтры как шаблоны 235
7.5.1. Свертка как скалярное произведение 235
7.5.2. Смена базиса 236
7.6. Метод: нормированная корреляция и поиск модели 237
7.6.1. Управление телевизором: нахождение руки
с помощью нормированной корреляции 237
7.7. Метод: масштаб и пирамиды изображений 239
7.7.1. Гауссова пирамида 240
7.7.2. Применение масштабных представлений 240
7.8. Примечания 243
8 ОПРЕДЕЛЕНИЕ КРАЕВ 247
8.1. Шум 248
8.1.1. Аддитивный стационарный гауссов шум 249
8.1.2. Почему конечная разность чувствительна к шуму 251
8.2. Оценка производных 252
8.2.1. Производная от гауссова фильтра 253
8.2.2. Чем полезно сглаживание 254
8.2.3. Выбор фильтра сглаживания 255
8.2.4. Почему для сглаживания используют гауссиан 257
8.3. Определение краев 259
8.3.1. Применение лапласиана для определения краев 260
8.3.2. Детекторы краев на основе градиентов 263
8.3.3. Метод: представление ориентации и углов 266
8.4. Примечания 272
9 ТЕКСТУРА 277
9.1. Представление текстуры 278
9.1.1. Определение структуры изображения с помощью
блоков фильтров 278
9.1.2. Описание текстуры с помощью статистики выходов
фильтров 283
9.2. Анализ и синтез с помощью ориентированных пирамид 286
9.2.1. Лапласова пирамида 287
12
Содержание
9,2.2. Фильтры в области пространственных частот 289
9.2.3. Ориентированные пирамиды 294
9.3. Приложение: синтез текстуры для создания изображений 296
9,3.1. Однородность 297
9.3.2. Синтез с помощью локальных моделей выборки 298
9.4. Определение формы по текстуре 300
9.4.1. Восстановление формы по текстуре для плоскостей 300
9.5. Примечания 303
Часть III Первые этапы: несколько изображений 307
10 ГЕОМЕТРИЯ НЕСКОЛЬКИХ ПРОЕКЦИЙ 309
10.1. Две проекции 310
10.1.1. Эпиполярная геометрия 310
10.1.2. Откалиброванные камеры 311
10.1.3. Слабое движение 313
10.1.4. Неоткалиброванные камеры 313
10.1.5. Слабая калибровка 314
10.2. Три проекции 317
10.2.1. Трифокальная геометрия 319
10.2.2. Откалиброванные камеры 320
10.2.3. Неоткалиброванные камеры 322
10.2.4. Оценка трифокусного тензора 324
10.3. Большее число проекций 324
10.4. Примечания 329
11 СТЕРЕОЗРЕНИЕ 333
11.1. Восстановление 334
11.1.1. Очистка изображения 336
11.2. Стереозрение человека 337
11.3. Бинокулярное совмещение изображений 341
11.3.1. Корреляция 341
11.3.2. Многошкальное согласование краев 344
11.3.3. Динамическое программирование 345
11.4. Использование большего числа камер 348
Содержание
13
11.4.1. Три камеры 348
11.4.2. Множественные камеры 349
11.5. Примечания 351
12 ОПРЕДЕЛЕНИЕ АФФИННОЙ СТРУКТУРЫ ПО ДВИЖЕНИЮ 355
12.1. Элементы аффинной геометрии 358
12.1.1. Аффинные пространства и барицентрические
комбинации 358
12.1.2. Аффинные подпространства и аффинные координаты 360
12.1.3. Аффинные преобразования и аффинные проекционные
модели 364
12.1.4. Аффинная форма 365
12.2. Определение аффинной структуры и движения по двум
изображениям 366
12.2.1. Геометрическое восстановление сцены 366
12.2.2. Алгебраическая оценка движения 368
12.3. Определение аффинной структуры и движения по нескольким
изображениям 372
12.3.1. Аффинная структура последовательности аффинных
изображений 372
12.3.2. Использование факторизации для нахождения
аффинной структуры по движению 373
12.4. От аффинных изображений к евклидовым 376
12.4.1. Евклидовы ограничения и откалиброванные
аффинные камеры 377
12.4.2. Вычисление евклидового уточнения структуры
на основе нескольких изображений 378
12.5. Сегментация аффинного движения 380
12.5.1. Ступенчатая форма информационной матрицы
(с уменьшенным числом строк) 380
12.5.2. Матрица взаимодействия форм 382
12.6. Примечания 384
13 ОПРЕДЕЛЕНИЕ ПРОЕКТИВНОЙ СТРУКТУРЫ ПО ДВИЖЕНИЮ 387
13.1. Элементы проективной геометрии 388
13.1.1. Проективные пространства 389
14
Содержание
13.1.2. Проективные подпространства и проективные
координаты 390
13.1.3. Аффинные и проективные пространства 393
13.1.4. Гиперплоскости и дуальность 394
13.1.5. Ангармоническое отношение 396
13.1.6. Проективные преобразования 398
13.1.7. Проективная форма 401
13.2. Определение проективной структуры и движения по
бинокулярным соответствиям 401
13.2.1. Геометрическое восстановление сцены 401
13.2.2. Алгебраическая оценка движения 404
13.3. Оценка проективного движения по полилинейным условиям 405
13.3.1. Оценка движения по фундаментальным матрицам 406
13.3.2. Оценка движения по трифокусным тензорам 407
13.4. Определение проективной структуры и движения по
множественным изображениям 408
13.4.1. Использование факторизации для определения
проективной структуры по движению 408
13.4.2. Выравнивание пучков 411
13.5. От проективных изображений к евклидовым 412
13.6. Примечания 415
Часть IV Компьютерное зрение: средний уровень 421
14 СЕГМЕНТАЦИЯ ЧЕРЕЗ КЛАСТЕРИЗАЦИЮ 423
14.1. Что такое “сегментация” 424
14.1.1. Модельные задачи 426
14.1.2. Сегментация как кластеризация 427
14.2. Человеческое зрение: группировка и гештальт 428
14.3. Приложение: вычитание фона и определение границ кадров 433
14.3.1. Вычитание фона 434
14.3.2. Определение границ кадров 436
14.4. Сегментация изображения через кластеризацию пикселей 438
14.4.1. Сегментация с использованием простых методов
кластеризации 438
14.4.2. Кластеризация и сегментация через К-средние 440
Содержание
15
14.5. Сегментация через теоретико-графовую кластеризацию 443
14.5.1. Терминология теории графов 443
14.5.2. Общая схема 444
14.5.3. Меры сходства 444
14.5.4. Собственные векторы и сегментация 448
14.5.5. Нормированные разрезы 451
14.6. Примечания 455
15 СЕГМЕНТАЦИЯ ЧЕРЕЗ ПОДБОР МОДЕЛИ 459
15.1. Преобразование Хоха 459
15.1.1. Подбор линий с помощью преобразования Хоха 461
15.1.2. Практические сложности при использовании
преобразования Хоха 462
15.2. Подбор прямых 462
15.2.1. Подбор прямой по схеме наименьших квадратов 464
15.2.2. Какая точка принадлежит какой прямой 467
15.3. Подбор кривых 469
15.3.1. Неявные кривые 469
15.3.2. Параметрические кривые 472
15.4. Подбор как задача вероятностного вывода 473
15.5. Устойчивость 475
15.5.1. М-оценочная функция 475
15.5.2. RANSAC 479
15.6. Пример: использование алгоритма RANSAC для подбора
фундаментальных матриц 482
15.6.1. Выражение для ошибки подбора 482
15.6.2. Соответствие как шум 483
15.6.3. Применение алгоритма RANSAC 483
15.6.4. Нахождение расстояния 485
15.6.5. Подбор фундаментальной матрицы по известным
соответствиям 487
15.7. Примечания 487
16 СЕГМЕНТАЦИЯ И ПОДБОР С ИСПОЛЬЗОВАНИЕМ
ВЕРОЯТНОСТНЫХ МЕТОДОВ 491
16.1. Задачи с недостающими данными, подбор и сегментация 491
г
16 Содержание
16.1.1. Задачи с недостающими данными 492
16.1.2. ОМ-алгоритм 496
16.1.3. ОМ-алгоритм в общем случае 498
16.2. ОМ-алгоритм на практике 498
16.2.1. Пример: сегментация изображения (возвращаясь к
сказанному) 498
16.2.2. Пример: подбор линии с помощью ОМ-алгоритма 502
16.2.3. Пример: сегментация движения и ОМ-алгоритм 504
16.2.4. Пример: использование ОМ-алгоритма для
определения посторонних значений 507
16.2.5. Пример: вычитание фона с использованием
ОМ-алгоритма 508
16.2.6. Пример: ОМ-алгоритм и фундаментальная матрица 509
16.2.7. Сложности при использовании ОМ-алгоритма 509
16.3. Выбор модели: какая модель дает наилучшее соответствие 510
16.3.1. Основные идеи 511
16.3.2. AIC — информационный критерий 511
16.3.3. Методы Байеса и критерий Шварца 512
16.3.4. Длина описания 512
16.3.5. Другие методы оценки аномальности 513
16.4. Примечания 513
17 СОПРОВОЖДЕНИЕ С ИСПОЛЬЗОВАНИЕМ ЛИНЕЙНЫХ
ДИНАМИЧЕСКИХ МОДЕЛЕЙ 517
17.1. Сопровождение как абстрактная задача логического вывода 519
17.1.1. Допущения о независимости 519
17.1.2. Сопровождение как задача логического вывода 520
17.1.3. Обзор 521
17.2. Линейные динамические модели 521
17.2.1. Дрейфующие точки 522
17.2.2. Постоянная скорость 522
17.2.3. Постоянное ускорение 524
17.2.4. Периодическое движение 525
17.2.5. Модели высших порядков 526
17.3. Фильтр Кальмана 526
17.3.1. Фильтр Кальмана для одномерного вектора состояния 527
Содержание
17
17.3.2. Обновление уравнений для общего вектора состояния 530
17.3.3. Реверсивное сглаживание 531
17.4. Ассоциация данных 537
17.4.1. Учет ближайших соседей 537
17.4.2. Селекция и вероятностная ассоциация данных 540
17.5. Примеры и применение 542
17.5.1. Сопровождение транспортных средств 543
17.6. Примечания 546
Часть V Верхний уровень компьютерного зрения: геометрические
методы 549
18 ЗРЕНИЕ НА ОСНОВЕ МОДЕЛИ 551
18.1. Исходные допущения 552
18.1.1. Получение гипотез 553
18.2. Получение гипотез из совместимости поз 554
18.2.1. Совместимость поз для перспективных камер 556
18.2.2. Аффинная и проективная модели камеры 557
18.2.3. Линейная комбинация моделей 560
18.3. Получение гипотез через кластеризацию поз 561
18.4. Получение гипотез с использованием инвариантов 563
18.4.1. Инварианты для плоских изображений 563
18.4.2. Геометрическое хэширование 567
18.4.3. Инварианты и индексация 568
18.5. Верификация 572
18.5.1. Близость краев 572
18.5.2. Сходство текстуры, шаблона и интенсивности 574
18.6. Приложение: наложение в медицинских системах
визуализации 575
18.6.1. Модели представления изображений 575
18.6.2. Применение наложения 576
18.6.3. Методы геометрического хэширования в медицинских
приложениях 578
18.7. Криволинейные поверхности и выравнивание 580
18.8. Примечания 580
18
Содержание
19 ГЛАДКИЕ ПОВЕРХНОСТИ И ИХ КОНТУРЫ 585
19.1. Элементы дифференциальной геометрии 587
19.1.1. Кривые 588
19.1.2. Поверхности 594
19.2. Геометрия контуров 600
19.2.1. Затеняющий контур и контур изображения 600
19.2.2. Точки возврата и перегиба на контуре изображения 601
19.2.3. Теорема Коендеринка 603
19.3. Примечания 605
20 АСПЕКТНЫЕ ГРАФЫ 607
20.1. Визуальные события: снова обращаемся к дифференциальной
геометрии 611
20.1.1. Геометрия отображения Гаусса 612
20.1.2. Асимптотические кривые 614
20.1.3. Асимптотическое сферическое отображение 615
20.1.4. Локальные визуальные события 617
20.1.5. Многообразие бикасательных лучей 619
20.1.6. Мульти локальные визуальные события 620
20.2. Расчет аспектного графа 622
20.2.1. Этап 1: Отслеживание визуальных событий 625
20.2.2. Этап 2: Построение областей 626
20.2.3. Оставшиеся этапы алгоритма 627
20.2.4. Пример 628
20.3. Аспектные графы и локализация объектов 629
20.4. Примечания 633
21 ДАЛЬНОСТНЫЕ ДАННЫЕ 637
21.1. Активные датчики расстояния 638
21.2. Сегментация дальностных данных 640
21.2.1. Элементы аналитической дифференциальной
геометрии 640
21.2.2. Нахождение на дальностном изображении
ступенчатых и скатообразных краев 643
21.2.3. Сегментация дальностных изображений в плоские
области 650
Содержание
19
21.3. Наложение дальностных изображений и получение моделей 651
21.3.1. Кватернионы 652
21.3.2. Наложение дальностных картин с использованием
итеративного метода ближайших точек 653
21.3.3. Совмещение нескольких дальностных изображений 656
21.4. Распознавание объектов 657
21.4.1. Согласование кусочно-плоских поверхностей
с использованием интерпретационных деревьев 657
21.4.2. Согласование свободных поверхностей
с использованием спиновых изображений 661
21.5. Примечания 667
Часть VI Верхний уровень: вероятностные методы и методы
логического вывода 671
22 ПОИСК ШАБЛОНОВ С ИСПОЛЬЗОВАНИЕМ
КЛАССИФИКАТОРОВ 673
22.1. Классификаторы 674
22.1.1. Использование потерь для определения решений 674
22.1.2. Методы построения классификаторов: обзор 677
22.1.3. Пример: сменный классификатор для классов
с нормальным распределением 679
22.1.4. Пример: непараметрический классификатор
по ближайшим соседям 680
22.1.5. Оценка и улучшение производительности 682
22.2. Построение классификаторов по гистограммам классов 684
22.2.1. Поиск пикселей кожи с использованием
классификатора 684
22.2.2. Поиск лиц в предположении о независимых откликах
на шаблоны 686
22.3. Выбор признаков 688
22.3.1. Анализ главных компонентов 690
22.3.2. Идентификация людей с помощью анализа главных
компонентов 692
22.3.3. Канонические переменные 695
22.4. Нейронные сети 700
20
Содержание
22.4.1. Ключевые идеи 700
22.4.2. Минимизация ошибки 704
22.4.3. Когда прекратить настройку 705
22.4.4. Поиск лиц с использованием нейронных сетей 706
22.4.5. Сверточные нейронные сети 708
22.5. Машина опорных векторов 710
22.5.1. Машина опорных векторов для линейно
сепарабельных наборов данных 712
22.5.2. Поиск пешеходов с использованием машины опорных
векторов 715
22.6. Примечания 716
22.7. Приложение I: обратное распространение ошибки 720
22.8. Приложение И: машина опорных векторов для наборов
данных, не являющихся линейно сепарабельными 724
22.9. Приложение III: использование машины опорных векторов
с нелинейными ядрами 725
23 РАСПОЗНАВАНИЕ ЧЕРЕЗ СВЯЗЬ ШАБЛОНОВ 727
23.1. Поиск объектов через голосование за связи между шаблонами 728
23.1.1. Описание фрагментов изображения 728
23.1.2. Голосование и простая порождающая модель 729
23.1.3. Вероятностные модели для голосования 730
23.1.4. Голосование за связи 733
23.1.5. Голосование и трехмерные объекты 734
23.2. Рассуждения о связях с использованием вероятностных
моделей и поиска 735
23.2.1. Соответствие и поиск 735
23.2.2. Пример: поиск лиц 739
23.3. Использование классификаторов для сокращения поиска 740
23.3.1. Определение приемлемых совокупностей
с использованием проективных классификаторов 741
23.3.2. Пример: поиск людей и лошадей с использованием
пространственных отношений 742
23.4. Метод: скрытые марковские модели 745
23.4.1. Формальные вопросы 746
Содержание
21
23.4.2. Вычисления с использованием скрытых марковских
моделей 747
23.4.3. Разнообразие скрытых марковских моделей 755
23.5. Приложение: скрытые марковские модели и понимание языка
жестов 758
23.5.1. Модели языка: предложения из слов 759
23.6. Приложение: поиск людей с использованием скрытых
марковских моделей 762
23.7. Примечания 766
24 ГЕОМЕТРИЧЕСКИЕ ШАБЛОНЫ ЧЕРЕЗ
ПРОСТРАНСТВЕННЫЕ СВЯЗИ 769
24.1. Простые связи объекта и изображения 770
24.1.1. Связи для криволинейных поверхностей 770
24.1.2. Группировка на основе классов 779
24.2. Примитивы, шаблоны и геометрический вывод 781
24.2.1. Обобщенные цилиндры как объемные примитивы 781
24.2.2. Ленты 782
24.2.3. Что можно представить с помощью лент 789
24.2.4. Связывание трехмерных и двумерных данных для
цилиндров известной длины 791
24.2.5. Связывание трехмерных данных и данных образа
с использованием явных геометрических соображений 793
24.3. Послесловие: распознавание объектов 798
24.3.1. Подтвержденные факты 800
24.3.2. Существующие подходы к распознаванию объектов 801
24.3.3. Ограничения 802
24.4. Примечания 803
Часть VII Приложения 807
25 ПОИСК В ЦИФРОВЫХ БИБЛИОТЕКАХ 809
25.1. Основа: организация коллекций информации 812
25.1.1. Насколько эффективна система 812
25.1.2. Чего хотят пользователи 814
25.1.3. В поисках изображений 814
25.1.4. Структурирование и навигация 816
25.2. Резюмирующее представление всего изображения 817
25.2.1. Гистограммы и коррелограммы 818
25.2.2. Текстуры и текстуры текстур 819
25.3. Представление частей изображения 823
25.3.1. Сегментация 823
25.3.2. Сравнение с шаблоном 827
25.3.3. Форма и соответствие 828
25.3.4. Кластеризация и организация коллекций 830
25.4. Видео 832
25.5. Примечания 835
26 ВИЗУАЛИЗАЦИЯ НА ОСНОВЕ ИЗОБРАЖЕНИЙ 837
26.1. Построение трехмерных моделей по последовательности
изображений 838
26.1.1. Моделирование сцены по наложенным изображениям 838
26.1.2. Моделирование сцены по несовмещенным
изображениям 846
26.2. Визуализация на основе переноса 849
26.2.1. Синтез аффинных проекций 850
26.2.2. Синтез евклидовых проекций 853
26.3. Световое поле 857
26.4. Примечания 860
ЛИТЕРАТУРА 865
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ 908
Моей семье /Д. Форсайт/
Камилле и Оскару /Д. Понс/
Предисловие
Компьютерное зрение — это пограничная область знаний. И как всякая погра-
ничная область она интересна для изучения и непредсказуема; здесь часто нет
авторитетов, на которые можно сослаться, — многие полезные идеи не имеют
под собой теоретической основы, а некоторые теории бесполезны на практике;
изученные области весьма различаются, и часто кажется, что всякая связь меж-
ду ними отсутствует. Тем не менее, в этой книге мы попытались представить
в некоторой степени упорядоченную картину этой области знаний.
В нашем понимании "компьютерное зрение”, или просто “зрение” (заранее
просим прощения у специалистов по зрению людей или животных) — это вид
деятельности, в котором для извлечения данных применяются статистические
методы и используются модели, построенные с помощью геометрии, физики
и теории обучения. Таким образом, на наш взгляд компьютерное зрение осно-
вывается на четком представлении о камерах и физическом процессе форми-
рования изображения (часть I), получении простых выводов на основе изуче-
ния набора отдельных пикселей (часть II), умении суммировать информацию,
полученную из множества изображений (часть III), упорядочении группы пик-
селей с целью их разделения или получения информации о форме (часть IV),
распознавании объектов с помощью геометрической информации (часть V) или
вероятностных методов (часть VI). Компьютерное зрение применяется довольно
Предисловие
25
широко как в относительно старых областях (например, управление мобильны-
ми роботами, промышленные средства наблюдения, военные приложения), так
и в сравнительно новых (взаимодействие человек/компьютер, поиск изображе-
ния в цифровых библиотеках, анализ медицинских изображений и реалистич-
ная передача смоделированных сцен в компьютерной графике). Некоторые из
этих приложений обсуждаются в части VII.
ЗАЧЕМ ИЗУЧАТЬ ЗРЕНИЕ
Отличительная черта компьютерного зрения — это извлечение описаний из
изображений или последовательности изображений. Это весьма полезная осо-
бенность. Процесс снятия изображения обычно недеструктивен, кроме того, он
достаточно прост и на сегодняшний момент недорог. Описания, необходимые
пользователям, могут в большой мере зависеть от области их применения. На-
пример, такой аспект компьютерного зрения, как определение структуры по
движению, позволяет из серии изображений получить представление о том,
что изображено на рисунке и как движется камера. В индустрии развлечений
подобные методы применяются для отсеивания движения и построения трех-
мерных компьютерных моделей зданий с сохранением структуры. Эти модели
применяются там, где нельзя использовать настоящие здания (их поджигают,
взрывают и т.п.). С помощью небольшого числа фотографий можно получить
хорошие, простые, точные и удобные модели. Рассмотрим другую ситуацию:
люди, желающие контролировать работу мобильных роботов. В этом случае
сведения об области, где используется робот, обычно не представляют значи-
тельного интереса, важно лишь местонахождение робота в этой области. Таким
образом, здесь отсеивается информация о структуре и отслеживается движе-
ние, что позволяет определить точное местонахождение робота.
Есть еще целый ряд других важных областей применения компьютерного
зрения. Это, например, работа с медицинскими изображениями: создание про-
граммных систем, которые могут улучшать набор изображений, выявлять на
них важные моменты или события либо визуализировать информацию, полу-
ченную из изображений. Другая важная область — различные технические
проверки, когда по изображениям объектов определяется, соответствуют ли
объекты спецификации. Третья сфера применения компьютерного зрения —
интерпретация фотографий, сделанных со спутника, как в военных целях (на-
пример, может потребоваться программа, выявляющая интересные, с военной
точки зрения, события в указанном регионе или определяющая вред, нанесен-
ный в результате бомбардировки), так и в гражданских (какой урожай куку-
рузы будет в этом году? сколько осталось тропических лесов?). Четвертая об-
ласть — это упорядочение и структурирование коллекций картин. Теперь поль-
зователь уже умеет находить нужную информацию в текстовых библиотеках
(хотя и здесь имеется ряд сложных, нерешенных вопросов), но еще не всегда
знает, что делать с библиотеками статических или движущихся изображений.
26
Предисловие
Компьютерное зрение сейчас находится в особой точке своего развития. Эта
тема стала популярной еще в 1960-х, но только недавно появилась возможность
создания полезных компьютерных программ, использующих идеи компьютерно-
го зрения, поскольку компьютеры и программы обработки изображений стали
доступны большому количеству пользователей. Не так давно для получения хо-
рошего цветного цифрового изображения нужно было потратить не один деся-
ток тысяч долларов; сейчас для этого нужно не более нескольких сотен. Не так
давно цветной принтер можно было найти только в некоторых исследователь-
ских лабораториях; сейчас их используют повсеместно. Таким образом, прово-
дить серьезные исследования и решать многие повседневные задачи (например,
упорядочить коллекцию фотографий, создать трехмерную модель окружающего
мира, управлять и вносить изменения в коллекцию видеозаписей) теперь можно
с помощью методов компьютерного зрения. Наши знания по геометрии и фи-
зике зрения и, что еще важнее, умение их применять в нужном направлении
значительно развились. Мы уже можем решать задачи, интересующие многих
людей, хотя еще не решена ни одна из действительно сложных задач, кроме
того, существует множество простых задач, которые можно использовать для
поддержания интеллектуальной формы людей, бьющихся над решением труд-
ных задач. Итак, сейчас самое время начать изучение этого предмета!
Что есть в этой книге
Эта книга предназначена как для специалиста по компьютерному зрению,
так и для широкого круга читателей. Она окажется полезным источником ин-
формации для тех, кто работает с изображениями и робототехникой, а также
занимается вычислительной геометрией, компьютерной графикой, обработкой
изображений. Эта книга также будет доступна для студентов, поверхностно
интересующихся зрением. В каждой главе освещается отдельный аспект дан-
ного предмета, и, как видно из табл. 1, главы относительно независимы между
собой. Это означает, что книгу можно читать как выборочно, так и “от корки до
корки”. Материал в каждой главе подается в порядке возрастания сложности. В
конце каждой главы приводятся краткие примечания, содержащие любопытные
исторические сведения, и полезные замечания, относящиеся к рассматриваемо-
му вопросу. В книге описаны идеи, представляющие интерес или кажущиеся
перспективными, авторы попытались как можно более доступно связать теорию
с реальными приложениями. При изложении материала внимание акцентирова-
лось на базовых вопросах геометрии и физики изображений, а также приклад-
ной статистики, поскольку именно эти области оказали огромное влияние на
компьютерное зрение.
Читателю, который решил изучить этот труд досконально, следует учесть,
что данная книга содержит очень большой набор информации, поэтому усво-
ить полученные знания за один семестр весьма сложно. Конечно, будущим (или
настоящим) профессионалам в области компьютерного зрения стоит прочитать
каждое слово, выполнить все упражнения и сообщить обо всех обнаруженных
ошибках для исправления второго издания (которое наверняка будет велико-
Предисловие
27
ТАБЛИЦА 1. Связь между главами: читать главу будет трудно, если вы предварительно не изучите
главы, указанные в графе "требуемое"; если при прочтении главы обнаружится один-два непонятных
момента, скорее всего они освещены в главах, указанных в графе "полезное"
Част1 * Глава Требуемое Полезное
I 1: Камеры 2: Геометрические модели камер 3: Геометрическая калибровка камер 4: Радиометрия — измерение света 5: Источники, тени и затенение 6: Цвет 1 2 4, 1 5
II 7: Линейные фильтры 8: Определение краев 9: Текстура 7 7 8
III 10: Геометрия множественных проекций 11: Стереозрение 12: Аффинная структура по движению 13: Проективная структура по движению 3 10 10 12
IV 14: Сегментация посредством кластеризации 15: Сегментация посредством выбора модели 16: Сегментация на основе вероятностных методов 17: Сопровождение на основе динамических моделей 9, 6,5 14 15,10
V 18: Зрение на основе модели 19: Гладкие поверхности и их контуры 20: Аспектные графы 21: Дистанционные данные 3 2 19 20, 19, 3
VI 22: Поиск шаблонов с помощью классификаторов 23: Распознавание по связям между шаблонами 24: Геометрические шаблоны 2, 1 9, 8, 7, 6, 5 9, 8, 7, 6, 5 16, 15, 14
VII 25: Приложение: поиск в цифровых библиотеках 26: Приложение: визуализация на основе изображений 10 16, 15, 14, 6 13, 12, 11, 6, 5, 3, 2, 1
лепной книгой, о которой стоит подумать уже сейчас!). Поскольку для изучения
компьютерного зрения не требуются глубокие познания в математике, здесь не
нужен и слишком обширный математический аппарат. Мы попытались сделать
эту книгу самодостаточной, чтобы читателям с математическим образованием
на уровне выпускника инженерного вуза не приходилось обращаться к другим
источникам. Математические выкладки сведены к необходимому минимуму, —
в конце концов, это книга о компьютерном зрении, а не о прикладной матема-
28
Предисловие
тике! — поэтому требуемые формулы включены в основной текст главы, а не
вынесены в отдельные приложения.
Взаимозависимость между главами сведена к минимуму, чтобы читателю,
которого интересуют отдельные темы, не пришлось штудировать всю книгу.
Разумеется, сделать каждую главу полностью самодостаточной невозможно,
поэтому в табл. 1 показаны связи между главами.
Чего нет в этой книге
По компьютерному зрению доступно немало материалов, и было нелегко со-
здать такой труд, который могли бы осилить простые смертные. Чтобы сделать
это, пришлось урезать материал, пренебречь некоторыми темами и т.д. В самый
последний момент было решено убрать целых две главы: введение в теорию ве-
роятности с описанием соответствующих следствий, а также перечисление ме-
тодов сопровождения объектов с нелинейной динамикой. Эти главы можно най-
ти на Web-сайте книги http://www.cs.berkeley.edu/~daf/book.html.
Некоторые темы мы обошли либо по собственному усмотрению, либо пото-
му, что наши возможности уже были исчерпаны, о некоторых темах мы узнали
слишком поздно, чтобы вставить их в книгу, а какие-то главы необходимо было
сократить. Вместо подробных рассуждений по вопросам, которые представля-
ют в основном исторический интерес, в конце каждой главы помещены краткие
исторические примечания. Никто из нас не считает себя хорошим “археологом
мысли”, так что у некоторых идей история может быть намного глубже, чем мы
это показали. В книге также отсутствует подробное описание деформируемых
таблиц и мозаик — две темы, которые имеют большое практическое значение;
мы попытаемся ввести их во второе издание данной книги.
БЛАГОДАРНОСТИ
Выходу этой книги в свет мы обязаны многим людям. Несколько ано-
нимных рецензентов читали черновики этой книги и сделали ценные за-
мечания, за что мы чрезвычайно благодарны. Наш редактор, Алан Апт
(Alan Apt), упорядочил сделанные рецензии, в чем ему весьма помог Джейк
Вард (Jake Warde). Мы благодарим их обоих. Лесли Гален (Leslie Galen),
Джо Альбрехт (Joe Albrecht) и Диана Пэриш (Dianne Parish) из компании
Integra Technical Publishing помогли нам во многих вопросах, связанных
с иллюстрациями и корректурой. Некоторые приведенные в книге изоб-
ражения мы получили из Master Photos Collection IMSI, 1895 Francisco
Blvd. East, San Rafael, CA 94901-5506, USA. Подготавливая библиографию,
мы использовали материал по компьютерному зрению Кейта Прайса (Keith
Price), который можно найти по адресу http://iris.usc.edu/Vision-
Notes/bibliography/contents.html.
Наши коллеги изучали как отдельные главы, так и всю книгу в целом, после
чего вносили ценные и детальные предложения. Мы благодарим Кобуса Барнар-
да (Kobus Barnard), Маргарет Флек (Margaret Fleck), Дэвида Кригмена (David
Предисловие
29
Kriegman), Джайтендру Малик (Jitendra Malik) и Эндрю Циссермана (Andrew
Zisserman). Некоторые наши студенты также вносили предложения, выдвига-
ли идеи по поводу рисунков, давали комментарии по корректуре и выполняли
другую ценную работу. Мы благодарим Окан Арикан (Okan Arikan), Себастья-
на Блайнда (Sebastien Blind), Марту Цепеда (Martha Cepeda), Стефана Ченни
(Stephen Chenney), Френка Чо (Frank Cho), Якапа Генка (Yakup Gene), Джо-
на Гаддона (John Haddon), Сергея Иоффе (Sergey Ioffe), Светлану Лазебник
(Svetlana Lazebnik), Кетти Ли (Cathy Lee), Сунг-иль Пэ (Sung-il Рае), Дэвида
Паркса (David Parks), Фреда Ротгангера (Fred Rothganger), Аттавис Садсенг
(Attawith Sudsang) и слушателей наших курсов по компьютерному зрению при
Калифорнийском университете в Беркли. Многие преподаватели в различных
университетах в своих лекциях по зрению использовали наши (часто необра-
ботанные) черновики этой книги. В число учебных заведений, где студентам
пришлось изучать “сырой” материал, вошли Университет Карнеги-Меллона,
Стэнфордский университет, Университет штата Висконсин в Мэдисоне, Кали-
форнийский университет в Санта-Барбаре, Университет Южной Калифорнии
и другие, о которых мы не знаем. Мы благодарны редакторам за все полез-
ные комментарии, особенно хочется выделить Криса Брэглера (Chris Bregler),
Чака Дайера (Chuck Dyer), Мартиала Хеберта (Martial Hebert), Дэвида Криг-
мена (David Kriegman), Б.С. Маньюнат (B.S. Manjunath) и Рэма Неватья (Ram
Nevatia), которые посылали нам множество подробных и полезных коммента-
риев и исправлений. Книга во многом выиграла благодаря замечаниям Айдин
Алалиоглу (Aydin Alalioglu), Сринивас Акелла (Srinivas Akel la), Мэри Банич
(Marie Banich), Сержа Белонги (Serge Belongie), Аджиит М. Чаудхари (Ajit
М. Chaudhari), Навнит Далал (Navneet Dalal), Ричарда Хартли (Richard Hart-
ley), Глена Хилеи (Glen Healey), Майка Хеса (Mike Heath), Хейли Ибен (Hayley
Iben), Стефани Джонквирес (Stephanie Jonquires), Тони Льюиса (Tony Lewis),
Бенсона Лимкеткай (Benson Limketkai), Симона Маскела (Simon Maskell), Бра-
яна Милха (Brian Milch), Тамары Миллер (Tamara Miller), Корделии Шмид
(Cordelia Schmid), Бриджит (Brigitte) и Джерри Серлин (Gerry Serlin), Ила-
на Шимшони (Ilan Shimshoni), Эрика де Штурлера (Eric de Sturler), Камилло
Дж. Тейлор (Camillo J. Taylor), Джеффа Томпсона (Jeff Thompson), Клер Вал-
лат (Claire Vallat), Даниель С. Вилкерсон (Daniel S. Wilkerson), Джинган Ю
(Jingahn Yu), Хао Жанг (Hao Zhang) и Женджиоу Жанг (Zhengyou Zhang).
Если вы обнаружите опечатку, пожалуйста, сообщите об этом подробно по ад-
ресу daf@cs.berkeley.edu, использовав в сообщении фразу “book typo”;
во втором издании мы попытаемся отблагодарить всех, кто первым обнаружит
каждую опечатку.
Мы благодарим П. Бесл (Р. Besl), Б. Боуфама (В. Boufama), Дж. Костерия
(J. Costeira), П. Дебевека (Р. Debevec), О. Фаугераса (О. Faugeras), Я. Ген-
ка (Y. Gene), М. Хеберта (М. Hebert), Д. Хьюбера (D. Huber), К. Икеучи
(К. Ikeuchi), А. Е. Джонсона (А. Е. Johnson), Т. Кенеда (Т. Kanade), К. Ку-
тулакоса (К. Kutulakos), М. Левоя (М. Levoy), С. Махамуда (S. Mahamud),
Р. Мора (R. Mohr), X. Моравека (Н. Moravec), X. Мураса (Н. Murase), Й. Ох-
30
Предисловие
ту (Y. Ohta), М. Окутами (М. Okutami), М. Поллефейса (М. Pollefeys), X. Са-
йто (Н. Saito), К. Шмида (С. Schmid), С. Салливана (S. Sullivan), К. Томаси
(С. Tomasi), М. Тека (М. Turk) за предоставление оригиналов некоторых ри-
сунков, приведенных в этой книге.
В число самых важных персон из длинного списка тех, кому должен Д.
Форсайт, входят Джеральд Алансвайт (Gerald Alanthwaite), Майк Бреди (Mike
Brady), Том Фейр (Tom Fair), Маргарет Флек (Margaret Fleck), Джайтендра
Малик (Jitendra Malik), Джо Мунди (Joe Mundy), Майк Родд (Mike Rodd),
Чарли Ротвелл (Charlie Rothwell) и Эндрю Циссерман (Andrew Zisserman).
Дж. Понс выражает признательность Оливеру Фаугерасу (Olivier Faugeras),
Майку Бреди (Mike Brady) и Тому Бинфорду (Tom Binford). Он также хотел бы
поблагодарить за помощь Шерон Коллинз (Sharon Collins). Без нее эта книга,
как и большинство его работ, возможно никогда не была бы закончена. Оба
автора также хотели бы отметить огромное влияние работ Жана Коендеринка
(Jan Koenderink).
ВОЗМОЖНЫЕ КУРСЫ ЛЕКЦИЙ
Всю книгу можно изучить за два (довольно насыщенных) семестра. Авторы
предлагают изучить одну главу-приложение (возможно, главу о визуализации
на основе изображений) в первом семестре, а другую — во втором. Стоит отме-
тить, что полный и подробный курс необходим небольшому числу факультетов,
поэтому данная книга построена так, чтобы преподаватель мог выбирать разде-
лы для изучения по своему вкусу. В табл. 2-6 показаны примерные программы
курсов, рассчитанных на 15-недельный семестр, хотя, естественно, преподава-
тели могут перестроить приведенные программы по своему усмотрению.
В табл. 2 предлагается программа односеместрового ознакомительного кур-
са по компьютерному зрению для старшеклассников или первокурсников фа-
культетов компьютерных наук, электротехники или иных технических либо
научных дисциплин. Студенты получат довольно полное представление о ком-
пьютерном зрении, включая такие области его применения, как цифровые биб-
лиотеки и визуализация на основе изображений. Основные моменты геомет-
рии и физики формирования изображений рассмотрены полностью, хотя самый
сложный теоретический материал опущен. Уровень подготовки студентов может
быть очень разным, поэтому на второй или третьей неделе им может понадо-
биться изучение литературы по теории вероятности (с этой целью на web-сайте
данной книги выложена соответствующая глава). Мы предлагаем перенести
главы о прикладном применении на конец семестра, но, возможно, главу 20 сто-
ит пройти приблизительно на десятой неделе обучения, а главу 21 — на шестой.
В табл. 3 представлена программа для студентов факультетов компьютерной
графики, которые желают ознакомиться с вопросами компьютерного зрения,
связанными с их специальностью. Особое внимание уделяется методам, кото-
рые позволяют восстановить модели объектов по информации, содержащейся
в рисунках; чтобы понять освещаемые вопросы, требуются знания о камерах
Предисловие 31
ТАБЛИЦА 2. Односеместровый ознакомительный курс по компьютерному зрению для старше-
классников или первокурсников факультетов компьютерных наук, электротехники или иных техни-
ческих или научных дисциплин
Неделя Глава Разделы Ключевые темы
1 1, 4 1.1, 4 (резюме) камеры-обскуры, радиометрическая терминология
2 5 5.1-5.5 модели локального затенения; точечные, линейные и плоские источники; фотометрическое стерео;
3 6 все цвет
4 7, 8 7.1-7.5, 8.1-8.3 линейные фильтры; сглаживание с целью подавления шумов; определение краев
5 9 все текстура как статистика выходов фильтров; синтез; восстановление формы
6 10, 11 10.1, 11 основы стереометрии; стерео
7 14 все сегментация как вид кластеризации
8 15 15.1-15.4 подбор линий, кривых; подбор как оценка максимального правдоподобия; устойчивость
9 16 16.1,16.2 скрытые значения и ОМ-алгоритм
10 17 все сопровождение с помощью фильтра Кальмана; ассоциация данных
11 2, 3 2.1, 2.2, все из 3 калибровка камер
12 18 все зрение на основе модели с использованием соответствий и калибровки камер
13 22 все сопоставление с шаблоном с помощью классификаторов
14 23 все сопоставление по связям
15 25, 26 все поиск изображений в цифровых библиотеках; визуализация на основе изображений
и фильтрах, поэтому в программу включены соответствующие главы и разделы.
Одним из важных вопросов в современном мире графики стало сопровожде-
ние движущихся объектов, описание которого также включено в предлагаемый
курс. Мы допускаем, что у студентов может быть разный уровень подготовки,
поэтому в книге приводятся некоторые базовые знания из теории вероятности.
В табл. 4 приведена программа для студентов, которые интересуются в ос-
новном применением компьютерного зрения. Здесь выделена информация, ко-
торая представляет непосредственный практический интерес. Для некоторых
студентов на второй или третьей неделе может понадобиться чтение дополни-
тельной литературы по теории вероятности.
В табл. 5 предложена программа для студентов, изучающих познание или
искусственный интеллект и желающих получить представление об основных
32
Предисловие
ТАБЛИЦА 3. Курс для студентов, изучающих компьютерную графику
Неделя Глава Разделы Ключевые темы
1 1, 4 1.1, 4 (резюме) камеры-обскуры, радиометрическая терминология
2 5 5.1-5.5 модели локального затенения; точечные, линейные и плоские источники; фотометрическое стерео
3 6.1-6.4 все цвет
4 7, 8 7.1-7.5, 8.1-8.3 линейные фильтры; сглаживание с целью подавления шумов; определение краев
5 9 9.1-9.3 текстура как статистика выходов фильтров; синтез
6 2, 3 2.1, 2.2, все из 3 калибровка камер
7 10, 11 10.1, 11 основы стереометрии; стерео
8 12 все аффинная структура по движению
9 13 все проективная структура по движению
10 26 все визуализация на основе изображений
11 15 все подбор; устойчивость; алгоритм RANSAC
12 16 все скрытые значения и ОМ-алгоритм
13 19 все поверхности и контуры
14 21 все дистанционные данные
15 17 все сопровождение, фильтры Кальмана и ассоциация данных
понятиях компьютерного зрения. Эта программа менее нагружена, чем преды-
дущие, и она допускает более слабый уровень математической подготовки. При-
мерно на 2-3 неделе обучения студентам придется немного почитать о вероят-
ности (например, главу на web-сайте книги).
В табл. 6 показана программа для студентов факультетов прикладной мате-
матики, электротехники или физики. Эта программа предполагает весьма за-
груженный семестр; некоторые вопросы рассматриваются обзорно (считается,
что студенты могут самостоятельно обработать значительный объем математи-
ческих выкладок). В зависимости от уровня подготовки, некоторым студентам
на второй или третьей неделе может понадобиться литература по теории ве-
роятности. Для организации небольшого перерыва в довольно сухой и слож-
ной программе мы предлагаем рассмотреть цифровые библиотеки; вместо этого
можно также изучить главу по визуализации на основе изображений, или по
дистанционным данным.
ОБОЗНАЧЕНИЯ
В книге использованы следующие обозначения: точки, прямые и плоско-
сти обозначаются греческими или курсивными латинскими буквами (напри-
мер, Р, Д или П). Векторы обычно обозначаются латинскими или греческими
Предисловие
33
ТАБЛИЦА 4. Курс для студентов, интересующихся применением компьютерного зрения
Педеля Глава Разделы Ключевые темы
I I, 4 1.1, 4 (резюме) камеры-обскуры, радиометрическая терминология
2 5, 6 5.1.5.3-5.5, 6.1—6.4 модели локального затенения; точечные, линейные и плоские источники; фотометрическое стерео; цвет: физика, человеческое восприятие, цветовые пространства
3 2, 3 все модели камер и калибровка камер
4 7, 9 все из 7; 9.1-9.3 линейные фильтры; текстура: как статистика выходов фильтров; синтез текстуры
5 10, 11 все стереометрия
6 12,13 все аффинная структура по движению; проективная структура по движению
7 13, 26 все проективная структура по движению; визуализация на основе изображений
8 14 все сегментация с помощью кластеризации; определение границ и вычитание фона
9 15 все подбор линий, кривых; устойчивость; алгоритм RANSAC
10 16 все скрытые значения и ОМ-алгоритм
И 25 все поиск изображений в цифровых библиотеках
12 17 все сопровождение, фильтры Кальмана и ассоциация данных
13 18 все зрение на основе моделей
14 22 все поиск шаблонов с помощью классификаторов
15 20 все дистанционные данные
полужирными буквами (например, v, Р или £), но вектор, соединяющий две
точки Риф, часто будет обозначаться как PQ. Строчные буквы обычно упо-
требляются для обозначения геометрических фигур на плоскости изображений
(например, р, р, 3), а прописные — для объектов сцены (например, Р, П).
Матрицы обозначаются рукописными латинскими буквами (например, И).
Привычное трехмерное евклидово пространство будет обозначаться как Е3,
векторное пространство, образованное наборами из п действительных чисел,
которые подчиняются обычным законам сложения и умножения на скаляр,
обозначается как Rn, а для обозначения нулевого вектора в таких простран-
ствах обычно употребляется запись 0. Подобным образом, векторное простран-
ство, образованное действительными матрицами mxn, обозначается как RTnxn.
При т = п (квадратная матрица) символом Id обозначается единичная матри-
ца, т.е. матрица п х п, диагональные элементы которой равны 1, а все осталь-
34
Предисловие
ТАБЛИЦА 5. Курс для студентов, изучающих познание или искусственный интеллект
Неделя Глава Разделы Ключевые темы
1 1, 4 1, 4 (резюме) камеры-обскуры; линзы; камеры и глаз; радиометрическая терминология
2 5 все модели локального затенения; точечные, линейные и плоские источники; фотометрическое стерео; взаимное отражение; определение яркости
3 6 все цвет: физика, человеческое восприятие, цветовые пространства; постоянство цвета
4 7 7.1-7.5, 7.7 линейные фильтры; выборка; масштаб
5 8 все определение краев
6 9 все текстура; представление; синтез; восстановление формы
7 10.1,10.2 все основы стереометрии
8 И все стереозрение
9 14 все сегментация с помощью кластеризации
10 15 все подбор линий, кривых; устойчивость; алгоритм RANSAC
11 16 все скрытые значения и ОМ-алгоритм
12 18 все зрение на основе модели
13 22 все поиск шаблонов с помощью классификаторов
14 23 все распознавание по связям между шаблонами
15 24 все геометрические шаблоны по пространственным отношениям
ные — 0. Транспонированная матрица матрицы U размера т х п с коэффици-
ентами Uij — это матрица UT, имеющая размер п х т и коэффициенты Uji.
Элементы пространства R” часто отождествляются с векторами-столбцами или
матрицами п х 1, например, а = {ai,a2,as)T — это транспонированная матри-
ца 1 х 3 {вектор-строка), т.е. матрица 3x1 {вектор-столбец), или элемент
пространства К3.
Скалярное (или внутреннее) произведение двух векторов а = (гц,... ,ап)Т
кЬ = (i>i,..., Ьп)т в пространстве Кп определяется следующим образом:
а • Ь = dibi + • • + a,nbn.
Его также можно записать в виде произведения двух матриц, т.е. а-Ь = атЬ =
= Ьта. Под |а|2 = а-а мы подразумеваем квадрат евклидовой нормы вектора а,
а под d — расстояние, следующее из определения Евклидовой нормы вектора
в пространстве Еп, т.е. d{P,Q) — |FQ|. Для матрицы U в пространстве R7nxn
через |С7| обычно будет обозначаться ее фробениусова норма, т.е. корень квад-
ратный из суммы квадратов ее элементов.
Предисловие
35
ТАБЛИЦА 6. Программа для студентов факультетов прикладной математики, электротехники или
физики
Неделя Глава Разделы Ключевые темы
1 1, 4 все камеры, радиометрия
2 5 все модели локального затенения; точечные, линейные и плоские источники; фотометрическое стерео; взаимное отражение и примитивы затенения
3 6 все цвет: физика, человеческое восприятие, цветовые пространства, постоянство цвета
4 2, 3 все параметры и калибровка камер
5 7, 8 все линейные фильтры и определение краев
6 8, 9 все определение краев (окончание); текстура: представление, синтез, восстановление формы
7 10, 11 все стереометрия
8 12, 13 все структура по движению
9 14, 15 все сегментация с помощью кластеризации; подбор линий, кривых; устойчивость; алгоритм RANSAC
10 15, 16 все подбор (окончание); скрытые значения и ОМ-алгоритм
11 17, 25 все сопровождение; фильтры Кальмана, ассоциация данных; поиск изображений в цифровых библиотеках
12 18 все зрение на основе модели
13 19 все поверхности и их контуры
14 20 все аспектные графы
15 22 все сравнение с шаблоном
Если норма вектора а равна единице, то скалярное произведение а-b равно
длине (с соответствующим знаком) проекции b на а. В общем случае
а • b = |а| |fe| cos#,
где в — угол между двумя векторами. Из приведенного определения следу-
ет, что необходимым и достаточным условием ортогональности двух векторов
является равенство нулю их скалярного произведения.
Векторное (или внешнее) произведение двух векторов а = (01,02, оз)г
и b = (di,Ь2,Ьз)Т в пространстве К3 — это вектор
(O2&3 ~ 03^2
азЬг — сцЬз
СЦ#2 — 02^1
36
Предисловие
Отметим, что а х Ъ — [ах]Ь, где
Векторное произведение двух векторов а и b в R3 ортогонально к этим двум
векторам, а необходимым и достаточным условием коллинеарности а и Ь яв-
ляется равенство нулю векторного произведения а х b = 0. Если угол между
векторами а и Ъ снова обозначить 0, то можно показать, что
|а х Ь| = |а| |b| |sin0|.
УПРАЖНЕНИЯ И РЕСУРСЫ
Для выполнения упражнений, предлагаемых на протяжении всей книги,
иногда могут понадобиться стандартные программы для численных расчетов
по линейной алгебре, разложения сингулярных значений, а также линейных
и нелинейных вычислений по методу наименьших квадратов. Значительное
число таких средств предлагается в пакете MATLAB, а также в свободно рас-
пространяемых библиотеках, таких как LINPACK, LAPACK и MINPACK, кото-
рые можно загрузить из архива Netlib (http://itfww.netlib.org/). На web-
сайте книги http://www.cs.berkeley.edu/~daf/book.html предлага-
ются ссылки и на другие программы. По этому адресу также можно найти
массивы данных (или ссылки на массивы) для заданий по программированию.
----------- ЧАСТЬ I -----------
Формирование изображений и модели
изображений
1
Камеры
Существует множество устройств формирования изображения: от глаз живот-
ных до видеокамер и радиотелескопов. Не все эти устройства могут содержать
линзы. Например, у первой модели камеры-обскуры (что буквально означает
“темная комната”), изобретенной в XVI веке, линз не было, вместо них исполь-
зовалось отверстие, которое позволяло лучам света фокусироваться на стенке
или полупрозрачной пластинке и таким образом демонстрировать законы пер-
спективы, которые за сто лет до этого открыл Брунеллеччи (Brunelleschi). Уже
в 1550 году отверстия стали заменять все более и более усложняющимися лин-
зами, а современная цифровая или фотокамера — это, по сути, камера-обскура,
способная регистрировать количество света, которое попадает на каждый ма-
ленький участок ее задней панели (рис. 1.1).
Поверхность камеры, на которой формируется изображение, обычно пред-
ставляет собой прямоугольник, а форма человеческой сетчатки намного ближе
к сферической поверхности, поэтому панорамные фотоаппараты могут обору-
доваться цилиндрическими чувствительными поверхностями. Помимо формы,
датчики изображения имеют и другие характеристики. Они могут фиксировать
изображение, дискретное в пространстве (как, например, в человеческом глазе
с палочками и колбочками, 35-миллиметровых камерах с эмульсионными зер-
нами и цифровых камерах с прямоугольными элементами изображений, или
40
Часть I. Формирование изображений и модели изображений
Рис. 1.1. Формирование изображения на задней панели фотокамеры. Рисунок из учебника “US
NAVY MANUAL OF BASIC OPTICS AND OPTICAL INSTRUMENTS", подготовленного Коми-
тетом no управлению военно-морским персоналом США, перепечатан корпорацией. Dover
Publications (1969)
пикселями) или непрерывное (как, например, в старых телевизионных труб-
ках). Сигнал, фиксируемый датчиком изображения в определенной точке своей
чувствительной поверхности, может быть дискретным или непрерывным и со-
стоять из одного числа (черно-белая камера), нескольких значений (например,
интенсивности красного, зеленого и синего цветов для цветной камеры или
реакции трех типов колбочек для человеческого глаза), большого набора чи-
сел (например, реакции гиперспектральных сенсоров) или даже непрерывной
функции длины волны (спектрометры). Изучению перечисленных выше харак-
теристик и посвящена данная глава.
1.1. КАМЕРЫ-ОБСКУРЫ
1.1.1. Перспективная проекция
Возьмем коробку, в одной из ее стенок сделаем булавкой маленькое отвер-
стие, а затем заменим противоположную стенку полупрозрачной пластинкой.
Если держать эту коробку перед собой в комнате со слабым освещением так,
чтобы отверстие было направлено на какой-то источник света (скажем, свечу),
то на полупрозрачной пластинке можно увидеть перевернутое изображение све-
чи (рис. 1.2). Это изображение образуют лучи света, идущие от сцены, находя-
щейся перед коробкой. Если отверстие уменьшить до точки (что, конечно же,
физически невозможно), то через плоскость пластинки (или плоскость изобра-
жения), отверстие и некоторую точку сцены будет проходить ровно один луч.
В действительности, отверстие имеет конечный (хотя и небольшой) размер,
и в каждой точке плоскости изображения собирается свет от целого конуса лу-
Глава 1. Камеры
41
Плоскость
изображения
Рис. 1.2. Модель формирования изображения через отверстие
чей, образующих определенный телесный угол, так что эта идеализированная
и чрезвычайно упрощенная геометрическая модель формирования изображения
не совсем строго описывает действительность. Кроме того, настоящие каме-
ры обычно оснащены линзами, что также весьма усложняет ситуацию. Тем не
менее, модель точечной перспективы (ее еще называют центральной перспек-
тивой), впервые предложенная Брунеллеччи в начале XV века, удобна с ма-
тематической точки зрения. Несмотря на свою простоту, она часто является
приемлемым приближенным описанием процесса формирования изображения.
В результате перспективной проекции возникает перевернутое изображение,
поэтому иногда вместо него удобно рассматривать мнимое изображение, рас-
положенное в плоскости, лежащей перед отверстием на таком же расстоянии,
как и реальная плоскость изображения (рис. 1.2). Это мнимое изображение не
перевернуто, но во всем остальном оно точно соответствует настоящему. В за-
висимости от ситуации, удобнее может быть одно или другое. На рис. 1.3, а по-
казан очевидный эффект перспективной проекции: относительный размер объ-
ектов зависит от расстояния до них. Например, изображения В' и С столбиков
В и С кажутся одинаковыми по высоте, а в действительности столбики А и С
в два раза меньше, чем В. На рис. 1.3, б иллюстрируется еще один общеиз-
вестный эффект: проекции двух параллельных прямых, лежащих в некоторой
плоскости П, сходятся на горизонтальной линии Н, образованной пересечени-
ем плоскости изображения с плоскостью, параллельной П и проходящей через
отверстие. Заметим, что прямая L на плоскости П, параллельная плоскости
изображения, вообще не дает никакого изображения.
Названные свойства легко доказать чисто геометрически. В то же время,
часто бывает удобно (кроме того, элегантно) оперировать такими понятиями,
как система отсчета, координаты и уравнения. Рассмотрим, например, систе-
му координат (О, связанную с камерой-обскурой, начало координат О
которой совпадает с отверстием, а векторы i и j образуют базис векторной
плоскости, параллельной к плоскости изображения П', которая находится на
расстоянии f от отверстия в положительном направлении вектора к (рис. 1.4).
Прямая, проходящая через отверстие и перпендикулярная к П', называется оп-
42
Часть I. Формирование изображений и модели изображений
Рис. 1.3. Эффекты перспективы: а) объекты, которые находятся дальше, кажутся меньшими, чем
те, которые находятся ближе: расстояние d от отверстия О до плоскости, в которой лежит точка С,
в два раза меньше, чем расстояние до плоскости, в которой лежат точки А и В; б) изображения
параллельных прямых пересекаются на горизонтальной линии ([Hilbert and Cohn-Vossen, 1952],
fig. 127). Заметим, что в случае а плоскость изображения находится за отверстием (физическая
сетчатка), а в случае б — перед ним (мнимая плоскость изображения). На большинстве схем
в этой главе и далее в книге фигурирует именно физическая плоскость изображения, хотя при
необходимости будут использованы и мнимые изображения
тической осью, а точка С, в которой она пересекается с П', называется цен-
тром изображения. Эту точку можно использовать в качестве начала системы
координат, связанной с плоскостью изображения, и она играет важную роль
в процедурах калибровки камер.
Обозначим через Р точку сцены с координатами (х, у, z), а через Р* — ее
изображение с координатами z'). Так как Р' лежит в плоскости изобра-
жения, то z' = f. Поскольку три точки Р, О и Р' лежат на одной прямой, то
О?1 = ХОР для некоторого числа А. Отсюда следует, что
Глава 1. Камеры
43
Рис. 1.4. Для вывода уравнений перспективной проекции в этом разделе использован тот факт,
что точка Р, ее изображение Р' и отверстие О лежат на одной прямой
х = Хх
< у' =
/' = Az
следовательно,
(1.1)
1.1.2. Аффинная проекция
Как было сказано в предыдущем разделе, точечная перспективная проекция
только приблизительно описывает геометрию процесса построения изображе-
ния. В этом разделе представлен ряд грубых приближений, называемых аф-
финными проекционными моделями, которые иногда также могут оказаться
полезными. Рассмотрим две аффинные модели: слабоперспективную и орто-
гональную. Третья модель из семейства аффинных, параперспективная, пред-
ставлена в главе 12.
Фронтально-параллельная плоскость По определяется уравнением z = z0
(рис. 1.5). Для любой точки Р на По уравнение перспективной проекции (1.1)
можно переписать как
х' = —тх
У1 = — -ту
Г
т =-----.
zo
(1-2)
44
Часть I. Формирование изображений и модели изображений
Рис. 1.5. Слабоперспективная проекция: все линейные элементы на плоскости По проектируются
с одинаковым увеличением
По физическим соображениям zq должно быть отрицательным (плоскость
должна находиться перед отверстием), так что коэффициент увеличения т,
связанный с плоскостью По, больше нуля. Название параметра объясняется
следующими соображениями: рассмотрим две точки Р и Q на плоскости По
и их изображения Р' и Q' (рис. 1.5); очевидно, что векторы PQ и P'Q' парал-
лельны, поэтому IF'Q'I = m|PQ|. Это выражение и представляет зависимость
размера изображения от расстояния до объекта, о которой упоминалось ранее.
Когда глубина сцены мала по сравнению со средним расстоянием до камеры,
увеличение можно считать постоянным. Эта проекционная модель называется
слабой проекцией, или масштабной ортографией. Если заранее известно, что
камера постоянно остается на приблизительно одинаковом расстоянии от сцены,
можно нормировать координаты изображения таким образом, чтобы т = — 1.
Это будет уже ортогональная проекция, которая определяется как
Причем все лучи света параллельны оси к и перпендикулярны плоскости изоб-
ражения П' (рис. 1.6). Хотя слабоперспективная модель приемлема при описа-
нии многих процессов формирования изображения, применение чистой ортого-
нальной проекции обычно дает нереалистичные результаты.
1.2. КАМЕРЫ С ЛИНЗАМИ
Большинство камер оснащены линзами. Можно назвать две основные при-
чины такого технического решения. Первая — аккумуляция света, так как оди-
ночный световой луч сможет достичь каждой точки на плоскости изображения
Глава 1. Камеры
45
Рис. 1.6. Ортогональная проекция. В отличие от других геометрических моделей процесса форми-
рования изображения, при ортогональном проектировании элементы изображения не переворачи-
ваются. Соответственно, увеличение берется отрицательным, что немного неестественно, но зато
упрощает проекционные уравнения
Рис. 1.7. Отражение и преломление света на границе двух однородных сред с показателями пре-
ломления П1 И 712
только при идеальной точечной проекции. У реальных отверстий, конечно, есть
определенный размер, так что каждая точка на плоскости изображения освеща-
ется конусом световых лучей, образующих определенный телесный угол. Чем
больше отверстие, тем шире конус и ярче изображение, но большие отверстия
дают расплывчатое изображение. Сокращение размера отверстия повышает чет-
кость изображения, но уменьшает количество света, который попадает на плос-
кость изображения, следствием чего могут быть эффекты дифракции. Вторая
основная причина использования линз — это удержание изображения строго
в фокусе при сборе света с большой площади.
Если не принимать во внимание дифракцию, интерференцию и другие фи-
зические явления, то поведение линз подчиняется законам геометрической оп-
тики (рис. 1.7): 1) в однородной среде свет распространяется по прямой линии
(луч); 2) при отражении луча от поверхности падающий луч, отраженный луч
и нормаль к отражающей поверхности лежат в одной плоскости, а сумма углов
46
Часть I. Формирование изображений и модели изображений
между нормалью и двумя лучами равна 90°; 3) при переходе луча из одной сре-
ды в другую происходит его преломление (т.е. луч изменяет свое направление).
Согласно закону Снелла (Snell’s law), если ri — луч, падающий на границу раз-
дела двух прозрачных сред с показателями преломления и П2, а т2 - отра-
женный луч, то ri, г2 и нормаль к поверхности отражения лежат в одной плос-
кости, а углы di и а2 между нормалью и двумя лучами связаны соотношением
тц sin«i = П2 sin 02- (1.4)
В этой главе эффекты отражения не рассматриваются, мы рассмотрим только
преломление. Другими словами, мы сконцентрируем наше внимание на линзах,
которые отличаются от используемых в оптических системах с зеркаль-
ными линзами, или катадиоптрических системах (например, телескопах-
рефлекторах), в которые входят как отражающие (зеркала), так и преломля-
ющие элементы. Проследить за ходом лучей света через линзу проще, если
углы между этими лучами и преломляющими поверхностями линз считаются
небольшими. В следующем разделе описан именно такой случай.
1.2.1. Параксиальная геометрическая оптика
В этом разделе рассмотрена параксиальная геометрическая оптика (или оп-
тика первого порядка), где углы между всеми лучами, проходящими через
линзу, и нормалью к преломляющей поверхности малы. Кроме того, мы пред-
полагаем, что линзы обладают аксиальной симметрией относительно прямой,
называемой оптической осью, и что все преломляющие поверхности сфериче-
ские. Такая симметрия позволяет определить геометрию проекции, если рас-
сматривать линзы с круглыми краями, лежащие в плоскости, которая содержит
оптическую ось.
Пусть луч света проходит через точку Pi на оптической оси и преломляется
в точке Р сферической поверхности радиуса R, разделяющей две прозрачные
среды с показателями преломления п\ и п2 (рис. 1.8). Обозначим через Р2
точку, в которой преломленный луч пересекает оптическую ось во второй раз
(точки Pi и Р2 полностью симметричны), а через С — центр сферической
поверхности.
Пусть через ац и а2 обозначены, соответственно, углы между двумя лу-
чами и прямой, соединяющей точки Р и С. Если /31 (соответственно, /32) —
угол между оптической осью и прямой, соединяющей точку Pi (соответственно,
точку Р2) с точкой Р, то угол между оптической осью и прямой, соединяющей
точки Р и С (см. рис. 1.8), равен 7 = ai —/?1 = а2+/3г. Обозначим теперь через
h расстояние от точки Р до оптической оси, а через R — радиус сферической
поверхности. Если считать, что все углы малы и в первом приближении равны
своим синусам и тангенсам, получим
/1 i\ /1 1 \
«1 = 7 + Pi ~ h | —I-1 и а2=7 — /?2 « М--------I •
\Rdij \R di I
Глава 1. Камеры
47
Рис. 1.8. Параксиальное преломление: луч света, проходящий через точку Pi, преломляется в точке
его пересечения со сферической поверхностью, Р. Преломленный луч пересекается с оптической
осью в точке Р2. Центр сферической поверхности находится в точке С оптической оси, а ее
радиус — R. Предполагается, что углы сц, (31,а2 и малы
Если записать закон Снелла для малых углов, получим уравнение параксиаль-
ного преломления:
П1 712 П2 — 711
71101 ~ 7Z2O2 ---1---— ------- (1.5)
dl с?2 R
Заметим, что отношение di к d2 зависит от R, п* и п2, но не от 61 или Ь2. Это
главное упрощение, которое дает параксиальное приближение. Уравнение (1.5)
справедливо и тогда, когда некоторые (или все) величины di, d2 и R становятся
отрицательными, что соответствует расположению точек Pi, Р2 и С по другую
сторону оптического центра.
Разумеется, настоящие линзы имеют, по меньшей мере, две преломляю-
щих поверхности. Соответствующие пути прохождения лучей можно построить,
несколько раз применяя уравнение параксиального преломления. В следующем
разделе это выполнено для тонкой линзы.
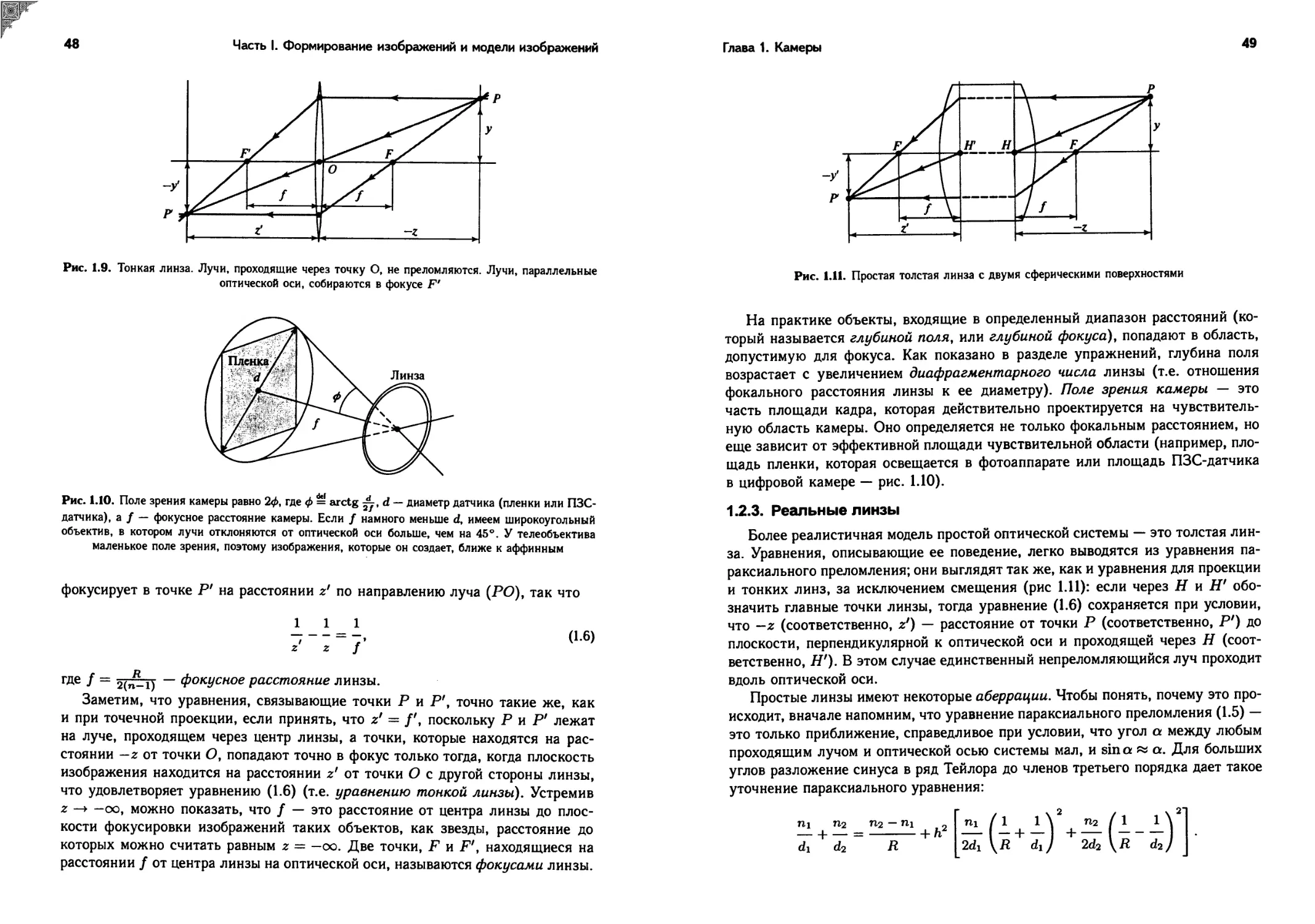
1.2.2. Тонкие линзы
Рассмотрим линзу с двумя сферическими поверхностями радиуса R с пока-
зателем преломления п. Допустим, что линза находится в вакууме (или, для
более точного приближения, в воздухе), показатель преломления которого ра-
вен 1, и что эта линза тонкая (т.е. луч, попадая на линзу и преломляясь на ее
правой грани, немедленно снова преломляется на ее левой грани).
Рассмотрим точку р, расположенную на расстоянии z (в отрицательном на-
правлении оси отсчета) от оптической оси, и обозначим через (РО) луч, про-
ходящий через эту точку и центр О линзы (рис. 1.9). Как показано в разделе
упражнений, из закона Снелла и уравнения (1.5) следует, что луч (РО) не пре-
ломляется и что все остальные лучи, проходящие через точку Р, тонкая линза
48
Часть I. Формирование изображений и модели изображений
Рис, 1.9. Тонкая линза. Лучи, проходящие через точку О, не преломляются. Лучи, параллельные
оптической оси, собираются в фокусе F*
Рис. 1.10. Поле зрения камеры равно 2ф, где ф = arctg d — диаметр датчика (пленки или ПЗС-
датчика), a f — фокусное расстояние камеры. Если f намного меньше d, имеем широкоугольный
объектив, в котором лучи отклоняются от оптической оси больше, чем на 45°. У телеобъектива
маленькое поле зрения, поэтому изображения, которые он создает, ближе к аффинным
фокусирует в точке Р' на расстоянии z' по направлению луча (РО), так что
1 1 1
z z f
(1.6)
где f = ~ ФокУсное расстояние линзы.
Заметим, что уравнения, связывающие точки Р и Р', точно такие же, как
и при точечной проекции, если принять, что z' = поскольку Р и Р' лежат
на луче, проходящем через центр линзы, а точки, которые находятся на рас-
стоянии —z от точки О, попадают точно в фокус только тогда, когда плоскость
изображения находится на расстоянии z' от точки О с другой стороны линзы,
что удовлетворяет уравнению (1.6) (т.е. уравнению тонкой линзы). Устремив
z —> —оо, можно показать, что f — это расстояние от центра линзы до плос-
кости фокусировки изображений таких объектов, как звезды, расстояние до
которых можно считать равным z — —оо. Две точки, F и F', находящиеся на
расстоянии f от центра линзы на оптической оси, называются фокусами линзы.
Глава 1. Камеры
49
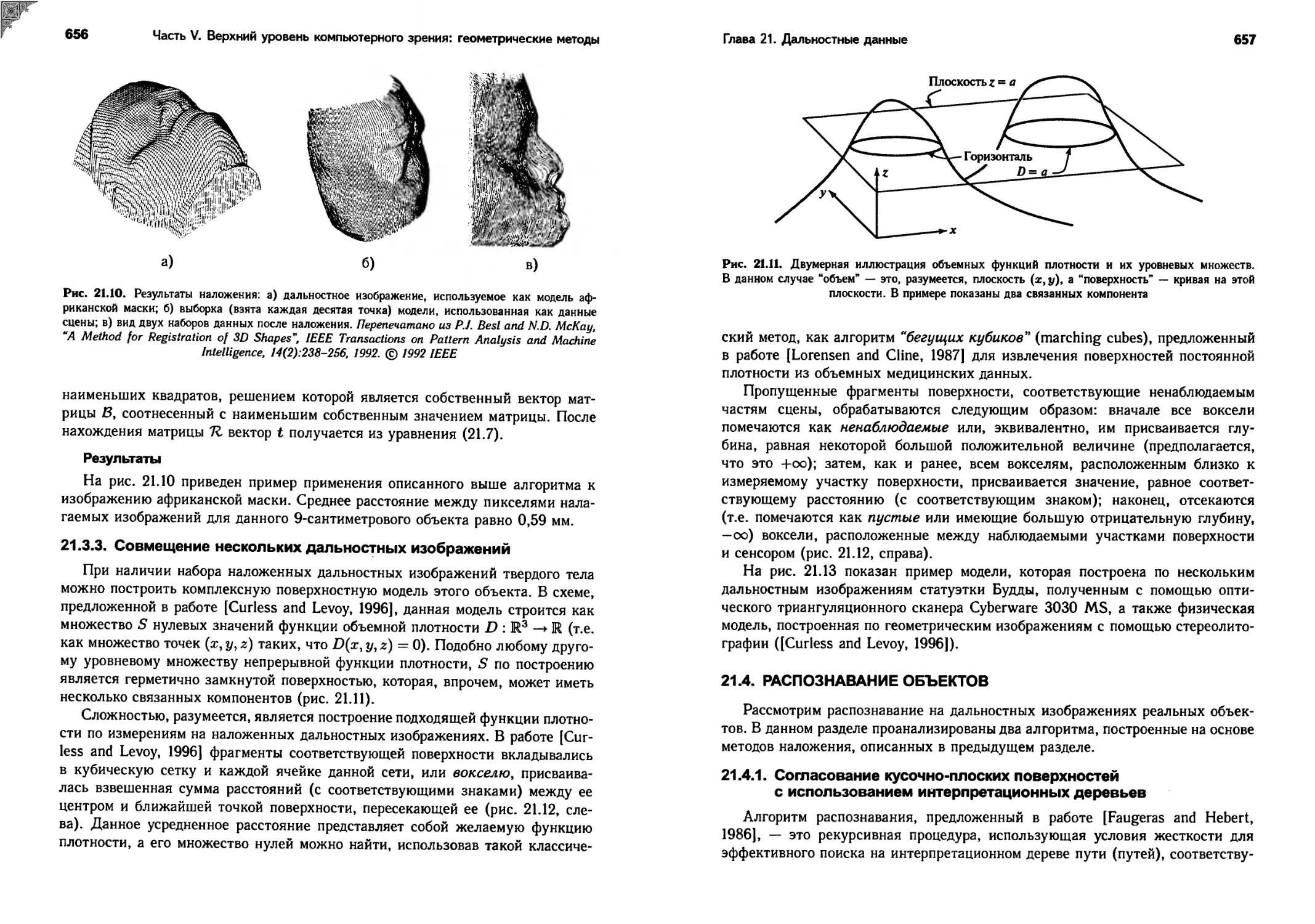
Рис. 1.11. Простая толстая линза с двумя сферическими поверхностями
На практике объекты, входящие в определенный диапазон расстояний (ко-
торый называется глубиной поля, или глубиной фокуса), попадают в область,
допустимую для фокуса. Как показано в разделе упражнений, глубина поля
возрастает с увеличением диафрагментарного числа линзы (т.е. отношения
фокального расстояния линзы к ее диаметру). Поле зрения камеры — это
часть площади кадра, которая действительно проектируется на чувствитель-
ную область камеры. Оно определяется не только фокальным расстоянием, но
еще зависит от эффективной площади чувствительной области (например, пло-
щадь пленки, которая освещается в фотоаппарате или площадь ПЗС-датчика
в цифровой камере — рис. 1.10).
1.2.3. Реальные линзы
Более реалистичная модель простой оптической системы — это толстая лин-
за. Уравнения, описывающие ее поведение, легко выводятся из уравнения па-
раксиального преломления; они выглядят так же, как и уравнения для проекции
и тонких линз, за исключением смещения (рис 1.11): если через Н и Н' обо-
значить главные точки линзы, тогда уравнение (1.6) сохраняется при условии,
что —z (соответственно, z') — расстояние от точки Р (соответственно, Р') до
плоскости, перпендикулярной к оптической оси и проходящей через Н (соот-
ветственно, Н'). В этом случае единственный непреломляющийся луч проходит
вдоль оптической оси.
Простые линзы имеют некоторые аберрации. Чтобы понять, почему это про-
исходит, вначале напомним, что уравнение параксиального преломления (1.5) —
это только приближение, справедливое при условии, что угол а между любым
проходящим лучом и оптической осью системы мал, и sin а « а. Для больших
углов разложение синуса в ряд Тейлора до членов третьего порядка дает такое
уточнение параксиального уравнения:
П1 П2 П2 — П1
— + — =-------------+ h2
di d2 R
2,d2 \R d2
50
Часть I. Формирование изображений и модели изображений
Здесь через h обозначено (как и на рис. 1.8) расстояние от оптической оси до
точки, в которой падающий луч пересекается с границей раздела. В частно-
сти, лучи, которые попадают на границу раздела дальше от оптической оси,
фокусируются ближе к границе раздела.
Тот же эффект имеет место и для линз, он является причиной двух типов
сферических аберраций (рис. 1.12, а). Рассмотрим точку Р на оптической оси
и ее параксиальное изображение Р'. Расстояние от точки Р' до точки пересече-
ния оптической оси с лучом, выходящим из точки Р и преломляемым линзой,
называется продольной сферической аберрацией этого луча. Заметим, что ес-
ли плоскость изображения П' поставить в точку Р, то луч пересекал бы эту
плоскость на некотором расстоянии от оси, что называется поперечной сфери-
ческой аберрацией луча. Все лучи, проходящие через точку Р и преломляемые
линзой, при пересечении с плоскостью П' образуют пятно рассеяния с центром
в точке Р. Размер этого пятна будет меняться, если двигать П' вдоль опти-
ческой оси. Пятно минимального размера называется пятном наименьшего
рассеяния, и (в общем случае) оно не находится в точке П'.
Кроме сферической аберрации, существует еще четыре других типа первич-
ных аберраций, вызванных отличием оптических явлений первого и третьего
порядка, а именно: кома, астигматизм, кривизна поля изображения и дис-
торсия. Точное определение этих аберраций в данной книге мы приводить не
будем. Достаточно сказать, что подобно сферическим аберрациям, они ухудша-
ют изображение, делая расплывчатой каждую точку объекта. Искажение дает
несколько иной эффект, изменяя форму изображения в целом (рис. 1.12, б).
Это вызвано тем, что в различных частях линзы фокусное расстояние немного
меняется. Все упоминавшиеся ранее аберрации монохроматичны (т.е. они не
зависят от преломления линзой волн различной длины). В то же время, пока-
затель преломления прозрачной среды зависит от длины волны (рис. 1.12, в);
из уравнения тонкой линзы (1.6) следует, что фокусное расстояние также за-
висит от длины волны. Таким образом, возникает явление хроматической
аберрации: преломленные лучи разной длины волны пересекают оптическую
ось в разных точках (продольная хроматическая аберрация) и образуют раз-
ные пятна рассеяния на одной и той же плоскости изображения (поперечная
хроматическая аберрация).
Аберрации можно свести к минимуму, сочетая несколько простых линз с хо-
рошо подобранными формой и показателями преломления, разделенных соот-
ветствующими промежутками. Такие составные линзы можно точно так же
смоделировать с помощью уравнений толстой линзы. Впрочем, у них есть еще
один недостаток, важный в контексте компьютерного зрения: пучок света, исхо-
дящий от точек объекта, которые находятся не на оси, частично перекрывается
различными диафрагмами (включая отдельные компоненты линзы), находящи-
мися внутри линзы для ограничения аберраций (рис. 1.13). Это явление, кото-
рое называют виньетированием, приводит к снижению яркости на периферии
изображения. Виньетирование может создавать проблемы для программ авто-
матического анализа изображения, но оно не настолько важно в фотографии
Глава 1. Камеры
51
Рис. 1.12. Аберрации; а) сферическая аберрация: область серого цвета — параксиальная зона, где
лучи, выходящие из точки Р, пересекаются в ее параксиальном изображении Р'. Если поставить
плоскость изображения ГГ в точку Р, то изображение Р* точки в этой плоскости будет выглядеть
как пятно рассеяния диаметром d'. Фокальная плоскость, которая дает пятно наименьшего рас-
сеяния, обозначена пунктирной линией; 6) искажение. Слева направо: номинальное изображение
прямо-параллельного квадрата, подушкообразное искажение и бочкообразное искажение; в) хро-
матическая аберрация: показатель преломления прозрачной среды зависит от длины волны (или
цвета) падающих лучей. Здесь белый свет, проходя через призму, распадается на спектр цветов.
Рисунок из руководства US NAVY MANUAL OF BASIC OPTICS AND OPTICAL INSTRUMENTS,
подготовленного Комитетом no управлению военно-морским персоналом США, перепечатан-
ный корпорацией Dover Publications, (1969)
52
Часть I. Формирование изображений и модели изображений
Рис. 1.13. Эффект виньетирования в системе, состоящей из двух линз. Затененная часть пуч-
ка никогда не попадет на вторую линзу. Дополнительные диафрагмы и промежутки еще больше
усиливают виньетирование
благодаря замечательной способности человеческого глаза сглаживать гради-
ент яркости. Пожалуй, если уж мы заговорили о человеческом глазе, стоит
рассмотреть его подробнее.
1.3. ЧЕЛОВЕЧЕСКИЙ ГЛАЗ
Ниже предлагается краткий обзор анатомического строения человеческого
глаза (по большей части он основан на представлении Ванделла [Wandell,
1995]). На рис. 1.14 (слева) изображено глазное яблоко в разрезе по его вер-
тикальной плоскости симметрии и показаны главные части глаза: радужная
оболочка и зрачок, контролирующие количество света, который проникает
в глазное яблоко; роговица и хрусталик, на которых преломляется свет для
создания изображения на сетчатке; и, наконец, собственно сетчатка, где
образуется изображение.
Несмотря на свою шарообразную форму, человеческое глазное яблоко по
функциональным возможностям напоминает камеру с полем зрения 160° по ши-
рине и 135° по высоте. Как и любая другая оптическая система, глаз подвержен
различным видам геометрических и хроматических аберраций. Было предло-
жено несколько моделей глаза, которые описываются законами геометрической
оптики первого порядка. На рис. 1.14 (справа) показана, например, схемати-
ческая модель глаза по Гельмольцу. Здесь имеется только три преломляю-
щих поверхности с бесконечно тонкой роговицей и однородным хрусталиком.
На рис. 1.14 изображен глаз, сфокусированный на бесконечности (несфокуси-
рованный взгляд). Разумеется, данная модель позволяет лишь приближенно
описать реальные оптические характеристики глаза
Обратимся еще раз к составляющим частям глаза: роговица — это прозрач-
ное, сильно изогнутое, преломляющее свет окно, через которое свет попадает
в глаз до того, как он частично перекрывается цветной и непрозрачной поверх-
ностью радужной оболочки. Зрачок — это отверстие в центре радужной обо-
Глава 1. Камеры
53
Рис. 1.14. Слева: основные части человеческого глаза. Перепечатано с разрешения American
Society for Photogrammetry and Remote Sensing из. A.L. Nowicki, "Stereoscopy". MANUAL OF
PHOTOGRAMMETRY, edited by M.M. Thompson, R.C. Eller, W.A. Radlinski, and J.L. Speert, third
edition, pp. 515-536. Bethesda: American Society of Photogrammetry, (1966). Справа: схема глаза
по Гельмольцу, модифицированная Лаурансом (согласно (Driscoll and Vaughan, 1978]). Расстояние
от полюса роговицы до передней главной плоскости — 1,96 мм, а радиусы роговицы, передней
и задней поверхностей линз — 8 мм, 10 мм и 6 мм, соответственно
ломки, диаметр которого меняется от 1 до 8 мм в зависимости от освещения.
При слабом освещении зрачок расширяется, чтобы увеличить энергию, кото-
рая попадает на сетчатку, при нормальном освещении зрачок сужается, чтобы
противостоять сферическим аберрациям в глазном яблоке и получить более
четкое изображение. Преломляющая сила (аналог фокусного расстояния) глаза
по большей части зависит от преломления на границе раздела воздух/роговица
и хорошо регулируется изменением формы хрусталика, который аккомодирует-
ся для того, чтобы удерживать объект строго в фокусе. У здорового взрослого
человека она меняется от 60 (неаккомодированный глаз) до 68 диоптрий (1 ди-
оптрия = 1 м-1), что соответствует изменению фокусного расстояния в пределах
15-17 мм. Сама сетчатка — это тонкая, однослойная мембрана, состоящая из
двух видов фоторецепторов — палочек и колбочек, — которые реагируют на
свет с длиной волны 330-730 нм (от фиолетового до красного). Существует
три вида колбочек с различной спектральной чувствительностью, и это играет
ключевую роль при восприятии цвета. В человеческом глазе приблизительно
100 млн палочек и 5 млн колбочек. Их распределение по поверхности сетчатки
меняется: желтое пятно — это область в центре сетчатки, где концентрация
колбочек особенно высока, и изображение попадает точно в фокус, если глаз
фокусирует внимание на объекте (рис. 1.14). Самая высокая концентрация кол-
бочек в ямке — углублении в центре желтого пятна, где она достигает значе-
ния 1,6 х 105/мм2, когда расстояние между центрами двух соседних колбочек
составляет всего полминуты угла зрения (рис. 1.15). И наоборот, в центре ямки
нет палочек, зато их плотность растет по направлению к периферии поля зре-
ния. Еще на сетчатке есть слепое пятно, в котором узел аксона соединяется
с сетчаткой и образует оптический нерв.
54
Часть I. Формирование изображений и модели изображений
Рис. 1.15. Распределение палочек и колбочек по сетчатке. Перепечатано из В. Wandell, FOUN-
DATIONS OF VISION, Sinauer Associates, Inc., 1995
Палочки представляют собой чрезвычайно чувствительные фоторецепторы;
они способны отреагировать на один фотон, но, несмотря на их большое число,
палочки дают относительно мало информации о пространственном расположе-
нии объекта, поскольку многие из них связаны с одним и тем же нейроном на
сетчатке. Колбочки, наоборот, становятся активными при более высоком уровне
освещенности, но сигнал, который подает каждая колбочка в ямке, расшиф-
ровывается несколькими нейронами, что сказывается на высоком разрешении
в этой области. В общем случае, область сетчатки, которая влияет на реакцию
нейронов, обычно называют чувствительным полем сетчатки, хотя теперь
этим словом обозначают также реальную электрическую реакцию нейронов на
оптические изображения.
Конечно, о человеческом глазе можно (и нужно) сказать намного больше —
например, о том, как оба наши глаза согласуют свою работу и фиксируются
на цели, взаимодействуют друг с другом при стереозрении и т.п. Кроме того,
в этой телекамере человеческого мозга зрение только начинается, что ставит
захватывающую (и по большей части еще не решенную) задачу выяснения роли
различных участков нашего мозга в зрении человека. Некоторые аспекты этой
проблемы обсуждаются в следующих главах.
1.4. ВОСПРИЯТИЕ
Отличие камер (в сегодняшнем смысле этого слова) от переносной камеры-
обскуры XVII века заключается в способности записывать изображения, кото-
рые формируются на ее задней стенке. Хотя еще в Средние века было известно,
что некоторые соли серебра быстро темнеют под действием солнечного света,
только в 1816 году Нипс (Niepce) получил первые настоящие фотографии, под-
вергнув бумагу, обработанную хлоридом серебра, действию лучей света, по-
Глава 1. Камеры
55
Рис. 1.16. Наиболее ранняя из сохранившихся фотографий, la table servie, полученная Ничипором
Нипсом (Nicephore Niepce) в 1822 году. Коллекция Харлинжд-Виолетт (Harlinge-Viollet)
падающих на плоскость изображения камеры-обскуры, а затем зафиксировав
изображения с помощью азотной кислоты. Эти первые изображения были нега-
тивами, и Нипс вскоре перешел на другие чувствительные к свету химикаты,
чтобы получить позитивное изображение. Самые первые фотографии были уте-
ряны, а самая первая из сохранившихся — это la table servie (накрытый стол),
воспроизведенная на рис. 1.16.
Нипс изобрел фотографию, а Дагерре (Daguerre) можно считать ее первым
популяризатором. С 1826 года эти ученые стали работать вместе. Дагерре про-
должил разрабатывать свой собственный фотографический процесс, пользуясь
парами ртути для закрепления и проявления скрытого изображения, образовав-
шегося на меди, покрытой йодидом серебра. Такие дагерротипы пользовались
большим успехом, когда Араго (Arago) представил процесс Дагерре во Фран-
цузской Академии Наук в 1839 году, через три года после смерти Нипса. Дру-
гими вехами в длинной истории фотографии были: введение мокроколлоидного
процесса создания негатива/позитива Легре (Legray) и Арчером (Archer) в 1850
году (фотографию требовалось создавать сразу же, но при этом оставались от-
личные негативы); изобретение желатинового процесса Маддоксом (Maddox)
в 1870 году (после этого процесс создания фотографии уже не требовалось вы-
полнять немедленно после съемки); введение в 1889 году фотопленки (которая
заменила стеклянные пластинки в большинстве современных аппаратов) Ист-
маном (Eastman); изобретение кино братьями Люмьер (Lumiere) в 1895 году
и цветной фотографии в 1908 году.
Изобретение телевидения в 1920-х Беардом (Baird), Фансвортом (Farnsworth)
и Зворыкиным (Zworykin) было, конечно, главным толчком к развитию элек-
тронных сенсоров. Видикон — это общий тип телевизионной электронно-
лучевой трубки. Это стеклянная колба с электронной пушкой на одном конце
и плоским экраном на другом. Задняя сторона экрана покрыта тонким слоем
56
Часть I. Формирование изображений и модели изображений
фоторезистора, на который наложена прозрачная пленка из положительно заря-
женного металла. Это двойное покрытие представляет собой мишень. Трубку
окружают фокусирующие и отклоняющие катушки, которые используются для
многократного прохождения электронного пучка, выходящего из пушки, по ми-
шени. Этот пучок оставляет слой электронов на мишени, компенсируя, таким
образом, ее положительный заряд. Когда свет попадает на маленькую область
экрана, он выбивает электроны из этого места, тем самым заряд мишени умень-
шается. Проходя по этой области, электронный пучок восполняет утраченные
электроны, и возникает ток, пропорциональный интенсивности падающего све-
та. Затем схема видикона преобразует эти изменения силы тока в видеосигнал.
1.4.1. ПЗС-камеры
Рассмотрим теперь, чем отличаются камеры на приборах с зарядовой свя-
зью (ПЗС-камеры), которые были предложены в 1970 году и заменили ви-
диконы в большинстве современных устройств, от портативных видеокамер,
рассчитанных на широкого потребителя, до специализированных камер, пред-
назначенных для применения в микроскопии или астрономии. В ПЗС-датчике
используется прямоугольная решетка из узлов, где собираются электроны, по-
крытая тонкой кремниевой пластинкой, для регистрации количества световой
энергии, попадающей на каждый из них (рис. 1.17). Каждый узел образуется
путем наращивания слоя диоксида кремния на пластинке и последующим оса-
ждением на диоксид проводящей затворной структуры. Когда фотон падает на
кремниевую пластинку, рождается пара электрон-дырка (имеет место фотопе-
реход), и электроны попадают в потенциальную яму, полученную вследствие
приложения положительного электрического потенциала к соответствующему
затвору. Электроны, появляющиеся на каждом узле, собираются за фиксиро-
ванный период времени Т.
На данном этапе заряды, хранимые на отдельных узлах, перемещаются по-
средством зарядовой связи: для перемещения зарядовых пакетов от одного
узла изменяются потенциалы затворов, при этом пакеты распространяются по
отдельности. Изображение считывается с прибора с зарядовой связью построч-
но, каждая строка передается параллельно к регистру последовательного вы-
вода, содержащему по одному элементу в каждом столбце. Между считыва-
нием двух рядов регистр последовательно передает свои заряды на выходной
усилитель, который генерирует сигнал, пропорциональный полученному заря-
ду. Этот процесс продолжается, пока не будет считано все изображение. Он
может повторяться до 30 раз за секунду (телевидение) или с намного мень-
шей скоростью, предоставляя большой промежуток времени (секунды, минуты
и даже часы) для сбора электронов в устройствах, работающих при низком
уровне освещенности (например, астрономия). Следует отметить, что цифровая
выходящая информация в большинстве ПЗС-камер преобразуется в аналого-
вый видеосигнал, а лишь потом попадает в механизм захвата кадра, который
создает окончательное цифровое изображение.
Глава 1. Камеры
57
Рис. 1.17. Устройство ПЗС
В цветных ПЗС-камерах потребительского уровня, по сути, используются
те же микросхемы, что и в черно-белых, за исключением того, что задейство-
ванные строки или столбцы датчиков чувствительны к красному, зеленому или
синему свету (это часто достигается с помощью фильтра, который пропускает
только нужный цвет). Возможны и другие модели фильтров, например, моза-
ика из блоков 2x2, состоящих из двух зеленых, одного красного и одного
синего рецепторов (модель Байера). Пространственное разрешение камер на
одном ПЗС, конечно, ограничено, и в высококачественных камерах применя-
ется расщепитель пучка, чтобы распределять изображение по трем различным
ПЗС через цветные фильтры. Затем отдельные цветные каналы оцифровыва-
ются также раздельно (RGB-сигнал) или объединяются в сложный цветной
видеосигнал (сигнал NTSC в США, SECAM или PAL в Европе и Японии) или
в составной видеоформат, где информация о цвете и яркости разделяется.
1.4.2. Модели датчиков
В этом разделе описаны черно-белые ПЗС-камеры, поскольку цветные каме-
ры можно считать точно такими же, если рассмотреть каждый цветовой канал
в отдельности и непосредственно учесть связанную с этим реакцию фильтров.
Количество электронов I, зарегистрированных в клетке, расположенной
в строке г и в столбце с схемы ПЗС, можно представить как
I(r,c) = T f [ E(p,A)R(p)g(A)dpdA,
JpeS(r, с)
58
Часть I. Формирование изображений и модели изображений
где Т — время сбора электронов, а интеграл вычисляется по всей области клет-
ки S(r, с) и диапазону длин волн, на которые ПЗС дает ненулевую реакцию.
В этом интеграле Е — сила света на единицу площади и единицу длины волны
(т.е. освещенность, формальное определение см. в главе 4) в точке р, R — про-
странственная реакция узла, a q — квантовый выход устройства (т.е. количе-
ство рождающихся электронов на единицу энергии падающего света). В общем
случае, и Е, и q зависят от длины волны А, а Е и R зависят от расположения
точки р в области S(r, с).
Усилитель на выходе ПЗС преобразует заряд, собранный на каждом узле,
в напряжение, которое можно измерить. В большинстве камер это напряже-
ние затем с помощью электроники камеры преобразуется в низкочастотный1
видеосигнал, пропорциональный I. Аналоговое изображение можно еще раз
преобразовать в цифровое посредством механизма захвата кадра, который про-
странственно сверяет видеосигнал и квантует значение яркости в каждой точке
изображения, или пикселе (от picture element — элемент изображения).
Существует несколько физических явлений, для учета которых следует кор-
ректировать идеальную модель камеры, приведенную выше: если источник све-
та, освещающий узел сбора, настолько ярок, что заряд, накапливаемый на узле,
распространяется и на соседние узлы, изображение размывается. Этого можно
избежать, контролируя освещение, но остальные факторы, такие как дефекты
изготовления, тепловые и квантовые эффекты, квантовый шум — неотъемлемая
часть процесса создания изображения. Как будет показано дальше, эти факторы
учитываются в соответствующих простых статистических моделях. Эффекты
квантовой физики вносят внутреннюю неопределенность в процесс фотопере-
хода на каждом узле (дробовый шум). Более точно, количество электронов,
возникающих в результате этого процесса, можно обозначить случайным це-
лым числом Nj(r,c), которое подчиняется закону распределения Пуассона, со
средним значением /3(г,с)1(г,с), где /3(г, с) — число от 0 до 1, которое по-
казывает изменение пространственной реакции и квантовый выход по всему
изображению, а также подсчитывает плохие пиксели. Электроны, вылетающие
из кремния в результате теплового движения, добавляются к заряду каждо-
го узла сбора. Их вклад называют теневым током, и его можно обозначить
случайным целым числом Ndc(t,c), среднее значение рвс(г, с) которого рас-
тет с температурой. Эффект теневого тока можно контролировать охлаждением
камеры. Дополнительные электроны исходят из электроники ПЗС (ток смеще-
ния), и их число также можно обозначить случайной, подчиняющейся распреде-
лению Пуассона, величиной Ад (г, с) со средним значением рв(г,с). Усилитель
на выходе добавляет шум считывания, его можно смоделировать действитель-
ным числом R (которое подчиняется распределению Гаусса) со средним значе-
нием рп и среднеквадратическим отклонением сгц.
Есть и другие источники неопределенности (например, эффективность пере-
носа заряда), но ими часто можно пренебречь. Наконец, дискретизация анало-
'Грубо говоря, усредненный по времени или пространству; подробнее от этом — далее.
Глава 1. Камеры
59
гового напряжения механизмом захвата кадра порождает как геометрические
эффекты (дрожание строк), которые можно устранить с помощью калибровки,
так и шум квантования, который можно обозначить случайным числом Q(r,c),
среднее значение которого равно нулю, с однородным распределением в интер-
вале [— ^<5, |5] и дисперсией j4><52, где <5 — шаг квантования. Это дает такую
модель цифрового сигнала D(r, с):
D(r,c) — *y(Ni(r,c) + Ndc(t,c) + Ав(г,с) 4- R(r,c)) 4- Q(r,c).
В приведенном выше уравнении 7 — это общий коэффициент усиления уси-
лителя и камеры. Статистические свойства данной модели можно оценить с
помощью радиометрической калибровки камеры: например, теневой ток можно
оценить, измеряя число пробных изображений в темноте (I = 0).
1.5. ПРИМЕЧАНИЯ
Отличное введение в геометрическую оптику — классический учебник
[Hecht, 1987], где подробно рассматривается параксиальная оптика, а также
различные аберрации, о которых вкратце упоминалось в этой главе (см. так-
же [Driscoll and Vaughan, 1978]). Виньетирование проанализировано в [Horn,
1986] и [Russ, 1995]. Работа [Wandell, 1995] дает прекрасное описание процес-
са образования изображения в зрительной системе человека. Схематическая
модель глаза по Гельмольцу подробно описана в [Driscoll and Vaughan, 1978].
ПЗС-устройства представлены в [Boyle and Smith, 1970] и [Amelio, et al.,
1970]. Научное применение ПЗС-камер в микроскопии и астрономии обсужда-
ется в [Aiken, et al., 1989], [Janesick, et al., 1987], [Snyder, et al., 1993] и [Tyson,
1990]. Статистическая модель датчика, представленная в этой главе, описана
согласно работе [Snyder, et al., 1993] с добавлением понятия шума квантования,
взятого из [Healey and Kondepudy, 1994]. В этих двух статьях рассказывается
о применении моделирования датчиков для восстановления изображений в аст-
рономии и радиометрической калибровки камер в компьютерном зрении.
Основные уравнения, выведенные при изложении данной главы, представ-
лены в табл. 1.1.
Задачи
1.1. Постройте уравнение перспективной проекции для мнимого изображе-
ния, расположенного на расстоянии /' перед отверстием.
1.2. Докажите геометрически, что проекции двух параллельных прямых, ле-
жащих в плоскости П, сходятся на горизонтальной прямой Н, образован-
ной пересечением плоскости изображения с плоскостью, параллельной
к П и проходящей через отверстие.
1.3. Докажите то же самое алгебраически, воспользовавшись уравнением
перспективной проекции (1.1). Для простоты можно принять, что плос-
кость П перпендикулярна к плоскости изображения.
60
Часть I. Формирование изображений и модели изображений
ТАБЛИЦА 1.1. Справочная таблица: модели камер
Перспективная проекция < I'C n |H x,у: координаты реального объекта (z < 0) х',у': координаты изображения f: расстояние от отверстия до чувствительной поверхности
Слабо- перспективная проекция ( х' — —тх 1 у' = -ту 1 f' 1 ТП = 1 Zo х, у: координаты реального объекта х',у': координаты изображения расстояние от отверстия до чувствительной поверхности zq: глубина точки отсчета (< 0) т: коэффициент увеличения (> 0)
Ортографическая проекция x' — X < y1 = У х, у: координаты реального объекта х',^: координаты изображения
Закон Снелла Ш smoq = sina2 711,712: показатели преломления ai,a2: углы между лучом и нормалью
Параксиальное преломление 711 712 _ n2 - П1 С?1 tf2 R Til, т12: показатели преломления <31,с?2- расстояние от точки до границы раздела R: радиус кривизны границы раздела
Уравнение тонкой линзы 1 1 _ 1 z' z f z: глубина точки объекта (< 0) z': глубина точки изображения (> 0) /: фокусное расстояние
1.4. Воспользуйтесь законом Снелла и покажите, что лучи, которые проходят
через оптический центр тонкой линзы, не преломляются. Выведите урав-
нение тонкой линзы. Подсказка: рассмотрите луч го, проходящий через
точку Р, и постройте лучи ri и г2, которые получаются при преломлении
луча го на правой грани линзы и преломлении луча ri на ее левой грани.
Глава 1. Камеры
61
1.5.
1.6.
1.7.
Рассмотрите камеру с тонкой линзой, плоскость изображения которой
находится на расстоянии z', а плоскость точек кадра в фокусе — на рас-
стоянии z. Представьте, что плоскость изображения перемещается в точ-
ку z1. Покажите, что диаметр соответствующего пятна рассеяния равен
I t
\z — Z
d'------
z
где d — диаметр линзы. Воспользуйтесь этим результатом, чтобы по-
казать, что глубина поля (т.е. расстояния между дальней и ближней
плоскостями, на которых диаметр пятна рассеяния не превышает неко-
торого порогового значения е) задается как
D = 2ef z(z + /)
d
г2 >2 2 2’
f d -£ Z
и убедитесь, что для фиксированного фокусного расстояния глубина по-
ля возрастает с уменьшением диаметра линзы, т.е. с увеличением диа-
фрагменного числа. Подсказка: решайте задачу для глубины z точки,
изображение которой находится в фокусе на плоскости изображения
в точке zf, рассматривая случаи, когда z' > z't и z' < z'.
Выполните геометрическое построение изображения Р' точки Р, если
заданы два фокуса F и F' тонкой линзы.
Выведите уравнение толстой линзы для случая, когда у обеих сфериче-
ских поверхностей линзы одинаковые радиусы кривизны.
2
Гэометрические модели камер
О фундаментальных законах перспективной проекции в системе координат,
центр которой соотнесен с камерой, рассказывалось в главе 1. В этой же главе
говорилось об аналитическом аппарате, необходимом для установления коли-
чественных связей между точками изображений, положением и ориентацией
геометрических фигур, которые задаются во внешней системе координат. Дан-
ная глава начинается с краткого изложения элементарных понятий аналити-
ческой евклидовой геометрии, включая понятия однородных координат и мат-
ричное представление геометрических преобразований. Затем будут рассмотре-
ны различные физические параметры (так называемые внутренние и внешние
параметры), которые связывают реальную систему координат и систему ко-
ординат, соотнесенную с камерой. С помощью этих систем координат будет
выведен общий вид уравнения перспективной проекции. В заключение главы
представлены аффинные модели процесса формирования изображения (вклю-
чая ортогональную и слабоперспективную модели, кратко описанные в главе 1),
которые являются приближенным описанием перспективной точечной проекции
для удаленных объектов.
64
Часть I. Формирование изображений и модели изображений
Рис. 2.1. Правосторонняя система координат и координаты х, у и z точки Р
2.1. ЭЛЕМЕНТЫ АНАЛИТИЧЕСКОЙ ЕВКЛИДОВОЙ ГЕОМЕТРИИ
Предполагается, что читатели немного знакомы с элементарной евклидовой
геометрией и линейной алгеброй. В этом разделе речь пойдет о таких полез-
ных аналитических понятиях, как системы координат, однородные координаты,
матрицы вращения и т.п.
2.1.1. Системы координат и однородные координаты
В главе 1 трехмерная система координат уже использовалась. В этой главе
такие системы представлены немного формальнее. Предполагается использова-
ние определенной системы единиц измерения, скажем, метрической, так что
единица длины точно определена.
Выбор точки О в физическом трехмерном пространстве Е3 и трех взаимно
перпендикулярных единичных векторов г, j и к задает ортонормированную
систему координат (F) как четырехвектор (О, i,j, к). Точка О — это начало
координат системы (F), а г, j и к — ее базисные векторы. Мы ограничим-
ся изучением правосторонних систем координат, т.е. таких, где векторы i, j
и к можно изобразить пальцами правой руки, когда большой палец направлен
вверх, указательный — вперед, а средний — влево (см. рис. 2.1)1.
Координаты х, у и z точки Р в этой системе координат задаются как дли-
ны (с соответствующим знаком) перпендикулярных проекций вектора OI^ на
векторы г, J, и к (рис. 2.1, справа), где
’Это традиционный способ определения правосторонней системы координат. Один из авто-
ров, левша от природы, всегда считал его немного неудобным и предпочитает определять подобные
системы координат так: если смотреть вдоль оси к в направлении плоскости (г, j), то вектор г при
повороте против часовой стрелки на 90° накладывается на вектор j (рис. 2.1). Левосторонние
системы координат — это поворот по часовой стрелке. Такое определение одинаково удобно как
для левшей, так и для правшей.
Глава 2. Геометрические модели камер
65
х — ОР • г
4 у = ОР • j <=> О? — xi + yj 4- zk.
z = OP-k
Вектор-столбец
6 К3
называется координатным вектором точки Р в системе (F). Аналогично мож-
но задать координатный вектор, соотнесенный с любым вектором г>, использо-
вав длины его проекций на базисные векторы системы (F). Разумеется, эти
координаты не будут зависеть от выбора начала координат О. Рассмотрим те-
перь плоскость П, произвольную точку А на плоскости П и единичный век-
тор и, перпендикулярный к этой плоскости. Точки, лежащие на плоскости П,
характеризуются следующим образом:
АР • п = 0.
В системе координат (F), где координаты точки Р — х, у и г, а координаты
вектора п — а, b и с, это можно записать как О? • 71 — оа • п = 0 или
ах 4- by 4- cz — d = 0,
(2.1)
где d = оА • п не зависит от выбора точки А на плоскости П и представля-
ет собой расстояние (с соответствующим знаком) от начала координат О до
плоскости П (рис. 2.2).
Иногда для представления точек, векторов и плоскостей удобно пользо-
ваться однородными координатами. Формально их введение будет обоснова-
но немного позже, после ввода понятия аффинной и проекционной геометрии
в главах 12 и 13. Уравнение (2.1) можно переписать в виде
или, точнее, как
П • Р = 0,
( а >
b
с
\~dj
(2-2)
66
Часть I. Формирование изображений и модели изображений
Рис. 2.2. Геометрическое определение уравнения плоскости. Расстояние d от начала координат до
плоскости измеряется расстоянием до точки Н, в которой вектор, перпендикулярный к плоскости П
и проходящий через начало координат, пересекается с плоскостью
Вектор Р называют однородным координатным вектором точки Р в системе
координат (F), он получается простым добавлением единичной четвертой коор-
динаты к обычному координатному вектору Р. Подобным образом, вектор П —
это однородный координатный вектор плоскости П в системе координат (F), а
уравнение (2.2) называется уравнением плоскости П в этой системе координат.
Отметим, что вектор П определен только с точностью до масштаба, поскольку
умножение этого вектора на любое ненулевое число не влияет на решения урав-
нения (2.2). В дальнейшем однородные координаты всегда будут определены
только с точностью до масштаба, независимо от того, описывают ли они точки
или плоскости (для точек это может показаться немного нелогичным, но обос-
нование такого подхода дано в главе 13). Для возврата к обычным неоднород-
ным координатам точек можно просто разделить все координаты на четвертую.
Основное внимание в этой главе обращено на трехмерную евклидову геомет-
рию, однако описанные принципы применимы также в планиметрии: система
координат (F) задается на плоскости через ее начало координат о и правосто-
ронний ортонормированный базис (г, j); координаты точки р в этой системе —
x = op-iny = opj, можно также определить и однородные координаты;
в частности, уравнение прямой 5 на плоскости имеет такой вид:
(а \ ( х
b I и р = I у
-dj \1
Здесь через а, b и с обозначены, соответственно, координаты единичной норма-
ли к 6 в системе (F) и расстояние (с соответствующим знаком) от о до 6.
Вернемся к трехмерной геометрии и покажем, что однородными координа-
тами можно пользоваться для описания более сложных геометрических фигур,
чем точки и плоскости. Рассмотрим в качестве примера сферу S' радиуса R,
центр которой совпадает с началом координат. Необходимым и достаточным
Глава 2. Геометрические модели камер
67
условием того, что точка Р с координатами х, у и z принадлежит S, конечно,
является
х2 + у2 + г2 = R\
что равнозначно следующему условию2:
/1 0 0 0 \ (х\
0 10 0 У
x,y,z, 1) = 0.
0 0 1 0 Z
^0 0 0 -R2/ \1J
В более общем случае, поверхность второго порядка — это геометрическое
место точек Р, координаты которых удовлетворяют следующему уравнению:
2 2 2
«200^ + «иоЗД 4- aozoj/ 4- aonj/z 4- aoozz 4- аю^хг 4- fliooi 4- OoioJ/ 4- aooi^ 4- aooo = 0
Можно непосредственно убедиться в том, что это равнозначно такому условию:
( 0,200 i „ 2a110 |«ioi |«100^
5 «110 <1020 9 «Oil |<1010
PTQP = 0, где Q = 2 J 2 2 j (2.3)
2аЮ1 2 <1011 «002 2 <1001
\|<iioo |«010 |<tooi «ООО /
В этом уравнении Р — однородный координатный вектор точки Р. Отметим,
что Q — это симметричная матрица 4x4, определенная, как и параметры
только с точностью до масштаба.
2.1.2. Переход от одной системы координат к другой и строгие
преобразования
Если одновременно рассматривается несколько систем координат, удобно
(как это сделано в [Craig, 1989]) координатный вектор точки Р (соответственно,
вектор Fv) в системе (F) обозначать через FP (соответственно, Fv); т.е.
Верхние и нижние индексы перед точками, векторами и матрицами в систе-
ме обозначений Крейга могут вначале показаться неудобными, но легкость их
2Любознательный читатель может спросить о прямых в пространстве Е3. Разумеется, пря-
мую можно задать как пересечение двух плоскостей. В более общем случае, прямые в Е3 можно
задавать с помощью координат Плюкера (Plucker coordinates), см. раздел упражнений.
68
Часть I. Формирование изображений и модели изображений
Рис. 2.3. Переход от одной системы координат к другой: чистая трансляция
применения станет очевидной по мере дальнейшего изложения. Рассмотрим
две системы координат: (А) = (OA,iA, jA, кА) и (В) = (Ов, iB, jB, кв}. Далее
в этом разделе будет показано, как ВР можно выразить через АР. Вначале
предположим, что базисные векторы обеих координатных систем параллельны
друг другу (т.е. iA = iB, jA = jB и kA = кв), но начала координат ОА и Ов
находятся на некотором расстоянии друг от друга (рис. 2.3).
В таком случае говорят, что две системы координат можно совместить чи-
стой трансляцией, а поскольку ОВР = ОВОА + ОАР, тогда
ВР = ар+воа.
Если начала координат двух систем совпадают (т.е. ОА = Ов = О), то две си-
стемы координат можно совместить чистым вращением (рис. 2.4). Определим
матрицу вращения ВИ как массив чисел 3x3:
(гА гв За гв
‘Зв 3 А ' 3 в
г а ’ кв За кв
к а 1в\
кл•jB I •
кл-кв/
Отметим, что первый столбец ВИ образуют координаты вектора iA в базисе
(*в,5в,^в). Подобным образом, третья строка этой матрицы — координаты
вектора кв в базисе (iA,jА->кА) и т.д. В общем случае, матрицу можно
записать в более компактном виде, использовав комбинацию трех векторов-
столбцов или трех векторов-строк:
Глава 2. Геометрические модели камер
69
Рис. 2.4. Переход от одной системы координат к другой: чистое вращение
Отсюда следует, что ВЯ. = дЯ^.
Как отмечалось ранее, все эти верхние и нижние индексы вначале могут по-
казаться чем-то непонятным. Чтобы все стало ясно, будет нелишним напомнить,
что при переходе от одних координат к другим нижние индексы соотносятся
с описываемыми объектами, тогда как верхние индексы соотносятся с система-
ми координат, в которых описываются эти объекты. Например, АР обозначает
координатный вектор точки Р в системе координат (A), BjA — координаты
вектора jA в системе координат (В), a A1Z — это матрица вращения, которая
описывает систему координат (А) в системе координат (В).
Приведем пример чистого вращения. Пусть кд = кв — к, а через 0 обозна-
чим такой угол, чтобы вектор iB можно было получить поворотом вектора гд
по часовой стрелке на угол 0 вокруг оси к (рис. 2.5). В этом случае угол между
векторами jA и jв также равен 0, тогда
/ COS0 sine 0
— sm0 cose 0
\ 0 0 1
(2.4)
Подобные формулы можно записать для двух систем координат, которые полу-
чаются одна из другой поворотом вокруг оси iA или jA (см. раздел упражне-
70
Часть I. Формирование изображений и модели изображений
Рис. 2.5. Две системы координат, которые совмещаются поворотом на угол 0 вокруг их общей
оси к. Как показано на правом рисунке, iA = ciB — sjD и jA = siB + cjB, где с = cosO
и s = sin 0
ний). В общем случае любую матрицу вращения можно записать в виде произ-
ведения трех элементарных поворотов вокруг осей i, j и к некоторой системы
координат.
Вернемся к описанию перехода от одних координат к другим, на этот раз
при произвольной матрице вращения. Записав
О? = (г д jA к а)
в системе координат (В) получим
вр = %RAP,
поскольку очевидно, что матрица вращения равна единичной матрице. От-
метим, что нижний индекс совпадает со следующим верхним индексом. Это
свойство сохраняется и для более общих переходов от одних координат к дру-
гим, и, после некоторой практики, его можно использовать для восстановления
соответствующих формул без вывода.
Матрица вращения (см. раздел упражнений) характеризуется следующими
свойствами: 1) для ее обращения достаточно ее транспонировать и 2) ее детер-
минант равен 1. По определению, столбцы матрицы вращения образуют пра-
востороннюю ортонормированную систему координат. Из перечисленных выше
свойств матрицы вращения следует, что ее строки также образуют систему
координат с аналогичными свойствами.
Следует отметить, что набор матриц вращения вместе с правилом умноже-
ния матриц формирует группу, т.е. а) произведение двух матриц вращения так-
Глава 2. Геометрические модели камер
71
Рис. 2.6. Переход от одних координат к другим: общее строгое преобразование
же будет матрицей вращения (это свойство очевидно и легко доказывается ана-
литически); б) произведение матриц подчиняется ассоциативному закону — это
значит, что для любых матриц вращения 71, 71' и 71" справедливо соотношение
(TVR^TV1 = TZ^TZ'TZ’')-, в) существует единичный элемент, единичная матрица Id
размером 3x3, которая действительно является матрицей вращения, и для лю-
бой матрицы вращения 7Z справедливо: TZId — Id 7^ = 71; г) у каждой матрицы
вращения 72. есть обратная матрица 71“1 = 7ZT такая, что 7Z7Z~A = 7Z-17Z = Id.
Эта группа, однако, некоммутативна (т.е. для двух данных матриц вращения 71
и 71' два произведения 7171' и 7£'7£ в общем случае не равны).
Если и начала координат, и базисные векторы двух систем различны, систе-
мы можно совместить с помощью общих строгих преобразований (рис. 2.6), т.е.
ВР = %КаР+вОа,
(2-5)
где д7£ и ВОА определены так же, как и ранее. Таким образом, переходы от
одних координат к другим для однородных координатных векторов плоскостей
и симметричных матриц, связанных с поверхностями второго порядка, описы-
ваются сходными формулами (см. раздел упражнений).
Однородные координаты можно использовать, чтобы переписать уравне-
ние (2.5) в виде произведения матриц. Отметим вначале, что матрицы можно
умножать блоками — т.е. если
Л =
Л11 Л12
Л21 Л22
и 23 =
23ц В12\
В?! #22 /
(2-6)
72
Часть I. Формирование изображений и модели изображений
Рис. 2.7. Строгое преобразование переводит точку Р в точку Р" с помощью поворота TZ и транс-
ляции t, которая переводит точку Р” в Р'. В примере, показанном на рисунке, 1Z — это поворот
на угол 0 вокруг оси к системы координат (F)
где количество столбцов в подматрицах Лц и Л21 (соответственно, Л12 и Л22)
равно количеству строк в матрицах 0ц и 012 (соответственно, 021 и 02г). то
Л110Ц + Л12021 Л11012 + Л12022
Л210Ц + Л 22 021 Л21012 + Л22022
В частности, уравнение (2.6) позволяет переписать переход от одних координат
к другим, заданный уравнением (2.5), в таком виде:
и 0 = (0,0,0)г. Другими словами, однородные координаты позволяют записать
общее правило перехода от одной системы координат к другой как произведение
матрицы 4x4 и 4-вектора. Легко показать, что набор строгих преобразований,
заданных уравнением (2.7), плюс оператор умножения матриц также формиру-
ют группу.
Строгие преобразования выражают одну систему координат через другую.
В заданной системе координат (F) их можно также рассматривать как отобра-
жения точек — т.е. точка Р отображается в точку Р' так, что
Fp' = 'R,FP + t<‘==> I
Fpt
(2-8)
где Tl — матрица вращения, at — элемент пространства R3 (рис. 2.7). Неслож-
но показать, что набор строгих преобразований, который рассматривается как
отображение пространства Е3 в само себя, плюс закон композиции опять
же формирует группу. При строгих преобразованиях сохраняется расстояние
Глава 2. Геометрические модели камер
73
между двумя точками и угол между двумя векторами. В то же время, мат-
рица 4x4, соотнесенная со строгими преобразованиями, зависит от выбора
системы координат (F).
Рассмотрим, например, поворот на угол в вокруг оси к системы коорди-
нат (F). Как показано в разделе упражнений, это отображение можно предста-
вить следующим образом:
/cos в ~ sin в О
FPf = PFР, где 1Z = I sin# cos# О
\ 0 0 1
В частности, если (F') — система координат, которая получается после при-
менения этого поворота к системе (F), то согласно уравнению (2.4) F Р =
pFfP иР — plZ .В более общем случае, матрица, представляющая переход
от одной системы координат к другой, — это матрица, обратная к отображению
первой системы во вторую.
Что будет, если заменить 1Z произвольной невырожденной матрицей А раз-
мера 3x3? Уравнение (2.8) по-прежнему представляет отображение точек (или
переход от одних координат к другим), но в этом случае длины и углы могут
больше не сохраняться (или, эквивалентно, оси новой системы координат не
обязательно будут ортогональны и иметь ту же единицу длины). Таким обра-
зом, матрица 4x4
представляет аффинное преобразование. Если матрица 7 — произвольная
несингулярная матрица 4x4, тогда это проекционное преобразование. Аффин-
ные и проекционные преобразования также образуют группы (подробнее они
рассмотрены в главах 12 и 13).
2.2. ХАРАКТЕРИСТИКИ КАМЕР И ПЕРСПЕКТИВНАЯ ПРОЕКЦИЯ
В главе 1 было показано, что координаты х, у и z точки сцены Р, наблю-
даемой через камеру-обскуру, связаны с координатами ее изображения хг и у’
перспективным уравнением (1.1). В действительности, это уравнение справед-
ливо только в том случае, когда все расстояния измеряются в системе отсчета
камеры, а начало координат изображения находится в ее главной точке, где ось
симметрии камеры пересекается с ее чувствительной плоскостью. На практике
реальная система координат и система координат камеры связаны рядом физи-
ческих параметров, таких как фокусное расстояние линзы, размеры пикселей,
положение главной точки, положение и ориентация камеры.
Данный раздел посвящен описанию названных параметров. Будем разли-
чать внутренние параметры, которые связывают систему координат камеры
74
Часть I. Формирование изображений и модели изображений
Рис. 2.8. Физическая и нормированная системы координат изображения
с идеальной системой координат, введенной в главе 1, и внешние параметры,
связывающие систему координат камеры с фиксированной реальной системой
координат, а также описывают ее положение и ориентацию в пространстве.
В этой главе не учитывается то, что у камер с линзами точка попадает в фо-
кус только тогда, когда ее глубина и расстояние от оптического центра камеры
до ее плоскости изображения описываются уравнением тонкой линзы (1.6).
Подобным образом в уравнении (1.1) не учитываются нелинейные аберрации,
присущие реальным линзам. В этой главе мы также будем пренебрегать та-
кими аберрациями, но в главе 3 при рассмотрении задачи оценки внутренних
и внешних параметров камеры (процесс, известный под названием геометри-
ческой калибровки камер) будет сказано о радиальной дисторсии.
2.2.1. Внутренние параметры
С камерой можно соотнести нормированную плоскость изображения, па-
раллельную ее физической чувствительной области, но расположенную на еди-
ничном расстоянии от отверстия. К этой плоскости мы привяжем ее собствен-
ную систему координат, начало которой будет находиться в точке С — точке
пересечения плоскости с оптической осью (рис. 2.8). Уравнение перспектив-
ной проекции (1.1) в этой нормированной системе координат можно записать
следующим образом:
х
< О- <29>
V = — '
Z
Глава 2. Геометрические модели камер
75
где р == (й, г>, 1)т — вектор однородных координат проекции р точки Р на
нормированную плоскость изображения.
Физическая и нормированная чувствительные области камеры в общем слу-
чае не совпадают (рис. 2.8): физическая плоскость находится на расстоянии /
1 от отверстия3, а координаты (u, v) точки изображения р обычно выражают-
ся в пикселях (а не, скажем, в метрах). Кроме того, пиксели обычно берутся
прямоугольными, а не квадратными, так что у камеры появляется два допол-
нительных масштабных параметра к и I, таким образом
х
и = к/-,
z
v = If-.
Z
(2.Ю)
Скажем немного о единицах измерения: f — это расстояние, которое из-
меряется, например, в метрах, а размерность пикселя — | х |, где к и I
выражаются в пикселях х м-1. Параметры к, I и f не являются независимыми,
их можно заменить множителями а = к/и[3 = 1/, выраженными в единицах
измерения пикселей.
В общем случае начало системы координат камеры находится в углу С чув-
ствительной области (например, для случая, изображенного на рис. 2.8, это
левый нижний угол; иногда это левый верхний угол, если координаты изобра-
жения — индексы строк и столбцов пикселя), а не в ее центре; центр ПЗС-
матрицы обычно не совпадает с главной точкой Со. Таким образом добавляется
еще два параметра uq и г?о, которые определяют положение (в единицах из-
мерения пикселей) точки Со в системе координат чувствительной области, а
система (2.10) заменяется системой
х
и = а—Ь ио,
z
<
У
v = /3—I- w.
z
(2-П)
Наконец, система координат камеры может быть наклонной вследствие некото-
рой производственной ошибки, так что угол 0 между двумя осями изображения
не будет равен 90° (но, конечно, весьма близок к этому значению). В данном
случае легко показать, что уравнение (2.11) преобразуется к виду
3С этого момента будем предполагать, что камера сфокусирована на бесконечности, так что
расстояние от отверстия до плоскости изображения равно фокусному расстоянию.
76
Часть I. Формирование изображений и модели изображений
и = а---actgfl—Ь uq,
z z
/3 У t
V =------------1- W-
sin# z
(2.12)
Уравнения (2.9) и (2.12) позволяют записать правило перехода от системы коор-
динат физического изображения к нормированной системе координат как плос-
кое аффинное преобразование, т.е.
(и
V
1
ctg#
/3
sin О
О
Объединив полученные результаты, приходим к выражению
р = -Л1Р, где М = (к О
(2.14)
Через Р = (х, у, z, 1)т на этот раз обозначен однородный вектор координат точ-
ки Р в системе координат камеры. Другими словами, однородные координаты
можно использовать для представления отображения перспективной проекции
матрицей Л4 размером 3x4.
Отметим, что для данных камеры и механизма фиксации кадра физический
размер пикселя и наклон постоянны и, в принципе, их можно измерить при
изготовлении (конечно, эта информация может оказаться недоступной, если,
например, неизвестна скорость оцифровки механизма фиксации кадра). В объ-
ективах с переменным фокусным расстоянием меняться может не только фо-
кусное расстояние, но и положение центра изображения, если оптическая ось
не строго перпендикулярна к плоскости изображения. Изменение фокуса ка-
меры также влияет на увеличение, так как при этом меняется расстояние от
линзы до чувствительной области, но далее будет предполагаться, что камера
сфокусирована на бесконечность.
2.2.2. Внешние параметры
Рассмотрим случай, когда система отсчета камеры (С) отличается от реаль-
ной системы отсчета (IV). Запишем, что
Глава 2. Геометрические модели камер
77
теперь сделаем замену в уравнении (2.14) и получим
р=-Л4Р, где Л4 = К(Т1 t), (2.15)
где Р = — это матрица вращения, t = cOw — вектор трансляции, а
через Р = {wx,wy,wz, 1)г обозначен однородный вектор координат точки Р
в системе координат (ГУ).
Выше приведен самый общий вид уравнения перспективной проекции. Его
можно использовать для определения положения оптического центра О ка-
меры в реальной системе координат. Действительно, как показано в разделе
упражнений, для однородного координатного вектора О справедливо ЛЮ = 0.
(Интуитивно это достаточно очевидно, поскольку оптический центр — это един-
ственная точка, в которой изображение не определено однозначно.) В частно-
сти, если Л4 = (-4 Ь), где А — несингулярная матрица 3x3, а 6 - вектор
в пространстве Ж3, то неоднородный вектор координат точки О — это про-
сто —A~*b.
Важно понимать, что глубина z в уравнении (2.15) не зависит от Л4 и Р,
поскольку если через mf, mJ и mJ обозначить три строки матрицы Л4, то
непосредственно из уравнения (2.15) следует, что z = т3 • Р. Фактически,
иногда бывает удобно переписать уравнение (2.15) в эквивалентной форме
7П1 • Р
14 = ------,
ТПЗ • Р
т. 2 • Р
V = -------.
тз Р
(2.16)
Проекционную матрицу можно записать в явном виде как функцию ее пяти
внутренних (а, /3, uq, i’o и 0) и шести внешних параметров (три угла, опреде-
ляющие TZ, и три координаты вектора £).
Л1 =
^arj ~ 4- uorj atx — a cig 0ty 4- Uotz^
P T T p
----r2 4- vor3 ----ty 4- votx
sin в sin в
I rj tz )
(2-17)
где rj, rj и гз соответствуют трем строкам матрицы 7£, a tx, ty и tz — коорди-
наты вектора t. Если записать матрицу 1Z как произведение трех элементарных
поворотов, то векторы г» (г = 1,2,3) можно, конечно же, явно представить
через три соответствующих угла.
78
Часть I. Формирование изображений и модели изображений
2.2.3. Описание матриц перспективной проекции
В этом разделе описываются условия, при которых матрицу Л4 разме-
ра 3 х 4 можно записать в форме (2.17). Не нарушая общности положим,
что Л4 = (Л Ь), где А — матрица 3 х 3, а b — элемент пространства R3,
и обозначим через а? третью строку матрицы А. Очевидно, что если Л4 —
частный случай матрицы (2.17), то а% должен быть единичным вектором,
поскольку он равен rj’ — последней строке матрицы вращения. Отметим,
впрочем, что замена М в уравнении (2.16) величиной ХМ для некоторого
произвольного А 0 не меняет соответствующие координаты изображения.
На основании этого далее в книге проекционные матрицы будем считать од-
нородными объектами, определенными только с точностью до масштаба, для
которых каноническую форму (2.17) можно получить выбором масштабного
множителя такого, что |аз| = 1. Отметим, что параметр z в уравнении (2.15)
единственно правильно можно интерпретировать как глубину точки Р, если
матрица М записана в указанной канонической форме. Отметим также, что
число внутренних и внешних параметров камеры соответствует 11 свободным
параметрам (однородной) матрицы М.
Матрица 3x4, которую можно записать (с точностью до масштаба) в фор-
ме (2.17) для некоторого набора внешних и внутренних параметров, — это мат-
рица перспективной проекции. Она представляет практический интерес для
определения ограничений, накладываемых на внутренние параметры камеры,
поскольку, как отмечалось ранее, некоторые из этих параметров фиксированы
и могут быть известными. В частности, матрица 3x4 — это матрица перспек-
тивной проекции нулевого наклона, если ее можно переписать (с точностью до
масштаба) в форме (2.17) с углом 0 — тг/2; если же данную матрицу можно пе-
реписать (с точностью до масштаба) в форме (2.17) с углами 0 = тг/2 и а — (3,
то это перспективная матрица с нулевым наклоном и единичным форма-
том изображения. Камеру с известным ненулевым наклоном и неединичным
форматом изображения можно превратить в камеру с нулевым наклоном и еди-
ничным форматом изображения с помощью соответствующих преобразований
координат изображений. Будет ли произвольная матрица 3x4 матрицей пер-
спективной проекции? Ответ на этот вопрос дает следующая теорема.
Теорема 1. Пусть М — (А Ь) — матрица 3 х 4, а аТ (i = 1,2,3) —
строки матрицы А, образованной тремя крайними левыми столбцами мат-
рицы М.
• Необходимое и достаточное условие того, что М — матрица перспек-
тивной проекции: Det(A) 0.
• Необходимое и достаточное условие того, что М — матрица перспек-
тивной проекции с нулевым наклоном: Det(A) 0 и
(ai х аз) («2 х аз) = 0.
Глава 2. Геометрические модели камер
79
• Необходимое и достаточное условие того, что Л4 — матрица перспек-
тивной проекции с нулевым наклоном и единичным форматом изобра-
жения: Det(A) ^0 и
(ai х аз) • (аг х аз) = О,
(ai х а3) • (ai х а3) = (аг х а3) • (а2 х а3).
Необходимость условий этой теоремы очевидна: согласно (2.15) А = K.7Z,
т.е. определители матриц А и К. одинаковы и А — несингулярная матри-
ца. Далее, с помощью простых вычислений можно показать, что строки K.7Z
в уравнении (2.17) удовлетворяют условиям теоремы при различных указан-
ных предположениях. Доказательство достаточности условий данной теоремы
можно найти в [Faugeras, 1993], а также в упражнениях к этой главе.
2.3. АФФИННЫЕ КАМЕРЫ И УРАВНЕНИЯ АФФИННОЙ ПРОЕКЦИИ
Если рельеф сцены меняется незначительно по сравнению с расстоянием
от сцены до камеры, для приблизительного описания процесса формирования
изображения можно использовать модели аффинной проекции. В их число
входят модели ортогональной и слабоперспективной проекций, о которых
говорилось в главе 1, а также параллельные и параперспективные модели, о
которых речь пойдет ниже. Названия моделей объясняются в главе 12.
2.3.1. Аффинные камеры
При ортогональной проекции процесс формирования изображения модели-
руется как ортогональная проекция на плоскость изображения. Это разумное
приближение перспективной проекции для отдаленных объектов, которые на-
ходятся на приблизительно одинаковом расстоянии от камер, наблюдающих
за ними. Модели параллельной проекции также относятся к ортогональным
и с их помощью можно описывать объекты, расположенные не на оптической
оси камеры. В этой модели рассматриваемые лучи параллельны друг другу, но
не обязательно перпендикулярны к плоскости изображения.
Модели слабоперспективной и параперспективной проекции — это обобще-
ние моделей ортогональной и параллельной проекций, которое допускает изме-
нение глубины объекта относительно наблюдающей камеры (рис. 2.9). Обозна-
чим через О оптический центр этой камеры, а через Р — контрольную точку
сцены; слабоперспективная проекция точки сцены Р формируется в два эта-
па: вначале точка Р ортогонально проектируется в точку Р' на плоскости Пг,
параллельной к плоскости изображения П' и проходящей через затем с помо-
щью перспективной проекции точка Р' переводится в точку р (рис. 2.9, ввер-
ху). Поскольку Пг — это фронтопараллельная плоскость, то суммарный эф-
фект двух преобразований — масштабирование координат изображения. В па-
раперспективной модели учитываются как искажения, связанные с тем, что
контрольная точка не лежит на оптической оси камеры, так и возможные от-
80
Часть I. Формирование изображений и модели изображений
Рис. 2.9. Модели аффинной проекции: слабоперспективная (вверху) и параперспективная (внизу)
проекции
клонения глубины (рис. 2.9, внизу): используя принятые ранее обозначения
и обозначив через Д прямую, соединяющую оптический центр О с контрольной
точкой R, вначале применяется параллельная проекция в направлении прямой
Д для отображения точки Р в точку Р', принадлежащую плоскости Пг; за-
тем используется перспективная проекция для отображения точки Пг в точку
изображения р.
2.3.2. Уравнения аффинной проекции
Выведем уравнение слабоперспективной проекции. Если через zr обозначить
глубину контрольной точки R, то два этапа проектирования Р —> Р' —> р можно
следующим образом записать в нормированной системе координат, привязанной
к камере:
или, в матричной форме,
Глава 2. Геометрические модели камер
81
Если ввести калибровочную матрицу камеры /С и
и t, получим общий вид уравнения проекции
ее внешних параметров Р
где через Р, как обычно, обозначен неоднородный координатный вектор точ-
ки Р во внешней системе отсчета. Наконец, отметив, что величина zr постоян-
на, можем записать
/С =
/С2
от
def
где К.2 -
—a ctg 6
sin0
def
И Ро =
о
Это позволяет переписать уравнение (2.18) в таком виде:
р =
(2-19)
р = (и, v)T — это неоднородный координатный вектор точки р, а Л4 — проек-
ционная матрица 2x4 (сравните полученный результат с общим уравнением
проекции (2.15)). В этом выражении матрица А размера 2 х 3 и 2-вектор Ь
задаются, соответственно, такими формулами
А = —/С2Т^2 и Ь = —/C2t2 + р0,
zr zr
где 7^2 — матрица 2x3, образованная двумя первыми строками матрицы Р,
a t2 — 2-вектор, образованный двумя первыми координатами вектора t.
Отметим, что в выражении для Л4 не фигурирует tzt и что <2 и р0 в этом
выражении объединены: проекционная матрица не изменится, если заменить t2
на £2 + а и Ро — на Ро — ^-^2а- Эта избыточность позволяет произвольно по-
ложить и0 = v0 — 0. Другими словами, положение центра изображения для
слабоперспективной проекции неважно. Отметим, что значения zrt а и (3 в вы-
ражении для Л4 также объединены, и что значение zr, как правило, заранее не
известно, поэтому можно записать следующее:
82
Часть I. Формирование изображений и модели изображений
М =
(2.20)
где через к и s обозначены, соответственно, формат изображения и. наклон
камеры. В частности, матрица слабоперспективной проекции задаете») двумя
внутренними параметрами (к и з), пятью внешними параметрами (т^и угла,
определяющие 7^2> и две координаты t2) и одним структурным параметром,
зависящим от сцены, — zr.
Легко показать (см. раздел упражнений), что уравнения параперспективной
проекции можно также записать в общей аффинной форме (2.19) с
лл 1 (к
ЛЛ — — |
zr \0
(2.21)
где через хг, уг и zr обозначены координаты контрольной точки R в нормиро-
ванной системе координат камеры. Заметим, что выражение (2.21) сводится (как
и следовало ожидать) к уравнению слабоперспективной проекции (2.20) при
условии хг = уг = 0. Согласно уравнению (2.21) матрица параперспективной
проекции задается двумя внутренними параметрами (к, з), пятью внешними
параметрами (три угла, определяющие 1Z, и две координаты t2) и тремя струк-
турными параметрами хг, уг и zr. На практике, в качестве контрольной точки
часто берется какая-то характерная точка, проекцию которой легко наблюдать
на изображении. Конечно, нельзя измерить на изображении координаты xrt уг
и zr этой точки, но координаты ее проекции иг и vr доступны. Уравнение (2.21)
легко переписать в виде
(2.22)
При такой формулировке матрица параперспективной проекции задается че-
тырьмя внутренними параметрами (к, з, '«□ и т?о), пятью внешними параметрами
(три угла, определяющие 7£, и две координаты t2) и единственным структурным
параметром zr.
Уравнения ортогональной и параллельной проекций получаются из уравне-
ний слабоперспективной и параперспективной проекций, если положить зна-
чение переменной zr равным некоторой фиксированной величине (на практике
часто берут zr — 1) и подставить результат в выражения (2.20), (2.21) или
(2.22). Если одна сцена наблюдается с помощью нескольких различных ортого-
нальных (соответственно, параллельных) камер (или, что то же самое, после-
довательность изображений снимается с помощью камеры с переменным фо-
кусным расстоянием), становятся важными реальные коэффициенты увеличе-
ния изображения, и упрощенные калибровочные матрицы, которые фигурируют
в уравнениях (2.20), (2.21) или (2.22), следует заменить матрицей /С2.
Глава 2. Геометрические модели камер
83
2.3.3. Описание матрицы аффинной проекции
Матрица Л4 — (Л Ь) размера 2x4, где А — произвольная матрица ранга 2
размера 2 х 3, а b — произвольный вектор в пространстве Ж2, называется мат-
рицей аффинной проекции. Условие на ранг следует из того факта, что матрица
первого ранга проектировала бы все точки сцены на одну линию изображения;
отметив также, что матрица А, соотнесенная со слабоперспективными и пара-
перспективными камерами, имеет по построению ранг 2, поскольку, согласно
уравнениям (2.20), (2.21) и (2.22), ее можно записать в виде произведения двух
матриц ранга 2.
Как матрица слабоперспективной проекции, так и общая матрица аффин-
ной проекции задается восемью независимыми параметрами. Матрицы пара-
перспективной проекции, напротив, имеют 10 степеней свободы. Разумеется,
матрицы слабоперспективной и параперспективной проекции являются аффин-
ными. И наоборот, подсчитав параметры, можно убедиться, что должна суще-
ствовать возможность записи произвольной матрицы аффинной проекции в ви-
де слабоперспективной или параперспективной, хотя последнее представление
не будет однозначным, если не наложить дополнительных условий. Сказанное
можно сформулировать в виде следующей теоремы.
Теорема 2. Матрицу аффинной проекции можно единственным об-
разом (с точностью до знака) записать как общую матрицу слабопер-
спективной проекции (2.20) либо как матрицу параперспективной проек-
ции (2.21) или (2.22), причем k = 1 и s = 0.
Доказательство этой теоремы приводится в работе [Faugeras at al., 2001]
и фигурирует в одном из упражнений к данной главе. Из теоремы 2 следует,
что любую аффинную проекцию можно записать как слабоперспективную или
параперспективную, а также что геометрические свойства этих проекционных
моделей присущи и общей аффинной проекции. Например, при слабоперспек-
тивной проекции сохраняется параллельность линий (см. главу 12), а из теоре-
мы 2 следует, что это свойство сохраняется также для произвольной аффинной
проекции. Произвольную матрицу 2x4 всегда можно записать как матрицу
параперспективной проекции с к = 1 и s = 0, однако из этого не следует, что
формат изображения или его наклон не важны.
2.4. ПРИМЕЧАНИЯ
В работе [Craig, 1989] предлагается детальное введение в системы координат
и кинематику. Полное описание геометрических моделей камер можно найти
в публикациях [Faugeras, 1993], [Hartley and Zisserman, 2000] и [Faugeras et
al., 2001]. Модель параперспективной проекции была введена в компьютерное
зрение в работе [Ohta, Maenobu, and Sakai, 1981], а ее свойства исследованы
в [Aloimonos, 1990]. Связь между моделями параперспективной и аффинной
проекции рассмотрена в книге [Basri, 1996]. Уравнения перспективной проек-
84
Часть I. Формирование изображений и модели изображений
ции прямых линий в координатах Плюкера выводятся в работе [Faugeras and
Papadopoulo, 1997], это уравнение также используется в одном из упражнений
к данной главе. Аппарат, представленный в этой главе, используется в главе 3
для решения задачи калибровки камеры (т.е. вычисления ее внутренних и внеш-
них параметров, исходя из положения изображений реперных точек). Он так-
же является ключом к пониманию методов стереозрения и анализа движения,
представленных в главах 10-13. Основные формулы, которые были выведены
в этой главе, собраны в табл. 2.1.
Задачи
2.1. Запишите формулы для матриц ^11, если (В) можно получить из (А)
поворотом на угол 0 вокруг осей г а, /д и &д, соответственно.
2.2. Покажите, что матрицы вращения обладают следующими свойствами: а)
обратная к матрице вращения равна транспонированной и б) ее опреде-
литель равен 1.
2.3. Покажите, что набор матриц, соотнесенный со строгими преобразовани-
ями, плюс правило умножения матриц составляет группу.
2.4. Пусть АТ — матрица, соотнесенная со строгим преобразованием Т в си-
стеме координат (А), где
. (АК
\ 0 1 )
Постройте матрицу ВТ, соотнесенную с Т в системе координат (В) как
функцию АТ и строгое преобразование, переводящее (А) в (В).
2.5. Покажите, что если система координат (В) получается в процессе при-
менения преобразования 7 к системе координат (А), то ВР = Т~1АР.
2.6. Покажите, что поворот на угол 0 вокруг оси к в системе отсчета (В)
можно представить как
(cos 0 — sin 6 о\
sin# cost? 0 I .
0 0 1/
2.7. Покажите, каким образом при переходе от одних координат к другим, ко-
торый выполняется как строгое преобразование, сохраняются углы и рас-
стояния.
2.8. Покажите, что когда система координат камеры наклонена и угол 0 меж-
ду двумя осями изображения не равен 90°, то уравнение (2.11) переходит
в уравнение (2.12).
2.9. Пусть О — однородный координатный вектор оптического центра ка-
меры в некоторой системе отсчета, а Л4 — соответствующая матрица
перспективной проекции. Покажите, что Л1(О) =0.
2.10. Докажите необходимость условий теоремы 1.
Глава 2. Геометрические модели камер
85
2.11. Докажите достаточность условий теоремы 1. Формулировка этой теоремы
немного отличается от приведенной в работах [Faugeras, 1993] и [Неу-
den, 1995], где вместо условия Det(A) Ф 0 указано условие аз -f- 0.
Разумеется, из Det(A) ф 0 следует, что аз 0.
2.12. Если ЛП — однородный координатный вектор плоскости П в системе
координат (А), то каким будет однородный координатный вектор ВП
плоскости П в системе координат (В)?
2.13. Если AQ — симметричная матрица, соотнесенная с поверхностью второго
порядка в системе координат (А), то какой будет симметричная матри-
ца BQ, соотнесенная с этой поверхностью в системе координат (В)?
2.14. Докажите теорему 2.
2.15. Плюкеровские координаты прямой. Внешнее произведение двух век-
торов и и v в пространстве К4 задается как
(U\V2 — «2^1^
щг>з — U3U1
def U1V4 — U4V1
и A v =
U2V3 — U3V2
«2^4 ” ^4^2
\U3U4 ~ U1V3J
Для данной фиксированной системы координат и однородных координат-
ных векторов А и В, соотнесенных с двумя точками А и В в простран-
стве Е3, вектор L = А/\В называется вектором плюкеровских координат
прямой, соединяющей точки А и В.
а) Пусть L = (Li, L2, L3, L4, L&, L6)T. Обозначим через О начало коор-
динат системы, а через Н — его проекцию на L. Определим также
векторы оА и ОВ через их неоднородные координатные векторы.
Покажите, что АВ = — (£3, £5, Lg)t и О А х ОВ = ОН х АВ =
(£4, — £2, Li)T. Покажите, что плюкеровские координаты прямой под-
чиняются квадратическому условию £1£б — L2L5 4- L3L4 — 0.
б) Покажите, что смещение положения точек А и В вдоль прямой £ вли-
яет только на общий масштаб вектора L. Убедитесь, что координаты
Плюкера являются однородными.
в) Докажите, что следующее тождество справедливо для любых векто-
ров х, у, z и t в пространстве R4:
(я Л у) • (z Л t) = (х • z)(y • £) — (х • t)(y • z).
г) Используйте это тождество, чтобы показать, что отображение прямой
с вектором плюкеровских координат £ в ее образ I с однородными
86
Часть I. Формирование изображений и модели изображений
координатами I можно представить следующим образом:
((тпг л тпз)т
(тпз ЛШ1)Г
(mi Лтп2)т
(2.23)
Через mf, тп^ и тп? обозначены строки матрицы М, р — соот-
ветствующий масштабный множитель. Подсказка, рассмотрите пря-
мую L, соединяющую точки А и В и обозначьте через а и b проекции
этих двух точек, имеющие однородные координаты а и Ь. Учтите, что
точки а и b лежат на Z, следовательно, если I — однородный коорди-
натный вектор этой прямой, то I а — I Ъ = 0.
д) Покажите, что для данных прямой L с вектором плюкеровских коор-
динат L = (L1,L2,L3)L4,L5,L6)t и точки Р с однородным коорди-
натным вектором Р необходимое и достаточное условие принадлеж-
ности точки Р прямой L имеет такой вид:
( 0 Ьб —L5 L4 \
гт» п гdel ~L& 0 £з —Li I
£Р = 0, где £ =
Lb —L3 0 Li I
L4 L2 —Lx 0 /
е) Покажите, что необходимое и достаточное условие принадлежности
прямой L плоскости П с однородным координатным вектором П имеет
такой вид:
£*П = 0,
/ 0
где -f1
—L2
\-L3
Lx L2
0 L4
-l4 0
—Lb —L&
Lz\
Lb
L6
oj
3
Гэометрическая калибровка
камер
В этой главе рассматриваются вопросы, связанные с оценкой внутренних
и внешних параметров камеры, т.е. процессом, известным как геометрическая
калибровка камер. В данной книге предполагается, что камера наблюдает
набор характерных элементов, таких как точки или прямые, положение ко-
торых известно относительно определенной фиксированной внешней системы
координат (рис. 3.1). В таком случае калибровку камеры можно смоделировать
как процесс оптимизации, при котором разница между элементами наблю-
даемого изображения и их теоретическими положениями (предсказанными
через уравнения перспективной проекции, которые были выведены в главе 2)
минимизируется относительно внешних и внутренних параметров камеры.
Эта глава начинается с обзора схем наименьших квадратов, предназначен-
ных для решения такого типа задач по оптимизации, затем будет представ-
лено несколько линейных и нелинейных подходов к калибровке. Если камера
откалибрована, то с произвольной точкой изображения можно связать строго
определенный луч, проходящий через эту точку и оптический центр камеры,
а также выполнить точные трехмерные измерения с помощью оцифрованных
изображений. В конце главы описывается применение калибровки для опреде-
ления местонахождения мобильного робота.
88
Часть I. Формирование изображений и модели изображений
Рис. 3.1. Установка для калибровки камеры. В этом примере устройство калибровки состоит из
трех сеток, расположенных во взаимно перпендикулярных плоскостях. Существуют и другие моде-
ли, в которых фигурируют прямые или другие геометрические фигуры
3.1. ОЦЕНКА ПАРАМЕТРОВ ПО СХЕМЕ НАИМЕНЬШИХ КВАДРАТОВ
Калибровка камеры состоит в оценке внутренних и внешних параметров, при
которых среднеквадратическое отклонение наблюдаемых элементов изображе-
ния от теоретически предсказанных становится минимальным. В этом разделе
представлена группа методов оптимизации, известных под названием схем наи-
меньших квадратов, которые применяются для решения задач указанного типа.
Эти методы используются также и в некоторых других ситуациях, описанных
в данной книге.
3.1.1. Линейные схемы наименьших квадратов
Рассмотрим вначале систему р линейных уравнений с q неизвестными:
UllXl + И12ГГ2 -I------h UlqXg = J/l
«21^1 + «22 ^2 -I--h U2qXg = 7/2
<=> Ux = y.
(3.1)
, «pl 3*1 71р2'Г'2 “H * 4“ UpgXg ------ Ур
В этом уравнении
«12 •
и = «21 «22 • U2q
k«pl UP2 ' upqJ
У2
\Ур/
Из линейной алгебры мы знаем, что (в общем случае)
Глава 3. Геометрическая калибровка камер
89
• если р < q, набор решений этого уравнения образует (q — р)-мерное под-
пространство пространства R9;
• если р = q, существует единственное решение;
• если р > q, решений нет.
Это утверждение справедливо, если ранг (т.е. максимальное число неза-
висимых строк или столбцов) матрицы U максимален — т.е. равен min(p, q)
(именно это и имелось в виду, когда мы говорили в общем случае). Если ранг
меньше, чем min(p, g), то существование решений уравнения (3.1) зависит от
значений у и от того, попадают ли они в область значений матрицы U (т.е.
подпространство пространства Rp, натянутое на ее столбцы).
Нормальные уравнения и псевдообратная матрица
Далее в этом разделе рассматривается только ситуация р < q в предполо-
жении, что ранг q матрицы U максимален. В данном случае точного решения
нет, поэтому мы ограничимся определением вектора х, который минимизирует
меру ошибки
Е = ч-----1- UiqXq - yi)2 ~ |Z^C - J/|2.
Мера Е пропорциональна среднеквадратической ошибке, связанной с урав-
нениями, поэтому методы ее минимизации называются схемами наименьших
квадратов.
Теперь можно записать Е — ее, где е = Ux—y. Для нахождения вектора х,
минимизирующего Е, запишем, что производные этой меры по координатам х±
(г = 1,..., q) вектора х должны равняться нулю, т.е.
дЕ де
---=2----- е = 0 для г=1,...,д.
dxi dxi
Если столбцы матрицы U — это векторы Cj = (и^,... ,umj)T (j = l,...,q),
имеем
1 / X1 I
c9 I • - - у
/ \^/
de
dxt
dxi
= ----(XlCl 4-----Г XqCq — у) = C*.
dxi
В частности, при записи дЕ/dxi = 0 подразумевается, что c[(Ux — у) — 0, а
наложение дополнительных условий, связанных с q координатами вектора х,
дает нормальные уравнения задачи наименьших квадратов, т.е.
90
Часть I. Формирование изображений и модели изображений
(т\
^1 \
• • (W® - у) = UT(Ux - у) <=> UTUx = UTy.
ст
/
Если ранг q матрицы U максимален, то легко показать, что матрица UTU об-
ратима, а решение нормальных уравнений — ж — U^y, где W = [(L/TW)-1L/T].
Матрицу W размера q х q называют псевдообратной к U. Если матрица U
квадратная и несингулярная, то совпадает с Линейные задачи наи-
меньших квадратов можно решать без сложных вычислений псевдообратных
матриц, используя, например, QR-разложение или разложение по сингулярным
числам матрицы (более подробно см. главу 12), которые, как известно, имеют
лучшее численное поведение.
Однородные системы и задачи на собственные значения
Рассмотрим теперь исходную задачу, если есть система из р линейных урав-
нений с q неизвестными, но вектор у равен нулю, т.е.
U11X1 4- U12X2 -I--Ь UlqZq = 0
«21X1 + «22^2 4----+ U24X4 = 0
(3.2)
UplXl 4- Up2X2 -I--Ь UpqXq = 0
Это однородное уравнение по х (т.е. если х — решение, решением будет также
и Л ж для любого А / 0). Если р = q и матрица U несингулярна, то допускает-
ся существование единственного решения уравнения (3.2) ж = 0. И наоборот,
если р > q, то нетривиальное (т.е. ненулевое) решение может существовать
только если U сингулярна, и ее ранг строго меньше q. В таком случае ми-
нимизация Е = |27ж|2 имеет смысл только тогда, когда на ж накладываются
какие-то дополнительные условия, поскольку значение ж = 0 дает глобальный
минимум Е в нуле. Из однородности следует, что Е(Хх) = Х2Е(х), и разум-
ным будет выбор условия |ж|2 = 1, что поможет избежать тривиальных решений
и даст единственный результат.
Ошибку Е можно переписать как |£Уж|2 = xT(UTU)x. Матрица UTU раз-
мера q х q по построению является симметричной положительной полуопре-
деленной матрицей (т.е. все ее собственные значения положительны или рав-
ны нулю) и может быть диагонализована в ортонормированном базисе соб-
ственных векторов ei (i = 1, ...,g), соотнесенных с собственными значения-
ми 0 < А1 < • • • < Ад. Таким образом, любой единичный вектор можно записать
как ж = p^ei -|--к Мдвд, где р2 4-4- /х2 = 1. В частности,
Е(х) - E(ei) = xT(UTU)x - е?(UTU)ei = А?д? + • + Х2р2 - Xj >
> Al (mi +--------------1- /I, — 1) = 0.
Глава 3. Геометрическая калибровка камер
91
Рис. 3.2. Прямую, которая лучше всего соответствует п точкам на плоскости, можно определить
как прямую 5, среднеквадратическое расстояние от которой до этих точек (на этом рисунке —
среднеквадратическая длина коротких параллельных отрезков прямой, соединяющих прямую 6
с этими точками) минимально
Из этого следует, что единичный вектор х, минимизирующий Е, — это соб-
ственный вектор ej, соотнесенный с минимальным собственным значением
матрицы UTUt а соответствующее минимальное значение Е — А?. Суще-
ствуют различные способы вычисления собственных векторов и собственных
значений симметричных матриц, включая преобразования Якоби и приведение
к тридиагональному виду с последующим QR-разложением. Для вычисления
собственных векторов и собственных значений без построения матрицы UTU
можно воспользоваться также разложением по сингулярным числам.
Перед тем как перейти к иллюстрации применения линейных методов наи-
меньших квадратов, рассмотрим более общую задачу минимизации |Wa:|2 при
условии |Уж|2 = 1, где V — матрица размера г х q (задача сводится к примене-
нию однородной линейной схемы наименьших квадратов при У = Id). Вектор х
и скаляр А, такие что
UrUx=АУтУя,
называются, соответственно, обобщенным собственным вектором и обобщен-
ным собственным значением симметричных матриц UTli и VTV размера qxq.
Как показано в разделе упражнений, решение этой ограниченной задачи опти-
мизации — в точности единичный обобщенный собственный вектор, соотнесен-
ный с минимальным обобщенным собственным значением (которое в данном
случае обязательно будет положительным или равным нулю по построению).
Для вычисления обобщенных собственных векторов и собственных значений
пары симметричных матриц разработаны эффективные методы.
92
Часть I. Формирование изображений и модели изображений
Пример 3.1. Подбор прямой по точкам на плоскости
Рассмотрим п точек pi (г = 1,.... п) на плоскости с координатами (х*,у*) в неко-
торой фиксированной системе координат (рис. 3.2). Как лучше всего провести
прямую по этим точкам? Чтобы ответить на поставленный вопрос, сперва сле-
дует определить, насколько прямая S соответствует набору точек или, что то же
самое, найти некоторую функцию ошибок Е, являющуюся мерой отличия этой
прямой и точек. Таким образом, самую подходящую прямую можно будет найти,
минимизируя Е.
В качестве функции ошибок разумным будет выбрать среднеквадратическое рас-
стояние от точек до прямой (рис. 3.2). В главе 2 было показано, что уравнение
прямой с единичной нормалью п — (а, Ь)т, лежащей на расстоянии d от нача-
ла координат, выглядит так: ах + by — d. Действительно, легко показать, что
расстояние от точки с координатами (х,у)т до этой прямой равно |ах + by — d|.
Следовательно, можно использовать величину
п
Е(а, b, d) = ^^(axj 4- byi — d)2
1=1
в качестве функции ошибок, и задача подбора прямой сводится к минимизации Е
относительно a, bud при условии a2 + b2 = 1. Дифференцируя Е по d и учитывая,
что в минимуме этой функции 0 = dE/dd = -2127=1(“3'’ + byi — d), получаем:
1 " 1 "
d — ax + by, где а: = — и у= — / yi, (3.3)
п £=1 п 1=1
а два скаляра х и у — это координаты центра масс заданных точек. Подставив
в определение Е вместо d данное выражение, получим
п !х\ - х yi - у
Е = lo(x* -+ b(yi — у)]2 = |£6г|2, где U = I
1=1 \^п - х уп - у
Таким образом, наша исходная задача сводится к минимизации |Wn|2 относитель-
но п при условии |n|2 = 1. При такой формулировке можно узнать однородную
линейную задачу наименьших квадратов, решением которой является единичный
собственный вектор, связанный с минимальным собственным значением матри-
цы UTU размера 2x2. Вычислив а и Ь, из уравнения (3.3) можно сразу получить
значение d. Легко показать, что матрица UTU равна
/ п 71 '
У^Д2 — пх2 y^Xiyi — пху
1=1 1=1
П Т1
J^^iyi - пху У^уг? - пу2
1=1 1=1 ‘
Глава 3. Геометрическая калибровка камер
93
т.е. матрице вторых моментов инерции точек р*. Фактически, прямая, которая луч-
ше всего соответствует этим точкам (как она определена выше) — это просто их
ось наименьшей инерции, определение которой дается в элементарной механике.
3.1.2. Нелинейные схемы наименьших квадратов
Рассмотрим теперь общий случай: система из р уравнений с q неизвестными:
.. ,хч) = О
/2(х1,х2,...,х,) = 0 ^f(x}=Q (34)
fp(Xl,X2,. . . ,Xq) — О
Здесь через fa (i = обозначены (возможно, нелинейные) дифференци-
руемые функции из BF в К при f = (Д,..., fp)T и х = (xi,..., xq)T. В общем
случае,
♦ если р < д, решения образуют (q — р)-мерное подмножество К9;
• если р = q, существует конечное множество решений;
• если р > q, решений нет.
Подчеркнем главные отличия от линейной задачи: в общем случае размер-
ность множества решений при отсутствии дополнительных ограничений все
еще q — р, но это множество уже не образует векторного пространства. Его
структура зависит от природы функций fa. Кроме того, в случае р = q обыч-
но существует конечное число решений вместо единственного решения. Точное
определение общих условий, при которых семейство функций Д (i = 1,...,р)
удовлетворяет предыдущему условию, в данной книге не рассматривается. От-
метим также, что не существует общего метода нахождения всех решений урав-
нения (3.4) в случае р — q или определения глобального минимума ошибки
схемы наименьших квадратов
р
Е(«)Й|/(х)Г =
1=1
в случае р > q. Вместо этого далее представлен ряд итеративных методов лине-
аризации данной задачи, чтобы найти хотя бы одно подходящее решение. Все
эти методы основаны на разложении функций fa в ряд Тейлора в окрестности
точки х.
dfa dfa 9
fa(x Ч- 6х) = fa(x) Ч- 6xi----(х) Ч-----Ь 6х9-----(х) Ч- О(|<5ж|2) « Д(х) Ч- Х7Д(а;) • 5х
дху дхч
94
Часть I. Формирование изображений и модели изображений
Здесь 57Л(гс) = (dfi/dxi,... ,dfi/dxq)T — градиент функции fa в точке х, а
членом второго порядка О(|£г|2) мы пренебрегаем. Из этого непосредственно
следует, что
f(x + баз) ~ f(x) + Jf(x)Sx,
(3-5)
где Jj (ж) — якобиан функции / — т.е. матрица р х q
Jf№ =
(Bfl. ' (ж) * дх± dfa. X “ (ж) dXq
dfP( .
(ж) .. (a?)
\&Е1 дхчК
Метод Ньютона: квадратные системы нелинейных уравнений
Как уже упоминалось ранее, уравнение (3.4) допускает (в общем случае)
конечное число решений при р = q. Хотя общего метода для нахождения всех
этих решений для произвольной функции f не существует, в качестве простого
итеративного алгоритма для определения одного решения можно использовать
уравнение (3.5): если есть какая-то текущая оценка решения х, то далее вы-
числяется возмущение ёх этой оценки, чтобы f(x + ёх) ~ О, или, согласно
уравнению (3.5),
Jj(x)Sx = -/(ж).
Если якобиан несингулярен, то ёх легко находится как решение указанной
системы q х q линейных уравнений, и этот процесс повторяется до схождения.
Метод Ньютона дает быструю сходимость при приближении к решению: он
обладает квадратической скоростью сходимости (т.е. ошибка на шаге k -|- 1
пропорциональна квадрату ошибки на шаге к). Если первоначальная оценка
далека от решения, то метод Ньютона может оказаться ненадежным. Для уси-
ления его надежности применяются различные стратегии, но в этой книге они
не описаны.
Метод Ньютона: системы нелинейных уравнений с дополнительными
условиями
При р > q нужно найти локальный минимум среднеквадратической ошиб-
ки Е. Метод Ньютона можно модернизировать для такого случая, поскольку
требуемый минимум соответствует нулю градиента функции ошибок. Введем
функцию F(x) = -VE(x) и воспользуемся методом Ньютона для нахожде-
ния требуемого минимума как решения системы q х q нелинейных уравне-
Глава 3. Геометрическая калибровка камер
95
ний F(x) = О. Дифференцирование Е дает
F(x) = jJ(x)/(x),
(3.6)
а из дифференцирования этого выражения, в свою очередь, видно, что якобиан
функции F равен
Л-(х) = Jj (x)Jt(x) + £ Л(х)ЯЛ (х).
(3.7)
В этом уравнении Нц(х) — гессиан функций т.е. матрица вторых произ-
водных размера q х q
/ d2fif . 02fi \
—^(я:) ... -----(х)
НЛ(®)
-----(х) ---J* (ж)
\dxiXq дх2 /
Член 6х в методе Ньютона удовлетворяет условию ^р(х)5х — — F(x). Эквива-
лентно, из уравнений (3.6) и (3.7) следует, что 5х — это решение уравнения
5j(x)y/(x) + £ Л(х)НЛ(х) Зх = -J^(x)/(x).
(3.8)
Алгоритмы Гаусса-Ньютона и Левенберга-Макардта
Метод Ньютона требует вычисления гессианов функций fi, что может ока-
заться слишком сложным и/или дорогим. Ниже описаны два других подхода
к нелинейным схемам наименьших квадратов, которые не требуют вычисления
гессианов. Рассмотрим вначале алгоритм Гаусса-Ньютона: при этом подходе
для минимизации Е снова используем разложение вектора 6х в ряд Тейлора
до членов первого порядка, но на этот раз будем искать значение 6х, которое
минимизирует величину Е(х 4- 8х) при данном значении х. Подстановка (3.5)
в (3.4) дает такой результат:
Е(х 4- <5х) = |/(ж 4- <5х)|2 ~ |/(ж) 4- Jj(х)6х|2.
Обратимся повторно к выкладкам для линейной схемы наименьших квадратов
и рассчитаем поправку 8х как решение уравнения J^(x)8x = — f(x) или, что
то же самое (согласно определению псевдообратной матрицы),
jj(x)jf(x)5x = -J}(x)f(x).
(3.9)
Сравнивая уравнения (3.8) и (3.9), можно заключить, что алгоритм Гаусса-
Ньютона — это приближение метода Ньютона, в котором пренебрегают членом,
96
Часть I. Формирование изображений и модели изображений
содержащим гессиан Такой подход справедлив, когда значения функций fa
(остатки) малы, поскольку в уравнении (3.8) матрицы Н/, умножаются на эти
остатки. В данном случае производительность алгоритма Гаусса-Ньютона срав-
нима с производительностью метода Ньютона, который имеет (почти) квадра-
тичную сходимость в окрестности решения. В то же время, если остатки очень
велики, сходимость может быть медленной или вовсе отсутствовать.
Если уравнение (3.9) заменить уравнением
[Jf (®) + /zld]6aj = (3.10)
где параметр р может варьироваться при каждой итерации, получается алго-
ритм Левенберга-Макардта, распространенный в областях, связанных с ком-
пьютерным зрением. Это еще одна разновидность метода Ньютона, в которой
член, содержащий гессианы, считается кратным единичной матрице. Сходи-
мость алгоритма Левенберга-Макардта сравнима со сходимостью другого пред-
ставителя этого семейства, — алгоритма Гаусса-Ньютона, — но этот алгоритм
несколько устойчивее: например, его можно использовать, когда якобиан
не имеет максимального ранга и не существует его псевдообратной матрицы.
3.2. ЛИНЕЙНЫЙ ПОДХОД К КАЛИБРОВКЕ КАМЕРЫ
Вернемся к задаче геометрической калибровки камер. В этом разделе бу-
дем считать, что камера наблюдает калибровочную установку, и что положе-
ния п точек изображения Pi (г = 1, ...,п) с известными однородными
координатными векторами Pi были определены (автоматически или вручную)
на сетке установки. Разделим процесс калибровки на а) вычисление матрицы
перспективной проекции Л4, соотнесенной с камерой в этой системе координат,
и б) оценку внутренних и внешних параметров камеры по данной матрице. О
вырожденных точечных конфигурациях, для которых первый шаг этого про-
цесса неосуществим, речь пойдет в разделе 3.2.3. Легко показать, что если
точки pi — перспективные изображения точек Л, получается набор из п ли-
нейных условий на 11 независимых коэффициентов соответствующей проекци-
онной матрицы. При п > 11 эти уравнения обычно не имеют общего корня, но
для эффективного построения их решения с точки зрения схемы наименьших
квадратов можно использовать методы, описанные в разделе 3.1.1.
3.2.1. Оценка проекционной матрицы
Допустим, что камера имеет ненулевой перекос. Согласно теореме 1 из гла-
вы 2, матрица /Л несингулярная, но произвольная. Избавляясь от знаменателя
в уравнении перспективной проекции (2.16), получаем
{(ТП1 — и,П1з) • Р = О,
(m2 — verna) • Р = 0.
Глава 3. Геометрическая калибровка камер
97
Рассмотрев все условия, связанные с п точками, получим систему 2п однород-
ных линейных уравнений на двенадцать коэффициентов матрицы Л4, а имен-
но Рт = 0, где
ог от Р1 -«1РП -ViPf def и тп = (mi тп2
р1 к ог от рТ * п Еч с Еч С Йч о, £ С 3 & 1 1 <тп3
= 0.
Если п > 6, то для вычисления минимизирующего (Pm)2 значения единичного
вектора т (следовательно, и матрицы Л4) как решения задачи на собствен-
ные значения можно использовать однородную линейную схему наименьших
квадратов.
3.2.2. Оценка внутренних и внешних параметров
После оценки проекционной матрицы М ее выражение через внутренние
и внешние параметры камеры (уравнение (2.17) в главе 2) можно использовать
для нахождения этих параметров: записываем Л4 = (Л Ь), где через af, а?
и аз обозначены строки матрицы А, и получаем:
Л1 \
«2 =
oj /
^ar^ — a ctg Or J + «01*3
0 Т , т
----Г2 +ЗДГз
sin#
k )
где р — неизвестный масштабный коэффициент, который вводится для учета
того факта, что найденная матрица М. имеет единичную фробениусову форму,
поскольку |Л4| = |m| = 1.
Учитывая, что строки матрицы вращения имеют единичную длину и пер-
пендикулярны друг другу, непосредственно получаем
р = £/|о3|,
гз = ра3,
ио = p2(ai • аз),
k vo = р2(а2 • аз),
где е = =fl.
(З.П)
Так как в всегда находится в положительной окрестности тг/2, имеем
р2(сц х аз) = — аг2 — actg0ri,
р (а2 х а3) =-----ri,
sin#
21 „ I II
р [ai х а3| =--------,
sin#
2| . I
р |а2 х а3| =--------.
sin#
(3.12)
98
Часть I. формирование изображений и модели изображений
Отсюда следует, что
(ai х а3) (аг х а3)
cost* =------------------------,
|ai х а3||а2 х а3|
а = p2|ai х a3|sin0,
/3 = р2|а2 х а3| sin0,
(3.13)
поскольку знак множителей а и Д обычно известен заранее, вследствие чего
эти коэффициенты можно принять положительными.
Теперь из второй части уравнения (3.12) можно вычислить ri и
р2 sinO 1
ri =--------fa2 х a3) -------------(a2 x a3
' /3 |a2 x a3|
(3.14)
r2 = r3 x Ti.
Отметим, что выбрать матрицу Р можно двумя способами в зависимости от
значения е. Найдем теперь параметры трансляции, использовав условие JCt =
pb, откуда t = р/С-1Ь. На практике знак tz обычно известен заранее (это
равнозначно тому, что известно, где находится начало координат: перед камерой
или за ней), что позволяет выбрать единственное решение для калибровочных
параметров.
3.2.3. Вырожденные точечные конфигурации
Теперь рассмотрим вырожденные конфигурации точек Pi (г = 1,...,п),
которые могут вызвать сбой в процессе калибровки камеры. Сосредоточим наше
внимание на (идеальном) случае, когда заданные точки (г = 1,..., п) можно
измерить с нулевой ошибкой и определим нуль-пространство матрицы Р (т.е.
подпространство пространства R12, образованное векторами I, причем Р1 ~ О).
Пусть I — вектор, удовлетворяющий заданным условиям. Введем векто-
ры, образованные последовательными четверками его координат (т.е. А =
Р = и I/ = (/g,/ioJii,ii2)T), теперь можно запи-
сать, что
/рТх-и1р1иУ
Plp-ViPfu
Р7пХ - ипР?„
{РпР - УпрТ&)
(3.15)
Объединение уравнений (2.16) и (3.15) дает
Глава 3. Геометрическая калибровка камер
99
Избавляясь от знаменателя и приводя подобные слагаемые, наконец, получим
р[(Хтпз — mivT)Pi == О,
РТ(1лтпз — m2VT)Pi = О,
для i = 1,... ,п.
(3.16)
Как и ожидалось, вектор I, соотнесенный с Л = mi, д = т2 и I/ = тп^,
представляет решение этих уравнений. Существуют ли другие решения?
Рассмотрим сперва случай, когда все точки Pi (г = 1,..., п) лежат в некото-
рой плоскости П — т.е. согласно уравнению (2.2), для какого-то 4-вектора П:
П . = 0. Очевидно, что выбор (Л, д, 1/) в виде (11,0,0), (0,11,0), (0,0,11)
или любой другой линейной комбинации этих векторов даст решение уравне-
ния (3.16). Другими словами, нуль-пространство матрицы Р содержит четырех-
мерное векторное пространство, образованное этими векторами и тп. На прак-
тике это означает, что исходные точки Р» не обязательно должны все лежать
в одной плоскости.
В общем случае, для заданного ненулевого значения вектора Z, точки Р»,
удовлетворяющие уравнению (3.16), должны лежать на линии пересечения двух
поверхностей второго порядка, которые описываются соответствующими урав-
нениями. Если повнимательнее присмотреться к уравнению (3.16), можно обна-
ружить, что линия пересечения плоскостей, которые описываются уравнениями
тп3-Р = 0 и и Р ~ 0, принадлежит обеим поверхностям второго порядка. Мож-
но показать, что линия пересечения этих двух поверхностей состоит из этой
прямой и неплоской кривой третьего порядка Г, проходящей через начало ко-
ординат. Неплоская кривая третьего порядка полностью определяется шестью
точками, лежащими на ней, а из этого следует, что случайно выбранные семь
точек не лежат на Г. Так как эта кривая проходит через начало координат,
выбор п > 6 случайных точек обычно гарантирует, что ранг матрицы Р будет
равен И и что проекционную матрицу можно восстановить однозначно.
3.3. УЧЕТ РАДИАЛЬНОГО ИСКАЖЕНИЯ
До сих пор считалось, что рассматриваемая камера оснащена совершенными
линзами. Как отмечалось в главе 1, реальные линзы обладают рядом аберра-
ций. В этом разделе показано, как учитывается радиальное искажение — тип
аберрации, который зависит от расстояния, отделяющего оптическую ось от
рассматриваемой точки. Предположим, что центр изображения известен, поэто-
му можно положить uq = vo — 0 и следующим образом смоделировать процесс
проектирования:
О 0\
1/А О I МР,
0 V
(3.17)
где А — полиномиальная функция квадрата расстояния d2 от центра изображе-
ния до точки р изображения. В большинстве приложений успешно использу-
100
Часть I. Формирование изображений и модели изображений
ются полиномы малых степеней (т.е. А = 1 + Sp=i «р^2р> где q < 3), а коэф-
фициенты искажения Кр (р = 1,..., q) обычно считаются малыми. Отметим,
что d2 естественно выражается через нормированные координаты изображения
точки р (т.е. d2 = й2 + г)2). Подстановка ид = 0 и vq — 0 в уравнение (2.13)
позволяет после некоторых алгебраических преобразований переписать d2 как
функцию и и v:
d2 =
и2
а2
V2 UV
4—- + 2— cos0.
02
(3.18)
Используем уравнение (3.18) для записи А как явной функции и и v и подста-
вим результат в уравнение (3.17), что даст сильно нелинейные условия на д+11
параметров камеры. Хотя все эти параметры можно найти с помощью общих
нелинейных схем наименьших квадратов, представленных в следующем разде-
ле, удобнее использовать двухэтапный подход к решению задачи калибровки:
исключение А из уравнения (3.17) позволяет использовать линейную схему наи-
меньших квадратов для оценки девяти параметров камеры. Оставшиеся q + 2
параметра рассчитываются из уравнений (3.17) и (3.18) с помощью простого
нелинейного процесса.
3.3.1. Оценка проекционной матрицы
С геометрической точки зрения радиальное искажение изменяет расстояние
от центра изображения до точки изображения р, но не влияет на направле-
ние вектора, соединяющего эти две точки. Данное утверждение — условие
радиального выравнивания — было введено Тсаи ([Tsai, 1987а]). Это условие
можно представить алгебраически, записав
(mi РУ
тз • Р
ТП2 • Р
\тпз Р)
=Ф v(m± • Р) — и(тп2 • Р) = 0.
(3.19)
Для данных п исходных точек получается п линейных уравнений, содержащих
восемь коэффициентов векторов mi и тпг-
(viPi
Qn = 0, где Q = I
Рт
\ип* п
(3.20)
Отметим сходство с предыдущим случаем. При п > 8 эта система уравнений
в общем случае является переопределенной, а решение с единичной нормой
можно найти с помощью линейного метода наименьших квадратов.
Глава 3. Геометрическая калибровка камер
101
3.3.2. Оценка внутренних и внешних параметров
Как только оценены mi и тпг» можно, как и ранее, найти соответствующие
значения ai и аг и записать
Р
arf — actgffr^ 4- uorj
0 Т . т
----r2 +и0Г3
sin 6
Вычислив норму и скалярное произведение векторов ai и аг, непосредственно
получаем характеристическое соотношение и перекос камеры:
£ _ la2l
a |ai |
0,1 • 0,2
И COS0 =--------------.
|ai||a2|
(3-21)
Использовав тот факт, что ?2 — это вторая строка матрицы вращения и, еле
довательно, данный вектор имеет единичную норму, получим
a = £p|ai|sin0 и /3 = ep|a2| sinfl,
(3.22)
где, как и прежде, е = ^1. После некоторых простых алгебраических преобра-
зований получим
€ / 1 COS 0 \
П = ------- I --<21 ч-----0,2 I ,
sin# \|ai| |a2| /
е
г2 = -—-а2.
|а2|
Применение этих уравнений и соотношения г3 = п хгг позволяет восстановить
матрицу вращения TL с точностью до двойной неопределенности. Можно также
восстановить два параметра трансляции, записав
atx — a etg 0ty\
0 , = Р
sin# J
где и Ьг - первые две координаты вектора Ь, что, в свою очередь, позволяет
рассчитать эти параметры tx и ty как
£ /61 62COS0
= ----- I-------1------
sin# \|ai| |a2|
e62
tv = •
|a2|
Без дополнительных условий, имея только значения mi и тпг, невозможно
определить tz и абсолютный масштаб коэффициентов увеличения или зна-
чение р. Чтобы оценить эти параметры, вернемся к исходным проекционным
102
Часть I. Формирование изображений и модели изображений
уравнениям: перепишем левую часть уравнения (3.19) как
(mi - Aum3) - Р = О,
(m2 — Х-итпз) Р = 0.
Здесь mi и m2 известны и, согласно уравнению (2.17), тп^ — (rj t2), где
также известно гз. Подставив теперь выражение для d2 (уравнение (3.18)) в вы-
ражения для а, (3 и cos# (уравнения (3.21) и (3.22)), получим
2 1 |uo2 — fai|2
d —---------------,
р2 |си х а2|2
а если подставить это значение в уравнение (3.23), получится нелинейное
уравнение по р, tz и параметрам искажения кр (р = 1,..., д). При доста-
точном числе точек, для определения этих параметров можно использовать
нелинейные схемы наименьших квадратов, которые были представлены в раз-
деле 3.1.2. Эти методы итеративны и требуют начальных предположений обо
всех неизвестных. Разумную оценку р и tz можно найти, применив линейную
схему наименьших квадратов с начальным предположением А = 1. Подобным
образом, разумным будет начальное предположение, что параметры искажения
равны нулю. Как и прежде, двойной неопределенности можно избежать, если
знак tz известен заранее.
3.3.3. Вырожденные точечные конфигурации
Определим вырожденные точечные конфигурации, для которых векторы
mi и m2 нельзя определить однозначно. При заданном векторе I в нуль-
пространстве можно определить векторы А = W4)T и д = (15,1б>17,1&)т
и записать
O = QZ =
ViP^X — uiPip.
VnP?X - UnpTp,
Подставляя значения щ и перегруппируем члены и избавимся от знаменате-
ля, в результате
РТ(чгП2Хт — mip,T)Pi = 0 для i = 1,..., п. (3.24)
Решением данных уравнений (при отсутствии помех, т.е. когда все точки изоб-
ражения точны) является вектор I, связанный с А = mi и д = m2. Когда
все точки Pi (i = 1,..., п) лежат в некоторой плоскости П или, что то же
самое, для какого-то 4-вектора П справедливо П • Рг = 0, можно выбрать
(А,д) равными (П, О), (0,П) или любой линейной комбинации этих двух век-
торов и построить решение уравнения (3.24). Нуль-пространство матрицы Q
включает трехмерное векторное пространство, натянутое на эти векторы и I.
Глава 3. Геометрическая калибровка камер
103
Таким образом, для описанного метода калибровки нельзя использовать точки,
которые лежат в одной плоскости.
В результате при заданных значениях Аид, точки Р», если они лежат
на поверхности второго порядка, которая описывается уравнением (3.24), об-
разуют вырожденную конфигурацию. Отметим, что эта поверхность содержит
четыре прямых линии, которые определяются уравнениями Л • Р = д • Р = 0,
АР = mi • Р — 0, д Р = тп2 • Р ~ 0 и mi • Р — т2 • Р = 0. Следовательно,
поверхность должна состоять из двух плоскостей или быть конусом, однолист-
ным гиперболоидом или гиперболическим параболоидом. В любом случае, для
достаточно большого числа точек с общим расположением данная задача наи-
меньших квадратов допускает существование единственного решения.
3.4. АНАЛИТИЧЕСКАЯ ФОТОГРАММЕТРИЯ
Во всех рассмотренных ранее методах не учитывались некоторые условия,
связанные с процессом калибровки. Например, перекос камеры в разделе 3.2
считался произвольным, а не нулевым (или очень близким к нулю). В этом раз-
деле описан нелинейный подход к калибровке камеры, в котором учитываются
все важные условия. Этот подход пришел из фотограмметрии — инженерной
области, которая занимается количественной обработкой геометрических дан-
ных, полученных из одного или нескольких изображений, которые применяются
в картографии, военном деле, городском планировании и т.д. На протяжении
многих лет фотограмметрия основывалась на сочетании геометрических, опти-
ческих и механических методов изучения трехмерных данных, получаемых из
рисунков, но наступление эры компьютеров в 1950-х сделало возможным чисто
вычислительный подход к этой задаче. Здесь стала широко применяться анали-
тическая фотограмметрия, где внутренние параметры камеры определяют ее
внутреннюю ориентацию, а внешние параметры — ее внешнюю ориентацию.
Предположим снова, что наблюдаются п исходных точек Р» (г — 1,...,п),
положения которых известны в какой-то внешней системе координат. Мини-
мизируем среднеквадратическое расстояние от измеренного положения
их изображений до положений (и,, и,), предсказанных уравнением перспектив-
ной проекции по отношению к вектору параметров камеры £ = (Ci>--->Cg)T
(9 > 11), который, кроме обычных внутренних и внешних параметров, может
включать различные коэффициенты искажения. Ошибку метода наименьших
квадратов можно записать как
я«) = £[(&«) - ш)2 + (й«) - и)’],
1=1
где
.^dermi^.P* der^2(€) Pi
= -------- и Vi(f) = --------.
т3(€)-Р* т3(€)Р«
104
Часть I. Формирование изображений и модели изображений
В противоположность случаям, которые рассматривались ранее, зависимость
каждого вектора ошибок от неизвестных параметров £ нелинейна. Она пред-
ставляет собой комбинацию полиномиальных и тригонометрических функций.
Минимизация общей ошибки, измерений включает применение нелинейных
алгоритмов по схеме наименьших квадратов, которые обсуждались в раз-
деле 3.1.2. Перепишем функцию ошибок согласно форме записи, введенной
в этом разделе.
в«) = 1/«)|2 = Е f? (О, где ( для i = 1...п.
I =vi(()-vi
Для методов Гаусса-Ньютона и Левенберга-Макардта, описанных в разделе
3.1.2, необходим градиент функций fj, а для метода Ньютона необходимы и их
градиент, и гессиан. Здесь мы рассчитаем только градиент или якобиан /.
Для сокращения выражений введем аргумент £ и определим £* = тп^ • Р», & =
т2 • Pi и Zi = m3 - Pi (г = 1,..., п), так что щ = Xi/ii и v, = yi/zi. Получаем
д£з
df2i
д£з
дй{ 1 dii Xi dzi
dvi 1 dyi yi dzi
— I Pi) ~ й^(тз •Pi)
1 ( д d S
— I ~(m2 • P0 “ ^ — (^3 • Pi)
zi \ &£з &£з /
Последнее выражение легко переписать в виде
д^з _±(рТ °Т -“‘РП 'Т
dhi "ii\oT PT -viPTJ
\ /
где m — вектор из пространства R12, соотнесенный с матрицей Л4, а через Згп
обозначен ее якобиан относительно В результате якобиан / будет получен
в следующем виде:
Глава 3. Геометрическая калибровка камер
105
Рис. 3.3. Эксперименты по калибровке. Слева: одно из 20 данных изображений; имеется сильное
радиальное искажение. Вверху фотографии изображен мобильный робот с характерным светодио*
дом. Справа: средняя и максимальная ошибка проектирования (в пикселях) по 20 изображениям.
Программное обеспечение для калибровки и локализации любезно предоставлено Мишелем Дэ-
ви (Michel Devy). Экспериментальные данные любезно предоставлены Фредом Ротгангером
(Fred Rothganger)
В этом выражении щ, vi, Zi и Pi зависят от рассматриваемых точек, a Jm
зависит только от внутренних и внешних параметров камеры. Отметим, что
этот метод требует явной параметризации матрицы Я. Подобная параметриза-
ция через три элементарных поворота вокруг координатных осей упоминалась
в главе 2. Вообще, существует множество параметризаций, которые можно ис-
пользовать (см. раздел упражнений и главу 21).
3.5. ПРИЛОЖЕНИЕ: ОПРЕДЕЛЕНИЕ МЕСТОНАХОЖДЕНИЯ
МОБИЛЬНОГО РОБОТА
Методы калибровки, представленные в этой главе, могут применяться в ря-
де областей, от метрологии до стереозрения и определения местонахождения
объекта в задачах с использованием роботов. Ниже вкратце описан нелиней-
ный подход к калибровке камеры, предложенный Дэви ([Devy, et al., 1997]),
и его применение для определения местонахождения мобильного робота. В от-
личие от рассмотренных методов, здесь для калибровки неподвижной каме-
ры используется несколько изображений (в описанных экспериментах — 20)
плоской прямоугольной сетки (рис. 3.3). Одно из этих изображений включает
расположенную на земле сетку и применяется для определения внешней си-
стемы координат. После ручного установления местонахождения “на глаз” на
каждом рисунке определяются углы сетки с точностью до 1/10 пикселя, для
чего используется параметрическая модель поверхности с градацией яркости
в окрестности угла.
106
Часть I. Формирование изображений и модели изображений
Геометрия изображения моделируется так же, как и в разделе 3.3, с тремя
коэффициентами радиального искажения и нулевым перекосом. Калибровоч-
ный алгоритм дает один набор внутренних параметров и один набор внешних
параметров для каждого исходного изображения. Начальное предположение о
внутренних параметрах можно получить из информации, предоставленной про-
изводителями камеры и механизма фиксации кадра. Начальное предположение
о внешних параметрах можно получить для каждого отдельного изображе-
ния с помощью одного из алгоритмов Тсаи ([Tsai, 1987а]). Таким образом,
проекционная матрица оценивается с помощью линейного метода наимень-
ших квадратов путем выбора координатной оси z внешней системы координат,
перпендикулярной к калибровочной сетке. Таким образом, уравнение (3.20)
приобретает вид
/ V1X1
Q'n = 0,
где Q' =
\г?пх,
viyi
УпУп
V1 —ЩХ1
Vn UnXn
-uiyi
—Uiyn
-Ui
-Un
н n1 = (mn,mi2,mi4,ni2i,ni22,ni24)T-
Отметим, что явное наложение условия Zi — 0 помогает избежать вырож-
дения, характерного для описанных ранее алгоритмов, в которых фигурируют
компланарные точки. Если известен вектор п', можно без особых трудностей
рассчитать внешние параметры, при этом предполагается, что внутренние пара-
метры (приблизительно) известны (см. раздел упражнений). Приняв разумные
начальные предположения о внешних и внутренних параметрах, можно исполь-
зовать нелинейную схему оптимизации (в данном случае алгоритм Левенберга-
Макардта) для минимизации среднеквадратического расстояния между пред-
сказанными и наблюдаемыми элементами изображения.
На рис. 3.3 показаны результаты экспериментов, проводившихся с помощью
камеры 576 х 768, оснащенной 4,5-миллиметровой линзой, и приводится график
ошибок при проектировании углов сетки калибровочной модели на 20 изобра-
жений. Как только камера будет откалибрована, ее можно будет использовать
для отслеживания положения и ориентации мобильного робота относительно
системы координат, привязанной к относительному изображению земли. У каж-
дого робота есть набор инфракрасных светодиодов, имеющих индивидуальное
излучение (рис. 3.3). Во время экспериментов по установлению местонахожде-
ния робота на камеру ставится инфракрасный фильтр, который эффективно бло-
кирует все излучения, кроме излучения светодиода заданного робота. Каждого
робота можно идентифицировать с помощью простого алгоритма сравнения с
шаблоном излучения, а его положение и ориентация выводятся из положения
диода на изображениях и параметров камеры. Если поднять камеру на 4 м
над землей, то характерная ошибка локализации в пределах всего поля зрения
камеры не превышает 2 см в положении и 1° в ориентации, а максимальная
ошибка может достигать 5 см и 5°.
Гпава 3. Геометрическая калибровка камер
107
3.6. ПРИМЕЧАНИЯ
Линейный метод калибровки, описанный в разделе 3.2, подробно рассмотрен
в работе [Faugeras, 1993]. Разновидность этого метода, в которой учтено ради-
альное искажение, изложена согласно [Tsai, 1987а]. В публикации [Haralick
and Shapiro, 1992] дано краткое введение в аналитическую фотограмметрию.
Классикой, конечно, является Manual of Photogrammetry и новички (такие,
как авторы этой книги) смогут по достоинству оценить оригинальные механиз-
мы и изысканные методы, описанные в различных изданиях этого руководства
([Thompson et al., 1966], [Slama, 1980]). К фотограмметрии мы еще вернемся
в главе 10 при изучении нескольких изображений. Общие методы оптимиза-
ции обсуждаются, например, в работах [Luenberger, 1985], [Bertsekas, 1995]
и [Heath, 2002]. Отличный обзор схем наименьших квадратов в контексте
аналитической фотограмметрии можно найти в [Triggs et al., 2000]. Мето-
ды наименьших квадратов допускают статистическую интерпретацию с точки
зрения наибольшей вероятности, если координаты исходных точек задавались
как случайные отклонения, подчиняющиеся закону нормального распределения.
К такой интерпретации мы вернемся в главе 15, где будет еще раз затронута
проблема подбора прямой линии, близкой к набору точек на плоскости.
Задачи
3.1. Покажите, что вектор х, который минимизирует |£6г|2 при условии |Ух|2 =
1, — это единичный обобщенный собственный вектор, соотнесенный
с минимальным обобщенным собственным значением симметричных
матриц UTU и УГУ. Подсказка: задача эквивалентна минимизации (без
дополнительных условий) ошибки Е = |г/ж|2/|Ух|2 относительно х.
3.2. Покажите, что матрица llTU размера 2 х 2 из примера в разделе 3.1.1 —
это матрица вторых моментов инерции точек р, (г = 1,... ,п).
3.3. Модернизируйте метод подбора прямой из раздела 3.1.1 для решения
задачи подбора плоскости по п точкам из Е3.
3.4. Выведите выражение для гессиана функций /2г-1(£) = йг(£) — щ
и /2г(€) = £{(£)— Ui (г = 1,..., п), введенных в разделе 3.4.
3.5. Углы Эйлера. Покажите, что результат, полученный после одного пово-
рота вокруг оси z какой-то системы координат на угол а последующего
поворота вокруг оси у новой системы координат на угол (3 и последнего
поворота вокруг оси z полученной системы координат на угол 7, можно
представить в исходной системе координат как
cos a cos (3 cos 7 — sin a sin 7
sin a cos /3 cos 7 4- cos a sin 7
— sin /3 cos 7
— cos a cos /3 sin 7 — sin a C0S7
— sin a cos Д sin7 4- cos a C0S7
sin (3 sin 7
cos a sin /3
sin a sin /3
cos/3
3.6. Формула Родригеса. Рассмотрим поворот матрицы TZ на угол 0 вокруг
оси и (единичного вектора). Покажите, что TZx — cos&x + sin&u х х 4-
108
Часть I. Формирование изображений и модели изображений
(1 — cos#)(u • х)и. Подсказка: при повороте проекция вектора х на на-
правление и его оси не изменяется, но происходит плоский поворот на
угол 0 проекции вектора х на плоскость, перпендикулярную и.
3.7. Используйте формулу Родригеса, чтобы показать, что матрица, соотне-
сенная с 7£, имеет следующий вид:
и2(1 — с) 4-с uv(l — с)— ws izw(l — с) 4-t’S
uv(l — с) 4-ws v2(l — с) 4- с vw(l — c) — us
uw(l — с) — vs vtu(l — с) 4- us w2(l — c) 4- c
где c = cos 0 и s = sin 0.
3.8. Предположим, что внутренние параметры камеры известны. Покажите,
как можно рассчитать ее внешние параметры, если известен вектор п',
определение которого дано в разделе 3.5. Подсказка: используйте тот
факт, что строки матрицы вращения имеют единичную норму.
3.9. Предположим, что камера наблюдает п исходных линий с известными
координатами Плюкера.
а) Покажите, что проекционную матрицу прямой А4, введенную в упраж-
нениях к главе 2, можно найти с помощью линейного метода наи-
меньших квадратов при условии п > 9.
б) Покажите, что при известной матрице А4 можно также найти про-
екционную матрицу А4, использовав для этого линейный метод наи-
меньших квадратов. Подсказка: рассмотрите строки тг матрицы A-f
как координатные векторы трех плоскостей П», а строки тп» матрицы
А4 — как координатные векторы трех прямых, и используйте отноше-
ние инцидентности между этими плоскостями и прямыми для вывода
дополнительных линейных условий на векторы тп;.
Упражнения
3.10. С помощью линейного метода наименьших квадратов подберите плос-
кость по п точкам в R3 с координатами (х», yi, Zi)T (г = 1,..., п).
3.11. С помощью линейного метода наименьших квадратов по п точкам
в R2 (xi,yi)T (i — 1,...,п) подберите коническое сечение, которое
определяется уравнением ах2 + Ьху 4- су2 + dx 4- еу 4- f — 0.
3.12. Реализуйте линейный алгоритм калибровки, представленный в разде-
ле 3.2.
3.13. Реализуйте введенный в разделе 3.3 алгоритм калибровки, в котором
учитывается радиальное искажение.
3.14. Реализуйте нелинейный алгоритм калибровки из раздела 3.4.
4
Радиометрия — измерение
света
В этой главе вводится словарь определений и понятий, с помощью которых
можно описать поведение света. На стр. 125 приводится резюме, в котором
собраны определения основных терминов, введенных в главе.
4.1. СВЕТ В ПРОСТРАНСТВЕ
Измерение света относится к области знаний, известной под названием ра-
диометрии. Для того чтобы понять, как энергия от источника света переносит-
ся к участку поверхности и что происходит с этой энергией при попадании ее
на поверхность, необходим определенный набор величин. Для получения этого
набора рассмотрим поведение света в пространстве.
4.1.1. Ракурс
Если источник находится под углом к направлению распространения излу-
чения, то со стороны участка поверхности, на который попадает свет от этого
источника, он “кажется меньше”. Подобным образом, если участок поверхно-
сти расположен под углом к направлению распространения света, он “кажется
меньше” со стороны источника. Это явление связано с понятием ракурса.
110
Часть I. Формирование изображений и модели изображений
Рис. 4.1. Точка на поверхности "видит” мир по направлениям, образующим полусферу с центром
в этой точке; нормаль к поверхности обычно используется для формирования сферической систе-
мы координат (0, ф). Обычно в задачах об излучении освещенность поверхности рассчитывается
как суммарный эффект, оказываемый на эту поверхность со стороны всех направлений, поэтому
направление ф = 0 можно выбирать произвольным образом
Ракурс имеет большое значение, поскольку действие отдаленного источника
на поверхность зависит от того, как выглядит источник со стороны поверхно-
сти. Рассмотрим полусферу направлений от определенной точки поверхности
(рис. 4.1). Излучение может попасть на поверхность только по этим направлени-
ям. Более того, если два разных источника будут давать абсолютно одинаковое
излучение по каждому из этих направлений, то они должны оказывать одинако-
вое действие на поверхность — для поверхности такие источники неразличимы.
Те же аргументы можно привести для участка поверхности, который виден
со стороны источника. Если заменить один участок поверхности, освещаемый
источником, другим, то для источника эти два различных участка поверхности
будут “выглядеть” абсолютно одинаковыми — здесь имеется ввиду, что в каж-
дом направлении от поверхности находится вещество с одинаковыми свойства-
ми — т.е. источник не может отличить один участок от другого, следовательно,
энергия каждому из них передается с одинаковой скоростью.
4.1.2. Телесный угол
Действие источника на заданную полусферу направлений можно описать,
введя понятие телесного угла, который образует этот источник. Телесный угол
определяется по аналогии с углом на плоскости.
Угол, который образует на плоскости бесконечно малый отрезок прямой dl
в точке р, можно получить проектированием этого отрезка на единичную
Глава 4. Радиометрия — измерение света
111
Рис. 4.2. Вверху: угол, который образует отрезок кривой в выбранной точке, можно найти, спроек-
тировав кривую на единичную окружность, центр которой находится в этой точке, а затем измерив
длину проекции. Для малого отрезка угол равен d</> = (l/r)dlcos#i. Внизу: сфера, иллюстри-
рующая понятие телесного угла. Маленькие окружности вокруг координатных осей позволяют
представить трехмерное изображение. Бесконечно малый участок поверхности проектируется на
единичную сферу с центром в требуемой точке; площадь результата — это телесный угол рассмат-
риваемого участка. В данном случае участок мал, так что площадь (а следовательно, и телесный
угол) равна (l/r2)dAcos0„
окружность с центром в р\ длина полученной проекции является искомым уг-
лом в радианах (см. рис. 4.2). Так как отрезок прямой бесконечно мал, он
образует бесконечно малый угол, который зависит от расстояния до центра
окружности и от ориентации прямой:
dl cos Bi
аф =--------.
г
Угол, образованный кривой, можно найти, разбив ее на бесконечно малые от-
резки и просуммировав (проинтегрировав!) соответствующие малые углы.
Подобным образом, телесный угол, образованный участком поверхности
в точке х, можно найти, проектируя этот участок на единичную сферу с цен-
тром в ж; полученная площадь — это искомый телесный угол, который теперь
измеряется в стерадианах. Телесный угол обычно обозначают символом о>. За-
метим, что понятие телесного угла позволяет интуитивно почувствовать поня-
тие ракурса — участки на заданной полусфере, которые “выглядят одинаково”,
образуют одинаковые телесные углы.
112
Часть I. Формирование изображений и модели изображений
Если площадь участка dA мала (что предполагается, когда мы говорим о
бесконечно малой форме), тогда бесконечно малый телесный угол, который она
образует, легко рассчитать через площадь участка и расстояние до него:
, d A cos 0п
d^ =-----=--.
г2
Условные обозначения приведены на рис. 4.2.
Телесный угол можно записать через обычные угловые координаты на сфере
(см. рис. 4.2). Из рис. 4.1 и выражения для длины дуги окружности получаем,
что бесконечно малые приросты (d0, d</>) по углам 0 и ф вырезают на сфере
элемент телесного угла, который представляется таким выражением:
duj = sin 0d0dф.
Оба приведенных выражения стоит запомнить, поскольку они используются
довольно часто.
4.1.3. Излучение
Распределение света в пространстве — это функция положения и направ-
ления. Рассмотрим, например, свет электрического фонарика с узким лучом
ночью в пустой комнате — необходимо знать, откуда падает свет и в каком
направлении. Эффект освещения можно представить через энергию, которая
приходится на бесконечно малый участок поверхности, что выбирается в опре-
деленной точке пространства с определенной ориентацией. Далее этот подход
будет использован для выбора единицы измерения.
Определение излучения
Подходящая единица измерения распределения света в пространстве — это
излучение, которое определяется как
мощность (энергия за единицу времени), попадающая в определенную точку в за-
данном направлении, на единичную поверхность, перпендикулярную направлению
распространения света, на единицу телесного угла.
Единица измерения излучения — это ватт на квадратный метр на стерадиан
(Вт х м-2 х ср-1). Приведенное определение удобно для описания большинства
базовых явлений в радиометрии. Маленький участок поверхности, расположен-
ный по отношению к источнику во фронтальной плоскости, получает больше
энергии, чем такой же участок, расположенный почти параллельно к направле-
нию распространения света — энергия, которая попадает на участок, зависит
как от того, насколько большим выглядит источник со стороны участка, так и
от того, насколько большим выглядит участок со стороны источника. Необходи-
мо помнить, что для учета этого явления поверхность при измерении излучения
берется с учетом ракурса (т.е. перпендикулярно к направлению распростране-
ния света).
Глава 4. Радиометрия — измерение света
113
Излучение — это функция положения и направления (хорошая модель, по-
стоянно напоминающая об этом, — фонарик с узким лучом, который можно
перемещать и вращать). Для данной точки Р и некоторого (возможно, нееди-
ничного) вектора v излучение в точке Р в направлении v обычно обозначается
через L(Pt v). Точка Р может лежать как в свободном пространстве, так и на
поверхности. В последнем случае излучение в точке Р в сферических коорди-
натах 6 и ф системы, ось z которой направлена вдоль нормали к поверхности,
иногда обозначается через ЦР,0, ф).
Вдоль прямой излучение постоянно
В подавляющем большинстве задач, связанных со зрением, вполне оправда-
но предположение, что свет не взаимодействует со средой, в которой распро-
страняется, т.е. что система находится в вакууме. Излучение обладает очень
полезным свойством: для двух точек Pi и Р2 (которые находятся в прямой ви-
димости друг друга) излучение, покидающее точку Pi в направлении точки Р2,
равно излучению, попадающему в точку Р2 со стороны точки Pi.
Следующее доказательство может на первый взгляд показаться бессодержа-
тельным, но его следует внимательно изучить, так как это — ключ к понима-
нию ряда других выкладок. На рис. 4.3 показан участок поверхности, излучаю-
щий в определенном направлении. Если излучение участка равно L(Pi,0,0), то
энергия, которую этот участок передает бесконечно малому элементу телесного
угла dw в направлении (0, ф) за время dt, равна
L(Pi, 6,0)(cos0idAi)(do;) (dt).
Это излучение, с учетом ракурса умноженное на площадь участка, умноженное
на телесный угол, в который происходит излучение, и умноженное на время
этого излучения.
Рассмотрим теперь два участка, один в точке Pi с площадью cL4i, а другой
в точке Р2 с площадью dA2 (см. рис. 4.3). Во избежание путаницы с угловыми
системами координат, обозначим направление от точки Pi до точки Р2 как
Р1Р2. Углы 01 и 02 определены на рис. 4.3.
Излучение, покидающее точку Pi в направлении точки Р2, — это L(Pi, Р1Р2),
а излучение, попадающее в точку Р2 со стороны Pi, — P(P2,PiP2).
Из сказанного следует, что за время dt энергия, передаваемая из точки Pi
в направлении точки Р2, равна
d3Pi_2 — ЦР1, PiP2)(cos0id.Ai)(dw2(i)) (dt),
где dcj2(1) — телесный угол, образованный участком 2 на участке 1 (энергия,
излучаемая в этот телесный угол, прибывает на участок 2; вся остальная
рассеивается в вакууме). Запись d3£i_2 означает, что задействованы три бес-
конечно малых элемента. Из приведенного выше выражения для телесного угла
114
Часть I. Формирование изображений и модели изображений
Рис. 4.3. Интенсивность света удобнее всего измерять излучением, поскольку излучение не умень-
шается при распространении по прямой линии в вакууме (или на разумное расстояние в чистом
воздухе). Доказательство этого следует из закона сохранения энергии
следует, что
, cos 62dAz
^2(1) = ---------•
Таким образом, энергия, которая передается от 1 к 2, равна
d3Е^2 = ЦР^Р^) (cosflicosflgX dt
у /
Так как средой в данном случае является вакуум, энергия не поглощается,
и в 2 из 1 поступает такая же энергия, что была передана из 1 в направлении
2. Энергия, попадающая на участок 2 из 1, равна
d3Sl_2 = L(P2,PlP2)(cOS02<bl2)(dWl(2)) (<Й) =
Г / г> \ ( COS &2 COS Алл » л j.
= ЦР2,Р1Р2) I -----5----- I dAidAzdt =
\ г2 J
— d3Ei-,2 =
= L(Pi, Pd?) (<?t>s.e2^osgl-A dA2dA! dt.
у тл J
Из этого следует, что ЦР^Р^Ръ) = L(Pi, Р1Р2), поэтому вдоль прямой линии
(без преград) излучение остается постоянным.
Глава 4. Радиометрия — измерение света
115
4.2. СВЕТ НА ПОВЕРХНОСТЯХ
Когда свет попадает на поверхность, он может поглощаться, передавать-
ся или рассеиваться; обычно имеют место все три явления. Например, свет,
попадающий на кожу, может рассеиваться на тканях на различной глубине
и отражаться от крови и меланина в них, может поглощаться или рассеивать-
ся параллельно коже в пределах тонкого слоя жира, а затем выходить наружу
в какой-то другой точке.
Картина еще более усложняется способностью некоторых поверхностей по-
глощать свет одной длины волны с последующим излучением света другой
длины волны. Этот эффект, называемый флуоресценцией, общеизвестен: под
рентгеновским излучением скорпионы излучают свет в видимом диапазоне; че-
ловеческие зубы флуоресцируют бледно-голубым светом под действием ультра-
фиолетового излучения (нейлоновое белье также обладает тенденцией к флу-
оресценции, а вставные зубы обычно нет — по этим причинам ультрафиолет
уже не используется на дискотеках); с помощью стиральных порошков, кото-
рые флуоресцируют под действием ультрафиолетового излучения, одежде после
стирки можно придать яркость. Кроме того, если поверхность нагреть доста-
точно сильно, она будет излучать в видимом диапазоне.
4.2.1. Упрощения
Разумно допустить, что все эффекты локальны, и их можно объяснить
с помощью макроскопической модели без флуоресценции или излучения;
назовем эту модель моделью локального взаимодействия. Это вполне ре-
зонная модель для такого типа поверхностей и решений, которые обычно
возникают в сфере компьютерного зрения. Перечислим характерные элементы
этой модели.
• Излучение, исходящее из точки, зависит только от излучения, попадаю-
щего в эту точку (хотя направление излучения в точке на поверхности
может измениться, будем считать, что от точки к точке оно изменяется не
скачкообразно).
• Считается, что весь свет, который излучает поверхность на данной длине
волны, обусловлен падающим на эту поверхность светом этой же длины
волны.
• Считается, что поверхности не излучают сами по себе, поэтому источники
света рассматриваются обособленно.
4.2.2. Функция распределения двунаправленного отражения
Опишем связь между падающим и отраженным излучением. Это функция
направления, по которому свет попадает на поверхность, и направления, по
которому он отражается.
116
Часть I. Формирование изображений и модели изображений
Плотность потока излучения
Подходящая величина для описания полученной мощности — это плот-
ность потока излучения, которая определяется как
мощность падающего света на единицу площади без учета ракурса.
Это определение означает, что на участок поверхности площадью dA, ко-
торый освещается излучением Li(P, попадающим в дифференциальный
элемент телесного угла du) с координатами (0£,<&), приходится плотность пото-
ка излучения
(l/dA)(Li(P,0i,</>i))(cos0idA)du) = Li(P, Qi, ф*) cos6idu>,
Поэтому чтобы получить плотность потока излучения, нужно умножить излу-
чение на коэффициент ракурса и на телесный угол. Главная особенность этой
величины состоит в том, что можно вычислить всю мощность, которая попадает
в точку поверхности, просуммировав плотность потока излучения по всей за-
данной полусфере. Таким образом, получена естественная единица измерения
поступающей мощности.
ФРДО
Самая общая модель локального отражения — это использование функции
распределения двунаправленного отражения, для обозначения которой обыч-
но применяется аббревиатура ФРДО. ФРДО определяется как
отношение излучения в уходящем направлении к плотности падающего потока
излучения,
т.е. если бы поверхность, на дифференциальный элемент телесного угла du)
с координатами 0.) которой приходится излучение Li(P,Gi,<f)i), отражала
излучение LO(P, 6О, фо), то ее ФРДО имела бы такой вид:
= г-Й
Li(Р, Ui, фг) cos 6idu>
ФРДО измеряется в обратных стерадианах (ср-1) и может иметь значение от О
(в этом направлении свет не отражается) до бесконечности (единичное излуче-
ние на выходе при произвольно малом падающем излучении). ФРДО на вход-
ном и выходном направлениях симметрична — этот факт известен как принцип
обратимости Гельмгольца.
Глава 4. Радиометрия — измерение света
117
Вычисление излучения поверхности через ее ФРДО
Излучение поверхности, обусловленное потоком излучения в определенном
направлении, легко найти из определения ФРДО:
Ьо(Р,во,фо) = ры(0о, Фо, Gi, cos Gidu;.
Излучение поверхности, обусловленное ее потоком излучения (независимо от
направления потока), можно найти, просуммировав вклады света, падающего
по всем направлениям:
Ьо(Р,0о,фо)= I pbd(Go^o,6i^i)Li(P,6i^i)cos6idu.
JQ
Здесь Q — полусфера направлений падающего света.
Условия на ФРДО
ФРДО — это не произвольная симметричная функция четырех переменных.
Предположим, что участок поверхности площадью dA освещается излучени-
ем Li(P, Вт х м-2 х ср-1. Это означает, что суммарная энергия, которая
попадает на поверхность за отрезок времени dt, равна
Ьг(Р,в{,фд cos GiduJi^ dA dt= J Li(P, в^фд cosGi sinG^dGidфi^ dAdt.
Мы приняли, что вся энергия, излучаемая с поверхности, выходит из той же
точки, на которую падает излучение, и что сама поверхность энергии не гене-
рирует. Следовательно, суммарная энергия, излучаемая с поверхности за этот
отрезок времени, должна быть меньше или равна поступающей. Таким образом,
получаем
Li(P,6i, фд cos Giduii'j dAdt > LO(P, &о,фа) cos Goda>o^ dAdt.
В то же время энергию, которая излучается поверхностью, можно записать как
( / / pbd(G<>^o,Gi^i)Li(P, 0i,0i) cosGiduJi cosGo(Ldo I dAdt.
\JnoJni /
Это значит, что, в общем случае, независимо от выбора Li для ФРДО должно
быть справедливым следующее выражение:
I Li(P,Gi^i) cosGidwi > I J pbd(Go,фо, Gi^i)Li{P,Gi^i) cosGidwiCosGodWo.
J Qi JQoJQi
Таким образом, ФРДО может быть большой для некоторых (но не всех) пар
углов падения и отражения. Фактически, среднее значение должно быть доста-
точно малым: на основании этого свойства можно доказать, что максимальное
значение ФРДО, которая не зависит от угла, составляет 1/тг.
118
Часть I. Формирование изображений и модели изображений
Рис. 4.4. Излучение объекта и плотность потока излучения изображения
4.2.3. Пример: радиометрия тонких линз
Чтобы проиллюстрировать некоторые из введенных понятий, рассмотрим
участок изображения 6А' с центром в точке Р', где с помощью тонкой линзы
собирается свет, идущий от участка сцены ЛА с центром в точке Р (рис. 4.4),
и свяжем излучение L объекта в точке Р с плотностью потока излучения Е
изображения в точке Ра. Если через бы обозначить телесный угол, образован-
ный ЛА (или ЛА') и центром О линзы, получится
<5 A' cos а ЛА cos /3 ё A cos о / z \
Ли? = —---------- =---------следовательно, —- =------------I — J .
(z'/cosct)2 (z/cosa)2 5A’ cos/3 \z' J
Теперь площадь линзы диаметром d равна ^d2, и если через Я обозначить
телесный угол, образованный линзой и точкой Р, получим
2 / \
тг d cosct к ( d\ „
Q _--------------= — I — 1 COS3 Ct.
4 (z/ cos a) 4 \z J
Мощность 6P, излучаемую участком ЛА и попадающую на линзу, можно вы-
разить через излучение L объекта:
ёР = ЬПёА cos /3 =
2
ЬёА cos3 a cos 0.
Мощность 5Р собирается линзой на участке 6А' плоскости изображения, и это
вся мощность, которая попадает на этот участок. Таким образом, плотность
'Для краткости параметры излучения и плотности потока опущены, однако стоит помнить,
что через L обозначено излучение в точке Р в направлении Р', а через Е — плотность потока
излучения в точке Р'.
Глава 4. Радиометрия — измерение света
119
потока излучения изображения равна
SP 7Г fd\2 SA
Е =----= — I — | L----cos3 a cos /?.
SA' 4 \zJ SA'
Подставив в это уравнение значение SA/SA', получим
(4-1)
Это соотношение важно по нескольким причинам: во-первых, из него следует,
что плотность потока излучения пропорциональна излучению объекта. Други-
ми словами, то, что мы измеряем (Е), пропорционально тому, что нас инте-
ресует (L). Во-вторых, плотность потока излучения пропорциональна площади
линзы и обратно пропорциональна расстоянию от ее центра до плоскости изоб-
ражения. Величина а — d/f — это относительная апертура, которая обратно
пропорциональна числу /, определенному ранее. Из уравнения (4.1) следует,
что если линза сфокусирована на бесконечность, то Е пропорционально а2
(в этом случае z' = /). Наконец, плотность потока излучения пропорциональ-
на cos4 а и уменьшается с отклонением лучей света от оптической оси. При
небольших значениях а этот эффект едва различим как для человеческого гла-
за, так и для алгоритмов анализа изображения, поскольку глаза поразительно
нечувствительны к гладким градиентам яркости, в то время как алгоритмы
анализа обычно более восприимчивы к виньетированию — явлению, которое
в большинстве случаев дает более сильный вклад, чем сцад по закону cos4 а.
4.3. ВАЖНЫЕ ЧАСТНЫЕ СЛУЧАИ
Излучение — это очень “тонкая” величина, поскольку она зависит от угла.
Эта универсальность иногда бывает важна — например, при описании распре-
деления света в пространстве из рассмотренного выше примера с фонариком.
Приведем еще один пример: зафиксируем компакт-диск и посветим фонариком
на его нижнюю поверхность. Интенсивность и цвет света, отраженного от
поверхности диска, очень сильно зависят от угла зрения на эту поверхность
и от угла падения света. Попытайтесь провести опыт с CD самостоятельно и вы
почувствуете, насколько странным может быть поведение отражающей поверх-
ности, а также убедитесь насколько человеческий глаз привык к поверхностям,
которые такого поведения не проявляют. Для многих поверхностей — хоро-
шим примером может послужить хлопчатобумажная одежда — зависимость
отраженного света от угла мала или вообще отсутствует, так что здесь очень
полезной будет система величин, которые не зависят от угла.
120
Часть I. Формирование изображений и модели изображений
4.3.1. Диффузное отражение
Если излучение поверхности не зависит от угла, то нет смысла описывать
его с помощью величин, которые по определению зависят от направления. Под-
ходящей величиной будет диффузное отражение, которое определяется как
суммарная мощность, излучаемая точкой на поверхности на единицу площади по-
верхности.
Диффузное отражение, которое обычно обозначается как В(Р), измеряется
в ваттах на квадратный метр (Вт х м-2). Чтобы найти диффузное отражение
поверхности в точке, можно просуммировать излучение, уходящее с поверх-
ности в этой точке по всей полусфере направлений. Следовательно, если Р —
точка на поверхности с излучением Ь(Р^0,ф), то диффузное отражение в этой
точке равно
В(Р)= [ Ь(Р,6,ф) cos
Jo
где Q — это полусфера выходящих направлений, а множитель cos# превра-
щает площадь с учетом ракурса в просто площадь (обратитесь еще раз к
определениям); div, как и ранее, можно записать через 0 и ф.
Диффузное отражение поверхности с постоянным излучением
Следует запомнить один результат — связь между диффузным отражением
и излучением участка поверхности, когда излучение не зависит от угла.
В этом случае Lo(x, 0о,Фо) = LO(P). Теперь можно найти диффузное отраже-
ние, просуммировав излучение, покидающее поверхность, по всем исходящим
направлениям.
В(Р) = [ LO(P) cos0dv =
Jti
r2*
= LO(P) I I cos 6sin0dcf>d6 =
Jo Jo
= 7tLo(P).
4.3.2. Отражательная способность
ФРДО — это “тонкая” величина, а измерения ФРДО обычно сложны, тре-
буют больших затрат, и их не всегда можно повторить, так как процессы за-
грязнения и старения поверхности могут сильно влиять на измерение ФРДО;
например, после касания к поверхности на ней остается жир (с кончиков паль-
цев) обычно в виде маленьких бороздок, которые могут действовать как линзы
и вносить существенные изменения в направленное поведение поверхности.
Свет, отражающийся от многих поверхностей, по большей части не зависит
от угла отражения. Естественной мерой отражательных свойств поверхности
в этом случае выступает отражательная способность, которая обычно обо-
значается через рак и определяется так:
Глава 4. Радиометрия — измерение света
121
доля потока излучения, падающего в заданном направлении, которая отражается от
поверхности независимо от направления отражения.
Отражательную способность поверхности можно найти, просуммировав из-
лучение, уходящее от поверхности по всем направлениям, и разделив его на
плотность потока излучения в направлении падения света, что дает следующий
результат:
/а Л. X Jq Lo(PI @о, фо) COS 6odu)o
= Ц(Р,е,.ф,)с^ё^,{ =
_ f ( Lo(P,0o, фо) cos eo 1 _
Jq ( Li (P, 0i, фг ) COS Otdwi J
= I Pbd(6o^o,et,$i) cos60da>0.
Jq
Эта величина безразмерна и принимает значения от 0 до 1.
Отражательную способность можно рассчитать для любой поверхности. Для
некоторых поверхностей она изменяется строго в зависимости от угла облуче-
ния. Хорошим примером может послужить поверхность с мелкими симметрич-
ными треугольными вырезами, черными с одной стороны и белыми с другой.
Если эти вырезы достаточно малы, разумно будет воспользоваться макроскопи-
ческим описанием поверхности как плоской, но с отражательной способностью,
значение которой велико, если свет попадает на белые стороны, и меньше, если
свет попадает на черные стороны.
4.3.3. Ламбертовские поверхности и альбедо
Для некоторых поверхностей отражательная способность не зависит от
направления облучения. Примеры таких поверхностей — хлопчатобумажная
ткань, большинство покрытий, матовая бумага и матовые краски. Формальная
модель описания — поверхность, ФРДО которой не зависит от направления
отражения (а также, согласно принципу обратимости, от направления падения
света). Это значит, что излучение, уходящее с поверхности, не зависит от
угла. Такие поверхности называют поверхностями с идеальным рассеянием,
или ламбертовскими поверхностями (в честь Иоганна Ламберта, который
впервые сформулировал эту идею).
Было бы естественно использовать диффузное отражение в качестве меры
энергии, отражающейся от ламбертовской поверхности. Как говорилось выше,
отражательная способность ламбертовских поверхностей не зависит от направ-
ления. В подобных случаях отражательную способность часто называют коэф-
фициентом диффузного отражения, или альбедо, и записывают как рл. Для
ламбертовской поверхности с ФРДО рьа(!&о, Фо, Фг) ~ Р имеем
Pd = I Pbd(&o, фо, &i, фг) COS eoda>o =
Jn
= I pcos0odwo =
Jq
122
Часть I. Формирование изображений и модели изображений
1
cos 0О sin 6od0od(/)o
= 7Гр,
ИЛИ
л _ pd
Рфрдо — •
7Г
Постарайтесь запомнить это выражение.
Поскольку наше восприятие яркости соответствует (приблизительно!) мере
излучения, то ламбертовские поверхности будут выглядеть почти одинаково
ярко из любой точки, независимо от направления освещения. Таким образом,
можно узнать, в каких случаях следует применять ламбертовское приближение.
4.3.4. Зеркальные поверхности
Второй значительный класс поверхностей — это стеклянные или зеркаль-
ные поверхности. Идеальный зеркальный отражатель ведет себя как идеаль-
ное зеркало. Излучение, приходящее по определенному направлению, может
отразиться только в зеркальном направлении, которое получается как отобра-
жение направления падающего излучения относительно нормали к поверхно-
сти. Обычно некоторая часть падающего излучения поглощается; на идеальной
зеркальной поверхности в каждом направлении поглощается равная часть па-
дающего излучения, остальное отражается в зеркальном направлении. ФРДО
идеальной зеркальной поверхности имеет интересную форму (см. раздел упраж-
нений), поскольку излучение, приходящее в определенном направлении, может
отразиться только в одном направлении.
Зеркальные лепестки
Приближение идеального зеркального отражателя применимо к довольно
малому числу поверхностей. Чтобы проверить, является ли плоская поверхность
идеальным зеркальным отражателем, следует посмотреть, можно ли пользо-
ваться ею в качестве зеркала. Хорошие зеркала чрезвычайно сложны в из-
готовлении; до недавнего времени зеркала делали из полированного металла.
Обычно, пока металл не будет тщательно отполирован и обработан, излуче-
ние, приходящее в одном направлении, отражается по небольшому лепестку
направлений вокруг зеркального направления. Это дает характерный эффект
размывания. Хороший пример — плоское металлическое блюдо. В новом блюде
можно увидеть искаженное изображение своего лица, но это блюдо было бы
сложно использовать в качестве зеркала; в более старом блюде будет отражать-
ся только набор искаженных пятен.
Чем больше зеркальные лепестки, тем более темным и искаженным является
зеркальное изображение (поскольку падающее излучение должно равномерно
распределяться по всем направлениям отражения). Как правило, можно увидеть
зеркальное отражение только относительно ярких объектов (например, источ-
ников света). Таким образом, на блестящих поверхностях в зеркальном направ-
Глава 4. Радиометрия — измерение света
123
Рис. 4.5. Зеркальные поверхности обычно отражают свет по лепестку направлений вокруг зеркаль-
ного направления; интенсивность отражения зависит от направления (слева). Форму этого лепестка
можно описать с помощью модели Фонга через угол отклонения от зеркального направления
лении от источников света видны, кроме других эффектов зеркального отра-
жения, яркие пятна, которые часто называют бликами. Чтобы смоделировать
форму зеркального лепестка можно воспользоваться моделью Фонга, соглас-
но которой только точечные источники света отражаются зеркально (рис. 4.5).
В этой модели излучение, исходящее от зеркальной поверхности, пропорцио-
нально cosn(<50) = cosn(Oo—0s), где 0О ~~ угол, под которым излучение покидает
поверхность, 0а — зеркальное направление, ап — параметр. Большие значе-
ния п дают узкие лепестки и небольшое четкое отражение; малые значения
дают широкие лепестки и крупное отраженное изображение с достаточно раз-
мытыми краями.
4.3.5. Ламбертовская + зеркальная модель
Относительно немногие поверхности можно считать либо идеально рассе-
ивающими, либо совершенно зеркальными. ФРДО большинства поверхностей
можно аппроксимировать комбинацией ламбертовской составляющей и зер-
кальной, которая в основном имеет форму узкого лепестка. Обычно зеркальная
составляющая оценивается через зеркальное альбедо. Опять же, поскольку
отражение нельзя точно измерить, форма лепестка остается неопределенной.
В этом случае излучение с поверхности в заданном направлении (поскольку
теперь оно должно зависеть от направления) обычно аппроксимируется таким
выражением:
Ь(Р,0о,фо) = pd(P) [ Ь(Р,0^ф^со5б^ + ря(Р)Ь(Р,0в,фя)со&п(ея-6о),
Jn
где 6а, фа задает зеркальное направление, а ра — зеркальное альбедо. Точное
значение величины зеркального излучения обычно не указывается.
Использование этой модели полностью исключает из описания “слишком уз-
кие” зеркальные лепестки, поскольку в подавляющем большинстве алгоритмов
учитываются случайные малые имеющие оптимальную форму блики, вызван-
ные источниками света. Поверхности со слишком узкими зеркальными лепест-
ками (зеркала) дают очень подробные отражения. Подобным образом также
исключаются “слишком широкие” лепестки, поскольку отражения, полученные
с их помощью, было бы трудно идентифицировать.
124
Часть I. Формирование изображений и модели изображений
4.4. ПРИМЕЧАНИЯ
В книгах [Francois Sillion, 1994] и [Nayar, Ikeuchi and Kanade, 19916] четко
и понятно изложены радиометрические вычисления. Анализ отражения в тек-
сте главы был достаточно поверхностным. Модель “зеркальное отражение плюс
рассеяние” ввели Кук, Торренс и Спарроу ([Torrance and Sparrow, 1967], [Cook
and Torrance, 1987]). Разнообразные модификации этой модели встречаются
в компьютерном зрении и компьютерной графике. Модель отражения можно
вывести, объединив статистическое описание неровностей поверхности и элек-
тромагнитную теорию (см., например, [Beckmann and Spizzichino, 1987]) или
модифицировав модель рассеяния (как в работах [Torrance and Sparrow, 1967],
[Cook and Torrance, 1987]).
Основное понятие, не рассмотренное в этой главе, — зеркальные блики, ко-
торые дают обратное зеркальное рассеяние. Зеркальные блики обычно возни-
кают на шероховатых поверхностях, причем большая часть поверхности ориен-
тирована под значительным углом к макроскопической нормали к поверхности.
Это приводит к появлению второго зеркального лепестка в данной области. Та-
кие эффекты могут внести путаницу в алгоритмы расчета формы лепестков по
отражению, если этот расчет производится достаточно строго. Обратное зер-
кальное рассеяние происходит, когда свет от поверхности отражается в направ-
лении источника, причиной чего обычно являются все те же зеркальные блики.
Этот эффект может привести к усложнению алгоритмов вычисления формы по
отражению. Некоторые модели отражательной способности, где учтены эти яв-
ления, описаны в [Tagare and de Fiegueiredo, 1991].
Обычно неровные поверхности считают ламбертовскими, однако это не все-
гда так, поскольку неровные поверхности часто имеют локальные эффекты за-
тенения, которые приводят к достаточно сильной зависимости отраженного из-
лучения от угла освещения. Например, оштукатуренная стена, если ее осве-
щать почти параллельно, выглядит как мозаика из светлых и темных пятен,
где грани поверхности направлены в сторону света или затенены. Если на эту
же стену свет будет падать параллельно нормали, мозаика исчезнет. При опи-
сании на более высоком уровне подобные эффекты обычно усредняются, чтобы
отклонения неровных поверхностей от ламбертовской модели можно было счи-
тать незначительными (подробнее см. [Koenderink, van Doorn, Dana and Nayar,
1999], [Nayar and Oren, 1993, 1995], [Oren and Nayar, 1995] и [Wolff, Nayar and
Oren, 1998]).
Еще один пример объекта, который нельзя описать посредством простой
макроскопической модели поверхности, — цветочное поле. Удаленному наблю-
дателю это поле может показаться “поверхностью” с достаточно странными
свойствами: если смотреть на это поле по направлению нормали, то главным
образом видны цветы; при взгляде по касательной будут видны и цветы, и стеб-
ли, т.е. с изменением направления цвет будет сильно меняться (это явление
исследовано в работе [Leung and Malik, 1997]).
ТАБЛИЦА 4.1. Справочная таблица: терминология радиометрии
Тема Что необходимо знать
Ракурс Большая площадь, на которую смотрят почти параллельно касатель- ной, выглядит точно так же, как и маленькая, на которую смотрят прямо. Это явление имеет большое значение, поскольку два разных приемника будут получать равное излучение от источника, если они выглядят со стороны источника абсолютно одинаково; два разных ис- точника будут одинаково действовать на приемник, если со стороны приемника они выглядят абсолютно одинаково
Излучение Определение: энергия, попадающая в точку в заданном направле- нии за единицу времени на единицу площади, перпендикулярной к направлению распространения света, на единицу телесного угла. Единица измерения: Вт х м-2 х ср-1. Применение: для описания света, распространяющегося в пространстве; для отражения света от поверхности, когда оно сильно зависит от направления
Плотность потока излучения Определение: суммарная падающая мощность на единицу площади поверхности. Единица измерения: Вт х м~2. Применение: для опи- сания света, падающего на поверхность
Диффузное отражение Определение: суммарная мощность, исходящая из точки на поверхно- сти на единицу площади поверхности. Единица измерения: Вт хм-2. Применение: для описания света, отраженного от рассеивающей по- верхности
ФРДО Определение: отношение излучения в определенном направлении к плотности потока падающего излучения. Единица измерения: ср-1. Применение: для описания отражения от всей поверхности, если от- ражение сильно зависит от направления
Отража- тельная способность Определение: доля излучения, падающего в заданном направлении, которая отражается от поверхности независимо от направления отра- жения. Единица измерения: безразмерная величина. Применение: для описания отражения от поверхности, когда направление не имеет значения
Альбедо Определение: отражательная способность рассеивающей поверхно- сти. Единица измерения: безразмерная величина. Применение: для описания рассеивающей поверхности
Рассеивающая поверхность; ламбертовская поверхность Определение: поверхность, ФРДО которой постоянна. Примеры: хлопчатобумажная ткань; многие шероховатые поверхности; многие краски и бумага; поверхности, относительная яркость которых не за- висит от угла зрения
Зеркальная поверхность Определение: поверхность, которая ведет себя как зеркало. Приме- ры: зеркала; отполированный металл
Блики Определение: маленькие яркие участки поверхности, возникающие вследствие наличия зеркальной составляющей ФРДО. Примеры: ча- сто наблюдаются на пластических поверхностях, на шероховатых ме- таллических поверхностях, на некоторых красках, на блестящей тка- ни. Важная особенность: при изменении угла зрения блики переме- щаются по поверхности
126
Часть I. Формирование изображений и модели изображений
Задачи
4.1. Сколько стерадиан содержит полусфера?
4.2. Доказано, что в непоглощающей среде излучение не уменьшается вдоль
прямой линии (это делает его весьма удобной величиной). Покажите, что
если в качестве параметра взять мощность на единицу площади с учетом
ракурса (иными словами, плотность потока излучения), то эта величина
будет изменяться вдоль прямой с расстоянием. Насколько существенна
эта разница?
4.3. Поглощающая среда. Допустим, что наш мир представляет собой изо-
тропную поглощающую среду. Хорошую простую модель такой среды
можно получить, рассмотрев прямую, вдоль которой распространяется
излучение. Если излучение по прямой в точке х равно Лг, то в точ-
ке х 4- dx оно будет равно N — (adz).
а) Покажите как изменится излучение при переходе в этой среде от
одного участка поверхности к другому.
б) Теперь качественно опишите распределение света в комнате, запол-
ненной такой средой, для а малых и больших положительных чисел.
Комната имеет форму куба, а источник света — маленький участок
в центре потолка. Помните, что если а большое и положительное, то
на стены комнаты попадет очень мало света.
4.4. Выведите связь между излучением сцены и плотностью потока излучения
изображения для камеры-обскуры с отверстием диаметра d.
4.5. Выведите связь между излучением сцены и плотностью потока излучения
изображения для сферической камеры с отверстием диаметра d.
4.6. Дайте общее определение поверхностей, которые не являются ни лам-
бертовскими, ни зеркальными, используя пример внутренней стороны
компакт-диска. Отметим, что довольно большое число биологических ор-
ганизмов имеет голубой цвет. Назовите хотя бы две причины, по которым
организму выгодно иметь неламбертовские поверхности.
4.7. Покажите, что для идеальной рассеивающей поверхности отражающая
способность постоянна; покажите, что если поверхность обладает по-
стоянной отражающей способностью, то это идеально рассеивающая
поверхность.
4.8. Покажите, что ФРДО идеальной зеркальной поверхности равна
Pbd(#o, Фо, Oi, ф{) = pe(0i){2(5(sin2 0О - sin2 {<5(<£о - <^тг)},
где pa(0i) — доля излучения, уходящего с поверхности.
4.9. Почему зеркальное отражение ярче рассеянного?
4.10. ФРДО поверхности постоянна. Какое максимально возможное значение
этой константы? Допустим, известно, что поверхность поглощает 20%
излучения, падающего на нее (остальное отражается); чему равна ФРДО?
4.11. Глаз реагирует на излучение. Объясните, почему нам часто кажется,что
яркость ламбертовских поверхностей не зависит от угла зрения.
4.12. Покажите, что телесный угол, образованный сферой радиуса с на рас-
стоянии г от центра сферы, приблизительно равен тг(^)2 при г^>е.
5
Источники, тени и затенение
На степень яркости поверхности влияют два фактора: их альбедо и то, сколько
света на них попадает. Модель нахождения яркости объекта обычно называют
моделью затенения. Модели затенения имеют большое значение, поскольку
с помощью соответствующей модели затенения можно интерпретировать значе-
ния пикселей. Правильно подобрав модель затенения, можно восстанавливать
объекты и их альбедо всего по нескольким изображениям. Более того, можно
интерпретировать тени и объяснять их загадочное и редко замечаемое отсут-
ствие на большинстве кадров, сделанных в помещении.
5.1. КАЧЕСТВЕННАЯ РАДИОМЕТРИЯ
Рассмотрим, как будут выглядеть “яркие” поверхности при различном осве-
щении, и как эта “яркость” зависит от локальных свойств поверхности, от
формы поверхности и от освещения. Из главы 4 следует, что различные источ-
ники могут оказывать одинаковое действие на поверхность. Наиболее удачный
способ проанализировать этот вопрос — рассмотреть, как выглядит источник
со стороны поверхности. Такая качественная радиометрия — один из тех
методов, которые кажутся простыми (никакой сложной математики), но ока-
зываются чрезвычайно действенными. В некоторых случаях эти методы могут
128
Часть 1. Формирование изображений и модели изображений
Рис. 5.1. Геометрия для нахождения качественного радиометрического решения при рассмотрении
мира с позиции участка поверхности. Хотелось бы знать, какова яркость на двух различных бес-
конечно высоких стенах. В этой геометрии бесконечно высокая матовая черная стена перекрывает
вид на пасмурное небо, которое представляет собой полусферу бесконечного радиуса и однородной
“яркости". Справа указаны направления, по которым из соответствующих точек виден или не виден
источник, полученные проектированием полусферы на круг направлений (или, что то же самое, при
взгляде на нее сверху). Поскольку для каждой точки бралась одна и та же исходная полусфера,
яркость должна быть одинаковой
дать качественное описание “яркости”, даже не требуя определения значения
этого термина.
