













































































































































































































































































































































































































Автор: Комарцова Л.Г. Максимов А.В.
Теги: общее машиностроение технология машиностроения кибернетика информатика нейронные сети машинное обучение
ISBN: 5-7038-2554-7
Год: 2004




Текст
Информатика в техническом университете
... Л.Г. Комащова, А.В. Максимов
JJ
* Ф
II I
I
I 'I
I
та) S3 6» С5Э
|ммм| ими! «мяк йммк
'1 I
13.
-■■ЦЦи
ft
Til
«У
if'}
Издательство
МГТУ имени
Н.Э. Баумана
s s s s
15Э 69 6^1 i55
Информатика в техническом университете
Информатика в техническом университете
Серия основана в 2000 году
РЕДАКЦИОННАЯ КОЛЛЕГИЯ:
чл.-кор. РАН КБ. Федоров — главный редактор
д-р техн. наук 77.77. Норенков — зам. главного редактора
д-р техн. наук Ю.М. Смирнов — зам. главного редактора
д-р техн. наук В. В. Девятков
д-р техн. наук В. В. Емельянов
канд. техн. наук 77.77. Иванов
д-р техн. наук В.А. Матвеев
канд. техн. наук Н.В. Медведев
д-р техн. наук В. В. Сюзев
д-р техн. наук Б.Г. Трусов
д-р техн. наук В.М. Черненький
д-р техн. наук В.А. Шахнов
Л.Г. Комарцова, А.В. Максимов
Нейрокомпьютеры
Издание второе, переработанное и дополненное
Допущено Министерством образования
Российской Федерации
в качестве учебного пособия
для студентов высших учебных заведений,
обучающихся по специальности
«Вычислительные машины, комплексы, системы и сети»
направления подготовки дипломированных специалистов
«Информатика и вычислительная техника»
Москва
Издательство МГТУ имени Н.Э. Баумана
2004
УДК 621(075.8)
ББК 32.818
К 63
Рецензенты:
кафедра «Нейрокомпьютеры»
Московского физико-технического института
(зав. кафедрой докт. техн. наук А.И. Галушкин);
профессор Г.А. Полтавец
(Московский авиационный институт)
Комарцова Л.Г., Максимов А.В.
К 63 Нейрокомпьютеры: Учеб. пособие для вузов. - 2-е изд., перераб. и
доп. - М.: Изд-во МГТУ им. Н.Э. Баумана, 2004. - 400 с: ил. -
(Информатика в техническом университете.)
ISBN 5-7038-2554-7
Изложены вопросы современной теории нейрокомпьютеров. Приведен анализ
различных архитектур вычислительных устройств с параллельной организацией работы.
Рассмотрен биологический аналог параллельной организации обработки информации.
Большое внимание уделено разновидностям построения формальных нейронов,
технологии сетей и классическим методам их обучения, методам подготовки задач для решения на
нейрокомпьютерах. Приведены оригинальные результаты применения нейронных сетей
для решения систем дифференциальных уравнений и степенных рядов в
конструировании нейросетевых алгоритмов; обучения нейронных сетей на базе генетического
алгоритма и теории адаптивного резонанса. Представлены программные системы эмуляции
нейронных сетей, разработанных в Калужском филиале МГТУ им. Н.Э. Баумана. Уделено
внимание аппаратной реализации нейрокомпьютеров, в том числе и на отечественной
элементной базе.
Второе издание (1 -е - 2002 г.) переработано и дополнено исследованием новых типов
нейронных сетей, в том числе гибридных, построенных на основе интеграции с нечеткими
системами и генетическими алгоритмами. Добавлен материал, иллюстрирующий
использование нейрокомпьютеров при решении прикладных задач.
Содержание учебного пособия соответствует курсу лекций, которые авторы читают
в Калужском филиале МГТУ им. Н.Э. Баумана.
Для студентов, инженеров, аспирантов и научных сотрудников кибернетических
специальностей.
УДК 621(075.8)
ББК 32.818
© Л.Г. Комарцова, А.В. Максимов, 2002; 2004 с изменениями
ISBN 5-7038-2554-7 О МГТУ им. Н.Э. Баумана, 2002; 2004 с изменениями
ОГЛАВЛЕНИЕ
Предисловие 8
1. Введение в системы с параллельной организацией
вычислительного процесса 10
1.1. Работа вычислительной системы в реальном масштабе времени 10
1.2. Предпосылки создания параллельных ЭВМ 16
1.3. Анализ эффективности параллельных архитектур
вычислительных систем 19
1.4. Биологический аналог параллельной организации обработки
информации 27
1.5. Нейрокомпьютеры и их место среди высокопроизводительных
ЭВМ 30
2. Модели операционного блока нейрокомпьютеров 36
2.1. Обобщенная структурная схема нейрокомпьютера 36
2.2. Модели формальных нейронов 39
2.3. Классификация нейронных сетей 47
2.4. Методика решения задач в нейросетевом базисе 55
3. Конструирование формируемых нейронных сетей 58
3.1. Общие сведения 58
3.2. Синтез нейронной сети для решения нормальной системы
дифференциальных уравнений 59
3.3. Применение степенных рядов при синтезе формируемых
нейронных сетей 73
4. Настройка нейронной сети на решение прикладных задач 83
4.1. Компоненты нейрокомпьютера 83
4.2. Предварительная обработка информации 87
4.3. Интерпретатор ответов сети 91
4.4. Оценка качества работы нейронной сети 93
4.5. Конструирование нейронных сетей 95
4.6. Отбор информативных данных 102
4.7. Обучение нейронной сети 104
4.8. Пример решения задачи классификации на основе нейронной
сети 108
5
Оглавление
5. Обучение нейронных сетей без обратных связей 112
5.1 Эволюция развития персептронных алгоритмов обучения 112
5.2. Обучение многослойной нейронной сети без обратных связей 122
5.3. Анализ стандартных методов оптимизации в процедуре обучения
многослойного персептрона 130
5.4. Пример использования многослойной нейронной сети для решения
задачи выбора архитектуры сервера 136
5.5. Решение задачи прогнозирования временного ряда с помощью
многослойного персептрона 139
6. Обучение нейронных сетей на основе генетического алгоритма... 143
6.1. Суть генетического алгоритма 143
6.2. Формирование популяции 148
6.3. Классификация генетических операторов 149
6.4. Селекция решений 151
6.5. Способы отбора решений в популяцию 152
6.6. Кодирование потенциальных решений 154
6.7. Теорема схем в генетическом алгоритме 158
6.8. Многопопуляционный генетический алгоритм 160
6.9. Исследование ГА для решения задачи обучения НС 162
б.Ю.Управляемый алгоритм обучения нейронной сети на основе
генетического поиска и имитации отжига 168
7. Рекуррентные и ассоциативные нейронные сети 175
7.1. Характеристики ассоциативной памяти 175
7.2. Рекуррентные нейронные сети 177
7.3. СетьХопфилда 178
7.4. Машина Больцмана (вероятностная сеть) 181
7.5. Сеть Хемминга 183
7.6. Ассоциативно-проективные нейронные сети 187
7.7. Нейронная сеть СМАС 195
7.8. Двунаправленная ассоциативная память 199
8. Самоорганизующиеся нейронные сети 203
8.1. СетьКохонена 203
8.2. Сети на основе теории адаптивного резонанса 215
8.3. Сети встречного распространения 224
9. Радиально-базисные и другие модели нейронных сетей 227
9.1. Радиально-базисные нейронные сети 227
9.2. Другие типы нейронных сетей без обратных связей 234
9.3. Перспективы использования НС для создания интеллектуальных
систем 237
6
Оглавление
10. Математические основы построения нечетких систем 239
10.1. Основные положения нечеткой математики 239
10.2. Структура и принципы работы нечеткой системы 251
10.3. Пример использования СНЛ 264
11. Гибридные нейронные сети 267
11.1. Интеграция нейросетевых и нечетких систем 267
11.2. Нейросетевые элементы нечетких систем 268
11.3. Нейросетевая модель нечеткого композиционного вывода 271
11.4. Нечеткие элементы нейросетевых систем 274
11.5. Алгоритм обучения нечеткого персептрона 276
11.6. Нечеткая нейронная сеть Кохонена 279
11.7. Нечеткое управление параметрами обучения нейронных сетей 282
12. Программная эмуляция нейрокомпьютеров 289
12.1.Классификация нейроимитаторов 289
12.2. Программный комплекс Neurolterator 292
12.3. Нейросетевой пакет ЛОКНЭС 311
12.4. Работа двухмерной нейронной сети 324
12.5. Нейропакет Neural Networks IDE 327
12.6. Пакет STATISTICA Neural Networks 343
12.7. Пакет Fuzzy Expert 347
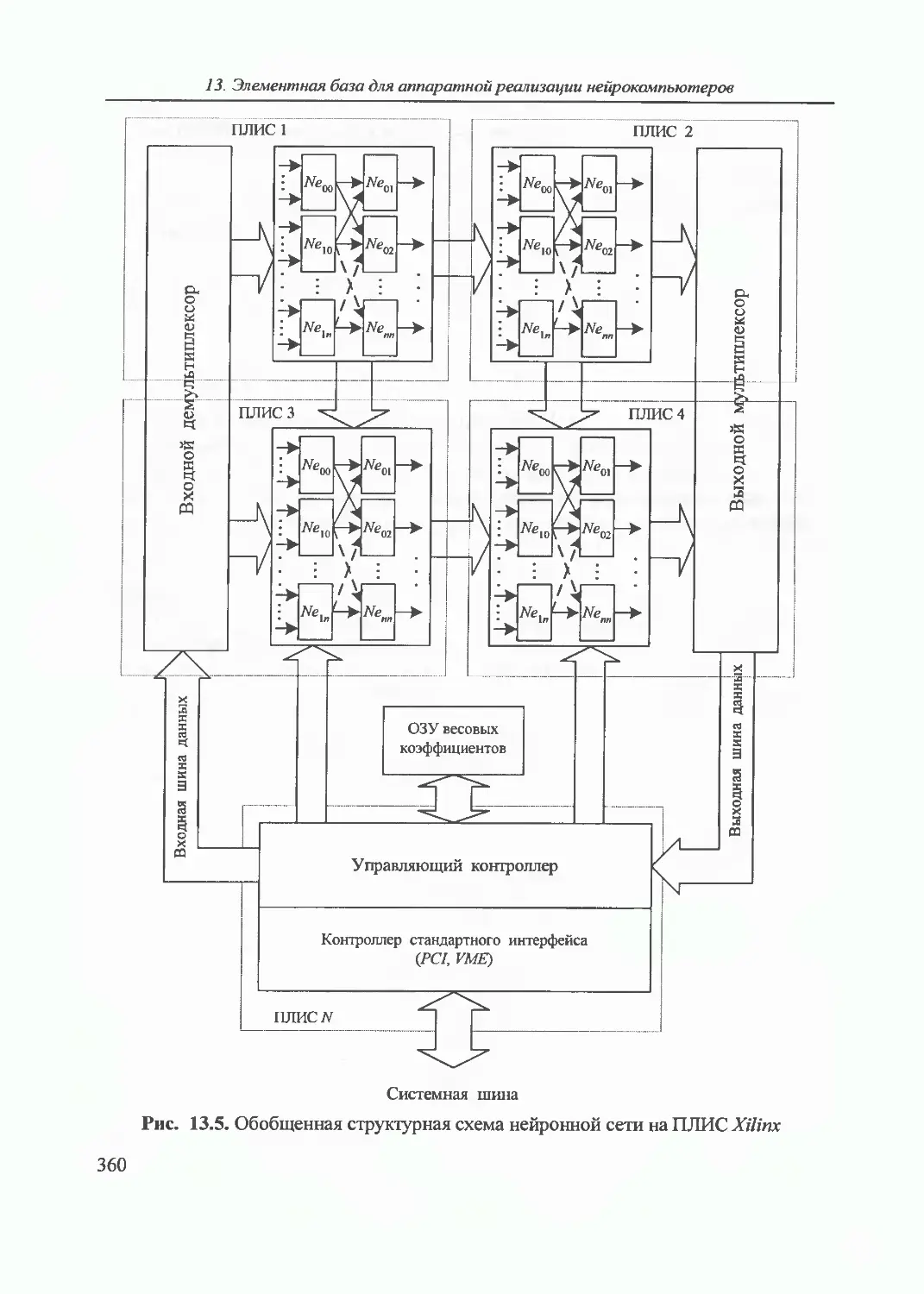
13. Элементная база для аппаратной реализации нейрокомпьютеров... 353
13.1. Общие сведения 353
13.2. Особенности ПЛИС как элементной базы нейрокомпьютеров 354
13.3. Особенности ЦСП как элементной базы нейрокомпьютеров 363
13.4. Нейрочипы 366
Заключение 394
Список литературы 397
Предметный указатель 398
К 175-летию МГТУ имени Н.Э. Баумана
ПРЕДИСЛОВИЕ
В последние годы наблюдается активизация теоретических и практических
разработок в области нейрокомпьютеров. Все больше и больше
разработчиков различных областей обращаются к ним. Это объясняется многими
причинами, которые действуют, как правило, в совокупности.
Во-первых, теория нейровычислителей - ровесница теории машин фон
Неймана. Поэтому для этого научного направления давно определен свой предмет
исследования. За более чем 50-летнюю историю сформировались и
развиваются свои методы исследования.
Во-вторых, теория и практика классических машин фон Неймана начинает
качественное перерождение. Наступает эра параллельных, многопроцессорных
вычислительных устройств.
В-третьих, достижения микроэлектроники стимулируют практическую
реализацию быстродействующих и недорогих вычислительных систем, с успехом
используемых во многих областях деятельности человека.
Поскольку нейрокомпьютеры занимают самостоятельное и весомое место
среди высокопроизводительных вычислительных машин с параллельной
организацией работы, то было бы непростительным не включать нейротематику в
учебные планы подготовки инженеров по кибернетическим направлениям и
специальностям.
Предлагаемое учебное пособие ориентировано на базовую подготовку
студентов по направлению «Информатика и вычислительная техника», а также
других родственных направлений.
Книга состоит из тринадцати глав. В главе 1 рассмотрены особенности
работы ЭВМ как элемента системы управления, приведены предпосылки
создания параллельных ЭВМ, проведен анализ эффективности различных структур
параллельной организации вычислительного процесса, показано место
нейрокомпьютеров среди высокопроизводительных ЭВМ. В главе 2 приведены
обобщенная структурная схема нейрокомпьютера и сравнение ее со схемой
машины фон Неймана. Большое внимание уделено различным топологиям
нейронных сетей. В заключении приводится методика решения задач в нейросете-
вом базисе, предложенная А. И. Галушкиным.
В главе 3 приведены теория и практические результаты проектирования
формируемых нейронных сетей для решения линейных систем
дифференциальных уравнений. Рассмотрен практический пример применения степенных
рядов для конструирования нейронной сети, воспроизводящей полиномы. Глава
4 посвящена решению проблем настройки нейронной сети (НС) на конкретную
решаемую задачу.
8
Предисловие
В главах 5,6,8,9 представлена эволюция развития алгоритмов обучения на
основе многослойного персептрона, рассмотрены проблемы построения,
обучения и использования рекуррентных и ассоциативных НС на примерах сетей
Хопфилда, Хемминга, машины Больцмана, двунаправленной ассоциативной
памяти. Исследуются основные особенности алгоритмов обучения без учителя
для сети Кохонена и сетей адаптивного резонанса, обсуждаются вопросы
построения и использования радиально-базисных, функциональных и других
типов сетей. Показана целесообразность построения комбинированных НС для
повышения качества решения прикладных задач. Для каждой из
рассмотренных видов сетей определены классы задач, которые наиболее эффективно ими
решаются, приведены примеры решения таких задач.
Глава 7 посвящена изложению перспективного эвристического метода
оптимизации в процедуре обучения многослойной НС, основанного на
генетическом алгоритме (ГА). Приведен анализ различных генетических операторов
и схем построения ГА, обеспечивающих минимизацию ошибки обучения НС.
В главах 10 и 11 представлены основные положения теории нечеткой логики
Л. Заде применительно к НС, определены задачи, которые необходимо решать
при построении нечетких систем, и способы их реализации. Исследованы
возможности построения некоторых гибридных нейросетевых нечетких и
нечетких нейросетевых систем, позволяющих повысить эффективность их
использования при решении прикладных задач классификации и распознавания.
В главе 12 рассмотрены программные пакеты нейроимитаторов и нечетких
систем, разработанные на кафедре «Компьютерные системы и сети»
Калужского филиала МГТУ им. Н. Э. Баумана, а в главе 13 - элементная база
аппаратной реализации нейрокомпьютеров. Особое внимание уделено
программируемым логическим схемам фирмы XILINX и сигнальным процессорам, как
наиболее перспективным элементам для построения нейрокомпьютеров.
Авторы стремились изложить материал в доступной для студентов форме и
восполнить пробелы в учебной литературе по данной тематике. Именно
поэтому в книге подробно рассматриваются типы НС, получившие наибольшее
распространение на практике.
Во втором издании книги существенно переработаны главы 9,10, добавлен
новый материал в главы 7,10,11 по проблемам построения на принципах
синергизма гибридных нейро-генетических и нейро-нечетких систем, а также в
главу 13, в которой приведены характеристики элементной базы нейрокомпьютеров.
Главы 4-11 написаны Л.Г. Комарцовой; главы 2,3,13 - А.В. Максимовым;
главы 1 и 12 написаны авторами совместно.
Авторы глубоко признательны рецензентам: кафедре «Нейрокомпьютеры»
Московского физико-технического института (зав. кафедрой докт. техн. наук
А.И. Галушкин) и профессору Г.А. Полтавец (Московский авиационный
институт) за ценные замечания и рекомендации, которые были учтены авторами
при работе. Хочется выразить также благодарность студентам и аспирантам,
пр i i : i участие в написании отдельных па» • и «в:И.В. Винокурову (§12.2),
А.В. Бобкову (§ 12.3 ), В.А. Алексееву (§§ 2.3, 12.4), А.К. Злобину (12.5), а
также А.Ю. Солодовникову (12.7).
Авторы
9
1. ВВЕДЕНИЕ В СИСТЕМЫ
С ПАРАЛЛЕЛЬНОЙ ОРГАНИЗАЦИЕЙ
ВЫЧИСЛИТЕЛЬНОГО ПРОЦЕССА
Обоснована необходимость создания параллельных ЭВМ, приведен анализ
эффективности существующих архитектур вычислительных систем с параллельной
организацией обработки информации. Кратко рассмотрен биологический аналог
параллельных вычислителей, дано определение нейрокомпьютерам, рассмотрена их роль и
место среди высокопроизводительных ЭВМ.
1.1. Работа вычислительной системы в реальном
масштабе времени
Первые ЭВМ появились еще в прошлом веке. За это время сменилось уже
несколько поколений вычислительных машин. Менялись элементная база,
конструктивные решения, языки программирования, программное обеспечение, но
основы архитектуры, заложенные при создании машин первого поколения,
практически без изменения перешли на машины последующих и успешно
работают до настоящего времени. Нет сомнений, что идеи машин первого поколения
еще послужат человеку. Однако все настоятельнее требуются системы,
наделенные элементами интеллекта при обработке колоссального объема
информации и в то же время работающие в темпе управляемых процессов.
Наиболее ярким примером таких систем являются системы автоматического (и/или
автоматизированного) управления техническими объектами с ЦВМ в контуре.
Рассмотрим работу такой системы.
В классической теории управления техническими объектами
рассматривают различные варианты схем систем управления с ЦВМ в контуре. Для
лучшего понимания принципа построения нейрокомпьютеров рассмотрим
несколько отличную от привычных схему, представленную на рис. 1.1.
10
F(0
Задатчик
программного
движения
Y„P(0
<т(0
*..,«
ЦАП
Исполнительные
механизмы
УЦВМ
U(0
*»««)
Объект
управления
АЦП
Датчики
Х(0
}
Рис. 1.1. Система управления с ЦВМ в контуре:
Х(/)-вектор состояния объекта; Х^С*)- вектор измеряемых параметров состояния объекта;
Yiiri(/) - вектор вычисленных параметров; Y (/) - вектор программного входного воздействия;
<У(/)- сигнал ошибки; U(/)-управляющее воздействие; F(/)-возмущение
1. Введение в системы с параллельной организацией вычислительного процесса
Система, приведенная на рис. 1.1, работает следующим образом. Под
действием управления U(t) объект движется по программной траектории. Однако
случайные, неуправляемые возмущения ¥(t) отклоняют его движение от
заданного. Отдельные компоненты вектора состояния объекта Хюм(?)
измеряются датчиками, затем квантуются по амплитуде и по времени
аналого-цифровыми преобразователями (АЦП) и передаются в управляющую ЦВМ
(УЦВМ). Последняя, преобразовав измеренную входную информацию по
заданному алгоритму, подает на узел сравнения вектор вычисленного
воздействия Y ыч(0> соответствующий состоянию объекта на момент измерения. Узел
сравнения вырабатывает сигнал ошибки a(t) и передает его исполнительным
механизмам. Сформированное исполнительными механизмами управление U(t),
воздействуя на объект, возвращает его на программную траекторию.
Очевидно, что ЦВМ, включенная в контур рассмотренной системы
управления, должна удовлетворять следующим требованиям:
• осуществлять возложенные на нее вычисления с точностью,
позволяющей системе нормально выполнять свои функции;
• проводить обработку входной информации в темпе работы системы.
Иначе говоря, управляющая ЦВМ должна вьщавать результаты с требуемой
точностью и работать в реальном масштабе времени.
Современный уровень развития элементной базы вычислительной техники
позволяет выполнять задатчик программного движения и узел сравнения в виде
программных модулей, размещаемых в памяти той же УЦВМ, что и основной
алгоритм обработки входной информации. В этом случае УЦВМ будет
вырабатывать непосредственно сигнал ошибки и, очевидно, будет иметь большую
вычислительную нагрузку. На рис. 1.2 представлена система управления с
расширенными функциями УЦВМ.
Практическим примером систем, представленных на рис. 1.1 и 1.2,
является бесплатформенная инерциалъная система ориентации, структурная
схема которой показана на рис. 1.3. Работа системы заключается в
следующем. Под действием маршевых двигателей подвижный объект движется в
пространстве в общем случае по произвольной пространственной траектории.
Изменение направления движения объекта в пространстве определяется
положением его рулей, которые приводятся в действие рулевым приводом. Рулевой
привод на схеме 1.3 является исполнительным механизмом на рис. 1.1, 1.2.
Изменение положения рулей изменяет ориентацию объекта, что в свою
очередь приводит к изменению его пространственной траектории движения. В
качестве датчиков текущего состояния объекта в рассматриваемой системе
используют лазерные датчики угловых скоростей (ЛДУС). Это объясняется
тем, что в настоящее время нет простых и сравнительно недорогих датчиков
углового положения подвижных объектов, которые измеряли бы углы в диапа-
12
Модуль программного
движения
Модуль вычисления
рассогласования
(ошибки)
УЦВМ
Модуль реализации
основного алгоритма
-К
ЦАП
а(0
-►^Исполнительные
механизмы
и(0
F(0
хюм(0
АЦП
■<.>•
Объект
управления
х(0
3
Датчики {
Рис. 1.2. Система управления с расширенными функциями УЦВМ
Программные
значения
угловых скоростей
w
Блок
интегрирования
кинематических
уравнений
i
УЦВМ
к
Рулевой
привод
Объект
управления
Лазерный датчик
угловых скоростей
(ЛДУС)
Параметры
ориентации
Рис. 1.3. Структурная схема бесплатформенной инерциальной системы ориентации
1. Введение в системы с параллельной организацией вычислительного процесса
зоне ±360°в трех плоскостях. Поэтому для подвижных объектов, имеющих
произвольную пространственную эволюцию, применяют датчики угловых
скоростей с последующим интегрированием кинематических уравнений.
Естественно, что это интегрирование ложится на УЦВМ. Наименьших затрат при
интегрировании кинематических уравнений можно достичь, если в качестве
параметров ориентации применять так называемые параметры Родрига-
Гамильтона, называемые еще кватернионами. Матричное
кинематическое уравнение в кватернионах имеет вид
А= 0,5(0-0^,
где Л = (Я,0, A,j, Х2, Я,3)т - вектор параметров ориентации (составляющие
кватерниона); Q, Q - матрицы, составленные из текущих и программных
значений проекций вектора угловой скорости объекта на связанную с ним систему
прямоугольных координат со,, со , со_. Обе матрицы имеют одинаковый вид
О -со, -со, -сог
Q= со, 0 со, -со,
СО, -СО, О СО,
сог со, -со, О
Значительное повышение качества работы системы дает ее
интеллектуализация. Систему управления можно назвать интеллектуальной, если она
способна на основе заложенных в ней знаний и полученных извне сведений
сформулировать программу движения объекта и найти способ оптимальной
реализации этой программы. На рис. 1.4 приведена схема системы
управления, обладающая элементами интеллекта.
Вычислительная часть этой системы имеет три пополняемых в ходе
эксплуатации базы данных: состояния среды (БД ССр); алгоритмов управления (БД
АУ); состояния объекта (БД СОб). Анализируя ситуацию, в которой находится
объект управления, при этом учитывая динамику изменения состояния
окружающей среды, формирователь управляющих воздействий (ФУВ)
корректирует программу движения объекта (МКПД) и вырабатывает команды на
изменение структуры исполнительных механизмов (МКСИМ) с тем расчетом, чтобы
объект достиг цели оптимальным способом. Критерии оптимальности зависят
от конкретного исполнения и назначения системы.
Очевидно, что выполнить такой огромный объем вычислительных работ
машина с последовательной архитектурой не в состоянии. Выход можно найти
лишь в применении параллельных принципов организации обработки
информации.
14
Q,
пр
-СО
хпр
СО
хпр
-СО
СО
.упр
■со
znp
хпр
-СО
.упр
СО
.упр
СО
хпр
СО
znp
СО
.упр
О
■со
со
хпр
хпр
г
БД ССр
БД АУ
ЬД
ч
w
МОССр
V
ФУВ
J
к
МКСИМ
МКПД
АЦП
ЦАП
ЦАП
АЦП
ДССр
1
г
ИМ
11
F(f)
г
Объект
управления
^
ДСОб
X®
W
пр ■■■ • | • щая вычислительная система
Рис. 1.4. Система управления с элементами интеллекта:
БД ССр - база данных состояния среды; МОССр - модуль оценки состояния среды; ДССр - датчики состояния среды;
БД АУ - база данных алгоритмов управления; ФУВ - формирователь управляющих воздействий;
ЦАП - цифроаналоговые преобразователи; МКСИМ - модуль коррекции структуры исполнительных механизмов;
МКПД - модуль коррекции программного движения; БД СОб - база данных состояния объекта; МОСОб - модуль оценки
состояния объекта; ДСОб - датчики состояния объекта; АЦП - аналого-цифровые преобразователи;
ИМ - исполнительные механизмы
1. Введение в системы с параллельной организацией вычислительного процесса
1.2. Предпосылки создания параллельных ЭВМ
В таких прикладных областях деятельности человека, как космология,
молекулярная биология, гидрология, охрана окружающей среды, медицина,
экономика и многих других, сформулированы проблемы, решение которых
потребует вычислительных машин, обладающих колоссальными ресурсами. Например:
быстродействие, TFLOPS 0,2... 200
оперативная память, Гбайт 100... 200
дисковая память, Тбайт 1 ...2
пропускная способность
устройств ввода-вывода, Гбайт/с 0,2... 0,5
На сегодняшний день нижняя граница указанных технических
характеристик реализуется только с помощью дорогостоящих уникальных архитектур от
CRAY, SGI, Fujitsu, Hitachi с несколькими тысячами процессоров. Чтобы
достичь верхней границы этих характеристик, необходимы интенсивные
исследования в области разработки новой элементной базы и новых архитектур
вычислительных систем (ВС).
В настоящее время концептуально разработаны методы достижения
высокого быстродействия, которые охватывают все уровни проектирования ВС. На
самом нижнем уровне - это передовая технология конструирования и
изготовления быстродействующей элементной базы и плат с высокой плотностью
монтажа. Это наиболее простой и прямой путь к увеличению
производительности ЭВМ. Так, например, если бы удалось все задержки при распространении
сигналов в ЭВМ сократить в к раз, то это привело бы к увеличению
быстродействия в такое же число раз. В последние годы достигнуты огромные
успехи в создании быстродействующей микропроцессорной элементной базы и
адекватных методов монтажа. В соответствии с законом Гордона Мура количество
транзисторов на кристалле удваивается каж-
N дые 18 месяцев (рис. 1.5), производительность
микропроцессора также увеличивается вдвое.
К 2006 г. на одной плате предполагается раз-
106 ^^г мещать 350 млн транзисторов (для сравнения
кристалл микропроцессора Pentium Pro
содержит 5,5 млн транзисторов).
Дальнейшая эволюция микропроцессоров,
по всей видимости, будет проходить по следу-
ю'
ю4
ю2
-I 1-
1970 1980 1990 2000 Гпп1Л
i оды ющим направлениям:
Рис. 1.5. Иллюстрация закона • уменьшение ширинь! проводника с 0,3 5 мкм
Мура- до 0,18 мкм (1/500 человеческого волоса);
N -число транзисторов на кристалле • уменьшение потребляемого напряжения;
16
1.2. Предпосылки создания параллельных ЭВМ
• увеличение металлических слоев (Pentium Pro содержит 5 слоев,
предполагается 8 слоев);
• усложнение архитектуры микропроцессора.
' К 2011 г. предполагается выпустить микропроцессор под условным
названием «Micro-2011» со следующими характеристиками: 1 млрд транзисторов на
кристалле; тактовая частота 10 Ггц; производительность 2,5 тыс. MFLOPS
(1MFLOPS = 106 операций с плавающей точкой в 1 с). Таким образом, основ-
i ная тенденция в развитии современной элементной базы направлена на
повышение степени интеграции так, чтобы на одной плате можно было реализовать
суперЭВМ. Это требует развития новых прогрессивных технологий (оптоэлект-
ронной технологии, нанотехнологии) и материалов (например, арсенид гал-
, лия - GaAs).
Теоретически совершенствование элементной базы — самый простой
метод повышения производительности вычислительных систем. Однако на
практике он приводит к существенному удорожанию новых разработок. Поэтому
наиболее приемлемым путем к созданию высокопроизводительных ЭВМ,
оцениваемых по критерию «производительность/стоимость», может быть путь
исследования и разработки новых методов логической организации систем, а
также новых принципов организации вычислений. Основной способ повышения
производительности с этой точки зрения - использование параллелизма.
' Параллельной называется такая обработка на ЭВМ, которая
предусматривает одновременное выполнение программ или их отдельных частей на
независимых устройствах.
Известны следующие базовые способы введения параллелизма в архитек-
\ туру ЭВМ:
• конвейерная обработка - применение методов конвейерной сборки для
повышения производительности арифметико-логического и управляющего
устройства;
' • функциональная обработка - предоставление нескольким независимым
устройствам возможности параллельного выполнения различных функций,
таких, как операции логики, сложения, умножения, приращения и т. д., и
обеспечение взаимодействия с различными данными;
i • матричная обработка - производится большим числом идентичных
процессорных элементов (ПЭ) с общей системой управления и организованных в
! виде матриц, при этом все ПЭ выполняют одну и ту же операцию, но с
различными данными, хранящимися в локальной памяти каждого процессора, т. е.
I жестко связанные пошаговые операции;
• мультипроцессорная обработка - осуществляется несколькими
процессорами, каждый из которых имеет свои команды; взаимодействие процессоров
осуществляется через общее поле памяти.
г
17
1. Введение в системы с параллельной организацией вычислительного процесса
Естественно, что в отдельных проектах могут объединяться некоторые или
все эти способы параллельной обработки. Например, процессорная матрица в
качестве ПЭ может иметь конвейерные арифметические усгройства или одно
функциональное устройство в компьютере, содержащем множество таких
устройств.
На основе сопоставления структуры ЭВМ фон Неймана и
многопроцессорной системы были сформулированы критерии оценки производительности:
закон Гроша и гипотеза Минского.
Закон Гроша гласит, что производительность одного процессора
увеличивается пропорционально квадрату его стоимости (см. рис. 1.6, а). Следуя
этому закону, многопроцессорные системы строить нецелесообразно. Так, для
двукратного увеличения производительности в двухпроцессорной системе
требуется четырехкратное увеличение стоимости. По этой причине применение
многопроцессорных систем долгое время ограничивалось сферой военных
приложений, где необходима очень высокая надежность. В пределе закон Гроша
не может быть справедлив, поскольку конечность скорости распространения
электронов в проводнике ограничивает возможность увеличения
производительности. Поэтому на практике в верхней области графика зависимость имеет
совершенно иной вид (рис. 1.6, б ). В соответствии с практикой можно
расходовать все больше средств, не получая при этом скорости вычислений,
предсказываемой законом Гроша.
Гипотеза Минского утверждает, что в параллельной системе с и
процессорами производительность каждого из которых равна единице, общая
производительность растет лишь как log2 n (рис. 1.7) из-за необходимости обмена
данными. Вычислительные системы 60 - 70-х годов прошлого века, которые
имели по два, три, четыре процессора, как бы подтверждали эту гипотезу.
Однако загруженность п процессоров может быть гораздо выше logj и.
Производительность
Стоимость одного процессора
Производительность
▲
Область
ВЫПОЛН1
закона
Грош;
Стоимость одного процессора
Рис. 1.6. Графики закона Гроша:
а - теоретический; б- практический
18
1.3. Анализ эффективности параллельных архитектур вычислительных систем
В более совершенных
многопроцессорных системах за счет введения
соответствующих механизмов управления, например
мультипрограммирования, можно
значительно повысить коэффициент использования
процессоров, что и было реализовано в
вычислительных системах 80 и 90-х годов.
Гипотеза Минского является чересчур
пессимистичной. Линейного роста
производительности, т. е. при увеличении числа
процессоров в Р раз производительность также
увеличивается в Р раз, можно достичь
только в истинной параллельной системе при
полной загрузке процессоров.
max
6 Число
процессоров
Рис. 1.7. График, иллюстрирующий
гипотезу Минского:
Р— производительность
1.3. Анализ эффективности параллельных архитектур
вычислительных систем
Эффективность использования различных способов организации ВС
напрямую зависит от структур реализуемых алгоритмов. Алгоритмические
структуры отличаются друг от друга содержанием вычислительных процедур и
отношением их следования при выполнении программ. Вычислительная процедура,
в свою очередь, может состоять из других вычислительных процедур. В
контексте организации параллелизма это приводит к понятию детализации
параллелизма. Детализацию называют мелкой {мелкозернистой), если
вычислительные процедуры являются примитивными (т. е. реализуются одной
командой), и крупной {крупнозернистой), если эти процедуры являются
сложными (т. е. состоят из других процедур). Спектр значений уровня детализации
простирается от очень мелкого (на уровне совмещения отдельных фаз
выполнения команд) до очень крупного (на уровне выполнения независимых программ).
В современных ВС может также использоваться и комбинированная
детализация.
Сравним возможности различных видов алгоритмических структур для
организации высокоскоростных вычислений (рис. 1.8).
Важное преимущество последовательного подхода, реализующего
архитектуру ОКОД - одиночный поток команд и одиночный поток данных по
классификации Флинна, состоит в том, что для машин такого вида разработано
большое число алгоритмов и пакетов прикладных программ, созданы обширные
базы данных, накоплен богатый опыт программирования, разработаны
фундаментальные языки и технологии программирования. Поэтому дальнейшее
совершенствование организации ЭВМ (мэйнфреймов и микропроцессоров) шло
19
1. Введение в системы с параллельной организацией вычислительного процесса
Рис. 1.8. Виды алгоритмических структур:
а — последовательная; б- последовательно-групповая;
в — слабо связанные потоки; г - параллельная структура общего вида
таким образом, что последовательная структура сохранялась, а к ней
добавлялись механизмы, позволяющие выполнять несколько команд одновременно.
До последнего времени параллельная обработка на уровне команд
(instruction -level-parallelism - ILP) утвердилась как единственный подход,
позволяющий добиваться высокой производительности без изменения программного
обеспечения.
В последовательно-групповой алгоритмической структуре вычислительные
процедуры объединены в группы, а отношение следования состоит в том, что
процедуры внутри группы могут выполняться одновременно, а сами группы -
последовательно. Вычислительные процедуры внутри одной группы могут быть
одинаковыми или разными. Наиболее типичным является случай, когда
одинаковые вычислительные процедуры образуют одиночный поток команд и
множественный поток данных (ОКМД). Примерами групп, составленных из
идентичных операций, могут служить векторные команды.
Для выполнения программ, алгоритмическая структура которых относится
к классу ОКМД, применяют два типа вычислительных систем: векторные
(Parallel Vector Processor — PVP) и матричные (Massively Parallel Processor -
MPP). В системах PVP вычислительные процедуры внутри групп исполняют-
20
1.3. Анализ эффективности параллельных архитектур вычислительных систем
ся конвейерным процессором, в то время как в МРР используются несколько
одновременно работающих процессоров (процессорные матрицы).
К типу МРР относятся следующие практически реализованные суперЭВМ:
ILLIAC-TV (Иллинойский университет, США), DAP (ICL), BSP {Burroughs),
STARAN {Goodyear Aerospace), СУММА, МИНИМАКС, ПС-3000 (СССР).
Основные проблемы реализации матричных систем - программирование
параллельной работы нескольких сотен процессоров и при этом обеспечение
минимума затрат счетного времени на обмен данными между ними. Развитие
суперЭВМ с матричной архитектурой дало следующие положительные результаты:
• удалось доказать возможность практической реализации параллельной
сверхскоростной обработки (производительность ILLIAC-TV в 1972 г.
составляла 20 MFLOPS, а даже самая скоростная ЭВМ для научных исследований
того времени последовательная CDC-7600 могла обеспечить не более
5 MFLOPS);
• на волне интереса к матричным структурам была разработана
теоретическая база для построения коммутационных сетей, объединяющих
множество процессов;
• в прикладной математике сформировалось самостоятельное научное
направление, связанное с параллельными вычислениями.
Более простая и «прозрачная» архитектура векторной обработки PVP с
возможностью использования стандартных языков высокого уровня типа FORTRAN
была реализована в первой векторно-конвейерной суперЭВМ STAR-100 (конец
60-х годов, производительность 50 MFLOPS), созданной под руководством С.
Крея. Существенной особенностью векторно-конвейерной архитектуры
является то, что данные всех параллельно исполняемых операций выбираются
и записываются в единую память, в связи с этим отпадает необходимость в
коммутаторе процессорных элементов, ставших камнем преткновения при
проектировании матричных суперЭВМ.
Итоги развития суперЭВМ на основе PVP первого поколения
американских - CYBER-205 {CDC), CRAY-l, CRAYX-MP{Cray Research) и японских -
£-810 {Hitachi), FACOM VP-200 {Fujitsu), SX{Nippon Electric - NEC) со
средней производительностью 1-2 GFLOPS и следующих поколений: CRAY-2, CRAY
Y-MP, SR-2201, VPP-500, SX-4 (свыше 400 MFLOPS) показали перспективность
их использования для соответствующего класса задач. Однако эти модели
являются дорогостоящими {CRAYX-MP - 20 млн долл.).
Следующий путь ускорения вычислений за счет параллельного выполнения
операций - это использование алгоритмов, структура которых представляет
совокупность слабо связанных потоков команд (последовательных процессов).
В этом случае программа может быть представлена как совокупность
процессов, каждый из которых может выполняться на отдельном последовательном
процессоре и при необходимости осуществлять взаимодействие с другими
процессорами. Вычислительные системы, отвечающие особенностям данной ал-
21
1. Введение в системы с параллельной организацией вычислительного процесса
горитмической структуры, - это многопроцессорные системы архитектуры
МКМД (множественный поток команд и множественный поток данных),
особенностью которых является необходимость синхронизации и взаимосвязи
между процессами. По этому принципу все архитектуры МКМД делятся на
два класса: взаимодействующие через общую память (класс а) и путем
обмена сообщениями (класс б). На рис. 1.9 показаны оба класса архитектур.
В архитектуре класса а память является общей для всех процессоров. Это
означает, что здесь существуют задержки в коммутационном устройстве, а
также доступе в память. Таким образом, в подобных системах требуется, чтобы
коммутационное устройство имело высокое быстродействие, а при доступе в
память количество конфликтов было минимальным. Примеры практической
реализации такой архитектуры: ЕТА-10 (CDC), Эльбрус-1, Эльбрус-2 (ИТМ и ВТ).
Класс архитектуры б предназначен для систем с большим числом
процессоров. Именно поэтому матричный коммутатор так же, как и коммутационная
сеть, оказываются малопригодными из-за высокой стоимости и
недостаточного числа входов. Наиболее перспективным классом коммутационных
устройств являются многоступенчатые сети (рис. 1.10) и гиперкубы. К классу б
относятся экспериментальные системы Cosmic Cube (Калифорнийский
технологический институт), Cm*, Ultracomputer (Нью-Йоркский университет).
В последнее время все более широкое распространение получают
транспьютеры, из которых строят системы класса б. Транспьютер является одно-
кристалльной системой, содержащей процессор и оперативную память.
Для объединения транспьютеров в систему используют механизмы связи (лин-
Коммутационная сеть
j
у
ПЭ
i
у
к
лп
i
у
к
ПЭ
J
У
к
ЛП
1
у
к
>
ПЭ
J
У
к
лп
Коммутационная
сеть
t
У
к
ПЭ
у
к
ПЭ
а б
Рис. 1.9. Архитектура МКМД:
а - с общей памятью; б - с обменом сообщениями;
ПЭ - процессорный элемент; ЛП-локальная память
22
1.3. Анализ эффективности параллельных архитектур вычислительных систем
Глобальная коммутационная сеть
>к
Локальная коммутационная
сеть
j
ПЭ
...
К]
1
к
ПЭ
настер ]
...
1'
ПЭ
...
ik
Локальная коммутационная
сеть
"" >к
ПЭ
...
ik
ПЭ
Кластер j
...
N
>к
ПЭ
Рис. 1.10. Архитектура ВС с двухуровневой коммутационной сетью:
ПЭ - процессорный элемент
ки) - встроенные специальные средства обмена сообщениями. Поскольку лин-
ки различных транспьютеров совместимы, то через коммутационную матрицу
можно конфигурировать системы различной мощности.
Максимальный коэффициент ускорения вычислений, который можно
получить в МКМД, состоящей из Р процессоров, равен Р (линейный рост
производительности). Однако действие отрицательных факторов снижает реальный
коэффициент ускорения. К этим факторам относятся:
• недостаточный параллелизм алгоритма, приводящий к неполной загрузке
процессоров (известно не так много алгоритмов, в которых при их вьшолнении
число параллельных ветвей сохранялось бы достаточно большим; поэтому для
эффективного использования ресурсов в таких системах целесообразно
одновременно выполнять несколько разных программ);
• конфликты и задержки при обращениях к памяти (в случае общей памяти).
Этот отрицательный фактор можно устранить путем назначения каждому
процессору локальной памяти. Однако при этом коэффициент использования
памяти и гибкость ВС снижаются;
• большие накладные расходы, связанные с механизмом синхронизации
между взаимодействующими потоками команд.
В последние 10-15 лет высокопроизводительные ВС (суперкомпьютеры),
являясь уникальными установками, строятся путем объединения
крупносерийных микропроцессоров широкого применения. Намечено создание
многопроцессорных СБИС и выход на уровень производительности квадриллион оп/с
(PFLOPS) - проект суперкомпьютера Blue Gene фирмы ЮМ (срок окончания
работ 2005-2013 гг.).
23
1. Введение в системы с параллельной организацией вычислительного процесса
По современным представлениям объединяющей основой
функционирования и поэтапного развития суперкомпьютерных систем являются концепции и
стандарты открытых систем, в которых реализуются свойства
масштабируемости, портабельности и т. д. Использование с этих позиций компьютерных
функциональных модулей массового промышленного применения открывает
возможности системной интеграции с высокими технико-экономическими
показателями в сжатые сроки. Такой подход в мировой практике за последние
2-3 года (данные на конец 2003 г.) выражен в развитии кластерных
вычислительных систем (рис. 1.10), которые занимают в настоящее время
доминирующее положение на рынке суперкомпьютеров и составляют четверть списка
ТОР500 - наиболее высокопроизводительных систем в мире.
На основе кластерных принципов построения высокопроизводительных
систем с учетом опыта создания транспьютерных систем в России в 2001 г.
введена в действие отечественная 768-процессорная система МВС-1000 М
производительностью 1 TFLOPS. Освоен выпуск установок типа МВС на базе
быстродействующих микропроцессоров Pentium-IV, Xeon, Itanium (фирмы Intel),
Power (фирмы ЮМ), Opteron (фирмы AMD). Межпроцессорный обмен в
системах МВС-1000 М осуществляется с применением мощных коммутаторов
высокоскоростных сетей Myrinet и Gigabit Ethernet.
Дальнейшее развитие архитектур МКМД связывается с комбинированием
различных принципов вычислений. Наиболее эффективным является
объединение архитектур МКМД и PVP. К таким системам относится, например,
вычислительный комплекс IBM-ICAP/3090. Этот комплекс объединяет в
различных сочетаниях мультипроцессорные комплексы, например, IBM-3090, с
векторными процессорами в единую систему. Другим примером является
архитектура НЕР-\ (Heterogenerous Element Processor) фирмы Denelcor.
Особенностью HEP-1 является организация мультипроцессора как нелинейной
системы, состоящей из группы процессоров команд, каждый из которых генерирует
«свой» процесс (поток команд). Обработка множества формируемых таким
образом процессов осуществляется на одном и том же арифметическом
устройстве конвейерного типа в режиме разделения времени (МКМД-конвейери-
зация) без использования коммутационной сети, что значительно снижает
стоимость системы, поскольку на реализацию АЛУ обычно приходится до 60 %
аппаратных ресурсов центрального процессора.
Основным недостатком МКМД-архитектур является отсутствие
возможности составления программ на стандартных языках последовательного типа,
в отличие от векторных суперЭВМ. Для эффективного программирования
таких систем потребовалось введение совершенно новых языков параллельного
24
1.3. Анализ эффективности параллельных архитектур вычислительных систем
программирования, таких, как Parallel Pascal, Modula-2, Occam, Ада, Val, Sisal
и создание новых прикладных пакетов программ.
В России одной из первых вычислительных систем с элементами
неоднородной архитектуры была система обработки данных АС-6. В ее состав
входила ЭВМ БЭСМ-6, ЦП АС-6 и периферийная машина ПМ-6, на которой был
решен ряд важных научных задач фундаментального плана.
Реализация алгоритмической структуры сильно связанных потоков (см.
рис.1. 8, г) требует организации такой архитектуры ЭВМ, которая
обеспечивала бы наибольшие возможности для параллельных вычислений. Принцип
вычислений, использующийся в такого рода системах, отличается от фон
Неймановского (управление потоком команд) и определяется как управление
потоком данных (Data Flow). Этот принцип формулируется следующим
образом: все команды выполняются только при наличии всех операндов
(данных), необходимых для их выполнения. Поэтому в программах, используемых
для потоковой обработки, описывается не поток команд, а поток данных.
Отметим следующие особенности управления потоком данных, характерные для
Data Flow:
• команду со всеми операндами (с доставленными операндами) можно
выполнять независимо от состояния других команд, т. е. появляется возможность
одновременного выполнения множества команд (первый уровень
параллелизма);
• отсутствует понятие адреса памяти, так как обмен данными происходит
непосредственно между командами;
• обмен данными между командами четко определен, поэтому отношение
зависимости между ними обнаруживается легко (функциональная обработка);
• поскольку управление командами осуществляется посредством передачи
данных между ними, то нет необходимости в управлении
последовательностью выполнения программы, т. е. имеет место не централизованная, а
распределенная обработка.
Таким образом, параллелизм в таких системах может быть реализован на
двух уровнях:
• на уровне команд, одновременно готовых к выполнению и доступных для
параллельной обработки многими процессорами (при наличии
соответствующих операндов);
• на уровне транспортировки команд и результатов их выполнения через
тракты передачи информации (реализуемые в виде сетей).
Достоинством машин потоков данных является высокая степень
однородности логической структуры и трактов передачи информации, что
позволяет легко наращивать вычислительную мощность.
25
1. Введение в системы с параллельной организацией вычислительного процесса
Примерами реализации архитектур такого типа являются системы Thinking
Machines (Connection Machine), Cedar (Cedar). Для архитектуры Data Flow
существует ряд факторов, снижающих максимальную производительность:
• в случае, когда число команд, готовых к выполнению, меньше числа
процессоров, имеет место недогрузка обрабатывающих элементов;
• перегрузка в сетях передачи информации; из соображений стоимости
максимальная пропускная способность сетей достигается только для
ограниченного числа вариантов взаимодействия между командами, что приводит к
временным задержкам.
Существенный недостаток Data Flow-машая заключается в том, что
достижение сверхвысокой производительности целиком возлагается на
компилятор, осуществляющий распараллеливание вычислительного процесса, и
операционную систему, координирующую функционирование процессоров и трактов
передачи информации. В связи с этим, как и в случае с МКМД, необходима
разработка соответствующих языков программирования высокого уровня и
подготовка пакетов приложений для решения реальных задач.
Несмотря на некоторые отрицательные черты архитектуры Data Flow, она
является очень перспективной в смысле достижения высокой
производительности, поскольку в ней устраняются основные недостатки, свойственные
архитектуре фон Неймана. В последнее время, благодаря успехам
микроэлектроники, в частности - создание однокристальной ассоциативной памяти для
хранения готовых к выполнению команд, стало возможным построение на
одном чипе сверхвысокопроизводительного процессора, работающего по
принципу управления потоком данных типа Data Flow (подобные разработки ведутся
в институте проблем информатики РАН).
Таким образом, ни один из рассмотренных принципов организации
вычислительных систем не является абсолютно адекватным для всех прикладных
областей. Более того, существуют задачи, которые являются неформализуемы-
ми и которые нельзя представить в виде рассмотренных классических
алгоритмических структур. К ним относятся: различные аспекты синтеза и
распознавания речи; распознавание символов; задачи классификации
объектов; субъективные процессы принятия решений (техническая и медицинская
диагностика, прогнозирование на финансовом рынке); проектирование
сложных объектов; сложные проблемы управления, требующие идентификации и
выработки решения для систем в реальном времени; создание адекватных
систем биологического зрения; моделирование функций понимания,
восприятия и др. Следовательно, требуется разработка новых принципов вычислений,
позволяющих ставить и решать задачи подобного типа, а также способных
значительно повысить скорость обработки традиционных вычислительных
алгоритмов.
26
1.4. Биологический аналог параллельной организации обработки информации
1.4. Биологический аналог параллельной
организации обработки информации
Основатель кибернетики Норберт Винер назвал свой главный труд
«Кибернетика или управление и связь в животном и машине». Этим названием он
подчеркнул, что законы управления являются общими для живой и неживой
природы, тем самым предопределил фундаментальность кибернетики.
Рассмотрим в общем виде функции сенсорных систем человека с точки зрения
кибернетики.
Информацию об окружающем мире и о внутренней среде организма
человек получает с помощью сенсорных систем, названных Павловым
анализаторами. С точки зрения современной нейрофизиологии под сенсорными
системами понимаются специализированные части нервной системы, состоящей из
периферических рецепторов (органов чувств), отходящих от них нервных
волокон (проводящие пути) и клеток центральной нервной системы,
сгруппированных вместе в так называемые сенсорные центры.
В сенсорных органах происходит преобразование энергии стимула в нервный
сигнал (рецепторный потенциал), который трансформируется в импульсную
активность нервных клеток (потенциалы действия). По проводящим путям эти
потенциалы достигают сенсорных центров, на клетках которых происходит
переключение нервных волокон и преобразование нервного сигнала
(перекодировка). На всех уровнях сенсорной системы одновременно с кодированием и
анализом стимулов осуществляется декодирование сигналов (считывание
сенсорного кода). Декодирование осуществляется на основе связей сенсорных
центров с двигательными и ассоциативными отделами мозга. Нервные
импульсы клеток двигательных систем вызывают возбуждение или торможение.
Результатом этих процессов является движение или остановка (действие и
бездействие). Следует подчеркнуть, что природа носителя информации в
сенсорных системах является электрической. Таким образом, основными
функциями сенсорных систем являются: рецепция сигнала; преобразование рецептор-
ного потенциала в импульсную активность проводящих путей; передача
первичной активности в сенсорные центры; преобразование первичной
активности в сенсорных центрах; анализ свойств сигналов; идентификация свойств
сигналов; принятие решения [8].
Нетрудно заметить, что приведенное описание восприятия человеком
влияния внешней среды есть описание работы системы управления с ЦВМ в
контуре по рис. 1.1 в терминах физиологии. Роль датчиков системы управления
играют рецепторы, роль управляющей ЦВМ - головной мозг человека, роль
исполнительных механизмов — двигательная система человека (его мышцы),
роль задатчика программного движения - головной мозг.
Очевидно, центральным звеном в биологических системах управления
является мозг, состоящий из более 100 млрд нервных клеток - нейронов, каждая
из которых имеет в среднем 10000 связей.
27
1. Введение в системы с параллельной организацией вычислительного процесса
Дендриты Нейрон имеет тело (сому), дерево
входов - дендритов, и выход - аксон
(рис. 1.11). Длина дендритов может
достигать 1 мм, длина аксона - сотен
миллиметров. На соме и дендритах
располагаются окончания других
нервных клеток. Каждое такое
окончание называется синапсом. Проходя
через синапс, электрический сигнал
меняет свою амплитуду: увеличивает
или уменьшает. Это можно
интерпретировать как умножение амплитуды
сигнала на весовой (синаптический)
коэффициент. Взвешенные в дендритном
дереве входные сигналы суммируют-
Рис. 1.11. Биологический нейрон ся в соме> и затем на аксонном
выходе генерируется выходной импульс
(спайк) или пачка импульсов. Выходной сигнал проходит по ветви аксона и
достигает синапсов, которые соединяют аксон с дендритными деревьями других
нейронов. Через синапсы сигнал трансформируется в новый входной сигнал
для смежных нейронов. Этот сигнал может быть положительным или
отрицательным (возбуждающим или тормозящим) в зависимости от вида синапса.
Величина сигнала, генерируемого на выходе синапса, определяется синапти-
ческим коэффициентом (весом синапса), который может меняться в процессе
функционирования синапса.
В настоящее время нейроны разделяют на три большие группы:
рецепторные, промежуточные и эффекторные. Рецепторные нейроны предназначены для
ввода сенсорной информации в мозг. Они преобразуют воздействие
окружающей среды на органы чувств (свет на сетчатку глаза, звук на ушную улитку) в
электрические импульсы на выходе своих аксонов. Эффекторные нейроны
передают приходящие на них электрические сигналы исполнительным органам,
например мышцам, также через специальные синапсы своих аксонов.
Промежуточные нейроны образуют центральную нервную систему и предназначены
для обработки информации, полученной от рецепторов и передачи
управляющих воздействий на эффекторы.
Головной мозг человека и высших животных состоит из серого и белого
вещества. Серое вещество есть скопление дендритов, аксонов и нейронов.
Белое вещество образовано волокнами, соединяющими различные области
мозга друг с другом, с органами чувств, мускулами. Волокна покрыты спецальной
миэлинированной оболочкой, играющей роль электрического изолятора. В
мозге существуют структурно обособленные отделы, такие, как кора, гиппокамп,
таламус, мозжечок, миндалина и т. п. (рис. 1.12). Каждый из отделов имеет
Шх
28
1.4. Биологический аналог параллельной организации обработки информации
Молекулярный слой
Наружный зернистый слой
Слой пирамидных клеток
Внутренний зернистый слой
Ганглионарный слой
Слой полиморфных клеток
Белое вещество
Рис. 1.12. Схема слоев коры больших полушарий
сложное модульное строение. Особое место в мозге занимает церебральная
кора, которая является его новейшей частью. В настоящее время принято
считать, что именно в коре происходят важнейшие процессы ассоциативной
переработки информации.
Связи между сенсорными областями и корой, между различными
участками коры физически параллельны. Один слой клеток проецируется на другой,
причем проекции состоят из множества разветвляющихся и сливающихся
волокон (проекции дивергируют и конвергируют). В настоящее время наиболее
изучен ввод в мозг зрительной информации. Возбуждение от сетчатки
достигает коры топографически упорядочным образом, т. е. ближайшие точки
сетчатки активируют ближайшие точки коры. По реакции на зрительные стимулы
различной сложности различают простые, сложные и гиперсложные нейроны.
Имеется тенденция к усложнению рецепторных свойств нейронов по мере
удаления от входных областей коры. Можно предположить, что
функциональная роль нейронных структур, примыкающих к органам чувств, включая
сенсорные области коры, заключается в преобразовании сенсорной информации
путем выделения все более сложных и информативных признаков входных
сигналов. Ассоциативная обработка получающихся при этом совокупностей
сенсорных признаков осуществляется в ассоциативных зонах коры, куда
поступают и другие сенсорные образы.
Приведенное весьма поверхностное описание принципа обработки
информации в живой природе позволяет сделать вывод, что техническая
кибернетика вплотную подошла к решению задачи управления в реальном времени
методами, отшлифованными за миллионы лет Создателем. Поэтому будет вполне
резонным появление в настоящее время термина «нейроуправление», под
которым понимается «область теории управления, занимающаяся вопросами
применения нейронных сетей для решения задач управления динамическими
объектами...»[1].
29
1. Введение в системы с параллельной организацией вычислительного процесса
Нейрокомпьютером называют ЭВМ (аналоговую или цифровую), основной
операционный блок (центральный процессор) которой построен на основе
нейронной сети и реализует нейросетевые алгоритмы.
1.5. Нейрокомпьютеры и их место среди
высокопроизводительных ЭВМ
Нейрокомпьютеры - это ЭВМ нового поколения, качественно
отличающиеся от рассмотренных классов реально действующих классических
вычислительных систем параллельного типа тем, что для решения задач они
используют не заранее разработанные алгоритмы, а специальным образом подобранные
примеры, на которых учатся. Их появление обусловлено объективными
причинами: отмеченное выше развитие элементной базы, позволяющее на одной плате
реализовать персональный компьютер (PC) - полнофункциональный
компьютер (модель нейрона), и необходимость решения важных практических задач,
поставленных действительностью. Попытки создания ЭВМ, моделирующих
работу мозга, предпринимались еще в 40-х годах специалистами по нейронной
кибернетике. Они стремились разработать самоорганизующиеся системы,
способные обучаться интеллектуальному поведению в процессе взаимодействия
с окружающим миром, причем, компонентами их систем обычно являлись
модели нервных клеток. Однако зарождавшаяся в это же время вычислительная
техника и связанные с нею науки, особенно математическая логика и теория
автоматов, оказали сильное влияние на области исследования, связанные с
мозгом.
К концу 50-х годов сформировался логико-символьный подход к
моделированию интеллекта. Его развитие создало такие направления, как
эвристическое программирование и машинный интеллект, и способствовало угасанию
интереса к нейронным сетям. Неблагоприятным моментом, затормозившим
развитие нейросетевой тематики на два с лишним десятилетия, явилось
опубликование тезиса, выдвинутого авторитетнейшими учеными 60-х годов М.
Минским и С. Пейпертом, о невозможности воспроизведения произвольной
функции нейронной сетью и, следовательно, о невозможности создания
универсального вычислительного устройства на ее основе. Таким образом, в
течение длительного времени основным направлением в развитии
искусственного интеллекта являлся логико-символьный подход, который может быть
реализован на традиционных вычислительных системах. Было получено решение
многих «интеллектуальных» задач из определенных предметных областей. К
началу 80-х годов были созданы условия для возрождения интереса к нейро-
сетевым моделям. Это было связано с накоплением новых данных при
экспериментальных исследованиях мозга. Кроме того, были получены важные
теоретические результаты, позволившие разработать алгоритмы обучения для
различных искусственных нейронных сетей (НС).
30
1.5. Нейрокомпьютеры и их место среди высокопроизводительных ЭВМ
К настоящему времени сформировался обширный рынок нейросетевых
продуктов. Подавляющее большинство продуктов представлено в виде
моделирующего программного обеспечения. Ведущие фирмы разрабатывают также
и специализированные нейрочипы или нейроплаты в виде приставок к
персональным ЭВМ. При этом программное обеспечение может работать как без
нейроприставок, так и с ними. В последнем случае быстродействие гибридной
ЭВМ возрастает в сотни и тысячи раз. Однако при ближайшем рассмотрении
оказывается, что эти приставки представляют собой классические
процессоры (универсальные или специализированные, например сигнальные), в
некоторых случаях учитывающие специфику НС (например, за счет аппаратной
реализации операции адаптивного суммирования). При использовании такого
подхода представляется проблематичным реализация суперЭВМ с «истинным
параллелизмом», когда каждый нейрон работает в соответствии с логикой
работы НС.
Основываясь на достижениях микроэлектроники, можно реализовать ЭВМ
с большим числом элементов - нейронов (порядка тысяч и десятков тысяч).
При этом возникает проблема организации связей между элементами,
отвечающих архитектуре НС, которая на сегодняшний момент для произвольных НС
пока не решена. Поэтому, как указано в [1], современные
супернейрокомпьютеры строятся по традиционной архитектуре МКМД (либо комбинированной
МКМД+PVP, либо МКМД + конвейеризация), но не из стандартных процессо-
эов (i860, Альфа, Мерсед и др.), а из элементов в виде СБИС нейрочипов, аппа-
ратно реализующих фрагмент НС. Наиболее ярким прототипом
супернейрокомпьютера является система обработки аэрокосмических изображений,
разработанная в США по программе «Силиконовый мозг». Объявленная
производительность супернейрокомпьютера составляет 80 PFLOPS (80 -1015
операций с плавающей точкой в 1 с) при физическом объеме, равном объему
человеческого мозга, и потребляемой мощности 20 Вт. Естественно, что такая
производительность не может быть обеспечена с помощью рассмотренных
традиционных архитектур суперЭВМ.
Основные проблемы создания нейрокомпьютеров - разработка
сверхпараллельных нейросетевых алгоритмов формализумых задач и их
распараллеливание в соответствии с архитектурой коммутационной системы, а также
разработка новых методик решения неформализуемых задач. При этом
рассматриваются три вида моделей нейронных сетей: физические,
математические, технологические. Львиную долю публикаций по вопросам создания
нейросетевых моделей составляют работы по реализации различных видов нейро-
процессоров на основе СБИС, оптической, ПЛИС и т. п. технологий
(технологические модели НС). Работы по исследованию физических моделей
НС, в которых отображаются физические принципы функционирования головного
мозга, привели к созданию проекта Кремниевой Мозговой Коры {Silicon Cortex -
SCX), возглавляемого немецким биологом М. Маховальдом. Тем не менее,
несмотря на значительные достижения в разработке физических моделей моз-
31
1. Введение в системы с параллельной организацией вычислительного процесса
га, пока не создано такой модели, которая адекватно отображала бы работу
мозга и позволяла генерировать новое знание. Более того, главная проблема -
моделирование зрения, внимания, координированного управления поведением
не имеет удовлетворительного решения в рамках нейросетевой технологии.
С этих позиций наиболее важными представляются работы по созданию
математических моделей нейросетевых вычислений, которые позволяют
отрабатывать и создавать новые принципы организации параллельной работы
многих вычислительных элементов - формальных нейронов.
Идея коннекционизма
Большое влияние на разработку теории искусственных нейронных сетей
оказал коннекционизм - раздел искусственного интеллекта, связанный с
созданием, исследованием и развитием моделей мозга (мышления) человека. С
точки зрения коннекционизма {connection - связь) в основу концепции НС
положена идея о том, что нейроны можно моделировать довольно простыми
автоматами, а вся сложность мозга, гибкость его функционирования и другие
важнейшие качества определяются связями между нейронами. Каждая связь
представляется как простой элемент, служащий для передачи сигнала. При
таком подходе для нейросетевой модели характерно следующее:
• однородность системы (элементы нейронной сети одинаковы и просты,
все определяется структурой связи);
• надежность системы, построенной из ненадежных элементов, за счет
избыточного числа связей;
• «голографичность», предопределяющая, что при разрушении части
система сохраняет свои свойства.
Предполагается, что широкие возможности систем связи -
демаскирование старых связей и добавление новых - компенсирует бедность набора
элементов, из которых строится модель, их ненадежность, а также возможные
разрушения части связей. На первых этапах развития нейросетевых моделей
коннекционизм сыграл исключительную роль, поскольку были поняты
основные механизмы индуктивного вывода, осуществляемого НС, позволившие
решить множество прикладных задач. Однако для создания математических
нейросетевых моделей, адекватных реальным задачам, требуются более
глубокие исследования биологических принципов функционирования головного мозга.
Направления развития и использования нейрокомпьютеров
Выделим четыре направления, которые представляются наиболее важными
и интересными.
1. Решение задач, традиционных для искусственного интеллекта:
распознавание образов (зрительных, слуховых, обоняния и т. д.), классификация,
извлечение знаний из данных, заполнение пропусков в таблицах данных, построение
32
1.5. Нейрокомпьютеры и их место среди высокопроизводительных ЭВМ
отношений на множестве объектов и т. д. Успешное решение этих задач дает
возможность создавать искусственные органы, например, искусственный глаз,
ухо, нос, предсказывать явления, действия, ситуации, разрабатывать
специальные устройства - миниатюрные, дешевые, быстродействующие (в виде
приставок к персональным компьютерам), обеспечивать потребности
диалогового общения человека с ЭВМ и т. д.
2. Значительного повышения производительности суперкомпьютера можно
ожидать при использовании идеологии НС для решения сложных задач теории
вычислений, так как при этом можно получить естественные параллельные
алгоритмы, позволяющие значительно ускорить вычисления. Нейросетевая
реализация классических задач и алгоритмов вычислительной математики
(решение систем линейных уравнений, решение задач математической физики
сеточными методами, оптимизированных задач, гидро- и аэродинамических
расчетов, молекулярного конструирования лекарств, структурного исследования
человеческих генов и т. д.) может позволить получить значительный прогресс
в области вычислительной и прикладной математики.
3. Использование нейрокомпьютера как инструмента для моделирования
работы структур человеческого мозга, чтобы понять принципы его работы. В
настоящее время успехи нейрофизиологии в области исследования процессов,
происходящих в мозге, позволили создать искусственные НС, решающие
сложные задачи распознавания, восприятия, прогнозирования и т. д. Однако
все еще недостаточно знаний о работе отдельных нейронов, взаимодействия
групп нейронов при обработке разнородной информации, формирования
логического мышления и т. д. Поэтому особенно важным представляется
исследование различных моделей НС и возможности их гибридизации с другими
информационными технологиями для создания теоретической базы построения
интеллектуальных систем, имитирующих функции человеческого мозга. Это
даст возможность строить различные схемы и проверять гипотезы об
устройстве и функционировании структур мозга.
4. Создание на основе концепции НС пр 11 i .но новых систем обработки
информации. Эти системы должны объединять в себе основные достоинства
традиционных ЭВМ, такие, как высокое быстродействие отдельного элемента,
высокую скорость передачи сигналов, большой объем памяти, и основные
достоинства нейрокомпьютеров, связанных с высокой скоростью обработки
как дискретной, так и аналоговой информации, возможностью управления
сложными системами и процессами, возможностью решения в реальном
времени различных типов оптимизационных задач, а также обеспечения
высокой степени надежности и способности адаптации к быстро меняющейся
обстановке.
33
1. Введение в системы с параллельной организацией вычислительного процесса
Новые функции
Теоритические
основы
Массивные параллельные
н распределенные системы
Рис. 1.13. Основные направления развития вычислительных
технологий по программе RWCP
Рассмотренные направления зафиксированы в названиях и идеологии
всемирных научно-технических суперпроектов (программ) прошлого и
нынешнего века. Одним из таких проектов является программа, принятая в
июле 1992 г. (действующая и поныне) в Японии и связаннная с созданием
координационного исследовательского центра по реализации международного
проекта Real World Computing Partnership (RWCP) - организация вычислений
в реальном мире. Основная цель этой программы — объединение усилий в
международном масштабе по разработке методов и средств, позволяющих
вычислительным и управляющим системам самостоятельно, без участия
34
1.5. Нейрокомпьютеры и их место среди высокопроизводительных ЭВМ
человека, воспринимать воздействия внешнего мира и действовать в нем: иными
словами, обучаться и адаптироваться в заданной проблемной среде.
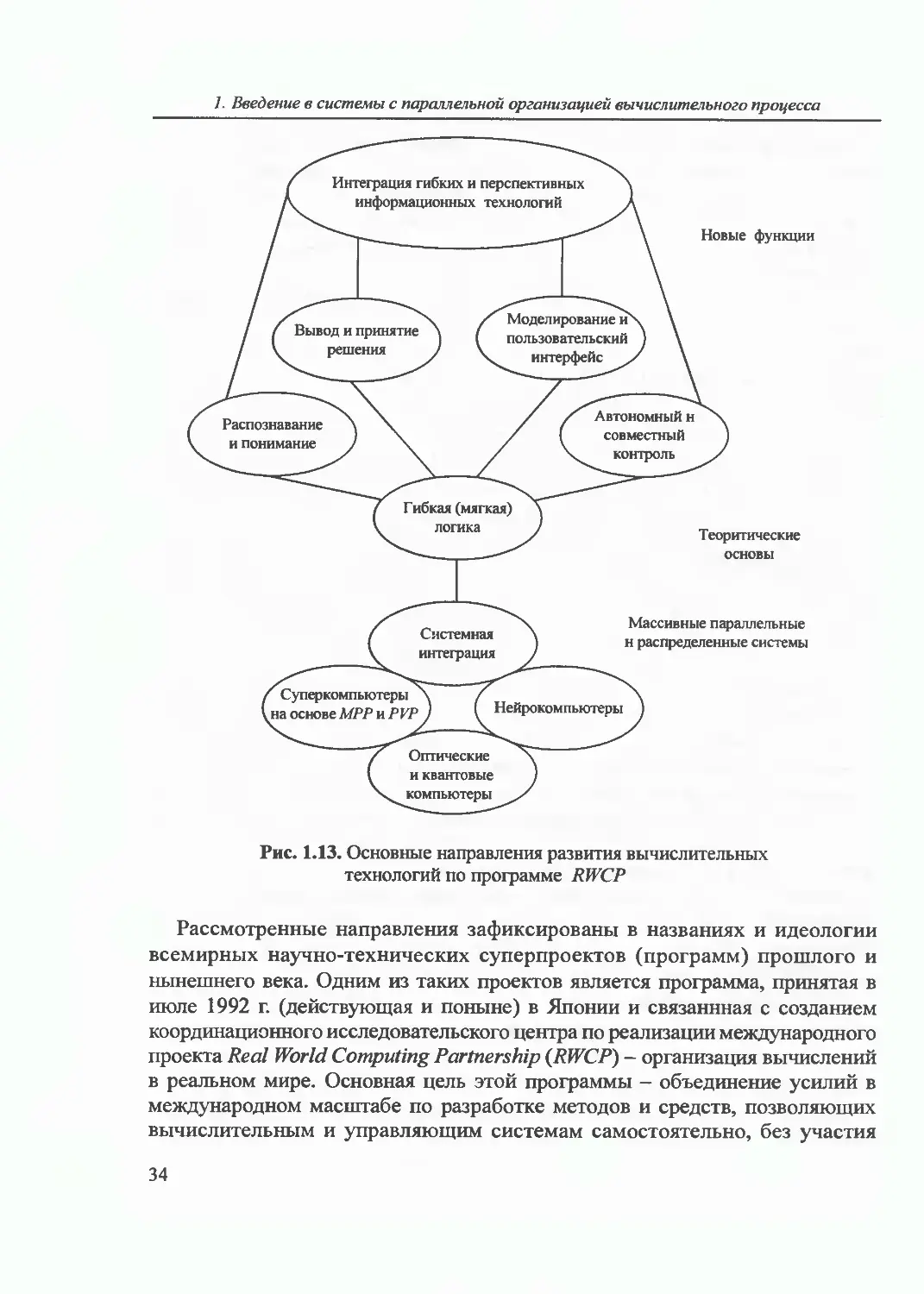
Главными являются следующие направления развития этой программы
(рис. 1.13):
• фундаментальные исследования;
• создание новых методов и алгоритмов для решения практических задач,
включая нейросетевые методы и гибридные методы и технологии;
• развитие технологии организации вычислительных процессов в
массивных параллельных вычислительных системах и НС;
• проработка вопросов создания и использования оптических и квантовых
компьютерных систем.
Авторы программы огромную роль (до 30 - 40% ее содержания) отводят
исследованию естественных и созданию искусственных НС. Уже сейчас
искусственные НС применяются для решения очень многих задач обработки
изображений, управления роботами и непрерывными производствами, для
понимания и синтеза речи, для диагностики заболеваний людей и технологических
неполадок в машинах и приборах, для предсказания курсов валют и
результатов спортивных соревнований и т. д. Таким образом, искусственные НС
являются одним из «слонов», на которых сейчас стоит платформа
научно-технического прогресса, и одним из важнейших его направлений является разработка
методов и средств для решения задач реального мира.
Вопросы для самоконтроля
1. Воспроизведите схему системы управления с ЦВМ в контуре и опишите ее работу.
2. В чем особенность интеллектуальных систем?
3. Сформулируйте закон Мура.
4. Дайте определение параллельной ЭВМ.
5. В чем отличие теоретического и практического представления закона Гроша?
6. В чем суть гипотезы Минского?
7. Назовите и дайте характеристику базовых способов введения параллелизма в
архитектуру ЭВМ.
8. Назовите особенности векторных и матричных ЭВМ.
9. Дайте определение нейрокомпьютера.
10. В чем суть идеи коннекционизма?
35
2. МОДЕЛИ ОПЕРАЦИОННОГО БЛОКА
НЕЙРОКОМПЬЮТЕРОВ
Сформулированы задачи, реишемые на нейрокомпьютерах, приведено описание
работы абстрактного нейрокомпьютера (аналог машины фон Неймана). Подробно
рассмотрены модели формальных нейронов, их функции активации, классификация
нейронных сетей. Приведены математические модели многослойных нейронных сетей.
Завершается глава методикой решения задач в нейросетевом базисе (методика A.M.
Галушкина).
2.1. Обобщенная структурная схема нейрокомпьютера
Задачи, решаемые на нейрокомпьютерах
Все задачи, которые решают с помощью средств вычислительной техники,
с точки зрения формализма разработки алгоритма решения удобно разделить
на три класса: формализуемые; трудноформализуемые; неформализуемые [1].
Формализуемая задача имеет четко сформулированный алгоритм
решения. Ярким примером таких задач являются вычислительные задачи: решение
алгебраических, дифференциальных, интегральных и других уравнений,
сортировка данных и т. п. Для решения этого класса задач вычислительной
математикой разработано много эффективных методов, ориентированных именно на
применение в ЭВМ.
Трудноформализуемая задача имеет алгоритм решения, качество
которого трудно оценить или трудно оценить достижимость решения. Этот класс
включает задачи моделирования систем большой размерности (известное
выражение «проклятия размерности»). К ним можно отнести моделирование сложных
электронных устройств в системах автоматизированного проектирования,
задачи интегрированной подготовки производства и т. п.
Неформализуемая задача имеет в своей постановке неявно заданные
функции и параметры. К этому классу относят задачи распознавания образов, кла-
36
2.1. Обобщенная структурная схема нейрокомпьютера
стеризации данных, предсказания, аппроксимации функций и т. п. Для
понимания сути задач этого класса дадим их краткую характеристику.
Задача распознавания образов состоит в отнесении входного набора
данных, представляющего распознаваемый объект, к одному из заранее
известных классов. Это может быть задача распознавания рукописных и печатных
символов при оптическом вводе в ЭВМ, распознавание типов клеток крови,
распознавание речи и пр.
Задача кластеризации данных состоит в группировке входных данных по
присущей им «близости». Алгоритм определения близости данных
(определение расстояния между векторами, вычисление коэффициента корреляции и другие
способы) закладываются в НК при построении. Нейронные компьютеры
кластеризуют данные на заранее неизвестное число кластеров. Кластеризация
применяется при сжатии данных, анализе данных и поиске в них закономерностей.
Задача предсказания заключается в определении значения какого-то
параметра системы (или нескольких параметров) на будущий, еще не наступивший
момент времени по известным значениям этого параметра (или параметров) в
предыдущие моменты времени. Такие задачи актуальны для банков при
принятии решения об объеме страхового запаса финансов, при управлении
складскими запасами.
Задача аппроксимации функции заключается в определении по
экспериментальным данным функции, наилучшим образом приближающейся к
неизвестной и удовлетворяющей определенным критериям. Эта задача актуальна
при моделировании сложных динамических систем.
До недавнего времени НК использовались в основном для решения нефор-
мализуемых задач. Именно необходимость решения таких задач породило
появление реальных нейронных ЭВМ в бывшем СССР еще 30 лет назад [1].
Однако развитие теории и элементной базы последних лет позволило
разработать методы проектирования НК для решения и формализуемых, и труднофор-
мализуемых задач. Таким образом, сегодня НК приобретает черты
универсальной вычислительной машины.
Схема абстрактного нейрокомпьютера
На рис. 2.1 представлена структурная схема абстрактного НК. Такую
схему можно назвать обобщенной, так как она поясняет принцип работы любого
НК независимо от его конкретного конструктивного исполнения. Эта схема
напоминает классическую схему однопроцессорной машины Дж. фон
Неймана, предложенную им еще в 1945 г. Однако НК в принципе отличается от этой
машины.
Основным операционным блоком НК, его процессором, является
искусственная нейронная сеть. В первом, грубом приближении сеть представляет
собой совокупность простейших модулей, называемых формальными нейронами,
соединенными каналами передачи информации. Количественная
характеристика каждого канала определяется решаемой задачей.
37
2. Модели операционного блока нейрокомпьютеров
Устройство ввода
А
1
1
Запоминающее
устройство
Нейронная сеть
1
1
Блок обучения
1 *
1
1
<—'
Устройство вывода
ФФФФФ
Устройство
управления
Рис. 2.1. Структурная схема абстрактного НК
Нейронная сеть не производит вычислений, как это делает арифметиколо-
гическое устройство машин фон Неймана. Она трансформирует входной
сигнал (входной образ) в выходной в соответствии со своей топологией и
значениями коэффициентов межнейронной связи.
В запоминающем устройстве НК хранится не программа решения задачи,
как это имеет место в машинах фон Неймана, а программа изменения
коэффициентов связи между нейронами. Устройства ввода и вывода информации в
принципе выполняют те же функции, что и в машине фон Неймана. Устройство
управления служит для синхронизации работы всех структурных блоков НК
при решении конкретной задачи.
В работе абстрактного НК выделяют два главных режима работы -
обучения и рабочий. Для того чтобы НК решал требуемую задачу, его НС должна
пройти обучение на эту задачу. Суть режима обучения заключается в
настройке коэффициентов межнейронных связей на совокупность входных образов этой
задачи. Установка коэффициентов осуществляется на примерах,
сгруппированных в обучающие множества. Такое множество состоит из обучающих пар, в
которых каждому эталонному значению входного образа соответствует
желаемое (эталонное) значение выходного образа.
При первой подаче очередного эталонного входного образа выходной
сигнал отличается от желаемого. Блок обучения оценивает величину ошибки и
корректирует коэффициенты межнейронных связей с целью ее уменьшения.
При каждой последующей подаче этого же эталонного входного образа
ошибка уменьшается. Процесс продолжается до тех пор, пока ошибка не достигнет
требуемого значения. С математической точки зрения процесс обучения
представляет собой решение задачи оптимизации, целью которой является
минимизация функции ошибки (или невязки) на данном множестве примеров путем
выборки коэффициентов межнейронных связей. Рассмотренный пример
обучения называют контролируемым обучением, или обучением с учителем. В ра-
38
2.2. Модели формальных нейронов
бочем режиме блок обучения, как правило, отключен, и на вход НК подаются
сигналы, требующие распознавания (отнесения к тому или иному классу). На
эти сигналы (входные образы), как правило, наложен шум. Обученная
нейронная сеть фильтрует шум и относит образ к нужному классу.
Сравнение нейрокомпьютера с машиной фон Неймана
Структура ЭВМ, получившая имя Дж. фон Неймана, была описана им в
«Первом наброске отчета по ЭДВАКу» (First Draft jf a Report on the EDVAC,
1945 г.). В отчете приводится ставшее впоследствии классическим деление
компьютера на арифметическое устройство, устройство управления и память.
Здесь же высказана идея программы, хранимой в памяти.
Отделяя теорию от инженерной реализации, Дж. фон Нейман берет за
основу не электромеханические реле, электронные лампы или линии задержки,
представлявшие тогда элементную базу, а теоретические нейроны, в том виде, в
каком они были введены У. Мак-Каллаком и У. Питтсом в «Логическом
исчислении идей, имманентных нервной активности» [2].
Существенным недостатком машин фон Неймана является принципиально
низкая производительность, обусловленная последовательным характером
организации вычислительного процесса. Наличие одного процессора
обусловливает и другой недостаток этих машин - низкую эффективность использования
памяти. В самом деле, память однопроцессорных ЭВМ можно представить
как длинную последовательность ячеек. Центральный процессор выбирает
содержимое одной из них, дешифрирует, исполняет команду и, при
необходимости, возвращает результат памяти в заранее обусловленную ячейку. Затем
обращается к очередной ячейке для считывания следующей команды, и процесс
повторяется до тех пор, пока не будет выбрана последняя команда
исполняемой программы. Нетрудно заметить, что подавляющее большинство ячеек
памяти бездействуют. Если ввести понятие коэффициента использования
аппаратуры как отношение числа одновременно работающих элементов ЭВМ к
общему числу этих элементов, то для машин фон Неймана этот коэффициент
будет очень низким.
Машины фон Неймана и НК различаются также по принципу
взаимодействия структуры машины и решаемой задачи. Для однопроцессорных машин, с
их «жесткой» структурой, разработчику приходится подстраивать алгоритм
решения задачи под структуру машины. При использовании НК разработчик
подстраивает структуру машины под решаемую задачу.
2.2. Модели формальных нейронов
В дальнейшем будем говорить о нейронах, нейронных сетях, понимая под
этим искусственно созданные технические объекты, принцип работы которых
сравним с работой одноименных биологических объектов. Как и в живой
природе, искусственный нейрон является элементарной ячейкой (процессором) НС,
но сети искусственной. В § 1.4 было дано определение НК.
39
2. Модели операционного блока нейрокомпьютеров
Нейронной сетью (НС) называется динамическая система, состоящая из
совокупности связанных между собой по типу узлов направленного графа
элементарных процессоров, называемых формальными нейронами, и способная
генерировать выходную информацию в ответ на входное воздействие.
Нейронная сеть является основной операционной частью НК (нейронных
ЭВМ), реализующей алгоритм решения задачи.
Формальным нейроном называется элементарный процессор,
используемый в узлах нейронной сети. Математическую модель формального нейрона
можно представить уравнением
*=Л*) = /(2>Д +а0),
(2.1)
где у - выходной сигал нейрона; J(g) - функция выходного блока нейрона;
at - постоянный коэффициент - вес /-го входа; xt - i-й входной сигнал; а0 -
начальное состояние (возбуждение) нейрона; i = 1,2, 3,..., и - номер входа нейрона;
п - число входов. Выражению (2.1) может быть поставлена в соответствие
структурная схема формального нейрона, представленная на рис. 2.2. Как
видно из рисунка, схема формального нейрона включает п входных блоков
умножения на коэффициенты а, один сумматор (часто называемый разными авторами
адаптивным сумматором) и выходной блок функционального преобразования.
Функция, которую реализует выходной блок, получила название функции
активации (или функции возбуждения, или переходной функции).
Коэффициенты at получили название синоптических коэффициентов или
коэффициентов межнейронной связи. Эти коэффициенты являются аналогами синапсов
биологических нейронов. Если значение коэффициента а отрицательное, то
принято считать г-ю связь тормозящей, если положительное - возбуждающей.
В общем случае работа формального нейрона заключается в следующем
(см. рис. 2.2). Перед началом работы на блок сумматора подают сигнал
начального состояния (начального возбуждения) а0. На каждый i-й вход нейрона
поступают сигналы х. либо от других нейронов, либо с устройства ввода НК.
Каждый i-й входной сигнал jc(
умножается на коэффициент межнейронной
связи (синаптический коэффициент) а.
В блоке сумматора взвешенные
входные сигналы и начальное
возбуждение а0 алгебраически складываются.
Результат суммирования (взвешенная
сумма) g подается на блок
функционального преобразования^^).
Нейрон, схема которого
приведена на рис. 2.2, является классическим,
в некотором смысле стандартным.
Однако разработчики нейронных се-
, г
*1 1
хч \
"о
а\
"п
°0
х\а1
S
~1
g
Ж)
1 У
Ne I
Рис. 2.2. Структурная схема
фО]
эмальи
ого те
:ирона
40
2.2. Модели формальных нейронов
тей применяют и нестандартные модели нейронов. К таким нейронам
относится паденейрон, нейрон с квадратичным сумматором, нейрон со счетчиком
совпадений [3].
Паде-нейрон (рис. 2.3) состоит из двух сумматоров, элемента,
вычисляющего частное от взвешенных сумм, блока нелинейного преобразования
(выходной блок). Свое название этот нейрон получил от аппроксимации Паде-ме-
тода рациональной аппроксимации функций. Нетрудно заметить, что он имеет
в два раза больше настраиваемых параметров по сравнению с обычным
нейроном. Математическую модель паде-нейрона можно представить в таком виде:
y=f(g) = f
8i
8г
Ч = /
Га ^
>=1
п
J^b,x+b0
Здесь Ъ — синаптические коэффициенты второго сумматора.
У нейрона с квадратичным сумматором (рис. 2.4) на выходной блок
подается взвешенная квадратичная форма входного сигнала. Математическая
модель этого нейрона описывается следующим выражением:
п
В этом случае нейрон имеет и(и+1)/2 настраиваемых параметров.
1 1
х\ 1
1
х" 1
1 '
.
*» 1
"о
"l
.
"п
ъ0
ь1
■
к
"о
*1а1
хпап
К
*А
*А
^
^2
g
Яг
-5-
Si
Ne
М
1
1 У
Рис. 2.3. Структурная схема паде-нейрона
41
2. Модели операционного блока нейрокомпьютеров
1 1
1
ХУ 1
1
■
. 1
*" 1
1
^0
^1
■
■
■
а„
Z
g = Z "в*'^ +
"о
Л0
№
Рис. 2.4. Схема нейрона с квадратичным сумматором
Нейрон со счетчиком совпадений, получая на вход «-мерный двоичный
вектор X, на выходе выдает целое число, равное числу совпадений х с а, т. е.
число тех I, для которых х. = а.
В практике разработки НК применяют и другие модели нейронов,
определяемые характером конкретной решаемой задачи, качеством
инструментального средства, требованиями заказчика, опытом разработчика.
Виды функций активации
Вид функции активации во многом определяет функциональные
возможности нейронной сети и метод обучения этой сети. Рассмотрим некоторые виды
функций активации, применяемые при конструировании нейронных сетей.
Пороговая функция. В общем случае эта функция активации
описывается следующим выражением:
sign (g) = -<
b, если g < 0;
c, если g > 0 ,
(2.2)
где Ъ и с - некоторые постоянные. На практике чаще всего используют две
пары постоянных Ъ и с: первая ( -1, 1); вторая - (0, 1). Первая пара
коэффициентов определяет так называемую симметричную пороговую функцию,
вторая — смещенную.
Математическая модель нейрона с пороговой функцией активации имеет
вид: п
y(t) = sign(g(r)) = sign£(a,x, (t) + a0). (2.3)
i=i
На рис. 2.5 приведены графики пороговых функций активации, а на рис. 2.6 -
условное графическое обозначение (УГО) нейрона с этой функцией активации.
Этого обозначения будем придерживаться в дальнейшем изложении.
На первый взгляд может показаться, что нейрон со смещенной пороговой
функцией активации (Ь = 0ис=1) ничем не отличается от схем, построенных
на обычных элементах И, ИЛИ, НЕ. Однако практика разработки НК показала
следующие преимущества такого нейрона [1]:
42
2.2. Модели формальных нейронов
М)
Ж),
Рис. 2.5. Графики пороговых функций активации:
а - симметричная; б - смещенная
• нейрон выполняет более сложные логические функции, что обеспечивает
реализацию заданной логической функции меньшим числом элементов, тем
самым сокращая объем проектируемого устройства;
• сети из нейронов имеют повьппенную устойчивость к выходу из строя
отдельных элементов;
• сети из нейронов имеют повьппенную устойчивость к изменению
параметров элементов, их реализующих;
• для однородных нейронных сетей возможна минимизация базовых СБИС,
их реализующих, тем самым упрощается
САПР этих СБИС.
Пороговая функция относится к классу
дискретных функций, в котором имеется много
других функций. Теория НС, например,
рассматривает модели нейронов с
многопороговыми функциями активации. Однако
широкого распространения эти модели пока не нашли.
Сигмондная функция активации. Эта
функция относится к классу непрерывных
функций. Выбираемая разработчиком для
решения конкретной задачи непрерывная функция
Ne
/о
Рис. 2.6. УГО нейрона с пороговой
функцией активации
43
2. Модели операционного блока нейрокомпьютеров
Рис. 2.7. Графики сигмоидных функций на базе экспоненты:
о-смещенная; б-симметричная
активации должна удовлетворять следующим условиям: быть непрерывной,
монотонно возрастающей и дифференцируемой. Сигмоидная функция
полностью удовлетворяет этим требованиям. Как и для пороговой, для этой функции
различают смещенный и симметричный вид. Математически оба вида сигмо-
идной функции представляются следующим образом:
смещенная
/№)]
1
1 + е-в '
(2.4а)
симметричная
шт
1 +e~g
(2.46)
Графики сигмоидных функций на базе экспоненты приведены на рис. 2.7.
В практике НС применяют и другие непрерывные функции, также
называемые «сигмоидами», но в основе
формирования которых лежит не
экспонента, а, например, арктангенс или
гиперболический тангенс.
Особый интерес представляет
функция вида
git)
l+g(0
которую назовем «упрощенной сигмо-
идой». График этой функции на рис. 2.8.
Рис. 2.8. График функции «упрощенной "^«У10 Функцию просто реализовывать
сигмоиды» в программных системах.
44
2.2. Модели формальных нейронов
ЛЯ) А
1 -
0,5
-5
Рис. 2.9. График «сигмоиды» вида Рис. 2.10. График сигмоиды вида
/[£(')] = ВД /Ш\ =| arcflife)
На рис. 2.9 и 2.10 представлены графики симметричных «сигмоид» на базе
2
гиперболического тангенса /[g(f)] = th(g) и арктангенса f[g(t)] = ^arcth(g)
соответственно. После несложных преобразований из последних
симметричных «сигмоид» легко получаются смещенные, также широко используемые на
практике.
Линейная функция активации. Эта функция также относится к классу
непрерывных. Графики смещенной и симметричной функций этого типа
представлены на рис. 2.11. Линейный участок такой функции активации позволяет
оперировать с непрерывными сигналами. Зоны нечувствительности
определяются физической реализуемостью этих функций.
Степенные функции активации. Функции этого вида используют при
проектировании НС, предназначенных для решения задач аппроксимации функций
одной и/или многих переменных, для реализации степенных рядов, для
реализации сложных вычислительных алгоритмов. Математическая модель таких
функций имеет вид
МШ = gV),
где и = 2,3,4,5... - показатель степени. (Очевидно, что при и=1 имеем случай
линейной функции).
В настоящее время наиболее распространены функции второй и третьей
степени (« = 2,3). Лишь степенные функции с нечетными показателями
степени в полной мере отвечают требованиям, предъявляемым к функциям
активации-монотонны, дифференцируемы, непрерывны.
В практике разработки НС применяют функции активации и других видов,
отличных от перечисленных выше. Все определяется характером решаемой
задачи. В каждом конкретном случае разработчик должен обосновать свой
выбор.
-■-►
45
2. Модели операционного блока нейрокомпьютеров
1
0,5
-•>
-0,5
1
0,5у
-1
к
0
1
1
g
Рис. 2.11. Графики линейной функции активации:
а - симметричная; б- смещенная
Перспективным направлением в теории НС является применение функции
активации с переменной «крутизной» [1]. В этом случае уравнение
формального нейрона, например со степенной функцией активации, можно представить в
следующем виде: .
I п л
>> = £> 2>,х,.+я0 . (2.5)
V <=1 )
В этой модели коэффициент Ъ изменяет крутизну параболы k-й степени, что
значительно расширяет функциональные возможности как отдельного
нейрона, так и всей нейронной сети, состоящей из таких нейронов.
Непосредственная реализация выражения (2.5) требует наличия в устройстве управления НК
двух контуров настройки (адаптации) нейрона: один для коэффициентов а,
другой - для Ъ. Чтобы уменьшить время настройки сети, а в конечном счете и
время решения задачи, можно, видоизменив выражение (2.5), отказаться от
второго контура настройки. Очевидно,что если коэффициент Ъ внести под знак
суммы, то можно записать
У = Ь\Т£а1х1+а0) = 5>Ч*,+*Ч = ЁСЛ+М' (2"6)
.1=1
.1=1
где коэффициенты с =bka (J=0, 1, 2,
.,*)•
46
2.3. Классификация нейронных сетей
Выражение (2.6) показывает, что крутизной функции активации можно
варьировать при общей настройке синаптических коэффициентов нейронной сети.
Основным недостатком нейронов с пороговым элементом является
отсутствие достаточной гибкости при обучении и настройке нейронной сети на
решаемую задачу. Если значение вычисляемого скалярного произведения х.а.
даже незначительно не достигает заданного порога, то выходной сигнал не
формируется, и нейрон «не срабатывает». Это означает, что теряется
интенсивность выходного сигнала данного нейрона и, следовательно, формируется
невысокое значение уровня на взвешенных входах в следующем слое нейронов.
Такого недостатка в большей степени лишена линейная (в общем случае
кусочно-линейная) функция активации, реализация которой обеспечивает
невысокую вычислительную сложность.
Сигмоидальная функция является некоторым компромиссом между
линейной и ступенчатой функцией, и содержит достоинства обеих. По аналогии со
ступенчатой функцией она нелинейна, и это дает возможность выделять в
поисковом пространстве исследуемых объектов области сложной формы, в том
числе невыпуклые и несвязные. С другой стороны, в отличие от ступенчатой
функции, она позволяет переходить от одного значения входного сигнала к
другому без разрывов. Однако любую из преобразующих функций активации
(возбуждения) необходимо рассматривать как приближенную. Учитывая сложность
архитектуры и трудность настройки ее параметров на решение определенной
задачи, необходимо переходить к более гибким произвольным нелинейным
функциям.
Формальный нейрон фактически представляет собой процессор с очень
ограниченной специальной системой команд (в литературе принято называть ней-
росетевой базис). Формальные нейроны по способу представления
информации бывают аналоговые и цифровые. И те и другие выполняют единообразные
вычислительные действия и не требуют внешнего управления. Большое число
параллельно работающих процессоров обеспечивает высокое быстродействие.
2.3. Классификация нейронных сетей
Классификация нейронных сетей по виду топологии
Под топологией нейронной сети будем понимать графическую
иллюстрацию соединения нейронов между собой в этой сети.
По виду топологии нейронные сети разделяют на однослойные и
многослойные.
Однослойные нейронные сети. В однослойных сетях нейроны
соединяются либо по принципу каждый с каждым - полносвязанные сети, либо
регулярно - регулярные сети.
Топология простейшей однослойной нейронной сети показана на рис. 2.12.
Здесь для простоты изображения нейроны представлены р виде кружков и распо-
47
2. Модели операционного блока нейрокомпьютеров
> Ух
> У г
> Уз
У*
Рис. 2.12. Однослойная регулярная сеть:
х\> х2> хз - входной образ; yt- у4 - выходной образ
ложены в узлах сети. Линии связи с двусторонними стрелками условно
означают передачу информации по двум физически различным каналам. В сетях
этого вида любой из нейронов может быть входным и выходным.
Регулярность сети заключается в строгой определенности числа связей для
каждого нейрона. Причем число связей нейрона зависит от места его
расположения в сети. Так, для сети, приведенной на рис.2.12, нейроны, расположенные
в углах сети, связаны лишь с двумя ближайшими нейронами, расположенными
на вертикальной и горизонтальной границе. Пограничные нейроны имеют
связи с тремя ближайшими нейронами: с двумя, расположенными вдоль границы,
и с одним внутренним. Внутренние нейроны соединены с четырьмя соседними.
Возможен случай, когда для сети, представленной на рис. 2.12, пограничные
нейроны двух параллельных границ связывают между собой. Это приводит к
трансформации НС из плоскости в цилиндр. Если же разработчик считает
необходимым, то, соединяя далее пограничные нейроны двух других
параллельных границ (т. е. торцов цилиндра), трансформирует цилиндр в тор. Отметим,
что у тора все нейроны будут иметь по четыре связи с ближайшими соседними
нейронами.
Регулярная топология нейронной сети, приведенная на рис. 2.12, не является
единственной. Возможно другое число связей у угловых, граничных и
внутренних нейронов. На рис. 2.13 приведен пример регулярной гексагональной
топологии. Как видно из этого рисунка, пограничные нейроны в этом случае имеют
по четыре связи, а внутренние - по шесть (отсюда и название вида топологии).
Для этой сети также может иметь место трансформация плоскости в цилиндр,
а далее - в тор.
Характерной особенностью сетей с регулярной топологией является один
вид функции активации для всех нейронов этой сети.
48
2.3. Классификация нейронных сетей
Рис. 2.13. Гексагональная топология сети:
Х\,х2, х3 - входной образ; у\,уг - выходной образ
Многослойные нейронные сети. В многослойных сетях нейроны
группируют по слоям. Внешние слои многослойной сети называют входным и
выходным слоями. Внутренние слои называют скрытыми. Число скрытых слоев
неограниченно. Известны также двухслойные сети, у которых имеется только
входной и выходной слои.
Наиболее простыми являются сети с прямыми, перекрестными,
обратными и латеральными связями. Рассмотрим топологии этих сетей.
Сеть с прямыми связями. Двухслойный и трехслойный варианты сетей с
прямыми связями представлены на рис. 2.14 и 2.15. Характерной особенностью
таких сетей является равенство числа нейронов по слоям и, кроме того, все
нейроны входного слоя активизируются вектором входного сигнала, а все
нейроны выходного слоя определяют выходной вектор.