Напомним (см. раздел 4.1.1 и рис. 4.1), что участок поверхности восприни-
мает окружающую среду по полусфере направлений от этого участка. Излуче-
ние, попадающее на этот участок с определенного направления, проходит через
точку на полусфере. Если у двух участков поверхности эти полусферы одинако-
вые, то они должны облучаться одинаково независимо от внешней среды. Это
значит, что любая разница в “яркости” участков с одинаковыми полусферами
направлений — следствие разных свойств поверхностей. В частности, если два
участка поверхности с одинаковыми БФРО (бинарная функция распределения
отражения) имеют одинаковые полусферы направлений, то их излучение также
будет одинаковым.
В работах Ламберта проанализировано распределение “яркости” по однород-
ной плоскости, на которой стоит бесконечно высокая черная стена и которая
освещается пасмурным небом (см. рис. 5.1). В этом случае каждая точка на
поверхности имеет одну и ту же полусферу направлений — половина этой
полусферы перекрывается стеной, а другая половина “видит” однородное небо;
поскольку плоскость также однородна, то “яркость” всех точек должна быть
одинаковой.
Глава 5. Источники, тени и затенение
129
Рис. 5.2. Возьмем черную матовую бесконечно тонкую, полубесконечную стену на бесконечной бе-
лой плоскости (как показано слева). В этой геометрии также имеется пасмурное небо бесконечного
радиуса и однородной “яркости”. На рисунке показано, как определяются кривые с одинаковой “яр-
костью” на плоскости. Эти кривые, изображенные справа, построены при рассмотрении плоскости
сверху; стена показана жирной линией. На линии наложены обозначения полусфер направлений
некоторых из изофот (кривых равной яркости). Вдоль этих линий полусфера направлений остается
постоянной (что можно доказать геометрически), но при переходе между кривыми она меняется
Второй пример несколько сложнее: бесконечно тонкая черная стена с беско-
нечной длиной только в одном направлении, которая находится на бесконечной
плоскости (рис. 5.2). Качественное описание — это определение того, как вы-
глядят линии равной “яркости”. Из рис. 5.2 следует, что все точки любой пря-
мой, проходящей через точку р, имеют одну и ту же полусферу направлений
и поэтому должны иметь одну и ту же “яркость”. Более того, распределение
“яркости” на плоскости должно быть симметричным относительно прямой, на
которой стоит стена — самые яркие точки будут находиться на продолжении
линии стены, а самые темные — у ее основания.
5.2. ИСТОЧНИКИ СВЕТА И ИХ ДЕЙСТВИЕ
5.2.1. Радиометрические свойства источников света
Определим источник света как нечто, излучающее непосредственно гене-
рируемый (а не только отражаемый) свет. Для описания источника необходимо
описать излучение, исходящее от него в каждом направлении. Обычно излуче-
ние, которое генерирует сам источник, рассматривают отдельно от отраженного
излучения (это потому, что отраженный свет, в отличие от генерируемого света,
зависит от среды).
130
Часть I. Формирование изображений и модели изображений
Полностью описывать излучение, которое исходит от источника в каждом
направлении, нет необходимости. Привычнее считать, что источники дают по-
стоянное излучение во всех направлениях (возможно, имеется некоторое число
направлений с нулевым излучением, как, например, у прожектора). Соответ-
ствующей величиной в этом случае будет светимость, определяемая как
энергия излучения, которая генерируется за единицу времени единицей площади
излучающей поверхности.
Светимость подобна плотности потока излучения, и ее можно рассчитать
следующим образом:
Е(Р) = I Le (Р, 6О, фо) cos 0О dw.
Помимо описания светимости необходимо знать геометрию источника, силь-
но влияющую на пространственное распределение света вокруг источника и на
тени, которые отбрасывают объекты вблизи источника. Можно назвать две при-
чины, по которым геометрия источников обычно принимается достаточно про-
стой: во-первых, многие искусственные источники можно достаточно эффектив-
но представить как точечные, линейные или плоские; во-вторых, даже источ-
ники с простой геометрией могут производить удивительно сложные эффекты.
5.2.2. Точечные источники
В качестве обычного приближения часто принимается, что источник све-
та — это очень маленькая сфера, фактически точка; такие источники называют
точечными. Это естественная модель, поскольку многие источники физически
малы по сравнению со средой, в которой они находятся. Модель действия то-
чечного источника можно вывести, представив источник как очень маленькую
сферу, каждая точка которой излучает свет, а светимость по всей поверхности
сферы одинакова.
Пусть участок поверхности (часто называемый лоскутом) освещается сфе-
рой радиуса е, которая находится на расстоянии г от него, и € С г (рис. 5.3).
Предположение о том, что сфера находится на большом расстоянии от участка
по сравнению с ее радиусом, почти всегда применимо к реальным источникам.
Теперь телесный угол, который образует источник, равен Па. Он приблизитель-
но пропорционален величине
г2
Распределение освещенности, которое получается при попадании света от ис-
точника на полусферу, также (грубо говоря) изменяет свой масштаб. Если сфера
отдаляется, то лучи, покидающие участок поверхности и попадающие на сферу,
сближаются (грубо говоря) равномерно, и освещенность изменяется незначи-
тельно (в область добавляется лишь небольшое количество новых лучей; вклад
Глава 5. Источники, тени и затенение
131
Лоскут постоянного
излучения, обусловленного
источником
Рис. 5.3. Участок поверхности “видит” отдаленную сферу небольшого радиуса; сфера освещает
небольшой участок на полусфере направлений. В тексте приводятся рассуждения о масштабном
поведении этого участка при отдалении сферы или ее увеличении и выводится выражение, описы-
вающее поведение точечного источника
этих лучей будет небольшим, поскольку они приходят в направлении, касатель-
ном сфере). На границе, где б стремится к нулю, новые лучи не добавляются.
Диффузное отражение, вызванное источником, можно найти интегрирова-
нием излучения источника, умноженного на cos^, по элементу телесного угла.
Если с стремится к нулю, то участок уменьшается и cosOi приближается к по-
стоянному значению. Если р — альбедо поверхности, то из сказанного следует,
что выражение для диффузного отражения, обусловленного точечным источни-
ком, выглядит следующим образом:
р Есозв,
где Е — светимость источника, проинтегрированная по малому участку. Более
точное выражение для Е нам не требуется (для его получения нужно было бы
вычислить упомянутый выше интеграл).
132
Часть I. Формирование изображений и модели изображений
Близлежащие точечные источники
Зависимость от угла в приведенной выше формуле можно записать че-
рез N(P) (единичную нормаль к поверхности) и S(P) (вектор, соединяющий
точку Р с источником, длина которого равна с2Е) и найти стандартную модель
близлежащего точечного источника:
P<(P)N{P}S(P}
РЛ( 1 г(Р)1
Это крайне удобная модель, поскольку она выражает явную связь между диф-
фузным отражением и формой (член, содержащий нормаль). В этой модели S
обычно называют вектором источника. Отметим, что часто (и неправильно!)
в этой модели не учитывается зависимость от расстояния до источника.
Точечный источник на бесконечности
Солнце находится далеко от нас, поэтому члены 1/г(Р)2 и S(P) можно
считать постоянными. В этом случае говорят, что точечный источник нахо-
дится на бесконечности. Если все интересующие нас участки поверхности
расположены близко друг к другу по сравнению с расстоянием до источника,
тогда т(Р) = г0 + Дг(Р), где г0 » Дг(Р). Более того, S(P) = So + AS(P),
где | So |»| AS(P) |. Получаем:
N • S(P) = N • (So + AS(P)) =~
r(P)2 (ro + Ar(P))2 ~ rg
Теперь и So, и го постоянны и нет смысла сохранять их в выражении в явном
виде. Вместо этого можно ввести S = (1/г2)5о, и модель диффузного отраже-
ния, обусловленного точечным источником, приобретает следующий вид:
В(Р) = pd(P)(N • S).
Вектор S называют вектором источника. Обычно в этой модели соответству-
ющий вектор источника подбирают с помощью логических рассуждений, а не
вычисляют его значение через светимость источника и его геометрию.
Выбор модели точечного источника
Точечный источник на бесконечности — это хорошая модель, например, для
солнца, поскольку телесный угол, который образует солнце, мал, и его мож-
но считать постоянным независимо от положения источника в поле зрения
(подобная проверка доказывает, что выбранное приближение применимо). Ес-
ли использовать, например, линейные датчики с неизвестным коэффициентом
усиления, то можно переопределить понятие вектора источника, внеся в него
интенсивность источника и неизвестный коэффициент усиления — обычно так
и делается без дополнительных оговорок.
Как можно ожидать из построения, модель точечного источника на бес-
конечности неприменима в том случае, если расстояние между объектами
Глава 5. Источники, тени и затенение
133
имеет тот же порядок величины, что и расстояние до источника. В этом
случае нельзя применять ряд приближений, в которых считается, что диффуз-
ное отражение, обусловленное точечным источником, не уменьшается с увели-
чением расстояния до источника.
Суть проблемы несложно понять, если рассмотреть, как выглядит источник
со стороны различных участков поверхности. Чем ближе находится участок к
источнику, тем больше должен казаться источник (каким бы малым не был
его радиус); это значит, что диффузное отражение, обусловленное источником,
должно возрастать. Если источник достаточно удален — например, солнце —
этим эффектом можно пренебречь, поскольку относительный размер источника
не изменяется при любом разумном движении.
В то же время для таких систем, как электрическая лампа в центре ком-
наты, телесный угол, образуемый источником, увеличивается обратно пропор-
ционально квадрату расстояния, и это значит, что диффузное отражение, обу-
словленное этим источником, будет вести себя точно так же. В данном случае
подходящей моделью будет точечный источник из раздела 5.2.2. Недостаток
этой модели в том, что из нее следует, что диффузное отражение резко меняет-
ся в пространстве, а это не соответствует реальным наблюдениям. Например,
если разместить точечный источник в центре куба, то из модели следует, что
диффузное отражение в углах куба будет приблизительно равно одной третьей
от того, что будет в центре каждой стороны — но углы реальной комнаты
никогда не бывают настолько темными. На практике в модели близлежащего
точечного источника для учета этого явления принято пренебрегать членом,
зависящим от расстояния — это некорректно с точки зрения радиометрии, но
модель становится точнее. Объяснение такого кажущегося противоречия будет
дано позднее, после рассмотрения моделей затенения.
5.2.3. Линейные источники
Геометрия линейного источника — это прямая линия; в качестве нагляд-
ного примера можно привести флуоресцентную лампу. Линейные источники не
очень распространены в природе или в модельной среде, поэтому в данной книге
они рассмотрены кратко. Основной интерес эта модель представляет в задачах
по радиометрии; в частности, диффузное отражение участков, расположенных
в разумной близости от линейного источника, меняется как величина, обратная
расстоянию до источника (а не квадрату расстояния). Объяснение этого факта
интереснее, чем само явление. Представим линейный источник как тонкий ци-
линдр диаметра е. Предположим, что линейный источник имеет бесконечную
длину, и рассмотрим участок, который находится во фронтальной плоскости
относительно источника (рис. 5.4).
На рис. 5.4 приведен внешний вид источника со стороны участка 1; теперь
передвинем участок ближе и рассмотрим участок 2 — ширина области полу-
сферы, соответствующей источнику, изменилась, в отличие от длины (так как
длина источника бесконечна). В свою очередь, поскольку ширина приблизи-
тельно равна е/r, диффузное отражение, обусловленное источником, должно
134
Часть I. Формирование изображений и модели изображений
Рис. 5.4. Диффузное отражение, обусловленное линейным источником, в точках, которые располо-
жены близко к источнику, уменьшается обратно пропорционально расстоянию. Слева: два участка,
выходящие на бесконечно длинный узкий цилиндр с постоянной светимостью по всей поверхности
и диаметром с. Справа: вид источника со стороны каждого участка, изображенный как внут-
ренняя сторона полусферы направлений (вид снизу). Обратите внимание, что длина источника на
этой полусфере не меняется, в отличие от ширины (меняется как с/т)
уменьшаться обратно пропорционально расстоянию. Несложно видеть, что для
источника, длина которого не бесконечна, рассуждения применимы до тех пор,
пока участок находится на разумно близком расстоянии от источника.
5.2.4. Плоские источники
Плоский источник — это плоскость, которая излучает свет. Плоские ис-
точники очень важны по двум причинам. Во-первых, они достаточно часто
встречаются в природе (хороший пример — пасмурное небо) и в искусственной
среде (например, прямоугольные флуоресцентные лампы на потолках мно-
гих предприятий). Во-вторых, исследование плоских источников позволяет
объяснить различные эффекты затенения и взаимного отражения. Плоские ис-
точники обычно представляют в виде участков поверхности, излучение которых
не зависит от положения и направления, и описываются их светимостью.
Как и для линейных источников, в данном случае можно доказать, что для
точек, не слишком удаленных от источника, диффузное отражение, обуслов-
ленное плоским источником, не зависит от расстояния до источника. Это про-
исходит потому, что для достаточно большой (по сравнению с расстоянием до
источника) поверхности, площадь, которую источник образует на какой-либо
полусфере направлений, остается приблизительно той же, когда мы приближа-
емся к источнику или удаляемся от него. Этим объясняется распространенность
плоских источников в осветительной инженерии — они обычно дают достаточ-
но однородное освещение. Для наших целей необходимо более точное описание
диффузного отражения, обусловленного плоским источником, поэтому вычис-
лять интеграл все же придется.
Глава 5. Источники, тени и затенение
135
Рис. 5.5. Рассеивающий источник освещает рассеивающую поверхность. Светимость источника —
E(Q), требуется найти диффузное отражение участка, обусловленное данным источником. Это
можно сделать с помощью преобразования интеграла от падающего излучения по поверхности
в интеграл по площади источника. Такое преобразование удобно, поскольку позволяет не рассмат-
ривать различные диапазоны углов для различных поверхностей. Впрочем, при таком подходе все
же появляется интеграл, который обычно нельзя найти аналитически
Точное диффузное отражение, обусловленное плоским источником
Пусть имеется участок рассеивающей поверхности, который освещается
плоским источником со светимостью E(Q) в точке источника Q. Вместо того
чтобы записывать углы через координаты, введем вектор QP, идущий от Q к Р
(остальные обозначения см. на рис. 5.5). Диффузное отражение поверхности
можно найти, просуммировав падающее излучение по всем направлениям. Этот
интеграл можно преобразовать в интеграл по источнику:
B(P) = W(P) [ L.fP.Q?') cos Oi div =
= pd(P) f Le(Q, Q?) cosOidiv =
jq
= Pd(P) J COsffi =
136 Часть I. Формирование изображений и модели изображений
= Pd(P) f (-E(Q)] cosfli fcos0a^
J ПО источнику \ / \
COS0iCOS0e
= pd(P) / E(Q)-----------—------dAQ.
J по источнику ** '
Данное преобразование применимо, поскольку излучение вдоль прямой линии
постоянно и поскольку E(Q) = (1/тг)£е(<Э). Последнее важно, так как те-
перь нет необходимости выбирать подходящую сферическую систему коорди-
нат. Впрочем, несмотря на преобразования, интегралы, описывающие действие
плоских источников, обычно очень трудно или даже невозможно вычислить
в явном виде.
5.3. ЛОКАЛЬНЫЕ МОДЕЛИ ЗАТЕНЕНИЯ
Физика света дает возможность узнать, насколько яркими будут объекты
(и почему), и помогает извлечь из моделей информацию об объектах. На дан-
ный момент известно диффузное отражение участка, обусловленное источни-
ком, но это еще не модель затенения. Излучение может попадать на участок по-
верхности и другим путем (например, после отражения от других участков по-
верхности); необходимо знать, какие компоненты при этом следует учитывать.
Самая простая в использовании модель — это локальная модель затенения,
где диффузное отражение на участке поверхности представляется как суммар-
ное диффузное отражение, обусловленное только светом, который дает непо-
средственно сам источник. Таким образом, предполагается, что свет не отража-
ется от поверхности к поверхности, а исходит от источника, попадает на какую-
то поверхность и направляется прямо в камеру. Эта модель совершенно не фи-
зическая, но легко поддается анализу. Она допускает ряд алгоритмов и теорий
(см. раздел 5.4). К сожалению, такая модель часто дает очень неточные пред-
сказания. Более того, весьма трудно определить область ее применения.
Альтернативный подход — учитывать все излучение (раздел 5.5). В такой
модели рассматривается излучение, поступающее от источников и излучающих
поверхностей. Это точная модель с физической точки зрения, но с ней доста-
точно сложно работать.
5.3.1. Локальные модели затенения для точечных источников
Локальную модель затенения для системы точечных источников можно най-
ти, записав диффузное отражение, обусловленное светом, который непосред-
ственно генерируется источниками. В результате
В(Р)= 22 В.(Р),
я£ источники, видные из Р
где Вз(-Р) — диффузное отражение, обусловленное источником s. Обратите
внимание, что если все источники будут точечными на бесконечности, это вы-
Глава 5. Источники, тени и затенение
137
Рис. 5.6. Тени, отбрасываемые точечным источником на плоскость, выглядят просто. Собствен-
ная тень — следствие удаленности поверхности от света, а отбрасываемая тень — преграждения
источника с точки зрения удаленной поверхности
ражение приобретет такой вид:
В(Р) = 52 Pd(P)N(P) s..
ее источники, видные из Р
Таким образом, если ограничиться изучением области, где все точки видят одни
и те же источники, можно сложить все векторы источников и получить один
условный источник, который будет давать такой же суммарный эффект. Связь
между формой и затенением здесь довольно проста: диффузное отражение —
это мера одного компонента нормали к поверхности.
Для точечных источников, которые находятся не на бесконечности, модель
приобретает вид
в € источники, видимые из Р ' '
где га(Р) — расстояние от источника до Р; присутствие этого члена означа-
ет, что связь между формой и затенением сложнее, чем могло показаться на
первый взгляд.
Возникновение теней
В локальной модели затенения тени появляются, когда участок не может
видеть один или несколько источников. В этой модели точечные источники по-
рождают ряд теней с четкими границами; особенно темны затененные области,
откуда не виден ни один источник. Тени, отбрасываемые одним источником,
138
Часть I. Формирование изображений и модели изображений
Плоский
источник
Затеняющий
объект
Рис. 5.7. Плоские источники порождают сложные тени со сглаженными границами, поскольку если
смотреть на источник из точки, находящейся на участке поверхности, то он медленно скрывается
за затеняющим объектом. Области, откуда источник не виден вообще, называют тенью; области,
откуда видна некоторая часть источника, называют полутенью. Представьте себя лежащим на
спине и смотрящим вверх. Из точки 1 вам будет виден весь источник; из точки 2 вы сможете
увидеть его часть; а из точки 3 вы его не увидите
могут быть четкими и черными в зависимости от размера источника и альбе-
до остальных соседних поверхностей (которые могут отражать свет в эту тень
и делать ее границы размытыми). В XIX веке было популярно отбрасывать та-
кие тени на бумагу, а затем обводить их карандашом, в результате чего полу-
чались силуэты, которые иногда еще можно увидеть в антикварных магазинах.
Геометрия тени, отбрасываемой точечным источником на плоскость, анало-
гична геометрии наблюдения через перспективную камеру (рис. 5.6). Любой
участок поверхности будет находиться в тени, если луч, идущий от участка
к источнику, проходит через объект. Это означает, что существует два вида
тени: 1) собственная тень возникает, когда поверхность удалена от источника
света, и луч от участка поверхности к источнику идет перпендикулярно поверх-
ности; 2) отбрасываемая тень — это когда источник неожиданно исчезает за
затеняющим объектом. Отметим, что тени, отбрасываемые на искривленную
поверхность, могут иметь чрезвычайно сложную геометрию.
Если источников много, то тени выглядят светлее (кроме тех точек, откуда
не виден ни один источник), и может существовать множество качественно раз-
ных областей тени (каждый источник отбрасывает свою собственную тень —
некоторые точки могут видеть только один источник). Один из примеров этого
явления можно наблюдать при телевизионной трансляции футбольных матчей.
Глава 5. Источники, тени и затенение
139
Поскольку стадион освещается множеством ярких отдаленных точечных источ-
ников — прожекторов, равномерно распределенных по всему периметру стадио-
на, — вокруг каждого игрока образуется набор равномерно окружающих его те-
ней. При перемещении игрока по полю эти тени обычно становятся темнее или
светлее, чаще всего потому, что освещение, обусловленное другими источника-
ми и взаимным отражением в области тени, увеличивается или уменьшается.
5.3.2. Плоские источники и их тени
Локальная модель затенения для системы плоских источников намного
сложнее, поскольку участки могут наблюдать только часть данного источника.
Если использовать терминологию с рис. 5.5, модель приобретает такой вид:
= Е / = диффузное отражение источника > —
вевс« источники видимая часть источника a J
Г cosflqcosfl, 1
/ SE(Q)-----±2-----dAQ f •
аевсе источники Jвидимая часть источника з I 7ГГ )
Обычно считается, что Е постоянно по всему источнику.
Плоские источники не дают темных теней с четкими границами. Это проис-
ходит потому, что при перспективном рассмотрении участка источник медленно
появляется из-за затеняющего объекта (вспомните лунное затмение — это точ-
ная аналогия). Принято различать точки в полной тени, которые не могут
видеть источник вообще, и точки в полутени, которые видят часть источника.
Подавляющее большинство источников в помещении — плоские источники той
или иной формы; такие явления очень легко наблюдать, поднеся руку близко
к стене и посмотрев на тень, которую она отбрасывает. Будет видна темная се-
редина, которая становится больше при приближении руки к стене (это тень),
окруженная более светлой областью с нечеткими границами (полутень). Соот-
ветствующая геометрия показана на рис. 5.7.
5.3.3. Естественное освещение
Одна проблема, связанная с локальной моделью затенения, заметна сразу:
данная модель предсказывает, что некоторые области тени будут относительно
темными, поскольку они не видят источник. Это предсказание почти никогда не
сбывается, поскольку тени освещаются светом, исходящим от других рассеива-
ющих поверхностей (это явление может иметь огромное значение). В комнатах
со светлыми стенами и плоскими источниками тень можно увидеть, только под-
неся объект очень близко к стене или к источнику. Это происходит потому, что
участок стены видит все остальные стены комнаты; до тех пор, пока объект не
будет находиться слишком близко к стене, он перекрывает только небольшую
часть видимой полусферы направлений каждого участка.
При определенных обстоятельствах суммарное излучение, которое получает
участок поверхности от других участков, почти постоянно и приблизитель-
140
Часть I. Формирование изображений и модели изображений
но равномерно распределено по полусфере направлений. Это справедливо для
внутренней поверхности сферы с постоянным распределением диффузного от-
ражения (что следует из симметрии) и почти справедливо для внутреннего по-
мещения комнаты с белыми стенами (если моделировать куб подобно сфере).
В таких средах иногда можно построить модель действия остальных участ-
ков, добавив к диффузному отражению каждого участка член, отвечающий за
естественное освещение. Существует два способа определения этого члена.
Первый: если все участки видят одинаковые части окружающего мира (на-
пример, внутренняя поверхность сферы), необходимо добавить один и тот же
постоянный член к диффузному отражению каждого участка. Величина этой
добавки обычно просто угадывается.
Второй способ: если одни участки видят большую или меньшую часть
окружающего мира по сравнению с другими (когда какие-то части окружаю-
щей среды частично перекрывают поле зрения участка — например, участок,
который находится на дне желобка), это нужно иметь в виду, для чего пона-
добится модель окружающей среды с учетом перспективы данного участка.
Представим окружающую среду как большой удаленный многогранник с по-
стоянным диффузным отражением, причем из некоторых участков поверхности
этот многогранник виден частично (см. рис. 5.8). В результате получится,
что для участков, которые видят меньшую часть окружающей среды, член,
отвечающий за естественное освещение, будет меньше. Эта модель часто ока-
зывается точнее, чем простое прибавление постоянного члена, отвечающего за
естественное освещение. К сожалению, из данной модели намного труднее по-
лучить нужную информацию (пожалуй, настолько же сложно, как и из общей
модели затенения).
5.4. ПРИЛОЖЕНИЕ: ФОТОМЕТРИЧЕСКОЕ СТЕРЕО
Попытаемся восстановить участок поверхности по ряду изображений, по-
лученных при различном освещении. Воспользуемся ортогональной камерой
и выберем систему координат таким образом, чтобы точка (х, у, z) простран-
ства проектировалась в точку (х,у) изображения (описываемый метод приме-
ним и для других типов камер, которые перечислены в главе 1).
В этом случае, чтобы определить форму поверхности, нужно знать ее глуби-
ну. Выразим поверхность как (х,у, — представление в виде участков
Монга (Monge), названное так в честь французского военного инженера, впер-
вые применившего его на практике (рис. 5.9). Это представление привлекает
тем, что для данных координат изображения можно определить единственную
точку на поверхности. Обратите внимание, что для определения размеров объ-
емного тела нужно восстановить несколько участков, чтобы увидеть и обратную
сторону объекта.
Фотометрическое стерео — это метод, помогающий найти представление
участка Монга по информации, полученной из изображения. В этот метод вхо-
дит логическое выведение значения интенсивности изображения для несколь-
Глава 5. Источники, тени и затенение
141
Рис. 5.8. Естественное освещение — член, который добавляется к предсказанному диффузному
отражению в локальной модели затеиения для учета эффекта диффузного отражения от отдален-
ных отражающих поверхностей. Для системы наподобие внутренней поверхности сферы или куба
(слева на рисунке), где из каждой точки участка видно примерно одно и то же, в модель вводится
постоянный член, описывающий естественное освещение. Б более сложных системах из некоторых
участков поверхности видно намного меньше, чем из других. Например, с участка на дне желобка
на правом рисунке видна относительно небольшая часть окружающей среды, которую мы пред-
ставляем как бесконечный многогранник с постоянной светимостью; ниже показана его полусфера
видимых направлений
ких различных изображений поверхности в фиксированном поле зрения при
освещении различными источниками. С помощью этого метода находят высоту
поверхности в точках, соответствующих каждому пикселю; в кругах специа-
листов по компьютерному зрению получаемое представление часто называют
картой высоты, картой глубины, или картой плотности глубины.
Зафиксируем положение камеры и поверхности и осветим поверхность то-
чечным источником, который находится на большом расстоянии по сравнению
с размерами поверхности. Будем придерживаться локальной модели затенения
и считать, что естественного освещения нет (подробнее см. ниже), так что
диффузное отражение в точке Р на поверхности равно
В(Р) = p(P)N(P) Si,
где N — единичная нормаль к поверхности, a Si — вектор источника. В данной
модели камеры для каждой точки изображения существует только одна
142
Часть I. Формирование изображений и модели изображений
Рис. 5.9. Участок Монга — это представление участка поверхности как функции высоты. В об-
ласти фотометрического стерео, например, считается, что участок Монга исследуется с помощью
ортогональной камеры (которая проектирует точку пространства (x,y,z) в точку камеры (х,у)).
Это значит, что форму поверхности можно передать как функцию положения на изображении
точка Р на поверхности, т.е. вместо В(Р) можно записать В(х,у). Теперь
допустим, что реакция камеры на диффузное отражение поверхности линейна,
так что значение пикселя в точке (я, у) записывается как
1(х,у) = кВ(х,у) =
= кр(х, y)N(x, у) Si —
= 9(x,y)Vi,
где к — константа, связывающая реакцию камеры с падающим излучени-
ем, д(х,у) = p(x,y)N(x,у), a Vi =к8г.
В этих уравнениях д(х,у) описывает поверхность, a Vi — свойства освеще-
ния и камеры. Можно измерить скалярное произведение векторного поля д(х, у)
и вектора Vi; при достаточном количестве таких скалярных произведений мож-
но восстановить д и, следовательно, саму поверхность.
5.4.1. Нормаль и альбедо по многим изображениям
Предположим, что есть п источников, для каждого из которых известно Vi.
Сведем все векторы V, в известную матрицу V, где
Глава 5. Источники, тени и затенение
143
Рис. 5.10. Пять искусственных изображений сферы, полученных ортогональным способом с од-
ной и той же точки зрения. Эти изображения описаны с помощью локальной модели затенения
и отдаленного точечного источника. Наблюдается объемный предмет, так что единственный вид,
на котором нет видимой тени, можно получить тогда, когда источник светит параллельно направ-
лению взгляда. Яркость меняется при различном кодировании формы исходной поверхности
Для каждой точки изображения образуем вектор
»(х, у) = {Ц (х, у), I2(x, у),..., 1п(х, у)}т.
Обратите внимание, что для каждой точки изображения есть один вектор; каж-
дый вектор содержит все значения яркости изображения, наблюдаемые в этой
точке при различных источниках. Теперь получим
*(*,!/) = Vg(x,y),
а д можно найти, решив эту линейную систему или, точнее, решив по одной
линейной системе для каждой точки изображения. Обычно п > 3, так что
удобно использовать решение по схеме наименьших квадратов. В этом есть
свое преимущество: по остаточной ошибке можно проверить измерения.
Сложность описанного подхода состоит в том, что значительные области по-
верхности при том или ином освещении могут находиться в тени (см. рис. 5.10).
Впрочем, есть простой метод работы с тенью. Если естественное освещение
отсутствует, то из вектора изображения можно составить матрицу и умножить
обе стороны уравнения на эту матрицу; данная операция превратит в нуль те
уравнения, которые описывают точки, находящиеся в тени. Построим такую
144
Часть I. Формирование изображений и модели изображений
матрицу:
/ Ц(х,у)
О
1г(х,у) •••
1(х,у) =
0 \
О ••• 1п(х,у) /
Ti = TVg(x, у).
Матрица Т обнуляет вклады затененных областей, поскольку значимые эле-
менты матрицы в точках, находящихся в тени, равны нулю. Снова получаем по
одной линейной системе для каждой точки изображения; решаем эту линейную
систему для каждой точки и находим вектор д в этой точке.
Измерение альбедо
Альбедо можно получить из измерений вектора д. Поскольку N — это
единичная нормаль, то |g(x, т/)| = р(х,у). Проверим наши измерения: так как
альбедо принадлежит диапазону от нуля до единицы, все пиксели, где | д|
больше единицы, находятся “под подозрением” — или пиксель не дает вклада,
или матрица V записана неверно. На рис. 5.11 показано альбедо, найденное
с помощью этого метода для изображений с рис. 5.10.
Определение нормалей
Нормаль к поверхности можно найти из д, так как нормаль — это следую-
щий единичный вектор:
На рис. 5.12 приведены значения нормали, полученные по изображениям
рис. 5.10.
5.4.2. Определение формы по нормалям
Поверхность можно представить в виде (я,у,/(я,?/)), так что нормаль как
функция (х, у) имеет следующий вид:
Чтобы найти карту глубин, нужно определить f(x,y) из измеренных значений
единичной нормали.
Допустим, что измеренное значение единичной нормали в какой-то точ-
ке (х,у) — (а(х,у), Ъ(х,у), с(х,у)\ Тогда
df _ а(х,у) df _ b(x,y)
"о- - / х И ~------ — ————.
дх с(х, у) ду с(х, у)'
145
Глава 5. Источники, тени и затенение
Рис. 5.11. Величина векторного поля д(х,у), найденная из исходных данных рис. 5.10 и представ-
ленная визуально как отражение от поверхности
Рис. 5.12. Поле нормалей, найденное из исходных данных рис. 5.10
146
Часть I. Формирование изображений и модели изображений
Получена еще одна возможность для проверки нашего набора данных, поскольку
д2/ _ а2/
дхду дудх'
Таким образом, можно ожидать, что величина
ду дх
будет малой в каждой точке. В принципе, она должна равняться нулю, но если
оценивать частные производные численно, то вернее ожидать, что они будут
просто малыми. Данная проверка называется проверкой на интегрируемость
и в приложениях компьютерного зрения она всегда сводится к проверке равен-
ства смешанных вторых производных.
Определение формы интегрированием
Будем считать, что частные производные прошли указанную выше проверку.
Теперь можно восстановить поверхность с точностью до некоторой постоянной
ошибки по глубине. Частные производные показывают изменение высоты по-
верхности с небольшим шагом как по х, так и по у. Это значит, что теперь
можно найти поверхность, просуммировав изменения высоты по какому-то пу-
ти. В частности,
/(х,у)=/ dl + c,
Jc \дх ду)
где С — это кривая, которая начинается в некоторой фиксированной точке
и заканчивается в точке (x,y)t а с — константа интегрирования, которая пред-
ставляет (неизвестную) высоту поверхности в начальной точке. Найденная по-
верхность не зависит от выбора кривой (см. раздел упражнений).
Например, можно восстановить поверхность в точке (u, v), начиная с (0,0),
просуммировав производные по у вдоль прямой х = 0 до точки (0, v), а затем
просуммировав производные по х вдоль прямой у = v до точки (и, и):
/(u,v)= [ ^-(O,y)dy + f ~(x,v)dx + с.
Jq оу Jq Ox
Этот путь интегрирования принят в алгоритме 5.1. Любой другой набор путей
даст аналогичный результат, хотя, пожалуй, лучше всего использовать множе-
ство различных путей и усреднять полученные результаты, чтобы таким обра-
зом уменьшить ошибку оценки производных. На рис. 5.13 показан результат,
полученный из рис. 5.10.
Еще один способ восстановления формы — выбрать функцию /(х, у), част-
ные производные которой ближе всего к измеренным частным производным.
Этот подход будет рассмотрен в разделе 6.5.2.
Глава 5. Источники, тени и затенение
147
Алгоритм 5.1. Фотометрическое стерео
Получить много изображений с фиксированной точки наблюдения при разном
освещении
Определить матрицу V из информации об источнике и камере
Создать массивы для альбедо, нормали (3 компонента),
р (измеренное значение и q (измеренное значение
Для каждой точки в массиве изображения
Преобразовать значения изображения в вектор i
Построить диагональную матрицу I
Решить уравнение ТМд = 1г, чтобы найти д для этой точки
Альбедо в этой точке равно |р|
Нормаль в этой точке равна
р в этой точке равно
q в этой точке равно $я
конец
Проверить: везде ли (|е - |я)2 мало?
Значение в верхнем левом углу карты высоты — нуль
Для каждого пикселя в левом столбце карты высоты
значение высоты = предыдущее значение высоты + соответствующее
значение q
конец
Для каждой строки
Для каждого элемента строки, кроме крайнего левого
значение высоты — предыдущее значение высоты + соответствующее
значение р
конец
конец
5.5. ВЗАИМНОЕ ОТРАЖЕНИЕ: ГЛОБАЛЬНЫЕ МОДЕЛИ ЗАТЕНЕНИЯ
Локальные модели затенения могут вводить в заблуждение. В реальном ми-
ре каждый участок поверхности освещается не только источниками, но еще
и светом, отраженным от других участков поверхности (явление, известное
как взаимное отражение). Модель, в которой учитываются эффекты взаимно-
го отражения, называется глобальной моделью затенения. Взаимное отраже-
ние дает ряд сложных явлений затенения, пока что недостаточно изученных.
К сожалению, эти явления встречаются очень часто, и пока еще не ясно, как
упростить глобальную модель затенения без потери существенных качествен-
ных свойств.
148
Часть I. Формирование изображений и модели изображений
Рис. 5.13. Поле высот, найденное интегрированием поля нормалей из рис. 5.12. Описание метода
см. в тексте
Например, на рис. 5.14 показан вид изнутри двух разных комнат. В одной
комнате черные стены, и в ней находятся черные предметы; в другой стены
белые, и в ней находятся белые предметы. Каждая комната освещается (при-
ближенно!) удаленным точечным источником. Если считать, что интенсивность
источника подобрана правильно, из локальной модели затенения следует, что
эти картинки должны быть неразличимы. На самом деле, в черной комнате
тени в складках многоугольников намного темнее, а их границы четче, чем
в белой комнате. Это объясняется тем, что от поверхностей в черной комна-
те отражается и попадает на другие поверхности меньше света (они темнее),
тогда как в белой комнате другие поверхности можно считать существенны-
ми источниками излучения. Сечения реакции камеры на диффузное отражение
(пропорциональные диффузному отражению рассеивающих поверхностей), по-
казанные на рисунке, очень сильно отличаются качественно. В черной комнате
диффузное отражение на участках постоянно, как и предсказывает локальная
модель затенения, тогда как в белой комнате наблюдается плавное изменение
градиентов — это происходит в вогнутых углах, где стороны предметов отра-
жают свет друг на друга. С помощью этого явления можно также объяснить
и то, почему в комнате, которая освещается точечным источником, нет рез-
ких градиентов освещения, которые предсказывает локальная модель затенения
(вспомните раздел 5.2.2). Стены и пол комнаты отражают освещение в обрат-
ном направлении, и поэтому освещаются углы, которые в противном случае
были бы темными.
Глава 5. Источники, тени и затенение
149
Рис. 5.14. В левом столбце показаны данные, полученные в комнате с черными матовыми стенами
и набором черных матовых многоугольных предметов; справа показаны данные из белой комнаты
с белыми предметами. Эти изображения отличаются качественно: в черной комнате тени темнее,
их границы четче, а в белой наблюдаются яркие блики в вогнутых углах. На графиках изображено
сечение интенсивности изображения вдоль соответствующих прямых изображений
5.5.1. Модель взаимного отражения
Несложно понять, как предсказать диффузное отражение набора участков
рассеивающей поверхности. Общее диффузное отражение, излучаемое с участ-
ка — это его светимость, которая равна нулю для всех поверхностей, кроме
источников, плюс все диффузное отражение участка:
В(Р) = Е(Р) + Вотр(Р).
Что касается рассматриваемого участка, нет разницы между энергией, излуча-
емой другим участком (собственная светимость или отражение). Это значит,
что можно взять выражение для плоского источника и использовать его для
нахождения выражения для B(Q). В частности, с учетом перспективы данного
участка, участок, находящийся в точке R внешнего мира, равнозначен плоскому
источнику со светимостью B(R). Это значит, что
г созОрсозво
Втр(Р) = pd(P) / вид(Р, Q)B(Q)---------------- dAQ =
J среда 7Г dpQ
= pd(P) [ Bvm(P,Q)K(P,Q)B(Q)dAQ.
J среда
150
Часть I. Формирование изображений и модели изображений
Рис. 5.15. Система обозначений (объяснения см. в тексте)
Обозначения представлены на рис. 5.15. Далее,
{1, если Р может видеть О,
0, если Р не может видеть Q.
Член вид(Р, Q)K(P, Q) обычно называютядрол взаимного отражения. Под-
становка в выражение для В(Р) дает такой результат:
В(Р) = Е(Р) + pd(P) [ вид(Р, Q)K(P, Q)B(Q) dAQ.
Jсреда
В частности, решение входит в интеграл. Уравнения такого вида называют ин-
тегральными уравнениями Фредгольма второго рода. Это конкретное уравнение
является довольно неприятным представителем своего семейства, поскольку яд-
ро взаимного отражения в общем случае не непрерывно и может иметь сингу-
лярности. Решения данного уравнения могут дать достаточно хорошие модели,
описывающие рассеивающие поверхности, и для читателей, серьезно интересу-
ющихся компьютерной графикой, можно в этой связи порекомендовать работы
[Cohen and Wallace, 1993] или [Sillion, 1994]. Здесь остается лишь отметить,
что эта модель дает хорошие предсказания наблюдаемых явлений (рис. 5.16).
Глава 5. Источники, тени и затенение
151
Освещение со стороны бесконечно
удаленного точечного источника
в направлении, указанном стрелкой
Положение
Рис. 5.16. Описанная в тексте модель дает довольно точные качественные предсказания о взаим-
ном отражении. Вверху показан вогнутый прямоугольный желобок, который освещается точечным
источником на бесконечности, причем направление освещения параллельно одной стороне. Слева
в нижнем ряду приведен ряд предсказаний о диффузном отражении для такой конфигурации. Эти
предсказания расположены так, чтобы одно находилось над другим; случай р —+ 0 соответствует
локальной модели затенения. Справа показана наблюдаемая интенсивность изображения для та-
кой формы угла, сделанного из белой бумаги, которая дает крышеподобный градиент диффузного
отражения края. Локальная модель затенения предсказывает резкий скачок на графике
5.5.2. Решения для диффузного отражения
Для иллюстрации методов решения в глобальной модели затенения приве-
дем схему одного из них. Разделим систему на маленькие плоские участки
и будем считать, что диффузное отражение в пределах участка постоянно. Та-
кое приближение разумно, поскольку при работе с маленькими участками мож-
но найти точное представление. Построим теперь вектор В, который содержит
значение диффузного отражения каждого участка. В частности, г-й компонент
вектора В — это диффузное отражение г-го участка.
Запишем диффузное отражение i-го участка, обусловленное диффузным от-
ражением j-ro участка как
В^(Р) = Pd(P) [ вид(Р, Q)K(P, Q) dAQBj,
./участок j
152
Часть I. Формирование изображений и модели изображений
где Р — координата г-го участка, a R — координата J-ro участка. Получен-
ное выражение не равно константе, поэтому необходимо усреднить его по г-му
участку:
= Pd(P) [ WR(P,Q)K(PtQ)dApdAQBj,
'*» Jучасток i J участок j
где Ai — площадь г-го участка. Если принять, что светимость каждого участка
также постоянна, то получим следующую модель:
Bi = Ei+
по всем j
= £<+ 52
по всем j
где
Кц = [ Pd(P) [ Bw(P,Q)K(P,Q)dAPdAQ.
Элементы этой матрицы иногда называют форм-факторами.
Полученный результат — это система линейных уравнений по Bi (очень
большая — размеры матрицы Kij могут достигать значения миллион на милли-
он), и, как таковая, в принципе, решаема. Для эффективного, быстрого и точ-
ного решения этой системы можно использовать определенные уловки, которые
в данной книге не рассматриваются, но их перечень можно найти в публика-
циях [Sillion, 1994] или [Cohen and Wallace, 1993].
5.5.3. Качественное описание эффектов взаимного отражения
Из диффузного отражения хотелось бы получить информацию о форме. Это
относительно просто сделать с помощью локальной модели (о некоторых по-
дробностях см. раздел 5.4), но данная модель не очень хорошо описывает ре-
альные ситуации, и пока еще мало известно о том, насколько сильно это ска-
зывается на полученной из нее информации о форме. Извлечь информацию о
форме из глобальной модели затенения сложно по двум причинам. Во-первых,
связь между формой и диффузным отражением усложняется зависимостью от
ядра взаимного отражения. Во-вторых, почти всегда существуют поверхности,
которые не видны, но их излучение попадает на объекты, находящиеся в поле
зрения. Это так называемые “удаленные поверхности”, и их существование го-
ворит о том, что с помощью модели взаимного отражения очень сложно учесть
все излучение на сцене, поскольку некоторые излучатели не видны и мы можем
не знать о них или знать недостаточно.
Из сказанного следует, что качественное понимание локальных эффектов
взаимного отражения имеет большое значение; таким образом можно как пре-
небрегать явлениями взаимного отражения, так и использовать их. Эта тема
Глава 5. Источники, тени и затенение
153
Рис. 5.17. Маленький участок видит плоскость с синусоидальным диффузным отражением единич-
ной амплитуды. У этого участка (приблизительно) синусоидальное диффузное отражение, обуслов-
ленное действием этой плоскости. Амплитуду данного элемента мы будем называть приростом
участка. На графике показаны численные оценки прироста по 10 углам наклона от 0 до тг/2
как функции пространственной частоты на плоскости. Прирост очень быстро уменьшается; это
означает, что большие члены с высокими пространственными частотами должны быть местны-
ми явлениями, а не результатом действия удаленных излучателей. По этой причине так трудно
идентифицировать оконную мозаику из цветного стекла, смотря на пол у окна
Пространственная частота источника
в радианах на единицу длины
по большей части остается открытой для исследований, но кое о чем можно
сказать уже сейчас.
Сглаживание и местные эффекты
Во-первых, взаимное отражение обладает характерным эффектом сглажива-
ния. Например, если попытаться идентифицировать оконную мозаику по изоб-
ражению, которое она дает на полу, это изображение почти всегда будет пред-
ставлять собой набор неразличимых цветных пятен. Данное явление лучше
всего можно понять с помощью грубой модели, показанной на рис. 5.17. Гео-
метрия модели — участок, фронтально смотрящий на бесконечную плоскость,
которая находится на единичном расстоянии от него и имеет диффузное от-
ражение sin lux. Изменять расстояние от участка до плоскости бессмысленно,
поскольку решения задач на взаимное отражение инвариантны относительно
изменения масштаба — это значит, что решение для участка, находящегося на
вдвое большем расстоянии, можно найти, читая график со скоростью 2lu. Уча-
сток достаточно мал, так что его вкладом в диффузное отражение плоскости
можно пренебречь. Если участок наклонить на угол а относительно плоско-
сти, его диффузное отражение будет почти периодическим, с пространственной
частотой и> cos ст. Амплитуда элемента с такой частотой называется приростом
участка; график прироста представлен на рис. 5.17. Одна из важных особенно-
стей этого графика состоит в том, что при высоких пространственных частотах
скачкообразные переходы от плоскости к участку выглядят сложнее. Это зна-
154
Часть I. Формирование изображений и модели изображений
чит, что эффекты затенения с высокой пространственной частотой и большой
амплитудой обычно не могут вызываться удаленными поверхностями (если они
не обладают аномальной яркостью).
Чрезвычайно быстрый спад амплитуды с ростом пространственной часто-
ты, который наблюдается в членах, связанных с удаленными поверхностями,
означает, что если наблюдать член с большой амплитудой при высокой про-
странственной частоте, то вероятность того, что он является результатом
действия удаленного пассивного источника, будет очень незначительна
(поскольку этот эффект очень быстро сходит на нет). Явления затенения
принято относить к обусловленным отражательной способностью, если они
быстрые (“края”), а их динамический диапазон относительно узкий, и к обу-
словленным освещением во всех остальных случаях (об этом еще будет сказано
в разделе 6.5.2). Эту договоренность можно расширить. Выделим промежуточ-
ный диапазон пространственных частот, на которые, по большей части, не
влияет взаимное освещение от отдаленных поверхностей, поскольку в этом
случае прирост очень мал. Пространственные частоты этого диапазона не мо-
гут передаваться от удаленных пассивных излучателей, если эти излучатели
не обладают невероятно высокой отражательной способностью. В результате
пространственные частоты этого диапазона можно считать местными свой-
ствами, которые могут происходить только от взаимного отражения в пределах
отдельной области.
Самыми замечательными местными свойствами, пожалуй, являются бли-
ки — маленькие яркие участки, которые возникают главным образом на вогну-
тых областях (см. рис. 5.18 и 5.19). Второе важное явление — это окрашивание,
когда цветная поверхность отражает свет на другую цветную поверхность. Это
довольно распространенный эффект, который люди обычно не замечают, по-
ка не начинают специально обращать на него внимание. Впрочем, художники
воспроизводят его довольно часто.
5.6. ПРИМЕЧАНИЯ
Модели затенения в литературе по компьютерному зрению рассмотрены до-
вольно несистематично. Приближением точечного источника часто злоупотреб-
ляют; мы рекомендуем применять его с осторожностью и критически относить-
ся к случаям, когда его используют другие. В данной книге проведена четкая
грань между физическим действием источника и моделью затенения.
Локальные модели затенения
Большое достоинство локальных моделей затенения — простота анализа.
Основная характеристика локальной модели затенения: на поверхности с посто-
янным альбедо диффузное отражение участка поверхности является функцией
только нормали. Это значит, что можно избежать абстрактных понятий отража-
тельной способности и источника, а вместо этого просто кодировать свойства
поверхности и источника посредством карты отражения. Карта страже-
Глава 5. Источники, тени и затенение
155
Освещение со стороны бесконечно
удаленного точечного источника
в направлении, указанном стрелкой
\z
Рис. 5.18. Отблески на загибающихся краях — обычное качественное следствие взаимного от-
ражения. Такая ситуация показана на верхнем рисунке: вогнутый прямоугольный желобок, осве-
щаемый точечным источником света на бесконечности, вектор источника которого направлен по
биссектрисе угла. На графике слева представлена интенсивность, предсказанная моделью взаимно-
го отражения для этой конфигурации; случай р —» 0 описывается локальной моделью затемнения.
Для простоты сравнения графики выровнены. Поскольку альбедо поверхности уменьшается, по-
является крышеподобная структура. На графике справа показаны наблюдения этого явления на
изображении реальной сцены. Рисунок из D.A. Forsyth and A.P.Zisserman, "Mutual Illumination",
Proceedings CVPR. © 1989 IEEE
Положение в пикселях
ния — это функция, входом которой является нормаль, а выходом — значение
диффузного отражения, которое можно ожидать в точке с такой нормалью.
Систематически изучать затенение в компьютерном зрении начал Хорн, вы-
пустив важные статьи по определению формы в локальной модели затенения
с использованием точечного источника ([Ноги, 1970, 1975]), в несколько пере-
работанном виде результаты были представлены в работе [Horn, 1990]. Пред-
лагаемые методы сильно критиковались (по крайней мере, отчасти из-за того,
что они оказались неспособными справиться с проблемами глобальной модели
затенения), поэтому их обзор мы не приводим. Заинтересованному читателю
можно порекомендовать работу [Horn and Brooks, 1989], где предложен весьма
удачный обзор этих методов. Форма и альбедо неоднозначны; если соответству-
ющим образом изменить альбедо, поверхности различных форм будут давать
одинаковые изображения ([Belhumeur, Kriegman and Yuille, 1999], [Kriegman
and Belmeur, 1998]). Поскольку нормаль к поверхности — это ключевой элемент
в локальных моделях затенения, такие модели обычно позволяют элегантно свя-
зать затенение поверхности и ее кривизну ([Koenderink and van Doorn, 1980]).
156
Часть I. Формирование изображений и модели изображений
Рис. 5.19. Отблески встречаются достаточно часто; обычно они вызваны наблюдением большой
отражающей поверхности. В геометрии, показанной сверху, затененная область цилиндрической
выпуклости видит плоскость, лежащую в основе, под достаточно удобным углом — если фон
довольно велик, то почти половина полусферы направлений участка в основании выпуклости будет
видеть плоскость. Это означает, что рядом с краем выпуклости появится значительный отблеск,
находящийся в пределах отбрасываемой тени (которая, по предсказанию локальной модели, должна
быть черной). С другой стороны будет еще один отблеск, что видно из набора решений, показанных
слева (для удобства сравнения решения нормированы). Справа показан результат для реальной
сцены. Рисунок из D.A. Forsyth and A.P.Zisserman, "Mutual Illumination", Proceedings CVPR,
1989. © 1989 IEEE
Взаимное отражение
К сожалению, глобальное затенение описано в литературе недостаточно,
а взаимное отражение часто не рассматривается, поскольку его чрезвычайно
сложно анализировать, особенно с учетом перспективы и свойств объекта, ко-
торые получаются как следствие применения глобальной модели затенения. Ес-
ли взаимное отражение не сильно влияет на результат применения метода, то,
пожалуй, его можно игнорировать. К сожалению, показать, что метод устойчив
по отношению ко взаимному отражению, достаточно трудно, поэтому данный
момент обычно не рассматривается. Вопросы пространственной частоты пред-
ставлены в публикации [Haddon and Forsyth, 1998а], а первоначальная идея
была высказана в [Koenderink and van Doorn, 1983]. Кроме того, довольно мало
известно обо всех свойствах взаимного отражения и связанного с ним затене-
ния. Альтернативный подход — итеративная оценка формы с помощью модели
визуализации ([Nayar, Ikeuchi and Kanade, 1991a]).
Глава 5. Источники, тени и затенение
157
Хорн первым указал на значение явлений глобального затенения ([Horn,
1997]). В работе [Koenderink and van Doorn, 1983] отмечено, что диффузное
отражение в глобальной модели затенения можно найти через затенение из
локальной модели, применив линейный оператор с последующим анализом ре-
зультата. Иногда собственные функции этого оператора (их часто называют
геометрическими модами) несут некоторую полезную информацию. В после-
дующих работах ([Forsyth and Zisserman, 1989, 1990, 1991]) был продемонстри-
рован ряд качественных явлений, обусловленных взаимным отражением.
Фотометрическое стерео
В первоначальной форме фотометрическое стерео появилось благодаря Вуд-
хаму (Woodham). Существует несколько различных вариантов самой идеи
([Horn, Woodham and Silver, 1978], [Woodham, 1979, 1980, 1989, 1994]), а так-
же ряд вариаций на тему фотометрического стерео. Одна интересная идея —
освещать поверхность тремя источниками света разных цветов (из разных
положений) и использовать цветное изображение. При правильном подборе
цветов это равнозначно наличию трех изображений, так что требуемые изме-
рения значительно упрощаются.
Фотометрическое стерео применяется в ситуациях, когда освещение доста-
точно легко контролировать, так что можно быть уверенным, что на изоб-
ражении не будет естественного освещения. Ввести естественное освещение
в приведенные выше формулы относительно несложно: достаточно расширить
матрицу V, добавив столбец, отвечающий за естественное освещение. В этом
случае д(х, у) становится четырехмерным вектором, и его четвертая координа-
та — член, отвечающий за естественное освещение. Впрочем, данный метод не
гарантирует, что этот член будет постоянным по всему пространству. Время от
времени пришлось бы проверять, действительно ли этот член постоянен, и если
нет, уточнять соответствующую модель.
Фотометрическое стерео зависит только от адаптации локальной модели
затенения. Для этой модели не нужна ламбертовская поверхность, которая
освещается удаленным точечным источником. Фотометрическое стерео возмож-
но, если диффузное отражение поверхности — известная функция нормали к
поверхности, удовлетворяющей небольшому количеству условий. Это действи-
тельно так, поскольку интенсивность пикселя на одном изображении определя-
ет нормаль с точностью до одного параметра. Это значит, что два изображения
полностью определяют нормаль. Самый простой пример — поверхность с из-
вестным альбедо освещается удаленным точечным источником.
Фактически, фотометрическое стерео возможно, если диффузное отражение
поверхности — это функция к параметров нормали к поверхности. Интенсив-
ность пикселя на одном изображении определяет нормаль с точностью до +1
параметра, а к 4-1 изображение описывает нормаль. Для успешного примене-
ния этого подхода диффузное отражение должно быть задано как функция,
которая подчиняется указанной арифметике (например, если диффузное от-
ражение поверхности — это постоянная функция нормали к поверхности, то
158
Часть I. Формирование изображений и модели изображений
никаких условий на нормаль относительно диффузного отражения наложить
нельзя). Затем можно одновременно восстанавливать форму и карты отраже-
ния ([Garcia-Bermejo, Diaz Pernas and Coronado, 1996], [Mukawa, 1990], [Nayar,
Ikeuchi and Kanade, 1990] и [Tagare and de Figueiredo, 1992, 1993]).
Альтернативные представления затенения
Информацию о форме можно извлекать из затененного сигнала, а мож-
но попытаться подобрать по набору различных возможных образцов. Набор
возможных затенений довольно ограничен ([Belhumeur and Kriegman, 1998])
и знать структуру этого набора крайне важно, поскольку это позволяет по-
нять, как сравнивать затененные изображения, и не запутаться при изменении
освещения. Изменение освещения вызывает множество проблем в определении
сторон и распознавании ([Adini, Moses and Ullman, 1997], [Phillips and Vardi,
1996]). Похоже, что здесь может помочь знание возможных вариантов освеще-
ния ([Georghiades, Kriegman and Belhumeur, 1998, 2000], [Jacobs, Belhumeur
and Barsi, 1998]).
Еще одна возможность — расширить понятие качественного анализа вза-
имного отражения с целью поиска элементарного затенения — образец за-
тенения, которое можно считать характерным и устойчиво связанным с об-
разцом формы. Например, узкие щели и глубокие отверстия на поверхностях
всегда темные, а тень от цилиндра имеет характерную вытянутую форму. Таких
элементов известно немного, но некоторые из них кажутся очень полезными
([Haddon and Forsyth, 1998а,Ь]).
Задачи
5.1. Какую форму может приобрести тень сферы, если она отбрасывается на
плоскость, а источником выступает точечный источник?
5.2. Квадратный плоский источник и квадратный затеняющий предмет парал-
лельны плоскости. Источник имеет такой же размер, что и затеняющий
предмет, оба расположены вертикально один над другим, а их центры
находятся на одной оси.
а) Какую форму будет иметь тень?
б) Какую форму будет иметь внешняя граница полутени?
5.3. Квадратный плоский источник и квадратный затеняющий предмет па-
раллельны плоскости. Длина источника в два раза больше длины зате-
няющего предмета, они расположены вертикально один над другим, а их
центры находятся на одной оси.
а) Какую форму будет иметь тень?
б) Какую форму будет иметь внешняя граница полутени?
5.4. Квадратный плоский источник и квадратный затеняющий предмет па-
раллельны плоскости. Длина источника в два раза меньше длины зате-
няющего предмета, они расположены вертикально один над другим, а их
центры находятся на одной оси.
Глава 5. Источники, тени и затенение
159
а) Какую форму будет иметь тень?
б) Какую форму будет иметь внешняя граница полутени?
5.5. Маленькая сфера отбрасывает тень на большую сферу. Опишите воз-
можную форму ее границ.
5.6. Объясните, почему границы тени трудно использовать для определения
формы, особенно если тень отбрасывается на искривленную поверхность.
5.7. Бесконечно малый участок поверхности выходит на круглый плоский
источник с постоянной светимостью фронтально к оси симметрии источ-
ника. Рассчитайте диффузное отражение участка, обусловленное свети-
мостью источника Е(и) как функцию площади источника и расстояния
от центра источника до участка. Значения соответствующих интегра-
лов можно найти в таблицах (если вы справитесь сами — можете собой
гордиться), это один из редких случаев, когда их можно найти аналити-
чески. Считать интегралы будет легче, если записать их через косинусы.
5.8. Маленький участок видит бесконечную плоскость на единичном рассто-
янии, как на рис. 5.17. Участок достаточно мал, так что он отражает
на плоскость ничтожно малое количество света. Диффузное отражение
плоскости В(х,у) = 1 +sin ах. Участок и плоскость параллельны друг
другу. Участок перемещается параллельно плоскости. Рассмотрите его
диффузное отражение в различных точках.
а) Покажите, что при перемещении участка его диффузное отражение
меняется периодически с изменением координаты х.
6) Зафиксируем центр участка в точке (0,0); найдите выражение в ана-
литическом виде для диффузного отражения участка в этой точке
как функцию а. Для этого вам понадобится таблица интегралов (ес-
ли вы справитесь сами — можете гордиться).
5.9. Если смотреть днем на противоположный берег большого залива, часто
бывает трудно заметить там горы; ближе к закату они видны четко. Это
явление связано с рассеянием света в воздухе — большой объем воздуха
можно считать источником света. Объясните, что при этом происходит.
Предполагается, что воздух — это вакуум и при распространении света
по прямой в вакууме энергия не поглощается. Оцените расстояния, на
которых применима эта модель.
5.10. Прочитайте книгу Lynch и Livingstone, Colour and Light in Nature, Cam-
bridge University Press, 1995.
Упражнения
5.11. Плоский источник можно аппроксимировать как сеть точечных источни-
ков. Недостаток этого приближения состоит в том, что полутень описыва-
ется некорректно из-за ошибок квантования, что может сильно бросаться
в глаза.
а) Объясните указанный факт.
160
Часть I. Формирование изображений и модели изображений
б) Опишите это явление для квадратного источника и одного затеняю-
щего предмета, отбрасывающего тень на бесконечную плоскость. При
стационарной геометрии вы найдете, что при увеличении количества
точечных источников ошибка квантования уменьшается.
в) У этого приближения есть одна неприятная особенность — изменяя
геометрию при любой конечной сети, можно получить весьма боль-
шую ошибку квантования. Это происходит потому, что существу-
ют конфигурации источника и затеняющего предмета, которые дают
большие полутени. Объясните этот факт, используя квадратный ис-
точник, затеняющий предмет и отбрасывающий тень на бесконечную
плоскость.
5.12. Создайте систему из нескольких черных и систему из нескольких белых
предметов (вам понадобятся бумага, клей и краски) и понаблюдайте эф-
фект взаимного отражения. Есть ли у вас интуитивный критерий, кото-
рый помогает точно сказать по изображению, где какая система? (Если
есть, можете его опубликовать; задача кажется простой, но на самом
деле это не так).
5.13. (Это упражнение требует некоторых знаний по численному анализу.)
Возьмите численно интегралы и восстановите рис. 5.17. Эти интегралы
не очень простые: если воспользоваться координатами на бесконечной
плоскости, то трудность представляет размер области; если преобразо-
вать координаты в полусферу направлений участка, то на границах по-
лусферы частота излучения становится бесконечной. Наилучший способ
оценки этих интегралов — применение метода Монте-Карло к полусфе-
ре. Рекомендуем использовать выборку по значимости, поскольку вклад
в интеграл на границах намного меньше, чем на вершине.
5.14. Составьте и решите линейные уравнения для взаимного отражения
на внутренней поверхности куба с маленьким квадратным источником
в центре потолка.
5.15. Реализуйте схему фотометрического стерео.
а) Насколько точны ее измерения (т.е. как они согласуются с известной
информацией о форме)? Влияет ли на точность взаимное отражение?
б) Повторимы ли эти измерения (т.е. если вы получите еще один набор
изображений, возможно, при другом освещении, и определите форму
по ним, то как будет отличаться новая форма от старой)?
в) Сравните метод минимизации с восстановлением посредством инте-
грирования; какой из них точнее и почему? Проявляется ли эта раз-
ница при проведении эксперимента?
г) Один из возможных способов улучшения интегрального метода —
найти глубины интегрированием по многим различным путям, а затем
усреднить эти глубины (будьте очень внимательными с константами).
Улучшает ли это точность или повторяемость метода?
6
Цвет
Цвет — это богатое и сложное явление, обычно возникающее из-за различ-
ной реакции зрительной системы на свет разной длины волны (в число других
причин входят давление на глазное яблоко и сны). Хотя цвет предметов кажет-
ся довольно удобной характеристикой для их идентификации, на самом деле
применять его с такой целью довольно трудно.
6.1. ФИЗИКА ЦВЕТА
Расширим наш радиометрический словарь, чтобы описать энергию, кото-
рая по-разному передается волнами различной длины, и опишем характерные
особенности цветных поверхностей и цветных источников света.
6.1.1. Радиометрия цветного света: спектральные величины
Все физические единицы, которые описывались ранее, можно определить
повторно с дополнением на единицу длины волны и таким образом получить
спектральные единицы. Это позволит описать различия в энергии, БФРО (би-
нарной функции распределения отражения) или альбедо при различных длинах
волн. Далее не будут рассматриваться такие взаимодействия, как флуоресцен-
ция, при которой изменяется длина волны; таким образом, чтобы получить то,
162
Часть I. Формирование изображений и модели изображений
что называют спектральными величинами, к определениям из главы 4 просто
добавляется фраза “на единицу длины волны”.
Первая спектральная величина, спектральное излучение, обычно записы-
вается как Lx(x, 6, ф), а излучение в диапазоне длин волн [А, А + dA] равно
Lx(x, 6, ф)(1Х. Спектральное излучение измеряется в ваттах на кубический метр
на стерадиан (Вт х м~3 х ср-1 — кубические метры появились из-за допол-
нительного множителя, длины волны). В задачах, где угловое распределение
источника не имеет значения, удобной характеристической величиной будет
спектральная светимость’, спектральная светимость измеряется в Вт х м-3.
Подобным образом, спектральная БФРО — это отношение спектрально-
го излучения в уходящем направлении к плотности потока спектрального
излучения в падающем направлении. Поскольку БФРО определяется как отно-
шение, то спектральная БФРО имеет те же единицы — ср-1.
6.1.2. Цвет источников
Под созданием источника света обычно подразумевают нагревание некото-
рого элемента до тех пор, пока он не начнет светиться. Рассмотрим вначале
идеализированный пример такого процесса, после чего опишем спектральное
распределение мощности дневного света и обсудим ряд искусственных источ-
ников света.
Абсолютно черное тело
Тело, которое не отражает свет, обычно называют абсолютно черным те-
лом’, оно является самым эффективным излучателем. Нагретое черное тело
излучает в диапазоне электромагнитных волн. Стоит отметить, что спектраль-
ное распределение мощности этого излучения зависит только от температуры
тела. Довольно хорошее представление о черном теле можно получить, если
смотреть внутрь полого куска металла через крошечное отверстие — из света,
проникающего через отверстие, отразится и попадет в глаз очень малая часть.
Спектральное распределение мощности горячего черного тела можно измерить,
нагрев подобную полость. Если Т — это температура тела в кельвинах, h —
постоянная Планка, к — постоянная Больцмана, с — скорость света, а А —
длина волны, то получаем следующее выражение:
°" A® (exp(/ic/fcA) - 1) *
Это означает, что существует однопараметрический набор цветов, соответ-
ствующий абсолютно черному излучателю (параметром является температура),
и что можно говорить о цветовой температуре источника света. Под этим под-
разумевают температуру абсолютно черного тела, при которой будет получаться
точно такое же излучение. При относительно низких температурах абсолютно
черные тела имеют красный цвет, с возрастанием температуры они становятся
оранжевыми, потом бледно-желтыми и белыми (см. схему на рис. 6.9).
Глава 6. Цвет
163
Рис. 6.1. Существуют значительные различия в относительной спектральной мощности дневного
света, измеренной в разное время суток и при различных условиях. На рисунке показана серия
из семи различных измерений мощности дневного света, проведенных Джусси Паркиненом (Jussi
Parkkinen) и Перти Сильфстен (Pertti Silfsten) при освещении образца из сульфата бария (хорошая
отражающая поверхность белого цвета). Графики построены по данным, которые можно найти
на сайте http://www.it.lut.fi/research/color/lutcs_database.html
Солнце и небо
Самым важным естественным источником света является солнце. Обычно
солнце представляют как удаленную яркую точку. Известно, что солнечный
свет рассеивается в воздухе. В частности, свет от солнца может рассеиваться
в воздухе, попадать на поверхность и, отражаясь от нее, попадать в камеру или
глаз. Это значит, что небо — это также существенный естественный источник
света. Грубая геометрическая модель неба — это источник света в виде по-
лусферы с постоянной светимостью. В то же время, предположение о том, что
светимость везде одинакова, не совсем справедливо, поскольку небо значитель-
но ярче на горизонте, чем в зените. Более естественную модель неба можно
получить, предположив, что воздух излучает постоянное количество энергии на
единицу объема; из этого следует, что на горизонте небо ярче, чем в зените, по-
скольку луч, идущий вдоль линии горизонта, проходит больший путь по небу.
Участок поверхности вне помещения в течение дня освещается как светом,
идущим непосредственно от солнца, который обычно называют дневным све-
том, так и солнечным светом, рассеянным в воздухе (его иногда называют
небесным, или воздушным светом); на общий эффект может сильно влиять
164
Часть I. Формирование изображений и модели изображений
наличие облаков или снега. Цвет дневного света меняется в зависимости от
времени суток (рис. 6.1) и времени года. В настоящее время эти явления ин-
тенсивно изучаются.
В чистом воздухе интенсивность света, рассеянного в единице объема,
зависит от частоты в четвертой степени; это значит, что свет с большой дли-
ной волны до рассеяния может распространиться намного дальше, чем свет
с малой длиной волны (данное явление известно под названием Релеевского
рассеяния). Это объясняет следующий факт: когда солнце находится высоко
в небе, то по пути от солнца до земли голубая составляющая света рассеива-
ется в воздухе (солнце кажется желтым) и, отражаясь от воздуха, попадает
в глаз (небо кажется голубым). Существуют также стандартные модели спек-
трального излучения неба в разное время суток на разных широтах. Стоит
сказать, что когда в небе присутствуют мельчайшие частички пыли, можно
наблюдать удивительные вещи (а большие частички приводят к гораздо более
сложным эффектам рассеяния, которые обычно можно более грубо описать
с помощькшодели рассеяния Ми, о которой рассказано в (Lynch and Liv-
ingston, 2001] или [Minnaert, 1993]). Один из авторов помнит яркие закаты
в Йоханнесбурге, вызванные наличием в воздухе пыли от угольных отходов;
имеются также сообщения о синей и даже зеленой луне, что было вызвано
присутствием в воздухе вулканической пыли.
Искусственное освещение
Обычные искусственные источники света, как правило, бывают нескольких
видов.
• Лампы накаливания состоят из металлической нити, которая нагревает-
ся до очень высокой температуры. Спектр приблизительно совпадает со
спектром абсолютно черного тела, т.е. в большинстве случаев лампы на-
каливания дают красноватый оттенок, поскольку цветовая температура
источника ограничена температурой плавления рабочих элементов.
• Флуоресцентные лампы работают на основе быстрых электронов, бом-
бардирующих газ в трубке; это вызывает излучение в ультрафиолетовом
диапазоне, что приводит к свечению фосфорного покрытия внутренней по-
верхности трубки. Как правило, покрытие делается из трех или четырех
слоев фосфора, что дает излучение в достаточно узком диапазоне длин
волн. Большинство флуоресцентных ламп дают голубоватый свет, хотя
все большее распространение получают лампы, имитирующие естествен-
ное дневное освещение (рис. 6.2).
• Некоторые лампы заполняются атмосферой, состоящей из смеси газооб-
разных металлов и инертных газов. Свет вырабатывается электронами
в атомах металлов, где происходит переход из возбужденного состояния
в состояние с более низкой энергией. Для таких источников характерно
сильное излучение на нескольких частотах, соответствующим отдельным
переходам. Самые распространенные из ламп описанного типа — натри-
Глава 6. Цвет
165
Рис. 6.2. Существует множество моделей осветительных элементов; на трафике слева показано
распределение относительной спектральной мощности двух стандартных моделей МКО (Меж-
дународной комиссии по освещению): иллюминат А, который моделирует свет от 100-ваттной
лампы накаливания с цветовой температурой 2800 К; и иллюминат D-65, моделирующий
дневной свет. График построен на основе информации из базы данных Исследовательских
лабораторий по цвету и зрению (Color and Vision Research Laboratories)(http: //www-
cvrl.ucsd.edu/index.htm/ обработанной Эндрю Стокманом (Andrew Stockman) и Линдсе-
ем Шарпе (Lindsey Sharpe). Справа показано распределение относительной спектральной
мощности четырех различных ламп по данным корпорации Mitsubishi Electric. Обратите внимание
на яркие узкие полосы, которые дает светящийся фосфор в флуоресцентной лампе. График постро-
ен на основе информации, доступной на сайте http://colorpro.com/info/index.html;
измерения проведены Хироаки Сигвирой (Hiroaki Sugiura)
евые разрядные лампы и ртутные разрядные лампы. Натриевые раз-
рядные лампы дают желтовато-оранжевый свет, который чрезвычайно эф-
фективно и довольно широко применяется для освещения дорог. Ртутные
лампы дают голубовато-белый свет и часто используются при освещении
охраняемых объектов.
Примеры спектров излучения различных ламп приведены на рис. 6.2.
6.1.3. Цвет поверхности
Цвет поверхности — это результат воздействия многих механизмов, вклю-
чая выборочное поглощение на различных частотах, отражение и рассеяние
света лампы (подробнее см., например, [Lamb and Bourriau, 1995], [Lynch and
Livingston, 2001], [Minnaert, 1993] или [Williamson and Cummins, 1983]). Как
правило, эти явления объединяют и описывают общей макроскопической мо-
делью БФРО, причем БФРО в этом случае обычно представляет собой сумму
ламбертиана и члена зеркального приближения; далее будем использовать тер-
мины спектральная отражательная способность (иногда, для краткости, —
отражательная способность) или (в менее общих случаях) спектральное
альбедо. На рис. 6.3 и 6.4 приведены примеры спектральной отражательной
способности для ряда объектов естественного происхождения.
166
Часть I. Формирование изображений и модели изображений
Рис. 6.3. Спектральное альбедо для различных естественных поверхностей, измеренные Эса Ко-
ивисто (Esa Koivisto), физический факультет University of Kuopio, Финляндия. Слева приведены
альбедо для природных поверхностей с указанием цвета каждой. Справа, также с указанием цветов,
приведены альбедо для листьев различных цветов. Графики построены по данным, доступным
на сайте http://www.it.lut.fi/research/color/lutcs_database.html
На цвет света, попадающего в глаз, влияет как спектральное излучение
(цвет) источника, так и спектральная отражательная способность (цвет) по-
верхности. Если использовать подход “ламбертиан плюс спектральная модель”,
можно записать следующее:
Е(А) = рад(А)5(А) х геометрические члены + зеркальные члены,
где Е(А) — спектральное диффузное отражение поверхности, pdhW — спек-
тральная отражательная способность, a S(A) — спектральная плотность потока
излучения. Зеркальные величины могут иметь разный цвет в зависимости от
типа поверхности — т.е. теперь необходимо ввести понятие спектрального зер-
кального альбедо.
Цвет и зеркальное отражение
Вообще, у всех металлических поверхностей есть зеркальная составляю-
щая, которая зависит от длины волны — блестящая медная монета имеет
желтоватый оттенок. Зеркальная составляющая непроводящих поверхностей —
диэлектриков — не зависит от длины волны (например, блики на блестя-
щих пластмассовых предметах всегда того же цвета, что и падающий свет).
В разделе 6.4.3 рассказано о том, как эти свойства можно использовать для
нахождения бликов и областей отражения, соответствующих металлическому
или пластмассовому предмету.
6.2. ЧЕЛОВЕЧЕСКОЕ ВОСПРИЯТИЕ ЦВЕТА
Чтобы можно было описывать цвета, вначале необходимо знать, как на них
реагируют люди. Человеческое восприятие цвета — это очень сложная функция
среды; свою роль играет и освещение, и память, и сам предмет, и эмоции. Самое
Глава 6. Цвет
167
Рис. 6.4. Еще несколько спектральных альбедо для естественных поверхностей, измеренных Эса
Коивисто. Слева приведены альбедо для нескольких цветков красного цвета. В каждом случае ука-
зано название цветка на финском языке. Справа показаны альбедо зеленых листьев, также с указа-
нием финского названия. Видно, что альбедо не очень отличаются друг от друга, поскольку суще-
ствует относительно немного механизмов окрашивания растений. Графики построены по данным,
доступным на сайте http://www.it.lut.fi/research/color/lutcs_database.htrnl
простое здесь — понять, какое спектральное излучение вызывает одинаковую
реакцию людей при одних и тех же условиях (раздел 6.2.1). Напрашивается
простая линейная теория подбора цветов, которая оказывается достаточно точ-
ной и чрезвычайно удобной для описания цвета. Ниже, в разделе 6.2.2, кратко
описан механизм, лежащий в основе передачи цвета.
6.2.1. Подбор цветов
Простейший пример восприятия цвета - это когда в поле зрения попадает
только два цвета на черном фоне. Проведем характерный эксперимент — будем
освещать половину некоторой поверхности цветным светом — тестовым све-
том (рис. 6.5). Задача: подобрать на другой половине поверхности комбинацию
цветов, которая будет точно соответствовать тестовому цвету. Подбор включает
в себя изменение интенсивности элементов некоторого фиксированного набо-
ра основных цветов. При такой постановке задачи для подбора пары может
потребоваться очень много цветов (существуют и другие методы подбора).
Обозначим через Т тестовый цвет, знак равенства будет означать, что па-
ра подобрана правильно, отличные от нуля весовые коэффициенты обозначим
через Wi, а основные цвета — через Рг. Тогда пару можно записать в алгебра-
ической форме как
Т = wi Pi + W2P2 + • • .
Приведенная запись означает, что тестовый свет Т совпадает с определенной
комбинацией основных цветов, которая задается коэффициентами (wi,...).
Ситуация упрощается, если разрешено разностное сопоставление, при кото-
168
Часть I. Формирование изображений и модели изображений
Тестовый свет, Т Взвешенная смесь основных цветов
Рис. 6.5. Человеческое восприятие цвета можно изучить, предложив наблюдателям смешать раз-
личные цвета с целью подбора пары к тестовому свету, который показан на поверхности, разде-
ленной надвое. На рисунке изображена схема такого эксперимента. Наблюдатель видит тестовый
свет Т; ему предлагается комбинация из трех основных цветов, расположенная рядом с тестовым
светом. Наблюдателя просят подобрать необходимую интенсивность каждого цвета, чтобы в резуль-
тате эта комбинация выглядела точно так же, как и тестовый свет. Комбинацию основных цветов
можно записать как wiPi + W2P2+W3P3', если комбинация соответствует цвету тестового освеще-
ния, можно записать Т = wiPi + w2Pa + адз-Рз- Стоит отметить, что для большинства людей трех
основных цветов оказывается достаточно, чтобы найти пару ко многим или даже всем цветам, ес-
ли разрешить разностное сопоставление (т.е. когда для точного подбора соответствия определенное
количество основного цвета смешивается с тестовым цветом). Некоторым людям требуется меньше
основных цветов. Более того, большинство людей одинаково выбирает весовые коэффициенты при
определении соответствия данному тестовому освещению
ром наблюдатель имеет право добавлять некоторое количество одного из основ-
ных цветов к тестовому свету, а не к подбираемому парному изображению.
Алгебраически это означает, что весовые коэффициенты в вышеприведенном
выражении могут иметь отрицательные значения.
Трехцветность
Эксперименты показывают, что для того, чтобы подобрать пару к тестово-
му освещению, большинству наблюдателей достаточно трех основных цветов.
Здесь нужно сделать несколько оговорок. Во-первых, должно быть разрешено
разностное сопоставление; во-вторых, основные цвета должны быть незави-
симыми, т.е. никакая комбинация двух основных цветов не должна давать
третий основной цвет. Это называют принципом трехцветности. Данное яв-
ление можно объяснить, предположив, что глаз воспринимает свет трех типов,
что подтверждается недавними генетическими исследованиями ([Nathans, Pi-
antanida, Eddy, Shows and Hogness, 1986a], [Nathans, Thomas and Hogness,
1986b]). При одинаковых исходных основных цветах и тестовом освещении
большинство наблюдателей выбирали одинаковые комбинации основных цве-
тов, которые, по их мнению, идентичны тестовому освещению. Обычно это
объясняется предположением, что для большинства людей характерно воспри-
ятие трех основных различных цветов. Результаты генетических исследований,
похоже, также подтверждают эту точку зрения.
Глава 6. Цвет
169
Законы Грассмана
При описанных выше условиях подбор пары (в достаточно точном прибли-
жении) является линейным. Из этого вытекают следующие законы Грассмана.
Во-первых, если смешать два тестовых цвета, смесь их пар будет парой к
полученному цвету — т.е. если
Та = WalPl + Wa2P2 + ШазРз
И
Ть = WblPl + Wb2jF*2 + "ШЬзРз,
то
Та + Ть = (Wai + Wbl)Pl + (wa2 + Wb2)P2 + (wa3 + Wb3)P3.
Во-вторых, если для двух тестовых цветов можно найти пары с одинаковыми
весовыми коэффициентами, то эти цвета являются парой друг для друга, т.е.
если
Та = W1P1 4- W2P2 4- W3P3
и
Ть = wiPi 4- W2P2 4- W3P3,
то
Та = Ть.
Наконец, подбор пары является линейным; если
Та = wiPi 4- W2P2 4- W3P3,
тогда
кТа = (fcwi)Pi 4- (kw2)P2 4- (fcw3)P3
для любого неотрицательного к.
Исключения
При одинаковом тестовом освещении и наборе основных цветов большин-
ство людей, подбирая пару, выбирают одинаковые весовые коэффициенты. Та-
ким образом, трехцветность и законы Грассмана справедливы настолько же,
насколько любые законы, описывающие биологические системы. Исключения
из этих закономерностей наблюдаются:
170
Часть I. Формирование изображений и модели изображений
• у людей с искаженным восприятием цвета вследствие ошибки на гене-
тическом уровне (такие люди могут подобрать любую пару с помощью
меньшего количества основных цветов);
• у людей с искаженным восприятием цвета вследствие болезни нервной си-
стемы (у таких людей могут проявляться различные отклонения, включая
полное отсутствие чувствительности к цвету);
• у некоторых пожилых людей (их выбор весовых коэффициентов отлича-
ется от нормы из-за появления в глазу пигментных пятен);
• при очень ярком свете (который из-за оттенка и насыщенности отличается
от менее ярких вариантов того же света);
• при очень темной среде (в которой механизм передачи цвета несколько
отличается от наблюдаемого в более яркой среде).
6.2.2. Цветовые рецепторы
Трехцветность предполагает, что существуют базовые ограничения на спо-
соб восприятия цвета глазом. Одна из гипотез, удовлетворительно объясняю-
щих это явление, — это предположение, что глаз имеет три различных вида
рецепторов, которые служат посредниками при восприятии цвета. Каждый из
этих рецепторов преобразует падающий свет в электрический сигнал, переда-
ющийся посредством нервных клеток. О чувствительности рецепторов можно
судить по результатам экспериментов по подбору цветовой пары. Если два те-
стовых освещения с разными спектрами выглядят одинаково, значит они ока-
зывают одинаковое действие на рецепторы.
Принцип инвариантности
Согласно принципу инвариантности рецепторы являются однотипными
(т.е. их реакция может быть сильнее или слабее, но она не зависит от длины
волны падающего света). Экспериментально подтвердить это можно, аккуратно
отделив светочувствительные клетки друг от друга и измерив их реакцию на
свет разной длины волны или на основании логических выводов из экспери-
ментов по подбору цветовой пары. Вообще, инвариантность — это мощный
принцип, так как она дает хорошую и простую модель человеческого восприя-
тия цветного света: два цвета можно считать одинаковыми, если они вызывают
одинаковую реакцию рецепторов независимо от спектрального излучения.
Так как принцип подбора пары линеен, то и реакция рецепторов должна
быть линейной. Запишем реакцию fc-ro типа рецептора какрд:, его чувствитель-
ность — как с7>(А), свет, попадающий на рецептор, — как Е(А), а диапазон длин
волн видимого света — как Л. Просуммировав реакцию на каждую отдельную
длину волны падающего света, можно найти полную реакцию рецепторов:
Рк= [ <Tk(X)E(X)dX.
Jл
Глава 6. Цвет
171
Рис. 6.6. В человеческом глазе есть три типа цветовых рецепторов, которые обычно называют
колбочками. Эти рецепторы реагируют на все фотоны однотипно, но с разной интенсивностью.
На рисунке показана зависимость логарифма относительной спектральной чувствительности от
длины волны для трех типов цветовых рецепторов человеческого глаза. Первые два рецептора —
их иногда называют красными и зелеными колбочками, соответственно, хотя более уместным на-
званием будет длинно- и средневолновые рецепторы — имеют максимумы чувствительности при
довольно близких значениях длины волны. Максимум чувствительности рецепторов третьего типа
(синих колбочек, или, точнее, коротковолновых рецепторов) находится совершенно на другой
длине волны. Реакцию рецептора на падающий свет можно найти, сложив произведения чувстви-
тельности на спектральное излучение света по всем длинам волн. Графики построены на основе
информации из базы данных Исследовательских лабораторий по цвету и зрению (Color and Vi-
sion Research Laboratories) (http://www-cvrl.ucsd.edu/index.htm), обработанной Эндрю
Стокманом (Andrew Stockman)
Палочки и колбочки
Из анатомии известно, что сетчатка глаза состоит из двух типов клеток,
которые реагируют на свет по-разному в зависимости от своей формы. Све-
точувствительная область колбочки имеет приблизительно коническую форму,
тогда как у палочек она приблизительно цилиндрическая. Колбочки играют
основную роль в цветном восприятии и полностью покрывают ямку глаза. Кол-
бочки менее чувствительны к свету, чем палочки, т.е. при слабом освещении
цветное зрение хуже и читать уже невозможно (не хватает пространственной
точности, поскольку ямка не используется).
172
Часть I. Формирование изображений и модели изображений
Исследования генетики цветного зрения подтверждают предположение о су-
ществовании трех типов колбочек, отличающихся своей чувствительностью (ре-
цепторы одного человека могут слегка отличаться от однотипных рецепторов
другого человека). Чувствительность трех различных типов рецепторов к раз-
ным длинам волн можно найти, сравнивая информацию по подбору цветовой
пары, представленную обычными наблюдателями, с результатами таких же экс-
периментов наблюдателей с недостатком одного из типов колбочек. Найденные
таким способом схемы чувствительности показаны на рис. 6.6. Три типа колбо-
чек называют S-колбочками, М-колбочками и L-колбочками (так как их мак-
симумы чувствительности лежат, соответственно, в коротковолновой (S), сред-
неволновой (М) и длинноволновой (L) областях). Другое название — синие, зе-
леные и красные колбочки — не совсем правильно, поскольку восприятие крас-
ного цвета определенно не вызывается стимуляцией красных колбочек и т.д.
6.3. ПРЕДСТАВЛЕНИЕ ЦВЕТА
Точное описание цвета имеет большое коммерческое значение. Многие ви-
ды продукции тесно связаны со специальными цветами (например, золотые ду-
ги, цвет различных популярных компьютеров или цвет коробок фотопленки),
и производители готовы многое отдать, чтобы убедиться, что две различные
партии товара имеют один и тот же цвет. Здесь нужна стандартная система цве-
тов, поскольку простых названий цветов недостаточно: относительно немногие
люди знают разнообразные названия цветов, кроме того, большинство людей
по-разному трактуют названия цветов.
6.3.1. Линейные цветовые пространства
Существует естественный механизм передачи цвета: нужно договориться о
стандартном наборе основных цветов, а затем описывать любое цветное осве-
щение тремя весовыми коэффициентами, которые бы люди выбрали в процессе
описанной выше задачи подбора. В принципе, такое решение довольно просто.
Для описания цвета организовывается и проводится эксперимент по подбору
пары, а из него получаются весовые коэффициенты. Кроме того, если для осве-
щения поверхности использовать стандартный свет, то описанный подход поз-
воляет передавать цвет такой поверхности (разумеется, если все описываемые
поверхности будут одинаково чистыми).
Эксперимент по подбору цветовой пары целесообразно проводить при каж-
дой попытке описать цвет. Например, эту схему используют в магазинах красок:
вы показываете требуемый цвет и вам смешивают краски, пока не будет найдена
соответствующая пара. Это делается потому, что предсказать цвет смеси кра-
сок сложно из-за эффектов рассеяния. Впрочем, из законов Грассмана следует,
что комбинации цветного света — по крайней мере те, что видны на обычном
дисплее — смешиваются линейно-, это означает, что возможна намного более
простая процедура.
Глава 6. Цвет
173
Функции подбора цвета
Если цвета смешиваются линейно, можно построить простой алгоритм опре-
деления весовых коэффициентов смеси основных цветов из данного фиксиро-
ванного набора. Спектральное излучение источника можно считать взвешенной
суммой излучений отдельных источников (причем каждый источник излуча-
ет свет с единственной длиной волны). Поскольку операция подбора цвета
линейна, комбинацию основных цветов, которая образует пару к взвешенной
сумме отдельных источников, излучающих на одной длине волны, можно по-
лучить, подбирая цвета к каждому отдельному источнику, а затем суммируя
эти весовые коэффициенты.
Если есть весовые коэффициенты всех основных цветов, определяющие па-
ру для каждого отдельного источника (набор функций подбора света), то
можно найти весовые коэффициенты цветовой пары для произвольного спек-
трального излучения. Функции подбора цвета, которые далее обозначаются
как /1(А), /г(А) и /з(А), получаются из набора основных цветов Pi, Р2 и Рз
на основе эксперимента. Таким образом, чтобы найти пару для отдельного ис-
точника излучения U\X), подбирается весовой коэффициент каждого основного
цвета. Этот процесс можно записать как
ЩА) = Л (A) Pi + /2(А)Р2 + /3(А)Рз
(т.е. для каждой длины волны А функции Л(А), /г(А) и /з(А) дают весовые
коэффициенты, необходимые для нахождения пары для отдельного источника,
излучающего на этой длине волны).
Источник, который обозначен как S(X), — это сумма огромного количества
источников, излучающих на своей длине волны с определенной интенсивно-
стью. Подберем теперь пару к основным цветам каждого отдельного источника,
а затем сложим полученные весовые коэффициенты:
5(А) — W1P1+ W2P2 + W3P3 =
-{У A(A)S(A)Ja} Рх + /2(А)5(А)</а}р2 + {У /3(A)S(A)dA J Рз.
Общие вопросы линейных цветовых пространств
Линейную систему названий цветов можно получить из определения основ-
ных цветов (что подразумевает использование функций подбора цвета) или из
определения функций подбора цвета, в которых используются основные цве-
та. Неприятный факт: если основные цвета — это реальное освещение, то на
определенной длине волны по крайней мере одна из функций подбора цвета
будет отрицательной. Это не противоречит законам природы, а просто говорит
о том, что для подбора некоторых видов освещения необходимо пользоваться
разностным соответствием независимо от принятого набора основных цветов.
Этой проблемы можно избежать, если, например, определить функции под-
бора цвета, которые будут всегда положительными (при этом основные цвета
174
Часть I. Формирование изображений и модели изображений
Рис. 6.7. Слева изображены функции подбора цвета для основных цветов RGB. Отрицательные
значения указывают на то, что для подбора цвета на этой длине волны с основными цветами
красный-зеленый-синий необходимо пользоваться разностным сопоставлением. Справа показаны
функции подбора цветов для системы МКО с основными цветами X, Y и Z; эти функции все-
гда положительны, но основные цвета не являются реальными. Графини построены по данным
из базы данных Исследовательских лабораторий по цвету и зрению, собранной Эндрю Сток-
маном (Andrew Stockman) и Линдсеем Шарпом (Lindsey Sharpe). База доступна по адресу
http://www-cvrl.ucsd.edu/index.htm
будут нереальными, поскольку на определенной длине волны их спектральное
излучение будет отрицательным).
Хотя это и кажется проблематичным — как можно составить настоящий
цвет из нереальных основных цветов? — на самом деле это не так, поскольку
в системах именования цветов эта схема не применяется. Как правило, произ-
водится простое сравнение весовых коэффициентов, а потом делается вывод,
насколько похожи цвета, а для этого достаточно знать только функции подбора
цвета. Разнообразные системы именования были стандартизованы МКО (Меж-
дународная комиссия по освещению — Commission International d’Ёс lairage) —
организации, предназначенной для разработки подобных стандартов.
Цветовое пространство XYZ согласно стандартам МКО
Самым распространенным стандартом является цветовое пространство
XYZ, определенное МКО. Функции подбора цвета выбраны так, чтобы они
были всегда положительными; поэтому координаты любого реального цвета
всегда положительны. В системе МКО определить основные цвета X, Y или Z
невозможно, поскольку на некоторой длине волны значение их спектрального
излучения будет отрицательным. В то же время, при данных функциях подбора
цвета можно найти координаты XYZ, следовательно, описать цвет.
Линейные цветовые пространства дают ряд полезных графических конструк-
ций, которые намного сложнее изобразить в трех измерениях, чем в двух, по-
этому принято строить сечение пространства XYZ плоскостью X + Y 4- Z = 1
Глава 6. Цвет
175
Рис. 6.8. Пространство видимых цветов (стандарт МКО) в координатах XYZ — это конус, вершина
которого находится в начале координат. Как правило, для упрощения подбора цвета удобно снизить
его яркость (это можно делать, поскольку восприятие цвета почти линейно) — изображенный конус
разрезается плоскостью X 4- Y + Z — 1, в результате чего получается ху-пространство МКО,
показанное на рис. 6.9 и 6.10
(как показано на рис. 6.8) и изображать полученную фигуру в координатах
Это пространство показано на рис. 6.9 и 6.10. Еще несколько полезных кон-
струкций представлено на рис. 6.11. Пространство МКО (ху) широко использу-
ется в учебниках по компьютерному зрению и компьютерной графике, а также
в некоторых прикладных областях, но профессионалы, работающие с цветом,
обычно называют этот подход несовременным.
Цветовые пространства RGB
Цветовые пространства обычно предназначены для практических целей,
поэтому придумано их много.Одним из линейных цветовых пространств явля-
ется пространство RGB, в котором для каждого основного цвета формально
определена длина волны (645,16 нм для красного, 526,32 нм для зеленого
и 444,44 нм для синего; см. рис. 6.7). Неформально в системе RGB исполь-
зуются все цвета, какие могут появиться на экране в качестве основных.
Имеющиеся цвета обычно можно представить единичным RGB-кубом, грани
которого соответствуют весовым коэффициентам красного, зеленого и синего
цвета. Этот куб показан на рис. 6.12.
CMY и черный цвет
Как только мы начинаем рисовать, интуиция подсказывает, что основными
цветами должны быть красный, желтый и синий, и что желтый можно полу-
чить, смешав красный и зеленый. Это интуитивное представление неприменимо
к мониторам, поскольку здесь речь идет о пигментах, которые смешиваются по
176
Часть I. Формирование изображений и модели изображений
Рис. 6.9. На рисунке изображено сечение постоянной яркости стандарта МКО 1931 цветового
пространства ху. Имеем две координатные оси. Кривую границы часто называют спектральной
траекторией' она показывает цвет при наблюдении освещения определенной длины волны. На ри-
сунке показана траектория цветов спектра излучения абсолютно черного тела при разных темпе-
ратурах и спектральная траектория неба. Приблизительно в центре диаграммы есть нейтральная
точка — цвет, для которого равны весовые коэффициенты трех основных цветов. В системе МКО
основные цвета выбраны таким образом, чтобы эта точка была бесцветной. Как правило, цвета,
которые находятся дальше от нейтральной точки, насыщеннее (так темно-красный отличается от
бледно-розового) и при перемещении вокруг нейтральной точки меняется их оттенок (от красного
до зеленого)
разностному принципу, а не об освещении. Пигмент частично поглощает па-
дающий свет, забирая некоторые составляющие, в результате чего отраженный
свет приобретает определенный цвет. Таким образом, красные чернила — это на
самом деле краситель, который поглощает синий и зеленый цвет, а падающий
красный свет проходит сквозь краситель и отражается от бумаги.
Цветовые пространства с таким типом разностного соответствия могут быть
очень сложными. В простейшем случае смешивание цветов линейно (или до-
статочно близко к линейному), и тогда можно пользоваться пространством
CMY. В этом пространстве есть три основных цвета: cyan (сине-зеленый), ma-
genta (оттенок пурпурного) и yellow (желтый). Эти основные цвета можно счи-
Глава 6. Цвет
177
Рис. 6.10. На рисунке показано сечение постоянной яркости стандарта МКО 1931 цветового
пространства ху. Обозначены названия цветов. Как правило, цвета, которые находятся дальше
от нейтральной точки, насыщеннее (так темно-красный отличается от бледно-розового) и при
перемещении вокруг нейтральной точки меняется их оттенок (от красного до зеленого)
тать результатом отнимания исходного цвета от белого; голубой — это W — R
(белый — красный); пурпурный — это W — G (белый — зеленый), а желтый —
это W В (белый —синий). Теперь то, как выглядят комбинации цветов, можно
оценивать относительно цветового пространства RGB. Например, комбинация
голубого и пурпурного цветов
(W - R) + (W - G) = R + G + В - R - G = В,
т.е. синий. Обратите внимание, что W + W — W, поскольку считается, что чер-
нило не может повлиять на бумагу таким образом, чтобы она отражала больше
света, чем чистая бумага. На практике в печатающих устройствах использу-
ется по меньшей мере четыре краски (голубая, пурпурная, желтая и черная),
так как комбинация цветных чернил дает плохой черный цвет, потому что до-
178
Часть I. Формирование изображений и модели изображений
Рис. 6.11. Линейная модель системы цветов дает ряд полезных конструкций. Если есть два цвета
с координатами МКО Ан В, то все цвета, которые можно получить из неотрицательных комбина-
ций этих цветов, можно представить на отрезке прямой, соединяющем Ан В. Подобным образом,
при заданных В, С и D цвета, которые получаются из их комбинаций, лежат в треугольнике,
образованном тремя этими точками. Это важно при разработке мониторов — у каждого монитора
есть только три цвета, и чем насыщеннее цвет каждого из них, тем больше цветов можно изоб-
разить. Именно поэтому одни и те же цвета выглядят иначе на различных мониторах. Кривизна
спектральной траектории — вот причина того, почему ни один набор из трех реальных основных
цветов не может передать все цвета без разностного сопоставления
вольно трудно достичь хорошего согласования трех красок, чтобы избежать
цветного ореола вокруг текста, и потому что цветные чернила обычно дороже,
чем черные. Добиться хороших результатов от процесса цветной печати все еще
достаточно сложно: разные чернила значительно отличаются друг от друга по
своим спектральным свойствам, у разной бумаги также разные спектральные
свойства, кроме того, краски могут смешиваться нелинейно.
6.3.2. Нелинейные цветовые пространства
Координаты цвета в линейном пространстве не обязательно кодируют свой-
ства, принятые в языке, или важные для применения. В число полезных
понятий, касающихся света, входят: оттенок — свойство цвета, которое ме-
няется от красного до зеленого, насыщенность — свойство цвета, которое
изменяется от красного до розового и яркость (иногда его называют светло-
стью, или значением) — свойство, которое изменяется от черного до белого.
Например, если нужно проверить, попадает ли цвет в особенную область
красного цвета, следует закодировать непосредственно оттенок цвета.
Еще одна неприятность, связанная с линейными пространствами, — это то,
что координаты цвета не соответствуют человеческому пониманию топологии
Глава 6. Цвет
179
Рис. 6.12. Слева мы видим RGB-куб — пространство всех цветов, которые получаются из ком-
бинаций трех основных цветов (красного, зеленого и синего — это обычно определяется цветной
реакцией монитора) с весовыми коэффициентами от нуля до единицы. Представленный куб принято
рассматривать вдоль его нейтральной оси — от начала координат до точки (1, 1, 1) — в этом случае
виден шестиугольник, изображенный посредине. Шестиугольник кодирует оттенок (свойство, кото-
рое изменяется при изменении цвета от зеленого до красного) как угол, который подбирается интуи-
тивно. Справа мы видим конус, образованный этим сечением, где длина оси конуса равна значению
(или яркости) цвета, угол наклона дает оттенок, а расстояние до начала координат — насыщенность
цвета; принято считать, что оттенки образуют круг, в том смысле, что оттенок
изменяется от красного через оранжевый до желтого, а затем до зеленого и го-
лубого, синего, фиолетового и опять красного. Другой подход — это понятие
о локальной связи оттенков: красный соседствует с фиолетовым и оранже-
вым, оранжевый — с красным и желтым, желтый — с оранжевым и зеленым,
зеленый — с желтым и голубым, голубой — с зеленым и синим, синий —
с голубым и фиолетовым, а фиолетовый — с синим и красным. Каждая из этих
локальных связей работает, и глобально их можно смоделировать, расположив
оттенки по кругу. Это значит, что оттенок нельзя смоделировать с помощью
отдельных координат линейного цветового пространства, так как у координат
есть максимальное значение, которое сильно отличается от минимального.
Оттенок, насыщенность и значение
Обычный способ решить эту проблему — создать цветовое пространство,
которое будет отражать эти связи с помощью нелинейных преобразований
в пространстве RGB. Существует множество таких пространств. Одно, назы-
ваемое пространством HSV (Hue-Saturation-Value — оттенок-насыщенность-
значение), можно получить, направив луч зрения по центральной оси RGB-
куба. Поскольку RGB — линейное пространство, то яркость, которую в про-
странстве HSV называют значением, изменяется при удалении от начала ко-
ординат. Можно спроектировать RGB-куб и получить двумерное пространство
180
Часть I. Формирование изображений и модели изображений
с постоянным значением, а для повышения точности преобразовать его в ше-
стиугольник. Это даст структуру, показанную на рис. 6.12, где оттенок опре-
деляется углом, который изменяется при повороте вокруг нейтральной точки, а
при удалении от нее изменяется насыщенность.
Существует множество других возможных преобразований координат при
переходе от одного линейного цветового пространства к другому или от линей-
ного к нелинейному (хорошим справочником по этому вопросу является книга
[Fairchild, 1998]). Очевидного преимущества одних координат над другими нет
(особенно если эти системы отличаются только одним преобразованием), если
не рассматривать вопросы кодирования, скорости передачи информации и т.п.
или однородности восприятия.
Равномерные цветовые пространства
Как правило, точно воспроизвести цвет нельзя. Это значит, что требуется
знать, заметит ли человек разницу в цвете. В общем случае полезно сравни-
вать между собой небольшие различия в цвете, но опасно пытаться сравнивать
большие различия, например искать ответ на вопрос: “Какая разница больше:
между синим и желтым участком или между красным и зеленым?”.
Можно определить едва заметную разницу, модифицируя цвет, который
показывается наблюдателю, до тех пор, пока наблюдатель не заметит, что по
сравнению с первоначальным вариантом цвет изменился. Если эти различия
отобразить в цветовом пространстве, они сформируют границу области цветов,
неотличимых от исходного цвета. Обычно едва различимые отличия образуют
эллипсы. Оказывается, что в пространстве МКО (х, у) эти эллипсы довольно
сильно зависят от того, в какой части пространства они расположены, как
показано на рис. 6.13.
Из сказанного следует, что величина отличий по координатам (х,у), которая
задается как ((Аз?)2 4- (А?/)2/1/2), — это плохой показатель значения отличий
в цвете (если бы это был хороший показатель, то эллипсы, представляющие
неотличимые цвета, были бы кругами). В этой связи полезно ввести однород-
ное цветовое пространство — пространство, в котором расстояние однозначно
указывает на величину отличия двух цветов; если в таком пространстве рассто-
яние не будет превышать некоторого порогового значения, человек не сможет
отличить один цвет от другого.
Более однородное пространство можно получить из пространства МКО
XYZ, воспользовавшись проекционными преобразованиями и приведя эллипсы
к симметричному виду; это даст пространство МКО (u'v'), показанное на
рис. 6.14. Координаты этого пространства будут следующими:
z / л = ( 4Х_______________9У \
4 15У+ 3Z’X + 15У + ЗУ; ’
Как правило, расстояние между координатами в пространстве (ur, v') однознач-
но указывает на величину отличия двух цветов. Конечно, здесь не учитывается
отличие в яркости. На сегодняшний день почти универсальным и самым рас-
Глава 6. Цвет
181
Рис. 6.13. На рисунке показаны варианты подбора цветовой пары в пространстве МКО (х,у).
В центре эллипса расположен цвет пробного освещения; размер эллипса показывает разброс цве-
тов, которые испытатели выбирали в качестве пары для пробного цвета; граница показывает, где
находятся едва различимые цвета. Для наглядности эллипсы на рисунке слева увеличены в 10 раз;
справа они изображены в выбранном масштабе. Такие эллипсы называют эллипсами МакАдама
(Mac Ad am ellipses). Обратите внимание, что эллипсы в верхней части фигуры больше, чем в ниж-
ней, и что они меняют свою ориентацию. Это значит, что величина отличия в координатах (х, у) —
плохой показатель отличия в цвете. Эллипсы построены на основе данных из [MacAdam, 1942]
пространенным однородным цветовым пространством является пространство
МКО LAB. Координаты цвета в пространстве LAB можно найти как нелиней-
ную проекцию координат XYZ:
* / У \ з
£ = 116 ( ) - 16,
\ /
а* = 500
Здесь Хп, Yn и Zn — это координаты X, Y и Z эталонного белого участка.
Пространство LAB популярно потому, что оно однородно по своей природе.
В некоторых задачах необходимо знать, насколько разными два цвета будут
казаться человеку, а отличия координат пространства LAB позволяют получить
однозначный ответ на этот вопрос.
182
Часть I. Формирование изображений и модели изображений
Рис. 6.14. На рисунке показан стандарт МКО 1976 пространства которое представля-
ет собой проекцию пространства МКО (х,у). Целью было преобразование эллипсов МакАдама
в однородные круги, что дало бы однородное цветовое пространство. Для того чтобы сделать про-
странство более однородным, используются различные нелинейные преобразования (подробнее см.
[Fairchild, 1998J)
6.3.3. Пространственные и временные эффекты
Трудно предсказать, как будет выглядеть на экране сложное цветное изоб-
ражение (т.е. в котором фигурирует намного больше двух цветов). Если на
зрительную систему некоторое время воздействовать определенным осветите-
лем, это приведет к адаптации к цвету — данный процесс известен под назва-
нием хроматическая адаптация. Адаптация приводит к искажению цветовой
диаграммы в том смысле, что два наблюдателя, привыкшие к разным источни-
кам освещения, могут сказать, что два спектральных излучения с совершенно
различными спектрами одинаковы по цвету. Причиной адаптации может быть
присутствие в поле зрения участков поверхности. Другие немаловажные меха-
низмы — это ассимиляция, когда окружающий цвет создает видимость того,
что цвет участка поверхности смещается в сторону окружающего цвета, и кон-
трастность, когда влияние окружающего цвета приводит к тому, что цвет
участка поверхности отдаляется от окружающего цвета. Оказывается, что эти
явления связаны с проблемой кодирования сигнала в оптическом нерве и ста-
бильностью цвета (см. раздел 6.5).
Глава 6. Цвет
183
6.4. МОДЕЛЬ ЦВЕТА ИЗОБРАЖЕНИЯ
Для правильной интерпретации значений цветов, которые выдает камера,
необходимо понять, что делает камера и какие физические явления нужно смо-
делировать. Наша модель описывает несколько довольно простых и мощных
обобщающих механизмов.
6.4.1. Камеры
Большая часть цветных камер содержит одно устройство формирования
изображения. В каждом чувствительном элементе есть один из трех фильтров,
обеспечивающий требуемую спектральную чувствительность (грубо говоря,
чувствительность к синему, зеленому или красному). Эти фильтры располо-
жены в виде мозаики, а для их описания используется множество различных
моделей. Информация на выходе ПЗС затем обрабатывается, чтобы полно-
стью восстановить красные, зеленые и синие изображения. Конечно, некоторая
информация о сигнале при этом теряется; потери зависят от особенностей ка-
меры и мозаики, но обычно они не влияют на качество изображения, как оно
воспринимается зрителем, хотя могут сильно повлиять на различные простран-
ственные расчеты, например, при определении положений краев (поскольку
пространственное разрешение по интенсивности может быть не таким, каким
кажется).
Желательно иметь систему ПЗС-элементов и фильтров, спектральная чув-
ствительность с точностью до линейного преобразования описывается функци-
ей подбора цвета в пространстве МКО XYZ. Это свойство означает, что камера
будет подбирать цвет точно так, как это делают люди. Похоже, что на практике
этого добиться довольно трудно, поскольку опыт показывает, что большинство
камер в действительности не обладают этим желаемым качеством.
Элементы ПЗС — это линейные устройства. В то же время большинство
пользователей привыкло к пленкам, которые сжимают входящий динамиче-
ский диапазон (различия в яркости на верхнем краю диапазона уменьшаются
так же, как и на нижнем). Информация на выходе линейного устройства вы-
глядит слишком резкой (темные места слишком темны, а светлые — слишком
светлы), так что производители применяют различные формы сжатия выхо-
дящей информации. Самый распространенный способ — это гамма-коррекция.
Такая форма сжатия изначально предназначалась для учета нелинейности экра-
на. Обычно интенсивность на экране равна VT, где Vtn — напряжение, которое
подается на электронную трубку (для экранов дисплеев у = 2,2). В боль-
шинстве устройств с дисплеями напряжение на электронной трубке — это
линейная функция значения в буфере кадра. Таким образом если требуется
интенсивность I, то значение в буфере кадра должно быть пропорциональным
. Обычно камеры допускают гамма-коррекцию, т.е. чтобы получить нуж-
ную интенсивность, можно взять значение, которое дает камера, и поместить
его непосредственно в буфер кадра. Это значит, что информация на выходе
камеры является нелинейной функцией входящей информации.
184
Часть I. Формирование изображений и модели изображений
Поступающее
спектральное
Реакция рецептора
к-го класса рецепторов,
^(Л)р(Л) Е(Л)с1Л
Спектральное альбедо,
Р(Я)
Рис. 6.15. Если участок идеально рассеивающей поверхности с коэффициентом спектрального
рассеяния р(А) освещается светом, спектр которого — Е(Х), то спектр отраженного света будет
равен р(Л)Е'(Л) (умноженное на некоторую постоянную, связанную с ориентацией поверхности,
которой мы договорились пренебрегать). Следовательно, если линейный светочувствительный дат-
чик к-го типа видит этот участок поверхности, то его реакцией будет рк = <jk(X)p(X)E(X)dX,
где Л — это диапазон всех существенных длин волн, а crfe(A) — чувствительность к-го светочув-
ствительного датчика
Было время, когда ПЗС-камеры оснащались отдельной коробкой управля-
ющей электроники, имевшей переключатель, который отключал нелинейные
элементы; эти счастливые времена теперь уже в прошлом. Теперь соотношение
входящей и выходящей информации в камере нужно калибровать, посколь-
ку нелинейных элементов существует множество (см., например, [Barnard and
Funt, 2002], [Holst, 1998] или [Vora, Farell, Tietz and Brainard, 1997]). Сто-
ронники крайних мер иногда вносят изменения в электронику камеры, но это
решение требует определенной смелости. В дальнейшем будем считать, что
связь входа и выхода камеры известна и учитывается таким образом, чтобы
камера казалась линейной.
6.4.2. Модель цвета изображения
Цвет света, попадающего в камеру, зависит от двух факторов: во-первых,
от спектральной отражающей способности той поверхности, от которой посту-
пает свет, во-вторых, от спектрального излучения света, попадающего на эту
поверхность. Если участок идеально рассеивающей поверхности с коэффици-
ентом спектрального рассеяния р(Л) освещается светом, спектр которого 2?(А),
то спектр отраженного света будет равен р(Л)Е?(А) (умноженное на некоторую
постоянную, связанную с ориентацией поверхности, которой мы договорились
пренебрегать). Следовательно, если линейный светочувствительный датчик к-
го типа видит этот участок поверхности, то его реакцией будет
Рк= [ tTk(X)p(X)E(X)dX,
JA
Глава 6. Цвет
185
Рис. 6.16. Источники света могут иметь совершенно разные цвета. На рисунке цвет четырех источ-
ников света (рис. 6.2) сравнивается с цветом однородного распределения спектральной мощности.
Изображение построено в координатах МКО (г, у)
где Л — это диапазон всех существенных длин волн, а а*; (А) — чувствитель-
ность к-го светочувствительного датчика.
Цвет света, падающего на поверхность, может быть разным — от голубого
флуоресцентного уличного света до теплого оранжевого света, который дает
лампочка накаливания, или красного цвета солнца на закате — так что цвет
света, попадающего в камеру, не всегда дает точное представление о цвете
рассматриваемой поверхности (рис. 6.16, 6.17, 6.18 и 6.19).
Опустив подробности физических моделей, описанных в главе 5, значение
пикселя камеры можем представить как
С(х) = gd(x)d(x) + gs(x)s(x) + i(x).
В этой модели
186
Часть I. Формирование изображений и модели изображений
Рис. 6.17. При различном освещении может казаться, что поверхности имеют совершенно разные
цвета. На рисунке показан цвет синего и фиолетового цветков (рис. 6.3) при освещении четырьмя
различными источниками (рис. 6.2) и при однородном распределении спектральной мощности
• d(x) — цвет изображения эквивалентной плоской фронтальной поверх-
ности при таком же освещении;
• g<i(x) — пространственно-зависимый множитель, который указывает на
изменение яркости, вызванное изменением ориентации поверхности;
• s(x) — цвет изображения зеркального отражения от эквивалентной плос-
кой фронтальной поверхности;
• да(х) — пространственно-зависимый множитель, который указывает на
изменение энергии зеркального отражения;
• г(а?) — множитель, который указывает на взаимное отражение цветов,
пространственные изменения освещения и т.п.
В первую очередь интересна информация, которую можно извлечь из цвета
на локальном уровне, поэтому не будем подробно останавливаться на структуре
множителей ^(гс) и г(х). Как из г(а?) можно извлечь информацию — неизвест-
но; опыт показывает, что это достаточно сложно. Иногда этот множитель может
быть очень малым по сравнению с другими, кроме того, он обычно медленно
изменяется в пространстве. Далее удобно будет пренебрегать этим множите-
лем, поэтому предположим, что он мал (или что его присутствие не оказывает
критического воздействия на приведенные алгоритмы). В то же время, множи-
тель 5d(x) можно рассмотреть подробно.
6.4.3. Приложение: нахождение бликов
Отблески могут сильно сказываться на внешнем виде предмета. Как прави-
ло, это маленькие, яркие пятна, которые называют зайчиками. Зайчики значи-
тельным образом влияют на наше восприятие свойств поверхности; изобразите
на рисунке маленький, похожий на зайчик, участок, и предмет покажется глян-
цевым или блестящим. Часто эти блики бывают слишком яркими для камеры,
Глава 6. Цвет
187
Рис. 6.18. При различном освещении может казаться, что поверхности имеют совершенно разные
цвета. На рисунке показан цвет желтого и оранжевого цветков (рис. 6.3) при освещении четырьмя
различными источниками (рис. 6.2) и при однородном распределении спектральной мощности
Рис. 6.19. При различном освещении может казаться, что поверхности имеют совершенно
разные цвета. На рисунке показан цвет белого лепестка (рис. 6.3) и зеленого листа (рис. 6.4)
при освещении четырьмя различными источниками (рис. 6.2) и при однородном распределении
спектральной мощности
поэтому определить цвет сложно. Впрочем, поскольку внешний вид самого
отблеска достаточно строго ограничен, существует ряд эффективных схем его
создания, а результат можно использовать в качестве ключа к определению
формы.
Динамический ряд практически доступных альбедо относительно мал. По-
верхность с очень большим или очень малым альбедо создать трудно, рсвеще-
ние, как правило, бывает однородным, а большинство камер по своему рабоче-
му диапазону приближаются к линейным. Это значит, что очень яркие участки
не могут быть результатом диффузного отражения; здесь должны фигуриро-
вать либо источники (в той или иной форме — возможно, застекленное окно
188
Часть I. Формирование изображений и модели изображений
с ярким светом за ним), либо блики. Более того, блики обычно малы. Следо-
вательно, если искать маленькие яркие участки, то с большой вероятностью
будут обнаружены именно блики ([Brelstaff and Blake, 1988]).
На цветных изображениях блики на диэлектриках и проводящих веществах
часто выглядят совершенно по-разному. Эта связь с проводимостью объясняет-
ся тем, что электрическое поле не может проникнуть в проводник (электроны
внутри проводника начинают двигаться в противоположном направлении, что-
бы нейтрализовать поле), поэтому свет, попадающий на металлическую поверх-
ность, либо поглощается, либо зеркально отражается от нее. Тусклые металли-
ческие поверхности кажутся тусклыми из-за шероховатости поверхности, а на
блестящих металлических поверхностях есть блестящие участки характерного
цвета, поскольку проводник поглощает разную энергию на разных длинах волн.
В то же время свет, попадающий на диэлектрик, поглощается.
Многие диэлектрические поверхности можно представить в виде однородной
матрицы со случайным образом вкрапленной окраской; данная модель особенно
удачна для пластмасс и некоторых красок. Согласно этой модели есть две со-
ставляющие отражения, которые соответствуют нашим понятиям зеркальности
и рассеяния: объемное отражение, которое происходит, когда свет проникает
в матрицу, попадает на различные окрашенные элементы, а затем покидает по-
верхность; и поверхностное отражение, которое происходит при зеркальном
отражении света от поверхности. Допустим, что окраска распределена случай-
ным образом (небольшими участками, не на поверхности и т.д.) и матрица име-
ет разумные размеры. Тогда составляющая, названная объемным отражением,
ведет себя как составляющая спектрального альбедо, соответствующая рассе-
янию, которая зависит от окраски, а поверхностная составляющая не зависит
от длины волны. Допустим, что наблюдается некий диэлектрический предмет
одного цвета. Далее будем считать, что множителем, отвечающим за взаимное
отражение, можно пренебречь, и модель яркости пикселя камеры приобретет
такой вид:
р(х) = gd(x)d + gs(x)s,
где в — цвет источника, d — цвет рассеянного света, дл(х) — геометрический
множитель, который зависит от ориентации поверхности, gs(x) — множитель,
который показывает степень зеркального отражения. Если предмет искривлен,
то величина gs(x) мала на большей части поверхности и становится большей
только вблизи бликов; величина gd(x) с изменением ориентации поверхности
изменяется намного медленнее. Построим карту цветов, которые дает эта по-
верхность в пространстве реакции датчика и посмотрим, какие структуры здесь
появляются (рис. 6.20).
Множитель gd(x)d дает прямую, которую можно продолжить до начала
координат, поскольку она представляет все тот же вектор реакции датчика,
умноженный на пространственно-зависимый коэффициент. Если есть отблеск,
то будет видна вторая линия, обусловленная gs(x)s, которая в общем случае не
Глава 6. Цвет
189
Рис. 6.20. Допустим, что есть изображение отдельной однородно окрашенной поверхности. Ис-
пользуемая модель отраженного света должна дать ту же гамму цветов, что и на рисунке. Считает-
ся, что отраженный свет состоит из рассеянной и зеркальной составляющих, а зеркальная часть —
это цвет источника света. Большинство точек на поверхности не обладают большим зеркальным
отражением, а просто представляют собой более темные или более светлые варианты одного и то-
го же цвета рассеивающей поверхности. В некоторых точках зеркальная составляющая намного
больше, и это приводит к “излому” функции из-за прибавления к множителю, соответствующему
источнику, члена, отвечающего за рассеяние. Если рассеянный свет достаточно ярок, тот или иной
цветовой канал может засветиться (перенасытиться) (точка Т); подобным образом, канал может
засветиться и в том случае, если будет ярким зеркальное отражение (точка S)
проходит через начало координат (из-за члена, отвечающего за рассеяние). Это
прямая, а не часть плоскости, так как gs(x) будет большим только в небольшой
области нормалей к поверхности. Так как поверхность искривлена, это будет
соответствовать небольшому участку поверхности. Множитель в этой
области будет приблизительно постоянным. Ожидается, что это будет прямая,
а не значение отдельного пикселя, поскольку поверхность обладает (возмож-
но, узкими) зеркальными лепестками, т.е. зеркальный коэффициент — это не
фиксированная величина, а некоторый диапазон значений. Эта вторая прямая
может пересечь грань цветного куба и изменить свое направление.
Полученная модель излома почти непосредственно дает алгоритм определе-
ния блика — вначале найти модель, а затем найти линию блика. Все пиксели
этой линии будут зеркальными пикселями, и можно будет легко оценить
зеркальную и рассеивающую составляющие. Для повышения эффективности
метода нужны гарантии, что набор пикселей описывает только один предмет.
190
Часть I. Формирование изображений и модели изображений
Рис. 6.21. Линейные кластеры бликов на пластмассовых предметах можно определить с помощью
рассуждений об окнах пикселей изображения. Для системы пластмассовых предметов на черном
фоне окно на заднем плане дает область пикселей, которые подобны точкам в цветовом простран-
стве (все пиксели имеют одинаковый цвет). Окно, расположенное вдоль тела, дает кластер точек
в цветовом пространстве в виде прямой, поскольку интенсивность меняется, но цвет остается
прежним. На границе блика окна дают кластеры в виде плоскостей, так как здесь точки — это
взвешенные комбинации двух различных цветов (зеркального отражения и цвета предмета). На-
конец, внутри области отражения окна дают объемные кластеры, так как камера засвечивается,
и отражение окна может содержать как окно, определяющее границу блика, так и засвеченные точ-
ки. Будет ли эта область прямой, плоскостью или объемным образованием можно легко определить
при изучении собственных значений ковариантного тензора пикселей
Этого можно достичь с помощью локальных окон изображения, как показано
на рис. 6.21. Соображения, определяющие метод, сохраняют силу даже тогда,
когда поверхность не монохроматична (например, кофейная чашка с узором), но
определение полученных структур в цветовом пространстве редко освещается
в литературе.
6.5. ОПРЕДЕЛЕНИЯ ЦВЕТА ПОВЕРХНОСТИ ПО ЦВЕТУ ИЗОБРАЖЕНИЯ
Требуется алгоритм постоянства цвета, который из данного изображе-
ния позволял бы вычесть влияние освещения и сообщить настоящий цвет рас-
сматриваемой поверхности. Постоянство цвета — это интересная подзадача,
которая, похоже, весьма актуальна как общая задача компьютерного зрения:
по неоднозначным показателям изображения определяются некоторые внешние
Глава 6. Цвет
191
параметры, требуется использовать некоторую модель, чтобы понять значение
этих параметров, и как результат нужно представление неопределенности, сле-
дующей из измерений (возможно, интервалы доверия, ковариантность апосте-
риорного значения или ряды репрезентативных решений).
6.5.1. Человеческое восприятие цветной поверхности
Некоторое подобие алгоритма постоянства цвета имеет человеческая зри-
тельная система. Люди часто не знают об этом, так что начинающие фотогра-
фы иногда удивляются, почему фотографируя в помещении при флуоресцент-
ном освещении, получают голубоватую сцену, а фотография той же сцены при
уличном освещении может иметь теплый оранжевый оттенок.
Принято отличать постоянство цвета, под которым обычно понимают незави-
сящее от интенсивности описание цвета (оттенок и насыщенность) и постоян-
ство освещенности, что представляет собой способность человека различать
белую, серую или черную поверхность (освещенность поверхности) независимо
от изменения интенсивности освещения (яркости). Постоянство цвета нельзя
считать ни корректно определенным, ни обязательно необходимым понятием.
Люди могут определить:
• каким будет цвет поверхности при освещении белым светом (что обычно
и называют цветом поверхности)',
• цвет света, попадающего в глаз; эта способность помогает художникам
рисовать поверхности, которые освещаются цветным светом;
• а также иногда цвет света, падающего на поверхность.
Всю указанную выше информацию можно получить из алгоритма постоянства
цвета.
Колориметрические теории из раздела 6.3 позволяют предсказать, какой
цвет увидит наблюдатель, которому покажут изолированное пятно света с за-
данным распределением спектральной мощности. Человеческий алгоритм по-
стоянства цвета, оказывается, может дать ключ к структуре сложных сцен, т.е.
предсказания колориметрических теорий могут оказаться очень неточными, ес-
ли изучаемое пятно света будет частью большей и более сложной сцены. Убеди-
тельный пример этого явления — демонстрации Лэнда и МакКанна ([Land and
McCann, 1971]), показанные на рис. 6.22. Совсем непросто было предсказать,
какие цвета увидит человек на сложной сцене ([Fairchild, 1998], [Helson, 1938а,
19386, 1934, 1940]), причем это всего лишь одна из многочисленных проблем,
которые препятствуют созданию хорошей системы воспроизведения цвета.
Человеческий механизм постоянства цвета исследован на удивление плохо.
В основных экспериментах ([Arend and Reeves, 1986], [McCann, McKee and
Taylor, 1976]) учитывались не все обстоятельства. Например, неизвестно, на-
сколько устойчив механизм постоянства цвета, или до какого верхнего предела
суждение о цвете остается справедливым. Иногда алгоритм постоянства цвета
не срабатывает (иначе фото/киноиндустрия просто не могла бы возникнуть),
192
Часть I. Формирование изображений и модели изображений
Показания фотометра
Мнение аудитории —
“красный”
Показания фотометра
Белый свет
Цветной свет Мнение аудитории —
“синий”
Рис. 6.22. Лэнд (Land) показывал зрителям одеяло, сшитое из плоских цветных бумажных пря-
моугольников (которое называют “мондрианом” за очевидное сходство с работами этого художни-
ка), освещаемое тремя прожекторами с различными оттенками красного, синего и зеленого цвета,
соответственно. С помощью фотометра он измерял энергию, исходящую из отдельной точки по
трем различным каналам, соответствующим трем типам рецепторов человеческого глаза. Показа-
ния приборов фиксировались, после чего зрителей просили назвать цвет участка. Предположим,
что ответом было “красный” (слева). Затем Лэнд перемещал прожекторы, чтобы свет отражался
от другого участка, который даст точно такие же показание фотометра, и снова просил зрителей
назвать участок. Ответ должен был соответствовать цвету участка при освещении белым цветом,
т.е. если участок в белом свете выглядит синим, то ответом должно было быть “синий” (справа).
При более поздних демонстрациях Лэнд устанавливал на прожекторы клиноподобные нейтральные
плотностные фильтры, так что цвет света, падающего на бумажное одеяло, можно было изменять
плавно. Снова, хотя показания фотометра очень сильно отличались в разных частях одеяла, зрители
видели участок таким, каким бы он был при постоянном цвете
но обстоятельства, при которых это происходит, изучены еще недостаточно.
Существует множество данных по восприятию освещенности поверхности при
ахроматизме. Так как яркость поверхности зависит от ее ориентации и от ин-
тенсивности освещения, можно было бы ожидать, что человеческий алгоритм
постоянства освещенности будет неустойчивым. На самом же деле он чрезвы-
чайно эффективен в широком диапазоне изменения освещения ([Jacobsen and
Gilchrist, 1998]).
6.5.2. Определение освещенности
Существует множество доказательств того, что человеческий механизм по-
стоянства освещенности включает в себя два процесса: сравнение яркости раз-
личных участков изображения и использование результатов этого сравнения
для определения того, какие участки выглядят светлее, а какие темнее; затем
устанавливается некий абсолютный стандарт, с которым можно сравнивать яр-
кость участков (см., например, [Gilchrist, Kossyfidis, Bonato, Agostini, Cataliotto,
Li, Spehar, Annan and Economou, 1999]). Рассмотрим вначале алгоритмы опреде-
ления освещенности, поскольку они проще, чем алгоритмы постоянства цвета.
Глава 6. Цвет
193
Простая модель яркости изображения
Излучение, попадающее в пиксель, зависит от освещения рассматриваемой
поверхности, ее БФРО, положения поверхности относительно источника и ха-
рактеристик камеры. Ситуация значительно упрощается, если предположить,
что сцена плоская и расположена относительно камеры во фронтальной плос-
кости, поверхности ламбертовские, а реакция камеры линейна по входному
излучению. Такие предположения позволяют записать реакции камеры С в точ-
ке X в виде произведения освещения, альбедо и константы, представляющей
коэффициент усиления камеры:
С(х) = кс1(х)р(х).
Если взять логарифм от левой и правой частей, получим следующее:
log С(х) = log кс + log 1(х) + log р(х).
Теперь можно сделать новые предположения.
• Во-первых, будем считать, что альбедо изменяются в пространстве быст-
ро — это значит, что набор альбедо будет выглядеть как мозаика из бума-
ги различных оттенков серого. Данное предположение достаточно легко
обосновать: в природе встречается относительно мало примеров непрерыв-
ного изменения альбедо (лучший пример — процесс созревания фруктов),
наоборот, чаще всего альбедо меняется при затенении одного предме-
та другим (так что можно ожидать, что эти изменения будут простран-
ственно резкими). Это значит, что пространственные производные вели-
чины logp(®) либо равны нулю (альбедо неизменно), либо очень большие
(альбедо меняется быстро).
• Во-вторых, освещение изменяется в пространстве только медленно. Это
достаточно реалистичное предположение. Например, свет от точечного
источника будет изменяться относительно медленно до тех пор, пока ис-
точник будет очень близок. В качестве подходящего примера такого источ-
ника можно привести солнце. Еще один пример: освещение в помещении
также меняется очень медленно, поскольку белые стены комнат играют
роль плоских источников. В то же время такое предположение нельзя при-
менять для границ теней. Последние нужно рассматривать как отдельный
случай и считать, что границы тени либо отсутствуют, либо известно, где
они проходят.
Определение освещенности по модели
Алгоритмы, в которых будет использоваться приведенная выше модель, со-
здать относительно просто. Самый первый алгоритм, предложенный в работе
[Land and McCann, 1971], в настоящее время уже не используется. Другой
194
Часть I. Формирование изображений и модели изображений
естественный подход — это продифференцировать логарифм преобразования,
отбросить малые градиенты и проинтегрировать результат ([Horn, 1974]). По-
скольку константа интегрирования неизвестна, можно найти только отношение
освещенностей, а не абсолютное значение. Пример этого процесса для одномер-
ного случая (где несложно выполнить интегрирование и дифференцирование)
приведен на рис. 6.23.
Описанный способ применим и в двумерном случае. Дифференцировать
и сравнивать с порогом здесь также несложно: в каждой точке оценивается
модуль градиента; если он не превышает некоторого порогового значения, ему
присваивается нулевое значение или он отбрасывается еще как-либо. Трудно-
сти начинаются при интегрировании градиентов и составлении карты логариф-
ма альбедо. Значения градиентов после сравнения с порогом могут не иметь
никакого отношения к градиентам изображения, поскольку смешанные вторые
частные производные могут быть разными (снова возвращаемся к вопросу ин-
тегрируемости; см. раздел 5.4.2).
Поставленную задачу можно переформулировать как задачу минимизации:
требуется выбрать такую карту логарифма альбедо, градиент которой будет бли-
же всего градиенту, прошедшему сравнение с порогом. Это относительно про-
стая задача, поскольку вычисление градиента изображения является линейной
операцией. Координата х градиента после сравнения с порогом превращается
в вектор р, а координата у — в вектор q. Вектор, описывающий логарифм аль-
бедо, запишем как I. Теперь процесс нахождения производной по координате х
становится линейным; значит, есть матрица Atx такая, что ЛМ является про-
изводной по х некоторой функции; соответствующая матрица ЛЛУ записывается
для производной по у.
Задача сводится к нахождению вектора Z, который минимизирует величину
Алгоритм 6.1. Определение освещенности участка изображения
Построить градиент логарифма изображения
Для каждого пикселя, если значение градиента не превышает порогового
значения, заменить этот градиент нулем
Построить логарифм альбедо, решив задачу минимизации (описана в тексте)
Найти константу интегрирования
Добавить константу к логарифму альбедо и восстановить освещенность
по логарифму
Это задача минимизации второго порядка, и ее решение можно найти с по-
мощью линейного процесса. Здесь можно использовать некоторые уловки,
поскольку прибавление постоянного вектора к I не влияет на производные (так
Глава 6. Цвет
195
dlgp
dx
после сравнения с порогом
Проинтегрировать
результат для
получения
освещенности,
которая равна
lg р + constant
Рис. 6.23. Механизм освещенности легче всего проиллюстрировать на примере одномерного изоб-
ражения. В верхнем ряду на левом графике показана величина logp(r), в центре — log/(a:), а
справа — сумма этих величин, которая равна log С. Производные логарифма интенсивности изоб-
ражения велики в точках изменения отражательной способности поверхности и малы только тогда,
когда изменение обусловлено градиентом освещенности. Освещенность можно найти, если продиф-
ференцировать логарифм интенсивности, сравнить с порогом, чтобы отсеять малые производные,
и проинтегрировать, подставив недостающую константу интегрирования
196
Часть I. Формирование изображений и модели изображений
что задача не имеет единственного решения). Подробнее задача минимизации
исследована в разделе упражнений.
Константу интегрирования можно найти из других предположений. Есть два
очевидных направления:
• можно предположить, что самый яркий участок имеет белый цвет;
• можно предположить, что средняя освещенность остается постоянной.
К чему приводят подобные предположения описано в разделе упражнений.
Линейные модели конечной размерности
Модель цвета изображения из раздела 6.4.2 можно записать следующим
образом:
С(х) = gd(x)d(x) + ga(a)s(x) + i(x).
Договоримся пренебрегать членом, отвечающим за взаимное отражение г(х).
В принципе, можно использовать методы из раздела 6.4.3 и построить новое
изображение без бликов. Это даст величину gd(x)d(x). Предположим также,
что gd(x) имеет постоянное значение, т.е. наблюдается плоская фронтальная
поверхность.
Полученная величина d(x) описывает систему как мозаику из плоских
фронтальных рассеивающих цветных поверхностей. Предположим, что есть
один источник света с постоянным цветом по всей площади изображения. Ука-
занная величина содержит информацию об источнике, светочувствительном
датчике и отражающей способности, причем в реальных задачах полностью
избавиться от нее невозможно. Впрочем, предложенные алгоритмы могут поз-
волить оценить цвет поверхности по цветам изображения при заданных системе
цветных поверхностей и источнике.
Величина d(x) описывает связь спектрального излучения источника, спек-
трального альбедо поверхностей и чувствительности камеры. Требуется модель,
учитывающая эту взаимосвязь. Напомним (раздел 6.4.2), что если участок
идеально рассеивающей поверхности со спектральной отражательной способ-
ностью р(А) освещается светом, спектр которого Е(Х), то спектр отраженного
света будет равен р(Х)Е(Х) (умноженное на некоторую константу, связанную
с ориентацией поверхности, которой мы договорились пренебрегать).
Итак, если линейный светочувствительный датчик fc-ro типа видит указан-
ный участок поверхности, то его реакцию можно записать следующим образом:
Pk = [ afc(A)p(A)E?(A)dA,
J л
где Л — это диапазон всех существенных длин волн, а сгЦА) — чувствитель-
ность fc-ro датчика (рис. 6.15).
Глава 6. Цвет
197
Эта реакция линейна по отражательной способности поверхности и линейна
по освещению, поэтому напрашиваются линейные модели описания возможных
отражательных способностей поверхностей и осветителей. Линейная модель
конечной размерности описывает спектральные альбедо поверхностей и спек-
тральное излучение источников как взвешенную сумму п базисных функций.
Отметим, что один и тот же базис для отражательных способностей и для
осветителей выбирать не обязательно.
Если линейная модель конечной размерности для отражательной способно-
сти поверхности является разумным описанием окружающего мира, то отража-
тельную способность любой поверхности можно записать следующим образом:
71
р(А) =
где 0j(A) — это базисные функции модели отражательной способности, а ве-
личина rj различна для различных поверхностей.
Подобным образом, если принятие линейной модели конечной размерности
для осветителя обосновано, то любой осветитель можно записать следующим
образом:
ТП
- t=l
где V’i(A) ~ базисные функции модели осветителя.
Если принять обе модели, то реакция датчика fc-ro типа запишется следую-
щим образом:
Рк = У er fc(A) e^i(A)^ dA =
= etFj <Tfc(A)^(A)V'»(A)^ dA =
т.п
= У eirj9ijki
i=l,j=l
причем ожидается, что величины
9ijk = f ак(Х)фз(Х)^(Х)дХ
известны, поскольку они являются параметрами используемой модели (их мож-
но узнать из наблюдений; см. раздел упражнений).
198
Часть I. Формирование изображений и модели изображений
6.5.3. Цвет поверхности согласно линейной модели конечной
размерности
Все величины с индексами можно интерпретировать как компоненты некото-
рого вектора; далее будем использовать запись р для обозначения вектора, к-я
координата которого равна рь- Цвет поверхности можно передать либо прямо
через вектор коэффициентов г, либо косвенно, рассчитав г, а затем определив,
как будет выглядеть поверхность при белом свете. Последнее представление
практичнее; помимо других достоинств, очень упрощается интерпретация ре-
зультатов.
Нормирование средней отражательной способности
Предположим, что среднее пространственное значение отражательной спо-
собности по всем кадрам постоянно и известно (например, можно предполо-
жить, что среднее пространственное значение всех кадров — тусклый серый
цвет). В базисе конечной размерности для отражательной способности это сред-
нее можно записать следующим образом:
22»7&(А)-
Если среднее значение отражательной способности постоянно, то средняя реак-
ция датчика должна быть также постоянной (если процесс создания изображе-
ния линеен — см. ниже), а среднюю реакцию fc-ro датчика можно записать как
Рк = eiQijkTj-
Если р — вектор с к~й координатой рк (используется введенная выше система
обозначений), а А — матрица с координатами k,i
rj9ijk,
то предыдущее выражение можно переписать как
р = Ле.
При правильном подборе датчиков матрица А будет иметь полный ранг, т.е.
можно определить осветитель е, который дает требуемое освещение, если раз-
мерность линейной модели освещения совпадает с количеством датчиков. Ко-
нечно, если освещение известно, то можно узнать отражательную способность
поверхности в каждом пикселе или исправить изображение, чтобы оно выгля-
дело так же, как при белом свете.
Глава 6. Цвет
199
Алгоритм 6.2. Постоянство цвета при известной средней отражательной способ-
ности
Рассчитать средний цвет изображения р
По р = Де рассчитать е
Получить вариант изображения при белом свете, ew
Для каждого пикселя по рк — рассчитать г
Заменить значение пикселя величиной = $2<=1 J=lm п
Базовое предположение о том, что средняя отражательная способность —
это известная константа, опасно, поскольку обычно оно даже близко не соот-
ветствует истине. Например, если предположить, что средняя отражательная
способность равна среднему серому цвету (распространенный выбор; см., на-
пример, [Buchsbaum, 1980], [Gershon, Jepson and Tsotsos, 1986]), то зеленая
лесная поляна будет представляться как набор объектов различных оттенков
серого цвета, которые освещаются зеленым светом. Один из способов избежать
этого заключается в том, чтобы менять среднее значение для разных типов
сцен ([Gershon, Jepson and Tsotsos, 1986]), но как определить, какое среднее
значение выбрать? Еще один подход — рассчитать среднее значение, которое
не будет чистым пространственным средним. Например, можно усреднить цве-
та, которые представлены десятью или больше пикселями, не определяя их
весовые коэффициенты.
Нормирование цветовой гаммы
Не все возможные значения пикселей можно получить, создавая изображе-
ния реальных поверхностей при освещении белым светом. Как правило, зна-
чение получить невозможно, если один канал имеет большую характеристику
по одному цвету и слабую по другим (например, 255 по красному каналу и 0
по зеленому и синему). Это означает, что цветовая гамма изображения (набор
значений всех пикселей) несет информацию об источнике света. Если, напри-
мер, наблюдается пиксель со значением (255,0,0), то источник света вероятнее
всего имеет красный цвет.
Если цветовая гамма изображения состоит из значений двух пикселей, ска-
жем, рг ир2, тогда появляется возможность получить изображение при том же
осветителе, содержащее значение tpr + (1 —t)p2 для 0 < t < 1 (поскольку цве-
та на поверхности можно смешивать). Это значит, что выпуклое пространство
цветовой гаммы изображения несет информацию об осветителе. Эти условия
можно использовать для сужения круга предположений о цвете осветителя.
Пусть G — это цветовая оболочка гаммы данного изображения, W — про-
странство цветовой гаммы изображения многих поверхностей при белом свете,
а Л4е — отображение изображения, полученного при осветителе е, на изобра-
жение при белом свете. Тогда стоит рассматривать только те осветители, для
200
Часть I. Формирование изображений и модели изображений
которых Л4е(<2) G W. Это очень удобно, если семейство Л4е имеет опреде-
ленную разумную структуру (например, если величины Л4е — диагональные
матрицы).
Если принять линейную модель конечной размерности, то /Ле линейно
зависит от е, поэтому семейство осветителей, которые удовлетворяют указан-
ному выше условию, также является выпуклым. Это семейство можно получить
как пересечение набора выпуклых оболочек, каждая из которых соответствует
семейству отображений, причем в качестве вершины оболочки G берется неко-
торая точка внутри W (или можно записать длинный набор линейных условий
на е).
Алгоритм 6.3. Постоянство цвета через отображение цветовой гаммы
Получить цветовую гамму W многих изображений нескольких различных
цветных поверхностей при освещении белым светом (выпуклая оболочка
значений всех пикселей изображений)
Получить цветовую гамму G изображения (выпуклая оболочка значений
всех пикселей изображения)
Получить каждый элемент семейства отображений осветителей /Ле, таких что
/AeG € W, представляя все возможные осветители
Выбрать какой-то элемент из этого семейства и применить его к каждому
пикселю изображения
Если указанное семейство найдено, остается только выбрать подходящий
осветитель. Здесь существует множество всевозможных путей. Если, например,
известно что-либо о правдоподобии отдельных осветителей, из них можно выби-
рать самый правдоподобный. Если предположить, что большинство изображе-
ний состоит из многих различных цветных поверхностей, придем к выбору осве-
тителя, при котором цветовая гамма принимает самое большое значение. Мож-
но использовать и другие условия, накладываемые на осветитель (например, у
всех осветителей должна быть неотрицательная энергия на всех длинах волн),
что позволит еще больше ограничить выбор ([Finlayson and Hordley, 2000]).
6.6. ПРИМЕЧАНИЯ
Использование цвета в компьютерном зрении на удивление примитивно.
В работе [Mollon, 1995], например, отмечается, что зрительную систему при-
матов можно рассматривать как аппарат для узнавания различных фруктовых
деревьев.
Имеется ряд важных общих работ по применению цвета. Авторы рекомен-
дуют следующие: [Hardin and Maffi, 1997], [Lamb and Bourriau, 1995], [Lynch
and Livingston, 2001], [Minnaert, 1993], [Trussell, Allebach, Fairchild, Funt and
Wong, 1997], [Williamson and Cummins, 1983]. Массу полезной информации
содержит также публикация [Wyszecki and Stiles, 1982].
Глава 6. Цвет
201
Трехцветность и цветовые пространства
До недавнего времени трехцветность не была достаточно аргументирована,
хотя считается, что это обусловлено тремя различными типами светочувстви-
тельных рецепторов в глазе человека. Эту идею подтверждают работы по
генетике фоторецепторов (см. [Nathans, Piantanida, Eddy, Shows and Hogness,
1986a] и [Nathans, Thomasand Hogness, 19866]), хотя до окончательного объ-
яснения еще далеко, поскольку можно предположить, что многие люди имеют
больше трех типов фоторецепторов ([Mellon, 1995]).
Существует поразительно много цветовых пространств и моделей внешне-
го вида цветов. Важный вопрос здесь — не в каких координатах измеряется
цвет, а как считается разность, т.е. некоторую информацию могут нести в себе
системы цветовых единиц.
Вообще системы единиц — не такая уж новая тема; как правило, тензор
величин подбирают по эллипсам МакАдама. Сложность этого метода состоит
в том, что тензор величин сильно зависит от возможности измерения разности
в большом интервале с помощью интегрирования, тогда как на самом деле
в большом диапазоне цветов основательно сравнить два цвета очень трудно.
Еще одна проблема: весовые коэффициенты, которые наблюдатель присваивает
разности, и семантическое значение разности цветов изображения — это две
разные вещи.
Нахождение бликов
Описанный способ нахождения бликов взят из работы [Shafer, 19856] с неко-
торыми усовершенствованиями из работ [Klinker, Shafer and Kanade, 1987a,6,
1990] и [Maxwell and Shafer, 2000]. Кроме того, блики можно выделить ввиду
того, что они маленькие и яркие ([Brelstaff and Blake, 1988]), или из-за того,
что они отличаются по цвету и перемещаются относительно фона ([Lee and
Bajcsy, 1992а, 6]).
Освещенность
Ряд экспериментов по цветному зрению описан в работах ([Land, 1959а,6,с,
1983]). В более позднее время проводилось не очень много исследований, по-
священных механизму постоянства освещенности. При обсуждении в тексте
главы были использованы идеи из работы [Land and McCann, 1971]. Специа-
листам по компьютерному зрению также будет полезно изучить работу [Horn,
1974]. Один из вариантов алгоритма Хорна усовершенствован Блейком ([Blake,
1985]), именно этот вариант приводится в тексте. Первоначально данный алго-
ритм имел несколько иную форму ([Land and McCann, 1971]), но в таком виде
его на удивление сложно анализировать (см. [Brainard and Wandell, 1986]).
Методы работы с освещенностью не так широко распространены, как они
того заслуживают, тем более уже доказано, что они дают полезную инфор-
мацию о реальных изображениях ([Brelstaff and Blake, 1987]). Классификация
освещения по альбедо с использованием простой величины градиента достаточ-
202
Часть I. Формирование изображений и модели изображений
но груба и не учитывает важные ключевые моменты. Один из таких моментов
состоит в том, что большие изменения должны сказываться на освещенности,
как бы быстро они не происходили; другой —• что изменения цвета на границах
тени отличаются от изменений цвета на границах поверхностей с разными аль-
бедо. Вопрос о том, какие изменения связаны с изменением альбедо, а какие —
с осветителем, можно решить (совсем несложно написать модель правдоподо-
бия). Несколько попыток решения этой задачи с помощью локальной модели
описаны в работах [Freeman, Pasztor and Carmichael, 2000].
Постоянство цвета
Линейные модели конечной размерности для спектральной отражательной
способности можно обосновать, обратившись к физике поверхностей: линии
спектрального поглощения уширяются вследствие твердотельных эффектов.
Основное экспериментальное подтверждение линейных моделей конечной раз-
мерности для отражательной способности поверхностей ([Cohen, 1964]) — это
измерение отражательной способности стандартных тестовых поверхностей
и природных объектов ([Krinov, 1947]). В работе [Cohen, 1964] описаны спо-
собы получения набора базисных функций, а в работе [Maloney, 1984] описан
подбор взвешенных сумм этих функций, чтобы получить хорошее совпадение
с модельными производными. В каждом случае объясняется высокий процент
разброса данных измерений (около 99%), следовательно, линейная комбинация
функций достаточно хорошо согласуется с функциями образца. В более позд-
них работах [Maloney, 1986], [Cohen, 1964] векторы подбирались для большого
набора данных (приведенных, например, в [Krinov, 1947]), был сделан вывод,
что размерность точной модели отражательной способности поверхности будет
равна пяти или шести.
Линейные модели конечной размерности — важнейший инструмент для опи-
сания постоянства цвета. Существует большой набор алгоритмов, которые есте-
ственным образом следуют из этого метода. В некоторых алгоритмах использу-
ются свойства линейных пространств ([Maloney, 1984], [Maloney and Wandell,
1986], [Wandell, 1987]). На таких поверхностях, как пластмассы, зеркальная
составляющая отраженного света будет иметь тот же цвет, что и осветитель.
Если можно определить области отражения от таких объектов на изображении,
то цвет осветителя считается известным. Эта идея, популярная на протяжении
долгого времени, в старой работе [Judd, 1940] называется “наиболее привыч-
ным подходом” ([D’Zmura and Lennie, 1986], [Flock, 1984], [Klinker, Shafer and
Kanade, 1987a, 6], [Lee, 1986]). Еще один распространенный подход — предпо-
ложить, что средний цвет постоянен ([Buchsbaum, 1980], [Gershon, 1987]).
Схема отображения цветовой гаммы изложена согласно [Forsyth, 1990]. Во-
обще, этот метод интенсивно развивался ([Barnard, 2000], [Finlayson and Hord-
ley, 1999, 2000]), например, изучался состав семейства отображений, связанных
с изменениями освещения, Л4е- Первая работа в этой области принадлежит
фон Крису (Von Kries), который предполагал, что постоянство цвета является,
по сути, результатом независимых расчетов освещенности по каждому каналу,
Глава 6. Цвет
203
а это означает, что можно исправить изображение, откалибровав независимо
каждый канал. Этот принцип известен под названием закона фон Криса. В по-
нимании авторов этот закон сводится к предположению о том, что Л4е состоит
из диагональных матриц. Было доказано, что закон фон Криса дает хорошие
результаты на практике ([Finlayson, Drew and Funt, 1994a]). В настоящий мо-
мент он заключается в применении линейных преобразований с последующей
калибровкой результатов с помощью диагональных отображений ([Finlayson et
al., 1994а,ft]).
Постоянству цвета посвящено на удивление мало работ, в которых исследо-
вания пространственных изменений освещения объединялись бы с решениями
для цветных поверхностей, поэтому в модели цвета приходится пренебрегать
рядом членов. В идеале в модели должна учитываться тень и ориентация по-
верхности. Главные работы, посвященные этой чрезвычайно важной теме, —
это [Barnard, Finlayson and Funt, 1997] и [Funt and Drew, 1988].
Взаимное отражение цветных поверхностей приводит к явлению, называемо-
му окрашиванием, когда каждая поверхность отражает цветной свет на другие
поверхности. На практике это явление встречается довольно часто. Было заме-
чено, что человек может абсолютно не замечать его, большинство людей даже
не осознают, что оно вообще существует. При отбрасывании лишнего цвета,
вероятно, играют роль пространственные привычки. Требуется определенный
опыт, чтобы не попасться на некоторые распространенные иллюзии. Пример
из личных наблюдений авторов: в Южной Калифорнии у обочин дороги есть
много живых изгородей из белого олеандра (темные листья и белые цветы);
иногда, при ярком солнечном свете, можно увидеть изгородь с желтыми цве-
тами олеандра; в этом случае наблюдатель осознает, что желтый цвет вызван
отражением на белые цветы желтого света от ремонтного фургона, припарко-
ванного у дороги. В приведенном примере на способность не учитывать эффект
окрашивания влияют темные листья растения, которые разрушают однородную
пространственную модель. Отметим также, что понятие окрашивания включа-
ет понимание цвета поверхности, в котором довольно трудно разобраться (см.
[Drew and Funt, 1990], [Funt and Drew, 1993] и [Funt, Drew and Ho, 1991]).
Постоянство цвета можно сформулировать как обобщающую задачу ([Forsyth,
1999], [Freeman and Brainard, 1997]. Преимущество такого подхода заключает-
ся в том, что по известным данным можно получить информацию о диапазоне
возможных цветов поверхности.
Цвет при распознавании
Как будет показано в следующих главах, довольно сложно создать систему,
в которой цвет предмета способствовал бы распознаванию. Доказано, что посто-
янство цвета — это процесс, который должен улучшить сопоставление с данным
образцом, поскольку мы имеем дело со свойствами предмета, а не со свойства-
ми определенной его проекции ([Finlayson, Chatterjee and Funt, 1996], [Funt,
Barnard and Martin, 1998], [Funt and Finlayson, 1995]). Здесь могут помочь од-
204
Часть I. Формирование изображений и модели изображений
неродные цветовые пространства, если принять достаточно расплывчатый ар-
гумент: различия в цвете стоит изучать с позиции их восприятия человеком.
ЗАДАЧИ
6.1. Вместе с другом возьмите пачку цветной бумаги и сравните, какими
названиями цветов вы пользуетесь. Вам понадобится большая пачка бу-
маги. Часто встречаются наборы Pantone — Международный стандарт-
ный каталог составных цветов (CMYK). Лучше всего начать с названий
основных цветов — красный, розовый, оранжевый, желтый, зеленый,
синий, фиолетовый, коричневый, белый, серый и черный, которые (плюс
еще немного других названий) обладают замечательными каноническими
свойствами и широко используются во всех языках (в статье [Hardin and
Maffi, 1997] дается хороший современный обзор этого вопроса). Вы уви-
дите, как быстро вы придете к разногласиям по поводу того, например,
какой цвет называть синим, а какой — зеленым.
6.2. Выведите уравнения для преобразования из пространства RGB в МКО
XYZ и обратно. Эти преобразования линейны; достаточно выписать вы-
ражения для элементов линейного преобразования, численные значения
функций подбора цвета искать не нужно.
6.3. Линейные цветовые пространства получаются при выборе основных цве-
тов и построении функций подбора цвета для этих основных цветов.
Покажите, что существует линейное преобразование координат цвета
из одного линейного цветового пространства в другое; самый простой
способ это сделать — записать преобразование через функции подбора
цвета.
6.4. Из сказанного выше следует, что при формировании линейного цветово-
го пространства выбор основных цветов может быть произвольным, но
есть ограничения, касающиеся выбора функций подбора цвета. Почему?
Каковы эти ограничения?
6.5. Две поверхности, цвет которых одинаков при одном освещении и раз-
ный при другом, часто называют метамерами. Оптимальный цвет —
это спектральная отражательная способность или излучение, значение
которого равно нулю при одной длине волны и 1 — при остальных. Хотя
оптимальный цвет на практике не встречается, это очень полезный (со-
гласно работам Оствальда (Ostwald)) аппарат для объяснения различных
явлений.
а) Объясните с помощью оптимального цвета механизм метамеризма.
б) Известно значение спектрального альбедо. Покажите, что существует
бесконечное множество спектральных альбедо, метамерических дан-
ному.
в) С помощью оптимального цвета создайте поверхности, которые бу-
дут выглядеть разными при одном свете (скажем, красная и зеленая)
и одинаковыми при другом.
Глава 6. Цвет
205
г) С помощью оптимального цвета создайте поверхности, которые будут
изменять цвет при изменении освещения (например, при освещении
I поверхность 1 выглядит красной, а поверхность 2 — зеленой, а при
освещении II поверхность 1 выглядит зеленой, а поверхность 2 —
красной).
6.6. Нужно отобразить цветовую гамму принтера в цветовую гамму монитора.
В каждой цветовой гамме есть цвета, которые не встречаются в другой.
Для заданного цвета монитора, который нельзя передать точно, нужно
подобрать самый близкий цвет принтера. Почему эта идея не подходит
для воспроизведения изображений? Будет ли она пригодной для “бизнес-
графики” (таблицы, диаграммы и т.п., которые состоят из многих раз-
личных больших блоков отдельного цвета)?
6.7. Объемный цвет — явление, наблюдаемое в связи с цветными прозрачны-
ми веществами, самый яркий пример — бокал вина. Окрашивание про-
исходит из-за различных коэффициентов поглощения на разных длинах
волн. Объясните: а) почему маленький бокал красного вина с достаточ-
но насыщенным цветом (например, кагора) кажется черным и б) почему
большой бокал светлого вина также кажется черным. Проведите оптиче-
ский эксперимент.
6.8. (Для выполнения этого задания необходимы некоторые знания из обла-
сти численного анализа.) В разделе 6.5.2 задача определения логарифма
альбедо для набора поверхностей сформулирована как задача минимиза-
ции величины
I Л4xl - Р I2 + I Myl - q I2,
где — полная производная по х от I, а Л4У — полная производная
по у.
а) Будем считать, что и Л4У существуют. Возьмите выражение для
прямой разности (или центральной разности, или любое другое раз-
ностное приближение производной) и постройте эти матрицы. Почти
все элементы этой матрицы будут равны нулю.
б) Задачу минимизации можно записать в виде:
выбрать I, минимизирующее (Al + Ь)Т (А1 + Ь).
Определите значения А и Ь и покажите, как решить эту общую зада-
чу. Следует помнить, что матрица А имеет неполный ранг, поэтому
обратную к ней найти нельзя.
6.9. В разделе 6.5.2 назывались два предположения, позволяющие получить
константу интегрирования.
а) Покажите, как с помощью этих предположений построить карту аль-
бедо.
206
Часть I. Формирование изображений и модели изображений
б) Для каждого предположения опишите ситуацию, когда оно не работа-
ет (объясните, почему). Ваши примеры должны быть эффективными
даже тогда, когда в поле зрения попадает множество плоскостей с раз-
личными альбедо.
6.10. Прочитайте книгу Lamb and Bourriau, “Color: Art and Science”, изда-
тельство Cambridge University Press, 1995.
Упражнения
6.11. Описание спектров осветителей и поверхностей можно найти в Internet
(например, http://www.it.lut.fi/research/color/lutcs_data
base.html). Подберите линейную модель конечной размерности для
набора осветителей и отражательных способностей поверхностей, поль-
зуясь анализом главных составляющих; постройте полученную модель
и сравните ваше построение с точным вариантом. Где вы допустили са-
мые значительные ошибки? Почему?
6.12. Напечатайте цветное изображение на цветном струйном принтере на раз-
ной бумаге и сравните картинки. Особенно полезно будет а) убедить-
ся в том, что драйвер “знает”, на какой бумаге будет печатать принтер
(в идеальном случае это не важно) и б) “обмануть” принтер по поводу
того, на какой бумаге идет печать (т.е. печатать на простой бумаге, а
в настройках указать, что печать выполняется на фотобумаге). Може-
те ли вы объяснить различие в картинках? Почему фотобумагу делают
глянцевой?
6.13. Подбор линейной модели конечной размерности отдельно для осветите-
лей и отдельно для отражательных способностей является неправильным
подходом, так как нет гарантии, что будут правильно описаны взаи-
модействия (они не входят в ошибку подбора). Оказывается, что тен-
зор gijk можно найти с помощью подбора, в котором не фигурируют
базисные функции. Реализуйте эту процедуру (подробно описана в [Ма-
rimont and Wandell, 1992]) и сравните результаты с полученными в преды-
дущих упражнениях.
6.14. Постройте алгоритм постоянства цвета, пользуясь предположением о
том, что среднее пространственное значение отражательной способно-
сти постоянно. Воспользуйтесь линейной моделью конечной размерности.
В качестве значений дгзь можно взять полученные в упражнении 3.
6.15. В использованной модели цвета поверхности взаимное отражение цветов
пренебрегается. Проведите эксперимент, чтобы получить представление о
возможной величине смещения цвета в результате взаимного отражения
(окажется удивительно большой). Отметим, что люди редко воспринима-
ют взаимное отражение как цвет поверхности. Подумайте о том, почему
это происходит, руководствуясь рассуждениями о механизме постоянства
светлости.
6.16. Напишите программу для поиска бликов (общий подход описан в в раз-
деле 6.4.3)
--------- ЧАСТЬ II ---------
Первые этапы: одно изображение
7
Линейные фильтры
Изображение зебры или далматинца состоит из черных и белых пикселей, при-
чем их число примерно одинаковое. Друг от друга эти два изображения от-
личаются не значениями отдельных пикселей, а характерным внешним видом
небольших групп пикселей. В данной главе рассказано, как можно описать
внешний вид таких небольших групп пикселей.
Основная стратегия, используемая при работе с изображениями, состоит
в том, чтобы применять взвешенные суммы значений пикселей, используя раз-
личные наборы весовых коэффициентов для поиска различных моделей изоб-
ражений. Несмотря на свою простоту, этот процесс чрезвычайно полезен. Он
позволяет сглаживать шумы на изображениях, определять края и другие эле-
менты изображения.
7.1. ЛИНЕЙНЫЕ ФИЛЬТРЫ И СВЕРТКА
Для описания многих явлений достаточно довольно простой модели. Соста-
вим новый массив данных того же размера, что и изображение. Элементами
этого массива будут взвешенные суммы значений пикселей, окружающих со-
ответствующую точку изображения, причем набор весовых, коэффициентов
всегда будет одним и тем же. Для описания другого изображения можно
210
Часть II. Первые этапы: одно изображение
Рис. 7.1. Хотя на первый взгляд может показаться, что однородное локальное усреднение дает
хорошую модель размывания, в действительности оно приводит к эффектам, которые обычно не
встречаются при расфокусировке линзы. На данных изображениях уравниваются результаты од-
нородного локального усреднения и взвешенного усреднения. Левый рисунок — это изображение
травы. В центре — это же изображение, но размытое с помощью однородной локальной моде-
ли, а справа — результат размывания этого изображения с помощью набора гауссовых весовых
коэффициентов. Степень размывания в каждом случае приблизительно одинакова, но однородное
усреднение дает набор узких вертикальных и горизонтальных полос — это явление часто назы-
вают окантовкой. На рисунках в графической форме указаны весовые коэффициенты, которые
использовались для размывания изображения; яркие точки соответствуют большим значениям, а
темные — малым (в этом примере самое малое значение — нуль)
использовать иной набор весовых коэффициентов. Пример: вычисление локаль-
ного среднего значения в фиксированной области. Здесь можно усреднить все
значения в пределах блока пикселей размером (2k +1) х (2/с + 1). Если на входе
дано изображение то на выходе получим
= (2fc+ip £
7 u=i—fc v=j — k
Весовые коэффициенты в этом примере простые (все они равны некоторой
константе), но можно принять и более интересный набор весовых коэффи-
циентов, например, такой, чтобы в центре значения весовых коэффициентов
были большими, а с увеличением расстояния от центра быстро уменьшались.
Этот набор применяется при одном из видов сглаживания, которое наблюдается
в расфокусированных системах линз.
Независимо от выбора весовых коэффициентов выход этой процедуры ин-
вариантен относительно сдвига, т.е. значение на выходе зависит от окру-
жающих пикселей, а не от их положения, и линеен, т.е. выход суммы двух
изображений будет равен сумме двух выходов, полученных отдельно для каж-
дого изображения. Эта процедура называется линейной фильтрацией.
7.1.1. Свертка
Введем несколько новых понятий. Стандартный набор весовых коэффициен-
тов, которым пользуются при линейной фильтрации, обычно называют ядром
Глава 7. Линейные фильтры
211
фильтра. Процесс применения фильтра называют сверткой. Здесь есть один
нюанс: по причинам, которые мы назовем позже (в разделе 7.2.1), этот процесс
удобнее записывать в неявном виде. В частности, если известно ядро филь-
тра 7Y, то свертка ядра с изображением F j&crt изображение 7£. Компонент
(г, j) матрицы определяется следующим образом:
Rij — Hj-uJ-y
Это и есть определение свертки — матрица 7Y была свернута с матрицей F,
что дало Я. Повнимательнее присмотритесь к этому выражению — по сравне-
нию с корреляцией “направление” фиктивной переменной и (соответственно, v)
изменилось на обратное. Это важно, и если об этом забыть, при вычисле-
нии будет получен неверный результат. О том, почему происходит такая смена
направления, рассказано в разделе 7.2.1. Диапазон суммирования не уточняет-
ся; фактически, предполагается, что суммирование проводится по достаточно
большой области и и и, где учитываются все ненулевые значения. Более то-
го, считается, что все неопределенные значения равны нулю; т.е. ядро можно
представить как небольшой островок ненулевых значений в море нулей. Отме-
тим, что свертку можно определить по-разному, но далее будет использовано
определение, приведенное выше.
Пример 7.1. Сглаживание через усреднение
Как правило, значение пикселя изображения слабо отличается от соседних. Пусть
на изображение влияет такой шум, при котором это свойство сохраняется. Напри-
мер, изредка попадаются “мертвые” пиксели или пиксели, к значениям которых
добавляются случайные числа с нулевым средним значением. Естественно будет
попытаться уменьшить влияние этого шума, заменив каждый пиксель взвешенным
средним значением его соседей, такой процесс часто называют сглаживанием.
Замена каждого пикселя на невзвешенное среднее значение, рассчитанное для
некоторой фиксированной области с центром в этом пикселе, равнозначна сверт-
ке с ядром, которое представляет собой блок единиц, умноженных на константу.
Выбор этой точки можно (и нужно) согласовать с областью суммирования. Дан-
ная модель сглаживания плоха, поскольку результат ее применения не похож на
изображение расфокусированной камеры (рис. 7.1). Причина ясна. Допустим, что
есть изображение, каждая точка которого, кроме центральной, — это нуль, а цен-
тральная — единица. Если сгладить это изображение с помощью невзвешенного
среднего в каждой точке, то результат будет выглядеть как маленький яркий пря-
моугольник, а это не совсем то, что дает расфокусированная камера. Хотелось бы
получить такое сглаживание, при котором маленькая яркая точка превращается
в симметричную круглую размытую область, которая ярче всего в центре и мед-
ленно бледнеет по направлению к краям. Как показано на рис. 7.1, при таком
наборе весовых коэффициентов получается намного более убедительная модель
расфокусировки.
212
Часть II. Первые этапы: одно изображение
Рис. 7.2. Симметричное гауссово ядро в двумерном пространстве. На рисунке выбран такой мас-
штаб, чтобы сумма элементов ядра была равна единице; этот масштаб применяется довольно часто.
Для данного ядра а = 1. Свертка с ядром образует взвешенное среднее, которое ориентируется на
точку в центре окна свертки и на которое относительно слабо влияют точки на границе. Обратите
внимание, что качественно гауссиан напоминает описание функции распределения точек при раз-
мывании изображения; он обладает круговой симметрией, самая сильная реакция — в центре, а на
границах она сходит на нет
Пример 7.2. Сглаживание с помощью гауссиана
Хорошая формальная модель размытого пятна — симметричное гауссово ядро
G0(x,y) =
2^еХр
( (*2 + У2)\
\ 2а2 )
изображенное на рис. 7.2. Здесь а — это среднеквадратическое отклонение гаус-
сиана, измеряемое в расстояниях между пикселями (обычно такую единицу из-
мерения называют просто пикселем). Интеграл по всей области от постоянного
члена равен единице, поэтому при описании сглаживания его часто опускают.
Название ядра объясняется тем, что именно такой вид имеет плотность вероятно-
сти для двумерной нормальной (или гауссовой) случайной переменной с заданной
ковариантностью.
Глава 7. Линейные фильтры
213
Данное ядро сглаживания образует такое взвешенное среднее, для которого в цен-
тре ядра весовые коэффициенты пикселей намного больше, чем на его границах.
Этот подход можно обосновать качественно: сглаживание подавляет шум, под-
держивая требование, чтобы пиксели были похожи на своих соседей. Уменьшая
весовые коэффициенты для отдаленных пикселей, можно быть уверенным, что
для них это требование будет не таким жестким. Качественный анализ приводит
к таким выводам.
• Если среднеквадратическое отклонение гауссиана очень мало (скажем, меньше,
чем один пиксель), то сглаживание даст незначительный результат, поскольку
весовые коэффициенты всех пикселей, находящихся не в центре, будут очень
малыми.
• Для большего среднеквадратического отклонения у соседних пикселей весовые
коэффициенты при применении схемы взвешенного среднего будут больше, что
в свою очередь означает, что среднее значение будет сильно стремиться к со-
гласованию с соседями — это будет хорошая оценка значения пикселя, а за счет
размывания исчезнет большая часть шума.
• Наконец, ядро с большим среднеквадратическим отклонением приведет к тому,
что вместе с шумом исчезнет и большая часть элементов изображения.
Это явление проиллюстрировано на рис. 7.3. Заметно, что гауссово сглаживание
эффективнее подавляет шум.
При наличии конкретной задачи дискретное ядро сглаживания можно получить,
построив массив 2к 4-1 х 2к 4-1, значение элемента (г, j) которого равно
Я« = 2^еХР
2о-2
Обратите внимание, что если о слишком мало, то ненулевым будет только один
элемент матрицы. Если же а велико, то к также должно быть большим, иначе не
будет учтен вклад пикселей, которые должны входить со значительными весовыми
коэффициентами.
Пример 7.3. Производная и конечная разность
Производные по изображению можно приблизительно описать с помощью еще
одной свертки. Поскольку
df = lim f(x4-€,y)-f(x,y)
дх €—0 €
214
Часть II. Первые этапы: одно изображение
Рис. 7.3. В верхней строке приведены изображения плоскости однородного серого цвета с допол-
нительным гауссовым шумом. При таком шуме к каждому значению пикселя прибавляется случай-
ная переменная с нормальным распределением и нулевым средним значением. Значения пикселей
лежат в диапазоне от нуля до единицы, так что среднеквадратическое отклонение шума в первом
столбце составляет приблизительно 1/20 от всего диапазона. В средней строке показан резуль-
тат сглаживания соответствующего изображения из верхней строки с гауссовым фильтром, где а
равно одному пикселю. Отметим раздражающую громоздкость определения; здесь есть и гауссов
шум, и гауссовы фильтры, и для них имеются свои а. Для того чтобы различать данные пара-
метры, можно использовать контекст, хотя это не всегда помогает, поскольку гауссовы фильтры
часто (и удачно) применяются для подавления гауссова шума. Это происходит потому, что шумовые
значения в каждой точке независимы, т.е. ожидаемый результат их усреднения будет средним шу-
мом. В нижней строке показан результат сглаживания соответствующего изображения из верхней
строки с гауссовым фильтром, о которого равна двум пикселям
частную производную можно оценить как симметричную конечную разность'.
dh
дх
Это равносильно свертке с ядром
О '
-1 ► -
О
О О
Н = 1 О
0 0
Обратите внимание, что это ядро можно интерпретировать как некоторый шаблон:
оно дает болыш/ю положительную реакцию на такую конфигурацию изображения,
Глава 7. Линейные фильтры
215
Рис. 7.4. В верхней строке приведены оценки производных, полученные с помощью конечных раз-
ностей. На левом рисунке показан фрагмент изображения зебры. В центре показана частная произ-
водная по у, которая сильно реагирует на горизонтальные полосы и слабо на вертикальные, а спра-
ва — частная производная по х, которая сильно реагирует на вертикальные полосы и слабо на гори-
зонтальные. В то же время конечная разность сильно реагирует на шумы. На рисунке в центре сле-
ва показан фрагмент изображения зебры; следующее изображение в этой же строке получено при
прибавлении к каждому пикселю случайного числа с нулевым средним значением и нормальным
распределением (ст = 0,03; самое темное значение на изображении равно 0, а самое светлое — 1),
а третье изображение получено при прибавлении к каждому пикселю случайного числа с нулевым
средним значением и нормальным распределением (<т = 0,09). В нижней строке показаны част-
ные производные по координате х изображения, стоящего в начале строки. Обратите внимание, как
сильно процесс дифференцирования подчеркивает шумы — изображения производных кажутся еще
более зернистыми. На изображениях производных нейтральному серому цвету приписывается ну-
левое значение, темно-серый цвет имеет отрицательное значение, а светло-серый — положительное
которая положительна с одной стороны и отрицательна с другой, и большую от-
рицательную реакцию на зеркальное отражение такого изображения.
Как показано на рис. 7.4, конечная разность дает самую неудовлетворительную
оценку производной, поскольку конечная разность сильно реагирует (т.е. дает
большое значение на выходе) на быстрые изменения, характерные для шума, так
как пиксели изображения стремятся быть похожими друг на друга. Например,
если вы купили уцененную камеру, и некоторые ее пиксели заклинены либо на
черном, либо на белом значении, то при определении конечной разности вы полу-
чите в этих пикселях большие значения, поскольку они, в общем случае, силь-
но отличаются от своих соседей. Таким образом, до дифференцирования стоит
воспользоваться каким-то видом сглаживания; подробнее этот вопрос рассмотрен
в разделах 8.1 и 8.2.
216
Часть II. Первые этапы: одно изображение
7.2. ЛИНЕЙНЫЕ СИСТЕМЫ, ИНВАРИАНТНЫЕ ОТНОСИТЕЛЬНО
СДВИГА
Свертка представляет результат действия большого класса систем. В част-
ности, большинство систем формирования изображений имеет, в достаточно
хорошем приближении, три важных свойства.
• Суперпозиция.
ад+5) = я(/)+ад.
Реакция на сумму стимуляторов — это сумма реакций на каждый стиму-
лятор.
• Масштабирование. Реакцией на нуль будет нуль. Объединив это с су-
перпозицией, получим, что реакция на масштабированный стимулятор —
это масштабированный вариант реакции на исходный стимулятор, т.е.
R(kf) = kR(f).
Устройство, обладающее свойствами суперпозиции и масштабирования,
линейно.
• Инвариантность относительно сдвига. В системах, инвариантных от-
носительно сдвига, реакция на смещенный стимулятор представляет со-
бой смещение реакции на исходный стимулятор. Это означает, что если,
например, изображение небольшого источника в центре камеры представ-
ляет собой небольшое яркое пятно, то при смещении источника на пери-
ферию будет видно то же самое небольшое пятно, только смещенное.
Линейное устройство, инвариантное относительно сдвига, называют линейной
системой, инвариантной относительно сдвига, или просто системой.
Реакцию линейной инвариантной относительно сдвига системы на стимуля-
тор можно найти с помощью свертки. Покажем, как это делается для систем
с дискретным входом (векторами или матрицами) и выходом. Затем на ос-
нове полученных результатов опишем поведение систем, которые оперируют
непрерывными функциями (прямые и плоскости), а из этого анализа узнаем
несколько полезных фактов о свертке.
7.2.1. Дискретная свертка
В одномерном случае линейная система, инвариантная относительно сдви-
га, получает на вход вектор и выдает вектор. Это самый простой случай, так
как нужно следить за небольшим количеством индексов. От него несложно пе-
рейти к двумерному случаю, когда система воспринимает матрицу и отвечает
матрицей. В каждом случае мы будем считать, что входные и выходные данные
имеют бесконечную размерность. Это позволяет пренебрегать незначительными
эффектами, которые возникают на границах входных данных (см. раздел 7.2.3).
Глава 7. Линейные фильтры
217
Дискретная свертка для одномерного случая
Дан входной вектор f. Для удобства примем, что вектор бесконечен, а
индексы его координат — целые числа (т.е. существует, скажем, элемент
с индексом —1). Координата i этого вектора — fc. Теперь f — это взвешенная
сумма базисных элементов. Удобным базисом будет набор элементов, одна из
координат которых равна единице, а остальные — нулю. Запишем
е0 = ...0,0,0,1,0,0,0,...
Это вектор данных с единицей на месте нулевой координаты и нулями на всех
остальных местах. Определим операцию сдвига, которая смещает заданный
вектор. В частности, J-й координатой вектора Shift(/, г) будет (j — г)-я коор-
дината вектора /. Например, первой координатой вектора Shift(eo, 1) будет
нуль. Теперь можно записать
f = /iShift(eo,i)-
i
Запишем реакцию системы на вектор f как
R(f)-
Из инвариантности данной системы относительно сдвига следует, что
7?(Shift(f, к)) = Shift(7?(/), к).
Более того, из ее линейности следует, что
R(kf) = kR(f),
а значит
Й(У) = R ^52 /»Sbift(eo,t)
= 7?(/iShift(eo, г)) =
i
= A^(Shift(eo,»)) =
t
= /tSbif t(/?(eo), г)).
Таким образом, чтобы найти реакцию системы на любой вектор данных, нужно
знать только ее реакцию на вектор ео- Это обычно называют импульсным
218
Часть II. Первые этапы: одно изображение
откликом системы, или ее импульсной характеристикой. Предположим, что
импульсную характеристику можно записать как д, тогда получим
R(f) - 52 Asbift(p,i) = g*f.
i
Это определение операции (одномерного дискретного варианта свертки), кото-
рая обозначена звездочкой (*).
Однако данное определение не позволяет достаточно просто описать выход.
Если рассмотреть J-й элемент R(f), который записывается как Ri, то должно
получиться выражение
Rj = 5 —
г
которое можно привести к форме, указанной в разделе 7.1.1.
Дискретная свертка для двумерного случая
Рассмотрим теперь массив значений и запишем (г, элемент матрицы D
как Dij. Подходящая аналогия для импульсного отклика — реакция на такой
стимулятор:
... О О О
£оо= ... О 1 О
... О О О
Если <7 — реакция системы на этот стимулятор, то с помощью рассуждений,
подобных приведенным для одномерного случая, можно найти отклик системы
на стимулятор Т7, т.е.
Rij —
tX,t»
что записывается следующим образом:
'R, = д * *7/.
7.2.2. Непрерывная свертка
Существуют линейные инвариантные относительно сдвига системы, кото-
рые дают непрерывный отклик на непрерывный вход; например, линза камеры
воспринимает набор лучей и выдает другой набор, причем инвариантными от-
носительно сдвига можно считать многие линзы. Кратко ознакомившись с таки-
ми системами, можно восполнить недостаток информации, возникающий из-за
приблизительного описания непрерывной функции (значений падающего излу-
чения на плоскость изображения) дискретной функцией (значением в каждом
пикселе).
Глава 7. Линейные фильтры
219
Естественным будет использовать реакцию системы на довольно необычную
функцию, так называемую (5-функцию, которая не является функцией в обыч-
ном смысле этого слова. Рассмотрим вначале одномерный случай.
Одномерный случай
Из выражения для дискретной системы найдем характеристику непрерывной
линейной системы, инвариантной относительно сдвига. Каждое значение дис-
кретного входа можно заменить прямоугольником, окружающим данное значе-
ние; это даст непрерывную функцию на выходе. Постепенно уменьшая прямо-
угольники, проанализируем, что происходит при переходе к граничному значе-
нию.
И входом, и выходом данной системы будут одномерные функции. Запи-
шем реакцию на любые входные данные f(x) как R(f); если нужно подчерк-
нуть, что f — это функция, иногда пишут /?(/(аг)). Характеристика — это
также функция (когда необходимо это подчеркнуть, пишут Кроме
того, можно сделать акцент на линейности:
R(kf) = kR(f)
(для некоторой константы к) и инвариантности относительно сдвига, введя
оператор сдвига Shift, следующим образом действующий на функции:
Shift(/, с) = f(u - с).
Воспользовавшись этим оператором сдвига, можно записать свойство инвари-
антности относительно сдвига:
7?(Shif t(/, с)) = Shift (/?(/), с).
Введем объемную функцию box, такую что
box^x) —
abs(x) > |
abs{x) < |
О
1
Значение функции Ьохс(е/2) не важно. Входная функция — это f(x). Постро-
им равномерную решетку из точек х^, где rri+i — Xi — е. Теперь построим
вектор f, i-я координата которого (обозначенная как fi)— Именно этот
вектор служит для представления функции.
Функцию f можно представить в виде ]Гг .AShift(b6.)irf,.T2). Возьмем это вы-
ражение в качестве входных данных для линейной инвариантной относительно
сдвига системы; откликом будет взвешенная сумма смещенных откликов на
объемные функции. Это означает, что
220
Часть II. Первые этапы: одно изображение
/iShift(boxe, Xi)) — 7?(/iShift(6oxe,Xi)) =
i i
= fiR(Shif t(boxe, Xi)) =
t
= y^/iShift ,Xi^ =
= У2 /«Shift ( R
i '
Итак, сказанное совпадает с рассуждениями для дискретных функций. В итоге
получено выражение, напоминающее соответствующий интеграл при е —> 0.
Рассмотрим теперь член Ьох€/е — 5-функцию. Пусть
тогда 5-функция — это
5(х) = limde(x).
Совсем не обязательно пытаться оценить эту границу, т.е. незачем знать значе-
ние 5(0). Все, что следует знать об этой функции (что необходимо для линей-
ных инвариантных относительно сдвига систем) — это то, что реакция системы
на 5-функцию существует и является компактным носителем (т.е. равна нулю
везде, кроме конечного числа интервалов конечной длины). Хороший пример 5-
функции в двумерном пространстве — это очень маленький и очень яркий
источник света. Если делать этот источник меньше и ярче до тех пор, пока
полная энергия не станет равна константе, то в конце концов можно получить
очень (но не бесконечно) малое пятно, обусловленное расфокусировкой линзы.
Отметим, что 5-функция — это аналог вектора во для непрерывного случая.
Сказанное означает, что выражение для отклика системы
У2 /«Shift (R
i '
при e —» 0 превращается в интеграл. Получаем
R(f) = [ {R(6)(u - х')} /(х') dx'
д(и — x'j/fx') dx',
причем R(6) (которое обычно называют импульсной характеристикой систе-
мы) записано как д и опущены границы интегрирования. Эти интегралы можно
Глава 7. Линейные фильтры
221
брать от —оо до оо, но если д и h — компактные носители, то область интегри-
рования может быть более строгой. Эта операция также называется сверткой,
и предыдущее выражение можно переписать как
Свертка симметрична, т.е.
(ff *7i)(x) = (h*g)(x).
Свертка подчиняется ассоциативному закону:
(/* (g*h)) = ((/ *g)*h).
Последнее свойство означает, что можно найти одну линейную инвариантную
относительно сдвига систему, которая будет вести себя как комбинация двух
различных систем. Далее это пригодится при изучении шаблонов.
Свертка для двумерного случая
Для выполнения операции свертки в двумерном случае понадобится еще
несколько новых понятий. Объемная функция теперь задается как boxt?(x, у) =
Ьохе(х)Ьохе(уУ, и получаем
. boxtz(x,y)
de(x,y) = --
причем ^-функция — это граница функции d€(x, у) при е —> 0. И наконец, сумма
состоит из большего числа слагаемых. Окончательно получаем выражение
R(h)(x,y) = У У g(x-x\y-y')h(x',y‘)dxdy
= (д* *h)(x,y),
в котором двумя звездочками обозначена свертка в двумерном пространстве.
Свертка в двумерном пространстве также симметрична, т.е.
(д * *h) — (Л * *д)
и ассоциативна:
((/ * *9) ♦ *Л) = (/ * *(д * *h)).
Естественной моделью импульсного отклика для двумерной системы будет
изображение, которое дает камера, наблюдающая очень маленький удаленный
источник света (образующий очень малый телесный угол). Для реальных линз
это изображение представляет собой нечеткое пятно (откуда следует второе
222
Часть II. Первые этапы: одно изображение
название импульсной реакции двумерной системы — функция точечного рас-
сеяния). Функцию точечного рассеяния линейной системы называют ее ядром.
7.2.3. Краевые эффекты при дискретной свертке
В реальных системах нет бесконечных массивов данных. Это означает, что
при вычислении свертки нужно считаться с краями изображений; на краях есть
пиксели, для вычисления свертки которых нужны значения, в действительности
не существующие. В таких случаях можно поступить следующим образом.
• Пренебречь этими пикселями — учитываются только те пиксели, для
которых известны все необходимые значения. Преимущество этого подхо-
да — строгость вычислений, но существуют и недостатки: выход получа-
ется меньше, чем вход. Повторная свертка может привести к достаточно
сильному сокращению размеров изображения.
• Дополнить изображение постоянными значениями — если рассматри-
вать выход ближе к краю изображения, то степень того, насколько ре-
зультат свертки зависит от изображения, снижается. Это очень удобно,
поскольку изображение не сокращается, но и здесь есть свои недостат-
ки — вблизи границы изображения могут возникать большие градиенты.
• Дополнить изображение каким-то другим способом — например, мож-
но считать изображение двойной периодичной функцией, так что если
имеется изображение п х т, то (т + 1)-й столбец, необходимый для вы-
полнения операции свертки, будет таким же, как и (т — 1)-й. Это может
привести к появлению вблизи границы больших значений второй произ-
водной1.
7.3. ПРОСТРАНСТВЕННАЯ ЧАСТОТА И ПРЕОБРАЗОВАНИЕ ФУРЬЕ
В предыдущем разделе сигнал д(х, у) рассматривался как взвешенная сумма
большого (или бесконечного) числа малых (или бесконечно малых) объемных
функций. В этой модели делается акцент на том, что сигнал — это элемент век-
торного пространства; объемные функции образуют удобный базис, а весовые
коэффициенты выступают координатами в этом базисе. Теперь же требуется но-
вый метод для решения двух взаимосвязанных задач (до сих пор нерешенных).
• Хотя ясно, что дискретный вариант изображения не несет полной инфор-
мации о сигнале, еще не определено, что именно теряется.
• Сокращать изображение простым выбором каждого к-го пикселя нель-
зя (при этом изображение шахматной доски может оказаться полностью
’ В зависимости от того, где взяты оси симметрии, можно задать (т + 1)-й столбец равным
m-му; (т + 2)-й — равным (т — 1)-му, уменьшив, таким образом, вторую производную. — Прим,
рецензента.
Глава 7. Линейные фильтры
223
белым или черным). В этой связи хотелось бы знать, как правильно со-
кратить изображение.
Во всех этих задачах особое внимание следует обращать на резкие переходы
на изображении. Например, при сокращении изображения эти резкие пере-
ходы, вероятнее всего, будут упущены, кроме того, при резких изменениях
производные будут иметь большие значения.
Исследовать эти явления можно с помощью смены базиса. Перейдем в базис
набора синусоид и представим сигнал в виде бесконечной взвешенной суммы
бесконечного числа синусоид. Это означает, что резкие переходы в сигнале
будут явными, поскольку они соответствуют большому количеству высокоча-
стотных синусоид в новом базисе.
7 .3.1. Преобразование Фурье
Смена базиса описывается преобразованием Фурье. Это такое преобразова-
ние сигнала д(х, у), при котором
F(g(x, у))(и, v) = J J р(х, J/)e-2’ri(ui+t'*) dx dy.
Допустим, что выполнены все условия существования данного интеграла. Для
этого достаточно, чтобы все моменты д были конечными; перечень остальных
возможных условий можно найти в работе [Bracewell, 1995]. Берется комплекс-
ная функция от х, у и на выходе получается комплексная функция от и, v (изоб-
ражения — это комплексные функции, мнимая часть которых равна нулю).
Зафиксируем и и v, а затем рассмотрим преобразование в этой точке. Пред-
ставленную выше экспоненту можно переписать в виде
е2’r*(UI+’J»> = cos(27r(wr + vy)) -I- г sin(27r(ux + vy)).
Получаем синусоиды на плоскости х, у, ориентация и частота которых задает-
ся с помощью и, V. Рассмотрим, например, член, постоянный при фиксирован-
ном значении их + vy (т.е. рассматриваем прямую линию на плоскости х, у,
ориентация которой задается выражением tg# = v/u). Градиент этого члена
перпендикулярен к прямым, для которых их + vy постоянно, а частота сину-
соиды равна х/и2 г>2. Эти синусоиды часто называют пространственными
гармониками-, их разнообразие проиллюстрировано на рис. 7.5.
Данный интеграл можно рассматривать как скалярное произведение. При
фиксированных значениях и и v он равен скалярному произведению исходной
функции на синусоиду по координатам х и у. Такое сравнение очень выгодно,
поскольку скалярное произведение дает проекцию одного вектора на другой.
По аналогии, преобразование для конкретных и и v можно считать измере-
нием количества синусоид с заданной частотой и ориентацией сигнала. Функ-
ция от х и у преобразуется в функцию от и и v, значение которой в отдельной
224
Часть II. Первые этапы: одно изображение
Рис. 7.5. Действительная часть элементов базиса Фурье. Значение самой яркой точки равно еди-
нице, а самой темной — нулю. Рассматриваемая область — участок размером [—1,1] х [—1,1]
с началом отсчета в центре изображения. Слева (и, и) = (0;0,4); в центре (и, и) = (1;2), а спра-
ва (и,и) = (10,—5). Изображены синусоиды с различными частотами и ориентацией (объяснение
см. в тексте)
точке (u,v) — это количество определенных синусоид в исходной функции.
Таким образом, преобразование Фурье действительно можно представлять как
смену базиса.
Линейность
Преобразования Фурье линейны:
у) 4- h(x, у)) = F(g(x, у)) 4- !F(h(x, у))
и
= к?(д(х,у}).
Обратное преобразование Фурье
Иногда приходится восстанавливать сигнал по его Фурье-образу. Это другая
смена базиса вида
g(x,v)= JJ
— ОС
Фурье-пары
Преобразования Фурье в неявном виде применяются во многих ситуациях;
множество примеров вы найдете в книге [Bracewell, 1995], некоторые из них
приведены в табл. 7.1. В последней строке этой таблицы записана теорема о
свертке-, свертка сигнала — это то же, что и умножение в Фурье-пространстве
(пространстве Фурье-образов). На эту теорему мы будем ссылаться в разде-
ле 9.2.2.
Глава 7. Линейные фильтры
225
ТАБЛИЦА 7.1. Примеры двумерных функций и их Фурье-образов. Таблица может использоваться
в обоих направлениях (после подстановки вместо u, v и ®, у соответствующих функций), поскольку
применение преобразования Фурье к Фурье-образу дает исходную функцию. Наблюдательные чи-
татели могут заметить, что в результате бесконечного суммирования 6-функций якобы нарушается
линейность преобразования Фурье. Аккуратно проделав все вычисления (и обратив особое внима-
ние на пределы), можно убедиться, что это не так (см., например, [Bracewell, 1995]). Также можно
отметить, что выражение для можно получить из двух других строк таблицы
Функция Фурье-образ
д(х,у) /7 s(x,»)e-a'<’“+”«> dxdy —oo
И ^F(g(x,y))(utv)ei2ir{ux+vv'ldudv —оо F(g(x, y))(u, v)
<5(а?,у) 1
v)
0,56(х 4- а, у) 4- 0.56(х — а, у) COS 27FOU
е-»г(х2+у2) e-»r(u2+t)2)
box\(xt у) sin и sin v U V
f(ax,by) T{f){u/a,v/b) ab
И п-8 । 8 И । 8 On 1 е». «С 1 N Г8 i 8 N II 8 i 8 On 'e' 1 e 1
(f**g)(xty)
f(x - а, у - Ь) e~i2w(au+bv)
/(xcos0 — j/sin0,2?sin0 4- ycos0) cosO - vsin 0, usin0 4- v cos0)
Фаза и амплитуда
Преобразование Фурье состоит из действительной и мнимой части:
F(g(x,y))(u,v) = J J д(х, у) cos(2tt(u3; + vy)) dx dy+
4-г J J g(x,y)sin(2n(ux + vy))dxdy =
= ^(р)) + г*9(Др)) =
= ?ц(д) 4- г * J7(p).
Комплексные функции неудобно изображать на плоскости. Один из выходов —
изображать отдельно и 7v(p); другой способ — ввести понятия ампли-
туды и фазы комплексной функции и изображать именно эти величины. То-
226
Часть II. Первые этапы: одно изображение
Рис. 7.6. На втором изображении в каждой строке показан логарифм амплитудного спектра пер-
вого изображения этой строки; на третьем изображении показан фазовый спектр, причем фаза —я-
обозначена темным, а я- — светлым. Последние изображения были получены путем дополнитель-
ного учета информации с амплитудного спектра. Возникающие при этом значительные шумы не
сильно влияют на интерпретацию изображения в предположении, что фазовый спектр более важен
при восприятии, чем амплитудный
гда представление будет называться соответственно амплитудным и фазовым
спектрами.
Значение Фурье-образа функции в отдельной точке (и, v) зависит от функ-
ции в целом, что непосредственно вытекает из определения, поскольку область
интегрирования представляет собой всю область значений функции. Получаем
несколько коварных нюансов. Во-первых, локальные изменения в функции (на-
пример, обнуление блока точек) может привести к изменениям Фурье-образа во
всех точках. Это значит, что Фурье-образом нельзя пользоваться в качестве
представления (например, по Фурье-образу очень сложно определить, соответ-
ствует ли изображение какому-то шаблону). Во-вторых, амплитудные спектры
изображений похожи друг на друга2, т.е. амплитудный спектр изображения
оказывается на удивление неинформативным (см., например, рис. 7.6).
7.4. ДИСКРЕТИЗАЦИЯ И НАЛОЖЕНИЕ
Преобразования Фурье рассматриваются главным образом для того, чтобы
почувствовать разницу между дискретными и непрерывными изображениями.
К примеру, в ходе работы с дискретным набором пикселей часть информа-
ции теряется, но какая именно? Хороший, простой пример можно получить из
2Это простое следствие того факта, что в изображениях естественного происхождения основ-
ную энергию несут низкие пространственные гармоники, а основную информацию — высокие. —
Прим, рецензента.
Глава 7. Линейные фильтры
227
изображения шахматной доски (рис. 7.7) — это задача изучения количества
выбранных точек по отношению к функции; имея достаточно мощную модель,
этот эффект можно довольно точно описать формально.
7.4.1. Дискретизация
Переход от непрерывной функции (например, плотности потока излуче-
ния на задней стенке камеры) к дискретному набору значений (значения
пикселей, которые сообщает камера) называется дискретизацией. Построим
модель, позволяющую получить точное представление о том, что теряется при
дискретизации.
Одномерная дискретизация
При одномерной дискретизации берется функция и выдается дискретный на-
бор значений. Один из примеров — выборка по однородной дискретной решетке,
причем считается, что данная выборка проводится по точкам с целыми значе-
ниями. Это процесс, входом которого служит какая-то функция, а выходом —
вектор значений:
sample1D(/(x)) = f.
Опишем процесс дискретизации в предположении, что компоненты данного
вектора — это значения функции f(x) в выбранных точках. Допустим, что
индексы вектора могут быть отрицательными (рис. 7.8). Это означает, что г-я
координата вектора f — это
Двумерная дискретизация
Двумерная дискретизация очень похожа на одномерную. Несмотря на то,
что дискретизация может происходить на неправильной решетке (наилучший
пример — это сетчатка человеческого глаза), будем считать, что выбираются
точки с целыми координатами. В результате получим однородную правильную
решетку, которая служит хорошей моделью большинства камер. После про-
ведения выборки, изображения становятся правильными массивами конечного
размера (все значения за пределами решетки равны нулю).
Формально, вместо одномерной дискретизуется двумерная функция, в ре-
зультате чего получаем массив данных (рис. 7.9). Допустим, что в этом мас-
сиве могут быть отрицательные индексы по обеим координатам. Тогда можно
записать
sample2D(F(z, у)) = F,
где (г, j)-fi элемент матрицы Т — это Р(тг,у7) = F(i,j).
В реальных системах выбранные точки не всегда равномерно распределены
в пространстве. Часто это вызвано растущим влиянием телевидения: отношение
ширины телеэкрана к его высоте обычно равно 4:3. Достаточно часто камеры
приспосабливаются к таким размерам путем выбора точек на немного большем
228
Часть II. Первые этапы: одно изображение
Рис. 7.7. Две верхние шахматные доски — пример удачной процедуры дискретизации (успех за-
висит от деталей, о которых будет сказано немного позже). Серыми кружками показана выборка;
если выборка удачна, то выбранные пиксели передают особенности исходной функции. Внизу пока-
заны определенно неудачные выборки — берется меньше пикселей, чем нужно в действительности.
Иллюстрируются два важных явления: во-первых, удачные схемы дискретизации приводят к то-
му, что информация берется с достаточной частотой; во-вторых, неудачные схемы дискретизации
приводят к преобразованию высокочастотной информации в низкочастотную
Рис. 7.8. При одномерной дискретизации берется функция, а выдается вектор, компоненты кото-
рого представляют значения этой функции в выбранных точках. Для данного примера достаточно,
чтобы выбранные точки были целыми значениями аргумента. Допускается, что вектор может быть
бесконечным и иметь как положительные, так и отрицательные индексы
Глава 7. Линейные фильтры
229
Рис. 7.9. При двумерной дискретизации берется функция, а выдается матрица. Как и прежде,
допускается, что эта матрица может быть бесконечной и иметь как положительные, так и отрица-
тельные индексы
расстоянии друг от друга по горизонтали, чем по вертикали (на жаргоне это
называется неквадратными пикселями).
Непрерывная модель дискретного сигнала
Требуется непрерывная модель дискретного сигнала. Как правило, этой мо-
делью пользуются при оценке интегралов. Преобразование Фурье, в частности,
включает интегрирование произведения данной модели с комплексной экспо-
нентой. Не вызывает сомнений, что значение интеграла следует искать путем
сложения значений в каждой целой точке. Это значит, что нельзя описывать
дискретный сигнал как функцию, которая равна нулю везде, кроме целых точек
(где она приобретает значение сигнала), поскольку при таком подходе интеграл
будет равен нулю.
230
Часть II. Первые этапы: одно изображение
Подходящая непрерывная модель дискретного сигнала основана на одном из
свойств 5-функции:
Zoo /*оо
а5(х)/(х) dx = a lim / d(x-t е)/(х) dx =
-oo e—оо
= a lim f dx =
e~J—oo £
= a lim 52 bar(x,e) _
i=—oo
= af (0).
Здесь использован тот факт, что интеграл — это граница суммы по маленьким
участкам.
Подходящая непрерывная модель дискретного сигнала состоит из 5-функции
в каждой целой точке с коэффициентом, соответствующим значению в этой точ-
ке. Данную модель можно получить, умножив дискретный сигнал на набор 5-
функций, по одной на каждую выбранную точку. В одномерном случае такая
функция называется гребенчатой функцией (потому что ее график похож на
гребень). Подобным образом в двумерном случае такую функцию называют
щеточной функцией.
Работая в двумерном пространстве и считая, что выбираются целые точки,
получаем
ОО оо
sample2D(/) = 52 =
i= — оо j=—оо
{оо оо
52 52 s(x ~ у ~ •
i=—ooj=—оо )
Данная функция равна нулю везде, кроме целых точек (поскольку 5-функция
равна нулю везде, кроме целых точек), а ее интеграл — это сумма значений
функции в этих целых точках.
7.4.2. Наложение
При дискретизации часть информации теряется. Как показано в данном раз-
деле, слишком медленная дискретизация приводит к неправильной передаче
сигнала; элементы исходного сигнала с высокой пространственной частотой
в дискретном сигнале превращаются в элементы с низкой пространственной
частотой. Это явление называют наложением.
Фурье-образ дискретного сигнала
Дискретный сигнал задается как произведение исходного сигнала на щеточ-
ную функцию. Из теоремы о свертке следует, что Фурье-образ этого произве-
дения представляет собой свертку Фурье-образов двух функций. Это значит,
Глава 7. Линейные фильтры
231
Выборка
сигнал Фурье
Амплитудный
спектр
Рис. 7.10. Фурье-образ дискретного сигнала состоит из суммы элементов Фурье-образов исходного
сигнала, смещенных относительно друг друга на частоту дискретизации. Возможны два варианта.
Если смещенные элементы не пересекаются (как в данном случае), то исходный сигнал можно вос-
становить по дискретному (просто выделяется один элемент Фурье-образа и выполняется обратное
преобразование). Если же они пересекаются (как на рис. 7 11), то области пересечения складыва-
ются, поэтому нельзя выделить отдельный элемент Фурье-образа, и сигналы накладываются
что Фурье-образ дискретного сигнала можно найти с помощью свертки Фурье-
образа сигнала с другой щеточной функцией.
При свертке функции со смещенной 5-функцией получается просто смещен-
ная функция (см. раздел упражнений). Это значит, что Фурье-образ дискретно-
го сигнала представляет собой сумму смещенных Фурье-образов сигнала, т.е.
-^(sample2D(/(x,i/))) =5’ I f(x,y) J ^2 12 6(Х~^У~
-г,у-
232
Часть II. Первые этапы: одно изображение
Преобразование
Фурье
Амплитудный
спектр
Выборка
Копирование-смещение
Дискретный Преобразование
сигнал Фурье
Амплитудный
спектр
После пропускания
через полосовой фильтр
вырезается фрагмент
Неточно Обратное
восстановленный преобразование
Амплитудный
спектр
Рис. 7.11. Фурье-образ дискретного сигнала состоит из суммы элементов Фурье-образов исходного
сигнала, смещенных относительно друг друга на частоту дискретизации. Возможны два варианта.
Если смещенные элементы не пересекаются (как на рис. 7.10), то исходный сигнал можно восста-
новить по дискретному (просто выделяется один элемент Фурье-образа и выполняется обратное
преобразование). Если же они пересекаются (как в данном случае), то области пересечения скла-
дываются, поэтому нельзя выделить отдельный элемент Фурье-образа, и сигналы накладываются
ОС
= 52
г= —оо
где Фурье-образ функции f(x, у) записывается как F(u,v).
Если носители этих смещенных Фурье-образов сигнала не пересекаются,
то можно без труда восстановить сигнал по его дискретному варианту. Берет-
ся дискретный сигнал, находится его Фурье-образ, из этого преобразования
выделяется один элемент и снова находится его Фурье-образ (рис. 7.10)
Однако если области носителей перекрываются, сигнал восстановить невоз-
можно, поскольку невозможно определить Фурье-образ сигнала в области пе-
рекрывания, где разные элементы Фурье-образов складываются друг с другом.
Это выражается в характерном явлении, которое часто называют наложением,
когда высокие пространственные частоты становятся низкими (см. рис. 7.12, а
Глава 7. Линейные фильтры
233
256 х 256
128 х 128
64x64
32 х 32
16 х 16
Рис. 7.12. В верхней строке показаны дискретные варианты изображения решетки, полученные
перемножением двух синусоид с линейно возрастающей частотой — одна по координате х, а
другая — по у. Остальные изображения в серии получены с помощью повторной дискретизации при
уменьшении в два раза, без сглаживания (т.е. размер следующего изображения будет 128 х 128,
затем — 64 х 64, и т.д.; на рисунке все изображения приведены к одинаковому размеру). Обратите
внимание на значительное наложение; высокие пространственные частоты накладываются на низ-
кие, и самое маленькое изображение — это чрезвычайно отдаленное подобие большого. В нижней
строке показана амплитуда Фурье-образа каждого изображения, которая для сокращения шкалы
интенсивности представлена в виде логарифма. В центре находится неизменный элемент. Обратите
внимание, что Фурье-образ изображения, подвергшегося повторной дискретизации, можно полу-
чить путем масштабирования Фурье-образа исходного изображения с последующим клеточным
разбиением. Интерференция между элементами исходного Фурье-образа приводит к тому, что вос-
становить значения в некоторых точках невозможно — это основоположный механизм наложения
также раздел упражнений). Такие рассуждения приводят к теореме Найкви-
ста: чтобы по дискретной версии можно было восстановить исходный сигнал,
частота дискретизации должна быть не менее чем в два раза больше, чем самая
высокая частота сигнала.
7.4.3. Сглаживание и повторная дискретизация
Из теоремы Найквиста следует, что сокращать изображение путем простой
выборки каждого /г-го пикселя опасно (что подтверждается на рис. 7.12). Вместо
этого следует фильтровать изображение таким образом, чтобы устранить про-
странственные частоты, превышающие новую частоту дискретизации. Это мож-
но сделать точно, умножив Фурье-образ изображения на двумерную полосовую
функцию, которая выполняет роль низкочастотного фильтра. Эквивалентным
действием была бы свертка изображения с ядром вида (sinxsiny)/(xy). Но это
слишком сложно и дорого (а точнее невозможно), поскольку носитель этой
функции бесконечен.
Самый интересный случай — это когда требуется уменьшить ширину и вы-
соту изображения в два раза. Предположим, что в дискретном изображении
234
Часть II. Первые этапы: одно изображение
256 х 256
128 х 128
64x64
32x32
16 х 16
Рис. 7.13. Вверху: варианты изображения рис. 7.12, подвергшегося повторной дискретизации,
при уменьшении частоты в два раза, но теперь каждое изображение до повторной дискретизации
сглаживалось гауссианом с а в один пиксель. Этот фильтр низкочастотный, т.е. он подавляет
элементы с высокой пространственной частотой, уменьшая наложение. Внизу: действие низ-
кочастотного фильтра легко понять по изображениям логарифма амплитуды: чтобы снизить
наложение, низкочастотный фильтр подавляет элементы с высокой пространственной частотой,
так что интерференция уменьшается
нет наложения (если бы оно было, мы ничего не смогли бы с ним сделать;
если изображение подверглось дискретизации, то все возможное наложение
уже произошло, и без модели изображения можно сделать очень немного). Это
означает, что Фурье-образ дискретного изображения будет состоять из набо-
ра элементов определенных Фурье-образов, центры которых смещены в целые
точки пространства и, v.
Если подвергнуть данный сигнал повторной дискретизации, то центры этих
элементов попадут в полуцелые точки пространства и, v. Это означает, что
во избежание наложения следует воспользоваться фильтром, который значи-
тельно уменьшает содержание исходного Фурье-образа за пределами обла-
сти |п| < 1/2, |г>| < 1/2. Конечно, если уменьшить содержание сигнала внутри
этой области, можно также потерять часть информации. Фурье-образ гауссиа-
на — это гауссиан, а гауссиан очень быстро спадает до нуля. Следовательно,
желаемого результата можно достичь, если свернуть изображение с гауссианом
(или, что то же самое, умножить его Фурье-образ на гауссиан).
Выбор гауссиана зависит от области применения: если <т большое, то нало-
жение будет меньше (поскольку значение ядра за пределами данной области
очень мало), но информация будет теряться из-за того, что ядро в данной об-
ласти не плоское; подобным образом, если <т мало, то внутри области будет те-
ряться меньше информации, однако наложение будет значительнее. На рис. 7.13
и 7.14 показаны результаты различного выбора а.
Глава 7. Линейные фильтры
235
256 х 256
128 х 128
64x64
32 х 32
16 х 16
Рис. 7.14. Вверху: варианты изображения рис. 7.12, подвергшегося повторной дискретизации, при
уменьшении частоты в два раза, причем каждое изображение до повторной дискретизации сглажи-
валось гауссианом с а в два пикселя. Этот фильтр подавляет компоненты с высокой пространствен-
ной частотой сильнее, чем на рис. 7.13. Внизу: действие низкочастотного фильтра легко понять по
изображениям логарифма амплитуды: чтобы снизить наложение, низкочастотный фильтр подавляет
элементы с высокой пространственной частотой, так что интерференция уменьшается
Выше в качестве низкочастотного фильтра использовался гауссиан, посколь-
ку его реакция на высокие пространственные частоты низкая, а на низкие
пространственные частоты — высокая. На самом деле гауссиан не особенно
хорош в роли низкочастотного фильтра. Здесь нужен фильтр, реакция кото-
рого в определенном диапазоне низких пространственных частот достаточно
близка к постоянной (полоса пропускания), а для высоких пространственных
частот также достаточно близка к околонулевой постоянной (полоса задержки).
Можно создать низкочастотный фильтр, который будет значительно эффектив-
нее гауссиана. Разработка включает в себя хорошо продуманный выбор между
критериями волнистости (насколько плоской будет реакция полосы пропуска-
ния и полосы задержки?) и спада (как быстро реакция снижается до нуля
и как долго остается такой?). Основные этапы повторной дискретизации сведе-
ны в алгоритме 7.1.
Алгоритм 7.1. Повторная дискретизация при уменьшении изображения в два раза
Применить к исходному изображению низкочастотный фильтр (как правило,
здесь подходит гауссиан с ст от одного до двух пикселей)
Создать новое изображение, размеры которого будут в два раза меньше
предыдущего
Присвоить значение (i, j)-ro пикселя нового изображения (2г, 2J)-My пикселю
отфильтрованного изображения
236
Часть II. Первые этапы: одно изображение
7.5. ФИЛЬТРЫ КАК ШАБЛОНЫ
Оказывается, что фильтры представляют собой естественный механизм по-
иска простых шаблонов, поскольку сильнее всего фильтры реагируют на эле-
менты, похожие на сам фильтр. Например, фильтры сглаживания производных
склонны давать сильную реакцию в точках, где производная велика. В этих точ-
ках ядро фильтра похоже на тот объект, который фильтр должен определить.
Фильтры производных по координате х представляют собой вертикальное пят-
но света, следующее за темным пятном (конфигурация, для которой характерна
большая производная по х), и т.д.
Очень часто фильтры, которые склонны сильно реагировать на шаблоны,
сами выглядят как шаблоны (рис. 7.15). Это простое геометрическое следствие.
7.5.1. Свертка как скалярное произведение
В разделе 7.1.1 было сказано, что для ядра Q некоторого линейного фильтра
реакция этого фильтра на изображение 7Y записывается как
Rij = Gi—u,j—vHuv-
u,v
Теперь рассмотрим реакцию фильтра в точке, где i и j равны нулю, а именно
R = Y^g-u,-vHu,v.
11, V
Эту реакцию можно найти, соотнеся элементы изображения с элементами
ядра, перемножив соотнесенные элементы и просуммировав их. Можно пре-
образовать изображение в вектор, а ядро фильтра — в другой вектор таким
образом, что соответствующие элементы будут приходиться на одни и те же
компоненты. Подставляя в нужные места нули, можно убедиться, что раз-
мерность этих двух векторов одинакова. После этого процесс перемножения
соответствующих элементов и их суммирование превращается в вычисление
скалярного произведения.
Это достаточно точная аналогия, поскольку скалярное произведение стано-
вится максимальным, когда вектор, представляющий изображение, параллелен
вектору, представляющему ядро фильтра. Это значит, что сильнее всего фильтр
реагирует, когда встречает модель изображения, напоминающую сам фильтр.
Кроме того, реакция фильтра будет сильнее в более яркой области.
Теперь рассмотрим реакцию изображения на фильтр в другой точке. Суще-
ственно модель не изменится. Как и прежде, можно преобразовать изображение
в один вектор, а ядро фильтра — в другой, чтобы соответствующие элемен-
ты приходились на одни и те же компоненты. Результатом применения этого
фильтра будет скалярное произведение. Ниже описаны два основных подхода
к работе со скалярным произведением.
Глава 7. Линейные фильтры
237
Рис. 7.15. Ядро фильтра выглядит так же, как и элемент, который он определяет. Слева показан
гауссов фильтр сглаживания производных, который фиксирует большие изменения по координате х
(темное пятно, следующее непосредственно за светлым); справа — гауссов фильтр сглаживания
производных, который фиксирует большие изменения по координате у
7.5.2. Смена базиса
Свертку можно представлять как скалярное произведение изображения
и различных векторов в каждой точке (поскольку ядро фильтра сдвинуто
в какую-то другую точку изображения). Новый вектор можно найти, преоб-
разовав старый таким образом, чтобы можно было найти сумму элементов,
попадающих в нужные компоненты. Это означает, что при свертке изображе-
ния с фильтром результат представляется в новом базисе векторного простран-
ства изображений — базисе, заданном различными смещенными вариантами
фильтра. Исходными базисными элементами были векторы с нулями во всех
положениях, кроме одного. Новые базисные элементы — это смещенные копии
одного образца.
Для многих из упоминавшихся здесь ядер описанный процесс связан с по-
терей информации — по той же причине, что и снижение шума при сглажи-
вании — так что коэффициенты в этом базисе избыточны. Несмотря на то,
что коэффициенты могут быть избыточными, они служат полезным описани-
ем структуры изображения. Такие преобразования базиса ценны при анализе
текстуры. Как правило, выбирается базис, состоящий из мелких полезных эле-
ментов модели. Большие значения коэффициентов базиса предполагают, что
компоненты модели существуют, и текстуру можно передать, представив связь
между этими компонентами, как правило, в форме вероятностной модели.
7.6. МЕТОД: НОРМИРОВАННАЯ КОРРЕЛЯЦИЯ И ПОИСК МОДЕЛИ
Свертку можно представлять как сравнение фильтра с участком изображе-
ния с центром в точке, реакцию которой мы рассматриваем. При таком подходе
окружение изображения, соответствующее ядру фильтра, преобразуется в век-
238
Часть II. Первые этапы: одно изображение
тор, который и сравнивается с ядром. Само по себе это скалярное произведение
плохо помогает находить элементы, поскольку какое-то значение может быть
большим просто потому, что соответствует яркому участку изображения. Про-
водя аналогию с векторами, нужно знать косинус угла между вектором фильтра
и вектором окружения изображения; это подразумевает вычисление квадратно-
го корня из суммы квадратов значений соответствующей области изображения
(элементов изображения, которые попадали бы под ядро фильтра) и деление
результата на полученную величину.
Если область изображения выглядит как ядро фильтра, то эта величина
будет большой и положительной, а если область изображения выглядит как
изображение, обратное по контрастности к ядру фильтра, — маленькой и отри-
цательной. Если обратная по контрастности картинка не важна, корень квад-
ратный можно не брать. Это недорогой, но эффективный метод поиска модели,
который часто называют нормированной корреляцией.
7.6.1. Управление телевизором: нахождение руки с помощью
нормированной корреляции
Возможно создать системы, которые реагировали бы на человеческие же-
сты. Например, можно было бы включать свет в комнате одним взмахом ру-
ки или изменять температуру в помещении, указав пальцем на кондиционер,
а каким-то другим соответствующим жестом переключить телевизор на дру-
гую программу, если вас раздражает выступающий там политик. Как правило,
в потребительских приложениях существуют строгие ограничения на объем
возможных вычислений, т.е. важно, чтобы система распознавания жестов была
простой. Однако такие системы, как правило, достаточно ограничены в своих
возможностях.
Управление телевизором
Как правило, пользовательский интерфейс находится в определенном со-
стоянии (возможно, на дисплей выведено меню) и когда происходит какое-то
событие (возможно, нажатие клавиши удаленного управления), состояние ин-
терфейса изменяется (скажем, высвечивается новая позиция меню), а в целом
процесс продолжается. В некоторых состояниях определенные события застав-
ляют систему выполнять определенные действия (можно переключить канал).
Все это означает, что смена состояний — это удобная основа для создания
пользовательского интерфейса.
Зрение можно включить в эту схему только одним способом — возможно-
стью предвидеть события. Это неплохо, поскольку существует только несколько
различных видов событий, причем известно, какие события должны касаться
системы в любом отдельно взятом состоянии. Итак, системе нужно только
уметь определять, произошло событие (одно из небольшого числа известных)
или нет. Возможность создания системы, соответствующей таким требованиям,
достаточно реальна.
Глава 7. Линейные фильтры
239
Для имитации удаленного управления необходим относительно небольшой
набор событий: нужны события, похожие на нажатие кнопки (например, для
включения или выключения телевизора) и на поворот переключателя (напри-
мер, для увеличения громкости, но и это можно сделать с помощью кнопки).
Совершая предопределенные действия, можно включить телевизор и управлять
меню на экране.
Поиск руки
В работе [Freeman, Anderson et al., 1998] разработан интерфейс, в котором
телевизор включатся разжатием ладони. Это выполнимо, поскольку все, что
требуется от системы, — это определить, есть ли рука в поле зрения. Более
того, пользователь будет взаимодействовать с ней путем поднятия и раскрытия
ладони. Поскольку пользователь, скорее всего, будет находиться на прибли-
зительно постоянном расстоянии от камеры (т.е. можно считать, что размер
ладони приблизительно известен, поэтому нет необходимости искать шкалу ве-
личины) перед телевизором, то область, где можно искать раскрытую ладонь,
относительно невелика.
Поднятая рука имеет достаточно стандартную форму и ориентацию и, как
правило, находится на одном и том же расстоянии от телевизора, так что из-
вестно, как это должно выглядеть. Это означает, что для поиска руки можно
успешно пользоваться оценкой нормированной корреляции. Любые точки кор-
реляционного изображения, в которых эта оценка достаточно высока, соответ-
ствуют руке. Данный метод можно применять для контроля громкости и т.п.,
а также для включения или выключения телевизора. Следовательно, нужно
иметь представление о том, куда движется рука (при движении в одну сторону
громкость увеличивается, а при движении в другую — уменьшается), а этого
можно достичь сравнением настоящего положения объекта с предыдущим. Си-
стема показывает значок, говорящий о ее интерпретации положения руки, так
что у пользователя есть некое подобие обратной связи с системой (рис. 7.16).
Заметим, что привлекательная черта такого подхода — это способность к само-
настройке: когда вы ставите телевизор, вы садитесь перед ним и несколько раз
показываете свою руку, чтобы дать системе возможность оценить расстояние,
на котором она появляется.
7.7. МЕТОД: МАСШТАБ И ПИРАМИДЫ ИЗОБРАЖЕНИЙ
При различном масштабе изображения выглядят абсолютно по-разному. На-
пример, морду зебры на рис. 7.17 можно изобразить в виде отдельных волосков
(которые можно закодировать с помощью реакции ориентированных фильтров,
масштаб работы которых — несколько пикселей) или в виде полос зебры. В слу-
чае с зеброй не хотелось бы пользоваться большими фильтрами для определе-
ния полос, поскольку эти фильтры склонны к излишней точности — совсем
не обязательно знать о расположении каждого волоска в полоске. Кроме того,
большие фильтры неудобно создавать и они работают очень медленно. Более
240
Часть II. Первые этапы: одно изображение
Рис. 7.16. Примеры системы управления телевизором Фримана. Слева показано, что “видит” те-
левизор при каждом состоянии, а справа — что видит пользователь: а) телевизор выключен, но
происходит процесс наблюдения за пользователем; б) раскрытая ладонь заставляет телевизор вклю-
читься и показать пользователю панель интерфейса; в) значок на панели перемещается вслед за
открытой ладонью пользователя; г) пользуясь этим, можно переключать каналы, перемещая изоб-
ражение по экрану; д) пользователь показывает закрытую ладонь, чтобы выключить телевизор.
Перепечатано из W. Freeman et al., “Computer Vision for Interactive Computer Graphics", IEEE
Compuer Graphics and Applications, 1998. © 1998 IEEE
практичный подход — применять маленькие фильтры к сглаженным и прошед-
шим повторную дискретизацию изображениям.
7.7.1. Гауссова пирамида
Пирамида изображения — это набор представлений изображения. Проис-
хождение названия объясняется зрительной ассоциацией. Как правило, каждый
слой пирамиды в два раза меньше по высоте и по ширине, чем предыдущий;
если складывать их друг на друга, то как раз и получится пирамида.
Алгоритм 7.2. Построение гауссовой пирамиды
Выбрать слой с наилучшим масштабом изображения
Для каждого слоя, кроме первого
Получить этот слой сглаживанием предыдущего с помощью гауссиана,
а затем провести его дискретизацию
конец
Глава 7. Линейные фильтры
241
Рис. 7.17. Гауссова пирамида изображения, начиная с размера 512 х 512 и до 8 х 8. В верхней
строке все изображения имеют один размер (так что отличаются только размеры пикселей), а
в нижней части рисунка изображения приведены в соответствии с масштабом. Заметим, что если
свернуть каждое изображение с фильтром фиксированного размера, это даст совершенно различные
результаты. Блок пикселей размером 8x8 наилучшего масштабного уровня может содержать
несколько волосков, на более грубом уровне он может содержать всю полоску, а на самом грубом
уровне он содержит всю морду животного
В гауссовой пирамиде каждый слой сглаживается симметричным гауссо-
вым ядром и подвергается повторной дискретизации, чтобы получить следую-
щий слой (рис. 7.17). Эти пирамиды удобнее всего строить, когда размерность
изображения кратна двум. Самое маленькое изображение сглаживать труднее
всего. Эти слои часто называют грубой шкалой изображения.
Используя небольшое число обозначений, можно записать простые выраже-
ния для слоев гауссовой пирамиды. Оператор снижает уровень дискретиза-
ции изображения; в частности, (J, А:)-й элемент оператора S^(P) — это (2j, 2/с)-й
элемент I. Уровень п пирамиды обозначен как Р(Т)п- Пользуясь этими
242
Часть II. Первые этапы: одно изображение
обозначениями, получим
/^GauB8ian(^)n+l = ♦ */^3aussian(7)n) =
— 5'^G'CT(7:>GauBsian(^)n),
где Ga обозначает линейный оператор, который превращает изображение
в свертку этого изображения с гауссианом. Наилучший уровень — это ис-
ходное изображение:
Pg auseian (T)t = z.
7.7.2. Применение масштабных представлений
Гауссовы пирамиды очень эффективны, поскольку они позволяют получать
представления различных типов структуры изображения. Имеется три стан-
дартных области их применения.
Поиск по масштабу
Многие объекты можно представить как маленькие модели изображений.
Характерный пример — это изображение человеческого лица в анфас. Как пра-
вило, при низком разрешении изображение лица имеет достаточно характерный
вид: глаза похожи на темные углубления под темными полосами (бровями), раз-
деленные более светлой полосой (зеркальное отражение от носа), а ниже нахо-
дится еще одна темная полоска (рот). Существуют различные методы определе-
ния изображения лица, в которых используются эти свойства (см. главу 22). Во
всех этих методах предполагается, что размеры лица не выходят за рамки опре-
деленных пределов. Все остальные лица находятся подбором пирамиды. Чтобы
найти лицо большего размера, берутся более грубые слои, а чтобы найти лицо
меньшего размера, берутся слои высшего качества. Эта уловка используется во
многих различных случаях, о чем будет рассказано в последующих главах.
Пространственный поиск
Еще одно из приложений — это пространственный поиск, обычная тема
компьютерного зрения. Как правило, есть точка одного изображения и нужно
найти точку на втором изображении, которая ей соответствует. С этой пробле-
мой сталкиваются в стереозрении, когда точка движется или из-за того, что
движется камера, или из-за того, что она соответствует движущемуся объекту.
Поиск соответствия по исходным парам изображений неэффективен, по-
скольку придется разбираться с большим количеством деталей. Более удачный
подход, который сейчас считается почти универсальным, — это искать соот-
ветствие по более сглаженному и повторно дискретизованному изображению,
а затем совершенствовать его, изучая более подробные варианты изображения.
Например, можно уменьшить изображение размером 1024 х 1024 до 4 х 4, подо-
брать к нему соответствие, а потом рассмотреть вариант 8x8 (так как известно
приблизительное соответствие, то его несложно уточнить); затем рассматрива-
Глава 7. Линейные фильтры
243
ется вариант 16 х 16 и т.д., вплоть до версии 1024 х 1024. Такой метод поиска
чрезвычайно эффективен, поскольку шаг в один пиксель в версии 4x4 равно-
значен шагу в 256 пикселей в версии 1024 х 1024. Такая стратегия называется
подбор от худшего к лучшему.
Отслеживание особенностей
Большинство особенностей, которые можно обнаружить на грубых уровнях
сглаживания, связаны с большими, высококонтрастными событиями на изобра-
жении, поскольку для того, чтобы особенность была заметна на грубых уров-
нях, ее существование не должно противоречить большой области пикселей.
Как правило, поиск на грубых уровнях дает неправильную оценку как разме-
ра, так и положения этих особенностей. Например, ошибка в один пиксель
на изображении грубого уровня превращается в ошибку во много пикселей на
изображении мелкого масштаба.
При мелком масштабе появляется множество особенностей, некоторые из
них связаны с еще меньшими, низкоконтрастными событиями. Один из спо-
собов улучшения набора особенностей, которые проявляются при мелком мас-
штабе, — это отслеживать особенности вплоть до самого грубого масштаба
и принимать только те особенности мелкого масштаба, у которых есть замет-
ные предшественники на более грубых уровнях. Этот метод, который называ-
ют отслеживанием особенностей, в принципе, может помочь избавиться от
особенностей, обусловленных текстурой некоторых областей изображения (что
часто считают шумом), и особенностей, обусловленных настоящим шумом.
7.8. ПРИМЕЧАНИЯ
Мы не претендуем на исчерпывающее описание линейных систем, но не
ознакомившись с идеями, изложенными в этой главе, невозможно было бы
читать литературу о фильтрах в компьютерном зрении. Здесь приведен доста-
точно полный перечень; более подробно об этом можно прочитать в книгах
[Bracewell, 1995] и [Bracewell, 2000].
Реальные системы создания изображений и линейные инвариантные
относительно сдвига системы
Системы создания изображений можно считать линейными только в некото-
ром приближении. Пленки не линейны — они не реагируют на слабые стимуля-
торы и засвечиваются под действием слишком ярких стимуляторов, — но в ра-
зумных пределах можно пользоваться линейной моделью. ПЗС-камеры линейны
во всем рабочем диапазоне. Вследствие теплового шума они дают небольшую,
но не нулевую реакцию на нулевой вход (вот почему астрономы охлаждают
свои камеры), а под действием слишком ярких стимуляторов — засвечиваются.
ПЗС-камеры часто оснащены электроникой, благодаря которой их выход более
похож на поведение пленки (поскольку потребители привыкли к пленкам). Ин-
вариантность относительно сдвига также приблизительна, поскольку линзам
244
Часть II. Первые этапы: одно изображение
свойственно искажать реакцию на границах изображения. Некоторые линзы
(например, в виде рыбьего глаза) не инвариантны относительно сдвига.
Масштаб
По вопросам масштабирования пространства и масштабных представлений
был проведен большой объем работ. Начало было положено в работе [Witkin,
1983], а развитие идеи изложено в работе [Koenderink and van Doorn, 1986].
С тех пор вышло множество литературы (можно начать с [Haar Romeny, Flo-
rack, Koenderink and Viergever, 1997] или [Nielsen, Johansen, Olsen and Weick-
ert, 1999]). В главе кратко описывается современное состояние вещей, посколь-
ку детальный анализ был бы слишком сложным. О пользе этих методов все
еще ведутся горячие споры.
Анизотропное масштабирование
Еще одна сложность при составлении моделей масштабирования простран-
ства связана с тем, что в процессе сглаживания симметричным гауссианом
наблюдается тенденция к размыванию краев, слишком сильная, чтобы не об-
ращать на нее внимания. Например, если есть изображение двух деревьев на
горизонте, стоящих рядом друг с другом, то при крупном масштабе пятна,
соответствующие каждому дереву, могут начать сливаться еще до того, как
смажутся все мелкомасштабные пятна. Из этого следует, что точки на краях
нужно сглаживать отдельно от остальных. Например, можно оценить значе-
ние и ориентацию градиента: при больших градиентах можно воспользоваться
ориентированным оператором сглаживания, который сильно сглаживает в пер-
пендикулярном направлении, и не очень сильно — параллельно градиенту; при
небольших градиентах можно воспользоваться симметричным оператором сгла-
живания. Эта идея известна под названием сглаживания с сохранением краев.
В современном, более формальном подходе (работа [Perona and Malik,
1990а,6]) отмечается семейство представлений масштабирования пространства,
которое выступает решением уравнения диффузии
дФ __ а2Ф а2Ф _
да дх2 ду2
= Х72Ф
с начальными условиями
Ф(ж, у, 0) = Т(х,у).
Если это уравнение привести к виду
дФ
да
= V • (с(х, у, а)Х7Ф) =
= с(х, у, о-) Х?2Ф + (Vc(x, У, О')) • ^Ф)
Глава 7. Линейные фильтры
245
с теми же начальными условиями, то тогда если с(х,у,а) — 1, мы получим
исходное уравнение диффузии, а если с(х, у, а) = 0, то сглаживания не про-
исходит. Предположим, что с не зависит от а. Если знать, где проходят края
изображения, можно создать трафарет, который будет состоять из областей (где
с(х, у) = 1), изолированных от крайних участков, где с(х,у) = 0; в этом случае
внутри каждой отдельной области, кроме краев, решение будет сглаженным.
Несмотря на то, что о положении краев ничего не известно — в противном слу-
чае задача не имела бы смысла — по величине градиента изображения можно
разумно выбрать с(х,у). Если градиент большой, то с должно быть малым,
и наоборот. В литературе есть очень много информации об этом методе, и если
он вас интересует, начать можно с книги [Haar Romeny, 1994].
Задачи
7.1. Покажите, что вычисление невзвешенного локального среднего, т.е. опе-
рация вида
U = i + fc v=j + fc
= (2*4-1)» S
' u=i~kv^j~k
является сверткой. Каким будет ядро этой свертки?
7.2. Запишите для изображения, которое состоит из всех нулей с един-
ственной единицей в центре. Покажите, что свертка этого изображения
с ядром
^=2^еХр
2<т2
(которое представляет собой дискретный гауссиан) дает размытое пятно
с круговой симметрией.
7.3. Покажите, что свертка изображения с дискретным раздельным двумер-
ным ядром фильтра эквивалентна свертке с двумя одномерными ядра-
ми. Оцените число операций для изображения размера N х N и яд-
ра (2к + 1) х (2k + 1).
7.4. Покажите, что свертка функции с ^-функцией дает исходную функцию.
Теперь покажите, что свертка функции со смещенной (5-функцией сдви-
гает функцию.
7.5. Свертка изображения с ядром вида (sin resin у)/(гг?/) невозможна, по-
скольку у этой функции бесконечный носитель. Почему нельзя най-
ти Фурье-образ изображения, умножить его на объемную функцию
и применить обратное преобразование Фурье? (Подсказка-, подумайте о
носителе.)
7.6. При наложении высокие пространственные частоты превращаются в низ-
кие. Объясните, почему происходят следующие явления.
а) В старых вестернах, когда показывают движущийся вагон, часто ка-
жется, что колеса остаются неподвижными или движутся в обратную
246
Часть II. Первые этапы: одно изображение
сторону (например, вагон движется слева направо, а колеса вращают-
ся против часовой стрелки).
б) Белые блузки с тонкими темными полосками часто приводят к воз-
никновению мерцающего набора цветов на телеэкране.
в) На изображениях, полученных методом лучевого зондирования,
мягкие тени, порожденные плоскими источниками, выглядят как
мозаика.
Упражнения
7.7. Один из способов получить гауссово ядро — это свернуть постоянное
ядро само с собой много раз. Сравните этот метод с оценкой гауссова
ядра.
а) Сколько раз нужно повторить свертку, чтобы получить хорошее при-
ближение? (Нужно определиться с тем, что такое хорошее приближе-
ние, построить график зависимости качества изображения от числа
проведенных сверток).
б) Есть ли в этом методе какие-то преимущества? (Подсказка: не каж-
дый компьютер оснащен устройством для выполнения операций с пла-
вающей запятой.)
7.8. Напишите программу, которая строит гауссову пирамиду изображения.
7.9. Дискретное гауссово ядро должно накладываться, поскольку ядро содер-
жит элементы с достаточно высокой пространственной частотой. Предпо-
ложим, что ядро дискретизовалось на бесконечной решетке. С уменьше-
нием среднеквадратического отклонения энергия наложения возрастает.
Постройте график зависимости энергии наложения от среднеквадрати-
ческого отклонения гауссова ядра в пикселях. Теперь предположим, что
гауссово ядро задано на решетке 7x7. Если энергия наложения бу-
дет того же порядка величины, что и ошибка, вызванная прерыванием
гауссиана, то какое самое маленькое среднеквадратическое отклонение
можно показать на этой решетке?
8
Определение краев
Резкое изменение яркости изображения интересно по нескольким причинам.
Во-первых, такие резкие изменения чаще всего возникают на границах объ-
ектов — это может быть изображение светлого предмета на темном фоне или
темного предмета на светлом фоне. Во-вторых, резкие изменения яркости ча-
сто бывают следствием изменения отражательной способности на достаточно
характерных структурах — как полосы на зебре или пятна на леопарде. Нако-
нец, к резким изменениям яркости изображения также часто приводят резкие
изменения ориентации поверхности.
Точки изображения, в которых яркость изменяется особенно сильно, часто
называют краями, или краевыми точками. Требуется связать краевые точки
с границами предметов или другими значащими элементами. При этом сложно
точно определить изменения, которые стоит выделять, — можно ли определять
границу предмета по голубому небу, которое просвечивается сквозь листья?
Как правило, сложно выделить края, имеющие определенное семантическое
значение, поскольку для этого необходима информация более высокого уровня.
Тем не менее, опыт создания зрительных систем подсказывает, что изучение
краев необходимо и полезно, поэтому стоит знать, где эти края проходят.
248
Часть II. Первые этапы: одно изображение
Рис. 8.1. В верхней строке приведены три примера реализации случайного процесса стационарного
аддитивного гауссова шума. Чтобы показать как положительные, так и отрицательные значения
шума, яркость изображений была увеличена на половину всего диапазона. Среднеквадратическое
отклонение шума составляет, соответственно (слева направо), 1/256, 4/256 и 16/256 от полной
яркости. Это приблизительно соответствует нулю, двум и пяти битам для камеры, выходное раз-
решение которой равно восемь битов на пиксель. В нижней строке показана сумма этого шума
и изображения. В каждом случае отрицательным значениям или значениям, выходящим из задан-
ного диапазона, присваивалось, соответственно, нулевое или максимальное значение
8.1. ШУМ
Основная проблема задачи определения краев — это шумы изображения.
Детекторы краев построены таким образом, что дают большой выход при рез-
ких изменениях, а одна из причин возникновения резких изменений — это
прибавление к пикселям посторонних значений (поскольку шумы в разных пик-
селях, как правило, не коррелируют, т.е. могут очень сильно отличаться друг
от друга). Как показано в разделе 7.3, использовать метод оценки производных
изображения с помощью конечной разности невозможно именно из-за шума.
Исходя из этого наблюдения, шумы изображения стоит изучить более глубоко.
Глава 8. Определение краев
249
Термином шум обычно обозначают такие данные, из которых невозмож-
но (или неизвестно как, или ненужно) извлечь информацию; все остальное
называется сигналом. Неправильно считать, что шум не содержит никакой ин-
формации — с его помощью, например, можно оценить температуру камеры,
обработав изображения, полученные в темной комнате с закрытой линзой. Бо-
лее того, поскольку без модели шума сказать о шуме что-то существенное
нельзя, будет неверным считать, что шум не моделируется. Вообще, шум — это
все то, чем не желают пользоваться, и в этом заключается его суть.
8.1.1. Аддитивный стационарный гауссов шум
В модели аддитивного стационарного гауссова шума к каждому пиксе-
лю прибавляется значение, которое выбирается на основе гауссова распределе-
ния вероятностей. Почти всегда среднее значение этого распределения равно
нулю. В качестве параметра этой модели используется среднеквадратическое
отклонение. Модель предназначена для описания теплового шума в камерах
и иллюстрируется на рис. 8.1.