Скрытый слой
Входной слой ' Выходной слой Входной слой' ' Выходной слой
Рис. 2.14. Двухслойная сеть Рис. 2.15. Трехслойная сеть
с прямыми связями с прямыми связями
49
2. Модели операционного блока нейрокомпьютеров
О
о
1'
о
1 г
о
Входной слой
у т V Т Выходной слой
Ух У2 Уъ У*
Рис. 2.16. Двухслойная сеть с перекрестными связями
Сеть с перекрестными связями. Вариант двухслойной сети с
перекрестными связями приведен на рис. 2.16. Как видно из этого рисунка, нейроны
второго слоя имеют настраиваемые синаптические связи как с выходов нейронов
первого слоя, так и непосредственно с устройства ввода НК.
В общем случае в многослойных сетях произвольной структуры возможны
различные конфигурации перекрестных связей.
Сеть с обратными связями. Введение обратных связей в НС, как и в
любую другую динамическую систему, существенно меняет ее
функциональные возможности. Обратной связью можно охватывать как отдельный слой,
так и несколько слоев и даже всю сеть. На рис. 2.17 представлена четырех-
слойная сеть с различными обратными связями.
Входной слой
Выходной слой
Скрытые слои
Рис. 2.17. Четырехслойная сеть с обратными связями
50
2.3. Классификация нейронных сетей
h&
У\ Уг
О
Т
Уз
\
W
У* У%
Рис. 2.18. Слой нейронной сети с латеральными связями
Сеть с латеральными связями. Введение в скрытые слои нейронной сети
латеральных (боковых, от лат. lateralis — боковой) связей позволяет
контрастировать изображение на случайном фоне, что повышает эффективность
распознавания графических образов. Латеральные связи бывают тормозящими и
возбуждающими. В живой природе эти связи довольно частое явление. На рис.
2.18 показан пример контрастирования сигналов соседних нейронов в
отдельном слое. Подавая сигналы через отрицательные коэффициенты синаптичес-
кой связи с центрального нейрона на два левых, добиваются снижения
активности этих нейронов. Подача сигналов на два правых нейрона через
положительные коэффициенты синаптической связи увеличивает степень
активности этих нейронов. В результате центральный и два правых нейрона будут
значительно активнее двух левых, что эквивалентно повышению
контрастности входного образа (входного изображения).
Двухмерные многослойные нейронные сети. При решении задачи
распознавания широко используют многослойные сети, в которых каждый нейрон
текущего слоя связан с каждым нейроном следующего слоя (рис. 2.19). Такой
подход доказал свою работоспособность в различных практических
применениях, но у него есть один недостаток - большая избыточность нейронных
связей. Так, если число нейронов в слое равно п, то число связей между двумя
соседними слоями для полносвязанной сети равно и2. Практическая
реализация такого числа связей сопряжена с большими трудностями как на
аппаратном, так и на программном уровнях даже при сравнительно небольшом числе
нейронов в слое (100 - 50).
При использовании в качестве входных
данных двухмерных графических образов,
взятых из реального мира, можно
предположить, что каждый элемент входного
набора оказывает влияние только на
небольшую область вокруг своей
топологической проекции на следующий слой
сети и практически не влияет на отдален-
Рис. 2.19. Одномерная полносвязанная
трехслойная сеть
51
2. Модели операционного блока нейрокомпьютеров
г ^
< ~^
V.
/о
№
w
°/
/о
~^\Г\
*Ол°
—». л
г
°/ —
/
J
I
Рис. 2.20. НС с двухмерными нейронными слоями
ные от этой области участки. Отдаленные связи, как правило, очень малы, и
ими можно пренебречь. При подобном уменьшении числа межнейронных
связей можно значительно сократить объем вычислений при программном
моделировании сети и объем аппаратуры при аппаратной реализации. Таким
образом, может получиться сеть с топологией, показанной на рис 2.20. Здесь каждый
нейрон своими синаптическими связями проецируется на небольшую область
следующего слоя. Для наглядности слои этой сети стоит представлять не
одномерными, а плоскими, т. е. двухмерными.
Обобщенная структурная схема нейронной сети. Несмотря на большое
разнообразие топологий НС, имеющихся в настоящее время в распоряжении
разработчика (часть из которых рассмотрена в этой главе), целесообразно при
их конструировании исходить из обобщенной структурной схемы, приведенной
на рис. 2.21. По сути эта схема представляет собой структурную схему
операционного блока НК (аналог арифметическо-логического устройства машины
фон Неймана). Физическая реализация перекрестных и обратных связей
может быть осуществлена, например, на резистивных матрицах и управляемых
ключах, что позволит строить схемы с переменными (нестационарными )
весовыми коэффициентами. При этом чем меньше градаций имеют
перестраиваемые коэффициенты (т. е., чем меньше размерность резистивных матриц),
тем больше потребуется нейронов для решения одной и той же задачи. В
схеме, представленной на рис. 2.21, управление коммутацией синаптических
(весовых) коэффициентов осуществляется от общего управляющего автомата по
программе, хранимой в запоминающем устройстве.
Классификация нейронных сетей по способу решения задачи
Классификация сложных систем, а нейронные сети являются таковыми,
всегда проводится по определенному признаку. Ранее была приведена
классификация нейронных сетей по топологии. Кроме того, НС классифицируют по
способу решения задач. С точки зрения этого признака, сети делят на
формируемые, сети с формируемой матрицей связи, обучаемые и комбинированные
(смешанные).
52
2.3. Классификация нейронных сетей
Р5
К устройству вьшода
ft
1
Выходной слой
с
Y
V
Аг-й скрытый слой
I
о
«
о
е-
и
н
о
н V
f
1-й скрытый слой
V
I
-N
Входной слой
т
$=>
\
в
о
>5
о
&
о
н
О
С устройства ввода
53
2. Модели операционного блока нейрокомпьютеров
Формируемые сети. Сети этого вида проектируют для формализуемых
задач, имеющих четко сформулированный в нейросетевом базисе алгоритм
решения конкретной задачи.
Сети с формируемой матрицей связей. Сети этого вида применяют для
трудноформализуемых задач. Как правило, эти сети имеют одинаковую
структуру и различаются лишь матрицей связи (сеть Хопфилда). Достоинством
таких сетей является их наглядность в работе.
Обучаемые сети. Этот вид сетей используют для решения неформализуе-
мых задач. В процессе обучения сети автоматически изменяются такие ее
параметры, как коэффициенты синаптической связи, а в некоторых случаях и
топология. Серьезным препятствием в широком применении НК все еще
остается большое время обучения сети. Поэтому выбор или разработка алгоритма
обучения являются ключевой задачей разработчика нейронных систем.
Комбинированные (смешанные) сети. Этот класс сетей сочетает в себе
признаки двух, а то и трех основных видов. Как правило, эти сети
многослойные, каждый слой которых представляется различной топологией и обучается
по определенному алгоритму. В настоящее время этот класс получает
наибольшее распространение, так как дает самые широкие возможности
разработчику.
Математическое описание многослойных нейронных сетей
На основе математической модели одиночного нейрона [уравнение (2.1)]
можно составить математическое описание (математическую модель) всей
нейронной сети. Рассмотрим некоторые из них.
Двухслойная нейронная сеть с прямыми связями:
( n ( к \\
где/ = 1,2, ...^-число нейронов второго слоя;£=1,2, ...,К- число нейронов
первого слоя; fx,f2 — функции активации нейронов первого и второго слоев;
аш - начальное возбуждение 1-го нейрона первого слоя; а20к - начальное
возбуждение к-ro нейрона второго слоя; a2j, au - весовые коэффициенты /-го
нейрона второго слоя и к-ro нейрона первого слоя;^(/) - i-я координата выходного
вектора; xk(t) - к-я координата входного вектора. В общем случае K*N.
Предполагается также, что функции активации нейронов одного слоя
одинаковые.
Трехслойная сеть с прямыми связями:
( n ( м (к \\\
^ 1=1 V т=\ \к=\
*Ш
(2.8)
JJ)
Здесь к = 1, 2, ..., К- число нейронов первого слоя; т = 1, 2, ..., М- число
нейронов второго слоя; i = 1,2, ...,N, аш, а20т, аш - начальные возбуждения
к-то, m-ro и i-ro нейронов первого, второго и третьего слоев соответственно.
54
2.4. Методика решения задач в нейросетевам базисе
Аналогично могут быть получены выражения для сети с любым числом
слоев. В конкретных случаях могут отсутствовать в отдельных нейронах или
слоях начальные возбуждения.
Двухслойная сеть с перекрестными связями:
( n С к \ n \
V'=l V*=l J j J
Выражение (2.9) описывает двухслойную сеть с полными перекрестными
связями. Здесь приняты те же обозначения, что и в выражениях (2.7) и (2.8).
При решении одной и той же задачи сеть с перекрестными связями, как
правило, значительно проще сети с прямыми последовательными связями по
числу нейронов, используемых в сети.
Сеть с обратными связями:
*М=/(1алМ+М'-1)]- (2Л0)
V <=i J
где Ь — синаптический коэффициент обратной связи;y(t-l) - значение
выходного сигнала нейрона в момент времени (/-1); п - число входов нейрона. Для
двухслойной сети, имеющей Nнейронов во втором слое и ^нейронов в первом,
математическая модель имеет вид:
Г N (К N,K \ N \
y{t)=fi 2ХЛ ZM^+W'-iM+E^C'-1) +ZM'-i)
(2Л1)
Здесь b2ik - синаптические коэффициенты обратной связи с выходов нейронов
второго слоя на входы нейронов первого слоя; Ъъ - коэффициенты обратной
связи с выходов нейронов второго слоя на входы нейронов второго слоя; blk -
коэффициенты обратной связи нейронов первого слоя. Остальные обозначения
такие же, как в выражениях (2.8) и (2.9). Синаптические коэффициенты
обратных связей могут быть как положительными, так и отрицательными.
2.4. Методика решения задач в нейросетевом базисе
При конструировании нейронных сетей разработчик имеет, как правило,
следующие исходные данные:
размерность вектора входного сигнала(ов);
размерность вектора выходного сигнала(ов);
формулировку решаемой задачи;
точность решения задачи.
При этом он должен определить и назначить:
вид топологии сети;
общее число нейронов в сети и число нейронов по слоям;
вид функции активации нейронов;
55
2. Модели операционного блока нейрокомпьютеров
способ задания коэффициентов синаптической связи;
метод доказательства работоспособности новой сети.
Предлагаемая в этом разделе методика разработана А.И. Г. i. со
своими сотрудниками и учениками. Эта методика успепшо применялась для
решения многих классов задач и доказала свою эффективность.
Основные этапы методики.
1. Математическая постановка задачи.
2. Геометрическая постановка задачи.
3. Нейросетевая постановка задачи:
3.1) описание исходных данных;
3.2) определение входного сигнала НС;
3.3) формирование функционала первичной оптимизации НС при
решении поставленной задачи;
3.4) определение выходного сигнала НС;
3.5) определение желаемого выходного сигнала НС;
3.6) определение вектора сигнала ошибки нейронной сети при
решении задачи;
3.7) формирование функционала вторичной оптимизации НС через
сигналы в системе;
Входной
сигнал
Нейронная
сеть
i
к
Алгоритм
настройки
сети
t
к
Функционал
первичной
оптимизации
Выходной сигнал
Указания
учителя
Поиск
экстремума
ФВО
Г
Формирование
ФВО
1
г
Вычисление
ошибки
'
Вычисление
градиеь
ггаФВО
Рис. 2.22. Этапы разработки НС
56
2.4. Методика решения задач в нейросетевом базисе
3.8) выбор метода поиска экстремума функционала вторичной
оптимизации НС;
3.9) аналитическое определение преобразования, осуществляемое НС;
выбор конкретной структуры сети;
3.10) нахождение аналитического выражения для градиента
функционала вторичной оптимизации поставленной задачи;
3.11) формирование алгоритма настройки НС при решении
поставленной задачи;
3.12) выбор начальных условий при настройке сети;
3.13) выбор типовых входных сигналов для тестирования процесса
решения задачи;
3.14) разработка плана эксперимента.
В представленном виде методика является обобщенной. Для решения
конкретных задач отдельные ее пункты могут быть опущены. На рис. 2.22
представлена взаимосвязь основных этапов методики.
Вопросы для самоконтроля
1. Перечислите задачи, которые решают НС, и дайте им краткую характеристику.
2. Воспроизведите схему абстрактного НК и поясните принцип его работы.
3. В чем отличие НК от машины фон Неймана?
4. Что такое формальный нейрон? Приведите его структурную схему и опишите
работу. Разновидности формальных нейронов.
5. Что такое функции активации? Приведите графики этих функций.
6. Приведите примеры однослойных НС.
7. Приведите примеры топологий двухслойных НС.
8. Приведите примеры топологий многослойных НС.
9. Как классифицируются НС с точки зрения решаемых задач?
10. Воспроизведите формулы математических моделей НС.
11. Воспроизведите схему обобщенной НС и поясните ее работу.
57
3. КОНСТРУИРОВАНИЕ ФОРМИРУЕМЫХ
НЕЙРОННЫХ СЕТЕЙ
Глава посвящена проектированию формируемых нейронных сетей. Рассмотрены
два важных направления применения этого класса сетей: интегрирование стационарных
и нестационарных нормальных систем дифференциальных уравнений; воспроизведение
различных функций, разложенных в ряды Маклорена.
3.1. Общие сведения
Как уже отмечалось, формируемые НС эффективны при решении задач,
для которых имеется хорошо сформулированный в нейросетевом базисе
алгоритм решения. Вычислительная математика специализируется на разработке
таких методов решения задач, которые могут быть реализованы на ЭВМ.
Базой для многих методов, разработанных вычислительной математикой,
является аппроксимация функций. В общем виде идею аппроксимации функции
можно представить следующим выражением:
Выбор базисных функций <pj[x) в приведенном выражении определяется
особенностью решаемой задачи, используемым методом, опытом разработчика и
его техническими возможностями. Нетрудно заметить, что это выражение при
определенных <pj[x) описывает однослойную НС.
Значительно больше функциональных возможностей можно получить, если
использовать для аппроксимации функций многослойные нейронные сети. Так,
аппроксимация с помощью двухслойной сети может быть записана в
следующем виде: / г \\
У(х) = /г I>2,/i !>„*, •
V ' V J J J
Поскольку нейросетевой базис представляет собой операцию
нелинейного преобразования взвешенной суммы, то естественно говорить об эффектив-
58
3. Конструирование формируемых нейронных сетей
где А - квадратная матрица постоянных коэффициентов размера пу-п;
Y - и-мерный вектор искомой функции аргумента /.
Хорошо известны различные варианты аналитического решения системы
(3.1), определяемые видом корней характеристического уравнения. Именно
наличие вариантов и затрудняет разработку единого метода решения
произвольной системы.
Обобщенное приближенное решение системы (3.1) численными методами
Рунге-Кутта можно представить в следующем виде:
У|+1=ехр(ЛА)Х, (3.2)
где h - шаг интегрирования, а / - его номер.
Элементы матричной экспоненты ехр(ЛА) - постоянные коэффициенты.
Произведение вектора Yt на разложение этой экспоненты в степенной ряд Мак-
лорена есть не что иное, как взвешенное суммирование. Поэтому
итерационный процесс (3.2) полностью удовлетворяет требованиям нейросетевого
базиса. Удерживая в разложении экспоненты два, три, четыре и более членов
(включая единицу), можно получить нейросетевую реализацию решения
системы (3.1) методами Рунге-Кутта первого, второго, третьего и более порядков
аппроксимации.
Реализация процесса численного интегрирования (3.1) возможна в том
случае, если нейронная сеть синхронная, а функции активации нейронов -
линейные. Элементы матрицы А (ак, j, k= 1, 2, ..., п) определяют связь между
компонентами вектора Y (у,, у2, у3, у4) в прямом направлении (оту, к у2 - аи,
от)', к у3 - ап и т. д.), в обратном (от у2 к ух — a2i и т. д.) и самого
компонента на себя (элементы главной диагонали матрицы А). Поэтому для
нейросетевой реализации необходимо, чтобы нейроны в слое, реализующем
интегрирование по формуле (3.2), соединялись между собой по принципу
«каждый с каждым», включая связь с выхода нейрона на свой же вход. Далее,
поскольку размерность вектора искомой функции Y не зависит от
используемого численного метода, то число нейронов, необходимых для интегрирования
системы (3.1), в соответствии с выражением (3.2), определяется
размерностью вектора Y (в нашем случае п).
Рассмотрим конкретные примеры. Решение системы (3.1) методом
прямоугольников (метод Рунге-Кутта первого порядка аппроксимации) имеет вид
Y1+I=Y,+AAY,. (3.3)
Представим последнее равенство (3.3.) в следующем виде:
YftI=(E + *A)Y,=BIY,, (3.4)
где Е - единичная матрица размера п х п.
60
3.2. Синтез НС для решения нормальной системы дифференциальных уравнений
ности реализации методов вычислительной математики при решении задач
управления динамическими объектами.
В теории и практике систем управления для повышения качества
проектируемых технических устройств широко используют блоки аппаратного и/или
программного интегрирования и дифференцирования сигналов, блоки
аппаратной и/или программной аппроксимации функций, блоки решения систем
алгебраических линейных или нелинейных уравнений. Так, например, в системах
бесплатформенной инерциальной навигации и ориентации (см. пример в § 1.1)
принципиально необходимо интегрировать кинематические уравнения по
данным, получаемым с датчиков угловой скорости и датчиков линейного
ускорения (акселерометров). Это интегрирование ложится на бортовую УЦВМ.
Кроме того, в таких системах УЦВМ должна решать задачу преобразования
координат, что всегда связано с вычислением тригонометрических и обратных
тригонометрических функций. Таким образом, общая размерность решаемой
УЦВМ системы уравнений для обеспечения качественного управления
полетом в отдельных случаях составляет 100-120.
Следует особо выделить тот факт, что в настоящее время
специалисты по системам управления разрабатывают новые методы анализа, синтеза
систем, ориентированные на программно-аппаратную реализацию на ЦВМ. К
таким методам можно отнести спектральные методы [5]. Реализация этих
методов в общем случае предполагает применение операций над матрицами,
которые в свою очередь сводятся к арифметическим. Размерность матриц
при описании современных систем управления, как правило, очень большая.
Это открывает широкий фронт для исследования возможности реализации
спектральных методов в нейросетевом базисе.
3.2. Синтез нейронной сети для решения нормальной
системы дифференциальных уравнений
Как уже отмечалось, нейросетевой базис представляет собой операцию
взвешенного суммирования нескольких входных сигналов с последующим
преобразованием этой суммы посредством функцией активации формального
нейрона, которая может быть как линейной, так и нелинейной. Рассмотрим, в
какой мере численные методы решения дифференциальных уравнений могут
удовлетворять нейросетевому базису, какую при этом необходимо иметь
функцию активации, какова будет топология НС.
Не уменьшая общности рассуждений, с целью упрощения выкладок
рассмотрим вначале случай стационарной системы, а затем распространим
полученные результаты на случай нестационарных систем.
Интегрирование стационарных систем
дифференциальных уравнений
Пусть задана нормальная система и дифференциальных уравнений первого
порядка
Y(/) = AY(0, (3.1)
59
3.2. Синтез НС для решения нормальной системы дифференциальных уравнений
Ne\
£10
\+ha„
ha,.
go
x.
/и
У к
#20
Ne/.
ha..
l+ha22
«о
xx
X2
I
/,.
Уг
(3.5)
Рис. 3.1. Схема НС для интегрирования системы двух
дифференциальных уравнений методом прямоугольников
Элементы матрицы Bt = Е + Ah есть первые два члена разложения
матричной экспоненты ехр(ЛА) в степенной ряд. Для системы двух уравнений (при
п = 2) выражение (3.4) в развернутом виде принимает вид
Уь+1 = ЬцУи + КУъ = (1 + *Оц )Уь + ЬОхгУгг;
Уил = КУн + Ь1гу 2= ha2lyb+{\ + ^)y2i.
Уравнения (3.5) содержат лишь операции взвешенного суммирования.
Поскольку решаемая система является системой двух уравнений, то выходные
сигналы ух,у2 снимаются с двух нейронов. При этом выход первого нейрона,
как следует из первого уравнения (3.5), должен быть соединен со входом этого
же нейрона через синаптический коэффициент (l+hau). Co входом второго
нейрона первый нейрон соединяется, как следует из второго уравнения (3.5), через
коэффициент (ha2l). Выход второго нейрона соединяется со входом первого
через синаптический коэффициент hal2 и подается на собственный вход через
коэффициент (l+ha22).
Поскольку решение (3.5) -рекурентное выражение, то нейронная сеть,
реализующая это решение, должна быть синхронной, а нейроны должны иметь
линейную симметричную функцию активации (/„ по принятому обозначению
в § 2.2).
На рис. 3.1 представлена схема соединения нейронов, реализующая
решение системы (3.1) в соответствии с выражением (3.5). На этом рисунке Nel,
Ne2 - нейроны, участвующие в операции интегрирования. Выходом сети
являются сигналы у , у2. Входные сигналы g10 и g10 вводят в нейроны начальное
возбуждение, эквивалентное начальным условиям решения системы уравне-
61
3. Конструирование формируемых нейронных сетей
ний. Функция активации у обоих нейронов - симметричная линейная функция.
Схема на рис. 3.1 является универсальной, так как применима для любых
систем двух уравнений. В каждом конкретном случае разработчик должен ввести
лишь конкретные значения коэффициентов а .
Рассмотрим систему трех уравнений (и = 3). Выражение (3.4) в скалярной
форме записи для этого случая имеет вид:
Ухт=ЪпУи+ ЪмУ*+ ЬпУ31>
Уш1=Ь2гУи+ ЪггУг>+ Ь2зУз,>
У*» = ЬзгУи + КУь+ КУж
После замены коэффициентов Ъ.. (i,j = 1, 2, 3) в последнем выражении на
элементы разложения матричной экспоненты ехр(АА) в ряд Маклорена
получим:
Уин = (1+кап)Уи+ hanУг>+ Ып У»
Уън = ЫгхУм + О + ка22)У2,+ Чз>У (3-6)
Узт = капУи + ЫъгУг,+ (1+ Чз ) Уге
Здесь, как и в случае системы двух уравнений в (3.6), присутствуют лишь
операции взвешенного суммирования, следовательно, и она тоже удовлетворяет
нейросетевому базису. На рис. 3.2 показана схема соединения нейронов для
решения системы трех уравнений методом прямоугольников. Нетрудно
заметить, что при а31, а32, агъ, а2Ъ, а13, равных нулю, выражения (3.6) переходят в
выражение (3.5), а следовательно, и схема, показанная на рис. 3.2, переходит в
схему, представленную на рис. 3.1
Используя описанный выше прием, можно получить выражения, подобные
(3.5) и (3.6), для системы с любым числом уравнений.
Рассмотрим решение системы (3.1) численным методом Рунге-Кутта
второго порядка аппроксимации (метод трапеции). В этом случае общее решение
имеет вид:
YI+I=Y,+0,5A(K1 + K2); (3.7)
Kl = AYi5 K2 = A(Y,+/?K1)-
Подставим выражения для К1 и К2 в первое уравнение системы (3.7) и
после несложных преобразований получим
Y.+1 = B2Y.=(E + AA + 0,5A2A2)Y.. (3.8)
Элементы матрицы В2= (Е + АА + 0,5МА2), как и элементы матрицы В,
удовлетворяют нейросетевому базису, а сама матрица определяет топологию
нейронной сети для решения системы (3.1) рассматриваемым методом.
Решение (3.8) для случая системы двух уравнений (и = 2) в развернутом
виде можно представить следующим образом:
62
3.2. Синтез НС длярешения нормальной системы дифференциальных уравнений
S\o \
1 '
2 ,
3 1
#20
1 '
2 ,
3 1
#зо |
1 '
2 ,
3 1
Ne\
\+han
hau
Чз
Ne2
ha2l
1+han
Чз
Ne3
ha3l
han
1+4l
So
xj
I
/..
So
xi
*з
I
/..
So
xx
xi
X3
I
/..
1
1 2
1 3
У\
W
Уг
►
Уъ
Рис. 3.2. Схема НС для интегрирования
системы трех дифференциальных уравнений
методом прямоугольников
уи+1= (1 + han+ 0,5hWn+ 0,5h\2a2l)yu+ (ha12+ 0,5t?anan+ G,bWana22)y2;,
y2i+1= (ha2+ 0,5tfana21+ 0,5h2a2la22)yu + (1 + ha22+ 0,5^lA,0,5^222) ^.(3.9)
Сопоставляя (3.5) с (3.9), можно заметить, что топология сети в обоих
случаях одинакова. Меняются лишь значения синаптических коэффициентов. В
63
3. Конструирование формируемых нейронных сетей
решении (3.9) появились слагаемые в синаптических коэффициентах,
определяемые третьим членом ряда разложения матричной экспоненты ехр(АА),
членом, пропорциональным квадрату аргумента экспоненты - 0,5А2А2.
Для случая и — 3 выражение (3.8) принимает вид:
у1М= (1 + han+ 0,5h2a2u+ 0,5h2ana2 + 0,5h2al3a3l) yu +
+ (hau+ 0,5tfana12+ 0,5h2ana2+ 0,5^aI3a32) y2 +
+ (hau+ 0,5h2auan+ 0,5#a13a23+ 0,5#a13a33) y3i;
Уъ»= (Ч.+ b>Waua2+ 0,5#я21я22+ 0,5h2a23a31)yb +
+ (1 + ha22+ 0,5h>ana21 + 0,5tfc?22+ 0,5h>a23a32) y2i + (3.10)
+ (ha23+ 0,5h2al3a2l + 0,5h2a22a23+ 0,5h2a23a33) y3i;
Уи» = (Ч.+ 0.5*4*,,+ 0,5^a2la3+ 0,5h2a3}a33)y„ +
+ (ha32+ 0,5h2a12a3l+ 0,5h2a22a32+ 0,5Л2азАз) у2 +
+ (1 + ha3+ 0,5h2ana3l+ 0,5h2a23a32+ 0,5hW33)y3i .
Топология сети, построенной по выражению (3.10), очевидно, будет
полностью совпадать с топологией сети, приведенной на рис. 3.2. Как и в
предыдущем случае (при и = 2), изменение порядка численного метода привело к
изменению лишь коэффициентов синаптической связи.
Решение системы (3.1) методом Рунге-Кутта третьего порядка
аппроксимации в общем случае имеет вид:
Y+1 = Y + | /г(К1 + 4К2 + КЗ);
Kl=AY,K2 = A(Y+0,5/?Kl); (3.11)
K3 = A(Y+fcKl + 2K2).
После подстановки выражений Kl, K2, КЗ в первое уравнение (3.11) и
соответствующих преобразований получим
Y+1 = B3Y = ( Е + ЛА + 0,5 Л2А2+ | /г3А3) Y . (3.12)
Аналогичные рассуждения и преобразования для метода Рунге-Кутта
четвертого порядка аппроксимации дают следующий результат:
Y+1 = B3Y = ( Е + hA + 0,5 h2A2+ ^ й3А3 + |>4А4) Y . (3.13)
Очевидно, что в выражениях (3.4), (3.8), (3.12) и (3.13) матрицы В,, В2, В3 и
В4 представляют собой ряд разложения матричной экспоненты аргумента hA,
ограниченный до двух, трех, четырех и пяти членов соответственно.
Следовательно, решение системы (3.1) методом Рунге-Кутта в общем виде можно
представить как
YM = ехр(АА)Y, « BtY, , (3.14)
где к - порядок метода интегрирования, а матрица Bt определяется по
следующей зависимости:
64
3.2. Синтез НС для решения нормальной системы дифференциальных уравнений
В = ( Е + АА + 0,5 Л2А2+ ^/г3А3+ ... + £/г*А*). (3.15)
о л!
Любая из матриц Bt полностью удовлетворяет нейросетевому базису и
определяет схему решения системы (3.1).
Выражения (3.14) и (3.15) делают возможным построения нейронных сетей,
интегрирующих систему (3.1) с любой, наперед заданной точностью.
Анализируя особенности матриц Bt по выражению (3.15), можно сделать вьшод, что
Блок перекрестных связей
#10
£л0
Ne\
*..
Nen
*11_
/н
/и
У\
У.
■>у1
->Уг
■>Уп
Рис. 3.3. Схема универсальной НС для интегрирования
нормальной системы дифференциальных уравнений
65
3. Конструирование формируемых нейронных сетей
точность решения системы (3.1) в формируемых нейронных сетях будет
определяться точностью установки коэффициентов синоптической
связи, а не числом используемых нейронов.
На рис. 3.3 представлена универсальная схема НС для интегрирования
нормальной системы дифференциальных уравнений (3.1) размерности и по
выражениям (3.14) и (3.15).
Особенности интегрирования нестационарных
систем дифференциальных уравнений
В нестационарных системах элементы матрицы А являются в общем
случае произвольными функциями аргумента /:
Y'(') = A(/)Y(/).
Для таких систем не существует аналитических выражений решений.
Однако практика моделирования и разработки различных сложных объектов,
процессов и систем управления показывает, что решение нестационарных систем
численными методами, в том числе и методами Рунге-Кутта, дает вполне
приемлемые результаты. При разработке алгоритмов решения
нестационарных систем предполагают, что элементы матрицы А(/) не меняют своего
значения в пределах шага интегрирования. Следовательно, можно применять
формулы (3.14), (3.15) на каждом шаге интегрирования
Здесь двойной индекс при матрице синаптических коэффициентов B.k
означает зависимость этих коэффициентов от шага интегрирования /.
Высокая точность решения достигается- при скорости изменения
элементов матрицы A(t) хотя бы на порядок ниже скорости изменения искомой
функции Y(/) (требования гладкости компонентов матрицы A(f) и удовлетворению
условию Липшица). Это условие накладывает довольно жесткие требования
на шаг интегрирования, который должен быть очень маленьким. А это, в свою
очередь, предопределяет высокие требования к быстродействию
управляющих вычислительных устройств.
На рис. 3.4 представлена универсальная схема НС для интегрирования
нормальной системы дифференциальных уравнений с переменными
коэффициентами размерностью п. Как видно из рисунка, в модель нейрона введен блок
установки синаптических коэффициентов, который должен обеспечить смену
этих коэффициентов в такт поступления элементов матрицы А(/).
Пример. Рассмотрим синтез НС для интегрирования кинематических
уравнений в параметрах Родрига—Гамильтона в с • % : • :ии с методикой Галушкина.
Математическая постановка задачи. Задача ориентации является
основной задачей (интегрирования кинематических уравнений) в бесплатформенных
системах ориентации и навигации. Схема такой системы приведена на рис. 1.3.
В этой системе в качестве датчиков входной информации применяют датчики
66
3.2. Синтез НС для решения нормальной системы дифференциальных уравнений
Блок перекрестных связей
Ne\
аи, аи,...,а1п
►
£ю
Блок установки синаптических
коэффициентов
g
Ах
У\
Nen
%м
*.
аяХ, аг2,...,аю
Блок установки синаптических
коэффициентов
/п
У.
Рис. 3.4. Схема универсальной НС для интегрирования
нормальной системы дифференциальных уравнений
с переменными коэффициентами
67
3. Конструирование формируемых нейронных сетей
угловой скорости вращения управляемого объекта. Три датчика расположены
в центре масс подвижного объекта, по одному на каждой оси декартовой
системы координат, связанной с этим объектом. Управление ориентацией объекта
требует знания угловых координат, поэтому их вычисление осуществляется в
бортовом вычислителе путем интегрирования соответствующих
кинематических уравнений. (Применение датчиков углов в таких системах технически не
представляется возможным и экономически не целесообразно.) В настоящее
время наибольшее распространение для этой системы параметров ориентации
получили параметры Родрига—Гамильтона. Матричное кинематическое
уравнение в параметрах имеет вид:
Л' = 0,5ПЛ,
(3.16)
где матрица коэффициентов
£1 =
О
со,
со,
-со,
О
со,,
-со.
со,
-cov
-со,
-со.
cov
о
(3.17)
со ,со , со. — проекции вектора угловой скорости объекта на связанную систему
координат.
Не изменяя сущности решаемой задачи, рассмотрим более упрощенный
вариант интегрирования кинематических уравнений без учета программной
составляющей. Матричное кинематическое уравнение с программной
составляющей приведено в § 1.1. Запишем кинематические уравнения в параметрах
Родрига-Гамильтона в развернутом виде, предварительно умножив на 0,5 все
члены матрицы П в соответствии с матричным уравнением (3.16):
0,5со X, - 0,5со X,- 0,5со X, ;
7 х 1 ' у 2 ' z 3 '
к-
Х',= 0,5со Хп+ 0,5со \- 0,5со "к.;
1 ' дг О * г 2 * у 3 '
X 2 = 0,5со \- 0,5co.X,- 0,5(0^3 ;
Х\ = 0,5со Х„+ 0,5со X,- 0,5со X,.
3 ' z 0 9 у \ ' х 2
(3.18)
Здесь Х0, X,, Х2, Х3 - параметры ориентации Родрига—Гамильтона.
Пусть в ходе исследования методов достижения требуемой точности
решения задачи ориентации разработчик пришел к выводу о необходимости
интегрировать систему (3.18) численным методом второго порядка
аппроксимации (методом трапеций или методом Рунге—Кутта второго порядка) с
шагом h = 0,03125 = 2~5. (Шаг интегрирования, равный целой степени двойки,
проще реализуется в цифровых вычислительных устройствах.)
68
3.2. Синтез НС для решения нормальной системы дифференциальных уравнений
Проведя необходимые преобразования в соответствии с формулой (3.8),
получим численное решение системы (3.18) выбранным методом в общим виде:
Х01+Г (1- 0,125Л2(<+<-ио2..))\- 0,5/гсоД,- 0,5/*co/2i- 0,5йсоЛ3| ;
Xv+r 0,5hcoX0 + (1 - 0,125А^-к^+со2Ж+ 0,5/коЛ,,- 0,5ЛсоД; (ЗЛ9)
X2i+r 0,5/гсоД,,- 0,5^^,,+ (1 - 0,125^(0^+со2у+со2.))Х21- 0,5йсо>3, ;
Хуп= 0,5fccoA0l+ 0,5hay\- 0,5/*co>2i + (1 - 0,125A2(co2x+co2,+co2.))X.3i.
Здесь i = 0, 1,2,... - номер шага интегрирования.
Система (3.19) является исходным для дальнейшей работы. На этом
первый этап методики Галушкина можно считать выполненным.
Геометрическая постановка задачи. Поскольку формируемые НС
проектируют для формализуемых задач, этот этап проектирования может быть
пропущен.
Нейросетевая постановка задачи. Ввиду специфики формируемых сетей
на этом этапе методики проектирования пропускаем пункты 3.3,3.6 - 3.11 (см.
§ 2-4).
Входными сигналами для проектируемой сети являются данные,
поступающие с датчиков угловых скоростей в виде цифрового кода - со, со , со.. Такт
поступления входной информации много больше времени одного шага
интегрирования. Поэтому изменения значения сох, со , со. происходят значительно реже
по сравнению с изменениями номера шага интегрирования, а, следовательно, и
итерационными вычислительными процессами, реализующими решения
системы (3.19) на каждом шаге.
Выходными данными нейронной сети должны быть параметры ориентации
\, "Кх, Ху Хъ, представленные в цифровом виде. Частота съема выходных
данных определяется из условия устойчивости работы всей навигационной
системы, но, как правило, не превышает частоту итерационного процесса
интегрирования. Точность решения поставленной задачи определяется выбранным
методом и шагом интегрирования h.
Проанализируем численное решение системы (3.19) для определения
топологии проектируемой сети. Во всех коэффициентах при искомых параметрах в
правых частях уравнений системы (3.19) можно выделить постоянные
составляющие: 0,5/гсо^ 0,5йсо , 0,5йсо_. Значение шага интегрирования h определено на
этапе математической подготовки задачи: h = 0,03125 = 2~5. Вычисление этих
составляющих может быть осуществлено во входном слое проектируемой сети.
На рис. 3.5 представлен входной слой нейронной сети, реализующей
систему (3.19). Поскольку нейроны входного слоя лишь изменяют масштаб входной
информации, то их функция активации должна быть линейной.
69
3. Конструирование формируемых нейронных сетей
Ne\
ь>_
2"*
/..
0,5Асо
Ne2
-| 2-6 |- .
/..
0,5Асо
Ne3
/и
0,5 Аса
Рис. 3.5. Входной слой НС,
реалгоующей систему (3.19)
В коэффициентах при искомых параметрах ориентации в (3.19) есть
составляющая вида 0,125/z2 ( ю2^ + to2 + to2.). Ее можно вычислить во втором слое
проектируемой сети - слое возведения в квадрат. Более подробно реализация
операции возведения в квадрат описана в § 3.3. Там же определено число
необходимых нейронов и виды функций активации этих нейронов. Входными
сигналами для слоя возведения в квадрат являются сигналы с выходов нейронов
входного слоя. Выходными сигналами этого слоя будут следующие сигналы
(см. систему 3.19):
0,125/z2 ((я\ + (02у + to2z); 0,5йюх; 0,5Лео,; 0,5Аю..
С учетом конкретного значения шага интегрирования h = 2"5 получаем:
0,00390625 (<о2х + (о2у + <о2у, 0Д5625Ю;0,15б25со;0,15625ю_.
Эти сигналы подаются на вход блока установки синаптических коэффициентов
нейронов следующего, выходного слоя. Значения синаптических
коэффициентов нейронов выходного слоя определяются блоками установки этих
коэффициентов в зависимости от изменения информации с датчиков угловых скорос-
70
3.2. Синтез НС для решения нормальной системы дифференциальных уравнений
0,5/хо.
3§
>Х X
as
с? 5?
со S
O.USiHfaf-boJ + fB,1)
-> 0,5/ко„
0,5/хо,
-> 0,5йш
тей. Однако в нашем случае имеется
возможность использования одного блока ус- 0,5/ко,
тановки синаптических коэффициентов на
все нейроны выходного слоя. Эта
возможность определяется особенностью матрицы
Q [см. (3.16), (3.17)]. На рис. 3.6
представлено упрощенное изображение второго слоя о,5/ко_
проектируемой сети.
Выходной слой НС должен состоять из
четырех нейронов с линейной функцией
активации (fu). Каждый из таких нейронов дол- Рис-3-6- Упрощенное изображение
жен иметь четыре синаптических входа, ин- ВТ0Р0Г0 слоя проектируемой сети
формация на которые подается с блока перекрестных связей. Выход каждого
нейрона является выходом нейронной сети, то есть соответствующим
параметром ориентации. Кроме того, выходной сигнал каждого нейрона выходного
слоя поступает на вход блока перекрестных связей.
На рис. 3.7 приведена структурная схема выходного слоя проектируемой
нейронной сети, реализующей систему (3.9). Объединяя представленные слои
в единое целое, получим полную НС, реализующую систему 3.19. Укрупненная
структурная схема синтезированной нейронной сети представлена на рис. 3.8.
Представленный вариант нейронной сети для решения задачи
ориентации не единственный. В зависимости от имеющихся в распоряжении
разработчика ресурсов могут быть предложены и другие варианты. Так,
например, блок установки синаптических коэффициентов можно заменить
дополнительным скрытым слоем, реализующим операции умножения двух
переменных - информации с датчиков и текущего значения параметров
ориентации типа (ok (j = О,1,2,3, tOj=(Ох, со2 = со , со3 = со.). Таких операций, как следует
из (3.19), будет шестнадцать. Метод умножения двух переменных в нейросе-
тевом базисе рассматривается в § 3.3.
При проектировании разработчику необходимо предусмотреть тестовые
варианты, на которых он хотел бы проверить работоспособность своей сети.
Для нашего случая эффективным является тест на так называемое коническое
движение — когда по одному из каналов угловая скорость довольно высокая
(для нашего случая, например - 1 ...2 рад/с), а по второму - низкая
(например - 0,1.. .0,2 рад/с). По третьему каналу угловая скорость должна быть
равна нулю. Кроме того, необходимо предусмотреть введения начальных условий
(входы g0 в нейронах выходного слоя). При этом необходимо также учитывать,
что решение уравнения (3.16) имеет первый интеграл
Х\+ Х\+ Х\+ Х\= 1.
71
3. Конструирование формируемых нейронных сетей
Блок перекрестных связей
к
hi
^
х>\
Отвторог
1 J
ЛИ
■*..
i
0
к
*#> -
°п
t
к
*»
1
к.
ь»
)
к
So
xi
Х2
Xl
Х4
X
/и
—
]Уо
| №3 JLrt)i
Л. '
1
\\
*«
м
x2i
>3l
J '
°32
il
*зз
1L
*34
J
к
Блок установки синаптических коэффициентов
1 1
"«
|
*,1
Ч
'
- ь21
<
х'\
1
\
г
Ь21
'
1
*24
N"~>
'
А /гл
lV«/
'
*23
So
*i
х1
хз
Х4
I
/и
1 •"
1 1 1
£i
0 I
м
1
г
*«.
я 1
1
'
Й42
л2 1
>.,1
'
f
*43
u
'
X
So
х\
Х2
*з
Х4
X
/..
|У2
3(0)
■
'
*4«
So
х1
Х2
хг
Х4
X
/..
-
1Уз
J
■я.,
Рис, 3,7. Структурная схема выходного слоя
проектируемой НС:
fcn = fc22 = fc33 = fc44 = 0,00390625 (со2, + со2, + со2,);
fc2i = -fc.2= fc34= - &4з= 0.°15625ю,;
fc3i fci3 =
к—к-
■-by=b„ = 0,0lS625a ;
24 42 ' >>'
= fc =-fc3 =0,015625co.
72
3.3. Применение степенных рядов при синтезе формируемых НС
"4
ЮХ> °У Ю2
>s
о
5
X
ш
—v
р
(В
V
N^ к
II
Блок перекрестных
связей
I
Л
У
ш
о
^•0» ^1» ^2' ^3
Рис. 3.8. Структурная схема НС,
реализующей систему (3.19)
На этом рассмотрение примера закончим. В заключение отметим, что все
сложности, встречающиеся при решении нормальных систем
дифференциальных уравнений на обычных ЦВМ, встречаются и при их решении на
формируемых нейронных сетях. В первую очередь это относится к понятию
устойчивости решения.
3.3. Применение степенных рядов при синтезе
формируемых нейронных сетей
Степенные ряды имеют огромное значение при конструировании
алгоритмов УЦВМ. Воспроизведение элементарных функций, аналитических нелиней-
ностей проводится в вычислительной технике с помощью степенных рядов.
Поэтому актуальность постановки задачи о реализации вычислительных
алгоритмов на базе степенных рядов в НС несомненна.
Рассмотрим, в какой мере степенные ряды могут удовлетворять
требованиям нейросетевого базиса. Попытаемся также дать ответы на вопросы:
какие функции активации должны иметь нейроны для успешной реализации
алгоритмов, основанных на степенных рядах; какова должна быть топология сети,
реализующей эти алгоритмы?
По определению степенным рядом называется функциональный ряд вида:
а0 + а, (х - с) + а2 (х - cf+... + а (х - с)"-1 + ап(х- с)"+ ,
(3.20)
где коэффициенты ряда аг (/ = 0,1, 2,...) и с - некоторые постоянные числа.
Частичная сумма ряда (3.20), определенная для и его членов с заранее
известным методом задания коэффициентов а., применяется для приближенного
вычисления аналитически нелинейных функций, например ряды Тейлора и Мак-
лорена. Хорошо известна методология применения этих рядов для
приближения функций. Существенным ограничением на класс функций, приближенное
73
3. Конструирование формируемых нейронных сетей
значение которых определяется с помощью рядов Тейлора или Маклорена,
является требование непрерывности производных этих функций до (и + 1)-го
порядка. Это ограничение не уменьшает значимости решения поставленной
задачи.
Рассмотрим разложение функции q(x) в ряд Маклорена:
,(х).,(0) + Ч(0) + ^+ ... +^>+ ... 0-21)
Задаваясь требуемой точностью вычисления q(x), ограничивают ряд (3.21)
конечным числом членов и. На практике для многих известных элементарных
функций высокая точность достигается уже при п = 5...7. Выражение (3.21)
является основой для получения ответов на поставленные выше вопросы.
Покажем это на примере .
Пусть для конкретности п = 5. Введем обозначения:
ао = д(0), а^дЩ, я2 = <Д0), о, = ?Ш(0), а4 = д™(0), а5 = q v(0).
Тогда
q(x) w a0 + ах х + а2 х2 + а3 х3 + а4 х4 + а5 х5. (3.22)
Нетрудно заметить, что приближенное равенство (3.22) есть взвешанная
сумма степеней аргумента искомой функции. Следовательно, в идеальном
случае для реализации этого выражения на НС необходимы нейроны с линейной,
квадратичной, кубичной и т. д. функциями активации. В этом (идеальном)
случае топология НС может быть определена как однослойная, двухслойная,
трехслойная и т. д.
Рассмотрим двухслойную сеть. В этом случае аргумент искомой функции
должен подаваться на пять нейронов входного слоя. Функции активации этих
нейронов являются соответственно линейной, квадратичной, кубичной,
параболами 4-й и 5-й степеней. Выходные сигналы нейронов первого слоя через
коэффициенты синаптической связи, равные я,, а2, ау а4, а} , поступают на
единственный нейрон выходного слоя. На сумматор этого же нейрона
поступает также сигнал, эквивалентный единице.
Сигнал с сумматора нейрона выходного слоя и есть искомое значение q(x).
Чтобы это значение не претерпевало дальнейших искажений, функция
активации нейрона выходного слоя должна быть линейной. Уравнение такой сети
может быть записано в виде
(3.23)
я(х) = /21\ flb+5/%/u(*)
где суммирование ведется по г (/ = 1, 2, 3, 4, 5); /п - линейная функция
активации нейрона; /12- квадратическая; fl3— кубичная и т. д. Первая цифра
индекса при/ указывает номер слоя.
74
3.3. Применение степенных рядов при синтезе формируемых НС
Л
Ne\
/2
Nel
/з
Nei
Л
Ne4
/5
Ne5
Входной слой
Ле21
/.
Ф)
Выходной слой
Рис. 3.9. Идеальная НС ряда Маклорена из шести членов
На рис. 3.9 представлена идеальная НС, реализующая степенной ряд
Маклорена из шести членов (включая о0) и описываемая уравнением (3.23).
В настоящее время разработчик ограничен в выборе типа функций
активаций нейронов на аппаратном уровне. В лучшем случае он имеет возможность
применять линейную, квадратичную и кубичную функции. Покажем,чго и в этом
случае возможно решение поставленных задач.
Пусть разработчик может использовать лишь линейную и квадратичную
функции активации. Перепишем функцию (3.22) в следующем виде:
q(x) *a0 + alX + a2x2 + a, ((x2 )(*))+ а4 (x>f+ a5 ((х2)(х)(х2)). (3.24)
Здесь введены следующие обозначения - члены взвешенного суммирования
без скобок реализуются в одном слое на нейронах, имеющих линейную
симметричную (fn) или квадратичную функции активации (f2); члены в скобках
реализуются через операцию умножения переменных по нейросетевому
алгоритму. Как видно из выражения (3.24) для реализации х5 необходимо дважды
применить операцию нейросетевого умножения.
75
3. Конструирование формируемых нейронных сетей
Операции умножения двух переменных в нейросетевом базисе
Метод реализации операции умножения двух переменных основывается на
следующем выражении:
z —
1
J((* +yf~(x-y)),
(3.25)
где х , у - переменные сомножители; z — произведение хну. Для реализации
выражения (3.25) потребуется два нейрона с квадратичной функцией
активации и один нейрон, алгебраически суммирующий с весовым коэффициентом
0,25 результаты работы первых двух.
Преобразуем выражение (3.25) к следующему виду:
z = /гп (/ш ( 2х + 2~У)~f™ (j*~ 2у^'
(3.26)
Здесь три цифры нижнего индекса при^ к соответственно означают: i - номер
слоя J - тип функции, к- номер нейрона в слое. В этой записи нейроны первого
слоя, имеющие квадратичную функцию активации, возводят свои аргументы в
квадрат. При этом умножение каждого из сомножителей на 0,5 эквивалентно
умножению на 0,25 в (3.25). Один нейрон второго слоя имеет линейную
функцию активации. Коэффициенты синаптических связей нейронов первого слоя
равны 0,5; 0,5; 0,5; 0,5 соответственно для первого и второго нейронов, а
нейрона второго слоя 1 и -1. На рис. 3.10 приведена схема для реализации
операции умножения двух переменных на НС.
0,5
0,5
№121
h
0,5
0,5
ЛеШ
/2
Первый слой
№211
А,
Второй слой
Рис. 3.10. Схема НС для реализации операции
умножения двух переменных
76
3.3. Применение степенных рядов при синтезе формируемых НС
Возведение аргумента в куб в нейросетевом базисе
Уравнение возведения аргумента в третью степень в нейросетевом базисе
можно записать в следующем виде:
х> = (*2)(х) =f2i\l-f^2x2+ х)~ ^/"{l*2- l2x]\-
Здесь два нейрона первого слоя, имеющие квадратичные функции активации,
возводят в квадрат сумму и разность половинных сомножителей х2 и х. Нейрон
второго слоя имеет линейную функцию активации.
Для большей конкретизации введем, как и в уравнении (3.26), индексацию
для функций активации нейронов тройными индексами и преобразуем в нейро-
сетевой базис внутренние скобки последнего выражения:
3 = ((*)(*))(*) =/3.l[l-/22.[^2+ \ Х) + ^{l*2- \X]\ =
(3.27)
Таким образом, для возведения аргумента в куб необходима трехслойная
сеть, в которой в первом слое будут два нейрона с функциями активации /п и
f2, во втором - два нейрона с функциями/^, в третьем - один нейрон с функцией
f . Коэффициенты синаптической связи у нейронов первого слоя будут равны 1,
у нейронов второго слоя: 0,5 и 0,5 для первого нейрона, 0,5 и - 0,5 для второго;
у нейрона третьего слоя 1 и -1. На рис. 3.11 приведена схема нейронной сети
для возведения аргумента в куб. Если разработчик имеет возможность
применять НС, которая позволяет вводить входные данные и в первый, и во второй
слои, то схему, представленную на рис. 3.11, можно упростить, исключив в
первом слое нейрон Ne 112 с функцией активации/п.
№121
/2
№111
/и
0,5
0,5
№221
fi
0,5
-0,5
№222
/2
№311
/и
Первый слой i Второй слой ! Третий слой
Рис. 3,11. Схема НС возведения аргумента в куб
77
3. Конструирование формируемых нейронных сетей
NeU
Ne2l
/2
Возведение аргумента в куб в четвертую степень
Получим выражение и синтезируем по
нему схему соединения нейронов для вы-
А_ числения четвертой степени аргумента
(5-й член в (3.24)).
х<= (х2)2=/22 (х2) =/22 (hfn (х)). (3.28)
fi
Рис. 3.12. Схема НС возведения
аргумента в четвертую степень
Для реализации этого выражения
необходима двухслойная сеть, в каждом слое
из которой будет по одному нейрону с функцией активации типа^. На рис. 3.12
приведена схема НС возведения аргумента в четвертую степень.
Возведение аргумента в куб в пятую степень
Член выражения (3.24) - возведение аргумента в пятую степень можно
представить в следующем виде:
х' = (х^хХх2) = ((х2)(х))(х2) = (х3)(х)(х2) .
В нейросетевой форме записи это выражение имеет вид:
Х5= (хз)(*2) = ^^ + \_х^ _ Л jT^a _ ^2]] (3.29)
Учитывая, что х, х2, Xs можно представить как
х = /,(х), х2 = /2(х),
х3 = /,(1-/2(0,5х2+0,5х) - 1-/2(0,5х2 - 0,5х)) =
= /1(1-/2(0,5/2(х)-Ю,5/1 (х))- 1-/2(0,5/2(х) -0,5/;(х))) ,
тогда, подставляя последние вьфажения в (3.29), получаем:
*5= -А [1'Ь [К1'72 [У2(Х) + У^\ ~ l'f* (У*(д° ~ l2fl(x)) + У2(Х)1\ ~
- i-/2 [\f{i-f2 [j/2W + \fS*)\- i-Л (}/2М - ^(х)]- ^w]]}
Введя трехзначные индексы обозначения функций активации, окончательно
получим:
(3.30)
На рис. 3.13 изображена схема НС, реализующая возведение аргумента в
пятую степень в соответствии с выражением (3.30). В данную схему
искусственно введен нейрон Ne213. Это сделано в предположении, что разработчик не
78
№121
№112
A
Первый слой
№221
0,5
0,5
0,5
-0,5
Ne222
№213
/.
Второй слой
№311
№322
Третий слой
№421
0,5
0,5
0,5
-0,5
к
№422
Четвертый слой
Рис. 3.13. Схема НС, • • • *■ • щей возведение аргумента в пятую степень
№511
1
-1
/.
Пятый слой
^1
3. Конструирование формируемых нейронных сетей
имеет возможность осуществлять связь нейронов первого слоя с нейронами
третьего слоя минуя второй. Если такую связь возможно осуществить, то
рассматриваемая схема упрощается. Из нее исключается не только нейрон Ne213,
нои.Ме322.
Нейронная сеть, воспроизводящая ряд Маклорена
из шести членов
Таким образом синтезированы схемы для составляющих уравнения (3.24),
степень при аргументе х которых превышает 2. Что же касается второго и
третьего членов этого уравнения, то для их реализации необходимо по одному
нейрону с функциями активации fx и/2 соответственно. Постоянный
коэффициент а0 можно учесть в нейроне последнего слоя в виде коэффициента синапти-
ческой связи входа, на который подают сигнал, равный 1. Таким образом вся
подготовительная работа по синтезу схемы по уравнению (3.24) проведена.
Полная схема НС, реализующей ряд Маклорена, может быть получена
объединением схем, представленных на рис. 3.11,3.12и3.13с добавлением к ним
двух нейронов для реализации второго и третьего слагаемых уравнения (3.24).
Выходы х, х2, х3, х4, х5, а также постоянный сигнал «1» необходимо подать на
входы нейрона шестого слоя с коэффициентами синаптической связи а,, а2, а3,
а4, а5, а0 соответственно. Полная схема НС для реализации ряда Маклорена из
шести членов представлена на рис. 3.14. Данная сеть является в некотором
роде универсальной, так как может применяться для вычисления любой
функции, разложенной в ряд Маклорена до шести членов. С различием функций
меняются лишь коэффициенты синаптической связи <х. Очевидно, что
предлагаемая топология сети не является единственной. Можно рассматривать сеть
и с большим числом слоев, и с иным числом нейронов в слоях. Все
определяется опытом разработчика и его реальными условиями.
Схема, приведенная на рис. 3.14, была испытана на функциях sin(x) и cos(x)
на имитаторе НС Neurolterator, разработанном в Калужском филиале МГТУ
им. Н.Э. Баумана. Коэффициенты синаптической связи имели следующие
значения:
для функции sin: а0=0, а=\, а2=0, а = -0,16667, а4=0, а = 0,00833;
для функции cos: a0=l, а,=0, а2=-0,5, а3=0, а4= 0,04667, а5=0.
Диапазон изменения аргумента составлял —1,8 ... +1,8 рад. Ряд разлагался
в точке с координатами х = 0 и у = 0. Для этого диапазона была получена
точность в 1,1%.
На практике используют разложение функций sin(x), cos(x) в ряд Тейлора
для диапазона от - j до + j . В этом случае ряд хорошо сходится. Если же
практический диапазон изменения аргумента превышает +1 рад, то для
повышения точности при минимальных аппаратных (или программных) затратах
необходимо привести представляемый угол к диапазону ± \ , а затем уже
80
1
№121
Л
№112
Л
Первый слой
№221
к
0,5
-0,51
№222
№213
/2
Второй слой
1
-1
№311
/i
Третий слой
0,5
0,5
№421
АМ\
0,5
-0,51
№422
/2J
Четвертый слой \ Пятый слой
№511
Я
Xs
№611
Л
Шестой слой
Рис. 3.14. Схема НС, воспроизводящей ряд Маклорена из шести членов
3. Конструирование формируемых нейронных сетей
вычислять тригонометрические функции. На практике часто приходится
учитывать ортогональную связь функций sin(jc) и cos(x):
sin2(jc) + cos2(jc) = 1.
Нетрудно заметить, что в этом случае резко возрастает нагрузка на УЦВМ.
В заключение отметим, что применение степенных рядов для
проектирования нейросетевых алгоритмов вычисления простейших функций, так же как и
решение дифференциальных уравнений, сопровождается теми же
трудностями, что и реализация этих функций на машинах с фоннеймановской архитектурой.
Задачи
1. Синтезируйте НС для воспроизведения функции:
а).у=ехр(х), х=(-2...2);
б)у=Щх), х=(0,01...4);
B)y=tg{x), x=(-l,l...l,l);
г)у=лГх, x=(0,01...5).
2. Разработайте НС для решения следующих систем дифференциальных уравнений:
а) /, = У2,
Уг = ~Ух
при следующих начальных условиях: ^(0)=-!, у2(0) = 0, t=(0...2n);
б) dyx
dt
dy2
dt
dy3
dt
-У2
У\-
~У\
+ УЗ,
-Уз,
+ У2
при следующих начальных условиях: у1(0) = 0,у2(0)=0, у3(0) = 1,/=(0...15);
в) Х'(0 = А(0Х(/),
ще
А(0 =
/ 0 1-/
-2/ / 0 -1
t -t t 0
0
0
при следующих начальных условиях: х,(0) = 0, х2(0)=-1, х3(0)=0, х4(0) = 1, t=(0... 12).
82
4. НАСТРОЙКА НЕЙРОННОЙ СЕТИ
НА РЕШЕНИЕ ПРИКЛАДНЫХ ЗАДАЧ
Рассмотрены основные проблемы, связанные с предобработкой обучающих
примеров, отбором информативных признаков, обучением и тестированием НС,
интерпретацией выходных данных, построением логически прозрачных для пользователя сетей.
На примере решения задач классификации с помощью НС показаны трудности
настройки НС на решаемую задачу и пути их преодоления.
4.1. Компоненты нейрокомпьютера
Использование НК для решения задач распознавания образов,
классификации, аппроксимации неизвестной функции, предсказания значений временного
ряда, заполнения пробелов в таблицах данных, построения ассоциативной
памяти, логического вывода и т. д. требует проведения ряда предварительных
процедур, связанных с кодированием входной и выходной информации,
выбором архитектуры НС, алгоритмов обучения, способов оценки и интерпретации
получаемых результатов и т. д., т. е. настройки НК на конкретную задачу
пользователя.
Каждая прикладная задача, решаемая на НК, имеет определенные
особенности в средствах обработки и представления данных, поэтому вначале
необходимо выполнить априорный анализ объекта исследования. Если этот этап
будет исключен, то возможно получение неадекватных действительных
результатов на этапе эксплуатации НК. Технология априорного анализа предметной
области и решаемой прикладной задачи при нейросетевом моделировании
отличается от аналогичных процедур при статистическом моделировании и
включает следующие действия: обобщение опыта и профессиональных знаний об
объекте, получение предварительных рекомендаций от экспертов, изучение
литературных источников и существующих прототипов, сбор данных и
формирование обучающей выборки для нейросети.
83
4. Настройка нейронной сети на решение прикладных задач
Интерфейс вывода
1
Интерпретатор
г
Нейроимнтатор
Алгоритмы
обучения
^^
НС
^-^
Отбор
признаков
Оценки
_^г
^ --^
Алгоритмы
формирования
топологии сети
>'
База данных
t
Препроцессирование
1
—>
к
о
н
с
т
р
У
к
т
О
р
п
р
О
е
к
т
а
с
е
т
и
Рис. 4.1. Структура нейрокомпьютера
В состав НК входят следующие основные блоки (рис. 4.1): конструктор,
интерфейсы ввода и вывода, предобработчик (препроцессор), интерпретатор,
нейроимитатор. В свою очередь, нейроимнтатор включает нейросеть (НС),
алгоритмы обучения, алгоритмы формирования топологии, блок оценки и блок
отбора информативных признаков. Основным компонентом нейроимитатора
является искусственная НС. В последующих разделах будут рассмотрены
основные архитектуры НС, используемые на практике.
Блок алгоритмов формирования топологии предназначен для формирования
сети, соответствующей модели предметной области. В связи с тем, что
отсутствует формальная процедура определения архитектуры НС (число слоев, число
нейронов в каждом слое, вид связи между нейронами и т. д.), используются
эвристические процедуры, которые основываются на предшествующем
опыте работы с аналогичными нейросетевыми моделями предметной области.
Если такой опыт отсутствует, выбор архитектуры выполняется путем
перебора большого количества возможных вариантов построения НС.
Алгоритмы обучения, используемые в сетях с обучением, могут иметь
множество возможных реализаций. При выборе определенной стратегии обучения
84
4.1. Компоненты нейрокомпьютера
необходимо учитывать класс решаемых задач, планируемую точность и
время получения результатов. Для каждого вида нейронных сетей разработаны
алгоритмы обучения, которые более подробно будут рассмотрены в
следующих главах.
Блок отбора информативных признаков предназначен для определения
минимально необходимого или «разумного» числа связей и нейронов сети. С
помощью этого блока также удается уменьшить число градаций входной
переменной. Наиболее важным следствием применения процедуры отбора
(контрастирования) является получение логически прозрачных сетей, т. е.
таких сетей, функционирование которых можно описать и понять на языке логики.
Качество обучения НС определяется оценкой (ошибкой обучения) на
примерах из обучающей выборки, а эффективность решения конкретной задачи
предметной области определяется оценкой (ошибкой обобщения) на тестовой
(контрольной) выборке. Эти оценки вычисляются в блоке оценки. В случае,
если указанные ошибки превышают заданные допустимые пределы,
необходимо вернуться на предыдущие этапы построения нейросетевой модели и
изменить ее параметры.
Наиболее важным блоком НК является база данных, содержащая примеры
для обучения и контроля функционирования НС. Важность этого блока
определяется тем, что обучение сетей всех видов с использованием любых
алгоритмов обучения выполняется на известных примерах решения поставленной
задачи. Кроме того, база данных содержит правильные ответы для НС, обучаемых
с учителем. Очевидно невозможно предусмотреть все варианты интерфейса
между пользователем и базой данных, так как примеры могут иметь числовые
поля, содержать графическую информацию или представлять собой текст.
Наиболее подходящим форматом представления входной информации
является формат табличных (реляционных) баз данных.
Сигналы, подаваемые на вход НС, должны быть представлены в
соответствующем формате данных, при этом очень часто приходится их
масштабировать, чтобы в максимальной степени использовать диапазон их изменения.
Поэтому необходимо проводить предобработку (препроцессирование) входных
сигналов, причем для каждого вида должен быть реализован определенный
способ предобработки.
Формат ответов НС в явном виде часто оказывается непонятным для
интерпретации человеком получаемых результатов. Ответ, выдаваемый НС, как
правило, является вещественным числовым вектором. Если при решении
какой-то прикладной задачи требуется получить ответ, например в градусах по
шкале Кельвина или в дюймах, то необходимо преобразование выходного
вектора. Представление ответа НС при решении задач классификации, когда
необходимо для каждого входного вектора определить принадлежность его
определенному классу, также вызывает определенные трудности. Эта задача может
быть решена следующим образом. Пусть имеется К классов. Каждому
выходному нейрону НС поставим в соответствие номер класса. При подаче на
85
4. Настройка нейронной сети на решение прикладных задач
вход обученной НС некоторого входного вектора на ее выходе будет получен
вектор, состоящий из К сигналов. Единого универсального правила
интерпретации этого вектора не существует. Наиболее часто используют оценку по
максимуму: номер нейрона, выдавшего максимальный по величине сигнал,
является номером класса, к которому относится предъявленный сети вектор.
Интерпретатор напрямую взаимодействует с пользователем через интерфейс
вывода, следовательно, от качества его организации зависит эффективность
работы НК.
Управление операциями подготовки входных данных, обучения,
тестирования НС, интерпретации выходных данных осуществляется конструктором НС.
Рассмотрим более подробно технологию настройки НС на решение
прикладной задачи (рис. 4.2).
Предварительная обработка
данных
Формирование и анализ обучающей выборки
Фильтрация
Нормирование, центрирование,
масштабирование, кодирование
Выбор структуры НС
Выбор вида оценки
Выбор функции активации
Выбор метода оптимизации
Обучение
Тестирование
Перекрестное оценивание
Рис. 4.2. Технология настройки НС на решаемую задачу
86
4.2. Предварительная обработка информации
Технология настройки НС является итерационной процедурой. Если
построенная модель НС не удовлетворяет требованиям пользователя или
технического задания, приходится многократно возвращаться к отдельным блокам
для уточнения параметров модели.
4.2. Предварительная обработка информации
Прежде всего необходимо решить проблемы, связанные с представлением
обучающей информации, поскольку от этого во многом зависит скорость и
качество обучения НС.
Шкалы представления исходных данных в НС
Данные, подаваемые на вход нейронной сети, могут быть измерены в
различных шкалах.
Шкалой называется тройка
<Е, N, ф >,
где Е - некоторая «эмпирическая система» с отношениями Е={S, R}, в которой
5- множество свойств объектов, a R — множество отношений между объектами
по этим свойствам; N— некоторая знаковая система (обычно числовая), может
быть представлена в следующем виде: N=M, Pv P2, ..., Рп, где М-
множество чисел (например, множество всех действительных чисел), а Рг -
определенные отношения на числах, выбранных так, чтобы с их помощью
однозначно отображались соответствующие отношения R из эмпирической
системы; ф - конкретный способ отображения Е на N.
Упорядоченная тройка <Е, N, ф > называется абсолютной шкалой, если ее
допустимое преобразование является тождественным преобразованием:
ф(х) = х. Примером может служить шкала, опирающаяся на процедуру счета.
Результатом измерения при этом является число, выражающее количество
элементов в множестве. Если это число заменить другим, то потеряется
основная информация о множестве.
Примером шкалы более слабого типа является шкала отношений. Для
шкалы отношений допустимым преобразованием данных является умножение
их на одно и то же число (масштабирование, например ф(х) = ах, а > 0).
Примером шкалы отношений является шкала для измерения длины, веса,
производительности.
Шкала интервалов допускает положительные линейные преобразования
(ф является положительным линейным преобразованием тогда, когда для
каждого х ф(х) = ах + Ъ, где Ъ - действительное число, а - положительное
действительное число. Это означает, что здесь можно менять как начало отсчета, так
и единицы измерения. Примеры шкалы интервалов: шкала для измерения
температуры, давления, промежутков времени и т. п.
87
4. Настройка нейронной сети на решение прикладных задач
Шкала порядка - это шкала, допустимым преобразованием которой
является произвольное монотонное преобразование, т. е. такое, при котором не
изменяется порядок чисел. Количество разных используемых значений чисел в
общем случае не ограничено. При измерениях в шкалах такого типа получаем
информацию лишь о том, в каком порядке объекты следуют друг за другом по
какому-то свойству. Примером может служить шкала, по которой измеряется
твердость материала, схожесть объектов, типы алгоритмов решения
конкретной задачи, способы диспетчеризации вычислительного процесса и т. д. К этой
группе шкал относится большинство шкал, используемых, например, в
социологических исследованиях. Частным случаем шкал порядка служат балльные
шкалы, используемые, например, в практике спортивного судейства или оценок
знаний в школе. Количество баллов, используемых в этих шкалах, фиксировано.
Самой простой шкалой является шкала наименования. Для этих шкал
требуется, чтобы их допустимые преобразования были всего лишь взаимно
однозначными. В этих шкалах числа употребляются только с целью придания
предметам или объектам имен. Кроме сравнения на совпадение, любые
арифметические действия над цифрами, обозначающими имена, бессмысленны.
Переменные, представляемые в шкале наименований, называются
номинальными.
Рассмотренные выше шкалы не исчерпывают все возможные типы шкал.
В зависимости от конкретной задачи можно использовать любую из известных
шкал или придумать новую для представления данных. Важно лишь то, что
результаты вычислений, получающиеся по ходу решения задачи, должны
оставаться инвариантными по отношению ко всем преобразованиям, допустимым
для данной шкалы.
Способы предобработки
Нейронная сеть может обрабатывать только числовые данные. Однако
исходные данные, подаваемые на НС, могут включать номинальные
переменные, указывающие на принадлежность к одному из нескольких классов, даты,
целочисленные значения, текстовые строки, графические данные и т. д.,
поэтому необходимо кодирование данных. В мощных иностранных универсальных
нейропакетах, таких, как NeuroSolutions - фирмы NeuroDimension Inc.,
NeuralWorks Professional II/Plus — фирмы NeuralWare, поддерживаются
основные типы представления данных: текстовые данные в формате ASCII,
изображения в формате .bmp и т. д. С целью удобства работы проводят
статистическую обработку данных, исключение аномальных наблюдений, а также
нормирование и центрирование данных для того, чтобы каждая компонента
входного вектора данных лежала на отрезке [0,1] или [—1,1].
При известном диапазоне изменения входной переменной, например [дс , x^J,
целесообразно использовать простейший вид преобразования, выполняемый по
формуле (4.1):
88
4.2. Предварительная обработка информации
рть-х+)Ф-4+аш (4Л)
v-^max *min /
где [а, Ь] - диапазон приемлемых входных сигналов; [xmin, хтю\ - диапазон
изменения значений входной переменной х; р — преобразованный входной
сигнал, подаваемый на вход НС.
При кодировании параметров исследуемых объектов необходимо
учитывать тип переменных, которые описывают этот объект: непрерывные,
дискретные или качественные, количественные.
Качественные переменные (признаки) принимают конечное число
значений. Примером качественных признаков может служить состояние больного
(тяжелое, средней тяжести, среднее, удовлетворительное и т. д.), знания
студентов по определенному предмету (отличные, хорошие, не очень хорошие,
отсутствие каких-либо знаний), характеристика погоды (хорошая, плохая,
солнечная, дождливая) и т. п. Если качественная переменная принимает два
значения, ее называют бинарной.
Качественные признаки могут быть упорядоченными, частично
упорядоченными или неупорядоченными. Соответственно различается и их кодировка.
Известно, что любой частично упорядоченный признак можно представить в
виде комбинации нескольких упорядоченных и неупорядоченных признаков.
Исходя из этого, далее будет рассмотрено кодирование только упорядоченных
и неупорядоченных признаков.
Упорядоченные качественные признаки кодируются в шкале порядка.
Поскольку никакие два состояния неупорядоченного признака не связаны
отношением порядка, их нельзя кодировать разными величинами одного и того же
входного сигнала сети. Поэтому для кодирования неупорядоченных
качественных признаков целесообразно использовать шкалу наименований и
рассматривать переменные, соответствующие этим признакам, как номинальные.
При кодировании количественных переменных, принимающих числовые
значения, необходимо учитывать содержательное значение признака,
расположение признака в интервале значений, точность измерения его значений.
Стандартные преобразования для каждого элемента исходной выборки X
могут быть выполнены следующим образом:
X.
I
или
Xi:=
х,-Щх,)
а(*,)
х,-М(х,)
max | х, - M(Xj) |
где xt - i-я координата входного вектора;
п - размерность вектора X;
89
4. Настройка нейронной сети на решение прикладных задач
M(xt) = —Tix. — выборочная оценка математического ожидания х (сред-
'" нее значение);
a(xt) =\ — Jjx. — M(xf))2 - выборочная оценка среднего квадратичного
'~ отклонения.
Если эти преобразования не делать, то необходимо выбирать пределы
изменения параметров нейрона в зависимости от данных.
Дополнительно рассмотрим три вида предобработки числовых данных -
модулярный, позиционный и функциональный. Основная идея этих методов
состоит в том, чтобы сделать значимыми малые изменения больших величин.
Например, если значение входной переменной может достигать 1000, а для
ответа существенным является изменение этой переменной на 1, то это
изменение не будет улавливаться НС. Для того чтобы эти изменения могли быть
учтены НС, в рассмотренных ниже методах каждая входная переменная
кодируется не единственным значением, а вектором, формируемым по
определенным правилам.
Для простоты изложения сути методов предположим, что в каждом
примере ответ НС является вектором чисел из диапазона изменения выходных
сигналов [а, Ь].
Модулярная предобработка. Зададимся набором положительных чисел
yv ..., yk. Определим операцию сравнения по модулю для действительных
чисел следующим образом:
х mod у = х - у ЪА(х1у), (4.2)
где Int(jc /у) — функция, вычисляющая целую часть величины х путем
отбрасывания дробной части. Примеры кодирования входных сигналов при
модулярной предобработке представлены в табл. 4.1.
Таблица 4.1
X
5
10
15
xmod3
2
1
0
л mod 5
0
0
0
xmod7
5
3
1
Кодирование входного признака х при модулярной предобработке вектором
Z проводят по следующей формуле:
(( х mod у) + у)(Ь- а)
z = + а,
где z. — /-я компонента вектора Z.
Функциональная предобработка. Рассмотрим общий случай
функциональной предобработки, отображающей входной признак х в ^-мерный вектор Z.
90
4.3. Интерпретатор ответов сети
Выберем к чисел, удовлетворяющих следующим условиям:
х <У< — <У1, .< 3\<* •
nun y I y k~\ s к щах
Пусть ф -функция, определенная на интервале [х^-ук, xmi^yl], а фт!п, ф^
- минимальное и максимальное значения функции ф на этом интервале. Тогда
1-я координата вектора Z вычисляется по формуле
(ф(^-^)-фт1п)(6-«)
z. — + а.
ф - ф
'max Tmin
Позиционная предобработка.Основпая идея позиционной предобработки
совпадает с принципом построения позиционных систем счисления. Выберем
положительную величину у такой, что yk > (*max- х^. Сдвинем признак х так,
чтобы он принимал только неотрицательные значения. В качестве сигналов
сети будем использовать результат простейшей предобработки _у-ичных цифр
представления сдвинутого признаках, формулы вычисления которых приведены
ниже:
z0=(x- x^mody,
z = bit ({x - xmJ/y') mody,
где операция сравнения по модулю действительных чисел определена в (4.2).
Предварительное, до подачи на вход сети, преобразование данных с
помощью стандартных статистических приемов может существенно улучшить как
параметры обучения (длительность, сложность алгоритма обучения), так и
работу системы в целом. Например, очень часто ненормально
распределенные данные предварительно подвергают нелинейному преобразованию:
исходная совокупность значений переменной преобразуется с помощью некоторой
функции, и последовательность данных, полученная на выходе, принимается за
новую входную переменную. Типичные способы преобразования входных
переменных — возведение в степень, извлечение корня, взятие обратных
величин, экспоненты или логарифмов. Часто это уменьшает требования к
обучению. Необходимо проявлять осторожность в отношении функций, которые не
всюду определены (например, логарифм отрицательных чисел не определен).
Для улучшения информационной структуры данных могут оказаться
полезными определенные комбинации переменных - произведения, частные, так как
это существенно сокращает размерность входных векторов НС.
4.3. Интерпретатор ответов сети
Основное назначение этого блока - интерпретировать выходной вектор сети
как ответ, понятный пользователю. При определенном построении
интерпретатора и правильно построенной по нему оценке интерпретатор ответа может
также оценивать уровень уверенности сети в выданном ответе. Ниже рассмат-
91
4. Настройка нейронной сети на решение прикладных задач
риваются способы интерпретации, получившие наибольшее распространение
на практике.
В задачах классификации наиболее распространено правило
интерпретации «победитель забирает все»: число выходных нейронов равно числу
распознаваемых классов, номер нейрона с максимальным сигналом
интерпретируется как номер класса. Однако, если классов много, для реализации метода
требуется много выходных нейронов.
Знаковая интерпретация требует log 2 М нейронов (М- число классов).
Допустим, что ух,уг,...,ут- совокупность выходных сигналов нейронов.
Заменим в этой последовательности положительные числа единицами, а
отрицательные - нулями. Полученная последовательность нулей и единиц
рассматривается как номер класса в двоичной записи.
Порядковая интерпретация позволяет для М выходных нейронов
описать принадлежность к Ml классам (а в знаковой 2м ). Если провести
сортировку выходных сигналов нейроновyv y2,...,ym и обозначить nt -номер i'-го
сигнала после сортировки (1 соответствует самому маленькому сигналу, М- самому
большому), то перестановку
12 3 ... М
и, п2 «з ... пм
можно рассматривать как слово, кодирующее номер класса. Всего возможно
Ml перестановок. Для использования этого интерпретатора необходимо, чтобы
характерная ошибка выходного сигнала была меньше \1М. Даже при числе
нейронов М = 10 требование к точности б < 0,1, а число возможных
классифицируемых объектов равно 10!
Интерпретацию 2-на-2-кодироваиие используют для улучшения
качества распознавания (более точного проведения разделяющей поверхности).
В этом случае для распознавания Мклассов необходимо иметь М(М-\)\12
нейронов, каждый из которых реагирует только на два класса. Окончательное
присваивание элементу /-го номера класса осуществляется с помощью
булевой функции; выходы с нейронов подают на вход элемента, реализующего эту
и til».
Рассмотрим проблему кодирования выхода на примере двумерной задачи
с тремя классами (рис. 4.3). С помощью 2-на-2-кодирования задача
классификации решается просто, тогда как в методе «победитель забирает все»
необходимо строить нелинейные разделяющие границы.
Нечеткая интерпретация для классификаторов также основывается
на правиле «победитель забирает все». Выходные сигналы нейронов (после
масштабирования - приведения значений в отрезок [0,1]) могут
рассматриваться как функции принадлежности к соответствующим классам. В этом
случае возможны следующие способы интерпретации:
• выбирается класс, у которого значение выхода является максимальным;
достоверность распознавания определяется как разность максимального
сигнала и следующего за ним по величине;
92
4.4. Оценка качества работы нейронной сети
х\ х1 Х3 Х| Х2 *)
а б
Рис. 4.3. Кодирование выхода:
а - «победитель забирает все»;
б - 2-на-2-кодирование
• значения выходов нейронов (классов) интерпретируются как меры
уверенности принадлежности к тому или иному классу с указанием наилучшего
приближения к какому-то классу.
Перечень приведенных способов интерпретации ответов НС не является
полным. Для каждой предметной области при решении конкретных задач
необходимо их экспериментальное исследование.
4.4. Оценка качества работы нейронной сети
Поскольку обучение НС основывается на минимизации значения некоторой
функции, показывающей отклонение результатов, которые выдает сеть на
данном обучающем множестве, от идеальных требуемых, то необходимо
выбирать соответствующую оценку. Обычно в качестве такой оценки берется
средняя квадратичная ошибка Е (MSE - Mean Squared Error), определяемая как
усредненная на Р примерах сумма квадратов разностей между желаемой
величиной выхода dt и реально полученными на сети значениями у. для каждого
примера i: j p
Я=р.ВД-^)2 (4.3)
93
4. Настройка нейронной сети на решение прикладных задач
В некоторых случаях удобной является оценка, равная корню квадратному
из MSE, обозначаемая как RMSE {Square Root of the Mean Squared Error).
Оценка MSE используется в тех случаях, когда выходные сигналы сети
должны с заданной и одинаковой для всех сигналов точностью е совпадать с
известными векторами, где е определяется как уровень надежности.
Для учета уровня надежности обучения обычно используют
модифицированную MSE: p ,
E=-JJ ^- )2' (44)
где е имеет различный диапазон изменения в зависимости от способов
интерпретации: 0 < е < 1 - для знаковой интерпретации; 0 < е < 2 - для правила
«победитель забирает все»; 0< б < 2 / (7V — 1) — для порядковой
интерпретации , где N— размерность вектора входных сигналов.
Уровень надежности обучения вводится для обеспечения устойчивой
работы сети. Критерий устойчивости НС формулируется следующим образом:
работа сети считается устойчивой, если при изменении выходных сигналов сети
на величину, меньшую б, интерпретация ответов сети не меняется. Этот
критерий можно использовать для обеспечения ускоренного обучения сети.
Целесообразно при вычислении оценки по формуле (4.4) использовать только
такие выходные сигналы (множество правильных ответов), интерпретация которых
не меняется при изменении их значений на величину, меньшую 6.
Оценку MSE можно обобщить, если использовать суммирование
квадратов разностей (d. - у)2 с соответствующими весами:
Е = ±т<1,-у,У, (4.5)
Pi=\
где V. — вес /-го примера в обучающей выборке.
Использование оценки (4.5) позволяет выделить наиболее важные примеры
из обучающей выборки, уст- : пая для этого соответствующий вес. Кроме
того, эту оценку целесообразно использовать для уравновешивания различных
групп примеров в задачах классификации. Для этого необходимо назначать
веса V так, чтобы суммарный вес обучающих примеров в каждом классе не
зависел от класса (например, можно назначить для любого примера V. — \1т,
где i — номер класса, т - число примеров в классе). В случае нечеткой
экспертной оценки «учителя» отдельных вариантов примеров при формировании
обучающей выборки также целесообразно увеличить вес этих вариантов, чтобы
они могли влиять на процесс обучения сети.
Наряду с оценкой MSE используют и другие оценки, например оценку Куль-
бака-Лейблера, связанную с критерием максимума правдоподобия:
£ = £rfiiQg^+a-4)iogJ-£-'
1=1 Уг 1 У'
где М— число выходов сети.
94
4.5. Конструирование нейронных сетей
Более простыми являются оценки качества работы НС, часто
используемые при аппаратной реализации НС (например, ZISC Accelerator cards для
IBM Compatible PC) и в нейроимитаторах:
м
E = T.\y,-dtU
i=i
Е - max | yt -dt\.
Для решения задач анализа временного ряда (эти задачи будут
рассмотрены в следующей главе) целесообразна оценка по средней относительной вари-
ai-vO?) = -iss —_ = iss_,
Ш-{х,)У No*
где S - временной ряд; et - разность (истинное значение dt минус jc() в момент t;
(jc() - оценка для среднего значения ряда; N- число данных в ряду.
4.5. Конструирование нейронных сетей
Классификация нейронных сетей с точки зрения организации и реализации
межнейронных связей дана в гл. 3. Вопрос выбора архитектуры для различных
классов сети, адекватной решаемой задаче, является сложным.
Теоретические исследования этого вопроса проведены в [1, 3]. Для наиболее часто
используемых на практике многослойных НС задача оптимизации архитектуры
(минимизация числа нейронов и числа слоев) может быть поставлена только
либо в плане ликвидации избыточности числа нейронов, либо при наличии
ограничений на число нейронов. Для сетей такого типа количество нейронов во
входном слое, как правило, определяется размерностью входного вектора, а в
выходном - особенностями решаемой задачи (один нейрон при решении задачи
аппроксимации функции, к— нейронов при решении задачи классификации на к
классов и т. д.). Предварительная оценка числа нейронов в скрытых слоях
многослойных НС с прямым распространением сигналов может быть
выполнена по следующей формуле [3]:
NyNp
<N <n(^+ lW + N + \) + N ,
i w y\N J x y y
1 + log^)
где N - размерность выходного вектора НС; N - число элементов
обучающей выборки; Nx - размерность входного вектора; Nw - общее число нейронов
Оценив Nw, можно рассчитать число нейронов в скрытых слоях.
Отсутствие в настоящее время эффективных методов для точного решения задач
выбора класса и архитектуры НС обусловливает использование различных
эвристических методов, которые реализуются конструктором сети. Рассмотрим
некоторые из них.
95
4. Настройка нейронной сети на решение прикладных задач
С математической точки зрения задача обучения НС сводится к
продолжению функции, заданной в конечном числе точек, на всю область определения.
При таком подходе входные данные сети считаются аргументами функции, а
ответ сети - значением функции.
Для решения задачи выбора количества слоев и нейронов в каждом слое
НС, аппроксимирующей заданную функцию, существуют два основных
метода. Первый из них связан с тем, что, чем больше нейронов, тем более
надежной будет работа сети. Если же начинать с небольшого количества нейронов,
то сеть может оказаться неспособной обучиться решению задач, и весь
процесс придется начинать сначала.
Второй метод опирается на эмпирическое правило: чем больше число
подгоночных параметров полинома, аппроксимирующего функцию, тем хуже
воспроизведение функции в тех областях, где ее значения были заранее
неизвестны. На рис. 4.4 приведен пример аппроксимации табличной функции полиномами
третьей и седьмой степеней. Очевидно, что аппроксимация,полученная с
помощью полинома третьей степени, больше соответствует интуитивному
представлению о «правильной» аппроксимации. Аналогично, чем больше число
подгоночных параметров НС (слоев, нейронов в каждом слое, порогов), тем хуже
аппроксимация функции, воспроизводимая НС, за счет избыточности этих
параметров. Данный подход определяет нужное число нейронов как минимально
необходимое. Однако это число заранее неизвестно, а процедура постепенного
наращивания количества нейронов является трудоемкой.
Таким образом, сеть с минимальным числом нейронов должна лучше
(более гладко) аппроксимировать воспроизводимую функцию, но определение этого
X
F(x)
1
5
2
4
3
6
4
3
F(x)
6
5
4
3
2
1
О 12 3 4 \ х 0 1V 2 3 V 4 '*
а б
Рис. 4.4. Аппроксимация табличной функции:
а - полиномом третьей степени; б- полиномом седьмой степени
96
F(xf
6
5
4
3
2
1
i
-
-
\
\
\ /
1 /
1 /
Л 1 \ 1 ' \ /■
—ь
4.5. Конструирование нейронных сетей
минимального числа нейронов требует проведения большого количества
экспериментов по обучению сетей. Если число нейронов избыточно, то сеть
можно обучить за меньший промежуток времени. При этом существует риск
построить «плохую» аппроксимацию.
В литературе по НС эти два метода соответственно называют
деструктивным (прореживание сети) и конструктивным (постепенное нар. : е).
Примером деструктивного подхода является метод «ослабления» весов, который
предотвращает чрезмерный рост весов. При этом в функцию оценки (4.3)
вводится дополнительный элемент - штрафное слагаемое:
р
£ = i £ (rf -у.у + -Zw2 , (4.6)
где г|<1.
Дополнительный элемент вызовет изменение весов
>v(,=(l-il)>V (4.7)
при этом будут уменьшаться те веса, на которые не действует первый
элемент формулы (4.6). Очевидно, что чем больше вес, тем большее влияние он
оказывает на функцию ошибки. Другой вариант введения штрафа (4.3) в
функцию оценки имеет вид:
р w2
E = -Il(d-y)2 + -Il , ",, (4.8)
р*=Л ' ^ 2',i 1+w2 v '
ч
В результате подсчета оценки по формуле (4.8) малые коэффициенты
убывают быстрее, чем большие. Кроме того, уменьшение весов помогает
быстрее найти минимальное значение оценки на ранних стадиях обучения.
Для практического использования был предложен также метод
уменьшения числа связей - «минимизация вреда для мозга», суть которого состоит в
том, чтобы находить в сети те веса, которые можно удалить, не меняя
существенно среднюю квадратическую ошибку MSE на обучающем множестве. С
этой целью для каждого веса w( вводится показатель s. («выпуклость» веса),
определяемый по формуле
1 82MSE
' 2 dw] '
Удаление весов с малыми «выпуклостями» и повторное обучение урезанной
сети улучшают ее общие характеристики.
Таким образом, в деструктивном подходе вначале на основе априорных
знаний о задаче определяется избыточная архитектура сети, которая в процессе
обучения сети или по его завершении упрощается путем исключения наименее
значимых весов или нейронов.
Конструктивный подход, •: ■ «щийсяальтернатгаой деструктивному,
базируется на предварительном построении сети минимального размера с неболь-
97
4. Настройка нейронной сети на решение прикладных задач
шим числом скрытых слоев и нейронов (в некоторых типах НС эти слои и
нейроны могут отсутствовать). В процессе обучения НС число слоев и нейронов в
каждом слое постепенно увеличивается для получения необходимой ошибки
обобщения.
Одним из наиболее известных конструктивных алгоритмов формирования
топологии НС считается алгоритм, базирующийся на методе динамического
наращивания узлов. Процесс создания НС совмещается с ее обучением и
начинается с одного нейрона в скрытом слое. При падении скорости уменьшения
ошибки до определенного уровня в скрытый слой добавляется еще один
нейрон. Каждый добавляемый нейрон подключается ко всем входным и ко всем
выходным нейронам. Схема изменения мониторинга слежения за скоростью
изменения ошибки на всем интервале обучения определяется по формуле:
'-! ^ -<П (/<>*,8, el,8), (4.9)
о
где Е{ _ 6 и Е( _ 5 - ошибки на интервале обучения 8: Q - некоторая заданная
минимально возможная скорость изменения ошибки, при превышении которой
принимается решение об изменении архитектуры НС; 8 - количество
итераций, прошедших после вычисления очередной оценки скорости изменения
ошибки обучения; tk - заданное время обучения.
Выражение (4.9) учитывает возможность наличия периодов временного
роста ошибки на интервале 8, причем за счет эффекта усреднения эти периоды
отсекаются.
Схема формирования НС в методе динамического наращивания узлов
сводится к следующему:
1) сформировать начальную топологию НС с одним скрытым слоем и
единственным нейроном в нем. Задать максимальное число слоев г и число
нейронов в слое р;
2) провести 8 итераций обучения. Если полученный результат является
удовлетворительным с точки зрения ожидаемой или допустимой погрешности,
процесс формирования архитектуры сети и обучения завершить;
3) в противном случае выполнить по формуле (4.9) оценку скорости
изменения ошибки обучения;
4) если условие (4.9) выполняется, то по определенным правилам
необходимо добавить один или несколько дополнительных нейронов в скрытый слой, но
при этом, если текущее число нейронов п в слое п =р, добавить новый слой в НС;
5) повторить действия по приведенной схеме, начиная с п. 2, до тех пор, пока
не будут достигнуты желаемые цели.
Существует довольно много модификаций приведенной схемы, с помощью
которых можно улучшить работу алгоритма формирования топологии НС либо
в плане уменьшения вычислительной сложности, либо времени обучения.
Например, одна из таких модификаций заключается в том, чтобы некоторые
связи добавляемых нейронов «замораживать», т. е. не обучать на следующих итера-
98
4.5. Конструирование нейронных сетей
Выходы
о- о
Скрытые
нейроны
(£>
Входы
Рис. 4.5. Топология сети каскадной корреляции Фальмана
циях при добавлении очередных нейронов. Если условие (4.9) не выполняется,
то коэффициенты межнейронных связей нейронов, добавленных после
момента t, фиксируются и при дальнейшем обучении НС не изменяются. Это можно
интерпретировать следующим образом: если скорость изменения ошибки
обучения невелика, то нейроны, добавленные после момента t, не внесли
существенного улучшения в качество обучения, поэтому они должны участвовать в
дальнейшем обучении. Связи нейронов последнего (выходного) слоя с
нейронами скрытых слоев всегда являются обучаемыми.
Другой известный конструктивный подход предложен к формированию
специализированной многослойной сети - сети каскадной корреляции Фальмана,
топология которой представлена на рис. 4.5.
Особенность этой сети состоит в том, что в каждом ее скрытом слое
находится по одному нейрону, т. е. она представляет собой некоторый каскад. Как
и в методе динамического наращивания узлов, на каждом шаге итерации при
обучении НС в скрытые слои добавляются нейроны. В сети Фальмана каждый
очередной нейрон добавляется в «свой» слой и подключается к входным узлам
и ко всем существующим скрытым нейронам, а выходы всех скрытых
нейронов и входных узлов НС напрямую подключаются к выходным нейронам. При
подключении нейрона к ранее созданной структуре «замораживаются»
весовые коэффициенты его связей с входными нейронами, которые не обучаются,
поэтому при обучении НС модифицируются только связи добавляемого
нейрона с выходными нейронами. Процесс формирования топологии сети и обучение
завершается, как и в методе динамического наращивания, при достижении
заданной погрешности сети.
99
4. Настройка нейронной сети на решение прикладных задач
Отличительной чертой процедуры формирования структуры НС Фальмана
является подключение к сети скрытого нейрона как некоторого кандидата,
взятого из пула нейронов, при этом вся сеть обучается на основе не одной, а
множества обучающих выборок. Цель обучения состоит в подборе весов, при
которых достигается максимум корреляции между активностью добавляемого
нейрона, определяемой выходным сигналом и значением погрешности на
выходе сети. Эта корреляция определяется коэффициентом корреляции
м р
* = Z Z (v<'> - v)(<?(/) - ё) ,
где p — количество обучающих выборок; М— количество выходных
нейронов; v*0 - выходной сигнал нейрона-кандидата при /-обучающей выборке;
е(/) - значение погрешности/'-го выходного нейрона для /-обучающей выборки,
е.(0 = <tf.w -у(Г>\ v и ё - средние значения одноименных переменных, расчитан-
ные по всему множеству обучающих выборок.
После достижения максимального значения коэффициента корреляции
нейрон-кандидат включается в существующую к данному моменту структуру НС,
подобранные веса его входных связей фиксируются. Затем подбираются
значения весовых связей выходных нейронов, при этом не требуется применение
алгоритма обратного распространения ошибки, поскольку на данном этапе
обучаются только весовые коэффициенты выходного слоя, что приводит к
значительному уменьшению времени обучения и формирования структуры НС.
Качество корреляционного обучения можно повысить за счет
параллельного обучения НС с использованием нескольких нейронов-кандидатов. Каждый
нейрон-кандидат, который претендует на включение в сеть, может иметь свою
дискриминангную функцию и функцию : 11 : сигмоидальную, радиальную,
гауссову и т. д. Побеждает нейрон, который обеспечивает наименьшую
ошибку сети, поэтому сеть каскадной корреляции Фальмана может объединять
различные нейроны. Это, в свою очередь, позволяет расширить ее
функциональные возможности при решении прикладных задач.
На основе рассмотренных методов формирования топологии НС можно
сделать следующие выводы.
1. Деструктивные методы требуют полноты топологии НС до начала
исследования и могут быть рекомендованы как вспомогательные (для улучшения
построенной архитектуры).
2. Конструктивные методы являются простыми (вычислительная сложность
алгоритмов на их основе невелика), обеспечивают быстрое построение
топологии НС, но их можно применять там, где не предъявляется жестких
требований к эффективности решений, поскольку не гарантируется получение
оптимального решения.
Отмеченные трудности применения каждого из подходов требуют для
построения эффективных алгоритмов формирования топологии НС исследовать
новые и модифицировать используемые методы. Одним из таких алгоритмов
является генетический алгоритм, изучаемый в последующих главах.
100
4.5. Конструирование нейронных сетей
Логически прозрачные сети
Одним из недостатков НС, с точки зрения многих пользователей, является
отсутствие объяснительного компонента получаемых результатов, т. е. из обученной
НС невозможно извлечь алгоритм решаемой задачи. Конечным результатом
работы алгоритма обучения является некоторый вектор весов межнейронных
связей сети, в котором, в соответствии с принятым коннекционистским
подходом к формализации НС, и сосредоточены все знания. Каждая компонента этого
вектора представляет собой некоторое число, которое никаким образом
невозможно интерпретировать.
В 1995 г. Красноярской группой НейроКомп была сформулирована идея
логически прозрачных сетей, т. е. сетей, на основе структуры которых можно
построй! ft вербальное описание алгорима получения ответа. Это достигается
при помощи специальным образом построенной процедуры уменьшения
сложности (прореживания) сети.
Рассмотрим возможность получения явного знания из данных на примере
задачи выбора президента США. База данных включает 31 пример, каждый
из которых содержит результаты выборов и ответы на следующие 12 вопросов.
1. Правящая партия была у власти более одного срока?
2. Правящая партия получила больше 50% голосов на прошлых выборах?
3. В год выборов была активна третья партия?
4. Была серьезная конкуренция при выдвижении от правящей партии?
5. Кандидат от правящей партии был президентом в год выборов?
6. Год выборов был временем спада или депрессии?
7. Был ли рост среднего национального валового продукта на душу
населения больше 2,1%?
8. Произвел ли правящий президент существенные изменения в политике?
9. Во время правления были существенные социальные волнения?
10. Администрация правящей партии виновна в серьезной ошибке или
скандале?
11. Кандидат от правящей партии - национальный герой?
12. Кандидат от оппозиционной партии - национальный герой?
Ответы на вопросы описывают ситуацию на момент, предшествующий
выборам. Ответы кодировались следующим образом: «да» - единица, «нет» -
минус единица. Отрицательный сигнал на выходе
сети интерпретируется как предсказание победы
правящей партии.
В качестве начальной сети была выбрана сеть
следующей архитектуры: все входные сигналы
подаются на все нейроны входного слоя, а все
нейроны каждого следующего слоя принимают
выходные сигналы всех нейронов предыдущего слоя.
Логически прозрачной считается сеть, у которой
каждый нейрон имеет не более трех входных
сигналов. Один из возможных вариантов логически Рис. 4.6. Пример логически
прозрачной сети приведен на рис. 4.6. прозрачной сети
101
4. Настройка нейронной сети на решение прикладных задач
После автоматической генерации вербального описания был получен
следующий текст.
«Выход 1_Уровня1 равен 1, если выражение Симптом_4 + Симптом_6 -
Симптом_ 8 больше либо равно нулю, и —1 — в противном случае.
Выход2_Уровня1 равен 1, если выражение СимптомЗ + Симптом_4 + Сим-
птом_9 больше либо равно нулю, и -1 - в противном случае.
ВыходЗ_Уровня2 равен 1, если выражение Выход 1_Уровня1 + Выход2_Уров-
ня1 больше либо равно нулю, и -1 - в противном случае.»
На следующем этапе специалист в предметной области должен дать
осмысленные названия всем выходам. В результате выполнения этого этапа
получается окончательный текст, содержащий явный алгоритм решения задачи.
В приведенном выше примере этот текст имеет следующую интерпретацию.
1. Правление плохое, если верны хотя бы два из следующих высказываний:
«Была серьезная конкуренция при выдвижении от правящей партии», «Год
выборов был временем спада или депрессии», «Правящий президент не произвел
существенных изменений в политике».
2. Ситуация политически нестабильна, если верны хотя бы два из
следующих высказываний: «В год выборов была активна третья партия», «Была
серьезная конкуренция при выдвижении от правящей партии», «Во время правления
были существенные социальные волнения».
3. Оппозиционная партия победит, если правление плохое или ситуация
политически нестабильна».
Приведенный пример показывает, что в некоторых случаях логически
прозрачная сеть может быть построена, что позволяет интерпретировать и
объяснять получаемые на НС результаты. Однако в сложных случаях построение
логически прозрачных сетей связано с проведением большого числа
экспериментов и не всегда экономически выгодно.
4.6. Отбор информативных данных
При подготовке решения задачи на НС не всегда удается точно определить,
сколько и какие входные данные нужно подавать на ее вход при обучении. В
случае недостатка данных сеть не сможет обучиться решению задачи.
Проблема усугубляется тем, что в большинстве плохо формализуемых областей
человеческой деятельности (примером такой области может служить
медицина) эксперт часто не может точно сказать, какие именно данные являются
важными. Поэтому обычно на вход сети подается избыточный набор данных.
Для уменьшения времени обучения и повышения качества работы НС
требуется определить, какие данные необходимы для решения конкретной задачи,
поставленной для НС. Кроме того, в ходе решения этой задачи определяются
значимости входных сигналов, что во многих предметных областях
представляет самостоятельную ценность. Уменьшение числа входных параметров
приводит к упрощению реализации обученной НС.
102
4.6. Отбор информативных данных
При отборе данных для НС необходимо учитывать следующие факты:
• при решении реальных задач с помощью НС довольно часто трудно
установить связь выходного показателя с имеющимися данными, поэтому
проводят сбор как можно большего числа данных;
• наличие корреляции между данными не позволяет произвести их
ранжирование и, следовательно, невозможно использовать простой алгоритм отсева по
степени важности;
• для того чтобы снизить действие фактора «проклятия размерности», очень
часто просто удаляют некоторое число переменных; при этом возможно
удаление таких, которые несут существенную информацию.