Реакция линейного фильтра на аддитивный гауссов шум
Предположим, что дан дискретный линейный фильтр с ядром Q, и подей-
ствуем им на шум изображения J\f, представляющий собой стационарный ад-
дитивный гауссов шум со средним значением р и среднеквадратическим откло-
нением ст. Реакция фильтра в некоторой точке i,j будет следующей:
RWt.1 =Y,Gi-UJ-.Nu,v.
u,v
Поскольку шум стационарен и рассчитываемые величины не зависят от выбора
точки, для простоты можно считать, что i и j равны нулю и таким образом из-
бавиться от индексов. Предположим, что носитель ядра конечен, так что вклад
дает только некоторое подмножество случайных переменных; запишем это под-
множество как по,о,Математическое ожидаемое этой характеристики
будет следующим:
/оо
{7?(X)}p(Wo,o, • •, Nr,.)dN0,0... dNr,„ =
•оо
NU,vP(Nu,v)dNu,v
Данный результат можно получить после замены переменных и интегрирова-
ния по всем переменным, отсутствующим во всех членах суммы. Поскольку
все NUjV — независимые нормально распределенные случайные величины со
средним значением р, получаем такой результат:
E[R(Ar)\ = p^Gi-uj-v.
u,v
250
Часть II. Первые этапы: одно изображение
Несложно найти и дисперсию шумовой характеристики. Определим величину
е[{Я(ЛОм-е[Я(лом1П
или, что то же самое, величину
У ~ E[^(A/')i)J]}2p(No.o, - - -, №,e)dNo,o. • • dNr,s.
Это, в свою очередь, можно представить в таком виде:
У |£ G-u,-v(Nu,v - Д)| р(ЛГо,о, - - •, M-JdNo.o... dNr,a.
Данное выражение можно разложить на сумму интегралов двух типов. Члены
вида
у G\_V(NU,V - rfp(No,o, - - •, Nr,s)dN0,0... dNr,s
(для произвольных и и v) можно проинтегрировать без особого труда, посколь-
ку все NUtV независимы; интеграл будет равен a2G^_и _v, где а — среднеквад-
ратическое отклонение случайного процесса. Члены вида
У G—U'-vG-a'-biNu,» — p)(Na,b — p)p(No,o,..., AV,s)<iA/o,o . - • dNr,a
(для произвольных и, v и а, Ъ) дают нули, опять же потому, что все составля-
ющие шума независимы. Теперь получаем следующее выражение:
в [{Я(ЛО,.> - ЧВДу]}2] = S £ Gi,v.
Недостатки модели аддитивного стационарного гауссова шума
При буквальном рассмотрении модель аддитивного стационарного гауссова
шума оказывается плохой моделью шума изображения. Во-первых, эта модель
допускает существование положительных (и, что более тревожно, отрицатель-
ных!) значений пикселей произвольной величины. Впрочем, при правильном вы-
боре среднеквадратического отклонения для обычных камер, снимающих вне
помещения или при дневном освещении, это не представляет большой пробле-
мы, поскольку такие значения пикселей вряд ли появятся на практике. При
восстановлении изображения с шумами проблемным пикселям присваивается,
соответственно, нулевое или максимальное значение.
Во-вторых, шумовые значения совершенно независимы, т.е. в этой модели
не учитывается возможность существования групп пикселей, реакция которых
скоррелирована, возможно, из-за особенностей электроники камеры или из-за
тепловых пятен в интегральной схеме камеры. Эту проблему решить немного
Глава 8. Определение краев
251
сложнее, поскольку модели шума, описывающие данное явление, достаточно
сложны с аналитической точки зрения. Наконец, эта модель не описывает
“мертвые" пиксели (пиксели, которые при любых обстоятельствах не да-
ют никакой реакции на падающее излучение или постоянно перенасыщены).
“Мертвые” пиксели встречаются тогда, когда среднеквадратическое отклонение
достаточно велико и существует некоторое пороговое значение отображаемых
пикселей, при этом среднеквадратическое отклонение может быть настолько
большим, что остальную часть изображения описать невозможно. Решающее
преимущество модели аддитивного гауссова шума — это простота оценки ре-
акции фильтров на смоделированные таким образом случайные процессы. Это,
в свою очередь, помогает оценить, насколько эффективно фильтр реагирует на
сигнал и не воспринимает шум.
8.1.2. Почему конечная разность чувствительна к шуму
Изучение реакции линейных фильтров на аддитивный стационарный гаус-
сов шум требует более глубокого взгляда на реакцию конечной разности на
шум. Предположим, что имеется изображение стационарного гауссова шума
с нулевым средним значением; рассмотрим дисперсию характеристики филь-
тра конечной разности, который последовательно оценивает производные. Для
оценки первой производной воспользуемся ядром
О О
1 -1 .
О О
Теперь вторая производная — это просто первая производная от первой произ-
водной, так что ядро будет выглядеть так:
О 0 0
1-21.
0 0 0
Теперь можно убедиться, что, согласно этой схеме, коэффициенты ядра к-и
производной можно взять из (fc + 1)-й строки треугольника Паскаля. Средняя
реакция каждого из этих фильтров производных на гауссов шум равна нулю,
но дисперсия этой характеристики быстро возрастает; для fc-й производной
это сумма квадратов (к + 1)-й строки треугольника Паскаля, умноженная на
среднеквадратическое отклонение. Иллюстрирует данный результат рис. 8.2.
Есть и другое объяснение. Согласно табл. 7.1, дифференцирование функ-
ции — это то же самое, что и умножение ее Фурье-образа на частотную со-
ставляющую; это означает, что компоненты с высокой пространственной часто-
той очень усиливаются за счет низкочастотных составляющих. Это интуитивно
понятно — при дифференцировании функции постоянные члены превращаются
в нуль, тогда как амплитуда производной от синусоиды возрастает с часто-
той. Более того, именно из-за этого свойства нас интересуют производные:
252
Часть II. Первые этапы: одно изображение
Рис. 8.2. По причинам, описанным в разделе 8.1.2, конечная разность может существенно подчерк-
нуть гауссов шум. Слева вверху приведено изображение гауссова шума с нулевым средним зна-
чением и среднеквадратическим отклонением, составляющим 4/256 от всего диапазона. В центре
вверху показана оценка методом конечной разности третьей производной по х, а справа вверху —
шестой производной по х. В каждом случае для центрирования изображения ко всем значениям
прибавлялась половина диапазона (таким образом показаны отклонения как в положительную, так
и в отрицательную сторону). Все изображения приведены в одной яркостной шкале; при изобра-
жении шестой производной некоторые значения вышли за пределы этой шкалы. На графике внизу
показаны среднеквадратические отклонения изображений шума для первых восьми производных
(для оценки использовался метод на основе треугольников Паскаля)
резкие изменения (которые приводят к высоким пространственным частотам)
дают большие производные.
8.2. ОЦЕНКА ПРОИЗВОДНЫХ
Как показано на рис. 7.4, простые фильтры конечной разности имеют силь-
ную реакцию на шум, так что применение двух фильтров конечной разности
(по одному для каждой координаты) — это плохой способ оценки градиента.
Один из способов решения этой проблемы заключается в том, чтобы сгладить
изображение, а затем продифференцировать его (хотя можно также сглаживать
производные). На практике изображение почти всегда сглаживается гауссовым
фильтром; фактически, сглаживается оператор конечной разности. Рассмотрим
вначале этот метод, а затем обсудим, чем полезно сглаживание и почему гаус-
сиан считается хорошим фильтром для сглаживания.
Глава 8. Определение краев
253
Рис. 8.3. Сглаживание стационарного аддитивного гауссова шума дает сигнал, в котором значения
пикселей стремятся все больше и больше походить на своих соседей. Это происходит приблизитель-
но на уровне ядра фильтра, поскольку источником корреляции является ядро фильтра. На рисунке
показан шум, сглаженный с помощью последовательно увеличивающихся гауссовых ядер. Серые
пиксели имеют нулевое значение, более темные — отрицательное, а более светлые — положитель-
ное. Ядра в верхнем левом углу каждого изображения определяют пространственный масштаб ядра
(яркость ядра, представляющего собой гауссиан, нормирована таким образом, чтобы центральный
пиксель был белым, а крайние пиксели — черными). Из рисунка видно, что сглаженный шум по
виду приближается к естественной текстуре
8.2.1. Производная от гауссова фильтра
Сглаживание изображения с последующим его дифференцированием анало-
гично его свертке с производной ядра сглаживания. Легче всего это увидеть,
рассмотрев непрерывную свертку.
Во-первых, дифференцирование линейно и инвариантно относительно сдви-
га. Это означает, что есть некоторое ядро (его точный вид пока не конкре-
тизируется), которое выполняет дифференцирование. Если известна функ-
ция 1(х,у), то
01
дх
— К(д/дх) * */•
Теперь нужно взять производную от сглаженной функции. Запишем ядро сверт-
ки при сглаживании как S. Напомним, что свертка подчиняется ассоциативно-
му закону, т.е.
(^(з/Эх) * *(5' **/)) = (Х(а/ах) * *S) **/=( — I ♦ */.
Если сглаживающей функцией является гауссиан, можно записать следующее
выражение:
254
Часть II. Первые этапы: одно изображение
Рис. 8.4. Производные гауссовых фильтров меньше реагируют на шум, чем фильтры конечной
разности. На изображении вверху слева показан фрагмент изображения зебры; вверху в центре
показано то же изображение, подверженное стационарному аддитивному гауссову шуму с нулевым
средним значением и а — 0,03 (значения пикселей принадлежат диапазону от 0 до 1). Вверху
справа показано то же изображение, подверженное стационарному аддитивному гауссову шуму
с нулевым средним значением и а — 0,09. Во второй строке показаны частные производные по
координате х для каждого изображения, в каждом случае оцененные с помощью производной от
гауссова фильтра с а в один пиксель. Обратите внимание на то, как сглаживание способствует
снижению влияния шума
т.е. необходима только свертка с производной гауссиана, а не свертка с последу-
ющим дифференцированием. Результат сглаживания намного меньше реагирует
на шум, чем оценка производных (рис. 8.4).
8.2.2. Чем полезно сглаживание
В общем случае любое изменение значения отражается на целом блоке пик-
селей. Например, контуры предмета могут превратиться в длинную цепочку
точек, в которых производная изображения будет большой. Во многих моделях
шума большие производные изображения, обусловленные шумом, являются,
по сути, локальными событиями. Это означает, что сглаживание продифферен-
цированного изображения — это некоторое объединение искомых изменений
и подавление эффекта шума. Альтернативная интерпретация: искомые измене-
ния не будут подавляться при сглаживании, при котором подавляются шумовые
эффекты.
Существует еще одно объяснение того, чем полезно сглаживание. Предполо-
жим, что изображение с шумами было сглажено, а затем продифференцирова-
но. Во-первых, ядро сглаживания снижает дисперсию шума, поскольку обычно
стараются применять положительные ядра сглаживания, для которых
22^ = 1,
а это означает, что
UV
Глава 8. Определение краев
255
Во-вторых, стремление пикселей быть похожими на своих соседей возрастает:
если взять стационарный аддитивный гауссов шум и сгладить его, то значе-
ния пикселей в полученном сигнале больше не будут независимыми. По сути
в этом и состоит сглаживание — вспомните, что сглаживание было введено
как способ предсказания значения пикселя по значениям соседних с ним пик-
селей. В то же время, если пиксели стремятся быть похожими на соседние, то
производные должны быть меньше (поскольку они показывают то, насколько
пиксели отличаются от соседних с ними).
Попробуем рассуждать с позиции пространственных частот. Можно пока-
зать, что энергия стационарного аддитивного гауссова шума одинакова для
всех частот. Если не пытаться улучшить данную ситуацию, то карта величи-
ны градиента, вероятнее всего, будет содержать случайные большие значения,
обусловленные шумом. Фильтрация с помощью гауссова фильтра подавляет
эти высокие пространственные частоты, как это было при повторной выборке
(раздел 7.4.3).
Имеются и практические сферы применения сглаженного шума. Как пока-
зано на рис. 8.3, сглаженный шум напоминает некую естественную текстуру,
поэтому сглаженные шумы широко используются в компьютерной графике в ка-
честве источника текстур (см. работы [Ebert, Musgrave, Peachey, Worley and
Perlin, 1998] и [Perlin, 1985]).
8.2.3. Выбор фильтра сглаживания
Фильтр сглаживания можно подобрать, взяв модель краев и воспользовав-
шись некоторым набором критериев для выбора фильтра, который лучше всего
реагирует на данную модель. Эту задачу сложно сформулировать для двумер-
ного случая, поскольку края в двумерном пространстве могут оказаться ис-
кривленными. Условно выбор фильтра сглаживания состоит в формулировании
одномерной задачи с последующим применением ротационно-симметричного ва-
рианта двумерного фильтра.
Одномерный фильтр следует искать, исходя из модели краев. Общепринятая
модель — это ступенчатая функция с неизвестными весовыми коэффициентами
при наличии стационарного аддитивного гауссова шума, которая задается как
край(х) = AU(x) 4- п(х),
где
О, если х < О
1, если х > О
(значение £7(0) не существенно). Величину А обычно называют контрастом
края. Для одномерной задачи определение величины градиента эквивалент-
но вычислению квадрата реакции производной. Поэтому обычно ищут фильтр
оценки производной, а не сглаживающий фильтр (который затем можно вос-
становить по фильтру оценки производной).
t/(x) =
256
Часть II. Первые этапы: одно изображение
Рис. 8.Б. Масштаб (т.е. ст) гауссиана, которым пользуются при выводе гауссова фильтра, сильно
влияет на результат. На трех рисунках показаны оценки производной по х для изображения го-
ловы зебры, полученного с помощью производной от гауссова фильтра с ст (слева направо) в один
пиксель, три пикселя и семь пикселей. Обратите внимание, что на изображении с более мелким
масштабом видны отдельные волоски, при среднем масштабе исчезают усы животного, а при самом
грубом масштабе исчезают мелкие полосы на морде
В работе [Саппу, 1986] описан метод выбора фильтра оценки производной
с помощью непрерывной модели оптимального подбора трех критериев.
• Отношение сигнал/шум — фильтр должен сильнее реагировать на край
при х = 0, чем на шум.
• Локализация — реакция фильтра должна достигать максимального зна-
чения при приближении к х = 0.
• Низкий уровень ложных совпадений — характеристика должна иметь
только один максимум в разумной близости от х = 0.
Когда непрерывный фильтр найден, его следует дискретизовать. Назван-
ные критерии можно комбинировать множеством различных способов, что дает
множество различных фильтров. Замечено, что оптимальные фильтры сгла-
живания, полученные при многих комбинациях этих критериев, очень сильно
напоминают гауссианы — это интуитивно понятно, поскольку в фильтре сгла-
живания для центральных пикселей весовые коэффициенты должны быть боль-
ше, чем для удаленных, как и у гауссиана. На практике оптимальные фильтры
сглаживания часто заменяют гауссианами без каких-либо особых потерь.
Выбор а для оценки производной часто называют выбором масштаба сгла-
живания. Реакция фильтра производной сильно зависит от масштаба. Предпо-
ложим, что имеется узкая линия на постоянном фоне (на рисунке — усы зебры).
Сглаживание при масштабе, меньшем, чем ширина линии, означает, что будут
различимы начало и конец линии. Если ширина фильтра намного больше, то
линия сглаживается до уровня фона и фильтр на нее не реагирует (рис. 8.5).
Глава 8. Определение краев
257
8.2.4. Почему для сглаживания используют гауссиан
Хотя гауссиан не является единственным возможным ядром размывания,
он удобен, поскольку обладает рядом важных особенностей. Во-первых, если
выполнить свертку гауссиана с гауссианом, получим еще один гауссиан:
Следовательно, можно получить сильно сглаженное изображение, повторно
сгладив уже сглаженное изображение. Это очень важное свойство, поскольку
дискретная свертка может оказаться слишком трудоемкой операцией (особенно
при большом ядре фильтра), а обычно нужны варианты изображения с различ-
ной степенью сглаживания.
Эффекти вность
Рассмотрим свертку изображения с гауссовым ядром с ст в один пиксель. Хо-
тя гауссово ядро ненулевое по всей бесконечной области, большую часть этой
области заполняют (благодаря экспоненциальной форме) чрезвычайно малые
значения. Для а в один пиксель точки за пределами целочисленной решет-
ки 5 х 5 с центром в начале координат имеют значения меньше, чем е~4 =
0,0184, а точки за пределами целочисленной решетки 7 х 7 с центром в на-
чале координат имеют значения меньше, чем е-9 = 0,0001234. Это означает,
что вкладом этих точек можно пренебречь и представить дискретный гауссиан
как небольшой массив (5x5 или 7 х 7, в зависимости от желания и согласно
количеству битов, которым описывается ядро).
Однако если а равна 10 пикселей, может понадобиться массив 50 х 50, а то
и больше. Подсчитав количество операций, можно убедиться, что свертка изоб-
ражения разумных размеров с массивом 50 х 50 представляет собой довольно
непривлекательную перспективу. Альтернатива — повторная свертка с намного
меньшим ядром — гораздо эффективнее, поскольку уже не нужно запоминать
промежуточные значения каждого пикселя. Это объясняется тем, что сгла-
женное изображение в некоторой степени избыточно (большинство пикселей
содержит немалую часть значений своих соседей). Следовательно, некоторы-
ми пикселями можно пренебречь. Таким образом, получается довольно эффек-
тивная стратегия: сглаживание, подвыборка, сглаживание, подвыборка и т.д.
В результате имеем изображение, содержащее ту же информацию, что и силь-
но сглаженное изображение, но при этом оно намного меньше, и его легче
получить. Подробнее этот метод рассмотрен в разделе 7.7.1.
Центральная предельная теорема
Гауссиан обладает еще одним важным свойством, которое здесь не доказы-
вается, но проиллюстрировано на рис. 8.6. Для семейства функций, представля-
ющих практический интерес, многократная свертка любого члена этого семей-
ства функций с самим собой дает гауссиан. Вместе с ассоциативностью свертки
это предполагает, что если выбирать различные ядра сглаживания и многократ-
258
Часть II. Первые этапы: одно изображение
Рис. 8.6. В центральной предельной теореме утверждается, что многократная свертка положи-
тельного ядра с самим собой в результате дает ядро, которое будет гауссианом. На графике это
продемонстрировано для одномерной свертки; треугольник — это свертка прямоугольной функции
с самой собой; каждая последующая функция получается при свертке предыдущей с самой собой
но применять их к изображению, то результат будет таким же, как если бы
изображение сглаживали с помощью гауссиана.
Гауссианы можно разделять
Наконец, изотропный гауссиан можно факторизовать следующим образом:
Ч 2<г2,М кк/2?<7 Ч
и получить произведение двух одномерных гауссианов. В общем случае, функ-
ция f(x,y), которая раскладывается на f(x,y) — g(x)h(y), называется тен-
зорным произведением. Обычно ядра фильтров, которые являются тензорными
произведениями, называют разделяющимися ядрами. Данное свойство крайне
полезно. В частности, свертка с разделяющимся ядром фильтра эквивалентна
свертке с двумя одномерными ядрами — по направлению х и по направлению у
(см. раздел упражнений).
Разделяющимися являются и многие другие ядра. Разделяющиеся ядра
фильтров дают дискретные представления, которые также можно разделять.
В частности, если 7Y — дискретное разделяющееся ядро фильтра, то существу-
Глава 8. Определение краев
259
ют векторы f и д, такие что
Hij = fi91-
Это свойство можно определить с помощью методов численной линейной ал-
гебры, поскольку ранг матрицы Н должен равняться единице. В коммерческих
пакетах для выполнения сверток перед применением ядра к изображению его
часто проверяют на разделяемость. Это выгодно в тех случаях, когда ядро
оказывается неразделяемым. Многие ядра можно выгодно аппроксимировать
суммой разделяемых ядер. Если число ядер мало, то такая аппроксимация поз-
воляет хорошо сэкономить на свертках. Эта стратегия особенно привлекательна
тогда, когда необходимо свернуть изображение со многими различными филь-
трами; в таком случае стараются представить каждое из этих ядер как взвешен-
ную сумму разделяемых ядер, которые являются тензорными произведениями
небольшого количества базисных элементов. После этого можно сворачивать
изображения с базисными элементами, а затем формировать различные взве-
шенные суммы с целью свертки изображения с различными фильтрами.
Наложение в передискретизованных гауссианах
Исследование наложения позволяет глубже изучить доступные параметры
сглаживания. Любое практически используемое гауссово ядро является дис-
кретным приближением гауссиана, дискретизованного по сетке в один пиксель.
Это означает, что для того чтобы исходное ядро можно было восстановить по
его дискретному приближению, оно не должно содержать элементов с простран-
ственной частотой, превышающей 0,5 пиксель-1. Для гауссиана это невозмож-
но, поскольку его Фурье-преобразование также является гауссианом, следова-
тельно, имеет неограниченную полосу частот. Все, что можно сделать, — при-
нять, что энергия в накладываемом сигнале не должна превышать некоторого
порогового значения — здесь, в свою очередь, подразумевается, что существует
минимальное значение ст, доступное для фильтра сглаживания на дискретной
сетке (для значений меньших, чем этот минимум, фильтр сглаживания накла-
дывается плохо; см. раздел упражнений).
8.3. ОПРЕДЕЛЕНИЕ КРАЕВ
В обоих основных методах определения краев края моделируются как рез-
кие изменения яркости. В первом методе используется то, что самые быстрые
изменения происходят при исчезновении двумерного аналога второй производ-
ной (раздел 8.3.1). Этот подход представляет лишь историческую ценность и на
практике уже не применяется. Альтернативный метод состоит в явном поиске
точек, в которых градиент достигает экстремума (раздел 8.3.2).
260
Часть II. Первые этапы: одно изображение
Рис. 8.7. Лапласиан гауссова ядра фильтра, показанный здесь для а в один пиксель, можно счи-
тать результатом вычитания центрального пикселя из взвешенного среднего значения окружения
(отсюда следует аналогия с нерезкой маскировкой, описанной в тексте). Достаточно часто это ядро
заменяют разницей двух гауссианов — один с маленьким значением а, а другой — с большим
значением а
8.3.1. Применение лапласиана для определения краев
В одномерном случае вторая производная сигнала равна нулю, если значение
первой производной достигает экстремума. Это означает, что для того, чтобы
найти большие перепады, нужно искать там, где вторая производная равна ну-
лю. Этот метод применим и в двумерном случае. Теперь остается только найти
подходящий аналог второй производной. Он должен быть инвариантным отно-
сительно поворотов. Несложно показать, что этим требованиям удовлетворяет
лапласиан. Лапласиан двумерной функции — это величина
(V2/)(x.!,) = g + g.
Естественно, прежде чем действовать на изображение лапласианом, изображе-
ние необходимо сгладить. Отметим, что лапласиан — это линейный оператор
(если вы в этом не уверены, проверьте), т.е. действие лапласиана равносильно
свертке изображения с неким ядром (которое обозначают К^ъ). Из ассоциа-
Глава 8. Определение краев
261
Рис. 8.8. Переходы через нуль лапласиана гауссиана при различном масштабе и различных по-
роговых значениях градиента. В каждом столбце показан фиксированный масштаб при пороговом
значении величины градиента t, возрастающем сверху вниз (в два раза при переходе к следующему
изображению). В каждом ряду показано фиксированное значение t при масштабе, увеличивающем-
ся за каждый шаг в два раза от ст в один пиксель до ст в восемь пикселей. Отметим, что края
на изображениях с мелким масштабом и низким пороговым значением несут большое количество
информации, которая может быть полезной в зависимости от того, интересуют ли нас волоски на
носу зебры. С увеличением масштаба количество деталей уменьшается; при увеличении порогового
значения выпадают мелкие участки краев. Ни при одном масштабе или пороговом значении не по-
лучаются очертания головы зебры; во всех случаях есть реакция на полосы, хотя при увеличении
масштаба узкие полоски вверху морды неразличимы
тивности свертки следует, что
{KV2 ♦ *(GCT * */)) = (KV2 * *GO) **I = (V2Ga) * */.
Это важно, поскольку, как и для первой производной, сглаживание с последую-
щим применением лапласиана равнозначно свертке изображения с лапласианом
ядра, которое применялось при сглаживании. Ядро, которое получается в ре-
зультате таких действий, показано на рис. 8.7.
Эти рассуждения приводят к простому и представляющему большое истори-
ческое значение методу определения краев, проиллюстрированному на рис. 8.8.
262
Часть II. Первые этапы: одно изображение
Рис. 8.9. Переходы через нуль лапласиана гауссовых данных могут странно вести себя в углах.
Во-первых, при прямом угле переход через нуль выпячивается (но проходит через вершину). Это
явление возникает не из-за оцифровки (или квантования), оно также встречается и в непрерыв-
ном случае. В углах, где сходятся три или больше линий, контуры ведут себя необычно, детали
зависят от структуры алгоритма обозначения контура — в результате действий этого алгоритма
(имеющегося, кстати, в Matlab) возникают причудливые петли. Это явление можно свести к мини-
муму, тщательно разработав процесс обозначения контура, который должен включать достаточно
подробную модель построения вершин
Проводится свертка изображения с лапласианом гауссиана в определенном
масштабе и отмечаются точки, в которых функция равна нулю, — переходы
через нуль. Далее следует проверить, действительно ли в этих точках градиент
достаточно велик. Изначально этот метод был предложен в работе [Marr and
Hildreth, 1980].
Реакция лапласиана гауссова фильтра положительна с одной стороны края
и отрицательна с другой. Это значит, что прибавление некоторой части этой
реакции к исходному изображению дает картину, на которой края четче, а
детали увидеть намного легче. Впервые это наблюдение было использовано
в развивающемся фотографическом методе, который называется нерезкой мас-
кировкой (чтобы на ярких участках размытого позитива лучше были видны
детали, от значения яркости отнимается локальное среднее значение в этой
области). Приблизительно того же результата можно достичь, если отфиль-
тровать изображение с помощью разницы гауссианов, умножить результат на
небольшую константу и прибавить полученное значение к исходному изобра-
жению. Теперь разница между двумя гауссовыми ядрами похожа на лапласиан
гауссова ядра, и довольно часто одно заменяют другим. Это значит, что при
нерезкой маскировке слагаемое, соответствующее краю, прибавляется к исход-
ному изображению.
Ныне определение краев с помощью лапласиана гауссиана не пользуется
популярностью. Поскольку лапласиан гауссова фильтра не ориентирован, его
характеристика состоит из перпендикулярной и параллельной к краю состав-
ляющих. Это означает, что на углах, где меняется направление параллельной
Глава 8. Определение краев
263
Рис. 8.10. Величину градиента можно оценить путем сглаживания изображения с последующим
его дифференцированием. Это равнозначно свертке с производной ядра сглаживания. Степень сгла-
живания влияет на величину градиента; на этом рисунке показана величина градиента для изоб-
ражения зебры при различном масштабе. В центре величина градиента была оценена с помощью
производных гауссиана с <т = 1 пиксель; справа величина градиента была оценена с помощью
производных гауссиана с а = 2 пикселя. Отметим, что большие значения градиента дают широкие
полосы
составляющей, возникают некоторые проблемы. Границы острых углов обозна-
чаются очень неточно, а в трехгранных и более сложных углах это создает
большие трудности для правильной записи топологии углов, как показано на
рис. 8.9. Во-вторых, параллельные компоненты фильтра склонны реагировать
на шум, а не только на края; это означает, что переход через нуль не обяза-
тельно точно указывает на край.
8.3.2. Детекторы краев на основе градиентов
В детекторах краев на основе градиентов оценивается величина градиента
(почти всегда с помощью гауссиана в качестве фильтра сглаживания), и эта
оценка используется для определения положения краевых точек. Как правило,
величина градиента может быть большой вдоль широких полос на изобра-
жении (рис. 8.10). Однако контуры объектов — это обычно кривые, поэтому
хотелось бы получить кривую, составленную из наиболее характерных точек
этой полосы.
Естественным кажется подход поиска точек, в которых величина градиента
максимальна в направлении, перпендикулярном к краю. При таком подходе
перпендикулярность направления к краю можно оценить по направлению гра-
диента (рис. 8.11). Такие рассуждения приводят к алгоритму 8.1. Большинство
программ поиска краев действуют согласно этому алгоритму, хотя все еще
продолжаются жаркие дискуссии о необходимости точного следования всем
его этапам.
264
Часть II. Первые этапы: одно изображение
Алгоритм 8.1. Определение краев на основе градиентов
Оценить градиент изображения
Из этой оценки найти величину градиента
Найти точки изображения, в которых значение
величины градиента максимально в направлении, перпендикулярном к краю,
и велико по модулю; эти точки являются краевыми точками
Немаксимальное подавление
При известных оценках величины градиента нужно найти краевые точки.
Как и ранее, точного объективного определения нет, придется руководствовать-
ся здравым смыслом и интуицией. Величину градиента можно рассматривать
как цепь невысоких холмов. Локальные экстремумы дают отдельные точки —
по аналогии с вершинами холмов. Самый лучший критерий — разрезать гради-
ент на маленькие участки вдоль направления градиента, которое должно быть
перпендикулярным к краю, и отметить точки участка, в которых эта величина
максимальна. В результате получится ряд точек вдоль вершин изначальной це-
пи холмов; этот процесс называется немаксимальным подавлением (рис. 8.12).
Алгоритм 8.2. Немаксимальное подавление
Пока есть непроверенные точки с большим значением градиента
Найти начальную точку, которая является локальным максимумом в направ-
лении, перпендикулярном градиенту, исключая уже проверенные точки
Пока возможно, расширяем цепь, проходящую через текущую точку,
для этого:
1) предсказываем набор последующих точек с помощью направления,
перпендикулярного градиенту
2) находим точку (если такая есть) локального максимума в направлении
градиента
3) проверяем, является ли величина градиента в максимуме достаточно
большой
4) отмечаем, что эта точка и ее окружение уже проверены
фиксируем следующую точку, которая становится текущей
конец
конец
Глава 8. Определение краев
265
Рис. 8.11. Величина градиента обычно больше в направлении вдоль широких полос на изображе-
нии. Как правило, эти полосы группируют в кривые, отображающие краевые точки. Проше всего
это сделать, разрезав полосу перпендикулярно к ее направлению и найдя пик. В качестве на-
правления, по которому следует резать полосу, берется направление градиента. На рисунке слева
показана полоса с большой величиной градиента; на рисунке в центре показано соответствующее
направление разреза; на рисунке справа показан пик в этом направлении
Рис. 8.12. При немаксимальном подавлении получают точки, в которых величина градиента мак-
симальна вдоль направления градиента. На рисунке слева показано, как восстанавливается ве-
личина градиента. Точками изображена сетка пикселей. Рассмотрим пиксель q и попытаемся опре-
делить, максимален ли градиент в этой точке; вектор градиента, проходящий через q, не проходит
ни через один из удобных пикселей как справа, так и слева от него, поэтому выполняют интерпо-
ляцию и находят величину градиента в точках риг; если величина в точке q больше, чем в этих
двух точках, то q является краевой точкой. Как правило, значения величины восстанавливаются
путем линейной интерполяции, при которой для определения значения в этих точках использу-
ются пиксели слева и справа от р и г, соответственно. Справа изображено, как определяются
кандидаты на следующую краевую точку при условии, что q — краевая точка; соответствующее
направление поиска — это перпендикуляр к градиенту, так что точки s и t следует рассматривать
как следующие краевые точки. Отметим, что, в принципе, не нужно ограничиваться пикселями
сетки изображения, поскольку известно, где предположительно находится край между s и t. Сле-
довательно, снова можно провести интерполяцию, чтобы найти значение градиента в точках, не
принадлежащих сетке
266
Часть II. Первые этапы: одно изображение
Следование по краю
Как правило, ожидается, что краевые точки будут расположены вдоль кри-
вой по цепочке. Перечислим важные этапы немаксимального подавления:
• определить, является ли данная точка краевой;
• если это так, найти следующую краевую точку.
После обдумывания этих этапов несложно выделить все цепочки краевых точек.
Находим первую краевую точку, отмечаем ее, продлеваем все цепи, проходящие
через эту точку, отмечая все точки на этих цепях, и делаем то же самое для
всех неотмеченных краевых точек.
Два основных этапа очень просты. Предположим пока, что края следует
отмечать по положениям пикселей (а не по какому-то более мелкому делению
сетки пикселей). Определить, является ли величина градиента в данном пиксе-
ле максимальной, можно, сравнивая ее со значениями в точках справа и слева
по направлению градиента (рис. 8.11). Это функция расстояния вдоль направ-
ления градиента; как правило, на следующем шаге выполняется переход вправо
на следующую строку (или столбец) пикселей и влево на предыдущий, чтобы
определить, больше ли величина градиента в данном пикселе (рис. 8.12). Век-
тор градиента обычно не проходит через следующий пиксель, поэтому проводят
интерполяцию, чтобы определить значение градиента в интересующих точках;
интерполяция, как правило, линейна.
Если пиксель оказывается краевой точкой, то следующую краевую точку
кривой можно угадать, сделав шаг перпендикулярно градиенту. В общем случае
этот шаг не заканчивается на пикселе; естественная реакция — рассмотреть
соседние пиксели, находящиеся вблизи от этого направления (см. рис. 8.12).
Такой подход дает набор кривых, которые можно представить, изобразив их на
черном или белом фоне (рис. 8.13, 8.14 и 8.15).
Гистерезис
Слишком многие из полученных кривых позволяют разумно описать грани-
цы объекта. Частично это вызвано тем, что максимумы величины градиента
отмечались вне зависимости от того, насколько велико значение этого макси-
мума. Чаще применяют пороговую проверку, чтобы убедиться, что максимум
превышает некую нижнюю границу. Это, в свою очередь, приводит к разрыву
кривой края (см. рис. 8.13-8.15). В данном случае обычно применяется концеп-
ция гистерезиса', есть два пороговых значения, и в начале цепи используется
большее, а затем, следуя по ней, меньшее. Эта уловка помогает улучшить по-
лученный результат (см. раздел упражнений).
8.3.3. Метод: представление ориентации и углов
Хорошо известно, что определять края на углах сложно, поскольку здесь
предположение о том, что для оценки ориентации градиента достаточно оце-
нить частные производные по х и у, не срабатывает. В острых или неудачно
Глава 8. Определение краев
267
Рис. 8.13. Краевые точки, отмеченные на сетке пикселей для изображения вверху. Краевые точки
слева получены с помощью гауссова фильтра сглаживания при а в один пиксель; чтобы определить,
является ли точка краевой, величина градиента проверялась при высоком пороговом значении. Кра-
евые точки в центре получены с помощью гауссова фильтра сглаживания при а в четыре пикселя;
чтобы определить, является ли точка краевой, величина градиента проверялась при высоком поро-
говом значении. Краевые точки справа получены с помощью гауссова фильтра сглаживания при <т
в четыре пикселя; чтобы определить, является ли точка краевой, величина градиента проверялась
при низком пороговом значении. При мелком масштабе мелкие детали с высокой контрастностью
приводят к возникновению краевых точек, которые исчезают при более грубом масштабе. При
высоком пороговом значении кривые краевых точек часто прерываются, поскольку величина гради-
ента опускается ниже порогового значения; при низком пороговом значении появляется множество
новых неоднозначных краевых точек
расположенных углах эти оценки частных производных обычно оказываются
неверными, поскольку их носитель будет пересекать угол. Существует множе-
ство специальных детекторов краев на углах, в которых ищутся области изоб-
ражения с сильными колебаниями градиента (рис. 8.16). В более общем случае
достаточно полезное описание области изображения дает статистика градиента
в этой области. Окна изображения условно можно разделить на четыре каче-
ственных типа:
• с гладкой выборкой, когда уровень яркости приблизительно равен кон-
станте;
• со ступенчатой выборкой, где в пределах окна есть резкие изменения
яркости изображения вдоль одного направления;
• с анизотропной текстурой, где в пределах окна есть несколько мелких
линий (например, волосы или шерсть);
• с изотропной текстурой, где в пределах окна есть какая-либо двумерная
текстура (скажем, пятна или угол).
268
Часть II. Первые этапы: одно изображение
Рис. 8.14. Краевые точки, отмеченные на сетке пикселей для изображения вверху. Краевые точки
слева получены с помощью гауссова фильтра сглаживания при а в один пиксель; чтобы определить,
является ли точка краевой, величина градиента проверялась при высоком пороговом значении. Кра-
евые точки в центре получены с помощью гауссова фильтра сглаживания при а в четыре пикселя;
чтобы определить, является ли точка краевой, величина градиента проверялась при высоком поро-
говом значении. Краевые точки справа получены с помощью гауссова фильтра сглаживания при а
в четыре пикселя; чтобы определить, является ли точка краевой, величина градиента проверялась
при низком пороговом значении. При мелком масштабе мелкие детали с высокой контрастностью
приводят к возникновению краевых точек, которые исчезают при более грубом масштабе. При
высоком пороговом значении кривые краевых точек часто прерываются, поскольку величина гради-
ента опускается ниже порогового значения; при низком пороговом значении появляется множество
новых неоднозначных краевых точек
Все эти ситуации соответствуют различным типам поведения градиента изоб-
ражения. В окнах с гладкой выборкой вектор градиента короткий; в окнах
со ступенчатой выборкой существует небольшое количество длинных векторов
градиента, которые все направлены в одну сторону; в окнах с анизотропной
текстурой существует множество векторов градиента, указывающих по двум
направлениям; а в окнах с изотропной текстурой вектор градиента колеблется.
Эти различия можно довольно легко изобразить, посмотрев на колебания
ориентации в пределах окна. В частности, матрица
н = £{(V/)(W)T}»
окно
Глава 8. Определение краев
269
Рис. 8.15. Краевые точки, отмеченные на сетке пикселей для изображения вверху. Краевые точки
слева получены с помощью гауссова фильтра сглаживания при а в один пиксель; чтобы определить,
является ли точка краевой, величина градиента проверялась при высоком пороговом значении. Кра-
евые точки в центре получены с помощью гауссова фильтра сглаживания при а в четыре пикселя;
чтобы определить, является ли точка краевой, величина градиента проверялась при высоком поро-
говом значении. Краевые точки справа получены с помощью гауссова фильтра сглаживания при а
в четыре пикселя; чтобы определить, является ли точка краевой, величина градиента проверялась
при низком пороговом значении. При мелком масштабе мелкие детали с высокой контрастностью
приводят к возникновению краевых точек, которые исчезают при более грубом масштабе. При
высоком пороговом значении кривые краевых точек часто прерываются, поскольку величина гради-
ента опускается ниже порогового значения; при низком пороговом значении появляется множество
новых неоднозначных краевых точек
dG,
ду
8G,
ду
хорошо описывает поведение ориентации в пределах окна. В окне с гладкой вы-
боркой оба собственных значения этой матрицы малы, поскольку малы все эле-
менты. В окне со ступенчатой выборкой можно ожидать, что одно собственное
значение, связанное с градиентами края, будет большим, а другое — малым, так
как несколько градиентов направлены в другие стороны. В окне с анизотроп-
270
Часть II. Первые этапы: одно изображение
Рис. 8.16. Изображение дерева Джошуа (Joshua tree) (слева) и его ориентация, показанная в виде
векторов, наложенных на изображение (справа). Ориентация накладывается на изображение в фор-
ме маленьких векторов. Отметим, что вокруг углов и в текстурных областях вектор ориентации
сильно колеблется
ной текстурой можно ожидать такие же собственные значения, за исключением
того, что большое значение будет еще больше, поскольку краев, вносящих свой
вклад, будет больше. Наконец, в окне с изотропной текстурой оба собственных
значения будут большими.
Поведение этой матрицы легче всего понять, построив эллипсы
(х,у)т'Н~1(х,у) = €
для некоторой малой константы е. Эти эллипсы накладываются на окна изоб-
ражения. Их главная и малая оси направлены вдоль собственных векторов
матрицы 7Y, а длина главной и малой осей соответствует величине собствен-
ных значений; это означает, что большой круг соответствует окну с изотропной
текстурой, а узкий вытянутый эллипс указывает на окно со ступенчатой выбор-
кой (как на рис. 8.17 и 8.18). Таким образом, углы можно обозначать, отмечая
точки, в которых площадь этих эллипсов имеет экстремальное и большое значе-
ние. Точность локализации, предлагаемая этим методом, ограничена размером
окна и поведением градиента. Более точной локализации можно достичь за
счет более подробной модели искомого угла (см., например, работы [Harris and
Stephens, 19881 или [Schmid, Mohr and Bauckhage, 2000]).
Глава 8. Определение краев
271
Рис. 8.17. Поле ориентаций элемента изображения дерева Джошуа. Слева ориентация показана
в виде векторов, наложенных на изображение. Ориентация сравнивалась с порогом, и слишком ма-
ленькие значения градиента отбрасывались. На рисунке справа показаны эллипсы (см. объяснение
в тексте) для окна размером 3x3 пикселя
Рис. 8.18. Поле ориентаций элемента изображения дерева Джошуа. Слева ориентация показана
в виде векторов, наложенных на изображение. Ориентация сравнивалась с порогом, и слишком ма-
ленькие значения градиента отбрасывались. На рисунке справа показаны эллипсы (см. объяснение
в тексте) для окна размером 5x5 пикселей
272
Часть II. Первые этапы: одно изображение
8.4. ПРИМЕЧАНИЯ
Тема определения краев освещается во многих работах. Самая первая из
известных авторам публикаций — это [Julez, 1959]. Если вы хотите ознако-
миться с ранней литературой более подробно, следует начать с обзорных работ
[Davis, 1975]; [Herskovits and Binford, 1970]; [Horn, 1971] и [Hueckel, 1971] (где
описано моделирование краев и определение модели).
Определение краев — тема непрекращающихся споров, многие из которых
оказываются неинформативными. В данной главе только очерчены контуры про-
блемы. Существует множество критериев оптимизации детекторов края и до-
статочно “оптимальные” детекторы. Ключевой среди этой литературы считает-
ся работа [Саппу, 1986]; также следует обратить внимание на работы [Deriche,
1987] и [Spacek, 1986]. Подробное и доступное изложение основных вопросов
содержит учебник [Faugeras, 1993]. В конце прошлого века большинство схем
сводилось к сглаживанию изображения посредством ядер, очень похожих на
гауссиан, с последующим измерением градиента.
Границы объекта не следует отождествлять с резкими изменениями зна-
чений на изображении. Во-первых, в наихудшей ситуации объекты могут не
очень отличаться по цвету от фона. Во-вторых, на объекты часто наклады-
вается текстура или отметки, которые имеют собственные края, и их бывает
настолько много, что часто сложно отыскать среди них значимые участки
границ объекта. Наконец, края, не имеющие никакого отношения к границам
объектов, могут возникать благодаря теням и т.п. Назовем несколько способов
избежать этих трудностей.
В некоторых ситуациях есть возможность управлять освещением; если мож-
но выбирать освещение, то с помощью тщательного подбора можно достичь
огромной разницы в цвете и устранить тени. Затем, установив большие пара-
метры сглаживания и высокое пороговое значение контрастности, можно убе-
диться, что края, обусловленные текстурой, сглажены и больше не выделя-
ются. Этот метод сомнителен, поскольку трудно подобрать нужные параметры
сглаживания и пороговые значения, а текстура не только мешает, но и несет
определенную информацию.
Существуют другие способы борьбы с неприятными различиями между кра-
ями и границами объектов. Во-первых, можно работать над усовершенствовани-
ем детекторов края. Такой подход широко освещается в литературе по вопросам
определения положения, топологии углов и т.п. Авторы склоняются к мысли,
что в этой области весьма часты повторные открытия. Начать изучение мож-
но с работ [Bergholm, 1987], [Deriche, 1990], [Elder and Zucker, 1998], [Fleck,
1992a], [Kube and Perona, 1996], [Olson, 1998], [Perona and Malik, 1990a,6] или
[Torre and Poggio, 1986].
Во-вторых, можно полностью отрицать пользу от детекторов краев. Такой
подход развился из наблюдения, что на некоторых этапах определения краев,
особенно при немаксимальном подавлении, отбрасывается информация, кото-
рую чрезвычайно сложно восстановить. Это происходит вследствие принятия
Глава 8. Определение краев
273
важного решения — проверять результат с помощью порогового значения. Вза-
мен предлагается сохранять эту информацию в “неявном” (терминология из
области теории вероятностей) виде. Изучив эти доводы, авторы сошлись на
мнении не принимать данную точку зрения, поскольку на сегодняшний день
нет практических механизмов обработки неявной информации.
Наконец, определение краев можно рассматривать как вопрос, связанный со
всеми элементами структуры системы — фаталистическая позиция, состоящая
в том, что почти у каждого процесса визуализации имеются свои трудности,
а правильный подход к этой проблеме состоит в том, чтобы понять, как инте-
грируется визуальная информация и построить систему, толерантную к такой
интеграции. Хотя это выглядит как заметание мусора под коврик (а именно:
непонятно, как можно создать такую структуру), авторы считают этот путь
наиболее привлекательным и постоянно его обсуждают.
Все детекторы краев плохо ведут себя в углах; различны только детали по-
ведения. Переход лапласиана гауссиана через нуль хорошо рассмотрен в работе
[Berzins, 1984]. Плохое поведение гауссиана породило два направления в лите-
ратуре: 1) что не так? 2) как с этим бороться? Существует множество хитроум-
ных детекторов углов, главным образом построенных на наблюдении, что углы
обладают довольно хорошими точечными элементами, подходящими для алго-
ритмов определения соответствий и широко используемых в таких областях,
как стереопсис, реконструкция или восстановление по движению. Это дает
достаточно подробные практические знания о возможности локализации с по-
мощью детекторов углов (см., например, [Schmid, Mohr and Bauckhage, 2000]).
Еще одно направление в литературе — определять, насколько хорошо рабо-
тают детекторы краев. Можно изучать точность локализации (см., например,
[Kakarala and Hero, 1992], [Lyvers and Mitchell, 1988]) или устойчивость ([Cho,
Meer and Cabrera, 1997, 1998]); можно проводить аналогии с человеческими
способностями (работы [Bowyer, Kranenburg and Dougherty, 1999], [Dougherty
and Bowyer, 1998], [Heath, Sarkar, Sanocki and Bowter, 1997]) или сравнивать
схемы в контексте конкретных задач, таких как восстановление структуры по
движению ([Shin, Goldgof and Bowyer, 1998]) или распознавание ([Shin, Goldgof
and Bowyer, 1999]). Некоторые недостатки свойственны всем детекторам краев
(например, поведение в углах рассматривается в работе [Fleck, 19926]).
Края, на которые реагируют детекторы краев, иногда называют ступенча-
тыми краями, поскольку для них характерно скачкообразное изменение значе-
ний, которое иногда моделируют в виде ступенек. Изучается множество других
видов краев. Самый распространенный пример — это крышеподобный край,
который состоит из растущего сегмента, соединенного со спадающим, что до-
вольно похоже на следствие взаимного отражения (рис. 5.16). Другим следстви-
ем взаимного отражения является комбинация ступенчатого и крышеподобного
краев. Найти эти элементы можно, применив, по сути, те же действия, что бы-
ли описаны выше (найти “оптимальный” фильтр и выполнить немаксимальное
подавление), см. [Саппу, 1986], [Perona and Malik, 1990а,Ь]. На практике это
делается редко, чему есть два объяснения. Во-первых, в теории (и на практи-
274
Часть II. Первые этапы: одно изображение
ке) нет удобного базиса для принятых моделей. Какие именно составные края
следует искать? Простой ответ — те, для которых легко найти оптимальный
фильтр — самый неудовлетворительный. Во-вторых, семантика крышеподобнйх
и более сложных составных краев еще неопределеннее, чем для ступенчатых
краев. Кроме того, неизвестно, что делать с крышеподобным краем после того,
как он будет найден.
Края сложно определить и трудно найти, но задачи с выходом схемы опре-
деления краев решаются. Крышеподобные края точно так же трудно определить
и сложно найти; к тому же ни одна задача с выходом схемы детекторов кры-
шеподобных краев не была решена. Реальная проблема заключается в том, что
не существует надежного механизма предсказания того, что стоит искать. Гра-
ницы этой очень сложной задачи будут очерчены далее.
ЗАДАЧИ
8.1. Все значения пикселей на изображении Т размером 500 х 500 пиксе-
лей — независимые нормально распределенные случайные числа с нуле-
вым средним значением и единичным среднеквадратическим отклонени-
ем. Оцените количество пикселей, значения которых больше 3, причем
абсолютное значение производной по х оценивается с помощью правой
разности (т.е. |Д+1 j - 4 J).
8.2. Все значения пикселей на изображении Т размером 500 х 500 пиксе-
лей — независимые нормально распределенные случайные числа с нуле-
вым средним значением и единичным среднеквадратическим отклонени-
ем. Изображение Т свернуто с ядром G размером 2fc +1 х 2fc +1 . Какова
будет ковариантность значений пикселей в результате свертки? Есть два
способа решения: в специальном базисе (например, в точках, которые
больше, чем 2к + 1, либо по координате х, либо по у, значения обя-
зательно независимы) или в базисе, образованном быстро спадающими
векторами. Значения пикселей на границе не важны.
8.3. Камера выдает целые значения от 0 до 255. Пространственное разреше-
ние камеры — 1024 х 768 пикселей, и она делает 30 кадров в секунду.
Камеру устанавливают таким образом, чтобы при отсутствии шума она
выдавала постоянное значение 128. Выходные данные подвержены шу-
му, который моделируется стационарным аддитивным гауссовым процес-
сом с нулевым средним значением и среднеквадратическим отклонением,
равным 1. Сколько придется ждать, чтобы по модели шума можно было
предсказать, что появятся пиксели с отрицательными значениями? Под-
сказка’. стоит использовать логарифмирование, поскольку прямая оцен-
ка ехр(—1282/2) даст 0; фокус состоит в том, что нужно пренебречь
большими положительными и большими отрицательными логарифмами.
8.4. В разделе 8.3.1 говорилось, что чувствительный двумерный аналог од-
номерной второй производной должен быть инвариантным относительно
вращения. Почему?
Глава 8. Определение краев
275
Упражнения
8.5. Почему нужно проверять величину градиента при переходах через нуль
лапласиана изображения? Назовите типы краев, для которых эта провер-
ка очень важна.
8.6. Лапласиан гауссиана похож на разницу между двумя гауссианами при
различном масштабе. Сравните эти два ядра для различных значений
двух масштабов. Какой выбор даст хорошую аппроксимацию? Насколько
существенна ошибка аппроксимации при определении края с помощью
метода переходов через нуль?
8.7. Получите реализацию детектора края Кэнни (Саппу) (можно поискать на
домашней странице данной книги; реализация также есть в пакете MAT-
LAB) и создайте ряд изображений, иллюстрирующих действие порогов
контрастности и масштаба на обнаруживаемые края. Насколько сложно
настроить детектор на обнаружение только границ объектов? Можете ли
вы представить области применения, где это будет несложно?
8.8. Эффект гистерезиса детекторов краев, в которых он реализуется, доста-
точно просто свести на нет — по сути, для одного значения устанавли-
ваются меньший и больший пороги. Воспользуйтесь этой хитростью для
сравнения поведения детектора краев с гистерезисом и без него.
а) Что вы будете делать с результатами работы детектора краев? Иногда
полезны связанные цепочки краевых точек. Важна ли здесь помощь
гистерезиса?
б) Подавление шума: часто хочется заставить детектор краев игнори-
ровать некоторые краевые точки и отмечать другие. Считается, что
края полезны при высокой контрастности (это действительно так).
Насколько уверенно можно пользоваться гистерезисом для подавле-
ния низкоконтрастных краев, не нарушая высококонтрастные края?
9
Текстура
Текстура — это широко распространенное явление, которое легко распознать,
но которому сложно дать определение. Как правило, относится эффект к тек-
стуре или нет, — зависит от масштаба, при котором он рассматривается. Ли-
сток, занимающий почти все изображение, — это объект, но листва дерева —
это текстура. Источников текстуры множество. Во-первых, изображения, со-
стоящие из большого количества мелких предметов, лучше всего считать тек-
стурой. В качестве примеров можно назвать траву, листву деревьев, гравий,
шерсть, щетину. Во-вторых, многие поверхности покрыты правильными узора-
ми, которые выглядят как большое количество мелких предметов. Примеры:
пятна на шкуре животных, как у гепарда или леопарда; полосы, как у тигра
или зебры; узоры на коре деревьев, древесине и коже.
С текстурой обычно связаны три основные задачи.
• Сегментация текстуры — это задача, которая состоит в разбиении изоб-
ражения на участки с постоянной текстурой. Сегментация текстуры вклю-
чает в себя как представление текстуры, так и вычисление базиса, в ко-
тором будут определяться границы сегментов. В данной главе будет рас-
смотрено только представление текстуры (раздел 9.1); в главах 14 и 16
будет рассказано о том, как с помощью этого представления проводить
сегментацию текстурированных изображений.
278
Часть II. Первые этапы: одно изображение
ЛЛ л
М’т'М*
чг^-*^*^**
Рис. 9.1. Примеры текстуры для экспериментов — людям предлагается описать внешний вид раз-
личных текстур. Обратите внимание, что примеры включают достаточно стилизованные элементы,
повторяющиеся в определенном порядке. Перепечатано из J. Malik and Р. Perona, "A computa-
tional model of texture segmentation”, IEEE Conference on Computer Vision and Pattern Recognition,
1989. © 1989 IEEE
• Синтез текстуры служит для создания больших текстурных областей
из маленьких элементов изображений. Это делается с помощью пробных
изображений, по которым строятся вероятностные модели текстуры, а за-
тем эти вероятностные модели применяются для создания изображений
с текстурой. Существует множество способов построения вероятностных
моделей; три удачных современных метода описаны в разделе 9.3.
• Определение формы по текстуре состоит в восстановлении ориентации
поверхности или ее формы по текстуре изображения. Это можно сделать,
допустив, что текстура “выглядит одинаково” в различных точках поверх-
ности, т.е. изменение структуры от одной точки к другой может быть
ключом к форме поверхности. В разделе 9.4 описаны основные положе-
ния этой (достаточно технической) отрасли знаний.
9.1. ПРЕДСТАВЛЕНИЕ ТЕКСТУРЫ
Текстура изображения обычно включает упорядоченные узоры, состоящие
из правильных элементов (которые иногда называют те кетонами). Например,
одна из текстур на рис. 9.1 состоит из треугольников. Другая текстура на этом
рисунке состоит из стрелочек. Естественный способ представления текстуры —
это найти текстоны и описать их расположение.
Недостаток описанного метода заключается в том, что нет известного кано-
нического набора текстонов, т.е. не ясно, что следует искать. Вместо того, чтобы
искать узоры на уровне стрелочек и треугольников, можно искать еще более
простые элементы — скажем, точки и полосочки — и рассуждать об их про-
странственном расположении. Преимущество такого метода состоит в том, что
простые элементы узора нетрудно найти с помощью фильтрации изображения.
9.1.1. Определение структуры изображения с помощью блоков
фильтров
В разделе 7.5 говорилось, что свертка изображения с линейным фильтром
представляет изображение в другом базисе. Преимущество преобразования
изображения в новый базис, которое дает его свертка с фильтром, состоит
в том, что этот процесс выявляет структуру изображения. Это происходит бла-
Глава 9. Текстура
279
Рис. 9.2. Типичные текстурированные изображения. Человеческое восприятие и распознавание
таких материалов, как шерсть, трава, листва и вода тесно связано с текстурой (какой будет поверх-
ность, изображенная на рисунке слева, если ее коснуться пальцами? мокрая или сухая? и т.д.).
Обратите внимание, сколько информации о виде растений, их форме и т.п. можно получить из
текстуры на рисунке справа. Эти примеры текстуры также состоят из довольно стилизованых эле-
ментов, создающих впечатление некоторого узора
годаря тому, что реакция фильтра сильнее тогда, когда узор изображения на
каком-либо участке похож на ядро фильтра, и слабее в противном случае.
Таким образом можно представить текстуру изображения в виде реакции на-
бора фильтров. Набор различных фильтров должен состоять из серий узоров —
как правило, пятен и полос — при определенной последовательности масштабов
(чтобы, например, можно было определять размер этих пятен или полос). Зна-
чение каждой точки полученного изображения будет описывать “пятнистость”
(“полосатость” и т.д.) в соответствующей точке изображения при определен-
ном масштабе. Несмотря на то, что на данный момент такой подход является
сильно избыточным, он дает представление структуры (ее “пятнистости”, “по-
лосатости” и т.д.), которое оказалось очень полезным.
Следует отметить, что фильтры пятен полезны благодаря сильной реакции
на небольшие участки, которые отличаются от соседних (например, это может
быть либо одна сторона края, либо пятно). Еще одна привлекательная черта —
фильтры пятен могут определять неориентированную структуру. Фильтры по-
лос, с другой стороны, ориентированы и лучше реагируют на ориентированную
структуру.
280
Часть II. Первые этапы: одно изображение
Рис. 9.3. Набор из восьми фильтров, которые используются для разложения изображения на
серию характеристик. Масштаб фильтров представлен таким образом: нуль обозначен нейтрально
серым цветом, более светлые значения положительны, а более темные — отрицательны. Представ-
лены два отдельных пятна и шесть полос (набор фильтров аналогичен использованному в работе
[Malik and Perona, 1990])
Выделение пятен и полос с помощью взвешенных сумм гауссианов
Какими фильтрами стоит пользоваться? Ответа на этот вопрос нет. Точнее,
могут подойти многие ответы. По аналогии с процессами, происходящими в ко-
ре головного мозга человека, обычно берется по меньшей мере один фильтр
пятен и набор ориентированных фильтров полос для различных направлений,
масштабов и фаз. Фазой полосы называют фазу поперечного сечения пер-
пендикулярно полосе, которую определяют по аналогии с фазой синусоиды
(например, если поперечное сечение проходит через нуль в начале координат,
фаза равна 0°).
Один из способов получить требуемый фильтр — это найти взвешенную
разность гауссовых фильтров при различных масштабах; именно этот метод
применялся для получения рис. 9.3. Перечислим элементы фильтров приведен-
ного примера.
• Пятно, которое задается взвешенной суммой трех концентрических сим-
метричных гауссианов с весовыми коэффициентами 1; —2 и 1, причем
соответствующие дисперсии равны 0,62; 1 и 1,6.
• Другое пятно, которое задается взвешенной суммой двух концентриче-
ских симметричных гауссианов с весовыми коэффициентами 1 и —1, при-
чем соответствующие дисперсии равны 0,71 и 1,14.
• Набор ориентированных полос, состоящий из взвешенной суммы трех
ориентированных гауссианов, которые расходятся в разные стороны. Су-
ществует шесть вариантов таких полос; каждая из них представляет собой
Глава 9. Текстура
281
Рис. 9.4. Вверху показано изображение бабочки с мелким масштабом, а ниже — результат дей-
ствия на это изображение каждого из фильтров (рис. 9.3). Результаты представлены как абсолют-
ные значения на выходе, более светлые пиксели указывают на более сильную реакцию; изображе-
ния расположены согласно порядку фильтров на верхнем рисунке
повернутую под некоторым углом горизонтальную полосу. Весовые коэф-
фициенты полос равны —1; 2 и —1, причем дисперсия у них отличается по
осям х и у, все ах равны 2, а все ау равны 1. Центры полос расположены
на оси у в точках (0,1); (0,0) и (0, —1).
Следует понимать, что выбор фильтра почти всегда происходит интуитив-
но. Опыт подсказывает, что фильтр должен состоять из набора пятен и полос
различного масштаба и направления (что и представляет собой данный набор),
но очень мало причин верить, что оптимизируя выбор фильтра, можно достичь
серьезного улучшения.
На рис. 9.4 и 9.5 показано абсолютное значение реакции блока фильтров
на заданное изображение бабочки. Обратите внимание, что несмотря на то,
что фильтры полос не выступают абсолютно надежными детекторами полос
(поскольку фильтр полос при определенной ориентации реагирует на полосы
различного размера и направления), данные с фильтра неплохо передают ин-
формацию об изображении. Вообще говоря, фильтры полос сильно реагируют
на ориентированные полосы и слабо — на другие узоры, а фильтры пятен реа-
гируют на отдельные пятна.
282
Часть II. Первые этапы: одно изображение
Рис. 9.5. Исходное изображение бабочки и реакция фильтров (рис. 9.3) при более грубом мас-
штабе, чем на рис. 9.4. Обратите внимание, что ориентированные полосы дают реакцию на усики,
края крыльев и полосы на крыльях; тот факт, что наблюдается реакция на одну полосу, вовсе не
означает, что не будет реакции на другую, но величина реакции говорит об ориентации полосы на
изображении
Сколько нужно фильтров и с какой ориентацией?
Точно неизвестно, какое количество фильтров будет “самым лучшим” для
хороших текстурных алгоритмов. В работе [Регопа, 1995] исследовано, сколько
масштабов и направлений стоит применять в ряде систем; число масштабов ко-
леблется от четырех до одиннадцати и число направлений — от двух до восем-
надцати. Количество направлений меняется в зависимости от задачи и не имеет
большого значения, по крайней мере, до тех пор, пока используется около шести
направлений. Как правило, фильтрами “пятен” выступают гауссианы, а фильтры
“полос” определяются дифференцированием ориентированных гауссианов.
Подобным образом, не особо выгодно пользоваться более сложными набо-
рами фильтров, чем основная комбинация фильтров пятен и полос. В этом есть
тонкий момент: применение большего числа фильтров приводит к более подроб-
ному (и более перегруженному) описанию изображения; кроме того, придется
находить свертку изображения со всеми этими фильтрами, что само по себе
достаточно недешево. Единственное, как можно упростить процесс, — постро-
ить пирамиду, чтобы контролировать объем лишней информации, с которой
приходится иметь дело.
Глава 9. Текстура
283
9.1.2. Описание текстуры с помощью статистики выходов фильтров
Набор отфильтрованных изображений сам по себе не является описанием
текстуры, поскольку еще требуется описание общего распределения элементов
текстуры. Например, поле желтых цветов может состоять из множества малень-
ких желтых пятен с вертикальными зелеными полосками; зебра может состоять
из черных полос на белом фоне. Неявно предполагается, что масштаб тексту-
ры описан. Маленькое окно изображения поля желтых цветов может вмещать
только один цветок; для изображения зебры оно может состоять из однородного
черного или белого участков. Подобным образом, слишком большое окно может
содержать не только нужную текстуру, но и фон. Обратите внимание, что здесь
есть два масштаба: во-первых, масштаб фильтров, а во-вторых — масштаб, при
котором рассматривается распределение фильтров.
Предположим, что известен размер значимого окна изображения, для кото-
рого нужно описать текстуру. Характерное описание состоит из набора стати-
стических данных с выходов фильтров для этого окна. Выходные данные обыч-
но возводят в квадрат (помимо всего прочего, это позволяет подсчитать число
черных полос, следующих за белыми, и число белых, следующих за черными).
Например, на рис. 9.6 показано возможное представление через вертикальную
и горизонтальную текстуры. Это представление было получено путем отбора
с выходов фильтров вертикальных (или горизонтальных) полос и возведения
их в квадрат. Затем результат сглаживался при более грубом масштабе. Это
сглаживание эквивалентно оценке среднего значения возведенных в квадрат
выходов фильтров для определенного окна. Наконец, сглаженные данные по-
падают в классификатор, который собственно и дает представление текстуры.
На рис. 9.6 текстура относится к одному из четырех классов по такому прин-
ципу: большое значение выходов вертикального либо горизонтального фильтра,
обоих или ни одного из них.
Выбор статистики
То, какую статистику следует собирать, зависит в некоторой степени от опи-
сываемого объекта. Однако работа над синтезом текстуры налагает некоторые
ограничения на выбор соответствующей модели, поэтому данная тема подробно
рассмотрена в разделе 9.3. Предположим, что масштаб окна, по которому нуж-
но собрать статистику, установлен (один из путей — найти среднее значение
квадрата выходов фильтра для ряда фильтров; см. работу [Malik and Perona,
1989]). Затем окно описывается вектором значений, каждое из которых — это
квадрат средней по окну реакции определенного фильтра. С помощью этого ме-
тода можно отличить, например, пятнистые окна — те, в которых будет высокой
средняя реакция фильтров пятен, — от полосатых окон, где высокой будет сред-
няя реакция фильтров полос. Этот метод проиллюстрирован на рис. 9.6, правда
там набор фильтров несколько богаче.
Альтернативный подход — вычислять среднее значение и среднеквадрати-
ческое отклонение выходов фильтров по всему окну и пользоваться результа-
284
Часть II. Первые этапы: одно изображение
Вертикальный фильтр
Горизонтальный фильтр
Квадрат отклика
Сглаженное среднее
Классификация
Рис. 9.6. Предположительное представление текстуры через выходы фильтров. Количество филь-
тров значительно уменьшено (два фильтра производных, один вертикальный и один горизонталь-
ный). Слева показано исходное изображение; обратите внимание, что его составляющие можно
корректно описать как горизонтальную, вертикальную и с неопределенной ориентацией. Слева
в центре показаны возведенные в квадрат выходы фильтров (переходы от черного к белому учи-
тываются так же, как и от белого к черному). Значения приведены к одинаковому линейному
масштабу, причем более светлые точки указывают на более сильную реакцию. В центре справа
показано сглаженное изображение (которое можно интерпретировать как среднее значение квадра-
та реакции по малому окну). Средняя реакция на вертикальные полосы сильнее на вертикальной
карте, а на горизонтальные полосы — на горизонтальной карте. Наконец, эти два изображения
сравнивались с порогом, их комбинация показана на рисунке справа (черные значения не относят-
ся ни к вертикальным, ни к горизонтальным; темно-серые значения горизонтальны; светло-серые —
вертикальны; а белые значения относятся и к тем, и к другим)
тами этих вычислений для построения характеристического вектора (см. [Ма
and Manjunath, 1996]). Такое представление текстуры можно использовать для
восстановления окон изображения на основе примеров (рис. 9.7). Аналогичным
способом на спутниковых изображениях по текстуре определяют, обозначает ли
данная область жилой массив или сельскохозяйственные угодья. Это означает,
что если подобрать текстуру, то на спутниковом изображении можно найти все
изображения, скажем, сельскохозяйственных угодий. Отметим, что две тексту*
ры с совершенно различными характеристическими векторами могут оказаться
очень похожими; этого можно избежать, изменив способ измерения разницы
характеристических векторов.
Глава 9. Текстура
285
Область запроса
Области, для которых
найдено соответствие
Области, для которых соответствие
найдено с использованием
модифицированной метрики подобия
Рис. 9.7. Текстуру можно представить средним значением и среднеквадратическим отклонением
выходов фильтров, взятых по окну. Если пользоваться набором различных фильтров, будет
получен вектор значений, описывающих окно; у пятнистой текстуры будет большое среднее
значение на выходе фильтров пятен, у полосатой текстуры — большое среднее значение на выходе
фильтров полос и т.д. Это означает, что окно изображения можно сравнить с другими, вычислив
длину характеристического вектора. В качестве подобной длины можно использовать обычное
евклидово расстояние (рис. слева), хотя несколько модифицировав эту меру, результаты можно
значительно улучшить (рис. справа). Перепечатано из W.Y. Ma and B.S. Manjunath, “Texture
Features and Learning similarity”, Proceedings IEEE Conference on Computer Vision and Pattern
Recognition, 1996. (c) 1996 IEEE
Ни само no себе среднее значение, ни среднее значение плюс среднеквадра-
тическое отклонение не являются идеальным представлением, поскольку связь
между характеристиками фильтров может быть существенной. Например, пред-
ставьте себе текстуру, состоящую из небольших пятен, расположенных ряда-
ми, — так выглядит сверху, скажем, капустное поле. При подобной текстуре
фильтр мелких пятен будет давать сильную реакцию, но реакции фильтров
коррелируют и фильтр больших полос дает значительную реакцию там же,
где и фильтр мелких пятен. Если текстура состоит из множества больших по-
лос, разбросанных на фоне мелких пятен, фильтр мелких пятен, как и фильтр
286
Часть II. Первые этапы: одно изображение
больших полос, будет давать сильную реакцию, но эти реакции могут не корре-
лировать. Можно попытаться записать ковариантность выходов фильтров (на-
пример, для того же капустного поля), но для точной оценки понадобилось
бы учесть слишком много членов. Вместо этого обычно определяют несколько
ковариантных членов, необходимых для конкретной задачи.
Выбор масштаба
Еще один вопрос, с которым обычно сталкиваются на практике, — это вы-
бор масштаба для описания текстуры. Как правило, выбирают небольшое окно
с центром в требуемой точке, а затем увеличивают размер этого окна до тех
пор, пока увеличение размеров окна перестанет приводить к значительным из-
менениям. Например, представьте себе выбор пикселя на изображении зебры.
В пределах очень маленького окна вокруг этого пикселя значение яркости по-
стоянно (например, черное). Если немного увеличить окно, то он будет вклю-
чать область резкого перехода и несколько черных и белых пикселей. Если окно
будет еще больше и в него будут попадать несколько полос, то последующее
увеличение окна не даст никаких существенных изменений — это будет просто
большое полосатое окно.
Оценить момент, когда следует прекратить расширение окна, позволяет по-
лярность. Определим вначале доминирующую ориентацию окна — среднее
направление градиента. Теперь для каждого вектора градиента найдем скаляр-
ное произведение вектора градиента и доминирующей ориентации. Затем вы-
числим среднее сглаженное значение положительных скалярных произведений
и сглаженное среднее значение модуля отрицательных скалярных произведений
и найдем их разность. Это даст величину градиентов в данной области в на-
правлении доминирующей ориентации (положительные скалярные произведе-
ния) относительно направления, противоположного доминирующей ориентации
(отрицательные скалярные произведения).
Эту величину можно измерить для произвольного масштаба окна. Как пра-
вило, так и делают для ряда окон различных размеров, а затем, начиная с са-
мого мелкого масштаба и далее в порядке возрастания, отмечают, когда при
изменении масштаба полярность изменяться не будет. Заметим, что в некото-
рых случаях этот критерий может быть неоднозначным. Например, возьмем
фотографию зебры с очень высоким разрешением. Если начать с довольно ма-
ленького окна (которое может содержать один волосок), то этот критерий опре-
делит масштаб, при котором окно будет содержать несколько волосков. Если
же начать с немного большего окна, содержащего много волосков, то этот же
критерий определит масштаб, охватывающий несколько полос.
9.2. АНАЛИЗ И СИНТЕЗ С ПОМОЩЬЮ ОРИЕНТИРОВАННЫХ ПИРАМИД
Для описания текстуры с помощью статистических данных блока филь-
тров необходима свертка изображения с несколькими фильтрами при несколь-
ких масштабах. Существует множество способов систематического выполнения
Глава 9. Текстура
287
этой операции, некоторые из них описаны в данном разделе. Если читателям
этот вопрос не интересен, они могут переходить к разделу 9.3.
Процесс свертки изображения с блоком фильтров называется анализом;
свертку изображения с блоком ориентированных фильтров иногда (и, по мне-
нию авторов, достаточно неточно) называют анализом ориентации или пред-
ставлением ориентации. Примером анализа изображения с помощью блока
фильтров (в данном случае — фильтров сглаживания) является гауссова пи-
рамида (раздел 7.7.1). Гауссова пирамида перебирает масштаб систематически,
проводя повторную выборку изображения после его сглаживания. Это означа-
ет, что следующий по величине масштаб получить легче, поскольку лишняя
информация не обрабатывается.
Фактически, гауссова пирамида — это очень избыточное представление, по-
скольку каждый слой является результатом действия низкочастотного фильтра
на предыдущий слой, т.е. самые низкие пространственные частоты описыва-
ются множество раз. Слой гауссовой пирамиды предсказывает вид следующего
уровня с более мелким масштабом. Это предсказание неточное, но оно говорит
о том, что не обязательно сохранять все детали слоя с более мелким масшта-
бом. Нужно только зафиксировать ошибки предсказания. Эта идея и лежит
в основе лапласовой пирамиды.
Лапласова пирамида служит для представления различных масштабов при
достаточно низком уровне избыточности, но она не описывает непосредствен-
но ориентацию. В разделе 9.2.2 при рассмотрении пирамид в области Фурье-
образов определяется метод декодирования информации об ориентации. В раз-
деле 9.2.3 представлен альтернативный метод описания ориентации.
9.2.1. Лапласова пирамида
В лапласовой пирамиде используется то, что более грубый слой гауссовой
пирамиды предсказывает общий вид следующего слоя с более мелким масшта-
бом. Если есть такой оператор, который дает более грубую версию слоя того
же размера, что и следующий слой с более мелким масштабом, то нужно толь-
ко указать разницу между этим предсказанием и следующим слоем с более
мелким масштабом.
Ясно, что информацию об изображении создать из ничего нельзя, но можно
дополнить изображение с грубым масштабом, продублировав некоторые пиксе-
ли. Запишем соответствующее преобразование через оператор перевыборки
который переводит изображение уровня п+1 в изображение уровня п. В частно-
сти, 5T(Z) увеличивает изображение в два раза в каждом направлении. Все че-
тыре элемента полученного изображения с координатами (2J—1,2fc—1); (2J, 2к—
1); (2j — 1,2k) и (2j, 2к) имеют такое же значение, как и j, к-й элемент изоб-
ражения Т.
Анализ: построение лапласовой пирамиды по изображению
Самый нижний уровень лапласовой пирамиды (наиболее грубый масштаб)
аналогичен нижнему уровню гауссовой пирамиды. Каждый следующий уровень
288
Часть II. Первые этапы: одно изображение
лапласовой пирамиды представляет собой разность между слоем гауссовой пи-
рамиды и предсказанием, полученным при действии оператора на предыду-
щий слой гауссовой пирамиды. Это означает, что
Рл(2)™ = PG(l)m
(где т — самый грубый масштаб, L — лапласов, G — гауссов), а
Рь(Т)к = Ра(Т)ь - S\PG(l)k+1) =
= (/d~STSiGCT)PG(Z)fc.
Следствием подобных соображений является алгоритм 9.1. Название “лапласов
фильтр” несколько неточно (здесь нет операторов дифференцирования), но оно
допустимо, поскольку каждый слой приблизительно равен результату вычита-
ния гауссова фильтра.
Алгоритм 9.1. Построение лапласовой пирамиды по изображению
Построить гауссову пирамиду
Положить нижний слой лапласовой пирамиды равным нижнему слою гауссовой
пирамиды
Для каждого слоя снизу вверх
Определить этот слой в лапласовой пирамиде, действуя на предыдущий слой
оператором и вычитая результат из соответствующего слоя гауссовой
пирамиды
конец
Каждый слой лапласовой пирамиды можно рассматривать как реакцию
полосового фильтра, поскольку берется изображение с определенным разреше-
нием и отсекаются компоненты, которые можно предсказать по версии с более
грубым разрешением, что соответствуют компонентам изображения с низкими
пространственными частотами. Это, в свою очередь, означает, что изображение
набора полос с определенной пространственной частотой может дать сильную
реакцию на одном уровне пирамиды и слабую реакцию на других уровнях
(рис. 9.8).
Поскольку различные уровни пирамиды описывают различные простран-
ственные частоты, лапласовой пирамидой можно пользоваться в качестве до-
статочно эффективной схемы сжатия изображения.
Синтез: восстановление изображения по его лапласовой пирамиде
Лапласовы пирамиды имеют одно очень важное свойство: по ним нетрудно
восстановить изображение. Для этого гауссова пирамида переводится в лапла-
сову, а затем берется уровень с самым мелким масштабом гауссовой пирамиды
(который и является изображением). Найти гауссову пирамиду по лапласовой
Глава 9. Текстура
289
несложно. Во-первых, самый грубый масштаб гауссовой пирамиды аналогичен
самому грубому масштабу лапласовой пирамиды. Следующий масштаб гауссо-
вой пирамиды находится путем применения оператора к самому грубому
масштабу и прибавления полученного результата к следующему уровню лапла-
совой пирамиды (и т.д. по всем масштабам). Этот процесс называется синтезом
и описан в алгоритме 9.2.
Алгоритм 9.2. Синтез: восстановление изображения по лапласовой пирамиде
Принять текущее изображение в качестве самого грубого слоя
Для каждого слоя, от следующего за самым грубым до самого мелкого
Подействовать на текущее изображение оператором S'T и прибавить
к результату текущий слой
Принять текущим изображением результат предыдущей операции
конец
Конечное текущее изображение является исходным изображением
9.2.2. Фильтры в области пространственных частот
Лучше понять действие фильтров и то, какую информацию содержат пира-
миды, помогает теорема о свертке (свертка в пространственной области рав-
носильна умножению Фурье-образов). Проиллюстрируем эту теорему, указав
на естественную аналогию между сглаживанием и действием низкочастотного
фильтра, а также показав, что некоторые виды полосовых фильтров естественно
реагируют на ориентированные структуры и что одну схему локального анали-
за пространственных частот можно осуществить с помощью особого семейства
фильтров.
Сглаживание и низкочастотные фильтры
Теорема о свертке говорит о том, что свертка изображения с изотропным
гауссианом со среднеквадратическим отклонением а равносильна умножению
Фурье-образа изображения на изотропный гауссиан со среднеквадратическим
отклонением 1/сг. Теперь гауссиан спадает достаточно быстро, особенно если
его среднеквадратическое отклонение велико. Это означает, что Фурье-образ
результата при высоких пространственных частотах будет обладать достаточ-
но небольшой энергией, так как высокая пространственная частота несколько
раз умножается на 1/<т. Это можно интерпретировать как применение низко-
частотного фильтра, который хорошо пропускает низкие пространственные
частоты и плохо — высокие. Довольно удачная интерпретация: если сглаживать
гауссиан с очень малым среднеквадратическим отклонением, будут сохранены
все пространственные частоты, кроме самых высоких; а если сглаживать гаус-
сиан с очень большим среднеквадратическим отклонением, то результат будет
мало отличаться от среднего значения изображения. Это означает, что гаус-
290
Часть II. Первые этапы: одно изображение
512 256 128
Рис. 9.8. Лапласова пирамида изображений размером от 512 х 512 до 8 х 8. Нулевая реакция
показана нейтральным серым цветом, положительные значения светлее, а отрицательные — темнее.
Обратите внимание, что реакция на полосы сильнее всего при определенном масштабе, поскольку
каждый слой соответствует (приблизительно) выходу полосового фильтра
сова пирамида, по сути, является набором различных вариантов изображения,
подверженных действию низкочастотных фильтров.
Полосовые фильтры и операторы выбора ориентации
Полосовой фильтр хорошо пропускает некоторый диапазон пространствен-
ных частот и плохо пропускает более высокие или более низкие частоты.
Некоторые полосовые фильтры нечувствительны к ориентации. Естественным
примером такого фильтра может быть сглаживание изображения с помощью
разности двух изотропных гауссианов, одного с малым среднеквадратическим
отклонением, а другого — с большим. В Фурье-области ядро этого фильтра вы-
глядит как кольцо больших значений (рис. 9.9, справа); это означает, что ядро
выбирает диапазон пространственных частот, но не селективно относительно
Глава 9. Текстура
291
Пирамида Лапласа
Рис. 9.9. Каждый слой лапласовой пирамиды состоит из элементов сглаженного и перевыбран-
ного изображений, которые не представлены в следующем слое сглаживания. Предположив, что
гауссиан — это достаточно хороший фильтр сглаживания, каждый слой можно считать описа-
нием компонентов изображения в пределах определенного диапазона пространственных частот.
Это означает, что Фурье-образ каждого слоя представляет собой кольцо значений из пространства
Фурье-образов (u,v) (напомним, что модуль вектора (и, и) описывает пространственную частоту).
Сумма этих колец — это Фурье-образ всего изображения, так что каждый слой вырезает коль-
цо из Фурье-образа изображения. Ориентированная пирамида разрезает каждое кольцо на набор
клиньев. Если пространство (u,v) задано в полярных координатах, то каждый клин соответствует
отрезку значений радиуса и отрезку значений угла (напомним, что arctg(u/v) показывает ориен-
тацию базисного элемента в Фурье-пространстве)
ориентации (поскольку точки на одинаковом расстоянии от начала координат
соответствуют в Фурье-пространстве базисным частотным элементам с различ-
ными ориентациями). Идеальный полосовой фильтр выдает единичное значение
внутри кольца и нулевое значение за его пределами, поэтому у такого фильтра
будет бесконечным пространственный носитель (что значительно усложняет
работу с ним), следовательно приемлемым практическим выбором ядра являет-
ся разность гауссианов. Конечно, эта разность гауссианов представляет собой
фильтр, который используется для нахождения лапласовой пирамиды, так что
лапласова пирамида состоит из набора различных вариантов изображения, под-
верженного действию полосовых фильтров.
Имеется другой тип полосовых фильтров, Фурье-образы которых дают боль-
шое значение в пределах клина кольца, и маленькое — за его пределами
(рис. 9.9, справа) — этот фильтр ориентационно селективен, т.е. он силь-
нее всего реагирует на сигналы, которые попадают в определенный диапазон
пространственных частот и имеют определенную ориентацию.
292
Часть II. Первые этапы: одно изображение
Рис. 9.10. Ядро фильтра Габора является произведением симметричного гауссиана и ориентиро-
ванной синусоиды; форма ядра описана в тексте. На рисунках показаны ядра фильтров, где ней-
тральный серый цвет обозначает нулевые значения, более темным цветом показаны отрицательные
значения, а более светлым — положительные. В верхней строке показан антисимметричный ком-
понент, в нижнем — симметричный. Разность фаз между симметричным и антисимметричным
компонентами составляет тг/2 радиан, поскольку перпендикулярное к полосе поперечное сечение
(в данном случае горизонтальное) дает синусоиды именно с такой разностью фаз. Масштаб пока-
занных фильтров постоянен, фильтры изображены для трех различных пространственных частот.
На рис. 9.11 представлены фильтры Габора для более мелкого масштаба
Локальный анализ пространственных частот и фильтры Габора
Одна из сложностей, касающихся преобразований Фурье, — это то, что
коэффициенты ряда Фурье зависят от изображения в целом; для вычисления
значения Фурье-образа отдельного вектора (и, v) используются все пиксели
изображения. Это неудобный способ работы с изображением, поскольку теря-
ется вся пространственная информация. Например, на рис. 9.12 при перемеще-
нии вдоль изображения полосы становятся шире. Если рассуждать в терминах
пространственных частот, определенных только локально, то это явление мож-
но считать изменением содержания изображения при перемещении по нему.
В некотором окне вокруг точки узкие полосы выглядят как члены с высокой
пространственной частотой, а широкие полосы кажутся членами с низкой про-
странственной частотой.
Отмеченных недостатков не имеют фильтры Габора. Их ядра выглядят как
элементы базиса Фурье, умноженные на гауссианы; таким образом, фильтры
Габора дают сильную реакцию в тех точках изображения, где есть компоненты
Глава 9. Текстура
293
Рис. 9.11. На рисунках показаны ядра фильтров Габора, причем нейтральный серый цвет обо-
значает нулевые значения, более темным цветом показаны отрицательные значения, а более свет-
лым — положительные. В верхней строке показан антисимметричный компонент, в нижием —
симметричный. Масштаб показанных фильтров постоянен, и они изображены для трех различных
пространственных частот. Фильтры представлены при более мелком масштабе, чем на рис. 9.10
с локальными особенностями пространственной частоты и ориентации. Филь-
тры Габора используются парами, которые часто называют квадратурными
парами", один фильтр из этой пары служит для определения симметричных
компонентов определенного направления, а другой — антисимметричных. Ма-
тематически симметричное ядро записывается так:
Ссим(^, у) = cos {kxx 4- kyy) exp -
{2 । 2
s 4-т/ 1
2cr2 J
тогда как антисимметричное имеет вид
СанТисим(х, у) = sin (кох 4- kiy) exp -
„2 । .,2
X +У
2а2
Эти фильтры показаны на рис. 9.10 и 9.11; вектор (кх,ку) определяет простран-
ственную частоту, на которую фильтр реагирует сильнее всего, а а называет-
ся масштабом фильтра. В принципе, с помощью очень большого количества
фильтров Габора с различными масштабами, ориентациями и пространственны-
ми частотами можно дать подробное локальное описание изображения. Фильтр
Габора с = оо аналогичен Фурье-образу, вот почему существует два вида
294
Часть II. Первые этапы: одно изображение
«vm
Рис. 9.12. На рисунке вверху показан элемент изображения зебры, содержащий полосы несколь-
ко разного масштаба и ориентации. Была выполнена свертка этого изображения с ядром фильтра
Габора, изображенным в центре. На рисунке внизу показано абсолютное значение результата; за-
метим, что большая реакция наблюдается там, где пространственная частота полос приблизительно
совпадает с частотой гауссиана в ядре гауссова фильтра, (т.е. полосы в одном ядре имеют прибли-
зительно ту же ширину и ориентацию, что и в другом ядре), если полосы больше или меньше, ре-
акция снижается; следовательно, фильтр осуществляет некий анализ локальных пространственных
частот. Приведенный фильтр является одним из фильтров квадратурной пары (ее симметричный
компонент). Реакция антисимметричного компонента обладает сходной частотной селективностью.
Данные две реакции можно рассматривать как два компонента локального преобразования Фурье
(комплексного значения), так что из них можно извлечь информацию о модуле и фазе
фильтров и почему можно считать, что фильтр Габора выполняет локальный
анализ пространственных частот.
9.2.3. Ориентированные пирамиды
Лапласова пирамида не содержит достаточно информации, чтобы судить о
текстуре изображения, поскольку в ней нет явного описания ориентации по-
лос. Естественная стратегия, которой стоит в связи с этим придерживаться, —
брать каждый слой и раскладывать его дальше, чтобы получить набор ком-
понентов, каждый из которых задает энергию при определенной ориентации.
Любой из этих компонентов можно считать реакцией ориентированного филь-
Глава 9. Текстура
295
Ядра фильтра
Рис. 9.13. Ориентированная пирамида, построенная по изображению вверху слева, с четырьмя
ориентациями в слое. Изображение получено первоначальным разложением данного рисунка на
подзоны, представляющие собой зоны пространственной частоты (как и в случае лапласовой пира-
миды), с последующим применением к этим подзонам ориентированных фильтров (вверху справа)
для разложения их на ряд отдельных изображений, каждое изображение указывает на объем
энергии при определенном масштабе и ориентации изображения. Обратите внимание, как сильно
реагируют ориентированные слои на края при одних направлениях, и как слабо при других. Код
для создания ориентированных пирамид, написанный и распространяемый Иеро Симончелли (Eero
Simoncelli), можно найти на http://www.cis.upenn.edu/~eero/steerpyr.html. Перепе-
чатано из Simoncelli et al., “Shiftable MultiScale Transforms", IEEE Transactions on Information
Theory, 1992. © 1992 IEEE
тра при заданном масштабе и ориентации. Результатом будет подробный анализ
изображения, который называют ориентированной пирамидой (рис. 9.13).
Всестороннее обсуждение построения ориентированных пирамид увело бы
нас в сторону от основной темы, так что отметим лишь несколько важных мо-
ментов. При решении практической задачи первое ограничение состоит в том,
что фильтр должен пропускать небольшой диапазон пространственных частот
и ориентаций, как на рис. 9.9. Есть и другое ограничение: синтез должен
быть несложным. Если рассматривать ориентированную пирамиду как разло-
жение лапласовой пирамиды (рис. 9.14), то синтез подразумевает восстанов-
ление каждого слоя лапласовой пирамиды, а затем по лапласовой пирами-
де восстанавливается изображение. Идеальный метод — воспользоваться на-
бором фильтров, которые дают ориентированные характеристики и для ко-
торых легко осуществляется синтез. Можно создать такой набор фильтров,
296
Часть II. Первые этапы: одно изображение
Уровень
пирамиды
Лапласа
Рис. 9.14. Ориентированная пирамида получена из слоев лапласовой пирамиды, к которым приме-
нены ориентированные фильтры (на схеме показаны прямоугольниками). Каждый слой лапласовой
пирамиды соответствует диапазону пространственных частот; ориентированные фильтры раскла-
дывают этот диапазон пространственных частот на набор ориентаций
для которого восстановление слоя по его компонентам подразумевало бы по-
вторную фильтрацию изображения с помощью того же фильтра (как предла-
гается на рис. 9.15). Рабочую реализацию такой пирамиды можно найти на
http://www.cis.upenn.edu/~eero/steerpyr.html. Процесс разработ-
ки пирамиды подробно описан в работах [Karasaridis and Simoncelli, 1996]
и [Freeman, 1995].
9.3. ПРИЛОЖЕНИЕ: СИНТЕЗ ТЕКСТУРЫ ДЛЯ СОЗДАНИЯ
ИЗОБРАЖЕНИЙ
Изображения предметов выглядят реальнее при наличии текстуры (кстати,
стоит задуматься, почему это так, даже если это утверждение воспринима-
ется как очевидное). Существует множество методов отображения текстуры;
основная идея состоит в следующем: при изображении предмета значение от-
ражательной способности, которое используется для затенения пикселя, нахо-
дится по текстурной карте. К поверхности предмета привязывается некоторая
система координат, чтобы связать элементы текстурной карты с точками на по-
верхности. От выбора системы координат зависит внешний вид изображения,
и не всегда легко убедиться в том, что текстура лежит на поверхности так,
как надо (например, возьмем изображение полос на зебре — как должны быть
расположены полосы, чтобы выглядеть естественно?). Несмотря на эту пробле-
му, составление текстурных карт оказалось полезной уловкой, которая помогает
сделать смоделированные сцены реалистичнее.
Для составления текстурных карт требуются текстуры, а для отображения
текстуры большого объекта может понадобиться значительная текстурная кар-
та. Это особенно важно, когда предмет находится недалеко от точки наблю-
дения, т.е. когда текстура его поверхности видна с высоким разрешением, так
Глава 9. Текстура
297
Уровень
пирамиды
Лапласа
Рис. 9.15. Как показано на схеме, для ориентированной пирамиды синтез возможен путем по-
вторной фильтрации слоев с последующим их сложением (это возможно при правильном выборе
фильтров)
что обязательно возникнет вопрос о разрешении текстурной карты. Мозаич-
ное изображение текстуры дает плохие результаты, поскольку иногда бывает
трудно представить изображение в виде мозаики (например, границы должны
образовывать ровные линии), и даже если это условие выполняется, то полу-
чающаяся периодическая структура может раздражать. Текстуры изображения
можно покупать, но идеальным представляется написание программы, кото-
рая сама могла бы создавать большие текстурные изображения по маленькому
примеру. Такие программы могут быть довольно сложными, отражающими тот
факт, что описывать текстуру с помощью фильтров действительно выгодно.
9.3.1. Однородность
Обычно при синтезе текстуры ее рассматривают как элемент с каким-то
вероятностным распределением, а затем пытаются найти другие элементы с та-
ким же распределением. Чтобы сделать этот подход более практичным, стоит
найти вероятностную модель для элемента текстуры. Первое, что для этого
требуется, — предположить, что текстура однородна. Это означает, что отдель-
ные окна текстуры выглядят “одинаково”, в какой бы точке текстуры они не
находились. Более формально, вероятностное распределение значений пикселей
определяется свойствами некоторого окружения этих пикселей, а не, скажем,
положением пикселя.
Предположение об однородности означает, что за пределами области-
примера можно построить модель текстуры, основанную на свойствах этой
области-примера. Данное предположение часто применяется к естественным
текстурам в разумном диапазоне масштабов. Например, полосы на шкуре зеб-
ры однородны, но нужно помнить о том, что на спине они вертикальны, а
на ногах — горизонтальны. Примеры текстуры для построения вероятностных
моделей можно использовать различными способами; здесь описан только один
из них.
298
Часть II. Первые этапы: одно изображение
fems
И
«Шкапом «onto tat»
«иМ HmU, К*Ш> Mr |
rtatnooik.'MKawDe
aoMkbnftU H<M
«Ы kftutofk* foMfa
«wrunofMoabXrrk
WU Trtp,FTkrtwraao
Mltfcu смш41ап JU Frx
Ort ЙОХ kf «Ж «tolr wfll
«1Ли««>ОкЛ«ТП«>*хх»,’иИгЛЬ<йЛ»!П
inirtkoaiHkxwoaxfekIHbnor.hmkaeeJU,
kMAiTMfHlrrkyvoniaUMMiandaU S
к Ли JUtetfel сж»4» Lrtk-.V»» tlrwdli
«Ь»кШ ВлигжЧ кхжо.’иКоияО» Ы<1 D
ип4Шо1<«имоиаМ*1и<М1 KaUl.Katf
H «НмаИНМ* к Uftk и<«*4 gaoika U*to
кш аиаш,~апамг«аа«<М«*>1л1Гк»<г><«>
I Пм Fr»< (МОИ иожйжм гама иl<ft a Kwwa
^аопЫМй IdftJl/ntakdM ЦишлкхпШ
4кфГТ*»ааИ,>»к<ММоапч4Па»к«#а
макиo*OTtrw»«fM<M<tall HaiUIUek
mrOn>tn>bTtt^Tta<.№bc>All<1tta»<ir'
aSaTalnartdWrtlCTreilaoJUrtkatWMrt^qu
olnkal u« urtan «Г Uantranwtai IГ art Meat
jMUO'MUniUnrlltJfnqantayiofer.atkao
Рис. 9.16. В алгоритме синтеза текстуры (алгоритм 9.3, см. также работу [Efros and Leung, 1999])
окружение на изображении подбирается путем применения синтеза к изображению-примеру с по-
следующим случайным выбором из возможных значений, которые дают подобранные окружения.
Это значит, что с помощью данного алгоритма можно восстанавливать сложные пространственные
структуры. Маленький прямоугольник слева — это пример текстуры; справа показан прямоуголь-
ник, синтезированный алгоритмом. Обратите внимание, что синтезированный результат выглядит
как текст, поскольку он составлен из слов различной длины, расположенных в виде текста, и ка-
жется, что наблюдается набор слов, составленных из букв (хотя эта иллюзия рассеивается, если
присмотреться поближе). Перепечатано из A. Efros and Т.К. Leung, “Texture Synthesis by Non-
parametric Sampling", Proceedings International Conference on Computer Vision, 1999. (c) 1999 IEEE
9.3.2. Синтез с помощью локальных моделей выборки
Как указано в работе [Efros and Leung, 1999], пример изображения может
служить вероятностной моделью. Предположим, что у нас есть все пиксели син-
тезированного изображения, кроме одного. Чтобы найти вероятностную модель
для значения этого пикселя, нужно сравнить окружение этого пикселя с приме-
ром изображения. Все похожие окружения на примере изображения дают веро-
ятные значения искомого пикселя. Произведя равномерную случайную выборку
из этого набора, получим значение, согласующееся с примером изображения.
Поиск подходящего окружения на изображении
Суть проблемы состоит в том, чтобы сравнить определенное окружение ин-
тересующего нас пикселя с окружением на примере изображения. Размер и фор-
ма этого окружения имеют большое значение, поскольку они несут информацию
об области, пиксели которой могут непосредственно влиять на значения друг
друга (см. рис. 9.17). В работе [Efros and Leung, 1999] используется окружение
в виде квадрата с центром в искомом пикселе.
Сходство двух окружений изображения можно измерить, найдя сумму квад-
ратов разностей значений соответствующих пикселей. Это значение будет ма-
Глава 9. Текстура
299
действия алгоритма 9.3. На этом рисунке текстуры справа синтезированы из небольших блоков,
расположенных слева с использованием окружения, размер которых увеличивался слева направо.
Если подбирались очень маленькие окружения, то для алгоритма оказывалось сложным охватить
эффекты большого масштаба. Например, если текстура представляла собой набор пятен и окруже-
ние было слишком мало, чтобы охватить структуру пятен (поэтому видны только отдельные участки
кривой), то алгоритм синтезирует текстуру, состоящую из сегментов кривой. С увеличением раз-
мера окружения алгоритм способен охватить структуру пятен, но их распределение в пространстве
неверно. При очень большом окружении охватывается уже и расположение в пространстве. Перепе-
чатано из A. Efros and Т.К. Leung, "Texlure Synthesis by Non-parametric Sampling'', Proceedings
International Conference on Computer Vision, 1999. © 1999 IEEE
лым, если окружения похожи, и большим, если они разные (по сути, это длина
вектора разности). Конечно, в сумме квадратов разностей не учитывается зна-
чение синтезируемого пикселя.
Синтез текстуры с помощью окружения
Итак, теперь ясно, как найти значение одного пропущенного пикселя: равно-
мерно выбрать случайным образом из значений пикселей изображения-примера,
окружение которого подходит к окружению искомого пикселя (т.е. когда сум-
ма квадратов разностей двух окружений не превышает некоторого порогового
значения).
Обычно необходимо синтезировать больше, чем один пиксель. Как правило,
значения нескольких пикселей из окружения пикселя, который нужно синтези-
ровать, неизвестны, т.е. эти пиксели также нужно синтезировать. Найти набор
примеров для интересующего нас пикселя можно, учитывая при вычислении
суммы квадратов разностей только известные значения и подобрав пропорцио-
нально этому пороговое значение. Процесс синтеза можно начать со случайного
выбора блока пикселей из примера изображения (алгоритм 9.3).
300
Часть II. Первые этапы: одно изображение
Алгоритм 9.3. Непараметрический синтез текстуры
Случайным образом выбрать на примере изображения небольшой квадрат
пикселей
Вставить этот квадрат значений в синтезируемое изображение
Пока не будут подобраны значения для всех точек на синтезируемом изображении
Для каждого такого положения на границе блока имеющихся значений
Подобрать окружение этого положения по примеру изображения, игнорируя
при вычислении оценки схожести положения с неопределенными
значениями
Равномерно и случайным образом выбрать значение для этого положения
из набора значений соответствующих положений подобранных окружений
конец
конец
9.4. ОПРЕДЕЛЕНИЕ ФОРМЫ ПО ТЕКСТУРЕ
Участок текстуры, рассматриваемый во фронтальной плоскости, сильно от-
личается от того же участка, рассматриваемого под большим углом, посколь-
ку изменение ракурса приводит к тому, что элементы текстуры (и промежут-
ки между ними!) в одних направлениях уменьшаются сильнее, чем в других.
Отсюда следует, что по текстуре можно получить некоторую информацию о
форме, применив модель текстуры. Данная задача успешно решена человеком
(рис. 9.18). Замечательно, что довольно общие модели текстуры, как оказалось,
содержат достаточно информации для восстановления формы. Легче всего это
увидеть на примере плоскостей (раздел 9.4.1); для искривленных поверхностей
детали процесса не настолько прозрачны, хотя общая задача остается той же.
9.4.1. Восстановление формы по текстуре для плоскостей
Если известно, что наблюдается плоскость, то задача восстановления формы
по текстуре сводится к определению положения плоскости относительно каме-
ры. Допустим, что есть некая гипотеза о положении плоскости; тогда можно
спроектировать текстуру изображения обратно на эту плоскость. Если есть
какая-то модель “однородности” текстуры, то можно проверить, сохраняется ли
это свойство для спроектированной текстуры. После этого находится плоскость,
наилучшим образом соответствующая плоскости, восстановленной по тексту-
ре. Эта общая схема работает для различных моделей текстуры. Ограничимся
рассмотрением ортогональной камеры. Если камера не ортогональна, используе-
мые доказательства также действительны, но требуют намного больших усилий
и большего числа замечаний (несколько подробнее об этих ситуациях расска-
зано в разделе примечаний).
Глава 9. Текстура
301
Рис. 9.18. Люди получают информацию о форме поверхности в пространстве, исходя из внешнего
вида текстуры на поверхности. На рисунке слева показан пример этого эффекта — далеко от конту-
ров единственным источником информации об изображенной поверхности является искажение тек-
стуры на поверхности. Справа: по текстуре кустов кажется, что они образуют округлые поверхности
Представление плоскости
Предположим, что через ортогональную камеру наблюдается плоскость
с единой текстурой. Поскольку камера ортогональна, расстояние до плоскости
измерить нельзя, однако можно рассмотреть ориентацию плоскости. Будем
рассуждать в системе координат камеры. Прежде всего необходимо знать угол
между нормалью к плоскости с текстурой и направлением взгляда на нее
(иногда этот угол называют плоским углом), а также угол, который образует
проекция нормали в системе координат камеры (его еще называют углом на-
клона) (рис. 9.19). На изображении плоскости есть направление наклона —
направление на плоскости, параллельное проекции нормали.
Предположения об изотропности
Текстура называется изотропной, если вероятность нахождения элемента
текстуры не зависит от ориентации данного элемента. Это означает, что ве-
роятностная модель изотропной текстуры не должна зависеть от ориентации
системы координат, связанной с плоскостью текстуры.
Если предположить, что текстура изотропна, то и плоский угол, и угол на-
клона можно определить по изображению. Можно синтезировать ортогональ-
ный вид плоскости с текстурой с помощью поворота системы координат на
угол наклона и сжатия по направлению одной из координат на косинус плос-
кого угла — назовем этот процесс визуальным преобразованием. Легче все-
го понять это преобразование, предположив, что текстура состоит из набора
окружностей, рассеянных по плоскости. При ортогональном рассмотрении эти
окружности в процессе проектирования превратятся в эллипсы, малая ось кото-
302
Часть II. Первые этапы: одно изображение
Рис. 9.19. Ориентацию наблюдаемой плоскости относительно плоскости камеры можно задать
с помощью плоского угла (угла между нормалью к поверхности текстуры и направлением взгляда)
и угла наклона (угла, который образует проекция нормали в системе координат камеры). На рисунке
показан угол наклона, и то, как окружность превращается при проектировании в эллипс
рых показывает наклон, а характеристическое отношение — плоский угол (см.
раздел упражнений и рис. 9.19).
Ортогональная проекция изотропной текстуры не изотропна (если плоскость
не параллельна плоскости изображения). Это так, поскольку на изотропность
текстуры влияет сжатие в направлении плоского угла. Элементы, расположен-
ные вдоль направления сжатия, становятся короче. Более того, если элемент
имеет составляющую в направлении сжатия, то эта составляющая сокращается.
Теперь визуальному преобразованию соответствует обратное визуальное пре-
образование (которое переводит текстуру плоскости изображения в текстуру
плоскости предмета, при заданных плоском угле и угле наклона). Отсюда следу-
ет метод определения ориентации плоскости: найти обратное визуальное преоб-
разование, которое превращает текстуру изображения в изотропную текстуру,
и восстановить плоский угол и наклон по этому обратному преобразованию.
Это визуальное преобразование можно найти множеством способов. Один из
естественных путей — воспользоваться энергетическим выходом набора ориен-
тированных фильтров (возведенная в квадрат характеристика, просуммирован-
ная по всему изображению). Для изотропной текстуры можно ожидать, что
энергетический выход будет одинаковым для всех ориентаций при любом за-
данном масштабе, поскольку вероятность появления рисунка не зависит от ори-
ентации. Следовательно, мерой изотропности выступает среднеквадратическое
отклонение энергетического выхода как функции ориентации. Можно просум-
мировать эту меру по всем масштабам, нормируя ее на общую энергию при
Глава 9. Текстура
303
определенном масштабе. Чем меньше мера, тем более изотропна текстура. Те-
перь с помощью стандартных методов оптимизации можно найти обратное ви-
зуальное преобразование, которое делает изображение наиболее изотропным
при этой мере.
Заметим, что описанный подход является непосредственным развитием кон-
цепции перспективной проекции, сферической проекции и других видов визу-
альных преобразований. Необходимо выбрать из большого семейства преобра-
зований такое, при котором текстура изображения будет выглядеть наиболее
изотропной. Однако при этом следует быть очень внимательным. Например,
изменение масштаба изотропной текстуры даст еще одну изотропную текстуру,
т.е. параметр масштаба восстановить нельзя. Основная трудность в использова-
нии предположения об изотропности для восстановления ориентации плоскости
состоит в том, что в мире существует очень мало изотропных текстур.
Предположения об однородности
При ортогональной проекции ориентацию плоскости восстановить нель-
зя, если считать, что текстура однородна (определение см. в разделе 9.3.1),
поскольку при визуальном преобразовании одна однородная текстура превра-
щается в другую однородную текстуру. Однако для перспективной проекции
это возможно.
Чтобы понять это, сперва отметим, что однородность — это когда на плос-
кость наложена большая равномерная сетка и число событий в каждой ячейке
(приблизительно) одинаково. Например, если текстура представляет собой од-
нородный узор из пятен, можно ожидать, что количество пятен во всех ячейках
будет одинаковым. Однако если рассматривать перспективную проекцию тек-
стурированной плоскости с наложенной на плоскость сеткой, то одни элементы
сетки проектируются в большие четырехугольники, а остальные — в очень ма-
ленькие (если только проекция не фронтальна). Это, в свою очередь, означает,
что проекция текстуры на плоскости изображения не может быть однород-
ной — поскольку некоторые элементы сетки на плоскости изображения будут
содержать много проекций четырехугольников и, следовательно, много текстур-
ных событий, а другие — мало. Для примера с пятнистой плоскостью это озна-
чает, что пятна, которые проектируются недалеко от горизонта плоскости, ока-
зываются маленькими. Правильная стратегия здесь — выбрать преобразование,
при котором текстура на плоскости изображения будет “наиболее однородной”;
отметим, что можно определить ориентацию плоскости по отношению к плос-
кости камеры, но не расстояние до нее, поскольку фронтальная проекция од-
нородной текстуры однородна — масштаб всех элементов меняется одинаково.
9.5. ПРИМЕЧАНИЯ
Рекомендации по литературе для этой главы были существенно сокращены.
За долгие годы разработано множество методов описания текстуры изображе-
ния, которые, как правило, представляют собой статистику расположения узо-
304
Часть II. Первые этапы: одно изображение
ров относительно друг друга. Расходятся эти методы лишь в том, как следует
описывать узор и какую статистику искать. Пока еще рано говорить о том, что
описание узоров с помощью линейных фильтров является самым правильным,
на данный момент оно доминирует, главным образом, потому, что позволяет
очень легко решать задачи. Читатели, изучающие вопрос текстуры, вероятно,
будут удивлены, почему в главе не описана модель марковского случайного по-
ля, но выбор материала для главы осуществлялся по принципу минимизации
математических выкладок, необходимых для построения модели, а приемлемые
алгоритмы логического вывода для марковских случайных полей отсутствуют.
Заинтересованным читателям мы рекомендуем изучить работы [Chellappa and
Jain, 1993], [Cross and Jain, 1983], [Manjunath and Chellappa, 1991] или [Speis
and Healey, 1996].
Кроме того, был опущен еще один важный вопрос: описание текстуры мето-
дом небольших волн. Хотя этот метод в общих чертах совпадает с тем, который
описан выше (текстура представляется как результат действия множества филь-
тров), за этими фильтрами стоит сложная громоздкая теория. В данном случае
читателям будет полезно ознакомиться с работами [Ma and Manjunath, 1995,
1996] или [Manjunath and Ma, 19966, с].
Фильтры, пирамиды и эффективность
Если текстуру нужно описать с помощью выходов большого числа филь-
тров при многих масштабах и ориентациях, то интересна эффективность
фильтрации. Этот вопрос привлекает много внимания; обычный подход — попы-
таться построить базисное тензорное произведение, которое хорошо описывает
доступное семейство фильтров. При соответствующем построении требуется
произвести свертку изображения с небольшим количеством разделимых ядер,
а реакции многих различных фильтров можно оценить, каким-то образом объ-
единив результаты (отсюда и следует требование, чтобы базис был тензорным
произведением). К важным работам в этой области относятся [Freeman and
Adelson, 1991], [Greenspan, Belongie, Perona, Goodman, Rakshit and Anderson,
1994], [Hel-Or and Teo, 1996], [Perona, 1992, 1995], [Simoncelli and Farid, 1995]
и [Simoncelli and Freeman, 1995].
Синтез текстуры
Если вас интересует этот вопрос, вы можете попытаться осилить работу
[Zhu, Wu and Mumford, 1998], в которой используются очень сложные крите-
рии, во-первых, выбора фильтров, с помощью которых описывается текстура,
во-вторых, построения вероятностной модели для этой текстуры.
Форма по текстуре
Существует на удивление мало методов восстановления модели поверхно-
сти по проекции поля текстуры, которая предположительно находится на этой
поверхности. С помощью глобальных методов можно восстановить полностью
всю модель поверхности, используя предположения о распределении элементов
Глава 9. Текстура
305
текстуры. Эти предположения — изотропность (работа [Witkin, 1981]) (недо-
статок этого метода в том, что существует относительно мало изотропных тек-
стур) или однородность (публикации [Aloimonos, 1986], [Blake and Marinos,
1990]). В методах, опирающихся на однородность, предполагается, что пиксели
возникают как следствие однородного случайного пуассонова процесса на плос-
кости; тогда градиент плотности центров пикселей дает параметры плоскости.
Впрочем, здесь не учитывается искажение отдельных элементов текстуры.
С помощью локальных методов в точке на поверхности находятся неко-
торые дифференциальные геометрические параметры (как правило, нормаль
и кривизна). Этот класс методов, основные принципы которых были перво-
начально описаны в работе [Garding, 1992], показал успешные результаты для
ряда поверхностей (см. работы [Malik and Rosenholtz, 1997] и [Rosenholtz and
Malik, 1997]); другая формулировка, в терминах небольших волн, впервые пред-
ставлена в работе [Clerc and Mallat, 1999]. Данные методы имеют очень важный
недостаток: необходимо либо знать, что системы координат элементов текстуры
образуют поле, локально параллельное в окрестности интересующей нас точ-
ки, либо знать дифференциальный поворот этого поля (см. [Garding, 1995] для
данной точки, что подчеркивается выбором текстур, приведенных в [Rozenholtz
and Malik, 1997]; это предположение известно под названием стационарно-
сти текстуры). Например, чтобы определить кривизну пончика, посыпанного
шоколадной стружкой, потребовалось бы убедиться, что все стружки располо-
жены параллельно друг другу (или что известно поле углов между отдельными
стружками). Итак, этот метод работает только с довольно небольшим классом
текстур на поверхностях. Вторая, не менее важная, проблема касается восста-
новления информации; все названные методы дают локальную оценку нормали
и кривизны. Но кривизна — это производная нормали; поэтому в то время
как одна оценка может быть полезной, нет причин считать, что набор локаль-
ных оценок не будет противоречивым. Это проблема интегрируемости. Попу-
лярность методов интерполяции поверхностей в компьютерном зрении сильно
снизилась из-за неопределенного семантического статуса участков поверхности
в тех областях, где нет информации. Восстановление формы по текстуре —
это задача, в которой интерполяция несомненно играет важную роль — она
говорит о том, что поскольку изначально считается, что поверхность изменяет-
ся довольно медленно, неполные локальные измерения нормали к поверхности
могут служить граничными условиями друг для друга и давать хорошую гло-
бальную оценку нормали в некоторых точках.
Задачи
9.1. Покажите, что при ортогональной проекции окружность превращается
в эллипс и что малая ось этого эллипса является направлением наклона.
Чему равно характеристическое отношение этого эллипса?
9.2. Рассмотрим измерение ориентации плоскости при ортогональной про-
екции, если известно, что текстура состоит из точек, подчиняющихся
однородному распределению Пуассона. Напомним, что, согласно этому
306
Часть II. Первые этапы: одно изображение
распределению, единственный способ построения точек — осуществить
равномерную и случайную выборку по координатам точки х и у. Предпо-
ложим, что точка, фигурирующая в этом процессе, находится в пределах
единичного квадрата.
а) Покажите, что вероятность попадания этой точки в определенное мно-
жество пропорциональна площади этого множества.
б) Предположим, что площадь разделена на несвязанные между собой
множества. Покажите, что количество точек в каждом множестве
имеет полиномиальную вероятность распределения.
Воспользуемся этими наблюдениями для определения ориентации плос-
кости. Разделим текстуру изображения на ряд несвязанных множеств.
в) Является ли площадь каждого множества, восстановленного на
плоскости текстуры, функцией ориентации плоскости?
г) Можно ли с помощью этой информации определить ориентацию плос-
кости? Воспользуйтесь результатом п.в.
Упражнения
9.3. Синтез текстуры. Реализуйте алгоритм непараметрического синтеза
текстуры из раздела 9.3.2. Воспользуйтесь вашей реализацией для изу-
чения следующих вопросов.
а) Влияние размера окна на синтезированную текстуру.
б) Влияние формы окна на синтезированную текстуру.
в) Влияние критерия подбора (т.е. применение взвешенной суммы квад-
ратов вместо просто суммы квадратов и т.п.) на синтезированную
текстуру.
9.4. Представление текстуры. Создайте классификатор текстуры, который
может различать не менее шести типов текстур; воспользуйтесь механиз-
мом отбора масштаба из раздела 9.1.2 и рассчитайте статистику выхода
фильтров. Рекомендуется использовать среднее значение и ковариант-
ность выходов приблизительно шести ориентированных фильтров полос
и фильтра пятен. При выполнении упражнения может быть полезной до-
полнительная информация о классификации из главы 22; воспользуйтесь
простым классификатором (должны помочь уловка с ближайшим соседом
и критерий расстояния Махаланобиса (Mahalanobis)).
------------- ЧАСТЬ III ----------
Первые этапы: несколько изображений
10
Гэометрия нескольких проекций
В фотографии содержится довольно много информации, однако сведения о
глубине точки сцены и соответствующем луче проекции по единственному
изображению получить нельзя. В то же время, при наличии минимум двух
изображений, глубину можно измерить посредством триангуляции. Этим, отча-
сти, объясняется то, что большинство животных имеет, по крайней мере, два
глаза и/или поводит головой при изучении потенциального друга или врага; ,
по этой же причине автономного робота снабжают системой анализа стерео-
изображений или движения. Перед созданием подобной системы следует по-
нять, какие ограничения налагают на трехмерную структуру сцены несколько
ее проекций и какую роль во всем этом играет конфигурация камер. Изучению
этого вопроса и посвящена данная глава. В частности, мы рассмотрим геометри-
ческие и алгебраические ограничения, возникающие при наличии нескольких
проекций одной сцены. В привычном контексте бинокулярного стереозрения
показано, что первое изображение любой точки должно находиться на плоско-
сти, которая формируется вторым изображением и оптическими центрами двух
камер. Данное эпиполярное ограничение (или условие) можно алгебраически
представить матрицей 3x3, именуемой существенной, если известны внут-
ренние параметры камер, и фундаментальной, если о внешних параметрах
310
Часть III. Первые этапы: несколько изображений
ничего сказать нельзя. Три изображения одной прямой дают другое условие —
вырождение пересечения плоскостей, которые формируются прообразами этих
прямых. Алгебраически это геометрическое условие можно представить трифо-
кусным тензором 3x3x3. Большее число изображений вводит дополнительные
ограничения, например, четыре проекции одной точки удовлетворяют некото-
рым квадрилинейным соотношениям, коэффициенты которых составляют квад-
рифокусный тензор. Стоит отметить, что уравнения, которым удовлетворяют
множественные изображения одной сцены, можно записать, не имея никаких
знаний о камерах или объекте, который наблюдают камеры; в то же время,
оценить эти параметры можно непосредственно из видеоданных; несколько со-
ответствующих методов приводится в этой главе.
Компьютерное зрение — это не только отрасль науки, связанная с гео-
метрией множественных проекций. Точное восстановление количественной
геометрической информации по нескольким изображениям — это цель фото-
грамметрии (см. главу 3). В данной главе кратко рассматривается приложение
эпиполярных и трифокусных ограничений к классической задаче фотограм-
метрии — переносу (т.е. как предсказать положение точки на изображении,
зная ее положение на определенном числе имеющихся изображений), приво-
дится также несколько примеров. В последующих главах описываются другие
разделы области анализа стереоизображений и движения.
10.1. ДВЕ ПРОЕКЦИИ
10.1.1. Эпиполярная геометрия
Рассмотрим два изображения (р и р') точки Р, которая наблюдается двумя
камерами с оптическими центрами в точках О и О'. Эти пять точек находят-
ся на эпиполярной плоскости, которая определяется двумя пересекающимися
лучами ОР и О’Р (рис. 10.1). В частности, точка р' находится на линии V —
линии пересечения данной плоскости и чувствительной области П' второй ка-
меры. Линия V — это эпиполярная линия, соотнесенная с точкой р; линия I'
проходит через точку е' — точку пересечения базовой линии, соединяющей
оптические центры О и О', с плоскостью П'. Подобным образом, точка р нахо-
дится на эпиполярной линии I, соотнесенной с точкой р', и эта линия проходит
через точку е — точку пересечения базовой линии с плоскостью П.
Точки е и е! называются эпиполюсами двух камер. Эпиполюс е' — это проек-
ция оптического центра О первой камеры на изображение, наблюдаемое второй
камерой, и наоборот. Как отмечалось ранее, если р и р’ — изображения одной
точки, то точка р' должна находиться на эпиполярной линии, соотнесенной с р.
Описанное эпиполярное ограничение играет фундаментальную роль в анализе
стереоизображений и движения.
Предположим, например, что известны внутренние и внешние параметры
двух камер стереоустройства. Как показано в главе 11, наиболее сложная
часть анализа стереоданных — определение соответствий между двумя изоб-
ражениями (т.е. определение того, какие точки второго изображения совпа-
Глава 10. Геометрия нескольких проекций
311
Рис. 10.1. Эпиполярная геометрия: точка Р, оптические центры О и О' двух камер и два изобра-
жения р и р' точки Р находятся на одной плоскости. На всех рисунках данной главы камеры пред-
ставлены через угол их обзора, а виртуальная плоскость изображения расположена перед камерой
с точечной диафрагмой (обскурой). Это сделано лишь для упрощения графического представления:
геометрические и алгебраические аргументы, представленные в главе, с равным успехом примени-
мы и к физическим плоскостям изображений, расположенным за соответствующими камерами
дают с точками первого). Эпиполярное ограничение сильно сокращает про-
цедуру поиска таких соответствий. Действительно, поскольку предполагается,
что устройство откалибровано, координаты точки р полностью определяют луч,
соединяющий О и р, а следовательно, соответствующие эпиполярную плос-
кость ОО'р и эпиполярную линию I'. В процессе поиска соответствий можно
ограничиться этой линией и не рассматривать все изображение (рис. 10.2).
При анализе движения на основе двух кадров может случиться так, что каж-
дая камера откалибрована внутренне, но строгое преобразование, связывающее
системы координат двух камер, неизвестно. В этом случае эпиполярная геомет-
рия налагает ограничения на возможные перемещения наблюдаемого объекта.
Некоторые варианты данной ситуации рассматриваются в следующих разделах.
10.1.2. Откалиброванные камеры
Предположим, что внутренние параметры каждой камеры известны, так что
р = р. Очевидно, что из эпиполярного ограничения следует компланарность
трех векторов Ор, О'р' и ОО'. Эквивалентное утверждение: один из указанных
векторов должен лежать в плоскости, натянутой на другие два, или
Ор [ОО' х О'р'] = 0.
Данное выражение можно переписать в системе координат, связанной с первой
камерой:
р • [* х №')L
(10.1)
312
Часть III. Первые этапы: несколько изображений
Рис. 10.2. Эпиполярное ограничение: при наличии откалиброванного стереоустройства набор
возможных образов точки р ограничивается набором точек, находящихся на соответствующей эпи-
полярной линии Г
где через р — (u, v, 1)г и р' = (uf, vf, 1)г обозначены два вектора изображе-
ний р и р’ (в однородных координатах), t — координатный вектор трансляции
ОО1, связывающей две системы координат, aft- матрица поворота (свобод-
ный вектор с координатами w' во второй системе координат имеет в первой
системе координаты В данном случае проекционные матрицы записаны
в системе координат, связанной с первой камерой: (Id 0) и (Ит — TZTt).
Окончательно уравнение (10.1) можно переписать в следующем виде (данное
выражение называется соотношением Лонгета-Хиггинса (Longuet-Higgins)):
рт£р' = О, (10.2)
где через £ = [tx]7?. и [ах] обозначены кососимметричная матрица, такая что
[ах]ж = а х х — векторное произведение векторов а и х. Матрица £ назы-
вается существенной матрицей, и впервые она была использована в работе
[Longuet-Higgins, 1981]. Девять ее коэффициентов определяются с точностью
до масштаба и их можно параметризовать тремя степенями свободы матрицы
поворота TZ и двумя степенями свободы, определяющими направление вектора
трансляции t.
Отметим, что произведение £р’ можно интерпретировать как координат-
ный вектор, представляющий эпиполярную линию, которая соотнесена с точ-
кой р' первого изображения: действительно, линию образа I можно определить
ее уравнением аи 4- bv 4- с = 0, где через (и, v) обозначены координаты точки
на прямой, (а, Ь) — единичная нормаль к прямой, —с — расстояние (с соот-
ветствующим знаком) между началом координат и прямой I. Альтернативно
уравнение прямой можно определить через вектор (в однородных координа-
тах) р = (и, v, 1)т точки на прямой и вектор I = (a, b, с)Т: I • р = 0; в этом
случае условие а2 4- Ь2 — 1 ослабляется, поскольку уравнение справедливо при
любом изменении масштаба вектора I. В этом контексте уравнение (10.2) от-
ражает тот факт, что точка р находится на эпиполярной линии, соотнесенной
Глава 10. Геометрия нескольких проекций
313
с вектором £р'. С точки зрения симметрии очевидно также, что £тр — это
координатный вектор, представляющий эпиполярную линию второго изображе-
ния, соответствующую р. Очевидно, что существенные матрицы сингулярны,
поскольку вектор t параллелен координатному вектору е первого эпиполюса,
так что £те — —7£г[4х]е — 0. Подобным образом легко показать, что е' при-
надлежит нулевому пространству £. Как показано в работе [Huang, Faugeras,
1989], существенные матрицы характеризуются тем, что они сингулярны с дву-
мя равными ненулевыми сингулярными значениями (см. раздел упражнений).
10.1.3. Слабое движение
Исследуем подробнее инфинитезимальное перемещение. Рассмотрим дви-
жущуюся камеру со скоростью трансляции v и скоростью вращения ш и пере-
пишем уравнение (10.2) для двух кадров, разделенных небольшим промежут-
ком времени St. Обозначим через р = (it,v,0)T скорость точки р, или поле
движения. Используя экспоненциальное представление вращения (см. раздел
упражнений), можно показать, что (с точностью до членов первого порядка)
t — St v,
< = Id + St [wx], (10.3)
p' = p + Stp.
Подставляя данное выражение в уравнение (10.2) и пренебрегая всеми членами,
имеющими второй и более высокие порядки по St, получаем такой результат:
PT([vx][wx])p-(pxp)-v = 0. (10.4)
Уравнение (10.4) — это просто мгновенная форма отношения Лонгета-Хиггинса
(10.2), в которой эпиполярная геометрия записывается в дискретном случае. От-
метим, что при чистой трансляции получаем и> = 0, следовательно, (р хр) v —
0. Другими словами, три вектора, р = ор, р и v, должны быть компланарными.
Если через е обозначить инфинитезимальный эпиполюс, или фокус расшире-
ния (т.е. точку пересечения плоскости изображения линией, проходящей через
оптический центр параллельно вектору скорости v), получим хорошо известный
результат: при чисто трансляционном движении поле движения направлено к
фокусу распространения (рис. 10.3).
10.1.4. Неоткалиброванные камеры
Отношение Лонгета-Хиггинса справедливо для внутренне откалиброван-
ных камер. Если внутренние параметры неизвестны (неоткалиброванные ка-
меры), можно записать р = /Ср и pr = К'р, где /С и /С' -- калибровочные матри-
цы 3 х 3, а р и р — нормированные векторы координат точек изображений. Для
этих векторов справедливо отношение Лонгета-Хиггинса, поэтому получаем
рТУр = 0, (10.5)
где матрица Т = /С~Т£/С'~1, именуемая фундаментальной, не является, в об-
щем случае, существенной матрицей. Ранг этой матрицы также равен двум,
314
Часть III. Первые этапы: несколько изображений
Рис. 10.3. Фокус распространения: при чистой трансляции поле движения в каждой точке изоб-
ражения направлено к фокусу распространения
и собственный вектор Т (соответственно, матрицы ^?г), соответствующий
ее нулевому собственному значению, — это положение вектора е! (соответ-
ственно, е) эпиполюса. Отметим, что Ур' (соответственно, Угр) представляет
эпиполярную линию, соответствующую точке р' (соответственно, р) на первом
(соответственно, втором) изображении.
Ограничение, следующее из того, что ранг матрицы равен двум, означает,
что в фундаментальной матрице может быть только семь независимых пара-
метров. Возможны несколько способов параметризации, но наиболее естествен-
ный — это использовать координатные векторы е — (а, (3)т и ег = (а',{3')т двух
эпиполюсов и эпиполярное преобразование, переводящее один набор эпиполяр-
ных линий в другой. В главе 13 свойства этого преобразования будут иссле-
дованы в контексте изучения структуры по движению. На данный же момент
просто отметим (без доказательства), что его можно параметризовать (с точ-
ностью до масштаба) четырьмя числами — a, b, с, d — и что фундаментальную
матрицу можно записать следующим образом:
(Ь а
—d -с
dfi' — ba' с/3' — аа'
—а/3 — Ьа
с/3 + da
—с{3/3' — d(3'a + а(3а' + baa'
(Ю.6)
10.1.5. Слабая калибровка
Как отмечалось ранее, существенная матрица определяется (с точностью
до масштаба) пятью независимыми параметрами. Следовательно, можно (по
крайне мере, теоретически) вычислить ее, записав уравнение (10.2) для пяти
точечных соответствий. Подобным образом, фундаментальная матрица опре-
деляется семью независимыми коэффициентами (параметры a, b, c,d в уравне-
нии (10.6) определены с точностью до масштаба) и может, в принципе, опре-
деляться из семи точечных соответствий. Методы, позволяющие вычислить
Глава 10. Геометрия нескольких проекций
315
существенную и фундаментальную матрицы по минимальному числу парамет-
ров, существуют (см. раздел примечаний), но они слишком сложны. В этом
разделе рассматривается простейшая задача оценки эпиполярной геометрии по
избыточному набору точечных соответствий между двумя изображениями, по-
лученными камерами с неизвестными внутренними параметрами — процесс,
известный как слабая калибровка.
Отметим, что уравнение (10.5) линейно по девяти коэффициентам фунда-
ментальной матрицы Т'.
/7*п
(u,v, 1) F2i
\F3i
7*12 Г13\ (и'\
7*22 7*23 I I v' I = 0.
7*32 7*зз/ \ 1 /
(Ю.7)
Поскольку данное уравнение однородно по коэффициентам можно поло-
жить 7*зз = 1 и использовать восемь точечных соответствий pi <-» (г =
1,... ,8) для записи соответствующих экземпляров уравнения (10.7) в виде си-
стемы 8x8 неоднородных линейных уравнений:
ui viUi г»1 щ гр /FiA
^2^2 U2V2 и2 V2U2 V2V2 V2 и'2 Ь’2 7*12 1
U3U3 U3V3 из V3U3 V3V3 V3 из и'з Тчз 1
U4U4 U4V4 U4 V4U4 V4V4 V4 U4 V4 7*21 1
U5U'5 U5V8 U5 V5U5 V5V5 V5 U5 V'5 7*22 1
U8Ue U6l*6 u6 VgUq Vev'6 V6 U8 V8 7=23 1
U7u!7 U7V7 U? V7U7 V7V7 V7 U7 V7 7*31 1
\U8U8 U8V8 U8 V8U8 V8V8 V8 U8 V8) ^7*32^ V/
Использование этой системы для определения фундаментальной матрицы
дает восьмиточечный алгоритм, первоначально предложенный Лонгетом-
Хиггинсом в 1981 году для откалиброванных камер. Использование алгоритма
некорректно, если матрица 8x8 сингулярна. Как показано в работе [Faugeras,
1993] и в приведенных далее примерах, это происходит только в том случае,
если восемь точек и два оптических центра лежат на поверхности второго
порядка. Однако такая ситуация маловероятна, поскольку поверхность второго
порядка полностью определяется девятью точками, откуда следует, что прак-
тически не существует поверхностей второго порядка, проходящих через 10
произвольных точек.
Если доступно п > 8 соответствий, матрицу Т можно рассчитать, миними-
зировав (по схеме наименьших квадратов) величину
г=1
по коэффициентам считая, что вектор, сформированный этими коэффици-
ентами, имеет единичную норму.
316
Часть III. Первые этапы: несколько изображений
Отметим, что и в восьмиточечном алгоритме, и в его разновидности, в ко-
торой используется схема наименьших квадратов, не учитывается, что фун-
даментальная матрица имеет ранг два1. Для введения в действие этого огра-
ничения в работах [Luong et al., 1993, 1995] было предложено использовать
матрицу J7, полученную на выходе восьмиточечного алгоритма, в качестве ос-
новы для двухэтапного процесса оценки: вначале для нахождения эпиполюсов е
и е', минимизирующих |.FTe|2 и j.Fe'l2, используется линейная схема наимень-
ших квадратов; затем координаты этих точек подставляются в уравнение (10.6).
В результате получаем линейную параметризацию фундаментальной матрицы
коэффициентами эпиполярного преобразования, которое можно найти, мини-
мизировав уравнение (10.8) по схеме наименьших квадратов.
В разновидности восьмиточечного алгоритма с использованием схемы наи-
меньших квадратов минимизируется среднеквадратическое алгебраическое
расстояние, связанное с эпиполярным ограничением (т.е. среднеквадратиче-
ское значение е(р,р') = prFp', рассчитанное по всем точечным соответстви-
ям). Данная функция ошибок допускает геометрическую интерпретацию:
е(р,р ) — = X1d(p ,ТТр),
где через d(p, I) обозначено евклидово расстояние (с соответствующим знаком)
между точкой р и линией I, а ?р и Э-Тр! — эпиполярные линии, соотнесенные
с векторами р и р'. Масштабные множители А и А' — это нормы векторов,
образованных двумя первыми компонентами J-p’ и Ттр, а их зависимость от
наблюдаемой пары информационных точек может влиять на процесс оценки.
Разумеется, масштабные множители можно оценить и непосредственно ми-
нимизировать среднеквадратическое геометрическое расстояние между точка-
ми изображения и соответствующими эпиполярными линиями:
$2 [d2(Pi, Fp'i} + d2(p',^тр£)] -
t=i
Данная задача нелинейна вне зависимости от выбранной параметризации
фундаментальной матрицы, но минимизацию можно производить на выходе
восьмиточечного алгоритма. Такая схема была предложена в работе [Luong
et al., 1993], где показано, что данный результат чрезвычайно близок к ре-
зультату, который можно получить с помощью восьмиточечного алгоритма.
В качестве альтернативной схемы в работе [Hartley, 1995] было предложено
нормировать линейный восьмиточечный алгоритм. Данный подход основан
на следующем наблюдении: слабая эффективность исходного метода вызвана,
большей частью, плохим численным расчетом необходимых параметров. Это
предполагает трансляцию и масштабирование данных, чтобы они были центри-
рованы в начале координат и среднее расстояние до начала координат было
’В первоначальном алгоритме, предложенном Лонгетом-Хиггинсом, не учитывалось ни то,
что существенная матрица имеет ранг 2, ни то, что она имеет два равных сингулярных значения.
Глава 10. Геометрия нескольких проекций
317
равно х/2 пикселей. На практике эта нормировка значительно улучшает началь-
ные условия линейного процесса вычисления по схеме наименьших квадратов.
Таким образом, алгоритм разбивается на четыре этапа. Во-первых, происходит
преобразование координат изображения с использованием соответствующих
операторов трансляции и масштабирования: Т : р{ —> р4 и Г : р< -> р<. Во-
вторых, используется метод наименьших квадратов для расчета матрицы
минимизирующей величину
Е(рГ/р')2.
i=l
В-третьих, используется условие “ранг матрицы равен двум”; это можно сде-
лать, применив описанный ранее метод Луонга, но Хартли воспользовался ме-
тодом, предложенным в работе [Tsai and Huang, 1984] для откалиброванных
камер, на выходе которого получается разложение матрицы Р по сингуляр-
ным значениям, J- = USVT. Разложение матрицы по сингулярным значениям
формально будет определено в главе 12, а пока отметим, что S = diag(r,s,t) —
это диагональная матрица 3 х 3 с элементами г > s > t; U, У — это ортого-
нальные матрицы 3x3 и матрица ранга два У (см. главу 12), минимизирующая
фробениусову норму Т — Т, имеет вид Т = Z7diag(r, s, 0)Ут. На последнем
этапе алгоритма в качестве окончательной оценки фундаментальной матрицы
берется Т = ТтТТ.
На рис. 10.4 показаны эксперименты для случая слабой калибровки, в ко-
торых в качестве входных данных использовался набор из 37 точечных соот-
ветствий между двумя изображениями игрушечного домика. Информационные
точки показаны на рисунке в виде небольших дисков, а восстановленные эпи-
полярные линии — небольшими сегментами линий. На рис. 10.4, а показан
выход восьмиточечного алгоритма с использованием схемы наименьших квад-
ратов, а на рис. 10.4, б представлены результаты, полученные с использованием
схемы Хартли. Как и следовало ожидать, во втором случае результаты лучше
и, фактически, ближе к результатам, полученным с использованием критерия
геометрического расстояния, который был предложен в работах [Luong et al.,
1993, 1995].
10.2. ТРИ ПРОЕКЦИИ
Вернемся теперь к случаю откалиброванных камер, где р = р, и рассмотрим
геометрические ограничения, возникающие при наличии трех изображений од-
ной сцены. Проанализируем систему из трех перспективных камер, наблюдаю-
щих одну точку Р, изображения которой обозначим через pi, р2 и (рис. 10.5).
Оптические центры Оь О% и О3 камер определяют трифокусную плоскость,
пересекающую их чувствительные области по трем трифокусным линиям t?
и i3. Каждая из этих линий проходит через соотнесенный с нею эпиполюс (на-
318
Часть III. Первые этапы: несколько изображений
а) б)
Линейная схема наименьших квадратов [Hartley, 1995J [Luong et al., 1993]
Среднее расстояние 2,33 пикселя 0,92 пикселя 0,86 пикселей
Рис. 10.4. Экспериментальное изучение слабой калибровки с использованием 37 точечных соот-
ветствий между двумя изображениями игрушечного домика. На рисунке показаны эпиполярные
линии, полученные а) при использовании восьмиточечного алгоритма (схема наименьших квадра-
тов), б) при использовании нормированной версии этого алгоритма, предложенной Хартли. Обрати-
те внимание, что для точки, расположенной ближе ко дну кружки, в случае а ошибка получается
больше. Количественные сравнения приведены в таблице, где указаны средние расстояния между
информационными точками и соответствующими эпиполярными линиями. Данные любезно предо-
ставили Бубакер Буфама (Boubakeur Boufama) и Роджер Mop (Roger Mohr)
пример, линия ^2, соотнесенная со второй камерой, проходит через проекции
612 и вз2 оптических центров двух других камер).
Каждая пара камер определяет эпиполярное ограничение, т.е.
' pf512p2 = °,
< Р2 ^2зРз = 0, (10.9)
k Рз ^31Р1 = о,
где через £ij обозначена существенная матрица, соотнесенная с парой изоб-
ражений i <-♦ j. Данные три условия не являются независимыми, поскольку
должно выполняться условия е^^гезг = е^азвхз = с2з^з1б21 — 0 (чтобы
понять, откуда взялось это условие, рассмотрите эпиполюса ез1 и езг; они пред-
ставляют собой первое и второе изображения оптического центра Оз третьей
камеры, следовательно, подчиняются эпиполярному ограничению).
Любые два уравнения из системы (10.9) независимы. В частности, если из-
вестна существенная матрица, положение точки pi можно предсказать по поло-
жениям двух соответствующих точек р% и рз. Действительно, первое и третье
условие в системе (10.9) определяет систему двух линейных уравнений для
Глава 10. Геометрия нескольких проекций
319
Рис. 10.5. Тринокулярная эпиполярная геометрия. Обратите внимание, что точка Р, в общем
случае, не лежит на трифокусной плоскости, определяемой точками Ох, О2 и О3
двух неизвестных координат р\. Геометрически находится как пересечение
эпиполярных линий, соотнесенных с р2 и рз (рис. 10.5). Следовательно, трино-
кулярная эпиполярная геометрия предлагает решение задачи переноса, упоми-
навшейся в начале главы.
10.2.1. Трифокальная геометрия
Второй набор ограничений можно получить при рассмотрении трех изоб-
ражений линии, а не точки. Набор точек, которые проектируются на линию
изображения Z, образуют плоскость L, содержащую линию и камеру. Данную
плоскость можно охарактеризовать следующим образом: если через Л4 обозна-
чить проекционную матрицу 3x4, точка Р на L проектируется в точку р на I
в том случае, если zp = Л4Р, или
1тМР = 0, (10.10)
где Р = (x,y,z,l)T — 4-вектор однородных координат Р, а I = (а,Ь,с)т —
3-вектор однородных координат I. Уравнение (10.10) записано для плоскости L,
320
Часть III. Первые этапы: несколько изображений
которая содержит как оптический центр камеры О, так и линию I, a L = Л4Т1 —
это координатный вектор этой плоскости.
Два изображения Zi и I2 одной линии не ограничивают относительные по-
ложения и ориентацию связанных с ними камер, поскольку соответствующие
плоскости Li и L/2 всегда пересекаются (если это не так и плоскости параллель-
ны, их можно считать пересекающимися на бесконечности-, подробнее об этом
см. главу 13). Рассмотрим три изображения Ц, I2 и 13 одной линии I и обозначим
через Li, L2 и L3 соотнесенные с ними плоскости (рис. 10.6). Пересечение этих
плоскостей дает прямую (хотя в общем случае пересечение трех плоскостей —
точка). С алгебраической точки зрения это означает, что система
Р = 0
трех уравнений с тремя неизвестными х, у и z должна быть вырожденной, т.е.
ранг матрицы 3x4
def
I2M2
должен быть равен 2. Из этого, в свою очередь, следует, что детерминанты
всех миноров 3x3 данной матрицы должны быть равны нулю. Очевидно, что
эти детерминанты записываются как трилинейные комбинации координатных
векторов G, I2 и 13. Как показано ниже, только два из четырех детерминантов
независимы.
10.2.2. Откалиброванные камеры
Для получения трилинейных условий в явном виде выберем систему ко-
ординат, связанную с первой камерой в качестве глобальной системы отсче-
та и запишем проекционные матрицы как A4i = (Id 0), JVI2 = (7^2 Ъ)
и Л4з = (Т^з t3). Теперь можно переписать матрицу £:
£ =
0 \
1^2 %_
l^1Z3 l^t3J
'2 *2 .
(10.11)
Как показано в разделе упражнений в конце главы, три минора можно записать
следующим образом:
h x llgfla = 0,
xgglll)
(10.12)
Глава 10. Геометрия нескольких проекций
321
Рис. 10.6. Три изображения линии определяют ее как (вырожденное) пересечение трех плоскостей
где
Gi = t2R% - для i =1,2,3, (10.13)
и через W2 и R^ {i — 1,2,3) обозначены столбцы матриц 7^2 и IZ3. Четвертый
детерминант записывается как |h 7Z2l2 7^Мз|» он равен нулю, когда нормали к
плоскостям Li, Ь2 и L$ компланарны. Математически последнее утверждение
равносильно приравниванию к нулю линейной комбинации трех детерминан-
тов, фигурирующих в уравнении (10.12) (см. раздел упражнений). Разумеется,
только два из этих детерминантов линейно независимы.
Три матрицы размером 3x3 определяют трифокусный тензор 3 х 3 х
3 с 27 коэффициентами (или 26 с точностью до масштаба). {Тензор — это
многомерный массив коэффициентов, соотнесенный с полилинейной формой
так же, как матрицы связаны с билинейными формами.) Поскольку Oi — это
начало системы координат, в которой записаны все уравнения для проекций,
векторы t2 и £3 можно интерпретировать как наборы однородных координат
изображений эпиполюсов ехг и ехз. В частности, из уравнения (10.13) следует,
что 125[1з = 0 для любой пары соответствующих эпиполярных линий 12 и 1$.
322
Часть III. Первые этапы: несколько изображений
Уравнение (10.12) можно переписать следующим образом:
(10.14)
где запись а ос b обозначает, что два вектора а и b отличаются только мас-
штабом. Из сказанного следует, что трифокусный тензор также налагает усло-
вия на положения трех соответствующих точек. Действительно, предположим,
что Р — точка на I. Ее первое изображение лежит на li, так что pf/i = 0.
В частности,
рТ ilQlh
(10.15)
Имея три точечных соответствия pi «-> р2 Рз (рис. 10.7), получаем четы-
ре независимых условия, для чего нужно переписать уравнение (10.15) для
независимых пар линий, проходящих через р2 и рз (например, = [1,0, — и^\т
и I" ~ [0,1, —гу}г для i — 2,3). Эти ограничения трилинейны по координатам
точек рх, р2 и рз. Как только известен тензор, его можно использовать для
предсказания положения, скажем, точки рх, зная размещение точек р2 и рз на
других изображениях (это второй способ решения задачи перехода).
10.2.3. Неоткалиброванные камеры
Трилинейные условия на координаты линий изображения также можно
определить и при неизвестных внутренних параметрах трех камер. Посколь-
ку в этом случае р = К.р и линия изображения, соотнесенная с вектором I,
определяется условием 1Тр — 0, сразу можно записать I = К.~т1, или I = )СТ1.
В частности, уравнение (10.11) справедливо, когда рг = р- и = Ц. В общем
случае получаем следующее:
/ liKi 0 \
<zl/c37£3 фс3*3;
и
/ И
<#л3
ранг(£) = 2 <=> ранг
= ранг
0 \
1%Ь2 =2,
Глава 10. Геометрия нескольких проекций
323
Рис. 10,7. Имея три изображения р\,р3 и р3 одной точки Р и две произвольных линии изображе-
ния /2 и 13, проходящих через р2 и р3, получаем условие: луч, проходящий через СЦ и рь должен
пересекать линию, которая представляет собой геометрическое место точек пересечения проекций
плоскостей L2 и L3 на линии Z2 и G
где Ai K.i'R.iK.y1 и bi = для i — 2,3. Отметим, что проекционные
матрицы, соотнесенные с тремя камерами, теперь имеют вид Лй = (Ка 0),
Л^2 = (Л2/С1 Ь2) и Л4з — (Дз^1 Ьз). В частности, 62 и по-прежнему
можно интерпретировать как векторы однородных координат изображений эпи-
полюсов ei2 и 613, а трилинейное условие, выраженное в форме (10.14) и (10.15),
по-прежнему справедливо, когда
где через Д2 и (* = I? 2,3) обозначены столбцы матриц Л2 и Д-з- Выражение
Z2 Q\l$ = 0 верно для любой пары соответствующих эпиполярных линий Z2 и /3.
10.2.4. Оценка трифокусного тензора
Рассмотрим задачу оценки трифокусного тензора на основе имеющихся то-
чечных и линейных соответствий, полученных при изучении трех изображений.
324
Часть III. Первые этапы: несколько изображений
Уравнения, определяющие тензор, линейны по своим коэффициентам и зависят
только от измерений на изображениях. Как и при слабой калибровке, для оцен-
ки требуемых 26 параметров можно использовать линейные методы. Каждая
тройка соответствующих точек дает четыре независимых линейных уравнения,
а каждая тройка соответствующих линий налагает два дополнительных линей-
ных условия. Таким образом, коэффициенты тензора можно вычислить, имея р
точек и I линий (причем 2р +1 > 13). Например, достаточно 7 троек точек или
13 троек линий, или 3 троек точек и 7 троек линий и т.д. Как и при слабой ка-
либровке, численную устойчивость процесса оценки тензора можно улучшить,
нормировав координаты изображения так, чтобы информационные точки были
центрированы в начале координат со средним расстоянием от начала коорди-
нат \/2 пикселей.
В методах, описанных до этого момента, не учитывалось, что 26 параметров
трифокусного тензора не являются независимыми. Кстати, этот факт нельзя на-
звать неожиданным: существенная матрица имеет всего пять независимых ко-
эффициентов (параметры вращения и трансляции, причем последние определя-
ются с точностью до масштаба), а фундаментальная матрица — семь. Подобным
образом параметры, определяющие трифокусный тензор, удовлетворяют множе-
ству условий, в том числе вышеупомянутые уравнения = 0 (г — 1,2,3)
удовлетворяются любой парой соответствующих эпиполярных линий I? и /3.
Кроме того, легко показать, что матрицы сингулярны (это свойство будет
изучено в главе 13). В работе [Faugeras and Mourrain, 1995] показано, что
коэффициенты трифокусного тензора неоткалиброванного тринокулярного сте-
реоустройства удовлетворяют восьми независимым условиям, что уменьшает
общее число независимых параметров до 18. В методе, описанном в [Hartley,
1995], эти ограничения вводятся апостериорно путем восстановления эпипо-
люсов ei2 и €1з (или, эквивалентно, векторов *2 и в уравнении (10.13))
по линейной оценке трифокусного тензора, после чего посредством линейной
процедуры восстанавливается набор коэффициентов тензора, который удовле-
творяет наложенным условиям.
10.3. БОЛЬШЕЕ ЧИСЛО ПРОЕКЦИЙ
Что можно сказать о четырех проекциях одной сцены? В данном разделе мы
будем придерживаться взглядов, изложенных в работе [Faugeras and Mourrain,
1995], и вначале отметим, что сокращение знаменателей в уравнении для пер-
спективной проекции (2.16), полученном в главе 2, дает следующий результат:
иЛ43 — Л4Г\
wM3 — Л42)
(10.16)
где через Л41, Л42 и Л43 обозначены три строки матрицы Л4. (Отметим, что
здесь мы отклонились от принятой договоренности обозначать строки проек-
ционной матрицы через mJ, mJ и mJ, чтобы далее в этом разделе избежать
Глава 10. Геометрия нескольких проекций
325
возможной путаницы между различными строками различных матриц. Очевид-
но, что Мг и пг[ обозначают один и тот же вектор-строку.)
Предположим теперь, что дано четыре проекции, с каждой из которых
соотнесена своя проекционная матрица Mj (j — 1,2,3,4). Запишем уравне-
ние (10.16) для каждой камеры:
/щМ^ ~ М J\
QP — 0, где С =' е е й « W М КЭ •—* i £ £ £ GOW MW MW —w Illi i £ £ £ Ww MM MI-1 *—1M (10.17)
- Ml щМ% - M\ VM-Mj - Ml)
Эта система восьми однородных уравнений с четырьмя неизвестными имеет
нетривиальное решение. Отсюда следует, что ранг соответствующей матрицы Q
размером 8 х 4 не превышает 3, или, эквивалентно, все ее миноры 4x4 должны
иметь нулевые детерминанты. Геометрически каждая пара уравнений в систе-
ме (10.17) представляет луч Ri (г = 1,2,3,4), связанный с точкой изображе-
ния pi, а чтобы эти лучи пересекались в точке Р (рис. 10.8), матрица Q должна
иметь ранг 3.
Матрица Q содержит миноры 4x4 трех типов.
1. Миноры, включающие две строки из одной проекционной матрицы и две
строки — из другой. Ниже приведен пример уравнений, связанных с шестью
минорами этого типа 2:
Det
(щМ} — At}
гцЛ41 — Л42
изМ? — Л<2
- Л4?
-0.
(10.18)
Данные детерминанты дают билинейные условия на положения соответству-
ющих точек изображения. Легко показать (см. раздел упражнений), что
система (10.18) сводится к эпиполярным условиям в форме (10.2), если по-
ложить Л41 — (Id 0) и Л4г = (РТ — PTt).
2. Миноры второго типа содержат две строки из одной проекционной матрицы
и по одному из двух остальных матриц. Всего имеется 48 таких миноров, а
2Вместо записи (и, г») можно использовать запись (и1, и2) и после кропотливой работы
с индексами и тензорной формой записи получить компактные общие формулы.
326
Часть III. Первые этапы: несколько изображений
Рис. 10.8. Четыре изображения р1г р?, рз и р4 одной точки Р определяют эту точку как пересе-
чение соответствующих лучей Rt (г = 1,2,3,4)
соответствующие уравнения выглядят, например, так:
Det
- Л4}\
u2^2 — -^2
(10.19)
Эти миноры налагают трилинейные условия на соответствующие точки изоб-
ражения. Легко показать (см. раздел упражнений), что соответствующие
уравнения сводятся к трифокусным условиям в форме (10.15), если поло-
жить = (Id 0). В частности, их можно выразить через матрицы
(г = 1,2,3). Отметим, что этот факт дополняет геометрическую интерпрета-
цию трифокусных условий и выражает следующее наблюдение: лучи, свя-
занные с тремя изображениями одной точки, пересекаются в пространстве.
3. Детерминант последнего типа включает по одной строке из каждой матрицы.
Всего имеется 16 миноров этого типа, а система соответствующих уравнений
Глава 10. Геометрия нескольких проекций
327
выглядит подобным образом:
Det
U2JM2 ~ М%
V3M3 - jM|
\v4jM4 - М%/
= 0.
(10.20)
Эти уравнения дают квадрилинейные условия на положения точек pi (i =
1,2,3,4). Геометрически каждая строка матрицы Q соотнесена с линией
изображения, или, эквивалентно, с плоскостью, проходящей через оптиче-
ский центр соответствующей камеры. Таким образом, каждое квадрилиней-
ное условие отражает тот факт, что четыре рассматриваемые плоскости пе-
ресекаются в одной точке (для четырех плоскостей общего вида это не так).
Рассмотрим квадрилинейные уравнения подробнее. При записи детерминан-
тов, подобных (10.20), относительно координат изображения сразу видно, что
коэффициенты квадрилинейных условий можно записать следующим образом:
^ijki Det
/А4П
М%
(10.21)
\M‘J
где Cijki = Т1. а Л Ь к и I пробегают значения от 1 до 3 (см. раздел упраж-
нений). Эти коэффициенты определяют квадрифокусный тензор (см. работу
[Triggs, 1995]).
Квадрифокальный тензор, как и трифокусный тензор, можно интерпрети-
ровать геометрически с использованием точек и линий. В частности, рассмот-
рим четыре изображения pi (i — 1,2,3,4) точки Р и четыре произвольных
линии изображения lit проходящих через эти точки. Четыре плоскости Li
(г — 1,2,3,4), которые формируются прообразами этих линий, должны пере-
секаться в точке Р, откуда следует, что матрица 4x4
I2M2
11Мз
должна иметь ранг 3 и что ее детерминант должен быть равен нулю. Это
условие дает квадрилинейное условие на коэффициенты четырех линий L (г =
1,2,3,4). Кроме того, поскольку каждая строка Lf = if Mi матрицы £ пред-
ставляет собой линейную комбинацию строк соответствующей матрицы Mi, ко-
эффициенты квадрилинейных соотношений, полученные из вычисления Det(£)
328
Часть III. Первые этапы: несколько изображений
Рис. 10.9. Дано четыре изображения plt р2, рз и Р4 одной точки Р и три произвольных линии
изображения 12,13 и 14, которые проходят через точки р2, Рз и р4. Луч, проходящий через Oi и pi,
должен также проходить через точку пересечения трех плоскостей L2, L3 и L4, сформированных
прообразами этих линий
для координат линий Ц, — это коэффициенты квадрифокусного тензора, как
определяется уравнением (10.21).
Наконец, отметим, что поскольку Det(£) — это линейная функция ко-
ординат Zi, обращение этого детерминанта в нуль можно записать как Ц •
<7(^2, i3,U) = 0. где q — (трилинейная) функция координат прямых Ц (г =
2,3,4). Поскольку это соотношение справедливо для любой прямой Zi, про-
ходящей через pi, из этого следует, что р1 ос Геометрически это
означает, что луч, проходящий через C>i и pi, должен также проходить через пе-
ресечение плоскостей, которое сформировано прообразами 1%, 1з и U (рис. 10.9).
Алгебраически это означает, что при данном квадрифокусном тензоре и произ-
вольных линиях, проходящих через три изображения точки, можно предсказать
положение этой точки на четвертом изображении. Таким образом, получаем
еще один метод решения задачи переноса.
Отметим, что квадрифокусные условия справедливы как для откалиброван-
ных, так и для неоткалиброванных камер, поскольку предположений относи-
Глава 10. Геометрия нескольких проекций
329
тельно вида матрицы сделано не было. Квадрифокальный тензор определя-
ется 81 коэффициентом (или 80 с точностью до масштаба), но можно показать,
что на эти коэффициенты накладывается 51 независимых условия, что сокра-
щает общее число независимых параметров до 29. Можно также показать,
что хотя четверка изображений одной точки дает 16 независимых условий на
80 коэффициентов тензора (подобных (10.20)), существует линейная зависи-
мость между 32 уравнениями, соотнесенными с каждой парой точек. Таким
образом, для оценки квадрифокусного тензора с помощью линейной процедуры
требуется шесть точечных соответствий. Алгоритмы выполнения этой задачи
с использованием 51 условия, соотнесенных с реальными квадрифокусными
тензорами, можно найти в работе [Hartley, 1998]. Наконец, в [Faugeras and
Mourrain, 1995] показано, что квадрилинейный тензор алгебраически зависит
от связанных с ним существенной или фундаментальной матрицы и трифо-
кусного тензора, следовательно, тензор не вводит новых независимых условий.
Подобным образом можно показать, что дополнительные проекции также не
вводят новых независимых условий.
10.4. ПРИМЕЧАНИЯ
Существенная матрица как алгебраическая форма эпиполярного ограниче-
ния была открыта Лонгетом-Хиггинсом в 1981 году, а ее свойства были исследо-
ваны Хуангом (Huang) и Фаугерасом (Faugeras) в 1989 году. Фундаментальную
матрицу ввели Луонг ([Luong, 1992]) и Фаугерас ([Faugeras, 1995]). Устойчи-
вые методы оценки фундаментальной матрицы на основе точечных соответствий
приведены в [Zhang et al., 1994]. Свойства фундаментальной матрицы и эпипо-
лярного преобразования представлены в главе 13, где рассматривается задача
восстановления структуры объекта и движения камеры по последовательно-
сти перспективных изображений. Мгновенная версия эпиполярного ограниче-
ния (10.4), выведенная в разделе 10.1.3, справедлива только для откалибро-
ванных камер. Камеры с переменными внутренними параметрами рассмотрены
в работе [Vieville and Faugeras, 1995]. Трилинейные условия, связанные с тремя
проекциями линии, независимо ввели Спектакис и Алоимонос [Spektakis and
Aloimonos, 1990], а также Венг, Хуанг и Эхуджа [Weng, Huang and Ahuja, 1992]
в контексте анализа движения для внутренне откалиброванных камер. Эти по-
нятия были расширены Шашуа [Shashua, 1995] и Хартли [Hartley, 1997] для
случая некалиброванных камер. Квадрифокальный тензор ввел Тригге [Triggs,
1995], а его свойства исследовали Фаугерас и Моран [Faugeras and Mourrain,
1995], Фаугерас и Пападопуло [Faugeras and Papadopoulo, 1997], Хартли [Hart-
ley, 1998] и Хейденом [Heyden, 1998].
Во введении упоминалось, что одна из задач фотограмметрии — получение
количественной информации из множественных изображений. В таком кон-
тексте бинокулярные и тринокулярные геометрические ограничения рассматри-
ваются как источник связей, которые определяют внутренние и внешние па-
раметры (называемые в фотограмметрии параметрами внутренней и внешней
330
Часть III. Первые этапы: несколько изображений
Рис. 10.10. Тринокулярные ограничения при наличии ошибок калибровки или измерения. Лу-
чи /?1, /?2 и #з могут не пересекаться
ориентации} стереопары или стереотройки. В частности, отношение Лонгета-
Хиггинса появляется, хотя и в несколько иной форме, как уравнение условия
компланарности, а тринокулярные условия дают уравнение ограничения мас-
штаба, учитывающее ошибки калибровки и измерения изображения ([Thompson
et al., 1966], глава 10). В этом случае лучи, соотнесенные с тремя изображени-
ями одной точки, уже не пересекаются гарантированно (рис. 10.10).
Процедура требуемого расчета выглядит следующим образом. Если лучи R\
и Ri (i = 2,3), соотнесенные с точками изображения pi и pi, не пересекаются,
минимальное расстояние между ними — это расстояние между точками Pi
и Pi, причем линия, соединяющая эти точки, перпендикулярна и Pi, и Ri.
Алгебраически это можно записать следующим образом:
О1Р1 = 2JO1P1 = ОД + ZiOipi + Л;(С>1Р1 х Qpi) для i = 2, 3. (10.22)
Предполагая, что камеры внутренне откалиброваны, так что проекционные
матрицы, соотнесенные со второй и третьей камерами равны (Rj —
Глава 10. Геометрия нескольких проекций
331
и — ?Фз), уравнение (10.22) можно переписать в системе координат, свя-
занной с первой камерой:
= ti + ZiKipi + Ai(Pi х для i = 2,3. (10.23)
Отметим, что подобные уравнения можно записать и для абсолютно неотка-
либрованных камер, включив члены, зависящие от неизвестных внутренних
параметров. В любом случае уравнение (10.23) можно использовать для выра-
жения неизвестных Zi, X, и z{ через Pi, Pi и проекционные матрицы, связанные
с камерами (см. раздел упражнений). Затем записывается условие ограничения
масштаба: — zf. Хотя это условие сложнее трифокусного ограничения (по-
скольку не является трилинейным по координатам точек pi, р2 и рз), оно не
содержит координат наблюдаемой точки и может использоваться (теоретиче-
ски) для оценки трифокусной геометрии непосредственно по данным изобра-
жения. Потенциальное преимущество такого метода состоит в том, что функция
ошибок zl — zf имеет явное геометрическое значение: отличие оценок глуби-
ны Р, полученных с использованием пары камер 1 < > 2 и 1 3. Интересным
представляется дальнейшее исследование связи между трифокусным тензором
и условием ограничения масштаба, а также ее практическое применение к оцен-
ке трифокусной геометрии.
Задачи
10.1. Покажите, что одно из сингулярных значений существенной матрицы —
0, а два других равны. (В работе [Huang and Faugeras, 1989] показано,
что справедливо также обратное — т.е. любая матрица 3 х 3 с одним
сингулярным значением, равным 0, и двумя другими, равными между
собой, является существенной матрицей.) Подсказка: сингулярные зна-
чения матрицы £ — это собственные значения матрицы ££т.
10.2. Экспоненциальное представление матриц поворота. Можно пока-
зать, что матрица, соответствующая повороту, оси которого — единичные
векторы а, а угол равен 0, равна ее[ах1 ^(^[ах])’- Используя это
представление, получите уравнение (10.3).
10.3. Инфинитезимальное эпиполярное условие (10.4) получено в предположе-
нии, что наблюдаемый объект статичен, а камера движется. Покажите,
что при неподвижной камере и объекте, движущемся с трансляционной
скоростью v и вращательной скоростью эпиполярное условие можно
переписать как pT([vx][‘*’x])p + (р х р) v — 0. Обратите внимание, что
данное уравнение представляет собой сумму двух членов, фигурирую-
щих в уравнении (10.4), а не их разность. Подсказка: обозначив через "R,
и t матрицу вращения и вектор трансляции, фигурирующие в опреде-
лении существенной матрицы для движущейся камеры, покажите, что
замена объектов, дающая то же поле движения для статической камеры,
представляется матрицей вращения Т1т и вектором трансляции
332
Часть III. Первые этапы: несколько изображений
10.4. Покажите, что если матрица 8x8, фигурирующая в восьмиточечном ал-
горитме, сингулярна, восемь точек и два оптических центра лежат на
поверхности второго порядка ([Faugeras, 1993J). Подсказка-, используйте
следующий факт: если матрица сингулярна, существует некоторая нетри-
виальная линейная комбинация ее столбцов, которая равна нулю. Также
обратите внимание на то, что матрицы, представляющие две проекции
в системе координат, связанной с первой камерой, имеют в данном слу-
чае вид (Id 0) и (7£г — 7£Tt).
10.5. Покажите, что три детерминанта миноров 3x3 матрицы
(1Т о >
можно записать как Ц х
is)
Покажите, что четвертый детерминант можно записать как линейную
комбинацию трех, указанных выше.
10.6. Покажите, что при Л41 = (Id 0) и Мо = С^т — 7£Tt) уравнение (10.18)
сводится к (10.2).
10.7. Покажите, что при A4i = (Id О) уравнение (10.19) сводится к (10.15).
10.8. Выведите уравнение (10.20) для координат изображения и докажите, что
его коэффициенты действительно можно записывать в виде (10.21).
10.9. Используйте уравнение (10.23) для расчета неизвестных Zi, А; и z\ че-
рез рх, pit IZi и ti (i — 2, 3). Покажите, что значение Xi непосредственно
связано с эпиполярным условием, и охарактеризуйте степень зависимо-
сти zl — Zj от информационных точек.
Упражнения
10.10. Реализуйте восьмиточечный алгоритм для слабой калибровки, используя
бинокулярные точечные соответствия.
10.11. Реализуйте версию данного алгоритма на основе схемы наименьших
квадратов с использованием и без использования этапа предваритель-
ных условий Хартли.
10.12. Реализуйте алгоритм оценки трифокусного тензора на основе точечных
соответствий.
10.13. Реализуйте алгоритм оценки трифокусного тензора на основе линейных
соответствий.
11
Стереозрение
Совмещение изображений,которые регистрируют человеческие глаза, и исполь-
зование их отличий (или расхождений) позволяет получить представление о
глубине объекта. В данной главе рассматриваются идеи и реализации алгорит-
мов, имитирующих способность человека (известную как стереозрение) выпол-
нять названную задачу. В качестве очевидных областей применения надежных
компьютерных программ стереоскопического восприятия можно назвать нави-
гацию “зрячих роботов” (рис. 11.1), картографию, разведку с воздуха и фото-
грамметрию близкого радиуса действия. Данные программы также важны при
решении таких задач, как сегментация изображений с целью распознавания
объектов или конструирование трехмерных моделей объектов для приложений
компьютерной графики.
Стереозрение включает два процесса: совмещение деталей, наблюдаемых
двумя (или большим числом) камерами и восстановление их трехмерного
прообраза. Последний процесс относительно прост: прообраз соответствующих
точек можно (в принципе) найти как точку пересечения лучей, проходящих
через эти точки и центры соответствующих диафрагм камер (см. рис. 11.2,
слева). Следовательно, если характерную точку изображения можно наблю-
дать в любой момент времени, стереозрение реализуется просто. В то же
334
Часть III. Первые этапы: несколько изображений
Рис. 11.1. Слева: на стенфордской тележке установлена одна камера, которая при движении те-
лежки по прямой линии предоставляет снимки внешних сцен через определенные промежутки
времени. Справа: мобильный робот 1NRIA использует три камеры для отображения среды, в ко-
торой он находится. Как видно из примеров, несмотря на то, что двух глаз вполне достаточно для
стереоскопического восприятия окружающей среды, мобильные роботы часто оборудуются тремя
(или большим числом) камерами. Преимущественная часть данной главы посвящена бинокуляр-
ному восприятию, алгоритмы стереозрения с использованием множественных камер рассмотрены
в разделе 11.4. Фотографии любезно предоставлены Гансом Моравеком (Hans Moravec) и Оли-
вером Фаугерасом (Olivier Faugeras)
время, каждая сцена состоит из сотен тысяч пикселей, а характерных элемен-
тов изображения (например, углов) насчитывается десятки тысяч, так что для
определения точных соответствий между точками различных изображений сце-
ны требуются некоторые методы, исключающие ошибочные измерения глубины
(рис. 11.2, справа). В этом процессе основную роль играет эпиполярное условие,
поскольку тогда поиск соответствий выполняется только на соответствующих
эпиполярных линиях.
Далее в этой главе предполагается, что все камеры тщательно откалиброва-
ны, так что их внутренние и внешние параметры точно известны относительно
некоторой внешней системы отсчета (из этого следует, что также известны су-
щественные матрицы и/или трифокусные тензоры, соотнесенные с парами или
тройками камер). Случай неоткалиброванных камер рассматривается в контек-
сте определения структуры по движению в главах 12 и 13.
11.1. ВОССТАНОВЛЕНИЕ
При наличии откалиброванного стереоустройства и двух согласованных
точек изображений р и рг задача восстановления соответствующей точки про-
образа — это, в принципе, простой процесс: требуется найти пересечение двух
лучей, R = Ор и R' = О'р’. В то же время, на практике лучи R и R' нико-
гда не пересекаются, поскольку имеются ошибки калибровки и локализации
характерных точек образа (рис. 11.3). В таком контексте для решения задачи
восстановления можно применять различные разумные подходы. Например,
можно построить сегмент прямой, перпендикулярный R и R', который Пересе-
Глава 11. Стереозрение
335
Рис. 11.2. Задача бинокулярного совмещения изображений. В простейшем случае (диаграмма сле-
ва) неоднозначности не существует и восстановление стереоизображения представляется довольно
простой задачей. В более распространенном случае (справа) любая из четырех точек левого изоб-
ражения может, априори, совпадать с любой из четырех точек правого изображения. Справедливы,
однако, только четыре из таких соответствий, остальные дают неверно восстановленные точки
прообраза, показанные маленькими серыми дисками
чет оба данных луча: средняя точка Р этого сегмента — ближайшая к двум
лучам, и ее можно считать прообразом р и р{. Здесь следует отметить, что
подобное построение было использовано в конце главы 10 для алгебраического
описания геометрии множественных точек наблюдения при наличии ошибок
калибровки или измерения. Уравнения (10.22) и (10.23), выведенные в этой
главе, легко переписываются для вычисления координат Р на кадре, который
был получен первой камерой.
Точку прообраза можно восстановить и с помощью альтернативного, чисто
алгебраического подхода: для данных проекционных матриц Л4 и Л4' и согла-
сованных точек р и р' условия zp = ЛАР и z'p' = ЛАР можно переписать
следующим образом:
р х ЛАР = 0
р х ЛА'Р = 0
([Pxl-ЛЛ р = 0
\[Рх]-^7
Эту переопределенную систему четырех независимых линейных уравнений по
координатам Р легко решить, использовав линейные схемы наименьших квад-
ратов, введенные в главе 3. В отличие от предыдущего подхода этот метод
восстановления не имеет очевидной геометрической интерпретации, но легко
обобщается на случай трех или больше камер — каждое новое изображение
всего лишь вводит два дополнительных условия.
Наконец, можно восстановить точку прообраза, соотнесенную с р и р',
как точку Q с образами q и q', минимизировав величину d2(p,q) + d?(p',q')
(рис. 11.3). В отличие от двух других методов, представленных в этом разделе,
данный подход не позволяет аналитически вычислить восстановленную точку,
336
Часть III. Первые этапы: несколько изображений
Рис. 11.3. Триангуляция при наличии ошибок измерения (объяснения см. в тексте)
так что она оценивается посредством нелинейной схемы наименьших квадратов,
подобной введенной в главе 3. Восстановленная точка, полученная любым из
двух описанных методов, может использоваться как разумное предположение,
с которого можно начать процесс оптимизации. Данный нелинейный подход
также легко обобщается на случай множественных изображений.
11.1.1. Очистка изображения
Вычисления, требуемые в двух описанных алгоритмах стереозрения, ча-
сто разумно упрощаются, если рассматриваемые изображения очищены (т.е.
заменены двумя эквивалентными изображениями с общей плоскостью изоб-
ражения, параллельной базовой линии, соединяющей два оптических центра;
см. рис. 11.4). Процесс очистки можно реализовать, спроектировав исходные
изображения на новую плоскость изображения. При соответствующем выборе
системы координат очищенные эпиполярные линии — это линии сканирования
новых изображений и они также параллельны базовой линии. При выборе плос-
кости очищенного изображения есть две степени свободы: а) расстояние между
этой плоскостью и базовой линией, которое не является существенно важным,
поскольку влияет только на масштаб очищенных изображений — для ком-
пенсации данного эффекта достаточно изменить масштаб координатных осей
изображения; и б) направление нормали очищенной плоскости на плоскости,
перпендикулярной базовой линии; естественные варианты: выбор плоскости, па-
раллельной линии пересечения двух исходных чувствительных областей камер,
и минимизация искажения, связанного с процессом повторного проектирования.
Для очищенного изображения можно строго определить расхождение, вве-
денное ранее в этой главе: для двух точек р и р', расположенных на одной ли-
Глава 11. Стереозрение
337
Рис. 11.4. Очищенная стереопара: две плоскости изображения, П и П', проектируются на общую
плоскость П — П', параллельно базовой линии. Эпиполярные линии I и I1, соотнесенные с точ-
ками р и р' на двух изображениях, отображаются в общую линию сканирования I = V, также
параллельную базовой линии и проходящую через точки проекций р и р'. Очищенные изображе-
ния легко получаются с помощью современных аппаратных и программных компьютерных средств:
каждое входное изображение рассматривается как многогранная сетка, а для представления про-
екции этой сети на плоскость П = П' используется текстурное отображение
нии сканирования правого и левого изображений, имеющих координаты (w, г»)
и расхождение определяется как разность d = и' — и. С этого момента
будем предполагать, что на изображениях используются нормированные коор-
динаты. Как показано в разделе упражнений, если через В обозначить рассто-
яние между оптическими центрами, в этом контексте также именуемое базо-
вой линией, глубина точки Р в (нормированной) системе координат, связанной
с первой камерой, равна z = —В/d. В частности, вектор координат точки Р на
кадре, полученном первой камерой, равен Р — —(B/d)p, где р = (u,v, 1)т —
вектор нормированных координат изображения точки р. Это еще один метод
восстановления для очищенных стереопар.
11.2. СТЕРЕОЗРЕНИЕ ЧЕЛОВЕКА
Перед тем как приступить к рассмотрению алгоритмов определения бино-
кулярных соответствий, обсудим механизмы, лежащие в основе человеческого
стереозрения. Прежде всего, стоит отметить, что в отличие от камер, жестко
соединенных со стационарным стереоустройством, глаза человека могут вра-
щаться внутри впадин. В каждый момент времени взгляд фиксируется на
определенной точке пространства (т.е. глаза вращаются так, что соответствую-
щие изображения формируются в центрах их впадин).
338
Часть III. Первые этапы: несколько изображений
Рис. 11.5. На данной диаграмме глаза фиксируются на близлежащей точке, так что она проекти-
руется в центр их впадин с нулевым расхождением. Два изображения дальней точки расположены
на разном расстоянии от центрального положения, что указывает на разную глубину этой точки
по отношению к глазам
На рис. 11.5 показана упрощенная двумерная схема механизма человеческо-
го зрения. Если через I и г обозначить (отсчитываемые против часовой стрелки)
углы между вертикальными плоскостями симметрии двух глаз и двумя луча-
ми, которые проходят через точку объекта, мы определим соответствующее
расхождение как d ~ г — I (рис. 11.5). Имея элементарные знания из области
тригонометрии, легко показать, что d = D — F, где D — угол между этими
лучами, a F — угол между двумя лучами, проходящими через точку, на ко-
торой зафиксирован взгляд. Точки с нулевым расхождением лежат на окруж-
ности Виета-Мюллера (Vieth-Miiller circle), которая проходит через наблюда-
емую точку и передние полюсы глазных яблок. Точки, лежащие внутри этой
окружности, имеют положительное расхождение, точки, лежащие снаружи (см.
рис. 11.5), — отрицательное, а наборы точек с равными расхождениями d фор-
мируют семейство окружностей, проходящих через полюсы двух глаз. Этого
свойства, очевидно, достаточно для упорядочения по глубине точек, располо-
женных вблизи точки, на которой фиксируются глаза. В то же время очевидно
также, что для восстановления абсолютного положения точек объекта должны
быть известны граничные углы между двумя лучами фиксации и вертикальной
медианной плоскостью симметрии головы и двух глаз.
Трехмерный случай, естественно, более сложен. Геометрическое место то-
чек с нулевым расхождением — это уже плоскость, гороптер, но общий вывод
звучит так же, как и для двумерного случая, а для определения абсолютно-
го местоположения требуется знание граничных углов. Как сказано в работе
[Wundt and Helmholtz, 1909], похоже, что наша нервная система не может точно
измерить эти углы. В то же время относительная глубина (или упорядочение
по глубине) точек вдоль линии прямой видимости можно произвести достаточ-
но точно. Например, можно определить, какой из объектов вблизи гороптера
находится ближе к наблюдателю для расхождения по углу порядка нескольких
Глава 11. Стереозрение
339
Рис. 11.6. Стереограммы со случайными точками: встряхивание (виртуальной) перечницы над
двумя пластинками
секунд {порог остроты стереозрения), что согласуется с минимальным раз-
решением одного глаза {порог повышенной монокулярной остроты зрения).
Рассматривая соответствия между элементами левого и правого изображе-
ний, Джулец ([Julesz, I960]) сформулировал следующий вопрос: что является
базовым механизмом бинокулярного совмещения изображений — монокулярный
процесс (где перед совмещением определяются локальные схемы распределения
яркости [микрообъекты] или более крупные структуры точек объектов [макро-
объекты]), бинокулярный процесс (когда два изображения объединяются в одно
поле, где проходят все дальнейшие процессы) или их комбинация? Некоторые
жизненные ситуации говорят в пользу бинокулярного механизма. Процитируем
Джулеца: “В воздушной разведке известно, что объекты, закамуфлированные
сложным фоном, очень трудно обнаружить, но они просто бросаются в глаза
при стереоскопическом наблюдении”. Для сбора более содержательных дан-
ных Джулец ввел новый аппарат, стереограмму со случайными точками: па-
ру искусственных изображений, полученных путем случайного разбрасывания
черных точек на белых объектах, обычно небольшой квадратной пластинке,
дрейфующей над большой пластинкой (рис. 11.6). Еще одна цитата: “При моно-
кулярном рассмотрении изображения кажутся абсолютно случайными. Но при
стереоскопическом рассмотрении пара изображений создает впечатление квад-
рата, заметного на фоне окружающего (или за окружающими объектами)”. Вы-
вод очевиден: человеческий механизм бинокулярного совмещения изображений
нельзя объяснить периферийными процессами, непосредственно связанными
с физическими сетчатками. Вместо этого в объяснении должна фигурировать
центральная нервная система и воображаемая циклопическая сетчатка, объеди-
няющая левый и правый раздражители-объекты в один элемент.
Дипольная модель стереозрения, предложенная Джулецом, является коопе-
ративной — соседствующие согласованные элементы влияют один на другой,
вследствие чего устраняется неоднозначность и становится возможным гло-
бальный анализ объекта. Другой пример кооперативного процесса, достаточно
точно проходящего проверку стереограммами со случайными точками — это
340
Часть III. Первые этапы: несколько изображений
Рис. 11.7. Кооперативный подход к стереозрению: алгоритм Марра-Поггио (1976). На левой части
рисунка показаны два профиля интенсивности вдоль одной линии сканирования двух изображе-
ний. Пики соответствуют черным точкам. Сегменты линий, соединяющие два профиля, обозначают
возможные соответствия между точками в пределах некоторого заданного максимального диапазо-
на расхождений. Возможные варианты согласования показаны также в правой части рисунка, где
они формируют узлы графа. Вертикальные и горизонтальные ребра этого графа соединяют узлы,
соотнесенные с одной точкой на левом и одной точкой на правом изображениях. Диагональные
ребра графа соединяют узлы со сходными расхождениями
подход, предложенный Марром и Поггио в работе [Marr and Poggio, 1976].
Этот алгоритм основан на следующих условиях: а) совместимость (черные
точки могут согласовываться только с черными точками, или, в более общем
случае, два характерных элемента изображения могут соответствовать друг
другу, только если они могли возникнуть из одного физического прообраза);
б) единственность (черная точка на одном изображении соответствует не бо-
лее чем одной точке на другом) и в) непрерывность (изменение расхождения
происходит плавно почти по всему изображению). Имея несколько черных то-
чек на паре соответствующих эпиполярных линий, Марр и Поггио создают
граф, отражающий возможные соответствия (рис. 11.7).
Узлы графа — это пары черных точек в пределах некоторого диапазона рас-
хождений, отражающего условие совместимости; вертикальные ребра представ-
ляют запрещенные соединения, связанные с условием единственности (любое
соответствие между двумя точками должно препятствовать другим соответ-
ствиям как с левой точкой пары — горизонтальный запрет, — так и с правой
точкой — вертикальный запрет); диагональные ребра представляют начальные
соединения, связанные с условием непрерывности (если определено какое-то
соответствие, то с большой вероятностью рядом обнаружится еще одно с по-
добным расхождением).
При описанном подходе с каждым узлом сопоставляется качественная ме-
ра. Ее начальное значение — 1 для каждой пары потенциальных соответствий
в пределах некоторого диапазона расхождений. Процесс согласования явля-
ется итеративным и параллельным — каждому узлу при каждой итерации
присваивается взвешенная комбинация значений соседних узлов. Начальным
Глава 11. Стереозрение
341
Рис. 11.8. Слева направо: стереограмма со случайными точками для четырехуровневой пирами-
дальной структуры (“свадебный пирог”) и карта расхождений, полученная после 14 итераций коопе-
ративного алгоритма Марра-Поггио. Перепечатано с разрешения Henry Holt and Company, LLC
из David Marr, “Vision: a computational investigation into the human representation and processing
of visual information”. © 1982 David Marr
соединениям присваиваются весовые коэффициенты 1, а запрещающим присва-
иваются весовые коэффициенты — w (где w — подходящий весовой коэффици-
ент). Узлу присваивается значение 1, если соответствующая взвешенная сумма
превышает некоторый порог, и 0 — в противном случае. Данная схема дает
достаточно достоверные результаты для стереограмм со случайными точками
(рис. 11.8), но не для естественных изображений. В следующем разделе пред-
ставлено несколько методов, которые дают лучшие результаты для большинства
реальных картин, но первоначальный алгоритм Марра-Поггио и его реализа-
ция все же представляют определенный интерес как ранний пример теории
стереозрения, позволяющий совмещать стереограммы со случайными точками.
11.3. БИНОКУЛЯРНОЕ СОВМЕЩЕНИЕ ИЗОБРАЖЕНИЙ
11.3.1. Корреляция
Корреляционные методы — это нахождение пиксельных соответствий пу-
тем сравнения профилей яркости в окрестности потенциально соответствую-
щих точек разных изображений объекта. Корреляционные схемы были одни-
ми из первых, предложенных для решения задачи бинокулярного совмещения
изображений ([Kelly et al., 1977], [Gennery, 1980]). Рассмотрим конкретный
пример — очищенную стереопару и точку (и, v) на первом изображении. С ок-
ном размера р — (2т 4- 1) х (2п 4- 1), центрированном на (u,v), соотнесем
вектор w(u, v) Е Rp, который получен путем построчного сканирования значе-
ний окна (на самом деле, порядок сканирования не имеет значения, достаточно
лишь, чтобы он был фиксированным). Теперь для данной точки второго изобра-
жения (u + d, и), потенциально соответствующей точке (и, v), можно построить
второй вектор w'(u+d,v) и определить соответствующую нормированную кор-
342
Часть III. Первые этапы: несколько изображений
Рис. 11.9. Корреляция двух окон 3x5 вдоль соответствующих эпиполярных линий. Положение
второго окна отделено от положения первого расстоянием d. В пространстве К15 указанные окна
представляются векторами ги и го', а корреляционная функция — это мера угла О между век-
торами ги — ш и го' — ги', полученными вычитанием из компонентов го и го' средней яркости
в соответствующих окнах
реляционную функцию как
<?(<*) = ;---------;—Г77 - w) • (w' ~ ™')] >
|го — го | |го — го |
где индексы и, v и d опущены для облегчения восприятия формулы, а через w
обозначен вектор, все координаты которого равны среднему от координат век-
тора w (рис. 11.9).
Нормированная корреляционная функция С, очевидно, принимает значения
из диапазона от —1 до +1. Своего максимального значения она достигает, когда
яркости двух окон связаны аффинным преобразованием Г = XI+ р с некоторы-
ми константами А и р при А > 0 (см. раздел упражнений). Другими словами,
максимум этой функции соответствует участкам изображения, которые отли-
чаются постоянным смещением и положительным масштабным множителем, а
соответствующие точки стереоизображения можно найти, определив максимум
функции С в пределах некоторого предопределенного диапазона расхождений1.
’Инвариантность С относительно аффинных преобразований функции яркости позволяет
использовать корреляционные схемы согласования, имеющие некоторую устойчивость в ситуациях,
когда наблюдаемая поверхность не является строго ламбертовской либо когда две камеры имеют
разное усиление или объективы с разными диафрагментарными числами.
Глава 11. Стереозрение
343
Рис. 11.10. Ракурс наклонных плоскостей зависит от положения наблюдающих их камер:
l/L # V/L
Теперь стоит сделать несколько замечаний относительно методов согласова-
ния на основе корреляции. Во-первых, легко показать (см. раздел упражнений),
что максимизация нормированной корреляционной функции эквивалентна ми-
нимизации величины
2
1 _ 1 ,
(го — го) (го — го ) ,
|го — го|--------|ioz — го |
или суммы квадратов разностей между пиксельными значениями двух окон
после того, как они подверглись соответствующему процессу нормировки. Во-
вторых, хотя расчет нормированной корреляционной функции в каждом пикселе
изображения для некоторого диапазона расхождений — вычислительно доро-
гой процесс, его можно эффективно реализовать, если применить рекурсивные
методы (см. раздел упражнений). Наконец, важнейшая проблема, связанная
с корреляционными методами установления стереосоответствий, заключается
в неявном предположении о (локальной) параллельности наблюдаемой поверх-
ности двум плоскостям изображений (рис. 11.10).
Таким образом, следует использовать двухэтапный алгоритм, когда первона-
чальные оценки расхождения применяются для деформации окна корреляции,
чтобы компенсировать неравные ракурсы двух изображений. Соответствующий
пример приведен на рис. 11.11, где для каждого прямоугольника на левом изоб-
ражении определено деформированное окно на правом изображении; при этом
использованы значения расхождений в центре каждого прямоугольника и его
производная ([Devernay and Faugeras, 1994]). Для поиска значений расхож-
дения и его производных, максимизирующих корреляцию между левым прямо-
угольником и правым окном, используется процесс оптимизации с применением
интерполяции для получения подходящих значений на правом изображении.
344
Часть III. Первые этапы: несколько изображений
Рис. 11.11. Согласование стереоизображений с использованием корреляции: а) пара стереоизоб-
ражений; б) текстурное отображение восстановленной поверхности; в) применение методов корре-
ляции к обычной (слева) и очищенной (справа) области носа. Очевидно, что в последнем случае
получаются лучшие результаты. Перепечатано из F. Devernay and O.D. Faugeras, Proceedings
IEEE Conference on Computer Vision and Pattern Recognition, “Computing Differential Properties of
3D Shapes from Stereopsis Without 3D Models”, 1994. (c) 1994 IEEE
11.3.2 . Многошкальное согласование краев
Если принять процесс согласования на основе корреляции, то при наличии
наклонных плоскостей возникнут проблемы. Другие аргументы против исполь-
зования корреляции можно найти в работах [Julesz, I960] и [Marr, 19776J, где
предлагается искать соответствия по множеству различных шкал, согласовы-
вая (по возможности) физически значимые элементы изображения (например,
края), что предпочтительнее согласования значений яркости отдельных пиксе-
лей. Эти принципы отражены в алгоритме 11,1, который был предложен в работе
[Marr and Poggio, 1979].
Алгоритм 11.1. Алгоритм Марра-Поггио (1979) многошкального совмещения би-
нокулярных изображений
1. Свернуть два (очищенных) изображения с фильтрами 42GO, среднеквадрати-
ческие отклонения которых идут по возрастающей: cti < <Т2 < <г3 < ст4.
2. Найти точку перехода через нуль величины 42GO, двигаясь по горизонталь-
ным линиям сканирования отфильтрованных изображений.
3. Для каждой шкалы фильтра а согласовать переход через нуль с точкой, име-
ющей тот же порядок величины и приблизительно ту же ориентацию в диапа-
зоне расхождений [—wCT, +wCT], где wa = 2у/2а.
4. Использовать несоответствия, найденные при больших шкалах (масштабах),
для смещения изображений в окрестности найденных соответствий и перейти
к согласованию областей при меньших шкалах.
Глава 11. Стереозрение
345
Согласования определяются при каждом масштабе в диапазоне расхожде-
ний [—wa,wa], где wa = 2\/2а — ширина центральной отрицательной части
фильтра V2Gcr. Такой выбор мотивируется физиологическими и статистиче-
скими соображениями. В частности, предполагая, что свернутые изображения
описываются белыми гауссовыми случайными процессами, Гримсон ([Grimson,
1981а]) показал, что вероятность ошибочного соответствия в диапазоне рас-
хождений [—wCT, +wCT] при данном переходе через нуль равна всего 0,2, если
ориентация согласовываемых элементов лежит в пределах 30°. Для выбора
из множества потенциальных соответствий, которые могут обнаруживать-
ся в искомом диапазоне, можно использовать простой механизм, описанный
в работе [Grimson, 1981а]. Разумеется, ограничение поиска соответствий диа-
пазоном [—wa, +wff] не позволяет алгоритму сопоставить корректные пары
переходов через нуль, расхождение которых не входит в данный интервал. По-
скольку wa пропорционально масштабу а, при котором ищутся соответствия,
то для приведения потенциально согласуемых пар переходов через нуль в диа-
пазон, где происходит сопоставление при меньшем масштабе, следует смещать
взгляд (или, эквивалентно, смещать изображение) согласно сведениям, полу-
ченным при больших масштабах. Данная процедура выполняется на этапе 4
алгоритма и проиллюстрирована на рис. 11.12. Как только соответствия найде-
ны, полученные расхождения можно занести в буфер, именуемый 2 ±-мерным
эскизом ([Marr and Nishihara, 1978]). Данный алгоритм, реализованный Грим-
соном ([Grimson, 1981а]), был всесторонне протестирован на стереограмме
со случайными точками и на естественных изображениях. Соответствующая
иллюстрация приведена на рис. 11.12 (внизу).
11.3.3 . Динамическое программирование
Разумно предположить, что порядок согласуемых элементов изображения
вдоль пары эпиполярных линий является обратным к порядку соответствую-
щих параметров поверхностей вдоль кривой пересечения эпиполярной плоско-
сти с границами наблюдаемого объекта (рис. 11.13, слева). Это так называемое
условие упорядочения, введенное в начале 1980-х ([Baker and Binford, 1981],
[Ohta and Kanade, 1985]). Интересно отметить, что для реальных сцен это
условие может не выполняться, особенно если на изображении небольшие
твердые тела закрывают части больших объектов (рис. 11.13, справа) или, что
бывает значительно реже в сфере роботов наблюдения, если задействованы
прозрачные объекты.
Несмотря на сделанные оговорки, условие упорядочения можно использо-
вать при установлении стереосоответствий (рис. 11.14) для разработки эффек-
тивных алгоритмов с применением динамического программирования ([Forney,
1973], [Aho et al., 1974]). В частности, предположим, что на эпиполярных ли-
ниях найдено некоторое число характерных точек (скажем, углов). Цель заклю-
чается в согласовании интервалов, разделяющих эти точки вдоль двух профи-
лей интенсивности (рис. 11.14, слева). Согласно условию упорядочения порядок
характерных точек должен быть тем же, хотя некоторый интервал одного из
346
Часть III. Первые этапы: несколько изображений
Согласование переходов через нуль при одном масштабе
Согласование переходов через нуль при нескольких масштабах
Рис. 11.12. Вверху, согласование при одном масштабе. В середине-, согласование при нескольких
масштабах. Внизу: результаты. Слева внизу: входные данные (включая одно из входных изобра-
жений, выход четырех фильтров V2G„ и соответствующие переходы через нуль). Справа внизу:
вид с двух точек наблюдения на карту глубин, созданную в процессе согласования, и на поверх-
ность, полученную при интерполяции восстановленных точек. Перепечатано с разрешения Henry
Holt and Company, LLC из David Marr, "Vision: a computational investigation into the human
representation and processing of visual information”, (c) 1982 David Marr
изображений может сокращаться до точки на другом образе, что равнозначно
потерям соответствий в связи с затененными элементами и/или помехами.
Такой образ действий позволяет переформулировать задачу согласования
как оптимизацию стоимости пути по графу, узлы которого соответствуют парам
характерных элементов правого и левого изображений; ребра графа представ-
ляют соответствия между интервалами левого и правого профилей интенсив-
ности, которые ограничиваются характерными элементами соответствующих
узлов (рис. 11.14, справа). Стоимость ребра — это мера несовпадения соот-
ветствующих интервалов (например, квадрат разности значений средней ин-
тенсивности). Данную задачу оптимизации можно решить с использованием
динамического программирования, как показано в алгоритме 11.2.
Глава 11. Стереозрение
347
Рис. 11.13. Условие упорядочения. В (обычном) случае, представленном на левой части диаграммы,
характерные точки вдоль двух (ориентированных) эпиполярных линий идут в одном порядке.
В случае, представленном на правой части рисунка, небольшой объект заслоняет часть большого.
На одном из изображений не видны некоторые точки (например, точка А не видна на правом изоб-
ражении) и порядок точек изображения на двух изображениях различен; на левом изображении
точка b находится слева от точки d, а на правом изображении наблюдаем обратный порядок
Алгоритм 11.2. Алгоритм динамического программирования для согласования
двух соответствующих линий сканирования с угловыми точками тип (для удоб-
ства включены конечные точки линий сканирования). Использованы две вспо-
могательные функции: Inferior-Neighbors(fc, I) возвращает список соседей (i,j)
узла (к, Г), причем i < к и j < I, а функция Arc-Cost(z, j, к, I) оценивает и воз-
вращает стоимость согласования интервалов (г, к) и (J, /). Для точной работы
алгоритма начальным значением С(1,1) должен быть нуль.
% Упорядочить все узлы (к, I) по возрастанию
for к = 1 to т do
for I = 1 to n do
% Задать начальные значения оптимальной стоимости C(fc, I)
% и обратного указателя В(к, /)
С(к,1) <- +oo;B(fcJ) <- nil;
% Упорядочить всех ближайших соседей (i,j) узла (к, Г)
for (z,j) G Inferior-Neighbors(A:, /) do
% Вычислить новую стоимость пути и, при необходимости,
% обновить обратный указатель
d «— С(г, j) + Arc-Cost(z, j, к, /);
if d< C(fc,Z) then C(k,l) d;B(k,l) <- (ij) endif;
endfor;
endfor;
endfor;
% Определить оптимальный путь, проследовав за обратными
% указателями от узла (т, п).
Р «- (?n,n);
while B(i, j) ± nil do (i, j) «— B(i, j); P <— {(?, j)} U P
endwhile.
348
Часть III. Первые этапы: несколько изображений
Рис. 11.14. Динамическое программирование и стереозрение. На левой части рисунка показаны два
профиля интенсивности вдоль согласованных эпиполярных линий. Многоугольники, соединяющие
два профиля, обозначают число соответствий между последовательными интервалами (некоторые
согласованные интервалы могут иметь нулевую длину). На правой части диаграммы та же инфор-
мация представлена в графической форме: ребро (тонкий сегмент линии) соединяет два узла (»,»')
и (j.j'). если интервалы (i,j) и профилей интенсивности согласованы между собой
Вычислительная сложность алгоритма 11.2 равна O(mn), где т и п, соответ-
ственно, — число краевых точек на согласованных левой и правой линии ска-
нирования2. Разновидности описанного подхода были реализованы Бейкером
и Бинфордом ([Baker and Binford, 1981]), которые объединили “грубо-точную”
процедуру поиска вне линий сканирования с кооперативным процессом для
получения межлинейного согласования, и Охтой и Кенедом ([Ohta and Kanade,
1985]), которые использовали динамическое программирование для оптимиза-
ции как в переделах линий сканирования, так и между линиями сканирования.
Последняя процедура была проведена в трехмерном пространстве поиска. При-
меры результатов, полученных в работах [Ohta and Kanade, 1985], приведены
на рис. 11.15.
11.4. ИСПОЛЬЗОВАНИЕ БОЛЬШЕГО ЧИСЛА КАМЕР
11.4.1. Три камеры
Добавление третьей камеры устраняет (большей частью) неоднозначность,
присущую задаче согласования двух изображений. По сути, третье изображе-
ние может использоваться для проверки гипотетических соответствий между
первыми двумя (рис. 11.16): трехмерная точка (найденное соответствие) внача-
ле восстанавливается, а затем проектируется на третье изображение. Если на
2В данной версии алгоритма предполагается, что все края согласованы. Чтобы учесть помехи
и ошибки обнаружения краев, разумно разрешить алгоритму согласования пропускать конечное
число краевых точек, но эта оговорка не влияет на его асимптотическую сложность ([Ohta and
Kanade, 1985J).
Глава 11. Стереозрение
349
Рис. 11.15. Два изображения Пентагона и изометрический график карты расхождений, вычис-
ленный с помощью алгоритма динамического программирования. Перепечатано из Y. Ohta and
Т. Kanade, “Stereo by Intra- and Inter-Scanline Search”, IEEE Transactions on Pattern Analysis
and Machine Intelligence, 7(2):I39-I54, 1985. © 1985 IEEE
некотором расстоянии от спроектированной точки не обнаруживается сопоста-
вимой точки третьего изображения, соответствие считается ложным. Факти-
чески, процесса восстановления/повторного проектирования можно избежать,
если указать (как было сделано в главе 10), что для трех данных слабо (а тем
более сильно) откалиброванных камер и двух изображений точки всегда можно
предсказать ее положение на третьем изображении, найдя пересечение соответ-
ствующих эпиполярных линий.
11.4.2. Множественные камеры
Большинство алгоритмов тринокуляркого стереозрения построено по такому
принципу: на основе изучения двух изображений делаются предположения о со-
ответствиях, которые затем проверяются с использованием третьего изображе-
ния. В противоположность этому подходу, в работе [Okutami and Kanade, 1993]
был предложен многокамерный метод, где соответствия искались с одновремен-
ным изучением всех изображений. Принцип достаточно прост, но элегантен:
предполагается, что все изображения были очищены, а поиск точных расхож-
дений заменяется поиском точной глубины, т.е. обратным процессом. Разуме-
ется, для каждой камеры обратная глубина точки прообраза пропорциональна
расхождению, но расхождение различно для разных камер, а обратную глуби-
ну можно использовать как общий индекс поиска. Взяв первое изображение за
эталон, Окутами и Кенед добавили в глобальную оценочную функцию Е суммы
квадратов разностей, связанных со всеми другими камерами (это эквивалентно
добавлению корреляционных функций, соотнесенных с изображениями).
На рис. 11.17 представлена зависимость Е от обратной глубины для раз-
личных наборов камер. Следует отметить, что соответствующие изображения
содержат повторяющиеся структуры, и что использование только двух или трех
камер не дает одного четко выраженного минимума. В то же время, введение
дополнительных камер позволяет обнаружить достаточно четкий минимум, от-
вечающий действительному соответствию.
350
Часть III. Первые этапы: несколько изображений
Рис. 11.16. Небольшие серые диски обозначают неверно восстановленные точки, определенные
по левому и правому изображениям четырех точек. Добавление центральной камеры устраняет
неоднозначность определения соответствий: ни один из рассматриваемых лучей не пересекает ни
один из шести дисков. Возможна альтернативная трактовка: правильность сопоставления точек
первых двух изображений можно проверить, спроектировав соответствующие трехмерные точки
на третье изображение. Например, соответствие между bi и а2 найдено неверно, поскольку рядом
с проекцией гипотетической точки (на диаграмме обозначена 1) на третье изображение нет ни
одной характерной точки третьего изображения
40000 г-
30000 -
15000 Н
0
35000
25000
20000
10000
5000
Обратное расстояние
Рис. 11.17. Объединение многих точек наблюдения. Сумма квадратов разностей здесь изображена
как функция обратной глубины при разном числе входных изображений. Данные взяты с линии
сканирования, расположенной возле вершины изображений, которые представлены на рис.11.18
(интенсивность на этой линии представляет почти периодическую функцию). Из диаграммы четко
видно, что минимум функции определяется все точнее по мере добавления новых изображений. Пе-
репечатано из М. Okutami and Т. Kanade, "A Multiple-Baseline Stereo System”, IEEE Transactions
on Pattern Analysis and Machine Intelligence, 15(4):353-363, 1993. (c) 1993 IEEE
Глава 11. Стереозрение
351
Рис. 11.18. Последовательность 10 изображений и соответствующая восстановленная поверхность.
Клетчатая поверхность возле вершины изображений представляет собой источник почти перио-
дического сигнала яркости, дающего вклад в неоднозначности на рис. 11.17. Перепечатано из
М. Okutami and Т. Kanade, "A Multiple-Baseline Stereo System", IEEE Transactions on Pattern
Analysis and Machine Intelligence, 15(4):353-363, 1993. © 1993 IEEE
На рис. 11.18 показана последовательность 10 очищенных изображений и по-
верхность, которая была восстановлена с помощью описанного алгоритма.
11.5. ПРИМЕЧАНИЯ
Тот факт, что расхождение изображений, получаемых человеческими гла-
зами, является причиной стереозрения, впервые был проиллюстрирован при
изобретении Уитстоном стереоскопа ([Wheatstone, 1838]). То, что расхождения
достаточно для стереозрения при отсутствии движения глаз, было показано
немного позже ([Dove, 1841]) на опытах с искровыми разрядами, происходя-
щими настолько близко, что глаза просто не успевали реагировать и, соответ-
ственно, менять положение ([Helmholtz, 1909], р. 455). Впоследствии человече-
ское стереозрение было рассмотрено в классической книге [Helmholtz, 1909] —
захватывающей работе, которую стоит прочесть всем, кто интересуется исто-
рией данной области. Весьма познавательны также книги Джулеца ([Julesz,
1960], [Julesz, 1971]), Фризби ([Frisby, 1980]) и Марра ([Marr, 19776]). Для
сокращения объема изложения в данной главе не были рассмотрены теории
бинокулярного человеческого восприятия, которые заинтересованный читатель
может найти в публикациях [Koenderink and Van Doorn, 1976a], [Pollard et al.,
1985], [McKee et al., 1990] и [Anderson and Nakayama, 1994].
Великолепную трактовку машинного стереозрения можно найти в книгах
Гримсона [Grimson, 19816], Марра [Marr, 1982], Хорна [Horn, 1986] и Фау-
гераса [Faugeras, 1993]. В работах Марра основное внимание уделяется вы-
числительным аспектам человеческого стереозрения, а Хорн делает акцент
на роли фотограмметрии в искусственных стереосистемах. Гримсон и Фау-
352
Часть III. Первые этапы: несколько изображений
герас исследуют геометрические и алгоритмические аспекты стереозрения.
Ограничения, связанные с согласованием стереоизображений, рассмотрены
в работе [Binford, 1984]. Ранние методы согласования линий при бинокулярном
стереозрении описаны в работах [Medioni and Nevatia, 1984] и [Ayache and
Faugeras, 1987]. Алгоритмы совмещения тринокулярных изображений пред-
ставлены в [Milenkovic and Kanade, 1985], [Yachida et al., 1986], [Ayache and
Lustman, 1987] и [Robert and Faugeras, 1991]. Как показано в [Robert and
Faugeras, 1991] (см. также раздел упражнений), трифокусный тензор, введен-
ный в главе 10, также можно использовать для предсказания тангенса угла
наклона и кривизны некоторой кривой одного изображения, причем далее эти
параметры можно использовать для вычисления соответствующих величин на
других изображениях. На основе такого подхода можно разработать схему
эффективного согласования и восстановления кривых по трем изображениям.
Как отмечалось ранее, при определении бинокулярных соответствий в ка-
честве основы часто используются края изображений, по крайней мере из-за
того, что их (теоретически) можно идентифицировать, учитывая физические
свойства процесса формирования изображения, соответствующие, например,
изменениям параметров на границах областей с разными альбедо, цветом или
окклюзией. Довольно часто при согласовании стереоизображений упускается
из виду, что бинокулярное совмещение изображений всегда дает неверные ре-
зультаты вдоль контуров твердых тел, ограниченных гладкими поверхностями
(рис. 11.19). Действительно, в этом случае соответствующие края изображений
зависят от точки наблюдения и их согласование дает ошибочно восстановлен-
ные элементы. Как показано в работах [Arbogast and Mohr, 1991], [Vaillant
and Faugeras, 1992], [Cipolla and Blake, 1992] и [Boyer and Berger, 1996], для
восстановления локальной модели поверхности второго порядка в этом случае
достаточно трех камер.
На данный момент не совсем очевидно, что предпочтительнее: согласова-
ние на основе характерных точек или на основе яркостной шкалы. Первая
схема точнее возле краев поверхности, но позволяет получить лишь разре-
женное множество измерений, тогда как вторая схема может давать худшие
результаты в однородных областях, но предлагать большое число соответ-
ствий в текстурированных областях. В этом контексте важна тема плотной
интерполяции поверхности из разреженных выборок. Читателям, которые ин-
тересуются данным вопросом, мы рекомендуем изучить работы [Grimson, 1981]
и [Terzopoulos, 1984].
Еще один подход к стереозрению, не рассмотренный в этой главе, включает
использование высокоуровневого процесса интерпретации — например, мето-
дов предсказания/проверки, проводимых над описаниями графических изоб-
ражений ([Ayache and Faverjon, 1997]), или иерархические схемы согласования
кривых, поверхностей и объемных фигур, обнаруженных на двух изображениях
([Lim and Binford, 1988]).
Во всех алгоритмах, представленных в данной главе, предполагалось (хотя
об этом не говорилось), что совмещаемые изображения достаточно подобны, что
Глава 11. Стереозрение
353
Рис. 11.19. Согласование стереоизображений дает сбой на границах гладких объектов. При ис-
пользовании большинства алгоритмов, основанных на согласовании углов, и работе с образами
с узкими базовыми линиями, пары (c,d') и (а, Ь') часто сопоставляются, что приводит к появле-
нию на трехмерной реконструкции ложных точек F и Е
эквивалентно рассмотрению короткой базовой линии. Эффективный алгоритм
обработки широких базовых линий предложен в публикации [Pritchett and Zis-
serman, 1998]. Еще один подход, основанный на использовании моделей, будет
рассмотрен в главе 26.
Наконец, мы ограничили рассмотрение данной темы стереоустройствами
с фиксированными внутренними и внешними параметрами. Здесь стоит упомя-
нуть активное зрение, связанное с созданием систем компьютерного зрения,
которые могут динамически менять свои параметры (например, изменение углов
увеличения и фокусировки камеры, использование этих возможностей в зада-
чах восприятия и робототехники; см. работы [Aloimonos et al., 1987], [Bajcsy,
1988], [Ahuja and Abott, 1993], [Brunnstrom et al., 1996]).
Упражнения
11.1. Покажите, что для очищенной пары изображений глубина точки Р в нор-
мированной системе координат, связанной с первой камерой, равна z =
—В/d, где В — базовая линия, ad — расхождение.
11.2. Используйте определение расхождения для описания точности восста-
новления стереоизображения как функции длины базовой линии и глу-
бины точки объекта.
11.3. Выведите формулы восстановления для точек плоскости, находящихся
близко к глазам.
11.4. Предложите алгоритм генерации неоднозначной стереограммы со слу-
чайными точками, на которой можно изобразить две разных плоскости,
висящих над третьей.
354
Часть III. Первые этапы: несколько изображений
11.5. Покажите, что корреляционная функция достигает максимального зна-
чения 1, когда яркости изображений двух окон связаны аффинным пре-
образованием Г = XI + /1 при некоторых константах Аид, где А > 0.
11.6. Докажите эквивалентность корреляции и суммы квадратов разностей
для изображений с нулевым средним и единичной фробениусовой нор-
мой.
11.7. Рекурсивное вычисление корреляционной функции.
а) Покажите, что (w — w) • (w' — w') = w-w,~ (2m 4- l)(2n + 1)77'.
б) Покажите, что среднюю интенсивность I можно вычислить рекурсив-
но. Оцените стоимость последовательного вычисления.
в) Обобщите проведенные вычисления; постройте корреляционную функ-
цию и оцените общую стоимость корреляции по паре изображений.
11.8. Покажите, как расширение первого порядка функции расхождения для
очищенных изображений можно использовать при деформации окна пра-
вого изображения соответственно прямоугольной области левого изобра-
жения. Покажите, как в этом случае вычислить корреляцию, используя
интерполяцию для оценки значений на правом изображении в точках,
соответствующих центрам пикселей левого окна.
11.9. Покажите, как трифокусный тензор можно использовать для предска-
зания касательной к кривой изображения имея касательные, которые
определены на двух других изображениях.
Упражнения
11.10. Реализуйте процесс очистки.
11.11. Реализуйте подход к стереозрению на основе корреляции.
11.12. Реализуйте многошкальный подход к стереозрению.
11.13. Реализуйте подход к стереозрению с использованием динамического про-
граммирования.
11.14. Реализуйте тринокулярный подход к стереозрению.
12
Определение аффинной
структуры по движению
В данной главе продолжается анализ задачи оценки трехмерной формы объ-
екта с использованием нескольких его изображений. В контексте задачи сте-
реозрения камеры, используемые для получения входных изображений, обычно
калибруются так, что их внутренние параметры известны, а внешние опреде-
лены относительно некоторой глобальной системы отсчета. Это значительно
упрощает процесс восстановления и объясняет, почему основное внимание
уделяется задаче бинокулярного (или тринокулярного) совмещения изображе-
ний в обычных системах стереонаблюдения. В данной главе рассмотрен более
сложный случай, когда положения камер и, возможно, их внутренние пара-
метры не известны априори и могут меняться со временем. Такая ситуация
обычна для приложений визуализации на основе анализа изображений, где
видеоклип, записанный посредством ручной камеры с изменением в процессе
съемки масштаба, используется для фиксации формы объекта и визуализации
его при новых условиях наблюдения (глава 26). Такая задача также важна
в системах активного зрения, калибровочные параметры которых динамически
варьируются, и автоматических планетарных зондах, где эти параметры могут
меняться вследствие большого ускорения при взлете и посадке. Разумеется,
в контексте навигации мобильных роботов важна не только оценка формы
объекта, но и восстановление положений камер.
356
Часть III. Первые этапы: несколько изображений
Далее в этой главы мы не будем рассматривать задачу определения соответ-
ствий, предполагая, что проекции п точек согласованы по т изображениям1.
Вместо этого сосредоточим внимание на чисто геометрической задаче опреде-
ления структуры по движению — использования согласованных элементов
изображения для оценки трехмерных положений соответствующих точек объ-
екта в некоторой глобальной системе отсчета (т.е. восстановления структуры
сцены) и проекционных матриц, соотнесенных с камерами, наблюдающими
объект (или, эквивалентно, движения точек относительно камер). В данной
главе рассматриваются сцены, рельеф которых меняется незначительно по
сравнению с их общей глубиной относительно камер, наблюдающих эти сцены,
так что перспективу можно аппроксимировать простыми аффинными моде-
лями процесса формирования изображения, представленных в главах 1 и 2.
Полная задача определения перспективной структуры по движению рассмотре-
на в следующей главе. В частности, при данных п фиксированных точках Pj
(j — 1, ...,п), которые наблюдаются т аффинными камерами, и соответ-
ствующих тп векторах (в неоднородных координатах) этих изображений
аффинные проекции из формулы (2.19) можно переписать следующим образом:
/рД
р^=Л4<1 1 I = AiPj + bi для i = l,...,m и j = l,...,n. (12.1)
Таким образом, определение аффинной структуры по движению — это зада-
ча оценки т матриц Mi = (Ai bi) размера 2 х 4 и п положений Pj точек Pj
в некоторой глобальной системе координат по тп соответствиям элементов
изображения ргу.
Если проекционные матрицы Mi могут иметь любой вид (т.е. когда неиз-
вестны внутренние и внешние параметры камер, см. главу 2), из формулы (12.1)
получаем 2тп условий на 8m + Зп неизвестных коэффициентов, из которых
определяются матрицы Mi и положения точек Pj. Поскольку для достаточно
больших т и п число 2тп значительно больше 8m + Зп, очевидно, что боль-
шое число точек наблюдения и достаточное число точек объекта позволяют
восстановить соответствующую структуру и параметры движения посредством,
скажем, схем наименьших квадратов, описанных в главе 3. В то же время важ-
но понимать, что если Mi и Pj — это решения уравнения (12.1), то решениями
также являются М[ и Р' такие, что
и (12.2)
где Q — матрица произвольного аффинного преобразования. Другими слова-
ми, матрицу Q можно записать (см. главу 2 и следующий раздел данной главы)
'Методы определения таких соответствий для непрерывных последовательностей изображе-
ний и для набора разных точек наблюдения рассмотрены в главах 17 и 23.
Глава 12. Определение аффинной структуры по движению
357
так:
й=(от 1) и С14)’ (12-3)
где С — несингулярная матрица 3 х 3, a d — вектор в пространстве R3.
Иначе говоря, любое решение задачи нахождения аффинной структуры по
движению можно определить только с точностью до аффинного преоб-
разования. Учитывая, что общее аффинное преобразование задается 12 па-
раметрами, стоит ожидать, что число возможных решений будет конечным,
поскольку 2тп > 8т + Зп — 12. При т = 2 для определения (с точностью до
аффинного преобразования) двух проекционных матриц и положения в трех-
мерном пространстве любой точки должно быть достаточно четырех точечных
соответствий. Формально это утверждение доказано в разделе 12.2.
Если внутренние параметры камер известны, так что соответствующие
калибровочные матрицы можно считать единичными, на параметры проек-
ционных матриц Л4г = (А нужно наложить дополнительные условия.
Например, согласно формуле (2.20) матрица Аг, соотнесенная с (откалиброван-
ной) слабоперспективной камерой, формируется из первых двух строк матрицы
поворота, умноженных на обратную глубину соответствующей наблюдаемой
точки. Как показано в разделе 12.4, подобные ограничения могут использовать-
ся для устранения аффинной неоднозначности при наличии достаточного числа
изображений. Таким образом, решение поставленной задачи логично разбить на
два этапа: а) вначале использовать, по крайней мере, два изображения сцены
для создания однозначного (с точностью до произвольного аффинного преобра-
зования) трехмерного представления сцены, именуемого ее аффинной формой',
а затем б) использовать дополнительные точки наблюдения сцены и условия,
связанные с известными калибровочными параметрами камер и конкретны-
ми аффинными моделями, для однозначного определения жесткой евклидовой
структуры сцены. На первом этапе описанного сценария получается необхо-
димая часть решения: аффинная форма — это завершенное трехмерное пред-
ставление сцены, которое, как показано в главе 26, само может использоваться
для синтеза новых проекций сцены. На втором этапе находится евклидово
уточнение сцены (т.е. определяется аффинное преобразование, отвечающее
жесткой структуре сцены и отображающее ее аффинную форму в евклидову).
Если использовать три или большее число изображений, задача опреде-
ления структуры по движению получается переопределенной, т.е. можно (по
схеме наименьших квадратов) получить более устойчивые решения. Поэтому
значительная часть данной главы посвящена задаче восстановления аффинной
формы сцены по нескольким (по возможности — многим) ее изображениям.
В завершение рассмотрены методы сегментации множества информационных
точек в объекты, которые движутся независимо друг от друга.
358
Часть III. Первые этапы: несколько изображений
12.1. ЭЛЕМЕНТЫ АФФИННОЙ ГЕОМЕТРИИ
Определим некоторые элементарные понятия аффинной геометрии. Соот-
ветствующие геометрические и алгебраические средства позволят нам сфор-
мулировать и доказать фундаментальные свойства аффинных проекционных
моделей. Кроме того, эти средства используются как элементарные составля-
ющие алгоритмов определения структуры по движению, представленные далее
в этой главе.
Как отмечено в работе [Snapper and Troyer, 1989], аффинная геометрия —
это, грубо говоря, то, что остается после удаления из евклидового пространства
всякой возможности измерения длины, площади и углов. Впрочем, остается по-
нятие параллельности, а также возможность измерения отношения расстояний
между точками на коллинеарных прямых. Мы считаем, что строгое аксиомати-
ческое введение в аффинную геометрию здесь будет неуместным. Вместо этого
использован довольно неформальный подход и указаны основные факты о дей-
ствительных аффинных пространствах, необходимые для понимания остальной
части главы. Читатель, знакомый с такими понятиями, как барицентрические
комбинации, аффинные системы координат и аффинные преобразования, может
сразу переходить к следующему разделу.
12.1.1. Аффинные пространства и барицентрические комбинации
Действительное аффинное пространство — это набор точек X плюс
действительное векторное пространство X и действие ф аддитивной груп-
пы X на X. Векторное пространство X лежит в основе аффинного простран-
ства X. Неформально, действие группы на множество отображает элементы
этой группы во взаимно однозначное соответствие этого множества. Здесь дей-
ствие ф соотносит с каждым вектором и G X взаимно однозначное соответ-
ствие фи : X —> X, причем для любых векторов и, и в X и любой точки Р
в X, Фи+vkP) = Ф-и. ° Фъ(Р)> Фо(Р) = Р и для любой пары точек P,Q в X
существует единственный вектор и в X такой, что фи(Р) = Q- Эти определе-
ния могут звучать несколько абстрактно, поэтому для их пояснения приведем
пару конкретных примеров. Привычным аффинным пространством является Е3,
где X — множество физических точек, а X — множество трансляций вектора X
на себя. Другое аффинное пространство можно построить, выбрав X и X рав-
ными йп, а действие ф определив как фи(Р) = Р+и, где Р и и — элементы К",
а через “4-и обозначено сложение в этом векторном пространстве.
Далее будем обозначать точку фи(Р) как Р + и, а вектор и, такой что
Фи(Р) = Q, — как PQ, или, эквивалентно, Q — Р. Выбор точки О как начала
координат X позволяет сопоставить любой другой точке Р вектор и = ОР,
такой что фи(О) = Р. Действительно,
Q = P + P$^O$ = Op + PQ и Q- P = PQ ^O$-OP = PQ.
Глава 12. Определение аффинной структуры по движению
359
Пример 12.1. R2 — аффинная плоскость
Векторное пространство R2 можно считать аффинным, положив X = Л = R2.
Для данных Р = (х, у)т и и = (а, Ь)т определим фи(Р) = Р+и = (х+а,у+Ь)т.
Для данных Р = (х,у)т и Q = (х',у')т единственным вектором и, таким
что Р + и = Q, является и = Q — Р = Р^ = (х' — х,у' — у)т.
Введение начала координат обычно удобно для начинающих, кто стремится
аккуратно записывать все выражения в аффинной системе координат. В то же
время, очевидно, что точка Р+и и вектор PQ = Q — P абсолютно не зависят
от выбора какого бы то ни было начала координат. Подобным образом, символы
“+” и ” в этих выражениях используются для удобства записи и не имеют
привычного значения сложения и вычитания в аддитивной группе векторного
пространства.
Хотя “прибавление” вектора к точке и “вычитание” двух точек математиче-
ски корректно, "сложение" двух точек или “умножение" точки на скаляр невоз-
можно (см. раздел упражнений). В то же время, можно определить конечный
набор “линейных комбинаций” точек: рассмотрим т + 1 точек Ло,А1---»Ап
и пг + 1 весовых коэффициентовс>о,«1,... ,ат, таких что qq+oiH = 1;
соответствующая барицентрическая комбинация точек от До до Ат — это
точка
m т
Yl^Ai = Ai+ £ (12.4)
i=0
где j — целое число от 0 до тп. В правой части приведенного уравнения
точка определяется путем прибавления вектора (линейной комбинации век-
торов Л - Aj) к точке (Aj). Легко показать (см. раздел упражнений), что
данное определение не зависит от значения j — это объясняется симметрич-
ным вхождением точек А, (г = 0,...,т) в выражение ££10а»А,. Справедли-
вость данной записи можно проверить, введя начало координат О и отметив,
что ХХо при a0 + Q1 4----h Otm = 1.
Впрочем, определение барицентрических комбинаций в форме (12.4) предпо-
чтительнее, поскольку оно не зависит от выбора начала координат.
360
Часть III. Первые этапы: несколько изображений
Хорошим примером барицентричной комбинации будет центр масс т + 1
точки; в этом случае все весовые коэффициенты равны 1/(т4-1). Впрочем, при-
емлемая барицентрическая комбинация получается при любом наборе весовых
коэффициентов, сумма которых равна 1.
12.1.2. Аффинные подпространства и аффинные координаты
Аффинное подпространство X определяется точкой О и векторным под-
def
пространством U пространства X как множество точек О + U = {O + u,u G
U}. Его размерность равна размерности соответствующего векторного подпро-
странства. Два аффинных подпространства О' + U' и О" 4- U" такие, что U' —
подпространство U" или U" — подпространство U', называются параллельны-
ми. Аффинные подпространства размерности 1 и 2 называются, соответственно,
прямой и плоскостью. Если пространство X имеет конечную размерность п,
его аффинные подпространства размерности п — 1 называются гиперплоско-
стями. В аффинных пространствах, связанных с физическим трехмерным про-
странством и Кп, аффинные прямые, плоскости и гиперплоскости имеют свое
обычное значение прямых, плоскостей и гиперплоскостей.
Пример 12.2. Пересечение двух аффинных подпространств является либо
пустым множеством, либо аффинным подпространством
Рассмотрим два подпространства Y' = О' + U' и Y" = О" + U" некоторого
аффинного пространства X и обозначим их пересечение через Z. Пусть Ро —
некоторая точка в Z. По определению, Ро = О' + и'о = О" 4- и" для некоторых
векторов и'о в U* и uq в U". Подобным образом, для любой данной точки Р в Z
можно записать Р = О' 4- и — О” + и" для некоторых векторов и' в U' и и"
в (7". В частности, нужно получить
Р — Ро 4- и — «о = Ро 4- и" — г»о-
Отсюда следует, что а) и —и'о = и" — u'q принадлежит U' Л U" и б) Р принад-
лежит Ро 4- U1 Л U". И наоборот, любую точку Р в Ро 4- U' Л U" можно записать
как Р = Ро 4- и для некоторого вектора и в U* П U"; таким образом,
Р = О1 4- (Ро — О') + и — О' + и' + и = О" 4- (Ро — О"} 4- и = О" 4- и" 4- и.
Из этого следует, что Р принадлежит Z. Окончательно получаем, что Z = Ро 4-
U1 nW. Отметим, что пересечение двух аффинных пространств может быть пу-
стым. Например, две параллельные прямые не пересекаются. Не пересекаются
также две скрещивающиеся прямые в пространстве, хотя параллельными они не
являются.
Аффинные подпространства можно также определить непосредственно через
точки: пусть 5(Ао, Ai..., Am) — множество всех барицентрических комбина-
Глава 12. Определение аффинной структуры по движению
361
ций тп + 1 точки Aq, Ai,..., Ат. Легко проверить, что S^Ao, Ai,..., Am) дей-
ствительно представляет собой аффинное подпространство (см. раздел упраж-
нений) и что его размерность не превышает т (например, две разных точки
определяют прямую, три точки — плоскость (в общем случае), и т.д.). Будем
говорить, что т +1 точки независимы, если они не принадлежат подпростран-
ству размерности меньше т, так что т +1 независимых точек определяют или
(накрываются) m-мерным подпространством.
Пример 12.3. Два дополняющих определения аффинной плоскости
Возьмем три точки До, Ai и Д2, лежащие на неколлинеарных прямых в простран-
стве R3, рассматриваемом как аффинное пространство. Эти точки определяют
плоскость П = До 4- U пространства R3, связанную с точкой До, и векторную
плоскость U, натянутую на два вектора ги = Д0Д1 и и? = Д0Д2-
Эквивалентно, плоскость П можно рассматривать как аффинное подпростран-
ство 5(До,Д1,Д2) пространства R3, а любую точку Р в П можно представить
как барицентрическую комбинацию точек До, Д1 и Аз-
Аффинная система координат для пространства O+U состоит из точки До
(именуемой началом этой системы) в O + U и системы координат (ui,... ,ит)
для U, Аффинные координаты точки Р в О + U определяются как координаты
вектора АоР в системе координат (гц,..., ит). Важно понимать, что евклидовы
координаты точек, которые использовались в главе 2 и применяются в обыч-
ной евклидовой геометрии, являются аффинными. Векторы u, (i = l,...,m),
которые использовались для определения соответствующих систем координат,
имеют дополнительное свойство: единичную длину и ортогональность между
собой. Это свойство не является необходимым в общей аффинной системе коор-
динат, следовательно, в общих аффинных пространствах могут не определяться
понятия “длина” и “угол”.
362
Часть III. Первые этапы: несколько изображений
Пример 12.4. Изменения аффинных координат
Пусть имеется некоторая система координат (F) — (O,u,v,w) для аффинного
пространства Е3 и точки Р в Е3, причем О? = хи + yv + zw. Тогда можем опре-
делить, используя ту же форму записи, что и в главе 2, (аффинный) координатный
вектор Р как FP = (x,y,z)T.
Для двух данных аффинных систем координат (Л) = (Оа^а, и a, wa) и (В) =
(Ов,ив,ъв,шв) и аффинного пространства Е3 определим матрицу 3x3
аС = (виА bva bwa)
где через ва обозначен вектор координат а в векторной системе коорди-
нат (ua,va,wa)- Легко показать, что ВР = ВСАР + вОа, или, в однородных
(аффинных) координатах,
Отметим очевидное сходство с формулой для перехода между евклидовыми си-
стемами координат, которая приводилась в главе 2. Впрочем, в данном случае
базисные векторы двух систем координат не формируют ортонормированного ба-
зиса, так что аС — это обычная несингулярная матрица 3 х 3, а не матрица
поворота; — матрица аффинного преобразования.
Альтернативный способ определения системы координат в n-мерном аффин-
ном пространстве X — это выбрать п 4-1 независимую точку Ао, Ai ..., Ап
в X. Барицентрические координаты а, (г = 0,1,..., п) точки Р в Y един-
ственным образом определяются соотношением Р = аоАо 4-aiAi 4----|-anAn.
Их связь с аффинными координатами проста: выбор j = 0 в уравнении (12.4)
дает следующее:
Р = аоАо 4- aiАх 4-1- апАп = Ао 4- ai(Ai — Ao) 4--1- an(An — Ao).
Отсюда видно, что аффинные координаты точки Р в базисе, сформированном
точками А, (г — 0,1,..., т), имеют вид ai, ..., am.
Если в n-мерном аффинном пространстве X имеется аффинный базис, необ-
ходимым и достаточным условием того, чтобы т 4-1 точка А, определяли р-
мерное аффинное подпространство X (причем т > р и п > р), является следу-
ющее: матрица (п 4-1) х (т 4-1)
/ ®oi
Xml\
г =
я: on
\ 1
Л1П
1
1 /
Глава 12. Определение аффинной структуры по движению
363
Рис. 12.1. Аффинное преобразование плоскости. Точки А, В, С и D преобразуются в точ-
ки А', В*, С* и D'. Аффинные координаты D в базисе плоскости, сформированной точками А, В
и С, совпадают с координатами точки D' в базисе, сформированном точками А', В' и С', а
именно — 2/3 и 1/2
сформированная координатными векторами (з:»!,..., Xin)T (г = 0,1,..., тп),
должна иметь ранг р + 1. Действительно, если ранг матрицы меньше р + 1, то
любой столбец этой матрицы — барицентрическая комбинация не более чем р
других столбцов, а если ранг больше р + 1, то по крайней мере р + 2 точек
являются независимыми.
Пример 12.5. Уравнение прямой на плоскости
Рассмотрим три точки Ао, Ai и Аз на аффинной плоскости, которые определяются
координатными векторами (ха,уо)т, (xi,yi)T и (хз,уз)т в некотором базисе этой
плоскости. Как отмечалось в предыдущем абзаце, необходимым и достаточным
условием принадлежности этих точек аффинному подпространству размерности 1
(т.е. три точки лежат на прямой) является следующее: ранг матрицы
tXQ ЯЦ Х3
уо У1 У2
1 1 1
равен двум. Эквивалентное условие: детерминант этой матрицы должен быть ра-
вен нулю. Отметим, что
Det(V) = хц/2 - rrai/i + хзуо - хоу2 + xoj/i - zil/o = I Х° I х I Х2 Хо I ,
\yi~yo/ \У2—Уо]
где через “х" обозначен оператор сопоставления двум векторам в R2 детерминан-
тов их координат. Таким образом, условие Det(D) = 0 действительно эквивалент-
но параллельности векторов AoAi и АоАз или коллинеарности трех точек. Если
точки Ао и Ai фиксированы, условие Det(P) — 0 можно рассматривать как урав-
нение, определяющее прямую, которая проходит через Ао и Ai, записанное через
координаты Аз. Данное уравнение имеет вид ах2 + Ьуз + с = 0. Описанный метод
можно обобщить на случай аффинных подпространств, определенных произволь-
ным числом точек: соответствующие уравнения получаются при приравнивании к
нулю детерминантов подходящих миноров матрицы Т>.
364
Часть III. Первые этапы: несколько изображений
12.1.3. Аффинные преобразования и аффинные проекционные
модели
Аффинное преобразование между двумя аффинными пространствами X
и У - это взаимно однозначное отображение X в Y, которое переводит т-
мерные подпространства X в m-мерные подпространства У, отображает па-
раллельные подпространства в параллельные подпространства и сохраняет ба-
рицентрические комбинации (или, эквивалентно, аффинные координаты; см.
рис. 12.1). Аффинные преобразования можно также охарактеризовать таким
(на первый взгляд — более слабым) свойством: прямые отображаются в пря-
мые и сохраняется отношение (с соответствующим знаком) длин отрезков
на параллельных прямых.
Аффинное преобразование между двумя аффинными пространствами X
и У размерности т полностью определяется изображениями Во,..., Вт т + 1
независимой точки Ao, ...,Ат. Действительно, изображение любой другой
точки с аффинными координатами ог (г = 0,..., т) в базисе X, сформиро-
ванном точками имеет те же координаты в базисе У, сформированном
точками Bi. Можно также доказать обратное: для любых данных независимых
точек Bq, ..., Вт в У существует единственное аффинное преобразование,
переводящее точки Л» в точки Bi. Таким образом, при аффинных преобразо-
ваниях не сохраняются углы или расстояние, подтверждение чему можно на-
блюдать на рис. 12.1. Фактически, аффинные преобразования пространства R3
всегда можно записать как комбинацию трансляции, вращения, неравномерного
изменения масштаба и сдвига.
Из связи между векторным и аффинным пространствами следует связь ли-
нейного и аффинного преобразований. В частности, легко показать (см. раздел
упражнений), что аффинное преобразование ф : X —> У между двумя аффин-
ными подпространствами X и У, связанными с векторными пространствами X
и У, можно записать следующим образом:
Ф(Р) = ф(О) + ф(Р - О),
где О — некоторое произвольно выбранное начало координат, ф : X —> У —
линейное отображение из X в У, которое не зависит от выбора О. Если про-
странства X и У имеют (конечную) размерность т и выбрана аффинная систе-
ма координат с началом в точке О, получаем знакомое выражение
Ф(Р) = d + CP = CP + d,
где через Р обозначен вектор координат Р в выбранном базисе, через d —
вектор координат ф(О), a С — это матрица т х т, которая в той же системе
координат представляет ф. Таким образом, определение аффинных преобра-
зований из главы 2 действительно эквивалентно определению, приведенному
в данной главе.
Глава 12. Определение аффинной структуры по движению
365
Фундаментальное свойство параллельных проекций состоит в том, что они
переводят аффинные преобразования, выполненные на плоскостях, в преобразо-
вания на их проекциях, причем пропорциональные расстояния между точками,
лежащими на коллинеарных прямых, сохраняются. Треугольники ОАа, ОВЪ^
и ОСс на рис. 12.2 (слева) подобны, из чего следует, что АВ/ВС = ab/bc
для любых ориентаций линий ОС и Ос. Чтобы показать, что при параллель-
ных проекциях сохраняется параллельность линий, используем тот факт, что
пересечение плоскости с двумя параллельными плоскостями — это две па-
раллельные прямые (см. раздел упражнений). Рассмотрим теперь ситуацию,
изображенную на рис. 12.2 (справа), где две параллельные прямые Ai и Аг
проектируются на плоскость. Плоскости, определенные, соответственно, этими
двумя прямыми и направлением параллельной проекции, параллельны между
собой, следовательно, пересекают плоскость изображения по двум параллель-
ным линиям <51 и &2-
Слабо- и параперспективные проекции одной плоскости на другую также яв-
ляются аффинными преобразованиями, поскольку эти проекции всегда можно
записать как суперпозицию параллельной проекции и аффинного преобразо-
вания плоскости проекции, что равнозначно изменению масштаба по шкале
обратных глубин и внутренних параметров камер. Как следует из теоремы 2
в главе 2, общее аффинное преобразование всегда можно записать как сла-
боперспективное преобразование, таким образом, аффинные проекции одной
плоскости на другую действительно являются аффинными преобразованиями.
Из сказанного следует, что при аффинных проекциях сохраняются парал-
лельность прямых и барицентрические комбинации. В частности, центр масс
набора точек прообраза проектируется в центр масс изображений этих точек
(что предлагает простой метод выбора контрольной точки параперспективной
камеры; см. главу 2), а отношение расстояний между коллинеарными точками
(взятых с соответствующими знаками) является инвариантом аффинного про-
ектирования (что полезно в контексте распознавания объектов; см., например,
главу 23).
12.1.4. Аффинная форма
Два (возможно, бесконечных) множества точек S и S' в некотором аффин-
ном пространстве X аффинно эквивалентны, если существует аффинное пре-
образование ф : X -* X такое, что S’ — это образ S в ф. Легко показать, что
аффинная эквивалентность — это отношение эквивалентности, так что мож-
но определить аффинную форму множества точек S в X как класс эквива-
лентности всех аффинно эквивалентных множеств точек. Теперь определение
аффинной структуры по движению можно рассматривать как задачу восстанов-
ления аффинной формы наблюдаемой сцены (и/или классов эквивалентности,
которые формируются соответствующими матрицами) по характерным точкам,
согласованным для последовательности изображений.
366
Часть III. Первые этапы: несколько изображений
Рис. 12.2. При параллельных проекциях сохраняются: (слева) отношение расстояний между точ-
ками на коллинеарных прямых (с соответствующими знаками) и (справа) параллельность прямых
Направление
проектирования
12.2. ОПРЕДЕЛЕНИЕ АФФИННОЙ СТРУКТУРЫ И ДВИЖЕНИЯ ПО ДВУМ
ИЗОБРАЖЕНИЯМ
Пусть для начала дано два аффинных изображения одной сцены (наличие
большего числа изображений рассматривается в следующем разделе). Ниже
представлены две взаимодополняющих технологии определения структуры по
движению: первая — это использование геометрических соображений для выяв-
ления аффинной формы сцены (из которой, если требуется, можно определить
проекционные матрицы), а вторая — это оценка проекционных матриц с по-
мощью простых алгебраических манипуляций (как результат — можно легко
вычислить положения точек наблюдаемого объекта).
12.2.1. Геометрическое восстановление сцены
Как уже упоминалось, двух аффинных проекций четырех точек Л, В, С, D
должно быть достаточно для вычисления аффинных координат любой другой
точки Р в базисе (Л, В, С, D). Это действительно так, и ниже предлагается
конструктивное доказательство, взятое из работы [Koenderink and Van Doorn,
1990]. Напомним, что аффинная проекция плоскости на другую плоскость пред-
ставляет собой аффинное преобразование. В частности, если точка Р принадле-
жит плоскости П, которая содержит треугольник АВС, ее аффинные координа-
ты в базисе П, сформированном тремя этими точками, можно непосредственно
измерить на любом из двух изображений. Обозначим через Е (соответственно,
Q) пересечение прямой, которая проходит через точки D и d! (соответствен-
но, Р и р'), с плоскостью П (рис. 12.3). Проекции е" и q" точек Е и Q на
плоскость П" имеют те же аффинные координаты в базисе (а",Ь",с"), что
и точки d' и р' в базисе (а', У, с').
Кроме того, поскольку два сегмента ED и QP параллельны направлению
первой проекции, параллельными являются и два сегмента прямой e"d" и q"p”,
Глава 12. Определение аффинной структуры по движению
367
Рис. 12.3. Геометрическое построение аффинных координат точки Р в базисе, сформированном
четырьмя точками Д, В, С и D. Представленная диаграмма соответствует параллельному про-
ектированию, но соображения, изложенные в данном разделе, справедливы для любой аффинной
структуры
так что можно записать отношение
q"p" QP
end" ED
где через АВ обозначено расстояние (с соответствующим знаком) между точка-
ми Л и В для некоторой произвольной (но фиксированной) ориентации прямой,
проходящей через эти точки.
Обозначив теперь через (с^/, (3d') и (арг,[Зр>) координаты точек d! = е' и р' —
д' в базисе (а', У,с'), можно записать следующее:
А? = AQ + Qp = ар> АВ + (Зр> А& + ЛЁЗ =
= (ар. - Xad>)AB + (J3p. - X(3d')AC + XAD.
368
Часть III. Первые этапы: несколько изображений
Рис. 12.4. Аффинное восстановление по двум проекциям. Слева и в центре: три проекции лица;
на левой части рисунка перекрываются изображения О и I, а на центральной — изображения
1 и 2. Справа: профиль аффинного лица, рассчитанный по изображениям 0 и 1 (использование
третьего изображения для превращения аффинного лица в евклидово описано в разделе 12.4).
Перепечатано с разрешения авторов из J.J. Koenderink and A.J. Van Doorn, “Affine Structure
from Motion", Journal of the Optical Society of America A, 8:377-385, (1990). © 1990 Optical
Society of America
Иными словами, аффинные координаты точки Р в базисе (А,В,С, D) имеют
вид (о?/ — Xcitf,flpr — АД//, А). Сформулируем теорему об определении аффин-
ной структуры по движению: для двух данных аффинных проекций четырех
некомпланарных точек аффинная форма сцены определяется однозначно ([Koen-
derink and Van Doorn, 1990]). На рис. 12.4 показаны три проекции смоделиро-
ванного лица, которые использовались в экспериментах Коендеринка и Ван До-
орна, а также аффинный профиль, определенный по двум из этих изображений.
12.2.2. Алгебраическая оценка движения
Рассмотрим теперь совершенно иной подход, когда мы несколько пренебре-
гаем геометрической природой объекта и производим простые алгебраические
действия по упрощению вида проекционных матриц, позволяющие почувство-
вать аффинную неопределенность рассматриваемой задачи. В результате полу-
чаем крайне простой метод восстановления этих матриц и соответствующей
аффинной формы.
Для начала введем аффинный эквивалент эпиполярного условия. Рассмот-
рим два аффинных изображения и перепишем соответствующие проекционные
уравнения:
р = АР + Ь
р* = А’Р + Ь'
при
Необходимое и достаточное условие наличия нетривиального решения данных
уравнений имеет такой вид:
Глава 12. Определение аффинной структуры по движению
369
или
Рис. 12.5. Аффинная эпиполярная геометрия. Для двух данных изображений, полученных посред-
ством параллельного проектирования, точка р на первом изображении и два направления проек-
тирования определяют эпиполярную линию I*. Как и для перспективных проекций, любая точка,
соответствующая р‘ и р, должна находиться на этой линии
ГЙ=0’
р — О I
Det [ А
аи + fiv + а1и' 4- /З'и' 4- 6 = О,
(12.5)
где а, (3, а', /3' и <5 — константы, зависящие от Л, б, Аг и 6'. Данное условие
называется аффинным эпиполярным условием. Действительно, для точки р
на первом изображении соответствующая точка р' (согласно уравнению (12.5))
может лежать только на прямой I', которая определяется уравнением а'и' 4-
/З'г/ + у = 0, где у = аи 4- /Зи 4- ё, и наоборот (рис. 12.5).
Отметим, что эпиполярные линии, связанные с каждым изображением,
параллельны между собой. Например, движение р изменяет или, эквива-
лентно, расстояние от начала координат до эпиполярной линии V, но не меняет
направления I*.
Аффинное эпиполярное условие можно записать в более привычной форме:
/ / ° 0 Q
(и, v, 1)7^ I v' 1 = 0, где Г = I 0 0 /3
\ 1 / /з' <5
370
Часть III. Первые этапы: несколько изображений
представляет аффинную фундаментальную матрицу. Отсюда следует вывод,
что аффинную эпиполярную геометрию можно рассматривать как предельный
случай перспективной. Действительно, можно показать, что аффинное изобра-
жение является пределом последовательности изображений, полученных пер-
спективной камерой, увеличивающей масштаб изображения сцены при одно-
временном удалении от нее (подробнее см. раздел упражнений).
Покажем теперь, что проекционные матрицы можно оценить с помощью эпи-
полярного условия. Характерная неопределенность решения рассматриваемой
задачи на самом деле позволяет упростить необходимые вычисления: согласно
уравнениям (12.2) и (12.3), если Л4 = (Л б) и /Л' = (Д' Ь') — решения
поставленной задачи, решениями также являются Л4 — A4Q и Л4' = A4'Q, где
представляют произвольное аффинное преобразование. Новые проекционные
матрицы можно записать как Л4 = (AC Ad + b) и Л4' = (А'С A'd + b').
Отметим, что согласно уравнению (12.3) применение этого преобразования к
проекционным матрицам равнозначно применению обратного преобразования
ко всем точкам объекта Р, которые при этом переходят из положения Р в по-
ложение Р — C~l(P — d).
Обозначим теперь через af и а2 (соответственно, а\Т и а'27) две строки
матрицы А (соответственно, Д') и введем векторы b = (6i,t>2)T и b' — (b^b^)7.
Теперь эпиполярное условие можно переписать следующим образом:
SCq-Sd
где
5 =
Глава 12. Определение аффинной структуры по движению
371
Если матрица 5 несингулярна, можно положить С = S 1 и d = — S гг. Если
с — (а,Ь,с)т, две проекционные матрицы сводятся к канонической форме:
М =
1 0 0 0\
О 1 о оу
(° 0
и М = ,
\а о
(12.6)
1
с d) '
Это позволяет следующим образом переписать эпиполярное условие:
и \
/1 О
О 1
О О
<а Ъ
v
и'
с v' ~dj
= ~аи — bv — си + v' — d = 0.
О
О
1
Здесь коэффициенты а, Ь, с и d связаны с параметрами л, /?, a1, fl nS:a:a =
b : /3 = с : = —1 : /?' = d : 6.
При наличии достаточного числа точечных соответствий коэффициенты
а, Ь, с и d можно оценить по схеме наименьших квадратов, подобной той, что
была использована для перспективных проекций в главе 10. Как только найде-
ны требуемые параметры, две проекционные матрицы становятся известными
и положение любой точки можно оценить по координатам ее изображений,
при этом для решения соответствующей системы четырех уравнений с тремя
неизвестными координатами Р
/10 0 и \
010 v п
0 0 1 и' \-1)~U
b с v' — dj
(12.7)
снова используется линейная схема наименьших квадратов.
Отметим, что первых трех уравнений системы (12.7), в принципе, достаточно
для нахождения Р как (и, и, и‘)т, не определяя коэффициенты а, Ь, с и d и не
требуя минимального числа соответствий. Это не настолько неожиданно, как
может показаться на первый взгляд: если имеется две откалиброванных ор-
тографических камеры с перпендикулярными направлениями проектирования
и параллельными осями v, то положив х = и, у = v и z — и', получаем кор-
ректное восстановление евклидовой формы (обратитесь снова к рис. 12.5, пред-
полагая ортографическое проектирование и считая эпиполярные линии парал-
лельными осям и и и'). На практике, разумеется, использование всех четырех
уравнений может дать более точные результаты. В предложенном методе первая
строка матрицы А' приводится к виду (0,0,1) посредством аффинного преобра-
зования Q. Если «S сингулярна (или близка к сингулярной), вместо этого можно
применить некоторое преобразование второй строки матрицы Л'. Если матри-
ца «S и матрица, созданная описанным выше способом, сингулярны, две плоско-
сти изображения параллельны и структуру объекта восстановить невозможно.
372
Часть III. Первые этапы: несколько изображений
12.3. ОПРЕДЕЛЕНИЕ АФФИННОЙ СТРУКТУРЫ И ДВИЖЕНИЯ ПО
НЕСКОЛЬКИМ ИЗОБРАЖЕНИЯМ
Методы, представленные в предыдущем разделе, направлены на восстанов-
ление структуры аффинной сцены и/или соответствующих проекционных мат-
риц при минимальном числе изображений. Рассмотрим теперь задачу оценки
аналогичной информации с помощью потенциально большого набора изобра-
жений. Вначале будет показано, что любой фиксированный набор аффинных
изображений сцены имеет аффинную структуру; далее это свойство будет ис-
пользовано для вывода метода факторизации Томаси и Кенеда ([Tomasi and
Kanade, 1992]), позволяющего оценить аффинную структуру и движение объ-
екта по последовательности изображений.
12.3.1. Аффинная структура последовательности аффинных
изображений
Начиная с данного раздела будем считать, что статичная сцена наблюда-
ется с помощью фиксированного набора т аффинных камер. Через
будем обозначать т проекций точки сцены Р. Записывая соответствующие т
вариантов уравнения (12.1), получаем:
q = г + АР,
где
Если через I обозначить множество всех изображений, полученных на т ка-
мерах, получим такой результат:
I = {г + АР\Р е R3} = г + VA,
где через Уд обозначен диапазон возможных значений матрицы А разме-
ра 2т х 3 (т.е. трехмерное векторное подпространство R2m, натянутое на
векторы-столбцы матрицы. Другими словами, I — это трехмерное подпростран-
ство аффинного пространства R2m). В частности, если, как и ранее, рассмот-
реть п точек Pi,..., Рп, наблюдаемых т камерами, можно определить матрицу
данных (2тп 4-1) х п:
Яг
1
Из раздела 12.1 следует, что ранг этой матрицы не превышает 4.
Глава 12. Определение аффинной структуры по движению
373
12.3.2. Использование факторизации для нахождения аффинной
структуры по движению
В работе [Tomasi and Kanade, 1992] для нахождения аффинной структуры
аффинных изображений использовалась одна устойчивая схема факторизации.
В результате структура сцены и соответствующее движение камеры оценива-
лась с использованием разложения по сингулярным значениям (см. вставку).
Разложение по сингулярным значениям
Пусть А — матрица т х п с т > п, тогда А всегда можно представить
следующим образом:
А = Z/WVT,
где
• U — матрица m х п с ортогональными столбцами (т.е. UTU — Idn);
• W — диагональная матрица, диагональные элементы которой w» (г =
1,...,п) являются сингулярными значениями матрицы А, причем wi >
w2 > - • > wn > 0;
• V — ортогональная матрица п х п, т.е. = WT — Idn.
Это представление получило название разложения по сингулярным зна-
чениям (singular value decomposition — SVD, далее — SVD-представление)
матрицы А, его вычисление описано в [Wilkinson and Reich, 1971].
Как следует из приведенной ниже теоремы, в SVD-представлении матрицы
фигурируют собственные векторы матрицы и собственные значения квадрата
матрицы.
Теорема 1. Сингулярные значения матрицы А — это собственные зна-
чения матрицы АТА, а столбцы матрицы V являются соответствующими
собственными векторами.
Данную теорему можно использовать для решения переопределенных од-
нородных линейных уравнений вида Ах = 0, как предлагалось в главе 3, т.е.
без явного вычисления соответствующей матрицы АТА. Решением является
вектор-столбец матрицы V в SVD-представлении матрицы А, который соотне-
сен с наименьшим сингулярным значением.
Разложение по сингулярным значениям матрицы можно также использовать
для описания матрицы с недостаточным рангом. Предположим, что ранг мат-
рицы А равен р < п. Тогда матрицы Z7, W и V можно записать следующим
образом.
иР 1^п-~р
И'Р 0
0 0
V
374
Часть III. Первые этапы: несколько изображений
причем:
• столбцы матрицы Up формируют ортонормированный базис пространства,
натянутого на столбцы матрицы А (т.е. диапазона ее значений)',
• столбцы матрицы Уп-Р формируют ортонормированный базис простран-
ства, натянутого на решения уравнения Ах = 0 (т.е. нулевого простран-
ства этой матрицы).
Столбцы матриц т х р и п х р, Up и Ур, ортогональны, кроме того, А =
UpWpVj.
Из приведенной ниже теоремы следует, что разложение по сингулярным зна-
чениям также предлагает ценную процедуру аппроксимации. В обоих случаях
через 1ЛР и Ур обозначены, как и ранее, матрицы, сформированные р левыми
крайними столбцами матриц U и V, a Wp — это диагональная матрица р х р,
сформированная р наибольшими сингулярными значениями. Здесь, впрочем,
ранг матрицы А может принимать максимальное значение п, а остальные син-
гулярные значения могут быть ненулевыми.
Теорема 2. Если ранг матрицы А превышает р, то наилучшей возмож-
ной аппроксимацией с рангом р матрицы А в смысле фробениусовой нормы
является UpVVpVp.
Данная теорема играет фундаментальную роль в использовании факториза-
ции для решения задачи определения структуры по движению, рассматривае-
мой в данной главе.
Предполагая, что началом системы координат объекта является одна из
наблюдаемых точек или их центр масс, скажем, Ро, можно перенести нача-
ло системы координат изображения в соответствующую точку изображения,
скажем, р0. Преобразование р —+ р — р0 фиксирует начало координат набора
изображений I, которое теперь становится трехмерным векторным простран-
ством Уд. Другими словами, для любой точки Р и для г ~ 1, ...,т можно
записать, что рг = AiP. Эквивалентно, q = АР и
I = {ЛР|Р е R3} = Уд.
При данных m изображениях п точек Pi,..., Рл можно теперь определить мат-
рицу данных 2т х п:
®=(<h 9„)=ЛР. при Р='(р, ... Р„).
В общем случае ранг произведения матрицы Т>, размером 2m х 3, и матрицы
размером 3 х п равен 3. Если UWVT — SVD-представление этой матрицы, это
означает, что только три сингулярных значения являются ненулевыми, следо-
вательно, Т> = , где через U3 и Уз обозначены матрицы 2m х 3 и 3 х п,
Глава 12. Определение аффинной структуры по движению
375
Рис. 12.6. Евклидова реконструкция по трем проекциям лица, приведенным на рис. 12.4. Перепеча-
тано с разрешения авторов из J.J. Koenderink and A.J. Van Doorn, "Affine Structure from Motion",
Journal of the Optical Society of America A, 8:377-385, (1990). © 1990 Optical Society of America
сформированные тремя левыми крайними столбцами матриц W и V, a W3 — это
диагональная матрица 3x3, сформированная соответствующими ненулевыми
сингулярными значениями.
В качестве представления истинного (аффинного) движения камеры и фор-
мы сцены можно взять матрицы До = и Ро = Действительно,
столбцы матрицы Д, по определению, формируют базис диапазона значений
Уд матрицы Т>, тогда как столбцы матрицы До. по построению, формируют
другой базис этого векторного пространства. Отсюда следует существование
матрицы Q размером 3x3 такой, что Д = AqQ. и, следовательно, Р — Q,~1Pq.
И наоборот, Т> = (ДоС)(С-1Ро) для любой обратимой матрицы Q разме-
ром 3x3. Если же помимо этой линейной неоднозначности учесть степени
свободы, соответствующие возможности выбора положения начала координат
глобальной системы отсчета, то получим еще одно подтверждение аффинной
неоднозначности задачи определения структуры по движению. Еще один вывод:
разложение по сингулярным значениям позволяет получить репрезентативные
оценки аффинного движения и структуры сцены.
Все приведенные до этого момента соображения справедливы только для
идеализированной ситуации отсутствия помех. На практике существует так
называемый шум изображения (image noise), который приводит к ошибкам
при локализации характерных элементов изображения. Наличие такого шу-
ма объясняется тем, что реальные камеры не являются аффинными, уравне-
ние Т> = АР не выполняется строго, а матрица Т> имеет (в общем случае)
полный ранг. Покажем теперь, что разложение по сингулярным значениям все
же дает в этом случае разумную оценку аффинной структуры и движения:
оптимальная стратегия действий — это минимизировать выражение
Е =' Е |ру - = Е 1’5 - ^1’ = I® -
3
относительно матриц Д$ (г = 1,...,т) и векторов Pj (j = или,
эквивалентно, относительно матриц А и Р.
376
Часть III. Первые этапы: несколько изображений
Согласно теореме 4 матрица ДоРо представляет наиболее близкую аппрокси-
мацию с рангом 3 матрицы Т>. Поскольку ранг матрицы АР равен 3 для любых
матрицы А ранга 3 размером 2m х 3 и Р ранга 3 размером Зхп, минималь-
ное значение Е достигается при А — До и Р = Pq, что подтверждает тот факт,
что До и Ро — это оптимальные оценки истинного движения камеры и структу-
ры сцены. Это не противоречит характерной неоднозначности решения задачи
определения аффинной структуры по движению: все аффинно эквивалентные
решения дают одинаковое значение Е. В частности, как показано в алгорит-
ме 12.1, для оценки аффинной структуры и движения по матрице данных Т>
можно использовать разложение матрицы по сингулярным значениям.
Алгоритм 12.1. Алгоритм факторизации Томаси-Кенеда для определения аффин-
ной формы по движению. Отметим, что в первоначальном алгоритме, предло-
женном в [Tomasi and Kanade, 1992], использовались матрицы До = Мзх/Жз
и Ро = х/И’зУз - Математически и численно оба решения эквивалентны.
1. Найти SVD-представление матрицы V = UYVVT.
2. Построить матрицы W3, У3 и W3 из трех левых крайних столбцов матриц U
и V и соответствующей подматрицы 3x3 матрицы W.
3. Определить
и P0 = W3V3T.
Матрица До размером 2m х 3 — это оценка движения камеры, а матрица Ро
размером 3 х п - оценка структуры сцены.
12.4. ОТ АФФИННЫХ ИЗОБРАЖЕНИЙ К ЕВКЛИДОВЫМ
Предположим, что жесткий объект наблюдается двумя откалиброванными
ортографическими камерам, а точки изображений представляются их норми-
рованными координатными векторами. В этом случае преобразование между
координатными системами, связанными с камерами, из аффинного становится
евклидовым (т.е. его можно записать как суперпозицию вращения и трансля-
ции). При ортографической проекции трансляция по глубине не имеет видимого
результата, а трансляция в плоскости изображения (фронтально-параллельная
трансляция) легко устраняется выравниванием двух проекций некоторой точ-
ки объекта А. Любое вращение вокруг направления наблюдения также легко
определяется и устраняется. На данном этапе две точки наблюдения связаны
вращением вокруг некоторой оси во фронтально-параллельной плоскости, ко-
торая проходит через проекцию точки А. В работе [Koenderink and Van Doorn,
1990] показано, что существует однопараметрическое семейство таких враще-
ний, которое определяет форму с точностью до изменения масштаба по глубине
Глава 12. Определение аффинной структуры по движению
ЗП
и сдвига, и что добавление третьей точки наблюдения окончательно ограничи-
вает решение одной или двумя парами точек, связанными через отражение во
фронтально-параллельной плоскости (рис. 12.4). Подробности такого построе-
ния слишком сложны и здесь они не приводятся. Далее в этом разделе вводится
простой метод перехода от аффинной структуры к евклидовой при условии, что
аффинные проекционные матрицы камер приблизительно известны.
12.4.1. Евклидовы ограничения и откалиброванные аффинные
камеры
Обратимся вначале к ортографической, слабоперспективной и параперспек-
тивной моделям процесса формирования изображения (параллельное проекти-
рование не рассматривается подробно, поскольку на практике оно используется
редко), предполагая, что камеры откалиброваны. Очевидно, можно использо-
вать аффинные проекции уравнения (12.1), но теперь к ним добавляются неко-
торые условия на компоненты проекционной матрицы Л4 = (А Ъ).
Напомним (см. уравнение (2.20) в главе 2), что слабоперспективную проек-
ционную Матрицу можно записать следующим образом:
1 (к s\ / \
Л4 = ;(о Ч’
где ?г2 — матрица 2x3, сформированная первыми двумя строками матрицы
вращения, a t2 — вектор в пространстве R2. Если камера откалибрована, можно
использовать нормированные координаты изображения и положить к ~ 1 и s =
0. При этом проекционная матрица принимает такой вид:
М = (Л Ь) = — (Иг t2). (12.8)
2Г
Ортографическая камера — это слабоперспективная камера с zr — 1, и из
уравнения (12.8) следует, что матрица А является частью матрицы вращения,
а единичные векторы-строки а? и а2 ортогональны между собой. Другими
словами, ортографическая камера — это аффинная камера jc дополнительными
условиями
di • а,2 = 0 и |di|2 = |d2|2 = 1. (12.9)
Общий случай слабоперспективной камеры подобен рассмотренному, но строки
матрицы А уже не являются единичными векторами. Следовательно, слабопер-
спективная камера — это аффинная камера с двумя условиями:
di а2 = 0 и |di|2 = |d2|2. (12.10)
Наконец, используя параметризацию параперспективных камер, представлен-
ную в форме (2.22), легко показать (см. раздел упражнений), что парапер-
спективная камера — это аффинная камера, удовлетворяющая следующим
378
Часть III. Первые этапы: несколько изображений
условиям:
. Л Urvr .А .2 , UrVr .. .2 1«1|2 1®2|2
O1-“2 = ^rn?jl“l1 +^п^)|в21 и (ГП?) = (1Т^’
(12.11)
где через (ur,vr) обозначены координаты перспективной проекции опорной
точки Rt определенной в параперспективной проекционной модели.
12.4.2. Вычисление евклидового уточнения структуры на основе
нескольких изображений
Рассмотрим ортографическую проекцию и предположим, что аффинная фор-
ма объекта и проекционная матрица М, соотнесенная с каждой точкой наблю-
дения, восстановлены. Известно, что все решения задачи определения структу-
ры по движению равны с точностью до аффинной неопределенности. В частно-
сти, если положение точки объекта в евклидовой системе координат равно Р,
а соответствующая проекционная матрица имеет вид Л4 = (Л Ь), то должно
существовать некоторое аффинное преобразование
Q =
С
0т
d
1
такое, что М = A4Q и Р = С-1(Р — d). Подобное преобразование называется
евклидовым уточнением (евклидово уточнение), поскольку оно отображает
аффинную форму в евклидову.
Покажем, как такое уточнение вычисляется при наличии т > 3 ортогра-
фических изображений. Пусть Mi = (Л^ 6») — соответствующие проекцион-
ные матрицы, оцененные, например, посредством метода факторизации, кото-
рый описан в разделе 12.3.2. Если = MiQ, ортографическое условие (12.9)
можно переписать:
• di2 = 0, а^ССТаг2 — О,
< |a*i|2 = l, <=> < а^ССтац = 1, для t = l,...,m, (12.12)
. 1«<2|2 = 1, аТ2ССтаа = 1,
где через и обозначены строки матрицы Л*. Данную переопределенную
систему Зтп квадратных уравнений на коэффициенты матрицы С можно решить
с помощью нелинейной схемы наименьших квадратов. Альтернатива: рассмот-
реть уравнение (12.12) как множество линейных условий на матрицу V = ССТ.
В этом случае коэффициенты матрицы V находим с помощью линейной схе-
мы наименьших квадратов, затем вычисляем матрицу С как y/Vt используя
разложение Холецкого. Необходимо, чтобы восстановленная матрица D была
положительно определенной, что не всегда выполняется при наличии помех.
Отметим также, что решение уравнения (12.12) определено только с точностью
до произвольного поворота. Для однозначного определения матрицы Q и упро-
Глава 12. Определение аффинной структуры по движению
379
Рис. 12.7. Евклидова структура по движению — экспериментальные результаты. Слева: некоторые
изображения домика из последовательности 150 кадров. Справа: вид восстановленной структуры
(вверху) и реальное изображение домика (внизу), полученное с подобной точки наблюдения. Пе-
репечатано из С. Tomasi and Т. Kanade, "Factoring image Sequences into Shape and Motion”,
Proceedings, IEEE Workshop on Visual Motion, (1991). © 1991 IEEE
щения вычислений можно привести A4i (и возможно, Л4г) к канонической
форме и повторить процедуру, описанную в предыдущем разделе.
Представленные выше соображения проиллюстрированы на рис. 12.7, где об-
работаны результаты съемки домика; для сравнения приведено реальное изоб-
ражение, полученное с подобной точки наблюдения.
Вычисление евклидового уточнения слабо- и параперспективных проек-
ций происходит приблизительно так же, за исключением того, что два усло-
вия (12.10) или (12.11), записанные для т изображений, заменяются 3m услови-
ями (12.12). Отметим, что в этих случаях невозможно определить абсолютный
масштаб объекта, поскольку евклидовы условия (12.10) и (12.11) однородны.
Другими словами, структуру объекта можно восстановить только с точностью
до произвольного преобразования подобия (например, строгого преобразования
с последующим изотропным изменением масштаба). Соответственно, теперь
под евклидовой формой мы будем понимать класс эквивалентности, который
формируется наборами точек, связанных подобием (некоторые авторы в этом
случае используют термин метрическая форма для акцентирования внимания
на масштабной неоднозначности).
380
Часть III. Первые этапы: несколько изображений
12.5. СЕГМЕНТАЦИЯ АФФИННОГО ДВИЖЕНИЯ
До настоящего момента предполагалось, что все п наблюдаемых точек дви-
жутся как единое целое. Что произойдет, если эти точки будут принадлежать к
разным объектам, движущимся по разным схемам? В данном разделе представ-
лены два метода сегментации информационных точек в подобные независимо
движущиеся объекты.
12.5.1. Ступенчатая форма информационной матрицы
(с уменьшенным числом строк)
Определим информационную матрицу так, как это было сделано в разде-
ле 12.3.1:
<Рп •••
V= ............. .
Рml " • • Р тп
\ 1 ... 1 /
Теперь ранг матрицы Т> уже не равен 4. Вместо этого столбцы информационной
матрицы, соответствующие каждому объекту, определяют четырехмерное под-
пространство Di (г = 1,..., к), а полный ранг матрицы V не превышает ^к. Как
отмечено в работе [Gear, 1998), ступенчатая форма с уменьшенным числом
строк (reduced row-echelon form (RREF), далее RREF-форма) информацион-
ной матрицы Т> определяет подпространства Di и векторы-столбцы, которые
находятся в нем, что обеспечивает сегментацию входных точек в жесткие
объекты (или, более точно, в объекты, которые могут испытывать аффинные
деформации).
RREF-форма матрицы U — это матрица V, строки которой представляют
линейные комбинации строк матрицы U и удовлетворяют следующим условиям.
1. Все строки, состоящие из одних нулей, расположены внизу матрицы.
2. Первая ненулевая позиция каждой строки равна 1 — данная величина име-
нуется ведущей 1.
3. Ведущая 1 в каждой строке находится правее всех ведущих 1 вышестоящих
строк.
4. Каждая ведущая 1 — это единственный ненулевой элемент столбца.
Базовым столбцом называется столбец, который содержит ведущую 1. По
построению, единственные ненулевые элементы любого небазового столбца рас-
положены в строках, в которых 1 содержит ровно один базовый столбец. Кроме
того, любой небазовый столбец v принадлежит подпространству, натянутому
на базовые столбцы т»71,..., Vjk, соотнесенные с его ненулевыми элемента-
ми Qi,... ,ckfc, при этом v можно записать как ---\-ctkVjk. Число базовых
столбцов равно рангу г матрицы.
Глава 12. Определение аффинной структуры по движению
381
Проиллюстрируем эти свойства на простой матрице U размером 7 х 6 и ее
RREF-форма У (элементы матрицы U выбирались для упрощения вида матри-
цы V):
(1 0 1 -5 2 -9> л 0 1 0 0 2 >
2 4 10 0 1 1 0 1 2 0 0 0
-1 1 1 3 0 1 0 0 0 1 0 1
и = 0 1 2 -1 3 -10 —*У = 0 0 0 0 1 -3
3 -2 -1 0 1 3 0 0 0 0 0 0
0 5 10 2 -2 8 0 0 0 0 0 0
I-2 3 4 1 0 -з) 0 0 0 0 о/
Обозначим через ut и v* (г = 1,..., 6) столбцы матриц U и У. Всего имеет-
ся четыре базовых столбца, «1, г>2> «4 и «5, так что ранг матрицы U равен
4. Ненулевые элементы v$ расположены в тех же строках, что и ведущие 1
в базовых столбцах «1 и г>2, откуда следует, что вектор «з лежит в подпро-
странстве R7, натянутом на векторы г>1 и г>2- Эти значения равны 1 и 2, откуда
следует, что «з = «1 4- 2г>2- Подобным образом, ненулевые элементы векто-
ра «6 расположены в тех же строках, что и ведущие 1 векторов i?i, «4 и г>5,
откуда следует, что вектор г>б принадлежит подпространству R7, натянутому
на векторы vi, «4 и г>5, и эти значения равны 2, 1 и —3, откуда следует,
что v6 = 2vi + v4 — 3«5. Фактически, указанные свойства также справедливы
для исходной матрицы U (т.е. 113 = ui + 2г1г и uq = 2ui + — Зг<5, что легко
подтверждается изучением матрицы Z7). Все приведенные наблюдения следуют
из того, что строки матрицы У — это линейные комбинации строк матрицы U.
Сказанное справедливо и для произвольных матриц и их RREF-форм, от-
куда следует, что RREF-форму информационной матрицы D можно, теоретиче-
ски, использовать для сегментации аффинного движения. Действительно, эта
матрица определяет базис диапазона значений Т> (столбцы этой матрицы соот-
ветствуют базовым столбцам ее RREF), а также для всех векторов-столбцов,
которые принадлежат подпространствам, натянутым на подмножества этого ба-
зиса. Если четырехмерные подпространства Di, соотнесенные с каждым объ-
ектом, пересекаются только в начале координат (чего и следует ожидать для
достаточно больших значений тп), соответствующие группы точек формируют
связные компоненты графа, узлами которого являются столбцы RREF-формы,
а ребра соединяют пары столбцов с ненулевыми элементами по крайней мере
в одной общей строке.
К сожалению, на практике ситуация усложняется из-за помех и числен-
ных ошибок. Чистая реализация RREF-формы с использованием, скажем, раз-
ложения Жордана-Гаусса с выбором главного элемента обычно дает матрицу
с полным рангом и ни один из небазовых столбцов не лежит в четырехмер-
ном пространстве диапазона ее значений (см. раздел упражнений). В работе
[Gear, 1998] предлагается несколько методов вычисления RREF-формы матри-
382
Часть III. Первые этапы: несколько изображений
цы, имеющих повышенную устойчивость, включая разложение Жордана-Гаусса
с отбросом малых величин и QR-исключением с последующим разложением по
схеме Жордана-Гаусса, применяемым к соответствующей треугольной матри-
це Р. В этой же работе представлены успешные эксперименты по сегментации,
в которых использовались как смоделированные, так и реальные последова-
тельности изображений.
12.5.2. Матрица взаимодействия форм
Подход, представленный в предыдущем разделе, зависит только от аффин-
ной структуры аффинных изображений. Другой метод, основанный на фактори-
зации информационной матрицы, был предложен в работе [Costeira and Kanade,
1998]. Ниже этот метод представлен для двух групп точек, движущихся по
разным схемам. Обобщение для произвольного числа независимо движущихся
объектов очевидно.
При определении сегментации движения информационную матрицу ранга
3 для каждого объекта определить невозможно, поскольку неизвестен центр
тяжести соответствующих точек. Вместо этого предположим, что помехи от-
сутствуют и определим информационные матрицы Т>^ (г = 1,2) как
/о(<)
I Ри
р(») = I
L(O
\Prnl
Pin,
р(<) /
ГТПП^/
где п* — число точек, соотнесенных с объектом г, и щ + пг = п. Ранг каждой
матрицы равен 4, поскольку ее можно переписать как — ЛЛ^Р^\ где
и Р(<) =
1
1
Определим составную информационную матрицу 2т х п V = (2/1) Р^2)) , а
также составные матрицы 2т х 8 (движение) и 8 х п (структура):
_d.( (?m О \
и = I •
I о Р(2))
Используя введенные обозначения, получаем V = МР, откуда видно, что
ранг матрицы 2? не превышает 8. Теперь строки матрицы Р формируют ба-
зис 8-мерного подпространства пространства R2m, натянутого на строки мат-
рицы Т). Как показано в работе [Strang, 1980], оператор, выполняющий отоб-
ражение любого вектора в его ортогональную проекцию в пространстве, на-
тянутом на столбцы матрицы А, можно представить в виде матрицы Z =
А(АТА)~1АТ. В частности, матрица Z, соотнесенная со строками матрицы
Глава 12. Определение аффинной структуры по движению
383
Рис. 12.8. Сегментация движения — экспериментальные результаты. Слева вверху: один кадр
последовательности изображений двух цилиндров с треками-метками. Справа вверху: восстанов-
ленные формы после сегментации движения. Слева внизу: матрица взаимодействия форм. Справа
внизу: матрица после сортировки. Перепечатано из J. Costeira and Т. Kanade, "A Multi-Body Fac-
torization Method for Motion Analysis”, Proceedings of the International Conference on Computer
Vision, 1995. © 1995 IEEE
V (или, эквивалентно, co столбцами матрицы Рт), является, по построению,
блочно-диагональной, поскольку матрица Рт также блочно-диагональная.
Разумеется, в данном случае матрица Р неизвестна, но с равным успехом
может использоваться любая другая матрица, строки которой формируют базис
в пространстве строк матрицы V. Например, если SVD-представление ранга
8 матрицы V выглядит как , можно использовать строки матрицы У^
как базис. Таким образом, Z = УвСУв^в)-1^ = УвУГ> поскольку Ув орто-
гональна. Блочно-диагональная матрица Z, созданная с помощью описанного
выше способа, в работе [Costeira and Kanade, 1998] была названа матрицей
взаимодействия форм.
В приведенном выше построении предполагалось, что информационные точ-
ки согласованно упорядочены в пределах объекта, к которому они принадле-
жат. В общем случае это не так. Можно показать, что значения элементов
матрицы Z не зависят от порядка точек. Изменение этого порядка приводит
всего лишь к перестановке столбцов матрицы Т> и соответствующей переста-
новке строк и столбцов матрицы Z. Следовательно, восстановление точного
упорядочения (и соответствующей сегментации в объекты) равнозначно поиску
384
Часть III. Первые этапы: несколько изображений
такой перестановки строк и столбцов матрицы 3, которая сводит ее к блочно-
диагональной форме.
В работе [Costeira and Kanade, 1998] было предложено несколько методов
нахождения точных перестановок при наличии помех. Одна возможность — это
минимизировать сумму квадратов недиагональных блоков элементов по всем
перестановкам строк и столбцов. На рис. 12.8 показаны экспериментальные
результаты, в том числе изображения двух объектов и соответствующих меток,
график соответствующей матрицы взаимодействия форм до и после сортировки,
а также полученные результаты относительно сегментации.
12.6. ПРИМЕЧАНИЯ
Впервые задача определения структуры по движению была рассмотрена для
откалиброванного ортографического устройства в работе [Ullman, 1979]. Пер-
вое ее аффинное решение было описано в [Koenderink and Van Doorn, 1990].
Алгоритм факторизации, рассмотренный в разделе 12.3.2, был изложен соглас-
но [Tomasi and Kanade, 1992]. Как показано в этой главе, разложение задачи
определения структуры по движению на аффинный и евклидов этап позволяет
ввести простые и устойчивые методы восстановления формы по последова-
тельности изображений. По сути, это линеаризует процесс оценки структуры
и/или движения, задерживая введение нелинейных евклидовых условий до
завершения восстановления аффинной формы сцены. Аффинный этап важен
также сам по себе, поскольку он представляет фундамент для методов опре-
деления сегментации на основе движения, представленных в работах [Gear,
1998] и [Costeira and Kanade, 1998] и рассмотренных в разделе 12.5; другие
подходы к этой задаче изучены в публикациях [Boult and Brown, 1991]. Как по-
казано в главе 26, другие области применения описанных принципов включают
интерактивный синтез изображений в расширенной реальной области. Кроме
рассмотрения аффинной структуры изображений (или, эквивалентно, наличия у
информационных матриц, соотнесенных с аффинной последовательностью дви-
жения, ранга 4) можно использовать следующие соображения: аффинное изоб-
ражение является линейной комбинацией трех изображений моделей ([Ullman
and Basri, 1991]), траектории точек объекта на образах описываются линейными
комбинациями траекторий трех опорных точек ([Weinshall and Tomasi, 1995]).
Нелинейная схема наименьших квадратов для вычисления евклидового уточне-
ния матрицы Q изложена согласно [Tomasi and Kanade, 1992], а подход Холец-
кого к той же задаче — согласно [Poelman and Kanade, 1997]; другие варианты
можно найти в работе [Weinshall and Tomasi, 1995]. В последнее время появи-
лись различные модификации подхода, представленного в данной главе, в том
числе последовательное восстановление структуры и движения ([Weinshall and
Tomasi, 1995], [Morita and Kanade, 1997]), расширение аффинного/евклидового
разложения до проективного/аффинного/евклидового ([Faugeras, 1995]), а так-
же алгоритмы соответствующей оценки проективной формы ([Faugeras, 1992],
[Hartley et al., 1992], см. также следующую главу), и обобщения схемы фак-
Глава 12. Определение аффинной структуры по движению
385
торизации, предложенной в [Tomasi and Kanade, 1992], для перспективных
проекций ([Sturm and Triggs, 1996]) и других задач компьютерного зрения
с естественной билинейной структурой ([Koenderink and Van Doorn, 1997]).
Задачи
12.1. Объясните, почему любое определение “сложения” двух точек или “умно-
жения” точки на скаляр обязательно будет координатно-зависимым.
12.2. Покажите, что определение барицентрической комбинации
тп тп
52 «iAi = Aj 4- 52 oti(Ai~Aj)
i=O
не зависит от выбора j.
12.3. Докажите, что
12.4. Покажите, что набор барицентрических комбинаций m 4-1 точки Ао> • •>
Ащ в X формирует аффинное подпространство X и что размерность
этого пространства не превышает т.
12.5. Выведите уравнение линии, определяемой двумя точками в К3. (Под-
сказка: в действительности требуется два уравнения.)
12.6. Покажите, что пересечение плоскости с двумя параллельными плоско-
стями состоит из двух параллельных прямых.
12.7. Покажите, что аффинное преобразование ф : X —> Y между двумя аф-
финными подпространствами X и У, соотнесенными с векторными про-
странствами X и Y, можно записать как ф(Р) = ip(O)^-ip(P— О), где О —
некоторое произвольно выбранное начало координат, а ф : X —> У — ли-
нейное отображение из X в У, не зависящее от выбора О.
12.8. Покажите, что изображения, даваемые аффинными камерами (и соот-
ветствующую эпиполярную геометрию), можно рассматривать как пре-
дел последовательности перспективных изображений с увеличивающим-
ся фокальным расстоянием и удалением от сцены.
12.9. Обобщите понятие полилинейности, введенное в главе 10, на аффинный
случай.
12.10. Докажите теорему 1.
12.11. Покажите, что откалиброванная параперспективная камера — это аф-
финная камера, удовлетворяющая условиям
. « UrVr i2 . UrVr г i2 l“iI2 1“2|2
01-02 =-------z- |О1| 4-----?”1а2 и --------5” =-----
2(1 4-и*) 2(14- V*) (14-Ur) (14-Vr)
где (ur,vr) — координаты перспективной проекции точки R.
386
Часть III. Первые этапы: несколько изображений
12.12. Какой вероятнее всего будет RREF-форма матрицы т х п со случайными
элементами, если т > п? Если т < п? Почему?
Упражнения
12.13. Реализуйте подход Коендеринка-Ван Доорна к определению аффинной
структуры по движению.
12.14. Реализуйте схему оценки аффинной эпиполярной геометрии по соответ-
ствиям на изображениях и схему оценки структуры сцены по соответ-
ствующим проекционным матрицам.
12.15. Реализуйте подход Томаси-Кенеда к определению аффинной формы по
движению.
12.16. Добавьте случайные числа, равномерно распределенные в диапазоне
[0; 0,0001], к элементам матрицы U и вычислите RREF-форму полу-
ченной матрицы (используйте, например, процедуру rref в MATLAB);
затем снова вычислите RREF-форму, используя версию “с повышенной
устойчивостью” алгоритма разложения (используйте, например, проце-
дуру rref с ненулевым допуском). Результаты прокомментируйте.
13
Определение проективной
структуры по движению
В этой главе рассматривается восстановление структуры сцены и/или движения
камеры по соответствиям, установленным путем согласования изображений п
точек на т изображениях, на примере перспективной проекционной модели.
Запишем соответствующие уравнения перспективных проекций для п данных
фиксированных точек Pj (j = 1,...,п), наблюдаемых т камерами, и соот-
ветствующих тп векторов однородных координат р- = Vij, 1)т этих
изображений.
(тц • Pj
— р
77113 для i = l,...,т и J = 1,. ..,п, (13.1)
тпг2 Pj J v '
Vij = ---
ТП£3 . Pj
где через тп^, и обозначены строки проекционной матрицы Mi разме-
ра 3 х 4, соотнесенной с камерой г в некоторой стационарной системе координат,
а через Pj обозначен вектор однородных координат точки Pj в этой системе
координат. Сформулируем задачу определения проективной структуры по
движению как оценку т матриц Mi и п векторов Pj по тп соответствиям на
изображениях р^.
388
Часть III. Первые этапы: несколько изображений
Если матрицы A4i и векторы Pj — решения уравнения (13.1), тогда для
любых ненулевых значений Xi и щ решениями являются XiMi и PjPj. В част-
ности, как уже отмечалось в главе 2, матрицы Л4ь удовлетворяющие урав-
нению (13.1), определены только с точностью до масштаба и имеют 11 неза-
висимых параметров, то же относится и к векторам Pj, которые имеют 3
независимых параметра (при необходимости их можно свести к каноническому
виду (xj,yj,Zj, 1)т, если четвертая координата не равна 0, как обычно и бы-
вает). Подобно соответствующей задаче для аффинных проекций, задача опре-
деления проективной структуры по движению имеет неоднозначное решение:
если калибровочные параметры камер неизвестны, проекционные матрицы
представляют собой, согласно теореме 1 (глава 2), произвольные матрицы 3x4
ранга 3. Следовательно, если матрицы и векторы Pj — решения уравне-
ния (13.1), решениями также являются = МгО, и Pj = Q~lPj, где Q —
матрица проективного преобразования (т.е. произвольная несингулярная
матрица 4 х 4). Матрицу Q можно определить только с точностью до масштаба
с 15 свободными параметрами, поскольку умножение ее на ненулевой скаляр
равносильно изменению масштаба величин, обратных A4i и Pj. Поскольку из
уравнения (13.1) следует 2тп условий на 11m параметров матриц A4i и Зп
параметров векторов Pj, то учитывая проективную неоднозначность решения
рассматриваемой задачи, напрашивается вывод, что данная задача допускает
конечное число решений при 2тп > 11m+ 3п —15. При т = 2 для определения
(с точностью до проективного преобразования) двух проекционных матриц
и положений любой другой точки должно быть достаточно семи точечных со-
ответствий. Формально это утверждение доказывается в разделах 13.2 и 13.3.
Далее в этой главе будет использована методология, подобная примененной
в главе 12, только вместо аффинной геометрии теперь будет фигурировать
проективная геометрия. Если игнорировать (на первых этапах) евклидовы
условия, связанные с калибровкой камер, то процесс восстановления проек-
тивной структуры сцены и движения камеры по точечным соответствиям
можно линеаризовать. Затем рассматриваются геометрические условия, связан-
ные с (полностью или частично) откалиброванными камерами для уточнения
проективной реконструкции до евклидовой.
13.1. ЭЛЕМЕНТЫ ПРОЕКТИВНОЙ ГЕОМЕТРИИ
Средства измерений, доступные в проективной геометрии, являются даже
более примитивными, чем средства аффинной геометрии. Здесь уже неприме-
нимы аффинное понятие отношений длин отрезков параллельных прямых и,
фактически, само понятие параллельности. Впрочем, без изменения остают-
ся понятия точек, прямых и плоскостей, также имеется новая, более слабая,
скалярная мера упорядочения коллинеарных точек — ангармоническое отно-
шение. Как и в аффинном случае, строгое аксиоматическое введение в проек-
тивную геометрию будет в данной книге неуместным, и до конца этой главы
будет использоваться неформальный стиль изложения.
Глава 13. Определение проективной структуры по движению
389
13.1.1. Проективные пространства
Рассмотрим действительное векторное пространство X размерности п + 1.
Если v — ненулевой элемент пространства X, множество Rv всех векто-
ров, пропорциональных вектору г>, называется лучом и единственным образом
определяется любым своим ненулевым элементом. Действительное проек-
тивное пространство X = Р(Х) размерности п, соотнесенное с вектором
X, — это множество лучей в X или, эквивалентно, фактор-группа множе-
ства Х\0 ненулевых векторов в X, для которых выполняется соотношение
эквивалентности "v ~ v' тогда и только тогда, когда v = kv* для некото-
рого k G R”. Элементы X называются точками-, семейство точек является
линейно зависимым (соответственно, независимым), если векторы, представля-
ющие соответствующие лучи, линейно зависимы (соответственно, независимы).
Отображение р : Х\0 —> Р(Х) соотносит с любым ненулевым элементом v век-
тора X соответствующую точку р(у) пространства X.
Пример 13.1. Модель P(R3)
Рассмотрим аффинную плоскость П в пространстве R3. Лучи пространства R3,
непараллельные П, находятся в однозначном соответствии с точками этой плос-
кости. Например, лучи Ra, Rb и Rc, соотнесенные с векторами г?д, vb и vc,
можно отобразить в точки А, В и С — точки их пересечения с плоскостью П.
Векторы va, vb и vc линейно независимы, такими же (по определению) являются
точки А, В и С.
Если луч почти параллелен П, точка его пересечения с этой плоскостью уходит
на бесконечность, фактически, можно показать, что модель проективной плоско-
сти P(R3) (т.е. проективное пространство П размерности 2, изоморфное P(R3))
можно построить добавлением к П одномерного множества точек на бесконеч-
ности, соотнесенных с лучами, которые параллельны этой плоскости. В данном
примере луч Rd, параллельный плоскости П, отображается в точку на бесконеч-
ности D пространства П.
390
Часть 111. Первые этапы: несколько изображений
Поскольку любую аффинную плоскость можно отобразить в R2, выбрав
некоторую аффинную систему координат, то из примера 13.1 следует, что аф-
финные плоскости, а значит и пространство Е3 или любое другое аффинное
пространство, можно каким-то образом вложить в проективные пространства,
для завершения вложения соответствующим образом выбрав точки на беско-
нечности. Подобный процесс представлен в разделе 13.1.3.
13.1.2. Проективные подпространства и проективные координаты
Рассмотрим (т + 1)-мерное векторное подпространство У пространства X.
Множество У = Р(У) лучей в пространстве У называется проективным
подпространством пространства X, а его размерность равна тп. В дан-
ном базисе (eo,ei,... ,em) пространства У с каждой точкой Р в У можно
соотнести однопараметрическое семейство элементов Rm+1, а именно, — ко-
ординаты (а^яь• • • iZm)T векторов v е Y таких, что Р = p(v). Эти наборы
пропорциональны между собой, а набор, выбранный выше, называется множе-
ством однородных проективных координат точки Р.
Однородные координаты можно также описать локально через семейства то-
чек в У: рассмотрим m +1 (т < п) линейно независимых точек Ао, Ai,..., Ат
и т 4-1 векторов Vi (г = 0,1,..., тп), представляющих соответствующие лучи.
Если дополнительная точка А* линейно зависима от точек А* и вектор г>*
представляет соответствующий луч, можем записать следующее:
v* = uovo + + • • • +
Коэффициенты д, определены неоднозначно, поскольку каждый вектор
задан только с точностью до ненулевого масштабного множителя. Впрочем,
если ни один из коэффициентов щ, не обращается в нуль (т.е. когда вектор v*
не лежит в векторном подпространстве, натянутом на любые т векторов vt,
или, эквивалентно, когда соответствующие точки линейно независимы), можно
однозначно определить т 4-1 ненулевых векторов е» = таких, что
v* = во 4- ei 4- • + ет.
В частности, любой вектор и, линейно зависимый от векторов и», можно теперь
единственным образом записать как
v = хоео 4- £161 4-1- хтет.
Этим определяется взаимно-однозначное соответствие между лучами R(so>
xi,..., £т)т пространства JRm+1 и проективным подпространством Sm про-
странства X. Подпространство Sm — это, фактически, проективное простран-
ство У, соотнесенное с векторным подпространством У пространства X, на-
тянутым на векторы и, (или, эквивалентно, на векторы е»). Если Р = р(у) —
Глава 13. Определение проективной структуры по движению
391
точка Sm, соотнесенная с лучом Йг>, числа гго, ®i, • • называются однород-
ными (проективными) координатами Р в проективной системе координат,
которая определяется т+1 фундаментальными точками Л, и единичной точкой
А*. Отметим, что поскольку соотнесенный с лучом вектор v определен только
с точностью до масштаба, так же определены и однородные координаты точки.
Довольно просто проверить, что векторы координат фундаментальных точек
и единичной точки в соответствующей проективной системе координат имеют
чрезвычайно простой вид:
Очевидно, что два определения однородных координат, которые были пред-
ставлены в данном разделе, совпадают. Единственное их различие — выбор
координатных векторов во, еь..., ern, которые даны априори в первом случае
и строятся по точкам данной проективной системы координат во втором.
Пример 13.2. Изменение проективных координат
Пусть дана некоторая система координат (А) = (Ао, Ai, Аг, Аз, А*) в трехмер-
ном проективном пространстве X. Определим вектор (однородных проективных)
координат любой точки Р как АР = (Ах0,А XiA Х2,А хз)Т и рассмотрим вторую
проективную систему координат (В) = (Во, Bi, Вг, В3, В*) в X. Легко показать
(см. раздел упражнений), что соответствующее изменение координат можно запи-
сать следующим образом:
рвР = %ТАР, (13.2)
где ВТ — матрица 4x4 проективного преобразования, определенная с точностью
до масштаба, ар — скаляр, выбранный для согласования масштабов обеих ча-
стей уравнения. Покажем теперь, как рассчитать эту матрицу. Записывая уравне-
ние (13.2) для точек, определяющих систему координат (А), получаем следующее:
/Л
<0?
/0\
, РзвАз = ВТ 0
\1>
и
рва- = ват J
392
Часть III. Первые этапы: несколько изображений
Поскольку матрица дТ определена с точностью до некоторого множителя, можно
положить р* = 1, после чего получаем
дТ = (ровA) piBAi ргв Аг рзвАз^ ,
где скаляры р* — это решения линейной системы
(вАо
Л*>\
вА2 ваЛ Р'
/ р2
\РЗ/
ВА\
Отметим очевидное сходство данных формул с результатами, полученными для
преобразований евклидовых или аффинных систем координат в главах 2 и 12.
Подобные формулы для изменений координат можно записать и для произвольного
проективного пространства конечной размерности.
Проективное подпространство Si размерности 1 пространства X называ-
ется прямой. Линейные подпространства размерности 2 и п — 1 именуются,
соответственно, плоскостями и гиперплоскостями. Гиперплоскость Sn-i со-
стоит из множества точек Р, линейно зависимых от п линейно независимых
точек Pq, Pi,..., Pn-i.
Пример 13.3. Проективные прямые и плоскости
Проективная прямая однозначным образом определяется двумя принадлежащими
ей различными точками А и В, но определение проективной системы координат
требует трех различных точек Ao, Ai и А* на этой прямой. Подобным образом,
плоскость однозначно определяется тремя точками А, В и С, которые находятся
в данной плоскости, но для определения проективной системы координат тре-
буется четыре точки на плоскости: три фундаментальных точки Ao, Ai и Аг,
формирующих невырожденный треугольник, и единичная точка А*, не лежащая
ни на одной из сторон этого треугольника.
Впрочем, если в некоторой проективной системе координат обозначить через А
и В векторы координат двух различных точек прямой, то вектор Р координат
любой точки на этой прямой можно будет единственным образом записать как
Р = ХА + рВ. Это следует непосредственно из того факта, что лучи Ra и Rb,
соотнесенные с различными точками А и В, — линейно независимы, а луч Rp,
соотнесенный с точкой Р на той же прямой в векторной плоскости, определяет-
ся лучами Ra и Rb- Подобным образом, если в некоторой проективной системе
координат через А, В и С обозначить векторы координат трех неколлинеарных
точек плоскости, вектор координат Р любой точки в этой плоскости можно един-
ственным образом записать как Р — ХА + рВ + иС.
Глава 13. Определение проективной структуры по движению
393
13.1.3. Аффинные и проективные пространства
В примере 13.1 представлена (неформально) идея вложения аффинной плос-
кости в проективную плоскость с добавлением одномерного множества точек
на бесконечности. Обобщая, можно построить проективное замыкание X
аффинного пространства X размерности п, добавляя к нему множество то-
чек на бесконечности, соотнесенных с направлениями прямых этой плоскости.
Эти точки формируют гиперплоскость X, именуемую гиперплоскостью на
бесконечности и обозначаемую оох-
Выберем некоторую точку А на X и введем X = Р(Х х R), где X — вектор-
ное пространство, лежащее в основе X. Вложить X в X можно посредством
инъективного отображения (инъекции) Ja ‘ X —> X, которое определяется
как Ja(?) —р(аР, 1) (рис. 13.1)1. Дополнение Ja(X) в X — это упоминавша-
яся ранее гиперплоскость на бесконечности оох = Р(Х х {0}).
Рассмотрим теперь стационарную аффинную систему координат (Aq, Ai,...,
Ап) в пространстве X и вложим X в X, используя Уд0- Векторы АоА*
(г = 1,..., п) формируют базис X, следовательно, п + 1 векторов е; = (ЛоА, 0)
(г = 1,...,п) и en+i = (0,1) формируют в X х R базис. В частности, ес-
ли (#1,..., хп) — аффинные координаты Р в базисе (Ao, Ai, -.., Ап) простран-
ства X, имеем следующее:
Ja0(P) = р(АоА 1) = p(xiA0Ai -I---F хпА0Ап, 1) =
= p(xjei 4----1- хпеп + en+i),
‘Здесь мы задаем X и лежащее в основе векторное пространство X, сопоставляя с каждой
точкой Р в X вектор аА Этот процесс векторизации, разумеется, зависит от выбора начала
координат А, но можно легко показать, что пространство X действительно не зависит от этого
выбора. Более строгий подход к построению проективного дополнения — это ввести универ-
сальное векторное пространство, соотнесенное с аффинным пространством, но такой подход
здесь не рассматривается. Подробнее — см. [Berger, 1987, chapter 5]. Отметим также несколько
некорректное использование формы записи: строго нужно писать не p(v, X), а р((т?, А)).
394
Часть Ш. Первые этапы: несколько изображений
Рис. 13.1. Проективное дополнение аффинного пространства
Однородные проективные координаты Ja0(P), соотнесенные с базисом X х
R, который сформирован векторами (ei,... , en+i), имеют, следовательно,
вид (xi,... , rrn, 1)- С другой стороны, координаты точек в оох имеют вид (xi,..
з:п,0). Из процесса проективного дополнения теперь видно удобство представ-
ления точек изображений и сцены однородными координатами, которые были
введены в главе 2.
Введение точек на бесконечности позволяет при рассмотрении проектив-
ной геометрии не задумываться о многочисленных исключениях, характерных
для аффинного случая. Например, прямые, параллельные в некоторой аффин-
ной плоскости П, не пересекаются, если они не являются совпадающими.
В противоположность, любые две различных линии в проективной плоскости
пересекаются ровно в одной точке (так как соответствующие векторные про-
странства пересекаются по лучу), а пары параллельных прямых в плоскости П
пересекаются в точке на бесконечности в П, которая соотнесена с их общим
направлением (см. раздел упражнений).
13.1.4. Гиперплоскости и дуальность
Как отмечалось ранее, две различные прямые на проективной плоскости
имеют ровно одну общую точку. Подобным образом, две различных точки при-
надлежат ровно одной прямой. Эти два утверждения в действительности можно
принять как аксиомы инцидентности, которые приводят к чисто аксиомати-
ческому построению проективной плоскости. Точки и прямые играют в этих
утверждениях симметричную, или, точнее, дуальную роль.
Чтобы ввести дуальность несколько более общим способом, введем в п-
мерном проективном пространстве X стационарную проективную систему от-
Гпава 13. Определение проективной структуры по движению
395
счета и рассмотрим п+1 точку Ро, Pi,..., Рп, принадлежащую некоторой гипер-
плоскости Sn-i пространства X. Поскольку, по построению, эти точки линейно
зависимы, матрица (п + 1) х (n + 1), сформированная путем записи векторов
их координат, является сингулярной. Раскрывая детерминант этой матрицы по
последнему столбцу, получаем
ito^o + гця 1 -I-h ипхп = 0, (13.3)
где через (xo,xi,... ,хп) обозначены однородные координаты Рп, а («го, ui,...,
ип) являются функциями координат точек Po,Pi,..., Pn-i- Отметим, что мы
положили последнюю координату точки Рп равной 1, чтобы акцентировать вни-
мание на симметрии скаляров щ и х*.
Уравнение (13.3) удовлетворяется любой точкой Рп гиперплоскости Sn-i
и называется уравнением гиперплоскости Sn_\ (обратите внимание на сход-
ство с аффинным случаем). И наоборот, легко показать, что любое уравнение
вида (13.3) с по крайней мере одним отличным от нуля коэффициентом щ —
это уравнение некоторой гиперплоскости. Поскольку коэффициенты щ в урав-
нении (13.3) определены только с точностью до некоторого общего масштабного
множителя, существует взаимно-однозначное соответствие между лучами про-
странства ]Rn+1 и гиперплоскостями X, отсюда также следует, что можно опре-
делить второе проективное пространство X* = Р(Х*), которое формируется
этими гиперплоскостями и называется дуальным пространству X (можно пока-
зать, что X* — проективное пространство, соотнесенное с дуальным векторным
пространством X* пространства X). Скаляры (ito,«i, - - - ,ип) определяют одно-
родные проективные координаты точек, соответствующих гиперплоскости Sn-i
в X*, и можно считать, что уравнение (13.3) определяет множество гиперплос-
костей, проходящих через точку Рп.
В завершение данного раздела отметим (без доказательства), что любая
геометрическая теорема, которая справедлива для точек пространства X, имеет
соответствующую ей теорему для гиперплоскостей (т.е. точек в X*) и наоборот.
Подобную пару теорем называют дуальными.
Пример 13.4. Иллюстрация понятия дуальности
Точки и прямые являются дуальными понятиями в Р2 = Ё2, точки и плоскости
дуальны в Р3 = Ё3, но точки и прямые не дуальны в Р3. Вообще, какой объект
дуален прямой в X? Прямая — это одномерное линейное подпространство X, эле-
менты которого линейно зависят от двух точек прямой. Подобным образом, прямая
в X* — это одномерное подпространство дуального объекта, именуемого пучком
гиперплоскостей, элементы которого линейно зависят от двух гиперплоскостей
пучка. На плоскости прямой дуален пучок прямых, пересекающихся в одной точке.
396
Часть III. Первые этапы: несколько изображений
В трехмерном пространстве прямой дуален пучок плоскостей, которые пересека-
ются по общей прямой.
13.1.5. Ангармоническое отношение
В данном разделе рассматривается трехмерное проективное пространство
Е3. Неоднородные проективные координаты точки можно определить геомет-
рически, используя ангармонические отношения. Определим в аффинном
случае ангармоническое отношение для четырех данных коллинеарных точек
А, В, С, D, причем точки А, В и С различны.
{A,B,C,D} = = х =,
г s СВ DA
где через PQ обозначено расстояние (с соответствующим знаком) между
двумя точками Р и Q при некотором выборе ориентации соединяющей их
прямой Д. Ориентация этой прямой фиксирована, но произвольна, поскольку
ее обращение, очевидно, не меняет ангармонического отношения. Отметим,
что отношение {А, В; С, D} априори определено только при D Ф А, посколь-
ку при D = А в формуле будет присутствовать деление на нуль. Определение
ангармонического отношения (очевидным образом) расширяется на всю аффин-
ную прямую, при этом для обозначения результата деления любого ненулевого
действительного числа на нуль используется символ бесконечности (ос), а вся
проекционная прямая Д представляется записью {А, В, С, оод} = СА/СВ.
В качестве альтернативы можно показать, что для трех данных точек А, В
и С на проективной прямой Д существует единственное проективное преоб-
разование h : Д —> R, отображающее Д в проективное дополнение Е = Ки оо
реальной прямой так, что /г(А) = оо, h(B) = 0 и h(C) — 1. Кроме того,
ангармоническое отношение можно определить как {А, В; С, В} = h(D).
Для данной проективной системы координат (Ао, Ai,A*) прямой Д и лежа-
щей на Д точки Р с однородными координатами (rr0, a^i) в этой системе коорди-
нат неоднородную координату Р можно определить как ко = xq/xi. Скаляр ко
Глава 13. Определение проективной структуры по движению
397
Рис. 13.2. Определение ангармонического отношения: а) четырех прямых, б) четырех плоскостей.
Как показано в разделе упражнений, ангармоническое отношение {A, B-C,D} зависит только от
трех углов а, /3 и у. В частности, имеем {А, В\ C,D} = {А', В'; C',D'}
иногда еще называют проективным параметром точки Р, и легко показать,
что к0 = {Ао, Ai; А2, Р}.
Как отмечалось ранее, набор прямых, проходящих через одну точку О, на-
зывается пучком прямых. Ангармоническое отношение четырех компланарных
прямых Ai, Д2, Дз и Д4 в некотором пучке определяется как ангармоническое
отношение пересечений этих прямых с любой другой прямой Д в плоскости,
которая не проходит через точку О. Легко показать, что определенное таким
образом отношение не зависит от выбора Д (рис. 13.2, а).
Рассмотрим теперь четыре плоскости ГЦ, П2, Пз и ГЦ одного пучка и обо-
значим через Д их общую прямую. Ангармоническое отношение этих плос-
костей определяется как ангармоническое отношение пучка прямых, которые
формируются пересечением этих плоскостей с любой другой плоскостью П, не
содержащей Д (рис. 13.2, б). Как и ранее, легко показать, что ангармоническое
отношение не зависит от выбора П.
На плоскости неоднородные проективные координаты (ко, fci) точки Р в ба-
зисе (Ао, Ai, А2, А*) определяются как ко = хо/х2 и к^ = х\/х2\ можно пока-
зать, что
{ко = {AiAo, AiA2; AiA*, AiP},
ki = {AqAi, АоА2; АоА*, AqP},
где через MN обозначена прямая, соединяющая точки М и N, а {Д1, Д2; Дз,
Д4} — ангармоническое отношение пучка прямых Дь Д2, Дз, Д4.
Подобным образом, неоднородные проективные координаты (ko,ki,k2)
точки Р в базисе (Ао, Ai,А2, Аз, А*) определяются соотношениями к0 —
398
Часть III. Первые этапы: несколько изображений
хо/^з. ki = ^i/^з и &2 = а’г/^з; можно также показать, что
ко = {А1А2А0, А1А2А3', А1А2А*, A1A2JP},
< fci = {А2А0А1, А2А0А3; А2А0А*, А2А0Р},
k ^2 = {А0А1А2, -AoAiA3; AqAiA*, A0A1P},
где через LMN обозначена плоскость, проходящая через три точки L, М и N, а
через {П1, П2;Пз,П4} — ангармоническое отношение пучка плоскостей Щ, П2,
П3, П4.
13.1.6. Проективные преобразования
Рассмотрим взаимно однозначное линейное отображение ф : X —> X' между
двумя векторными пространствами X и X1. Вследствие линейности отоб-
ражает лучи X в лучи Хг. Поскольку отображение взаимно-однозначное, оно
также переводит ненулевые вектора в ненулевые вектора и для любого v О
в X соотношением ip(p(v)) = p(V’C^)) можно определить индуцированное отоб-
ражение ф : Р(Х) —> Р(Х'). Отображение ф является взаимно-однозначным
и называется проективным преобразованием (или гомографией). Легко по-
казать, что проективные преобразования формируют группу относительно
композиции отображений. Если X' = X, эта группа называется проективной
группой пространства X = Р(Х).
Пример 13.5. Проективное соответствие компланарных точек и их изобра-
жений
Рассмотрим две плоскости и точку О, лежащую вне этих плоскостей в простран-
стве Е3. Как показано в разделе упражнений, перспективная проекция, отобража-
ющая любую точку А в проективном замыкании первой плоскости в пересечение
прямой АО с проективным замыканием второй плоскости, представляет собой
проективное преобразование.
Глава 13. Определение проективной структуры по движению
399
Это свойство не должно быть неожиданным, поскольку, как следует из приме-
ра 13.1, две (проективных) плоскости можно рассматривать как модели проектив-
ных пространств, соотнесенных с множеством лучей, проходящих через точку О.
Проективную геометрию можно использовать для изучения свойств про-
ективных пространств, сохраняющихся при гомографиях. В качестве примера
подобного инварианта можно привести линейную независимость (или зависи-
мость) семейства точек. Для данного проективного преобразования ф : X —> X'
рассмотрим т +1 линейно независимый вектор votVi>- •* в X и соответ-
ствующие точки Ao,Ai,...,Am в X. Поскольку ф — взаимно-однозначное
преобразование, векторы ф(у^ линейно независимы, также линейно неза-
висимыми являются точки А[ = ^?(At). Из сказанного следует, что ес-
ли (А) = (Ao,Ai,...,An+i) — это проективная система координат в п-
мерном проективном пространстве X, то в пространстве X' проективной
системой координат является (А') = (Ад, А'15..., А^+1). И наоборот, для
двух данных n-мерных проективных пространств X и X1, имеющих, соот-
ветственно, базисы (Ao, Ai,..., An+i) и (Ад, А'п..., А^+1), можно показать,
что существует единственная гомография ф : X —> X' такая, что ^(А») = А£
для г = 0,1,... ,n + 1.
Второй инвариант формируют проективные координаты. Действительно,
вследствие линейности преобразования ф, если точка Р имеет координа-
ты (20,^1,...,хп) в проективной системе координат (Ao,Ai,...,An+i) про-
странства X, точка ф(Р) будет иметь такие же координаты в системе коор-
динат пространства X', сформированной точками А- — ^(А*). Фактически,
проективные преобразования можно описать как отображение, переводящее
прямые в прямые и сохраняющее ангармонические отношения (а следователь-
но, и проективные координаты). Возвращаясь к примеру 13.1.6., получаем
следствие: образ набора компланарных точек полностью определяет проектив-
ные координаты этих точек относительно системы координат, сформированной
четырьмя такими точками. Этот факт весьма полезен при проектировании си-
стем распознавания, основанных на инвариантах, которые будут рассмотрены
в последующих главах.
Подобно строгому или аффинному преобразованию, гомографию ф между
двумя проективными пространствами размерности п удобно представить мат-
рицей (n + 1) х (n +1) непосредственно после выбора систем координат (F)
и (F') в этих пространствах: как и ранее, это возможно из-за линейности опера-
тора ф. Таким образом, если Р' = ф(Р), можно записать F Р' = QFP, где Q —
несингулярная матрица (п+1) х (п+1), определенная с точностью до масштаба,
поскольку однородные проективные координаты также определены с точностью
до масштаба.
400
Часть III. Первые этапы: несколько изображений
Пример 13.6. Параметризация фундаментальной матрицы Рассмотрим по-
вторно задачу определения эпиполярной геометрии неоткалиброванных камер.
Эта задача была представлена в главе 10, где без доказательства приводилась
явная параметризация фундаментальной матрицы. Для того, чтобы получить эту
параметризацию, определим эпиполярное преобразование как отображение од-
ного набора эпиполярных прямых в другой набор. Как видно из диаграммы, это
преобразование является гомографией.
Действительно, эпиполярные плоскости, соотнесенные с двумя камерами, фор-
мируют пучок, ось которого — это базовая линия, соединяющая два оптических
центра. Пучок пересекает соответствующие плоскости изображений вдоль двух
семейств эпиполярных линий, причем ангармоническое отношение любой чет-
верки линий в любом семействе равно ангармоническому отношению соответ-
ствующих плоскостей. Из этого следует, что при эпиполярном преобразовании
сохраняется ангармоническое отношение, следовательно, оно является проектив-
ным преобразованием.
Определим через (а,/3)т и (аффинные) координаты двух эпиполю-
сов е и е' в соответствующих системах координат образов и используем (и, v)T
и («', v')T для обозначения координат точек на соответствующих эпиполярных ли-
ниях I и I'. Учитывая тот факт, что линейное отображение, соотнесенное с эпипо-
лярным преобразованием, переводит луч R(u—a, v—0)т в луч R(u'—/З')т,
легко показать (см. раздел упражнений), что наклоны тит' прямых I и V удо-
влетворяют следующему соотношению:
а-Т -ь b def v — /3 , def v' - /3'
------При Т = — и Т = —.
ст + а и —а и1 — а'
(13.4)
Избавляясь от знаменателей в уравнении (13.4), получаем билинейное выражение
по и, v и u', v’, которое легко переписывается в виде pTFp = 0, где матрица Т
Глава 13. Определение проективной структуры по движению
401
записана в форме, которая без доказательства приводилась в главе 10, т.е.
( b а —ар — ba
—d —с ср + da
\dft — ba' eft — аа1 —cppf — dp1 a 4- apa' + baa'
13.1.7. Проективная форма
Применяя тот же подход, что и для аффинного случая, скажем, что два
набора точек S и S' в некотором проективном пространстве X проективно эк-
вивалентны, если существует проективное преобразование ф : X —> X такое,
что S' — образ S при преобразовании ф. Как и в аффинном случае, легко по-
казать, что проективная эквивалентность является соотношением эквивалент-
ности и что проективная форма набора точек S в X определяется как класс
эквивалентности всех проективно эквивалентных наборов точек. Подобным об-
разом, задачу определения проективной структуры по движению можно теперь
переопределить как задачу восстановления проективной формы наблюдаемой
сцены (и/или классов эквивалентности, формируемых соответствующими про-
екционными матрицами) по характерным точкам, согласованным на последова-
тельности изображений.
13.2. ОПРЕДЕЛЕНИЕ ПРОЕКТИВНОЙ СТРУКТУРЫ И ДВИЖЕНИЯ ПО
БИНОКУЛЯРНЫМ СООТВЕТСТВИЯМ
Далее в этой главе рассматривается восстановление трехмерной проектив-
ной структуры сцены в предположении, что были отслежены п точек на т
изображениях этой сцены. В данном разделе предполагается наличие двух
изображений. В следующих двух разделах эта задача рассмотрена для трех
и большего числа изображений. Предполагается, что эпиполюса известны, для
чего, как показано в главе 10, требуется установить не менее семи точечных
соответствий.
13.2.1. Геометрическое восстановление сцены
Начнем с описания геометрического метода оценки проективной формы сце-
ны при известных эпи полюсах. Эту работу упрощает характерная неоднознач-
ность задачи определения проективной структуры по движению, поскольку
в качестве проективной системы координат можно выбирать удобные точки.
Предположим, что мы наблюдаем четыре некомпланарных точки А, В, С, D
посредством слабооткалиброванного стереоустройства (рис. 13.3). Пусть О' (со-
ответственно, О") — положение оптического центра первой (соответственно,
второй) камеры. Для любой точки Р обозначим через р' (соответственно, р")
положение проекции Р на первое (соответственно, второе) изображение, а че-
рез Р' (соответственно, Р") — пересечение луча О’Р (соответственно, О"Р)
402
Часть III. Первые этапы: несколько изображений
Рис. 13.3. Геометрическое построение проективных координат точки D в базисе, сформированном
пятью точками А, В, С, О* и О"
с плоскостью АВС. Эпиполюсами являются е' и е", а базовая линия пересекает
плоскость АВС в точке Е. (Очевидно, Е' = Е" = Е, А1 = А" = Ам т.д.)
Выберем А, В,С,О',О" как базис проективного трехмерного простран-
ства, дальнейшая цель состоит в восстановлении положения точки D. Вы-
бирая а'в качестве базиса первой плоскости изображения, можно
измерить координаты точки d* в этом базисе и восстановить точку D' в бази-
се А, В, С, Е плоскости АВС. Подобным образом можно восстановить точку D"
по проективным координатам точки d" в базисе а,,,Ь",е',,е" второй плоско-
сти изображения. Окончательно точка D восстанавливается как пересечение
прямых O'D' и O"D".
Выразим теперь геометрическое построение в алгебраической форме. Для
этого проще всего переупорядочить точки проективной системы координат
и вычислить неоднородные проективные координаты точки D в базисе, сфор-
мированном тетраэдром АО" О'В и единичной точкой С. Эти координаты
определяются следующими ангармоническими отношениями:
к0 = {О"О'А, О" О'В ; О" О'С, О" O'D},
* fci = {О'АО", О'АВ; О'AC, O'AD},
fc2 = {АО"О', АО"В; АО"С, AO"D}.
Находя пересечение соответствующих пучков плоскостей с двумя плоскостями
изображения, сразу получаем значения &о,&ь&2 как ангармонические отноше-
ния, измеренные непосредственно на двух изображениях:
' ко = {е'а', e'b'; е'с', e'd'} = {е"а", е"Ь"; е"с", e"d"},
< к\ = {а'е', а'Ь'; а'с', a'd?},
к2 = {а"е", a"b"; а"с", a"d"}.
Глава 13. Определение проективной структуры по движению
403
Рис. 13.4. Геометрическое восстановление точек: а) входные данные, б) чисто проективные ко-
ординаты, в) уточненные проективные координаты. Перепечатано из J. Ponce, Т.А. Cass, and
D.H. Marimont, “Relative Stereo and Motion Reconstruction”, Technical Report UIUC-B1-AI-RCV-
93-07, Beckman Institute, University of Illinois (1993). Данные любезно предоставили Бобейкер
Боуфама (Boubakeur Boufama) и Роджер Mop (Roger Mohr)
На рис. 13.4 описанный метод иллюстрируется на примере, в котором исполь-
зованы 46 точечных соответствий, определенных между двумя изображениями,
полученными со слабо откалиброванных камер. На рис. 13.4, а показаны вход-
ные изображения и точечные соответствия. На рис. 13.4, б показан вид соответ-
ствующей реконструкции проективной сцены, для визуализации изображения
были использованы чисто проективные координаты. Поскольку приведенное
изображение не является достаточно наглядным, на рис. 13.4, в представлена
реконструкция, полученная посредством применения к точкам объекта про-
ективного преобразования, переводящего три опорных точки (показаны как
небольшие окружности) и центры камер в их откалиброванные евклидовы
аналоги. Для сравнения обозначены также истинные положения точек.
404
Часть III. Первые этапы: несколько изображений
13.2.2. Алгебраическая оценка движения
В данном разделе представлен чисто алгебраический подход к задаче опенки
проективной формы сцены по бинокулярным точечным соответствиям в пред-
положении, что стереоустройство откалибровано слабо. Перспективная проек-
ция уравнения (2.15), введенного в главе 2, естественным образом расширяется
на проективное замыкание пространства Е3 и имеет одинаковый вид в лю-
бой проективной системе координат этого пространства. Действительно, если
переписать уравнение (2.15) как zp = МР в некоторой евклидовой системе
координат (F), получим похожее уравнение zp = АГР' в проективной системе
координат (F'), где Р’ = F'P = $ТР иМ' = М
В частности, выберем пять точек А0М1> А2, Аз, А4 и примем их как базис
пространства Е3, при этом А4 играет роль единичной точки. Будем считать,
что камера, наблюдающая эти точки, описывается проекционной матрицей Л4,
и обозначим через ао,а1,а2,аз,а4 изображения этих точек, выбрав в качестве
проективного базиса плоскости изображения точки от ао до аз. единичной точ-
кой теперь будет аз. Обозначим также через а, /3 и у координаты точки а4
в этом базисе.
Записывая = MAi для г = 0,1,2,3,4, получаем следующее:
0 0 ЗзХ
0 zi 0 гз I и
0 0 Z2 гз)
z4a = z0 + гз,
< Z40 = Z1+ Z3,
Z4y = Z2 + Z3.
Поскольку перспективная проекционная матрица определена только с точно-
стью до масштаба, можно разделить ее коэффициенты на 23 и определить
Л = 24/23:
/ Ха -1 0 0 1
М= 0 А/3 — 1 0 1
\ 0 0 A7-I 1
Предположим теперь, что есть второе изображение той же сцены с проекци-
онной матрицей ЛЛ' и точками изображения а^а^а^а^а^. Применяя то же
построение, что и ранее, получаем такой результат.
М' =
/Х'а' - 1 0 0 1
0 Х'{3' - 1 0 1
\ о 0 X'Y - 1 1
Таким образом, стереоконфигурация двух камер полностью определена двумя
параметрами: А и А'. Теперь для вычисления этих параметров можно использо-
вать эпиполярную геометрию устройства. Обозначим через С оптический центр
первой камеры, а через е' — соответствующий эпиполюс на плоскости изобра-
жения второй камеры, который в соответствующих проективных базисах будет
описываться координатными векторами С и е'. Имеем Л4С = О, следовательно,
Глава 13. Определение проективной структуры по движению
405
С =
1 1 1
--------,--------,----------, 1
1 — Ла 1 — А/? 1 — А7
Подстановка в уравнение выражения ЛЛ'С = е' дает такой результат:
, ( Аа—1 А'/З'-l А'7-1\
е — I 1--------, 1--------, 1-------
\ Ха -1 АД-1 А7-1 /
Если теперь обозначить через р' и 1/ неоднородные координаты точки е' в про-
ективном базисе, сформированном точками aj, окончательно получим:
J //(А7 — A,7/)(Aa — 1) = (Ла — A'a/)(A7 — 1),
{ р'(Л7 - - 1) = (АХ? - Х'РНХ'у - 1).
(13.5)
Система двух квадратных уравнений для двух неизвестных А и А', подоб-
ная (13.5), в общем случае имеет четыре решения, которые можно рас-
сматривать как четыре точки пересечения в плоскости (А, А') конических
сечений, определенных двумя приведенными уравнениями. Изучая уравне-
ние (13.5), сразу видим, что их решениями всегда являются (А, А') = (0,0)
и (А, А') = (1/7,1/7'). Легко (только долго) показать, что два оставшихся
решения идентичны (геометрически два конуса касательны друг другу в точке
их пересечения), а соответствующие значения параметров А и А' определяются
такими соотношениями:
л/
Det и'
V
I р'а а а'
Det 1/0 0 Д'
\ 7 7 7*.
(р а
0 0' \
1 7 77
и л =-------------------
( ра' а а1
Det v/3' 0 Д'
\ 7' 7 7.
По этим величинам однозначно определяются проекционные матрицы М и Л4'.
Отметим, что учет уравнений, которые определяют второй эпиполюс, не вво-
дит независимых условий, поскольку существует эпиполярное ограничение,
связывающее соответствующие эпиполярные линии. Как только найдены про-
екционные матрицы, восстановить точки сцены — дело техники.
13.3. ОЦЕНКА ПРОЕКТИВНОГО ДВИЖЕНИЯ ПО ПОЛИЛИНЕЙНЫМ
УСЛОВИЯМ
Методы, представленные в двух предыдущих разделах, позволяют восста-
новить сцену относительно пяти ее точек, следовательно, качество восстанов-
ления зависит от точности локализации этих точек на двух изображениях.
406
Часть III. Первые этапы: несколько изображений
В подходе, представленном в данном разделе, наоборот, на равных правах учи-
тываются все точки и для восстановления движения камеры (соответствующих
проекционных матриц) используются полилинейные условия, представленные
в главе 10.
13.3.1. Оценка движения по фундаментальным матрицам
Предположим, что фундаментальная матрица У, соотнесенная с двумя
изображениями, оценена по бинокулярным соответствиям. Как и в аффинном
случае, проекционные матрицы можно, фактически, оценить по параметризации
матрицы Т, из которой видна внутренняя неоднозначность задачи определе-
ния проективной структуры по движению. Поскольку проективные параметры
задачи вычисления структуры сцены и движения камеры определены толь-
ко с точностью до произвольного проективного преобразования, две матрицы
можно свести к каноническим формам Л4 = A4Q и Л4' = MQ!, домножив
их справа на подходящую матрицу Q размера 4 х 4. В этот раз мы счита-
ем, что /Л' пропорциональна (Id О), а матрицу Л4 оставляем в общем виде
(Д Ь). В процессе разложения определяется 11 элементов матрицы Q, и мы
вольны использовать 4 оставшихся степени свободы матрицы Q для приведения
матрицы Л4 к простейшему виду.
Выведем новое выражение для фундаментальной матрицы, используя кано-
ническую форму матрицы Л4'. Если через Р = (ж, у, г, 1)г обозначить вектор
однородных координат точки Р в соответствующей внешней системе коорди-
нат, проекционные уравнения, соотнесенные с двумя камерами, можно записать
как zp = (Д Ь)Р и z'p' = (Id 0)Р или, эквивалентно,
гр = Д(1д 0)P + b = zAp' + Ь.
Отсюда следует, что zb х р = z'b х Др'; записывая скалярное произведение
этого выражения с р, окончательно получаем:
ртУр' = 0, где У = (ЬХ]Д.
Отметим сходство полученного результата с выражением для существенной
матрицы, выведенным в главе 10.
В частности, имеем РТЬ = 0, поэтому (как и следовало ожидать) Ь — вектор
однородных координат первого эпиполюса в соответствующей системе коорди-
нат изображения. Новая параметризация матрицы У позволяет проще вычис-
лить проекционную матрицу М. Отметим, что поскольку общий масштаб JVI
не важен, всегда можно положить |Ь[ = 1. Это позволяет вначале вычислить
(по схеме наименьших квадратов) b как решение уравнения РТЬ = 0, имеющее
единичную норму, затем принять До = —[ЬХ]У как значение матрицы Д. Легко
Глава 13. Определение проективной структуры по движению
407
показать, что для любого вектора а, [ах]2 — аат — |a|2Id; следовательно,
[Ьх]Ло = - [Ьх ]2? = -ЬЬТГ+ = Л
поскольку ?ТЪ = О и |b|2 = 1. Отсюда видно, что Л4 = (Ао Ь) является
одним из решений данной задачи. Как показано в разделе упражнений, фак-
тически существует 4-параметричное семейство решений, общий вид которого
приведен ниже.
/4 = ^А b) при А = ААо + ( pb | ub | тЬ ).
Четыре параметра соответствуют, как и следовало ожидать, оставшимся степе-
ням свободы проективного преобразования Q. Как только известна матрица Л4,
можно вычислить положение любой точки Р, решив (по схеме наименьших
квадратов) неоднородную линейную систему уравнений по z и У, определенную
соотношением zp — z'Ap' + b.
13.3.2. Оценка движения по трифокусным тензорам
Перепишем проективные проекции трилинейных условий, соотнесенных
с трифокусным тензором, которые были введены в главе Ю. Как и в предыду-
щем разделе, проекционные матрицы можно домножить справа на подходящую
матрицу 4x4, чтобы привести их к такому виду:
Л41 = (Id 0), Л42 = (А2 Ь2) и Л^з = (Аз Ьз)-
При таком преобразовании Ьг и Ъз можно интерпретировать как неоднородные
координаты изображений эпиполюсов ei2 и ei3, трилинейные условия в урав-
нениях (10.14) и (10.15) сохраняют силу, а трифокусный тензор в этот раз
определяется тремя матрицами^
е; = - а№, (1з.б)
где через Аг2 и A3 (г — 1,2,3) обозначены столбцы матриц Аг и Аз.
Предполагая, что трифокусный тензор был оценен по точечным или линей-
ным соответствиям, как описано в главе 10, цель в этом разделе заключается
в восстановлении проекционных матриц Л4г и М3. Отметим вначале, что
(Ь2 х А^)тд\ = [(Ь2 х А^)тЬ2] Af - [(b2 х А2)тА^ bl = 0,
2Формально, умножение справа трех проекционных матриц на Q равнозначно тому, что
в уравнении для (неоткалиброванного) трифокусного тензора в главе 10 положить калибровочную
матрицу SC1 равную единичной. Отметим, впрочем, что здесь мы не предполагаем, что известны
калибровочные параметры. Вместо этого для упрощения формы проекционных матриц используется
подходящее изменение проективных координат.
408
Часть III. Первые этапы: несколько изображений
и, подобным образом,
{/1(Ьз х A3) = ^АзТ(Ьз х Ag)j ~ [«£(Ьз х Аз)^ Ад = о.
Из сказанного следует, что матрица сингулярна (о чем уже говорилось в гла-
ве 10), а векторы Ь2 х А2 и &з х Ад лежат, соответственно, в левом и правом
нуль-пространствах. Это в свою очередь означает, что если известен трифо-
кусный тензор, можно вычислить эпиполюс 62 (соответственно, Ьз) как об-
щую нормаль к левому (соответственно, правому) нуль-пространству матриц
(г = 1,2,3).
Как только известны эпиполюса, можно записать уравнение (13.6) для г =
1,2,3, в результате получится 27 однородных линейных уравнения для 18 неиз-
вестных элементов матриц Aj (j = 2,3). Эти уравнения можно решить с точ-
ностью до масштаба, использовав схему наименьших квадратов. В качестве
альтернативы можно оценить матрицы Aj непосредственно из трилинейных
условий, соотнесенных с парами соответствующих точек или линий, записав
коэффициенты трифокусного тензора как функции этих матриц, что снова поз-
волит использовать линейный процесс оценки.
После нахождения проекционных матриц можно также восстановить про-
ективную структуру сцены, использовав уравнения перспективных проекций
как линейные условия на векторы однородных координат наблюдаемых точек
и линий.
13.4. ОПРЕДЕЛЕНИЕ ПРОЕКТИВНОЙ СТРУКТУРЫ И ДВИЖЕНИЯ ПО
МНОЖЕСТВЕННЫМ ИЗОБРАЖЕНИЯМ
В разделе 13.3 для восстановления движения камеры и соответствующей
структуры сцены по двум-трем изображениям были использованы эпиполяр-
ные и трифокусные условия. Подобным образом квадрифокусный тензор, вве-
денный в главе 10, можно, в принципе, использовать для оценки проекционных
матриц, соотнесенных с четырьмя камерами, и соответствующей проективной
структуры сцены. В то же время, полилинейные условия не дают прямого ме-
тода единообразной обработки т > 4 точек наблюдения. Взамен этого, пара-
метры структуры и движения, оцененные по парам, тройкам или четверкам
последовательных изображений, должны вводиться в решение итеративно. Ни-
же представлена альтернативная схема обработки данных, когда одновременно
учитываются все изображения и применяется нелинейная схема оптимизации.
13.4.1. Использование факторизации для определения проективной
структуры по движению
В данном разделе представлен алгоритм факторизации, применяющийся для
анализа движения, который является обобщением на проективный случай ал-
горитма Томаси-Кенеда, представленного в главе 12. Для т данных изображе-
Глава 13. Определение проективной структуры по движению
409
ний п точек можно переписать уравнение (13.1) следующим образом:
V = МР, (13.7)
где
212Р12 zlnPln 1М,\
Т> = 221Р21 ^22Рз2 z2nP<2n , м = Мч иР = (Pi Р2 ... Р„
2тп2Рт2 \AU/
Как произведение матриц Зт х 4 и 4 х п, матрица V размера Зт х п имеет (са-
мое большее) ранг 4; следовательно, если известны проективные глубины Zij,
можно вычислить матрицы Л4 и Р, подобно тому, как это делалось для аф-
финного случая: с использованием для факторизации матрицы V разложения
по сингулярным значениям. С другой стороны, если известны матрицы М и Р,
значения проективных глубин z^ можно вычислить из уравнения (13.7). Это на-
водит на мысль использовать для оценки неизвестных z^, М и Р итеративную
схему, поэтапно фиксируя одни переменные и оценивая другие.
Для решении поставленной задачи минимизируем квадрат фробениусовой
нормы выражения Т) — МР, т.е.
Е =' |Р - Л1Р|Е 2 * * * * * В = £ |^р, - AIjPjI2
i,3
относительно неизвестных A4j, Pj и z^. Отметим, что минимизация Е некор-
ректна, если только на параметры Mi, Pj и z^ не наложены определенные
условия. Действительно, как упоминалось ранее, эти неизвестные не являются
независимыми: матрицы Mi и векторы Pj определены только с точностью до
масштаба. Если Mi, Pj и z^ — решения уравнения (13.1), решениями также
ЯВЛЯЮТСЯ &iMi, PjPj И OtifijZij При ПРОИЗВОЛЬНЫХ ЗНЗЧеНИЯХ скаляров а» И Pj.
В частности, уравнение (13.1) всегда допускает тривиальное решение Mi =
0, Pj = 0, z^ = 0. Фактически, это уравнение допускает значительно более ши-
рокий класс тривиальных, нефизических решений — например, z^ = 0, Mi =
Мо и Pj = Ро, где A4o — произвольная матрица размера 3x4 ранга 3, а Ро —
единичный вектор ее ядра. Указанных тривиальных решений можно избежать,
если ввести условие, что столбцы dj матрицы V имеют единичную норму.
На некотором этапе процесса минимизации зафиксируем значения М в их
текущем состоянии и вычислим для j = 1,..., п значения Zj = (z^,..., zmj)T
и Pj, которые минимизируют величину
ш
Ei^^z^-MiPrf.
i=l
При этих же значениях будет достигаться минимум Е. Записывая, что гра-
диент Ej по направлению вектора Pj должен в минимуме равняться нулю,
410
Часть III. Первые этапы: несколько изображений
получаем
dEj
0 = —^ = 2 £ (гУРу - MiPj),
1=1
или
MTd3 = МТМР] <=> Pj = Л4%,
где = (Л4ТЛ4)_1Л4Г — псевдообратная матрица матрицы Л4. В свою оче-
редь, подстановка этого значения в определение Ej дает Ej = |(Id—Л4Л4*)<^|2.
Теперь Л4 — это матрица 3m х 4 ранга 4, разложение по сингулярным значе-
ниям которой формируется произведением ортогональной по столбцам
матрицы U (3m х 4), несингулярной диагональной матрицы W (4 х 4) и ортого-
нальной матрицы VT (4 х 4). Псевдообратной матрицей матрицы является
= VVV~lllT\ подставляя это значение в выражение для Ej и учитывая,
что |dj|2 = 1, получаем
Е, - |[Id - UUT]dj^ = 1 - |Wdj|2.
В свою очередь, это означает, что минимизация Ej относительно Zj и Pj экви-
валентна максимизации $Adj|2 при условии |с?>|2 = 1. Окончательно получаем
выражение
fPij
J Z-1 def О
dj — QjZj., где Qj —
о
P2j
О
0 \
о
Pmj)
\ О
Отсюда видно, что минимизация Ej эквивалентна максимизации I'Rj-zjI2 отно-
сительно Zj при условии |Qj«j|2 = 1, где Hj =UTQj. Полученное уравнение
называется обобщенной задачей на собственные значения, решением которой
является единичный вектор Zj, соответствующий наибольшему скаляру А, та-
кому что 'R.J'RjZj — XQjQjZj.
Этап минимизации, на котором фиксируются проекционные глубины, а мат-
рицы Л4 и Р варьируются, проводится по схеме Томаси-Кенеда, описанной для
задачи определения аффинной структуры по движению. Общий процесс све-
ден в единое целое в алгоритме 13.1. Исходные значения проекционных глубин
выбираются равными 1 или же их можно рассчитать так же, как описывалось
выше: по оценкам эпиполярной геометрии.
Легко показать, что ошибка Е со временем стремится к некоторому значе-
нию Е*. Действительно, пусть Eq — текущее значение ошибки в начале итера-
ции; на первых двух этапах алгоритма векторы Zj не меняются, но Е минимизи-
руется относительно неизвестных Л4 и Pj. Если Е2 — значение ошибки в конце
Глава 13. Определение проективной структуры по движению
411
этапа 2, имеем Кг < Eq. Далее, на этапе 3 матрица М не меняется, но каждый
ошибочный член Ej минимизируется относительно векторов Zj и Pj. Следова-
тельно, ошибка Кз в конце этого этапа меньше или равна Кг. Отсюда видно, что
ошибка монотонно уменьшается с каждой итерацией. Поскольку снизу это зна-
чение ограничено нулем, делаем вывод, что значения ошибок сходятся к некото-
рой величине К* > 0. Сходимости ошибки недостаточно, чтобы гарантировать
сходимость алгоритма оптимизации к локальному минимуму. Впрочем, доказа-
тельство сходимости алгоритма 13.1, основанное на теореме о глобальной сходи-
мости ([Luenberger, 1985]) из сферы численного анализа, слишком сложно, по-
этому здесь не приводится, но его можно найти в [Mahamud et al., 2001]. Явля-
ется ли этот локальный минимум глобальным — зависит, разумеется, от выбора
исходных значений различных независимых параметров. Возможный выбор, ко-
торый использовался в экспериментах, представленных в [Mahamud and Hebert,
2000], — это выбор начальных проективных глубин Zij равными 1, что равно-
значно началу решения задачи со слабоперспективной проекционной модели.
Алгоритм 13.1. Алгоритм факторизации для задачи определения проективной
формы по движению.
1. Вычислить начальные оценки проективных глубин при i = 1,..., тп и j =
1,... , п.
2. Нормировать каждый столбец информационной матрицы V.
3. Итерация:
а) использовать разложение по сингулярным значениям для вычисления мат-
риц 2тп х4Ми4хпР, которые минимизируют |7? — Л4Р[2;
б) для j от 1 до п, вычислить матрицы IZj и Qj и найти значение zit которое
максимизирует I'lZjZjj2 при условии |QjZj|2 = 1, как решение обобщенной
задачи на собственные значения;
в) соответствующим образом обновить значение Т>.
Повторять до схождения.
На рис. 13.5, а показано первое изображение в последовательности 20 изоб-
ражений некоторого пейзажа. По всей последовательности были вручную отсле-
жены тридцать точек, а ошибка локализации равна пиксель. На рис. 13.5, б
приведены графики изменения средней и максимальной ошибок между наблю-
даемыми и предсказанными точками изображения для различных подмножеств
последовательности изображений, использованных для расчета и проверки.
13.4.2. Выравнивание пучков
Первоначальные оценки матриц (г = 1,..., т) и векторов Pj (j =
1,..., п) можно переписать, использовав нелинейную схему наименьших квад-
412
Часть III. Первые этапы: несколько изображений
а)
Рис. 13.5. Итеративная проективная оценка движения камеры и структуры сцены: а) одно из изоб-
ражений последовательности; б) график зависимости средней и максимальной ошибки повторного
проектирования от числа итераций. Обработаны результаты двух экспериментов: в первом в ка-
честве пробной последовательности использовались изображения последовательности через одно,
а для тестирования использовались оставшиеся изображения; во втором эксперименте в качестве
пробной последовательности использовались первые и последние пять изображений, а для провер-
ки результатов использовались средние изображения. В обоих случаях средняя ошибка снижалась
ниже 1 пикселя после 15 итераций. Перепечатано из S. Mahamud and М. Hebert, “Iterative Pro-
jective Reconstruction from Multiple Views”, Proceedings IEEE Conference on Computer Vision and
Pattern Recognition, 2000. © 2000 IEEE
б)
ратов для минимизации глобальной меры погрешности
Г / \ 2 /
1 _ / mil • Pj \ I тгц2 • Pj
Е =------- У I и*з--------------------I + I vii-----------------
77W1* ifj у ^Hi3 * IPj J у ^Hi3 * j
Название выравнивание пучков пришло из области фотограмметрии. Хотя дан-
ная схема может быть трудоемкой, она позволяет объединить все измерения
и минимизировать физически значимую меру ошибки — именуемую средне-
квадратической ошибкой между реальными положениями точек и предсказан-
ными с использованием оценки структуры сцены и движения камеры.
13.5. ОТ ПРОЕКТИВНЫХ ИЗОБРАЖЕНИЙ К ЕВКЛИДОВЫМ
Хотя проективная структура полезна сама по себе, в большинстве случаев
искомой является все же евклидова структура сцены. В главе 12 было показано,
что абсолютный масштаб сцены нельзя восстановить по слабоперспективным
или параперспективным изображениям даже при известных внутренних пара-
метрах соответствующих камер. Та же неоднозначность сохраняется и в пер-
спективном случае: для данной камеры с известными внутренними параметрами
калибровочную матрицу можно положить равной единичной и следующим об-
разом записать перспективные проекции уравнения (2.15) в некоторой внешней
Глава 13. Определение проективной структуры по движению
413
евклидовой системе координат (W):
1 (р\ 1 (А р\
p = -(R t) = -(7Z At)
z \ / Az \ 1 /
для любого ненулевого масштабного множителя А. Эта неоднозначность не яв-
ляется неожиданной, если вспомнить, что вектор t определен в формуле (2.15)
как положение начала системы координат (W) относительно камеры: одновре-
менное перемещение сцены и камеры, ее наблюдающей, от этой точки (или к
этой точке) с постоянной скоростью меняет кажущуюся глубину сцены, но не
меняет ее изображение. Введение дополнительных камер не помогает; макси-
мум, что можно сделать — это оценить евклидову форму сцены, определенную,
как и в главе 2, с точностью до произвольного преобразования подобия.
С этого момента будем предполагать, что для оценки проекционных мат-
риц Mi (г = 1,..., т) и положений точек Pj (j = 1,..., п) по т изображениям
этих точек используется один из методов, представленных в разделе 13.4. Из-
вестно, что любая другая реконструкция сцены, в частности, евклидова, отли-
чается от данной проективным преобразованием. Другими словами, если обо-
значить через Mi и Pj параметры формы и движения, измеренные в некоторой
евклидовой системе координат, должна существовать матрица Q размера 4x4
такая, что Mi = MiQ и Pj = Q~xPj. Далее в этом разделе представлен
метод вычисления матрицы евклидового уточнения Q и, следовательно, вос-
становления евклидовой формы и движения по соответствующим проективным
величинам при (некоторых) известных внутренних параметрах камеры.
Отметим вначале, что поскольку отдельные матрицы Mi определены только
с точностью до масштаба, также с точностью до масштаба определены матри-
цы Mi, которые можно записать (в наиболее общем случае, когда неизвестны
некоторые внутренние параметры камер) следующим образом:
Mi = ti),
где параметр /э, введен для учета неизвестного масштаба матрицы Mi, а К* —
калибровочная матрица, как она определена в формуле (2.13). В частности, если
записать матрицу евклидова уточнения как Q = (Q3 q4), где Q3 — матрица
4 х 3, a q4 — вектор в R4, то получаем
MiQ3 = pJCini. (13.8)
Используя это уравнение, аффинные методы, введенные в главе 12, неслож-
но адаптировать к проективной среде с известными внутренними параметрами
всех камер, так что матрицы /С» можно принять равными единичными: согласно
уравнению (13.8) матрицы MiQs размера 3 х 3 в этом случае являются мас-
штабированными матрицами поворота. Записывая, что строки этих матриц тп^
(j = 1,2,3) перпендикулярны между собой и имеют равные нормы, получаем
414
Часть III. Первые этапы: несколько изображений
следующее:
m^QsQlrriiz = О,
mT2Q3Ql пцз = О,
< m^QsQlmn = 0, (13.9)
mjQaQj’mii - mT2Q3^mi2 = О,
k mT2Q3Qlmi2 - m^QsQlmis = 0.
Матрица уточнения Q определена только с точностью до произвольного подо-
бия. Для однозначного ее определения можно предположить, что глобальная
система координат и система координат первой камеры совпадают. Для тп дан-
ных изображений получаем 12 линейных и 5(тп — 1) квадратных уравнений на
коэффициенты матрицы Q. Эти уравнения можно решить по нелинейной схеме
наименьших квадратов.
Альтернативный подход: условия (13.9) линейны по коэффициентам сим-
метричной матрицы А = Q3Q3, что позволяет оценить эту матрицу минимум
по двум изображениям, используя линейную схему наименьших квадратов.
Отметим, что ранг матрицы А равен 3 — условие, которое не следует из
построения. При восстановлении матрицы Q3 пригодится также следующий
факт: поскольку матрица А симметрична, ее можно диагонализовать в ор-
тонормированием базисе как А = UVUT, где Т> — диагональная матрица,
сформированная собственными значениями матрицы А, тогда как W — ортого-
нальная матрица, сформированная ее собственными векторами. При отсутствии
помех А — неотрицательно определенная матрица с тремя положительными
и одним нулевым собственными значениями, а матрицу Q3 можно вычис-
лить как U3\f^3, где Ы3 — матрица, сформированная столбцами матрицы W,
соотнесенными с положительными собственными значениями матрицы А, а
матрица Т>3 — соответствующий блок матрицы Р. Впрочем, из-за помех ранг
матрицы А обычно максимален, а ее наименьшее собственное значение может
даже быть отрицательным. Как показано в работе [Ponce, 2000], если принять,
что W3 и Рз - фрагменты матриц U и Р, соотнесенные с тремя наибольши-
ми (положительными) собственными значениями матрицы А, то U3D3UJ —
лучшая неотрицательно определенная аппроксимация А с рангом 3 в смысле
фробениусовой нормы3, теперь, как и ранее, можно принять Q3 = Нзх/^з-
На данном этапе вектор последнего столбца q4 матрицы Q можно определить,
(произвольным образом) выбрав в качестве начала внешней системы координат
начало координат системы, связанной с первой камерой.
Этот метод легко адаптируется к ситуации, когда известны только некоторые
внутренние параметры камер: используя тот факт, что 7Zi — ортогональная
матрица, можно записать следующее:
MiAMf = Р?1С(>СТ. (13.10)
3Отметим очевидное сходство данного результата с теоремой 4.
Глава 13. Определение проективной структуры по движению
415
Рис. 13.6. Смоделированное текстурное отображение вида замка, созданное посредством ана-
лиза проективного движения с последующим евклидовым уточнением. Главная точка считается
известной. Перепечатано из М. Pollefeys, “Self-Calibration and Metric 3D Reconstruction from
Uncalibrated Image Sequences”, PhD Thesis, Katholieke Universiteit, Leuven, (1999)
Таким образом, каждое изображение дает набор условий на элементы мат-
риц ICi и А. Предполагая, например, что центр изображения известен для каж-
дой камеры, можно положить uq = vq = 0 и записать квадрат матрицы /С»:
ACi/C/
а?——
sin2 6i
cos Oi
-OCifii-2--
sin2 0i
0
cosOi
sin2 Oi
Sin2 0i
0
Q
0
1>
В частности, часть уравнения (13.10), соответствующая нулевым позициям мат-
рицы /Cj/CT, дает два независимых линейных уравнения на 10 коэффициентов
симметричной матрицы Л (4 х 4). При наличии т > 5 изображений эти па-
раметры можно оценить по линейной схеме наименьших квадратов. Как толь-
ко известна матрица А, матрицу Q можно оценить по описанной выше схеме.
На рис. 13.6 показано текстурное отображение трехмерной модели замка, полу-
ченное с помощью разновидности этого метода (работа [Pollefeys et al., 1999]).
13.6. ПРИМЕЧАНИЯ
Краткое введение в проективную геометрию, предложенное в начале главы,
сфокусировано на аналитической стороне этого вопроса. Подробное введение
в аналитическую проективную геометрию представлено, например, в публика-
циях [Todd, 1946], [Berger, 1987] и [Samuel,1988], а в работе [Coxeter, 1974] оно
дано аксиоматически. Задача определения проективной структуры по движе-
416
Часть III. Первые этапы: несколько изображений
нию подробно рассмотрена в книгах [Hartley and Zisserman, 2000] и [Faugeras,
Luong, and Papadopoulo, 2001].
Как упоминается в [Faugeras, 1993], задача вычисления эпиполюсов и эпи-
полярных преобразований, совместимых с семью точечными соответствиями,
впервые была рассмотрена в [Chasles, 1855] и решена в [Hesse, 1863]. Задача
оценки эпиполярной геометрии по пяти точечным соответствиям для внут-
ренне откалиброванных камер была решена в [Кгирра, 1913]. Великолепную
современную переработку методов Хесса и Круппе можно найти в работе
[Faugeras and Maybank, 1990], где для вывода двух условий на касательные,
компенсирующих отсутствующие точечные соответствия, используется абсо-
лютное коническое сечение, — инвариантное (относительно преобразования
подобия) воображаемое коническое сечение. Эти методы, разумеется, представ-
ляют в основном теоретический интерес, поскольку они направлены на работу
с минимальным числом соответствий и абсолютно не устойчивы к помехам. На-
дежные и точные альтернативы — слабокалибровочные методы Луонга ([Luong
et al., 1993, 1996]) и Хартли ([Hartley, 1995]), описанные в главе 10.
Идею использования пары неоткалиброванных камер для восстановления
проективной структуры сцены независимо ввели Фаугерас ([Faugeras, 1992])
и Хартли ([Hartley et al., 1992]). Другими достойными упоминания работами
в этой области можно назвать [Mohr et al., 1992] и [Shashua, 1993]. В раз-
деле 13.2.2 изложен первоначальный метод Фаугераса, а его геометрический
вариант, представленный в разделе 13.2.1, взят из работы [Ponce et al., 1993].
Методы анализа движения по двум и трем изображениям, также описанные
в этой главе, — это разновидности методов, предложенных Хартли ([Hart-
ley, 1992, 19946, 1997]) и Бердсли ([Beardsley et al., 1997]). Если камеры
откалиброваны, можно также, как показано в разделе упражнений и публи-
кации [Longuet-Higgins, 1981], восстановить (с точностью до двусторонней
неоднозначности) преобразование подобия, соотнесенное с соответствующей
существенной матрицей. Итеративный алгоритм для восстановления перспек-
тивного движения и структуры с использованием откалиброванных камер
представлен в [Christy and Horaud, 1996]. Расширение схем факторизации для
восстановления структуры и движения впервые было предложено в работе
[Sturm and Triggs, 1996]. Вариант, представленный в разделе 13.4.1, изло-
жен согласно [Mahamud and Hebert, 2001] и отличается тем, что является
доказуемо сходящимся ([Mahamud et al., 2001]). Алгоритмы итеративного до-
бавления пар, троек и четверок последовательных изображений представлены
в [Beardsley et al., 1997] и [Pollefeys et al., 1999].
Задача вычисления евклидового уточнения проективных реконструкций при
некоторых известных внутренних параметрах рассматривалась многими авто-
рами (например, [Heyden and Astrom, 1996], [Triggs, 1997], [Pollefeys, 1999]).
Матрицу A = Q3Q3, введенную в разделе 13.5, можно интерпретировать гео-
метрически как проективное представление объекта, дуального абсолютному
коническому сечению — абсолютной дуальной квадрики ([Triggs, 1997]).
Подобно абсолютному конусу, данная поверхность второго порядка инвари-
Глава 13. Определение проективной структуры по движению
417
антна относительно преобразования подобия, а дуальное коническое сечение,
соотнесенное с , — это проекция данной поверхности второго порядка
на соответствующее изображение. Упомянем еще самокалибровку — процесс
вычисления внутренних параметров камеры по точечным соответствиям с неиз-
вестными евклидовыми положениями. Первой работой в этой области была
[Faugeras and Maybank, 1992], где рассматривались камеры с фиксированными
внутренними параметрами. В настоящее время разработано множество на-
дежных методов самокалибровки ([Hartley, 1994а], [Fitzgibbon and Zisserman,
1998], [Pollefeys et al., 1999]), которые также можно использовать для перево-
да проективных реконструкций в евклидовы. Задача вычисления евклидового
уточнения проективных реконструкций при минимальном числе условий, нала-
гаемых на камеры, рассмотрена в [Heyden and Astrom, 1998, 1999], [Pollefeys
et al., 1999] и [Ponce, 2000].
Задачи
13.1. Используйте простой счетчик, чтобы вычислить минимальное число то-
чечных соответствий, требуемых для решения задачи определения про-
ективной структуры по движению в тринокулярном случае.
13.2. Покажите, что изменение координат при переходе между системами от-
счета (Л) и (В) можно представить уравнением (13.2).
13.3. Покажите, что две различные прямые в проективной плоскости пересе-
каются точно в одной точке, и что две параллельные прямые Д и Д'
в аффинной плоскости пересекаются в точке на бесконечности, соотне-
сенной с вектором их общего направления v в проективном замыкании
этой плоскости. (Подсказка: используйте JA для вложения аффинного
пространства в его проективное замыкание, и запишите вектор П х R,
соотнесенный с любой точкой в /д(Д) (соответственно, в 7д(Д')) как
линейную комбинацию векторов (АВ, 1) и (АВ + v, 1) (соответственно,
----------> -------->
(АВ', 1) и (АВ' 4- v, 1)), где В и В' — произвольные точки в Д и Д'.)
13.4. Покажите, что перспективная проекция между двумя плоскостями про-
странства Р3 — это проективное преобразование.
13.5. Что для данного аффинного пространства X и аффинной системы ко-
ординат (Ао,..., Ап) в этом пространстве является проективным бази-
сом X, соотнесенным с векторами е, = (ДоА,0) (г = 1,...,п) и векто-
ром en+i = (0,1)? Являются ли частью этого базиса точки JAo(Ai)?
13.6. Покажите, что ангармоническое отношение четырех коллинеарных то-
чек А, В, С и D равно величине
, sin(o 4- /?) sin(/3 4- 7)
{А, В; С, D} = —---------------,
sin(a 4- /3 4- 7) sin 0
где углы а, /3 и 7 определены на рис. 13.2.
418
Часть III. Первые этапы: несколько изображений
а) Покажите, что площадь треугольника PQR равна
A(P,Q, R) = ^PQ *RH= IpQ x PR sin 0,
где через PQ обозначено расстояние между двумя точками PhQ,H —
проекция R на прямую, проходящую через Р и Q, а 0 — угол между
прямыми, соединяющими точку Р с точками Q и R.
б) Отношение трех коллинеарных точек А, В, С определяется как
АВ
R(A, В.С) =---
ВС
для некоторой ориентации прямой, содержащей эти точки. Покажите,
что
R(A, В, С) = А(А, В, О)/А(В, С, О),
где О — некоторая точка, не лежащая на данной прямой.
в) Докажите, что ангармоническое отношение {А, В; С, D} действитель-
но описывается представленной выше формулой.
13.7. Покажите, что гомографию двух эпиполярных пучков прямых можно за-
писать следующим образом:
, _ ат + 6
ст 4* d’
где т и т' — наклоны прямых.
13.8. Ниже повторно рассматривается задача трехточечного восстановления
в контексте однородных координат точки D в проективном базисе, сфор-
мированном тетраэдром (А, В, С, О') и единичной точкой О". Отметим,
что упорядочение опорных точек, а следовательно, упорядочение коорди-
нат, отличается от использованного ранее: данный выбор сделан, чтобы
облегчить восстановление.
Обозначим (неизвестные) координаты точки D через (ж, у, z, w), введем
в первой (соответственно, второй) плоскости изображения опорный тре-
угольник а'Ь'с' (соответственно, а"Ь"с") и единичную точку е' (соответ-
ственно, е") и обозначим через (x',y',z') (соответственно, (x",y",z"))
координаты точки d' (соответственно, d"). (Подсказка: нарисуйте диа-
грамму, подобную приведенной на рис. 13.3.)
а) Чему равны однородные проективные координаты точек D', D" и Е,
если прямые O'D, O"D и О'О" пересекают плоскость треугольника?
б) Запишите координаты D как функцию координат точек О' и D' (со-
ответственно, О" и D") и некоторых неизвестных параметров. (Под-
сказка: используйте тот факт, что точки D, О' и D' — коллинеарные.)
Глава 13. Определение проективной структуры по движению
419
в) Предложите метод вычисления этих неизвестных параметров и коор-
динат точки D.
13.9. Покажите, что если Л4 = (Д Ь) и Л4' = (Id 0) — две проекционных
матрицы и если через Р обозначить соответствующую фундаментальную
матрицу, то [ЬХ]Л пропорционально Р, если РТЬ = 0 и
Л = — A[bx]-^ + дЬ | уЬ | тЬ ) .
13.10. В этой задаче выводится метод вычисления минимальной параметриза-
ции фундаментальной матрицы и оценки соответствующих проекцион-
ных матриц. Эта схема подобна методу, представленному в разделе 12.2.2
главы 12 для аффинного случая.
а) Покажите, что посредством подходящего проективного преобразова-
ния две проекционных матрицы Л4 и Л4' всегда можно свести к сле-
дующим каноническим формам:
/1 0 0 о\ /а?
М = I 0 10 0 и А4' = т 02
\0 0 1 0/ 1/
(Примечание: чтобы упростить вычисления, можно предположить, что
все матрицы, фигурирующие в решении, — несингулярные.)
б) Отметим, что применение данного преобразования к проекционным
матрицам равнозначно применению обратного преобразования ко всем
точкам сцены Р. Обозначим через Р = (x,y,z)T положение преоб-
разованной точки Р в глобальной системе координат, а через р =
(и, v, 1)т и р' = (u',v‘, 1)т — векторы однородных координат изобра-
жений. Покажите, что
(и — bi)(a2 р) = (у - b2)(ai р).
в) Выведите из этого уравнения восьмипараметрическую параметриза-
цию фундаментальной матрицы и используйте тот факт, что матрица
Р определена только с точностью до масштабного множителя, для
создания минимальной семипараметрической параметризации.
г) Используйте полученную параметризацию для оценки проективной
формы сцены и вывода алгоритма оценки Р минимум по семи точеч-
ным соответствиям.
13.11. Данная задача восстановления вращения ("R.) и трансляции (t), соот-
несенных с существенной матрицей 8 = [tx]7£, любезно предоставлено
Эндрю Циссерманом (Andrew Zisserman). Трансляцию найти легко —
t можно восстановить (с точностью до масштаба, поскольку структура
сцены определяется только с точностью до преобразования подобия) как
единичный вектор, равный £Tt,
420
Часть III. Первые этапы: несколько изображений
а) Покажите, что SVD-представление существенной матрицы можно за-
писать следующим образом:
£ = Z/diag(l, 1,0)Ут,
и убедитесь, что t — это вектор третьего столбца матрицы U.
б) Покажите, что две матрицы
= ttwvT и тг2 = иютут
удовлетворяют условию £ = [tx ]7£, где
/О -1 0\
W = 1 0 0 I .
<° 0 V
Упражнения
13.12. Реализуйте геометрический подход к оценке проективной сцены, введен-
ный в разделе 13.2.1.
13.13. Реализуйте алгебраический подход к оценке проективной сцены, введен-
ный в разделе 13.2.2.
13.14. Реализуйте подход к оценке проективной сцены с использованием фак-
торизации, введенный в разделе 13.4.1.
------------ ЧАСТЬ IV -----------
Компьютерное зрение: средний уровень
14
Сегментация через
кластеризацию
Принято считать, что компьютерное зрение — это задача логического вывода:
имеются некоторые измерения и модель, а нужно определить, что дало такие
измерения. Следует, однако, отметить что компьютерное зрение отличается от
многих иных задач логического вывода. Во-первых, имеется чрезвычайно много
данных; во-вторых, неизвестно, что из имеющейся информации пригодится, а
что — нет. Например, одна из основных трудностей в создании хороших про-
грамм распознавания объектов состоит в определении того, какие пиксели рас-
познавать, а какие — игнорировать. Просто глядя на рис. 14.1, трудно сказать,
лежит ли какой-то отдельно взятый пиксель на какой-либо поверхности. Для
решения этой задачи следует изучить компактное представление рассматрива-
емых данных, при этом будут выделены интересующие нас особенности. По-
лучение такого представления называется сегментацией, группировкой, пер-
цептивной организацией, или сборкой. Далее термин сегментация будет
употребляться для обозначения многих процессов, которые, хотя и несколь-
ко различаются, связаны общей идеей: получением компактного представления
полезного содержимого объекта. К сожалению, доступной теории сегментации
не существует (по крайней мере, так было на момент написания книги), и не
последнюю роль здесь сыграло то, что лишь из конкретного приложения опре-
деляется, что на объекте представляет практический интерес. Кроме того, сам
424
Часть IV. Компьютерное зрение: средний уровень
Рис. 14.1. Как можно предположить из данных изображений, важной составляющей зрения являет-
ся организация информации, содержащейся в изображении, в значимые компоненты. Человеческая
система зрения, похоже, справляется с этим на удивление хорошо. На трех предложенных изоб-
ражениях пятна расположены так, что создается впечатление структурированной поверхности, вы-
пячивающейся над страницей (кажется, что изображены полусферы). Пятна создают впечатление
единого целого, “поскольку они формируют поверхности”, — мало удовлетворительное объяснение,
которое напрашивается на сложные последующие вопросы. Обратите внимание, что если сказать,
что пятна сгруппированы вместе, поскольку в сумме они представляют части одного объекта, также
возникнут дополнительные вопросы (например, откуда мы это знаем?). Для поверхности, изобра-
женной слева, может быть трудно написать программу, которая сможет распознать единую коге-
рентную текстуру. Отметим также, что описанный в тексте процесс организации можно применить
ко множеству различных входных данных. Перепечатано из D.A. Forsyth, "Shape from texture and
integrability". Proceedings of the International Conference on Computer Vision, 2001. © 2001 IEEE
этот термин разные авторы используют в разном значении. В данной главе
описываются процессы сегментации, которые в настоящее время не имеют ве-
роятностной интерпретации. Более сложные вероятностные алгоритмы будут
рассмотрены в последующих главах.
14.1. ЧТО ТАКОЕ “СЕГМЕНТАЦИЯ”
Предположим, что требуется распознать объекты на изображении. Итак, да-
но слишком много пикселей, чтобы обрабатывать их по отдельности. Вместо
этого предпочтительно некоторое компактное, резюмирующее представление,
которое зависит от поставленной задачи, но его общие желательные характе-
ристики наметить просто. Во-первых, в представлении типичного изображения
должно быть относительно немного компонентов (не больше, чем могут обра-
ботать алгоритмы, описанные ниже). Во-вторых, эти компоненты должны быть
содержательными. Из них должно быть достаточно очевидно, где находятся
искомые объекты (для типичных изображений).
Разработанные методы предназначены для наборов данных различных ти-
пов: одни предназначены для изображений, другие — для видеорядов, а третьи
применяются для токенов — заполнителей, указывающих на наличие в изобра-
жении искомой структуры, скажем, пятна, точки или края. Токены, фактически,
могут также появляться в видеорядах; пример — пятно, движущееся согласно
некоторому параметрическому закону.
Глава 14. Сегментация через кластеризацию
425
Хотя внешне представленные методы могут казаться достаточно разными, на
самом деле они весьма сходны (поэтому их и рассматривают вместе!). Каждый
метод — это попытка получить компактное представление набора данных с по-
мощью некоторой модели сходства (иногда подбор модели может быть весьма
сложной задачей). Эти общие особенности проявляются в различных задачах.
Ниже рассмотрены несколько характерных примеров.
* Резюме видеоинформации. Возможно, пользователям понадобится про-
сматривать большие коллекции видеорядов. Требуется создать представ-
ление, которое инкапсулирует “суть видеоряда’’. Один подход к решению
поставленной задачи — разбить каждый ряд последовательности на кад-
ры — сходно выглядящие подряды, — а затем представить его как коллаж
снимков, по одному с каждого кадра. Таким образом, задача сегментации
формулируется как сегментация последовательности на кадры.
• Поиск деталей машинной обработки. Предположим, что требуется най-
ти на изображении деталь машинной обработки (что бывает значительно
реже, чем вы могли бы подумать). Объекты, подвергающиеся машинной
обработке, обычно содержат линии — места стыковки поверхностей —
где были просверлены отверстия. Таким образом, теперь задача сегмен-
тации — это разбиение изображения на набор линий и окружностей; как
правило, вначале необходимо найти края, а затем связать с ними линии
и окружности.
• Поиск людей. Пусть требуется найти на изображении человека. На мо-
мент написания книги проблема оставалась открытой, но общая схема
решения была известна. Вначале нужно найти сегменты тела, а затем со-
брать их в единое целое. Эти сегменты находятся на изображении как
довольно большие области; если люди носят нетекстурированную одежду,
они представляют собой большие области одного цвета, так что в этом
случае следует искать полосы постоянного цвета.
* Поиск зданий на спутниковых снимках. Подавляющее большинство
зданий представляет собой многогранники, особенно в том масштабе,
в котором они видны со спутника. Отсюда следует предложение пред-
ставить изображение как набор многоугольных областей, расположенных
на некотором фоне. Как правило, для этого изучается набор краевых то-
чек, которые можно собрать в сегменты прямых, с последующим сбором
этих сегментов в многоугольники.
• Поиск в коллекции изображений. Чтобы пользователь мог найти тре-
буемое в коллекции, представления изображений должны быть значимы-
ми для пользователя и при этом связанными с содержанием (“сутью”)
изображения. Поскольку обычно содержание — это изображенные объек-
ты, а объекты, как правило, имеют когерентные цвета и текстуры, есте-
ственным будет попытаться разбить изображение на области когерентных
цветов и текстур, а затем использовать эти области как представление
изображения.
426
Часть IV. Компьютерное зрение: средний уровень
14.1.1. Модельные задачи
Существует множество примеров задач сегментации. Естественные модель-
ные задачи — это те, где полезно знать несколько методов решения. Далее
в книге будет использована одна из перечисленных ниже задач.
* Формирование сегментов изображений. Хотелось бы разложить изоб-
ражение на “суперпиксели” — участки изображений, имеющие приблизи-
тельно когерентные цвет и текстуру. Как правило, форма этих областей не
очень важна, а вот за когерентностью следить стоит. Данная задача до-
статочно широко изучается (часто под сегментацией подразумевают один
только этот процесс) и, как правило, является первым этапом распозна-
вания изображения.
* Согласование линий с краевыми точками. Как отмечалось ранее, су-
ществует несколько причин, по которым может быть удобно подобрать на-
бор линий по набору точек. Эта задача может быть как довольно простой
(например, если известно, сколько должно быть линий, и какие точки при-
надлежат какой линии), так и достаточно сложной (в большинстве дру-
гих случаев). Данная задача также относится к задачам сегментации —
здесь упорядочиваются токены, собранные вместе, поскольку они принад-
лежат одной линии. Если попытаться подобрать линию по набору точек,
некоторые из которых расположены далеко от всех линий, полученный
результат (если не быть очень аккуратным) может оказаться бессмыслен-
ным. Данный пример иллюстрирует важный и достаточно общий принцип:
пренебрежение соответствиями может приводить к тем же последствиям,
что и шум. Вообще, обычно требуется одновременно оценивать параметры
линий и соответствия между точками и линиями.
* Согласование фундаментальной матрицы с набором характерных то-
чек. Предположим, что дано две проекции набора характерных точек.
Как правило, трудно с уверенностью сказать, какие точки двух изобра-
жений следует сопоставить друг другу, хотя некоторые предположения
сделать все же можно. Определить, насколько верно сделанное предполо-
жение, можно, например, изучая связывающую точки фундаментальную
матрицу. Эту матрицу хотелось бы определить заранее, еще не зная то-
чечных соответствий. В защиту такого подхода можно назвать несколько
соображений. Во-первых, не зная решения указанной задачи, по несколь-
ким изображениям невозможно построить разумное представление фор-
мы. Во-вторых, по решениям данной задачи можно определить, какие
наборы точек движутся как единое целое. Если на последовательности
изображений представлены два движущихся объекта, у них будут разные
фундаментальные матрицы. Как и выше, неверные соответствия могут
приводить к тем же последствиям, что и шум.
Глава 14. Сегментация через кластеризацию 427
На основе описанных задач далее проиллюстрированы различные алгорит-
мы сегментации, при этом стоит помнить, что далеко не каждая схема дает
приемлемое решение каждой модельной задачи.
14.1.2. Сегментация как кластеризация
Естественно думать, что сегментация — это попытка определить, какие ком-
поненты набора данных естественно связать вместе. При такой формулировке
приходим к задаче кластеризации, широко освещенной в литературе. В общем
случае кластеризацию можно проводить двумя способами.
• Разбиение. Имеется большой набор данных, который расчленяется со-
гласно определенным представлениям об ассоциации элементов набора.
Разбиение принято проводить по частям, которые удобны для используе-
мой модели. Например, можно
- разбить изображение на области когерентных цвета и текстуры;
- разбить изображение на большие пятна, состоящие из областей-
сегментов когерентных цвета, текстуры и движения;
- разбить видеоряд на кадры — сегменты, имеющие приблизительно
те же объекты, которые видны примерно с одинаковых точек наблю-
дения.
* Группировка. В этом случае имеется набор различных информационных
изображений и необходимо собрать наборы элементов, значимых с точ-
ки зрения используемой модели. Наличие эффектов, подобных затенению,
означает, что компоненты изображения, которые принадлежат одному объ-
екту, на изображении могут быть разнесенными. Приведем примеры груп-
пировки.
- Сбор токенов, в результате которого формируется линия.
- Сбор токенов, которые предположительно имеют одинаковую фунда-
ментальную матрицу.
Разумеется, ключевой вопрос здесь — определить, какое представление под-
ходит для поставленной задачи. Как правило, при выборе модели руководству-
ются знаниями о том, как они работают, так что выбор обычно информативен.
Но даже в этом случае требуется знать критерий, согласно которому схема
сегментации будет определять, какие пиксели (или токены) группировать вме-
сте. Плодотворный источник необходимых знаний — человеческая зрительная
система, которая способна решать данную задачу в наиболее общей форме и,
что еще более замечательно, легко и уверенно подбирать критерий группировки
токенов.
428
Часть IV. Компьютерное зрение: средний уровень
Рис. 14.2. Известная оптическая иллюзия Мюллера-Лайера (Muller-Lyer); длины горизонтальных
линий равны, хотя линия на нижнем рисунке кажется длиннее. Причина данного эффекта — вос-
приятие свойства целого (гештальтквалитат, gestaltqualitat), а не свойств отдельных сегментов
14.2. ЧЕЛОВЕЧЕСКОЕ ЗРЕНИЕ: ГРУППИРОВКА И ГЕШТАЛЬТ
Ключевая особенность человеческой зрительной системы заключается в том,
что на восприятие окружающего мира влияет контекст (рис. 14.2). Это наблюде-
ние привело к возникновению школы гештальт-психологии. Приверженцы этой
школы отвергали изучение реакции на внешние раздражители и делали акцент
на группировке как основе к пониманию зрительного восприятия. Для после-
дователей данной школы группировка — это тенденция зрительной системы
собирать некоторые компоненты изображения в единое целое и воспринимать
их именно как целое. Группировка, например, это причина оптической иллюзии
Мюллера-Лайера (рис. 14.2) — зрительная система воспринимает компоненты
двух стрелочек как единое целое, поэтому горизонтальные линии кажутся раз-
ными, поскольку воспринимаются они не как отдельные объекты, а как эле-
менты стрелочек. Более того, многие эффекты группировки нельзя разрушить
даже зная об их наличии; например, линии на рис. 14.2 не будут выглядеть
одинаково, даже если вы решите не обращать внимания на стрелочки.
Общий подход к сегментации — всегда предполагать, что изображение мож-
но разрешить в рисунок (как правило, значимый, важный объект) и фон —
основу, на которой расположен рисунок. В то же время (см. рис. 14.3) не всегда
можно однозначно определить, что является рисунком, а что — фоном, откуда
следует, что предложенная теория является недостаточной.
В школе гештальта в качестве центрального компонента идей использует-
ся понятие гештальта — целого или группы — и его гештальтквалитата
(gestaltqualitat) — совокупности внутренних отношений, которые делают це-
лое целым (например, как на рис. 14.2). Для работ этой школы характерны
попытки записать набор правил, посредством которых элементы изображения
будут соотноситься вместе и интерпретироваться как группа. Кроме того, бы-
ли (представляющие исключительно исторический интерес) попытки построить
алгоритмы использования этих правил (см. [Gordon, 1997], где описаны базовые
понятия, давшие основу для последующих работ).
Психологи школы гештальта определили ряд факторов, согласно которым,
по их мнению, объединяется множество элементов. Эти факторы важны, по-
скольку совершенно очевидно, что человеческая зрительная система как-то их
использует. Более того, разумно ожидать, что эти факторы представляют набор
Глава 14. Сегментация через кластеризацию
429
Рис. 14.3. Распространенный подход к сегментации: определять, какие компоненты изображения
формируют рисунок, а какие — фон. Выше иллюстрируется неоднозначность, характерная для
такой точки зрения; белую окружность можно считать рисунком на черном прямоугольном фоне
или фоном, на котором изображен черный прямоугольник с круглым отверстием (в последнем
случае фон — это большой белый квадрат)
предпочтительных суждений о том, к какому объекту отнести данный токен,
что позволяет ввести удобное промежуточное представление.
Существует множество факторов, некоторые из них были открыты после
первоначальных работ психологов школы гештальта.
• Соседство. Естественно сгруппировать токены, расположенные рядом.
• Подобие. Естественно сгруппировать подобные токены.
• Общее поведение. Естественно сгруппировать токены, имеющие коге-
рентное движение.
• Общая область. Естественно сгруппировать токены, расположенные
внутри одной замкнутой области.
• Параллельность. Естественно сгруппировать параллельные кривые или
токены.
• Замкнутость. Естественно сгруппировать токены или кривые, формиру-
ющие замкнутые объекты.
• Симметрия. Группируются кривые, .принадлежащие симметричным груп-
пам.
• Непрерывность. Естественно сгруппировать токены, проявляющие непре-
рывность (не только в формальном смысле).
• Знакомая конфигурация. Естественно сгруппировать токены, которые
в сумме дадут знакомый объект.
430
Часть IV. Компьютерное зрение: средний уровень
Общая область
Рис. 14.4. Примеры гештальт-факторов, согласно которым происходит группировка (подробнее —
в тексте)
Определенные выше законы иллюстрируются на рис. 14.1, 14.4, 14.5 и 14.7.
Данные правила можно использовать при объяснениях, но они недостаточно
строги, чтобы их можно было ввести в алгоритм. Психологи школы гештальта
столкнулись с серьезными сложностями при определении области применения
каждого отдельного правила. Вообще, удовлетворительный алгоритм исполь-
зования этих правил предложить сложно, в гештальте, например, для этого
пытались приспособить принцип экстремальности.
Отдельную проблему представляет то, что выше было названо “знакомы-
ми конфигурациями”. Ключевой вопрос состоит в том, чтобы понять, какая
знакомая конфигурация применима к поставленной задаче, и как ее выбрать.
Обратимся, например, к рис. 14.1. С первого взгляда кажется, что пятна мож-
но сгруппировать, поскольку они формируют сферу. Сложность заключается
в том, чтобы объяснить, как это происходит — откуда взялась мысль о сфере?
Одно возможное объяснение: изучить все изображения всех объектов, но в та-
ком случае придется объяснить, как организовать подобное исследование. Как
проверить каждое изображение каждой сферы с каждым набором пятен? Как
это сделать эффективно?
Глава 14. Сегментация через кластеризацию
431
Рис. 14.5. Примеры гештальт-факторов, согласно которым происходит
группировка (подробнее — в тексте)
432
Рис. 14.6. Важным ключом при группировке является затенение. Набор слева трудно идентифици-
ровать как совокупность цифр, тогда как справа вполне очевидно угадываются заслоненные цифры.
Черные области в обоих случаях совпадают. Похоже, зрительная система воспринимает черные об-
ласти не как отдельные обособленные объекты, а как части, разделенные некоторым образом
Часть IV. Компьютерное зрение: средний уровень
Правила гештальта предлагают иначе взглянуть на эту проблему, поскольку
они объясняют, что происходит в различных случаях. Эти объяснения кажутся
разумными, поскольку они предлагают решение задач на визуальные эффекты,
которые встречаются в реальном мире, — т.е. они экологически действенны.
Например, непрерывность может позволить решить задачу затенения, когда
части контура затеняемого объекта можно сгруппировать по принципу непре-
рывности (см. рис. 14.6).
Данная тенденция отдавать предпочтение интерпретации, в которой фигури-
руют затеняющие объекты, приводит к любопытным эффектам. Один из них —
кажущиеся контуры, показанные на рис. 14.8. Здесь имеется набор токе-
нов, из размещения которых напрашивается предположение о наличии объекта,
большая часть контура которого сливается с фоном. Токены кажутся сгруппи-
рованными вместе, поскольку они создают впечатление наличия затеняющего
объекта, причем это впечатление настолько сильно, что можно дорисовать недо-
стающие фрагменты контура, которые приходятся на неконтрастную область.
Данный экологический аргумент достаточно важен, поскольку с его помо-
щью можно интерпретировать большинство факторов группировки. Общее по-
ведение можно рассматривать как следствие того факта, что компоненты объек-
та имеют сходное движение. Подобным образом, симметрия — это также полез-
ный критерий группировки, поскольку контуры большинства реальных объек-
тов в той или иной степени симметричны. По сути, приведенный экологический
аргумент можно переформулировать следующим образом: “токены группируют-
ся именно так, поскольку при этом создаются представления, значимые в зри-
тельном мире людей”. Экологический аргумент имеет привлекательную (хотя
Глава 14. Сегментация через кластеризацию
433
Рис. 14.7. Пример явления группировки в реальной жизни. Кнопки лифта в здании факультета
компьютерных наук Калифорнийского университета в Беркли выглядели так, как показано на
верхнем рисунке. Довольно часто люди оказывались не на том этаже, поскольку нажимали не
на ту кнопку — с первого взгляда кнопки сложно однозначно соотнести с правильной подписью.
Некто, преисполненный гражданского долга, обвел правильные пары “кнопка-цифра” (нижний
рисунок), и путаница прекратилась, поскольку неоднозначность была разрешена
Рис. 14.8. Из расположения токеиов на данных изображениях можно предположить наличие зате-
няющих объектов, размеры которых сопоставимы с размерами изображения. Обратите внимание,
что по одному изображению можно получить ясное представление о контуре затеняющего объекта.
Называются такие контуры кажущимися
и неявную) статистическую природу. Отметим также что гештальт-факторы
дают интересные подсказки, но их стоит рассматривать не как локальные про-
цессы группировки, а как следствия глобальных процессов группировки.
14.3. ПРИЛОЖЕНИЕ: ВЫЧИТАНИЕ ФОНА И ОПРЕДЕЛЕНИЕ ГРАНИЦ
КАДРОВ
Простые алгоритмы сегментации часто оказываются полезными в серьезных
практических задачах. Как правило, простые алгоритмы дают хорошие резуль-
таты, если можно определить, какой должна быть искомая декомпозиция. Дву-
434
Часть IV. Компьютерное зрение: средний уровень
Рис. 14.9. На рисунке представлен каждый пятый кадр из 120-кадровой последовательности
снимков ребенка, играющего на узорчатом диване. Разрешение снимков — 80x60, причины такого
выбора объясняются при обсуждении рис. 14.11. Обратите внимание, что ребенок перемещается
по дивану
мя важными частными случаями являются вычитание фона, когда интерес
представляет все, что не выглядит как известный фон, и определение границ
кадров, когда искомым являются существенные изменения в видеорядах.
14.3.1. Вычитание фона
Довольно часто искомые объекты располагаются на относительно стабиль-
ном фоне. Характерные примеры: выявление деталей на конвейерной ленте;
подсчет автомобилей, проезжающих через определенный участок дороги (от-
носительно стабильный объект); взаимодействие человек-компьютер, где, как
правило, интерес для наблюдения представляет все, что не выглядит как ком-
ната.
В приложениях подобного рода полезную сегментацию часто можно полу-
чить, вычтя из изображения оцененный фон с последующим подробным изу-
чением остатка. Основной вопрос здесь — получение хорошей оценки фона.
Один из возможных подходов к решению данной задачи — извлечь из кадра
рисунок. Это не самый удачный подход, поскольку фон обычно со временем
меняется (хотя и медленно). Например, дорога может становиться более бле-
стящей во время дождя и менее блестящим — по мере высыхания; люди могут
переставлять книги (или мебель) в другое место комнаты и т.д.
Достаточно хорошо работающей альтернативой является оценка значения
пикселей фона с использованием скользящего среднего. При таком подхо-
де значение определенного пикселя фона оценивается как взвешенное среднее
Глава 14. Сегментация через кластеризацию
435
Рис. 14.10. Результат вычитания фона из снимков, представленных на рис. 14.9, с использованием
кадров 80 х 60. Сравнивается два метода определения фона: а) среднее по всем 120 кадрам (обра-
тите внимание, что на одном крае дивана ребенок провел больше времени, поэтому при усреднении
получено несколько размытое изображение); 6) пиксели, отличие которых от среднего превышает
некоторый порог; в) пиксели, отличие которых от среднего превышает меньший порог (обратите
внимание, что во всех случаях наблюдаются избыточные пиксели и недостающие пиксели); г) фон,
вычисленный с использованием несколько усложненного метода (кратко описан в разделе 16.2.5);
д) пиксели, которые считаются отличными от фона (снова имеем потерянные пиксели)
предыдущих значений. Как правило, далекие (по времени) пиксели учитывают-
ся с нулевыми весовыми коэффициентами, а по мере приближения к искомому
пикселю весовые коэффициенты плавно увеличиваются. В идеальном случае
скользящее среднее позволяет отслеживать изменения фона, т.е. если пого-
да меняется быстро (или книги перемещаются хаотически), нулевые весовые
коэффициенты будут иметь относительно немного пикселей, а если измене-
ния медленны, число давних пикселей с нулевыми весовыми коэффициентами
должно увеличиваться. В результате получаем алгоритм 14.1. Данный алго-
ритм можно назвать реализацией фильтра, сглаживающего функцию времени,
причем желательно, чтобы он подавлял частоты, превышающие характерные
частоты изменений фона, и пропускал все остальное. При описанном подхо-
де можно получить довольно удачные результаты, но он применим только для
изображений с достаточно грубым масштабом, как на рис. 14.10 и 14.11.
Алгоритм 14.1. Вычитание фона
Сформировать оценку фона В(о). Для каждого кадра Т7
Обновить оценку фона, например, построив —1
при подходящем выборе весовых коэффициентов wa, Wi и wc
Вычесть оценку фона из кадра, сообщить о значении каждого пикселя,
где величина отличия больше некоторого порога
конец
436
Часть IV. Компьютерное зрение: средний уровень
Рис. 14.11. При вычитании фона значительную сложность (особенно при наличии текстур) пред-
ставляет точное наложение. На рисунках изображены результаты, полученные для видеоряда
с рис. 14.9 при использовании кадров 160 х 120. Сравнивается два метода определения фона.
а) Среднее из всех 120 кадров; обратите внимание, что на одном краю дивана ребенок прово-
дит больше времени, в результате при усреднении изображение заметно размывается, б) Пиксели,
отличие которых от среднего превышает некоторый порог, в) Пиксели, отличие которых от сред-
него превышает меньший порог, г) Фон, определенный с использованием несколько усложненного
метода (кратко описанного в разделе 16.2.5). <Э) Пиксели, которые алгоритм счел отличными от фо-
на. Обратите внимание, что значительно возросло число “проблемных пикселей”, где узор дивана
ошибочно был соотнесен с объектом-ребенком. Это объясняется тем, что небольшое перемещение
может привести к значительному пространственному рассогласованию узора дивана, а это является
причиной появления больших разностей при определении расстояния
14.3.2. Определение границ кадров
Длительные видеоряды состоят из кадров — более коротких подрядов, на
которых в основном изображены одни объекты. Кадры — это обычно тот мате-
риал, с которым работают при монтаже, очень редко можно встретить видеоряд,
в котором отсутствуют границы между кадрами. Таким образом, видео удобно
представить именно как набор кадров; каждый кадр можно затем представить
ключевым кадром, а на основе последнего представления можно организовать
поиск нужного видео.
Автоматическое нахождение границ кадров — определение границ кад-
ров — это важная сфера практического приложения простых алгоритмов
сегментации. Искомым является алгоритм, находящий видеокадры, которые
значительно отличаются от предыдущих. При определении “значительности”
в данном контексте следует учитывать, что в пределах данного кадра угол
наблюдения и объектов, и фона может сильно меняться. Как правило, в таких
случаях используется сравнение с порогом: граница кадров считается найден-
ной, если некоторая мера (“расстояние”) превышает определенный порог (см.
алгоритм 14.2).
Глава 14. Сегментация через кластеризацию
437
Алгоритм 14.2. Определение границ кадров с помощью различий между кадрами
Для каждого кадра видеоряда
Вычислить расстояние между данным и предыдущим кадрами
Если расстояние превышает некоторый порог, считать кадр граничным
конец
Для определения “расстояния” между кадрами используются различные ме-
тоды. Некоторые из них описаны ниже.
• В алгоритмах вычитания кадров по значениям пикселей определяется
отличие каждых двух кадров видеоряда и сумма квадратов разностей
пикселей. Эти алгоритмы не очень популярны: для получения результата
нужно посчитать множество разностей, а если камера, дающая изображе-
ния, несколько дрожит, будет получено довольно большое число кадров.
• В алгоритмах на основе гистограмм для каждого кадра вычисляются
цветовые гистограммы, после чего определяются разности между гисто-
граммами. Разность цветовых гистограмм — это удобная мера, поскольку
она нечувствительна к пространственному распределению цветов в кадре
(например, на гистограмму не повлияет небольшая дрожь камеры).
• В алгоритмах блочного сравнения кадры сравниваются путем разреза-
ния на квадратную сетку с последующим сравнением квадратов. Это де-
лается для того, чтобы избежать сложностей, характерных для цветовых
гистограмм, когда красный объект, исчезнувший из поля зрения в ле-
вом нижнем углу, сопоставляется с красным объектом, вошедшим в кадр
сверху. Как правило, в подобных алгоритмах блочного сравнения опре-
деляется межкадровое расстояние, которое представляет собой функцию
(например, максимальное значение) расстояний между блоками, каждое
из которых вычислено с помощью методов, подобных тем, что применя-
ются для расчета расстояния между кадрами.
• В алгоритмах вычитания краев для каждого кадра определяется карта
краев. Как правило, сравнение — это подсчет числа потенциально соот-
ветствующих краев (соседство, подобная ориентация и т.д.) в следующем
кадре. Если потенциально соответствующих краев мало — имеем грани-
цу кадров. Расстояние в данном случае можно определить через число
соответствующих краев.
Все перечисленные методы являются специальными, т.е. они применимы
для частных случаев, но при наличии конкретной задачи какой-то из них обыч-
но дает довольно хорошие результаты.
438
Часть IV. Компьютерное зрение: средний уровень
14.4. СЕГМЕНТАЦИЯ ИЗОБРАЖЕНИЯ ЧЕРЕЗ КЛАСТЕРИЗАЦИЮ
ПИКСЕЛЕЙ
Кластеризация — это процесс замены набора данных кластерами, которые
представляют собой множества связанных информационных точек. Действи-
тельно, сегментацию изображения естественно представлять как кластериза-
цию (далее изображение будет представляться как набор кластеров связанных
пикселей). Конкретный критерий, согласно которому производится кластериза-
ция, будет зависеть от поставленной задачи. Пиксели могут связываться из-за
общего цвета, текстуры, из-за того, что они находятся рядом и т.д.
14.4.1. Сегментация с использованием простых методов
кластеризации
Выбрать метод кластеризации и на его основе построить и реализовать
алгоритм сегментации довольно просто. Большая часть литературы по сегмен-
тации изображений — это работы по кластеризации (хотя об этом не всегда
говорится прямо).
Простые методы кластеризации
Существует два естественных алгоритма кластеризации. При разделитель-
ной кластеризации имеющийся набор данных трактуется как кластер, кото-
рый рекурсивно расщепляется на меньшие кластеры (алгоритм 14.3). При аг-
ломеративиой кластеризации кластером считается каждый элемент данных,
а для получения лучшего представления кластеры рекурсивно сливаются (ал-
горитм 14.4).
При рассмотрении кластеризации важны два вопроса.
• Какое расстояние между кластерами? При агломеративной кластериза-
ции для слияния близлежащих кластеров используется расстояние между
кластерами; при разделительной кластеризации это же расстояние ис-
пользуется для разделения недостаточно когерентных кластеров. Даже
если известно естественное расстояние между информационными точка-
ми (что далеко не всегда справедливо для задач компьютерного зрения),
канонического определения расстояния между кластерами не существует.
В общем случае, расстояние выбирается на основе изучения набора дан-
ных. Например, в качестве расстояния между кластерами можно выбрать
расстояние между ближайшими элементами — для такого подхода харак-
терны протяженные кластеры (в статистике этот метод называется одно-
связной кластеризацией). Другой естественный выбор — максимальное
расстояние между элементом первого кластера и элементом второго — для
такого подхода характерны округлые кластеры (в статистике этот метод
называется полносвязная кластеризация). Наконец, можно использовать
среднее из расстояний между элементами кластеров — при таком подходе
также появляются “округлые” кластеры (в статистике этот метод называ-
ется кластеризация через среднее по группе).
Глава 14. Сегментация через кластеризацию
439
• Сколько кластеров? В действительности, при отсутствии модели генера-
ции кластеров провести этот процесс довольно трудно. Описанные выше
алгоритмы генерируют иерархию кластеров. Как правило, данная иерархия
предоставляется пользователю в форме древовидной схемы — структуры
в виде иерархии кластеров, которая отображает расстояние между класте-
рами, — и соответствующий выбор кластеров делается именно по такой
схеме (см. пример на рис. 14.12).
Алгоритм 14.3. Агломеративная кластеризация через слияние
Каждую точку считать отдельным кластером
Пока кластеризация не будет признана удачной
Объединить два кластера с наименьшим расстоянием между кластерами
конец
Алгоритм 14.4. Разделительная кластеризация, или кластеризация через рас-
щепление
Построить один кластер, содержащий все точки
Пока кластеризация не будет признана удачной
Расщепить кластер, если в результате получится два компонента с
наибольшим расстоянием между кластерами
конец
Реализация алгоритмов сегментации с использованием методов
кластеризации
Используемое “расстояние” зависит исключительно от конкретной задачи,
но довольно часто в качестве “расстояния” выбирается мера отличия цвета и ме-
ра отличия текстуры. Часто желательными являются пятнообразные кластеры;
в этом случае в качестве “расстояния” можно взять отличие пространственного
положения.
Основная сложность при прямом использовании агломеративной или разде-
лительной кластеризации заключается в том, что на изображении присутствует
огромное число пикселей. Разумного пути исследования древовидной схемы не
существует, поскольку из-за избытка данных анализ в любом случае потребует
недопустимо большого времени.
На практике сказанное означает, что реализация алгоритмов сегментации
включает набор пороговых проверок; например, слияние при агломеративной
кластеризации может прекращаться, когда расстояние между кластерами ста-
новится достаточно малым или когда количество кластеров достигает некото-
рого предопределенного значения.
440
Часть IV. Компьютерное зрение: средний уровень
Рис. 14.12. Слева — набор данных; справа — древовидная схема, полученная при агломеративной
односвязной кластеризации. Выбору определенного значения расстояния на диаграмме соответ-
ствует горизонтальная линия, расщепляющая схему на кластеры. Данное представление позволяет
предположить количество и качество кластеров
Другая сложность, следующая из большого числа пикселей, состоит в том,
что поиск наилучшего расщепления кластера (для схемы разделения) или наи-
лучшего слияния кластеров (для агломеративной схемы) непрактичен. Методы
разделения обычно модифицируются и для получения хорошего расщепления
используется некоторое обобщение кластера. Естественное обобщение можно
получить на основе гистограмм цветов пикселей (или уровней яркости).
Агломеративные методы также нуждаются в модификации. Во-первых,
большое число пикселей означает, что нужно аккуратно обращаться с расстоя-
нием между кластерами (часто используется расстояние между центрами масс
кластеров). Во-вторых, сливаются обычно только кластеры с общими граница-
ми (не хотелось бы получить представление флага США в виде трех класте-
ров — красного, белого и синего). Наконец, может быть полезно объединить
области, просто прочитав изображение и объединив все пары, расстояние меж-
ду которыми меньше определенного порога, вместо того, чтобы искать пару
кластеров, расположенных на наименьшем расстоянии.
14.4.2. Кластеризация и сегментация через К-средние
В простых методах кластеризации для постепенного получения хорошего
общего представления используются поглощающие взаимодействия с существу-
ющими кластерами. Например, при агломеративной кластеризации постоянно
Глава 14. Сегментация через кластеризацию
441
выполняется наилучшее (из доступных) слияние. В то же время данные мето-
ды нельзя назвать явными относительно целевой функции, которую пытаются
оптимизировать. Альтернативный подход — записать целевую функцию, кото-
рая выражает, насколько хорошим является представление, а затем построить
алгоритм получения наилучшего представления.
Естественную целевую функцию можно получить, предположив, что имеет-
ся к кластеров, где к — известное число. Предполагается, что у каждого класте-
ра есть центр; центр г-го кластера обозначается с». Элементу, подлежащий кла-
стеризации, описывается характеристическим вектором Xj. Например, если сег-
ментируются рассеянные точки, х — это координаты точек; если сегментирует-
ся распределение яркости, в качестве х может использоваться яркость пикселя.
Предположим, что элементы находятся близко к центрам кластеров, и за-
пишем целевую функцию:
Ф(кластеры, данные) = (xj — d)T(xj — Ci) ►.
г € кластеры j € i-й кластер
Обратите внимание, что если известно соотнесение точек с кластерами, лег-
ко вычислить наилучший центр каждого кластера. В то же время имеется
слишком большое число возможных группировок точек в кластеры, чтобы це-
лесообразно искать в этом пространстве минимум. Взамен определим алгоритм,
в котором будут итеративно повторяться такие два действия:
• предположим, что центры кластеров известны и отнесем каждую точку к
центру ближайшего кластера;
• предположим, что известно распределение точек по кластерам, и вычис-
лим новый набор центров кластеров; каждый центр — это среднее точек,
отнесенных к данному кластеру.
Для начала произвольным образом выбираем центры кластеров, а затем итера-
тивно повторяем описанные выше этапы. Со временем данный процесс сойдется
к локальному минимуму целевой функции (на каждом этапе значение функ-
ции не меняется или уменьшается, плюс она ограничена снизу). Сходимость
к глобальному минимуму не гарантируется. Кроме того, не обязательно по-
лучится к кластеров, если специально не оговорить, что каждый кластер
должен содержать ненулевое число точек. Данный алгоритм обычно называет-
ся схемой к-средних. Применяя схему fc-средних при различных значениях к
и сравнивая результаты, можно найти подходящее число кластеров (подробнее
этот вопрос обсуждается в разделе 16.3).
Одна из трудностей описанного подхода к сегментации изображений за-
ключается в том, что сегменты не соединены и могут быть существенно рас-
сеянными (рис. 14.13 и 14.14). С этим можно бороться, используя координаты
пикселей как элементы топологии, в результате чего получим раздробленные
большие области (рис. 14.15).
442
Часть IV. Компьютерное зрение: средний уровень
Рис. 14.13. Слева изображены различные овощи, в центре и справа показан результат сегмен-
тации по схеме fc-средних. Каждый пиксель был заменен средним значением соответствующего
кластера; результат несколько похож на тот, что ожидается при адаптивной дискретизации.
В центре показана сегментация, полученная с использованием только информации об интенсив-
ности. Справа сегментация получена с использованием информации о цвете. В каждом случае
предполагалось наличие пяти кластеров
*
Рис. 14.14. Изображение овощей, сегментированных с использованием схемы fc-средних в пред-
положении о наличии 11 компонентов. Слева все сегменты показаны вместе, первоначальные
значения заменены средними. На других рисунках показаны четыре сегмента. Отметим, что
при таком подходе не обязательно получаются связанные сегменты. Для данного изображения
некоторые сегменты действительно довольно близко соотнесены с объектами, но один сегмент
может представлять несколько объектов (перцы); другие могут быть бессмысленными. Отсутствие
текстурной меры создает серьезные трудности — например, из ломтика краснокочанной капусты
получается множество различных сегментов
Рис. 14.15. Пять сегментов, полученных при сегментации изображения овощей посредством
алгоритма на основе схемы fc-средних, в котором в качестве элемента характеристического вектора,
описывающего пиксели, использовались положения пикселей. В данном случае используется уже
не 11 сегментов, а 20. Отметим, что большие фоновые области, которые должны быть когерент-
ными, были разбиты на составляющие, поскольку точки этих областей находятся слишком далеко
от центров кластеров. Отдельные перчинки теперь сгруппированы удачнее, но краснокочанная
капуста по-прежнему разбита на составляющие, поскольку отсутствует текстурная мера
Глава 14. Сегментация через кластеризацию
443
Алгоритм 14.5. Кластеризация через /с-средние
Выбрать к информационных точек в качестве центров кластеров
Пока не прекратится изменение центров кластеров
Соотнести каждую информационную точку с кластером, расстояние до
центра которого минимально
Убедиться, что каждый кластер содержит хотя бы одну точку
Для этого каждый пустой кластер можно дополнить случайной точкой,
расположенной далеко от центра кластера
Центр каждого кластера заменить средним от элементов кластера
конец
14.5. СЕГМЕНТАЦИЯ ЧЕРЕЗ ТЕОРЕТИКО-ГРАФОВУЮ
КЛАСТЕРИЗАЦИЮ
Кластеризацию можно рассматривать как задачу расчленения графов на
удобные части. По сути, каждый элемент данных соотносится с вершиной
взвешенного графа, где весовые коэффициенты ребер графа между элемен-
тами велики, если элементы подобны, и малы — в противном случае. Далее
граф необходимо разрезать на связанные компоненты с относительно больши-
ми внутренними весовыми коэффициентами (компоненты соответствуют кла-
стерам), вырезая для этого ребра с относительно малыми весовыми коэффици-
ентами. Данный подход реализован в нескольких довольно удачных алгоритмах
сегментации.
14.5.1. Терминология теории графов
Ниже приводится краткий обзор терминологии теории графов.
• Граф — это совокупность вершин V и ребер Е, соединяющих различ-
ные пары вершин. Граф можно записать как G = {V, Е}. Каждое ребро
графа можно представить парой вершин, т.е. Е С V х V. Графы часто
изображаются как множества точек и соединяющих их кривых.
• Ориентированным называется граф, ребра которого (а, Ь) и (6, а) раз-
личны; при изображении такого графа используются стрелочки-указатели
направления.
• Неориентированным называется граф, ребра (а, Ь) и (6, а) которого не
отличаются.
• Взвешенным называется граф, с каждым ребром которого соотнесен ве-
совой коэффициент.
444
Часть IV. Компьютерное зрение: средний уровень
• Петля — это ребро, начальная и конечная вершины которого совпадают;
в практических задачах, характерных для компьютерного зрения, петли
не встречаются.
• Две вершины называются связанными, если существует последователь-
ность ребер, которая начинается в одной вершине и заканчивается в дру-
гой; если граф ориентированный, обход вершин должен совершаться по
стрелкам.
• Связным называется граф, каждая пара вершин которого связана.
• Любой граф состоит из множества непересекающихся связных компонен-
тов — т.е. G = {Vi U V2.. .Vn, Ei и Е2... Еп}, где — связные
графы, причем для i j в Е не существует ребра, соединяющего элемент
множества V» с элементом множества Vj.
14.5.2. Общая схема
Взвешенный граф можно представить квадратной матрицей (рис. 14.16).
Каждой вершине соответствует пара (строка, столбец). Элемент (i, j) матрицы
представляет весовой коэффициент ребра из вершины i к вершине j; для неори-
ентированного графа используется симметричная матрица, причем элементы
(г, j) и (j, г) равны половинам соответствующего весового коэффициента.
Как графы применяются при кластеризации? Каждый элемент набора, ко-
торый предполагается разбить на кластеры, соотносится с вершиной графа.
Далее между всеми парами вершин строятся ребра, с каждым ребром соотно-
сится весовой коэффициент, который представляет степень сходства элементов.
Затем ребра графа разрезаются так, чтобы в результате получился хороший на-
бор связанных компонентов, в идеальном случае весовые коэффициенты ребер
внутри компонентов должны быть велики по сравнению с коэффициентами
связующих ребер. Каждый компонент — это кластер. Например, на рис. 14.17
показан набор удачно разделенных точек и матрица весовых коэффициентов
(т.е. неориентированный взвешенный граф, только иначе изображенный), по-
лученные в результате сравнения сходства; хороший алгоритм покажет, что
матрица весьма близка к блочно-диагональной (поскольку сходство элементов,
принадлежащих к различным кластерам, мало), и расщепит ее на две матрицы,
каждая из которых будет представлять собой блок исходной. Важными направ-
лениями исследования здесь являются поиск критериев, позволяющих опреде-
лить хорошо связанные компоненты, и разработка алгоритмов формирования
этих связанных компонентов.
14.5.3. Меры сходства
Если сегментацию рассматривать только как кластеризацию, требуется
несколько упростить измерение сходства кластеров. В данной модели сегмен-
тации просто нужно соотнести с каждым ребром графа весовой коэффициент;
в литературе эти весовые коэффициенты обычно называются мерами сход-
ства. Очевидно, что мера сходства зависит от поставленной задачи. Весовой
Глава 14. Сегментация через кластеризацию
445
Рис. 14.16. Слева вверху изображен неориентированный взвешенный граф; справа вверху пред-
ставлена матрица весовых коэффициентов, соотнесенная с графом (большие значения изображены
более светлыми). Сопоставляя в различном порядке вершины со строками (и столбцами), можно
получать различные матрицы (отличающиеся перестановкой элементов). В изображенном случае
нумерация вершин выбрана так, чтобы была лучше видна структура матрицы, близкая к блочно-
диагональной. Внизу показано, как граф можно разделить на два тесно связанных компонента.
При таком разбиении матрица графа разделяется по диагонали на два основных блока
коэффициент ребра графа, соединяющего две подобных вершины, должен быть
большим, а весовой коэффициент ребра, соединяющего различные вершины,
должен быть малым.
Измерение сходства через расстояние
После некоторого порогового расстояния сходство должно довольно быстро
падать. Данное соображение можно записать в следующей удобной математи-
ческой форме:
aff(a?,|/) = ехр{ — ((х-у)\х — з/)/2сга)} ,
где ad — параметр, значение которого велико, если достаточно удаленные од-
на от другой точки можно сгруппировать вместе, и мало, если сгруппировать
446
Часть IV. Компьютерное зрение: средний уровень
2>5|—I—I—I—I—I—I—I—I—I—
2- • . / . -
1,5 - •
1 .
• •
0,5 - * ,
01--|---1-]-----1-1---1-1-----1---1-
0,2 0,4 0,6 0,8 1 1,2 1,4 1,6 1,8 2 2,2
Рис. 14.17. Слева изображен набор точек на плоскости. Справа — матрица сходства для этих
точек, рассчитанная с использованием экспоненты, затухающей с расстоянием (раздел 14.5.3),
где большие значения изображены более светлыми, а малые — темными. Обратите внимание на
блочно-диагональную структуру матрицы: два недиагональных блока содержат элементы, близкие
к нулю. Диагональные блоки соответствуют внутренним связям двух наблюдаемых кластеров, а
недиагональные — связям между этими кластерами
можно только близлежащие точки (данное выражение было использовано при
получении рис. 14.17; обратите внимание, что результат сильно зависит от вы-
бора масштаба, как можно видеть на рис. 14.18).
Определение сходства через интенсивность
Сходство должно быть большим для подобных интенсивностей и меньше —
для разных. Как и выше, напрашивается запись этого утверждения в экспонен-
циальной форме:
aff(a,?/) = exp{- ((!(«) - 1(г/))‘(1(ж) -.
Сходство по цвету
Для построения значимой функции сходства по цвету нужна метрика цвета.
Здесь удобно использовать равномерное цветовое пространство и неудобно —
пространство RGB (причины должны быть очевидны; если это не так — верни-
тесь к разделу 6.3.2). Меру сходства удобно записать в виде
aff(a,3/) = exp {- (dist(c(ie), с(т/))2/2сг2)} ,
где Ci — цвет пикселя г.
Глава 14. Сегментация через кластеризацию
447
Рис. 14.18. Выбор масштаба определения сходства влияет на матрицу сходства. В верхней строке
указан набор данных, состоящий из четырех групп по 10 точек, которые получены из осесим-
метричного нормального распределения при четырех различных средних. Для этих точек средне-
квадратическое отклонение в каждом направлении равно 0,2. Во второй строке матрицы сходства
вычислены для того же набора, но при иных значениях ad. На рисунке слева ad = 0,1; на рисунке
в центре crd = 0,2; на рисунке справа crd = 1. При наиболее мелком масштабе сходство между все-
ми точками получается довольно слабым; при следующем масштабе в матрице сходства явно видны
четыре основных блока; при наиболее грубом масштабе количество блоков определить сложно
Сходство по текстуре
Сходство должно быть большим для подобных текстур и меньше — при
увеличении отличий. Применим набор фильтров и опишем текстуры
через выходы этих фильтров, что позволит охватить разнообразные масштабы
и ориентации. Теперь для большинства текстур выходы фильтров отличаются
в каждой точке текстуры (представьте шахматную доску), но гистограмма выхо-
дов фильтров, построенная по разумно сгруппированным соседям, будет иметь
довольно хорошее поведение. Напрашивается следующая схема: вначале в каж-
дой точке устанавливается локальный масштаб (возможно, для этого следует
рассмотреть энергию на выходе крупномасштабных фильтров), а затем вычис-
ляется гистограмма выходов фильтров по областям, которые определены этим
масштабом (возможно, по круговым областям с центрами в рассматриваемых
точках). Далее для этой гистограммы записываем h и используем экспоненци-
448
Часть IV. Компьютерное зрение: средний уровень
альное выражение
aff(x,j/) = ехр{— ((/(«) - - f .
14.5.4. Собственные векторы и сегментация
Предположим вначале, что имеется к элементов и с кластеров. Кластер
можно представить fc-компонентным вектором. Элементы могут сопоставляться
с кластерами посредством некоторых непрерывных весовых коэффициентов,
поскольку нужно получить определенное представление о семантике этих
весовых коэффициентов, но искомым является реализация следующего утвер-
ждения: если компонент в определенном векторе имеет малое значение, то
этот компонент слабо связан с кластером; если значение велико — компонент
сильно связан с кластером.
Извлечение одного хорошего кластера
“Хорошим” будем называть кластер, элементы которого, сильно связанные
с кластером, имеют большие перекрестные значения в матрице сходства. Запи-
шем матрицу, представляющую сходство элементов, как А, а вектор весовых
коэффициентов, связующих элементы с n-м кластером, как wn. В частности,
можно построить такую целевую функцию:
W^AWn.
Данная функция — это сумма членов вида
{связь элемента г с кластером п} х {сходство г и j} х
х {связь элемента j с кластером п}.
Кластер можно получить, выбрав набор весовых коэффициентов связей, кото-
рый максимизирует целевую функцию. Сама по себе целевая функция беспо-
лезна, поскольку при изменении масштаба wn в А раз масштаб связи изме-
няется в А2 раз. Впрочем, весовые коэффициенты можно нормировать, поло-
жив w^wn = 1.
Таким образом, можно максимизировать w„Awn относительно w^wn = 1.
Лагранжиан записывается в следующей форме:
WnAwn + A (w^wn -- 1
(где А — множитель Лагранжа). Дифференцируя, получаем следующее:
Awn = Awn
Глава 14. Сегментация через кластеризацию
449
Это означает, что wn — собственный вектор матрицы А. Отсюда следует, что
кластер можно сформировать, найдя собственный вектор, отвечающий наиболь-
шему собственному значению (весовые коэффициенты кластера — это элемен-
ты собственного вектора). Для задач, в которых ожидается получить разумные
кластеры, данные весовые коэффициенты кластеров должны быть большими
для элементов, принадлежащих кластеру, и близкими к нулю для остальных
элементов (рис. 14.19). Фактически, весовые коэффициенты других кластеров
можно получить, найдя другие собственные векторы матрицы А.
Извлечение весовых коэффициентов для набора кластеров
В типичных задачах компьютерного зрения весовые коэффициенты, указы-
вающие на сильную связь, обнаруживаются для относительно малого числа
пар элементов. В реальных ситуациях разумно ожидать, что кластеры будут
довольно компактными и различными.
Изучая данные свойства, получаем напрашивающуюся характеристическую
структуру матрицы сходства. В частности, перенумеруем узлы графа, чтобы
перемешать строки и столбцы матрицы А. Ожидается, что число наборов узлов
с сильными внутренними связями будет малым. Более того, ожидается, что эти
наборы в действительности формируют ряд относительно когерентных, несов-
местимых кластеров. Это означает, что строки и столбцы М можно переупо-
рядочить и получить матрицу, приблизительно имеющую блочно-диагональную
форму (блоки соответствуют кластерам). Переупорядочение матрицы М при-
водит к простой перестановке элементов ее собственных векторов, так что ис-
следовать собственные векторы можно на основе переупорядоченной версии
матрицы М (см. рис. 14.16).
Собственные векторы блочно-диагональных матриц — это совокупность соб-
ственных векторов блоков, причем недостающие элементы векторов — ну-
ли. Ожидается, что каждый блок будет иметь собственный вектор, соответ-
ствующий относительно большому собственному значению (кластер), и набору
небольших собственных значений, не представляющих особого практического
интереса. Из сказанного следует, что если имеется с явно выраженных класте-
ров (где с < к), кластеры представляют собственные векторы, соответствую-
щие с наибольшим собственным значениям.
Сказанное означает, что каждый из этих собственных векторов — это соб-
ственный вектор блока, дополненного нулями. В частности, типичный собствен-
ный вектор содержит несколько больших значений (соответствующих его бло-
ку) и набор значений, близких к нулю. Ожидается, что только один из данных
собственных векторов имеет большое значение любого компонента; все осталь-
ные будут малыми (рис. 14.20). Таким образом, собственные векторы, соот-
ветствующие с собственным значениям с наибольшими амплитудами, можно
интерпретировать как весовые коэффициенты первых с кластеров. Для получе-
ния дискретных кластеров весовые коэффициенты кластеров обычно полагают
равными нулю или единице; именно такой подход использован на представлен-
ных рисунках.
450
Часть IV. Компьютерное зрение: средний уровень
Рис. 14.19. Собственный вектор, соответствующий наибольшему собственному значению матрицы
сходства для набора данных с рис. 14.18 (crd = 0,2). Обратите внимание, что большинство
значений малы, но имеются и большие (соответствующие элементам основного кластера). Знак
связи значения не имеет, поскольку масштабированный собственный вектор также является
собственным вектором
Рис. 14.20. Три собственных вектора, соответствующих следующим трем наибольшим собствен-
ным значениям матрицы сходства для набора данных с рис. 14.18 (ста = 0,2). Собственный вектор,
соответствующий наибольшему значению, представлен на рис. 14.19. Обратите внимание, что боль-
шинство значений мало, но для непересекающихся множеств элементов соответствующие значения
велики — это следствие блочной структуры матрицы сходства. Знак связи значения не имеет,
поскольку масштабированный собственный вектор также является собственным вектором
Глава 14. Сегментация через кластеризацию
451
Данный аргумент является качественным и существуют графы, для которых
он звучит откровенно сомнительно. Более того, неизвестно, как определить с,
хотя из приведенных соображений следует, что результат можно получить из
изучения спектра матрицы А: можно надеяться обнаружить небольшой набор
больших собственных значений и большой набор малых собственных значений
(рис. 14.21).
Алгоритм 14.6. Кластеризация посредством собственных векторов графа
Построить матрицу подобия
Вычислить собственные значения и собственные векторы матрицы сходства
Пока не будет получено достаточное число кластеров
Взять собственный вектор, соответствующий наибольшему необработанному
собственному значению; положить равными нулю все компоненты,
соответствующие элементам, уже соотнесенным с кластерами, и
сравнить оставшиеся компоненты с порогом, чтобы определить элементы,
принадлежащие данному кластеру (порог предопределен или выбирается
при кластеризации компонентов)
Кластеров достаточно, если рассмотрены все элементы
конец
14.5.5. Нормированные разрезы
Качественный аргумент, рассмотренный в предыдущем разделе, довольно
нечеток. Например, если собственные значения блоков подобны, в результа-
те можно получить собственные векторы, которые не позволяют расщепить
изображение на кластеры, поскольку любая линейная комбинация собствен-
ных векторов с одним собственным значением также является собственным
вектором (рис. 14.22).
Альтернативный подход — разрезать граф на два связанных компонента так,
чтобы в каждой группе стоимость разрезания была мала по сравнению с общим
сходством. Этот подход можно формализировать, разделив взвешенный граф V
на два компонента А и В и записав декомпозицию графа как
cut (А, В) cut(A, В)
assoc(A, V) assoc(B, V) ’
где cut(A, В) — сумма весовых коэффициентов всех ребер графа V, один конец
которых лежит в А, а другой — в В\ assoc(A, V) — сумма весовых коэффициен-
тов всех ребер, один конец которых находится в А. Данный параметр мал, если
при разрезании получаются два компонента, имеющих между собой мало ребер
с малыми весовыми коэффициентами и много внутренних ребер с большими
весовыми коэффициентами. Хотелось бы найти разрез с минимальным значени-
452
Часть IV. Компьютерное зрение: средний уровень
Рис. 14.21. Число кластеров отражено в собственных значениях матрицы сходства. На рисунке по-
казаны собственные значения матрицы сходства для каждой ситуации, изображенной на рис. 14.18.
Слева <7d = 0,1; в центре ал = 0,2; справа ал = 1. При наиболее мелком масштабе наблюдается
довольно много больших собственных значений, поскольку сходство всех точек мало. При боль-
шем масштабе наблюдается четыре собственных значения, которые заметно больше остальных. При
наиболее грубом масштабе заметно выделяются только два собственных значения
ем выбранного параметра, именуемый нормированным разрезом. Отметим, что
данный критерий неплохо зарекомендовал себя на практике (рис. 14.23 и 14.24).
Запишем у — вектор элементов узлов графа, значения которых равны
либо 1, либо —Ь. Значения вектора у используются для различения компонен-
тов графа: если г-й компонент вектора у — 1, соответствующий узел графа
принадлежит одному компоненту; если компонент равен —Ъ, узел принадлежит
другому компоненту. Запишем матрицу сходства как А и обозначим через Т>
матрицу степени, каждый диагональный элемент которой является суммой
весовых коэффициентов, связанных с соответствующим узлом:
Du =
3
а недиагональные элементы матрицы D равны нулю. При такой записи предло-
женный критерий можно переформулировать в таком виде:
уТ(Т> - А)у
yTDy
Теперь найдем вектор у, минимизирующий данную величину. Полученная зада-
ча относится к области целочисленного программирования. Поскольку данная
задача эквивалентна задаче разрезания графа, она ничуть не легче. Сложность
здесь представляют дискретные значения элементов вектора у — в принципе за-
дачу можно решить, перебрав все возможные векторы у, но это включает поиск
в пространстве, размер которого экспоненциально растет с увеличением числа
пикселей, поэтому поиск может быть чрезвычайно медленным. Данную задачу
обычно решают в следующем приближении: вычисляется минимизирующий
требуемую величину вещественный вектор у, элементы которого относятся к
Глава 14. Сегментация через кластеризацию
453
Рис. 14.22. Собственные векторы матрицы сходства могут порождать неверные предположения
относительно кластеров. Набор данных на рисунке слева вверху состоит из четырех копий
одного набора точек; поэтому в матрице сходства, изображенной вверху в центре, наблюдается
повторяющаяся блочная структура. Спектры блоков одинаковы, в результате получаем спектр
матрицы сходства, который представлен (приблизительно) четырьмя копиями одного собственного
значения (справа вверху). В нижней строке показаны собственные векторы, соответствующие
четырем наибольшим собственным значениям; обратите внимание, что а) при изучении значений
нельзя сделать предположение о кластерах, и б) линейная комбинация собственных векторов
позволяет провести достаточно удачную кластеризацию
тому или иному значению путем сравнения с порогом. Таким образом, имеем
два новых вопроса: получение вещественного вектора и выбор порога.
Получение вещественного вектора
Получить требуемый вектор довольно просто. Читателю предлагается в ка-
честве самостоятельного упражнения показать, что решение данной задачи
в вещественных числах аналогично решению уравнения
(V - А)у = XDy.
Остается решить один вопрос: какой из обобщенных собственных векторов
использовать. Наименьшее собственное значение почти наверняка равно нулю,
так что подходящим является собственный вектор, соответствующий второму
по величине собственному значению. Данный собственный вектор проще всего
определить, выполнив преобразование z = Т№у и получив
Р"1/2(Р - Д)7?-1/22 = Az,
454
Часть IV. Компьютерное зрение: средний уровень
Рис. 14.23. Изображения вверху сегментированы на показанные компоненты с использованием
схемы нормированного разреза. Меры сходства — интенсивность и текстура, как они описаны
в разделе 14.5.3. Изображение плавающего тигра дает такие сегменты: собственно тигр (относи-
тельно большой сегмент), трава и четыре сегмента, соответствующие озеру. Подобным образом,
перила представлены как три разумно когерентных сегмента. Отметим улучшение по сравнению
с сегментацией по схеме fc-средних, обусловленное наличием меры текстуры. Перепечатано из
I. Shi at al., ’’Image and video segmentation: the normalized cut framework”, Proceedings IEEE
International Conference on Image Processing, 1998. © 1998 IEEE
Рис. 14.24. Вверху: два кадра видеоряда, на которых изображен движущийся человек. Внизу:
пространственно-временные сегменты, определенные с использованием нормированных разрезов,
и пространственно-временная функция сходства (см. раздел 14.5.3). Перепечатано из J. Shi and
I. Malik, “Normalized cuts and сегментация изображения", IEEE Trans. PAM12000. © 2000 IEEE
Глава 14. Сегментация через кластеризацию
455
после чего легко находится вектор у. Отметим, что решения поставленной за-
дачи также являются решениями уравнения
Mz = T>-1I2AD-1/2z = pz,
а матрица N иногда называется нормированной матрицей сходства.
Выбор порога
Поиск подходящего порога особых трудностей не вызывает. Пусть есть N
узлов графа, так что вектор у имеет N элементов и нужно найти не более N
различных величин. Если теперь записать ncut(y) для значения параметра
нормированного разреза при определенном пороговом значении v, получим не
более N + 1 значений ncut(v). Каждое из этих значений можно рассчитать
и выбрать порог, дающий наименьшее из них. Обратите внимание, что при
таком формализме естественно возникает рекурсия: каждый полученный ком-
понент графа является графом, который также можно расщепить. Отметим, что
на практике успешно используется более простой подход: при поиске кластеров
перебирают собственные значения в порядке уменьшения и ищут собственные
векторы, соответствующие меньшим собственным значениям.
14.6. ПРИМЕЧАНИЯ
Сегментация — это сложная тема, и литературы, освещающей данную тему,
написано немало. В качестве обзорных работ, представляющих в основном ис-
торический интерес, можно назвать [Fu and Mui, 1981], [Haralick and Shapiro,
1985], [Nevatia, 1986] и [Riseman and Arbib, 1977]. Более поздние обзоры ред-
ки — это, например, работа [Pal and Pal, 1993]. Одной из причин отсутствия
удачных обзорных публикаций можно назвать то, что производительность ал-
горитма сегментации трудно оценить на более высоком уровне, чем простой
разбор нескольких конкретных примеров (что сделано, например, в работах
[Hartley, Wang, Kitchen and Rosenfeld, 1982], [Ranade and Prewitt, 1980], [Yas-
noff, Mui and Bacus, 1977] и [Zhang, 1996].
Первый алгоритм сегментации через кластеризацию был предложен в пуб-
ликации [Ohlander, Price and Reddy, 1978]. Методы кластеризации разрабатыва-
ются с помощью разных подходов (помните, это не означает, что какой-то под-
ход неперспективен!), поскольку хорошей теоретической основы, позволяющей
предсказать, что и как следует разбивать на кластеры, пока еще не существу-
ет. Очевидно, что кластеры следует формировать так, как удобно в отдельно
взятом случае, но такое утверждение очень трудно формализовать. В данной
главе мы попытались, не вдаваясь в подробности, представить общую картину,
поскольку детальное изложение того, что было сделано в этой области, было
бы громоздким и запутанным.
В системах компьютерного зрения используются разнообразные методы, ос-
нованные на теории графов (см. [Sarker and Boyer, 1998], [Wu and Leahy, 1993];
456
Часть IV. Компьютерное зрение: средний уровень
краткое резюме по описанным методам представлено в работе [Weiss, 1999].
Формализм нормированного разреза изложен согласно публикациям [Shi and
Malik, 1997] и [Shi and Malik, 2000]. Разновидности этого метода применяют-
ся в задачах сегментации движения ([Shi and Malik, 1998а]) и вывода метрик
сходства ([Shi and Malik, 19986]). Возможны различные альтернативные крите-
рии (см., например, [Сох, Zhong and Rao, 1996], [Perona and Freeman, 1998]).
В данной главе основное внимание уделено методам кластеризации на основе
теории графов, поскольку они имеют привлекательную особенность: их можно
применять к любой функции сходства.
Сегментация — это еще одна ключевая открытая проблема в компьютерном
зрении (поэтому описание всех достижений в этой области было бы весьма
долгим). До недавнего времени распознавание и сегментацию не связывали
вместе. Такая точка зрения неразумна, поскольку в области сегментированного
представления крайне мало таких тем, изучение которых не помогло бы ре-
шить какие-то конкретные задачи. Более того, если удастся сформулировать,
что нужно распознать, это позволит определить, как будет выглядеть сегмен-
тированное представление.
Сегментация и группировка
О роли группировки в человеческом зрительном восприятии написано много.
Например, можно назвать учебники гештальта [Kanizha, 1979] и [Koffka, 1935].
Субъективные контуры впервые были описаны Канишей; большое итоговое об-
суждение этой темы представляет работа [Kanizha, 1976]. Авторитетная книга
[Palmer, 1999] охватывает данную тему значительно шире, чем можно было
сделать в данной главе. В публикации [Gordon, 1997] представлена обширная
информация, связанная с разработкой различных теорий зрения и истоками
постулатов гештальта. Некоторые из найденных групп нашли отражение в от-
носительно ранних алгоритмах распознавания ([Triesman, 1982]).
Перцептуальная группировка
При изучении сегментации иногда различаются перцептуальная (основан-
ная на восприятии) организация, которая рассматривается как кластеризация
токенов изображения в удобные группы, и собственно сегментация, которая
рассматривается как декомпозиция изображений на области. В данной кни-
ге такого разделения не проводится; преимущество рассмотрения этих задач
как проявлений одного процесса состоит в легкости переноса алгоритмических
находок с одной задачи на другую. В главе не были детально рассмотрены
некоторые аспекты перцептуальной организации в основном потому, что цель
заключалась в представлении общей единообразной картины, а не в соблюдении
исторической точности. Написано немало работ, где анализируется кластери-
зация угловых точек изображения или сегментов линий в конфигурации, воз-
никновение которых на практике маловероятно. Некоторые из перечисленных
идей рассмотрены в следующей главе, а для тех, кто заинтересовался данным
вопросом, рекомендуем работы [Amir and Lindenbaum, 1996], [Huttenlocher and
Глава 14. Сегментация через кластеризацию
457
Wayner, 1992], [Lowe, 1985], [Mohan and Nevatiam 1992], [Sarkar and Boyer,
1993] и [Sarkar and Boyer, 1994]. При построении интерфейсов пользователя
полезно будет знать, что является перцептуально значимым (см., например,
[Saund and Moran, 1995]).
ЗАДАЧИ
14.1. Требуется разбить на кластеры набор пикселей, используя отличия цвета
и текстуры. Целевая функция
Ф(кластеры, данные) = У^ < У~^ (х3 — а)т(х3с») ► ,
кластеры йкластер
которая использовалась в разделе 14.4.2, может быть неподходящей (на-
пример, отличия в цвете могут учитываться с чересчур большими весо-
выми коэффициентами, если цвет и текстура измеряются по различным
шкалам).
а) Расширьте описание алгоритма для схемы ^-средних, чтобы его мож-
но было использовать с целевой функцией такого вида:
Ф(кластеры, данные) = У^ < У^ (xj — Ci)TS(xj — с») >,
»€кластеры j'Ci-й кластер
где S — симметричная, положительно определенная матрица.
б) Для более простой целевой функции мы гарантировали, что каждый
кластер содержит по крайней мере один элемент (в противном случае
было бы невозможно вычислить центр кластера). Сколько элементов
должен содержать кластер при более сложной целевой функции?
в) Как отмечалось в разделе 14.4.2, не существует гарантии, что к-
средние дают глобальный минимум целевой функции; покажите, что
локальный минимум данный алгоритм должен давать в любом случае.
г) Покажите, как можно получить два локальных минимума при при-
менении схемы fc-средних для кластеризации информационных точек,
которые описываются двумерным характеристическим вектором. Для
простоты используйте пример только с двумя кластерами (большое
число точек вам не потребуется). Данное упражнение следует проде-
лать для обеих целевых функций.
14.2. Прочитайте работу [Shi and Malik, 2000] и изучите доказательство того
факта, что критерий нормированного разреза приводит к задаче целочис-
ленного программирования, представленной в тексте главы.
14.3. В данном упражнении исследуется использование нормированных разре-
зов для получения больше двух кластеров. Одна из возможных страте-
гий — строить для каждого нового компонента новый граф и рекурсивно
458 Часть IV. Компьютерное зрение: средний уровень
использовать алгоритм. Следует обратить внимание на сильное сходство
этого подхода с классическими алгоритмами разделительной кластериза-
ции. Другая стратегия — поиск собственных векторов, соответствующих
меньшим собственным значениям.
а) Объясните, почему данные стратегии неравнозначны.
б) Предположим, что имеется граф с двумя связанными компонентами.
Опишите собственный вектор, соответствующий наибольшему соб-
ственному значению.
в) Опишите собственный вектор, соответствующий второму по величине
собственному значению.
г) Используйте полученную информацию для защиты аргумента — при
определенных условиях две описанных стратегии будут давать до-
вольно сходные результаты. Назовите эти подходящие условия.
Упражнения
14.4. Постройте алгоритм вычитания фона, используя скользящее среднее
и эксперимент с фильтром.
14.5. Постройте систему определения границ кадров, используя две описанных
схемы, и сравните их производительность на различных видеорядах.
14.6. Реализуйте алгоритм сегментации с использованием /с-средних для фор-
мирования сегментов по сходству цвета и положения. Опишите, на что
будет влиять выбор числа сегментов, и исследуйте, как это скажется на
различных локальных минимумах.
15
Сегментация через подбор
модели
Можно сказать, что сегментация заключается в группировке пикселей (токены
и т.д.), соответствующих некоторой модели. Этот подход подобен кластериза-
ции; основное отличие — модель определена явно и в ней могут фигурировать
связи не только на уровне переходов между отдельными токенами, но и на
более высоком уровне. Например, представим программу, собирающую токены
в группы, которые “выглядят подобно” линии (в некотором смысле, на дан-
ном этапе точная формулировка не важна). Намеченное нельзя сделать, изучив
только попарные отношения между токенами; вместо этого нужно исследовать
некоторые свойства набора токенов, определяемые при выборе модели, а затем
Лринять какой-то критерий хорошего соответствия.
Альтернативный подход — собирать токены в кластеры, если при этом фор-
мируется знакомая геометрическая конфигурация; например, все они лежат на
прямой или окружности. Такой подход обычно называется подбором.
15.1. ПРЕОБРАЗОВАНИЕ ХОХА
При подборе прямой существует три проблемы. Во-первых, если есть точ-
ки, принадлежащие прямой, то что является прямой? Во-вторых, какие точки
460
Часть IV. Компьютерное зрение: средний уровень
Рис. 15.1. Преобразование Хоха сопоставляет каждой точке (токену) кривую возможных линий
(или других параметрических кривых), проходящих через эту точку. На рисунках иллюстрируется
преобразование Хоха для прямых. В левом столбце показаны точки, а в правом — соответствую-
щие аккумуляторные массивы (число голосов указано уровнем яркости, чем больше голосов — тем
ярче точка). В верхней строке показано, что произойдет, если применить метод к набору 20 точек,
полученных из прямой. На рисунке справа вверху приведен аккумуляторный массив для соответ-
ствующего преобразования Хоха. Каждой точке соответствует кривая голосов в аккумуляторном
массиве; наибольшее число голосов равно 20 (соответствует наиболее яркой точке). Горизонтальной
переменной в аккумуляторном массиве является 0, вертикальной — г; в каждом направлении рас-
смотрено 200 шагов, г принадлежит диапазону [0; 1,55]. На нижнем рисунке точки были смещены
на случайный вектор, каждый компонент которого равномерно распределен в диапазоне [0; 0,05];
видно, что при этом сдвигаются кривые, показанные в аккумуляторном массиве справа от точек;
теперь максимальное число голосов равно 6 (соответствует наиболее яркому значению на изобра-
жении; при том же масштабе, что и на верхнем изображении, рассмотреть такое значение непросто)
Глава 15. Сегментация через подбор модели
461
принадлежат каким прямым? И наконец, сколько должно быть прямых? Ре-
шение этих трех задач обещает преобразование Хоха (Hough transform) (хотя
на практике данное решение получается редко). Этот метод стоит разобрать,
поскольку он имеет достаточную общность и применяется во множестве прак-
тических задач.
Один из способов кластеризации точек, потенциально принадлежащих од-
ной структуре, запись всех структур, которым принадлежит каждая точка, с по-
следующим выбором структуры, получившей большее число голосов. Данный
(достаточно общий) метод называется преобразованием Хоха. Берется каждый
токен изображения и определяются все структуры, которые могут проходить
через этот токен. Полученный набор записывается (данный процесс можно
представить как подачу голосов) и процесс повторяется для каждого токена.
Решение принимается по мажоритарному принципу. Например, если группиру-
ются точки, принадлежащие прямым, берется каждая точка и считаются голо-
са, поданные за все линии, которые могут проходить через эту точку; процесс
повторяется для всех точек. Полученная линия (линии) должна проявиться оче-
видно, поскольку она проходит через множество точек, следовательно, получает
множество голосов.
15.1.1. Подбор линий с помощью преобразования Хоха
Преобразование Хоха дает наиболее удачные результаты при поиске линий.
Проиллюстрируем данный метод на примере, подчеркнув его недостатки. Обыч-
ная параметризация прямой как набора точек (х, у) выглядит так:
х cos 6 4- у sin в 4- г = 0.
Каждая пара (0, г) представляет уникальную прямую, где г > 0 — кратчайшее
расстояние от прямой до начала координат и 0 < 0 < 2тг. Набор пар (0,г)
называется пространством прямой; представить данное пространство мож-
но как полубесконечный цилиндр. Это семейство прямых, проходящих через
любой точечный токен. В частности, все прямые, которые лежат на некото-
рой кривой (расположенной в пространстве прямой, определяемой выражени-
ем г = —zocos# 4- yosinO), проходят через токен в точке (а?о, З/о)-
Поскольку размер изображения известен, имеется некоторое R, причем пря-
мые, для которых г > R, интереса не представляют — эти прямые слишком
далеки от начала координат, чтобы их можно было увидеть. Это означает, что
линии, представляющие практический интерес, формируют ограниченное под-
множество плоскости, которую можно дискретизовать с помощью некоторой
удобной сетки (что будет рассмотрено позже). Элементы сетки можно рассмат-
ривать как урну, в которую помещаются голоса. Данная сетка урн называется
аккумуляторным массивом. Каждый точечный токен добавляет голос каж-
дому элементу сетки, лежащему на кривой, соответствующей этому токену.
Если имеется много коллинеарных точечных токенов, следует ожидать, что за
462
Часть IV. Компьютерное зрение: средний уровень
элемент сетки, соответствующей прямой, на которой лежат эти коллинеарные
точки, будет отдано много голосов.
15.1.2. Практические сложности при использовании преобразования
Хоха
К сожалению, преобразованию Хоха сопутствуют несколько важных прак-
тических проблем.
• Ошибки квантования. Подходящий размер сетки подобрать трудно.
Слишком крупная сетка может привести к тому, что большое число го-
лосов будет ошибочно отдано урне, которой соответствует множество
довольно отличающихся линий. Слишком мелкая сетка может привести
к тому, что линии вообще не будут найдены, поскольку голоса, поданные
за не совсем коллинеарные токены, окажутся в разных урнах, и ни одна
урна не получит большого числа голосов (рис. 15.1).
• Влияние шума. Привлекательность преобразования Хоха заключается
в том, что оно связывает довольно отдаленные токены, которые располо-
жены близко к некоторой параметрической кривой. Это также является
и минусом: обычно при изучении большого набора токенов, распределен-
ных более менее равномерно, можно найти множество довольно хороших
фантомных линий (рис. 15.2). Это означает, что области текстуры могут
генерировать пики в массиве голосования, большие пиков, соотнесенных
с предполагаемыми линиями (рис. 15.3 и 15.4).
Преобразование Хоха все же стоит рассмотреть подробнее, поскольку
несмотря на недостатки, его часто можно удобно реализовать для некоторых
прикладных задач. Преобразование Хоха обычно используют для нахождения
линий по набору угловых точек. При реализации этой схемы стоит учесть
следующие рекомендации.
• Обеспечить минимум несущественных токенов. Это можно сделать,
если указать программе обнаружения углов сгладить текстуру и создать
высококонтрастные углы.
• Продуманно выбрать сетку. Для этого обычно используется метод проб
и ошибок. Может оказаться полезным проголосовать за всех соседей эле-
мента сетки одновременно с голосованием за элемент.
15.2. ПОДБОР ПРЯМЫХ
Подбор прямых крайне важен. Во многих ситуациях для объектов характер-
но наличие прямых линий. Например, может понадобиться построить модели
зданий по изображениям (см. разбор примера в главе 26). Здесь используются
Глава 15. Сегментация через подбор модели
463
1
0,8
0,6
0,4
0,2
0
Рис. 15.2. Преобразование Хоха для набора случайных точек может давать большие наборы голо-
сов в аккумуляторном массиве. Как и на рис. 15.1, слева показаны точки, а справа — соответству-
ющие аккумуляторные массивы (число голосов обозначено уровнем яркости, чем больше голосов —
тем ярче точка). В этом случае предоставленные точки — это шум (обе координаты равномерно
распределены в диапазоне [О; 1]); аккумуляторный массив теперь содержит большое число точек
перекрытия, а максимальное число голосов равно 4 (по сравнению с 6 на рис. 15.1). На рис. 15.3
и 15.4 показано еще несколько зашумленных изображений
8
о
5
0,08
0,09 0,1
0,02 0,03 0,04 0,05 0,06 0,07
Уровень шума
Рис. 15.3. Преобразование Хоха неустойчиво к присутствию шума. На графике показано
максимальное число голосов в аккумуляторном массиве для применения преобразования Хоха к
20 точкам прямой, возмущенных равномерно распределенным шумом в зависимости от амплитуды
шума. Шум смешивает кривые и быстро приводит к хаосу в аккумуляторном массиве. График
усреднен для 10 проб. Во всех рассмотренных случаях использовалось одно квантование
аккумуляторного массива
464
Часть IV. Компьютерное зрение: средний уровень
12
11
10
'20 40 60 80 100 120 140 160 180 200
Число шумовых точек
Рис. 15.4. График зависимости максимального числа голосов в аккумуляторном массиве от числа
точек для преобразования набора точек, координаты которых представляют собой случайные числа,
равномерно распределенные в диапазоне [0; 1]. По мере роста уровня шума число голосов в правой
урне уменьшается, а перспектива получения сильно ложного голоса в аккумуляторном массиве
растет. Графики усреднены по 10 пробам. Сравните данный рисунок с рис. 15.3 (учтите, что у них
разные масштабы); из сравнения видно, что при наличии шума получить линию с помощью пре-
образования Хоха может быть достаточно сложно (поскольку число голосов за линию может быть
сравнимо с числом голосов за линии, полученные вследствие шума). На рисунках иллюстрируется
важность максимального исключения шумовых токенов перед применением преобразования Хоха
многогранные модели зданий (на изображениях важны прямые линии). Подоб-
ным образом, многие промышленные объекты имеют ярко выраженные углы; ес-
ли требуется распознать такие объекты на изображении, также могут оказаться
полезными прямые линии. В любом случае сообщение обо всех прямых изобра-
жения — это крайне полезная сегментация изображения. Общий обзор прямых
представлен в разделе 3.2, ниже приводится разбор одного частного случая.
15.2.1. Подбор прямой по схеме наименьших квадратов
Предположим вначале, что все точки, принадлежащие определенной прямой,
известны, а найти требуется параметры прямой.
Чтобы упростить изложение введем обозначение
и к '
Схема наименьших квадратов
Схема наименьших квадратов — это процедура подбора, имеющая долгую
традицию (единственная причина, по которой эта схема описана в данной кни-
Глава 15. Сегментация через подбор модели
465
Рис. 15.5. Слева: в общей схеме наименьших квадратов информационные точки моделируются
как порожденные абстрактной точкой на прямой, к которой добавлен вектор, перпендикулярный
линии. Требуется выбрать линию, минимизирующую сумму расстояний к измеренным токенам по
перпендикулярам к прямой (что обычно и считают расстоянием!). Справа: в схеме наименьших
квадратов используется тот же общий подход, но предполагается, что ошибка появляется только
по координате у. В результате получаем (незначительно) более простую математическую задачу
за счет плохого подбора
ге!). Анализ с помощью схемы наименьших квадратов прост, но для него ха-
рактерна значительная систематическая ошибка.
Представим прямую как у = ах + Ь. В каждой информационной точке име-
ем (xi^yi\, задача — выбрать прямую, которая наилучшим образом предсказы-
вает измеренную координату у для каждой измеренной координаты х.
Сказанное означает, что выбирается линия, минимизирующая величину
^(yi - axi - Ь)2.
i
Преобразовывая выражение, получаем, что прямая определяется как решение
задачи
Получить требуемое решение довольно просто, но не стоит забывать, что при-
менимо к сфере компьютерного зрения данная модель является исключительно
плохой. Сложность заключается в том, что ошибка измерения зависит от си-
стемы координат — вертикальные отклонения от прямой считаются ошибками,
а это означает, что почти вертикальные линии будут давать довольно большие
ошибки и весьма неожиданные результаты подбора (рис. 15.5). Фактически,
процесс настолько зависит от системы координат, что он вообще не позволяет
представить вертикальные линии.
466
Часть IV. Компьютерное зрение: средний уровень
Общая схема наименьших квадратов
Можно работать с действительным расстоянием между точкой и прямой (а
не с расстоянием по вертикали). Это дает задачу общих наименьших квадра-
тов. Линию можно представить как набор точек, где ах+Ьу + с = 0. Так можно
представить каждую прямую, и вместо линии можно рассматривать тройку зна-
чений (а, Ь, с). Обратите внимание, что для А 0 линия, которая определяется
А(а, д, с), совпадает с линией, которая определена тройкой (а, д, с). В разде-
ле упражнений предлагается доказать простой, но крайне полезный результат:
расстояние по перпендикуляру от точки (u, v) до прямой (а,д,с) выражается
следующим образом:
abs(au 4- bv 4- с), если а2 4- b2 = 1.
По мнению авторов, данный факт настолько полезен, что его стоит запомнить.
Для минимизации суммы перпендикулярных расстояний между точками
и прямыми нужно минимизировать величину
y^(axj + byi 4-с)2,
i
где a2 4- Ь2 = 1 и с — некоторая нормированная константа, не представляющая
особого интереса. Таким образом, наиболее вероятное решение получается при
максимизации указанного выражения. Используя теперь множитель Лагран-
жа А, запишем
Это означает, что
с = —ах — by
и данное выражение можно подставить в предыдущее, в результате чего полу-
чится задача на собственные значения
х2 — х х
ху — х у
ху — х у
у2 — у у
I а
= р Ь
Поскольку это двумерная задача на собственные значения, можно с точностью
до масштаба аналитически получить два решения (на практике это обычно
делается численно). Правильный масштаб выбирается из условия а2 + b2 = 1.
Данные два решения — это прямые, пересекающиеся под прямым углом, одна
из которых минимизирует искомое выражение.
Глава 15. Сегментация через подбор модели 467
15.2.2. Какая точка принадлежит какой прямой
Данная задача может быть сложной, поскольку она включает поиск в боль-
шом комбинаторном пространстве. Один из подходов к решению — отметить,
что изолированные точки встречаются редко, поэтому линии можно подби-
рать по угловым точкам. Ориентацию угловой точки можно использовать как
подсказку о положении следующей точки линии. Если же будут встречаться
изолированные точки, можно применять схему Аг-средних.
Последовательный подбор
В алгоритмах последовательного подбора линий берутся связанные кри-
вые угловых точек и подбираются линии, идущие вдоль точек кривых. Связан-
ные кривые угловых точек довольно просто получить при обнаружении углов
(см. раздел упражнений). После этого программа последовательного подбора
начинает работу с одного края кривой угловых точек и проходит по кривой,
отсекая серии пикселей, хорошо совпадающих с линией (см. соответствующий
алгоритм 15.1). Последовательный подбор может давать хорошие результаты,
несмотря на отсутствие в его основе статистической модели. Одна из его ха-
рактерных особенностей состоит в том, что он выявляет группы прямых, фор-
мирующих замкнутые области. Данная особенность привлекательна, когда ра-
зумно ожидать, что интересующие нас линии формируют замкнутую кривую
(как, например, иногда бывает в задачах распознавания объектов), поскольку
это означает, что алгоритм сообщает об естественных группах, не требующих
дальнейшего уточнения. Данная стратегия часто приводит к тому, что пре-
гражденные углы дают несколько подобранных линий. С данной сложностью
можно бороться путем последующей обработки линий и нахождения (прибли-
зительно) совпадающих пар, но такой процесс не сильно привлекает, поскольку
сложно реализовать чувствительный критерий, на основе которого можно было
бы решить, когда две линии совпадают.
Сопоставление точек с линиями посредством схемы К-средних
Пусть точки не позволяют предположить, к каким линиям они принадлежат
(т.е. отсутствует информация о цвете и т.п., которую можно было бы исполь-
зовать; кроме того, точки не связаны). Можно попытаться определить, какие
точки принадлежат каким линиям, использовав модифицированную версию
схемы fc-средних. В этом случае модель описывается так: имеется к прямых,
каждая из которых генерирует некоторое подмножество данных точек; наи-
лучшее решение, связывающее точки и прямые, получается при минимизации
выражения
$2 52 dist(li,Xj)2
линии данные, отнесенные
К i-й ЛИНИН
по соответствиям и линиям. Как и выше, соответствий слишком много, чтобы
в этом пространстве целесообразно было проводить прямой поиск.
468
Часть IV. Компьютерное зрение: средний уровень
Для решения поставленной задачи можно использовать модифицированную
схему /г-средних. Получаем такие две фазы:
• соотнести каждую точку с ближайшей линией;
• подобрать наилучшую линию по точкам, соотнесенным с каждой линией.
В результате приходим к алгоритму 15.2. Сходимость можно проверить, изу-
чив масштаб изменений линий (пожалуй, наилучший тест) или рассмотрев
сумму перпендикулярных расстояний к точкам от соотнесенных с ними ли-
ний (дает приблизительно тот же результат, что и изучение логарифмического
правдоподобия).
Алгоритм 15.1. Последовательный подбор линий с помощью перемещения вдоль
кривой, сопоставления линии с сериями пикселей вдоль кривых и разбивания
кривой, если остаток слишком велик
Поместить все точки в список кривой в порядке от начала кривой к концу
Очистить список точек прямой
Очистить список прямых
Пока в кривой не останется слишком мало точек
Перевести несколько первых точек кривой в список точек линии
Подобрать линию по списку точек линии
Пока подобранная линия достаточно хороша
Перевести следующую точку кривой
в список точек линии и повторить процедуру подбора линии
конец
Вернуть оставшиеся точки кривой
Повторить процедуру подбора линии
Добавить линию в список линий
конец
Алгоритм 15.2. Подбор линий в схеме fc-средних как соотнесение точек с бли-
жайшими линиями и проведение в полученных наборах наилучших линий
Предположить, что имеется к линий (распределенных равномерно и случайно)
или
предположить, как прямые соотнесены с точками, а затем подобрать линии
Повторять до схождения
Сопоставить каждую точку с ближайшей линией
Повторить процедуры подбора линий
конец
Глава 15. Сегментация через подбор модели
469
ТАБЛИЦА 15.1. Некоторые неявные кривые, используемые в компьютерном зрении. Отметим,
что не все эти кривые гарантированно будут содержать действительные точки; например, кривая
я:2 + у2 + 1 = О не имеет действительных точек. Кривые более высоких степеней используются
редко, поскольку подобрать по точкам устойчивую такую кривую довольно сложно
Кривая Уравнение
Прямая ах 4- by -Г с = 0
Окружность с центром в точке (а, Ь) и радиусом г х2 + у2 — 2ах — 2Ьу + а2 + Ь2 — г2 = 0
Эллипсы (включая окружности) ах2 4- Ьху 4- су2 4- dx 4- еу 4- f = 0, где Ь2 — 4ас < 0
Гиперболы ах2 4- Ьху 4- су2 4- dx 4- еу 4- f = 0, где Ъ2 — 4ас > 0
Параболы ах2 4- Ьху 4- су2 4- dx 4- еу 4- f = 0, где Ь2 — 4ас = 0
Конические сечения общего вида ах2 4- Ьху 4- су2 4- dx 4- еу 4- f = 0
15.3. ПОДБОР КРИВЫХ
В принципе, подбор кривых подобен подбору прямых, поскольку так же ми-
нимизируется сумма квадратов расстояний между точками и кривой. Впрочем,
здесь возникают достаточно разнообразные практические проблемы: обычно до-
вольно трудно сказать, чему равно расстояние между точкой и кривой. Можно
либо решать данную задачу, либо использовать различные аппроксимации (так
обычно и поступают, причем потому, что это вычислительно просто, а не пото-
му, что аппроксимация описывается какой-то аналитической моделью). Опишем
схематически несколько методов определения расстояния для двух основных
представлений кривых.
15.3.1 . Неявные кривые
Координаты неявных кривых удовлетворяют некоторому параметрическому
уравнению; если это уравнение полиномиальное, кривая называется алгебра-
ической, причем данный случай наиболее распространен. Некоторые общие
примеры неявных кривых приведены в табл. 15.1.
470
Часть IV. Компьютерное зрение: средний уровень
Расстояние от точки до неявной кривой
Определим расстояние от данной точки до ближайшей точки на неявной
кривой. Предположим, что кривая задана в виде ф(х, у) — 0. Вектор от ближай-
шей точки неявной кривой до данной точки — это нормаль к кривой, так что
для определения ближайшей точки необходимо рассмотреть все точки (u,v),
которые имеют следующие свойства:
1. (u,v) — точка кривой; это означает, что ф(и, v) = 0;
2. з — (dx,dy) — (it, v) — нормаль к кривой.
Как только найдены все з, удовлетворяющие названным условиям, расстоянием
от данной точки до кривой считается длина наименьшего такого вектора.
Второе условие требует определения нормали. Нормаль к неявной кривой —
это направление, в котором кривая покидается максимально быстро. Вдоль дан-
ного направления значение ф должно меняться максимально быстро. Это озна-
чает, что нормаль в точке (и, v) — это величина
дф дф\
дх' ду)
определенная в точке (и, v). Если касательной к кривой является вектор Т, то
должно получиться Т.з = 0. Поскольку рассматривается двумерное простран-
ство, касательную в точке (it, v) можно определить по нормали:
ф(и, v; dx, dy) = ^(u, v) {dx — u} — ^~(п’г') — «} = 0.
Теперь имеем два уравнения для двух неизвестных, которые теоретически
можно решить. Впрочем, обычно они не настолько просты, как выглядят на
первый взгляд (см. пример 15.1).
Пример 15.1. Расстояние между точкой и коническим сечением
Коническое сечение определяется уравнением ах2 4- Ьху 4- су2 4- dx 4- еу 4- f = 0.
Для данной точки (dx,dy) ближайшая точка кривой удовлетворяет следующим
двум уравнениям:
аи2 4- buv 4- си2 4- du 4- ev 4- f = 0
и
2(a — c)uv — (2ady 4- e)u 4- (2cdx 4- d)v 4- (edx — ddy) = 0.
Представленная выше пара уравнений может иметь до четырех действительных
решений (в разделе упражнений это предлагается продемонстрировать для данного
Глава 15. Сегментация через подбор модели
471
алгоритма поиска решений и рассмотреть различные частные случаи). Выбрав
в качестве примера эллипс 2х2 + у2 — 1 = 0, получим уравнения
2и2 + v2 — 1 = 0 и 2uv — 4dyu 4- 2dxv = 0.
Рассмотрим семейство информационных точек (dx,dy) = (О, Л); указанные урав-
нения можно переписать следующим образом:
2и2 4- v2 — 1 = 0 и 2zw — 4Аи = 2u(v — 2А) = 0.
Из второго уравнения следует, что и — 0 или v = 2А. Двумя искомыми решениями
будут (0,1) и (0, —1). Два других получаются при решении уравнения 2и2 4-
4А2 — 1 = 0, причем решения существуют, только если —1/2 < А < 1/2. Данная
ситуация проиллюстрирована на рис. 15.6.
Аппроксимации расстояния
Обратите внимание, что для относительно простой кривой решения требует
трудная задача. Кривая с несколько более сложной геометрией (например, если
выбрать ф в виде полинома высокой степени, скажем, d) приводит к возник-
новению проблем, поскольку ближайшая точка кривой — это одновременное
решение двух полиномиальных уравнений, причем оба уравнения имеют сте-
пень d. Можно показать, что это даст d2 решений, которые обычно сложно
получить на практике. Таким образом, естественным будет каким-то образом
аппроксимировать расстояние от точки до неявной алгебраической кривой.
Лучшая аппроксимация известна как алгебраическое расстояние. В этом
случае расстояние между кривой и точкой измеряется путем оценки полиноми-
ального уравнения в этой точке, т.е. принимается приближение
расстояние между (dx,dy) и ф(х,у) = 0 равно ф(с1х^у).
Данная аппроксимация удачна (даже почти точна), когда точки лежат близко
к кривой. Для точки, достаточно близкой к кривой, в первом порядке ф(<1х^у)
растет при перемещении (dx,dy) по нормали к кривой (поскольку нормаль к
кривой определяется градиентом ф) и не увеличивается, когда (dx, dy) движется
по касательной к кривой. Одна из существенных трудностей заключается в том,
что алгебраическое расстояние (как оно сформулировано выше) определено не
совсем удачно, поскольку одной кривой соответствует множество различных
полиномов. В частности, кривая, которая определяется уравнением рф(х, у) = 0,
совпадает с кривой, определяемой выражением ф(х, у) = 0. Данную проблему
можно решить, некоторым образом нормировав коэффициенты полинома.
472
Часть IV. Компьютерное зрение: средний уровень
Четыре значения
минимального
расстояния, если
информационные
точки расположены
внутри жирной
кривой
Два решения
для точек вне
жирной кривой
Рис. 15.6. На рисунке слева (описание примера см. в тексте) исследуется число возможных реше-
ний уравнений расстояния от точки до эллипса. Рассматриваются точки, лежащие на вертикальной
оси. На рисунке справа изображено решение для эллипса в общем случае
Один пример данного процесса приводился в разделе 15.2, где линия
(Ф(х, у) = ах + by + с — 0) подбиралась по набору точек с помощью ми-
нимизации алгебраического расстояния при условии а2 + b2 = 1. В данном
случае алгебраическое расстояние совпадает с реальным. Отметим важность
выбора нормировки. Например, если пытаться подобрать коническое сечение
(ax2+bxy+cy2+dx+ey+f — 0) с использованием условия b = 1, окружность по-
добрать не удастся. Альтернативная аппроксимация — использовать выражение
^(^х, dy^
Г?Ж,4)Г
Преимущество такого подхода заключается в том, что условие нормировки не
требуется; при подборе линии аппроксимация точна. Обратите внимание, что
это приближение имеет те же свойства, что и алгебраическое расстояние: оно
увеличивается, если двигаться вдоль нормали и т.д. Достоинство такой ап-
проксимации состоит в том, что она несколько точнее предыдущей, поскольку
нормирована на длину нормали. Это означает, что ее можно считать (грубо)
как выраженное в процентах расстояние вдоль нормали от кривой до точки.
На практике эта аппроксимация используется редко, в основном из-за того, что
при выборе алгебраического расстояния возникают более простые численные
проблемы.
Оба описанных приближения стоит использовать осторожно, поскольку их
поведение для информационных точек, расположенных вдали от кривой, явля-
ется недостаточно понятным. В результате связь между подобранной кривой
и набором информационных точек становится загадочной, если точки не ле-
жат близко к кривой этого класса. Алгебраическое расстояние применяется
Глава 15. Сегментация через подбор модели
473
ТАБЛИЦА 15.2. Параметрические кривые часто используются в задачах компьютерного зрения.
Вполне естественно собрать набор кривых третьего порядка, наложив условие на их коэффици-
енты, чтобы в результате получилась единая непрерывная дифференцируемая кривая; результат
называется аппроксимацией кубическими сплайнами
Кривые Параметрическая форма Параметры
Окружности с центром в начале координат (г sin(t),r cos(t)) 0 = r t e [0,2тг)
Окружности (г sin(t) 4- а, г cos(t) + Ь) 0 = (r, a, b) t G [0,2тг)
Эллипсы, оси которых совпадают с координатными осями (ri sin(t) 4- а, Г2 cos(t) 4- Ь) 0 = (ri, r2, a, 6) t G [0, 2tf)
Эллипсы (cos ф (и sin(t) + а) — — sin ф (г2 cos(t) + Ь); sin ф (ri sin(£) 4- а) + + cos ф (г2 cos(t) 4- Ь)) 0 = (ri,r2,a,6,0) t G [0,2тг)
Сегменты кривых третьего порядка (а£3 4- bt2 4- ct 4- d, et3 4- ft2 4- gt + h) 0 = (a, b, c, d, e, f, g, h) t e [o, 1]
несколько шире, поскольку оно порождает более простые численные проблемы
и может использоваться в задачах более высоких размерностей, например, при
аппроксимации расстояния между точками и неявными поверхностями. Точное
расстояние в подобных задачах определить обычно сложно.
15.3.2 . Параметрические кривые
Координаты параметрической кривой представлены как параметрические
функции параметра, меняющегося вдоль кривой. Параметрические кривые име-
ют такой вид:
y(t)) - (x(t;0) , y(t;0)), t G
Разнообразные полезные параметрические кривые представлены в табл. 15.2.
Расстояние от точки до параметрической кривой
Пусть дана точка (d^dy). Ближайшую к ней точку параметрической кривой
можно определить по значению параметра точки кривой, который далее будем
обозначать т. Данная точка может лежать на одном из концов кривой. В про-
тивном случае вектор от информационной точки до ближайшей к ней точки кри-
вой — это нормаль к кривой, из чего следует, что s(r) = (dx,dy) — (х(т\у(г)) —
нормаль к касательному вектору, причем з(т).Т — 0. Касательный вектор за-
474
Часть IV. Компьютерное зрение: средний уровень
писывается следующим образом:
Это означает, что параметр т должен удовлетворять уравнению
^(т) {t - ж(т)} + ^(т) {</„ - у(т)} = 0.
at at
Итак, теперь имеем не два уравнения, а одно, но общая картина улучшилась
не сильно по сравнению со случаем параметрических кривых. Практически
всегда ar(t) и y(t) — полиномы, поскольку процедура поиска корней проще всего
выглядит для полиномов. Если x(t) и y(t) — дробно-рациональные выражения,
левую часть уравнения можно переписать и свести задачу к рассмотрению
полиномов. В то же время все равно придется учитывать возможность большого
числа корней.
Имеется еще одна сложность, которая делает подбор параметрических кри-
вых непопулярным. Одну и ту же кривую могут представлять параметрические
кривые с различными коэффициентами: например, кривая (x(t), y(t)) при t е
[0,1] совпадает с кривой (x(2t),y(2t)) при t € [0,1/2]. Ситуация может услож-
няться в зависимости от используемого класса параметрических кривых.
15.4. ПОДБОР КАК ЗАДАЧА ВЕРОЯТНОСТНОГО ВЫВОДА
До этого момента используемые критерии сравнения с моделью выбирались
произвольным образом. Общая схема наименьших квадратов кажется разум-
ным критерием, но (как и следовало ожидать!) критерий должен зависеть от
типа модели ожидаемых ошибок — нужно знать, почему токены не были со-
браны в линию при первой попытке. Вернемся к задаче подбора прямой по
набору точек, которые заведомо получены из прямой. Здесь естественным ве-
роятностным критерием является общая схема наименьших квадратов. Начнем
с модели, показывающей, как происходят измерения изображения.
Генерирующая модель
Предположим, что измерение — это выбор точки вдоль прямой, которая за-
тем возмущается гауссовым шумом, перпендикулярным прямой. Предположим,
что процесс выбора точек вдоль прямой равномерен — в принципе, такого быть
не может, поскольку прямая имеет бесконечную длину, но на практике можно
предположить, что любое отклонение от равномерного распределения слишком
мало, чтобы его учитывать. Это означает, что имеется последовательность к
измерений (xi,yi)t полученных из следующей модели:
v
а
b
Глава 15. Сегментация через подбор модели
475
где п ~ 2V(0, сг), аи + bv + с = 0 и а2 4 Ь2 = 1. Из модели получаем функцию
вероятности:
^(измерения | а, 6, с) = P(xi, yi | а, Ь, с).
i
Теперь на основе модели линию можно выбирать либо по принципу максималь-
ного правдоподобия, либо по принципу максимальной апостериорной вероят-
ности. Как правило, никаких особых причин предпочитать одну линию другой
нет, так что приемлемым является выбор согласно максимальному правдоподо-
бию. Теперь логарифмическое отношение правдоподобий записывается так:
_2о2 +с)2
i
при условии а2 + b2 = 1. Максимизация правдоподобия сводится к миними-
зации суммы перпендикулярных расстояний между точками и линиями (см.
раздел 15.2.1). При использовании описанного критерия придется столкнуться
с двумя явлениями.
• Устойчивость. Критерий на основе общей схемы наименьших квадратов
присваивает большим ошибкам огромные весовые коэффициенты, что
может стать серьезной проблемой. Например, если одна данная точка
лежит далеко от линии, причем с другими точками линия совпадает до-
статочно хорошо (как может возникнуть такая ситуация, будет сказано
ниже), получающаяся подобранная линия будет сильно отклоняться от
данных точек. Это явление может стать серьезной проблемой. Например,
если к набору данных подбирать фундаментальную матрицу, требуются
соответствия между точками правого и левого изображений; но если одно
соответствие будет найдено неверно, в набор данных попадет потенциаль-
но большая ошибка. Подробнее данный вопрос рассмотрен в следующих
двух разделах.
• Потерянные данные. В рассуждениях выше предполагается, что из-
вестно, какие точки принадлежат линии; в общем случае это не так.
Например, может быть дан набор измеренных точек, причем некоторые
из них получены из линии, а некоторые возникли вследствие шума. Если
известно, какие точки отвечают линии, определить саму линию просто.
Подобным образом, если известно, какая линия порождает точки, мож-
но легко определить, какие точки получены из этой линии. Критичным
моментом здесь являются потерянные данные (информация о том, какие
точки — это шум, а какие — данные). Большинство задач сегментации
можно рассматривать как задачи о потерянных данных; подробнее этот
вопрос освещается в главе 16.
476
Часть IV. Компьютерное зрение: средний уровень
15.5. УСТОЙЧИВОСТЬ
Все описанные методы подбора линий имеют квадратичную ошибку. На прак-
тике это может привести к плохому подбору, поскольку единственная неумест-
ная точка может дать ошибки, которые подавят вклад от множества реальных
точек; данные ошибки могут привести к тому, что результат процесса подбора
(линия) будет не совсем обычно смотреться на фоне точек (рис. 15.7).На прак-
тике также сложно избежать таких неуместных точек (обычно называемых
посторонними значениями, или выбросами). Одним из важных источников
посторонних значений являются ошибки при сборе или описании информаци-
онных точек. Другой обычный источник — проблемы модели; возможно, не
учтены некоторые редкие, но важные эффекты, или неверно оценена величина
эффекта. Наконец, выбросы часто порождаются ошибками, полученными при
нахождении соответствий. Отметим, что в практических задачах компьютерно-
го зрения выбросы встречаются очень часто.
Здесь стоит отметить некоторую некорректность модели: модель предска-
зывает, что выбросы появляются в единичных случаях, но на практике они,
очевидно, встречаются гораздо чаще. Естественная реакция — либо улучшить
модели (навязать шуму “тяжелый хвост”, см. раздел 15.5.1), либо построить яв-
ную модель посторонних значений. Вторая стратегия требует изучения задачи
потерянных данных (неизвестно, какая точка посторонняя) и обсуждение дан-
ной темы откладывается до раздела 16.2.4 следующей главы. Альтернативный
подход заключается в поиске точек, которые кажутся хорошими (раздел 15.5.2).
15.5.1. М-оценочная функция
Сложность при моделировании источника выбросов заключается в том, что
неверной может быть модель. В общем случае максимум, на что можно надеять-
ся при вероятностной модели процесса, — приблизить процесс к верной модели
при условии, что расстояние между функциями плотности распределения ве-
роятности в некотором смысле меньше е. Это условие можно использовать при
выборе процедуры оценки параметров модели. В частности, процедуру оценки
можно выбрать, исходя из наихудших предположений. Этот подход разумен
в любых обстоятельствах; в реальном мире существует много возможностей
получить неблагоприятные и дорогие уроки в области прикладной статисти-
ки. Придерживаясь такой линии размышлений, оценим качество программы
оценки, предположив, что где-то в наборе процессов, близких к используемой
модели, находится реальный процесс, и что это — процесс, на котором про-
грамма оценки работает наихудшим образом. Наилучшей оценочной функцией
является та, что ведет себя наилучшим образом при наихудшем распределе-
нии, близком к параметрической модели. Это и есть критерий, который можно
использовать для получения большого числа оценочных функций.
М-оценочная функция оценивает параметры, минимизируя выражение вида
Глава 15. Сегментация через подбор модели
Рис. 15.7. Подбор линии по схеме наименьших квадратов крайне чувствителен к посторонним
значениям по обеим координатам (т и у). На рисунке слева вверху показан удачный подбор линии
по точкам (использована схема наименьших квадратов). На рисунке справа вверху показан тот
же набор данных, но координата х одной точки задана неверно. В этом случае наблюдается силь-
ное изменение наклона подобранной линии. Слева внизу показан тот же набор точек, но теперь
изменена координата у одной точки. Первые три рисунка поданы в одном масштабе, при этом не
совсем хорошо видно, насколько неудачен подбор в третьем случае; справа внизу показан фрагмент
третьего рисунка в увеличенном масштабе — видно, что линия действительно подобрана неудачно
где 0 — параметры модели, к которой выполняется подбор, и ri(xi,0) — остаточ-
ная ошибка модели по г-й точке. В общем случае, р(и\ <т) подобно и2 в некоторой
области диапазона значений, а затем спадает; обычно выбирают
Параметр ст — это характеристика точки, в которой функция начинает спадать;
разнообразные примеры таких функций приведены на рис. 15.8. Имеется мно-
жество других М-оценок, обычно они описываются через функции влияния,
которые определяются как
др
дв'
478
Часть IV. Компьютерное зрение: средний уровень
Рис. 15.8. Функция р(х;а) — х2/(а2 4- х2), изображенная при <т2 = 0,1; 1 и 10, с графи-
ком у ~ х2 для сравнения. Замена квадратных членов параметром р снижает влияние посторонних
значений — точка, которая расположена от подобранной кривой на расстоянии, в несколько раз
превышающем <т, практически не будет влиять на коэффициенты подобранной кривой, поскольку
значение р будет близко к 1 и крайне медленно меняться с удалением от подобранной кривой
Это естественно, поскольку тогда искомый критерий выглядит так:
=т0.
<7С7
1
Для задач рассматриваемого типа стоит ожидать, что хорошая функция вли-
яния будет антисимметричной (нет разницы между слабым недостаточным
предсказанием и слабым избыточным предсказанием) и спадать до нуля при
больших значениях (поскольку желательно уменьшить влияние посторонних
значений).
В использовании М-оценок есть два тонких момента. Во-первых, задача на-
хождения экстремума нелинейна и ее нужно решать итеративно. Появляются
стандартные трудности: может быть несколько локальных минимумов, метод
может расходиться, поведение метода может сильно зависеть от начальной точ-
ки. Общая стратегия борьбы с этими трудностями заключается в создании
подвыборки данных точек, подбор по ним прямой с использованием схемы наи-
меньших квадратов и принятие этой прямой в качестве начальной точки обще-
го процесса подбора. Эта процедура проводится для большого числа различных
подвыборок — достаточно большого, чтобы обеспечить высокую вероятность
того, что в данном наборе есть по крайней мере одно множество, состоящее
целиком из хороших точек.
Во-вторых, как видно из рис. 15.9 и 15.10, оценочная функция требует
чувствительной оценки параметра а, который часто называется масштабом.
Глава 15. Сегментация через подбор модели
479
Рис. 15.9. В верхней строке показаны линии, подобранные по второму набору данных (рис. 15.7)
с использованием весовой функции, сглаживающей вклад отдаленных точек (функция ф на
рис. 15.8). На рисунке слева а имеет почти верное значение; вклад постороннего значения учтен
с малым весовым коэффициентом, в результате подбор достаточно хорош. На рисунке в центре
значение ст слишком мало, поэтому на подбор слабо влияет положение всех точек, таким образом,
связь подобранной линии с данными неясна. На рисунке справа значение а слишком велико, поэто-
му постороннее значение дает почти такой же вклад, что и при использовании схемы наименьших
квадратов. В нижней строке крупным планом показана подобранная линия на фоне хороших точек
1 । ।—«тп 6 » । г ! । » । । т,"гп 6 г 1 । । । '"г* । । ।—г
Рис. 15.10. В верхней строке показаны линии, подобранные по третьему набору данных (рис. 15.7)
с использованием весовой функции, сглаживающей вклад отдаленных точек (функция ф на
рис. 15.8). На рисунке слева tr имеет почти верное значение; вклад постороннего значения учтен
с малым весовым коэффициентом, в результате подбор достаточно хорош. На рисунке в центре
значение а слишком мало, поэтому на подбор слабо влияет положение всех точек, таким образом,
связь подобранной линии с данными неясна. На рисунке справа значение ст слишком велико, поэто-
му постороннее значение дает почти такой же вклад, что и при использовании схемы наименьших
квадратов. В нижней строке крупным планом показана подобранная линия на фоне хороших точек
480
Часть IV. Компьютерное зрение: средний уровень
Как правило, оценка масштаба производится при каждой итерации; популярной
оценкой масштаба является
— 1,4826 MeflHaHai |г<п\ге£;0<п-1))|.
М-оценку можно считать трюком, который обеспечивает вынесение ос-
новных событий, связанных с вероятностью, в хвост функции распределе-
ния (в противном случае они давали бы квадратичную ошибку). Миними-
зируемая функция подобна расстоянию для малых значений вектора х (та-
ким образом, для точек, не относящихся к шуму, поведение М-оценочной
функции должно сильно напоминать функцию максимального правдоподо-
бия), а для больших значений вектора х эта функция — почти констан-
та (вероятностный компонент вынесен в хвост распределения). Стратегия,
описанная в предыдущем разделе, может считаться схемой использования
М-оценочной функции, но ее сложность заключается в том, что функция вли-
яния разрывна, поэтому получение минимума представляет сложную задачу.
Алгоритм 15.3. Использование Л/-оценки для подбора вероятностной модели
Для s от 1 до к
Взять подмножество г различных точек, выбранных случайно и равномерно
Подобрать по этому набору прямую, используя принцип максимального
правдоподобия (обычно по схеме наименьших квадратов); результат — 0°
Оценить сг°, используя 0°
Повторять до схождения (обычно величина |0" — 0"~х| мала)
Выбрать шаг минимизации, используя 0"~х, ст"“х, и получить 0”
Вычислить ст"
конец
конец
Сообщить о лучшей подобранной линии в наборе, используя в качестве критерия
медиану остатков
15.5.2. RANSAC
Альтернативой модификации порождающей модели с целью получения бо-
лее тяжелых хвостов является выбор хороших точек из набора данных. Это
довольно просто сделать с помощью итеративного процесса: вначале выбирает-
ся небольшое подмножество исходного набора точек, по нему подбирается объ-
ект, а затем исследуется, сколько других точек согласовывается с полученным
объектом. Данный процесс продолжается до тех пор, пока не будет обеспечена
большая вероятность того, что полученная структура является искомой.
Предположим, например, что подбирается линия по набору точек, примерно
50% из которых — посторонние значения. Если выбирать пары точек равно-
Глава 15. Сегментация через подбор модели
481
мерно и случайно, то порядка четверти выбранных таким образом пар будут
состоять из хороших точек. Для выделения хорошей пары достаточно отме-
тить, что большое число прямых, подобранных по других парам, лежат близко
к прямой, подобранной по рассматриваемой паре. Разумеется, затем следует
получить наилучшую оценку линии, подобрав ее по точкам, лежащим близко
к грубо оцененной линии.
При таком подходе получаем алгоритм 15.4 — поиск случайной выборки,
приводящей к подбору объекта, который согласуется с большим числом име-
ющихся точек. Обычно этот алгоритм называют RANSAC (от RANdom SAmple
Consensus — соглашение по случайным выборкам). Для практической реализа-
ции этого алгоритма требуется выбрать три параметра.
Алгоритм 15.4. RANSAC: подбор линий с использованием соглашения по слу-
чайным выборкам
Определить параметры:
п — наименьшее число требуемых точек
к — число требуемых итераций
t — порог, используемый для определения подходящих точек
d — число соседних точек, необходимых для заявления
об удачном выборе модели
До завершения к итераций
Равномерно и случайно выбрать из данных п точек
Подобрать объект по этим п точкам
Для каждой точки, не вошедшей в набор
Сравнить расстояние от точки до линии с t; если расстояние от точки
до линии меньше t, считать точку близлежащей
конец
Если к числу близлежащих отнесено d или больше точек, считать, что
линия подобрана удачно
Повторить подбор, используя близлежащие точки
конец
Используя в качестве критерия ошибку подбора, определить, какой объект
наилучшим образом подходит точкам
Число требуемых выборок
Сделанные выборки — это наборы точек, равномерно извлеченных из набора
данных. Каждая выборка содержит минимальное число точек, требуемых для
подбора желаемой абстракции. Например, если подбираемым объектом являют-
ся линии, выборки — это пары точек; если подбираются окружности — берутся
тройки точек и т.д. Предполагается, что требуется извлечь п точек и что w —
482
Часть IV. Компьютерное зрение: средний уровень
доля хороших точек (необходима только разумная оценка этого числа). Теперь
ожидаемое число выборок к, требуемых для получения одной точки, записыва-
ется как
E[fc] = 1Р(одна хорошая точка в одной выборке) 4- 2Р(одна хорошая точка в двух
выборках) Ч--= wn Ч- 2(1 - wn)wn + 3(1 - wn)2wn Ч-= w~n
(на последнем этапе производятся незначительные манипуляции с алгебраиче-
скими рядами). Чтобы удостовериться, что получена хорошая выборка, придет-
ся сделать более w~n выборок; к этой величине естественно добавить несколько
его среднеквадратических отклонений.
Среднеквадратическое отклонение величины к можно записать как
\/1 - w"
SD<fc) = ——
Альтернативный подход к этой задаче заключается в следующем: найти число
выборок, при котором вероятность z взятия только плохих выборок будет малой.
Из выражения
(1 — wn)fc = z.
следует, что
los(z)
log(l — wn)
Часто w неизвестно. Впрочем, каждая попытка выбора данных дает инфор-
мацию о w. В частности, если требуется п точек, можно предположить, что
вероятность успешного подбора равна wn. Если наблюдается длительная после-
довательность попыток подбора, из этой последовательности можно оценить w.
Напрашивается такая схема: начать с относительно малого числа оценок w,
создать последовательность попыток подбора, а затем улучшить имеющуюся
оценку w. Если попыток подбора произведено больше, чем требуется для по-
лучения нового w, процесс можно остановить. Сложность задачи уточнения
оценки w при данной последовательности подборов равнозначна оценке веро-
ятности того, что подбрасываемая монета выпадает “орлом” или “решкой".
Близка ли точка
Нужно определить, лежит ли точка близко к прямой, подобранной по выбор-
ке. Сделаем это, определив расстояние между точкой и подобранной линией,
а затем сравнив результат с порогом d; если расстояние меньше порога, точка
лежит близко. Вообще, определение параметра d — это часть процесса мо-
делирования. Например, если подбирать прямые по принципу максимального
правдоподобия, с данной целью можно использовать параметр а (исчезающий
при поиске максимума). Этот параметр определяет средний масштаб отклоне-
ний от подбираемой модели.
Глава 15. Сегментация через подбор модели
483
Получить значение этого параметра относительно просто. Как правило, тре-
буется всего лишь оценить порядок величины и установить значение, получа-
емое во множестве различных проб. Для определения параметра часто прове-
ряют несколько значений и смотрят на результат; другой подход — изучить
несколько характерных наборов данных, подобрать линию “на глаз” и оценить
средний масштаб отклонений.
Число точек, не противоречащих модели
Предположим, что линия подобрана по некоторой случайной выборке из
двух точек. Требуется определить, хороша ли данная линия. Для этого нужно
посчитать число точек, которые находятся в некоторой окрестности проведен-
ной линии (об определении расстояния до линии рассказано в предыдущем
разделе). В частности, предположим, что известна вероятность того, что в на-
боре точек имеются посторонние значения; обозначим эту вероятность как у.
Хотелось бы выбрать такое число точек t, чтобы величина у1 была малой (ска-
жем, меньше 0,05).
Далее имеется два пути. Один — отметить, что у < (1—го) и выбрать t такое,
что (1 — го)* — мало. Другой путь — оценить у по некоторой модели посторон-
них значений; например, если точки лежат в единичном квадрате, посторонние
значения распределены равномерно, а порог близости — d, то у < 2%/2с£.
15.6. ПРИМЕР: ИСПОЛЬЗОВАНИЕ АЛГОРИТМА RANSAC ДЛЯ
ПОДБОРА ФУНДАМЕНТАЛЬНЫХ МАТРИЦ
Трехмерная точка дает два измерения: одно — на левом изображении и од-
но — на правом. Запишем реальные координаты трехмерной точки как Xi, коор-
динаты на левом (соответственно, правом) изображении как хц (соответствен-
но, Xri), измеренные координаты на левом (соответственно, правом) изображе-
нии как тпц (соответственно, тг1). Фундаментальная матрица — это выраже-
ние эпиполярного условия. В частности, если использовать “шляпку” для выра-
жений в однородных координатах, получим, что для любой точки х^Рхц = 0.
Здесь F — фундаментальная матрица.