Чтобы гарантированно получить только полезные (информативные) данные,
необходимо выполнить перебор большого количества наборов данных и
архитектур НС. Однако практически это реализовать трудно даже при наличии
мощных и эффективных нейроимитаторов. Решение этой задачи дает
использование генетического алгоритма, принцип действия которого изложен в гл. 6.
Другой способ отбора данных связан с понижением размерности входного
вектора, предполагающий удаление неинформативньгх переменных. Идея
способа заключается в таком преобразовании входных данных, чтобы та же
информация была записана с помощью меньшего числа переменных.
Реализация одного из методов понижения размерности - использование
анализа главных компонент (Bishop, 1995). Метод представляет собой такое
линейное преобразование входных данных, при котором количество
переменных уменьшается до априорно заданного предела, при сохранении
максимальной вариации данных. Однако не всегда максимальная вариация данных
соответствует максимальной информации. Недостаток метода состоит в том, что
преобразование данных является линейным. Нелинейный вариант этого
метода основан на использовании автоассоциативных сетей, рассмотренных в
следующей главе.
Отбор данных на основе показателей значимости
С помощью отбора данных на основе показателей значимости можно
удалять как входные сигналы, так и параметры сети. Далее будем предполагать,
что уменьшается число параметров сети. При уменьшении количества
входных сигналов процедура остается той же, но вместо показателей значимости
параметров сети используются показатели значимости входных сигналов.
Обозначим Хр - показатель значимости р-то параметра; м>% - текущее
значение р-то параметра; w*p - ближайшее выделенное значение для р-го
параметра. Используя введенные обозначения, процедуру отбора можно
записать следующим образом:
1. Вычисляем показатели значимости.
2. Находим минимальный среди показателей значимости - Хр* ■
103
4. Настройка нейронной сети на решение прикладных задач
3. Заменим соответствующий этому показателю значимости параметр w°P*
на w*p* и исключим его из процедуры обучения.
4. Предъявим сети все примеры обучающего множества. Если сеть не
допустила ни одной ошибки, то переходим к п. 2 процедуры.
5. Обучаем полученную сеть. Если сеть обучилась безошибочному
решению задачи, то переходим к п. 1 процедуры, в противном случае переходим к п. 6.
6. Восстанавливаем сеть в состояние до предшествующего выполнению
п. 3. Если в ходе выполнения п. 2 - 5 был удален хотя бы один параметр (число
обучаемых параметров изменилось), то переходим к п. 1. Если ни один
параметр не был удален, то получена минимальная сеть.
Возможно использование различных обобщений этой процедуры. Например,
удалять за один шаг не один параметр, а заданное пользователем число
параметров. Наиболее радикальная процедура состоит в ликвидации половины
параметров связей. Если это не удается, делается попытка ликвидировать
четверть и т. д.
Существует несколько методов определения показателей значимости. Чаще
всего для этой цели используют метод разложения функции оценки в ряд
Тейлора по обучаемым параметрам с точностью до линейных членов.
4.7. Обучение нейронной сети
Технология обучения
Стандартный способ обучения НС заключается в том, что сеть обучается
на одном из множеств базы данных, а на другом проверяется результат, т. е.
проверочное множество для обучения не используется. Первое из этих
множеств называют обучающим, второе - тестовым.
Таким образом, обучение многослойной НС можно представить дзумя
этапами:
• предъявление НС обучающего множества примеров до тех пор, пока не
будет выполнено условие останова обучения:
а) вычисляемая ошибка сети Е (например, по формуле (4.1)) становится
меньше заданной или перестает изменяться в течение определенного числа
итераций («эпох»);
б) по истечении заданного числа итераций;
• проверка правильности работы сети на тестовом множестве: если ошибка
обобщения Еоб>Ъ (5 - заданная ошибка обобщения) - проводится
увеличение числа итераций, либо числа обучающих примеров, либо происходит
модификация архитектуры НС.
Если использовать небольшой набор обучающих данных, то при обучении
сеть будет слишком близко следовать обучающим данным (переобучаться) и
воспринимать не столько структуру данных, сколько содержащиеся в ней
помехи.
104
4.7. Обучение нейронной сети
Способность сети не только учиться на обучающем множестве, но и
показывать хорошие результаты на новых данных (хорошо предсказывать)
называется обобщением. Качество обобщения данных можно определить,
наблюдая за величиной ошибки, вычисленной на тестовом множестве данных. Эта
ошибка должна быть меньше заданной. Если после нескольких итераций
обучающего алгоритма ошибка обучения падает почти до нуля, в то время как
ошибка обобщения сначала убывает, а потом снова начинает расти, то это
признак переобучения, и при росте ошибки обобщения обучение следует
прекратить. В описанном случае тестовое множество используется при обучении НС
для определения момента «ранней остановки», поэтому по окончании обучения
следует проверить работу сети еще на одном - третьем множестве
(«подтверждающем»).
Если тестовое (контрольное) множество используется на каждой итерации
при обучении НС для определения «ранней остановки», то такой процесс
называется обучением с перекрестной проверкой. На рис. 4.7 представлены
стратегии обучения с перекрестной (или кросс-) проверкой; при этом переключение
между типами множеств (обучающим, тестовым, подтверждающим) во
время процедуры обучения может осуществляться вероятностным способом.
Такой подход позволяет остановить обучение, когда частота появления ошибок
обобщения начнет расти.
Метод «ранняя остановка» обучения НС по сравнению со стандартными
методами остановки имеет ряд преимуществ:
• сокращение времени обучения;
• его можно успешно использовать в сетях, в которых размерность вектора
весовых коэффициентов существенно превышает размерность вектора
входных данных;
г, т п —т
П П
а
1°1Т|° |Т|° I—Н>
П П I
б
О-обучающее Т-тестовое П- подтверждающее
множество множество множество
Рис. 4.7. Обучение с перекрестной проверкой:
а, б - варианты чередования О, Т, П (/ - время)
105
4. Настройка нейронной сети на решение прикладных задач
<i /, П
Шаг1 |
Шаг 2 |
ШагЗ |-
Шаг4 \
Рис. 4.8. Обучение по меняющимся промежуткам времени:
/, - начало обучения; t, '*•••- моменты поступления новых данных
• он требует от пользователя только выполнения одного указания -
проверочных вариантов из всей выборки имеющихся данных.
Недостатками этого метода являются следующие:
• необходимость разделения всех имеющихся данных на обучающую,
тестовую и подтверждающую выборки, что сокращает объем обучающей
выборки и снижает качество обучения;
• указание способа распределения данных по этим выборкам;
• необходимость определения момента времени, начиная с которого ошибка
обобщения начинает расти.
Статистики относятся к методу «ранней остановки» скептически,
поскольку он представляется неэффективным с точки зрения статистического
подхода к анализу результатов экспериментов из-за того, что ни при обучении, ни при
проверке не используется вся выборка, а также вследствие того, что не
применима обычная статистическая теория. Однако Вант (1994) доказал, что если
скорость обучения достаточно мала, последовательность весовых векторов на
каждой итерации будет приближаться к траектории непрерывного
наискорейшего уменьшения функции ошибок. В методе «ранней остановки» выбирается
такая точка на этой траектории, которая оптимизирует оценку ошибки
обобщения, вычисляемую на тестовом наборе.
При решении задач анализа временных рядов используют так называемые
адаптивные НС, в которых весовые коэффициенты межнейронных связей
непрерывно уточняются с помощью процедуры обучения на все новых
временных промежутках. Пример такого алгоритма обучения, который учитывает
вновь поступающую информацию, показан на рис. 4.8.
Для повышения эффективности работы алгоритма «ранней остановки»
необходимо решить следующие проблемы:
1) определить способ оптимального разбиения множества имеющихся
примеров в базе данных на три указанных выше подмножества;
2) для сокращения времени обучения найти способ определения номера
итерации, начиная с которой Е^ начинает расти (при перекрестной проверке она
может многократно увеличиваться или уменьшаться за время обучения). При-
106
4.7. Обучение нейронной сети
0,07
0,06
0,05
0,04
0,03
0,02
0,01
0
0 0,01 0,02 0,03 0,04 0,05 0,06
Рис. 4.9 Зависимость изменения ошибки обобщения
при обучении НС с перекрестной проверкой
мер зависимости изменения Е^. при обучении от ошибки обучения Е0 в
многослойной НС представлен на рис. 4.9.
В предлагаемом ниже модифицированном алгоритме «ранней остановки»
решена вторая проблема. Идея алгоритма сводится к тому, чтобы зафиксировать
момент, когда ошибка обобщения на тестовой выборке становится меньше
ошибки обобщения на подтверждающей выборке. Алгоритм сводится к
выполнению следующих шагов.
1. Провести обучение НС.
2. Вычислить ошибку обобщения Ех на тестовой выборке.
3. Установить количество итераций г.
4. Снова провести обучение НС.
5. Вычислить ошибку обобщения Е2 на подтверждающей выборке.
6. Установить г:=к*г, где к - скорость обучения, тх< к < т2, где 0 < тх < 1,
0 < т2< 1, тх < т2. Параметры тх,т2ик выбираются экспертом перед началом
процедуры обучения, исходя из предварительных прогонов НС-модели.
7. Если Ех-Е2> 0, то ЕХ:=Е2 и перейти к ш. 3, в противном случае перейти
кш. 8.
8. Останов обучения.
Этот алгоритм не только позволяет избежать переобучения сети, но и
значительно уменьшает время обучения. Ниже представлены результаты
экспериментальной проверки работоспособности данного алгоритма.
Ошибка обобщения на тестовой выборке: Е 0,043; 0,030; 0,018
Ошибка обобщения на подтверждающей выборке: Еп 0,035; 0,028; 0,025
Алгоритм заканчивает работу, когда Ет становится меньше, чем Ев и число
итераций для получения той же ошибки обобщения уменьшается вдвое
приблизительно с 10000 до 5000.
107
4. Настройка нейронной сети на решение прикладных задач
4.8. Пример решения задачи классификации
на основе нейронной сети
Основная задача обучения НС - приблизить функцию, которую реализует
реальная сеть, к неизвестной функции, которую, как предполагается, можно
определить по имеющемуся множеству примеров - обучающему множеству.
Как в задачах классификации, так и в задачах прогноза, цель при построении
сети должна состоять не в том, чтобы запомнить обучающую информацию, а в
том, чтобы на основании изучения прошлого (имеющихся знаний) сделать
обобщения, которые можно будет затем применить к новым образцам. В конечном
счете, эффективность сети определяется тем, как она работает с
совокупностью всех возможных примеров (пространством возможных ситуаций).
Наиболее важные виды приложений НС - это решение задач
классификации. Задача классификации с помощью обученных НС понимается как задача
отнесения некоторого примера к одному из нескольких попарно не
пересекающихся множеств объектов. В реальных ситуациях при классификации
объектов выделяют три уровня сложности (рис. 4.10):
• классы можно разделить прямыми линиями (или гиперплоскостями, если
пространство параметров более двух) - линейная отделимость;
• классы можно разделить несколькими гиперплоскостями - нелинейная
отделимость;
• классы пересекаются, поэтому их разделение можно трактовать только в
вероятностном смысле.
Нейронная сеть может осуществлять классификацию на всех трех уровнях
сложности с заданной ошибкой обобщения. Решение задачи классификации с
помощью НС сводится к предъявлению обученной сети набора входных
векторов, не включенных в обучающую выборку. Нейронная сеть должна каждый
из этих векторов отнести к определенному классу. Используемое при этом
решающее правило зависит от выбранного метода интерпретации ответов сети.
Так, если выбран метод «победитель забирает все», то сеть относит
предъявляемый ей входной вектор только к одному из классов. Если же выбран метод
нечеткой классификации, то сеть выдает последовательность чисел, например
в интервале [0; 1], каждое из которых определяет вероятность отнесения входно-
а бег
Рис. 4.10. Уровни сложности в разделении классов:
а - линейно отделимые; б, в- нелинейно отделимые; г- неразделимые
108
4.8. Пример решения задачи классификации на основе НС
го вектора к тому или иному классу. В такой постановке решение задачи
классификации будет идентично решению задачи распознавания. В этом случае на
вход сети подается вектор с неизвестными ранее значениями параметров, сеть
относит входной образ к определенному классу.
Алгоритмы классификации в НС основаны на использовании мер близости
между объектами. Простейшая мера близости объектов - квадрат евклидова
расстояния между векторами значений параметров, характеризующих объект
(чем меньше расстояние между векторами значений их параметров, тем
ближе объекты). Другая мера близости, обычно использующаяся при обработке с
помощью НС сигналов, изображений и т. п., - квадрат коэффициента
корреляции (чем он больше, тем ближе объекты).
Для различных мер близости в каждом классе обычно выбирают типичный
объект, вектор значений параметров которого получается путем усреднения по
всему классу.
Для минимизации ошибки распознавания с помощью НС необходимо
определить степень близости между объектами, принадлежащими к одному
классу и степень удаленности объектов, относящихся к разным классам. В
качестве оценки близости между объектами будем использовать усредненное
расстояние между объектами i'-го класса, вычисленное в соответствии с
выбранной метрикой:
К,-\ К,
"I 1 = 1 J=l
где N.= (К. К. - 1)/2 - количество связей между объектами в классе К..
Оценка близости образов, принадлежащих двум разным классам,
вычисляется по формуле
п ч • -1 j-1
где Nt - количество связей между объектами классов Kt и К.
Интегральные оценки, вычисленные в результате усреднения по всем
классам имеют вид:
-I 1 т~\ т
*=*£*. е=—— Е £еУ>
т(т— 1)/2 > = i j=\
где т - количество классов. _ _
В идеальном случае, когда R —> 0 и Q —> со, минимизация ошибки сети Е
при обучении на любом подмножестве обучающей выборки обеспечит
минимизацию ошибки распознавания. Если при этом Q < R, то можно
предположить несколько гипотез, объясняющих этот факт:
109
4. Настройка нейронной сети на решение прикладных задач
1) имеются ошибки при определении соответствия между объектами и
заданными классами;
2) выбранные примеры образцов в обучающем множестве не •: i ся
достаточно информативными;
3) используемый способ предобработки данных неадекватен решаемой
задаче.
Первые два предположения связаны в основном с общей организацией
работ по синтезу НС для решения задач распознавания. Последняя гипотеза имеет
непосредственное отношение к проблеме обучения НС. Если после процедуры
обучения сети Q< R, необходимо провести коррекцию выбранной НС или
изменить способ представления входного вектора.
Таким образом, при построении классификаторов на основе нейронной сети
выделим следующие этапы.
1. Подготовка данных:
- составить базу данных из примеров, характерных для поставленной задачи;
- разбить всю совокупность данных на два подмножества - обучающее и
тестовое;
- в некоторых случаях для предотвращения переобучения выбрать
подтверждающее множество; если подходящий метод разбиения отсутствует, разбить
случайным образом.
2. Предобработка данных:
- преобразовать данные для подачи на вход сети (нормировка,
стандартизация и т. д. ), т. е. провести препроцессирование данных;
- выбрать способ интерпретации ответов сети;
- выбрать функцию оценки работы сети.
3. Конструирование и обучение сети:
- сконструировать топологию сети: число элементов и структуру связей
(входы, слои, выходы);
- выбрать функцию активации нейрона;
- определить подходящую стратегию обучения;
- сформулировать критерий останова обучения;
- провести процедуру обучения сети на обучающем множестве;
- оценить качество работы сети по подтверждающему множеству;
- выбрать сеть с наилучшей способностью к «обобщению» и оценить
правильность работы сети по тестовому множеству.
4. Диагностика:
- протестировать использование различных решающих правил в режиме
классификации;
- вычислить ошибку классификации;
- при необходимости вернуться к п. 2, изменив способ представления
образцов.
Рассмотренная в данной главе стратегия настройки параметров НС дает
наиболее общий подход, который можно использовать для решения реальных
задач.
ПО
4.8. Пример решения задачи классификации на основе НС
Вопросы и упражнения для самоконтроля
1. Что такое обучающее, тестовое и подтверждающее множество?
2. Перечислите возможные методы окончания процедуры обучения НС. Что
понимается под методом «ранняя остановка»?
3. Сформулируйте алгоритм получения логически «прозрачной» сети.
4. Как создать сеть, адекватную решаемой задаче?
5. Перечислите способы представления исходных данных в сети. Почему необходимо
проводить препроцессирование данных?
6. Как оценить качество работы НС? По каким критериям?
7. Перечислите способы интерпретации результатов работы сети.
8. Перечислите виды используемых на практике шкал измерения и области их
применения.
9. В чем различие качественных и количественных признаков, характеризующих
объект исследования?
10. Перечислите этапы создания классификатора на основе НС. Какой из них является
наиболее трудоемким?
П. Сравните различные способы отбора информативных признаков объекта с помощью
НС. Какой из них является наиболее эффективным?
12. Что понимают под нечеткой классификацией?
5. ОБУЧЕНИЕ НЕЙРОННЫХ СЕТЕЙ
БЕЗ ОБРАТНЫХ СВЯЗЕЙ
Представлена эволюция развития алгоритмов обучения наиболее
распространенной НС - многослойного персептрона. Проведен анализ алгоритма обратного
распространения ошибки, исследованы возможности повышения качества его работы.
Рассмотрены примеры решения практических задач классификации и прогнозирования.
5.1. Эволюция развития персептронных алгоритмов обучения
В 1957 г. американский физиолог Ф. Розенблатт предпринял попытку
технически реализовать физиологическую модель восприятия, что позволило бы
имитировать человеческие способности правильно относить наблюдаемый
объект к тому или иному понятию, к тому или иному классу. При создании
устройства, наделенного чертами разума, Розенблатт исходил из
предположения, что восприятие осуществляется сетью нейронов (при организации сети
использовалась модель нейрона Мак-Каллока - Питтса).
Схематически процесс восприятия может быть представлен следующим
образом (рис. 5.1). Внешнее раздражение воспринимается рецепторами -
нервными окончаниями нейронов, которые образуют рецепторный слой
элементов восприятия. Каждый рецептор связан с одним или несколькими нейронами
преобразующего слоя, при этом каждый нейрон преобразующего слоя может
быть связан с несколькими рецепторами.
Выходы преобразующих (ассоциативных) нейронов, в свою очередь,
соединены с входами нейронов третьего слоя. Нейроны этого слоя - реагирующие -
тоже имеют несколько входов (дендритов) и один выход (аксон), который
возбуждается, если суммарная величина входных сигналов превосходит порог
срабатывания (функция активации нейронов - пороговая). Но, в отличие от
нейронов второго слоя, где суммируются сигналы с одним и тем же коэффициентом
усиления (имеющими, возможно, разные знаки), для реагирующих нейронов
коэффициенты суммирования различны по величине, и, возможно, по знаку.
112
5.1. Эволюция развития персептронных алгоритмов обучения
Рецепторный Преобразующий Реагирующий
слой слой слой
Рис. 5.1. Модель восприятия
Каждый рецептор может находиться в одном из двух состояний:
возбужденном или невозбужденном. Рецептор возбуждается и посылает импульс в
том случае, когда число сигналов, поступающих по возбуждающим входам,
превосходит число сигналов, пришедших по тормозным входам. В
зависимости от характера внешнего раздражения в рецепторном слое образуется
некоторая пачка импульсов, которая, распространяясь по нервным путям, достигает
слоя преобразующих нейронов. Здесь в ответ на пачку пришедших импульсов
образуется пачка импульсов второго слоя, которая поступает на входы
реагирующих нейронов.
Восприятие какого-либо объекта определяется возбуждением
соответствующего нейрона третьего слоя. Различным пачкам импульсов рецепторного слоя
может соответствовать возбуждение одного и того же реагирующего нейрона.
Коэффициенты усиления реагирующего нейрона подбираются так, чтобы в
случае, когда объекты принадлежат к одному классу, отвечающие им пачки
импульсов возбуждали бы один и тот же нейрон реагирующего слоя. Например,
наблюдая какой-либо предмет в разных ракурсах, человек обобщает
увиденное: каждый раз на различные внешние раздражения реагирует один и тот же
нейрон, ответственный за узнавание этого предмета.
Среди огромного числа (порядка 1010 - 1012) нейронов человека,
обеспечивающих восприятие, лишь некоторая часть занята уже сформированными
понятиями, другая служит для образования новых понятий. Формирование новых
понятий, по существу, заключается в установлении коэффициентов усиления
реагирующих нейронов. В схеме Розенблатта этот процесс установления
коэффициентов описывается в терминах поощрения и наказания.
Допустим, что появился сигнал, соответствующий вновь
вырабатываемому понятию. Если при его появлении нужный реагирующий нейрон не
возбудился (т. е. пришедший сигнал не был отнесен к данному понятию), то
реагирующий нейрон «штрафуется»: в этом случае коэффициенты усиления тех входов,
по которым поступил сигнал, :• >•■ »тся на единицу. Если нейрон правиль-
113
5. Обучение нейронных сетей без обратных связей
но реагировал на пришедшие импульсы, то коэффициенты усиления не
меняются. Если же окажется, что некоторый набор сигналов будет ошибочно отнесен
к данному понятию, то нейрон тоже «штрафуется», но при этом коэффициенты
усиления тех входов, по которым пришел импульс, уменьшаются на единицу.
Такая модель восприятия может быть реализована на однородных элементах
- пороговых.
Пороговым называется элемент, имеющий и входов (jcp x2, ..., хп), и один
выходу, причем сигнал на выходе >> может принимать только два значения 0 и
1 и связан с входами xv х2,..., хп соотношением:
и
1, если £ ^iXj>X0;
О,
i = i
и
если £ XjXj < к0,
i = i
где 7ц ,%2 v . Ki~ коэффициенты усиления сигналов хх, х2, ..., хп; Х0- порог
срабатывания элемента.
Моделью преобразующего нейрона может служить пороговый элемент, у
которого коэффициенты X=± 1, а моделью реагирующего нейрона - пороговый
элемент, у которого коэффициенты X - некоторые фиксированные числа.
На основе таких моделей Розенблаттом была построена физическая
модель зрительного восприятия - персептрон (от слова «персепция» -
восприятие). Первый рецепторный слой S модели Розенблатта состоял из набора 400
фотоэлементов, которые образовывали поле рецепторов (20x20). Сигнал с
фотоэлемента поступал на входы пороговых элементов - нейронов
преобразующего слоя (элементов А). Всего в модели Розенблатта было 512 элементов.
Каждый элемент А имел 10 входов, которые случайным образом были
соединены с рецепторами - фотоэлементами. Половина входов считалась
тормозными и имела коэффициент усиления -1, другая половина - возбуждающими с
коэффициентом усиления, равным+1. Порог срабатывания нейрона
принимался равным 0. Выходы элементов А поступали на входы реагирующего нейрона
- элемента R (рис. 5.2).
Рис. 5.2. Физическая модель персептрона
114
5.1. Эволюция развития персептронных алгоритмов обучения
Персептрон предназначался для работы в двух режимах: обучения и
эксплуатации. В режиме обучения у персептрона по описанному выше принципу
подбирались значения коэффициентов "Кх ,Х2,... Дто реагирующих нейронов. В
рабочем режиме эксплуатации персептрон классифицировал предъявленные ему
ситуации: если возбуждался р-й реагирующий элемент и не возбуждались
остальные R элементов, то ситуация относилась кр-му классу. ЭВМ, созданная
по принципу персептрона, получившая название «Марк-1», и была построена
для экспериментальной проверки возможности персептрона образовывать
понятия.
Математическая модель персептрона
Основные положения, введенные Розенблаттом для построения
математической модели персептрона, сводятся к следующему.
1. В рецепторном поле образуется сигнал, соответствующий внешнему
раздражителю, представленному некоторым вектором X. Каждое нервное
окончание передает простой сигнал - либо передает, либо не передает импульс,
поэтому вектор X является бинарным, т. е. его координаты могут принимать
только два значения 0 и 1.
2. В сети импульсы распространяются до тех пор, пока с помощью
нейронов второго слоя они не будут преобразованы в новые импульсы, т. е. бинарный
вектор X преобразуется в бинарный вектор Y. Характер этого преобразования
имеет особенности:
• преобразование осуществляется пороговыми элементами;
• входы преобразующих пороговых элементов соединены рецепторами
случайно.
3. Считается, что персептрон относит входной вектор кр-му понятию, если
возбуждается р-й реагирующий нейрон и не возбуждаются другие
реагирующие нейроны. Формально это означает, что для вектора Y(yvy2,..., у )
выполняется система неравенств:
Г •"
£ yjXj> 0, для t=p;
J 7 = 1
т
£ yjkj < 0, для i Фр,
где X'i, ^2,..., Xjj, - коэффициенты усиления /-го реагирующего нейрона.
4. Формирование понятий в сети сводится к определению коэффициентов
(весов) каждого из элементов R. Процедура формирования весов элементов R
заключается в следующем.
Пусть к данному моменту времени существуют некоторые веса элементов R и
7i\, kp2,..., Wm- весар-го элемента Rp В момент времени т на вход персептрона
поступает сигнал, соответствующий вектору Хх, который может либо
соответствовать понятию р либо не соответствовать ему. Рассмотрим оба эти
случая.
115
5. Обучение нейронных сетей без обратных связей
Случай 1. Вектор Хх соответствует понятию р. Правильной реакцией
элемента R на сигнал Yx (У\,Уг,... ,У£) должно быть выполнение неравенства
т т
Щу, >о.
1 = 1
Если веса элемента R обеспечивают правильную реакцию на вектор Yx, то
они не меняются. Если же веса не обеспечивают правильной реакции элемента
т х
R , т. е. они таковы, что £ V-У,- < О, то веса элемента R изменяются по
правилу: '=1
Х,р(новое) = АДстарое) +y](i =1,2, 3,..., т).
Случай 2. Вектор Хх не соответствует понятию р. Правильной реакцией
элемента R на входной сигнал будет выполнение неравенства
W т
I,Wy, <o.
Если веса элемента R обеспечивают правильную реакцию этого элемента
на вектор Yx, то они не меняются. Если же веса не обеспечивают правильной
т х
реакции элемента R , т. е. £ Х/'.У,- > 0, то веса элемента R изменяются по
правилу: '='
Х,р(новое) = ХДстарое) -yf (i =1,2, 3,..., т).
Аналогично при обучении персептрона меняются веса всех элементов R.
Представленная модель персептрона явилась основой для разработки
многих современных сложных алгоритмов обучения с учителем.
Рассмотрим его модель, которая изучалась и исследовалась многими
учеными, в том числе и советскими. Персептрон представляет собой
однослойную нейронную сеть (рис. 5.3). В нем используется алгоритм обучения с
учителем: обучающая выборка состоит из к входных векторов Хр,р= 1,..., к, для
каждого из которых указан требуемый выходной вектор Yp. Компоненты
входного вектора задаются непрерывным диапазоном значений; компоненты
требуемого выходного вектора являются бинарными.
Обучение персептрона Розенблатта проводится в соответствии со
следующим алгоритмом:
1. Всем весам сети присваиваются некоторые
малые случайные значения (чтобы сеть сразу не
могла войти в насыщение).
2. На вход сети подается очередной входной
вектор X и вычисляется суммарный сигнал по
•ут всем входам для каждого нейронау:
п
s = у1 xw
Рис. 5.3. Однослойная НС J Л4, ' у'
116
5.7. Эволюция развития персептронных алгоритмов обучения
где п — размерность входного вектора; jc/ - i-я компонента входного вектора;
Wij - весовой коэффициент связи нейрона^" и входа i.
3. Вычисляется значение выхода каждого нейрона (функция активации в
персептроне Розенблатта является пороговой)
[у,= 0, если sj< by;
"1 yj= 1, в противном случае,
где Ь. - порог, соответствующий нейрону j (в простейшем случае все нейроны
имеют один и тот же порог).
4. Вычисляется ошибка сети для каждого нейрона
ej = dj-yj.
5. Проводится модификация весового коэффициента связи
Wij (t + 1) = Wij{f) + axt ej,
где t—номер такта функционирования сети; а- коэффициент обучения.
6. Повторение пп. 2-5 до тех пор, пока ошибка сети не станет меньше заданной.
Процедура Уидроу-Хоффа
Уидроу и Хофф модифицировали персептронный алгоритм Розенблатта,
используя сигмоидальную функцию активации и непрерывные выходные
вектора. Их модели Адалин (с одним выходным нейроном) и Мадалин (много
выходных нейронов) получили широкое распространение. Кроме того, они доказали,
что сеть при определенных условиях будет сходиться к любой функции,
которую она может представить.
Процедура Уидроу-Хоффа разработана применительно к «черному ящику»,
в котором между входами и выходами существуют только прямые связи.
Процедура обучения Мадалин состоит в том, что веса всех внутренних связей между
нейронами подстраиваются до тех пор, пока не установится требуемое
соответствие между входными и выходными векторами. Этот процесс обучения
включает две чередующиеся фазы.
В первой фазе на входах задается входной вектор, а на выходах - нужный
выходной вектор. Затем веса всех связей, соединяющих активные входы и
выходы, увеличиваются на некоторую малую величину 8. Во второй фазе на
входе фиксируется тот же входной вектор, однако теперь самому «черному
ящику» предоставлено право решать, какой вектор сформировать на выходе. При
этом должно соблюдаться следующее правило: выход активизируется только
тогда, когда сумма весов его связей с активными входами положительна.
После этого веса всех связей, соединяющих активные входные и выходные
элементы, уменьшаются на величину 8. Если сеть выработала правильный
выходной вектор, то эти уменьшения весов в точности компенсируют их увеличение,
117
J. Обучение нейронных сетей без обратных связей
произведенное в первой фазе, поскольку в обеих фазах активны одни и те же
пары вход-выход. Если же сеть вьфаботала не тот выходной вектор, который
нужен, то изменения весов, выполненные в первой фазе, сохраняются.
Описанный процесс обладает тем свойством, что если долго продолжать
применение описанной двухфазной процедуры, многократно пропуская через
«черный ящик» все пары входных и выходных векторов, то придем к такому
распределению весов, при котором для каждого входного вектора
обеспечивается выработка правильного выходного вектора, однако при условии, что хотя
бы одно такое распределение существует.
При реализации алгоритма обучения персептрона Адалин появляются
отличия от классического персептронного алгоритма в четвертом шаге, где
используются непрерывные сигналы вместо бинарных.
Существенным недостатком приведенной процедуры, из-за которого при
практической реализации НС от нее отказались, является то, что в трудных
задачах требуемого распределения весов не существует. Зависимости между
входными и выходными векторами оказываются слишком сложными для того,
чтобы система, у которой вход и выход непосредственно связаны, могла их
усвоить. Необходимо, чтобы в структуре «черного ящика» имелись некоторые
промежуточные слои, а лежащие в этих слоях элементы должны уметь
выделять из входного вектора иерархию тех его признаков, которые и определяют в
конечном итоге выбор выходного вектора.
Если попытаться распространить процедуру Уидроу-Хоффа на сеть с
промежуточными слоями, то возникают сложности, связанные с тем, что заранее
не ясно, какого поведения следует потребовать от этих слоев. Поэтому
алгоритм обучения должен не только вычислять веса связей, обеспечивающих
требуемые реакции выходов, но и решить, при каких условиях должен
активизироваться каждый из слоев. Ниже будут рассмотрены возможные пути решения
этой проблемы.
Теорема Новикова
Американский ученый А. Новиков показал, что если обучающую
последовательность, состоящую из множества векторов хх,х2, ...,хк и yvy2, ...,yt,
предъявить персептрону достаточное число раз, то он в конце концов разделит ее
(если, конечно, разделение с помощью гиперплоскости возможно) на два класса.
Графическая интерпретация теоремы А. Новикова представлена на рис. 5.4.
Утверждение, что данные множества разделимы гиперплоскостью,
эквивалентно тому, что выпуклая оболочка множества векторов х1,х2,...,хки выпуклая
оболочка множества векторовyv y2, ...,yt не пересекаются. (Выпуклой
оболочкой множества называется минимальное выпуклое множество, содержащее
эти элементы. В свою очередь, выпуклым множеством . .%-..- я множество,
которое наряду с любыми двумя точками содержит и отрезок, их соединяющий.)
Нарис. 5.4 показаны выпуклые оболочкиXj,^, ...,xku.yvy2, ...,yr Обозначим
расстояние между двумя множествами через р , оно определяется как мини-
118
5.7. Эволюция развития персептронных алгоритмов обучения
*г, •••»**
Рнс. 5.4. Иллюстрация теоремы Новикова:
По- оптимальная разделяющая гиперплоскость;
IIi ~ неоптимальная разделяющая гиперплоскость;
х — элементы первого множества;
у — элементы второго множества
мальное расстояние между элементами различных выпуклых оболочек. Если
выпуклые оболочки не пересекаются, то р > 0, если они пересекаются, р = 0.
Таким образом, формальное утверждение о том, что множества Ху,х2,...,хки
yv у2, ■■-,У1 разделены гиперплоскостью, дается в виде р = р0 > 0.
Новиков для формулировки своей теоремы вводит также понятие диаметра
множества, которое представляет собой наибольшее расстояние между
элементами множества. Используя эти понятия, Новиков доказал, что если
расстояние между выпуклыми оболочками двух множеств отлично от нуля (р = р0
), а диаметр множества ограничен (D < оо), то после многократного
предъявления обучающей последовательности, составленной из всех элементов этих
множеств, будет построена разделяющая гиперплоскость, причем во время ее по-
D2'
строения будет произведено не более чем
Р2
исправлении весовых
коэффициентов (символ [а] означает целую часть числа а).
На рис. 5.4 показан отрезок прямой р, длина которого определяет
расстояние между выпуклыми оболочками двух множеств, причем плоскость,
проходящая через его середину и ортогональная отрезку, такова, что из всех
разделяющих плоскостей, которые можно построить, она наиболее удалена от
ближайшей из точек множестваТакая разделяющая гиперплоскость
называется оптимальной и она единственна.
Согласно теореме Новикова, в результате многократного предъявления
последовательности элементов из обучающего множества будет построена
разделяющая гиперплоскость. Этот факт оказался очень важным для
дальнейшего развития обучающих алгоритмов.
119
5. Обучение нейронных сетей без обратных связей
Алгоритмы Айзермана и Бравермана
Большой вклад в разработку алгоритмов обучения НС внесли также
советские ученые. Рассмотрим алгоритмы обучения, основанные на построении
разделяющей гиперплоскости, предложенные нашими соотечественниками
М.А. Айзерманом и Э.М. Браверманом в начале 60-х годов. Эти алгоритмы
базируются на выдвинутой этими учеными гипотезе компактности.
Гипотеза компактности утверждает, что разбиение множества
многомерных объектов на классы возможно, и каждому классу соответствует
обособленная группа объектов.
Примечание. В работах М. Айзермана и Э. Бравермана классам соответствовали
графические образы (цифры), а объектами являлись случайно сгенерированные
изображения этих цифр.
В процессе обучения машине показывается некоторое количество
случайно выбранных изображений первого и второго образов, т.е. некоторое
количество случайных точек соответственно из первого и второго классов,
определяющих образы. Задача машины состоит в том, чтобы, зная только эти точки,
провести разделяющую плоскость так, чтобы эти классы оказались
расположенными по разные стороны плоскости.
По окончании процесса обучения машине предъявляются новые
изображения (новые точки в многомерном пространстве) и она должна правильно
определить, к каким образам они принадлежат, в зависимости от того, по какую
сторону от разделяющей поверхности лежат эти точки.
Алгоритм «случайных плоскостей». Пусть вначале в процессе обучения
предъявлены две точки (крестик и кружок), и машине сообщено, что они
соответствуют разным образам. Тогда она проводит плоскость, которая
выбирается случайно, с единственным ограничивающим условием - необходимостью
разделения двух точек (рис. 5.5, а). Если предъявлена еще одна точка и
окажется, что две точки, принадлежащие разным образам, не разделены
плоскостью, то проводится новая случайная разделяющая плоскость (рис. 5.5, б),
затем процесс обучения продолжается.
В конце процесса обучения в памяти машины хранится большое число
проведенных случайных плоскостей (рис. 5.5, в). Они разбивают все пространство
точек на классы, в которых размещаются любые одноименные
предъявляемые точки, либо в которых вообще нет ни одной точки. Затем по
определенному алгоритму из памяти машины «стираются» части плоскостей, по обе
стороны которых расположены одноименные точки, либо части плоскостей, у которых
с одной стороны расположены точки, показанные в процессе обучения, а с
другой - показанных точек нет вообще. В результате образуется
кусочно-ломаная гиперповерхность, составленная из кусков плоскостей (рис. 5.5, г). По
разные стороны от этой гиперповерхности расположены точки, принадлежащие
разным классам. Построенная таким образом гиперповерхность принимается
120
5.1. Эволюция развития персептронных алгоритмов обучения
в г
Рис. 5.5. Процедура формирования гиперповерхности
за разделяющую, и при предъявлении нового образа относит его к
определенному классу в зависимости от того, по какую сторону от гиперповерхности
находится соответствующая образу точка.
Поскольку при повторении эксперимента плоскости проводятся каждый раз
случайно, то это приводит к построению другой разделяющей поверхности. В
этом случае появляется возможность параллельно реализовать несколько
вариантов разделения пространства, благодаря чему значительно увеличится
вероятность точных ответов, так как выбирается вариант, обеспечивающий
минимальную вероятность ошибок при классификации.
Алгоритм построения потенциальных функций. При предъявлении
машине какой-либо точки она строит функцию точки пространства, которая
достигает максимума в показанной точке, оставаясь всюду положительной,
уменьшается при удалении от нее в любом направлении. Когда предъявляется
несколько точек, относящихся к одной области (классу), то машина строит
такие функции для каждой из этих точек, а затем складывает их. Если в процессе
обучения предъявлено несколько относительно равномерно распределенных
по некоторому классу точек, то в результате будет построена поверхность -
своеобразная потенциальная функция, которая имеет большие значения (горб)
в точках, соответствующих некоторому классу области, и резко падает при
удалении от них. Если необходимо разделить, например, два класса, то машина
строит по предъявленным точкам этих классов две такие функции; одна из них
имеет горб над первым классом, а другая над вторым (рис. 5.6). Если при класси-
121
5. Обучение нейронных сетей без обратных связей
фикации элементов обучающей
последовательности с помощью суммарного
потенциала совершается ошибка, потенциал
меняется так, чтобы по возможности
исправить ошибку.
Таким образом, результатом обучения в
методе потенциальных функций является
построение на пространстве точек X
потенциального поля, которое разбивает все
пространство на две части: часть пространства
X, где значение суммарного потенциала по-
Рис 5.6. Построение потенциальных ложительно (все точки в этой части про-
функций для разделения двух странства считаются принадлежащими
классов К, и К,: ч
1 2 первому классу), и часть, где значения по-
вектор X, е К,; векторы X,, X, е К, ,
1 ' г -2> -2 2 тенциала отрицательны (точки в этой
части пространства считаются принадлежащими второму классу). Поверхность,
на которой потенциал принимает нулевое значение, считается разделяющей.
Браверманом было доказано, что для потенциала любого вида может быть
предложена система функций q>j(X), ...,q>k(X), такая, что все возможные
разделяющие поверхности, которые можно получить методом потенциальных
функций, можно также получить и с помощью персептрона Розенблатта, где
соответствующее спрямляющее пространство задается преобразованиями
(Pj(X), ...,фл(Х). С другой стороны, для каждого персептрона находится
соответствующая потенциальная функция. Таким образом, гипотеза компактности
Айзермана и Бравермана позволила не только разработать новые обучающие
алгоритмы, но и понять суть процедуры обучения с помощью персептрона.
Минский и Пейперт в работе «Персептроны» показали, что однослойные
НС с прямым распространением сигналов не являются универсальными
вычислительными устройствами. Поэтому были предприняты попытки разработки
алгоритмов обучения для многослойных сетей персептронного типа.
Перейдем к рассмотрению методов обучения персептронов, содержащих
промежуточные слои.
5.2. Обучение многослойной нейронной сети
без обратных связей
Пусть НС имеет и входов и т выходов. Каждому входу НС соответствует
входной сигнал xt, г = 1... и, а каждому выходу - выходной сигнал y„j = 1 ...т.
Тогда входу НС соответствует вектор X с координатами (xv х2,..., хп), выходу -
вектор Y с координатами (yvy2, —>Ут)- Основным функциональным назначе-
122
5.2. Обучение многослойной нейронной сети без обратных связей
нием искусственной НС является преобразование входных сигналов в
выходные сигналы (понятия о внешней среде). Нейронная сеть в этом случае
представляется как некоторая многомерная функция F: X—> Y .
Если множество весовых коэффициентов входных сигналов НС не
упорядочено, то функция F, реализуемая сетью, является произвольной.
Совокупности всех весовых коэффициентов всех нейронов соответствует вектор W. Пусть
множество векторов W образует пространство состояний НС. Начальному
состоянию сети соответствует некоторый произвольный вектор W0. Тогда
обученной НС соответствует W*, т. е. такое состояние, при котором реализуется
однозначное отображение F: X->Y. В этом случае задача построения функции
F, заданной в неявном виде (задача обучения НС), формально сводится к
задаче перехода от некоторого начального состояния сети, соответствующего W0, к
конечному состоянию, соответствующему W*.
В основе процедуры построения отображения F лежит известная теорема
Колмогорова о представлении непрерывных функций нескольких переменных в
виде суперпозиции непрерывных функций одной переменной, обобщенная Хехт-
Нильсеном применительно к НС. Основным результатом этого обобщения
является возможность реализации произвольной функции многих переменных
нейронной сетью. Хехт-Нильсен показал, что для любого множества пар векторов
X и Y существует двухслойная однородная (с одинаковыми функциями
активации) НС с прямым распространением сигналов, которая выполнит
отображение X—>Y, выдавая на каждый входной сигнал правильный выходной. Таким
образом, уже с помощью даже двухслойной НС отображение F может быть
построено. Из этого следует вывод о том, что многослойный персептрон с
числом слоев более двух является универсальным аппроксиматором функций.
Этот результат имеет огромное значение для развития теории НС, поскольку
обосновывает возможность решения сложных трудно формализуемых задач,
для которых в настоящее время не существует строгих математических
моделей.
Пусть имеется обучающая выборка, состоящая из А: пар векторов (при
стратегии обучения с учителем):
(X.,Y.),i=l,...,*. (5.1)
Ошибка сети Е, появляющаяся в некотором состоянии W., может быть
представлена как средняя квадратичная ошибка, усредненная по выборке
£(W) = ±Z2>,(X,>W)-Y,.] , (5.2)
к i i
где к- число примеров в обучающей выборке; Y. - эталонный выходной
вектор /-го примера.
Если при этом сеть не делает ошибки, то Е = 0. Следовательно необходимо
добиваться того, чтобы в обученном состоянии сети ошибка сети стремилась
123
5. Обучение нейронных сетей без обратных связей
к минимальному значению. Таким образом, задача обучения НС является
задачей поиска минимума функции ошибки (5.2) в пространстве состояний W, и
для ее решения могут быть использованы стандартные методы теории
оптимизации.
Особенности задач оптимизации при обучении многослойной НС
Алгоритм обучения многослойной НС задается набором обучающих
правил, которые определяют, каким образом изменяются межнейронные связи в
ответ на входное воздействие. На рис. 5.7 схематично показана процедура
обучения многослойной НС.
Вначале определенным образом устанавливаются значения весовых
коэффициентов межнейронных связей. Затем из базы данных в соответствии с
некоторым правилом поочередно выбираются примеры (пары обучающей выборки
Х(., Y,: входной вектор Х(. подается на вход сети, а желаемый результат Y. на
выход сети). По формуле (5.2) вычисляется ошибка сети Е0. Если ошибка
велика, то осуществляется подстройка весовых коэффициентов для ее
уменьшения. Это и есть процедура обучения сети. В стандартной ситуации описанный
процесс повторяется до тех пор, пока ошибка не станет меньше заданной, либо
закончится время обучения.
Простейший способ обучения НС - по очереди менять каждый весовой
коэффициент сети (далее просто - вес связи) таким образом, чтобы
минимизировалась ошибка сети. Этот способ является малоэффективным, целесообразнее
вычислить совокупность производных ошибки сети по весовым
коэффициентам - градиент ошибки по весам связей - и изменить все веса сразу на
величину, пропорциональную соответствующей производной. Один из возможных
База примеров
1
Выбор
алгоритма
подачи
примеров
/
/
Г
Нейросеть
ш
t
Коррекция
весовых
коэффициентов .
1
Нейросеть
обучена
Ответ
сети
Интерпретация
ответа и вычис -
ление ошибки
обучения £
£>е
Рис 5.7 Процедура обучения многослойной НС
124
5.2. Обучение многослойной нейронной сети без обратных связей
методов, позволяющих вычислить градиент ошибки, - алгоритм обратного
распространения (рассмотрен ниже) - наиболее известен в процедурах обучения НС.
Специфические ограничения при решении задачи обучения. По
сравнению с традиционными задачами оптимизации при обучении НС существует
ряд специфических ограничений, обусловленных как правило большой
размерностью задачи: даже в простейших нейроимитаторах, реализованных на ПК,
количество параметров составляет 103-104, что предъявляет к алгоритмам
оптимизации следующие требования:
• ограничения по памяти; если производится оптимизация по и
переменным, а алгоритм требует затрат порядка 2 , то его нельзя применить для
обучения НС, желательна линейная зависимость объема памяти от числа
оптимизируемых переменных, т. е. v = си, где v - объем памяти, с — некоторый
коэффициент;
• организация НС предопределяет возможность параллельного выполнения
вычислительных операций по каждой связи вход-выход, поэтому
целесообразна организация процедур обучения параллельных вычислений, что может
значительно снизить время обучения НС.
Необходимо также учитывать следующие обстоятельства. Согласно
теореме Геделя о неполноте, никакая система не может быть логически замкнутой:
всегда можно найти такую теорему, для доказательства которой потребуется
внешнее дополнение. Поэтому критерии выбора модели сложных объектов
необходимо разделять на внутренние и внешние.
Внутренние критерии вычисляются на основе результатов
экспериментирования с моделью объекта путем подачи на вход сети некоторого входного
вектора и фиксации эталонного выходного на ее выходе. При обучении НС на
основе примеров (пар) из обучающего множества вычисляется
среднеквадратичная (или средняя квадратичная ошибка) обучения Епо формуле (5.2),
которая является внутренним критерием. В этом случае ошибка Е0 называется
ошибкой обучения.
Для оценки полученной ошибки обучения необходимо использовать внешний
критерий, которым является ошибка обобщения ^щ, вычисляемая по
проверочной (тестовой) выборке. Основная цель обучения НС - создание модели
объекта, обладающей свойством непротиворечивости, т. е. такой, в которой
ошибка обобщения сохраняется на приемлемом уровне при реализации
отображения не только для примеров исходного множества пар (Xf., Yt), i = 1 ...к, но
и для всего множества возможных входных векторов.
Таким образом, если ставится задача синтеза НС для отображения
зависимости F: X—> Y с наименьшей ошибкой обучения, то для получения
объективного результата проводится разделение исходных данных на две части,
называемые обучающей и тестовой выборкой. Критерием правильности
окончательных результатов является среднеквадратичная ошибка обобщения,
вычисленная по тестовой выборке. Так создается первое внешнее дополнение.
Если ставится задача оптимизации разделения данных на обучающую и
проверочную части, то требуется еще одно внешнее дополнение. База данных в
125
J. Обучение нейронных сетей без обратных связей
этом случае разбивается на три части: обучающую, тестовую,
подтверждающую выборки. В этом случае на подтверждающей выборке проверяется
адекватность получаемого отображения F: X—> Y объекту с задаваемой ошибкой
обобщения. При конструировании такого отображения задача обучения НС
является многокритериальной задачей оптимизации, поскольку необходимо
найти общую точку минимума большого числа функций. Для обучения НС
необходимо принятие гипотезы о существовании общего минимума, т. е. такой точки
в поисковом пространстве, в которой значение всех оценочных функций по
каждой связи вход-выход близки к экстремуму. Опыт, накопленный при решении
практических задач на НС показывает, что такие точки существуют.
Многокритериальность и сложность зависимости функции оценки Е от
параметров НС приводит к тому, что адаптивный рельеф (график функции
оценки) может содержать много локальных минимумов. Таким образом, при
поиске минимальной ошибки Е желательно использовать глобальные методы
оптимизации.
Кроме того, к методам оптимизации, использующимся в процедуре
обучения НС, добавляют еще следующие требования. Во время процедуры
обучения необходимо, чтобы НС могла обретать новые навыки без потери старых,
т. е. ошибка обобщения должна оставаться на приемлемом уровне. Это
означает, что в достаточно большой окрестности существования точки общего
минимума значения функции оценки Е^^ не должны существенно отличаться от
минимума. Иными словами, точка общего минимума должна лежать в
достаточно широкой области изменения функций оценки.
Подводя итоги вышеизложенному, можно выделить следующие
особенности, отличающие обучение НС от общих задач оптимизации:
• большое число параметров НС;
• необходимость обеспечения параллельности вычисления;
• многокритериальность задачи оптимизации;
• необходимость нахождения достаточно широкой области, в которой
значения всех минимальных функций стремятся к минимуму.
Анализ алгоритма обратного распространения
ошибки (Back Propagation - ВР)
Рассмотрим наиболее известный алгоритм обучения многослойной НС и
определим условия повышения эффективности процедуры обучения. ВР - это
итеративный градиентный алгоритм обучения многослойных НС без обратных
связей (рис. 5.8). В такой сети на каждый нейрон первого слоя подаются все
компоненты входного вектора. Все выходы скрытого слоя т подаются на слой
т+1 и т. д., т. е. сеть является полносвязной. При обучении ставится задача
минимизации ошибки НС, которая определяется методом наименьших
квадратов: . р
где у. - значение j-ro выхода НС; d. - желаемое значение j-ro выхода; р -
число нейронов в выходном слое.
126
5.2. Обучение многослойной нейронной сети без обратных связей
Входной
слой 1
(л нейронов)
Скрытый
слой 2
(/нейронов)
Выходной
слой it
(р нейронов)
Рис. 5.8. Многослойная НС
Обучение НС осуществляется методом градиентного спуска, т. е. на
каждой итерации изменение веса производится по формуле
л и8Е
где h - параметр, определяющий скорость обучения.
_8^=8Е_^_^ (5.3)
Bwjj дуj dSj dWy
здесь v. - значение выхода j-ro нейрона ; S,— взвешенная сумма входных сиг-
налов. При этом множитель = дг,-, где л:. - значение i-ro выхода нейрона.
доопределим первый множитель формулы (5.3):
8Е _ у SE фк_д^ =у дЕ dyk (w+d
dyj ^8ykdSkdyj ^dykdSk *
где к - число нейронов в слое и +1. ,г .
Введем вспомогательную переменную 6 ■ = —. Тогда можно опреде-
1 ду, dS,
лить рекурсивную формулу для определения б^ и-го слоя,
чение этой переменной следующего (и +1)-го слоя:
dyj
, если известно зна-
6<"> =
2>ГЧ+,)
jdSj
(5.4)
Нахождение б ^ для последнего слоя НС не представляет трудностей, так
как априорно известен вектор тех значений, который должна выдавать сеть
при заданном входном векторе:
«P-w-of-
(5.5)
127
5. Обучение нейронных сетей без обратных связей
В результате всех преобразований получим следующее выражение для
вычисления приращения весов связи в НС:
Awg = -hbfx". (5.6)
Таким образом, можно сформулировать полный алгоритм обучения ВР.
1. Подать на вход НС очередной входной вектор из обучающей выборки и
определить значения выходов нейронов в выходном слое.
2. Рассчитать 8 по формуле (5.5) и Aw,7- по формуле (5.6) для выходного
слоя НС.
3. Рассчитать 8 и Aw,7 по формулам (5.4) и (5.6) для остальных слоев НС.
4. Скорректировать все веса НС:
Hf(0 = v*f(>-1) + Anf(0,
где / - номер текущей итерации.
5. Если ошибка существенна, то вернуться к п. 1, в противном случае -
конец.
Рассмотрим некоторые трудности, связанные с применением данного
алгоритма в процедуре обучения НС.
Блокировка сети. Рассмотренный алгоритм не эффективен в случае,
когда производные по различным весам сильно отличаются. Это соответствует
ситуации, когда значения функций S для некоторых нейронов близки по
модулю к 1 или когда модуль некоторых весов много больше 1. В этом случае для
придания процессу коррекции весов некоторой инерционности, сглаживающей
резкие скачки при перемещении по поверхности целевой функции, в формулу
(5.6) вводится некоторый коэффициент инерционности ц, позволяющий
корректировать приращение веса на предыдущей итерации:
Дополнительным преимуществом от введения инерционности алгоритма
обучения является способность алгоритма преодолевать мелкие локальные
минимумы.
Медленная сходимость процесса обучения. Сходимость ВР строго
доказана для дифференциальных уравнений, т. е. для бесконечно малых шагов в
пространстве весов. Но бесконечно малые шаги означают бесконечно большое
время обучения. Следовательно, при конечных шагах сходимость алгоритма
обучения не гарантируется.
Переобучение. Высокая точность, получаемая на обучающей выборке,
может привести к неустойчивости результатов на тестовой выборке. Чем лучше
сеть адаптирована к конкретным условиям (к обучающей выборке), тем
меньше она способна к обобщению и экстраполяции. В этом случае сеть
моделирует не функцию, а шум, присутствующий в обучающей выборке. Это явление
128
5.2. Обучение многослойной нейронной сети без обратных связей
называется переобучением или эффектом «бабушкиного воспитания».
Кардинальное средство борьбы с этим недостатком - использование
подтверждающей выборки примеров, которая используется для выявления переобучения сети.
Ухудшение характеристик НС при работе с подтверждающей выборкой
указывает на возможное переобучение. Напротив, если ошибка последовательно
уменьшается при подаче примеров из подтверждающегося множества, сеть
продолжает обучаться. Недостатком этого приема является уменьшение
числа примеров, которое можно использовать в обучающем множестве (уменьшение
размера обучающей выборки снижает качество работы сети). Кроме того,
возникает проблема оптимального разбиения исходных данных на обучающую,
тестовую и подтверждающую выборку. Даже при случайной выборке разные
разбиения базы данных дают различные оценки.
«Ловушки», создаваемые локальными минимумами.
Детерминированный алгоритм обучения типа ВР не всегда может обнаружить глобальный
минимум или выйти из него. Одним из способов, позволяющих обходить
«ловушки», является расширение размерности пространства весов за счет увеличения
скрытых слоев и числа нейронов скрытого слоя. Другой способ -
использование эвристических алгоритмов оптимизации, один из которых - генетический
алгоритм - рассматривается в следующем разделе.
Выбор стратегии обучения НС
Можно выделить три основных фактора, которые влияют на выбор
наилучшей стратегии обучения: формирование последовательности подачи входных
векторов из обучающей выборки; выбор шага обучения; выбор направления
обучения.
В стандартном алгоритме ВР, основанном на методе градиентного спуска,
предполагается такая последовательность действий: решение сетью
очередного примера - вычисление градиента ошибки - корректировка весов - переход к
следующей задаче. Однако после завершения обучения сети последнему
примеру первые уже забыты, и процесс обучения надо начинать сначала. При этом
трудно гарантировать сходимость подобного алгоритма. Чтобы этого избежать,
применяют усреднение градиента по всем примерам обучающей выборки. При
использовании стратегии усреднения все примеры обучающей выборки
участвуют в обучении одновременно и на равных правах.
Еще одна из возможных стратегий состоит в следующем - НС обучается
при помощи стратегии усреднения лишь некоторому множеству примеров, в
которое по мере обучения сети постепенно включаются все новые и новые
примеры. Такая стратегия в среднем в 1,5-2 раза быстрее стратегии
усреднения, однако в этом случае процесс обучения зависит от взаимного
расположения задач в обучающей выборке. Максимальное ускорение обучения
достигается, если «типовые» задачи расположены ближе к началу обучающей выборки.
Выбор величины шага имеет ключевое значение для успешной работы
обучающего алгоритма, так как от значения шага h зависит скорость сходимости
129
5. Обучение нейронных сетей без обратных связей
алгоритма. Так как к моменту выбора шага для следующей итерации градиент
ошибки в методе ВР уже вычислен, то можно интерпретировать функцию
ошибки как функцию шага E(h). Тогда, учитывая, что значение E(h) вычислено на
предыдущем шаге, можно записать следующий алгоритм А1 :
1. Сделать пробный шаг h, полученный на предыдущем шаге обучения и
вычислить E(h);
2. Если E(h) > E(h0), то h:=h/4 («наказание»); переход к п. 1;
3. Если E(h) < E(h ), то h:=2h («поощрение»).
Приведенный алгоритм А1 является оптимальным для стратегии, при
которой НС обучается на множестве примеров поочередно. Для повышения
качества алгоритма А1 при обучении по стратегии усреднения может быть
использован алгоритм А2:
1. См. п. 1 вА1.
2. Если E(h) > E(h0), то:
2.1) hx:=hl2;
2.2) если E(hx) > E(h0), то h :=hx, переход к п. 2.1;
2.3) если E(hx ) < E(h^, то переход к п. 4.
3. Если E(h)<E(h0), то:
3.l)hx:=h,h:=2hx;
3.2) если EQi) < E(hx), то переход к п. 3.1;
3.3) если E(h) > E(hx), то переход к п. 4.
4. По значениям h, hv E(h0), E(h), E(hx) строим параболу и находим ее
вершину h (из-за выбора точек Л, и Л парабола всегда будет выпуклой вниз).
5. Если E(h) < E(hx), то искомый шаг - hx , иначе - h .
Алгоритм А2 позволяет повысить скорость обучения примерно в 2-3 раза,
однако при его использовании возникают сложности с выводом сети из
локальных минимумов.
Наиболее важным в процедуре оптимизации является выбор направления
обучения. Последовательность действий, составляющих суть градиентных
методов, используемых в стандартном ВР: вычисление градиента - шаг вдоль
антиградиента не является единственно возможным. Проведем краткий
обзор методов оптимизации, которые могут быть использованы в ВР.
5.3. Анализ стандартных методов оптимизации
в процедуре обучения многослойного персептрона
Градиентные методы обучения
Все градиентные методы основаны на использовании градиента функции
как основы для вычисления направления спуска.
Метод наискорейшего спуска. Это наиболее известный из всех
градиентных методов. Идея его заключается в следующем. Поскольку вектор градиента
указывает направление наискорейшего возрастания функции, то минимум фун-
130
5.3. Анализ стандартных методов оптимизации
кции ошибки сети Е следует искать в обратном направлении, направлении
антиградиента. Алгоритм метода следующий:
1. Вычислить текущую оценку Е1ЮВ.
2. Установить En= £'1ЮВ.
3. Вычислить антиградиент.
4. Произвести очередной шаг h вдоль выбранного направления.
5. Вычислить ■Снов-
6. Если W^-E^J > 5, то переход к п. 2 (5 - заданная точность приближения
к экстремуму).
7. Конец.
Здесь Е - новое значение ошибки; £'ст- значение ошибки на предыдущей
итерации.
Этим методом определяют только локальный минимум, в область
притяжения которого попадает начальная точка спуска. Для нахождения глобального
экстремума часто используют случайное изменение параметров алгоритма с
дальнейшим повторным обучением методом наискорейшего спуска (мульт-
старт). Такая процедура в некоторых случаях позволяет найти глобальный
минимум. На рис. 5.9, а показана траектория спуска при использовании данного
метода в случае, когда в окрестности минимума линии уровня функции ошибки
являются кругами (двумерный случай). В этом примере минимум
достигается за один шаг.
На рис. 5.9, б приведена траектория спуска в случае эллиптических линий
уровня. В такой ситуации за один шаг минимум достигается только из точек,
расположенных на осях эллипсов. Из любой другой точки спуск будет
происходить по ломаной, каждое звено которой ортогонально к соседним звеньям, а
длина звена убывает. В этом случае для точного достижения минимума потре-
Рис. 5.9. Иллюстрация метода наискорейшего спуска при различных типах
окрестности минимума, представленной в виде линий равного уровня:
а - окрестность в виде круга; б - окрестность в виде оврага
131
5. Обучение нейронных сетей без обратных связей
Рис. 5.10. Иллюстрация работы
кРагТап-мегода оптимизации
буется бесконечное число шагов метода
градиентного спуска. Такой эффект называется
овражным, а методы оптимизации, позволяющие
бороться с ним, - антиовражными.
ParTiwi-методы. Эти методы относятся к
антиовражным методам. Идея РагТап-метода
состоит в том, чтобы запомнить начальную
точку, из которой совершается спуск, и выполнить
некоторое число шагов оптимизации по методу
наискорейшего спуска. Затем выполнить шаг по
направлению из начальной точки в конечную.
Рассмотрим одну из реализаций ParTan-ыепо-
да - kParTan-стратегто.
Схема kParTan (рис. 5.10) стратегии совпадает с вышеописанной; при этом
по методу наискорейшего спуска совершается ровно к шагов оптимизации.
Алгоритм кРагТоп-мегоца состоит из следующих шагов:
1. Вычислить текущую оценку ошибки сети Енов.
2. Установить Ea~Em.
3. Запомнить вектор весовых коэффициентов Wr
4. Выполнить к шагов вдоль антиградиента. Вычислить W2.
5. Выполнить очередной шаг обучения по направлению (Wj-W2).
6. Вычислить Енов.
7. Если I^ct-^hoJ > Б»то переход к шагу 2.
8. Конец.
На рис. 5.10 представлен один шаг оптимизации по kParTan-методу при
к = 2. Для этого примера (случай двумерной функции) после двух шагов по
методу наискорейшего спуска (точки 2 и 5) движение вдоль направления из
начальной (точки 1) в точку 3 сразу привело в минимум. В многомерном
случае направление кРагТап не ведет прямо в точку минимума, но спуск в этом
направлении, как правило, приводит в окрестность минимума меньшего
радиуса, чем при еще одном шаге метода наискорейшего спуска (см. рис. 5.9, б).
Для выполнения третьего шага по этому методу вычислять градиент не
требуется, что приводит к экономии времени. Для реализации данной стратегии
необходим объем памяти только для хранения одного вектора весовых
коэффициентов НС.
Усовершенствованный кРагТап-метод. Этот метод требует
дополнительного объема памяти для хранения двух последних векторов весов. Алгоритм
метода сводится к такой последовательности шагов:
1. Вычислить текущую ошибку сети Е{юв.
2. Установить £ст = £нов.
3. Запомнить вектор весовых коэффициентов Wr
132
5.3. Анализ стандартных методов оптимизации
4. Выполнить шаг обучения вдоль антиградиента.
5. Запомнить W2.
6. Выполнить шаг обучения вдоль антиградиента.
7. Запомнить W3.
8. Выполнить шаг обучения с использованием (W3-Wj).
9. Вычислить текущую ошибку Енов.
10. Если I^ct-^hoJ < 8, то Wj:=W2; W2:=W3; переход к шагу 6.
11. Конец.
Хотя приведенный метод при реализации на ЭВМ требует больше памяти,
чем классический кРагТап-метод, но при длительной процедуре обучения
требуется только одно вычисление градиента на 2-м шаге обучения, тогда как в
kParTan-методе требуется вычисление градиента на (&+1)-х шагах обучения.
Для повышения качества обучения необходимо использовать информацию
о производных второго порядка от функции ошибки Е. Соответствующие
методы оптимизации назьшают квадратичными (квазиньютоновский метод,
метод сопряженных градиентов). Для вычисления градиента в этих методах
требуется довольно большой объем памяти и вычислительных операций.
Квазииьютоновские методы. Идея квазиньютоновских методов с
ограниченной памятью состоит в учете информации о кривизне минимизируемой
функции, содержащейся в так называемой матрице Гессе G; причем данные
относительно кривизны функции накапливаются на основе наблюдения за
изменением градиента g во время итераций спуска. Матрицей Гессе назьшают
матрицу вторых частных производных целевой функции по управляемым
параметрам. Теория квазиньютоновских методов опирается на возможность
аппроксимации кривизны нелинейной оптимизируемой функции без явного
формирования ее матрицы Гессе. Сама матрица при этом не хранится.
К началу очередной к-й итерации квазиньютоновского поиска известна
некоторая аппроксимация матрицы Гессе минимизируемой функции, которая
служит средством отображения информации о кривизне, накопленной на
предыдущих итерациях. Используя ее в качестве матрицы Гессе модельной
квадратичной формы, очередное направление Pt квазиньютоновского поиска
на к-м шаге определяют как равенство:
где Вк - матрица, аппроксимирующая матрицу Гессе; gt - градиент функции
оценки в начальной точке к-ro шага (конечная точка к-то шага является
начальной для (£+1)-го). Исходное приближение В0, если нет какой-либо
дополнительной информации, обычно полагают равным единичной матрице. При
таком выборе В0 первая итерация квазиньютоновского поиска будет эквивалентна
шагу наискорейшего спуска. После того, как определится новая точка Х^р
приближение Вк матрицы Гессе обновляется с учетом вновь полученной
информации о кривизне, т. е. совершается переход от матрицы Bt к матрице В^,.
Этот переход задается формулой пересчета типа:
133
5. Обучение нейронных сетей без обратных связей
Вж= B,+U„
где \Jk - некоторая поправочная матрица.
Обозначим через S^. - вектор, равный изменению X на к-й итерации
(St = Хк+1 - Xt); Yk - соответствующее приращение градиента (Yt=gfc+1- gt).
Тогда основное свойство всех квазиньютоновских правил пересчета
выразится равенством (квазиньютоновское условие):
B*+iS*=Y*-
Самой эффективной формулой пересчета является BFGS-^ормула (Broyden
С, Fletcher R., Goldfarb D., Shanno D.)
- [<Sfc,*,,)/<¥,,SpiRl + <¥„Yt)/(Yt,St))]St,
где [.]обозначает обычное скалярное произведение - сумму произведений
координат.
Если при поиске опмимального шага одномерную оптимизацию проводить
достаточно точно, то новый градиент будет практически ортогонален
предыдущему направлению спуска, т. е. (S^, g^j) = 0. В этом случае формула (5.7)
сильно упростится:
P^-g^i + C^g^s^A).
Так как в Д^С^-формуле используются результаты предыдущего шага, то
первый шаг обучения нужно проводить каким-либо другим методом, например
методом наискорейшего спуска.
Рассмотренный метод BFGS является очень эффективным и часто
используется в процедуре обучения НС, несмотря на большие вычислительные затраты.
Неградиентные методы обучения
Метод покоординатного спуска. Идея этого метода состоит в том, что
если в задаче сложно или долго вычислять градиент, то можно построить вектор,
обладающий приблизительно теми же свойствами, что и градиент. Для этого
дадим малое положительное приращение первой координате вектора. Если
оценка Е при этом увеличилась, то пробуем отрицательное приращение. Далее
таким же образом поступаем со всеми остальными координатами. В
результате получаем вектор, в направлении которого оценка убывает. Для вычисления
этого вектора потребуется, как минимум, столько вычислений функции
оценки, сколько координат у вектора (в худшем случае число вычислений в 2 раза
больше числа координат). Время, используемое для вычисления градиента при
использовании алгоритма ВР, обычно оценивается как время двух - трех
вычислений функции оценки. Учитывая этот факт, можно констатировать, что
метод покоординатного спуска нецелесообразно применять в обучении НС.
134
5.3. Анализ стандартных методов оптимизации
Метод Нелдера-Мида. Это наиболее быстрый неградиентный метод
многомерной оптимизации. Идея метода состоит в следующем. В пространстве
оптимизируемых параметров генерируется случайная точка. Затем строится
«-мерный симплекс с центром в этой же точке и длиной стороны /. Далее в
каждой из вершин симплекса вычисляется значение критерия оптимизации.
Выбирается вершина с наибольшим значением критерия. Вычисляется центр
тяжести остальных п вершин. Проводится оптимизация шага в направлении от
наихудшей вершины к центру тяжести остальных вершин. Такая процедура
повторяется до тех пор, пока не окажется, что положения вершин не
меняются. Затем выбирается вершина с наилучшей оценкой и вокруг нее снова
строится симплекс с меньшими размерами (например, 112). Процедура
продолжается до тех пор, пока размер симплекса, который необходимо построить, не
окажется меньше заданной величины.
Основным недостатком этого метода является большая размерность
пространства параметров, что приводит к значительному увеличению времени
обучения нейронной сети.
Метод случайного поиска. Идея метода сводится к генерации
случайного вектора вместо градиента. Метод использует одномерную оптимизацию для
подбора шага. Подбор оптимального шага h состоит в том, что при наличии
направления, в котором производится спуск, задача многомерной оптимизации
в пространстве параметров сводится к одномерной - подбору шага.
Пусть заданы начальный шаг h и случайное направление спуска.
Вычисляем величину оценки Е^ - оценку в текущей точке пространства параметров.
Изменив параметры на вектор направления, умноженный на величину
пробного шага, вычислим значение оценки в новой точке Z?„. Если Z? < Е„, то увели-
НОВ НОВ СТ *
чиваем шаг и снова вычисляем оценку. Продолжаем эту процедуру до тех пор,
пока не получим оценку больше предыдущей. Зная три последних значения
величины шага и оценки, используем квадратичную оптимизацию - по трем
точкам построим параболу и следующий шаг сделаем в вершину параболы.
После нескольких шагов квадратичной оптимизации получаем приближенное
значение оптимального шага.
Если после первого пробного шага ЕИОН > Е^, то уменьшаем шаг до тех пор,
пока не получим E^<En. После этого производим квадратичную
оптимизацию.
Выбор эффективного обучающего алгоритма всегда включает в себя
компромисс между сложностью решаемой задачи и техническими
ограничениями (быстродействие, время, цена, объем памяти) инструментальной ЭВМ,
на которой реализуются данные алгоритмы. Поэтому необходимо
исследовать новые алгоритмы обучения НС, позволяющие достигать лучшей
эффективности.
135
5. Обучение нейронных сетей без обратных связей
5.4. Пример использования многослойной нейронной сети
для решения задачи выбора архитектуры сервера
Решим типичную задачу классификации на примере проектирования
архитектуры сервера с конвейером команд и встроенной кэш-памятью первого
уровня. Выберем следующие варианты построения структуры сервера, исходя из
диаграммы выполнения в процессоре типовых инструкций (рис. 5.11).
Вариант В1 - 2 уровня совмещения. В этом варианте предусмотрено
совмещение начала распаковки (и +1)-й команды с последним тактом выполнения
и-й операции. Продвижение адреса инструкций может выполняться в момент
обращения за операндом, в результате отпадает необходимость в счетчике
инструкций.
Вариант В2 — 3 уровня совмещения, отсутствует буфер операндов и счетчик
инструкций. Из-за отсутствия счетчика команд продвижение адреса
осуществляется на основном сумматоре, что увеличивает время выполнения отдельной
операции. Этот вариант экономичен с точки зрения затрат аппаратуры в блоке
обработки инструкций. Добавление несовмещенного цикла изменения адреса
инструкций снижает производительность процессора. При большом объеме
буфера инструкций потери могут быть незначительными.
Вариант ВЗ - 3 уровня совмещения обработки инструкций. Имеется
счетчик команд. Преимущества данного варианта состоят в том, что с большей
вероятностью выборка операнда длится всего два такта обращения к
кэш-памяти. Выборка операндов для (и + 1 )-й инструкции и распаковка (и + 2)-й команды
в этом случае совмещаются с последним тактом операции и-й инструкции (см.
рис. 5.11).
Вариант В4 - 5 уровней совмещения обработки инструкций. Выполнение
операции в и-й команде совмещается с выборкой операнда в (л +1)-й команде
ВК ДШ ФА ВО АЛУ ЗР
ВК ДШФАВО АЛУЗР
.ВК ДШ.ФА ,ВО ,АЛУ ЗР,
Рис. 5.11. Диаграммы выполнения инструкции в процессоре
с конвейером команд:
ВК - продолжительность выборки команды; ДШ - время дешифрации кода операции;
ФА - продолжительность формирования адреса операнда; ВО - время выборки операнда;
АЛУ - время выполнения операции в арифметико-логическом устройстве;
ЗР - время записи результата
136
5.4. Пример использования многослойной нейронной сети
Тип команды
1. Умножение
2. Сложение
3. Короткие операции
4. Загрузка(регистров)
S. Запись
6. Переход
7. Логические операции
8. Прочие
Итого
Встречаемость, %
7
12
35
7
15
20
10
4
100
(это достигается за счет введения бу- Таблица 5.1. Пример смеси команд
фера операндов). Потери, вызванные
необходимостью обращения к
оперативной памяти вместо кэш-памяти, могут
быть сведены к минимуму.
Задача выбора архитектуры сервера
вычислительной сети, работающего в
пакетном режиме, ставится следующим
образом: необходимо для поддержки
заданного трафика при определенном
классе решаемых задач
(пользовательских приложений) выбрать архитектуру
процессора при минимальных затратах
оборудования. Как правило, при
проектировании вычислительных систем с сетевой организацией для обеспечения
требований заказчика в полном объеме выбираемое оборудование является
избыточным, при этом не учитываются характеристики решаемых задач. Для
установления соответствия алгоритм-структура необходимо проводить
исследование структуры с использованием генератора моделей внешней среды.
Основной формат представления решаемых задач - смесь команд, заданная в
процентах или на интервале [0, 1]. В табл. 5.1 представлен пример смеси
команд, используемой в имитационных экспериментах.
В качестве критерия оценки проектируемой структуры выберем
эмпирический закон Гроша. В соответствии с этим критерием при выбранной
технической базе производительность процессора пропорциональна числу V2 (V-
обобщенный показатель стоимости). Тогда для выбора варианта реализации
сервера можно воспользоваться зависимостью Р = kV 2, где Р - его
производительность; к- коэффициент пропорциональности.
При изменении структуры сервера (при выборе определенного варианта)
его производительность может увеличиться на АР, а стоимость на AV. Если за
базовый выбрать некоторый вариант, например В2, то вариант ВЗ будет лучше
варианта В2, когда
Р + АР (У + АУУ
(5.8)
или после соответствующих преобразований,
получим
АР „ДК
>2 .
Р V
малость
AVY
(5.9)
По выражению (5.9) можно оценить эффективность структуры процессора.
137
5. Обучение нейронных сетей без обратных связей
База данных и предварительная обработка. База данных формировалась
следующим образом. Для каждого варианта модели внешней среды
(различной смеси команд), задаваемого пользователем, определялся наилучший
вариант реализации структуры процессора из возможных В1, В2, ВЗ и В4 путем
имитационного моделирования и оценки результатов экспериментов по
критерию (5.11). В результате был сформирован входной файл, состоящий из 20 строк
(по 5 для каждого варианта). Вся база случайным образом была разбита на два
подмножества: обучающее и тестовое (по 10 примеров в каждом множестве).
Предобработка данных не требуется, так они изменяются на интервале [0; 1].
В качестве методов интерпретации ответов сети были выбраны два
метода: — «победитель забирает все» и нечеткая классификация (процентное
распределение ответов по каждому выходу). В качестве ошибки обучения сети
рассматривалась среднеквадратическая ошибка, вычисляемая по формуле (5.2).
Обучение. Для рассматриваемой задачи были исследованы три
различные конфигурации сети, при этом использовались сети с прямой связью пер-
септронного типа с тремя слоями. Все сети имели 8 входных узлов (каждый
тип команды подавался на свой входной узел), 4 выходных узла (по каждому
варианту структуры процессора), число скрытых элементов менялось от 4 до 8
(4; 5; 8). В качестве функции активации была взята сигмоидная функция,
принимающая на выходе нейрона значения от 0 до 1.
Обучение было проведено с помощью нейроимитатора, разработанного на
кафедре «Компьютерные системы и сети» КФ МГТУ с использованием метода
обратного распространения ошибки по BFGS-методу. Начальные значения
весов брались случайным образом в интервале [-0.1; 0.1]. Обучение занимало от
5 до 10 итераций (в зависимости от архитектуры сети). Оказалось, что сети с
большим числом элементов в скрытом слое обучаются быстрее.
Работа сети в режиме распознавания. На вход сети 8:8:4 подавались
примеры различных классов задач, характеризующихся соответствующим
процентным составом операций (запись архитектуры сети 8:8:4 означает, что сеть
является трехслойной и имеет 8 входов, 4 выхода и один скрытый слой, состоящий
из 8 нейронов.) При подаче на вход сети вектора, определяющего некоторую
смесь команд, соответствующего определенному классу решаемых задач и не
входящего в обучающую последовательность, сеть определяла (распознавала)
архитектуру процессора, адекватную решаемому классу задач. Оказалось, что
процент правильных ответов сети растет с увеличением количества
обучающих примеров, однако при достижении определенного числа примеров в
обучающей выборке качество распознавания остается примерно таким же.
Реальные значения, полученные сетью, сравнивались с результатами имитационного
моделирования, процент правильных ответов составил 60 - 70 от общего
количества. Для проверки возможности уменьшения ошибки классификации
увеличили число входных переменных (до 12) и взяли расширенный набор команд;
138
5.5. Решение задачи прогнозирования временного ряда
число элементов в скрытом слое (12). В
табл. 5.2 представлен расширенный
состав операций.
С сетью 12:12:4 были проделаны те
же эксперименты. Ошибка
уменьшилась (максимальная ошибка составила
10%), так как были добавлены
дополнительные команды, определяющие
внешнюю среду: деление короткое, деление
длинное; расширены операции
умножения (короткое и длинное) и сложения
(короткое и длинное).
Полученные результаты показывают,
что обученная НС может быть
использована в системах поддержки принятия
решений для генерации альтернативных
вариантов при проектировании сложных
технических устройств (например,
вычислительных систем) на различных
уровнях их детализации.
Таблица S.2. Расширенный состав
операций
Тип команды
1. Деление (короткое)
2. Деление (длинное)
3. Умножение (короткое)
4. Умножение (длинное)
5. Сложение (короткое)
6. Сложение (длинное)
7. Короткие операции
8. Загрузка
9. Запись
10. Переход
11. Логические операции
12. Прочие
Встречаемость, %
0.5
1.3
1.4
3.3
1.5
5.8
35
7.2
15.4
20
4.6
4
5.5. Решение задачи прогнозирования временного ряда
с помощью многослойного персептрона
В задачах классификации, решаемых НС, данные представляются в виде
набора наблюдений, каждое из которых содержит значения нескольких
переменных. Цель классификации состоит в том, чтобы предсказать значение одной
или нескольких выходных переменных по значениям входных переменных, при
этом предполагается, что наблюдения независимы друг от друга (Bishop, 1995).
Существуют задачи другого типа - задачи анализа временных рядов, в
которых значения переменных измеряются в различные моменты времени, при
этом существует зависимость между последовательными значениями одной и
той же переменной. В этом случае целью исследования временного ряда
может быть прогноз значений некоторой переменной в определенный момент
времени по ее значениям и/или значениям других переменных в предшествующие
моменты времени.
Чаще всего наблюдается значение одной числовой переменной, а цель
заключается в том, чтобы спрогнозировать ее следующее значение по нескольким
предыдущим. При этом можно использовать либо одно предыдущее значение
целевой переменной xt-i, либо несколько предыдущих: xt-i, Xt-2,...; в этом
случае увеличивается количество входов в НС. В задаче прогноза временного ряда
необходимо определить, сколько предьщущих значений одной переменной взять
139
5. Обучение нейронных сетей без обратных связей
и как далеко вперед прогнозировать значение выходной переменной. При
анализе временного ряда порядок наблюдений существен (они должны быть
упорядочены во времени).
В простейшем случае формирование пары обучающих примеров
осуществляется по принципу «движущегося окна»: т. е. берется некоторый отрезок
временного ряда и из него выделяется несколько наблюдений, например 10; эти
наблюдения и будут представлять собой входной вектор. Значением желаемого
выхода в обучающем примере будет следующее по порядку наблюдение (т. е.
одиннадцатое). Затем «движущееся окно» сдвигается на одну позицию в
направлении возрастания времени, и процесс формирования следующей пары
обучающей выборки повторяется. Размер используемого временного ряда для
обучения НС должен быть равен объему обучающей выборки (количеству
примеров). Таким образом, в приведенном примере сеть, работающая в режиме
прогноза, должна иметь десять входов и один выход.
С помощью обученной НС можно решить задачу прогноза следующим
образом. Предположим, что необходимо прогнозировать значение рьшочной цены
на определенный вид продукции. Обучим НС на отрезке реального
временного ряда, например предыдущего месяца (30 дней), выбрав размер «окна»,
равный неделе (7 дней). Нейронная сеть в этом случае будет иметь 7 входов (семь
предыдущих дней) и один выход (следующий день). Количество примеров в
обучающей выборке равно 29 (при этом часть примеров необходимо оставить
для тестирования). Тогда подавая на входы обученной НС значения рыночной
цены за последние 7 дней предыдущего месяца, на ее выходе получим
прогнозное значение цены в первый день текущего месяца. Кроме того, можно
выполнить так называемую проекцию временного ряда. Вначале сеть
обучается на выделенных примерах. Затем выдается прогноз следующего значения,
после чего этот полученный результат вместе с предыдущей обучающей
выборкой снова подается на вход сети. Выдается очередное прогнозное значение.
Такую проекцию можно повторять произвольное число раз, хотя очевидно, что
в дальнейшем качество прогноза будет ухудшаться.
Из приведенного примера видно, что объем обучающей выборки зависит от
выбранного количества входов. Если, например, имеется временной ряд из 50
наблюдений рьшочной цены, то можно создать обучающую выборку из 49
примеров для НС с одним входом (предыдущее значение рьшочной цены) и одним
выходом (следующее значение) или иметь всего лишь один пример для сети с
49 входами (предыдущие значения) и одним выходом (следующее значение).
При выборе числа входов НС, работающей в режиме предсказания временного
ряда, следует учитывать эти соображения, выбирая разумный компромисс
между глубиной предсказания (число входов) и качеством обучения (размер
«движущегося окна»).
В случае отсутствия реального временного ряда используется его
моделирование. Рассмотрим простую модель временного ряда, в которой для
продавцов привлекательна высокая, а для покупателей - низкая рыночная цена. Если
140
5.5. Решение задачи прогнозирования временного ряда
при достаточно низких ценах покупатели испытывают трудности с
финансированием, то характер обратной связи будет нелинейным. Этот эффект можно
учесть, возводя уровень цены в степень, большую единицы, например в
квадрат. Если коэффициент обратной связи для продавцов обозначить Ъ , а для
покупателя - Ъ, то рыночная цена для продавцов и покупателей запишется в
виде:
pt = b"0 + b\ pt-\+bs2 /jVi ; (5.10)
pt = br0+ brlpt-\+br2p2t-\, (5.11)
где pi - текущая рыночная цена;^?ы - рыночная цена на предыдущем
временном отрезке; fcr0> 0, Ъ*х< 1, b"0< 0, b\> 1. Учитывая (5.10) и (5.11), получаем
рыночную цену для продавцов и покупателей:
pi = с0 + с j pt-\+c2 /Л-i, (5.12)
где с0 = 0,5(ЬГ0 + Ь*0), с,= 0,5 (Ь\ + b\), с2= 0,5 {b\ + b\).
Зная с0, ср с2 позначениям цены (предполагается, что они лежат в
интервале от 0 до 1), в предыдущий момент времени можно вычислить текущую цену.
В этом случае для решения задачи моделирования финансового рынка можно
использовать простую сеть, например 1—2—1 (один входной элемент, на
который подается значение ptl, два элемента в скрытом слое и один выходной
элемент, с которого снимается значение^, вычисляемое по формуле (5.12)).
Качество моделирования временного ряда с помощью нейронной сети в этом
случае во многом определяется достоверностью выбранной модели (5.12).
Упражнения и вопросы для самоконтроля
1. Дайте определение персептрона.
2. Какую функцию вычисляет персептрон, схема которого приведена на рис. 5.12?
Определите значения выхода Fb персептроне при следующих значениях входных
сигналов: 1.Л = 0;Я=0; 2. А = 1;Я=0;3. А = 0; В=\.
3. Как происходит вычисление функции в персептроне?
4. Какие виды функций может выполнять персептрон, а какие нет? Приведите примеры.
5. Сформулируйте и обоснуйте гипотезу компактности.
6. В чем суть процедуры Уидроу-Хоффа?
7. Как строится гиперповерхность в методе потенциаль- +1
НЫХ фуНКЦИЙ? 1-0,5
8. Какие трудности возникают при обучении НС метод об- о,35 —
ратного распространения? Перечислите способы их
устранения.
9. В чем суть антиовражных методов оптимизации?
10. Какие основные факторы влияют на процедуру обу-
10,35
D
Рис. 5.12. Однонейрон-
„„„ ныи персептрон
чения НС? F *
141
5. Обучение нейронных сетей без обратных связей
11. Какова основная идея квазиньютоновских методов оптимизации?
12. Почему метод наискорейшего спуска нецелесообразно использовать в обучении
НС?
13. Сформулируйте и рассмотрите возможность решения задачи прогнозирования
временного ряда с помощью НС в одной из прикладных областей.
6. ОБУЧЕНИЕ НЕЙРОННЫХ СЕТЕЙ НА ОСНОВЕ
ГЕНЕТИЧЕСКОГО АЛГОРИТМА
Рассмотрены проблемы создания ГА оптимизации для обучения
однонаправленных НС. Исследованы основные генетические операторы, влияющие на процесс
сходимости ГА. Предложены методы, повышающие эффективность функционирования ГА.
6.1. Суть генетического алгоритма
Рассмотрим возможность использования в процедуре обучения
многослойной НС одного из методов эвристической оптимизации - генетического
алгоритма (ГА), моделирующего процессы природной эволюции и относящегося к
так называемым эволюционным методам поиска.
При практической реализации данных алгоритмов на каждом шаге
используются стандартные операции, изменяющие решение. С помощью ГА можно
получить решение, соответствующее глобальному оптимуму или близкое к нему,
при этом на каждом шаге проводятся некоторые стандартные операции
одновременно над множеством решений (популяций), что позволяет значительно
увеличить скорость приближения к экстремуму.
ГА основаны на генетических процессах биологических организмов:
биологические популяции развиваются в течение нескольких поколений,
подчиняясь закону естественного отбора, открытому Ч. Дарвином, и с учетом
принципа «выживает наиболее приспособленный индивидуум» (survival of the fittest).
Подражая этому процессу, ГА способны «развивать» лучшее решение
реальных задач и получать результаты, близкие к глобальному оптимуму. В своей
теории происхождения видов Ч. Дарвин открыл и обосновал основной закон
развития органического мира, охарактеризовав его взаимодействием трех
следующих факторов:
• наследственной изменчивости;
• борьбы за существование;
• естественного отбора.
143
6. Обучение НС на основе генетического алгоритма
Дарвиновская теория получила подтверждение и развитие в генетике и
других науках. Нашим соотечественником И.И. Шмальгаузеном были уточнены
необходимые и достаточные условия, определяющие неизбежность эволюции:
• наследственная изменчивость, т. е. мутации как предпосылка эволюции,
ее материал;
• борьба за существование как контролирующий и направляющий фактор;
• естественный отбор как преобразующий фактор.
Основные принципы ГА были сформулированы Дж. Холландом. В отличие
от эволюции, происходящей в природе, ГА моделируют только те процессы в
популяциях, которые являются существенными для развития. В природе особи
в популяции конкурируют друг с другом за различные ресурсы, такие,
например, как пища или вода. Кроме того, члены популяции (индивидуумы) одного
вида часто конкурируют за привлечение брачного партнера. Те индивидуумы,
которые наиболее приспособлены к окружающим условиям, будут иметь
больше шансов воспроизвести потомков (рис. 6.1).
Слабо приспособленные индивидуумы либо совсем не произведут
потомства, либо их потомство будет очень немногочисленным. Это означает, что гены
от высоко адаптированных или приспособленных к окружающей среде особей
будут передаваться в увеличивающемся количестве потомкам в каждое после-
Среда обитания
I
Взаимодействие со
средой обитания
Борьба за существование
Извлечение
энергии
Защита от
нападения
Размножение
Соревнование
особей
Популяция
особей
Гибель, отстранение от
размножения
Естественный
отбор
Изменение генетического состава
популяции
Рис. 6.1. Факторы эволюции и их взаимодействие при развитии популяции
144
6.1. Суть генетического алгоритма
дующее поколение. Комбинация характеристик от различных родителей
иногда может приводить к появлению «суперприспособленного» потомка, чья
приспособленность больше, чем приспособленность любого из его родителя.
Таким образом, вид развивается, лучше и лучше приспосабливаясь к среде
обитания.
Генетические алгоритмы используют прямую аналогию с таким
механизмом. Они работают с совокупностью «особей» — популяцией, которая
представляет собой совокупность возможных решений рассматриваемой задачи
оптимизации. Каждая особь оценивается мерой ее «приспособленности»
согласно тому, насколько «хорошо» соответствующее ей решение задачи.
Наиболее приспособленные особи получают возможность «воспроизводить»
потомство с помощью «перекрестного скрещивания» с другими особями популяции.
Это приводит к появлению новых особей, которые сочетают в себе некоторые
характеристики, наследуемые ими от родителей. Наименее приспособленные
особи с меньшей вероятностью смогут воспроизвести потомков, так что те
свойства, которыми они обладали, будут постепенно исчезать из популяции в
процессе эволюции. Таким образом, воспроизводится новая популяция
допустимых решений с выбором лучших представителей предыдущего поколения
путем их скрещивания.
Каждое новое поколение будет содержать большее число особей с
лучшими характеристиками, и эти характеристики будут передаваться из поколения
в поколение. Скрещивание наиболее приспособленных особей приводит к тому,
что исследуются наиболее перспективные участки пространства поиска.
Поэтому в конечном итоге популяция будет сходиться к оптимальному (или
квазиоптимальному) решению задачи.
Основные отличия ГА от стандартных локальных (например, градиентных)
и глобальных (например, случайных) алгоритмов оптимизации:
• поиск субоптимального решения основан на оптимизации случайно
заданного не одного, а множества решений, что позволяет одновременно
анализировать несколько путей приближения к экстремуму; при этом оценка получаемых
результатов на каждом шаге позволяет учитывать предыдущую информацию,
т. е. происходит эволюционное развитие оптимальных решений;
• решения рассматриваются как некоторые закодированные структуры
(символьные модели), а не как совокупность параметров, что позволяет в
некоторых случаях значительно уменьшить время преобразования данных, т. е.
увеличить скорость приближения к экстремуму;
• для оценки «пригодности» решения и последующего эволюционного
развития наряду с использованием целевой функции дополнительно моделируются
«правила выживания», которые расширяют разнообразие множества решений
и определяют эволюционное развитие;
• при инициализации, преобразовании и других видах операций с решениями
используются вероятностные, а не детерминированные правила, которые
вносят в направленность генетического поиска элементы случайности; тем
самым решается проблема выхода из локальных оптимумов;
145
6. Обучение НС на основе генетического алгоритма
Формирование
начальной
популяции
^
Текущая
популяция
I
(^Т^^^Л условие
У_операторы^^остановки
1^—
Остановка
эволюции
Оптимальное
решение
Рис. 6.2. Схема простого генетического алгоритма
• отсутствует необходимость расчета производных от целевой функции (как
в градиентных методах) или матрицы производных второго порядка (как в
квазиньютоновских).
Схема простого генетического алгоритма представлена на рис. 6.2.
Алгоритм записывается следующим образом.
НАЧАЛО /* генетический алгоритм */
Создать начальную популяцию
Оценить приспособленность каждой особи
останов := FALSE
ПОКА НЕ останов ВЫПОЛНЯТЬ
НАЧАЛО /* создать популяцию нового поколения */
ПОВТОРИТЬ (размерпопуляции /2) РАЗ
НАЧАЛО /* цикл воспроизводства */
Выбрать две особи с высокой приспособленностью из предыдущего
поколения для скрещивания
Провести операцию скрещивания над выбранными особями и получить
двух потомков
Оценить приспособленности потомков
Поместить потомков в новое поколение
КОНЕЦ
ЕСЛИ популяция сошлась ТО останов := TRUE
КОНЕЦ
КОНЕЦ
Новые
хромосомы
146
6.1. Суть генетического алгоритма
В последние годы реализовано много ГА, которые различаются способами
реализации параметров, характеризующих ГА: типами операторов кроссинго-
вера, мутации, функций «пригодности» и т. д.
Генетическим алгоритмом называется следующий объект:
rA(P0,r,/,s/,Fit,cr,/w),
где ГА - генетический алгоритм; Р° - исходная популяция; г - количество
элементов популяции; / - длина битовой строки, кодирующей решение; si -
оператор селекции; Fit - функция фитнесса (функция полезности), определяющая
«пригодность» решения; сг - оператор кроссинговера, определяющий
возможность получения нового решения; т - оператор мутации; ot- оператор отбора.
Будем считать, что область поиска решения D задачи однокритериального
выбора является конечным множеством решений, в котором каждое
допустимое решение X е D является л-мерным вектором X = (jcp x2,..., хп).
Наименьшей неделимой единицей биологического вида, подверженной
действию факторов эволюции, является особь Н'к {к - номер особи, t - момент
времени эволюционного процесса). В качестве аналога особи в задаче
оптимизации принимается произвольное допустимое решение X е D, которому
присвоено имя Н'к. Действительно, вектор X - это наименьшая неделимая
единица, характеризующая в экстремальной задаче внутренние параметры объекта
оптимизации на каждом t-м шаге поиска оптимального решения, которые
изменяют свои значения в процессе минимизации некоторого критерия
оптимальности ДХ).
Качественные признаки особи Н'к определяются как соответствующие
точке X с именем Н'к (в простейшем случае битовой строке). Интерпретация этих
признаков проводится в терминах хромосомной наследственности. В качестве
гена - единицы наследственного материала, ответственного за формирование
альтернативных признаков особи, - принимается бинарная комбинация h,
которая определяет фиксированное значение параметра xt в двоичном коде.
Некоторая особь Н'к будет характеризоваться п генами, каждый из которых
отвечает за формирование целочисленного кода соответствующей переменной. Тогда
структуру битовой строки можно интерпретировать хромосомой, содержащей
п сцепленных между собой генов. Местоположение /-го гена в хромосоме -
локус, значение - алпель h.
Хромосома, содержащая в своих локусах конкретные значения генов,
называется генотипом (генетическим кодом), который содержит всю
наследственную генетическую информацию об особи Н'к. Конечное множество всех
допустимых генотипов называют генофондом.
При взаимодействии особи с внешней средой ее генотип Н'к порождает
фенотип F(H'k), который можно оценить количественно с помощью функции
приспособленности (функции фитнесса) к внешней среде. Фитнесс Y\X(H'k) каждой
особи Н'к равен численному значению функции ДХ), вычисленной для допус-
147
6. Обучение НС на основе генетического алгоритма
тимого решения XeD с его именем Н'к. Чем больше значение функции финтес-
са при решении задачи нахождения max ДХ), тем лучше особь приспособлена
к внешней среде.
6.2. Формирование популяции
Совокупность особей (Н\,..., /f) образуют популяцию Р' (численностью г).
Эволюция популяции Р рассматривается как чередование поколений (рис. 6.3).
Номер поколения отождествляется с моментом времени t = 0,1,...,Г, где Т —
жизненный цикл популяции, определяющий период ее эволюции. Совокупность
генотипов всех особей Н'к образует хромосомный набор, который полностью
содержит в себе генетическую информацию.
Способы создания начальной популяции Р°. В настоящее время
наиболее известными являются три стратегии создания начального множества
решений:
1) формирование полной популяции;
2) генерация случайного множества решений, достаточно большого, но не
исчерпывающего все возможные варианты;
3) генерация множества решений, включающего разновидности одного
решения.
При первой стратегии должен быть реализован полный набор
всевозможных решений, но это невозможно из-за чрезмерных вычислительных затрат и
большой области поиска для задач высокой размерности. Стартовая
популяция, созданная на основе данной стратегии, не может развиваться, т. е. в ней
уже содержатся все решения, в том числе и оптимальные.
Третью стратегию применяют, когда есть предположение, что некоторое
решение является разновидностью известного. В этом случае происходит
выход сразу в область существования экстремума, и время поиска оптимума
значительно сокращается.
Текущая
популяция
Роди
Текущая
популяция:
родители +
потомки
гели-..
1
г Родители
S ""-
' Скре
щивание
1 Потомки
( Мутации j
Рис. 6.3. Формирование популяции
6.3. Классификация генетических операторов
Для большинства задач проектирования первая (вследствие
проблематичности полного перебора) и третья (из-за сужения области поиска и большой
вероятности попадания в локальный экстремум) стратегии неприемлемы.
Наиболее перспективной является вторая стратегия, так как она в результате
эволюции популяции создает возможность перехода из одной подобласти области
поиска D в другую и имеет сравнительно небольшую размерность задачи
оптимизации.
Эффективность ГА, качество получаемого решения и успех дальнейшего
развития эволюции во многом определяются структурой и качеством
начальной популяции. Наиболее целесообразным представляется подход, основанный
на комбинировании второй и третьей стратегии: путем предварительного
анализа решаемой задачи выявляются подобласти в области поиска D, в которых
могут находиться оптимальные решения, т. е. определяются особи с высоким
значением фитнесса, а затем случайным образом формируются стартовые
решения в этих подобластях.
6.3. Классификация генетических операторов
Выделяют два основных способа генерации новых решений (рис. 6.4):
1) путем перекомпоновки (скрещивания) двух родительских решений
(оператор скрещивания или кроссинговер сг);
2) путем случайной перестройки отдельных решений (оператор мутации /и).
Кроссинговер сг производит структурированный и рандомизированный
обмен информацией внутри родительской пары, т. е. между двумя хромосомами,
формируя новые решения. Задача создания потомков состоит в выборе такой
комбинации участков хромосом, которая давала бы наилучшее решение. Та-
Хромосома А
Хромосома В
Потомок А
<>4
А
Потомок В
А
h
Рис. 6.4. Одноточечный кроссинговер
149
6. Обучение НС на основе генетического алгоритма
ким образом, основная цель скрещивания заключается в накоплении всех
лучших функциональных признаков, характеризующих отдельные участки
хромосом, копируемых в конечном решении.
Рассмотрим одноточечный оператор кроссинговера Холланда, который
реализуется следующим образом. Сначала случайным образом определяется
точка скрещивания. Затем цепочка генов, ограниченная точкой скрещивания
одной хромосомы, меняется местами с аналогичной частью генов второй
хромосомы (рис. 6.4), т. е. путем перекомпоновки двух родительских решений
генерируются два качественно новых решения (потомки). Помимо
одноточечного применяются и многоточечные кроссинговеры. В результате применения
сг могут появиться повторяющиеся кодовые комбинации хромосом. Поэтому
для использования генетического алгоритма в задачах оптимизации
необходимо разрабатывать новые типы операторов сг.
Одним из таких алгоритмов является мобильный ГА. В отличие от
классического ГА, использующего строки постоянной длины, в мобильном алгоритме
имеют дело со строками переменной длины, которые могут быть
переопределены (т. е. несут избыточную информацию) или недоопределены (т. е. могут
быть дополнены другой информацей). В такой алгоритм вводят два
дополнительных оператора: CUT (разрезание) и SPLICE (сцепление) вместо обычного
оператора кроссинговера, оперирующего хромосомами фиксированной длины.
Предусмотрена возможность объединения отдельных участков наиболее
хороших (конкурентоспособных) хромосом, полученных на предыдущих этапах
развития популяции, для формирования оптимальных решений последующего
этапа с возможностью улучшения глобального решения.
Характерной особенностью мобильного ГА является то, что он не
накладывает ограничений на позиционирование генов внутри хромосом, допуская их
различные перестановки внутри строк, вследствие чего не требуется знание
априорной информации о наиболее оптимальном расположении битов внутри
строки, что очень важно в приложениях.