15.6.1. Выражение для ошибки подбора
Приведенное выше условие обычно не выполняется для измеренных значе-
ний. Предполагается, что измерения подвержены аддитивному гауссову шуму
с равномерным осесимметричным вторым моментом. Запишем тпц и тп^ в аф-
финных (обычных или неоднородных) координатах. Это означает, что
1
2сг2
Р(тпц, nirilajri, хц, F) ос ехр —
(хн “ mri)T(xri — mri) +
(хц - 7Пц)Т(хц - ТПц)
Теперь имеем сложную функцию данных с параметрами Т7, xri, yri и хц. Впро-
чем, при достаточном числе точек можно (теоретически) найти ее экстремум.
На данном этапе этого сделать нельзя, поскольку неизвестны точечные соот-
484
Часть IV. Компьютерное зрение: средний уровень
ветствия между правым и левым изображениями. Более того, следует пред-
полагать, что использование логарифмического правдоподобия в форме суммы
квадратов приведет к проблемам с устойчивостью.
15.6.2. Соответствие как шум
Один из подходов к задаче поиска соответствий заключается в предположе-
нии, что два изображения — это снимки с двух незначительно отличающихся
точек наблюдения. Далее это утверждение можно распространить на характер-
ные точки, положение которых на втором изображении “близко” к положени-
ям, которые соответствуют определенным точкам первого изображения. Данное
предположение опасно: оно может привести к подбору линий, которые выглядят
удачными, но на самом деле такими не являются. Сложность состоит в том, что
ошибка определения соответствия приводит к тем же последствиям, что
и посторонние значения. Альтернативная стратегия — поиск в соответствиях
набора, согласующегося с хорошей фундаментальной матрицей.
Подобный поиск можно упростить, если в окрестность каждой точки до-
бавить представление локальной окрестности изображения. Это означает, что
имеется более детальное описание каждой точки. Например, может присутство-
вать набор выходов фильтров, вычисленных в этой точке для разных масштабов.
Ожидается, что окрестности согласованных точек не будут сильно отличаться.
Такой критерий даст набор возможных соответствий, который может содержать
ошибки, причем они будут выглядеть как посторонние значения. Затем к полу-
ченному набору предполагаемых соответствий применяется алгоритм RANSAC.
15.6.3. Применение алгоритма RANSAC
Как показано далее, семь точечных соответствий определяют фундаменталь-
ную матрицу. Если знать это и использовать один трюк, применение алгоритма
RANSAC к набору возможных соответствий не представляет особой сложно-
сти. Хотя может быть неизвестно, какая часть соответствий является хорошей;
эту величину можно оценить, используя (как выше) попытки подбора. Порог
близости, по которому определяется принадлежность точки к посторонним зна-
чениям, обычно выбирается порядка пикселя (выбор также может зависеть от
качества камер и т.д.).
Получение фундаментальной матрицы по семи точкам
Пусть дано семь предположительных соответствий. Считается, что в каждой
точке измеренное значение совпадает с реальным. Каждое условие х^Рхн — О
дает одно линейное уравнение на коэффициенты фундаментальной матрицы для
известных xri, хц. Более того, уравнение х^Рхн = 0 однородно по элемен-
там фундаментальной матрицы, т.е. если U удовлетворяет указанным условиям,
то им удовлетворяет также матрица AZ7. Наконец, напомним из главы 10, что
фундаментальная матрица имеет ранг 2, поэтому такой же ранг имеет матри-
ца det(77) — 0.
Глава 15. Сегментация через подбор модели
485
Из сказанного следует, что для оценки матрицы F требуется только семь
точечных соответствий. Каждая точка дает однородное уравнение по элементам
матрицы Т7. Решение семи таких однородных уравнений — это двумерное ли-
нейное пространство, которое можно записать следующим образом: +
для известных Tq и и произвольных Л, р. Далее требуется элемент этого
пространства с нулевым детерминантом; получаем уравнение det^AJ^o + м^1) =
О — однородное уравнение третьего порядка по А, р. Обе части уравнения мож-
но разделить на р и решить его для Х/р. В результате получится либо один
действительный корень (соответственно, одно решение), либо три.
Алгоритм 15.5. RANSAC: подбор фундаментальной матрицы с использованием
соглашения по случайным выборкам
Определим параметры:
наименьшее число требуемых точечных соответствий равно семи
к — число требуемых итераций
t — порог, используемый для определения хорошо подходящих точек
d — число требуемых близлежащих точек для подтверждения,
что модель подобрана хорошо
До завершения к итераций
Произвести выборку семи соответствий (случайно и равномерно)
Использовать семиточечный алгоритм для получения оценки
фундаментальной матрицы
Для каждого предполагаемого соответствия, не вошедшего в выборку
Сравнить расстояние от ближайших точек до измеренных точек на
согласованность с матрицей (порог t);
если расстояние меньше t, соответствие не противоречит матрице
конец
Если имеется не менее d соответствий, которые согласуются с
фундаментальной матрицей, подбор выполнен хорошо.
Повторить процедуру подбора с использованием всех хороших точек
конец
Выделить наилучший результат подбора из набора имеющихся, использовав
в качестве критерия ошибку подбора
Сравнение других точек с полученной фундаментальной матрицей
Предположим теперь, что оценка фундаментальной матрицы найдена. Нуж-
но знать, согласуется ли конкретное соответствие с этой оценкой. Для соот-
ветствия известны измеренные точки тгг, тпц и некоторая оценка фунда-
ментальной матрицы. Реальные точки жгг и хц, давшие полученные измерения,
неизвестны. При этом имеются соотношения
486
Часть IV. Компьютерное зрение: средний уровень
Р(тпц, mri |ajrt, хц, Т7) ос ехр —
1
2<т2
- 7Пн)Т(®Н - ТПГ*) +
(хн - Шц)т(хц - тпи)
Если оценка фундаментальной матрицы удачна и если соответствие является
хорошим, имеется несколько реальных точек, расположенных близко к измерен-
ным и согласующихся с оценкой фундаментальной матрицы. Это означает, что
требуется знать расстояние между ближайшими точками и измерениями: если
расстояние мало, соответствие является хорошим. Предположим, что это рас-
стояние можно восстановить (о том, как это сделать, будет рассказано позже).
Получить фундаментальную матрицу, используя алгоритм RANSAC, просто.
В результате получаем суммарный алгоритм 15.5.
15.6.4. Нахождение расстояния
Дана пара измеренных точек тц и тг;, требуется найти расстояние от
них до ближайшей пары точек, согласующейся с оценкой фундаментальной
матрицы. Это означает, что ближайшая пара точек должна иметь следующее
свойство: — 0. Обрисуем оригинальное решение данной задачи, при-
веденное в работе [Hartley and Sturm, 1997].
Отметим вначале, что одновременные вращение и трансляция систем коор-
динат изображения на обоих изображениях не влияет на расстояние. Будем
пренебрегать возможностью того, что лучшая пара точек находится в эпиполю-
сах, поскольку на практике такого не наблюдается (иными словами, такая ситу-
ация необычна). Обе системы координат можно привести трансляцией в такое
положение, что начало координат совпадет с эпиполюсом. Теперь для правого
эпиполюса ТеТ — 0, а для левого — efТ — 0г. Это означает, что в системе
координат, где эпиполюсы левого и правого изображений совпадают с началом
координат (а с помощью вращения и трансляции этого можно добиться, если,
конечно, эпиполюсы не находятся на бесконечности), справедливо следующее:
( At О \
\ °Т 0 ) '
Это матрица 3x3, поскольку Л4 — несколько блоков 2x2. Посмотрим, что про-
изойдет, если обернуть систему координат вокруг начала координат. Запишем
Ufi — ^ri^rit ГДе
г . — ( ^ri 0
— it* I
\ 0 0 /
и 7^ — чистое вращение (для левого изображения соответствующие выраже-
ния будут отличаться индексами “11”). Если теперь перейти в координаты и,
новая фундаментальная матрица будет иметь такой вид:
rt г? г r ( 'R'Ti-M'Rii 0 \
Со — briJ~oCu =1 т | .
\ О 0 1
Глава 15. Сегментация через подбор модели
487
Это означает, что при подходящем выборе вращения, фундаментальную матри-
цу можно привести к диагональному виду.
Рассмотрим вопрос расстояния. Расстояние от измеренной точки до реаль-
ной точки на левом изображении равно расстоянию от измеренной точки до
некоторой эпиполярной линии на левом изображении. Данная линия преоб-
разуется в некоторую эпиполярную линию правого изображения, а в какую
именно, — сообщает фундаментальная матрица. Расстояние от измеренной
точки до реальной точки правого изображения — это расстояние от измеренной
точки до этой эпиполярной линии. Таким образом, остается минимизировать
сумму указанных расстояний.
Эпиполюсы расположены на каждом изображении в начале координат.
На левом изображении эпиполярные линии — это семейство прямых (s,t, 0)
(т.е. sx + ty = 0; все такие прямые проходят через начало координат, а меняя
параметры s и t, получаем различные линии). Поскольку на правом изоб-
ражении система координат была повернута для диагонализации фундамен-
тальной матрицы, соответствующие линии имеют вид (s, At,O) (это означает,
что sx + Xty — 0) для некоторого Л в зависимости от фундаментальной мат-
рицы. Обозначим mxri координаты х вектора mri и т.д. Теперь расстояние
определяется выражением
[sTH,xli 4” tUlyli) f (sTTlajri 4” tXtYlyri)
(s'2 +t2) + (s2 + A2t2) ’
эту величину требуется минимизировать как функцию s и t. Фактически данное
выражение однородно по s и t, так что достаточно рассмотреть его только как
функцию и — s/t. Максимизируем эту функцию, а затем (на всякий случай,
если имеется максимум при t = 0) рассмотрим ее как функцию v = t/s. Мак-
симизация сложности не представляет, поэтому проанализируем ее только для
параметра и. Рассмотрим рациональную функцию, зависящую от и, числитель
и знаменатель которой имеют степень 4. Должна существовать аналогичная
рациональная функция от и такого вида: некоторая константа плюс дробь, чис-
литель которой имеет степень 3, а знаменатель — степень 4 (это так, поскольку
выполнив деление, можно убрать из числителя член степени 4). Теперь числи-
тель производной от этого выражения (полином шестой степени по и) следует
приравнять к нулю. Находим корни и получаем искомый результат.
15.6.5. Подбор фундаментальной матрицы по известным
соответствия м
Итак, имеется система известных соответствий, согласно которой требует-
ся подобрать фундаментальную матрицу. Чтобы получить матрицу Т7, которая
представляет максимально правдоподобное решение (причем выражение для
логарифмического правдоподобия уже есть, но в нем фигурирует набор неиз-
вестных точек хгг, хц), можно попытаться исключить эти точки из выражения
(что кажется довольно сложным) либо вычислить их.
488
Часть IV. Компьютерное зрение: средний уровень
Подходящая в данном случае стратегия — искать эти точки как точки
в трехмерном пространстве. Одну камеру можно зафиксировать в начале
координат, вторая матрица при этом будет описываться функцией, зависящей
только от фундаментальной матрицы. Далее минимизируем отрицательное ло-
гарифмическое правдоподобие как функцию фундаментальной матрицы и трех-
мерной конфигурации точек. В начале этого процесса используется имеющаяся
оценка соответствий и фундаментальной матрицы.
15.7. ПРИМЕЧАНИЯ
В данной главе рассмотрено только несколько из множества возможных тех-
ник. Подбор — это задача, которая встречается во многих контекстах; практиче-
ски всегда возможно, а часто просто полезно, рассматривать конкретную задачу
именно как задачу подбора. Это означает, что нужная информация наверняка
где-то изложена, но найти ее в литературе часто бывает затруднительно.
Как правило, на практике сложность представляет один из следующих мо-
ментов: а) определение расстояния (что в действительности может быть очень
сложно); б) обеспечение слабого влияния посторонних значений на хорошие
данные; и в) принятие начального решения о том, что подбирать.
Приближенный расчет расстояния от точки до кривой или поверхности опи-
сывается во многих работах; в частности, читателю будет полезно прочесть
публикации [Agin, 1981], [Bookstein, 1979], [Cabrera and Meer, 1996], [Porrill,
1990], [Sabin, 1994], [Sullivan, Sanford and Ponce, 1994a,6], [Sullivan and Ponce,
1998], [Taubin, Cukierman, Sullivan, Ponce and Kriegman, 1994a,bj.
В сфере компьютерного зрения устойчивость — это не особо важный во-
прос. Начать изучение этой темы можно с публикаций [Huber, 1981], [Meer,
Mintz, Kim and Rosenfeld, 1991], [Rousseeuw, 1987] и [Stewart, 1999]. Идеи,
представленные в этих работах, исключительно полезны. Мы не сильно углуб-
лялись в подробности темы в основном потому, что приведенных фактов вполне
достаточно для решения любой задачи, которая может встретиться на практике.
Вычисление фундаментальной матрицы проводилось с использованием ал-
горитма RANSAC потому, что на настоящий момент это — наилучший метод.
Читателям, которые интересуются применением данного алгоритма, стоит об-
ратить внимание на задачу определения структуры по движению, в частности,
на работу [Hartley and Zisserman, 2000], где показаны огромные возможности
этой схемы. Рекомендуются также работы [Fischler and Bolles, 1981] и [Torr and
Murray, 1997]. Ожидается, что в будущем данная схема будет использована для
создания ОМ-алгоритмов; более подробно об этом будет сказано в главе 16.
В приведенном обсуждении подбор не рассматривался как задача логическо-
го вывода. Достоинство задач логического вывода заключается в том, что лю-
бую информацию о подобранных объектах можно использовать для последую-
щего подбора, причем скорость получения новой информации довольно велика.
Несколько соответствующих примеров приводится в следующей главе, но стоит
сказать, что здесь также применимы многие соображения, изложенные в главе,
посвященной вероятности (доступна на Web-сайте книги). В частности, можно
Глава 15. Сегментация через подбор модели
489
использовать вывод по схеме максимума апостериорной вероятности; все, что
потребуется, — добавить к ошибке подбора априорный член. Ранее строились
априорные члены, отсеивавшие модели, быстро отклонявшиеся от верных ре-
зультатов. Данная практика полезна, но похоже, что в последние годы она пере-
стала быть популярной; прочесть об этом можно в работах: [Horn and Schunck,
1981], [Bertero, Poggio and Torre, 1988] и [Poggio, Torre and Koch, 1985].
Подбор можно также использовать для восстановления изображений. По
данным изображениям подбирается поверхность (которая интерпретируется как
карта высот), причем в углах поверхность разрывается. Затем важно правильно
учесть стоимость разрыва по сравнению со стоимостью плохого подбора. Дан-
ную общую стратегию можно также применить к восстановлению карт глубин,
стереокарт и т.д. Использовать при этом можно различные условия. В публика-
ции [Grimson, 19816] для сглаживания используется знание об отсутствии ха-
рактерных элементов (принцип “Отсутствие новостей есть хорошая новость”).
В более поздних работах в различных формах учитывается разрывность, в том
числе дыры и складки [Blake and Zisserman, 1987], [Mumford and Shah, 1985]
и [Mumford and Shah, 1988].
Задачи
15.1. Докажите простой, но крайне полезный результат: расстояние по пер-
пендикуляру от точки (и, v) до прямой (а, Ь, с) определяется выражени-
ем abs(au + bv + с), если а2 + Ь2 = 1.
15.2. Получите задачу на собственные значения
(х2 — х х хуI а \
ху — ху у2 -у у ) \ b J \ b J
из порождающей модели для общей схемы наименьших квадратов. Это
простое упражнение (достаточно найти максимальное правдоподобие
и немного его преобразовать) стоит проделать аккуратно, а результат —
запомнить.
15.3. Как из программы определения углов, возвращающей ориентацию пря-
мых, получить кривую угловых точек? Приведите соответствующий ре-
курсивный алгоритм.
15.4. Несколько более устойчивая разновидность последовательного подбора —
вырезать из списка точек, относящихся к линиям, несколько первых
и несколько последних пикселей, поскольку они могут отвечать углам,
а) Почему названная модернизация — это улучшение?
б) Как принять решение о количестве выбрасываемых пикселей?
15.5. Коническое сечение определяется выражением ах2 + bxy+су2 +dx + еу +
/ = 0.
а) Покажите, что ближайшая к данной точке ((/ж,с?у) точка конического
сечения (и, и) удовлетворяет двум уравнениям:
аи2 + buv + cv2 + du + ev + f — О
490
Часть IV. Компьютерное зрение: средний уровень
и
b(u2 4- v2) 4- 2(а — с) uv — (2а dy + е)и 4- (2cdx + d)v + (edx — d dv) = 0.
б) Имеем два квадратных уравнения. Обозначим через и вектор (u,v, 1).
Покажите, что данные уравнения можно переписать в виде итМ\и —
0 и итЛ42и = 0 при симметричных матрицах Лй и Л4г-
в) Покажите, что имеется преобразование Т такое, что ТтМ\Т = Id
и Т7— диагональная матрица.
г) Покажите, как это преобразование можно использовать для получе-
ния набора решений уравнений; в частности, покажите, что число
действительных решений может доходить до четырех.
д) Покажите, что данные уравнения могут иметь четыре, два или вообще
не иметь действительных решений.
е) Нарисуйте эллипс и покажите точки, для которых будет два или че-
тыре решения.
15.6. Покажите, что кривая
/1 -12 2t \
\ 1 +12 ’ 1 + е2)
является дугой окружности (длина дуги зависит от интервала, в котором
определен параметр).
а) Запишите уравнение по t для точки дуги, ближайшей к некоторой
точке (dx,dy). Каков порядок этого уравнения? Сколько решений по t
может оно иметь?
б) Подставьте в параметрическое уравнение s3 = t и запишите уравнение
для точки дуги, ближайшей к некоторой данной точке. Чему равен
порядок этого уравнения? Почему он так высок? Какой вывод можно
сделать?
15.7. Покажите, что конус наблюдения для конуса — это семейство плоско-
стей, проходящих через фокальную точку и вершину конуса. Покажите
теперь, что контур конуса состоит из набора прямых, проходящих через
вершину. Данное задание можно выполнить, не прибегая к вычислениям,
используя один простой аргумент.
Упражнения
15.8. Реализуйте последовательный подбор линий. Определите порядок отли-
чий, если из списка точек линий удалить несколько первых и несколько
последних пикселей (данное упражнение стоит проделать аккуратно, по-
скольку полученная программа — это опыт, который пригодится в даль-
нейшем).
15.9. Реализуйте поиск линий по схеме Хоха.
15.10. Подсчитайте число линий, которые получаются при использовании про-
граммы поиска по схеме Хоха. Насколько она хороша?
16
Сегментация и подбор
с использованием
вероятностных методов
Во всех алгоритмах сегментации, описанных в предыдущей главе, использо-
вались существенно локальные модели подобия. Хотя в некоторых алгоритмах
строятся кластеры, которые хороши глобально, в основоположной модели по-
добия сравниваются отдельные пиксели. Более того, ни в одном из описанных
алгоритмов не используется явная вероятностная модель того, как измеренные
объекты отличаются от искомой основоположной абстракции.
В этой главе рассмотрены явные вероятностные методы сегментации. С по-
мощью этих методов можно объяснить данные, исходя из глобальных моделей
и используя малый набор параметров. Например, можно взять набор токенов
и подобрать по ним линию или взять пару изображений и попытаться подобрать
параметрический набор векторов движения, которые объяснят, как пиксели пе-
реходят с одного изображения на другое.
16.1. ЗАДАЧИ С НЕДОСТАЮЩИМИ ДАННЫМИ, ПОДБОР
И СЕГМЕНТАЦИЯ
Многие важные задачи компьютерного зрения можно сформулировать как
задачи с некоторыми отсутствующими важными элементами данных. Напри-
мер, сегментацию можно рассматривать как задачу определения из множества
492
Часть IV. Компьютерное зрение: средний уровень
данных источника, который породил измеренное значение. Считается, что сег-
ментация изображения на области включает определение источника цветных
и текстурных пикселей, который породил пиксели изображения; сегментация
набора токенов в коллинеарные группы включает определение того, какие то-
кены лежат на какой линии; сегментация видеоряда на движущиеся области
включает сопоставление движущихся пикселей моделям движения. Каждая
из этих задач может оказаться простой, если восстановить некоторые данные,
отсутствующие на начальный момент (соответственно, из какой области “при-
шел” пиксель, какая линия породила токен, какая модель движения породила
пиксель).
16.1.1. Задачи с недостающими данными
Задача с недостающими (или пропущенными) данными — это задача ста-
тистики, в которой фигурируют некоторые отсутствующие данные. Существует
два важных контекста, в которых отсутствующие данные играют значительную
роль: 1) когда пропущены некоторые элементы вектора данных; 2) часто в сфере
компьютерного зрения проблему логического вывода можно значительно упро-
стить, переписав ее с использованием некоторых переменных с неизвестными
значениями. Существует эффективный алгоритм обработки задач с недостаю-
щими данными; по сути, делается некоторое предположение об отсутствую-
щих данных. Этот метод и соответствующие алгоритмы продемонстрированы
на двух следующих примерах.
Пример 16.1. Сегментация изображения
В каждом пикселе изображения вычисляется d-мерный характеристический век-
тор х, в котором собрана информация о положении, цвете и текстуре. Данный
вектор может содержать различные представления цвета и выход набора фильтров,
центрированных на конкретных пикселях. Моделирование изображения заклю-
чается в том, что каждый пиксель считается порожденным участком плотности,
соотнесенным с одним из g сегментов изображения. Таким образом для полу-
чения пикселя выбирается сегмент изображения, а затем из участка плотности,
соотнесенного с этим сегментом, генерируется пиксель.
Предполагается, что l-н сегмент выбирается с вероятностью пг, участок плот-
ности, соотнесенный с /-м сегментом, моделируется гауссианом с параметра-
ми = (pt,Ei), зависящими от конкретного сегмента. Это означает, что вероят-
ность генерации вектора пикселя можно записать как
р(аг) = У^р(ж I
г
Модель такого типа называется моделью смеси (поскольку она представляет собой
взвешенную сумму элементов смеси, описываемых вероятностными моделями;
параметры тг/ обычно называются весовыми коэффициентами элементов смеси).
На практике подобные модели встречаются довольно часто.
Глава 16. Сегментация и подбор с использованием вероятностных методов
493
Один из способов интерпретации описанной модели смеси — представить ее как
обобщенную модель. При таком подходе каждый пиксель изображения получается
в два этапа: а) выбор Z-ro компонента модели с вероятностью ттг б) взятие выбор-
ки из р(х | Oi). Представить данную модель можно как распределение плотности
в пространстве характеристического вектора, состоящее из набора g “пятен”,
каждое из которых соотнесено с сегментом изображения. Требуется определить:
а) параметры каждого такого пятна, б) весовые коэффициенты элементов смеси
и в) компонент, который дал каждый пиксель (в результате придем к сегментации
изображения).
Все названные параметры собираются в вектор параметров, причем весовые ко-
эффициенты записываются как at, а параметры каждого пятна как Ot =
В результате получаем G = (ai,..., as, 0i,..., 6g). Таким образом, модель смеси
принимает следующий вид:
9
р(х | 6) = y^atpt(a; | 0t).
t=i
Плотность каждого компонента — это обычный гауссиан:
р,(х 1 ft) = - M()Tsr‘(« - м<)} •
Функция правдоподобия для изображения записывается следующим образом:
(в \
Е aipt(xj | 0i) j .
Z=1 '
Каждый компонент соотнесен с сегментом, а вектор G неизвестен.
Важный момент: если знать компонент, который породил пиксель, вектор G опре-
делить просто. Для каждого элемента 0i можно использовать оценку по принципу
максимального правдоподобия, тогда оц — это доля компонента I в изображении.
Подобным образом, если знать G, то для каждого пикселя можно определить
компонент, который наиболее вероятно породил этот пиксель, — таким образом,
получим сегментацию изображения. Сложность заключается в том, что неизвестна
ни одна из названных величин.
Пример 16.2. Подбор прямых по набору точек
На плоскости расположено g различных линий. Линия I параметризована век-
тором ai и генерирует токены с вероятностью тп. В результате измерения каж-
дого токена получается ТУ, а значение j-ro измерения — IVj. Обозначим че-
рез p(W | at) функцию плотности вероятности для Z-й прямой, описывающую,
494
Часть IV. Компьютерное зрение: средний уровень
как прямая выдает токены. Это означает, что функция плотности вероятности для
набора измерений токена имеет следующий вид:
pW=E’r‘*'(w । °')-
l
Это еще одна модель смеси, в которой правдоподобие набора наблюдений записы-
вается как
(д \
£>1P(l¥3|a,) .
1=1 /
Хотелось бы знать at и тг/. Как и для случая сегментации, если известно, какая
точка сгенерирована какой прямой, задача решается легко. Вектор at можно
оценить по схеме подбора прямых и получить tti, подсчитав число токенов, сге-
нерированных Z-й прямой и разделив эту величину на общее число прямых.
Сложность заключается в том, что доступны только измерения токенов, но не
связь токенов и прямых.
Формальная постановка задач с недостающими данными
Предположим, что есть два пространства — полное пространство дан-
ных X и неполное пространство данных У. Существует отображение f, пере-
водящее X в У. При этом отображении “теряются” данные, которые называются
недостающими; в качестве примера подобного преобразования можно назвать
проектирование. В контексте сегментации изображения полный набор данных
включает измерения всех пикселей, а также набор переменных, указываю-
щих, какой компонент смеси дал какое измерение; неполный набор данных
получается при отбрасывании этого второго набора переменных. Для приме-
ра с прямыми и токенами полное пространство данных состоит из измерений
токенов (обязательно положения, но возможно еще цвета и формы), а также
набора переменных, указывающих, к какой линии относится токен; неполный
набор данных получается при отбрасывании второго набора переменных.
Имеется также пространство параметров U. В контексте сегментации изоб-
ражения пространство параметров состоит из весовых коэффициентов компо-
нентов смеси и параметров каждого компонента смеси; для примера с прямы-
ми и токенами пространство параметров состоит из весовых коэффициентов
компонентов смеси и параметров каждой прямой. Требуется по принципу мак-
симального правдоподобия найти оценку указанных параметров при наличии
только неполного набора данных. Если дан полный набор данных, в пол-
ном пространстве данных можно записать функцию плотности вероятности
рс{х\и). Логарифмическая вероятность полного набора данных записывается
следующим образом:
Глава 16. Сегментация и подбор с использованием вероятностных методов
495
Lc(x;u) = log < JJpc(aj>; и) > =
I з )
= 22log(pc(a^;4)-
з
В любом из приведенных примеров это логарифмическое правдоподобие мож-
но использовать относительно просто. При сегментации изображения проблему
может представлять только оценка параметров каждого сегмента изображения,
если известно, какой сегмент дал каждый пиксель. В примере с прямыми и то-
кенами задача формулируется как оценка весовых коэффициентов смеси и па-
раметров при условии, что известно, к какой линии относится каждый токен.
Проблема заключается в том, что имеющиеся данные являются неполны-
ми. Функция плотности вероятности для неполного пространства данных —
это Pi(y,u). Функция плотности вероятности для неполного пространства
данных получается интегрированием функции плотности вероятности для пол-
ного пространства данных по всем значениям, дающим одинаковый у. Таким
образом,
Pi(y\u)= / pc(x\u)dT]
•/{ac|/(ac)=l/}
(где т] — мера объема пространства вектора гс, причем f(x) — у). Правдоподо-
бие неполных данных записывается следующим образом:
П Pi(yj'>u)-
зе наблюдения
Оценку функции максимального правдоподобия можно сформировать для и при
данном у, записав правдоподобие и максимизировав его. Это не так просто,
поскольку и интеграл, и процедура нахождения максимума могут быть доволь-
но сложными. Обычная стратегия взятия логарифма от искомого выражения
не подходит, поскольку интеграл находится под логарифмом. Имеем:
Ь.(у;«) = log < JJpifi/yjt*) > =
I 3 )
= 22iog(pi(y/,n)) =
3
= V log I / Pc(«; и) dr} I .
Выражение в такой форме довольно громоздко. С правдоподобием неполно-
го набора данных приходится иметь дело потому, что неизвестно, какой из
496
Часть IV, Компьютерное зрение: средний уровень
множества векторов х, которые соответствуют наблюдаемому вектору у, дей-
ствительно ему соответствует. Построение правдоподобия неполных данных
включает усреднение по всем таким векторам х.
Стратегия
Приведем соображения, справедливые для каждого из описанных приме-
ров. Если известны недостающие данные, можно эффективно оценить искомые
параметры. Подобным образом, если известны параметры, будут найдены от-
сутствующие данные. Таким образом, напрашивается следующий алгоритм.
1. Получить некоторую оценку недостающих данных, используя предположе-
ние о параметрах.
2. Используя оценку недостающих данных, построить оценку свободных пара-
метров по принципу максимального правдоподобия.
Данная процедура повторяется до схождения (если повезет!). В контексте за-
дачи сегментации изображения данную процедуру удобно сформулировать сле-
дующим образом.
1. Получить некоторую оценку компонента, породившего характеристический
вектор пикселя, использовав оценку 6i.
2. Обновить значение 0i и весовых коэффициентов элементов смеси, используя
данную оценку.
В примере с токенами и прямыми алгоритм будет выглядеть следующим обра-
зом.
1. Получить некоторую оценку соответствия между токенами и прямыми, ис-
пользуя предположение относительно сц.
2. Построить уточненную оценку сц, используя оцененное соответствие.
16.1.2 . ОМ-алгоритм
Особых причин надеяться на то, что процедуры, описанные для недостаю-
щих данных, сойдутся, нет. Фактически же, если на каждом этапе совершать
надлежащие выборы, данные процедуры все-таки сходятся. Наиболее простой
способ показать это — доказать, что приведенные выше схемы являются част-
ными случаями общего алгоритма ожидания-максимизации (далее — ОМ-
алгоритм).
ОМ-алгоритм для моделей смесей
На данном этапе предполагается, что логарифмическое правдоподобие пол-
ного набора данных линейно по отсутствующим переменным. Такая ситуация
обычна, поскольку она характерна для моделей смесей; данным свойством об-
ладают все приведенные выше примеры.
Глава 16 Сегментация и подбор с использованием вероятностных методов
497
В модели смеси недостающие данные — это переменные, указывающие, из
какого компонента смеси извлечен элемент данных (например, информация о
том, какая прямая породила точку, или о том, что точка возникла вследствие
шума). Для представления данной информации с каждой информационной точ-
кой соотносится вектор х, имеющий д элементов (напомним, что каждая смесь
в наших примерах составлена из д компонентов). Если j-я информационная точ-
ка поступила от Z-го компонента смеси, то М компонент вектора Zj (записыва-
ется как Zji) равен единице, в противном случае он равен нулю. Таким образом,
rcj = [l/j,Zj] и модель смеси можно теперь переписать следующим образом:
р(з/) = 22 । а1У
i
Логарифмическое правдоподобие полного набора данных записывается как
(з \
22 losp(y, I ai) 1
i=i /
(и оно линейно по отсутствующим переменным).
Основная идея ОМ-алгоритма заключается в получении набора рабочих зна-
чений отсутствующих данных (и вектора х), для чего вместо каждого требуе-
мого значения подставляется предполагаемое. В частности, при некотором зна-
чении фиксируются параметры, а затем вычисляется ожидаемое значение каж-
дого вектора Zj, в результате чего получаем значение вектора yj и значения
параметров. Затем ожидаемое значение вектора Zj подставляется в логарифми-
ческое правдоподобие полного набора данных (поскольку с ним гораздо проще
работать) и при максимизации полученного выражения получаются значения
параметров. На этом этапе ожидаемые значения вектора Zj могут меняться.
Получаем такой алгоритм: чередование этапа ожидания и этапа максимизации
до схождения процесса.
В общем сказанное можно сформулировать так: при данном векторе иа с по-
мощью описанного ниже процесса формируется ns+1.
1. Вычисляется ожидаемое значение полного набора данных, для чего исполь-
зуются неполные данные и текущее значение параметров. Известно ожида-
емое значение у?, так что вычислить требуется только ожидаемые значе-
ния Zj для каждого j. Эти значения записываются как XjS\ Верхний индекс
использован, чтобы указать, что ожидание зависит от текущего значения
параметров. Данный процесс называется этапом ожидания.
2. Логарифмическое правдоподобие полного набора данных максимизируется
относительно вектора и с использованием ожидаемого значения полного
набора данных, которое было получено на этапе ожидания. Таким образом
498
Часть IV. Компьютерное зрение*, средний уровень
вычисляется величина
u*+1 = arg max Lc(®*; u) =
u
= argmax£c([y,5'];u).
Данный процесс называется этапом максимизации.
Можно показать, что логарифмическое правдоподобие неполного наоора дан-
ных увеличивается на каждом этапе, это в свою очередь означает, что по-
следовательность и* сходится к (локальному) максимуму логарифмического
правдоподобия неполного набора данных (см., например, [Dempster, Laird and
Rubin, 1977] или [Mclachlan and Krishman, 1996J). Разумеется, не существует
гарантии, что данный алгоритм сходится к истинному локальному максиму-
му; в некоторых последующих примерах показано, что нахождение подобного
истинного максимума может быть сложным.
16.1.3 . ОМ-алгоритм в общем случае
Если логарифмическое правдоподобие полного набора данных нелинейно по
недостающим данным, просто подставлять ожидания этих переменных нельзя.
Необходимо работать с отсутствующими переменными, используя в вычислени-
ях ожидание логарифмического правдоподобия полного набора данных относи-
тельно отсутствующих переменных при условии, что параметры имеют текущие
значения. Пусть известна оценка параметров Теперь усредним логариф-
мическое правдоподобие полного набора данных по всем значениям полного
набора данных, умноженных на весовой коэффициент — вероятность каждо-
го случая при такой оценке параметров и знаниях о неполном наборе данных.
В результате получим такую функцию:
Q(u;u^) = J Lc(x,u)p(x | u^*\y)dx,
представляющую зависимость от предыдущей оценки параметров. Теперь мак-
симизируем данную функцию относительно вектора и и получим, что —
argmaxuQ(i*; «<*)). Из данного (простого на первый взгляд) примера видно,
что задача сводится к алгоритму, описанному для линейного случая.
16.2. ОМ-АЛГОРИТМ НА ПРАКТИКЕ
Недостающие данные фигурируют во всех задачах компьютерного зрения.
Общую картину позволяют представить примеры, приведенные в книге. Ход вы-
числений обычно понятен, а повторить их на другом примере — дело техники.
16.2.1. Пример: сегментация изображения (возвращаясь к сказанному)
Пусть дано п пикселей. Недостающие данные формируют массив п х д ин-
дикаторных переменных Z. В каждой строке имеется одна единица, остальные
Глава 16. Сегментация и подбор с использованием вероятностных методов
499
позиции заполнены нулями — таким образом указывается пятно, породившее
характеристический вектор пикселя. Далее используется форма записи, введен-
ная в примере 16.1.
Этап ожидания
Элемент (Z, т) матрицы Т равен единице, если l-й пиксель был порожден
т-м пятном, в противном случае элемент равен нулю. Это означает, что
Е(Лт) =1Р(/-й пиксель порожден m-м пятном)+
4- O.P(Z-fi пиксель не порожден тп-м пятном) =
=Р(1-й пиксель порожден m-м пятном).
Предполагая, что параметры при s-й итерации записываются как ©<*>, имеем
-J _ с№рт(х1 10f(a))
(где Qm — значение ат при s-й итерации).
Этап максимизации
Как только получено ожидаемое значение Т, остальное — дело техники. Факти-
чески остается по принципу максимального правдоподобия сформировать оцен-
ку @s+1. Как и ранее, ожидаемое значение индикаторных переменных в общем
случае не равно нулю или единице — они принимают какие-то значения из
диапазона [0; 1]; т.е. данный случай наблюдается с указанной частотой, а па-
раметр в функции правдоподобия, соответствующий определенной переменной-
индикатору, возводится в степень, равную ожидаемому значению. При вычисле-
ниях получаются знакомые выражения для взвешенного среднего и взвешенной
дисперсии:
а£+1) = I ®i,6(s)) ,
t=i
(,+1)
ЕГ=1 Р (m 1 e<S)) {(®« - Am) (®l~Mm) I
5Xip(m I ®t>e(s))
(где — значение am при s-й итерации).
Осталось задать подходящие характеристические векторы и обсудить такие
вопросы, как начало ОМ-алгоритма. Результаты показаны на рис. 16.1 и 16.2,
при этом использованы три характерных цветовых элемента (координаты пиксе-
ля в пространстве L*a*6* после сглаживания изображения) и три характерных
500
Часть IV. Компьютерное зрение: средний уровень
а) б)
в)
Рис. 16.1. Изображение зебры а) сглаженное при различных шкалах для получения результата
б. Сглаживание выполняется с использованием локальных оценок масштаба, которые являются,
по сути, измерениями масштаба изменений в окрестности пикселя; в окрестности углов масштаб
мелкий, в районе полос — крупный. Выделенные в результате характерные элементы показаны
на рис. в на трех верхних изображениях приведены сглаженные цветовые координаты, а на трех
нижних — характерные текстурные элементы. Перепечатано из S. J. Belongie et al., "Color and
Texture Based Image Segmentation Using EM and Its Application to Content Based Image Retrieval”,
Proceedings of the International Conference on Computer Vision, 1998. © 1998 IEEE
Рис. 16.2. Для сегментации каждый пиксель изображения зебры (того же, что и на рис. 16.1)
помечен значением т, для которого величина p(m\xi,Qs) максимальна. На изображениях показан
результат этого процесса при К = 2,3,4,5. С каждым изображением сопоставлено К значений
яркости, соответствующих индексам сегмента. Перепечатано из S. J. Belongie et al., "Color and
Texture Based Image Segmentation Using EM and Its Application to Content Based Image Retrieval”,
Proceedings of the International Conference on Computer Vision, 1998. © 1998 IEEE
Глава 16. Сегментация и подбор с использованием вероятностных методов
501
текстурных элемента (для оценки локального масштаба, анизотропии и контра-
ста, использующие выходы соответствующих фильтров). Отметим, что более
эффективными могут быть другие характерные элементы (например, положе-
ние пикселя).
Алгоритм 16.1. Сегментация цвета и текстуры с использованием ОМ-алгоритма
Выбрать число сегментов
Построить набор вспомогательных отображений (по одному на сегмент), каждый
элемент которых отвечает пикселю. Эти отображения будут содержать
весовые коэффициенты, соотнесенные с пикселем внутри сегмента
Задать начальное состояние вспомогательных отображений:
либо оценив параметры сегмента по небольшим блокам пикселей,
а затем посчитав весовые коэффициенты, используя этап ожидания
либо
случайным образом присвоив значения элементам отображения
Повторять до схождения
Обновить вспомогательные отображения в ходе этапа ожидания
Обновить параметры сегмента в ходе этапа максимизации
конец
Алгоритм 16.2. Сегментация по цвету и текстуре с использованием
ОМ-алгоритма: этап ожидания
Для каждого положения пикселя I
Для каждого сегмента тп
Ввести a^pm(xi | в положение пикселя I во вспомогательном
отображении m
конец
Сложить значения вспомогательного отображения для получения
a^P^(xi | ^з)) и разделить на эту величину каждое значение I
в каждом вспомогательном отображении
конец
Какую информацию нужно получить от программы сегментации? Можно,
например, для каждого пикселя выбирать значение тп, при котором величи-
на р(тп | o?j,Gs) максимальна. Еще можно сообщать о данных вероятностях
и строить по ним схему логического вывода.
502
Часть IV. Компьютерное зрение: средний уровень
16.2.2. Пример: подбор линии с помощью ОМ-алгоритма
Схема подбора линий с использованием ОМ-алгоритма является логичным
продолжением разобранного выше примера сегментации; недостающие дан-
ные — это массив индикаторных переменных М, элемент (fc, I) которого ты
равен единице, если точка к получена из линии I, и нулю — в противном
случае. Как и в приведенном выше примере, ожидаемое значение получается
при определении вероятности Р(ты = 1 | точка fc, параметры линии I) и эта
вероятность пропорциональна следующей величине:
еХр (расстояние от точки к до прямой Q2
Алгоритм 16.3. Сегментация по цвету и текстуре: этап максимизации
Для каждого сегмента т
Построить новые значения параметров сегмента, используя выражения
a<J+1) = l£J>(m|«4.eW).
г 1=1
ЕГв1р(»п|®ье('>) ’
_ £Г»1р(т I жьв(<)) {(»< - дУ)(«?1 - мУ)т}
*" ЕГ=1Р(т I
Здесь р(т | ац, ©(,)) — значение m-го вспомогательного значения
для положения пикселя I
конец
Алгоритм 16.4. Подбор прямой с помощью ОМ-алгоритма: присвоение положе-
ниям точек весовых коэффициентов относительно каждой линии, причем наи-
больший весовой коэффициент получает ближайшая линия
Выбрать к прямых (возможно, распределенных случайно и равномерно)
или
Выбрать £
Повторять до схождения
Этап ожидания:
Пересчитать £, использовав расстояния по перпендикуляру
Этап максимизации:
Провести линии, используя весовые коэффициенты из матрицы £
конец
Глава 16. Сегментация и подбор с использованием вероятностных методов
503
Рис. 16.3. На верхнем рисунке показан хороший результат подбора прямых с использованием
ОМ-алгоритма. Два плохих результата показаны в нижнем ряду, где число линий выбрано верно,
но алгоритм сходится к плохим результатам — явным локальным минимумам, которые при этом
могут давать достаточно хорошую интерпретацию входных данных. При использованной реализа-
ции в модель смеси вводится член, описывающий точки, случайно и равномерно распределенные по
области; точка, которая с большой вероятностью порождена таким компонентом, считается шумом.
Еще несколько примеров плохого подбора приведены на рис. 16.4
при таком же а, что и ранее. Коэффициент пропорциональности проще всего
определить, использовав следующий факт:
= 1 | точка к, параметры прямой /) =
к
— Р(тм = 1 | точка к, параметры прямой 1) = 1.
i
Максимизация проводится подобно тому, как это было проделано в примере
подбора одной линии по набору точек, только теперь эта схема повторяется д
раз, а координаты точек взвешены значениями Сходимость можно прове-
рить, изучая сумму расстояний по перпендикуляру от точек до соответствую-
щих прямых (аналогичный результат получается при использовании логариф-
мического правдоподобия; см. раздел упражнений).
504
Часть IV. Компьютерное зрение: средний уровень
Рис. 16.4. Несколько плохих результатов подбора по данным, приведенным на рис. 16.3. В этих
примерах по набору данных приведены попытки подбора семи линий. Обратите внимание, что ре-
зультаты являются довольно хорошими интерпретациями данных; они представляют локальные экс-
тремумы функции правдоподобия. При использованной реализации в модель смеси вводится член,
описывающий точки, случайным образом равномерно распределенные по области; точка, которая
с большой вероятностью порождена таким компонентом, считается шумом. На рисунке справа
внизу несколько точек были отнесены к шуму, а по оставшимся проведены весьма удачные линии
16.2.3. Пример: сегментация движения и ОМ-алгоритм
Видеоряды часто состоят из больших областей, имеющих сходное внутрен-
нее движение. Предположим, что дана очень короткая последовательность —
два кадра — и требуется определить поле движения в каждой точке перво-
го кадра. Предполагается, что для получения поля движения используется
модель смеси. Напомним, что общая модель смеси — это взвешенная сумма
плотностей, причем компоненты не обязательно имеют гауссову форму, ис-
пользованную в разделе 16.1.1 (в задачах компьютерного зрения недостающие
данные, ОМ-алгоритм и общие модели смеси естественным образом формируют
связанное целое).
Базовая модель видеоряда должна иметь следующую форму:
* в каждом пикселе каждого изображения имеется вектор движения, соеди-
няющий его с пикселем следующего изображения;
• имеется набор различных параметрических полей движения, каждое из
которых получено на основе своей вероятностной модели;
• общее движение определяется моделью смеси, т.е. чтобы проследить дви-
жение пикселя изображения, следует знать, к какому компоненту движе-
ния относится пиксель, и выдать движение этого компонента.
В данной модели определяется набор различных, но внутренне сходных полей
движения, которые могут отвечать, скажем, твердым телам, расположенным
на различном расстоянии от движущейся камеры (рис. 16.5). Отдельные поля
Глава 16. Сегментация и подбор с использованием вероятностных методов
505
Рис. 16.5. Кадры 1, 15 и 30 изображения цветочного сада в формате MPEG (данное изображение
часто используется для демонстрации алгоритмов сегментации движения). Создается впечатление,
что изображение получено с транслирующей камеры, причем дерево расположено значительно
ближе к камере, чем дом, а цветочный сад расположен на заднем фоне. В результате кажется, что
дерево быстро перемещается по кадрам, а дом — медленно; плоскость генерирует аффинное поле
движения. Перепечатано из J.Wang and Е.Н. Adelson, “Representing moving images with layers”,
IEEE Transactions on Image Processing, 1994. © 1994 IEEE
движения часто называются уровнями, а модель — моделью многоуровневого
движения.
Предположим теперь, что поле движения задано в параметрической форме
и что имеется д различных полей движения. Для данной пары изображений
требуется определить: а) к какому полю движения относится каждый пиксель
и б) значения параметров каждого поля. При такой формулировке задача кажет-
ся весьма подобной двум рассмотренным выше — если известно одно, второе
определяется легко, а если известно второе, легко определяется первое. Это
снова задача с недостающими данными: отсутствующие данные представляют
собой поле движения, к которому принадлежит пиксель, а параметры — это
параметры каждого поля и весовые коэффициенты элементов смеси.
Предположим, что пиксель в точке (u,v) первого изображения принадле-
жит к l-му полю движения, имеющему параметры &i. Это означает, что на вто-
ром изображении этот пиксель переместился в точку (и, v) +m(u,v,0i), и что
интенсивность этих двух пикселей равна с точностью до ошибки измерения.
Интенсивность в точке (и, v) первого изображения записывается как Ii(u,v)
и т.д. Недостающие данные — это информация о том, к какому полю движения
относится пиксель. Это можно представить переменной-индикатором Vuv,i, где
1 — если пиксель (и, v) относится к i-му полю движения
0 — в противном случае
Предполагается, что на значения интенсивностей пикселей изображения влияет
гауссов шум с дисперсией а, так что логарифмическое правдоподобие полного
набора данных записывается следующим образом:
цу 0) _ _ V W**»v) ~ h(u + mi(u,v;0i)tv + т2(и,у;ft)))2
2сг2
506
Часть IV. Компьютерное зрение: средний уровень
Рис. 16.6. На рисунке слева вверху изображена карта, на которой показано, к какому уровню при-
надлежат пиксели кадра видеоряда с изображением цветочного сада. Карта получена в процессе
кластеризации локальных оценок движения на изображении. Каждый яркостный уровень отвечает
уровню движения, а каждый уровень движется со своей аффинной моделью движения. Карту мож-
но очистить, проверив, насколько движение соседних пикселей согласуется с движением соседей на
минувших и будущих кадрах. Результат подобной очистки показан справа вверху. Три уровня и их
модели движения показаны на рисунке внизу. Перепечатано из J. Wang and E.U. Adelson, “Repre-
senting moving images with layers”, IEEE Transactions on Image Processing, 1994. © 1994 IEEE
где 0 = (0i,...,09). Дальнейшая реализация ОМ-алгоритма очевидна. Как
и ранее, основным является определение величины
Данные вероятности часто представляются как вспомогательные отображе-
ния — карты яркостного представления максимально вероятного уровня для
каждого пикселя (рис. 16.6). Более интересен здесь вопрос подходящего выбо-
ра параметрической модели движения. Обычно принимают аффинную модель
движения, где
ТП1
7712
Оц
«21
«12
«22
=
1 ( 1 1 + ( 013
J ( 3 ) ( «23
и Oi = (ац,... ,«2з)- Представления в виде многоуровневого движения полезны
по нескольким соображениям. Во-первых, они связывают точки, движущиеся
“в одном направлении”. Во-вторых, они определяют границы движения. Нако-
нец, новые последовательности можно восстановить по уже имеющимся уров-
ням, для чего используются весьма интересные схемы (рис. 16.7).
Глава 16. Сегментация и подбор с использованием вероятностных методов 507
Рис. 16.7. Одна из особенностей представления движения в виде многоуровневой схемы заключа-
ется в том, что последовательность движения можно восстановить без некоторых уровней. В при-
веденном примере видеоизображение сада в формате MPEG восстановлено с тремя пропущенными
уровнями. На рисунке слева показан кадр 1, на рисунке в центре — кадр 15, а справа изображен
кадр 30. Перепечатано из 1. Wang and Е.Н. Adelson, “Representing moving images with layers”,
IEEE Transactions on image Processing, 1994. © 1994 IEEE
16.2.4. Пример: использование ОМ-алгоритма для определения
посторонних значений
Описанные схемы подбора линий усложняются при наличии посторонних
значений, поскольку модель не предсказывает частоту появления таких зна-
чений. Часто говорят, что посторонние значения “находятся в хвостах" функ-
ций распределения. Если распределение вероятностей — это нормальный закон,
имеется множество значений с малой вероятностью, которые находятся в хво-
сте функции распределения. Естественный механизм обработки посторонних
значений заключается в такой модификации модели, чтобы распределение име-
ло более тяжелый хвост (т.е. чтобы попасть в хвост функции распределения
было более вероятно).
Один из способов достичь намеченного результата — построить явную мо-
дель посторонних значений, что обычно довольно просто. Для этого формиру-
ется взвешенная сумма правдоподобия Р(измерения | модель) и члена посто-
ронних значений Р(выбросы). Получаем
(1 - А)Р(измерения | модель) + АР(выбросы).
Здесь А Е [0,1] моделирует частоту появления посторонних значений, а
Р(выбросы) — некоторая вероятностная модель посторонних значений. По-
скольку что-либо лучшее предложить довольно трудно, считается, что ве-
роятность появления посторонних значений равномерна во всем диапазоне
представленных данных.
Естественный способ использования этой модели — построить перемен-
ную, указывающую, какой компонент генерирует каждую точку. Имея эту
переменную, получаем функцию правдоподобия полного набора данных до-
вольно простой формы. Разумеется, данная переменная неизвестна — это уже
привычная задача с недостающими данными, далее используем ОМ-алгоритм
и т.д. (подробнее — см. раздел упражнений). Здесь также возникают обычные
проблемы ОМ-алгоритма (рис. 16.8). В частности, легко попасть в локальный
508
Часть IV. Компьютерное зрение: средний уровень
Рис. 16.8. ОМ-алгоритм может использоваться для очистки данных от посторонних значений.
На рисунке демонстрируется подбор линии по второму набору данных (рис. 15.7). На рисунках
в верхнем ряду показаны корректные локальные минимумы, а внизу изображен другой набор ло-
кальных минимумов. В первом столбце показана прямая, наложенная на данные точки с исполь-
зованием тех же осей, что и на рис. 15.7; во втором столбце показано увеличенное изображение
прямой, на котором видна область вокруг данных точек; наконец, в третьем столбце показан
график вероятности того, что точка порождена прямой, а не шумом, в зависимости от номера
точки. Обратите внимание, что в правильном локальном минимуме все точки, кроме одной, соот-
несены с прямой, тогда как в неверном локальном минимуме с прямой соотнесены две точки, а все
остальные отнесены к шуму
минимум, кроме того, следует аккуратно следить за численным представлением
малых вероятностей.
16.2.5. Пример: вычитание фона с использованием ОМ-алгоритма
Как отмечалось в разделе 14.3.1, оценка фона может быть сложной. Про-
стое усреднение по всем кадрам имеет один недостаток: объект, проводящий
много времени на одном месте, может сильно влиять на значение среднего. Дан-
ную задачу также можно рассматривать как задачу с недостающей переменной:
изображения в каждом кадре видеоряда неизменно (с точностью до умножения
на некоторую константу, чтобы учесть изменения, производимые схемой авто-
матической регулировки усиления), но к нему добавляется шум. При моделиро-
вании шума считается, что он поступает от некоторого равномерного источника.
Такой подход имеет дополнительный плюс: каждый пиксель, принадлежащий
шуму, не относится к фону; “вычитание” можно произвести, просто посмотрев
на ожидаемые значения недостающих переменных в экстремуме. Вычисления
прямолинейны; подобным образом получены части г и д рис. 14.10 и 14.11.
Глава 16. Сегментация и подбор с использованием вероятностных методов
509
16.2.6. Пример: ОМ-алгоритм и фундаментальная матрица
Подбор фундаментальной матрицы также можно рассматривать как задачу
с недостающими данными; теперь отсутствующие данные — это информация
о соответствии. Предположим, что дано п точек на левом и правом изображе-
ниях, а требуется найти матрицу С размером п х п, переводящую один набор
точек в другой. В частности, элемент — единица, если г-я точка левого
изображения соответствует j-й точке правого, и нуль — в противном случае.
Детальный вид этапов ожидания и максимизации слишком сложен, поэтому
здесь не приводится; ограничимся общей схемой, ее реализацию предлагает-
ся провести читателям в качестве самостоятельного упражнения. Матрица С
представляет отсутствующие данные; если известна эта матрица, можно вы-
числить логарифмическое правдоподобие полного набора данных и с помощью
метода экстремалей найти параметры, которыми для каждой точки являют-
ся xri, yri, хц и матрица А. Подобным образом, имея оценку параметров, отно-
сительно прямой задачей является вычисление ожидаемого значения матрицы С
(каждая точка левого изображения предсказывает точку на правом; ожидае-
мые значения дают расстояния между этими точками и их измерениями). Как
и ранее, предполагается, что математическое ожидание матрицы С — в общем
случае величина нецелая. Как и ранее, данный весовой коэффициент интерпре-
тируется как частота и при вычислении правдоподобия вероятность возводится
в соответствующую степень.
Данный метод маловероятно даст хорошие результаты, если удачно не
выбрать стартовые значения. Проблема проста: ОМ-алгоритм может сгла-
дить эффект компонента комбинаторного поиска в задаче с недостающими
переменными, но не может устранить его полностью. Пространство соответ-
ствий, представленное матрицей С, огромно — (п!), и значительная часть
этого пространства имеет мало хороших соответствий (или вообще не имеет).
Поскольку в алгоритме ищется наилучшая доступная фундаментальная мат-
рица при данном наборе соответствий, плохое начало весьма вероятно может
привести к серьезным проблемам. Это объясняется тем, что исходный набор
соответствий может быть неверным, что приведет к плохой оценке фундамен-
тальной матрицы, а затем к предсказанию еще более неверных соответствий
и т.д. Одно из средств борьбы с этим эффектом — запустить вначале алго-
ритм RANSAC, а затем — ОМ-алгоритм. Преимущество такого подхода перед
обычным применением алгоритма RANSAC состоит в том, что при использова-
нии ОМ-алгоритма в заключительной фазе можно должным образом взвесить
подходящие соответствия.
16.2.7. Сложности при использовании ОМ-алгоритма
ОМ-алгоритм имеет склонность попадать в локальные минимумы. Эти ми-
нимумы обычно связаны с комбинаторными аспектами исследуемой задачи (по
крайней мере для примеров с подбором прямой или фундаментальной матри-
цы). Эти сложности следуют из предположения о том, что точки взаимозаме-
510
Часть IV. Компьютерное зрение: средний уровень
няемы (см. рис. 16.3 и рис. 16.4). Этого можно избежать, отметив, что конечная
конфигурация любой схемы подбора — это детерминистическая функция ее на-
чальной точки, а также использовав тщательно выбранные начальные точки.
Один из подходов заключается в том, чтобы начать со многих различных (вы-
бранных случайным образом) конфигураций и просеивать результаты, стремясь
к наилучшему подбору. Другой подход — предварительная обработка данных
с использованием метода, подобного преобразованию Хоха, для получения хо-
рошего начального предположения о подбираемой линии. Впрочем, ни один
из подходов не дает никаких гарантий (обычно это результат некорректной
формулировки задачи). Если точки не являются неразличимыми и обладают
некоторой связанной структурой, выбрать хорошую начальную точку должно
быть значительно проще.
Вторая сложность ОМ-алгоритма состоит в том, что некоторые точки будут
иметь очень малые ожидаемые весовые коэффициенты. Здесь возникает про-
блема численного характера: не ясно, что произойдет, если принять, что малые
весовые коэффициенты равны нулю (вообще, так поступать неразумно в любом
случае). В свою очередь, возможно, потребуется численное представление, поз-
воляющее суммировать множество очень малых чисел с получением ненулевого
результата. Хотя подробнее данный вопрос в книге рассматриваться не будет,
недооценивать его значимость все же не стоит.
16.3. ВЫБОР МОДЕЛИ: КАКАЯ МОДЕЛЬ ДАЕТ НАИЛУЧШЕЕ
СООТВЕТСТВИЕ
На всех этапах обсуждения задач с недостающими переменными предпо-
лагалось, что число компонентов в модели смеси известно. Как правило, на
практике это не так. По сути, нахождение числа компонентов — это проблема
выбора модели, поскольку здесь производится поиск в наборе моделей (а раз-
личнее модели имеют различное число компонентов) с целью определения того,
какая модель дает наилучший результат подбора при данных точках.
Как правило, значение отрицательного логарифмического правдоподобия —
это плохой указатель на число компонентов, поскольку в общем случае мо-
дель с большим числом параметров дает лучший результат подбора по набору
данных, чем модель с меньшим числом параметров. Это означает, что простая
минимизация отрицательного логарифмического правдоподобия как функции
числа компонентов имеет тенденцию к получению слишком большого числа
компонентов. Например, набор линий можно подобрать крайне точно, проведя
линию через каждую пару точек; число линий в таком случае может оказать-
ся очень большим, но ошибка подбора будет нулевой. Эту сложность можно
обойти, если ввести член, увеличивающийся с ростом числа компонентов; этот
штраф компенсирует спад логарифмического правдоподобия, вызванный увели-
чением числа параметров.
Важно понимать, что канонической модели процесса выбора не существу-
ет. Вместо этого можно выбирать из множества схем, в каждой из которых
Глава 16. Сегментация и подбор с использованием вероятностных методов
511
использован иной принцип счета, соответствующий своему методу нахождения
экстремали (и своим аппроксимациям используемых критериев!).
16.3.1. Основные идеи
Основная проблема в задачах параметрического подбора — выбор модели.
Сформулировать ее можно следующим образом: дан набор данных, являющийся
выборкой параметрической модели, которая представляет собой элемент семей-
ства моделей. Требуется определить а) из какой модели получен набор данных
и 6) какими были параметры модели. Надлежащий выбор параметров предска-
зывает дальнейшие выборки из модели — пробный набор, — а также набор
данных (который часто называется настроечным набором). К сожалению, эти
дальнейшие выборки недоступны. Более того, оценки параметров модели, полу-
ченные с использованием набора данных, с большой вероятностью будут смеще-
ны, поскольку выбранные параметры обеспечивают оптимальное соответствие
модели настроечному набору, а не полному набору возможных данных. Такой
эффект называется смещением вследствие выбора. Настроечный набор — это
подмножество полного набора данных, которое можно извлечь из модели; он
представляет модель только в том случае, если является бесконечно большим.
Именно поэтому при выборе модели не стоит руководствоваться отрицательным
логарифмическим правдоподобием: результат подбора выглядит лучше только
потому, что он постепенно смещается.
Какой штраф стоит использовать? Для ответа определим понятие аномаль-
ности:
удвоенное (логарифмическое правдоподобие наилучшей модели минус ло-
гарифмическое правдоподобие текущей модели)
(определение взято из [Ripley, 1996]). Наилучшая модель должна быть истин-
ной моделью. В идеальном случае аномальность должна быть равна нулю; из
приведенных выше аргументов следует, что аномальность настроечного набора
больше аномальности тестового. Естественно использовать такой штраф, как
разность между данными аномальностями, усредненными по пробному и на-
строечному наборам. Этот штраф применяется к удвоенному логарифмическо-
му правдоподобию подобранного объекта (почему применяется множитель 2 —
авторам неизвестно, никакого практического эффекта он не дает). Обозначим
наилучший выбор параметров как в*, а логарифмическое правдоподобие объ-
екта, подобранного по набору данных, — как Z(x;G*).
16.3.2. AIC — информационный критерий
Акайке (Akaike) предложил штраф, часто называемый критерием AIC (от
“Ап Information Criterion”, не “Akaike Information Criterion”), в котором исполь-
зуется минимизация выражения
—2L{x\ в*) + 2р,
512
Часть IV. Компьютерное зрение: средний уровень
где р — число свободных параметров. В настоящее время о данном крите-
рии ведутся статистические дебаты. Один из главных вопросов заключается
в том, что в критерии не фигурирует член с числом данных точек. Это вызы-
вает подозрения, поскольку отклонение подбираемой модели от действительной
должно уменьшаться с увеличением числа данных точек. Вторая тема для де-
батов — достаточное число экспериментов, показывающих, что критерий AIC
имеет склонность к переобучению — т.е. выбору модели со слишком большим
числом параметров, которая подбирается к настроечному набору, но не дает
хороших результатов на пробных наборах.
16.3.3. Методы Байеса и критерий Шварца
Для простоты запишем данные как 7>, модель — как «Л4, а параметры —
как 0. Далее из правила Байеса получаем следующее:
S P(v\Mi,e)p(e)dep(M)
р(р)
Теперь можно выбрать модель, для которой велика указанная апостериорная
вероятность. Вычисление ее может оказаться сложным, впрочем, после ряда
приближений можно получить следующий критерий:
-Ь(7?;в-) + |logN,
именуемый информационным критерием Байеса (Bayes Information Crite-
rion — BIC).
16.3.4. Длина описания
Для выбора моделей могут использоваться и нестатистические критерии.
Естественный критерий — это выбор модели, максимально эффективно кодиру-
ющей набор данных (критерий минимальной длины описания). Чтобы передать
и набор данных, кодируются, а затем передаются параметры модели, после че-
го с использованием этих параметров модели передаются данные. Если данные
плохо соответствуют модели, то этот последний элемент больше, поскольку
кодирования требует шумоподобный сигнал.
Мы не будем рассматривать вариации описанного критерия, используемые
на практике. Детальное описание этих схем можно найти в работах [Rissanen,
1983] и [Rissanen, 1987] или [Wallace and Freeman, 1987]; сходные идеи, осно-
ванные на информационной теории Колмогорова, описаны в работе [Cover and
Thomas, 1991]. Кстати, такой подход также позволяет получить критерий BIC:
-L(C;e’)+ | log N.
Глава 16. Сегментация и подбор с использованием вероятностных методов
513
16.3.5. Другие методы оценки аномальности
Основная сложность при выборе модели заключается в том, что требуется
использовать величину, которую невозможно измерить — способность модели
предсказывать данные не входит в настроечный набор. При наличии достаточ-
но большого настроечного набора его можно расщепить на два компонента,
использовать один для подбора модели, а другой — для тестирования резуль-
татов подбора. Данный подход называется перекрестной проверкой.
Перекрестную проверку можно использовать для определения числа компо-
нентов модели через расщепление набора данных, подбора нескольких различ-
ных моделей по одной части данных с последующим выбором модели, дающей
наилучший результат на другой части данных. Ожидается, что этот процесс
оценит число компонентов, поскольку модель со слишком большим числом
параметров даст хороший результат на одном наборе данных, но плохой — на
другом.
Использование простого расщепления на два компонента вводит еще одну
разновидность отклонения вследствие выбора; безопаснее всего здесь усред-
нить оценку по всем таким разбиениям. Поступать подобным образом неразум-
но, если пробный набор велик, поскольку число возможных разбиений огромно.
Как правило, используется перекрестная проверка по принципу “исключение
одного". При таком подходе модель подбирается для каждого из N — 1 настро-
ечного набора, вычисляется ошибка в оставшейся точке, а затем такие ошибки
суммируются и дают оценку ошибки модели. После этого выбирается модель,
минимизирующая данную оценку.
По мнению авторов, такой подход (обычный при выборе модели во множе-
стве задач) не должен использоваться в схемах подбора. Безусловно, он подхо-
дит для оценки числа компонентов. Но предположим, что требуется определить
ошибку модели для модели с числом компонентов, слишком малым, чтобы точ-
но описать изображение. В данном случае ошибка модели велика, поскольку
для многих пикселей эта модель недостаточно гибка, чтобы описать отброшен-
ный пиксель. Подобным образом, если использовать слишком большое число
компонентов, модель одинаково плохо предскажет отброшенный пиксель.
16.4. ПРИМЕЧАНИЯ
Важность моделей с недостающими переменными должна быть очевидной.
ОМ-алгоритм впервые был формально описан в литературе по статистике (на-
пример, [Dempster, 1977]). Хорошей резюмирующей работой по данной теме яв-
ляется [Mclachlan and Krishnan, 1996], где описаны различные вариации этой
схемы. Например, не обязательно находить максимум Q(u\u^)-, все, что тре-
буется, — получить лучшее значение. Кроме того, ожидание можно оценить,
используя методы стохастического интегрирования.
514
Часть IV. Компьютерное зрение: средний уровень
ОМ-алгоритм и модели с недостающими переменными
Похоже, что модели с недостающими переменными становятся популярными
везде, где только возможно. Все модели, распространенные в области компью-
терного зрения, развились из моделей смесей (поэтому логарифмическое прав-
доподобие полного набора данных в них линейно по недостающим переменным),
поэтому данной теме было уделено немало внимания. Модели с недостающими
переменными естественно используются при сегментации ([Adelson and Weiss,
1996], [Belongie, Carson, Greenspan and Malik, 1998], [Feng and Perona, 1998],
[Vasconcelos and Lippman, 1997], [Wells, Grimson, Kikinis and Jolesz, 1996]).
В настоящее время модели модернизируются с учетом новых знаний о чело-
веческом восприятии нескольких изображений (это относится и к наблюдению
чего-то в движении, и к стереоизображениям). Общая идея: набор изображений
разбивается на различные уровни, причем элементы уровня движутся одинако-
во ([Adelson and Weiss, 1996], [Dellaert, Seitz, Thorpe and Thrun, 2000], [Tao,
Sawhney and Kumar, 2000], [Wang and Adelson, 1994], [Weiss, 1997]), распо-
ложены на одинаковой глубине от средства наблюдения ([Baker, Szeliski and
Anandan, 1998], [Brostow and Essa, 1999], [Torr, Szeliski and Anandan, 19996])
или имеют некоторое иное общее свойство. Другой интересный частный слу-
чай — движение, следующее из прозрачности, зеркального отражения и т.д.
([Black and Anandan, 1996], [Darrell and Simoncelli, 1993], [Hsu, Anandan and
Peleg, 1994], [Jepson and Black, 1993], [Szeliski, Avidan and Anandan, 2000]).
Получающееся в таких случаях представление может использоваться для до-
вольно эффективной визуализации на основе изображения ([Shade, Gortler, Li-
wei and Szeliski, 1998]). Это также является моделью смеси. Данная задача не
всегда рассматривается как задача со скрытыми переменными (скрытая пере-
менная — это уровень, к которому принадлежит пиксель, или, что то же самое,
уровень, который генерирует этот пиксель), но такая возможность существует.
Ожидается, что вскоре эта тема получит более широкое развитие.
Алгоритм ожидания-максимизации является крайне эффективным, но не
всесильным. Основной источник проблем — локальный максимум. Вообще,
для задач с большим числом отсутствующих переменных характерно большое
число локальных максимумов. С этим можно бороться, начав оптимизацию
около правильного решения. На практике многие задачи компьютерного зре-
ния, которые могут решаться с помощью ОМ-алгоритма, выглядят значительно
проще решения, полученного при данном числе отсутствующих переменных.
Значит, должен существовать какой-то способ получения менее громоздких ре-
шений. Исследование сложности задачи с недостающими переменными кажется
перспективным.
Выбор модели
Выбор модели — это тема, которой уделяется гораздо меньше внимания,
чем она заслуживает. По изучению движения проделана значительная работа;
вопрос в том, какую модель камеры использовать (ортографическую, парапер-
Глава 16. Сегментация и подбор с использованием вероятностных методов
515
спективную и т.д.)(см. работы [Kinoshita and Lindenbaum, 2000], [Maybank and
Strum, 1999], [Torr, 1997], [Torr, 1999]).
Многое достигнуто в области сегментации отдаленных изображений, где
нужно определить, с каким набором параметрических поверхностей следует
сопоставлять данные (т.е. изображено две плоскости или три и т.д.; публика-
ция [Bubna and Stewart, 2000]). В задачах восстановления иногда требуется
решить, присутствует ли вырожденная последовательность движений камеры
([Torr, Fitzgibbon and Zisserman, 1999a]). Обычная проблема при сегмента-
ции — определить число сегментов ([Adelson and Weiss, 1996], [Belongie et aL,
1998], [Raja, McKenna and Gong, 1998]). Если модели используются предсказу-
емым образом, иногда стоит вычислить взвешенное среднее по предсказаниям
моделей (методы Байеса не позволяют однозначно выбрать модель — см. работу
[Ripley, 1996], [Torr and Zisserman, 1998]). В главе описаны только некоторые
из доступных методов; в частности, пропущен критерий геометрической инфор-
мации Канатани [Kanatani, 1998].
Задачи
16.1. Выведите выражение для сегментации, приведенное в разделе 16.1. Од-
на из его возможных модификаций заключается в использовании ново-
го среднего в оценке ковариационных матриц. Проведите эксперимент
и определите, изменит ли это что-нибудь на практике.
16.2. Опишите подробно использование ОМ-алгоритма для вычитания фона.
Полезно ли иметь более сложную основоположную модель, усредняю-
щую случайный шум?
16.3. Опишите использование перекрестной проверки по принципу “исключе-
ние одного” для выбора числа сегментов.
Упражнения
16.4. Напишите программу вычитания фона с использованием ОМ-алгоритма.
Удобно ли для устранения проблем с высокими пространственными ча-
стотами (рис. 14.11) ввести член возмущения?
16.5. Разработайте программу сегментации на основе ОМ-алгоритма, исполь-
зующую для сегментации изображений цвет и положение (идеальный
вариант — еще и текстуру). Используйте схему выбора модели для опре-
деления числа сегментов. Насколько значимым является эффект локаль-
ного минимума?
16.6. Напишите программу подбора прямой с использованием ОМ-алгоритма,
работающую с фиксированным числом линий. Исследуйте эффект ло-
кального минимума. Один из способов не попасть в ловушку локального
минимума — это начать с нескольких стартовых точек и выбрать из набо-
ра лучший результат. Насколько успешна разработанная схема? Сколько
локальных минимумов пришлось исследовать, чтобы получить хороший
результат подбора по типичному набору данных? Можно ли улучшить
схему с помощью преобразования Хоха?
516
Часть IV. Компьютерное зрение: средний уровень
16.7. В программу из предыдущего упражнения введите схему выбора модели,
чтобы можно было определять число линий, требуемых для представле-
ния набора данных. Сравните критерии AIC и BIC.
16.8. Введите в программу смоделированный шум, чтобы теперь подбор линий
был устойчивым. Как шум отразился на числе локальных минимумов?
Отметьте, что если вероятность того, что точка порождена шумом, ма-
ла, с линиями будет соотнесено большинство точек, но общий результат
будет достаточно плохим. При большой вероятности того, что точка по-
рождена шумом, точки будут соотноситься с линиями только при очень
удачном подборе линии. Как шум влияет на число локальных миниму-
мов?
16.9. Постойте схему подбора линий на основе алгоритма RANSAC, которая
будет проводить произвольное (но известное) количество линий по пред-
ложенному набору данных. Что потребуется для того, чтобы эта програм-
ма определяла наилучшее число линий?
17
Сопровождение
с использованием линейных
динамических моделей
Сопровождение — это задача определения движения объекта по данной после-
довательности изображений. Удачные решения этой задачи находят применение
во множестве областей.
• “Захват движения* *1. Если движущийся объект удается сопровождать
точно, можно получить точную запись его движения. По этой записи
можно выполнить процесс визуализации; например, можно контролиро-
вать мультипликационный персонаж, тысячи отдельных лиц в толпе или
детали виртуального трюка. Более того, запись движения можно модифи-
цировать и получить несколько иное изображение. Это означает, что актер
при желании может получить изображение того, чего в действительности
он не делал.
• Распознавание по движению. Движение существенно характеризует
объекты. По движению объекта, возможно, удастся идентифицировать
сам объект, по крайней мере, можно будет сказать, что этот объект
делает.
• Наблюдение. Знание о том, что делают объекты наблюдения, может быть
весьма полезным. Например, движение различных механических аппа-
ратов в аэропорту должно происходить по разным схемах; если это не
518
Часть IV. Компьютерное зрение: средний уровень
так, что-то делается неверно. Подобным образом, имеются комбинации
мест и схем движения, которые никогда не должны возникать (напри-
мер, никакой аппарат никогда не должен останавливаться на используе-
мой взлетно-посадочной полосе). Полезно иметь компьютерную систему,
которая может отслеживать активность и выдавать предупреждение при
обнаружении проблемной ситуации.
* Прицеливание. Значительная часть литературы по системам наведения
ориентирована на освещение двух вопросов: а) принятие решения о том,
по чем стрелять; б) собственно поражение цели. Как правило, в подоб-
ной литературе описывается сопровождение с использованием сигналов,
поступающих от радаров или детекторов инфракрасного излучения (а не
от устройств визуального наблюдения), но основные вопросы при этом
не меняются: что можно предположить о будущем положении объекта по
данной последовательности данных и куда целиться?
В типичной задаче сопровождения известна модель движения объекта и некото-
рый набор данных (измерения), полученных по последовательности изображе-
ний. Эти данные могут касаться положения некоторых точек изображений или
чего-то другого, кроме того, они не обязательно будут относиться к рассматри-
ваемому объекту — возможно, источником данных был шум или другой объект.
Сопровождение стоит рассматривать как задачу логического вывода. Движу-
щийся объект имеет определенное внутреннее состояние, которое измеряется
на каждом кадре. Чтобы оценить состояние объекта, требуется максимально
эффективно обобщить полученные измерения. Возможны два частных случая.
Если и динамика, и измерения линейны, задача логического вывода является
прямолинейной и имеет стандартное решение. Если же требуется рассмотреть
нелинейную динамику, то следует помнить, что даже слабая нелинейность
динамики системы имеет огромное значение. В результате построение логи-
ческих выводов может быть затрудненным и в общем случае невозможным.
Впрочем, существует один удачный алгоритм, который можно использовать при
низкой размерности пространства состояний и который часто дает приемлемые
результаты. Задача сопровождения в системе с нелинейной динамикой, связан-
ной с некоторой технической деятельностью, подробно рассмотрена в главе,
размещенной на web-сайте данной книги.
В этой главе основное внимание уделяется формулировке задачи сопровож-
дения при линейной динамике. В разделе 17.1 сопровождение схематически
описано как задача логического вывода. В разделе 17.2 рассмотрена линейная
динамика и фильтры Кальмана. Затем в разделе 17.5 в общих чертах описаны
несколько примеров применения сопровождения. Наиболее интересной такой
областью является сопровождение людей. Поскольку данная задача требует
обсуждения нелинейной динамики, она рассмотрена в главе, размещенной на
web-сайте книги.
Глава 17. Сопровождение с использованием линейных динамических моделей
519
17.1. СОПРОВОЖДЕНИЕ КАК АБСТРАКТНАЯ ЗАДАЧА ЛОГИЧЕСКОГО
ВЫВОДА
Большая часть данной главы посвящена алгоритмическому описанию сопро-
вождения. В частности, сопровождение рассматривается как задача логическо-
го вероятностного вывода. Ключевой технической сложностью здесь являет-
ся поддержание (причем эффективное!) точного представления апостериорной
вероятности положения объекта при имеющихся данных. При моделировании
объекта считается, что он имеет некоторое внутреннее состояние; состояние
объекта на г-м кадре обычно записывается как Xi. Заглавные буквы использу-
ются для обозначения случайных переменных; если потребуется указать кон-
кретное значение, которое может принять данная переменная, будут использо-
ваться строчные буквы. Измерения, выполненные на г-м кадре, — это значения
случайной переменной Yзначение, полученное при измерениях, будем за-
писывать как иногда будет использоваться запись У» = yt. Большинство
практических ситуаций можно свести к одной из трех основных задач.
• Предсказание. Дана последовательность у0,..., у^ и требуется опре-
делить, какое состояние для г-го кадра она предсказывает. Для реше-
ния этой задачи необходимо представление вероятности P(Xi | Уо —
3/о,...,У;-1 =Vi-i)-
• Ассоциация данных. О состоянии объекта могут сообщить некоторые
измерения, полученные из г-го кадра. Как правило, для извлечения этих
данных используется вероятность P(Xi | Уо = Уо, = ^_х).
• Коррекция. Теперь дана величина у{ (существенные данные) и требуется
вычислить представление вероятности Р(Х{ | Уо = у0, • •, У» = 3/»)-
17.1.1 . Допущения о независимости
Задача сопровождения сложна, если не сделать следующие допущения.
* Важно только непосредственно предшествующее состояние. Формаль-
но, это обозначает следующее требование:
P(Xi | Xi,..., Xi-i) = P(Xi | Xi-j).
Как будет показано далее, данное предположение очень сильно упрощает
структуру алгоритмов. Более того, оно не является чрезмерно разруши-
тельным, если знать, как интерпретировать Xi (см. следующий раздел).
* Измерения зависят только от текущего состояния. Предполагается,
что величина У» — условно независима от других измерений при данном
значении Х{. Это означает, что
P(Y<, Yj,... Yk | Xi) = P(Yi | Х»)Р(УЬ..., У fc | Xi).
520
Часть IV. Компьютерное зрение: средний уровень
Как и ранее, это допущение не является особенно ограничивающим или
спорным, но значительно упрощает задачу.
Приведенные допущения означают, что задача сопровождения имеет структуру
задачи вывода по скрытой марковской модели (где и состояние, и измерения
могут принимать значения из непрерывного диапазона). Данную главу стоит
сравнить с разделом 23.4, где описывается использование скрытых марковских
моделей при распознавании.
17.1.2 . Сопровождение как задача логического вывода
Продолжим рассуждать индуктивно. Во-первых, предположим, что дана ве-
личина P(Xq) — первоначальное, ничем не обоснованное предсказание. Даль-
нейшая корректировка этой величины очевидна: как только получено значе-
ние Уо (которым является у0), можно записать следующее:
РГХ IV I Хо)Р(Хо) _
Р(Хо | Уо - у0) ---------------=
Р(Ро I Хо)Р(Хо)
fP(yo\Xo)P(Xo)dXo
ос Р(Ро I Хо)Р(Хо).
Все это — просто запись теоремы Байеса, причем либо коэффициент пропор-
циональности вычисляется, либо внимание на нем не акцентируется (в зави-
симости от конкретной ситуации). Теперь можно предположить, что имеется
представление Р(Х£~1 ( у0,..., у^).
Предсказание
Предсказание включает представление величины
P(Xi|j/0,...,2/i_1).
Принятые допущения о независимости позволяют записать следующее:
P(Xi|3/0,...,2/i_1) = J P(Xi,Xi-1\y0,...,yi^)dXi-1 =
= j P(Xi\Xi_1,yOt...,yi_1)P(Xi-1\yOi...,yi_1)dXi-1 =
= I P{Xi\Xi-1)P(Xi-i\y0,...,yi_1)dXi-1.
Коррекция
Коррекция включает получение представления величины
Р(Х^?/0,...,рД
Глава 17. Сопровождение с использованием линейных динамических моделей
521
Принятые допущения о независимости позволяют записать следующее:
I Уо, =
Р(ХьУо,...,у{)
Р(Уо,- -,2/i)
= P(yj 1Х^у0,...,у^)Р(Х< |Уо, --,У,1)Р(Уо,---,У£1) =
Р(Уо>--чУ{.)
f P(Vi | Xi)P(Xi | 2/0, - , Vi-i)dXi'
17.1.3 . Обзор
При разработке алгоритмов ключевой вопрос состоит в поиске представле-
ния значимых функций плотности вероятности, которые а) достаточно точны
для удовлетворения поставленных целей и б) позволяют легко и быстро вычис-
лить две приведенных выше суммы. В разделе 17.2 рассмотрена простейшая
ситуация, когда динамика и модель измерений линейны, а шум моделируется
гауссовым случайным процессом. Ассоциация данных рассмотрена в разде-
ле 17.4, а примеры систем сопровождения в действии представлены в раз-
деле 17.5. С появлением нелинейностей возникают значительные проблемы;
некоторые современные методы работы с нелинейными системами рассмотрены
в главе, размещенной на web-сайте данной книги.
17.2. ЛИНЕЙНЫЕ ДИНАМИЧЕСКИЕ МОДЕЛИ
Между линейными преобразованиями и гауссовыми функциями плотности
вероятности существует удобная связь. Практическим ее следствием является
то, что если ограничить рассмотрение линейными динамическими моделями
и линейными моделями данных (причем в обеих учитывается аддитивный гаус-
сов шум), все функции плотности вероятности, представляющие практический
интерес, будут описываться гауссианами. Более того, можно обойтись без сче-
та различных интегралов, встречающихся в обычных задачах, поскольку су-
ществуют трюки, позволяющие непосредственно определить, каким является
искомый гауссиан.
В простейшей возможной динамической модели изменение состояний за-
ключается в умножении предыдущего состояния на известную матрицу (кото-
рая может зависеть от номера кадра) с последующим прибавлением случай-
ной переменной с нормальным распределением, нулевым средним и известной
дисперсией. Подобным образом, данные измерений получаются как состояние,
умноженное на матрицу (которая может зависеть от номера кадра), с после-
дующим прибавлением случайной переменной с нормальным распределением,
нулевым средним и известной дисперсией. Далее будет использоваться следу-
522
Часть IV. Компьютерное зрение: средний уровень
кидая форма записи:
х ~ N(p, S),
где аг — значение случайной переменной с нормальным распределением веро-
ятности со средним д и дисперсией Е; обратите внимание, что если вектор х
одномерный (записывается как х ~ 7V(/x, v)), то его среднеквадратическое от-
клонение — y/v. Теперь рассматриваемую динамическую модель можно запи-
сать следующим образом:
Xi ~ N('DiXi-i,,'Ldi)‘,
Обратите внимание, что дисперсии и матрицы могут изменяться при переходе
между кадрами. Хотя приведенная модель кажется ограниченной, фактически
она является крайне мощной; ниже будет показано, как моделируются некото-
рые распространенные ситуации.
17.2.1. Дрейфующие точки
Предположим, что вектор х описывает положение точки. Если Di — Id,
тогда точка движется случайными шагами — ее новое положение отличается
от старого на некоторую случайную гауссову переменную. Динамика такого
типа не очень интересна, поскольку кажется, что сопровождается стационарный
объект. Данная модель применяется только к объектам, для которых неизвестна
более удачная динамическая модель.
Данная модель также позволяет проиллюстрировать понятие матрицы из-
мерений ЛЧ. Самое важное здесь — помнить, что не требуется на каждом этапе
измерять каждый аспект состояния точки. Предположим, например, что точка
расположена в трехмерном пространстве: если теперь ЛЛзк = (0,0,1), ЛЧз/с-ы =
(0,1,0) и Л4зан-2 = (1,0,0), то на каждом третьем кадре измеряется, соот-
ветственно, координата z, у или х точки. Обратите внимание, что точку по-
прежнему можно сопровождать, несмотря на то, что на каждом кадре изме-
ряется только один компонент ее положения. Если по измерениям собрано до-
статочно данных, можно восстановить состояние — говорят, что состояние яв-
ляется наблюдаемым. Подробнее возможность наблюдения будет рассмотрена
в разделе упражнений.
17.2.2. Постоянная скорость
Предположим, что вектор р описывает положение, а вектор v — скорость
точки, движущейся с постоянной скоростью. В этом случае р£ = р^Ч^Д^гч-х
и Vi = Это означает, что положение и скорость можно собрать в одном
векторе состояния и применить описанную выше модель (рис. 17.1). В частно-
Глава 17. Сопровождение с использованием линейных динамических моделей
523
Рис. 17.1. Динамическая модель системы точки с постоянной скоростью движения по прямой.
В данном случае пространство состояний двумерно — одна координата описывает положение точ-
ки, другая — скорость. На рисунке слева вверху показан график состояний; каждая звездочка
обозначает иное состояние. Обратите внимание, что на вертикальной оси (скорость) видны неко-
торые небольшие изменения по сравнению с горизонтальной осью. Эти изменения объясняются
случайным компонентом модели, так что скорость постоянна с точностью до случайного возмуще-
ния. На рисунке справа вверху показан первый компонент состояния (положение) в зависимости от
времени. Видно, что наблюдается объект, движущийся с почти постоянной скоростью. На рисунке
внизу на данный график наложены результаты измерений (кружки). Предполагается, что изме-
рения касаются только положений объекта и выполняются довольно неточно; как будет показано
далее, на возможности сопровождения это сказывается незначительно
524
Часть IV. Компьютерное зрение: средний уровень
Рис. 17.2. На данном рисунке иллюстрируется модель точки, движущейся по прямой с постоянным
ускорением. На рисунке слева приведен график первых двух компонентов состояния — положе-
ния (ось х) и скорости (ось у). В данном случае следовало ожидать, что график будет выглядеть
подобно графику функции (t2,t), что и наблюдается в действительности. На рисунке справа по-
казана зависимость положения от времени; видно, что точка удаляется от начального положения
с постоянно растущей скоростью
СТИ,
И
(At)Jd
Id
Обратите внимание, что, как и ранее, для получения необходимых данных не
требуется рассматривать весь вектор состояния. Например, во многих ситуаци-
ях можно ожидать, что будет справедливой следующая запись:
Mi = { Id 0 |
(т.е. что наблюдается только положение точки). Поскольку известно, что точка
движется с постоянной скоростью (выбрана такая модель), ожидается, что эти
данные можно также использовать для оценки всего вектора состояния.
17.2.3. Постоянное ускорение
Предположим, что вектор р описывает положение, вектор v — скорость, а
вектор а — постоянное ускорение точки. В этом случае + (A£)vi_lt
Vi = v^i + (At)oi-i и ai = ai-i. Как и выше, положение, скорость и ускоре-
ние точки можно собрать в один вектор состояния и применить используемую
модель (рис. 17.2). В частности,
Глава 17. Сопровождение с использованием линейных динамических моделей
525
х = v ►
Id
T>i= \ О
О
(M)Id
Id
о
(At)7d ► .
Id
Обратите внимание, что, как и ранее, для получения необходимых данных не
требуется рассматривать весь вектор состояния. Например, во многих ситуаци-
ях можно ожидать, что будет справедливой следующая запись:
Л4, = { Id 0 0 }
(т.е. что наблюдается только положение точки). Поскольку известно, что точка
движется с постоянным ускорением (выбрана такая модель), ожидается, что
эти данные можно также использовать для оценки всего вектора состояния.
17.2.4. Периодическое движение
Предположим, что дана точка, совершающая периодическое движение по
прямой. Как правило, положение такой точки р удовлетворяет уравнению,
подобному
d2p
Данное выражение можно преобразовать в линейное дифференциальное урав-
нение первого порядка, обозначив скорость как v и собрав положение и ско-
рость в вектор и = (р, v). Получаем такое уравнение:
Предположив, что данное уравнение интегрируется по явной схеме Эйлера
с шагом At, получаем следующее:
Ui = Ui-i + At— =
ut
= Ui-i + AtSui-i =
526
Часть IV. Компьютерное зрение: средний уровень
Это выражение можно использовать как уравнение состояния либо можно при-
нять другую схему интегрирования. В последнем случае возможно появление
выражений, зависящих от ...,так что в один вектор потребуется
собрать и соответствующим образом переупорядочить матри-
цу (см. раздел упражнений). Данный метод хорошо работает для точек на
плоскости, в трехмерном пространстве и т.д. (см. раздел упражнений).
17.2.5. Модели высших порядков
Возможен другой подход к рассмотрению модели с постоянной скоростью:
отказаться от предположения Р(я?» | ®х,... ,я?*-1) = P(&i | srt-i). В этом слу-
чае модель системы с постоянной скоростью можно переписать только через
положение точки (если удобно использовать положение (г — 2)-й точки при на-
личии положения (г — 1)-й точки). В частности, обозначив положение как р,
получаем следующее:
P(Pi I Pi,- • • .P.-i) = W(Pi-i + (Pi-i -Pi-2),Edi)-
B данной модели предполагается, что разность pi и р£-1 равна разности
и р,_2. т.е. что скорость постоянна с точностью до случайного возмущения.
Подобные замечания можно сделать и для модели системы с постоянным уско-
рением, переписав ее через векторы Pj_lt р,_2 и р»_3.
В модели системы с постоянной скоростью формируется вектор состояния,
включающий вектор положения точки и вектор скорости (который представля-
ет разность р£-1 — р{_2). Подобным образом в модели системы с постоянным
ускорением вектор состояния формируется как объединение вектора положе-
ния точки, вектора скорости и вектора ускорения. В этой модели вектор уско-
рения представляет величину (pi-i — Pi-2) ~ (Pi-2 ~ Рг-з)- Разумно ожидать,
что новое положение точки будет зависеть от вектора pi-4 или других точек,
расположенных дальше по истории пути точки. Для представления подобной
динамики требуется всего лишь расширить вектор состояния до подходящего
размера. Отметим, что при этом может быть трудно представить себе поведение
модели. Существует два подхода к определению искомых матриц Р»: первый
(описан выше) — что-то известно о динамике и матрицу можно записать явно;
второй — матрица определяется по данным.
17.3. ФИЛЬТР КАЛЬМАНА
Важной особенностью линейных динамических моделей является то, что все
фигурирующие в задаче функции условного распределения вероятностей имеют
нормальное распределение. В частности, это относится к вероятностям Р(Хг |
у1,..., 3/j_i) и P(Xi | уъ..., у*). Из сказанного следует, что данные вероятно-
сти относительно легко представить; все, что требуется — поддерживать в фа-
зах предсказания и коррекции представление среднего и дисперсии. В частно-
Глава 17. Сопровождение с использованием линейных динамических моделей
527
сти, используемая модель допускает относительно простой процесс обновления
представлений среднего и дисперсии в фазах предсказания и оценки.
17.3.1. Фильтр Кальмана для одномерного вектора состояния
Динамическая модель для данного случая выглядит следующим образом:
Xi ~ N^diXi-i'CTdi);
yi ~ N(miXi,CT^.).
Для решения поставленной задачи требуется поддерживать представление ве-
роятностей P(Xi | уо,... и P(Xi | yo,...,yi). В каждом случае нужно
представить только среднее и среднеквадратическое отклонение, поскольку оба
распределения являются нормальными и полностью определяются указанными
параметрами.
Система обозначений
Среднее вероятности P(Xi | уо, ...,у»-1) будем обозначать как , а
среднее вероятности Р(Х{ | уо,---,Уг) — как X*; верхние индексы исполь-
зованы для обозначения представлений о Xi непосредственно до и сразу
после г-го измерения. Подобным образом, среднеквадратическое отклоне-
ние P(Xi | уо>---,Уг-1) записывается как а среднеквадратическое от-
клонение P(Xi | уо,...,у») — как </+. В каждом случае предполагается,
что | уо,.. - ,у»-1) известно, т.е. что известны Х^_г и сг^-г
Уловки при вычислении интегралов
Основная причина использования нормальных распределений заключается
в том, что интегралы при этом имеют довольно хорошее поведение. Как прави-
ло, для вычисления интегралов (определения значений различных параметров)
достаточно простой замены переменной. При текущей системе обозначений вы-
бор подходящих замен может быть несколько затрудненным, поэтому введем
такую величину:
у(х; р, v) = exp
Константа была отброшена, кроме того, для удобства была представлена дис-
персия (v), а не среднеквадратическое отклонение. Приведенное выше выра-
жение делает возможными некоторые удобные преобразования; в частности,
можно записать
(х-р)2\
2v J
g(x;p,v) = g(x-p;O, v);
g(m; n, v) = p(n; m, t>);
g(ax; p, v) = y(x; p/at v/a?).
528
Часть IV. Компьютерное зрение: средний уровень
Кроме того, пригодится следующее соотношение:
/ОС
д(х - u; ц, va)g(u; 0, vb) du ос д(х; ft, v% + vf).
оо
Проверить последнее выражение можно по-разному: проще всего использовать
таблицы; можно также вывести его из определения свертки; или же рассмотреть
сумму двух независимых случайных переменных. Далее потребуется еще одно
тождество:
g(x',a,b)g(x;c,d) =д (х\ f(a’b,c,d),
у о 4- а о 4- a J
причем вид функции / значения не имеет, хотя важно то, что она не являет-
ся функцией от х. Путь доказательства данного тождества указан в разделе
упражнений.
Предсказание
Имеем
P(Xi = J \y0,...,yi-1)dXi-i.
Теперь
= jP(Xi |i/0,...,J/i-i)<*Xi_1)oc
ос ос
J —oo
ос Г g^Xi-diXi-^a^g^Xi^-Xti^^t-i^dXi-! ос
J — oo
ос f g((Xi-di(u + X^.1))\Q,(adi')2)g(u',GAat-i)2)du<x
J —oo
oc f g(.(Xi — diu)\diX+~i,ad.)g(u\O,(tr+_i)2)du oc
J — oc
oc f g((Xi ~v)-,diXt-i, cr^)р(и;0, oc
J — oo
«fl(x,;d,x;L<4 + (dfaj. ,)2).
Здесь были применены различные описанные выше преобразования и две за-
мены переменных. Таким образом,
Х~ =d,Xti;
(O2 = <4, + (W-i)2-
Глава 17. Сопровождение с использованием линейных динамических моделей
529
Коррекция
Имеем
............., _ Р(у< | Х,)Р(Х, | уо....Pi-1)
(X. | уо,..., у.) j. (Х.)Р(Л । , Vi^)dXi
«Р(у(|Х()Р(Х<|уо,...,у;-1).
Величины и erf, определяющие функцию Р(Х» | уо, • -, yi-i), известны.
Используя систему обозначений, введенную ранее для гауссианов, можно
записать следующее:
P(Xi | уо, • • •, у7) ос g(yi\miXi,ail.)g(Xi:,Xi , (<т~)2) =
= 9(тЛ;у,,<7^)у(Х;;Х7, (О2) =
= д (х<; 9(Х(;ХГ, (О2).
\ mi т± J
Алгоритм 17.1. С помощью одномерного фильтра Кальмана обновляются оценки
среднего и смешанного второго момента различных распределений, встречаю-
щихся при сопровождении одномерной переменной с использованием данной
динамической модели
Динамическая модель:
ге, ~ -1, <7^,)
yi ~ N(miXi,a
mi ) I
Начальные предположения: Известны х$ и erf
Обновить уравнения: Предсказание
х~ =
Обновить уравнения: Коррекция
+ _ ( + rmyi (<Т~ )2 \
\ O’mi +т?((Т')2 /
+ = If <7™, (О2 А
V +«1i(a.7)2)/
530
Часть IV. Компьютерное зрение: средний уровень
Рис. 17.3. Фильтр Кальмана для точки, которая движется по прямой с постоянной скоростью
(сравните с рис. 17.1). Состояния (незакрашенные кружки) изображены как функция шага i. Зна-
ками обозначена величина xf, изображение которой несколько смещено влево от состояния,
чтобы акцентировать внимание на том, что данная оценка делается до измерения. Знаками “х”
обозначены результаты измерений, а знаками “+" — величина set, которая смещена относительно
состояния несколько вправо. Вертикальные полоски вокруг знаков “•* и “+” представляют собой
значения среднеквадратических отклонений оценки дисперсии, полученные, соответственно, до
и после измерения. Если измерения проводятся в условиях значительного шума, полоски не так
сильно сужаются после получения результатов измерений (сравните с рис. 17.4)
Сопоставляя с имеющимися тождествами, получаем следующее:
х+ _ (+ miyi(°*~)2 -
\ + 7ni(°7)2 /
If ^(°T)2 X
V )2)/
На рис. 17.3 показан фильтр Кальмана, используемый для сопровождения точ-
ки, движущейся по прямой с постоянной скоростью, а на рис. 17.4 показан
фильтр Кальмана, используемый для сопровождения точки, движущейся по
прямой с постоянным ускорением.
17.3.2. Обновление уравнений для общего вектора состояния
Благодаря использованию особых свойств нормальных распределений схема
одномерного сопровождения была получена без какого бы то ни было интегри-
рования. Предложенный подход применим к вектору состояния произвольной
размерности, но процесс угадывания значений интегралов с последующими вы-
числениями стоит провести более скрупулезно, чем это сделано в разделе 17.3.1.
Опустим требуемые несложные, но громоздкие выкладки (провести их можно
самостоятельно, доказав для начала приведенные тождества) и просто предста-
вим результат — алгоритм 17.2.
Глава 17. Сопровождение с использованием линейных динамических моделей
531
Рис. 17,4. Фильтр Кальмана для точки, которая движется по прямой с постоянным ускорени-
ем (сравните с рис. 17.2). Состояния (незакрашенные кружки) изображены как функция шага г.
Знаками обозначена величина х, , изображение которой несколько смещено влево от состоя-
ния, чтобы акцентировать внимание на том, что данная оценка делается до измерения. Знаками
“х" обозначены результаты измерений, а знаками “+" — величина xf, которая смещена относи-
тельно состояния несколько вправо. Вертикальные полоски вокруг знаков и “+” представляют
собой значения среднеквадратических отклонений оценки дисперсии, полученные, соответственно,
до и после измерения. Если измерения проводятся в условиях отсутствия шума, после получения
результатов измерений полоски сжимаются
17.3.3. Реверсивное сглаживание
Важно отметить, что вероятность P(Xj | у0, ...,Уг) не является наилуч-
шим представлением X», поскольку при таком представлении не учитывает-
ся дальнейшее поведение точки. В частности, последующие измерения могут
противоречить оценкам, полученным до настоящего момента, поэтому на пред-
ставление X» могут влиять все измерения после у±; возможно, дальнейшее
движение точки будет предсказываться точнее, если несколько иначе оценить
текущее ее положение. Впрочем, наилучшей оценкой на i-м шаге является
именно P(Xi | у0,..., t/i).
Что делать с этими наблюдениями — зависит от обстоятельств. Если постав-
ленная задача требует немедленной оценки положения (допустим, наблюдается
машина, идущая по встречной полосе), выбор представления не особо богат.
Если сопровождение проводится в автономном режиме (возможно, эксперимент
судмедэкспертизы — требуется наилучшая оценка действий объекта, наблюда-
емого на пленке), то можно использовать все данные (точки) и представить
вероятность P(Xj | у0,... ,2/дг). Кроме того, задача часто формулируется так:
необходима немедленная грубая оценка с получением более точного значения
по прошествии некоторого числа этапов обработки. Это означает, что искомой
является величина P(Xj | у0,..., yi+k), но для получения этого представления
нужно подождать i 4- к шагов, причем оно будет улучшенным значением по
сравнению с Р(Х£ ] у^,., у J.
532
Часть IV. Компьютерное зрение: средний уровень
Алгоритм 17.2. С помощью одномерного фильтра Кальмана обновляются оценки
среднего и смешанного второго момента различных распределений, встречаю-
щихся при сопровождении переменной в пространстве конечной размерности при
данной динамической модели
Динамическая модель:
~ 7V(2)1xt_ 15 Ed])
Ui ~ JVfjM.iCi.EmJ
Начальные предположения: Известны и Eq
Обновить уравнения: Предсказание
Е^ = Е<^ Ч-
Обновить уравнения: Коррекция
ICi = Ъ~мТ [мЧ- Ет<] ”1
х+ = «7 ч- zc, [?/, - ]
s+ = [Id - /С.Л4,] E“
Введение обратного фильтра
Имеем
pfY . . v P(Xityi+lf...,yN |з/01-• • ,У»)Р(у0. • > Уг)
Р{Х' 1 “°....“N)------------ P(V0,:..VN)------------------ =
= Р(Уг+1,- ,Уы I Xi,yQ, -4yi)P(Xi | Уо.---.У<)Р(Уо.- -.У«)
Р(Уо,---,У;у)
= P(yi+1 ,---,yN\ XijPtXi I y0>..,yi)P(y0,..., 1/J _
Р(Уо,-‘,Ум)
гпр =P(Xi |2/i+i,. | j/o, ---.У.)»,
= /р(у.+1>- •-.Ук)р(Уо. -.Уг)\
V P(Xi)P(y0,...,yN) )-
Последний член может казаться источником потенциальных проблем; факти-
чески, о нем можно попросту “забыть”, если использовать один хитрый трюк.
Глава 17. Сопровождение с использованием линейных динамических моделей
533
Все, что требуется — объединить Р(Х; ] у0,...,у^ (известно, как вычис-
лить) и P(Xi | yi+1,... ,yN). В действительности, известно также, как полу-
чить представление вероятности Р(Хг | yi+l,... ,yN). Можно просто активи-
зировать фильтр обратно по времени, используя обратную динамику и взяв
предсказанное представление Xi (подробности изменения индексов ряда и т.д.
предлагаются читателям в качестве самостоятельного упражнения).
Объединение представлений
Теперь имеется два представления Х^. одно получено при использовании
прямого фильтра и с учетом всех измерений до у±, а второе получено при
активизации обратного фильтра и с учетом всех измерений после у{. Данные
представления следует объединить. Вместо явного определения значения а
(что кажется довольно сложным), ответ можно получить, отметив, что полу-
ченные данные подобны результатам еще одного измерения. В частности,
имеется новое измерение, порожденное Xi (т.е. результат применения фильтра
в обратном направлении), которое можно объединить с имеющейся оценкой,
полученной на выходе прямого фильтра. Как объединять оценки и измере-
ния известно, поскольку уравнения фильтра Кальмана записаны именно для
подобного случая.
Все, что требуется на данном этапе, — несколько новых обозначений.
К оценке, полученной на прямом фильтре, добавим верхний индекс /, а к оцен-
ке, полученной на обратном фильтре, — индекс Ь. Среднее P(Xi | у0,..., yN)
будем записывать как Xit а второй смешанный момент P(Xi | Уо,---,у^) —
как Е*. Представление величины Х^ рассматривается как измерение величины
Xi со средним X/ и вторым моментом (знак “минус” появился потому,
что г-е измерение нельзя использовать дважды, а обратный фильтр предсказы-
вает Xj с использованием yN,..., j/i+1). Данное измерение следует объединить
с P(Xi | у0,..., уД которое имеет среднее х{’+ и второй момент е{’+ (при
подстановке в уравнения Кальмана данная величина играет роль представления
до измерения, поскольку измеренной величиной теперь является X/ ).
Подставляя полученную вероятность в уравнения Кальмана, находим, что
/С* = Е{’+ [sf+ + Е?’"]-1;
Е* = [7- K.JS.4'-';
х* = х{,+ + г; [х-~ - х{+].
После небольших преобразований (самостоятельное упражнение!) эти выраже-
ния упрощаются до схемы, описанной в алгоритме 17.3. Отметим (см. рис. 17.5),
что реверсивные оценки могут значительно изменить результат.
534
Часть IV. Компьютерное зрение: средний уровень
Рис. 17.5. Реверсивная оценка для динамической оценки точки, движущейся по прямой с посто-
янной скоростью. На рисунке изображена зависимость координатного компонента состояния от
времени. На рисунке слева вверху показаны оценки с выхода прямого фильтра, причем как и на
предыдущих рисунках состояние обозначается кружочком, данные — знаком “х", предсказание —
знаком а скорректированная оценка — знаком вертикальные полоски обозначают сред-
неквадратическое отклонение оценки. Предсказанная оценка показана перед состоянием, а скор-
ректированная — после. Следует отметить, что измерения зашумлены. На рисунке справа вверху
показаны оценки с выхода обратного фильтра. Время теперь идет в обратном направлении (хотя обе
кривые изображены на одной оси), так что предсказание изображено перед измерением, а уточнен-
ная оценка — после. Как априорное значение использовалась конечная скорректированная оценка
прямого фильтра. Вертикальные полоски обозначают среднеквадратическое отклонение каждой пе-
ременной. На рисунке внизу показана суммарная реверсивная оценка. Квадратиками обозначены
оценки состояния. Обратите внимание на значительное улучшение оценок
Глава 17. Сопровождение с использованием линейных динамических моделей
535
Рис. 17.6. На данном рисунке показано следствие использования различных априорных значений
в качестве положения конечной точки в реверсивном алгоритме. Рассматривается движение точки
по прямой с постоянной скоростью. На рисунке слева вверху показаны оценки с выхода прямого
фильтра, причем как и на предыдущих рисунках состояние обозначается кружочком, данные — зна-
ком “х”, предсказание — знаком а скорректированная оценка — знаком вертикальные по-
лоски обозначают среднеквадратическое отклонение оценки. Предсказанная оценка показана перед
состоянием, а скорректированная — после. Следует отметить, что измерения зашумлены. На ри-
сунке справа вверху показаны оценки с выхода обратного фильтра. Время теперь идет в обратном
направлении (хотя обе кривые изображены на одной оси), так что предсказание изображено перед
измерением, а уточненная оценка — после. Как априорное значение использовалась конечная скор-
ректированная оценка прямого фильтра. Вертикальные полоски обозначают среднеквадратическое
отклонение каждой переменной. На рисунке внизу показана суммарная реверсивная оценка. Квад-
ратиками обозначены оценки состояния. Обратите внимание на значительное улучшение оценок
536
Часть IV. Компьютерное зрение: средний уровень
Алгоритм 17.3. В реверсивном алгоритме объединяются оценки состояния
в прямом и обратном (по времени) направлениях, в результате чего получается
улучшенная оценка
Прямой фильтр: Получить среднее и дисперсию P(Xi | у0,... ,у{), используя
фильтр Кальмана. Искомыми значениями являются и Е{’+
Обратный фильтр: Получить среднее и дисперсию Р(Х, | .. ,2/jv). ис-
пользуя фильтр Кальмана, запущенный обратно по времени. Искомыми значени-
ями являются Х*’- и
Объединить оценки прямого и обратного фильтров: Рассмотреть оценку с об-
ратного фильтра как новое измерение значения X, и ввести его в уравнения для
фильтров Кальмана. В результате получим следующее:
Заблаговременные оценки
В типичных задачах компьютерного зрения сопровождение ведется по пря-
мому ходу времени. Это приводит к неудобной асимметрии: возможно, име-
ется хорошее предположение о том, где объект находился вначале, но плохое
о том, где он остановился (т.е., скорее всего, предшественники Р(гсо) извест-
ны неплохо, но при определении предшественников Р(ждг) могут возникнуть
проблемы, а для использования схемы реверсивного фильтра требуются имен-
но эти значения). Как вариант, в качестве предшествующего значения мож-
но использовать Р(хм | у0,..., у к). Такое решение сомнительно, поскольку
функция распределения вероятностей в действительности не отражает априор-
ных предположений о Р(х^) — для ее получения использовались все изме-
рения. Последствием такого шага может стать то, что данное распределение
занизит неопределенность по acjv и даст реверсивные оценки со значительно
уменьшенными дисперсиями поздних состояний. Альтернатива — использовать
среднее, полученное в прямом фильтре, но существенно увеличить дисперсию;
в результате реверсивная оценка будет завышать дисперсию для последующих
состояний (сравните рис. 17.5 с рис. 17.6).
Данная асимметрия характерна не для всех задач. Например, если прово-
дится судебное исследование видеоленты, сопровождение в прямом и обратном
направлении можно инициировать вручную и в каждом случае получить хо-
рошую априорную оценку. Подобная информация, возможно, облегчит выбор
соответствий (сопровождение в прямом направлении должно завершаться при-
близительно там же, где начнется сопровождение в обратном) и т.д.
Глава 17. Сопровождение с использованием линейных динамических моделей
537
Сглаживание по интервалу
Хотя приведенная формулировка реверсивного сглаживания подразумевает,
что обратный фильтр начинает работу с последней точки, его можно запустить
и с другой точки, на определенное число шагов отстоящей от первой. При та-
ком подходе оценку состояния можно получить в реальном времени (по сути,
сразу после измерения), а улучшенную оценку — после конечного числа после-
дующих измерений. Иногда это бывает полезно. Более того, это эффективный
способ получения от обратного фильтра максимальной отдачи, если предполо-
жить, что влияние отдаленного будущего на полученные оценки относительно
мало по сравнению с влиянием ближайшего будущего. Обратите внимание,
что требуется внимательно следить за априорными значениями для обратного
фильтра; можно принимать оценку с прямого фильтра и несколько увеличивать
ее дисперсию.
17.4. АССОЦИАЦИЯ ДАННЫХ
Не все аспекты каждого измерения содержат информацию о состоянии
сопровождаемого объекта. Фактически, до настоящего момента совсем не
было сказано о “содержимом” у-. Как правило, имеются информативные дан-
ные и данные, которые таковыми не являются (последние часто называются
фоном).
Определение того, какие данные являются информативными, как правило,
связано с ассоциацией данных. Обычно требуется отобразить набор измере-
ний в набор путей, возможно, отбросив часть из них (или почти все). Типич-
ные практические задачи здесь обычно связаны с сопровождением движущихся
объектов (самолеты, ракеты и т.д.) с помощью отраженных радиолокационных
сигналов. Как правило, в любой момент времени подобных сигналов может
быть несколько, причем представление движения сопровождаемых объектов
желательно обновлять, не беспокоясь о том, какой сигнал был порожден ка-
ким объектом. Как было показано ранее, алгоритмы сопровождения сложны
(по структуре), но не трудны (по сути). Ассоциация данных — это, пожалуй,
главный источник сложностей, кроме того, она редко рассматривается в ли-
тературе. Ожидается, что при наличии реальных задач такое положение дел
будет меняться. Рассмотрим один движущийся объект. Проблема в этом слу-
чае заключается в том, что очень информативными являются лишь некоторые
пиксели изображения и задача состоит в определении этих пикселей.
17.4.1. Учет ближайших соседей
В простейшем случае требуется отследить единственный объект, движущий-
ся при наличии шума. Например, может отслеживаться шар, движущийся на
фоне стабильной или слабо меняющейся среды. Изображение сегментируется на
области, причем разумно ожидать, что искомый шар будет сопоставлен с одной
областью, а сегментация фона может меняться со временем. Интуитивно кажет-
ся, что шар с областью фона смешать будет довольно трудно, поскольку имеется
538
Часть IV. Компьютерное зрение: средний уровень
Рис. 17.7. Ассоциация данных с помощью фильтра Кальмана для точки, движущейся по пря-
мой, при использовании модели постоянной скорости (рис. слева) и постоянного ускорения (рис.
справа). Сравните с рис. 17.1 в случае постоянной скорости и с рис. 17.2 в случае постоянного уско-
рения. Использовались те же соглашения, что указаны для рис. 17.3. В данном случае три полоски
среднеквадратических отклонений для измерений совмещены (пунктирные полоски, проходящие
через состояние). Результаты получены с использованием оценки состояния до измерения и знаний
о дисперсии процесса измерения. Обратите внимание, что измерения лежат внутри данных окон
сильная модель движения шара. Это означает, что в худшем случае появится
область фона, которую а) будет легко перепутать с областью шара и которая б)
не впишется в динамическую модель. При таком раскладе напрашивается одна
достаточно популярная стратегия ассоциации данных: из r-й области получа-
ется измерение у\ и выбирается область с наилучшим значением величины
P(Yi = У\ I З/о. • • •. 3/i-i) = / РФ* = УГг I y0,..., | y0,..., y^dXi
= j P(Yi = yri\Xi)P(Xi\y0,...,yi_1)dxi.
Особенно просто Р(У» = р, | 2/о. • • •. 2/»-i) можно определить с помощью
фильтра Кальмана. Известно, как У» получается из Xi — берется случайная
переменная с нормальным распределением, средним Х{ и вторым момен-
том на нее действуют линейным оператором T>it после чего, к результату
добавляется некоторая иная случайная переменная. Выход линейного операто-
ра должен иметь среднее Т\Х; и второй момент Т>г^Т)т. К этой величине
требуется прибавить случайную переменную с нулевым средним и вторым
моментом полученный результат должен иметь среднее
РгХГ
и второй момент
'DJZ'DT+ Zmi.
Глава 17. Сопровождение с использованием линейных динамических моделей
539
Рис. 17.8. Предсказание положения точки позволяет определить “хорошие” измерения для фильтра
Кальмана. Фильтр Кальмана используется для определения точки, движущейся с постоянной скоро-
стью по прямой линии, причем значение мало в каждом состоянии. Кроме того, имеется 10 то-
чек, движущихся хаотически. На графике показано положение данных 10 точек и сопровождаемой
точки в зависимости от времени (которое показано как сплошная линия). Траектория искомой точки
показана пунктиром, а каждое измерение на этой траектории показано квадратиком. Использованы
те же соглашения, что приводились для рис. 17.3 (т.е. состояние изображено незакрашенным круж-
ком как функция этапа £; знаком “*” указано значение величины которое изображено несколько
левее состояния, чтобы показать, что оценка выполняется до измерения; знаком “х” обозначены из-
мерения, а знаком “+” — величина act, которая изображена несколько правее состояния; вертикаль-
ные полоски, окружающие знаки “*” и — это три среднеквадратических отклонения, в которых
использована оценка дисперсии, полученная до и после измерения, соответственно; в каждом слу-
чае одно среднеквадратическое отклонение сливается с другим). Данный фильтр на каждом этапе
выбирает измерение, для которого величина Р(у^\у0,. • • максимальна; обратите внимание,
что не на каждом этапе выбирается верное измерение (т.е. “х” не всегда совпадает с квадратиком),
но хорошая оценка состояния поддерживается постоянно (т.е. знаки “+* близки к кружкам)
На рис. 17.7 показано, как будут выглядеть границы положения ожидаемо-
го измерения, если применить фильтр Кальмана к различным динамическим
моделям.
Обратите внимание, что данная стратегия может быть относительно устой-
чивой в зависимости от точности динамической модели. Если удастся подобрать
точную динамическую модель, все, что сможет реально повлиять на сопровож-
даемый объект, должно быть более похожим на предсказанные измерения, чем
сам объект. Это означает, что случайные неверные выводы не смогут создать
существенных проблем, поскольку мала вероятность нахождения области, кото-
рая одновременно похожа на предсказанные измерения и сильно не вписывается
в используемую динамическую модель. На рис. 17.8 показан фильтр Кальма-
на, сопровождающий состояние точки путем выбора наилучшего измерения на
540
Часть IV. Компьютерное зрение: средний уровень
Рис. 17.9. Если динамическая модель ограничена недостаточно, то выбор измерения, дающего наи-
лучшее значение величины 1’(у\|?/о, • • • может привести к катастрофе. На рисунке слева
изображены 20 этапов обработки траектории точки (с помощью фильтра Кальмана), движущейся
периодически по прямой при фоне, который создают 20 точек, движущихся хаотически. Исполь-
зуются те же соглашения, что приводились для рис. 17.3. Теперь сравнительно велико на
каждом этапе, поэтому существует большая возможность сопровождения по неверным данным.
Кажется, что фильтр хорошо отслеживает состояние, а фактически (как видно из рисунка справа,
где изображены 100 этапов обработки) искомая точка быстро и безнадежно теряется
каждом этапе; точка идентифицируется не всегда корректно, но оценка состо-
яния всегда эффективна.
Обратите внимание, что используются только измерения, не противореча-
щие предсказаниям. В некоторых случаях это может оказаться опасным (таким
образом могут легко отслеживаться несуществующие объекты) или полезным
(объект можно будет сопровождать, даже не используя измерения, полученные
от него). Если динамическая модель может давать только слабые предсказания
(т.е. объект в действительности не ведет себя так или постоянно увеличи-
вается) могут возникнуть серьезные трудности, поскольку требуется полагаться
на измерения. Данные проблемы возникают потому, что ошибки могут накап-
ливаться — последовательно отслеживать неверную точку длительный период
времени сложно, причем чем дольше это делается, тем меньше шансов вос-
становления верной точки. На рис. 17.9 показан фильтр Кальмана, неуклонно
удаляющийся от истинных точек.
17.4.2. Селекция и вероятностная ассоциация данных
Как и ранее, предполагается, что сопровождается один объект при наличии
шума и в качестве примера используется шар, движущийся на медленно ме-
няющемся или стабильном фоне. Вместо выбора области, наиболее подобной
предсказанным измерениям, можно исключить все области, слишком отличаю-
щиеся от искомой, а оставшиеся затем использовать с весовыми коэффициен-
тами, отражающими степень их сходства с предсказанной областью.
Первый этап называется селекцией. Исключаются все измерения, слишком
отличающиеся от предсказанного. Что подразумевается под словами “слишком
Глава 17. Сопровождение с использованием линейных динамических моделей
541
отличающиеся” — зависит от поставленной задачи: если исключение произво-
дится слишком энергично, может не остаться ни одной точки. Обычно исклю-
чаются измерения, находящиеся от предсказанного среднего на расстоянии,
в несколько раз (обычно — в три раза) превышающем среднеквадратическое
отклонение. Более гибкая стратегия требуется, если сопровождаемый объект
имеет несколько динамических схем поведения (например, военный самолет,
часто переходящий в режим высокоскоростных маневров). В подобных случаях
обычно используют несколько селективных фильтров и учитывают все измере-
ния, полученные на выходе фильтра, пропустившего хотя бы одно измерение.
Следующий этап называется вероятностной ассоциацией данных (Probabi-
listic Data Association — PDA). Предположим, что в фильтре имеется набор N
областей, каждая из которых порождает вектор измерений у*, где область ука-
зывает верхний индекс. Требуется обработать набор возможных гипотез: либо
ни одна область не порождена объектом (назовем данную гипотезу /го), либо
область к порождена объектом (набор гипотез /г*,). Измерение записывается
следующим образом:
Еь [2/J = $2 P(hi I Уо» • • •» Vi-M.
з
причем математическое ожидание определяется по пространству гипотез (имен-
но для этого с данной величиной соотнесен нижний индекс /г). Теперь веро-
ятность того, что ни одно из измерений не порождено объектом, зависит от
деталей используемого процесса обнаружения. При некоторых процессах обна-
ружения данный параметр можно вычислить (см. работу [Blackman and Popoli,
1999], глава 4, где рассматривается пример с радарной системой). В других
случаях требуется найти значение параметра, при котором будет хорошим по-
ведение набора калибровочных примеров. Предположим, что данный параметр
известен изначально или вычислен в процессе и обозначим его /3. Кроме то-
го, необходимо предположить, что либо объект не обнаружен, либо лишь одно
измерение было получено от объекта. Теперь можно записать следующее:
P(hi I Уо. • • • -У.-1) = I I XJPtXi | у0,... ,у^Х. =
= P(Yi = y3i | Уо> - •, У»—i )Р(объект обнаружен) =
= PlYt = yi \ г/0,...,^_1)(1 -/?)•
Далее будем записывать P(hj | у0,..., какр^-. На практике данный метод
обычно используется совместно с фильтром Кальмана. Для этого измерение
У1=^РзУ1
3
вводится в уравнения обновлений Кальмана. Отметим, что член, описывающий
отсутствие измерений, входит в выражения для pj как множитель (1 — (3), но
542
Часть IV. Компьютерное зрение: средний уровень
неопределенность относительно того, какое измерение должно вносить вклад
в обновление, должна также влиять на обновление второго момента. Перепи-
шем уравнение обновления второго момента в следующей форме:
Ef = (1 -0) [Zrf - Ef + ДЕГ +АС<
52 - уЫ'Н&~ - Vi)T - y'i(Vi)T
Здесь первый член описывает обновление в обычном фильтре Кальмана, взве-
шенное вероятностью того, что хорошим является одно измерение, во второй
член входит вероятность того, что плохими являются все измерения, а третий
член описывает неопределенность вследствие неопределенности определения
соответствия.
17.5. ПРИМЕРЫ И ПРИМЕНЕНИЕ
Сопровождение — это технология, которую можно использовать в разнооб-
разных сферах. Среди них выделяются три основных.
* Системы сопровождения транспортных средств могут сообщать о проб-
ках на дорогах, ДТП и опасном либо запрещенном поведении транспорт-
ных средств. Сообщения о пробках на дорогах полезны для потенци-
альных “пользователей дороги” (людей, которые могут изменить предпо-
лагаемый маршрут поездки) и государственных органов регулирования
(которые могут принимать решения об удалении машин, блокирующих
движение и т.д.). Сообщения о ДТП могут использоваться для оповеще-
ния аварийных (технических) служб; если система сопровождения может
считывать номерные знаки машин, она может использовать сводки об
опасном или запрещенном поведении для передачи владельцам машин
судебных повесток.
• Системы наблюдения сообщают о недозволенных действиях людей. Поли-
ции, например, предоставляется возможность узнать, кто из болельщиков
бросил бутылку на футбольное поле, или проверить, не посещало ли
некоторое лицо указанные банки непосредственно перед их ограблением.
Таможенным службам может понадобиться информация о том, кто про-
изводит погрузку/разгрузку самолетов, отправляющихся в иностранные
порты.
• Системы взаимодействия человек/компьютер используют действия лю-
дей для управления различными устройствами. Например, основываясь
на действиях людей, компьютер может самостоятельно принимать ре-
шение о том, что уместным будет приглушить свет и включить тихую
музыку. Телевизор может переключать каналы, повинуясь одному жесту.
Компьютер может наблюдать за записями фломастером на белой доске
и переносить их в память при получении соответствующей команды.
В настоящее время наиболее распространены задачи из области сопровожде-
ния транспортных средств. Подобные системы работают надежно в большом
диапазоне внешних условий. Ниже кратко рассмотрены системы сопровожде-
Глава 17. Сопровождение с использованием линейных динамических моделей
543
Рис. 17.10. В работе [Sullivan et al., 1996] стационарная камера сопровождает машины с ис-
пользованием набора областей интереса, которые показаны на рисунке слева. Первоначальный
захват цели производится путем поиска характерных форм в определенной области интереса;
данные формы проектируются на три различных координатных оси, и если спроектированные углы
достаточно коррелируют с ожидаемой формой, машина начинает сопровождаться (рис. справа).
Перепечатано с разрешения K.D. Baker из G.D. Sullivan, et al., “Model-based Vehicle Detection
and Classification using Orthographic Approximation”, Proceedings British Machine Vision
Association Conference, 1996
ния транспортных средств, а на web-сайте данной книги размещена глава о
сопровождении людей.
1 7.5.1. Сопровождение транспортных средств
Системы, которые могут сопровождать машины, используя для этой цели
видеокадры, полученные со стационарных камер, могут применяться для пред-
сказания интенсивности движения транспорта и транспортного потока; в идеале
подобная система должна сообщать о дорожных проблемах и ликвидировать их
в кратчайшие сроки. В настоящее время уже существуют системы, эффективно
отслеживающие транспортные средства. Критичным вопросом здесь является
начальный автоматический захват машины. В двух описанных ниже системах
использованы разные подходы к этой проблеме. В работе [Sullivan, Baker,
Worrall, Attwood and Remagnino, 1997] предлагается на каждом кадре строить
области интереса (Region of Interest — ROI). Поскольку камера стационарна,
эти области могут изначально соотноситься с полосами дороги (рис. 17.10); это
означает, что практически все машины должны проходить непосредственно че-
рез область интереса в известном направлении (не будем пока останавливаться
на менее критичном вопросе — машине, решившей сменить полосу в пределах
области интереса). Затем данные системы ищут в области интереса характер-
ные формы, указывающие на присутствие машины (рис. 17.10). Данные формы
могут незначительно варьироваться — как правило, машина начинает сопро-
вождаться при въезде в область интереса, хотя начальным состоянием может
быть машина, расположенная посреди области или покидающая ее.
Каждый инициированный трек отслеживается на последовательности кад-
ров, причем в это же время определяется его качество — как правило, это
оценка точности предсказания следующего положения. Если данная мера ка-
чества достаточно высока, трек принимается как гипотеза. Вокруг каждой
544
Часть IV. Компьютерное зрение: средний уровень
Рис. 17.11. В системе, предложенной в работе [Sullivan et al., 1996], треки машин непрерывны,
если они измеряются достаточно качественно по сравнению с треками, предсказанными по сделан-
ным измерениям. Треки являются взаимоисключающими: к тому моменту, когда машина достигает
верхней границы поля зрения, система должна решить, какой предполагаемый трек считать истин-
ным. Для этого система сравнивает предсказание трека с другой областью интереса. На рисунке
изображен набор треков (положение отложено по вертикали, а время — по горизонтали). Обратите
внимание, что типичное наложение треков (возникающее вследствие того, что перед и зад машины
для системы обнаружения отличаются слабо) разрешается довольно быстро; указан также реаль-
ный трек (и его области исключения). Если два трека не совместимы, оставляется трек, имеющий
более высокое качество. Перепечатано с разрешения K.D. Baker из G.D. Sullivan, et al., “Model-
based Vehicle Detection and Classification using Orthographic Approximation”, Proceedings British
Machine Vision Association Conference, 1996
гипотезы строится область исключения в пространстве и во времени, причем
в данной области должен быть только один трек; если области перекрывают-
ся, выбирается трек с более высоким качеством. Требование непересечения
областей исключения следует из того факта, что две машины не могут одно-
временно занимать одну область пространства. Если трек прошел указанные
проверки, можно предсказать, когда и где он перейдет в другую область инте-
реса. Окончательно трек принимается или отклоняется при сравнении данной
области интереса в подходящее время с шаблоном, предсказывающим вид
машины. Обычно к моменту последней проверки остается лишь малая часть
инициированных треков (рис. 17.11).
Альтернативный метод инициации треков машин заключается в сопро-
вождении отдельных характерных элементов с последующей группировкой
полученных треков в треки машин. Именно такая стратегия использована
в работе [Beymer, McLauchlan, Coifman and Malik, 1997], причем довольно
успешно. Поскольку дорога представляет собой плоскость, а камера стационар-
на, можно определить гомографию, связывающую плоскость дороги и камеру.
Эту гомографию затем можно использовать для определения расстояния между
Глава 17. Сопровождение с использованием линейных динамических моделей
545
Рис. 17.12. На рисунке слева показаны отдельные треки для системы, описанной в работе [Веутег
et al., 1997]. Данные треки получены при сопровождении угловых точек с помощью фильтра Каль-
мана. Поскольку положение камеры относительно плоскости дороги известно, можно определить
преобразование, переводящее точки на изображении в точки на дороге. Таким образом, можно опре-
делить пары точек, расстояние между которыми остается постоянным. На рисунке справа показаны
группы подобных точек. Все эти группы предположительно соотносятся с машинами. Перепечата-
но из D. Веутег et al., "A Real-Time Computer Vision System for Measuring Traffic Parameters”,
Proceedings IEEE Conference on Computer Vision and Pattern Recognition, 1997. (c) 1997 IEEE
точками; точки могут собираться в объект (машину), только если расстояние
между ними не меняется со временем. Описанная в работе система отслеживает
угловые точки, определенные с использованием матрицы вторых моментов (см.
раздел 8.3.3) с помощью фильтра Кальмана. Точки группируются с использо-
ванием простого алгоритма, основанного на графах: каждый трек характерной
точки — это вершина, а ребра представляют группирующее отношение между
треками. При попадании в поле зрения нового характерного элемента (соот-
ветственно, инициации нового трека) появляются ребра, соединяющие его со
всеми треками характерных элементов, расположенных на данном кадре неда-
леко от нового трека. Если в некоторый последующий момент расстояние между
точками трека слишком возрастет, ребро отбрасывается. Определяется также
область выхода, в которой машины покидают кадр. Когда треки достигают
области выхода, связанные компоненты считаются машинами. Подобная схема
группировки удачно работает и на модельных изображениях (рис. 17.12), и при
определении параметров движения по длительным видеорядам (рис. 17.13).
Преобразование, переводящее точки на дороге в точки изображения, может
дать много информации. Выше данное преобразование уже использовалось
для определения того, принадлежат ли точки жестким объектам (посредством
вычисления скорости на плоскости дороги и сравнения скоростей различных
точек). Это позволяет связать характерные точки в объекты. Кроме того, как
только объект начинает сопровождаться целиком, данное преобразование мож-
но использовать для получения информации о пространственном размещении
и затенении. Более того, машины можно отслеживать с движущихся транс-
портных средств. В этом случае имеется два основных вопроса: во-первых, это
движение платформы, на которой расположена камера (так называемое соб-
ственное движение); во-вторых это движение других транспортных средств.
546
Часть IV. Компьютерное зрение: средний уровень
Рис. 17.13. Система, предложенная в работе [Beymer et al., 1997J, может давать довольно точные
оценки транспортного потока и скорости движения. На рисунке слева изображен график рассеяния
оценок потока в зависимости от реальных данных; на рисунке справа приведен график рассеяния
оценок скорости в зависимости от реальных данных. Перепечатано из D. Beymer et al., "A Real-
Time Computer Vision System for Measuring Traffic Parameters", Proceedings IEEE Conference on
Computer Vision and Pattern Recognition, 1997. © 1997 IEEE
В работе (Ferryman, Maybank and Worrall, 2000] собственное движение оце-
нивается посредством сопоставления снимков дороги на различных кадрах
(рис. 17.14). После получения оценки томографии и собственного движения,
треки других движущихся машин можно отобразить в системе координат,
связанной с дорогой, и сопоставить со всеми машинами, видимыми на дороге
с движущейся машины (рис. 17.14).
17.6. ПРИМЕЧАНИЯ
Фильтр Кальмана — крайне полезный аппарат, который регулярно перест-
ирывается и появляется в той или иной форме в различных прикладных обла-
стях. Часто нелинейную динамику можно считать достаточно линейной, чтобы
можно было использовать фильтр Кальмана. Читателям, интересующимся дан-
ным вопросом, будет полезно изучить работы [Chui, 1991], [Staff of the Analyt-
ical Sciences Corporation, 1974] и [West and Harrison, 1997].
В данной главе не рассматривался процесс подбора линейной динамиче-
ской модели. Этот вопрос относительно понятен, если известен порядок модели,
естественное пространство состояний, которое можно использовать, и разумная
модель измерений. В противном случае ситуация усложняется — существует
целая область теории управления, посвященная теме, которая в данном случае
именуется идентификацией системы. В качестве весьма авторитетной работы
рекомендуется книга [Ljung, 1995].
Задачи
17.1. Предположим, что дана модель ж» = Р»ж*-1 и yi = Здесь изме-
рение yi — это одномерный вектор (т.е. число) для каждого г, а ж, —
fc-мерный вектор. Назовем модель наблюдаемой, если состояние можно
восстановить по любым к последовательным измерениям.
Глава 17. Сопровождение с использованием линейных динамических моделей
547
Рис. 17.14. Как только известно преобразование, которое переводит точки изображения в систему
координат, связанную с дорогой, треки других машин, полученные с использованием движущейся
камеры, можно перевести в систему координат, связанную с плоскостью дороги. Это позволяет
провести подробную реконструкцию геометрии транспортного потока, показанную слева. Более
того, движение стационарных объектов в плоскости дороги (таких как белые метки) можно ис-
пользовать для оценки движения камеры. Из сказанного следует, что можно а) интерпретировать
геометрию транспортного потока, например, предсказывая грозящие столкновения между платфор-
мой камеры и некоторыми другими машинами б) визуализировать проекции транспортного потока
с некоторых других платформ (показано справа). Перепечатано из J.M. Ferryman, S.J. Maybank
and A.D. Worrall, "Visual Surveillance for Moving Vehicles", Proceedings 1998 IEEE Workshop on
Visual Surveillance. © 1998 IEEE
а) Покажите, что данное требование эквивалентно следующему: матри-
ца
[m-D? Mi+iDTvT+1Mi+2 ...V?...
имеет полный ранг.
б) Точка, которая движется в трехмерном пространстве, где Мзк =
(0,0,1), Л4з*+1 = (0,1,0) и Л43*:+2 — (1,0,0), наблюдаема.
в) Точка, движущаяся с постоянной скоростью в пространстве любой
размерности (причем матрица наблюдений содержит информацию
только о положении), является наблюдаемой.
г) Точка, движущаяся с постоянным ускорением в пространстве лю-
бой размерности (причем матрица наблюдений содержит информацию
только о положении), является наблюдаемой.
17.2. Точка дрейфует вдоль прямой линии. В частности, имеем Xi ~ Nfa-i, 1).
Движение точки начинается в жо = 0.
а) Чему равна средняя скорость? (Помните, скорость — это величина со
знаком.)
б) Чему равен средний модуль скорости? (Помните, величина по модулю
всегда неотрицательна.)
548
Часть IV. Компьютерное зрение: средний уровень
в) На каком шаге (в среднем) расстояние между текущим и начальным
положениями точки превысит две единицы (т.е. чему равно ожидаемое
число шагов и т.д.)?
г) На каком шаге (в среднем) расстояние между текущим и начальным
положениями точки превысит десять единиц (т.е. чему равно ожида-
емое число шагов и т.д.)?
д) Предположим, что дано два непересекающихся интервала длиной 1
и 2 единицы; чему равен предел отношения (средняя доля времени,
проведенного в интервале 1)/ (средняя доля времени, проведенного
в интервале 2) при числе шагов, стремящемся к бесконечности?
е) Скорее всего, вы определили отношение в предыдущей задаче; смоде-
лируйте теперь данную ситуацию и определите, как быстро отношение
выйдет на предполагаемое значение.
17.3. Докажите истинность следующего утверждения:
(ad + cb bd\ . .
ТП-’ ~b + d) b’с’d''
Подсказка: Проще всего прологарифмировать приведенное соотношение,
а затем переупорядочить дроби.
17.4. Пусть дана следующая динамика:
Xi ~ N(diXi-itadi)‘,
Уг ~ сг^,).
a) P(xi | Zi-i) — функция плотности вероятности с нормальным распре-
делением со средним diXi-i и дисперсией Чему равно Р(хг1 |
*<)?
б) Покажите, как, используя фильтр Кальмана, можно получить пред-
ставление P(xi | . ,yN).
Упражнения
17.5. Реализуйте схему двумерного сопровождения на основе фильтра Кальма-
на для сопровождения некоторого объекта по простому видеоряду. Пред-
лагается использовать процесс вычитания фона и отслеживать пятно
с переднего плана. Пространство состояний, вероятно, должно включать
положение пятна, его скорость, ориентацию (которую можно определить,
вычислив матрицу вторых моментов) и угловую скорость.
17.6. Если имеется некоторая оценка фона, фильтр Кальмана позволяет улуч-
шить вычитание фона путем отслеживания колебаний освещения и из-
менений коэффициента усиления камеры. Реализуйте фильтр Кальмана,
выполняющий описанные действия; насколько существенно полученное
улучшение? Обратите внимание, что в разумной модели колебаний осве-
щения фон множится на шумовую составляющую, примерно равную еди-
нице, — для учета этого факта в линейной динамике можно использовать
логарифмирование.
-------------- ЧАСТЬ V --------------
Верхний уровень компьютерного зрения:
геометрические методы
18
Зрение на основе модели
В данной главе распознавание объектов рассматривается как задача установ-
ления соответствий — “какой характерный элемент изображения соответствует
какому характерному элементу какого объекта?”. Данный подход к распозна-
ванию, при котором естественным образом акцентируется внимание на взаимо-
связи характерных элементов изображения и объекта, а также моделями камер,
является простым, но крайне полезным.
Ниже рассмотрены разнообразные алгоритмы, в основе которых лежит схе-
ма определения соответствий. Ключевым наблюдением, давшим толчок к раз-
витию этой группы алгоритмов, является то, что характерные элементы рас-
сматриваемых объектов не разбросаны по всему изображению; если известны
соответствия для небольшого набора характерных элементов, довольно про-
сто получить соответствия для значительно большего набора. Это объясняется
тем, что камеры представляют собой строго упорядоченные структуры, которые
имеют относительно мало степеней свободы.
Существует ряд практических причин, из-за которых следует изучить вза-
имосвязь положения характерных элементов изображения, а также положения
и ориентации объекта. В разделе 18.6 рассматривается практическая задача,
в которой описанная ниже схема используется для наложения медицинских
552
Часть V. Верхний уровень компьютерного зрения: геометрические методы
изображений на реальных пациентов с тем, чтобы хирург мог видеть, как эле-
менты изображения соотносятся с пациентом.
18.1. ИСХОДНЫЕ ДОПУЩЕНИЯ
При обсуждении всех алгоритмов предполагается, что существует набор
геометрических моделей объектов, которые требуется распознать. Данный на-
бор обычно называется базой моделей. Предполагается, что если некоторая
информация об объекте будет нужна в алгоритме, ее можно получить из базы
моделей.
Все алгоритмы, описанные в данной главе, принадлежат к простейшему
типу, который обычно называют "гипотеза-проверка". Каждый такой алгоритм
включает следующие этапы.
• Сделать предположение о соответствии между набором характерных эле-
ментов изображения и набором характерных элементов объекта, а затем
использовать эту информацию для формирования гипотезы о проектиро-
вании из системы координат, связанной с объектом, в систему координат,
связанную с изображением. Гипотезы можно формировать по-разному. Ес-
ли известны внутренние параметры камеры, гипотеза эквивалентна пред-
положительному положению и ориентации — позе объекта.
• Использовать эту гипотезу для визуализации объекта. Данный этап обыч-
но называется восстановление сцены по проекциям (backprojection) (ав-
торы считают, что более удачными терминами были бы проектирование
(projection), прямое проектирование (forward projection) или визуализа-
ция (rendering)).
• Сравнить визуализированное изображение с реальным и при достаточном
их сходстве принять гипотезу.
Чтобы данный подход (проиллюстрирован на рис. 18.1) был эффективным,
необходимо относительно быстро сгенерировать сравнительно немного гипотез
и иметь хорошие методы сравнения визуализированных и наблюдаемых изоб-
ражений. Процесс сравнения, называемый верификацией, может быть доволь-
но ненадежным; существующие методы верификации описаны в разделе 18.5.
Обычно в этих методах определяется некоторая величина — характеристика
гипотезы о том, что объект располагается в определенной позе; далее эту ве-
личину будем называть параметром верификации.
Данный подход можно успешно применять к характерным точкам и криволи-
нейным поверхностям, хотя последний случай гораздо сложнее. В подавляющем
большинстве работ рассматриваются модели объектов, состоящих из геометри-
ческих компонентов, которые проектируются как точечные объекты. Это
означает, что различные проекции объекта дают различные проекции одного
и того же набора составляющих (хотя при определенных проекциях некоторые
составляющие могут затеняться). Далее будет рассматриваться преимуществен-
но этот случай (на настоящий момент он наиболее полезен на практике). Впро-
Глава 18. Зрение на основе модели
553
Рис. 18.1. Применение методов выравнивания к плоскому объекту. На рисунке слева представле-
но изображение объекта; в центре — изображение, содержащее два экземпляра данного объекта
плюс некоторые другие вещи (помехи). Характерные точки уже определены, ищутся соответствия
между группами на изображении (в данном случае — тройками точек); каждое соответствие вно-
сит вклад в определение аффинного преобразования модели в изображение. Удовлетворительные
соответствия позволяют выравнять многие краевые точки модели по краевым точкам изображения,
что показано на рисунке справа. Представленные изображения взяты из одной из первых работ по
данной теме, так что их качество объясняется плохой репродуктивной техникой тех времен. Пере-
печатано из D.P. Huttenlocher and. S. Ullman, "Object recognition using alignment", Proceedings
of the International Conference on Computer Vision, 1986. © 1986 IEEE
чем, в разделе 18.7 будут описаны некоторые методы получения и верификации
гипотез для изображений, состоящих из криволинейных поверхностей.
Вопрос сопоставления элементов изображений в данной главе рассматри-
ваться не будет. В большинстве представленных алгоритмов выполняется неко-
торый поиск среди характерных элементов; очевидно, что если удачно описать
характерные элементы, поиск можно сократить. Например, если характерные
элементы — это просто точки на изображении, полученные при пересечении
краевых кривых, все точки эквивалентны и поиск придется выполнять по пол-
ной программе. Если же точки описаны с использованием локального пред-
ставления изображения (скажем, вектор, составленный из выходов фильтров),
то число возможных соответствий уменьшается, следовательно, сокращается
и требуемый поиск.
1 8.1.1. Получение гипотез
Алгоритмы в основном отличаются механизмом получения гипотез. Наибо-
лее очевидный подход — принять все М геометрических элементов изображе-
ния и все N геометрических элементов каждого из L объектов, пронумеровать
все возможные соответствия между элементами объекта и изображения (т.е.
гипотезами будут утверждения вида “элемент 3 соответствует элементу 5 объ-
екта 7” и т.д.). Однако число возможных соответствий в данном алгоритме
огромно — O(LMN).
Размер пространства сужают геометрические ограничения на точки объек-
та. Например, если необходимо соотнести трехмерную модель с трехмерными
данными, можно ожидать, что расстояния между парами точек модели будут
такими же, как и расстояния между соответствующими точками набора дан-
ных. Любое соответствие, для которого это условие не выполняется, можно
отбросить, вне зависимости от того, каковы другие его компоненты. Данный
подход эквивалентен отсечению ветвей дерева поиска; поиск по агрессивно усе-
554
Часть V. Верхний уровень компьютерного зрения: геометрические методы
ченному дереву поиска, называемый алгоритмом дерева интерпретации, был
введен в работе [Grimson and Lozano-Perez, 1984].
Геометрические ограничения также применимы в том случае, когда трех-
мерную модель требуется сопоставить с двумерными данными. Это объясня-
ется тем, что параметры проекционной модели обычно можно определить по
относительно небольшому числу точечных соответствий. Как только найдены
эти параметры, известными можно считать и положения проекций всех других
характерных элементов, причем это утверждение также является ограничени-
ем — положения данных характерных элементов нельзя выбрать произвольным
образом. Чтобы использовать данные ограничения, можно явно определить про-
екционные параметры по небольшому числу соответствий, а затем использовать
проекционную модель для предсказания других соответствий (см. раздел 18.2,
где описана эта популярная стратегия, истоки который неизвестны).
Фактически, проекционные параметры определять не обязательно. Как
только установлено соответствие между небольшим числом элементов объекта
и небольшим числом элементов изображения (базовый набор), для предсказа-
ния положений других элементов изображения можно использовать ограниче-
ния камеры. Это означает, что в определенном смысле положения остальных
элементов изображения фиксированы относительно базового набора. Соот-
ветствующим образом интерпретируя это относительное положение, можно
получить измерения, независимые от проекционных параметров, и использо-
вать их для идентификации объекта (раздел 18.4).
18.2. ПОЛУЧЕНИЕ ГИПОТЕЗ ИЗ СОВМЕСТИМОСТИ ПОЗ
Предположим, что дано изображение некоторого объекта, полученное с ис-
пользованием модели камеры известного типа, но с неизвестными параметрами
(например, объект может наблюдаться через Откалиброванную перспективную
камеру, внешние параметры которой неизвестны относительно системы коорди-
нат, связанной с объектом). Если сделать предположение о соответствии между
достаточно большой группой элементов на изображении и достаточно большой
группой элементов объекта, по этой гипотезе можно восстановить отсутству-
ющие параметры камеры (и таким образом визуализировать оставшуюся часть
объекта). Методы такого типа (алгоритм 18.1 и рис. 18.2) известны как методы
совместимости поз, ниже они иллюстрируются на примерах. Подобные алго-
ритмы все чаще начинают называть алгоритмами выравнивания', термин отра-
жает основной принцип данных алгоритмов — совмещение объекта с его изоб-
ражением. Название было придумано для относительно новой версии алгорит-
ма, но стоит отметить, что этот алгоритм встречается в литературе в различных
формах, причем сходство данных форм было отмечено относительно недавно.
Глава 18. Зрение на основе модели
555
Рис. 18.2. В методах кластеризации поз координатные группы используются для оценки поз с по-
следующей кластеризацией на основе результатов оценки. Вверху: две модели, которые исполь-
зовались в ранней системе кластеризации поз. Слева в центре: краевые точки, отмеченные для
изображения, которое использовалось при тестировании. Справа в центре: края модели, которые
были признаны закрытыми от наблюдения. Слева внизу: новая проекция схемы моделей в простран-
стве, используемая для идентификации их позы; обратите внимание на забавную позу самолета вне
взлетно-посадочной полосы. Справа внизу: для каждой группы некоторые проекции лучше других,
поскольку оценка позы более устойчива; рядом с моделью самолета видна сфера, представляю-
щая различные точки наблюдения, причем светлые области соответствуют проекциям пары сильно
ошибочных характерных элементов, отмеченных на модели. Перепечатано из J.L. Mundy and
A. Heller, “The evolution and testing of a model-based object recognition system”, Proceedings of the
International Conference on Computer Vision, 1990. © 1990 IEEE
556
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Алгоритм 18.1. Выравнивание: совмещение групп объекта и изображения для вы-
вода модели камеры
Для всех групп объекта, О
Для всех групп на изображении, F
Для всех соответствий С между элементами множества F и элементами
множества О
Использовать F, С и О для определения отсутствующих параметров в
модели камеры
Использовать оценку модели камеры для визуализации объекта
Если визуализированное изображение соответствует наблюдаемому,
объект присутствует
конец
конец
конец
В действительности мы рассматриваем семейство методов, поскольку дета-
ли алгоритма зависят от того, что известно о камере, и являются ли объекты
двумерными или трехмерными. Группы, которые будут использоваться для
получения гипотез, будем называть группами объекта или группами на изоб-
ражении.
18.2.1. Совместимость поз для перспективных камер
Предположим, что дана перспективная камера с известными внутренними
параметрами. С помощью данной камеры наблюдается объект в базе моделей.
Будем работать в системе координат, связанной с объектом; внешние пара-
метры в этом случае сводятся к положению и ориентации камеры в системе
координат, связанной с объектом. Далее используем алгоритм 18.1 и получим
соответствие между группой элементов изображения в системе координат, свя-
занной с изображением, и группой элементов объекта в системе координат,
связанной с объектом. Из этой информации можно определить внешние па-
раметры камеры. После этого становится известной вся информация о камере
и ее можно использовать для визуализации оставшейся части объекта.
Для решения поставленной задачи можно использовать разнообразнейшие
доступные группы. Как правило, хорошие группы содержат несколько характер-
ных элементов нескольких различных типов (это полезно для снижения числа
соответствий, среди которых производится поиск). Назовем наиболее популяр-
ные группы:
• три точки;
• три направления (часто именуемые трехгранной вершиной) и точка
(необходима для установления масштаба);
• двугранная вершина (два направления, связанные общим началом) и
точка.
Глава 18. Зрение на основе модели
557
Как правило, направления определяются с использованием сегментов пря-
мых. Такой подход привлекателен, поскольку, как правило, найти на изображе-
нии фрагмент прямой достаточно реально, но точно определить его конечные
точки обычно затруднительно.
Внутренние параметры
В литературе часто предполагается, что внутренние параметры камеры так-
же неизвестны. Это не сильно усложняет поставленную задачу — хотя, воз-
можно, потребуется использовать более сложные группы, но это же позволит
применять более агрессивные критерии совместимости. На изображениях, со-
держащих больше одного объекта, можно использовать такое условие: внут-
ренние параметры камеры одинаковы для разных объектов.
Схема рассуждений достаточно проста: для распознавания отдельных объ-
ектов используется алгоритм 18.1, с каждым объектом связываются предполо-
жения о параметрах камеры. Теперь для каждой пары распознанных объектов
сравниваются предположительные внутренние параметры камеры: если они (до-
статочно) отличаются, исходные две гипотезы несовместимы.
18.2.2. Аффинная и проективная модели камеры
Калибровка перспективных камер сложна, поскольку во внешних парамет-
рах фигурирует вращение. Часто можно использовать модель камеры, допуска-
ющую более простую калибровку за счет большей неоднозначности при опре-
делении модели. Укажем два важных упрощения.
• Аффинные камеры, в которых перспективная проекция моделируется
как аффинное преобразование с последующим ортографическим проекти-
рованием.
• Проективные камеры, в которых перспективная проекция моделируется
как проективное преобразование с последующим перспективным проекти-
рованием.
Обе названных ситуации рассмотрены ниже с определенной степенью детали-
зации. Следует помнить, что единственным важным вопросом здесь является
получение модели камеры по предположительным соответствиям между груп-
пой в системе координат, связанной с объектом, и группой в системе координат,
связанной с изображением; остальные шаги описаны в алгоритме 18.1.
Аффинные камеры
В однородных координатах аффинную камеру можно представить как ПЛ,
где А — общее аффинное преобразование, а П — преобразование ортографиче-
ской камеры. Это означает, что
(10 0 0
0 10 0
0 0 0 1
558
Часть V. Верхний уровень компьютерного зрения: геометрические методы
и
Л =
f <1оо <Ю1 <102 <103
«10 ац <112 <113
«20 <121 <122 <123
\ 0 0 0 1 /
Заглавные буквы использованы для точек модели, строчные — для точек изоб-
ражения, а нижние индексы обозначают соответствия (так что рг = ПЛР1).
Одна из возможных групп состоит из четырех точек. В этом случае требует-
ся определить камеру (по сути, матрицу Л) по соответствиям между четырьмя
точками изображения и четырьмя точками объекта. Предположим теперь, что
имеется (предположительное) соответствие между четырьмя точками изобра-
жения (pj и четырьмя точками объекта (Pi). Условие = ПЛРг можно
интерпретировать как два линейных уравнения для первых двух строк матри-
цы А; т.е.
РгО ] _ ( аО°^»О 4- GOlPtl + (102Pi2 + «03
рп J \ аюЛо + аиРи + а^ + щз
В первых двух строках матрицы А восемь элементов; имея четыре точки в об-
щем положении, данные уравнения можно решить и получить единственное
решение для первых двух строк матрицы А. Обратите внимание, что осталь-
ная часть матрицы А не вносит вклада в проектирование и для вычисления
проекций остальных точек знать ее не требуется. Это означает, что первые две
строки матрицы А — это все, что необходимо для восстановления сцены по
проекциям.
Некоторые модели, отличающиеся вращением и трансляцией, при наблюде-
нии с помощью аффинных камер неоднозначны. Предположим, что некоторая
модель представлена набором точек Pj, вторая — набором Qj, а также имеет-
ся некоторое аффинное преобразование 13 такое, что для каждого j имеет место
условие Pj = 8Qj. Для аффинной камеры данные модели неразличимы. Про-
екция первой модели в аффинную камеру — это набор точек на изображении
Pj = ILAiPj, а проекция второй модели в некоторую другую аффинную камеру
представлена набором точек на изображении Qj = IIA2Qj. Если Аг = AJ3,
получаем
Я, = ПЛ2О, = = ПЛ1Р, = pd,
т.е. имеется аффинная камера, для которой вторая модель выглядит точно
так же, как проекция первой модели в некоторую аффинную камеру — таким
образом, данные модели неразличимы.
Глава 18. Зрение на основе модели
559
Проективные камеры
В однородных координатах проективную камеру можно записать как ПЛ,
где Л — общее проективное преобразование, а П — преобразование перспек-
тивной камеры. Это означает, что
ООО
1 О О
О 1 О
1 аоо <^О1
и
аю
020
азо
ап
021
«31
ао2 аоз
012 013
022 023
аз2 азз /
Как и ранее, заглавные буквы использованы для точек модели, строчные — для
точек изображения, а нижние индексы обозначают соответствия (так что pj =
ПЛР1). Обратите внимание, что поскольку используются однородные коорди-
наты, матрицы А и АЛ представляют одно и то же преобразование, если Л 0.
Здесь одна из возможных групп состоит из пяти точек. В этом случае камеру
(по сути, матрицу Л) требуется определить по соответствиям между пятью точ-
ками изображения и пятью точками объекта. Предположим теперь, что имеется
(гипотетическое) соответствие между пятью точками изображения (pj и пя-
тью точками объекта (PJ. Выражение рг = ПЛРг можно интерпретировать
как два нелинейных уравнения на две первых строки матрицы Л, т.е.
(Pio \ _ 1 I аооРо + aoiHi 4-аогРг + аоз \
ри I азоРго + asiPii + аз2р»2 + азз \ аюРго + ацРн 4-ai2Pi2 + ai3 J
В первых двух строках матрицы Л имеется 12 элементов; при наличии пяти
произвольно размещенных точек данные уравнения можно решить и получить
единственное решение для первых трех строк матрицы Л. Обратите внимание,
что остальная часть матрицы Л не вносит вклада в проектирование и для вы-
числения проекций остальных точек знать ее не требуется. Это означает, что
первых трех строк матрицы Л достаточно для восстановления сцены по проек-
циям. Обратите также внимание, что все действия в данном разделе формально
повторяют вывод в разделе 18.2.2.
Некоторые модели, различные для аффинных камер (т.е. отличающиеся бо-
лее чем вращением и трансляцией), являются неоднозначными для проектив-
ных камер. Предположим, что одна модель представлена набором точек Pj, вто-
рая — набором Qj, а также имеется некоторое проективное преобразование 13
такое, что для каждого j имеет место условие Pj = BQj- Для проективной
камеры данные модели неразличимы. Проекция первой модели в проективную
камеру — это набор образов точек = IIAiPj, а проекция второй модели
560
Часть V. Верхний уровень компьютерного зрения: геометрические методы
в некоторую другую проективную камеру представлена набором образов то-
чек — ПЛ2<Э7- Если Д2 = -41/3, получаем
= IIAQj = = ПАР., = рр
т.е. существует проективная камера, в которой вторая модель выглядит точно
так же, как проекция первой модели в некоторую проективную камеру; таким
образом, данные модели неразличимы.
18.2.3. Линейная комбинация моделей
Для явной калибровки аффинных камер используются соответствия, причем
процесс калибровки камеры можно описать, обратившись к линейной алгебре.
Используем однородные координаты и запишем неоткалиброванную аффинную
камеру в общем случае как IL4, где А — общее аффинное преобразование и
(10 0 0
0 10 0
0 0 0 1
Заглавные буквы использованы для точек модели, строчные — для точек изоб-
ражения, а нижние индексы обозначают соответствия (так что рг — ПЛР1).
Выделим одну точку модели в качестве начала координат и рассмотрим
смещения от этой точки (это означает, что трансляция пока не учитывается).
Используем обозначения Vi = рг — р0 и Vi = Pi — Pq. Запишем теперь три
проекции объекта в различные аффинные камеры с помощью аффинных пре-
образований А, В и С, так что для г-й точки объекта получаем:
vf = ПЛ Vi;
vf = nBV£;
vf = ПС Vi.
Поскольку П содержит много нулевых элементов, а четвертая строка Vi нуле-
вая, данные три проекции позволяют значительно упростить рассматриваемую
задачу.
Запишем j-ю строку матрицы А как aTj. Получаем следующее:
= (al.Vi,aT.Vi,0f-
v? = (b^.Vi,br.Vi,0)T;
vf = (c^.Vi,cr.Vi,0)T
Допустим, требуется сгенерировать некоторую новую произвольную проекцию
объекта, чего можно добиться, подействовав на точки преобразованием ПР,
где Р — некоторое новое аффинное преобразование. Для получения данной
Глава 18. Зрение на основе модели
561
проекции вначале следует решить, где лежит вектор р0; после этого требуется
определить вектор vP для г-й точки.
Теперь vP = (dg .Vi, .Vi, 0). Предполагая, что матрицы А, 13 а С имеют
общий вид, получаем, что вектор dj должен быть фиксированной линейной
комбинацией векторов a,j, bj и Cj, скажем,
dj — Xfa^cij 4- \b^bj 4- X(Cj)Cj.
Таким образом, выражение
v? = (А(о0)ао -Vi 4- Афо)Ьо - Vi 4- A(c0)cJ.VA^^af.Vг 4- A^^bf .Vi 4- A(C1)cf .Vi, 0)
означает, что при трех данных аффинных проекциях объекта четвертую можно
восстановить, определив значения указанных выше параметров А.
Описанная стратегия получила название линейной комбинации моделей.
Генерация гипотез при использовании такого метода также требует поиска со-
ответствий; на изображениях выбираются несколько точек в качестве р0, р±
и т.д., а затем ищутся значения А. После этого объект можно визуализиро-
вать, особое внимание следует уделить удалению невидимых линий. Обратите
внимание, что данный подход — это альтернативная версия калибровки аффин-
ной камеры. Его привлекательная особенность заключается в том, что модель
объекта относительно просто строится по трем проекциям объекта. Из этого
следует, что модель объекта также легко построить по трем проекциям, фигу-
рирующим в подходе, который описан в разделе 18.4.
18.3. ПОЛУЧЕНИЕ ГИПОТЕЗ ЧЕРЕЗ КЛАСТЕРИЗАЦИЮ ПОЗ
Большинство объектов имеют множество групп. Это означает, что между
группами объекта и изображения должно существовать множество соответ-
ствий, успешно проходящих верификацию. Каждое из этих соответствий долж-
но давать приблизительно одинаковую оценку положения и ориентации объекта
относительно камеры (или камеры относительно объекта — это не принципи-
ально). В то же время, группы элементов на изображении, порожденные поме-
хами (термин используется для объектов, не представляющих интереса или не
принадлежащих базе моделей), скорее всего, будут давать некоррелирующие
между собой оценки поз. По этой причине после верификации стоит профиль-
тровать гипотезы, использовав некоторую схему кластеризации.
Для каждого объекта формируется аккумуляторный массив, представляю-
щий пространство поз — каждый элемент в массиве соответствует сегменту
в пространстве поз. Теперь берется каждая группа на изображении и форми-
руется гипотеза о соответствии между ней и каждой группой образов каждого
объекта. Для каждого из таких соответствий определяются параметры позы
и делается запись в аккумуляторном массиве для текущего объекта и значе-
ния, определяющего позу. Если за некоторый объект в аккумуляторном масси-
562
Часть V. Верхний уровень компьютерного зрения: геометрические методы
ве отдано большое число голосов, это можно понимать как очевидное наличие
данного объекта в искомой позе; данное предположение можно проверить, ис-
пользуя метод верификации. Стоит также отметить сходство данного метода
(представленного в алгоритме 18.2) и преобразования Хоха (раздел 15.1).
Алгоритм 18.2. Кластеризация поз: голосование за позу, установление соответ-
ствия и отождествление
Для всех объектов О
Для всех групп в пространстве объекта, F(O)
Для всех групп в пространстве образов, F(7)
Для всех соответствий С между элементами пространства F(I) и
элементами пространства F(Q)
Использовать F(I), F(O) и С для вывода позы объекта Р(О)
Добавить в пространстве поз О голос в урну, соответствующую Р(О)
конец
конец
конец
конец
Для всех объектов О
Для всех элементов Р(О) пространства поз О, которые получили достаточное
число голосов
Использовать Р(О) и оценку модели камеры для визуализации объекта
Если визуализированный объект соответствует наблюдаемому, объект
считается присутствующим
конец
конец
При использовании данных методов возникают две трудности (зеркальная
копия трудностей, возникающих при использовании преобразования Хоха на
практике).
1. На изображении, содержащем помехи или текстуру, которая порождает мно-
жество побочных групп, в массиве поз может быть отдано меньше голосов
за истинные объекты, чем за подобные побочные группы (подробнее этот
вопрос рассмотрен в работе [Grimson and Huttenlocher, 1990&]).
2. Сложен выбор размера сегментов в массивах поз; слишком маленькие
сегменты означают, что накопление голосов не происходит (поскольку точ-
но вычислить позу сложно); если сделать сегменты очень большими, то
слишком много сегментов получат достаточно голосов, чтобы пройти вери-
фикацию.
Глава 18. Зрение на основе модели
563
Устойчивость метода к помехам можно улучшить, если не учитывать голоса,
поданные за очевидно нереальные позы объектов; например, если при предпо-
лагаемой позе объекта группы точек объекта будут невидимыми. При таких
улучшениях вполне можно построить реальные рабочие системы (рис. 18.2).
18.4. ПОЛУЧЕНИЕ ГИПОТЕЗ С ИСПОЛЬЗОВАНИЕМ ИНВАРИАНТОВ
В методах кластеризации поз собираются соответствия, из которых следуют
сходные гипотезы о калибровке и позе камеры. Возможен другой путь получе-
ния гипотез: использовать измерения, независимые от свойств камеры. Такой
подход легче всего реализовать для изображений плоских объектов, хотя он
применим и к другим ситуациям (см. работы [Forsyth, Mundy, Zisserman and
Rothwell, 1992], [Forsyth, 1996], [Huang, 1981]).
18.4.1. Инварианты для плоских изображений
Напомним, что аффинную камеру можно записать как ПЛ, где А — общее
аффинное преобразование, а П — преобразование ортографической камеры.
Предположим, что имеется набор точек модели Pj, расположенных в одной
плоскости; не нарушая общности можно предположить, что все точки лежат
в плоскости 2 = 0. Получаем уравнение
(использована форма записи, введенная в разделе
18.2.2). Можно подставить
значения П и А и получить следующее:
Данный результат важен; он означает, что проекции набора компланарных то-
чек в аффинную камеру порождаются плоскими аффинными преобразования-
ми — это, в свою очередь, означает, что камеру можно абстрагировать и изу-
чать только влияние на модель данных преобразований.
Подобный результат можно получить для проекций точек на плоско*,
в проективную камеру — в этом случае преобразование является плоским про-
ективным преобразованием. Для получения искомого результата напомним,
что проективную камеру можно записать как ПЛ, где А — общее проектив-
ное преобразование, а П — преобразование проективной камеры. Предположим,
что дан набор точек модели Pjt расположенных в одной плоскости; не нару-
шая общности можно предположить, что все точки лежат в плоскости 2 = 0.
564
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Получаем уравнение
PiO
Рн
1
= ПЛ
/ Ро \
Рн
О
\ 1 /
(использована форма записи, введенная в
значения П и Л и получить следующее:
PiO \ _ 1
PH J в2оРо + в21Р*1 + 023
разделе 18.2.2). Можно подставить
0.00 «01
аю ац
Напомним, что использование однородных координат позволяет получить более
удобное представление результата:
РгО \ / 0.00 tloi 003
Рн I = I ою ац 013
Pi2 / \ «20 021 023
/ Ро
Рн
\ Рз
Как и выше, данный результат означает, что проекции набора компланарных
точек в проективную камеру порождаются плоскими проективными преобра-
зованиями — это, в свою очередь, означает, что камеру можно абстрагировать
и изучать только влияние на модель данных преобразований.
Аффинные инварианты для компланарных точек
Предположим, что дана модель, представляющая набор точек, лежащих
в одной плоскости. Выберем три таких точки Р$, Pi и Р^. Это даст си-
стему координат, и любую другую точку Pi этой модели можно выразить
как Ро -I- pn(Pi — Ро) + Ргъ^Ръ — Ро). Для вычисления значений р, связан-
ных с каждой точкой, достаточно элементарных знаний из области линейной
алгебры.
Теперь камера переводит точки модели Рг в точки изображения р,. Если
имеется неоткалиброванная аффинная камера, с помощью которой наблюда-
ется набор точек на плоскости, преобразование камеры можно записать как
неизвестное плоское аффинное преобразование. Камеру можно записать как С.
Таким образом,
Pi = CPi =
= С(Ро + PH (Р1 — Ро) + Pi2 (Рз — Ро)) =
= (1 — рп — Pi2)(CPo) + рн(СР1) + Рг2(СР2) =
= (1 — рп — Pi2)Po + PHP} + Pi2P2 =
= Ро + - Ро) + Pi2(p2 - Pl)-
Глава 18. Зрение на основе модели
565
Это означает, что набор величин описывает геометрию объекта и не зави-
сит от точки наблюдения (т.е. если вычислить в плоскости модели или
по некоторой аффинной проекции, будут получены одинаковые результаты).
Данные, обладающие подобной особенностью, часто называются аффинными
инвариантами (другие конструкции, являющиеся аффинными инвариантами,
описаны в разделе упражнений).
Проективные инварианты для компланарных точек и прямых
В однородных координатах связь между точками изображения и модельны-
ми точками (на плоскости) можно записать как = APi, где А — общая
матрица 3x3. Теперь получаем следующее:
det
det [PiPj-Pt] det [p,Pkp7J
равно
det det [(ЛРОСДРОСЛР™)]
det [(ЛРОСДР^ХЛРО] det [(ЛР£)(ЛРь)(ЛР™)] ’
это также равно
det jldet [PiPjPfc] det A det \P,PiPJtl]
det A det [PiPjPi] det A det [PiP^Pm] ’
что, в свою очередь, равно
det [PjPjPk] det [PjPfPm]
det [PiPjPi] det [PjPfcPm]
(причем никакие два из индексов i, j, к, I и т не совпадают, и никакие три
точки не лежат на одной прямой). Существуют и другие комбинации детерми-
нантов, также являющиеся инвариантами (см. раздел упражнений).
Плоские алгебраические кривые и проективные преобразования
Алгебраические кривые состоят из всех точек плоскости, где полиномы при-
нимают нулевое значение. Примером алгебраической кривой является прямая
линия. Если точку в однородных координатах записать как рг = [pnj,pn,Pi2]T,
прямая — это геометрическое место точек р, для которых IqPq + Z^ + Z2p2 = 0.
Это можно записать следующим образом: 1Тр ~ 0, причем прямая представлена
вектором I. Если теперь подействовать на точки преобразованием р — АР, то
прямые будут преобразованы по закону I — A~TL. Наиболее простой способ
понять это соотношение — отметить, что
lTp = iTAP = LTA~XAP.
Таким образом, если р лежит на прямой I, то Р лежит на прямой L.
566
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Поскольку прямые (в основном) преобразуются как точки, имеем
det [МЛ] det[lihlm] _det[^-TLi)^-TLj)(^-TZfc)]
det [liljh] det [lilklm] ~ det [(А-тЬг)(А-т1^(А~тЬ1)] X
det [(Л-г£0(-4”ТЬ/)(Л~гЬт)] _
x аеМ(л-тьо(л-гед(л-гЬт)] “
det A det [LjLjLk] det A det _
det A det [LiLjLi] det Xdet [ZiZfcbm]
det [LiLjLk] det {LiLiLm]
det [LtLjLi[ det [^iJDk^m]
(причем никакие два из индексов i, j, к, I и m не совпадают, и никакие три
прямых не пересекаются в одной точке).
Фактически, при исследовании проективной камеры можно найти множество
алгебраических инвариантов. Особо полезные представители этого семейства
обнаруживаются при изучении плоских конических сечений. Плоское кониче-
ское сечение — это геометрическое место точек х, таких, что х{Л4х = О,
где х — вектор однородных координат, описывающих точку, а матрица Л4 со-
держит коэффициенты конического сечения. Если теперь некоторым образом
преобразовать систему координат (скажем, перейдя от точек к наблюдающей
их камере), получим х' — Рх для некоторого плоского проективного преобра-
зования Р. Уравнение конического сечения в новой системе координат можно
получить, отметив, что новое уравнение должно превращаться в нуль в любой
точке, лежащей на старом коническом сечении (т.е. для каждой точки, для ко-
торой предыдущее уравнение конического сечения в старой системе координат
превращается в нуль). В частности, если обратить преобразование и подста-
вить полученную точку в уравнение старого конического сечения, должен по-
лучиться нуль. Из подобных рассуждений следует, что Л4' = Р~1Л4Р~Г — это
уравнение конического сечения в новой системе координат.
Предположим теперь, что дано два конических сечения, Л4 и ЛА Каждое
преобразовывается описанным выше образом, т.е. Amn = переходит
в A'MN — РЛ/[~1ЛГР~1, которое и наблюдается в камере. Это, в свою очередь,
означает, что собственные значения матрицы A'MN идентичны собственным
значениям матрицы Amn- Наблюдать можно и матрицу Amn (наблюдая мо-
дель), и матрицу A'mn (наблюдая изображение), но в обоих случаях только
с точностью до постоянного масштабного множителя. Это означает, что наблю-
даемые собственные значения могут множиться на постоянный, но неизвестный
коэффициент; впрочем, соответствующим образом выбранные отношения соб-
ственных значений являются инвариантами. В частности, это справедливо для
величины 1г(ЛмлО3/йеЦЛмдг).
Достаточно просто также можно построить инварианты для смешанных на-
боров точек и прямых. Например, предположим, что дан набор точек р* и набор
прямых lj. Отметим, что
Глава 18. Зрение на основе модели
567
VTpMlJPt) (ХГЛ-МРОСЧ'-А-МРь)
(LTPk)(LjP,)
(LTPt)(LjPtY
Это означает, что данное выражение инвариантно (причем индексы i и j не
равны, и индексы к и I не равны).
Проективные инварианты для различных смешанных наборов точек, прямых
и конических сечений известны и успешно используются при распознавании
объектов (некоторые примеры исследуются в разделе упражнений). Проектив-
ные инварианты известны для алгебраических кривых высоких степеней, но
они редко применяются на практике, поскольку подобные кривые редко встре-
чаются в природе и их трудно подобрать точно.
18.4.2. Геометрическое хэширование
Геометрическое хэширование — это алгоритм, в котором для голосования
за гипотезы относительно объектов используются геометрические инварианты.
В качестве аналогии можно привести кластеризацию поз (снова используется
голосование), но теперь голоса отдаются за геометрию, а не за позу. Основной
принцип изначально был предложен для неоткалиброванных аффинных проек-
ций плоских моделей и именно в этом контексте его проще всего объяснить.
Для любого набора из трех точек модели можно использовать методы, пред-
ложенные в разделе 18.4.1, и вычислить значения /ij и р? для каждой точки
модели. Заводится таблица, в качестве индексов которой используются значе-
ния р\ и р2- Для каждой модели в базе моделей и для каждой группы из трех
точек в этой модели вычисляются значения р для всех остальных точек. Ис-
пользуя эти р как индексы, в таблицу вводится позиция, в которой записано
название модели и три точки модели, на основе которых получены значения.
Таким образом, пара величин р выступает как гипотеза о модели и трех точках
в этой модели.
После заполнения таблицы можно искать модель, определяя соответствия.
Берется любая тройка точек изображения и вычисляются значения р для всех
остальных точек изображения. Согласно индексам (р) восстанавливается со-
держимое таблицы. Если тройка соответствует тройке объекта, за комбинацию
объекта и трех точек должно быть получено много голосов. Будем надеяться,
что голоса, отданные за шум, не коррелируют, т.е. что имеется множество раз-
бросанных голосов за различные тройки в различных объектах и много голосов
за комбинации трех точек объекта. Из сказанного следует, что если за некото-
рый объект, а также три точки на этом объекте, отдано много голосов, объект
вероятнее всего присутствует. Обратите внимание, что данный набор трех то-
чек может выступать как группа в процессе верификации. Схема голосования
за значения р описана в алгоритме 18.3.
568
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Алгоритм 18.3. Геометрическое хэширование: голосование за объект и точечные
метки
Для всех групп из трех точек изображения, Т(1)
Для каждой другой точки изображения, р
По р и Т(1) вычислить значения р
Получить значение позиции таблицы с данными индексами
если значение получено, будут помечены три точки в Т(1) с
наименованием объекта и наименованиями данных точек
Собрать метки в кластеры;
если имеется достаточное число меток, инициировать процессы
восстановления сцены по проекциям и верификации
конец
конец
конец
Данный алгоритм можно обобщить и применять для других геометрических
групп, отличных от точек (см. раздел упражнений). Если даны неоткалиброван-
ные аффинные проекции трехмерных объектов, то для каждой точки имеется
три значения р, и для каждой точки их нельзя определить единственным об-
разом, хотя возможно дальнейшее развитие предложенной схемы (снова см.
раздел упражнений). Как и в случае кластеризации поз и преобразования Хоха
(которым, по сути, и является описанный метод), сложно выбрать размер урн
для голосования; трудно точно определить значение слова “достаточно”; кро-
ме того, имеются опасения, что таблица будет засорена (работа [Grimson and
Huttenlocher, 1990а]).
18.4.3. Инварианты и индексация
При геометрическом хэшировании соответствия также ищутся, но для этого
из хэш-таблицы извлекаются приемлемые метки. Основная особенность гео-
метрического хэширования заключается в том, что во время распознавания не
требуется производить поиск среди моделей — хэш-таблица заранее заполне-
на соответствующим образом. Эта желательная особенность часто называется
индексацией. Одна из разновидностей индексации применяется, когда различ-
ные модели имеют группы различных типов. Очевидно, что группа объекта
определенного типа должна проверяться только на соответствие с моделями,
в которых применяются группы этого типа.
При геометрическом хэшировании можно использовать такой подход: ис-
кать группы изображения, которые содержат информацию, независимую от по-
зы объекта и изменяющуюся при переходе между объектами (значения р). Из
этих р затем извлекается информация об объекте. При геометрическом хэши-
ровании изучаются все возможные группы точек, так что описанную уловку
Глава 18. Зрение на основе модели
569
можно расширить на все типы характерных геометрических объектов. Груп-
пы характерных элементов, которые несут информацию, независимую от позы
объекта и изменяющуюся при переходе между объектами, будем называть груп-
пами, содержащими инварианты', несколько примеров таких групп приведе-
но в разделе 18.4.1. Предположим, что известны и доступны различные типы
групп, содержащих инварианты. Модифицируем теперь алгоритм выравнивания
(результат представлен как алгоритм 18.4).
Алгоритм 18.4. Индексация инвариантов с использованием групп, содержащих
инварианты
Для каждого типа Т групп, содержащих инварианты
Для каждой группы на изображении G, принадлежащей к типу Т
Определить значения V инвариантов группы G
Для каждой группы характерных элементов модели М, принадлежащей к
типу Т, инварианты которой имеют значения V
Определить преобразование, переводящее М в G
Визуализировать модель, используя это преобразование
Сравнить результат с изображением и принять его в случае сходства
конец
конец
конец
Данный подход может быть крайне эффективным, если группы, содержа-
щие инварианты, своеобразны в том смысле, что существует мало групп ха-
рактерных элементов модели с одинаковыми значениями инвариантов. Далее
требуется точно измерить значения инвариантов. Обратите внимание, что нуж-
но рассмотреть все группы характерных элементов модели, имеющих такие же
значения, что и группы характерных элементов изображения, поскольку неиз-
вестно, какая группа исследуется. Итак, снова имеем поиск по соответствиям
с (оправданной) надеждой, что число соответствий, среди которых будет вы-
полняться поиск, будет малым.
Индексация в неоткалиброванной перспективной проекции с помощью
прямых и конических сечений
Существует множество содержащих инварианты групп, которые можно вве-
сти в представленный выше общий алгоритм. Лучшие результаты описанный
процесс дает на плоских объектах, наблюдаемых с помощью неизвестной пер-
спективной камеры, где инварианты преобразования формирования изображе-
ния буквально “лежат на поверхности”. Вообще, наиболее важные частные
случаи — это, похоже, инварианты таких групп: пять прямых, два конических
сечения; коническое сечение и две прямые.
При таких функциях типичная система (проиллюстрирована на рис. 18.3)
обрабатывается следующим образом.
570
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 18.3. На данных рисунках показана общая структура системы, которая распознает плос-
кие объекты с помощью инвариантов. На рисунке слева вверху представлено изображение; справа
вверху показаны краевые точки, по которым подбирались прямые или конические сечения; наконец,
внизу наведены точки, принадлежащие объектам, которые были распознаны и прошли верифика-
цию. Перепечатано из С.А. Rothwell et al., “Efficient model library access by projectively invariant
indexing functions”, Proceedings Computer Vision and Pattern Recognition, 1992. © 1992 IEEE
• Извлекаются примитивные группы. Изображения пропускаются через
детектор краев, и к группам краевых точек подбираются конические сече-
ния и прямые. Краевые точки отбрасываются, а подобранные кривые со-
храняются. Проверять все группы из пяти сегментов прямых на предмет
формирования инвариантов чрезвычайно обременительно. Кроме того, это
ненужно, поскольку объекты не формируются из разрозненных прямых,
так что требуются только незамкнутые кривые, состоящие из сегментов
прямых. Группа — это когда при одной конечной точке некоторого сегмен-
та прямой имеется конечная точка по крайней мере еще в одном сегменте.
* Строится индекс с использованием инвариантов. Для получения ги-
потез относительно объектов используется уместная группировка прямых
и конических сечений, причем обычно выполняется индексация масси-
вов с использованием квантованных значений инвариантов. Обычно для
каждого типа групп имеется один-два инварианта и относительно малое
число моделей, так что использование массива не является слишком ре-
сурсоемким. Размер сегментов квантования обычно определяется методом
проб и ошибок; при оптимальной схеме также изучаются соседи выбран-
ного сегмента. Как и ранее, для группы каждого типа имеется один-два
инварианта, так что подобную схему нельзя назвать неэкономной.
Глава 18. Зрение на основе модели
571
Рис. 18.4. Поскольку определение касательной и наклона ковариантны (т.е. при изменении систе-
мы координат касательная остается касательной), конструкции, основанные на касании и наклоне,
определяют каноническую систему координат. На рисунке показана конструкция, именуемая М-
образной конструкцией (M-curve construction). Для М-образной кривой (для удобства перевер-
нута вверх ногами) бикасательная дает две точки (1 и 4), через которые можно провести прямые,
касающиеся кривой в точках 2 и 3; таким образом, получаем четыре точки. Поскольку любой на-
бор четырех точек, никакие три из которых не лежат на одной прямой, можно отобразить в любой
другой набор с таким же свойством, данные точки можно перевести в единичный квадрат на плос-
кости и исследовать кривую в этой канонической системе координат. Любое измерение в данной
системе является инвариантом
* Восстановление сцены по проекциям и верификация. Для каждой ги-
потезы относительно объекта определяется преобразование, переводящее
группы модели в группы изображения. На основе этого преобразования
сцена восстанавливается по проекциям и инициируется процесс верифи-
кации.
Индексация инвариантами для плоских кривых
Одним из источников геометрических инвариантов являются ковариантные
конструкции, которые коммутируют с искомым преобразованием (это означает,
что применение конструкции и преобразование результата равносильно преоб-
разованию геометрии с последующим построением в ней конструкции). При та-
ком подходе конструкция дает систему координат, которая затем преобразуется
в некоторую удобную универсальную систему координат, в которой и произ-
водятся измерения (обычно эта последняя система координат называется ка-
нонической). Поскольку измерения проводятся в строго определенной системе
координат, любая характеристика, измеренная в канонической системе коорди-
нат, является инвариантом. Стоит обратить внимание на сходство описанной
идеи с тем, что используется при геометрическом хэшировании: параметры р
измеряются именно в канонической системе координат.
Например, возьмем кривую и построим прямую, касательную к ней в двух
различных точках (для невыпуклых замкнутых плоских кривых такую прямую
572
Часть V. Верхний уровень компьютерного зрения: геометрические методы
построить можно, для выпуклых — нельзя, о незамкнутых кривых ничего опре-
деленного сказать нельзя). Теперь применим преобразование так, чтобы одна
из точек касания перешла в начало координат, а касательная прошла по оси х.
В подобной системе координат любое искомое измерение является инвариантом,
с одной оговоркой: может быть неизвестно, какую точку поместить в начало
координат (рис. 18.4). Однако возникает поврос: если можно сделать множество
инвариантных измерений, то какое из них выбрать?
18.5. ВЕРИФИКАЦИЯ
Точная верификация требует хороших тестов, на которых проверяется сход-
ство визуализированной модели объекта с изображением. Выбор тестов зависит
от объема информации, доступной при визуализации. Например, если и освеще-
ние сцены, и характеристика камеры, связанная с освещением, точно известны
(это, например, возможно для системы наблюдения за деталями на конвейерной
ленте), разумно ожидать, что визуализация будет точно предсказывать положе-
ния пикселей на изображении. В этом случае чувствительным тестом будет
сравнение значений пикселей.
Как правило, все, что известно об освещении, — это то, что оно достаточно
велико, чтобы позволить сгенерировать гипотезу. Это означает, что сравнение
должно быть устойчивым к изменениям освещения. На практике используется
единственный тест: визуализация силуэта объекта с последующим сравнением
его с краевыми точками изображения. Ниже описаны еще несколько возмож-
ных тестов, которые, впрочем, на практике не применяются.
18.5.1. Близость краев
Естественным тестом является наложение силуэта объекта на изображение
с использованием модели камеры и сравнение гипотез по числу точек, которые
совпали с реальными краевыми точками изображения. Параметр сравнения —
это обычно доля длины кривой предсказанного силуэта, лежащей близко к
реальным краевым точкам изображения. Данная величина инвариантна отно-
сительно вращения и трансляции системы координат камеры (это радует), но
меняется при изменении масштаба (а с этим можно бороться). Как правило, при
вычислении параметра верификации краевые точки учитываются только тогда,
когда их ориентация подобна ориентации точек силуэта, с которыми произво-
дится сравнение. Основная идея: чем подробнее описание краевой точки, тем
реальнее определить, порождена ли она объектом.
При вычислении параметра верификации не стоит включать в него невиди-
мые компоненты силуэта, поскольку при визуализации придется удалять неви-
димые линии. Силуэт используется потому, что края, внутренние для силуэта,
могут быть неконтрастными при плохом выборе освещения. Это означает, что
их отсутствие может объясняться освещением, а не наличием или отсутствием
некоторого объекта.
Глава 18. Зрение на основе модели
573
Рис. 18.5. Ориентация краев может вводить в заблуждение при верификации. Краевые точки,
отмеченные на рисунке, порождены моделью гаечного ключа, который, как показал процесс вери-
фикации, с 52%-ной вероятностью имеет обозначенную ориентацию. К сожалению, краевые точки
изображения были порождены ориентированной текстурой стола, а не гаечного ключа. Этого эф-
фекта можно избежать, использовав лучшее нетекстурированное описание внутренней части ключа,
которое не будет согласовываться с ориентированной текстурой стола. Перепечатано из С. A. Roth-
well et al., “Efficient model library access by protectively invariant indexing functions”. Proceedings
Computer Vision and Pattern Recognition, 1992. © 1992 IEEE
Тесты по принципу близости краев могут быть достаточно ненадежными.
Даже информация об ориентации не позволяет полностью избавиться от этих
сложностей. Если при проектировании набора границ модели на изображение
наблюдается отсутствие краев, расположенных возле этих границ, — это до-
стоверное указание на то, что модели здесь нет. Если же края присутствуют,
то это не является особо надежным указанием на то, что объект здесь есть.
Такие выводы объясняются тем, что края могут порождаться множеством ис-
точников, и нет гарантий, что края, использованные при вычисления параметра
верификации, действительно являются корректными.
Плохая оценка позы может привести к тому, что края силуэта на восстанов-
ленном объекте будут лежать далеко от реальных краевых точек изображения.
Например, если имеется объект, который проектируется в протяженную узкую
область (например, гаечный ключ), и его плоская ориентация оценивается с ис-
пользованием одного конца, восстановленные края, соответствующие другому
концу, могут находиться совсем не там, где следует (рис. 18.5). Данный при-
мер иллюстрирует понятие накопления ошибки — по сути, оценка параметров
камеры хороша для элементов, расположенных вблизи элементов, породивших
используемые данные, но последовательно увеличивается с удалением от этих
элементов. Существует несколько способов борьбы с описанным эффектом.
• Максимизация по оценкам позы. Иногда ситуацию можно улучшить,
максимизировав параметр верификации относительно позы. Это срабаты-
вает не всегда; если исходная оценка позы плоха, объект может в действи-
тельности лежать близко к краям, но не к тем краям (представьте попытку
верифицировать наличие объекта на текстурированном фоне). Более того,
574
Часть V. Верхний уровень компьютерного зрения: геометрические методы
оптимизация может быть сложной, особенно, если для проверки близле-
жащих точек использовать сравнение с пороговым расстоянием.
* Учитывать только края, для которых надежна оценка параметров
камеры. По сведениям авторов, такой подход никогда не применялся на
практике. Его достоинством является относительная легкость обработки
ситуаций, подобных изображенной на рис. 18.5; недостатком — вероятное
неиспользование в процессе верификации значительной части объекта,
т.е. велика вероятность ложного определения положения.
Другой существенный источник проблем — учет в параметре верификации
ложных краев. В текстурированных областях имеется множество краевых то-
чек, собранных в небольшие группы. Общая цель верификации заключается
в использовании модели для связи данных об изображении, которые слишком
трудно собрать на этапе формирования гипотез, с тем, чтобы из параметра вери-
фикации нельзя было исключить небольшие группы краевых точек. Это означа-
ет, что в высокотекстурированных областях можно получить большое значение
параметра верификации для практически любой модели в практически любой
позе (см. рис. 18.5). Обратите внимание, что учет в параметре верификации
подобия в ориентации краев никак не влияет на результат.
Детектор краев можно настроить так, чтобы текстура сильно сглаживалась
в надежде, что текстурированные области исчезнут. Эта уловка опасна, по-
скольку ее применение обычно сказывается на чувствительности к контрасту
и исчезнуть может сам объект. Впрочем, при корректном применении такой
подход дает хорошие результаты, поэтому используется довольно широко.
18.5.2. Сходство текстуры, шаблона и интенсивности
Если учесть совпадения краев, то текстура будет небольшой помехой. В то
же время, некоторые объекты имеют довольно своеобразные текстуры (напри-
мер, камуфлирующая раскраска) и это, вероятно, стоит использовать. Области
модели можно описать с помощью дескрипторов текстуры (подобных статистике
выходов фильтров; см. главу 9), а затем сравнить эти дескрипторы с изображе-
нием. При сравнении потребуется оценить значимость отличия областей изоб-
ражения от областей восстановленного объекта. Наиболее обещающий подход
здесь — это сравнить вероятность получения области изображения путем на-
ложения текстуры из семейства текстур объекта с вероятностью получения
данной текстуры при отсутствующем объекте.
При сравнении краев силуэта отбрасывается значительная часть полезной
информации. Если объект узорчатый (т.е. имеются крупные цветные области,
подобно маркировке на контейнерах с содой), можно также сравнивать края узо-
ров на восстановленном и наблюдаемом объектах. Более изощренный подход
заключается в сравнении узорчатых областей восстановленного объекта с обла-
стями изображения посредством дескрипторов текстуры (которые требуется со-
гласовать при отсутствии текстуры), а также дескрипторов цвета и насыщения.
Глава 18. Зрение на основе модели
575
Как правило, доступной информации об освещении недостаточно для пред-
сказания интенсивности фрагментов объекта. В результате на практике при
верификации на интенсивность внимания не обращают. Такой подход ошибо-
чен. Отличие в интенсивности очень редко связано с источниками света —
например, требуется учитывать только необычные источники света, такие как
видеопроекторы, дающие структуры с текстурированной интенсивностью. От-
сюда следует, что параметр верификации можно получить, сравнивая отличия
в абсолютной интенсивности с практически имеющимся отличием и отличием,
которое не может быть получено на практике.
18.6. ПРИЛОЖЕНИЕ: НАЛОЖЕНИЕ В МЕДИЦИНСКИХ СИСТЕМАХ
ВИЗУАЛИЗАЦИИ
Можно назвать множество случаев, когда более важно как размещен объ-
ект (поза), а не что это за объект (процесс распознавания). Многие алгоритмы
распознавания были разработаны в ожидании, что наблюдаться будут техноло-
гические детали, случайным образом размещенные в ящике или на столе; на
практике же технологи обычно следят за тем, чтобы детали разных типов не
смешивались, но при этом их интересует точная поза, в которой они находят-
ся. Здесь также можно упомянуть медицинские задачи, когда обычно известно,
что ищется, но критичным является вопрос, где это находится.
18.6.1. Модели представления изображений
Разработано множество технологий представления изображения, в том числе
методы магнитного резонанса (МР), в которых магнитное поле использует-
ся для измерения плотности протонов и которые обычно служат для описания
органов и мягких тканей; методы компьютерной томографии, в которых из-
меряется плотность поглощения рентгеновских лучей и которые обычно при-
меняются для описания костей; методы атомных меток, которые измеряют
плотность различных введенных радиоактивных молекул и которые обычно ис-
пользуются для построения функциональных изображений; и методы ультра-
звукового исследования (УЗИ), которые измеряют изменение скорости распро-
странения ультразвука и часто используются для получения информации о дви-
жущихся органах (иллюстрация методов приведена на рис. 18.6). Все описан-
ные технологии могут использоваться для получения срезов данных, которые
позволят восстановить трехмерную картину. Обычной проблемой здесь явля-
ется сегментация этих картин в различные структуры. На рис. 18.7 показано
сегментированное изображение мозга, желудочков мозга и опухоли, получен-
ное методом магнитного резонанса. Поскольку опухоли, по сути, неподвижны
относительно черепа и кожи, представленные данные позволяют локализовать
положение опухоли относительно головы.
Наложение медицинских изображений — это обычно задача преобразова-
ния трехмерного изображения в трехмерное, причем единственными рассмат-
риваемыми преобразованиями являются трехмерное вращение и трансляция.
576
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 18.6. Изображения, полученные для четырех различных моделей представления изображений.
На рисунке слева вверху представлено изображение разреза черепа, полученное методом магнит-
ного резонанса; справа вверху — изображение, полученное методом компьютерной томографии;
слева внизу — изображение мозга, полученное методом атомных меток; наконец, справа внизу —
УЗИ-снимок плода в утробе. Обратите внимание, что в каждом случае различные детали пред-
ставлены различными способами; на изображениях, полученных с помощью магнитного резонанса,
с высоким разрешением поданы детали мозга, а на снимках, полученных методами компьютерной
томографии, — детали черепа. ЯМ-снимок имеет низкое разрешение, но (фактически) отражает
функционирование объекта, поскольку области, имеющие сильную реакцию, получили некоторое
количество реагента. Наконец, УЗИ-снимки сильно зашумлены, но показывают детали мягких тка-
ней, например, у плода можно различить ногу, тело, голову и руку. Перепечатано с разрешения
Elsevier Science из N. Ayache, “Medical computer vision, virtual reality and robotics”, Image and
Vision Computing, v. 13, p. 196. (c) 1995 Elsevier Science
В основном используется механизм геометрического хэширования, поскольку
на его основе можно эффективно определять соответствия. Стоит также отме-
тить, что в литературе ведутся жаркие споры относительно того, какие данные
следует использовать.
18.6.2. Применение наложения
При операциях на головном мозге опухоль пытаются удалить при нане-
сении пациенту минимального ущерба. Приведенные ниже примеры описаны
согласно данным Гримсона (Grimson) и его коллег. Общий подход заключает-
ся в получении изображений мозга пациента, сегментации этих изображений
с целью определения опухоли и отображения изображения для хирурга. Изоб-
ражение накладывается на голову пациента, лежащего на столе, причем для
получения изображения пациента используется камера, дающая тот же вид,
Глава 18. Зрение на основе модели
577
Рис. 18.7. На рисунке слева вверху представлен срез MP-данных с наложенной автоматиче-
ской сегментацией. Сегментация выделяет мозг, вакуоли в пределах мозга, вакуоли вне моз-
га и опухоль. Магнитный резонанс дает набор срезов, позволяющий получить объемную мо-
дель; проекция сегментированной объемной модели, на которой различными цветами показаны
различные области, приведена на рисунке справа вверху. После получения обозначенных дан-
ных производится их совмещение с пациентом, лежащим на столе. Для совмещения использу-
ются данные относительно глубины, полученные с помощью лазерного дальнометра; вид паци-
ента с наложенными данными показан на рисунке внизу. Перепечатано с любезного разреше-
ния Эрика Гримсона (Eric Grimson), более подробную информацию можно получить на сайте
http://www.ai.mit.edu/people/welg/welg.html
который наблюдает хирург. На изображение мозга накладываются функцио-
нальные метки (как правило, стимулируется одна область мозга и изучается
результат) и эта информация также может отображаться для хирурга (цель —
минимизировать ущерб, причиняемый операцией). Проблему здесь представля-
ет плохая оценка позы, поскольку изображение мозга и измерения, производи-
мые на мозге, следует отобразить относительно пациента.
Подобные задачи возникают в реконструктивной хирургии. Например,
при планировании реконструкции лица хирургам могут быть доступны снимки
лица пациента в движении, на основе которых можно точнее визуализировать
череп пациента. Результаты этой визуализации также требуется отобразить
для хирурга при операции, причем также наложенными на лицо пациента.
578
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Диагностика включает трехмерную визуализацию с целью отображения
результатов, полученных с помощью многих различных методов. Например,
хирургу могут предоставляться MP-снимки (как правило — с относительно
высоким разрешением) и снимки, полученные средствами томографии на основе
позитронной эмиссии (Positron Emission Tomography — РЕТ), которые связаны
с функциональными возможностями. Для того, чтобы совместить указанные
изображения, их снова требуется наложить на пациента.
18.6.3. Методы геометрического хэширования в медицинских
приложениях
Основное различие прикладных алгоритмов заключается в типе измерений,
используемых при геометрическом хэшировании. Несколько распространенных
ситуаций рассмотрены ниже.
Точечные соответствия
Процесс поиска точечных соответствий был описан ранее. Например, МР-
снимки черепа можно наложить на голову пациента, лежащего на столе, вы-
полнив трехмерные измерения головы на операционном столе с помощью ла-
зерного дальнометра и использовав эти измерения для наложения изображения
на кожу с нанесенными MP-данными. Имея пару точек на коже, полученных
методом магнитного резонанса, можно определить расстояние до них и угол
между их нормалями, а затем сопоставить с данными, полученными с помо-
щью лазера. Пары с подобными расстояниями и сходными углами могут соот-
ветствовать друг другу. Используя соответствующие пары, можно оценить позу,
а затем проверить общую ошибку этой оценки. Хотя истинного соответствия
между такими данными нет, ни точки на коже, полученные с MP-снимка, ни
данные, полученные с лазерного дальнометра, не состоят из изолированных
точек; это выборки с поверхностей, причем выборка производится достаточ-
но плотно, чтобы можно было получить хорошие начальные гипотезы о позе.
Если затем разумно измерить ошибку при наложении, учтя только составляю-
щие, перпендикулярные поверхности (чтобы картину не запутывали небольшие
ошибки локализации), то последующей минимизацией ошибки можно добиться
великолепной оценки позы. Главным защитником подобных систем выступает
Гримсон, пример одной из них приведен на рис. 18.8.
Кривые
Для управления процессом геометрического хэширования можно также ис-
пользовать кривые. В этом случае по набору данных подбирается поверхность, а
затем на этой поверхности отмечаются значимые кривые. Использование пара-
болических кривых непрактично, поскольку в некоторых наборах данных име-
ется много плоских областей. В работах [Ayache, 1995а,6] успешно использу-
ются кривые, в которых максимальная нормальная кривизна — это экстремаль,
проходящая вдоль кривой максимальной нормальной кривизны поверхности.
Впрочем, какая бы кривая не использовалась, в любой точке кривой имеется
Глава 18. Зрение на основе модели
579
Рис. 18.8. На рисунке слева вверху показаны поверхностные данные, наложенные на пациента
в процессе регистрации. Как только данные зарегистрированы на пациенте, использовать их мож-
но множеством способов. На рисунке справа вверху показан вид пациента на операционном столе
с MP-образом (на котором видна часть мозга и опухоль), наложенным на информацию для хирурга.
На рисунке внизу виден образ, полученный наложением положения хирургического инструмента на
набор MP-данных. Это означает, что положение инструмента можно отобразить для хирурга неза-
висимо от того, насколько глубоко инструмент проник в мягкие ткани. Перепечатано с любезного
разрешения Эрика Гримсона (Eric Crimson), более подробную информацию можно получить на
сайте http://www.ai.mit.edu/people/welg/welg.html
полная трехмерная система отсчета (система Серрета-Френета (Serret-Frenet)),
и данную систему можно использовать как каноническую при получении изме-
рений, необходимых при геометрическом хэшированиии. В качестве параметров
естественно выбрать кривизну и кручение кривой, а также угол между норма-
лью кривой и нормалью поверхности.
Пары систем координат
При двух данных системах координат преобразование одной в другую инва-
риантно относительно общего преобразования, поэтому может использоваться
для записи индексов хэширования. Введем понятие пары систем координат.
Естественный способ получения данных пар состоит в подборе поверхности
по набору данных, определении значимых кривых или точек с последующим
580
Часть V. Верхний уровень компьютерного зрения: геометрические методы
использованием локальных систем координат. Для значимой точки поверхно-
сти (например, омбилической точки) систему координат можно определить по
нормали и двум направлениям экстремальной кривизны. Для любой точки на
значимой кривой можно использовать либо систему Серрета-Френета, либо си-
стему координат на поверхности (еще можно сравнить две системы координат
и выбрать лучшую). Исследованию использования кривых и пар систем коорди-
нат посвящены работы группы Айяча; эта тема всесторонне изучена в работах
[Ayache, 1995а, 6].
18.7. КРИВОЛИНЕЙНЫЕ ПОВЕРХНОСТИ И ВЫРАВНИВАНИЕ
Криволинейные поверхности также можно выравнивать. Гипотезы, иниции-
рующие процесс, могут быть более сложными, но обобщение процессов визуа-
лизации и верификации выполняется довольно понятно.
Естественная стратегия здесь — найти группы, содержащие системы коор-
динат и ведущие себя подобно точкам. Например, если криволинейная поверх-
ность в точке ведет себя разрывно, процесс генерации гипотез выполняется так,
как описано выше. Затем геометрическую модель поверхности можно спроек-
тировать на изображение и использовать процесс верификации, как описано
выше.
Более сложный подход заключается в трактовке выравнивания как мини-
мизации, а не как подбора линейной комбинации моделей (см. подход, опи-
санный ранее). В таком случае очертание поверхности предсказывается как
функция позы поверхности. В качестве целевой функции можно принять сум-
му минимальных расстояний краевых точек, выбранных с этой поверхности,
и минимизировать целевую функцию по позам, как показано на рис. 18.9. Ме-
ханизм предсказания предположительных кривых упрощается для алгебраиче-
ских поверхностей; по этой причине для иллюстрации в литературе использу-
ются исключительно алгебраические поверхности. Подробнее об этом подходе
рассказано в работе [Kriegman and Ponce, 19906]. Алгебраические поверхности
настолько жестки, что единственный контур полностью определяет геометрию
поверхности; подробнее этот вопрос освещен в работе [Forsyth, 1996].
18.8. ПРИМЕЧАНИЯ
Как правило, системы, построенные на алгоритмах, которые описаны в дан-
ной главе, могут распознавать несколько объектов на достаточно зашумленных
сценах. Эти алгоритмы стоит изучить, поскольку восстановление позы и на-
ложение важны в прикладных задачах и поскольку слабости этих алгоритмов
выделяют важные вопросы темы распознавания.
Термин “выравнивание” (alignment) трактуется согласно работе [Hutten-
locher and Ullman, 1990]. Его удобно использовать применимо к общему классу
алгоритмов, связанных с согласованностью поз. Трудно сказать, кто первым на-
чал использовать изложенный подход, можно назвать работу [Roberts, 1965], а
Глава 18. Зрение на основе модели
581
Рис. 18.9. Алгебраическая поверхность наблюдается посредством перспективной камеры. Генератор
контура очевидно является алгебраической кривой (поскольку можно записать систему полино-
миальных уравнений, которым он удовлетворяет) и эскиз также является алгебраической кривой.
Данная кривая представляет функцию позы поверхности. На рисунке слева показано семейство
кривых, полученное наложением эскиза поверхности на изображение с последующим определением
позы посредством минимизации суммы минимальных расстояний между выбранными краевыми
точками и эскизом. В процессе минимизации используются кривые, определяемые различными
точками. На рисунке справа показаны две различных алгебраических поверхности, успешно вырав-
ненных по контурам изображения; используемые поверхности определяют две различные бутылки.
Перепечатано из D.J. Kriegman and J. Ponce, "On Recognition and positioning curved 3d objects
from image контур”, IEEE Trans. Pattern Analysis and Machine Intelligence, 1990. (c) IEEE 1990
также [Faugeras, Hebert, Pauchon and Ponce, 1984]. Современный обзор данной
темы представляет книга [Chin and Dyer, 1986]. Выравнивание — это довольно
общая тема, поскольку почти для всех вероятных изображений большинства
потенциальных объектов имеется одно связанное с камерой условие, которое
требует изучения. Кроме того, выравнивание достаточно помехоустойчиво (т.е.
объекты можно найти даже на сильно зашумленном фоне), поскольку для по-
строения гипотезы относительно объекта требуется собрать относительно мало
очевидных элементов. Устойчивое тестирование больших гипотез легче, чем
сбор таких гипотез, поскольку тестируемые гипотезы требуют точного опре-
деления того, какие элементы изображения очевидно должны вносить вклад
в решение. Поведение некоторых алгоритмов выравнивания в условиях шу-
ма детально изучается в публикациях [Grimson, Huttenlocher and Alter, 1992],
[Grimson, Huttenlocher and Jackobs, 1994], [Grimson, Lozano-Perez and Hutten-
locher, 1990] и [Sarachik and Grimson, 1993]. В результате различные варианты
алгоритмов выравнивания получили широкое распространение.
В то же время концепция выравнивания плохо переносится на большое
число моделей, так как здесь наблюдается линейный рост числа моделей, по-
скольку база моделей плоская. Какой-либо иерархической структуры моделей
нет, поэтому каждая модель рассматривается независимо. Более того, если по-
иск присутствующей модели при наложении некоторых условий можно провести
эффективно, определять отсутствие модели вычислительно дорого (см. работу
[Grimson, 1992]).
582
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Кластеризация позы была изложена согласно работе [Thompson and Mundy,
1987]. Аналогия с преобразованием Хоха означает, что данный метод может
иметь довольно плохое поведение при наличии шума ([Grimson and Hutten-
locher, 19906]). Геометрическое хэширование в различных формах было изло-
жено согласно [Lamdan, Schwartz and Wolfson, 19906] и [Wolfson, 1990]. Ис-
пользование различных инвариантов для индексирования гипотез схемы рас-
познавания описано в работе [Forsyth, Mundy, Zisserman, Coelho, Heller and
Wothwell, 1991]; в сборниках и книгах [Mundy and Zisserman, 1992], [Mundy,
Zisserman and Forsythm 1993], [Rothwell, 1995], публикациях [Barrett, Pay-
ton, Haag and Brill, 1991], [Forsyth et al., 1992], [Rothwell, Zisserman, Forsyth
and Mundy, 1995], [Rothwell, Zisserman, Marinos, Forsyth and Mundy, 1992],
[Zisserman, Forsyth, Mundy, Rothwell, Liu and Pillow, 1995а]. Область актив-
ных исследований (не описанная в главе), которая заключается в измерении
инвариантных свойств трехмерных объектов по множественным неоткалибро-
ванным проекциям, изучается в работах [Barret, Brill, Haag and Payton, 1992J;
процесс вычисления инвариантных значений при имеющихся сведениях о мо-
дели описан в [Shashua, 1995], [Weinshall, 1993]. Работа в области изучения
кругов зрения, также посвященная выводу инвариантов, описана в [Csurka and
Faugeras, 1998, 1999].
Совместимость поз может использоваться в разных ситуациях. Например,
гипотезы процесса распознавания позволяют оценить внутренние параметры
камеры. Это означает, что если на изображении присутствует несколько объек-
тов, все они должны давать непротиворечивые оценки внутренних параметров
камеры (работа [Forsyth, Mundy, Zisserman and Rothwell, 1994]).
Каждый алгоритм — это попытка получить достаточный объем информации,
чтобы выполнить верификацию при минимальных затратах, снизив при этом
число ложных попыток верификации. Данная зависимость от верификации на
уровне изображения не согласуется с абстракцией модели. Большинство сфер
практического применения распознавания очень сильно нуждаются в абстрак-
циях. Например, если требуется найти в Internet фотографии папы римского,
не должна требоваться его точная геометрия. Подобным образом, если нужно
создать реализацию автомобиля для реальных дорог, он должен принимать ре-
шения относительно того, где свернуть в сторону, чтобы объехать препятствие,
и с чем он может столкнуться. Вместо того, чтобы согласовывать характерные
элементы (такие как точки и прямые), можно согласовывать токены (причем
токеном может быть участок тела или что-либо подобное) с моделью, содер-
жащей токены. В этом случае искомой абстракцией является токен ([Ettinger,
1988], [Ullman, 1996]).
Основная цель процесса верификации — предоставить заключение о гипо-
тезе, которое невозможно получить иными средствами. Поскольку сбор таких
заключений — недостаточно исследованная область, существующие системы
распознавания работают успешно только при удачных алгоритмах верифика-
ции. Верификация выполняется при наличии достаточного объема эффективно
обработанной информации. К сожалению, эти соображения трудно записать
Глава 18. Зрение на основе модели
583
в виде машинного алгоритма. Как для центральной темы, связанной с про-
изводительностью систем распознавания, верификация изучена крайне плохо
(впрочем, см. работу [Grimson and Huttenlocher, 1991]). Верификация, осно-
ванная на общих фактах (скажем, краевых точках), не дает точных сведений
о том, какие факты следует учитывать. Подобным образом, если использовать
специфические факты (скажем, определенную камуфляжную расцветку), воз-
никают проблемы с абстракцией. Для включения в процесс верификации фак-
тов, относящихся к разным типам, можно использовать механизм согласования
с шаблоном и подбора по виду, который подробно рассмотрен в главе 22.
Медицинские приложения
При разработке этой темы мы обращались к специалистам. В качестве посо-
бий для самостоятельного ее изучения можно порекомендовать работы [Ayache,
1995а,Ь], [Duncan and Ayache, 2000], [Gerig, Pun and Ratib, 1994].
Тремя важнейшими темами в данной области являются сегментация, кото-
рая используется для определения областей изображений (часто трехмерных),
соответствующих определенным органам; регистрация, которая используется
для построения соответствий между изображениями, полученными различны-
ми средствами, и пациентами; и анализ морфологии (насколько велик данный
объект? как он развивается?) и функции. Родственная тема использования де-
формированных моделей удачно описана в работе [McInerney and Terzopolous,
1996]. Методы регистрации и родственные вопросы изучены в [Lavallee, 1996],
[Maintz and Viergever, 1998], сравнение результатов регистрации и “назем-
ных данных” описывается в [West, Fitzpatrick, Wang, Dawant, Maurer, Kessler,
Maciunas, Barillot, Lemoine, Collignon, Maes, Suetens, Vandermeulen, van der
Eisen, Napel, Sumanaweera, Harkness, Hemler, Hill, Hawkes, Studholme, Antoine
Maintz, Viergever, Malandain, Pennec, Noz, Maguire, Pollack, Pelizzari, Robb,
Hanson and Woods, 1997].
Задачи
18.1. Предположим, что с помощью откалиброванной перспективной камеры
наблюдаются объекты, для распознавания которых требуется использо-
вать алгоритм согласованности поз.
а) Покажите, что три точки образуют группу.
б) Покажите, что прямая и точка не образуют группу.
в) Объясните, почему стоит иметь группы, составленные из характерных
элементов различных типов.
г) Составляют ли группу окружность и не принадлежащая ей точка?
18.2. Дан набор точек на плоскости Pj, которые подвергаются плоскому аф-
финному преобразованию. Покажите, что
det [PjPjPfc]
det [PiРjPi]
584
Часть V. Верхний уровень компьютерного зрения: геометрические методы
является аффинным инвариантом (причем никакие два из индексов г, j, к
и I не совпадают и никакие три точки не лежат на одной прямой).
18.3. Используйте результат предыдущей задачи для построения аффинных
инвариантов для следующих объектов:
а) четыре прямых;
б) три точки, лежащих на одной прямой;
в) прямая и две точки (над последними двумя пунктами придется немно-
го подумать).
18.4. При сопоставлении пиксель можно обновлять на каждом шаге, если из-
вестны расстояния от некоторых или всех его соседей до ребра. В работе
[Borgeforsm, 1997] расстояние от пикселя до ближайшего соседа по вер-
тикали или горизонтали считалось равным 3, а до ближайшего соседа по
диагонали — равным 4 (чтобы значения пикселей всегда были целыми).
Почему величина у/2 аппроксимировалась отношением 4/3? Хорошей ли
идеей будет использование лучшей аппроксимации?
18.5. Оценку позы можно улучшить, определив параметр верификации, а за-
тем оптимизировав его как функцию позы. Данная оптимизация может
быть трудной, особенно если в качестве критерия того, близка ли восста-
новленная кривая к наблюдаемой, использовать расстояние. Почему при
оптимизации возникают сложные проблемы?
18.6. Наблюдение набора точек на плоскости посредством неоткалиброванной
аффинной камеры можно записать как неизвестное плоское аффинное
преобразование. Докажите это. Что можно сказать о неоткалиброванной
перспективной камере, наблюдающей набор точек на плоскости?
18.7. Подготовьте резюме по методам регистрации в медицинской сфере, от-
личным от описанных в главе. Не забывайте о практических ограничени-
ях, также укажите наиболее предпочтительный по вашему мнению метод
и аргументируйте ваш выбор.
18.8. Подготовьте резюме по немедицинским приложениям регистрации и со-
гласованности поз.
Упражнения
18.9. Представление объекта в виде линейной комбинации моделей часто рас-
сматривается как абстракция, поскольку подбор коэффициентов можно
считать получением одинаковой проекции различных моделей. Более то-
го, можно получить геометрическое семейство моделей, введя в простран-
ство базисный элемент. Исследуйте эти идеи, построив систему сравне-
ния прямоугольных зданий (неизвестные параметры — высота, длина
и ширина). Идею линейных комбинаций следует расширить на ортогра-
фические камеры; необходимо будет ввести коэффициенты, представля-
ющие вращение.
19
Гладкие поверхности и их
контуры
В предыдущих главах книги рассматривалась количественная связь простых
геометрических фигур, таких как точки, прямые и плоскости, с параметрами
их проекций на изображение. В данной главе исследуется качественная связь
трехмерных форм и их изображений, причем внимание акцентируется на конту-
рах твердых тел, ограниченных гладкими поверхностями. Рассмотрим подобное
твердое тело и предположим, что отражательная функция его поверхности
также является гладкой. Если не принимать в расчет тени (камера значительно
удалена от точечного источника света), изображение будет гладким, исключая
область очертания твердого тела, также именуемого силуэтом объета, или
контуром изображения. Изучению такой системы и посвящена данная глава
(рис. 19.1).
Контур формируется при пересечении чувствительной области камеры ко-
нусом наблюдения (или цилиндром, если речь идет об ортографической про-
екции), вершина которого совпадает с точечной диафрагмой камеры, а поверх-
ность касается объекта по поверхности, называемой затеняющим контуром,
или ободом. Можно показать, что затеняющий контур является в общем слу-
чае гладкой кривой, сформированной точками складки, в которых луч на-
блюдения касается поверхности, и дискретным множеством точек возврата,
586
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 19.1. Границы затенения гладкой поверхности
в которых луч дополнительно касается затеняющего контура. Контур изоб-
ражения является кусочно-гладким, все его сингулярности — это дискретное
множество точек возврата, которые формируются проекциями точек возврата
объекта, и Т-образных соединений, сформированных трансверсальными супер-
позициями пар точек возврата (рис. 19.2). Данные экзотические термины мож-
но интерпретировать следующим образом: точка складки — это точка, в ко-
торой поверхность заворачивает от наблюдателя, в точке возврата на контуре
поверхность неожиданно возвращается обратно, проследовав другим путем к
той же самой цели (сказанное справедливо только для прозрачных объектов:
контуры непрозрачных объектов в точке возврата просто заканчиваются; см.
рис. 19.2). Подобным образом, два гладких участка контура могут пересекать-
ся в Т-образном соединении (если объект не является прозрачным и одна из
ветвей не заканчивается в соединении).
Интересно, что связанные тени разграничиваются затеняющими контурами,
порожденными источниками света, а отбрасываемые тени ограничены контура-
ми соответствующих объектов (рис. 19.3). Таким образом, также известно, на
что похожи эти объекты. (Предупреждение: объекты, на которые отбрасывают-
ся тени, могут иметь искривленные поверхности. Даже в этом случае границы
связанных теней представляют собой всего лишь затеняющие контуры. Разу-
меется, ситуация усложняется еще и тем, что источники света редко являются
точечными.)
Контур изображения твердой поверхности обязан лежать в пределах со-
ответствующего конуса наблюдения, но в процессе его изучения невозмож-
но определить затеняющий его контур. Дополнительную информацию можно
получить, если твердое тело ограничено гладкой поверхностью. В частности,
Глава 19. Гладкие поверхности и их контуры
587
Рис. 19.2. Составляющие контура: складки, точки возврата и Т-образные соединения. Перепе-
чатано из S. Petitjean, J. Ponce and DJ. Kriegman, “Computing Exact Aspect Graphs of Curved
Objects: Algebraic Surfaces”, International Journal of Computer Vision, 9(3):231-255, 1992. (c) 1992
Kluwer Academic Publishers
плоскость, которая определяется положением глаза и касательной к контуру
изображения, является касательной к поверхности. Таким образом ориентация
контура определяет ориентацию поверхности вдоль затеняющего контура. Даль-
нейшая часть данной главы посвящена более общему случаю — геометрическим
соотношениям между криволинейными поверхностями и их проекциями, а так-
же типам информации о геометрии поверхностей, которую можно извлечь из
геометрии контура (например, доказано, что кривизна контура содержит ин-
формацию о кривизне поверхности). Введем для начала элементарные понятия
дифференциальной геометрии, создающие естественный математический базис
для дальнейших исследований. Дифференциальная геометрия пригодится и при
изучении следующей главы, где будут рассмотрены изменения вида объекта
в зависимости от точки наблюдения.
19.1. ЭЛЕМЕНТЫ ДИФФЕРЕНЦИАЛЬНОЙ ГЕОМЕТРИИ
В данном разделе представлены основы евклидовой дифференциальной гео-
метрии, необходимые для понимания локальных зависимостей между лучами
света и твердыми объектами. Ограничимся рассмотрением поверхностей, гра-
ницы которых принадлежат пространству Е3. Данная тема интересует нас, ра-
зумеется, с технической точки зрения, но при изложении будем придержи-
ваться неформального стиля рассуждений, акцентируя внимание на наглядных
моментах аналитической геометрии. В частности, удержимся от выбора в Е3
глобальной системы координат, хотя в некоторых случаях будут использо-
ваться локальные системы координат, привязанные к кривой или поверхности
в окрестности одной из ее точек. Такой подход удобен при количественных
геометрических рассуждениях, на которых и делается акцент в данной гла-
ве. Аналитическая дифференциальная геометрия в количественном контексте
анализа дальностных данных рассмотрена в главе 21.
588
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 19.3. Границы тени и затеняющие контуры. Перепечатано из J.J. Koenderink, “Solid Shape",
MIT Press, 1990. © 1990 The Massachusetts Institute of Technology
19.1.1. Кривые
Начнем с изучения кривых, лежащих на плоскости. Будем исследовать кри-
вую 7 в непосредственной близости некоторой точки Р и предположим, что
кривая 7 не пересекает саму себя или, если и пересекает, заканчивается в точ-
ке Р. Если провести через Р прямую линию L, в общем случае она пересечет
кривую 7 в некоторой точке Q, определив таким образом секущую данной
кривой (рис. 19.4). По мере приближения Q к Р секущая L будет вращаться
вокруг Р и достигнет предельного положения Т, именуемого касательной к
кривой 7 в точке Р.
Касательная Т по построению имеет более тесный контакт с кривой 7, чем
любая другая прямая, проходящая через Р. Проведем через Р и перпендикуляр
к Т вторую прямую N, которую назовем нормалью к кривой 7 в точке Р, При
произвольном выборе единичного касательного вектора t вдоль Т можно по-
строить правостороннюю систему координат, начало которой будет лежать в Р,
а осями будут t и единичный вектор нормали п, направленный вдоль N. Та-
кая локальная система координат крайне удачно подходит для изучения кривой
в окрестности точки Р: ее оси делят плоскость на четыре квадранта, которые
можно пронумеровать против часовой стрелки (см. рис. 19.5, первый квадрант
выбран так, чтобы он содержал точку, перемещающуюся вдоль кривой к нача-
лу координат). Следующий вопрос: в каком квадранте окажется точка после
перехода через Р?
Как показано на рисунке, на поставленный вопрос возможны четыре отве-
та, которые характеризуются формой кривой в окрестности точки Р. Говорят,
что точка Р является неособой, если движение точки завершается во втором
квадранте, и сингулярной — в противном случае. Если точка проходит по каса-
тельной и завершает движение в третьем квадранте, точка Р называется точ-
кой перегиба кривой; в двух оставшихся случаях точку Р называют точкой
Глава 19. Гладкие поверхности и их контуры
589
Рис. 19.4. Касательные и нормали: а) касательная как предел секущих; б) система координат,
определенная ориентированной касательной и нормалью
Рис. 19.5. Классификация точек кривой: а) неособая точка, б) точка перегиба, в) точка возврата
первого рода, г) точка возврата второго рода. Обратите внимание, что в неособых точках кривая
расположена с одной стороны касательной
возврата, соответственно, первого или второго рода. Предложенная класси-
фикация не зависит от ориентации, выбранной для 7, также из нее следует,
что практически все точки почти всех кривых относятся к разряду неособых, а
сингулярности возникают только в изолированных точках.
Как отмечалось ранее, касательная к кривой 7 в точке Р — это ближайшая
линейная аппроксимация 7, которая проходит через эту точку. В свою очередь
построение ближайшей круговой аппроксимации позволяет определить кри-
визну кривой в точке Р — еще одну фундаментальную характеристику формы
кривой. Рассмотрим точку Р', приближающуюся к Р вдоль кривой, и обозна-
чим через М пересечение нормалей N и N', построенных в точках Р и Р'
(рис. 19.6). По мере приближения Р' к Р точка М достигает предельного поло-
жения С вдоль нормали N, именуемого центром кривизны кривой 7 в точке Р.
В то же время, если через 60 обозначить малый угол между нормалями N
и N', а через 6s — длину короткой дуги, соединяющей Р и Р', отношение 60/6s
590
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 19.6. Определение центра кривизны как предела точек пересечения нормалей с соседями Р
также стремится к пределу к, именуемому кривизной кривой в Р при 6s стре-
мящемся к нулю. Из этого следует, что к — величина, обратная расстоянию г
между С и Р (это следует непосредственно из того факта, что для малых уг-
лов sin u «-и; см. раздел упражнений). Окружность с центром в С и радиусом
г называется кругом кривизны в Р, а г — радиусом кривизны.
Можно также показать, что окружность, проходящая через Р и две смеж-
ные точки Р' и Р", переходит в круг кривизны с приближением Р' и Р"
к Р. Данный круг действительно является ближайшей круговой аппроксима-
цией кривой 7, проходящей через Р. В точках перегиба кривизна равна нулю
и круг кривизны вырождается в прямую (касательную к кривой в этой точке):
точки перегиба — это “наиболее плоские” точки кривой.
Введем аппарат, доказавший свою эффективность в области изучения
кривых и поверхностей — отображение Гаусса. Зафиксируем ориентацию
кривой 7 и соотнесем с каждой точкой Р кривой 7 точку Q на единичной
окружности, в которой конец соответствующего вектора нормали пересекает
окружность (рис. 19.7). Этот переход 7 в единичную окружность именуется
отображением Гаусса1.
Вернемся к процессу предельного перехода, использованного для определе-
ния кривизны. С приближением Р' по кривой к Р Гаусс-образ Q' точки Р'
переходит в образ Q точки Р. Угол (малый) между N и N' равен длине дуги,
соединяющей Q и Q' на единичной окружности. Следовательно, кривизна —
это предел отношения стремящихся к нулю длин соответствующих дуг Гаусс-
образа и кривой.
Отображение Гаусса также позволяет интерпретировать классификацию то-
чек кривой, которая была введена выше. Рассмотрим точку, движущуюся вдоль
'Отображение Гаусса можно также определить, соотнеся с каждой точкой кривой вершину
ее единичного касательного вектора на единичной окружности. Для плоских кривых данные два
представления эквивалентны, а при обобщении отображения Гаусса на пространственные кривые
и поверхности ситуация усложняется.
Глава 19. Гладкие поверхности и их контуры
591
Рис. 19.7. Гаусс-образ плоской кривой. Посмотрите, как направление обхода Гаусс-образа меняется
на противоположное в точке перегиба кривой Р'. Обратите также внимание на то, что по обе сто-
роны Р' имеются смежные точки с параллельными касательными/нормалями. В соответствующей
точке Q' отображение Гаусса сворачивается
кривой, и движение ее Гаусс-образа. Направление прохождения кривой 7 не ме-
няется в неособых точках и точках перегиба, но меняется на обратное в точках
возврата обоих родов (рис. 19.5). С другой стороны, направление обхода Гаусс-
образа не меняется в неособых точках и точках возврата первого рода, но меня-
ется на обратное в точках перегиба и точках возврата второго рода (рис. 19.7).
Таким образом, возле данных сингулярностей единичная окружность накрыва-
ется дважды: говорят, что преобразование Гаусса в этих точках сворачивается.
В каждой точке плоской кривой 7 кривизне можно присвоить знак, выбрав
некоторую ориентацию и приняв, скажем, что кривизна (выбор является про-
извольным) считается положительной в выпуклой точке, где центр кривизны
лежит с той же стороны кривой 7, что и вершина ориентированного вектора
нормали, и отрицательной в вогнутой точке, где две названных точки лежат
с противоположных сторон кривой 7. Таким образом, кривизна меняет знак
в точках перегиба, и обращение ориентации кривой также меняет знак ее
кривизны.
Более сложный случай по сравнению с плоскими кривыми — пространствен-
ные кривые. Хотя касательную, как и ранее, можно определить через предел
секущих, существует бесконечное множество прямых, перпендикулярных каса-
тельной в точке Р, которые формируют нормальную плоскость, перпендику-
лярную кривой в данной точке (рис. 19.8).
В общем случае пространственная кривая не лежит в какой-то плоскости
в окрестности одной из своих точек, но существует единственная плоскость,
ближайшая к данной кривой. Эта плоскость, именуемая соприкасающейся,
определяется как предел плоскостей, которые содержат касательную в точ-
ке Р и некоторую смежную точку кривой Q, приближающуюся к Р. Чтобы
завершить построение локальной системы координат в точке Р, нужно про-
вести через Р перпендикулярно нормальной и соприкасающейся плоскостям
спрямляющую плоскость . Оси этой системы координат, называемые сопро-
вождающим трехгранником, или системой Френета (Frenet frame), образуют
592
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 19.8. Локальная геометрия пространственной кривой: N, О и R, соответственно, — нор-
мальная, соприкасающаяся и спрямляющая плоскости; t, п и Ь, соответственно, — касательная,
(главная) нормаль и бинормаль, С — центр кривизны
касательная, главная нормаль, которая формируется пересечением нормаль-
ной и соприкасающейся плоскостей, и бинормаль, которая определяется как
пересечение нормальной и спрямляющей плоскостей (рис. 19.8).
Как и в плоском случае, кривизну пространственной кривой можно ввести
по-разному: как величину, обратную к радиусу граничной окружности, опреде-
ляемой тремя сближающимися точками кривой (этот круг кривизны лежит на
соприкасающейся плоскости); и как предел отношения угла между касательны-
ми в двух смежных точках к расстоянию между этими точками, стремящемуся
к нулю, и т.д. Подобным образом, понятие отображения Гаусса можно расши-
рить на пространственные кривые, но теперь вершины касательных, главных
нормалей и бинормалей описывают кривые на единичной сфере. Отметим, что
кривизне пространственной кривой нельзя приписать знак, имеющий какой-
либо смысл. В общем случае подобная кривая не имеет точек перегиба, а ее
кривизна везде положительна.
Кривизну можно рассматривать как меру скорости, с которой направление
касательной меняется вдоль кривой. Можно также определить скорость измене-
ния направления соприкасающейся плоскости вдоль пространственной кривой.
Действительно, рассмотрим две смежных точки Р и Р' кривой; можно изме-
рить угол между их соприкасающимися плоскостями или, эквивалентно, между
соответствующими бинормалями и разделить этот угол на расстояние между
двумя данными точками. Предел этого отношения при приближении Р' к Р
называется кручением кривой в точке Р (см. рис. 19.9). Величина, обратная
Глава 19. Гладкие поверхности и их контуры
593
Рис. 19.9. Геометрическое определение кручения кривой как предела отношения угла между би-
нормалями к расстоянию между соответствующими точками поверхности при обеих величинах,
стремящихся к нулю
к данной, является пределом отношения длин соответствующих дуг кривой к
сферическим образам бинормалей.
Далее можно выбрать ориентацию пространственной кривой, рассмотрев
кривую как траекторию движения частицы и выбрав для этой частицы направ-
ление движения. Более того, можно выбрать на кривой произвольную опорную
точку Ро и определить длину дуги s, соотнесенную с любой другой точкой Р,
как длину (с соответствующим знаком) дуги, соединяющей точки Ро и Р. Хотя
длина дуги зависит от выбора точки Ро, ее дифференциал от выбора не зави-
сит (изменение положения точки Ро вдоль кривой равнозначно прибавлению
константы к длине дуги), так что иногда для параметризации кривой бывает
удобно использовать длину дуги с предполагаемым, но не конкретизируемым
выбором начала координат Ро. В частности, касательный вектор t в точке Р
представляет единичную скорость ^Р (которая определяется как предел век-
торов ^РР' при точке кривой Р', стремящейся к точке Р, и стремящемуся к
нулю расстоянию 6s между ними, взятому с соответствующим знаком). Обра-
,2
щение s также приводит к обращению t. Можно показать, что ускорение j^P,
кривизна к и главная нормаль п связаны следующим соотношением:
d2 d
--~Р = --1 = КП.
ds2 ds
Отметим, что к и п не зависят от ориентации кривой (при обращении направле-
ния обхода появляются знаки “минус”, которые исчезают при дифференцирова-
нии), а кривизна равна модулю ускорения. Вектор бинормали можно определить
как b = t х п; подобно вектору t он зависит от выбранной ориентации кривой.
594
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Легко показать, что в общем случае справедливо следующее:
d
—t = кп
ds
< —n = —nt + тЪ ,
ds
d
—Ь = — тп
k ds
где через т обозначено кручение кривой в точке Р. В отличие от кривизны,
для пространственной кривой общей формы кручение может быть больше ну-
ля, меньше нуля или равно нулю. Его знак зависит от выбранного направления
обхода кривой и имеет геометрическое значение: в общем случае кривая пересе-
кает свою соприкасающуюся плоскость во всех точках с ненулевым кручением,
причем выходит она с положительной стороны кривой (т.е. с той же сторо-
ны, что и бинормаль), если кручение больше нуля, и с отрицательной стороны
в противном случае. Для плоских кривых кручение равно нулю.
19.1.2. Поверхности
Как правило, рассуждения о локальных характеристиках плоских и про-
странственных кривых легко обобщаются на плоскости. Рассмотрим точку Р
на поверхности S и все кривые, проходящие через Р и лежащие в S. Мож-
но показать, что касательные к этим кривым лежат в той же плоскости П,
именуемой касательной плоскостью в точке Р (рис. 19.10, а). Прямая АГ, про-
ходящая через Р и перпендикулярная П, называется нормалью к Р в точке S, а
для выбора (локальной) ориентации поверхности можно определить единичный
вектор нормали вдоль Аг (в отличие от кривых, плоскости в любой точке могут
иметь одну нормаль, но бесконечное множество касательных). Для поверхно-
сти, ограничивающей твердое тело, можно выбрать каноническую ориентацию,
при определении которой считается, что векторы нормали локально направлены
9
наружу твердого тела .
Пересечение поверхности плоскостями, содержащими нормаль в точке Р,
определяет однопараметрическое семейство плоских кривых, которые называ-
ются нормальными сечениями (рис. 19.10, б). В общем случае эти кривые не
имеют особенности в точке Р или же эта точка может быть точкой перегиба.
Кривизна нормального сечения именуется нормальной кривизной поверхности
в соответствующем направлении касания. Условимся, что нормальная кривизна
будет считаться положительной, если нормальное сечение (локально) лежит
Разумеется, в равной степени приемлема и обратная ориентация, например, как она опреде-
лена в работе [Koenderink, 1990J, “вектор нормали указывает в сторону “материи” пятна, подобно
стрелкам на шляпе генерала Кастера”. Главное, что при любом выборе определяется когерентная
глобальная ориентация поверхности. Некоторые поверхности (например, лента Мебиуса) не дают
возможности ввести глобальную ориентацию, но они не ограничивают твердые тела.
Глава 19. Гладкие поверхности и их контуры
595
Рис. 19.10. Касательная плоскость и нормальные сечения: а) касательная плоскость П и соот-
ветствующая нормаль N в точке Р поверхности; -у — кривая на поверхности, проходящая через
точку Р, ее касательная Т лежит в плоскости П; б) при пересечении поверхности S с плоскостью,
натянутой на вектор нормали N и вектор касательной t, формируется нормальное сечение 7*
поверхности S
с той же стороны касательной плоскости, что и внутренняя нормаль к по-
верхности, и отрицательной, если она лежит с другой стороны. Разумеется,
если Р — точка перегиба соответствующего нормального сечения, нормальная
кривизна равна нулю.
Приняв такую договоренность, нормальную кривизну можно записать как
секущую плоскость, которая вращается вокруг нормали к поверхности. Обычно
предполагается, что максимальное значение «х кривизны лежит в определен-
ном направлении касательной плоскости, а минимальное значение кг ~ во
втором определенном направлении. Два этих направления называются глав-
ными направлениями в точке Р, и можно показать, что если нормальная
кривизна не является постоянной по всем возможным ориентациям, главные
направления ортогональны между собой (см. раздел упражнений). Две глав-
ных кривизны Ki и К2, а также соотнесенные с ними направления определяют
наилучшую квадратичную аппроксимацию поверхности. В частности, в Р мож-
но построить систему координат, оси х и у которой будут идти вдоль главных
направлений, а ось z будет направлена вдоль внешней нормали; в этой системе
поверхность можно описать (с точностью до членов второго порядка) парабо-
лоидом Z = -1/2(К12!2 + К2У2).
Окрестность точки поверхности локально может принимать три различных
формы в зависимости от знака параметров «1 и «2 (рис. 19.11). Точка Р, в ко-
торой обе величины имеют одинаковый знак, называется эллиптической, а по-
верхность в окрестности такой точки имеет яйцеобразную форму (рис. 19.11, а).
Подобная поверхность не пересекает свою касательную плоскость и выглядит
как внешняя оболочка яйца (кривизна положительна) или как внутренняя часть
596
Часть V. Верхний уровень компьютерного зрения: геометрические методы
а)
в)
Рис. 19.11. Локальная форма поверхности: а) эллиптическая точка, б) гиперболическая точка,
в) параболическая точка (в действительности имеются параболические точки двух различных ти-
пов; к этому вопросу мы еще вернемся в главе 20). Перепечатано из S. Рае and J. Ponce, “On
Computing Structural Changes in Evolving Surfaces and their Appearance”, International Journal of
Computer Vision, 43(2):l13-131, 2001. © 2001 Kluwer Academic Publishers
разбитого яйца (кривизна отрицательна). Говорят, что в первом случае точка Р
выпуклая, а во втором — вогнутая. Если параметры главной кривизны име-
ют разные знаки, наблюдается гиперболическая точка. Локально поверхность
напоминает седло и пересекает свою касательную плоскость по двум кривым
(рис. 19.11, б). Соответствующие нормальные сечения имеют точки перегиба
в Р, а их касательные называются асимптотическими направлениями поверх-
ности в точке Р. Главными направлениями эти касательные делятся пополам.
На поверхности эллиптические и гиперболические точки формируют лоскуты.