Применение оператора мутации т в процессе биологической эволюции
предотвращает потерю важного генетического материала; в генетических
алгоритмах т используется для выхода из локальных экстремумов. На практике
при использовании ГА для решения за-
Результат дач оптимизации встречаются класси-
мутации ческие операторы генной мутации:
изменение величины случайно выбранного
гена (рис. 6.5). Для улучшения технологии
генетического поиска оптимальных
решений целесообразно применять операторы
Ь4 хромосомной мутации.
Значительное улучшение качества и
скорости сходимости ГА дает
комбинирование ГА с классическими детерминиро-
Мутация
Мутация
потомка А
К
Рис. 6.5. Оператор мутации
150
6.4. Селекция решений
ванными методами оптимизации, разработка модифицированных операторов
кроссинговера и мутации, основанные на знании решаемой задачи.
6.4. Селекция решений
Качество поколений потомков во многом зависит от выбора операторов
селекции si родительской пары. Поэтому для аккумуляции всех лучших
функциональных признаков, имеющихся в популяции, используют подбор хромосом для
скрещивания. Наиболее часто в ГА применяют следующие типы операторов
si:
1) случайный выбор пар;
2) предпочтительный выбор на основе функции фитнесса.
При случайном выборе частота к образования родительской пары не
зависит от «качества» хромосом Н[ и полностью определяется численностью
популяции/-: ,
к= — .
г(г-1)
Таким образом, реализации si в виде стратегии 1 соответствует случайный
выбор Н[.
Второй способ реализации si связан с использованием функции фитнесса Fit,
при этом реализуются два типа выбора. В первом случае предпочтение
отдается парам хромосом с близкими и высокими значениями Fit, но
отличающимися по структуре; во втором — хромосомам, характеризующимися
функциями Fit, которые сильно различаются между собой.
Для реализации первой стратегии случайным образом с вероятностью
pk=(VYxt(H<k))/jyit(H<)), к=й
выбирают две разные хромосомы Щ, Н'к+1 е Р' (Н'к * Н'ы).
Вторая стратегия реализуется следующим образом: одна из хромосом
Н'к е Р' выбирается случайным образом, а другая Н'ы е Р' с вероятностью
A=l/Fit(#;)/]Tl/Fit(#;')), к=Ъ?.
Частным случаем первой стратегии является введение уровня «отсечки»:
если Fit(#^) < FitOTc, то для улучшения качества популяции Щ временно
устраняется из процедуры скрещивания; например, можно положить FitOTC= Fitc (/), где
Fitc (0 - среднее значение функции фитнесса в популяции.
С помощью оператора селекции si моделируют естественный отбор.
Выбор случайных и сильно отличающихся хромосом для скрещивания
способствует повышению генетического разнообразия в популяции, что, в свою очередь,
151
6. Обучение НС на основе генетического алгоритма
повышает скорость сходимости ГА на начальном этапе оптимизации и
позволяет выходить из локальных экстремумов. На конечном этапе поиска
целесообразно применять выбор подобных в соответствии с определенным
критерием хромосом, т. е. искать решение только среди лучших Щ.
6.5. Способы отбора решений в популяцию
Необходимой составляющей естественного отбора является устранение
неудачных решений. Основная проблема устранения - нахождение компромисса
между разнообразием генетического материала и качеством решений. Схема
отбора включает два этапа:
• формирование репродукционной группы из всех решений, образовавшихся
в популяции Р';
• естественный отбор решений в следующую Pt+l популяцию.
Если в этой схеме в репродукционную группу входят все решения,
полученные в t-м поколении, то численность новой популяции
R^r + r^+rb
где г - численность популяции Р'; г'сг - «потомки», полученные в результате
применения оператора скрещивания сг\ г'т - «мутанты», полученные в
результате применения оператора мутации т.
Для учета информации о степени приспособленности особей к внешней
среде Fit и сокращения численности репродукционной группы популяции P'+l
используют следующие схемы.
1. Элитарная схема (ot3). В репродукционную группу включаются все
Н^ е?'и только те потомки и мутанты, для которых выполняются условия:
УН[ ePt,k = U3Hkcr(¥it(Hkcr)>¥it(H'k));
VH'k eP',k = l,r Э tf^Fit^J> Fit(tfO),
где Ньг - потомки, Hkm— мутанты.
2. Селекционная схема (pts). Осуществляется упорядочение по убыванию
функций Fit для всей репродукционной группы. Задается численность г°
популяции. В следующую популяцию Р т включают только первые из г° хромосом,
т. е. те, для которых в упорядоченном ряде ранг КЩ) ^ г°- Данную схему
можно модифицировать следующим образом. Определяется средняя Fit для
всех решений, полученных в популяции Р':
FitcP=:rZFit(*')'
где R' - численность репродукционной группы популяции Pl; R'= r + r'cp+r'm.
152
6.5. Способы отбора решений в популяцию
В следующую популяцию включим хромосомы, у которых функция Fit выше
или равна средней Fit'c, т. е.
Rt+1 =\H'k\Fit(H'k)>Fit'cp,k = l^}.
При использовании селекционной схемы часть полученных на t-м шаге
решений устраняется из дальнейшего анализа в процессе естественного отбора.
3. Схема пропорционального отбора (ot ). В соответствии с ot r решений
популяции Рм выбираются из R' случайным образом с вероятностью
рк(Н[) = Fit (tfO/£Fit (#/), к = \^ ■
В этом случае каждое решение H'k e Р' может потенциально войти в состав
популяции Рт в виде одной или нескольких копий с одним и тем же генотипом.
4. Схема на основе линейно упорядоченного отбора (ot). В данной схеме of,
выбирает хромосомы из репродукционной группы R' с вероятностью
p(Hl) = ±-(a-(a-b)±p\), k = hR1,
К К —1
где а - параметр, выбираемый случайным образом с равной вероятностью из
интервала [1,2]; Ъ — 2-а.
Частный случай линейного упорядочения при а = 1 - равновероятный
отбор (од
p(H'k) = —,k = l,R'.
К
При использовании otR все решения Н'ке Р имеют одинаковую вероятность
быть выбранными в следующую популяцию Рм.
Рассмотренные операторы отбора ot3, ots, ot, otp otk производят выбор Н'к,
к=1, R' до тех пор, пока в популяцию Р1*1 не будет включено г решений (Н[+1,
Я2'+1,..., H'r+l). Затем процесс развития популяции повторяется для
следующего (t + 1)-го поколения.
Анализ операторов отбора показывает, что случайный отбор приводит к
высокому генетическому разнообразию, однако многие качественные решения
могут быть утеряны. Элитный отбор сохраняет качество решения, но после
смены нескольких поколений хромосомы становятся подобными. Таким
образом, на начальных этапах оптимизации с помощью ГА ot3 дает значительное
ускорение роста качества решения, оцениваемое по Fit, в сравнении с ots,
однако дальнейшее повышение качества становится проблематичным из-за
скудного генетического разнообразия.
153
6. Обучение НС на основе генетического алгоритма
6.6. Кодирование потенциальных решений
Определим набор требований, которым должен отвечать способ
кодирования.
1. Однозначность, т. е. каждая закодированная строка должна
соответствовать единственному решению исходной задачи. Выполнение данного критерия
необходимо для статистической прогнозируемости поведения алгоритма и
улучшения нахождения алгоритмом областей оптимальных решений.
2. Возможность кодирования любого допустимого решения.
3. Получение в результате генетических операций корректных вариантов
решений.
4. Возможность перехода от любого корректного решения к любому
другому корректному решению.
В данном случае будем считать решение корректным, если выполняются
ограничения на состав решения (например, возможность появления
одинаковых значений генов) и ограничения на допустимые значения варьируемых
параметров.
Пункты 2, 4 требований являются необходимыми условиями обхода
алгоритмом всего пространства решений.
Существует несколько способов кодирования решения:
1) битовая строка;
2) вещественные (целые) числа;
3) с использованием кода Грея;
4) применение эвристик.
Первый способ кодирования был предложен Холландом и считается
классическим. В этом случае каждый ген представляет собой двоичную строку 0 и 1.
При кодировании мы переводим целые значения в их двоичное представление.
Для декодирования необходима обратная операция.
Преимущества:
• для хранения параметров используется минимально необходимое
количество памяти;
• возможность использования классических операций ГА.
Недостатки:
• операция скрещивания является неконсервативной (так как хранится
целое число в двоичном формате, то точка разделения может попасть между
битами одного числа и обмен частями строк приводит к изменению этого числа);
• возможность появления запрещенных комбинаций;
• необходимость переведения параметров из целого представления в
двоичное при кодировании решений и обратно при декодировании;
154
6.6. Кодирование потенциальных решений
• низкая вероятность изменения значения параметра на любое другое за
один шаг операцией мутации (например, из 1 в 2: 01b в 10Ь). Вероятность
составляет (pm)"B"J, где nBits - количество подряд идущих битов, которые
необходимо изменить (изменения битов являются независимыми событиями,
поэтому мы можем применять теорему умножения вероятностей). Данная
вероятность может быть увеличена за счет реализации операций
скрещивания, в случае, если она допускает точку разбиения внутри одного кодируемого
параметра. Поскольку в случае бинарного кодирования два близких по
значению параметра решения могут находиться на большом расстоянии по Хэммин-
гу (например, бинарное представление чисел 127и 128: 01111111 и 10000000;
расстояние по Хеммингу - число не совпадающих бит в одноименных
разрядах - равно 8). Низкая вероятность такого перехода приводит к замедлению
обхода пространства решения. Существенное увеличение вероятности
мутации ведет к разрушению «хороших» решений и сводит ГА к простому
случайному поиску.
При втором способе кодирования значения генов хранятся в числовом
формате.
Преимущества:
• кодируемые параметры представляются непосредственно (удобство
кодирования-декодирования);
• операция скрещивания является консервативной, что соответствует
классическому представлению (деление решения происходит всегда между
числами и значение параметров не изменяется);
• любое значение параметра может быть изменено на любое другое за один
шаг операцией мутации с вероятностью, равной рт.
Недостатки:
• излишний расход памяти (для хранения параметра всегда используется 4
байт);
• необходимость введения «своей» операции мутации (классическая
мутация работает с битовыми строками). Такая операция обычно представляет
собой изменение значение числа на случайную величину в пределах 10...30%;
• возможность появления запрещенных комбинаций.
Кроме обычного бинарного кодирования для представления хромосом
может быть использован любой двоично-десятичный код.
При третьем способе кодирования наиболее часто применяется код Грея,
первые 16 слов этого кода для размера хромосомы, равной 4, представлены в
табл. 6.1.
Из табл. 6.1 видно, почему код Грея имеет явные преимущества по
сравнению с двоично-десятичным кодом, например, 8-4-2-1. Отличительной
характеристикой кода Грея является его высокая помехозащищенность, поскольку
при его использовании соседние числа отличаются друг от друга только на
один бит (в одном разряде).
155
6. Обучение НС на основе генетического алгоритма
Таблица 6.1. Код Грея
Код Грея
0000
0001
ООП
0010
ОНО
0111
0101
0100
1100
1101
1111
1110
1010
1011
1001
1000
Двоично-десятичный код
0000
0001
0010
ООП
0100
0101
ОНО
0111
1000
1001
1010
1011
1100
1101
1110
1111
Десятичное представление числа
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
В качестве примера рассмотрим любые три рядом стоящие строки из
табл. 6.1, например, кодирующие числа 4, 5 и 6. Пусть фрагменты хромосом,
стоящие в пятой строке и кодирующие число 5, принадлежат оптимальному
вектору, являющемуся решением некоторой задачи, а лучшая особь из
текущей популяции содержит фрагмент хромосомы из строки 4. Достаточно
выполнить всего одну операцию - заменить в четвертом разряде лучшей
хромосомы 0 на 1, и решение будет найдено. Если-лучшая особь содержит фрагмент из
строки 6, то замена 0 на 1 в третьем разряде опять приведет к успеху. Это
позволяет значительно уменьшить вычислительные затраты при поиске решения.
В то же время при использовании двоично-десятичного кода для перехода
из шестой строки в пятую необходимо выполнить последовательно две
операции - заменить 1 на 0 в третьем разряде и 0 на 1 в четвертом. В других
случаях переход к близлежащим решениям связан с еще большими
вычислительными затратами.
Таким образом, если привлечь геометрическую интерпретацию
представления пространства решений в виде гиперкуба, то применение кода Грея
гарантирует, что две соседние вершины гиперкуба, принадлежащие одному
ребру, на котором осуществляется поиск, всегда декодируются в две
ближайшие точки пространства вещественных чисел и отстоят друг от друга
156
6.6. Кодирование потенциальных решений
на одно дискретное значение. Двоично-десятичный код подобным свойством
не обладает.
Четвертый способ кодирования. В комбинаторных задачах, например, при
выборе топологии НС очень часто решение представляет собой перестановку
некоторой последовательности. При использовании методов кодирования 1—3
возможно появление запрещенных комбинаций, например дублирование или
отсутствие некоторого элемента последовательности. Для устранения этого
недостатка в генах хранят не само решение, а совокупность эвристик, выполнив
которые над исходной последовательностью, мы и получим решение.
Например, для решения задачи коммивояжера возможно использование следующего
способа кодирования.
Пусть имеются города 1,2,3... ./V. Хромосомой будет заданное число пар (I, J),
где значения / и J лежат от 0 до N - 1 включительно. Декодирование пути
осуществляется по следующей схеме:
• создание массива Buf размером, равным числу городов;
• заполнение его некоторой последовательностью: Buf={l, 2, 3, ..., N}. В
массиве перечисляются все города, расположенные в некотором порядке, и
сам массив может выступать в роли решения - очереди обхода городов;
• проход по массиву пар (I, J), образованному конкретной хромосомой и
перестановка местами элементов массива / и J.
Особенности кодирования заключаются в том, что хромосома - это набор
перестановок некоторой постоянной исходной последовательности, а не сама
последовательность обхода. Тогда, если число городов является степенью 2,
то при кодировании определяется, сколько нужно выделить бит каждой паре
(7, J): l = 2*log2(A0, где / - количество бит, необходимое для кодирования /-го
гена. Если число городов не является степенью 2, тогда либо вводятся
фиктивные города, либо выделяется количество бит с запасом, а при обработке
информации игнорируются неверные значения.
Преимущества:
• для хранения параметров используется минимально необходимое
количество памяти;
• возможность использования классических операций ГА;
• операция скрещивания является консервативной, что соответствует
классическому представлению (точка деления выбирается между числами, а сами
значения параметров не изменяются);
• невозможность появления запрещенных комбинаций.
Недостатки:
• необходимость переведения параметров из целого представления в
двоичное при кодировании решений и обратно при декодировании, что связано с
дополнительными затратами времени при функционировании алгоритма.
157
6. Обучение НС на основе генетического алгоритма
6.7. Теорема схем в генетическом алгоритме
Несмотря на успешное использование ГА в большом количестве задач
оптимизации, универсальных методов построения и настройки ГА в настоящее
время не существует. Объяснение работы ГА дано в работах Дж. Холланда
(G. Holland) и Д. Голдберга (D. Goldberg). Теорема схем, предложенная ими,
отражает основные механизмы работы ГА и дает качественную картину того,
как ГА мог бы работать. Для объяснения самой теоремы схем введем
следующие понятия.
Схема (schema) - описывает набор строк (подмножество всех возможных
строк) с подобными значениями в некоторых позициях. В качестве примера
представим строку с пятью битами. Схема **000 представляет все строки с 0 в
последних трех позициях: это 00000, 01000, 10000 и 11000. Каждая строка,
представленная схемой, называется примером схемы. Фиксированные
позиции в схеме - позиции, в которых находятся 0 или 1: в * *000 это третья,
четвертая и пятая позиции. Количество фиксированных позиций в схеме - ее порядок:
например, **000 имеет 3 порядок. Определяющая длина схемы - расстояние
между самыми дальними фиксированными позициями. Так у схемы **000
определяющая длина равна 2, у 1*00* - равна 3. Каждая строка одновременно
является примером в 2'схем (/ - длина строки).
Поскольку схема определяет набор строк, то можно ввести понятие среднего
значения функции выживаемости схемы. В популяции это понятие
определяется средним значением функции выживаемости примеров схемы.
Следовательно, среднее значение функции выживаемости схемы варьируется вместе
со структурой популяции, изменяющейся в результате развития популяции.
Какое значение имеют схемы в понимании процесса развития популяции?
Представим схему с к фиксированными позициями. Существует 2*- 1 других
схем с теми же самыми фиксированными позициями, которые могут быть
получены перестановками 0 и 1 в этих к позициях. В целом, для этих к позиций
существует 2* различных схем, которые представляют часть всех возможных
строк. Каждый такой набор фиксированных позиций образует соревнование
схем, борьбу за выживание среди 2* схем. Поскольку существует 2'
возможных комбинаций фиксированных позиций - следовательно, возможно 2'
различных соревнований. Таким образом, с помощью ГА осуществляется
одновременный анализ 2' схем и выделяется лучшая схема для каждого набора
фиксированных позиций.
Можно представить себе поиск оптимального решения с помощью ГА как
одновременное соревнование между схемами за увеличение количества их
представительства в популяции. Если описать оптимальную строку в виде
сопоставления схем с маленькими определяющими длинами и высокими средними
158
6.7. Теорема схем в генетическом алгоритме
значениями функции выживаемости, тогда победители индивидуальных
соревнований схем потенциально могут сформировать оптимальную строку. Таким
схемам с маленькими определяющими длинами, низким порядком и высокими
средними значениями функции выживаемости дали название строительных
блоков. Представление о том, что строки с высокими коэффициентами
выживания могут быть получены путем использования строительных блоков с
высокими коэффициентами выживания и их комбинаций, называется гипотезой
строительных блоков.
Генетические операторы скрещивания и мутации, согласно Дж. Холланду,
создают, улучшают и сопоставляют различные строительные блоки, чтобы
получить оптимальную строку. Оператор скрещивания предназначен для
сохранения генетической информации, имеющейся в скрещиваемых строках.
Оператор мутации позволяет создавать совершенно новые строительные
блоки. Отбор обеспечивает увеличение в популяции количества строительных
блоков с высокими значениями функции выживаемости.
Гипотеза строительных блоков утверждает, что сопоставление хороших
строительных блоков дает хорошую строку. Это не всегда справедливо. Очень
плохие строки могут быть созданы из хороших строительных блоков.
Формальное описание теоремы схем можно представить следующим
уравнением:
Aht)
N(h, t+l)>N(h, t)-—
5(h)
l-Pc — -pmo(h)
/«
где N(h, t + 1) - ожидаемое количество примеров схемы h на шаге t;j[h, t) - среднее
значение функции выживаемости схемы h на шаге t; f(i) - среднее значение
функции выживаемости популяции на шаге t; pc — вероятность скрещивания;
рт - вероятность мутации; 5(й) - определяющая длина схемы; о(й) - порядок
схемы h; I - количество бит в строке.
Теорема схем дает нижнюю границу ожидаемого числа N(h, t + 1) примеров
схемы h в популяции на t + 1 шаге. Нижняя граница определяется отношением
fih, t) - среднего значения функции выживаемости схемы h на шаге t к
среднему значению функции выживаемости популяции на этом шаге, а также
возможностью разрушения схемы. Фактор pb(h)l[l —1]определяет возможность
того, что пример схемы h будет разрушен скрещиванием, &pmo(h) - мутацией.
Таким образом, теорема схем отражает основные механизмы работы ГА и
дает качественную картину функционирования ГА, а также снабжает
разработчика знаниями о хороших способах кодирования, реализации и применении
операторов ГА. Однако ее очень трудно применить к конкретным вариантам
реализации ГА и конкретным прикладным задачам с целью количественного
159
6. Обучение НС на основе генетического алгоритма
анализа динамики работы и выбора его параметров для обеспечения высокой
скорости сходимости на основе использования имеющихся хороших решений.
Бесполезность теоремы схем с этой точки зрения широко обсуждалась.
Одним из основных моментов критики данной теории составляло замечание,
что теорема схем дает лишь нижнюю границу ожидаемого количества
представителей схемы в популяции на следующем шаге алгоритма. Поэтому
теорему нельзя использовать для прогнозирования развития ГА на несколько
шагов вперед. (Если предположить размер популяции неограниченным, то
теорема позволяет делать долговременные предсказания, однако они могут
давать большие погрешности в реальных задачах.) В дальнейшем было
предложено несколько других трактовок этой теоремы.
На основании одной из таких трактовок можно определить, при каких
требованиях к начальной популяции алгоритм будет сходиться к решению за
определенное число итераций. Однако при этом должны быть введены очень
жесткие требования к параметрам ГА: использование схемы пропорциональной
селекции, одноточечное скрещивание со 100%-ной вероятностью и отсутствие
мутации.
Было предложено также обобщение теоремы схем под названием теорема
форм. Данную теорему можно применять в случаях, когда обычная теорема
схем, основанная на применении двоичных строк, неприменима. В этой теореме
понятие cjceMw(schemata) заменяется понятием формы (formae), которая
представляет собой некоторые закодированные подмножества пространства
поиска. В теореме форм используются стандартные операторы скрещивания
для форм. Основная проблема, возникающая при этом: необходимость
априорного знания или метода выделения областей пространства поиска,
приводящих к «хорошим» решениям. Для многих задач данная проблема
является неразрешимой, но, зная такие области, можно было бы разработать
эффективные эвристики для решения рассматриваемой прикладной задачи.
6.8. Многопопуляционный генетический алгоритм
Рассмотрим вопросы повышения эффективности ГА.
В сложных поисковых пространствах возможно существование нескольких
глобальных и множества локальных экстремумов. Для повышения
вероятности нахождения одного или нескольких глобальных экстремумов целесообразно
одновременно просматривать несколько областей поиска. Поэтому один из
способов повышения эффективности ГА связан с параллельным развитием
нескольких популяций и применением генетических операторов к хромосомам из
разных популяций, что позволяет повысить генетическое разнообразие
наследственного материала и приводит к улучшению окончательного решения.
Мотивом создания этого подхода является известный из генетики факт: из
аллелей формируются генотипы особей, из особей популяции, из популяций
биоценозы, являющиеся итогом прогрессивного развития нескольких популяций.
160
6.8. Многопопуляцыонный генетический алгоритм
В соответствии с вышесказанным, ГА, в котором генетические операторы
применяются к хромосомам разных популяций, будем называть многопопуляци-
онными (биоценозными).
В многопопуляционном ГА одновременно создается iV начальных популяций
Р,°, Р20,..., Pw°, которые развиваются независимо друг от друга до
определенного момента tv (начало периода взаимодействия), после которого популяции
обмениваются хромосомами и затем снова развиваются независимо. Норму
взаимодействия (количество обменных хромосом) можно регулировать с тем,
чтобы каждая из популяций могла также создать «свои» уникальные
хромосомы. Главные проблемы реализации многопопуляционного алгоритма ГА
заключаются в следующем: 1) определение момента начала периода
взаимодействия tv и 2) выбор принципа отбора обменных хромосом.
Первая проблема решается следующим образом. Вводится условие
наступления события t\ если сумма отклонений Fit в текущих поколениях от
предыдущих за последние / поколений не превосходит некоторого заданного
положительного числа 5, то развитие популяции не приводит к появлению лучших
решений и наступает период взаимодействия. Пусть /-количество поколений,
за которое проводится оценка развития популяции; 5 - уровень улучшения
решений, определяется как разность | Fit* — Fit1^ I; тогда процесс определения
момента tv может быть описан следующим образом.
1. Установка начальных значений / и 5.
2. Fir*^ = 0; максимальное значение Fit в предыдущем поколении.
3. t = 1; счетчик номера поколения.
4. £ = 0; сумма отклонений I Fit1 - Fit'-1 I.
' J max max
5. k — 1; счетчик числа поколений.
6. Если k < 1, то переход к п. 7, иначе к п. 12.
7. Fit*max= max Fit'(//^); определение максимума Fit в текущем поколении.
8.£=Т+iFi^ -Fit'"' |.
max max
9. Fit'-' = Fit1 .
max max
10.* = *+l;f = f+l.
11. Переход к п. 6.
12. Если S > 5, то переход к п. 4, иначе к п. 13.
13. Конец.
Если условие наступления момента tv выполняется хотя бы для одной
популяции, то происходит обмен хромосомами между этой популяцией и другой,
выбранной случайным или детерминированным способом.
Для решения проблемы выбора обменных хромомсом происходит
ранжирование всех хромосом по функции Fit по возрастанию в обменивающихся
популяциях. Из каждой популяции удаляется q-r худших хромосом (д - процент
161
6. Обучение НС на основе генетического алгоритма
исключения; 0 < q < 1; г — количество хромосом в популяции), и на их место
включается q ■ г лучших хромосом из другой популяции. Выбор обменных
хромосом из каждой популяции осуществляется с вероятностью
Fit(/#)
*• r-q-r
2>щт#)
i=\
Условие останова многопопуляционного ГА - разность функций фитнесса
разных популяций, участвующих в обмене за несколько последних поколений
меньше 5. Так, если развиваются только две популяции, то условие останова за
последние / поколений имеет вид
Z|FitL-FitL|<5.
6.9. Исследование ГА для решения задачи обучения НС
Для повышения достоверности принимаемых на основе НС решений
необходимо исследовать алгоритмы оптимизации, являющиеся альтернативой
методу обратного распространения. Наиболее перспективными в этом плане и
являются рассмотренные выше генетические алгоритмы оптимизации.
Для выполнения процедуры оптимизации по ГА необходимо:
1) подобрать представление оптимизационных параметров в виде
определенного формата данных: строки, вектора, таблицы, массива и т. д.;
2) разработать или выбрать из набора генетических операторов такие,
которые наилучшим образом учитывают особенности поискового пространства;
3) определить размер начальной популяции;
4) разработать методику использования генетических операторов;
5) задать функцию фитнесса или приспособленности (целевую функцию,
по которой производится отбор вариантов в популяцию);
6) разработать методику отбора вариантов в новую популяцию;
7) задать критерий останова эволюционного процесса.
Для минимизации ошибки обучения НС на основе ГА каждому варианту
вектора весовых коэффициентов будем ставить в соответствие некоторую
хромосому, представленную в виде битовой строки.
Как оказалось, использование классических операторов селекции является
не всегда эффективным, необходимы новые операторы выбора хромосом для
скрещивания - операторы рекомбинации, которые позволяют уменьшить
число переборов и, соответственно, время сходимости алгоритма оптимизации
(рис. 6.6). Введение операторов рекомбинации связано с тем, что в реальном
биологическом пространстве существования генотипов имеет место
неравномерность их распределения по классам, наличие видов, семейств, родов. По-
162
6.9. Исследование ГА для решения задачи обучения НС
Я„
Им
Яя
я„
«1
«2
«3
«4
«5
*i
*>2
*3
*4
ъ,
С\
с2
сз
с4
<Ч
4
rf2
</3
rf4
ds
°i
<h
c,
C2
C3
c,
C2
*>1
ь2
6,
«i
«2
«3
4
<*2
J,
^2
4
*,
Ь
Я,
Я,
я.
я.
Рис. 6.6. Оператор рекомбинации:
А, В- классы хромосом в двумерном пространстве
этому в целях исследования «дальнего родства» целесообразно производить
скрещивание хромосом, находящихся на самом дальнем расстоянии друг от друга.
В результате применения операторов рекомбинации «дальнего родства» к
различным классам генотипов (см. рис. 6.6) происходит переход в другие
области поискового пространства. Выбор хромосом, относящихся к различным
классам для выполнения операции рекомбинации, осуществляется по
вычисляемой между хромосомами мере различия («радиусу скрещивания») R; в
рекомбинации участвуют хромосомы, мера различия которых является
наибольшей. Если хромосомы рассматривать как точки метрического пространства,
например, как n-мерные векторы Н = (Л,, h2, ..., hn), координатами которых
являются значения генов, то в качестве меры различия двух хромосом можно
принять евклидово расстояние между ними. В случае представления
хромосом в виде двоичных строк качестве меры различия используется расстояние
Хемминга.
При входе в область существования экстремума для повышения скорости
сходимости алгоритма скрещивание осуществляется между хромосомами,
расстояние между которыми является наименьшим («близкое родство»).
Оператор рекомбинации имеет естественный аналог, при этом в операции
скрещивания участвуют две пары хромосом. В соответствии с этим правилом из
популяции выбираются по две пары хромосом из каждого класса Нп, Нп и Н21,
Н22. Между двумя хромосомами первой пары и двумя хромосомами второй пары
выполняется оператор скрещивания. В результате получаются четыре новых
163
6. Обучение НС на основе генетического алгоритма
решения H3,H4,HS, H6 (см. рис. 6.6).
Применение предлагаемых операторов
скрещивания позволяет во многих случаях
переходить из одной локальной области
пространства решений в другую, а в
пределах одной области осуществлять поиск
лучших решений.
Процент хромосом, подвергающихся
мутации, задается коэффициентом
мутации, который определяется эксперимен-
Рис. 6.7. Типы хромосомной мутации: тально. Эффективным (с точки зрения
а - инверсия, б-транслокация выхода из локального экстремума)
является использование кроме генной
мутации (изменение одного гена в хромосоме) хромосомной мутации (хромосомной
перестройки). В генетике рассматриваются типы хромосомной мутации,
изменяющие структуру целой хромосомы: делеция (потеря участка хромосомы),
дефишенси (концевые нехватки хромосом), дупликация (удвоение участков
хромосом), инверсия (перестройка части генов в обратном порядке),
транслокация, т. е. перенос части генов в той же хромосоме на новое место (образование
изохромосомы, рис. 6.7).
Данные типы перестроек играют очень важную роль в естественной
эволюции организмов, позволяя переходить к другим видам. Построение операторов
мутации генетического алгоритма на их основе, как показали эксперименты,
позволяет обходить локальные экстремумы. В процессе отбора проводится
направленный поиск хромосом, которые являются ценными в смысле некоторой
заданной целевой функции (функции фитнесса), в качестве которой в процедуре
обучения НС используется функция ошибки обучения Е.
Будем считать, что топология сети задана. В топологии МНС некоторые связи
между нейронами различных слоев могут отсутствовать или существовать
перекрестные связи между нейронами в слоях, не являющихся соседними.
Хромосома будет представлять собой вектор действительных чисел, кодирующий
вектор весовых коэффициентов связей нейронов входного слоя с нейронами
одного или нескольких скрытых слоев, а также связи между нейронами скры-
Фенотип
wn
wu
...
Wu
W2\
...
W2l
...)
Генотип
Ли
Л12
...
Л,/
Л2)
...
Л2/
...)
Рис. 6.8. Кодирование потенциальных решений
164
6.9. Исследование ГА для решения задачи обучения НС
Xi X2 Х„ Xi Х2 Х„ Х{ Х2 Х„
НС, НС2 HQ
Рис. 6.9. Популяция НС
тых слоев и нейронами выходного слоя. Таким образом, каждой i-й
реализации, i = 1, ..., к вектора весовых коэффициентов W = {wn, wn, ..., wkn, ...}на
уровне генотипа соответствует хромосома Н. = {hu, й12, ..., Л1/5 ...}(рис. 6.8).
Начальная популяция формируется из Этаких хромосом (рис.6.9).
Для нахождения варианта W*, соответствующего заданной минимальной
ошибке обучения Е, необходимо знать, насколько близко каждое из
полученных на /-м этапе эволюции решений к оптимальному. Это означает, что должен
быть механизм соответствия генотипов и фенотипов для вычисления
значений функции качества Fit фенотипа.
Для определения Е каждый г-й вектор весовых коэффициентов W( (фенотип),
закодированный в хромосоме /У (генотип), обучается на «своей» НС. Тогда ошибка
обучения г-й НС Е. может быть вычислена по результатам ее обучения:
£ = HC(\V), (6.1)
где НС( - НС для обучения вектора W.
Ошибка Е, и будет функцией фитнесса Fit для хромосомы, кодирующей
вектор W.
Само понятие обучения НС при использовании ГА, в отличие от
традиционных методов обучения, имеет несколько иной смысл: обучение здесь
заключается в применении генетических операторов к генотипу вектора весовых
коэффициентов, т. е. к хромосоме Ht, а обучающая выборка служит для вычисления
ошибки обучения НС с конкретными значениями Wf.
При отборе хромосом в новую популяцию используется следующее
правило: чем меньше целевая функция для данной хромосомы ТУ (чем меньше
ошибка сети), тем выше вероятность выбора этой хромосомы для репродукции.
165
6. Обучение НС на основе генетического алгоритма
При определении лучшего варианта используется: лучшая Нъ текущей
популяции (элитная хромосома) и лучшая Ht в нескольких популяциях (в этом
случае функция фитнесса Fit может быть вычислена на текущей либо на
последних / популяциях).
Сравнение вариантов хромосом в текущей популяции проводится на основе
нормализованного Fitnorm. Оценочная функция такого вида показывает вес
данного варианта во всей популяции. Вычислить Fit можно по формуле
Fitnorm (#,) = -
Fit(#, )
2>t(", )
(6.2)
i=i
где Hi - i-я хромосома (i-й вариант реализации W); k - количество вариантов
впопуляции.
На основе ошибки обучения (6.2) на следующем шаге работы алгоритма
осуществляется отбор хромосом (вариантов W) для репродукции новых
поколений. Размер текущей популяции в этом случае обычно уменьшается до
размера начальной популяции по соответствующим алгоритмам. Для этого может
быть использован модифицированный оператор пропорционального отбора oth
(рис. 6.10).
Таким образом, процедура оптимизации по ГА является итерационной и
включает два повторяющихся этапа:
1) синтез новых хромосом (скрещивание и мутация);
2) отбор хромосом в новую популяцию.
Процесс продолжается до тех пор, пока не будет получено оптимальное
решение или заданное число поколений. При этом каждая последующая
популяция должна быть лучше предыдущей. Решению задачи соответствует
хромосома с минимальным значением фитнесс-функции, определяющая оптимальный
вектор весовых коэффициентов W, при этом ошибка обучения Е должна быть
Исходная
популяция
g
Новая
популяция
Рис. 6.10 Схема отбора хромосом в новую популяцию:
а, Ь, с, d, e,f,g,h- хромосомы текущей популяции; Ъ, d, e, g- хромосомы новой популяции
166
6.9. Исследование ГА для решения задачи обучения НС
меньше заданной величины 6. Если условие останова обучения по
оптимальному решению не может быть выполнено, то происходит завершение процедуры
обучения по заданному числу поколений с выбором элитной хромосомы в
одном или нескольких поколениях. В зависимости от вида используемых
генетических операторов и схемы отбора можно сконструировать различные ГА для
обучения НС, каждый из которых будет эффективным с точки зрения скорости
сходимости и наилучшего приближения к минимуму ошибки обучения.
Запишем алгоритм обучения МНС с помощью ГА.
1. Задать обучающую и тестовую выборку.
2. Сформировать топологию МНС.
3. Задать функцию Fit в виде
р
E = \YA.d-yy, (6.3)
Г /=i
где Р - число примеров в обучающей выборке; d, - желаемая величина
выхода; у, - реальное значение выхода.
4. Используя метод числового кодирования, представить хромосомы с
учетом заданной топологии МНС. Установить соответствие между генотипом и
фенотипом, введя ограничения на возможные значения весовых
коэффициентов, учитывая вид функции активации (для сигмоидальной функции
активации диапазон изменения значений весовых коэффициентов (-1, +1)).
5. С учетом результатов экспериментального исследования ГА выбрать
генетические операторы, являющиеся наилучшими при оптимизации
многоэкстремальных функций и функций многих переменных. Задать максимально
возможную ошибку обобщения Ео6щ - е.
6. Сформировать популяцию ГА из г хромосом, выбрать число поколений
(итераций - с).
7. Применить оператор селекции для выбора пар хромосом для скрещивания.
8. Применить генетические операторы кроссинговера и мутации к популяции.
9. Вычислить функцию Fit, соответствующую ошибке обучения Е для
каждой хромосомы по формуле (6.3).
10. Применить оператор отбора хромосом в новую популяцию из родителей,
потомков и мутантов с ограничением популяции до г. Лучшая хромосома из
каждой популяции сохраняется в архиве.
11. с:= с - 1. Если с = 0, перейти к п. 12, иначе к п. 7.
12. Выбрать лучшую хромосому из всех популяций.
13. Вычислить £'о6щна тестовой выборке по формуле (6.3), где Р - число
примеров в тестовой выборке.
14. Если £'о6щ<= е, перейти к п. 15, иначе к п. 6.
15. Конец.
167
б. Обучение НС на основе генетического алгоритма
Ошибку распознавания НС, обученной с помощью ГА, можно существенно
уменьшить, если использовать двухэтапныи алгоритм. Двухэтапныи алгоритм
обучения НС на основе ГА представляется следующим образом.
Шаги с 1 по 11 алгоритма двухэтапного обучения не отличаются от
приведенного выше алгоритма.
Шаг 12. Выбрать лучшую хромосому из всех популяций. Выполнить cl
итераций по какому-либо методу локальной оптимизации на фенотипе (метод
оптимизации и параметр с/ задаются пользователем).
Далее шаги с 13 по 15 те же, что и для ГА.
Эффективность функционирования алгоритма обучения МНС на основе ГА
во многом определяется выбранными значениями его параметров: типом
операторов кроссинговера и мутации, вероятностью скрещивания и мутации,
размерностью популяции, способом формирования популяции и т. д. Методики
выбора этих параметров не являются однозначными. Использование
Конструктора ГА для подбора его параметров при решении задач обучения
конкретных НС позволяет значительно сократить время формирования ГА.
6.10. Управляемый алгоритм обучения нейронной сети
на основе генетического поиска и имитации отжига
Алгоритм имитации отжига {simulated annealing) основывается на понятии
тепловой энергии, введенной С. Кирпатриком. Автор алгоритма использовал
«тепловой шум» для выхода из локальных минимумов и для повышения
вероятности попадания в более глубокие минимумы. При решении сложных задач,
когда вычислительные затраты на решение задачи оптимизации аналогичны
энергии шарика, перемещающегося по поверхности, поиск более дешевых
решений разумно начинать в ситуации с высоким уровнем «теплового шума», а в
дальнейшем постепенно уменьшать его; этот процесс Кирпатрик назвал
«имитацией отжига».
Метод имитации (моделирования) отжига базируется на аналогии с
процессом отжига металла, в результате которого металл приобретает новые
свойства. При отжиге металл вначале подвергается нагреву почти до точки
плавления, а потом медленно охлаждается до обычной температуры. Эта процедура
делает металл более гибким и позволяет легко придать ему необходимую
форму. Когда металл быстро нагревается до высокой температуры, его атомы
начинают двигаться случайно, и, если его также быстро остудить, то атомы
фиксируются в случайных состояниях. Но если металл охлаждать медленно,
то атомы пытаются выстроиться некоторым регулярным образом. Поэтому
основой процесса отжига металла является процедура управления графиком
снижения температуры.
168
6.10. Управляемый алгоритм обучения НС
Аналогично методу имитации отжига металла можно действовать при
поиске глобального экстремума (например, минимума) некоторой функции.
Вначале выбирается диапазон, в котором будут оцениваться значения функции в
случайно выбранных точках, при этом запоминаются наименьшие из них.
Затем диапазон уменьшается, и снова оцениваются значения функции в
случайно выбранных точках, при этом сохраняются меньшие из этих значений.
Процесс повторяется с постепенным уменьшением диапазона исследования
функции.
Выбор диапазона и постепенное его уменьшение аналогично установке
начальной температуры и изменению этой температуры на последующих
стадиях. Схема работы алгоритма имитации отжига в наиболее простом виде может
быть представлена в следующем виде.
1. Выбирается начальное приближение Xf, счетчика времени t и начальной
температуры 7.
2. В точке Х( вычисляется значение функции Е(Х).
3. Случайным образом генерируется новая точка в пространстве
допустимых решений: Х<+1 = т(Х ,7), где т - функция генерации, и вычисляется значе-
ние£(Хм).
4. Точка Хг+1 становится текущей с вероятностью 1, если E(Xl+t) < £(Х() и с
вероятностью ехр{[ £(Х() - E(XM)]/T(t)}, если £(Х+1) > £(Х).
5. Если заданное число итераций в температуре 7 не достигнуто, то 7":= аТ,
где а - коэффициент уменьшения температуры (a g [0, 1]).
6.t:=t + l.
7. Если критерий останова не достигнут, то шаги 2-7 повторяются.
Алгоритм имитации отжига обладает следующими характеристиками:
• простота структуры, легкость понимания и реализации, гибкая настройка
на специфику решаемой задачи (посредством выбора функции генерации тп и
коэффициента а, значение которого обычно выбирается из диапазона от 0,8 до
0,9999, а начальное значение 7 выбирается так, что для всех изменений
функций Е имеет место неравенство: ехр(-АЕ/Т) > 0,9999;
• допускается использование алгоритма для решения оптимизационных
задач различной природы, для оптимизации недифференцируемых, разрывных,
зашумленных функций;
• пространство оптимизируемых параметров может быть разнородным и
включать как комбинаторные структуры, так и действительные параметры;
• алгоритм комбинирует методы как глобальной, так и локальной
оптимизации: на начальных стадиях оптимизации, когда температура высока,
исследуется все пространство допустимых решений и с высокой вероятностью
отыскивается область «хороших решений»; при снижении температуры
осуществляется быстрая сходимость к точке локального минимума.
169
6. Обучение НС на основе генетического алгоритма
Определим алгоритм обучения НС на основе ГА и имитации отжига в
следующем виде.
1. Сформировать начальную популяцию. Вычислить функции фитнесса для
всех хромосом популяции: Fit(/^), k = 1,2,..., г. Установить начальное и
конечное значение параметров имитации отжига Г0и Тк. Задать число а в интервале
[0,1], определяющее скорость изменения параметра Т:
2. Применить к популяции генетические операторы.
3. Вычислить новые значения функций фитнесса для всех г хромосом текущей
популяции. Определить приращение функции фитнесса AFit(//A), к = 1,2,..., г,
где AFit(//A) = Fit' (Нк) - Fit ,х(Нк), а / - номер текущей популяции. Вычислить
среднее значение AFitc (H) по всей популяции.
4. Определить вероятность развития популяции. Если exp(-AFitc )/T) > 0, то
переход к п. 2, иначе к п. 5.
5. Изменить параметр Г в соответствии с заданным законом изменения Т.
6. Проверить критерий останова. Если за последние с популяций суммарное
изменение AFit(//A) > е (где сие задается пользователем), переход к п. 2, в
противном случае - переход к п.7. Альтернативный вариант: если текущее
значение t < tk, то переход к п. 2, иначе - к п. 7.
7. Останов.
Значительное влияние на эффективность метода имитации отжига
оказывает выбор начальной температуры Т, значения коэффициента уменьшения
температуры а, а также количества циклов с, выполняемых на каждом
температурном уровне.
Максимальная температура и коэффициент а обычно определяются путем
проведения большого числа предварительных экспериментов и
статистической оценкой результатов. Количество циклов с удается сократить более
частым изменением температуры при сохранении общего объема итераций.
Наибольшее ускорение процесса имитации отжига при обучении МНС может быть
достигнуто, если предварительно определить значения весовых
коэффициентов с использованием любых доступных методов статистической обработки
исходных данных.
Другая идея повышения эффективности работы комбинированного
алгоритма на основе генетического поиска и алгоритма имитации отжига связана с
коррекцией операторов ГА в процессе поиска решения. Рассмотрим
реализацию этой идеи.
170
6.10. Управляемый алгоритм обучения НС
Модификация оператора генной мутации
Применение оператора случайной мутации в ГА фактически означает
формирование новых генов, что, в конечном итоге, приводит к расширению
области поиска и повышению вероятности нахождения оптимального решения.
Однако случайные мутации с равной вероятностью могут привести как к
увеличению значения функции фитнесса, так и к ее уменьшению. Поэтому на
этапе сходимости генетического алгоритма к оптимуму целесообразно
уменьшать вероятность случайной мутации. Таким образом, желательно
динамически управлять вероятностью случайной мутации в процессе работы ГА: на
начальном этапе поиска значение вероятности должно быть достаточно высоким
(0,05 ...0,1), а на конечном этапе - стремиться к нулю.
Для реализации этой процедуры воспользуемся аналогией имитации
отжига. В соответствии с формулой Н. Метрополиса (Metropolis N.) вероятность
принятия изменения состояния системы пропорциональна управляющему
параметру Г (аналога температуры). При больших значениях Т вероятность
принятия измененного состояния велика, что соответствует большой величине
вероятности случайной мутации на начальном этапе работы алгоритма (для
увеличения генетического разнообразия). Чем меньше Т, тем меньше
вероятность принятия измененного состояния, что имеет место на этапе сходимости
ГА. Таким образом, вероятность случайной мутации должна динамически
изменяться от итерации к итерации (при переходе от одного поколения к
другому), для этого:
где/?0 - начальное значение вероятности случайной мутации; Т-
управляющий параметр.
Модификация операторов селекции
Применение стандартных и разработанных операторов кроссинговера
требует определения стратегии выбора пар хромосом в операциях скрещивания
на отдельных этапах работы ГА с целью повышения качества получаемого
решения. Организация динамической стратегии скрещивания на основе
имитации отжига позволяет варьировать методы селекции пар хромосом: случайный
выбор, лучший с лучшим, лучший с худшим, «близкое родство», «дальнее
родство», лучший со всеми и т. д.
Случайный выбор пар хромосом позволяет разнообразить генофонд на
ранних стадиях работы ГА. Вероятность этого выбора должна снижаться при
эволюции поколений. Тогда
где г - размер популяции; р*
бора пар.
р = ро^-ЦП,
■ начальное значение вероятности случайного вы-
171
6. Обучение НС на основе генетического алгоритма
Вероятность скрещивания лучших хромосом с худшими р ,
оцениваемыми по значению функции Fit, также должна уменьшаться при эволюции
поколений.
Выбор первой хромосомы Ht осуществляется с вероятностью
Fit,
Pl = -exp[-l/7].
ZFit
Выбор второй хромосомы Н
*=1 *
1 1
7^ = — ехр[-1/7].
Щ £±
« Fit,
Вероятность скрещивания лучших хромосом с лучшими (р ) должна
увеличиваться на последних этапах алгоритма для закрепления желаемых
признаков в хромосомах. В этом случае вероятность выбора хромосом
Fit,
Рт=г (1-ехр[-1/7]).
ZFit
«Близкое родство». Вероятность выбора хромосом, подлежащих
скрещиванию, определяется следующим образом:
- для первой хромосомы Н\
/b=V^(l-exp[-l/7]),
где р\ - вероятность «близкого родства» на последних стадиях работы
алгоритма;
- для второй хромосомы Hj вероятность pJc вычисляется по приведенной
выше формуле, но из оставшихся хромосом Р\ {Н.}, где Р - текущая популяция.
Затем вычисляется Хеммингово расстояние между выбранными
хромосомами текущей популяции dist(i//( H), равное количеству позиций с
несовпадающими значениями генов в хромосомах. Хромосомы подлежат скрещиванию,
если dist<i?, где R - радиус скрещивания, задаваемый априорно. Вероятности
р'6 и р>ъ возрастают на конечных стадиях работы алгоритма.
«Дальнее родство». В этом случае вероятность выбора хромосом Н. и Н.
осуществляется по формуле
^= V^expR/7],
где р° - вероятность «дальнего родства» на начальных стадиях работы ГА, с
учетом особенностей вычисления для первой и второй хромосомы.
172
6.10. Управляемый алгоритм обучения НС
Хромосомы //и Н подлежат скрещиванию, если Хеммингово расстояние
между ними dist > R. Вероятностир npJ уменьшаются на конечных стадиях
поиска оптимального решения.
Модификация операторов отбора
Для формирования репродукционной группы в комбинированном алгоритме
на основе ГА и имитации отжига использовались две схемы отбора:
1) равновероятный отбор с вероятностью
р{Нк) = \1г,
где г - размер популяции;
2) пропорциональный
Fit
!*#*) =-Г-*-,
ZFit
где FitA - значение фитнеса для к-й хромосомы.
Для динамической стратегии отбора на основе имитации отжига имеем:
1 Fit.
р(Нк) = -±- ехр[-1/7] + ^- (1 - ехр[-1/7]).
iFit
i=i *
Тогда при t -» оо р{Нк) -> 1/г (равновероятный отбор);
Fit,
при Т-> Ор(Нк) -» (пропорциональный отбор).
iFit
Таким образом, с помощью операторов отбора на ранних стадиях работы
комбинированного алгоритма происходит выбор хромосом без учета значений
их функции ¥ЩНк), т. е. имеет место случайный отбор, на заключительной
стадии определяющим фактором при отборе является значение функции Fit(Hk):
чем выше Fit(Hk), тем выше вероятность отбора Нк в следующую популяцию.
Совокупность рассмотренных динамических стратегий на основе
имитации отжига для основных генетических операторов (мутации, селекции пар
хромосом для скрещивания и отбора) определяет механизм управления
процессом генетического поиска. Данный механизм в процессе поиска
оптимального решения позволяет на начальных стадиях работы комбинированного
алгоритма проводить больше случайных операций с целью повышения генетического
разнообразия популяций: большой процент случайной генной мутации,
«дальнее родство», скрещивание лучших и худших хромосом, случайный отбор.
173
6. Обучение НС на основе генетического алгоритма
На заключительной стадии проводится уменьшение случайных операций и
постепенно увеличивается процент направленных операций: «близкое родство»,
скрещивание лучших хромосом, пропорциональный отбор.
Упражнения и вопросы для самоконтроля
1. Дайте определение генетического алгоритма и перечислите основные
генетические операторы.
2. Каковы основные преимущества ГА оптимизации по сравнению с методом
обратного распространения ошибки при обучении НС?
3. Как повысить эффективность работы ГА?
4. Сформулируйте основную идею алгоритма имитации отжига.
5. Что такое многопопуляционный алгоритм?
6. Перечислите возможные модификации генетических операторов.
7. Как оценивается получаемое с помощью ГА решение?
7. РЕКУРРЕНТНЫЕ И АССОЦИАТИВНЫЕ
НЕЙРОННЫЕ СЕТИ
Рассмотрены архитектуры и проблемы функционирования НС с обратным
распространением информации, а также ассоциативные НС. Приведены алгоритмы обучения сетей
Хопфилда, Хемминга, машины Больцмана и НС на основе ассоциативной памяти. Даны
решения некоторых прикладных задач.
7.1. Характеристики ассоциативной памяти
Ассоциативная память (или память с адресацией по содержанию) -
запоминающее устройство, состоящее из ячеек, в которых хранятся данные.
Выборка и запись в эти ячейки проводится в зависимости от содержащейся в них
информации.
Выборка данных на основе их содержания обычно предполагает ту или иную
форму сравнения задаваемого извне класса, по которому должен
осуществляться поиск, с некоторой частью или со всей информацией, которая хранится
в ячейках памяти. Целью сравнения не обязательно должно быть появление
информации, совпадающей с ключевой. Если, например, записанные в памяти
данные имеют числовые значения, поиск по содержанию может заключаться в
отборе только тех ячеек, в которых хранятся величины, удовлетворяющие
определенным числовым отношениям (больше или меньше некоторого значения,
или располагающиеся внутри заданного интервала). Поиск по содержанию
может осуществляться и без задания внешней ключевой информации,
например, при нахождении максимального либо минимального значения из
хранимого набора. Возможен также вариант поиска, при котором необходимо среди
совокупности данных найти такие, которые наилучшим образом (в смысле
некоторой заданной меры) соответствуют задаваемой ключевой информации. В
такой постановке задача ассоциативной выборки близка к задаче
распознавания образов.
175
7. Рекуррентные и ассоциативные НС
С ассоциативной памятью связано понятие ассоциаций. Для формирования
ассоциации простейшего вида достаточно установить непосредственную связь
между хранимыми в памяти двумя или большим числом объектов или
событий. Существование связи между двумя или несколькими объектами может
обнаружиться также в том случае, когда их представления объединены
косвенно посредством некоторой цепочки перекрестных ссылок. Наличие такой
цепочки проявляется лишь на этапе выборки информации. При этом в памяти
должно иметься несколько прямых ассоциаций, в состав которых входят
общие или идентичные объекты.
По степени соответствия объектов различают автоассоциации и гетероассо-
циации. Автоассоциации реализуются при условии соответствия соотносимых
объектов, при этом объект обнаруживается по его произвольным частям,
имеющим большую или меньшую корреляцию с искомым объектом. Для гетероас-
социаций характерно то, что определяемый объект структурно не
соответствует ни одному из хранимых объектов и формируется как ответ на ключевой образ.
Ассоциативной памяти человека присущи следующие особенности:
• поиск информации в памяти основывается на некоторой мере,
определяющей меру сходства с ключевым образом;
• память способна хранить образы структурированных
последовательностей;
• выборка информации из памяти представляет собой динамический
процесс.
На основе исследования ассоциативной памяти человека был построен Ас-
социатрон {Накано К., 1969) - модель ассоциативной памяти. Ассоциатрон -
это упрощенная модель НС, состоящей из нейронов, каждый из которых
связан со всеми остальными нейронами синаптическими связями, причем все
нейроны работают параллельно. С помощью такой сети смоделирована одна из
функций человеческого мозга - ассоциативность мышления. Ассоциатрон
запоминает образы, представленные в виде бинарного вектора. По части
входного образа сеть может восстановить полный образ, при этом может
запоминаться любое количество образов, но точность и полнота воспроизведения
уменьшаются с увеличением числа образов.
Элемент обучающей выборки (образ) в сети Накано представлял собой
w-мерный вектор X = (*,, х2, ..., хп), где xt = -1, 0, 1. Образ мог включать
несколько понятий, в том числе и имя образа. Например, понятия «большой»,
«красивый», «красный» и «дом» задают входной образ. Возбуждение одного из
понятий приводит к возбуждению всего образа с его именем и всеми
свойствами. Таким образом, Накано К. объединил в одной конструкции имя объекта и
его свойства, что является особенно важным для построения систем принятия
решений.
176
7.2. Рекуррентные нейронные сети
7.2. Рекуррентные нейронные сети
В рекуррентных НС выходы некоторых нейронов соединены обратной
связью с входами других нейронов. Пример такой сети показан на рис. 7.1. Эта
НС состоит из (К + Р + Q) нейронов {К - число выходных нейронов, Q -
скрытых нейронов, Р — входных нейронов).
Отличительная особенность рекуррентных НС заключается в передаче
сигналов с выходного или скрытого слоя на входной слой. Состояние сети
определяется Р входными сигналами дс,, х2, ..., хр, Q задержанными сигналами от
скрытого слоя м,, иу ..., uQ и К сигналами от выходного слоя_у15>>2,.. .,ук.
Вследствие существования обратной связи, изменение состояния одного нейрона в
сети приводит к переходному процессу, в результате которого в сети
формируется новое устойчивое состояние. Полученное состояние в общем случае
может отличаться от предыдущего. Выходной сигнал /-го нейрона в
рассматриваемой сети вычисляется по формуле:
'—^"
>-
s-1
=-1
_-1
_-|
" ^^^^"^^ ~^^^Sm \- ^/
\\/^><СГ///
Л^" \ \ г ft^l \
•Sv_ \ v / л ЗЖ )
ф£>^ X^Tff Л "1
//Lf>~y9c\
лГ^'' /// ^М ] "с
- ■ • /// X / ^Jw\ J—
У\
—>-
Ук
Скрытый
слой
*1
Хр
Рис. 7.1. Пример рекуррентной НС: г"1 - задержка на один временной такт
177
7. Рекуррентные и ассоциативные НС
где t - номер такта изменения сигнала: 0, 1,2,...; w(1),wjf,wj?' - веса нейронов
от входа, скрытого и выходного слоев соответственно. Использование символа
<</7» в приведенной формуле означает, что могут существовать не все связи между
нейронами, т. е. некоторые связи являются нулевыми.
Таким образом, приведенное уравнение описывает динамическую
систему, в которой выходы могут быть детерминированными, если известны
начальные условия и входные сигналы. Если конструировать сеть без входных
сигналов и без скрытого слоя (Q=0), то получим сеть Хопфилда, в которой входные
сигналы рассматриваются как начальные условия системы. Выходные
сигналы наблюдаются после определенного числа итераций. Сеть Хопфилда имеет
конечное число состояний и может рассматриваться как ассоциативная память.
7.3. Сеть Хопфилда
В 80-е годы прошлого столетия НС, реализующими ассоциативную память,
начал заниматься Дж. Хопфилд из Калифорнийского технологического
института. В общем виде анализ ассоциативных сетей является затруднительным.
Дж. Хопфилд показал, что существует частный вариант такой сети.
Структурная схема сети Хопфилда приведена на рис. 7.2. Эта сеть состоит
из единственного слоя нейронов, число которых является одновременно
числом входов и выходов сети. Каждый нейрон связан со всеми остальными
нейронами, а также имеет один вход, через который осуществляется ввод сигнала.
Выходы
Рис. 7.2. Структурная схема сети Хопфилда
178
7.3. Сеть Хопфилда
В сети Хопфилда нейроны принимают решения асинхронно, связь между ними
осуществляется мгновенно и все связи симметричны, т. е. wt . = w . При этих
ограничениях все возможные состояния сети образуют некое подобие
холмистой поверхности, а текущее состояние сети аналогично поведению тяжелого
шарика, пущенного на эту поверхность: он движется вниз по склону в
ближайший локальный минимум. Каждая точка поверхности соответствует
некоторому сочетанию активностей нейронов в сети, а высота подъема поверхности в
данной точке характеризует «энергию» этого сочетания (называемую
функцией Ляпунова), которую можно представить следующим образом:
1 " п п
(7.1)
1=1 7=1
i=l
где w,j- вес связи нейронов i иу; у, - выходной сигнал нейрона г; у - выходной
сигнал нейронау; х, - входной сигнал нейрона /.
Обычно Е интерпретируется как некоторая обобщенная энергия. Если связь
между какими-то нейронами имеет большой положительный вес, то
сочетания, в которых эти нейроны активны, характеризуются низким уровнем
энергии - именно к таким сочетаниям будет стремиться вся сеть. И наоборот,
нейроны с отрицательной связью при активизации добавляют к энергии сети
большую величину, поэтому сеть стремится избегать подобных состояний.
Такая интерпретация берет начало от известной модели Изинга, в которой
совокупность взаимодействующих магнитных диполей (спинов) стремится
занять такое положение, в котором суммарная энергия будет минимальна.
Модель Хопфилда по сравнению с моделью Изинга имеет следующие особенности:
• коэффициенты связей могут принимать любые значения, как
положительные, так и отрицательные;
• значения коэффициентов связи не являются фиксированными и могут
изменяться в процессе обучения.
Чтобы обучить сеть, необходимо
сформировать соответствующий профиль
энергетической поверхности (рис. 7.3),
т. е. выбрать веса таким образом, чтобы
при фиксировании каждого входного
вектора сеть приходила к энергетическому
минимуму, соответствующему нужному
выходному вектору.
Важнейшее свойство сети Хопфилда
состоит в том, что одна и та же сеть с
одними и теми же весами связей может хра-
179
т
Начальное состояние
5 s
i4 H
«и о
п.
в
Г)
Эталон 1 Эталон 2 Эталон 3
Рис. 7.3. Состояния сети
7. Рекуррентные и ассоциативные НС
нить и воспроизводить несколько различных эталонов. Каждый эталон
является аттрактором, вокруг которого существует область притяжения. Любая
система с несколькими аттракторами, к которым она тяготеет, может
рассматриваться как содержательно адресуемая память, т. е. как ассоциативная память.
Если системе задается некоторое начальное состояние, отличное от
эталонного, то это равносильно заданию частичной информации об эталоне. Если
начальное состояние близко к эталону и попадает в область его притяжения, то
система начинает двигаться к этому эталону - «вспоминает» его. Это можно
представить как процесс восстановления неверно заданных или
отсутствующих признаков эталонного образа, восстановление полной информации о нем.
Если одним из признаков, предъявлявшихся при обучении, является имя
класса, то его восстановление будет равносильно отнесению образа к
определенному классу, т. е. распознаванию.
Задача, решаемая данной сетью, рассматриваемой как ассоциативная
память, как правило, формулируется следующим образом. Известен некоторый
набор двоичных сигналов (изображений, звука, данных, описывающих
некоторые объекты или характеристики процессов), которые считаются
образцовыми. Сеть должна уметь из произвольного неидеального сигнала, поданного
на ее вход, выделить («вспомнить» по частичной информации)
соответствующий образец (если такой есть) или «дать заключение» о том, что входные
данные не соответствуют ни одному из образцов. В общем случае, любой сигнал
может быть описан вектором X = { х: i = 0,.... и-1}, где и - число нейронов в
сети и размерность входных и выходных векторов.
Каждый элемент х. равен либо +1, либо -1. Обозначим вектор,
описывающий k-й образец, через X*, а его компоненты соответственно - хД к=О,..., т-\,
где т - число образцов. Когда сеть распознает (или «вспомнит») какой-либо
образец на основе предъявленных ей данных, ее выходы будут содержать
вектор выходных значений сети Y = X*, при этом Y = { у: i = 0,..., п-\}. В
противном случае, выходной вектор не совпадет ни с одним образцом.
V
F
0
X
+1
0
,
X
-1
а б
Рис. 7.4. Функции активации сетей
Хопфилда (а) и Хемминга (б)
180
7.4. Машина Больцмана (вероятностная сеть)
Алгоритм обучения сети Хопфилда основывается на правиле Хебба и
включает следующие шаги.
1. Начальная установка значений выходов (активационные функции имеют
вид, представленный на рис. 7.4, а:
yi(0) = xi,i = 0,l,...,n-l.
2. Рассчет новых состояний нейронов:
п-1
Sjif +1) = 2>0ЛО. у=0,..., п-1,
/=о
и новые значения выхода
где t - номер текущей итерации;/- ступенчатая функция активации с
порогами (+1,-1).
3. Проверка изменения выходного сигнала. Если да - переход к шагу 2,
иначе (если выходной сигнал находится в зоне притяжения определенного
аттрактора и не меняется) - конец. При этом выходной вектор представляет
собой образец, наилучшим образом сочетающийся с входными данными.
7.4. Машина Больцмана (вероятностная сеть)
Одним из основных недостатков сети Хопфилда является тенденция
«стабилизации» выходного сигнала в локальном, а не в глобальном минимуме.
Желательно, чтобы сеть находила глубокие минимумы чаще, чем мелкие, и чтобы
относительная вероятность перехода сети в один из двух различных
минимумов зависела только от соотношения их глубин. Это позволило бы управлять
вероятностями получения конкретных выходных векторов путем изменения
профиля энергетической поверхности системы за счет модификации весов
связей.
Идея использования «теплового шума» для выхода из локальных
минимумов и повышения вероятности попадания в более глубокие минимумы
принадлежит С. Кирпатрику. На основе этой идеи разработан алгоритм имитации
отжига.
Введем некоторый параметр t— аналог уровня теплового шума. Тогда
вероятность активности некоторого нейрона к определяется на основе
вероятностной функции Больцмана:
Рк= \ , (7.2)
* 1 + ехр(-Д£*/0
где t - уровень теплового шума в сети; АЕк - сумма весов связей к-то нейрона
со всеми активными в данный момент нейронами. Кривая изменения
вероятности активности к-го нейрона показана на рис. 7.5. При уменьшении /
колебания активности нейрона уменьшаются; при t = 0 кривая становится пороговой.
181
7. Рекуррентные и ассоциативные НС
Рис. 7.5. Изменение вероятности активности
нейрона в зависимости от параметра /
Специалисты по статистике называют такие сети случайными
марковскими полями. Сеть, использующая для обучения алгоритм имитации отжига,
названа машиной Больцмана в честь австрийского физика Л. Больцмана, одного
из создателей статистической механики. Сформулируем задачу обучения
вероятностной сети, в которой вероятность активности нейрона вычисляется по
формуле (7.2). Пусть для каждого набора возможных входных векторов
требуется получить с определенной вероятностью все допустимые выходные
вектора. В большинстве случаев эта вероятность близка к нулю.
Процедура обучения машины Больцмана сводится к выполнению
следующих чередующихся шагов:
1. Подать на вход сети входной вектор и зафиксировать выходной (как в
процедуре обучения с учителем). Предоставить сети возможность приблизиться
к состоянию теплового равновесия:
а) приписать состоянию каждого нейрона с вероятностью/^ (7.2) значение
единица ( активный нейрон) и с вероятностью l-pk - нуль (не активный
нейрон);
б) уменьшить параметр /; перейти к а).
В соответствии с правилом Хебба увеличить вес связи между активными
нейронами на величину б. Эти действия повторить для всех пар векторов
обучающей выборки.
2. Подать на вход сети входной вектор и зафиксировать выходной (как в
процедуре обучения с учителем). Предоставить сети возможность приблизиться
к состоянию теплового равновесия:
а) приписать состоянию каждого нейрона с вероятностью^ (7.2) значение
единица (активный нейрон) и с вероятностью l-pk - нуль (не активный
нейрон);
б) уменьшить параметр /; перейти к а).
182
7.5. Сеть Хемминга
В соответствии с правилом Хебба увеличить вес связи между активными
нейронами на величину 5. Эти действия повторить для всех пар векторов
обучающей выборки.
3. Подать на вход сети входной вектор без фиксации выходного вектора.
Повторить пункты а), б). Уменьшить вес связи между активными нейронами
на величину 8.
Результирующее изменение веса связи между двумя произвольно взятыми
нейронами на определенном шаге обучения будет пропорционально разности
между вероятностями активности этих нейронов на 1-м и 2-м шаге. При
повторении шагов 1 и 2 эта разность стремится к нулю.
7.5. Сеть Хемминга
Когда нет необходимости, чтобы сеть в явном виде выдавала образец, т. е.
достаточно, скажем, получать номер образца, ассоциативную память успешно
реализует сеть Хемминга. Данная сеть, по сравнению с сетью Хопфилда,
характеризуется меньшими затратами на память и объемом вычислений, что
очевидно из ее структуры (рис. 7.6).
Сеть Хемминга состоит из двух слоев. Первый и второй слои имеют по т
нейронов, где т - число образцов. Каждый нейрон первого слоя имеет по и
синапсов, соединенных со входами сети (образующими фиктивный нулевой
Входы
Рис. 7.6. Сеть Хемминга
183
7. Рекуррентные и ассоциативные НС
слой). Нейроны второго слоя связаны между собой ингибиторными
(отрицательными обратными) синаптическими связями. Единственный синапс с
положительной обратной связью для каждого нейрона соединен с его же
аксоном.
Идея работы сети состоит в нахождении расстояния Хемминга от
тестируемого образца до всех образцов. Расстоянием Хемминга называется число
отличающихся битов в двух бинарных векторах. Сеть должна выбрать образец с
минимальным расстоянием Хемминга до неизвестного входного сигнала, в
результате чего будет активизирован только один выход сети,
соответствующий этому образцу.
На стадии инициализации весовым коэффициентам первого слоя и порогу
активационной функции (см. рис. 7.4, б) присваиваются следующие значения:
хк
tf, =—'—, 1=0,.... и- 1, А: = 0,..., от- 1;
ik 2
Ьк = п/2, к = 0,..., от- 1.
Здесь xf - 1-й элемент к-то образца.
Весовые коэффициенты тормозящих связей во втором слое принимают
равными некоторой величине 0 < е < 1/от. Связь входа нейрона с его выходом
имеет вес +1.
Алгоритм функционирования сети Хемминга состоит из следующих
шагов:
1. Подача на входы сети неизвестного входного вектора X = {х: i = 0, ...,
w-1}, исходя из которого рассчитываются состояния нейронов первого слоя
(верхний индекс в скобках указывает номер слоя):
и-1
ym=sm= J)wx +b;j = 0,...,m-l.
1-0
После этого полученными значениями инициализируются значения
выходов второго слоя:
y™=y?\j = 0,...,m-\.
2. Вычисление новых состояний нейронов второго слоя:
m-l
s?\t +1) = yfl) - e2>i2)(0* *j, j = 0,.... m - 1
ft=0
и значения их выходов:
yV> (t + 1) =f[sfKt + 1)], j = 0,.... m-l,
где / - номер текущей итерации.
Активационная функция/имеет вид порога, причем значение F должно быть
достаточно большим, чтобы любые возможные значения аргумента не
приводили к насыщению (см. рис. 7.4, б).
184
7.5. Сеть Хемминга
3. Проверить, изменились ли выходы нейронов второго слоя за последнюю
итерацию. Если да - перейти к шагу 2. Иначе - конец.
Из алгоритма видно, что роль первого слоя весьма условна:
воспользовавшись один раз на 1-м шаге, вектор весовых коэффициентов первого слоя
используется только в п. 1, поэтому этот слой может быть вообще исключен из
сети (заменен на матрицу весовых коэффициентов).
Применение сети Хопфилда к решению задач комбинаторной
оптимизации. Ассоциативность памяти НС Хопфилда и ее модификаций не
единственное достоинство. Класс целевых функций, которые могут быть
минимизированы НС достаточно широк: в него входят все билинейные и квадратичные
формы с симметричными матрицами. С другой стороны, весьма широкий круг
математических задач может быть сформулирован на языке задач
оптимизации. Сюда входят решения дифференциальных уравнений в вариационной
постановке систем нелинейных алгебраических уравнений и др. Исследования
возможности использования НС для решения таких задач сформировали
новую научную дисциплину - нейроматематику.
Рассмотрим использование НС для решения задачи комбинаторной
оптимизации. Многие задачи оптимального размещения и планирования ресурсов,
выбора маршрутов, задачи САПР и другие, при внешней кажущейся простоте
постановки имеют решения, которые можно получить только полным
перебором вариантов. Часто число вариантов быстро возрастает с числом
структурных элементов N в задаче (например, как N\), и поиск точного решения для
практически полезных значений N становится заведомо неприемлимо
дорогим. Такие задачи называют неполиномиально сложными, или NP-полными.
Примечание. NP-попной называется задача, вычислительные алгоритмы для
решения которой требуют затрат, возрастающих быстрее, чем любая степень числа
переменных или элементов N.
Рассмотрим классический пример ЛТ-полной задачи - так называемую
задачу коммивояжера (бродячего торговца). Графически задачу можно
представить следующим образом (рис. 7.7, а). , т
\т , Начало пути
На плоскости расположены yv городов (в I A ОООО*
данном случае N=5), определяемые пара- sr^\ в •ОСЮО
ми их географических координат: (л ,у), Д/ ^S^, d OOoSo
i =1, ..., N. Торговец должен, начиная с V Iе ОО0ОО
произвольного города, посетить все эти \ / 12 345
города, при этом в каждом побывать ров- 4 Q< Q 3
но один раз. Проблема заключается в вы- « б
боре маршрута путешествия с ■ ■ .- „ __ _
„ - w ~ "ис. 7.7. Решение задачи коммивояжера:
но возможной общей длиной пути. а_ ^.g, представление нейронной
Полное число возможных маршрутов матрицы
185
7. Рекуррентные и ассоциативные НС
равно , и задача поиска кратчайшего из них методом перебора весьма тру-
2N
доемка. Приемлемое приближенное решение может быть найдено с помощью НС.
Для решения этой задачи может быть использована сеть Хопфилда, состоящая
из ./V2 нейронов, расположенных в виде матрицы N х N нейронов (рис. 7.7, б):
i-я строка матрицы соответствует i'-му городу (одному из А, В, С, D, Е), /-й
столбец соответствует i-му порядку посещения города. Выход узла сети на
пересечении строких (А, В, С, D, Е) и столбца / обозначим^f, где х представляет
город, a i - порядок посещения. Тогда один из возможных путей имеет вид:
В -> С -> Е -> D -> А -> В.
Этот путь представлен на рис. 7.7, б, на котором зачерненные (+1) и светлые
(0) кружки обозначают выходы узлов соответственно. Еслиух,, = 1, то это
означает посещение города х на шаге /. Поскольку каждый город может быть
посещен только один раз, то в матрице нейронов в каждом столбце и в каждой
строке должно быть только по одному зачерненному кружку, соответствующему
единичному выходу.
Таким образом, функция энергии Е сети Хопфилда может быть получена
при учете следующих факторов: каждый город должен быть посещен не более
чем один раз (в каждой строке матрицы имеется не более одной единицы), под
каждым номером должно посещаться не более одного города (в каждом
столбце - не более одной единицы) и, кроме того, общее число посещений равно
числу городов N (в матрице всего имеется ровно N единиц).
Предположим, что расстоянием между городами х и у является: d = d ,
гдех,у е{А, В, С, D, Е).
Составим теперь целевую функцию Е задачи поиска оптимального
маршрута, которая представляет собой функцию энергии и может быть определена
следующим образом:
N N N N N N
Е~?) / I/ //'Ух.i^x,j 9 / i/ i/1Ух.iУх,]
*■ x=l i-1 jr-1 z i=l x-=l y=\
i*y y*x
+7 zz (^. -n >2+ssi d„y„ ч..+.-ч„-.) = <7-з)
^ j:=1 i=l ^ jc=1 j>=1 i=l
= El + E2 + E3 + E4,
где у л+1=ух ^х0~Ух^, Pt Я>г,з — положительные константы.
В уравнении (7.3) первое слагаемое обращается в нуль, если имеется только
один активный нейрон в каждом ряду, т. е. если каждый город посещается только
один раз в каждом туре. В противном случае Е^ > 0. Аналогично, Е = 0 тогда и
только тогда, когда имеется один активный нейрон в каждом столбце, т. е. в
каждый данный момент времени посещается только один город. Посещение iV
186
7.6. Ассоциативно-проективные нейронные сети
заданных городов в каждом туре определяет Еу Таким образом, первые три
слагаемых уравнения (7.3) отвечают за допустимость маршрута. Видно, что
каждое из этих слагаемых обращается в нуль на допустимых маршрутах и
принимает значения больше нуля на недопустимых. Последнее, четвертое,
слагаемое минимизирует длину маршрута. Отрезок пути между двумя городами
включается в сумму только тогда, когда один из городов является относительно
текущего города х либо предыдущим, либо последующим.
Приведем целевую функцию (7.3) к основной форме уравнения сети Хоп-
филда - функции Ляпунова (7.1) для двумерной N* N нейронной матрицы:
. (N,N) (N,N) (N,N)
E=~i Z Z wi*j*yj)y*jyyj - Z x*&*4- (7-4)
z (*,i>(U) OvXU) (*,0=(U)
(>vX*,0
Путем сопоставления коэффициентов уравнения (7.3) и (7.4) можно
определить весовые коэффициенты:
wi*JXyJ) =-2^(1-6(/)-298у(1-5хУ)- (7.5)
-2у-Isd^bj^ + 57.,_,), xxi = 2rN,
где 6„ = 1 при i =j, 6„-= О-в противном случае.
Теперь можно заменить алгоритм обучения Хебба прямым заданием
указанных весов для НС, вычисленных по формуле (7.5), и функционирование
полученной системы будет приводить к уменьшению длины маршрута
коммивояжера.
Хопфилдом и Тэнком представленная модель была опробована в
вычислительном эксперименте. Нейронной сети удавалось находить близкие к
оптимальным решения за приемлемое время даже для задач с несколькими
десятками городов.
7.6. Ассоциативно-проективные нейронные сети
Работа по моделированию мышления и психики, созданию систем
искусственного интеллекта началась в СССР в отделе Биокибернетики Института
кибернетики АН УССР под руководством Н.М. Амосова более 40 лет назад. В
работах Н.М. Амосова обоснована гипотеза о функциональной организации
человеческого мозга, механизмах мышления и предложены модели и методы
ее практической реализации. Гипотеза Амосова о механизмах мышления и
психики человека основана на общих принципах моделирования и переработки
информации. Информация (представления об объектах, ситуациях и т. д.)
отражается в структуре нейронных элементов или в связях между ними. А
возбуждение некоторой части элементов может распространяться на другие
элементы. Каждому образу, понятию внешнего мира соответствует своя нейронная
187
7. Рекуррентные и ассоциативные НС
структура. Амосов называет такие нейронные структуры моделями
конкретных образов и понятий. Переработка информации мозгом, с его точки зрения,
заключается в возбуждении одних моделей другими.
Моделирование НС, по мнению Амосова, требует некоторых постулатов,
которые в известной степени отражают данные нейрофизиологии:
• закон связей. Связь между двумя нейронами (степень ее «проходимости»)
может быть разной;
• закон тренировки. При повторении воздействия ответ нейрона становится
более «мощным»;
• необходимость первичной структуры из нейронов с избыточностью
связей; дальнейшее развитие структуры НС является следствием обучения и
самоорганизации.
В информационном плане такая модель представляет собой множество
нейронов, объединенных «хорошо проторенными» связями. Связи с нейронами
других моделей имеют гораздо меньшую проходимость. Это означает, что при
возбуждении извне нескольких нейронов возбуждается вся модель. На этом
основано явление «узнавания» целого по части; при этом один и тот же нейрон
может быть составной частью множества моделей.
Переработка информации в сети — это движение возбуждения по связям и
моделям. С рецепторных элементов возбуждение передается в НС. Различные
модели возбуждаются в разной степени, а поскольку возбуждение будет
охватывать новые модели, то в какой-то момент времени в сети начинается хаос. Во
избежание этого Н.М. Амосов предложил ввести в сеть регулятор активности,
названный системой усиления-торможения (СУТ). Эта система возбуждает
наиболее активную модель и тормозит все остальные, тем самым
моделируется механизм внимания. Внимание обеспечивает в каждый данный момент
целесообразную реакцию на главный раздражитель, при этом в сознании
активизируется одна модель, а по связям от нейронов активной модели возбуждаются
другие модели, ассоциативно связанные с первой. Перераспределение
картины возбуждений приводит' к тому, что в следующий момент времени СУТ
выберет другую наиболее возбужденную модель. Движение возбуждения по
модели имитирует мысль, при этом сохраняется связность мышления.
Ассоциативно-проективные модели отражают не только понятия внешнего
мира, но и состояние индивида, его чувства, эмоции как оценки
эффективности тех или иных его действий. Эти модели служат как бы критериями
поведения человека. Между моделями чувств также существует конкуренция за
возбуждение в сети. Доминирующее чувство во многом определяет ход мыслей и
выбор необходимых решений. Отличие важного от неважного также
определяется по чувственной оценке, введенной Н.М. Амосовым, определяемой по
уровню душевного комфорта (УДК) как разница между всеми положительными и
отрицательными эмоциями.
188
7.6. Ассоциативно-проективные нейронные сети
Архитектура ассоциативно-проективных нейронных сетей
Идея ассоциативно-проективных
сетей (АПНС) была предложена Э.М.
Куссуль на основе многолетней
работы и развита Т.М. Байдык. Эти сети
позволяют строить иерархические
системы переработки информации.
Модель нейрона в АПНС представлена на
рис. 7.8.
В этой модели сигнал на выходе
может принимать два значения - нуль
и единица. Если сигнал на выходе ра-
Рис. 7.8.
Формальная модель нейрона
АПНС
вен единице, то нейрон возбужден. Различают несколько типов входов:
установочные (S), тормозящие (/?), ассоциативные входы (А), обучающий вход (7>),
вход синхронизации (С), вход установки порога (ТИ). На установочные (S),
тормозящие (/?), ассоциативные (А , А2,..., Ап,п - количество ассоциативных
входов), вход синхронизации (С) могут поступать только двоичные сигналы (0,1):
сигнал присутствует на входе, если он равен 1 или отсутствует, если равен 0.
На входы Тг и Th поступают градуальные сигналы, -1 <tr< 1, а 0 < th < п.
(Входы и выход нейрона обозначаются заглавными буквами, а сигналы на
них - соответствующими строчными.)
Нейрон работает следующим образом. На вход синхронизации поступает
сигнал, имеющий попеременно низкий (0) и высокий (1) уровень. Сигнал на
выходе нейрона {q) может изменяться только в момент перехода сигнала
синхронизации с низкого уровня на высокий. Если в этот момент хотя бы на одном
из тормозящих входов (К) присутствует сигнал, то сигнал на выходе
принимает нулевое значение (q = 0), независимо от того, какие сигналы поступают на
другие входы.
Если на входах R сигналы отсутствуют и хотя бы на одном из входов S
присутствует сигнал, то на выходе появляется единичный сигнал (q = 1). Если
сигналы на входах S и R отсутствуют, то значение сигнала на выходе определяется
в соответствии с выражением
4 =
1, если ~S\ aiwi > th;
п
0, если V а,!!', < th,
где а — сигнал на i-м ассоциативном входе нейрона; wt - синаптический вес /-го
входа нейрона, может принимать только значение 0 или 1; th - значение порога
на входе Th.
189
7. Рекуррентные и ассоциативные НС
В качестве алгоритма обучения в АПНС используется модифицированное
правило Хебба. Обучение нейрона осуществляется за счет изменения его си-
наптических весов, которое происходит, когда сигнал на обучающем входе не
равен нулю (tr Ф 0). Различается обучение при положительном tr
(положительное подкрепление) и отрицательном (отрицательное подкрепление) сигнале.
При положительном подкреплении изменение синаптических весов
осуществляется в соответствии с выражением
w* = wv(a,&tf&/r), (7.6)
где v - дизъюнкция; & - конъюнкция; w' - вес связи после обучения; w - вес
связи до обучения; at — сигнал на /-м ассоциативном входе; q - сигнал на
выходе нейрона; ht - двоичная случайная величина, у которой вероятность
единичного значения равна величине подкрепления tr:
р\К J = tr.
При отрицательном подкреплении изменение синаптического веса
описывается выражениями
w* = wi8c{a&.q&.hi), ^ ^
/#,_,) = М-
Рассмотренный тип формального нейрона используют для построения
АПНС.
Основной структурной единицей АПНС является нейронное поле, которое
состоит из подмножества нейронов, выполняющих одинаковый набор
функций. У нейронов одного поля связи между собой и с нейронами других полей
формируются по общим правилам для всех нейронов поля (количество
нейронов в поле и). В АПНС существуют два типа нейронных полей: ассоциативное
и буферное. Ассоциативное предназначено для формирования нейронных
ансамблей в режиме обучения НС и ассоциативного восстановления нейронных
ансамблей в режиме распознавания. Буферное нейронное поле предназначено
для сбора, временного хранения и нормирования размеров нейронных
ансамблей. С помощью буферного нейронного поля можно определить различия двух
возбужденных нейронных ансамблей.
Примечание. В 50-х годах XX в. Хеббом были рассмотрены НС, в которых каждому
понятию соответствовало множество нейронов, связанных взаимными
возбуждающими связями. Учитывая данные нейрофизиологии, Хебб пришел к выводу, что при
повторных предъявлениях одного и того же стимула эффективность синаптических
связей между нейронами, реагирующими только на этот стимул, увеличивается. Тем самым
в НС формируется множество нейронов, связи между которыми имеют более высокую
проходимость, чем связи между остальными нейронами сети. Это множество
нейронов Хебб назвал ансамблем. Если возбуждается часть нейронов ансамбля, благодаря
высокой проходимости связей с другими нейронами внутри ансамбля возбуждается
весь ансамбль. В нейронных сетях Хебба ансамбль нейронов соответствует любому
конкретному понятию. Часто повторяемые определенные стимулы ведут к
образованию нейронных ансамблей, т. е. формируют в памяти устойчивую систему понятий.
190
7.6. Ассоциативно-проективные нейронные сети
Нейроны ассоциативного поля в
АПНС связаны друг с другом
ассоциативными связями, веса которых могут
изменяться в процессе обучения.
Проективные связи соединяют выходы одного
нейронного поля с входами другого (или
того же самого) нейронного поля. Эти
связи не изменяются в процессе
обучения и предназначены для объединения
нейронныхполейвсложныеиерархичес- Рис'7А "Р™* РВДппшных свя-
кие структуры. Проективная связь меж- зей R межДУ полями S и В
ду полями может быть смещенной или несмещенной. При несмещенной связи
выход 1-го нейрона первого поля связывается с входами i-ro нейрона второго
поля; при смещенной - выход i-ro нейрона первого поля связывается с
входами \i+S\ второго поля, где S- смещение, a \i+S\n - сумма по модулю и. Сигналы
по проективным связям между полями передаются только при наличии
разрешающего сигнала, который является общим для всех связей между нейронами
двух полей.
Кроме перечисленных выше связей в АПНС существуют также
рецептивные связи (по аналогии с физиологией зрения), которые устан : :. »т
отображение подмножества нейронов одного поля, . . ■:. - мого рецептивным, в один
нейрон другого поля (рис. 7.9). Способ задания рецептивных связей - прямое
перечисление нейронов рецептивного поля либо в виде некоторой
функциональной зависимости.
Для построения иерархических структур с помощью АПНС используются
ассоциативные и буферные поля, а также проективные и рецептивные связи, с
помощью которых информация передается с одного уровня на другой или между
полями одного уровня. Пример АПНС приведен на рис. 7.10.
Структура включает два уровня JLj и Lr Первый уровень состоит из
ассоциативного поля Ах, буферных полей Вх, В2. Ассоциативное поле А2 и буферное
поле В3 относятся к следующему уровню. Внутри ассоциативных полей
существуют ассоциативные связи (на рис. 7.10 не показаны), а между полями
возбуждающие (В2->А2; ВЪ->А2; АХ->А2) и тормозящие (Z?,, Л,).
Рис. 7.10. Пример структуры АПНС
191
7. Рекуррентные и ассоциативные НС
Функционирование ассоциативно-проективной нейронной сети
Во время процедуры обучения входные векторы вначале подаются для
обучения ассоциативного поля. Каждая единица в векторе соответствует нейрону
в активном состоянии, нуль — нейрон не возбужден. Между двумя активными
нейронами устанавливается синаптическая связь, вес которой является
бинарной величиной (если связь существует, ее вес равен 1, в противном случае 0).
Ассоциативно-проективные нейронные сети являются стохастическими
сетями. Это означает, что связи между активными нейронами устанавливаются с
некоторой заданной вероятностью. Если на вход сети подаются векторы,
состоящие из одних и тех же признаков, то вероятность формирования связей
между активными нейронами, соответствующими этим признакам, будет
увеличиваться. Таким образом, в сети формируются множества нейронов,
вероятность существования связей между которыми выше, чем вероятность связей
между нейронами остальной сети. Такие нейронные множества называются
нейронным ансамблем (по аналогии с определением Хебба).
В ансамбле различают ядро и бахрому. .Ядро составляют те нейроны
ансамбля, вероятность связи между которыми выше. На содержательном уровне ядру
соответствует наиболее типичная информация о предъявляемом образе.
Бахроме соответствуют индивидуальные отличия отдельных представителей,
относящихся к одному классу объектов. Например, если ядро - дом, то бахромой
может быть «большой», «деревянный», «одноэтажный».
Нейронный ансамбль является основным информационным элементом всех
иерархических уровней сети и может соответствовать признаку, описанию
объекта, ситуации, отношению между объектами и т. д., т. е. формируется из
совокупности элементов более низких иерархических уровней. Тот факт, что
при возбуждении части ансамбля он возбуждается целиком, позволяет в
пределах одного иерархического уровня рассматривать ансамбль как единый и
неделимый элемент, но при переходе на другие иерархические уровни ансамбль
дробится так, что только часть нейронов, принадлежащих ему, включается в
описание более сложных объектов верхнего иерархического уровня.
Пусть, например, необходимо построить описание такого типа объекта, как
дерево, состоящее из ствола, ветвей и листьев. Ствол, ветви, листья имеют
каждый свое описание: листья могут иметь форму, цвет, текстуру, ветви могут быть
с шипами, ствол также может иметь определенные признаки. Предположим,
что каждый из признаков в ассоциативном поле сети нижнего уровня
закодирован в виде подмножества нейронов, из которых сформирован
соответствующий нейронный ансамбль. Тогда на следующем иерархическом уровне
формируются нейронные ансамбли, соответствующие листьям, стволу, ветвям.
В ансамбль, соответствующий стволу, войдут нейроны, которые на нижнем
уровне описывают его форму, цвет, текстуру. Чтобы размеры ансамбля на
верхнем уровне не были слишком большими, в ансамбль верхнего уровня попада-
192
7.6. Ассоциативно-проективные нейронные сети
ет только часть нейронов из ансамблей нижнего уровня. Например, при
построении ансамбля, соответствующего целому дереву, в него включатся только
часть нейронов каждого из ансамблей, описывающих ствол, ветви, листья.
Процедура выбора части нейронов для передачи в верхний уровень называется
нормированием нейронного ансамбля. Ансамбль формируется таким образом,
чтобы по тем нейронам, которые вошли в ансамбль верхнего уровня, можно было
полностью восстановить ансамбль нижнего уровня за счет ассоциативного
воспроизведения целого ансамбля по его части. В соответствии с
вышесказанным, организация ассоциативно-проективных нейронных сетей позволяет
сформировать иерархию по типу «часть - целое».
Пример применения АПНС в задачах распознавания образов
Рассмотрим применение АПНС для решения задачи распознавания
текстур. Под текстурными признаками обычно понимают некоторые
статистические характеристики локального участка изображения. Примерами участков
изображений, имеющих одинаковую текстуру, могут служить листва дерева,
трава, асфальтовое покрытие и т. д.
Структурная схема НК, предназначенного для текстурного анализа,
представлена на рис. 7.11. Пунктиром обведены блоки, реализуемые в нейропро-
цессоре. Процедура обучения и распознавания АПНС состоит из следующих
шагов.
1. Подготовка обучающей выборки заключается в разметке оператором
изображения, определении имени текстуры для каждого возможного положения
окна телекамеры и записи этой информации в память управляющей машины.
т
|-
1
1
1
-э
БВТ
/
v
]
i
1
1
БК
У
^
*--н
, БНП
У
< *
АНП
;
УВМ
V
-э
ДБК
>
к
Рис. 7.11. Схема НК для текстурного анализа:
Т - телекамера; БВТ - блок выделения текстур; БК - кодирующий блок;
БНП - буферное нейронное поле; АНП - ассоциативное нейронное поле;
ДБК - декодирующий блок; УВМ - управляющая вычислительная машина
193
7. Рекуррентные и ассоциативные НС
2. Ввод первого изображения из обучающей выборки и установление окна
телекамеры в начальное положение (например, в левый верхний угол
изображения). Блок выделения текстур начинает выделение текстурных признаков в
пределах окна и передает их в БК, из которого коды признаков поступают в
буферное нейронное поле (БНП). Полученный код нормируется и передается в
ассоциативное поле АНП, в котором проводится пересчет активности
нейронов в течение нескольких тактов и затем выходной вектор АНП передается в
декодирующий блок ДБК для определения кода текстурного имени, с которым
выходной вектор имеет наибольшее пересечение. Это текстурное имя
считается распознанной текстурой. Оно сравнивается с именем текстуры, которое
задал оператор для этого положения окна, и если имена совпали, то обучение не
требуется и УВМ переводит окно в следующее положение (например, вправо
на половину длины окна). В начале обучения распознанное имя текстуры чаще
всего будет неправильным, в этом случае включается процедура обучения,
которая содержит три этапа:
2.1. Обучение правильному имени. С этой целью УВМ вводит в
кодирующий блок БК правильное имя той текстуры, которая соответствует текущему
положению окна. БК генерирует маску правильного имени и передает ее в БНП,
где она объединяется с кодом текстурных признаков и передается для
формирования соответствующего ансамбля в АПН. Формирование ансамбля
осуществляется за счет изменения весовых коэффициентов по формуле (7.6) с
положительным подкреплением.
2.2. «Разобучение» с неправильным именем. Для выполнения этого этапа
УВМ дает команду повторить вычисление, кодирование и нормирование
текстурных признаков, после чего посылает в БК то имя текстуры, которое было
ошибочно указано распознающей системой. Кодирующее устройство
отыскивает маску этого ошибочного имени, передает ее в буферное поле БНП, откуда
код признаков вместе с этой маской передается в ассоциативное поле АНП, где
проводится изменение весов с отрицательным сигналом подкрепления по
формуле (7.7). Смысл этой операции заключается в необходимости уменьшения
общего количества синаптических связей от кода анализируемой текстуры к
маске неправильно распознанного имени, чтобы в будущем снизить
вероятность такой ошибки. В данной задаче целесообразно формировать ансамбли
таким образом, чтобы ядром служило имя текстуры. Тогда в процессе
пересчета активности ассоциативного поля возбуждение перемещается на ядро, и
соответствующее текстурное имя легко опознается. Выполненное на втором
этапе разобучение имеет побочное действие. Оно частично разрушает ядро,
соответствующее неправильно распознанному имени. Поскольку это
нежелательно, выполняется третий этап.
2.3. Восстановление ядра. Для этого буферное поле БНП гасится и в него
передается одна только маска неправильного имени, которая без изменения
поступает в ассоциативное поле АНП, где выполняется формирование ансамб-
194
7.7. Нейронная сеть СМАС
ля с положительным подкреплением по формуле (7.6); при этом величина
подкрепления выбирается большой, например / = 1.
По окончании всех трех этапов обучения УВМ переводит окно на
следующий участок и процедура повторяется.
7.7. Нейронная сеть СМАС
В основу рассматриваемой НС СМАС (Cerebellar Model Articulation
Controller) - суставной модели мозжечкового регулятора - положена
нейрофизиологическая модель мозжечка, разработанная американским ученым Альбу-
сом Дж., 1975. Нейронная сеть СМАС может не только выступать в роли
регулятора системы управления или робота-манипулятора, но и использоваться в
качестве ассоциативной памяти. Основное назначение СМАС - запоминание,
восстановление и интерполяция функций многих переменных. Для решения
этой задачи вначале обучают СМАС по известным значениям функций с
использованием алгоритма Альбуса, а затем применяют ее для восстановления
недостающих значений.
НС СМАС характеризуется некоторыми особенностями:
• значения компонентов входного вектора являются целочисленными;
• вычисление неизвестного значения функции проводится неявно с
помощью алгоритма определения адресов ячеек ассоциативной памяти, в которых
хранятся числа, соответствующие значениям функции.
Область определения функции, подлежащей восстановлению, задается на
гиперпараллелепипеде, вершинами которого являются максимальные и
минимальные значения аргументов функции. Ребра параллелепипеда квантуются с
постоянным шагом по каждому ребру, а дискретизованным значениям
аргументов присваиваются целочисленные номера. При построении алгоритма
вычисления адресов ассоциативной памяти Альбус исходил из принципа,
согласно которому входной сигнал возбуждает не один нейрон, а целый ансамбль
нейронов (некоторую область мозжечка); при этом становятся активными р*
ячеек ассоциативной памяти, суммарное содержимое которых равно значению
запоминаемой функции. Параметр р* является обобщающим параметром
(generalization parameter), его значение определяет разрешающую способность
СМАС и требуемый объем памяти.
Для функции одной переменной Y(x) аргумент связан со своим номером i
соотношением
х=х . +0-1)Ах, (7.8)
А max min
где i — 1 - шаг квантования; х ..х — минимальное и максималь-
^* *mav ' лип' msv
mvy max
ное значения аргумента х из области определения; i = 1, /max, здесь imax - число
точек, на которых задана функция Y(x). Номер i можно рассматривать как
относительный аргумент функции, а соотношение (7.8) описывает процедуру
195
7. Рекуррентные и ассоциативные НС
сдвига и масштабирования исходной области определения функции (для
предобработки данных). Значениями аргументов запоминаемой в СМАС функции
могут быть только целочисленные значения, т. е. функция Y(x) от N
переменных определена на целочисленной Л'-мерной сетке X:
Х= {х, = 1.x™ ; х, = 1,х<2> ;... х = 1,х<"» }.
* 1 ' max '2 ' max ' n ' max '
Алгоритм преобразования аргументов для сети СМАС сводится к
алгоритму вычисления адресов ассоциативной памяти. Автор алгоритма обучения
Альбус исходил из нейробиологического подхода, согласно которому каждый
входной сигнал возбуждает определенную область мозжечка, суммарная
энергия которой соответствует значению запоминаемой функции. В ассоциативной
НС СМАС предполагается, что каждый входной сигнал (аргумент функции)
возбуждает, или делает активным, ровно р* ячеек памяти. Поэтому даже в
случае скалярного аргумента Х=дг, ему соответствует /?*-мерный вектор номеров
активных ячеек памяти.
Максимальному значению аргумента в случае одномерного входного
вектора л;, = дс*1^ соответствуют ячейки памяти с номерами
х"> ,**'> +1,*о> +2, ...**'> +р*-1,
max ' max ' max ' max * '
откуда следует, что число ячеек памяти, необходимое для хранения функции
одной переменной в ассоциативной НС, равно
М(1> = х(1) +р'-\,
max * '
что на р*-\ больше числа значений функции, запоминаемых НС. Поэтому в
одномерном случае НС СМАС, с точки зрения требуемого объема памяти,
неэффективна. Ее эффективность проявляется при восстановлении
запоминаемой Л'-мерной функции большей размерности с достаточно высокой
точностью при предъявлении числа примеров k в обучающей последовательности
к« Мт.
Алгоритм обучения сети СМАС в упрощенном виде сводится к такой
последовательности действий:
1. Вычисление на и-м шаге обучения М-мерного вектора памяти сети W(«),
каждая j-я компонента которого w (n), j =1, М соответствует содержимому
у-й ячейки памяти.
2. Вычисление предсказанного НС значения функции по формуле
Г(Х,.) = А\У(и).
В этой формуле элементы вектора А, номера которых совпадают с
номерами активных ячеек памяти, равны единице, все остальные элементы вектора
равны нулю. Следовательно, в векторе А всегда только р' элементов равны
196
7.7. Нейронная сеть СМАС
3. Вычисление ошибки предсказания, определяемой как разность
4. Определение величины коррекции VW(«) = zip*, которая прибавляется к
содержимому только активных ячеек памяти. Неактивные ячейки коррекции
не подвергаются, поэтому вычислительная сложность алгоритма мала.
Таким образом, НС СМАС целесообразно использовать для восстановления
значений многомерных функций. При этом эффективность работы СМАС во
многом зависит от вида восстанавливаемой функции.
Пример использования НС СМАС для решения
задачи аппроксимации функций
Основная цель исследования заключалась в определении ошибок при
восстановлении различных видов функций сетью СМАС. Точность
аппроксимации задаваемой функции определялась величиной среднего квадратичного
отклонения, осредненного по реализациям:
E = ±-fjy{Xi)~y'(Xi)y,
" 1=1
где N - число реализаций; i - номер реализации; у(Х} - запоминаемая
функция; у'(Х) - воспроизведенная НС функция в i-й реализации.
Предполагается, что входные вектора независимы, равномерно
распределены на отрезке [0,1]. Для удобства графического представления результатов
исследования входной вектор задавался двумерным. В соответствии с
выбранным уровнем квантования функции, задававшейся на сетке, содержащей
соответствующее число узлов.
Аппроксимация линейной функции
y(X) = b0 + bxl + bx2; 0<дг, < 1; 0<лт2< 1;
Z>0=-0,8; bt = 0,05; Z>2 = 0,08.
В табл. 7.1 представлены результаты аппроксимации, в зависимости от
числа шагов обучения « и числа активных ячеек памяти р*.
Таблица 7.1. Ошибка аппроксимации при восстановлении
линейной функции
•
р
2
4
8
16
л= 10
0,543
0,286
0,125
0,101
п=20
0,3617
0,547
0,0101
0,0103
и = 30
0,1003
0,0214
0,0031
0,0031
п = 40
0,0472
0,0178
0,0015
0,00118
л = 60
0,0104
0,0073
0,0008
0,00028
п=100
0,0053
0,0012
0,00009
0,000084
197
7. Рекуррентные и ассоциативные НС
)Л
!%,
<ат
if s
Рис 7.12. Восстановление нейронной сетью линейной зависимости:
а - 8 примеров (2 % от общего числа значений функции);
6-16 примеров (4 %); в - 92 примера (23 %)
На рис. 7.12 показаны результаты восстановления НС линейной
зависимости от количества примеров в обучающей выборке. При количестве примеров в
обучающей выборке от 8 до 16 ошибка аппроксимации велика - от 20 до 50 %,
а при числе примеров равна 92, функция почти полностью восстановлена
(ошибка аппроксимации не превышает 0, 01 %).
Из проведенных исследований можно сделать следующие выводы:
1. Линейная функция с большой точностью может быть аппроксимирована
ассоциативной НС. Для получения ошибки аппроксимации менее 0,0001
достаточной обучающей выборкой будет 16...23 % вычисленных значений
функции от общего числа точек исследуемой области существования функции.
2. Увеличение числа активных ячеек памяти р* приводит к увеличению
скорости сходимости процесса обучения.
Аппроксимация нелинейной функции
j(X) = sin -1 sin
7t
Л
|; 0<дг, < 1; 0<дг2< 1.
Результаты исследования по запоминанию нелинейной функции
приведены в табл. 7.2, а на рис. 7.13 показаны результаты обучения функции в
зависимости от числа примеров в обучающей выборке
Таблица 7.2. Ошибка аппроксимации при восстановлении
нелинейной функции
•
р
4
8
16
п= 10
0,019
0,122
0,111
п=20
0,00039
0,006
0,014
л = 30
0,000075
0,0019
0,0039
л = 50
0,00007
0,00046
0,00084
п=70
0,000075
0,00012
0,00036
п=100
0,000075
0,00024
0,000111
Анализ полученных результатов позволяет сделать следующие выводы:
1. Нелинейные функции не могут быть абсолютно точно восстановлены НС.
Точность восстановления повышается при увеличении времени обучения и чис-
198
7.8. Двунаправленная ассоциативная память
У£Й>*^,'
Рис. 7.13. Восстановление нейронной сетью нелинейной функции:
а - 8 примеров (2 % от общего числа значений функции);
6-16 примеров (4 %); в - 92 примера (23 %)
ла примеров в обучающей выборке, причем последний параметр более
критичен для нелинейной функции, чем для линейной. Так, погрешность
восстановления нелинейной функции уменьшается с 0,1872 (для р = 8, и = 100, число
примеров равно 16 % от всех примеров в обучающей выборке) до 0,0955 (для
р = 8, п = 100, число примеров равно 23 %).
2. Процесс обучения при больших параметрах/?*, например при/?* = 10,
заканчивается быстрее, так как это связано с увеличением памяти для хранения
запоминаемых значений функции.
Таким образом, с помощью нейронной сети СМАС можно
аппроксимировать как линейные, так и нелинейные функции. Ошибка аппроксимации
линейной функции в проведенных экспериментах не превышала 0,01%, для
нелинейных функций эта ошибка может быть уменьшена при увеличении числа
примеров в обучающей выборке или при увеличении времени обучения.
Небольшой объем памяти для запоминания значений воспроизводимой функции
делает перспективным использование этого типа сети при работе с
многомерными объектами, причем с увеличением мерности функции эффект от
применения сети СМАС становится большим. К этому необходимо также добавить,
что обученную сеть такого вида целесообразно использовать для
формирования обучающей выборки при работе с другим типом НС.
7.8. Двунаправленная ассоциативная память
Дальнейшее развитие структуры ассоциативной
памяти получили в работах Б. Коско (1987). Им была
предложена двунаправленная ассоциативная память
ВАМ {Bidirectional Associative Memory),
являющаяся гетероассоциативной памятью, состоящей из
двух слоев (рис. 7.14). Эта память может
рассматриваться как расширение сети Хопфилда.
В двунаправленной ассоциативной памяти (ВАМ)
запоминаются ассоциации между парами образов.
Запоминание происходит так, что при предъявлении
сети одного из образов восстанавливается второй
слои
Рис. 7.14. Структура
двунаправленной
ассоциативной памяти
199
7. Рекуррентные и ассоциативные НС
член пары. В отличие от сетей Хопфилда и Хемминга входной образ может
быть ассоциирован с другим, не коррелирующим с ним образом. Это
возможно за счет того, что выходной вектор формируется на другом наборе нейронов,
отличном от того, на который подается входной.
Рассмотрим функционирование сети БАМ. Предположим, что слой Y имеет
п нейронов, а слой X - т нейронов. Пусть начальный вектор X подается на
вход слоя Y (см. рис. 7.14). Тогда на выходе слоя Y для каждого /-го нейрона
У,=/
Л
TwvxJ
\J=
,i=l,2,...,#i, (7.9)
где/- пороговая функция активации.
Полученный вектор Y направляется к слою X и формирует следующий выход
j-то нейрона
( т \
*;=/£>w M=1'2,...,in. (7Л0>
V >=i )
Затем X подается на вход Y и формирует следующие выходные сигналы
нейронов у! в соответствии с уравнением (7.9).
В процессе итерационного функционирования состояния нейронов слоя X
вызывают изменения состояний нейронов слоя Y, те, в свою очередь,
модифицируют состояния нейронов X, и т. д. На каждой итерации происходит
уточнение выходного вектора. Этот процесс продолжается до тех пор, пока вектора
на выходе слоев X и Y не перестанут изменяться.
Итерационная процедура, так же, как и в сети Хопфилда, сходится, поскольку
матрица связей нейронов симметрична. При предъявлении сети только образа
на слое X будет восстановлен также и соответствующий образ на слое Y, и
наоборот.
Пример 1. Рассмотрим процесс функционирования ВАМна примере. Пусть
заданы следующие пары векторов:
Х'=(1,-1,-1, 1, 1,-1, 1,-1,-1, 1); Y'=(-l,-l, 1, 1, 1, 1);
XHL1.1. -1.1.1.1» -1.1» -О; y2= (-1, -l, l, l, -l, -l).
Сформируем матрицу связей W по следующей формуле
р
гдер- заданное число пар векторов:
200
7.8. Двунаправленная ассоциативная память
w =
-2 0 0 0-2 0-2 2 00
-2 0 0 0-2 0-2 2 00
2 000 2 0 2-2 00
2 0 0 0
0-2-2 2
0-2-2 2
2 0 2-2 0 0
0-2 0 0-2 2
0-2 0 0-2 2
В качестве начального приближения выберем вектор X1: Х°=(1, -1, -1, 1, 1,
-1,1,-1,-1,1). Используя уравнения (7.9) и (7.10), рекурсивно получаем:
Y(')=/(-4, -4,4,4, 8, 8) = (-1, -1,1,1,1,1);
Х<2ь=/(8,^,^,4,8,^,8,-8,^,4) = (1,-1,-1,1,1,-1,1,-1,-1,1);
YPb=/l, 1,-1, -1,-1,-1) = ¥<•>.
Следовательно, сеть ВАМ в этом случае работает устойчиво и вызывает
ранее сохраненные пары.
Анализ стабильности ВАМ базируется на определении функции энергии
Ляпунова. ВАМ находится в стабильном состоянии, если
Y <*) -> Y (*+,) -> Y (*+2) и Y (*+2) -> Y (*+1) -> Y т,
что соответствует минимуму функции энергии.
Двунаправленная ассоциативная память имеет ограничения на
максимальное число хранимых образов, при превышении которого сеть может выдать
неверный ответ, воспроизводя ассоциации, на которых не проводилось
обучение.
Устойчивость работы ВАМ зависит от вместимости р сети, т. е. от числа
образов, которые она может хранить и воспроизводить. Обычно используется
следующая оценка: р < тт(т, п)
Основными достоинствами двунаправленной ассоциативной памяти
являются следующие:
• свойство автоассоциативности, т. е. если одновременно известны
некоторые фрагменты образов на слое X и Y, то в процессе функционирования будут
одновременно восстановлены оба образа пары;
• структурная простота;
• быстрая сходимость процесса обучения и восстановления информации.
201
7. Рекуррентные и ассоциативные НС
Упражнения и вопросы для самоконтроля
1. Чем отличаются рекуррентные НС от НС персептронного типа?
2. Дайте определение ассоциативной памяти. В чем различие между
автоассоциативной и гетероассоциативной памятью?
3. Перечислите основные особенности в алгоритме обучения сети Хопфилда. Какое
значение имеет эта модель для дальнейшего развития НС?
4. В чем отличие машины Больцмана от сети Хопфилда и сети Хемминга?
5. Приведите примеры М'-полных задач. Представьте алгоритм решения одной из
них с помощью НС.
6. Что понимается под системой «усиления-торможения»?
7. Сформулируйте принцип действия и алгоритм обучения
ассоциативно-проективной НС.
8. Определите понятие нейронного ансамбля в трактовке Хебба.
9. Перечислите основные достоинства НС СМАС.
10. В каких случаях целесообразно использовать НС на основе двунаправленной
ассоциативной памяти?
11. Почему сеть Хопфилда можно использовать в качестве ассоциативной памяти?
8. САМООРГАНИЗУЮЩИЕСЯ НЕЙРОННЫЕ СЕТИ
Рассмотрены основные проблемы построения самоорганизующихся НС (self organising
networks), на примере сетей Кохонена и адаптивного резонанса, а также особенности
алгоритмов обучения НС без учителя. Показана целесообразность построения
комбинированных НС для повышения качества решения прикладных задач на примере построения сетей
встречного распространения сигналов.
8.1. Сеть Кохонена
Особенности обучения без учителя
Описанные в гл. 5 алгоритмы обучения характерны тем, что необходимым
участником процесса обучения является «учитель», который заранее
производит классификацию используемых при обучении объектов и результаты этой
классификации вводит в машину. Однако в биологических системах такой
механизм обучения трудно себе представить. Способность разных людей в
общем одинаково проводить классификацию «без учителя» заставляет думать,
что различия, на которых основывается такая способность, имеют
объективный и безусловный характер. Поэтому алгоритмы обучения без учителя
называют также алгоритмами объективной классификации.
Для реализации этих алгоритмов на практике необходимо решить два
вопроса. Первый связан с выбором способа разбиения объектов на классы без
учителя, второй - с выработкой правила отнесения входного образа к
определенному классу.
Разбиение на классы должно предусматривать наличие некоторого
достаточно общего свойства классифицируемых объектов. Это свойство состоит в
компактности образов. В этом случае под объективной классификацией
подразумевается разбиение некоторой совокупности многомерных объектов на
классы, основанное только на том, что каждому классу соответствует обособлен-
203
8. Самоорганизующиеся нейронные сети
ная группа точек в пространстве параметров. При
такой постановке вопроса задача классификации
сводится к разделению в многомерном
пространстве на части множества точек, про которое
известно только то, что оно состоит из нескольких
изолированных групп. Двумерной аналогией такого
Рис. 8.1. Классы объектов множества может служить рис. 8.1.
в двумерном пространстве Визуально разделение множества точек,
представленных на рис. 8.1, на две группы не составляет труда. Задача состоит в
том, чтобы описать способ проведения границы между множествами
объектов и сформулировать алгоритм ее построения. Процесс разбиения некоторого
множества объектов на классы называется кластеризацией.
Критерием разбиения служит некоторая мера близости или сходства.
Кластеризация и обучение проводятся на основе определенных математических
методов, использующих соответствующие им математические модели
пространства объектов. Например, если объекты рассматривать как и-мерные векторы
X = (jc,, х2,..., jcn) e R", в качестве меры близости двух объектов X, и Х2 можно
принять евклидово расстояние между ними:
ОД.ХзНХ, -Х2||= J|>X,)2. (8Л)
Наряду с евклидовым расстоянием в качестве меры сходства между
объектами можно использовать, например, максимальную разность значений
компонент векторных описаний:
D= max |*„ - x2J.
1=1,...,П
Введенные меры сходства могут служить критерием для отнесения
некоторого объекта к соответствующему классу.
Нейронным сетям, работа которых основана на использовании алгоритма
объективной классификации, свойствен принцип самообучения или
самоорганизации. Сеть такого типа рассчитана на самостоятельное обучение: при
обучении правильные ответы ей не сообщаются. Во время процедуры обучения
происходит формирование кластеров на основе обобщения имеющейся
входной информации, сосредоточенной в обучающей выборке. Обученная сеть
относит каждый вновь поступающий входной вектор к одному из кластеров,
руководствуясь некоторым критерием сходства.
Конкурентное обучение
Конкурентное (соревновательное ) обучение НС - наиболее популярная
схема реализации процедуры кластеризации без учителя. На рис. 8.2 представлен
204
8.1. Сеть Кохонена
М<34
Рис. 8.2. Конкурентное обучение с использованием векторов единичной длины:
х - центры вновь образующихся кластеров
пример НС, имеющей три входа и четыре выхода. Все входы НС х. (/' = 1,2, 3)
соединяются со всеми ее выходами j (j = 1, 2, 3, 4) посредством связей с
весовыми коэффициентами wr
Число входов НС соответствует размерности входных векторов, а число
выходов задает количество кластеров, на которое должно быть разделено
входное пространство. Расположение центра каждого кластера определяется
весовым вектором, соединенным с соответствующим выходом. На рис. 8.2
трехмерное входное пространство разделяется на четыре кластера, причем
кластерные центры, описываемые векторами, изменяются во время
процедуры кластеризации на основе правил конкурентного обучения.
Входной вектор X и весовой вектор W,, соответствующий выходу, в общем
случае предполагаются нормализованными. Нормализация осуществляется
следующим образом:
|X|=/Z^=1;|\V| = ]fb^=l.
i i
Величина нейронной активности а выхода./ определяется по формуле
«=!>>V (8.2)
Между выходами НС осуществляется конкуренция на основе (8.2). Нейрон-
победитель определяется по наибольшему значению активности.
Предположим, что наибольшая нейронная активность соответствует выходу к. Тогда
весовые коэффициенты связей выхода Ах входами НС будут изменяться в
соответствии с правилом конкуренции (или правилом «победитель забирает все»)
по следующей формуле:
\у/о + ц(Х/о-\ВД)
Wt(f + 1) = , (8.3)
HW/o+KX/O-zW/O)!!
где 0 < ц < 1 - скорость обучения.
205
8. Самоорганизующиеся нейронные сети
В формуле (8.3) используются нормализованные вектора, и при
предъявлении очередного входного вектора обновляются только веса
нейрона-победителя, а остальные веса не изменяются. Таким образом, в качестве
нейрона-победителя выбирается такой нейрон, весовой вектор которого наиболее близок к
входному вектору, именно поэтому весовые векторы выходных нейронов на
каждом шаге обучения будут перемещаться в направлении кластеров входных
образов. Иллюстрация этого динамического процесса представлена на рис. 8.2.
В случае использования Евклидова расстояния в качестве меры
непохожести векторов выбирается активность выходных нейронов, которая
вычисляется по формуле
a, = /£(x-w.)2 = ||X-W,||. (8.4)
По формуле (8.4) определяется нейрон-победитель с номером к, который
будет соответствовать минимальному Евклидову расстоянию между
входным образом и весовым вектором этого нейрона. Среднекадратичная ошибка
для Анго нейрона-победителя равна
Е= ZllW/0w-5y|, (8.5)
где/(Хр) - нейрон-победитель; ХР - входной вектор; W/(x - центр кластера,
которому принадлежит Хр.
В настоящее время существует довольно большое число пакетных (off- line)
алгоритмов кластеризации, которые можно использовать для нахождения
кластерных центров с целью минимизации (8.5). Наиболее часто используются
следующие четыре метода кластеризации: метод «.^-средних» (или K-means
clustering, или C-means clustering), нечеткий «/^-средних» (fuzzy C-means
clustering), пикового группирования (the mountain clustering method) и
разностного группирования (subtractive clustering).
Основная идея кластерных алгоритмов заключается в том, чтобы разделить
входное пространство на группы. При этом сходство векторов внутри группы
должно быть больше сходства с векторами других групп. Для реализации этой
идеи вводятся специальные метрики схожести. Большинство известных
метрик являются чувствительными к интервалу изменения входных переменных,
поэтому входные переменные, как правило, нормализуются и приводятся к
единичному интервалу. В дальнейшем, если не оговорено другое,
предполагается, что входные переменные нормализованы внутри единичного гиперкуба.
Рассмотрим наиболее простой в программной реализации метод «АТ-сред-
них». Этот метод с успехом был использован для решения задач кластеризации
в различных прикладных областях: в распознавании речи, образов, сжатии
данных, в системах обработки данных, при обучении радиально-базисных НС и
при решении задач декомпозиции в гетероассоциативных сетях и т. д.
206
8.1. Сеть Кохонена
Пусть имеются и векторов X/(у = 1,2,...,«) и т групп кластеров Gj(i= 1,
2,..., т), а также известны кластерные центры в каждой такой группе. Если
в качестве меры сходства выбирается Евклидово расстояние между
векторами XtB группе i с центром кластера d, то стоимостная функция может быть
определена по формуле
•^Хл-Е ( Е IIXt-c.ii2), (8.6)
i-l i=l *, X* е С/
где J, = ^ ||Xt - C,||2 является стоимостной функцией внутри группы i.
k, Xt e G,
Величина J, зависит от геометрических свойств области G, и местоположения
центра кластера С,. В общем случае для вектора ХАв группе i может быть
применена функция расстояния dist (Xt- С); тогда стоимостную функцию
/можно записать в другом виде:
т т
-/=ЕЛ = 1 ( £ dist (X,-С,)). (8.7)
1-1 1=1 *, X; Е G,
Разделяемым группам векторов поставим в соответствие матрицу
принадлежностей U размерностью (тхп), в которой элемент щ = \, если j-й вектор Ху
принадлежит группе i, и utJ, = 0 в противном случае. Поскольку центры
кластеров фиксированы, то минимизация иув (8.6) может быть определена как
fl, если ||Х - С ||2< ЦХ - С.||2 VA; ^ i; ,„ ч
и.. = < " ' '" " ' *" (8.8)
L 0 в противном случае.
Вновь поступивший вектор X принадлежит группе i, если С( является
ближайшим центром среди всех центров. Поскольку входные вектора могут
принадлежать только одному кластеру, функции принадлежности в U обладают
следующими свойствами:
т
E"w = U У/= 1,2,..., и;
i-i
т п
.-17-1
С другой стороны, если и0 является фиксированной, то оптимальный центр,
минимизирующий стоимостную функцию (8.6), будет являться средним всех
векторов группы /:
С=^, 2 X,, (8.9)
|Ц/ *,Х,еС,
207
8. Самоорганизующиеся нейронные сети
где \G\ - размерность группы G., т. е. |GJ = ^щ.
Опишем работу алгоритма «К-средних» в пакетном режиме (off-line).
1. Инициализировать т кластерных центров путем случайного выбора т
точек среди всех входных векторов Х.(У = 1» 2, -.., п).
2. Определить матрицу U функций принадлежностей в соответствии с (8.8).
3. Вычислить стоимостную функцию в соответствии с (8.6). Перейти к ш. 5,
если достигнута заданная точность либо сумма разностей (8.6) становится
меньше заданного порога.
4. Обновить кластерные центры в соответствии с (8.9). Перейти к ш. 2.
5. Конец.
Приведенный алгоритм является итеративным, поэтому нет гарантии
получения оптимального решения. Успешность вьшолнения алгоритма «А-средних»
зависит от начального расположения центров кластеров, поэтому
целесообразным является предварительное определение кластерных центров или прогонка
алгоритма несколько раз с различным расположением этих центров. Другой
путь поиска наилучшего расположения центров связан со случайной
инициализацией матрицы U с последующим запуском итерационной процедуры
уточнения местоположения центров.
Рассматриваемый алгоритм может работать в режиме on-line (в реальном
времени), когда формирование кластерных центров и распределение групп
векторов по кластерам осуществляется на некотором промежутке времени путем
усреднения (8.9). Таким образом, для заданной входной точки X алгоритм
находит ближайший кластерный центр и обновляет его расположение по формуле
on-line
ДС = ц((Х(0-С(0)-
Эта on-line формула наиболее часто используется во многих алгоритмах
обучения без учителя в НС.
Принцип работы сети Кохоиена
Примером сети, использующей алгоритм обучения без учителя, является
введенная Т. Кохоненом (1982) «самоорганизующаяся карта признаков» {Self-
Organizing feature Maps, SOM). Другое, часто используемое название сети
Кохонена - KCN (Kohonen Clustering Networks). KCN используют для
отображения нелинейных взаимосвязей данных на достаточно легко интерпретируемые
(чаще всего двумерные) сетки, представляющие метрические и
топологические зависимости входных векторов, объединяемых в кластеры. Рассмотрим
более подробно архитектуру сети KCN и правила ее обучения. Нейронная сеть
20$
8.1. Сеть Кохонена
Рис. 8.3. Сеть Кохонена
Кохонена показана на рис. 8.3. Она имеет один слой нейронов. Число входов
каждого нейрона равно размерности входного образа. Количество нейронов в
слое непосредственно определяет, сколько различных кластеров сеть может
распознать. При достаточном количестве нейронов и удачных параметрах
обучения сеть Кохонена может не только выделить основные группы образов, но и
установить некоторые особенности полученных кластеров. При этом близким
входным образам будут соответствовать близкие карты нейронной
активности. Идея сети Кохонена возникла при изучении некоторых свойств головного
мозга. Кора человеческого мозга представляет собой большую поверхность,
площадью приблизительно 0,5 м2, свернутую складками. Эта поверхность
характеризуется определенными свойствами: например, участок, ответственный
за ступни ног, примыкает к участку, контролирующему движение всей ноги и т.
д., т. е. все элементы человеческого тела отображаются на эту поверхность.
Основная цель обучения в KCN состоит в выявлении структуры в «-мерных
входных данных и представлении ее на карте в виде распределения нейронных
активностей. Пример одного из распределений на двумерной сетке 8x8
нейронов приведен на рис. 8.4, а. Пример другого распределения, в виде поверхности
уровней двумерной функции (для большей наглядности), приведен на рис. 8.4,
б. Здесь высоким степеням возбуждения выходных нейронов соответствует
более темная окраска (на двумерной сетке) и большая «высота» уровней.
Каждый нейрон несет информацию о кластере, объединяющем в группу сходные
по критерию близости входные вектора, формируя для данной группы
некоторый собирательный образ.
Подобные вектора активизируют подобные нейроны, т. е. KCN способна к
обобщению. Конкретному кластеру может с%% -.- •. вать и несколько
нейронов с близкими значениями векторов весов, поэтому выход из строя одного
нейрона не так критичен к ошибке распознавания для функционирования этой
сети, как это имеет место, например, в случае сети Хемминга. Таким образом,
209
8. Самоорганизующиеся нейронные сети
"<
$
Рис. 8.4. Распределение нейронных активностей в KCN:
а - двумерная сетка; б - поверхность уровней двумерной функции
сеть Кохонена позволяет понизить размерность пространства представления
многомерных входных данных, сохранив топологию связей между ними.
В большинстве случаев каждый выходной элемент сети соединен со
своими соседями. Эти внутрислойные связи играют важную роль в процессе
обучения, так как корректировка весов происходит не для всех весов сети, а
только в окрестности того элемента, который наилучшим образом откликается на
очередной вход.
Сеть Кохонена использует соревновательный (конкурентный) алгоритм
обучения, рассмотренный выше. Выигрывает тот нейрон, чей вектор весов
наиболее близок к текущему входному вектору в смысле расстояния,
определяемого, например, евклидовой метрикой 8.1. У элемента-победителя это расстояние
будет меньше, чем у всех остальных.
В другом варианте алгоритма обучения победителем считается элемент,
весовой вектор которого имеет наибольшее скалярное произведение с
входным вектором. Эта величина также является некоторой мерой близости,
поскольку скалярное произведение - это проекция входного вектора на вектор
весов. Очевидно, такая проекция будет наибольшей, если векторы имеют
близкие направления. При этом методе, однако, оба вектора - весовой и входной -
должны быть нормализованы по длине, например, быть равными единице.
Напротив, евклидово расстояние позволяет работать с векторами произвольной
длины.
На текущем шаге обучения веса меняются только у нейрона-победителя
т*, а также, возможно, и у его непосредственных соседей; веса остальных
нейронов при этом «замораживаются». Нейронная активность соседнего
нейрона s уменьшается при увеличении расстояния между нейроном s и
выигравшим нейроном т* (рис. 8.5).
■■■■
■■■■■
■■■■
210
8.1. Сеть Кохонена
Нейронная
активность
ооооо
op m p о
ооюо
ооооо
Выходные
нейроны
dist (s,m*)
Рис. 8.5. Распределение нейронной активности соседей нейрона - победителя:
dist (s,m*) - расстояние между выигравшим нейроном т* и его соседом s
Подстройка весового вектора выигравшего нейрона и его соседей
осуществляется путем их перемещения в сторону входного вектора. После обучения
на достаточном числе обучающих примеров совокупность весовых векторов
приходит в соответствие со структурой входных векторов, т. е. векторы весов
в буквальном смысле моделируют распределение входных образов.
Для правильного понимания сетью входного распределения нужно, чтобы
каждый элемент сети становился победителем одинаковое число раз,
следовательно, появление различных весовых векторов должно быть равновероятно.
С этой целью в процедуру обучения вводится некоторый механизм
«справедливости». Один из возможных способов осуществления этого механизма
связан с увеличением расстояния между входным и весовым вектором на
некоторую величину добавки для часто выигрывающих нейронов и уменьшения этого
расстояния на ту же величину для тех нейронов, которые чаще проигрывают.
Таким образом, шансы проигрывающих нейронов повышаются. Величина
добавки меняется в процессе обучения в соответствии с изменениями частоты
выигрывающих нейронов.
Алгоритм обучения сети Кохонена
Вход каждого нейрона характеризуется весовым вектором той же
размерности, что и входной, следовательно, число параметров сети можно
определить как пк, где к - число нейронов (классов), а п - число входов.
Свойства сети определяются размерностью массива нейронов, числом
нейронов в каждом измерении, формой окрестности выигравшего нейрона,
определяющей его непосредственных соседей, законом сжатия окрестности и
скоростью обучения. Локальная окрестность может быть квадратом,
прямоугольником или окружностью. Начальный размер окрестности часто
устанавливается в пределах от 1/2 до 2/3 размера сети и сокращается согласно
определенному закону (например, по обратно пропорциональной зависимости).
Рассмотрим соревновательный алгоритм обучения в KCN.
211
8. Самоорганизующиеся нейронные сети
1. Инициализировать весовые вектора для всех выходных нейронов
(матрицы связей Wn*) случайной малой величиной. Вычислить усредненное
начальное расстояние D0 (далее будем обозначать через Dt усредненное расстояние
после t итераций) между обучающими векторами и установленными
векторами весовых коэффициентов:
Do=^E(f,mintdist(XI,W„0, (8ЛО)
где N- число примеров в обучающей выборке;У - номер нейрона, для которого
расстояние dist=min.
Установить размер окрестности для выигрывающего нейрона г («радиус
стимуляции»).
2. Положить D = Д.
old t
3. Подать на вход сети очередной входной вектор из обучающей выборки
X.(t), где t — текущий шаг итерации.
4. Для каждого нейрона/ определить его расстояние dist (X,(f),W.(0) по
формуле (8.1) для любого/
5. Выбрать нейрон победитель т = т, для которого это расстояние
минимально (поиск победителя ведется по величине отклонения входного вектора
от весового вектора каждого нейрона).
6. Модифицировать весовые коэффициенты выигравшего нейрона:
W m\t + 1) = W ffl(0 + ц dist (X(0, WJ(0) (8.11)
и тех нейронов s, которые находятся в окрестности выигравшего:
W'(/ + 1) = W'(f) + ц dist (X(0, W|(f)), (8.12)
где у = 1, 2,..., т - 1, т + 1,..., s; ц - скорость обучения (ц < 1).
7. Повторить п. 3 - 6 для всех векторов обучающей выборки.
8. Положить W* (f+ 1) = W*(0 и вычислить .D, по формуле (8.10).
Подсчитать е ж= dist (Dl+V Dty Df. Если e r+1 < rj, где rj - априорно заданная
положительная пороговая величина, то перейти к п. 9, иначе положить t = t+\,
откорректировать ц, размер окрестности и перейти к п. 2.
9. Конец.
В приведенной схеме скорость обучения ц должна быть определена так,
чтобы она понижалась со временем для ускорения стабилизации вектора
весовых коэффициентов каждого нейрона. Это может быть выполнено в
соответствии с графиком, приведенным на рис. 8.6.
Более того, необходимо определять и изменять со временем также и
функцию обновления соседних нейронов, а также размер окрестности г (рис. 8.7). В
этом случае формула (8.12) перепишется в следующем виде:
212
8.]. Сеть Кохонена
max/
max/
Рис. 8.6. Изменение скорости обучения Рис. 8.7. Изменение радиуса окрестности
w'(f + l) = W''(0 + e ndw/(X,(0,Wny(0),
_ 1 (ri"'j у
где элемент е 2 Т определяет латеральное (побочное) торможение
активности соседних нейронов; rm, - расстояние между победившим m и соседним
нейроном^; г - текущий размер окрестности.
Механизм латерального торможения в нейрофизиологии был детально
исследован применительно к сенсорным системам и, в частности к зрению, где
он использовался для повышения контрастности. Исследования показали, что
возбуждающий входной сигнал приводит к уменьшению активности соседних
клеток в коре головного мозга. Этот эффект в биологических системах
проявляет свое действие на расстоянии 100...200 мкм от точки возбуждения или
стимуляции, причем в области стимуляции R это действие положительное, а за
пределами области — отрицательное. На более далеких расстояниях (свыше
1 мм) от точки возбуждения снова существует небольшой положительный
(стимулирующий) эффект,
обусловленный подкорковыми
межнейронными связями (рис. 8.8).
В сети Кохонена используется
только положительный
стимулирующий эффект, действующий в
окрестности выигравшего нейрона.
Этим достигается возможность уже
на первых шагах обучения выявить
группы нейронов, отображающих
топологическую карту
взаимосвязи входных векторов. С каждой
новой итерацией скорость обучения ц
и размер окрестности г
уменьшаются, тем самым внутри участков
0фффффффф®0
Рис. 8.8. Демонстрация эффекта
латерального торможения в коре головного мозга
213
8. Самоорганизующиеся нейронные сети
топологической карты выявляются все более мелкие различия. Это, в
конечном итоге, приводит к более точной настройке каждого нейрона.
Кривая е ° , являющаяся функцией г, представлена на рис. 8.9. Она
определяет латеральное распределение нейронной активности для соседел
победившего нейрона в сети Кохонена. Как видно из рисунка, функция
нейронной активности достигает максимального значения около узла победителя
для каждого X..
После того, как сеть обучена, необходимо определить, как соотносятся между
собой на топологической карте различные кластеры (поскольку обучение
происходило без учителя). Иными словами, каждой группе входных векторов
должен быть поставлен в соответствие определенный выходной нейрон (кластер),
т. е. все нейроны топологической карты должны быть помечены
содержательными по смыслу метками. Когда все кластеры определены, на вход KCN
можно подавать новые входные вектора, отсутствовавшие в обучающей выборке.
Если выигравший нейрон помечен именем класса, то сеть осуществляет
классификацию, относя входной вектор к этому классу. В противном случае сеть
Кохонена выполняет функцию фильтра новизны, т. е. создается новый класс.
В центральной нервной системе человека имеются функциональные
элементы, предназначенные для выявления новизны образа, т. е. того, является ли
рассматриваемый образ новым или старым; при этом степень новизны
информации является относительным понятием. В одном крайнем случае можно
утверждать, что всякий уже встречавшийся образ - старый, и только образ,
встречающийся впервые, - новый. Другая точка зрения основана на том, что
выявление новизны следует рассматривать как многошаговый процесс,
включающий повторные предъявления
Нейронная
О® ® ® ® ® ® ©О
Окрестность выигравшего нейрона
Рис. 8.9. Представление механизма
латерального торможения в KCN
того же образа с некоторыми
стохастическими отклонениями. В этом
случае новизна определяется
относительно некоторого стереотипа или
усредненного образа. Фильтр новизны
как раз и является моделью
гипотетической НС, способной действовать
как эффективный адаптивный фильтр.
У сети Кохонена есть ряд
недостатков. Во-первых, метод
обучения является эвристическим,
поэтому завершение процедуры обучения
не основывается на оптимизации
какой-либо математической модели
214
8.2. Сети на основе теории адаптивного резонанса
процесса или относящихся к нему данных. Во-вторых, итоговые весовые
векторы выходных нейронов обычно зависят от входной последовательности. В-
третьих, различные начальные условия обычно порождают различные
результаты. В-четвертых, некоторые параметры алгоритмов KCN. скорость обучения,
размер окрестности и вид функции обновления весовых векторов соседей, а
также методика изменения этих параметров во время обучения делает
необходимым переход, если это возможно, от одной обучающей выборки к другой,
чтобы добиться желаемых результатов. Поэтому более выгодными
оказываются комбинированные сети.
8.2. Сети на основе теории адаптивного резонанса
Решение проблемы стабильности-пластичности восприятия
Понимание процессов человеческого мышления - чрезвычайно трудная
проблема. Одной из самых сложных и трудно решаемых задач при построении
искусственных НС, моделирующих восприятие и понимание, является
проблема стабильности-пластичности. Характер восприятия внешнего мира
человеком постоянно связан с решением дилеммы, является ли некоторый
воспринимаемый образ новой информацией либо он представляет вариант старой, уже
знакомой ситуации, и ее не требуется запоминать. Таким образом, память
должна оставаться пластичной, способной к восприятию новых образов, и в то же
время сохранять стабильность, гарантирующую неразрушение старых
образов.
Рассмотренные ранее НС не приспособлены к решению этой задачи.
Например, многослойный персептрон, обучающийся по методу обратного
распространения, запоминает всю обучающую информацию, при этом образы
обучающей выборки предъявляются в процессе обучения многократно. Если затем
требуется, чтобы обученный персептрон запомнил новый вектор, весовые
коэффициенты могут быть изменены (память разрушена) настолько, что,
возможно, необходимо будет полное переобучение.
Аналогичная ситуация имеет место и в сетях Кохонена, обучающихся на
основе самоорганизации. Данные сети всегда выдают положительный
результат при классификации. Тем самым, эти НС не в состоянии отделить новые
образы от искаженных или зашумленных версий старых образов.
Семейство НС, построенное на основе теории адаптивного резонанса,
разработанной С. Гроссбергом применительно к биологическим структурам,
обладает свойствами стабильности и пластичности, т. е. сети ART {Adaptive
Resonance Theory Network) могут обучаться новым данным, не теряя при этом
ранее накопленную информацию.
Принцип адаптивного резонанса. Наиболее важной особенностью НС с
адаптивным резонансом является то, что они сохраняют пластичность при
запоминании новых образов, и, в то же время, предотвращают модификацию
старой памяти.
215
8. Самоорганизующиеся нейронные сети
ART имеет внутренний детектор новизны - тест на сравнение
предъявленного образа с содержимым памяти. При удачном поиске в памяти
предъявленный образ классифицируется с одновременной уточняющей модификацией
весовых коэффициентов. О такой ситуации говорят как о возникновении
адаптивного резонанса в сети в ответ на предъявление образа. Если резонанс
не возникает в пределах некоторого заданного порогового уровня, то
успешным считается тест новизны, и образ воспринимается сетью как новый.
Модификация весов нейронов, не испытавших резонанса, при этом не
производится. Запомненный образ не будет изменяться, если текущий входной вектор не
окажется достаточно похожим на него. Таким образом, решается проблема
стабильности-пластичности. Новый образ может создавать новые классы,
однако при этом существующая память не разрушается.
Первым важным понятием в теории адаптивного резонанса является так
называемый шаблон критических черт информации. Этот термин показывает,
что не все черты (признаки), представленные в некотором образе, являются
существенными для системы восприятия. Результат распознавания
определяется присутствием специфичных критических особенностей в образе. Одна и
та же черта образа может быть не существенной в одном случае и критической
в другом. Задачей НС является формирование правильной реакции в обоих
случаях: «пластичное» решение о появлении нового образа и «стабильное»
решение о совпадении со старым образом. При этом выделение критической
части информации должно происходить автоматически в процессе работы и
обучения сети на основе ее индивидуального опыта.
В общем случае одного лишь перечисления признаков (даже если его
предварительно выполнит человек, предполагая определенные условия
дальнейшей работы сети) может оказаться недостаточным для успешного
функционирования искусственной НС, критическими могут оказаться и специфические
связи между несколькими отдельными признаками.
Вторым важным понятием теории адаптивного резонанса является
самоадаптация алгоритма поиска образов в памяти.
В ART используется управляемый алгоритм обучениия, основным свойством
которого является динамическая самоорганизация классов прототипов,
соответствующих классам векторов в признаковом пространстве, путем
наращивания числа нейронов в выходном слое (слое распознавания). Если поиск
класса, попадающего в «резонанс» с входным вектором (по соответствующему
критерию сходства), не привел к успеху, то создается новый класс
(добавляется новый нейрон), в противном случае согласно обучающему правилу
модифицируется прототип того класса, сходство с входным вектором которого
максимально (для этого проводится обучение весового вектора выигравшего нейрона
слоя распознавания).
Эти и другие особенности теории адаптивного резонанса нашли свое
отражение в нейросетевых архитектурах, которые получили такое же название -
ART.
216
8.2. Сети на основе теории адаптивного резонанса
Нейронная сеть ART-l
Имеется несколько разновидностей сетей ART Исторически первой
явилась сеть, в дальнейшем получившая название ART-1 (S. Grossberg, G Carpenter,
1987). Эта сеть ориентирована на обработку образов, содержащих двоичную
информацию. CemART-2, ART-3 могут работать с непрерывной информацией.
Нейронная сеть ART-l является классификатором входных двоичных
образов по нескольким сформированным сетью категориям (классам) прототипов.
Так же, как и в KCN, в ART-l используется алгоритм обучения без учителя на
основе конкуренции. Решение в такой сети принимается в виде возбуждения
одного из нейронов распознающего слоя, в зависимости от степени похожести
образа на шаблон критических черт данной категории. Если эта степень
похожести невелика, т. е. образ не соответствует ни одному из имеющихся классов,
то для него формируется новый класс, который в дальнейшем будет
модифицироваться и уточняться другими образами, формируя свой шаблон
критических признаков. Для описания новой категории отводится новый, ранее не
задействованный нейрон в слое распознавания. Из-за этого число нейронов в
выходном слое в процессе обучения растет, что является большим
недостатком сети ART.
Математическое описание ART сложное, но основные идеи и принципы
реализации алгоритма обучения достаточно просты для понимания и машинного
моделирования.
Сеть ART-l состоит из пяти функциональных модулей (рис. 8.10): двух
слоев нейронов - слоя сравнения и слоя распознавания, и трех управляющих
специализированных нейронов - сброса, управления G1 и управления G2.
Начальное значение нейрона управления G1 полагается равным единице:
Gl = l. Входной двоичный вектор X поступает на слой сравнения, который
первоначально пропускает его без изменения, при этом выходной вектор слоя
сравнения С = X. Это достигается применением так называемого правила 2/3 для
нейронов слоя сравнения. Каждый из нейронов этого слоя имеет три двоичных
входа: входной сигнал, сигнал от соответствующего нейрона управления G1 и
+
г>
+
-►
G2
+ -
G1
+
->
+
-►
Слой распознавания
1
R
А
с
Слой сравнения
А
X
^
ч
ь
1
Сброс
Контроль
<
Рис. 8.10. Общая схема функционирования нейронной сети ART-l
217
8. Самоорганизующиеся нейронные сети
сигнал обратной связи из слоя распознавания R (который в начальный момент
равен нулю). Для активизации нейрона в слое сравнения требуется, чтобы, по
крайней мере, два из трех сигналов были равны единице, что и достигается в
начальный момент единичным входом от управления G1 и активными
компонентами вектора X.
Выработанный слоем сравнения сигнал С поступает на входы нейронов
слоя распознавания. Каждый нейрон слоя распознавания имеет вектор весов
В, — действительных чисел, при этом возбуждается только один нейрон этого слоя,
вектор весов которого наиболее близок к С. Это может быть достигнуто,
например, за счет механизма латерального торможения типа «победитель
забирает все» в алгоритме соревновательного обучения. Выход
нейрона-победителя устанавливается равным единице, остальные нейроны полностью
заторможены. Конкуренция между нейронами слоя распознавания
реализуется введением связей между ними с отрицательными весами. Поэтому нейрон
с большим выходным сигналом тормозит все остальные нейроны в слое.
Кроме того, каждый нейрон имеет связь с положительным весом со своего вькода
на свой собственный вход. Если нейрон имеет единичный выходной уровень, то
эта обратная связь стремится усилить и поддержать его. Сигнал обратной связи
от нейрона-победителя поступает обратно в слой сравнения через весовые
коэффициенты вектора Т. Вектор Т, по существу, является носителем
критических черт категории, определяемой выигравшим нейроном.
Выход нейрона G1 равен единице в том случае, когда входной образ X
имеет ненулевые компоненты. Таким образом, этот нейрон выполняет функцию
детектора новизны поступающего входного образа. Однако, когда возникает
ненулевой отклик нейронов слоя распознавания R, значение нейрона G1
становится равным нулю.
Сигнал нейрона G2 также устанавливается в единицу при ненулевом
векторе X. Задачей этого нейрона является погашение активности на слое
распознавания, если в сеть не поступило никакой информации.
При генерации отклика R слоя распознавания выход Gl= 0, нейроны слоя
сравнения активизируются сигналами образа X и отклика R. Правило 2/3
приводит к активизации только тех нейронов слоя сравнения, для которых и X, и R
являются единичными. Таким образом, выход слоя сравнения С теперь уже не
равен в точности X, а содержит лишь те компоненты X, которые соответствуют
критическим чертам победившего класса. Этот механизм в теории ART
получил название адаптивной фильтрации образа X.
Теперь задачей системы является установить, достаточен ли набор этих
критических черт для окончательного отнесения образа X к классу
нейрона-победителя. Эту функцию осуществляет нейрон сброса, который измеряет
сходство между векторами X и С. Выход нейрона сброса определяется отношением
числа единичных компонент в векторе С к числу единичных компонент
исходного образа X. Если это отношение ниже некоторого определенного уровня
218
8.2. Сети на основе теории адаптивного резонанса
сходства, нейрон выдает сигнал сброса, означающий, что уровень резонанса
образа X с чертами рассматриваемого класса не достаточен для
положительного заключения о завершении классификации. Условием возникновения
сигнала сброса является соотношение р = (Qr\H )1Н, где р < 1 - параметр
сходства; Н— количество единиц в векторе X; Q- количество единиц в векторе С,
П - знак пересечения.
Пример 1. Примем X = 11001100; Я = 4; С = 11001000; £ = 3.
Тогда р = (6ПЯ)/Я = 0,75.
Таким образом, р может изменяться от 1 (полное соответствие) до 0 (наихуцшее
соответствие).
Сигнал сброса выполняет полное торможение
нейрона-победителя-неудачника, который не принимает в дальнейшем участия в работе сети.
Рассмотрим процесс функционирования сетей ART.
Начальное состояние сети. Нулевые значения компонент входного
вектора X устанавливают сигнал G2 в нуль, одновременно устанавливая в нуль
выходы нейронов слоя распознавания. При возникновении ненулевых значений
X оба сигнала управления (G1 и G2) будут равны единице. При этом по
правилу 2/3 выходы нейронов слоя сравнения С в точности равны компонентам X.
Вектор С поступает на входы нейронов слоя распознавания, которые в
конкурентной борьбе определяют нейрон-победитель, описьшающий
предполагаемый результат классификации. В итоге выходной вектор R слоя
распознавания содержит ровно одну единичную компоненту, остальные значения равны
нулю. Ненулевой выход нейрона-победителя уст .; ;ает в нуль сигнал
управления G1=0. По обратной связи нейрон-победитель посылает сигналы в слой
сравнения, и начинается фаза сравнения.
Фаза сравнения. В слое сравнения вектор сигналов отклика слоя
распознавания сравнивается с компонентами вектора X. Выход слоя сравнения С
теперь содержит единичные компоненты только в тех позициях, в которых
единицы имеются и у входного вектора X, и у вектора обратной связи Р. Если в
результате сравнения векторов С и X не будет обнаружено значительных
отличий, то нейрон сброса остается неактивным. Вектор С вновь вызовет
возбуждение того же нейрона-победителя в слое распознавания. В противном случае
будет выработан сигнал сброса, который затормозит нейрон-победитель в слое
распознавания, и начнется фаза поиска.
Фаза поиска. В результате действия тормозящего сигнала сброса все
нейроны слоя распознавания получат нулевые выходы, и, следовательно, сигнал
G\ примет единичное значение активности. Снова выходной сигнал слоя
сравнения С установится равным в точности X, как и в начале работы сети. Однако
теперь в конкурентной борьбе в слое распознавания предыдущий
нейрон-победитель не участвует, и будет найден новый класс - кандидат. После чего опять
повторяется фаза сравнения.
219
8. Самоорганизующиеся нейронные сети
Итерационный процесс поиска завершается одним из двух способов:
• найдется запомненный класс, сходство которого с входным вектором X
будет достаточным для успешной классификации. Затем происходит
обучающий цикл, в котором модифицируются веса Ь, и t, векторов В и Т
возбужденного нейрона, осуществившего классификацию;
• в процессе поиска все запомненные классы проверенны, но ни один из
них не дал требуемого сходства. В этом случае входной образ X объявляется
новым для нейросети, и ему выделяется новый нейрон в слое распознавания.
Весовые вектора этого нейрона В и Т устанавливаются равными вектору X.
Важно понимать, зачем нужна фаза поиска и почему окончательный
результат классификации не получается с первой попытки. Дело в том, что
обучение и функционирование сетиЛЛГпроисходят одновременно.
Нейрон-победитель определяет в пространстве входных векторов ближайший к заданному
входному образу вектор памяти, и если бы все черты исходного вектора были
критическими, это и была бы верная классификация. Однако множество
критических черт стабилизируется лишь после относительно длительного
обучения. На данной фазе обучения только некоторые компоненты входного вектора
принадлежат множеству критических признаков, поэтому может найтись
другой нейрон-классификатор, который на множестве критических признаков
окажется ближе к исходному образу. Он и определяется в результате поиска.
После относительной стабилизации процесса обучения классификация
выполняется фактически без фазы поиска.
Обучение сети ART. В начале функционирования все веса В и Т векторов,
а также параметр сходства получают начальные значения. Согласно теорииЛЛГ,
эти значения должны удовлетворять условию
btJ <L/(L-l + m);
',=1 yUj,
где Ъ — вес связи, соединяющий нейрон i в слое сравнения с нейроному в слое
распознавания; т - число компонент входного вектора X; L - константа, L > 1
(например, L = 2).
Такой выбор весов приводит к устойчивому обучению. Начальная
установка весов bt в малые величины гарантирует, что несвязанные нейроны не будут
получать большего возбуждения, чем обученные нейроны в слое распознавания.
Уровень сходства г выбирается на основе требований решаемой задачи. При
высоких значениях этого параметра сформируется большое число классов, к
каждому из которых относятся только очень похожие вектора. При низком уровне
р сеть формирует небольшое число классов с высокой степенью обобщения
(«грубая» классификация). Для повышения гибкости работы ART необходима
220
8.2. Сети на основе теории адаптивного резонанса
реализация стратегии динамического изменения критерия сходства р во время
процедуры обучения, обеспечивающая грубую классификацию в начале
обучения (при низких р) и увеличивающая р для выработки точной классификации в
конце обучения.
Обучение происходит без учителя и проводится для весов
нейрона-победителя в случае как успешной, так и неуспешной классификации. При этом веса
вектора В стремятся к нормализованной величине компонент вектора С:
A LCi
bij-L-l + Zck'
к
где Ъ{ - вес связи, соединяющий нейрон / в слое сравнения с нейроному в слое
распознавания; ct — i-я компонента выходного вектора слоя сравнения;^ -
номер выигравшего нейрона в слое распознавания; L — константа.
При этом роль нормализации компонент крайне важна. Вектора с большим
числом единиц приводят к небольшим значениям весов Ъ, и наоборот. Таким
образом, произведение (Ь- с) = £ Ь с оказывается масштабированным.
Масштабирование приводит к тому, что сеть может правильно различать вектора,
даже если один из них является подмножеством другого.
Пусть вектор XI соответствует образу (100000), а вектор Х2 - образу
(111100). Эти образы являются, очевидно, различными. При обучении без
нормализации (т. е. Ь, —> с,) при поступлении в сеть первого образа он даст
одинаковые скалярные произведения, равные единице, как с весами вектора XI, так
и Х2. Вектор Х2 в присутствии небольших шумовых отклонений в значениях
весов может выиграть конкуренцию. При этом веса его вектора Т установятся
равными (100000), и образ (111100) будет безвозвратно «забыт» сетью.
При применении нормализации исходные скалярные произведения будут
равны единице для вектора XI и 2/5 для вектора Х2 (при L = 2), поэтому вектор
XI выиграет конкурентное соревнование.
Компоненты вектора Т, как уже говорилось, при обучении устанавливаются
равными соответствующим компонентам вектора С.
t =c Vi,
ч ч '
где t - вес связи между выигравшим нейроном у в слое распознавания и
нейроном i в слое сравнения.
Если какая-то из компонент t равна нулю, то при дальнейшем обучении на
фазах сравнения соответствующая компонента с никогда не получит
подкрепления по правилу 2/3, и, следовательно, единичное значение t не может быть
восстановлено. Таким образом, обучение сопровождается приведением все
большего числа компонент вектора Т к нулю, оставшиеся ненулевыми
компоненты определяют множество критических признаков данного класса.
Таким образом, алгоритм обучения ART-1 состоит из двух фаз (рис. 8.11).
Первая связана с определением нейрона-победителя путем вычисления степе-
221
8. Самоорганизующиеся нейронные сети
Слой
распознавания
Слой
сравнения
Рис. 8.11. Схема обучения в сети ART-1
ни активности выходных нейронов сети в ответ на подачу некоторого входного
вектора; нейрон-победитель имеет наибольшую степень активности. Во
второй фазе вычисляется рассогласование между входным образом и
прототипом, связанным с нейроном-победителем. Если это рассогласование ниже
необходимого, этот прототип обновляется в соответствии с новым вектором, а
если превышает, то процедура продолжается для других нейронов или
создается новый нейрон.
Алгоритм обучения ART-X записывается в следующем виде.
1. Инициализация весовых коэффициентов:
т.
t9:=U Ъ1} := 1/(1 + и) V/ = 1, 2,..., n;j = 1, 2,
2. Установка параметра сходства из условия: 0 < р < 1.
3. WHILE (имеются входные вектора) DO:
а) подача на вход сети нового входного вектора:
X = (хх, хг,..., xj;
б) вычисление значений выходов сети:
т
У, =Hbiixj Vl'= Ь 2> ■••> т>
в) определение номера нейрона-победителяу* с наибольшей величиной
выхода;
г) определение сходства входного вектора X (образа) с прототипом Т „
который соответствует нейрону-победителюу*: IF (число единиц в двоичном
представлении пересечения векторов X и Т„ деленное на число единиц в X больше,
чем р, THEN GOTO (e)
ELSE
д) выход нейронау* сбрасывается, и продолжается процедура поиска
нового нейрона-победителя; GOTO (б);
222
8.2. Сети на основе теории адаптивного резонанса
Вход Выход 1 Выход 2
Рис. 8.12. Пример обучения ceniART-1 трем образам
е) входной вектор X ассоциируется с прототипом Т.„ поэтому
производится изменение весовых коэффициентов прототипа:
t := t + х „ V/ = 1, 2,..., и;
I) Ij* IJ" 5 5 5 5
ж) весовые коэффициенты Ь.. также изменяются:
л
Ь :=b., + t ,х /(0,5 + У> .xt).
4. Конец. ,=1
Пример 2. Рассмотрим пример обучения сети ЛЯГ-1 трем образам, поступающим на вход
сети Вход (рис. 8.12). При поступлении первого образа на выходе Выход 1 создается первый
выходной нейрон, второй образ связывается с тем же нейроном, а для третьего на выходе
Выход 2 создается новый выходной нейрон.
Сеть ART является единственным типом сетей, в которой реализована
возможность создания оптимальной топологии сети (минимальное число
нейронов в выходном слое). Важное достоинство сетей этого типа также
проявляется в способности решить проблему стабильностипластичности. Однако это
вызывает необходимость управлять ростом сети, что в оригинальном
алгоритме осуществляется путем выбора пользователем желаемой величины
параметра сходства р е[0,1]. Как уже указывалось, чем выше значение этого
параметра, тем большее число классов прототипов, и, соответственно, нейронов
выходного слоя будет создано сетью. В предельном случае (р = 1) происходит
223
8. Самоорганизующиеся нейронные сети
образование отдельного класса для каждого экземпляра обучающей выборки.
Очевидно, что в этом случае существенно снижается способность НС к
обобщению.
Увеличение числа классов приводит к неэффективному использованию
компьютерных ресурсов и замедлению классификации. Слишком малое
количество образованных категорий прототипов, в свою очередь, может вызвать
неудовлетворительное воспроизведение сетью обучающей выборки и обусловить
низкую точность распознавания. Задача выбора числа необходимых классов,
которые может распознать сеть, перекладывается на пользователя, который
должен выбрать значение параметра р. Оптимальный выбор этого параметра
трудоемок и требует проведения большого числа экспериментов. Поэтому
первостепенное значение приобретает автоматизация процесса роста НС без
задания пользователем параметра сходства.
8.3. Сети встречного распространения
Одной из наиболее популярных комбинированных сетей, использующихся
на практике, является двухслойная сеть встречного распространения CPN
(Counterpropagation Network), первым слоем которой является сеть Кохонена,
а вторым - сеть С. Гроссберга.
Идеи С. Гроссберга, связанные с исследованиями в области биологической
кибернетики (S. Grossberg, 1969), реализуются во многих НС. В частности,
конфигурации входных и выходных звезд Гроссберга используют для
создания иерархических НС.
Нейрон в форме входной звезды имеет и входов, которым соответствуют
весовые коэффициенты W = (w,, wy ..., wn), и один выход Y, являющийся
взвешенной суммой входов. Входная звезда обучается выдавать сигнал на выходе
всякий раз, когда на входы поступает определенный вектор. Таким образом,
входная звезда является своего рода детектором состояния входов и реагирует
только на свой входной вектор. Подстройка весовых коэффициентов
проводится по следующей формуле:
w,(/+i)=w,(o + M(x>-wf(0),
где Wf (t) - весовой вектор i-й входной звезды на t-м такте обучения; Х(
-входной вектор; ц - скорость обучения. Скорость обучения ц имеет начальное
значение в пределах 0,1.. .0,2 и постепенно уменьшается в процессе обучения.
Выходная звезда Гроссберга выполняет противоположную функцию - при
поступлении сигнала на вход выдается определенный вектор. Нейрон этого
типа имеет один вход и т выходов с весами W = (wv wv ..., wm), которые
подстраиваются в соответствии с формулой
W,(/+l) = Wi(0 + a(Yj-Wi.(0), (8.13)
где W( (f) - весовой вектор /-и выходной звезды на t-м такте обучения; Yf -
224
8.3. Сети встречного распространения
выходной вектор; а - скорость обучения. Рекомендуется начать обучение со
значения а в пределах единицы, постепенно уменьшая до значений, близких к
нулю. Итерационный процесс, реализуемый по формуле (8.10), будет
сходиться к некоторому усредненному образу, полученному из совокупности
обучающих векторов.
Особенностью нейронов в форме звезд Гроссберга является избирательность
памяти. Каждый нейрон в форме входной звезды помнит «свой» относящийся
к нему образ и игнорирует остальные. Каждой выходной звезде соответствует
некоторая конкретная командная функция. Образ памяти связывается с
определенным нейроном, а не возникает вследствие взаимодействия между
нейронами в сети.
Сеть со встречным распространением CPN представляет собой соединение
самоорганизующейся сети Кохонена и выходной звезды Гроссберга.
Топология сети встречного распространения приведена на рис. 8.13. В рамках этой
архитектуры элементы сети Кохонена не ■ ■; • i я выходом сети, а служат лишь
входами для выходного слоя - выходной звезды Гроссберга. Создатель сети
встречного распространения Р. Хехт-Нильсен (R. Heht Nilsen, 1987)
рекомендует использовать эти архитектуры для решения задач аппроксимации
функций и заполнения пробелов в таблице данных.
Обучение CPN состоит из двух шагов. На первом шаге весовые векторы
слоя Кохонена настраиваются таким образом, чтобы провести распределение
входных векторов по классам, каждый из которых соответствует одному
нейрону-победителю. Обучение проводится без учителя. Точность кластеризации
в этом случае будет гарантирована только тогда, когда обучающая выборка
является представительной.
На втором шаге осуществляется обучение с учителем. Проводится
подстройка весовых коэффициентов выходного слоя Гроссберга на примерах с
заданным выходом с использованием формулы (8.13). При этом настраиваются
только веса, соответствующие связям с теми элементами слоя Кохонена,
которые являются «победителями» в текущем такте обучения (выигравшие эле-
Выход Y
У\ Уг Утл Ут
Слой Гроссберга
Слой Кохонена
Х\ Xi X„_i Х„
ВходХ
Рис. 8.13. Топология сети встречного распространения
225
8. Самоорганизующиеся нейронные сети
менты посылают выходной сигнал, равный единице). Темпы обучения
нейронов Кохонена и Гроссберга должны быть согласованы; кроме того, в слое Ко-
хонена подстраиваются также веса всех нейронов в окрестности победителя,
которая постепенно сужается до одного нейрона.
При функционировании сети в режиме распознавания нейроны слоя
Гроссберга по сигналу нейрона-победителя в слое Кохонена воспроизводят на
выходах сети образ в соответствии со значениями его весовых коэффициентов. В
случае, когда слой Гроссберга состоит из единственного элемента,
получающийся скалярный выход равен одному из весов, соответствующих связям
этого элемента (с выигравшим нейроном).
Одной из особенностей CPN является возможность восстановления пары
векторов (X,Y) по одной известной компоненте. При предъявлении сети на этапе
распознавания только входного вектора X (с нулевым начальным Y)
проводится прямое отображение, т. е.восстанавливается Y, и, наоборот, при известном
Y может быть восстановлен соответствующий ему X. Возможность решения
как прямой, так и обратной задачи, а также гибридной задачи по
восстановлению отдельных недостающих компонент делает данную нейросетевую
архитектуру очень важным инструментом исследования различных процессов и
объектов.
Обученная нейронная CPN может функционировать и в режиме
интерполяции, когда в слое Кохонена может быть несколько победителей. В этом случае
уровни их нейронной активности нормируются таким образом, чтобы в сумме
составлять единицу; тогда выходной вектор определяется по сумме выходных
векторов каждой из активных звезд Гроссберга. Таким образом, CPN будет
осуществлять линейную интерполяцию между значениями выходных векторов,
отвечающих нескольким кластерам.
Сети данного вида успешно применяют в финансовых и экономических
приложениях, таких, как рассмотрение заявок на предоставление займов,
предсказание трендов цен акций, товаров и курсов обменов валют. Можно ожидать
успешного применения CTW-сети в задачах интерполяции.
Упражнения и вопросы для самоконтроля
1. Что такое кластеризация?
2 Дайте определение самоорганизующейся НС.
3. Опишите алгоритм кластеризации «JC-средних». Как выполняется начальная
установка центров кластеров?
4. Сформулируйте алгоритм обучения сети Кохонена.
5 Перечислите алгоритмы обучения НС.
6. Каким образом решается проблема стабильности-пластичности в НС?
7. В чем состоит особенность обучения НС ART-1 ?
8. С какой целью используется латеральное торможение при обучении НС?
9. Приведите примеры комбинированных НС.
10. Как повысить эффективность работы сети Кохонена nART-1 ?
11. Для какого типа НС автоматически формируется оптимальная топология?
12. Что такое on-line- и о^-Ипе-обучеиие?
226
9. РАДИАЛЫЮ - БАЗИСНЫЕ И ДРУГИЕ МОДЕЛИ
НЕЙРОННЫХ СЕТЕЙ
Рассмотрены перспективные радиалъно-базисные НС, обеспечивающие, в отличие от
многослойных НС персептронного типа, более быстрое обучение за счет использования
комбинированного алгоритма обучения. Показана целесообразность применения на
практике древовидных сетей,обеспечивающих возможность построения сетевых
классификаторов, а также НС с функциональными связями для решения линейно неразделимых задач.
9.1. Радиально-базисные нейронные сети
В отличие от метода разбиения пространства гиперплоскостями при
решении задач классификации с помощью многослойного персептрона в сетях типа
радиальной базисной функции используется подход, основанный на
разбиении пространства окружностями или (в общем случае) гиперсферами.
Гиперсфера при этом задается своим центром и радиусом. Приведем
математическое описание нейрона, используемого в RBF (Radial Basis Function).
Математическая модель формального нейрона была определена в гл. 3:
>> = /(net(X,W)),
где у - выходной сигнал;/- функция активации; net(X,W ) - дискриминантная
N
функция net(X,W) = ^w,m,(X) = WU(X)s X - входной вектор; W - вектор ве-
i=i
совых коэффициентов.
Дискриминантная функция представляет собой скалярное произведение
iV-мерного вектора весовых коэффициентов и вектора U (X), каждая
компонента которого является некоторой функцией входного вектора X. Структура
вектора U (X) задает свойства нейрона.
Дискриминантная функция net (X,W) может представлять собой отрезок
многомерного ряда Тейлора степени L. Если степень L = 1, то соответствую-
227
9. Радиалъно-базисные и другие модели нейронных сетей
щий нейрон называется нейроном первого порядка, в противном случае
говорят о нейронах высших порядков. В этом случае коэффициенты разложения
отрезка многомерного ряда Тейлора образуют вектор весовых коэффициентов
W. Дискриминантная функция нейрона первого порядка имеет вид:
N
neti(X,W) = *ь +5>Л- = WU(X),
И-
где W = (wQ, w,, ..., wN) - вектор весовых коэффициентов нейрона;
U(X) = (\,xv ...,xN)- расширенный вектор входа нейрона; х —j-я компонента
Л'-мерного входного вектора X.
Для нейрона второго порядка дискриминантная функция:
N N J
net2(X, W) = w0+ Y™jxj + ZZ™/**/** = WU(X), (9. i)
j=\ j=\k=i
где w0, w^j = l,N,wt,j=l,N,k= 1, j - компоненты вектора W весовых
коэффициентов, а расширенный входной вектор имеет вид:
U(X) = (1,xv ...,xN,xt2,x2xt, ...,xN2).
Компоненты вектора U(X) могут быть более сложными функциями, чем
функции в (9.1), образующие отрезок ряда Тейлора. В частности, довольно
распространенной функцией мДХ) является функция
м(Х)=/(гД (9.2)
Т 1/2
где г, = ((X - Q ) (X - Q )) - евклидово расстояние от точки X до заданной
точки С,. Нейронную сеть, использующую такой нейрон, называют сетью
радиальных базисных функций RBF. Вид базисной функции fir) в (9.2)
определяет название сети. Так, если функция /(г.) задается выражением
/(/;.) = ехр(^г),
где а - задаваемый параметр, определяющий размах базисной функции, то
такая сеть RBF называется сетью гауссовых базисных функций.
Нейрон многослойного персептрона полностью определяется значениями
своих весов и порогов, которые в совокупности определяют уравнение
разделяющей прямой. В случае RBF нейрон (радиальный элемент) задается центром
(некоторой разделяющей окружности) и радиусом (отклонением от кривой
разделения). Поскольку положение точки в Л'-мерном пространстве определяется
N числовыми параметрами (весовыми коэффициентами нейрона для
многослойного персептрона), то по аналогии координаты центров радиальных
элементов можно рассматривать как «веса», а радиус как «порог». Топология сети
RBF представлена на рис. 9.1.
228
9.1. Радиально-базисные нейронные сети
Claster m
Входной слой Скрытый слой Выходной слой
Рис. 9.1. Топология сети RBF
Сеть типа RBF имеет один промежуточный слой, состоящий из
радиальных элементов, каждый из которых воспроизводит гиперсферу. Поскольку
воспроизводимые базисные функции нелинейны, то нет необходимости выбирать
более одного промежуточного слоя. Для моделирования любой функции
достаточно взять определенное число радиальных элементов. Обучение
промежуточного слоя осуществляется по алгоритму объективной классификации.
Выход сети RBF формируется в результате комбинации выходов скрытых
радиальных элементов. Оказывается, что достаточно взять их линейную
комбинацию. Поэтому сети RBF имеют выходной слой, состоящий из элементов с
линейными функциями активации, что позволяет не проводить их обучение.
Сети RBF перед многослойными персептронами имеют ряд преимуществ.
Во-первых, они моделируют произвольную нелинейную функцию с помощью
всего одного промежуточного слоя, поэтому избавляют конструктора сети от
необходимости решать вопросы о числе слоев. Во-вторых, параметры
линейной комбинации в выходном слое можно полностью оптимизировать с
помощью хорошо известных методов линейной оптимизации (при обучении
отсутствует возможность попадания в локальный минимум), поэтому RBF обучается
на порядок быстрее, чем многослойный персептрон. Однако в промежуточном
слое для радиальных элементов необходимо определять положения их центров
и величины отклонений.
Радиально-базисные сети обучаются при помощи комбинированных
методов. На первом этапе проводится предварительная кластеризация для
определения эталонных векторов с использованием алгоритмов обучения без
учителя. На втором этапе - вычисление значений весов связей нейронов скрытого
слоя с нейронами выходного слоя в общем случае с помощью алгоритмов
обучения с учителем.
Для реализации первого этапа вначале случайным образом выбирается
определенное число центров, которые образуют классы. В качестве центров мо-
229
9. Радиалъно-базисные и другие модели нейронных сетей
х\
Сравнение расстояний: dist (В) < dist (A)< dist (С)
Claster A
[х\, хг\ — координаты
входного вектора
О
Рис. 9.2. Иллюстрация классификации
по алгоритму «к ближайших соседей»
гут служить случайно выбранные векторы из обучающей выборки.
Функционирование алгоритма классификации «к ближайших соседей», который часто
используют в сетях RBF, поясняется на рис. 9.2.
Формирование кластеров из обучающей выборки происходит путем
сравнения расстояний текущего вектора, поступающего на вход сети, до центров
кластеров к ближайших соседей. Предположим, что на вход сети поступает
входной вектор X (на рис. 9.2 рассматривается двумерный вектор). Проводится
вычисление расстояния dist этого вектора до центров кластеров А, В, С. В
рассматриваемом случае наименьшим оказалось расстояние до кластера В, к
которому должен быть отнесен текущий вектор.
Расстояние dist вычисляется в соответствии с выбранной нормой. Наиболее
часто выбирается евклидова норма. Однако, например, в нейронном
акселераторе ZISC 036, нейропроцессор которого представляет RBF-сетъ, используются
две нормы:
1) £|Х. -PJ , где Х( - входной вектор; Р( - прототип (эталонный вектор);
2) max |X -PJ.
Для решения задачи отнесения входного вектора к одному из кластеров ус-
тан : : ется еще так называемое поле влияния около каждого прототипа (рис.
9.3). Каждый прототип ассоциируется с кластером и полем : ■ i •,
представляющим часть Л-мерного пространства вокруг прототипа, где возможно
обобщение. Прототип - это вектор, определяющий координаты точки на iV-мер-
ном пространстве. Несколько прототипов могут ассоциироваться с одним
кластером и поля влияния могут пересекаться.
Задача классификации состоит в выяснении, лежит ли iV-мерный входной
вектор в поле влияния какого-либо прототипа, хранимого в сети. Это осуще-
230
9.1. Радиалъно-базисные нейронные сети
О
[ри р2] - прототипы координат
\х\, х2] - координаты входного вектора
Поле влияния
Claster A
Claster В
Рис. 9.3. Представление прототипов и их полей
влияния в двумерном пространстве
ствляется путем вычисления расстояния между входным вектором и всеми
хранящимися прототипами с последующим сравнением его с полем влияния
каждого прототипа.
Решение сетью принимается по результату следующих сравнений:
• если вводимый вектор не лежит ни в каком поле влияния, он не
распознается;
• если вводимый вектор лежит в поле влияния одного или более
прототипов, относящихся к одному кластеру, он объявляется как принадлежащий к
этому кластеру;
• если вводимый вектор лежит в поле влияния двух или более прототипов,
относящихся к различным кластерам, он объявляется узнанным, но
формально неопределенным.
Задача обучения сети состоит в заполнении пространства прототипами и
настройке полей влияния в соответствии с к соседями. Причем, во время
обучения эталоны остаются неизменными, а поля влияния могут увеличиваться или
уменьшаться (для этого используются различные эвристические методы).
Обычно эвристические методы связаны с определением необходимого
числа скрытых нейронов, обеспечивающих заданную ошибку обучения. В одном
из таких методов (Cheng Y.H., 1994) вычисляется среднее изменение значений
весов после заданного числа обучающих циклов. Если это значение слишком
мало, то в скрытый слой добавляются два нейрона с базисными функциями,
соответствующими наибольшей и наименьшей ошибке обучения, после чего
обучение расширенной таким образом сети продолжается. Одновременно
происходит отбор нейронов на основе показателей значимости (см. гл. 4). Как
231
9. Радиально-базисные и другие модели нейронных сетей
удаление нейронов, так и их добавление осуществляется после прохождения
определенного числа циклов и продолжается до тех пор, пока не будет
получена заданная ошибка обучения.
В другом методе (Piatt Y., 1989) используется комбинированный подход к
выбору числа скрытых нейронов. Этот метод основан на совместном
использовании методов обучения с учителем и без учителя. В каждом цикле обучения
вычисляется евклидово расстояние между примерами обучающей выборки и
ближайшими к ним кластерными центрами. Если это расстояние превышает
установленный порог 5, то к скрытому слою добавляется новый нейрон и
создается кластерный центр с новой радиальной функцией. После этого сеть
обучается по методу Back Propagation. Таким образом, чередуя циклы обучения с
учителем и без него, НС обучается до тех пор, пока не будет достигнута
заданная ошибка обучения. В данном методе 5 экспоненциально изменяется от
значения 5 в начале обучения до 5mjn в конце обучения. Основной проблемой
при реализации данного метода является подбор значений 5 (в настоящее
время эта процедура не автоматизирована).
Как только зафиксированы размеры полей влияния и центров, выходные
веса RBF могут быть настроены очень эффективно, поскольку вычисления
сводятся к линейной или обобщенной линейной модели (например, линейной
регрессии). Таким образом, комбинированное обучение существенно быстрее
нелинейной оптимизации, которая потребовалась бы для обучения с учителем
всех весов в сети.
Комбинированное обучение редко применяется для многослойного персепт-
рона, поскольку пока неизвестны эффективные методы обучения без учителя
скрытых элементов (кроме случая с одним входом). Это обучение обычно
требует больше скрытых элементов, чем обучение с учителем. Поскольку обучение
с учителем оптимизирует положение центров, тогда как комбинированное
этого не делает, обучение с учителем будет обеспечивать лучшее приближение к
изучаемой функции при заданном числе скрытых элементов. Таким образом,
лучшее соответствие, которое обеспечивает обучение с учителем, часто
позволяет обойтись меньшим числом скрытых элементов для достижения заданной
точности приближения. Основное достоинство RBF- быстрое и простое
обучение.
Выходной сигнал сети RBF можно вычислить двумя способами. В первом
случае (рис. 9.4. а) выход представляет собой взвешенную сумму выходных
сигналов нейронов скрытого слоя, каждый из которых связан с определенным
кластером:
ЯХ) = 2с,^=5]с,7;(Х), (9.3)
i=i i=i
232
9.1. Радиалъно-базисные нейронные сети
где с- связь выхода RBF с i-м кластером; /•.(•) - радиальная базисная функция,
являющаяся гауссовой функцией.
В более общем случае для вычисления выхода у(Х) берется средняя
взвешенная сумма: „ „
у(Х)=Ч—=-*
W\
Х\ х2
5>, Х^(х)
/=1 i=i
(9.4)
щ
W\
х\ х2
Х\ х2
Рис. 9.4. Формирование выхода в сети RBF:
а - единственный выход с взвешенной суммой выходов нейронов скрытого слоя; б- единственный
выход со средней взвешенной суммой; в—RBF с двумя выходами с взвешенной суммой выходов
нейронов скрытого слоя; г - RBF с двумя выходами со средней взвешенной суммой
233
9. Радиалъно-базисные и другие модели нейронных сетей
Формула (9.4) используется в том случае, когда поля влияния прототипов
могут перекрьшаться. При этом, если каждый нейрон скрытого слоя имеет
«свою» радиально базисную функцию г.(Х), то необходима их нормализация
гt(X) I £ ^(Х), и тогда выход сети будет вычисляться по формуле (9.4). Для
более ясного представления этой процедуры на рис. 9.4, б добавлен блок
деления взвешенной суммы (^ c.w.) на общую сумму (^ м>). Рис. 9.4, виг
иллюстрируют процедуру вычисления выходных сигналов для сети RBF с
двумя выходами.
9.2. Другие типы нейронных сетей без обратных связей
Рассмотрим некоторые дополнительные типы однослойных и
многослойных НС с прогнозированием, которые интересны разработчикам
нейрокомпьютеров благодаря удачным применениям на практике.
Нейронные сети с функциональными связями
Сети с функциональными связями представляют собой однослойные НС,
способные решать линейно неразделимые задачи, используя соответствующим
образом расширенное представление входов. Нахождение подходящего
расширенного представления входных данных является ключевым моментом в
реализации функциональных НС. Дополнительные входные данные,
используемые в функциональных НС, искусственно увеличивают размеры пространства
входной информации и наряду с реальными данными составляют обучающую
выборку. При этом дополнительные данные подбираются таким образом, что
они были линейно независимыми от исходных реальных данных. За счет
этого и достигается линейная разделимость входного пространства.
На рис. 9.5, а показан пример сети с функциональными связями, которую
можно использовать для работы с непрерывными функциями. Дополнитель-
X /^~\
sin (пх) /^\ \
sin (2яд) /^~У—Л
cos (2юе) Г~у /
/ *1*2
sin (4ях) /~~у
а б
Рис. 9.5. НС с функциональными связями:
а - функциональная модель; б — решение проблемы XOR
234
9.2. Другие типы нейронных сетей без обратной связи
ные входные данные генерируются на основе ортогонального базиса функций,
таких, как sin roc, cos юс, sin 2nx и cos 2nx.
Другой тип сети с функциональными связями показан на рис. 9.5, б. В этой
сети, используемой для решения проблемы XOR, которая является линейно
неразделимой, дополнительный входной сигнал представляет собой
произведение входных сигналов. Расширенным входам (л,, х2,х1х2) = (-1,-1,1), (-1,1,
-1), (1, -1, -1) и (1,1,1) соответствуют желаемые выходы: 1, -1, -1 и 1. Таким
образом, сеть с функциональными связями изображенная на рис. 9.5, б, может
решить проблему воспроизведения логической функции XOR.
Поскольку сеть с функциональными связями имеет только один слой, она
может быть обучена с помощью простейшего правила обратного
распространения. Следовательно, скорость обучения у сетей с функциональными связями
гораздо выше, чем у многослойных НС.
Древовидные нейронные сети
Решающие деревья, представленные в виде многоуровневых НС без
обратных связей, могут быть использованы для более эффективного решения задач
классификации и распознавания. Построение древовидных НС {Tree Neural
Network - TNN) основано на идее использования небольшой многоуровневой
сети в каждом узле бинарного дерева классификации для принятия
адекватного решения. В настоящее время в теории искусственного интеллекта деревья
классификации применяются для организации процедуры последовательного
принятия решений. Древовидные НС - TNN- используют особенности
древовидных классификаторов, связанные с учетом локальных свойств
классифицируемых объектов на каждом уровне и в каждом узле дерева.
Бинарное дерево классификации показано на рис. 9.6. Каждый
терминальный узел имеет связанную с ним метку класса с (в рассматриваемом случае с
/i(X)<5,
Yes
/2(Х)<52
/з(Х)<53
Yes^
с=1
\No
с=2
Yes/'
с=\
—\ No
( /4(Х)<54 )
Yes/
с=\
\"No
с=Ъ
Рис. 9.6. Бинарное дерево классификации для разделения образов на три класса:
(^)- узлы решения; Ц - терминальные узлы
235
9. Радиально-базисные и другие модели нейронных сетей
может принимать значения, равные 1, 2 или 3). Каждый узел решения имеет
связанное с ним правило разделения J(X) < 5, которое определяет, относится
входной образ (вектор) к правой или левой ветви, где^ДХ) и 5 - это некоторая
характеристика и пороговое значение, соответственно. Образу присваивается
метка класса терминального узла, в который он приходит. Достоинство
классификационного дерева состоит в том, что необходимые характеристики могут
быть выбраны на различных узлах и уровнях дерева. Сложные проблемы
распознавания и классификации образов, связанные с трудностью выделения
признаков и их взаимосвязей, приводят к необходимости использования в каждом
узле решения НС. Таким образом, в TNN для представления правила
разделения в каждом узле решения классификационного дерева используется
маленькая многоуровневая НС.
Свойство^ =/(Х), генерируемое многоуровневой НС в некотором узле
решения /, используется следующим образом. Если>> < 0, то X направляется к его
левому узлу-потомку tL; если у > О, то X направляется к его правому
узлу-потомку^.
Алгоритм создания (обучения) TNN состоит из двух фаз: роста и
сокращения дерева. Во время фазы роста дерева путем рекурсивного определения
правил разделения строится большое дерево до тех пор, пока все терминальные
узлы не будут принадлежать к определенному классу. Во время фазы
сокращения дерева из поддеревьев выделяются меньшие деревья для устранения
избыточности классов.
Идея алгоритма обучения в фазе роста дерева состоит в следующем. Для
каждого узла с :- : »щие ему классы делятся на две группы. Пусть С = {с,, с2,
..., см} - множество Мклассов для узла t. Обучение подразумевает решение
двух оптимизационных проблем. При решении первой задачи оптимизации
для узла t алгоритм обратного распространения используется для обучения
сети, имеющей два выходных класса: CL и CR, где CL и CR представляют собой
текущие (выбранные) множества классов, связанные с левым узлом-потомком
yL и правым узлом-потомком >>л, соответственно. При решении внешней задачи
оптимизации используется эвристический поиск для нахождения лучшей пары
классов следующих узлов С[ и С^, влияющих на итоговое разбиение.
После окончания фазы роста дерева полученное дерево Г должно быть
редуцировано. Начиная с терминальных узлов, алгоритм сокращения дерева Т
проверяет, как удаление ветви, выходящей из некоторого узла, повлияет на
итоговый уровень ошибки обобщения. Ветвь удаляется тогда и только тогда, когда
итоговый уровень ошибки не увеличивается. При этом алгоритм
редуцирования проверяет каждый узел-потомок перед проверкой узла родителя, и
минимальное оптимально сокращенное поддерево Т получается за один проход снизу
вверх по дереву Т.
236
9.3. Перспективы использования НС
Основное достоинство TNN заключается в уменьшении времени обучения
по сравнению с многослойным персептроном, а также в возможности
построения сетевого классификатора.
9.3. Перспективы использования НС для создания
интеллектуальных систем
Одной из характерных черт нашего времени является лавинообразный рост
передаваемой и получаемой информации, которую должен обрабатывать
человек для успешной работы в различных областях науки, производства и
бизнеса. Поэтому значительно возрос интерес к интеллектуальному анализу данных
(НАД или Data mining), применение которого позволяет переложить решение
трудных задач обработки информации с человека на компьютер.
Использование НС, как одного из средств реализации технологии Data mining, позволяет
решать следующие задачи:
- моделировать сложные нелинейные зависимости между данными и
целевыми показателями;
- выявлять тенденции в данных (при наличии временных рядов) для
построения прогнозов;
- работать с зашумленными и неполными данными;
- получать содержательные результаты при относительно небольшом
объеме исходной информации с возможностью дальнейшего усовершенствования
модели по мере поступления новых данных;
- выявление аномальных данных, значительно отклоняющихся от
«открытых» устойчивых закономерностей и т. д.
Основная проблема использования НС в интеллектуальных системах
состоит в трудности интерпретации получаемых результатов. Необходимо НС
сделать «прозрачной» для пользователя. Решение этой задачи будет
способствовать продвижению технологии НС на рынок программных продуктов,
реализующих технологию Data mining. Интеграция НС с логическими
системами (в том числе, построенными на основе нечеткой логики) позволит
представить результаты в наглядном виде (в виде правил IF— THEN), понятном для
пользователя. С этой целью в гл. 11 рассмотрены перспективные гибридные
нейросетевые нечеткие системы.
Упражнения и вопросы для самоконтроля
1. Приведите математическое описание нейрона, используемого в RBF-cemx.
2. Что собой представляет дискриминантная функция для нейронов второго порядка ?
3. Рассмотрите топологию RBF. Сколько слоев она содержит?
4. Сформулируйте алгоритм обучения радиально-базисной сети.
5. Как формируется выход в сети RBF1
237
9. Радиалъно-базисные и другие модели нейронных сетей
6. Дайте характеристику алгоритму обучения с учителем и без учителя.
7. Почему в сети RBF реализуется более быстрое обучение по сравнению с
многослойным персептроном?
8. Что такое «поле влияния» прототипа сети в RBF1
9. Сформулируйте достоинства и недостатки сети RBF.
10. Каким образом подбираются дополнительные данные в функциональных сетях?
11. Почему в функциональных НС может быть решена проблема линейной
неразделимости?
12. Дайте характеристику древовидным НС.
13. Каким образом на основе древовидных НС может быть построен сетевой
классификатор?
14. Каковы перспективы использования НС для создания интеллектуальных систем?
10. МАТЕМАТИЧЕСКИЕ ОСНОВЫ ПОСТРОЕНИЯ
НЕЧЕТКИХ СИСТЕМ
Приведены общие представления и математические понятия теории нечетких
множеств. Рассмотрены различные базовые понятия, связанные с выводом в нечетких
системах, а также теоретико-множественные операции и свойства четких и нечетких
множеств. Определены задачи, которые необходимо решать при построении нечетких систем,
и способы их реализации.
10.1. Основные положения нечеткой математики
Аппарат нечеткой математики позволяет формализовать нечеткие
понятия и знания, оперировать этими знаниями и делать нечеткие выводы. Основу
этого аппарата составляет математическая теория нечетких множеств,
предложенная американским ученым Л. Заде четверть века назад. Как следует из
названия, эта теория предполагает неточные, неполные, приблизительные оценки
объектов, ситуаций, явлений. Необходимость использования такого подхода
вызвана следующими обстоятельствами:
• при решении некоторых проблем не нужна точная оценка параметров
объектов и явлений;
• по утверждению Л. Заде, с ростом сложности системы постепенно
падает способность человека делать точные и в то же время значащие
утверждения относительно ее поведения, пока не будет достигнут порог, за которым
точность и значимость становятся взаимоисключающими характеристиками.
Наиболее существенные особенности моделей реальных систем,
построенных с использованием аппарата нечеткой математики, состоят в следующем:
1) большая гибкость по сравнению с традиционными четкими, так как они
позволяют описывать знания и опыт человека в привычной для него форме;
2) большая адекватность реальному миру, поскольку позволяют получить
решение, по точности соотносимое с исходными данными;
239
10. Математические основы построения нечетких систем
3) возможность в ряде случаев более быстрого получения окончательного
результата, чем на «точных» моделях, в силу специфического построения и
простоты используемых нечетких операций.
Нечеткие методы, основанные на теории нечетких мнжеств,
характеризуются тремя отличительными чертами:
• использованием так называемых лингвистических переменных вместо
числовых переменных или в дополнение к ним;
• простые отношения между переменными описываются с помощью
нечетких высказываний;
• сложные отношения описываются нечеткими алгоритмами.
Лингвистические переменные и их использование
Рассмотрим основные различия четких и нечетких множеств.
Классическое (четкое) множество - совокупность четко различимых элементов. Оно
имеет четкую границу, отделяющую принадлежащие ему элементы от не
принадлежащих. Четкое множество можно определить с помощью так
называемой характеристической функции. Пусть U— универсальное множество.
Характеристическая функция \i.A(x) четкого множества Л в U принимает значения
из набора {0,1} и определяется таким образом, чтобы \\.А(х) = 1, если х
является элементом А (т. е. х е А) и 0 в противном случае. Следовательно,
, ч Г1, если и только если х е А;
А [0, если и только если х g А.
Отметим следующие особенности четких множеств:
• граница отделения элементов некоторого четкого множества А от других
элементов универсального множества является четкой и выполняет функцию
разделения на два класса (хеАихй А);
• универсальное множество U является четким множеством.
Нечеткое множество не имеет четкой границы, строго отделяющей
элементы этого множества от других элементов универсального множества. Иными
словами, некоторые элементы могут одновременно принадлежать двум и
более нечетким множествам, т.е. множества этого типа пересекаются. В этой
связи переход от принадлежности элемента нечеткому множеству к его
непринадлежности является постепенным, а не скачкообразным, как в случае четкого
множества. Следовательно, нечеткие множества можно рассматривать как
расширение и обобщение основных понятий четких множеств.
Нечеткое множество А в универсальном множестве U определим как набор
упорядоченных пар:
А = {(х,цА(х))\хе U},
где \i/*) назьюается функцией принадлежности (или характеристической
функцией) A; a nj(x) - уровень принадлежности х в А, который показывает степень,
в которой х принадлежит А.
240
10.1. Основные положения нечеткой математики
Функция принадлежности ц^») отображает U -> D, где D — пространство
принадлежности. Для нечетких множеств D, т. е. диапазон изменения функции
принадлежности, является подмножеством неотрицательных вещественных
чисел с ограниченным верхним пределом. В наиболее общих случаях этот
диапазон представляет собой единичный интервал [0,1].
Лингвистической называется переменная, значением которой являются
нечеткие подмножества, описываемые в форме слов или предложений на
естественном или искусственном языке. Формально лингвистическая переменная
задается набором:
{X,T(X),U,G,M},
где Х- название переменной; 1\Х) - терм-множество переменной X, т. е.
множество ее лингвистических значений; U- универсальное множество; G -
синтаксическое правило, порождающее названия значений переменной X; М-
семантическое правило, которое ставит в соответствие каждому значению
лингвистической переменной ее смысл.
В отличие от классической теории множеств, оперирующей понятием
принадлежности и не принадлежности элемента множеству, теория нечетких
множеств допускает различную степень принадлежности к ним, определяемую
функцией принадлежности элемента, значения которой изменяются в
интервале [0,1]. При этом границы интервала характеризуют соответственно полную
принадлежность нулю или полную принадлежность единице элемента
нечеткому множеству. Могут использоваться и другие интервалы, например [1,100],
[1,5] и т. д. Таким образом, каждое значение лингвистической переменной X
определяется некоторой функцией принадлежности: \i: (/-► [0,1], которая
каждому элементу и е U ставит в соответствие число из интервала [0,1].
Пример 1. Пусть Х- это Пользователи одноранговой локальной сети (количество
пользователей в таких сетях обычно не превышает 10). Тогда терм-множество
лингвистической переменной Пользователи может включать следующие значения:
Т(Пользователи) ={«мало»; «не очень мало»; «не мало и не много»; «не очень
много»; «много»}.
Для лингвистической переменной Пользователи числовая переменная х,
принимающая значение из интервала [1,10], является базовой переменной.
Процедура преобразования значений базовой переменной в нечеткую
(лингвистическую) переменную, характеризующуюся функцией принадлежности,
называется фаззификацией.
Каждому значению лингвистической переменной, например «мало»,
«средне», «много», соответствует свой диапазон изменения базовой переменной X.
В практике использования нечеткой математики для решения реальных задач
наиболее часто используют треугольные, трапецеидальные и «колоколообраз-
ные» функции принадлежности (рис. 10.1).
241
10. Математические основы построения нечетких систем
Мало Средне Много
а б в
Рис. 10.1 Виды функций принадлежности:
а - треугольная; б - трапецеидальная; в - «колоколообразная»;
х0, xt— начальное и конечное значение диапазона, соответствующего некоторому
значению лингвистической переменной; х — значение базовой переменной,
при котором достигается наибольшее значение т
Например, функция принадлежности колоколообразной формы может быть
определена следующим образом:
Г -(x-mfl
\ix(x) = exp |^ ^-i- I.
где т. - определяет значение базовой переменной, при котором функция
принадлежности достигает наибольшего значения, ас,- среднеквадратичное
отклонение функции принадлежности от максимального значения.
На рис. 10.1, в представлены в виде графиков функции принадлежности для
значений лингвистической переменной: мало, средне, много. Такое
представление показывает, что использование лингвистических значений позволяет
осуществлять «сжатие» данных, когда одним значением охватьшается целый
интервал допустимых значений базовой переменной.
Существование различных видов и форм ц^ (•) показывает, что задание
функции принадлежности нечеткого множества зависит от достоверности
исходных данных и во многих случаях—от опыта эксперта. Для представления Ц^(#)
в некоторых случаях может оказаться достаточной качественная оценка
характера расположения элементов в А. Поскольку процедура построения
достаточно сложна, то наилучшим подходом к ее формированию является
использование НС, позволяющих обучать Ц^(ш) на исходной выборке данных и
подстраивать ее при получении новых данных.
Приведенный выше пример показывает, что нечеткость является видом
неточности, возникающей в результате группирования элементов в классы, не
имеющих четко определенных границ, и поэтому не является недостатком зна-
242
10.1. Основные положения нечеткой математики
ний об элементах классов. Следует обратить внимание на то, что \хЛ(х) е [0,1]
показывает лишь степень принадлежности элемента х е U нечеткому
множеству А (в дальнейшем просто А) и не является вероятностью, поскольку
Y,\iA(x) *■ 1. Степени принадлежности по существу отражают порядок
расположения элементов в нечетком множестве А.
Пример 2. Пусть все возможные оценки на экзамене есть U= {10, 20,..., 100}.
Рассотрим три нечетких подмножества Л = «высокие оценки», В=«средние оценки» и
С=«низкие оценки», функции принадлежности которых приведены в табл. 10.1.
Таблица! 0.1. Нечеткие множества для примера 2
Значение
базовой
переменной
10
20
30
40
50
60
70
80
90
100
Значение функций принадлежности для нечетких подмножеств А, В, С
высокие оценки (А)
0
0
0
0
од
03
0,5
0,8
1
1
средние оценки (В)
0
0
0,1
0,5
0,8
1
0,8
0,5
0
0
низкие оценки (С )
1
1
0,9
0,7
0,5
0,3
0,1
0
0
0
В этом примере терм-множество лингвистической переменной Оценки включает
три нечетких пересекающихся подмножества Л, В и С:
Т(Оценки) = {«высокие оценки»; «средние оценки»; «низкие оценки»}.
Таким образом, в отличие от способа квантования значений четких
переменных по интервалам, каждое значение лингвистической переменной
представляется в виде нечеткого подмножества, которое может пересекаться с
другими нечеткими подмножествами.
Для представления нечеткого множества может быть использовано
понятие «носителя нечеткого множества». Носителем S нечеткого множества А
является четкое множество всех х, таких, что \*А(х) > 0, т. е.
S(A)={xeU\ViJix)>0},
Для примера 2 носители нечетких множеств могут быть представлены в
следующем виде:
243
10. Математические основы построения нечетких систем
^(«высокие оценки») = {50,60,70,80,90,100}.
^(«средние оценки») = {30,40,50,60,70,80}.
S («низкие оценки») ={ 10,20,30,40,50,60,70}.
Ядро нечеткого множества А содержит элемент со степенью
принадлежности, равной 1, т. е. ker(A) = {х | цА(х) =1}. Элемент х е U, для которого
ЦА(х) = 0,5, называется точкой перехода. Высота нечеткого множества А - это
верхняя граница ^-А(х) на U. Таким образом,
Высота (А) = sup \i.(x).
X А
Нечеткое множество нормализовано, когда его высота равна единице
(Высота (А) = 1), в противном случае оно субнормально. Три нечетких
множества из примера 2 являются нормализованными. Непустое нечеткое
множество А всегда можно нормализовать делением \iA(x) на высоту А.
Для дискретного универсального множества (некоторой предметной области)
U= {*,, х2,..., xj нечеткое множество А можно представить в виде множества
упорядоченных пар:
А = {(*, ,VA(xj), (x2,Цр2)), -, (хп,црп))}.
В примере 2 нечеткое подмножество В («средние оценки») задается
следующим образом:
Я= {(10,0), (20,0), (30,0.1), (40,0.5), (50,0.8), (60,1), (70,0.8), (80,0.5), (90,0), (100,0)}.
Используя понятие носителя нечеткого множества, можно упростить его
представление, т. е. для записи функций принадлежности рассматриваются
только те элементы универсального множества, которые имеют ненулевую степень
принадлежности нечеткому множеству.
В этом случае функция принадлежности первичных термов, входящих в терм-
множество, может быть записана в следующем виде:
Ц (ДО = Sh (*.У*. (А-е [0,1]; ц (*) <= [0,1]), (10.1)
где £ обозначает объединение элементов, a \i. - степень принадлежности х,
некоторому подмножеству, например \i. = \*А(х) > 0 (А - нечеткое подмножество).
Для примера 1 с пользователями одноранговой сети, если количество
пользователей равно «мало», запись функции принадлежности «мало» может быть
представлена в следующем виде:
ц («мало») = 1/1 + 0,98/2+0,9/3+ 0,8/4+ 0,5/5+ 0,3/6+ 0,15/7+ 0,1/8+ 0,08/9+ 0/10.
244
10.1. Основные положения нечеткой математики
Так, например, 0,9/3 означает ц (3) = 0,9 для числа пользователей сети,
равного трем, степень принадлежности нечеткому подмножеству «мало» равно 0,9.
Функция принадлежности (10.1) запоминается в базе данных и затем
используется для оперирования понятием «мало». Формулу (10.1) можно
запомнить как информацию в одномерном массиве, индексы в котором
соответствуют возможному числу пользователей, т. е. в рассматриваемом примере
элементам (1... 10). Аналогично можно определить функции принадлежности
для других значений лингвистической переменной, например, «средне»,
«много» и т. д.
Например, функция принадлежности нечеткого множества В из примера 2
представляется в виде:
В=0,1/30 +0,1/40 + 0,8/50 +1/60 + 0,8/70 + 0,5/80.
При разработке нечетких систем необходимо также учитывать, что сумма
степеней принадлежности нечеткого множествами^*.), где п - число
элементов множества А, не обязательно равна 1. В пустом нечетком множестве эта
сумма равна 0, т. е. в этом случае функция принадлежности назначает 0 всем
элементам универсального множества U.
Если в нечетком множестве А имеется единственная точка в Uc \iA(x) = 1, то
это множество называется нечетким одноэлементным (одноточечным)
множеством или нечетким синглетоном. Элемент х е U, для которого
\iA(x) = 0.5, называется точкой перехода.
Одним из наиболее важных понятий нечетких множеств, связанных с их
практическим применением в интеллектуальных системах и системах
управления, является понятие а-срезов (или множеств а-уровня). а-срез (или
множество а-уровня) нечеткого множества А - четкое множество Аа,
содержащее все элементы универсального множества U, имеющее степень
принадлежности в А большую или равную а. Таким образом,
Аа= {xeU\ »А(х) > а}, а е [0, 1]. (10.2)
В соответствии с (10.2) функция принадлежности нечеткого множества А
может быть выражена в терминах характеристических функций ее а-срезов
следующим образом:
р/х) = sup[aл iiA(x)], Vx e U,
где л означает операцию взятия минимума, а цА (х) - является
характеристической функцией четкого множества Аа:
245
10. Математические основы построения нечетких систем
K.W:
■ft
если и только если х е Аа;
в противном случае.
Если через а Аа обозначить нечеткое множество с функцией
принадлежности 1
Ма(*) = [« Л М„(*)]. V* e U>
то нечеткое множество А может быть выражено в форме:
А= U а А , где лА = {а | ц (х) — а, Зх е U,
аели
С одной стороны, введение понятия а-срезов позволяет нечеткое
множество А разложить на а Аа, а е (0, 1], а с другой - множество А можно
восстановить как объединение его а Аа, т. е., иными словами, нечеткое
множество можно выразить в терминах его а-срезов, не прибегая к функции
принадлежности (рис. 10.2).
ПримерЗ. ПустьЛ0={1,2,3,4,5};A0={2,3,5};A0J={2,3};A={3}.
Нечеткое множество А в этом случае может быть представлено следующим
образом:
А= U aAa= U аАа = 0,1(1/1 + 1/2 +1/3 + 1/4 + 1/5) +
аелА ае[0,1;0,4;0,8;1]
+ 0,4(1/2 + 1/3 + 1/5) + 0,8(1/2 +1/3) + 1(1/3) = 0,1/1 + 0,8/2 +1/3 + 0,1/4 + 0,4/5.
1 , ,
Математическая теория нечетких
множеств позволяет при построении нечетких
систем оперировать нечеткими понятиями
и знаниями, делать нечеткие заключения и
выводы. Их использование
представляется особенно полезным в тех случаях, когда
исходные знания об исследуемом процессе
или объекте являются приближенными,
неточными, а в ряде случаев и
недостоверными. Рассмотрим основные операции,
которые можно выполнять над нечеткими
Рис. 10.2. Разложение нечеткого множествами при организации нечеткого
множества вывода.
246
10.1. Основные положения нечеткой математики
Операции над нечеткими множествами
По аналогии с четкими рассматриваются различные операции над
нечеткими множествами. Наиболее распространенные операции вложения,
дополнительного нечеткого множества, пересечения и объединения нечетких множеств
записываются в следующем виде:
А а В -> цА(х) < цв(х) для у* е X;
Ц/00 = 1 ~ \*А(х) Для ух е X; Л
"л^ОО = РА(Х) Л VjM JW\/xeX;
К^Л*) = Ц#) v h,(*) Для V* e JT.
(10.3)
Для «колоколообразной» функции принадлежности эти операции
представлены графически на рис. 10.3.
Если обозначить через R(X) совокупность всех нечетких множеств в X, то
система (R(X), с,', и, п) образует булеву алгебру. Однако для операции
вложения ( с ) справедливы рефлексивность, антисимметричность, транзитивность.
Выполняются также законы идемпотентности, коммутативности,
ассоциативности, двойного отрицания и закон де Моргана.
Пусть имеются нечеткие подмножества А, В, С в множестве X. Тогда для
них будут справедливы следующие соотношения, представленные в табл. 10.2.
Рис. 10.3. Основные операции над нечеткими множествами:
а - вложение АсВ; б - дополнительное нечеткое множество А;
в - пересечение нечетких множеств АпВ; г - объединение нечетких множеств AkjB
247
10. Математические основы построения нечетких систем
Таблица! 0.2. Соотношения операций над нечеткими множествами
AkjB=BkjA, АпВ=ВпА
(АпВ)пС = Ап(ВпС), (AkjB)<uC = Akj{B<uC)
A \jA =A, Аг\А=А
А п(Я г>С) = {А г,В )и(Л пС ), A kj(B kjC ) = {AkjB )п(Л kjC )
-(-4)
-.(Лп.0) = -Akj-,B, -*(A<jB) = -,An~,B
Коммутативность
Ассоциативность
Идемпотентность
Дистрибутивность
Двойное отрицание
Теоремы де Моргана
для нечетких множеств
Но закон комплементарности для этих множеств не выполняется, т. е. в
случае нечеткого множества выполняются соотношения:
An A' Z) 0, А С\ А' с X,
причем равенство не удовлетворяется, что видно из рис. 10.4.
Кроме указанных выше операций можно определить (неограниченно) много
операций над нечеткими множествами. Для практического использования можно
выделить наиболее важные операции.