Эти области в общем случае разделяются кривыми, образованными парабо-
лическими точками, в которых одна или другая главная кривизна становится
равной нулю. Соответствующее главное направление также является асимпто-
тическим направлением, и пересечение поверхности с ее касательной плоско-
стью имеет в этом направлении (в общем случае) точку возврата (рис. 19.11, в).
Гаусс-образ поверхности можно определить, отобразив каждую точку в ме-
сто пересечения соответствующей единичной нормали с единичной сферой
(в дальнейшем последняя иногда будет называться гауссовой сферой). Для
плоских кривых отображение Гаусса является взаимно-однозначным в окрест-
ности неособых точек, но в окрестности некоторых сингулярностей направление
обхода Гаусс-образа меняется на противоположное. Подобным образом, можно
показать, что отображение Гаусса является взаимно-однозначным в окрестности
эллиптических или гиперболических точек. Ориентация небольшой замкнутой
кривой, центр которой расположен в эллиптической точке, сохраняется при
отображении Гаусса, но ориентация кривой с центом в гиперболической точке
меняется на противоположную (рис. 19.12).
Параболическая точка — это несколько усложненная ситуация. В данном
случае любая малая окрестность особенности содержит точки с параллельными
нормалями, что является показателем двойного накрытия сферы возле парабо-
Глава 19. Гладкие поверхности и их контуры
597
Рис. 19.12. Слева: поверхность в форме фасоли, сформированная выпуклой областью, гиперболиче-
ской областью и параболической кривой, их разделяющей. Справа: соответствующий Гаусс-образ.
Затененные фрагменты обозначают гиперболические области, слегка затененные фрагменты — эл-
липтические области. Обратите внимание, что “фасоль” не является выпуклой, но в то же время не
имеет вогнутых частей. Перепечатано из S. Рае and J. Ponce, “On Computing Structural Changes
in Evolving Surfaces and their Appearance", International Journal of Computer Vision, 43(2): 113-131,
2001. © 2001 Kluwer Academic Publishers
лической точки (рис. 19.12). Будем говорить, что вдоль параболических кривых
отображение Гаусса сворачивается. Здесь также стоит отметить сходство со
случаем пересечения плоских кривых.
Рассмотрим кривую 7 на поверхности, проходящую через точку Р и пара-
метризованную своей длиной дуги s в окрестности точки Р. Поскольку нормаль
к поверхности кривой 7 имеет постоянную (единичную) длину, ее производная
по s лежит на касательной плоскости в точке Р. Легко показать, что величина
производной зависит только от единичной касательной t к кривой 7 и не зависит
от самой 7. Таким образом, можно определить отображение dN, которое свя-
зывает каждый единичный вектор t плоскости, касательной поверхности в точ-
ке Р, с соответствующей производной от нормали к поверхности (рис. 19.13).
Используя условное обозначение dN(Xt) — XdN(t) при А 1, можно рас-
ширить dN на линейное преобразование, определенное на всей касательной
плоскости и именуемое дифференциалом отображения Гаусса в точке Р.
Вторая фундаментальная форма в точке Р — это билинейная форма,
которая связывает с любыми двумя векторами и и v, лежащими в касательной
плоскости, такую величину.
II(u,v) = и dN(y).
Поскольку легко показать, что величина II симметрична, т.е. II(u, v) =
II(v,u), отображение, связывающее с каждым касательным вектором и ве-
3Вторая фундаментальная форма иногда определяется как II(u,v) = — u-dN(v) (см., на-
пример, работы (do Carmo, 1976J, (Struik 1988J). Определение, приведенное в тексте, позволяет
положить, что поверхности, которые ограничивают выпуклые твердые тела с нормалями, направ-
ленными наружу, имеют положительную нормальную кривизну.
598
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 19.13. Производная по направлению для нормали к поверхности. Если Р и Р' — смеж-
ные точки кривой 7, а через N и 7V' обозначены соответствующие нормали к поверхности,
где <^7V = N' — N, производная определяется как предел при стремящейся к нулю длине
кривой, разделяющей Р и Р'
личину Щи, и), является квадратичной формой. В свою очередь, данная квад-
роформа близко связана с кривизной кривых поверхности, которые проходят че-
рез точку Р. Действительно, отметим, что касательная t к кривой поверхности
везде ортогональна нормали к поверхности N. Дифференцируя скалярное про-
изведение двух данных векторов по длине дуги кривой, получаем следующее:
кп • N + t • dN(t) — О,
где через п обозначена главная нормаль к кривой, а через к — ее кривизна.
Данное соотношение можно переписать следующим образом:
II(t, t) = — KCOS0, (19.1)
где ф — угол между нормалями к поверхности и кривой. Для нормальных сече-
ний имеем: п = а из этого следует, что нормальная кривизна в некотором
направлении t — это
Kt = II(t,t),
где, как и ранее, использована договоренность, что нормальная кривизна поло-
жительна, если главная нормаль к кривой и нормаль к поверхности направлены
в противоположные стороны. Кроме того, из уравнения (19.1) следует, что кри-
визна к кривой на поверхности, главная нормаль которой составляет угол ф
с нормалью к поверхности, связана с нормальной кривизной Kt в направлении
ее касательной t соотношением ксовф — —Kt. Данное утверждение известно
как теорема Мезниера (Meusnier's theorem) (рис. 19.14).
Из сказанного следует, что главные направления являются собственными
векторами линейного преобразования d,N, а кривизна в главных направлени-
ях — соответствующими собственными значениями. Детерминант К данного
Глава 19. Гладкие поверхности и их контуры
599
Рис. 19.15. Пространственная кривая и ее проекция. Обратите внимание, что касательная к 7
является проекцией касательной к Г (подумайте, например, о касательной как о скорости частицы,
движущейся вдоль кривой). Нормаль к 7 в общем случае не является проекцией нормали п к Г
преобразования называется гауссовой кривизной, он равен произведению одной
главной кривизны на другую. Таким образом, знак гауссовой кривизны опреде-
ляет локальную форму поверхности: точка является эллиптической при К > О,
гиперболической при К < 0 и параболической при К — 0.
Если через 6А обозначить площадь плоского участка с центром в точке Р
на поверхности S, а через SA' — площадь соответствующего участка Гаусс-
образа S, можно также показать, что гауссова кривизна — это предел отно-
шения 6А'/ЗА при обеих величинах, стремящихся к нулю (по договоренно-
сти отношение положительно, если границы обоих участков имеют одинаковую
ориентацию, и отрицательно в противном случае; см. рис. 19.12). Снова отме-
тим сильное сходство с соответствующими понятиями (Гаусс-образ и плоская
кривизна), введенными в контексте плоских кривых.
600
Часть V. Верхний уровень компьютерного зрения: геометрические методы
19.2. ГЕОМЕТРИЯ КОНТУРОВ
Перед тем как приступить к изучению геометрии контуров поверхности, об-
ратим внимание на связь между локальной формой пространственной кривой Г
и локальной формой ее ортографической проекции 7 на некоторую плоскость П
(рис. 19.15). Обозначим через q угол между плоскостью П и касательной t к
кривой Г, а через /3 — угол между П и соприкасающейся плоскостью кривой Г
(или, эквивалентно, между нормалью к П и бинормалью Ь к Г). Данные углы
полностью определяют локальную ориентацию кривой относительно плоскости
образа.
Если через к обозначить кривизну в некоторой точке кривой Г, а через ка —
ее видимую кривизну (т.е. кривизну 7 в соответствующей точке образа), то
легко показать (см. раздел упражнений), что
cos в
ка = к----—. (19.2)
COSJ Ct
В частности, если направление наблюдения лежит в соприкасающейся плоско-
сти (cos/? = 0), видимая кривизна ка становится равной нулю, и образ кривой
получает точку перегиба. Если кроме этого направление наблюдения касатель-
но кривой (cosct = cos/? = 0), то параметр ка не является вполне определенным
и на проекции появляется точка возврата.
Два названных свойства проекций пространственных кривых хорошо извест-
ны и упоминаются во всех учебниках по дифференциальной геометрии. Можно
ли подобным образом связать локальную форму поверхности, ограничивающей
твердое тело, с формой контура ее изображения? Ответом на этот вопрос (как
следует из работы [Koenderink, 1984), озаглавленной “Что говорит затеняющий
контур о форме твердого тела?”) является уверенное "да!”. В данном разде-
ле рассматриваются некоторые элементарные свойства контуров изображения,
представлено доказательство основной теоремы из работы [Koenderink, 1984],
некоторые следствия теоремы анализируются.
19.2.1. Затеняющий контур и контур изображения
Как отмечалось ранее, образ тела с гладкой поверхностью ограничивается
кривой образа, именуемой контуром, силуэтом, или очертанием тела. Данная
кривая является пересечением чувствительной поверхности с конусом наблюде-
ния, вершина которого совпадает с точечной диафрагмой камеры, а поверхность
касается объекта по другой кривой, называемой затеняющим контуром, или
ободом (рис. 19.1).
Далее в этом разделе будем предполагать, что используется ортографическая
проекция. В таком случае диафрагма камеры перемещается на бесконечность
и конус наблюдения переходит в цилиндр, порождающие поверхности которого
параллельны фиксированному направлению наблюдения. Нормаль к поверхно-
сти постоянна вдоль каждой такой порождающей поверхности и параллельна
плоскости изображения (рис. 19.16). Плоскость, касательная точке затеняюще-
Глава 19. Гладкие поверхности и их контуры
601
Рис. 19.16. Границы затенения при ортографическом проектировании
го контура, проектируется в касательную к контуру изображения, и из этого
следует, что нормаль к контуру равна нормали к поверхности в соответствую-
щей точке затеняющего контура.
Важно отметить, что направление наблюдения v в общем случае не пер-
пендикулярно касательной затеняющего контура t (как отмечается, например,
в работе [Nalwa, 1988&], затеняющий контур наклонного цилиндра паралле-
лен его оси и не параллелен плоскости образа). Данные направления являются
сопряженными (см следующий раздел), что крайне важно при исследовании
затеняющих контуров.
19.2.2. Точки возврата и перегиба на контуре изображения
Два направления и и v на касательной плоскости называются сопряжен-
ными, когда II(u,v) = 0. Например, главные направления — сопряженные,
поскольку они представляют ортогональные собственные векторы dN, тогда
как асимптотические направления являются самосопряженными.
Легко показать, что касательная t к затеняющему контуру всегда сопряже-
на с соответствующим направлением проектирования v. Действительно, v —
касательная к поверхности в любой точке затеняющего контура, а дифферен-
цирование тождества N - v = 0 по длине дуги данной кривой дает следующий
результат:
(d \
0 = — N v = dN(t) • v = II(t, v).
yds J
Рассмотрим гиперболическую точку Ро и спроектируем поверхность на плос-
кость, перпендикулярную одному из ее асимптотических направлений. По-
602
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 19.17. Точки перегиба контура являются изображениями параболических точек. В левом
верхнем углу данной диаграммы показаны фасолеобразная поверхность с наложенным затеняю-
щим контуром, а в правой верхней части — соответствующий контур изображения. Как показано
в нижней части диаграммы, преобразование Гаусса сворачивается в параболической точке, то же
справедливо и для его сужения (большого круга), которое сформировано образами затеняющего
контура и контура изображения
скольку асимптотические направления самосопряженные, затеняющий контур
в точке Ро должен идти вдоль этого направления. Как следует из уравне-
ния (19.2), кривизна контура в этом случае должна быть бесконечной и на
контуре появляется точка возврата первого рода.
Приведем теорему из работы [Koenderink, 1984], дающую количественную
связь между кривизной контура образа и гауссовой кривизной поверхности. До-
кажем пока (неформально) более слабое, но достойное внимания утверждение.
Теорема 1. При ортографической проекции точки перегиба контура яв-
ляются образами параболических точек (рис. 19.17).
Чтобы убедиться в справедливости данной теоремы, вначале отметим, что
при ортографическом проектировании нормаль к поверхности в точке затеня-
ющего контура совпадает с нормалью в соответствующей точке контура об-
раза. Поскольку отображение Гаусса сворачивается в параболической точке,
Гаусс-образ контура изображения должен в такой точке менять направление на
противоположное. Как показывалось ранее, Гаусс-образ плоской кривой обра-
щается в точках перегиба и точках возврата второго-рода. Можно показать,
что для точки наблюдения общего вида последняя сингулярность не возникает,
что и доказывает требуемое утверждение.
Подведем итоги. Затеняющий контур формируется точками, в которых на-
правление наблюдения v касательно к поверхности (точки свертки, которые
упоминались в начале главы). Иногда поверхность становится касательной к v
в гиперболической точке возврата или пересекает параболическую линию, при
Глава 19. Гладкие поверхности и их контуры
603
Рис. 19.18. Затеняющий контур и контур образа: направление наблюдения v и касательная к
затеняющему контуру t являются сопряженными, а радиальная кривизна в видимой точке контура
непрозрачного тела всегда неотрицательна
этом, соответственно, на контуре появляются точки возврата (первого рода)
или точки перегиба. В отличие от ранее упоминавшихся кривых, контур изоб-
ражения может также самопересекаться (трансверсально), когда две различных
ветви затеняющего контура проектируются в одну точку образа, в результате
чего формируется Т-образное соединение (рис. 19.1). Для точек наблюдения
общего вида это является единственной возможной особенностью: здесь нет
ни точек возврата второго рода, ни самопересечений по касательной. Изучение
необычных точек наблюдения и соответствующих сингулярностей образа будет
продолжено в следующей главе.
19.2.3. Теорема Коендеринка
Сформулируем наконец теорему Коендеринка [Koenderink, 1984J, неодно-
кратно упоминавшуюся ранее. Снова предполагается использование ортогра-
фической проекции. Итак, рассмотрим точку Р контура, затеняющего поверх-
ность S, и обозначим через р ее образ на этом контуре.
Теорема 2. Гауссова кривизна К поверхности S в точке Р и кривизна
контура кс в точке р связаны соотношением
К — кскг,
где через кг обозначена кривизна радиальной кривой, сформированной пере-
сечением S с плоскостью, которая определяется нормалью к S в точке Р
и направлением проектирования (рис. 19.18).
604
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Это удивительно простое соотношение имеет несколько важных следствий:
отметим, что вдоль затеняющего контура радиальная кривизна кг остается
положительной (или равной нулю), поскольку луч проектирования локально
лежит внутри изображаемого объекта в любой точке, где выполняется соотно-
шение кг < 0. Из этого следует, что величина кс положительна, когда гауссо-
ва кривизна положительна, и отрицательна в противном случае. В частности,
теорема показывает, что выпуклые элементы контура соответствуют эллипти-
ческим точкам поверхности, тогда как вогнутые элементы — гиперболическим
точкам, а точки перегиба контура — параболическим точкам.
Из эллиптических точек поверхности, очевидно, вогнутые точки никогда
не будут видны на затеняющем контуре непрозрачного тела, поскольку их ка-
сательная плоскость (локально) лежит полностью внутри этого тела. Таким
образом, выпуклые элементы контура также соответствуют выпуклым элемен-
там поверхности. Подобным образом, когда направление наблюдения является
асимптотическим, точки возврата контура относятся к разряду гиперболиче-
ских. Для непрозрачного тела это означает, что вогнутые дуги контура могут
заканчиваться в подобных точках возврата, где преграждается ветвь контура.
Итак, теорема Коендеринка усиливает и уточняет предпринятую ранее попытку
охарактеризовать геометрические свойства контуров изображений.
Докажем приведенную теорему. Для этого нужно сослаться на общее свой-
ство сопряженных направлений: если ки и kv — параметры нормальной кри-
визны в сопряженных направлениях и и v, а К — гауссова кривизна, то
К sin2 в = kukv, (19.3)
где в — угол между ад и ад. Данное соотношение легко доказать, используя тот
факт, что матрица, соотнесенная со второй фундаментальной формой, Диаго-
нал ьна в базисе касательной плоскости, который сформирован сопряженными
направлениями (см. раздел упражнений). Очевидно, что приведенное тождество
выполняется для главных (в = тг/2) и асимптотических (в = 0) направлений.
В контексте теоремы Коендеринка получаем следующее:
К sin2# = кг Kt,
где через Kt обозначена нормальная кривизна поверхности вдоль направления
затеняющего контура t (которая, разумеется, отличается от реальной кривизны
затеняющего контура). Для завершения доказательства используем еще одно
общее свойство поверхностей: видимая кривизна любой кривой на поверхности
с касательной t записывается в таком виде:
Kt
ка = ——, (19.4)
cos а
где а — угол между t и плоскостью образа. Как показано в разделе упражнений,
данное свойство легко выводится из уравнения (19.2) и теоремы Мезниера.
Глава 19. Гладкие поверхности и их контуры
605
Другими словами, видимая кривизна любой поверхностной кривой полу-
чается делением соответствующей нормальной кривизны на квадрат косинуса
угла между ее касательной и плоскостью образа. Отметив, что кс — это просто
видимая кривизна затеняющего контура, можем записать следующее:
Kt
кс = —z- (19.5)
sin2 0
(поскольку а = 0 — тг/2). Для завершения доказательства теоремы осталось
только подставить уравнение (19.5) в уравнение (19.3).
19.3. ПРИМЕЧАНИЯ
Среди множества учебников по дифференциальной геометрии можно отме-
тить книги [do Carmo, 1976] и [Struik, 1988]. Текст главы близок к наглядному
введению в дифференциальную геометрию, которое можно найти в замеча-
тельной книге [Hilbert and Cohn-Vossen, 1952] под названием “Geometry and
the Imagination”.
В литературе не всегда отмечается, что контур изображения содержит важ-
нейшую информацию о форме поверхности (в доказательство обратного см.
[Marr, 1977], [Horn, 1986]). Ситуацию проясняет доказанная в главе теорема,
которая впервые была опубликована в работе [Koenderink, 1984]. Приведенное
выше доказательство отличается от оригинального, но по духу оно близко к
доказательству, которое приведено в книге [Koenderink, 1990] (данную книгу,
“Solid Shape”, как и названную выше “Geometry and the Imagination” советуем
прочесть тем читателям, кто серьезно заинтересован геометрическими аспекта-
ми компьютерного зрения). Выбор такого доказательства объясняется нежела-
нием авторов использовать формулы, требующие выбора определенной системы
координат. Альтернативные доказательства для различных проективных гео-
метрий можно найти в работах [Brady et aL, 1985], [Arbogast and Mohr, 1991],
[Cipolla and Blake, 1992], [Vaillant and Faugeras, 1992] и [Boyer, 1996b].
Задачи
19.1. Какова (в общем случае) форма силуэта сферы, полученного с помощью
перспективной камеры?
19.2. Какова (в общем случае) форма силуэта сферы, полученного с помощью
ортографической камеры?
19.3. Докажите, что кривизна к плоской кривой в точке Р является величиной,
обратной к радиусу кривизны г в этой точке. {Подсказка: для малых
углов sin и ~ и.)
19.4. Дана стационарная система координат, в которой точки пространства Е3
определены векторами их координат. Рассмотрим параметрическую кри-
вую х : I с R —> R3, параметризованную не обязательно длиной дуги.
Покажите, что кривизна этой кривой записывается следующей формулой:
606
Часть V. Верхний уровень компьютерного зрения: геометрические методы
где через х' и х" обозначены, соответственно, первая и вторая производ-
ные от х по параметру кривой t. Подсказка-, повторно параметризуйте х
длиной дуги и проследите, как изменяются производные при смене пара-
метра дифференцирования.
19.5. Докажите, что если нормальная кривизна не является постоянной по
всем возможным направлениям, главные направления ортогональны меж-
ду собой.
19.6. Докажите, что вторая фундаментальная форма билинейна и симмет-
рична.
19.7. Обозначим через о угол между плоскостью П и касательной к кривой Г,
через Р — угол между нормалью к П и бинормалью к Г, а через к —
кривизну в некоторой точке кривой Г. Докажите, что если через ка обо-
значить видимую кривизну образа Г в соответствующей точке, то
cos/3
Ка = К--—.
cos се
Примечание: данный результат можно найти в работе [Koenderink, 1990).
Подсказка: запишите координаты векторов I, п и b в системе координат,
ось z которой ортогональна плоскости изображения, затем из уравне-
ния (19.6) определите ка.
19.8. Обозначим через и kv нормальную кривизну в сопряженных направ-
лениях и и v в точке Р, а через К — гауссову кривизну. Докажите,
что
К sin2 в — kukv,
где 0 — угол между ад и v. Подсказка: свяжите выражения, полученные
для второй фундаментальной формы в базисах касательной плоскости,
сформированных, соответственно, сопряженными и главными направле-
ниями.
19.9. Покажите, что затеняющий контур является гладкой несамопересекаю-
щейся кривой. Подсказка: используйте отображение Гаусса.
19.10. Покажите, что видимая кривизна любой кривой на поверхности с каса-
тельной t равна
Kt
Ка = ---
COS о
где а — угол между плоскостью образа и t. Подсказка: запишите коорди-
наты векторов t, п и Ь в системе координат, ось z которой ортогональна
плоскости изображения, затем используйте уравнение (19.2) и теорему
Мезниера.
20
Аспектные графы
В данной главе продолжается исследование количественной связи формы твер-
дых тел с их изображениями. На этот раз внимание будет акцентироваться
на описании характеристик множества всех проекций тела с использованием
аппарата дифференциальной геометрии и теории особенностей, что позволит
сгруппировать изображения с общей топологической структурой в классы эк-
вивалентности. Для иллюстрации данной идеи обратимся к Плоскомиръю,
стране с двумерным ландшафтом, в которой живут крошечные одноглазые
существа, и рассмотрим плоский объект, ограниченный гладкой замкнутой
кривой, который наблюдается одним из этих существ (рис. 20.1). Смодели-
руем глаз существа ненаправленной круговой камерой (т.е. перспективной
камерой-обскурой с круговой поверхностью формирования изображений и по-
лем наблюдения в 360°), и предположим, что чувствительная поверхность
ориентирована (скажем, положительное направление — это обход окружности
против часовой стрелки), так что можно говорить о том, как точки упорядочены
вдоль этой поверхности.
В описанном случае “затеняющий контур” состоит из точек, в которых лучи
света, испускаемые оптическим центром, касаются границ объекта, а “контур
изображения” формируется как пересечение данных касательных лучей и кру-
говой чувствительной поверхности камеры. Объекты в Плоскомирье могут быть
608
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 20.1. Формирование изображений в Плоскомирье: три круговые камеры, которые способны
видеть точки в любом направлении, используются для наблюдения из близлежащих точек за дву-
мерным твердым телом. При подобных точках наблюдения порядок и число точек контура (или,
эквивалентно, соотнесенных с ними лучей проектирования) одинаковы для всех камер, что указы-
вает на гладкое отображение точек наблюдения в структуру изображения
прозрачными или светонепроницаемыми; в последнем случае касательные лучи,
трансверсально пересекающие некоторую часть границы объекта, блокируются
и уже не достигают чувствительной поверхности. В любом случае незначитель-
ное движение камер может приводить к небольшому изменению положения то-
чек контура, но не меняет (в общем случае) их числа и упорядочения вдоль
чувствительной поверхности.
Стоит отметить, что при определенных точках наблюдения небольшое дви-
жение камеры может приводить к значительным изменениям структуры изоб-
ражения: если рассматривать прозрачные объекты, то близлежащие точки сли-
ваются при пересечении глазом бикасательной (т.е. прямой, которая касается
границы объекта в двух различных точках), а затем снова разделяются, но
порядок их расположения меняется на обратный (рис. 20.2, а). Для непрозрач-
ных объектов при пересечении глазом бикасательной появляются новые точки
(или исчезают старые), так что проекция также меняется радикально, но уже
по-иному: наблюдается изменение порядка (или исчезновение) точек контура
(рис. 20.2, б). Подобным образом пара точек контура появляется или исчезает,
когда глаз пересекает касательную в точке перегиба кривой прозрачного объ-
екта (рис. 20.2, в). Для непрозрачных тел видна только одна из таких точек,
вторая скрывается за объектом (рис. 20.2, г).
Описанные структурные изменения изображения называются визуальными
событиями. Являются ли события, соотнесенные с бикасательными или каса-
тельными в точках перегиба, единственно возможными? Разумеется, еще могут
пересекаться две бикасательных, касательная в точке перегиба и бикасатель-
ная и т.д., в результате чего будут наблюдаться более сложные изменения вида
объекта. Теоретически возможны трикасательные и бикасательные в точках
перегиба. В то же время понятно, что три касательная исчезнет при малейшей
деформации соответствующей кривой (рис. 20.3), но бикасательная или пере-
Глава 20. Аспектные графы
609
в)
Рис. 20.2. При особых точках наблюдения происходит качественное изменение изображения: а) из-
менение упорядочения точек контура вдоль чувствительной поверхности, б), в), г) изменение числа
этих точек. Чтобы не загромождать рисунки, чувствительные поверхности на них не изображены;
объяснения см. в тексте
сечение двух касательных в точках перегиба при деформации просто несколько
сместится.
Далее в главе ограничимся рассмотрением кривых или поверхностей обще-
го положения, элементы которых не подвержены малым деформациям. Здесь
стоит упомянуть о универсальности, математической концепции, связанной
с интуитивным представлением об общих положениях и топологических по-
нятиях открытости, плотности и трансверсальности. Формальное определение
данной концепции является техническим и приводить его в данной книге пред-
ставляется неуместным. Отметим лишь, что хотя предположение об универ-
сальности исключает из рассмотрения некоторые простые геометрические фи-
гуры (прямые, плоскости и т.д.), границы всех реальных объектов являются
общими (в реальной жизни нарисовать действительную прямую линию невоз-
можно). Кроме того (что пожалуй даже более важно, по крайней мере, в кон-
тексте текущего изложения), рассмотрение только кривых и поверхностей об-
щего положения также ограничивает число и тип возможных визуальных со-
бытий: действительно, можно показать, что структурные изменения контура
610
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 20.3. Особые и обычные кривые: в отличие от бикасательных, трикасательные неустойчивы
к малым деформациям кривой
Рис. 20.4. Аспектный граф (непрозрачного) объекта в Плоскомирье. Слева: двумерный объект,
ограниченный замкнутой гладкой кривой и ячейки его (ненаправленного кругового) перспектив-
ного аспектного графа; обратите внимание на две небольшие области с номерами 7 и 8. Справа:
соответствующий ортографический аспектный граф. Ребра, соединяющие пары соседствующих ас-
пектов, и сами аспекты не показаны. В качестве легкого упражнения изобразите аспекты. Как
изменится аспектный граф, если объект будет прозрачным?
происходят в соответствии с предсказаниями, которые дает раздел математики,
именуемый теорией особенностей, или теорией катастроф. В Плоскоми-
рье принятые допущения равносильны тому, что единственными визуальными
событиями с кривыми общего положения становятся те, которые связаны с би-
касательными, касательными в точках перегиба и их пересечениями.
Для ненаправленных круговых камер аспект объекта (т.е. число и поря-
док точек его контура) зависит исключительно от положения глаза (рис. 20.2).
Визуальные события соответствуют контактам определенного типа между кри-
выми и лучами проектирования и не зависят от положения точек пересечения
данных лучей с чувствительной поверхностью. Таким образом набор точек на-
Глава 20. Аспектные графы
611
блюдения для камеры в Плоскомирье можно смоделировать плоскостью, в кото-
рой лежит оптический центр этой камеры. Данную плоскость можно преобра-
зовать в ячеистую структуру, аспектный граф, где лучи визуальных событий
и их пересечения устанавливают очертания максимальных ячеек, в которых
внешний вид объекта не меняется (рис. 20.4, слева).
Для отдаленных наблюдателей рассматриваемые ненаправленные круговые
камеры можно заменить удобными ортографически ми камерами, поскольку
в этом случае направление наблюдения определяет направление линейной чув-
ствительной поверхности, и наоборот, ориентацию прямой изображения всегда
можно выбрать так, чтобы рассматриваемый объект всегда лежал перед этой
прямой. При таком размещении пространство наблюдения превращается в еди-
ничную окружность (ориентированных) проекционных векторов, разделенных
на конечный набор аспектов направлениями бикасательных и касательных
в точках перегиба (рис. 20.4, справа).
Те же принципы справедливы и для трехмерного мира: как и в примере
с Плоскомирьем выбор проекционной модели (ненаправленная сферическая пер-
спективная камера, плоская перспективная камера или ортографическая каме-
ра) и точки наблюдения определяет внешний вид объекта (в этом случае — гра-
фическое представление контура изображения, вершины графа соответствуют
Т-образным соединениям и точкам возврата, а ребра — это гладкие фрагменты
контура между этими точками). Диапазон возможных точек наблюдения снова
разбивается границами визуальных событий на максимальные ячейки, в кото-
рых вид объекта не меняется, и эти ячейки формируют вершины трехмерного
аспектного графа, ребра которого, привязанные к границам визуальных собы-
тий, разграничивают соседние ячейки. Впервые аспектные графы были пред-
ставлены в работе [Koenderink and Van Doorn, 1979], где они назывались ви-
зуальными возможностями. В следующем разделе вводятся дополнительные
элементы дифференциальной геометрии, необходимые для понимания структу-
ры аспектных графов. Далее рассматриваются алгоритмы построения точных
и приблизительных аспектных графов твердых объектов и их использование
в задачах извлечения деталей из контейнера.
20.1. ВИЗУАЛЬНЫЕ СОБЫТИЯ: СНОВА ОБРАЩАЕМСЯ
К ДИФФЕРЕНЦИАЛЬНОЙ ГЕОМЕТРИИ
С этого момента будем предполагать использование ортографической про-
екции (перспективная проекция кратко рассмотрена в разделе 20.4), и смо-
делируем набор всех точек наблюдения единичной сферой ориентированных
направлений проектирования. Точки перегиба, точки возврата и Т-образные
соединения являются устойчивыми элементами контура изображения, которые
обычно не исчезают при небольших перемещениях наблюдающего глаза: рас-
смотрим, например, точку перегиба на контуре; как показано в главе 19, она
является проекцией точки пересечения затеняющего контура и параболической
кривой соответствующей поверхности (как правило, эти объекты пересекают-
612
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 20.5. По мере изменения точки наблюдения большая окружность гауссовой сферы, соотне-
сенная с (ортографическим) затеняющим контуром, становится касательной к сферическому образу
параболической кривой. Затем окружность пересекает данную кривую в двух смежных точках, ко-
торые соответствуют двум точкам перегиба на контуре
ся под ненулевым углом). Любое малое изменение точки наблюдения приводит
к небольшой деформации затеняющего контура, но две данных кривых по-
прежнему будут трансверсально пересекаться в близкой точке, которая спроек-
тируется в точку перегиба на контуре.
Естественно, возникает вопрос: каким должно быть (пекулярное) движение
глаза, чтобы появился или исчез некоторый элемент контура. Чтобы ответить
на этот вопрос, обратимся к отображению Гаусса и введем асимптотическое
сферическое отображение, которое связывает границы изображений на по-
верхности с появлением и исчезновением точек перегиба и точек возврата на
их контурах. Таким образом можно охарактеризовать локальные визуальные
события (т.е. изменения структуры контура, связанные с дифференциальной
геометрией поверхности на этих границах). Учитываются также множественные
контакты лучей наблюдения с поверхностью. Это приводит к концепции много-
образия бикасателъных лучей, а описание характеристик границ поверхности
позволяет понять, как возникают и исчезают Т-образные соединения, и ввести
соответствующие мулътилокалъные визуальные события. В сумме локальные
и мультилокальные события охватывают всю полноту структурных изменений
контура, которые определяют аспектный граф.
20.1.1. Геометрия отображения Гаусса
Отображение Гаусса предлагает естественную основу для изучения контура
изображения и его точек перегиба. Действительно, при ортографическом про-
ектировании, как было показано в главе 19, затеняющий контур отображается
в большую окружность на единичной сфере, а точки пересечения этой окруж-
ности со сферическим образом параболических кривых дают точки перегиба
на контуре. Следовательно, контур получает (или теряет) две точки перегиба,
Глава 20. Аспектные графы
613
когда движение камеры приводит к тому, что соответствующий большой круг
пересекает образ параболической кривой (рис. 20.5).
Создание пар точек перегиба можно понять лучше, тщательнее изучив гео-
метрию отображения Гаусса. Как показано в главе 19, образ поверхности на
гауссовой сфере сворачивается вдоль образов ее параболических кривых. При-
мер этой свертки приведен на рис. 20.6, где сфера с одной стороны параболиче-
ской кривой накрывается один раз, а с другой стороны — трижды. Проще всего
визуализировать создание подобной складки — это представить кусок резино-
вой оболочки спущенного шарика, мысленно его сдавить и завернуть. Как пока-
зано на рисунке, при этом процессе обычно вводится не только складка сфери-
ческого образа, но еще две точки возврата (прообразы которых в дифференци-
альной геометрии называются гауссовыми точками возврата). Точки возвра-
та и точки перегиба образа параболической кривой обычно появляются парами
(в приведенном примере — две пары точек перегиба и пара точек возврата,
хотя, разумеется, может и вообще не быть точек возврата или перегиба). Точки
перегиба расщепляют складку на Гаусс-образе на вогнутую и выпуклую части,
прообразы которых называются точками стока (gutterpoints) (рис. 20.6).
Что произойдет с затеняющим контуром, если соответствующий большой
круг пересечет сферический образ параболической кривой — зависит от того,
где это случится. Как показано на рис. 20.4, возможны несколько ситуаций:
когда пересечение происходит вдоль выпуклой складки Гаусс-образа, на сфери-
ческом образе затеняющего контура появляется изолированная точка, которая
затем развивается в небольшой замкнутый цикл на единичной сфере (рис. 20.4,
справа внизу). Если же пересечение происходит вдоль вогнутой складки, два
отдельных цикла сливаются, а затем снова разделяются на два с другими связ-
ностями (рис. 20.4, справа вверху). Разумеется, данные изменения отражаются
на контуре изображения, подробности этого процесса описаны в следующих
разделах.
Большой круг, связанный с затеняющим контуром, может также пересекать
образ параболической кривой в точке возврата. В отличие от пересечений,
происходящих в неособых точках складки, данная точка, в общем случае,
трансверсальна и не налагает условия касания на ориентацию большого круга.
Топология пересечения не меняется, но на контуре изображения появляются
или исчезают две точки перегиба. Наконец, большой круг может пересекать
Гаусс-образ параболической кривой в одной из его точек перегиба. Изменение
топологии в этом случае слишком сложно и здесь не описывается. Радует то,
что число точек наблюдения, для которых возможна такая ситуация, конечно
(поскольку конечно число точек стока на поверхности общего положения).
В то же время имеются другие типы пересечений складки, возможные для бес-
конечных однопараметрических семейств точек наблюдения. Это объясняется
тем, что пересечения по касательной, связанные с выпуклыми или вогнутыми
участками складки, могут появляться где угодно на протяженном участке дуги,
проведенном на единичной сфере, тогда как пересечения по трансверсальным
кривым, связанные с точками возврата, происходят только в изолированных
614
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 20.6. Складки и точки возврата отображения Гаусса. Точки стока представляют собой про-
образы точек перегиба сферического образа параболической кривой. Чтобы лучше представить
структуру складки, слева и справа она изображена как поверхность, свернутая в пространстве. Из-
менения топологии пересечений большого круга и Гаусс-образа поверхности по мере пересечения
кругом складки иллюстрируются на правой дальней части рисунка. Перепечатано из S. Рае and
J. Ponce, "On Computing Structural Changes in Evolving Surfaces and their Appearance", Interna-
tional Journal of Computer Vision, 43(2):113-13I, 2001. © 2001 Kluwer Academic Publishers
точках, но при произвольной ориентации большого круга. Соответствующие
семейства сингулярных точек наблюдения определяются в следующем разделе.
20.1.2. Асимптотические кривые
В главе 19 говорилось, что обычные гиперболические точки допускают две
различных асимптотических касательных. В более общем случае множество
всех асимптотических касательных к гиперболическому участку можно так
разделить на два семейства, что для каждого из них будет существовать
гладкое поле интегральных кривых, именуемых асимптотическими. Согласно
работе [Koenderink, 1990] присвоим каждому семейству свой цвет и будем го-
ворить о красной и синей асимптотических кривых. Данные кривые покрывают
только гиперболическую часть поверхности, следовательно, должны быть син-
гулярными в окрестности ее параболических границ. Действительно, красная
асимптотическая кривая сливается с синей в обычной параболической точке,
в результате чего формируется точка возврата, и пересекает параболическую
кривую под ненулевым углом (рис. 20.7, а)1.
Исследуем поведение асимптотических кривых при применении отображе-
ния Гаусса. Напомним из главы 19, что асимптотические направления явля-
*В гауссовых точках возврата ситуация несколько иная: асимптотические кривые встреча-
ются с параболической кривой по касательной. Это необычное поведение также характерно для
плоских параболических кривых необщих объектов (например, две круговых параболических кри-
вых вверху и внизу лежащего на боку тора или параболические линии тела вращения, соотнесенные
с локальными экстремумами сечения тела вдоль его оси).
Глава 20. Аспектные графы
615
Рис. 20.7. Контакт асимптотической и параболической кривых а) на поверхности и б) на гауссовой
сфере
ются самосопряженными. Это (буквально) означает, что производная нормали
поверхности вдоль асимптотической кривой ортогональна касательной к этой
кривой: асимптотическая кривая и ее сферический образ имеют перпендикуляр-
ные касательные. С другой стороны, все направления в касательной плоскости
являются сопряженными к асимптотическим направлениям в параболической
точке, так что Гаусс-образ любой поверхностной кривой, проходящей через
параболическую точку, перпендикулярен соответствующему асимптотическому
направлению. В частности, Гаусс-образ параболической кривой является оги-
бающей асимптотических кривых, пересекающих ее образы (т.е. он касается
этих кривых в каждой точке; см. рис. 20.7, б).
Теперь можно охарактеризовать точки наблюдения, для которых появляются
(или исчезают) пары точек перегиба. Поскольку большой круг, связанный с за-
теняющим контуром, становится касательным к образу параболической кривой
на сфере Гаусса в момент их пересечения, направление наблюдения перпенди-
кулярно данному большому кругу проходит вдоль соответствующего асимпто-
тического направления параболической кривой. Пара точек перегиба может, ра-
зумеется, появляться при пересечении большим кругом изображения гауссовой
точки возврата или, эквивалентно, при пересечении лучом зрения касательной
плоскости в такой точке. Как отмечалось ранее, топология контура изображе-
ния в этом случае не меняется; она просто приобретает (или теряет) шерохо-
ватость (т.е. небольшая вогнутая впадина в одной из выпуклых частей или
небольшое вздутие на одной из вогнутых частей). В следующем разделе пока-
зано, как меняется структура контура при появлении других сингулярностей.
20.1.3. Асимптотическое сферическое отображение
Отображение Гаусса соотносит с каждой точкой поверхности точку пере-
сечения единичной сферы вершиной соответствующей нормали. Определим
асимптотическое сферическое отображение, которое соотносит с каждой
(гиперболической) точкой соответствующие асимптотические направления. Пе-
616
Часть V. Верхний уровень компьютерного зрения: геометрические методы
ред тем как продолжить изложение, следует сделать несколько замечаний. Во-
первых, в действительности существует только один асимптотический сфериче-
ский образ каждого семейства асимптотических кривых, и два образа на сфере
могут перекрываться или не перекрываться. Во-вторых, для эллиптических то-
чек асимптотического сферического образа очевидно нет, и единичная сфера
может не полностью накрываться образами гиперболических точек. Впрочем,
она может и полностью накрываться и, по крайней мере локально, накрываться
несколько раз элементами одного семейства асимптотических направлений.
Поскольку точки возврата контура изображения появляются, когда линия
наблюдения проходит вдоль асимптотического направления, то пара точек воз-
врата появляется (или исчезает), когда линия наблюдения пересекает складку
асимптотического сферического отображения (обратите внимание на близкую
аналогию с точками перегиба контура и складками Гаусс-образа). Как и сле-
довало ожидать, асимптотический сферический образ асимптотической кривой
имеет сингулярность на границе складки. Снова возможны два варианта (изоб-
ражение может сливаться с границей по касательной или в точке возврата),
так что могут наблюдаться два типа точек складки: точки, связанные с асимп-
тотическими направлениями вдоль параболических кривых (поскольку на их
эллиптической стороне нет асимптотических направлений), и точки, связанные
с асимптотическими направлениями в точках, самокасания (fiecnodal point).
Названные точки являются точками перегиба проекций асимптотических кри-
вых на касательную к ним плоскость (рис. 20.8, а), причем точки самокасания
формируют кривые, трансверсально пересекающие соответствующие асимпто-
тические кривые. Подобно последним, этим точкам можно присвоить один из
двух цветов в зависимости от асимптотического семейства точки перегиба.
Асимптотический сферический образ точек возврата имеет точку возврата на
асимптотической кривой в точке самокасания (рис. 20.8, б). Следует также
отметить, что самокасательные кривые пересекают параболические кривые по
касательной в гауссовых точках возврата.
Очевидно, что структура контура меняется при пересечении линией наблю-
дения параболической или самокасательной границы асимптотического сфери-
ческого образа. Подобное изменение называется визуальным событием, а со-
ответствующие границы именуются кривыми визуальных событий. Перед тем
как перейти к подробному изучению различных визуальных событий, отме-
тим альтернативный способ представления названных границ. Если изобразить
сингулярную асимптотическую касательную в каждой точке параболической
или самокасательной поверхности, получим линейчатую поверхность, замета-
емую касательными. Визуальное событие имеет место, когда линия наблюде-
ния пересекает одну из этих линейчатых поверхностей, пересечения которых
со сферой на бесконечности являются в точности кривыми визуальных собы-
тий. Преимуществом рассуждений об эволюции контура с позиции линейчатых
поверхностей является возможность обобщения концепции визуальных собы-
тий на перспективную проекцию (проекции меняются при прохождении через
Глава 20. Аспектные графы
617
Красная самокасательная кривая
а)
Рис. 20.8. Контакт асимптотической и самокасательной кривых а) на поверхности и б) на асимп*
готическом сферическом образе
Красная самокасательная кривая
них оптического центра) и наглядной визуализации связи сингулярных точек
наблюдения и формы поверхности.
20.1.4. Локальные визуальные события
Наша цель — понять, как структура контура меняется на границах визу-
альных событий. Возможны три типа локальных визуальных событий, которые
полностью характеризуются геометрией локальной дифференциальной поверх-
ности: "гг/ба”(Ир), "пирамида ”(beak-to-beak) и "ласточкин хвост ’’(swallowtail).
Такие колоритные названия взяты из каталога элементарных катастроф [Thom,
1972]2 и удачно описывают форму контура возле соответствующих событий.
Исследуем вначале событие типа губа, имеющее место, когда линия наблю-
дения пересекает асимптотический сферический образ выпуклой параболиче-
ской точки или, эквивалентно, линейчатую поверхность, определяемую соответ-
ствующими асимптотическими касательными (рис. 20.9, вверху). Ранее было
показано, что пересечение большого круга, связанного с затеняющим контуром,
и Гаусс-образа поверхности получает при событии цикл (рис. 20.6, справа вни-
зу) с созданием на контуре двух точек перегиба и двух точек возврата. Точнее,
до события контура изображения не существует, имеется изолированная точка
контура, возникающая в сингулярности из ниоткуда, а затем расширяющаяся
до замкнутого цикла, который состоит из пары ветвей, встречающихся в двух
точках возврата (рис. 20.9, внизу). Одна из ветвей формируется проекциями
эллиптических и гиперболических точек и имеет две точки перегиба, а другая
ветвь формируется проекциями только гиперболических точек. У непрозрачных
объектов одна из ветвей всегда затеняется предметом.
Событие типа пирамида имеет место, когда линия наблюдения пересека-
ет асимптотический сферический образ вогнутой параболической точки или,
2Аналоги названий, принятые в русскоязычной литературе, взяты из замечательной книги
Арнольд В.И. Теория катастроф, 1990. — Прим. ред.
618
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 20.9. Событие типа “губа”. Название объясняется формой контура, изображенной на рисунке
справа. На этом и следующих рисунках часть контура, изображенная пунктиром, у непрозрачно-
го объекта будет невидимой. В приведенном примере две точки перегиба находятся на видимой
стороне контура, а невидимая часть является гиперболической, но если наблюдать предмет с про-
тивоположной стороны, ситуация будет обратной. Перепечатано из S. Рае and J. Ponce, "On
Computing Structural Changes in Evolving Surfaces and their Appearance”, International Journal of
Computer Vision, 43(2):113-131, 2001. (c) 2001 Kluwer Academic Publishers
эквивалентно, линейчатой поверхности, которая определена соответствующи-
ми асимптотическими касательными (рис. 20.10, вверху). Как было показано
ранее, при событии меняется топология пересечения большого круга, соотнесен-
ного с затеняющим контуром, и Гаусс-образа поверхности: два цикла сливают-
ся, а затем разделяются, но уже с другими связностями (рис. 20.6, справа ввер-
ху). На образе есть две различных части контура (встречаются в точке образа),
каждая из которых имеет точку возврата и точку перегиба. Перед событием
каждая ветвь делится соответствующей точкой возврата на чисто гиперболиче-
скую часть и смешанную эллиптически-гиперболическую дугу, причем одна из
двух частей всегда затеняется. После события две точки возврата и две точки
перегиба исчезают при расщеплении контура на две гладких дуги с различны-
ми связностями. Одна из этих дуг является чисто эллиптической, а другая —
чисто гиперболической, причем или та, или другая всегда затенена (разумеет-
Глава 20. Аспектные графы
619
ся, сказанное относится только к непрозрачным объектам) (рис. 20.10, внизу).
Как и для других визуальных событий возможен также обратный переход.
Наконец, событие типа ласточкин хвост имеет место при пересечении гла-
зом поверхности, направляемой асимптотическими касательными, по самокаса-
тельной кривой того же цвета. Известно, что при этом событии появляются (или
исчезают) две точки возврата. Как показано на рис. 20.11, а и б, пересечение
поверхности и ее касательной плоскости в точке самокасания состоит из двух
кривых, одна из которых содержит точку перегиба. Соответствующая асимпто-
тическая касательная соотнесена с семейством асимптотических кривых с точ-
кой перегиба. В отличие от обычных асимптотических лучей (рис. 20.11, в),
которые блокируются наблюдаемым телом, этот касается поверхности тела (см.
[Koenderink, 1990]), что приводит к возникновению в точке сингулярности на
контуре изображения V-образной составляющей. До перехода контур был глад-
ким, а после получает две точки возврата и Т-образное соединение (рис. 20.11,
внизу). Все точки поверхности, участвующие в событии, являются гиперболи-
ческими. У непрозрачных тел одна ветвь контура заканчивается в Т-образном
соединении, а другая — в точке возврата.
20.1.5. Многообразие бикасательных лучей
Напомним из главы 19, что точки возврата и точки перегиба — это не
единственные устойчивые элементы контура: в открытых множествах точек на-
блюдения также встречаются Т-образные соединения. Они формируются при
проектировании двух различных участков затеняющего контура в одно место
образа. Соответствующие нормали к поверхности должны быть ортогональны-
ми к бикасательной линии наблюдения, соединяющей две точки, но (в общем
случае) они не параллельны. Интуитивно понятно, что Т-образные соединения
устойчивы при небольших изменениях положения глаза: рассмотрим выпуклую
точку Р и ее касательную плоскость (рис. 20.12, слева). Данная плоскость
(в общем случае) пересекает поверхность по замкнутой (но, возможно, пустой)
кривой, кроме того, имеется четное число точек (на рисунке — Р* и Р") та-
ких, что лучи, проведенные из Р через эти точки, касательны к кривой. Каждое
такое касание дает бикасательный луч и соотнесенное с ним Т-образное соеди-
нение. Небольшое смещение точки наблюдения приводит к малым деформациям
кривой пересечения, но не меняет (в общем случае) число касательных точек.
Таким образом, Т-образные соединения действительно устойчивы.
Бикасательные лучи формируют двумерное многообразие бикасательных
лучей? в четырехмерном пространстве, образованном всеми прямыми. Посколь-
ку при проектировании бикасательные отображаются в Т-образные соединения,
Многообразие — это топологическая концепция, которая обобщает поверхности, определен-
ные в евклидовом пространстве, на более абстрактные объекты; формальное определение понятия
“многообразие” в данной книге приводиться не будет. Интуитивно понятно, что многообразие би-
касательных лучей является двумерным, поскольку с каждой точкой наблюдаемого (двумерного)
пространства соотнесено конечное число бикасательных лучей.
620
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 20.10. Событие типа “пирамида” (название объясняется формой контура, изображенной на
рисунке слева). Перепечатано из S. Рае and J. Ponce, "On Computing Structural Changes in
Evolving Surfaces and their Appearance”, International Journal of Computer Vision, 43(2):113-131,
2001. © 2001 Kluwer Academic Publishers
очевидно, что данные элементы контура создаются или уничтожаются на грани-
цах многообразия. Поскольку Т-образное соединение появляется или исчезает
при переходе типа ласточкин хвост, очевидно также, что одну из этих границ
формируют сингулярные асимптотические касательные, проходящие по само-
касательным кривым. Не так очевидно, из чего составлены остальные границы;
данный вопрос подробно рассмотрен в следующем разделе.
20.1.6. Мультилокальные визуальные события
Пара Т-образных соединений появляется или исчезает при пересечении
лучом обзора границы многообразия бикасательных лучей. Соответствующее
изменение структуры контура называется мультилокальным визуальным со-
бытием. В данном разделе показано, что существует три типа мультилокальных
событий, именуемых, соответственно, пересечение по касательной, пересече-
ние в точках возврата и тройная точка, помимо сингулярности, связанной
с пересечением самокасательной кривой, о которой упоминалось в предыдущем
разделе.
Глава 20. Аспектные графы
621
Рис. 20.11. Событие типа “ласточкин хвост”. Вверху: форма поверхности в окрестности точки
самокасания (а) и сравнение пересечения соответствующего тела с его касательной плоскостью
в окрестности такой точки (б) и обычной гиперболической точки (в). Внизу, собственно событие.
Перепечатано из S. Рае and J. Ponce, “On Computing Structural Changes in Evolving Surfaces and
their Appearance", International Journal of Computer Vision, 43(2):113-131, 2001. (c) 2001 Kluwer
Academic Publishers
Обратимся вначале к событию, именуемому пересечением по касательной.
Очевидная граница многообразия бикасательных лучей формируется предель-
ными (ограничивающими) бикасателъными (рис. 20.12, справа), возникающи-
ми, когда кривая, сформированная пересечением плоскости, касательной в неко-
торой точке, и остальной поверхности, сжимается в точку и плоскость стано-
вится дважды касательной к поверхности. Предельные бикасательные заметают
линейчатую поверхность, называемую предельной дважды касательной огиба-
ющей. Пересечение по касательной происходит при пересечении лучом зрения
данной поверхности (рис. 20.13, вверху), причем при событии два отдельных
участка контура становятся касательными один к другому, а затем трансвер-
сально пересекаются в двух Т-образных соединениях (рис. 20.13, внизу). У
непрозрачных объектов либо после перехода становится видимой ранее скры-
тая часть контура, либо (как на приведенном рисунке) вследствие затенения
исчезает еще одна дуга контура.
В многообразии дважды касательных лучей возможны границы еще двух ти-
пов, также связанные с бикасательными, которые касаются поверхности вдоль
множества кривых и заметают огибающие поверхности: асимптотические би-
касательные, которые пересекают поверхность по асимптотическому направ-
622
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 20.12. Бикасательные лучи. Слева: плоскость, касательная к поверхности в точке Р, пере-
секает ее по замкнутой кривой и два бикасательных луча, РР' и РР", касающиеся поверхности
по данной кривой. Справа: ограничивающая бикасательная развертываемая поверхность, направ-
ляемая прямыми, в которых плоскость дважды касается поверхности. Показано слияние по ка-
сательной двух кривых, в которых плоскость касается наблюдаемой поверхности. Точка слияния
относится к семейству гауссовых точек возврата и называется узлом (unode). Перепечатано из
S. Рае and J. Ponce, “Toward a Scale-Space Aspect Graph: Solids of Revolution”, Proceedings IEEE
Conference on Computer Vision and Pattern Recognition, 1999. © 1999 IEEE
лению в одной из их конечных точек (рис. 20.14, а), и трижды касательные,
которые касаются поверхности в трех различных точках (рис. 20.14, б). Соот-
ветствующие визуальные события имеют место при пересечении лучом зрения
одной из соответствующих огибающих поверхностей, и они также включают по-
явление или исчезновение пары Т-образных соединений: пересечение в точке
возврата имеет место, когда гладкий участок контура изображения пересека-
ет другую часть контура в точке возврата (или конечной точке, если объект
непрозрачен) последней (рис. 20.14, в). В процессе создаются (или уничтожа-
ются) два Т-образных соединения, причем у непрозрачных объектов видимо
только одно из них. Тройная точка формируется при одновременном пересече-
нии трех различных участков контура под ненулевыми углами (рис. 20.14, г).
У прозрачных объектов три Т-образных соединения сливаются в точке сингу-
лярности, а затем опять разделяются. У непрозрачных объектов исчезают (или
появляются) ветвь контура и два Т-образных соединения, при этом появляется
(или исчезает) другое Т-образное соединение.
20.2. РАСЧЕТ АСПЕКТНОГО ГРАФА
Предположим, что имеется некоторая модель границы твердого тела (в виде
многогранника, приравненной к нулю объемной плотности или любой другой
модели, на которую способна ваша фантазия). Следует естественный вопрос:
“Как на деле построить соответствующий аспектный граф?”. В данном разде-
ле предполагается, что выбрана стационарная евклидова система координат,
так что точки пространства Е3 можно отождествить с векторами их коорди-
нат в R3. Геометрические определения параболических точек, ограничивающих
Глава 20. Аспектные графы
623
Рис. 20.13. Событие “пересечение по касательной". Взаимное затенение пространственно разне-
сенных частей затеняющего контура изменяется при переходе точки наблюдения через граничную
дважды касательную огибающую поверхность в точке В. Перепечатано из S. Рае and J. Ponce, “On
Computing Structural Changes in Evolving Surfaces and their Appearance”, International Journal of
Computer Vision, 43(2):113-131, 2001. © 2001 Kluwer Academic Publishers
бикасательные лучи и т.д., легко записать (см. [Petitjean et al., 1992]) через
производные (до третьей) параметрического представления поверхности, соот-
несенного с данной моделью и записанного для одной, двух или трех точек
поверхности. В каждом случае кривые на поверхности, соотнесенные с опре-
деленными ранее линейчатыми поверхностями, можно охарактеризовать в про-
странстве Rn+1 с помощью системы п уравнений по п + 1 неизвестным:
Р1(хо,Х1,...,хп) = 0,
* ...
Pn(xo,xi,...,xn) = 0,
(20.1)
где 1 < п < 8, в зависимости от типа события и того, определена поверхность
параметрически или явно. Например, если поверхность определена параметри-
чески как приравненная к нулю некоторая функция плотности F(x, y,z) = 0,
имеем п = 2 для локального события и п = 8 для тройной точки, в которую
проектируются три различных точки поверхности (см. раздел упражнений).
Имея указанные уравнения, можно очертить общую схему построения ас-
пектного графа данного объекта: а) отслеживание кривых визуальных событий
прозрачного объекта; б) построение областей на сфере наблюдения, разграни-
чиваемых данными кривыми; в) исключение затененных событий и слияние
инцидентных областей; г) построение соответствующих аспектов. При постро-
ении аспектного графа прозрачного тела из общей схемы удаляется п. в.
624
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 20.14. Мульти л скальные события: а) асимптотический дважды касательный луч, б) трижды
касательный луч, в) пересечение в точке возврата, г) тройная точка. Согласно работе [Petitjean
et al., 1992]
Рассмотрим задачу построения аспектного графа тела, ограниченного алгеб-
раической поверхностью (т.е. граница тела описывается приравненной к нулю
объемной полиномиальной функцией плотности):
S = < (x,y,z) е К3| 52 o,ijkXly3zk = 0 > .
I i+j+k<d
В качестве примеров алгебраических поверхностей можно назвать плоскости
и поверхности второго порядка (т.е. эллипсоиды, гиперболоиды и параболо-
иды), а также приравненные к нулю полиномиальные функции плотности
высших степеней. Что более важно: в каждом случае все условия, которые
определяют визуальные события в уравнении (20.1), являются полиномами
по искомым неизвестным. Данная особенность — это ключ к успешной ре-
ализации различных этапов описанного ранее общего алгоритма, поскольку
Глава 20. Аспектные графы
625
Рис. 20.15. Отслеживание кривой в R2. В данном случае гиперплоскости являются прямыми
линиями. Исследуемая кривая имеет две экстремальных точки, Ег и Е2, а также четыре несингу-
лярных ветви, представленных выборками — точками Sx-S4. Точка Е2 сингулярна. Перепечатано
из S. Petitjean, J. Ponce and D.J. Kriegman, “Computing Exact Aspect Graphs of Curved Objects:
Algebraic Surfaces”, International Journal of Computer Vision, 9(3):231-255, 1992. (c) 1992 Kluwer
Academic Publishers
доступны средства и численного, и аналитического решения многомерных
полиномиальных уравнений.
20.2.1. Этап 1: Отслеживание визуальных событий
Визуальное событие соотносится с двумя кривыми: первая, назовем ее Г,
либо проводится на поверхности объекта, либо (если имеют место мультило-
кальные события) в пространстве более высокой размерности; вторая, назовем
ее Д, проводится на сфере наблюдения как множество соответствующих точек
наблюдения. Кривая Г определяется п уравнениями системы (20.1) в простран-
стве Kn+1.
В данном разделе рассмотрена задача отслеживания кривой Г (т.е. опреде-
ления ее гладких дуг и сингулярностей с последующим определением связности
различных компонентов кривой). Простое решение этой задачи представлено
в алгоритме 20.1, проиллюстрированном на рис. 20.15. Входом данного алго-
ритма являются п уравнений по п + 1 неизвестным, которые определяют Г,
а выходом — граф G, вершины которого представляют экстремальные точки
кривой Г (в том числе сингулярные точки) в направлении хо, ребра графа G —
это гладкие участки кривой, соединяющие экстремальные точки.
626
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Алгоритм 20.1. Алгоритм отслеживания кривой
(1.1) Вычислить все экстремальные точки (включая сингулярные точки) кривой Г
в некотором направлении, скажем, х0. Эти точки формируют узлы графа G
(1.2) Вычислить все точки пересечения Г с гиперплоскостями, ортогональными
оси хо в экстремальных точках.
(1.3) Для каждого интервала на оси хо, ограниченного данными гиперплоско-
стями, найти пересечение Г и гиперплоскости, проходящей через середину
интервала. В результате будет получено по одной выборке для каждой ре-
альной ветви.
(1.4) Численно пройти от точек выборки (этап (1.3)) до точек пересечения
(этап (1.2)), используя для предсказания новых точек разложение в ряд
Тейлора и уточняя их положение с помощью итерации уравнений по схеме
Ньютона.
(1.5) Объединить гладкие ребра Г, которые встречаются в точках пересечения,
не являющихся экстремальными, и добавить в G ребро для каждой пары
экстремальных (или сингулярных) точек, соединенных ветвью кривой.
На этапе (1.1) требуется вычислить экстремумы Г в направлении xq. Эти
точки характеризуются системой п + 1 полиномиального уравнения по п 4-1
неизвестным, которая получается прибавлением уравнения Det(/7) = 0 к си-
стеме (20.1), где J — якобиан матрицы (dPi/dxj), причем i,j — 1,...,п. Для
нахождения экстремумов можно использовать гомотопное продолжение (см.
[Morgan, 1987]), численный метод определения всех корней квадратной си-
стемы полиномиальных уравнений. На этапах (1.2) и (1.3) требуется вычис-
лить точки пересечения кривой с гиперплоскостью. Эти точки также являются
решениями полиномиальных уравнений, и для их определения используется
гомотопное продолжение. Собственно отслеживание (в классическом смысле
этого термина) происходит на этапе (1.4) с использованием схемы предсказа-
ния/коррекции Ньютона на основе разложения в ряд Тейлора величин Pi. При
этом требуется найти обратную к матрице С7, которая гарантированно является
несингулярной на интервалах, не содержащих экстремумов.
После построения G подобное графическое описание D кривой Д легко по-
лучается посредством отображения точек кривой Г в соответствующем асимп-
тотически касательном или бикасательном направлении.
20.2.2. Этап 2: Построение областей
Предположим, что построены графы Di, соотнесенные со всеми кривыми
визуальных событий Дг (г = 1,...,р). Для построения областей аспектного
графа, которые разграничены на сфере наблюдения кривыми Д;, отобразим
данные кривые на плоскость, использовав, например, сферические координа-
Глава 20. Аспектные графы
627
ты, и преобразовав алгоритм построения кривой в процедуру декомпозиции на
ячейки (см. алгоритм 20.2 и рис. 20.16), выходом которой будет описание об-
ластей, ограничивающих их кривых и информация об отношениях соседства.
Отметим, что такое преобразование алгоритма возможно только для плоских
кривых. На практике входом алгоритма являются полиномиальные кривые, по-
лученные отображением дискретного представления кривых Д^, соотнесенных
с графом Di, на плоскость; причем точки экстремумов и пересечения соответ-
ствующих плоских кривых легко находятся из этих многоугольников. Кривые
визуальных событий и ячейки, которые получены на выходе алгоритма, при
необходимости легко отображаются обратно на сферу наблюдения.
Алгоритм 20.2. Алгоритм декомпозиции ячеек. Входом данного алгоритма явля-
ется множество плоских кривых, выходом — описание областей, ограниченных
данными кривыми, а также информация об отношениях соседства между ячей-
ками (две области называются соседними, если у них имеется общая граница —
т.е. вертикальный сегмент прямой или ветвь кривой).
(2.1) Вычислить все экстремальные точки кривой в направлении х0.
(2.2) Вычислить все точки пересечения этих кривых.
(2.3) Вычислить все точки пересечения кривых с вертикальными прямыми, орто-
гональными оси хо в точках экстремумов и точках пересечения.
(2.4) Для каждого интервала на оси zo, ограниченного указанными прямыми,
выполнить следующее:
(2.4.1) пересечь кривые с вертикальными прямыми, проходящими через
середину интервала, и получить по одной выборке для каждой ветви
кривой;
(2.4.2) рассортировать точки-выборки по возрастанию ц;
(2.4.3) пройти от выборок до точек пересечения, найденных на этапе (2.3);
(2.4.4) область ограничивают две последовательные ветви, лежащие в ин-
тервале хо, и два вертикальных сегмента, соединяющих их края.
(2.5) Для каждой области взять выборку посредине последовательных выборок,
определенных на этапе (2.4.1).
(2.6) Слить области, соседствующие по вертикальным сегментам прямых, в мак-
симально большие области.
20.2.3. Оставшиеся этапы алгоритма
На этапах (3) и (4) алгоритма построения аспектного графа устраняются
затененные визуальные события и строятся выборочные аспекты каждой обла-
сти. Концептуально оба этапа просты. Обратите внимание, что все визуальные
628
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 20.16. Пример декомпозиции ячеек. Показаны две кривые, их экстремальные точки Е, и пе-
ресечения Ij. Заштрихованный прямоугольник, ограниченный линиями Ц и разделен на пять
областей, выборочные точки — с Si по S5. Область, соответствующая S3, изображена более тем-
ной. Перепечатано из S. Petit jean, J. Ponce and D.J. Kriegman, “Computing Exact Aspect Graphs of
Curved Objects: Algebraic Surfaces", International Journal of Computer Vision, 9(3):23l-255, 1992.
(c) 1992 Kluwer Academic Publishers
события прозрачных объектов находятся на этапе (1) алгоритма, а их пересе-
чения — на этапе (2). У непрозрачных объектов некоторые события затенены
и их следует исключить из рассмотрения. Поскольку видимость кривой визу-
ального события меняется только в сингулярных точках и точках пересечения
с другими визуальными событиями, затененные события можно исключить,
проследив траекторию луча в выборочных точках каждой ветви, которые были
найдены на этапе (3). Области, соседствующие с затененными событиями, легко
подвергаются слиянию. На конечном этапе алгоритма происходит определение
структуры контура одной проекции каждой области. Имея в каждой области
выборочную точку наблюдения, к контуру изображения применяется алгоритм
отслеживания кривой, описанный в разделе 20.2.1, в результате чего строится
граф структуры изображения, вершины которого являются точками экстре-
мумов и сингулярностей контура (точки возврата и Т-образные соединения), а
ребра — соединяющими их гладкими ветвями. Как и ранее, следующий шаг
состоит в отслеживании луча, в результате определяется, какие выборочные
точки, соотнесенные с каждой ветвью, затеняются.
20.2.4. Пример
На рис. 20.17 (вверху) приведены два схематических изображения кабач-
кообразного тела, поверхность которого определена через нулевые значения
полиномиальной функции плотности. Две кривые, идущие на рис. 20.17 (слева
вверху) практически параллельно, являются параболическими кривыми кабач-
ка, они расщепляют его поверхность на два выпуклых пятна, разделенных сед-
лообразной областью. На рисунке также изображена самопересекающаяся кри-
Глава 20. Аспектные графы
629
вая, которая является самокасательной (справа вверху) и показывает гранич-
ную бикасательную огибающую, соотнесенную с кабачком. Образующие дан-
ного тела — линии, соединяющие пары точек на поверхности кабачка, имеющие
одинаковые бикасательные плоскости. Параболическая и самокасательная кри-
вые, а также граничная бикасательная огибающая найдены с использованием
представленного в разделе алгоритма отслеживания кривой. Асимптотические
дважды или трижды касательные в данном случае отсутствуют. На рис. 20.17
(внизу) показан ортографический аспектный граф непрозрачного кабачка, для
вычисления которого был использован представленный ранее алгоритм деком-
позиции ячеек.
20.3. АСПЕКТНЫЕ ГРАФЫ И ЛОКАЛИЗАЦИЯ ОБЪЕКТОВ
Аспектные графы удобны и математически элегантны. На практике, однако,
точные аспектные графы, как они описаны в предыдущих разделах, (пока) еще
не оправдали возлагаемых на них ожиданий, например, в области распознава-
ния объектов; частично это объясняется тем, что надежное извлечение харак-
терных элементов контура (таких как оконечные точки и Т-образные соедине-
ния) из реальных изображений представляет собой крайне трудную задачу, а
частично — тем, что даже относительно простые объекты могут давать крайне
сложные аспектные графы. С другой стороны приблизительные аспектные гра-
фы успешно применяются во многих практических задачах, от локализации
частей до распознавания объектов. В частности, в данном разделе рассмотре-
на задача извлечения деталей из контейнера, которая исследована в работах
[Ikeuchi and Kanade, 1987] и [Ikeuchi and Kanade, 1988], где фигурировали мно-
жественные экземпляры одного объекта (как правило, это механические детали
в контексте автоматизированного производства, но в рассматриваемом случае
использовалась пластмассовая игрушка), случайным образом нагроможденные
роботом, причем с помощью сенсорной информации требуется определить их
трехмерное положение и ориентацию (или позу). Предполагается, что доступ-
ны многогранные модели данных деталей и что детали состоят из игольчатых
карт, построенных по исходным изображениям с использованием схем фото-
метрического стерео, представленных в главе 5.
Сконцентрируемся на части, расположенной вверху контейнера и предполо-
жим, что она наблюдается издалека (ортографическая проекция) без параллель-
ного затенения со стороны других объектов. Данное предположение оправдано
для задач, в которых размер частей мал по сравнению с расстоянием до на-
блюдающей камеры. Итак, видимость любой точки поверхности верхней части
можно определить исключительно по направлению наблюдения (которое здесь
определяется ориентацией вертикали относительно локальной системы коорди-
нат, привязанной к объекту). Соответствующий аспект определяется как пере-
чень видимых граней, упорядоченных по уменьшению размеров поверхности.
Для части в форме многогранника аспект, соотнесенный с данной ориентацией
объекта, легко определить с помощью простой схемы оценки скрытых поверх-
630
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 20.17. Вверху: кабачкообразное тело с соответствующими параболическими и самокасатель-
ными кривыми (слева) и граничной дважды касательной огибающей (справа). Внизу, соответству-
ющий (тело предполагается непрозрачным) ортографический аспектный граф с ячейками сферы
наблюдения (слева) и соответствующими аспектами (справа). Обратите внимание, что на приве-
денной полусфере видимы только 9 из 14 реальных ячеек, причем некоторые из них, например,
область 7, довольно малы
ностей, такой как z-буферизация. Объекты, подобные пластмассовой игрушке
(как в приведенном примере), ограниченные кусочно-гладкими поверхностями
и аппроксимируемые многогранными сетками, также не представляют пробле-
мы. Их искривленные грани считаются видимыми, когда видима хотя бы одна
из ячеек, посредством которых аппроксимируются данные поверхности. При та-
ких оговорках легко построить приблизительный аспектный граф; подробности
построения приведены в алгоритме 20.3.
Алгоритм 20.3. Алгоритм построения приблизительного аспектного графа
1. Разбить единичную сферу на фрагменты, соотнесенные с направлениями на-
блюдения.
2. Вычислить аспект, соотнесенный с центром каждой такой ячейки.
3. Сгруппировать соседние аспекты в классы эквивалентности и пометить по-
следние бинарными строками (единица — грань видима, нуль — не видима).
Глава 20. Аспектные графы
631
Рис. 20.18. Приблизительные аспектные графы. Вверху, слева направо-, две фотографии пласт-
массовой игрушки, ее многогранная модель (обратите внимание, что каждая цилиндрическая по-
верхность аппроксимируется несколькими плоскими гранями, но при построении аспектного графа
рассматривается как единая грань объекта) и квазирегулярная сотообразная структура с 60 тре-
угольными гранями. Перепечатано из К. Ikeuchi and Т. Kanade, "Automatic Generation of Object
Recognition Programs," Proceedings of the IEEE, 76(8):IOI6-1O35, 1988. (c) 1988 IEEE. Внизу, со-
ответствующие семь аспектов. Перепечатано из К. Ikeuchi, "Precompiling a Geometrical Model
into an Interpretation Tree for Object Recognition in Bin-Picking Tasks, ” Proceedings DARPA Image
Understanding Workshop, 1987
В данном алгоритме предполагается, что видимость не зависит от точек
наблюдения, соотнесенных с каждой ячейкой дискретизованной сферы наблю-
дения, так что строится только аппроксимация истинного аспектного графа.
На рис. 20.18 иллюстрируется построение аспектного графа для пластмассовой
игрушки. На данном этапе можно ввести ограничения, связанные с процессом
получения данных. В частности, грань можно обнаружить только стереофо-
тометрическими методами, когда угол между нормалью к грани и линией на-
блюдения достаточно мал: в примере, приведенном на рис. 20.18, ни одну из
видимых граней в аспекте 7 на самом деле невозможно обнаружить согласно
используемому критерию, так что все они получают метки со всеми нулями.
Появления “лица” игрушки (на рис. 20.18 фрагмент № 4) стоило бы ожидать на
аспекте 6, в действительности оно соответствует немоделированному гнезду на
поверхности, и для этого аспекта не создается представительной проекции. Для
вычисления представительной проекции каждого оставшегося аспекта находит-
ся поза, максимизирующая площадь изображения объекта по соответствующе-
му диапазону точек наблюдения, а затем с горизонтальным направлением на
изображении совмещаются оси максимальной инерции игрушки.
Для облегчения процесса локализации удобно организовать аспекты в дере-
во решений, именуемое деревом интерпретации. Каждый узел такого дерева
соотнесен с диапазоном точек наблюдения, перечнем соответствующих аспек-
тов и гранью объекта. Дерево строится итеративно: на каждом шаге грань F,
соотнесенная с узлом N, используется для расщепления множества соответ-
ствующих точек наблюдения на подмножество V, где F видима, и подмноже-
ство V", где F невидима. Левая ветвь-потомок N соотносится с диапазоном
точек наблюдения V7, соответствующим подмножеством аспектов и следую-
щей по величине гранью, видимой из некоторой точки в множестве V. Правая
ветвь-потомок подобным образом строится из V" и соответствующего подмно-
632
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 20.19. Слева: пример изображения контейнера; верхняя игрушка указана стрелкой. В центре:
путь (жирная линия) следования по дереву интерпретации к соответствующей области изображе-
ния. Справа: программа локализации нашла игрушку (приведена оцененная поза игрушки). Пере-
печатано из К. Ikeuchi, "Precompiling a Geometrical Model into an Interpretation Tree for Object
Recognition in Bin-Picking Tasks, ” Proceedings DARPA Image Understanding Workshop, 1987
жества аспектов. Если две грани имеют одинаковую площадь, они обе исполь-
зуются в процессе деления, и V становится множеством точек наблюдения, из
которых видима одна из данных граней, а V" становится множеством точек
наблюдения, из которых не видна ни одна из этих граней. Построение дере-
ва начинается с корневого узла, соотнесенного с наибольшей гранью объекта,
полной сферой наблюдения и списком всех возможных аспектов.
Чистое дерево интерпретации можно улучшить, добавив к нему множество
правил классификации и определения позы. Эти правила конструируются вруч-
ную из геометрических и топологических особенностей, связанных с каждой
гранью геометрической модели, включая направление их осей инерции и со-
ответствующих моментов; классификацию общей формы модели как плоской,
цилиндрической, эллиптической или гиперболической; ее расширенный гаусс-
образ (РГО\ т.е. гистограмму нормалей к поверхности в пределах грани, вычис-
ленную по дискретизованной сфере Гаусса); информацию о контуре, получен-
ную из одного из входных изображений с помощью детектора краев; информа-
цию об отношениях соседства между гранью и ее окружением. В типичном пра-
виле может использоваться сравнение, скажем, моментов наблюдаемой грани
и моментов модели с целью принятия решения относительно того, по какой вет-
ви следовать в процессе интерпретации. В правилах определения позы объекта
используется геометрическая информация, связанная с гранями сопоставляемо-
го объекта. Например, направления наблюдения можно определить, совместив
предсказанный центр масс РГО грани с наблюдаемым, и по предсказанным
и наблюдаемым осям инерции этой грани можно определить ориентацию объ-
екта на плоскости, перпендикулярной линии наблюдения.
На рис. 20.19 показаны результаты эксперимента по локализации. В дан-
ном случае имеются три источника сенсорных данных. Основной источник —
игольчатая карта, полученная по нескольким изображениям с одной точки
наблюдения при различных схемах освещения. При сопоставлении игольчатых
карт, соотнесенных с двумя камерами, также получается грубая карта глубин
Глава 20. Аспектные графы
633
(дуальное фотометрическое стерео). Наконец, контурная карта находится
с помощью запуска детектора краев на одном из входных изображений. Три на-
званные карты совмещаются в одной системе координат, затем по карте глубин
определяется верхняя область (рис. 20.19, слева), которая передается дереву
интерпретации. Локализация продолжается в процессе обхода дерева, причем
для выбора правильных ветвей с каждым узлом соотносится проверка, в итоге
успешно идентифицируется наблюдаемый аспект (рис. 20.19, в центре), соот-
ветствующее направление наблюдения и вращение вокруг линии наблюдения,
при котором совмещаются предсказанный и наблюдаемый аспекты (рис. 20.19,
справа).
20.4. ПРИМЕЧАНИЯ
Материал данной главы большей частью основан на работах Коендеринка
и Ван Доорна, в том числе монументальных публикациях, в которых вводилась
идея аспектного графа ([Koenderink and Van Doorn, 1976ft, 1979]), статье, в ко-
торой были весьма доступно изложены геометрические основы представления
формы ([Koenderink, 1986], см. также [Platonova, 1981], [Kergosien, 1981]), и,
разумеется, несколько более сложной (но также и полезной для настойчиво-
го студента) книге [Koenderink, 1990]. Великолепное неформальное введение
в аспектные графы можно также найти в работе [Callahan and Weiss, 1985].
Универсальность, теории катастроф и сингулярностей рассмотрены во мно-
гих работах, среди которых можно выделить [Whitney, 1955], [Arnol’d, 1984]
и [Demazure, 2000]. Еще можно порекомендовать работы [Koenderink, 1990]
и [Thom, 1972], содержащие некоторые оригинальные идеи. Алгоритм, пред-
ставленный в разделе 20.2, изложен согласно [Petitjean et al., 1992], в которой
описан численный метод гомотопного продолжения, первоначально предло-
женный в книге [Morgan, 1987] для нахождения всех корней (в том числе
комплексных и равных бесконечности) квадратной системы многомерных по-
линомиальных уравнений. Помимо этого существуют символические методы,
такие как схемы с многомерными результантами ([Macaulay, 1916], [Collins,
1971], [Саппу, 1988], [Manocha, 1992]) и цилиндрической алгебраической де-
композицией ([Collins, 1975], [Amon et al., 1984]), которые в серии работ
[Rieger, 1987, 1990, 1992] использовались для создания алгоритма построения
аспектного графа алгебраической поверхности.
В данной главе внимание акцентировалось на ортографических аспектных
графах, но сингулярные касательные и бикасательные, рассмотренные в разде-
ле 20.1, также формируют границы визуальных событий и при перспективном
проектировании, причем соответствующие линейчатые поверхности разрезают
трехмерное пространство наблюдения на ячейки, формирующие узлы перспек-
тивного аспектного графа. Строго говоря, модель построения изображения,
которая использовалась в перспективных аспектных графах, справедлива толь-
ко для камер с полем наблюдения в 360° х 360°, таких как ненаправленные
634
Часть V. Верхний уровень компьютерного зрения: геометрические методы
сферические камеры, рассмотренные в начале главы4 *. Для наблюдателей, распо-
ложенных вне выпуклой оболочки объекта, можно использовать более привыч-
ную перспективную проекционную модель, причем ориентация чувствительной
поверхности выбирается так, чтобы объект располагался перед точечной диа-
фрагмой. Это возможно в любом случае, поскольку а) точку, расположенную
вне выпуклого объекта, всегда можно отделить от объекта плоскостью и б) лег-
ко показать, что топологическая структура контура изображения не зависит
от ориентации плоскости изображения, если объект находится перед точечной
диафрагмой.
Разработано множество алгоритмов построения аспектных графов много-
гранника при ортографической или перспективной проекции (см., например,
[Castore, 1984], [Stewman and Bowyer, 1987, 1988], [Watts, 1987], [Gigus and
Malik, 1990], [Plantinga and Dyer, 1990], [Wang and Freeman, 1990], [Gigus
et al., 1991]), некоторые из этих алгоритмов были реализованы практически.
Имеется только два типа кривых визуальных событий (так называемые события
EV и ЕЕЕ), которые имеют место при касании лучом зрения многогранника
в ребре (edge — Е) и вершине (vertex — V) или касании поверхности в трех раз-
личных точках. Также предлагались и реализовывались алгоритмы построения
точного аспектного графа простого кривого объекта, такого как твердое тело,
ограниченное поверхностью второго порядка ([Chen and Freeman, 1991], [Eg-
gert and Bowyer, 1989, 1991], [Kriegman and Ponce, 1990a]) Наиболее общими
в настоящее время являются, пожалуй, алгоритмы, представленные в данной
главе (изложены согласно [Rieger, 1987, 1990, 1992]), и алгоритмы, основанные
на цилиндрической декомпозиции.
К сожалению, аспектные графы слишком велики: ортографический аспект-
ный граф для многогранника с п гранями имеет О(п6) ячеек ([Gigus et al.,
1991]). Для кусочно-гладкой поверхности, составленной из п полиномиаль-
ных участков степени d ([Petitjean, 1995]), размер увеличивается до O(n6d12).
В перспективном случае ситуация, разумеется, становится еще хуже. Сто-
ит ли списывать огромный размер аспектного графа на само представление?
Или же это следствие (комбинаторной и/или алгебраической) сложности ис-
ходной модели поверхности (например, число граней или степень участков,
используемых для аппроксимации относительно простой свободной поверх-
ности)? Данный вопрос изучается в работе [Noble et al., 1996ft], где строится
аспектный граф твердого тела, определенного его объемной плотностью (напри-
мер, граница органа на изображении, полученном средствами компьютерной
томографии) и формулируются предварительные результаты. Другим аспек-
том проблемы большого размера является соответствующее моделирование
оптического искажения, вводимого реальными линзами, и конечного простран-
ственного разрешения камер. Предварительные наброски подходов к решению
4 Разумеется, истинные ненаправленные камеры являются абстракцией, но существуют ком-
мерческие модели, основанные на технологии катадиоптрических ненаправленных камер, предло-
женной в работе [Nayar, 1997].
Глава 20. Аспектные графы
635
этих задач изложены в работах [Eggert et al., 1993], [Shimshoni and Ponce,
1996] и [Pae and Ponce 2000] и они частично основаны на недавних иссле-
дованиях влияния однопараметрических семейств деформации на поверхности
общего положения ([Bruce et al., 1996а, ft]).
Приблизительные аспектные графы многогранников успешно используются
в задачах локализации объектов. В разделе 20.3 представлен подход, предло-
женный в работах [Ikeuchi and Kanade, 1987ft, 1988] (разновидности этого под-
хода описаны в [Chakravarty, 1982] и [Hebert and Kanade, 1985]). Расширенный
Гаусс-образ введен в работе [Horn, 1984], а метод дуально фотометрического
стерео — в работе [Ikeuchi, 1987а].
Описание алгоритмов отслеживания луча и z-буферизации для скрытых
поверхностей можно найти в классическом труде [Foley et al., 1990].
ЗАДАЧИ
20.1. Изобразите ортографический и сферический перспективный аспектные
графы приведенного ниже прозрачного объекта в Плоскомирье, а также
соответствующие аспекты.
20.2. Изобразите ортографический и сферический перспективный аспектные
графы непрозрачного объекта, а также соответствующие аспекты.
20.3. Может ли объект с единственной параболической кривой (например, ба-
нан) совсем не иметь гауссовой точки возврата? Ответ аргументируйте.
20.4. Используйте алгоритм подсчета уравнений для проверки следующего
факта: для поверхностей общего положения невозможно касание прямой
и поверхности в шести или большем числе точек. (Подсказка', подсчи-
тайте число параметров, определяющих контакт.)
20.5. Асимптотическая кривая и ее сферический образ имеют перпендикуляр-
ные касательные. Линии кривизны — это интегральные кривые поля
главных направлений. Покажите, что эти кривые и их Гаусс-образы име-
ют параллельные касательные.
20.6. Используйте тот факт, что Гаусс-образ параболической кривой являет-
ся огибающей пересекающих ее асимптотических кривых, для вывода
альтернативного доказательства того, что при событии типа “губа” или
“пирамида” создается (или исчезает) пара точек возврата.
20.7. События типа “губа” или “пирамида” на поверхностях, заданных
неявно. Можно показать (см. [Рае and Ponce, 2000]), что параболи-
ческие кривые поверхности, определенной неявно как F(x,y,z) = О,
636
Часть V. Верхний уровень компьютерного зрения: геометрические методы
описываются системой из этого уравнения и уравнения VFTAVF — О,
где \7F — градиент F, а А — симметричная матрица
(FyyFzz - Fyz
FxzFyz — FzzFxy
FxyFyz - FyyFxz
FxzFyz — FzzFxy
FZZFXX — FxZ
FxyFxz — FxxFyz
Можно также показать, что асимптотическое направление в параболиче-
ской точке — это A5JF.
а) Покажите, что АН = Det(H)Id, где Н — гессиан функции F.
б) Покажите, что гауссовы точки возврата — это параболические точки,
удовлетворяющие уравнению VPTASJF = 0. {Подсказка-, используй-
те тот факт, что асимптотические направления в гауссовых точках
возврата касательны к параболической кривой, и что вектор VF пер-
пендикулярен к касательной плоскости поверхности, определяемой со-
отношением F = 0.)
в) Наметьте алгоритм отслеживания событий типа “губа” или “пирами-
да” на поверхностях, заданных неявно.
20.8. Событие типа “ласточкин хвост” на поверхностях, заданных неявно.
Можно показать, что асимптотические направления а в гиперболической
точке удовлетворяют двум уравнениям: VF- а = 0 и атНа = 0, где Н —
гессиан функции F. Из двух данных уравнений просто следует, что поря-
док контакта между поверхностью и ее асимптотическими касательными
не меньше трех. Асимптотические касательные вдоль самокасательных
кривых имеют с поверхностью контакт четвертого порядка, что описыва-
ется следующим уравнением:
аТНха\
атНуа I • а = 0.
aTH.zO. /
Наметьте алгоритм отслеживания события типа “ласточкин хвост” на
неявно заданных поверхностях.
20.9. Выведите уравнения, характеризующие мультилокальные события на по-
верхностях, заданных неявно. Можно использовать тот факт (см. преды-
дущую задачу), что асимптотические направления а в гиперболической
точке удовлетворяют двум уравнениям: VF • а — 0 и атНа = 0.
Упражнения
20.10. Напишите программу обнаружения мультилокальных событий. Рассмот-
рите две сферы с различными радиусами и считайте проекции ортогра-
фическими. Программа должна позволять интерактивно менять точку
наблюдения, а также находить пересечения по касательным, связанные
с граничными дважды касательными огибающими.
20.11. Напишите подобную программу, обнаруживающую точки возврата и их
проекции. (Здесь потребуется отслеживать плоскую кривую.)
21
Далы-юстные данные
В данной главе обсуждаются дальностные изображения (или карты глу-
бин), которые содержат информацию не о яркости либо цвете, а о расстоянии
{глубине) до первого пересечения луча, соотнесенного с каждым пикселем,
со сценой, наблюдаемой посредством камеры. По сути, дальностное изображе-
ние — это желаемый выход схемы “определения формы по X”, где “X” может
обозначать стереоизображение, движение и т.д. В данной главе внимание
сфокусировано на дальностных изображениях, которые получены с активных
сенсоров, проектирующих некоторое оптическое изображение на сцену, ис-
пользующих результат для обхода сложной и дорогой задачи установления со-
ответствий и создающих компактную и точную карту глубин. Глава начинается
с краткого обзора технологии дальнометрии, затем обсуждаются сегментация
изображения, совмещение множественных изображений, построение трехмер-
ных моделей и распознавание объектов, причем внимание акцентируется на
тех аспектах указанных задач, которые связаны с информацией о расстоянии
до рассматриваемых объектов.
638
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 21.1. Дальномер использует плоскость света для сканирования поверхности объекта
21.1. АКТИВНЫЕ ДАТЧИКИ РАССТОЯНИЯ
Активные дальномеры, основанные на триангуляции, используются с на-
чала 1970-х (см., например, [Agin, 1972], [Shirai, 1972]). Они работают по
тому же принципу, что и пассивные системы стереозрения, только одна из
камер замещается источником управляемого освещения (структурированного
света), что снимает задачу определения соответствий, описанную в главе И.
Например, может использоваться система лазера и пары вращающихся зер-
кал, последовательно сканирующая поверхность. В этом случае (как и при
использовании обычной стереопары) положение пятна света (места падения
лазерного луча на рассматриваемую поверхность) находится как точка пересе-
чения лазерного луча с лучом проектирования. В то же время (и это отличает
описанную установку от обычной стереопары) лазерное пятно можно легко
опознать однозначно, поскольку оно обычно гораздо ярче других точек сцены
(особенно если на лицевую сторону камеры установить фильтр, настроенный
на длину волны лазера), что также снимает задачу установления соответствий.
Возможно альтернативное техническое решение: лазер заменяется цилиндриче-
ской линзой, расположенной в плоскости света (рис. 21.1), при этом упрощается
механическая структура дальномера, поскольку требуется только одно враща-
ющееся зеркало. Пожалуй, есть даже более важное улучшение — уменьшается
время, требуемое для получения дальностного изображения, так как на каждом
кадре можно легко получить лазерную полоску (эквивалент столбца изображе-
ния). Следует отметить, что подобная установка не порождает неоднозначности
по соответствиям, поскольку лазерное пятно, связанное с каждым пикселем
изображения, можно (единственным образом) определить как пересечение
соответствующего луча проектирования с освещенной плоскостью.
Существуют различные модификации двух схем, описанных выше, — ис-
пользование нескольких камер (для повышения точности измерений) и ис-
пользование (возможно, закодированных во времени) двумерных оптических
Глава 21. Дальностные данные
639
изображений (для ускорения процесса получения данных). Основные недо-
статки техники активной триангуляции — это относительно низкая скорость,
потеря информации в точках, в которых лазерное пятно закрыто от камеры
объектом, и потеря информации или получение ложной информации вслед-
ствие зеркального отражения. Последняя сложность характерна для всех схем
активной дальнометрии: чисто зеркальная поверхность не отражает свет в на-
правлении камер, если, конечно, камера не расположена в соответствующем
зеркальном направлении. Хуже другое — отраженный луч может приводить
ко вторичному отражению и, как следствие, давать неверные оценки глуби-
ны. Помимо названных трудностей еще сложно удержать лазерную полоску
в фокусе в течение всей процедуры сканирования, также возможно снижение
точности, присущее всем схемах на основе триангуляции. Это снижение точ-
ности происходит при увеличении глубины (см. раздел упражнений в главе 11;
интуитивно понятно, что это объясняется тем, что рассогласование обратно
пропорционально глубине). В настоящее время уже доступны коммерческие
версии сканеров, работающих по принципу триангуляции. На рис. 21.2 пред-
ставлено изображение, полученное с помощью дальномера Minolta VIVID,
который позволяет получать дальностное изображение 200 х 200 с наложенным
цветным изображением 400 х 400 за 0,6 с при рабочем диапазоне 0,6-2,5 м.
Другой основной подход к активной дальнометрии включает использова-
ние передатчика сигнала, приемника и схемы измерения времени прохожде-
ния сигнала от сенсора до объекта и обратно. Подобные дальномеры обычно
снабжаются механизмом сканирования, приемник и передатчик часто делают
коаксиальными, что устраняет обычную для триангуляционных дальномеров
проблему потери информации. Сенсоры, использующие опорный сигнал, де-
лятся на три основных класса: схема задержки времени распространения
импульса — непосредственное измерение времени прохождения лазерного
импульса до объекта и обратно; дальномеры амплитудно-модулированного
фазового сдвига, в которых измеряется разность фаз между лучом, излу-
чаемым амплитудно-модулированным лазером, и принятым лучом (величина,
пропорциональная времени распространения); сенсоры, определяющие биение
частот, в которых измеряется частотный сдвиг (или частота биения) между
частотно-модулированным лазерным лучом и его отражением (еще одна величи-
на, пропорциональная времени прохождения луча). По сравнению с системами,
которые работают по принципу триангуляции, сенсоры, использующие время
распространения, имеют больший рабочий диапазон (до нескольких десятков
метров), что важно в задачах внешней навигации роботов.
Продолжают возникать и развиваться новые технологии, в число которых
входят дальномеры, оборудованные акустико-оптическими системами скани-
рования и позволяющие получать изображения с очень высокой скоростью, а
также камеры, вообще не использующие сканирование, но содержащие боль-
шой массив приемников, с помощью которых анализируется лазерный импульс,
охватывающий всю зону обзора.
640
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 21.2. Два дальностиых изображения, полученные со сканера Minolta VIVID. Информация о
глубине подана как заштрихованная сетка точек (х, у, z(x, у)), наблюдаемых в перспективе (такая
форма подачи информации будет использоваться и на некоторых других рисунках этой главы).
Данные любезно предоставили D. Huber и М. Hebert
21.2. СЕГМЕНТАЦИЯ ДАЛЬНОСТНЫХ ДАННЫХ
В данном разделе некоторые методы определения краев и сегментации, вве-
денные в главах 8 и 14, адаптируются к изучению дальностных изображений.
Как будет показано далее, тот факт, что геометрию поверхности определить лег-
ко, значительно упрощает процесс сегментации, поскольку дает объективные,
физически значимые критерии нахождения разрывов поверхности и слияния
непрерывных участков со сходной формой. Введем для начала некоторые эле-
ментарные понятия аналитической дифференциальной геометрии, создающие
основу для переноса схемы определения краев на дальностные изображения.
21.2.1. Элементы аналитической дифференциальной геометрии
Вернемся к понятиям дифференциальной геометрии, введенным в главе 19,
на этот раз акцентируя внимание на аналитической стороне вопроса. В част-
ности, предполагается, что в пространстве Е3 введена стационарная система
координат; будем считать это пространство пространством К3 и определим каж-
дую точку вектором ее координат. Рассматривается параметрическая поверх-
ность, определенная как гладкое (т.е. бесконечное число раз дифференцируе-
мое) отображение х : U cK2->R3, которое соотносит с каждой парой (u,v)
открытого подмножества U пространства R2 точку х(и, v) в пространстве R3.
Чтобы гарантировать, что касательная плоскость определена в любой точке,
предположим, что частные производные хи = дх/ди и xv = dx/dv линейно
независимы. Действительно, пусть а. : I с R —♦ U — гладкая плоская кривая,
причем cn(t) = (iz(t), v(i)), тогда /3 = хо а представляет собой параметризован-
ную пространственную кривую, лежащую на поверхности. Согласно цепному
правилу, вектор, касательный к /Зв точке /3(f), — это u'(t)xu + v'(t)xv, отсюда
следует, что плоскость, касательная поверхности в x(u,v), параллельна век-
Глава 21. Дальностные данные
641
торной плоскости, натянутой на векторы хи и xv. Таким образом, (единичная)
нормаль к поверхности записывается как
1
N =-------------(хи х xv).
|xu X Xv|
Рассмотрим вектор t = и'хи 4- u'ajv, принадлежащий касательной плоскости,
в точке х. Легко показать, что вторая фундаментальная форма определяется
соотношением1
= t dN(t) = ей'2 4- 2fu'v' 4- gv'2, где
e = —N xUu,
* f — ‘ Xuv,
g = —N xvv.
Отметим, что в общем случае вектор t имеет неединичную норму. Определим
первую фундаментальную форму как билинейную форму, которая соотносит
с двумя векторами в касательной плоскости их скалярное произведение (т.е.
I(u, v) = и • «). Далее можем записать
I(t, t) = |t12 = Ей 2 4- 2Du v 4- Gv 2, где
E = xu •
< F = Xu • Xv,
G Xv * Xv,
откуда следует, что нормальная кривизна в направлении t выражается следую-
щим образом:
II(t,t) ей2 + 2fuv' 4- gv'2
Kt ~ I(t, t) " Eu 2 4- 2Du v 4- Gv'2'
Легко показать, что матрица, соотнесенная с дифференциалом преобразования
Гаусса в базисе (хи, xv) касательной плоскости, записывается так:
dN(t)=(/ 0(р Э '
Поскольку гауссова кривизна равна детерминанту оператора dN, она записы-
вается следующим образом:
EG-F2
С помощью данной параметризации также легко определяются асимптотиче-
ские и главные направления: поскольку для асимптотических направлений
‘В данном определении подразумеваются договоренности относительно ориентации, приня-
тые в главе 19. Часто коэффициенты e,f,g определяются с противоположными знаками (см., на-
пример, [do Carmo, 1976J, [Struik, 1988J).
642
Часть V. Верхний уровень компьютерного зрения: геометрические методы
справедливо соотношение lift, t) = 0, соответствующие значения и' и v' яв-
ляются однородными решениями уравнения ей'2 -I- 2/uV -I- gv'2 = 0. Можно
также показать, что главные направления удовлетворяют уравнению
v'2 —u'v'
Е F
е /
(21.1)
Пример 21.1. Лоскуты Монга
Важным примером параметрических поверхностей являются лоскуты Монга
(Monge patches). Рассмотрим поверхность х(и, v) — (и, v,h(u, и)). В этом случае
имеем
1 , Т
N = -------2------2~Г/2 ~hv, 1) ,
(l + AS + nS)I/2
4 Е = 1 + hl. F = huhv, G = 1 + hl.
/i-U.lt /iltV /ivf
.e="(i+fcj+л:)1'2’f=“(i+^+h2)1'2’9=-(i+hi+ht)1'2'
и кривизна имеет следующий простой вид:
(1+/£+ц)2'
Пример 21.2. Локальная параметризация поверхности
Другой фундаментальный пример — это локальная параметризация поверхности
в системе координат, образованной главными направлениями этой поверхности.
Описанная поверхность является частным случаем лоскута Монга. Записав,
что начало системы координат лежит в касательной плоскости, сразу получа-
ем ЦО, 0) = /ги (0,0) = hv(0, 0) = 0. Как и следовало ожидать, нормалью в начале
координат является вектор N — (0,0,1)т, а первая фундаментальная форма
в данном случае равна единичной матрице. Как показано в разделе упражнений,
из уравнения (21.1) легко выводится, что необходимым и достаточным условием
того, что кривая на параметризованной поверхности идет вдоль главного направ-
ления, является f = F = 0 (из этого, например, следует, что линии кривизны
поверхности вращения — это ее меридианы и параллели). В данном контексте уже
известно, что F = 0, и приведенное условие сводится к /iMt,(0,0) = 0. Параметры
главной кривизны в данном случае записываются как = е/Е — httit (0,0)
Глава 21. Дальностные данные
643
Рис. 21.3. Бутылка для масла: а) дальностное изображение бутылки (фон убран); б) схема мест
разрыва функций глубины и ориентации. Данное изображение 128x128 получено с использованием
дальномера INRIA ([Boissonnat and Germain, 1981]), точность определения глубины составляет
порядка 0,5 мм
и к2 = g/G — — hrv(0,0). В частности, функцию глубин можно разложить в ряд
Тейлора в окрестности точки (0,0):
h(u, v) = h(0,0) + (hu, hv)
1
+ —(u, v)
2
где для краткости был опущен аргумент (0,0) при производных h. Из приведен-
ного выражения видно, что лучшей аппроксимацией поверхности в окрестности
данной точки с точностью до членов второго порядка является параболоид, кото-
рый определяется выражением
h(u, v) = —(kiu2 4- K2V2)
2
(т.е. получено выражение, которое уже встречалось в главе 19),
21.2.2. Нахождение на дальностном изображении ступенчатых
и скатообразных краев
В этом разделе представлен метод нахождения на дальностных изображени-
ях краев различных типов ([Ponce and Brady, 1987]). В данном методе аппарат
аналитической дифференциальной геометрии и пространственный анализ изоб-
ражения используются для выявления и локализации на дальностном изобра-
жении разрывов функций глубины и ориентации. Концепции, представленные
в данном разделе, иллюстрирует дальностное изображение бутылки моторного
масла, приведенное на рис. 21.3.
644
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Поверхность бутылки можно смоделировать как лоскут Монга z(x, у) в си-
стеме координат, привязанной к датчику, причем наблюдаются разрывы двух
типов: ступенька, где разрыв имеет собственно функция глубины; и скат, где
функция глубины непрерывна, но скачкообразно меняется ориентация. Как по-
казано в следующем разделе, поведение аналитических моделей ступенчатого
и скатообразного краев можно охарактеризовать посредством гауссова сгла-
живания, чтобы показать, что они дают параболические точки и экстремумы
доминирующей функции главной кривизны в соответствующем главном направ-
лении. Данные соображения дали начало схеме многошкального обнаружения
краев, описанной в алгоритме 21.1.
Алгоритм 21.1. Алгоритм обнаружения краев на основе модели ([Ponce and Brady,
1987])
1. Сгладить дальностное изображение, используя гауссовы распределения и на-
бор масштабов <т, (г = 1,... ,4). Вычислить главные направления и кривизну
в каждой точке сглаженных изображений zai(x,y).
2. Отметить на каждом сглаженном изображении zOi(x,y) переход через нуль
гауссовой кривизны и экстремумов доминирующей главной кривизны в соот-
ветствующем главном направлении.
3. Использовать аналитические модели ступеньки и ската для согласования ха-
рактерных элементов, найденных при различных масштабах, и выдать точки,
лежащие в этих разрывах поверхности.
Модели краев
В окрестности разрыва форма поверхности меняется в направлении разрыва
быстрее, чем в ортогональном направлении. Соответственно, далее в этом раз-
деле будем предполагать, что направление разрыва является одним из главных
направлений, а соответствующая (доминирующая) главная кривизна меняется
быстро в этом направлении, тогда как другая главная кривизна приблизительно
равна нулю. Такое предположение позволяет ограничиться цилиндрическими
моделями разрывов поверхности (т.е. моделями вида z(x,y) = А(а?)). Доста-
точно, чтобы данные модели были справедливы в окрестности края, причем
будем считать, что направление плоскости х — z совпадает с соответствующим
доминирующим главным направлением.
В частности, ступенчатый край можно смоделировать двумя наклонными
полуплоскостями, которые разделены вертикальной щелью и нормали которых
лежат в плоскости x—z. Данная модель является цилиндрической, и достаточно
изучить ее одномерную форму (рис. 21.4, слева), уравнение которой записыва-
Глава 21. Дальностные данные
645
ется следующим образом:
kix + с
к2х + с + h
при
при
х < О,
х > 0.
(21-2)
В данном выражении с и h — константы, h — размер щели, a fci и &2 —
наклоны двух полуплоскостей. Если ввести новые константы к — (ki + к2)/2
и 6 = &2 — fci, то можно легко показать (см. раздел упражнений), что свертка
функции z со второй производной гауссиана дает такой результат:
it def
—
д2
да2
(21.3)
Как показано в разделе упражнений к главе 19, кривизна пространственной
параметрической кривой записывается как к = \х' х х"|/|я/|3. Для плоских
кривых кривизне можно приписать знак и записать данную формулу в ви-
де к = (х1 х зг")/|аг'|3, где через “х” на этот раз обозначен оператор, соот-
носящий с двумя векторами в R2 детерминант, построенный из их координат.
Из сказанного следует, что соответствующая кривизна становится равной
нулю в точке xff = o28/h. Эта точка совпадает с началом координат толь-
ко при fci = к2, в противном случае ее положение описывается квадратичной
функцией от а. Таким образом напрашивается идея применить для определения
ступенчатых краев переходы через нуль одной главной кривизны (или, эквива-
лентно, гауссовой кривизны), положение которых меняется при изменении мас-
штаба. Для качественного описания поведения этих элементов как функции а
отметим также, что поскольку z" = 0 в ха, то
Другими словами, отношение второй производной кривизны к первой не зави-
сит от а.
Аналитическая модель скатообразных краев получается, если в модели сту-
пенчатого края положить h ~ 0 и <5 / 0 (рис. 21.4, справа). В этом случае легко
показать (см. раздел упражнений), что
(21.4)
Из этого следует, что при х2 — Aa?i и g2 = Acri должно получиться па2(х2) ==
(-г1 )/А. В свою очередь, максимальное значение |Ксг| должно быть обратно
пропорционально а, а свое максимальное значение оно получает в точке, рассто-
яние от которой до начала координат пропорционально а. При а, стремящемся
646
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 21.4. Модели краев: ступенька состоит из двух полуплоскостей, разделенных расстояни-
ем h (разрыв происходит в начале координат), а скатообразный край состоит из двух полуплос-
костей, имеющих различные наклоны (встреча происходит в начале координат). Согласно [Ponce
and Brady, 1987]
к нулю, данный максимум стремится к бесконечности, т.е. скатообразные края
можно искать как экстремумы локальной кривизны. В реальных дальностных
изображениях данные экстремумы следует искать в направлении доминирую-
щего главного направления, что согласуется с предположениями относительно
локальных изменений формы в окрестности краев поверхности.
Вычисление главной кривизны и главных направлений
Согласно модели, которая была выведена в предыдущем разделе, ступен-
чатые и скатообразные края можно найти, определив переходы через нуль
гауссовой кривизны и экстремумы доминирующей главной кривизны в соответ-
ствующем направлении. Вычисление этих дифференциальных величин требует
оценки в каждой точке первой и второй частных производных функции глубины
дальностного изображения. Это можно сделать (см. главу 8), свернув изобра-
жение с производными распределения Гаусса. В то же время, дальностные изоб-
ражения отличаются от обычных: например, значения пикселей на фотографии
обычно считаются кусочно-постоянными в окрестности ступенчатых краев2, что
выполняется для ламбертовских объектов, поскольку форма поверхности явля-
ется (с точностью до членов первого порядка) кусочно-постоянной в окрестно-
сти края и имеет в данном случае кусочно-плоскую глубину. При этом кусочно-
постоянные (локальные) модели дальностных изображений обычно неудовле-
творительны. Подобным образом, обычно считается, что максимальные значе-
ния контраста вдоль значимых краев фотографии имеют приблизительно оди-
наковую величину. В дальностных изображениях наблюдаются два типа сту-
пенчатых краев: большие разрывы функции глубины, отделяющие твердые тела
друг от друга и от фона, и более мелкие щели, обычно присутствующие между
участками одной поверхности. В следующем разделе рассмотрена схема опре-
деления краев, предназначенная для обработки именно небольших разрывов.
2Это равнозначно тому, что в модели, представленной в предыдущем разделе, положить fci =
к2 = 0; в этом случае изменение масштаба не влияет на положение переходов через нуль.
Глава 21. Дальносткые данные
647
Рис. 21.5. Сглаживание дальностного изображения. Вверху: срез дальностного изображения, при-
веденного на рис. 21.3. Фон отсеян с помощью пороговой проверки. В центре: результат гауссова
сглаживания. Внизу: сглаживание с использованием вычислительных молекул. Перепечатано из
J.M. Brady, J. Ponce, A. Yuille, and Н. Asada, “Describing Surfaces,” Proceedings of the International
Symposium on Robotics Research, H. Hanafusa and H. Inoue (eds.), pp. 5-16, MIT Press, 1985. (c)
1985 The Massachusetts Institute of Technology
Прямое применение гауссова сглаживания вдоль границ объекта приводит к
радикальным изменениям формы, при которых могут подавляться интересую-
щие нас детали поверхности (рис. 21.5, вверху и в центре). Поэтому для начала
стоит найти наибольшие разрывы функции глубины (обычно достаточно про-
стой пороговой проверки), а затем как-то ограничить процесс сглаживания, что-
бы он применялся только к участкам поверхности, расположенным внутри най-
денных границ. Для этого можно свернуть дальностное изображение с вычис-
лительными молекулами (см. [Terzopoulos, 1984]), представляющие собой ли-
нейные шаблоны, которые в сумме дают усредняющий шаблон 3x3; например,
2 4 2
1 2 1
2 12 2
1 2 1
Последовательная свертка изображения с шаблоном 3x3 (нормированным
так, чтобы весовые коэффициенты в сумме давали единицу) дает, согласно цен-
тральной предельной теореме, хорошую аппроксимацию гауссова сглаживания
с шаблоном, значение ст которого после п итераций пропорционально у/п. Чтобы
избежать сглаживания в местах разрыва, молекулы, пересекающие эти разры-
вы, не используются, а оставшиеся молекулы повторно нормируются, чтобы
сумма всех весовых коэффициентов была равна единице. Результат описанного
процесса показан на рис. 21.5 (внизу).
После сглаживания поверхности можно вычислить производные функции
высоты (по схеме конечных разностей). Градиент функции высоты вычисляется
648
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 21.6. Два поля главных направлений для бутылки масла. Перепечатано из J.M. Brady,
J. Ponce, A. Yuille, and Н. Asada, “Describing Surfaces”, Proceedings of the International Sympo-
sium on Robotics Research, H. Hanafusa and H. Inoue (eds.), pp. 5-16, MIT Press, 1985. © 1985
The Massachusetts Institute of Technology
посредством свертки сглаженного изображения с шаблонами
1 1 1
0 0 0
-1 -1 -1
Гессиан вычисляется нами посредством свертки сглаженного изображения с шабло-
д2 1 дх2 з 1 -2 1 д2 1 ’ дхду 4 -1 0 1 S 'Ъ| ы II W 1 W 1 1 1
1 -2 1 0 0 0 -2 -2 -2
1 -2 1 1 0 -1 1 1 1
После того как найдены производные, легко вычисляются главные направления
и кривизна в этих направлениях. На рис. 21.6 показаны два набора главных
направлений, найденные для бутылки масла после 20 итераций схемы молекул.
Как и следовало ожидать, главные направления проходят вдоль меридианов
и параллелей данной поверхности вращения.
Согласование элементов при различных масштабах
Если известны главные направления и кривизна в этих направлениях, па-
раболические точки можно определить как ненаправленный переход через
нуль гауссовой кривизны, тогда как локальные экстремумы главной кривизны
вдоль соответствующего главного направления можно найти, использовав схе-
му немаксимального подавления, описанную в главе 8. Хотя при очень мелком
масштабе (т.е. после малого числа итераций) могут наблюдаться значительные
помехи, при дальнейшем сглаживании ситуация улучшается. Элементов, по-
рожденных помехами, можно (по крайней мере, частично) избежать, применив
пороговую проверку к огибающей переходов через нуль для параболических
Глава 21. Дальностные данные
649
Рис. 21.7. Определение ступенчатых и скатообразных краев бутылки масла. Слева: элементы, най-
денные после 20, 40, 60 и 80 итераций сглаживания и сравнения с порогом. Величины порогов
выбирались эмпирически, чтобы устранить максимальное число ложных элементов, но сохранить
элементы, отвечающие действительным разрывам поверхности. Тем не менее на рисунке присут-
ствуют артефакты (ложные изображения), такие как экстремумы кривизны параллельно оси бу-
тылки. Справа: выход схемы обнаружения краев на основе моделей. Корректно определены три
ступенчатых края и два скатообразных разрыва. Перепечатано из J. Ponce and J.M. Brady, “To-
wards a Surface Primal Sketch", in THREE-DIMENSIONAL MACHINE VISION. T. Kanade (ed.), pp.
195-240, Kluwer Academic Publishers, 1987. © 1987 Kluwer Academic Publishers
точек и к амплитуде кривизны для экстремумов главной кривизны. Однако
эксперименты показывают, что сглаживания и пороговых проверок недоста-
точно для устранения несущественных элементов. В частности, как видно из
рис. 21.7 (слева), по мере сглаживания все отчетливее проявляется экстремум
линии кривизны, параллельной оси бутылки. Это объясняется тем, что точки
возле затеняющей границы бутылки не сглаживаются так сильно вычислитель-
ными молекулами, как точки, расположенные ближе к ее центру.
Проблему решает многошкальный подход к обнаружению краев. Элементы
отслеживаются при изменении масштаба от грубого до точного; все элементы,
не имеющие “предка” при более грубом масштабе, исключаются из рассмотре-
ния. Также отслеживается эволюция параметров главной кривизны и их про-
изводных. Выжившие параболические элементы, такие, что отношение
остается (приблизительно) постоянным при разных масштабах, считаются на
выходе точками ступенчатых краев, а точки, в которых наблюдается направ-
ленный экстремум главной кривизны, причем величина ака остается (прибли-
зительно) постоянной, считаются точками скатообразных краев. Наконец, по-
скольку для обеих используемых моделей расстояние между истинным разры-
вом и соответствующим переходом через нуль или экстремумом увеличивается
при укрупнении масштаба, для локализации краев используется наиболее мел-
кий масштаб. На рис. 21.7 (справа) показаны результаты применения данной
стратегии к бутылке масла.
650
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 21.8. На диаграмме иллюстрируется одна итерация схемы роста областей, в ходе которой
сливаются два участка, разделенные дугой минимальной стоимости (на рисунке помечена как а).
При итерации также обновляется куча, показанная в нижней части рисунка: удаляются ребра а, Ь,
сие, создаются и вводятся в кучу два новых ребра, fug.
21.2.3. Сегментация дальностных изображений в плоские области
В предыдущем разделе было сказано, что определение краев реализуется
достаточно различными процессами на фотографиях и картах глубин. Для
сегментации изображений на области имеем сходную ситуацию. В частности,
в области интенсивностей трудно сформулировать значимый критерий сегмен-
тации, поскольку яркость (или цвет) пикселей — это только ключ к физическим
свойствам, таким как форма или отражательная способность. В то же время,
в области расстояний геометрическая информация доступна непосредственно,
так что в качестве эффективного критерия сегментации можно использовать,
скажем, среднее расстояние между набором точек поверхности и плоскостью,
наилучшим образом его аппроксимирующей. Хорошим примером такого под-
хода является метод роста областей, предложенный в работе [Faugeras and
Hebert, 1986]. В данном алгоритме итеративно сливаются плоские участки,
при этом поддерживается граф, вершины которого — это участки, а соседние
участки соединяют ребра, соотнесенные с общей границей участка. Каждо-
му ребру присвоена стоимость, равная средней ошибке между точками двух
участков и плоскостью, наилучшим образом аппроксимирующей данные точ-
ки. Далее выбирается лучшее (в смысле стоимости) ребро, и соответствующие
участки сливаются. Отметим, что оставшиеся ребра, связанные с этими участ-
ками, следует удалить и ввести новые ребра, соединяющие новый участок с его
соседями. Описанная ситуация иллюстрируется на рис. 21.8.
Глава 21. Дальностные данные
651
Рис. 21.9. Часть автомобиля “Рено”: а) снимок части, б) ее модель. Перепечатано с разрешения
Sage Publications из O.D. Faugeras and М. Hebert, "The Representation, Recognition, and Locating
of 3D Objects", International Journal of Robotics Research, 5(3):27-52, 1986. (c) 1986 Sage
Publications
Графовая структура создается с использованием триангуляции дальностных
изображений, а для ее эффективного обновления поддерживается куча актив-
ных ребер. Триангуляцию можно либо непосредственно проводить по даль-
ностному изображению (расщепив четырехугольники, соотнесенные с пикселя-
ми, вдоль одной из их диагоналей), либо по глобальной модели поверхности,
построенной по нескольким изображениям, как описано в следующем разде-
ле. Кучу, в которой хранятся активные ребра, можно представить, например,
массивом ячеек, проиндексированных по возрастанию цены, что способствует
быстрому вводу и удалению элементов (рис. 21.8, внизу). На рис. 21.9 пока-
зан пример, где сложная форма части автомобиля “Рено” аппроксимируется 60
плоскими участками.
21.3. НАЛОЖЕНИЕ ДАЛЬНОСТНЫХ ИЗОБРАЖЕНИЙ И ПОЛУЧЕНИЕ
МОДЕЛЕЙ
Геометрические модели реальных объектов полезны на производстве (на-
пример, для планирования процесса, сборки, или в случае инспекции). Кроме
того, геометрические модели также являются ключевыми компонентами многих
систем распознавания объектов, спрос на них в индустрии развлечений быст-
ро растет, поскольку смоделированные изображения реальных объектов вовсю
используются в фильмах и видеоиграх (к этому вопросу мы еще вернемся в гла-
ве 26). Дальностные изображения — это прекрасный источник информации при
построении точных геометрических моделей реальных объектов, но на одном
изображении видна (в лучшем случае) половина поверхности данного тела, а
построение модели всего объекта требует нескольких дальностных изображе-
ний. В данном разделе рассмотрены дуальные задачи наложения нескольких
картин в одной системе координат и объединение трехмерной информации,
652
Часть V. Верхний уровень компьютерного зрения: геометрические методы
полученной с этих картин, в единую комплексную модель поверхности. Перед
тем как приступать к этим двум задачам, введем кватернионы, таким образом
можно будет использовать для оценки строгих преобразований по соответ-
ствующим точкам и плоскостям линейные методы как в контексте наложения
изображений (данный раздел), так и в контексте распознавания (следующий
раздел). Далее в этой главе предполагается, что в пространстве Е3 введена
стационарная система координат, это пространство определено как R3, а для
представления каждой точки использован вектор ее координат.
21.3.1. Кватернионы
Понятие кватернионов ввел Гамильтон (см. [Hamilton, 1844]). Как комплекс-
ные числа на плоскости, кватернионы удобно использовать для представления
вращения в пространстве. Кватернион q определяется его действительной
частью, скаляром а, и его мнимой частью, вектором а в пространстве К3,
и обычно записывается как q = а 4- ct. Таким образом, действительные числа
можно определить как кватернионы с нулевой мнимой частью, а векторы — как
кватернионы с нулевой действительной частью, причем сложение кватернионов
происходит по следующему закону:
(а + о) + (Ь + /3) = (а + Ь) 4 (а 4 (3).
Умножение кватерниона на скаляр естественным образом определяется как
А(а 4- л) = Ха + Act, и данные две операции придают множеству всех ква-
тернионов структуру четырехмерного векторного пространства. Также можно
определить операцию умножения, которая сопоставляет двум кватернионам
кватернион
(а 4 а)(Ь 4 /3) = (аЬ — а • /3) 4 (а/З 4 bet 4 ot х /3).
Кватернионы с операциями сложения и умножения (как они определены выше)
формируют некоммутативное поле, нулевым и единичным элементом которого
являются, соответственно, скаляры 0 и 1. Сопряженным кватерниона q = а + сл
является кватернион q = а — сл с противоположной мнимой частью. Квадрат
нормы кватерниона определяется следующим образом:
|q| = qq = qq = а 4 |а| ,
причем легко проверить, что |qq'| = |q||q'| для любой пары кватернионов q и q'.
Теперь можно показать, что кватернион
О . О
q = cos - 4 sm -и
Глава 21. Дальностные данные
653
представляет вращение Н на угол 0 вокруг единичного вектора и в следующем
смысле: если а — некоторый вектор в пространстве R3, тогда
На = qaq.
(21.5)
Отметим, что |q| = 1, поэтому —q также представляет вращение Н. Матрица
вращения Н, соотнесенная с данным единичным кватернионом q = a + ac а =
(5, с, d)T, равна
(2 , ьД 2 >2
а + b — с —а
2(bc 4- ad)
2(bd — ас)
2(bc — ad)
„1 l2 . „2 >2
~~ О т с — d
2 (cd 4- ab)
2(bd 4- ас)
2 (cd — ab)
a2 — b2 — c2 + d2
(21-6)
что легко получить из уравнения (21.5). (Отметим, что четыре парамет-
ра а, Ь, c,d не являются независимыми, поскольку они удовлетворяют усло-
вию а2 4- Ь2 4- с2 + d2 = 1.)
Наконец, если qi и q2 — единичные кватернионы, а Ki и Т^2 - соответ-
ствующие матрицы вращения, оба кватерниона qiq2 и —qiq2 являются пред-
ставлениями матрицы вращения 72-172.2-
21.3.2. Наложение дальностных картин с использованием
итеративного метода ближайших точек
В работе [Best and McKay, 1982] предложен алгоритм наложения двух набо-
ров трехмерных точек (т.е. вычисления строгого преобразования, переводящего
первый набор точек во второй). В данном алгоритме просто минимизирует-
ся среднее расстояние между двумя наборами точек, для чего итеративно
повторяются следующие этапы: вначале устанавливаются соответствия между
элементами сцены и модели путем согласования каждой точки сцены с ближай-
шей к ней точкой модели, оценивается строгое преобразование, отображающее
точки сцены в их образы, и наконец, вычисленное смещение применяется к
сцене. Итерации прекращаются, когда изменение среднего расстояния меж-
ду согласованными точками опускается ниже некоторого заданного порога.
Далее представлен псевдокод данного алгоритма (итеративный алгоритм
ближайших точек, Iterated Closest-Point — ICP-алгоритм).
Легко показать, что ошибка алгоритма 21.2, Е, монотонно уменьшается
с каждой итерацией: действительно, на этапе наложения средняя ошибка
уменьшается, а в процессе определения пар ближайших точек уменьшаются
отдельные ошибки. Само по себе это не гарантирует сходимость к глобальному
(или даже локальному) минимуму, так что требуется обеспечить разумную
догадку относительно искомого строгого преобразования. Для этой цели раз-
работано множество методов, в том числе грубая дискретизация набора все-
возможных преобразований и использование для оценки этого преобразования
моментов наборов точек сцены и модели.
654
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Алгоритм 21.2. Итеративный алгоритм ближайших точек Бесля и МакКея [Besl
and McKay, 1992]. Вспомогательная функция Initialize-Registration использует
некоторый глобальный метод наложения (например, на основе моментов) для
вычисления грубой начальной оценки строгого преобразования, отображающего
сцену в модель. Функция Return-Closest-Pairs возвращает индексы (i,j) точек на
наложенных сцене и модели таких, что j-я точка является ближайшей к точке г.
Функция Update-Registration оценивает строгое преобразование между выбран-
ной парой точек сцены и модели, а функция Apply-Registration применяет строгое
преобразование ко всем точкам сцены.
Function ICP(ModeI, Scene);
begin
E’ «—Foo;
(Rot, Trans) +- Initialize-Registration(Scene, Model);
repeat
E <- E’;
Registered-Scene «— Apply-Registration(Scene, Rot, Trans);
Pairs «— Return-Closest-Pairs(Registered-Scene, Model);
(Rot, Trans, E’) «— Update-Registration(Scene, Model, Pairs, Rot, Trans);
until |E’ — E| < r;
return (Rot, Trans);
end
Нахождение пар ближайших точек
В ходе каждой итерации алгоритма нахождение точки М модели, ближай-
шей к данной точке S (наложенной) сцены, требует (интуитивное предположе-
ние) времени О(п), где п — число точек модели. Фактически, для разрешения
запроса относительно ближайшей точки в R3 можно использовать различные
алгоритмы со временем ответа O(logn) за счет дополнительной предваритель-
ной обработки модели, например, k-d дерево (см. [Friedman et al., 1977], где
время ответа на запрос является логарифмическим только в среднем) или бо-
лее сложные структуры данных. Например, в работе [Clarkson, 1988] предложен
общий алгоритм на базе случайных величин, время предварительной обработ-
ки в котором составляет О(п2+е), где е — произвольно малое положительное
число, а время ответа на запрос составляет O(logn). Эффективность последо-
вательных запросов можно также улучшить, кэшируя результаты предыдущих
расчетов. Например, в публикации [Simon et al., 1994] на каждой итерации ICP-
алгоритма запоминаются к точек, ближайших к каждой точке сцены (типичное
значение к — 5). Поскольку последовательное обновление строгого преобра-
зования обычно незначительно, весьма вероятно, что ближайший сосед точки
после итерации находится среди ее к ближайших соседей, определенных на
Глава 21. Дальностные данные
655
предыдущей итерации. Фактически, можно эффективно и окончательно опреде-
лить, находится ли ближайшая точка в кэшированном множестве (подробности
см. в [Simon et al., 1994]).
Оценка строгого преобразования
При строгом преобразовании, определенном матрицей вращения 1Z и векто-
ром трансляции t, точка х отображается в точку х' = TZx 4-t. Следовательно,
имея п пар согласованных точек Xi и х'г, при i — 1,...,п ищем матрицу вра-
щения 1Z и вектор трансляции t, минимизирующие ошибку
Е = ^\х[ -Kxi-tf.
i=l
Отметим вначале, что значение t, минимизирующее Е, должно удовлетворять
условию
дЕ А ,
О =---— —2 — Ехг — t)
dt
или
t = x—'Rx, где через x = — Xi и я/=—(21.7)
n i=i n i=i
обозначены, соответственно, центры масс двух наборов точек хг и х\.
Введем точки в системе центра масс = ж?- — х и у\ — х\ — х (г — 1,..., п)
и получим
Е = -TlViI2.
г=1
Теперь для минимизации Е можно использовать кватернионы: обозначим че-
рез q кватернион, соотнесенный с матрицей Л. Используем факт, что |q|2 = 1,
и свойство мультипликативности нормы кватерниона, и запишем
Е = \у\ - q2/iQl2|q|2 = £ l^q - qyj2-
i=l 1=1
Как показано в разделе упражнений, это позволяет записать ошибку вращения
как Е = q7Z3q, где В = А[ А и
A=f ° y*~y?Y
yy'i-yi 1Уг+У^х)
Отметим, что матрица А антисимметрична с (в общем случае) рангом 3, но
матрица В имеет, при наличии шума, ранг 4. Как показано в главе 3, миними-
зация Е при условии |q|2 = 1 — это задача, решаемая по (однородной) схеме
656
Часть V. Верхний уровень компьютерного зрения: геометрические методы
а)
Рис. 21.10. Результаты наложения: а) дальностное изображение, используемое как модель аф-
риканской маски; б) выборка (взята каждая десятая точка) модели, использованная как данные
сцены; в) вид двух наборов данных после наложения. Перепечатано из PJ. Best and N.D. McKay,
“A Method for Registration of 3D Shapes”, IEEE Transactions on Pattern Analysis and Machine
Intelligence, 14(2):238-256, 1992. © 1992 IEEE
в)
наименьших квадратов, решением которой является собственный вектор мат-
рицы В, соотнесенный с наименьшим собственным значением матрицы. После
нахождения матрицы вектор t получается из уравнения (21.7).
Результаты
На рис. 21.10 приведен пример применения описанного выше алгоритма к
изображению африканской маски. Среднее расстояние между пикселями нала-
гаемых изображений для данного 9-сантиметрового объекта равно 0,59 мм.
21.3.3. Совмещение нескольких дальностных изображений
При наличии набора наложенных дальностных изображений твердого тела
можно построить комплексную поверхностную модель этого объекта. В схеме,
предложенной в работе [Curless and Levoy, 1996], данная модель строится как
множество S нулевых значений функции объемной плотности D : R3 —» К (т.е.
как множество точек (х, г/, z) таких, что D(x, у, z) = 0). Подобно любому друго-
му уровневому множеству непрерывной функции плотности, S по построению
является герметично замкнутой поверхностью, которая, впрочем, может иметь
несколько связанных компонентов (рис. 21.11).
Сложностью, разумеется, является построение подходящей функции плотно-
сти по измерениям на наложенных дальностных изображениях. В работе {Cur-
less and Levoy, 1996] фрагменты соответствующей поверхности вкладывались
в кубическую сетку и каждой ячейке данной сети, или векселю, присваива-
лась взвешенная сумма расстояний (с соответствующими знаками) между ее
центром и ближайшей точкой поверхности, пересекающей ее (рис. 21.12, сле-
ва). Данное усредненное расстояние представляет собой желаемую функцию
плотности, а его множество нулей можно найти, использовав такой классиче-
Глава 21. Дальностные данные
657
Рис. 21.11. Двумерная иллюстрация объемных функций плотности и их уровневых множеств.
В данном случае “объем” — это, разумеется, плоскость (х,у), а “поверхность” — кривая на этой
плоскости. В примере показаны два связанных компонента
ский метод, как алгоритм '‘бегущих кубиков" (marching cubes), предложенный
в работе [Lorensen and Cline, 1987] для извлечения поверхностей постоянной
плотности из объемных медицинских данных.
Пропущенные фрагменты поверхности, соответствующие ненаблюдаемым
частям сцены, обрабатываются следующим образом: вначале все воксели
помечаются как ненаблюдаемые или, эквивалентно, им присваивается глу-
бина, равная некоторой большой положительной величине (предполагается,
что это +оо); затем, как и ранее, всем вокселям, расположенным близко к
измеряемому участку поверхности, присваивается значение, равное соответ-
ствующему расстоянию (с соответствующим знаком); наконец, отсекаются
(т.е. помечаются как пустые или имеющие большую отрицательную глубину,
—оо) воксели, расположенные между наблюдаемыми участками поверхности
и сенсором (рис. 21.12, справа).
На рис. 21.13 показан пример модели, которая построена по нескольким
дальностным изображениям статуэтки Будды, полученным с помощью опти-
ческого триангуляционного сканера Cyberware 3030 MS, а также физическая
модель, построенная по геометрическим изображениям с помощью стереолито-
графии ([Curless and Levoy, 1996]).
21.4. РАСПОЗНАВАНИЕ ОБЪЕКТОВ
Рассмотрим распознавание на дальностных изображениях реальных объек-
тов. В данном разделе проанализированы два алгоритма, построенные на основе
методов наложения, описанных в предыдущем разделе.
21.4.1. Согласование кусочно-плоских поверхностей
с использованием интерпретационных деревьев
Алгоритм распознавания, предложенный в работе [Faugeras and Hebert,
1986], — это рекурсивная процедура, использующая условия жесткости для
эффективного поиска на интерпретационном дереве пути (путей), соответству-
658
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 21.12. Двумерная иллюстрация метода Курлесса-Левоя (Curless-Levoy) — совмещение
нескольких дальностных изображений. В левой части рисунка три изображения, наблюдаемые
одним сенсором, который расположен в точке О, сливаются посредством вычисления множества
нулей взвешенных средних расстояний (с соответствующим знаком) между центрами векселей
(например, точки А, В и С) и точками поверхности (например, а, Ь и с) вдоль лучей наблюде-
ния. Вместо этого можно использовать расстояния до различных сенсоров. Светло-серая область
в правой части рисунка — это набор векселей, помеченных при заполнении щелей (один из этапов
общего алгоритма) как пустые
ющего наилучшей последовательности (последовательностям) плоских парных
элементов. Псевдокод базовой процедуры представлен в алгоритме 21.3. Для
корректной обработки случаев затенения (кроме того, следует учесть, что дат-
чики расстояния наблюдают максимум лицевую половину объекта) алгоритм
должен на каждом этапе поиска рассматривать возможность того, что модель-
ная плоскость может не совпадать с плоскостью сцены. Для этого в список
потенциальных соответствий данной плоскости вводится пустая плоскость
токенов.
Выбор потенциальных эквивалентов
Выбор потенциальных эквивалентов данной модельной плоскости основыва-
ется на различных критериях в зависимости от уже установленных соответ-
ствий, причем каждое новое соответствие дает новое геометрическое условие
и более строгие критерии. В начале поиска известно только, что модельная
плоскость с площадью А должна сопоставляться только с плоскостями сцены,
имеющими сравнимую площадь (т.е. лежащими в диапазоне [с*Д/М]). Разум-
ными значениями двух порогов являются 0,5 и 1,1, что допускает некоторое
несоответствие незатененных областей и степень затенения до 50%.
Глава 21. Дальностные данные
659
Рис. 21.13. Трехмерное факсовое изображение статуэтки Будды. Слева направо: фотография ста-
туэтки; дальностная картина; суммарная трехмерная модель; модель после заполнения пустот;
физическая модель, полученная средствами стереолитографии. Материалы любезно предоставлены
Марком Левоем (Marc Levoy). Перепечатано из В. Curless and М. Levoy, “A Volumetric Method
for Building Complex Models from Range Images", Proceedings SIGGRAPH, 1996. © 1996 ACM
Алгоритм 21.3. Алгоритм согласования плоскостей ([Faugeras and Hebert, 1986]).
Рекурсивная функция Match возвращает наилучший набор пар согласовываю-
щихся плоскостей, для чего рекурсивно вызывается интерпретационное дерево.
Изначально функция вызывается с пустым списком пар и нулевыми значения-
ми аргументов вращения (rot) и трансляции (trans). Вспомогательная функция
Potential-Matches возвращает подмножество плоскостей сцены, совместимых с мо-
дельной плоскостью П и текущей оценкой отображения строгого преобразования
модельных плоскостей в их эквиваленты на сцене (подробности см. в тексте).
Вспомогательная функция Update-Registration-2 использует пары согласованных
плоскостей для обновления текущей оценки строгого преобразования.
Function Match(model, scene, pairs, rot, trans);
begin
bestpairs «— nil; bestscore <— 0;
for П in model do
for П' in Potential-Matches(scene, pairs, П, rot, trans) do
(rot,trans) <— Update-Registration-2(pairs, П, П', rot, trans);
(score, newpairs) «— Match(model—П, scene—П', pairs+(n,n'), rot, trans);
if score>bestscore then bestscore «— score; bestpairs «— newpairs endif;
endfor;
endfor;
return (bestscore,bestpairs);
end
660
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 21.14. Нахождение всех векторов v, для которых угол с вектором и попадает в диапа-
зон [0 - е,0 4- е]. Следует отметить, что единичная сфера не допускает “мозаичного представле-
ния” с произвольным уровнем точности посредством правильных (сферических) многоугольников.
Представление, приведенное на диаграмме, составлено из шестиугольников с неравными сторонами
(обсуждение данной проблемы и различных схем представления можно найти, например, в работе
[Horn, 1986J)
После установления первого соответствия оценивать строгое преобразова-
ние, отображающее модель в сцену, еще рано, но ясно, что угол между норма-
лями к любой парной плоскости должен быть (приблизительно) равен углу 0
между нормалями к первой паре плоскостей; скажем, угол должен принадле-
жать интервалу [0 — е,0 + е]. Нормали к соответствующим плоскостям лежат
в полосе гауссовой сферы, и их можно эффективно извлечь, построив дискрет-
ное представление этой сферы и соотнеся с каждым элементом ячейку, где
будут указаны плоскости сцены, нормали к которым проходят через данный
сегмент (рис. 21.14).
Второй найденной пары достаточно для полного определения вращения,
связывающего модель и сцену: это очевидно из геометрических соображений
(в следующем разделе данный факт доказан аналитически), поскольку если
имеется пара согласованных векторов, то оси вращения обязаны находиться
на биссекторной плоскости этих векторов. По двум парам согласованных плос-
костей определяются оси вращения (как пересечение соответствующих бис-
секторных плоскостей), а угол вращения легко определяется по любой паре.
Зная вращение и третью модельную плоскость, можно предсказать ориентацию
нормали к ее возможной паре на сцене, которая затем эффективно восстанав-
ливается с использованием дискретной гауссовой сферы, упоминавшейся ранее.
После нахождения трех пар также можно оценить трансляцию и использовать
ее для предсказания расстояния между началом координат и любой плоскостью
сцены, парной к четвертой согласовываемой плоскости сцены. Тот же подход
применяется и при подборе следующих пар.
Оценка строгого преобразования
Рассмотрим плоскость П, определенную уравнением п • х — d = 0 в некото-
рой стационарной системе координат. Через п обозначена единичная нормаль
Глава 21. Дальностные данные
661
к плоскости, a d — ее расстояние (с соответствующим знаком) от начала ко-
ординат. При строгом преобразовании, определенном матрицей вращения 7Z
и вектором трансляции t, точка х отображается в точку х' = Их 4- t, а П
отображается в плоскость П', уравнение которой имеет вид п’ • х‘ — d' = 0 при
п = Tin,
d' = п' t + d.
Таким образом, оценивая строгое преобразование, которое отображает п плос-
костей П* в парные плоскости П< (г = 1, ...,п), ищется матрица вращения 1Z,
минимизирующая ошибку
Ег = ^\п[-Пт\2,
t=i
и вектор трансляции t, минимизирующий ошибку
Et = ^(d’i -di- n'i • t)2.
i=l
Матрицу вращения К, минимизирующую ошибку Ег, можно найти, как описа-
но в разделе 21.4.1, т.е. с использованием кватернионного представления мат-
риц и решения задачи на собственные числа. Вектор трансляции t, миними-
зирующий ошибку Et, находится с помощью неоднородной схемы наименьших
квадратов, а соответствующее решение можно представить с использованием
метода, предложенного в главе 3.
Результаты
На рис. 21.15 показаны результаты распознавания, полученные с использо-
ванием контейнера запчастей к “Рено” (таких как на рис. 21.9). Дальностное
изображение контейнера было сегментировано на плоские участки, при этом ис-
пользовалась техника, представленная в разделе 21.2.3. Алгоритм согласования
прогонялся по сцене трижды, причем участки, пары к которым были подобра-
ны в ходе прогонки алгоритма, на следующей итерации удалялись со сцены.
Как показано на рисунке, были корректно определены три экземпляра деталей,
имевшихся в контейнере, а точность процесса оценки позы проверялась повтор-
ным проектированием на дальностное изображение модели в вычисленной позе.
21.4.2. Согласование свободных поверхностей с использованием
спиновых изображений
Как показано в разделе 21.2.2, дифференциальная геометрия предоставля-
ет удобный язык для описания формы поверхности локально (т.е. в малой
окрестности каждой из ее точек). С другой стороны, алгоритм роста обла-
стей, рассмотренный в разделе 21.2.3, предназначен для построения глобально
непротиворечивого описания поверхности в терминах плоских участков. В дан-
ном разделе вводится полулокалъное представление поверхности — спиновое
662
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 21.15. Результаты распознавания: а) контейнер частей; б-г) — три экземпляра запчасти "Ре-
но”, найденные в данном контейнере. В каждом случае модель показана и сама по себе (в том
положении и с той ориентацией, которые были оценены алгоритмом), и наложенной (пунктир-
ные линии) в этой позе на соответствующие плоскости дальностного изображения. Перепечатано
с разрешения Sage Publications из O.D. Faugeras and М. Hebert, "The Representation, Recognition,
and Locating of 3D Objects," International Journal of Robotics Research, 6(3):27-52, 1986. © 1986
Sage Publications
изображение (согласно [Johnson and Hebert, 1998, 1999]), которое содержит
представление формы поверхности в относительно большой окрестности каж-
дой точки этой поверхности. Как показано далее в этом разделе, спиновое изоб-
ражение инвариантно относительно строгих преобразований, и оно допускает
использование эффективного алгоритма точечного согласования поверхностей,
таким образом делая ненужным сегментацию в процессе распознавания.
Определение спинового изображения
Предположим, как в разделе 21.2.3, что рассматриваемая поверхность S дана
в форме треугольной сетки. Нормаль к поверхности (положительное направле-
ние — наружу) в каждой вершине можно оценить, подобрав плоскость по этой
вершине и ее окрестности и переведя триангуляцию в сеть ориентированных
точек. Для данной ориентированной точки Р спиновые координаты любой
другой точки Q можно определить как неотрицательное расстояние а, отделя-
ющее Q от ориентированной нормали в точке Р и расстояние (с соответству-
Глава 21. Дальностные данные
663
Рис. 21.16. Определение спинового отображения, соотнесенного с точкой поверхности Р. Спино-
вые координаты (о,/3) точки Q определяются, соответственно, длинами проекций вектора PQ на
касательную плоскость и нормаль к ее поверхности. Отметим, что в данном примере имеется еще
три точки с такими же, как у Q, координатами (о, /3)
ющим знаком) /3 от касательной плоскости до Q (рис. 21.16). Соответственно,
спиновое отображение sр : X К2, соотнесенное с F, следующим образом
определяется для любой точки Q в X:
sP(Q) = (|PQ xn|,PQ-n).
а fl
Как показано на рис. 21.16, данное отображение не является инъективным. Это
не удивляет, поскольку спиновое отображение дает только частичную специфи-
кацию цилиндрической системы координат: пропущена третья координата (угол
между некоторым опорным вектором в касательной плоскости и проекцией PQ
на эту плоскость). В качестве направления такого вектора естественно выбрать
одно из главных направлений, но использование спиновых координат делает их
вычисление ненужным. Это радует, поскольку данный процесс чувствителен к
шуму, так как включает вычисление вторых производных и для многих (почти
всех) плоских или сферических участков он может быть неоднозначным.
Спиновое изображение, соотнесенное с ориентированной точкой, — это ги-
стограмма координат а,/3 в окрестности данной точки. Конкретизируем: плос-
кость а,/3 делится на массив прямоугольных ячеек 5а х 5/3, они вмещают всю
плоскую поверхность, заполненную точками, координаты а,/3 которых попа-
дают в указанный диапазон3. Как показано в работе [Carmichael et al., 1999]
и разделе упражнений, каждый треугольник поверхностной сетки отображается
в область плоскости а,/3, границы которой представляют собой гиперболиче-
ские дуги. Вклад этой области в спиновое изображение можно вычислить при-
3Соответствующий набор точек может в действительности разбиваться на несколько связан-
ных компонентов. Например, при достаточно малых значениях ба и <5/3 в примере, показанном на
рис. 21.16, наблюдается четыре связанных компонента, которые соответствуют небольшим участ-
кам, центрированным в точках с теми же координатами а,/3, что имеет точка Q.
664
Часть V. Верхний уровень компьютерного зрения: геометрические методы
Рис. 21.17. Построение спинового образа: треугольник, показанный на диаграмме слева, отобра-
жается в область на спиновом образе с гиперболическими границами; значение каждой ячейки,
в которой находится область, увеличивается на площадь части треугольника, пересекающей коль-
цо, соотнесенное с ячейкой. Согласно [Carmichael et al., 1999J
своением каждой ячейке, по которой проходит область, площади пересечения
треугольника с кольцевой областью в пространстве R3, соотнесенной с ячейкой
(рис. 21.17). Для эффективного нахождения ячеек можно использовать схему
отсечения при растеризации (scan conversion) (см. [Foley et al., 1990]) —
процесс, широко применяемый в компьютерной графике для нахождения оп-
тимального времени прохождения пикселей через обобщенный многоугольник
с прямыми или кривыми сторонами.
Спиновые изображения определяются несколькими ключевыми параметра-
ми (см. [Johnson and Hebert, 1999]): первый — это расстояние поддержки d,
ограничивающее область поддерживаемых точек, используемых для постро-
ения изображения, сферой радиуса d с центром в точке Р. Данная сфера
должна быть достаточно большой, чтобы иметь хорошую описательную силу,
но и достаточно малой, чтобы поддерживать процесс распознавания в присут-
ствии посторонних предметов и при наличии затенения. На практике удачным
выбором d может быть десятая часть диаметра объекта: таким образом, как
отмечалось ранее, спиновое изображение действительно является полулокаль-
ным описанием формы поверхности в расширенной окрестности одной из ее
точек. Устойчивость к наличию посторонних предметов можно улучшить, огра-
ничив диапазон нормалей к поверхности в поддерживаемых точках конусом
половинного угла О с центром в п. Как и в случае расстояния поддержки, вы-
бор правильного значения 0 включает компромисс между описательной силой
и устойчивостью к помехам; эмпирически удовлетворительной была признана
величина 60°. Последний параметр, определяющий спиновое изображение, —
это его размер (в пикселях) или, эквивалентно (если дано расстояние под-
держки), размер его ячейки (в метрах). Можно показать, что подходящим
выбором размера ячейки является среднее расстояние между вершинами сетки
модели. На рис. 21.18 показано спиновое изображение, соотнесенное с тремя
ориентированными точками на поверхности резиновой уточки.
Глава 21. Дальностные данные
665
Двумерные точки
Спиновое изображение
Рис. 21.18. Три ориентированных точки на поверхности резиновой уточки и соответствующие
спиновые изображения. Рядом с действительными спиновыми изображениями показаны коорди-
наты а,(3 вершин сетки. Перепечатано из А.Е. Johnson and М. Hebert, “Using Spin Images for
Efficient Object Recognition in Cluttered 3D Scenes", IEEE Transactions on Pattern Analysis and
Machine Intelligence, 21(5):433-449, 1999. © 1999 IEEE
Спиновое изображение
Спиновое изображение
Согласование спиновых изображений
Одним из наиболее важных свойств спиновых изображений является то,
что они (очевидно) инвариантны относительно строгих преобразований. Таким
образом, в принципе можно использовать некоторую схему сравнения изобра-
жений (например, основанную на корреляции) и согласовать спиновые изобра-
жения, соотнесенные с ориентированными точками сцены и модели объекта.
Тем не менее, все не так просто. Выше отмечалось, что спиновое отображение
не является инъективным; в общем случае оно и не сюръективное, и пустые
ячейки (или, эквивалентно, пиксели с нулевым значением) могут появляться
при значениях а и /3, не соответствующих физическим точкам поверхности
(обратите, например, внимание на пустые области на рис. 21.18). Появление
нулевых пикселей на изображении сцены может объясняться затенением, то-
гда как помехи могут вводить посторонние ненулевые ячейки. Следовательно,
сравнение двух спиновых изображений разумно ограничить их общими ненуле-
выми пикселями. В таком контексте в работе [Johnson and Hebert, 1998] было
666
Часть V. Верхний уровень компьютерного зрения: геометрические методы
показано, что
3
S(I, J) = [Arcth(C(/, J))l2 - ——
/V о
является удобной мерой сходства двух спиновых изображений, область пере-
крытия которых содержит N пикселей и представляется векторами I и J про-
странства В приведенной выше формуле через C(l, J) обозначена норми-
рованная корреляция векторов I и J, a Arcth — гиперболический арктангенс.
Имея данную меру сходства, теперь можно сформулировать процедуру распо-
знавания (алгоритм 21.4), в которой для установления точечных соответствий
используются спиновые изображения.
Различные этапы данного алгоритма по большей части прямолинейны. От-
метим, впрочем, что этап подбора/группировки зависит от сравнения спиновых
координат точек модели, определенных относительно других вершин сетки, со
спиновыми координатами соответствующих точек сцены, определенных отно-
сительно их групп.
Алгоритм 21.4. Алгоритм Джонсона-Герберта [Johnson and Hebert, 1998, 1999]
точечного согласования свободных поверхностей с использованием спиновых
изображений.
Подготовка:
Вычислить спиновые изображения, соотнесенные с ориентированными точками
модели поверхности, и занести их в таблицу.
Активная часть:
1. Сформировать соответствия между набором спиновых изображений, которые
случайным образом были выбраны на сцене, и их наилучшими парами в таб-
лице моделей, использовав для упорядочения пар меру сходства S.
2. Отфильтровать и сгруппировать соответствия, используя условия геометриче-
ской непротиворечивости, и вычислить строгие преобразования, наилучшим
образом совмещающие парные элементы сцены и модели.
3. Проверить правильность подбора пар, использовав 1СР-алгоритм.
Как только определены непротиворечивые группы, вычисляется исходная
оценка строгого преобразования, совмещающего сцену и модель, при этом ис-
пользуются пары ориентированных точек и метод наложения с использованием
кватернионов, описанный в разделе 21.3.2. Наконец, непротиворечивые наборы
соответствий проверяются, для чего процесс согласования итеративно расширя-
ется на окрестности соответствий и обновляется преобразование, совмещающее
сцену и модель.
Глава 21. Дальностные данные
667
а)
б)
Рис. 21.19. Результаты распознавания спиновых изображений: а) зашумленное изображение иг-
рушек и сетка, построенная по соответствующему дальностному изображению; б) распознанные
объекты, наложенные на исходные изображения. Перепечатано из А.Е. Johnson and М. Hebert,
"Using Spin Images for Efficient Object Recognition in Cluttered 3D Scenes”, IEEE Transactions on
Pattern Analysis and Machine Intelligence, 21(5):433-449, (1999). © 1999 IEEE.
Результаты
Алгоритм согласования, представленный в предыдущем разделе, был интен-
сивно протестирован на различных задачах распознавания с зашумленными за-
крытыми сценами, которые содержали технологические детали и различные иг-
рушки (см. [Johnson and Hebert, 1998, 1999]). Данная схема также использова-
лась в задачах наружной навигации/отображения с большими наборами данных
и значительной (тысячи квадратных метров) территорией охвата ([Carmichael
et al., 1999]). Пример результатов, полученных на сценах с игрушками, приве-
ден на рис. 21.19.
21.5. ПРИМЕЧАНИЯ
Великолепные обзоры технологий активной дальнометрии можно найти в ра-
ботах [Jarvis, 1983], [Nitzan, 1988], [Besl, 1989] и [Hebert, 2000]. Обнаружение
краев на основе моделей, описанное в разделе 21.2.2, — это только одна из
многих схем, предложенных для сегментации дальностных изображений с ис-
пользованием понятий дифференциальной геометрии (см., например, [Fan et al.,
668
Часть V. Верхний уровень компьютерного зрения: геометрические методы
1987], [Besl and Jain, 1988]). Альтернативой использования вычислительных
молекул для сглаживания дальностных изображений является анизотропная
диффузия, где величина сглаживания в каждой точке зависит от величины гра-
диента ([Perona and Malik, 1990с]). Метод сегментации поверхности в (почти)
плоские участки, представленный в разделе 21.2.3, легко расширяется на участ-
ки второго порядка (см. [Faugeras and Hebert, 1986] и раздел упражнений).
Расширение на поверхности более высоких порядков проблематично, отчасти
потому, что в этих случаях затрудняется подбор поверхностей. В литературе
широко освещается решение данной задачи с использованием суперквадрик
(см., например, работы [Pentland,1986а], [Bajcsy and Solina, 1987], [Gross and
Boult, 1988]) и алгебраических поверхностей (см. [Taubin et al., 1993a,d], [Keren
et al., 1994], [Sullivan et al., 1994a,b]).
Различные варианты ICP-алгоритма, представленного в разделе 21.3.2 и ра-
боте [Besl and McKay, 1992], включают устойчивые схемы, в которых возможна
обработка недостающих и/или посторонних данных (публикации [Zhang, 1994],
[Wheeler and Ikeuchi, 1995]), причем эти схемы были протестированы на зада-
чах глобального наложения (см., например, [Shum et al., 1995], [Curless and
Levoy, 1996]).
Альтернативы схемы слияния нескольких дальностных изображений, кото-
рая была предложена в работе [Curless and Levoy, 1996], включают триангуля-
цию Делонея (Delaunay), описанную в [Boissonnat, 1984], схему сжатых много-
угольных сеток (zippered polygonal meshes), проанализированную в [Turk and
Levoy, 1994], и схему настила (crust algorithm), в работе [Amenta et al., 1998].
Использование кватернионов для оценки строгих преобразований, описанное
в данной главе, было независимо предложено в работах [Faugeras and Hebert,
1986] и [Horn, 1987]. Метод распознавания, рассмотренный в разделе 21.4.1,
тесно связан с другими алгоритмами использования интерпретационных дере-
вьев для контроля суммарной стоимости согласования элементов в дву- и трех-
мерном случаях ([Gaston and Lozano-Perez, 1984], [Ayache and Faugeras, 1986],
[Grimson and Lozano-Perez, 1987], [Huttenlocher and Ullman, 1987]).
Спиновые изображения, рассмотренные в разделе 21.4.2, используются для
оценки точечных соответствий между дальностными изображениями и моделя-
ми поверхностей. Родственные подходы к данной задаче —• это использование
методов структурной индексации ([Stein and Medioni, 1992]) и определения зна-
ка точек ([Chua and Jarvis, 1996]). Разновидность (локальная) данной идеи рас-
смотрена в главе 23 в контексте распознавания объектов по фотографиям (ра-
бота [Schmid and Mohr, 1997]). В заключение отметим, что первоначальный
алгоритм, описанный в разделе 21.4.2, расширялся в различных направлениях:
сцену можно согласовывать с несколькими моделями с использованием анализа
главных компонентов (см. [Johnson and Hebert, 1999]) или же на зашумленных
сценах можно отсекать ложные пары (см. [Carmichael and Hebert, 1999]).
Глава 21. Дальностные данные
669
Задачи
21.1. Используя уравнение (21.1), покажите, что необходимым и достаточным
условием того, что координатные кривые параметризованной поверхности
совпадают с ее главными направлениями, является f — F — 0.
21.2. Покажите, что линии кривизны поверхности вращения являются ее ме-
ридианами и параллелями.
21.3. Модель ступеньки. Вычислите ^(z) = Ga * г(х), где z(z) представле-
но в уравнении (21.2). Покажите, что z" выражается формулой (21.3).
Проверьте, что = — 25/К в точке Жег, где z" и ка равны нулю.
21.4. Модель ската. Покажите, что выражается формулой (21.4).
21.5. Покажите, что кватернион q = cos |+sin представляет вращение 71 на
угол в вокруг единичного вектора и в смысле уравнения (21.5). Подсказ-
ка-. используйте формулу Родригеса, выведенную в разделе упражнений
главы 3.
21.6. Покажите, что матрица вращения соотнесенная с данным единичным
кватернионом q = a + a с ct — (b,c,d)T, выражается формулой (21.6).
21.7. Покажите, что матрица А, построенная в разделе 21.3.2, равна
Ai=( ° У^-yfX
\У'г-Уг +
21.8. Как упоминалось ранее, ICP-алгоритма можно расширить на различ-
ные типы геометрических моделей. Ниже рассматривается случай мно-
гоугольных моделей и кусочно-параметрических участков.
а) Предложите метод вычисления точки Q многоугольника, ближайшей
к некоторой точке Р.
б) Предложите метод вычисления точки Q на параметрическом участ-
ке х : I х J —> R3, ближайшей к некоторой точке Р. (Подсказка:
используйте итерации по схеме Ньютона.)
21.9. Разработайте линейную схему наименьших квадратов для аппроксима-
ции поверхностью второго порядка набора точек при условии, что квад-
роформа имеет единичную фробениусову норму.
21.10. Покажите, что треугольник на поверхности отображается в участок с ги-
перболическими краями в пространстве спиновых изображений а,/3.
Упражнения
21.11. Реализуйте сглаживание на основе молекул, вычислите главные направ-
ления и кривизну в этих направлениях.
21.12. Реализуйте описанную в данной главе схему роста областей для сегмен-
тированной плоскости.
670 Часть V. Верхний уровень компьютерного зрения: геометрические методы
21.13. Реализуйте алгоритм вычисления линий кривизны поверхности по ее
дальностному изображению. {Подсказка-, примените алгоритм роста кри-
вых, аналогичный алгоритму роста областей, используемому при сегмен-
тации плоскостей.)
21.14. Реализуйте алгоритм наложения Бесля-МакКея.
21.15. Двумерные “бегущие кубики”. Разработайте и реализуйте алгоритм
нахождения множества нулей плоской функции плотности. {Подсказка-.
вычислите возможные пути, по которым кривая может пересекать края
пикселя, и используйте эти края для определения множества нулей.)
21.16. Реализуйте этап наложения алгоритма Фаугераса-Герберта.
------------- ЧАСТЬ VI --------------
Верхний уровень: вероятностные методы
и методы логического вывода
22
Поиск шаблонов
с использованием
классификаторов
Существует множество важных задач распознавания объектов, которые вклю-
чают поиск на изображении окон, имеющих простую форму и стилизованное
содержимое. Например, лицо анфас имеет вид овального окна, причем (при
грубом масштабе) все лица выглядят приблизительно одинаково: темные гори-
зонтальные полоски на уровне глаз и рта, светлая вертикальная полоска вдоль
носа и слаботекстурные образования в районе щек и лба. Другой пример: для
камеры, установленной в передней части машины, все красные знаки светофо-
ров выглядят однотипно.
Исходя из приведенных соображений, напрашивается такой подход к распо-
знаванию объектов: определить все окна изображений, имеющие определенную
форму, и проверить их на предмет наличия значимого объекта. Если о разме-
рах искомого объекта ничего не известно, поиск можно проводить при разных
масштабах; если не известна ориентация предмета, можно дополнительно про-
водить поиск в пространстве ориентаций и т.д. В общем случае этот подход
называется сравнением с шаблоном. Действительно, имеются определенные
объекты, для эффективного поиска которых можно использовать схему срав-
нения с шаблоном. Важными примерами практических сфер применения этой
технологии являются поиск лиц и определение красных сигналов светофора.
674 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Кроме того, хотя с помощью простой схемы сравнения с шаблоном многие объ-
екты найти трудно (подобным образом трудно, например, найти конкретного
человека, поскольку набор возможных окон, представляющих это лицо, необъ-
ятен), очевидно, что для нахождения объектов можно эффективно использовать
соображения относительно связи различных типов шаблонов. Развитие описан-
ного подхода будет продолжено в главе 23.
Чтобы ответить на главный вопрос в теме сравнения с шаблоном — пред-
ставляет ли данный овал лицо — необходимо разработать тесты для проверки.
В идеале для получения данного теста используется большой набор образцов, а
именуется этот тест классификатором} входом классификатора является набор
элементов, а выходом — метка класса. В данной главе описываются различ-
ные схемы построения классификаторов и примеры их использования в при-
ложениях компьютерного зрения. Вначале будут представлены ключевые идеи
и терминология (раздел 22.1); затем описаны два удачных классификатора, по-
строенных с использованием гистограмм (раздел 22.2); для построения более
сложных классификаторов необходимо выбрать признаки, на основе которых
будет работать классификатор; два соответствующих метода описаны в разде-
ле 22.3. В заключение представлены два различных метода построения клас-
сификаторов для существующих приложений в области компьютерного зрения.
Раздел 22.4 представляет собой введение в использование для классификации
нейронных сетей, а в разделе 22.5 описана полезная схема классификации,
известная как метод опорных векторов.
22.1. КЛАССИФИКАТОРЫ
Для построения классификаторов берется набор меченых образцов, кото-
рый затем используется в правиле присвоения метки любому новому образцу.
В общем случае имеется настроечный набор данных (ж*, з/$); каждый вектор
Xi состоит из результатов замеров свойств объектов различных типов, а век-
торы yi — это метки, которые присваиваются объектам того типа, к которым
принадлежат образцы. Изначально известна относительная стоимость невер-
ного присвоения метки, а в дальнейшем нужно определить правило, согласно
которому любому приемлемому вектору х присваивается метка класса.
На принимаемое решение сильно влияет стоимость ошибки (раздел 22.1.1).
Ключевым вопросом здесь является вероятность метки класса, обусловленная
данными. В разделе 22.1.2 описываются некоторые методы построения подхо-
дящих моделей в общем случае. Наконец, в разделе 22.1.5 рассказано, как
оценить качество данного классификатора.
22.1.1. Использование потерь для определения решений
Выбор правила классификации должен зависеть от стоимости ошибки. На-
пример, доктор участвует в процессе классификации постоянно: дан пациент,
на выход подается название болезни. Доктор, который принял решение, что
пациент, имеющий ярко выраженные признаки опасной болезни, здоров, неком-
Глава 22. Поиск шаблонов с использованием классификаторов
675
петентен. При не совсем определенном решении лучше перестраховаться и оши-
бочно отнести здорового пациента к больным, чем ошибиться в обратную сторо-
ну, хотя при таком подходе некоторые действительно здоровые пациенты будут
испытывать определенные неудобства.
Стоимость зависит от того, какой объект был ошибочно отнесен к какому
классу. В общем случае исход записывается как (г —> J); это означает, что пред-
мет г-го типа классифицируется как предмет j-ro типа. Каждый исход имеет
свою стоимость, которая называется потерей. Таким образом имеем функцию
потерь, которую запишем как L(i —» j); это означает потери, понесенные при
определении объекта г-го типа как объекта j-ro типа. Поскольку потери, свя-
занные с правильной классификацией, не должны влиять на структуру клас-
сификатора, L(i —> г) должно равняться нулю, а другие потери представляют
собой некоторые положительные величины.
Функция риска данной стратегии классификации — это ожидаемые потери
при ее использовании как функции типа предмета. Суммарный риск — это
общие ожидаемые потери при использовании классификатора. Итак, если дано
два класса, суммарный риск использования стратегии s запишется как
P(s) =Рг{1 —> 2 | при использовании s} L(1 -* 2)+
+Рг {2 —► 1 | при использовании s} L(2 —» 1).
Желаемой является стратегия, минимизирующая суммарный риск.
Построение классификатора для двух классов, минимизирующего
суммарный риск
Предположим, что классификатор может выбирать из двух классов плюс
дана функция потерь. В пространстве признаков имеется граница (которую
назовем граница областей решений)^ когда точки по одну сторону границы
принадлежат к классу 1, а точки с другой стороны — к классу 2.
Чтобы определить, где проходит граница областей решений, обратимся к
одной уловке. Справедливо, что для точек на границе областей решений оп-
тимального классификатора выбор любого класса имеет одинаковые ожидае-
мые потери — если это не так, можно получить лучший классификатор, отнеся
точку к одному из классов, и соответственно, переместив границу. Это означа-
ет, что для замеров на границе областей решений выбор класса 1 дает те же
ожидаемые потери, что и выбор класса 2.
Выбор класса 1 для точки х на границе областей решений дает следующие
ожидаемые потери:
Р{класс — 1 | х} Ц2 —> 1) + Р {класс — 2 | ж} L(1 -» 1) =
= Р {класс - 2 | ж} L(2 — 1) + 0 = р(2 | х)Ц2 -> 1).
676 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Здесь следует весьма аккуратно следить за цифрами “1” и “2”. Подобным обра-
зом, если отнести эту же точку к классу 2, получим такие ожидаемые потери:
Р {класс — 1 | «} L(1 -* 2) — р(1 | гс)Л(1 —+ 2),
причем полученные два выражения должны быть равными. Это означает, что
граница областей решений состоит из точек х, где
р(11 ®)L(1 -+ 2) =; р(2 | x)L(2 -* 1).
Используя теорему Байеса, можно прийти к более удобному выражению. Пе-
репишем последний результат следующим образом:
р(х|1)р(1) = р(Ц2^(2) _
р(х) р(х)
избавимся от знаменателей и получим
р(х | l)p(l)L(l - 2) = р(х | 2)p(2)L(2 -> 1).
Последний результат — это уравнение точек х, лежащих на границе классов;
теперь требуется определить, каким образом классифицировать точки, лежащие
не на границе.
Для точек, не принадлежащих границе, следует выбрать класс с наимень-
шими ожидаемыми потерями. Напомним, что если точку х отнести к классу 2,
ожидаемые потери составят
р(1 | x)L(l -+ 2),
и т.д. Это означает, что класс 1 следует выбирать в том случае, если
р(1 | х)L(1 — 2) > р(2 | x)L(2 1),
а класс 2, — если
р(1 | ®)L(1 —* 2) < р(2 | x)L(2 —> 1).
Классификатор для большего числа классов
Далее будем предполагать, что L(i —> j) равно нулю при г = j и единице —
в противном случае; т.е. все исходы имеют одинаковые потери. В некоторых
задачах это не так — тогда следует не относить объект ни к какому классу.
Подобное решение также включает некоторые потери, причем предполагается,
что они d < 1 (если потери, связанные с неразрешением неопределенности,
больше потерь, связанных с любым решением, неопределенность будем разре-
шать всегда).
Глава 22. Поиск шаблонов с использованием классификаторов
677
В алгоритме 22.1 представлен классификатор Байеса — наилучшая страте-
гия для выбранной функции потерь. Суммарный риск, связанный с этим прави-
лом, называется байесовым риском-, это наименьший возможный риск, который
можно получить при использовании классификатора. Как правило, довольно
сложно определить, что является классификатором Байеса (а следовательно,
и байесов риск), поскольку фигурирующие в расчете вероятности не извест-
ны точно. Записать данное правило в явном виде можно лишь в нескольких
случаях. Эффективность технологии построения классификаторов определяет-
ся при изучении поведения риска с ростом числа образцов (например, может
требоваться, чтобы функция риска сходилась по вероятности к риску Байеса
при увеличении числа образцов). Как видно из рис. 22.1, байесов риск редко
бывает равным нулю.
Алгоритм 22.1. Для определения точек к одному из классов классификатор Бай-
еса использует апостериорные вероятности принадлежности объекта к классу,
функцию потерь и возможность отказа от принятия решения
Для функции потерь
1
L(i-j) = <
d<l
i^3
i = j
нет решения
наилучшей является стратегия
• если Pr{k | х} > Pr{i | х} для всех г, не равных к, и если вероятность
больше 1 — d, выбрать тип к;
• если имеется несколько классов Ац ... kj, для которых Pr{kt | х} = Pr{k? |
х} = • • • = Pr{kj | х} > Pr{i | х} для всех i, не принадлежащих ki,... kj,
случайно и равномерно выбрать тип из ki,... kj;
• если для всех к имеем Pr{k | х} < 1 — d, отказаться от принятия решения
22.1.2. Методы построения классификаторов: обзор
Как правило, величины Рг{х | к} (часто называемые плотностями услов-
ных вероятностей классов) или Рг{к} точно не известны, и классификатор
требуется определить по предложенному набору образцов. К такой задаче име-
ется два достаточно общих подхода.
• Явные вероятностные модели. Предложенный набор данных можно ис-
пользовать для построения вероятностной модели (или же функции прав-
доподобия либо апостериорной вероятности, дело вкуса). Это можно сде-
лать по-разному, некоторые способы будут рассмотрены в следующих раз-
678 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 22.1. На данном рисунке представлены типичные элементы задачи классификации при нали-
чии двух классов. Величина р(класс|т) изображена как функция признака ж. Границы классифи-
катора обозначены в предположении, что L(1 2) = L(2 —» 1). В данном случае байесов риск
представляет собой сумму величин апостеорных вероятностей попадения представителя класса 1
в область класса 2 и попадения представителя класса 2 в область класса 1 (на рисунке обозначены
заштрихованными областями). Для примера, изображенного слева, классы достаточно разнесены,
т.е. байесов риск мал; для примера справа байесов риск сравнительно велик
делах. В простейшем случае известно, что плотности условных вероятно-
стей принадлежности к классу подчиняются некоторому известному па-
раметрическому распределению. В таком случае по набору данных можно
оценить параметры и применить к этим оценкам теорему Байеса. Подоб-
ный подход часто называется сменным классификатором (plug-in classi-
fier) (раздел 22.1.3). Такой же подход применим и к другим параметриче-
ским моделям плотности и иным методам оценки параметров. Одной из
тонкостей данной стратегии является то, что оценки параметров могут не
давать наилучшего классификатора, поскольку параметрическая модель
может быть неточной. Другая тонкость — это то, что хороший класси-
фикатор можно получить, используя параметрическую модель плотности,
не являющуюся точным описанием данных (см. рис. 22.2). Вообще, во
многих случаях при малом числе параметров удовлетворительную модель
получить сложно. Для получения более гибких моделей следует исполь-
зовать более сложные средства, настраиваемые на основе данных (в раз-
деле 22.4 описан пример одного из таких средств — нейронной сети).
* Прямое определение границ областей решений. Как видно из рис. 22.2,
довольно плохие вероятностные модели могут давать хорошие классифи-
каторы. Это объясняется тем, что качество классификатора определяют
границы областей решений, а не подробности вероятностной модели (ос-
новное, для чего требуется вероятностная модель в классификаторе Байе-
са, — это определение границ областей решений). Отсюда напрашивается
предложение не обращать внимания на вероятностную модель и попы-
Глава 22. Поиск шаблонов с использованием классификаторов
679
Рис. 22.2. На рисунке показаны плотности апостериорных вероятностей для двух классов. Пунк-
тиром показана оптимальная граница областей решений. Обратите внимание, что хотя нормаль-
ная функция распределения может сильно отличаться от функций апостериорных вероятностей,
качество соответствующего классификатора зависит только от того, насколько точно она пред-
сказывает положение границ. В данном случае, заменяя апостериорные вероятности функцией
нормального распределения, можно получить довольно хороший классификатор, поскольку P(2jx)
уже похоже на нормальное распределение, а среднее и дисперсия Р(1|х) позволяют удачно пред-
сказать положение границы
таться прямо построить границы областей решений. Такой подход часто
дает удивительно удачные результаты; особенно он привлекателен, когда
отсутствуют разумные предположения относительно того, как смоделиро-
вать источник данных. В одной из возможных стратегий предполагается,
что граница областей решений порождается каким-либо из классов и да-
лее формулируется задача нахождения экстремума, при решении которой
выбирается наилучший элемент этого класса. Важным частным случаем
являются линейно сепарабельные данные (это означает, что существует
гиперплоскость, на одной стороне которой находятся все положительные
точки, а на другой — все отрицательные), и решение задачи сводится к
поиску гиперплоскости, разделяющей данные (раздел 22.5).
22.1.3. Пример: сменный классификатор для классов с нормальным
распределением
Важный настраиваемый классификатор появляется в том случае, когда из-
вестно, что плотности условной вероятности классов заведомо имеют нормаль-
ное распределение. Можно либо предположить, что априорные вероятности из-
вестны, либо оценить их, подсчитав число элементов данных в каждом классе.
Далее требуется определить, что будет параметрами для функций плотности
условных вероятностей. Рассмотрим это как задачу оценки и используем эле-
менты данных для оценки среднего {лк и второго момента £* каждого класса.
Поскольку из logo > logb следует, что а > Ь, далее можно использовать ло-
гарифм апостериорной вероятности. Полученный в результате классификатор
представлен в алгоритме 22.2.
680 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Алгоритм 22.2. Если известно, что плотности условных вероятностей принад-
лежности к классу имеют нормальное распределение, для разделения объектов
по классам можно использовать сменный классификатор
Предположим, что дано N классов и fc-й класс содержит N& образцов, г~й из
которых обозначается х^л
Для каждого класса к оценивается среднее и среднеквадратическое отклонение
плотности условной вероятности класса
J Nfc 1 Nfc
I1 к = ~N~ = ДГ _ | — №к)(Хк,1 ~ Р'к) •
1=1 1=1
Для классификации образца х следует
Выбрать класс к с наименьшим значением <5(x;/zfc, S*)2 — Рг{&} + | log|S*|,
где
<5(x;Mfc,Sfe) = | ((х- рЛ)тЕ*1(х- pfc)}( 7 }.
Член <5(x; pifc, в этом алгоритме называется расстоянием Махаланобиса
(Mahalanobis distance) (см., например, [Ripley, 1996]). Данный алгоритм мож-
но интерпретировать геометрически, — сказать, что истинным является класс,
среднее которого ближе всего к элементу данных с учетом дисперсии. В част-
ности, расстояние от среднего по направлению, в котором дисперсия мала,
имеет большой весовой коэффициент, а расстояние от среднего в направле-
нии с большой дисперсией имеет малый весовой коэффициент. Классификатор
можно упростить, если предположить, что все классы имеют одинаковый вто-
рой момент (плюс такого предположения в том, что оценивать придется меньше
параметров). В этом случае, поскольку член xTY>~1x является общим для всех
выражений, классификатор в действительности сравнивает выражения, линей-
ные по х (см. раздел упражнений). Если имеется только два класса, процесс
сводится к простому определению того, больше либо меньше нуля выражение,
линейное по х (см. раздел упражнений).
22.1.4. Пример: непараметрический классификатор по ближайшим
соседям
Разумно предположить, что на класс неклассифицированной точки должны
указывать точки в ее окрестности. Это эвристическое соображение дало начало
классификаторам, построенным по методам ближайших соседей. Для класси-
фикации точки можно использовать соседние точки с известным классом или
же взять несколько точек-образцов и применить схему голосования. Разумно
Глава 22. Поиск шаблонов с использованием классификаторов
681
требовать, чтобы при принятии решения относительно класса число голосов за
точку превышало некоторую минимальную величину.
Итак, (fc, /)-классификатор по ближайшим соседям находит к точек-
образцов, ближайших к рассматриваемой точке, и относит эту точку к классу,
получившему наибольшее число голосов, если это число превышает порог
в I голосов (в противном случае точка классифицируется как неопределен-
ная). Работающий по описанной схеме (&,0)-классификатор часто называется
классификатором по к ближайшим соседям, а (1,0)-классификатор обычно
называют классификатором по ближайшему соседу.
Классификаторы по ближайшим соседям заведомо хороши в том смысле,
что риск использования классификатора по ближайшим средним при доста-
точно большом числе образцов с хорошей точностью совпадает с байесовым
риском. При увеличении к разница между байесовым риском и риском исполь-
зования классификатора по к соседям уменьшается как l/\/fc. На практике
редко используется более трех ближайших соседей. Более того, если байесов
риск равен нулю, ожидаемый риск использования классификатора по к бли-
жайшим соседям также равен нулю (подробнее об этом см. [Devroye, Gyorfi
and Lugosi, 1996]).
Классификаторы по ближайшим средним приводят, впрочем, к некоторым
вычислительным тонкостям. Первая — это вопрос нахождения к ближайших
точек, что далеко не так просто сделать в пространстве высокой размерности
(как ни странно, но вычисление расстояния от отдельно взятой точки-образца
до всех остальных является в настоящее время довольно проблемным алгорит-
мом). Данная задача упрощается, если отметить, что некоторые точки-образцы
могут быть лишними. Если при удалении точки из набора образцов классифи-
кация каждой точки пространства не меняется (иными словами, не перемеща-
ются границы областей решений), тогда точка является лишней, и ее можно
удалить. В то же время трудно сказать, какие точки удалять. Области реше-
ний для (А:, /)-классификатора — это выпуклые политопы; так что в двумерном
случае можно использовать известные алгоритмы (где реализацией классифи-
катора по ближайшему соседу являются диаграммы Вороного), но при переходе
к более высоким размерностям возникают проблемы.
Алгоритм 22.3. Использование (к, 1)-классификатором по ближайшим соседям
типа ближайших настроечных образцов для классификации вектора признаков
Для данного вектора признаков х
а) определить к ближайших настроечных образцов, ®i,... ,хк',
б) определить класс с, имеющий наибольшее число представителей п в этом
множестве;
в) если п > I, классифицировать х как с, в противном случае отказаться от
классификации.
682 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Вторая сложность в построении описанных классификаторов заключается
в выборе расстояния. Если признаки относятся к одному типу (например, дли-
на), довольно хорошей может быть обычная метрика. Но что делать, если один
признак — это длина, другой — цвет, а третий — угол? В таком случае одной из
возможностей является вычисление расстояния Махаланобиса (или иной мет-
рики, построенной по сходному принципу) с помощью оценки второго момента.
22.1.5. Оценка и улучшение производительности
Как правило, выбираются классификаторы, хорошо работающие на настро-
ечных наборах, но это может означать, что производительность классифика-
тора на настроечном наборе — плохой показатель общего качества. Одним из
примеров подобной проблемы является (неразумная крайность) классификатор,
который принимает любую точку и при совпадении с точкой из настроечного
набора, выдает ее класс, иначе случайным образом выбирает из всех классов.
Этот классификатор обучен по данным и имеет нулевой коэффициент ошибок
на настроечном наборе данных; в то же время при любом другом наборе данных
этот классификатор бесполезен.
Сложности появляются, поскольку классификаторы подвержены эффектам
переобучения (overfitting). Данное явление, известное под разными названиями
(например, широко используется название систематическая ошибка, связан-
ная с отбором (selection bias)), связано с тем, что классификатор выбирается
исходя из хороших результатов на настроечном наборе данных, но ведь на-
строечные данные — это подмножество (возможно, представительное) доступ-
ных возможностей. Термин систематическая ошибка, связанная с отбором,
наглядно указывает источник проблемы — производительность классификатора
на настроечном наборе данных может подстраиваться под нетипичных пред-
ставителей класса, которые не появляются в других наборах образцов. Если
классификатор выбирается именно по такому принципу, вполне вероятно, что
он покажет хорошие результаты на настроечном наборе данных и плохие — на
всех остальных наборах (это явление часто называется плохим обобщением).
В общем случае ожидается, что на настроечном наборе классификаторы
будут показывать несколько лучшие результаты, чем на тестовом (см, напри-
мер, рис. 22.18, где представлены ошибки настроечного и тестового наборов для
хорошего классификатора). Переобучение подбор может приводить к значитель-
ному отличию производительности, показываемой на настроечном наборе, от
производительности, наблюдаемой на тестовом наборе. Таким образом, вопрос
предсказания производительности остается открытым. Чтобы ответить на него,
можно использовать два подхода: иметь некие настроечные данные для провер-
ки производительности классификатора (данный подход был описан выше) или
же использовать теоретические методы, чтобы ограничить будущую частоту
ошибок классификатора (см., например, [Vapnik, 1996] или [Vapnik, 1998]).
Глава 22. Поиск шаблонов с использованием классификаторов
683
Оценка суммарного риска посредством перекрестной проверки
Ожидаемый риск использования классификатора можно оценить непосред-
ственно, если расщепить набор данных на два подмножества, настроить клас-
сификатор на одном поднаборе и протестировать на другом. Конечно, это неэко-
номное использование данных (особенно если в некотором классе имеется лишь
несколько элементов данных) и в результате можно получить плохой классифи-
катор. В то же время если размер тестового поднабора мал, данная сложность
может быть несущественной. В частности, далее можно оценить суммарный
риск, усреднив его по всем возможным разбиениям исходного набора. Данная
схема, известная как перекрестная проверка, позволяет оценить вероятную бу-
дущую производительность классификатора за счет значительных вычислений.
Алгоритм 22.4. Перекрестная проверка
Выбрать некоторый класс поднаборов настроечного набора, например,
одноэлементные множества
Для каждого элемента этого класса построить классификатор, избегая
элементов настроечного набора, и вычислить ошибку (или риск) классификации
по изъятому поднабору
Усреднить эти ошибки по классу подмножеств для оценки риска использования
классификатора, настроенного по всему настроечному набору данных
Наиболее распространенной является разновидность данного алгоритма,
в которой из набора данных исключаются отдельные элементы данных, и на-
зывается она перекрестная проверка “без одного" (leave-one-out). Для оценки
ошибок обычно используется простое усреднение по классу, хотя разработаны
и более сложные схемы (см., например, [Ripley, 1996]). Мы не будем приво-
дить математическое обоснование данной технологии, но стоит отметить, что
в некотором смысле перекрестная проверка по принципу “без одного” позволяет
узнать чувствительность классификатора к небольшим изменениям настроеч-
ного набора. Если классификатор хорошо проходит эту проверку, то большие
поднаборы набора данных выглядят подобно между собой, откуда следует, что
представление соответствующих вероятностей, полученных из набора данных,
может быть достаточно хорошим.
Использование самонастройки для улучшения производительности
В общем случае, чем больше настроечных данных, тем лучше классифика-
тор. В то же время настройка классификаторов при больших наборах данных
может представлять проблему, наблюдается снижение полезности такого клас-
сификатора. Как правило, при оценке поведения классификатора на результат
влияет относительно мало образцов (более подробно это явление рассмотрено
в разделе 22.5), причем действительно важные образцы встречаются доволь-
но редко и их сложно распознать. Это объясняется тем, что данные элементы
684 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
сильнее влияют на положение границы областей решений. Чтобы обеспечить
присутствие таких элементов, требуются большие наборы данных, но работа
с таким наборами данных, большинство элементов которых не представляют
практической значимости, себя не оправдывает.
Чтобы избежать излишней работы, можно использовать полезную уловку.
Настраиваем классификатор на подмножестве образцов, запускаем полученный
классификатор на остальных образцах, а затем вводим в настроечный набор
ложные положительные и ложные отрицательные результаты классификации
и перенастраиваем классификатор. Такой подход оправдан тем, что ложные
результаты дают наибольшую информацию об ошибках в конфигурации границ
областей решений. Называется данная стратегия самонастройкой.
22.2. ПОСТРОЕНИЕ КЛАССИФИКАТОРОВ ПО ГИСТОГРАММАМ
КЛАССОВ
Для простого построения вероятностной модели для классификатора мож-
но использовать гистограммы. Если величины на гистограмме разделить на
общее число пикселей, получим представление функции плотности вероятно-
сти принадлежности к классу. Доказано, что при увеличении набора данных
и уменьшении ячеек гистограммы гистограмма, деленная на общее число эле-
ментов данных, будет почти достоверно сходиться к функции плотности ве-
роятности (см., например, [Devroye, Gyorfi and Lugosi, 1996], [Vapnik, 1996,
1998]). В низкоразмерных задачах данный подход может давать весьма хоро-
шие результаты (раздел 22.2.1). Он не настолько целесообразен для высоких
размерностей, поскольку число требуемых ячеек гистограмм быстро становится
труднообрабатываемым, если для борьбы с этой сложностью не использовать
сильные допущения о независимости (раздел 22.2.2).
22.2.1. Поиск пикселей кожи с использованием классификатора
Аппараты нахождения кожи полезны, например, при построении интерфей-
сов на основе жестов. Кожа имеет довольно характерный диапазон цветов, так
что предположительно устройство обнаружения кожи можно построить, класси-
фицируя пиксели по их цвету. В работе [Jones and Rehg, 1999] построена гисто-
грамма RGB-значений, полученных для пикселей кожи, и другая гистограмма,
полученная для пикселей, не относящихся к коже. Далее данные гистограммы
использовались как модели плотностей условных вероятностей классов.
Запишем через х вектор, содержащий цветовые значения пикселя. Разделим
данное цветовое пространство на квадратики и подсчитаем процентную часть
пикселей телесного цвета, попадающих в каждую ячейку; данная гистограмма
будет содержать значения величины р(х | пиксели кожи), которые можно оце-
нить, определив квадратик, соответствующий х, а затем сообщив процентное
содержание пикселей в этой ячейке. Подобным образом, определяя процент-
ное содержание в каждом квадратике пикселей нетелесного цвета, получим
величину р(х | иные пиксели). Итак, требуются вероятности ^(пиксели кожи)
Глава 22. Поиск шаблонов с использованием классификаторов
685
Рис. 22.3. На рисунке применимо к изображениям показан выход детектора кожи. Пиксели, отме-
ченные черным, принадлежат коже, а отмеченные белым — фону. Обратите внимание, что данный
процесс относительно эффективен и может использоваться для фокусирования внимания, скажем,
на руках и лицах. Перепечатано из M.J. Jones and J. Rehg, "Statistical color models with applica-
tion to skin detection”, Proceedings, Conference on Computer Vision and Pattern Recognition, 1999.
© 1999 IEEE
и р(иные пиксели) (точнее, требуется только одна из этих величин, посколь-
ку в сумме они дают единицу). Предположим пока, что известна первая ве-
личина. Далее для построения классификатора можно использовать теорему
Байеса (помним, что р(х) легко вычисляется как р(х | пиксели кожи) +р(х |
иные пиксели)).
Для оценки априорной вероятности можно, например, смоделировать р(кожа)
как долю пикселей телесного цвета в некотором (идеально большом) настроеч-
ном наборе. Обратите внимание, что полученный классификатор сравнивает
р(а;|кожа)Р(кожа)£(ко>|(а^иное)
р(®)
С
р(х I иное)Р(Иное)£ ое
р(ж)
686 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Теперь переупорядочим члены, отметим, что ^(пиксели кожи | х) ~ 1 —
р(иные пиксели | х), и получим такой классификатор:
• если р(кожа | аз) > 0, отнести к пикселям кожи
• если р(кожа | х) < в, отнести к иным пикселям
• если р(кожа | ас) = 0, случайно и равномерно выбрать из классов.
Здесь 0 — выражение, которое не зависит от х и вмещает относительные по-
тери. В результате получаем семейство классификаторов, по одному для каж-
дого выбора 0. При подходящем выборе 0 классификатор может быть удачным
(рис. 22.3).
Каждый классификатор данного семейства имеет свой коэффициент ложно-
положительных и ложноотрицательных выходов. Данные величины являются
функциями 0, так что можно изобразить параметрическую кривую, отражаю-
щую производительность данного семейства классификаторов. Данная кривая
называется кривой срабатывания приемника (Receiver Operating Curve —
ROC). На рис. 22.4 кривая ROC показана для устройства обнаружения кожи,
построенного с использованием описанного подхода. Данная кривая инвари-
антна относительно априорного выбора (см. раздел упражнений); это означает,
что при изменении значения р(кожа) можно выбрать некоторое новое значе-
ние 0 и получить классификатор с той же производительностью. Таким образом
получаем другой подход к оценке априорных значений. Вначале выбираются
некоторые значения (можно сказать, произвольно), потери на настроечном
наборе изображаются как функция 0, а затем выбирается значение 0, миними-
зирующее эти потери.
22.2.2. Поиск лиц в предположении о независимых откликах на
шаблоны
Модели на основе гистограмм непрактичны в пространствах высокой размер-
ности, поскольку число требуемых ячеек описывается степенной зависимостью
от размерности. Это можно обойти. Напомним, что вследствие допущений о
независимости число параметров, необходимых в вероятностной модели, умень-
шается (см., например, посвященную вероятности главу на web-сайте книги);
предполагая, что члены независимы, размерность можно уменьшить настолько,
что можно будет использовать гистограммы. Хотя такой подход кажется чрез-
мерно агрессивным упрощением (он известен под уничижительным названием
"наивный Байес”,) он позволяет получить полезные системы. В одной подоб-
ной системе (согласно [Scheneiderman and Kanade, 1998]) описанная модель
используется для нахождения лиц. Предположим, что все лица имеют пред-
определенный размер (для нахождения лиц большего размера можно использо-
вать поиск в сглаженных и перевыбранных версиях изображения) и занимают
область известной формы. Для лиц, наблюдаемых спереди, данная область —
овал или квадрат; для лиц, наблюдаемых сбоку, это может быть несколько
более сложный многоугольник. Далее требуется модель образа, генерируемого
Глава 22. Поиск шаблонов с использованием классификаторов
687
Кривые срабатывания приемников
тестового набора, показывающие, что дает
увеличение размера элементов гистограммы
Вероятность ложного обнаружения
Рис. 22.4. Кривая срабатывания приемника для детектора кожи, ([Jones and Rehg, 1999]). Изоб-
ражена частота детектирования в зависимости от частоты ложноотрицательных выходов при раз-
личных значениях параметра 6. Идеальный классификатор имеет кривую срабатывания, которая
при данных осях изображается горизонтальной прямой со 100% детектированием. Обратите вни-
мание, что характеристика незначительно зависит от числа ячеек гистограммы. Перепечатано из
M.J. Jones and J. Rehg, “Statistical color models with application to skin detection”, Proceedings,
Conference on Computer Vision and Pattern Recognition, 1999. © 1999 IEEE
лицом. Это вероятностная модель, поскольку требуется, чтобы она выдавала
вероятность Р(образ | лицо). Как обычно, удобно рассуждать в терминах обоб-
щенных моделей и рассмотреть процесс, посредством которого лицо дает вклад
во фрагмент изображения. Работа с большим количеством возможных фрагмен-
тов изображений затруднительна, но в данном случае фрагмент изображения
можно разделить на набор подобластей, а затем использовать небольшой набор
меток для маркировки подобластей.
Для подходящей маркировки можно использовать алгоритм кластеризации
и большое число изображений-образцов. Например, можно кластеризовать под-
области на большом наборе образцов изображений, используя схему fc-средних;
теперь центр каждого кластера представляет типичную форму подобласти. За-
тем подобласти рассматриваемого фрагмента изображения могут помечаться
центром ближайшего кластера. Плюсом данного подхода является подавление
незначительных вариаций образов (возможно, вызванных шумом, дефектами
кожи и т.д.).
На сегодня доступно много моделей. Простейшая практическая модель —
предположить, что вероятность появления каждого образа не зависит от кон-
фигурации других образом (но не от положения) при условии, что лицо при-
сутствует. Это означает, что наша модель записывается как
Р(изображение | лицо) = Р(метка 1 в (xi, yi),..., метка k в (rrt, ук) | лицо) =
= Р(метка 1 в (rci,з/i) | лицо)... Р(метка k в (хк,Ук) | лицо).
688 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
В этом случае каждый член вида Р(метка к в (хк,Ук) | лицо) можно настро-
ить довольно легко, снабдив метками большое число изображений-образцов, а
затем построив гистограмму. Поскольку теперь гистограммы двумерны, число
их элементов уже не представляет проблемы. Сходная схема рассуждений при-
водит к модели вероятности Р(изображение | иные элементы). Классификатор,
получающийся при таком подходе, был описан ранее. Данный подход успешно
использовался Шнайдерманом (Schneiderman) и Кенедом (Kanade) для постро-
ения детекторов лиц и машин (рис. 22.5).
22.3. ВЫБОР ПРИЗНАКОВ
Допустим, что дан набор пикселей, которые предположительно связаны вме-
сте и должны быть классифицированы. Какие признаки следует представить
классификатору? Одно из возможных решений — представить значения всех
пикселей: это даст классификатору максимально возможный объем информа-
ции о наборе пикселей, но создаст множество проблем.
Во-первых, пространства высокой размерности велики в том смысле, что
потребуется большое число образцов для простого представления доступных
возможностей. Например, лицо при низком разрешении имеет довольно про-
стую структуру: оно состоит (грубо) из нескольких темных полосок (брови
и глаза) и светлых полосок (зеркальное отражение от носа и лба) на бестек-
стурном фоне. В то же время, если рассматривать лица с высоким разрешением,
может быть затруднительно поддерживать достаточное число образцов, чтобы
определить, является ли данная структура существенной, и что незначитель-
ные изменения текстуры кожи несущественны. Взамен этого удобно выбрать
пространство признаков, которое сделает эти свойства очевидными, для этого,
как правило, вводится некоторая структура образцов.
Во-вторых, заранее могут быть известны некоторые свойства образов. На-
пример, имеется модель динамики освещения. Использовать классификатор для
обработки образцов, в результате чего получится модель, которая нам уже из-
вестна, — это неразумное использование образцов. Лучше использовать при-
знаки, согласующиеся с нашими знаниями об образе. Такое решение может
включать использование предварительно обработанных областей (например,
для удаления эффектов изменения освещения) или выбор признаков, инвари-
антных при определенных преобразованиях (например, масштабируя область
изображения до стандартного размера).
Стоит обратить внимание на сходство выбора признаков и выбора модели
(как описывалось в разделе 16.3). При выборе модели мы пытаемся получить
модель, наилучшим образом объясняющую набор данных; при выборе призна-
ков мы пытаемся найти набор признаков, наилучшим образом классифицирую-
щий набор данных. Данные процессы — это, по сути, одно и то же, реализо-
ванное в несколько отличных формах (набор признаков можно рассматривать
как модель, а классификацию — как объяснение). Ниже описываются мето-
ды, используемые преимущественно для выбора признаков. Внимание будет со-
Глава 22. Поиск шаблонов с использованием классификаторов
689
Рис. 22.5. Нахождение лиц с использованием метода, описанного в разделе 22.2.2. Окна изоб-
ражения при различных масштабах классифицируются как лицо спереди, лицо сбоку или как
другой объект, для чего используется вероятностная модель, обучающаяся на данных. Подобласти
окна изображения классифицируются в набор классов, обучающихся на данных; в модели лица
предполагается, что метки в этих классах присваиваются независимо для разных положений лица.
Вероятностная модель дает апостериорные значения для каждого класса и каждого окна, и эти зна-
чения используются для идентификации окна. Перепечатано из Н. Schneiderman and Т. Kanade,
“A Statistical Method for 3D Object Detection Applied to Faces and Cars”, Proceedings, Computer
Vision and Pattern Recognition, 2000. (c) 2000 IEEE
690 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
6
4
2
0
-2
-6
-8 -6 -4 -2 0 2 4 б 8
Рис. 22.6. Набор данных удачно представляется посредством анализа главных компонентов. Оси
представляют направления, полученные посредством анализа; вертикальная ось — первый главный
компонент, также это направление максимальной дисперсии
средоточено на двух стандартных методах получения линейных признаков —
признаков, являющихся линейной функцией исходного набора признаков.
22.3.1. Анализ главных компонентов
Основная цель выбора признаков заключается в получении меньшего набо-
ра признаков, точно представляющего исходный набор. Что означает послед-
нее высказывание — зависит от конкретной задачи. Впрочем, в любом случае
желательно, чтобы новый набор признаков максимально полно передавал раз-
нообразие старого. Простейшей иллюстрацией сказанного является крайность.
Если значение одного признака можно точно предсказать по значению других,
этот признак очевидно является избыточным, и его можно опустить. Соглас-
но такому аргументу, если требуется отбросить признак, то первый кандидат
на отсев — признак, значение которого наиболее точно предсказывается по
значениям остальных признаков. Следует также отметить, что отбрасывание
признаков — это не единственная доступная возможность: можно создавать
и новые признаки, являющиеся функциями старых.
При анализе главных компонентов (Principal Component Analysis — РСА)
новые признаки являются функциями старых. В ходе названного процесса бе-
рется набор информационных точек и строится линейное подпространство мень-
шей размерности, наилучшим образом объясняющее варьирование данных то-
чек по их среднему значению. Данный метод (также известный как преобразо-
вание Карунена-Лоэва (Karhunen-Loeve transform)) — это классическая схема
статистического распознавания образов ([Duda and Hart, 1973], [Oja, 1983],
[Fukunaga, 1990]).
Глава 22. Поиск шаблонов с использованием классификаторов
691
Предположим, что дан набор п векторов признаков аз< (г = 1, ...,п) в про-
странстве Rd. Среднее этого набора — д (в данном случае среднее можно
представить как центр масс), а вторые моменты собраны в матрицу Е. Далее
примем это среднее в качестве начала координат, и будем изучать смещения
относительно среднего (х, — /х).
Используемые признаки являются линейными комбинациями исходных; это
означает, что естественно рассмотреть проекции указанных смещений в раз-
личных направлениях. Возьмем единичный вектор v, представляющий направ-
ление в первоначальном пространстве признаков; это направление можно ин-
терпретировать как новый признак v(x). Значение и в i-й точке представляется
величиной v(xi) = vT(xi — р). Хороший признак максимально представляет
разнообразие исходного набора данных. Обратите внимание, что v имеет нуле-
вое среднее; в таком случае второй момент v записывается как
var(v) = ^7 Ё =
1=1
= ~ 12 vT(Xi ~ - ^))т =
£=1
{п~ 1
- А*)(хг — р)Т > V =
1=1 J
= vTY/v.
Теперь хотелось бы максимизировать г>тЕг>, используя условие vTv — 1.
Это типичная задача на собственные значения; искомым решением является
собственный вектор матрицы Е, соответствующий наибольшему собственному
значению. Если теперь спроектировать данные в пространство, перпендикуляр-
ное указанному собственному вектору, получим набор (d — 1)-мерных векторов.
Признаком с наибольшим вторым моментом для данного набора будет соб-
ственный вектор матрицы Е, отвечающий второму по величине собственному
значению и т.д.
Сказанное означает, что собственные векторы матрицы Е (которые будем за-
писывать как vi,vz,... ,Vd, причем предполагается, что векторы упорядочены
по убыванию собственных значений, вектор vi отвечает наибольшему собствен-
ному значению) определяют набор признаков со следующими свойствами:
• они независимы (поскольку собственные векторы ортогональны);
• проекция в базис {«i,.. . дает fc-мерный набор линейных признаков,
максимально передающих разнообразие исходного набора (имеющих наи-
большую дисперсию).
692 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Следует отметить, что в зависимости от источника данных главные компо-
ненты могут давать хорошее или плохое представление набора данных (см.
рис. 22.6, 22.7 и 22.9).
Алгоритм 22.5. В ходе анализа главных компонентов определяется набор неза-
висимых линейных признаков и максимально передается разнообразие набора
данных
Пусть дан набор п векторов признаков (г = 1,...,п) в пространстве
Введем обозначения
1 V—'
^=п^Х‘
г
е = 52^ - ^Xi ~
i
Единичные собственные векторы Е (которые будем записывать как v i, v?,... ,va,
причем предполагается, что векторы упорядочены по убыванию собственных
значений, вектор г>1 отвечает наибольшему собственному значению) определяют
набор признаков со следующими свойствами:
• они независимы (поскольку собственные векторы ортогональны);
• проекция в базис {vi....,Vk} дает fc-мерный набор линейных признаков, мак-
симально передающих разнообразие исходного набора (имеющих наибольшую
дисперсию)
22.3.2. Идентификация людей с помощью анализа главных
компонентов
Людям легко удается помнить и узнавать большое число лиц, а для ими-
тации подобной способности в автоматизированных компьютерных системах
можно найти множество сфер применения, в том числе в области взаимодей-
ствия человек/компьютер и системе безопасности. В работе [Kanade, 1973] бы-
ла разработана первая полностью автоматическая система распознавания лиц,
вскоре было предложено множество иных подходов для решения различных
частных случаев данной задачи (например, при фиксированной ориентации го-
ловы, фиксированном выражении лица, и т.д.; современный обзор данной темы
см. в работе [Chellappa, Wilson and Sirohey, 1995]). Нахождение лиц обычно
включает одну из следующих составляющих: а) методы согласования на основе
признаков, где признаки (или характерные элементы) лица, такие как нос, губы,
глаза и т.д., извлекаются и согласовываются с использованием их геометриче-
ских параметров (высота, ширина) и связей (относительного положения); или
б) методы сравнения с шаблоном, где непосредственно сравниваются распреде-
ления яркости на двух лицах (обсуждение и сравнение этих двух подходов см.
Глава 22. Поиск шаблонов с использованием классификаторов
693
-10 -5 0 5 10
Рис. 22.7. Не каждый набор данных можно удачно представить с помощью анализа главных ком-
понентов. Основные компоненты набора, изображенного на рисунке, относительно неустойчивы
из-за равной дисперсии во всех направлениях. Это означает, что различные наборы данных, по-
рожденные таким источником, могут давать весьма отличающиеся главные компоненты. Впрочем,
данная проблема вторична, основная сложность — это то, что при проектировании набора данных
на некоторую ось теряется его главный признак — круговая структура
в работе [Brunelli and Poggio, 1993]). Предположим, лицо найдено, возникает
вопрос: чье это лицо? Если имеется удобная пространственная система коорди-
нат, для простого и эффективного решения данной задачи могут использоваться
методы, основанные на анализе главных компонентов.
Собственные изображения
Люди быстро распознают огромное число лиц, и в работе [Sirovitch and
Kirby, 1987] высказывается предположение, что зрительная система человека
может использовать для хранения и индексирования изображений лиц малое
число параметров. Соответственно, авторы работы исследовали использование
анализа главных компонентов как метода сжатия изображений лиц. Действи-
тельно, данный анализ позволяет каждой выборке Si е (г = 1,...,п) пред-
ставляться всего лишь р <С d числами, координатами ее проекции в базисе,
сформированном векторами Uj (j = 1,...,р). Разумеется, данные векторы так-
же нужно хранить, так что общий объем требуемой памяти составляет (n + d)p
против исходного nd. Сирович и Кирби назвали векторы ui “собственными
изображениями” (eigenpictures), поскольку они имеют ту же размерность, что
и исходные изображения. Проделанные эксперименты показали, что 40 соб-
ственных изображений достаточно для восстановления элементов базы изобра-
жений, содержащей 115 лиц 128 х 128, при 3% уровне ошибок. Отметим, что
при таких значениях параметров (р = 40, п = 115 и d = 128 х 128) размер
представления в форме собственных изображений (включая проекции изобра-
г
694 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
жений) занимает менее половины размера исходной базы данных. В данной
публикации также было показано, что при работе с изображениями лиц людей,
не фигурирующих в базе данных, уровень ошибок получается ниже 8% даже
при неблагоприятных условиях освещения, откуда следует, что данная схема
имеет великолепные экстраполирующие возможности.
Собственные лица
Хотя идея использования собственных изображений для распознавания лиц
в работе [Sirovich and Kirby, 1987] подразумевается, явного алгоритма распозна-
вания там предложено не было. Это упущение было исправлено в работе [Turk
and Pentland, 1991а], где представлена полная система распознавания, основан-
ная на разновидности схемы классификации по ближайшим соседям, кратко
описанной в начале текущего раздела. В этой системе собственные изображе-
ния были переименованы в “собственные лица” (eigenfaces).
Итак, алгоритм распознавания разбит на следующие этапы.
Автономный
1. Собрать набор изображений т людей, отражающий вариации выражений
лиц, поз и освещения.
2. Вычислить собственные лица щ (г = 1,... ,р).
3. Для каждого человека в базе данных вычислить соответствующий представ-
ляющий вектор Wj (j = в подпространстве собственных лиц Vp.
Оперативный
4. Вычислить проекцию w любого нового изображения t в Vp.
5. Если расстояние d = |t—w| больше некоторого предопределенного порога elt
классифицировать изображения как “иной объект”.
6. В противном случае, если минимальное расстояние dk = |w — wjt| меж-
ду проекцией нового изображения и известным представителем набора лиц
меньше некоторого заданного порога вг. классифицировать изображение как
“человек номер к”.
7. В оставшемся случае (d < £i и dk > £2) классифицировать изображения как
“неизвестный человек”, а также (необязательно) добавить новое изображе-
ние в базу данных и заново вычислить собственные лица.
В этом месте стоит уточнить, как вычисляются векторы Wj (этап 3). В ра-
боте [Turk and Pentland, 1991а] предложено усреднение векторов образов соб-
ственных лиц (т.е. проекций изображений, соотнесенных с классом j, в Sp).
Данный подход является альтернативой классификации по схеме ближайших
соседей, описанной ранее.
В экспериментах Тека и Пентланда использовалась база из 2 500 изображе-
ний 128 х 128 шестнадцати различных людей, в которой отражались все комби-
нации трех ориентаций лица, трех масштабов головы и трех условий освещения
(рис. 22.8).
Глава 22. Поиск шаблонов с использованием классификаторов
695
Рис. 22.8. Подмножество базы изображений, использованной в экспериментах Тека и Пентлан-
да. В оригинальной работе в базе данных учитывалось также изменение освещения, ориентации
и масштаба, но на приведенной иллюстрации это не отражено. Перепечатано из М. Turk and
A. Pentland, Proceedings, Computer Vision and Pattern Recognition, 1991. © 1991 IEEE
В табл. 22.1 представлены количественные результаты распознавания. В со-
ответствующих экспериментах из групп по 16 изображений исходной базы дан-
ных выбирались настроечные наборы, причем в каждом настроечном наборе
был представлен каждый человек. Затем все изображения в базе данных клас-
сифицировались. Статистика собиралась при измерениях среднего разброса на-
строечных и тестовых условий, причем освещение, масштаб и ориентация ва-
рьировались независимо.
22.3.3. Канонические переменные
Анализ главных компонентов дает набор линейных признаков определенной
размерности, наилучшим образом представляющий разнообразие набора дан-
ных более высокой размерности. При этом нет гарантии, что данный набор
признаков хорошо подходит для классификации. Например, на рис. 22.9 пока-
зан набор данных, где первый главный компонент дает плохой классификатор,
а второй главный компонент — хороший, хотя и не передает при этом разнооб-
разие исходного набора данных.
Линейные признаки, наилучшим образом передающие разницу между клас-
сами, называются каноническими переменными. Для построения канониче-
ских переменных предположим, что дан набор элементов данных ж, при i G
{1,...,п}. Предположим, что всего имеется р признаков (т.е. что гс, — это 77-
мерные векторы). Имеется д классов, и среднее j-ro класса — p.j. Запишем
696 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
ТАБЛИЦА 22.1. Результаты распознавания. Экспериментальные условия накладывались путем из-
менения значения ei (например, ei — -f-oo для принудительной классификации). Низкие (соответ-
ственно, высокие) значения ех дают более (соответственно, менее) точные результаты распознава-
ния, но и более (соответственно, менее) неопределенные результаты классификации
Экспериментальное условие Процент точного распознавания/неопределенной классификации
Освещение Ориентация Масштаб
Принудительная классификация 96/0 85/0 64/0
100% точность распознавания 100/19 100/39 100/60
20% неопределенность классификации 100/20 94/20 74/20
через р среднее средних классов, т.е.
Введем величину
1 9
в = 7Т1 52^ - ~
у 3=1
Обратите внимание, что В — это дисперсия средних классов. В простейшем
случае предполагается, что все классы имеют равные вторые моменты Е, при-
чем матрица Е имеет полный ранг. Хотелось бы так получить набор осей, что-
бы кластеры информационных точек, принадлежащих к определенному классу,
компактно группировались вместе, тогда как различные классы были бы раз-
несены. Это включает поиск набора признаков, максимизирующих отношение
расстояния между средними классов (дисперсии) к дисперсии каждого класса.
Расстояние между средними классов обычно называется межклассовой дис-
персией, а дисперсия в пределах класса именуется внутриклассовой.
Поскольку нас интересуют линейные функции признаков, ограничимся
классом
v{x) = vTx.
Далее следует максимизировать отношение межклассовых дисперсий к внут-
риклассовым по Vi.
Используя те же аргументы, что приводились при описании анализа главных
компонентов, требуемого можно достичь, выбрав вектор v, максимизирующий
Глава 22. Поиск шаблонов с использованием классификаторов
697
Рис. 22.9. При анализе главных компонентов не учитывается, что в наборе данных могут быть
элементы нескольких классов. Это может привести к существенным проблемам. При использова-
нии классификатора желательно получить набор признаков, при котором снижается число призна-
ков и разница между классами становится более очевидной. При использовании набора данных,
представленного на графике вверху, один класс обозначен кружочками, а другой — звездочками.
Анализ главных компонентов привел бы к проектированию на вертикальную ось, поскольку при
этом будет сохранена дисперсия набора данных, но такое решение неприемлемо, так как невозмож-
но будет различить представителей классов, что видно по осям, полученным после анализа (они
наложены на набор данных). В нижней строке показаны проекции на эти оси. На графике слева
внизу видна проекция на первый главный компонент, который имеет более высокую дисперсию, но
плохо разделяет классы, а справа внизу показана проекция на второй основной компонент, который
имеет значительно меньшую дисперсию (см. масштаб), но дает лучшее разделение
величину
v^Bvi
wJ’Evi *
Данная задача равносильна максимизации v^Bvi при условии, что = 1.
В свою очередь, решение обладает следующим свойством:
+ ASt>i = О
для некоторой константы Л. Это называется задачей на обобщенные соб-
ственные значения — если S имеет полный ранг, задачу можно решить, найдя
698 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
1
0,8
0,6
0,4
0,2
0
-0,2
-0,4
-0,6
-0.8
— 1
-1,5 -1 -0,5 0 0,5 1 1,5 2 2,5 3 3,5
Рис. 22.10. При использовании концепции канонических переменных с помощью класса каждого
элемента данных и признаков находится хороший набор линейных признаков. В частности, стро-
ятся оси, максимально разносящие различные классы. На рисунке слева показан набор данных
с рис. 22.9, на график наложена ось, соответствующая первой канонической величине. На рисунке
справа показана проекция на эту ось, причем видно, что классы достаточно разнесены
собственный вектор матрицы 'Е~1В с наибольшим собственным значением
(в противном случае можно использовать специальные программы численного
расчета).
Теперь для каждого vi при 2 < I < р нужно найти признаки, при которых
критерий достигает экстремума и которые независимы от предыдущих vi. Это-
го можно достичь, использовав другие собственные векторы матрицы
Собственные значения описывают разнообразие признаков (которые незави-
симы между собой). Выбрав т < р собственных векторов с наибольшими
собственными значениями, получаем набор признаков, снижающий размер-
ность пространства признаков, сохраняя при этом разнесение классов. Это
не гарантирует наилучшей частоты ошибок классификатора с уменьшенным
числом признаков, но является удобной стартовой точкой процесса снижения
числа признаков относительно структуры категории (рис. 22.11). Подробно-
сти данного процесса и соответствующие примеры можно найти в работах
[Mclachlan and Krishnan, 1996] и [Ripley, 1996].
Если классы имеют разные вторые моменты, это не мешает ввести канони-
ческие переменные. В таком случае матрица Е оценивается как второй момент
всех смещений элементов данных от средних их классов, дальнейший процесс
проходит без изменений. Повторимся, данный подход не является гарантиро-
ванно оптимальным, но на практике он может давать вполне приемлемые
результаты.
Глава 22. Поиск шаблонов с использованием классификаторов
699
X X ЧЧЧЧЧЧЧЧЧ-ч-w———»>XXXZZZXXX Л Л ЛЛЛЛЛЛЛЛ Л Л №wh»>«»x« мчччччч—’^*»^ у V ч х X X X X
Н 1 1 И liHi *** •‘MMMMMMMMMMi'H'i'l M-MiM f J f ! ! i } } i 5 J
n>«w*->w*#www>« »..»««« ^ ^ » «•»«•—»»»»•>
1111»t»% > % туигм<м?? ? mi n 111111 j и i Min л л л z f ? м »? п I?
miw imiirnnHi mHmmm nnyшшшH m
Рис. 22.11. Канонические переменные — эффективное средство решения простых задач сравнения
с шаблоном. На рисунке вверху показаны 10 объектов в различных позах на черном фоне (данные
изображения представляют собой перевыбранные и сглаженные версии изображений из широко
известной базы COIL Нина (Nene) и Нейера (Nayar) и доступны по адресу http://www.es.
columbia.edu/CAVE/research/softlib/coil-20.htnil — версия с 20 объектами — или
http://www.cs.columbia.edu/CAVE/research/softlib/ coil-100.html — версия со
100 объектами). Определить объект по одному из этих изображений относительно просто, по-
скольку объекты наблюдаются на постоянном фоне; они не требуют сегментации. Далее на основе
60 изображений каждого объекта определялся набор канонических переменных. На рисунке внизу
показаны первые две канонические переменные для 71 изображения — 60 настроечных изображе-
ний и 11 дополнительных — каждого объекта (разные объекты помечены различными символами).
Обратите внимание, что кластеры компактны и хорошо разнесены; использовав лишь эту пару
канонических переменных, уже можно добиться эффективной классификации
700 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Алгоритм 22.6. Канонические переменные определяют набор линейных призна-
ков, максимально разделяющих классы
Предположим, что имеется набор элементов данных д различных классов. В каж-
дом классе Пк элементов, элементом данных fc-ro класса является Xk,i при i е
{1,.. .,Пк}. Среднее j-ro класса равно Предполагается, что всего имеется р
признаков (т.е. что Xi — р-мерные векторы).
Обозначим через Ji среднее средних классов, т.е.
Запишем
В = —у - д)(м3 - Д)т
У 3=1
Предположим, что все классы имеют одинаковый второй момент S, который либо
известен, либо оценен как
1 _ ( Пс 1
е = т?—т 52 {52^^ - - рс)т >
1V -** £ I I
с=1 \i=l J
Единичные собственные векторы матрицы (которые записаны
как vi, V2,... ,vd, причем предполагается, что векторы упорядочены по
убыванию собственных значений, вектор п отвечает наибольшему собственному
значению) определяют набор признаков со следующим свойством:
• проекция в базис {vi,..., vjt} дает fc-мерный набор линейных признаков, наи-
лучшим образом разделяющий средние классов
22.4. НЕЙРОННЫЕ СЕТИ
Как правило, ни простые параметрические модели плотности, ни модели на
основе гистограмм использовать нельзя. Тогда нужно либо применять более
сложные модели плотности (этот подход рассмотрен в данном разделе), либо
непосредственно искать границы областей решений (раздел 22.5).
22.4.1. Ключевые идеи
Нейронная сеть — это метод параметрической аппроксимации, доказавший
свою полезность в построении моделей плотности. Нейронные сети обычно ап-
проксимируют векторную функцию f некоторого входного вектора х рядом
уровней. Каждый уровень формирует вектор выходов, каждый из которых пред-
Глава 22. Поиск шаблонов с использованием классификаторов
701
ставляет собой результат действия некоторой нелинейной функции, которую
обозначим ф, на различные аффинные функции входов. Используем удобную
уловку — добавим ко входным значениям дополнительный компонент с фикси-
рованным значением “1”, в результате чего получим линейную функцию этого
расширенного входного вектора. Сказанное означает, что уровень с расширен-
ным входным вектором и и выходным вектором v можно записать как
V = [0(wi • tl), ф(Ы2 • и), . . . 4>(wn • **)] ,
где Wi — это подгоночные параметры, которые используются для улучшения
аппроксимации.
Обычно нейронная сеть использует для аппроксимации функции последова-
тельность уровней, причем каждый уровень использует расширенные входные
векторы. Например, если аппроксимировать векторную функцию д вектора х
двухуровневой сетью, получим следующее:
р(а?) « /(®) = [0(W21 • ?/),0(w22 • ?/),.• . </>(w2n • 3/)] ,
где
y(z) - [0(шц z), 0(wi2 z), . . . 0(W17n • z), 1]
И
z(a?) = [an, X2,, Xp, 1].
Некоторые элементы адць или W2fc можно положить равными нулю; в этом слу-
чае f(x) не завит от некоторых элементов вектора у. Если это так, уровень
называется частично связанным; в противном случае он именуется полно-
связным. Разумеется, уровень 2 может также быть полностью или частично
связанным. Параметр п ограничивается размерностью f, а р — размерностью
вектора х, но нет оснований утверждать, что т должно быть равно п или р.
Как правило, т больше обоих этих чисел. Использовав аналогичное построе-
ние, можно получить трехуровневую сеть (или сеть с большим числом уровней,
что бывает редко). Для графического представления нейронных сетей обычно
используются окружности, изображающие переменные, и стрелочки, изобража-
ющие соединения, которые могут быть ненулевыми; таким образом получается
представление, раскрывающее базовую структуру аппроксимации (рис. 22.12).
Выбор нелинейности
Имеется множество возможных выборов функции ф. Например, можно ис-
пользовать пороговую функцию, принимающую значение 1, если аргумент
больше нуля, и 0 в противном случае. Представить отклик уровня, использую-
щего пороговую функцию, довольно легко: каждый компонент уровня меняет
702 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 22.12. Для иллюстрации нейронных сетей часто используются диаграммы вида, приведенно-
го на рисунке. Каждая окружность представляет переменную, и окружности обычно маркируются
переменными. При таком изображении “уровни” очевидны. Представленная сеть является двух-
уровневой сетью, описанной в тексте; стрелочки указывают, что коэффициент, связывающий две
переменные в аффинной функции, может быть ненулевым. Данная сеть является полносвязной,
поскольку представлены все стрелочки. Возможно существование сетей, стрелочки которых про-
пускают уровни
значение с нуля на единицу вдоль некоторой гиперплоскости. Это означает, что
выходной вектор принимает различные значения в каждой ячейке распределе-
ния гиперплоскостей в пространстве входов. Сети, использующие уровни такого
вида, трудно настроить, поскольку пороговая функция недифференцируема.
Гораздо чаще используется функция ф, меняющаяся гладко (но относи-
тельно быстро) от нуля до единицы, которая часто называется сигмоидальной
функцией. Один из популярных примеров таких функций — логистическая
функция вида
= ------7-,
v 14- ех^
где и отвечает за резкость изменения функции при х — 0. Отметим, что го-
ризонтальными асимптотами не обязательно являются у = 0 и у = 1. Другая
популярная сигмоидальная функция — это функция
ф(х-, р, А) = A th (глг) ,
горизонтальные асимптоты которой проходят через А и —А. Данные нелиней-
ности иллюстрируются на рис. 22.13.
Глава 22. Поиск шаблонов с использованием классификаторов
703
Рис. 22.13. На рисунке слева приведена последовательность сигмоидальных функций, полученных
с использованием ф(х\р) = при различных значениях 1л На рисунке справа приведен ряд
сигмоидальных функций, полученных с использованием А) = A th (х/р) при различных
значениях v. В обоих случаях указаны соответствующие значения р. В общем случае при х,
близком к центру диапазона, функция линейна; при больших или меньших х она существенно
нелинейна
Создание классификатора с помощью нейронной сети
Для создания нейронной сети, аппроксимирующей некоторую функцию
д(х), собирается набор образцов хе. Далее требуется построить сеть, дающую
один выход на каждую размерность вектора д. Запишем эту сеть как п(я:;р),
где р — вектор параметров, содержащий все u)zj. Для данного входа желатель-
ным вектором выхода является ое; как правило, ое = д(хе}. Теперь получаем
вектор р, минимизирующий величину
Error (р) = 521п^е;р) - °е12>
х ' е
используя подходящие программные средства оптимизации (| введена для
упрощения последующих выражений, каких-либо математических причин для
ввода такого коэффициента нет).
Наиболее важный частный случай — когда величина д{х) предназначена
для аппроксимации апостериорной вероятности классов при имеющихся дан-
ных. Подобная апостериорная вероятность неизвестна, так что ее значение
нельзя использовать в процессе настройки. Взамен этого требуется, чтобы сеть
давала один выход для каждого класса. Для данного образца хе желаемый вы-
ход ое строится как вектор, содержащий единицу в компоненте, соответствую-
щем классу данного образца, и нуль — во всех остальных компонентах. Далее
сеть настраивается как и ранее, и выход нейронной сети рассматривается как
модель апостериорной вероятности. Для классификации входа х формируется
п(х;р), а затем выбирается класс, соответствующий наибольшему компоненту
этого вектора.
704 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
22.4.2. Минимизация ошибки
Напомним, что сеть настраивается через минимизацию по всем образцам
суммы разностей желательного и реального выходов, т.е. минимизацию вели-
чины
Error(p) = “ °ei2
как функции параметров р. Получить р, набор параметров, минимизирующих
ошибку, можно различными способами. Один из них — метод спуска градиента:
по некоторой начальной точке pi вычисляется новая точка pl+1:
Pi+i = Pi ~ e(v Error),
где € — некоторая малая константа.
Стохастический градиентный спуск
Запишем ошибку для образца е как Error{p\xe), так что общая ошибка —
это Error(p) — Error(р; хе). Если теперь использовать метод градиентного
спуска, для обновления параметров можно применить алгоритм
Pi+i = Pi~ Error
(где градиент берется относительно р и оценивается в точке р?). Такой подход
обоснован, поскольку если е — достаточно малая величина, получаем
Error(pi+1) = Error(pi — eV Error) ~
~ Error(j^) — e(V Error • V Error) <
< Errorfjp^,
причем равенство достигается только в экстремуме. Здесь возникает проблема:
оценка ошибки и ее градиента включает работу с суммой по всем образцам, ко-
торая может быть довольно большой. Хотелось бы избежать вычисления данной
суммы; это возможно, если образцы выбирать случайным образом, вычислять
градиент только для этого отдельного образца и обновлять параметры с ис-
пользованием этого градиента. При таком подходе, именуемом стохастическим
градиентным спуском, для обновления параметров используется следующий
алгоритм:
Pi+l =Pi~^ Error(p-, Xе)
(где градиент берется относительно точки р, оценивается в точке pit а образцы
выбираются случайно и равномерно, причем выборка производится на каждом
этапе). В таком случае ошибка не обязательно будет снижаться при каждой
Глава 22. Поиск шаблонов с использованием классификаторов
705
выборке, но математическое ожидание ошибки будет снижаться до относи-.
тельно малого значения б. В частности, имеем
E(Error(pi+1)) = E(Error(pi — eV Error(p- xe)) «
« Е(Егтог(рг) — e(V Error • V Error (p; sce)) =
= Error^Pi) — e— ^^(V Error • V Error(p; xe)) =
= Еггог(рг) — е I V Error •
— Error (рЛ — — (V Error • V Error) <
n
< Errortpi), если |VE| > 0.
После достаточного числа этапов, на которых градиент вычисляется по одно-
му образцу (образцы выбираются случайно и равномерно на каждом этапе),
функция фактически минимизируется. Это объясняется тем, что математиче-
ское ожидание снижается на каждом этапе, за исключением случая попадания
в минимум. Собственно градиент можно вычислять по-разному; одна эффек-
тивная стратегия — это обратное распространение ошибки (backpropagation),
описанное в разделе 22.7.
Алгоритм 22.7. В схеме стохастического градиентного спуска при минимиза-
ции ошибки нейронной сети производные вычисляются по схеме обратного рас-
пространения ошибки
Выбрать ро (случайным образом)
С помощью обратного распространения (алгоритм 22.9) вычислить
V Еггог(хе\р0)
рп=ро~ eV Error (®е;ро)
Пока \Еггог(рп) — £?гтог(ро)| не станет малым или |ро — р„| не станет малым
Ро=РП
Выбрать образец (sce,oe) случайно и равномерно из настроечного набора
С помощью обратного распространения (алгоритм 22.9) вычислить
V Еггог(хе-,р0)
рп=ро- eV Error (хе\ро)
конец
22.4.3. Когда прекратить настройку
Как правило, градиентный спуск не прекращается, пока не будет найден
точный минимум. Как ни странно, но именно это обеспечивает устойчивость.
706 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Для примера рассмотрим форму функции ошибок в окрестности минимума.
Если функция ошибок резко меняется в минимуме, то производительность се-
ти достаточно чувствительна к выбору параметров. Отсюда следует, что сеть
обобщается плохо. Предположим, что настроечные образцы составляют поло-
вину большего набора; если настроить сеть по другой половине, будет получен
незначительно отличающийся набор параметров. Это означает, что сеть с те-
кущими параметрами будет плохо работать с этой второй половиной данных,
поскольку при небольшом изменении параметров ошибка меняется значительно.
Если функция ошибок меняется в минимуме нерезко, особого смысла стре-
миться именно к точке минимума нет, достаточно войти в разумную ее окрест-
ность, поскольку известно, что данного минимального значения ошибки с помо-
щью настроечного набора мы не достигнем. Как правило, схема стохастического
градиентного спуска используется до тех пор, пока а) каждый образец не будет
использован хотя бы один раз (в среднем) и б) уменьшение значения функции
не упадет ниже определенного порога.
Более сложный вопрос — это сколько уровней использовать, и сколько эле-
ментов использовать на каждом уровне. Данный вопрос (выбор модели) обыч-
но разрешается с помощью экспериментов. Читателям, которых заинтересовала
данная тема, стоит прочесть работы [Ripley, 1996] и [Haykin, 1999].
22.4.4. Поиск лиц с использованием нейронных сетей
Одним из приложений, иллюстрирующих полезность классификаторов, яв-
ляется поиск лиц. При фронтальной проекции и довольно грубой шкале все
лица выглядят приблизительно одинаково. Имеются светлые области в районе
лба, щек и носа, темные области вокруг глаз, бровей, основания носа и рта.
Отсюда следует предложение организовать поиск лиц как изучение всех окон
изображения фиксированного размера на предмет нахождения окон, которые
выглядят как лицо. Изучая изображения более крупного или мелкого масшта-
ба, можно найти большие или меньшие лица.
Поскольку лицо, которое освещается слева, выглядит отлично от лица, кото-
рое освещается справа, окна изображения должны корректироваться с учетом
освещения. В общем случае эффекты освещения выглядят как набор быстрых
изменений по линейному закону (одна сторона светлая, другая темная, с глад-
ким переходом между ними), так что можно просто подобрать по значениям
яркости характеристику освещения и отнять ее от окна изображения. Дру-
гой способ — прологарифмировать изображение, а затем вычесть линейную
характеристику, подобранную по логарифмам. Плюсом такого подхода (при от-
носительно грубой модели) является то, что эффекты освещения при логариф-
мировании становятся аддитивными. Впрочем, в литературе не упоминается,
что логарифмирование существенно улучшает положение дел на практике. Еще
один подход — это выравнивание окна с помощью гистограмм, цель которого —
добиться, чтобы гистограммы окна и набора эталонных изображений совпали
(выравнивание с помощью гистограмм описано на рис. 22.14).
Глава 22. Поиск шаблонов с использованием классификаторов
707
Рис. 22.14. Выравнивание с помощью гистограмм. Для отображения уровней яркости одного
изображения так, чтобы оно имело такую же гистограмму, что и другое изображение, использу-
ются кумулятивные гистограммы. На рисунке вверху изображены две кумулятивные гистограммы
с вложенными соответствующими изображениями. Для преобразования левого изображения (чтобы
оно имело ту же гистограмму, что и правое) берутся значения с левого изображения, считывается
процентное значение с кумулятивной гистограммы этого изображения и с обратной кумулятивной
гистограммы правого изображения получается новое значение. Изображение слева описывается
линейной пилообразной функцией (которая выглядит как нелинейная, поскольку связь яркости
и освещенности описывается нелинейной функций); изображение справа — это корень кубический
из пилообразной функции. Результат — линейная пилообразная функция, уровни яркости которой
отображены так, чтобы они давали ту же гистограмму, что и корень кубический из пилообразной
функции — показан на рисунке в нижней строке
Как только с изображения удалены эффекты освещения, требуется опре-
делить, присутствует ли на нем лицо. Ориентация лица неизвестна, так что
следует либо определить ее, либо использовать классификатор, нечувствитель-
ный к ориентации. В работе [Rowley, Baluja and Kanade, 19986] описано весьма
удачное средство поиска лиц, которое вначале определяет ориентацию окна
с помощью одной нейронной сети, а затем окно переориентируется так, чтобы
оно представляло собой фронтальную проекцию, и передается другой нейрон-
ной сети (см. рис. 22.15 и цикл работ [Rowley, Baluja and Kanade, 1996, 1998a]).
Средство определения ориентации имеет 36 выходных блоков, каждый из ко-
торых кодирует диапазон ориентаций в 10°; новая ориентация окна выбирается
по наибольшему выходу. Примеры выходов данной системы представлены на
рис. 22.16.
708 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 22.15. Архитектура системы поиска лиц, описанной в [Rowley, Baluja, and Kanade, 1998а].
Окна изображения, имеющие фиксированный размер, корректируются под стандартное освещение
с использованием концепции выравнивания гистограмм; после того они передаются нейронной сети,
которая оценивает ориентацию окна. Затем окна переориентируются и передаются второй нейрон-
ной сети, которая определяет, присутствует ли лицо. Перепечатано из Н.А. Rowley, S. Baluja and
Т. Kanade, "Rotation invariant neural-network based face detection", Proceedings, Computer Vision
and Pattern Recognition, 1998. © 1998 IEEE
22.4.5. Сверточные нейронные сети
Нейронные сети не ограничиваются архитектурой, описанной ранее; суще-
ствует множество альтернатив (хорошее начальное представление об этом во-
просе можно получить из работ [Bishop, 1995] или [Haykin, 1999]). Одной архи-
тектурой, доказавшей свою полезность в приложениях компьютерного зрения,
является сверточная нейронная сеть. Основная ее идея — области изображе-
ния удобно представлять выходами фильтров. Более того, можно получить ком-
позиционное представление, подействовав фильтрами на собственно представ-
ление, полученное посредством выходов фильтров. Предположим, например,
что ищутся рукописные знаки; здесь, похоже, удобно будет использовать от-
клик фильтров ориентированных полос. Если получить карту ориентированных
полос на изображении, на эту карту можно подействовать другим фильтром,
и выход этого фильтра укажет пространственную связь полосок.
Исходя из данных соображений предлагается использовать систему филь-
тров для построения набора связей между примитивами, а затем использо-
вать сверточную нейронную сеть для классификации на основе полученного
представления. Особых преимуществ предварительного выбора фильтров нет;
взамен их можно определять при решении конкретной задачи.
В работе [Lecun, Bottou, Bengio and Haffner, 1998] строится несколько клас-
сификаторов рукописных цифр, в которых используются сверточные нейронные
сети. Базовая архитектура этой системы представлена на рис. 22.17. Классифи-
катор применяется к окну изображения 32 х 32. На первом этапе (на рисун-
ке — С1) используется шесть характеристических карт. Для получения карты
изображение сворачивается с ядром фильтра 5 х 5, к результату прибавляется
константа, а затем на него действуют сигмоидальной функцией. Каждая карта
Гпава 22. Поиск шаблонов с использованием классификаторов
709
Рис. 22.16. Типичные выходы системы поиска лиц; на каждое окно наложено схематическое изоб-
ражение маски, которое используется для определения присутствия лица. Ориентация лица ука-
зывается конфигурацией глазных отверстий маски. Перепечатано из Н.А. Rowley, S. Baluja and
Т. Kanade, “Rotation invariant neural-network based face detection”. Proceedings, Computer Vision
and Pattern Recognition, 1998. © 1998 IEEE
710 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
вход
32x32
Cl:карты
признаков
6 штук 28 х 28
СЗ: карты
признаков
16 штук 10 х 10
S4: карты
признаков
КштукЗхЗ
CS: уровень F6: уровень ВЫХОД
84 10
признаков
6 штук 14 х 14
Полное соединение
Свертки
Подвыборка Свертки
Гауссово соединение
Полное соадхиамме
Рис. 22.17. Архитектура сверточной нейронной сети LeNet 5, используемой для распознавания
рукописных символов. Уровни, помеченные буквой “С", являются сверточными, уровни, помечен-
ные “S", — субдискретизованные. Для представления окна изображения при увеличении масштаба
в классификаторе общего вида увеличивается число признаков. Наконец, окно передается пол-
носвязной нейронной сети, дающей очищенный выход, который затем классифицируется через
определение расстояния до элементов набора канонических шаблонов символов. Перепечатано из
Y. Lecun et al., "Gradient-Based Learning Applied to Document Recognition”, Proceedings, IEEE,
1998. © 1998 IEEE
имеет собственное ядро и константу, причем данные параметры настраиваются,
а не выбираются заранее.
Поскольку точное положение характерного элемента не должно быть важ-
ным, разрешение характеристической карты уменьшается, что дает новый набор
из шести карт (на рисунке — S2). Данные карты — это субдискретизован-
ные версии предыдущего уровня; такая субдискретизация достигается за счет
усреднения соседей по участку 2x2, умножения на параметр, прибавления
параметра и пропускания результата через сигмоидальную функцию. Парамет-
ры умножения и сложения определяются. Далее идут наборы пар уровней по-
добного типа, причем число карт увеличивается с уменьшением разрешения.
Наконец, приходим к уровню с 84 выходами, каждый из которых снабжается
блоком, принимающим в качестве выхода любой элемент предыдущего уровня.
Описанная сеть используется для распознавания рукописных печатных сим-
волов. Выходы рассматриваются как изображение 7 х 12 символа, очищенного
по сравнению с рукописной версией, и могут теперь сравниваться с канониче-
ским образом этого символа. Отметим, что данная сеть может успешно очищать
искаженные символы. Выходной символ определяет класс знака, каноническое
изображение которого наиболее близко к очищенной версии знака. Тестовая
ошибка конечной сети равна 0,95% (рис. 22.18).
22.5. МАШИНА ОПОРНЫХ ВЕКТОРОВ
С точки зрения сообщества компьютерного зрения классификаторы — это
не цель, а средство. Таким образом, когда появляется простая, надежная и эф-
фективная техника, она получает довольно широкое распространение. Одной
Глава 22. Поиск шаблонов с использованием классификаторов
711
.? И / 79 Ь И I
^757**39?$-
Л(7?9/Л1У'б'
Ч / I 9 0 1 g 3 9 Ч Частота ошибок (%)
4 £ ( У / 4 / <5 i О 5%|.
7542^^1197 4% \
4 4 22139910 3% Л
в АЗ X О 7 3 Г Л' 7 2*"\^
о I «-и ь о к? ъ ‘*т
7/iMfelSt/ 0 4 8 12 16 20
z ’ Итерации с настроечным набором
Рис. 22.18. На рисунке слева показан небольшой поднабор базы данных MNIST рукописных
знаков, которые использовались для настройки и тестирования LeNet 5. Обратите внимание на
значительное разнообразие в пределах одного знака. На рисунке справа частота ошибок LeNet 5 на
настроечном и тестовом наборах изображена как функция числа итераций схемы спуска градиента,
проведенных на наборе из 60 000 образцов (т.е. если на горизонтальной оси отложено значение 6,
процесс настройки требовал 360 000 итераций). Обратите внимание, что в некоторой точке ошибка
настройки уменьшается, а ошибка теста — нет; это связано с тем, что производительность системы
оптимизирована относительно настроечных данных. Значительное отличие ошибок является
указателем на переобучение (overfitting). Перепечатано из Y. Lectin et al., "Gradient-Based
Learning Applied to Document Recognition", Proceedings, IEEE, 1998. © 1998 IEEE
из подобных техник является машина опорных векторов (Support Vector Ma-
chine — SVM), которую используют, когда требуется построить классификатор
по образцам (возможен один вариант, когда это неразумно, — если выборки
подчиняются известному распределению; впрочем, такое бывает очень редко).
Ниже представлен обзор основных идей этого подхода и приводится несколько
примеров, демонстрирующих пригодность названной техники.
Предположим, что дан набор N точек Xi, принадлежащих к двум классам,
которые мы обозначим 1 и —1. Данные точки снабжены метками классов, ко-
торые будем записывать как гц\ таким образом, предлагаемый набор данных
можно записать следующим образом:
{(®Ь1/1)» • • • »(®n,уи}} -
Требуется определить правило, согласно которому предсказывается знак у для
любой точки х\ данное правило и есть искомый классификатор.
Далее разделим задачу на два случая: либо данные линейно сепарабельные,
либо нет. Поскольку линейно сепарабельные данные — более легкий случай,
начнем с него.
712 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 22.19. Построение гиперплоскости для плоского набора данных с использованием класси-
фикатора на основе опорных векторов. Черные кружочки представляют данные, относящиеся к
одному классу, а белые — к другому. На рисунке также изображена выпуклая оболочка каждого
набора данных. Наиболее консервативным является выбор гиперплоскости, максимизирующей
минимальное расстояние от оболочек до гиперплоскости. Для построения такой гиперплоскости
строится кратчайший отрезок, соединяющий оболочки, и через его середину перпендикулярно
строится гиперплоскость. Отметим, что при таком подходе гиперплоскость определяется лишь
частью данных. Отдельный интерес представляют точки каждой выпуклой оболочки, соотнесенные
с минимальным отрезком между оболочками. Использование этих точек для определения
гиперплоскости описано в тексте
22.5.1. Машина опорных векторов для линейно сепарабельных
наборов данных
В линейно сепарабельных наборах данных можно так выбрать w и b (кото-
рые представляют гиперплоскость), что
yi (w xj + Ь) > О
для любой точки-образца (обратите внимание на отдельный учет знака yt). Та-
кое выражение записывается для каждой информациоииой точки, а набор всех
выражений — это система условий на выбор w и Ь. Данные условия выражают
следующее ограничение: все образцы с отрицательными yi должны лежать с од-
ной стороны гиперплоскости, а все образцы с положительными yi — с другой.