Унарная операция степени нечетного множества А (показатель степени а
- положительный параметр) может быть определена следующим образом:
М« (*) = {^(*)}а ДОЯ ух е X. (10.4)
Если задать наиболее часто используемые степени порядка 2 и 1/2 , то
получим графическое представление функции принадлежности (рис. 10.5).
Когда с помощью нечеткого множества А представляют некоторую нечеткую
информацию, то А2 - это «более чем» А, Ат - это «почти что» А. Аналогично
часто используют степени 4 и 1/4, интерпретируя их как А4= более чем более
чем А, т. е. А = (более чем)2Л и т. д.
Рассмотрим бинарные операции. Наиболее часто используется
алгебраическое произведение А и В, обозначаемое как А*В, которое определяется
следующим образом:
VauA'(x)
V-Ar,A'(x)
МоМ
Рис. 10.4. Невыполнение
закона комплементарности
Рис. 10.5. Степень а нечеткого
множества (а = 2,1/2)
248
10.1. Основные положения нечеткой математики
Алгебраическая сумма А и В обозначается как А +В и определяется по
формуле
Н*а W = ^W + МЛ*) ~ КДО * **Л*) ух е *■
Для алгебраической суммы и произведения нечеткого множества
справедливы свойства коммутативности, ассоциативности, а также выполняются
правила де Моргана. Не выполняются идемпотентность и дистрибутивность.
Основные операции нечеткой логики
Так же как в основе теории четких множеств лежит четкая логика, в
нечетких множествах существует нечеткая логика - основа для операций над
нечеткими множествами.
Рассмотрим расширения четких логических операций НЕ, И, ИЛИ до
нечетких операций; эти расширения называются соответственно нечетким
отрицанием, /-нормой и 5-нормой (или /-конормой).
В нечетком пространстве число состояний неограниченно велико, поэтому
невозможно описать эти операции с помощью таблицы истинности, как в
случае двузначной логики.
Нечеткое отрицание — аналог четкой операции НЕ - представляет собой
унарную операцию отрицания в нечетком смысле, которая дает в ответе оцен-
ку[1,0].
Типичная операция нечеткого отрицания - «вычитание из 1»:
х= 1-х ухе[0,1].
С точки зрения нечетких множеств это соответствует понятию
дополнительного нечеткого множества.
Операция нечеткого отрицания (обозначим ее N °) удовлетворяет
следующим условиям:
№ : [0,1]->[0,1],
№(0) = 1; №(1) = 0 - граничные условия;
№(№(х)) = х ухе [0,1 ] - двойное отрицание;
х1 < х2 -> N °(x,) > N °(jc2) - инвертирование оценок.
При х — 0,5 (не знаю) N ° (х) =0,5, т. е. неизменно, в этом смысле 0,5
является центральным значением, и в этом случае обычно х и № (х) принимают
симметричные значения относительно 0,5.
Нечетким расширением И является t-норма. Это действительная
функция двух переменных, принимающая значение в интервале [0,1],
249
10. Математические основы построения нечетких систем
Г:[0,1]х[0,1]->[0,1],
удовлетворяющая следующим условиям:
хТ\ = х, хТО = 0 ухе [0,1] - граничные условия;
ххТх = х2Т хх- операция коммутативность;
ххТ(х2 Тх3) = (хгТх2) Тх3- операция ассоциативность;
х1<х2—> х^Тх3 < х2Тхг- операция упорядоченность.
Типичной операцией f-нормы является операция минимума (min) или
логическое произведение
ххТх2= min (xt, x2) = х,л х2.
В некоторых случаях используют операцию алгебраического произведения:
х, ■ х2 — х{ хг
Нечеткое расширение ИЛИ- s-норма (называется также f-конормой).
Среди условий, которым должна удовлетворять .s-норма, только граничные
условия отличаются от случая f-нормы, остальные - совпадают:
5:[0,1]х[0,1Н>[0,1]
juSl = 1, xSO = хухе[0,1] - граничные условия;
xlSx2= x2S Xj- операция коммутативность;
xlS(x2 Sx3 )= (x^S x2) S x3- операция ассоциативность;
xf <x2 -> xtSx3 < XjSXj- операция упорядоченность.
Типичной ^-нормой является логическая сумма, определяемая с помощью
операции max:
xfi x2 = max (xv x2) = хх v xr
Возможно также использование алгебраической суммы:
х1 + х2=х + х2-х1 х2.
В четкой логике закон противоречия «некоторое свойство и отрицание этого
свойства одновременно несправедливы» и закон исключенного третьего -
«некоторое свойство и отрицание этого свойства охватывают все состояния,
никакого промежуточного состояния нет» оперируют только с двузначными
оценками. В нечеткой логике, которая допускает также некоторые промежуточные
оценки, можно считать вполне естественным то, что эти законы
несправедливы, т. е. не выполняется закон комплементарности:
хл(1-х)>0, Jtv(l-x)<l,
250
10.2. Структура и принцип работы нечеткой системы
а все другие свойства, справедливые в четкой логике, также справедливы. В
связи с этим на практике чаще всего используют стандартные нечеткие
логические операции, а алгебраические - в отдельных случаях.
10.2. Структура и принцип работы нечеткой системы
Типовая структура системы нечеткой логики (СНЛ), представленная на
рис. 10.6, состоит из четырех главных компонент: входного преобразователя
четкой переменной в нечеткую (другое название блок фаззификации, от слова
fuzzy - нечеткий), база правил нечеткой логики, блок нечеткого логического
вывода и выходной преобразователь из нечеткой переменной в четкую (блок
дефаззификации). Если выходной сигнал блока дефаззификации является
управляющим сигналом для объекта, то СНЛ будет являться системой
управления на базе нечеткой логики.
Блок фаззификации осуществляет преобразование измеренных реальных
данных (например, скорости, температуры, давления и т.д.) в подходящие для
этого значения лингвистических переменных. Нечеткая база правил содержит
опытные данные о процессе управления и знания экспертов в проблемной
области. Блок вывода, являющийся ядром СНЛ, моделирует процедуру
принятия решения человеком. Организация вывода основана на проведении
нечетких рассуждений для достижения необходимой цели управления. Блок
дефаззификации применяется для выработки четкого решения или
управляющего воздействия в ответ на результаты, полученные в блоке вывода. Более
детально работа этих компонент описывается в следующих разделах.
В процессе функционирования СНЛ вычисляются значения управляющих
переменных (или значений некоторой выходной функции) на основе данных,
получаемых при наблюдении или измерении состояния внешней среды.
Следовательно, правильный выбор переменных, характеризующих состояние
внешней среды или управляющих переменных объекта управления, очень важен для
X
Блок
фаззификации
Ц(*)
——Л
Блок
вывода
I
Нечеткая
база правил
|Н(У)
i ^-
Блок
дефаззификации
У
Объект
управления
X
Рис. 10.6. Структура СНЛ
251
10. Математические основы построения нечетких систем
характеристики работы СНЛ и оказывает основное влияние на ее
производительность. Особую роль здесь играют опыт эксперта и инженерные знания.
Обычно входными сигналами для СНЛ являются состояние среды, ошибка
вычисления состояния, производная по ошибке, интеграл от ошибки и т. п.
Следуя правилам задания лингвистических переменных, входной вектор X и
вектор выходного состояния Y, который содержит все возможные состояния
внешней среды, могут быть определены соответственно как:
х = {(?,. и, {Г, г, ...,^},{ц;, II», ....фи.,, „}, (Ю-5)
y = {(у,, vt, {r, r, ...,f%{^, v-l, -,^»UU J, (ю.6)
где входные лингвистические переменные jc( образуют нечеткое
множество - пространство входов U = £/,х{/2х ....х(/я, а выходные
лингвистические переменные уг, образуют нечеткое множество -
пространство выходов V = KjXK2x xKm.
Из уравнений (10.5) и (10.6.) следует, что входная лингвистическая
переменная х. в предметной области С/ характеризуется T(xt) = {Г1, "П, --.TJ}
и и.(х) = {ц1, ц2, ...,н '}, где Т(х) множество термов для х, т. е'. множество
имен значении лингвистической переменной xt, связанных с каждым из этих
значений. Например, если х. означает скорость, то Г(х() = {7/J, Г2, ■■■,Тх'}
может означать {«очень медленно», «медленно», «средне», «быстро» и т. д."}.
Аналогично, выходная лингвистическая переменная у связана с множеством
Т(У) ={Г, Г, ...,2j) и д(у,) = Щ. ц* ^}.
Размер (или мощность) множества термов \Т(х)\ = kt определяет число
нечетких разбиений входного пространства на подмножества в соответствии с
выбранной степенью детализации описания внешней среды. На рис. 10.7, а
изображены три нечетких подмножества, реализуемые на одном интервале
[-1, +1]. Случай семи нечетких пересекающихся подмножеств представлен на
рис. 10.7, б. Количество разбиений входного нечеткого множества при решении
определенной задачи управления определяет максимальное число правил
нечеткой логики. Например, в случае СНЛ с двумя входами и двумя выходами,
если |Г(х,)| = 3, а |Г(х2)| = 7, то максимальное число правил нечеткой логики
будет равно \T(xt)\ х |Г(х2)| = 21. Входные функции принадлежности \ix, k=l, 2,
..., kt и выходные функции принадлежности ц'/ =1, 2, ..., /, используемые в
СНЛ, обычно • ■■ ч »тся параметрическими функциями, такими, как, например,
треугольные, трапецеидальные и др.
Правильный выбор нечеткой декомпозиции входного и выходного
пространств, а также правильный выбор функций принадлежности играют
ключевую роль в процессе достижения успешного результата при проектировании
252
10.2. Структура и принцип работы нечеткой системы
NB NM
Рис. 10.7. Графическое представление нечеткой декомпозиции:
а - грубая нечеткая декомпозиция с тремя нечеткими подмножествами (N - отрицательный;
Z - ноль; Р - положительный); 6— более детальная нечеткая декомпозиция с семью
компонентами (NB - отрицательный большой; NM - отрицательный средний; NS - отрицательный
маленький; ZE - ноль; PS - положительный маленький; РМ - положительный средний;
РВ - положительный большой)
СНЛ. К сожалению, эти задачи не имеют универсального решения. Обычно
для поиска оптимальной нечеткой декомпозиции используется эвристический
метод проб и ошибок, при этом выбор входных и выходных функций
принадлежности основан на субъективных критериях. Перспективный подход к
автоматизации и ускорению процедуры выбора функций принадлежности связан с
использованием нейронных сетей, обеспечивающих возможность обучения на
примерах входных и выходных функций принадлежности, применяемых в
заданной предметной области.
Фаззификация
Блок фаззификации выполняет функцию преобразования четких значений
входных переменных в нечеткие. Такое преобразование фактически является
своего рода нормированием, необходимым для перевода измеренных входных
данных в субъективные оценки. Следовательно, оно может быть определено
как отображение наблюдаемых значений входных переменных в метки
нечетких множеств заданного входного пространства. В реальных СНЛ
наблюдаемые данные обычно являются четкими (хотя они могут быть зашумлены).
Естественный и простой метод фаззификации, часто используемый в нечетких
253
10. Математические основы построения нечетких систем
системах, заключается в том, чтобы преобразовать четкое значение х0 в
нечеткий синглетон (singleton) А. Это означает, что функция принадлежности цА(х)
будет равна 1 в точке х0 и 0 во всех остальных точках. В этом случае всякое
конкретное значение x.(t), измеренное в момент времени t, отображается на
нечеткое множество Т1 со значением u'(x.(0) и на нечеткое множество Т2 со
Х- Xj I X
значением ц* (x.(t)) и т. д. Этот метод широко применяется в реальных СНЛ
поскольку он существенно облегчает процесс построения функций
принадлежности. В более сложных случаях, когда наблюдаемые данные идут, например,
вперемешку со случайными шумами, блок фаззификации должен
преобразовывать вероятностные данные в нечеткие числа.
База правил нечеткой логики
Правила нечеткой логики представляются набором нечетких «IF-THEN»
конструкций, в которых условия (антецеденты) и следствия (консеквенты)
подразумевают использование лингвистических переменных. Этот набор правил
нечеткой логики (или нечетких утверждений) характеризует простую связь входа
системы с ее выходом. Наиболее часто используемый в прикладных системах
формат правил нечеткой логики для случая СНЛ с множеством входов и одним
выходом (MISO - multi-input - single-output) имеет следующий вид:
R : IFx is At,..., AND у is В, THENz = С,, i = 1,2,..., и, (10.7)
где х, ...,ynz- лингвистические переменные, представляющие переменные
состояния некоторого управляемого процесса и управляющие переменные
соответственно, А., ...,ЯиС- лингвистические значения переменныхх,...,у
иг в предметных областях U, ...,Ки ^соответственно.
В другом варианте формата MISO выход СНЛ представляется как функция
переменныхх, ...,у, характеризующих состояние внешней среды, т. е.:
R: IFx isA„ ...,ANDy is В, THENz=ft(x, ...,y), i= 1,2,..., n, (10.8)
где/^х, ..., у) - функция переменных х, ..., у, характеризующих состояния
процесса.
Нечеткие правила в уравнениях (10.7)и(10.8) вычисляют состояние процесса
(ошибку определения состояния, интегральную ошибку состояния и т. д.) в
момент времени/и затем расе ■ . :. »т и принимают решение об управляющих
воздействиях, реализуемых в виде функции переменных состояния процесса
(х, ..., у). Необходимо отметить, что в обоих видах правил нечеткой логики
входные переменные имеют лингвистические значения, а выходные имеют либо
лингвистические значения (как в уравнении (10.7)), либо точные значения (как
в уравнении (10.8).
254
10.2. Структура и принцип работы нечеткой системы
Блок вывода
Блок вывода представляет собой ядро СНЛ, используемое для
моделирования приближенных рассуждений и процесса принятия решений человеком в
сложных ситуациях.
Нечеткие выводы, нечеткие или приближенные рассуждения - это
основные методы в нечеткой логике. Для организации нечетких выводов
необходимо определить понятие отношения.
Предположим, что знание эксперта А—>В отражает нечеткое причинное
отношение предпосылки А и заключения В, которое называется нечетким R.
R = A-+B.
Почти все реально работающие прикладные системы, использующие
промежуточные нечеткие оценки, это системы, основанные на нечетких
продукционных правилах. При выполнении нечетких выводов используются нечеткие
отношения R, заданные между одной областью (множество X) и другой
областью (множество Y) в виде нечетного подмножества прямого произведения Хх. Y,
определяемого по формуле
п т
R= ZZ«Mw,)l(w,))b (ю.9)
.=1 7=1
где {xr x2, ..., xj - область посылок; (у,, у2, ..., ут} - область заключений;
ц/х,, у) — функция принадлежности (х., у) нечеткому отношению R:
цл(х, у )е[0,1]; знак X означает совокупность (объединение) множеств.
Для продукционных правил типа «IF A THEN В», использующих нечеткие
множества A(AczX ) и B(B<zY ), один из способов построения нечеткого
соответствия R состоит в следующем:
и т
R = AxB = 2E«M*,)aiib0s)|(W,))}
1=1 7=1
или
h, (*. У) = К, (*) л Цв (у) = min (\xA (х), \хв (у)), (10.10)
где цА(х)> Цв(у) _ функции принадлежности элементов х,у соответственно
множествам А и В.
Пример 4. Пусть Хи Y— области натуральных чисел от 1 до 4. Определим следующим
образом нечеткие множества: А - «маленькие», В - «большие». X=Y= {1,2,3,4}, т. е. для
примера взят частный случай соответствия—отношение на множестве {1,2,3,4}.
А = {^(х)I (х)} = {(1| 1), (0,б| 2XC0.ll 3), (0| 4)},
В= ВД| (у.)} = {(0| 1),(0,1| 2),(0,б| 3),(1| 4)}.
Для примера «если х маленькое, то у большое» (или А->В, где -> означает операцию
нечеткой импликации) можно построить нечеткое отношение R следующим образом. В
качестве элементов матрицы R (табл. 10.3) записываются значения ц, вычисленные по
формуле (10.10).
255
10. Математические основы построения нечетких систем
Таблица 10.3
Таблица 10.4
R =
Х\
хг
хз
х,
У\
0
0
0
0
Уг
0,1
0,1
0,1
0
Уз
0,6
0,6
0,1
0
У*
1
0,6
0,1
0
5 =
У\
Уг
Уг
Ул
Vl
0
0
0
0
v2
0
0
0
0
v3
0
0,4
0,5
0,5
v4
0
0,4
0,9
1
Для свертки (композиции) нечетких отношений чаще выбирается свертка тах-
min (максминная композиция). Пусть R - нечеткое отношение множества А" и
множества Y, a S - нечеткое отношение множества У и множества V. Тоща
нечеткое отношение между А"и V определяется как свертка (композиция), R°S,t. е.
или
R°S = max гшп(цЛ (х., у}, \is (у,, vj) \ (x, vk).
(10.11)
Пример 5. Пусть V={ 1,2,3,4} и заданы нечеткие множества A(AczY)=«не маленькие»,
ЩНаУ) = «очень большие», где
Л = {(0|1),(0,4|2),(0,9|3),(1|4)},
Я={(0|1),(0|2),(0,5|3),(1|4)}.
Тогда для правил «если>> не маленькое, то v очень большое» (или А—*Н), в
соответствии с формулой (10.10) нечеткое отношение S определяется табл. 10.4.
Если теперь по формуле (10.11) вычислить свертку max-min с нечетким отношением
R, полученным в примере 1, то из двух соотношений: «если х «маленькое», то
^«большое»», «если у «не маленькое», то v «очень большое»» можно построить нечеткое
отношение изХв К(табл. 10.5):
R°S= v {(\xR(x,y),& vs(y, v))} = max min(цл(*,у), ^(у, v)).
yj*r
У j**
X\
хг
*3
*4
У\
0
0
0
0
Уг
0,1
0,1
0,1
0
Уъ
0,6
0,6
0,1
0
У*
1
0,6
0,1
0
о
,У|
Уг
Уг
У*
Vl
0
0
0
0
Т
V2
0
0
0
0
аблица 10.5
v3
0
0,4
0,5
0,5
v4
0
0,4
0,9
1
Xl
Хг
х3
*4
Vl
0
0
0
0
V2
0
0
0
0
v3
0,5
0,5
ОД
0
V4
1
0,6
0,1
0
256
10.2. Структура и принцип работы нечеткой системы
Нечеткое отношение R, в свою очередь, можно рассматривать как
нечеткое множество на декартовом произведении Ху. Y полного пространства
предпосылок Л"и полного пространства заключений Y. Таким образом, процесс
получения (нечеткого) результата вывода В' с использованием данных
наблюдений А' и знания А—>В можно представить в виде формулы
B' = A'°R = A' °(A^>B), (10.12)
где о - композиционное правило нечеткого вывода (нечеткий modus ponens). В
основе этой логической операции лежит нечеткое отношение.
Рассмотрим операцию нечеткой импликации, положенную в основу
нечеткого вывода с позиций нечеткой логики.
Возьмем за образец случай четкой логики, в которой реализуется операция
II м м
*,->*2 s xxv х2.
Следовательно, если заменить операцию отрицания (в четкой логике) на
«вычитание из 1» (для нечеткой логики), и ИЛИ - на максимум, то одна из
стандартных операций импликации в нечеткой логике будет иметь вид:
jc,-»2 = (1-jc,)vjc2. (10.13)
Интерпретация формулы (10.13) в виде
xx-*x2 = (1-х^ х^л1 (10.14)
представляет собой граничную сумму нечеткого отрицания по типу
«вычитания из 1» х, и хг В многозначной логике эта формула известна как импликация
Лукасевича. Л. Заде использовал формулу (10.14) и предложил нечеткий
вывод, сделав следующую замену:
V-R(x ,у) = Ц^в(х ,у)= (1- цА№ +Цв(у)) л1.
Мамдани, в свою очередь, использовал нечеткую импликацию в виде:
х.—>х, — х л X..
По свойствам эта операция представляет собой f-норму типа логического
произведения (или операцию минимум).
В зависимости от выбора операции композиции и операции нечеткой
импликации можно получать различные схемы нечеткого вывода.
Кроме нечеткой композиции и нечеткой импликации существуют другие типы
композиционных операторов, которые можно использовать в композиционном
правиле вывода. К этим операторам относятся операторы, связанные с
^-нормами: операция минимума Заде, операция произведения Кауфмана, операция
граничного произведения и др. В применяемых на практике СНЛ
композиционные операторы минимума и произведения используются наиболее широко
благодаря их вычислительной простоте и эффективности. Если обозначить через
«*» любой из возможных композиционных операторов, то уравнение (10.12)
257
10. Математические основы построения нечетких систем
приметвид:
B'=A"R = A"(A-+B);
Mv) = suP{Kf(") * ^в(и> v)},
где' означает операции /-нормирования такие, как операции минимума,
произведения, граничного произведения и т. д.
Таблица 10.6. Правила нечеткой импликации
Правило нечеткой и ы • i ■
Правило минимума (Мамдани)
Логическое произведение (Лар-
сен)
Г», i ч «произведение
Драстическое произведение
Арифметическое правило Заде
Правило максимума-минимума
Заде
Правило Шарпа
Правило Буля
Правило Геделя
Правило Гогена
Формула
it ii.ii
х->у=хлу
х->у=ху
х->у =
= 0v(x+>>-1)
— ■
х->у=
х,если.у = 1;
у, еслих=1;
0, еслих,д><1
х->у=
= 1л(1 -х+у)
х->у=
= (kax)v(1 -x)
х->у=
f 1,еслих<у,
= 1 0,еслих>д>
х-ъу=(1—х) vy
x-»j>=
Г 1,еслих<^
[0, еслих>д>
х->у=
Г 1, еслих<^
[Ух,еслих>.у
Нечеткая i ■
\iA-m(u,v)= цА(и) AHfi(v)
\iA ->B (И, V) = llA (И) • Ця (V)
V-a->b(u,v) =
= 0v(^(M) + p.s(v)-l)
= .
цу4_>в(м,у) =
\хА(и),^в(у) = 1;
Mv),\iAW)=l;
.0, \iA(u),Mv)<l
= 1a(1-u«(")+Mv))
\ia^b(u,v) =
= \iA (и) л p.s (v) v (1 - \iA (m))
\ia^b(u,v) =
_{h\Kt(u)<\iB(y);
Va^b(u,v) =
= (1-\1А(и))\/Цв(у)
Va^b(u,v) =
_fl, цА(и)<\1В(у);
\\1в(у),рА(и)>\1В(у)
p. a^b(u,v) =
[Vb (v) / \iA (и), Ца (и) > йв (v)
258
10.2. Структура и принцип работы нечеткой системы
Что касается нечеткой импликации Л—»2?, то существует около 40 разных
функций нечеткой импликации, описанных в соответствующей литературе. В
табл. 10.6 представлены некоторые правила нечеткой импликации, часто
применяемые в СНЛ.
Можно заметить, что правила нечеткой ■ ■■ определенные в табл. 10.6,
являются обобщениями операций нечеткой конъюнкции, нечеткой дизъюнкции
или нечеткой импликации, выполненными на основе применения различных
f-норм или f-конорм. Так, первые четыре типа правил нечетких импликаций,
приведенные в табл. 10.6, являются ^-нормами. Например, нечеткая
импликация минимума Мамдани получается, если в нечеткой конъюнкции
использовать оператор пересечения, если же в нечеткой конъюнкции использовать
алгебраическое произведение, то имеет место операция произведения Ларсена.
Арифметическое правило Заде получается при использовании оператора
ограниченной суммы, а правило максимума-минимума Заде - при использовании
операторов пересечения и объединения. Остальные правила нечеткой
импликации, приведенные в табл. 10.6, формируются за счет применения различных
определений операции нечеткой импликации.
Нечеткий вывод на основе правила композиции
Модель принятия решений на основе композиционного правила вывода
описывает связь всех возможных состояний сложной системы с управляющими
решениями. Формально модель задается в виде тройки (X, R, Y ), где Х= {xv
x2,...,xj; Y= {yl,y2,...,ym} - базовые множества, на которых заданы,
соответственно, входы At и выходы В. системы; R - нечеткое соответствие «вход-
выход». Соответствие R строится на основе словесной качественной
информации специалиста (эксперта) путем непосредственной формализации его нечетких
стратегий. Эксперт описывает особенности принятия решений при
функционировании сложной системы в виде ряда высказываний типа «IF Al THEN Bt,
ELSE IF A2 THENB2,..., ELSE IF AN THENВ„». Здесь A{,A2,...,AN- нечеткие
подмножества, определенные на базовом множествеX,aBvB2,...,BN-
нечеткие подмножества из базового множества Y. Все эти нечеткие
подмножества задаются функциями принадлежности \iAj(x) и цв1(у), х е X, у е Y.
Правило «IFA. ELSE2?» характеризуется функцией принадлежности 11К_А_+В(х,у),
определяемой по формуле (10.10). Связка ELSE между правилами понимается
или как связка, поскольку общее нечеткое отношение состоит из: правило 1,
или правило 2, или..., или правило N Поэтому общее отношение R формально
определяется следующим образом:
R = kjR. =max[min(u^ (x), ц (у))],
mei=l,N ' '
Если предположить, что мы имеем нечеткое событие А,т.е. входную
ситуацию, представленную нечетким подмножеством, и известно общее
отношение R, тогда результирующее действие выводится по композиционному прави-
259
10. Математические основы построения нечетких систем
лу вывода: B-AoR. Значение функции принадлежности для В вычисляется
посредством максминной операции:
ЦВ'(У)= v (у.А.(х) л \i.R (х, у)) = v Ц/1'(л)л(ц/1(д:)лцв(у))) =
хех хеХ (10.15)
= ( v (^.(х) л \iA (х))) л цв (у) = v ц,^ (х) л цв (у) = а л цв (у) = ц (у).
хеХ хеХ
Уравнение (10.15) наиболее часто используют в нечетких системах
вывода, поскольку на основе этого уравнения при известных функциях
принадлежности конечные результаты вычисляются довольно просто. Кроме того,
обеспечивается графическая интерпретация механизма нечеткого вывода,
показанного ниже. г
Рассмотрим наиболее важные модификации нечеткого вывода. Для простоты
положим, что в базе данных имеется два правила, представленные в виде:
/?,: IFx is A^ANDy is BJHEN z is C,;
R2: IFx is A2ANDy is B2THENz is C2,
где x, у - имена входных переменных; z - имя выходной переменной; А , А2, Вх,
В2, Ср С2 - определенные функции принадлежности.
Необходимо найти четкое значение переменной zQ на основе задаваемых
значений х0 ,yQ. Уровень истинности для первого /?j и второго правила R2 может
быть выражен как «а-срез»:
Рис. 10.8. Диаграмма нечеткого вывода по Мамдани
260
10.2. Структура и принцип работы нечеткой системы
ai= ^,Ц>) Л (|Лв, ty>) и а2= *Ч(*0) л (Ив2СУ0)» (10.16)
где щС*,,) и ^в\ &() опРеДеляют степень соответствия между конкретными
значениями входных переменных и данными, задаваемыми в правиле.
Приведем более детальное описание получения четкого значения
переменной z на основе известных х иу . Для этого необходимо выполнить
следующие действия:
1) провести фаззификацию четких переменных х иу , т. е. вычислить
степени истинности ai и а2 по формуле (10.16) на основе функции принадлежности,
определенных для х иу;
2) выполнить нечеткий вывод по заданной стратегии (Мамдани, Ларсену и
т. д.) и вычислить итоговую функцию принадлежности цс(г);
3) преобразовать полученную в п. 2 нечеткую величину в четкую (т. е.
провести дефаззификацию).
Алгоритмы нечеткого вывода различаются в основном видом
используемого правила нечеткой импликации.
Нечеткий вывод по Мамдани. В этом варианте нечеткого вывода
используют операцию взятия минимума в качестве нечеткой импликации (рис.
10.8). Тогда каждое i-e нечеткое правило приводит к следующему решению:
цс(г) = а лцс(г). (10.17)
На следующем этапе проводится объединение получаемых нечетких
подмножеств (10.16) с использованием операции взятия максимума, в результате
чего получаем итоговое заключение (рис. 10.9):
Ис(г) = IV,v »V2 = [", Л Не, (*)] v К л ^с2 (*)]•
/
Нечеткий вывод по Ларсену. В качестве операции нечеткой импликации
при нечетком выводе по Ларсену используется
операция умножения (рис. 10.10). В этом случае получаем i,o
следующее решение:
Нс.(г) = а.-цс_(г).
На заключительном этапе функция
принадлежности ц„ определяется путем объединения нечетких под- „ ^„„ __.
с , ,. ,,: Рис. 10.9. Формирование
множеств (рис. 10.11): шаговой функции
, ч г , ч, г , ч1 принадлежности при
uJz) = ur-vn . = [а,лц_ (г)Ма,лц_ (г)]. w
пл / re, t~c2 l i r~c \ /\ l 2 i~c v /j выводе по Мамдани
261
10. Математические основы построения нечетких систем
Рис. 10.10. Диаграмма нечеткого вывода по Ларсену
Нечеткий вывод по Цукамото. В варианте нечеткого вывода по
Цукамото используется тот же алгоритм, что и при выводе по Мамдани, но
требуется, чтобы функция принадлежности С, являлась монотонной.
В этом методе результаты вывода из первого и второго правила (рис. 10.12)
представляются как:
zi= Нс.Ча,) иг2= Цс-'(а2)-
1,0 -
с
Рис. 10.11. Формирование
итоговой функции
принадлежности при
нечетком выводе по Ларсену
Тогда четкое значение выходной переменной
получается сразу как взвешенная комбинация:
_alzi+a2z2
а, +а2
Заключительная процедура нечеткого
логического вывода, за исключением вывода по Цукамото,
связана с получением четкого значения z для
выходной переменной. Рассмотрим наиболее
известные методы выполнения этой процедуры.
262
10.2. Структура и принцип работы нечеткой системы
Рис. 10.12. Диаграмма процедуры нечеткого вывода по Цукамото
Дефаззификация
Под дефаззификацией понимается процедура преобразования нечетких
величин, получаемых в результате нечеткого вывода, в четкие. Эта процедура
необходима в случаях, когда требуется интерпретация нечетких выводов
конкретными четкими величинами, т. е. когда на основе функции принадлежности
цДя) необходимо определить для каждой точки в выходном пространстве Z
числовые значения переменных z.
В настоящее время отсутствует систематическая процедура выбора
стратегии дефаззификации. На практике часто используют два наиболее общих
метода - метод центра тяжести (ЦТ — центроидный) и метод максимума (ММ).
В дискретном случае для центроидного метода формула для вычисления
четкого значения выходной переменной имеет вид:
z щ—
я
п
У=1
263
10. Математические основы построения нечетких систем
в общем случае
z цт~
mc(z )zdz
Hc(z )dz
Стратегия дефаззификации ММ предусматривает подсчет всех z, функции
принадлежности которых достигли максимального значения. В этом случае
(для дискретного варианта) получим
. Z ;
ММ"~ __
~\ т
в общем случае \zdz
¥'
Z = —
^ мм
где z - выходная переменная, для которой функция принадлежности достигла
максимума; т - число этих переменных.
10.3. Пример использования СНЛ
Рассмотрим основные моменты нечеткого вывода по Мамдани на примере,
приведенном в [11].
Пусть дана система управления нечеткой логики с двумя правилами
нечеткого управления:
Rule l:IFxisAl AND у isBl THENz isCt;
Rule 2:IFx is A2 AND у is B2 THEN z isCr
Предположим, что величины х0 и у0, считываемые сенсорами, являются
четкими входными величинами для лингвистических переменных х и у и что
заданы следующие функции принадлежности для нечетких подмножеств Ах,
А2, Вх, В2, С,, С2 этих переменных:
:-2)/Зпри2<*<5, _ j(x - 3)/3 при 3 < х < 6,
М*) l^-jc)/3npH5<jc<8; ^i.*) 1(9 - *)/3 при 6 < * < 9;
1(8-
ц(л) = (0^-5)/Зпри5<>,<8, ц(у) = Ь-4
Me,W |(U _уу3 при 8 <^ < 11; **-*У' \\0 -
Mc,W |(8-х)/Зпри5<х<8; ^w p-
-4)/Зпри4<>><7,
у)/3щ>и7<х<10;
3)/ЗприЗ<*<6,
л:)/3при6<дс<9.
Предположим, что в момент времени /, были считаны значения датчиков
jc0(/j) = 4 и у$х) = 8. Проиллюстрируем, как при этом будет вычисляться
величина выходного сигнала. Вначале находим а-срезы для первого и второго
264
10.3. Пример использования СИЛ
правила на основе заданных функций принадлежности и с учетом значений х0 и
у0. С этой целью вычисляем величины функций принадлежности в заданных
точках для первого и второго правил:
^ = 4) = 2/3 и цВ|(уо=8)=1;
h„2(*o=4) = 1/3 и нВ2(Уо=8)=2/3;
Затем вс : ии с правилом вывода по Мамдани (выбор минимального
значения функций принадлежности) определяем следующие значения а-уровней:
а, = min (ЦЛ(*0), Цв(у0)) = min (2/3, 1) = 2/3;
а2 = min (u^(*0), Чв(у0)) = min (1/3,2/3) = 1/3.
Результат применения вычисленных значений а, и а2 к консеквентам
правила 1 (для С,) и правила 2 (для С2) показан на рис. 10.13.
0 1 3 !~5 7 \>
Рис. 10.13. Иллюстрация нечеткого вывода по Мамдани для рассматриваемого
примера
265
10. Математические основы построения нечетких систем
Окончательный результат получается путем объединения (агрегирования)
полученных функций принадлежности с использованием оператора максимума
(с учетом стратегии вывода по Мамдани). Результирующая функция
принадлежности представлена на рис. 10.13.
Для вычисления искомой выходной величины z проводим дефаззификацию
нечеткой величины цс. По методу центра тяжести получаем:
ф _ 2(1/3) + 3(2/3) + 4(2/3) + 5(2/3) + 6(1/3) + 7(1/3) + 8(1/3)_
2цг (1/3) + (2/3) + (2/3) + (2/3) + (1/3) + (1/3) + (1/3) ' '
При использование метода максимума подсчитываем число значений z,
при которых было достигнуто максимальное значение функций
принадлежности цс: их три: 3,4 и 5 (со значением функции принадлежности 2/3). Тогда
<,м = (3+4 + 5)/3=4>°-
Таким образом, использование основных математических понятий теории
нечетких множеств позволяет формировать нечеткие, неполные и
недостоверные знания, оперировать этими знаниями и моделировать процесс принятия
человеком решений в сложных трудных формализуемых задачах.
Упражнения и вопросы для самоконтроля
1. Чем вызвана необходимость использования аппарата нечеткой математики при
решении реальных задач в технике?
2. Дайте определение лингвистической переменной. Приведите примеры ее
использования.
3. В чем различие в выполнении операций над нечеткими и четкими множествами?
4. Сравните различные стратегии нечеткого вывода. Перечислите задачи, в которых
целесообразно использовать каждую из них.
5. Заданы два нечетких множества/! и В, чьи функции принадлежности определяются
как:
Л = 0,2/х,+ 0,8/х2+1/х3,
В=0,5/У1+0,Щ + 0,6/уу
Найти R такое, что AR = B
6. Рассмотрите выполнение нечеткого вывода по Ларсену в примере по
использованию системы нечеткой логики.
7. Определите выход нечеткой системы В в max-min композиционном правиле вывода.
8. Приведите основные типы используемых на практике правил нечеткой
импликации.
9. Перечислите способы реализации операций /-норм и /-конорм?
266
11. ГИБРИДНЫЕ НЕЙРОННЫЕ СЕТИ
Проанализированы проблемы, возникающие при интеграции нейросетевой технологии
с нечеткими системами для получения положительного синергетического эффекта их
совместного применения. Исследованы возможности построения некоторых гибридных
нейросетевых нечетких и нечетких нейросетевых систем, позволяющих повысить
эффективность их использования при решении прикладных задач классификации и
распознавания.
11.1. Интеграция нейросетевых и нечетких систем
Основное преимущество нечетких систем в отличие от НС заключается в
том, что знания в этих системах представляются в форме легко понимаемых
человеком гибких логических конструкций, таких, как «IF... - THEN...».
Кроме того, необходимо отметить, что, в соответствии с теоремой, доказанной
Б. Коско (1993), любая математическая функция может быть
аппроксимирована системой, основанной на нечеткой логике, следовательно, такие системы
являются универсальными. Основные трудности при использовании нечетких
систем на практике связаны с априорным определением правил и построением
функций принадлежности для каждого значения лингвистических переменных,
описьшающих структуру объекта, которые обычно проектировщик вьшолняет
вручную. Поскольку вид и параметры функций принадлежности выбираются
субъективно, они могут быть не вполне адекватны реальной действительности.
Основное преимущество нейросетевого подхода - возможность выявления
закономерностей в данных, их обобщение, т. е. извлечение знаний из данных, а
основной недостаток - невозможность непосредственно (в явном виде, а не в
виде вектора весовых коэффициентов межнейронных связей) представить
функциональную зависимость между входом и выходом исследуемого объекта.
Недостатком нейросетевого подхода является также трудность формирования
представительной выборки, большое число циклов обучения и забывание
«старых» примеров, трудность определения размера и структуры сети.
267
11. Гибридные нейронные сети
Эти два подхода исследования сложных объектов на основе НС и нечетких
систем взаимно дополняют друг друга, поэтому целесообразно их
объединение на основе принципа «мягких» вычислений (Soft Calculation). Основы
построения таких систем с использованием разнородных методов были
сформулированы Л. Заде в 1994 г. Они сводятся к следующему: терпимость к нечеткости
и частичной истинности используемых данных для достижения
интерпретируемости, гибкости и низкой стоимости решений.
Реализация объединения рассмотренных двух подходов возможна в
следующих гибридных системах:
• нейросетевые нечеткие системы, в которых нейросетевая технология
используется как инструмент в нечетких логических системах;
• нечеткие НС, в которых с помощью аппарата нечеткой математики
осуществляется фазификация отдельных элементов нейросетевых моделей;
• нечетко-нейросетевые гибридные системы, в которых осуществляется
объединение нечетких и нейросетевых моделей в единую систему.
Рассмотрим возможности реализации некоторых элементов гибридных
систем, которые являются более эффективными с точки зрения расширения класса
решаемых задач, формирования новых знаний из данных, объяснения
получаемых результатов.
11.2. Нейросетевые элементы нечетких систем
Нейросетевой нечеткой системой называется такая система, в которой
отдельные элементы нечеткости (функции принадлежности, логические
операторы, отношения) и алгоритмы вывода реализуются с помощью НС.
Рассмотрим вопросы, связанные с обучением НС для представления
функций принадлежности произвольной формы. Построение простых форм функции
принадлежности, таких, как треугольная или колоколообразная,
осуществляется на одном нейроне путем подстройки функции активации к желаемой
функции принадлежности. Например, для представления колоколообразной функции
принадлежности может быть использован нейрон, функция активации которого
имеет вид:
/(net) = ехр
Г-(п&-т)2Л
а2
(11.1)
где net - сумма частных произведений входов нейрона; т - значение нечеткой
переменной, при которой достигается наибольшее значение функции
принадлежности; а - среднеквадратичное отклонение функции принадлежности от
максимального значения.
В качестве примера рассмотрим возможность построения функций
принадлежности для трех значений некоторой лингвистической переменной: «мало
(S - Small)», «средне (М- Medium)», «много (L - Large)». Для этого
используем НС, представленную на рис. 11.1, а. На этом рисунке выходы УгУ2'Уз опРе~
268
11.2. Нейросетееые элементы нечетких систем
тгх.(х) X
а б
Рис. 11.1. Нейросетевая реализация функций принадлежности:
а — структура НС; б - график функций принадлежности
деляют величины соответствующих функций принадлежности - us(jc), |\/*),
\ll(x). Узлы со знаком «+» суммируют сигналы входов нейронов, а узлы с
символом/реализуют сигмоидальные функции. Например, для значения
лингвистической переменной «мало» функцию принадлежности можно определить
следующим образом:
yi=»s(*) = - , * . u, (И.2)
l + exp(-wg(x + wc))
где wc - весовой коэффициент для смещения и wg- вес суммарного сигнала на
входе нелинейного преобразователя. Путем подстройки весовых
коэффициентов формируются функции принадлежности (рис. 11.1,6).
Реализация нечетких И (AND), ИЛИ (OR) и других операторов в нейросе-
тевом логическом базисе дает основу для построения нейросетевых нечетких
моделей. Определим процедуру реализации базовых нечетких логических
операторов. Возможность использования различных функций активации нейрона
позволяет разрабатывать различные (желаемые) логические операторы, т. е.
можно задать функцию активации, реализующую min-оператор для нечеткой
операции AND, max-оператор для нечеткой операции OR. Возможность
применения не дифференцируемых функций активации в процедуре обучения НС не
обеспечивается использованием генетических алгоритмов оптимизации,
рассмотренных в гл. 6. В некоторых случаях, когда процедура обучения
связывается с алгоритмом Back Propagation в НС прямого распространения,
возможна замена или аппроксимация желаемой не дифференцируемой функции
дифференцируемой. Например, следующий «мягкий» (softmin) оператор может
быть использован для замены оригинального нечеткого оператора И:
(а /\Ъ) = softmin(a,b) =
ае
-ка
+ Ье
-кЬ
(11.3)
+ е
269
11. Гибридные нейронные сети
где к — параметр, контролирующий «soft» : при к—>оо реализуется обычный
min-оператор. При конечных А: имеем обычную дифференцируемую функцию.
Априорно : :•! • различные тшгааптюксимирующихфункхшйтипа (11.3), можно
разработать большое количество «мягких» логических операторов, способных
наилучшим образом адаптироваться к решаемой задаче.
Нейросетевая реализация нечетких отношений
Как было показано выше, возможны различные способы реализации
нечетких отношений в системах нечеткого логического вывода. Основные
трудности построения нечетких отношений связаны с настройкой большого числа
функций принадлежности. Для устранения этих трудностей можно
использовать подход, основанный на обучении НС с весовыми коэффициентами,
соответствующими этим функциям принадлежности.
Пусть Xn Y- нечеткие множества в U и К соответственно, и R - нечеткое
отношение в Ux V. Рассмотрим уравнение нечеткого отношения
Y=X°R, (11.4)
где о - операция композиции (например, max-min операция).
Пусть 17={хх, х2,..., хп} и V={yl,y2, •••»>'„}• Тогда можно записать max-min
композицию
МУ) = тах(тт(цДх), Цд(х,^))), (11.5)
где X— нечеткое множество на U; Y- нечеткое множество на Vyl R - нечеткое
отношение R:UxV—>[0,1], описываемое всеми отношениями принадлежности
(связями) между входом и выходом. Выражение (11.5) можно записать в
другом виде, представив отношение R в виде матрицы:
X°R = [цх(х,),цх(д:2),...,цх(д:п)] о
М*2».И) ■•• М*2»>0
M*„»>,i) - М*п>;0
(11.6)
Уравнение (11.6) определяет величину \ir(y) путем композиции векторами
у-й колонки матрицы отношения R. Такое отношение может быть реализовано
НС, структура которой показана на рис. 11.2. В этой сети выходной узел
выполняет max-min композицию вместо обычной операции суммирования,
реализуемой НС.
Однако, следуя уравнению (11.5), на определенном выходном узле
необходимо получить сигнал (max или min), отличающийся от сигналов на других
узлах. Если использовать обычную операцию суммирования сигналов на входах
нейрона, то результирующий сигнал может быть слишком низким для
активизации выхода. В связи с этим к каждому выходному узлу рассматриваемой НС
270
11.3. Нейросетевая модель нечеткого композиционного вывода
Их(*1>
Их(*2>
М*>.)
My(Vi)
Myty)
Vyfyn,)
Рис. 11.2. Нейросетевая модель нечетких отношений
добавляется порог (bias), обозначаемый Ъ. е[0,1]. Тогда уравнение (11.5)
можно представить в виде:
ц,(у)= тах[тах(тт(цДх), \iR{x., у))), Ь(у)].
(11.7)
Добавление порога (точно так же, как в обычном нейроне) может
рассматриваться как введение дополнительного входа в нейронный узел, значение
которого изменяется от 0 до 1. Таким образом, уравнение (11.7) можно
рассматривать как функцию активации, используемую в выходном узле. Из этого
уравнения также следует, что возможный уровень сигнала, получаемого на
выходном узле сети, не может быть ниже порога. Для обучения такой сети
можно использовать стандартные алгоритмы обучения и определения ошибок
обучения и обобщения.
11.3. Нейросетевая модель нечеткого
композиционного вывода
Анализ процедуры классического нечеткого вывода позволяет выделить две
главные проблемы, возникающие при организации вывода на основе нечеткой
логики, которые более эффективно можно реализовать на основе нейросетево-
го подхода. Первая связана с определением функций принадлежности,
использующихся в условной части правил, а вторая - с выбором одного правила,
определяющего решение, из совокупности правил. Рассмотрим модель, в которой
НС используется для организации вывода, аналогичного композиционному
нечеткому выводу.
Один из вариантов реализации нейросетевого нечеткого вывода (для базы
из трех правил /?р /?2, R3), позволяющего формировать функцию
принадлежности условной части /Оправил и управлять выводом на основе сформированной
функции принадлежности, представлен на рис. 11.3.
Правила нечеткого вывода в рассматриваемой модели имеют следующий
формат:
271
11. Гибридные нейронные сети
Рис. 11.3. Нейросетевая модель нечеткого вывода
Rs: IFX= (*,,..., jc„) isAs THENys = HC5(x,, ...,*„), s = 1,2,...,/-, (11.8)
где r - число правил вывода; As - представляет нечеткое множество условной
части каждого правила; НС^-) - определяет структуру нейросетевой модели
(многослойный персептрон) со входами хх, х2,..., хп и выходом ys, причем для
каждого правила используется своя НС. Для определения функций
принадлежности условной части правил используется нейронная сеть НСу(ц)
(многослойный персептрон).
Нейронная сеть НС^(ц) обучается на входных данных из обучающей
выборки. Выходы обученной НС рассматриваются как величины функций
принадлежности нечетких множеств в условной части IF правил, так как величина
выходного сигнала определяет принадлежность данных к каждому правилу.
Предположим, что в рассматриваемой нейросетевой модели нечеткой
системы, состоящей из нескольких НС, имеется п входов xv x2, ..., хп и
единственный выход у. Обозначим через HCS - НС, которая вычисляет выход ys
272
11.3. Нейросетевая модель нечеткого композиционного вывода
для каждого 5-го правила. Тогда процедура нечеткого вывода на основе нейро-
сетевой модели реализуется следующим алгоритмом:
1. Формирование обучающей N и тестовой Nr выборки; N=N +N - общее
число примеров из базы данных.
2. Кластеризация обучающей выборки. Делим обучающую выборку на г
классов Rs (по числу правил), где s =1,2,..., г. Каждая обучающая подвыборка
для класса Rs определяется парой (x',yf), где i=\,2,...,Ns,aN- число
примеров в обучающей выборке для класса Rg. Разделение и-мерного входного
пространства на г в данном случае означает, что число правил вывода равно г.
3. Обучение НС(ц). Для каждого входного вектора Х,.е R определим
вектор функций принадлежности к правилу Ш{=(тУ, /иД..., mfy такой, что m "— 1
и mtk=0 для к * s. Нейронная сеть НС(ц) с п входами и г выходами обучается
на парах (X,, М(.), i = 1,2,..., N0, следовательно, после обучения и
тестирования такая сеть будет способна определить степень принадлежности mf для
каждого входного вектора, принадлежащего классу Rs. Таким образом,
функция принадлежности к части IF правила определяется как выходная величина
mf обученной НС., т. е.
mAp^ii= mt> *= Ь 2»---' N'>s = l> 2> ■■■» г->
где As соответствует нечеткому множеству условной части 5-го правила.
4. Обучение НС5. Обучающая выборка с входами дсД xf2t ...,x?„ и выходной
величиной yf;i=l,2,...,Ns подается на вход и выход НС„ которая является
нейросетевой моделью части THEN в Rs. С помощью тестовой выборки
вычисляется ошибка обобщения:
N
где *и (X,) - наблюдаемый выход НС,. Если Е < 8, где 8 - априори заданная
величина, НС5 - обучена.
5. Принятие решения. Для заданного входного вектора проводится
вычисление выходной величины по аналогии с формулой дефаззификации,
используемой в классическом композиционном выводе:
Z^(x,H(x,)
у* = .
±mApQ
s=l s
В рассмотренном варианте нейросетевой модели нечеткого вывода
формализована процедура определения функций принадлежности из базы данных, что
позволяет при изменении содержимого базы данных в результате получения
новых данных от экспертов или в процессе вывода подстраивать функции
принадлежности и тем самым получать более достоверные результаты.
273
11. Гибридные нейронные сети
11.4. Нечеткие элементы нейросетевых систем
Использование нечеткости в нейросетевых моделях означает большую
гибкость в реализации алгоритмов обучения, представления входной и выходной
информации, выбора функций активации за счет их фаззификации. Нечеткой
НС называется такая система, в которой отдельные элементы (нейроны,
функции активации и т. д.) и алгоритмы обучения являются нечеткими.
Нечеткие нейроны
Рассмотрим три базовых типа нечетких нейронов, на основе которых
можно построить нечеткие НС:
• нечеткий нейрон с четкими входными сигналами, но с нечеткими весами;
• нечеткий нейрон с нечеткими входными сигналами и нечеткими весами;
• нечеткий нейрон, описываемый посредством нечетких логических
уравнений.
Нечеткий нейрон первого типа и, (рис. 11.4) имеет п четких входов
дс,, х2, ..., хп. Весовые коэффициенты такого нейрона представляют собой
нечеткие множества At, i = 1,..., и, т. е. операции взвешивания входных сигналов
в классическом нейроне заменяются функциями принадлежности и происходит
их объединение (агрегирование) в узле и, с выдачей сигнала у = Цп1(х,, х2,. ..,хп),
принадлежащего интервалу [0,1], который может рассматриваться как
«уровень правдоподобия».
Операцию агрегирования взвешенных сигналов обозначим как <8>, для
реализации которой можно использовать нечеткие операторы /-нормы и /-конор-
мы. В зависимости от типа используемой операции <8> можно получить
различные схемы нечетких нейронов. Математическое описание нейрона может быть
представлено в виде:
цв1(дг,, х2,..., хп) = ц^х,) <8> \хА{х2) ®... ®»А{хп), (11.9)
где <8> - знак операции агрегирования; xt - i-й (не нечеткий) вход нейрона;
Ц^О)- функция принадлежности /-го (нечеткого) веса; цп1- выходная функция
нейрона.
Нечеткий нейрон второго типа п2 подобен нейрону первого типа, но все
входы и выходы нейрона являются нечеткими множествами (рис. 11.5).
Хг \ ~^\Цу ** у = ц'" (*ь Хъ - • *п)
Хп л„
Рис. 11.4. Модель нечеткого нейрона с четкими входными
сигналами и нечеткими весами
274
11.4. Нечеткие элементы нейросетевых систем
Рис. 11.5. Модель нечеткого нейрона с нечеткими
входами и выходами
Каждый сигнал на каждом нечетком входе Xt преобразуется путем
операции взвешивания в нечеткое множество Xj=Ai*Xi,i=l,...,n,c
использованием некоторого оператора *, где At — i-й нечеткий вес. Операция взвешивания
здесь не является функцией принадлежности, как в нейроне первого типа;
вместо нее проводится модификация каждого нечеткого входа. Математическое
описание нейрона второго типа имеет вид:
Xi = Ai*X,i=l,2,...,n; (11.10)
Y=X,®X0®...®X ,
12 n'
где Y - нечеткое множество, представляющее собой выход нейрона и2; X. и
X— i-й вход до и после операции взвешивания соответственно; А. - вес на i-й
связи; Ф - операция агрегирования, аналогичная формуле 11.9; * - оператор
взвешивания двух нечетких множеств (например, операция произведения двух
нечетких множеств).
Нечеткий нейрон третьего типа и}си нечеткими входами и одним
нечетким выходом показан на рис. 11.6. Отношение входа - выхода нечеткого
нейрона этого типа представляется с помощью одного нечеткого правила IF-THEN:
IF X, AND X0 AND... AND X THEN Y,
12 n '
гдеXvXv ...,Xn-текущие входы, Y- текущий выход. Тип нейрона п3 можно
описать нечетким отношением, например,
R=XxX7x...xXx Y
I £, П
или в общем случае
R=f(XvX2,...,Xn,Y),
где /(•) - функция импликации. Следовательно, нейрон рассматриваемого типа
описывается нечетким отношением R. Задавая соответствующие входы (чет-
Рис. 11.6. Модель нечеткого нейрона,
реализующего нечеткое отношение
275
11. Гибридные нейронные сети
кие или нечеткие) хх, х2, ..., хп, в соответствии с композиционным правилом
вывода получим
г=х° (л;о(...о (Хо/?)...), (н.и)
где о представляет оператор композиционного правила вывода.
На основе рассмотренных типов нечетких нейронов можно конструировать
нечеткие НС различной архитектуры, которые в отличие от обычных НС
обладают расширенными возможностями представления и обработки входной и
выходной информации.
11.5. Алгоритм обучения нечеткого персептрона
Рассмотрим возможность построения нечетких НС, в которых нечеткость
проявляется на этапе ее обучения. В этом случае модифицируется либо
стратегия самого обучения, либо отдельные его параметры, заметно влияющие на
качество обучения. В качестве примера рассмотрим нечеткий персептрон.
В алгоритме обучения простого персептрона каждый вектор обучающей
выборки вносит определенный вклад в модификацию весовых коэффициентов.
В случае неразделимости классов объектов, т. е. когда отдельные классы
перекрываются, образцы (примеры обучающей выборки), лежащие в зоне
перекрытия, в основном определяют неустойчивое поведение алгоритма обучения.
Поэтому основная идея построения нечеткого персептрона и алгоритма его
обучения заключается в уменьшении влияния векторов, лежащих в зоне
перекрытия, на изменение весовых коэффициентов.
Рассмотрим реализацию стандартного алгоритма обратного
распространения ошибки в случае разбиения входного пространства векторов на два
пересекающихся класса (рис. 11.7).
Пусть имеется обучающая выборка, состоящая из векторов {X,, Х2, ...,
X }, и функция принадлежности ц. (Хк), i=\,2;k=\, 2, ...,р, определяемая как
мера нечеткого разбиения пространства входов на два класса по отношению к
этим векторам, показывающая степень принадлежности каждого из этих
векторов к каждому из двух классов. Эти предположения могут быть
представлены следующими соотношениями:
£ ц, <Хк) =1 0 < tn, <Хк) <р ц, <Хк) е [О, 1]. (11.12)
1=1 *=i
причем для векторов, чей класс является менее опре-
^ j деленным, функция принадлежности находится в
интервале до 0,5 (рис. 11.8).
Степень влияния образца Хк на модификацию
весовых коэффициентов можно определить как разность
I Ц,(Х^) - ц2(Х^)Г, где т - константа, которая в случае
Рис. 11.7. Неразделимые неопределенности отнесения к одному из двух клас-
классы объектов сов вектора Х^ близка к нулю. Учитывая этот факт,
276
11.5. Алгоритм обучения нечеткого персептрона
Класс 1
Рис. 11.8. Представление функций принадлежности двух
пересекающихся классов объектов
можно модифицировать формулу (5.16), определяющую коррекцию весовых
коэффициентов в алгоритме обратного распространения ошибки для четкого
персептрона: т
Wj(f)= w,(/-l) + /ilh(X*('-D)-h(Xt(/-l))l x (nl3)
х[с1к-у(1-1)]х™,1<]<п+1,
где h - скорость обучения; dk - желаемый выходной сигнал при Хк входном
векторе; t - текущий такт обучения НС.
Из уравнения (11.13) следует, что влияние неопределенных векторов на
модификацию весовых коэффициентов можно уменьшить за счет изменения
константы т. Действительно, подобно четкому персептрону, в нечетком персепт-
роне также можно найти разделяющую поверхность за конечное число итераций.
При этом, если
|ц,(Хдо)-ц2(Х/0)Г=1,
когда Ц,(ХД |i2(Xt)e[0,1], нечеткий персептрон становится четким, тогда
значения величин функций принадлежности также будут четкими. При выборе
стратегии обучения, как было показано в гл. 5, большое значение имеет выбор
шага обучения, в особенности на ранних итерациях, когда определяется выбор
направления поиска, поэтому для векторов, значения функций принадлежности
которых близки к 0,5, можно установить значение т >1 и на последующих
итерациях постепенно его уменьшать.
При разработке алгоритма обучения нечеткого персептрона необходимо
решить две задачи:
277
77. Гибридные нейронные сети
1) определить способ вычисления функций принадлежности на каждом
этапе итерации;
2) определить критерий останова.
При решении первой задачи используют формулы разделения двух
пересекающихся классов. Тогда для некоторого вектора Хк в классе 1 получаем:
e/(dist 2 - dist, ydist _ -f
ц,(Х,) = 0,5+ 2(с/_е_/} ; (П14)
М2(Х4)=1-ц1(Х4),
где distj - расстояние вектора Хк до среднего значения класса 1; distj -
расстояние вектора Хк до класса 2; dist - расстояние между средними значениями двух
классов; /- положительная константа, подбираемая опытным путем (/"> 2).
Формулы (11.4) для Хк в классе 2 носят противоположный характер.
При решении второй задачи необходимо учесть тот факт, что, когда вектор
не может быть однозначно отнесен к определенному классу, значение его
функции принадлежности близко к величине 0,5, поэтому для останова процедуры
обучения выбирается значение 8, показывающее близость функции
принадлежности к величине 0,5. Тогда критерием останова будет выполнение
следующего условия:
Hj(Xt) > 0,5 + 8 или ц,(ХЛ) > 0,5 - 8, для ук,к=\,...,р. (11.15)
Алгоритм обучения нечеткого персептрона состоит из следующих шагов:
1. Инициализация весовых коэффициентов. Установление допусков т и 8.
2. Вычисление степеней функции принадлежности на всех образцах
обучающей выборки в каждом классе в соответствии с формулами (11.14).
3. Установление флага «Обучение» в состояние «True».
4. Предъявление НС нового образца, Х^ = {х^, х^,..., х^к\ - 1}, где х®+ = 1
(порог), с желаемым выходом <&е {1, -1 }и вычисление действительного выхода:
Л
y{t) = sign
л+1
(11.16)
5>,« х<;>
Если y(t) = <4> то переход к шагу 7.
5. Коррекция весовых коэффициентов по формуле (11.13).
6. Если не выполняются условия (11.15), хотя бы для одного к, к = 1,..., р,
флаг «Обучение» установить «False».
7. Если все примеры из обучающей выборки просмотрены, перейти к
следующему шагу, в противном случае перейти к шагу 4.
8. Если флаг «Обучение» находится в «True», то Останов и выдача весовых
коэффициентов, определяющих границу разбиения, в противном случае -
переход к шагу 3.
278
11.6. Нечеткая нейронная сеть Кохонена
11.6. Нечеткая нейронная сеть Кохонена
Дальнейшее повышение эффективности KCN связывают с использованием
теории нечетких множеств. В нечеткой неиросетевой модели Кохонена {Fuzzy
KCN - FKCN) так же, как и в нечетком персептроне, нечеткость вводится на
уровне выделения кластеров.
Рассмотрим алгоритм обучения FKCN Основной проблемой, решаемой этим
алгоритмом, в отличие от KCN, является автоматическое завершение
процедуры обучения. Структура нечеткой сети Кохонена представлена на рис. 11.9.
На этом рисунке сеть FKCN является двухслойной: первый слой - слой
расстояний стандартной KCN. Для заданного входного вектора X узел i, i = 1,2,..., к в
слое расстояний вычисляется расстояние dist (X.,W ) точно так же, как и для
KCN по формуле (8.4). В отличие от KCN, в FKCN введена мера
принадлежности входного образа классу - функция принадлежности ц#, i=1,2,..., к,
j - номер примера в обучающей выборке^' = 1, ..., N.
Суммарная степень принадлежности входного вектора ко всем классам
равна 1:
Eh,= l (П.17)
для у'= 1,2, ...,N
Второй слой FKCN- слой функций принадлежности - отображает
расстояния dist (X ,W ), гдеу = l,...,N,(N- количество примеров в обучающей
выборке; i=l,..., к, к - количество классов) в значение функций принадлежности
входного вектора некоторому классу в соответствии с уравнением
Г * dist Г1
■> Lp=idist J
^ pj
где ц#.= 1, если dist. = 0 и ц..= О, если dist = 0,р * /.
Слой функций
принадлежности
Слой выходных
нейронов
Рис. 11.9. Структура нечеткой сети Кохонена
Щ/А Ц2/А И*, А
пь ъ ... ъ
Обратная
связь
279
11. Гибридные нейронные сети
Обратная связь в схеме позволяет производить обновление весовых
коэффициентов на каждом шаге итерации.
Запишем алгоритм обучения сети FKCN.
1. Задать начальные значения весов W. 1=1,2, .., к (случайным образом
или на основе определенного алгоритма) и установить величину окрестности
г = к 12, где к - априорно заданное число кластеров.
2. Для каждого входного вектора X. выбирается узел Г в слое расстояний,
такой, что 1 < Г < к, для которого dist, = min, где dist. определяется как
Евклидово расстояние. Обновить веса W| по следующему правилу:
W,(/ + 1) = W,W + h,(0 dist (X, W(0), (11.18)
где t — номер итерации; i — выходной узел в слое расстояний и все г соседей
вокруг него.
3. Проверить равенство г = 0. Если г = 0, алгоритм завершен, в противном
случае г: = г — 1 и переход к ш. 2.
4. Останов.
При выполнении шага 2 (при обновлении весов) так же, как и в алгоритме
обучения KCN, выигрыш во времени при вычислениях достигается за счет
обновления только весов соседей. Количество обновлений весов меньше, чем
в KCN, за счет введения нечеткости - функций принадлежности \xt входных
векторов кластерам. Завершение процедуры обучения автоматизировано:
работа алгоритма заканчивается, когда г становится равным нулю.
Как и в алгоритме KCN, большое влияние на сходимость алгоритма
обучения FKCN оказывает закон изменения скорости обучения и окрестности
соседних нейронов.
Модификация алгоритма FKCN связана с введением нечеткости для
скоростей обучения по каждому вектору для каждого класса ht, i = 1, 2, ..., к;
j = 1,2, ..., N.B алгоритме нечеткой кластеризации FCM (fuzzy c-means)
используется понятие экспоненциального веса т. Величина т влияет на степень
нечеткости функций принадлежности входных векторов классу и принимает
значения из интервала [1, оо]. Используя величину т, каждую из скоростей
обучения свяжем с функцией принадлежности:
\ = Щг))т, (11.19)
где т — экспоненциальный вес, т > 1, который будет меняться во время
процедуры обучения. Таким образом, для каждого вектора можно установить свою
скорость, в зависимости от т и \it. Для завершения процедуры обучения
установим максимально возможное число итераций t .
Выберем для т начальное значение т0> 1. Тогда на каждом шаге итерации t
будут производиться следующие вычисления т = т0- tAm, где Ат= (m0-l) I fmax.
280
П.б. Нечеткая нейронная сеть Кохонена
Величину Л., зависящую от ц., будем вычислять на основе формул
алгоритма FKCN. Алгоритм обучения модифицированной FKCN представляется
следующим образом.
1. Случайным образом задать начальные значения весов W,, i = 1, 2, ..., k.
Выбрать mQ> 1, /max, e, определяющую максимально возможную ошибку
обучения, задаваемую как расстояние между весовыми векторами в
последовательных итерациях.
2. For/:=l,2,...,/max
1) вычислить все k*n скоростей обучения {Л.,1= 1,2, ...,k,j— 1,2, ...,N}
по формуле (11.19), а также функцию принадлежности (как в FKCN):
(l/dist(X W,))1/w-!
*V= 1 ;
I(l/dist(X W))1^1
2) обновить все k весовых векторов Wfj), i = 1,2, ..., Л по формуле:
N
I^.(0dist(Xy,W,.(>))
W,(> + 1) = W.(>) +7^ ; (11.20)
£ V*
3) вычислить 8 j = dist(W.(/ + 1), W,(f));
4) если e . < e, перейти к шагу 3, иначе повторить шаг 2.
3. Останов.
При подаче на вход нечеткой KCN входного вектора обновляются все к
весовых векторов, при этом распределение вкладов каждого из X. в
следующее обновление веса обратно пропорционально расстоянию весового вектора
от X.. Поэтому победитель при вычислении обновлений - это W,(f)» ближайший
к X, При mt= 1 (при t —> оо) правило обновления превращается в правило
«победитель забирает все».
Эффективная окрестность выигравшего нейрона при увеличении числа
итераций будет изменяться. При больших значения тр близких к начальному
значению т0, все к весовых вектора изменяются с низкой скоростью, а затем эта
скорость по мере приближения т к 1 будет равна 1 или 0, в зависимости от
значений функций принадлежности классу: (lim \x (t) = 1 или 0).
т,->1 у
Поскольку латеральное торможение скорости обучения является функцией
t, то функция будет иметь наибольшее значение около узла-победителя для
каждого X .
281
11. Гибридные нейронные сети
Нечеткая база
изменения параметров
обучения
Адаптированный
параметр
обучения
>
Обучающая
выборка
У
Нейронная сеть
Выход
Реальное значение параметра
Рис. 11.10. Общая схема подстройки параметров обучения НС
Данная модификация алгоритма FKCN приводит-к более быстрому
обучению, так как обеспечивает автоматическое управление как изменением
скоростей обучения, так и окрестностью обновления, что, в конечном итоге
обеспечивает меньшее число итераций.
11.7. Нечеткое управление параметрами обучения
нейронных сетей
Рассмотрим возможности нечеткой логики для управления параметрами
обучения НС. Общая схема подстройки параметров обучения НС с помощью
нечеткой логики представлена на рис. 11.10.
Нечеткая база правил, содержащая экспертные знания, используется для
адаптивного изменения значений параметров обучения, в зависимости от
состояния сети и реального значения параметров обучения.
Нечеткое управление параметрами обучения в алгоритме
Back Propagation
Правило обновления весовых коэффициентов в стандартном алгоритме
обратного распространения представляется формулой:
с(„) дЕ ^i
где6(л,= —■——
■Л/ j
Awfi) = - «iJV + nAwft - 1), (H.21)
; E - ошибка обучения; h - скорость обучения; я - коэффи-
номер слоя; xi — значение
циент инерционности; t — текущая итерация; п
входа 1-го нейрона в слое п.
Основная проблема получения более быстрой сходимости состоит в
автоматической подстройке параметров обучения Лия, влияющих на процесс схо-
димости.
282
11.7. Нечеткое управление параметрами обучения НС
В нечетких контроллерах для регулирования параметров управления
используются средства нечеткой логики. С помощью экспертов также можно
сформулировать правила регулирования Лия, которые будут использовать
информацию об изменении значений градиента ошибки Е-Ш и информацию о градиенте
второго порядка (изменение Ш-ПЕ), связанного с ускорением сходимости.
Примеры нечетких правил, в которых IE и НЕ являются нечеткими
переменными, представлены ниже.
Правило 1. IF IE становятся малой величиной без изменения знака за
несколько последних итераций (задается пользователем), THEN величину h
следует увеличить.
Правило 2. IF происходит изменение знака Ш для нескольких
последовательных итераций, THEN величину h следует уменьшить, независимо от
значений ПЕ.
Правило 3. IF Ш становится очень малой величиной AND IIE становится
очень малой величиной без изменения знака за несколько последних итераций,
THEN величину h и коэффициент инерционности я следует увеличить.
Чтобы определить, изменялось ли значение градиента и градиента второго
порядка на некоторой итерации, введем параметр изменения знака:
Var(0 =1-| l/2[sign(IE(f - 1)) + sign(IE(0)]|, (11.22)
где sign(*) — знаковая функция, а множитель 1/2 гарантирует, что Var будет
равен либо О-в случае отсутствия изменения знака на некоторой итерации t,
либо 1, если есть изменение знака. Тогда некоторое значение накопленной
суммы Sum(Var) за определенное количество итераций (например, за последние
три итерации) можно использовать для интерпретации поведения алгоритма
обучения с использованием средств нечеткой логики:
Sum(Var(0) = Van7) + Va«7 -1) + Van7 -2), (11.23)
где Sum будет определять частоту изменения знака.
Проведено всестороннее исследование стандартного алгоритма ВР,
использующего градиентный спуск [11]. На основе данных этого анализа построены
функции принадлежности для нечетких переменных IE и ПЕ (рис. 11.11) и
определены следующие нечеткие множества: NB - отрицательное большое; NS -
отрицательное малое; ZE - нуль; PS - положительное малое; РВ -
положительное большое.
Суммарное количество изменений знака к моменту времени t за г+1
последних итераций запишем в следующем виде:
i
Sum(Var(0) = £ Van», (11.24)
m=t-r
где г задается пользователем.
Если Sum = 0, то изменений знака не происходило, в противном случае знак
менялся на последних (г+1) итерациях. Это условие определяет
необходимость изменения направления спуска.
283
11. Гибридные нейронные сети
ц i
1.0
0.8
0.6
0.4
0.2
00
к
NB
V
у
л
/\/
/ V
\?
у
л
;\/
V
\А
V \
Л /
f\
V
РВ
/
/
\
\
\
—>-
-0.2 -0.1 0 0.1 0.2 Ш,ПЕ
Рис. 11.11. Функции принадлежностей для нечетких переменных IE и IIE
Значения переменных Ah и Ая могут быть как четкими, так и нечеткими.
Фрагмент нечетких правил для определения нечетких Ah, заданных
экспертом, который может быть использован в нечетком алгоритме ВР, представлен
в табл. 11.1.
Таблица!!.!
ПЕ
NB
• NS
ZE
PS
РВ
IE
NB
NS
NS
ZE
NS
NS
NS
NS
ZE
PS
ZE
NS
ZE
NS
PS
PS
PS
NS
PS
NS
ZE
PS
ZE
NS
PB
NS
NS
ZE
NS
NS
Из табл. 11.1, например, можно извлечь следующее правило:
IF Ш есть положительное малое (PS) AND IIE есть положительное
большое (РВ) THEN Ah есть отрицательное малое (NS).
Далее по правилам нечеткой логики, зная вид функции принадлежности
нечеткой переменной Ah и используя дефаззификацию, извлекается числовое
значение приращения h. Аналогично формируется база нечетких правил для Дя.
Схема вычисления искомого значения приращения соответствующего
параметра обучения (рис. 11.12), например, для параметра h соответствует
базовой схеме нечеткого контроллера (см. рис. 10.6).
Алгоритм обучения ВР с использованием нечеткой логики для коррекции
параметров обучения Лия представляет собой алгоритм, в котором имеются
изменения на шаге 2 и на шаге 3 (см. гл. 5).
Перед запуском алгоритма необходимо установить начальные значения
параметров обучения Л, я и числа итераций г, на которых осуществляется про-
284
11.7. Нечеткое управление параметрами обучения НС
1Е.ПЕ
1
1
Фаззификация
H<jIE)
Многослойная
НС
Блок вывода
Логический
вывод
л
Нечеткая база
правил
i
i
i
i
цфй)
i >
i
i
i
i
i
i
■
i
i
i
i
i
i
i
i
i
i
i
ДЛ
Дефаззификация
Рис. 11.12. Схема вычисления параметра обучения Ah
верка условия изменения знака, а перед вычислением Aw*n) в текущей
итерации на шаге 2 проводятся следующие действия:
1) подсчитывается сумма Sum (Var), по значению которой определяется
факт изменения знака IE и ПЕ, который влияет на выбор правил вычисления
параметров обучения;
2) по вычисленным значениям изменения градиента ошибки Е- (IE) на
текущей итерации и приращения IE - (ПЕ) осуществляется фаззификация Ш и ПЕ
(см. рис. 11.12);
3) из таблиц, интерпретирующих нечеткие правила (с учетом значения Sum
(Var)), в зависимости от реализуемой версии алгоритма, либо сразу
извлекаются четкие значение Ah и Дл, либо производится извлечение нечетких
приращений параметров обучения (см. табл. 11.1) с последующей дефаззификацией
нечетких Ah и Дл.
Аналогичные действия выполняются на шаге 3.
В конкретной реализации модифицированного алгоритма ВР (ВР2) с
коррекцией параметров обучения Лил использовалось три нечетких множества: NS,
ZE, PS. Результаты моделирования стандартного ВР и модифицированных ВР1
и ВР2 при выборе топологии корпоративной сети (гл. 12) представлены на рис.
11.13 (алгоритм ВР с динамическим выбором шага обучения приведен в гл. 5).
Проведенные эксперименты показали, что алгоритмы ВР1 и ВР2 с
нечетким управлением обеспечивают существенно более быструю сходимость, чем
классический ВР.
Достижение той же ошибки обучения (25 %) достигается для ВР2 при
числе итераций в пять раз меньше, а для ВР1 в 3 раза меньше.
285
11. Гибридные нейронные сети
1000 2000 5000 10000
Число итераций
Рис. 11.13. Зависимость процента ошибок от числа итераций
Н - стандартный алгоритм Back Propagation (BP);
Г]- алгоритм ВР с динамическим шагом (ВР1);
I I - ВР с коррекцией h и я(ВР2)
Управление ростом сети ART-1 на основе методов нечеткой логики
В настоящее время известны два, наиболее часто применяемые на
практике, типа алгоритмов обучения нечеткой сети ART: алгоритмы быстрого
обучения и использующие нормализацию входных векторов с помощью
комплементарного (дополнительного) кодирования [11]. Нечеткость сетиЛ/гГопределяется
видом используемого логического оператора AND (вместо оператора
пересечения (п) в ART-1 используется оператор минимума (min) в fuzzy ART-1). В
алгоритмах быстрого обучения в формуле обновления векторов
т (/ + 1) = р(х л т/о + (1 - руг/о,
где Р — коэффициент обучения, вначале устанавливается Р = 1, благодаря чему
входной вектор X быстро сходится к некоторому кластеру или создается
новый нейрон. Когда определится кластер для входного вектора, Р принимает
значение, меньшее 1.
Для более сложного алгоритма в случае нормирования входных
векторов в качестве меры нечеткости вводится функция выбора нейрона—победителя:
|Х л Т.|
где е > 0 - константа, а нечеткий AND представляет собой оператор л и
определяется как оператор min, |*| - норма вектора. Функция выбора показывает
степень, с которой весовой вектор Т является нечетким подмножеством
входного вектора X.
286
11.7. Нечеткое управление параметрами обучения НС
В рассматриваемом алгоритме fuzzy ART-l методы нечеткой логики
используются для управления параметром сходства р и нечеткость вводится на
уровне задания приращений параметра сходства Др, в зависимости от
ситуации, возникающей в ART-1 при кластеризации.
Предположим, что априорно известно число кластеров Л^. Проведем
первоначальную кластеризацию по приведенному в гл. 8 алгоритму: например,
количество реальных кластеров равно Nr. Если Nr* Na, то требуется подстройка
параметра Др с последующим новым предъявлением входных данных. В
случае Nr < N, необходимо увеличивать р, в противном случае, при N > Na — p
должно уменьшаться.
Таким образом, в алгоритме обучения нечеткой сегги ART-l после
проведения очередной кластеризации по алгоритму ART-1, необходимо определять
величину изменения р, т. е. Др, которое позволит Nr приблизиться к Na.
Нечеткие правила, построенные на основе проведенного эмпирического
анализа результатов работы нечеткой сети ART, позволили определить процедуру
изменения р в соответствии с табл. 11.2. Здесь Е = Na - TV, и Ш - изменение Е.
Определены следующие нечеткие множества: NB — отрицательное большое;
NS - отрицательное малое; ZE - нуль; PS - положительное малое; РВ -
положительное большое.
Таблица 11.2
IE
NB
NS
ZE
PS
PB
E
NB
-
NB
NB
NB
-
NS
NS
NS
NS
NS
NS
ZE
ZE
ZE
ZE
ZE
ZE
PS
PS
PS
PS
PS
PS
PB
-
PB
PB
PB
-
Из табл. 11.2 можно извлечь, например, следующее правило:
IF E есть положительное малое (PS) AND IE есть положительное большое
(PB), THEN Др есть положительное малое (PS).
Далее по правилам нечеткой логики, зная вид функции принадлежности
нечеткой переменной Др (рис. 11.14), и, используя дефаззификацию, извлекается
числовое значение приращения.
Определив значение Др, сетьАРТ-1 выполняет повторную классификацию
при новом значении р. Алгоритм заканчивает свою работу (устанавливает
соответствующее значение р), когда Nr сравняется с Na.
Следует отметить, что на этапе распознавания в нечеткой сети ART-l
используется стандартная процедура поиска нейрона - победителя с р = 0,
поскольку в общем случае образование новых классов не происходит.
Таким образом, использование методов нечеткой логики для управления
параметрами обучения многослойных персептронов и сетей адаптивного
резонанса ART-l позволяют автоматизировать процедуру обучения НС. Прове-
287
11. Гибридные нейронные сети
И
1 О
0.8
0.6
0.4
0.2
00
,
NB
\
\
\
/
1 /
NS
л
/ \
/ /
1 /
\ /
ZE PS
/К Л
/
\
\
\
У \
А
/ \
/ \ /
PB
/
/
{
к
' \ 1
»-
0.08
Др
-0.08 -0-04 0 0.04
Рис. 11.14. Функции принадлежности для Ар
денные исследования, например, для сети ART-X, показывают, что в этих
случаях точность распознавания алгоритма практически не уступает точности
стандартного алгоритма ART-1 при больших значениях параметра сходства, а
число образуемых кластеров оказывается меньше. Кроме того, на основе
данного алгоритма по желанию пользователя можно регулировать соотношение
точность — размер сети.
Рассмотренные в данном разделе гибридные нейросетевые и нечеткие
модели, в отличие от других подобных моделей, позволяют повысить качество
работы нейропроцессора за счет использования лучших свойств каждой из
объединяемых технологий.
1.
3.
4.
Упражнения и вопросы для самоконтроля
Дайте определение нейросетевой нечеткой системы. Для решения каких задач
целесообразно ее использовать?
Приведите примеры реализации функций принадлежности и логических
операторов в нечеткой системе с помощью НС.
В чем состоят основные особенности организации нечеткого вывода с помощью НС?
Дайте определение нечеткой нейросетевой системы. Для решения каких задач
целесообразно ее использовать?
5. Постройте нечеткую НС для нечеткой экспертной системы, используя нечеткий
нейрон третьего типа.
6. Сформулируйте алгоритм обучения нечеткого персептрона. Каковы его
особенности ?
7. Каким образом можно использовать нейроны второго типа для решения задач
индентификации систем?
8. Приведите базовую схему нечеткого контроллера и рассмотрите возможность ее
применения для управления скоростью обучения в алгоритме обратного
распространения ошибки.
9. В чем заключается преимущество нечетких НС по сравнению с обычными НС?
10. Как управлять ростом сети ART-1 на основе методов нечеткой логики?
11. Дайте определение нечеткой сети Кохонена. В чем состоит модификация алгоритма
кластеризации fuzzy c-meams?
288
12. ПРОГРАММНАЯ ЭМУЛЯЦИЯ
НЕЙРОКОМПЬЮТЕРОВ
Рассмотрены особенности нейроимитаторов, разработанных на кафедре
«Компьютерные системы и сети» Калужского филиала МГТУ имени Н.Э. Баумана: Neurolterator,
ЛОКНЭС и Neural Networks IDE, а также популярный коммерческий пакет STATISTICA
Neural Networks.
12.1. Классификация нейроимитаторов
Любой нейроимитатор предназначен для осуществления следующих
действий по реализации конкретного нейросетевого алгоритма:
• выбрать топологию сети;
• реализовать желаемый алгоритм обучения НС;
• зафиксировать обученную НС;
• обеспечить формирование тестовых входных воздействий;
• обеспечить удобный контроль работы сети на тестовых и рабочих вариантах.
Приведенные функции нейроимитаторов определяют их функциональную
структуру. На рис. 12.1 представлена обобщенная структурная схема нейро-
имитатора, в которой учтена потребность разработчика хранить библиотеки
типовых и собственных наработок как отдельных элементов, так и готовых к
работе НС. Очевидно, что функциональные возможности пакета, его
коммерческая ценность во многом определяются качеством визуализации различных
этапов разработки этих сетей, а наличие дружественного пользовательского
интерфейса обязательно для любых программных продуктов, в том числе и
нейропакетов.
В настоящее время используют несколько признаков, по которым
классифицируют нейропакеты. Одним из важнейших является признак по
функциональному назначению (по предметной области). На рис. 12.2 приведена
классификация нейроимитаторов по этому признаку.
Средства разработки представляют собой библиотеки отработанных
элементов структуры НС, алгоритмов обучения, формирователей входных воз-
289
12. Программная эмуляция нейрокомпьютеров
Типовые топологии
нейронных сетей
N*
Нейросетевой алгоритм
Средства создания >*у
собственной топологии '
Топология нейронной
сети
Средства визуализации
топологии
Типовые алгоритмы
обучения
Средства создания
собственных
алгоритмов обучения
Средства визуализации
обучения
Средства визуализации
работы сети
Рис. 12.1. Обобщенная структурная схема нейроимитатора
—э
-*
—3
—э
ч
'
Средства • • •. • •
Нейронные
экспертные
системы
Генетические
нейропакеты
Пакеты нечеткой
логики
Интегрированные
сист
емы
Г"
'п
е-'
Нейропакеты
v
Специализированные
нейропакеты
N
'
Управление
динамическими
системами
Обработка сигналов
(г-
(г-
(
к
—э
—)
—3
>
Универсальные
нейропакеты
Обработка
изображений
Распознавание
образов
Распознавание
рукописей
Рис. 12.2. Классификация нейроимитаторов по функциональному назначению
290
72.7. Классификация нейроимитаторов
действий, средств визуализации результатов работы сетей. К таким пакетам
относят Neuro Windows фирмы Ward Systemxs Group, NNet+ фирмы NeuroMetric
Vision Systems Inc. Универсальные пакеты предоставляют большие
возможности разработчику. Они позволяют исследовать предлагаемые им нейросете-
вые алгоритмы на нескольких различных топологиях сетей, при различных
алгоритмах обучения, провести статистическую обработку результатов
эксперимента (или же сохранить результаты в форматах известных
статистических пакетов). Эту группу представляют такие пакеты, как NeuroSolutions
(NeuroDemension, Inc.), NeuroShelYl {Ward Systemxs Group), NeuralWorks
Professional {NeuralWare, Inc), BrainMeker Pro {Califonia Scientifik Software) и др.
В отличие от универсальных, специализированные нейроимитаторы
разрабатываются для ограниченного класса решаемых задач, что делает их более
компактными и мобильными. Вполне понятна неполнота приведенной схемы
классификации пакетов этой группы. Областей применения НС много и
зачастую эти области перекрываются.
Генетические нейропакеты используют генетический алгоритм обучения.
По своей реализации некоторые из них можно отнести к классу
специализированных пакетов, что отражено на рис. 12.2 пунктирной линией.
Представителями этой группы пакетов являются пакеты GeneHunter {Ward Systemxs Group),
Evolver {Axcellis, Inc.), The Genetic Object Desinger {Man Machine Interface),
Genesis {Neural Systems).
Пакеты нечеткой логики используют алгоритмы нечеткой логики Заде,
которая рассматривается как подмножество нейронной логики. По характеру
исполнения их также можно рассматривать и как специализированные (см.
пунктир на рис. 12.2). К этой группе относятся следующие пакеты Fuzzi Calc {Fuzi
Ware, Inc.), Fuzzle {Modico), Fuzzi Logic Toolbox for Matlab {MathWors, Inc.),
Flops for fuzzy logic {Kemp Carraway Heart Institute), Judgement Maker {Fuzzy
Systems Engeneering) и др.
Пакеты для нейросетевых экспертных систем можно рассматривать и как
универсальные нейроимитаторы, и как специализированные. Эту группу
представляют пакеты G1 {Gensym Corp.), Nexpert Object {Neuron Data, Inc.), GURU
{Micro Data Base Systems, Inc.) и др.
В интегрированных пакетах нейросетевые структуры и топологии тесно
переплетены с реализациями широко распространенных математических
алгоритмов, чаще всего со статистическими.
Группа пакетов для решения задач управления динамическими системами
представлена такими разработками, как Process Advisor {AlWare, Inc.), Process
Insight {Pavilion Tehnologies), Insecta {Ublige Software and Robotic Corp.),
NT5000 Control System {California Scientific Software Inc.).
Пакеты группы обработки сигналов предназначены для решения задач
радио- и гидролокации, к ним относятся пакеты Data Sculptor {Neural Ware, Inc.),
DADiSP/Neural Net {DSP Developer Corp.), DateEngine {MIT) и др.
Обработка изображений - одна из традиционных областей применения НС.
Группу нейроимитаторов этой предметной области представляют ImageLib {LNK
291
12. Программная эмуляция нейрокомпьютеров
Corp.), Wizard Neural Vision System (Computer Recognition Systems), NIP2G
(Neural Engines Corp.), Neural Network Alarm Monitor (Neural Solutions) и
многие другие пакеты.
Группу пакетов для решения задач распознавания образов составляют
следующие разработки Application Programmer Interfacing (Expansion Programm Intl.,
Inc.), NNetSheet-C (Inductive Solutions, Inc.), ICPAK (Tektrend International, Inc.).
Задачи распознавания рукописных текстов, с точки зрения нейросетевой
постановки, являются подмножеством задач распознавания образов. Однако
особенности этого подмножества позволяют выделить инструментальные
средства для решения таких задач в самостоятельную группу специализированных
пакетов. Эту группу представляют пакеты Propagator (ARD Corp.), Synaptics
(Synaptics Corp.), MetaMorph (Expansion Program, Inc.).
Группу нейроимитаторов для решения задач распознавания речи
представляют пакеты Neural Intelligence Voc (Cogito Software, Inc.), AQIRE System
(Gradient Technology).
12.2. Программный комплекс Neurolterator
Программный комплекс Neurolterator предназначен для разработки и
исследования нейросетевых алгоритмов решения различных задач как на
формируемых, так и обучаемых НС. Он позволяет создавать различные модели
нейронов, формировать из них сети произвольной структуры, обучать сети с
прямыми связями и исследовать работу НС практически любой сложности.
Для того чтобы сформировать НС, в пакете Neurolterator необходимо
задать модели нейронов, образующих сеть, описать структуру будущей сети,
задать весовые коэффициенты межнейронных связей для формируемых
нейронных сетей или определить эти коэффициенты в результате процедуры обучения
для сетей с прямыми связями.
Модели нейронов
Пакет Neurolterator предоставляет пользователю возможность
формировать модели нейронов четырех
Таблица 12.1. Функции актнвацнн
нейронов в Neurolterator
Модель нейроноподобного
элемента
Кусочно-линейная
Пороговая
Сигмовидная
Гауссова
Функция ■
у = х + х(
y=yt
у=У1/(1-е<х + х^
у^у^"*"?'
классов (рис. 12.3): с
кусочно-линейной функцией активации
(кусочно-линейная модель), с
пороговой функцией :• I (пороговая
модель), с сигмовидной функцией
активации (сигмовидная модель) и
с функцией, к II гауссова
распределения (гауссова модель).
Параметры, xt, лг, и >>,
определяют смещение, порог
срабатывания и уровень насыщения функции
292
12.2. Программный комплекс Neurolterator
л
*1
У
X,
,х
л
У
X
х1
Л
*1
У
X,
X
Л
X!
У
i \
xt
^Х
а б в г
Рис. 12.3. Классы функций активации в пакете Neurolterator:
а — кусочно-линейный; б—пороговый; в — сигмовидный;
г — гауссова
активации модели любого нейрона. Аналитические выражения применяемых
функций активации приведены в табл. 12.1.
Каждая модель нейрона в Neurolterator имеет идентифицирующий ее
уникальный код, используемый в дальнейшем при описании НС. Коды
идентификации для кусочно-линейных функций активации лежат в диапазоне 1.. .200, для
ступенчатых - 201.. .400, для сигмовидных - 401.. .600, для гауссовых - в
диапазоне 601...800. Таким образом, каждая из моделей нейроноподобных
элементов может иметь до 200 модификаций.
Для формирования модели конкретного нейрона (или группы нейронов) при
решении конкретной задачи в Neurolterator необходимо определить
параметры xt, х, nyt, его функции активации и присвоить ей идентификационный код.
Диалоговое окно формирования модели нейрона показано на рис. 12.4
Описание модели
■> >под»■ iro
Параметры
ции актиБаци
vi = ji.o
н1 = 1-10.0
Kt = j-0.5
Код идентификации: |401
-**
*
У- 1
Г"
* - —►■ ;
*1 *t iX
Линейная / Ступенчатая j Сигмовидная j Гауссова /
1
Закрыть
|)э£ Модель нейрона
Справка 1 Из Файла...
В файл... I
Рис. 12.4. Формирование функции активации в Neurolterator
293
12. Программная эмуляция нейрокомпьютеров
Модели нейронов хранятся в виде текстовых файлов со следующими
параметрами:
[Модель нейронов]
ID = код идентификации модели нейронов
Y1 = уровень насыщения функции активации
XI = порог срабатывания функции активации
Xt = смещение функции активации
Имя файла описания модели нейроноподобного элемента должно совпадать
с кодом его идентификации, расширением должно быть пей. Например, файл
407.neu, описывающий сигмовидную модель нейроноподобного элемента с
кодом идентификации ID = 407, уровнем насыщения Л = 1.0, порогом
срабатывания XI = -100.5 и смещением Xt = 0.0777 должен быть следующим:
[Сигмовидная]
ID = 407
Y1 = 1.0
XI = -700.5
Xt = 0.0777
Описание нейронной сети
Для описания НС в Neurolterator используется внутренний макроязык.
Макроязык включает десять операторов: NEURONS, SIMTIME, TIMESTEP, MODEL,
SUSPEND, INITSTATE, INPUTLAYER, OUTPUTLAYER, NETWORKLAYOUT,
END. Рассмотрим операторы.
NEURONS number;
Оператор NEURONS определяет общее число нейроноподобных элементов
в сети (number), которое не должно превышать 200.
SIMTIME < inittime,> endtime;
Оператор SIMTIME задает модельное время работы НС от момента
модельного времени inittime до момента модельного времени endtime. Если
параметр inittime не указан, то он принимается равным нулю.
TIMESTEP step;
Оператор TIMESTEP задает шаг моделирования работы НС (step) —
интервал модельного времени, по истечении которого считываются состояния
нейроноподобных элементов выходного слоя.
MODEL {
neuron., neuronID;
(neuron,...,neuronk), neuronsID;
}
294
12.2. Программный комплекс Neurolterator
Оператор MODEL ассоциирует модель нейрона по его
идентификационному коду с отдельным нейроном (пеигопЮ) или с группой нейронов (neuronsID).
При описании сети оператор MODEL может отсутствовать, в этом случае
используется модель нейроноподобного элемента по умолчанию — файл 0.neu.
Содержимое этого файла может быть переопределено пользователем.
SUSPEND {
neuron^ cycles;
(neuron,...,neuron ), cycles;
Оператор SUSPEND определяет число шагов ожидания, или, иными
словами, число шагов моделирования работы сети (cycles), в течение которых
состояние отдельного нейрона (neuron^) или группы нейронов (neuron,..., neuron^ не
изменяется. По умолчанию число шагов ожидания равно нулю. При описании
сети оператор SUSPEND может быть опущен, в этом случае для всех нейронов
сети используется число шагов ожидания по умолчанию.
INITSTATE {
neuron, init;
(neuron,....neuron.), inits;
> '
Оператор INITSTATE задает начальное состояние (возбуждение) нейрона
(init) или группы нейронов (inits). По умолчанию оно равно нулю. При
описании сети оператор INITSTATE может быть опущен, в этом случае за начальные
состояния нейронов принимаются их состояния по умолчанию.
INPUTLAYER {
neuron ;
V
neuron,..., neuron'
} '
Оператор INPUTLAYER описывает входной слой НС. При описании сети
этот оператор может отсутствовать, в этом случае НС не имеет входного слоя.
OUTPUTLAYER {
neuronf weight value;
(neuron,..., neuron Л, weight value;
}
Оператор OUTPUTLAYER описывает выходной слой НС и определяет
весовые коэффициенты связи отдельного нейрона или группы нейронов выходного
слоя сети (value), число которых не должно превышать четырех. По
умолчанию весовые коэффициенты межнейронных связей для нейронов выходного
слоя сети равны единице.
295
12. Программная эмуляция нейрокомпьютеров
NETWORKLAYOUT {
пеигопт, пеигоПр weight value;
neuron, (neuron,...,neuron ), weight value,....value.;
I J * J К
Оператор NETWORKLAYOUTпозволяет описать структуру НС и задать
весовые коэффициенты межнейронных связей отдельного нейрона с другим
нейроном (value) или с группой нейронов (value,...,valuek). По умолчанию
весовые коэффициенты межнейронных связей между нейронами равны нулю, т. е.
связи отсутствуют.
END
Оператор END завершает описание НС.
Описание НС может быть прокомментировано. Комментарии во
внутреннем макроязыке описания НС Neurolterator однострочные и должны
начинаться с символов //.
Описание НС на внутреннем макроязыке Neurolterator может выглядеть,
например, следующим образом:
// Общее число нейроноподобных элементов в сети
NEURONS 10;
//Модельное время работы нейронной сети
SIMTIME 0,60;
//Модельный шаг работы нейронной сети
TIMESTEP 0.1;
//Модели нейроноподобных элементов
MODEL {
(neuronl, neuron2, пеигопЗ), 1;
пеигоп4, 207;
пеигопЗ, 402;
(neuron/, пеигопв, пеигоп9, neuron 10), 610;
}
// Число шагов ожидания
SUSPEND {
(neuronl, neuron2, пеигопЗ, пеигопб), 2;
(пеигоп4, пеигопЗ), 7;
neuronl0, 3;
}
//Начальные состояния нейроноподобных элементов
INITSTATE {
(пеигоп2, пеигоп4, пеигопб), 1;
}
// Описание входного слоя нейронной сети
296
12.2. Программный комплекс Neurolterator
INPUTLAYER {
пеигоп5, пеигопб;
}
// Описание выходного слоя нейронной сети
OUTPUTLAYER {
пеигопЗ, weight 1;
пеигопб, weight 0.5;
neuron8, weight 0.5;
пеигопЯ, weight 1;
>
// Описание структуры нейронной сети
NETWORKLAYOUT {
neuron 1, (neuron!, neuronS, neuron 10), weight-1, 0.001,-0.001;
neuron2, (neuron!, пеигопЗ, пеигоп4, neuron5, пеигопб),
weight 0.001, 1, -1, -1, 1, 1;
пеигопЗ, (neuronl, neuron4, пеигопЯ), weight-0.001, 0.001, -1;
пеигопЗ, (пеигоп2, пеигопЗ, пеигопб, neuronl),
weight-0.01, 0.001, -1, 0.01;
пеигоп8, пеигопЯ, weight -1;
пеигопЯ, (neuronl, neuron2, пеигопЗ, пеигоп4, пеигопЗ),
weight 1, 1, 1, -1, -1;
>
//Завершение описания нейронной сети
END
Описание НС на внутреннем макроязьпсе Neurolterator можно сохранить в
текстовом файле. По умолчанию этому файлу присваивается расширение net.
Пакет Neurolterator позволяет выявить все неоднозначности и ошибки,
допущенные при описании НС. Сообщения обо всех ошибках и неоднозначностях,
которые могут быть обнаружены при описании сети, приведены в табл. 12.2.
Таблица 12.2. Сообщения об ошибках в Neurolterator
Тип сообщения
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Содержание сообщения
Пропущен оператор NEURONS
Пропущен оператор SIMTIME
Пропущен оператор TIMESTEP
Пропущен оператор OUTPUTLAYER
Пропущен оператор NETWORKLAYOUT
Пропущен оператор END
Пропущена правая фигурная скобка
Пропущена левая фигурная скобка
Пропущена правая круглая скобка
Пропущена левая круглая скобка
297
12. Программная эмуляция нейрокомпьютеров
Окончание табл. 12.2
Тип сообщения
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Предупреждение
Предупреждение
Предупреждение
Предупреждение
Предупреждение
Предупреждение
Предупреждение
Предупреждение
Предупреждение
Предупреждение
Предупреждение
Предупреждение
Содержание сообщения
Пропущена точка с запятой
Пропущена запятая
Пропущено ключевое слово 'neuron''
Пропущено ключевое слово 'weight'
Должно быть указано числовое выражение
Ноль является недопустимым выражением
Пустой список нейронов
Пустой список весов
Множественное использование нейроноподобного элемента
Множественное описание межнейронной связи
Лишний символ в строке
Число нейроноподобных элементов и весов не совпадает
Номер нейроноподобного элемента больше, чем общее
число нейроноподобных элементов в сети
Конечное время моделирования должно быть больше
начального
Возможно ошибочное описание оператора SIMTIME
Возможно ошибочное описание оператора INITSTATE
Возможно ошибочное описание оператора MODEL
Возможно ошибочное описание оператора SUSPEND
Возможно ошибочное описание оператора INPUTLAYER
Возможно ошибочное описание оператора OUTPUTLAYER
Возможно ошибочное описание оператора
NETWORKLAYOUT
За начальные состояния нейроноподобных элементов будет
принято значение по умолчанию
В качестве числа тактов ожидания нейроноподобных
элементов будет принято значение по умолчанию
В качестве модели нейроноподобного элемента будет
использована модель по умолчанию
Пропущен оператор INITSTATE
Пропущен оператор MODEL
298
12.2. Программный комплекс Neurolterator
Организация обучения нейронной сети с прямыми связями
Пакет Neurolterator позволяет обучить НС с прямыми связями
распознавать и классифицировать образы методом обучения с обратным
распространением ошибки по правилу Хебба и методом конкуренции. Для обучения НС
одним из вышеуказанных методов необходимо, прежде всего, описать
входной, выходной и скрытые (при их наличии) слои сети. Описание слоя сети в
Neurolterator заключается в определении числа нейронов в слое и их модели.
Для скрытых слоев сети, если это необходимо, может быть определено число
нейронных ансамблей. На рис. 12.5 представлено диалоговое окно описания
сети.
Обучение НС с прямыми связями проводится на наборах входных и
выходных эталонных образов. Входные и соответствующие им выходные эталонные
образы описываются в текстовых файлах соответствующего формата. По
умолчанию эти файлы имеют расширениеptn. Содержимое р^и-файлов должно
представлять собой определенное количество векторов входных или выходных
эталонных образов. К параметрам обучения НС в Neuro-Iterator относится число
итераций обучения и скорость обучения. На рис. 12.6 показано диалоговое окно
назначения параметров обучения.
По достижении нейронной сетью локального минимума процесс ее
обучения может быть завершен.
Формирование и обучение нейронной сети
I
8
4
2
Рис. 12.5. Описание слоя НС с прямыми связями
299
12. Программная эмуляция нейрокомпьютеров
Формирование и > • ■ ■ >
Ф Описание сети Обучение сети ]Х Рабата сети )
Число эталонных образов: |7 ~\
<Р айл входных эталонным образов:
|С \Neurolteralor\BxQqHbie эталонные образы.pin
Файл выходных эталонных образов:
JD\Neurolterator\BbixoAHbieэталонные образы ptn
■■ ч • ■ и меток обучения-
Метод обучения:
| Back propagation randomized *j
P Определять локальный минимум
: jo 25
Число итерааий обучения • J2000
£■
Образ: Итерация обучения: Норма:
Закрыть 1
1
..-.••J
Обучить 1
Пр.- «s-rt
Недоступна
Справка
Рис. 12.6. Задание параметров обучения НС
Исследование работы формируемых НС
Пакет Neurolterator позволяет исследовать работу формируемых,
обучаемых НС и сетей с формируемой матрицей межнейронных связей.
Необходимым условием для исследования работы формируемых нейронных сетей и
нейронных сетей с формируемой матрицей межнейронных связей является наличие
файла их описания на внутреннем макроязыке пакета Neurolterator и файлов
описания моделей нейронов, образующих сеть.
Если при описании НС в ней определяется
входной слой, то для каждого нейрона этого
слоя в пакете Neurolterator предусмотрена
возможность формирования активирующего
этот нейрон воздействия. Функциональная
зависимость активирующего воздействия
должна представлять собой комбинацию
константных выражений и математических функций
(табл. 12.3).
Диалоговое окно формирования
функциональных зависимостей входных воздействий,
активирующих нейроны входного слоя в
Neurolterator, приведено на рис. 12.7.
Таблица 12.3. Математические
функции, поддерживаемые НИ
Neurolterator
Математическая
функция
sin(*)
cos(jt)
ех
>/Зс
л2
ы
Запись
в Neurolterator
sin(x)
cos(x)
ехр(х)
sqrt(x)
sqr(x)
abs(x)
300
12.2. Программный комплекс Neurolterator
Активирование нейронов в < ■ кого слоя
X neurorfi ■ X neutongl
8 i i
Посчитать
Активирующая Функция:
|exp(-2*n]"sin[x)
®Д
Считать
1
Закрыть
Справка
-3,!Н:,Г'
Рис. 12.7. Формирование функциональных зависимостей
входных воздействий
Результаты моделирования работы НС пакет Neurolterator позволяет
представить в виде гистограмм, графиков, числовых значений. На рис. 12.8, 12.9 и
12.10 показаны окна результатов работы сети в виде гистограммы, графика,
числовых данных.
Пакет Neurolterator позволяет получить оценку максимальной абсолютной
погрешности воспроизводимых НС значений функциональных зависимостей.
Для этого предусмотрена возможность формирования эталонных значений этих
функциональных зависимостей.
Формирование эталонных значений исследуемых функциональных
зависимостей осуществляется комбинацией постоянных и математических функций,
Динамика - c:\neuroiterator4 ример описания
Г 4i,l!-"Kli:..Tt,lK-.ict-r. :t. ._>
F Or,..-.
п.
-0.273062
2.3639e-06
0.47578b
-0.427458
neuronG
neuron4
neuron?
neurone
Инаикзгор процесса :
'■ | Прервать I
Справка
Рис. 12.8. Динамика активности нейроноподобных элементов
301
12. Программная эмуляция нейрокомпьютеров
Графики - cAneuioitetatoiMlpMMep описания нейронной сети.пем.
W Сетка Размер ячейки: I 15:15 -1 Высота графиков: | 100 X Ч _ _ М Л
1 —' > —' w Растянуть графики ' —J
L
—к —5Е —ташЛ! —ai_^ п Д^Г д ^Т—ш •>— — * п —55 —АЬавС! —шмк: н Н^. —ттмЛ;^т-—ШЛ „— — ■ i Т . , 1^ьпшщ -
J UuU^^kUuULJLr|[Ju
11 1267 neuron3(y 1)0 426786 neuron4(y2) 3 С7537е-06 neuron5(y3)0 181244 neuron6(y4)-10 4394
Активность нейронов сети
17 у1 |7 у2 p уЗ J7 у4 Г
Г л
Г ;■:■ .Г 5-: Г /• Г у- Г у? Г i
П j Закрьггь [ Справка
Рис. 12.9. Графики активности нейронов
поддерживаемых пакетом Neurolterator. На рис. 12.11 представлено
диалоговое окно задания четырех эталонных функций. Перечень функций,
используемых для формирования эталонных значений, такой же, как и при формировании
входных воздействий (см. табл. 12.3).
Чненовые значения - - ■ - . . -. >
х(304]
х(305)
х(306)
х(307)
х(300)
х(309)
х(310)
х(311)
KJ3J21
х(314)
х(315)
x[31G)
х(317)
х(318)
х(319)
х(320)
К321]
= З.С4С000е+01
= 3.050000е+01
^ЗОбООООе+01
= 3.070000е+01
= 3.080000е+01
= 3.0Э0000е+01
= 3100000е+01
= 3.110000е+01
= 3.120000е*01
3.140000е+01
:3.150000е+01
:3.160000е+01
:3170000е+01
:3180000е+01
:3.1Э0000е+01
■- 3.200000е+01
:3.210000е+01
сети
yl = -9.969222е+00 X
у2 = -5.054890е-05 i
уЗ = -1.000000е+С1 !
у4 = -1.0С0000е+01 '
Аппроксимация Ранге-Кутта
yl=-1.156670e-01 j
у2 = 9.932880е-01 ;
уЗ= 1.000000е+00 j
у4 = 8.907720е-01 j
Точные значения
yl=-1.156671e-01
у2 = 9.932860е-01
уЗ = 1.115667е+00
у4 = -9.328804е-02
Оценка максимальной абсолютной погрешности
работы нейроннной сети:
аппроксимации Рунге-Кутта:
1.199993е+01
2.002038е+00
Закрыть I Справка ]
Рис. 12.10. Числовые значения активности нейронов
302
12.2. Программный комплекс Neurolterator
Вычисление значений аналитических Функций - сЛпешоИета[ш\Пример описания
sin(2"x)
ji2» 1-100"abs(1+cos(x/2))
уЗ = trunc(sin(x))
Посчитать
у4 = 1-exp(sin(x))
Закрыть
Справка
" Эталонные
Считать Записать..
Рис. 12.11. Формирование эталонных функций
При исследовании нейросетевых алгоритмов решения систем линейных
дифференциальных уравнений возникает необходимость в эталонных значениях
решения этих систем. Пакет Neurolterator предоставляет пользователю
возможность формировать эталонные решения систем линейных
дифференциальных уравнений методами Рунге-Кутта (1- 4)-го порядков аппроксимации.
Диалоговое окно формирования таких уравнений в Neurolterator и выбора порядка
метода Рунге-Кутта приведено на рис. 12.12. Как видно из рисунка, пакет
Интегрирование системы линейных дифференциальных уравнений - е:\пешо№ега(шЧЛример описания,,,
Коэффициенты системы
уГ=[Т0
у2' - |0.01
уЗ' = |0.01
у4' = |0 01
у1+|0 02
'у1+|1.0
"у1+|0.02
Начальные значения
хО = П
уЦхО) = 10.01
ф
Порядок аппроксимации методов Рунге-Кутта:
f первый С второй <~ третий (*
четвертый
' у2 +10.03
' у2 +10.02
"j,1+|rl02 v2 + flJ0~
у2 +10.03
у2(х0) = -0.01
уЗ ♦ |0.04
*уЗ + )0.02
"y3 + |l.O
" уЗ +|0.04
уЗ(хО) = 0.01
у4 + |0.05
' у4+|0.02
' у4 + |0.03
'у4 + |1.0
у4(х0) = -0.01
Посчитать
Рис. 12.12. Формирование и выбор порядка аппроксимации метода Рунге-Кутта
303
12. Программная эмуляция нейрокомпьютеров
предоставляет возможность получить эталонные решения для систем до
четырех уравнений, ввести начальные значения переменных, выбрать шаг
интегрирования, установить интервал изменения аргумента и получить решение.
Отображение оценок максимальных абсолютных погрешностей
воспроизводимых НС функциональных зависимостей и результатов решения систем
дифференциальных уравнений методами Рунге-Кутта совмещено с выводом
числовых значений активности нейронов выходного слоя сети (см. рис. 12.10).
Исследование работы обучаемых НС
Пакет Neurolterator позволяет отображать результаты работы обученной
НС с прямыми связями для каждого входного эталонного образа (рис. 12.13). В
столбец Входной образ выводятся входные воздействия, активирующие
нейроны входного слоя сети, в столбец Выходной образ выводятся соответствующие
входным образам эталонные значения выходных образов. В столбец Отклик
сети выводятся результаты работы НС, а в столбец Погрешность -
относительная погрешность восстановления НС выходных эталонных образов в
процентах. Например, для НС, результаты работы которой представлены на рис.
12.13, для первого входного эталонного образа х=\, х=2, сетью
восстанавливается образ 0,123117 с относительной погрешностью 18,8% от эталона (0,1).
Формирование и обучение нейронной сетн
[[р Описание сети j %, Обучение сети X Работа сети
Входной образ.[„Выходной образ | Отклик сети | Погрешность
X 1 2 01 0123117 -18 8%
X 3 4 0 2 0 43431 -53 9%
X 51 0.3 0.423531 -29 2%
Х23 0.4 0 391536 2.162:
Х45 0.5 0 443229 12.8%
JjJ
Исслеаовать I
| Закрыть :| Справке
Рис. 12.13. Результаты работы НС
с прямыми связями
304
12.2. Программный комплекс Neurolterator
[Исследование работы обучаемой нейронной сети
Входной образ
к1:|ПГ
х2:ЩГ
j. и., г
Выходной образ
neuronKyU = 0.243681
Рабата
Закрыть } Справка I
Рис. 12.14. Исследование работы НС с прямыми
связями на промежуточных входных образах
Пакет Neurolterator позволяет исследовать работу обученной НС на
образах, которые не были использованы при ее обучении. На рис. 12.14 показано
окно результатов работы НС на промежуточных входных образах. Как видно
из рисунка, для входного образа x,=l,5, *2=1,5 (который отсутствовал в
обучающей выборке), сеть формирует выходной образ 0,243681.
По результатам обучения НС тем или иным методом пакет Neurolterator
позволяет создать файлы описания моделей нейронов, образующих сеть, и файл
описания НС на своем внутреннем макроязыке. Например, для НС, результаты
работы которой приведены на рис. 12.13, 12.14, Neurolterator создал
следующие файлы:
описания моделей нейронов
2.neu
3.neu
402.neu
[Линейная]
ID = 2
Yl = 100.0
XI = -100.0
Xt =-1.08269
[Линейная]
ID = 3
Yl = 100.0
XI = -100.0
Xt = 0.0
[Сигмовидная]
ID = 402
Yl = 1.0
XI = -100.0
Xt = -1.23749
305
12. Программная эмуляция нейрокомпьютеров
403.neu [Сигмовидная]
ID = 403
Y1 = 1.0
XI =-100.0
Xt = -0.482549
описания нейронной сети:
//Описание нейронной сети с прямыми связями
//сгенерировано нейроимитатором Neurolterator
//Метод обучения - back propagation online
// Число эталонных образов - 5
// Число итераций обучения - 2000
// Скорость обучения -0.25
// Общее число нейроноподобных элементов в сети
NEURONS 5;
//Модельное время работы нейронной сети
SIMTJME 0, 100;
//Модельный шаг работы нейронной сети
TIMESTEP 0.1;
//Пороги срабатывания (xt) функций активации
//нейронов
//neuronl: xt = -1.08269
//neuron2: xt = -1.23749
//пеигопЗ: xt = -0.482549
//Модели нейронов
MODEL {
neuronl, 2;
neuron2, 402;
пеигопЗ, 403;
(пеигоп4, пеигоп5), 3;
}
// Описание входного слоя сети
INPUTLAYER {
пеигоп4,
пеигоп5;
}
// Описание выходного слоя сети
OUTPUTLAYER {
neuronl, weight 1;
}
// Описание структуры нейронной сети с прямыми связями
306
12.2. Программный комплекс Neurolterator
NETWORKLAYOUT {
neuron2, neuronl, weight 1.53755;
пеигопЗ, neuronl, weight—0.129859;
neuron4, (neuron2, пеигопЗ), weight 1.71215, -0.0744284;
пеигоп5, (пеигоп2, пеигопЗ), weight 0.468064, -0.318275;
}
// Завершение описания нейронной сети
END
Файлы описания моделей нейронов, образующих сеть, и файл описания НС
с прямыми связями на внутреннем макроязыке могут быть использованы для
исследования ее работы наравне с формируемыми НС и НС с формируемой
матрицей межнейронных связей.
Примеры практического применения
пакета Neurolterator
В качестве примера практического применения пакета Neurolterator
рассмотрим моделирование формируемой НС, интегрирующей кинематические
уравнения в параметрах Родрига-Гамильтона для бесплатформенной инерци-
альной системы ориентации подвижного объекта (см. § 1.1).
Исходными данными для данного примера являются:
кинематические уравнения в параметрах Родрига-Гамильтона
А=0,5ПЛ,
где ЛТ=(Я,0, A.J, Я.2, Я.3) - транспонированный вектор-столбец параметров
ориентации (параметров Родрига-Гамильтона), а матрица проекций вектора
угловых скоростей Q имеет вид
О -<ах -со -со.
со. О со. -cov
Q = * ;
<йу -СО. О С0Л
со. &у -со, О
начальные значения параметров ориентации
А.о=-0,5, Х, = 0,5, \= -0,5, \= -0,5;
значения проекций вектора угловой скорости
ох = оу = nz = 0,5 (рад/с);
относительная погрешность интегрирования не должна превысить 0,5%,
время интегрирования t = 10 (с).
307
12. Программная эмуляция нейрокомпьютеров
Параметры передаточной функции
yl.JTT"
х1-1-1.0
у = х +хх.^хъщ
л «joo
Код идентификации модели: |1
Г Линейная j Ступенчатая / Сигмовидная / Гауссова /
У1 Модель нейрона
Закрыть ] ' Справка J Иг файла... | В Файл.
Рис. 12.15. Формирование модели нейронов сети
для интегрирования кинематических уравнений
Анализ исходных данных позволяет принять следующие решения:
• исходная система кинематических уравнений является системой четырех
уравнений, поэтому НС, интегрирующая эту систему, должна состоять из
четырех нейронов;
• все нейроны сети должны иметь линейную симметричную функцию
активации (/"„);
• НС для интегрирования кинематических уравнений в параметрах Родри-
га-Гамильтона должна быть полносвязной, синхронной сетью с шагом
синхронизации, не превышающим шага интегрирования h.
Сформируем модель нейронов (рис. 12.15):
[Линейная]
Ю = 1
Y1 = 1,0
XI =-1,0
Xt = 0,0
Для интегрирования заданных кинематических уравнений применим
численный метод трапеций (метод Рунге-Кутта второго порядка аппроксимации)
с шагом интегрирования, равным 0,125 с. В этом случае матрица весовых
коэффициентов межнейронных связей Q имеет вид:
"0,9985351563 -0,03125 -0,03125 -0,03125
0,03125 0,9985351563 0,03125 -0,03125
0,03125 -0,03125 0,9985351563 0,03125
0,03125 0,03125 -0,03125 0,9985351563
е=
308
12.2. Программный комплекс Neuroherator
Описание НС на внутреннем макроязыке нейроимитатора для принятых
условий выглядит следующим образом:
// Общее число нейронов в сети
NEURONS 4;
//Модельное время работы нейронной сети -10 секунд
SIMTIME О, 10;
//Модельный шаг работы нейронной сети - 0,125 секунды
TIMESTEP 0,125;
//Начальные состояния нейронов
INITSTATE {
neuronl, 0.5;
пеигоп2, -0.5;
пеигопЗ, 0.5;
пеигоп4, -0.5;
>
//Модели нейронов
MODEL {
(neuronl, neuron2, пеигопЗ, пеигоп4), 1;
>
// Описание выходного слоя нейронной сети
OUTPVTLAYER {
neuronl, weight 1.0;
neuron2, weight 1.0;
пеигопЗ, weight 1.0;
neuron4, weight 1.0;
}
// Описание структуры нейронной сети
NETWORKLAYOUT {
neuronl, (neuronl, neuron2, пеигопЗ, пеигоп4),
weight 0.9985351563, 0.03125, 0.03125, 0.03125;
neuron2, (neuronl, neuron2, пеигопЗ, пеигоп4),
weight-0.03125, 0.9985351563, -0.03125, 0.03125;
пеигопЗ, (neuronl, neuron2, пеигопЗ, пеигоп4),
weight-0.03125, 0.03125, 0.9985351563, -0.03125;
neuron4, (neuronl, neuron2, пеигопЗ, пеигоп4),
weight-0.03125, -0.03125, 0.03125, 0.9985351563;
}
//Завершение описания нейронной сети
END
Для того чтобы оценить погрешность интегрирования исходной системы при
принятых условиях, сформируем эталонное решение этой системы при тех
309
12. Программная эмуляция нейрокомпьютеров
Вычисление значений аналитических функций - с:\пешсм(е1а*ог\Интегрирование кинемэт.
- Аналитические фрикции
у1 « JO 28867513459"sin(0.43301270189"х)+0 5"cos(0 43301270189*х)
у2= |-0.5N;os(0.43301270189"х)+0 86E02540378"sin[0. 43301270189"х)
уЗ - |0.28867513459"sin(0.433012701 89"x)+0.5*cos(0.43301270189"х)
Ji4- I 0.28867513459*sin[0.433012701 B9"k)-0 5"cos(0.43301270189*x)
Посчитать
Закрыть
Справка
образы
Записать,
Рис. 12.16. Формирование эталонного решения
же начальных условиях на основе аналитического решения. На рис. 12.16
показано диалоговое окно формирования такого эталонного решения. Все
подготовительные действия вьшолнены, НС для интегрирования кинематических
уравнений сформирована и готова к работе.
На рис. 12.17 представлена работа сети в виде графиков активности нейронов,
а на рис. 12.18 - в виде числовых значений. Как видно из представленных
результатов, наибольшая ошибка интегрирования кинематических уравнений на
заданном временном интервале, с выбранными шагом и методом
интегрирования не превысила 0.001871013, что является вполне приемлемым результатом.
Графики - с.
а1о|\Интег
- ических
100 X
графики
шшш *
</ </ </ </
Справка
Рис. 12.17. Графики интегрирования кинематических уравнений
формируемых НС
310
12.3. Нейросетевой пакет ЛОКНЭС
Числовые значения ^ютлщ^Ш^ШШШ^ШтШшЯЯ
Работа нейронной сети:
~"у1 =~-4.723045е-01~
у2 = -5.752667е-01
уЭ = -4.723045е-01
у4 = 4.723045е-01
/и троксимация Рунге-Кутта"
Независимая переменная
х(621 =
к(63) =
у(641 =
х|65) =
«[66| =
к(67| =
у\БЩ --
х(6Э1 =
х(70) =
«(711 =
х|72| =
х[73) =
х|74| =
"(751
«(761
х(77)
-- 7 750000е+00 _-!
= 7.В75000е+00
= 8 OOOOOOe+OO
= 8125000е+0и
= 6 250000е+00
= 8375000е+00
= е.500000е+00
= 6.625000е+00
= 6.750000е+00
= 8 675000е+00
= Э ООООООе+ОО
= Э.125000е+00
= Э.250000е+00
= 9.375000е+00
= 9.S00000e+00
= 9.625000е+00
х(78) = Э 750000е+00 _
Точные значения:
" у1 = -4.729563e-0l"
у2 = 5.735304е-01
уЗ = 4.729563е-01
у4 = 4 729563е-01
Оценка максимальной абсолютной погрешности
работы нейроннной сети: | 1.87101 Зе-03
аппроксимации Рцнге-К^ггта: \
Закрыть
Справка
Рис. 12.18. Окно числовых значений
интегрирования кинематических уравнений
12.3. Нейросетевой пакет ЛОКНЭС
Нейропакет ЛОКНЭС (нейросетевая ЭС для проектирования локальных
вычислительных систем) разработан на кафедре «Компьютерные системы и
сети» КФ МГТУ им. Н.Э. Баумана и по замыслам должен был предназначаться
для создания нейросетевых ЭС. Однако на практике, как оказалось, он
обладает большими функциональными возможностями и может быть отнесен к
универсальным пакетам. В данном разделе рассматривается реализация и
возможности пакета для решения лишь задачи выбора характеристик локальной
вычислительной сети на ранних этапах ее проектирования.
При выборе средств реализации необходимо было учесть ряд
специфических требований:
• язык программирования должен предоставлять средства для удобного
моделирования работы НС. Для этого необходимо использовать
объектно-ориентированный подход, позволяющий в максимальной степени унифицировать
разработку модулей определенного назначения;
• реализация моделей НС предъявляет требования к развитой системе
работы с динамической памятью и большими (до 64 Кбайт) многомерными
массивами с динамически изменяющейся длиной по всем измерениям;
• повышенные требования к удобству интерфейса (оконная ориентация,
система меню, полная обработка ошибок, система диалога с пользователем,
возможность ввода информации на естественном языке);
311
12. Программная эмуляция нейрокомпьютеров
• возможность конструирования пользователем нейросетевой экспертной
системы без знания им языков программирования;
• возможность создания и обучения НС без знания пользователем математики.
Учитывая все вышеперечисленное, было решено в качестве средства
разработки использовать язык Delphi (Borland Corporation), который удовлетворяет
всем сформулиро -. ■ . выше требованиям, прост и надежен в эксплуатации,
позволяет создавать приложения с приемлемой скоростью работы и
обеспечивает удобные средства для разработки пользовательского интерфейса.
Нейросетевая ЭС ЛОКНЭС предназначена для решения следующих задач:
• выбор первоначальной конфигурации вычислительной системы или сети
в условиях неточной и неполной информации о требуемой конфигурации;
• определение степени влияния исходных параметров вычислительной
системы или сети на выбор конфигурации с целью корректировки
первоначальных требований к этим параметрам;
• оперативное построение новой или обновление уже имеющейся базы
знаний нейросетевой экспертной системы.
Выбор типа нейронной сети
В экспертной системе моделируется многослойная однонаправленная НС
персептронного типа с сигмоидной функцией активации нейронов. Такая
модель требует несколько больше памяти, чем полносвязные сети, однако
обладает значительно более простым и быстрым алгоритмом функционирования,
что в конечном итоге позволяет выигрывать в скорости обучения сети.
При распознавании (генерации) структуры проектируемого объекта
используется однокритериальная оптимизация, т. е. для каждого показателя качества
(тип топологии сети, среда передачи) строится соответствующая НС. Выходы
этой сети соответствуют отдельным вариантам решения данной задачи. При
этом максимальный уровень сигнала среди всех выходных элементов
трактуется как соответствующее решение данной задачи (стратегия «победитель
забирает все»), а разность между максимальным уровнем и вторым по величине
- как достоверность решения).
Нейропакет функционирует в двух режимах: в режиме непосредственного
использования накопленных знаний (распознавания) и в режиме модификации
базы знаний, который заключается в построении, обучении, тестировании
нейронной сети и установлении ее связей с другими имеющимися нейронными
сетями.
Структура нейросетевой экспертной системы ЛОКНЭС
Для реализации каждого режима работы ЛОКНЭС содержит четыре
программных модуля, которые отражают специфику того или иного режима
работы: редактор файлов образов; конструктор сети; эмулятор НС; база данных;
экспертная оболочка. На рис. 12.19 приведена схема взаимосвязи основных
модулей ЛОКНЭС.
312
12.3. Нейросетевой пакет ЛОКНЭС
Редактор
образов
/
База данных
—Э
Конструктор
сети
>
ЛОКНЭС
Эмулятор
сети
т
Экспертная
оболочка
-г)
Прогнозируемый
вариант
сети
Рис. 12.19. Взаимосвязь основных модулей в ЛОКНЭС
Редактор файлов образцов {(Create Sampes). Этот модуль осуществляет
формирование обучающей и тестовой выборки, на которых происходит
обучение НС, и решает следующие задачи:
• задание классов, по которым будет осуществляться генерация
проектируемых вариантов локальных вычислительных сетей;
• задание параметров, от значения которых будет зависеть выбор того или
иного класса;
• задание описаний типовых конфигураций и значений их параметров, на
основании которых будет проводиться обучение НС;
• редактирование уже имеющихся классов, параметров и образцов типовых
конфигураций.
Диалоговое окно взаимодействия пользователя с модулем Редактора
файлов образов представлено на рис. 12.20.
Образцы решения задачи включают примеры, построенные на основе
знаний специалиста, соображений здравого смысла, а также случаи, когда
правильное решение было получено другими методами (например, методами
имитационного моделирования). На основе имеющихся образцов строится и
обучается НС, которая далее будет решать эту задачу. Обучение НС на
образцах, в отличие от существующих механизмов работы традиционных ЭС,
позволяет не заботиться о выведении в явном виде закономерностей,
необходимых для решения данной задачи: НС находит эти закономерности сама, хранит
их в неявной форме в виде совокупности весов межнейронных связей. Отсюда
видны главные недостатки нейросетевого подхода, связанные с
необходимостью накопления образцов решения задач и невозможностью определить,
каким образом сетью было получено то или иное решение.
Эмулятор нейронной сети {Teacher & tester). Этот модуль предназначен
для:
• определения основных характеристик создаваемой НС;
• обучения построенной НС набору образцов, созданных при помощи
Редактора образцов;
313
12. Программная эмуляция нейрокомпьютеров
File
Create samples: Определение типа сети: одноранговая / с сервером'
Edit Help
D &
Classes
Parameters
: Samples
Параметры:
Значение:
T
Требуемый ответ:
Количество ЭВМ в сети
Требования к секретности и
1
4
3
3
Требования к администриро! 3
Возможность использование 2
Возможность будущего расы
Простота установки
Поменьше _ _j
Очень мало - Меньше сем»;
Особо секретная j
Надо предусмотреть I
Можно и посложнее - не ct
Есть короший администра1
Не нужна |
Одноранговая сеть
Сеть на основе сервера
Комбинированная сеть
Off
On
Off
«grey |Мех1>>] | Add | Lgejetej В of 15
Классов З Параметров 7 Образцов 15 Modified [♦]_
Рис. 12.20. Диалоговое окно Редактора образцов
• дообучения уже имеющейся НС дополнительным наборам образцов;
• обеспечения оперативного контроля пользователем за процессом обучения
НС;
• тестирования обученной нейронной сети и определения достоверности
обучения как по всей обучающей выборке, так и по отдельным образцам;
• исследования степени устойчивости НС к ее разрушению,
контрастированию и искажениям во входных образцах;
• изменения параметров имеющейся НС.
В общем случае обучение НС можно представить следующим образом. Сети
предъявляют задачу и сопоставляют полученный сетью ответ с заданным,
после чего связи в НС изменяют таким образом, чтобы полученный ответ
приближался к заданному. Для этого используют метод обратного распространения
ошибки. Далее возникает вопрос надлежащего выбора коэффициента
пропорциональности (величины шага обучения): при малом шаге обучение
чрезмерно затягивается, при большом - не обеспечивается сходимость процесса
обучения. Наилучшим решением оказался выбор динамически изменяющегося
шага обучения: при «удачной» итерации текущий шаг удваивается, при
«неудачной» - осуществляется восстановление предыдущей межнейронной
связи, а текущий шаг уменьшается в 4 раза. Более совершенная параболическая
314
12.3. Нейросетевой пакет ЛОКНЭС
оптимизация шага, как показали дополнительные исследования, в данном
случае не дает заметного выигрыша. Это связано с тем, что время вычисления
шага оказалось сопоставимым со временем вычисления градиента ошибки, а
в этом случае смысл точной оптимизации шага теряется.
Другим способом увеличения скорости обучения НС явилось
усовершенствование выбора направления обучения. Градиент ошибки не является
лучшим направлением обучения (он эквивалентен методу наискорейшего спуска).
Лучшие результаты были получены при использовании ParTan-методов,
которые учитывают не только текущее значение градиента ошибки, но и общее
направление обучения сети. Применение ParTan-иетодов позволяет сократить
как общее число необходимых итераций, так и продолжительность отдельных
итераций (поскольку требуется одно вычисление градиента ошибки на несколько
итераций обучения). Диалоговое окно эмулятора НС показано на рис. 12.21.
Еще одним способом ускорения обучения является выбор стратегии перебора
задач, на которых обучается НС. Простейшей стратегией является следующая:
сеть обучается сначала одной задаче, потом - другой, и т. д. до последней
задачи, после чего процесс повторяется. Очевидно, что такая процедура не
сходится к глобальному минимуму; когда обучение доходит до последних задач,
первые уже забыты. Выходом из ситуации является стратегия усреднения: значение
градиента ошибки усредняется по всем задачам. Все задачи при этом участвуют
Neural network tester S teacher
File Help
am bib в
-Teaching progress—
Time
4
0
8
10
12
14
2
JMark
№11
Step
10.0000000
3.0000000
0.3123000
1.2300000
0.0781230
0.0390623
7.3ППЛППП
Samples
invoked.
11
Trace
I J Start teaching, i
Q Stop teaching 1
£2 Contrast net 1
^ Make a hit |
Samples test If Stability lest jTrace j
Parameter
I Meaning
Количество ЭВМ в сети
Требования к секретности информации
Возможность будущего расширения
Простота установки
Требования к администрированию сети
Возможность использования разных сет^
Как можно ниже
Мало -7 10
Не секретная
Пока не будем
Лучше чего попроще
Пока хорошего администратора t
Нужна
Class name
Сеть на основе сервера
Комбинированная сеть
TlMet flnswd Real AnsJ Status
10 986 1 OOOOOOi
0 013 0 OOOOOOi
0 001 0 OOOOOOi
Samples. 1 of 10
<< Prev sample j Repeat, ___Jj | Next sample »
Options"
Mark type~~
(ft Middle squares
С Reliability
Teaching method ~
(• MultiTask
О mPaiTan
О Optimized Antigradient
О Antigradient lowering
О В FGS-formula
Autostop options
Max steps: Maik needed:
200
|0.25
Other
inner —— —jpi-.....ii...„ ~~—
Show progiess every [2 | Step
I nf ormation
i Total steps performed 8
! Mark reached 0 0052314
:Net$ize.3x25(11Kto)
Samples 10
Samplefile "C\DELPHIWII04SMP"
Net saved as ""
Рис. 12.21 Инструментальная среда Эмулятора
315
12. Программная эмуляция нейрокомпьютеров
в обучении одновременно и на равных правах. В данной работе была
использована комбинированная стратегия перебора — НС обучается лишь некоторому
множеству задач, в которое постепенно включаются все новые и новые задачи.
Расчеты показывают, что такая стратегия в среднем в два раза быстрее
стратегии усреднения.
Конструктор проекта сети (Link Organizer). Этот модуль предназначен для
решения следующих задач:
• конструирования (сборки) элементов нейросетевой ЭС:
• построения и редактирования файла-проекта ЭС;
• установления связей между исходными данными проектирования и
входами НС;
• установления связей между параметрами, подлежащими определению в
процессе проектирования, и выходами НС;
• установления перекрестных связей между входами и выходами НС;
• тестирования полученного проекта ЭС;
• централизованного управления остальными программными
компонентами нейросетевой ЭС.
Диалоговое окно Конструктора сети показано на рис. 12.22.
File Tools Help
i Exeerts*s»nn>raim manager«
й б в н * -
Current parametr:
Стоимость
Must be determined by:
Send answer to:
Стоимость parameter
Order 0
File:
Total parametres: 1G
[—IMPS"]
Current net:
j Выбор топологии сети
Parametres:
Стоимость
Требуемая скорость
Надежность сети
Количество ЭВМ в сети
Простота изменения конфигурации
Расположение ЭВМ в пространстве
Уже проложен кабель под соответс
Net: С:ЮЕ1_РН1\ТОРЗ.МЕТ
Nets total: 2
Рис. 12.22. Диалоговое окно для работы с Конструктором сети
316
12.3. Нейросетевой пакет ЛОКНЭС
Для отображения необходимых связей было выделено множество исходных
данных и множество задач проектирования. Элементы множества задач
проектирования хранят информацию о решаемом вопросе, необходимых исходных
данных, о НС, решающей данную задачу, а также дополнительную служебную
информацию. Элементы множества исходных данных содержат информацию
о состоянии исходных данных и вопросах, для решения которых требуются эти
исходные данные. Исходными данными могут быть как данные, задаваемые
пользователем, так и результаты решения предыдущих задач. Из построенных
множеств модуль оболочки ЭС формирует нижеописанную фреймовую
структуру.
Оболочка экспертной системы (Expert System). Этот модуль
представляет основу ЭС и использует файл-проект, созданный предыдущей
программой. В зависимости от элементов, содержащихся в нем, ЭС приобретает
свойства, заданные пользователем в программе Конструктор. Данный программный
модуль предназначен для решения следующих задач:
• непосредственного выбора конфигурации вычислительной системы или
сети в условиях нечетко заданной информации;
• определения степени влияния исходных параметров проектируемого
объекта на показатель качества;
• тестирования полученного проекта ЭС.
Диалоговое окно Оболочки ЭС показано на рис. 12.23.
File Help
iNetvrark <lesigj»;*ool0 <.
Current Task Определение типа сети: одноранговая / с сервером
Questions to determine
Status
1 Question
Answer
Solved
Solved
Solved
Solved
Solved
Solved
Solved
by user
by user
by user
bv user
by user
by user
by user
Стоимость
Количество ЭВМ в.сети
Требования к секретности информации
, Возможность будущего расширения
1 Простота установки _
Требования к администрированию сети
Средняя
. Средне -,10,J>p _
Секретная
Незначительно
Средняя сложность
Не знаю
. Возможность использования разных сетевь Не нужна
Question :Стоимость
Г~ * Как можно ниже
Г~ + Поменьше
|х + Средняя
Г~ + Не важно
Г" + Не знаю
| < Piev quest |
|Hext quest > j
I Restore j
■rw-gs
]
lipase
i.-ttaJ
Рис. 12.23. Диалоговое окно для работы с Оболочкой
317
12. Программная эмуляция нейрокомпьютеров
Выделение этого модуля позволяет рассматривать данную ЭС как
универсальную: загружая различные описания предметной области, можно решать
задачи определения архитектуры вычислительных систем самых
разнообразных классов. Вторая важная функция данного модуля - обеспечение
возможности установки ЭС в «облегченном» варианте - без средств модификации базы
знаний (если заведомо известно, что пользователю они не потребуются).
Оболочка ЭС управляет последовательностью решения вопросов проектирования,
обеспечивает функционирование и взаимосвязь всех используемых НС, а
также обеспечивает интерфейс с пользователем.
Алгоритм функционирования ЛОКНЭС
Для реализации взаимодействия нескольких НС в ЛОКНЭС был выбран
фреймовый механизм, в котором с каждым фреймом-вопросом
проектирования связана совокупность слотов исходных данных: имя файла с описанием
НС, текущее состояние решаемого вопроса (который также может являться
слотом другого фрейма), а также прочая служебная информация, отражающая
текущее состояние фрейма. После заполнения всех слотов исходных данных
(или по команде пользователя пропустить незаполненные слоты)
активизируется соответствующая НС, на ее входы подаются исходные данные, а на
выходе появляется предлагаемое решение (в виде соотношения сигналов выходных
элементов). Если пользователя устраивает полученное решение, то оно
сохраняется и рассылается во все слоты исходных данных, связанных с текущим
фреймом. После этого активным становится следующий фрейм, происходит
заполнение его слотов, и процесс повторяется, пока все вопросы не будут
решены. Выбранная модель позволяет отобразить сложную иерархическую
структуру взаимосвязей между входными и выходными данными.
Программная реализация ЛОКНЭС
Программный пакет ЛОКНЭС работает со следующими типами файлов:
• файлы описаний НС (*.nef). В каждом файле хранится одна НС,
решающая установленную подзадачу;
• файлы проектов (*.ехр), содержащие информацию о том, какую НС, на
каких данных и как обучить (стратегия, параметры, установки);
• файлы образцов (*.smp), представляющие собой списки примеров,
связанных между собой логически;
• файлы отчетов (*.txt), в которых хранятся результаты работы ЭС.
Режим формирования и изменения базы знаний. Пользователь начинает
работу с нейросетевой ЭС в режиме формирования и изменения базы знаний с
использованием блока Редактор образцов. В этой программе создаются и
заполняются файлы образцов, выбираются классы проектируемых вариантов ВС,
редактируются уже имеющиеся варианты. Здесь же формируется обучающее и
тестовое множество примеров, а в случае необходимости и подтверждающее
множество.
318
12.3. Нейросетевой пакет ЛОКНЭС
Структура данных файла образца имеет следующий вид.
1. Раздел имени образца:
*NAME = <имя образца>.
2. Раздел описания классов:
*CLASSES = <число распознаваемых классов>.
Список классов.
- <имя первого класса>
- <имя второго класса>
- <имя последнего классах
3. Раздел описания параметров:
* PARAMETRES= <число параметров>.
Список параметров:
- <имя первого параметра>
Список значений первого параметра:
+ <3начение1>[= Комментарий 1]
+ <3начение R >[= Комментарий N]
- <имя последнего параметра>
Список значений последнего параметра:
+<3начение1>[= Комментарий 1]
+<3начение ^[Комментарий N]
4. Раздел описания примеров:
* SAMPLES = <число примеров>
Список примеров:
#1
<№ градации>, <уровень активности>
<№ градации>, <уровень активности>
#N
<№ градации>, <уровень активности>
<№ градации>, <уровень активности>
Файлы образцов хранятся в виде текстового файла (в формате ASC П) и
могут быть открыты и отредактированы с помощью редакторов типа Write, Note
Pad и т. д.
319
12. Программная эмуляция нейрокомпьютеров
Для тестирования создаваемой базы знаний ЭС предлагается воспользоваться
непосредственно Оболочкой ЭС, которая позволяет пользователю загружать
произвольные файлы - описания предметной области. Структура и принцип
работы оболочки ЭС описан выше. Для тестирования отдельных НС можно
также воспользоваться средствами, которые предоставляет нейроимитатор.
Он позволяет проверить работу НС на контрольных образцах, а также
исследовать ее устойчивость к искажению исходных данных.
Режим прогнозирования. Для начала работы в этом режиме вначале
запускается оболочка ЭС. Ввод исходных данных осуществляется путем выбора
одного или нескольких наиболее близких ответов на соответствующий вопрос
ЭС в окне ввода исходных данных, либо считывается из файла образцов. Ввод
всех исходных данных не является обязательным. По умолчанию все входные
параметры проектируемого объекта устанавливаются в неопределенное
состояние («не знаю», «не имеет значения» и т. д.). После ввода ответа на последний
вопрос экспертная система переходит в режим прогнозирования. В выходной
таблице по-; • • ся ответы сети в интервале [0,1], интерпретируемые как
коэффициенты уверенности в полученном решении. На основании стратегии
«победитель забирает все» генерируется начальный вариант проектируемой
вычислительной сети. Результаты работы в этом режиме сохраняются в файле
отчета.
Структура данных файла отчета имеет следующий вид.
1. Раздел исходных данных:
<Исходный параметр 1>:
<3начение 1>;
<Исходный параметр N>:
<3начение N>;
2. Раздел выходных данных:
<Выходной параметр 1>:
<Прогноз 1> (<Статус 1>)
<Выходной параметр N>:
<Прогноз N> (<Статус N>).
Файлы отчетов также хранятся в виде текстового файла и могут быть
открыты и отредактированы при помощи редакторов типа Write, Note Pad и т. д.
Пример выбора конфигурации локальной вычислительной сети
с помощью ЛОКНЭС
Анализ предметной области. При анализе предметной области
(локальных вычислительных сетей - ЛВС) оказалось, что, несмотря на отсутствие
формализованных алгоритмов решения отдельных задач, общая стратегия
проектирования просматривается довольно четко - от задач выбора общей архи-
320
12.3. Нейросетевой пакет ЛОКНЭС
тектуры сети к задачам выбора отдельных компонентов аппаратного и
программного обеспечения.
ЛОКНЭС решает следующие задачи:
• выбор ранга сети;
• выбор топологии;
• выбор среды передачи;
• выбор необходимого программного обеспечения (операционной системы).
Решение задачи. Для решения задач отмеченного перечня была создана
экспериментальная версия системы, которая затем подверглась всестороннему
тестированию.
Рассмотрим пример диалога с пользователем.
Вопросы, задаваемые ЛОКНЭС
1. Стоимость
2. Количество ЭВМ в сети
3. Требования к секретности информации
4. Возможность будущего расширения
5. Простота установки
6. Требования к администрированию сети
Ответы проектировщика
ниже средней
среднее- 10...20
конфиденциальность
да
средняя сложность
необходимость
администрирования
не знаю
7. Возможность использования разных
сетевых ОС
8. Требуемая скорость 10 Мб/с
9. Надежность сети средняя
10. Простота изменения конфигурации не важно
11. Расположение ЭВМ в пространстве хаотично
12. Проложен кабель для соответствующей топологии нет
13. Максимальная длина сегмента до 100 м
14. Надежность информации и помехозащищенность средняя
15. Сложность установки низкая
16. Поддержка ОС предыдущих версий нужна
17. Поддержка сети Internet нужна
18. Простота использования простая
19. Мощные средства управления не нужны
Ответы проектировщика формируют вектор, состоящий в данном случае из
19 проектных параметров. Ввод всех исходных данных не является
обязательным. По умолчанию все входные параметры проектируемого объекта
устанавливаются в неопределенное состояние («не знаю», «не важно» и т. д.). После
ввода ответа на последний вопрос ЭС переходит в режим прогнозирования. В
выходной таблице интерфейсного окна появляются ответы сети в интервале
[0,1], интерпретируемые как коэффициенты уверенности в полученном
решении. На основании стратегии «победитель забирает все» генерируется вариант
проекта ЛВС. Результаты работы в этом режиме сохраняются в файле отчета.
321
12. Программная эмуляция нейрокомпьютеров
Результаты проектирования. Для заданного входного вектора результаты
работы ЛОКНЭС (выбранные варианты значений целевых параметров
подчеркнуты, уверенность в ответе дается в интервале [0,1]) представлены
следующим образом:
Определение типа сети
Одноранговая сеть 0,01
Сеть с выделенным сервером 0,99
Комбинированная 0,00
Выбор указанного варианта объясняется следующими соображениями. Хотя
число пользователей невелико (10 - 20), предполагается возможность
будущего расширения; информация является конфиденциальной, поэтому с помощью
ЛОКНЭС был выбран вариант сети на основе выделенного сервера, что
позволит предоставить возможности роста предприятию, для которого
разрабатывается сеть, и обеспечит централизованную защиту данных.
Выбор топологии сети
Шина 0,03
Звезда 0,77
Кольцо 0,00
Звезда + шина 0,14
Звезда + кольцо 0,04
Выбор топологии звезда определяется необходимостью обеспечения
централизованного управления, хаотичным расположением в пространстве
объединяемых в сеть ЭВМ, возможностью легкого расширения, обеспечением
надежности за счет резервного копирования и диагностики. Реализация топологии
кольцо является очень дорогой, поэтому при заданных входных условиях ее
нецелесообразно использовать.
Выбор типа кабеля
10 BASET (витая пара-) 0,90
10 BASET2 (тонкий Ethernet) 0,05
10 BASET5 (толстый Ethernet) 0,02
10 BASETFL (оптоволоконный) 0,03
Выбранный вариант кабеля витая пара (10 BaseT) оправдан тем, что он
является самым дешевым из всех видов кабелей, прост в установке (может быть
установлен при строительстве помещений), обеспечивает заданную скорость
передачи 10 Мбит/с, эффективная длина кабеля совпадает с заданной
максимальной длиной сегмента (100 м).
322
12.3. Нейросетевой пакет ЛОКНЭС
80
70
£ 60
| 50
1 40
S 30
с
$ 20
10
Ранг Топология Среда ОС
сети передачи
□ - верно;
^ - верно с достоверностью более 10%;
§§: - неверно
Рис. 12.24. Результаты работы ЛОКНЭС по выбору
целевых параметров ЛВС
Выбор типа операционной системы
Windows95 0,01
NetWare 3 .хх 0,01
Intranet Ware 0,32
Solaris 0,12
OS/2 Warp 0,01
Windows NT5.0 0,66
Поскольку во входном задании указана необходимость поддержки
операционных систем предыдущих версий, а возможность использования разных
сетевых операционных систем не определена, то выбран вариант универсальной
сетевой операционной системы.
Тестирование ЛОКНЭС при решении ряда задач показало, что система
правильно решает 70...85% контрольных примеров даже в условиях неполной и
частично противоречивой информации; результаты работы сети ЛОКНЭС в
режиме распознавания представлены на рис. 12.24. В нейроимитаторе
предусмотрены возможности задания уровня достоверности получаемых
результатов. Кроме того, реализован режим перекрестного тестирования, при котором
проверка работы сети осуществляется на промежуточных этапах процедуры
обучения сети.
Результаты тестирования устойчивости ЛОКНЭС к зашумлению исходных
данных для обучающей и тестовой выборки представлены на рис. 12.25. Даже
при уровне шума 20% среднеквадратичная ошибка сети не превышает
значения 0,5.
323
12. Программная эмуляция нейрокомпьютеров
<►—.
г-'
1
Л
f
'
^и^'
Ё1
MSE
0,8
0,7
0,6
0,5
0,4
0,3
0,2
0,1
0
О 4 8 12 16 20 24 28 32 36 40
Уровень шума, %
Рис. 12.25. Тестирование устойчивости работы НС
к зашумлению исходных данных:
—♦ обучающая выборка;
—■ контрольная выборка
Проведенное исследование позволяет говорить о перспективности
использования данного нейропакета для создания прикладной нейросетевой ЭС в
различных предметных областях поскольку база знаний легко настраивается на
решение задач определенной области.
12.4. Работа двухмерной нейронной сети
Для проверки работоспособности сети с двухмерными слоями была
разработана программа Visual Neural Network Designer, позволяющая представлять
сеть в виде отдельных блоков-компонентов. В том числе имеется возможность
комбинировать блоки сетей с двухмерными нейронными слоями с блоками
обычных сетей прямого распространения.
Для представления сети используются следующие блоки:
• Входной слой;
• Выходной слой;
• Группа нейронов;
• Двухмерная сеть.
Через компонент «Входной слой» в НС поступают входные сигналы,
которые в дальнейшем обрабатываются компонентами «Группа нейронов» или
«Двухмерная сеть». Компонент «Выходной слой» предназначен для сбора
выходных сигналов сети и представления их в графическом виде.
Компонент «Группа нейронов» представляет собой простую сеть прямого
распространения. Данный компонент может быть как обучаемым, так и иметь
324
12.4. Работа двухмерной нейронной сети
фиксированные синаптические коэффициенты. Для
обучения предусмотрен алгоритм обратного распространения
ошибки и его модификации.
Компонент «Двухмерная сеть» представляет собой сеть I I 1
с топологией, показанной на рис. 2.20. Пользователь мо- рис. 12.26. Пример
жет задать собственноручно вид маски нейронных соеди- маски нейрон-
нений. Например, для рис. 2.20 маска будет иметь вид, пред- ных соединений
ставленный на рис. 12.26. Для компонента «Двухмерная сеть» также
предусмотрены несколько методов обучения, базирующихся на алгоритме
обратного распространения ошибки. Данный компонент может иметь и
фиксированные весовые коэффициенты. Каждый из компонентов «Группа нейронов» и
«Двухмерная сеть» может обучаться как отдельно, так и в составе всей сети.
Для проверки эффективности работы НС с двухмерными слоями были
выбраны для сравнения две топологии НС. Обе сети обучались распознаванию
образов цифр размером 5x7 символов (рис. 12.27). На выходе каждая из НС
выдавала двоичный код цифры. Работоспособность обоих сетей испытыва-
лась под воздействием аддитивной ошибки, добавленной к входному образу. В
качестве оценки качества работы сети была выбрана средняя квадратичная
ошибка.
Первая из проверяемых сетей представляла собой обычную НС прямого
распространения (рис. 12.28) с 35 входами, одним скрытым слоем на 35 нейронов
и четырьмя выходами, представляющими собой двоичный код входного
образа. Сеть обучалась при помощи классического алгоритма обратного
распространения ошибки. Вторая НС представляла собой комбинацию сети с
двухмерными нейронными слоями и обычной сети прямого распространения (рис. 12.29).
Рис. 12.27. Набор входных образов цифр
325
12. Программная эмуляция нейрокомпьютеров
I
| Выход-35
1 Вход-35
Q.
3
О
I—
О
ч-
d
о
X
XI
m
1 Вход-4
Q.
О
Рис. 12.28. Нейронная сеть прямого распространения:
Inputl - компонент «Входной слой»; Group 1 - компонент
«Группа нейронов»; Outputl - компонент «Выходной слой»
I
1 Выход-35
I Вход-35
TwoDiml
У
со
■
d
О
X
Xl
ш
1 Вход-35
о.
3
о
■
d
о
X
XI
LB
| Вход-4
■s
о
Рис. 12.29. Комбинация нейронной сети с двухмерными слоями и сети
прямого распространения:
Inputl - компонент «Входной слой»; TwoDiml - компонент «Двухмерная сеть»,
Group 1 - компонент «Группа нейронов»; Outputl - компонент «Выходной слой»
Таблица 12.4. Результаты
эксперимента
Ошибка
на входе,
%
1
5
10
15
20
25
30
35
40
45
50
Средняя квадратичная
ошибка
Одномерные
слои
0.000125
0.00013
0.000147
0.000192
0.000309
0.000461
0.00076
0.001015
0.001405
0.001643
0.002141
Двухмерные
слои
8.63Е-05
8.65Е-05
8.80Е-05
9.91Е-05
0.000162
0.000232
0.000798
0.000967
0.001372
0.001577
0.001927
Первый компонент этой сети (однослойная
сеть с двухмерными слоями с маской
нейронных соединений) был предназначен для
восстановления входного сигнала (рис.
12.28). Второй компонент - обычная
однослойная сеть с 35 входами и четырьмя
выходами занимался собственно
классификацией образов.
Результаты проверки представлены в
табл. 12.4 и рис. 12.30. Как видно из
графиков средняя квадратичная ошибка при
работе обоих сетей примерно одинаковая,
но у первой сети количество синаптичес-
ких связей равно 1365, а при
использовании сети с двухмерными слоями
количество связей уменьшилось до 420.
326
12.5. Нейропакет Neural Networks IDE
0,0025
5
I 0,0020
|j 0,0015
S I o,ooio
к о
| 0,0005
о
о.
О 0 I I I 1 I I i I I f I I I i i I I 1 1 I i I I I I I I I 1 1 I I I I i 1 1 I I I I I 1 i 1 I I I (I
i—tTj-Г- .-tCIVOONCNWlOO — Tj-r-Tj-CIVOON
°. Ч °. о t ^. 1 1 'Ч 1 m. m. n. о 4 Ч Ч
сГсГсГ о" о" о" о о" о о" о" о сГсГсГ
Рис. 12.30. Графики ошибки для обычной сети (/) и сети с
двухмерными слоями (2)
Таким образом использование на входе сетей с двухмерными нейронными
слоями уменьшает количество вычислений при программной реализации сети
и сокращает объем аппаратуры, необходимой для ее технической реализации.
12.5. Нейропакет Neural Networks IDE
Нейросетевой программный продукт разработан на кафедре
«Компьютерные системы и сети» КФ МГТУ им. Н.Э. Баумана и предназначен для
моделирования работы НС с целью определения эффективности разнообразных
архитектур и алгоритмов обучения при решении практических задач. Архитектура
пакета является открытой, т. е. имеется возможность подключения,
тестирования и исследования различных типов НС в виде отдельно подгружаемых
модулей. В инструментальной среде пользователь дополнительно получает
возможность создавать вручную, загружать или модифицировать черно-белые или
цветные входные графические образы. На этой базе образов можно проводить
эксперименты с одним из модулей НС. Инструментальная среда позволяет по
шагам проследить процессы обучения и работы сети с одновременным
графическим отображением активности нейронных слоев. Реализована возможность
проведения исследования сетей на устойчивость в условиях различных
уровней зашумленности тестовых образов с построением графиков результатов
эксперимента, а также анализа максимального числа образов, которые сеть
может запоминать и правильно воспроизводить (определение вместимости сети).
Параметры исследуемой сети можно модифицировать в ходе проведения
экспериментов.
В качестве основных используются модули НС Кохонена и многослойного
персептрона, позволяющие выполнять набор операций по обучению,
тестированию, загрузке и сохранению основных параметров и состояний сети. В этом
программном продукте реализована возможность изменения таких характе-
^
327
12. Программная эмуляция нейрокомпьютеров
ристик сети, как число нейронов, порог обучения, максимальное число эпох
(число итерационных шагов обучения), скорость обучения и некоторых других
специфичных для разных методов обучения параметров.
Функции, реализуемые системой
Нейропакет обеспечивает выполнение следующих функций:
• загрузку, инициализацию, обучение и тестирование модуля НС с
возможностью изменения ее параметров;
• пошаговое обучение с отображением слоев активности и текущих
значений таких параметров, как математическое ожидание ошибки, дисперсия
ошибки, среднее отклонение ошибки, текущая итерация, максимальное и
минимальное значения активности данного слоя на любой стадии обучения; при этом
имеется возможность сохранения/загрузки состояния как всей системы на
любом ее этапе обучения или тестирования, так и разработанного проекта НС в
целом;
• создание, загрузка, сохранение, редактирование (а также наложение
бинарного шума) обучающих и тестовых графических образов с возможностью
их конвертирования из / в графический формат Ьтр;
• проведение экспериментов и графическое отображение результатов
тестирования.
Работа с инструментальной средой
Нейропакет представляет собой многодокументное приложение, где в поле
основного окна отображаются обучающие, тестовые образы (выборка -
совокупность образов), а в дополнительных окнах - результаты обучения и
тестирования, редактируемый образ и активность сети. Рассмотрим
функционирование среды на примере работы с графическими образами. Для загрузки или
создания нового проекта необходимо выбрать пункты Файл/Открыть,
Файл/Новый или нажать на кнопки акселераторов IQ или Щ.
На любой стадии обучения или тестирования текущее состояние проекта
нейросети можно сохранить (расширение *.пп), чтобы в дальнейшем можно
было к нему вернуться. Для этого необходимо выбрать пункт меню Файл\
Сохранить или Файл\Сохранить как..., более быстрым способом сохранения
является использование кнопки акселератора ■•. На рис. 12.31 показано окно
загрузки файлов.
Обучающая и тестовая выборка. Для обучения и тестирования сети
необходимо после загрузки модуля сети сформировать или загрузить обучающую и
тестовую выборку, используя пункт меню «Работа с выборками».
При создании новых образцов устанавливаются их параметры (размеры
образа: число точек по горизонтали, вертикали, тип образа и т. д.). Готовые
файлы образов имеют расширение * .ptn. Для сохранения или загрузки заранее
отредактированного образа в стандартном графическом формате *.Ьтр
необходимо выбрать пункты Файл\Экспорт или ФашЛИмпорт. На рис. 12.32
показано окно установки параметров новых образов.
328
12.5. Нейропакет Neural Networks IDE
Open
Jj pattern
"<": Kohonen
,K Nnidel
BD
' Jul й! ШМ
Filename' jt:ohonen|
Files of type | N nide F iles (". nni)
J
Open
Cancel
Рис. 12.31. Окно загрузки рабочих файлов
В нейропакете предусмотрена возможность редактирования образов в
специальном окне, а также установление цвета. Для редактирования необходимо
подвести указатель мыши на образ, который мы хотим отредактировать, и
двойным щелчком его выделить. В результате этот графический образ будет
отображен в «окно редактирования». Рис. 12.33 иллюстрирует возможность
редактирования цветов.
&ШШШШШШ1Ш№&яШ1ЯШЩ
Щ Файл Работ|
||Ь'с* Ы"
Параметры Образов
Число точек по горизонтали:
Число точек по вертикали:
Тип образа:
_ [выборочно
П араметры точек:
Число цветовых плоскостей: I Цвет|нои
Число бит на цвет: |1
tgmaMpzL
l/'fJK
JKCance!
Ш*1
fj*l
Значение
Значение не
Значение не
Значение
3
^
Готово
ТР936 /л
Рис. 12.32. Окно ввода параметров нового образа
329
12. Программная эмуляция нейрокомпьютеров
/* Neural networks IDE - [Nnide2]
°" Файл Работа с выборками Пуск Эксперимент Вид Окно Помошь
тыс
Обучающая выборка:
Окно редактирования
П
1 00
и /ь
иьи
V.Z5
Предел ^Активность
исперсия
Итерация
Макс значение
<
Цвет ЕЗ
ran
■
■ D
ПИ
е.
lejjy
Готово
Т {19:24 ^
Рис. 12.33. Окно редактора образа с выбором цвета
Исследование сети на устойчивость осуществляется путем добавления к
образу бинарного шума, уровень которого может регулироваться
пользователем (от 15 до 100%). На рис. 12.34 показано окно добавления к образу
бинарного шума.
/-Neural networks IDE - [Nnide4]
*™ Файл Работа с Выборг ами Паск Эксперимент Дид Дкно Помошь
!l Q 0g! | Обччающаявыборке *
Тестовая выборка ►
Результирующая выборка ►
Обучаюи
естовая выборка:
д
ш
~.:Ы*}
-г1!
1 00
и /ъ
иьи
Хс, ШУМГ12 Предел | jft Активность [
—| Название
—* . Дисперсия
Итерация
. Макс значение
«I
Наложить бинарный шум на образ
j Значение
Значение не опреде
Значение не опреде
Значение не опреде^]
аде—'
■к-эде
ipeneZJ
Рис. 12.34. Окно добавления к образу бинарного шума
330
12.5. Нейропакет Neural Networks IDE
Параметры сети
ИИЕЗ
Порог обучения
Максимальное число эпох:
Число нейронов по горизонтали:
Число нейронов по вертикали:
Скорость обучения
Начальный радиус стимуляции:
Интервал торможения
ОК |
0.00100 ;.
J500
|10
|ю
|1.000000
|10
I1
Отмена I
Рис. 12.35. Ввод параметров сети
Установка параметров сети. Для загрузки модуля НС нужно выбрать пункт
меню «ФашЛЗагрузить модуль». При настройке сети на решаемую задачу
параметры сети могут быть установлены по умолчанию, в противном случае
вызывается окно диалога. Установка параметров для сети Кохонена будет
выглядеть, как показано на рис. 12.35.
Пр имечание. Для сети Кохонена понятие «обучение» рассматривается как обучение без
учителя; с целью универсализации неиросетевого пакета это понятие рассматривается и как
«обучение с учителем» (в многослойном персептроне), и как без учителя. В соответствии с
этим при установке начальных параметров сети будут появляться различные диалоговые окна.
Обучение нейронной сети. Как только будет загружена НС и файлы
образов, то становятся доступными такие элементы управления, как обучение сети:
Ш- обучение НС (аналог ПускЮбучение пункта меню);
Шч— пошаговое обучение НС (аналог ПускХПошаговое обучение пункта
меню).
В нейропакете реализован следующий набор функций активации:
• линейная;
• гиперболический тангенс;
• сигмоидная.
На рис. 12.36 представлено окно задания параметров обучения сети.
331
12. Программная эмуляция нейрокомпьютеров
p?f Neural networks IDE - [Nnide4]
* айя Работас Пчо Эксперимент Ёид £[кно Помошь
О Ш» О $> Ч^ Р '' ' ^ Пошаговое обучение F11
■ Q4 Пбичение F10,
{Обучающая выборка:
Тестовая выборка:
■ПЕЗ
^ X
1 00
и tb.
иьи
!| {^ Шуи [tZ! Предел| ф Активность|
Задать параметры сети
Ч и •■
—■* Дисперсия
Итерация
Макс значение
ii
Значение *■]
Значение не опреде—'
Значение не опреде
Значение не опреде^
ipeflej
±3
I Г
TI2045 4
Рис. 12.36. Окно задания режима обучения
При работе с сетью Кохонена реализован алгоритм, описанный в § 6.8. Для
других архитектур НС реализованы такие алгоритмы, как стандартный
обратного распространения ошибки (устанавливаемый по умолчанию),
генетический алгоритм, случайный, стратегия BFGS, классический градиентный,
двухэтапный алгоритм, основанный на сочетании генетического поиска и
градиентного спуска. Для останова процесса обучения контрольными являются
следующие параметры;
• заданное число итераций (эпох) процесса обучения;
• значение ошибки обучения.
Тестирование нейронной сети. При тестировании сети проверяется ее обу-
ченность. Предусмотрены следующие режимы:
! - тестирование НС (аналог ПускУГестировать пункт меню) при условии
наличия тестовых образов;
| ? - тестирование НС (аналог ПускХПошаговое тестирование пункта меню)
с одновременным отображением слоя активности.
При тестировании НС в окне «окно отладчика» отображаются результаты
сравнений тестовой и результирующих выборок, а именно:
• математическое ожидание ошибки (первый начальный момент):
— 1 "
Х = -Ухг
где х - значение ошибки между результирующей и обучающей выборкой;
п - число выборок;
332
12.5. Нейропакет Neural Networks IDE
£? Neural networks IDE - [Nnide4]
" Файл Работа с выборками П
Эксперимент ^Бид
игап
DtSH, * *ИИ !|К|ЕЫВ1
{Обучающая выборка:
ииваьд
естовая выборка:
Г^ л ^ГЛ-': Гч. '.',7'?i vA-^ ti^ f'Y '
результирующая выборка:
iilid
|Г. —_
1g ff^Lfc...пРа°*!?*' ^ Активность |
Тестирование сети
Название
Мин значение
Макс значение
Итерация
Мат ожидание
Разброс
Дисперсия
1L
^Значение
648 236068
4363 212005
1
0 730088
0 024296
0 000590
I 21
~1~ ГГ2114 4
Рис. 12.37. Окно результатов сравнения тестовой и рабочей выборок
• дисперсия ошибки (второй центральный момент):
• среднее квадратичное отклонение (разброс) ошибки:
• минимальное и максимальное значения отображаемого слоя активности;
• текущая эпоха (эпоха - один шаг итеративного обучения).
На рис. 12.37 показано окно результатов сравнения тестовой и рабочей
выборок.
В ходе проведения обучения в окне «окно отладчика» отображаются
результаты сравнений обучающей выборки и отклик сети на обучающую выборку. В
пошаговом режиме обучения предоставляется возможность выбора
контрольных точек итерации, на которых будет проводиться отображение карты
активности (задание числа итераций доступно при первом нажатии на кнопку
акселератора или пункте ПускХПошаговое обучение; при последующих
нажатиях будет происходить дальнейшее обучение до следующей контрольной
точки и отображения состояния сети). Задание контрольных точек в пошаговом
режиме обучения представлено на рис. 12.38. На любом этапе пошагового
обучения сеть можно тестировать и наблюдать за результатами ее работы. Кроме
того, в этом случае текущее состояние сети можно как загружать, так и
сохранять в файле с расширением *.net. Для этого необходимо выбрать пункт меню
ФашЛЗагрузить сеть или Файл\Сохранить сеть.
333
12. Программная эмуляция нейрокомпьютеров
^3 3^айл с выборками Пуск Эксперимент Дид Окно Помощь
I! d & а. х сыр!» li'DiDj ■
-Ifftxl
Обучающая выборка:
АЬД
естовая выборка: Пошаговое обучение
^*Т? ftjk* ^tj' -Отобразить-
.г/.
Г* Последовательно все эпохи
£•" Остеновитьсяназпоие номер ]3
ОК
Cancel
tZ Шцм 1 fc Прадед ;# Активность |
Готово
ь'-
{ение
^ч»
j Паке значение
^ Итерация
i Мат ожидание
| Разброс
Дисперсия
■ние не определено
Значение не определено
Значение не определено
Значение нё'определено
Значение не определено
Значение не определено
I I2216
Рис. 12.38. Окно задания контрольных точек в
пошаговом режиме обучения
Кроме пошаговых вычислений с сетью можно проводить эксперименты,
направленные на определение ее устойчивости к шуму (для этого строится
зависимость вычисляемой ошибки сети от уровня бинарного шума). В
результате появятся окна соответствующих диалогов с указанием числа градаций
уровня зашумленности и числа повторов в каждой контрольной точке с целью
получения статистических данных по вычисляемым величинам.
Важной задачей при исследовании НС является определение вместимости сети,
т. е. числа образов, которое сеть может уверенно распознавать (построение
зависимости величины ошибки от числа подаваемых для запоминания образов).
Для подсчета вместимости сети необходимо поставить эксперименты по
определению такого максимального количества образов сети, при котором
ошибка сети сохраняется на приемлемом уровне.
В режимах пошаговой работы программы (режим тестирования и режим
обучения) в дополнительных окнах содержится полезная информация для
проведения исследований. В закладках «Шум» и «Предел» выводятся результаты
проведения экспериментов на устойчивость к шуму и на максимальное
распознаваемое число образов системой в графическом виде. Для проведения этих
экспериментов необходимо выбрать пункт меню Эксперимент Устойчивость
сети и Эксперимент УВместимость сети.
Выбор режима исследования НС на устойчивость к шуму или режима
оценки вместимости показан на рис. 12.39.
334
12.5. Нейропакет Neural Networks IDE
Д*- Neuial networks IDE - [Kohonen nni]
1ЛС Я£айп Работа с выборками Пуск Эксперимент Вид Окно Ломошь
D &&У| Л. ^|*.! f U I Устоичибость йети
«чч.т.1. Вместимость сети
ИИ С
Jal.xl
Обучающая выборка:
АЬД
Гестовая выборка:
результирующая выборка:
д
АЬ
1£1.ШУ*1 K..^Pe^ef1. ^ Активность |
Щ \ Название
—■" Мин значение
Макс значение
Итерация
Мат ожидание
Разброс
Дисперсия
JJU
Исследовать сеть на устойчивость к различным уровням зашумленности ос,
!23 23 х
Рис. 12.39. Окно выбора режима исследования на устойчивость
к шуму или оценки вместимости
Визуализация получаемых результатов обеспечивается с помощью
дополнительного окна «графики». В закладке «Активность» окна «графики»
отображается аксонометрическая проекция карты активности установленного слоя
активности, где на вертикальной оси различным цветом отображается
значение активности каждого элемента карты (рис. 12.39, 12.40). Временной
параметр процедуры тестирования с высвечиванием процента завершенности
отображается в виде окна индикатора состояния (рис. 12.41). В любом режиме
работы среды имеются индикаторы состояния, при помощи которых можно
отказаться от каких-либо проводимых действий (рис 12.42).
IS fJB^l.tC пРеде"" ■<* Активности f
Рис. 12.40 Аксонометрическая проекция карты
активности выбранного слоя
335
12. Программная эмуляция нейрокомпьютеров
Работа
DiiO * ft 6! ! It 1ШВ* ■ I f
Обучающая выборка:
АЬД
Тестовая выборка:
■■v.i_v- ;*V*y
результирующая вь
Индикация состояния
А
152
Cancel
Е
1.00
0 75
0 50
0 25
-аЫ
О
И
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 60 65 90 95 100
tg Шум ife Пределj ф Активность|
Готово I
ГГоою /,
Рис. 12.41. Окно процесса тестирования
УгЩШ;мМФШЫ:Ш%'*Ш*ШШттА:
^\ ££айл " с Пуск Эксперимент §ид Окно Цомашь
I'D с*Н, * *И| ! legist i
[Обучающая выборка:
АЬД
естовая выборка:
результирующая вьи
Л
даг>
ШВЕ
Идет обучение сети.
tg Шам 1 t£ Предел ^> активность | !
Готово
М акс. значение 4493 361103
± значение 648.2360Б8
шш
. [00:14 ji
Рис. 12.42. Окно состояния системы
336
12.5. Нейропакет Neural Networks IDE
Jf Neural networks IDE - [Nnidel]
Е^З Файл Работа t- еыборн ами Пуск Эксперимент Виц Дкно Осмошь
|D с* В 1 .* '.' *Ч t IJiQiBI ■ |f •
Обучающая выборка:
ABCDEFGHIJKLMNOPQRST
<\ i
Готово " {
НГаНЕЗ
_1£Ш
£J
и \
Г[50:2Э „^
Рис. 12.43. Обучающая выборка для лабораторной работы №1
Возможности нейропакета IDE
Рассмотрим возможности нейропакета на примере выполнения
лабораторных работ по курсу «Интеллектуальные системы».
Лабораторная работа №1. Целью данной лабораторной работы является
определение максимальной величины бинарной зашумленности графических
образов, при которой сеть Кохонена с выбранными параметрами может
уверенно их распознавать.
Для обучения сети создадим монохромные обучающую и тестовую
выборки с геометрическими размерами 30x30 пикселей. В качестве обучающей
выборки возьмем заглавные буквы шрифтов Times New Roman nArial (рис. 12.43).
В качестве тестовой выборки (для визуального контроля за процессом
обучения) используем копию обучающей выборки и зашумим ее бинарным шумом
от 36 до 100%. На рис. 12.44 показана зашумленная тестовая выборка.
Выберем следующие параметры сети:
Порог обучения 0.000000
Максимальное число эпох 500
Число нейронов по горизонтали 15
Число нейронов по вертикали 15
Скорость обучения 1.000000
Начальный радиус стимуляции 15
Интервал торможения 0
Проведем полное обучение сети по методике, изложенной выше, снимая
характеристики в следующих контрольных точках: 1,2, 5,10,20, 50,100, 150,
200,259 (конечная итерация). На рис. 12.45 и 12.46 представлены результаты
работы сети после первой и последней итераций.
" Файп Работа с выборками П^к Эксперимент Вив Окно Помощь _
iDeSH' » П'.-ej.t и\-мш: «|f
т™втттт&жшшж
«1 i
1311
±1
Г—Г" | П1204 ,„,
Рис. 12.44. Зашумленная тестовая выборка
337
12. Программная эмуляция нейрокомпьютеров
^Neural networks IDE - [lab.nni]
E5 Файл Работа с выборками Пуск Эксперимент Вид Дкно Помошь
НПО
D Е* У I % 4i fe
* И
Ш1*
f
Обучающая выборка: _^_|
ABCDEF
Тестовая выборка:
HI
' -£Й
& :' *
*Ф
1-1
Название
Значение
Дисперсия
Мат. ожидание
Разброс
Итерация
Мин. значение
Макс, значение
0.201313
0.279272
0.448679
1
3216 016169
4589.155151
.tZI Шчм] Eg Предел ^Активность
Готово
ТШв а
Рис. 12.45. Результат работы сети после первой итерации
Нейропакет имеет возможность представить результаты в виде графиков.
Причем предусмотрена возможность представлять как несколько графиков
вместе, так и порознь. На рис. 12.47 изображено окно с тремя графиками,
отражающими работу сети: математическое ожидание, стандартное отклонение и
дисперсия в зависимости от уровня зашумленности обучающей выборки.
На рис. 12.48, 12.49 и 12.50 показаны раздельно графики математического
ожидания, стандартного отклонения и дисперсии соответственно. Из графика
среднего квадратичного отклонения (см. рис. 12.49) видно, что дискретное
распределение ошибки является распределением с большим рассеянием.
Таким образом, сеть Кохонена с объявленными параметрами обучилась за
относительно небольшое число итераций - 260 эпох. Из графиков
математического ожидания, дисперсии и среднего квадратичного отклонения видно, что
сетью гарантируется уверенное распознавание при наличии бинарной
зашумленности образов до 20 %.
338
12.5. Нейропакет Neural Networks IDE
p^p Neural networks IDE - [lab.nni]
£5 Файл Работа с выборками Пуск Эксперимент Дид Окно Помошь
■ iyy , 1му .ц^,. .Д—у... .ЦД .
HOD
JffJxl
Тестовая выборка: . I
А В С D E F
Результирующая выборка:
^ В С D E F ^
Название
Дисперсия
Мат. ожидание
Разброс
Итерация
I Мин значение
i Макс значение
Значение
"о оооооо
О 000000
0.000000
2466.560358
3710 565995
■fcjjJM±l-^_D£g5g£L ^ft Активность |~
Готово
"Г"
Т*1315
Рис. 12.46. Результаты работы сети после 259-й итерации
р^ Neural networks IDE - [lab.nni]
|Э Файл Работа с выборками Пуск Эксперимент Вия Окно Помошь
jl D с£ У ; *
ЯП Б
JsJxJ
ШЩ\ \%\Dl DI и j f
1.00
0 75
0 50
0 25
! I !
? -* 4
: i :
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 65 90 95 100
fa» Шум |Z Предел] ф Активность]
Готово
I 11352 4
Рис. 12.47. Графики работы сети
12. Программная эмуляция нейрокомпьютеров
$*- Neural networks IDE - [lab.nni]
c" 5Е.айл Работа с выборками Пуск Эксперимент ЕЗид Дкно Домошь
d с* в | * щ-, т! ! и ,Qim
Е У
1 00
0 75
0.50
0.25
.
0 5 10
15 20
УГХ
/l I I
^Г\ I I I
< i м м
25 30 3S 40 45 50
I II I I II I
I I I I I I I I
I II II II I
I I I I I I I I
I I I I I I I I
55 60 65 70 75 80 85 90
I I
I |
I I
I I
9S 100
tZ"UlyM| fc Преявя | <ft Активность |
Готово
ГГ1353 A
Рис. 12.48. График математического ожидания
eP^- Neural networks IDE - [lab.nni]
«■°c файл Работа с выборками Пуск Эксперимент Вид (Зкно ромошь
jj D с# Н . *. Чз Ш | • <* | т В* ■ | f !
:
г
•J
от
1 00
0 75
0 50
0 25
..... <1 1 |ЧГ'П 7 Т Т Т- т т т .
Rls!E3
--=Jftl*J
—
0 5 10 15 20 25 30 3S 40 45 50 55 60 65 70 75 80 85 90 95 100
изо
* Предел} -40b Активность |
• ■ • ! Г — Г
— П1354
/А
Рис. 12.49. График стандартного разброса
J^*- Neural networks IDE - [lab.nni]
D*c ^аил Работа с выборками Пуск ксперимент Цид Цкно 0омошь
| d' с* а у, Sle'T'i ~!$ | D4 ш ■ 11 "j"
В1Й1ЕЗ
Е i
1 00
0 75
050
0.25
С
,
J 5 10
I
.. i I
TIM
15 20 25 30
I т
I I
I I
35 40
ill!
I I l l
45 50 55 60
65 70
! !
I
75 80
T т
I I
85 90
I ,n-
95 100
fc Шум IR ПруЦ»?..!..^ Дктмвмость1
Готово
"Г ГП'§55 уЛ
Рис. 12.50. График дисперсии
340
12.5. Нейропакет Neural Networks IDE
Карты активности демонстрируют, как различные классы образов
разместились по нейронам сети. Сходные образы, поступившие на вход сети
Кохонена, определяются одними и теми же областями на карте и, следовательно,
будут восприняты и отнесены в одни и те же классы.
Лабораторная работа №2. Целью данной работы является определение
информационной вместимости сети, т. е. максимального числа образов,
которое сеть может запомнить и уверенно воспроизвести.
Для проведения этой работы в целях уменьшения машинного времени
выберем монохромные образы с геометрическими размерами 10x10 пикселей, а
также установим следующие параметры сети Кохонена:
Порогобучения 0.000000
Максимальное число эпох 500
Число нейронов по горизонтали 3
Число нейронов по вертикали 3
Скорость обучения 1.000000
Начальный радиус стимуляции 3
Интервал торможения 0
Максимальное число образов 100
Построим зависимости изменения ошибки эксперимента от различной
вместимости сети Кохонена и определим тенденции изменения этой ошибки.
Яг Neural networks IDE - |1аЬ2 nni]
у, Файл Работа с выборками Паск Эксперимент Вт Окно Помошь
шш
J£]x|
и
100
0.75
0 50
0 25
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 Е0 85 90 95 100
tZ Шцм JZ Предел Ф Активность)
Готово
ТГкПй
Рис. 12.51. Зависимость математического ожидания
от вместимости сети Кохонена
341
12. Программная эмуляция нейрокомпьютеров
рЙ*- Neuial networks IDE - [1аЬ2 nni]
^£аГ.я Работа с выборками Пуск Эксперимент Цнд Йнно Домошь
НИ С
il
llll^NlllilPlillHllliinHlilici^HliliinillhilliliHHilhi^iiilMiilii
I ii ; и и :
III!
iinnipiiNhi^HiiniiMJiHHHhjiiijiMiiii/iiijiiHiiijiijiiiUjjiiiMi
0 5 10 15 20 25 30 35 40 45 SO 55 60 65 70 75 80 65 90 95 100
• .tS ,Р*" Xc. Лредеп l.ffr Активность |
Готово
11634
Рис. 12.52. Зависимость дисперсии от вместимости сети Кохонена
Для этого поставим эксперименты в точках, соответствующих значениям
максимального числа вместимого образов 5,10,15,20,..., 100. В качестве ошибки
сети будем использовать математическое ожидание, дисперсию и
среднеквадратичное отклонение по результатам всех экспериментов. Функциональные
зависимости для различной интерпретации ошибки эксперимента приведены
на рисунках 12.51,12.52 и 12.53.
c$f- Neural networks IDE - [Iab2.nni]
" ЗЦайл Работа с выборами Пуск. 3» сперименг виа 0*но Помошь
;| D G$ Н > Ph т '; ! «5 Ш D* ■ 1 ? |
■1
J
1
1
' _. . .j_™ -. -™: - - " . .
Е
1 00
0 75
0 50
0 25
, _
.■•'VI \' ,VA: J I "J I I .1 > li!:; , >:" -
■ПЕЗ
-lalxj
™ -- —
'l . . .,.
~ 5 10 1S 20 25 30 35 40 45 50 55 60 65 70 75 80 E5 90 95 100
£7; Шам {7° Предел ] ffe Активность |
Готово \ i
' I hear? л
Рис. 12.53. Зависимость среднеквадратичного отклонения
от вместимости сети Кохонена
342
12.6. Пакет STATISTICA Neural Networks
Анализ приведенных зависимостей математического ожидания, дисперсии
и среднеквадратичного отклонения показал, что сеть размером 3x3 нейронов
Кохонена уверенно распознает до 5 образов (ошибка не более 25%).
Максимальное число образов равно 7, при этом ошибка приблизительно равна 50%.
При обучении большему числу образов сеть способна к обобщению, что видно
из графика математического ожидания, где ошибка не превышает 85%.
12.6. Пакет STATISTICA Neural Networks
Нейросетевой пакет STATISTICA Neural Networks (STNN), позволяющий
реализовать НС, имеет удобный пользовательский интерфейс и предназначен для
профессионального моделирования (разработки) прикладных нейросетевых
алгоритмов.
Интерфейс прикладной системы программирования STATISTICA Neural
Networks API позволяет легко интегрировать разрабатываемые нейросетевые
приложения в уже существующие вычислительные среды. Сокращенная
версия API позволяет запускать созданные и обученные в среде STNN НС из
других программ-приложений, написанных на С, C++, Delphi или Visual Basic.
Полный API предоставляет пользователю доступ ко всем возможностям ядра
пакета STNN, включая создание, редактирование, ввод/вывод данных и
архитектур сетей, а также обучение сетей.
Интерфейс пользователя данного пакета отражает основные этапы работы
с НС: подготовка данных, обучение сети и работа с сетью.
Данный пакет является Windows-приложением и существует в виде
32-разрядной версии для Windows 95 и Windows NT и 16-разрядной версии для
Windows 3.1 (для 16-разрядной версии достаточно 486-го процессора и 4 Мбайт
оперативной памяти). Для более сложных вычислений рекомендуется
использовать Pentium с 16 Мбайт ОП.
Работа с данными
В программе STNN предусмотрена возможность непосредственно
считывать файлы данных системы STATISTICA, при этом автоматически
определяются номинальные переменные (т. е. переменные, которые могут принимать
одно из нескольких заданных текстовых значений, например, Пол ={Муж,
Жен}), а также типы данных, как даты и время, переводятся в числовое
представление (на вход НС могут подаваться только числовые данные). Возможен
также импорт данных средствами системы STATISTICA. Помимо функции
импорта реализованы также и другие возможности доступа к внешним
источникам информации:
• использование буфера обмена Windows (понимаются форматы данных
таких приложений, как Excel и Lotus);
• доступ к различным базам данных через функцию ODBC;
• ряд дополнительных специальных средств;
• ряд дополнительных специальных средств импорта данных с различными
форматами файлов.
343
12. Программная эмуляция нейрокомпьютеров
В рассматриваемом пакете реализованы основные операции с данными,
характерными для табличных процессоров.
Типы переменных
Все данные из файла данных делятся на четыре группы (множества):
обучающие, контрольные, тестовые и неучитываемые. Обучающее множество
служит для обучения НС, контрольное - для независимой оценки хода обучения,
тестовое - для окончательной оценки после завершения серии экспериментов.
Неучитываемое множество используется в тех случаях, когда часть данных
испорчена, ненадежна.
Все переменные делятся на входные, выходные, входные/выходные
(например, при анализе временных рядов) и неучитываемые (если их полезность для
построения прогноза заранее неясна). Тип переменной или наблюдения
обозначается цветом соответствующих ячеек в файле данных. В пакете имеется
возможность присваивать имена отдельным переменным и/или наблюдениям.
Для номинальных переменных существуют специальные методы
преобразования значений, а тип выходных переменных позволяет отличить задачи
классификации (где используются номинальные переменные) от задач регрессии
(где используются числовые переменные).
Добавлять, удалять, копировать и перемещать наблюдения и переменные
можно с помощью соответствующих пунктов меню.
Построение сети
Сеть пакета STNN может содержать слои для пре- и постпроцессирования, в
которых соответственно исходные данные преобразуются к виду, подходящему
для подачи на вход сети, а выходные данные - к виду, удобному для
интерпретации. При этом номинальные значения преобразуются в числовую форму,
числовые значения масштабируются в подходящий диапазон, проводится
подстановка пропущенных значений (используются соответствующие оценки этих
значений), а в задачах с временными рядами осуществляется формирование
блоков последовательных наблюдений.
Новая сеть создается в режиме диалога с пользователем, при этом
используется Советник -Advisor, который помогает выбрать тип сети и установить
основные параметры: число элементов в каждом слое, число слоев (для
многослойного персептрона). Количество промежуточных слоев можно менять
произвольно, однако обычно Советник предлагает эвристически определенные
различные значения по умолчанию. Количество входных и выходных
переменных обычно жестко связано с числом входных и выходных переменных пре- и
постпроцессирования, функцией преобразования и (в задачах анализа
временных рядов) размером временного окна.
Конструкцию сформированной сети можно менять с помощью Редактора
сети — Network Editor и Редактора пре (постпроцессирования — Pre/Post
Processing Editor). Имеется возможность менять имена и значения входных и
выходных переменных, их функции и параметры преобразования, а также до-
344
12.6. Пакет STATISTICA Neural Networks
бавления новых и удаления уже существующих переменных и изменения
параметров временного ряда.
Редактор сети позволяет также изменять тип функции ошибки, функции
активации в конкретных слоях сети, добавлять и удалять элементы
промежуточных слоев или слой целиком. Исключение составляют сети Кохонена, где
можно добавлять и удалять выходные элементы.
В визуально представляемой таблице весов представлены веса и пороги либо
для выделяемого слоя сети, либо для всей сети. Эти данные выводятся
главным образом для того, чтобы значения весов можно было переслать в другую
программу для дальнейшего анализа.
Обучение сети
В пакете STNN реализованы архитектуры сетей следующих типов:
многослойный персептрон, сеть Кохонена, радиально-базисная сеть.
Для обучения многослойных персептронов используются пять различных
алгоритмов обучения: обратного распространения, быстрые методы второго
порядка - спуск по сопряженным градиентам и Левенберга-Марквардта, а также
методы быстрого распространения и «дельта-дельта с чертой»
(представляющие собой вариации метода обратного распространения, но в некоторых
случаях работающие быстрее).
Рекомендации по использованию этих методов следующие. В большинстве
ситуаций нужно использовать метод сопряженных градиентов, так как в этом
случае обучение проходит значительно быстрее (иногда на порядок по
сравнению с обратным распространением). Метод Левенберга-Марквардта для
некоторых типов задач может оказаться гораздо эффективнее метода сопряженных
градиентов, но его можно использовать только в сетях с одним выходом,
среднеквадратичной функцией ошибки и небольшим числом весов (порядка 20 -
50), так что фактически область его применения ограничивается небольшими
по объему задачами регрессии.
Особенностями процедуры обучения в STNN являются следующие:
• кросс-проверка - Cross verification - проверка качества работы сети на
каждом шаге итерации с помощью специального контрольного множества (для
выявления эффекта переобучения сети);
• возможность задания различных условий остановки процедуры обучения:
максимальное число итераций (эпох); достижение определенного уровня
ошибки обучения; достижения состояния, при котором ошибка перестает
уменьшаться на определенную величину; установление числа итераций, на протяжении
которых наблюдается увеличение ошибки обучения (в STNN стандартное
значение этого показания равно пяти);
• сохранение лучшей сети - автоматическое сохранение наилучшей из
сетей, полученных в ходе обучения (по показателю контрольной ошибки); если
при этом включен режим учета всех прогонов, то сохраняется лучшая сеть и по
показателю ошибки обучения;
345
12. Программная эмуляция нейрокомпьютеров
• установка штрафа за элемент сети с тем, чтобы при сравнении различных
сетей штрафовать сети с большим числом элементов (наилучшая сеть обычно
представляет собой компромисс между качеством проверки и размером сети);
• автоматический конструктор сети, позволяющий создавать сеть,
наилучшим образом решающую поставленную задачу; для этого необходимо указать
типы исследуемых сетей, число итераций обучения, определяющее
продолжительность поиска, величину штрафа за элемент; поскольку время поиска
подходящей сети является очень большим, алгоритм автоматического
конструирования применяется обычно в задаче анализа временного ряда;
• генетический отбор входных данных, позволяющий найти наилучшую
комбинацию входов сети и устранить переменные, являющиеся наименее
информативными. В процессе работы алгоритма создается большое число
пробных битовых строк (параметр задается пользователем) с искусственным
скрещиванием их на протяжении заданного числа поколений, используя
генетические операторы мутации и скрещивания, интенсивностью которых
можно управлять. Данная процедура может потребовать много времени,
поэтому обычно применяется к сетям с большим числом входов.
Работа с сетью
В пакете STNN с помощью обученной сети можно проводить анализ
данных: прогонять сеть на отдельных наблюдениях из текущего набора данных,
на всем наборе данных или на произвольных, задаваемых пользователем
наблюдениях.
В пакете STNN предусмотрено три формата вывода: Переменные — Variables
(постпроцессированные переменные после масштабирования и
преобразования номинальных значений), Активации -Activations (значения активации для
выходных элементов сети, необходимые для показа доверительных уровней в
задачах классификации) и Кодировка - Codebook (этот формат применяется в
сетях Кохонена и представляет собой вектор весов выигравшего нейрона —
ближайшего к тестируемому наблюдению).
Выходные значения результата прогона (в одном из трех перечисленных
форматов) выдаются в виде одной таблицы, содержащей целевые значения и
ошибки (как ошибка для каждого значения, так и суммарная
среднеквадратичная ошибка). Для выяснения роли элементов скрытых слоев могут быть
выведены внутренние активации элементов сети, представленные в виде
гистограммы и таблицы чисел.
Представление выходных данных в двумерных проекциях осуществляется с
помощью диаграмм кластеров (Claster Diagram), на которых классы
представляются в виде двумерной диаграммы рассеяния или в виде графика
поверхности отклика (Response Surface), где кривая регрессии изображается в виде
двумерной поверхности, которую можно вращать с помощью линеек прокрутки.
346
12.7. Пакет Fuzzy Expert
Работа с сетями Кохонена имеет ряд особенностей. Во-первых,
необходимо представить топологическую карту (Topological Map), где в наглядном
виде представлены результаты нейронной активности выходных элементов для
каждого обрабатываемого наблюдения. Во-вторых, в сетях Кохонена для
обучения применяют алгоритмы без учителя, поэтому возникает необходимость
выявлять кластеры в топологической карте и помечать их, приписывая
элементам названия классов.
В пакете STNN в соответствующем окне графически представляется
Топологическая карта с определенными уровнями активности нейронов. Поскольку
сеть Кохонена всегда имеет одну номинальную переменную, то ее значения и
будут названиями классов.
Для отображения результатов анализа временного ряда также имеется
специальное окно.
После окончания обучения структура и параметры сети сохраняются в
файле и могут быть использованы в дальнейших исследованиях. Конечные
результаты (графические и числовые) также могут быть сохранены в формате
файлов данных системы STATISTICA Windows, являющегося мощным
математическим пакетом обработки статистических данных. Таким образом, пакет
STNN естественно встроен в весь огромный арсенал методов статистического
анализа и визуализации данных, который представлен в системе STATISTICA.
12.7. Пакет Fuzzy Expert
Программный пакет системы нечеткой логики - Fuzzy Expert (рис. 12.53),
разработанный в КФ МГТУ им. Н.Э. Баумана, может использоваться как
автономно, так и для организации совместной работы с нейроимитатором.
Для Fuzzy Expert при ее функционировании характерны следующие
информационные потоки (рис. 12.54):
1 - задание входного вектора X (в режиме диалога или установка по
умолчанию), представляющего собой список параметров, описывающих
корпоративную вычислительную сеть: количество пользователей сети, простота
установки, поддержка различных видов ОС, ограничения на стоимость и т. д.;
2 - задание целей вывода, т. е. указание наименования того параметра сети,
значение которого будет определяться в процессе вывода (одновременно
возможно задание нескольких целей): топологии сети, типа физической среды
передачи данных, типа сетевого или канального протокола и т. д.;
3 - определение нечетких значений входных параметров;
4 - задание пользователем метода формирования функции принадлежности;
J - задание пользователем метода нечеткого вывода;
6 - задание пользователем метода дефаззификации;
7 - взаимодействие Решателя с БЗ в процессе вывода;
8 - вычисление нечеткого результата вывода;
9 - формирование отчета;
347
12. Программная эмуляция нейрокомпьютеров
Пользователь
■' '
Методы
формирования
функции
принадлежности
Выбор домена
атрибутов для
вывода
1
Методы
нечеткого
вывода
Блок
ззификации
Блок задания
целей и
ограничений
Методы
дефаззификации
Блок вывода
решений
(Решатель)
База
знаний
L 4 -I—*-
ю
Блок редактора
базы знаний
Блок накопления
и приобретения
знаний
11
Блок
дефаззификации
X
Блок
формирования
отчетов
12
Блок
построения
дерева решений
13
Нейросетевая
программная
среда
Блок
объяснений
Рис. 12.54. Схема функционирования Fuzzy Expert
10 — редактирование правил и фактов;
// - пополнение БЗ новыми правилами и фактами;
12 — построение дерева решений;
13 - просмотр результатов вывода.
Наиболее важными проблемами, связанными с интеграцией подсистемы
нечеткого вывода в гибридных системах, являются проблемы поддержки
различных форматов представления информации и алгоритмов ее обработки,
импорта-экспорта данных, открытости системы. Рассмотрим некоторые
особенности Fuzzy Expert, позволяющие решать перечисленные проблемы.
Некоторые особенности реализации Fuzzy Expert
Внешний вид системы нечеткого вывода Fuzzy Expert и фрагмент базы
знаний представлены на рис. 12.55.
348
12.7. Пакет Fuzzy Expert
jFuzzyWin - lD:\DISTRIBS\D\Fuzzy4FuzzyWin\Lg_new fcs] НГСЗЕЗ
S. Full Base
| VAL свыше 500м((498,0),(502,1))
}
PROP ОС
{
QUE Возможно ли использование различных ОС?
VAL да, нет
}
}
RULES
{
IF (сеть стоииость=низкая) (сеть пользователи=менее 10) (сеть длина сегмента=до
100м) THEN (сеть среда передачи=коаксиал,1)
IF (сеть.стоииость=низкая) (сеть.пользователи=менее 10) (сеть.длина
сегиента=100-500м) THEN (сеть среда передачи=коаксиал,1)
IF (сеть стоииость=низкая) (сеть пользователи=менее 10) (сеть длина
Рис. 12.55. Внешний вид интерфейса системы нечеткого вывода
Требование поддержки введения новых признаков и свойств предметной
области привело к необходимости разработки специального
структурированного формата файлов баз знаний в виде объектов. Входной вектор X,
описывающий некоторый объект, включает координатыxvx2, ...,хл, каждая из которых
задает определенный параметр (базовую переменную), определяющую
свойство объекта. Например, входной параметр, задающий количество
пользователей компьютерной сети, описывается на подмножестве языка FLL (Fuzzy Logic
Language) следующим образом:
PROP пользователи
{
QUE Каково предполагаемое количество пользователей сети?
VAL менее 10((9,1),(11,0))
VAL 10 - 50((8,0),(10,1),(48,1),(52,0))
VAL более 50(48,0),(52,1))
}
Здесь PROP - задает имя параметра, QUE - вопрос, задаваемый в режиме
диалога с пользователем, VAL - определяет список значений лингвистической
переменной (первая цифра в круглых скобках - значение базовой переменной,
вторая - значение ФП), на основе которого при выполнении процедуры фаззи-
фикации средствами языка FLL вычисляется нечеткое значение входного па-
349
12. Программная эмуляция нейрокомпьютеров
раметра. Это позволяет при организации процедуры нечеткого вывода
исключить трудоемкий этап формирования функций принадлежности с помощью
эксперта.
Некоторые параметры (факты) в различных сеансах вывода могут быть как
входными, так и выходными (целевыми), например, физическая среда
передачи данных представляется в виде:
PROP среда передачи
{
TYPE OutVar
QUE Каков тип среды передачи?
VAL коаксиал;витая пара;оптоволокно;беспроводной
}
Тип факта (входной или целевой) помечается пользователем перед началом
вывода.
Разработанная система поддерживает технологию MDI-Multiple Document
Interface, что позволяет одновременно редактировать и создавать несколько баз
знаний. С помощью Редактора базы знаний (БЗ) пользователь может
добавлять и изменять объекты и их свойства, а также список значений функций
принадлежности по каждому параметру, что графически отображается в окне
Редактора БЗ (рис. 12.56).
При редактировании базы правил имеется возможность добавлять новые
правила, а также изменять содержимое предпосылок и заключений.
у Win for Wm9S/NT DatabaseEditor - Pacts EtBtor Made
f ' FactTUtoi"
-ЛЯ.К1
ObHects
«LI
if
Pigpafhes 1
среда передачи
сетевийпритогоп
каналвный протокол
пстмоватг-ли
простота угтаноеки
н эдежность
д пина сегмента
ОС
mjf i пая cnccohhi ( и rriv \yt/c]''
'" input Г Ou£>ul
VaMes
низкая
средняя
Ы I
NAN
5 NAM
NAN
\/
i
..J-L-
%щ
1100
6000
G200
&->
1
1
rEE
g
1000 1Ш1 2:JO0 25JU !3WH 3500 4 ШО 4 6UE, С 000 i 6^J 6000,
Рис. 12.56. Внешний вид Редактора знаний в режиме редактирования фактов
350
12.7. Пакет Fuzzy Expert
С целью уменьшения трудоемкости нечеткого вывода используется
собственный оригинальный формат внутреннего представления знаний. В отличие
от систем нечеткого вывода, в которых хранение нечеткой базы знаний
основано на стандартном представлении правил в виде матрицы отношений в
системе Fuzzy Expert база знаний логически делится на 2 части — базу правил и
базу фактов. Правила хранятся в виде списка, каждый элемент которого
представляет собой набор соответствующих предпосылок и заключений. Факты
(параметры) представлены в виде рассмотренных выше объектов,
объединенных также в список. Каждому факту сопоставляется набор относящихся к нему
правил. При этом правило считается относящимся к факту, если этот факт
входит в предпосылку данного правила. Для экономии памяти в этом случае
хранятся не сами правила, а указатели на уже существующие правила из базы
правил, что значительно упрощает механизма вывода.
При задании целевого факта во время процедуры вывода выполняются все
принадлежащие ему локальные правила, в результате чего список целевых
значений пополняется промежуточными фактами, входящими в заключения этих
правил. Далее процесс рекурсивно повторяется до определения фактов, список
правил которых пуст, с последующим выполнением всех целевых правил.
Таким образом, построение дерева нечеткого вывода осуществляется один раз на
этапе загрузки и инициализации системы (рис.12.57), а не каждый раз при
необходимости организации нечеткого вывода.
Очевидно, при этом существенно экономится время на просмотр
необходимых правил и значительно уменьшаются накладные расходы на организацию
нечеткого вывода.
Расширяемость системы в плане добавления новых алгоритмов обработки
информации обеспечивается Конфигуратором, с помощью которого осуще-
_ FuzzyWtn
f New Овео Save Facta
Ь среда передачи
*-■ Rule О
-+: Rulel
& Rule 2
■* Rule3
№ Rule 4
f+i Rule 5
Ф Rule 6
W- Rule 7
=+*■ Rule 8
+] RuleS
£ Rule 10
\*. Rule 11
*: Rule 12
<t Rule 13
i- Rule 14
сеть >проп. способность
сеть > стоимость
сеть >длина сегмента
-+j Rule 15
ф Rule 16
ft; Rill* 17 _
Рис. 12.57. Структура базы знаний
351
Rufei Oanoiusfe E ни
•й
12. Программная эмуляция нейрокомпьютеров
i object for conclude
ШШШЕШЯ
ш
s"' сеть
у/ среда передачи
'^ сетевой протокол
'„^Ч| канальный протокол
\"У простота установки
'."Ч| надежность
'"*' масштаб
'£> тип
у/ ТОПОЛОГИЯ
'„".' носитель
у/ соединение
\vl протокол
;S4' os
: ]Каково предполагаемое количества пользователей сети?
j.Cet*
Clear
Close
Рис. 12.58. Задание целевых
параметров
Рис. 12.59. Ввод значений
параметров сети
ствляется настройка параметров Fuzzy Expert путем выбора динамически
загружаемых модулей ( plug-ins). Например, модуль Input plug-in
обеспечивает ввод данных с определенного физического устройства в систему. При
выборе команды Open на главном окне системы нечеткого вывода
используется функциональность подгружаемого модуля.
Модуль Output plug-in осуществляет вывод (сохранение) данных на
определенное физическое устройство из системы (экран монитора, внешний
носитель или нечеткий контроллер). При выборе команды Save (Save As)
используется функциональность этого модуля.
Дополнительные возможности по интеграции Fuzzy Expert с нейроимитато-
ром (см. рис. 12.54), реализуются модулем GPU {General Performance Unit)
plug-in, с помощью которого между различными системами организуется
взаимный обмен информацией, представленной в заданном формате. Этот модуль
совместно с блоком объяснения обеспечивает также возможность
интерпретации результатов работы НС.
Рассмотрим алгоритм вывода на примере выбора аппаратных и
программных средств компьютерной сети (БЗ сформирована на основе результатов
натурного и модельного экспериментов, а также знаний экспертов).
1. Задание одного или нескольких целевых фактов (рис. 12.58), значения
которых необходимо определить при выводе.
2. Задание значений входных параметров в режиме диалога с
пользователем (пример ввода числа пользователей сети показан на рис. 12.59) или с
помощью модуля Input plug-in (либо используя ввод по умолчанию).
3. Выбор метода нечеткого вывода.
4. Организация вывода по выбранному методу и просмотр результатов.
Последующее уточнение полученного решения предполагается осуществлять
с помощью метода имитационного моделирования.
352
13. ЭЛЕМЕНТНАЯ БАЗА ДЛЯ АППАРАТНОЙ
РЕАЛИЗАЦИИ НЕЙРОКОМПЬЮТЕРОВ
Приведены особенности трех главных направлений аппаратной реализации НК:
программируемые логические интегральные схемы, цифровые сигнальные процессоры и нейрочипы.
Особое внимание уделено отечественному микропроцессору Л1879ВМ1. Рассмотрены его
структурная организация и система команд.