Фактически, поскольку набор образцов конечен, существует семейство раз-
деляющих гиперплоскостей. Каждая такая гиперплоскость должна отделять вы-
пуклую оболочку одного набора образцов от выпуклой оболочки другого. Наи-
более консервативным является выбор гиперплоскости, максимально удаленной
от обеих оболочек. Для этого ближайшие точки двух оболочек соединяются
и через середину этой линии перпендикулярно строится гиперплоскость.
Глава 22. Поиск шаблонов с использованием классификаторов
713
Алгоритм 22.8. Нахождение машины опорных векторов для линейно сепарабель-
ных данных
Условные обозначения: дан настроечный набор из N образцов
{(xi.S/i),.. .,(xN,yN)} , где 2/i принимает значения 1 или —1.
Найти машину опорных векторов: сформулировать и решить дуальную задачу
оптимизации:
N N
максимизировать У^а< — - У^ cti(yiyjXi • xj)aj
t t,j=i
при условии Qi > О
N
И У2 = 0
i=l
Теперь w = и Для любой точки-образца Xi, где не равно нулю,
получаем, что yi(w • sc< 4- Ь) = 1, откуда находится значение Ь.
Классифицировать точку: любая новая точка классифицируется следующим об-
разом:
/(sc) = sign (w х -I- Ь) =
= sign oayiX • sc^ 4- =
(n \
У2 + Ь) j
1 /
Данная гиперплоскость максимально удалена от каждого набора в том смыс-
ле, что она максимизирует минимальное расстояние от точек-образцов до ги-
перплоскости (рис. 22.19).
Теперь можно выбрать масштаб w и 6, поскольку одновременное умноже-
ние этих величин на положительное число не влияет на справедливость усло-
вий yi(w • Xi 4- b) > 0. Это означает, что w и b можно выбрать так, чтобы для
каждой информационной точки выполнялось условие
yi (w • sc< 4- b) > 1
и чтобы равенство достигалось по крайней мере в одной точке каждой ги-
перплоскости. Предположим теперь, что равенство достигается при Хк, при
этом ук = 1, и равенство достигается при xit при этом yi = —1. Сказанное
714 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
означает, что точка х^ находится с одной стороны гиперплоскости, a xi —
с другой. Более того, расстояние между xi и гиперплоскостью минимально
(по всем точкам, лежащим с той же стороны гиперплоскости, что и xi), то
же справедливо и для точки х^. Обратите внимание, что может существовать
несколько точек, для которых выполняется это условие.
Из сказанного следует, что w (а^ — aj2) — 2, так что
dist(xk, гиперплоскость) + dist(xi, гиперплоскость) = ‘ ~
(w b\ w , . 2
—т xi 4- —- I = — • (ал - ж2) = г—г.
|w| lwl/ lwl lwl
Это означает, что максимизация расстояния равносильна минимизации (1/2)w- w
Окончательно получаем следующую задачу условной минимизации:
минимизировать (1/2)to w
При УСЛОВИИ yi (w Х{ 4- 6) > 1,
причем условие записывается для каждой информационной точки.
Нахождение машины опорных векторов
Для решения задачи можно ввести множители Лагранжа oti и получить
лагранжиан
N
(l/2)w w — oti (yi (w • sci 4- b) — 1).
i
Этот лагранжиан требуется минимизировать относительно w и Ъ и максими-
зировать относительно а»; данное условие называется условием Каруша-Куна-
Такера (Karush-Kuhn-Tucker) и часто описывается в учебниках по оптимизации
(см., например, [Gill, Murray, Wright, 1981]). После незначительных преобра-
зований получаем следующие требования:
N
У2 аМ = °
1
и
N
to = У2
1
Второе выражение объясняет, почему аппарат называется машиной опорных
векторов. В общем случае гиперплоскость определяется относительно ма-
лым числом точек-образцов, а положение других точек несущественно (см.
рис. 22.19: все, что находится внутри выпуклой оболочки каждого набора об-
разцов, не влияет на выбор гиперплоскости, причем на выбор также не влияет
Глава 22. Поиск шаблонов с использованием классификаторов
715
большинство вершин оболочки). Поэтому ожидается, что большинство а» бу-
дут равны нулю, а информационные точки, соответствующие ненулевым а,
(которые и определяют гиперплоскость), называются опорными векторами
(support vectors).
Подставляя теперь данные выражения в исходную задачу, после преобразо-
ваний получим дуальную задачу:
N 1 N
максимизировать У^ а* — - У^ ca(yiyj&i • ®j)«j
i i,J=l
при условии а» > О
N
и У2Qijzi=°-
<=1
Следует обратить внимание, что в выведенном критерии фигурирует квадро-
форма из множителей Лагранжа. Данная стандартная задача численного ана-
лиза называется задачей квадратичного программирования. Для ее решения
можно успешно применять стандартные пакеты, но стоит также сказать, что
эта задача имеет специфические особенности (может быть много переменных,
большинство из которых равно нулю в решении), которые можно использовать
и которые рассмотрены в работе [Smola et al.t 2000].
22.5.2. Поиск пешеходов с использованием машины опорных
векторов
При довольно грубой шкале пешеходы имеют характерный “леденцовооб-
разный” вид — широкий торс на более узких ногах. Поэтому чтобы найти
пешеходов на снимках, предлагается использовать машину опорных векторов.
Общая стратегия аналогична описанной в разделе 22.4.4 для поиска лиц: каж-
дое окно изображения, имеющее фиксированный размер, передается классифи-
катору, который определяет, есть ли на изображении пешеход. Число пикселей
в окне может быть большим, кроме того, известно, что многие пиксели несу-
щественны. Для примера с поиском лиц эта проблема решалась сокращением
изображения до овальной формы, после чего проводился собственно поиск ли-
ца. К пешеходам подобный подход применить сложнее, поскольку здесь разброс
внешнего вида больше.
Требуется сформулировать признаки, которые помогут определить, присут-
ствует ли в окне пешеход. Естественное желание — попытаться получить набор
признаков из набора образцов. Для решения этой задачи можно предложить
множество алгоритмов (причем все они — это по-разному организованный по-
иск). В работе [Oren, Papageorgiou, Sinha, Osuna and Poggio, 1997] предлага-
ется исследовать локальные признаки — вейвлетные коэффициенты (wavelet
coefficient), представляющие собой отклик специально подобранных фильтров
с локальной поддержкой — и использовать усреднение. В частности, авторы
716 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 22.20. На рисунке слева показаны средние по настроечному набору различных импульсных
коэффициентов в различных положениях на изображении. Коэффициенты, превышающие (про-
странственное) среднее значение, показаны темным, остальные — светлым. Ожидается, что шум
имеет среднее значение, т.е. что сильно светлые или сильно темные коэффициенты — это инфор-
мация, которая может помочь определить пешеходов. На рисунке справа приведена сетка, изоб-
ражающая вспомогательную область для вычисленных признаков. Обратите внимание, что отсюда
достаточно точно определяются границы пешеходов. Перепечатано из С. Papageorgiou, М. Oren
and Т. Poggio, "A general framework for object detection”. Proceedings, International Conference on
Computer Vision, 1998. © 1998 IEEE
утверждают, что фон изображения пешехода выглядит как шум, а средний от-
клик предлагаемых фильтров на шум известен. Это означает, что привлекатель-
ными признаками являются те, усреднение которых по многим изображениям
пешеходов отличается от отклика на шум. Если усреднить отклик определен-
ного фильтра в определенном положении по большому числу изображений,
и среднее похоже на шумовую характеристику, то фильтр в таком положении
не является особо информативным (рис. 22.20).
После выбора признаков настройка выполняется так же, как описано в раз-
деле 22.5. Данный поход эффективен (рис. 22.21 и 22.22), хотя значительного
улучшения производительности можно добиться за счет самонастройки (раз-
дел 22.1.5).
22.6. ПРИМЕЧАНИЯ
До сих пор нет общепринятого мнения относительно того, какой класси-
фикатор использовать. Взамен этого обычно применяются те схемы и методы,
которые подходят к конкретной поставленной задаче. Для краткости не были
рассмотрены многие полезные техники; хорошими обзорами по ним являются
работы [Bishop, 1995], [Hastie, Tibshirani and Friedman, 2001], [Haykin, 1999],
[McLachlan and Krishnan, 1996], [Ripley, 1996] и [Vapnik, 1996, 1998].
Выбор границы областей решений определенно легче подбора апостериорной
модели, в то же время при использовании концепции границы областей реше-
ний невозможно строго сказать, насколько данный образец соответствует одно-
му или другому классу, что автоматически делается при наличии апостериорной
модели. Более того, подбор границы областей решений требует знания классов,
Глава 22. Поиск шаблонов с использованием классификаторов
717
Рис. 22.21. Примеры пешеходов, определенных с использованием метода, предложенного в работе
[Papageorgiou, Oren and Poggio, 1998]. Хотя обнаружены не все пешеходы, частота определения
довольно высока. Кривая срабатывания та же, что и на рис. 22.22. Перепечатано из С. Papageor-
giou, М. Oren and Т. Poggio, “A general framework for object detection”, Proceedings, International
Conference on Computer Vision, 1998. (c) 1998 IEEE
в которые должны распределяться рассматриваемые объекты. При этом отнюдь
не очевидно, что можно построить однозначную иерархию классов для объек-
тов, фигурирующих в задачах распознавания. Кроме того, оба подхода могут
требовать большого числа образцов. Как правило, чем сильнее используемая
модель, тем меньше образцов требуется для построения классификатора.
Когда объекты имеют большое число степеней свободы, действительно хо-
рошие классификаторы построить сложно, если нет детальной модели этой
свободы. Кроме того, классификатор будет сложно использовать, если образ-
цы имеют различное число признаков. В обоих случаях необходима какая-то
структурная модель или ее эквивалент. Впрочем, оценка, представление и рабо-
та с функциями плотности вероятности в пространствах большой размерности
(что характерно для задач компьютерного зрения) практически невозможны,
если не сделать очень сильные допущения. Более того, можно легко постро-
ить вероятностные модели, для которых логический вывод будет практически
неосуществим. Пока не ясно, как построить модели, с которыми будет легко
работать в тех масштабах, что требуются в задачах компьютерного зрения.
Данная тема в настоящее время является интенсивно исследуемым на-
правлением в сфере компьютерного зрения и обучающихся систем. Сложно
сказать, как для конкретной задачи выбрать метод, пожалуй, лучшей на насто-
ящий момент является адаптационная техника. В данной и следующей главах
приводятся примеры, которые иллюстрируют диапазон существующих подходов
(причем некоторые из них откровенно удачны), но четкой теории на настоящий
момент еще нет.
Альтернативный подход к настройке одного глобального классификатора —
настройка нескольких классификаторов с последующим объединением их вы-
ходов. Данная стратегия обычно именуется буферным подходом (boosting).
718 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Частота ложноположительных результатов
Рис. 22.22. Кривая срабатывания приемника для системы определения пешеходов, предложенной
в работе [Papageorgiou, Oren, and Poggio, 1998]. Перепечатано из С. Papageorgiou, М. Oren and
Т. Poggio, "A general framework for object detection", Proceedings, International Conference on
Computer Vision, 1998. © 1998 IEEE
Буферный подход наиболее успешно применяется в классификаторах со сравни-
тельно простыми границами областей решений; их обычно легко настроить, но
такие классификаторы, как правило, отличаются плохой производительностью.
Как правило, настраивается классификатор, а затем в образцах настроечного
набора определяются представители, на которых классификатор ошибся. Далее
эти образцы выделяются (либо ошибки, связанные с этими образцами, учи-
тываются с большими весовыми коэффициентами, либо в настроечный набор
вводятся копии этих образцов), а затем настраивается новый классификатор.
Определяются образцы, на которых ошибся новый классификатор, затем они
выделяются, и снова повторяется настройка; данный процесс осуществляется
итеративно. В конце выходы всех классификаторов объединяются с помощью
набора весовых коэффициентов.
Определение кожи
По теме определения кожи написано немало работ; в данной главе мы вы-
брали те, которые отвечают поставленным дидактическим целям. Область при-
менения данной технологии включает поиск обнаженных людей ([Fleck, Forsyth
and Bregler, 1996], [Forsyth and Fleck, 1999]), а также поиск и сопровождение
лиц и рук ([Par, Seo, An and Chung, 2000], [Yoo and Oh, 1999]). Существует
много техник, и чтобы получить о них общее представление, можно исполь-
зовать сравнительный анализ подходов (см. работу [Brand and Mason, 2000]).
Производительность систем поиска лиц, похоже, повышается при использова-
нии систем обнаружения кожи, определенным образом настроенных; естествен-
ным кажется изучение детекторов кожи параллельно с детекторами лиц, хотя
авторам неизвестны работы, в которых принят такой подход.
Глава 22. Поиск шаблонов с использованием классификаторов
719
Поиск лиц
В настоящее время довольно интересна тема построения детекторов лиц на
основе техник сравнения с шаблоном. Общая стратегия здесь — это предста-
вить области изображения, возможно, скорректированные с учетом изменения
освещения, для использования классификаторами того или иного вида. В на-
стоящей главе авторы не придерживались хронологического стиля изложения;
работа [Schneiderman and Kanade, 1998] вышла после работы [Rowley, Baluja
and Kanade, 1996], написанной одновременно с важной работой [Sung and Pog-
gio, 1998]. Последняя работа не рассматривалась только по дидактическим при-
чинам. Еще в одной важной работе, [Osuna, Freund and Girosi, 1997], описана
система поиска лиц, успешно использующая машину опорных векторов — этот
класс методов в настоящее время широко распространен.
Отметим, что также важна задача распознавания лиц (“чье это лицо?”),
и еще не ясно, стоит ли разделять задачи поиска и распознавания. Здесь сле-
дует отметить работы [Brunelli and Poggio, 1992, 1993]. В качестве примеров
важных направлений исследования можно назвать распознавание по очень ма-
лому числу образцов (хотелось бы добиться распознавания по одному образ-
цу; работа [Beymer and Poggio, 1995]); распознавание по различным проекци-
ям (публикация [Beymer, 1994]); и управление изменениями, возникающими
вследствие вариации освещения (см. [Adini, Moses and Ullman, 1994, 1997],
[Georghiades, Belhumeur and Kriegman, 2000], [Jacobs, Belhumeur and Basri,
1998], [Georghiades, Kriegman and Belhumeur, 1998]).
Поиск пешеходов
Здесь следует обратить внимание на то, что пешеходов можно найти с ис-
пользованием схемы сравнения с шаблоном. Как было показано выше, пешеход
имеет вид леденца на палочке. Пешеходы могут теряться, если они поднимают
руки (поскольку при этом они уже не имеют формы леденца), однако значи-
тельную часть времени они все же проводят с руками, вытянутыми по бокам,
так что сделать разумную оценку числа пешеходов можно всегда. Более того,
весьма характерно движение пешеходов (см. [Papageorgiou, Oren and Poggio,
1998], [Papageorgiou and Poggio, 1999, 2000]).
ЗАДАЧИ
22.1. Предположим, что рассматриваются измерения х в некотором простран-
стве признаков S. Имеется открытое множество D, каждый элемент ко-
торого относится к классу 1, а каждый элемент множества S — D опре-
деляется к классу 2.
а) Покажите, что
R(s) = Pr {1 —> 2 | с использованием s} L(1 —> 2)4-
+Pr {2 —> 1 [ с использованием s} L(2 —* 1) =
720 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
= f р(1 | ж) dxL(l 2) + [ р(2 j ж) dxL(2 —> 1).
Js-d Jd
б) Почему при вычислении суммарного риска не учитывается граница
множества D (которая совпадает с границей множества S — £>)?
22.2. В разделе 22.2 отмечалось, что если все функции плотности вероятности
принадлежности к классу имеют равные вторые моменты, классифика-
тор, представленный в алгоритме 22.2, сводится к схеме сравнения двух
выражений, линейных по х.
а) Покажите, что это так.
б) Покажите, что для двух классов необходима только проверка знака
выражения, линейного по я:.
22.3. В разделе 22.3.1 был определен признак и, где значение и в г-й информа-
ционной точке выражалось как щ = v • (ж» — р). Покажите, что и имеет
нулевое среднее.
22.4. В разделе 22.3.1 был определен ряд признаков и, где значение и в г-й
информационной точке выражалось как щ = и • (ж» — д). Там же было
сказано, что v — собственные векторы матрицы вторых моментов элемен-
тов данных Е. Покажите, что различные признаки линейно независимы;
примите во внимание, что собственные векторы симметричной матрицы
ортогональны.
22.5. В разделе 22.2.1 говорилось, что кривая срабатывания приемника ин-
вариантна относительно выбора априорной вероятности. Докажите это
утверждение.
Упражнения
22.6. Постройте программу, которая помечает на изображении пиксели, ве-
роятно принадлежащие коже; для этого следует сравнить минимум два
типа классификаторов. Данное упражнение стоит проделать аккуратно,
поскольку фильтры кожи имеют много сфер применения.
22.7. Постройте один из детекторов лиц, описанных в тексте.
22.7. ПРИЛОЖЕНИЕ I: ОБРАТНОЕ РАСПРОСТРАНЕНИЕ ОШИБКИ
Сложность при настройке нейронных сетей с использованием стохастиче-
ского спуска градиента состоит в том, что параметр V Error невозможно вы-
числить из-за его величины. Эффективная стратегия вычисления V Error назы-
вается обратным распространением (backpropagation). В этом подходе произ-
водные получаются через рассмотрение многоуровневой структуры нейронной
сети как функции функции функции и т.д.
Вернемся к двухуровневой нейронной сети, которую запишем как
/(ж) = [<Xw2i • у\0(w22 у), •. • у)],
Глава 22. Поиск шаблонов с использованием классификаторов
721
где
?/(*) = [0(WH • z), 0(W12 z), . . . • z), 1]
И
z(®) = [xi,X2,... ,xp, 1].
Требуется вычислить
d Error
dwkltm
где Wfc/.m — m-й компонент Wki- Поскольку нас интересует W2/,m» рассмотрим
вначале коэффициенты выходного уровня и запишем
д Error _ д Error dfk _
dW2l,m dfk dw2i,m
__ d Error dfi _
dfi dw2i,m
=E{wm-“?)^} =
=E {(/<(“') - °пй<(м«'))} =
e
e
Здесь использовано обозначение
ф21 - Ы
где производная оценивается в точке и — W21 • У, и введено обозначение
<5а = (/<(*')
Обратите внимание, что оценка этой производной включает члены, относящи-
еся КО ВХОДУ (?/т(я5е)) И ВЫХОДУ (<^) УРОВНЯ.
Рассмотрим теперь коэффициенты второго уровня. Нас интересует wu>m,
так что получаем
д Error _ ( д Error dfk 1 _ f d Error dfi dyj 1 _
dwu,m I dfk dwu,m) A* 1 dfi dyj dwu,m J
К
_ f d Error dfk 1 dyi _
I “ dfk dyi J dwu.m
722 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
= Yl{^^k^-ok^kw3k>1} 3^77) =
е к к ,гп J
= 1 52 “ °к)^2к^2к,(} Фи^тп > =
elk J
= 52 1 52 {^2kw2fc,l} ФиХтп > .
elk J
В этом выражении
оценивается в точке и = W2k • у и
Фи = вИ
оценивается в точке и = гиц • z. Если теперь записать
= 52
к
получим
’ в
Как и ранее, данная сумма включает член, вычисленный при определении
предыдущей производной, члены, зависящие от производной на этом уровне,
и члены, зависящие от входа. Отметим без доказательства, что если бы в се-
ти был третий уровень, производная ошибки по параметрам на этом третьем
уровне имела бы сходную структуру — функция членов, зависящих от произ-
водной второго уровня, зависящих от производных на третьем уровне и завися-
щих от входа (все это — следствие агрессивного применения цепного правила).
Отсюда следует двухэтапный алгоритм:
1. Оценить выход сети для каждого образца. Данный этап обычно называется
прямым проходом.
2. Оценить производные, используя промежуточные члены Этот этап обычно
называется обратным проходом.
Описанный процесс дает производные общей ошибки относительно пара-
метров. Можно получить еще одно упрощение: схема стохастического спуска
градиента была изменена так, чтобы не требовалось вычислять сумму оши-
бок и их градиентов по всем образцам. Поскольку вычисление градиента —
Глава 22. Поиск шаблонов с использованием классификаторов
723
это линейная задача, для определения градиента ошибки по одному образцу
сумма просто выносится перед выражениями для градиентов. Итоговая схема
представлена в алгоритме 22.7.
Алгоритм 22.9. Использование обратного распространения для вычисления про-
изводной ошибки подбора в двухуровневой нейронной сети по одному образцу
относительно его параметров
Обозначения:
Запишем двухуровневую нейронную сеть как
= [0(W2i ' J/),0(W22 • у), . . . 0(w2n ‘ J/)]
y(z) = [Ф(адц • z), ^>(wi2 • z),... • z), 1]
z(a:) = [zi, Z2,... ,xp, 1]
(p — вектор, содержащий все параметры). Запишем ошибку для отдельного об-
разца как
Error* = Error(p;x*) =
= (I) 1/(®е;р) -°е12
Требуется вычислить
д Error*
где Wki,m — пг-й компонент wkt.
Прямой проход: вычислить f(x*;p), сохранив все промежуточные переменные
Обратный проход: вычислить
<$21 = СМ®') - О*)ф21
,t &Ф
Ф21 — =—, оцененная в u = w2i • у
ди
OW2l,m
Теперь вычислить
= У {^2fcU>2k,l} Фи
к
дф
фи = -7Т-, оцененная в u = wn • z
ди
дЕ* гс . еч
}
724 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
22.8. ПРИЛОЖЕНИЕ II: МАШИНА ОПОРНЫХ ВЕКТОРОВ ДЛЯ НАБОРОВ
ДАННЫХ, НЕ ЯВЛЯЮЩИХСЯ ЛИНЕЙНО СЕПАРАБЕЛЬНЫМИ
Часто разделяющая гиперплоскость не существует. Для рассмотрения этого
случая введем набор фиктивных переменных, & > 0, представляющих сте-
пень нарушения указанного условия. Теперь новые условия можно переписать
следующим образом:
yi (w - + Ь) > 1 -
также модифицируем целевую функцию, чтобы учесть степень нарушения усло-
вий, в результате чего приходим к задаче
1 А
минимизировать -w w + С V, &
2 i^i
при условии yi (w - Х1 + b) > 1 - &
и & > 0.
Здесь С указывает, насколько существенно нарушение условий относительно
расстояния между точками и гиперплоскостью. Итак, получаем следующую
дуальную задачу:
N N
максимизировать ~ 2 52 °ь(У*Узх* ‘
» *J=i
при условии С > а* > 0
N
и otiyi = 0.
i=l
Снова получаем
N
W =y^otjyiXjt
1
но теперь восстановление b по решению дуальной задачи становится несколько
более интересным. Для каждой выборки, где С > &i > 0 (обратите внимание,
что это — строгое неравенство, в отличие от условий), фиктивная переменная &
будет равна нулю. Это означает, что
N
У2 ‘tDj + b-yi
J=1
для данных значений г. Из приведенных выражений получаем 6. Как и ранее,
задача оптимизации формулируется как задача квадратичного программирова-
ния, хотя нет гарантий, что условие а» = 0 будет выполняться для многих точек.
Глава 22. Поиск шаблонов с использованием классификаторов
725
22.9. ПРИЛОЖЕНИЕ III: ИСПОЛЬЗОВАНИЕ МАШИНЫ ОПОРНЫХ
ВЕКТОРОВ С НЕЛИНЕЙНЫМИ ЯДРАМИ
Для многих наборов данных маловероятно, что гиперплоскость даст хоро-
ший классификатор. Взамен этого обычно требуется граница областей реше-
ний с более сложной геометрией, для чего можно отобразить вектор признаков
в некоторое новое пространство и найти гиперплоскость в этом новом про-
странстве. Например, если имеется плоский набор данных, который наверняка
должен разделяться плоскими коническими сечениями, можно применить к на-
бору данных отображение
(х2,а:1/,2/2,гг,?/).
Граница классификатора, которая в данном новом пространстве признаков яв-
ляется гиперплоскостью, в старом пространстве является коническим сечением.
В таком виде описанная идея не очень полезна, поскольку может потребовать-
ся отображение данных в пространство более высокой размерности (например,
предположим, что известно, что граница классификатора имеет степень 2, а
данные — десятимерные, в этом случае придется отображать данные в про-
странство размерности 65).
Запишем отображение как х' — ф(х) и сформулируем задачу оптимизации
для новых точек х{-, обратите внимание, что х[ входит только в слагаемые вида
/ Z
что можно записать как Ф(хг) • ф(х3). Данный член (далеко не всегда поло-
жительный) дает мало информации о ф. В частности, в задаче оптимизации
отображение не фигурирует явно. Если все же решить эту задачу, то оконча-
тельный классификатор запишется как
(n \ /N \
(atytx' • x'i + b) j — sign I У2 (<*»2/»^(®) ’ Ф(х*) + 6) ) .
i / \ i /
Предположим, что дана функция к(х,у), положительная для всех пар х, у.
Можно показать, что при различных технических условиях, не представляю-
щих для нас интереса, имеется некоторое ф, при котором к(х, у) — ф(х) ф(у).
Это позволяет применить небольшую хитрость — взамен явного построения ф
получаем аппроксимацию к(х,у), которую и используем в качестве ф. В част-
ности, дуальная задача оптимизации формулируется следующим образом:
N N
максимизировать У^о;; ” х У7 ^(у»!/^®*,®^))0^
г ijj=l
726 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
ТАБЛИЦА 22.2. Некоторые ядра машины опорных векторов
Форма ядра Качественные свойства функции ф, представленной этим ядром
(ж • y)d все ф — одночлены степени d
(Х‘У + c)d все ф — одночлены степени d или ниже
th(a® • у + b)
eXp(_g.7^-y))
при условии а» > О
N
и ~ °-
i=i
В результате получаем такой классификатор
/ N
/(ж) = sign I У (aiyik(x,xi) + 6)
Разумеется, в полученных выше уравнениях предполагается, что набор данных
в новом пространстве признаков, представленном через к, является сепара-
бельным. Это может быть не так, и тогда задача формулируется следующим
образом:
максимизировать
n i N
52 оц(у1Уэк(Х',Хэ))аэ
i ij=l
При условии С > Сц > О
N
и у а*у* — °-
В результате получаем такой классификатор
(N
У ®i) + b)
1
Выбирать к(х,у) можно по-разному. Главное, чтобы эта функция была положи-
тельной для всех значений х и у. Некоторые типичные альтернативы показаны
в табл. 22.2. Похоже, принципиальных методов выбора ядер нет; на практике
обычно перебираются различные формы и выбирается та из них, которая дает
наименьшую ошибку при перекрестной проверке.
23
Распознавание через связь
шаблонов
Часто наблюдаемый объект обладает внутренними степенями свободы, а это
означает, что его внешний вид может сильно варьироваться (например, лю-
ди могут двигать руками и ногами, рыбы деформируются при плавании, змеи
извиваются и т.д.). Данное явление может чрезвычайно затруднить сравнение
с шаблоном, поскольку потребуется либо классификатор с гибкими границами
(и множество образцов), либо много различных шаблонов.
Многие объекты названного типа содержат небольшое число компонентов,
довольно строго упорядоченных. Можно попытаться согласовать данные компо-
ненты как шаблоны, а затем определить, какие объекты присутствуют, изучив
предложенные связи между найденными шаблонами. Например, вместо поиска
лица по одному полному шаблону лица, можно искать глаза, нос и рот с при-
емлемым взаимным расположением.
Данный подход имеет несколько потенциальных преимуществ. Во-первых,
узнать шаблон глаза может быть легче, чем узнать шаблон лица, поскольку
первая структура очевидно проще. Во-вторых, можно получить и использо-
вать относительно простые вероятностные модели, поскольку могут существо-
вать некоторые свойства независимости, которые можно будет использовать.
В-третьих, возможно, удастся согласовать большое число объектов с относи-
тельно небольшим числом шаблонов. Хороший пример этого явления — морды
728 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
животных; почти все животные с характерными мордами имеют глаза, нос
и рот, отличается лишь пространственное расположение этих элементов. На-
конец, из сказанного следует, что для построения сложных объектов можно
использовать простые отдельные шаблоны. Например, люди могут двигать ру-
ками и ногами, и похоже, что обучить цельный явный шаблон обнаруживать
людей целиком значительно сложнее, чем получить отдельные шаблоны для
частей тела и вероятностную модель, описывающую их степени свободы.
Рассматриваемая тема не настолько хорошо изучена, чтобы к ней выработал-
ся какой-либо стандартный подход. В то же время основной вопрос достаточно
очевиден — как закодировать набор связей между шаблонами в форму, с кото-
рой легко работать? В данной главе изучается ряд различных подходов к данной
задаче. Во-первых, каждый шаблон может голосовать за объекты, которые он
может представлять, а затем каким-то образом считается число голосов (раз-
дел 23.1). Если построить некоторую явную вероятностную модель, для описа-
ния деталей пространственных отношений можно использовать больше весовых
коэффициентов. Данную модель можно получить из функций правдоподобия;
по сути, нужна функция распределения вероятностей, дающая большое значе-
ние, когда конфигурация компонентов подобна объекту, и малое — в противном
случае. Тогда поиск объектов превращается в поиск шаблонов, которые при под-
становке в вероятностную модель дают большие значения (раздел 23.2). Нужно
отметить, что следует внимательно относиться к сокращению поиска; один со-
ответствующий подход рассмотрен в разделе 23.3. Сложность этого подхода
заключается в том, что даже при сокращении поиск может быть дорогим. В то
же время при определенном классе вероятностных моделей можно провести
эффективный поиск. Данные модели представлены в разделе 23.4, а два их
приложения описаны в разделах 23.5 и 23.6.
23.1. ПОИСК ОБЪЕКТОВ ЧЕРЕЗ ГОЛОСОВАНИЕ ЗА СВЯЗИ МЕЖДУ
ШАБЛОНАМИ
Простые модели объектов могут давать достаточно эффективное распозна-
вание. Простейшая модель — это рассматривать объект как набор фрагментов
изображения (небольших окрестностей элементов характерного вида) несколь-
ких различных типов, формирующих образ (pattern). Чтобы определить, какой
образ наблюдается, находятся все фрагменты, каждый из которых голосует за
все образы, в которые он входит. То изображение, за которое было отдано наи-
большее число голосов, и считается присутствующим. Хотя данная стратегия
проста, она довольно эффективна. Ниже описываются методы поиска фрагмен-
тов, а затем представляется ряд последовательно усложняющихся реализаций
данной стратегии.
23.1.1. Описание фрагментов изображения
Небольшие фрагменты изображения могут иметь достаточно характерный
вид, обычно если они имеют много ненулевых производных (например, в углах).
Глава 23. Распознавание через связь шаблонов
729
Ниже описана одна система (согласно работам (Schmid and Mohr, 1997а,&]), где
использовалось данное удачное свойство. Авторы этого цикла работ искали уг-
лы на изображении, часто именуемые точками интереса (см. [Schmid, Mohr
and Bauckhage, 2000]). Далее они оценивали набор производных функции ярко-
сти в этих углах и набор функций от производных, инвариантных относительно
вращения, трансляции, определенного изменения масштаба и изменения осве-
щения. Данные признаки назывались инвариантными локальными потоками
(invariant local jets). Подробное описание данных признаков уведет нас от ос-
новной темы, поэтому отметим лишь, почему данный подход ценен: поскольку
комбинации инвариантны, ожидается, что их значения будут одинаковыми на
различных проекциях объекта.
Далее будем предполагать, что фрагменты изображения можно разбить на
несколько классов. Представителей каждого класса можно получить, использо-
вав несколько изображений каждого объекта — как правило, соответствующие
фрагменты будут относиться к одному классу, но, возможно, вследствие шу-
ма иметь несколько отличающиеся инвариантные локальные потоки. Подходя-
щий набор классов можно определить либо посредством ручной классификации
фрагментов, либо посредством кластеризации фрагментов-образцов (несколько
лучший метод!). Теперь требуется определить, когда два набора инвариантных
локальных потоков представляют один класс фрагментов изображения. Шмид
(Schmid) и Mop (Mohr) для проверки использовали расстояние Махаланоби-
са (Mahalanobis distance) между векторами признаков тестируемого фрагмента
и фрагмента-образца; если замер был меньше некоторого порога, тестируемый
фрагмент считался идентичным образцу.
Обратите внимание, что по сути описан классификатор (он распределяет
фрагменты по классам, представленным образцами, или отказывается от клас-
сификации), а фрагменты — это шаблоны. Программу согласования шаблонов
можно построить с помощью любой техники, описанной в главе 22, не исполь-
зуя признаки, инвариантные относительно вращения. Для этого можно исполь-
зовать настроечный набор, содержащий версии каждого фрагмента-образца,
которые отличаются вращением и изменением масштаба, при варьирующихся
условиях освещения, так чтобы классификатор мог выучить, что вращение,
изменение масштаба и освещения не влияет на идентификацию фрагмента.
Преимущество использования инвариантных признаков заключается в том, что
классификатору не нужно узнавать об инвариантности из настроечного набора.
23.1.2. Голосование и простая порождающая модель
Дано изображение, для которого находятся интересные точки и в каждой
точке изображения классифицируется фрагмент изображения. Следующий во-
прос: какие образы находятся на изображении? Для ответа на этот вопрос
можно построить соответствие между фрагментами изображения и образами.
Предположим, что всего на изображении имеется Ni фрагментов. Более то-
го, предположим, что на изображении либо присутствует один образ из дан-
ной коллекции, либо ни одного. Отдельный фрагмент может порождаться либо
730 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 23.1. На графике показано число голосов за каждый образ, записанный для определенного
изображения при простой схеме голосования. Обратите внимание, что хотя корректное соответствие
(модель #0) получило максимальное число голосов, есть еще три кандидата, получивших более по-
ловины от такого числа голосов. Перепечатано из С. Schmid and R. Mohr, “Local grayvalue invari-
ants for image retrieval", IEEE Trans. Pattern Analysis and Machine Intelligence, 1997. © 1997 IEEE
единственным присутствующим образом, либо шумом. Впрочем, образы, как
правило, содержат фрагменты не всех классов. Это означает, что утвержде-
ние о присутствии определенного образа равнозначно утверждению о том, что
некоторые фрагменты изображения порождены шумом (поскольку может при-
сутствовать только один образ, а имеются фрагменты изображения, которые
принадлежат классам, не содержащимся в текущем образе).
Окончательно приходим к простой порождающей модели изображения. Ко-
гда образ присутствует, возникнуть могут только фрагменты некоторых опре-
деленных классов. Разрабатывая данную модель, получаем ряд алгоритмов со-
поставления образов с наблюдаемыми картинами.
Простейшая версия данной модели получается в предположении, что об-
раз порождает все фрагменты классов, которые он может породить, а значит
требуется, чтобы шумом порождалось минимальное число фрагментов. Данное
предположение сводится к простой схеме голосования. Берется каждый фраг-
мент изображения и отдается голос за каждый образ, который может породить
фрагменты этого класса. Побеждает образ, набравший наибольшее число го-
лосов, он же считается присутствующим на изображении. Данная стратегия
может быть эффективной, хотя ее использование приводит к некоторым про-
блемам (рис. 23.1).
23.1.3. Вероятностные модели для голосования
Полученный простой процесс голосования можно интерпретировать через
вероятностную модель, поскольку при этом проявляются сильные и слабые сто-
Глава 23. Распознавание через связь шаблонов
731
роны описанного подхода. Используемую порождающую модель можно превра-
тить в вероятностную, предположив, что фрагменты генерируются независимо
и случайным образом, причем также предполагается, что объект присутствует.
Запишем
Р{фргамент г-го типа есть на изображении | присутствует j-й образ} =
и
Р{фрагмент i-го типа | нет образа} = р,х.
В простейшей модели предполагается, что для каждого образа j, pij — р, ес-
ли образ может породить данный фрагмент, и 0 — в противном случае. Более
того, предполагается, что = А < р, для всех г. Наконец, предполагается,
что каждый наблюдаемый фрагмент на изображении может порождаться либо
отдельным образом, либо шумом. Всего на изображении фрагментов. При
таких допущениях для вычисления функции правдоподобия нужно знать толь-
ко, какие фрагменты порождены образом, а какие — шумом. В частности, если
взять функцию правдоподобия изображения при данном образе и предполо-
жить, что пр фрагментов порождены данным образом, а п» — пр фрагментов
порождены шумом, можно записать:
Р(интерпретация | образ) = ХПр р^п*~Пр\
причем данная величина больше для больших значений пр. В то же время,
поскольку не каждый образ может породить любой фрагмент, максимальный
доступный выбор пр зависит от выбранного образа. Принятый метод голосо-
вания равнозначен выбору образа с максимальным возможным правдоподобием
при данной (простой) порождающей модели.
Из таких рассуждений виден источник определенных сложностей: если об-
раз малоправдоподобен, следует учесть дополнительную (априорную) инфор-
мацию. Более того, вследствие шума некоторые фрагменты могут порождаться
легче, чем другие — если не учесть этот факт, при подсчете голосов некото-
рые образы будут в более выгодном положении. Наконец, при данном объекте
некоторые фрагменты могут быть более вероятными, чем другие. Например,
углы значительно чаще будут встречаться на образе шахматной доски, чем на
изображении полосок зебры.
Доработка порождающей модели
Учесть все вышесказанное и соответствующим образом усовершенствовать
простейшую модель (фрагменты появляются независимо при условии наличия
образа) относительно просто. Предположим, что имеется N различных типов
фрагментов. Далее предположим, что фрагменты каждого типа генерируются
со своей вероятностью всеми изображениями и шумом. Теперь предположим,
732 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
что на изображении присутствует пц экземпляров фрагментов Z-го типа. Более
того, Пк из них генерируется образом, а остальные — шумом.
Функция правдоподобия для j-ro образа равна
( П1 фрагментов типа 1 порождено образом, >
• • • »
р nN фрагментов типа N порождено образом j-й образ
и (nil — ni) типа 1 — шумом,
• - • э
\ (пллг — п,у) порождено шумом )
Теперь поскольку фрагменты возникают независимо при данном образе и шум
не зависит от образа, правдоподобие равно
^(фрагменты порождены образом | >-й образ)
Р(фрагментов порождено шумом).
Первый член равен
Р(тип 1 | j-й образ)”хР(тип 2 | j-й образ)”2 • •
Р(тип N | j-й образ) пЛГР(шум),
что можно оценить как
Р1з Ръз PNj
Теперь предположим, что фрагменты порождаются шумом независимо друг от
друга. Это означает, что шумовую составляющую можно записать следующим
образом:
Р(тип 11 шум)(гЧ1-"х) • • • Р(тип N | шум/п,Л'~Пл'\
что можно оценить как
(пи-щ) (niN-nN)
Это означает, что правдоподобие можно записать как
пп1пп2 . . "N _(п£1-"1) . , AniN-nN)
P13P23 PnjPix Pnx
Для каждого типа фрагментов к возможны два случая: если pkj > ркх, то мак-
симум достигается при nt — Щк', в противном случае максимум достигается
при Пк = 0. Обозначим через ttj априорную вероятность того, что изображение
Глава 23. Распознавание через связь шаблонов
733
Позиция базы данных и р ее Согласование
ближайших характерных элементов
Рис. 23.2. Взамен голосования за сопоставимые фрагменты можно голосовать за наборы фраг-
ментов. При таком подходе голос регистрируется только в том случае, когда фрагмент сопоставим
с определенным объектом, определенная доля его соседей также сопоставима с объектом, а углы
между тройками сопоставимых фрагментов имеют определенные значения. Такая стратегия су-
щественно снижает число случайных сопоставлений, что видно из рис. 23.3. Перепечатано из
С. Schmid and R. Mohr, "Local grayvalue invariants for image retrieval”, IEEE Trans. Pattern
Analysis and Machine Intelligence, 1997. (c) 1997 IEEE
содержит j-й образ, а через тго — априорную вероятность того, что оно не содер-
жит ни одного объекта. Это означает, что для каждого типа образов j макси-
мальное значение апостериорной вероятности запишется следующим образом:
где индекс т служит для подсчета значений признаков, для которых pmj > ртх,
al — для подсчета значений признаков, для которых pij < pix. Данная величина
формируется для каждого объекта, а затем выбирается та из них, которая имеет
наибольшее апостериорное значение. Обратите внимание, что данная модель
является реляционной, хотя в действительности мы не вычисляем геометриче-
ские признаки, связывающие образы. Это объясняется тем, что фрагменты свя-
зываются условными вероятностями их появления при данном образе, которые
отличаются для разных образов. Данную модель стоит сравнить с детектором
лиц, описанным в разделе 22.2.2; идейно вероятностные модели идентичны.
23.1.4 . Голосование за связи
Для улучшения простой стратегии голосования можно использовать геомет-
рические связи. Фрагмент сопоставляется с объектом, только когда с объектом
сопоставлены соседние фрагменты и все эти фрагменты образуют подходящую
конфигурацию. Термин “подходящая конфигурация” может быть источником
сложностей, но предположим пока, что объекты сопоставлены с точностью до
плоского вращения, трансляции и масштаба (это предположение разумно, на-
пример, для лиц анфас).
734 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 23.3. На практике использование полулокальных условий существенно увеличивает селектив-
ную силу исходной схемы голосования. На рисунке слева показано число голосов, записанных при
определенном изображении для каждой модели при исходной схеме голосования. Хотя корректное
соответствие (модель #0) получило максимальное число голосов, есть еще три кандидата, полу-
чивших более половины от такого числа голосов. При добавлении полулокальных условий (справа)
корректное соответствие выделяется более явно Перепечатано из С. Schmid and R. Mohr, "Local
grayvalue invariants for image retrieval", IEEE Trans. Pattern Analysis and Machine Intelligence,
1997. © 1997 IEEE
Предположим теперь, что дан фрагмент, соответствующий некоторому объ-
екту. Далее берем р ближайших фрагментов и проверяем, согласуется ли более
50% их с тем же объектом и совпадают ли углы между тройками согласован-
ных фрагментов с соответствующими углами объекта — все это называется
полулокальными условиями (см. рис. 23.2 и 23.3). Если эти две проверки
пройдены, голос за объект, поданный этим фрагментом, регистрируется. Дан-
ную стратегию (изложена согласно [Schmid and Mohr, 1997а,£>]) стоит сравнить
с геометрическим хэшированием (раздел 18.4.2). Отметим, что вероятностную
интерпретацию данного подхода построить довольно трудно — вероятности по-
явления фрагментов теперь зависят от того, где они расположены в образе, а
также от того, какой образ их генерирует.
23.1.5 . Голосование и трехмерные объекты
Хотя подход Шмида и Мора был описан с позиции двумерных образов, его
относительно просто расширить на распознавание трехмерных объектов. Для
этого каждый набор проекций объекта рассматривается как иной двумерный
образ. При наличии достаточного числа проекций этот подход работает, по-
скольку небольшие изменения в двумерном изображении, вызванные малыми
изменениями угла наблюдения, будут компенсироваться разрешенным уровнем
ошибок процесса согласования инвариантных локальных потоков и углов.
Данная стратегия сведения трехмерного распознавания к двумерному при-
меняется довольно широко, но имеет и свои сложности. Основная проблема —
это большое число моделей, что может привести к затруднению процедуры го-
Глава 23. Распознавание через связь шаблонов
735
лосования. Неизвестно также, каково минимальное число проекций, требуемых
для согласования в подобной схеме. Результаты применения данного подхода
можно наблюдать на рис. 25.9.
23.2. РАССУЖДЕНИЯ О СВЯЗЯХ С ИСПОЛЬЗОВАНИЕМ
ВЕРОЯТНОСТНЫХ МОДЕЛЕЙ И ПОИСКА
В предыдущем разделе рассмотрены методы, в которых предполагалось, что
шаблоны условно независимы при данном образе. Для большинства объектов
такое допущение необоснованно (хотя на практике оно может давать крайне
удачные результаты), поскольку между признаками обычно имеются весьма
строгие связи. Например, на лице редко бывает более двух глаз, одного носа
и одного рта; расстояние между глазами примерно равно расстоянию от перено-
сицы до рта; линия, соединяющая глаза, примерно перпендикулярна линии от
переносицы до рта и т.д. В разделе 23.1.4 некоторые из этих условий вводятся
в стратегию голосования, хотя авторам трудно очертить область, где названные
условия стоит разрабатывать.
Поставленная задача остается сложной. Требуется построить модели, кото-
рые представят, что является значимым, и позволят эффективно сформулиро-
вать задачу логического вывода. Мы не можем изложить общепринятый подход
к этому вопросу, поскольку он еще не сформировался; взамен этого ниже опи-
сываются основные подходы и альтернативы.
23.2.1. Соответствие и поиск
В данном разделе исследуются ключевые вопросы использования вероят-
ностной модели для сопоставления фрагментов. Ниже описан общий подход
к этому вопросу. Вначале извлекается интерпретация изображения и вычис-
ляется значение апостериорной вероятности этой интерпретации при данном
изображении. Далее принимаются интерпретации с достаточно большими апо-
стериорными вероятностями.
При такой формулировке не сразу видны практические проблемы (которых
на самом деле множество). Основная из них — неизвестно, какая информация,
полученная с изображения, порождена объектами, а какая — шумом. В общем
случае данная сложность обходится, и задача сводится к задаче установления
соответствий через согласование шаблонов с изображением с последующим ис-
следованием связей между шаблонами. Например, если требуется найти лица,
на изображение действуют рядом различных детекторов (скажем, детекторами
глаз, носа и рта), а затем ищутся допустимые конфигурации.
Соответствие
Из сказанного видна вторая важная проблема — соответствие. Плотность
апостериорной (или совместной) вероятности оценить невозможно, если не
знать значения всех переменных. Это означает, что, по сути, в процессе тре-
буется положить, что один отклик — это левый глаз, второй — правый глаз,
736 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
третий — нос, а четвертый — рот, а после этого оценить апостериорную веро-
ятность. Очевидно, этим поиском важно управлять аккуратно, чтобы не требо-
валось перебирать все возможные соответствия.
Техники, описанные в главе 18, переносятся на поставленную задачу отно-
сительно легко; требуется описать все это в терминах вероятности, но основной
ход рассуждений остается без изменений. Самый важный факт задачи распо-
знавания объектов — при жестких объектах для получения большого числа со-
ответствий можно использовать малое число соответствий — легко переводится
на язык вероятностей, где он звучит так: для жестких объектов соответствия
не являются независимыми.
Вообще, в используемой вероятностной модели для некоторого набора пе-
ременных оценивается плотность совместной вероятности. Назовем множество
значений этих переменных совокупностью (assembly) (используются и другие
термины — группа или гипотеза). Совокупность состоит из набора выходов
детекторов (каждый из которых может выдавать положение, положение и ори-
ентацию или даже больший объем информации) и метки для каждого выхода.
Данные метки определяют соответствия, причем здесь маркировка важна: если,
скажем, детектор глаз не различает левый и правый глаз, следует разделить его
выходы на левый и правый, но при этом нет смысла помечать выход детектора
рта как глаз.
Все совокупности сформировать и проверить невозможно, поскольку обыч-
но их очень много. Например, предположим, что есть детекторы глаз, которые
не различают левый й правый глаза, детекторы носа и детекторы рта, а лицо
состоит из двух глаз, носа и рта. Если всего имеется 7Ve откликов с детекторов
глаз, Nn откликов с детекторов носа и Nm откликов с детекторов рта, поиск
надлежит проводить в пространстве O(N^NnNm) совокупностей. Если вы вни-
мательно изучили главу 18, то вы должны понимать, что это необдуманное
усложнение задачи — основная мысль этой главы состоит в том, что нахо-
дится довольно малое число соответствий, а по нему предсказываются другие
соответствия.
Растущие совокупности и поиск
Итак, процесс согласования можно представлять следующим образом. Соби-
раются наборы откликов детекторов, которые при необходимости маркируются
для установления их роли в финальной совокупности. Процесс сборки явля-
ется последовательным —• малые совокупности расширяются для получения
больших. Вначале берется каждая рабочая совокупность, а затем определя-
ется, можно ли ее сократить, принять как есть или ее следует расширить.
Любая отдельная совокупность состоит из набора пар, каждая из которых —
отклик детектора и метка, причем некоторые доступные метки могут не иметь
соотнесенного с ними отклика детектора. В общем случае при поиске соответ-
ствий имеется рабочий набор гипотез, который может быть довольно большим.
Поиск включает принятие некоторой гипотезы о соответствии, прибавление к
Глава 23. Распознавание через связь шаблонов 737
ней некоторых новых пар и принятие результата в качестве объекта, полностью
устраняя его из рассмотрения или возвращаясь к базе рабочих гипотез.
Поиск соответствий включает три важных компонента.
• Что принять в качестве гипотезы. Если гипотеза о соответствии доста-
точно хороша, возможно, ее не придется расширять.
• Что делать дальше. При поиске соответствий нужно определить, какую
гипотезу о соответствии обрабатывать следующей. В общем случае, хоте-
лось бы использовать потенциально удачную гипотезу. Обычно же легче
определить, чего не надо делать дальше.
• Когда сократить гипотезу. Если нет набора откликов детекторов, кото-
рые можно было бы соотнести с каким-либо поднабором пустых меток
так, чтобы полученная в результате гипотеза удовлетворила бы критерию
классификатора, смысла расширять данный поиск нет.
Формулирование задачи поиска
Для иллюстрации основных идей продолжим использовать задачу поиска
лиц. Предположим, детектор левого глаза дает ненулевой отклик в точке «1,
детектор правого глаза — в точке х%, детектор рта - в ж3 и детектор носа —
в ж4. Предполагается, что лицо расположено в F, и все остальные отклики
детекторов вызваны шумом. Более того, предполагается, что на изображении
либо присутствует единственное лицо, либо лица нет вообще. Итак, требуется
сравнивать величины
Р(одно лицо в F | Хлг = sei, Хпг = жг, Хр = х3, Хн = ж4, все другие отклики)
и
Р(нет лица | Хлг = Ж1,ХПГ = ®2, Хр = жз, Хн — х4, все другие отклики).
Остановка поиска: детектирование
Предположим, что отклики, порожденные шумом, не зависят от присутствия
лица (что вполне правдоподобно). Получаем
Р(одно лицо в F | Хлг = Ж1, Хпг = ®2, Хщ — жз, Хп — Ж4, все другие отклики)
равно
Р(одно лицо в F | Ж1,Ж2,жз,ж4)Р(все другие отклики),
что, в свою очередь, пропорционально
Р(ж1,ж2,жз,ж4 | одно лицо в Р)Р(все другие отклики) Р(одно лицо в F)
738 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
(чтобы не загромождать выражение, некоторые элементы были записаны сокра-
щенно). Определенные группы откликов детекторов можно классифицировать
как порожденные лицом или шумом, сравнивая апостериорную вероятность то-
го, что данная конфигурация порождена лицом, с апостериорной вероятностью
того, что она порождена шумом. В частности, сравниваются величины
Р(®1,я:2,а:з,Ж4 | одно лицо в F)
и
(Р(отклики порождены шумом)Р(нет лица)/Р(одно лицо в F))
(коэффициент допустимой погрешности).
Напомним, что всего имеется две альтернативы — одно лицо и нет лица —
и рекомендуем обратиться к главе по вероятности (web-сайт книги), если сде-
ланные комментарии кажутся непонятными. Итак, наиболее интересным явля-
ется слагаемое, в котором фигурирует функция правдоподобия. Оно сообщает,
представляет ли полная совокупность лицо, но ведь лицо может представлять
и неполная совокупность, значит следует учесть и конфигурации с недоста-
ющими признаками. При этом нужно определить апостериорную вероятность
того, что лицо присутствует при данных некоторых признаках, и сравнить ее
с апостериорной вероятностью того, что данные признаки порождены шумом.
Когда группа признаков удовлетворяет критерию классификации (апосте-
риорная вероятность наличия лица превышает апостериорную вероятность от-
сутствия лица), поиск, безусловно, можно прекращать. Возможно, проверять
все возможные признаки для определения наличия лица будет не нужно. Если
конфигурация явно указывает на наличие лица, а не на последствия шума, то
можно утверждать, что лицо присутствует, и прекращать поиск.
Проиллюстрируем сказанное на примере. Предположим, что требуется опре-
делить, представляют ли правый глаз, рот и нос лицо. Для оценки совместной
вероятности необходимо (с использованием нашей модели) оценить ряд шумо-
вых составляющих и величину
Р(Хдг = пропущено, Хиг = ®2,Хр = хзДн = ®4 | одно лицо в F).
При этом необходимо, чтобы модель могла объяснить, как был пропущен при-
знак; проще всего предположить, что детектор не дал отклика (возможны и дру-
гие варианты) и что сбой детектора не зависит от откликов других детекторов.
Получаем
Р(пропущено,Х2, хз,Х4 | лицо)
Глава 23. Распознавание через связь шаблонов
739
равно
Р(лг
не дал отклика | Xi)P(Xi,X2,a:3,®4 | лицо)<£Х”1
(запись снова несколько сокращена). Если теперь вероятность сбоя детектора
не зависит от положения признака (как правило, в приложениях компьютерного
зрения так и бывает), получаем
Р(пропушено,Ж2, агз,®4 | лицо)
равно
Р(лг не дал отклика) J Р(.Х’1,я:2,®з}®4 | лицо)</Х1.
Это не означает, что поиск можно сокращать, если конфигурация не пред-
ставляет лицо при пропущенных признаках, поскольку может существовать
определенное положение пропущенного признака, при котором конфигурация
представляет лицо; как показано в разделе 23.3, нужно аккуратно определить
границы, в которых можно сокращать поиск. Если решение, что объект присут-
ствует, принято без согласования всех компонентов, это происходит по одной
из двух причин: а) пропущенные компоненты не были обнаружены, но кон-
фигурация найденных компонентов настолько характерна, что сбой детектора
является несущественным; б) другие компоненты еще не найдены, но конфи-
гурация остальных детекторов настолько характерна, что это несущественно.
Обратите внимание, что в случае б по-прежнему можно получить отклики дру-
гих детекторов.
23.2.2. Пример: поиск лиц
В цикле работ [Burl and Регопа, 1996], [Leung, Burl and Perona, 1995], [We-
ber, Einhaeuser, Welling and Perona, 2000] построен ряд детекторов лиц, в раз-
личной форме использующих вероятностные модели. В каждой работе выпол-
няется последовательный поиск среди совокупностей, определяются совокуп-
ности, которые следует расширять. Признаки получаются с выходов различных
фильтров, как показано на рис. 23.4. Ниже схематически описана система,
проанализированная в работе [Leung, Burl and Регопа, 1995].
Совокупность представляется вектором расстояний между признаками.
Предполагается, что данные векторы имеют гауссово распределение вероятно-
стей при условии присутствия лица, а для обработки пропущенных элементов
можно обособлять значимые элементы данного распределения. Привлекатель-
ной особенностью описанной модели является то, что после получения доста-
точно большой совокупности, положение новых признаков можно предсказать
следующим образом: а) определить расстояния, при которых условная вероят-
ность будет достаточно большой; б) предсказать по этим расстояниям диапазон
положений признаков (рис. 23.4).
740 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 23.4. Детектор лиц ищет определенные локальные структуры, которые с помощью откликов
фильтров классифицируются согласно их внешнему виду. Подходящее пространственно упорядо-
чение структур дает лица. Связи между точками лица представляются межэлементными расстоя-
ниями, а функции условной вероятности принадлежности к классу имеют гауссово распределение.
В свою очередь это означает, что как только получены некоторые отклики на признаки, положе-
ния других признаков можно предсказать. На рисунке слева иллюстрируется предсказание для
различных положений признаков. Признаки расположены возле глаз, носа и рта, а колебание ме-
жточечных расстояний объясняется индивидуальными вариациями структуры лица. На рисунке
справа иллюстрируется поведение детектора лица в целом, в столбце слева показано лучшее лицо
на изображении, а справа показано второе лучшее лицо, значение апостериорной вероятности для
которого обычно меньше на порядок. Перепечатано из Т. Leung, М. Burl, Р. Perona, “Finding faces
in cluttered scenes using random labeled graph matching", Proceedings, International Conference on
Computer Vision, 1995. (c) 1995 IEEE
23.3. ИСПОЛЬЗОВАНИЕ КЛАССИФИКАТОРОВ ДЛЯ СОКРАЩЕНИЯ
ПОИСКА
Предположим, что дана совокупность, состоящая из правого глаза, рта и но-
са. Если по вероятностной модели можно определить, что не существует воз-
можного положения левого глаза, при котором суммарная совокупность будет
приемлемым представлением лица, смысла расширять ее нет. Напомним, что
если положение для левого глаза есть, можно проверить, больше ли функция
правдоподобия лица, чем некоторая функция числа откликов вследствие шу-
ма, априорных вероятностей и допустимой погрешности. В частности, имеется
некоторое фиксированное значение, которое должна превысить функция прав-
доподобия, чтобы можно было утверждать, что лицо присутствует. Если же
можно утверждать, что не существует значения «1, при котором функция
правдоподобия превысит порог, поиск можно сократить.
Обратите внимание, что данную цепочку рассуждений можно продолжить.
Если есть отклик детектора правого глаза и детектора левого глаза, и если не
существует откликов детекторов носа и рта, при которых апостериорная ве-
роятность превысит порог, поиск можно сократить и не пытаться добавлять
к данной совокупности рот или нос. Впрочем, границы применимости данной
Глава 23. Распознавание через связь шаблонов
741
стратегии определить довольно сложно. Для дальнейшего решения поставлен-
ной задачи можно использовать классификатор.
Классификатор можно рассматривать как представление (грубое) вероят-
ностной модели апостериорной вероятности. Данная модель дает нулевое зна-
чение, когда апостериорная вероятность меньше порога, и ненулевое — когда
она превышает порог. Огромное преимущество данной модели состоит в том,
что ее довольно легко сократить: можно отклонить любую совокупность, если
не существует элемента, при добавлении которого получается что-либо, лежа-
щее в ненулевой области.
23.3.1. Определение приемлемых совокупностей с использованием
проективных классификаторов
Развивать рабочую совокупность нет смысла, если нет какого-либо возмож-
ного пути, согласно которому она может перейти в приемлемую финальную
совокупность. Предположим, что дан классификатор, который может опреде-
лять, приемлема ли финальная совокупность (данный классификатор можно
настроить на большой последовательности образцов).
Финальный классификатор можно использовать для предсказания проверок,
определяющих, стоит ли расширять небольшие группы. По сути, мы отбрасы-
ваем группы, для которых нет шансов, что любой возможный новый набор
элементов сделает группу приемлемой. В конце концов, приходим к проектиро-
ванию границ областей решений классификатора на набор различных факторов.
Например, предположим, что имеется два отклика детекторов глаз: должны ли
они формировать пару? Можно использовать только признаки, порожденные
данными глазами, поскольку неизвестно, какие еще элементы находятся в со-
вокупности, а следовательно, их нельзя использовать для сравнения признаков.
В частности, возникает вопрос: есть ли такой набор элементов (т.е. нос и рот),
что при присоединении его к этой группе результат прошел бы через классифи-
катор? На данный вопрос отвечает классификатор, граница областей решений
которого получена проектированием границы областей решений совокупности
лица в пространство, натянутое на признаки, вычисленные по имеющимся двум
глазам (рис. 23.5).
Проектируя классификатор в компоненты, в которых возможна обработка
малых групп, можно сократить набор групп, в котором производится поиск для
определения большого набора сегментов, передаваемых основному классифи-
катору. Использование описанной стратегии на практике требует определенной
аккуратности. Важно иметь хорошо проектирующиеся классификаторы — гра-
ницы областей решений должны проектироваться в границы областей решений,
которые можно представить разумно легко. С этим можно справиться (детали
мы здесь приводить не будем) и полученные в результате классификаторы мож-
но использовать для относительно эффективного нахождения людей и лошадей
в довольно простых случаях (рис. 23.6 и рис. 23.7; работы [Forsyth and Fleck,
1997], [Ioffe and Forsyth, 1998]).
742 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Характерный элемент,
вычисленный по
первой позиции
Характерный элемент, вычисленный по второй позиции
Рис. 23.5. Классификатор, который принимает большие группы, может использоваться для пред-
сказания проверок, определяющих потенциально полезные малые группы. Предположим, что требу-
ется сгруппировать два элемента: эта группировка приемлема только в том случае, если точка, вме-
щающая по одному признаку для каждого элемента, лежит в затененном множестве. Существуют
элементы, которые не могут появиться в данных группах, поскольку признаки, вычисленные по эле-
ментам, лежат вне приемлемого диапазона, так что не существует второго элемента, который сдела-
ет пару приемлемой. Таким образом можно получить классификаторы, определяющие приемлемый
диапазон путем проектирования основного классификатора в его факторы, как показано на рисунке
23.3.2. Пример: поиск людей и лошадей с использованием
пространственных отношений
Предположим, что на изображении требуется найти людей; естественный
подход — это найти возможные сегменты тела и поразмышлять об их конфи-
гурации. Эффективно это можно сделать в некоторых частных случаях. Один
(потенциально важный) — это если рассматриваемые люди неодеты (что поз-
волит либо искать такие изображения, либо избегать их). В этом случае для
поиска сегментов тела можно использовать поиск кожи (см. раздел 22.1.1), а
затем построить расширенные области изображений с (грубо) параллельными
краями (см. раздел 24.1), содержащими точки телесного цвета. Полученные рас-
ширенные области изображения потенциально представляют многие сегменты
тела на изображении.
Теперь с помощью совокупностей данных сегментов на изображении можно
проводить поиск людей. Например, предположим, что люди наблюдаются лишь
спереди; в таком случае можно искать совокупности девяти сегментов, содер-
жащих левый верхний сегмент руки, левый нижний сегмент руки и т.д. плюс
туловище. Все наборы из девяти сегментов принимать непрактично, так что бу-
дет использоваться описанная ранее технология сокращения поиска. В резуль-
тате получаем систему, которая относительно надежно может находить людей
на простых изображениях ([Ioffe and Forsyth, 1998]).
Глава 23. Распознавание через связь шаблонов
743
Рис. 23.6. Лошадь моделировалась как объект из двух ног, тела и шеи. Сегменты вначале
проверялись на предмет принадлежности к одному из названных классов. Затем тестировались
пары “тело+нога" и “тело+шея”. После этого пары “тело+нога” и “тело+шея" с общим телом
проверялись на предмет формирования допустимой тройки “тело+нога+шея”. Далее пары троек
с общим телом и шеей проверялись на предмет формирования четверок. Перепечатано из
D.A. Forsyth and М.М. Fleck, "Body Plans", Proceedings, Computer Vision and Pattern Recognition,
1997. © 1997 IEEE
Описанная методология расширяется и на поиск лошадей. Определяются
все пиксели, которые могут относиться к шкуре (это означает, что они лежат
в нужном диапазоне цветов и локально слаботекстурированны). Далее фор-
мируются расширенные области скрытых элементов (как при поиске людей)
и рассматриваются как потенциальные сегменты тела. Грубая модель лошади
представлялась группой из четырех сегментов (тело, шея, две ноги); порядок
применения тестов иллюстрируется на рис. 23.6. Грубая модель использовалась
по двум причинам: а) она устойчива к изменению ракурса и б) она не требует
точной локализации всех сегментов.
Описанный метод поиска объектов полезен в определенных сферах, как
следует из рис. 23.6 и 23.7, но имеются и существенные открытые вопросы.
Во-первых, не очевидно, в какой последовательности лучше всего тестировать
промежуточные группы. Данный вопрос можно сформулировать и так: какие
проекции границы областей решений приводят к малым спроектированным объ-
емам (и, хотелось бы, к относительно малому числу передаваемых групп). Дан-
ная задача кажется трудной, поскольку в ней фигурируют комбинаторные свой-
ства. Во-вторых, не очевидно, как эффективно обрабатывать множественные
объекты. Если отдельный шаблон встречается только в одном объекте, то при
наблюдении шаблона немедленно получаем гипотезу относительно объекта. Си-
туация существенно усложняется, когда шаблоны могут порождаться многими
объектами. Например, рассмотрим распознавание людей и лошадей: отдельный
744 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 23.7. Для нахождения лошадей можно построить классификатор, подобный описанному в тек-
сте. Эффективность этого подхода иллюстрируется на данном примере. Система находит области
изображения с цветом и текстурой шкуры, которые выглядят как цилиндры (см. раздел 24.1). Ло-
шадь определяется как набор четырех цилиндров — тела, шеи и двух ног — и классификатор,
принимающий данную совокупность, обучается на примерах. Данный классификатор проектиру-
ется в факторы, как описано в тексте, а проекции используются для построения совокупностей
в произвольно выбранном порядке. Результат — это система, которая, хотя и не является эффектно
точной, все же полезна. На рисунке показаны все изображения, которые, по мнению классифика-
тора, содержат лошадей. Набор изображений сформирован из контрольного набора 1 086 снимков,
не содержащих лошадей, и тестового набора, содержащего 100 снимков лошадей. Восстановленные
тестовые изображения содержат лошадей, ракурс наблюдения которых меняется довольно сильно;
одни контрольный снимок содержал животное, которое можно было принять за лошадь. Данный
рисунок аналогичен рис. 25.10. Перепечатано из D.A. Forsyth and. М.М. Fleck, “Body Plans”,
Proceedings, Computer Vision and Pattern Recognition, 1997. (c) 1997 IEEE
Глава 23. Распознавание через связь шаблонов
745
сегмент может порождаться любым из рассматриваемых существ, то же мож-
но сказать и о многих парах. Как упорядочить последовательность тестов для
минимизации работы, требуемой, чтобы решить, с каким объектом мы имеем
дело? Наконец, использование классификатора порождает некоторые досадные
проблемы с ложноотрицательными результатами.
23.4. МЕТОД: СКРЫТЫЕ МАРКОВСКИЕ МОДЕЛИ
До данного момента при обсуждении распознавания весьма важной счита-
лась адаптация вероятностной модели. Даже если для проверки и использо-
валась совместная вероятность, мы не отказывались от схемы поиска соответ-
ствий, весьма подобной той, что рассматривалась в главе 18. В данной главе
рассматривается метод сокращения поиска, аналогичный схеме интерпретаци-
онного дерева. В то же время, возможностей несколько больше: некоторые
вероятностные модели имеют структуру, позволяющую эффективно получить
точно оптимальное соответствие.
Программа чтения языка жестов по видеозаписи некоторого человека долж-
на для каждого жеста давать заключение о внутреннем состоянии. Вывод о
состоянии программа делает, исходя из измерений положения рук, которые ма-
ловероятно будут точными и выверенными, но которые зависят (в идеальном
случае — весьма сильно) от состояния. Жесты сменяют друг друга случайно,
но достаточно упорядочено. В частности, некоторые последовательности состо-
яний появляются редко (например, последовательность букв “wkwk” крайне
маловероятна). Это означает, что для определения реальной картины можно
использовать и измерения, и относительные вероятности различных последо-
вательностей жестов.
Перечислим составляющие задачи такого типа:
• имеется последовательность случайных переменных (в приведенном при-
мере — жесты), каждая из которых условно независима от всех других
при данном предшественнике;
• каждая случайная переменная дает измерение (в приведенном примере —
измерение положения руки), распределение вероятностей которых зависит
от состояния.
Сходные элементы можно найти в таких примерах, как интерпретация дви-
жения танцоров или военных. Этим элементам соответствует крайне полезная
формальная модель, известная как скрытая марковская модель.
Последовательность случайных переменных не обязательно будет вре-
менной. С равным успехом переменные можно упорядочить по пространствен-
ным отношениям. Рассмотрим руку: конфигурация предплечья (грубо говоря)
не зависит от конфигурации остального тела при данной конфигурации плеча;
конфигурация плеча (грубо говоря!) не зависит от иных частей тела при данной
конфигурации торса и т.д. Отсюда получаем последовательность случайных
746 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
переменных с описанными выше свойствами условной независимости. Теперь
у нас уже нет конфигурации предплечья — есть некоторые изменения с опре-
деленными вероятностными отношениями с конфигурацией предплечья (см.
выше).
23.4.1. Формальные вопросы
Последовательность случайных переменных Хп называется марковской це-
пью
Р(Хп = а | Xn-i = Ь.Хп-2 = с,... ,Х0 = ж) = Р(Хп = а | Xn-i = 6)
и однородной марковской цепью, если данная вероятность не зависит от п.
Марковские цепи можно рассматривать как последовательности с небольшой
памятью; новое состояние зависит от предыдущего состояния, но не от всей ис-
тории. Отсюда следует, что данное свойство крайне полезно в моделировании,
поскольку, похоже, что его имеют многие физические переменные, и посколь-
ку на его основе можно построить множество простых алгоритмов логического
вывода. Отметим, что формы записи, используемые при обсуждении марков-
ских цепей в дискретных и непрерывных пространствах состояний, несколько
отличаются; далее в этой главе рассматривается только дискретный случай.
Предположим, что дано дискретное пространство состояний. Размерность
пространства несущественна, хотя конечные пространства представить несколь-
ко легче. Запишем элементы пространства как Si и предположим, что всего
имеется к элементов. Предположим также, что дана последовательность слу-
чайных переменных, принимающих значения из этого конечного пространства
состояний, причем переменные формируют однородную марковскую цепь. Да-
лее запишем
Р(Хп — Sj | Хп—1 — St) — Piji
и поскольку цепь не зависит от п, от п также не зависит pij. Далее можно
записать матрицу Р, (г, j)-H элемент которой, р^, описывает поведение цепи.
Данная матрица называется матрицей переходов. Предположим, что Хо имеет
распределение вероятностей P(Xq = Si) = 7rit и запишем тг как вектор, г-й
элемент которого равен тгг. Это означает, что
к
Р(Х1 = Sj) = 52 Р(Х1 = s, I Хо = Si)P(X0 = St) =
t=i
к
= 52^1=5J |X0=St)7Ft =
t=l
к
Глава 23. Распознавание через связь шаблонов
747
1-р р
q
Рис. 23.8. Простая марковская цепь из двух состояний. В данной цепи вероятность перехода из
состояния 1 в состояние 2 равна р; из состояния 1 в состояние 1 она равна 1 — р и т.д. Данную цепь
можно описать матрицей переходов. Стационарное распределение цепи равно (?/(р+д),р/(р+<?))-
Это имеет смысл, например, если р малое, a q близко к единице — тогда цепь будет проводить
практически все время в состоянии 1. Обратите внимание, что если обе величины р и q малы, цепь
будет проводить значительный промежуток времени в одном состоянии, перескакивать в другое,
и там проводить значительный промежуток времени
так что распределение вероятностей для состояния Xi записывается как Ргтг.
Используя подобные аргументы, получаем, что распределение вероятностей для
состояния Хп описывается выражением (Рт)птг. Для всех марковских цепей
существует по крайней мере одно распределение тга такое, что tts = PT7rs.
Это называется стационарным распределением цепи. Доказано, что марков-
ские цепи позволяют создавать довольно простые и информативные картины.
Можно, например, изобразить взвешенный направленный граф с узлом для
каждого состояния и весовым коэффициентом на каждом ребре, указывающем
вероятность перехода между состояниями (рис. 23.8).
При наблюдении случайной переменной Хп данный логический вывод
прост — известно, в каком состоянии находится цепь. В то же время, это
плохая модель наблюдаемого. Гораздо более лучшую модель можно получить,
положив, что для каждого элемента последовательности наблюдается иная
случайная переменная, распределение вероятностей которой зависит от состо-
яния цепи — наблюдается некоторая переменная Уп, причем распределение
вероятностей в некоторой точке P(Yn | Хп = = qi(Yn). Данные элементы
можно собрать в матрицу Q. Для задания скрытой марковской модели требует-
ся обеспечить процесс перехода между состояниями, связи между состоянием
и распределением вероятности переменной Yn, а также знать исходное рас-
пределение состояний. Это означает, что модель записывается следующим
образом: (Р, Q, к), кроме того, предполагается, что пространство состояний
имеет к элементов.
23.4.2. Вычисления с использованием скрытых марковских моделей
Предположим, что рассматривается скрытая марковская модель в дискрет-
ном пространстве состояний (это существенно упрощает вычисления, причем,
как правило, цена данного допущения невелика). Имеется две важных задачи.
748 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 23.9. Вверху изображена простая модель переходов между состояниями. Внизу — решетка,
соответствующая данной модели. Обратите внимание, что каждый путь через решетку соответ-
ствует допустимой последовательности состояний для ряда из четырех измерений. Весовые коэф-
фициенты, соотнесенные с дугами, равны логарифму вероятностей соответствующих переходов, а
вершины — логарифму вероятностей ухода; чтобы не загромождать рисунок, весовые коэффициен-
ты не обозначены
• Логический вывод. Требуется определить, какой исходный набор состоя-
ний привел к наблюдаемому результату. Это позволяет, например, заклю-
чить, что делает танцор или какую песню поет певец.
• Подбор. Требуется выбрать скрытую марковскую модель, хорошо пред-
ставляющую последовательность предыдущих наблюдений.
Для каждой задачи найдено эффективное стандартное решение.
Решетчатая модель
Пусть дан набор из N измерений Yi, которые предположительно являют-
ся выходом скрытой марковской модели. Данные измерения можно поместить
в структуру, именуемую решеткой. Решетка — это взвешенный направлен-
ный граф, состоящий из N копий пространства состояний, которые располо-
жены столбцами, причем каждому измерению соответствует столбец. С узлом,
представляющим состояние Xi, в столбце, соответствующем Yj, соотносится
весовой коэффициент log(Kj).
Глава 23. Распознавание через связь шаблонов 749
Элементы различных столбцов обрабатываются следующим образом. Рас-
смотрим столбец, соответствующий У7-; элемент в данном столбце, представ-
ляющий состояние Xfc, объединяется с элементом в столбце, соответствую-
щем Vj+i и представляющим состояние Xi, если ры не равно нулю. Данное
ребро представляет возможность перехода между данными состояниями. Весо-
вой коэффициент этого ребра равен \ogpki. Решетка, построенная по соответ-
ствующей скрытой марковской модели, показана на рис. 23.9.
Решетка обладает следующим интересным свойством: каждый (направлен-
ный) путь через решетку представляет возможную последовательность состоя-
ний. Поскольку каждая вершина решетки умножается на весовой коэффициент,
равный логарифму вероятности ухода из вершины, а ребра учитываются с весо-
вым коэффициентом, равным логарифму вероятности перехода, правдоподобие
последовательности состояний можно получить, определив путь, соответству-
ющий данной последовательности, и просуммировав весовые коэффициенты
(ребер и вершин) вдоль пути. В результате получаем крайне эффективный
алгоритм поиска максимально правдоподобного пути, для именования кото-
рого используются термины динамическое программирование или алгоритм
Витерби.
Работа алгоритма начинается с последнего столбца решетки. Изначально
известен логарифм правдоподобия пути с одним состоянием, оканчивающего-
ся в каждой вершине, поскольку это — весовой коэффициент этой вершины.
Рассмотрим теперь путь с двумя состояниями, который начнется в предпослед-
нем столбце решетки. Далее легко получить наилучший путь, выходящий из
вершины в этом столбце. Рассмотрим вершину; известен весовой коэффициент
каждого ребра, покидающего вершину, и весовой коэффициент вершины в кон-
це ребра; таким образом можно выбрать сегмент пути с наибольшим значением
суммы; данное ребро — это наилучшее ребро, выходящее из данной вершины.
Для каждой вершины ее весовой коэффициент складывается со значением наи-
лучшего сегмента пути, покидающего вершину (т.е. весовой коэффициент ребра
плюс весовой коэффициент конечного узла). Данная сумма — наилучшее зна-
чение, которое можно получить при достижении данной вершины (далее будем
называть его значением вершины).
Поскольку известно наилучшее значение, которое можно получить при до-
стижении каждой вершины во втором с конца столбце, можно вычислить наи-
лучшее значение, получаемое при достижении каждой вершины в третьем
с конца столбце. Затем в каждой вершине третьего с конца столбца прове-
ряются ребра (каждое из них входит в вершину, значение которой известно).
Выберем ребро с наибольшим значением величины (вес ребра плюс значение
вершины), прибавим это значение к весовому коэффициенту начальной верши-
ны в третьем с конца столбце и получим таким образом значение начальной
вершины. Данный процесс можно повторять до получения значения каждой
вершины первого столбца; наибольшее значение является максимально правдо-
подобным.
750 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 23.10. Нахождение лучшего пути через решетку, изображенную на рис. 23.9 (или любую
другую), сложности не представляет. Предполагается, что с каждой вершиной с меткой 1 связан
логарифм правдоподобия —1, логарифм правдоподобия каждой вершины с меткой 2 равен —3, и ло-
гарифм правдоподобия каждого узла с меткой 3 равен —9. Предполагается также, что вероятности
ухода из вершины равны (обратите внимание на выбранные величины). Теперь значение каждой
вершины в предпоследнем столбце — это значение вершины плюс наилучшее значение, которое
получится при уходе из вершины. Все требуемые вычисления просты. В алгоритме нужно вычис-
лить значение каждой вершины в предпоследнем столбце, затем в третьем с конца столбце и т.д.,
как описано в тексте. Как только мы дойдем до начала решетки, наибольший весовой коэффициент
будет представлять максимум логарифма правдоподобия; поскольку отброшены все сегменты пути,
кроме лучших, оставшийся путь также является лучшим (показан пунктиром)
Кроме того, получен путь с максимальным значением функции правдоподо-
бия. При вычислении значения вершины удаляются все, кроме лучшего, ребра,
покидающие вершину. После достижения первого столбца далее просто сле-
дуем по пути от узла с наилучшим значением. Данный простой, но мощный
алгоритм иллюстрируется на рис. 23.10.
В последующих разделах динамическое программирование описывается бо-
лее формально. Наилучший путь можно найти либо через поиск в будущем, ли-
бо через изучение прошлого. При настройке решетки производится поиск в бу-
дущем. Для формального же описания будет использовано изучение прошлого.
Логический вывод и динамическое программирование
В задаче логического вывода имеется ряд наблюдений {УЬ, У1, . -, Уп} и тре-
буется получить последовательность пч-1 состояний S = {So, Si,..., Sn}, мак-
Глава 23. Распознавание через связь шаблонов
751
симизирующих величину
Р(5|{Уо,У1,...,Уп},(Р, С,тг)),
что равносильно максимизации совместного распределения
Р(5,{У0,У1....К} | (Р, е,тг)).
Для решения поставленной задачи существует стандартный алгоритм, име-
нуемый алгоритмом Витерби. Проверяется п + 1 путей через состояния (от So
до Sn). Всего существует Arn+1 таких путей, поскольку в каждом состоянии
можно выбирать любой элемент пути (предполагается, что в матрице Р нет
нулей; в большинстве случаев число путей составляет O(fc"+1)). Каждый путь
проверить невозможно, но на самом деле это и не требуется. Опишем общий
подход. Предположим, что для каждого возможного состояния si известно зна-
чение совместной вероятности для лучших путей из п элементов, оканчиваю-
щихся в Sn_i = s/; затем путь, максимизирующий (по значениям мест соеди-
нений) путь в п +1 элемент, должен состоять из одного из названных путей,
удлиненного на один шаг. Все, что для этого требуется, — это найти пропу-
щенный фрагмент.
Нахождение пути с максимальным значением совместной вероятности мож-
но сформулировать как задачу с индукцией. Предположим, что для каждо-
го значения j состояния St-i известно значение фрагмента наилучшего пути,
оканчивающегося в = j, которое запишем как
О') = е max, P({S0, S15..., = j}, {Yo, Yi,. • •, Yt-J | (P, Q, тг)).
Теперь получаем
ЗД) = (max&_i(i)Pij) 9j(Yt).
Требуется не только максимальное значение, но также путь, приводящий к
этому значению. Определим переменную
V’tO) = argmax^t-i^JPij)
(т.е. лучший путь, оканчивающийся в St = j). Таким образом, определен ин-
дуктивный алгоритм получения наилучшего пути.
Схема размышлений такова: известен наилучший путь в каждое состояние
для (t—1)-го измерения; для каждого состояния при t-ом измерении вычисляет-
ся наилучшее состояние при (t — 1)-ом измерении; поскольку известен лучший
путь из текущей точки, имеется лучший путь в каждое состояние для t-ro из-
мерения. Известен также лучший путь к каждому доступному состоянию на
первом шаге. Целиком данная схема представлена в алгоритме 23.1.
752 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Алгоритм 23.1. Алгоритм Витерби дает путь через скрытую марковскую мо-
дель, максимизирующий правдоподобие по местам соединений и значениям со-
единений этого пути. Здесь <5 и ip — удобные вспомогательные переменные (см.
объяснения в тексте); р* — максимальное значение места соединения; ag*— t-e
состояние на оптимальном пути
1. Инициализация:
i<j<N
Ipo(j) - о
2. Рекурсия:
<Mj) =
= argmax(5t-i(i)Pij)
3. Прекращение:
р* = max (<5n (г))
г
— arg max (<5П (г))
4. Возвратное отслеживание пути:
Подбор скрытой марковской модели с помощью ОМ-алгоритма
Имеется набор данных Y, для которого предполагается, что подходящей
моделью является скрытая марковская модель, но неизвестно, какую именно
скрытую марковскую модель использовать. Хотелось бы выбрать модель, наи-
лучшим образом представляющую набор данных. Для этого используем версию
алгоритма ожидания-максимизации (ОМ-алгоритм, см главу 16). В этом алго-
ритме предполагается, что дана скрытая марковская модель, (Р, далее
требуется использовать эту модель на нашем наборе данных, чтобы оценить
новый набор значений указанных параметров. Используя процедуру, описан-
ную ниже, оцениваем (Р, £2, к). Есть две возможности (без доказательства):
либо P(Y | (Р, Q,k)) > P(Y | (Р, Q,tt)), либо (Р, Q, тг) = (Р,
Глава 23. Распознавание через связь шаблонов
753
Обновленные значения параметров модели имеют вид
тг7 = ожидаемая частота нахождения в состоянии Si в момент 1
__ ожидаемое число переходов из а» в а,-
Pij ~-------------------------------------
ожидаемое число переходов из состояния а»
—тут- ожидаемое число единиц времени (время) нахождения в Sj и наблюдения Y = ук
q3 (Л) —--------------------------------------------------------------------
ожидаемое время нахождения в состоянии Sj
Далее требуется оценить данные выражения. В частности, нужно опреде-
лить величину
Р(ХТ = aitXt+i = а,- | У, (Р, Q, тг)),
которую запишем как &(г, j). Если известно значение получаем
ожидаемое число переходов из а» в Sj = 7
t=o
ожидаемое число попаданий в ai = ожидаемое число переходов из а»
п к
t=0 J=1
к
ожидаемая частота нахождения в а» в момент 0 =
3 = 1
n fc
ожидаемое время нахождения в Si и наблюдения (У = ук) — У*)»
t=0 j=l
где 6(u,v) — единица, если аргументы равны, и нуль — в противном случае.
Для оценки &(м) нужны две промежуточных переменных: прямая пере-
менная и обратная переменная. Прямая переменная — это = P(Yq,
У1,...,3^, Хт = Sj | (Р, Q, тг)). Обратная переменная (переменная обратного
пути) 0t(j) = P({yt+1, rt+2,..., У„} | Хт = Sj, (Л Q, тг)).
754 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Если предположить, что значения данных переменных известны, получаем
Ш) = Р(ХТ = Si.Xt+i = sj | Y, (P, <2,-tt)) =
Р(У, XT = sit Xt+1 = Sj | (P, Q, к))
P(Y |(P,<2,tt))
' P(Y0,Y1,...,Yt,X1 = Si\(PtQ,n)) '
< x P(¥t+i | Xt+i = Sj, (P, Q, 7г))
x P(Xt+i = Sj I Xr = Si, (P, Q, 7T))
, xP(yt+2,...,yN| Xt-ц = Sj, (P,Q,*)) J
P(Y\(P,Q,n))
_ Qt (*t+i )&+i (j) _
P(Y |(P,Q,7r))
_ at (ijpijqj (Yt+i)/3t+i (j)
Ef= i ZXi ^t(i)pijqj(Yt+1)(3t+i(j)
Обе переменные можно оценить по индукции. Для получения значения at(j)
отметим, что
q0(j) = Р(Уо,Хо = Sj I (Р, Q,7T)) = ад(Уо);
Qt+I(j) = Р(^о, У1, • - • ,yt+i,Xt+i = Sj I (P, Q.tt)) =
^P(Y0,Y1,...,Yt,Xt+i=sj | (P,Q,Tr))P(yt+1 |Xt+i =Sj) =
= ^[P(y0,yi,...,yt,XT = Si,Xt+i =sj | (P,Q,tt))
Z=1
X P(yf+1 I Xt+1 = Sj)] =
fc
52 Р(У0, У1,..., У, XT = sz j (P, Q, 7r))P(Xt+i = Sj | XT = Si)
J=i
x P(yt+1 I Xt+1 = Sj)
fc
52«t(Op«j
j=i
9j(^t+i)
1 < t < n- 1.
Обратную переменную можно также получить по индукции:
(3n(j) = Р(нет дальнейших состояний | Хп = Sj, (Р, Q, тг))
= 1;
Глава 23. Распознавание через связь шаблонов
755
= P({yt+i, Yt+2,..., К} | Xr = sjt (Р, <2,7г)) =
к
= Еу‘+2- • • • > У"Ь х' =S11 х*+> = ** е- "»! =
1=1
к
£P(XT = sf,K+i |Xt+i = Sj)
.1=1
р({у.+2,..., г„} । xt+i = в,г, (р, е, -я-» =
к
y^Pjiqi(^t+i)
.1=1
Z3t+i(j)
1 < t < к — 1.
В результате получаем простую схему подбора, приведенную в алгоритме 23.2.
Алгоритм 23.2. Подбор скрытых марковских моделей к последовательности
данных Y посредством разновидности ОМ-алгоритма. Делается предположение
о модели (Р, Q, 7г)г, а затем вычисляются коэффициенты новой модели; данная
итерация гарантированно сходится к локальному максимуму величины P(Y |
(Л<2,ТГ)).
Пока (Р, Q, 7r)i+i не станет равно (Р, Q,Tr)i
вычислить переменные а и /3,
используя процедуры, представленные в алгоритмах 23.4 и 23.5,
вычислить vn 1 —FT
вычислить обновленные параметры, используя процедуры алгоритма 23.3
Данные величины являются элементами набора (Р, Q,7r)i+i
конец
23.4.3 . Разнообразие скрытых марковских моделей
До настоящего момента ничего не говорилось о топологии графа, на основе
которого построена наша модель. Это может быть полный граф (граф, каждая
вершина которого связана со всеми другими вершинами в обоих направле-
ниях), хотя это и необязательно. Недостатком использования полных графов
является необходимость оценки большого числа параметров. В практических
приложениях обычно используются другие, хорошо себя зарекомендовавшие
варианты (рис. 23.11).
756 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Алгоритм 23.3. Вычисление новых значений параметров для процесса подбо- ра скрытой марковской модели = ожидаемая частота нахождения в состоянии Si в момент 0 = к = £&(м) 3=1 ожидаемое число переходов из s, в Sj Pij ожидаемое число переходов из состояния s» - Е"=о &(*>?) _ Etn=0E-=1ee(i,j) —777 ожидаемое число раз нахождения в s, и наблюдения Y = ук ожидаемое число попаданий в состояние si 52t=o j) здесь <5(u, v) — единица, если аргументы равны, и нуль — в противном случае.
Алгоритм 23.4. Вычисление прямой той марковской модели «o(j) = Г к «t+i(j) = ^at^Pij Li=i переменной для процесса подбора скры- <7j(Vt+i) 0 < t < п - 1
Алгоритм 23.5. Вычисление обратно» той марковской модели М) = 1 к 0t(j) = ^PjiQilXt+i) L(=i I переменной для процесса подбора скры- A+iU) 0<t<n-l
Лево-правая модель (left-right model), или модель Бакиса (Bakis model)
имеет следующее свойство: из состояния г модель может переходить только
в состояния j > i. Это означает, что для j < г, pij = 0. Более того, tti = 1
Глава 23. Распознавание через связь шаблонов
757
Рис. 23.11. Разнообразные топологии скрытых марковских моделей, используемые на практике.
На рисунке вверху показана эргодическая, или полносвязная, модель. В центре изображены
лево-правая модель с четырьмя состояниями. Данная модель была ограничена, так что рц = О
при j > i 4- 2. На рисунке внизу показана лево-правая модель с параллельными путями с шестью
состояниями. По сути, данная модель содержит две параллельных лево-правых модели с возмож-
ностью переключения между ними
и для всех г 7^ 1, = 0. Это означает, что матрица переходов Р —верхняя
треугольная. Более того, лево-правая модель с N состояниями после перехода
в TV-тое состояние будет оставаться в этом состоянии. Стоит отметить, что
в данной модели фиксируется порядок, в котором могут происходить события,
что может быть удобным, если скрытые марковские модели используются для
кодирования различной информации о движении (или речевой информации;
именно из данной области пришла эта технология).
Впрочем, общая лево-правая модель предполагает, что большое число со-
бытий может пропускаться (состояние может развиваться свободно). Это не
совсем согласуется с разумной моделью движения, поскольку хотя можно про-
пустить одно-два измерения или одно-два состояния, маловероятно, что будет
пропущен большой набор состояний. Обычно принято использовать дополни-
тельное условие, что для j > i 4- <5, Pij = 0. Здесь 5 обычно выбирается неболь-
шим числом (часто — 2).
На удивление, ограничение топологии модели не создает никаких проблем
с алгоритмами, описанными в предыдущих разделах. Можно проверить, что
алгоритм оценки сохраняет нуль, т.е. если начать с модели конкретной тополо-
гии, имеющей нули на определенных местах матрицы переходов, новая оценка
матрицы переходов будет иметь нули в тех же положениях.
758 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
23.5. ПРИЛОЖЕНИЕ: СКРЫТЫЕ МАРКОВСКИЕ МОДЕЛИ
И ПОНИМАНИЕ ЯЗЫКА ЖЕСТОВ
Язык жестов — это язык, визуализированный с использованием системы
жестов, а не посредством модуляции речевого тракта. Для многих людей овла-
деть языком жестов сложно; было бы неплохо иметь устройство, которое можно
направить на человека, говорящего на языке жестов, и услышать из устройства
аудиоречь. С данной задачей можно провести аналогии из широко разрабаты-
ваемой области распознавания речи.
Скрытые марковские модели крайне успешны в приложениях понимания
речи. Скрытые состояния описывают речевую (вокальную) систему; наблюде-
ния — это различные акустические измерения. Обычно с каждым словом соот-
несена скрытая марковская модель. Эти модели связываются воедино с исполь-
зованием модели языка, которая задает вероятность появления слова при дан-
ном встреченном слове. В результате получается другая (возможно, большая)
скрытая марковская модель. Предложение, представленное набором акустиче-
ских измерений, получается с помощью алгоритма логического вывода, приме-
ненного к модели языка. Данная методика хорошо работает в языковой среде
и естественно попытаться перенести ее на язык жестов.
Человеческие жесты подобны человеческим звукам — обычно имеется по-
следовательность событий и есть измерения, полученные вследствие этих со-
бытий, но не определяющие их. Хотя нет гарантии, что довольно сильные допу-
щения об условной независимости исходной марковской модели действительно
справедливы для человеческих жестов, модель определенно стоит попробовать,
поскольку для моделей речи такой гарантии тоже нет, но скрытые марковские
модели там работают.
В данной главе описаны системы, использующие скрытые марковские мо-
дели для интерпретации языка жестов, но данный подход также применим к
формальным системам жестов. Например, если требуется построить систему,
которая открывает окно при одном движении руки и закрывает его при другом,
данный набор жестов можно рассматривать как сильно ограниченный язык.
Существует много систем, использующих скрытые марковские модели для
интерпретации языка жестов. Обычно модели слов — это лево-правые модели,
но с условием — не пропускать слишком много состояний (т.е. Pij = 0 для
j > i 4- Д и |Д| малых). Обычно имеется небольшое число состояний; каж-
дое состояние имеет петлю, означающую, что данная модель может находиться
в одном состоянии несколько тактов; кроме того, есть переходы, пропускающие
некоторые состояния, что означает возможность относительно быстрого пере-
мещения через скрытые состояния. При построении системы требуется решить
всего два вопроса. Во-первых, модели слов следует объединить с некоторой
моделью языка; во-вторых, следует определиться с тем, что измерять.
Глава 23. Распознавание через связь шаблонов
759
Начало
Модель слова 2
-Модель слова 3
одель слова N
Модель слова 1
Конец
Рис. 23.12. Если взять скрытую марковскую модель для каждого слова в словаре и связать эти
модели вместе с независимыми вероятностями появления слов, получим модель языка. Модель
с независимыми словами и без ограничений на длину предложения относится к простейшему
типу; хотя такая модель обладает незначительной синтаксической структурой, она по-прежнему
относится к классу скрытых марковских моделей и допускает крайне простой логический вывод
23.5.1. Модели языка: предложения из слов
Если требуется распознать не отдельные слова, а выражения на языке же-
стов, нужно задать, как выглядят слова. Модели языка — это спецификация
того, как должны связываться скрытые марковские модели слов для получения
скрытой марковской модели, представляющей все предложение. В простейшей
модели языка слова появляются независимо от предыдущего слова. Данную
модель можно представить графом, изображенным на рис. 23.12. В этой модели
состояние переходит в начальное состояние, производя слово, затем либо оста-
навливается, либо возвращается к началу цикла, откуда может производиться
другое слово. Теперь необходимо найти экстремальную траекторию через этот
больший граф; по-прежнему можно применять алгоритм Витерби, просто теперь
нет наблюдений, соответствующих затененным состояниям.
Вообще желательны более сложные модели языка — модель английского
языка, допускающая случайную независимую генерацию слов, приведет к по-
явлению больших строк, состоящих из “and” и “the", — но эти же модели
порождают и сложные вычислительные проблемы. Естественный первый шаг
на пути усложнения модели — это биграмная (bigram language model), где веро-
ятность получения слова зависит от предыдущего слова. Вид соответствующей
модели языка приведен на рис. 23.13. В более сложных моделях языка исполь-
зуется предыстория по двум словам или более сложное изучение контекста по
предыдущим предложениям. Сложность такого подхода заключается в том, что
для словаря разумных размеров число состояний, в которых проводится по-
иск согласно алгоритму Витерби, будет огромным. Существует много методов
сокращения этого поиска (которые здесь рассматриваться не будут), примеры
можно найти в книге [Jelinek, 1999] или работе [Manning, Schutze, 1999].
760 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 23.13. В биграмной модели языка вероятность появления слова зависит от того, какое слово
появилось непосредственно перед этим. Данные модели можно изобразить как скрытые марковские
модели (снова связываются модели отдельных слов). Обратите внимание, что теперь топология
гораздо сложнее; для простоты предложение ограничено тремя словами
Признаки и типичные уровни производительности
В настоящее время существует несколько программ распознавания языка
жестов. В частности, имеется несколько программ (см. [Starner, 1998]), в кото-
рых используются разнообразные признаки. При простейшем подходе от поль-
зователя требуется надеть на правую руку желтую перчатку, а на левую — крас-
ную. Альтернативой этого иногда неудобного подхода является сегментация рук
с использованием цвета кожи (всегда предполагается, что в окрестности нет
больше ничего телесного цвета). Далее на изображении определяются пиксели
значимых цветов (красного и желтого или телесного). Как только обнаружен
подходящий пиксель, восемь его соседей проверяются на предмет принадлеж-
ности к тому же классу значимых элементов; данный процесс продолжается до
получения пятна одноцветных пикселей.
У полученного пятна имеется ряд признаков, которые можно использовать.
Два признака дает центр тяжести пятна, еще два — это изменение положе-
ния центра тяжести по сравнению с предыдущим кадром. Еще один признак —
площадь пятна. Кроме того, используя ориентацию и размер пятна, можно по-
строить матрицу вторых моментов:
f х2 dx dy
| f xydx dy
| J xydxdy
f y2 dx dy
Отношение собственных значений данной матрицы указывает на эксцентриси-
тет пятна, наибольшее значение — это оценка размера по главному направле-
нию, а ориентация собственного вектора, соответствующего данному собствен-
ному значению, определяет ориентацию пятна.
Система Старнера работает со словарем из 40 слов, представляющих четы-
ре части речи. Топология скрытых марковских моделей слов считается данной,
а параметры оцениваются с использованием ОМ-алгоритма, описанного в гла-
ве 16. Для задач распознавания отдельных слов и распознавания предложений
Глава 23. Распознавание через связь шаблонов
761
Рис. 23.14. Система распознавания языка жестов, в которой для получения моделей слов исполь-
зуются скрытые марковские модели. На рисунке представлен экспериментатор (“оратор”), как его
видит система; наблюдение ведется с камеры на рабочем столе
используется модель языка, в которой предложения состоят из пяти слов (слова
идут в следующем порядке: местоимение глагол существительное при-
лагательное местоимение), причем точность распознавания слов составля-
ет порядка 90%. В зависимости от используемых признаков и поставленной
задачи точность незначительно меняется в обе стороны.
В цикле работ [Vogler and Metaxas, 1998, 1999] построена система, которая
использует оценки положений рук, восстановленных либо с помощью физиче-
ского сенсора, размещенного на теле, либо с помощью системы из трех камер,
достаточно точно фиксирующих положения рук. Для словаря из 53 слов и мо-
дели языка с независимыми словами точность распознавания слов составляет
порядка 90%.
Будущее
Все результаты, описанные в литературе, относятся к небольшим словарям
и простым моделям языка. Несмотря на это, скрытые марковские модели кажут-
ся обещающим методом распознавания языка жестов. Пока не ясно, достаточно
ли простых признаков для распознавания сложных жестов. Одним возможным
направлением развития является использование признаков, дающих лучшую
оценку движений пальцев.
Хорошие модели языка (и подходящие алгоритмы логического вывода) —
это ключ к успеху современных систем распознавания речи. Данные моде-
762 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
ли обычно получаются через измерение частоты появления слова в некотором
контексте (например, частоты появления слова после двух данных). Построе-
ние таких моделей требует огромного объема данных, поскольку необходима
точная оценка относительных частот весьма редких событий. Например, как
отмечено в работе [Jelinek, 1999], для обработки словаря из 15 000 слов обыч-
но приходится работать с набором в 640 000 слов. Это означает, что некоторые
слова используются часто, и что измерение частот появления слов в небольшом
текстовом фрагменте крайне опасно. При работе в области распознавания речи
и изучения естественного языка возникает множество трудностей, разработаны
разнообразные уловки, позволяющие их обойти (см., например, [Jelinek, 1999]
или [Manning, Schutze, 1999]). Дальнейшие исследования в сфере распозна-
вания языка жестов должны включать изучение данных уловок и перенос их
в сферу компьютерного зрения.
23.6. ПРИЛОЖЕНИЕ: ПОИСК ЛЮДЕЙ С ИСПОЛЬЗОВАНИЕМ СКРЫТЫХ
МАРКОВСКИХ МОДЕЛЕЙ
Показать, что скрытая марковская модель является разумным выбором при
распознавании языка жестов, довольно просто — жесты идут в условно слу-
чайном порядке и порождают шумоподобные измерения. Имеются и другие,
не такие очевидные сферы применения скрытых марковских моделей. Важным
свойством такой модели является не временная зависимость, а условная неза-
висимость — Хг+i не зависит от прошлого при данном Xj.
Независимость такого рода проявляется в различных ситуациях. Несомнен-
но, самое важное приложение — это поиск людей. Предполагается, что люди
выглядят на изображениях как куклы, состоящие из девяти прямоугольных
сегментов тела (по два сегмента левой и правой руки и левой и правой ноги, а
также туловище). В частности, предполагается, что левое предплечье не зави-
сит от всех остальных сегментов при данном левом плече, что левое плечо не
зависит от всех других сегментов при данном туловище и т.д., при этом оче-
видным образом формулируются подобные допущения для правой руки и ног.
В результате получаем скрытую марковскую модель. Приведем эту модель для
иллюстрации сказанного. Обозначим через XBCJ)p конфигурацию верхнего сег-
мента левой руки и т.д., и получим
Р(Ху, ХвсЛр, ХнСЛр, Хвспр, Хнспр, ХвСЛН, ХнсЛН, Хвспн, Хнспн) —
= Р(Хт)Р(Хвслр I Хт)Р(ХНСЛр I Хвслр)Р(ХесПр I Хт)Р(Хнспр | Хвспр)Р(Хислн | Хт)х
х Р(ХНСЛН | ХВСЛн)Р(ХВсПН I Хт)Р(ХНсПН I Хвспн),
что можно изобразить как дерево зависимостей (рис. 23.15).
Предположим теперь, что наблюдаются некоторые измерения на изображе-
нии, связанные с конфигурацией сегментов. Предположим пока, что каждый
сегмент тела может находиться в одном из конечного набора дискретных со-
Глава 23. Распознавание через связь шаблонов
763
Рис. 23.15. Человека можно представить через скрытую марковскую модель. Дерево на рисунке ил-
люстрирует структуру одной возможной модели: туловище генерирует различные структуры (руки
и ноги), свойства которых условно независимы при данном туловище. Нижний сегмент левой ноги
условно независим от остальной модели при данном верхнем сегменте и т.д. Данные свойства неза-
висимости можно закодировать, изобразив вершину для каждой переменной и направленное ребро
от одной переменной к другой, если последняя зависит непосредственно от первой. Если подобное
изображение (направленный граф) имеет структуру дерева, получена скрытая марковская модель.
Обратите внимание, что семантика данного изображения несколько отличается от семантики изоб-
ражения, приведенного на рис. 23.8; в предыдущем случае были показаны возможные переходы
между состояниями и их вероятности, а здесь изображены зависимости между переменными
стояний — запишем событие вида “определенная конечность находится в опре-
деленном состоянии” как ХВс.чр = ®вслр- Данное событие даст измерение, услов-
ную вероятность которого можно записать как Р(М = т | Хвслр = жвслр) и т.д.
В частности, имеем на изображении систему сегментов, некоторые из них со-
ответствуют сегментам конечностей, а некоторые порождены шумом. Предпо-
лагается, что на изображении находится Ns сегментов. Более того, предпо-
лагается, что вероятность того, что сегмент порожден шумом, не зависит от
того, что можно измерить на данном сегменте. Теперь для каждого соответ-
ствия между сегментом на изображении и сегментом конечности можно оце-
нить функцию правдоподобия. Далее потребуется записать соответствие; обо-
значим через {ii,событие “сегмент 1 на изображении, «1, — туловище,
сегмент «2 — верхний сегмент левой руки и т.д. до г9 — нижнего сегмента пра-
вой ноги, а все остальные сегменты соответствуют шуму”. Обозначим через тгк
измерения на изображении, соотнесенные с г^-м сегментом на изображении.
764 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Предположим пока, что на каждом этапе должны присутствовать все сег-
менты тела. Далее требуется определить, какие сегменты на изображении пред-
ставляют сегменты тела и какова конфигурация тела человека, представленного
на изображении. Для ответа на поставленные вопросы можно использовать ло-
гарифм функции правдоподобия, который выглядит следующим образом:
log , - - -, ig} | Хт — Хт, - - - , Хнспн = ®нспн) —
= log P(mil I aiT) + log р(тъ2 ( xBC.ip) • 4- log | •Снспн)Ч"
4- (Na — 9)Р(сегмент порожден шумом).
Если теперь записать Р(Хвслр = асвслр | Хт = хт) как Р(зсВслр | гет), логарифм
совместной вероятности запишется как
log Р({Й, • • • , ig}, Хт — *Ет, • - • » Хнспн — *Енспн) =
= log P({ii,. - -, ig} | Хт = ЗСт, - - -, Хнспн = а;нспн)4"
4- log Р(аТт, ®ВСЛр, Я^нслр, ®вспр, ®нспр, 31вСЛН1 ®нслн, ®вспн, *Енспн) =
= log Р({й,..., ig} I Хт = хт,..., Хнспн = Жнспн) 4- log Р(жт)Р(гсвслр | ЖТ)4-
4- log Р(геНслр | асвелр) 4- log Р(хВСпр | гст)4-
4-logP(o: нспр | ®вспр) 4- log Р(з?вслн | ®т)4"
4" log Р(а?нслн | ®вслн) 4- logP(a?BcnH | ®т)4"
4- log Р(®НСПН | ®вспн) —
- log P(mil I хт) 4- log Р(тты2 I Жвслр)--F
4- log Р(пц0 | аснепн) 4- (Na — 9)Р(сегмент порожден шумом)4-
4- log Р(Хт) 4- log Р(Хвслр | 3!т) + log Р(®нслр | ®вслр)4-
4- log Р(а!вспр I гст) 4- log Р(а!нспр I Я!вспр)4-
4" log Р(хВслн | ®т) 4- log Р(Жнслн | ®вслн)4"
4- log Р(а?вспн I ®т) 4- log P(x НСПН | Я?вспн)-
Теперь все вышесказанное можно относительно легко отобразить в решетчатой
структуре, которая является основой динамического программирования. Для
каждого сегмента тела устанавливается столбец узлов, по одному для каждой
пары вида (сегмент на изображении, состояние сегмента тела). С каждым из
подобных узлов связан член вида logPtm^ | о?т), значение которого известно,
поскольку известны сегмент на изображении и состояние сегмента тела, пред-
ставленное узлом. Кроме того, имеется направленное ребро от каждого эле-
мента столбца, представляющего сегмент тела на дереве, к каждому элементу
Глава 23. Распознавание через связь шаблонов
765
Рис. 23.16. На рисунке изображена решетка, выведенная из простого дерева, основа которого —
упрощенная модель человека. Нога обозначена буквой “Н” и т.д. Элементы столбца отражают
различные возможные соответствия между сегментами на изображении, сегментами тела и пере-
менными, описывающими конфигурацию сегментов тела. Например, вершина может представлять
тот факт, что сегмент 2 на изображении соответствует сегменту “туловище” в определенном по-
ложении. Тот факт, что узлы в столбце, помеченном “Т”, имеют двух потомков (а не одного, как
в предыдущем примере), проблем не создает. Для каждого узла в этом столбце можно определить
наилучший доступный выбор и его значение. Для это определяется наилучший выбор элемента
“Р” (значение) и наилучший выбор элемента “Н” (и его значение). В свою очередь это дает зна-
чение узла “Т”. Данное наблюдение означает, что для приведенной древовидной модели можно
использовать динамическое программирование
столбца, представляющему его потомков. Данные ребра помечены логарифма-
ми вероятностей соответствующих переходов — например, Р(я?Вслр | жт) (см.
рис. 23.16). Далее требуется найти направленный путь с наибольшей суммой
значений узлов и ребер вдоль пути.
Из структуры модели следует, что некоторые узлы вдоль пути имеют более
одного потомка; принципиального значения это не имеет. Поставленная задача
связана с динамическим программированием, поскольку решетку можно об-
работать так, что в каждом узле будет известен наилучший выбор, который
можно сделать, находясь в этом узле. Значения передаются в предшествующее
состояние, как описывалось ранее; если узел имеет более одного потомка, наи-
лучшие выборы, которые можно сделать, находясь в потомках, суммируются.
На рис. 23.16 данный процесс демонстрируется на упрощенной решетке.
766 Часть VI. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 23.17. На рисунке слева вверху изображена древовидная модель человека. Цвет каждого сег-
мента соответствует цвету, ожидаемому внутри сегмента. Модель предназначена для нахождения
11 сегментов тела (8 сегментов конечностей, туловище, лицо и волосы), которые а) имеют соот-
ветствующий цвет и б) имеют человекоподобную конфигурацию. Для выполнения поставленной
задачи можно использовать средства динамического программирования, как описано в тексте. На
трех других кадрах изображены соответствия, полученные с помощью данного метода
Модели описанного вида можно использовать в довольно прямолинейной
схеме нахождения людей. Во-первых, требуется некоторая модель, связываю-
щая то, что наблюдается на изображении, с конфигурацией сегментов конеч-
ностей — т.е. модель правдоподобия. В работе [Felzenszwalb and Huttenlocher,
2000] предполагается, что цветовой растр сегментов известен (обычно это
смесь телесного цвета с голубым), а далее с этими растрами сравниваются
цвета реального изображения. В итоге получается достаточно удовлетвори-
тельная схема сопоставления (рис. 23.17) с оговоркой, что одежда человека
известна заранее.
23.7. ПРИМЕЧАНИЯ
На момент написания книги данная область все еще интенсивно исследу-
ются; поэтому представленный читателю материал уже может и не отражать
текущего состояния области. Авторы попытались определить интеллектуаль-
ные тропы, которые они считали наиболее значимыми — вот почему большое
внимание было уделено именно использованию для поиска методов логического
вывода. Первичным (и наиболее ярким) преимуществом скрытых марковских
моделей является именно простота логического вывода (или, эквивалентно, лег-
кость организации поиска соответствий).
Глава 23. Распознавание через связь шаблонов 767
Скрытые марковские модели
Для нахождения людей широко используются средства динамического про-
граммирования. В работе [Pio, 1999] динамическое программирование приме-
няется для предоставления рекомендации относительно гипотез в процессе их
приема или отклонения, основанном на том, являются ли сегменты тела общими
или нет — допущение об условной независимости не позволяет оговорить, что
сегменты тела не перекрываются. В цикле работ .[Song, Goncalves, di Bernardo
and Perona, 1999, 2000, 2001] задача нахождения людей формулируется как
поиск соответствий по вероятностной модели и использование динамического
программирования для разрешения поиска.
Скрытые марковские модели порождают несколько существенных сложно-
стей при использовании их для зрительного вывода. Первая — это их колеб-
лющаяся производительность, неприемлемая в современных задачах компью-
терного зрения. Вторая — легкость логического вывода проистекает от силь-
ных структурных ограничений модели; используемые допущения об условной
независимости могут затруднить введение довольно естественных условий. На-
пример, модель, используемая для поиска людей, не допускает условия, что
различные части изображения должны соответствовать различным сегментам
тела (поскольку при этом к дереву на рис. 23.17 следует прибавить ребро, по-
сле введения которого модель потеряет деревообразную структуру). Трудности
при использовании моделей с более сложными связями, которые формулируют-
ся в терминах условной вероятности, заключаются в потенциальной сложности
логического вывода. В связи с этим важной темой исследований в сфере рас-
познавания объектов является поиск моделей со следующими свойствами: а)
достаточно хорошее представление окружения в смысле получения хорошей
разрешающей способности; б) возможность использования относительно про-
стых алгоритмов логического вывода; в) возможность комбинации нескольких
моделей для получения новых.
Вопрос объединения важен, но пока ему не уделяется достаточное внимание.
Вообще, если требуется распознать большое число объектов различных типов,
это сделать трудно, если считать данную коллекцию однородной, т.е. пытать-
ся (одновременно или последовательно) независимо подобрать соответствие к
каждой модели. В то же время, если для каждого объекта характерен свой на-
бор признаков, это делать придется (найти признаки, соответствующие первому
объекту, второму и т.д.). Более привлекательна модель, когда признаки (в об-
щем виде) применимы к объектам различных типов, причем различие типов
проистекает из а) связей между признаками и б) конкретного вида признаков.
Кроме того, не совсем понятно, как вообще происходит данный процесс.
24
Гэометрические шаблоны через
пространственные связи
В предыдущих главах шаблоны рассматривались как небольшие блоки пиксе-
лей с характерным внешним видом. Однако на практике можно использовать
и более сложные шаблоны: например, в большинстве реальных перспективных
камер сферы приобретают приблизительно круговые контуры. Отсюда следует,
что если требуется отыскать сферы, то можно собрать краевые точки, в со-
вокупности формирующие окружность. Данный пример иллюстрирует понятие
шаблона, полученного через рассмотрение пространственных связей между
компонентами изображения. Исходя из этого можно предложить следующий
подход к согласованию объекта с изображением:
• определить связи, ограничивающие внешний вид объектов, представляю-
щих интерес;
• найти на изображении структуры, удовлетворяющие этим связям;
• согласовывать только эти структуры.
Большинство объектов имеют сложную геометрическую структуру, поэтому
данный подход неудобен для объектов в целом (поскольку связи могут быть
очень запутанными). Взамен этого приходится предполагать, что объекты со-
ставлены из частей, имеющих простую структуру. Поэтому вначале находятся
части (см. предыдущие главы), которые затем связываются в объект.
770 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Описанная схема рассуждений привлекательна, поскольку она связывает
представление объекта с сегментацией, предлагает, как можно распознать мно-
жество объектов (допустить, что объекты составлены из частей, найти части
и строить предположения относительно их наборов), к тому же виден путь
построения логических выводов.
24.1. ПРОСТЫЕ СВЯЗИ ОБЪЕКТА И ИЗОБРАЖЕНИЯ
Простейший пример объекта с ограниченным контуром — многогранник,
контур которого состоит из нескольких цепочек прямых отрезков. В большин-
стве практических задач фигурируют многогранники, грани которых относи-
тельно велики по сравнению с пикселями изображения, так что ожидается, что
размер указанных отрезков в краевых точках будет большим. Это означает, что
нет смысла искать на изображении многогранники, не содержащие фрагментов
прямых, а если потребуется найти многогранники, хорошей идеей будет фор-
мирование цепочек прямых отрезков. Можно выделить и другие условия на
контуры многогранника, если, конечно, удается определить внутренние гра-
ницы — компоненты контура, в которых видно несколько граней (см. работы
[Sugihara, 1986], [Huffman, 1997], [Clowes, 1971], [Rothwell, Forsyth, Zisser-
man and Mundy, 1993]). Как правило, внутренние границы сложно определить
относительно надежно, чтобы данные условия можно было использовать.
24.1.1. Связи для криволинейных поверхностей
Контур поверхности формируется как пересечение конуса лучей с плоско-
стью изображения. Лучи конуса касательны к поверхности, проходящей через
фокус камеры (если камера перспективная), или параллельны (если камера
аффинная). Далее этот конус будем называть конусом наблюдения. Если аф-
финная камера ортографическая (что бывает чаще всего), то плоскость сечения
перпендикулярна лучам. Отметим также, что анализировать конус обычно про-
ще, чем анализировать контур.
Конусы и цилиндры
Конус — это поверхность, образованная семейством лучей, проходящих че-
рез точку (вершину конуса) и точку плоской кривой, именуемой порождающей.
Обратите внимание, что данное определение является более общим, чем опре-
деление правильного кругового конуса, который большинство людей неверно
называет просто “конусом”; правильные круговые конусы обладают осевой сим-
метрией (рис. 24.1), а конус состоит из масштабированных и сдвинутых копий
порождающей функции. Выберем систему координат, в которой порождающую
функцию можно записать как (z(t), y(t), 1). Тогда конус можно записать как
(x(t)s,?/(t)s,s),
Глава 24. Геометрические шаблоны через пространственные связи
771
Правильный круглый конус
Рис. 24.1. Конусы — это поверхности, полученные как результат заметания пространства лучами,
проходящими через вершину конуса и точку порождающей функции. Частным случаем является
правильный круговой конус, порождающая функция которого — окружность, а прямая, соединяю-
щая вершину с центром окружности, перпендикулярна плоскости окружности
Рис. 24.2. Конус наблюдения фигуры “конус” — это семейство плоскостей, касательных к конусу
и одновременно проходящих через вершину конуса и фокус. Контур формируется как пересечение
конуса наблюдения с плоскостью и представляет собой набор прямых, проходящих через одну точ-
ку. Сказанное также относится к цилиндру; единственное отличие цилиндра от конуса заключается
в том, что вершина цилиндра считается расположенной на бесконечности
а его вершина расположена в точке (0,0,0). Конус, вершина которого располо-
жена на бесконечности, называется цилиндром; в подходящей системе коорди-
нат цилиндр можно записать как
Правильным круговым цилиндром называется цилиндр, порождающей функ-
ций которого является окружность.
Конус наблюдения конуса — это семейство плоскостей, касательных конусу
и одновременно проходящих через вершину конуса и фокус. Это означает, что
используется следующее условие группировки:
772 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 24.3. Пара кривых параллельна, если они переводятся друг в друга таким гладким соответ-
ствием, что касательные к кривым параллельны (слева). Справа: контур каналовой поверхности —
ортографическая проекция, которая состоит из набора параллельных симметричных кривых
контур конуса состоит из набора прямых, проходящих через вершину (рис. 24.2).
Все это должно быть очевидным (доказать сказанное предоставляется чита-
телю в виде упражнения), и к тому же на удивление полезным. Поскольку
единственное различие между цилиндром и конусом заключается в том, что
вершина цилиндра бесконечно удалена от наблюдателя, данное условие груп-
пировки применимо и к цилиндру. Обратите внимание, что изображение вер-
шины цилиндра не обязательно находится на бесконечности, если изображение
не представляет собой ортографической проекции.
Каналовые поверхности
Возьмем сферу фиксированного радиуса и будем перемещать ее центр вдоль
кривой. Затем сформируем огибающую полученного семейства сфер. Данная
огибающая представляет собой поверхность, именуемую каналовой поверхно-
стью', кривая обычно называется порождающей. Каналовые поверхности обыч-
но выглядят как изогнутые трубы (рис. 24.9), но при этом могут иметь сингу-
лярности. Простейший пример такой поверхности можно получить, если прове-
сти центр сферы фиксированного радиуса по окружности. Если радиус сферы
меньше радиуса окружности, получим тор, в противном случае будет получена
поверхность, самопересекающаяся по двум окружностям.
Локально каналовая поверхность представляет собой правильный круговой
цилиндр (повторимся, это то же, что и правильный круговой конус с вершиной
на бесконечности). Предположим, что дана ортографическая проекция, так что
контур цилиндра представляет собой две параллельных прямых; это означает,
что (локально) контур каналовой поверхности также представляет собой две
параллельных прямых. “Локально” означает, что касательные к контурам кана-
Глава 24. Геометрические шаблоны через пространственные связи
773
Рис. 24.4. Вид каналовой поверхности (в данном случае тора) при различных ортографических
проекциях. Обратите внимание, что между двумя сторонами имеется взаимно-однозначное соот-
ветствие, так что любая касательная одной стороны параллельна соответствующей касательной
с другой стороны, но это не означает, что кривые переводятся друг в друга трансляцией (в цен-
тре). На этом рисунке одна кривая изображена серым, а соответствующая ей вторая — черным
цветом; справа соответствующие кривые естественным образом формируют две группы, которые
изображены пунктиром. Обратите внимание, что изображены невидимые сегменты контура; на
практике их удаление нарушило бы процесс построения соответствий
ловой поверхности параллельны в соответствующих точках. Это не обязательно
означает, что кривые — это транслированные копии друг друга (см. рис. 24.4),
но позволяет использовать следующий принцип группировки:
контур каналовой поверхности состоит из двух параллельных кривых (см. рис. 24.3).
Опишем, как можно проводить группировку. Вначале находим параллельные
фрагменты контура, а затем пытаемся собрать эти фрагменты в контур. Первый
шаг — это нахождение краевых точек и всех других точек, в которых края идут
в одном направлении; далее проходим в направлении первой краевой точки, от-
слеживая все возможные соответствия, идущие параллельно; данный процесс
продолжается, пока не будут использованы все точки параллельных сегментов.
Здесь требуется внимательно проследить, чтобы одна сторона не проходилась
быстрее, чем вторая. Следующий шаг — это нахождение фрагментов с близ-
кими краями и (грубо) одинаковым направлением. Данные фрагменты можно
сгруппировать, предположив, что разнесение этих фрагментов вызвано сбоями
детектора краев или изменением условий видимости.
Если обрабатывается перспективная проекция, можно предположить, что
диапазон изменения глубин в пределах объекта мал по сравнению с расстоя-
нием до объекта; это означает, что перспективную проекцию можно считать
масштабированной ортографической. В качестве альтернативы можно исполь-
зовать условия на точки перегиба контура, которые выполняются строго при
перспективной проекции, но дают слабые критерии группировки при поверх-
ностях с плоскими порождающими кривыми (см. работу [Zisserman, Mundy,
Forsyth, Liu, Pillow, Rothwell and Utcke, 19956]).
774 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Поверхности вращения
Поверхность вращения — это поверхность, образованная окружностью, ко-
торая перемещается вдоль прямой линии, перпендикулярной плоскости окруж-
ности и проходящей через ее центр, причем при перемещении по прямой радиус
окружности может меняться. Это означает, что в некоторой системе координат
поверхность вращения можно записать как
(/(s) cos t, f(s) sin t, s(s))
(данная форма допускает, что порождающая окружность может возвращаться
при прохождении прямой, поверхность может быть сингулярной и т.д.).
Поверхность вращения обладает круговой симметрией, т.е. совмещается
с собой при вращении вокруг собственной оси. Это означает, что конус наблю-
дения для поверхности вращения симметричен. Представьте плоскость, прохо-
дящую через ось поверхности вращения и фокус; конус должен быть симмет-
ричным относительно этой плоскости. Это не означает, что контур поверхности
вращения зеркально-симметричен, поскольку контур — результат сечения кону-
са наблюдения плоскостью изображения. Если плоскость изображения не пер-
пендикулярна плоскости симметрии, контур не будет обладать зеркальной сим-
метрией (рис. 24.5). Взамен этого будет наблюдаться разновидность симметрии
изображения, иногда называемая сопряженной, симметрией (conjugate symme-
try). В реальных камерах углы между плоскостью изображения и плоскостью
симметрии близки к прямым, иначе объект располагался бы вне поля наблюде-
ния. Часто для уменьшения искажений, которые перспективная камера может
создать в дальней зоне, применяются системы линз (см. [Fleck, 1995]). Таким
образом для реальных камер искажение невелико, и в любом случае можно
считать, что контур поверхности вращения обладает зеркальной симметрией.
Из сказанного следует, что соответствующие точки по любую сторону кон-
тура поверхности вращения можно определить через такое условие группи-
ровки:
контур поверхности вращения обладает (почти) зеркальной симметрией.
Данное утверждение можно переформулировать в более удобной форме:
две точки, лежащие на кривых изображения, касательные к которым образуют
практически равные углы с прямой, соединяющей точки (рис. 24.6), могут распола-
гаться по разные стороны линии симметрии и, следовательно, могут принадлежать
поверхности вращения.
Данную конфигурацию будем называть локальной симметрией, а прямую,
соединяющую точки, — осью симметрии. Контур поверхности вращения мож-
но найти, изучив локальные группы, центры симметрии которых расположе-
ны на прямой, приблизительно перпендикулярной оси симметрии этих групп.
Основная сложность при использовании данного подхода заключается в том,
Глава 24. Геометрические шаблоны через пространственные связи
775
Рис. 24.5. Поверхность вращения и фокальная точка плюс плоскость симметрии, проходящая
через ось поверхности вращения и фокальную точку (слева). На этой плоскости порождающая
контура должна обладать зеркальной симметрией. Это не означает, что контур обладает точной
зеркальной симметрией, поскольку контур представляет собой сечение конуса наблюдения (для
простоты на рисунке не показан) плоскостью, которая может не быть перпендикулярной
плоскости симметрии. На рисунке справа показан вид сверху; конус наблюдения изображен
пунктиром, также показано сечение конуса плоскостью изображения при формировании контура.
На этом рисунке плоскость изображения далеко не перпендикулярна плоскости симметрии,
откуда следует, что на плоскости изображения объект удален от центра камеры, так что контур
поверхности вращения не обладает точной зеркальной симметрией, но обладает сопряженной
симметрией. Как правило, камеры имеют относительно небольшие поля наблюдения, так что
подобные необычные углы на практике встречаются редко. Для подавляющего большинства
реальных камер данная сопряженная симметрия неотличима от зеркальной
776 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 24.6. Локальная симметрия пары точек контура, в которых касательные к контуру образуют
почти равные углы с прямой, соединяющей точки контура (линия симметрии). Подобные симметрии
часто наблюдаются на контурах поверхностей вращения
что большинство изображений содержат чрезвычайно много групп симметрии,
большая часть которых удовлетворяет указанному условию.
Прямые однородные обобщенные цилиндры
Прямой однородный обобщенный цилиндр является обобщением поверхно-
сти вращения, который получается при перемещении плоской образующей пер-
пендикулярно плоскости, в которой она лежит, с уменьшением или увеличени-
ем размера образующей при перемещении (рис. 24.7). При подходящем выборе
системы координат порождающую кривую можно записать как (x(t),y(i),0), а
поверхность — как
(я(0/(«Ху(0/(*), £(«))•
Данная форма записи означает, что поверхность может заворачиваться на саму
себя. Прямые однородные обобщенные цилиндры не обладают удобной сим-
метрией, но имеют некоторые свойства, общие для поверхностей вращения.
Поверхность вращения локально представляет собой правильный круговой ко-
нус, и локально прямой однородный обобщенный цилиндр — это конус. Чтобы
в этом убедиться, зафиксируем значение s = «о и рассмотрим полоску поверх-
ности от s0 до so + е. Если полоска достаточно мала, /(s) можно аппрокси-
мировать us + v, a g(s) можно аппроксимировать cs + d, где и, и, с и d —
некоторые константы (подобный подход обычен при определении производной).
От d можно избавиться посредством подходящей трансляции, а от с — по-
средством замены параметров, так что данная полоска — это конус. Сказанное
означает, что все касательные векторы в направлении s в точке s = s0 фор-
мируют конус. Вершину данного конуса определить очень легко (в выбранной
системе координат): если us + v = 0, то при любом значении t все касательные
векторы проходят через точку (0,0,p(s)). Это означает, что вершина каждого
касательного конуса лежит на оси z выбранной системы координат.
Глава 24. Геометрические шаблоны через пространственные связи
777
Рис. 24.7. Прямой однородный обобщенный цилиндр получается при перемещении плоской об-
разующей перпендикулярно плоскости, в которой она лежит, с уменьшением или увеличением
размера образующей при перемещении (слева). В результате получается поверхность, локально яв-
ляющаяся конусом, в том смысле, что имеется коническая касательная к поверхности вдоль любой
образующей. На рисунке справа вырезана узкая полоска поверхности между двумя образующими
и обозначены касательные к ним. Данные касательные пересекаются в точке на оси, а это означает,
что все подобные полоски прямого однородного обобщенного цилиндра являются полосками конуса
(т.е. локально данный объект — конус)
Хотя данный результат был получен в координатном виде, это было сдела-
но исключительно для удобства. Поскольку результат касается инцидентных
свойств касательных, на которые не влияет изменение координат, он применим
к любому прямому однородному обобщенному цилиндру. Таким образом, для
любого прямого однородного обобщенного цилиндра в любой системе коор-
динат существует вполне определенная ось (представляющая собой прямую),
вдоль которой лежат вершины касательных конусов.
Поскольку локально поверхность — это конус, ее контур (локально) — это
контур конуса. Это означает, что если построить касательные в точках конту-
ра, соответствующих некоторому значению s, они пересекутся в одной точке.
При изменении значения s данная точка (проекция вершины касательного
конуса) будет перемещаться по прямой. Итак, получаем следующее условие
группировки:
имеется некоторое соответствие между компонентами контура, такое что касатель-
ные на соответствующих сторонах пересекаются в точках, которые образуют прямую.
778 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 24.8. Пара кривых параллельно симметрична, если они переводятся друг в друга гладким со-
ответствием, при этом касательные к кривым параллельны (рис. слева). Контур плоского кругового
обобщенного цилиндра с постоянным поперечным сечением при ортографической проекции состоит
из набора параллельных симметричных кривых (рис. справа). Чтобы показать, что изображение —
это контур, на рисунке представлен один край поверхности
Высказывание выше является критерием сегментации, поскольку не все наборы
кривых ему удовлетворяют. Впрочем, в такой формулировке использовать это
правило непросто.
Плоские круговые обобщенные цилиндры с постоянным поперечным
сечением
Другой фигурой, дающей четкий критерий группировки, является плоский
круговой обобщенный цилиндр с постоянным поперечным сечением (Planar
Right Constant Cross-section Generalized Cylinder — PRCGC, или трубка). Это
поверхность, полученная перемещением фиксированной плоской кривой, пер-
пендикулярно некоторой оси. Если данная плоская кривая — окружность, по-
верхность представляет собой каналовую поверхность, но данную концепцию
можно обобщить и на более сложные поперечные сечения.
Как и в случае каналовых поверхностей, локально плоский круговой обоб-
щенный цилиндр с постоянным поперечным сечением — это цилиндр. Ска-
занное означает, что конус наблюдения должен (локально) представлять со-
бой конус наблюдения, соответствующий цилиндру, и что ортографическая
проекция конуса наблюдения — это набор листов, параллельных между собой
и перпендикулярных оси.
В результате при ортографической проекции получаем такое условие груп-
пировки:
контур плоского кругового обобщенного цилиндра с постоянным поперечным сече-
нием состоит из набора параллельных кривых (т.е. существует гладкое отображение
точек кривой такое, что касательные в соответствующих точках параллельны;
рис. 24.8).
Глава 24. Геометрические шаблоны через пространственные связи
779
Вход
Края
Рис. 24.9. Пример системы группировки на основе классов; на рисунке слева приведено входное
изображение, края которого показаны в центре; на рисунке справа показаны группы кривых, по-
тенциально представляющих контуры объекта определенного типа. Края изображения имеют раз-
рывы, точки затенения и т.д. Подобрать пары к подобным точкам можно с помощью процессов, спе-
цифических для каждого типа объектов (т.е. система группировки для многогранника обрабатывает
проблемы с сегментами прямых; система группировки для поверхностей вращения, восстанавли-
вающая недостающие детали, обрабатывает пары, расположенные рядом с кривыми, обладающими
зеркальной симметрией и т.д.). Поскольку каждый класс — это несколько иная система группиров-
ки, контуры классифицируются в конце процесса; впрочем, данная классификация зависит только
от типа объекта, но не от конкретного представителя данного типа. Более подробный пример дан-
ного процесса приведен на рис. 24.10. Перепечатано из A. Zisserman et al., "Class-based grouping
in perspective images”. Proc. International Conference on Computer Vision, 1995. © 1995 IEEE
Выход
Наборы кривых, обладающие данным свойством, называются параллель-
но симметричными кривыми. Группировка набора параллельно симметричных
кривых уже рассматривалась ранее.
24.1.2. Группировка на основе классов
Описанные условия применимы к классам объектов (это означает, что при
группировке не требуется знать, какой объект подвергается этому процессу).
Поскольку объекты различных классов дают несколько отличные условия груп-
пировки, для группировки компонентов контура, порожденных объектами раз-
личных типов, нужно использовать различные стратегии, т.е. применять так
называемую группировку на основе классов. Это не проблема. Фактически,
это даже пример привлекательной особенности, поскольку довольно рано в про-
цессе группировки появляется информация, фокусирующая внимание на опре-
деленных кривых изображения и определенных классах объектов. Например,
если отсутствуют какие бы то ни было прямые, глупо пытаться сгруппиро-
вать данные в многогранник; если отсутствует зеркальная симметрия, не стоит
пытаться сгруппировать данные в поверхности вращения. Подобным образом,
в процессе группировки каналовых поверхностей ищутся только пары краевых
точек с параллельными касательными, так что значительный объем информа-
ции о краях может опускаться; при развитии этих пар до сегментов кривых
можно отбросить еще больше излишней информации.
Таким образом ищется небольшой набор классов объектов для использо-
вания в стратегиях группировки, каждая из которых дает иной набор точек
контура. Среди данных наборов нужно, в свою очередь, провести поиск, чтобы
780 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Выход
Рис. 24.10. Края изображения, приведенного на рис. 24.9, имеют разрывы, точки затенения и т.д.
Данные края используются как вход различных систем группировки. Система группировки много-
гранников строит группы и корректирует края через поиск прямых и сборку их в цепочки. Система
группировки каналовых поверхностей строит группы и корректирует края через поиск локально
параллельных краевых точек и группировку их в параллельные кривые. Система группировки по-
верхностей вращения строит группы и корректирует края через поиск пар кривых с зеркальной
симметрией. Подобная коррекция возможна, поскольку условия означают, что при наличии гипотез
о группировке, краевые точки, наблюдаемые в одном месте, могут давать подсказки относительно
разрывов. Перепечатано из A. Zisserman et al., “Class-based grouping in perspective images”, Proc.
International Conference on Computer Vision, 1995. © 1995 IEEE
определить, присутствует ли объект. Это означает, что при проведении поиска
в два этапа потенциально снижается общий объем необходимого поиска — если
нет прямых, не требуется искать многогранные модели. Хотя данный пример
краток, общий принцип достаточно мощный — извлекать на ранних этапах про-
цесса распознавания небольшие фрагменты информации, значительно уменьша-
ющие число моделей, среди которых требуется проводить поиск, и (в идеальном
случае) число процессов, которые можно применить к остальной части изоб-
ражения. Поведение одной такой схемы группировки, построенной согласно
работе [Zisserman, Mundy, Forsyth, Liu, Pillow, Rothwell and Utcke, 19956],
иллюстрируется на рис. 24.9 и 24.10.
Глава 24. Геометрические шаблоны через пространственные связи
781
24.2. ПРИМИТИВЫ, ШАБЛОНЫ И ГЕОМЕТРИЧЕСКИЙ ВЫВОД
Примеры в предыдущем разделе иллюстрируют привлекательность принятой
схемы рассуждений, но ограничены довольно простыми формами. Существует
множество более интересных примеров форм, которые, впрочем, имеют менее
строгие связи между поверхностью и изображением. Изучая данные ситуации,
приходим к нескольким широко известным системам распознавания объектов.
24.2.1. Обобщенные цилиндры как объемные примитивы
Объемные примитивы интересны, поскольку (как показывалось ранее) они
сродни геометрическим шаблонам: вначале группируется порция данных с изоб-
ражения, так как она принимает типичную, ограниченную форму, предполага-
ющую присутствие примитива, а затем изучаются связи между подобными на-
борами. В идеальном случае примитив выражается так, что подавляются несу-
щественные детали поверхности (например, бугорки вен и сухожилий по боль-
шому счету не мешают представить пальцы как набор цилиндров). Впрочем,
рассмотренные ранее примитивы достаточно ограничены.
Обобщенные цилиндры, предложенные Бинфордом (Binford) в знаменитой
(но, как ни парадоксально, неопубликованной) работе 1971 года, представляют
на настоящий момент наиболее популярную форму объемных примитивов. Пер-
воначально они были определены через “обобщенную трансляционную инвари-
антность”. Грубо говоря, это означает, что обобщенный цилиндр — это тело,
образованное одномерным набором секущих поверхностей, которые переходят
одна в другую плавной деформацией. Данное определение отражает следую-
щую идею: многие интересные объекты при надлежащем уровне детализации
являются поверхностями, образованными заметанием, — к примеру каналы,
трубки и цилиндры, но и машину можно представить (грубо!) как прямоуголь-
ник, движущийся по оси машины и увеличивающийся или уменьшающийся по
мере перемещения (при такой формулировке не учитываются колеса машины,
с которыми требуется что-то сделать отдельно). Для уточнения приведенной
формулировки можно расширить определение каналовых поверхностей, чтобы
разрешить заметание пространства сферой с увеличением или уменьшением
ее радиуса (рис. 24.12, слева). Впрочем, не все поверхности являются обоб-
щенными каналовыми поверхностями. Если для таких поверхностей строить
геометрическое место центров максимальных вписанных сфер, можно ожидать,
что получится кривая; но для большинства поверхностей такое построение дает
поверхность (см. рис. 24.12).
Альтернативный путь улучшения приведенного определения — это постро-
ить поверхность путем заметания плоской кривой, перемещающейся по про-
странственной кривой и сжимающейся, расширяющейся и наклоняющейся по
мере движения. Как правило, именно это и считается определением обобщенно-
го цилиндра (рис. 24.12, слева). Очевидно, это большой класс поверхностей —
есть свобода выбора поперечного сечения, правила масштабирования, образу-
ющей кривой, угла наклона и т.д. и не ясно, существует ли вообще поверх-
782 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 24.11. Возможные реализации обобщенного цилиндра. Обобщенная каналовая поверхность
изображена на рисунке слева; здесь сфера перемещается по некоторой пространственной кривой,
сжимаясь и расширяясь по мере движения. Обратите внимание, что образующие шары касаются
поверхности по окружностям. Не всякая поверхность относится к обобщенным каналовым. Чтобы
убедиться в этом, можно построить геометрическое место центров максимальных вписанных сфер
(сфер, касательные поверхности в более чем одной точке). Данный набор точек иногда называ-
ется скелетом поверхности. Для обобщенной каналовой поверхности скелет — это кривая, так
что всю поверхность можно получить, заметая сферами пространство вдоль этой кривой. Не все
поверхности имеют скелеты, обладающие подобной особенностью. На рисунке справа приведен па-
раллелепипед и его скелет, который состоит из многоугольных граней. Можно прийти к выводу, что
из такого набора граней нельзя удалить ни одной кривой, чтобы при этом сохранилось указанное
выше свойство, т.е. параллелепипед не является обобщенной каналовой поверхностью
ность, которая не является обобщенным цилиндром, определенным подобным
образом. Более того, достаточно очевидно, что, по крайней мере для некото-
рых обобщенных цилиндров, можно выбирать несколько поперечных сечений
(хороший пример — сфера). Возможно множество вариантов определения в за-
висимости от формы образующих (скажем, диски или произвольные плоские
области) и от класса разрешенных деформаций (простое изменение масштаба,
как в двумерном случае, или некоторые другие гладкие деформации). Однако
все же неясно, как вычислить поперечное сечение, правило масштабирования
и образующую кривую по поверхности, имея только данные на изображении.
24.2.2. Ленты
Связь обобщенного цилиндра и его изображения загадочна (и не только по-
тому, что нет четкого определения, что же такое обобщенный цилиндр). Таким
образом у нас не может быть точных геометрических соображений, подобных
тем, что фигурировали в последнем разделе. Впрочем, если принять, что обоб-
щенный цилиндр — это поверхность, построенная из деформируемых попереч-
ных сечений, можно предположить, что на изображении это будет выглядеть
как область, построенная путем заметания пространства деформированным сег-
ментом, движущимся по кривой. Отсюда следует предложение искать области
изображения, которые выглядят так, будто они порождены методом заметания.
Подобные области называются лентами.
Глава 24. Геометрические шаблоны через пространственные связи
783
Рис. 24.12. Обобщенные цилиндры: слева представлено первоначальное определение: плоские по-
перечные сечения, связанные деформацией; справа изображена модель самолета L-1011, полученная
системой ACRONYM. Данный экземпляр общей модели широкофюзеляжного самолета собран из
цилиндрических и конических примитивов с круговыми и многоугольными поперечными сечениями
Лента — это огибающая семейства копий геометрической фигуры (обра-
зующей ленты), которая движется по некоторой траектории (хребту ленты)
и сжимается или расширяется по мере движения (рис. 24.13). Обычно отмеча-
ют два важных примера лент. Лента Брукса (Brooks ribbon) получается, если
образующая — это фрагмент прямой, а если образующей является окружность,
получаем ленту Блюма (Blum ribbon) (рис. 24.14).
Предположим теперь, что данный объект, порожденный заметанием, свя-
зан с аналогичным объектом исследуемой поверхности. Далее внимание можно
сосредоточить на трех задачах.
• Интерпретация. Можно ли для данной плоской области восстановить
через ленты полезное представление данной области?
• Сегментация. Можно ли определить, какие данные на изображении фор-
мируют ленту, и можно ли по этой информации идентифицировать объект?
• Согласование. Можно ли с помощью представлений на основе лент иден-
тифицировать объекты?
Обратите внимание, что данные задачи взаимосвязаны; если любой набор дан-
ных на изображении формирует ленту, то в качестве подсказки при сегментации
ленты использовать не стоит.
Интерпретация
Задача интерпретации, как она формулируется при определении полезного
представления плоской области через ленты, рассмотрена во множестве работ.
Решить эту задачу можно, поскольку она кажется легкой, и поскольку похо-
же, что это решение позволит лучше разобраться в представлении объектов.
Довольно простые результаты можно получить для лент Блюма. В частности,
определим преобразование Блюма-Мантанари, часто называемое преобразо-
784 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 24.13. Интересные объекты на изображении часто выглядят как ленты; разумная модель
ленты — это взять кривую (ось) и отметить точки, лежащие по обе стороны кривой на равном
расстоянии в направлении нормали, причем расстояние, на которое мы отходим от оси, меняется
вдоль кривой. Для каждой ленты показана ось и несколько поперечных сечений, демонстрирую-
щих ее структуру. Под каждой лентой приведен график, на котором показано, как расстояние по
перпендикуляру от края ленты до оси зависит от длины дуги вдоль оси
Рис. 24.14. Лента Брукса (слева) и лента Блюма (справа). В обоих случаях центральная кривая —
это хребет ленты, определенный как траектория центра образующей данной ленты. Обратите вни-
мание, что при такой формулировке хребет ленты Брукса неопределен; обычно в подобных случаях
берут траекторию средней точки образующего сегмента прямой
Глава 24. Геометрические шаблоны через пространственные связи
785
ванием горящего луга (grassfire transform). Для данной двумерной области
строится семейство вписанных дисков, касательных границе по крайней мере
в двух точках. Геометрическое место центров этих дисков является результатом
применения преобразования Блюма-Мантанари к форме. Если дополнительно
учитывать касание на внутренних краях, то преобразование Блюма-Мантанари
корректно расширяется на углы.
Предположим теперь, что дана некоторая плоская кривая С. Получаем
С € преобразование Блюма-Мантанари(лента Блюма(С, правило сжатия)),
т.е. если перемещать окружность вдоль С при любом правиле сжатия (или
расширения), получим область, Блюм-образ которой содержит С. Более того,
имеется некоторое особое правило сжатия R, при котором
лента Блюма(преобразование Блюма-Мантанари(лента Блюма(С,правило сжатия)),/?)
равно
лента Блюма(С, правило сжатия).
Сказанное означает, что преобразование Блюма-Мантанари (или некоторые его
компоненты) плюс правило сжатия дает описание формы. Для реализации пре-
образования Блюма-Мантанари можно использовать простой алгоритм, в кото-
ром итеративно разъедается граница области цифрового изображения и стро-
ится его скелет (или срединная ось), т.е. кривая, сформированная центрами
дважды касательных дисков. Данное свойство позволяет по-иному взглянуть на
преобразование Блюма-Мантанари: если рассматривать область как луг и под-
жечь границы этого луга, Блюм-образ — это набор точек, в которых столкнут-
ся огненные фронты (и, будем надеяться, уничтожатся). Из таких соображений
и появился термин “преобразование горящего луга” (grassfire transform). Далее
интуитивно понятно вводятся бифуркации скелета (т.е. множественные точки,
в которых встречается несколько гладких ветвей), определяющие декомпози-
цию формы на части, что может быть весьма полезным (рис. 24.15 и 24.20).
Привлекательность лент Блюма в сфере распознавания объектов, к сожалению,
компенсируется чувствительностью преобразования Блюма-Мантанари к гра-
ничному шуму. Например, произвольно малая вмятина на границе прямоуголь-
ника существенно меняет структуру скелета (рис. 24.15, справа). Подобным
образом, бифуркации скелета также нестабильны при возмущении границы.
Можно ли подобным образом строго определить преобразование Брукса? Не
совсем понятно, хотя одна из попыток описана в разделе упражнений. Вообще,
о лентах Брукса и их трехмерных родственниках, обобщенных цилиндрах, мы
поговорим в следующем разделе, текущий раздел посвящен целиком преобра-
зованию Блюма-Мантанари.
786 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 24.15. Преобразование Блюма-Мантанари: а) скелет плоской области является геометриче-
ским местом дисков, вписанных в эту область и дважды касающихся ее границы; б) скелеты пря-
моугольника и его зашумленной версии. Обратите внимание, что для большинства точек внутри
плоской области минимальное расстояние до границы области достигается в единственной точке.
В точке же скелета, наоборот, минимум достигается одновременно в двух точках: двух местах, где
соответствующий диск касается границы. Таким образом, скелет можно рассматривать как геомет-
рическое место точек, в которых волновой фронт, пришедший с границы, сталкивается с самим
собой. На дискретных изображениях это дает алгоритм обгладывания формы, в котором форма
итеративно разъедается через удаление уровень за уровнем граничных точек, пока не останутся
только точки скелета. Подробнее см. раздел упражнений
Сегментация
Сегментация — это интересная и несколько сложная задача. Если форма
ленты существенно ограничена (как в примерах, приведенных выше), то на
изображении скорее всего окажется немного лент, которые, к тому же, бу-
дет достаточно легко найти. Если форма ограничена менее строго, для выбора
значимых лент требуются разнообразные эвристические методы. Система, рас-
смотренная в данной книге, описана согласно работам [Mohan and Nevatia,
1989, 1992].
Первый шаг при сегментации — это попытаться найти соединительные зве-
нья между краевыми фрагментами; хотелось бы найти такие соединения, кото-
рые бы корректировали пропущенные места (когда можно относительно гладко
соединить расположенные близко кривые), или соединения, которые образовы-
вали бы углы (когда конечные точки фрагментов расположены относительно
близко). Далее ищутся кривые, которые имеют участки, близкие к параллель-
ным, подобно тому, как это делалось ранее при группировке каналовых поверх-
Глава 24. Геометрические шаблоны через пространственные связи
787
Грани
Связанные кривые
Оси симметрии
Рис. 24.16. На рисунке слева приведены края изображения знакомых объектов; края имеют
разрывы, причем контуры объектов не формируют когерентных краевых кривых. Более того,
существуют края, не относящиеся к контурам объектов. На рисунке в центре краевые кривые
соединены с использованием двух критериев. Либо щель должна быть малой и края при объеди-
нении формируют гладкую кривую (криволинейная группировка), либо щель должна быть малой.
На рисунке справа изображены оси, полученные маркировкой точек, расположенных посредине
параллельных кривых. Существует много подобных осей, большинство из них бесполезны; многие
отсеиваются согласно критериям непротиворечивости. Перепечатано из R. Mohan and R. Nevada,
“Segmentation and description based on perceptual organization", Proc. Computer Vision and
Pattern Recognition, 1989. (c) 1989 IEEE
ностей. В результате получаем набор предположительных образующих кривых;
как правило, данный набор слишком велик, чтобы его можно было использо-
вать на практике (рис. 24.16).
Существуют интерпретации, противоречивые между собой. Например, как
видно из рис. 24.17, две образующих кривых не могут иметь общий контур, по-
скольку это предполагает весьма специфическую проекцию (а мы рассматрива-
ем кривые общего положения). В идеальном случае каждой ленте соответствует
оконечный элемент, и данное условие должно помочь определить, какая образу-
ющая кривая остается после разрешения противоречия. Другой пример: обычно
желательно отсеять обозначения на объекте, подавив ленты, целиком лежа-
щие внутри других лент (при этом возникают определенные следствия с точки
зрения затенения). Итак, теперь можно сформулировать задачу оптимизации:
ленты оцениваются по гладкости их соединений и другим критериям, а затем
параметры для разных лент фильтруются с учетом нарушений условий. Далее
требуется найти набор лент, дающих экстремальное значение параметра (авто-
ры применяли для этого метод релаксации; вообще, альтернатив здесь множе-
ство). Как видно из рис. 24.17, данный подход может быть крайне успешным.
Тот факт, что связь двумерных и трехмерных объектов выражается несколько
неинформативно, помехой не является. Схема оптимизации выгодна тем, что
в принципе можно отбросить гипотезы, приводящие к невозможным объектам;
впрочем, при таких условиях задача оптимизации может быть сложной.
788 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Несоответствие
Оси наилучшей симметрии
Лоскуты поверхности
Рис. 24.17. На рисунке слева проиллюстрирован один критерий непротиворечивости: две оси не
могут занимать один сегмент кривой (поскольку в противном случае проекция будет крайне нестан-
дартной). Теперь требуется определить набор осей, наилучших с точки зрения непрерывности и не
учтенных из-за нарушений непротиворечивости. Данная задача относится к разряду задач оптими-
зации; для ее решения можно применять различные методы (в работе [Mohan and Nevatia, 1989],
например, представлен метод релаксации). На рисунке в центре показан экстремальный набор
осей, которые можно связать с их граничными кривыми, в итоге получится предположительный
набор поверхностей; при дальнейшей обработке, связанной с решением вопросов затенения, полу-
чается набор предположительных поверхностей, приведенный на рисунке справа. Перепечатано
из R. Mohan and R. Nevatia, "Segmentation and description based on perceptual organization". Proc.
Computer Vision and Pattern Recognition, 1989. © 1989 IEEE
Согласование
Похоже, что представления, которые полезны на практике, дают симмет-
рии — например, используя представление на основе симметрии, можно с до-
вольно слабой точностью определить, присутствуют ли на изображении голые
люди. Подобные системы подробнее описаны в разделе 23.3.2; ниже данное
описание повторяется, на этот раз в свете примитивов.
Схема рассуждений такова: люди составлены (грубо!) из цилиндрических
сегментов. Данные цилиндры формируют на изображении длинные, прямые
ленты. Некоторые конфигурации лент предполагают наличие человека, тогда
как другие — нет. Таким образом, для поиска людей вначале ищутся ленты, а
затем ищутся совокупности лент, предполагающие наличие людей. Та же стра-
тегия, с соответствующими изменениями, используется для лошадей (см.
рис. 24.18).
Приходим к довольно привлекательной схеме рассуждений: вначале про-
веряются относительно небольшие наборы компонентов изображения на пред-
мет принадлежности к ленте; далее наборы, прошедшие первый отсев и теперь
формирующие ленты, собираются в большие области, которые выглядят как
человек. Это означает, что используется частичная модель того, на что похо-
жи объекты, таким образом собирается информация, на основе которой можно
утверждать, что объект присутствует. В частности, на каждом этапе задейство-
вана незначительная информация о модели, помогающая уменьшить диапазон
существующих возможностей. Следует отметить, что несмотря на то, что дей-
Глава 24. Геометрические шаблоны через пространственные связи
789
Рис. 24.18. Пример представления, которое можно получить из прямых сегментов с приблизитель-
но параллельными сторонами. На рисунке слева приведено цветное изображение двух лошадей;
в центре слева — получены пиксели с цветом и текстурой, соответствующими шкуре, остальные
отсеяны; в центре справа — края данного набора пикселей; на крайнем правом изображении
приведены все прямые сегменты с приблизительно параллельными сторонами, которые получены
с помощью механизмов, описанных ранее. Данные сегменты отображены с использованием абстрак-
ции, которую поддерживает программа (т.е. на края, порождающие сегменты, наложены стороны
абстрактного сегмента). Обратите внимание, что компоненты не точно соответствуют сегментам
тела. Хотя данное представление выглядит бесперспективным, его можно использовать для поиска
лошадей (раздел 25.3.3), несмотря на то, что информацию с изображения оно извлекает очень плохо
ствительной вероятностной модели нет, общая последовательность действий
напоминает логический вывод.
24.2.3. Что можно представить с помощью лент
Предположим теперь, что дан силуэт объекта (так что можно не рассмат-
ривать задачу сегментации); вопрос: что можно представить с помощью лент?
В двумерной системе распознавания FORMS, разработанной Жу и Юллем [Zhu
and Yuille, 1996J, предполагается, что как минимум можно представить людей
и животных. Объекты в этой системе представляются через разложение их си-
луэтов на ленты. Основная сложность заключается в том, что нужно избежать
неоднозначных разложений; в названной системе для этого находятся каса-
тельные к силуэту окружности, которые имеют большой радиус и захватывают
незначительную часть фона. Данные окружности, для определения которых
формулируется задача на нахождение экстремума, дают точки-зародыши, с ко-
торых начинается рост представления.
Далее в ходе рекурсивного алгоритма намечаются инцидентные ветви ске-
лета, начинающиеся в точках-зародышах, а затем ищутся бифуркации скелета.
Данные бифуркации могут показывать, что скелет расщепляется (возможно,
два пальца переходят в ладонь) и для каждого компонента должна начинаться
новая ветвь скелета. Как только скелет найден, каждая ветвь отождествляет-
ся с частью объекта; в описание части включаются диски, соотнесенные с ее
конечными точками (рис. 24.19).
Как показано на рис. 24.19, данный подход дает интуитивно удовлетвори-
тельные результаты для боковых проекций позвоночных существ, таких как
млекопитающие и рыбы. Как только найдены части, они переводятся в при-
митивы двух классов: червяки, соотнесенные с сегментами хребта, которые ле-
жат между двумя соединениями или обрываются, но имеют длину, большею по
сравнению с радиусом дисков, присоединенных к их конечным точкам, и круга-
790 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 24.19. Система FORMS в действии. Силуэт собаки слева вверху разбивается на части, по-
казанные слева внизу, для чего подбираются окружности максимального радиуса, несколько раз
касающиеся контура. Данные окружности предположительно являются точками разветвления си-
луэта, поэтому могут использоваться для разделения силуэта на части. Подобным образом разби-
вается силуэт рыбы справа вверху, результат разбиения показан под силуэтом. Обратите внимание,
что одна часть может располагаться поверх другой. Более того, из предположений о симметрии
на основе (видимого) брюшка рыбы выводится верхняя (невидимая) граница частей рыбы. Перепе-
чатано из S.-C. Zhu and A. Yuille, "FORMS: a flexible object recognition and modelling system",
Proc. International Conference on Computer Vision, 1995. (c) 1995 IEEE
вые секторы, соотнесенные с оставшимися (обрывающимися) сегментами (см.
разбиение рыбы на рис. 24.19). Каждый примитив представляется пятимерным
вектором признаков, записывающим его длину (для червяков) или угловой фак-
тор (для круговых секторов) плюс четыре деформационных параметра, которые
представляют функцию ширины или радиуса ленты и вычисляются с использо-
ванием анализа главных компонентов в базе моделей.
Для согласования используется метод, основанный на графах, в котором
фигурируют мера сходства частей, хэш-таблицы и схема голосования, в ре-
зультате чего эффективно извлекаются обещающие части модели и категории
объектов. Сходство части модели и наблюдаемого примитива о определяется
как s(m, о) = ехр(—|тп — о|2), где тп и о — пятимерные векторы признаков,
соотнесенные с двумя примитивами.
Каждый экземпляр объекта представляется графом, вершины которого —
места соединений и разрывов скелета, а ребра — части-примитивы между ними.
Каждую категорию объектов можно описать несколькими такими скелетными
графами, соответствующими наблюдаемым экземплярам объекта. Скелетные
графы, соотнесенные с наиболее обещающими моделями, выбираются посред-
ством хэширования, основанного на сходстве, затем они проходят голосование,
после чего согласовываются с наблюдаемыми данными. В последнем процес-
се используется процедура согласования, также основанная на графах. В ходе
данной процедуры отсекаются потенциально согласующиеся пары, стоимость
Глава 24. Геометрические шаблоны через пространственные связи
791
Рис. 24.20. После того как система FORMS определила бифуркации скелета (рис. 24.19), она
переходит к заполнению скелета. На данном рисунке приведены скелеты для различных силуэтов.
Данные скелеты выглядят разумно в том смысле, что они отражают наши интуитивные представ-
ления о наличии у животных голов, тел, ног и хвостов; пальцев на руках; и т.д. Перепечатано
из S.-C. Zhu and A. Yuille, "FORMS: a flexible object recognition and modelling system”, Proc.
International Conference on Computer Vision, 1995. (c) 1995 IEEE
которых превышает некоторый порог. Для придания этой процедуре устойчиво-
сти используется адаптивное согласование, позволяющее скелетным графам
моделей меняться в процессе согласования под действием скелетных операто-
ров, которые учитывают ошибки, возникающие на этапе восходящего выде-
ления скелета (например, учет ветвей, потерянных вследствие затенения или
введенных вследствие шума, расщепления места соединения на два вследствие
граничного шума или слияния двух соединений в одно). Каждое применение
одного из этих операторов имеет определенную цену, а искомыми являются
соответствия с минимальной ценой, не превышающей некоторого порога.
Пример распознавания приведен на рис. 24.21. Данный подход показал до-
вольно хорошие результаты при базе из 35 экземпляров объекта и 17 катего-
рий, использованной в экспериментах FORMS, так что если доступны проекции
объекта с заранее произведенной сегментацией, то с помощью лент описанного
рода можно представить достаточное число объектов.
24.2.4. Связывание трехмерных и двумерных данных для цилиндров
известной длины
Предположим, что дана единственная проекция фигуры человека, получен-
ная с неизвестной камеры, — известна ли конфигурация человека в трехмерном
варианте? Ответ — “да” (с оговорками). Такой ответ объясняется тем, что, как
792 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 24.21. Система FORMS в действии: примеры распознавания. Перепечатано из S.-C. Zhu
and A. Yuille, “FORMS: a flexible object recognition and modelling system”, Proc. International
Conference on Computer Vision, 1995. (c) 1995 IEEE
показано в работе [Taylor, 2000], априорная структура человека сильно огра-
ничивает связь трехмерной и двумерной конфигураций.
Мы моделировали человека как набор цилиндров. Теперь предположим, что
длина данных цилиндров известна (по крайней мере относительно друг дру-
га). Данный момент является ключевым, кроме того делается предположение,
что люди с руками, длинными относительно туловища, встречаются редко (или
не имеет значения, если конфигурация человека была оценена неверно). Для
получения относительных размеров цилиндров можно использовать различные
публикации, посвященные антропометрии (например, работу [Anthropology Re-
search Project, 1978]).
Предположим теперь, что дана проекция цилиндра известной длины I, по-
лученная с ортографической камеры с известным коэффициентом масштаби-
рования, s. Предполагается, что концы цилиндра можно определить, так что
цилиндр можно рассматривать как произвольно тонкий сегмент прямой (об-
ратите внимание, что за исключением экстремальных углов края цилиндров,
длинных относительно своего радиуса, не очень влияют на общую картину).
Приняв подобные приближения, длину спроектированного цилиндра можно за-
писать как
si cos 6,
где 0 — угол между плоскостью изображения и осью цилиндра. Это означает,
что местоположение цилиндра в трехмерном пространстве известно с точно-
стью до двух альтернатив (направлен ли он на камеру или от нее). В свою
очередь, если имеется незамкнутая цепочка из п таких цилиндров, то мож-
но узнать конфигурацию цепочки с точностью до 2П альтернатив — цилиндры
связаны и каждый определен с точностью до двукратной неоднозначности. Фи-
гура человека обычно моделируется 9 цилиндрами и сферой (шею и голову
можно слить в один цилиндр, но так поступают редко), так что данная неодно-
Глава 24. Геометрические шаблоны через пространственные связи
793
значность приемлема, особенно поскольку некоторые конфигурации запрещены
с точки зрения кинематики и их можно не рассматривать.
Разумеется, значение s обычно неизвестно. Это означает, что приведенное
уравнение использовать нельзя, но вот преобразованная его версия пригодится.
В частности, предположим, что дано два цилиндра длины li и I2', тогда отно-
шение их длин равно I1/I2, а отношение длин их образов можно записать как
Здесь 01 и 02 — углы между сегментами и плоскостью образа. Предположим
теперь, что имеется цепочка сегментов известных длин. Далее с изображения
можно получить отношения углов, т.е. если известен один угол (скажем, 01),
известны и все остальные. Более того, имеются условия на 0j и известно
значение всех г^, поскольку их можно измерить. Теперь можно записать
COS 01 = Fife COS0fc [ у-
набор условий, которые могут оказаться полезными. Приведенные выкладки
доказывают, что для любого значения cos0i, удовлетворяющего условию, мож-
но (с точностью до дискретной неоднозначности) восстановить трехмерную
конфигурацию набора цилиндров с известными относительными длинами.
Восстановление должно зависеть от выбора 01, но данный выбор ограничен
не только приведенными ранее условиями, но и кинематикой фигуры челове-
ка. В связи с этим в работах Тейлора предлагается использовать наибольшее
значение 01, которое допускают данные (рис. 24.22 и 24.23).
24.2.5. Связывание трехмерных данных и данных образа
с использованием явных геометрических соображений
Итак, имеется определение (довольно туманное) обобщенного цилиндра
и такое же неясное понятие связи геометрии обобщенного цилиндра с соответ-
ствующей информацией на изображении. Фактически, на основе этих понятий
можно строить системы, определяющие наличие совокупностей простых ци-
линдров по данным с изображения.
Смоделируем объекты как иерархические совокупности цилиндров или ко-
нусов с круговыми или многоугольными поперечными сечениями. Далее каж-
дый класс объектов представляется особой комбинаторной структурой (т.е. раз-
личным типам цилиндров присваиваются различные номера), и каждый объект
представляется своими значениями параметров (например, длиной оси, радиу-
сом поперечного сечения, положением одного цилиндра относительно другого
и т.д.). Далее структура категории представляется системами неравенств по
этим параметрам.
794 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 24.22. На рисунке слева изображена фигура человека с помеченными конечными точками
сегментов тела (маркировка выполнялась вручную). Поскольку относительные длины данных сег-
ментов известны, предположив, что данное изображение — это масштабированная ортографическая
проекция, можно восстановить трехмерную фигуру с точностью до небольшого набора неоднознач-
ностей. На рисунке справа приведен вид сбоку одной из таких реконструкций. Некоторые примеры
неоднозначностей вы найдете на рис. 24.23. Перепечатано из C.J. Taylor, “Reconstruction of Artic-
ulated Objects from Point Correspondences in a Single Uncalibrated Image", Proc. Computer Vision
and Pattern Recognition, 2000. (c) 2000 IEEE
Выше уже рассматривались контуры, порождаемые каждой частью объекта.
Некоторые компоненты комбинаторной структуры класса объектов проявляются
на изображении, поскольку при проектировании части могут теряться, но новые
части появиться не могут. Если к тому же известна модель камеры, можно
также кое-что сказать о неравенствах, определяющих категории объектов.
Подобный подход лег в основу разработанной в 1979 году системы ACRONYM
(см. [Brooks, Greiner and Binford, 1979, 1981a]).
В системе ACRONYM для распознавания объектов применяется последо-
вательное применение этапов предсказания, описания и интерпретации. Ос-
новную работу на данных этапах выполняет система геометрического вывода,
строящая заключения об условиях, следующих из пространственных отно-
Глава 24. Геометрические шаблоны через пространственные связи
795
Рис. 24.23. На рисунке вверху приведена проекция баскетболиста. Конечные точки сегментов
тела определены вручную; неоднозначность восстановления вызвана наличием ряда дискретных
альтернатив и одного непрерывного параметра, представляющего угол между одним сегментов
и плоскостью изображения. На рисунке внизу изображены различные реконструкции, соответству*
ющие разным выборам названного параметра. По сути, выбор большего значения этого угла — это
выбор более длинного тела, более сильно согнутого. Перепечатано из C.J. Taylor, "Reconstruction
of Articulated Objects from Point Correspondences in a Single Uncalibrated Image", Proc. Computer
Vision and Pattern Recognition, 2000. © 2000 IEEE
шений трехмерных (части объекта) и двумерных (компоненты изображения)
элементов.
Пример: связь фюзеляжа и крыльев
Рассмотрим, например, упрощенную модель самолета, которая состоит из
центрального цилиндра (фюзеляжа) высотой Н и диаметром D и двух сим-
метричных цилиндров (крыльев) высотой Н' и диаметром D', составляющих
угол в с фюзеляжем. Данный самолет наблюдается слабоперспективной ка-
мерой с направлением наблюдения v, которое определяется сферическими ко-
ординатами (а, (3) в системе координат, ось х которой совмещена с хребтом
фюзеляжа, а ось у лежит в плоскости, содержащей оси фюзеляжа и два крыла
(рис. 24.24; слева).
Как показано на рис. 24.24 (справа), цилиндр высоты Н и диаметра D,
наблюдаемый в направлении v под углом ф относительно оси цилиндра, орто-
графически проектируется в ленту Брукса длины h = Н sin ф и диаметра d = D
(здесь не учитывается, что ленты имеют эллиптические концы). При слабопер-
спективной проекции с коэффициентом увеличения у данные величины пере-
796 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Рис. 24.24. Параметры, определяющие проекцию простой модели самолета: слева, модель (чтобы
не загромождать рисунок, фюзеляж и крылья представлены их хребтами); справа: ортографическая
проекция цилиндра
ходят в такие: h = fiHsin ф и d = p,D. Следовательно три цилиндра, представ-
ляющие фюзеляж и два крыла, проектируются в ленты с длинами хребтов Л,
и h'T и диаметрами d, d't и d'r, причем
h = р.Ну/1 — sin2 /3 cos2 а,
< h't — pH' д/1 — sin2 /3 cos2 (0 + а),
h'r — pH' ^/1 — sin2 /3 cos2 (0 — о),
d = pD,
< d'i — pD',
(24.1)
Далее сразу получаем следующее инвариантное относительно точки наблюде-
ния условие на изображение:
, , d't d'r D'
d[ — dr и — = — — —
d d D
(24.2)
Определим углы 0/ и вг между осью ленты, соотнесенной с фюзеляжем, и хреб-
тами левого и правого крыльев. Легко показать (см. раздел упражнений), что
cos /3 sin в
tgffi = ------------2------7------------»
cos в — sin /3 cos(0 + a) cos a
cos /3 sin 0
(24.3)
tg От = - 2------------------
cos в — sin /3 cos(0 — о) cos ct
Из данных уравнений следует, что плоская двусторонне симметричная фигура
не проектируется в другую двусторонне симметричную фигуру (т.е. в общем
случае tg0j / tg0r).
Предположим далее, что угол /3 мал (допустим, рассматривается аэрораз-
ведка: самолет пролетает над аэродромом, причем его камера направлена вниз
Глава 24. Геометрические шаблоны через пространственные связи
797
почти строго вертикально). Опуская члены, порядок которых по (3 выше второ-
го, получаем
Ot = ет - е. (24.4)
Подобным образом с точностью до членов второго порядка получаем
, , h'i h'r Н'
hi = h'r и — = — = (24.5)
h h H
В системе ACRONYM при предсказании используются инварианты, квази-
инварианты и ограничивающие условия на размеры и углы. Подобные величи-
ны выводятся из моделей объектов и камер с помощью набора эвристических
правил и мощной системы геометрического вывода, способной обрабатывать
и упрощать сложные тригонометрические и алгебраические выражения, а так-
же выводить по этим выражениям верхние и нижние пределы.
Структурируя геометрическую дедукцию
Уравнения (24.1)-(24.3) можно использовать двумя способами. Во-первых,
имея некоторое условие на камеру, можно сузить набор лент, существенных для
поставленной задачи. Во-вторых, имея параметры обнаруженных лент и гипоте-
зу о соответствии, можно получить условие на камеру. Очевидно, что при этом
следует учитывать ошибки процесса описания изображения. Для этого в си-
стеме ACRONYM применяется расширение границ посредством устаревшего
метода, который мы рассматривать не будем. Более интересен процесс, кото-
рый стоит сравнить с рассуждениями о соответствиях, описанными в главе 18.
Предположим, что дан набор лент, который может соответствовать иденти-
фицированному объекту. Это, в свою очередь, дает условие на камеру, которое
сокращает возможное разнообразие интерпретаций других лент. Из этого сле-
дует, что небольшой набор соответствий можно развить в большой набор гипо-
тез распознавания. В результате получаем то, что называется задачей непроти-
воречивой маркировки: желательно получить наибольший набор гипотез рас-
познавания, который согласуется с геометрическими условиями.
Для устранения этой проблемы в системе ACRONYM применяется метод
расширения гипотез о соответствии: строится граф предсказания, представля-
ющий возможные экземпляры объектов, и граф наблюдения, представляющий
данные изображения;затем эти графы пробуют согласовать (подробности пред-
ставлены в алгоритме 24.1). Вначале делаются и фильтруются гипотезы об
отдельных соответствиях к лентам, для чего используются необходимые об-
ратные условия. Затем согласовываются пары лент, и опять в ходе проверки
на непротиворечивость используются обратные условия, соотнесенные с соот-
ветствующими ребрами графа предсказания. Затем согласование расширяется
на тройки лент и т.д., с помощью распространения условий на каждом эта-
пе поддерживается глобальная непротиворечивость. В конце данного процесса
определяются непротиворечивые связанные компоненты графа интерпрета-
798 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
ции, которые соответствуют предположительным моделям объектов (например,
отдельные самолеты на аэродроме). Проверка финальной глобальной непроти-
воречивости выполняется через поиск максимальных наборов связанных ком-
понентов, удовлетворяющих всем обратным условиям (например, все самолеты
на одном аэродроме должны определять параметры непротиворечивого наблю-
дения). Данная стратегия в действии иллюстрируется на рис. 24.25.
Алгоритм 24.1. Алгоритм распознавания ACRONYM
1. Предсказание. Построить граф предсказания, вершины которого — предска-
занные ленты на изображении с соответствующими диапазонами параметров,
а ребра соединяют соседние ленты.
2. Описание. Построить сходный граф, узлы которого — ленты на изображении,
параметры которых входят в диапазон, совместимый с графом предсказания.
3. Интерпретация:
3.1. Построить граф интерпретации, вершины которого — потенциальные со-
ответствия между предсказанными и наблюдаемыми лентами, используя
для построения обратные условия, соотнесенные с графом предсказания
(в результате должна гарантироваться совместимость параметров).
3.2. Использовать распространение условий для определения связанных ком-
понентов с соответствующими обратными условиями.
3.3. Использовать комбинаторный поиск для определения максимальных набо-
ров непротиворечивых связанных компонентов.
24.3. ПОСЛЕСЛОВИЕ: РАСПОЗНАВАНИЕ ОБЪЕКТОВ
Компьютерное зрение прошло долгий путь с момента зарождения в 1960-х.
Развитие этой области во многом объясняется существенным снижением цен на
компьютерные системы и системы визуализации. Большую роль также сыграло
лучшее понимание отдельных задач. Поэтому теперь множество практических
задач можно решить с использованием методов компьютерного зрения. Это три-
умф. В то же время существуют ключевые задачи (связанные с представлением
и распознаванием объектов), которые на данный момент не решены и относи-
тельно которых сложно строить продуктивные рассуждения.
Как представлять распознавание в целом? В ответе, пожалуй, должно фигу-
рировать многократное сравнение с шаблоном, но какие шаблоны, какие связи,
какие иерархии объектов использовать — вопрос совершенно неясный. При та-
ком подходе базовые процессы распознавания должны начинаться с использо-
вания информации изображения для сокращения числа категорий объектов,
потенциально присутствующих на изображении; присутствующие категории
должны допускать процедуры группировки; в результате будет собираться боль-
Глава 24. Геометрические шаблоны через пространственные связи
799
Рис. 24.25. Интерпретация системой ACRONYM надземного изображения аэродрома. Вход си-
стемы состоит из изображения (слева вверху) общей модели широкофюзеляжного пассажирского
самолета и спецификаций класса экземпляров самолета L-i01i (рис. 24.12), плюс модели условий
наблюдения (откалиброванная аэрофотокамера, высота которой — от 1 000 до 12 000 метров).
На рисунке справа вверху приведен результат детектирования краев на входном изображении,
а слева внизу показаны ленты, найденные системой ACRONYM. Размер данных лент не проти-
воречит тому, чтобы они представляли части самолета (фюзеляж, крылья, хвост), наблюдаемые
указанной камерой с указанной высоты. Самолеты, которые были опознаны, изображены на ри-
сунке справа внизу. Очевидно, несколько самолетов пропущено. Наиболее вероятные причины
этого: а) в процессе сегментации пропущены компоненты лент; б) границы, расширяемые системой
геометрических выводов, увеличились до такой степени, что они уже не очень полезно ограни-
чивают гипотезы о соответствии. Перепечатано из R.A. Brooks, "Model-based three-dimensional
interpretations of two-dimensional images", IEEE Trans. PAM I, 1983. (c) 1983 IEEE
ше информации, которая позволит более обстоятельно сократить поиск; фина-
лом процесса должна быть идентификация объектов. Здесь важно понимать,
что данная конструкция — исключительно гипотетическая. Хотя общая идея
сформулирована, еще нет рабочей программы, которую можно было бы назвать
действительно успешной, поскольку при реализации встречаются определенные
практические трудности: например, какие принципы группировки использовать?
как следует организовывать представление объекта? как к данному представ-
лению привязать новый объект? как обеспечить запуск процесса сокращения
с нужного момента, и как не дать ему сбиться с пути истинного?
Данные проблемы очень сложны; разумно ожидать, что прогресс в указан-
ных направлениях будет медленным. Помните, что еще не совсем ясно, что
800 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
рассматривать как объект; объект — это лицо или набор из совокупности глаз,
носа и рта? Грязь — это объект? Грех — это объект? Что распознавать на изоб-
ражении, понятно далеко не всегда. Возможно, потребуется распознать бег, но
как данную концепцию представить на уровне объектов?. Распознать понятие
“грех” применимо к изображениям может быть сложно. Впрочем, вне зависи-
мости от того, является ли лицо объектом или нет, распознавание лиц — это
все же нужная вещь. Мы не можем сказать, по какому принципу стоит отби-
рать первичные отличия, и какие признаки нужно будет распознавать затем.
Например, тигры и леопарды на некотором семантическом уровне выглядят до-
статочно похожими, но на самом деле они весьма отличаются; аналогично, хотя
зоологическое сходство пингвина с дельфином мало, визуально они могут быть
весьма подобными. В общем, удовлетворительной интеллектуальной базы для
обсуждения подобных вопросов пока не существует.
24.3.1. Подтвержденные факты
Люди могут дать название тысячам различных типов объектов. На эту воз-
можность не влияют незначительные изменения отдельных объектов (например
нарушение конфигурации пятен гепарда или изменение обивки или структуры
кресла). Более того, людям достаточно увидеть несколько представителей новой
категории, чтобы позднее распознавать других ее представителей.
Было бы неплохо иметь компьютерную программу, которая (хотя бы да-
же частично) обладала подобными способностями. Похоже,такие способности
людей имеют в первую очередь практическое значение (отбор еды; того, что
производит еду; того, с чем сражаться; того, от чего убегать; того, что мо-
жет съесть тебя и т.д.). Ключевой вопрос здесь — построение представлений
объекта, имеющих хорошее поведение при наличии большого числа различных
объектов, которые нужно распознать.
Для решения задачи масштабов специалисты из области компьютерного зре-
ния ввели иерархии, и широко распространено мнение, что ключом к пред-
ставлению и распознаванию больших наборов объектов является организация
объектов в некоторую иерархическую структуру. В общем случае считается,
что в данной иерархии легко выводятся различия высокого уровня, а различия
в деталях получаются позже. Как правило, это различия во внешнем виде, т.е.
объекты, которые выглядят достаточно похожими, но на самом деле сильно
отличаются (например, небольшой дельфин и большой пингвин), могут раз-
личаться только очень поздно в процессе распознавания, а объекты, которые
выглядят отлично, но на самом деле сходны (например, угорь и рыба), могут
различаться на ранних этапах процесса распознавания.
Идеальная система распознавания объектов должна иметь следующие
свойства.
• Распознавать много различных объектов.
Этот момент значительно сложнее, чем кажется. Для распознавания боль-
шого числа объектов требуется знать, как их организовать в структуры
данных, в которой легко провести поиск при наличии данных с изображе-
Глава 24. Геометрические шаблоны через пространственные связи
801
ния. В частности, требуется знать, какие измерения можно использовать
для различения объектов в противоположность различению экземпляров
объекта (одна кошка может быть полосатой, другая — серой, но обе они
являются кошками).
• Распознавать объекты, рассматриваемые на различных фонах.
Данный момент также выглядит сложным. В идеальном случае подходя-
щее представление объекта позволит разбить изображение на сегменты,
которые потенциально порождены категориями объектов (без уточнения
конкретного представителя), и которые не порождены доступными кате-
гориями.
• Распознавать объекты на надлежащем уровне абстракции.
Людям не нужно заранее видеть некоторый конкретный стул, чтобы ска-
зать, что это стул. В идеальном случае искомая программа должна вна-
чале распознавать леопардов и гепардов как полосатых кошек, а затем
делать различие между ними. Каким точно является подходящий уровень
абстракции — загадка; данный вопрос по крайней мере частично связан
с вопросом распознавания многих различных объектов.
Данные стратегии распознавания обычно плохо отвечают сформулирован-
ным принципам идеальной системы. Это не потому, что они плохи, просто
задача очень сложна.
24.3.2. Существующие подходы к распознаванию объектов
В подходах, основанных на согласованности поз, геометрические меха-
низмы используются для определения достаточного числа соответствий между
характерными элементами изображения и модели. Некоторые подходы включа-
ют схемы выравнивания и схемы с использованием аффинных и проективных
инвариантов, рассмотренные в главе 18. В первом случае согласование произво-
дится как поиск по дереву, причем потенциально степенная стоимость поиска
снижается за счет соображения, что нескольких соответствий достаточно для
полного определения позы объекта и предсказания, где на изображении нахо-
дятся любые последующие соответствия. В последнем случае небольшие груп-
пы точек используются для прямого вычисления вектора признаков, независи-
мого от точки наблюдения, который, в свою очередь, может использоваться для
индексации хэш-таблицы, где хранятся все модели. Достоинство этого подхода
заключается в том, что индексацию можно провести за сублинейное время.
В схемах согласования с шаблоном записывается описание всех изобра-
жений каждого объекта. Данные системы успешно использовались в таких
задачах, как идентификация лиц и трехмерное распознавание объектов (см.
главу 22). Основное достоинство таких систем заключается в том, что в от-
личие от чисто геометрических подходов в них используются значительные
селективные возможности информации о цвете/яркости. В то же время такие
методы обычно требуют отдельного этапа сегментации, на котором значимый
802 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
объект отделяется от фона, кроме того, они потенциально чувствительны к
изменению освещения.
В схемах согласования по связям объекты описываются через связи между
шаблонами. Обычно искомыми являются несколько стилизованные фрагменты
изображения, а затем изучаются связи между ними (см. главу 23). Данный
подход имеет две сложности: во-первых, некоторые реляционные (построенные
на связях) модели согласовать довольно легко; во-вторых, в существующих ме-
тодах хорошо обрабатываются локальные фрагменты (такие как уголки глаз)
и простые объекты (такие как лица), но пока сложно сказать, как можно по-
строить систему, которая по связям на изображении найдет, скажем, животных.
В аспектных графах явно записывается качественная информация по виду
объекта согласно изменению точек наблюдения. Методы распознавания, осно-
ванные на аспектных графах (рассмотрены в главе 20), — это что-то среднее
между методами, освоенными на структуре, и методами на основе внешнего ви-
да, поскольку в них как функция точки наблюдения описывается внешний вид
объекта через эволюцию его структуры. Поскольку сходные объекты имеют
сходный внешний вид, они могут иметь подобные аспектные графы, и пони-
мание структуры изображения может направлять сегментацию изображения.
На практике, впрочем, точные аспектные графы не оправдали ожиданий, отча-
сти из-за того, что надежное извлечение характерных элементов изображения,
таких как Т-образные соединения, из реальных изображений крайне сложно,
и отчасти из-за того, что даже относительно простые объекты могут иметь
крайне запутанные аспектные графы.
24.3.3. Ограничения
Описанные методы существенно ограничены. Главный вопрос — это масштаб
(управление большим числом объектов на огромном числе фонов), но в целом
все ограничения можно условно разделить на три класса.
Сегментация
Использование программ согласования по связям быстро становится неце-
лесообразным при большом числе кандидатов; подобным образом, программы
согласования с шаблоном дают плохие результаты, если неизвестные области
шаблонов, подлежащих согласованию, содержат несущественную информацию.
Скорее всего, здесь важно, чтобы процесс распознавания легко сегментировал-
ся, т.е. чтобы можно было сказать, какие кусочки изображения составляют це-
лое, без уточнения, каким является это целое (т.е. какой объект распознается).
Категории и абстракция
Пока неизвестно, как находить объекты на верном уровне абстракции. Хо-
тя распознавать животных на уровне млекопитающих может и не потребуется,
было бы неплохо найти пятнистых млекопитающих до того, как встанет вопрос
о том, кто это — леопард или гепард. Важно понимать, что пока очень мало
знаний о том, что является подходящим уровнем абстракции: как (визуаль-
Глава 24. Геометрические шаблоны через пространственные связи
803
но) описать ферму? Методы, которые описывались выше, не позволяют разбить
объекты по категориям. Классификация — это скорее не загадка познания, а
явление с довольно практическими истоками — чтобы распознать большое чис-
ло объектов, легче вначале сформировать грубые описания, а позже уточнить
их. Впрочем, как классифицировать — это все же загадка.
Степень общности
Удачные стратегии распознавания должны применяться ко многим типам ка-
тегорий объектов без значительной настройки. В идеальном случае, поскольку
удачные подходы организованы согласно базовым правилам структуры объекта,
обучиться узнавать модели новых объектов по небольшому числу образцов не
должно быть сложно. Описанные в данной книге методы легко обобщаются, но
эти обобщения нельзя назвать практически удовлетворительными.
24.4. ПРИМЕЧАНИЯ
Классы геометрических шаблонов, формирующих поверхности, то входят, то
выходят из моды (на момент написания книги этот подход откровенно немоден,
авторы данной книги даже считают, что у него остался единственный фана-
тичный приверженец). В любом случае, мы решили включить описание этого
подхода в книгу, поскольку по мнению авторов общая схема рассуждений весь-
ма разумна. Трудно поверить, что в книге по компьютерному зрению в качестве
наивысшего достижения рассматриваются обобщенные цилиндры, гораздо точ-
нее в завершение сказать что-то вроде “уделите значительное внимание связям
трехмерной структуры с изображением, и особое внимание любому принци-
пу, который позволит сгруппировать компоненты двумерного изображения”.
Во многие области компьютерного зрения вовсю внедряются идеи из сферы
вероятностного вывода; авторов удивляет, что этого нельзя сказать о назван-
ной выше области. Возможно, это объясняется тем, что поскольку многие
идеи в этой области сформулированы относительно нестрого, для дальнейшего
развития требуется определенное презрение к традициям. Другую проблему
представляет неоднозначность, и эту проблему срочно нужно решать. Кроме
того, пока не ясно, какую идею стоит разрабатывать: 1) условия на структуру
поверхности дают условия на изображение, или 2) если можно найти условия,
согласно которым объект сегментируется, то этот объект можно распознать.
Первая компьютерная программа, которая позволяла как-то провести трех-
мерное распознавание объектов, возникла после работы [Roberts, 1965], а моде-
ли процесса распознавания (как он происходит у человека и как он реализуется
на компьютере) рассмотрены в публикациях [Biederman, 1987], [Biilthoff, Tarr,
Blanz and Zabinski, 1995], [Marr, 1982], [Palmer, 1999], [Rosch, 1988], [Tarr, Hay-
ward, Gauthier and Williams, 1995] и [Ullman, 1996]. Впрочем, пока не совсем
ясно, какие модели объектов используются человеческим разумом в процес-
се распознавания, и сейчас ведутся дебаты между сторонниками проективных
теорий (см., например, [Biilthoff et al., 1995] или [Tarr et al., 1995]), и пред-
ставлений на основе примитивов (работы [Магг, 1982] или [Biederman, 1987]).
804 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
Скелет (или срединная ось) был введен в работе [Blum, 1967]. Скелеты
в цифровых изображениях изучались в контексте математической морфологии
(работа [Serra, 1982]). Сравнение различных типов лент, включая ленты Блю-
ма и Брукса, а также обсуждение гладких локальных симметрий (публикация
[Brady and Asada, 1984]) и кососимметрий ([Kanade, 1981]) можно также найти
в работах [Rosenfeld, 1986] или [Ponce, 1990]. Система FORMS была разра-
ботана в работе [Zhu and Yuille, 1996]. Родственной работой является [Siddiqi,
Shokoufandeh, Dickinson and Zucker, 19996].
Обобщенные цилиндры ввел Том Бинфорд [Binford, 1971]. Эти структуры
также известны как обобщенные конусы ([Marr and Nishihara, 1978], [Brooks,
1981a]). Большинство ранних попыток получения описаний обобщенных цилин-
дров по изображениям связывались с дальностными данными (см., например,
[Agin, 1972]). Среди работ по этой теме заслуживает внимания публикация
[Nevatia and Binford, 1977], в которой реализована разновидность обобщенной
трансляционной инвариантности: предложенный авторами алгоритм перебирает
все возможные ориентации поперечных сечений объектов, таких как куклы,
лошади и змеи, а затем выбирает подмножества вероятных поперечных сече-
ний с гладко меняющимися параметрами. Брукс и Бинфод разработали систему
ACRONYM ([Brooks and Binford, 1979, 1981a, 19816], [Brooks, 1981]). Прямые
однородные обобщенные цилиндры были введены в цикле работ [Shafer and
Kanade, 1983, 1995а] как часть общей систематики обобщенных цилиндров.
Как отмечалось ранее, рассмотрение класса обобщенных цилиндров позволяет
предсказать свойства проекций, независимые от проекции данных цилиндров.
Например, Налва (см. [Nalwa, 1987]) доказал, что силуэт поверхности вра-
щения, наблюдаемой при ортографической проекции, обладает двусторонней
симметрией, а в работе [Ponce et al., 1989] показано, что при ортографических
и перспективных проекциях касательные к силуэтам прямых однородных обоб-
щенных цилиндров в точках, соответствующих одним поперечным сечениям,
пересекаются на изображениях осей цилиндров. Подобные аналитические пред-
сказания дают строгий базис для поиска отдельных обобщенных цилиндров
на изображениях или распознавание отдельных обобщенных цилиндров на
основе проективных инвариантов. В этой области были получены потрясающие
результаты (см., например, [Zerroug and Medioni, 1995]). Предварительные
работы, направленные на определение трехмерных обобщенных цилиндри-
ческих преобразований, аналогичных преобразованию Блюма-Мантанари на
плоскости, описаны в работе [Ponce, Cepeda, Рае and Sullivan, 1999] (см.
также раздел упражнений). Преобразование срединной оси (преобразование
Блюма-Мантанари, преобразование горящего луга) до недавнего времени кри-
тиковалось из-за его неустойчивости, но было реабилитировано в двух формах:
в одной изучались шоковые графы (shock-graphs), представляющие свойства
преобразования ([Kimia, Tannenbaum and Zucker, 1990,1995], [Giblin and Kimia,
1999], [Siddiqi, Kimia, Tannenbaum and Zucker, 1999a,6]); в другой граница под-
вергалась последовательным малым деформациям, а затем искалось “среднее”
полученных в результате преобразований ([Zhu, 1999]).
Глава 24. Геометрические шаблоны через пространственные связи
805
Еще можно отметить обсуждение экранирующих примитивов (shading prim-
itives) в работе [Haddon and Forsyth, 1998а]. С определенной долей успеха
использовались в задачах распознавания и другие примитивы, например, су-
перквадрики (см. [Pentland, 1986]). Первоначальные попытки изучения роли
функции в распознавании объектов описаны в книге [Stark and Bowyer, 1996].
ЗАДАЧИ
24.1. Определение преобразования Брукса. Рассмотрим двумерную форму,
ограниченную кривой Г, которая определяется вектором х : I —> К2
и параметризуется длиной дуги. Сегмент прямой, соединяющий любые
две точки sc(si) и ®(«2) кривой Г, определяет поперечное сечение формы
с длиной /(si,S2) = |ас(«1) — х(«2)|- Таким образом, задачу изучения на-
бора поперечных сечений формы можно свести к изучению топографии
поверхности S, соотнесенной с функцией высот h : I2 —» IR+, определен-
ной как $2) = |^(«1,«2)2- В данном контексте ленту, соотнесенную
с кривой Г, можно определить (см. [Ponce et al., 1999]) как набор попе-
речных сечений, конечные точки которых соответствуют точкам мини-
мума поверхности S (т.е. согласно [Haralick, 1983] или [Haralick, Watson
and Laffey, 1983] набор nap (si,«г), где градиент V/i функции h явля-
ется собственным вектором гессиана V2/i, и где собственное значение,
соотнесенное с другим собственным вектором гессиана, больше нуля).
Обозначив через ti и п,, соответственно, единичную касательную и нор-
маль в точке Xi (г = 1,2), а через 0$ и Ki обозначив, соответственно,
угол между векторами и и ti и кривизну в точке xit покажите, что лен-
та, соотнесенная с Г, — это набор поперечных сечений данной формы,
конечные точки которых удовлетворяют условию
(cos20i — cos2 02)cos($i — (h) +1 cos Qi cos 0г(м sin Oi + «2 sin 62) = 0.
24.2. Обобщенные цилиндры. Определение точки минимума, данное в преды-
дущем разделе, справедливо для высотных поверхностей, которые рас-
сматриваются в n-мерных областях определения, причем точки минимума
формируют кривые в любом измерении. Кратко объясните, как расши-
рить определение лент, данное в этом упражнении, до нового определе-
ния обобщенных цилиндров. Возникнут ли трудности, не характерные
для двумерного случая?
24.3. Кососимметричность. Кососимметричный элемент — это лента Брук-
са с прямой осью и образующими, которые составляют фиксированный
угол 0 с осью. Кососимметрия играет важную роль в анализе рукописных
изображений, поскольку можно показать, что двусторонне симметричная
плоская фигура проектируется в кососимметричный фрагмент при орто-
графической проекции ([Кап, 1981]). Покажите, что две точки контура Pi
806 Часть V. Верхний уровень: вероятностные методы и методы логического вывода
и Р2, формирующие кососимметричную пару, удовлетворяют уравнению
«2
«1
Sin 02
sin со
где Ki — кривизна границы кососимметричного фрагмента в Р» (г = 1,2),
a Of — угол между прямой, соединяющей две точки, и перпендикуляр-
ной этой границе ([Ponce, 1990]). Подсказка-, постройте параметрическое
представление кососимметричного элемента.
Упражнения
24.4. Напишите программу выявления скелета на основе эрозии. Программа
должна итеративно обрабатывать двоичное изображение, пока оно не пе-
рестанет меняться. Каждая итерация делится на восемь этапов. На пер-
вом этапе пиксели входного изображения, окрестность 3x3 которого
согласуется с фрагментом, приведенным внизу слева (здесь означает,
что значение соответствующего пикселя не важно), присваивается нуле-
вое значение на вспомогательном изображении; всем другим пикселям на
Затем вспомогательное изображение копируется на входное, и данный
процесс повторяется с правым шаблоном. Оставшиеся этапы каждой ите-
рации подобны описанным, и в них используются шесть шаблонов, кото-
рые получаются из приведенных выше последовательными поворотами на
90°. Выход программы — 4-связанный скелет исходной области ([Serra,
1982]).
24.5. Реализуйте подход к выявлению скелета, как он принят в системе
FORMS.
24.6. Реализуйте преобразование Брукса.
24.7. Напишите программу поиска кососимметричных фрагментов. Для реа-
лизации можно использовать: а) примитивный (стоимость О(п2)) ал-
горитм сравнения всех пар точек контура; б) проекционный алгоритм
(стоимость О(кп)), предложенный в работе [Nevatia and Binford, 1977].
Последний метод можно вкратце сформулировать так: дискретизовать
возможные ориентации осей локальных лент; для каждого из получен-
ных к направлений спроектировать все точки контура в ячейки и прове-
рить условие локальной кососимметрии только в пределах данной ячейки;
в завершение сгруппировать полученные пары лент в большие ленты.
ЧАСТЬ VII
Приложения
25
Поиск в цифровых библиотеках
Похоже, что большие коллекции цифровых изображений возникают довольно
просто. Некоторые коллекции цифровых изображений оцифровываются в на-
дежде лучшей сохранности, более легкого распространения и лучшего доступа.
Другие являются цифровыми изначально; это, например, личные коллекции се-
мейных фотографий (которые могут быть большими и цифровыми), коллекции
домашнего видео (также могут иметь значительный размер и многие из них
в настоящее время являются цифровыми), кроме того, большая, неорганизо-
ванная коллекция — это Web.
Существующие средства взаимодействия с коллекциями документов или
данных довольно сложны. Как правило, для поиска в коллекции используют-
ся различные разновидности сравнения с текстовым шаблоном, кластеризация
коллекций текста или же методы информационной проходки (data mining). Ин-
формационная проходка включает использование сложных процедур статисти-
ческого подбора для поиска ранее неизвестных трендов; это полезное занятие
известно под именем “пояснительный анализ данных” (exploratory data analysis)
(менее яркое название) или же (если не нравится предыдущее название) “добы-
ча данных” (data dredging). Обычно ценность коллекции во многом определя-
ется наличием подобного средства. Чтобы понять, почему это так, представьте,
810
Часть VII. Приложения
что вы посетили букинистический магазин, книги в котором рассортированы,
скажем, по цвету суперобложки; хотя коллекция в данном магазине может быть
огромной, сомнительно, что вы воспользуетесь им, если у вас будет выбор.
В настоящее время удовлетворительно организовать коллекцию изображе-
ний или провести поиск в ней сложно, т.е. эти коллекции в чем-то сродни
плохо организованному книжному магазину. Сложность заключается в постро-
ении подходящего представления информации, содержащейся в изображении.
Вручную аннотировать каждую картину нет смысла, поскольку подготовка хо-
рошего текстового описания изображения — это весьма сложная задача. Более
того, некоторые коллекции огромны (десятки миллионов картин; см. работу
[Enser, 1995]). Ручная индексация большой коллекции требует значительного
объема работы, а в перспективе может потребоваться переиндексация разде-
лов коллекции (например, вследствие какого-то события ранее неизвестный
человек стал знаменитым и требуется узнать, содержатся ли его изображения
в коллекции). Наконец, часто просто трудно сказать, о чем данная картина.
Несмотря на все эти трудности, любая технология, которая помогает управ-
лять коллекциями изображений, имеет множество сфер практического при-
менения. Одним из важных средств является поиск (“найти изображение,
отвечающее таким критериям”), но это не единственное требуемое средство.
Например, изображения нужно организовать так, чтобы была возможной на-
вигация: изображения со сходным содержимым должны располагаться рядом.
Или же требуется организовать поиск трендов, или нужно средство, фиксиру-
ющее важные изменения.
Перечислим типичные сферы применения цифровых библиотек.
* Управление и планирование. Имеется множество спутниковых снимков
Земли, которые можно использовать для предоставления информации на
важных политических дебатах. Например, как далеко зашла урбаниза-
ция? какие площади засеяны зерновыми? каким будет урожай кукурузы?
сколько осталось тропических лесов? и т.д. (по этому поводу см., напри-
мер, работу [Smith, 1996]).
• Военная разведка. Изображения со спутников могут содержать инфор-
мацию, важную в военном плане. Типичные запросы в этой области —
это поиск изменений, интересных для военных, например, наблюдается
ли концентрация сил? какой ущерб был причинен последней бомбардиров-
кой? что произошло сегодня? и т.д., причем все подобные запросы обычно
привязаны к какой-то определенной территории (см., например, [Mundy
and Vrobel, 1994]).
* Архивы фото- и видеоматериалов. Коммерческие библиотеки, часто
располагающие огромными и разнообразными коллекциями, существуют
за счет продажи прав на использование определенных изображений (см.,
например, [Enser, 1993, 1995]).
• Доступ к музеям. Для привлечения посетителей музеи все активнее
представляют в Web свои коллекции, как правило, с ограниченным раз-
Глава 25. Поиск в цифровых библиотеках
811
решением (см., например, [Holt and Hartwick, 1994а,6], [Psarrou, Kon-
stantinou, Morse and O’Reilly, 1997]). В идеальном варианте посетители
Web-сайтов должны иметь возможность навигации по коллекции для по-
лучения представления о содержимом музея.
* Защита торговых марок и авторских прав. По мере развития электрон-
ной коммерции также увеличивается возможность автоматического поис-
ка случаев нарушения авторских прав (см., например, [Eakins, Boardman
and Graham, 1998], [Jain and Vailaya, 1998], [Kato, Shimogaki, Mizutori
and Fujimura, 1988], и [Kato and Fujimura, 1989]). Например, на момент
написания книги владельцы прав на картину могли зарегистрировать ее
в организации под названием BayTSP, которая затем проводила поиск
в Web пиратских копий картины.
• Индексация Web. Похоже, что индексация Web-страниц становится при-
быльным делом. Пользователям могут также потребоваться средства, ко-
торые помогут избежать навязчивых реклам или оскорбительных изобра-
жений. На основе техники, описанной ниже, были разработаны средства,
поддерживающие поиск изображений в Web (см., например, [Cascia, Sethi
and Sclaroff, 1998], [Chang, Smith, Beigi and Benitez, 19976] или [Smith
and Chang, 1997]).
* Медицинские информационные системы. Получение медицинских
изображений, подобных предоставленному образцу, может дать суще-
ственную информацию, на основе которой можно формулировать диагноз
или проводить эпидемиологические исследования (см., например, [Ко-
fakis and Orphanoudakis, 1991] или [Wong, 1998]). Более того, существует
возможность кластеризации медицинских изображений таким образом,
чтобы специалистам было легче выделять интересные и новые гипотезы.
* Информационная проходка по изображениям. Привлекательность ин-
формационной проходки заключается в том, что перед рыбалкой можно
собрать большую базу данных по возможному улову. Иногда методы ин-
формационной проходки предлагают исключительно полезные или новые
гипотезы, которые могут подтверждаться специалистами в данной обла-
сти. Многие коллекции изображений могут поддерживать подобную дея-
тельность. Например, имеется большая коллекция оцифрованных изобра-
жений буддистского искусства, а также информация относительно мест,
в которых были найдены данные предметы, плюс различные комментарии
специалистов. Если бы по изображениям удалось построить их представ-
ления, тогда можно было бы изучить, скажем, пространственную и вре-
менную эволюцию тенденций в изображении фигуры человека.
Главным вопросом во всех этих приложениях является природа представ-
ления изображений. Как только выбрано представление, поиск провести от-
носительно просто: найти изображения с представлением, подобным данному,
организовать, т.е. расположить изображения со сходными представлениями ря-
дом, или найти тренды (изучить связи между компонентами представлений).
812
Часть VII. Приложения
Одним (возможно, желательным) представлением является полное описание
всех объектов, присутствующих на изображении. На то, что в ближайшем бу-
дущем появятся компьютерные программы, генерирующие подобные описания,
надежды мало. Впрочем, в настоящее время полезными оказываются и доволь-
но грубые представления. В начале данной главы предлагается некоторая общая
информация относительно выборки информации, затем приводится ряд суще-
ствующих методов организации коллекций изображений и проведения поиска
в них с использованием средств компьютерного зрения.
25.1. ОСНОВА: ОРГАНИЗАЦИЯ КОЛЛЕКЦИЙ ИНФОРМАЦИИ
Выборка информации — это изучение систем восстановления элементов
коллекции с использованием информации разных типов. Данная тема интере-
сует нас потому, что исследователи выборки информации должны быть специ-
алистами в области анализа эффективности, что часто достаточно сложно.
25.1.1. Насколько эффективна система
Как правило, эффективность систем выборки информации описывается через
эффективность отбора (recall) — процент реально восстановленных значимых
элементов — и точность — процент действительно значимых отобранных эле-
ментов. Слово “значимый” в этом контексте определить несколько сложно; для
выполнения соответствующих замеров требуется знать, какие элементы важны
для автора запроса. Мнения специалистов по данному вопросу расходятся.
Требования зависят от приложения
Как правило, при изменении конфигурации системы для повышения эффек-
тивности отбора точность снижается. Хотелось бы верить, что хорошие систе-
мы могут иметь и высокую эффективность отбора, и хорошую точность, но на
практике это не так. На деле выбор компромисса между этими параметрами
зависит от конкретного приложения.
Программы поиска патентов. Патент недействителен, если обнаружен бо-
лее ранний материал, содержащий подобные идеи. Это означает, что важно
иметь возможность поиска подобного материала либо для проверки факта его
отсутствия (таким образом можно будет запатентовать новое изобретение), ли-
бо для его нахождения (для отмены неудобного патента). Запатентовать идею
часто обходится недешево, и для владельца патента бывает катастрофическим
(а для обвиняющей стороны — выгодным), когда патент аннулируется. Это
означает, что обычно дешевле заплатить за обработку малозначимого матери-
ала, чем пропустить существенный материал, т.е. для подобного приложения
эффективность отбора просто необходима, даже за счет низкой точности.
Фильтрация электронной почты и Web. Область применения услуг филь-
трации электронной почты и Web довольно широка. Например, в США ком-
пании часто беспокоятся, что значительный объем внутренней корреспонден-
ции содержит откровенные сексуальные изображения, которые могут привести
Глава 25. Поиск в цифровых библиотеках
813
к юридическим обвинениям. Один из путей предоставления подобной услу-
ги — программа, исследующая почтовый трафик на предмет наличия проблем-
ных изображений. Менеджер ожидает, что в ответ на его запрос будут про-
демонстрированы изображения, которые программа считает проблематичными.
На момент написания книги существовало несколько поставщиков подобных
программ; пока еще не ясно, выгодно ли это приложение, так что в момент, ко-
гда вы читаете эти строки, данного рынка может уже и не существовать. Итак,
в подобных приложениях высокая эффективность не важна, даже если эффек-
тивность отбора программы составляет всего 10%, незамеченными останется
лишь небольшое число изображений. Высокая точность, наоборот, важна, из-
за опасности ложных тревог. Люди не признают системы с большим уровнем
ложных тревог, поэтому не будут использовать (т.е. платить за эксплуатацию
и обновление) системы с низкой точностью.
Поиск информационных видеосюжетов. Имеются различные службы,
предоставляющие архивы фотографий или видео для информационных агенств.
Как правило, в данных коллекциях высок процент фотографий знаменито-
стей — от хорошей базы фотографий стоит ожидать, что там будет несколько
тысяч фотографий Нельсона Манделлы, принцессы Дианы и т.д. Это означа-
ет, что поиск с большим уровнем эффективности отбора будет утомительным
и ни один редактор не захочет просматривать тысячи изображений. Обычно
персонал фотоархивов использует собственную оценку и пожелания заказчика
и предоставляет относительно небольшой набор фотографий по сути дела.
Системы оценки
Должным образом оценить систему обычно довольно сложно. Как правило,
точность рассматривается при различных значениях эффективности отбора (для
этого перебираются различные пороговые значения), а затем эти зависимости
усредняются по типичным запросам. Эффективности отбора и точности можно
приписать весовые коэффициенты, отражающие их относительную важность
в конкретных случаях, и вычислить средний балл утилиты. Провести хорошие
эксперименты также сложно, а получить плохой эксперимент весьма легко. Это
объясняется тем, что часто довольно трудно сказать, что является значимым
(т.е. какие изображения следует выдавать в ответ на запрос “Queen”?). Мало то-
го, трудно даже сказать, сколько изображений, имеющих отношение к данному
слову, найдется в большой коллекции (представьте, что требуется подсчитать,
сколько в 10-миллионной коллекции изображений картин, имеющих отношение
к слову “Queen”1). Понятно, что использовать тестируемую систему для опре-
деления того, какие изображения является существенными, невозможно (это
может привести к неразумному требованию 100%-ного отбора); таким образом,
требуется какой-то другой способ подсчета существенных элементов в коллек-
1 Помимо названия известнейшей группы, “queen” в английском языке — это королева, шах-
матный ферзь, карточная дама, пчелиная матка. — Прим. пер.
814
Часть VII. Приложения
ции. При небрежном подсчете (в частности, при неполном учете) оценка отбора
системы будет завышенной.
25.1.2. Чего хотят пользователи
Наиболее полное исследование поведения пользователей коллекции изобра-
жений приведено в работах [Armitage and Enser, 1997], [Enser, 1993] и [Enser,
1995], посвященных коллекции Халтона-Дойча (Hulton-Deutsch collection) (к
настоящему времени владелец коллекции изменился и сейчас она называется
коллекцией Халтона-Гетти (Hulton-Getty collection)). Это коллекция оттисков,
негативов, слайдов и т.п., используемая в основном специалистами в области
средств массовой информации. В работе исследована форма запросов, заполняе-
мая клиентами; запросы классифицированы в четыре семантических категории
в зависимости от того, требуется ли уникальный представитель класса объ-
ектов или же данный представитель уточняется. Стоит сказать, что в данном
цикле работ используется специальный язык индексации, дающий только “гру-
бый указатель на области коллекции Халтона” ([Enser, 1993], р. 35), и широкая
и абстрактная семантика, используемая для описания изображений. Например,
пользователи могут запрашивать изображения пережитков прошлого, физиков
и коптильных аппаратов для рыбы. Все названные концепции пока невозможно
обработать с помощью существующих методов анализа изображения. В резуль-
тате очень редко можно получить средство, строго отвечающее требованиям
клиента. Что касается обозримого будущего, то основным фактором, ограни-
чивающим разработку средств поиска изображений, является недостаточное
понимание зрения.
Впрочем, полезные инструменты можно построить даже при ограниченном
понимании зрения (почему-то этот достаточно важный момент многими упус-
кается). Степень успешности средства измерить трудно. Энсер утверждает, что
наиболее надежным показателем успешности системы индексации Халтона-
Гетти является прибыльность данной организации. Данный “тест" трудновато
применить на практике, но продукты на этом рынке имеются. Компания IBM
выпустила средство поиска изображений QBIC (Query By Image Content — за-
прос по содержимому изображения), выходу которого на рынок предшествова-
ла рекламная компания и которое, похоже, пользуется популярностью. Быстро
развивается Virage — компания, главным продуктом которой является аппарат
поиска изображений (описание технологии можно найти в работе [Hampapur,
Gupta, Horowitz and Shu, 1997]).
25.1.3. В поисках изображений
Грубо говоря, имеется три способа представления изображения: на портрет-
ном уровне, где важны точные значения пикселей; на композиционном уровне,
где важен общий вид изображения; или на уровне семантики объектов, где
важны вещи, изображенные на картине.
Глава 25. Поиск в цифровых библиотеках
815
Портретное согласование
При портретном согласовании (iconic matching) ищутся изображения, макси-
мально близкие к предложенному изображению (можно предоставить готовое
или нарисовать). Идеально соответствующее изображение будет иметь точно
такие же значения пикселей в каждой точке. Наилучшая из известных систем
такого плана описана в работе [Jackobs, Finkelstein and Salesin, 1995], в ней к
изображению применяется набор фильтров при разных масштабах, а затем вы-
ходы фильтров сравниваются с предложенным изображением и другими изоб-
ражениями. Для структурирования процесса сравнения может использоваться
масштаб; если при грубой шкале выход фильтра плохо согласуется с предложен-
ным изображением, проверять выходы при более мелких масштабах нет смысла.
Программы портретного сравнения полезны только в том случае, если поль-
зователь точно знает, как выглядит искомое изображение. У обычных поль-
зователей (которые не знают коллекцию досконально) такая ситуация бывает
редко, но существует ряд важных приложений, в которых описанное средство
безусловно полезно. Одно — это защита авторских прав. Украсть (т.е. исполь-
зовать без ведома владельца) цифровое изображение легко, но если имеется
хорошая программа портретного поиска, так же легко и выследить пиратов^.
Опишем происходящий процесс. Владелец авторских прав регистрирует
изображение в организации, специализирующейся на поиске воров, и пла-
тит сумму за услуги. Затем данная организация использует некоторую раз-
новидность программы-паука для поиска в Паутине, загружая изображения
в процессе его работы. Данные изображения сравниваются с коллекцией заре-
гистрированных изображений посредством программы портретного сравнения;
любое совпадение порождает жесткое письмо от юриста и уведомление о штра-
фе и сборе за авторские права. Для эффективной работы процесса согласования
требуется возможность обработки обрезанных и повернутых изображений, но
в целом согласование на основе выходов фильтров довольно успешно применя-
ется в данной области.
Существуют и другие области применения программ портретного согласова-
ния. Например, известно, что подавляющее большинство детской порнографии,
циркулирующей в настоящее время по Web, датируется относительно давними
временами, 1970-ми годами или даже раньше. Более того, агенствам, которые
занимаются уголовным расследованием детской порнографии, требуется знать,
является ли полученный материал новым — в этом случае нужно не только
закончить дело о хранении или распространении снимков, нужно еще принять
во внимание документальное свидетельство жестокого обращения с детьми, что
может инициировать новое расследование. В этой сфере может использоваться
сравнение с данными из архивной библиотеки. Более того, этот процесс сопо-
ставления позволяет связывать расследования обвинителей разной юрисдикции,
2Для защиты авторских и других прав на цифровые данные и изображения проще восполь-
зоваться digital watermarking & fingerprinting — цифровыми метками, зачастую невидимыми. —
Прим,, рецензента.
816
Часть VII. Приложения
у которых разные обвиняемые, но одинаковые материалы. На момент написа-
ния книги правовые органы не использовали архивные коллекции описанным
образом, но подобное их применение широко обсуждалось.
Сопоставление с использованием целого изображения
В некоторых сферах важна структура всего изображения. В приложениях
подобного рода изображение рассматривается как упорядоченное размещение
цветных пикселей, а не как изображение объектов. Данная абстракция часто
называется днешним видом (appearance). Разницу между внешним видом и се-
мантикой объекта определить сложно (откуда мы знаем, что присутствует на
изображении кроме его внешнего вида?), но данный подход важен на практике,
поскольку внешний вид довольно легко представить автоматически, ведь для
этого не требуется сегментировать изображение.
Внешний вид крайне полезен, если важна структура изображения. На-
пример, в архиве может производиться поиск фотографии с использованием
комбинации подсказок относительно внешнего вида и ключевых слов, а от поль-
зователя потребуется исключить изображения с верной структурой, но ложной
семантикой. Основной технической проблемой при использовании внешнего
вида для представления изображения является определение полезного поня-
тия сходства изображений; различные подходы к этой задаче рассмотрены
в разделе 25.2.
Семантика уровня объектов
Из исследований Энсера следует, что люди, использующие архивные кол-
лекции, ищут изображения с определенной семантикой (например, коптильный
аппарат для рыбы). Обработать подобные запросы с помощью средств сопостав-
ления по внешнему виду довольно трудно. Более того, практически невозмож-
но построить программу распознавания объектов, которая сможет обрабаты-
вать семантические запросы. Впрочем, можно построить представления, кото-
рые попытаются представить семантику на уровне объектов. Как правило, это
включает сегментацию изображений с последующим построением представле-
ний сегментов. Неизвестно, каким образом можно построить средства поиска,
которые смогут обрабатывать высокоуровневые семантические запросы или как
создать пользовательский интерфейс для обычного средства поиска. Несмот-
ря на это, существующие технологии допускают создание довольно полезных
инструментов для различных частных случаев задачи (раздел 25.3).
25.1.4. Структурирование и навигация
Поиск изображений порождает некоторые сложные проблемы. Предполо-
жим, например, что дана идеальная система распознавания объектов; вопрос:
как описать искомое изображение? Впрочем, поиск часто не настолько важен,
как кажется на первый взгляд. Как правило, очертить сферу поиска сложно,
если не дана некоторая модель содержимого коллекции. Представьте, напри-
мер, свое поведение в новом магазине; первое, что вы сделаете — это попы-
Глава 25. Поиск в цифровых библиотеках
817
таетесь определить категории продаваемых вещей, а затем будете искать то,
что по вашему мнению здесь должно быть. В книжном магазине вы не буде-
те спрашивать у продавца об автомобиле. Отсюда следует, что навигация —
это необходимый элемент взаимодействия человека с коллекцией, но только
в том случае, если коллекция соответствующим образом организована. В иде-
але средства навигации должны выполнять следующее.
• Отображать сходные изображения (это означает, что изображения могут
выглядеть похожими, иметь сходный внешний вид, располагаться рядом
в коллекции, иметь сходное содержимое и т.д.) так, чтобы их сходство
было очевидным.
• Отображать представление кластеров изображений, чтобы пользователь
мог представить, что имеется в данной коллекции (например, сходные
кластеры могут располагаться рядом, большие кластеры могут выглядеть
большими и т.д.).
• Обеспечивать некоторую разновидность взаимодействия, чтобы коллек-
цию можно было просматривать с различным уровнем детализации (воз-
можно, посетителю требуется только элемент определенного кластера или
некоторое обобщение всех изображений рядом с набором кластеров) и пе-
ремещаться по коллекции в различных направлениях.
Средства навигации и поиска естественно дополняют одно другое. Пользова-
тель может вначале исследовать коллекцию, а затем провести поиск. После
поиска пользователь, возможно, захочет посмотреть на объекты, находящиеся
“рядом” с любой позицией, выданной средством поиска.
Построение полезных средств навигации также требует эффективного по-
нятия сходства изображений. Построение хорошего пользовательского интер-
фейса для такой системы является сложной задачей (что видно из примеров,
приведенных ниже); желательные особенности таких средств — простой и по-
нятный процесс детализации запроса, а также четкое отображение внутреннего
представления, используемого программой, с тем, чтобы неудачные запросы не
сильно запутывали пользователя. Как правило, считается, что пользователь
может предоставить примерное изображение того, что ему требуется, или за-
полнить электронную форму для поиска этого первого изображения, а затем
использовать средство навигации для перемещения по коллекции, щелкая на
образцах, предложенных средством.
25.2. РЕЗЮМИРУЮЩЕЕ ПРЕДСТАВЛЕНИЕ ВСЕГО ИЗОБРАЖЕНИЯ
Изображения часто бывают крайне стилизованными, особенно когда автор
делает акцент на каком-то предмете или настроении. Это означает, что об-
щая схема изображения может служить указателем на его содержание, так что
полезные механизмы запросов можно построить, собрав изображения, кото-
рые выглядят подобно данному образцу, наброску или текстовой спецификации
818
Часть VII. Приложения
внешнего вида. Успех подобных методов зависит от смысла, в котором изоб-
ражения считаются сходными. Пользователю важно передать, в каком смысле
изображения выглядят подобно, поскольку в противном случае незначительные
ошибки могут сильно затруднить взаимодействие человека с системой. Хоро-
шее понятие сходства также важно для эффективной навигации, поскольку
пользовательский интерфейс, который может сообщить, насколько различают-
ся изображения, может вывести на экран изображения и предложить общую
структуру раздела отображаемой коллекции.
25.2.1. Гистограммы и коррелограммы
При популярном измерении сходства подсчитывается и сравнивается чис-
ло пикселей в определенных цветовых категориях. Например, при такой мере
сцена заката и пасторальная сцена будут отличаться, поскольку сцена заката
содержит большое число красных, оранжевых и желтых пикселей, а на пасто-
ральных сценах преобладают зеленый (трава), голубой (небо) и возможно бе-
лый (облака) цвета (см., например, рис. 25.1). Более того, сцены заката сходны
между собой; большинство из них имеют много красных, оранжевых и желтых
пикселей и мало остальных.
Гистограмма цветов — это запись числа пикселей на изображении или
области, которое попадает в определенные квантовые ячейки в некотором цве-
товом пространстве (по неизвестным авторам причинам популярностью пользу-
ется пространство RGB). Если гистограмма цветов для изображения объекта
сопоставима с гистограммой для изображения, тогда, возможно, этот объект
присутствует на изображении (если все это не игра света). Данный тест мо-
жет быть довольно чувствительным к направлению наблюдения и масштабу,
поскольку относительное число пикселей данного цвета может при этом рез-
ко измениться. Несмотря на это, данный подход быстр и легок, и его можно
применять к таким вещам, как одежда, которая может иметь яркие цвета, но
форму которой трудно или невозможно распознать.
Сопоставление гистограмм цветов крайне популярно; этот подход известен
по крайней мере с момента выхода работы [Swain and Ballard, 1991] и исполь-
зовался в различных практических системах ([Fickner, Sqwhney, Niblack and
Ashley, 1995], [Holt and Hartwick, 19946], [Ogle and Stonebraker, 1995]). Полез-
ность гистограмм цветов несколько удивляет, учитывая, как много информации
об изображении отбрасывается. В работе [Chappelle et al., 1998] показано, что
изображения из коллекции Corel (коллекция из 60 000 изображений, довольно
широко используемая в исследованиях в области компьютерного зрения; три
части этой коллекции можно заказать по адресу Corel corporation, 1600 Car-
ling Avenue Ottawa, Ontario, Canada K1Z 8R7) можно классифицировать по их
категории в коллекции, использую только информацию с гистограммы цветов
([Chapelle, Haffner and Vapnik, 1999]).
В гистограмме цветов не записано, как цветные пиксели расположены один
относительно другого (согласно мере гистограммы цветов изображения флагов
Франции и США крайне похожи: на каждом имеется приблизительно поровну
Плава 25. Поиск в цифровых библиотеках
819
AU Ihpws
Utrhthf ГН***/ U*r*ry
Рис. 25.1. Результаты ответа на запрос в коллекции Calphotos (Калифорнийский Университет
в Беркли) относительно пасторальных сцен. Запрос был сформулирован как поиск изображений,
содержащих много зеленых и голубых пикселей. Как видно из результатов, подобные гистограммы
цветов могут быть довольно эффективными
красных, синих и белых пикселей; отличается только пространственное разме-
щение пикселей). Другая проблема — если изображение взято под несколько
иным углом наблюдения, то согласно гистограмме цветов оно сильно отличается
от исходного. Этот эффект можно смягчить, рассмотрев вероятность того, что
пиксель определенного цвета лежит внутри определенного пикселя другого цве-
та (для этого можно подсчитать число пикселей на различных расстояниях от
данного). При небольшом смещении камеры эти вероятности изменятся незна-
чительно, так что сходство этих коррелограмм цветов дает меру сходства изоб-
ражений. Требования сходства коррелограмм цветов дает другую меру сходства
изображений. Вычислительные подробности реализации данной идеи описаны
в работах [Huang, Kumar, Mitra, Zhu and Zabih, 1997], [Huang and Zabih, 1998].
25.2.2. Текстуры и текстуры текстур
Гистограммы цветов не содержат информации об расположении цветных
пикселей, поэтому следующий шаг — это явная запись схемы расположения.
820
Часть VII. Приложения
Например, изображение снежной вершины будет иметь голубые области ввер-
ху, белые области посредине и голубые области внизу (озеро у подножья го-
ры), тогда как изображение водопада будет иметь более темные области слева
и справа, и более светлую вертикальную полоску в центре. Такие шаблоны рас-
положений были представлены в работе [Lipson, Grimson and Sinha, 1997]; их
можно изучить для набора изображений, и они кажутся значительным улуч-
шением по сравнению с гистограммой цветов.
Следующий естественный шаг — это изучение текстуры изображения, по-
скольку, скажем, для поля цветов (множество маленьких оранжевых пятен)
и для отдельного цветка (одно большое оранжевое пятно) текстура отличается;
другой пример — далматинец и зебра. Многие люди узнают текстуру, когда ее
видят, хотя определить эту концепцию сложно (если вообще возможно). Обыч-
но текстуры рассматриваются как пространственное размещение небольших
узоров (например, шотландский плед — это структура из небольших квадратов
и линий, а текстура травяного поля — это набор тонких полосок).
Обычная стратегия при поиске подобных подузоров — это применить к
изображению линейный фильтр (см. главу 7), где ядро фильтра выглядит по-
добно элементу узора. Из теории фильтрации известно, что сильный отклик
этих фильтров означает присутствие определенного узора. Можно применить
несколько различных фильтров, а на основе статистики откликов в различных
местах можно получить декомпозицию изображения на пятнистые области, по-
лосатые области и т.п. ([Ma and Manjunath, 19975], [Malik and Perona, 1990]).
Гистограммы выходов фильтров — это первое возможное описание текстуры.
Например, могут запрашиваться изображения с несколькими небольшими жел-
тыми пятнами. Этот механизм был успешно использован на коллекции Calpho-
tos в Беркли (http://elib.cs.berkeley.edu/photos; по этому адресу
можно найти многие тысячи изображений Калифорнийских природных ресур-
сов, цветов и дикой природы).
Гистограммы текстур несколько проблематичны при движении камеры; по
мере приближения камеры к сцене детали на изображении становятся больше.
Для минимизации влияния этого эффекта можно определить семейство раз-
решенных преобразований изображения (например, изменение масштаба изоб-
ражения в определенное число раз). Применим теперь каждое из этих пре-
образований и измерим сходство двух изображений как наименьшее отличие,
которое можно получить с использованием преобразования. Например, можно
перевести одно изображение во все разрешенные масштабы, а затем определить
наименьшее отличие гистограмм цвета и текстуры. Это экскаваторное рассто-
яние (earth-mover’s distance; термин взят из [Rubner, Tomasi and Guibas, 1998])
допускает множество преобразований. Более того, оно связано с процессом ком-
поновки изображений так, чтобы расстояние между изображениями на экране
отражало отличие изображений коллекции. Этот подход обеспечивает быструю
и интуитивно понятную навигацию (рис. 25.3).
Мощным ключом является пространственное расположение текстур. Напри-
мер, на аэроснимках жилые застройки имеют довольно характерную текстуру,
Глава 25. Поиск в цифровых библиотеках
821
Очередь
Возвращенные
изображения
Ложноотрицательиые
результаты
Ложноположительные
результаты
Рис. 25.2. Пространственное размещение цветных областей — это естественный указатель на
содержание изображений многих типов. На рисунке слева вверху показано размещение цветных
областей, предполагающее сцену с заснеженными горами; справа вверху — восстановленные по
этому критерию рисунки, на которых действительно изображены заснеженные горы; в центре
представлены горы, которые присутствовали в коллекции, но которые не были выданы на запрос;
внизу приведены фотографии, удовлетворяющие поставленному критерию, но не изображающие
заснеженные горы. Рисунки взяты из Р. Lipson, Е. Grimson and Р. Sinha, "Configuration based
scene classification and image indexing,” Proceedings, IEEE Conference on Computer Vision and
Pattern Recognition, 1997. (c) 1997 IEEE
а расположение этой текстуры позволяет сделать предположения относитель-
но наблюдаемого региона. В системе Netra, построенной Ма (Ма) и Манжуна
(Manjunath) в Калифорнийском Университете в Санта-Барбаре, текстуры клас-
сифицируются в стилизованные семейства (в результате получается словарь
текстур), которые используются для сегментации больших аэроснимков; из дан-
ного подхода следует, что хотя имеется большое семейство возможных текстур,
только некоторые текстурные отличия являются существенными. Далее поль-
зователи могут применять предложенные регионы для запроса в коллекции
сходных изображений; например, получение аэроснимков определенного реги-
она в различное время для отслеживания таких вещей, как прогресс развития,
транспортное движение или рост сельскохозяйственных угодий (рис. 25.4; [Ма
and Manjunath, 19976, 1998], [Manjunath and Ma, 1996a, 19966,cj).
822
Часть VII. Приложения
Рис. 25.3. Изображения выстроены согласно их сходству по параметру EMD. Расстояния меж-
ду изображениями максимально близко отражают отличие их EMD; поскольку данный параметр
вычисляется быстро, подобное представление может строиться в процессе запроса. На рисунке
вверху приведено большое число изображений, возвращенных в ответ на запрос. Видна вся кол-
лекция, щелчок мышкой в окрестности изображения, которое выглядит подобно тому, что ищет
пользователь, сообщает поисковой системе сферу следующего поиска (место щелчка пользовате-
ля показано черной точкой вверху изображения; после этого на экране появляется изображение,
приведенное на рисунке справа внизу, следующее изображение приведено слева внизу). С помо-
щью данной технологии пользователи проходят через архив изображений подобно тому, как они
проходят по универмагу. Вследствие большого числа отображенных изображений и их простран-
ственно интуитивного упорядочения пользователи быстро получают представление о том, что есть
в архиве, и быстро определяют, где находится требуемое им изображение. Перепечатано из Y. Rub-
ner, С. Tomasi and L.J. Guibas, 'A metric for distributions with applications to image databases”,
Proceedings, IEEE International Conference on Computer Vision, 1998. © 1998 IEEE
Глава 25. Поиск в цифровых библиотеках
823
Области текстурных откликов также формируют узоры. Например, если на
изображении показан пешеход в пятнистой рубашке, фильтры пятен дадут
сильные отклики; область сильных откликов выглядит подобно большой по-
лоске. Группа пешеходов в пятнистых рубашках будет выглядеть как семейство
полосок, каждая из которых является текстурой. Из данных наблюдений сле-
дует предположение применить фильтры поиска текстур к выходам фильтров
поиска текстур (возможно, в несколько уровней) и использовать меры сход-
ства этих откликов как меру сходства изображений. Данный подход (изложен
согласно [Bonet and Viola, 1997] и [Tuie and Viola, 2000]) включает использо-
вание большого числа признаков, так что предлагать пользователям заполнить
форму поиска в данном случае непрактично. Для выхода из этой ситуации
можно предложить пользователю задать несколько примерных изображений,
иллюстрирующих тип искомого изображения. Затем случайным образом вы-
бирается подмножество коллекции и используется как отрицательные примеры
(это работает, поскольку изображение, выбранное случайным образом, — обыч-
но совсем не то, что ищет пользователь). Далее применяется эффективный ме-
ханизм для построения классификатора (который сортирует изображения на
существенные и несущественные), использующего этот набор положительных
и отрицательных образцов (детали этого процесса мы опустим, больше инфор-
мации по классификаторам можно найти в главе 22). Пример использования
описанного метода приведен на рис. 25.5.
25.3. ПРЕДСТАВЛЕНИЕ ЧАСТЕЙ ИЗОБРАЖЕНИЯ
Средства, описанные а данном разделе, более-менее непосредственно пыта-
ются оценить семантику на уровне объектов. Как правило, вначале подобные
системы сегментируют изображение, а затем фокусируются на некоторых сег-
ментах изображения.
При поиске по семантике полезным оказывается наличие у коллекции струк-
туры, поскольку эту структуру можно использовать для выбора определенных
механизмов поиска. Система Photobook (согласно [Pentland, Picard and Sclaroff,
1996]) предлагает три основных категории поиска: поиск по форме изолирован-
ных объектов (например, инструментов или рыб) с использованием формы кон-
тура, измеряемой при упругой деформации контура; поиск по внешнему виду
может применяться к лицам и использует небольшое число главных компонен-
тов; наконец, при поиске по текстуре для нахождения текстурных образчиков
материала используется представление текстуры.
25.3.1. Сегментация
Человек разделяет изображения на части согласно объектам, его интере-
сующих, и для получения данной сегментации можно использовать класси-
фикацию. Сегментация — это ключевой вопрос, поскольку она означает, что
при сравнении изображений можно отбросить несущественную информацию.
Например, если ищется изображение тигра, не должно иметь значение, что яв-
824
Часть VII. Приложения
а)
б)
в)
Рис. 25.4. Использование текстурного поиска на аэроснимках: а) субдискретизованная версия
аэроснимка, использованная для инициации запроса; б) элемент использованного в запросе реги-
она, приведенный с максимальным разрешением; регион содержит самолет, автомобили и здания;
в-д) три лучших результата, полученных в ответ на запрос. Результаты получены с трех различных
фотографий. На этот раз второй и третий результат датированы тем же годом (1972), что и фото-
графия в запросе, а первый снимок датирован иным годом (1966). Подробнее см. работу [Ma and
Manjunath, 1997а]. Рисунок, любезно предоставил B.S. Manjunath.
Глава 25. Поиск в цифровых библиотеках
825
Примеры, выбранные
пользователем
Изображения, восстановленные в ответ
Рис. 2S.5. Запрос с использованием схемы "текстура текстур". Пользователь определил три изоб-
ражения машины как положительные образцы; помимо прочего, эти изображения дали сильный
отклик на фильтры больших горизонтальных полос. Далее система случайным образом выбрала на-
бор изображений (которые далее считались несущественными); потом эти данные использовались
для построения классификатора, который определил другие потенциально существенные изображе-
ния. В ответ на запрос было выдано множество изображений, некоторые из них содержали машины.
Перепечатано из К. Tieu and Р. Viola, “Boosting image retrieval”, Proceedings, IEEE Conference
on Computer Vision and Pattern Recognition, 2000. ©2000 IEEE
ляется фоном — снег или трава; ключевой объект — тигр. В то же время, если
для генерации мер сходства используется изображение целиком, тигр на траве
будет отличаться от тигра на снегу. Из данных наблюдений следует предло-
жение сегментировать изображение на области пикселей, в некотором смысле
подходящих друг к другу (гармонирующих), а затем позволить пользователю
произвести поиск требуемых свойств в определенных областях. Наиболее есте-
ственно считать, что пиксели подходят друг к другу, если они принадлежат
одному объекту. В настоящее время данный критерий практически невозможно
использовать, поскольку неизвестно, как сообщить о принадлежности пиксе-
826
Часть VII. Приложения
Рис. 25.6. Запрос к системе Blobworld относительно изображений роз. Пользователи базы изобра-
жений обычно желают найти изображения, содержащие определенные объекты, а не изображения
с определенной общей статистикой. Blobworld облегчает подобные запросы, поскольку изображе-
ния в этой системе представляются как набор областей (или пятен, "blobs"), которые соответ-
ствуют объектам или частям объектов. Изображение сегментируется на области автоматически,
затем характеристики цвета, текстуры и формы каждой области кодируются. Пользователь создает
запрос, выбирая интересующие его области (рисунок слева). Blobworld восстанавливает изображе-
ния, определяет параметр сходства и выдает результат (справа). Показано представление каждого
выбранного изображения; области, соответствующие запросу, подсвечены; приведенное внутреннее
представление изображений делает более понятными результаты запроса и помогает пользователю
формулировать и уточнять запросы. Эксперименты показывают, что запросы своеобразных объек-
тов, таких как тигры и гепарды, с помощью системы Blobworld имеют более высокую точность,
чем при использовании подобных систем, основанных только на глобальном описании цвета и тек-
стуры. Весьма подробно система Blobworld описана в работах [Belongie et al., 1998], [Carson et al.,
1999]; ее демо-версию можно найти по адресу http://elib.cs.berkeley.edu.
лей одному объекту. Впрочем, объекты обычно дают на изображении области
когерентного цвета и текстуры, так что пиксели, принадлежащие одной такой
области, имеют большие шансы принадлежать одному объекту.
Средство VisualSEEK (согласно [Smith and Chang, 1996]) автоматически
разбивает изображение на области когерентного цвета и дает пользователю
возможность делать запросы по пространственному расположению и размерам
цветных областей. Таким образом запрос изображений заката солнца можно
формулировать как “оранжевый фон с расположенным на нем желтым пятном”.
Система Blobworld построена по работе [Belongie, Carson, Greenspan and
Malik, 1998], изображения в ней представляются как наборы областей коге-
рентного цвета и текстуры. Представление демонстрируется пользователю, при-
чем области цвета и текстуры помещаются внутрь эллиптических пятен, что
представляет форму областей изображения. Форма этих областей представлена
грубо, поскольку детали границ объекта не являются бесспорными. Пользо-
Глава 25. Поиск в цифровых библиотеках
827
Рис. 25.7. Система Blobworld также допускает простые текстовые запросы. На рисунке слева при-
веден запрос изображений, к которому присовокуплено слово “rose”. На рисунке справа показаны
лучшие из набора возвращенных изображений. Обратите внимание на наличие среди изображений
роз розовых колпиц (roseate spoonbills, Platalea Ajaja) и розовых жуков (rose beetles, Strigoderma
Arbicola); слова не всегда однозначны
ватель может сделать запрос к системе, задав, какие пятна в предложенном
изображении важны и какие пространственные связи должны использоваться
(рис. 25.6). В данные запросы можно дополнительно включать текстовую ин-
формацию; как видно из рис. 25.7 и 25.8, изображения и текст дополняют друг
друга. Некоторые примеры использования этой взаимодополняющей природы
описаны в разделе 25.3.4.