13.1. Общие сведения
Развитие элементной базы вычислительной техники всегда
стимулировалось теоретическими и инженерными разработками в области архитектуры
ЭВМ. В этом смысле НК не являются исключением. Современный уровень
теории НС, нейроматематики, теории и практики архитектуры и схемотехники
НК, достижения микроэлектроники позволяют создавать различные по
принципу построения нейро-ЭВМ. При практической реализации базового
элемента НК - формального нейрона, его отдельных компонентов, выбора способа
соединения нейронов по слоям в сеть и обучения сети разработчик может
выбрать одно из трех принципиально отличающихся направлений:
• программное - все элементы НК реализуются программно на
универсальных ЭВМ с архитектурой фон Неймана;
• аппаратнопрограммное - часть элементов реализуется агшаратно, а часть
- программно;
• аппаратное — все элементы НК выполнены на аппаратном уровне, кроме
специфических программ формирования синаптических коэффициентов (см.
рис. 2.1).
Сегодня существуют множество реализаций для каждого из этих
направлений. Программные системы, реализующие первое направление, даже если для
них требуется многопроцессорная или многомашинная аппаратная
поддержка, получили название нейроэмуляторы, нейроимитаторы. Такое
направление практической реализации НК рассматривалось в предыдущем разделе.
353
13. Элементная база для аппаратной реализации нейрокомпьютеров
Второе и третье направления аппаратно реализуются на заказных
кристаллах (ЗК - ASIC), встраиваемых микроконтроллерах (МК - дС), процессорах
общего назначения (GPP), программируемых логических интегральных
схемах (ПЛИС - FPGA), транспьютерах, цифровых сигнальных процессорах (ЦСП
-DSP), нейрочипах. Имеется много примеров практической реализации НК на
указанной элементной базе, однако все больше ученых и разработчиков
отдают предпочтение ЦСП, ПЛИС и нейрочипам.
Второе направление характерно тем, что аппаратная часть нейровычисли-
тельного модуля вьшолняется в виде платы расширения для универсальной
ЭВМ, имеющей, как правило, архитектуру фон Неймана. В таких платах
аппаратно может выполняться, например, операция взвешенного суммирования, а
операция нелинейного преобразования - программно-базовой ЭВМ. Такие
платы расширения получили название нейроускорители.
Если вычислитель спроектирован по архитектуре, представленной на рис. 2.1,
то его основной операционный блок выполняет все операции в нейросетевом
базисе, а в запоминающем устройстве хранится не программа решения
конкретной задачи, а программа формирования синаптических коэффициентов. Если
его блок обучения на аппаратном или программном уровне реализует
конкретный алгоритм обучения НС, то такой вычислитель следует отнести к
собственно НК.
Рассмотрим некоторые вопросы применения для построения нейровычис-
лителей второго и третьего направлений ПЛИС, ЦСП и нейрочипы.
13.2. Особенности ПЛИС как элементной базы
нейрокомпьютеров
Более подробно особенности ПЛИС как элементной базы НК рассмотрим
на примере ПЛИС фирмы XILINX-mna FPGA (FieldProgrammable Gate Array).
ПЛИС XILINX(b дальнейшем просто ПЛИС) представляет собой массив
конфигурируемых логических блоков (КЛБ) с полностью конфигурируемыми
высокоскоростными межсоединениями. На рис. 13.1 представлена обобщенная
структурная схема ПЛИС XILINXсерии ХС4000. Весь массив КБЛ и
конфигурируемые межсоединения расположены на кристалле. По периферии
кристалла расположены блоки ввода-вывода, из которых каждый включает два
триггера: один для ввода, другой для вывода информации. Кроме того, сюда включена
логика дешифрации и цепи контроля высокоомных состояний.
На рис. 13.2 приведена упрощенная структура КБЛ ПЛИС серии ХС4000/
Spartan. Каждый КБЛ состоит из следующих устройств: двух просмотровых
таблиц Xilinx 16x1 - ZC/Г-таблиц (Look Up Table), двух блоков логики
ускоренного переноса, двух триггеров. Время распространения сигналов через
устройства КБЛ составляет: через iC/Г-таблицу - около 0,5 не, через блок
ускоренного переноса - 0,1 не, время переключения триггеров - не более 0,5 не.
354
13.2. Особенности ПЛИС как элементной базы НК
ODD
-Конфигурируемые _._..--.
межсоединения N. | | | |
CD
CD
ЕЗ
Р(К-1)
R0C0
RI.C0
R2C0
R0CI
тех
R0C2
- + -1-
ДО
С(ЛЧ)
CD
СП
CZi
Массив КБЛ
CD
CD
Д(ЛЧ)
со
I I
-U
I I
II
R(N-l)
ocw-i)
CD
CD
CD
DD№
Блоки ввода-вывода
-ODD
Рис. 13.1. Обобщенная структура ПЛИС Xilinx серии ХС4000
GA -
СЪ -
G2-
G1-
BY-
F4-
F3-
F2-
F1-
ВХ-
LUT
COUT
carry
logic
LUT
SP
D
— YQ
EN
RC
carry
logic
SP
D
— XQ
EN
RC
YB
Y
■XB
■X
CIN
Рис. 13.2. Упрощенная структура КБЛ ПЛИС серии XC4000/Spartan
355
13. Элементная база для аппаратной реализации нейрокомпьютеров
Внутренние межсоединения ПЛИС конфигурируются пользователем и дают
задержку по кристаллу между двумя произвольными точками не более 5 не.
На одном КБЛ ПЛИС можно реализовать полный двухразрядный сумматор.
Каскадное соединение двухразрядных сумматоров позволяет построить
сумматор 16-разрядных чисел. Время суммирования двух 16-разрядных чисел
составит 5 не при тактовой частоте 200 МГц. Кроме того, каждый КЛБ ПЛИС
серии ХС4000 можно конфигурировать в виде блока высокоскоростного
синхронного ОЗУ 3281 или двух блоков 1681, или двухпортового ОЗУ 1681, что
позволяет совместно с имеющимся блочным ОЗУ строить мощные
высокопроизводительные системы.
Из рис. 13.1 видно, что ПЛИС имеет матричную структуру. Элементарной
ячейкой матрицы является КБЛ. Такое построение кристалла ПЛИС позволяет
организовывать иерархические структуры НС. На низшем иерархическом
уровне таких структур стоит двухразрядный полный сумматор, построенный на базе
КБЛ. Следующий уровень в иерархии занимает сумматор, например
16-разрядных двоичных чисел. На базе сумматоров строятся умножители. Далее на
более верхнем уровне иерархии стоит отдельный нейрон, а из нейронов строят
фрагменты НС. На рис. 13.3 показан принцип иерархического фрагмента НС.
Фирмой «Scan Engineering Telecom» на основе элементарного массива КБЛ
разработана библиотека простейших арифметических блоков, таких,
например, как сумматоры, умножители, компараторы, некоторые виды нейронов. Это
облегчает и ускоряет работу разработчика.
Многоуровневая конвейерная структура НС на базе ПЛИС серии ХС4000
обеспечивает время вычисления одного нейрона 6 не (для нейрона с 8-ю 8-
разрядными входами). А поскольку в такой структуре все нейроны работают
параллельно, то обработка в общем случае N-мерного входного вектора
происходит также за 6 не. Иерархическая структура по своей природе многотактная.
Поэтому выходной А"-мерный отклик сети поступает на выход относительно
входного с некоторой задержкой. В общем случае этот факт не снижает
быстродействия сети, так как конвейер обеспечивает единый такт приема входной
информации и выдачу выходной. Для рассматриваемой ПЛИС такт приема
может быть равен 6 не.
В нейронах фирмы «Scan Engineering Telecom» входной вектор может иметь
размерность от 2 до 16. Соответственно в этом диапазоне изменяется и число
синаптических коэффициентов. Разрядность входных данных, разрядность
коэффициентов может меняться независимо по каждой координате от 1 до 16.
Разрядность внутренних данных (выходные данные умножителей и дерева
сумматоров), как правило, устанавливается равной разрядности входных данных,
хотя при необходимости разработчик может ею варьировать. Наиболее просто
в рассматриваемой ПЛИС могут быть реализованы функции активации либо в
виде операции вычисления знака взвешенной суммы, либо в виде операции
сравнения с загружаемым порогом (аппаратный компаратор).
356
13.2. Особенности ПЛИС как элементной базы НК
один нейрон
а
■ умножитель
б
п
- параллельный
сумматор
КБЛ
в г
Рис. 13.3. Иерархия фрагмента НС:
а - фрагмент НС; б - топология одного нейрона;
в - топология одного умножителя; г - топология параллельного сумматора
В настоящее время фирмой «Scan Engineering Telecom» разработано пять
подходов реализации нейрона, отличающиеся быстродействием и
аппаратными затратами:
1) наибольшее быстродействие, значительные аппаратные ресурсы,
загрузка весовых коэффициентов (обучение) в реальном масштабе времени;
2) среднее быстродействие, малые аппаратные ресурсы, загрузка весовых
коэффициентов в реальном масштабе времен;
3) высокое быстродействие, средние аппаратные ресурсы, загрузка весовых
коэффициентов не в реальном масштабе времени;
357
13. Элементная база для аппаратной реализации нейрокомпьютеров
4) среднее быстродействие, малые аппаратные ресурсы, загрузка весовых
коэффициентов не в реальном масштабе времени;
5) среднее быстродействие, чрезвычайно малые аппаратные ресурсы,
загрузка весовых коэффициентов не в реальном масштабе времени, однобитные
высокоскоростные межсоединения.
В первом подходе используются восемь конвейерных умножителей 8x8 бит
в дополнительном коде, выполненных по алгоритму Бута, свертывающееся
дерево сумматоров и компаратор с загружаемым 8-разрядным порогом.
Реализация нейрона во втором подходе осуществляется с использованием
восьми параллельно-последовательных 8-разрядных умножителей,
16-разрядного аккумулятора частичных произведений с временным
мультиплексированием, использующих внутренние буферные регистры с тремя устойчивыми
состояниями. Компаратор с загружаемым пороговым значением аналогичен
используемому в предыдущем подходе. Синхронные элементы схемы
функционируют на частоте 80 МГц, в то время как период загрузки новых данных и
соответственно времени активизации нейрона составляет 100 не (100 МГц).
Смена значений 8-разрядных весовых коэффициентов и пороговой функции
может осуществляться также с периодом 100 не.
Следующие три подхода используют принципы распределенной
арифметики, что позволяет экономить аппаратные ресурсы, сохраняя быстродействие,
соизмеримое с реализациями традиционных методов. Применение
параллельной распределенной арифметики (PDA — Parallel Distributed Arithmetic) в
третьем подходе позволяет более чем вдвое сократить аппаратную реализацию,
сохраняя высокое быстродействие. Период полного обновления всех
8-разрядных весовых коэффициентов нейрона в этом случае составит 160 не.
Применение для четвертого подхода последовательной распределенной арифметики
(SDA - Serial Distributed Arithmetic) дает еще больший выигрыш в экономии
аппаратных ресурсов. В таком случае на один нейрон потребуется 85 КБЛ,
что составляет 3% от возможностей ПЛИС XC40&5XLA, а общее число
нейронов, которое возможно реализовать на кристалле, составит 30. Рабочая частота
нейронов равна 10 МГц, тактовая частота работы синхронных элементов
нейрона - 90 МГц, время полного обновления весовых коэффициентов составляет
160 не.
Наибольшую экономию аппаратных ресурсов обеспечивает реализация
нейрона на последовательно-последовательной распределенной арифметике. При
этом соответствующие нейроны связаны однобитными высокоскоростными
потоками, а загрузка коэффициентов осуществляется параллельно.
В табл. 13.1 сведены результаты реализации нейронов для различных ПЛИС.
Разработчики фирмы «Scan Engineering Telecom» предлагают несколько
этапов построения НС на основе ПЛИС Xilinx. На рис. 13.4 представлены этапы
создания НС на ПЛИС.
358
13.2. Особенности ПЛИС как элементной базы НК
Таблица13.1. Число нейронов на кристалле для различных ПЛИС ХШпх
Подход
реализации
нейрона
1
2
3
4
5
ПЛИС
XCS40
Spartan
1
5
4
9
19
XC4036XLA
ХС4000Х
2
8
6
15
31
ХСШ5ХЬА
ЛГ4000АГ
5
20
15
30
76
XCV10O
Virtex
2
8
6
14
30
XCV500
Virtex
12
46
34
81
171
АСП000
Virtex
20
80
60
144
305
Разработанный алгоритм НС проходит проверку и уточнение на
персональном компьютере (ПК). Здесь могут быть использованы любые имеющиеся в
распоряжении разработчика пакеты нейроимитаторов. На этом этапе
определяют такие технические характеристики, как быстродействие нейрона,
быстродействие всей сети, частоту обновления весовых коэффициентов, частоту
поступления входных сигналов.
По общей производительности НС определяют объем аппаратных ресурсов
ПЛИС. Для получения наибольшего экономического эффекта следует
проанализировать несколько вариантов реализаций сети. На основе имеющихся в
библиотеке типовых элементов разработчик далее формирует слои будущей сети.
Библиотека типовых элементов может постоянно пополняться как
специализированными фирмами, так и самим разработчиком.
Библиотека элементов
нейронной сети
Алгоритм функционирования
нейронной сети
4
г
Создание регулярного слоя
сети на основе
подключенных библиотек
1
'
Разбиение сети по
отдельным кристаллам
1
'
Построение законченной
сети со стандартным
внешним интерфейсом
Эмуляция нейронной сети
на ПК
Рис. 13.4. Этапы создания НС на ПЛИС ХШпх
359
13. Элементная база для аппаратной реализации нейрокомпьютеров
Контроллер стандартного интерфейса
(PCI, УМЕ)
IUm.CN
Системная шина
Рис. 13.5. Обобщенная структурная схема нейронной сети на ПЛИС Xilinx
360
13.2. Особенности ПЛИС как элементной базы НК
На следующем этапе по известной размерности сети и сформированным
слоям необходимо провести компоновку отдельных слоев по кристаллам ПЛИС
и определить их межсоединения. Здесь же определяют структуру контроллера
для обучения сети. Он может быть распределенным по всем ПЛИС или
сосредоточенным на одной из них. Заканчивают разработку определением
стандартного интерфейса сети с внешними устройствами. Это могут быть, например,
шины PCI, VME.
На рис. 13.5 приведена обобщенная структурная схема НС на ПЛИСXilinx.
Основой вычислителя является матрица из ПЛИС 1.. .4, связанных
максимально возможным числом межсоединений. Размерность матрицы определяется
разработчиком и в общем случае не имеет ограничений. В каждом столбце
матрицы из ПЛИС размещаются от одного до нескольких слоев НС.
Наращивание числа строк в матрице эквивалентно увеличению размерности входного
и выходного векторов.
Входной демультиплексор и выходной мультиплексор размещается
непосредственно в ПЛИС крайних столбцов и предназначены для ввода-вывода
данных на стандартный интерфейс (системную шину).
Управляющий контроллер служит для общей синхронизации работы сети,
организации процесса обучения и загрузки весовых коэффициентов. Он
связан с контроллером стандартного интерфейса (PCI, VME) и имеет
специфический набор команд, необходимых и задаваемых разработчиком. Через
стандартный интерфейс осуществляется связь сети с достаточно медленными по
сравнению с возможностями межсоединений ПЛИС периферийными
устройствами, например персональным компьютером, где осуществляется
визуализация и частичная обработка передаваемой и принимаемой из сети
информации.
Разработчики ПЛИС Xilinx предусмотрели возможность каскадирования
матрицы, что позволяет конструировать сети более высокой размерности.
Каскадирование осуществляется использованием корпусов BG560 (серия Virtex),
имеющих 514 пользовательских выводов, позволяющих осуществлять
двунаправленный ввод-вывод данных с пропускной способностью 103 Гбит/с.
Наращивание осуществляется через горизонтальные (ПЛИС 1 и ПЛИС 2, ПЛИС 3
и ПЛИС 4 на рис. 13.5) и вертикальные (ПЛИС 1 и ПЛИС 3, ПЛИС 2 и ПЛИС
4 на рис. 13.5) шины. Пропускная способность ограничивается лишь
пропускной способностью физических межсоединений.
Нейросетевая платформа XNeuro -1.0
Структурная схема системы XNeuro -1.0 приведена на рис. 13.6. Фирмой
«Scan Engineering Telecom» предложен следующий вариант реализации
аппаратно-программного направления конструирования нейровычислителеи. На
361
13. Элементная база для аппаратной реализации нейрокомпьютеров
Высокоскоростные порты обмена
XDSP-680
XDSP-ЪМ
Контроллер на базе
Pentium
К внешним устройствам
Контроллеры
ввода-вывода
Рис. 13.6. Структурная схема системы XNeuro-1.0
основе обрабатывающих модулей XDSP-680 и А2)57>-4Мсоставляется матрица
ПЛИС подобно приведенной на рис. 13.5. Модули объединяются двумя
путями: через стандартный интерфейс для осуществления управляющих и
обучающих функций и высокоскоростными прямыми портами межслойных и внутри-
слойных связей. В качестве управляющего контроллера можно использовать
универсальный процессор Pentium. Модули выполнены в соответствии со
стандартом на шину PCI и поддерживают Plug&Play протокол PCI версии 2.1.
Система XNeuro-1.0 допускает установку до 18 модулей типа XDS, имеет в
резерве два слота для установки контроллера на Pentium и платы видеоадаптера.
Нейронная сеть, реализованная на базе XNeuro-1.0, имеет следующие число
нейронов, рассмотренных выше (подход 4):
• 103000 для XDSP-бЯО с установленными ПЛИС XCV1000E;
• 7500 amXDSP-3Mc установленными ПЛИС ХСТ2600Е.
Автоматизированное проектирование НС на базе ПЛИС Xilinx проводится с
помощью пакета Foundation. Пакет полностью перекрывает весь маршрут
аппаратной реализации НС, а также позволяет осуществлять эмуляцию ее
работы на языке программирования VHDL, входящего в пакет.
362
13.3. Особенности ЦСПкак элементной базы НК
Алгоритм функционирования
нейронной сети
Эмуляция нейросетевого
алгортма на ПК
Создание библиотеки нейроэлементов
для схемотехнического редактора
Foundation или на VHDL
Внешняя библитека
нейроэлементов
Соединение нейронов в единую сеть
в редакторе Foundation или на VHDL
Функциональное и
временное
моделирование проекта
Компиляция проекта в выбранный
тип ПЛИС
J
Загрузка проекта (слоя сети) в ПЛИС
Пакет проектирования ПЛИС
Xilinx Foundation
на модули XDSP-6S0,
XDSP-3M
Рис. 13.7. Этапы САПР фирмы Xilinx
Рабочие этапы САПР фирмы Xilinx показаны на рис. 13.7. Существует
четыре конфигурации пакета Foundation, различающиеся своими
функциональными возможностями.
13.3. Особенности ЦСП как элементной базы
нейрокомпьютеров
Цифровые сигнальные процессоры (ЦПС - DSP - Digital Signal Processor)
появились в самом конце семидесятых годов прошлого столетия, что было
обусловлено желанием разработчиков систем управления сложными
динамическими объектами включать в свои проекты именно цифровые вычислительные
устройства, обеспечивающие высокие точностные характеристики систем.
Важным преимуществом ЦПС как элементной базы нейровычислителей
перед универсальными микропроцессорами является возможность работы на
максимальных тактовых частотах, а также возможность выполнять
практически все операции алгоритма управления на аппаратном уровне. Это
обеспечивает высокую производительность вычислительных устройств на их основе.
Платой за высокое быстродействие являются осложнения, связанные со сменой
алгоритмов управления, так как при этом практически все изменения
приходятся на изменения схемотехники вычислителя.
363
13. Элементная база для аппаратной реализации нейрокомпьютеров
ЦПС имеют ряд архитектурных особенностей, которые с успехом могут быть
использованы при построении НК. К таким особенностям следует отнести
наличие в их системе команд операции умножения с накоплением MAC (D:=A -B+D,
при этом в команде указывается глубина цикла и правило изменения индексов
элементов массивов А и В). Эта команда наилучшим образом соответствует
операции взвешенного суммирования в адаптивном сумматоре нейрона.
Операция умножения двух чисел в ЦПС выполняется за один командный
цикл, что также существенно повышает производительность
вычислительного устройства. Как известно, при выполнении любой арифметической
операции необходимо осуществить выборку двух операндов, собственно
арифметическую операцию и сохранить результат или удержать его до повторения.
Очевидно, что осуществить выборку двух операндов из памяти за один такт
невозможно, если архитектура вычислительного устройства имеет одну шину
данных. Гарвардская архитектура ( SHARC - Syper Harvard ARChitectur)
предполагает наличие двух физически разделенных шин: одну для команд,
вторую - для данных. Многие ЦПС построены по Гарвардской архитектуре.
Еще большей производительности можно достичь, если установить три
раздельных шины - для двух операндов и для команды. Но три шины
значительно повышают стоимость микросхемы. Осуществлять выборку из памяти сразу
двух операндов и в то же время иметь в чипе лишь две шины можно введением
в архитектуру процессора кэш-памяти. Кэш-память в этом случае хранит те
команды, которые будут вновь использоваться, оставляя свободными шины
команд и данных. Гарвардская архитектура с кэш-памятью получила название
расширенной Гарвардской архитектуры. Некоторые ЦПС построены по
расширенной Гарвардской архитектуре.
Перспективным является построение вычислительных устройств по новой
архитектуре - TrigerSHARC, сочетающей в себе высокую степень
конвейеризации и программируемость ./ДОС-процессоров, SHARC-щро, структуру
памяти, особенности реализации интерфейса ввода/вывода ЦПС, параллелизм на
уровне команд VLIW{Very Long Instruction Word) архитектур.
На рис. 13.8 приведена схема, поясняющая принцип архитектуры
TrigerSHARC. Как видно из рисунка, в системе имеются два вычислительных блока
Хи У(ВЪХи ВБУ), каждый из которых имеет регистровый файл (РгФ). Объем
РгФ составляет 32 слова по 32 разряда каждое. Вычислительный блок может
выполнять все операции обычного арифметическо-логического устройства
(модуль ALU), однотактного умножения, включая умножение с накоплением
(модуль MAC), различные регистровые операции (сдвиги, инверсия и т. п.,
модуль Shift). Данные для работы модулей ALU, MAC, Shift выбираются из
регистрового файла, туда же записываются результаты работы этих модулей.
Большое число регистровой памяти способствует эффективному применению
языков программирования высокого уровня.
364
Генератор адресов команд
128-разрядный буфер
конечного перехода
2>
,''
iz
128
128
;-алу
0
31
у-РгФ
Л.
к-АЛУ
0
31
Ы>гФ
Л
^
_sz
^
128
^ IP
128у/ 128/'
S2 SZ
Вычис
блок X
31
РгФ
ALU
MAC
Shift
ТС
128 /'
sz
-2±
у"' 128
S2
128
Вычислительный блок 7
31
РгФ
ЖС/
MAC
Shift
12.
Процессор
ввода/вывода
?
I
ж
ж
о
I
I
ж
о
Si
Й
On
Рис. 13.8. Архитектура TrigerSHARC
13. Элементная база для аппаратной реализации нейрокомпьютеров
Высокая внутренняя скорость передачи информации достигается
применением двух 128-разрядных шин, связывающих регистровый файл с тремя 128-
разрядными системными шинами. Обе шины вычислительного блока
позволяют одновременно выполнять операцию чтения из памяти (блоки ЗУ 1, ЗУ2, ЗУЗ),
а одна шина - операцию записи в память. Такая организация шин весьма
эффективна для вычислительных систем, реализующих большое число
математических операций.
Архитектура TrigerSHARC предполагает три независимых блока памяти
(модули ЗУ1, ЗУ2, ЗУЗ). Каждый модуль имеет 128-разрядную шину данных.
Адрес доступа к данным может состоять из одного, двух или четырех слов,
что позволяет пользователю отказаться от традиционной сегментации памяти
на память программ и память данных. Передача данных в/из памяти может
осуществляться одновременно двумя вычислительными блоками за один такт.
Архитектура TrigerSHARC предусматривает наряду с внутренней памятью
организацию и традиционной оперативной.
Генератор адресов команд определяет порядок и правильность их
выполнения во всех модулях. Буфер конечного перехода {Branch Target Buffer)
предсказывает переходы в программе и записывает адреса этих переходов. Объем
буфера составляет 128 ячеек. Предсказание переходов с сохранением их адресов
позволяет осуществлять эту операцию за один цикл вместо 3 - 6 в
традиционной организации.
Объединение процессоров, выполненных по архитектуре TrigerSHARC,
позволяет проектировать нейроускорители с обширными функциями.
Оценкой производительности ЦПС является число типовых операций
(обычно миллионов операций) цифровой обработки сигналов в единицу времени. К
таким типовым операциям относятся фильтрация, быстрое преобразование
Фурье, преобразование Уолша и др. Для оценки производительности нейро-
вычислителей используют следующие показатели:
• CUPS {connections update per second) - число изменений значений весов в
секунду (оценка скорости обучения);
• CPS {connections per second) — число соединений в секунду;
• CPSPW = CPS/Nw — число соединений на один синапс (здесь Nw - число
синапсов в нейроне);
• CPPS- число соединений примитивов в секунду, CPPS=CPUBw Bs (здесь
Bw - разрядность весов, Bs - разрядность синапсов);
• ММАС - миллион умножений с накоплением в секунду.
13.4. Нейрочипы
Классификация нейрочипов
Нейрочипом принято называть специализированную сверхбольшую
интегральную схему (СБИС-нейрочип), ориентированную на реализацию нейросе-
тевых алгоритмов. Разработкой нейрочипов занимаются многие фирмы в
различных странах. Значительный рост выпуска СБИС-нейрочипов наметился с
366
13.4. Нейрочипы
Нейрочипы
W
*
Аналоговые
С битовыми весовыми
коэффициентами
С фиксированными
весовыми
коэффициентами
С частотно-импульсной
модуляцией
Клеточные
I
->
->
-►
Цифровые
С жесткой
структурой
С переменной
структурой
Клеточные
С многоразрядными
весовыми
коэффициентами
С битовыми
весовыми
коэффициентами
С встроенными
фотоэлементами
<-
<-
<-
Гибридные
С аналоговыми весовыми
коэффициентами и
цифровой логикой
С цифровым весовыми
коэффициентами и
аналоговой логикой
Клеточные
Рис. 13.9. Схема классификации нейрочипов
середины 90-х годов XX в. По принципу построения, по назначению и
характеристикам они сильно отличаются друг от друга. На рис. 13.9 приведена
схема классификация СБИС-нейрочипов.
По виду информационного носителя нейрочипы делятся на аналоговые,
цифровые и гибридные.
Аналоговая элементная база характеризуется большим быстродействием и
низкой стоимостью, что в значительной мере способствует ее производству.
Самыми простыми являются СБИС с битовыми весовыми коэффициентами,
которые, как правило, настраиваются, с фиксированными весовыми
коэффициентами и полными последовательными связями. В аналоговой технике
широко применяется частотно-импульсная модуляция. Аппаратура,
использующая эту модуляцию, характеризуется низким энергопотреблением и высокой
367
13. Элементная база для аппаратной реализации нейрокомпьютеров
надежностью. Отметим, что в биологических НС сигналы представляются
именно частотно-импульсной модуляцией. Очевидно, что эти факторы и
способствовали появлению на рынке аналоговых СБИС-чипов с такой модуляцией сигнала.
По способу реализации нейроалгоритмов различают нейрочипы с
полностью аппаратной и с программно-аппаратной реализацией (когда нейроалгорит-
мы хранятся в программируемом запоминающем устройстве).
Как видно из схемы классификации (см. рис. 13.9), нейрочипы бывают как с
жесткой, так и с переменной структурой.
Отдельным классом выделяют нейросигнальные процессоры. Ядро этих
СБИС представляет сигнальный процессор, а реализованные на кристалле
специальные дополнительные модули обеспечивают выполнение нейросетевых
алгоритмов. Таким дополнительным модулем, например, может быть
векторный процессор.
Возможности микроэлектроники и запросы потребителей привели к
созданию проблемно-ориентированного направления выпуска нейрочипов. Можно
выделить следующие области их проблемной ориентации [4]:
• обработка, сжатие и сегментация изображения;
• обработка стереоизображений;
• выделение движущихся целей на изображении;
• обработка сигналов;
• ассоциативная память.
Особое место в проблемной ориентации нейрочипов занимает ориентация
на клеточную структуру. На такой структуре строятся резистивные решетки,
нейрочипы с внутрикристаллической реализацией слоя фоторецепторов, так
называемые ретины. Ретины используют в робототехнике, медицине (для
вживления в глаз слепого человека) и других областях.
В настоящее время значительно возрос выпуск нейрочипов, структурные
особенности которых определены совместной работой биолога и
схемотехника-электронщика. Такие чипы и вычислительные устройства на их основе
предназначены для решения конкретных технических задач путем моделирования
на аппаратном уровне функционирования тех или иных подсистем живых
организмов.
Нейропроцессор Л1879ВМ1 ( NeuroMatrix NM6403)
Структураная схема Л1879ВМ1 [14]. Нейропроцессор Л1879ВМ1
разработан в научно-техническом центре «Модуль» (Россия, Москва). Он
представляет собой высокопроизводительный микропроцессор со статической
суперскалярной архитектурой. Одно из назначений Л1879ВМ1 является аппаратная
эмуляция разнообразных типов нейронных сетей.
Л1879ВМ1 предназначен для обработки 32-разрядных скалярных данных и
данных программируемой разрядности, упакованных в 64-разрядные слова,
которые в дальнейшем будут называться векторами упакованных данных.
Структурная схема нейропроцессора Л1879ВМ1 приведена на рис. 13.10.
368
13.4. Нейрочипы
<J=£ СРО
VCP
СР\ (р=$>
>кМ
ф=ф
G
м
I
\г
▲А
Локальная шина адреса
v
Глобальная шина адреса
I
1-я шина ввода
И
2-я шина ввода
Кг
Шина вывод данных
Ф=£
мм
лЛ
м |$=>
RISC
CORE
Рис. 13.10. Структурная схема нейропроцессора Л1879ВМ1
Основой нейрочипа является центральный процессор RISC CORE. Он
предназначен для выполнения арифметическо-логических операций и операций
сдвига над 32-разрядными скалярными данными, формирования 32-разрядных
адресов команд и данных при обращении к внешней памяти и выполнения всех
основных функций по управлению работой нейропроцессора.
Рассмотрим основные функции структурных блоков нейропроцессора
Л187ВМ1 подробнее (см. рис. 13.10).
VCP - векторный сопроцессор. Он предназначен для выполнения
арифметических и логических операций над 64-разрядными векторами данных
программируемой разрядности.
LMI и GMI - два одинаковых блока программируемого интерфейса с
локальной и глобальной 64-разрядными внешними шинами. К каждой из шин
может быть подключена внешняя память, содержащая 231 32-разрядных ячеек.
Обмен данными с внешней памятью может осуществляться как
32-разрядными, так и 64-разрядными словами. В последнем случае нейропроцессор
одновременно выбирает две соседние ячейки памяти. Адресация внешней памяти
осуществляется страничным способом, при котором на одну и ту же внешнюю
15-разрядную адресную шину в режиме разделения времени выдаются как
младшие, так и старшие разряды адреса. Причем старшие разряды адреса
выдаются только при переходе к выборке новой страницы памяти. Каждый блок
369
13. Элементная база для аппаратной реализации нейрокомпьютеров
программируемого интерфейса обеспечивает эффективную работу
нейропроцессора с двумя банками внешней памяти различного объема, различного типа
и различного быстродействия без использования дополнительного
оборудования. В данных блоках предусмотрена аппаратная поддержка разделяемой
памяти для различных мультипроцессорных конфигураций внешних шин.
СРО, СР\ - два идентичных коммуникационных порта, каждый из которых
обеспечивает обмен информацией по двунаправленному байтовому линку между
нейропроцессором и его абонентом. Порты полностью совместимы с
коммуникационным портом ЦПС TMS320C4x фирмы Texas Instruments, что дает
возможность проектировать высопроизводительные мультипроцессорные
системы. Каждый порт имеет встроенный контроллер прямого доступа к памяти,
позволяющий обмениваться 64-разрядными данными с внешней памятью,
подключенной к локальной и/или глобальной внешним шинам.
Л1879ВМ1 имеет пять внутренних шин, через которые осуществляется
обмен информацией между его основными структурными блоками.
Локальная и глобальная адресные шины (LOCAL ADDRESS BUS, GLOBAL
ADDRESS BUS) служат для пересылки адресов команд, сформированных RISC-
ядром, и адресов данных, сформированных RISC-ядром в программном
режиме или коммуникационными портами в режиме прямого доступа к памяти, в
соответствующие блоки программируемого интерфейса при обращении к
внешней памяти.
Выходная шина данных (OUTPUT DATA BYS) служит для пересылки
данных, подлежащих записи в локальную или глобальную внешние памяти, из RISC-
ядра, векторного процессора и коммуникационного порта в блоки
программируемого интерфейса.
1-я и 2-я шины ввода (INPUT BUS #1, INPUT BUS #2) предназначены для
пересылки данных и команд, считанных из локальной или глобальной внешней
памяти, из блоков программируемого интерфейса в любой из основных узлов
нейропроцессора. Причем в программном режиме работы нейропроцессора
пересылка скалярных данных осуществляется только по INPUT BUS #2, а
пересылка векторных данных - по INPUT BUS #1. Пересылка данных в режиме
прямого доступа в память и пересылка команд могут осуществляться по любой
из этих внутренних шин.
Межрегистровые пересылки скалярных данных и пересылки констант из
регистра команд в программно доступные регистры осуществляется через
блоки программируемого интерфейса с использованием внутренних шин OUTPUT
DATA BYS и INPUT BUS №.
64-разрядные шины INPUT BUS #1, INPUT BUS #2 и OUTPUT DATA BYS
позволяют за один такт пересылать как 32-разрядные, так и 64-разрядные
данные. Поэтому с целью уменьшения числа выполняемых операций пересылок
типа «регистр-регистр» и «память-регистр» большинство 32-разрядных
регистров нейропроцессора могут программно объединяться в регистровые пары при
выполнении этих операций. Кроме того, нейропроцессор содержит несколько
64-разрядных управляющих регистров, что также позволяет говорить о
выполнении пересылок над 64-разрядными скалярными данными.
370
13.4. Нейрочипы
00000001ft
7FFFFFFEA
80000001ft
FFFFFFFEA
Разряды
63 32 31 0
l
i
Локальна^ память
i
i
i
i
Глобальная память
i
i
i
оооооооол
7FFFFFFF/,
80000000Л
FFFFFFFFA
Адрес
Рис. 13.11. Распределение адресного пространства
нейропроцессора Л1879ВМ1
Выборка команд из внешней памяти осуществляется 64-разрядными
словами, каждое из которых представляет собой одну 64- или две 32-разрядных
команды.
Нейропроцессор использует 32-разрядный вычисляемый адрес при
обращении к внешней памяти. Доступное адресное пространство нейропроцессора
равно 16 Гбайт. Оно делится на две равные части - локальное и глобальное. На
рис. 13.11 показано распределение адресного пространства нейропроцессора.
Если старший разряд адреса равен нулю, то идет обращение к локальной
памяти, если единице - к глобальной. Младший разряд вычисляемого адреса
используется при доступе к 32-разрядным данным. Если он равен нулю, то
используется младшая часть памяти (разряды 31 - 0). При обращении к 64-
разрядным данным или при выборке команд он игнорируется.
RISC-ядро нейропроцессора. Ядром нейропроцессора является блок RISC
CORE (см. рис. 13.10). Он состоит из регистрового арифметическо-логическо-
гоустройства (РАЛУ -RALU), двух генераторов адресов данных (DAGl,DAG2),
генератора адресов команд {Programm Seqimcer) и блока управления (Control Unit).
Регистровое АЛУ служит для оперативного хранения до восьми
32-разрядных скалярных данных и выполнения над ними операций сдвига, одно- и двух-
операндных арифметических и логических операций. При выполнении
операций в РАЛУ формируются признаки нулевого результата, переноса и
арифметического переполнения, которые могут фиксироваться в регистре
слова состояния процессора и использоваться при выполнении условных команд
управления. Данные, хранящиеся в РАЛУ, можно использовать в качестве
адресов или смещений адресов при выполнении ряда команд обращения к
памяти и команд управления.
РАЛУ включает следующие узлы:
• блок из семи регистров общего назначения (GR0-GR7);
371
13. Элементная база для аппаратной реализации нейрокомпьютеров
• собственно АЛУ;
• сдвигатель (Shister).
Регистры общего назначения (РОН) образуют основу регистрового файла,
который имеет два входных порта и три выходных. Входные порты
подключают к шине INPUT BUS #2 нейропроцессора и к шине результата работы АЛУ.
Выходные порты подключают к шине OUTPUT DATA BYS и к шинам первого и
второго операндов АЛУ. Кроме того, регистры GR0-GR3 имеют выходной порт,
подключенный к шине второго операнда арифметического устройства,
входящего в состав DAGI. Это позволяет использовать содержимое РОН при
формировании адресов команд и данных с помощью DAGI или при выполнении
модификации содержимого адресных регистров, входящих в состав DAGI.
АЛУ выполняет за один такт одну из шестнадцати логических или
одиннадцати арифметических операций над содержимым одного или двух любых
РОНов. Причем арифметические операции выполняются над данными,
представленными в дополнительном коде.
Сдвигатель Shister выполняет за один такт циклический, логический или
арифметический сдвиг на любое число разрядов вправо или влево
содержимого любого РОНа, выдаваемого на шину первого операнда АЛУ.
Первый генератор адресов данных DAGI служит для формирования
адресов данных при выполнении команд обращения к памяти и адресов переходов
при выполнении команд управления. Кроме того, DAGI обеспечивает
оперативное хранение и модификацию до четырех 32-разрядных адресов данных,
адресов переходов или смещение адресов переходов.
DAGI включает в себя следующие блоки:
• AR0-AR3 - адресные регистры;
• AUI- первое арифметическое устройство;
• MUX- мультиплексор.
AR0-AR3 ~ образуют регистровый файл, который имеет два входных порта,
подключенных соответственно к шине INPUT BUS #2 нейропроцессора и
выходам AU\, и два выходных порта, подключенных соответственно к шине
OUTPUT DATA BUS нейропроцессора и шине первого операнда AU\.
AU\— первое арифметическое устройство предназначено для выполнения
одно- или двухоперандных арифметических операций при вычислении адреса
или модификации содержимого одного из регистров AR0..AR3. В качестве
первого операнда может использоваться содержимое одного из регистров AR0..AR3,
а в качестве второго — содержимое одного из регистров общего назначения
GR0-GR3 или 32-разрядная константа из кода команды.
Мультиплексор MUX служит для выдачи на одну из внутренних адресных
шин нейропроцессора информации с выходов AU\ или с шины первого
операнда AU\ в зависимости от выполняемого метода адресации. При нулевом
значении старшего разряда адреса, сформированного на выходах данного
мультиплексора, выдача адреса из DAGI будет осуществляться на LOCAL ADDRESS
BUS, а при единичном - на GLOBAL ADDRESS BUS.
372
13.4. Нейрочипы
Второй генератор адресов данных DAG2 по своей структуре и
выполняемым функциям аналогичен DAGI. Специфика DAG2 заключается в том, что
один из его адресных регистров AR1{SP) дополнительно выполняет функции
системного указателя стека при обработке прерываний и выполнении команд
перехода к подпрограмме и возврата из подпрограммы или прерывания.
DAG2 включает в себя следующие блоки:
• APA..Affl(SP) - адресные регистры;
• AU2- второе арифметическое устройство;
• MUX- мультиплексор.
Адресные регистры AR4..AR7(SP) также образуют регистровый файл,
который имеет два входных порта, подключенных соответственно к шине INPUT
BUS #2 нейропроцессора и выходам AU2, и два выходных порта,
подключенных соответственно к шине OUTPUT DATA BUS нейропроцессора и шине
первого операнда AU2.
Второе арифметическое устройство A U2 служит для выполнения одно- или
двухоперандных арифметических операций при вычислении адреса или
модификации содержимого одного из регистров ARA.. .AR1. В качестве первого
операнда может использоваться содержимое одного из регистров ARA... AR1, а в
качестве второго - содержимое одного из регистров GR4.. .GR7 или
32-разрядная константа из кода команды.
Мультиплексор MUX предназначен для выдачи на одну из внутренних
адресных шин нейропроцессора информации с выходов A U2 или с шины
первого операнда A U2 в зависимости от выполняемого метода адресации. При
нулевом значении старшего разряда адреса, сформированного на выходах данного
мультиплексора, выдача адреса из DAG2 будет осуществляться на LOCAL
ADDRESS BUS, а при единичном - на GLOBAL ADDRESS BUS
Генератор адресов команд Programm Sequncer служит для формирования
адреса очередной 64-разрядной команды или очередной пары 32-разрядных
команд на линейных участках программы, когда вычисление адреса каждой
следующей команды осуществляется путем инкремента адреса текущей
команды. Кроме того, Programm Sequncer используется для формирования
адрес-векторов прерываний и для формирования адреса системного стека при
выполнении команд перехода к подпрограмме.
Programm Sequncer включает в себя следующие блоки:
• PC - счетчик команд;
• MUX- мультиплексор.
Счетчик команд PC предназначен для хранения адреса текущей
выбираемой из памяти 64-разрядной команды (или пары 32-разрядных команд) и
вычисления адреса следующей команды (или пары команд) путем увеличения
его содержимого на два. При выполнении команд перехода новое содержимое
поступает в PC с выходов A U\ или A U2, при переходах к подпрограммам
обработки прерываний - с выхода регистра INTR, а при выполнении команд
возврата из подпрограммы или прерывания - с шины INPUT BUS #2
нейропроцессора. Выходы PC подключают к шине OUTPUT DATA BUS нейропроцессора, что
делает данный регистр программно доступным по чтению.
373
13. Элементная база для аппаратной реализации нейрокомпьютеров
Мультиплексор MUX служит для выдачи на одну из внутренних адресных
шин нейропроцессора, увеличенного на два содержимого счетчика команд PC
или содержимого указателя стека AR1{SP). При нулевом значении старшего
разряда адреса, сформированного на выходах данного мультиплексора,
выдача адреса из Programm Sequncer будет осуществляться на LOCAL ADDRESS
BUS, а при единичном - на GLOBAL ADDRESS BUS.
Блок управления Control Unit выполняет предварительный анализ и
дешифрацию команд, выбранных из внешней памяти, формирует сигналы
управления всеми узлами нейропроцессора в процессе конвейерного выполнения
команд, обрабатывает все запросы на внутренние и внешние прерывания,
осуществляет арбитраж поступающих от различных узлов нейропроцессора
запросов на использование его внутренних и внешних шин, формирует
внешние сигналы.
Control Unit включает в себя следующие блоки:
• IB- буфер команд;
• IRI...IR6 - регистры команд;
• CR - регистр хранения константы;
• GMICR - регистр управления интерфейсом с глобальной шиной;
• LMICR - регистр управления интерфейсом с локальной шиной;
• ГО, 71 - программируемые таймеры;
• PSWR - регистр слова состояния процессора;
• INTR - регистр запросов на прерывания и прямого доступа к памяти.
Буфер команд IB обеспечивает хранение и предварительный анализ до
четырех 32-разрядных или до двух 64-разрядных команд, выбранных из внешней
памяти.
Регистры команд IR\ ...IR6 хранят текущие команды на различных ступенях
конвейера их выполнения.
Регистр хранения константы CR содержит постоянную величину,
используемую в текущей выполняемой команде.
Регистр управления интерфейсом с глобальной шиной GMICR своим
содержимым определяет конфигурацию глобальной шины, устанавливает
адресные границы между первым и вторым банками памяти, подключенными к
глобальной шине, и устанавливает для каждого банка памяти размеры адресной
страницы, режим работы (сихронный/асинхронный), тип используемых
микросхем памяти и длительности отдельных фаз в циклах обращения к памяти.
Регистр управления интерфейсом с локальной шиной LMICR выполняет те
же функции, что и GMICR, но в отношении локальной шины.
Программируемые таймеры 7D, 71 предназначены для формирования
через программируемые интервалы времени сигналов прерываний и сигналов на
выходе TIMER нейропроцессора. Режим работы каждого таймера
(однократный или периодический) задается соответствующими разрядами регистра
PSWR. Причем, если хотя бы в одном из регистров LMICR или GMICR
прописана работа с банком динамической памяти, то 71 будет использоваться в
качестве счетчика, определяющего период регенерации динамической памяти.
374
13.4. Нейрочипы
Регистр слова состояния процессора PSWR служит для хранения признаков
результата последней выполненной в РАЛУ операции, масок всех
обрабатываемых прерываний и управляющей информации, задающей режимы работы
таймеров 7D, 71 и внешнего вывода TIMER, режим инициализации обмена по
коммуникационным портам СРО и СР\, останов каналов приема и передачи
коммуникационных портов СРО и СР1, очистку AFIFO и WFIFO, запрет на
передачу управления локальной и глобальной шинами внешнему устройству.
Данный регистр и счетчик команд PC образуют регистровую пару,
содержимое которой запоминается в системном стеке при выполнении команд
перехода к подпрограмме и при переходе к подпрограмме обслуживания прерывания.
Регистр запросов на прерывания и прямого доступа к памяти INTR
обеспечивает хранения всех запросов на прямой доступ к памяти, поступивших от
коммуникационных портов СРО и СР1, и всех запросов на внутренние и
внешнее прерывания до момента начала их обслуживания. Кроме того, в данном
регистре хранится информация о состоянии AFIFO и WFIFO (пустое, полное),
о состоянии каждого из коммуникационных портов СРО и СР1
(прием/передача), о количестве 64-разрядных слов, хранящихся в AFIFO и RAM, и о
принадлежности локальной и глобальной шин нейропроцессору в данный момент
времени. Регист INTR, выходы которого подключены к шине OUTPUT DATA
BUS нейропроцессора, программно доступен только по чтению.
Регистры PSWR, GMICR, LMICR, ТО и 71 программно доступны как по
чтению, так и по записи. Их входы подключены к шине INPUT BUS #2, а
выходы - к шине OUTPUT DATA BUS нейропроцессора. При этом аппаратные
средства нейропроцессора поддерживают побитовую установку и побитовый
сброс регистра PSWR в программном режиме.
Нейропроцессор поддерживает одно внешнее прерывание и девять
внутренних:
• два прерывания от таймера;
• прерывание по переполнении при выполнении арифметических операций
в RISC-ядре;
• прерывание по запрещенной векторной команде;
• четыре прерывания от каналов ввода/вывода по завершении обмена через
коммуникационные порты;
• пошаговое прерывание в режиме отладки.
Векторный сопроцессор VCP Этот блок (см. рис. 13.10) ориентирован на
обработку данных произвольной разрядности от 1 до 64, упакованных в 64-
разрядное слово. Сопроцессор включает в себя следующие блоки:
• OU- операционное устройство;
• RCS - циклический сдвигатель вправо на один разряд;
• SU1, SU2 - узлы аппаратной реализации функции насыщения;
• FICR, F2CR - регистры управления узлами насыщения;
• SWITCH 3->2 - коммутатор 3 в 2;
• WBUF и WOPER - матрицы памяти весовых коэффициентов;
375
13. Элементная база для аппаратной реализации нейрокомпьютеров
• WFIFO — FIFO весовых коэффициентов;
• AFIFO - накопительное FIFO;
• RAM— векторный регистр;
• VR — регистр порогов.
Операционное устройство OU служит для выполнения арифметических и
логических операций над 64-разрядными словами упакованных данных
X={x,... xk} и Y={y, ...у), поступающих соответственно на входыХи YOU, и
матрицей весов WOPER, которая подается на входы Wf... Wj в видеу
64-разрядных слов упакованных весовых коэффициентов W,={»'11... wlt} ... Wj={»'j1 ... wj.
Результат каждой операции формируется на выходе R в виде 64-разрядного
слова упакованных данных R = {/?(... Л}. Переменная / может принимать
любое целочисленное значение от 1 до 64 в зависимости от содержимого
буферного регистра NB2 (/ равно количеству единиц в NB2), а переменная^ - от 1 до
32 в зависимости от содержимого регистра SB2 (/ равно количеству единиц в
SB2). Значения, принимаемые переменной к, зависят от типа выполняемой
операции: к=1~ для арифметических операций, к =j - для операции взвешенного
суммирования. Тип выполняемой операции задается кодом команды.
Операции выполняются в конвейере с темпом одна операция за такт. При этом
признаки результатов операций не формируются.
Циклический сдвигатель вправо на один разряд RCS оставляет без
изменения или сдвигает за один такт одно 64-разрядное слово как единый операнд
независимо от количества данных в слове. Необходимость сдвига слова
кодируется соответствующими битами команды.
Узлы аппаратной реализации функции насыщения SUl, SU2 служат для
вычисления нелинейных функций активации над 64-разрядными словами
упакованных данных. Для каждого нелинейного преобразователя в VCP
предусмотрен свой программно доступный регистр управления.
Регистры управления узлами насыщения Fl CR, F2CR (Fl CR для SUI и F1CR
для SUT) определяют количество и разрядность данных, составляющих
обрабатываемое слово, а также максимальное абсолютное значение результата
вычисления функции насыщения для каждого составляющего слова.
Коммутатор 3 в 2 SWITCH 3->2 обеспечивает выбор двух источников
векторных данных, поступающих на входы исполнительных узлов VCP. В
зависимости от кода команды через коммутатор 3 в 2 на вход каждого нелинейного
преобразователя могут поступать либо все нули, либо следующие векторы слов
упакованных данных:
• содержимое RAM с шины векторных данных VCP - VECTOR DATA BUS;
• содержимое AFIFO по цепи обратной связи VCP;
• векторы данных из внешней памяти.
Матрицы памяти весовых коэффициентов WBUFn WOPER, каждая из
которых имеет емкость 32x64 бита, позволяют хранить матрицу весов W в виде у
64-разрядных слов упакованных весовых коэффициентов. WOPER служит для
хранения матрицы весов, используемой в операциях взвешенного суммирова-
376
13.4. Нейрочипы
ния, выполняемых OU. Выходы всех ячеек WOPER соединены
непосредственно с соответствующими входами OU, а их входы - с выходами
соответствующих ячеек WBUF. Благодаря этому запись во все ячейки WOPER
осуществляется за один такт по команде LOAD. При этом содержимое WBUF целиком
копируется в WOPER. Одновременно с этим содержимое регистров SB\ nNBl
копируется в регистры SB2 и NB2.
Ячейка WBUF служит для подкачки из WFIFO новой матрицы весов на фоне
выполнения OU текущих операций взвешенного суммирования с
использованием старой матрицы весов, хранящейся в WOPER. Загрузка матрицы весов в
WBUF инициируется одной командой и осуществляется за 32 такта путем
последовательной записи/ 64-разрядных слов упакованных весовых
коэффициентов, выбираемых из WFIFO. При этом количество загружаемых слову
определяется содержимым SB\ (/' равно количеству единиц в SBI). В режиме записи
WBUF работает по аналогии с памятью магазинного (стекового) типа.
Причем первым загружается слово W(, а последним - слово W. Во всех
этих словах количество весовых коэффициентов и границы между ними
совпадают и определяются содержимым регистра NBI.
Очередь типа FIFO весовых коэффициентов WFIFO организована в виде
накопительного буфера емкостью 32x64 бит. Буфер WFIFO двухпортовый и
используется в процессе подкачки матрицы весов в WBUF из внешней памяти.
Запись и чтение из WFIFO ведется 64-разрядными словами упакованных
весовых коэффициентов. Загрузка WFIFO осуществляется через внутреннюю шину
данных нейропроцессора INPUTBUS'#2.
Накопительная очередь типа FIFO - AFIFO, так же, как и очередь WFIFO,
организована в виде двухпортового буфера, называемого аккумулятором.
Емкость аккумулятора 32x64 бит. Аккумулятор хранит один вектор 64-разрядных
слов упакованных данных, которые являются результатом выполнения
последней векторной операционной команды.
Векторный регистр &4Мпредставляет собой однопортовую память с
очередью записи/считывания типа FIFO и имеет емкость 32x64 бит. Регистр
подключен к шине векторных данных VCP- VECTOR DATA BUS. Основное
отличие RAM от обычного FIFO заключается в том, что после чтения из RAM его
содержимое не изменяется.
Регистр порогов VR служит для хранения 64-разрядного слова упакованных
порогов или смещений. Существуют команды, по которым при выполнении
операции взвешенного суммирования содержимое этого регистра подается на
вход У (Ж
Коммуникационные порты ввода/вывода СРО и СР1. Нейропроцессор
содержит два идентичных высокоскоростных коммуникационных порта, каждый
из которых обеспечивает двунаправленный интерфейс для связи с внешним
устройством. Порты включают следующие узлы:
• CPIx - устройство управления интерфейсом порта, которое осуществляет
арбитраж при передаче данных между нейропроцессором и внешним
устройством через шину данных коммуникационного порта;
377
13. Элементная база для аппаратной реализации нейрокомпьютеров
• MUX— мультиплексор для формирования адреса при запросе на прямой
доступ к памяти;
• ОССх - счетчик канала вывода, который определяет число выводимых
через коммуникационный порт 64-разрядных слов;
• ОСАх - регистр адреса канала вывода, который задает адрес памяти,
откуда будут в режиме прямого доступа к памяти считываться данные при выводе
через порт;
• OCDR — регистр данных канала вывода;
• ICCx — счетчик канала ввода, который определяет число вводимых через
коммуникационный порт 64-разрядных слов;
• ICAx - регистр адреса канала ввода, который задает адрес памяти, куда
будут в режиме прямого доступа к памяти записываться данные при вводе
через порт;
• ICDRx - регистр данных канала ввода.
Каждый коммуникационный порт содержит следующие двунаправленные
линии управления и данных:
CREQX - запрос на выдачу по шине данных коммуникационного порта;
САСКХ- подтверждение на захват шины данных коммуникационного порта
при получении сигнала;
CREQX— от другого нейропроцессора;
CSTRBX— строб порта коммуникации. Передающий нейропроцессор
устанавливает этот сигнал для индикации, что он выдал очередные данные на шину
данных коммуникационного порта;
CRDYX- сигнал готовности коммуникационного порта. Принимающий
нейропроцессор устанавливает этот сигнал для индикации, что он принял данные
через шину данных коммуникационного порта;
CxD(J - 0) - шина данных коммуникационного порта. По этой шине
пересылаются данные в обе стороны между двумя нейропроцессорами или между
нейропроцессором и другим внешним устройством.
Кроме того, имеется выход CDIRX, который указывает, в каком режиме
работает в данный момент коммуникационный порт - ввода (на выходе высокий
уровень) или вывода (на выходе низкий уровень).
Нейропроцессор Л1879ВМ1 поддерживает как однопроцессорный, так и
многопроцессорный режим работы по любой из двух внешних шин с
использованием двух коммуникационных портов СР0иСР1. На рис. 13.12 приведена
структурная схема линейной многопроцессорной системы. Если соединить выход
последнего каскада такой схемы со входом первого, как показано пунктиром
на рис. 13.12, то можно получить кольцевую многопроцессорную структуру.
На рис. 13.13 представлена структурная схема матричной
многопроцессорной системы на базе микропроцессора Ш879ВМ1. Если соединить через
коммуникационные порты СРО и СР\ выходы крайнего правого столбца схемы со
входами крайнего левого, то получится схема в виде вертикального цилиндра.
378
13.4. Нейрочыпы
«Т*
Память
А
L-bus
сро Л1879ВМ1 ср\
G-bus
*
Память
<-►
Память
л
V
L-bus
сро Л1879ВМ1 CPi
G-bus
Память
О
Память
>к
ГР0Л1879ВМ1 №i
G-fcus
>к
Память
<т>
Рис. 13.12. Структурная схема линейной многопроцессорной системы
А
Память
А
L-bus
СР0Л1879ВМ1 ср\
G-bus
а.
Память
L-bus
сро Л1879ВМ1 №1
G-fcus
Память
L-bus
сро Л1879ВМ1 ср\
G-bus
>k
Память
L-bus
сро Л1879ВМ1 о>1
G-fcuj
Память
L-bus
сро Л1879ВМ1 сп
G-bus
Память
Память
L-bus
сро Л1879ВМ1 ср\
G-bus
Память
•О
Память
1
L-bus
сро Л1879ВМ1 СР\
G-bus
<*■
Память
Рис. 13.13. Структурная схема матричной многопроцессорной системы
379
13. Элементная база для аппаратной реализации нейрокомпьютеров
Очевидно, что схему горизонтального цилиндра можно получить, соединив по
внешним шинам L-bus и G-bus входы/выходы крайних верхней и нижней
линеек процессоров. Если соединить правые и левые входы/выходы у
горизонтального цилиндра или верхние и нижние входы/выходы у вертикального
цилиндра, то получим тороидальные многопроцессорные системы. При обмене
информацией через общую память внешняя шина, соединяющая два нейро-
процессора, должна быть локальной (L-bus) для одного из них и глобальной
(G-bus) для другого. Скорость обмена информацией через порты СРО и СР\
составляет 20 Мбайт в секунду.
Система команд нейропроцессора Л1879ВМ1
В нейропроцессоре применяются четыре основные группы команд:
управления скалярные, управления векторные, пересылки, модификации адресных
регистров. В каждой команде программист имеет возможность задать
операцию обработки операндов. Команды имеют фиксированную длину 32 или 64
разряда. Все команды выполняются за один такт синхронизации. На рис. 13.14
показаны форматы некоторых команд. Как видно из рисунка, форматы команд
имеют следующие поля:
AM - метод адресации/ (Art, GR) с модификацией адресного регистра;
АМС - метод адресации с помощью константы с модификацией адресного
регистра AR.<-fM (AR, Смещение);
RM- метод модификации адресного регистра AR <-fu (ARt, GR);
RMC - метод модификации адресного регистра с константой AR~fu (AR.,
Смещение);
РМ — метод модификации PC при переходах;
РМС - метод модификации PC при переходах с константой;
Аг- адресный регистр г (i = 0,.. .,7);
AR - адресный регистру" (/ = 0,.. .,3 если содержимое 24-го разряда команды
равно 0 иу = 4,.. .,7 если 24-й разряд равен единице);
^ист/пр _ регистр, являющийся источником или приемником информации в
командах пересылки данных;
RJW- управление записью в RAM(0 - нет записи / 1 - есть запись);
W- управление загрузкой весов из WFIFO в OU(0 - нет загрузки / 1 - есть
загрузка);
КОП СК - код операции скалярной команды;
КОП ВК - код операции векторной команды;
Р - бит параллельной работы (0 - запрещен запуск данной команды на
исполнение, пока не закончатся все ранее выбранные команды / 1 - разрешен
запуск).
Для 32-разрядных команд пересылки типа регистр-память и для векторных
команд метод адресации задается полем AM. Коды трехбитного поля AM
позволяют использовать 8 методов адресации. Однако разработчики оставили в
резерве одну кодовую комбинацию. В табл. 13.2 представлены методы
адресации для 32-разрядных скалярных команд типа пересылки регистр-память и
векторных команд.
380
13.4. Нейрочипы
31 30 29 28
26
25
24
22 21
16 15
р
0 1
AM
R/W
AR,
ист/пр
коп ск
31
р
30
0
29
1
28
26
АМС
25
R/W
24
22
AR,
21 16
ист/пр
15
0
КОП СК
Смещение
63
31
Р
30
1
29 28 27
1 1
а
22 21 16
*пр
R
ист
15
32
0
КОП СК
31
Р
30
1
29
0
28
0
27
22
К
21
16
0 0 х х х х
15
0
КОП СК
Константа
63
31
Р
30
1
29
0
28
0
27
R/S
26
1 1 1
22 21
0 1
16
0 0 х х х х
15
32
0
КОП СК
Изменяемые биты
63
32
31
р
30
1
29
1
28
1
27 26
RM
25
1
24 22
AR,
21 18
0 1 х х
17 16
AR
з
15
0
КОП СК
Рис. 13.14. Форматы команд нейропроцессора Л1879ВМ1:
а - 32- и 64-разрядные команды пересылок типа регистр-память;
б - 32- и 64-разрядные команды пересылок типа регистр-регистр;
в — 32-разрядная команда модификации адресных регистров
Методы адресации 64-разрядных команд пересылки типа регистр-память
определяются содержимым поля АМС. Кодовые комбинации этого поля и
соответствующие им методы адресации показаны в табл. 13.3.
Методы модификации адресных регистров для соответствующих
32-разрядных команд задаются двухбитным полем RM. В табл. 13.4 представлены
кодовые комбинации поля RMn соответствующие им методы.
381
13. Элементная база для аппаратной реализации нейрокомпьютеров
Таблица 13.2. Методы адресации 32-разрядных скалярных команд
пересылки типа регистр-память и векторных команд
AM
0 0 0
0 0 1
0 1 0
0 1 1
1 0 0
1 0 1
1 1 0
1 1 1
f^AR^GR.)
GR,
AR,+GR,
GR,
Резерв
AR,
AR,
ARra
AR,
fM(AR„GR,)
AR,
AR.+GR,
GR,
Резерв
AR,
ARj+GR,
ARra
AR,+a
Содержимое разрядов двухбитного поля RMC определяет метод
модификации для 64-разрядных скалярных команд. Эти методы и соответствующие им
кодовые комбинации приведены в табл. 13.5.
Двухбитное поле РМ определяет метод модификации программного
счетчика (PC) для 32-разрядных скалярных команд перехода. Для 64-разрядных
скалярных команд перехода метод модификации PC определяется полем РМС,
также двухбитным. В табл. 13.6 приведено кодирование методов модификации
PC для 32-разрядных команд, в табл. 13.7 - для 64-разрядных.
Таблица 13.3. Методы адресации 64-разрядных скалярных команд
пересылки типа регистр-память
АМС
0 0
0 1
1 0
1 1
/>я> (AR,, Смещение)
Адрес
ЛЛ,+Смещение
Адрес (Смещение)
Резерв
fM (AR„ Смещение)
AR,
ЛЩ+Смещение
Адрес (Смещение)
Резерв
Таблица 13.4. Методы модификации адресного регистра
для соответствующих 32-разрядных скалярных команд
RM
0 0
0 1
1 0
1 1
AR,*-fM(AR„GR,)
AR,
AR,+ GR,
GR,
Резерв
Таблица 13.5. Методы модификации адресного регистра для
соответствующих 64-разрядных скалярных команд
RMC
0 0
0 1
1 0
1 1
MAR,, GR,)
AR,
ЛЛ,+Смещение
Константа-смещение
Резерв
382
13.4. Нейронтгы
Таблица 13.6. Методы
модификации PC для
32-разрядных скалярных команд
перехода
РМ
0 0
0 1
1 0
1 1
Модификация PC
PC.=AR,
PC:=Ari+GR,
PC.=GR,
PC:=PC+GR,
Таблица 13.7. Методы
модификации PC для
64-разрядных скалярных команд
перехода
РМС
0 0
0 1
1 0
1 1
Модификация PC
PC:=AR,
РС:=^Л,+Смещение
РС:=Адрес(Смещение)
РС:=РС+Смещеиие
Скалярные команды управления в зависимости от поля «Условие» (на рис.
13.14 не показано) могут быть безусловными или условными, т. е.
выполняться в зависимости от сочетания признаков слова состояния процессора: N—
признак знака, Z- признак нуля, V— признак переполнения, С- признак переноса.
В табл. 13.8 приведено кодирование анализируемых сочетаний признаков для
скалярных команд управления.
Для скалярных команд пересылок поле /?ии/ определяет регистры, которые
участвуют в операциях пересылки данных. В зависимости от кода в этом поле
обращение может быть как к 32- или 64-разрядным регистрам, так и к
64-разрядным регистровым парам. В табл. 13.9 приведено соответствие между
кодами поля кодирования Rmr/ регистров и регистровых пар.
Выполнение нейропроцессором арифметических и логических операций
задается как скалярными, так и векторными командами. В скалярной команде
можно задать арифметическую, логическую или операцию сдвига
содержимого регистров GR0 ... Gi?7. Каждая из таких операций задается своим разделом
Таблица 13.8. Кодирование анализируемых сочетаний признаков
для скалярных команд управления
Условие
0 0 0 0
0 0 0 1
0 0 10
0 0 11
10 0 0
10 0 1
10 10
10 11
Анализируемое сочетание
признаков
Переход, если С = 0
Переход, если V= 0
Переход, если N+Z = 0
Переход, если N = 0
Переход, если С = 1
Переход, если V=l
Переход, если N+Z=\
Переход, еслиЛГ= 1
Условие
0 10 0
0 10 1
0 110
0 111
110 0
110 1
1110
1111
Анализируемое сочетание
признаков
Переход, если (V®N) + Z = 0
Переход, если V®N = 0
Переход, если Z = 0
Переход безусловный
Переход, если (V®N) + Z = 1
Переход, если V®N = 1
Переход, если Z = 1
Перехода нет
383
13. Элементная база для аппаратной реализации нейрокомпьютеров
Таблица 13.9. Соответствие между кодами /?исг/пр и регистрами источника
и приемника данных
*^ист/гго
0 0 10 0 0
0 0 10 0 1
0 0 10 10
0 0 10 11
0 0 110 0
0 0 110 1
0 0 1110
0 0 1111
0 0 10 0 0
0 0 10 0 1
0 0 10 10
0 0 10 11
0 0 110 0
0 0 110 1
0 0 1110
0 0 1111
0 10 0 0 0
0 10 0 0 1
0 10 0 10
0 10 0 11
0 10 10 0
0 10 10 1
0 10 110
0 10 111
0 110 0 0
0 110 0 1
0 110 10
0 110 11
0 1110 0
0 1110 1
0 11110
0 11111
10 0 0 0 0
10 0 0 0 1
10 0 0 10
10 0 0 11
10 0 10 0
10 0 10 1
10 0 110
10 0 111
Регистр-источник
AR0
AR1
AR2
AR3
AR4
AR5
AR6
AR1(SP)
ОСЛО
ICA0
ОСА1
ICA1
ТО
LMICR
GMICR
PC
GR0
GRI
GR2
GRi
GRA
GR5
GR6
GRI
OCCO
ICC0
OCCl
ICC\
Л
Резерв
INTR
PSWR
GR0.AR0
GRI, ARl
GR2,AR2
GRb. AR3
GRA, ARA
GR5, AR5
GRb, AR6
GRI, ARl
Регистр-приемник
ARO
ARl
AR2
AR3
AR4
AR5
AR6
AR7(SP)
OCA0
ICA0
OCAl
ICAl
TO
LMICR
GMICR
PC
GR0
GRI
GR2
GR3
GRA
GR5
GR6
GRI
OCC0
ICC0
OCCl
ICCl
n
PSWRset
Резерв
PSWR
GR0, ARO
GRI, ARl
GR2.AR2
GRb, AR3
GRA. ARA
GR5, AR5
GRb, AR6
GR7, ARl
Разрядность
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
32
64(32+32)
64(32+32)
64(32+32)
64(32+32)
64(32+32)
64(32+32)
64(32+32)
64(32+32)
384
13.4. Нейрочипы
Окончание табл. 13.9
**ист/пр
10 10 0 0
10 10 0 1
10 10 10
10 10 11
10 110 0
10 110 1
10 1110
10 1111
110 0 0 0
110 0 0 1
110 0 10
110 0 11
110 10 0
110 10 1
110 110
110 111
1110 0 0
1110 0 1
1110 10
1110 11
11110 0
11110 1
111110
111111
Регистр-источник
ОСС0, ОСА0
ICCO, ICA0
ОСС1, 0СА1
ICC1, ICA1
Т1.Т0
DIR0
DIR1
PSWR, PC
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
Регистр-приемник
ОССО, ОСЛО
ICCO, ICA0
ОСС1, 0СА1
ICC1, ICA1
Т1, ТО
DIR0
DIR1
PSWR, PC
NBL
SBL
FXCRL
F2CRL
NBH
SBH
F1CRH
F2CRH
NB
SB
F1CR
F2CR
VR
PSWRset
VRL
VRH
Разрядность
64(32+32)
64(32+32)
64(32+32)
64(32+32)
64(32+32)
64
64
64(32+32)
32
32
32
32
32
32
32
32
64
64
64
64
64
32
32
32
поля кода операции (КОП СК). На рис. 13.15 показан формат поля КОП СК для
операции сдвига, а в табл. 13.10 - кодирование различных операций сдвига в
поле ТС.
На рис. 13.16 представлен формат поля КОП СК для Логических операций.
На этом рисунке КЛОП означает код логической операции, в котором
кодируется одна из 16 возможных логических операций. Все логические команды
выполняются по следующему правилу:
GR <-F (GR „GR ,),
Пр ЛОГ4 ИСТ2' ИСТ1-'7
где F - исполняемая логическая функция.
Поле 7Г кодирует управление записью в GR и регистр PSWR признаков. В
табл. 13.11 приведены коды управления записью признаков.Формат поля КОП
СК для арифметических команд, представленный на рис. 13.17, отличается от
385
13. Элементная база для аппаратной реализации нейрокомпьютеров
формата логических операций лишь значением 13-го разряда, который в этом
случае равен единице. В табл. 13.12 приведено кодирование арифметических
операций.
В векторных командах можно задавать арифметические или логические
операции с помощью поля КОП ВК. Особенностью этих команд является
наличие упакованных в 64-разрядных данных. На рис. 13.18 представлены
форматы поля КОП ВК для логических и арифметических команд. Как видно, они
отличаются лишь содержимым 11-го рязряда. Все 16 логических операций
выполняются по правилу
AFIFO^Fmr{X,Y),
где AFIFO- регистр-приемник результата векторных операций; X, Y-
операнды, адреса которых определяются полями Хи Y соответственно.
Таблица 13.10. Кодирование операций сдвига в поле ТС
ТС
0 0
0 1
1 0
1 1
Тип операции сдвига
Циклический сдвиг
Логический сдвиг
Арифметический сдвиг
Логический сдвиг через "С "
Таблица 13.11. Кодирование управления записью в GR,
и регистр PSWR признаков
W
0 0
0 1
1 0
1 1
Управление записью в GR^, и регистр PSWR
признаков
Комбинация не определена
Есть запись в GRm, нет записи признаков
Есть запись признаков, нет записи в GRm
Есть запись в GR^, есть запись признаков
15 14 13 12 И 6 5 3 2 О
0
0
ТС
Величина сдвига
GR
ИСТ
np
Рис. 13.15. Формат поля КОП СК для операций сдвига
15 14 13 12 9 8 6 5 3 2 О
W
0
клоп
GR**
GR^,
np
Рис. 13.16. Формат поля КОП СК для логических операций
15 14 13 12 9 8 6 5 3 2 О
W
1
КАОП
GR ,
ист2
OU
np
Рис. 13.17. Формат поля КОП СК для арифметических операций
386
13.4. Нейрочипы
Таблица 13.12. Кодирование арифметических
операций
КАОП
0 0 0 0
0 0 0 1
0 0 10
0 0 11
0 10 0
0 10 1
0 110
0 111
10 0 0
10 0 1
10 10
10 11
110 0
110 1
1110
1111
Арифметическая операция
GRm <— С/?ист2 - G/^hctI
GRm <- GR^j - GR„^rl+ "С "
GRm <- GR^ + 1
GRm <— GRIKT2 + "C "
GRm, <— GRikt2 ~ 1
GRno<~GRHCT2-l + "C"
GRm <— GR^i + GRxti
GRm *- GRikt2 ~ GR„„i + "C "
Первый шаг умножения
Шаг умножения
Резерв
Резерв
GRm <— G7?hct2
Резерв
Резерв
Резерв
12 11 10 7 6 5 4 3 2 10
1 0
клоп
FPX | FPY
X
Y
L
а
12 И 10 7 6 5 4 3 2 10
1 1
КАОП
FPX
FPY
X
Y
L
б
Рис. 13.18. Форматы поля КОП ВК для логических и арифметических операций:
а - формат для логических операций; б - формат арифметических операций
Если код поля X (или Y) равен 00, то операнд равен 0, если 01 - операнд
выбирается из RAM, если 10 операнд выбирается из AFIFO, если 11 - из
внешней памяти.
Кодирование четырех арифметических операций векторных команд
приведено в табл. 13.13.
Нейропроцессор Л1879ВМ1 может выполнять операции маскирования и
взвешенного суммирования. Форматы поля КОП ВК для таких операций
показаны на рис. 13.19.
Операция маскирования реализуется в соответствии со следующим
выражением:
X-M+Y-M.
387
13. Элементная база для аппаратной реализации нейрокомпьютеров
Таблица 13.13. Кодирование арифметических
операций
КАОП
* 0 0 *
* 0 1 *
* 1 0 *
* 1 1 *
Арифметическая операция
AFIFO+-X-Y
AFIFO*-X+l
AFIFO<r-X-\
AFIFO+-X+Y
* произвольное состояние
12 11 10 98 7 6 54 32 10
0 1
м
0
SH
FPX
FPY
X
Y
L
а
12 11 10 98 7 6 54 32 10
0 0
м
VR
SH
FAX
FAY
X
Y
L
б
Рис. 13.19. Форматы поля КОП ВК для операций маскирования
и взвешенного суммирования:
а - формат для операции маскирования; б - формат для операции взвешенного суммирования
Здесь Xи Y — упакованные в 64 разряда данные, а М- операнд-маска.
Управление выбором маски осуществляется кодами поля М. Если код поля
равен 00 - маскирование отсутствует, если 01 - маска выбирается из RAM, если
10 - из AFIFO, если 11 - из внешней памяти.
Операция взвешенного суммирования выполняется в соответствии с
выражением
W- X+Y.
При выполнении этой операции можно осуществить циклический сдвиг
операнда А" на один разряд вправо. Управление циклическим сдвигом
определяется содержимым поля SH. Если SH= 1 - сдвиг осуществляется, если SH=
0 - сдвига нет. Выборка операнда Уможет происходить из регистра VR,b
зависимости от значения бита VR. Если бит VR установлен в 1, то содержимое
регистра VR является операндом Y; если в 0, то нет.
Однобитные поля FPXh FPY управляют пороговой функцией для
операндов Хи Г соответственно. Нулевое значение бита этих полей показывает, что
функция соответствующего операнда не используется. Поля FAXh FAY также
однобитные. Они предназначены для управления функцией насыщения
операндов Хи ^соответственно. Насыщения функции нет, если бит поля
установлен в 0. В противном случае пороговая функция имеет насыщение.
Поле L управляет перезаписью весов из теневой матрицы WBUFb рабочую
WOPER. Если L = 1, перезапись осуществляется, если L = 0 , перезаписи нет.
388
13.4. Нейрочипы
Нейропроцессор Л1879ВМ1 выполнен по 0,5 мкм
КМОП-технологии. Тактовая частота его генератора ::
равна 33... 50 МГц. Расчеты и эксперименты показали, Лтиг ;;
что на специальных векторно-матричных операциях •:
этот процессор дает увеличение производительности в ::
десятки раз по сравнению с процессором 7MS320C40 ::
фирмы Texas Instruments. Благодаря наличию коммуни- ♦*«»•—.-.*.-...,..
кационных портов с интерфейсом, идентичным портам Рис. 13.20. Внешний
7MS320C40, нейропроцессор Л1879ВМ1 может быть ВВД нейропроцессора
интегрирован в многопроцессорную систему, имеющую
разнородные микропроцессоры.
Для нейропроцессора Л1879ВМ1 в НТЦ «Модуль» разработан полный
пакет системного программного обеспечения, включая символьный отладчик, и
ряд прикладных библиотек.
Внешний вид нейропроцессора Л1879ВМ1 приведен на рис. 13.20.
На базе нейропроцессора Л1879ВМ1 в НТЦ «Модуль» разработан
инструментальный блок, предназначеный для работы в составе ПЭВМ с системной
шиной PCL С помощью такого узла возможна отработка функционального
программного обеспечения вычислительных систем на базе процессора
Л1879ВМ1.
Модуль МС4.31 содержит один Л1879ВМ1 с двумя банками однотактовой
статической памяти по 2 Мбайт (по одному банку на каждой шине
процессора). Один банк памяти доступен для записи и чтения как со стороны
процессора, так и со стороны шины PCI.
На внешние разъемы МС4.31 выведены два коммуникационных порта
нейропроцессора, которые предназначены для объединения нескольких модулей
или подсоединения устройств ввода/вывода. Коммуникационные порты могут
быть использованы в качестве отладочного интерфейса для сопряжения ПЭВМ
с бортовой аппаратурой на базе Л1879ВМ1. Для шины PC/узел МС4.31
является 32-разрядным ведущим устройством в пространстве адресов ввода/вывода.
Программный драйвер узла МС4.31 поддерживает его работу под
управлением операционных систем Windows 95/98/2000/NT.
Основные технические характеристики узла МС4.31:
Количество процессоров Л1879ВМ1 1
Тактовая частота, МГц 40,0
Напряжене питания, В 5,0/3,3
Мощность потребления, Вт не более 2,0
Общее ОЗУ статического типа, Мбайт 4
Системная шина PCI
389
13. Элементная база для аппаратной реализации нейрокомпьютеров
2 коммуникационных порта с пропускной способностью, Мбайт/с до15 каждый
Пиковый темп обмена по шине PCI, Мбайт/с до 132
Скалярные операции над 32-разрядными данными, MOPS до 120
Векторные операции над 8-разрядными данными, ММАС до 960
НТЦ «Модуль» выпустил новую, более производительную версию нейро-
чипа- 1879ВМ2Е (NeuroMatix NM6404)''.
Новый микропроцессор является дальнейшим развитием микропроцессора
Л1879ВМ1 и полностью совместим с ним. В состав К1879ВМ2Е входят два
основных блока: 32/64-разрядный /J/SC-npoueccop и 1-64-разрядный
векторный сопроцессор для поддержки операций над векторами с элементами
переменной разрядности, упакованными в 64-разрядные слова.
Процессор будет иметь два идентичных 32/64-программируемых интерфейса
с внешней памятью и два коммуникационных порта, способных работать в
синхронном или асинхронном режиме.
Общие технические характеристики нового нейропроцессора ожидаются
быть следующими:
Тактовая частота задающего генератора, Мгц 133
Технололгия КМОП, мкм 0,25
Тип корпуса BGA576
Напряжения питания, В:
RISC-ящю 2,5
ввод/вывод 3,3
Потребляемая мощность, Вт не более 2,0
Температурный диапазон эксплуатации, °С —60...+85
Характеристики RISC-ядра:
5-ступенчатый 32-рарядный конвейер;
поле команд составляет 32- или 64-бит (обычно выполняется две операции в одной
команде);
внутреннее ОЗУ - 2 Мбит;
доступ к внутренней памяти соседей;
два адресных генератора, адресное пространство - 16 Гбайт;
два 32/64-бит программируемых интерфейса с SDRAMISRAMIDRAM/Flash
ROM с разделяемой памятью;
четыре одновременных доступа к ОЗУ;
формат данных - 32-разрядные целые;
четыре канала DMA;
два коммуникационных порта ввода/вывода;
.ЛИО-совместимый отладочный интерфейс;
система управления потребляемой мощностью.
'http://www.module.ru/ruproducts/proc/nm6404.shtml
390
13.4. Нейрочипы
Особенности Г£С7Ю/?-сопроцессора:
длина векторных операндов и результатов от 1 до 64 битов разрядов;
формат данных - целые числа, упакованные в 64-разрядные блоки, в форме слов
переменной длины от 1 до 64 разрядов каждое;
поддержка векторно-матричных и матрично-матричных операций;
число тактов на перезагрузку матрицы коэффициентов зависит от разбиения
матрицы;
свопирование рабочей и теневой матрицы; два типа функций
насыщения на кристалле.
Ожидаемая производительность нейропроцессора:
• скалярные операции:
133 MIPS;
399 MOPS для 32-разрядных данных;
• векторные операции:
от 199 до 37000 + ММАС (миллионов умножений с накоплением в секунду);
• I/O и интерфейсы с памятью:
64-разрядные интерфейсы с внешней памятью (до 1000 Мбайт/с каждый);
коммуникационные порты (до 133 Мбайт/сек каждый).
Новый нейропроцессор предназначен для применения в системах
цифровой обработки сигналов, обработки видеоизображений, эмуляции НС, для
выполнения векторно-матричных вычислений, обработки видеоизображений, как
элементная база при построении бортовых вычислительных систем и
мультипроцессорных супер-ЭВМ.
Элементную базу сложных технических изделий технически и
экономически целесообразно проектировать и выпускать в виде комплектов.
Составляющие таких комплектов выполняют различные функции, но обязательно
совместимы между собой по технико-технологическим параметрам. Это позволяет
разработчикам проектировать на одной и той же элементной базе, по единой
методологии изделия, имеющие разные функциональные назначения, что
значительно снижает затраты на проектирование и эксплуатацию новых изделий.
Не исключение в этом смысле является и микропроцессорная элементная база
вообще и отечественный микропроцессорный комплект серии 1879.
НТЦ «Модуль» к двум описанным выше микропроцессорам разработал и
подготовил производство третьего - К1879ВМЗ. Его применение совместно с
Л1879ВМ1 и К1879ВМ2 значительно расширяет возможности разработчиков
при проектировании сложнейших вычислительных систем реального
времени*.
Основой К1879ВМЗ является быстродействующий программируемый 128-
битный контроллер со встроенными АЦП и ЦАП. Микросхема предназначена
для предварительной обработки широкополосных аналоговых сигналов, фор-
• http://www.module.ru/ruproducts/proc/nm6404.shtml
391
13.4. Нейрочипы
• программируемый цифровой интерфейс - 16 входов и 20 выходов;
• максимальная частота цифрового интерфейса - 150 МГц;
• внутренняя двухпортовая память команд объемом 64 Кбайт;
• внутренняя трехпортовая память данных объемом 192 Кбайт;
• программируемый интерфейс с внешней 64- или 32-разрядной шиной
данных (совместимый с нейропроцессорами Л1879ВМ1/1879ВМ2);
• тип внешней памяти - асинхронная статическая {SRAM), синхронная
статическая {SSRAM) или синхронная динамическая {SDRAM);
• максимальная скорость обмена с SRAM- 600 Мбайт/с;
• максимальная скорость обмена с SSRAM, SDRAM- 800 Мбайт/с;
• адресуемое пространство внешней памяти - 64 Мбайт;
• работа микросхемы и внешнего процессора с общей памятью в режиме
разделения времени;
• произвольный доступ внешнего процессора к внутренней памяти
контроллера;
• 10 внешних прерываний и 140 внутренних прерываний;
• 24-разрядный счетчик реального времени;
• восемь программно настраиваемых каналов, каждый из которых
содержит канал прямого доступа к памяти, 18-разрядный счетчик задержек,
12-разрядный счетчик внешних и внутренних событий, а также аппаратуру для
генерации прерываний по этим событиям;
• минимальная длительность процессорного такта - 6,666 не (150 МГц);
• основной формат данных - 64-разрядные слова, в которых упакованы
однобайтовые данные, представленные в дополнительном коде;
• разрядность команд - 128 бит. Каждая команда выполняется за два
процессорных такта;
• степень интеграции - 2.230.000 эквивалентных вентилей;
• технология изготовления - 0,25 мкм КМОП;
• напряжение питания - 3,3 В и 2,5 В;
• потребляемая мощность - не более 4,2 Вт;
• рабочий диапазон температур - от -40 до +85 °С;
• тип корпуса - 576-выводный BGA.
Более подробную информацию об отечественных нейрочипах, об
особенностях его программирования можно получить на приводимом выше сайте
НТЦ «Модуль».
393
13. Элементная база для аппаратной реализации нейрокомпьютеров
мирования потока данных для вторичной обработки цифровым процессором
сигналов (ЦПС), восстановления аналогового сигнала после вторичной
обработки. В качестве ЦПС предпочтительно использование процессоров Л1879ВМ1
или перспективного К1879ВМ2, которые имеют совместимый цифровой
интерфейс.
Внутренняя память К1879ВМЗ объемом 2 Мбит позволяет ему принимать и
сохранять высокочастотные аналоговые сигналы. Большое количество
программируемых счетчиков и развитая система внутренних и внешних прерываний
обеспечивают выдачу на аналоговые выходы однократных и периодических
высокочастотных сигналов, хранящихся во внутренней памяти контроллера, в
реальном масштабе времени с требуемыми задержками и длительностями.
Встроенные быстродействующие арифметические узлы обеспечивают
программируемое усиление входных сигналов, их суммирование с выходными
сигналами, программируемое изменение сдвига частоты выходных сигналов.
Внешняя 64-разрядная шина обеспечивает быстрый обмен командами и данными
с внешней памятью или ЦПС как в режиме прямого доступа к памяти, так и в
режиме произвольного доступа ЦПС к внутренней памяти контроллера.
Контроллер имеет следующие характеристики:
• синхронизация от внешнего источника с частотой Fs от 5 до 600 МГц;
• два 6-разрядных АЦП осуществляют преобразование ■. • тых
составляющих/и Q входного сигнала с частотой Fs, Fs/2 и Fs/4, т. е. до 600 Мвыбо-
рок/с;
• четыре 8-разрядных ЦАП формируют четные и нечетные выборки
квадратурных составляющих /и Q выходного сигнала с частотой Fs/2, Fs/4 и Fs/S, т. е.
до 300 Мвыборок/с каждый;
• функции цифровой обработки входных и выходных квадратурных
сигналов:
детектирование входного сигнала;
вычисление максимальной амплитуды входного сигнала;
определение моментов совпадения квадратурных составляющих входного
сигнала;
цифровое усиление входного сигнала;
сложение входного сигнала с выходным или эталонным сигналом;
программирование задержек однократных и частоты следования
периодических выходных сигналов с дискретностью 13,33 не (минимальная
задержка прохождения сигнала от аналогового входа до аналогового выхода
-48 нс);
программирование сдвига частоты выходного сигнала в диапазоне от
-250 до +250 КГц с дискретностью 8,94 Гц;
микширование двух выходных сигналов (частота микширования- от 18,75
до 75 МГц);
392
ЗАКЛЮЧЕНИЕ
Как было показано в книге, в истории развития вычислительной техники
известно много направлений по разработке высокопроизводительных машин,
комплексов и систем, обеспечивающих параллельную обработку информации.
Однако, несмотря на значительные успехи в области развития компьютерной
индустрии, все еще не решены проблемы построения вычислительных систем
с «истинным» параллелизмом. Перспективы создания таких систем
связываются с развитием нейросетевых технологий. Приведенные в книге примеры
свидетельствуют о том, что уже сейчас НК могут решать широкий круг
прикладных задач.
Основная проблема создания НК - выбор нейросетевой модели, адекватной
решаемой задаче. Поэтому в развитии теории НС каждое десятилетие
отмечено определенными ведущими направлениями исследований различных типов
НС. В 60-е годы XX века- это однослойный персептрон Розенблатта, нейросе-
тевые модели Адалин и Мадалин, в 70-е годы XX века - модели ассоциативной
памяти Кохонена, Марра, Амосова и другие, в 80-е годы XX века -
многослойные персептроны, обучающиеся по правилу обратного распространения
ошибки, рекуррентные сети Хопфилда, Хемминга и др., в 90-е годы XX века -
разработка новых типов НС (например, RBF - сетей, являющихся конкурентом
многослойному персептрону) и комбинированных (сети встречного
распространения). Принципиально важным для взаимодействия НС с другими
информационными технологиями является результат, демонстрирующий
функциональную эквивалентность между RBF-сетями и системами нечеткого вывода
(Jang J.S.R., 1993). В конце XX и начале XXI века направление исследований
НС переместилось в сторону создания гибридных моделей (нейро-нечетких,
нейро-генетических и др.). Итог многолетних исследований различных типов
НС заключается в том, что на основе зарубежного и отечественного опыта
сформулирована единая методика настройки многослойных НС различной
структуры, работающих в различных режимах, пригодная для разработки
нейросетевых алгоритмов решения задач общей и прикладной нейроматематики.
Отметим несколько наиболее значимых достижений в области развития
теории НС за последние годы, позволяющих повысить эффективность
применения НК при решении прикладных задач:
• формирование нейроматематики, нового раздела вычислительной
математики, связанного с созданием алгоритмов решения задач в нейросетевом
логическом базисе;
• создание нейроалгоритмов и нейрокомпьютеров на их основе;
• разработка вычислительных моделей мозга (на основе изучения
зрительной коры мозга, мозжечка, субнейронных и квантовых процессов в мозге,
сознания), что в значительной мере способствовало пониманию процессов
восприятия, формированию языковых конструкций и знаний;
• развитие и использование ГА при структурном и параметрическом
обучении НС, что делает возможным достижение глобального минимума ошибки
обучения;
• развитие теории квантовых НС, позволяющих за счет достоинств
квантовых вычислений решать сложные комбинаторные задачи;
394
Заключение
• разработка динамических рекуррентных сетей, позволяющих работать с
временными рядами, и методов их обучения;
• слияние на основе принципов синергизма нейросетевого и нечеткого
подходов, позволяющих строить нейро-нечеткие системы, особенно эффективные
при решении задач управления и искусственного интеллекта;
• формирование широкого рынка применений нейрокомпьютеров.
Наиболее значимые примеры применения нейросетевых технологий
относятся к области распознавания сложных визуальных образов реального мира
(лиц людей на фотографиях, движущихся объектов), речи, рукописных
символов; прогнозирования в бизнесе, экономике и медицине (анализ финансовых,
валютных рынков и рынков ценных бумаг, предсказание курсов активов,
валют, политических событий, постановка диагноза и прогноз развития
заболевания); управления в космосе, авиации, робототехнике (посадка летательного
аппарата, маневрирование вертолетов, интегральное управление мобильными
роботами и т.д.); решения физических задач в реальном времени (выполнение
обратных некорректных преобразований, моделирование процессов,
описываемых уравнениями с частными производными и т. д.), использования в
биометрических системах обеспечения безопасности, в черной металлургии для
управления доменной печью, в химическом машиностроении, в нефте- и
газодобывающей промышленности и т. д.
Одним из важных вопросов дальнейшего использования НК остается
осознание различия между НК и традиционными ЭВМ. С одной стороны, можно
полагать, по словам Ю. Шурманна, что фундаментальное различие между
традиционными вычислениями и НК заключается в том, что НК обрабатывает
аналоговые сигналы, а традиционные ЭВМ - цифровые, т.е. различие - в
обработке чисел и символов на обычных компьютерах и широкополосных сигналов
(образов) на НК. С другой стороны, если учитывать способ обработки
информации мозгом человека, то традиционный компьютер может ассоциироваться
с левым полушарием мозга, ответственным за выполнение вычислительных
функций, а НК - с правым, ответственным за функции восприятия,
понимания, распознавания и пр. Это различие и определяет наиболее эффективную
область использования НК, связанную с решением трудно формализуемых и
плохо структурированных прикладных задач, требующих моделирования
функций мозга человека (например, поведение робота в незнакомой среде). Трудно
гарантировать решение подобных задач даже на ЭВМ кластерного типа в
реальном масштабе времени.
Таким образом, с одной стороны, НК можно рассматривать как новый класс
суперЭВМ, предназначенный для решения сложных математических задач и
позволяющий за счет естественного параллелизма, свойственного НС,
обеспечить решение этих задач в заданное время, а с другой НК - это
вычислительная среда, предназначенная для имитации функций мозга человека, дающая
возможность решать задачи искусственного интеллекта.
Прогноз развития нейросетевых технологий в ближайшем будущем
опирается на уже достигнутые успехи их применения для решения прикладных за-
395
Заключение
дач науки и техники, а также строится с учетом наиболее значимых
достижений в области вычислительной техники. Например, объединение мощных
вычислительных центров в единую сетевую конфигурацию и создание
глобальной информационной среды Internet ставит перед мировым сообществом новые
задачи, связанные с организацией взаимодействия с этой средой. Огромные
массивы информации, доступные в Internet, требуют создания новых средств
анализа смыслового содержания текстов и извлечения из них знаний,
автоматической рубрикации, аннотирования и навигации в больших текстовых
массивах, фильтрации информации с помощью электронных агентов,
представляющих интересы пользователей в Сети. Проблемы коллективного взаимодействия
и самообучения, организации и автономной эволюции агентов могут быть
решены на основе НС.
Другим примером является создание управляемых на основе НС средств,
предназначенных для инвалидов (протезы, вживляемые имитаторы ощущений,
системы искусственного зрения, слуха, обоняния, распознающие и
интерпретирующие обучающие системы для слепых и пр.).
Для успешного применения НС небходимым также является понимание
работы мозга. Но чтобы достигнуть этого понимания, требуются объединенные
усилия многих специалистов разных областей знаний.
Перспективными направлениями развития НК являются:
• создание антропоморфных роботов;
• решение задач расп ; ■ ■ объектов на изображениях, лица человека и т. п.;
• решение проблем комбинаторного взрыва;
• создание квантового НК;
• исследование надежности НС при выходе из строя отдельных элементов
или групп элементов;
• развитие нейроматематики, создание алгоритмов решения задач в нейро-
сетевом логическом базисе (систем линейных и нелинейных алгебраических
уравнений и неравенств; задач оптимизации; нелинейных обыкновенных
дифференциальных уравнений; дифференциальных уравнений в частных
производных и т. д.), что позволит создать новый класс суперЭВМ с точки зрения
критерия отношения производительности к стоимости;
• новые разработки НК из нейрочипов на базе заказных СБИС, ПЛИС,
аналоговых и аналого-цифровых СБИС; при этом необходимо отметить
тенденцию разработок широкого спектра специализированных и
проблемно-ориентированных нейрочипов и НК на их базе, где особенно эффективно применение
НК по сравнению с традиционными ЭВМ;
• слияние нейросетевой технологии с другими информационными
технологиями для быстрого извлечения знаний из данных и их вербализации.
Слияние нейросетевой технологии с нечеткими системами позволит
строить интеллектуальные системы с образной и логической обработкой
информации подобно тому, как это реализовано в мозге человека.
Мы надеемся, что прочитав и проработав материалы этого учебного
пособия, у студентов появится желание испытать себя на «нейросетевом» поприще.
Желаем вам больших успехов!
396
СПИСОК ЛИТЕРАТУРЫ
1. Галушкин А.И. Теория нейронных сетей. Кн.1/Под ред. А.И. Галушкина.
М: ИПРРЖР, 2000.
2. VcCulloc W.S., Pitts W. A logical calculus of the ideas immanent in nervous
activity // Bull. Math. Biophysic- 1943. № 5. Pp. 115-133. Русский перевод:
Нейро-компьютер, № 3,4,1992. С. 40-53.
3. Нейронные сети на персональном компьютере / А.Н. Горбань, Д.А. Рос-
сиев. Новосибирск: Наука, Сибирская издательская фирма РАН, 1996.
4. Галушкин А.И. Нейрокомпьютеры. Кн. 3/ Под общ. ред. А.И. Галушкина.
М: ИПРЖР, 2000.
5. Методы анализа, синтеза и оптимизации нестационарных систем
автоматического управления/ К.А. Пупков, Н.Д. Егупов, В.Г. Коньков и др.; Под ред.
Н.Д. Егупова. М: Изд-во МГТУ им. Н.Э. Баумана, 1999.
6. ЛоговскийА.С, Якушин Д.Ж. Нейропакеты: что, где, зачем. - Зарубежная
радиоэлектроника, № 2,1977. С. 11-18.
7. Миркес Е.М. Нейрокомпьютер. Проект стандарта. Новосибирск: Наука.
Сибирская издательская фирма РАН, 1998.
8. Нейрокомпьютеры и интеллектуальные роботы /Н.М. Амосов, Т.М. Байдык,
А.Д. Гольцев и др.; Под ред. Н.М. Амосова; АН УССР Ин-т кибернетики.
Киев: Наукова думка, 1991.
9. Foundation of Genetic Algorithms, editedby Rowling Gregory.Morgan Kaufman
Publishers.San meteo.Caiifornia, 1991.
10. Байдык Т.Н. Нейронные сети и задачи искусственного интеллекта. Киев:
Наукова Думка, 2001.
11. Chin-Teng Lin, George Lee. Neural Fuzzy Systems to Intelligent Systems.//A.
Simon and Schuster Company.Upper Saddle River, NJ07458. - 1996 by Prentice Hall.
12. Шахнов В.А., Власов А.И., Кузнецов А.С., Поляков Ю.А. Элементная
база для реализации параллельных вычислений: тенденции развития // Труды
7-й Всероссийской конференции «Нейрокомпьютеры и их применение» НКП-2001.
С. 499-531.
13. Реализация нейронных сетей на ПЛИС XILINX. - Scan Engineering
Telecom, декабрь 2000 г.
14. Шевченко П.А., Фомин Д.В., Черников В.М., Виксне П.Е. Архитектура
нейропроцессора NeuroMatrix NM6403 II V Всероссийская конференция
«Нейрокомпьютеры и их применение». Сборник докладов. М. 17-19 февраля
1999 г. С. 70-80.
15. Бэстенс Д.Э., ВанДен Берг В.М., ВудД. Нейронные сети и финансовые
рынки/ Пер. с англ.; Под ред. А.П. Коваленко. М.: Научное изд-во ТВП, 1997.
397
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
А
Адаптивный резонанс 215
Алгоритм Аизермана-Бравермана 120
- потенциальных функций 121
Архитектура TrigerSharc 366
Ассоциативная память 175
Ассоциатрон 176
Ассоциативно-проективная сеть 189
Б
Бесплатформенная инерциальная система
ориентации 12
Блокировка сети 128
В
Векторно-конвейерная архитектура 21
Взвешенное умножение с
накоплением 364
д
Двунаправленная ассоциативная
память 199
Детализация параллелизма 19
- мелкая, мелкозернистая 19
- крупная, крупнозернистая 19
3
Задача аппроксимации функции 37
- кластеризации 37
- коммивояжера 185
- неформализуемая 37
- предсказания 37
- распознавания образов 37
- трудноформализуемая 36
- формализуемая 36
Закон Гроша 18
Закон Мура 16
Знаковая интерпретация 92
К
Кватернион 14
Кинематические уравнения 14
Кластеризация 204
Коннекционизм 32
Кроссинговер 147
Л
Лингвистическая переменная 240
Логически прозрачная сеть 101
М
Машина потоков данных 25
-БольцманаШ
Метод наискорейшего спуска 130
-покоординатного спуска 134
-усовершенствованный кРагТап 132
Методы РагТап 132
- кРагТап 132
МКМД22
Модулярная предобработка 90
Н
Нейрон биологический 28
- с квадратичным суммированием 41
- со счетчиком совпадений 42
- формальный 40
Нейронная сеть 40
Нейроимитатор 221
Нейрокомпьютер абстрактный 28
Нейропакет 223
Нейропроцессор NM6403 368
Нейросетевой базис 56
398
Учебное издание
ИНФОРМАТИКА В ТЕХНИЧЕСКОМ УНИВЕРСИТЕТЕ
Комарцова Людмила Георгиевна
Максимов Александр Викторович
Нейрокомпьютеры
Редактор Н.Е. Овчеренко
Художники С.С. Водчиц, КГ. Столярова
Корректор М.А. Василевская
Компьютерная верстка И.Ю. Бурова
Оригинал-макет подготовлен в Издательстве
МГТУ им. Н.Э. Баумана
Санитарно-эпидемиологическое заключение
№ 77.99.02.953.Д.005683.09.04 от 13.09.2004 г.
Подписано в печать 18.10.2004. Формат 70x100/16.
Бумага офсетная. Печать офсетная. Гарнитура «Тайме».
Печ. л. 25. Усл. печ. л. 32,5. Уч.-изд. л. 31,98. Тираж 2000 экз.
Заказ 11258
Издательство МГТУ им. Н.Э. Баумана.
105005, Москва, 2-я Бауманская, 5.
Отпечатано с оригинал-макета в ГУП ППП «Типография «Наука».
121099, Москва, Шубинский пер., 6.