25.3.2. Сравнение с шаблоном
Некоторые объекты имеют довольно характерный внешний вид при зна-
чительном изменении ракурса и условий наблюдения. В этом случае полезно
сравнение с шаблоном — стратегия распознавания объектов, позволяющая на-
ходить объекты путем сопоставления с предложенными образцами. Подробно
эти механизмы рассмотрены в главе 22, причем внимание акцентируется на по-
иске лиц (основные выводы, сделанные в этой главе, для удобства приводятся
ниже). Естественная сфера применения сравнения с шаблоном — это постро-
ить шаблоны изображений, соответствующие определенным семантическим ка-
тегориям (рис. 25.13 и [Chang, Chen and Sundaram, 1998a[). Данные шаблоны
можно построить заранее и использовать упрощенную форму запроса, так что
пользователь сможет применить готовый шаблон.
Крайне удачной сферой практического применения концепции сравнения
с шаблоном является поиск лиц. Лица анфас очень похожи, особенно при пло-
хом разрешении (основные признаки — темная полоса в районе глаз, светлые
участки в районе лба, носа и рта). Это означает, что лица можно найти незави-
828
Часть VII. Приложения
Рис. 25.8. Изображения и слова дополняют друг друга до разумного предела. На рис. 25.6 присут-
ствовали изображения, содержащие красные пятна, которые не были розами; подобным образом,
на рис. 25.7 слово ‘‘rose” трактуется неоднозначно. На рисунке слева изображен запрос, в котором
имеется большое красное пятно и слово “rose". На рисунке справа показаны лучшие из набора
возвращенных изображений, большинство из которых являются изображениями цветов
симо от личности человека, просто проведя поиск данной структуры. Типичные
системы поиска лиц извлекают небольшие окна изображений фиксированного
размера, усекают их до овальной формы, корректируют освещение по окну, а
затем используют обучающийся классификатор, чтобы сообщить, присутствует
ли в окне лицо ([Rowley, Baluja and Kanade, 1998a], [Rowley, et al., 1998b],
[Sung and Poggio, 1998]). Данный процесс работает для больших и малых
лиц, поскольку окна извлекаются из изображений при разном разрешении (при
низком разрешении изображений окна содержат большие лица, изображения
с высоким разрешением дают окна с маленькими лицами). Поскольку структу-
ра лица меняется при его наклоне, этот наклон требуется отследить, оценить
и скорректировать; для этого используется обучающийся механизм ([Rowley
Baluja Kanade, 1998с]). Крайне полезно знать, где расположены лица, посколь-
ку многие естественные запросы касаются людей, присутствующих на фото-
или видеоизображениях.
25.3.3. Форма и соответствие
Если внешний вид объекта может меняться, сравнение с шаблоном становит-
ся более сложным, поскольку требуется применить гораздо больше шаблонов.
Существует хорошая система сравнения с шаблоном для нахождения пешехо-
дов, которая, похоже, работает потому, что пешеходы обычно наблюдаются при
низком разрешении и с руками, идущими вдоль тела ([Oren et al., 1997]). Впро-
чем, построить систему сравнения с шаблоном для нахождения людей сложно,
поскольку одежда и очертание людей меняется в очень сильном диапазоне. Об-
Глава 25. Поиск в цифровых библиотеках
829
а)
б)
Рис. 25.9. Результаты распознавания, а) сопоставление изображений при аэрофотосъемке: изоб-
ражений справа извлекается верно с использованием любого из изображении слева; б) трехмерное
распознавание объектов: игрушечный динозавр верно распознается на обоих изображениях, несмот-
ря на значительные фоновые помехи. Перепечатано из С. Schmid and R.Mohr, “Local grayvalue
invariants for image retrieval", IEEE Transaction on Pattern Analysis and Machine Intelligence,
1997. © 1997 IEEE
щая стратегия при этом заключается в поиске меньших шаблонов (возможно,
соответствующим частям тела), а также их допустимых конфигураций.
В одной разновидности описанной схемы ищутся “интересные точки”, в ко-
торых комбинация замеров яркости и ее производных принимает необычные
значения (так бывает, например, в углах). Как показано в работах [Schmid and
Mohr, 1997а,Ь], пространственное расположение этих точек во многих случаях
достаточно характерно. Например (как видно из рис. 25.9), связь между инте-
ресными точками позволяет эффективно сравнивать даже трехмерные объекты.
Данный принцип согласования можно расширить и получить преобразование
изображение-изображение, которое можно использовать для совмещения изоб-
ражений. Совмещение еще больше уточняет сопоставление и может исполь-
830
Часть VII. Приложения
зоваться для сравнения двух изображений в определенных точках. Например,
применив этот подход к аэроснимкам, можно сравнивать транспортный поток
в различное время суток.
Описанную форму рассуждений о соответствии можно расширить на сопо-
ставление компонентов изображения с частями объекта на более абстрактном
уровне. Людей и многих животных можно рассматривать как набор цилиндров
(соответствующих сегментам тела). Естественная стратегия поиска — это сбор
компонентов изображения, соответствующих подходящим сегментам тела, или
других компонентов.
В работе [Forsyth and Fleck, 1999] данное представление используется для
определения изображений, содержащих людей, одетых легко или голых. Дан-
ный пример довольно интересен: во-первых, такой поиск легче, чем поиск
одетых людей, поскольку по сравнению с одеждой цвет и текстура кожи ме-
няется незначительно; во-вторых, многие люди заинтересованы в том, чтобы
найти (или избежать) изображения, содержащие неодетых людей. Описанная
в работе программа тестировалась на больших и разнообразных коллекциях
изображений; в коллекции, содержащей 565 изображений слабо одетых людей
и 4289 контрольных изображений с разнообразнейшим контекстом, программа
выделила 241 тестовых изображения и 182 контрольных изображений. Другой
пример — это использование представления, комбинаторная структура которого
(порядок применения тестов) выбирается вручную, но тесты являются самообу-
чающимися. Эта программа определяла изображения, содержащие лошадей, она
подробно описана в работе [Forsyth and Fleck, 1997]. В тестах использовалось
100 изображений, содержащих лошадей, и 1 086 контрольных изображений
с разнообразным контекстом; при типичной конфигурации программа выбирала
11 изображений лошадей и 4 контрольных изображения (рис. 25.10).
25.3.4. Кластеризация и организация коллекций
Альтернативная стратегия поиска определенных сегментов (или групп сег-
ментов с заданными связями) — это кластеризация изображений. Как правило,
требуется сформировать кластеры сходных изображений; это может подразу-
мевать подобие семантики или сходство по внешнему виду.
Стоит отметить, что хотя текст и изображение по отдельности неоднознач-
ны, их объединение в основном таким не является. Авторы текстовых описаний
изображений обычно не упоминают зрительно очевидных вещей (цвет цветов,
и т.д.) и свойств, которые трудно вывести средствами компьютерного зре-
ния (скажем, вид (в биологическом смысле) цветов). Отсюда напрашивается
вывод, что стоит попытаться формировать кластеры изображений, используя
информацию изображения, а также текст, соотнесенный с изображением. Ис-
пользование текста включает некоторые моменты, справиться с которыми пока
не в нашей власти. Во-первых, слова неоднозначны (например, коса может
быть у девушки или у реки). Во-вторых, слова часто входят в предложения
или, что еще хуже, в абзацы и требуется определить, какие слова значимые, а
Глава 25. Поиск в цифровых библиотеках
831
Рис. 25.10. Изображения лошадей, извлеченные из коллекции (100 изображений, содержащих
лошадей, и 1 086 контрольных изображений с различным контекстом). Отметим, что метод отно-
сительно нечувствителен к ракурсу наблюдения, но легко вводится в заблуждение коричневыми,
лошадеобразными областями. Более подробно см. работу [Forsyth and Fleck, 1997f. Перепечатано
из D.A. Forsyth and M.M. Fleck, "Body Plans", Proceedings, Computer Vision and Pattern Recigni-
tion, 1997. © 1997 IEEE
832
Часть VII. Приложения
какие можно опустить. В-третьих, нужно знать, как управлять ассоциациями
между словами и элементами модельного изображения.
В цикле работ ([Barnard and Forsyth, 2001], [Barnard, Duygulu and Forsyth,
2001]) была очерчена сфера применения этой потенциально интересной темы.
Результаты работы демонстрировались на двух коллекциях: наборе изобра-
жений от корпорации Corel, где каждое изображение поставляется с неболь-
шим набором кодовых слов, и коллекции изображений, принадлежащих Fine
Arts Museum в Сан-Франциско, каждое из которых поставляется с тексто-
вой аннотацией, написанной добровольцами (т.е. при написании аннотаций
не использовался компьютерный анализ). Данный текст был сжат до набора
существительных, глаголов, прилагательных и наречий с помощью средства
редактирования речи, описанного в [Brill, 1992]. Смысл слов выбирался с ис-
пользованием стратегии голосования, которая сравнивала различные значения
каждого слова с возможными значениями соседних слов в предположении,
что соседствующие слова близки по смыслу. Наконец, изображения и слова
разбивались на кластеры путем подбора образующей модели.
По сути, образующая модель — это модель смеси. Каждый компонент
смеси дает слова и пятна (области изображения с такими признаками, как
цвет, текстура и форма), а также вероятности, условно независимые при дан-
ном элементе и разные для разных компонентов. Подогнать модель к данным
с изображения можно только с использованием ОМ-алгоритма; после подгонки
изображение относится к компоненту смеси, наиболее вероятно его породив-
шему. Нет никаких указаний на то, что это лучший способ кластеризации,
но обычно он дает хорошие результаты. На рис. 25.11 показаны некоторые
кластеры, полученные для набора данных от Corel; здесь сравниваются кла-
стеризация с помощью данных изображения, кластеризация с помощью текста
и кластеризация, основанная на обоих источниках информации.
Хорошие кластеры можно использовать по-разному. Очевидно, на них мож-
но построить механизм навигации, хотя тот, что предложен в работе [Barnard
et al., 1997], выглядит несколько примитивно. Есть и другие сферы примене-
ния удачных кластеров: сперва нужно подобрать обобщенную модель, затем
строится функция распределения совместной вероятности для признаков изоб-
ражения и слов. Это означает, что можно а) провести поиск изображений,
используя слова (что в работе [Barnard et al., 1997] названо “автоиллюстраци-
ей”); б) провести поиск слов с использованием изображений (“автоаннотация”;
но следует уточнить, что последнее — это, по сути, распознавание объектов).
При удачных кластерах любой процесс может быть удивительно успешным.
Результаты процесса автоиллюстрации показаны на рис. 25.12.
25.4. ВИДЕО
Хотя видео — это более богатый источник информации, чем отдельное
изображение, основные моменты обработки видео остаются прежними. Обычно
видеоряд сегментируется на кадры — небольшие последовательности со сход-
Глава 25. Поиск в цифровых библиотеках
833
Слова
Образы
Рис. 25.11. На рисунке справа вверху показана коллекция изображений из одного кластера;
кластеризация производилась только по словам. Явно выделяется основная тема океана, но
изображения довольно сильно различаются между собой (прыжки в воду на фоне синего
моря, кораллы и т.д.). На рисунке слева вверху приведена коллекция изображений из одного
кластера, причем кластеризация производилась только по признакам сегментов изображений.
Теперь изображения выглядят родственными, но не семантически когерентными; есть несколько
изображений кораллов, на остальных изображены цветы. На рисунке внизу приведены два
кластера, полученных с использованием текста и признаков сегментов. В целом наблюдается
общая тема, плюс изображения выглядят похожими; т.е. имеем оба желательных свойства.
Перепечатано из “Learning the semantics of words and pictures”, Proceedings, IEEE Conference
on Computer Vision and Pattern Recognition, 2001. © 2001 IEEE
ным контекстом, а затем к кадрам применяется технология описанного типа.
Кратко тема определения границ кадров изложена в разделе 14.3.2.
Движение отдельных пикселей видеоряда обычно называется оптическим
потоком и измеряется в попытке найти на ближайшем снимке пиксели, со-
ответствующие пикселям предыдущего снимка (соответствие определяется как
подобие цвета, яркости и текстуры). В принципе, в каждом пикселе имеется
вектор оптического потока, в сумме эти векторы формируют поле движения.
На практике оптический поток очень сложно измерить в пикселях, не содер-
жащих характерных элементов, поскольку такие точки могут соответствовать
чему угодно. Рассмотрим, например, оптический поток яйца, вращающегося
вокруг своей оси; имеется очень мало информации о том, что делают пиксели
внутри видимой поверхности яйца, поскольку они выглядят подобно друг другу.
Поля движения могут быть очень сложными; причем если на кадре от-
сутствуют движущиеся объекты, поля движения, соответствующие текущему
834
Часть VII. Приложения
large fatgortsncc nttncbcd fact old dutch century note cmununtd whole ship won pur son
*м divided officer word меми 1st cutter ihun weds days wu general vceeri whale
hunting concanbritish tide old tfaKh offidri present nritmKb мам food Пашков
officer boat right wstcb ground CMsmnnd ship deck grand political set net aunt way
profcaetonri superior
*ЧЪ< 1*0* importMC* *tt**b*d ю lb*
ЬмроошагЧ voeMion 1* *vtnartl by Лл
fact, that ortgfaony hi the rid Dutch
Fishery, two centuries sad nuu* gga, dm
eonunand of a whriMMp was act
wholly lodged la the person now carted
the captata, but was divided botwsea
hhn and mt officer called dm
S|NKMyttd*e U*r*Uy dll* wovd im*m
Й**СМмп •**0*o huw*v*> hi th**
nude h equivalent to Olaf Hatpooawr.
ta dmadaya, foectgiaM authority
wb* F*nrict*cl to lb* м v|0*to* ***4
0вмп1 immb0*mm of the vbbbbIs whU*
over the whate-farN fag deportment and
all iu eoacemt, the Spockeynderm
Chief Hatpomwer reigned sapreme. fa
the British Oreealand Fishery, under lhe
corrupted tide of Specksioeecr, this old
Dutch official to still retained. hut Ms
former dignity to sadly abridged. At
present be raaks «imply as scalar
Harpounoor. and as such to but one of
tb* свугайвЧ мог* inferior мйчйсогмк
Nevordutaes, as upon the good conduct
of the baqpoonccn foe success of a
wbrifag troyage hugely dapnuh. aad
ihiC* awa*
Рис. 25.12. На рисунке справа приведен фрагмент текста из “Моби Дика**. После обработки данный
текст превратился в набор существительных, глаголов, прилагательных и наречий, причем значение
слов определялось путем голосования. Полученный текст использовался для построения функции
распределения совместной вероятности, а в результате последующего поиска были получены изоб-
ражения, имевшие высокую совместную вероятность с набором слов (эти изображения приведены
слева). Похоже, запрос был удачным (помимо прочего, имеется изображение китобойного судна,
матросы которого гарпунят кита). Перепечатано из К. Barnard, Р. Dutgulu and D.A. Forsyth,
“Clustering Art”, Proceedings, Computer Vision and Pattern Recognition, 2001. © 2001 IEEE
снимку камеры, можно классифицировать. Например, для панорамной съем-
ки характерно сильное поперечное движение, а наезд камеры на объект дает
радиальное поле движения. Эту классификацию обычно получают, сравнивая
измеренное поле движения с параметрическим семейством (см., например,
[Sawhney and Ayer, 1996] и [Smith and Kanade, 1997]).
Строить запросы к сложным видеорядам без сегментации сложно, посколь-
ку значительная часть картины может не иметь к запросу никакого отноше-
ния. Например, в футбольном матче несущественными могут быть перемещения
многих игроков. В системе VideoQ (рис. 25.13 и [Chang, Chen, Meng, Sundaram
and Zhong, 1997a,6]) видеоряды сегментируются в движущиеся пятна, а после-
дующие запросы строятся на основе цвета и движения определенного пятна.
Имеется также проект Informedia, подготавливающий подробные срезы ви-
деопоследовательностей. В этом случае видеосегмент разбивается на снимки,
снимки аннотируются движением камеры на снимке, наличием лиц или тек-
ста в кадре, ключевыми словами из текстового ряда фильма и уровнем звука
(рис. 25.14). Данная информация дает компактное представление (“срез”), отоб-
ражающее основной контекст видеоряда (подробности см. в работах [Smith and
Kanade, 1997], [Wactlar, Kanade, Smith and Stevent, 1996], [Smith and Christel,
1995] и [Smith and Hauptmann, 1995]).
Глава 25. Поиск в цифровых библиотеках
835
Рис. 25.13. Видео можно представить движущимися пятнами; в последующих запросах можно
использовать свойства пятен и характеристики их движения. В левом столбце показаны запросы
для различных типов движущихся пятен, изображенные для системы VideoQ. В правом столбце
показаны кадры из двух найденных последовательностей. Перепечатано из S-F. Chang et al., "Л
Fully Automated Content-Based Video Search Engine Supporting Spatiotemporal Queries”, IEEE
Transaction on Circuits and Systems for Video Technology, 1998. © 1998 IEEE
25.5. ПРИМЕЧАНИЯ
Данная область — пожалуй, наиболее интересная сфера применения ком-
пьютерного зрения. Она имеет сравнительно давнюю историю (среди важных
ранних работ можно выделить [Chang and Yang, 1983], [Kato, Shimogaki, Mizu-
tori and Fujimura, 1988], [Kofakis and Orphanoudakis, 1991]), но период значи-
тельной популярности эта сфера переживает в последнее время, потому что
появилась возможность решить задачи, выполнение которых 30 лет назад было
просто нереальным (для таких задач огромное значение имеет больший объем
дисков, более быстрые компьютеры, и т.д.). Несмотря на то, что написано по
этой теме очень много, авторы уверены, что относительно большой интерес к
данной области приведет к быстрому устареванию указанных источников.
В случаях, когда цвет, текстура и пространственное размещение элементов
изображения сильно коррелируют с типом желательного контекста, можно ис-
пользовать существующие средства поиска изображений на основе контекста.
Но поскольку цвет, текстура и пространственное размещение объектов явля-
ются, в лучшем случае, грубым указателем на содержимое изображения, более
чем вероятно получение неожиданных результатов поиска. На сегодняшний
836
Часть VII. Приложения
Setae Changes
Camera Motion
Object Detection
Text Detection
TF-IDF Weight
Transcript
Рис. 25.14. Вверху, определение характеристик видеоряда для создания среза. Видеоряд сегменти-
руется на сцены. По значимым объектам (лица и текст) отслеживается движение камеры. Полоски
указывают кадры с положительными результатами. Значимость слов в текстовом ряде фильма
определяется путем сравнения частоты появления термина с обратной частотой его появления
в документе (по сути, определяются термины, часто встречающиеся в этом документе, но редкие
вообще). На базе всех этих данных извлекается сокращенный набор кадров и слов, приведенный на
рисунке внизу, который представляет исходный видеоряд, но является значительно более коротким.
Используя информацию о тексте, движении, лицах и кадре можно получить срезы, которые будут
представлять значительное улучшение по сравнению, скажем, с прореженными кадрами, посколь-
ку длинные последовательности с относительно незначительными изменениями сжимаются более
агрессивно. Перепечатано из М. Smith and Т. Kanade, "Video Skimming and Characterization
through the combination of image and language understanding techniques", 1997. © 1997 IEEE
день еще нет удовлетворительной теории построения интерфейсов, миними-
зирующих данный эффект. Наиболее распространенной стратегией является
довольно плавная навигация.
Для получения хорошей производительности, в серьезных приложениях
требуются методы, извлекающие семантику изображения. В частности, для
построения качественных средств нужно научиться решать сложные и мало-
понятные задачи из сферы распознавания объектов. Как было показано ранее,
распознавание объектов, похоже, требует сегментации изображений на коге-
рентные участки с последующим изучением и этих участков (как при поиске
лиц), и связей между ними. Этот несколько невнятный подход к распозна-
ванию можно использовать для создания сегментированных представлений,
которые позволят провести поиск объектов независимо от фона, на котором
они изображены. Более того, некоторые частные случаи распознавания объек-
тов поддаются явной обработке. Пока не ясно, как построить систему, которая
может проводить поиск большого числа объектов; проблему также представляет
построение пользовательского интерфейса к подобной системе.
26
Визуализация на основе
изображений
С индустрией развлечений ежедневно сталкиваются сотни миллионов людей,
а синтезированные изображения наряду с реальными весьма широко исполь-
зуются в компьютерных играх, трансляции спортивных событий, телерекламе
и кинофильмах. Создание подобных изображений является сутью визуализа-
ции на основе изображений (image-based rendering) (которая здесь определена
как получение новых проекций сцены по существующим изображениям) и тре-
бует восстановления по изображениям количественной (хотя и необязательно
трехмерной) информации о форме. В данной главе представлено несколько под-
ходов к визуализации на основе изображений, разбитых (классификация услов-
ная) на а) методы восстановления трехмерной модели сцены по ряду изображе-
ний с последующей визуализацией классическими средствами компьютерной
графики (естественно, эти подходы часто связаны с анализом стереоизобра-
жений или движения); б) методы, не требующие восстановления параметров
сцены или камеры — строится явное представление всех возможных изображе-
ний наблюдаемой сцены, после чего используются положения на изображениях
точек привязки для уточнения новых проекций сцены и перенос всех других
точек на новое изображение в фотограмметрическом смысле (речь об этом шла
в главе 10); в) подходы, в которых изображение моделируется трехмерным на-
бором световых лучей (точнее, значением яркости вдоль этих лучей) и набором
838
Часть Vil. Приложения
Рис. 26.1. Подходы к визуализации на основе изображений. Сверху вниз: построение трехмерной
модели по последовательности изображений, синтез изображений на основе переноса, световое
поле. Слева направо: этапы визуализации на основе изображений: по выбранным изображениям
строится модель сцены (может не быть трехмерной), которая затем используется для визуализа-
ции новых изображений сцены. Схема визуализации может управляться посредством джойстика
(или, эквивалентно, заданием параметров камеры) либо же, если используются методы на основе
переноса, заданием положения на изображении нескольких точек привязки
всех изображений сцены, полученных посредством четырехмерного множества
лучей, именуемого световым полем (рис. 26.1).
26.1. ПОСТРОЕНИЕ ТРЕХМЕРНЫХ МОДЕЛЕЙ ПО
ПОСЛЕДОВАТЕЛЬНОСТИ ИЗОБРАЖЕНИЙ
В данном разделе рассмотрена задача построения и визуализации трехмер-
ной модели объекта по последовательности изображений. Разумеется, подобную
модель можно построить путем совмещения карт глубин, полученных дально-
мерами, как описано в главе 21, но в данной главе будет рассмотрен случай,
когда в качестве входных данных используются оцифрованные фотографии или
видеоклипы жесткой либо динамической сцены.
26.1.1. Моделирование сцены по наложенным изображениям
Объемное восстановление
Предположим, что по набору фотографий, совмещенных в одной глобальной
системе координат, был выделен (возможно, интерактивно) объект. Единствен-
ным образом восстановить форму объекта по контуру на изображениях невоз-
можно, поскольку, как отмечалось в главе 19, на контуре никогда не проявляют-
ся вогнутые участки его поверхности. В то же время, имея достаточно большой
набор изображений, можно построить разумную аппроксимацию поверхности.
Имеются два основных ограничения, накладываемых контуром изображения
на форму твердого тела: а) тело лежит в объеме, определяемом пересечением
конусов наблюдения, связанных с каждым изображением; б) конусы касатель-
Глава 26. Визуализация на основе изображений
839
ны к поверхности тела (имеются и другие, локальные ограничения; например,
как показано в главе 19, выпуклые (соответственно, вогнутые) части контура
являются проекциями выпуклых (соответственно, вогнутых) частей поверхно-
сти). Первое из этих условий исследовал Бомгарт (Baumgart) в своей док-
торской диссертации в 1974 году; Бомгарт изучал построение многогранных
моделей различных объектов через пересечение многогранных конусов, соот-
несенных с многоугольными аппроксимациями силуэтов тел. Идеи, представ-
ленные в данной работе, дали начало нескольким подходам к моделированию
объектов по силуэтам, в том числе технике, описанной далее в главе (изложе-
на согласно [Sullivan and Ponce, 1998]), в которой также учитывается условие
касания конусов наблюдения. Здесь, как и в системе Бомгарта, вначале стро-
ится многогранная аппроксимация наблюдаемого объекта, для чего находится
пересечение конусов наблюдения, соотнесенных с несколькими фотографиями
(рис. 26.2). Далее вершины полученного многогранника используются как кон-
трольные точки гладкой сплайн-поверхности, которая деформируется до тех
пор, пока на станет касательной к лучам наблюдения. Подробности построения
и деформации данной поверхности рассмотрены ниже.
Построение сплайнов. Сплайновая кривая — это кусочно-полиномиальная па-
раметрическая кривая, удовлетворяющая некоторым условиям на гладкость.
Например, в качестве условия может приниматься принадлежность кривой к
классу Ск (т.е. дифференцируемые функции с непрерывными производными
до к-го порядка), причем к обычно берется равным 1 или 2, или принадлеж-
ность к классу Gk (т.е. функции, не обязательно дифференцируемые в каждой
точке, но имеющие непрерывные касательные в случае G1 и непрерывную кри-
визну в случае G2). Сплайн-кривые обычно строятся путем сшивки дуг Безье
(Bezier arcs). Кривая Безье степени п — это полиномиальная параметрическая
кривая Р : [0,1] —> Е3, определенная как барицентрическая комбинация
i=O
(n 4-1) контрольной точки Р0,...,Рп, где весовые коэффициенты b\n\t) =
(”)t‘(l — t)n~l называются полиномами Бернстайна степени п1. Отметим, что
кривая Безье интерполирует первую и последнюю контрольные точки, но не
остальные (рис. 26.3, а). Как показано в разделе упражнений, касательные
в конечных точках идут по первому и последнему линейному сегменту кон-
трольного многоугольника, сформированного контрольными точками.
'Это действительно барицентрическая комбинация (как они определены в главе 12), посколь-
ку легко показать, что полиномы Бернстайна в сумме дают единицу. В частности, кривые Безье —
это аффинные конструкции; данное свойство желательно, поскольку позволяет определить назван-
ные кривые исключительно через их контрольные точки и не привязываться к внешней системе
координат.
840
Часть VII. Приложения
Рис. 26.2. Построение моделей объекта через нахождение области пересечения (многогранных)
конусов наблюдения: а) шесть фотографий заварочного чайника; б) чистое пересечение соответ-
ствующих конусов наблюдения; в) триангуляция, полученная после расщепления каждой проекции
на треугольники с последующим упрощением полученной сетки. Перепечатано из S. Sullivan
and J. Ponce, '‘Automatic Model Construction, Pose Estimation, and Object Recognition from Pho-
tographs Using Triangular Splines”, IEEE Transactions on Pattern Analysis and Machine Intelli-
gence, 20(10):1091-1096, 1998. © 1998 IEEE
Определение дуг Безье и сплайновых кривых естественным образом расши-
ряется на поверхности: треугольный лоскут Безье (Bezier patch) степени п —
это параметрическая поверхность Р : [0,1] х [0,1] —> Е3, определенная как
барицентрическая комбинация
P(u, v) = v, 1 - и - v)Pijk
i+j+k=n
треугольного массива контрольных точек Pijk, где однородные полиномы
w) = — это трехмерные полиномы Бершнштайна степе-
ни п. Далее в этом разделе будут использоваться лоскуты Безье четвертого
порядка (п = 4), каждый из которых определен 15 контрольными точками
(рис. 26.3, б). Границы этих лоскутов — это кривые Безье четвертого поряд-
ка P(u,0), Р(0, v) и Р(и, 1 — и). По определению, треугольный сплайн в G1 —
это сеть треугольных лоскутов Безье, имеющих общую касательную плоскость
вдоль их общих границ. Необходимое (но не достаточное) условие непрерыв-
ности в G1 звучит так: все контрольные точки, окружающие общую вершину,
лежат в одной плоскости. Построим вначале данные точки, а затем добавим
оставшиеся контрольные точки, чтобы гарантировать, что результирующий
сплайн действительно непрерывен в G1. Как отмечено в работе [Loop, 1994], из
набора р произвольно размещенных точек Ci,..., Ср можно как барицентриче-
скую комбинацию создать набор лежащих в одной плоскости точек Qi,... ,QP
(в нашем случае Ci — это центры масс р треугольников Tj, соседствующих
Глава 26. Визуализация на основе изображений
841
Рис. 26.3. Кривые и лоскуты Безье: а) кривая Безье третьего порядка и ее контрольный много-
угольник; б) треугольный лоскут Безье третьего порядка и его контрольная сетка. Использовав
прямоугольный массив контрольных точек, можно определить тензорное произведение лоскутов
Безье (см. [Farin, 1993]). Отметим, что лоскуты треугольной формы более удачны при моделирова-
нии свободных замкнутых поверхностей
с вершиной V в начале процесса триангуляции; рис. 26.4, слева вверху):
1 | 7Г / 7Г \ ]
Qi = ~ 11 + cos “ cos ^[2(j — ®) — 1]—J । Cj.
Данная конструкция помещает точки Q, на плоскость, проходящую через центр
масс О точек Ci. Транслируя эту плоскость, чтобы О совпало с V, получа-
ем новый набор точек Ai, который лежит на плоскости, проходящей через V
(рис. 26.4, вверху в центре).
Поскольку кривые Безье третьего порядка определяются четырьмя точками,
две соседних вершины V и V и точки Л» и А\, соотнесенные с соответствую-
щим ребром, можно интерпретировать как контрольные точки кривой третьего
порядка. Таким образом получаем набор ребер третьего порядка, интерполи-
рующих вершины контрольной сетки и формирующих границы треугольных
лоскутов. Построив эти кривые, на обеих сторонах границы можно так вы-
брать контрольные точки, чтобы обеспечить непрерывность в G1 внутренней
части лоскута. В данном построении поле касательных на границе линейно ин-
терполирует касательные в двух конечных точках линии границы. В конечной
точке V касательная t, идущая вдоль кривой, содержит точку Ai (точка вы-
бирается так, чтобы касательная была параллельна линии, соединяющей Ai-i
с A+i). Касательная t' строится аналогично. Внутренние контрольные точ-
ки F, Fr, G и G* (рис. 26.4, справа вверху) строятся как решение системы
линейных уравнений, описывающих указанное линейное условие ([Chiyokura,
1983]). В то же время, лоскут четвертого порядка не обладает достаточным
числом степеней свободы, чтобы можно было одновременно задать внутрен-
ние точки для всех трех границ. Следовательно, каждый лоскут можно рас-
842
Часть VII. Приложения
Рис. 26.4. Построение треугольного сплайна по треугольной многогранной сетке. Вверху, слева
направо-, контрольные точки (третьего порядка); линии границ, окружающие вершину сетки; по-
строение внутренних контрольных точек по заданной касательной. Внизу, расщепление лоскута
на три для обеспечения непрерывности в G1: белые точки — это контрольные точки, полученные
путем повышения степени контрольных кривых, серым показаны оставшиеся контрольные точки,
выбранные так, чтобы обеспечить непрерывность в G1. Согласно [Sullivan and Ponce, 1998}
щепить на три, использовав, например, метод, предложенный в [Shirman and
Sequin, 1987], и обеспечить непрерывность в новых лоскутах: увеличение сте-
пени линий границ приводит к их замене кривыми Безье четвертого порядка,
имеющими ту же форму (см. раздел упражнений). Далее по этим границам
можно построить три треугольных лоскута четвертого порядка, как показано
на рис. 26.4, внизу. В результате для каждой грани сетки получаем набор из
трех лоскутов четвертого порядка, непрерывных в G1 по всем границам.
Деформация сплайнов. Дан метод построения непрерывной в G1 треугольной
сплайн-аппроксимации поверхности после триангуляции, подобной показанной
на рис. 26.2, б. Покажем теперь, как деформировать данный сплайн так, чтобы
он был касательным к конусам наблюдения, соотнесенным со входными фото-
графиями. Форма сплайн-поверхности S определяется положением ее контроль-
Глава 26. Визуализация на основе изображений
843
ных вершин Запишем через Vjk (к = 1,2,3) координаты точки Vj
(j — в некоторой эталонной евклидовой системе координат, и исполь-
зуем эти Зр коэффициентов как параметры формы. Далее для данного набора
лучей jRi,...,Rq минимизируем функцию энергии
+ Л52 /f [lP“ul2 + 2|Puv|2 + |Pw|2]du^
относительно параметров Vjk поверхности S. Здесь через d(R, S) обозначено
расстояние между лучом R и поверхностью S, интеграл — это поверхностная
энергия сплайна, обеспечивающая гладкость в областях разреженных данных,
а Л — постоянный весовой коэффициент, введенный, чтобы уравновесить чле-
ны расстояния и сглаживания. Переменные и и v в данном интеграле — па-
раметры лоскута, а суммирование производится по г лоскутам, формирующим
поверхность сплайна. Расстояние (с соответствующим знаком) между лучом
и лоскутом поверхности можно вычислить по схеме Ньютона. Для лучей, кото-
рые не пересекают поверхность, определим d(R,S) — min{|Q?|,Q € R,P € S'}
и вычислим расстояние, минимизировав |Q^|2. Для лучей, которые пересекают
поверхность, используем схему, предложенную в [Brunie, Lavallee, and Szeliski,
1992], и измерим расстояние до точки, наиболее удаленной от луча, проходя-
щего по поверхности в направлении нормали к поверхности в соответствую-
щей точке затеняющего контура. В обоих случаях итерации схемы Ньютона
начинаются с дискретизации поверхности S. В процессе подгонки поверхно-
сти сплайн деформируется для минимизации среднеквадратического расстоя-
ния луч/поверхность, для чего используется простой метод спуска градиента.
Хотя каждое расстояние определяется численно, его производные относитель-
но параметров поверхности Vjk легко вычисляются через дифференцирование
условий, которым удовлетворяют точки поверхности и лучей, разделенные ис-
комым расстоянием.
С помощью метода, описанного в данном разделе, были построены три мо-
дели объектов, показанные на рис. 26.5. Данная схема не требует установле-
ния соответствий между входными изображениями, но область ее применения
(в настоящее время) ограничивается статическими сценами. Подход же, пред-
ставленный в следующем разделе, основан на стереозрении с использованием
нескольких камер и, как таковой, требует установления соответствий, но при
этом позволяет обрабатывать не только статические, но и динамические сцены.
Виртуализированная реальность
В работе [Kanade, Rander and Narayanan, 1997] была предложена концепция
виртуализированной реальности — новой визуальной среды для манипуля-
ции и визуализации записанных и смоделированных изображений реальных
сцен, зафиксированных в управляемой среде. Первая физическая реализация
данной концепции в Университете Карнеги-Меллона состояла из геодезиче-
ского колпака, оснащенного 10 синхронизированными видеокамерами, подклю-
844
Часть VII. Приложения
Рис. 26.5. Модель с тенями и модель текстурного отображения для чайника, горгульи и ди-
нозавра. Чайник построен по шести наложенным фотографиям; модели горгульи и динозавра
построены по девяти фотографиям каждая. Перепечатано из S. Sullivan and J. Ponce, “Automatic
Model Construction, Pose Estimation, and Object Recognition from Photographs Using Triangular
Splines”, IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(10):1091-1096, 1998.
© 1998 IEEE
ценными к потребляющим видеомагнитофонам. На момент написания данной
книги последней реализацией была “3D Room”, которая состояла из помеще-
ния 20 х 20 х 9 кубических футов, наблюдаемого с 49 цветных камер, соеди-
ненных с кластером компьютеров; изображения камер совмещались в единой
глобальной системе координат, причем существовала возможность оцифровки
в реальном времени синхронизированных видеопотоков всех камер. Трехмерная
модель сцены получалась путем наложения карт глубин, полученных посред-
ством стереонаблюдения с нескольких камер (см. [Okutami and Kanade, 1993],
chapter 11). Каждая такая карта строилась для каждой камеры и небольшого
числа ее соседей (от трех до шести). Затем каждое дальностное изображение
преобразовывалось в поверхностную сетку, которую можно было визуализи-
ровать с помощью классических средств компьютерной графики, таких как
текстурное отображение. Как показано на рис. 26.6, изображения сцены, по-
строенные по единой карте глубин, могут содержать щели. Данные щели мож-
но заполнить, визуализировав на том же изображении сетки, соответствующие
соседним камерам.
Можно также прямо соединить в единую модель поверхности поверхност-
ные сетки, соотнесенные с различными камерами. Эта задача сложна, посколь-
ку а) области, где перекрываются зоны обзора нескольких камер, дают про-
Глава 26. Визуализация на основе изображений
845
Рис. 26.6. Стереонаблюдение несколькими камерами. Слева направо: карта глубин, соотнесенная
с кластером камер; текстурное изображение соответствующей сетки, наблюдаемое с иной точки;
обратите внимание на темные области, отвечающие разрывам на карте глубин; текстурное изоб-
ражение, построенное по двум соседним кластерам камер; обратите внимание на заполненные
разрывы. Перепечатано из Т. Kanade, P.W. Rander and J.P. Narayanan, "Virtualized Reality:
Constructing Virtual Worlds From Real Scenes", IEEE Multimedia, 4(l):34-47, 1997. © 1997 IEEE
тиворечивые измерения одних и тех же лоскутов поверхности и б) некоторые
участки сцены не наблюдаются ни одной камерой. Обе проблемы можно ре-
шить, использовав объемную схему слияния дальностных изображений, пред-
ложенную в работе [Curless and Levoy, 1996] и рассмотренную в главе 21.
После построения глобальной модели поверхности к ней, как и ранее, мож-
но применить текстурное отображение. Также можно добиться синтетической
анимации, интерполировав две произвольных проекции из исходной последова-
тельности. Для этого на основе модели поверхности вначале устанавливаются
соответствия между данными двумя проекциями: находится точка пересечения
оптического луча, проходящего через любую точку первой проекции, с сеткой,
а на втором изображении находится аналог точки пересечения, в результате
получаем требуемую сетку2. После определения соответствий новые проекции
строятся путем линейной интерполяции положения и цвета согласованных то-
чек. Как показано в работе [Saito et al., 1999], этот простой алгоритм дает
только аппроксимацию истинного перспективного изображения, на практике
для работы с точками, видимыми на первом изображении, но невидимыми на
втором, требуется ввести дополнительную логику. В любом случае, описанная
схема может использоваться для реалистичной анимации динамических сцен
с меняющимися схемами затенения, что продемонстрировано на рис. 26.7.
’Классические методы узких базовых линий, подобные схемам на основе корреляции, были
бы в этой ситуации неэффективными, поскольку две проекции могут быть далеко друг от друга.
Сходный метод использован в системе Facade, описанной далее в этой главе, для установления
соответствий между далеко отстоящими друг от друга изображениями при грубо известной форме
наблюдаемой поверхности.
846
Часть VII. Приложения
а)
Рис. 26.7. Виртуализированная реальность: а) последовательность синтетических изображений;
обратите внимание на корректную обработку затенения в двух отмеченных эллипсами областях
первой проекции; б) соответствующая сетчатая модель. Перепечатано из Н. Saito, S. Baba,
М. Kimura, S. Vedula, and T. Kanade, “Appearance-Based Virtual View Generation of Temporally-
Varying Events from Multi-Camera Images in the 3D Room”, Technical Report CMU-CS-99-127,
School of Computer Science, Carnegie-Mellon University, 1999
26.1.2. Моделирование сцены по несовмещенным изображениям
В данном разделе снова рассматривается задача получения и визуализации
трехмерной модели объекта по набору его изображений, но в этот раз положе-
ния камер, наблюдающих сцену, неизвестны априори и должны определяться
по информации с изображений, для чего будут использоваться методы, род-
ственные представленным в главах 12 и 13. В данном разделе описаны схемы,
явно подходящие для приложений, связанных с компьютерной графикой.
Система Facade
Система Facade моделирования и визуализации архитектурных сцен по
оцифрованным фотографиям была разработана в Калифорнийском Универси-
тете в Беркли Дебевеком, Тейлором и Маликом [Debevec, Taylor, and Malik,
1996]. Данная система выгодно использует тот факт, что многие строения
имеют относительно простую общую геометрию, на основе чего упрощается
оценка структуры сцены и движения камеры, кроме того для уточнения деталей
грубых контуров здания используется простая, но мощная идея стереозрения
на основе модели (будет описана чуть позже). Пример данной схемы приведен
на рис. 26.8.
Глава 26. Визуализация на основе изображений
847
Рис. 26.8. Модель Facade для Колокольни (Беркли). Слева направо: фотография Колокольни
с наложенными выбранными краями; трехмерная модель, восстановленная фотограмметрическими
средствами; проектирование модели на фотографию; текстурное представление модели. Перепеча-
тано с разрешения авторов из Р. Debevec, C.J. Taylor, and J. Malik, "Modeling and Rendering
Architecture from Photographs: A Hybrid Geometry- and Image-Based Approach”, Proceedings SIG-
GRAPH, 1996. © 1996 ACM, Inc.
Модели Fagade — это иерархии с ограничениями параметрических прими-
тивов, таких как блоки, призмы и тела вращения. Данные примитивы опре-
деляются небольшим набором коэффициентов (например, для блока — это
длина, ширина и высота) и переводятся один в другой строгими преобразо-
ваниями. Любой из параметров, определяющих модель, — это либо константа,
либо переменная, причем между различными неизвестными могут задаваться
связующие условия (например, можно требовать, чтобы два блока имели оди-
наковую высоту). Иерархии моделей определяются интерактивно посредством
графического пользовательского интерфейса, а основной вычислительной зада-
чей системы Facade является использование информации с изображения для
присвоения определенных значений неизвестным параметрам модели. Система
в целом делится на три основных компонента: первый, фотограмметрический
модуль, формулирует оценку структуры и движения как нелинейную задачу оп-
тимизации — минимизацию несоответствия между сегментами линий, вручную
выбранных на фотографиях, и проектирование соответствующих частей пара-
метрической модели (подробности см. в разделе упражнений). Как показано
в работе [Debevec et al., 1996], этот процесс включает относительно малое чис-
ло переменных, а именно — положения и ориентации камер, использованных
при фотосъемке здания, и параметры модели здания, причем если ориентация
некоторых краев модели фиксирована (относительно глобальной системы коор-
динат), исходную оценку данных параметров можно легко найти с помощью
линейной схемы наименьших квадратов.
848
Часть VII. Приложения
Рис. 26.9. Стереозрение на основе модели. Вверху. Синтез искривленного сметенного изобра-
жения. Точка р' смещенного изображения отображается в точку Q модели поверхности, затем
находится ее аналог q искривленного смещенного изображения. Действительная точка поверхно-
сти Р, наблюдаемая обеими камерами, проектируется в точку р ключевого изображения. Обратите
внимание, что точка q должна лежать на эпиполярной линии ер, что облегчает поиск соответствий,
как и в обычном случае стереонаблюдения. Обратите также внимание, что расхождение между р
и q вдоль эпиполярной линии является мерой различия смоделированной и реальной поверхно-
стей. Согласно [Debevec et al., 1996], figure 15. Внизу, слева направо: ключевое изображение,
смещенное изображение, соответствующее искривленное смещенное изображение. Перепечатано
с разрешения авторов из Р. Debevec, C.J. Taylor, and J. Malik, "Modeling and Rendering Architec-
ture from Photographs: A Hybrid Geometry- and Image-Based Approach”, Proceedings SIGGRAPH,
1996. © 1996 ACM, Inc.
Второй основной компонент системы Facade — это зависимый от проекции
модуль текстурного отображения, визуализирующий архитектурную сцену
путем отображения различных фотографий на геометрическую модель, исполь-
зуя при этом положение пользователя-наблюдателя. Идейно камеры заменяются
диапроекторами, проектирующими исходные изображения на модель. Разуме-
ется, каждая камера наблюдает только часть здания, и для визуализации пол-
ной модели требуется несколько фотографий. В общем случае каждая часть
здания наблюдается несколькими камерами, так что визуализация — это не
только перенос деталей на модель, но и их соответствующее слияние. В систе-
ме Facade было принято следующее техническое решение: выбирать в качестве
значения каждого пикселя нового изображения взвешенное среднее значений,
предсказанных по наложенным входным изображениям, причем весовые коэф-
Глава 26. Визуализация на основе изображений
849
фициенты обратно пропорциональны углу между соответствующими световыми
лучами входной и виртуальной проекций.
Последний компонент системы Facade — это модуль стереозрения на осно-
ве модели, использующий стереопары для уточнения геометрических деталей
(относительно грубого) описания сцены, построенного модулем фотограммет-
рического моделирования. Основная сложность в использовании стереозрения
в рассматриваемой ситуации заключается в значительном разбросе камер, что
не позволяет непосредственно использовать схемы определения соответствий
на основе корреляции. В системе Facade было решено использовать априорную
информацию о форме для отображения стереоизображений в общую эталонную
систему координат (рис. 26.9, вверху). В частности, для данных ключевого
и смещенного изображений, последнее можно спроектировать на модель сцены
до визуализации с точки наблюдения камеры за ключевым изображением, что
даст искривленное смещенное изображение, подобное ключевому изображению
(рис. 26.9, внизу). В свою очередь, это позволит использовать корреляцию для
установления соответствий между последними двумя изображениями, а следо-
вательно, и между ключевым и смещенным изображениями. После установле-
ния соответствий между данными двумя изображениями стереовосстановление
сводится к обычному процессу триангуляции.
26.2. ВИЗУАЛИЗАЦИЯ НА ОСНОВЕ ПЕРЕНОСА
В данном разделе рассмотрен подход к визуализации на основе изоб-
ражений, абсолютно отличающийся от изученных выше. В нем никогда не
выполняется явное восстановление трехмерной сцены. Взамен этого новые
изображения создаются непосредственно по (возможно, небольшому) набору
проекций, между которыми были установлены точечные соответствия (посред-
ством отслеживания особенностей или обычного стереосогласования). Этот
подход связан с классической задачей переноса из области фотограмметрии,
уже упоминавшейся в главе 10. Зная положения на наборе опорных изображе-
ний и новом изображении нескольких точек привязки и зная положения на
опорных изображениях базовой точки, можно предсказать положение данной
точки на новом изображении.
Схемы визуализации на основе изображений, в которых используется пе-
ренос, были введены в работе [Laveau and Faugeras, 1994] для проективного
случая, там же было предложено вначале оценивать попарную эпиполярную
геометрию опорных проекций, затем находить аналоги точек сцены на вир-
туальном изображении, заданном проекциями нового оптического центра на
двух опорных изображениях (т.е. эпиполюсами) и положением четырех точек
привязки на новой проекции. По определению, местонахождение на опорных
изображениях аналогов восстанавливаемых точек ограничивается эпиполярны-
ми условиями. На новой проекции аналог точки сцены находится на пере-
сечении двух эпиполярных линий, соотнесенных с точкой и двумя опорными
изображениями. После нахождения проекций характерных точек синтезируется
850
Часть VII. Приложения
Рис. 26.10. Эксперимент в рамках расширенной реальности. Глобальная (аффинная) система коор-
динат определяется углами черных прямоугольников. Перепечатано из К. Kutulakos and J. Vallino,
"Calibration-Free Augmented Reality”, IEEE Transactions on Visualization and Computer Graphics,
4(l):l-20, 1998. © 1998 IEEE
реалистичное изображение, для чего используется отслеживание луча и тек-
стурное отображение. Впрочем, как отмечалось в работе [Laveau and Faugeras,
1994], поскольку евклидовы ограничения, связанные с откалиброванными каме-
рами, не задействованы, визуализированные изображения отличаются от истин-
ных произвольными плоскими проективными преобразованиями, если не учесть
дополнительные условия на сцену. Далее в этой главе рассмотрены два аффин-
ных варианта подхода с использованием переноса, в которых названная слож-
ность обходится. В обеих схемах строится параметризация набора всех изоб-
ражений жесткой сцены. В первом случае (раздел 26.2.1), аффинная структура
пространства аффинных изображений используется для визуализации синтети-
ческих объектов в системе расширенной реальности. Поскольку точки привяз-
ки в этом случае — это всегда геометрически значимые характерные элементы
изображения (например, углы калибровочных многоугольников; см. рис. 26.10),
синтезированные изображения автоматически являются евклидовыми. Во вто-
ром случае (раздел 26.2.2) при параметризации пространства изображений явно
учитываются метрические условия, связанные с откалиброванными камерами,
что также гарантирует синтез корректных евклидовых изображений.
Отметим еще раз специфику визуализации с использованием переноса, о ко-
торой уже упоминалось во вступлении: поскольку трехмерная модель не строит-
ся, для управления синтезом анимации нельзя использовать джойстик. Взамен
этого пользователь может интерактивно задавать положения точек привязки.
Это не проблема в контексте расширенной реальности, но вопрос, подходит ли
такой пользовательский интерфейс для приложений виртуальной реальности,
остается открытым.
26.2.1. Синтез аффинных проекций
В данном разделе рассмотрена задача синтеза новых (аффинных) изобра-
жений сцены по данным изображениям без определения явной трехмерной
Глава 26. Визуализация на основе изображений
851
евклидовой системы координат. Напомним из главы 12, что если записать
вектор координат точки сцены Р в некоторой глобальной системе координат
как Р — (x,y,z)T, а через р = (u,v)T обозначить вектор координат проек-
ции р точки Р на плоскость изображения, модель аффинной камеры (уравне-
ние (2.19)) можно записать как
/ О1
р = АР + Ь, где А = I
(26.1)
°2
Ъ — положение проекции на изображение начала системы координат, привязан-
ной к объекту, oi и аг - векторы в R3.
Рассмотрим четыре (некомпланарных) точки сцены, скажем Ро, Pi, Ръ и Рз.
Без потери общности эти точки можно выбрать в качестве опорной аффин-
ной системы координат, так что координатные векторы этих точек запишутся
следующим образом:
Точки Pi (i — 1,2,3) в общем случае не лежат не единичном расстоянии от Ро,
кроме того, векторы РоР, и PqPj не ортогональны между собой при г / j.
Впрочем, это несущественно, так как мы работаем в аффинной среде. Посколь-
ку матрица 3 х 3 со столбцами Pi, Рг и Рз равна единичной, уравнение (26.1)
можно переписать следующим образом:
р = АР + b =
[Р1|Р2|Рз]
+ Ь.
Наконец, поскольку мы выбрали Ро в качестве начала глобальной системы
координат, получаем Ь = р0 и
р = (1-х-у- z)p0 + arpi + ур2 + zp3. (26.2)
Данный результат связан с аффинной структурой аффинных изображений, что
обсуждалось в главе 12. В контексте визуализации на основе изображений по-
лучаем, что из уравнения (26.2) следует, что х, у и z можно вычислить по т > 2
изображениям точек Ро, Pi, Рг, Рз и Р с помощью линейной схемы наимень-
ших квадратов. После нахождения этих значений новые изображения можно
синтезировать, задавая положения на изображениях точек Ро,Р1,Р2,Рз и ис-
пользуя уравнение (26.2) для вычисления положений всех других точек (см.
[Kutulakos and Vallino, 1998]). Кроме того, поскольку аффинное представление
сцены является истинно трехмерным, можно также вычислить относительную
глубину точек сцены и использовать ее для устранения скрытых поверхностей
852
Часть VII. Приложения
при обработке z-буфера. Следует отметить, что задание произвольных поло-
жений для точек Ро,Р1,Р2,Рз обычно приводит к аффинно деформированным
изображениям. Это не проблема в приложениях расширенной реальности, где
на изображении совместно присутствуют графические и физические объекты.
В этом случае истинные точки изображения могут выбираться в качестве анкер-
ных точек ро,РьР2,Рз с гарантированно корректными евклидовыми положени-
ями. Сказанное иллюстрируется на рис. 26.10, где представлены синтетические
объекты, наложенные на реальные изображения.
Если доступны большие последовательности изображений, можно исполь-
зовать разновидность описанной схемы, в которой на равных правах учиты-
ваются все точки сцены. Предположим, что наблюдается стационарный набор
точек Ро, •, Pn-i с координатными векторами Pi (г = 0,..., п — 1) и пусть рг
обозначает координатные векторы соответствующих точек изображения. Запи-
сывая уравнение (26.1) для всех точек сцены, получаем
Другими словами, множество всех аффинных изображений п фиксированных
точек — это восьмимерное векторное пространство V, вложенное в К2п и па-
раметризованное векторами ai, аг и Ь3. Для данных т > 8 проекций п > 4
точек базис указанного векторного пространства можно определить, разложив
по сингулярным значениям матрицу 2п х т
где — положение г-й точки изображения в j-й системе координат4. После
построения базиса пространства V для создания новых изображений векто-
рам ai, аг и Ь можно присваивать произвольные значения. Если изображе-
ния требуется синтезировать интерактивно, можно добиться более интуитивно-
го контроля над геометрией процесса формирования изображения, задав, как
3Это не противоречит результату, полученному в главе 12, где говорилось, что множество т
фиксированных проекций произвольного набора точек — это трехмерное аффинное подпростран-
ство пространства R2m.
^Требование минимум восьми изображений может показаться излишней перестраховкой, по-
скольку, как сказано в главе 12, аффинную структуру сцены можно восстановить по двум изобра-
жениям. Действительно (см. раздел упражнений), базис V можно построить по двум изображениям
хотя бы четырех точек.
Глава 26. Визуализация на основе изображений
853
и ранее, положения четырех точек на изображениях, найдя соответствующие
значения а^сциЬи вычислив положения оставшихся точек.
26.2.2. Синтез евклидовых проекций
Как обсуждалось ранее, недостатком метода, представленного в преды-
дущем разделе, является то, что задание произвольных положений для то-
чек ро,pi,Р2,Рз обычно приводит к аффинно деформированным изображениям.
Этого можно избежать, изначально учтя евклидовы условия, связанные с от-
калиброванными камерами. В главе 12 было показано, что слабоперспективная
камера представляет собой аффинную камеру, удовлетворяющую двум квадра-
тичным условиям
ai a2=0 и |oi|2 = |ог|2.
В предыдущем разделе говорилось, что аффинные изображения стационарной
сцены формируют восьмимерное векторное пространство V. Если теперь огра-
ничиться в рассмотрении слабоперспективными камерами, набор изображения
становится шестимерным подпространством, определенным данными двумя по-
линомиальными условиями. Сходные условия применяются к параперспектив-
ным и чисто перспективным проекциям, которые в каждом случае определяют
шестимерное многообразие (т.е. подпространство, заданное полиномиальными
уравнениями).
Предположим, что наблюдаются три точки Ро, Pi, Рг, изображения которых
неколлинеарны. Без потери общности можно так выбрать евклидову систему
координат, чтобы координатные векторы трех точек в этой системе имели такой
вид:
где р и q не равны нулю, но (априори) неизвестны. Обозначим через pi про-
екцию точки Рг (г = 0,1,2). Поскольку Ро — это начало глобальной системы
координат, получаем b = pG. Можно также поместить ро в начало системы
координат изображения (это равносильно применению ко всем точкам изобра-
жения известной трансляции), так что уравнение (26.1) упрощается до вида
(26.3)
Применяя теперь уравнение (26.1) к Pi, Рг и Р, получаем
(26.4)
854
Часть VII. Приложения
где
/рП /1
О
О
z
О
Q
У
В свою очередь, из этого следует, что
ai = Qu и аг = Qv,
(26.5)
где
Q - Р~*
О
М
0/г
0 \
0 I
1/г/
> = -р/д,
м = 1/д,
а = — (х + Ху),
. /3 = ~РУ-
Используя уравнение (26.5) и положив 7Z = z2QTQ, слабоперспективное усло-
вие (12.10) можно переписать следующим образом:
ит TZu — vT7Zv = О,
uT1Zv = О,
(26.6)
при
6 = (1 + A2)z2 + а2,
< 6г = Xpz2 + а/?,
k &=p2z2 + /32.
Уравнение (26.6) определяет пару линейных условий на коэффициенты 6»
(г — 1,2,3), а и (3. Это можно переписать следующим образом:
(26.7)
где
< uj-vl >
2(111112 — V1V2)
2 2
«2 - г?2
2(tiiti — viv)
2(UiU — V2V)
u2 — v2 /
f UlVl >
Ull?2 + 1X2171 6г
, def 112 V2 + def &
<12 ~ nit; + uvi И = a
U2V + UV2
uv ) V/
Если четыре точки Ро, Рь Ла и Р жестко связаны между собой, пять струк-
турных коэффициентов 61 > 62, 6з, « и /3 фиксированы. Если жесткая сцена
Глава 26. Визуализация на основе изображений
855
образована п точками, выбор трех из этих точек в качестве опорного тре-
угольника и запись уравнения (26.7) для остальных точек дает систему 2п — 6
квадратных уравнений с 2п неизвестными, что определяет параметризацию
множества всех слабоперспективных изображений сцен. Согласно работе [Gene
and Ponce, 2001] это называется параметризованным многообразием образа
(Parameterized Image Variety — PIV).
Еще раз обратите внимание, что слабоперспективные условия (26.7) линей-
ны по пяти структурным коэффициентам. Следовательно, имея набор изоб-
ражений и точечных соответствий, данные коэффициенты можно оценить
посредством линейной схемы наименьших квадратов. После оценки вектора %,
в качестве трех опорных точек могут выбираться произвольные точки на изоб-
ражении. Для каждой характерной точки уравнение (26.7) дает два квадратных
уравнения с двумя неизвестными и и v. Хотя данная система априори должна
допускать четыре решения, как показано в разделе упражнений, существует
ровно два решения. Фактически, имея п точечных соответствий и зная положе-
ние на изображении трех точек привязки, можно показать (см. [Gene and Ponce,
2001]), что изображения оставшихся п — 3 точек определяются аналитически
с точностью до двусторонней неоднозначности. После определения положений
всех характерных точек сцену можно визуализировать, проведя триангуляцию
данных точек и текстурное отображение треугольников. Интересно отметить,
что традиционные методы z-буферизации позволяют также провести удаление
скрытых поверхностей, хотя при этом не производится явное трехмерное вос-
становление: идея состоит в присвоении вершинам треугольников, полученных
после триангуляции, относительных глубин, и она тесно связана с методом, ис-
пользованным в теореме о восстановлении аффинной структуры по движению,
приведенной в главе 12. Обозначим через П плоскость изображения одного из
входных изображений, а через П' — плоскость изображения синтезированного
образа. Для корректной визуализации двух точек Р и Q, проектирующихся
в одну точку г* синтезированного изображения, следует сравнить глубины этих
точек (рис. 26.11).
Обозначим через R пересечение луча наблюдения, соединяющего точки Р
и Q, с плоскостью, натянутой на опорные точки Ao, Ai и Aj, и обозначим
через р, д, г проекции точек Р, Q и R на опорное изображение. Будем пока
предполагать, что Р и Q — это две точки, отслеженные на входном изображе-
нии; отсюда следует, что положения точек р и q известны. Положение точки г
легко вычисляется, если заметить, что координаты этой точки в аффинном ба-
зисе плоскости П, формируемом проекциями опорных точек, совпада-
ют с координатами R в аффинном базисе, сформированном точками Ао,А1,Аг
в их плоскости, а следовательно совпадают с координатами точки г' в аф-
финном базисе плоскости П', сформированном проекциями опорных
точек. Отношение глубин точек Р и Q относительно плоскости П — это просто
отношение рг/дг. Обратите внимание, что для того, чтобы определить, какая
точка действительно видима, требуется ориентировать линию, содержащую точ-
ки р,д,г и представляющую собой просто эпиполярную линию, соотнесенную
856
Часть VII. Приложения
Рис. 26.11. Z-буферизация. Перепечатано из Y. Gene and J. Ponce, “Parameterized Image Va-
rieties: A Novel Approach to the Analysis and Synthesis of Image Sequences”, Proceedings of the
International Conference on Computer Vision, 1998. (c) 1998 IEEE
Рис. 26.12. Два изображения лица, синтезированных с использованием параметризованных мно-
гообразий образа. Рисунок любезно предоставил Якап Генк (Yakup Gene)
с точкой г'. Для всех эпиполярных линий следует выбрать когерентную ори-
ентацию (это легко, поскольку все они параллельны между собой). Обратите
внимание, что явного вычисления эпиполярной геометрии не требуется: имея
первую точку р', можно ориентировать линию рг, а затем использовать ту же
ориентацию для всех других точечных соответствий. Выбранная ориентация
должна также быть непротиворечивой на последовательных кадрах, но это не
проблема, поскольку при переходе между кадрами направление эпиполярных
линий меняется медленно, так что новая ориентация выбирается так, чтобы
угол, который она составляет с ориентацией на предыдущем кадре, был ост-
рым. Примеры синтезированных изображений, построенных с помощью данного
метода, показаны на рис. 26.12.
Глава 26. Визуализация на основе изображений
857
Рис. 26.13. Синтез проекции сцены при заданной точке наблюдения
26.3. СВЕТОВОЕ ПОЛЕ
В данном разделе рассмотрен иной подход к визуализации на основе изобра-
жений, единственное сходство которого с методами, рассмотренными в преды-
дущем разделе, заключается в том, что он также не требует построения явной
или неявной трехмерной модели сцены. Рассмотрим, например, панорамную
камеру, оптически фиксирующую излучение по направлениям, проложенным
через некоторую точку, и охватывающую полную полусферу направлений (см.,
например, [Peri and Nayar, 1997]; рис. 26.13, слева). Любое изображение, на-
блюдаемое виртуальной камерой, точечная диафрагма которой помещена в дан-
ную точку, можно создать путем отображения исходных лучей изображений
в виртуальные. Это позволяет пользователю произвольным образом вращать
и наклонять виртуальную камеру, интерактивно изучая окружающий мир. По-
добных эффектов можно добиться, сшивая смежные изображения, полученные
ручной видеокамерой, в мозаику (см., например, [Shum and Szeliski, 1998];
рис. 26.13, в центре) или комбинируя изображения, полученные при повороте
(и возможно наклоне) камеры относительно ее оптического центра в цилиндри-
ческую мозаику (см., например, [Chen, 1995]; рис. 26.13, справа).
Недостатком данных методов является то, что движение наблюдателя огра-
ничено чистым вращением вокруг оптического центра камеры. Можно разрабо-
тать более мощный подход, рассмотрев пленоптическую функцию (plenoptic
858
Часть VII. Приложения
Рис. 26.14. Пленоптическая функция и световое поле. Слева: пленоптическую функцию можно
параметризовать положением Р наблюдателя и направлением наблюдения v. Справа: световое поле
можно параметризовать четырьмя параметрами u,v, s, t, определяющими плиту света. На практике
для моделирования всего объекта и охвата всей сферы наблюдения требуется несколько плит света
function) ([Adelson and Bergen, 1991]), соотносящую с каждой точкой простран-
ства (зависимую от длины волны) энергию излучения по лучу, проходящему
через данную точку в данный момент времени (рис. 26.14, слева). Световое
поле ([Levoy and Hanrahan, 1996]) — это мгновенный снимок пленоптической
функции для света, распространяющегося в вакууме при отсутствии препят-
ствий. Таким образом, снимаем зависимость излучения от времени и положения
рассматриваемой точки на соответствующем луче (поскольку в непоглощающей
среде излучение вдоль прямой постоянно) и получаем представление пленопти-
ческой функции через излучение вдоль лучей света, образующих четырехмер-
ное множество. Данные лучи можно параметризовать по-разному (например,
используя координаты Плюкера, введенные в главе 3), но в контексте визуали-
зации на основе изображений удобной является параметризация плитой света
(light slab), когда каждый луч задается координатами точек его пересечения
с двумя произвольными плоскостями (рис. 26.14, справа).
Плита света позволяет сформулировать двухэтапный подход к визуализа-
ции на основе изображений. На этапе обучения создается множество проекций
сцены для получения дискретной версии плиты, которую можно рассматри-
вать как четырехмерную таблицу соответствий. На этапе синтеза определяется
виртуальная камера и нужная проекция находится по таблице соответствий.
Качество синтезированных проекций зависит от числа опорных изображений.
Чем ближе виртуальная проекция к опорным изображениям, тем выше каче-
ство синтезированного изображения. Построение модели плиты света светово-
го поля не требует установления соответствий между изображениями. Следует
отметить, что в отличие от большинства методов визуализации на основе изоб-
ражений, в которых используется текстурное отображение и, следовательно,
предполагается (неявно), что наблюдаемые поверхности являются ламбертов-
Глава 26. Визуализация на основе изображений
859
Рис. 26.15. Получение плиты света по изображениям и синтез новых изображений по плите
света можно смоделировать посредством проективных преобразований между плоскостью (х,у)
и определяющими плиту плоскостями (u,v) и (s,t)
скими, методы светового поля могут использоваться для визуализации (при
постоянном освещении) изображений объектов с произвольными БФРО.
На практике выборка светового поля осуществляется через отображение
координат пикселей большого числа изображений в координаты плиты. Общая
ситуация иллюстрируется на рис. 26.15: отображение между любым пикселем
на плоскости образа (х, у) и соответствующими областями плоскостей (u, v)
и (s, t), определяющими плиту света, является плоским проективным преоб-
разованием. Затем для заполнения светового поля на четырехмерной прямо-
угольной сетке может использоваться текстурное отображение, реализованное
на аппаратном или программном уровне. В экспериментах, описанных в работе
[Levoy and Hanrahan, 1996], для получения плит света использовалась простая
установка — камера, смонтированная на плоской подставке и оснащенная па-
норамной головкой, так что камера могла вращаться вокруг своего оптического
центра и всегда была направлена на центр наблюдаемого объекта. В этом кон-
тексте все вычисления можно упростить, положив, что плоскость (u,v) — это
плоскость, в которой обязан находиться оптический центр камеры.
В процессе визуализации для эффективного синтеза новых изображений
может использоваться проективное отображение между виртуальной плоско-
стью изображения и двумя плоскостями, определяющими световую плиту.
На рис. 26.16 показаны примеры изображений, сгенерированных с использо-
ванием концепции светового поля. Три верхние пары изображений сгенери-
рованы с использованием синтетических изображений различных объектов,
и они применялись для заполнения светового поля. Последняя пара изобра-
жений построена с использованием плоской подставки, упомянутой ранее, для
получения 2048 изображений 256 х 256 игрушечного льва, сгруппированных
в четыре плиты, каждая из которых состоит из 32 х 16 изображений.
860
Часть VII. Приложения
Важным вопросом здесь является размер представления в форме пли-
ты света: необработанные входные изображения льва занимают 402 Мбайта
дискового пространства. Разумеется, данные изображения сильно избыточ-
ны, причем то же справедливо и для последовательных кадров видеоленты.
Простой, но эффективный подход к сжатию/восстановлению данных был пред-
ложен в работе [Levoy and Hanrahan, 1996]: вначале плита света разбивается
на четырехмерные пластинки с указанием кода цвета; затем данные пластинки
кодируются с использованием векторного квантования (см. [Gersho and Gray,
1992]), метода сжатия с потерями, в котором 48-мерные векторы, представля-
ющие RGB-коды в 16 углах исходных пластинок, замещаются относительно
небольшим набором векторов воспроизведения (именуемых кодовыми слова-
ми), которые наилучшим образом (в смысле среднеквадратической ошибки)
аппроксимируют входные векторы. Таким образом, световая плита представ-
ляется набором индексов в кодовой книге, сформированной всеми кодовыми
словами. Для примера со львом кодовая книга имеет относительно небольшой
размер (0,8 Мбайта), а размер набора индексов — 16,8 Мбайта. Второй этап
сжатия — это применение к кодовой книге и индексам статистического ко-
дирования (конкретно — алгоритма gzip\ [Ziv and Lempel, 1977]). Конечный
размер представления — всего 3,4 Мбайта, что соответствует коэффициенту
сжатия 118:1. Статистическое декодирование в процессе визуализации произ-
водится при загрузке файла в оперативную память. Обращение квантования
производится по требованию в процессе отображения на экран и позволяет
интерактивно менять частоту дискретизации.
26.4. ПРИМЕЧАНИЯ
Визуализация на основе изображений представляет собой быстро развива-
ющуюся область. В завершение данной главы упомянем несколько альтерна-
тив подходам, описанным в предыдущих разделах. Пересечение всех конусов,
касающихся поверхности твердого тела, формирует его зрительную оболочку
(visual hull) (см. [Laurentini, 1995]). Тело всегда содержится в своей зрительной
оболочке, которая, в свою очередь, содержится в выпуклой оболочке тела. Объ-
емный подход к моделированию объектов по наложенным силуэтам, представ-
ленный в разделе 26.1, нацелен на построение аппроксимации зрительной обо-
лочки по конечному набору фотографий. В различных схемах для представле-
ния конусов и их пересечений используются многогранники или восьмеричные
деревья делений (octree) ([Martin and Aggarwal, 1983], [Connolly and Stenstrom,
1989], [Srivastava and Ahuja, 1990]), коммерческая система Sphinx3D ([Niem
and Buschmann, 1994]) автоматически строит многогранные модели по изобра-
жениям. Родственный подход, именуемый пространственной резьбой (space
carving), описан в работе [Kutulakos and Seitz, 1999], в нем пустые воксели ин-
терактивно удаляются с использованием условий на когерентность яркости или
цвета. Для восстановления поверхности по непрерывной последовательности
контуров при известном или неизвестном движении камеры в различных мо-
Глава 26. Визуализация на основе изображений
861
Рис. 26.16. Изображения, синтезированные с использованием концепции светового поля. Перепе-
чатано с разрешения авторов из М. Levoy and Р. Hanrahan, “Light Field Rendering,” Proceedings
SIGGRAPH, 1996. © 1996 ACM. Inc.
862
Часть VII. Приложения
дификациях используется условие касания ([Arbogast and Mohr, 1991], [Cipolla
and Blake, 1992], [Valliant and Faugeras, 1992], [Cipolla et al., 1995], [Boyer and
Berger, 1996], [Cross et al., 1999], [Joshi et al., 1996]). Варианты метода интер-
поляции проекций, рассмотренного в разделе 26.1, описаны в работах [Williams
and Chen, 1993] и [Seitz and Dyer, 1995, 1996]. Визуализация на основе изобра-
жений с использованием переноса включает помимо методов, описанных в раз-
деле 26.2, методы, предложенные в работах [Havaldar et al., 1996] и [Avidan
and Shashua, 1997]. Как упоминалось в разделе 26.3, разработано множество
методов интерактивного исследования пользовательской зрительной среды со
стационарной точки наблюдения. В настоящее время имеются действующие
коммерческие системы (например, QuickTime VR, разработанная в компании
Apple; см. [Chen, 1995]) и алгоритмы восстановления перспективных изобра-
жений панорамных картин, полученных специальными камерами с точечными
диафрагмами (см., например, [Peri and Nayar, 1997]). Подобных эффектов мож-
но добиться в менее управляемой среде, сшивая смежные изображения, по-
лученные ручной видеокамерой, в мозаику (см., например, [Irani et al., 1996],
[Shum and Szeliski, 1998]). Для изображений удаленной местности или камер,
вращающихся вокруг своих оптических центров, мозаику можно построить,
наложив последовательные плоские гомографии. В этом контексте оценка оп-
тического потока (т.е. векторного поля видимых скоростей движения изоб-
ражения в каждой точке изображения — понятие, которое в данной книге
преимущественно игнорировалось), может также оказаться полезной при каче-
ственном наложении и устранении ореола (deghosting) (см. [Shum and Szelis-
ki, 1998]). Разновидности подхода с использованием концепции светового поля,
рассмотренного в разделе 26.3, описаны в работах [McMillan and Bishop, 1995]
и [Gortler et al., 1996]. Великолепное введение в понятия дуг и лоскутов Безье,
а также сплайновых кривых и поверхностей можно найти в работе [Farin, 1993].
Задачи
26.1. Для данных (п+ 1) точки Ро,...,Рп параметрическая кривая Pf(t) ре-
курсивно определяется как P,°(t) = Р» и
Pi(t) = (1 -t)P*“1(0 + i^f+i1(O Для fc = l,...,п и i = 0,...,п- к.
Ниже показывается, что Pq (t) — кривая Безье степени п, связанная
с (п + 1)-й точкой Ро,...,Рп. Подобное построение кривой Безье назы-
вается алгоритмом де Кастелью (de Casteljeau algorithm).
а) Покажите, что полиномы Бернстайна удовлетворяют рекурсивному
соотношению
6<n>(t) = (1 - + tbj27X) (t)
при b^(t) = 1 и, по договоренности, b^(t) — 0 при j < 0 или j > n.
Глава 26. Визуализация на основе изображений
863
б) Используйте материал начала главы и покажите, что
к
Pi(t) = b^(t)Pj+j для каО,...,п и г = 0.......п - к.
з=о
26.2. Рассмотрим кривую Безье степени п, определенную п +1 контрольной
точкой Ро,..., Рп. Ниже изучается задача построения п + 2 контрольных
точек Qo, • , Qn+i кривой Безье степени п + 1 той же формы. Данный
процесс называется повышением степени. Покажите, что фо = Ро и
Qi = ~—Pj~i + (1-------— ] Pj при j = 1,..., п + 1.
п+1 у п+1/
(Подсказка: запишите барицентрические комбинации, соотнесенные
с двумя кривыми, но описывающие одну и ту же точку, и приравняйте
коэффициенты при соответствующих степенях.)
26.3. Покажите, что касательная к кривой Безье P(t) определяется п +1 кон-
трольной точкой Ро,..., Рп'
j=O
Подтвердите, что касательные в конечных точках дуги Безье идут по
первому и последнему сегментам контрольного многоугольника.
26.4. Покажите, что при построении точки Qi (раздел 26.1.1) помещаются на
плоскость, проходящую через центр масс О точек Ci.
26.5. Фотограмметрический модуль системы Facade. В разделе упражне-
ний к главе 3 было показано, что отображение прямой J с плюкеров-
скими координатами А в ее образ 6 с однородными координатами А
можно представить следующим образом: pS = А4Д. Здесь А — функ-
ция параметров модели, а М зависит от соответствующего положения
и ориентации камеры.
а) Предполагая, что линия д была согласована с краем изображения е
длины I, удобной мерой несоответствия предсказанных и наблюдае-
мых данных является I, умноженное на среднеквадратическое рассто-
яние, отделяющее точки е от линии 6. Определив d(t) как расстояние
(с соответствующим знаком) между краевой точкой р = (1 - t)po + tpi
и линией <5, покажите, что
г1 1
Е = / d2(t)dt==- (d(0)2 + d(0)d(l) + d(l)2),
Jo
где do и di — расстояния (с соответствующим знаком) между конеч-
ными точками е и <5.
864
Часть VII. Приложения
б) Если Ро и pi — однородные координатные векторы данных точек,
покажите, что
где [а]2 — вектор, сформированный первыми двумя координатами век-
тора а в пространстве R3.
в) Сформулируйте процесс восстановления параметров камеры и модели
как нелинейную задачу наименьших квадратов.
26.6. Покажите, что базис восьмимерного векторного пространства V, сфор-
мированного всеми аффинными изображениями фиксированного набора
точек можно построить минимум по двум изображениям
данных точек, если п > 4. (Подсказка: используйте матрицу
где — координаты проекции точки Pi на j-e изображение.)
26.7. Покажите, что множество всех проективных изображений стационарной
сцены — это восьмимерное многообразие.
26.8. Покажите, что множество всех перспективных изображений стационар-
ной сцены (для камеры с постоянными внутренними параметрами) — это
шестимерное многообразие.
26.9. В данной задаче показывается, что уравнение (26.7) допускает только
два решения.
а) Покажите, что уравнение (26.6) можно переписать как
X2 - У2 -I- et - е2 = О,
2XY + е = О,
(26.8)
где
X — и -|- ащ + (3u2,
Y = v -I- cwi 4- 0V2
и e, ej и C2 — коэффициенты, зависящие от tii, i?i, «2, V2 и структур-
ных параметров.
б) Покажите, что решениями уравнения (26.8) являются
X' — 4\/(ei - е2)2 -I- е2 cos (| arctg(e, ei - е2)) ,
Y' = 4y/(ei - е2)2 4-е2 sin (| arctg(e, ei - е2))
и (Х",У") = (—X',—У'). Подсказка: используйте замену перемен-
ных, чтобы переписать (26.8) как систему тригонометрических урав-
нений.
Литература
Adelson Е. and Bergen J. [1991] The plenoptic function and the elements of early vision,
M. Landy and J. Movshon, eds, Computational Models of Visual Processing, MIT
Press.
Adelson E. and Weiss Y. [1996] A unified mixture framework for motion segmentation:
Incorporating spatial coherence and estimating the number of models, IEEE Confer-
ence on Computer Vision and Pattern Recognition, pp. 321-326.
Adini Y., Moses Y. and Ullman S. [1994] Face recognition: The problem of compensating
for changes in illumination direction, European Conference on Computer Vision,
pp. A:286-296.
Adini Y., Moses Y. and Ullman S. [1997] Face recognition: The problem of compensating
for changes in illumination direction, IEEE Trans. Pattern Analysis and Machine
Intelligence, 19(7), pp. 721-732.
Agin G. [1972] Representation and description of curved objects, PhD thesis, Stanford
University.
Agin G. [1981] Fitting ellipses and general second-order curves. Technical report, CMU
Robotics Institute.
866
Литература
Aho A., Hopcroft J. and Ullman J. [1974] The Design and Analysis of Computer Algorithms,
Addison-Wesley.
Ahuja N. and Abbott A. [1993] Active stereo: Integrating disparity, vergence, focus, aper-
ture, and calibration for surface estimation, IEEE Trans. Pattern Analysys and Ma-
chine Intelligence, 15(10), pp. 1007-1029.
Aikens R., Agard D. and Sedat J. [1989] Solid-state imagers for microscopy, Methods Cell
Biol., 29, pp. 291-313.
Aloimonos Y. [1986] Detection of surface orientation from texture. I. the case of planes,
IEEE Conference on Computer Vision and Pattern Recognition, pp. 584-593.
Aloimonos Y. [1990] Perspective approximations, Image and Vision Computing, 8(3),
pp. 177-192.
Aloimonos Y., Weiss I. and Bandyopadhyay A. [1987] Active vision, International Journal
of Computer Vision, 1(4), pp. 333-356.
Amelio G., Tompsett M. and Smith G. [1970] Experimental verification of the charge
coupled device concept, Bell Systems Technical Journal, 49, pp. 593-600.
Amenta N., Bern M. and Kamvysselis M. [1998] A new Voronoi-based surface reconstruc-
tion algorithm, SIGGRAPH-98, pp. 415-421.
Amir A. and Lindenbaum M. [1996] Quantitative analysis of grouping processes, European
Conference on Computer Vision, 1996, pp. 1:371-384.
Anderson B. and Nayakama K. [1994] Toward a general theory of stereopsis — binocular
matching, occluding contours, and fusion, Psych. Review, 101(3), pp. 414-445.
Anthropology Research Project [1978] Anthropometric Source Book, Webb Associates.
NASA reference publication 1024, 3 Vols.
Arbogast E. and Mohr R. [1991] 3D structure inference from image sequences, Journal of
Pattern Recognition and Artificial Intelligence.
Arend L. and Reeves A. [1986] Simultaneous colour constancy, Journal of the Optical
Society of America — A 3, pp. 1743-1751.
Armitage L. and Enser P. [1997] Analysis of user need in image archives, Journal of
Information Science, 23(4), pp. 287-299.
Arnold V. [1984] Catastrophe Theory, Springer-Verlag, Heidelberg.
Arnon D., Collins G. and McCallum S. [1984] Cylindrical algebraic decomposition I and
II, SIAM J. Comput., 13(4), pp. 865-889.
Avidan S. and Shashua A. [1997] Novel view synthesis in tensor space, Proceedings, IEEE
Conference on Computer Vision and Pattern Recognition, pp. 1034-1040.
Ayache N. [1995a, b] Medical computer vision, virtual-reality and robotics, Image and
Vision Computing, 13(4), pp. 295-313.
Литература
867
Ayache N. and Faugeras O. [1986] Hyper: a new approach for the recognition and po-
sitioning of two-dimensional objects, IEEE Trans. Pattern Analysys and Machine
Intelligence, 8(1), pp. 44-54.
Ayache N. and Faugeras O. [1987] Building, registrating, and fusing noisy visual maps,
Proceedings of the International Conference on Computer Vision, pp. 73-82.
Ayache N. and Faverjon B. [1997] Efficient registration of stereo images by matching graph
descriptions of edge segments, International Journal of Computer Vision, pp. 101-137.
Ayache N. and Lustman F. [1987] Fast and reliable passive trinocular stereovision, Pro-
ceedings of the International Conference on Computer Vision, pp. 422-427.
Bajcsy R. [1988] Active perception, Proceedings of the IEEE, 76(8), pp. 996-1005.
Bajcsy R. and Solina F. [1987] Three-dimensional object representation revisited, Proceed-
ings of the International Conference on Computer Vision, pp. 231-240.
Baker H. and Binford T. [1981] Depth from edge- and intensity-based stereo, Proceedings
of the International Joint Conference on Artificial Intelligence, pp. 631-636.
Baker S., Szeliski R. and Anandan P. [1998] A layered approach to stereo reconstruction,
IEEE Conference on Computer Vision and Pattern Recognition, 1998, pp. 434-441.
Barnard K. [2000] Improvements to gamut mapping colour constancy algorithms, European
Conference on Computer Vision, 2000, pp. 390-402.
Barnard K. and Forsyth D. [2001] Learning the semantics of words and pictures, Interna-
tional Conference on Computer Vision, pp. 408-415.
Barnard K. and Funt B. [2002] Camera characterization for color research, Color research
and application.
Barnard K., Duygulu P. and Forsyth D. [2001] Clustering art, IEEE Conference on Com-
puter Vision and Pattern Recognition.
Barnard K., Finlayson G. and Funt B. [1997] Color constancy for scenes with varying
illumination, Computer Vision and Image Understanding, 65(2), pp. 311-321.
Barrett E., Brill M., Haag N. and Payton P. [1992] Some invariant linear methods in
photogrammetry and model-matching, IEEE Conference on Computer Vision and
Pattern Recognition, 1992, pp. 122-128.
Barrett E., Payton P., Haag N. and Brill M. [1991] General methods for determining
projective invariants in imagery, CVGIP: Image Understanding, 53(1), pp. 46-65.
Basri R. [1996] Parraperspective = affine, International Journal of Computer Vision, 19(2),
pp. 169-179.
Beardsley P., Zisserman A. and Murray D. [1997] Sequential updating of projective
and affine structure from motion. International Journal of Computer Vision, 23(3),
pp. 235-259.
Beckmann P. and Spizzichino A. [1987] Scattering of Electromagnetic Waves from Rough
Surfaces, Artech House.
868
Литература
Belhumeur Р. and Kriegman D. [1998] What is the set of images of an object under all
possible illumination conditions, International Journal of Computer Vision, 28(3),
pp. 245-260.
Belhumeur P., Kriegman D. and Yuille A. [1999] The bas-relief ambiguity, International
Journal of Computer Vision, 35(1), pp. 33-44.
Belongie S., Carson C., Greenspan H. and Malik J. [1998] Color- and texture-based image
segmentation using the expectation-maximization algorithm and its application to
content-based image retrieval, Proceedings, Sixth International Conference on Com-
puter Vision, 1998, pp. 675-682.
Berger M. [1987] Geometry, Springer-Verlag.
Bergholm F. [1987] Edge focusing, IEEE Trans. Pattern Analysis and Machine Intelligence,
9(6), pp. 726-741.
Bertero M., Poggio T. and Torre V. [1988] Ill-posed problems in early vision, Proceedings
of IEEE, 76(8), pp. 869-889.
Bertsekas D. [1995] Nonlinear Programming, Athena Scientific.
Berzins V. [1984] Accuracy of laplacian edge detectors, CVGIP: Image Understanding,
27(2), pp. 195-210.
Besl P. [1989] Active optical range imaging sensors, Machine vision and applications 1,
pp. 127-152.
Besl P. and Jain R. [1988] Segmentation through variable-order surface fitting, IEEE Trans.
Pattern Analysys and Machine Intelligence, 10(2), pp. 167-192.
Besl P. and McKay N. [1992] A method for registration of 3D shapes, IEEE Trans. Pattern
Analysys and Machine Intelligence, 14(2), pp. 239-256.
Beymer D. [1994] Face recognition under varying pose, IEEE Conference on Computer
Vision and Pattern Recognition, 1994, pp. 756-761.
Beymer D. and Poggio T. [1995] Face recognition from one example view, Proceedings,
Fifth International Conference on Computer Vision, 1995, pp. 500-507.
Beymer D., McLauchlan P., Coifman B. and Malik J. [1997] A real time computer vision
system for measuring traffic parameters, IEEE Conference on Computer Vision and
Pattern Recognition, 1997, pp. 495-501.
Biederman I. [1987] Recognition-by-components: A theory of human image understanding,
Psych. Review 94(2), pp. 115-147.
Binford T. [1971] Visual perception by computer, Proceedings, IEEE Conference on Systems
and Control.
Binford T. [1984] Stereo vision: complexity and constraints, International Symposium on
Robotics Research, MIT Press, pp. 475-487.
Bishop C. [1995] Neural Networks for Pattern Recognition, Oxford University Press.
Литература
869
Black М. and Anandan P. [1996] The robust estimation of multiple motions: Parametric
and piecewise-smooth flow-fields, Computer Vision and Image Understanding, 63(1),
pp. 75-104.
Blackman S. and Popoii R. [1999] Design and Analysis of Modern Tracking Systems,
Artech House.
Blake A. [1985] Boundary conditions for lightness computation in mondrian world, CVGIP:
Image Understanding, 32(3), pp. 314-327.
Blake A. and Marinos C. [1990] Shape from texture: estimation, isotropy and moments,
Artificial Intelligence, 45(3), pp. 323-380.
Blake A. and Zisserman A. [1987] Visual Reconstruction, MIT Press.
Blum H. [1967] A transformation for extracting new descriptors of shape, W. Wathen-
Dunn, ed., Models for perception of speech and visual form, MIT Press.
Boissonnat J.-D. [1984] Geometric structures for three-dimensional shape representation,
ACM Transaction on Computer Graphics, 3(4), pp. 266-286.
Boissonnat J.-D. and Germain F. [1981] A new approach to the problem of acquiring
randomly-oriented workpieces from a bin, Proceedings of the International Joint
Conference on Artificial Intelligence.
Bookstein F. [1979] Fitting conic sections to scattered data, Computer Graphics Image
Processing, 9(1), pp. 56-71.
Boult T. and Brown L. [1991] Factorization-based segmentation of motions, IEEE Workshop
on Visual Motion, pp. 179-186.
Bowyer K., Kranenburg C. and Dougherty S. [1999] Edge detector evaluation using empir-
ical roc curves, IEEE Conference on Computer Vision and Pattern Recognition, 1999,
pp. 1:354-359.
Boyer E. [1996] Object Models from Contour Sequences, Proceedings of Fourth European
Conference on Computer Vision, Cambridge, (England), pp. 109-118. Lecture Notes
in Computer Science, volume 1065.
Boyer E. and Berger M.-O. [1996] 3D surface reconstruction using occluding contours,
International Journal of Computer Vision.
Boyle W. and Smith G. [1970] Charge coupled semiconductor devices, Bell Systems Tech-
nical Journal, 49, pp. 587-593.
Bracewell R. [1995] Two-Dimensional Imaging, Prentice Hall.
Bracewell R. [2000] The Fourier Transform and Its Applications, 3ed, McGraw-Hill.
Brady J. and Asada H. [1984] Smoothed local symmetries and their implementation, Inter-
national Journal of Robotics Research.
Brady J., Ponce J., Yuille A. and Asada H. [1985a] Describing surfaces, Computer Vision,
Graphics and Image Processing, 32(1), pp. 1-28.
870
Литература
Brady J., Ponce J., Yuille A. and Asada H. [1985fr] Describing surfaces, H. Hanafusa and
H. Inoue, eds, Proceedings of the 2nd International Symposium on Robotics Research,
MIT Press, pp. 5-16.
Brainard D. and Wandel! B. [1986] Analysis of the retinex theory of color vision, Journal
of the Optical Society of America, 3, pp. 1651-1661.
Brand J. and Mason J. [2000] A comparative assessment of three approaches to pixel-
level human skin-detection, Proceedings of the International Conference on Pattern
Recognition, pp. Vol I: 1056-1059.
Brelstaff G. and Blake A. [1987] Computing lightness, Pattern Recognition Letters, 5,
pp. 129-138.
Brelstaff G. and Blake A. [1988] Detecting specular reflection using Lambertian con-
straints, Proceedings, Second International Conference on Computer Vision, 1988,
pp. 297-302.
Brill E. [1992] A simple rule-based part of speech tagger, Proceedings, Third Conference
on Applied Natural Language Processing.
Brooks R. [1981a] Symbolic reasoning among 3-D models and 2-D images, Artificial Intel-
ligence Journal, 17(1-3), pp. 285-348.
Brooks R. [19816] Symbolic Reasoning among 3-D Models and 2-D Images, PhD thesis,
Stanford University Computer Science Dept.
Brooks R., Greiner R. and Binford T. [1979] Model-based three-dimensional interpretation
of two-dimensional images, Proceedings of the International Joint Conference on
Artificial Intelligence, Tokyo, Japan, pp. 105-113.
Brostow G. and Essa I. [1999] Motion based decompositing of video, Proceedings, Seventh
International Conference on Computer Vision, 1999, pp. 8-13.
Bruce J., Giblin P. and Tari F. [1996a] Parabolic curves of evolving surfaces, International
Journal of Computer Vision, 17(3), pp. 291-306.
Bruce J., Giblin P. and Tari F. [19966] Ridges, crests and sub-parabolic lines of evolving
surfaces, International Journal of Computer Vision, 18(3), pp. 195-210.
Brunelli R. and Poggio T. [1992] Face recognition through geometrical features, pp. 792-800.
Brunelli R. and Poggio T. ]1993] Face recognition: Features versus templates, IEEE Trans.
Pattern Analysis and Machine Intelligence, 15(10), pp. 1042-1052.
Brunie L., Lavallee S. and Szeliski R. [1992] Using force fields derived from 3D distance
maps for inferring the attitude of a 3D rigid object, G. Sandini, ed., Proceedings,
European Conference on Computer Vision, Vol. 588 of Lecture Notes in Computer
Science, Springer-Verlag, pp. 670-675.
Brunnstrom K., Ekhlund J.-O. and Uhlin T. [1996] Active fixation for scene exploration,
International Journal of Computer Vision, 17(2), pp. 137-162.
Литература
871
Bubna К. and Stewart С. [2000] Model selection techniques and merging rules for range
data segmentation algorithms, Computer Vision and Image Understanding, 80(2),
pp. 215-245.
Buchsbaum G. [1980] A spatial processor model for object colour perception, J. Franklin
Inst. 310, pp. 1-26.
Biilthoff H., Tarr M., Blanz V. and Zabinski M. [1995] To what extent do unique parts
influence recognition across changes in viewpoint?, Perception, 24, p. 3.
Burl M. and Perona P. [1996] Recognition of planar object classes, IEEE Conference on
Computer Vision and Pattern Recognition, 1996, pp. 223-230.
Cabrera J. and Meer P. [1996] Unbiased estimation of ellipses by bootstrapping, IEEE
Trans. Pattern Analysis and Machine Intelligence, 18(7), pp. 752-756.
Callahan J. and Weiss R. [1985] A model for describing surface shape, Proceedings, IEEE
Conference on Computer Vision and Pattern Recognition, pp. 240-245.
Canny J. [1986] A computational approach to edge detection, IEEE Trans. Pattern Analysis
and Machine Intelligence, 8(6), pp. 679-698.
Canny J. [1988] The Complexity of Robot Motion Planning, MIT Press.
Carmichael O., Huber D. and Hebert M. [1999] Large data sets and confusing scenes
in 3-D surface matching and recognition, Second International Conference on 3-D
Digital Imaging and Modeling (3DIM99), pp. 358-367.
Carson C., Thomas M., Belongie S., Hellerstein J. and Malik J. [1999] Blobworld: A system
for region-based image indexing and retrieval, Third International Conference on Vi-
sual Information Systems, Lecture Notes in Computer Science 1614, Springer-Verlag,
pp. 509-516.
Cascia M. L., Sethi S. and Sclaroff S. [1998] Combining textual and visual cues for content
based image retrieval on the web, IEEE Workshop on Content Based Access of Image
and Video Libraries, pp. 24-28.
Castore G. [1984] Solid Modeling, Aspect Graphs, and Robot Vision, Pickett and Boyse,
eds, Solid modeling by computer, Plenum Press, pp. 277-292.
Chakravarty I. [1982] The use of characteristic views as a basis for recognition of three-
dimensional objects, Image Processing Laboratory IPL-TR-034, Rensselaer Polytech-
nic Institute.
Chang S. and Yang C. [1983] Picture information measures for similarity retrieval, CVGIP:
Image Understanding, 23, pp. 366-375.
Chang S.-F., Chen W. and Sundaram H. [1998a] Semantic visual templates — linking visual
features to semantics, IEEE International Conference Image Processing, pp. 531-535.
Chang S.-F., Chen W., Meng H., Sundaram H. and Zhong D. [1997a] Videoq — an au-
tomatic content-based video search system using visual cues, ACM Multimedia
Conference.
872
Литература
Chang S.-F., Chen W., Meng H., Sundaram H. and Zhong D. [19986] A fully automated
content based video search engine supporting spatiotemporal queries, IEEE Trans.
Circuits and Systems for Video Technology 8(8), pp. 602-615.
Chang S.-F., Smith J., Beigi M. and Benitez A. [19976] Visual information retrieval from
large distributed online repositories, Comm. ACM , 40(12), pp. 63-71.
Chapetle O.t Haffner P. and Vapnik V. [1999] Support vector machines for histogram-based
image classification, IEEE Neural Networks, 10(5), pp. 1055-1064.
Chasles M. [1855] Question no. 296, Nouv. Ann. Math.
Chellappa R. and Jain A. [1993] Markov Random Fields: Theory and Applications, Aca-
demic Press.
Chellappa R., Wilson C. and Sirohey S. [1995] Human and machine recognition of faces: a
survey, Proceedings IEEE, 83(5), pp. 705-740.
Chen S. [1995] Quicktime VR: An image-based approach to virtual environment navigation,
SIGGRAPH, pp. 29-38.
Chen S. and Freeman H. [1991] On the characteristic views of quadric-surfaced solids,
IEEE Workshop on Directions in Automated CAD-Based Vision, pp. 34-43.
Chin R. and Dyer C. [1986] Model-based recognition in robot vision, ACM Computing
Surveys, 18(1), pp. 67-108.
Chiyokura B. and Kimura F. [1983] Design of solids with free-form surfaces, Computer
Graphics, 17(3), pp. 289-298.
Cho K., Meer P. and Cabrera J. [1997] Performance assessment through bootstrap, IEEE
Trans. Pattern Analysis and Machine Intelligence, 19(11), pp. 1185-1198.
Cho K., Meer P. and Cabrera J. [1998] Performance assessment through bootstrap, IEEE
Trans. Pattern Analysis and Machine Intelligence, 20(1), p. 94.
Christy S. and Horaud R. [1996] Euclidean shape and motion from multiple perspective
views by affine iterations, IEEE Trans. Pattern Analysys and Machine Intelligence,
18(11), pp. 1098-1104.
Chua C. and Jarvis R. [1996] Point signatures: a new representation for 3D object recog-
nition, International Journal of Computer Vision, 25(1), pp. 63-85.
Chui C. [1991] Kalman Filtering: With Real-Time Applications, Springer-Verlag.
Cipolla R. and Blake A. [1992] Surface shape from the deformation of the apparent contour,
International Journal of Computer Vision, 9(2), pp. 83-112.
Cipolla R., Astrom K. and Giblin P. [1995] Motion from the frontier of curved surfaces,
Proceedings of the International Conference on Computer Vision, pp. 269-275.
Clarkson K. [1988] A randomized algorithm for closest-point queries, SIAM J. Computing,
17, pp. 830-847.
Clerc M. and Mallat S. [1999] Shape from texture through deformations, International
Conference on Computer Vision, pp. 405-410.
Литература
873
Clowes М. [1971} On seeing things, Artificial Intelligence, 2(1), pp. 79-116.
Cohen J. [1964] Dependency of the spectral reflectance curves of the munsell color chips,
Psychon. Science, 1, pp. 369-370.
Cohen M. and Wallace J. [1993] Radiosity and realistic image synthesis. Academic Press.
Collins G. [1971] The calculation of multivariate polynomial resultants, Journal of the
ACM, 18(4), pp. 515-522.
Collins G. [1975] Quantifier Elimination for Real Closed Fields by Cylindrical Algebraic
Decomposition, Vol. 33 of Lecture Notes in Computer Science, Springer-Verlag, New
York.
Connolly C. and Stenstrom J. [1989] 3D scene reconstruction from multiple intensity im-
ages, Proceedings, IEEE Workshop on Interpretation of 3D Scenes, pp. 124-130.
Cook R. and Torrance K. [1987] A reflectance model for computer graphics, ARPA Image
Understanding Workshop, pp. 1-19.
Costeira J. and Kanade T. [1998] A multi-body factorization method for motion analysis,
International Journal of Computer Vision, 29(3), pp. 159-180.
Cover T. and Thomas J. [1991] Elements of Information Theory, Wiley-Interscience.
Cox I., Zhong Y. and Rao S. [1996] Ratio regions: A technique for image segmentation,
Proceedings of the International Conference on Pattern Recognition, pp. 557-564.
Coxeter H. [1974] Projective Geometry, Springer-Verlag. Second edition.
Craig J. [1989] Introduction to Robotics: Mechanics and Control, Addison-Wesley. Second
edition.
Cross G. and Jain A. [1983] Markov random field texture models, IEEE Trans. Pattern
Analysis and Machine Intelligence, 5(1), pp. 25-39.
Cross G., Fitzgibbon A. and Zisserman A. [1999] Parallax geometry of smooth surfaces
in multiple views, Proceedings of the International Conference on Computer Vision,
pp. 323-329.
Csurka G. and Faugeras O. [1998] Computing 3-Dimensional project invariants from a pair
of images using the grassmann-cayley algebra. Image and Vision Computing, 16(1),
pp. 3-12.
Csurka G. and Faugeras O. [1999] Algebraic and geometric tools to compute projective
and permutation invariants, IEEE Trans. Pattern Analysis and Machine Intelligence,
21(1), pp. 58-65.
Curless B. and Levoy M. [1996] A volumetric method for building complex models from
range images, SIGGRAPH.
Darrell T. and Simoncelli E. [1993] ‘Nulling’ filters and the separation of transpar-
ent motions, IEEE Conference on Computer Vision and Pattern Recognition, 1993,
pp. 738-739.
874
Литература
Davis L. [1975] A survey of edge detection techniques, Computer Graphics Image Process-
ing, 4(3), pp. 248-270.
de Bonet J. and Viola P. [1997] Rosetta: An image database retrieval system, Proceedings,
DARPA IU Workshop, pp. 655-660.
Debevec P., Taylor C. and Malik J. [1996] Modeling and rendering architecture from
photographs: a hybrid geometry- and image-based approach, SIGGRAPH, pp. 11-20.
Dellaert F., Seitz S., Thorpe C. and Thrun S. [2000] Structure from motion without cor-
respondence, IEEE Conference on Computer Vision and Pattern Recognition, 2000,
pp. 11:557-564.
Demazure M. [2000] Bifurcations and Catastrophes, Springer-Verlag. Translated by
D. Chillingworth.
Dempster A., Laird N. and Rubin D. [1977] Maximum likelihood from incomplete data via
the EM algorithm, Journal of the Royal Statistical Society 39 (Series B), pp. 1-38.
Deriche R. [1987] Using Canny’s criteria to derive a recursively implemented optimal edge
detector, International Journal of Computer Vision, 1(2), pp. 167-187.
Deriche R. [1990] Fast algorithms for low-level vision, IEEE Trans. Pattern Analysis and
Machine Intelligence, 12(1), pp. 78-87.
Devernay F. and Faugeras O. [1994] Computing differential properties of 3D shapes from
stereopsis without 3D models, Proceedings, IEEE Conference on Computer Vision
and Pattern Recognition, pp. 208-213.
Devroye L., Gyorfi L. and Lugosi G. [1996] A Probabilistic Theory of Pattern Recognition,
Springer Verlag.
Devy M., Garric V. and Orteu J. [1997] Camera calibration from multiple views of a
2D object using a global non-linear minimization method, IEEE/RSJ International
Conference on Intelligent Robots and Systems, pp. 1583-1589.
do Carmo M. [1976] Differential Geometry of Curves and Surfaces, Prentice-Hall.
Dougherty S. and Bowyer K. [1998] Objective evaluation of edge detectors using a formally
defined framework, Workshop on Empirical Evaluation Methods in Computer Vision.
Dove H. [1841] Uber stereoskopie, Annals Phys. Series 2 110, pp. 494-498.
Drew M. and Funt B. [1990] Calculating surface reflectance using a single-bounce model of
mutual reflection, Proceedings, Third International Conference on Computer Vision,
1990, pp. 393-399.
Driscoll W. and Vaughan W., eds [1978] Handbook of Optics, McGraw-Hill.
Duda R. and Hart P. [1973] Pattern Classification and Scene Analysis, Wiley.
Duncan J. and Ayache N. [2000] Medical image analysis: Progress over two decades and
the challenges ahead, IEEE Trans. Pattern Analysis and Machine Intelligence, 22(1),
pp. 85-106.
Литература
875
D’Zmura М. and Lennie P. [1986] Mechanisms of colour constancy, Journal of the Optical
Society of America - A 3, pp. 1662-1672.
Eakins J., Boardman J. and Graham M. [1998] Similarity retrieval of trademark images,
IEEE Multimedia 5(2), pp. 53-63.
Ebert D. S., Musgrave F. K., Peachey D., Worley S. and Perlin K., eds [1998] Texturing
and Modeling, Morgan Kaufmann.
Efros A. and Leung T. [1999] Texture synthesis by поп-parametric sampling, Proceedings,
Seventh International Conference on Computer Vision, 1999, pp. 1033-1038.
Eggert D. and Bowyer K. [1989] Computing the orthographic projection aspect graph of
solids of revolution, Proceedings, IEEE Workshop on Interpretation of 3D Scenes,
pp. 102-108.
Eggert D. and Bowyer K. [1991] Perspective projection aspect graphs of solids of revolution:
An implementation, IEEE Workshop on Directions in Automated CAD-Based Vision,
pp. 44-53.
Eggert D., Bowyer K., Dyer C., Christensen H. and Goldgof D. [1993] The scale space as-
pect graph, IEEE Trans. Pattern Analysys and Machine Intelligence, 15(11), pp. 1114-
1130.
Elder J. and Zucker S. [1998] Local scale control for edge detection and blur estimation,
IEEE Trans. Pattern Analysis and Machine Intelligence, 20(7), pp. 699-716.
Enser P. [1993] Query analysis in a visual information retrieval context, J. Document and
Text Management 1(1), pp. 25-52.
Enser P. [1995] Pictorial information retrieval, Journal of Documentation 51(2), pp. 126-170.
Ettinger G. [1988] Large hierarchical object recognition using libraries of parameterized
model sub-parts, IEEE Conference on Computer Vision and Pattern Recognition,
1988, pp. 32-41.
Fairchild M. [1998] Color Appearance Models, Addison-Wesley.
Fan T., Medioni G. and Nevatia R. [1987] Segmented descriptions of 3D surfaces, IEEE
Transactions on Robotics and Automation 3(6), pp. 527-538.
Farin G. [1993] Curves and Surfaces for Computer Aided Geometric Design, Academic
Press, San Diego, CA.
Faugeras O. [1992] What can be seen in three dimensions with an uncalibrated stereorig?,
G. Sandini, ed., Proceedings, European Conference on Computer Vision, Vol. 588 of
Lecture Notes in Computer Science, Springer-Verlag, pp. 563-578.
Faugeras O. [1993] Three-Dimensional Computer Vision, MIT Press.
Faugeras O. [1995] Stratification of 3D vision: projective, affine and metric representations,
Journal of the Optical Society of America A 12(3), pp. 465-484.
Faugeras O. and Hebert M. [1986] The representation, recognition, and locating of 3-D
objects, International Journal of Robotics Research 5(3), pp. 27-52.
876
Литература
Faugeras О. and Maybank S. [1990] Motion from point matches: multiplicity of solutions.
International Journal of Computer Vision, 4(3), pp. 225-246.
Faugeras O. and Mourrain B. [1995] On the geometry and algebra of the point and line
correspondences between n images. Technical Report 2665, INRIA Sophia-Antipolis.
Faugeras O. and Papadopoulo T. [1997] Gaussman-Caylay algebra for modeling systems of
cameras and the algebraic equations of the manifold of trifocal tensors, Technical
Report 3225, INRIA Sophia-Antipolis.
Faugeras O., Hebert M., Pauchon E. and Ponce J. [1984] Object representation, identifi-
cation, and positioning from range data, Robotics Research: The First International
Symposium, MIT Press, pp. 425-446.
Faugeras O., Luong Q.-T. and Papadopoulo T. [2001] The Geometry of Multiple Images,
MIT Press.
Felzenszwalb P. and Huttenlocher D. [2000] Efficient matching of pictorial structures,
IEEE Conference on Computer Vision and Pattern Recognition, 2000, pp. 11:66-73.
Feng X. and Perona P. [1998] Scene segmentation from 3D motion, IEEE Conference on
Computer Vision and Pattern Recognition, 1998, pp. 225-231.
Ferryman J., Maybank S. and Worrall A. [2000] Visual surveillance for moving vehicles,
International Journal of Computer Vision, 37(2), pp. 187-197.
Finlayson G. and Hordley S. [1999] Selection for gamut mapping colour constancy, Image
and Vision Computing, 17(8), pp. 597-604.
Finlayson G. and Hordley S. [2000] Improving gamut mapping color constancy, IEEE
Trans. Image Processing, 9(10), pp. 1774-1783.
Finlayson G., Chatterjee S. and Funt B. [1996] Color angular indexing, European Confer-
ence on Computer Vision, 1996, pp. 11:16-27.
Finlayson G., Drew M. and Funt B. [1994a] Color constancy: Generalized diagonal trans-
forms suffice, Journal of the Optical Society of America, 11(11), pp. 3011-3019.
Finlayson G., Drew M. and Funt B. (19946] Spectral sharpening: Sensor transforma-
tions for improved color constancy, Journal of the Optical Society of America, 11(5),
pp. 1553-1563.
Fischler M. and Bolles R. [1981] Random sample consensus: A paradigm for model fitting
with applications to image analysis and automated cartography, Communications
of the ACM, 24(6), pp. 381-395.
Fitzgibbon A. and Zisserman A. [1998] Automatic 3D model acquisition and genera-
tion of new images from video sequences, European Signal Processing Conference,
pp. 311-326.
Fleck M. [1992a] Multiple widths yield reliable finite differences, IEEE Trans. Pattern
Analysis and Machine Intelligence, 14(4), pp. 412-429.
Литература 877
Reck М. [1992&] Some defects in finite-difference edge finders, IEEE Trans. Pattern Anal-
ysis and Machine Intelligence, 14(3), pp. 337-345.
Fleck M. [1995] Cs~tr 95-01: Perspective projection: the wrong imaging model, Technical
report, University of Iowa.
Fleck M., Forsyth D. and Bregler C. [1996] Finding naked people, European Conference
on Computer Vision, 1996, pp. 11:593-602.
Flickner M., Sawhney H., Niblack W. and Ashley J. [1995] Query by image and video
content: the QB1C system, Computer 28(9), pp. 23-32.
Flock H. [1984] Illumination: inferred or observed?, Perception and Psychophysics.
Foley J., van Dam A., Feiner S. and Hughes J. [1990] Computer Graphics: Principle and
Practice, Addison-Wesley. Second edition.
Forney G. [1973] The Viterbi algorithm. Proceedings of the IEEE.
Forsyth D. [1990] A novel approach to color constancy, International Journal of Computer
Vision, 5(1), pp. 5-36.
Forsyth D. [1996] Recognizing algebraic surfaces from their outlines, International Journal
of Computer Vision, 18(1), pp. 21-40.
Forsyth D. [1999] Sampling, resampling and colour constancy, IEEE Conference on Com-
puter Vision and Pattern Recognition, 1999, pp. 1:300-305.
Forsyth D. and Fleck M. [1997] Body plans, IEEE Conference on Computer Vision and
Pattern Recognition, 1997, pp. 678-683.
Forsyth D. and Fleck M. [1999] Automatic detection of human nudes, International Journal
of Computer Vision, 32(1), pp. 63-77.
Forsyth D. and Zisserman A. [1989] Mutual illumination, IEEE Conference on Computer
Vision and Pattern Recognition, 1989, pp. 466-473.
Forsyth D. and Zisserman A. [1990] Shape from shading in the light of mutual illumination,
Image and Vision Computing, 8, pp. 42-29.
Forsyth D. and Zisserman A. [1991] Reflections on shading, IEEE Trans. Pattern Analysis
and Machine Intelligence, 13(7), pp. 671-679.
Forsyth D., Mundy J., Zisserman A. and Rothwell C. [1992] Recognizing rotationally
symmetric surfaces from their outlines, pp. 639-647.
Forsyth D., Mundy J., Zisserman A. and Rothwell C. [1994] Using global consistency
to recognise euclidean objects with an uncalibrated camera, IEEE Conference on
Computer Vision and Pattern Recognition, 1994, pp. 502-507.
Forsyth D., Mundy J., Zisserman A., Coelho C., Heller A. and Rothwell C. [1991] Invariant
descriptors for 3-D object recognition and pose, IEEE Trans. Pattern Analysis and
Machine Intelligence, 13(10), pp. 971-991.
Freeman W. and Adelson E. [1991] The design and use of steerable filters, IEEE Trans.
Pattern Analysis and Machine Intelligence, 13(9), pp. 891-906.
878
Литература
Freeman W. and Brainard D. [1997] Bayesian color constancy, Journal of the Optical
Society of America, 14(7), pp. 1393-1411.
Freeman W., Anderson D. [1998] Computer vision for interactive computer graphics, Com-
puter Graphics and Applications, pp. 42-53.
Freeman W., Pasztor E. and Carmichael O. [2000] Learning low-level vision, International
Journal of Computer Vision, 40(1), pp. 25-47.
Friedman J., Bentley J. and Finkel R. [1977] An algorithm for finding best matches in
logarithmic expected time, ACM Trans, on Math. Software.
Frisby J. [1980] Seeing: Illusion, Brain and Mind, Oxford University Press.
Fu K. and Mui J. [1981] A survey of image segmentation, Pattern Recognition 13(1),
pp. 3-16.
Fukunaga K. [1990] Introduction to Statistical Pattern Recognition, Academic Press.
Second ed.
Funt B. and Drew M. [1988] Color constancy computation in near-mondrian scenes using
a finite dimensional linear model, IEEE Conference on Computer Vision and Pattern
Recognition, 1988, pp. 544-549.
Funt B. and Drew M. [1993] Color space analysis of mutual illumination, IEEE Trans.
Pattern Analysis and Machine Intelligence, 15(12), pp. 1319-1326.
Funt B. and Finlayson G. [1995] Color constant color indexing, IEEE Trans. Pattern Anal-
ysis and Machine Intelligence, 17(5), pp. 522-529.
Funt B., Barnard K. and Martin L. [1998] Is machine colour constancy good enough?,
European Conference on Computer Vision, 1998, pp. 445-459.
Funt B., Drew M. and Ho J. [1991] Color constancy from mutual reflection, International
Journal of Computer Vision, 6(1), pp. 5-24.
Garcia-Bermejo J., Diaz Pernas F. and Coronado J. [1996] An approach for determining
bidirectional reflectance parameters from range and brightness data, Proceedings of
the International Conference on Image Processing, P. 16A2.
Garding J. [1992] Shape from texture for smooth curved surfaces, European Conference on
Computer Vision, pp. 630-638.
Garding J. [1995] Surface orientation and curvature from differential texture distortion,
International Conference on Computer Vision, pp. 733-739.
Gaston P. and Lozano-Perez T. [1984] Tactile recognition and localization using object
models: The case of polyhedra in the plane, IEEE Trans. Pattern Analysys and
Machine Intelligence
Gear C. [1998] Multibody grouping in moving objects, International Journal of Computer
Vision, 29(2), pp. 133-150.
Литература
879
Gene Y. and Ponce J. [1998] Parameterized image varieties: A novel approach to the anal-
ysis and synthesis о/ image sequences, Proceedings of the International Conference
on Computer Vision, pp. 11-16.
Gene Y. and Ponce J. [2001] Image-based rendering using parameterized image varieties,
International Journal of Computer Vision, 41(3), pp. 143-170.
Gennery D. [1980] Modelling the environment of an exploring vehicle by means of stereo
vision, PhD thesis, Stanford University.
Georghiades A., Belhumeur P. and Kriegman D. [2000] From few to many: Generative mod-
els for recognition under variable pose and illumination, International Conference
on Automatic Face and Gesture Recognition, 2000, pp. 277-284.
Georghiades A., Kriegman D. and Belhumeur P. [1998] Illumination cones for recognition
under variable lighting: Faces, IEEE Conference on Computer Vision and Pattern
Recognition, 1998, pp. 52-59.
Gerig G., Pun T. and Ratib O. [1994] Image analysis and computer vision in medicine,
Computerized Medical Imaging and Graphics 18(2), pp. 85-96.
Gersho A. and Gray R. [1992] Vector quantization and signal compression, Kluwer Aca-
demic Publishers.
Gershon R. [1987] The Use of Color in Computational Vision, PhD thesis, University of
Rochester.
Gershon R., Jepson A. and Tsotsos J. [1986] Ambient illumination and the determination of
material changes, Journal of the Optical Society of America A-3(10), pp. 1700-1707.
Giblin P. and Kimia B. [1999] On the local form and transitions of symmetry sets, medial
axes, and shocks, Proceedings, Seventh International Conference on Computer Vision,
1999, pp. 385-391.
Gigus Z. and Malik J. [1990] Computing the aspect graph for line drawings of polyhedral
objects, IEEE Trans. Pattern Analysys and Machine Intelligence, 12(2), pp. 113-122.
Gigus Z., Canny J. and Seidel R. [1991] Efficiently computing and representing aspect
graphs of polyhedral objects, IEEE Trans. Pattern Analysys and Machine Intelligence,
Gilchrist A., Kossyfidis C., Bonato F., Agostini T., Cataliotti J., Li X., Spehar B., Annan V.
and Economou E. [1999] An anchoring theory of lightness perception, Psychological
Review 106(4), pp. 795-834.
Gill P., Murray W. and Wright M. [1981] Practical Optimization, Academic Press.
Gordon I. [1997] Theories of Visual Perception, John Wiley and Son.
Gortler S., Grzeszczuk R., Szeliski R. and Cohen M. [1996] The lumigraph, SIGGRAPH,
pp. 43-54.
Greenspan H., Belongie S., Perona P., Goodman R., Rakshit S. and Anderson C. [1994]
Overcomplete steerable pyramid filters and rotation invariance, IEEE Conference on
Computer Vision and Pattern Recognition, 1994, pp. 222-228.
880
Литература
Grimson W. [1981a] A computer implementation of a theory of human stereo vision
Philosophical Transactions of the Royal Society of London, pp. 217-253.
Grimson W. [1981b] From images to surfaces: A Computational Study of the Human Early
Visual System, MIT Press.
Grimson W. [1992] The cost of choosing the wrong model in object recognition by con-
strained search, International Journal of Computer Vision, 7(3), pp. 195-210.
Grimson W. and Huttenlocher D. (1990a] On the sensitivity of geometric hashing, Pro-
ceedings, Third International Conference on Computer Vision, 1990, pp. 334-338.
Grimson W. and Huttenlocher D. [1990b] On the sensitivity of the Hough transform for
object recognition, IEEE Trans. Pattern Analysis and Machine Intelligence, 12(3),
pp. 255-274.
Grimson W. and Huttenlocher D. [1991] On the verification of hypothesized matches in
model-based recognition, IEEE Trans. Pattern Analysis and Machine Intelligence,
13(12), pp. 1201-1213.
Grimson W. and Lozano-Perez T. [1984] Model-based recognition and localization from
sparse range or tactile data, International Journal of Robotics Research 3(3),
pp. 3-35.
Grimson W. and Lozano-Perez T. [1987] Localizing overlapping parts by searching the
interpretation tree, IEEE Trans. Pattern Analysys and Machine Intelligence, 9(4),
pp. 469-482.
Grimson W., Huttenlocher D. and Alter T. [1992] Recognizing 3D objects from 2D images:
An error analysis, IEEE Conference on Computer Vision and Pattern Recognition,
1992, pp. 316-321.
Grimson W., Huttenlocher D. and Jacobs D. (1994] A study of affine matching with bounded
sensor error. International Journal of Computer Vision, 13(1), pp. 7-32.
Grimson W., Lozano-Perez T. and Huttenlocher D. [1990] Object Recognition by Computer:
The Role of Geometric Constraints, MIT Press.
Gross A. and Boult T. [1988] Error of fit measures for recovering parametric solids,
Proceedings of the International Conference on Computer Vision, pp. 690-694.
Haddon J. and Forsyth D. [1998a] Shading primitives: Finding folds and shallow grooves,
Proceedings, Sixth International Conference on Computer Vision, 1998, pp. 236-241.
Haddon J. and Forsyth D. [1998b] Shape representations from shading primitives, European
Conference on Computer Vision, 1998, pp. 415-431.
Hamilton W. (1844] On a new species of imaginary quantities connected with a theory of
quaternions, Transactions of the Royal Irish Academy 2, pp. 424-434.
Hampapur A., Gupta A., Horowitz B. and Shu C.-F. [1997] Virage video engine, Storage and
Retrieval for Image and Video Databases V — Proceedings of the SPIE, Vol. 3022,
pp. 188-198.
Литература
881
Haralick R. [1983] Ridges and valleys in digital images, Computer Vision, Graphics and
Image Processing, 22, pp. 28-38.
Haralick R. and Shapiro L. [1985] Image segmentation techniques, CVGIP: Image Under-
standing, 29(1), pp. 100-132.
Haralick R. and Shapiro L. [1992] Computer and robot vision, Addison Wesley.
Haralick R., Watson L. and Laffey T. [1983] The topographic primal sketch, International
Journal of Robotics Research 2, pp. 50-72.
Hardin C. and Maffi L. [1997] Color Categories in thought and language, Cambridge
University Press.
Harris C. and Stephens M. {1988] A combined corner and edge detector, Alvey Conference,
pp. 147-152.
Hartley R. [1994a] An algorithm for self calibration from several views, Proceedings, IEEE
Conference on Computer Vision and Pattern Recognition, pp. 908-912.
Hartley R. [19946] Projective reconstruction and invariants from multiple images, IEEE
Trans. Pattern Analysys and Machine Intelligence, 16(10), pp. 1036-1041.
Hartley R. [1995] In defence of the 8-point algorithm, Proceedings of the International
Conference on Computer Vision, pp. 1064-1070.
Hartley R. [1997] Lines and points in three views and the trifocal tensor, International
Journal of Computer Vision, 22(2), pp. 125-140.
Hartley R. [1998] Computation of the quadrifocal tensor, Proceedings, European Conference
on Computer Vision, pp. 20-35.
Hartley R. and Sturm P. [1997] Triangulation, Computer Vision and Image Understanding,
68(2), pp. 146-157.
Hartley R. and Zisserman A. [2000] Multiple view geometry in computer vision, Cambridge
University Press.
Hartley R., Gupta R. and Chang T. [1992] Stereo from uncalibrated cameras, Proceedings,
IEEE Conference on Computer Vision and Pattern Recognition, pp. 761-764.
Hartley R., Wang C., Kitchen L. and Rosenfeld A. [1982] Segmentation of FLIR images:
A comparative study, IEEE Trans. Systems, Man and Cybernetics 12(4), pp. 553-566.
Hastie T., Tibshirani R. and Friedman J. [2001] The Elements of Statistical Learning: Data
Mining, Inference and Prediction, Springer Verlag.
Havaldar P., Lee M. and Medioni G. [1996] View synthesis from unregistered 2D images,
Graphics Interface’96, pp. 61-69.
Haykin S. [1999] Neural Networks: A Comprehensive Introduction, Prentice-Hall.
Healey G. and Kondepudy R. [1994] Radiometric CCD camera calibration and noise esti-
mation, IEEE Trans. Pattern Analysys and Machine Intelligence, 16(3), pp. 267-276.
Heath M. [2002] Scientific Computing: An Introductory Survey, McGraw-Hill. Second
edition.
882
Литература
Heath М., Sarkar S., Sanocki T. and Bowyer K. [1997} A robust visual method for assessing
the relative performance of edge detection algorithms, IEEE Trans. Pattern Analysis
and Machine Intelligence, 19(12), pp. 1338-1359.
Hebert M. [2000] Active and passive range sensing for robotics, IEEE International Con-
ference on Robotics and Automation.
Hebert M. and Kanade T. [1985] The 3D profile method for object recognition, Proceedings,
IEEE Conference on Computer Vision and Pattern Recognition, pp. 458-463.
Hecht E. [1987] Optics, Addison-Wes ley.
Hel-Or Y. and Teo P. [1996] Canonical decomposition of steerable functions, IEEE Confer-
ence on Computer Vision and Pattern Recognition, 1996, pp. 809-816.
Helmholtz H. [1909] Physiological Optics, Dover. 1962 edition of the English translation of
the 1909 German original, first published by the Optical Society of America in 1924.
Helson H. [1934] Some factors and implications of colour constancy, Journal of the Optical
Society of America 48, pp. 555-567.
Helson H. [1938a] Fundamental problems in color vision, I, Journal of Experimental Psy-
chology, Vol. 23.
Helson H. [19386] Fundamental problems in color vision, II, Journal of Experimental Psy-
chology, Vol. 26.
Herskovits A. and Binford T. [1970] On boundary detection, Technical report, MIT Al Lab.
Hesse O. [1863] Die cubische Gleichung, von welcher die Ltisung des Problems der Homo-
graphie von M. Chasles abhdngt, J. Reine Angew. Math. 62, pp. 188-192.
Heyden A. [1995] Geometry and algebra of multiple projective transformations, PhD thesis,
Lund University, Sweden.
Heyden A. [1998] A common framework for multiple view tensors, Proceedings, European
Conference on Computer Vision, pp. 3-19.
Heyden A. and Astrom K. [1996] Euclidean reconstruction from constant intrinsic param-
eters, International Conference on Pattern Recognition, pp. 339-343.
Heyden A. and Astrom K. [1998] Minimal conditions on intrinsic parameters for Euclidean
reconstruction, Asian Conference on Computer Vision.
Heyden A. and Astrom K. [1999] Flexible calibration: minimal cases for auto-calibration,
Proceedings of the International Conference on Computer Vision, pp. 350-355.
Hilbert D. and Cohn-Vbssen S. [1952] Geometry and the Imagination, Chelsea.
Holst G. [1998] CCD Arrays, Cameras and Displays, SPIE Press.
Holt B. and Hartwick L. [1994a] “Quick, who painted fish?”: searching a picture database
with the QBIC project at UC Davis, Information Services and Use 14(2), pp. 79-90.
Holt B. and Hartwick L. [19946] Retrieving art images by image content: the UC Davis
QBIC project, ASLIB Proceedings, Vol. 46, pp. 243-238.
Литература
883
Horn В. [1970] Shape from shading: A method for obtaining the shape of a smooth opaque
object from one view, Technical report, MIT Al Lab.
Horn B. [1971] The Binford-Horn line finder, Technical report, MIT Al Lab.
Horn B. [1974] Determining lightness from an image, Computer Graphics Image Processing,
3(1), pp. 277-299.
Horn B. [1975] Obtaining shape from shading information, The Psychology of Computer
Vision, McGraw-Hill, pp. 115-155.
Horn B. [1977] Understanding image intensities, Artificial Intelligence, 8(2), pp. 201-231.
Horn B. [1984] Extended Gaussian images, Proceedings of the IEEE, 72(12), pp. 1671-1686..
Horn B. [1986] Robot Vision, MIT Press, Cambridge, MA.
Horn B. [1987] Closed-form solution of absolute orientation using unit quaternions, Journal
of the Optical Society of America A 4(4), pp. 629-642.
Horn B. [1990] Height and gradient from shading, International Journal of Computer Vision,
5(1), pp. 37-76.
Horn B. and Brooks M. (1989] Shape from Shading, MIT Press.
Horn B. and Schunck B. [1981] Determining optical flow, Artificial Intelligence, 17,
pp. 185-203.
Horn B., Woodham R. and Silver W. [1978] Determining shape and reflectance using
multiple images, Technical report, MIT Al Lab.
Hsu S., Anandan P. and Peleg S. [1994] Accurate computation of optical flow by using lay-
ered motion representations, Proceedings of the International Conference on Pattern
Recognition, pp. A:743-746.
Huang J. and Zabih R. [1998] Combining color and spatial information for content-based
image retrieval, European Conference on Digital Libraries. Web version at http://
www.cs.cornell.edu/html/rdz/Papers/ECDL2/spatial.htm.
Huang J., Kumar S., Mitra M., Zhu W.-J. and Zabih R. [1997] Image indexing using
color correlograms, IEEE Conference on Computer Vision and Pattern Recognition,
pp. 762-768.
Huang T. [1981] Image Sequence Analysis, Springer-Verlag.
Huang T. and Faugeras O. [1989] Some properties of the E-matrix in two-view mo-
tion estimation, IEEE Trans. Pattern Analysys and Machine Intelligence, 11(12),
pp. 1310-1312.
Huber P. [1981] Robust Statistics, Wiley.
Hueckel M. [1971] An operator which locates edges in digitized pictures, Journal of the
ACM, 18(1), pp. 113-125.
Huffman D. [1977] Realizable configurations of lines in pictures of polyhedra, Machine
Intelligence, 8, pp. 493-509.
884
Литература
Huttenlocher D. and Ullman S. (1987J Object recognition using alignment, Proceedings of
the International Journal of Computer Vision, 8(1), pp. 7-27.
Ikeuchi K. [1987a] Determining a depth map using a dual photometric stereo, International
Journal of Robotics Research.
Ikeuchi K. [1987b] Precompiling a geometrical model into an interpretation tree for object
recognition in bin-picking tasks, Proceedings, DARPA Image Understanding Work-
shop, pp. 321-339.
Ikeuchi K. and Kanade T. [1988] Automatic generation of object recognition programs,
Proceedings of the IEEE, 76(8), pp. 1016-35.
Ioffe S. and Forsyth D. [1998] Learning to find pictures of people, NIPS.
Ioffe S. and Forsyth D. [1999] Finding people by sampling, Proceedings, Seventh Interna-
tional Conference on Computer Vision, 1999, pp. 1092-1097.
Irani M., Anandan P., Bergen J., Kumar R. and Hsu S. [1996] Mosaic representations of
video sequences and their applications, Signal Processing: Image Communication.
Jacobs C., Finkelstein A. and Salesin D. [1995] Fast multiresolution image querying, Proc
SIGGRAPH-95, pp. 277-285.
Jacobs D., Belhumeur P. and Basri R. [1998] Comparing images under variable illu-
mination, IEEE Conference on Computer Vision and Pattern Recognition, 1998,
pp. 610-617.
Jacobsen A. and Gilchrist A. [1988] The ratio principle holds over a million-to-one range
of illumination, Perception and Psychophysics 43, pp. 1-6.
Jain A. and Vailaya A. [1998] Shape-based retrieval: a case study with trademark image
databases, Pattern Recognition 31(9), pp. 1369-1390.
Janesick J., Elliott T., Collins S., Blouke M. and Freeman J. [1987] Scientific charge-coupled
devices, Optical Engineering, 26, pp. 692-714.
Jarvis R. [1983] A perspective on range finding techniques in computer vision, IEEE Trans.
Pattern Analysys and Machine Intelligence, 5(2), pp. 122-139.
Jelinek F. [1999] Statistical Methods for Speech Recognition (Language, Speech and Com-
munication), MIT Press.
Jepson A. and Black M. [1993] Mixture models for optical flow computation, IEEE Con-
ference on Computer Vision and Pattern Recognition, 1993, pp. 760-761.
Johnson A. and Hebert M. [1998] Surface matching for object recognition in complex
three-dimensional scenes, Image and Vision Computing, 16, pp. 635-651.
Johnson A. and Hebert M. [1999] Using spin images for efficient object recognition in
cluttered 3D scenes, IEEE Trans. Pattern Analysys and Machine Intelligence, 21(5),
pp. 433-449.
Jones M. and Rehg J. [1999] Statistical color models with application to skin detection,
IEEE Conference on Computer Vision and Pattern Recognition, 1999, pp. 1:274-280.
Литература
885
Joshi Т., Ahuja N. and Ponce J. [1999] Structure and motion estimation from dynamic
silhouettes under perspective projection, International Journal of Computer Vision,
31(1), pp. 31-50.
Judd D. [1940] Hue, saturation and lightness of surface colors with chromatic illumination,
Journal of the Optical Society of America, 30(1), pp. 2-32.
Julesz B. [1960] Binocular depth perception of computer-generated patterns, The Bell
System Technical Journal 39(5), pp. 1125-1162.
Julesz B. [1971] Foundations of Cyclopean Perception, The University of Chicago Press.
Julez B. [1959] A method of coding tv signals based on edge detection, The Bell System
Technical Journal, 38(4), pp. 1001-1020.
Kakarala R. and Hero A. [1992] On achievable accuracy in edge localization, IEEE Trans.
Pattern Analysis and Machine Intelligence, 14(7), pp. 777-781.
Kanade T. [1973] Picture processing by computer complex and recognition of human faces,
Technical report, Kyoto University, Dept, of Information Science.
Kanade T. [1981] Recovery of the three-dimensional shape of an object from a single view,
Artificial Intelligence Journal, 17, pp. 409-460.
Kanade T., Rander P. and Narayanan J. [1997] Virtualized reality: Constructing virtual
worlds from real scenes, IEEE Multimedia 4(1), pp. 34-47.
Kanatani K. [1998] Geometric information criterion for model selection, International Jour-
nal of Computer Vision, 26(3), pp. 171-189.
Kanizsa G. [1976] Subjective contours, Scientific American.
Kanizsa G. [1979] Organization in Vision: Essays on Gestalt Perception, Praeger.
Karasaridis A. and Simoncelli E. [1996] A filter design technique for steerable pyramid im-
age transforms, International Conference on Acoustics, Speech and Signal Processing,
pp. 2387-2390.
Kato T. and Fujimura K. [1990] Trademark: Multimedia image database system with
intelligent human interface, Systems and Computers in Japan 21(11), pp. 33-45.
Kato T., Shimogaki H., Mizutori T. and Fujimura K. [1988] Trademark: Multimedia
database with abstracted representation on knowledge base, Proceedings, Second
International Symposium on Interoperable Information Systems, pp. 245-252.
Kelly R., McConnell P. and Mildenberger S. [1977] The Gestalt photomapping system,
Photogrammetric Engineering and Remote Sensing 43(11), pp. 1407-1417.
Keren D., Cooper D. and Subrahmonia J. [1994] Describing complicated objects by im-
plicit polynomials, IEEE Trans. Pattern Analysys and Machine Intelligence, 16(1),
pp. 38-53.
Kergosien Y. [1981] La famille des projections orthogonales dune surface et ses singu-
larites, C.R. Acad. Sc. Paris 292, pp. 929-932.
886
Литература
Kimia В., Tannenbaum A. and Zucker S. [1990] Toward a computational theory of shape:
An overview, European Conference on Computer Vision, 1990, pp. 402-407.
Kimia B., Tannenbaum A. and Zucker S. [1995] Shapes, shocks, and deformations I: The
components of 2-dimensional shape and the reaction-diffusion space, International
Journal of Computer Vision, 15(3), pp. 189-224.
Kinoshita K. and Lindenbaum M. [2000] Camera model selection based on geometric AIC,
IEEE Conference on Computer Vision and Pattern Recognition, 2000, pp. 11:514-519.
Klinker G., Shafer S. and Kanade T. [1987a, 6] Using a color reflection model to separate
highlights from object color, Proceedings, First International Conference on Computer
Vision, pp. 145-150.
Klinker G.t Shafer S. and Kanade T. [1990] A physical approach to color image under-
standing, International Journal of Computer Vision, 4(1), January 1990, pp. 7-38.
Koenderink J. [1984] What does the occluding contour tell us about solid shape?, Percep-
tion, 13, pp. 321-330.
Koenderink J. [1986] An internal representation for solid shape based on the topological
properties of the apparent contour, W. Richards and S. Ullman, eds, Image Under-
standing: 1985-86, Ablex Publishing Corp., chapter 9, pp. 257-285.
Koenderink J. [1990] Solid Shape, MIT Press.
Koenderink J. and Van Doorn A. [1976a] Geometry of binocular vision and a model for
stereopsis, Biological Cybernetics 21, pp. 29-35.
Koenderink J. and Van Doorn A. [19766] The singularities of the visual mapping, Biological
Cybernetics 24, pp. 51-59.
Koenderink J. and Van Doorn A. [1979] The internal representation of solid shape with
respect to vision, Biological Cybernetics 32, pp. 211-216.
Koenderink J. and van Doorn A. [1980] Photometric invariants related to solid shape,
Optica Acta 27(7), pp. 981-996.
Koenderink J. and van Doorn A. [1983] Geometrical modes as a general method to treat
diffuse interreflections in radiometry, Journal of the Optical Society of America,
73(6), pp. 843-850.
Koenderink J. and van Doorn A. [1986] Dynamic shape, Biological Cybernetics 53,
pp. 383-396.
Koenderink J. and Van Doorn A. [1990] Affine structure from motion, Journal of the Optical
Society of America A 8, pp. 377-385.
Koenderink J. and Van Doorn A. [1997] The generic bilinear calibration-estimation problem,
International Journal of Computer Vision, 23(3), pp. 217-234.
Koenderink J., van Doorn A., Dana K. and Nayar S. [1999] Bidirectional reflection dis-
tribution function of thoroughly pitted surfaces, International Journal of Computer
Vision, 31(2/3), pp. 129-144.
Литература
887
Kofakis Р. and Orphanoudakis S. [1991] Graphical tools and retrieval strategies for medical
image databases, Proceedings of the International Symposium on Computer Assisted
Radiology, Springer-Verlag, pp. 519-524.
Koffka K. [1935] Principles of Gestalt Psychology, Harcourt Brace.
Kriegman D. and Belhumeur P. [1998] What shadows reveal about object structure, Euro-
pean Conference on Computer Vision, 1998, pp. 399-414.
Kriegman D. and Ponce J. [1990a] Computing exact aspect graphs of curved objects: solids
of revolution, International Journal of Computer Vision, 5(2), pp. 119-135.
Kriegman D. and Ponce J. [19906] On recognizing and positioning curved 3-D objects
from image contours, IEEE Trans. Pattern Analysis and Machine Intelligence, 12(12),
pp. 1127-1137.
Krinov E. [1947] Spectral reflectance properties of natural formations, Technical report,
National Research Council of Canada, Technical Translation: TT-439.
Kruppa E. [1913] Zur ermittung eines objektes aus zwei perspektiven mit innerer
orientierung, Sitz.-Ber. Akad. Wiss., Wien, Math. Naturw. KI., Abt. Ila. 122,
pp. 1939-1948.
Kube P. and Perona P. [1996] Scale-space properties of quadratic feature-detectors, IEEE
Trans. Pattern Analysis and Machine Intelligence, 18(10), pp. 987-999.
Kutulakos K. and Seitz S. [1999] A theory of shape by space carving, Proceedings of the
International Conference on Computer Vision, pp. 307-314.
Kutulakos K. and Vallino J. [1998] Calibration-free augmented reality, IEEE Transactions
on Visualization and Computer Graphics, 4(1), pp. 1-20.
Lamb T. and Bourriau J., eds [1995] Colour Art and Science, Cambridge University Press.
Lamdan Y., Schwartz J. and Wolfson H. [1990] Affine invariant model-based object recog-
nition, IEEE Trans. Robotics and Automation 6, pp. 578-589.
Land E. [1959a] Color vision and the natural image: Part i, Proceedings National Academy
Science USA 45(1), pp. 115-129.
Land E. [19596] Color vision and the natural image: Part ii, Proceedings National Academy
Science USA 45(4), pp. 636-644.
Land E. [1959c] Experiments in color vision. Scientific American 200, pp. 84-89.
Land E. [1983] Color vision and the natural image, Proceedings National Academy Science
USA 80, pp. 5163-5169.
Land E. and McCann J. [1971] Lightness and retinex theory, Journal of the Optical Society
of America, 61(1), pp. 1-11.
Laurentini A. [1995] How far 3D shapes can be understood from 2D silhouettes, IEEE
Trans. Pattern Analysys and Machine Intelligence, 17(2), pp. 188-194.
888
Литература
Lavallee S. [1996] Registration for computer integrated surgery: Methodology and state of
the art, R. Taylor, S. Lavallee, G. Burdea and R. Mosges, eds. Computer Integrated
Surgery, MIT Press.
Laveau S. and Faugeras O. [1994] 3D scene representation as a collection of images and
fundamental matrices, Technical Report 2205, INRIA Sophia-Antipolis.
Lecun Y., Bottou L., Bengio Y. and Haffner P. [1998] Gradient-based learning applied to
document recognition, Proceedings of the IEEE, 86(11), pp. 2278-2324.
Lee H. [1986] Method for computing the scene-illuminant chromaticity from specular
highlights, Journal of the Optical Society of America-A 3, pp. 1694-1699.
Lee S. and Bajcsy R. [1992a] Detection of specularity using colour and multiple views,
pp. 99-114.
Lee S. and Bajcsy R. [19926] Detection of specularity using colour and multiple views,
Image and Vision Computing, 10, pp. 643-653.
Leung T. and Malik J. [1997] On perpendicular texture or: Why do we see more flowers
on the distance?, IEEE Conference on Computer Vision and Pattern Recognition,
pp. 1007-1013.
Leung, T., Burl, M. and Perona, P. [1995], Finding faces in cluttered scenes using labelled
random graph matching, Proceedings, Fifth International Conference on Computer
Vision, 1995, pp. 637-644.
Levoy, M. and Hanrahan, P. [1996], Light field rendering, SIGGRAPH, pp. 31-42.
Lim, H. and Binford, T. [1988], Curved surface reconstruction using stereo correspondence,
Proceedings DARPA Image Understanding Workshop, pp. 809-819.
Lipson, P., Grimson, W. L. and Sinha, P. [1997], Configuration based scene classification
and image indexing, IEEE Conference on Computer Vision and Pattern Recognition,
pp. 1007-1013.
Ljung L. [1995] System identification, W. S. Levine, ed., The Control Handbook, CRC
Press, in cooperation with IEEE Press.
Longuet-Higgins H. [1981] A computer algorithm for reconstructing a scene from two
projections, Nature 293, pp. 133-135.
Loop C. [1994] Smooth spline surfaces over irregular meshes, Computer Graphics,
pp. 303-310.
Lorensen W. and Cline H. [1987] Marching cubes: a high resolution 3D surface construction
algorithm, Computer Graphics, 21, pp. 163-169.
Lowe D. [1985] Perceptual Organization and Visual Recognition, Kluwer.
Luenberger D. [1984] Linear and Nonlinear Programming, Addison-Wesley. Second edition.
Luong Q.-T. [1992] Matrice fondamentale et calibration visuelle sur I’environnement: vers
une plus grande autonomic des systemes robotiques, PhD thesis, University of Paris
XI, Orsay, France.
Литература
889
Luong Q.-T. and Faugeras O. [1996] The fundamental matrix: theory, algorithms, and
stability analysis, International Journal of Computer Vision, 17(1), pp. 43-76.
Luong Q.-T., Deriche R., Faugeras O. and Papadopoulo T. [1993] On determining the fun-
damental matrix: analysis of different methods and experimental results, Technical
Report 1894, INRIA Sophia-Antipolis.
Lynch D. and Livingston W. [2001] Color and Light in Nature, Cambridge University Press.
Lyvers E. and Mitchell O. [1988] Precision edge contrast and orientation estimation, IEEE
Trans. Pattern Analysis and Machine Intelligence, 10(6), pp. 927-937.
Ma W. and Manjunath B. [1995] A comparison of wavelet features for texture annota-
tion, Proceedings of the International Conference on Image Processing, 1995, pp. II:
256-259.
Ma W. and Manjunath B. [1996] Texture features and learning similarity, IEEE Conference
on Computer Vision and Pattern Recognition, 1996, pp. 425-430.
Ma W. and Manjunath B. [1997a] Netra: a toolbox for navigating large image databases,
IEEE International Conference Image Processing, pp. 568-571.
Ma W. and Manjunath B. [1998] A texture thesaurus for browsing large aerial pho-
tographs, Journal of the American Society for Information Science (special issue on
Al Techniques for Emerging Information Systems Applications) 49(7), pp. 633-648.
Ma W. Y. and Manjunath B. S. [19976] Edgeflow: a framework for boundary detection and
image segmentation, IEEE Conference on Computer Vision and Pattern Recognition,
pp. 744-749.
MacAdam D. [1942] Visual sensitivities to small color differences in daylight, Journal of
the Optical Society of America, 32, pp. 247.
Macaulay F. [1916] The Algebraic Theory of Modular Systems, Cambridge University Press.
Mahamud S. and Hebert M. [2000] Iterative projective reconstruction from multiple views,
Proceedings, IEEE Conference on Computer Vision and Pattern Recognition, pp. II-
430-437.
Mahamud S., Hebert M., Omori Y. and Ponce J. [2001] Provably-convergent iterative
methods for projective structure from motion, Proceedings, IEEE Conference on
Computer Vision and Pattern Recognition, pp. 1018-1025.
Maintz J. and Viergever M. [1998] A survey of medical image registration, Medical Image
Analysis, 2(1), pp. 1-16.
Malik J. and Perona P. [1989] A computational model of texture segmentation, IEEE
Conference on Computer Vision and Pattern Recognition, 1989, pp. 326-332.
Malik J. and Perona P. [1990] Preattentive texture discrimination with early visual mech-
anisms, Journal of the Optical Society of America 7A(5), pp. 923-932.
Malik J. and Rosenholtz R. [1997] Computing local surface orientation and shape from
texture for curved surfaces, International J. Computer Vision, pp. 149- 168.
890
Литература
Maloney L. [1984} Computational Approaches to Color Vision, PhD thesis, Stanford Uni-
versity.
Maloney L. [1986] Evaluation of linear models of surface spectral reflectance with
small numbers of parameters, Journal of the Optical Society of America, 3(10),
pp. 1673-1683.
Maloney L. and Wandell B. [1986] Color constancy: A method for recovering surface
spectral reflectance, Journal of the Optical Society of America, 3, pp. 29-33.
Manjunath B. and Chellappa R. [1991] Unsupervised texture segmentation using markov
random field models, IEEE Trans. Pattern Analysis and Machine Intelligence, 13(5),
pp. 478-482.
Manjunath B. and Ma W. [1996a] Browsing large satellite and aerial photographs, IEEE
International Conference Image Processing.
Manjunath B. and Ma W. [19966, c] Texture features for browsing and retrieval of image
data, IEEE Trans. Pattern Analysis and Machine Intelligence, 18(8), pp. 837-842.
Manning C. and Schiitze H. [1999] Foundations of Statistical Natural Language Process-
ing, MIT Press.
Manocha D. [1992] Algebraic and Numeric Techniques for Modeling and Robotics, PhD
thesis, Computer Science Division, University of California, Berkeley.
Marimont D. and Wandell B. [1992] Linear models of surface and illuminant spectra,
Journal of the Optical Society of America-A 9, pp. 1905-1913.
Marr D. [1977] Analysis of occluding contour, Proceedings, Royal Society, London B-197,
pp. 441-475.
Marr D. [1982] Vision, Freeman.
Marr D. and Hildreth E. [1980] Theory of edge detection, Proceedings of Royal Society of
London B-207, pp. 187-217.
Marr D. and Nishihara K. [1978] Representation and recognition of the spatial organization
of three-dimensional shapes, Proceedings, Royal Society, London B-200, pp. 269-294.
Marr D. and Poggio T. [1976] Cooperative computation of stereo disparity, Science, 194,
pp. 283-287.
Marr D. and Poggio T. [1979] A computational theory of human stereo vision, Proceedings
of the Royal Society of London В 204, pp. 301-328.
Martin W. and Aggarwal J. [1983] Volumetric description of objects from multiple views,
IEEE Trans. Pattern Analysys and Machine Intelligence, 5(2), pp. 150-158.
Maxwell B. and Shafer S. [2000] Segmentation and interpretation of multicolored objects
with highlights, Computer Vision and Image Understanding, 77(1), pp. 1-24.
Maybank S. and Faugeras O. [1992] A theory of self-calibration of a moving camera,
International Journal of Computer Vision, 8(2), pp. 123-151.
Литература
891
Maybank S. and Sturm P. [1999] MDL, collineations and the fundamental matrix, British
Machine Vision Conference.
McCann J., McKee S. and Taylor [1976] Quantitative studies in retinex theory, Vision
Research 16, pp. 445-458.
McInerney T. and Terzopolous D. [1996] Deformable models in medical image analysis:
a survey, Medical Image Analysis 1(2), pp. 91-108.
McKee S., Levi D. and Brown S. [1990] The imprecision of stereopsis, Vision Research
30(11), pp. 1763-1779.
McLachlan G. and Krishnan T. [1996] The EM Algorithm and Extensions, John Wiley &
Sons.
McMillan L. and Bishop G. [1995] Plenoptic modeling: an image-based rendering approach,
SIGGRAPH, pp. 39-46.
Medioni G. and Nevatia R. [1984] Matching images using linear features, IEEE Trans.
Pattern Analysys and Machine Intelligence, 6(6), pp. 675-685.
Meer P., Mintz D., Kim D. and Rosenfeld A. [1991] Robust regression methods for computer
vision: A review, International Journal of Computer Vision, 6(1), pp. 59-70.
Milenkovic V. and Kanade T. [1985] Trinocular vision using photometric and edge orienta-
tion constraints, Proceedings, DARPA Image Understanding Workshop, pp. 163-175.
Minnaert M. [1993] Light and Color in the Outdoors, Springer Verlag. Translator: L. Sey-
mour.
Mohan R. and Nevatia R. [1989] Segmentation and description based on perceptual or-
ganization, IEEE Conference on Computer Vision and Pattern Recognition, 1989,
pp. 333-341.
Mohan R. and Nevatia R. [1992] Perceptual organization for scene segmentation and de-
scription, IEEE Trans. Pattern Analysis and Machine Intelligence, 14(6), pp. 616-635.
Mohr R., Morin L. and Grosso E. [1992] Relative positioning with uncalibrated cameras,
J. Mundy and A. Zisserman, eds, Geometric Invariance in Computer Vision, MIT
Press, pp. 440-460.
Mollon J. [1995] Seeing colour, T. Lamb and J. Bourriau, eds, Colour Art and Science,
Cambridge University Press.
Montel P., ed. [1972] Toute la photographic, Librairie Larousse and Publications Montel.
Morgan A. [1987] Solving Polynomial Systems using Continuation for Engineering and
Scientific Problems, Prentice Hall.
Morita T. and Kanade T. [1997] A sequential factorization method for recovering shape
and motion from image sequences, IEEE Trans. Pattern Analysys and Machine In-
telligence,
892
Литература
Mukawa N. [1990] Estimation о/ shape, reflection coefficients and illuminant direction
from image sequences. Proceedings, Third International Conference on Computer
Vision, 1990, pp. 507-512.
Mumford D. and Shah J. [1985] Boundary detection by minimizing functionals, IEEE
Conference on Computer Vision and Pattern Recognition, IEEE Press, pp. 22-26.
Mumford D. and Shah J. [1988] Optimal approximations by piecewise smooth functions and
variational problems, Communications on Pure and Applied Mathematics XLII(5),
pp. 577-685.
Mundy J. and Vrobel P. [1994] The role of IU technology in RADIUS phase ii, Proceedings,
Image Understanding Workshop, pp. 251-264.
Mundy J. and Zisserman A. [1992] Geometric Invariance in Computer Vision, MIT Press.
Mundy J., Zisserman A. and Forsyth D. [1993] Applications of Invariance in Computer
Vision, Springer-Verlag.
Nalwa V. [1987] Line-drawing interpretation: bilateral symmetry, Proceedings, DARPA
Image Understanding Workshop, pp. 956-967.
Nalwa V. [1988] Line-drawing interpretation: A mathematical framework, International
Journal of Computer Vision, 2, pp. 103-124.
Nathans J., Piantanida T., Eddy R., Shows T. and Hogness D. [1986a] Molecular genetics
of inherited variation in human color vision. Science, 232, pp. 203-210.
Nathans J., Thomas D. and Hogness D. [19866] Molecular genetics of human color vision:
The genes encoding blue, green, and red pigments. Science, 232, pp. 193-203.
Navy U. [1969] Basic Optics and Optical Instruments, Dover. Prepared by the Bureau of
Naval Personnel.
Nayar S. [1997] Catadioptric omnidirectional camera. Proceedings, IEEE Conference on
Computer Vision and Pattern Recognition, pp. 482-488.
Nayar S. and Oren M. [1993] Diffuse reflectance from rough surfaces, IEEE Conference on
Computer Vision and Pattern Recognition, 1993, pp. 763-764.
Nayar S. and Oren M. [1995] Visual appearance of matte surfaces, Science, 267(5201),
pp. 1153-1156.
Nayar S., Ikeuchi K. and Kanade T. [1990] Determining shape and reflectance of hy-
brid surfaces by photometric sampling, IEEE Trans. Robotics and Automation 6(4),
pp. 418-431.
Nayar S., Ikeuchi K. and Kanade T. [1991a] Shape from interreflections, International
Journal of Computer Vision, 6(3), pp. 173-195.
Nayar S., Ikeuchi K. and Kanade T. [19916] Surface reflection: Physical and geomet-
rical perspectives, IEEE Trans. Pattern Analysis and Machine Intelligence, 13(7),
pp. 611-634.
Литература
893
Nevatia R. [1986] Image segmentation, K. Fu and T. Young, eds, Handbook of Pattern
Recognition and Image Processing, Academic Press, pp. 215-231.
Nevatia R. and Binford T. [1977] Description and recognition of complex curved objects,
Artificial Intelligence Journal, 8, pp. 77-98.
Nielsen M., Johansen P., Olsen O. F. and Weickert J., eds [1999] Scale-Space Theory in
Computer Vision, Vol. 1682, Springer Verlag LNCS.
Niem, W. and Buschmann, R. [1994], Automatic modelling of 3D natural objects from mul-
tiple views, European Workshop on Combined Real and Synthetic Image Processing
for Broadcast and Video Production.
Nitzan, D. [1988], Three-dimensional vision structure for robot applications IEEE Trans.
Pattern Analysys and Machine Intelligence, 10(3), pp. 291-309.
Noble A., Wilson D. and Ponce J. [1997] On Computing Aspect Graphs of Smooth Shapes
from Volumetric Data, Computer Vision and Image Understanding: special issue on
Mathematical Methods in Biomedical Image Analysis 66(2), pp. 179-192.
Ogle V. and Stonebraker M. [1995] Chabot: retrieval from a relational database of images,
Computer 28, pp. 40-48.
Ohlander R., Price K. and Reddy R. [1978] Picture segmentation by a recursive region
splitting method, Computer Graphics Image Processing, 8, pp. 313-333.
Ohta Y. and Kanade T. [1985] Stereo by intra- and inter-scanline search, IEEE Trans.
Pattern Analysys and Machine Intelligence, 7(2), pp. 139-154.
Ohta Y., Maenobu K. and Sakai T. [1981] Obtaining surface orientation from texels under
perspective projection, Proceedings of the International Joint Conference on Artificial
Intelligence, pp. 746-751.
Oja E. [1983] Subspace methods of pattern recognition, Research Study Press.
Okutami M. and Kanade T. [1993] A multiple-baseline stereo system, IEEE Trans. Pattern
Analysys and Machine Intelligence, 15(4), pp. 353-363.
Olson C. [1998] Variable-scale smoothing and edge detection guided by stereoscopy, IEEE
Conference on Computer Vision and Pattern Recognition, 1998, pp. 80-85.
Oren M. and Nayar S. [1995] Generalization of the lambertian model and implications for
machine vision. International Journal of Computer Vision, 14(3), pp. 227-251.
Oren M., Papageorgiou C., Sinha P., Osuna E. and Poggio T. [1997] Pedestrian detection
using wavelet templates, IEEE Conference on Computer Vision and Pattern Recog-
nition, 1997, pp. 193-199.
Osuna E., Freund R. and Girosi F. [1997] Training support vector machines: An application
to face detection, IEEE Conference on Computer Vision and Pattern Recognition,
1997, pp. 130-136.
894
Литература
Рае S. and Ponce J. [1999] Toward a scale-space aspect graph: Solids of revolution.
Proceedings, IEEE Conference on Computer Vision and Pattern Recognition, Vol. II,
pp. 196-201.
Pae S. and Ponce J. [2001] On computing structural changes in evolving surfaces and their
appearance, International Journal of Computer Vision, 43(2), pp. 113-131.
Pal N. and Pal S. [1993] A review on image segmentation techniques, Pattern Recognition
26(9), pp. 1277-1294.
Palmer S. [1999] Vision Science: Photons to Phenomenology, MIT Press.
Papageorgiou C. and Poggio T. [1999] A pattern classification approach to dynamical
object detection, Proceedings, Seventh International Conference on Computer Vision,
1999, pp. 1223-1228.
Papageorgiou C. and Poggio T. [2000] A trainable system for object detection, International
Journal of Computer Vision, 38(1), pp. 15-33.
Papageorgiou C., Oren M. and Poggio T. [1998] A general framework for object detection,
Proceedings, Sixth International Conference on Computer Vision, 1998, pp. 555-562.
Park J., Seo J., An D. and Chung S. [2000] Detection of human faces using skin color and
eyes, Multimedia and Exposition, pp. 133-136.
Pentland A. [1986] Perceptual organization and the representation of natural form, Arti-
ficial Intelligence Journal, 28, pp. 293-331.
Pentland A., Picard R. and Sclaroff S. [1996] Photobook: content-based manipulation of
image databases, International J. Computer Vision 18(3), pp. 233-254.
Peri V. and Nayar S. [1997] Generation of perspective and panoramic video from omnidi-
rectional video, Proceedings, DARPA Image Understanding Workshop.
Perlin K. [1985] An image synthesizer, SIGGRAPH-85, pp. 287-296.
Perona P. [1992] Steerable-scalable kernels for edge detection and junction analysis,
pp. 3-18.
Perona P. [1995] Deformable kernels for early vision, IEEE Trans. Pattern Analysis and
Machine Intelligence, 17(5), pp. 488-499.
Perona P. and Freeman W. [1998] A factorization approach to grouping, European Confer-
ence on Computer Vision, 1998, pp. 655-670.
Perona P. and Malik J. [1990a, 6] Detecting and localizing edges composed of steps, peaks
and roofs, Proceedings, Third International Conference on Computer Vision, 1990,
pp. 52-57.
Perona P. and Malik J. [1990c] Scale-space and edge detection using anisotropic diffusion,
IEEE Trans. Pattern Analysys and Machine Intelligence, 12(7), pp. 629-639.
Petitjean S. [1995] Geometric dnumerative et contacts de varietds lineaires: application
aux graphes daspects ddbjets courbes, PhD thesis, Institut National Polytechnique
de Lorraine.
Литература
895
Petitjean S., Ponce J. and Kriegman D. [1992] Computing exact aspect graphs of
curved objects: Algebraic surfaces, International Journal of Computer Vision, 9(3),
pp. 231-255.
Phillips P. and Vardi Y. [1996] Efficient illumination normalization of facial images, Pattern
Recognition Letters, 17(8), pp. 921-927.
Plantinga H. and Dyer C. [1990] Visibility, occlusion, and the aspect graph, International
Journal of Computer Vision, 5(2), pp. 137-160.
Platonova O. [1981] Singularities of the mutual disposition of a surface and a line, Russian
Mathematical Surveys 36(1), pp. 248-249.
Poelman C. and Kanade T. [1997] A paraperspective factorization method for shape and
motion recovery, IEEE Trans. Pattern Analysys and Machine Intelligence, 19(3),
pp. 206-218.
Poggio T., Torre V. and Koch C. [1985] Computational vision and regularization theory.
Nature 317, pp. 314-319.
Pollard S., Mayhew J. and Frisby J. [1970] A stereo correspondence algorithm using a
disparity gradient limit, Perception, 14, pp. 449-470.
Pollefeys M. [1999] Self-calibration and metric 3D reconstruction from uncalibrated image
sequences, PhD thesis, Katholieke Universiteit Leuven.
Pollefeys M., Koch R. and Van Gool L. [1999] Self-calibration and metric reconstruction
in spite of varying and unknown internal camera parameters, International Journal
of Computer Vision, 32(1), pp. 7-26.
Ponce J. [1990] On characterizing ribbons and finding skewed symmetries, Computer
Vision, Graphics and Image Processing, 52, pp. 328-340.
Ponce J. [2000] Metric upgrade of a projective reconstruction under the rectangular pixel
assumption, Second Workshop on Structure from Multiple Images of Large Scale
Environments, pp. 18-27. Preprints.
Ponce J. and Brady J. [1987] Toward a surface primal sketch, T. Kanade, ed., Three-
dimensional machine vision, Kluwer Publishers, pp. 195-240.
Ponce J., Cass T. and Marimont D. [1993] Relative stereo and motion reconstruction,
Technical Report UIUC-BI-AI-RCV-93-07, Beckman Institute, University of Illinois.
Ponce J., Cepeda M., Pae S. and Sullivan S. [1999] Shape models and object recognition,
D. Forsyth J. Mundy V. Gesu and R. Cipolla, eds. Shape, Contour and Grouping in
Computer Vision, Vol. 1681 of Lecture Notes in Computer Science, Springer-Verlag.
Ponce J., Chelberg D. and Mann W. [1989] Invariant properties of straight homogeneous
generalized cylinders and their contours, IEEE Trans. Pattern Analysys and Machine
Intelligence, 11(9), pp. 951-966.
Porrill J. [1990] Fitting ellipses and predicting confidence envelopes using a bias corrected
kalman filter, Image and Vision Computing, 8(1), pp. 37-41.
896
Литература
Pritchett Р. and Zisserman A. [1998] Wide baseline stereo matching, Proceedings of the
International Conference on Computer Vision, pp. 754-760.
Psarrou A., Konstantinou V., Morse P. and O’Reilly P. [1997] Content based search in
mediaeval manuscripts, TENCON-97 — Proceedings IEEE Region 10 Conference
Speech and Image Technologies for Computing and Telecommunications, pp. 187-
190.
Raja Y., McKenna S. and Gong S. [1998] Colour model selection and adaptation in dynamic
scenes, European Conference on Computer Vision, 1998, pp. 460-474.
Ranade S. and Prewitt J. [1980] A comparison of some segmentation algorithms for cytol-
ogy, Proceedings of the International Conference on Pattern Recognition, pp. 561-564.
Rieger J. [1987] On the classification of views of piecewise-smooth objects, Image and
Vision Computing, 5, pp. 91-97.
Rieger J. [1990] The geometry of view space of opaque objects bounded by smooth surfaces,
Artificial Intelligence Journal, 44(1-2), pp. 1-40.
Rieger J. [1992] Global bifurcations sets and stable projections of non-singular algebraic
surfaces. International Journal of Computer Vision, 7(3), pp. 171-194.
Ripley B. [1996] Pattern Recognition and Neural Networks, Cambridge University Press.
Riseman E. and Arbib M. [1977] Computational techniques in the visual segmentation of
static scenes, Computer Graphics Image Processing, 6(3), pp. 221-276.
Rissanen J. [1983] A universal prior for integers and estimation by minimum description
length, Annals of Statistics 11, pp. 416-431.
Rissanen J. [1987] Stochastic complexity (with discussion), J. Roy. Stat. Soc. Series В 49,
pp. 223-239.
Robert L. and Faugeras O. [1991] Curve-based stereo: figural continuity and curvature, Pro-
ceedings, IEEE Conference on Computer Vision and Pattern Recognition, pp. 57-62.
Roberts L. [1965] Machine perception of 3-D solids. Optical and Electro-Optical Informa-
tion Processing, MIT Press, pp. 159-197.
Rosch E. [1988] Principles of categorisation, A. Collins and E. Smith, eds, Readings in Cog-
nitive Science: A Perspective from Psychology and Artificial Intelligence, Morgan
Kauffman, pp. 312-322.
Rosenfeld A. [1986] Axial representations of shape, Computer Vision, Graphics and Image
Processing, 33, pp. 156-173.
Rosenholtz R. and Malik J. [1997] Surface orientation from texture: isotropy or homogene-
ity (or both)?, Vision Research 37(16), pp. 2283-2293.
Rothwell C. [1995] Object Recognition through Invariant Indexing, Oxford University
Press.
Литература
897
Rothwell С., Forsyth D., Zisserman A. and Mundy J. (1993] Extracting projective structure
from single perspective views of 3d point sets, Proceedings, Fourth International
Conference on Computer Vision, pp. 573-582.
Rothwell C., Zisserman A., Forsyth D. and Mundy J. [1995] Planar object recognition us-
ing projective shape representation, International Journal of Computer Vision, 16(1),
pp. 57-99.
Rothwell C., Zisserman A., Marinos C., Forsyth D. and Mundy J. [1992] Relative motion
and pose from arbitrary plane curves, Image and Vision Computing, 10, pp. 250-262.
Rousseeuw P. [1987] Robust Regression and Outlier Detection, Wiley.
Rowley H., Baluja S. and Kanade T. [1996] Neural network-based face detection, IEEE
Conference on Computer Vision and Pattern Recognition, 1996, pp. 203-208.
Rowley H., Baluja S. and Kanade T. [1998a] Neural network-based face detection, IEEE
Trans. Pattern Analysis and Machine Intelligence, 20(1), pp. 23-38.
Rowley FL, Baluja S. and Kanade T. [1998ft] Rotation invariant neural network-based
face detection, IEEE Conference on Computer Vision and Pattern Recognition, 1998,
pp. 38-44.
Rowley H., Baluja S. and Kanade T. [1998c] Rotation invariant neural network-based face
detection, IEEE Conference on Computer Vision and Pattern Recognition, pp. 38-44.
Rubner Y., Tomasi C. and Guibas L. J. [1998] A metric for distributions with applications
to image databases, International Conference on Computer Vision, pp. 59-66.
Russ J. [1995] The Image Processing Handbook, CRC Press. Second edition.
Sabin M. [1994] Acta Numerica 1994, Cambridge University Press, chapter Numerical
Geometry of Surfaces.
Saito H., Baba S., Kimura M., Vedula S. and Kanade T. [1999] Appearance-based virtual
view generation of temporally-varying events from multi-camera images in the 3D
room, Technical Report CMU-CS-99-127, Carnegie-Mellon University.
Samuel P. [1988] Projective Geometry, Springer-Verlag. English translation of Geometrie
Projective, Presses Universitaires de France, 1986.
Sandini G., ed. [1992] European Conference on Computer Vision, Vol. 588 of Lecture Notes
in Computer Science, Springer-Verlag.
Sarachik K. and Grimson W. [1993] Gaussian error models for object recognition, IEEE
Conference on Computer Vision and Pattern Recognition, 1993, pp. 400-406.
Sarkar S. and Boyer K. [1993] Integration, inference, and management of spatial in-
formation using Bayesian networks: Perceptual organization, IEEE Trans. Pattern
Analysis and Machine Intelligence, 15(3), pp. 256-274.
Sarkar S. and Boyer K. [1994] Computing Perceptual Organization in Computer Vision,
World Scientific.
898
Литература
Sarkar S. and Boyer K. [1998] Quantitative measures of change based on feature orga-
nization: Eigenvalues and eigenvectors, Computer Vision and Image Understanding,
71(1), pp. 110-136.
Saund E. and Moran T. [1995] Perceptual organization in an interactive sketch editing
application, Proceedings, Fifth International Conference on Computer Vision, 1995,
pp. 597-604.
Sawhney H. and Ayer S. [1996] Compact representations of videos through dominant
and multiple motion estimation, IEEE T. Pattern Analysis and Machine Intelligence,
18(8), pp. 814-830.
Schmid C. and Mohr R. [1997a, 6] Local grayvalue invariants for image retrieval, IEEE
Trans. Pattern Analysys and Machine Intelligence, 19(5), pp. 530-535.
Schmid C., Mohr R. and Bauckhage C. [2000] Evaluation of interest point detectors.
International Journal of Computer Vision, 37(2), pp. 151-172.
Schneiderman H. and Kanade T. [1998] Probabilistic formulation for object recognition,
IEEE Conference on Computer Vision and Pattern Recognition, 1998, pp. 45-51.
Seitz S. and Dyer C. [1995] Physically-valid view synthesis by image interpolation, Work-
shop on Representations of Visual Scenes.
Seitz S. and Dyer C. [1996] Toward image-based scene representation using view morphing,
Technical Report 1298, University of Wisconsin.
Serra J. [1982] Image Analysis and Mathematical Morphology, Academic Press.
Shade J., Gortler S., Li-wei H. and Szeliski R. [1998] Layered depth images, SIGGRAPH
98, pp. 231-242.
Shafer S. [1985a] Shadows and Silhouettes in Computer Vision, Kluwer Academic Publish-
ers.
Shafer S. [19856] Using color to separate reflection components, Color Res. A, pp. 10(4),
pp. 210-218.
Shafer S. and Kanade T. [1983] The theory of straight homogeneous generalized cylin-
ders and a taxonomy of generalized cylinders, Technical Report CMU-CS-83-105,
Carnegie-Mellon University.
Shashua A. [1993] Projective depth: a geometric invariant for 3D reconstruction from
two perspective/orthographic views and for visual recognition, Proceedings of the
International Conference on Computer Vision, pp. 583-590.
Shashua A. [1995] Algebraic functions for recognition, IEEE Trans. Pattern Analysys and
Machine Intelligence, 17(8), pp. 779-789.
Shi J. and Malik J. [1997] Normalized cuts and image segmentation, IEEE Conference on
Computer Vision and Pattern Recognition, 1997, pp. 731-737.
Shi J. and Malik J. [1998a] Motion segmentation and tracking using normalized cuts, Pro-
ceedings, Sixth International Conference on Computer Vision, 1998, pp. 1154-1160.
Литература
899
Shi J. and Malik J. [19986] Self-inducing relational distance and its application to image
segmentation, European Conference on Computer Vision, 1998, pp. 528-543.
Shi J. and Malik J. [2000] Normalized cuts and image segmentation, IEEE Trans. Pattern
Analysis and Machine Intelligence, 22(8), pp. 888-905.
Shimshoni I. and Ponce J. [1997] Finite-resolution aspect graphs of polyhedral objects,
IEEE Trans. Pattern Analysys and Machine Intelligence, 19(4), pp. 315-327.
Shin M., Goldgof D. and Bowyer K. [1998] An objective comparison methodology of edge
detection algorithms using a structure from motion task, IEEE Conference on Com-
puter Vision and Pattern Recognition, 1998, pp. 190-195.
Shin M., Goldgof D. and Bowyer K. [1999] Comparison of edge detectors using an object
recognition task, IEEE Conference on Computer Vision and Pattern Recognition,
1999, pp. 1:360-365.
Shirai Y. [1972] Recognition of polyhedrons with a range finder, Pattern Recognition 4,
pp. 243-250.
Shirman L. and Sequin C. [1987] Local surface interpolation with Bezier patches, CAGD
4, pp. 279-295.
Shum H. and Szeliski R. [1998] Construction and refinement of panoramic mosaics with
global and local alignment, Proceedings of the International Conference on Computer
Vision, pp. 953-958.
Shum H., Ikeuchi K. and Reddy R. [1995] Principal component analysis with missing data
and its application to polyhedral object modeling, IEEE Trans. Pattern Analysys and
Machine Intelligence, 17(9), pp. 854-867.
Siddiqi K., Kimia B., Tannenbaum A. and Zucker S. [1999a] Shapes, shocks and wiggles,
Image and Vision Computing, 17(5/6), pp. 365-373.
Siddiqi K., Shokoufandeh A., Dickinson S. J. and Zucker S. W. [19996] Shock graphs and
shape matching, International Journal of Computer Vision, 35(1), pp. 13-32.
Sillion F. [1994] Radiosity and Global Illumination, Morgan-Kauffman.
Simon D., Hebert M. and Kanade T. [1994] Real-time 3D pose estimation using a high-
speed range sensor, IEEE International Conference on Robotics and Automation,
pp. 2235-2241.
Simoncelli E. and Farid H. [1995] Steerable wedge filters, Proceedings, Fifth International
Conference on Computer Vision, 1995, pp. 189-194.
Simoncelli E. and Freeman W. [1995] The steerable pyramid: A flexible architecture for
multi-scale derivative computation, Proceedings of the International Conference on
Image Processing, 1995, pp. 444-447.
Sirovitch L. and Kirby M. [1987] Low-dimensional procedure for the characterization of
human faces, Journal of the Optical Society of America A 2, pp. 586-591.
900
Литература
Slama С., Theurer С. and Henriksen S., eds [1980] Manual of photogrammetry, American
Society of Photogrammetry. Fourth edition.
Smith J. and Chang S.-F. [1996] Visualseek: A fully automated content-based image query
system, ACM Multimedia Conference.
Smith J. and Chang S.-F. [1997] Visually searching the web for content, IEEE Multimedia
4(3), pp. 12-20.
Smith M. and Christel M. [1995] Automating the creation of a digital video library, ACM
Multimedia.
Smith M. and Hauptmann A. [1995] Text, speech and vision for video segmentation:
The informedia project, AAAI Fall 1995 Symposium on Computational Models for
Integrating Language and Vision.
Smith M. and Kanade T. [1997] Video skimming for quick browsing based on audio and
image characterization, IEEE Conference on Computer Vision and Pattern Recogni-
tion.
Smith T. [1996] A digital library for geographically referenced materials, Computer 29(5),
pp. 54-60.
Smola A. S., ed. [2000] Advances in Large Margin Classifiers, MIT Press.
Snapper E. and Troyer R. [1989] Metric Affine Geometry, Dover Publications Inc. Reprinted
from Academic Press, 1971.
Snyder D., Hammoud A. and White R. [1993] Image recovery from data acquired with a
charge-coupled-device camera, Journal of the Optical Society of America A 10(5),
pp. 1014-1023.
Song Y., Feng X. and Perona P. [2000a] Towards detection of human motion, IEEE Con-
ference on Computer Vision and Pattern Recognition, 2000, pp. 1:810-817.
Song Y., Goncalves L. and Perona P. [20006] Monocular percepton of biological mo-
tion: Clutter and partial occlusion, European Conference on Computer Vision, 2000,
pp. 719-733.
Song Y., Goncalves L., di Bernardo E. and Perona P. [1999] Monocular perception of biolog-
ical motion: Detection and labeling, Proceedings, Seventh International Conference
on Computer Vision, 1999, pp. 805-813.
Spacek L. [1986] Edge detection and motion detection, Image and Vision Computing, 4(1),
pp. 43-56.
Speis A. and Healey G. [1996] Feature-extraction for texture-discrimination via random-
field models with random spatial interaction, IEEE Trans. Image Processing, 5(4),
pp. 635-645.
Spetsakis M. and Aloimonos Y. [1990] Structure from motion using line correspondences,
International Journal of Computer Vision, 4(3), pp. 171-183.
Литература
901
Srivastava S. and Ahuja N. [1990] Octree generation from object silhouettes in perspective
views, Computer Vision, Graphics and Image Processing, 49(1), pp. 68-84.
Stark L. and Bowyer K. [1996] Generic Object Recognition Using Form and Function,
World Scientific Publishing.
Starner T., Weaver J. and Pentland A. [1998] Real-time american sign language recogni-
tion using desk and wearable computer based video, IEEE T. Pattern Analysis and
Machine Intelligence, 20(12), pp. 1371-1375.
Stein F. and Medioni G. [1992] Structural indexing: efficient 3D object recognition, IEEE
Trans. Pattern Analysys and Machine Intelligence,
Stewart C. [1999] Robust parameter estimation in computer vision, SIAM-Review 41(3),
pp. 513-537.
Stewman J. and Bowyer K. [1987] Aspect graphs for planar-face convex objects, Proceed-
ings, IEEE Workshop on Computer Vision, pp. 123-130.
Stewman J. and Bowyer K. [1988] Creating the perspective projection aspect graph of
polyhedral objects, Proceedings of the International Conference on Computer Vision,
pp. 495-500.
Strang G. [1980] Linear Algebra and its Applications, Academic Press, Inc. Second edition.
Struik D. [1988] Lectures on Classical Differential Geometry, Dover. Reprint of the second
edition [1961] of the work first published by Addison-Wesley in 1950.
Sturm P. and Triggs B. [1996] A factorization-based algorithm for multi-image projec-
tive structure and motion, Proceedings, European Conference on Computer Vision,
pp. 709-720.
Sugihara K. [1986] Machine Interpretation of Line Drawings, MIT Press.
Sullivan G., Baker K., Worrall A., Attwood C. and Remagnino P. [1997] Model-based vehicle
detection and classification using orthographic approximations, Image and Vision
Computing, 15(8), pp. 649-654.
Sullivan S. and Ponce J. [1998] Automatic model construction, pose estimation, and object
recognition from photographs using triangular splines, IEEE Trans. Pattern Analysys
and Machine Intelligence, 20(10), pp. 1091-1096.
Sullivan S., Sandford L. and Ponce J. [1994a, &] Using geometric distance fits for 3D object
modelling and recognition, IEEE Trans. Pattern Analysys and Machine Intelligence,
16(12), pp. 1183-1196.
Sung K.-K. and Poggio T. [1998] Example-based learning for view-based human face
detection, IEEE T. Pattern Analysis and Machine Intelligence, 20, pp. 39-51.
Swain M. and Ballard D. [1991] Color indexing. International J. Computer Vision 7(1),
pp. 11-32.
902
Литература
Szeltski R., Avidan S. and Anandan P. [2000] Layer extraction from multiple images
containing reflections and transparency, IEEE Conference on Computer Vision and
Pattern Recognition, 2000, pp. 1:246-253.
Tagare H. and de Figueiredo R. [1991] A theory of photometric stereo for a class of diffuse
non-Lambertian surfaces, IEEE Trans. Pattern Analysis and Machine Intelligence,
13(2), pp. 133-152.
Tagare H. and de Figueiredo R. [1992] Simultaneous estimation of shape and reflectance
map from photometric stereo, CVGIP: Image Understanding, 55(3), pp. 275-286.
Tagare H. and de Figueiredo R. [1993] A framework for the construction of reflectance
maps for machine vision, CVGIP: Image Understanding, 57(3), pp. 265-282.
Tao H., Sawhney H. and Kumar R. [2000] Dynamic layer representation with applications
to tracking, IEEE Conference on Computer Vision and Pattern Recognition, 2000,
pp. 11:134-141.
Tarr M., Hayward W., Gauthier I. and Williams P. [1995] Is object recognition mediated
by viewpoint invariant parts or viewpoint dependent features, Perception, 24, pp. 4.
Taubin G., Cukierman F., Sullivan S., Ponce J. and Kriegman D. [1994a, 6] Parameterized
families of polynomials for bounded algebraic and surface curve fitting, IEEE Trans.
Pattern Analysys and Machine Intelligence, 16(3), pp. 287-303.
Taylor C. [2000] Reconstruction of articulated objects from point correspondences in a
single uncalibrated image, IEEE Conference on Computer Vision and Pattern Recog-
nition, pp. 677-684.
Ter Haar Romeny B. [1994] Geometry-driven diffusion in computer vision, Geometry Driven
Diffusion in Computer Vision, Kluwer Academic Press.
Ter Haar Romeny B., Florack L. M., Koenderink J. J. and Viergever M. A., eds [1997]
Scale-Space Theory in Computer Vision, Vol. 1252, Springer Verlag LNCS.
Terzopoulos D. [1984] Multiresolution Computation of Visible-Surface Representations,
PhD thesis, Massachusetts Institute of Technology.
Thom R. [1972] Structural Stability and Morphogenesis, Benjamin.
Thompson D. and Mundy J. [1987] Three dimensional model matching from an un-
constrained viewpoint, International Conference on Robotics and Automation,
pp. 208-220.
Thompson M., Eller R., Radlinski W. and Speert J., eds [1966] Manual of Photogrammetry,
American Society of Photogrammetry. Third edition.
Tieu K. and Viola P. [2000] Boosting image retrieval, IEEE Conference on Computer Vision
and Pattern Recognition, 2000, pp. 1:228-235.
Todd J. [1946] Projective and Analytical Geometry, Pitman Publishing Corporation.
Tomasi C. and Kanade T. [1991] Factoring image sequences into shape and motion, IEEE
Workshop on Visual Motion, pp. 21-28.
Литература
903
Tomasi С. and Kanade T. [1992] Shape and motion from image streams under orthography:
a factorization method, International Journal of Computer Vision, 9(2), pp. 137-154.
Torr P. [1997] An assessment of information criteria for motion model selection, IEEE
Conference on Computer Vision and Pattern Recognition, 1997, pp. 47-52.
Torr P. [1999] Model selection for two view geometry: a review, D. Forsyth J. Mundy
V. diGesu and R. Cipolla, eds, Shape, Contour and Grouping in Computer Vision,
Springer-Verlag, pp. 277-301.
Torr P. and Murray D. [1997] The development and comparison of robust methods for
estimating the fundamental matrix, International Journal of Computer Vision, 24(3),
pp. 271-300.
Torr P. and Zisserman A. [1998] Concerning Bayesian motion segmentation, model aver-
aging, matching and the trifocal tensor, European Conference on Computer Vision,
1998, pp. 511-527.
Torr P., Fitzgibbon A. and Zisserman A. [1999a] The problem of degeneracy in structure
and motion recovery from uncalibrated image sequences, International Journal of
Computer Vision, 32(1), pp. 27-44.
Torr P., Szeliski R. and Anandan P. [19996] An integrated Bayesian approach to layer
extraction from image sequences, Proceedings, Seventh International Conference on
Computer Vision, 1999, pp. 983-990.
Torrance K. and Sparrow E. [1967] Theory for off-specular reflection from roughened
surfaces, Journal of the Optical Society of America, 57, pp. 1105-1114.
Torre V. and Poggio T. [1986] On edge detection, IEEE Trans. Pattern Analysis and Machine
Intelligence, 8(2), pp. 147-163.
Triesman A. [1982] Perceptual grouping and attention in visual search for features and
objects, Journal of Experimental Psychology: Human Perception and Performance
8(2), pp. 194-214.
Triggs B. [1995] Matching constraints and the joint image, Proceedings of the International
Conference on Computer Vision, pp. 338-343.
Triggs B., McLauchlan P., Hartley R. and Fitzgibbon A. [2000] Bundle adjustment —
a modern synthesis, B. Triggs A. Zisserman and R. Szeliski, eds, Vision Algorithms:
Theory and Practice, Springer-Verlag, pp. 298-372. Lecture Notes in Computer Sci-
ence 1883.
Triggs W. [1997] Auto-calibration and the absolute quadric, Proceedings, IEEE Conference
on Computer Vision and Pattern Recognition, pp. 609-614.
Trussell H., Allebach J., Fairchild M., Funt B. and Wong P. [1997] Special issue: Digital
color imaging, IEEE Trans. Image Processing, 6(7), pp. 897-900.
Tsai R. [1987a] A versatile camera calibration technique for high-accuracy 3D machine
vision metrology using off-the-shelf TV cameras, IF.EE Journal of Robotics and Au-
tomation RA-3(4), pp. 323-344.
904
Литература
Tsai R. [19876] A versatile camera calibration technique for high-accuracy 3D machine
vision metrology using off-the-shelf TV cameras, Journal of Robotics and Automation
RA-3(4), pp. 323-344.
Tsai R. and Huang T. [1984] Uniqueness and estimation of 3D motion parameters of rigid
bodies with curved surfaces, IEEE Trans. Pattern Analysys and Machine Intelligence,
6, pp. 13-27.
Turk G. and Levoy M. [1994] Zippered polygon meshes from range images, SIGGRAPH,
pp. 311-318.
Turk M. and Pentland A. [1991a] Face recognition using eigenfaces, Journal of Cognitive
Neuroscience.
Turk M. and Pentland A. [19916] Face recognition using eigenfaces, IEEE Conference on
Computer Vision and Pattern Recognition, pp. 586-591.
Tyson J. [1990] Progress in low-light-level charge-coupled device imaging in astronomy,
Journal of the Optical Society of America A 7, pp. 1231-1236.
Ullman S. [1979] The Interpretation of Visual Motion, MIT Press.
Ullman S. [1996] High-Level Vision: Object Recognition and Visual Cognition, MIT Press.
Ullman S. and Basri R. [1991] Recognition by linear combination of models, IEEE Trans.
Pattern Analysys and Machine Intelligence, 13(10), pp. 992-1006.
Vaillant R. and Faugeras O. [1992] Using extremal boundaries for 3D object modeling,
IEEE Trans. Pattern Analysys and Machine Intelligence, 14(2), pp. 157-173.
Vapnik V. [1996] The Nature of Statistical Learning Theory, Springer Verlag.
Vapnik V.N. [1998] Statistical Learning Theory, John Wiley & Sons.
Vasconcelos N. and Lippman A. [1997] Empirical Bayesian EM based motion segmentation,
IEEE Conference on Computer Vision and Pattern Recognition, 1997, pp. 527-532.
Vieviile T. and Faugeras O. [1995] Motion analysis with a camera with unknown, and
possibly varying intrinsic parameters, Proceedings of the International Conference
on Computer Vision, pp. 750-756.
Virage Virage home page at http://www.vi.rage. com/.
Vogler C. and Metaxas D. [1998] ASL recognition based on a coupling between HMMs
and 3D motion analysis, Proceedings, Sixth International Conference on Computer
Vision, 1998, pp. 363-369.
Vogler C. and Metaxas D. [1999] Parallel hidden markov models for American sign lan-
guage recognition, Proceedings, Seventh International Conference on Computer Vi-
sion, 1999, pp. 116-122.
Vora P., Farell J., Tietz J. and Brainard D. [1997] Digital color cameras 1: Response models,
Technical Report HPL-97-53, Hewlett-Packard Laboratory.
Wactlar H., Kanade T., Smith M. and Stevens S. [1996] Intelligent access to digital video:
The informedia project, IEEE Computer.
Литература
905
Wallace С. and Freeman P. [1987] Estimation and inference by compact encoding (with
discussion), J. Roy. Stat. Soc. Series В 49, pp. 240-265.
Wandell B. [1987] The synthesis and analysis of color images, IEEE Trans. Pattern Analysis
and Machine Intelligence, 9(1), pp. 2-13.
Wandell B. [1995] Foundations of Vision, Sinauer Associates, Inc.
Wang J. and Adelson E. [1994] Representing moving images with layers, IEEE Trans.
Image Processing, 3(5), pp. 625-638.
Wang R. and Freeman H. [1990] Object recognition based on characteristic views, Inter-
national Conference on Pattern Recognition, pp. 8-12.
Watts N. [1987] Calculating the principal views of a polyhedron, CS Technical Report 234,
Rochester University.
Weber M., Einhaeuser W., Welling M. and Perona P. [2000] Viewpoint-invariant learning
and detection of human heads, International Conference on Automatic Face and
Gesture Recognition, pp. 20-27.
Weinshall D. [1993] Model-based invariants for 3-D vision, IEEE Conference on Computer
Vision and Pattern Recognition, 1993, pp. 695-696.
Weinshall D. and Tomasi C. [1995] Linear and incremental acquisition of invariant shape
models from image sequences, IEEE Trans. Pattern Analysys and Machine Intelli-
gence,
Weiss Y. [1997] Smoothness in layers: Motion segmentation using nonparametric mixture
estimation, IEEE Conference on Computer Vision and Pattern Recognition, 1997,
pp. 520-526.
Weiss Y. [1999] Segmentation using eigenvectors: A unifying view, Proceedings, Seventh
International Conference on Computer Vision, 1999, pp. 975-982.
Wells W., Grimson W., Kikinis R. and Jolesz F. [1996] Adaptive segmentation of MRI data,
IEEE Transactions on Medical Imaging 15(4), pp. 429-442.
Weng J., Huang T. and Ahuja N. [1992] Motion and structure from line correspondences:
closed-form solution, uniqueness, and optimization, IEEE Trans. Pattern Analysys
and Machine Intelligence, 14(3), pp. 318-336.
West J., Fitzpatrick M., Wang M., Dawant B., Maurer C.R. J., Kessler R., Maciunas R.,
Barillot C., Lemoine D., Collignon A., Maes F., Suetens P., Vandermeulen D., van den
Eisen P., Napel S., Sumanaweera T., Harkness B., Hemler P., Hill D., Hawkes D.,
Studholme C., Antoine Maintz J., Viergever M., Malandain G., Pennec X., Noz M.,
Maguire G.Q. J., Pollack M., Pelizzari C., Robb R., Hanson D. and Woods R. [1997]
Comparison and evaluation of retrospective intermodality registration techniques,
J. Computer Assisted Tomography 21(4), pp. 554-566.
West M. and Harrison J. [1997] Bayesian Forecasting and Dynamic Models, Springer
Verlag.
906
Литература
Wheatstone С. [1838] On some remarkable, and hitherto unobserved, phenomena of binocu-
lar vision, Philosophical Transactions of the Royal Society (London) 128, pp. 371-394.
Wheeler M. and Ikeuchi K. [1995] Probabilistic hypothesis generation and robust localiza-
tion for object recognition, IEEE Trans. Pattern Analysys and Machine Intelligence,
17(3), pp. 252-265.
Whitney H. [1955] On singularities of mappings of Euclidean spaces. I. Mappings of the
plane into the plane, Annals of Mathematics 62(3), pp. 374-410.
Wilkinson J. and Reinsch C. [1971] Linear Algebra — Vol. II of Handbook for Automatic
Computation, Springer-Verlag. Chapter 1.10 by G.H. Golub and C. Reinsch.
Williams L. and Chen E. [1993] View interpolation for image synthesis, SIGGRAPH.
Williamson S. and Cummins H. [1983] Light and Color in Nature and Art, John Wiley &
Sons.
Witkin A. [1981] Recovering surface shape and orientation from texture, Artificial Intelli-
gence, 17, pp. 17-45.
Witkin A. [1983] Scale-space filtering, International Joint Conference on Artificial Intelli-
gence, pp. 1019-1022.
Wolff L., Nayar S. and Oren M. [1998] Improved diffuse reflection models for computer
vision. International Journal of Computer Vision, 30(1), pp. 55-71.
Wolfson H. [1990] Model-based object recognition by geometric hashing, European Con-
ference on Computer Vision, 1990, pp. 526-536.
Wolfson H. and Lamdan Y. [1988] Geometric hashing: A general and efficient model-based
recognition scheme, Proceedings, Second International Conference on Computer Vi-
sion, 1988, pp. 238-249.
Wong S. [1998] CBIR in medicine: still a long way to go, IEEE Workshop on Content Based
Access of Image and Video Libraries, p. 114.
Woodham R. [1979] Analyzing curved surfaces using reflectance map techniques, Artificial
Intelligence: An MIT Perspective, MIT Press, pp. 161-182.
Woodham R. [1980] Photometric method for determining surface orientation from multiple
images, Optical Engineering, 19(1), pp. 139-144.
Woodham R. [1989] Determining surface curvature with photometric stereo, International
Conference on Robotics and Automation, pp. 36-42.
Woodham R. [1994] Gradient and curvature from the photometric-stereo method, includ-
ing local confidence estimation, Journal of the Optical Society of America, 11(11),
pp. 3050-3068.
Wu Z. and Leahy R. [1993] An optimal graph theoretic approach to data clustering:
Theory and its application to image segmentation, IEEE Trans. Pattern Analysis and
Machine Intelligence, 15(11), pp. 1101-1113.
Литература
907
Wyszecki G. and Stiles W. [1982] Color Science: Concepts and Methods, Quantitative Data
and Formulas, Wiley.
Yachida M., Kitamura Y. and Kimachi M. [1986] Trinocular vision: new approach for cor-
respondence problem, Proceedings IAPR International Conference on Pattern Recog-
nition, pp. 1041-1044.
Yasnoff W., Mui W. and Bacus J. [1977] Error measures in scene segmentation, Pattern
Recognition 9(4), pp. 217-231.
Yoo T. and Oh I. [1999] A fast algorithm for tracking human faces based on chromatic
histograms, Pattern Recognition Letters, 20(10), pp. 967-978.
Zerroug M. and Medioni G. [1995] The challenge of generic object recongnition, M. Hebert
J. Ponce T. Boult and A. Gross, eds, Object Representation for Computer Vision,
number 994 in Lecture Notes in Computer Science, Springer-Verlag, pp. 217-232.
Zhang Y. [1996] A survey on evaluation methods for image segmentation, Pattern Recog-
nition 29(8), pp. 1335-1346.
Zhang Z. [1994] Iterative point matching for registration of free-form curves and surfaces,
International Journal of Computer Vision, 13(2), pp. 119-152.
Zhang Z., Deriche R., Faugeras O. and Luong Q.-T. [1995] A robust technique for matching
two uncalibrated images through the recovery of the unknown epipolar geometry,
Artificial Intelligence Journal, 78, pp. 87-119.
Zhu S. [1999] Stochastic jump-diffusion process for computing medial axes in markov
random fields, IEEE Trans. Pattern Analysis and Machine Intelligence, 21(11),
pp. 1158-1169.
Zhu S. and Yuille A. [1996] FORMS: a flexible object recognition and modeling system,
International Journal of Computer Vision, 20(3), pp. 187-212.
Zhu S., Wu Y. and Mumford D. [1998] Filters, random-fields and maximum-entropy
(frame): Towards a unified theory for texture modeling, International Journal of
Computer Vision, 27(2), pp. 107-126.
Zisserman A., Forsyth D., Mundy J., Rothwell C., Liu J. and Pillow N. [1995a] 3d object
recognition using invariance, Artificial Intelligence, 78(1-2), pp. 239-288.
Zisserman A., Mundy J., Forsyth D., Liu J., Pillow N., Rothwell C. and Utcke S. [1995ft]
Class-based grouping in perspective images, Proceedings, Fifth International Confer-
ence on Computer Vision, 1995, pp. 183-188.
Ziv J. and Lempel A. [1977] A universal algorithm for sequential data compression, IEEE
Transactions on Information Theory IT-23, pp. 337-343.
Предметный указатель
Символы
М-оценка, 475
21-мерный эскиз, 345
3D room, 844
F
Facade, 846
К
K-d деревья, 654
К-средние, 440
N
NTSC, 57
Р
PAL, 57
Q
QuickTime VR, 862
R
RANSAC, 479
RGB, 57
RGB-куб, 175
RREF-форма, 380
s
SECAM, 57
T
Т-образное соединение, 586', 603-628
Z
Z-буфер, 630; 852; 855
Z-буферизация, 635
A
Аберрации, 49-52
астигматизм, 50
дисторсия, 50
искажение радиальное, 99
кома, 50
кривизна поля изображения, 50
первичные, 50
пятно наименьшего рассеяния, 50
сферические, 50
хроматические, 50
Абсолютная дуальная квадрика, 416
Абсолютно черное тело, 162
Абсолютное коническое сечение, 416
Аккумуляторный массив, 461
Активное зрение, 353-355
Активные сенсоры, 637
Алгебраическая кривая, 469
Алгебраическая поверхность, 624
Предметный указатель
909
Алгебраическое расстояние, 316
подбор, 471
Алгоритм Витерби, 749
Альбедо, 121; 187
ламбертовской поверхности
с постоянной ФРДО, 122
определение, 122
Амплитуда, 225
Амплитудный спектр, 225
Анализ главных компонентов, 690
Анализ, 287
Анализ ориентации, 287
Ангармоническое отношение, 388
4 коллинеарных точек, 396
4 плоскостей пучка, 397
4 прямых плоского пучка, 397
Асимптотическая
бикасательная, 621
касательная, 614-626
кривая, 614-615
Асимптотические
направления, 596-604; 641
Аспект, 610-628
Аспектный граф
построение
приблизительное, 630
точное, 622-629
примеры, 611; 629
Ассимиляция, 182
Ассоциация данных, 537
Астигматизм, 50
Атомные метки, 575
Аффинная геометрия, 358-365
аффинная форма, 357; 365
аффинное подпространство, 360
размерность, 360
аффинное преобразование, 73; 366
отображение, 364
изменение координат, 362
аффинное пространство, 358
координаты
аффинные, 361
барицентрические, 362
система координат, 360-363
определение, 361
Аффинная камера, 79
Аффинная модель движения, 506
Аффинная проекционная матрица, 83
Аффинная проекционная модель, 43
Аффинная структура по движению
аффинная структура аффинных
изображений, 372
евклидово уточнение, 376-379
несколько точек
наблюдения, 378-379
неоднозначность, 357
определение, 356
по бинокулярным соответствиям
алгебраический подход, 368-371
геометрический подход, 366-368
по нескольким изображениям
факторизация, 373-376
сегментация движения, 380-384
RREF-форма, 380
матрица взаимодействия форм, 383
Аффинные инварианты, 565
Аффинные координаты, 361; 366; 393
Б
База моделей, 552
Базовая линия, 310
Барицентрическая комбинация, 359
Барицентрические координаты, 362
Безье
кривая, 839
Бикасательная, 608-619
асимптотическая, 621
направление, 626
ограничивающая, 621-623
Г)нкд<'атрл1.ная плоскость, 629
910
Предметный указатель
Бинормаль
вектор, 592-594; 600
прямая, 592
Ближайшие соседи, 680
Блики, 123; 154
Блочное умножение матриц, 71
Буфер, 717
В
Вейвлетные коэффициенты, 715
Вектор источника, 132
Векторное квантование, 860
Верификация, 552
Вероятностная ассоциация данных, 541
Вершина, 770
Взаимное отражение, 147
Взвешенный граф, 443
Видеоформаты
NTSC, 57
PAL, 57
RGB, 57
SECAM, 57
составной формат, 57
Видимая кривизна, 600; 604
Визуализация, 837
Визуальные события, 608; 616
кривая, 616
локальные, 617-619
мультилокальные, 620-622
уравнения, 623; 635
Виньетирование, 50; 119
Виртуальная реальность, 850
Виртуальное изображение, 41
Внешнее произведение, 85
Внешние параметры
аффинная камера, 81-82
перспективная камера, 76-77
Внешняя ориентация, 103; 330
Внутренние параметры
аффинная камера, 81-82
перспективная камера, 74-76
Внутренняя ориентация, 103; 330
Вогнутая точка, 604
плоская кривая, 591
поверхность, 596
Воздушный свет, 163
Воксель, 656
Восприятие цвета, 167; 192
Восстановлением по проекциям, 552
Восьмиточечный алгоритм, 315
Вспомогательное отображение, 506
Вторая фундаментальная форма, 597
Второго порядка
поверхность, 624
Выбор модели, 510-513
Выбор признаков, 688
Выборка информации, 812
Выбросы, 475
Выпуклая оболочка, 634
Выпуклая точка
плоской кривой, 591
поверхность, 596
Выравнивание, 554
Выравнивание пучков, 412
Вычислительные молекулы, 647
Вычитание фона, 434-436
с помощью ОМ-алгоритма, 508
Г
Габоровские фильтры, 292
Гамма-коррекция, 183
Гаусс-образ
кривой, 590
Гаусса-Ньютона алгоритм, 95
Гауссова кривизна, 599-604; 641
Гауссово сглаживание, 644
Геометрические моды, 157
Геометрия
аффинная, 358
дифференциальная, 587
Предметный указатель
911
евклидова, 64
проективная, 388
Геометрия прямых, 66; 85
проекционные уравнения, 863
уравнение прямой, 320
на плоскости, 66
Гессиан, 95
Гиперболическая точка, 596; 604
Гиперплоскость
аффинная, 360
дуальность, 394
на бесконечности, 393
проективная, 392
уравнение, 395
Гистерезис, 266
Главная
кривизна, 595
Главные
направления, 595; 601; 641
Главные точки, 49
Глобальная модель затенения, 147; 186
блики, 154
качественные эффекты, 152
окрашивание, 154
сглаживающий эффект взаимного
отражения, 153
черная и белая комнаты, 148
удаленные поверхности, 152
форм-фактор, 152
ядро взаимного отражения, 150
Глубина поля, 49
Глубина фокуса, 49
Голосование, 729; 736
Гомография, 398; 862
Гороптер, 338
Градиент, оценка, 213; 252-257
Граф, 443
Граф структуры изображения, 628
Гребенчатая функция, 228
Грубая шкала, 240
Группа, 556
Группа преобразований
аффинные преобразования, 73
вращение, 70
подобие, 379
проективные преобразования, 73
строгие преобразования, 72
Группы, содержащие инварианты, 569
д
Дважды касательная плоскость, 621
Двугранная вершина, 556
Дельта-функция, 220
Дерево интерпретации, 554; 631
Диафрагментарное число, 49; 342
Динамическое программирование, 345
Диоптрия, 53
Дискретизация, 225; 227
иллюстрация, 228; 229
наложение, 227; 230-235
неквадратные пиксели, 227
преобразование Фурье дискретного
сигнала, 230
теорема Найквиста, 231
формальная модель, 226-228
Дисторсия, 50
Дифракция, 45
Дифференциальная геометрия, 661
аналитическая, 640-643
описательное определение, 587-599
плоские кривые, 588-591
вектор нормали, 588
вогнутая точка, 591
выпуклая точка, 591
Гаусс-образ, 590
касательная, 588
касательный вектор, 588
кринизпа, 590; 645
локальийм система координат, 588
неособан 1<>чка, 588
912
Предметный указатель
нормаль, 588
отображение Гаусса, 590
сингулярная точка, 588
точка возврата второго рода, 589
точка возврата первого рода, 589
точка перегиба, 588; 590
поверхности, 594-599
асимптотические направления, 596
вектор нормали, 594
вогнутая точка, 596
выпуклая точка, 596
гауссова кривизна, 599; 603
гиперболическая точка, 596
главная кривизна, 595
главные направления, 595; 601
касательная плоскость, 594
локальная система координат, 595
модель второго порядка, 595
нормаль, 594
нормальная кривизна, 594
нормальное сечение, 594
отображение Гаусса, 596
параболическая точка, 596
эллиптическая точка, 595; 604
пространственные кривые, 591-594
вектор главной нормали, 593
главная нормаль, 592
касательная, 591
касательный вектор, 593
кривизна, 592
параметрическая кривая, 605
преобразование Гаусса, 592
Диффузное отражение, 120-121
определение и единицы, 120
поверхности с постоянным
излучением, 120
поверхности с известным
излучением, 120
Диэлектрики, 166
Длина дуги, 593-601
Дневной свет, 163
Доминирующая ориентация, 286
Дробовый шум, 58
Дрожание строк, 59
Дуальное фотометрическое стерео, 633
Дуальность, 394; 395
Е
Евклидова геометрия, 64-73
евклидова форма, 379; 413
евклидовы координаты
неоднородные, 64
однородные, 66
матрица вращения
кватернионы, 653
определение, 68
относительно оси к, 69
свойства, 70
углы Эйлера, 107
формула Родригеса, 107
система координат
изменение, 67-73
ортонормальная, 64
правосторонняя, 64
строгое преобразование
в однородной форме, 72
как отображение, 72
неоднородная форма, 71
при изменении координат, 71
Евклидово уточнение, 376-379; 413
Евклидовы координаты, 64
Единичная точка, 391
Естественное освещение, 140
Ж
Желтое пятно, 53
3
Задача на собственные значения, 91
обобщенная, 91
Предметный указатель
913
Задача потерянных данных, 492
Задача установления соответствий, 334
Задачи с недостающими
данными, 491-498
ОМ-алгоритм, 501-509; 753-757
подбор прямых, 504
практические трудности, 509
подбор прямых, 493
сегментация изображения, 492
формальная постановка, 494
Зайчики, 186
Закон Снелла, 46
Законы Грассмана, 169
Замкнутость, 429
Зарядовая связь, 56
Затеняющий контур, 585
точка возврата, 585; 602
точка складки, 585; 602
Захват кадра, 56
Зеркальное альбедо, 123
Зеркальное отражение
диэлектрических поверхностей, 166
Зеркальное направление, 122
Зеркальные лепестки, 122
Знакомая конфигурация, 429-430
Значение, 179
Зрение на основе модели, 552-571
база моделей, 552
верификация, 572
альтернативные стратегии, 574
через близость краев, 572; 573
через близость краев
и ориентацию, 572
выравнивание, 553-556
группы
три точки, 556
кластеризация поз, 561; 562
практические трудности, 562
линейная комбинация моделей, 560
подбор аффинной камеры
с использованием
соответствий, 558-560
подбор проективной камеры
с использованием
соответствий, 559
поза, 552
применение в медицине, 575-579
с использованием инвариантов, 563
аффинные инварианты для точек
на плоскости, 564
индексация, 568; 569
ковариантные конструкции, 571
общие плоские кривые, 571
плоские аффинные
преобразования, 563-564
проективные инварианты для
плоских алгебраических
кривых, 565
типичная система, 569; 570; 573
И
Идентификация системы, 546
Излучение, 112; 113
единицы, ИЗ
определение, 112
Изотропность, 301
Иллюзия Мюллера-Дайера, 428
Импульсная характеристика, 220
Импульсная реакция, 217
Инварианты, 364; 399
Инерция, 93
матрица вторых моментов, 93
Интегрируемость, 146
в фотометрическом стерео, 146
при расчете освещенности, 194
Использование инвариантов, 571
Источник света, 129
914
Предметный указатель
К
Кадр, 427; 436
Кажущиеся контуры, 432-433
Калибровка камеры, 100—101
линейная, 96-99
вырождение, 98-99
параметры камеры, 97-98
проекционная матрица, 96-97
с радиальным искажением, 99-103
вырождение, 102-103
параметры камеры, 102
проекционная матрица, 100
слабая, 314
фотограмметрия, 103-105
Камера
видикон, 55
обскура, 39-40; 55
ПЗС, 56
поле зрения, 49
фотографическая, 55
Камера-обскура, 43
перспективная, 41
Каноническая система координат, 571
Канонические переменные, 696
Карта
высот, 141
глубин, 141; 632-637
отражения, 154
плотности глубины, 141
Касательная плоскость, 594
Катадиоптрические оптические
системы, 46
Качественная радиометрия, 127; 128
Квадрилинейные условия, 327
Квадрифокусные ограничения, 324-329
1 точка, 3 прямых, 328
4 прямых, 328
4 точки, 327
Квадрифокусный тензор, 310; 327-329
оценка, 329
Квантовый выход, 58
Кватернионы, 652-653; 655; 661; 668
Классификатор, 681; 696
“наивный Байес", 687
сверточная нейронная сеть, 708
Байеса, 677
байесов риск, 677
выбор признаков, 688-715
граница областей решений, 675
для согласования по связям, 729
линейно сепарабельные данные, 679
машина опорных векторов, 711
нейронная сеть, 7Q0; 702
общие методы построения, 677
определение, 674
оценка производительности, 682
по ближайшим соседям, 680; 681
по гистограммам классов, 684
примеры, 684-718
расстояние Махаланобиса, 680
самонастройка, 684
сменный классификатор, 679
суммарный риск, 675
функция риска, 675
Кластеризация, 427; 438; 501
группировка и слияние, 427; 438
древовидная схема, 439; 440
пикселей изображения
с использованием К-средних, 440
с использованием разделения
и слияния, 439
разбиение и деление, 427; 438
теоретико-графовая, 443; 450
через среднее по группе, 438
Ключевой кадр, 436
Ковариантные конструкции, 571
Колбочки, 53; 171
Коллекции изображений, 816
Кома, 50
Компактный носитель, 220
Предметный указатель
915
Компьютерная томография, 575
Конечные разности, 214; 253
выбор сглаживания, 255-257
сглаживание, 252-255
шум, 25Г, 252
Контраст, 255
Контрастность, 182
Контрольный многоугольник, 839
Контур, 585-600
Т-образное соединение, 586
кривизна, 603
теорема Коендеринка, 603-605
точка возврата, 586; 601; 602
точка перегиба, 601; 602
Конус, 770
Конус наблюдения, 585; 770; 838
Коэффициент преломления, 47; 51
Коэффициент увеличения, 44
Край, 247
обнаружение, 640
крышеподобный, 645-646
ступенчатый, 644-645
Кривизна, 590-602
кривой, 590
знак, 591
поверхности
главная, 595; 598
нормаль, 598
нормальная, 604
Кривизна поля изображения, 50
Круг кривизны, 590
Крышеподобный край, 273
Л
Ламбертовская+зеркальная модель,
123; 188-190
Ламбертовская поверхность, 121
Лампы накаливания, 164
Лапласиан, 260
Лапласиан гауссиана, 262
Лапласова пирамиды, 287
Ласточкин хвост, 617-619
Левенберга-Макардта алгоритм, 95
Лево-правая модель, 757
Лента, 783; 785
возможность представления, 789; 791
интерпретация, 783
сегментация, 786; 787
согласование, 788; 789
Линейная схема наименьших
квадратов, 88-93
неоднородная, 88-90
нормальные уравнения, 89
псевдообратная матрица, 90
однородная, 90-93
обобщенная задача на
собственные значения, 91
Линейная фильтрация, 210
Линейные динамические модели, 521
Линейные признаки, 690
Линейные системы, 218-221
импульсная характеристика, 220
свертка как скалярное произведение,
235-237
свойства, 216
фильтрация как выход линейной
системы, 210
функция точечного рассеяния, 222
Линейные системы, инвариантные
относительно сдвига, 218
Линейный источник, 133; 134
определение, 133
Линейчатая поверхность, 616
Линза
виньетирование, 119
глубина поля, 49
диафрагментарное число, 49
относительная апертура, 119
фокусное расстояние, 48
Линии кривимы, 6J6
916
Предметный указатель
Локальная модель затенения, /36; 154
для точечных источников, 136
на бесконечности, 137
не на бесконечности, 137
тени, 138
карта отражения, 154
плоские источники
тени, 139
Локальные визуальные события, 612
Локальные модели затенения
естественное освещение, 140
точечные источники
тени, 138
Луч, 389
м
Магнитный резонанс, 575
Марковская цепь, 746
Марковски модели, скрытые, 745
Масштаб, 239; 479
эффективное сглаживание, 257-258
эффекты выбора масштаба, 256
Масштабирование, 216
Масштабная неоднозначность, 379
Масштабная ортография, 44
Матрица
ранг, 89
Матрица взаимодействия форм, 383
Матрица вращения, 68
Матрица перспективной проекции
нулевого наклона, 78
Матрица степени, 452
Медицина, 575
применение наложения, 576-579
“Мертвые" пиксели, 251
Меры сходства, 444
Местные свойства, 154
Метод Ньютона
нелинейная схема наименьших
квадратов, 94-95
нелинейные уравнения, 94, 626; 843
скорость сходимости, 94
Методы совместимости поз, 554
Метрическая форма, 379
Минимальная длина описания, 512
Минимизация расстояния
алгебраическая, 376
геометрическая, 316
Многообразие бикасательных
лучей, 612-620
Многоуровневое движение, 505
Мобильный робот
локализация, 105-106
навигация, 333; 355
Модели рассеяния Ми, 164
Модель Бакиса, 757
Модель затенения, 127
Модель камеры
аффинная, 79-83
внешние параметры, 81-82
внутренние параметры, 81-82
проекционные уравнения, 44; 81
перспективная, 73-79
внешние параметры, 76-77
внутренние параметры, 74-76
проекционные уравнения, 77
Модель Фонга, 123
Модель языка, 759
Мультилокальные визуальные
события, 612; 620-622
Н
Наложение, 230
Направление наклона, 301
Настроечный набор, 511
Натриевые разрядные лампы, 164
Нейронная сеть, 700
Неквадратные пиксели, 227
Нелинейная схема наименьших
квадратов, 93-96
Предметный указатель
917
Гаусса-Ньютона, 95-96
скорость сходимости, 96
Левенберга-Макардта, 96
Ньютона, 94
Немаксимальное подавление, 264
Неоднозначность
аффинная, 357
евклидова, 379; 413
проективная, 388
Неориентированный граф, 443
Неособая точка, 588
Неполное пространство данных, 494
Непрерывность, 429
Неявная кривая, 469
Низкочастотный фильтр, 289
Нормаль, 588
вектор, 588; 594
главная, 592
кривизна, 594
прямая, 594
сечение, 594
Нормальное сечение, 596
Нормальные уравнения, 89
Нормированная корреляция, 237; 342
Нормированная матрица сходства, 455
Нормированная плоскость
изображения, 74
Нормированное разрезание, 452
О
Обобщенный цилиндр, 780-782
Обод, 585
Образ, 728
Образующая, 783
Обскура, 39
Общая область, 429
Общего положения
кривая, 609
поверхность, 609
Общее поведение, 429
Объемное отражение, 188
Огибающая, 615
Однородная марковская цепь, 746
Однородность, 297
Однородные координаты
аффинные, 362
евклидовы, 65-67
проективные, 390
Односвязная кластеризация, 438
Окантовка, 210
Окрашивание, 154
Определение границ кадров, 425-436
Определение краев, 259; 266
крышеподобные края, 273
лапласиан гауссиана, 260-262
странное поведение в углах, 262
эффект масштаба, 261
на основе градиента, 263
поиск максимумов амплитуды
градиента, 263
примеры, 267-269
ступенчатые края, 273
через анализ поля градиентов, 271
Определение освещенности, 192; 196
Оптическая ось, 42; 46
Оптический поток, 833
Ориентированная пирамида, 295
Ориентированный граф, 443
Ортографическая проекция, 44
Ортонормальная система координат, 64
Освещенность поверхности, 191
Основных цветов, 167
Отбрасываемая тень, 138; 586
Относительная апертура, 119
Отображение Гаусса, 591
Отражательная способность, 120; 165
определение, 121
расчет по ФРДО, 121
Отслеживание луча, 635. 8Ы>
Отслеживание особенностей, 242
918
Предметный указатель
Очистка изображения, 336-337; 341
п
Палочки, 53; 171
Параболическая кривая, 611-616; 628
Параболическая точка, 596-604
Параболоид, 595
Параксиальное приближение
геометрическая оптика, 46-47
уравнение преломления, 47
Параллельность, 429
Параметр верификации, 552
Параметрическая кривая, 472; 605
Параметрическая поверхность, 640
Пары систем координат, 579
Первая фундаментальная форма, 641
Первичные аберрации, 50
Перекрестная проверка, 513
Перенос, 310; 319; 329; 837; 849
Переходы через нуль, 262
Перспектива
эффекты, 42
Перспективная камера, 73
Петля, 443
ПЗС-камера, 56-57
дробовый шум, 58
дрожание строк, 59
зарядовая связь, 56
квантовый выход, 58
потенциальная яма, 56
размывание изображения, 58
теневой ток, 58
ток смещения, 58
фотопереход, 56
Пиксель, 58; 212
Пирамида (тип катастрофы), 617
Пирамида изображения, 239; 239
анализ, 287
анализ текстурированных
изображений, 286
гауссова, 240; 241
анализ, 240
как низкочастотный фильтр, 289
приложения, 240-243
синтез, 288
грубая шкала, 240
лапласова, 287
анализ, 287; 290
как полосовой фильтр, 290-291
синтез, 288
ориентированная
анализ, 296
как полосовой фильтр, 291
как полосой фильтр, 291
пример, 295
синтез, 297
преобразование Фурье, 289-291
Плоский источник, 134; 135
определение и примеры, 134
Плоскость, 302; 591
аффинная, 360
проективная, 392
Плоскость изображения, 40
Плотность потока спектрального
излучения, 162
Плотность потока излучения, 116
определение, 116
Поверхностное отражение, 188
Поверхность вращения, 774
Поверхность второго порядка, 67
уравнение, 67
Подбор, 423; 459-473; 502-508
общая схема наименьших
квадратов, 465-466
с использованием к-средних, 467
выбросы, 475
как задача логического
вывода, 473-474
кривых, 469-473
преобразование Хоха, 459; 561
Предметный указатель
919
прямых, 426; 473-475; 493; 502-508
схема наименьших
квадратов, 464-473
токены, 424; 462
фундаментальной матрицы, 426; 482
Подбор от худшего к лучшему, 242
Подобие, 379; 429
Поза, 552
Поиск изображений, 809
Поле движения, 313; 833
Полное пространство данных, 494
Полная тень, 139
Полносвязная кластеризация, 438
Полулокальные условия, 734
Полутень, 139
Полярность, 286
Помехи, 553
Пороговая функция, 701
Постоянство цвета, 190
линейная модель конечной
размерности, 196; 198-200
определение освещенности, 192
Потенциальная яма, 56
Потеря, 675
Правильный круговой конус, 770
Правильный круговой цилиндр, 771
Правосторонняя система координат, 64
Представление ориентации, 287
Преобразование Фурье, 222; 289-291
дискретизация, 225
доказательство линейности, 224
локальный вариант, 292
низкочастотный фильтр, 289
определение для двумерного
сигнала, 223
пары, 224
применимо к полосовому
фильтру, 290
фазы и амплитуды, 225; 226
Преобразование Хоха, 461
Принцип инвариантности, 170
Принцип обратимости Гельмгольца, 116
Пробный набор, 511
Проективная геометрия, 388-401
дуальность, 394
проективная форма, 388; 401
проективное подпространство, 390
проективные координаты
ангармоническое отношение, 388
неоднородные, 396
однородные, 391
система координат, 390-393
единичная точка, 391
фундаментальные точки, 391
Проективная структура по движению
евклидово уточнение, 412
неоднозначность, 388
определение, 387
по бинокулярным соответствиям
алгебраический подход, 404-405
геометрический подход, 401-403
по нескольким изображениям
факторизация, 408-411
по полилинейным условиям
трифокусный тензор, 407-408
Проективные координаты, 390; 396
Проекционная матрица
аффинная, 83
характеристики, 83
аффинная параперспективная, 82
аффинная слабоперспективная
камера, 82
точечная перспектива
общий вид, 77
характеристики, 78-79
явная параметризация, 77
Проекционная модель, 40
аффинная, 43-44; 79-80
параперспективная, 79
аффинная ортографическая, 44; 79
920
Предметный указатель
аффинная параллельная, 79
аффинная параперспективная, 79
аффинная слабоперспективная
камера, 44; 79; 853
обскура, 40
перспективная обскура, 43
Проекционные уравнения
аффинная слабоперспективная
камера, 44
аффинные, 81
перспективная обскура, 43
точечная перспектива, 77
Производная гауссова фильтра, 254
оценка, 253
с использованием конечных
разностей, 213, 252-257
Пространственная частота, 222
Пространство HSV, 179
Пространство МКО LAB, 181
Пространство МКО u'v', 180
Пространство прямой, 461
Прямая
аффинная, 360
подбор, 92-93
проективная, 392
Псевдообратная матрица, 90
Пучок
гиперплоскостей, 395
компланарных прямых, 397
плоскостей, 396
прямых, 395
Пятно наименьшего рассеяния, 50
Р
Радиальная кривая, 603
Радиальная кривизна, 604
Радиальное искажение, 99
Радиометрия, 109
Радиус кривизны, 590
Разделяющиеся ядра, 258
Разложение по сингулярным
значениям, 90-91; 317;
374-409
Разностное сопоставление, 167
Ракурс, 109
определение, 109
Распознавание объектов, 552; 673
по дальностным
изображениям, 657-667
база моделей, 552
по связям, 728
Распределение вероятностей, 526
Расхождение, 333
Расчет освещенности
алгоритм, 195
Расширенная реальность, 850
Релеевское рассеяния, 164
Решетка, 748
Риск, 675
Рисунок/фон, 428
Ртутные разрядные лампы, 165
С
Самокалибровка, 417
Свертка, 211; 218
дискретная, 211
как скалярное
произведение, 235-237
непрерывная, 218; 221
импульсная характеристика, 220
одномерная производная, 219
свойства, 221
функция точечного рассеяния, 222
примеры, 211
конечные разности, 213-215
локальное среднее, 209
окантовка, 210
сглаживание, 211
разделяющиеся ядра, 258
условные обозначения, 218
Предметный указатель
921
ядро, 222
Свет на поверхностях, 115
Светимость, 130
Световое поле, 838; 858
Связанная тень, 586
Связанные вершины, 444
Связи, 330; 728
Связный граф, 444
Связный компонент, 444
Связь объекта с контуром, 770; 782
группировка на основе классов, 779
каналовые поверхности, 772
условие группировки, 773
конусы, 770
условие группировки, 771
многогранники, 770
обобщенные цилиндры, 782
поверхности вращения, 774
условие группировки, 774
прямые однородные обобщенные
цилиндры, 776
условие группировки, 777
цилиндры, 770
условие группировки, 771
явные геометрические
соображения, 793-797
Сглаживание, 211
взвешенное среднее, 210
гауссово, 210-212; 257
дискретное ядро, 213; 259
эффективность, 257
окантовка, 210
подавление независимого
стационарного аддитивного
шума, 214
центральная предельная теорема,
258
эффект масштаба, 213; 256
гауссово ядро, 212
дискретная аппроксимация, 259
для снижения наложения, 231;
233-235
реакция на шум, 249
Сглаживания с сохранением краев, 244
Сегментация, 423; 640
вычитание фона, 508
как задача с недостающими
данными, 492
кластеризация, 427
модельные задачи, 426
области, 426
подбор прямых, 426
подбор фундаментальной
матрицы, 426
применение в цифровых
библиотеках, 826
примеры приложений, 425; 433
вычитание фона, 434-436
определение границ кадров, 436
сегментация с помощью
ОМ-алгоритма, 498-501
сопоставление по семантике, 816
цели, 424
человек, 428
гештальтквалитат, 428
замкнутость, 429
знакомая конфигурация, 429-430
кажущиеся контуры, 433
непрерывность, 429
общая область, 429
общее поведение, 429
параллельность, 429
подобие, 429
примеры, 430-433
рисунок и фон, 428, 429
симметрия, 429
соседство, 429
факторы, предрасполагающие к
группировке, 429-433
Секущая, 588
922
Предметный указатель
Селекция, 541
Сигмоидальной функцией, 702
Сигнал, 249
Силуэт, 585
Симметричное гауссово ядро, 212
Симметрия, 429
Сингулярная точка, 588
Синтез, 289
Система координат, 64
аффинная, 360
евклидова, 64
локальная, 587
проективная, 390
Складка, 585; 602
Скорость, 593
Скрытая марковская модель, 745-759
Слабая калибровка, 314-317
восьмиточечный алгоритм, 315
нелинейная, 316
Слабоперспективная проекционная
модель, 44
Слепое пятно, 53
Смещение вследствие выбора, 511
Собственная тень, 138
Собственное движение, 546
Собственное значение
обобщенное, 91
Собственный вектор
обобщенный, 91
Совмещение бинокулярных
изображений, 333
Совмещение тринокулярных
изображений, 348
Совокупность, 736
Согласование по связям, 728-759
Соотношение Лонгета-Хиггинса, 309
Сопоставление по виду, 816
Сопоставление по семантике, 816
Сопровождение, 541
ассоциация данных, 537
с помощью вероятностной
ассоциации данных, 540
селекция, 540
учет ближайших соседей, 537
фон, 537
измерение
возможность наблюдения, 522
матрица измерений, 522
как задача логического
вывода, 519-520
ключевые допущения, 519
коррекция, 520
основные случаи, 518
предсказание, 520
линейные динамические модели, 521
дрейф, 522
модели высших порядков, 526
периодическое движение, 525
постоянная скорость, 522-523
постоянное ускорение, 524
определение, 517
основные задачи
ассоциация данных, 519
коррекция, 519
предсказание, 519
применение, 542
наблюдение, 517
прицеливание, 518
распознавание, 517
системы сопровождения
автомобилей, 543-547
сглаживание, 531-537
фильтры Кальмана, 526
коррекция (одномерный
случай), 529
одномерные гауссианы, 527
одномерный случай, 527
предсказание (одномерный
случай), 528
Предметный указатель
923
пример сопровождения точки на
прямой, 530; 531
реверсивное сглаживание, 531
система обозначений, 527
уравнения для одномерного
случая, 529
уравнения для произвольной
размерности, 532
Соседство, 429
Составной видеоформат, 57
Составные линзы, 50
Спад по закону cos4 а, 119
Спектральная БФРО, 162
Спектральные величины, 162
Спектральная отражательная
способность, 165
Спектральная светимость, 162
Спектральная траектория, 176
Спектральное альбедо, 165
Спектральное зеркальное альбедо, 166
Спектральное излучение, 162
Спектральные единицы, 161
Сплайн
кривая, 839
поверхность, 839; 840
Сравнение с шаблоном, 673-674
применение в цифровых
библиотеках, 827-831
Срединная ось, 785
Среднеквадратическое отклонение, 212
Стерадианах, 111
Стереограмма со случайными
точками, 339
Стереозрение
восстановление, 334-337
несколько точек
наблюдения, 349-351; 844
очистка, 336-337
расхождение, 333; 336; 338
совмещение бинокулярных
изображений, 341-348
динамическое
программирование, 345-348
многошкальное
согласование, 344-345
нормированная
корреляция, 341-343; 849
совмещение тринокулярных
изображений, 348-349
стереограмма со случайными
точками, 339
условия
единственность, 339
непрерывность, 339
совместимость, 339
упорядочение, 345
эпиполярные, 334
Стереозрение на основе модели, 849
Стереоустройство, 310
Стохастический градиентный
спуск, 705
Строгое преобразование, 71
Структурированный свет, 638
Ступенчатыми краями, 273
Суперпозиция, 216
Существенная матрица, 309
Сферическая аберрация, 50
Схема наименьших квадратов, 88; 465
линейная, 88; 335
неоднородная, 661
однородная, 656
нелинейная, 88; 336
Схема /с-средних, 441
т
Текстони, 278
TPKCiyprt
и ни |н»пн<»г гь, 301
Mrti ltlUlG, 2/7
924
Предметный указатель
однородность, 297
представление с помощью выходов
фильтров, 278-282
применение в цифровых
библиотеках, 823-825
примеры, 277-279
синтез, 296-299
статистика выходов фильтров, 283
выбор статистики, 283-285
масштаб окна, 286
пример, 284
форма по текстуре, 300
на примере плоскостей, 300-303
Телесный угол, 110-112
единицы, 111
определение, ПО
Теневой ток, 58
Тензорная форма записи, 325
Тензорное произведение, 258
Тень, 138
отбрасываемая, 138
плоские источники, 139
собственная, 138
точечные источники, 138
Теорема Коендеринка, 603-605
Теорема о восстановлении аффинной
структуры по
движению, 368\ 855
Теорема о свертке, 224
Теореме Найквиста, 231
Теория катастроф, 610
Тестовый свет, 167
Техника построения изображений, 575
Толстые линзы, 49
главные точки, 49
Тонкая линза, 47-49
спад по закону cos4 а, 119
уравнение, 48
уравнение излучения, 119
фокус, 48
фокусное расстояние, 48
Точечный источник, 130
близлежащий, 132-133
вектор источника, 132
выбор модели, 133
общие положения, 131
светимость, 131
точечный источник на
бесконечности, 132
Точка возврата, 586-628
второго рода, 589
гауссова, 615
первого рода, 589
Точка перегиба, 588-619
Точки на бесконечности, 389
Точки привязки, 837\ 849
Треугольный сплайн, 840
Трехгранная вершина, 556
Трехцветности, 168
Трилинейные условия, 320
Трифокусная линия, 317
Трифокусная плоскость, 317
Трифокусные условия, 319-329
1 точка, 2 прямых, 322
3 прямых, 322
3 точки, 322
3 точки, 3 луча, 327
Трифокусный тензор, 352
оценка, 324
Тройная точка, 620-622
У
Углы Эйлера, 107
Угол наклона, 301
Ультразвуковое исследование, 575
Уравнения диффузии, 244
Уровень, 505
Ускорение, 593
Условие ограничения масштаба, 330
Условие упорядочения, 345
Предметный указатель
925
Устойчивость, 474-475; 507-509
RANSAC, 479-481
выбросы, 475
Участок Монга, 140
Ф
Фаза, 225; 280
Фазовый спектр, 225
Фильтрация, 210
Фильтры Кальмана, 526
Флуоресцентные лампы, 164
Флуоресценция, 115
Фокус, 48
Фокус расширения, 313
Фокусное расстояние, 48
Форм-фактор, 152
Форма
аффинная, 357
евклидова, 413
проективная, 388
Формула Родригеса, 107
Фотограмметрия, 103; 310-333; 849
Фотометрическое стерео, 140
дуальное, 633
интегрируемость, 146; 194
Фотопереход, 56
Фрагменты, 728
Фробениусова норма, 374; 409; 414
Фундаментальная матрица, 309
подбор по семи точкам, 483
подбор с использованием RANSAC,
482-483
Фундаментальные точки, 391
Функция влияния, 477
Функция подбора света, 173
Функция распределения
двунаправленного
отражения, 116
единицы,116
определение, 116
принцип обратимости Гельмгольца,
116
Функция точечного рассеяния, 222
X
Хребет, 783
Хроматическая аберрация, 50
Хроматическая адаптация, 182
ц
Цвет, 183-200
Цвет поверхности, 191
Цветная фотография, 55
Цветовая температура, 162
Цветовые пространства, 174; 182
Целочисленное программирование, 452
Центр изображения, 42
Центр кривизны, 589
Центральная перспектива, 41
Цилиндр, 771
Цилиндр наблюдения, 585
Цифровые библиотеки, 809
видео, 832-835
выборка информации, 812
гистограмма цветов, 818
использование текста и изображения
коррелограмма цветов, 819
навигация, 816
основные стратегии поиска
оценка, 812
поиск новостей (пример), 813
пример поиска патента, 812
пример фильтрации Web, 812
точность, 812
поиск через сопоставление
с шаблоном, 827
приложения, 810
резюмирующие
представления, 817-825
гистограммы, 818
926
Предметный указатель
коррелограммы, 819
текстура, 821
текстура текстур, 823-825
сопоставление по виду, 816
сопоставление по семантике, 816
точность, 812
требования пользователей, 814
эффективность восстановления, 812
Ч
Части
применение в цифровых
библиотеках, 829-831
Частота биения, 639
Человек
глаз, 52-54
желтое пятно, 53
колбочки, 53
палочки, 53
слепое пятно, 53
чувствительное поле, 54
ямка, 53
стереозрение, 337-341; 351
гороптер, 338
стереограмма со случайными
точками, 339
Чувствительное поле, 54
ш
Шаблон, 769
Шум, 249; 251-255
аддитивный стационарный гауссов
шум, 248; 250
выбор сглаживающего фильтра, 255
гауссово ядро, 257
формальные критерии, 255
эффект масштаба, 256
выбор сглаживающего фильтра, 257
реакция линейного фильтра, 249
сглаживающий шум, 253
щ
Щеточная функция, 228
э
Экспоненциальное представление
матриц, 331
Элементарное затенение, 158
Эллиптическая точка, 595; 604
Эпиполюс, 310; 322-323; 400-404
Эпиполярная геометрия, 310; 849
Эпиполярная линия, 310; 334-349; 400
Эпиполярная плоскость, 310; 400
Эпиполярное преобразование, 314; 400
Эпиполярное ограничение, 309; 325
аффинная фундаментальная
матрица, 368-371
параметризация, 371
соотношение Лонгета-Хиггинса, 312
для неоткалиброванных камер, 313
мгновенная форма, 313
существенная матрица, 309
параметризация, 312
характеристики, 313
фундаментальная матрица, 310; 314
параметризация, 314; 400-401
характеристики, 314
Я
Ядро, 210; 222
Ядро взаимного отражения, 150
Якобиан, 94; 626
Ямка, 53
Яркость, 191
Научно-популярное издание
Дэвид А. Форсайт, Джин Понс
Компьютерное зрение. Современный подход
Литературный редактор
Верстка
Художественный редактор
Корректор
П. Н. Мачуга
А.В. Назаренко
С.А. Чернокозинский
А.В. Назаренко
Издательский дом “Вильямс”.
101509, Москва, ул. Лесная, д. 43, стр. 1.
Изд. лиц. ЛР № 090230 от 23.06.99
Госкомитета РФ по печати.
Подписано в печать 27.02.2004. Формат 70X100/16.
Гарнитура Times. Печать офсетная.
Усл. печ. л. 70,95. Уч.-изд. л. 66,78.
Тираж 3000 зкз. Заказ № 2056.
Отгчнпннн дишннипииж пФГУП " 1 Icuatiu.iU днпр”
Mmiiih t с [hi пи РФ ио иглам псгнги,
1ги<-|ШЛИ1»нг|)шинм и (|глст M4U t иныц коммуникации
I4/U0. Спим IktcpOypi, Чкнппыкий пр. 15.
Компьютерное
зрение
СОВРЕМЕННЫЙ ПОДХОД
ФОРСАЙТ ПОНС
Эту необычную книгу, отражающую современный взгляд на область компьютерного зре-
ния, можно назвать стратегическим обзором: здесь описана вся индустрия компьютер-
ного зрения в целом, но это сделано настолько подробно и доходчиво, что заинтересо-
ванный читатель сможет сам создавать полезные приложения. Темы, освещенные в книге, по-
добраны из соображений значимости (теоретической и практической), кроме того, авторы
старались показать максимально непротиворечивую картину существующих представлений
о компьютерном зрении и сакцентировать внимание на методах, которые нашли практичес-
кое применение. Данная книга будет полезным справочником для тех, кто занимается ком-
пьютерной графикой, робототехникой, обработкой изображений и изображениями вообще.
КЛЮЧЕВЫЕ ОСОБЕННОСТИ
Обзоры приложений. Множество примеров, иллюстрирующих, в частности, визуализацию
на основе изображений и работу с цифровыми библиотеками
Алгоритмы. Ключевые алгоритмы выделены визуально и представлены в псевдокоде
Самодостаточное руководство. Дополнительная литература не требуется
Исчерпывающие, подробные иллюстрации. Примеры входов и выходов существующих схем
Средства контроля. 150 задач и 50 упражнений
Дэвид Форсайт получил докторскую степень по специальности “Информатика”в Оксфордс-
ком университете. В настоящее время он занимает должность адъюнкт-профессора на фа-
культете информатики в Калифорнийском университете в Беркли. Профессор Форсайт — ав-
тор более 60 работ и соавтор 10 книг по компьютерному зрению, имеет многочисленные на-
грады.
Жан Понс получил докторскую степень по специальности “Информатика” в Парижском
университете в Орсе. В настоящее время он занимает должность профессора в институте Бек-
мана в Иллинойском университете в Урбана-Шампейн. Профессор Понс является автором
множества работ, журнальных статей и соавтором 15 книг по различным предметам, в том
числе робототехнике, компьютерному зрению и компьютерной графике.
Prentice
Hall
www.williamspubhshing.com
www.prenhall.com